
Exploitation of a parallel clustering algorithm on commodity hardware with P2P-MPI
21
J Supercomput (2008) 43: 21–41 DOI 10.1007/s11227-007-0136-2 Exploitation of a parallel clustering algorithm on commodity hardware with P2P-MPI Stéphane Genaud · Pierre Gançarski · Guillaume Latu · Alexandre Blansché · Choopan Rattanapoka · Damien Vouriot Published online: 5 May 2007 © Springer Science+Business Media, LLC 2007 Abstract The goal of clustering is to identify subsets called clusters which usually correspond to objects that are more similar to each other than they are to objects from other clusters. We have proposed the MACLAW method, a cooperative coevo- lution algorithm for data clustering, which has shown good results (Blansché and Gançarski, Pattern Recognit. Lett. 27(11), 1299–1306, 2006). However the complex- ity of the algorithm increases rapidly with the number of clusters to find. We propose in this article a parallelization of MACLAW, based on a message-passing paradigm, as well as the analysis of the application performances with experiment results. We show that we reach near optimal speedups when searching for 16 clusters, a typical problem instance for which the sequential execution duration is an obstacle to the MACLAW method. Further, our approach is original because we use the P2P-MP1 grid middleware (Genaud and Rattanapoka, Lecture Notes in Comput. Sci., vol. 3666, pp. 276–284, 2005) which both provides the message passing library and infrastruc- ture services to discover computing resources. We also put forward that the applica- tion can be tightly coupled with the middleware to make the parallel execution nearly transparent for the user. Keywords Clustering · Evolutionary algorithms · Grid · Parallel algorithms · Java S. Genaud · G. Latu · C. Rattanapoka LSIIT-ICPS, Louis Pasteur University, Strasbourg – UMR 7005 CNRS-ULP, Blvd. S. Brant, BP 10413, 67412 Illkirch, France S. Genaud e-mail: [email protected] P. Gançarski ( ) · A. Blansché · D. Vouriot LSIIT-AFD, Louis Pasteur University, Strasbourg – UMR 7005 CNRS-ULP, Blvd. S. Brant, BP 10413, 67412 Illkirch, France e-mail: [email protected]
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Exploitation of a parallel clustering algorithm on commodity hardware with P2P-MPI

J Supercomput (2008) 43: 21–41DOI 10.1007/s11227-007-0136-2
Exploitation of a parallel clustering algorithm oncommodity hardware with P2P-MPI
Stéphane Genaud · Pierre Gançarski ·Guillaume Latu · Alexandre Blansché ·Choopan Rattanapoka · Damien Vouriot
Published online: 5 May 2007© Springer Science+Business Media, LLC 2007
Abstract The goal of clustering is to identify subsets called clusters which usuallycorrespond to objects that are more similar to each other than they are to objectsfrom other clusters. We have proposed the MACLAW method, a cooperative coevo-lution algorithm for data clustering, which has shown good results (Blansché andGançarski, Pattern Recognit. Lett. 27(11), 1299–1306, 2006). However the complex-ity of the algorithm increases rapidly with the number of clusters to find. We proposein this article a parallelization of MACLAW, based on a message-passing paradigm,as well as the analysis of the application performances with experiment results. Weshow that we reach near optimal speedups when searching for 16 clusters, a typicalproblem instance for which the sequential execution duration is an obstacle to theMACLAW method. Further, our approach is original because we use the P2P-MP1grid middleware (Genaud and Rattanapoka, Lecture Notes in Comput. Sci., vol. 3666,pp. 276–284, 2005) which both provides the message passing library and infrastruc-ture services to discover computing resources. We also put forward that the applica-tion can be tightly coupled with the middleware to make the parallel execution nearlytransparent for the user.
Keywords Clustering · Evolutionary algorithms · Grid · Parallel algorithms · Java
S. Genaud · G. Latu · C. RattanapokaLSIIT-ICPS, Louis Pasteur University, Strasbourg – UMR 7005 CNRS-ULP, Blvd. S. Brant,BP 10413, 67412 Illkirch, France
S. Genaude-mail: [email protected]
P. Gançarski (�) · A. Blansché · D. VouriotLSIIT-AFD, Louis Pasteur University, Strasbourg – UMR 7005 CNRS-ULP, Blvd. S. Brant,BP 10413, 67412 Illkirch, Francee-mail: [email protected]

