
Evaluating IPv6 on a large-scale network
9
Evaluating IPv6 on a large-scale network Wen-Lung Shiau a, * , Yu-Feng Li b , Han-Chieh Chao c , Ping-Yu Hsu d a Department of Information Management, Ming Chuan University, No. 5, Teh-Ming Rd., Gwei-Shan District, Taoyuan, County 333, Taiwan, R.O.C b Computer & IT Center at National Dong Hwa University, Hualien, Taiwan, R.O.C c Department of Electrical Engineering, National Dong Hwa University, Hualien, Taiwan, R.O.C d Department of Business Administration, National Central University, Chung-Li, Taiwan, R.O.C Available online 9 January 2006 Abstract We evaluate an ideal model and a real large-scale network environment using available end-to-end measurement techniques that focuses on a large-scale IPv6 backbone and made performance comparisons between the current Internet (IPv4) and next generation Internet (IPv6). In this paper, we compiled the performance statistics of each network in terms of TCP and UDP throughput, delay jitters, packet loss rate, and round trip time. Our conclusions show that, in a real large-scale network environment, a minor degradation in the throughput of the TCP, a slightly higher throughput of the UDP, a somewhat emerging frequency of the delay jitter, a lower packet loss rate, and a slightly longer round trip time happens when we compare the IPv6 network to the IPv4 network. Ó 2005 Elsevier B.V. All rights reserved. Keywords: IPv4; IPv6; Performance measurement; End-to-end performance 1. Introduction More and more enterprise clients replace their mission- critical applications on the Internet in favor of cheaper and more ubiquitous Internet networks. For these applica- tions, business enterprises are evaluating Internet networks by their ability to meet much more rigorous standards of availability and performance [18]. Today network back- bones offering bandwidths in excess of 1000 Mbps with very low transmission error rates are becoming widespread. The capacities of IP backbones are growing quickly to meet customer requirements [18]. But sometimes users still have to wait for information longer than the desired time and endure unsatisfactory performance. Performance is a key factor in the development and implementation of modern computer systems and networks [3]. From general users to advanced researchers, each user seeks minimum service time. Since service time is composed of: (a) local hardware sending requests, (b) network trans- mitting time, and (c) remote hardware receiving requests, end-to-end performance evaluation becomes a very crucial part in network assessment. In order to understand the Internet performance of users, more and more researchers evaluate end-to-end per- formance from different viewpoints. Krishnamurthy and Wills [1] analyzed factors that influence end-to-end mea- surement of Web performance. They examined the compo- nents of delay or the effectiveness of the recent changes on the HTTP protocol. They found pipelining as an improve- ment over existing practice, but concluded that servers serving a small number of objects or closing a persistent connection without explicit notification can decrease or eliminate any performance improvement. ElAarag and Bassiouni [4] measured end-to-end performance of TCP connections in an ideal and non-ideal network environ- ment. In their ideal model, they provided an upper bound limit for the throughput and a lower bound limit for the transfer time of the TCP connection. For the non-ideal environment, the simulation results show the relative per- formance of four standard TCP implementations. Ferrari [16] measured end-to-end performance analysis with traffic aggregation. The effect aggregation is fundamental in evaluating the capability of a diffserv network to preserve 0140-3664/$ - see front matter Ó 2005 Elsevier B.V. All rights reserved. doi:10.1016/j.comcom.2005.11.011 * Corresponding author. Tel.: +886 3 350 7001; fax: +886 3 359 3875. E-mail address: [email protected] (W.-L. Shiau). www.elsevier.com/locate/comcom Computer Communications 29 (2006) 3113–3121
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Evaluating IPv6 on a large-scale network

www.elsevier.com/locate/comcom
Computer Communications 29 (2006) 3113–3121
Evaluating IPv6 on a large-scale network
Wen-Lung Shiau a,*, Yu-Feng Li b, Han-Chieh Chao c, Ping-Yu Hsu d
a Department of Information Management, Ming Chuan University, No. 5, Teh-Ming Rd., Gwei-Shan District, Taoyuan, County 333, Taiwan, R.O.Cb Computer & IT Center at National Dong Hwa University, Hualien, Taiwan, R.O.C
c Department of Electrical Engineering, National Dong Hwa University, Hualien, Taiwan, R.O.Cd Department of Business Administration, National Central University, Chung-Li, Taiwan, R.O.C
Available online 9 January 2006
Abstract
We evaluate an ideal model and a real large-scale network environment using available end-to-end measurement techniques thatfocuses on a large-scale IPv6 backbone and made performance comparisons between the current Internet (IPv4) and next generationInternet (IPv6). In this paper, we compiled the performance statistics of each network in terms of TCP and UDP throughput, delayjitters, packet loss rate, and round trip time. Our conclusions show that, in a real large-scale network environment, a minor degradationin the throughput of the TCP, a slightly higher throughput of the UDP, a somewhat emerging frequency of the delay jitter, a lowerpacket loss rate, and a slightly longer round trip time happens when we compare the IPv6 network to the IPv4 network.� 2005 Elsevier B.V. All rights reserved.
Keywords: IPv4; IPv6; Performance measurement; End-to-end performance
1. Introduction
More and more enterprise clients replace their mission-critical applications on the Internet in favor of cheaperand more ubiquitous Internet networks. For these applica-tions, business enterprises are evaluating Internet networksby their ability to meet much more rigorous standards ofavailability and performance [18]. Today network back-bones offering bandwidths in excess of 1000 Mbps withvery low transmission error rates are becoming widespread.The capacities of IP backbones are growing quickly to meetcustomer requirements [18]. But sometimes users still haveto wait for information longer than the desired time andendure unsatisfactory performance.
