
AUTOMATIC IDENTIFICATION OF TEXTUAL UNCERTAINTY
422
AUTOMATIC IDENTIFICATION OF TEXTUAL UNCERTAINTY A THESIS SUBMITTED TO THE UNIVERSITY OF MANCHESTER FOR THE DEGREE OF DOCTOR OF P HILOSOPHY IN THE FACULTY OF S CIENCE AND ENGINEERING 2019 Chrysoula Zerva School of Computer Science
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of AUTOMATIC IDENTIFICATION OF TEXTUAL UNCERTAINTY

AUTOMATIC IDENTIFICATION OFTEXTUAL UNCERTAINTY
A THESIS SUBMITTED TO THE UNIVERSITY OF MANCHESTER
FOR THE DEGREE OF DOCTOR OF PHILOSOPHY
IN THE FACULTY OF SCIENCE AND ENGINEERING
2019
Chrysoula Zerva
School of Computer Science


Contents
Abstract 19
Declaration 21
Copyright 23
Acknowledgements 25
Acronyms and Abbreviations 27
1 Introduction 311.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
1.1.1 Motivation for the focus on biomedical literature . . . . . . . . 33
1.2 Research Aims, Hypotheses, Questions and Objectives . . . . . . . . . 41
1.2.1 Aims . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
1.2.2 Research Questions and Hypotheses . . . . . . . . . . . . . . . 43
1.2.3 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
1.3 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
1.3.1 Thesis overview by chapter . . . . . . . . . . . . . . . . . . . . 46
1.3.2 Thesis publications . . . . . . . . . . . . . . . . . . . . . . . . 48
2 Event extraction 492.1 Information extraction for biomedicine . . . . . . . . . . . . . . . . . . 50
2.2 Event structure and event extraction methods . . . . . . . . . . . . . . 55
2.2.1 Event structure . . . . . . . . . . . . . . . . . . . . . . . . . . 56
2.2.2 Event extraction methods . . . . . . . . . . . . . . . . . . . . . 57
3

2.3 Dealing with incomplete events . . . . . . . . . . . . . . . . . . . . . . 62
2.3.1 Training and testing corpora . . . . . . . . . . . . . . . . . . . 65
2.3.2 Adding secondary arguments to incomplete events . . . . . . . 67
2.3.2.1 Evaluation metrics and results . . . . . . . . . . . . . 72
2.3.2.2 Interaction-informed cases . . . . . . . . . . . . . . 76
2.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
3 Definition and Classification 793.1 Overview of definitions and interpretations . . . . . . . . . . . . . . . . 80
3.1.1 Hedging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.1.1.1 Hedging as an element of vagueness and imprecision 84
3.1.1.2 Hedging in discourse analysis . . . . . . . . . . . . . 86
3.1.2 Epistemic modality . . . . . . . . . . . . . . . . . . . . . . . . 88
3.1.2.1 Epistemic modality and evidentiality . . . . . . . . . 89
3.1.3 Factuality . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
3.2 Categorisation of uncertainty expressions . . . . . . . . . . . . . . . . 92
3.2.1 Annotated corpora . . . . . . . . . . . . . . . . . . . . . . . . 98
3.3 Automated identification of uncertainty . . . . . . . . . . . . . . . . . 101
3.3.1 Evaluation methods and metrics . . . . . . . . . . . . . . . . . 104
3.3.1.1 Main evaluation metrics: . . . . . . . . . . . . . . . 104
3.3.1.2 Other metrics and concepts . . . . . . . . . . . . . . 106
3.3.2 Cue and sentence classification . . . . . . . . . . . . . . . . . . 106
3.3.3 Cue-scope approaches . . . . . . . . . . . . . . . . . . . . . . 108
3.3.4 Event-centred approaches . . . . . . . . . . . . . . . . . . . . 113
3.3.5 Confusions with existing annotations . . . . . . . . . . . . . . 116
3.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
4 Implementation and evaluation 1214.1 Demonstration of uncertainty related workflows . . . . . . . . . . . . . 123
4.1.1 Description of end-to-end workflow for linking to pathway models123
4.1.1.1 Document Reading . . . . . . . . . . . . . . . . . . 124
4.1.1.2 Document Pre-processing . . . . . . . . . . . . . . . 125
4.1.1.3 Named Entity Recognition . . . . . . . . . . . . . . 126
4

4.1.1.4 Dependency Parsing . . . . . . . . . . . . . . . . . . 127
4.1.1.5 Event Extraction . . . . . . . . . . . . . . . . . . . . 128
4.1.1.6 Negation Identification . . . . . . . . . . . . . . . . 128
4.1.1.7 Uncertainty Identification . . . . . . . . . . . . . . . 129
4.1.1.8 Linking to the model . . . . . . . . . . . . . . . . . 132
4.1.1.9 Other outputs . . . . . . . . . . . . . . . . . . . . . 134
4.1.1.10 Full workflow and access instructions . . . . . . . . . 134
4.1.2 Description of workflow processing large corpora with binaryuncertainty . . . . . . . . . . . . . . . . . . . . . . . . . . . . 137
4.1.2.1 Document Reading . . . . . . . . . . . . . . . . . . 137
4.1.2.2 Document pre-processing and Dependency parsing . 138
4.1.2.3 Uncertainty Identification . . . . . . . . . . . . . . . 139
4.1.2.4 Saving/displaying results . . . . . . . . . . . . . . . 139
4.1.2.5 Full workflow and access instructions . . . . . . . . . 140
4.1.3 Description of additional related components . . . . . . . . . . 141
4.1.4 Access to necessary resources . . . . . . . . . . . . . . . . . . 145
5 Automated identification of uncertainty 1515.1 A proposal for uncertainty classification . . . . . . . . . . . . . . . . . 152
5.1.1 Excluded categories . . . . . . . . . . . . . . . . . . . . . . . 154
5.1.1.1 Cases of certainty . . . . . . . . . . . . . . . . . . . 158
5.1.2 The role of negation . . . . . . . . . . . . . . . . . . . . . . . 159
5.1.3 Relation to existing annotations . . . . . . . . . . . . . . . . . 163
5.2 Datasets and corpora . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
5.2.1 Large, gold-annotated, published corpora . . . . . . . . . . . . 164
5.2.1.1 GENIA-MK corpus . . . . . . . . . . . . . . . . . . 165
5.2.1.2 BioNLP-ST corpus . . . . . . . . . . . . . . . . . . 168
5.2.2 Pathway related datasets . . . . . . . . . . . . . . . . . . . . . 170
5.2.2.1 Leukemia pathway and dataset . . . . . . . . . . . . 171
5.2.2.2 Melanoma pathway and dataset . . . . . . . . . . . . 173
5.3 A novel proposal for uncertainty identification . . . . . . . . . . . . . . 175
5.3.1 Modelling dependencies between uncertainty cues and events . 176
5.3.1.1 Definition of dependency . . . . . . . . . . . . . . . 177
5

5.3.1.2 Enju dependency parser . . . . . . . . . . . . . . . . 178
5.3.1.3 Dependencies and uncertainty identification . . . . . 181
5.3.2 Constraints and filters for the rule-based approach . . . . . . . . 188
5.3.2.1 Constraints for search space . . . . . . . . . . . . . . 189
5.3.2.1.1 Limiting maximum path length . . . . . . . 190
5.3.2.1.2 Limiting permitted TS tokens . . . . . . . . 192
5.3.2.1.3 Halting pattern generation when encounter-ing an event in the dependency path . . . . 192
5.3.2.2 Filtering rules based on informativeness . . . . . . . 193
5.3.3 Machine learning approach . . . . . . . . . . . . . . . . . . . . 201
5.3.3.1 Additional features . . . . . . . . . . . . . . . . . . 203
5.4 Evaluation and results . . . . . . . . . . . . . . . . . . . . . . . . . . . 206
5.4.1 Experiments on gold corpora . . . . . . . . . . . . . . . . . . . 206
5.4.1.1 Comparison with existing work on the same corpora . 209
5.4.1.2 Additional experiments on feature engineering . . . . 210
5.4.2 Evaluation on pathway models . . . . . . . . . . . . . . . . . . 214
5.4.2.1 The Leukemia use-case . . . . . . . . . . . . . . . . 214
5.4.2.2 Binary evaluation on Leukemia pathway corpus . . . 214
5.4.2.3 Multi-level uncertainty evaluation on the Leukemiapathway corpus . . . . . . . . . . . . . . . . . . . . 217
5.4.2.4 The Ras-melanoma case . . . . . . . . . . . . . . . . 222
5.5 Chapter conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
6 Adaptability to a new domain 2296.1 Uncertainty in the newswire domain . . . . . . . . . . . . . . . . . . . 231
6.2 Experimental setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . 234
6.2.1 Events in newswire . . . . . . . . . . . . . . . . . . . . . . . . 234
6.2.2 Datasets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235
6.3 An approach to uncertainty detection . . . . . . . . . . . . . . . . . . . 237
6.4 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
6.4.1 Automated classification of uncertainty . . . . . . . . . . . . . 240
6.5 Comparison of linguistic uncertainty patterns . . . . . . . . . . . . . . 243
6.5.1 Dependency based comparison . . . . . . . . . . . . . . . . . . 243
6

6.5.2 Lexical comparison . . . . . . . . . . . . . . . . . . . . . . . . 247
6.5.2.1 WordNet-based analysis . . . . . . . . . . . . . . . . 249
6.6 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255
7 Consolidating uncertainty 2577.1 Normalisation of event mentions . . . . . . . . . . . . . . . . . . . . . 257
7.2 Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
7.2.1 Text-mining for database curation and interaction network gen-eration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
7.2.2 Representation and fusion of uncertainty values . . . . . . . . 263
7.2.3 User perception of knowledge and uncertainty . . . . . . . . . . 270
7.3 Adapting subjective logic to uncertainty quantification . . . . . . . . . 272
7.4 Subjective Logic theory . . . . . . . . . . . . . . . . . . . . . . . . . . 273
7.4.1 Adaptation to uncertainty for events . . . . . . . . . . . . . . . 275
7.4.2 Fusion of opinions using subjective logic . . . . . . . . . . . . 277
7.5 Mapping event mentions to existing knowledge models . . . . . . . . . 283
7.5.1 Related work and challenges in integrating text-mined interac-tions to existing knowledge models . . . . . . . . . . . . . . . 284
7.5.1.1 Entity mapping . . . . . . . . . . . . . . . . . . . . 284
7.5.1.2 Interaction mapping . . . . . . . . . . . . . . . . . . 287
7.5.2 Proposed approach . . . . . . . . . . . . . . . . . . . . . . . . 290
7.6 Application to biomedical events and pathways . . . . . . . . . . . . . 294
7.6.1 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . . 294
7.6.2 Evaluation and results . . . . . . . . . . . . . . . . . . . . . . 297
7.6.2.1 The Leukemia pathway use-case . . . . . . . . . . . 297
7.6.2.2 The Ras-Melanoma use case . . . . . . . . . . . . . 302
7.7 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 305
8 Integrating uncertainty to pathway curation 3098.1 RW: Pathway visualisation with confidence metrics . . . . . . . . . . . 312
8.1.1 Literature-based certainty in interaction networks . . . . . . . . 312
8.1.2 Literature-based uncertainty visualisation . . . . . . . . . . . . 313
7

8.1.3 Integrating non-literature-based uncertainty parameters in visu-alisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315
8.2 Integrating evidence and uncertainty in a pilot . . . . . . . . . . . . . . 3198.2.1 Integrating evidence . . . . . . . . . . . . . . . . . . . . . . . 3208.2.2 Integrating textual uncertainty values . . . . . . . . . . . . . . 3258.2.3 Interactive integration of certainty . . . . . . . . . . . . . . . . 328
8.3 Textual uncertainty and citation patterns . . . . . . . . . . . . . . . . . 3308.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341
9 Conclusions 3439.1 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 349
9.1.1 Identification of textual uncertainty . . . . . . . . . . . . . . . 3499.1.2 Uncertainty in the newswire domain . . . . . . . . . . . . . . . 3509.1.3 Exploitation of citation networks . . . . . . . . . . . . . . . . . 350
Bibliography 353
Word Count: 81,400
8

List of Tables
1.1 Publications related to this PhD thesis, published during the course ofthe PhD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
2.1 Results on the Big Mechanism corpus before (EM) and after post-processing(+PP) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
2.2 Results on MLEE corpus before (EM) and after post-processing (+PP) . 75
3.1 Annotation specifications of available corpora annotated with uncertainty 101
5.1 Coverage of different uncertainty types for available corpora . . . . . . 164
5.2 Types of additional attributes assigned by Enju for sentence tokens. Thetense, aspect, voice and aux attributes refer exclusively to tokens iden-tified as verbs1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
5.3 Features used for uncertainty identification with the RF classifier. . . . . 205
5.4 Comparative evaluation of uncertainty classification approaches on GENIA-MK and BioNLP-ST corpora. . . . . . . . . . . . . . . . . . . . . . . . 208
5.5 Performance comparison against Miwa et al. and Kilicoglu et al. on the3-level classification problem applied to GENIA-MK corpus. . . . . . . 210
5.6 Ablation tests for different feature classes and their combination. . . . . 211
5.7 Comparison of performance on GENIA-MK corpus with other ML clas-sifiers, using the best-performing feature configuration for RF . . . . . 212
5.8 Comparative evaluation on GENIA-MK and BioNLP-ST corpora usingdifferent approaches for rule extraction and cue identification . . . . . . 214
5.9 Recall, precision, F-score and accuracy (at sentence and interactionlevel) of system annotations according to evaluation by 7 annotators . . 216
5.10 Inter-annotator agreement for each annotator pair (Kappa value) . . . . 217
9

5.11 Inter-annotator agreement for each annotator pair. . . . . . . . . . . . 220
5.12 Ratio of disagreement greater than 1 point on the 1-5 scale for eachannotator pair. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
5.13 Ratio of disagreement greater than 2 points on the 1-5 scale for eachannotator pair . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220
6.1 Comparison of event and entity definitions and annotations. . . . . . . . 236
6.2 Performance for uncertainty identification on each separate meta-knowledgedimension using GENIA-MK and ACE-MK cues. . . . . . . . . . . . . 241
6.3 Performance for uncertainty identification on GENIA-MK corpus usingdifferent cues. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241
6.4 WordNet sense description for the senses that were judged eligible forgraph generation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 250
6.5 WordNet sense description for the senses that were excluded graph gen-eration. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251
7.1 Results for the interaction scoring on the Leukemia dataset: predictionsbased on user uncertainty scores for events. . . . . . . . . . . . . . . . 301
7.2 Results for interaction scoring on the Leukemia dataset: predictionsbased on system uncertainty scores for events. . . . . . . . . . . . . . . 302
7.3 Results for interaction scoring on the Ras-melanoma dataset: predic-tions based on user uncertainty scores for events . . . . . . . . . . . . . 305
7.4 Results for interaction scoring on the Ras-melanoma dataset: predic-tions based on system uncertainty scores for events . . . . . . . . . . . 305
8.1 List of features and properties for visualisation tools that support linkingnetwork information with textual evidence. . . . . . . . . . . . . . . . 316
8.2 Availability and software properties for visualization tools that supportlinking network information with textual evidence. . . . . . . . . . . . 317
8.3 List of features and properties of visualisation tools that while not sup-porting literature-based evidence they provide other confidence scoringmetrics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 318
10

8.4 Availability and software properties of visualisation tools that while notsupporting literature-based evidence they provide other confidence scor-ing metrics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 319
8.5 Correlation between network centrality metrics and textual uncertainty. 337
11