22 S. Genaud et al.
1 Introduction
Classification algorithms are generally divided into two types, supervised and unsu-pervised. A supervised algorithm requires labeled training data i.e. its requires morea priori knowledge about the training set: the aim of supervised learning is to discovera function or model (also called classifier) from these training data which classifiesnew previously unseen examples correctly. A unsupervised classification also calledclustering, is an optimization problem aiming at partitioning a data set into subsets(clusters), so that the data in each subset share some similarity, where similarity isoften defined as proximity according to some defined distance measure. A cluster-ing algorithm does not need any a priori information about the data, except (in mostapproaches) the expected number of clusters. In this paper we only focus on dataclustering.
Algorithms designed to solve such problems often have a high complexity andhence parallel processing is a natural idea to speed-up computations. Thus, severalad hoc parallelizations of clustering algorithms have been proposed [6, 8, 21] basedon the message-passing programming paradigm (all implemented with MPI [23]).In these works, experimental runs often achieve quasi linear speed-ups on special-ized hardware (e.g. a parallel supercomputer, an homogeneous PC cluster, . . . ). Suchspeed-ups are appealing as most data-clustering applications rarely run for less thanseveral hours. However, in practical usage, the user must overcome the burden ofusing dedicated computing facility and subsequent constraints to benefit from ac-celerated runs. Constraints may include remote login to the computing facility site,mandatory reservation for an exclusive access (e.g. via batch schedulers such as LSFor PBS), limited number of processors on small or overloaded multi-processors com-puters. Another alternative maybe to install an MPI implementation (e.g. mpich,LAM/MPI) on some individual PCs connected to the LAN. In that case, keepingup-to-date the fixed configuration of available machines is so time-consuming that itis an unacceptable maintenance task.
In [2], a new clustering method called MACLAW (a Modular Approach for Clus-tering With Local Attributes Weighting) has been introduced. This method is basedon the evolutionary approach. However, it is well-known that the evolutionary algo-rithms require much computing time and thus that their parallelization is even morecrucial. In this paper we present the improvements we bring to the Java based imple-mentation of the MACLAW clustering method, called Mustic, in order to decreaseits execution times while preserving its ease of use. The contribution of this paper istwo-folds. First, we propose a parallelization of MACLAW. We explain the methodin Sect. 2.2, we analyze its complexity in Sect. 2.3 and we propose a parallelizationbased on the message-passing paradigm in Sects. 3.1 and 3.2. The second contribu-tion lies in the implementation with P2P-MPI [12], an original approach which en-ables to exploit MACLAW on computing grids. P2P-MPI is introduced in Sect. 3.3and we discuss its advantages over some other projects, in particular its dynamicresources discovery capabilities. We also put forward the ease of use with the inte-gration of parallel runs invocations in the Mustic GUI. Finally some experimentalresults are presented in Sect. 3.4 to illustrate the performances of our parallel versionof MACLAW both in homogeneous and heterogeneous environments.
Parallel clustering algorithm with P2P-MPI 23
2 MACLAW
2.1 Context
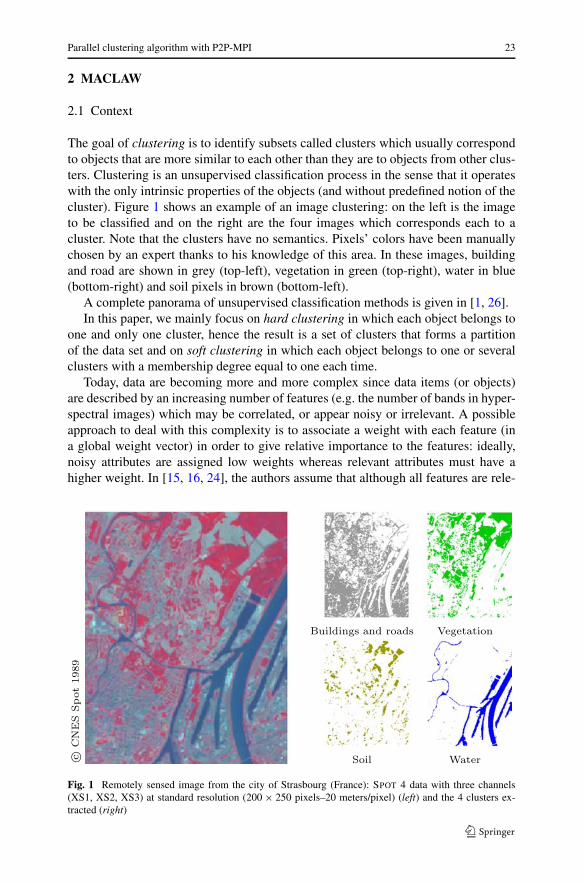
The goal of clustering is to identify subsets called clusters which usually correspondto objects that are more similar to each other than they are to objects from other clus-ters. Clustering is an unsupervised classification process in the sense that it operateswith the only intrinsic properties of the objects (and without predefined notion of thecluster). Figure 1 shows an example of an image clustering: on the left is the imageto be classified and on the right are the four images which corresponds each to acluster. Note that the clusters have no semantics. Pixels’ colors have been manuallychosen by an expert thanks to his knowledge of this area. In these images, buildingand road are shown in grey (top-left), vegetation in green (top-right), water in blue(bottom-right) and soil pixels in brown (bottom-left).
A complete panorama of unsupervised classification methods is given in [1, 26].In this paper, we mainly focus on hard clustering in which each object belongs to
one and only one cluster, hence the result is a set of clusters that forms a partitionof the data set and on soft clustering in which each object belongs to one or severalclusters with a membership degree equal to one each time.
Today, data are becoming more and more complex since data items (or objects)are described by an increasing number of features (e.g. the number of bands in hyper-spectral images) which may be correlated, or appear noisy or irrelevant. A possibleapproach to deal with this complexity is to associate a weight with each feature (ina global weight vector) in order to give relative importance to the features: ideally,noisy attributes are assigned low weights whereas relevant attributes must have ahigher weight. In [15, 16, 24], the authors assume that although all features are rele-
Fig. 1 Remotely sensed image from the city of Strasbourg (France): SPOT 4 data with three channels(XS1, XS2, XS3) at standard resolution (200 × 250 pixels–20 meters/pixel) (left) and the 4 clusters ex-tracted (right)

24 S. Genaud et al.
vant, their relative importance depend on the classes to extract. Thus, instead of as-signing a global weight vector for the entire data set, recent methods such as COSA(Clustering On Subsets of Attributes) [9] and LAC (Locally Adaptive Clustering) [7]algorithms assign a local weight vector for each cluster (i.e., a weight is assignedto each attribute in each cluster) which will be applied to the objects during classi-fication. A family of unsupervised methods based on the K-means algorithm [22]has been also developed [5, 10, 17]: the aim of these algorithms is to simultaneouslyoptimize the (local) weights and the classes built using these (local) weights. Likethe K-means algorithm, these methods try to minimize a cost function based on thedistance between the objects and the cluster centres through hill-climbing search.
Thus, the hybrid method presented by [5] wraps a feature optimization step intothe weighted K-means algorithm which is an extension of the well-known K-meansclustering paradigm [22]. By an iterative process, it attempts to optimize the costfunction:
CostWKM(D,K,W,C) =K∑
k=1
∑
xj ∈Sk
d∑
t=1
(wt
k · distt (xj , ck))
where W = ((w11, . . . ,w
d1 ), . . . , (w1
k , . . . ,wtk, . . . ,w
dk ), . . . , (w1
K, . . . ,wdK)) is the lo-
cal weight vector, C is a partition of the dataset D and distt (xj , ck) the distancebetween object xj and center ck of the k-th cluster on the t-th attribute.
This process is based on a hill-climbing approach where each step consists inthree partial optimizations. The first two are the same as in the weighted K-meansalgorithm (each object is assigned to the nearest center according to the distancemeasure, then each center is re-calculated as the gravity center of all objects whichare associated with it) while the last optimization consists in recomputing the localfeature weights according to the new centers.
2.2 The MACLAW method
In [2] we have proposed and validated an improved clustering method calledMACLAW which integrates a local feature weighting algorithm. Whereas [5] usesan hill-climbing approach, our clustering method is based on a cooperative coevo-lution algorithm with K populations of individuals. In MACLAW, we search for aglobal solution which consists of K clusters together with their associated weightvectors. For any of these clusters to come out, at the g-th generation each individuali of a population k extracts from the dataset D, one and only one cluster called X
i,gk .
The extraction consists in a weighted K-means execution, parameterized by the indi-vidual’s feature weights coded by its chromosome. The best extracted cluster (i.e. thecluster which yields the best clustering quality) in population k is then chosen as thek-th cluster for generation g. As clusters are independently computed, an object maytemporarily belongs to zero or more clusters in the global solution. Hence, such aglobal solution is called a weighted partial soft clustering (WPSC) and is representedby a vector of K elements, the k-th element being a cluster called Ck together withits associated weight vector Wk .
Finally, the goal of MACLAW is to produce the best WPSC as possible. Ideally,the clustering is a partition but in many cases there remains a few objects which are

