
Service Adaptable 3G Turbo Decoder for Indoor/Low Range Outdoor Environment
Upload
khangminh22Category
view
0download
0
DSPD: A deep spike-to-pattern decoder for themultimodality of brain-machine interface
Anonymous Author(s)AffiliationAddressemail
Abstract
Neural coding, including encoding and decoding, is one of the key problems in1
the brain-machine interface (BMI) for understanding how the brain uses neural2
signals to relate sensory perception and motor behaviors with neural systems.3
Moreover, it is also the cornerstone for building a robust pattern reconstruction for4
controlling the physical devices interplayed with neural signals. However, most of5
the existed studies only aim at dealing with the analogy signal of neural systems,6
while lacking a unique feature of biological neurons, termed spikes, which is the7
fundamental information unit for neural computation as well as a building block for8
neuromorphic computing. Aiming at these limitations, we propose a robust pattern9
reconstruction model named deep spike-to-pattern decoder (DSPD) to reconstruct10
multi-modal stimuli from the event-driven nature of spikes. Using about 5% of11
information represented in terms of spikes, the proposed DSPD can not only12
feasibly and accurately reconstruct dynamical visual and auditory scenes, but also13
rebuild the stimulus patterns from fMRI brain activities. The experimental results14
demonstrate the DSPD can achieve state-of-the-art performance. Importantly, it15
has a superb ability of noise-immunity for various types of artificial noises and16
background signals. The proposed framework provides efficient ways to perform17
multimodal feature representation and reconstruction in a high-throughput fashion,18
with potential usage for the next generation of BMI.19
1 Introduction20
Primates are remarkably good at computational intelligence tasks, such as pattern reconstruction [1].21
Although various engineering effort has been made in this area, the biological information processing22
system still outperforms the best artificial systems in many fields such as processing cross-modalities23
and noise-immunity. Currently, our brain brings various types of sensor information with different24
sensory modalities from numerous social behaviours. Among them, neural coding is very essential25
for comprehending how neural systems responding within the outside response [2]. Coding system26
consists of two elementary parts, neural encoding and decoding [3]. Encoding methods try to transfer27
the outside stimuli into the specific format response for further understanding by neural systems, then28
decoding aims to analyse and predict external stimuli within those specific format data encoded by29
encoding systems. In biological coding system, neurons transmit the information when they receive30
the external stimuli by changing their membrane potential to fire a series of fast event termed spikes,31
forming spatio-temporal representations [4]. Thus spikes have been suggested as a more biological32
format to represent the input-output relations in neural systems then any other artificial one, such as33
choosing real value based data as transmission media in artificial neural networks [5].34
In biological information processing system, there still remain big challenges to further understand35
those external stimuli with fundamental spiking activities. Although some traditional methods try to36
Submitted to 34th Conference on Neural Information Processing Systems (NeurIPS 2020). Do not distribute.

make significant progresses [6], most of them try to build artificial models with simple linear models37
and the area is limited either in brain activity pattern classification or visual stimuli recognition [7].38
On the other hand, deep learning based models have enjoyed a great success in many areas of39
computer vision [8], it is very common for modern artificial deep neural networks (DNNs) to40
have tens of millions of parameters which lead to high dimensional complexity and hierarchical41
structures. Inspired by human retinal systems, the hierarchical DNNs can use the convolutional and42
pooling units to code the external stimuli which has already shown in resembling some complex43
visual representations in human visual system [9] which adopted convolutional neural networks44
(CNNs) to build early visual systems where the organization and principles of understanding neural45
representations by neural circuitry is clear and simple, such as from retina to V1-V3 [10], even46
inferotemporal cortex [11]. There it is a promising way to build a more biological and reasonable47
coding system between external stimuli and human information processing with the aid of spiking48
activities and the structures of DNNs.49
Inspired by the aforementioned studies, this paper proposes a spike based reconstruction system50
named deep spike-to-pattern decoder (DSPD), this system is an uniform coding framework consists of51
two parts encoding and decoding, encoding part maps the outside stimuli to intermedia representations,52
then decoding tries to understand those output from encoding and make the final reconstruction53
as response. DPSP is a cross-multimodal pattern reconstruction which means this system could54
not only mimic the human visual pathway to understand visual input, but also can encode and55
decode other kinds of sensory signal such as human brain activities measured by functional magnetic56
resonance imaging (fMRI), but could also reconstruct the sound signals. Furthermore, we used the57
neural encoding as the outermost part to encode the outside stimuli to a series of action potentials58
or spikes, which are transimitted by the intermedia layers to the downstream DNN based decoder.59
This processing is very similar in human visual system. We evaluate the proposed DSPD model60
on three different modal input: image, fMRI and sound signals. In order to explore the generation61
ability of DSPD, we adopted the clean dataset MNIST and four its variations with strong noise62
background-MNIST, background-random MNIST, rotation-MNIST and rotation-random MNIST.63
We also take the subsets from those datasets to show the few-shot learning abilities. Experimental64
results demonstrate that the proposed DSPD is not only capable of perceiving and reconstructing65
corss-multimodal patterns (image, fMRI and sound), but also having gengration ability about noise-66
immunity. The qualitative and qualitative measurements show that the proposed DSPD could construct67
the multimodal pattern with a performance comparable to some other cognitive models. Moreover,68
our model introduce an uniform and consistent coding system to reconstruct various modal patterns69
which suggest a biological plausibility proof for how cross-multimodal patterns are perceived and70
represented by human neural processing systems.71
2 Overview of Deep spike-to-pattern Decoder72
SpikeEncoding
Sound Signal X4
Reconstructed X1
Brain Activity X3
Noisy Image X2
Spatio-temporal Pattern
Pattern to Image Decoder
Visual Image X1
Reconstructed X2
Reconstructed X3
Reconstructed X4
Encoding Decoding
Spike to Image Intermediary Converter
Figure 1: The schematic diagram of DSPD framework.
