
Enabling Knowledge Creation Through Associative Networks and Semantic Web Technologies
13
ENABLING KNOWLEDGE CREATION THROUGH ASSOCIATIVE NETWORKS AND SEMANTIC WEB TECHNOLOGIES L.Lella 1 ,A.F.Dragoni 1 , G.Giampieri 2 1 D.E.I.T., Università Politecnica delle Marche, Ancona, Italy 2 A.R.C.H.I. – Advanced Research Center for Health Informatics, Ancona, Italy ABSTRACT Nowadays the organizations operate in an evolving and dynamic environment and to keep an advantage over the other companies they need new management techniques as well as improved applications, where inter-operability can support innovative thinking. The goal of these tools is twofold. To improve the information retrieval processes and the finding of competencies within the organization in order to establish the conditions for the creation of knowledge and the generation of communities of practice. This objective cannot be resolved without flexible knowledge representation structured as associative networks, which are capable to define user models, i.e. representations of their knowledge, their competencies and their objectives. But this subsymbolic representation must be formalized to optimize the search of information. We think that, for knowledge management purposes, the better way is to reify the employees’ conceptualizations of the read documents. The obtained representations of the knowledge acquired every day by the workers can be further improved by the use of existing ontologies. We provide some examples of researches performed with the aid of these representations. 1.INTRODUCTION The growing interest towards the knowledge management field is justified by the new issues and challenges that the actual organizations have to deal with (Smith and Fatquhar, 2000). First of all companies are extending worldwide, leading to the establishment of a collaborative space that is now more virtual than physical. This inevitably creates new problems in the collaboration between peers that have to be solved in order to keep efficient the entire organization. Secondly the intellectual capital of a firm has become an important differentiation factor with respect to the other organizations. While in the 70s a key differentiator was the optimization of the working environment, in the 80s the quality, in 90s the customer satisfaction, nowadays an organization must be able to learn quickly and continuously from the environment where it operates and must be capable of reusing efficiently the acquired knowledge to sustain competition. Luckily information technologies through Internet, intranet and Web technologies, have all the necessary potentialities to capture, share and leverage the knowledge of a company.
Transcript of Enabling Knowledge Creation Through Associative Networks and Semantic Web Technologies

ENABLING KNOWLEDGE CREATION THROUGH ASSOCIATIVENETWORKS AND SEMANTIC WEB TECHNOLOGIES
L.Lella1,A.F.Dragoni1, G.Giampieri2
1D.E.I.T., Università Politecnica delle Marche, Ancona, Italy2A.R.C.H.I. – Advanced Research Center for Health Informatics, Ancona, Italy
ABSTRACTNowadays the organizations operate in an evolving and dynamic environment and to keep anadvantage over the other companies they need new management techniques as well as improvedapplications, where inter-operability can support innovative thinking.The goal of these tools is twofold. To improve the information retrieval processes and the finding ofcompetencies within the organization in order to establish the conditions for the creation ofknowledge and the generation of communities of practice.This objective cannot be resolved without flexible knowledge representation structured asassociative networks, which are capable to define user models, i.e. representations of theirknowledge, their competencies and their objectives.But this subsymbolic representation must be formalized to optimize the search of information. Wethink that, for knowledge management purposes, the better way is to reify the employees’conceptualizations of the read documents. The obtained representations of the knowledge acquiredevery day by the workers can be further improved by the use of existing ontologies.We provide some examples of researches performed with the aid of these representations.
1.INTRODUCTION
The growing interest towards the knowledge management field is justified by the new issues and
challenges that the actual organizations have to deal with (Smith and Fatquhar, 2000).
First of all companies are extending worldwide, leading to the establishment of a collaborative
space that is now more virtual than physical. This inevitably creates new problems in the
collaboration between peers that have to be solved in order to keep efficient the entire organization.
Secondly the intellectual capital of a firm has become an important differentiation factor with
respect to the other organizations. While in the 70s a key differentiator was the optimization of the
working environment, in the 80s the quality, in 90s the customer satisfaction, nowadays an
organization must be able to learn quickly and continuously from the environment where it operates
and must be capable of reusing efficiently the acquired knowledge to sustain competition.
Luckily information technologies through Internet, intranet and Web technologies, have all the
necessary potentialities to capture, share and leverage the knowledge of a company.

But they have to be used in the right way (Stenmark, 2003). This substantially means that the
implemented solutions must consider all the principal characteristics of knowledge.
