
Corpus-Based Speech Enhancement With Uncertainty
15
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013 983 Corpus-Based Speech Enhancement With Uncertainty Modeling and Cepstral Smoothing Robert M. Nickel, Member, IEEE, Ramón Fernández Astudillo, Member, IEEE, Dorothea Kolossa, Senior Member, IEEE, and Rainer Martin, Fellow, IEEE Abstract—We present a new approach for corpus-based speech enhancement that significantly improves over a method published by Xiao and Nickel in 2010. Corpus-based enhancement systems do not merely filter an incoming noisy signal, but resynthesize its speech content via an inventory of pre-recorded clean signals. The goal of the procedure is to perceptually improve the sound of speech signals in background noise. The proposed new method modifies Xiao’s method in four significant ways. Firstly, it employs a Gaussian mixture model (GMM) instead of a vector quantizer in the phoneme recognition front-end. Secondly, the state decoding of the recognition stage is supported with an uncertainty modeling technique. With the GMM and the uncertainty modeling it is possible to eliminate the need for noise dependent system training. Thirdly, the post-processing of the original method via sinusoidal modeling is replaced with a powerful cepstral smoothing opera- tion. And lastly, due to the improvements of these modifications, it is possible to extend the operational bandwidth of the proce- dure from 4 kHz to 8 kHz. The performance of the proposed method was evaluated across different noise types and different signal-to-noise ratios. The new method was able to significantly outperform traditional methods, including the one by Xiao and Nickel, in terms of PESQ scores and other objective quality measures. Results of subjective CMOS tests over a smaller set of test samples support our claims. Index Terms—Inventory-style speech enhancement, modified imputation, uncertainty-of-observation techniques. I. INTRODUCTION O VER the past forty years the research community has de- veloped many powerful single-channel methods for the perceptual enhancement of speech corrupted by additive noise. The majority of these methods rely on adaptive filtering or spec- tral subtraction to tackle the problem. Since both types are math- ematically equivalent we will refer to them both as filtering- Manuscript received May 11, 2012; revised August 29, 2012; accepted December 09, 2012. Date of publication January 29, 2013; date of current version February 13, 2013. The work of R. M. Nickel was supported by a Marie Curie International Incoming Fellowship through the European Union, Grant PIIF-GA- 2009-253003-InventHI. The work of R. F. Astudillo was supported by the Portuguese Foundation for Science and Technology under Grant SFRH/BPD/68428/2010 and Project PEst-OE/EEI/LA0021/2011. R. M. Nickel performed the work while at the Institute of Communication Acoustics, Ruhr-Universität Bochum, Bochum, Germany. The associate editor coordinating the review of this manuscript and approving it for publication was Prof. Thomas Fang Zheng. R. M. Nickel is with the Department of Electrical Engineering, Bucknell Uni- versity, Lewisburg, PA 17837, USA (e-mail: [email protected]). R. F. Astudillo is with the Spoken Language Systems Laboratory, INESC-ID Lisboa, 1000-029 Lisbon, Portugal (e-mail: [email protected]; [email protected]). D. Kolossa and R. Martin are with the Institute of Communication Acous- tics, Ruhr-Universität Bochum, 44801 Bochum, Germany (e-mail: dorothea. [email protected]; [email protected]). Digital Object Identifier 10.1109/TASL.2013.2243434 based methods for simplicity [1]. With filtering-based methods it has become possible to achieve remarkable results in noise re- duction and enhancement [2]. One of the most hampering fac- tors to further improvements, however, is that, up to this point in time, we do not have a mathematical model for speech that is: a) faithful enough to deliver perfectly natural sound and b) simple enough to allow robust and accurate estimation of its underlying model parameters in adverse noise conditions. Fil- tering-based methods typically capture only partial character- istics of a speech waveform through spectral envelope models and/or probability distributions of spectral samples for example. A summary of some important work and well known algorithms of this kind is provided in Section II-B. An alternative approach to filtering is an analysis/resynthesis procedure in which a noisy signal is not merely filtered, but resynthesized as a new “clean” signal from a prerecorded in- ventory of clean speech waveforms. The advantage of such an analysis/resynthesis scheme is that the resulting clean speech signal has the potential to be (almost) free of artifacts, at least to the degree that the resynthesis model allows. Technically feasible implementations of an analysis/resynthesis paradigm were published in 2010 by Xiao and Nickel [3] and in 2011 by Ming et al. [4] (see also [5]). These procedures employ a speech corpus- or inventory-driven resynthesis mechanism and are therefore termed corpus-based or inventory-style enhance- ment schemes. They provide a powerful means to infuse more knowledge about the specific characteristics of speech into the enhancement process by tightly restricting the enhanced signal to segments of prerecorded speech from a targeted individual. The implied “waveform-matching” has the advantage that, ef- fectively, not only the spectral magnitude of a speech signal is estimated but also its spectral phase 1 . Furthermore, in using pre- recorded waveforms the procedure shares desirable properties with corpus-based synthesis in producing high quality, naturally sounding output. This advantage, however, comes at the price of a significantly increased complexity, higher storage require- ments, speaker dependency, and substantial off-line training as implied in the method proposed by Xiao and Nickel [3]. Specific techniques for the reduction of complexity and storage require- ments have been discussed in [6]. In this paper we are presenting a substantial modification to the method of Xiao and Nickel. While the original approach required noise specific training [3], we now describe a system that does not require any a priori knowledge about the expected noise during the training process. At the heart of our new system is a GMM-driven recognition front-end. The state decoding of the recognizer is supported with an uncertainty modeling tech- 1 Filtering-based methods typically only estimate the magnitude and use the phase of the noisy signal. 1558-7916/$31.00 © 2013 IEEE
Transcript of Corpus-Based Speech Enhancement With Uncertainty

IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013 983
Corpus-Based Speech Enhancement With UncertaintyModeling and Cepstral Smoothing
Robert M. Nickel, Member, IEEE, Ramón Fernández Astudillo, Member, IEEE,Dorothea Kolossa, Senior Member, IEEE, and Rainer Martin, Fellow, IEEE
Abstract—We present a new approach for corpus-based speechenhancement that significantly improves over a method publishedby Xiao and Nickel in 2010. Corpus-based enhancement systemsdo not merely filter an incoming noisy signal, but resynthesizeits speech content via an inventory of pre-recorded clean signals.The goal of the procedure is to perceptually improve the soundof speech signals in background noise. The proposed new methodmodifies Xiao’s method in four significant ways. Firstly, it employsa Gaussian mixture model (GMM) instead of a vector quantizer inthe phoneme recognition front-end. Secondly, the state decodingof the recognition stage is supported with an uncertainty modelingtechnique. With the GMM and the uncertainty modeling it ispossible to eliminate the need for noise dependent system training.Thirdly, the post-processing of the original method via sinusoidalmodeling is replaced with a powerful cepstral smoothing opera-tion. And lastly, due to the improvements of these modifications,it is possible to extend the operational bandwidth of the proce-dure from 4 kHz to 8 kHz. The performance of the proposedmethod was evaluated across different noise types and differentsignal-to-noise ratios. The new method was able to significantlyoutperform traditional methods, including the one by Xiao andNickel, in terms of PESQ scores and other objective qualitymeasures. Results of subjective CMOS tests over a smaller set oftest samples support our claims.
Index Terms—Inventory-style speech enhancement, modifiedimputation, uncertainty-of-observation techniques.
I. INTRODUCTION
O VER the past forty years the research community has de-veloped many powerful single-channel methods for the
perceptual enhancement of speech corrupted by additive noise.The majority of these methods rely on adaptive filtering or spec-tral subtraction to tackle the problem. Since both types are math-ematically equivalent we will refer to them both as filtering-
Manuscript received May 11, 2012; revised August 29, 2012; acceptedDecember 09, 2012. Date of publication January 29, 2013; date of currentversion February 13, 2013. The work of R. M. Nickel was supported bya Marie Curie International Incoming Fellowship through the EuropeanUnion, Grant PIIF-GA- 2009-253003-InventHI. The work of R. F. Astudillowas supported by the Portuguese Foundation for Science and Technologyunder Grant SFRH/BPD/68428/2010 and Project PEst-OE/EEI/LA0021/2011.R. M. Nickel performed the work while at the Institute of CommunicationAcoustics, Ruhr-Universität Bochum, Bochum, Germany. The associate editorcoordinating the review of this manuscript and approving it for publication wasProf. Thomas Fang Zheng.R. M. Nickel is with the Department of Electrical Engineering, Bucknell Uni-
versity, Lewisburg, PA 17837, USA (e-mail: [email protected]).R. F. Astudillo is with the Spoken Language Systems Laboratory,
INESC-ID Lisboa, 1000-029 Lisbon, Portugal (e-mail: [email protected];[email protected]).D. Kolossa and R. Martin are with the Institute of Communication Acous-
tics, Ruhr-Universität Bochum, 44801 Bochum, Germany (e-mail: [email protected]; [email protected]).Digital Object Identifier 10.1109/TASL.2013.2243434
based methods for simplicity [1]. With filtering-based methodsit has become possible to achieve remarkable results in noise re-duction and enhancement [2]. One of the most hampering fac-tors to further improvements, however, is that, up to this pointin time, we do not have a mathematical model for speech thatis: a) faithful enough to deliver perfectly natural sound and b)simple enough to allow robust and accurate estimation of itsunderlying model parameters in adverse noise conditions. Fil-tering-based methods typically capture only partial character-istics of a speech waveform through spectral envelope modelsand/or probability distributions of spectral samples for example.A summary of some important work and well known algorithmsof this kind is provided in Section II-B.An alternative approach to filtering is an analysis/resynthesis
procedure in which a noisy signal is not merely filtered, butresynthesized as a new “clean” signal from a prerecorded in-ventory of clean speech waveforms. The advantage of such ananalysis/resynthesis scheme is that the resulting clean speechsignal has the potential to be (almost) free of artifacts, at leastto the degree that the resynthesis model allows. Technicallyfeasible implementations of an analysis/resynthesis paradigmwere published in 2010 by Xiao and Nickel [3] and in 2011by Ming et al. [4] (see also [5]). These procedures employ aspeech corpus- or inventory-driven resynthesis mechanism andare therefore termed corpus-based or inventory-style enhance-ment schemes. They provide a powerful means to infuse moreknowledge about the specific characteristics of speech into theenhancement process by tightly restricting the enhanced signalto segments of prerecorded speech from a targeted individual.The implied “waveform-matching” has the advantage that, ef-fectively, not only the spectral magnitude of a speech signal isestimated but also its spectral phase1. Furthermore, in using pre-recorded waveforms the procedure shares desirable propertieswith corpus-based synthesis in producing high quality, naturallysounding output. This advantage, however, comes at the priceof a significantly increased complexity, higher storage require-ments, speaker dependency, and substantial off-line training asimplied in the method proposed by Xiao and Nickel [3]. Specifictechniques for the reduction of complexity and storage require-ments have been discussed in [6].In this paper we are presenting a substantial modification to
the method of Xiao and Nickel. While the original approachrequired noise specific training [3], we now describe a systemthat does not require any a priori knowledge about the expectednoise during the training process. At the heart of our new systemis a GMM-driven recognition front-end. The state decoding ofthe recognizer is supported with an uncertainty modeling tech-
1Filtering-based methods typically only estimate the magnitude and use thephase of the noisy signal.