List of Figures
1.1 Yearly publication volume of biomedical publications stored in the PubMeddatabase since 1950. . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
1.2 Yearly publication volume of biomedical publications focusing on can-cer, since 1950. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
1.3 Yearly publication volume of biomedical publications focusing on theRas gene in cancer, since 1950. . . . . . . . . . . . . . . . . . . . . . . 34
1.4 HRas interaction network visualised with PCViz on PathwayCommons. 35
1.5 Integrated Breast Cancer Pathway from Wikipathways. . . . . . . . . . 36
1.6 Insulin pathway from PathwayCommons. . . . . . . . . . . . . . . . . 37
1.7 Holistic view of project pipeline and contributions . . . . . . . . . . . . 42
2.1 Example of interaction extraction using the entity co-occurrence (bot-tom) versus the event extraction (top) approach. . . . . . . . . . . . . . 51
2.2 Comparison of event extraction and relation extraction representations. . 52
2.3 Two different cases of phosphorylation events, with different numbersof arguments. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
2.4 Example of event structure for complex and simple events. . . . . . . . 56
2.5 Example of event extraction in the newswire (top) and biomedical (bot-tom) domains. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2.6 Visualised stages of event extraction . . . . . . . . . . . . . . . . . . . 59
2.7 Example of partial event identification visualised in Brat . . . . . . . . 64
2.8 Example of event annotation in the BM corpus versus BioNLP . . . . . 67
2.9 Correspondence between named entity annotations of the training andtesting corpora. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
2.10 Examples of mutually exclusive entities in instance generation . . . . . 69
13

2.11 Dependency path representation example for a biomedical sentence . . 70
2.12 Flattening coordination dependencies . . . . . . . . . . . . . . . . . . 71
2.13 Linking the nested event argument instead of the trigger: Compare cor-rect annotation (top) with produced one (bottom) . . . . . . . . . . . . 76
2.14 Multi annot. (top): Pathway entity erroneously considered a valid addi-tional argument Alias (bottom): Sorafenib and its superclass both con-sidered valid argument candidates that are not mutually exclusive . . . . 76
3.1 Redrawn diagram of Smithson’s taxonomy of ignorance. . . . . . . . . 81
3.2 Mind-map of uncertainty: Related concepts (right) and their coverageapproach to uncertainty (left). . . . . . . . . . . . . . . . . . . . . . . . 83
3.3 Diagram of Hyland’s classification of scientific statements . . . . . . . 87
3.4 Redrawn diagram of Willet’s taxonomy of evidentials. . . . . . . . . . 90
3.5 Redrawn diagram of Sauri’s suggestion for the induction of factuality. . 91
3.6 Mind-map of uncertainty classification schemes . . . . . . . . . . . . . 94
3.7 Redrawn diagram of Roy’s broad classification of different phenomenaof uncertainty in linguistics. . . . . . . . . . . . . . . . . . . . . . . . 97
3.8 Mind-map of automated uncertainty classification tasks (left) and meth-ods (right). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
3.9 Example of a sentence with an uncertainty cues, affecting only the toplevel event of the sentence . . . . . . . . . . . . . . . . . . . . . . . . 115
3.10 Time-line of uncertainty classification. . . . . . . . . . . . . . . . . . . 120
4.1 Conceptual schematic diagram of Argo workflow used for experimentsand end-to-end system. . . . . . . . . . . . . . . . . . . . . . . . . . . 123
4.2 End-to-end Argo workflow used for experiments on linking evidence toa pathway model using uncertainty as a scoring criterion. . . . . . . . . 136
4.3 Conceptual schematic diagram of Argo workflow used for experimentson gold-standard corpora. . . . . . . . . . . . . . . . . . . . . . . . . . 137
4.4 Standoff annotation example . . . . . . . . . . . . . . . . . . . . . . . 138
4.5 End-to-end Argo workflow used for experiments on annotating largecorpora with binary uncertainty values. . . . . . . . . . . . . . . . . . . 140
14

5.1 Uncertainty cues considered in the experiments grouped according tocategory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155
5.2 Coverage of uncertainty categories for biomedical text and corpora . . . 165
5.3 B-cell Acute Lymphoblastic Leukemia Overview : validated and cu-rated pathway, visualised in PathwayStudio. . . . . . . . . . . . . . . . 172
5.4 Document collection query for the Melanoma corpus . . . . . . . . . . 175
5.5 Example of dependency graph over a sentence . . . . . . . . . . . . . . 179
5.6 Comparison of phrase structure (syntactic) tree and dependency graphoutput by Enju output. . . . . . . . . . . . . . . . . . . . . . . . . . . 181
5.7 Relation between the influence of uncertainty cues on triggers and thesyntactic dependencies between them. . . . . . . . . . . . . . . . . . . 182
5.8 Example demonstrating the importance of dependency roles, for uncer-tain event identification . . . . . . . . . . . . . . . . . . . . . . . . . . 183
5.9 Example demonstrating the importance of intermediate tokens in de-pendency paths, for uncertain event identification . . . . . . . . . . . . 183
5.10 Example of dependency rule that “breaks” the directionality of the de-pendency graph . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
5.11 Illustration of rule induction steps from a sentence (top) and application(bottom) to a new sentence to be annotated. . . . . . . . . . . . . . . . 187
5.12 Example of a noisy rule pattern that does not generalise well to othersentences . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
5.13 Percentage of identified patterns for increasing n (chain length) on GENIA-MK and BioNLP-ST . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
5.14 Example of rule pattern filtered out when an intermediate term is an event194
5.15 Rule selection performance by different measures for a varying size ofrule-sets, for GENIA-MK . . . . . . . . . . . . . . . . . . . . . . . . . 197
5.16 Rule selection performance by different measures for a varying size ofrule-sets, for BioNLP-ST . . . . . . . . . . . . . . . . . . . . . . . . . 198
5.17 Coverage of different pattern categories based on Interest (Lift) value . 200
5.18 Coverage of different pattern categories based on Leverage value . . . . 200
5.19 Coverage of different pattern categories based on absolute Jaccard value 200
5.20 Coverage of different pattern categories based on J-measure value . . . 200
15

5.21 Heatmap demonstrating the proportion of different feature types in thetop k most informative features (ranked by mutual information). . . . . 212
5.22 Brat interface for binary evaluation of the uncertainty of events for theLeukemia pathway corpus. . . . . . . . . . . . . . . . . . . . . . . . . 215
5.23 Brat interface for 5-level evaluation of uncertainty events of the Leukemiapathway corpus. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 218
5.24 Brat interface for 5-level evaluation of uncertainty events of the Leukemiapathway corpus: Annotation panel . . . . . . . . . . . . . . . . . . . . 219
5.25 Distribution of scores for uncertainty when annotating events from in-dividual passages on a 1-5 scale. . . . . . . . . . . . . . . . . . . . . . 220
5.26 Performance in terms of precision, recall and F-score, for Leukemiapathway . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
5.27 Distribution of scores for uncertainty at the sentence/event level be-tween annotator 1 (blue) and annotator 2 (red) for the Ras-melanomadataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
5.28 Performance in terms of precision, recall and F-score, for Ras-melanoma 224
6.1 Redrawn diagram of Rubin’s certainty categorisation, proposed for thenewswire / generic domain. . . . . . . . . . . . . . . . . . . . . . . . . 232
6.2 Event examples extracted from GENIA-MK (a-b) and ACE-MK (c-d) . 234
6.3 Distribution of uncertainty types for ACE-MK uncertain events. . . . . 239
6.4 Examples of meta-knowledge cue annotations from ACE-MK and GENIA-MK. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
6.5 Histogram of length distribution for shortest dependency paths betweenuncertainty cues and triggers for ACE-MK and GENIA-MK. . . . . . . 244
6.6 Dependency paths between cue and trigger for ACE-MK . . . . . . . . 245
6.7 Heatmap showing which percentage of each feature class is representedin the top k features, when those are ranked by informativeness. . . . . 246
6.8 Histogram of words per cue distribution for ACE-MK and GENIA-MKcorpora . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 247
6.9 Lengthy cue examples for Subjectivity: positive (green) and negative (red).248
6.10 Distribution for the frequency of occurrence of annotated cues for theACE-MK and GENIA-MK corpora. . . . . . . . . . . . . . . . . . . . 248
16

6.11 Distribution for the frequency of occurrence of Subjectivity versus allthe annotated cues in the ACE-MK corpora. . . . . . . . . . . . . . . . 249
6.12 Generated word graph based on WordNet relations for ACE-MK cues. . 2536.13 Generated word graph based on WordNet relations for GENIA-MK cues. 254
7.1 Examples of entity and event mapping challenges . . . . . . . . . . . . 2597.2 Examples of mapping challenges in terms of uncertainty and polarity
value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2597.3 Subjective logic representation of the opinion model. . . . . . . . . . . 2767.4 Cumulative and averaging fusion comparison for three opinion tuples . 2827.5 Entity mapping procedure. . . . . . . . . . . . . . . . . . . . . . . . . 2917.6 Examples of different directionality handling according to event type. . 2937.7 Event-to-interaction mappings for the Leukemia pathway model . . . . 2957.8 Event-to-interaction mappings for the Ras 2-hop neighborhood network 2967.9 Distribution of scores for uncertainty, based on the annotations of users
on the Leukemia dataset . . . . . . . . . . . . . . . . . . . . . . . . . 2997.10 Distribution of scores for uncertainty, based on the annotations of users
on the Ras-Melanoma dataset . . . . . . . . . . . . . . . . . . . . . . . 304
8.1 Document collection query for the Breast cancer corpus. . . . . . . . . 3218.2 MEK related interactions before addition of discovered events . . . . . 3238.3 MEK related interactions after addition of discovered events . . . . . . 3238.4 Sample of evidence sentences for MEK and ERK binding, organised
under the related paper. . . . . . . . . . . . . . . . . . . . . . . . . . . 3248.5 Example of different confidence parameters and the averaged confi-
dence score . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3258.6 Example of ascending confidence sorted diagonal layout. . . . . . . . . 3268.7 Combined confidence values propagated from sentence level to paper
level. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3278.8 Breast Cancer citation network visualised via LargeVis . . . . . . . . . 3328.9 Distribution of certain and uncertain event for each centrality metric. . . 3388.10 Distribution of certain and uncertain events for Hubs values. . . . . . . 3398.11 Intuition for ranking events experiments. . . . . . . . . . . . . . . . . . 3418.12 Ranking results for related interactions. . . . . . . . . . . . . . . . . . 342
17

“Il n’est pas certain que tout soit incertain.”It is not certain that everything is uncertain.– Blaise Pascal, Pascal’s Pensees
“ ῾Ημεῖς δὲ κλέος οἶον ἀκούομεν οὐδέ τι ἴδμεν.”We know nothing, save by report
– Homer, Iliad B 486
18

Abstract
The exponential increase in published research progressively perplexes the navigationof existing literature and the search of specific information for researchers, rendering theincorporation of new knowledge increasingly difficult. Text mining, can aid in literatureexploration, by processing vast document collections to extract and organise informa-tion of interest. This is of particular importance in the biomedical domain, where textmining methods can extract mentions of bio-molecular reactions and automatically in-corporate them in pathway and interaction networks, thus contributing to their timelycuration and maintenance. However, current methods tend to ignore the context ofextracted interaction mentions, and treat them all as equally certain, overlooking specu-lative statements, hypotheses and admission of ignorance.
To address this problem, we investigate the use of textual uncertainty in biomedicalliterature, and propose novel methods to identify the (un)certainty value of extractedstatements. We study to which extent, such values, representing the confidence of theauthor in a statement (and thus the inferred certainty of the statement itself), can be usedto provide a more informative weighting of extracted knowledge.
Focusing on the biomedical use case, we propose an approach to accurately iden-tify uncertainty values for the mentions of interaction identified in different documents.We subsequently use subjective logic theory to combine multiple uncertainty valuesextracted from different sources for the same interaction, and obtain a consolidated con-fidence score.
Throughout this work, we validated the output of our methods against the judgementof researchers in bio-medicine. We thus confirmed that our methodology for inferringan overall interaction score can approximate well the scores attributed by researchers.We demonstrate the usability of textual uncertainty in the biomedical context, by inte-grating it as a confidence filter in a pilot interactive interface, providing literature-aidedpathway visualisation. We thus illustrate, that, along with other literature-based confi-dence filters, textual uncertainty can help researchers explore and discover interactionsof interest.
19


Declaration
No portion of the work referred to in this thesis has beensubmitted in support of an application for another degree orqualification of this or any other university or other instituteof learning.
21


Copyright
i. The author of this thesis (including any appendices and/or schedules to this thesis)owns certain copyright or related rights in it (the “Copyright”) and s/he has givenThe University of Manchester certain rights to use such Copyright, including foradministrative purposes.
ii. Copies of this thesis, either in full or in extracts and whether in hard or electroniccopy, may be made only in accordance with the Copyright, Designs and PatentsAct 1988 (as amended) and regulations issued under it or, where appropriate, inaccordance with licensing agreements which the University has from time to time.This page must form part of any such copies made.
iii. The ownership of certain Copyright, patents, designs, trade marks and other intel-lectual property (the “Intellectual Property”) and any reproductions of copyrightworks in the thesis, for example graphs and tables (“Reproductions”), which maybe described in this thesis, may not be owned by the author and may be owned bythird parties. Such Intellectual Property and Reproductions cannot and must notbe made available for use without the prior written permission of the owner(s) ofthe relevant Intellectual Property and/or Reproductions.
iv. Further information on the conditions under which disclosure, publication andcommercialisation of this thesis, the Copyright and any Intellectual Property and/orReproductions described in it may take place is available in the University IP Pol-icy (see http://documents.manchester.ac.uk/DocuInfo.aspx?DocID=487),in any relevant Thesis restriction declarations deposited in the University Library,The University Library’s regulations (see http://www.manchester.ac.uk/library/aboutus/regulations) and in The University’s policy on presentation ofTheses
23


Acknowledgements
There have been several people who have helped to make this study of uncertainty,much more certain and feasible. It is practically impossible to include all of them to thisacknowledgement section, but I will do my best.
First and foremost, I would like to express my sincere gratitude to my supervisorProf. Sophia Ananiadou for the continuous support throughout my PhD research, forher motivation and patience but most importantly for her enthusiasm and deep under-standing of the field that was truly inspirational. Her guidance was indispensable and Icould not have imagined having a better advisor and mentor for my Ph.D study.
I would also like to extend my thanks to my co-supervisor, Dr. Riza Batista Navarro,who I had the chance to also share an office with in the beginning of my PhD studies.She proved to be more than a colleague and and advisor, a true friend, always keen toprovide her help and support and share her knowledge and experience.
Also, I would like to thank my committee members, Prof. Anne De Roeck and Dr.Andre Freitas for the invaluable comments and suggestions towards the improvement ofmy thesis, as well as for letting my oral defence be an enjoyable rather than a horrifyingmoment.
Much of this work would not have been possible without the time and contributionsof other people. I am indebted to Paul Thompson and John McNaught for taking thetime to help me improve my English writing; I sincerely appreciate it, and I am surewhoever reads my first publications will appreciate it as well. I want to thank Dr. PhilipDay for his valuable insights on how biologists read text. I am indebted to him and allthe annotators who helped us evaluate our methods. I also want to thank Axel for beingpatient during my countless attempts to properly map events to LitPathExplorer.
I am also thankful that I was given the opportunity to join the AIST Institute andthe University of Tokyo in Japan. I would like to thank in particular Prof. Tsujii and
25