Performance is a key factor in the development andimplementation of modern computer systems and networks[3]. From general users to advanced researchers, each userseeks minimum service time. Since service time is composedof: (a) local hardware sending requests, (b) network trans-mitting time, and (c) remote hardware receiving requests,
0140-3664/$ - see front matter � 2005 Elsevier B.V. All rights reserved.
doi:10.1016/j.comcom.2005.11.011
* Corresponding author. Tel.: +886 3 350 7001; fax: +886 3 359 3875.E-mail address: [email protected] (W.-L. Shiau).
end-to-end performance evaluation becomes a very crucialpart in network assessment.
In order to understand the Internet performance ofusers, more and more researchers evaluate end-to-end per-formance from different viewpoints. Krishnamurthy andWills [1] analyzed factors that influence end-to-end mea-surement of Web performance. They examined the compo-nents of delay or the effectiveness of the recent changes onthe HTTP protocol. They found pipelining as an improve-ment over existing practice, but concluded that serversserving a small number of objects or closing a persistentconnection without explicit notification can decrease oreliminate any performance improvement. ElAarag andBassiouni [4] measured end-to-end performance of TCPconnections in an ideal and non-ideal network environ-ment. In their ideal model, they provided an upper boundlimit for the throughput and a lower bound limit for thetransfer time of the TCP connection. For the non-idealenvironment, the simulation results show the relative per-formance of four standard TCP implementations. Ferrari[16] measured end-to-end performance analysis with trafficaggregation. The effect aggregation is fundamental inevaluating the capability of a diffserv network to preserve

3114 W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121
the original stream profile, in particular, the delay and jit-ter-sensitive traffic. The author developed a study of prior-ity queuing in detail and compared the performance withweighted fair queuing. Zhang and Zheng [9] measuredend-to-end performance for the IPv6 traffic model withmultiple qualities of service (QoS) classes in virtual privatenetworks (VPN). They presented the performance trade-offbetween the delay sensitive traffic and delay insensitive traf-fic in terms of traffic throughput, packet loss probabilityand end-to-end delay in VPN networks.
The next generation Internet protocol version (IPv6)was designed to replace the current Internet protocol(IPv4) and cope up with the world’s needs in the future.Today the next generation Internet (NGI) has already beendeployed worldwide, but there have been no publicly avail-able end-to-end performance measurement that focuses ona large-scale IPv6 backbone. The reason is because thechance is scare and the time period for performing the mea-surement is very limited. The best time to measure the per-formance is in the duration when the network is completedand no traffic has traveled on the network yet. Traffic onthe network may skew the measurement. The paper pub-lishes a result measuring the performance of TWARENin the precious time period.
IPv6 end-to-end performance tests are needed when IPv6is moving towards commercial usage with high quality ser-vice requirements. The purpose of this paper is to evaluatea large-scale IPv6 backbone and make a performance com-parison between current Internet (IPv4) and next generationInternet (IPv6). The rest of the paper is organized as follows:Section 2 reviews related works. Section 3 presents our testbed and measurement procedures. Section 4 then followswith the results and discussions of this study. Finally, on Sec-tion 5, we have our final conclusions.
2. Related works
Performance measurement is valuable because it pro-vides historical data on how the network is fulfilling itsobjectives as well as revealing performance or configura-tion problems proactively [11]. Today the relocation fromthe IPv4 network to the IPv6 network is happening quitegradually. This probably means that dual stack transitionmechanism will exist for a while. Performance evaluationfor both the IPv4 and IPv6 networks are necessary becausewe want to know how each network will execute under thedual stack transition mechanism. The protocol stack isexpected to have a definite impact on end-to-end perfor-mance of the final system. More and more researchers havepublished performance comparisons between IPv4 andIPv6 protocol stacks at the end-system.
Draves and Zill [12] presented a performance evaluationon IPv6 network in comparison with IPv4 results on Win-dows NT using a Fast Ethernet adapter. The results showthat throughput is lower by about 2% in IPv6 cases com-pared to IPv4. The author conducted tests only onthroughput in a prototype IPv6 stack and did not perform
detailed parameter checks such as packet size testing onTCP and UDP for a real large-scale IPv6 network. Anand[10] measured network TCP stream throughput perfor-mance on an IPv6 network and compared them withIPv4 results on Linux using a gigabit Ethernet adapter.The author used different message sizes to measure theTCP stream throughput on both the server and the client.The results show throughput is higher in IPv4 cases com-pared to IPv6. That is, IPv6 is not driving the system hardenough to achieve greater throughput. According to theprofiling analysis, the author found out that the IPv6 net-work is doing a check-sum of the data in the software eventhough the data is already check-summed by the hardware.He, however, conducted only TCP tests by simulation anddid not compare the UDP of IPv4/IPv6 stacks for real IPv6networks. Zeadally and Raicu [14], evaluating IPv6 onWindows and Solaris, compared IPv4 and IPv6 networksusing the above-mentioned operating systems. They mea-sured throughput, round-trip time, CPU utilization, andother connection characteristics. The experimental resultsshow that IPv6 protocol stacks for Solaris outperformIPv6 stacks of the Windows operating system, while theIPv4 protocol stacks outperform IPv6 stacks on bothTCP and UDP. Ariga et al. [13] assessed the performanceof large data transmissions and applications such as digitalvideos with various security protocols over both IPv4 andIPv6 networks. The authors used ordinary personal com-puters (PC) to simulate routers and end-hosts with Free-
BSD2.2.8 and a KAME [7] IPv6 protocol stack. Theresults show that the typical PC can handle digital videotransmissions with IPSec over the IPv6 network. Theauthors conducted only TCP and UDP streams and didnot perform detailed testing for a real large-scale IPv6 net-work. Karuppiah [2] analyzed the performance of IPv6 andIPv4 networks using the Ping utility and FTP applications.The author used the Ping utility to find the latency andFTP applications to find out the throughput rates overthe IPv6 and IPv4 networks. He used a PC to simulatethe routers and end-hosts with FreeBSD and a KAME [7]IPv6 protocol stack. The results show the IPv6 networkhas an inferior performance compared to IPv4 for the filestransferred. He did not experiment with detailed parame-ters such as packet size on TCP and UDP, connection timeor protocol type (since they could not perform any UDPtests due to the nature of FTP).