1558-7916/$31.00 © 2013 IEEE

984 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
nique based on modified imputation [7]. In addition, we wereable to improve the post-processing stage of the procedure byswitching from a sinusoidal analysis/resynthesis scheme to acepstral smoothing algorithm [8]. The performance gains thatwe were able to obtain from these modifications allowed us to,furthermore, expand the bandwidth of the proposed system from4 kHz to 8 kHz (see also [9]).We structured the presentation in the remainder of this paper
as follows: a summary of important related work is discussedin Section II, implementation details of the proposed methodare comprehensively described in Sections III–VI, and theresults of an experimental performance analysis are reportedin Section VII. The palette of feasible technical applicationsfor the proposed method is, unfortunately, limited due to thespeaker specific training requirement. There are, however,important niche applications in which speaker specific trainingis, in fact, not only feasible but possibly of great advantage tothe system (e.g., for fighter jet pilots).
II. RELATED WORK
Before we delve into the details of the proposed method inSection III, it is helpful to first discuss a few concepts fromrelevant work by other authors. We have divided this sectioninto two subsections: a discussion of filtering-based methodsand a discussion of work related to inventory-style methods.
A. Filtering-Based Methods
Adaptive filtering and adaptive spectral subtraction are themost widely used methods for single-channel speech enhance-ment in use today. We refer to both methods collectively as fil-tering-based methods [1]. The adaptation of the respective filterparameters of these methods is typically performed with thehelp of two essential system components: 1) a noise spectrumestimator, such as the improved minima-controlled recursive av-eraging (IMCRA) algorithm proposed by Cohen [10] or theminimum statistics algorithm by Martin [11] for example, and2) an a-priori signal-to-noise ratio (SNR) estimator, such as thedecision-directed approach by Ephraim and Malah for example[12] (see also [2]). Filter gains are determined through short timespectral amplitude (STSA) estimators or the log spectral ampli-tude estimator (log-MMSE) [13] or other suitable mappings [2].In filtering-based techniques, the quality of the resulting
enhanced signal depends greatly on the quality of the corre-sponding SNR and STSA estimate. Improvements of adaptiveSNR and STSA estimators have, therefore, received a sig-nificant amount of attention in the research community. Aunified framework for a number of different STSA estimatorswas recently presented by Borgström and Alwan [14], mul-tidimensional STSA estimators were studied by Plourde andChampagne [15], a theoretical study of the performance ofenhancement schemes based on the decision-directed approachfor SNR estimation was published by Breithaupt and Martin[16], and the general relationship between spectral estimationand the resulting speech enhancement performance was studiedby Charoenruengkit and Erdöl [17]. Particularly challengingin STSA estimation is the accurate incorporation of spectralinter-frame dependencies for which Laska et al. proposed aparticle-filter-based approach in 2010 [18]. A related problemis the attenuation of rapidly transient noise types for which
Talmon et al. described a non-local diffusion filter approach in2011 [19].A fundamental problem of speech enhancement techniques in
general, and filtering-based techniques in particular, is that thereis usually an implied tradeoff between noise suppression andsignal distortion. Aggressive noise reduction schemes typicallydistort the underlying speech signal. Musical tones, unnaturalspectral shaping, temporal envelope fluctuations, and other arti-facts are often the result. Many authors have developed methodsfor the suppression and/or mitigation of artifacts in enhance-ment schemes [2]. Recent proposals include a method by Dinget al. to reduce some of these artifacts via the reconstruction ofover-attenuated spectral components [20], a method by Jo andYoo that exploits the masking threshold of human hearing tohide acoustic artifacts [21], and the method by Breithaupt et al.that employs cepstral smoothing for the reduction of musicalnoise [8].Further improvements in the quality of the enhanced signals
are only achievable with more refined models for, either, the tar-geted speech signals or, alternatively, the targeted noise types.Advancements that particularly exploit the harmonic structureof voiced speech, for example, were recently published by Dinget al. [22] and Jin et al. [23]. A refined statistical model forthe frequency coefficients of speech in the log-spectral domainwas exploited by Hao et al. [24] and an avenue for the in-corporation of an adaptive noise codebook was recently ex-plored by Rosenkranz and Puder [25]. Trained codebooks oflinear predictive coefficients for speech and noise were alsoused by Srinivasan et al. in [26]. Even though these methodshave made significant strides towards the development of highquality noise reduction schemes, they are all limited by the samefundamental tradeoff between noise suppression and signal dis-tortion, as they are all rooted in the filtering and/or spectral sub-traction paradigm.
B. Inventory-Style Methods
A key problem in inventory-style enhancement is the reliablerecognition of the underlying phonetic class of a noisy speechsegment. In standard approaches to automatic speech recogni-tion or phoneme classification, it is generally assumed that pre-processing delivers a good estimate of the clean speech signal.Under severely distorted conditions, however, any estimate ofthe clean speech will contain residual noise and possibly addi-tional distortions due to the applied signal processing. There-fore, instead of using just a point estimate of the clean speechsignal for phoneme recognition, it is valuable to consider cleanspeech as an underlying unknown process that can only be esti-mated with a residual, time-varying error variance.A good estimate of this variance can lead to significant im-
provements in recognition performance, since the recognizercan then focus on more reliable segments and/or features. Thesevariancesmay be obtained directly in the feature domain [27], orrespective variances can be estimated in the spectral domain andthen propagated into a cepstral feature domain with techniquesdescribed in [28] and [29]. The feature variances can then beused to improve recognition robustness via uncertainty-basedspeech decoding techniques. Such techniques may use the un-certainty for adaptively increasing the model variances, termedvariance compensation [30], for obtaining an additional HMM-based estimate of the clean features during decoding, so-called

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 985
modified imputation [7], or for HMM-based feature estimationin conjunction with variance adaptation [31].Alternatives to modified imputation can be found in other
approaches to environmental robustness of automatic speechrecognition. Some of these, such as speech fragment decoding[32], marginalization [33] or MAP imputation [34], work withbinary reliability estimates. Since we have continuous-valuedreliability estimates at our disposal, we have decided in this caseto use the more precise, continuous-valued uncertainty-of-ob-servation techniques. These also allow for observation uncer-tainties to be used in the more advantageous mel cepstrum do-main, rather than in the spectral domain, where binary uncer-tainties are typically derived.In contrast to other robustness techniques like model adap-
tation [35], [36] or parallel model combination [37], we try toremove the mean mismatch in our approach via filtering anduncertainty propagation as described in detail in Sections IVand VI. Thus, in contrast to mean-and-variance adaptation tech-niques, we only need to compensate the dynamic variance mis-match in the decoder. An even more efficient compensationcould be a joint static and dynamic variance compensation inconjunction with mean adaptation by MLLR, as described in[27]. In the specific case considered here, we opted for modifiedimputation, though, since this approach has offered high-qualityrecognition results at an only incrementally increased computa-tional effort in many experiments, see, e.g., [38], and also effec-tively improved performance for the task at hand.
III. SYSTEM OVERVIEW AND NOTATION
For our proposedmethodwemust have access to an inventoryof prerecorded clean, i.e., undistorted, speech from a targetedindividual. For notational simplicity we assume that all sepa-rately prerecorded inventory utterances are, first, properly en-ergy equalized via ITU-T P.56 [39] and then concatenated intoone long signal stream . For the description of the enhance-ment procedure we use to denote an observed noisy utter-ance from the targeted speaker. We consideras the input to our enhancement system, in which denotesthe underlying clean speech signal and denotes additivenoise. The output of our system, i.e., our estimate for , is de-noted as either or, after the proposed cepstral smoothing, as
. All signals are assumed to be bandlimited between 50 Hzand 8 kHz and sampled at a rate of 16 kHz.The proposed procedure employs signal segmentations with
varying grades of temporal “granularity,” i.e., with varyingframe lengths and varying amounts of overlap. We use thenotation to denote a vector of successive samples of
from to :
(1)
The extraction of the th element from a vector is written as:
forotherwise.
(2)
We, furthermore, define a triangular window of evenlength as:
for
for
otherwise.