This section will introduce the proposed deep spike-to-pattern decoder (DSPD) model which is73
a mixture of a biological encoding part and a DNN based autoencoder for decoding as shown in74
2

Figure 1. The whole encoding part of the DPSP consists of the encoding layer and a spike to image75
intermediary converter. This encoding part in DPSP acts as the V1-V4 of the visual processing system76
in human brain, which is an interesting sensory pathway to study neural information processing,77
because its functional organization and structure are well known. Meanwhile, it is also widely78
known that information transmitted from retina to brain codes the visual stimuli at each specific79
receptive field. Then after encoding, the encoded information will be delivered to the decoding80
part. In decoding system of DSPD, we adopt a deep autoencoder with reasonable convolutional and81
pooling units for decoding. Compared to the shallow layers in retinal system such as V1 to some82
shallow V4 neural circuits, the deep V4 to IT (inferior temporal) part is more complex [12], so here83
we used a deep neural network structure to mimic the IT for decoding the encoded information. The84
proposed DSPD model is a unified systematic with feature extraction, temporal encoding, spike to85
image converting and decoding part.86
2.1 Spike based Encoding87
A spiking based encoding method differs from which in conventional DNNs. For a pattern recognition88
such as image classification task, DNNs usually take the raw pixel based value as input directly. In89
contrast, the spiking based encoding method would map those pixels into binary spike events that90
happen over time. The typical spiking based methods as mentioned above could be categorized as91
temporal encoding and rate based encoding.92
Rated based encoding method would bring more redundancy and consume more computing power,93
the most important thing is that, [13] [14] found that in human brain system especially in retinal94
visual systems, temporal encoding method is more common. In DSPD as show in Figure 1, the95
outside various multimodal pattern such as visual image X1, noisy image X2, brain activity X3 and96
sound signal X4 were encoded through the neural encoding method to generate a firing of spike trains.97
Then an intermediary converter convert those spikes to some white-noise looked images which are98
used to train the downstream decoder, to reconstruct the different kinds of patterns. Such those four99
various multimodal patterns are chosen as the input stimuli to show the proposed DSPD is an uniform100
framework to rebuild the different pattern, the patterns are not imported into DSPD simultaneously ,101
this figure just showed how many kinds of patterns the DSPD could afford.102
2.2 Spike to Image Intermediary Converter103
The spike to image intermediary converter is a fully-connected based network model, which is similar104
to typical multilayer perceptron (MLP). The first layer in this three-layer converter receives the spikes105
come from spiking encoding layer and the number of the neurons in the first layer equals to the106
quantity of neurons of neural encoding layer. With the 512 neurons in second layer (hidden layer)107
and 4096 neurons in third layer (output layer).108
The pixel level intermediate image is produced after converting from spatio-temporal pattern. This109
pixel level image looks like the white-noise pictures. Four different intermediate images are repre-110
sented as the final results which after being encoded and intermediary converter from four different111
types of multimodal patterns ( visual image X1, noisy image X2, brain activity X3 and sound signal112
X4), [15] adopted the spatiotemporal white-noise images to evaluate the receptive field. And we113
make a reasonable supposition that if we added up all of different types of images through each114
detailed pixel, we would get a white-noise picture. In terms of this, we think this intermediary images115
are crucial for reconstructing the final output in the following decoding processing stage.116
2.3 Pixel Level based Decoder117
In the decoding stage of DSPD, we adopt a typical autoencoder based on convolutional neural118
networks (CNNs) as the decoder fundamental system. This autoencoder consists of two parts as119
shown in Figure 1. In the first phase, the convolutional parts down sample the input intermediate120
images produced by the spike- image intermediary converter, the most important parts of the images121
are kept for recovering the texture and increasing the size. Meanwhile, through the decreasing size of122
convolutional units, the noise and redundant components are filtered. Then the filtered images will123
recover through the increasing size of convolutional units in the up-sampling phase.124
The size of the autoencoder here we used is 64C7-128C5-256C3-256C3-US2-256C3-US2-128C3-125