The nature of knowledge has been well debated and investigated in literature (Nonaka, 1994;
Nonaka and Takeuchi, 1995; Alavi and Leidner, 2001).
Knowledge evolves continually. It is used to reflect upon data and information and when these have
been interpreted a new state of knowledge arise.
Moreover researchers in the field of KM seem to confirm the subjective and specific nature of
knowledge that adapts itself to every situation to which it is applicable. So, despite of the attempts
to manage knowledge centrally in organizations, knowledge is decentralized and it is best managed
in the area in which it is created and exchanged.
So, from these first considerations we can conclude that knowledge is dynamic, contextualized and
goal oriented and therefore the modern tools and systems for the creation of knowledge have to take
into account these principal features.
It must also be considered that organizations are particularly interested in the acquisition of the so
called “tacit knowledge” (Polanyi, 1967), a particular kind of knowledge deeply rooted in individual
actions and experiences that is very difficult to formalize.
According to Polanyi tacit knowledge is linked to the act of focusing the attention on particular
perceived aspects of reality. He distinguishes (Polanyi, 1975) between “proximal” and “distal”
aspects (by the analogy with the adjectives “proximal” and “distal” taken from anatomy) of
attention by stating that the proximal aspects are the ones we associate with ourselves and with our
perceptions, while the distal ones comprehend the world beyond ourselves.
When solving a comprehension or a recognition problem, the human cognitive processes of
association relate proximal situational knowledge through a process of cognition, selection and
mapping, which can trigger a tacit leap to distal situational knowledge.
The identikits used by police work exactly in this manner. A collection of different eyes, noses,
faces and ear-shapes that represent the proximal situational knowledge can serve as cues to compile
an identikit of the face of the searched person which is the distal situational knowledge.
This example made by Polanyi suggests that tacit knowledge should be structured as an associative
network, i.e. a graph that links nodes, representing proximal situational knowledge aspects through
weighted and not labelled links. Within this framework the distal knowledge should be related with
the most activated part of the network.

For example, within a knowledge management system, the distal knowledge represented by the
searched organizational documentation or the employees having the requested skills for a given task
should emerge from the proximal knowledge represented by the description of the situational
context (goals, requested competencies etc.).
The representation of the tacit knowledge through a formal language could facilitate and otpimize
the processes of information retrieval and the search of competencies. But this formalization should
follow the dynamic process of knowledge acquisition in order to achieve better results.
2.KNOWLEDGE NETS
The first problem to be solved is to find the most suitable representation schema for knowledge.
Classic knowledge representation forms like semantic networks, frames and scripts are static
(Kintsch, 1998b). Instead, as we have just explained, human mind generates contextualized
structures that are adapted to the particular context of use.
Given the fact that we are interested in systems capable to acquire knowledge from textual data, we
have choosen a psychologically valid model of discourse’s comprehension in order to update a
dynamic representation of the extracted knowledge.
“Networks of propositions” or “knowledge nets” (Kintsch, 1998a) are a formalism that combines
and extends the advantages of classic representation forms used in AI.
As can be seen in figure 2.1, networks of propositions link atomic propositions consisting in
predicate-argument schemas through weighted and not labeled arcs. According to this formalism the
meaning of a node is given by its position in the net.
From a psychologic point of view only the nodes that are active (i.e. that are maintained in the so
called working memory) contribute to specify the sense of a node. Hence the meaning of a concept
is not permanent and fixed but is built every time in the working memory by the activation of a
certain subset of propositions in the neighbour of the node that represents the concept. The context
of use (objectives, accumulated experiences, emotional and situational state etc.) determines which
nodes have to be activated.

Figure 2.1 – An example of network of proposition knowledge representation.
For the definition of retrieval modalities Ericsson and Kintsch have introduced the concept of long
term working memory (LTWM) (Kintsch, Patel and Ericsson, 1999).
According to this model the working memory, that can be seen as a repository where all the
knowledge for the correct reconstruction of the meaning of the analysed information is stored, can
be subdivided in a short term part (STWM) that has a limited capacity and a LTWM that is a part of
the long term memory represented by the network of propositions. The content of STWM
automatically generates the LTWM, because some objects present in the STWM are linked to other
objects in the LTM by fixed and stable memory structures called “retrieval cues”.