Parallel clustering algorithm with P2P-MPI 25
classified into several clusters or which are unclassified. The MACLAW implemen-tation integrates a final postprocessing stage to transform the WPSC obtained into apartition by assigning each misclassified object to the cluster with nearest center. Theabove mentioned goal translates into an optimization problem which consists in find-ing some appropriates sets of weights, and is solved through the evolution process.
A WPSC is evaluated according to the new quality criterion Q which takes intoaccount two criteria. The first one, called Qp(WPSC) judges the structure of theWPSC: if the clustering is a partition of the data set the quality will by high, whereasoverlapping and unclassified objects will yield poor quality. Its evaluation consists incounting the number noj
of clusters out of the K clusters Ck in the global solution towhich each object oj belongs:
Qp(WPSC) = max
(0,
1
Card(D)
∑
oj ∈D
(1 − |noj− 1|)
). (1)
One can notice that Qp(WPSC) = 1 if and only if WPSC is a partition otherwiseQp(WPSC) < 1.
The second one, called Qc(WPSC), judges the clusters quality. It is often basedon the cluster inertia as follows:
Qc(WPSC) =∏
(Ck,Wk)∈WPSC
r(Ck,Wk), (2)
where the inertia r of a cluster is defined as the sum of all the distances betweenobjects belonging to the cluster and the center of the cluster and where the distancemeasure takes into account the local feature weights associated with clusters.
Finally, the quality of a WPSC is defined by
Q(WPSC) = Qp(WPSC) × Qc(WPSC). (3)
In our context, the problem’s objective is thus to find which individuals (and hencewhich weights sets) lead to the clustering with maximum quality.
A straight way to find an optimal solution from the local solutions to the aboveproblem could be exhaustive evaluation: finding the optimal WPSC for K populationswith I individuals each, would then involve to evaluate IK combinations. But astypical values for K are between 5 and 20, and I typically ranges between 20 and 50,an exhaustive evaluation is untractable in most real cases. To circumvent this obstaclethe MACLAW method proposes to only evaluate an individual of the g-th generationaccording to improvements it produces on the following generations.
Let Bg = (Bg
1 , . . . ,Bgk , . . . ,B
gK) be the best solution at any generation g (also
called the current best WPSC) where Bgk = (C
gk ,W
gk ) with C
gk is the k-th cluster and
Wgk is its associated local feature weight vector.An overview of the method highlights three phases that are iterated at each gener-
ation g:
– Phase 1: Each individual extracts a cluster and is evaluated according to the im-provement it brings to the best current WPSC Bg . The best of each population isselected.

26 S. Genaud et al.
– Phase 2: All combinations made of best individuals from the previous generationand from the current generation are evaluated and the combination yielding to thehighest quality is selected as the new current best WPSC Bg+1.
– Phase 3: A classical reproduction process is performed to diversify individuals.
The method is detailed in Algorithm 1 hereunder.1
Algorithm 1 The MACLAW method
1We use argmax to denote the value which maximizes a function f :argmax
x∈Sf (x) = {x ∈ S | ∀y ∈ S ∧ y �= x,f (y) < f (x))}.

Parallel clustering algorithm with P2P-MPI 27
The aim of Phase 1 (lines 6 to 18) is to determine the best cluster Xi,gk in each
population, in the context of the current best WPSC. Some preliminary steps areperformed to extract the cluster X
i,gk :
– A clustering is performed on the data set D, by performing the weighted K-meansalgorithm using the feature weights W coded by the chromosome of the individual,to obtain a set of K clusters {S1, . . . , SK},
– The quality of each of these clusters is then evaluated (line 13): the intrinsic clus-ter quality assessed through r , the inertia criterion and cluster’s adequation withcurrent best WPSC is evaluated with Qp (1).
In Phase 2, we iterate over all of the 2K possible combinations (line 22) builtby replacing one or several clusters in Bg by their corresponding best local solu-tions from Yg . Each of them is evaluated (line 23). The combination with the highestquality is chosen as the new best WPSC Bg+1 (line 25) and will be used for nextgeneration.
In Phase 3, the genetic reproduction makes each individual evolve within its ownpopulation: a roulette-wheel method (fitness proportional selection) is used to selectindividuals according to their evaluations, crossing-over are carried out by combiningseeds and their associated weights, and mutation operators are used to disturb weightsor seeds.
These three phases are iterated while the average evaluation of the individualsvaries from one generation to the next more than the threshold given by the user orthe number of iterations is less than a maximum number of iterations specified by theuser.
2.3 Complexity analysis
The time complexity of the sequential MACLAW algorithm depends on the followingparameters: N and d are respectively the number of objects to be classified and thenumber of features, I is the number of individuals in each population and K is thenumber of clusters. Note that generally, N � d and N � K .
The global complexity of the method can be calculated by evaluating the succes-sive phases complexities.
To evaluate computation cost, we first evaluate the time complexity of a WPSCbuilding. A distance calculation on an attribute between an object and a cluster centeris considered as an elementary operation (tdist).
– Phase 1: individuals solutions production and evaluation
• (line 11) It is known that the complexity of the weighted K-means algorithm isin �(dKN).
• (line 13) The inertia evaluation of a cluster Cj requires dNj distance calcu-lations, where Nj = Card(Cj ). The evaluation of Qp consists in counting thenumber of clusters to which the object belongs (1), that is KN comparisonsand increments. Then, the evaluation of all clusters requires
∑Kk=1(dNk +KN)
arithmetic elementary operations (tarth) (i.e. N(d + K2) because a result pro-duced by a K-means based algorithm is always a partition).

28 S. Genaud et al.
• (line 15) The evaluation of the argmax function requires �(K) operations,which is negligible compared to the previous computation of Phase 1.
From several benchmarks, we evaluated the time of an elementary distance calcu-lation in the K-means algorithm to be 8 times longer than an elementary operationof the Qp evaluation (tdist ≈ 8 × tarth). This factor can not be neglected given thevalues of the parameters K and d . Given that IK individuals compose all thepopulations, the time complexity to extract and evaluate all the clusters is
T1 ≈ α1 IN(K3 + 8dK2 + dK), (4)
with α1 an unknown that depends on the deployment platform.– Phase 2: best WPSC updating
As explained in previous section, we can form 2K candidate combinations forthe new best WPSC (line 22). For each combination, the most expensive computa-tion is to evaluate Qp , that means �(KN) operations. Then, the time complexityof Phase 2 (depending on an unknown α2) is
T2 ≈ α22KKN. (5)
– Phase 3: reproduction processThe time needed to calculate a new population has a complexity linear in d
and I . Then the time required by the third phase, which is negligible compared toprevious phases (depending on an unknown α3), is
T3 ≈ α3IKd. (6)
In summary, because T3 is usually small, the overall time complexity T could beestimated as:
T = T1 + T2 + T3 = (α1 (IK3 + 8dK2 + IKd)︸ ︷︷ ︸Phase 1
+α2 (2KK)︸ ︷︷ ︸Phase 2
)N. (7)
One can notice that Phase 1 depends only on local information such as the bestcurrent WPSC, whereas Phase 2 needs all the best individuals Yg = (Y
g
1 , . . . , YgK)
that are outputs of Phase 1. Consequently, a parallel version of the algorithm willeventually imply the communication of data Yg at the end of Phase 1.
Phase 1 complexity mainly depends on the total number of individuals (i.e. IK)while in Phase 2, the complexity depends only on the number of clusters K , sinceonly one individual is selected within each population. This observation is useful toassess the role of parameters K and I in the duration of Phases 1 and 2, and to un-derstand the results of experiments presented in Sect. 3.4. For small values of K ,Phase 2 has an inexpensive computation cost. If the overhead in communication as-sociated with Phase 2 is not prohibitive, this phase will require a small amount oftime compared to Phase 1. Nevertheless, for K chosen big enough, Phase 2 will befar more costly than Phase 1 because of the multiplicative term 2K in T2. Thus, fora given value of I , the ratio of computation cost between Phases 1 and 2 mainlydepends on K . This fact will be used in the following to explain the performancesresults of the parallel version of MACLAW.