US2-64C5-US2. The activation function is ReLU and the dropout rate is 0.25, we also use strides (2,126
3

2) for padding and batch normalization for accelerating the training to achieve the convergence state127
respectively.128
3 Experimental Settings129
In this section, we evaluate the proposed deep spike-to-pattern decoder (DSPD) model on four various130
types of datasets: basic MNIST [16] , noisy MNIST [17], fMRI datasets [18] [19] and sound-image131
datasets [20]. The experiments are conducted on a server equipped with two-processor Intel(R)132
Xeon(R) Core CPU and one NVidia GeForce GTX 2080Ti GPU. The operating system is Ubuntu133
16.04. We use Tensorflow [21] and Keras [22] for training and testing the proposed DSPD and other134
compared models.135
3.1 Evaluation of Image Reconstruction Performance and Noise Immunity136
In order to show the capability of the proposed DSPD for the reconstruction of visual images which137
is regarded to mimic the static image reconstruction as one of the most important functions in human138
visual processing system. We applied DSPD on five static image datasets which are dividend into two139
categories: pure dataset MNIST and noisy datasets random-MNIST (with random noise), background-140
MNIST (with background), rotation-MNIST (with rotation noise) and rotation-background-MNIST141
(with both rotation and background noise). Each dataset consists of 28 × 28 grayscale images of142
handwritten digits from 0 to 9 and the dataset is divided into two parts: training set (50,000 training143
samples) and test set (10,000 test samples). Different from other reconstruction models [23] [24]144
which only focus on image without any other noise, DSPD have strong generation ability in noisy145
environment caused by random (rand), background (bg), rotation (rot) and background-rotation146
(bg-rot).147
In order to further explore the model’s generalization ability in noisy environment, we divide the sizes148
of the training set and test set to verify that the DSPD can achieve better performance on small-size149
datasets than any other models. For examples, when the training samples are 90 and test samples are150
10 means we choose 90 training samples from the whole 50,000 training samples randomly and they151
are evenly distributed in 0-9 ten classes.152
We choose standard MNIST and its four variations to show the noise immunity of DSPD, these four153
noisy MNIST datasets have random, background, rotation and rotation-background noise respectively.154
The first two rows in Fig.2 represent the qualitative evaluations about the proposed DSPD have strong155
anti-noise ability when it meets the random-MNIST and background-MNIST, the reconstructed156
images from random and background MNIST appear clear outline without noise. Although, when157
the datasets have strong rotation based noise, DSPD cannot reconstruct meaningful images with the158
clean MNIST labels this is because when these two kinds of rotation based datasets with too powerful159
rotation noise which drive the wrong directions, for instances, if a handwritten image 6 is rotated160
more than 90 degree or even 180 degree, then it becomes some wrong types such as 9, when you161
adopt the standard image 6 as label and noisy rotation image 9 as the input, you never get the correct162
clean image 6.163
In order to further show why the strong rotation based noise dataset could not be rebuilt very well, we164
used t-SNE [25] to present their corresponding white-noise like images after encoding. From Fig. 3,165
we can see that when we apply t-SNE on bg (background) spatio-temporal images, the 0-9 ten classes166
could be splitted better when adopting it on rot (rotation) MNIST. As shown in Fig. 3 B, the encoded167
spatio-temporal patterns from rotation MNIST are mixed together so that we cannot separate them168
well. Although the spatio-temporal images all look like white-noise, they are significantly different.169
From the encoding point of view, this could also explain the meaning about the patterns after encoding170
and give the reason why the reconstructed images from rotation and rotation-background MNIST171
look like strange zeros in the last two rows in Fig. 2.172
Not only limited by the quality evaluations on visualization, we also make some more detailed173
quantitative evaluations. Table 1. To show the advanced biological based encoding method and174
reasonable structure adopted by DSPD, we implement and compare our DSPD with another recent175
state-of-the-art method termed deep generative multi-view model (DGMM) [26]. DGMM is designed176
in the context of fMRI decoding, here we test it for reconstructing the clean images from noisy177
MNIST. Another limitation in DGMM is that it is designed for reconstructing small size datasets, in178
4

Table 1: Comparison of noise immunity between DSPD and DGMM on MNIST and its variations.