The approach of the network of propositions yields two project problems. The creation of the
LTWM and the activation of LTM nodes, i.e. the creation of the retrieval cues.
Kintsch has developed two methods for the definition of the LTWM.
The first, defined with Van Dijk (Van Dijk and Kintsch, 1983), is a manual technique that cannot be
automatized.
The second is based on the latent semantic analysis (LSA) (Landauer, Foltz and Laham, 1998). This
technique can infer, from the matrix of co-occurrence rates of the words, a semantic space that
reflects the semantic relations between words and phrases.
But this latter solution lacks of precise criteria for the correct definition of the LTWM by the

retrieval of concepts from the semantic space.
After the creation of the LTWM the integration process begins i.e. the activation of the nodes
correspondent to the meaning of the phrase. Kintsch developed a diffusion of an activation signal
procedure that is a simplified version of the one developed by McClelland and Rumelhart (1986).
Firstly an activation vector is defined whose elements are indexed over the nodes of LTWM. Any
element’s value is “1” or “0” depending on the presence or the absence of the corresponding node in
the analyzed phrase (i.e. in the STWM). This vector is multiplied by the matrix of the correlation
rates (the weights of the links of the LTWM) and the resulting vector is normalized. This becomes
the new activation vector that must be multiplied again by the matrix of the correlation rates. This
procedure goes on until the activation vector becomes stable. After the integration process, the
irrelevant nodes are deactivated and only those that represent the situation model remain activated.
3.AN ALTERNATIVE IMPLEMENTATION OF THE LTWM MODEL
The adoption of a network of propositions for the knowledge representation presents certainly great
advantages in comparison with the classic formalisms. While semantic networks, frames and scripts
organize knowledge in a more ordered and logical way, the networks of propositions are definitely
more disorganized and chaotic, but present the not negligible advantage that are capable to vary
dynamically not only in time, on the basis of the past experiences, but also on the basis of the
perceived context.
But the limits presented by the technique worked out by Kintsch and Ericsson have lead us to define
a different implementation of the LTWM model.
Unfortunately the lack of adequate textual parsers able to convert the paragraphs of a text in the
correspondent atomic propositions has driven us to develop, at least in this initial phase of the
project, simple dynamic models of associative networks of words.

Figure 3.1 - A possibile architecture of a system for the dynamical acquisition of knowledge.
The part of the document that is analysed, which is stored in a buffer, must be codified on the basis
of the context before being elaborated by the working memory block. The context represents the
theme, the subject of the processed text and for its correct characterization is necessary to take into
account the representation of the textual information (textbase) together with a part of the
knowledge acquired from previous documents (Long Term Memory), that can be retrieved by an
activation signal diffusion procedure similar to that one developed by Kintsch.
For the implementation of the working memory block, self organizing networks with suitable
procedures for the labeling of their nodes could be used, but this solution requires a lot of
computational time, especially for the analysis of entire repositories of documents. So we
considered alternative models based on the theory of scale free graphs for the implementation of an
associative network.
Recently it has been found that human knowledge seems to be structured as a scale free graph
(Steyvers and Tenenbaum, 2005). Representing words and concepts with nodes, some of these (the
hubs) establish much more links compared with the other ones.
This particular conformation seems to optimize the communication between nodes. Thanks to the
presence of the hubs, every pair of nodes can be connected by a low number of links in comparison
with a random network with the same dimensions.
The definition and the eventual updating of a scale free network does not require a lot of time and
the execution of particular processes, as the diffusion of the activation signal, is very fast.
The textual analysis is performed through the following steps.
The new text is analysed paragraph by paragraph. The buffer contains not only the words of the
analysed paragraph, but also words retrieved from the long term memory using the diffusion of the

activation procedure where the activation signal starts from the nodes in the LTM that represents the
words in the paragraph.
The buffer, the working memory and the activated part of the LTM block can be compared to the
LTWM defined by Kintsch and Ericsson.
During the acquisition of the content of the paragraph a stoplist of words that must not be
considered (as articles, pronouns etc.) is used.
For any word in the text, the paragraphs where it has appeared, or where it has been inserted after
the retrieval procedure, are stored. When the entire text has been parsed and the data of all the N not
filtered words have been memorized, the formation of the scale free graph of words begins within
the WM block.
The LTM is an associative network that is updated with the content of the WM. Whenever a link of
the WM corresponds to a link present in the LTM, the weight of this one is increased by “1” while
other links that are not present in the LTM are created from scratch.