Parallel clustering algorithm with P2P-MPI 29
3 Parallelization
The MACLAW method is implemented in the Mustic software tool which providesa convenient graphical user interface (GUI) to specify all classification parameters.From a user point of view, even if it is agreed that runs may last long, a strong require-ment was to keep using the same tool whatever the computing resources available.
We first developed a multi-threaded version of the application in order to benefitfrom shared memory multi-processor computers capabilities. The speed-ups obtainedare satisfying but are limited: though SMP (Symmetric Multiprocessor) computersare quite common and affordable nowadays, they typically have at most two or fourCPUs.
To go beyond this limit we have developed a parallelized version of the MACLAWmethod. The parallelization follows a message-passing paradigm and uses the MPIconstructs. Thus, we can potentially run this version on any multi-processor hard-ware, ranging from SMP to clusters or massively parallel computers. Our primarytarget however is what is commonly called NOWs (Networked Of Workstations),that is a set of computers connected to the LAN. In our context, keeping a limitedbudget for hardware is not the only reason for this target. As will be shown later, thesoftware solution we propose, enables a user to invoke parallel executions directlyfrom the Mustic GUI.
3.1 Parallelization strategy
Let us consider our application may use P processors, for K populations, with a totalof IK individuals. Note that often, P > K since the number of clusters is typicallyless than 20, whereas having 20 available processors is quite common in targetedenvironments.
A natural parallelization strategy is to distribute individuals and associated com-putations on processors. At first glance, the choice remains between two alternatives:
(i) Distribute whole populations to processors, with the objective of minimizinginter-populations interactions. Indeed, in Phase 1 the method finds its best individ-ual which requires to compare locally all individuals scores for a given population.
(ii) Distribute individuals without consideration of the population they belong to (inother terms, populations may be scattered across different processors) with theobjective of balancing computations as evenly as possible.
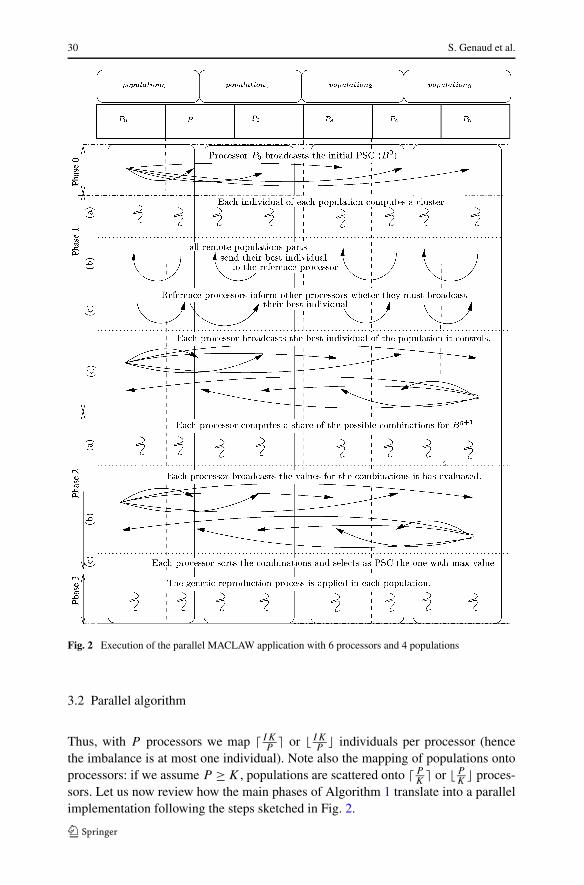
We have noticed that the latter solution performs better, so we adopt this paral-lelization scheme. Figure 2 depicts the parallelization for 6 processors and 4 popula-tions.
The adopted strategy has good performances because, even if a population canelect its best individual (Phase 1 in Algorithm 1 without communication in solu-tion (i), the counterpart is the imbalance in the number of individuals per proces-sor. Solution (ii) offers a good load-balance at the cost of a small communicationoverhead, namely processors owning a part of a population scattered onto differentprocessors, must send their best candidate individual so that a consensus is made onthe best individual for this population (as shown in Phase 1(b) of Fig. 2).
30 S. Genaud et al.
Fig. 2 Execution of the parallel MACLAW application with 6 processors and 4 populations
3.2 Parallel algorithm
Thus, with P processors we map � IKP
or IKP
� individuals per processor (hencethe imbalance is at most one individual). Note also the mapping of populations ontoprocessors: if we assume P ≥ K , populations are scattered onto � P
K or P
K� proces-
sors. Let us now review how the main phases of Algorithm 1 translate into a parallelimplementation following the steps sketched in Fig. 2.

Parallel clustering algorithm with P2P-MPI 31
• An initialization phase (Phase 0) is required to transmit the data, the classificationparameters, as well as an initial WPSC from a chosen master processor (processorP0 here) to all processors. Independently of the population they belong to, � IK
P or
IKP
� individuals are assigned to each processor. This communication takes placeonly once per run.
• In the cluster evaluation (Phase 1(a)), all processors proceed to the cluster extrac-tion associated with each individual they own, that is they evaluate the score ofeach of their assigned individuals with the fitness function. On each processor andfor each population or population part, the individual yielding the best score isselected as best individual candidate for the whole population.
• Next step (Phase 1(b)) aims at electing only one best individual for each popula-tion. We decide that each population has a reference processor which is the proces-sor where the first individual of the population resides. The scores and the indicesof the various candidates are sent to their reference processors which determineswhich is the best candidate. In the example on Fig. 2, P0, P1, P3 and P4 are ref-erence processors for populations 0,1,2 and 3 respectively. All population’s partsthat are not hosted on their reference processor are sent to it. For example, P1 hasa part of population 0 and sends the score of the best individual of that popula-tion part to its reference processor P0. During this step, K messages of 8 bytes areexchanged (0 or 1 message sent per processor in the case P > K).
• Phase 1(c): reference processors must then inform processors owning the best indi-vidual of the population they control, to broadcast the individual itself. This againrequires K messages of 8 bytes (sent in parallel).
• Phase 1(d): in the last step of this phase, processors instructed to broadcast thebest individual(s) they have locally, send to all other processors a message whosesize depends on the dataset to classify. It is about 450 KB for the image used inthe experiments (Sect. 3.4). Hence each processor receives K such messages (1message from K reference processors).
• Phase 2 aims at finding the best WPSC for this generation by evaluating all the 2K
distinct combinations of previous and current best individuals. In Phase 2(a), each
processor independently evaluates a part of the 2K
Pcombinations.
• Phase 2(b): when all processors have finished their evaluations, they all send theirbest candidate WPSC with its corresponding score to all other processors. Eachprocessor sends P messages made of a byte array of length K . Each processorthen sorts all its candidates WPSC and keeps the best one.
• Last, in Phase 3, the reproduction process takes place in parallel on each processor.
The algorithm then iterates with next generation, branching back to Phase 1.Notice that the communication costs described above for Phases 1 and 2 are linear
in the number of populations and processors, while the computation costs for thephases are respectively polynomial and exponential in the number of populations.Also, we observe that Phase 1 has a higher communication overhead than Phase 2: thecomparison of communications in Phase 1(d) and Phase 2(b) shows that the volumeof data sent per processor (4.5 · 105K bytes vs. PK bytes respectively) is largelybigger in first phase since P 105.
We now come to the implementation of the parallelization described above. Theimplementation is based on P2P-MPI, developed in our team, which provides a