(3)
In the phonetic classification stage of our procedure (seeSection IV) we use 20 ms frames with a 50% overlap. Fornotational simplicity, we write the associated signal segmentscompactly as:
(4)
The frame symbols , , , etc. are defined analogously.From a stream of frames with , 1, 2, and so forth it isalways possible to reconstruct the underlying signal via aninterlacing cross-fading procedure:
(5)
The same rule applies to the segment streams , , , andso forth. The signal segmentation for the correlation search stageof our procedure (see Section VI) operates on a finer grid thanthe one applied to the . Here, we employ 10 msec frameswith an 87.5% overlap:
(6)
Again, frame symbols , , and so forth are defined analo-gously and reconstruction is possible with the interlacing cross-fading procedure:
(7)
The reader may note that with (4)–(7) it is possible to easilyconvert the frame stream into and vice versa. This ap-plies similarly to other streams such as and for example.Throughout the description of the proposed procedure we will,therefore, move from a signal representation in into a repre-sentation in (and vice versa) without an explicit reference tothe details at each time. Furthermore, there is a unique temporalrelation between frames on the coarser -grid and a collectionof frames on the finer -grid. Information that is extracted for aframe is therefore passed on to and applied to the temporallyassociated collection of multiple frames on the -grid.A conceptual block diagram of the entire enhancement
system is shown in Fig. 1. First, the incoming signal issegmented. The resulting segment stream is passed tothree subsystems: (A) a conventional log-spectral minimummean square error (log-MMSE) filter after [13], (B) a voiceactivity detection (VAD) mechanism after Sohn and Kim [40](see also [2, Section 11.2]), and (C) the proposed inventorysearch procedure after Section VI. The employed log-MMSEfilter uses a decision-directed approach after [12] (see also[2, Section 7.4]) to estimate the underlying a priori SNR anda VAD-supported time-recursive averaging method after [2,Section 9.4], to estimate the underlying power of the noise. TheVAD block provides three important functions: (1) it activatesthe inventory search part of the algorithm only during times inwhich a speech signal is assumed to be present in the input,

986 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
Fig. 1. A block diagram of the proposed procedure.
(2) it provides the log-MMSE filter with information aboutwhen to update its internal estimate of the noise power spectraldensity (PSD), and (3) it is used to control the stream selectionand normalization procedure that fuses the output framesof the log-MMSE filter with the output frames of theinventory search procedure. The VAD selects streamduring times of voice activity and stream otherwise. Thedivision of the processing into separate streams andincreases the robustness of the proposed method during timesin which the VAD is inaccurate and/or unreliable, particularlyduring transition times between voice active and silence states.The output frames of the stream selection and normal-
ization block are subjected to a cepstral smoothing procedureand are then reconcatenated via cross-fading into the enhancedoutput signal .The implementation details for the proposed inventory search
are comprehensively described in the following subsections.The essential goal of the inventory search is to replace the in-coming frames with suitable waveforms from the in-ventory. We have divided our description into three sections:(Section IV) the robust feature extraction part that is required forboth training and enhancement, (Section V) the system trainingpart that organizes the inventory and learns its underlying statis-tical properties, and (Section VI) the actual speech enhancementprocedure as outlined in the block diagram from Fig. 1.
IV. FEATURE EXTRACTION AND UNCERTAINTY MODELING
To increase the robustness in the frame selection process de-scribed in Section VI, a robust feature extraction with short-time Fourier transform (STFT) domain uncertainty propagation(STFT-UP) was used. Our implementation followed the lines
of [28], using STFT-UP to compute a minimum mean squareerror (MMSE) estimate directly in the mel-frequency cepstralcoefficient (MFCC) domain. For this particular implementation,amplitude based MFCCs with cepstral mean subtraction wereused to attain improved performance. These correspond to theformulas
(8)
in which and are the Mel-filterbank and discrete cosinetransform (DCT) matrix, respectively and is the total numberof frames for a single utterance. Here denotes the discreteFourier transform of the unseen clean frame and magni-tude and logarithm transformations are assumed to operate ele-ment-wise. The second equation in (8) corresponds to the cep-stral mean subtraction (CMS) operation which needs knowledgeof all frames in the utterance. We are augmenting our 13-dimen-sional MFCC vectors with the usual and coeffi-cients after [41] or [42, Section 9.3.3] to arrive at a 39-dimen-sional feature vector . Inorder to compute an MMSE-MFCC estimate with STFT-UP, aconventional Wiener filter [43] with IMCRA [44] noise estima-tion is first applied in the STFT domain. However, rather thandirectly passing the filter point-estimate to the feature extrac-tion process, the whole posterior associated to the Wiener esti-mate is considered instead. Let and denote the discreteFourier transforms of the unseen clean frame and an observ-able noisy frame respectively. We can obtain the posteriorassociated to the Wiener filter by applying Bayes’ theorem tothe conventional complex Gaussian distortion model yielding[45]
(9)
where is a -dimensional complex Gaussian distribu-tion of Fourier coefficients , is a vector of Wiener-filter estimates of the clean Fourier coefficients for the givenmodel, and is a diagonal covariance matrix equal to the es-timated residual mean square error. Transforming the randomvariable specified by the Wiener posterior in (9), rather thana point-estimate, through the feature extraction in (8) leads toa corresponding feature posterior in the MFCC domain. It canbe proven that such a posterior yields MMSE estimates of themel-frequency cepstrum coefficients [28] like those from [46]and [47]. It can be demonstrated as well that the posterior forthe selected features is well approximated by the multivariateGaussian distribution [28, Ch. 7]
(10)
for which the mean and variance can be computed by using theconventional STFT-UP formulas. The mean of the MFCC partof our feature vector is computable via
(11)

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 987
Here is the Ephraim-Malah short-time spectral amplitudeestimate (the MMSE-STSA estimate) [48], and is thecovariance of the uncertain log-filterbank features, assuminglog-normally distributed, statistically independent filterbankoutputs. Both parameters can be computed from the Wienerposterior in (9) as described in [28, Ch.6]. The log-normalityassumption used here is a practical choice since it allowsthe easy computation of the resulting log-filterbank variance.The exact distribution remains, to the best of our knowledge,unknown.The covariances of the MFCC part of our feature
vector can be computed analogously with
(12)
where matrix denotes the same as matrix , but with all ofits elements squared. The extension of the MFCC parameters
and to the posterior parameters andof our full feature vector is trivial since it involves the usualand transformations. The resulting formulas are omitted
since the and operations merely perform a linear trans-formation on multivariate Gaussian random variables.Note that all derivations in this section were carried out with
the observation signal as the input. If the feature meansare computed from the inventory instead, then the notation
is used.
V. SYSTEM TRAINING AND INVENTORY DESIGN
The goal of the system training and inventory design stage istwofold: (1) we need to divide the inventory into collectionsof phonetically similar segments with varying lengthsfor , and (2) we need to arrive at a statistical de-
scription that tells us which set of collections is most likelyto contain the inventory subsection that best matches the under-lying clean frame of an incoming noisy frame .The division of the inventory into the collections is
performed in a step-by-step fashion. First, is segmentedand all silent segments are removed. The non-silent part of theinventory is then divided into sections that each belong to oneof 40 phonetic classes. In this work, we employed the phonetictranscription that was provided with our experimental database(see Section VII). If a phonetic transcription is not available thenone may also use the unsupervised clustering method describedin [3].We are applying the feature extraction mechanism that was
discussed in the previous section to the entire segment streamof the inventory. Because the inventory signal is as-
sumed to be virtually undistorted, it is sufficient to only retainthe resulting short-time MFCC feature means and to dis-card the associated variance estimates. The feature meansbecome, thereby, essentially feature vectors in their own rightand we can develop a cluster model for them. We have decidedto use the means and not the actual cepstral vectors atthis stage to ensure that the impact of the mean-extraction-pro-cessing is captured in our feature representation. Since there isa tight connection between an inventory frame and its asso-ciated feature mean it becomes possible to use the cluster
model to assign each segment of the inventory to a uniqueset that collects all segments/waveforms with similar pho-netic characteristics.A significant problem of the original inventory-style en-
hancement method of Xiao and Nickel [3] was that theirmodel for MFCC features (which corresponds to our modelfor the MFCC feature means ) was too restrictive inthe shape of the cluster boundaries to account for the variouscoarticulation effects that may be observed for a segment of acertain phonemic function. Furthermore, because the originalmethod lumped all waveforms that belong to a phonetic unitinto a single cluster it was impossible to exploit the statisticalinterdependencies between these coarticulation effects. Wetherefore moved to a model that allowed the distinction be-tween coarticulation effects by dividing each phonetic clusterinto a fixed number of subclusters. To this end, we trainedGaussian mixture models (GMMs) with mixtures and diag-onal covariance matrices with the corresponding vectorsfor each of the 40 phonetic classes. Choosing a “good” valuefor was not a trivial task. Obviously, larger values pro-vided a more intricate modeling of coarticulation effects. Withlarger values, however, we also needed more training datato reliably estimate the growing number of parameters of ourstatistical model. We experimented with a number of valuesand eventually settled on as a reasonable compromise2
given the experimental data available to us.A second issue associated with the division of our phonetic
clusters into subclusters pertains to the resulting computationalcomplexity of the proposed method. If we chose each of thethree Gaussians of our GMM as a model for the correspondingsubcluster then the amount of data assigned to each clusterwould exhibit a high variability. An unbalanced distribution ofdata between clusters, however, leads to long (and unbalanced)execution times for the inventory search process described inSection VI. It is helpful if the amount of data contained in eachcluster does not vary too much. Forcing each cluster to containthe exact same data size, however, is not likely to match verywell with the cluster’s intended phonemic function. Ideally,we would like to find a compromise that reduces the spread ofcluster sizes, yet does not dramatically impact the phonemicfunction associated with each cluster/state.In our simulations we employed the following heuristic
method to “gently” balance the distribution of cluster sizes.In a first step, we used the 40 phonetic GMMs to reclassifyeach anew. Most vectors remained in the same class.Yet, a significant number of the had to be reassignedso that strict decision boundaries could be enforced and thatcluster membership ambiguities could be avoided. We thendivided the vectors of each phonetic class into threesubclasses via a Euclidean k-means algorithm. A GaussianPDF model with a diagonal covariance structure was fit tothe vectors of each of the resulting 120 phonetic sub-classes. As a result we obtained 120 Gaussian PDF models
with mean vectorsand diagonal covariance matrices for .The proposed repartitioning procedure was able to reduce thestandard deviation of cluster sizes by approximately 30% andcontributed thereby to significantly faster execution times of the
2Our choice to use was partly driven by the fact that led tooverfitting problems in the GMM training for a number of smaller clusters.