Since the scale free network that represents the content of the WM is used to update the content of
LTM, this associative networks keeps the form of a scale free graph (Dragoni, Tascini, Lella and
Giordano, 2004).
The semantic validity of the LTM representation has been proved by comparing it with other
associative networks obtained from human subjects who read the same textual information (Licata,
Lella and Giordano, 2004).
4.THE KNOWLEDGE MANAGEMENT SYSTEM
The knowledge repository created through the model of discourse’s comprehension can indeed be
used to create a cognitive model of an employee.
The knowledge acquisition module can mine the textual content of the document daily visioned by
the workers of an organization as e-mails, newsgroups, reports and other documents in digital
format. The resulting representation can be considered as a good approximation of the knowledge
acquired by the employer’s, since the analysis takes into account not only the context, i.e. the
particular semantic domain of the texts and the objectives of the reader, but also his past cumulated
experience. Obviously the accuracy of the representation could be initially quite inaccurate, but it
improves in time after the analysis of new documents.
Even if each node within the LTM associative network is related to a string, in fact it represents a
concept because the pattern of links established by the word constrains its meaning.
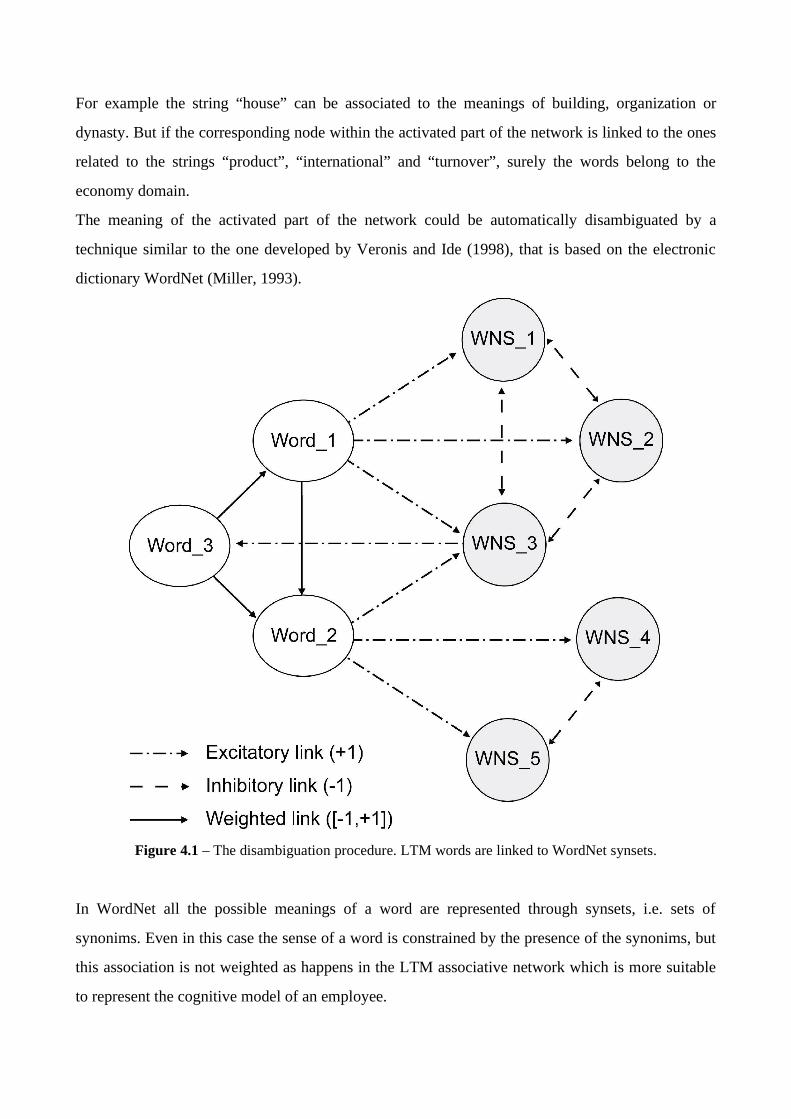
For example the string “house” can be associated to the meanings of building, organization or
dynasty. But if the corresponding node within the activated part of the network is linked to the ones
related to the strings “product”, “international” and “turnover”, surely the words belong to the
economy domain.
The meaning of the activated part of the network could be automatically disambiguated by a
technique similar to the one developed by Veronis and Ide (1998), that is based on the electronic
dictionary WordNet (Miller, 1993).