Dr. Nakata, for welcoming me in the AIRC group and advising me throughout myinternship. I am grateful for the collaboration with Dr. Mori and Dr. Ochi and I amgrateful for their valuable advice and help on citation network analysis.
I would like to thank all my current and former colleagues in the NaCTeM group formaking my PhD life more interesting: Jock, Piotr, Raheel, Minh, Nhung, Xiao, Claudiu,Yianni, Paul, Sunil, George, Matt, Thy, Mei, Maolin, Yifei, Fenaki, thank you for all thestimulating discussions, and more importantly for all the meals, cakes and fun activitieswe shared. Extra thanks to all the occasional climbing partners, and apologies to Piotrfor all the times we had to reschedule climbing.
I also want to thank my CDT cohort: the people who I started this journey with,and shared the first worries, struggles, excitements and wonders that all PhD freshers gothrough.
But it is not only colleagues who accompanied me through this journey. I owe alot to the support of my friends, who made all the successful moments twice as happyand helped me go through any disappointments. Angelina, my friend and companionin craziness even from a distance, this PhD wouldn’t have been the same if you hadn’thelped to make rainy Manchester homey and fun. And so did Papyia, Pj, Areti, Ale-jandro, Jo, Jonathan, and most recently Petros! I am also glad for all the friends whoaccompanied me from afar, and did not forget me despite the distance: Alikaki, Beat-rice, George, Kostantine, Tzotzo, Filippe, Renata, Marianna, Oresti, Nasso, Thanassi,Mike, Jan and so many others, thank you for your loyalty, friendship and patience.
I am tremendously lucky that somewhere in the midst of my PhD journey, I metHugo, and I am most grateful for his constant love, companionship and support alongthe way.
Last but definitely not least, words cannot describe how grateful I am to my ever-supportive parents and brother, Evagoras who always believed in me and encouragedme to pursue my dreams.
26

Acronyms and Abbreviations
API Application Programming Interface
AR Association Rule
ARM Association Rule Mining
Attr Attribute
AUC Area Under the Curve
BEP Break Even Point
BM Big Mechanism
CNN Convolutional Neural Networks
CRF Conditional Random Fields
CSL Cost Sensitive Learning
FN False Negative
FP False Positive
FPR False Positive Rate
HFLTS Hesitant Fuzzy Linguistic Model
HPRD Human Protein Reference Database
HPSG Head-driven Phrase Structure Grammar
27

28
ID Identifier
idf inverse document frequency
IDM Imprecise Dirichlet Model
KNN K Nearest Neighbours
LogReg Logistic Regression
LSTM Long Short Term Memory
MAE Mean Average Error
MaxEnt Maximum Entropy
ML Machine Learning
NE Named Entity
NER Named Entity Recognition
NLP Natural Language Processing
PAS Predicate Argument Structure
PDF Probability Density Function
POS Part of Speech
PPI Protein Protein Interaction
r Pearson’s correlation coefficient
RB Rule Based
RF Random Forest
RNN Recurrent Neural Networks
ROC Receiver Operating Characteristic
SMO Sequential Minimal Optimisation

29
SVM Support Vector Machine
tf term frequency
TN True Negative
TP True Positive
TPR True Positive Rate


Chapter 1
Introduction
1.1 Motivation
Uncertainty is a paramount component of science and essentially of life itself. As Ur-sula LeGuin puts it “The only thing that makes life possible is permanent, intolerable
uncertainty; not knowing what comes next” [LG12]. It could be argued that it is whatmotivates people to explore and discover, to hypothesise and experiment, to seek an-swers and envision solutions to the great mysteries of life. In any field of science, re-search revolves around those aspects that are still uncertain and thus suitable for furtherinvestigation and experimentation.
We would thus expect the output of science, the results produced and the informationcommunicated (in other words, the information in published scientific articles) to be theexact opposite of uncertainty. Ideally, scientific information would resolve any relateduncertainty, much like Shannon’s expectations in the definition of information [SW49].Yet, the reality is very different, and uncertainty is embedded to varying degrees in manyscientific statements.
Rather than an obstacle, uncertainty can be seen as a functional and necessary partof any scientific publication. It helps to define hypotheses, frame experiments and com-municate limitations and speculation about the results. While in theory, this may sounddistracting, human readers, and particularly researchers who are familiar with scientificwriting, can discriminate between certain and uncertain information and appreciate the
31

32 CHAPTER 1. INTRODUCTION
degree of certainty of written statements and claims. While evaluation of the credibil-ity of a particular statement or claim can be aided by related background knowledgeand expertise on the part of the reader, the level of certainty can be largely judged byinformation found in the context of that statement, i.e., the way in which the authorpresents it. Readers can thus assess the uncertainty expressed via fuzzy and vague ex-pressions, evasive or polite statements and phrases aiming to lessen the impact of anutterance (hedges). Most importantly, when reading a sentence, users can evaluate thedegree to which such expressions relate to and affect the main statement in question. Inother words, human readers can understand and evaluate the textual uncertainty of aninformation piece.
In this work, as textual uncertainty we refer to the expressions used within a givenpassage, which result in reducing the readers’ confidence in the truth of a given piece ofinformation mentioned within that same passage.
While assessing textual uncertainty seems intuitive for anyone familiar with scien-tific text, it is not an entirely straightforward matter for automated information extractionsystems. Information extraction systems can use natural language processing and textmining methods to identify and extract specific and fine-grained information within astatement, discarding the rest of the text as redundant. Of course, such tools are valu-able; with the rapid expansion of published digital content, the availability of robusttext mining and information extraction tools can greatly help readers to navigate largeamounts of textual data and quickly locate information of interest.
Yet, not all information extraction systems consider contextual information, nor dothey differentiate between hypothetical and factual statements as a human reader woulddo. Instead, many systems are uncertainty-agnostic, treating all extracted statementswith equal confidence. However, failure to identify uncertainty from the context of astatement can prove to be a critical weakness in applications that use text-mining toextract and re-use information from large document collections. If there is no measureof confidence for the extracted information, and all context is disregarded, the outputpresented to the user can be confusing and difficult to interpret, offering an illusion ofuniform certainty. In response, there has recently emerged a considerable body of workon building information extraction systems that complement extracted statements with
1.1. MOTIVATION 33
additional attributes that capture contextual information. Such contextual information,also called meta-knowledge, may include aspects such as negation, speculation or hy-pothesis, which are useful indicators of certainty.
The need to assign context-driven certainty values to extracted information is rel-evant not only for scientific literature, but rather for any domain where knowledge isdistributed across many documents: events from news articles, product reviews or evenhistorical texts. In this work, we focus mostly on biomedical literature, which is one ofthe domains that exhibits the greatest need for confidence-enhanced, text mining sup-port, since its readers are faced with the simultaneous expansion in both the amount ofliterature available and the number of digital knowledge bases.
1.1.1 Motivation for the focus on biomedical literature
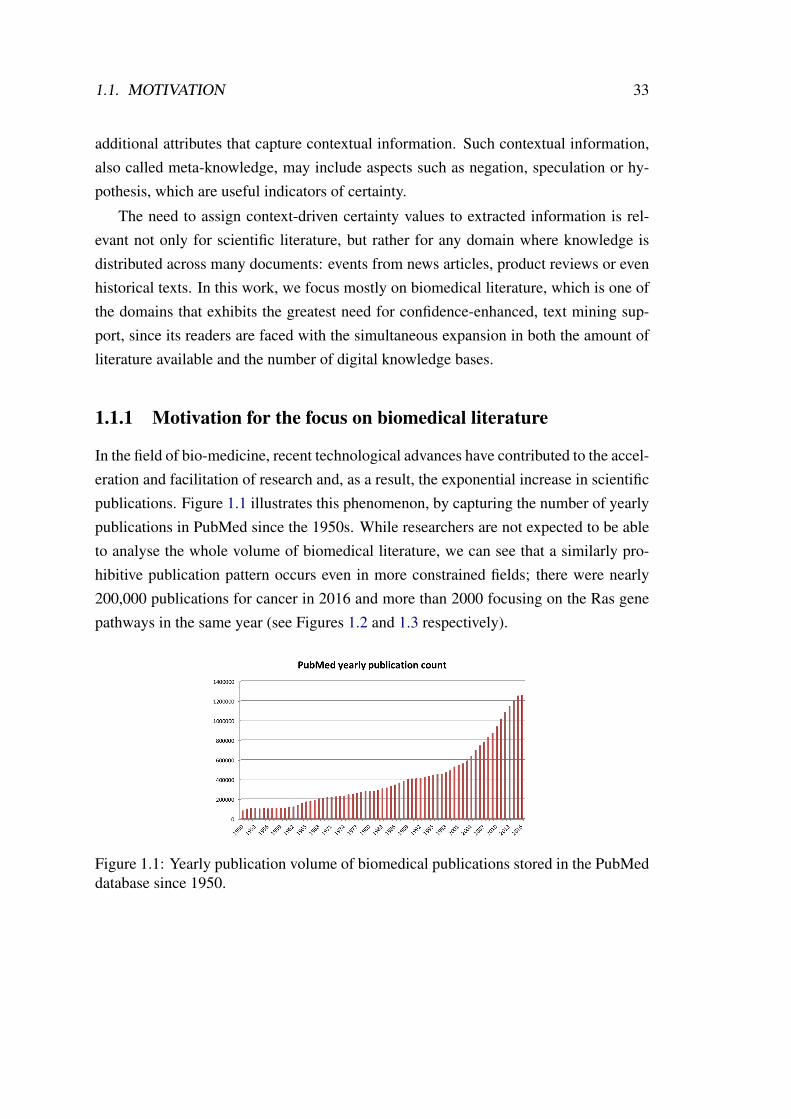
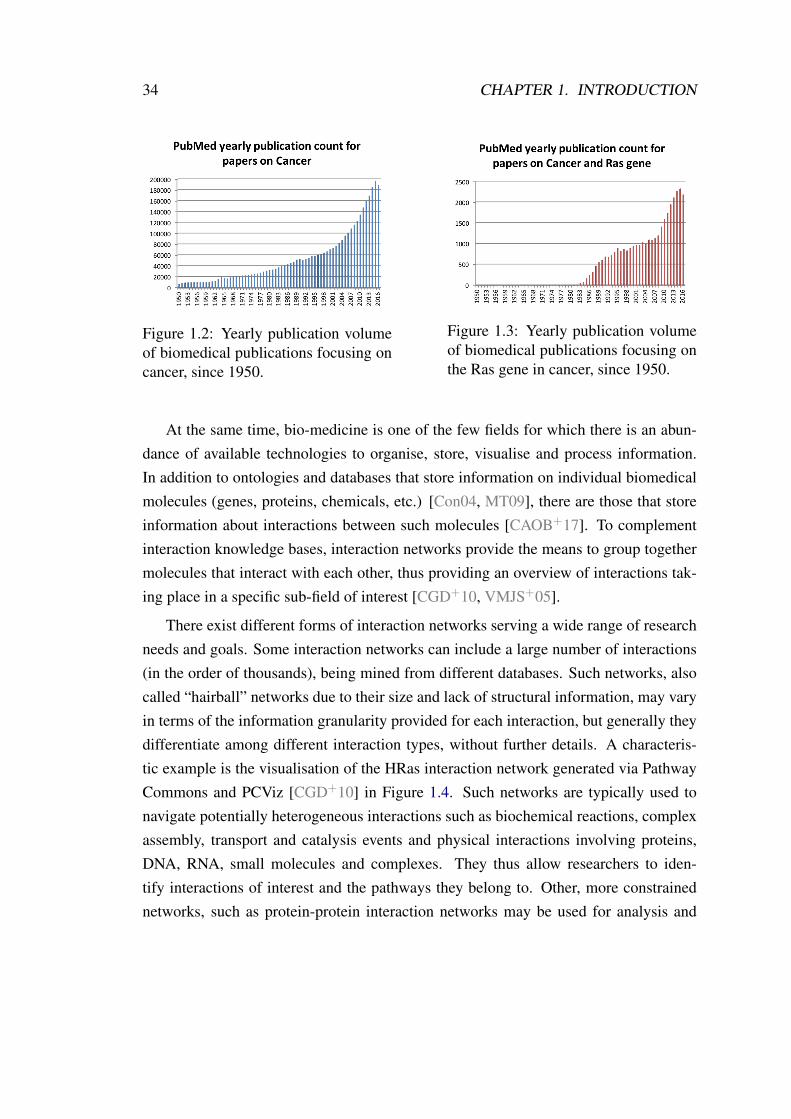
In the field of bio-medicine, recent technological advances have contributed to the accel-eration and facilitation of research and, as a result, the exponential increase in scientificpublications. Figure 1.1 illustrates this phenomenon, by capturing the number of yearlypublications in PubMed since the 1950s. While researchers are not expected to be ableto analyse the whole volume of biomedical literature, we can see that a similarly pro-hibitive publication pattern occurs even in more constrained fields; there were nearly200,000 publications for cancer in 2016 and more than 2000 focusing on the Ras genepathways in the same year (see Figures 1.2 and 1.3 respectively).
Figure 1.1: Yearly publication volume of biomedical publications stored in the PubMeddatabase since 1950.
34 CHAPTER 1. INTRODUCTION
Figure 1.2: Yearly publication volumeof biomedical publications focusing oncancer, since 1950.
Figure 1.3: Yearly publication volumeof biomedical publications focusing onthe Ras gene in cancer, since 1950.
At the same time, bio-medicine is one of the few fields for which there is an abun-dance of available technologies to organise, store, visualise and process information.In addition to ontologies and databases that store information on individual biomedicalmolecules (genes, proteins, chemicals, etc.) [Con04, MT09], there are those that storeinformation about interactions between such molecules [CAOB+17]. To complementinteraction knowledge bases, interaction networks provide the means to group togethermolecules that interact with each other, thus providing an overview of interactions tak-ing place in a specific sub-field of interest [CGD+10, VMJS+05].
There exist different forms of interaction networks serving a wide range of researchneeds and goals. Some interaction networks can include a large number of interactions(in the order of thousands), being mined from different databases. Such networks, alsocalled “hairball” networks due to their size and lack of structural information, may varyin terms of the information granularity provided for each interaction, but generally theydifferentiate among different interaction types, without further details. A characteris-tic example is the visualisation of the HRas interaction network generated via PathwayCommons and PCViz [CGD+10] in Figure 1.4. Such networks are typically used tonavigate potentially heterogeneous interactions such as biochemical reactions, complexassembly, transport and catalysis events and physical interactions involving proteins,DNA, RNA, small molecules and complexes. They thus allow researchers to iden-tify interactions of interest and the pathways they belong to. Other, more constrainednetworks, such as protein-protein interaction networks may be used for analysis and

1.1. MOTIVATION 35
Figure 1.4: HRas interaction network visualised with PCViz on PathwayCommons.Amounts to a total of 4826 interactions relating to the HRas gene.
mapping of interactions within a specific organism [BH03, RVH+05].
A more specific type of interaction networks that is used extensively is the biologicalpathway, i.e., the grouping of interactions among molecules in a cell that lead to a certainproduct or a change in a specific cell type. Pathways typically encapsulate and visualisemore detailed information, such as the exact location of entities and their interactions.Figures 1.5 and 1.6 depict two different pathway visualisations, from Wikipathways[SKH+17] and Pathway Studio [NEDM03] respectively. For both pathways, although

36 CHAPTER 1. INTRODUCTION
they contain different levels of visual details, the interaction information can be exportedas machine processable data (XML, BioPAX, sbml etc.). The ability to model pathwaysfor diseases such as cancer in digital form, combined with the advances in computa-tional modelling, provides support for experimental simulations (building executablemodels [Pet81]) as well as the identification of new hypotheses and the discovery ofnew knowledge.
Figure 1.5: Integrated Breast Cancer Pathway from Wikipathways. Visualises the breastcancer pathway for homo sapiens, including information about the type of regulatoryinteractions as well as cell location (visualised as greyed out shapes in the background).
While the aforementioned interaction networks facilitate and accelerate research,they quickly become outdated and should ideally be updated constantly. However, thecostly, time-consuming and often tedious nature of carrying out a continuous review ofthe ever-expanding literature in a manual fashion means that this is not always feasible.