988 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
subsequent inventory search procedure without dramaticallyimpacting the perceptual performance of the system.The resulting Gaussian models allow us to assign a unique
state to each non-silent inventory frame by convertingthe into a stream of MFCC feature means and thencomputing the associated states via
(13)
All transitions from class to class are tallied and a120 120-dimensional state transition probability matrix iscomputed by dividing the number of observed transitions from aparticular state through the observed total number of occurencesof that state. Transitions to and from silent frames are ignored.The cluster PDFs for and the matrixconstitute the hidden Markov model (HMM) that is used in theenhancement process to estimate the temporal development ofthe spectral content in the targeted speech signal. It should bepointed out, though, that the resulting HMM proposed here doesnor bear much resemblance to the HMMs of a speech recogni-tion system. The proposed HMM is fully connected in the sensethat no transition from any state to any other state is ruled outprior to training3.As a last step we need to partition the inventory into the col-
lections of phonetically similar waveforms . To thatend we consider sequences of consecutive frames with thesame state number . We use to denote the number of suchframes as a function of , i.e.,
(14)
For each such sequence we define a segmentthrough and and assignit to the collection . The procedure is repeated for all thatare not already covered by a previously considered range (14).The inventory is thereby divided into subsections of differentelementary waveforms for . The lengthof each subsection is a multiple of 160. All subsections with
similar phonetic content are assigned to the same set .
VI. INVENTORY-BASED SPEECH ENHANCEMENT
Speech enhancement is performed according to the block di-agram in Fig. 1. The input signal is segmented into a streamof frames . The frames are processed in two main tracks. Astandard log-MMSE filter is used to produce a first stream of en-hanced frames . We employed the standard log-MMSE ap-proach after Ephraim and Malah in combination with the usualdecision-directed approach [12] (see also [2, Section 7.4]) forthe estimation of the underlying a priori SNR in the short-timeDFT domain and a VAD-supported time-recursive averagingmethod after [2, Section 9.4], to estimate the underlying powerof the noise.A second stream is obtained from the inventory-search
subsystem. Enhanced frames are only computed for thosesegments that were flagged as “voice active” by a VAD sub-system. The VAD system uses a log-likelihood detector afterSohn and Kim [40] (see also [2, section 11.2]). It requires thea-priori and a-posteriori SNR estimates from the log-MMSE
3This is in contrast to the left-right or Bakis type HMMs that are more com-monly used in automatic speech recognition systems.
track as an input. The initial binary decisions at the output ofthe detector are smoothedby feeding them through a 7-tap median filter to reduce deci-sion-flickering at the activity boundaries.
A. The Inventory Search Procedure
The core of the proposed corpus-based speech enhancementprocedure is provided by the Inventory Search subsystem asoutlined in the block diagram from Fig. 1. Frames thatare flagged as “voice active” are subjected to an extraction ofMFCC feature means and the associated covariance esti-mates according to Section IV. A noise adapted featuremean estimate is produced for each of thephonetic class models from Section V according to themodifiedimputation approach:
(15)
With we can find likelihood values for each phoneticclass via:
(16)
Preliminary experiments comparing the phonetic cluster recog-nition accuracy (PCRA) using modified imputation and stan-dard decoding have confirmed a highly significantrelative improvement of 31.5%4 due to the use of observationuncertainties via (15) and (16). We, therefore, opted to use thisapproach throughout all following experiments despite its slightcomputational overhead.With the estimates of the likelihoods and the probabili-
ties contained in our state transition matrix from Section Vit is possible via a Viterbi algorithm to find the most likelysequence of phonetic class memberships for a given se-quence of “voice active” segments . The Viterbi search isexecuted across streams of consecutive “voice active” frames
only. The process is suspended across “silent” frames andrestarted as soon as a new “voice active” frame is encountered.We assume that the transition probabilities be-tween the silent state and any state are uniformly distributed.The same applies to , i.e.,
.We found that relying on just a single state estimate for
each frame is overly restrictive. In our experiments, de-tailed in Section VII, the estimated states rarely matchedthe true states of the underlying clean signals . Performanceis dramatically improved, however, if not one but multiple statecandidates for each frame are passed to the inventory search.Ideally, these candidates would be computed via a global mul-tipath Viterbi search. Unfortunately, global multipath searchescannot guarantee5 to deliver a fixed number of path alternativesfor each frame . Instead, we pursued a local multipath ap-proach, which, despite its suboptimality, delivered good exper-imental results. Let denote the element from matrixthat contains the transition probability from state to state .
4Normalized by the respective PCRA difference between the Inventory VQand the Inventory MI method as defined in Section VII and averaged over allspeakers, noise types, and signal-noise ratios.5Finding the best paths through a Viterbi grid does not guarantee that at
each stage we observe distinct paths through distinct states.

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 989
We compute the following ‘one-step’ log-probability for eachstate
(17)
in which denotes the Viterbi choice at time .At the onset of “voice active” streams we set
. As our state estimates for frame we chose thethree states , , and with the three largest ‘one-step’log-probabilities for , 2, 3. A slight weakness ofthis ‘one-step’ approach is that it is theoretically possible thatthe resulting set of states , , and may not includethe Viterbi choice . This is rarely observed in practice,though, and is of little to no consequence to the perceptualquality of the output of our system.A collection of candidate waveform models for frameis found by merging the inventory collections for the three
state estimates , , and :
(18)
The search for the best waveform representation for inis performed with the normalized matched filter approach pro-posed in [3]. For the search we move from our coarse grid seg-mentation, implied in our notation, to the fine grid segmen-tation, implied in our notation from (6). The state informa-tion extracted for segment applies to eight -grid segments
for with:
(19)
The correlation search finds the subsegments within thesegments of that maximize the normalized inner productbetween and , i.e.,
(20)
The resulting best-fitting inventory frames are normal-ized to match the energy of the frames in the correspondinglog-MMSE stream :
(21)
For merging the corresponding log-MMSE estimates andthe inventory search estimates , we are moving back to the-grid representation:
if frame is flagged as ``voice active'',otherwise.
(22)
The main purpose of the merging of the streams in (22) is toprotect against failures of the VAD system to accurately flagthe presence of speech in the current frame. VAD systems canbe designed “conservatively” such that, in low SNR conditions,they rather “miss” speech presence instead of reporting a “false-alarm” when no speech is present. If we assume that we have a“conservatively” designed VAD then the performance of the In-ventory MI system is bounded from below by the performanceof the adaptive filter that produces , i.e., even in very ad-verse conditions the results will not be worse than that of thelog-MMSE filter.
B. Postprocessing and Cepstral Smoothing
Lastly, a signal post-processing procedure with cepstralsmoothing (CS) is applied. The approach is inspired by thework of Breithaupt, Gerkmann, and Martin (see [8] and [49]).It reduces musical artifacts due to the slight pitch and phasemismatches at the frame boundaries of the frames. We use
to denote the 1024 point FFT of the stream vectors :
(23)
From we, again, use a log-MMSE method like the oneused for the computation of stream to generate an adaptivelog-MMSE based spectral gain function [13]. The gainfunction is transformed into the cepstral domain via:
(24)
In a first step, we attempt to find the cepstral pitch indexof the underlying frame by means of a simple peak pickingprocedure:
(25)
The computation of an index should technically be appliedto voiced sections only (see [8]). Limiting (25) to voiced sec-tions, however, would require the implementation of a voiced/unvoiced classifier that operates robustly in noise. Instead, weconsidered applying the peak picking in (25) to both voiced andunvoiced frames. We found that the resulting inclusion of spu-rious pitch indices in unvoiced sections did not seem to signifi-cantly affect the perceptual quality of our experimental results.We, therefore, decided to apply (25) to all frames.In the following we use to denote the corresponding
FFT-aliased location of , i.e., . Knowingand , we modify the cepstral gain representation by
setting all cepstral coefficients to zero which are not part of thespectral envelope of the underlying speech signal or its associ-ated pitch:
for ,,
andotherwise.
(26)The coefficient is determining the assumed cepstral widthof the spectral envelope. In [8] the proposed choice foris as low as 4 (for signals with a 4 kHz bandwidth). In [49]the authors suggest that the choice for may be as high as20 for signals with an 8 kHz bandwidth. An “exact” choice islargely speaker and noise type dependent. In our experiments weselected with good results. Our choice was guided bythe inspection of cepstral representations from our clean trainingdata. Experiments revealed also, however, that the procedure isnot very sensitive to small changes in the -value. Slightlysmaller or larger values may work perfectly well as well.Parameter essentially determines limits on the width
and variation of the pitch-peaks from one frame to the next. In[8] the authors propose a rather tight choice of for sig-nals with a 4 kHz bandwidth. In [49] the authors propose a much

990 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
wider spread that is chosen in a signal dependent manner. In ourexperiments we chose with good results. However,slightly smaller or larger values did, again, not seem to have anyappreciable impact on the perceptual quality of the proposed en-hancement scheme.The cepstral smoothing of the gain function is accomplished
with an adaptive 1st-order IIR low-pass filter with a time- andquefrency-dependent parameter :
(27)forand ,otherwise.
(28)
The recursion is initialized with for all . Pleaserefer to [8] and [49] for a comprehensive description of the ra-tionale behind this smoothing operation.The smoothed cepstral representation is transformed
back into the spectral domain to arrive at a smoothed spectralgain function :
(29)
We limit the smoothed gain function to a maximum value ofunity and apply it to the magnitude of the stream STFT :
(30)
An inverse FFT transforms the resulting smoothed stream STFTback into the time domain:
(31)
By denoting the output of the cepstral smoothing procedure withwe are slightly abusing the notation defined in (4) since
is a now a segment of length 1024 (and not of length 320).The final step in our enhancement procedure consists of
reconcatenating the frames back into an output samplestream . Again, we employ an interlacing cross-fadingprocedure similar to (5). This final step is referred to as segmentconcatenation in our block diagram from Fig. 1.