32 S. Genaud et al.
message-passing library as well as a middleware. In the following, we give a syn-thetic description of P2P-MPI.
3.3 P2P-MPI
P2P-MPI may be simply viewed as the MPI implementation we choose to code theparallel version of MACLAW. However, the functionalities of P2P-MPI go largelybeyond a simple communication library, which makes the exploitation of applicationmore comfortable than with traditional environments devoted to parallel program-ming. We only give here a short overview of P2P-MPI and the reader is referred to[12, 14] for details.
P2P-MPI overall objective is to provide a grid programming environment forparallel applications. P2P-MPI has two facets: its is a middleware and as such, ithas the duty of offering appropriate system-level services to users, such as findingrequested resources, transferring files, launching remote jobs, etc. The other facet isthe parallel programming API (Application Programming Interface) it provides toprogrammers.
API Most of the current research projects which target grid computing on commod-ity hardware enable the computation of jobs made of independent tasks only, and theunderlying proposed programming model is a client-server (or RPC) model. The ad-vantage of this model lies in its suitability to distributed computing environments butlacks expressivity for parallel constructs. P2P-MPI offers a more general program-ming model based on message passing, of which the client-server can be seen as aparticular case.
Contained in the P2P-MPI distribution is a communication library which exposesan MPI-like API. Actually, our implementation of the MPI specification is in Java andwe follow the MPJ recommendation [4]. Though Java is used for sake of portability ofcodes, the primitives are quite close to the original C/C++/Fortran specification [23].
Middleware A user can simply make its computer join a P2P-MPI grid (it becomesa peer) by typing mpiboot which runs a local gatekeeper process. The gatekeeperplays two roles:
– It advertises the local computer as being available to the peer group, and decidesto accept or decline other peers job request as they arrive.
– When the user issues a job request, it has the charge of finding the requested num-ber of peers and to organize the job launch.
Launching a MPI job requires to assign a unique number to each task (or process)and then synchronize all processes at the MPI_Init barrier. When a user issues a jobrequest involving several processes, its local gatekeeper initiates a discovery to findthe requested number of resources during a limited period of time.
P2P-MPI uses the JXTA library [18] to handle all usual peer-to-peer operationssuch as discovery. Resources can be found because they advertised their presencetogether with their technical characteristics when they joined the peer group. Onceenough resources have been selected, the gatekeeper transfers the program to executealong with the input data or URL to fetch data from, to each selected host. Once

Parallel clustering algorithm with P2P-MPI 33
all hosts have acknowledged the transfer, a list of numbers assigned to each process(in MPI terms, the rank of each process) is broadcasted to participating hosts. Onreception of its rank, the process passes the MPI_Init barrier and enters the effectiveapplication part.
Thus, P2P-MPI dynamically builds at each execution request and without any in-tervention from the user, an execution platform (i.e. selected hosts gathered for theexecution) to fulfill the user request. Users do not have to bother about which hostsare currently available since all available resources advertise their presence them-selves. The drawback of this seamless management lies in the random selection ofhosts, since several execution requests may lead to different execution platforms eachtime. However, we believe that this is an acceptable price to pay for alleviating theburden of locating resources. Moreover, next release of P2P-MPI will provide anoptional scheduler capable of selecting hosts so that the execution time of an applica-tion is nearly optimal. Note that such a scheduling requires precise information aboutthe application behavior as well as network and available processors performances,which is only realistic in a small size set of hosts. P2P-MPI can be compared tobatch schedulers present on most parallel supercomputers which select appropriateresources so as to complete the job request.
Integration P2P-MPI also enables for a tight integration of the Java code ofMACLAW using the P2P-MPI library with the middleware layer. In the MACLAWimplementation, a call to the MPI.Init() function with arguments like the num-ber of processors is sufficient to trigger in the middleware the resource discovery andselection mechanisms, the transfer of programs and remote executions on selectedhosts. In practice, this allows to keep using the same desktop PC that served for thesequential application, from where the middleware starts searching for other CPUs.By contrast, the parallelization of an application usually requires to move the appli-cation to the parallel system to run it. In our case, from the user point of view, asequential or parallel execution is simply requested via a simple menu in the usualgraphical interface.
Related work Let us briefly review what were the alternatives to the use of P2P-MPI. In the last decade, several projects have proposed message-passing librariesdesigned for grid environments. Amongst these are MagPie [20], PACX-MPI [11] ormpich-G2 [19] which relies on the Globus toolkit. However, the effort is put here onthe optimization of communications depending of the type of links, but little attentionis paid to the integration of the communication library with the middleware. For in-stance none of the above projects offers the feature of finding automatically availableprocessors—even mpich-G2 requires to write a description of the resources location(the RSL file) for each execution despite the presence of a directory of resources(MDS) in Globus. In addition, these MPI implementations require to distribute andmaintain OS-dependent binaries at each host, which is very error-prone.
An alternative approach, close to P2P-MPI is the P3 project [25]. To the best ofour knowledge, this is the only other project to combine a message-passing program-ming model with middleware services. In P3, JXTA is also used for discovery: hostsentities automatically register in a peer group of workers and accept work requests ac-cording to the resource owner policy. Secondly, a master-worker and message passing