Random Background Rotation Bg-rotationModel MSE SSIM PSNR MSE SSIM PSNR MSE SSIM PSNR MSE SSIM PSNRDSPD (90/10) 0.049 0.15 13.11 0.056 0.381 12.90 0.072 0.417 11.67 0.087 0.290 10.99DGMM (90/10) 0.062 0.36 12.02 0.080 0.358 11.33 0.124 0.243 9.39 0.090 0.288 10.59DSPD (40K/8K) 0.032 0.52 14.72 0.048 0.421 13.77 0.068 0.489 11.77 0.092 0.276 10.58
order to compare the reconstruction performance with DSPD, we extract a small subset from whole179
dataset as using 90 images for training and 10 images for rebuilding. And the MNIST and its four180
variations are uneven distributed in 50,000 training samples and 10,000 test samples, in order to avoid181
to the imbalanced training problem, we choose 40,000 and 8000 equally distributed training samples182
and 8000 test samples as the maximum experimental condition. From table 1, we can see that DSPD183
perform better than DGMM when in small size 90 training samples and 10 test samples on MSE,184
SSIM and PSNR. DSPD reaches a PSNR peak at 13.11 when reconstructing from random MNIST185
and the reconstruction performance is more worse on rotation and bg-rotation MNIST which is the186
same to previous conclusion in Fig. 2. If the training and test samples from small size dataset (90/10)187
to large size dataset (40,000/8000), these performance evaluation metrics of DSPD on random and188
background MNIST are better than these evaluated on 90 training and 10 test, and the reconstruction189
performance from rotation and bg-rotation is more worse than perform on 90 training and 10 test.190
On the whole, there is no huge performance gap on random (MSE: 0.032 SSIM: 0.52 PSNR: 14.72),191
background (MSE: 0.048 SSIM: 0.421 PSNR: 13.77) and on too noisy datasets rotation (MSE: 0.068192
SSIM: 0.489 PSNR: 11.77) and bg-rotation (MSE: 0.092 SSIM: 0.276 PSNR: 10.58). This is thought193
to be due to the increasing training samples from random and background MNIST could help train194
the framework and improve the decoding performance. As for increasing rotation and bg-rotation195
samples, which is a decrease on training performance as the aforementioned discussion that increasing196
wrong samples may hurt the training performance.197
Random
Background
Rotation
Bg-rotation
Figure 2: Reconstructed images from noisy MNIST.
A. t-SNE vsualization on bg based spatio-temporal patterns after encoding.
B. t-SNE vsualization on rot based spatio-temporal patterns after encoding.
Figure 3: Different t-SNE visualization images between bg based and rot based spatio-temporalpatterns after encoding.
3.2 Reconstruction of fMRI Signals198
The presented DSPD framework could not only reconstruct high-quality images and show strong199
noise immunity, but also perform well on fMRI signals. In this section, we choose two different200
fMRI based datasets for testing the proposed DSPD. Handwritten Digits [18] dataset consists of 100201
gray-scale 28 × 28 handwritten digit images (90 for training and 10 for testing). This dataset has202
5

B m e e IJ II n m II m D m Bl m m El II m lfJ El 11 II rt II B . ■ II ■ n II
Presented
DSPD
DGMM
Figure 4: Presented fMRI handwritten digits and Reconstructed Results of DSPD and DGMM.
Presented
DSPD-S1-V1
DSPD-S1-V2
DSPD-S2-V1
DSPD-S2-V2
DSPD-S3-V1
DSPD-S3-V2
Presented
DGMM-S1-V1
DGMM-S1-V2
DGMM-S2-V1
DGMM-S2-V2
DGMM-S3-V1
DGMM-S3-V2
Presented
DSPD-S1-V1
DSPD-S1-V2
DSPD-S2-V1
DSPD-S2-V2
DSPD-S3-V1
DSPD-S3-V2
Presented
DGMM-S1-V1
DGMM-S1-V2
DGMM-S2-V1
DGMM-S2-V2
DGMM-S3-V1
DGMM-S3-V2
A. Reconstructed samples of DSPDwith 90 training samples
B. Reconstructed samples of DGMMwith 90 training samples
C. Reconstructed samples of DSPDwith 300 training samples
D. Reconstructed samples of DGMMwith 300 training samples
Figure 5: Presented fMRI characters and Reconstructed Results of DSPD and DGMM with threesubjects S1, S2 and S3 from the V 1 and V 2 areas (A, B are with 90 training samples and C, D are
with 300 training samples).