Zeadally et al. [15] appraised IPv6 performance on Win-dows, Solaris, and Linux. The authors measured through-put of TCP and UDP, latency, CPU utilization, and otherweb-based performance characteristics. Their investigationshows that the IPv6 protocol stacks for Linux outperformsthe IPv6 stacks of the other operating systems. Loiaconoet al. [6] measured a worldwide network performance ofNASA’s Earth Observation System. They developed aWeb-based network-monitoring tool ENSIGHT to detectand troubleshoot performance problems. The results showa comprehensive view of relevant performance parameters.Although the authors conducted a very large network per-

Iperf test server1 Iperf test server2
Gigabit Ethernet
Fig. 1. An ideal network environment.
W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121 3115
formance measurement, they only tested the IPv4 networkand did not perform any IPv6 performance measurements.
There are three relevant evaluation techniques: analyti-cal modeling, simulation, and measurement experiment[8]. Analytical modeling involves the creation of a mathe-matical model, which describes the basic characteristicsof a network system. Simulation is a flexible technique thatis used to replicate almost any desired system behavior.The results, however, only show the behavior in controlledenvironments. Measurement experiment provides a collec-tion of raw data, which is then used in analyzing the char-acteristics of the targeted system. For end-to-endperformance evaluation, we did not focus on the mathe-matical portion of analytical modeling. Most researchersactually prefer simulation techniques because with it, it iseasier to control the environment as compared to measure-ment experiments. Based on the study of previous research-es, we made some comparisons between previous studiesconducted along this theme as Table 1.
This work differs from the previous efforts of otherresearchers in that we performed a performance evaluationon a real, large-scale network backbone and made a com-parison between the current Internet (IPv4) and next gener-ation Internet (IPv6).
3. Measurement procedures and test bed
For the purpose of this study, we followed the lead ofElArag and Bassiouni [4]. In the first stage, we measuredend-to-end performance in an ideal network environmentto provide upper bound limits for throughputs and lowerbound limits for latency. Two identical workstations wereconnected using a point-to-point link of gigabit Ethernetas projected in Fig. 1.
Both workstations were each equipped with an IntelPentium 2.8 GHz processor, 1000 MB of DDR RAM,36 Gb SEAGATE ALTRA 320 SCSI 10,000 RPM harddrives, and 1000 Mbit/s PCI64 Ethernet network adapters.The workstations were each loaded with the Linux FedoraCore II (kernel version 2.6.5-1) operating system.
In the second stage, we measured end-to-end perfor-mance in a real large-scale network including IPv6 andIPv4 backbones to get real end-to-end throughput andother characteristics. Two identical workstations were eachconnected to Cisco 3750 gigabit switches connected to
Table 1Comparisons between previous studies and this research
Researches Simulation or measurement experiment Sca
Draves and Zill [12] Simulation SmAnand [10] Simulation SmZeadally and Raicu [14] Simulation SmAriga et al. [13] Simulation SmKaruppiah [2] Simulation SmZeadally et al. [15] Simulation SmLoiacono et al. [6] Measurement experiment LaThis research Measurement experiment La
Cisco 7609 routers as shown in Fig. 2. Taiwan AdvancedResearch and Education Network (TWAREN) is a nextgeneration research and education network. TWARENhas the bandwidth of 10 Gbps and is based on the technol-ogy of Dense Wavelength Division Multiplexer (DWDM)technologies. There are eleven regional centers serve toget all major institutions of higher education and researchconnected to the backbone. Every institution will connectto the backbone at 1 Gbps [17]. In the future, total of morethan one hundred and fifty institutions will connect toTWAREN. The workstations have similar infrastructureas assembled in the ideal network environment. Eachworkstation were equipped with an Intel Pentium2.8 GHz processor, 1000 Mb of DDR RAM, 36 Gb SEA-GATE ALTRA 320 SCSI 10000 RPM hard drives, and1000 Mbit/s PCI64 Ethernet network adapters. The work-stations were each installed with Linux Fedora Core II(kernel version 2.6.5-1) operating systems.
The measurement tool which we used is Iperf [5] (avail-able from the National Lab for Advanced NetworkResearch (NLANR)) because of its rich set of features.An older program tcpwatch has been mostly phase-outalready [6]. Another famous tool ttcp is very old and pos-sesses confusing options [5]. Iperf was developed as a mod-ern tool to measure maximum TCP bandwidth, allow thetuning of various parameters such as UDP characteristics,report bandwidth, delay jitter, and datagram loss. We alsoused Ping to measure round trip time. After we did the per-formance evaluation, we show the results in the succeedingsection and make comparisons between the current Inter-net (IPv4) and next generation Internet (IPv6).