34 S. Genaud et al.
paradigm, both built upon a common library called object passing, are proposed. Un-like P2P-MPI, P3 uses JXTA for its communications (JxtaSockets). This allows tocommunicate without consideration of the underlying network constraints (e.g. fire-walls) but incurs an overhead when the logical route established goes through severalpeers. On the contrary in P2P-MPI, we have favored performance by implement-ing the MPI primitives with Java sockets. The collective operations also benefit fromwell-known optimizations. Last, P2P-MPI provides some transparent fault-tolerancefacility [13] which is important for long runs and that P3 lacks.
3.4 Experiments
Experiment settings In every day use, P2P-MPI enables MACLAW to accelerateruns by picking available processors automatically. Though very useful, using anheterogeneous set of processors makes impossible to evaluate to which degree theparallelization can accelerate the clustering execution. In this paper, we focus on ap-plication deployments using one to three clusters. The tests on a single cluster serveto assess the application’s scalability, while multi-cluster executions mainly aim atfinding how much overhead is paid for wide-area communications. The platform weuse to evaluate the application is the Grid’5000 testbed. Grid’5000 [3] is a federationof dedicated computers hosted across 9 campus sites in France, and organized in aVPN (Virtual Private Network) over Renater, the national education and research net-work. Each site has currently about 100 to 700 processors arranged in one to severalclusters at each site. The total number of processors is currently around 3000 andwill be funded to grow up to 5000 processors. The testbed is partly heterogeneousconcerning the processors since 75% are AMD Opteron, and Itanium2, Xeon and G5for the remainder.
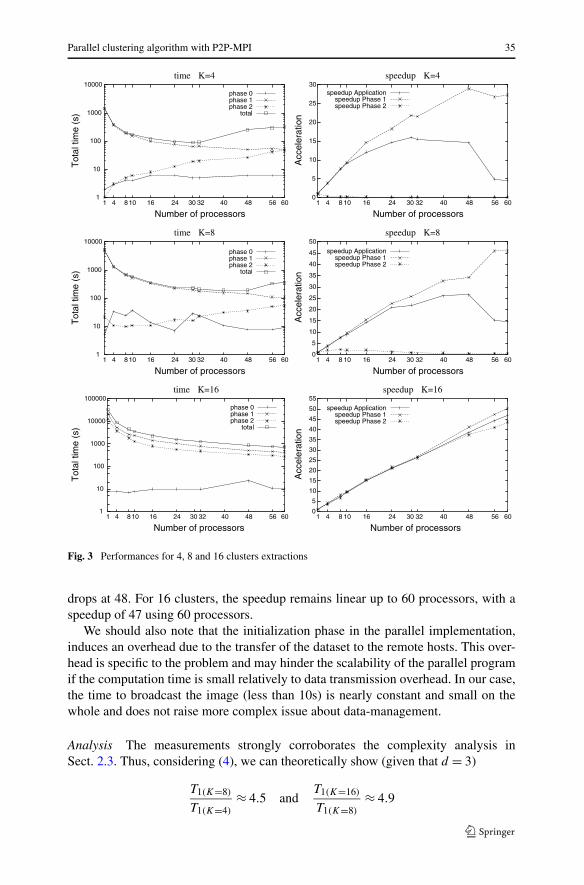
The first test which addresses the scalability of the application on a single clusteruses the cluster in Nancy, composed of AMD Opteron 2 GHz, 2 GB RAM. In Fig. 3are reported the performances for a clustering in K = 4, 8 and 16 clusters. We uselogarithmic scales to facilitate reading of the curves slopes. Right column figuresshow the corresponding speedups.
The data set to cluster is an image such as the one in Fig. 1 for which our pa-rameters are I = 20 individuals, d = 3 attributes and N = 50000 pixels. We iter-ate for G = 20 generations. These values correspond to the most common usage ofMACLAW even if they are slightly lower than what would be used to get accurateresults. Note also that the computation time for a given image only depends on theseparameters, and not on the image itself.
Results First, the figures give an illustration of typical execution time dependingon the number of clusters: the sequential execution takes 24 minutes for 4 clusters,85 minutes for 8 clusters and more than 8 hours for 16 clusters. For such probleminstance, we immediately see the practical benefit from the parallelization: the long-running clustering of 16 clusters has been done in 12 minutes in our tests with 60processors. Concerning the general behavior of the parallel application, the situationis contrasted. For 4 clusters, the speedup is linear up to 16 processors, then decreasesslowly, stabilizes at 30–32 processors and dramatically drops at 48 processors. Theplot is similar for 8 clusters, except that the speedup is linear until 24 processors and
Parallel clustering algorithm with P2P-MPI 35
Fig. 3 Performances for 4, 8 and 16 clusters extractions
drops at 48. For 16 clusters, the speedup remains linear up to 60 processors, with aspeedup of 47 using 60 processors.
We should also note that the initialization phase in the parallel implementation,induces an overhead due to the transfer of the dataset to the remote hosts. This over-head is specific to the problem and may hinder the scalability of the parallel programif the computation time is small relatively to data transmission overhead. In our case,the time to broadcast the image (less than 10s) is nearly constant and small on thewhole and does not raise more complex issue about data-management.
Analysis The measurements strongly corroborates the complexity analysis inSect. 2.3. Thus, considering (4), we can theoretically show (given that d = 3)
T1(K=8)
T1(K=4)
≈ 4.5 andT1(K=16)
T1(K=8)
≈ 4.9