1.1. MOTIVATION 37
Figure 1.6: Leukemia pathway from PathwayCommons. Visualises interactions for thehomo sapiens leukemia pathway. Includes information about cellular location whereinteractions take place (location denoted by the position of interactions in the picture,with respect to different cellular locations that are visualised in the background.
As a result, there is often a gap between the knowledge mentioned in a scientific articleand its representation in interaction networks, which can hinder the contextualisation ofnew discoveries and thus the discovery of new knowledge.
In this context, text mining can be a valuable tool in the quest for bridging textualknowledge with knowledge archived in interaction knowledge bases and networks. Inparticular, text mining makes it possible to automatically process large literature col-lections in order to identify mentions of interactions in text and then map them to cor-responding entries in digital knowledge sources [MOR+13, OKO+08a]. Such identi-fied textual references to biomedical interactions are often called bio-events (events forshort) in the text mining field [APTK10]; we will use the same term, “event”, to referto an interaction mention in text and distinguish it from the concept of the interactionitself, or an interaction entry in a database or pathway model. In Chapter 2 we elabo-rate on event extraction as opposed to other approaches for biomedical natural language

38 CHAPTER 1. INTRODUCTION
processing (NLP).
Thus, text mining can help to enhance biomedical knowledge bases and contributeto the automation of pathway reconstruction. Provision of literature-based evidence tousers of these knowledge bases minimises time needed to navigate related literature andenables them to assess the validity of interactions. Even so, the number of interactionsto be validated can be overwhelming (see for example the HRas interaction networkpresented in Figure 1.4), especially if there is no differentiation between interactionswith differing levels of certainty, since this means that the load of validation is placedexclusively on the user.
The need to score interactions in networks and pathways is also becoming stronger,according to the increasing number of methods being used to automate the generation ofthese resources. Indeed, alongside text mining, there are other methods based on bioin-formatics technologies (high throughput simulations, genomic data predictions, etc.)that are used to infer and integrate new interactions. However, not all of the interac-tions added are equally valid, and large networks need to provide scoring and filteringoptions to allow users to identify the information of greatest interest to them. So far,this task has been approached through scoring based on different criteria, such as sta-tistical interaction prediction methods, high-throughput lab experiments and genomiccontext predictions [ENB+07]. Text-mining methods are also used for scoring but onlyto account for the frequency with which interaction entities seem to co-occur in text[HKA+05, WZL+14, SSvM+16]. To the best of our knowledge, interaction scoringmethods for biomedical resources have so far disregarded any textual indication regard-ing the author’s certainly about the interaction.
However, textual indications of uncertainty could be used in more elaborate ways toprovide priors, or else to estimate confidence values regarding the validity of an interac-tion. More specifically, since events are part of scientific statements, not all of them willhave the same degree of confidence. Indeed, recent advances in text mining are mov-ing towards uncertainty-aware approaches for event-extraction, which are able to iden-tify additional contextual information as attributes of those events [MD09a, TNMA17].Such contextual and interpretative information, often called meta-knowledge, can iden-tify aspects such as negation [NTA13a], speculation [MD09b], investigation [NTMA10,NTA10] etc., which are useful indicators about the certainty of the event. However, this

1.1. MOTIVATION 39
certainty identification is usually limited to the sentence from which the event was ex-tracted, without associating it with the results of text mining from other articles or theinformation provided in knowledge bases.
Thus, there seems to be a missing link between identifying uncertainty in statementsfrom scientific text, mapping evidence from the literature to interaction networks andranking the interactions in terms of confidence. On the one hand, there are tools ableto extract biomedical events from text along with their textual certainty level, denotedby hypothetical, negated or speculated statements [NTMA10]. However, they do notattempt to link this information with other mentions of the same event, e.g. a molecularinteraction, which occur either elsewhere in the same article, in other articles or indigital knowledge-bases. On the other hand, there are valuable tools that can enhancedigital resources such as databases and interaction networks with text mined evidence,yet which disregard the elements of textual uncertainty and treat all statements equally.Accordingly, it has been so far left to the reader to fill in the gaps.
This apparent gap is the motivation for the work presented in this PhD thesis, whoseaim is to produce a more informative means to allow literature-based confidence, i.e., ex-pressions of uncertainty occurring across different biomedical statements extracted fromtext, to aid in ranking interactions in pathways and other digital knowledge sources.Our overarching goal is to integrate knowledge extracted from scientific papers (in theform of biomedical events) to existing pathways and interaction networks, in a context(and uncertainty) aware manner. In other words, to maintain information about the un-certainty expressed in the text over the event (and the interaction it refers to), and toincorporate this information in a way that is reflected in the confidence value of thecorresponding pathway interaction.
The aforementioned goal guides our research approach presented in this work. Theincorporation of textual uncertainty to interaction networks implies an end-to-end sys-tem that can parse raw text, extract events of interest and their (un)certainty context andmap them to interactions in pathways and networks. This goal definition demands thatwe direct our attention to different stages of the end-to-end process, and largely guidesour decisions in terms of the definition of uncertainty, the evaluation of our methods andthe type of information to be evaluated for uncertainty.
In terms of definition, the range of expressions that we identify as indicators of tex-tual uncertainty, is limited to the ones commonly found in scientific publications in the

40 CHAPTER 1. INTRODUCTION
biomedical domain. Hence, some phenomena that could convey uncertainty, such asirony or sarcasm, that are scarce in scientific writing are excluded from our definition,while other relating to biomedical experiments that might be irrelevant in other domainsare important for our purposes. We elaborate on the definition of uncertainty for thebiomedical domain in Section 5.1. We also compare more thoroughly the differencein the concept and expressions of uncertainty between the biomedical and the newswiredomain in Chapter 6. More specifically we compared uncertainty as expressed by scien-tists to uncertainty as expressed by journalists, in an attempt to shed light to the syntacticand lexical differences that define the concept of uncertainty in the two fields.
The expectation of mapping textual information from scientific articles to interac-tions also constrains the information units we focus the analysis on. Instead of looking atsentences or phrases we focus on biomedical events as the core information unit whichneeds to be annotated with uncertainty, since events can be then mapped to pathwayinteractions. We further elaborate on the choice of biomedical events, and the eventextraction approach that was chosen in Chapter 2.
Additionally, since researchers in the field of bio-medicine are the end-users, re-search in terms of the definition, identification and extraction of uncertainty revolvesaround their perception. Especially because of the scarcity of previous approaches tothis problem, we place an emphasis on evaluating our methods against gold-standardannotated corpora (where available) but also against the judgement of the end-users, ina selection of use cases that demonstrate the potential utility of the proposed methods.We thus ensure that our analysis and results are validated by researchers and fine-tunedfor their needs in several stages of the pipeline. For this reason, user-based evaluationexperiments along with qualitative interviews were designed, to allow researchers toassess the performance of our tools and permit us to fine-tune our methods and planfuture work accordingly. For example, the granularity of uncertainty levels, which ourmethods were trained to identify, was largely dictated by the related user evaluation (seethe experiments described in Section 5.4.2).
Moreover, the need to integrate textual uncertainty to pathway interactions, impliedthat apart from the identification of uncertainty for biomedical events, it is importantto be able to combine uncertainty values of several event mentions of the same typeinto one consolidated value, which could be used to assign a confidence score to thecorresponding interactions in biomedical networks. We hypothesise that it is possible

1.2. RESEARCH AIMS, HYPOTHESES, QUESTIONS AND OBJECTIVES 41
to combine (un)certainty values derived from mentions of the same event in differentpassages and produce a confidence score that will approximate the way human readerswould score the certainty of the corresponding interaction based on these passages. Weattempt to demonstrate the potential of using consolidated confidence values derivedby textual uncertainty to aid with the ranking of pathway interactions by confidence.We thus demonstrate the integration of events and textual, uncertainty-based confidenceinto a pathway visualisation tool, along with other confidence values, in order to providean enhanced pathway browsing experience for the user. Within this framework, wehave also investigated how textual uncertainty relates to and influences other confidenceparameters.
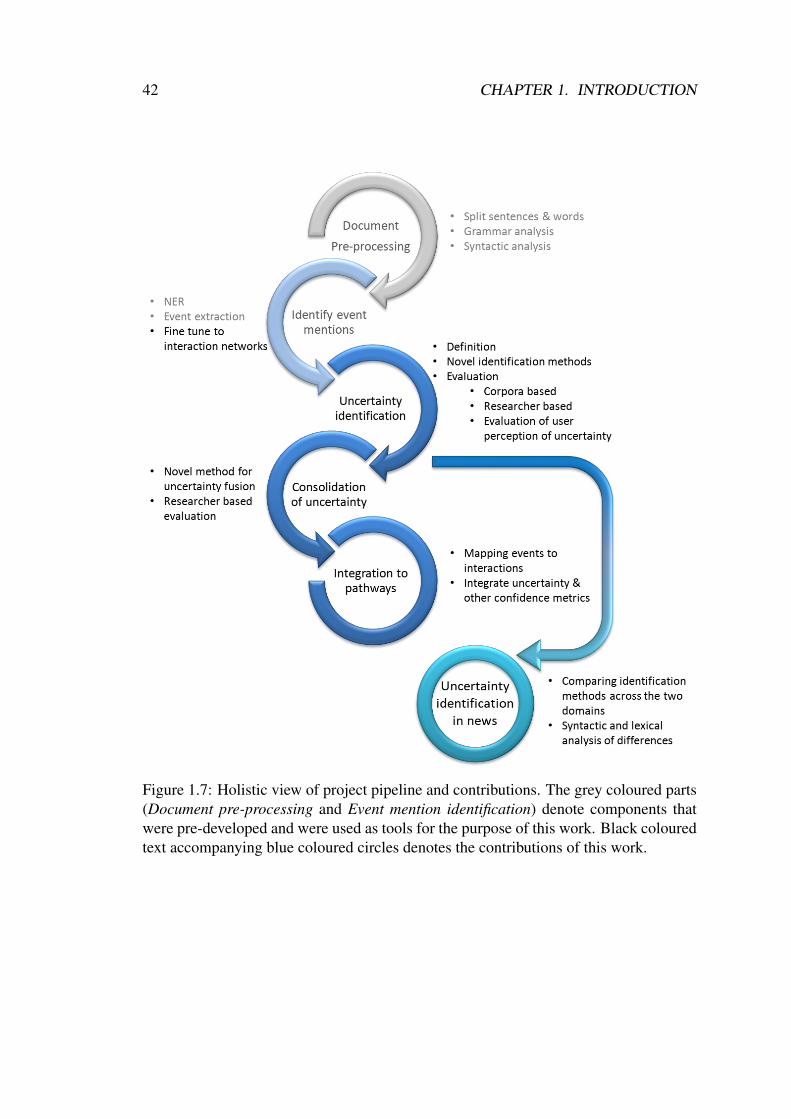
A schematic overview of the end-to-end pipeline highlighting our contributions inevery stage is presented in Figure 1.7. A more detailed overview of the components thatwere implemented in the course of this PhD as opposed to those that were adapted fromexisting components and tools is presented in Chapter 4.
1.2 Research Aims, Hypotheses, Questions and Objec-tives
Before setting finer-grained and specific aims, objectives and questions, we re-iteratehere the overarching goal of this work, which underpins our choices in terms of objec-tives, definitions, hypotheses and implementation.
Overarching goal:To integrate knowledge extracted from scientific, biomedical papers (in the form ofbiomedical events) to existing pathways and interaction networks, in an uncertainty-aware manner. In other words, to maintain information about the uncertainty expressedin the text over the event (and the interaction it refers to), and to incorporate this un-certainty related information in a way that is reflected in the confidence value of thecorresponding pathway interaction.
A brief description of the underlying research aims, hypotheses, questions and ob-jectives that helped us to address our main aim, is as follows:
42 CHAPTER 1. INTRODUCTION
Figure 1.7: Holistic view of project pipeline and contributions. The grey coloured parts(Document pre-processing and Event mention identification) denote components thatwere pre-developed and were used as tools for the purpose of this work. Black colouredtext accompanying blue coloured circles denotes the contributions of this work.

1.2. RESEARCH AIMS, HYPOTHESES, QUESTIONS AND OBJECTIVES 43
1.2.1 Aims
Our overall research aims are defined in the following points:
A1 To explore and optimise methods for automated identification of uncertain state-ments in the scientific literature, and more specifically in biomedical literature.
A2 To identify efficient methods for inferring a consolidated certainty value for aninteraction based on several different evidence passages.
A3 To combine biomedical event extraction and uncertainty identification methodsin order to facilitate automated enhancing and updating of biomedical interactionnetworks and proposed a literature-based ranking of biomedical interactions.
1.2.2 Research Questions and Hypotheses
In line with the three fundamental research aims, we formulate the following researchquestions and hypotheses:
RQ1 Can dependency relations in text be enriched in order to improve automated un-certainty identification?
H1 We hypothesise that by enriching dependency n-gram structures with withthe corresponding dependency types we can improve performance on auto-mated uncertainty identification.
RQ2 Is the intensity of textual uncertainty perceived and interpreted in the same wayby all readers of biomedical literature?
H2 We hypothesise that among biomedical scientists there is a large degree ofbetween-user variability in the interpretation of the uncertainty intensity intext.
RQ3 Is uncertainty expressed in the same way across different domains?
H3.1 Textual uncertainty expressions vary across domains, requiring domain-specificapproaches and knowledge extraction.

44 CHAPTER 1. INTRODUCTION
H3.2 Dependency based, ML methods that build on domain specific knowledgecan be equally efficient across different domains.
RQ4 Can we consolidate uncertainty values from independent mentions of the sameevent, in order to predict the confidence of the reader in the corresponding inter-action? Is subjective logic theory [Jos16] suitable for this task?
H4 We hypothesise that textual uncertainty of individual, independent eventmentions, affects the perception of users about the certainty of the cor-responding interaction in a consistent and measurable way, which can bemodelled. We can thus predict user scores for interactions, by their scoreson uncertainty of related events.
RQ5 How can textual uncertainty be integrated with other literature-based confidencevalues to complement event-based evidence linking to biomedical interaction net-works and pathway models?
1.2.3 Objectives
Based on the proposed aims and hypotheses, we establish the following research objec-tives:
O1.1 Study definitions and categorisations of uncertainty across various fields and do-mains and establish a definition that is suitable for scientific writing.
O1.2 Develop improved methods to take advantage of dependency relations betweenwords and apply them to uncertainty identification. Explore ways to improvedependency n-grams to achieve our goal.
O2 Validate our methods for uncertainty identification by taking into account thejudgements of researchers in different fields of bio-medicine. Construct multi-level scoring tasks, to assess their agreement on the interpretation of the intensityof uncertainty.
O3 Compare the expression of textual uncertainty between the biomedical and thenewswire domains, and evaluate the extent to which this definition is dependenton domain-specific knowledge.