Figure 4.1 – The disambiguation procedure. LTM words are linked to WordNet synsets.
In WordNet all the possible meanings of a word are represented through synsets, i.e. sets of
synonims. Even in this case the sense of a word is constrained by the presence of the synonims, but
this association is not weighted as happens in the LTM associative network which is more suitable
to represent the cognitive model of an employee.

This is due to the pattern of links that can be considered as a set of fuzzy relations. For example
there can be two representations related to different employees where the word “software” is linked
to the words “open” and “freeware”. But in the first representation “software” could be more
strongly connected with “open”, while in the second case the same couple of words could establish
a weaker connection with respect to the other one.
So for the first employee’s knowledge representation the static meaning of the word “software” is
more linked to the open source world. Probably the diffusion of an activation signal starting from
“software” could also lead many times to the activation of the word “open” with a lower activation
level for the word “freeware”.
But the meaning of a word within the associative network keeps a fuzzy form, while certain
processes that require a more clear disambiguation, as the information retrieval or the search of
competencies, need the word to be associated with a precise and shared meaning.
In these cases we can use the following procedure.
First the existing links with the associative network must be normalized i.e. the weight of each link
starting from a node must be divided by the greatest one. After that each node is linked to all the
possible related WordNet synsets and if a word within a given synset is present in the associative
network a link with weight 1 must be added between the node representing the synset and the node
representing the word as shown in figure 4.1.
Furthermore all the possible synsets related to a given word must be connected by inhibitory
connections with a negative (-1) weight , because they represent disjoined meanings of the same
word.
Finally an activation signal procedure similar to the one defined by Kintsch could be used to select
the most activated synset.
Once the words have been disambiguated, the knowledge of an existing ontology built over
WordNet, as the alignments of SUMO (Niles and Pease, 2003) and DOLCE (Gangemi, Guarino,
Masolo and Oltramari, 2003), can be recalled in order to provide a symbolic description of their
meanings.
A better representation particularly suited to represent the knowledge of an entire organization
could be obtained reifying the conceptualization of the document.
As depicted in fig. 4.2 the personal interpretation of the resource A made by the employee E1 could
be represented as a blank node connected by a relation “#regards” with the resources representing
the synsets of WordNet corresponding to that conceptualization.
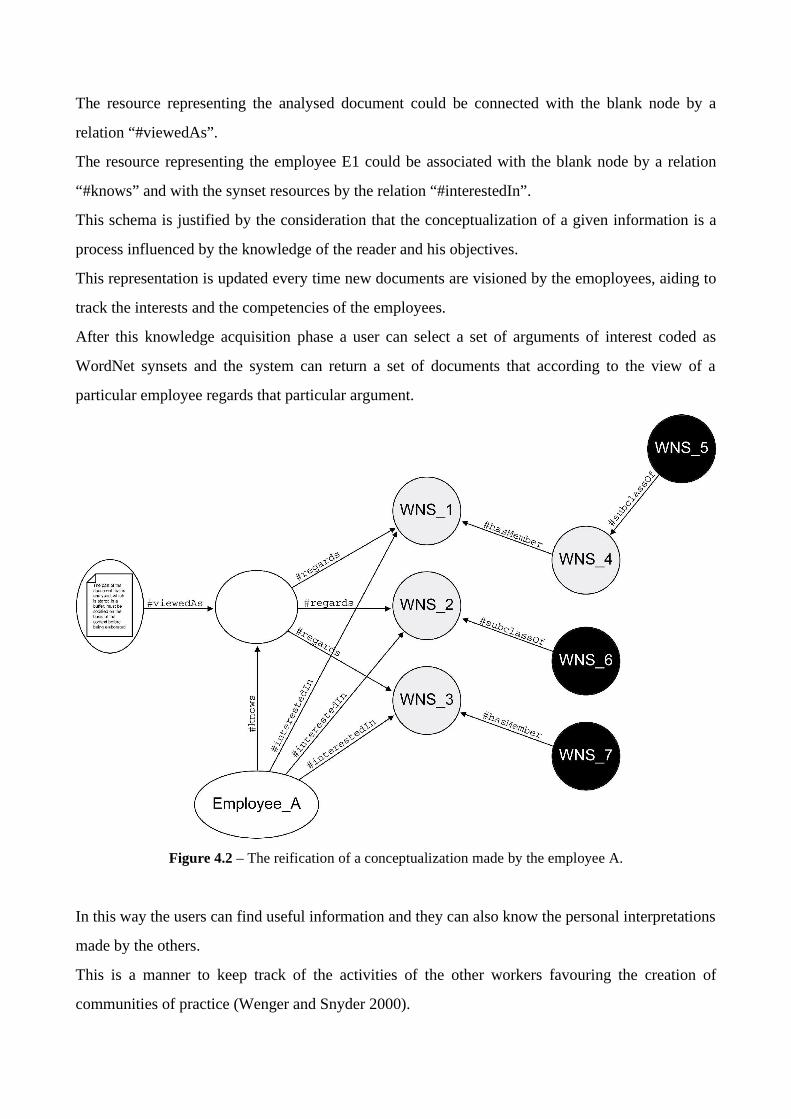
The resource representing the analysed document could be connected with the blank node by a
relation “#viewedAs”.