equal number of 6’s and 9’s. And the corresponding fMRI signals contain the brain voxels from V1,203
V2 and V3 areas from human visual system, each fMRI digit pattern has 3092 voxels. The other204
dataset named Handwritten characters [19] which is also an image-fMRI set contains 360 gray-scale205
handwritten character images. It has equal number of character B, R, A, I, N, S. The original image206
resolution is 56 times 56 and the corresponding fMRI signals contain voxels (each fMRI character207
pattern has 2420 voxels) from V1 and V2 areas of all three subjects S1, S2 and S3.208
In order to show the reconstruction ability of DSPD, we compared our DSPD with the model209
DGMM [26] which is used for testing its noise immunity in noisy image dataset. DGMM is designed210
for reconstructing the patterns from fMRI signals. Fig. 4 shows the reconstructed samples, the211
images in first line are the presented images digits 6 and 9, the last two lines represent the detailed212
reconstructed results with present images (labels) and their corresponding fMRI data. Visually213
we observe that the proposed DSPD can rebuild better quality patterns compared the results from214
DGMM.215
The three objective metrics on pattern quality shown in Table 2. From it we can see that the proposed216
DSPD performs better than DGMM on MSE, SSIM and PSNR. But the reconstruction performance217
gap is not very large, as DGMM (MSE: 0.037, SSIM: 0.653 and PSNR: 15.2) VS DSPD (MSE:218
0.026, SSIM: 0.780 and PSNR: 16.3).219
Fig. 5 represented the reconstructed samples produced by DSPD and DGMM. Fig. 5 A and B are220
reconstructed patterns of DSPD and DGMM with 90 training samples and 10 reconstructing samples,221
6
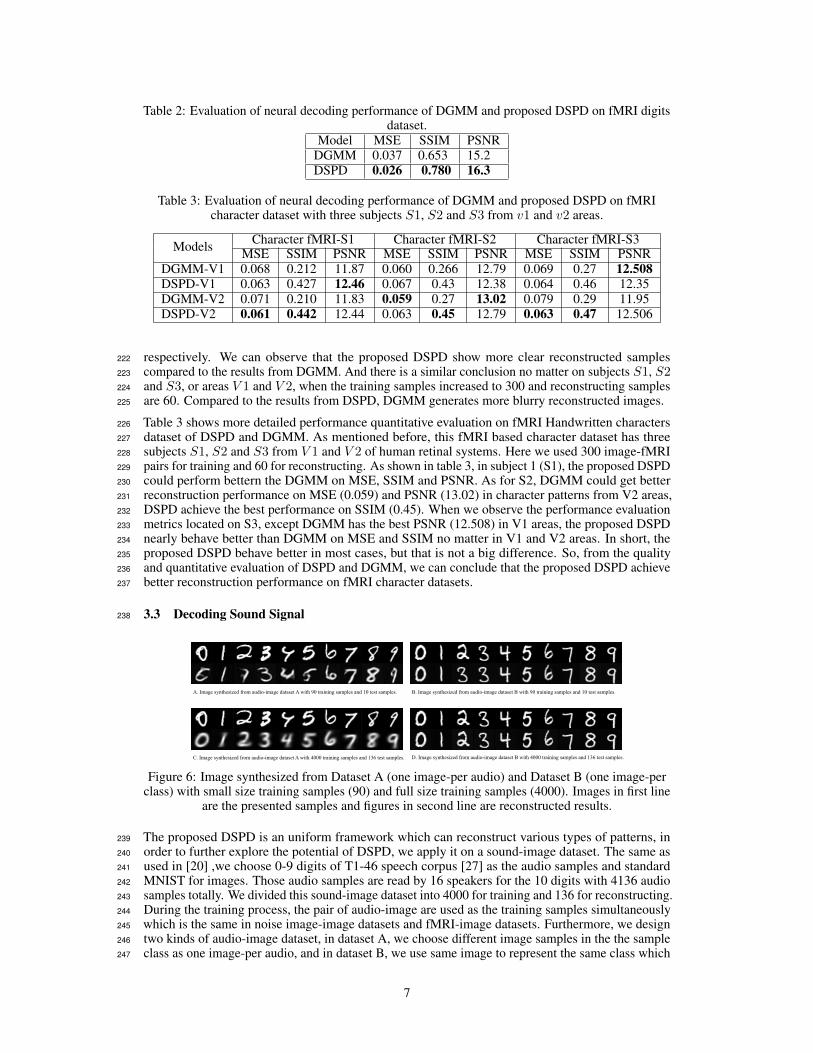
Table 2: Evaluation of neural decoding performance of DGMM and proposed DSPD on fMRI digitsdataset.
Model MSE SSIM PSNRDGMM 0.037 0.653 15.2DSPD 0.026 0.780 16.3
Table 3: Evaluation of neural decoding performance of DGMM and proposed DSPD on fMRIcharacter dataset with three subjects S1, S2 and S3 from v1 and v2 areas.
Models Character fMRI-S1 Character fMRI-S2 Character fMRI-S3MSE SSIM PSNR MSE SSIM PSNR MSE SSIM PSNR
DGMM-V1 0.068 0.212 11.87 0.060 0.266 12.79 0.069 0.27 12.508DSPD-V1 0.063 0.427 12.46 0.067 0.43 12.38 0.064 0.46 12.35DGMM-V2 0.071 0.210 11.83 0.059 0.27 13.02 0.079 0.29 11.95DSPD-V2 0.061 0.442 12.44 0.063 0.45 12.79 0.063 0.47 12.506
respectively. We can observe that the proposed DSPD show more clear reconstructed samples222
compared to the results from DGMM. And there is a similar conclusion no matter on subjects S1, S2223
and S3, or areas V 1 and V 2, when the training samples increased to 300 and reconstructing samples224
are 60. Compared to the results from DSPD, DGMM generates more blurry reconstructed images.225
Table 3 shows more detailed performance quantitative evaluation on fMRI Handwritten characters226
dataset of DSPD and DGMM. As mentioned before, this fMRI based character dataset has three227
subjects S1, S2 and S3 from V 1 and V 2 of human retinal systems. Here we used 300 image-fMRI228
pairs for training and 60 for reconstructing. As shown in table 3, in subject 1 (S1), the proposed DSPD229
could perform bettern the DGMM on MSE, SSIM and PSNR. As for S2, DGMM could get better230
reconstruction performance on MSE (0.059) and PSNR (13.02) in character patterns from V2 areas,231
DSPD achieve the best performance on SSIM (0.45). When we observe the performance evaluation232
metrics located on S3, except DGMM has the best PSNR (12.508) in V1 areas, the proposed DSPD233
nearly behave better than DGMM on MSE and SSIM no matter in V1 and V2 areas. In short, the234
proposed DSPD behave better in most cases, but that is not a big difference. So, from the quality235
and quantitative evaluation of DSPD and DGMM, we can conclude that the proposed DSPD achieve236
better reconstruction performance on fMRI character datasets.237
3.3 Decoding Sound Signal238
A. Image synthesized from audio-image dataset A with 90 training samples and 10 test samples. B. Image synthesized from audio-image dataset B with 90 training samples and 10 test samples.