36 S. Genaud et al.
which are close to the ratios 3.5 and 4.2 we observe in sequential executions. ForPhase 2, we predict T2(K=8) ≈ 16, T2(K=4) and T2(K=16) ≈ 512 T2(K=8), whichagrees with our measurements: we find 22 and 500 respectively for execution timeson a single processor.
If we consider the configuration with K = 4 and K = 8, Phase 1 is largely dom-inating and scales well up to 48 processors and 56 processors for 4 and 8 clustersrespectively. For such values of K Phase 2 has very few computations relatively toPhase 1.
Note that a heavy computation unbalance appears quickly. For instance, for K = 4there is a total of 80 individuals, so that using more than 40 processors involves thateach processor has a load of either 1 or 2 individuals.
There is no speedup in Phase 2 when we use more processors because the commu-nications (Phase 2(b)) is too important relatively to the small amount of computations.Moreover, it induces important idle times because of collective communications andresulting synchronizations, when the number of processors increases. In this applica-tion, there is no parallel overhead due to extra computation or large load imbalance.The extra communications when using many processors and collective synchroniza-tions are the cause of speedup decrease.
However, as the most time consuming phase benefits from a good speed-up, ac-ceptable execution times for K = 4 are reached with 16 processors (120s) while theminimum is 93s with 32 processors. Similarly for K = 8 a good trade-off seems tobe 24 processors to classify the image in 246s.
The figure for K = 16 is quite different: the execution times for the two phasesare nearly equal due to the increase of Phase 2 computation complexity. As a conse-quence, the overhead due to communications tend to be small relatively to the com-putation cost, resulting in a very good speed-up throughout the tests up to 60 proces-sors. Thus, in this case, the parallelization allows to achieve the clustering in tens ofminutes instead of several hours, which enhances the usability of the method.
3.5 Multi-site test
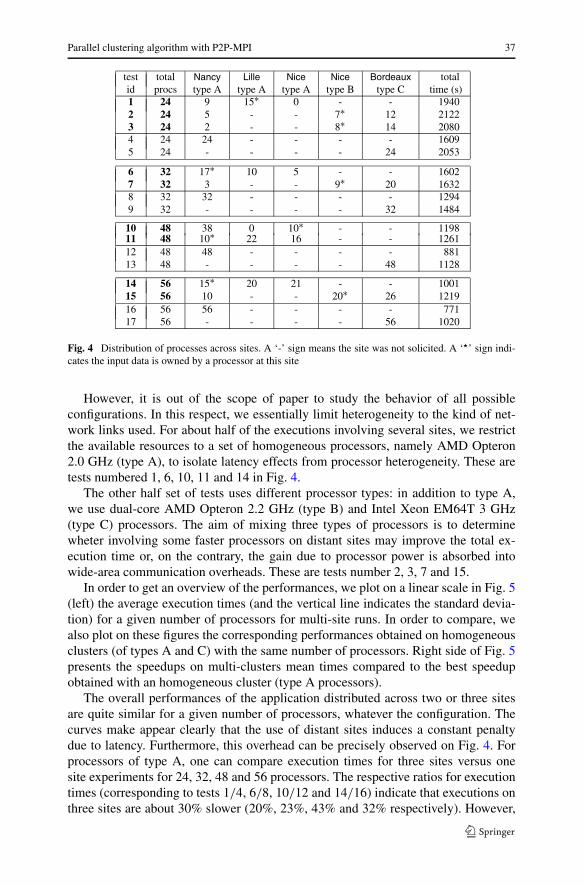
The second test consists in running the application distributed across a couple ofgeographically distant sites (Nancy, Lille, Nice or Bordeaux, parts of Grid’5000). Wetest the case K=16 since we have seen that many processors are of no use with 4 and8 clusters.
Among the multitude of possible configurations, we choose a few executionswhich we assume representative runs across several sites. We report the multi-siteperformances in the table of Fig. 4, on rows where the test number and total num-ber of processors used are in bold-face font. For the sake of comparison, we alsoreport underneath the performances for the same number of processors at a singlecluster.
Two factors should make the performances drop in this test. First, the wide-areanetwork communications (sites are distant from 1000 to 2000 kms) induces incom-pressible latency. As both local and wide-area links are used simultaneously, we mayexpect an imbalance for communication times. Secondly, multi-cluster executionsmay involve heterogeneity of processors used.
Parallel clustering algorithm with P2P-MPI 37
test total Nancy Lille Nice Nice Bordeaux totalid procs type A type A type A type B type C time (s)1 24 9 15∗ 0 - - 19402 24 5 - - 7∗ 12 21223 24 2 - - 8∗ 14 20804 24 24 - - - - 16095 24 - - - - 24 2053
6 32 17∗ 10 5 - - 16027 32 3 - - 9∗ 20 16328 32 32 - - - - 12949 32 - - - - 32 1484
10 48 38 0 10∗ - - 119811 48 10∗ 22 16 - - 126112 48 48 - - - - 88113 48 - - - - 48 1128
14 56 15∗ 20 21 - - 100115 56 10 - - 20∗ 26 121916 56 56 - - - - 77117 56 - - - - 56 1020
Fig. 4 Distribution of processes across sites. A ‘-’ sign means the site was not solicited. A ‘�’ sign indi-cates the input data is owned by a processor at this site
However, it is out of the scope of paper to study the behavior of all possibleconfigurations. In this respect, we essentially limit heterogeneity to the kind of net-work links used. For about half of the executions involving several sites, we restrictthe available resources to a set of homogeneous processors, namely AMD Opteron2.0 GHz (type A), to isolate latency effects from processor heterogeneity. These aretests numbered 1, 6, 10, 11 and 14 in Fig. 4.
The other half set of tests uses different processor types: in addition to type A,we use dual-core AMD Opteron 2.2 GHz (type B) and Intel Xeon EM64T 3 GHz(type C) processors. The aim of mixing three types of processors is to determinewheter involving some faster processors on distant sites may improve the total ex-ecution time or, on the contrary, the gain due to processor power is absorbed intowide-area communication overheads. These are tests number 2, 3, 7 and 15.
In order to get an overview of the performances, we plot on a linear scale in Fig. 5(left) the average execution times (and the vertical line indicates the standard devia-tion) for a given number of processors for multi-site runs. In order to compare, wealso plot on these figures the corresponding performances obtained on homogeneousclusters (of types A and C) with the same number of processors. Right side of Fig. 5presents the speedups on multi-clusters mean times compared to the best speedupobtained with an homogeneous cluster (type A processors).
The overall performances of the application distributed across two or three sitesare quite similar for a given number of processors, whatever the configuration. Thecurves make appear clearly that the use of distant sites induces a constant penaltydue to latency. Furthermore, this overhead can be precisely observed on Fig. 4. Forprocessors of type A, one can compare execution times for three sites versus onesite experiments for 24, 32, 48 and 56 processors. The respective ratios for executiontimes (corresponding to tests 1/4, 6/8, 10/12 and 14/16) indicate that executions onthree sites are about 30% slower (20%, 23%, 43% and 32% respectively). However,

38 S. Genaud et al.
Fig. 5 Performances for K = 16 on one cluster and several clusters
even if the multi-site speedups between 24 and 56 processors are lower than for onesite, the speedup increases steadily in this range.
The second observation is related to processors heterogeneity. We compare singlesite execution times on type A cluster versus type C cluster (tests 4/5, 8/9, 12/13,16/17). Type A configurations are from 14% to 32% faster than type C executions(27%, 14%, 28% and 32% for 24, 32, 48 and 56 processors respectively). So, it hap-pens that this difference due to CPU power is similar to the penalty paid in multi-sitecommunications. Not surprisingly, comparing 3-sites type A configurations and typeC single-cluster results (tests 1/5, 6/9, 10 or 11/13, 14/17) show nearly equal exe-cution times (ratios of the former to the latter show a difference ranging from −6%to +7%).
Last, we investigate 3-sites configurations involving either only type A processorsor all types of processors (with nearly half of the processors being of type C eachtime). The algorithm that we designed, only deals with homogeneous distribution ofwork between processors. Considering a platform made of processors with varied ca-pacities hence induces idle times on most powerful machines. The sequence of tests1/2, 6/7 and 14/15 exemplifies this situation. Whatever the number of processors,the use of some processors of type C slows down the execution in comparison to plat-form with only type A processors. Let us notice that the presence of type B processorsdoes not affect performance at all, because these are the fastest processors. At last, thedifference of performance is relatively small between these A and C processor types.So, depending on the availability of machines, the user could benefit from such amixed-processor configuration.
4 Conclusion
We have described in this paper the parallelization of MACLAW. MACLAW is aclustering method which integrates a local feature weighting through a cooperativecoevolution process, and whose aim is to eventually produces a hard clustering.
After a complexity analysis of the algorithm main phases, we have proposed aparallelization strategy based on the message-passing paradigm. Besides the paral-lelization, we propose an original implementation in the P2P-MPI framework. Inthis context, P2P-MPI provides both the communication library and a convenient