The resource representing the employee E1 could be associated with the blank node by a relation
“#knows” and with the synset resources by the relation “#interestedIn”.
This schema is justified by the consideration that the conceptualization of a given information is a
process influenced by the knowledge of the reader and his objectives.
This representation is updated every time new documents are visioned by the emoployees, aiding to
track the interests and the competencies of the employees.
After this knowledge acquisition phase a user can select a set of arguments of interest coded as
WordNet synsets and the system can return a set of documents that according to the view of a
particular employee regards that particular argument.
Figure 4.2 – The reification of a conceptualization made by the employee A.
In this way the users can find useful information and they can also know the personal interpretations
made by the others.
This is a manner to keep track of the activities of the other workers favouring the creation of
communities of practice (Wenger and Snyder 2000).

By the selection of the corresponding synsets it could be also possible to know all the employees
whose activities are involved within a given research area or knowledge domain.
The presence of an external ontology could make the information search more effective and
accurate. For example the selected synset WNS_4 in figure 4.1 could be identified as a subclass of a
synset WNS_3 that is mapped as a part of the conceptualization related to the employee E1.
Other selected synsets could be linked by meronimy relations with the mapped synsets.
We can consider the following case study regarding the medical domain that takes into account
DOLCE, a particular external ontology built over WordNet.
A user is interested in the concept of “$fungal_infection”. The ontology could retrieve the synsets
“$coccidioidomycosis” , a mycotic infection of lungs and skin that is a specialization of the
searched concept, and “$zymosis” that is the process of the development and spread of an infectious
disease caused by a fungus, that is a generalization of the searched concept.
These two retrieved synsets could be mapped within the conceptualization of two different medical
articles, the first one known by a specialist of mycotic infections and the second one known by
physician who made a search for a patient that presents zymotic symptoms.
The user could retrieve all the articles read by the specialist and the physician, knowing their
personal conceptualizations and so their interests and their actual pursuits and activities. After that
he could decide to contact one of the two mapped users.
This operation could also be performed automatically by the system, that could present a list of
documents and users interested in the same topic of the last analysed document, enhancing the
awareness of the users on the competencies of the others.
Suitable user interfaces for the treatment of the query are needed. A symple one could provide the
user with a list of all the possible synsets related to the exposed query to be selected.
But this solution is indeed slightly user-friendly.
Another solution could perform a disambiguation of the words constituent the query by the same
activation signal diffusion process presented before.
CONCLUSIONS
The knowledge acquisition module can be used to create and update the models of a group of
employees. The models are dynamic knowledge representations structured as associative networks
of words.
These particular schemas can be analysed in a static or dynamic manner.

The static or potential meaning of a word is given by the position that it occupies within the
network. It represents all the acquired knowledge regarding that word.
The actual meaning of a word can be determined by the diffusion of an activation signal starting
from the nodes which represent the content of the last information analysed by the user.
This process can be used to detect the actual interests of an employee, that can be better described
by the use of an external ontology.
The reification of the conceptualizations enables an intelligent search of information based on the
personal interpretations of the other workers.
This solution can favour the reflection on all the possible implications of the analyzed information
and the awareness of the actual activities and competencies of the other workers. These processes
are generally considered as the basis for the knowledge creation (Nonaka, Toyama and Konno,
2000) and the developing of communities of practice (Dieng, 2000) within an organization.
Future tests are needed to evaluate the effectiveness, the efficiency and the scalability of the
knowledge acquisition system.