4. Results and discussions
In this section, we present and discuss the resultsobtained from our tests for an ideal model and a real,large-scale network.
le IPv4 TCP /UDPthroughput
IPv6 TCP/UDPthroughput
IPv4latency
IPv6latency
all Only TCP Only TCP Yes Yesall Only TCP Only TCP No Noall Both Both Yes Yesall Both Both No Noall Only TCP Only TCP Yes Yesall Both Both Yes Yesrge Both No Yes Norge Both Both Yes Yes
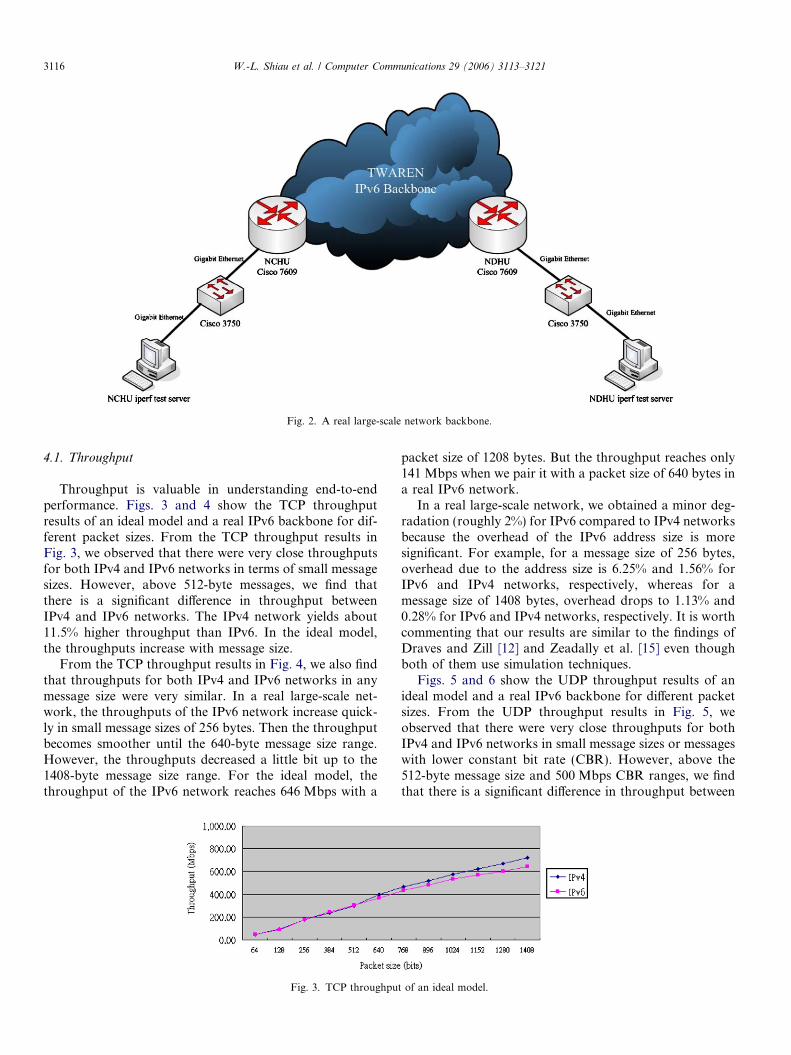
Fig. 2. A real large-scale network backbone.
3116 W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121
4.1. Throughput
Throughput is valuable in understanding end-to-endperformance. Figs. 3 and 4 show the TCP throughputresults of an ideal model and a real IPv6 backbone for dif-ferent packet sizes. From the TCP throughput results inFig. 3, we observed that there were very close throughputsfor both IPv4 and IPv6 networks in terms of small messagesizes. However, above 512-byte messages, we find thatthere is a significant difference in throughput betweenIPv4 and IPv6 networks. The IPv4 network yields about11.5% higher throughput than IPv6. In the ideal model,the throughputs increase with message size.
From the TCP throughput results in Fig. 4, we also findthat throughputs for both IPv4 and IPv6 networks in anymessage size were very similar. In a real large-scale net-work, the throughputs of the IPv6 network increase quick-ly in small message sizes of 256 bytes. Then the throughputbecomes smoother until the 640-byte message size range.However, the throughputs decreased a little bit up to the1408-byte message size range. For the ideal model, thethroughput of the IPv6 network reaches 646 Mbps with a
Fig. 3. TCP throughpu
packet size of 1208 bytes. But the throughput reaches only141 Mbps when we pair it with a packet size of 640 bytes ina real IPv6 network.
In a real large-scale network, we obtained a minor deg-radation (roughly 2%) for IPv6 compared to IPv4 networksbecause the overhead of the IPv6 address size is moresignificant. For example, for a message size of 256 bytes,overhead due to the address size is 6.25% and 1.56% forIPv6 and IPv4 networks, respectively, whereas for amessage size of 1408 bytes, overhead drops to 1.13% and0.28% for IPv6 and IPv4 networks, respectively. It is worthcommenting that our results are similar to the findings ofDraves and Zill [12] and Zeadally et al. [15] even thoughboth of them use simulation techniques.
Figs. 5 and 6 show the UDP throughput results of anideal model and a real IPv6 backbone for different packetsizes. From the UDP throughput results in Fig. 5, weobserved that there were very close throughputs for bothIPv4 and IPv6 networks in small message sizes or messageswith lower constant bit rate (CBR). However, above the512-byte message size and 500 Mbps CBR ranges, we findthat there is a significant difference in throughput between
t of an ideal model.

Fig. 4. TCP throughput of a real large-scale network.
Fig. 5. UDP IPv4 vs. IPv6 throughput of an ideal model.