C. Image synthesized from audio-image dataset A with 4000 training samples and 136 test samples. D. Image synthesized from audio-image dataset B with 4000 training samples and 136 test samples.
Figure 6: Image synthesized from Dataset A (one image-per audio) and Dataset B (one image-perclass) with small size training samples (90) and full size training samples (4000). Images in first line
are the presented samples and figures in second line are reconstructed results.
The proposed DSPD is an uniform framework which can reconstruct various types of patterns, in239
order to further explore the potential of DSPD, we apply it on a sound-image dataset. The same as240
used in [20] ,we choose 0-9 digits of T1-46 speech corpus [27] as the audio samples and standard241
MNIST for images. Those audio samples are read by 16 speakers for the 10 digits with 4136 audio242
samples totally. We divided this sound-image dataset into 4000 for training and 136 for reconstructing.243
During the training process, the pair of audio-image are used as the training samples simultaneously244
which is the same in noise image-image datasets and fMRI-image datasets. Furthermore, we design245
two kinds of audio-image dataset, in dataset A, we choose different image samples in the the sample246
class as one image-per audio, and in dataset B, we use same image to represent the same class which247
7
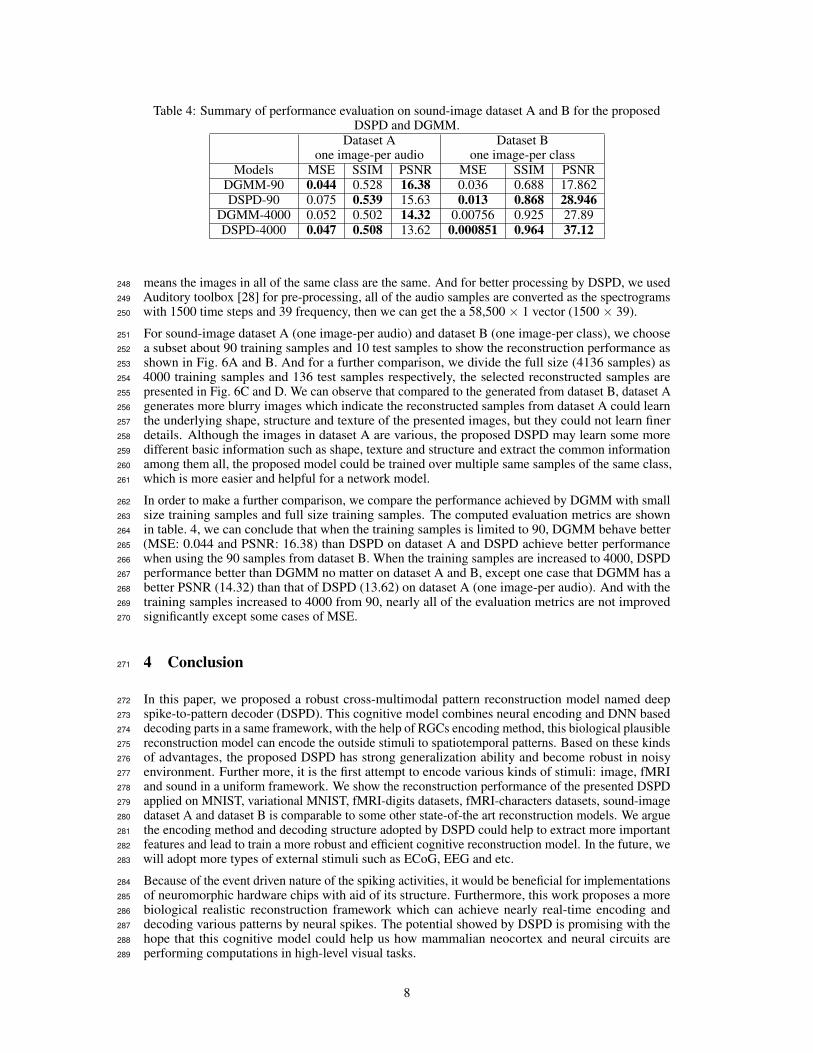
Table 4: Summary of performance evaluation on sound-image dataset A and B for the proposedDSPD and DGMM.