VII. EXPERIMENTAL RESULTS
We analyzed the performance of the proposed method withina variety of noise scenarios. Results were compared to fourestablished reference techniques. Two of these reference tech-niques were log-MMSE enhancers after Ephraim and Malah[50]. One of these methods, referred to as log-MMSE(MS),employed the Minimum Statistics technique developed byMartin [11] to estimate the underlying noise power. The othermethod, referred to as log-MMSE(RA), employed the sameVAD-supported Recursive Averaging that was also used in the“log-MMSE Filter” block of Fig. 1. The performance gains
between the log-MMSE(RA)method and the proposed methodare, therefore, directly attributable to the inventory search andthe subsequent cepstral smoothing. As a third reference methodwe chose the Multiband Spectral Subtraction (MBSS) tech-nique proposed by Kamath and Loizou [2] and lastly, we alsoimplemented a slightly modified version of the inventory-stylebaseline system proposed by Xiao and Nickel in [3].The main goal of the proposed procedure was to improve
over the reference methods in terms of the Perceptual Evalua-tion of Speech Quality (PESQ) measure by Rix et al. [51]. ThePESQ measure is one of the few objective quality measures thatcorrelate well with subjective quality of speech6 [52]. We chosethe log-MMSE(RA) and the MBSS approach specificallybecause they were the most competitive of all of the referencetechniques studied in [3]. Among all reference methods—theproposed one aside—the log-MMSE(RA) approach performedbest in terms of PESQ measures in stationary noise scenarios(see Tables IV and V) whereas the MBSS method performedbest in non-stationary noise scenarios (see Table VI). Thechosen log-MMSE(MS) approach was added as it strikes abalance between the log-MMSE(RA) and the MBSS perfor-mances. The log-MMSE(MS) method was more successfulthan the MBSS method in stationary noise (see Tables IV andV) and more successful than the log-MMSE(RA) method innon-stationary noise (see Table VI). It should be emphasizedthat neither the log-MMSE(RA), nor the MBSS, nor thelog-MMSE(MS) method require any speaker specific training.As such, the three methods were therefore somewhat at adisadvantage when compared to the proposed approach.As a baseline reference for inventory-style enhancement
we essentially used the method described in [3] with a fewmodifications. Since the method employs vector-quantizationfor phoneme classification we refer to it as Inventory VQ.The differences between the Inventory VQ method used inthis work and the one proposed in [3] were: (1) the underlyingspeech was sampled at 16 kHz instead of 8 kHz, (2) instead of50 phonetic clusters we used only 40 (to match the number ofphonemes in the transcription of our experimental database),and (3) the system was trained with 10 dB white noise only.Evaluations at different SNR values and with different noisetypes, therefore, establish mismatch scenarios between trainingand testing for the Inventory VQ case. The modifications werenecessary to guarantee a fair comparison between the InventoryVQ method and the method proposed in this paper, which doesnot require any noise specific training. The proposed methodwas implemented according to the procedures described inSections III–VI. We are referring to it as Inventory MI sincephoneme classification is accomplished with a modified impu-tation approach in this case.The database from the Language Technologies
Institute at Carnegie Mellon University7 was used for our ex-perimental evaluation. The database consists of recordings fromtwoUS Englishmale speakers with identifiers and , twoUS English female speakers with identifiers and , one
6Even though the PESQ measure was primarily developed for the evaluationof speech coding algorithms it has, nevertheless, been used frequently to eval-uate speech enhancement schemes as well.7The corpus is available at http://festvox.org/cmu_arctic/.

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 991
Canadian English male speaker with identifier , one Scot-tish English male speaker with identifier , and one IndianEnglish male speaker with identifier . The seven speakersets contain a minimum of 1132 phonetically balanced Englishutterances each. The length of most utterances is between oneand four seconds. The content of the recorded sentences wasspecifically designed to meet the requirements of concatenativespeech synthesis systems. The database includes full phonetictranscriptions of all utterances with (roughly) 40 elementaryphonetic units per speaker.The additive noise employed in our experiments was taken
from the database from the Institute for Perception-TNO, The Netherlands Speech Research Unit, RSRE, UK8. Inour study we used three types: (1) white noise, (2) buccaneer jetcockpit noise, and (3) speech babble. The buccaneer jet cockpitnoise served as an example for a stationary, non-white noisetype and the speech babble served as an example of a non-sta-tionary noise type. The noise was added to the speech data atsignal-to-noise ratios (SNR) of 5 dB, 10 dB, and 15 dB, underconsideration of the respective active speech level after ITU rec-ommendation ITU-T P.56 [39].The available speech data was split into two strictly disjoint
sets: (1) a training set, which served as our inventory for the In-ventory VQ and the proposed Inventory MI methods, and (2)a testing set for performance evaluations. The training set con-sisted of 1082 utterances per speaker and the testing set con-sisted of 50 utterances per speaker.All considered methods were subjected to a thorough quality
assessment with six standardized objective quality metrics. Inaddition, subjective listening tests with human listeners wereperformed over a subset of methods and with a limited scope.The results of the listening tests are discussed separately inSection VII-C.The six objective quality measures considered in this sec-
tion are the Perceptual Evaluation of Speech Quality (PESQ,[51]), the Cepstrum Distance Measure (CEPD, [53]), the Fre-quency-Weighted Segmental SNR (FSNR, [54]), as well as threeComposite Measures after Loizou et al. [2] for Signal Distor-tion (CMPs), Noise Distortion (CMPn), and Overall Quality(CMPo). The composite measures were computed via linearcombinations of standard objective measures such as PESQ,CEPD, FSNR, and four others. The weights for each measurewere determined by Loizou et al. through a multiple linear re-gression analysis to match over 40,000 subjective listener scoresfor signal distortion, noise distortion, and overall quality respec-tively in a variety of speech enhancement scenarios. The detailsare comprehensively described in [2].Before we review the results of our experiments in detail, we
should emphasize again that the goal of our proposed procedureis the perceptual enhancement of noisy speech for human lis-teners. We will, therefore, be focusing the discussion mostly onthe PESQ measure and the composite measures CMPs, CMPn,and CMPo. We have included the remaining two measuresCEPD and FSNR for the sake of completeness, and to shedsome light on the potential of the proposed scheme to act asan effective preprocessor to an automatic speech recognition(ASR) system.In order to ensure a robust determination of quality (for PESQ
in particular) we concatenated enhanced utterances in groups of
8The noise is available at http://spib.rice.edu/spib/select_noise.html.
five, so that all quality measures were computed from signalsof sufficient length. All quality scores are reported as averagesover all 10 concatenation groups (from the 50 testing utterances)and all 7 speakers.Specifically for the Inventory VQ and the Inventory MI
method we also computed the Phonetic Cluster RecognitionAccuracy (PCRA, [55]). The PCRA is an indirect measure ofquality that allows us to compare inventory-based enhancementmethods. At lower SNR values the PCRA correlates well withboth quality and intelligibility. PCRA scores report how oftenthe “true” cluster index is among the three estimated clusterindices computed by the proposed method (see Section VI.4).Please note that with the “true” phonetic cluster index we meanthe output of our recognizer when the corresponding cleansignal is the input9. For the proposed Inventory MI method,phonetic cluster recognition is performed only for segments forwhich the employed VAD, as described in Section III, signalsa “voice active” state. PCRA scores are therefore computed forsuch voice active sections only. We ensured that the computa-tion of PCRA scores for the Inventory VQ method was basedon the exact same sections to obtain a fair comparison.In reviewing the presented performance results in Tables I–VI
the reader should note that CEPD is a distortion measure,whereas all other measures are quality measures. Good en-hancement methods are, therefore, characterized by smallCEPD values and large scores in all other measures.The statistical significance of each quality and distortionmea-
sure is evaluated with a “matched-pairs” test after Gillick andCox [56]. For each testing utterance (or group of testing utter-ances) the respectively best score of all methods is matched withthe corresponding score of a reference method. The mean andstandard deviation of the differences between these matchedscores are computed. A -value at which the mean is signifi-cantly different from zero is obtained from a Student’s t-test.The details of this comparison are comprehensively described in[56]. In Tables I–VI the significance results are reported througha star notation. A single star refers to a significance levelof , two stars refers to , and threestars refers to . Scores reported with one andtwo stars are customarily considered significant. Scores reportedwith three stars are considered highly significant. Scores with
are typically not considered significant and receive nostar.
A. Comparison Between the Inventory VQ and the InventoryMI Method
Tables I–III specifically focus on a comparison betweenthe Inventory VQ and the Inventory MI method. Shown arethe resulting objective quality measures from all of the nineconsidered scenarios, i.e., the three considered noise typesand the three considered SNR levels each. The score of thebest performing algorithm, for each scenario respectively, isshown in bold-face letters. Significance levels are reportedwith the star notation introduced in the previous section. Notethat the “matched-pairs” test is always computed between therespectively best performing method and a reference method.In Tables I–III these two methods are always the Inventory VQ
9Ideally, one would use transcribed data here, but a transcription with sub-phonetic units was not available to us.