Fig. 6. UDP IPv4 vs. IPv6 throughput of a real large-scale network.
W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121 3117
IPv4 and IPv6 networks. The IPv4 network yields about13.7% higher throughput than the IPv6 network. In theideal model, the throughputs of UDP also increase withincreasing message sizes.
From the UDP throughput results in Fig. 6, we find thatthe trend is similar for both IPv4 and IPv6 networks insmall message sizes. The lower constant bit rate (CBR),the higher the slope needed to reach the upper bound ofthroughput. In a real large-scale IPv6 network, thethroughputs increase quickly under a constant bit rate(CBR) of 300 Mbps. Then it decreases with following anincrease in constant bit rate (CBR). Finally the throughputdecreases to the 50.5 Mbps level on a constant bit rate(CBR) of 1000 Mbps and a message size of 1408 bits.
For the ideal model, the throughput of the IPv6 networkreaches 300 Mbps with a packet size of 1152 bytes. Thisoccurrence also happens in a real large-scale network, butthe throughput of the IPv6 network in a real large-scaleenvironment decreases quicker than in an ideal model withan increasing constant bit rate (CBR).
In a real large-scale network, we found out that the IPv6network outperforms the IPv4 network with regards tosmall message sizes. Our results support the conclusionsof Zeadally and Raicu [14] in terms of small message size.But results of Zeadally and Raicu [14] do not provide infor-mation for ranges above 100 Mbps (CBR). Our resultsshow that the IPv6 network still outperforms the IPv4 net-work under scenarios with high large message sizes and
3118 W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121
high CBR (e.g., 1000 Mbps). We also believe that the dif-ference in throughput performance between IPv4 andIPv6 networks is more obvious for small messages withTCP than UDP mainly because of TCP optimization meth-ods such as the Nagle algorithm and delayed acknowledg-ment processes [14]. The protocol stack waits for anacknowledgment or data from the application before send-ing small amounts of data with high headers in the Naglealgorithm. The stack ‘‘piggybacks’’ acknowledgments alsoform sender-side delays. These optimization methods affectIPv6 packet performance more than the IPv4 networkbecause the overhead of the IPv6 address size is moresignificant.
4.2. Delay jitters
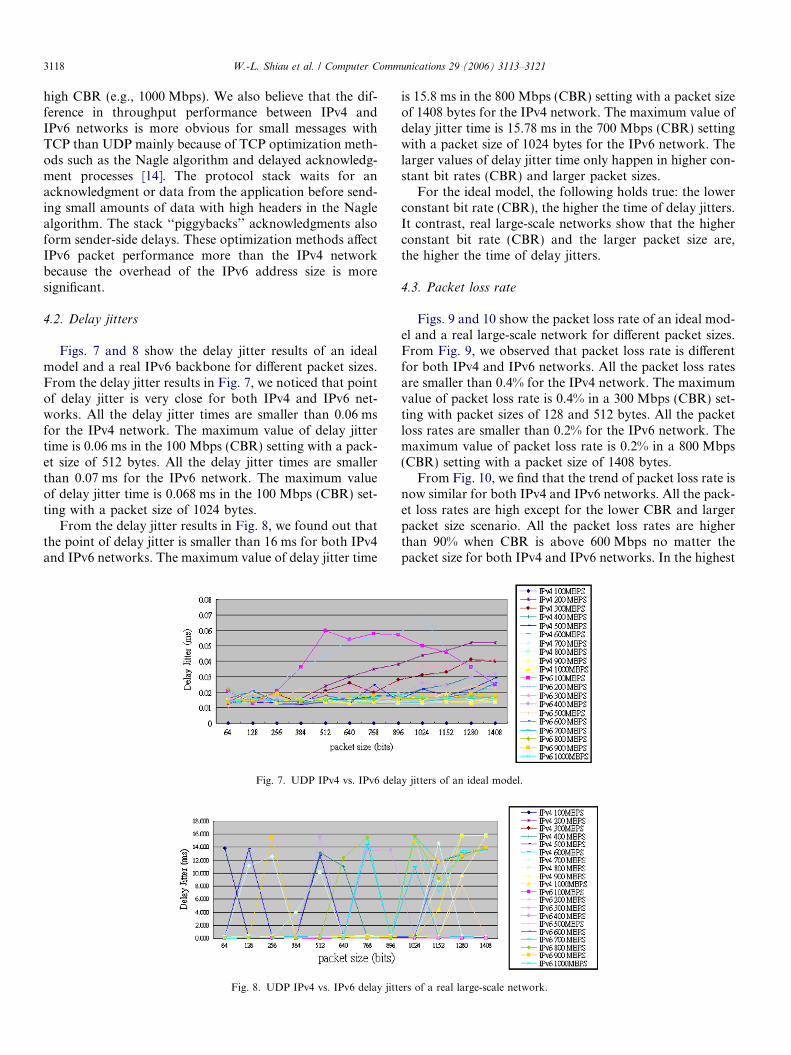
Figs. 7 and 8 show the delay jitter results of an idealmodel and a real IPv6 backbone for different packet sizes.From the delay jitter results in Fig. 7, we noticed that pointof delay jitter is very close for both IPv4 and IPv6 net-works. All the delay jitter times are smaller than 0.06 msfor the IPv4 network. The maximum value of delay jittertime is 0.06 ms in the 100 Mbps (CBR) setting with a pack-et size of 512 bytes. All the delay jitter times are smallerthan 0.07 ms for the IPv6 network. The maximum valueof delay jitter time is 0.068 ms in the 100 Mbps (CBR) set-ting with a packet size of 1024 bytes.