ACKNOWLEDGEMENTS
The authors are grateful to Dr. Alessandro Oltramari (Laboratory for Applied Ontology, Institute of
Cognitive Science and Technology, Italian National Research Council, Trento) for helpful
discussions, comments and criticisms.
Special thanks goes to Dr. Ebe Tartufo and Dr. Cristiana Machella for their kind help and support.
REFERENCIES
Alavi M. and Leidner D. (2001), “Knowledge Management and Knowledge ManagementSystems: Conceptual Foundations and Research Issues”, MIS Quarterly, 25 (1).
Dieng R. (2000), “Knowledge Management and the Internet”, IEEE Intelligent Systems.Dragoni A., Tascini G., Lella L. and Giordano W. (2004), "Knowledge Extraction Using
Dynamical Updating of Representation", Proceedings of the 3rd workshop on RObust Methods inAnalysis of Natural Language Data.
Gangemi A., Guarino N., Masolo C. and Oltramari A. (2003), “Sweetening WordNet withDOLCE”, AI Magazine 24(3): Fall 2003, 13-24.
Kintsch W. (1998a). “The Representation of Knowledge in Minds and Machines”. InternationalJournal of Psychology, 33(6), pp.411-420.
Kintsch W. (1998b). “Comprehension. A Paradigm for Cognition”. Cambridge University Press,1998.
Kintsch W., Patel V.L. and Ericsson K.A. (1999). “The role of long-term working memory in textcomprehension”. Psychologia, 42, pp.186-198.

Ide N. and Veronis J. (1998), “Word Sense Disambiguation : The State of the Art”.Computational Linguistics, no.24(1).
Landauer T.K., Foltz P.W., Laham D. (1998). “An Introduction to Latent Semantic Analysis”.Discourse Processes, 25, pp.259-284.
Licata I., Lella L. and Giordano W. (2004), "From Ontologies to Ontogenetic Models: KnowledgeExtraction Using Dynamical Updating of Representation", Proceedings of Dynamic Ontology.
McClelland J.L., Rumelhart D.E. (1986). “Parallel distributed processing”. Cambridge, MA: MITPress.
Miller G. A. (1993). “Five papers on WordNet”. Cognitive Science Laboratory Report 43.Niles, I. and Pease, A. (2003), “Linking Lexicons and Ontologies: Mapping WordNet to the
Suggested Upper Merged Ontology”. In Proceedings of the 2003 International Conference onInformation and Knowledge Engineering (IKE ’03), Las Vegas, Nevada, June 23-26, 2003.
Nonaka I. (1994), “A Dynamic Theory of Organizational Knowledge Creation”, OrganizationScience, Vol.5, No. 1, February 1994.
Nonaka I. and Takeuchi H. (1995), “The Knowledge-Creating Company : How JapaneseCompanies Create the Dynamics of Innovation”, Oxford University Press, New York, 1995.
Nonaka I., Toyama R. and Konno N. (2000), “SECI, ba and leadership: a unified model ofdynamic knowledge creation”, Long Range Planning (32), pp. 5-34.
Polanyi M. (1967), “The Tacit Dimension”, in Knowledge in Organizations, L. Prusak, Ed.Boston, MA: Buttreworth-Heinemann, 1997, pp. 135-146.
Polanyi M. (1975), “Personal Knowledge”, In Meaning. M.Polanyi and H Prosch (eds.),University of Chicago Press, Chicago, 1975, pp. 22-45.
Smith R.G. and A. Fatquhar (2000), “The Road ahead for Knowledge Management”, AIMagazine.
Stenmark D. (2003), “Knowledge Creation and the Web: Factors Indicating Why Some IntranetsSucceded Where Others Fail”, Knowledge and Process Management, vol.10, n.3, pp. 207-216.
Steyvers M. and Tenenbaum J. (2005), “The Large-Scale Structure of Semantic Networks:Statistical Analyses and a Model of Semantic Growth”, Cognitive Science n.29, pp. 41-78.
Van Dijk T.A., Kintsch W. (1983). “Strategies of discourse comprehension”. New York:Academic Press.
Wenger E.C. and Snyder W.M. (2000), “Communities of Practice: The Organisational Frontier”,In Harvard Business Review, Harvest Business School Publishing, Boston, MA, January-February,pp. 139-145.




