Parallel clustering algorithm with P2P-MPI 39
service for handling execution requests with almost no intervention from the user.We have carried out experiments with this implementation based on P2P-MPI. Ona single cluster, the application’s speedup is linear up to 16 or 24 processors for asmall number of clusters and drops afterwards because of the disadvantageous ra-tio of communications to computations in the second phase of the application. Fora larger number of clusters, the speedup is linear due to the increasing computingweight of this second phase. For this number of clusters, an experiment involvingthree distant sites shows a similar speedup curve evolution despite the overhead dueto the latency on WAN network links. Finally, the parallelization enhances the usabil-ity of the MACLAW method, allowing for clusterings with a large number of classesin tens of minutes instead of hours in the sequential version. In addition, a noteworthyaspect of P2P-MPI is that it improves usability in practice by allowing users to keeprunning the application from their usual computer, as the middleware transparentlydiscovers available computing resources.
References
1. Berkhin P (2002) Survey of clustering data mining techniques. Technical report, Accrue Software,San Jose, CA
2. Blansché A, Gançarski P (2006) MACLAW: a modular approach for clustering with local attributeweighting. Pattern Recognit Lett 27(11):1299–1306
3. Cappello F et al (2005) Grid’5000: a large scale, reconfigurable, controlable and monitorable gridplatform. In: Proceedings of the 6th IEEE/ACM international workshop on grid computing Grid’2005,November 2005. http://www.grid5000.org
4. Carpenter B, Getov V, Judd G, Skjellum T, Fox G (2000) MPJ: MPI-like message passing for Java.Concurr Pract Experience 12(11), September
5. Chan EY, Ching WK, Ng MK, Huang JZ (2004) An optimization algorithm for clustering usingweighted dissimilarity measures. Pattern Recognit 37:943–952
6. Dhillon IS, Modha DS (2000) A data-clustering algorithm on distributed memory multiprocessors. In:Revised papers from large-scale parallel data mining, workshop on large-scale parallel KDD systems,SIGKDD Springer, New York, pp 245–260
7. Domeniconi C, Gunopulos D, Ma S, Yan B, Al-Razgan1 M, Papadopoulos D (2007) Locally adaptivemetrics for clustering high dimensional data. Data Min Knowl Discov 14(1):63–97
8. Forman G, Zhang B (2000) Linear speedup for a parallel non-approximate recasting of centerbasedclustering algorithms, including k-means, k-harmonic means, and em. In: ACM SIGKDD workshopon distributed and parallel knowledge discovery, KDD-2000
9. Friedman JH, Meulman JJ (2004) Clustering objects on subsets of attributes. J Roy Stat Soc66(4):815–849
10. Frigui H, Nasraoui O (2004) Unsupervised learning of prototypes and attribute weights. PatternRecognit 34:567–581
11. Gabriel E, Resch M, Beisel T, Keller R (1998) Distributed computing in an heterogeneous computingenvironment. In: EuroPVM/MPI. Lecture notes in comput sci, vol 1497. Springer, New York, pp 180–187
12. Genaud S, Rattanapoka C (2005) A peer-to-peer framework for robust execution of message passingparallel programs. In: Di Martino B et al (eds) EuroPVM/MPI 2005. Lecture notes in comput sci,vol 3666. Springer, New York, pp 276–284, September
13. Genaud S, Rattanapoka C (2007) Fault management in P2P-MPI. In: Proceedings of internationalconference on grid and pervasive computing, GPC’07. Lecture notes in comput sci. Springer, May
14. Genaud S, Rattanapoka C (2007) P2P-MPI: a peer-to-peer framework for robust execution of messagepassing parallel programs. J Grid Comput 5:27–42
15. Gnanadesikan R, Kettenring JR, Tsao SL (1995) Weighting and selection of variables for clusteranalysis. J Classif 12(1):113–136
16. Howe N, Cardie C (1997) Examining locally varying weights for nearest neighbor algorithms. In:ICCBR, pp 455–466

40 S. Genaud et al.
17. Huang JZ, Ng MK, Rong H, Li Z (2005) Automated variable weighting in k-means type clustering.IEEE Trans Pattern Anal Mach Intell 27(2):657–668
18. JXTA http://www.jxta.org19. Karonis NT, Toonen BT, Foster I (2003) MPICH-G2: a grid-enabled implementation of the message
passing interface. J Parallel Distributed Comput special issue on Comput Grids 63(5):551–563, May20. Kielmann T, Hofman RFH, Bal HE, Plaat A, Bhoedjang RAF (1999) MagPIe: MPI’s collective com-
munication operations for clustered wide area systems. ACM SIGPLAN Notices 34(8):131–140, Au-gust
21. Kruengkrai C, Jaruskulchai C (2002) A parallel learning algorithm for text classification. In: EighthACM SIGKDD international conference on knowledge discovery and data mining, July
22. MacQueen JB (1967) Some methods for classification and analysis of multivariate observations. In:Proceedings of the 5th Berkeley symposium on mathematical statistics and probability, Berkeley, CA,1967. University of California Press, pp 281–297
23. MPI (1995) A message passing interface standard, version 1.1. Technical report, University of Ten-nessee, Knoxville, TN, USA, Jun
24. Parsons L, Haque E, Liu H (2004) Subspace clustering for high dimensional data: a review. SIGKDDexplorations, newsletter of the ACM special interest group on knowledge discovery and data mining6(1):90–106
25. Shudo K, Tanaka Y, Sekiguchi S (2005) P3: P2P-based middleware enabling transfer and aggregationof computational resource. In: 5th intl workshop on global and peer-to-peer computing, in conjuncwith CCGrid05. IEEE, May
26. Xu R, Wunsch D (2005) Survey of clustering algorithms. IEEE Trans Neural Netw 16(3):645–678
Stéphane Genaud received a Ph.D. in Computer Science from Strasbourg Univer-sity (France) in 1997. He has been an associate professor at Strasbourg Universitysince 1998. His research interests involve languages and methods for parallel pro-gramming, cluster and Grid computing.
Pierre Gançarski received his Ph.D. in Computer Science from the StrasbourgUniversity (France) in 1988. He has been an associate professor of Computer Sci-ence at Strasbourg University since 1992. His current research interests includecollaborative multi-strategical clustering with applications to complex data min-ing and remote sensing analysis.
Guillaume Latu received his Ph.D. in Computer Science from Bordeaux Univer-sity (France) in 2002. He has been an associate professor of Computer Scienceat Strasbourg University (France) since 2003. He is interested in parallel algorith-mics, simulation techniques, and high-performance computing.

Parallel clustering algorithm with P2P-MPI 41
Alexandre Blansché received his Ph.D. in Computer Science from StrasbourgUniversity (France) in 2006. His main research interests include unsupervisedlearning and feature weighting for clustering with a application to remote sens-ing analysis. He is currently on a post-doctoral position at the University of Tokyoand works on data mining for material design.
Choopan Rattanapoka received his B.Eng. in Computer Engineering fromKasetsart University (Thailand) and his master degree in Computer Science fromStrasbourg University (France) in 2004. He is currently a Ph.D. candidate in Stras-bourg University. His current research interests include peer-to-peer, grid and par-allel computing.
Damien Vouriot received his Master degree in Computer Science and EmbeddedSystems from Strasbourg University (France) in 2006. His master’s work was de-voted to the parallelization of clustering algorithms on various architectures. He isnow working in the industry.




