From the delay jitter results in Fig. 8, we found out thatthe point of delay jitter is smaller than 16 ms for both IPv4and IPv6 networks. The maximum value of delay jitter time
Fig. 7. UDP IPv4 vs. IPv6 dela
Fig. 8. UDP IPv4 vs. IPv6 delay jitt
is 15.8 ms in the 800 Mbps (CBR) setting with a packet sizeof 1408 bytes for the IPv4 network. The maximum value ofdelay jitter time is 15.78 ms in the 700 Mbps (CBR) settingwith a packet size of 1024 bytes for the IPv6 network. Thelarger values of delay jitter time only happen in higher con-stant bit rates (CBR) and larger packet sizes.
For the ideal model, the following holds true: the lowerconstant bit rate (CBR), the higher the time of delay jitters.It contrast, real large-scale networks show that the higherconstant bit rate (CBR) and the larger packet size are,the higher the time of delay jitters.
4.3. Packet loss rate
Figs. 9 and 10 show the packet loss rate of an ideal mod-el and a real large-scale network for different packet sizes.From Fig. 9, we observed that packet loss rate is differentfor both IPv4 and IPv6 networks. All the packet loss ratesare smaller than 0.4% for the IPv4 network. The maximumvalue of packet loss rate is 0.4% in a 300 Mbps (CBR) set-ting with packet sizes of 128 and 512 bytes. All the packetloss rates are smaller than 0.2% for the IPv6 network. Themaximum value of packet loss rate is 0.2% in a 800 Mbps(CBR) setting with a packet size of 1408 bytes.
From Fig. 10, we find that the trend of packet loss rate isnow similar for both IPv4 and IPv6 networks. All the pack-et loss rates are high except for the lower CBR and largerpacket size scenario. All the packet loss rates are higherthan 90% when CBR is above 600 Mbps no matter thepacket size for both IPv4 and IPv6 networks. In the highest
y jitters of an ideal model.
ers of a real large-scale network.
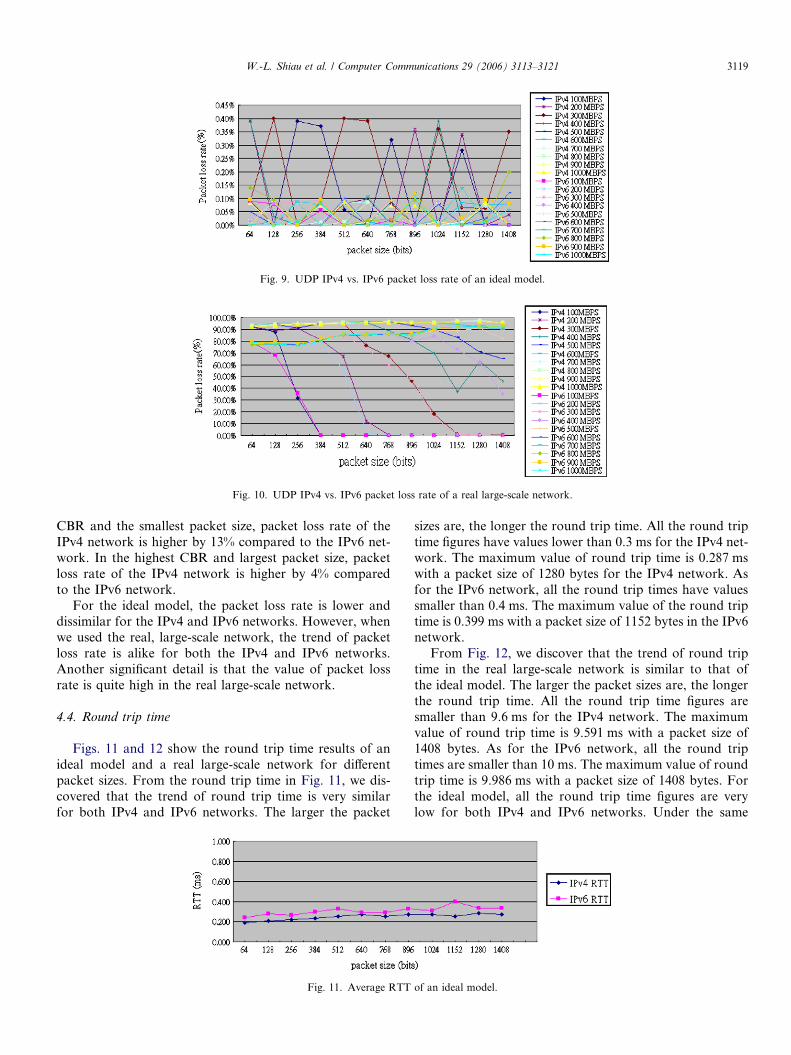
Fig. 9. UDP IPv4 vs. IPv6 packet loss rate of an ideal model.
Fig. 10. UDP IPv4 vs. IPv6 packet loss rate of a real large-scale network.
W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121 3119
CBR and the smallest packet size, packet loss rate of theIPv4 network is higher by 13% compared to the IPv6 net-work. In the highest CBR and largest packet size, packetloss rate of the IPv4 network is higher by 4% comparedto the IPv6 network.
For the ideal model, the packet loss rate is lower anddissimilar for the IPv4 and IPv6 networks. However, whenwe used the real, large-scale network, the trend of packetloss rate is alike for both the IPv4 and IPv6 networks.Another significant detail is that the value of packet lossrate is quite high in the real large-scale network.