1.3. CONTRIBUTIONS 45
O4 Adapt subjective logic theory to model event certainty and compare the use offusion methods against simple averaging baselines for uncertainty quantificationover several event mentions. Evaluate the consolidated confidence scores againstthe scoring of researchers in biomedicine.
O5 Define methods for uncertainty integration and mapping of events extracted fromliterature to enhance cancer-focused pathway networks.
1.3 Contributions
The main contributions of this thesis can be summarised as follows:
C1 We propose a unified definition of textual uncertainty, specifically tuned for sci-entific literature. Moreover, we detail how it relates to existing annotations ofbiomedical corpora, bridging the differences between previous annotation schemes(Chapters 3, 5).
C2 We explore the perception of uncertainty on the part of researchers and confirmthat Rubin’s findings in the newswire domain [Rub07] also apply to scientificwriting: user agreement on multi-level uncertainty evaluation indicates that a sim-pler binary classification of uncertainty is preferable to a five level annotation,since for multi-level uncertainty, user evaluations diverge significantly (Chapter5, Section 5.4.2).
C3 We define enhanced dependency n-grams as a method to capture the impact ofpotential uncertainty expressions on events identified in text. We demonstratetheir potential in rule induction and feature engineering for uncertain event iden-tification, and show that, combined with other supporting features, our proposedmethod achieves state-of-the-art performance (Chapter 5).
C4 We propose an adaptation of subjective logic theory [Jos16] in order to modelthe uncertainty and negation context of several event mentions of the same in-teraction using the opinion model framework. We compare different methodsto estimate an overall uncertainty score for interactions which are mentioned inseveral evidence passages. We evaluate these methods in a user-based evaluation

46 CHAPTER 1. INTRODUCTION
experiment in which users are asked to read the same evidence passages and scorethe interactions. We are able to show that using cumulative averaging formulasthe predicted scores approximate the user scores with minimal error rate. To thebest of our knowledge, this is the first detailed approach focusing on consoli-dating uncertainty from different mentions that moves beyond simple averagingapproaches (Chapter 7).
C5 As a result of our user evaluation experiments, we generate and make availabledatasets for enhancing interaction networks for testing. Each dataset containsa set of interactions, each scored for uncertainty with their accompanying evi-dence passages, where each evidence passage is annotated with sentence-levelevent annotations and uncertainty ratings. Both the Leukemia and Ras datasetsare available within an annotation environment, Brat [SPT+12], for future evalu-ation (Chapters 5 and 7).
C6 We examine domain adaptation and present a detailed account of the differencesin linguistic patterns expressing uncertainty between the scientific and the newswiredomains (Chapter 6).
1.3.1 Thesis overview by chapter
In Chapter 2, we present our motivation for choosing biomedical events as the target in-formation unit. We elaborate on the intricacies of mining events from text and mappingthem to external resources, and propose a post-processing method that is agnostic to theevent-extraction tool used and aims to alleviate issues of incomplete event extraction,and thus to improve mapping of events to external resources.
In Chapter 3 we review definitions and classifications of uncertainty in various fieldsas well as existing annotated resources. We identify and discuss apparent inconsisten-cies and differences between different approaches. We subsequently, examine methodsfor the automated identification of textual uncertainty, with a focus on uncertainty asexpressed in biomedical documents.
In Chapter 4, we provide a more detailed overview of the implemented text-mining

1.3. CONTRIBUTIONS 47
workflows, detailing the role of each component and separating between those imple-mented for this work and those that were used off-the-shelf. We also describe the pa-rameters that should be set, provide access to the necessary documents and detail theaccess process in order to facilitate reproduction of the experiments or adaptation to newtasks.
In Chapter 5, we introduce a definition for textual uncertainty, that has a broad cover-age over different uncertainty categories, tailored to the scientific domain and applicableto annotations in a range of existing corpora. We then proceed to propose methods toautomatically identify the uncertainty of events based on our proposed definition. Weexplore the potential of dependency parsing both using rule-based and machine-learning(ML) systems and propose enhanced dependency n-grams as a way to capture the im-pact of uncertainty expressions on the event in question. We show that our proposedmethod outperforms existing state-of-the-art methods for binary classification of uncer-tainty. We also evaluate the output of the system on sentences linked to pathway modelinteractions against the judgement of researchers in the area.
In Chapter 6, we examine the adaptability of uncertainty identification to other fields,motivated by an apparent gap in the performance of systems for uncertainty identifica-tion in biomedical text and corresponding systems in newswire text. We hypothesisethat this gap in performance is related to the increased complexity of linguistic patternsand phenomena employed by journalists to express reduced certainty for a describedevent. We confirm our hypotheses by exploring different linguistic aspects of uncer-tainty expressed in newswire text and comparing these against biomedical text.
In Chapter 7, we look into mapping several mentions of the same interaction to asingle, consolidated representation. In this context, we also examine the combinationof different certainty values of such mentions into a consolidated value that will rep-resent the evidence-based confidence of the interaction in question. We propose theuse of subjective logic and explain in detail how it can be adapted to the problem, aswell as demonstrating that our proposed solutions can outperform simple baselines inapproximating user-provided scoring.
In Chapter 8, we describe the choices and decisions involved in the integration ofuncertainty identification within a literature-aided pathway visualisation tool. We alsoexamine the interaction between textual uncertainty and other confidence parameters,focusing on citation-based confidence.

48 CHAPTER 1. INTRODUCTION
Finally in Chapter 9, we present the overall conclusions of this work and describeplans for future work and expansion of the areas of research covered in the thesis.
1.3.2 Thesis publications
A significant proportion of the work discussed here is already published. We have pub-lished the results from this thesis as they have arisen. In Table 1.1 we present a list ofthe publications, as well as their correspondence to the chapters of the thesis. In mostcases, the content of these publications is replicated with very little change.
Table 1.1: Publications related to this PhD thesis, published during the course of thePhD
Title Year Venue Reference Chapt.Event Extraction in pieces:Tackling the partial eventidentification problem on un-seen corpora.
2015 BioNLP@ACL [ZA15] 2
Using uncertainty to link andrank evidence from biomedi-cal literature for model cura-tion.
2017 Bioinformatics [ZBNDA17] 3,4,6
LitPathExplorer: aconfidence-based visualtext analytics tool for ex-ploring literature-enrichedpathway models. 1
2017 Bioinformatics [SZBNA17] 7
Paths for uncertainty: Explor-ing the intricacies of uncer-tainty identification for news.
2018 SemBeAR@NAACL [ZA18] 5
1This is a co-authored paper (second author). The author contributions are discussed in Chapter 8

Chapter 2
Event extraction for biomedicalinformation extraction
In this chapter we do the following:
• Provide a brief overview of information extraction methods for biomedical appli-cations
• Describe the structure of events and review event extraction methods
• Explain the event extraction methods used in this study
• Propose a post-processing method to remedy extraction of incomplete events
As stated in the introduction, this work focuses on detecting uncertainty of infor-mation extracted from scientific text. Prior to delving further into the conceptualisationand framing of uncertainty, an important preliminary step is to determine the informa-tion unit that will be the focal point of uncertainty identification. Since our target isthe biomedical literature, we focus on claims that have relevance to and contain infor-mation on biomedical interactions and processes. We have chosen focus on events, astheir structure (which is described in detail in this chapter) facilitates straightforwardmapping of information extracted from text to interaction entries in knowledge bases
49

50 CHAPTER 2. EVENT EXTRACTION
and interaction networks. However, events are not the only approach to biomedical in-formation extraction; there are several other methods used to infer information aboutbiomedical interactions from the literature, each of which has its own specific advan-tages and disadvantages. In the following section, we present the three main approachesto extracting such information from a sentence (co-occurrence, binary relations andevents) and justify our choice of events as our target information unit for the experi-ments described in this work.
2.1 Information extraction for biomedicine
The main approaches to literature-based evidence extraction for the enhancement ofknowledge bases or network, can be roughly classified to three main categories as wellas a number of hybrid solutions that combine different methods [LSCCP17]. The firstmethod, refers to extracting and mapping entities that co-occur in text, the second oneconcerns identification of relations in text, while the third one focuses on extraction ofmore detailed event structures (n-ary relations).
The co-occurrence method is the simplest of the ones that we present; its mainadvantage is that it can be applied straightforwardly to large volumes of text, without theneed for complex analysis of sentence structure. However, its simplicity brings potentialdisadvantages, in terms of both the accuracy of the identified relations, and the ease withwhich the uncertainty of these relations can be determined. Consider the sentence shownin Figure 2.1. Co-occurrence methods can correctly identify that some sort of relationexists between MEK and TOC1, and MEK and Belcin1. However, since such methodsare naıve to the structure of the sentence, they would erroneously extract an additionalrelation between TORC1 and Belcin1 (as shown by the dotted line in Figure 2.1). Ingeneral, there is considerable disagreement within the scientific community regardingthe ability of co-occurrence extraction to capture interactions with satisfying accuracy[VMKS+02, CTK+06] (this concern is further discussed in Chapter 7, Section 7.5).
It can also be difficult to associate uncertainty information with interactions thathave been extracted through co-occurrence methods. Although it is possible to identifyexpressions introducing uncertainty within the sentence, it is more difficult to assess the

2.1. INFORMATION EXTRACTION FOR BIOMEDICINE 51
Figure 2.1: Example of interaction extraction using the entity co-occurrence (bottom)versus the event extraction (top) approach. The scope of the uncertainty cue suggest isindicated with red brackets (all extracted interactions are within its scope).
degree to which such expressions would impact on the interpretation of such loosely-defined relations. A possible solution would be to adopt a cue-scope uncertainty identifi-cation approach, which assumes that if the entities co-occur within the (syntactic) scopeof the uncertainty expression then the interaction is uncertain 1 As shown in Figure 2.1,all of the entities occur within the indicated scope of the uncertainty expression suggest,and indeed, the two relations correctly identified by the co-occurrence method shouldbe considered as uncertain. However, depending on the complexity of the informationspecified in the sentence, combining the use of cue-scope uncertainty identification withco-occurrence based interaction detection may be inadequate.
In contrast to co-occurrence methods, binary relation extraction methods take intoaccount different aspects of the textual context of (biomedical) entities (e.g., specificterms or sentence structure), to allow the extraction of more accurate information units[GLR06, MSM+08, QWR14, PL17]. This type of information extraction is better fittedto the task of knowledge discovery and enrichment of knowledge bases, compared toentity co-occurrence. Moreover, we could expect the cue-scope approach of uncertaintyidentification to yield more accurate results [AS16, KRR17].
Consider the sentence shown in Figure 2.2. A typical binary relation extractionmethod would successfully identify that a relation of type binding holds between MEK
and ERK. However, the figure also illustrates a potential problem with binary relations,in that they are unable to capture more complex types of information, as is the case forthe inhibition described in Figure 2.2. Since binary relation extraction methods can onlydetect relations between entities, they are likely to extract (depending on system tuning)
1We provide more details about cue-scope uncertainty identification methods in Chapter 3, Section3.3.3.

52 CHAPTER 2. EVENT EXTRACTION
either two separate relations between MEK and TORC1 and ERK and TORC1 (markedby dotted lines in the figure) or completely miss the inhibition interaction. However,none of these is strictly correct, since, according to the sentence, it is the occurrence ofthe binding between MEK and ERK (i.e. the complete relation) that is suggested to beresponsible for the inhibition of TORC1.
Figure 2.2: Comparison of event extraction and relation extraction representations.
An additional issue is that the information units output by binary relation extractionmethods do not include the term that denotes the occurrence/type of the relation (e.g.,the word “binding” for the binding relation shown in Figure 2.2). This can make itproblematic to assess whether or not expressions of uncertainty present in the sentenceactually modify the information expressed in the relation. For example, Figure 2.2shows that the binding relation is within the scope of the uncertainty expression suggest,but yet the relation itself is not actually uncertain. Indeed, this uncertainty expressionactually only modifies inhibits, since it is the main verb in the clause falling underthe scope of suggest. Thus, determining which exact term denotes a relation can behelpful in determining whether or not it should be considered as uncertain. In contrastto binary relations, events constitute a more flexible type of relation. They may identifymultiple arguments, each of which may be either an entity or another event. Thus,as shown in Figure 2.2, we can use two events to fully capture the information aboutthe interactions specified. The binding event captures similar information to that whichwould be captured by a binary relation, with the entities MEK and ERK as its arguments.

2.1. INFORMATION EXTRACTION FOR BIOMEDICINE 53
However, the inhibition event has this complete binding event as one of its arguments,and the entity TORC1 as the other argument. It can also be noted that, it contrast tobinary relations, the role of each argument is identified. For example, the binding eventis identified as the cause of the inhibition event, in contrast to TORC1 which is assignedthe theme role, to distinguish it as the entity undergoing change.
A further feature of events that is particularly relevant for our research is the factthat the words that denote the presence/nature of each event (i.e., binds for the bindingevent and inhibits for the inhibition event in Figure 2.2) are explicitly identified as partof the extracted information unit. As we shall describe in later chapters, this feature ofevents is particularly important in helping to determine the specific information unitsthat are modified by the presence of an uncertainty expression in a sentence.
Events can also capture other related information, if it is specified in the same sen-tence [APTK10, KSB+14, NCG16]. Indeed, in text mining and natural language pro-cessing, events are currently the most complex information unit that can be extractedfrom raw text, in terms of their ability to capture n-ary dynamic relations between enti-ties. Moreover, event extraction methods allow for the identification of complex, nestedevents, i.e. structures that have as arguments other events, as indicated in Figure 2.2.Event extraction methods have the potential to efficiently distinguish the participantsof the interaction and disregard irrelevant parts of text that occur between participants.Currently, most event extraction methods focus on identifying events on the sentencelevel [BS13a, NCG16, LSL+15]. However, there has been some work that employsco-reference [MTA12], causality methods [DCR11, MT14] and cross-document infor-mation [JG08, JGCG09, YM16] in order to improve event extraction with informationthat exceeds the sentence boundaries. Moreover, there have been some attempts to ex-tract relations between entities across sentences [SS11]. However, so far there are nosufficient annotated resources (corpora, dictionaries or datasets) to support event extrac-tion across sentences.
Biomedical event extraction identifies and links all entities related to a specific in-teraction, and also specifies the role of each entity in the interaction. The outcome iscomparable to rule-based, template filling approaches such as the one used in BioRAT[CBLJ04] but it is more flexible, allowing for multiple configurations of the same eventtype to be learned, depending on the sentence content. Figure 2.3 illustrates such a case,

54 CHAPTER 2. EVENT EXTRACTION
where the two phosphorylation events shown have different numbers and types of argu-ments. According to their flexibility, events constitute the closest equivalent to human-extracted information, i.e., the way a reader would identify and combine different typesof information about an interaction from a sentence. The structured information repre-sentation of events can be used to enrich current knowledge sources such as ontologiesand databases in an automated manner [RIK+04].
Figure 2.3: Two different cases of phosphorylation events, with different numbers ofarguments.
Our focus is uncertainty identification for events. We can define event-based uncer-tainty as any case in which an expression of uncertainty modifies the trigger of an event(we elaborate on the definition of the trigger in the next section). Also, using events it ispossible to achieve a more detailed mapping between textual events and interactions inknowledge bases, by taking advantage of the rich information extracted, such as differ-ing interaction types, roles of the participants, directionality and existence of additionalparticipants (see also Chapter 7, Section 7.5). Thus, it is possible to distinguish, forexample, between events of inhibition, activation, or localisation.
Although they have the potential to detect extremely rich information, the perfor-mance of event extraction methods often suffers because of their need to identify de-tailed patterns of relations between entities. In striving for the identification of complex

2.2. EVENT STRUCTURE AND EVENT EXTRACTION METHODS 55
information structures, the precision and recall of event extraction systems is often com-promised, mainly because the machine learning methods employed often fail to pick upsome of the participating event arguments. This is because of the wide range of ways inwhich an event and its arguments may be mentioned in text; a newly encountered eventinstance may not comply with any of the patterns that they have been learned by thesystem.
However, improving accuracy and recall is a crucial step that in order to maximisethe benefits of mapping events to existing knowledge bases or biomedical network mod-els and consequently minimise the need for human intervention and manual revisionsof such resources. In systems with low recall, numerous potential matches betweeninformation in the literature and knowledge bases may be missed, due to incompleteor so-called partial events, i.e., events that are missing one or more participating argu-ments, despite the fact that those missing entities are present in the sentence. This par-ticular issue of missing participants can significantly reduce the efficiency of automated,literature-aided extension of biomedical resources, and thus we decided to explore itscauses as well as potential heuristic methods to alleviate it.
In the following sections, we describe the event structure in more detail (Section2.2.1) and provide a brief overview of the event extraction methods available, includ-ing the one that we employed for the experiments presented in Chapters 5 - 8 (Section2.2.2). In Section 2.3, we present an approach to alleviate issues of incomplete eventrecognition. Finally, in Section 2.3.2.2, we describe our approach to using and tailoringevent extraction to facilitate mapping events of events to existing interactions in path-ways and knowledge bases. We will refer to these methods later on in Chapters 7 and8.
2.2 Event structure and event extraction methods
In this section we describe event structures and event extraction methods and challenges.We justify our choice of event extraction methods utilised in the experiments presentedin the following sections.