992 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
TABLE ICOMPARISON BETWEEN THE INVENTORY VQ AND THE PROPOSED INVENTORY MI METHOD UNDER ADDITIVE WHITE NOISE
TABLE IICOMPARISON BETWEEN THE INVENTORY VQ AND THE PROPOSED INVENTORY MI METHOD UNDER ADDITIVE JET COCKPIT NOISE
TABLE IIICOMPARISON BETWEEN THE INVENTORY VQ AND THE PROPOSED INVENTORY MI METHOD UNDER ADDITIVE BABBLE NOISE
and the Inventory MI method, with the less successful one asthe reference.It is readily seen that the proposed Inventory MI method
dramatically outperforms the Inventory VQ method in thetwo most important categories, perceptual quality (PESQ) andoverall quality (CMPo), across all considered cases. Highlysignificant improvements across many scenarios are also ac-
complished in frequency-weighted segmental SNR (FSNR),signal distortion (CMPs), and noise distortion (CMPn). Theproposed method was not successful in cepstral distance(CEPD) in the stationary noise cases. The generally poorperformance of the Inventory VQ method in many categoriesis largely due to two factors. First of all, in our experimentsthe Inventory VQ method was explicitly trained for the 10 dB

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 993
TABLE IVCOMPARISON BETWEEN THE PROPOSED INVENTORY MI METHOD AND OTHER ENHANCEMENT METHODS UNDER ADDITIVE WHITE NOISE
TABLE VCOMPARISON BETWEEN THE PROPOSED INVENTORY MI METHOD AND OTHER ENHANCEMENT METHODS UNDER ADDITIVE JET COCKPIT NOISE
white noise scenario. All other scenarios establish a significantmismatch between training and testing.Secondly, the Inventory VQ method was, in its original form
[3], designed for a signal bandwidth of 4 kHz. The extensionto an 8 kHz bandwidth poses a formidable challenge10 for theInventory VQ method due to the typically weak energy contentof speech signals above 4 kHz. Therefore, the results reportedhere are significantly worse than the ones reported by Xiao andNickel in [3].The scores for the 10 dB white noise case are of particular
interest, since the Inventory MI method is competing against anInventory VQ method that does not suffer from the described
10These challenges are alleviated in the Inventory MI method through therefinement of the training process.
training and testing mismatch. It is remarkable that this advan-tage for the Inventory VQ method does not translate into a sig-nificant gain in PCRA score, but rather a slight loss. This is atestament to the robustness of the proposed modified imputa-tion technique.Overall, the Inventory MI method was able to eke out PCRA
gains over the Inventory VQ method at the 5 dB and 10 dBlevels. The PCRA gain was especially dramatic for 5 dB babblenoise. Here, the proposed method was able to achieve an abso-lute improvement of over 18%-points in PCRA score. The pro-posed method was, unfortunately, not able to improve PCRAscores in the 15 dB SNR scenarios. At such high SNR values,however, the losses in PCRA were not big enough to trans-late into measurable losses in perceptual quality (see PESQ andCMPo scores in Tables I–III).

994 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
TABLE VICOMPARISON BETWEEN THE PROPOSED INVENTORY MI METHOD AND OTHER ENHANCEMENT METHODS UNDER ADDITIVE BABBLE NOISE
It is important to point out that one may not interpretTables I–III as a study of PCRA scores vs. signal-to-noise ratio.A comparison across different SNRs is meaningless. The PCRAcomputation is a function of the underlying SNR-dependentVAD. The segments that are flagged by the VAD are differentfor different SNR scenarios and therefore PCRA scores canbe compared fairly between algorithms but not fairly acrossdifferent SNRs. The VAD bias also explains why the InventoryMI recognition rates seem to, paradoxically, improve withdecreasing SNR values.
B. Comparison Between the Inventory MI Method and theReference Methods
The resulting scores of all of the considered objective qualitymeasures for the proposed and the reference methods across allour experiments under the three considered SNR levels and thethree considered noise types are shown in Tables IV–VI. Again,the score of the best performing algorithm for each consideredscenario is shown in bold-face letters. Significance levels are,again, reported via a star notation. The matched-pairs test be-tween the Inventory MI method and the MBSS method is gen-erally reported with the superscripted stars. The matched-pairstest between the Inventory MI method and the log-MMSE(RA)method is reported with the subscripted stars respectively. Toavoid overly crowded tables we omitted the significance re-sults between the InventoryMImethod and the log-MMSE(MS)method, except in cases in which the log-MMSE(MS) methodprovided the superior score. If the Inventory MI method did notprovide the superior score then the significance results for thesuperior score were computed in reference to the Inventory MImethod.The main target of our study was to improve the resulting en-
hanced signals perceptually (i.e., subjectively) as measured byPESQ and CMPo. It is readily seen that the proposed InventoryMI method outperforms all of the reference methods in all ofthe considered noise scenarios in the PESQ measure and, withthe exception of the 15 dB babble noise case, also in the CMPomeasure. The improvements were particularly dramatic in the
5 dB white noise case with improvements of over 10% abovethe best performing reference method and around 50% abovethe worst performing reference method. Improvements in otherscenarios were less dramatic, but still significant.The performance of the proposed method in terms of the mea-
sures CEPD and FSNR was also very favorable for the whitenoise and jet cockpit noise cases. Particularly encouraging are,furthermore, the improvements over the reference methods withrespect to signal distortion, as measured by CMPs, and noisedistortion, as measured by CMPn.The dramatic “across the board” improvements that the pro-
posed method delivered in the stationary noise scenarios are,unfortunately, not observed in the non-stationary, i.e., babblenoise, cases. The proposed method still performs well in thePESQ and CMPo measure, yet superiority is not indicated inother measures, especially at high SNR levels. The performanceof the Inventory MI method in terms of the CEPD measureseems to suggest that it may not be highly effective as a pre-processor to an automatic speech recognition system under non-stationary noise conditions. This, however, would need to beverified separately and is not within the scope of this paper.In fairness to the proposed method, though, it should be noted
that no single one of the reference methods is able to consis-tently outperform all other referencemethods across all differentscenarios, either. Especially in the PESQ measure it is evidentthat the log-MMSE(RA) method performs best for stationarynoise scenarios and worst for non-stationary noise scenarios,whereas the performance of the MBSS method is worst for sta-tionary noise scenarios and best for non-stationary noise sce-narios. The log-MMSE(MS) method performs consistently be-tween the other two reference methods. Only the proposed In-ventory MI method is able to achieve superior scores in all sce-narios. The fact that this superiority is rather small at the 15 dBSNR level has to be seen in light of the also rather small dif-ference between the two most competitive reference methods.At higher SNR levels we seem to be generally reaching dimin-ishing levels of return across most approaches.
NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 995
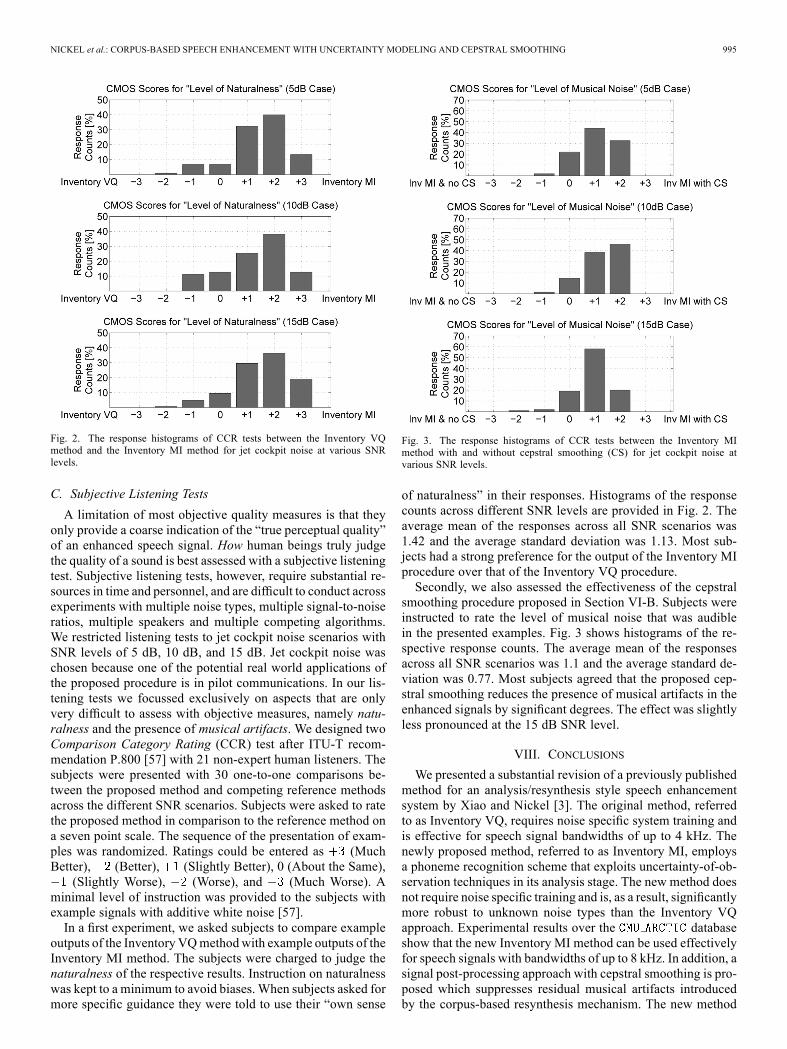
Fig. 2. The response histograms of CCR tests between the Inventory VQmethod and the Inventory MI method for jet cockpit noise at various SNRlevels.
C. Subjective Listening Tests
A limitation of most objective quality measures is that theyonly provide a coarse indication of the “true perceptual quality”of an enhanced speech signal. How human beings truly judgethe quality of a sound is best assessed with a subjective listeningtest. Subjective listening tests, however, require substantial re-sources in time and personnel, and are difficult to conduct acrossexperiments with multiple noise types, multiple signal-to-noiseratios, multiple speakers and multiple competing algorithms.We restricted listening tests to jet cockpit noise scenarios withSNR levels of 5 dB, 10 dB, and 15 dB. Jet cockpit noise waschosen because one of the potential real world applications ofthe proposed procedure is in pilot communications. In our lis-tening tests we focussed exclusively on aspects that are onlyvery difficult to assess with objective measures, namely natu-ralness and the presence of musical artifacts. We designed twoComparison Category Rating (CCR) test after ITU-T recom-mendation P.800 [57] with 21 non-expert human listeners. Thesubjects were presented with 30 one-to-one comparisons be-tween the proposed method and competing reference methodsacross the different SNR scenarios. Subjects were asked to ratethe proposed method in comparison to the reference method ona seven point scale. The sequence of the presentation of exam-ples was randomized. Ratings could be entered as (MuchBetter), (Better), (Slightly Better), 0 (About the Same),
(Slightly Worse), (Worse), and (Much Worse). Aminimal level of instruction was provided to the subjects withexample signals with additive white noise [57].In a first experiment, we asked subjects to compare example
outputs of the Inventory VQmethodwith example outputs of theInventory MI method. The subjects were charged to judge thenaturalness of the respective results. Instruction on naturalnesswas kept to a minimum to avoid biases. When subjects asked formore specific guidance they were told to use their “own sense
Fig. 3. The response histograms of CCR tests between the Inventory MImethod with and without cepstral smoothing (CS) for jet cockpit noise atvarious SNR levels.
of naturalness” in their responses. Histograms of the responsecounts across different SNR levels are provided in Fig. 2. Theaverage mean of the responses across all SNR scenarios was1.42 and the average standard deviation was 1.13. Most sub-jects had a strong preference for the output of the Inventory MIprocedure over that of the Inventory VQ procedure.Secondly, we also assessed the effectiveness of the cepstral
smoothing procedure proposed in Section VI-B. Subjects wereinstructed to rate the level of musical noise that was audiblein the presented examples. Fig. 3 shows histograms of the re-spective response counts. The average mean of the responsesacross all SNR scenarios was 1.1 and the average standard de-viation was 0.77. Most subjects agreed that the proposed cep-stral smoothing reduces the presence of musical artifacts in theenhanced signals by significant degrees. The effect was slightlyless pronounced at the 15 dB SNR level.