4.4. Round trip time
Figs. 11 and 12 show the round trip time results of anideal model and a real large-scale network for differentpacket sizes. From the round trip time in Fig. 11, we dis-covered that the trend of round trip time is very similarfor both IPv4 and IPv6 networks. The larger the packet
Fig. 11. Average RTT
sizes are, the longer the round trip time. All the round triptime figures have values lower than 0.3 ms for the IPv4 net-work. The maximum value of round trip time is 0.287 mswith a packet size of 1280 bytes for the IPv4 network. Asfor the IPv6 network, all the round trip times have valuessmaller than 0.4 ms. The maximum value of the round triptime is 0.399 ms with a packet size of 1152 bytes in the IPv6network.
From Fig. 12, we discover that the trend of round triptime in the real large-scale network is similar to that ofthe ideal model. The larger the packet sizes are, the longerthe round trip time. All the round trip time figures aresmaller than 9.6 ms for the IPv4 network. The maximumvalue of round trip time is 9.591 ms with a packet size of1408 bytes. As for the IPv6 network, all the round triptimes are smaller than 10 ms. The maximum value of roundtrip time is 9.986 ms with a packet size of 1408 bytes. Forthe ideal model, all the round trip time figures are verylow for both IPv4 and IPv6 networks. Under the same
of an ideal model.

Fig. 12. Average RTT of a real IPv6 backbone.
3120 W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121
packet size, the largest variance happens in the 1152 bytessetting. The round trip time of the IPv6 network is 56.4%higher than that of the IPv4 network. Nonetheless, all theround trip times are high for IPv4 and IPv6 networks ina real large-scale environment. Under the same packet size,the largest variance happens in 1152 and 1408 byte size cat-egories. The round trip time of the IPv6 network is higherby 4.1% compared to the IPv4 network.
In a real large-scale network, we noticed that the roundtrip time of the IPv6 network is always longer than that ofthe IPv4 network in any message size category because ofthe higher header overheads associated with IPv6 networks.
5. Conclusion
In this paper, we conducted an end-to-end performanceevaluation on a real large-scale network backbone andmade some comparisons between IPv4 and IPv6 networks.The following shows our investigative findings:
• For TCP throughputs, the IPv6 network does as well asthe IPv4 network in terms of end-to-end performance. Itis worthwhile to point out that we obtained a minor deg-radation for the IPv6 network compared to the IPv4 net-work. In a real large-scale environment, the throughputof the IPv6 network increased quickly in small messagesizes of 256 bytes, after which, it leveled out until the640-byte message size range. Onward, the throughputsdecreased a little bit until it reached the 1408 bytes mes-sage size range. The maximum throughput of the IPv6network reached only 141 Mbps with a packet size of640 bytes in a real environment.
• For UDP throughputs, the trend is similar for both theIPv6 and IPv4 networks in small packet size categories.The lower constant bit rate (CBR), the higher slope isneeded to reach the upper bound of throughput. In areal large-scale IPv6 network, the throughputs increaserapidly under a constant bit rate (CBR) of 300 Mbps.Then the throughput decreased under a correspondingincrease in constant bit rate (CBR). Finally, thethroughputs decrease to the level of 50.5 Mbps on a con-stant bit rate (CBR) of 1000 Mbps and message size of1408 bits.
• For delay jitters, the maximum value is similar for bothIPv6 and IPv4 networks in a large-scale environment.The appearing frequency is more for the IPv6 networkcompared to the IPv4 network. For both networks,the larger values of delay jitter time happen in a higherCBR and larger packet size setting.
• For packet loss rates, all rates are high except for thelower CBR and larger packet size categories for bothIPv6 and IPv4 networks in a large-scale environment.All the packet loss rates are higher than 90% whenCBR is above 600 Mbps with whichever packet sizefor both IPv4 and IPv6 networks. In the highest CBRand smallest packet size setting, packet loss rate of theIPv4 network is higher by 13% than that of the IPv6 net-work. In the highest CBR and largest packet size setting,the packet loss rate of the IPv4 network is higher 4 bypercent than the IPv6 network.
• For round trip time, the trend is similar for both IPv6and IPv4 networks in a large-scale network. The largerthe packet size is, the longer the round trip time. Allthe round trip times are high for both networks in a reallarge-scale backbone. Under the same packet size, thebiggest variance happens in 1152 and 1408 byte sizes.The round trip time of the IPv6 network is higher by4.1% compared to the IPv4 network.
Our conclusions show that, in a real large-scale networkenvironment, a minor degradation in the throughput of theTCP, a slightly higher throughput of the UDP, a somewhatemerging frequency of the delay jitter, a lower packet lossrate, and a slightly longer round trip time happens whenwe compare the IPv6 network to the IPv4 network.
Acknowledgments
This paper is a partial result under the sponsorship ofNational Center for High-performance Computing (TWA-REN testing project) and Taiwan Network InformationCenter (IPv6 R&D project). This study is also partiallysupported by the MOE Program for Promoting AcademicExcellence of Universities: Electronic Commerce Environ-ment, Technology Development, and Application (ProjectNumber: 91-H-FA08-1-4).

W.-L. Shiau et al. / Computer Communications 29 (2006) 3113–3121 3121
References
[1] B. Krishnamurthy, C.E. Wills, Analyzing factors that influence end-to-end Web performance, Computer Networks 33 (2000) 17–32.
[2] E.K. Karuppiah, IPv6 dual stack transition technique performanceanalysis: KAME on FreeBSD as the case, Faculty of InformationTechnology, Multimedia University, Jalan Multimedia, October(2000).