56 CHAPTER 2. EVENT EXTRACTION
2.2.1 Event structure
An event, as presented in Figure 2.4, consists necessarily of a trigger, i.e., one or morewords (typically continuous) that characterise the event and indicate its type. Most often,as we can observe in Figure 2.4, event triggers are verbs (e.g., “required”, “regulate”)or nominalised verbs and gerunds (e.g., “binding”, “regulation”).Additionally an eventusually consists of one or more arguments that denote the concepts that participate inthe event. Each argument linked to the trigger is classified using a particular relationtype, which represents the semantic role of the argument for that event (e.g., “Theme”,“Cause”, “Site”). Additionally, arguments are assigned concept labels or tags (usuallyidentified as named entity (NE) labels). Note that since an event is a structured infor-mation unit, it can itself act as an argument of a different event (as is the case for thebinding event in Figure 2.4). Events that have other events as arguments are usuallyreferred to as complex events, while the event that acts as an argument is referred to as anested event. On the other hand, events that have only named entities as arguments arereferred to as simple or flat events.
Figure 2.4: Example of event structure for complex and simple events. In this case,the event of type Binding is nested in the event of type Regulation, which is a complexevent.
While all the examples mentioned above concern the biomedical domain, the eventstructure described above is generic enough to be employed in various fields. Eventextraction methods have been used in the newswire domain to extract events such as

2.2. EVENT STRUCTURE AND EVENT EXTRACTION METHODS 57
Transaction, Conflict, Life, Contact, Death, etc. Extraction of such event types canaid in summarising news, linking news articles and improving search or even largerscale tasks such as global crisis monitoring [HFKDJ11, MBE+02, TPA08]. Figure 2.5compares events extracted from biomedicine and news texts. We discuss the similaritiesand differences between newswire and biomedical events in Chapter 6. However, in thissection, we focus on the extraction of biomedical events.
Figure 2.5: Example of event extraction in the newswire (top) and biomedical (bottom)domains.
2.2.2 Event extraction methods
Biomedical event extraction has been used in text mining tasks since the early 2000s[YTMT00] and is still widely used for a variety of tasks, since it can be used to ex-tract information as wide-ranging as protein-protein interactions [ZH08], drug effects[WHS+11], of even virulence processes [POR+11]. The literature reports a large num-ber of approaches to automated event extraction, ranging from rule and template basedmethods [BCvMK13, VEHPSH15], to supervised and unsupervised machine learningapproaches [MSKT10, BS11, RM11a, VC12, BS15, MA15] as well as deep learningattempts [NCG16, LZW+16, WWL+17].

58 CHAPTER 2. EVENT EXTRACTION
The availability of corpora with gold-standard event annotations, such as BioInfer[PGH+07], Genia [KOTT03a], GREC [TIMA09] or MLEE [POM+12] have signifi-cantly contributed towards the development and evaluation of supervised event extrac-tion approaches. More importantly, a series of event extraction challenges organised aspart of the BioNLP workshops, namely the BioNLP Shared Tasks of 2009 [KOP+09a],2011 [KPO+11a], 2013 [NBK+13a], and 2016 [NBK16] have further motivated the de-velopment of event extraction tools, and provided researchers with extended annotatedcorpora covering different application areas (e.g., cancer genetics [POA13], pathwaycuration [OPR+13], bacteria biotopes [DBC+16], etc.)
Regardless of the specific extraction method employed, the automated extraction ofstructures of the complexity illustrated in Figures 2.2 and 2.4 typically requires eventextraction systems to break the complete event extraction task down into multiple clas-sification tasks that have to be solved in order to produce the final structured eventrepresentation. These tasks, also visualised in Figure 2.6, can be categorised as follows:
(A) Named Entity Recognition (NER): Identification of NEs and their semantic labelsis a necessary prerequisite for event extraction to be carried out, but is not alwaysconsidered part of the event extraction pipeline. In the BioNLP shared tasks, NEswere already provided (annotated) in text, and often, NER tools are applied to thetext prior to the application of event extraction methods, which take the identifiedNEs as their input.
(B) Event trigger identification: This is the task of identifying within a sentence aword sequence of words that could act as an event trigger and the subsequentclassification of this sequence with the corresponding trigger type (event label).
(C) Argument detection: This is the task of identifying binary relations between en-tities (NEs or event triggers) and the event trigger candidates. The semantic typeof the relation is also assigned at this stage.
(D) Combination of identified relations between triggers and entities to form events.
(E) Identification of event attributes: Identification of expressions within the samesentence that modify the meta-knowledge aspects of the event, such as negation,speculation and modality, or even manner, knowledge type and source [TNMA11,MTM+12].
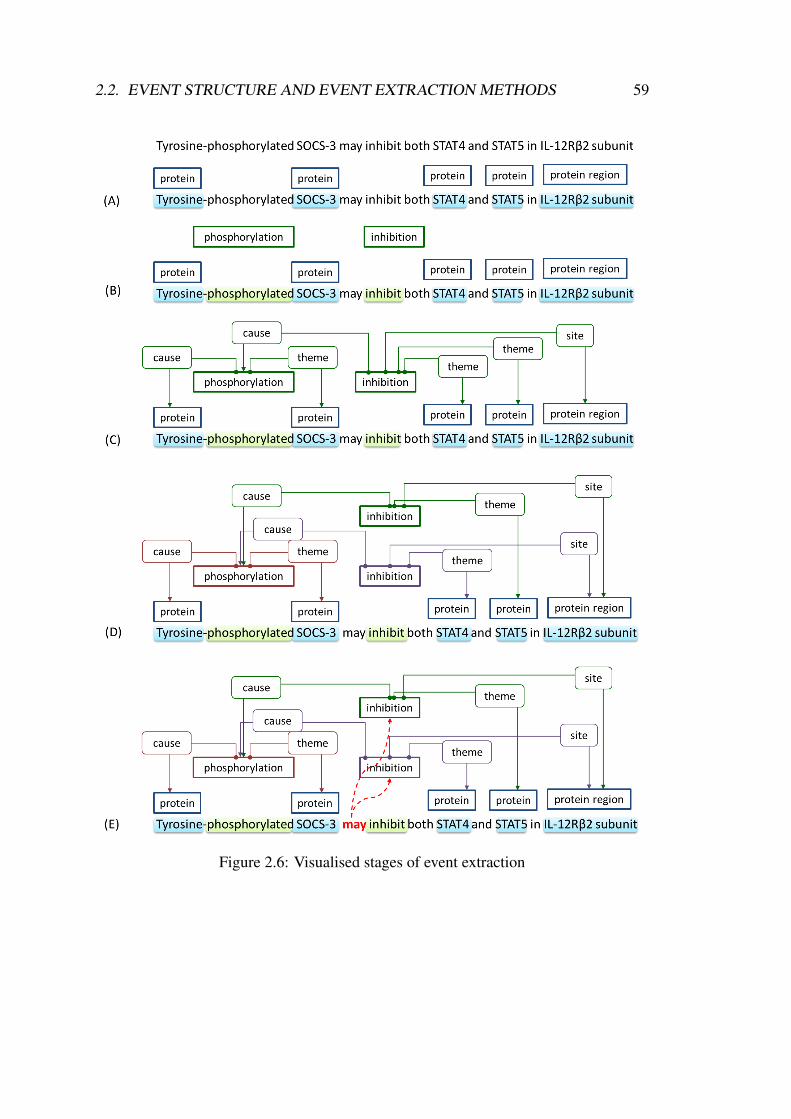
2.2. EVENT STRUCTURE AND EVENT EXTRACTION METHODS 59
Figure 2.6: Visualised stages of event extraction

60 CHAPTER 2. EVENT EXTRACTION
The learning process to carry out these tasks can be undertaken either sequentiallyin a pipelined manner, as is the case for EventMine [MA13a] and TEES [BS13b], or asa joint learning task, as in FAUST [RM11b]. In deep learning architectures, the outputof each step is typically embedded as input for the next layer [CXL+15, NCG16].
As stated in the introduction, we intend to apply our methods to assist in mappingtextual evidence to interaction and pathway networks. We focus specifically on cancerpathway models, and as such, it is important for the selected event extraction system tohave demonstrated efficient performance on cancer and pathway related corpora. Highperformance on a range of texts and event types is also of great importance, since theintention is to use event extraction on new and continuously updated document collec-tions, to extract events across a wide spectrum of biomedical interaction types (PPIs,chemical reactions, pathway signalling, etc.).
We have chosen to use EventMine, partly because it achieved the first and secondplace in the Pathway Curation (PC) [OPR+13] and Cancer Genetics (CG) [POA13]tracks of the BioNLP 2013 [NBK+13a] respectively (achieving an F-score of 53% onthe PC and 52% on the CG task); both of these tasks are highly relevant to our areaof interest. Furthermore, the wide coverage methodology for EventMine [MPOA13]as well as the demonstrated robustness when applied to new corpora [MTA12] furthermotivated our choice to selected this event extraction tool. We provide further detailsabout on the wide coverage and adaptation methods below, after describing EventMine’spipeline.
EventMine does not include any NER processing, so it requires the use of exter-nal tools and methods for NER as part of the sentence pre-processing [RBNR+13b,RBNR+14]. It makes use of the pipelined approach, and consists of four modules, cor-responding roughly to the steps B-E as illustrated in Figure 2.6. Each module performsa different multi-class classification task, learned in a supervised way. For all modules,the classifier is trained using one-versus-rest Support Vector Machine (SVM) imple-mentation of the LibLinear library [FCH+08]. The description of each module follows,based on [MA13b]:
• Trigger detector: Handles trigger identification. Builds trigger/entity word dic-tionaries that are used both in the training and testing phase. The classifier buildsinstances for each word that are classified according to the predicted trigger type

2.2. EVENT STRUCTURE AND EVENT EXTRACTION METHODS 61
(or the negative/null label).
• Argument detector: Links each trigger with all potentially related entities (andother event triggers) in order to identify argument candidates. Uses each potentialpair of entities as a relation instance to be classified using the set of potentialargument roles as labels (along with the negative/null label).
• Multiple argument detector: Constructs the final event structures. The modulebuilds event instances by identifying all possible relation combinations for eachtrigger and then classifies them using event types as labels (along with the nega-tive/null label).
• Modification detector: Identifies event modifications (meta-knowledge dimen-sions). Uses each event structure from the output of the previous module andclassifies it using the candidate modification labels (Negation, Speculation andnegative/null).
One of the problems usually encountered with supervised models, such as thoseused by EventMine, is that they are specifically tailored to the features and labellingconventions of the corpus on which they have been trained. As a result, their func-tionality is restricted to the trigger, argument and role types that they have been trainedto identify and extract. For example, some corpora focus only on protein-protein in-teractions, while others include chemical reactions, pathway signalling, disease effectsand/or a combination of the above [POM+12, POR+11, OPR+13]. Intuitively, in orderto capture events that encompass all of the types of interest to us, as detailed above, onewould either have to annotate a new corpus with all the required types of interest, orelse use some combination of either the different corpora containing the various eventtypes, or the models trained on them. This can have negative implications in terms ofthe adaptability and robustness of the trained model, even when applied to slightly dif-ferent tasks within the same domain. Especially for applications like the ones that formthe focus of the current work, where large amounts of literature need to be processedin order to detect a wide range of interaction types, and to map them to a variety ofinteractions in pathways and networks, adaptability and generalisability are crucial forrobust event extraction.

62 CHAPTER 2. EVENT EXTRACTION
With such applications in mind, several approaches have been proposed with afocus either on large scale, generic event extraction [BGP+10] or on domain adapt-ability [NG15, RM11c, PV10]. Some of these approaches are unsupervised [CHR04,VBSB09], and leverage external resources and inferencing. Other approaches havecombined information from a number of different corpora in order to avoid the trainingof tools that are over-fitted to a single corpus.
A particularly straightforward approach is to combine the models in a stacking man-ner as in [Wol92], where a method inspired from cross-validation is used to train differ-ent models on subsets of the different corpora, and then use the validation set to learnhow to combine their outputs to obtain the desired result. Other approaches attempt toadapt to a new corpus by either selectively training on the instances and/or features thatare expected to maximise performance [CWB11, XZHC13], or by attempting to tailorfeature distributions to the one of the new corpus [DI09, KSD11, PTKY11].
Building on the original EventMine system, Miwa in [MPOA13], suggests the useof a filtering model that considers the overlap of the available corpora and filters redun-dant and contradicting labels across different corpora. Subsequently, the filtered andunified instances from the corpora are merged to enable the training of a single modelon their combination. The filtering is heuristically achieved by limiting the generationof negative instances in each corpus to only those cases in which the correspondingsurface expression (i.e., the word representing the entities in the text) matches at leastone positive instance of an annotated type in any corpus that includes that type. Themethod, referred to as wide coverage, when implemented in EventMine, outperformsother stacking and domain adaptation methods as shown in [MPOA13]. Accordingly, itis our chosen approach for event extraction in this work.
2.3 Dealing with incomplete events
As discussed earlier, one of our main targets is the extraction of events that are rele-vant to interaction and pathway networks. One of our main use-cases concerns cancerand more specifically, mapping evidence from melanoma and breast cancer documentcollections to the a Ras-centred interaction network, as described in Chapter 5, Section5.2.2. In order to estimate the efficiency of the wide coverage approach to event ex-traction on new data, we carried out a pilot study, using a small collection of annotated

2.3. DEALING WITH INCOMPLETE EVENTS 63
passages focusing on cancer pathways, which were developed as part of the Big Mech-anism project [Coh15]. This dataset is described in details in Section 2.3.1. We haveused this dataset to re-purpose EventMine to the our domain of interest, and to evaluatethe performance of event extraction in this area, without the need for intervention ofexperts.
In this first evaluation phase, our model was evaluated using both strict and relaxedprecision. Based on the guidelines, strict precision would expect a full match of eventtrigger, argument types and roles in order for an event instance output by the model tobe classified as correct, while relaxed precision would accept an event as correct evenif one argument was missing or was erroneously identified. Our results showed an im-provement of more than 10 points, from 50.78 to 62.5, when switching from strict torelaxed mode. The boost in relaxed precision evaluation was encouraging, but revealeda critical issue for our use case of interest (i.e., mapping events to interaction networks).For some applications, an incomplete event (i.e., where only some of the arguments areextracted correctly), can still be informative and might be preferable to e.g., detectingan argument whose role is incorrectly identified. However, for our use case, incompleteevents could lead to missed or erroneous matching of textual events to the interactionentries of the networks. More specifically, in order to map an event to an interaction ofa pathway network or some other related resource, even the most relaxed mapping con-ditions would require that the entities participating in the interaction are mapped to thearguments of the event. Thus, an event missing an argument would never be mappedto the interaction, as opposed to an event with the correct argument identified, but apotentially erroneous argument role label, which would be mapped to the interaction(along with its accompanied sentence). In the latter case the event could then be fur-ther inspected and corrected by the pathway curator, while in the former case, the linkbetween the interaction and the event (and thus the link between the interaction and theevidence passage where the event is extracted from) will be fully missed.
Hence, for our use case, the correct identification of the arguments themselves canbe more important than other aspects of the event, e.g. the correct labelling of theevent roles and assignment of an appropriate event type. In fact, if the directionality ofthe relation(s) can be captured correctly by the event structure, then the exact type ofthe event and the roles of the arguments could be considered as secondary information

64 CHAPTER 2. EVENT EXTRACTION
(see the application in Chapter 7, Sections 7.5). Thus, we explore the reasons for in-complete events, and consider ways to improve event extraction results by applying apost-processing step to automatically detect missed arguments.
We can identify two types of incomplete events. In the first type, the missing ar-gument corresponds to a named entity that the NER tool applied during pre-processinghas failed to detect. Such cases are difficult to handle in a post-processing step, sinceevent extraction methods can only consider NEs that have been identified as potentialarguments. Thus, our post-processing method focuses on the second type of incom-plete event, which concerns cases where the event extraction model fails to correctlyidentify an event argument, even when the underlying NE has been correctly identifiedin the text. We hypothesise that such errors, which concern the failure to detect someof the arguments, are partially due to the complexity and potential variability of eventpatterns, sought by the supervised models. An example illustrating such a problematiccase is presented in Figure 2.7, in which BRAF has failed to be recognised as the causeof the Regulation event by EventMine. Based on this hypothesis, we propose the devel-opment of a post-processing method for application to event extraction results, whichattempts to identify arguments that were initially missed by EventMine (with a focus onimproving argument recall over argument precision) and thus aims to improve the recallof events that can be efficiently mapped to external interaction resources.
Figure 2.7: Example of partial event identification visualised in Brat (example takenfrom the Big Mechanism corpus). The BRAF gene is correctly identified in the text asan entity, and is a valid argument for the regulation event with “required” as its trigger,but it is missed by EventMine.
More specifically, approaches like the wide coverage approach of EventMine, at-tempt to combine information from multiple corpora, with different sets of labels, and a