VIII. CONCLUSIONS
We presented a substantial revision of a previously publishedmethod for an analysis/resynthesis style speech enhancementsystem by Xiao and Nickel [3]. The original method, referredto as Inventory VQ, requires noise specific system training andis effective for speech signal bandwidths of up to 4 kHz. Thenewly proposed method, referred to as Inventory MI, employsa phoneme recognition scheme that exploits uncertainty-of-ob-servation techniques in its analysis stage. The new method doesnot require noise specific training and is, as a result, significantlymore robust to unknown noise types than the Inventory VQapproach. Experimental results over the databaseshow that the new Inventory MI method can be used effectivelyfor speech signals with bandwidths of up to 8 kHz. In addition, asignal post-processing approach with cepstral smoothing is pro-posed which suppresses residual musical artifacts introducedby the corpus-based resynthesis mechanism. The new method

996 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 21, NO. 5, MAY 2013
is not only able to match, but outperform the earlier approachwith respect to a number of objective and subjective perceptualquality measures. Comparisons with other state-of-the-art en-hancement schemes are also very favorable.The number of feasible technical applications for the pro-
posed method is, unfortunately, still somewhat limited due toits requirement for speaker specific training. There are applica-tions, however, in aviation and/or military battlefield commu-nications, for example, in which speaker specific training is, infact, not only feasible but possibly of great advantage.
REFERENCES[1] P. Vary and R. Martin, Digital Speech Transmission: Enhancement,
Coding and Error Concealment. Chichester, U.K.: Wiley, 2006.[2] P. C. Loizou, Speech Enhancement—Theory and Practice. Boca
Raton, FL, USA: CRC, Taylor and Francis, 2007.[3] X. Xiao and R. M. Nickel, “Speech enhancement with inventory style
speech resynthesis,” IEEE Trans. Audio, Speech, Lang. Process., vol.18, no. 6, pp. 1243–1257, Aug. 2010.
[4] J. Ming, R. Srinivasan, and D. Crookes, “A corpus-based approach tospeech enhancement from nonstationary noise,” IEEE Trans. Audio,Speech, Lang. Process., vol. 19, no. 4, pp. 822–836, May 2011.
[5] J. Ming, R. Srinivasan, and D. Crookes, “A corpus-based approachto speech enhancement from nonstationary noise,” in Proc. INTER-SPEECH, Makuhari, Japan, Sep. 2010, pp. 1097–1100.
[6] R. M. Nickel and R. Martin, “Memory and complexity reduction forinventory-style speech enhancement systems,” in Proc. EUSIPCO,Barcelona, Spain, Sep. 2011, pp. 196–200.
[7] D. Kolossa, A. Klimas, and R. Orglmeister, “Separation and robustrecognition of noisy, convolutive speech mixtures using time-fre-quency masking and missing data techniques,” in Proc. WorkshopApplicat. Signal Process. Audio Acoust. (WASPAA), Oct. 2005, pp.82–85.
[8] C. Breithaupt, T. Gerkmann, and R. Martin, “Cepstral smoothing ofspectral filter gains for speech enhancement without musical noise,”IEEE Signal Process. Lett., vol. 14, no. 12, pp. 1036–1039, Dec. 2007.
[9] R. Nickel, R. F. Astudillo, D. Kolossa, S. Zeiler, and R.Martin, “Inven-tory-style speech enhancement with uncertainty-of-observation tech-niques,” in Proc. ICASSP, Kyoto, Japan, Mar. 2012, pp. 4645–4648.
[10] I. Cohen, “Noise spectrum estimation in adverse environments: Im-proved minima controlled recursive averaging,” IEEE Trans. SpeechAudio Process., vol. 11, no. 5, pp. 466–475, Sep. 2003.
[11] R. Martin, “Noise power spectral density estimation based on optimalsmoothing and minimum statistics,” IEEE Trans. Speech AudioProcess., vol. 9, no. 5, pp. 504–512, Jul. 2001.
[12] Y. Ephraim and D. Malah, “Speech enhancement using a minimummean-square error short-time spectral amplitude estimator,” IEEETrans. Acoust., Speech, Signal Process., vol. ASSP-32, no. 6, pp.1109–1121, Dec. 1984.
[13] Y. Ephraim and D. Malah, “Speech enhancement using a minimummean-square error log-spectral amplitude estimator,” IEEE Trans.Acoust., Speech, Signal Process., vol. ASSP-33, no. 2, pp. 443–445,Apr. 1985.
[14] B. J. Borgström and A. Alwan, “A unified framework for designingoptimal STSA estimators assumingmaximum likelihood phase equiva-lence of speech and noise,” IEEE Trans. Audio, Speech, Lang. Process.,vol. 19, no. 8, pp. 2579–2590, Nov. 2011.
[15] E. Plourde and B. Champagne, “Multidimensional STSA estimatorsfor speech enhancement with correlated spectral components,” IEEETrans. Audio, Speech, Lang. Process., vol. 59, no. 7, pp. 3013–3024,Sep. 2011.
[16] C. Breithaupt and R. Martin, “Analysis of the decision-directed SNRestimator for speech enhancement with respect to low-SNR and tran-sient conditions,” IEEE Trans. Audio, Speech, Lang. Process., vol. 19,no. 2, pp. 277–289, Feb. 2011.
[17] W. Charoenruengkit and N. Erdöl, “The effect of spectral estimation onspeech enhancement performance,” IEEE Trans. Audio, Speech, Lang.Process., vol. 19, no. 5, pp. 1170–1179, Jul. 2011.
[18] B. N. M. Laska, M. Bolic, and R. A. Goubran, “Particle filter enhance-ment of speech spectral amplitudes,” IEEE Trans. Audio, Speech, Lang.Process., vol. 18, no. 8, pp. 2155–2167, Nov. 2010.
[19] R. Talmon, I. Cohen, and S. Gannot, “Transient noise reduction usingnonlocal diffusion filters,” IEEE Trans. Audio, Speech, Lang. Process.,vol. 19, no. 6, pp. 1584–1599, Sep. 2011.
[20] H. Ding, I. Y. Soon, and C. K. Yeo, “Over-attenuated componentsregeneration for speech enhancement,” IEEE Trans. Audio, Speech,Lang. Process., vol. 18, no. 8, pp. 2004–2014, Nov. 2010.
[21] S. Jo and C. D. Yoo, “Psychoacoustically constrained and distortionminimized speech enhancement,” IEEE Trans. Audio, Speech, Lang.Process., vol. 18, no. 8, pp. 2099–2110, Nov. 2010.
[22] H. Ding, I. Y. Soon, and C. K. Yeo, “A DCT-based speech enhance-ment system with pitch synchronous analysis,” IEEE Trans. Audio,Speech, Lang. Process., vol. 19, no. 8, pp. 2614–2623, Nov. 2011.
[23] W. Jin, X. Liu,M. S. Scordilis, and L. Han, “Speech enhancement usingharmonic emphasis and adaptive comb filtering,” IEEE Trans. Audio,Speech, Lang. Process., vol. 18, no. 2, pp. 356–368, Feb. 2010.
[24] J. Hao, T.-W. Lee, and T. J. Sejnowski, “Speech enhancement usingGaussian scale mixture models,” IEEE Trans. Audio, Speech, Lang.Process., vol. 18, no. 6, pp. 1127–1136, Aug. 2010.
[25] T. Rosenkranz and H. Puder, “Improving robustness of code-book-based noise estimation approaches with delta codebooks,” IEEETrans. Audio, Speech, Lang. Process., vol. 20, no. 4, pp. 1177–1188,May 2012.
[26] S. Srinivasan, J. Samuelsson, and W. B. Kleijn, “Codebook-basedBayesian speech enhancement for nonstationary environments,” IEEETrans. Audio, Speech, Lang. Process., vol. 15, no. 2, pp. 441–452,Feb. 2007.
[27] M. Delcroix, K. Kinoshita, T. Nakatani, S. Araki, A. Ogawa, T. Hori,S. Watanabe, M. Fujimoto, T. Yoshioka, T. Oba, Y. Kubo, M. Souden,S.-J. Hahm, and A. Nakamura, “Speech recognition in the presenceof highly non-stationary noise based on spatial, spectral and temporalspeech/noise modeling combined with dynamic variance adaptation,”in Proc. CHiME Workshop Mach. Listening in Multisource Environ.,2011, pp. 12–17.
[28] R. F. Astudillo and R. Orglmeister, “A MMSE estimator in mel-cep-stral domain for robust large vocabulary automatic speech recognitionusing uncertainty propagation,” in Proc. INTERSPEECH, 2010, pp.713–716.
[29] R. F. Astudillo, “Integration of short-time Fourier domain speech en-hancement and observation uncertainty techniques for robust automaticspeech recognition,” Ph.D. dissertation, Technical Univ. Berlin, Berlin,Germany, 2010.
[30] L. Deng, J. Droppo, and A. Acero, “Dynamic compensation of HMMvariances using the feature enhancement uncertainty computed froma parametric model of speech distortion,” IEEE Trans. Speech AudioProcess., vol. 13, no. 3, pp. 412–421, May 2005.