[3] G. Simco, Performance evaluation and the Internet 2 performanceinitiative, The Internet and Higher Education 4 (2001) 125–136.
[4] H. ElAarag, M. Bassiouni, Performance evaluation of TCP connec-tions in ideal and non-ideal network environments, ComputerCommunications 24 (2001) 1769–1779.
[5] Iperf, <http://dast.nlanr.net/Projects/Iperf//>.[6] J. Loiacono, A. Germain, J. Smith, Network performance measure-
ments for NASA’s Earth Observation System, Computer Networks46 (2004) 299–320.
[7] KAME, <http//www.kame.net/>.[8] K. Kant, Introduction to computer system performance evaluation,
McGraw-Hill, New York, 1992.[9] L. Zhang, L. Zheng, Modeling and performance analysis for IPv6
traffic with multiple QoS classes, Computer Communications 24(2001) 1626–1636.
[10] M. Anand, Netperf3 TCP Stream Network performance on IPv6 USAGIPatch using 2.4.17 kernel, IBM Linux Technology Center, <http://www-124.ibm.com/developerworks/opensource/linuxperf/netperf/results/may_02/netperf3_ipv6_2.4.17resutls.htm/>, August (2002).
[11] R.E. Beverly IV, G.J. Miller, K. Thompson, Multicast performancemeasurement on a high-performance IP backbone, Computer Com-munications 24 (2001) 461–472.
[12] R.P. Draves, B.D. Zill, Implementing IPv6 for Windows NT, Proc. 2ndUSENIX Windows NT Symposium, Seattle, WA, USA, August (1998).
[13] S. Ariga, K. Nagahashi, A. Minami, H. Esaki, J. Murai, Performanceevaluation of data transmission using IPSec over IPv6 networks,Proc. INET (2000).
[14] S. Zeadally, I. Raicu, Evaluating IPv6 on Windows and Solaris, IEEEInternet Computing (2003) 51–57.
[15] S. Zeadally, R. Wasseem, I. Raicu, Comparison of end-system IPv6protocol stacks, IEE Proceedings-Communications 151 (3) (2004).
[16] T. Ferrari, End-to-end performance analysis with traffic aggregation,Computer Networks 34 (2000) 905–914.
[17] TWAREN, <http://www.twaren.net/english//>.[18] Y. Kogan, G. Maguluri, G. Ramachandran, Satisfying customer
bandwidth demand in IP data networks, Performance Evaluation 52(2003) 105–117.
Wen-Lung Shiau received the MS in ComputerScience from Polytechnic University, New York,U.S. in 1995 and the PhD degree from theDepartment of Business Administration, NationalCentral University, Chung-Li, Taiwan in 2006. Heis an assistant professor in the Information Man-agement department of Ming Chuan University inTaoyuan County, Taiwan, He was a certifiedinstructor of Cisco (CCSI), Novell (CNI), andMicrosoft (MCT) and trained innumerable certi-fied engineers. He wrote more than 40 books and
published the first IPv6 book in traditional Chinese. His current research
interests include ERP, Data Mining, Networking, and Telecommunication.His papers have been published or accepted in Journal of E-Business,International Journal of Internet Protocol Technology, Journal of InternetTechnology and Computer Communications.Yu-Feng Li is a technician of the UniversityComputer and IT Center at National Dong HwaUniversity, Hualien, Taiwan, ROC. His mainresearch focuses on the network related topicsincluding Wireless Networks, transition of IPv4/IPv6, and Network Mobility.
Han-Chieh Chao is a Full Professor of the
Department of Electronic Engineering and Deanof the Library and Information TechnologyOffice, National Ilan University, I-Lan, Taiwan,ROC. His research interests include High SpeedNetworks, Wireless Networks, IPv6 based Net-works, Digital Creative Arts, and Digital Divide.He received his MS and Ph.D. degrees in Elec-trical Engineering from Purdue University in 1989and 1993, respectively. He has authored or co-authored 4 books and has published about 140refereed professional research papers. He has completed 34 MSEE thesis
students. Dr. Chao has received many research awards, including PurdueUniversity SRC awards, and NSC research awards (National ScienceCouncil of Taiwan). He also received many funded research grants fromNSC, Ministry of Education (MOE), RDEC, Industrial Technology ofResearch Institute, Institute of Information Industry and FarEasToneTelecommunications Laboratory. Dr. Chao has been invited frequently togive talks at national and international conferences and research organi-zations. Dr. Chao is also serving as an IPv6 Steering Committee memberand co-chair of R&D division of the NICI (National Information andCommunication Initiative, a ministry level government agency which aimsto integrate domestic IT and Telecom projects of Taiwan), Co-chair of theTechnical Area for IPv6 Forum Taiwan, the executive editor of theJournal of Internet Technology and the Editor-in-Chief for InternationalJournal of Internet Protocol Technology and International Journal of AdHoc and Ubiquitous Computing. Dr. Chao is an IEEE senior member.Ping-Yu Hsu graduated from the CSIE depart-ment of National Taiwan University in 1987,received the master’s degree from the ComputerScience Department of New York University in1991, and the Ph.D. degree from the ComputerScience Department of UCLA in 1995. He is aprofessor in the Business Administration depart-ment of National Central University in Chung-Li,Taiwan, and the director of the ERP center in theUniversity. He also works as theSecretary-in-Chief of the Chinese ERP associa-
tion. His research interest focuses on business data applications, including
data modeling, data warehousing, data mining, and ERP applications inbusiness domains. His papers have been published in IEEE transactionson Software Engineering, Information Systems, Information Sciences, andvarious other journals.



