2.3. DEALING WITH INCOMPLETE EVENTS 65
wide range of targeted interactions and named entities, in order to achieve a broad cov-erage when applied to new data. However, such rich sets of learnt labels and patternsmay introduce unnecessary complexity in some tasks (i.e., make the task too complex toachieve high levels of performance). Thus, we explore whether we can reduce the com-plexity of learnt patterns, and thus facilitate linking of incomplete events with secondaryarguments.
2.3.1 Training and testing corpora
The wide coverage version of EventMine was trained on the instances of the followingcorpora: Genia09 of BioNLP ’09 [KOTT03a], Genia11, EPI [OPT11] & ID [POR+11]of BioNLP ’11 [KPO+11a], DNA-methylation [OPMT11], ePTM [POMT11], mTOR[CGM+10], and MLEE [POM+12], based on [MPOA13].
We use the same combination of corpora to train both the EventMine classifiersand the classifier used in the post-processing method that we propose and describe inSection 2.3.2 to tackle the issue of incomplete events. Training is carried out using boththe training and development sets of the corpora, unless otherwise specified in the text.
For testing purposes, we have tried to identify annotated corpora that are relatedto our use case. Our primary test corpus is the Big Mechanism collection of passagesbriefly mentioned earlier. It is a small, annotated set of six passages extracted fromfull-text biomedical research papers in PubMed 2. The documents are related to theRas gene and cancer pathway curation and have been manually annotated with biomed-ical named entities and events by expert biologists participating in the Big Mechanismproject [Coh14]. This small document collection will be henceforth referred to as theBig Mechanism (BM) corpus.
The Big Mechanism corpus consists of 155 event and 247 named entity annotationsin total. The annotated entity types span across Chemical, Protein and Cell instances,while the range of events annotated covers pathways, various protein interactions (Bind-
ing, Regulation, etc) and other cancer related events. Since there is no single relatedtraining corpus with a similar range of annotations, a model such as the wide cover-age EventMine, which can learn labels from different corpora, is necessary to facilitaterecognition of all of the above event and entity types. The event types and entities in
2PubMed ids: PMC2872605, PMC3058384

66 CHAPTER 2. EVENT EXTRACTION
the Big Mechanism corpus are covered by in the corpora listed in the beginning of thissection.
The scheme employed to annotate Big Mechanism corpus differs from the annota-tion scheme used in the other corpora in the following ways:
• The entity labels are different to those used in the training corpora, as illustratedin Figures 2.8 and 2.9. In some cases it is straightforward to determine the cor-respondences, e.g., “Chemical” labels from the training corpora correspond to“ChemicalOrDrug” in the Big Mechanism corpus. For others, however, a morethorough examination is necessary, as discussed in Section 2.3.2.
• No distinction is made between different event types. All event triggers are iden-tified as “predicates”, as shown in the regulation event examples of Figure 2.8
• A simplified argument role type annotation was adopted in the Big Mechanismcorpus, that discriminates only between simple arguments and arguments that in-dicate the site (cellular location) where the interaction described by the event takesplace. The directionality of the interaction (if it exists) is represented by the orderof the arguments (First Argument or Second Argument). If there is no underlyingdirectionality (e.g., in the case of a Binding event) the argument order is directedby the order of appearance in the text. As such, argument annotations contain lesssemantic information compared to the BioNLP schema on which EventMine wastrained (there is no discrimination between roles such as Instrument, Participant,Cause etc).
Figure 2.8 illustrates the differences in the labelling conventions between the BioNLPand the Big Mechanism annotation schema.
Due to the small size of the Big Mechanism corpus presented above, the simplifi-cation method was also tested on the development set of the MLEE corpus [POM+12].The MLEE corpus was chosen because, similarly to the Big Mechanism corpus, it con-tains events covering a wide range of entities and spanning across different levels ofbiological organisation (molecular to organ) instead of focusing only on protein-proteininteractions. Compared to the other available corpora described in the beginning of thesection, it covers a wider range of event and entity types (this is partly illustrated inFigure 2.9, as far as NEs are concerned).

2.3. DEALING WITH INCOMPLETE EVENTS 67
All four drugs blocked ERK activity in BRAFmutant A375 melanoma cells
ChemicalOrDrug ProteinFamily Predicate GeneOrProteinPredicate
CellLineSecondArg
SecondArg
FirstArg
Site
Chemical GGP Pos Regulation GGPNeg Regulation
CellularComponentTheme
Theme
Cause
Site
All four drugs blocked ERK activity in BRAFmutant A375 melanoma cells
Figure 2.8: Example of event annotation in the BM corpus (top) versus BioNLP (bot-tom) : we can observe the different labels used for entities, events and roles. For ex-ample the Cause and Theme role labels are simplified to FirstArg and SecondArg (stillmaintaining directionality). Also, different NE labels are used and the different eventlabels are unified into a single Predicate label in the Big Mechanism corpus.
2.3.2 Adding secondary arguments to incomplete events
In order to improve linking with missing arguments, we add a supervised, post-processingstep after the application of EventMine, which aims to relax the constraints related toargument roles and entity types that are learned by the event extraction classifiers. Thechoice of the post-processing step rather than re-training EventMine on simplified an-notations is preferred, as the post-processing method is more general, in that it can beapplied to the output of any available event extraction system.
Approaches that relax rule or pattern constraints have previously been shown toconstitute an efficient method for generalisation, and allow models to be more easilyadapted to different information extraction tasks such as NER in [TC11] and [ZS03] ormulti-level information extraction in [CL04]. In our case, the relaxed constraints permita re-evaluation of the possible relations between event triggers and recognised entities

68 CHAPTER 2. EVENT EXTRACTION
Protein
Chemical
OrganismCell
Cellular_Component
Organ
Multi_tissue_structure
Developing_structure
Immaterial_anatomical_entity
Organ_system
Organism_subdivision
Organism_substance
Pathological_formation
Tissue
GeneOrProtein
Cell
ChemicalOrDrugCellLine
ProteinSite
ProteinFamily
= All corpora
= MLEE only= ID and MLEE
= BM corpus
Training corpora BM corpus
Figure 2.9: Correspondence between named entity annotations of the training and test-ing corpora.
in a given sentence.
We thus hypothesised that we could reconsider argument candidates from sentencescontaining incomplete events, and rank them according to their likelihood of being re-lated to the event trigger. For the ranking process, all named entities and event triggersthat are not already linked to the event in question are considered as candidate argu-ments.
The ranking task is treated as a supervised problem, where an event trigger anda candidate argument constitute an instance for classification. Thus, we can treat theproblem as a binary classification task, whose aim is to classify each entity with respectto each trigger as a valid (positive case) or non-valid (negative case) pair. Then, intraining a classifier on the above binary classification task, we can make use of theprediction confidence of the classifier model to allow the entities to be ranked withrespect to their likelihood of constituting an argument of the event in question. The topranked entity is selected and added to the event.
The entity label is determined in a rule-based manner, depending on the alreadyidentified labels for other arguments of the same event. In other words, if there is an

2.3. DEALING WITH INCOMPLETE EVENTS 69
identified argument with a SecondArg label, then we would assign the newly foundargument the label of FirstArg, etc. If there is no such information, we assign labelsin a default order. Moreover, we apply the post-processing step once, without iteratingin order to identify several missing arguments (thus for each event trigger at most oneargument will be identified). In future work, we would like to address this point moreeffectively, looking into iterative approaches and suitable stopping conditions, to decidewhen we have identified a sufficient number of arguments.
Entities that are indirectly linked to events, i.e., those which occur as argumentsof nested events, are considered redundant. Thus, for each trigger, entities belongingto its parent event(s) or its nested event(s) are excluded from instance generation andsubsequent ranking. Additionally, entities that have already been assigned to a differentevent having the same trigger, as in Figure 2.10, are considered mutually exclusive andalso excluded from the instance generation process.
BRAF inhibitors hyperactivate CRAF and MEK in these cells
Pro PredicatePredicate
Pro ProSecondArg
SecondArg
Figure 2.10: CRAF and MEK are mutually exclusive entities: in the generation of in-stances for the event with hyperactivate as a trigger and with MEK as a SecondArgargument, CRAF will not be considered as candidate entity, as it is already linked to an-other event that is anchored to the same trigger. This would not prevent the generationof instances from MEK and CRAF for events with different triggers.
Furthermore, in order to account for potential nested events that were missed byEventMine, other extracted events within the same sentence are also considered as can-didate arguments, using the trigger as the representative text span in the generated in-stance.
Finally, a null-instance pair was added to avoid the addition of spurious argumentsto events. This was deemed necessary because EventMine extracts a considerable num-ber of events that require either a single argument or no arguments (usually Pathway orGene Expression events). For some event types, such as Gene Expression, such casesconstituted more than 80% of the events. In order to avoid the addition of spurious ar-guments, and inspired by [RN09], an artificial “null” named entity instance was created

70 CHAPTER 2. EVENT EXTRACTION
for each event, and assigned to the events in the training set that did not require a second(or even a first) argument. Thus, the classifier would consider and rank the null entitypair for each event, alongside other instances.
We assume that the most important information for identifying the trigger-argumentpairs relations can be captured by syntactic analysis and dependency parsing to iden-tify dependency relations for each instance pair. The underlying assumption is that foran entity to be linked to an event trigger as an argument, there has to be some kind ofsyntactic relation between the two terms. Accordingly, we use a similar (yet less expres-sive and simplified) set of features to the dependency features described for uncertaintyidentification in Chapter 5, Section 5.3.1. Dependency parsing is undertaken by theEnju syntactic parser [MT08a], using the Genia parsing model (trained on biomedicalcorpora). A more detailed analysis of Enju is presented in Section 5.3.1.2.
Since each dependency can be seen as an edge between two words, we can considerdependency relations in a sentence as a directed dependency graph. Simplifying thisgraph by removing directionality and flattening coordination cases (see Figure 2.12),we expect the non-directed path between a trigger word and its related arguments to beshorter than the path between the same trigger word and other, non-related entities inthe same sentence. Figure 2.11 illustrates such an example.
BRAF is not active and requirednot for MEK/ERK activationis
Figure 2.11: Dependency path representation example for a biomedical sentence asanalysed by Enju. The shortest dependency path length between the entity BRAF andthe event trigger (required) is equal to 1 (direct link).
In addition to the dependency path features, we employ a set of additional semanticand lexical features describing the instance. The main feature classes of the final featureset are listed below:
• Shortest dependency path (numeric)

2.3. DEALING WITH INCOMPLETE EVENTS 71
BRAF inhibitors hyperactivate andCRAF MEK
BRAF inhibitors hyperactivate andCRAF MEK
Figure 2.12: Flattening coordination dependencies
• Entity Type (nominal)
• Participation in other events (binary)
• PoS (Part of Speech) (nominal)
• Contextual PoS (surrounding tokens) (nominal)
– For window lengths of size 2 and 4
• Relative position to the event trigger (before/after) (nominal)
• Dependency on a prepositional token - type of prepositional token (binary-nominal)
• Event type (nominal)
• Token-based distance to trigger (numeric).
For the binary classification task, we compared the performance of an SVM, a logis-tic regression and an AdaBoost classifier (implemented with random tree models). Us-ing 10-fold cross validation on the training data, the AdaBoost classifier outperformedthe other two classifiers (F-score on training set: 0.93) and was thus used for the re-mainder of the experiments.
It is possible to generate large training datasets of the types of instances as describedabove, by using the events in existing annotated corpora. More specifically, we use thetraining corpora described in Section 2.3.1 by projecting (changing) the entity labels to

72 CHAPTER 2. EVENT EXTRACTION
the ones used in the Big Mechanism corpus. Instead of manually identifying the cor-respondences between the labels used in the different corpora, an automated, heuristicmethod was implemented, in order to map the labels of the target/test corpus (T L) tothose of the source/training one (SL). The heuristic is based on the idea that there will besome common text spans annotated in different corpora, but labelled with different cat-egories, according to the different annotation schemes, which can reveal the underlyinglabel mappings. Thus, label similarity was calculated based on the following formula:
T Li→ SL j⇒ SL j→ argmaxk
(#(AnnE T Li∩AnnE SLk)
#AnnE SLk) (2.1)
where AnnE T Li corresponds to an annotated text span with the label T Li in thetarget corpus, while AnnE SL j to the same annotated text span under the label SL jin thesource corpus. The aforementioned text spans can be either single or multi-word tokens.
Using this method, each label from the test corpus was assigned to the most sim-ilar label in the training corpus, whereby“similar” we refer to the category having thegreatest number of commonly annotated text spans.
2.3.2.1 Evaluation metrics and results
Most evaluation metrics whih are employed for the evaluation of event extraction meth-ods are based on recall, precision and F-score, calculated against gold-standard corpora[KOP+09a, NBK+13a, MPOA13]. Typically, an extracted event is counted as a truepositive instance, if and only if all of its arguments are correctly identified, and are as-signed the correct role labels. These measures make it straightforward to compare theoutputs of a large number of systems in a uniform manner. However, they are not ableto provide much insight into the different potential weaknesses of a system, since theydo not differentiate between the different types of errors that event extraction systemscan make, i.e., fully missed/wrong events, missed arguments, erroneous role labels orerroneous trigger labels. Thus, it is difficult to assess whether the events counted as falsepositives might still be interpretable or acceptable (e.g., correctly capturing the triggerand arguments but mislabelling some argument with an incorrect role). However, sincesupervised and unsupervised models are tuned to maximise performance based on the“strict” metrics, they aim to minimise events that would otherwise be considered to be“acceptable” solutions, in order to avoid the metrics being adversely affected (see also,