Dataset Aone image-per audio
Dataset Bone image-per class
Models MSE SSIM PSNR MSE SSIM PSNRDGMM-90 0.044 0.528 16.38 0.036 0.688 17.862DSPD-90 0.075 0.539 15.63 0.013 0.868 28.946
DGMM-4000 0.052 0.502 14.32 0.00756 0.925 27.89DSPD-4000 0.047 0.508 13.62 0.000851 0.964 37.12
means the images in all of the same class are the same. And for better processing by DSPD, we used248
Auditory toolbox [28] for pre-processing, all of the audio samples are converted as the spectrograms249
with 1500 time steps and 39 frequency, then we can get the a 58,500 × 1 vector (1500 × 39).250
For sound-image dataset A (one image-per audio) and dataset B (one image-per class), we choose251
a subset about 90 training samples and 10 test samples to show the reconstruction performance as252
shown in Fig. 6A and B. And for a further comparison, we divide the full size (4136 samples) as253
4000 training samples and 136 test samples respectively, the selected reconstructed samples are254
presented in Fig. 6C and D. We can observe that compared to the generated from dataset B, dataset A255
generates more blurry images which indicate the reconstructed samples from dataset A could learn256
the underlying shape, structure and texture of the presented images, but they could not learn finer257
details. Although the images in dataset A are various, the proposed DSPD may learn some more258
different basic information such as shape, texture and structure and extract the common information259
among them all, the proposed model could be trained over multiple same samples of the same class,260
which is more easier and helpful for a network model.261
In order to make a further comparison, we compare the performance achieved by DGMM with small262
size training samples and full size training samples. The computed evaluation metrics are shown263
in table. 4, we can conclude that when the training samples is limited to 90, DGMM behave better264
(MSE: 0.044 and PSNR: 16.38) than DSPD on dataset A and DSPD achieve better performance265
when using the 90 samples from dataset B. When the training samples are increased to 4000, DSPD266
performance better than DGMM no matter on dataset A and B, except one case that DGMM has a267
better PSNR (14.32) than that of DSPD (13.62) on dataset A (one image-per audio). And with the268
training samples increased to 4000 from 90, nearly all of the evaluation metrics are not improved269
significantly except some cases of MSE.270
4 Conclusion271
In this paper, we proposed a robust cross-multimodal pattern reconstruction model named deep272
spike-to-pattern decoder (DSPD). This cognitive model combines neural encoding and DNN based273
decoding parts in a same framework, with the help of RGCs encoding method, this biological plausible274
reconstruction model can encode the outside stimuli to spatiotemporal patterns. Based on these kinds275
of advantages, the proposed DSPD has strong generalization ability and become robust in noisy276
environment. Further more, it is the first attempt to encode various kinds of stimuli: image, fMRI277
and sound in a uniform framework. We show the reconstruction performance of the presented DSPD278
applied on MNIST, variational MNIST, fMRI-digits datasets, fMRI-characters datasets, sound-image279
dataset A and dataset B is comparable to some other state-of-the art reconstruction models. We argue280
the encoding method and decoding structure adopted by DSPD could help to extract more important281
features and lead to train a more robust and efficient cognitive reconstruction model. In the future, we282
will adopt more types of external stimuli such as ECoG, EEG and etc.283
Because of the event driven nature of the spiking activities, it would be beneficial for implementations284
of neuromorphic hardware chips with aid of its structure. Furthermore, this work proposes a more285
biological realistic reconstruction framework which can achieve nearly real-time encoding and286
decoding various patterns by neural spikes. The potential showed by DSPD is promising with the287
hope that this cognitive model could help us how mammalian neocortex and neural circuits are288
performing computations in high-level visual tasks.289
8

References290
[1] M. Parent, M. Lévesque, and A. Parent, “Two types of projection neurons in the internal291
pallidum of primates: single-axon tracing and three-dimensional reconstruction,” Journal of292
Comparative Neurology, vol. 439, no. 2, pp. 162–175, 2001.293
[2] J. K. Liu and T. Gollisch, “Spike-triggered covariance analysis reveals phenomenological294
diversity of contrast adaptation in the retina,” PLoS computational biology, vol. 11, no. 7, p.295
e1004425, 2015.296
[3] E. P. Simoncelli and B. A. Olshausen, “Natural image statistics and neural representation,”297