[31] V. Ion and R. Haeb-Umbach, “A novel uncertainty decoding rule withapplications to transmission error robust speech recognition,” IEEETrans. Audio, Speech, Lang. Process., vol. 16, no. 5, pp. 1047–1060,Jul. 2008.
[32] N. Ma, J. Barker, H. Christensen, and P. Green, “Recent advances infragment-based speech recognition in reverberant multisource environ-ments,” in Proc. CHiMEWorkshopMach. Listening inMultisource En-viron., 2011.
[33] M. Cooke, P. Green, L. Josifovski, and A. Vizinho, “Robust automaticspeech recognition with missing and unreliable acoustic data,” SpeechCommun., vol. 34, pp. 267–285, 2001.
[34] B. Raj, “Reconstruction of incomplete spectrograms for robust speechrecognition,” Ph.D. dissertation, Elect. Comput. Eng. Department,Carnegie Mellon Univ., Pittsburgh, PA, USA, 2000.
[35] C. J. Leggetter and P. C. Woodland, “Maximum likelihood linear re-gression for speaker adaptation of continuous density hidden Markovmodels,” Comput. Speech Lang., vol. 9, pp. 171–185, Apr. 1995.
[36] J. L. Gauvain and C. H. Lee, “Maximum a posteriori estimation formultivariate Gaussian mixture observations of Markov chains,” IEEETrans. Speech Audio Process., vol. 2, pp. 291–298, Apr. 1994.
[37] M. J. F. Gales, “Model-based technique for noise robust speech recog-nition,” Ph.D. dissertation, Gonville and Caius College, Cambridge,U.K., 1995.
[38] R. F. Astudillo, D. Kolossa, A. Abad, S. Zeiler, R. Saeidi, P. Mowlaee,J. P. da Silva Neto, and R. Martin, “Integration of beamforming anduncertainty-of-observation techniques for robust ASR in multi-sourceenvironments,” Comput. Speech Lang., Special Issue Multisource En-viron..
[39] “Objective Measurement of Active Speech Level,” ITU-T (Interna-tional Telecomm. Union), 1993, Rec. P.56.
[40] J. Sohn, N. S. Kim, and W. Sung, “A statistical model-based voiceactivity detection,” IEEE Signal Process. Lett., vol. 6, no. 1, pp. 1–3,Jan. 1999.
[41] S. Furui, “Cepstral analysis technique for automatic speaker verifica-tion,” IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-29, no.2, pp. 254–272, Apr. 1981.
[42] X. Huang, A. Acero, and H. W. Hon, Spoken Language Processing, AGuide to Theory, Algorithm, and System Development. Upper SaddleRiver, NJ, USA: Prentice-Hall, 2001.
[43] R. J. McAulay and M. L. Malpass, “Speech enhancement using a soft-decision noise suppression filter,” IEEE Trans. Acoust., Speech, SignalProcess., vol. ASSP-28, no. 2, pp. 137–145, Apr. 1980.

NICKEL et al.: CORPUS-BASED SPEECH ENHANCEMENT WITH UNCERTAINTY MODELING AND CEPSTRAL SMOOTHING 997
[44] I. Cohen, “Noise spectrum estimation in adverse environments: Im-proved minima controlled recursive averaging,” IEEE Trans. SpeechAudio Process., vol. 11, no. 5, pp. 466–475, Sep. 2003.
[45] R. F. Astudillo, D. Kolossa, and R. Orglmeister, “Accounting for theuncertainty of speech estimates in the complex domain for minimummean square error speech enhancement,” in Proc. INTERSPEECH,2009.
[46] D. Yu, L. Deng, J. Droppo, J. Wu, Y. Gong, and A. Acero, “A min-imum-mean-square-error noise reduction algorithm on mel-frequencycepstra for robust speech recognition,” in Proc. ICASSP, 2008, pp.4041–4044.
[47] K. P. A. Stark, “MMSE estimation of log-filterbank energies for robustspeech recognition,” Speech Commun., vol. 53, no. 3, pp. 403–416,2011.
[48] Y. Ephraim and D. Malah, “Speech enhancement using a min-imum-mean square error short-time spectral amplitude estimator,”IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-32, no. 6,pp. 1109–1121, Dec. 1984.
[49] C. Breithaupt, T. Gerkmann, and R. Martin, “A novel a priori SNRestimation approach based on selective cepstro-temporal smoothing,”in Proc. ICASSP, 2008, pp. 4897–4900.
[50] Y. Ephraim and D. Malah, “Speech enhancement using a minimummean square error log-spectral amplitude estimator,” IEEE Trans.Acoust., Speech, Signal Process., vol. ASSP-33, no. 2, pp. 443–445,Apr. 1985.
[51] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per-ceptual evaluation of speech quality (PESQ)—A new method forspeech quality assessment of telephone networks and codecs,” in Proc.ICASSP, 2001, vol. 2, pp. 749–752.
[52] Y. Hu and P. C. Loizou, “Evaluation of objective quality measures forspeech enhancement,” IEEE Trans. Audio, Speech, Lang. Process., vol.16, no. 1, pp. 229–238, Jan. 2008.
[53] N. Kitawaki, H. Nagabuchi, and K. Itoh, “Objective quality evaluationfor low bit-rate speech coding systems,” IEEE J. Sel. Areas Commun.,vol. 6, no. 2, pp. 262–273, 1988.
[54] J. Tribolet, P. Noll, B. McDermott, and R. E. Crochiere, “A study ofcomplexity and quality of speech waveform coders,” in Proc. ICASSP,1978, pp. 586–590.
[55] X. Xiao and R. M. Nickel, “Speech inventory based discriminativetraining for joint speech enhancement and low-rate speech coding,” inProc. INTERSPEECH, Makuhari, Japan, Sep. 2010, pp. 2398–2401.
[56] L. Gillick and S. J. Cox, “Some statistical issues in the comparison ofspeech recognition algorithms,” in Proc. ICASSP, 1989, vol. S10b.5,pp. 532–535.
[57] “Methods for subjective determination of transmission quality,” Int.Telecomm. Union, 1996, ITU-TRec. P.800.
Robert M. Nickel (M’98) received a Dipl.-Ing.degree in electrical engineering from the RWTHAachen University, Germany, in 1994, and a Ph.D.in electrical engineering from the University ofMichigan, Ann Arbor, Michigan, in 2001. Duringthe 2001/2002 academic year he was an adjunctfaculty in the Department of Electrical Engineeringand Computer Science at the University of Michigan.From 2002 until 2007 he was a faculty member atthe Pennsylvania State University, University Park,Pennsylvania. Since the fall of 2007 he is a faculty
member at the Electrical Engineering Department of Bucknell University,Lewisburg, Pennsylvania. During the 2010/2011 academic year he was aMarie Curie Incoming International Fellow at the Institute of CommunicationAcoustics, Ruhr-Universität Bochum, Germany. His main research interestsinclude speech signal processing, general signal theory, and time-frequencyanalysis.
Ramón Fernández Astudillo (M’12) studiedElectrical Engineering in the University of Oviedo(Spain) and the Technische Universität Berlin. Hereceived the Dipl.-Ing. degree in electronics andautomatics in 2005.In 2006 he received a DAAD and “La Caixa”
Foundation scholarship for research towards hisPh.D. thesis at the Electronics and Medical SignalProcessing group of the Technische UniversitätBerlin. He received the Ph.D. degree in electricalengineering in 2010.
Mr. Astudillo is currently associate researcher at the spoken language systemslab (L2F) where he researches both on robust speech recognition and robust nat-ural language processing speech applications in a Bayesian setting. His researchinterests include signal processing, machine learning and Bayesian statistics.
Dorothea Kolossa (M’03–SM’12) received theDipl.-Ing. degree in computer engineering and thePh.D. degree in electrical engineering from theTechnische Universität Berlin in 1999 and 2007,respectively.From 1999 until 2000, she worked on multi-ob-
jective algorithms for control systems design atDaimlerChrysler Research and Technology, and wasemployed as a research assistant at the TechnischeUniversität Berlin from 2000 until 2004, and asa postdoctoral researcher from 2004 until 2010,
also staying at UC Berkeleys Parlab as visiting faculty in 2009/2010. Since2010, she is head of the Digital Signal Processing Group at Ruhr-UniversitätBochum, where her research interests include speech recognition in adverseenvironments and robust classification methods for communication and tech-nical diagnostics. She has authored and co-authored more than 50 scientificpapers and book chapters.Dr. Kolossa is co-chair of the DEGA working group on speech acoustics,
and a member of the IEEE Audio and Acoustic Signal Processing TechnicalCommittee.
Rainer Martin (S’86–M’90–SM’01–F’11) receivedthe M.S.E.E. degree from Georgia Institute ofTechnology, Atlanta, in 1989 and the Dipl.-Ing. andDr.-Ing. degrees from RWTH Aachen University,Aachen, Germany, in 1988 and 1996, respectively.From 1996 to 2002, he was a Senior Research En-gineer with the Institute of Communication Systemsand Data Processing, RWTH Aachen University.From April 1998 to March 1999, he was on leaveto the AT&T Speech and Image Processing ServicesResearch Lab, Florham Park, NJ. From April 2002
until October 2003, he was a Professor of Digital Signal Processing at theTechnische Universität Braunschweig, Braunschweig, Germany.Since October 2003, he has been a Professor of Information Technology
and Communication Acoustics at Ruhr-Universität Bochum, Bochum, Ger-many, and from October 2007 to September 2009 Dean of the ElectricalEngineering and Information Sciences Department. His research interests aresignal processing for voice communication systems, hearing instruments, andhuman-machine interfaces. He is coauthor with P. Vary of Digital SpeechTransmission—Enhancement, Coding and Error Concealment (Wiley, 2006)and coeditor with U. Heute and C. Antweiler of Advances in Digital SpeechTransmission (Wiley, 2008). Dr. Martin served as an Associate Editor for theIEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING and isa member of the Speech and Language Processing Technical Committee of theIEEE Signal Processing Society.




