Annual review of neuroscience, vol. 24, no. 1, pp. 1193–1216, 2001.298
[4] H. Tang, K. C. Tan, and Z. Yi, Neural networks: computational models and applications.299
Springer Science & Business Media, 2007, vol. 53.300
[5] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, pp. 436–444,301
2015.302
[6] S. Schoenmakers, U. Güçlü, M. Van Gerven, and T. Heskes, “Gaussian mixture models and303
semantic gating improve reconstructions from human brain activity,” Frontiers in computational304
neuroscience, vol. 8, p. 173, 2015.305
[7] T. Naselaris, R. J. Prenger, K. N. Kay, M. Oliver, and J. L. Gallant, “Bayesian reconstruction of306
natural images from human brain activity,” Neuron, vol. 63, no. 6, pp. 902–915, 2009.307
[8] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in308
Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp.309
770–778.310
[9] Q. Xu, J. Peng, J. Shen, H. Tang, and G. Pan, “Deep CovDenseSNN: A hierarchical event-driven311
dynamic framework with spiking neurons in noisy environment,” Neural Networks, vol. 121, pp.312
512–519, 2020.313
[10] M. A. Van Gerven, B. Cseke, F. P. De Lange, and T. Heskes, “Efficient Bayesian multivariate314
fMRI analysis using a sparsifying spatio-temporal prior,” NeuroImage, vol. 50, no. 1, pp.315
150–161, 2010.316
[11] C. F. Cadieu, H. Hong, D. L. Yamins, N. Pinto, D. Ardila, E. A. Solomon, N. J. Majaj, and J. J.317
DiCarlo, “Deep neural networks rival the representation of primate IT cortex for core visual318
object recognition,” PLoS Comput Biol, vol. 10, no. 12, p. e1003963, 2014.319
[12] J.-D. Haynes and G. Rees, “Predicting the orientation of invisible stimuli from activity in human320
primary visual cortex,” Nature neuroscience, vol. 8, no. 5, pp. 686–691, 2005.321
[13] G. Buzsáki, R. Llinas, W. Singer, A. Berthoz, and Y. Christen, Temporal coding in the brain.322
Springer Science & Business Media, 2012.323
[14] G. Mueller-Putz, R. Scherer, G. Pfurtscheller, and C. Neuper, “Temporal coding of brain patterns324
for direct limb control in humans,” Frontiers in neuroscience, vol. 4, p. 34, 2010.325
[15] J. K. Liu, H. M. Schreyer, A. Onken, F. Rozenblit, M. H. Khani, V. Krishnamoorthy, S. Panzeri,326
and T. Gollisch, “Inference of neuronal functional circuitry with spike-triggered non-negative327
matrix factorization,” Nature communications, vol. 8, no. 1, pp. 1–14, 2017.328
[16] Y. LeCun, C. Cortes, and C. J. Burges, “The MNIST database of handwritten digits, 1998,” URL329
http://yann. lecun. com/exdb/mnist, vol. 10, p. 34, 1998.330
[17] H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio, “An empirical evaluation331
of deep architectures on problems with many factors of variation,” in Proceedings of the 24th332
international conference on Machine learning, 2007, pp. 473–480.333
[18] M. A. van Gerven, F. P. de Lange, and T. Heskes, “Neural decoding with hierarchical generative334
models,” Neural computation, vol. 22, no. 12, pp. 3127–3142, 2010.335
9

[19] S. Schoenmakers, M. Barth, T. Heskes, and M. Van Gerven, “Linear reconstruction of perceived336
images from human brain activity,” NeuroImage, vol. 83, pp. 951–961, 2013.337
[20] D. Roy, P. Panda, and K. Roy, “Synthesizing Images From Spatio-Temporal Representations338
Using Spike-Based Backpropagation,” Frontiers in neuroscience, vol. 13, p. 621, 2019.339
[21] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving,340
M. Isard et al., “Tensorflow: A system for large-scale machine learning,” in 12th {USENIX}341
Symposium on Operating Systems Design and Implementation ({OSDI} 16), 2016, pp. 265–283.342
[22] A. Gulli and S. Pal, Deep learning with Keras. Packt Publishing Ltd, 2017.343
[23] Y. Zhang, S. Jia, Y. Zheng, Z. Yu, Y. Tian, S. Ma, T. Huang, and J. K. Liu, “Reconstruction of344
natural visual scenes from neural spikes with deep neural networks,” Neural Networks, vol. 125,345
pp. 19–30, 2020.346
[24] Y.-T. Lin and G. D. Finlayson, “Physically Plausible Spectral Reconstruction from RGB Images,”347
arXiv preprint arXiv:2001.00558, 2020.348
[25] L. v. d. Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of machine learning349
research, vol. 9, no. Nov, pp. 2579–2605, 2008.350
[26] C. Du, C. Du, L. Huang, and H. He, “Reconstructing perceived images from human brain351
activities with bayesian deep multiview learning,” IEEE transactions on neural networks and352
learning systems, vol. 30, no. 8, pp. 2310–2323, 2018.353
[27] M. Liberman, R. Amsler, K. Church, E. Fox, C. Hafner, J. Klavans, M. Marcus, B. Mercer,354
J. Pedersen, P. Roossin et al., “Ti 46-word,” Philadelphia (Pennsylvania): Linguistic Data355
Consortium, 1993.356
[28] M. Slaney, “Auditory toolbox,” Interval Research Corporation, Tech. Rep, vol. 10, no. 1998,357
1998.358
10
Copyright © 2022 FDOKUMEN




