2.3. DEALING WITH INCOMPLETE EVENTS 73
the results and comments for “strict” and “loose” match in [MPOA13]).
Generally, the limitations of the typically adopted evaluation metrics are a concernacross many areas of NLP [CA18, WCWW18, PSR18, AGAV09], and it has been shownthat more task-oriented metrics that focus on assessing specific aspects of performancein complex tasks might be more suitable [CML18]. In our case, it was deemed neces-sary to define an argument-centred evaluation metric, which would separately captureprecision and recall for the number of arguments correctly identified. We compare theidentified arguments with the ones annotated in the gold corpus and define argumentrecall and precision as follows:
Recall =argEM ∩arggold
arggold(2.2)
Precision =argEM ∩arggold
argEM(2.3)
where argEM is the set of arguments EventMine identifies for this event and arggold
is the corresponding set of arguments identified in the gold standard 2.
The performance of the post-processing method on the Big Mechanism and MLEEtest sets is shown in Tables 2.1 and 2.2 respectively, compared to the original results ofEventMine prior to post-processing. The results are tabulated based on the original eventlabels attributed by EventMine in order to facilitate further analysis and interpretation.
For both corpora, the ranking method leads to a small increase in recall comparedto the default EventMine application. However, in many instances, and especially forsparsely occurring event types, this is accompanied by a drop in precision. Accordingly,there is still considerable room for improvement, especially in terms of decreasing in-correctly identified arguments, so as to minimise the drop in precision. We carried outan error analysis, which identified some recurring patterns that would be of interest inorder to further improve this method; these are listed below.
• Correct identification of the incomplete event but erroneous identification ofthe missing argument: In total, 60% of the noisy events constituted cases thatwere correctly identified as incomplete events, but where the ranking algorithmfailed to identify the correct entity to link to the trigger. This was a common
2For events that are not matched in the gold standard both values are zero.
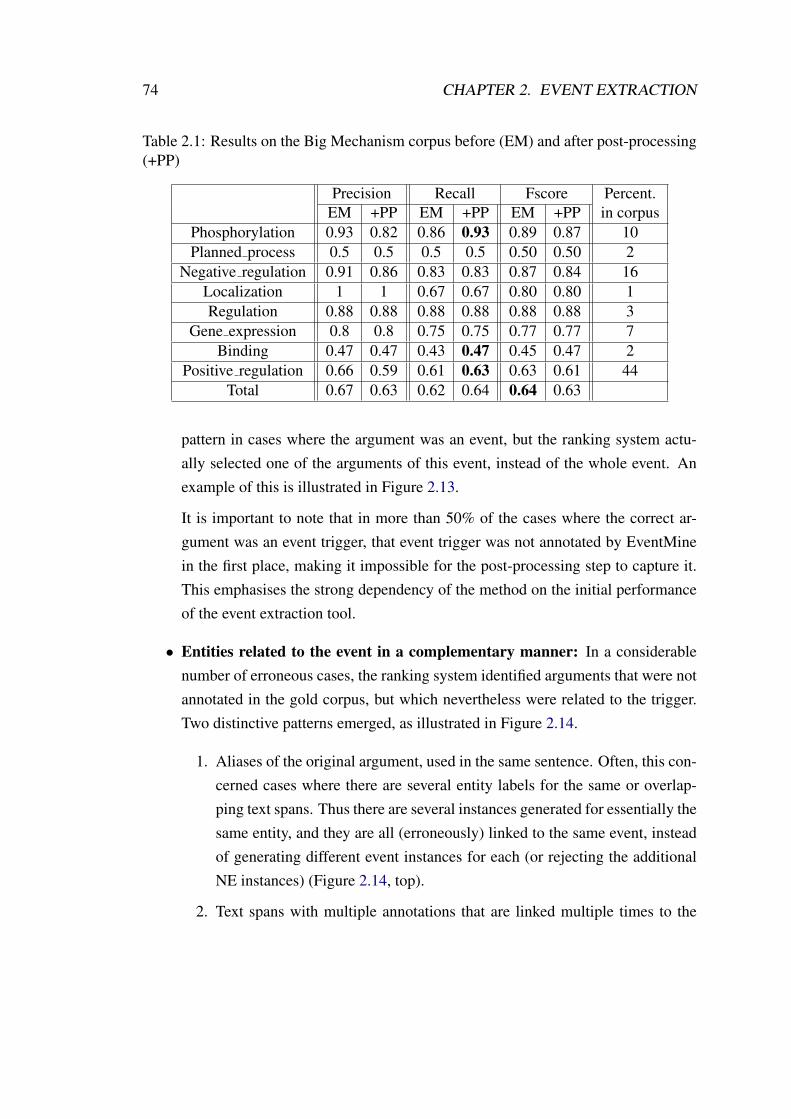
74 CHAPTER 2. EVENT EXTRACTION
Table 2.1: Results on the Big Mechanism corpus before (EM) and after post-processing(+PP)
Precision Recall Fscore Percent.EM +PP EM +PP EM +PP in corpus
Phosphorylation 0.93 0.82 0.86 0.93 0.89 0.87 10Planned process 0.5 0.5 0.5 0.5 0.50 0.50 2
Negative regulation 0.91 0.86 0.83 0.83 0.87 0.84 16Localization 1 1 0.67 0.67 0.80 0.80 1Regulation 0.88 0.88 0.88 0.88 0.88 0.88 3
Gene expression 0.8 0.8 0.75 0.75 0.77 0.77 7Binding 0.47 0.47 0.43 0.47 0.45 0.47 2
Positive regulation 0.66 0.59 0.61 0.63 0.63 0.61 44Total 0.67 0.63 0.62 0.64 0.64 0.63
pattern in cases where the argument was an event, but the ranking system actu-ally selected one of the arguments of this event, instead of the whole event. Anexample of this is illustrated in Figure 2.13.
It is important to note that in more than 50% of the cases where the correct ar-gument was an event trigger, that event trigger was not annotated by EventMinein the first place, making it impossible for the post-processing step to capture it.This emphasises the strong dependency of the method on the initial performanceof the event extraction tool.
• Entities related to the event in a complementary manner: In a considerablenumber of erroneous cases, the ranking system identified arguments that were notannotated in the gold corpus, but which nevertheless were related to the trigger.Two distinctive patterns emerged, as illustrated in Figure 2.14.
1. Aliases of the original argument, used in the same sentence. Often, this con-cerned cases where there are several entity labels for the same or overlap-ping text spans. Thus there are several instances generated for essentially thesame entity, and they are all (erroneously) linked to the same event, insteadof generating different event instances for each (or rejecting the additionalNE instances) (Figure 2.14, top).
2. Text spans with multiple annotations that are linked multiple times to the
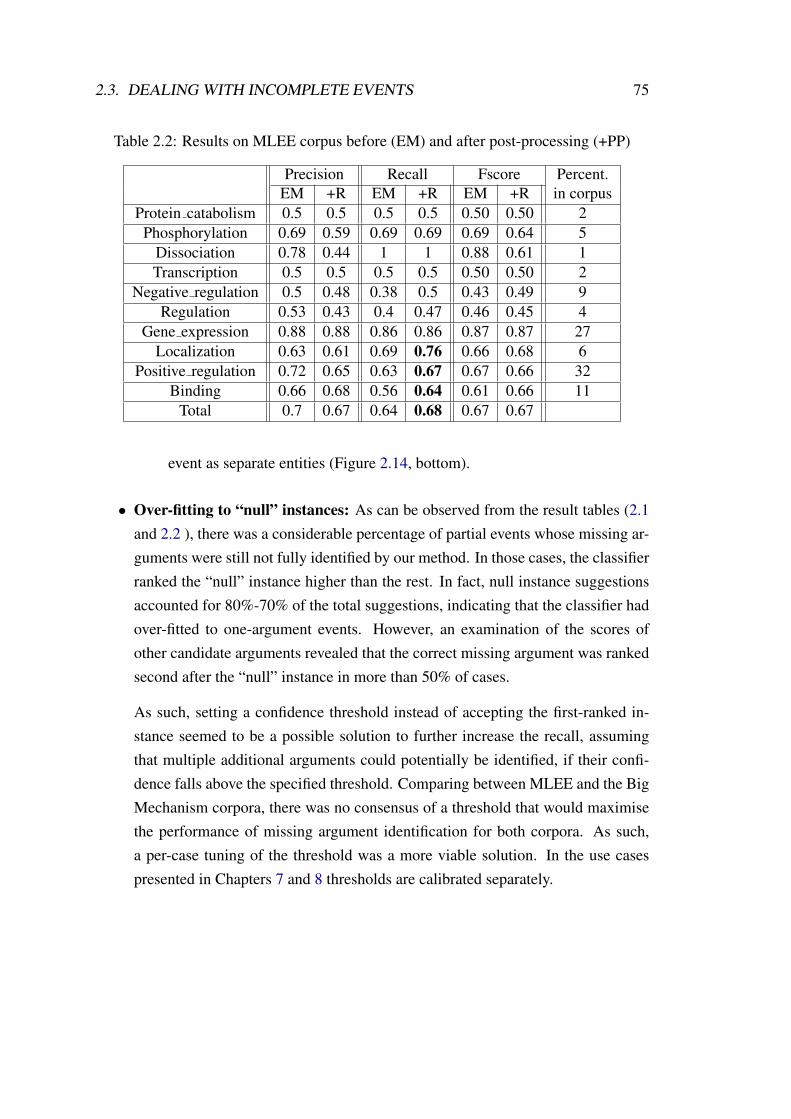
2.3. DEALING WITH INCOMPLETE EVENTS 75
Table 2.2: Results on MLEE corpus before (EM) and after post-processing (+PP)
Precision Recall Fscore Percent.EM +R EM +R EM +R in corpus
Protein catabolism 0.5 0.5 0.5 0.5 0.50 0.50 2Phosphorylation 0.69 0.59 0.69 0.69 0.69 0.64 5
Dissociation 0.78 0.44 1 1 0.88 0.61 1Transcription 0.5 0.5 0.5 0.5 0.50 0.50 2
Negative regulation 0.5 0.48 0.38 0.5 0.43 0.49 9Regulation 0.53 0.43 0.4 0.47 0.46 0.45 4
Gene expression 0.88 0.88 0.86 0.86 0.87 0.87 27Localization 0.63 0.61 0.69 0.76 0.66 0.68 6
Positive regulation 0.72 0.65 0.63 0.67 0.67 0.66 32Binding 0.66 0.68 0.56 0.64 0.61 0.66 11
Total 0.7 0.67 0.64 0.68 0.67 0.67
event as separate entities (Figure 2.14, bottom).
• Over-fitting to “null” instances: As can be observed from the result tables (2.1and 2.2 ), there was a considerable percentage of partial events whose missing ar-guments were still not fully identified by our method. In those cases, the classifierranked the “null” instance higher than the rest. In fact, null instance suggestionsaccounted for 80%-70% of the total suggestions, indicating that the classifier hadover-fitted to one-argument events. However, an examination of the scores ofother candidate arguments revealed that the correct missing argument was rankedsecond after the “null” instance in more than 50% of cases.
As such, setting a confidence threshold instead of accepting the first-ranked in-stance seemed to be a possible solution to further increase the recall, assumingthat multiple additional arguments could potentially be identified, if their confi-dence falls above the specified threshold. Comparing between MLEE and the BigMechanism corpora, there was no consensus of a threshold that would maximisethe performance of missing argument identification for both corpora. As such,a per-case tuning of the threshold was a more viable solution. In the use casespresented in Chapters 7 and 8 thresholds are calibrated separately.

76 CHAPTER 2. EVENT EXTRACTION
Dopamine pretreatment increases the translocation of SPH-2
Dopamine pretreatment increases the translocation of SPH-2
Chemical Predicate Predicate Predicate ProFirstArg FirstArg FirstArgSecondArg
Chemical Predicate Predicate Predicate ProFirstArg FirstArgSecondArg
FirstArg
Figure 2.13: Linking the nested event argument instead of the trigger: Compare correctannotation (top) with produced one (bottom)
Its PLX4720 phenotype was associated with MEK/ERK activation
Sorafenib is a class II drug that inhibits V600EBRAF at 40 nM
Pro Chemical Pro
Pathway
Pro
PredicatePredicate
ArgumentEquiv_ArgumentEquiv_ArgumentArgument
Chemical Chemical Predicate ProteinArgumentEquiv_Argument2
Argument2
Figure 2.14: Multi annot. (top): Pathway entity erroneously considered a valid addi-tional argumentAlias (bottom): Sorafenib and its superclass both considered valid argument candidatesthat are not mutually exclusive
2.3.2.2 Interaction-informed cases
As discussed earlier, the motivation to look into improving the problem of incompleteevents, was our intention to map events to interaction networks and other related re-sources, thus providing a link from the interaction to the relevant evidence passage(where the event was extracted from). In the experiments presented in the previous sec-tion, the classifier is agnostic to the types of interactions that are targets for literature-based enhancement. Thus, the classifier does not make use of any additional informa-tion indicating what type of events, or participating entities are expected to be extractedfrom text. As such, the post-processing classifier is constructed and trained in a genericmanner and can be readily applied to the output of different event extraction systems.
However, when targeting a specific use case (i.e., a specific pathway or interac-tion network) we can make use of the information included in that use case, to inform

2.4. CONCLUSIONS 77
our post-processing method. For example, in some of the examined use cases (see theLeukemia use case in 5.2.2.1), the textual evidence has already been manually attributedto a specific interaction with known participating entities. In such cases, the initial se-lection of candidate arguments can be restricted by identifying entities in the text thatpotentially match the participating entities in the interaction in question.
While there is no large-scale evaluation for this additional, “resource-informed” con-straint of the candidate instances, manual inspection of the output of the post-processingresults for the Leukemia use-case, showed considerable improvement in the number ofcorrectly mapped and meaningful (interpretable) results. We further discuss this case inChapter 7.
2.4 Conclusions
In this chapter, we firstly motivated our choice to employ events rather than other in-formation units as the target of our uncertainty identification methods. We provided adetailed description of the structure of events, since this has an important impact on ourdesign decisions for modelling uncertainty presented in the following chapters. More-over, we discussed the discussed the application of wide coverage event extraction meth-ods to extract a broad spectrum of event types from a range of different documents, withbiomedical network and knowledge-base enhancing applications in mind.
We furthermore analysed the most significant drawback of event extraction tools thatwe encountered when trying to extract events from text and map them to interactionsin knowledge bases, namely partial or incomplete events, i.e., automatically recognisedevents which are missing some of their arguments, which makes it impossible to mapthem to the targeted interactions. While this is not the main topic of the present thesis,alleviating this phenomenon even to a partial extent was considered to be a critical stepfor applications presented in later chapters. We thus briefly presented a post-processingmethod that can be applied to event-extraction outputs (being model agnostic, it can beapplied to the output of any event-extraction system) to attempt to correct partial events.In the following chapters we refer to this method and the interaction-informed variationwhen appropriate.

78 CHAPTER 2. EVENT EXTRACTION
However, there is ample scope for improvements in terms of generalising event ex-traction. While this topic is not further pursued in this work, studies on event extrac-tion accuracy as well as the impact of event extraction accuracy on the confidence ofliterature-based enhancement of interaction networks and knowledge bases would be ofgreat value. As future work, it would be interesting to repeat some of the experimentsusing deep neural network event extraction or domain independent event approachesand explore whether they result in an increased number of literature-based evidencemappings or more accurate and complete events. Moreover, the extraction of a confi-dence value denoting the estimated accuracy of the event in question could provide uswith an additional parameter for estimating the certainty of the event. In other words,the ability to take into account the likelihood of inaccuracies in automatically extractedevents, could be considered an additional source of event uncertainty, complementingtextual uncertainty expressed by the author.

Chapter 3
Definition and classification of textualuncertainty
In this chapter we do the following:
Summarise existing work, related to:
• Definitions and interpretations of uncertainty and related concepts
• Different classification schemes proposed for uncertainty
• Automated methods for uncertainty classification
The linguistic expressions an author chooses to use when presenting an argument ormaking a statement have the potential to impact the perceived certainty of the statementon the part of the reader. Such expressions may vary from the use of specific modalwords (may, might) to words indicating subjective bias (personally, I think), or evenexpressions that limit the validity of the statement to specific conditions (such as timeor space limitations). The identification and classification of the various aspects of dif-ferent linguistic expressions that can influence the perceived certainty of informationattracted the interest of linguists long before the evolution of computational linguistics.More recently, there has been resurgent interest in this topic, reflecting the latest de-velopments in the text mining and machine learning fields that have enabled automated
79

80 CHAPTER 3. DEFINITION AND CLASSIFICATION
processing of huge volumes of textual statements. However, up until now, there appearsto be no uniform classification of uncertainty, and its definition and interpretation seemsto change based on the intended task and the area of application, among other factors.Hence, examining different definitions is a crucial step towards a complete understand-ing of uncertainty and to the design of methods that can efficiently identify uncertaintyin text and classify statements accordingly.
This chapter presents a survey of existing work on textual uncertainty. We startby presenting different approaches to the interpretation of textual uncertainty, and thedefinition of concepts that are related to it in Section 3.1. We then provide a detailed de-scription and comparison of different approaches to uncertainty classification (see Sec-tion 3.2), as well as of corresponding annotation attempts and availability of annotatedcorpora (see Section 3.2.1). ). Finally, we cover approaches to automating uncertaintyidentification, based on the aforementioned corpora, and describe methods used for thispurpose and the performance levels achieved by these methods in Section 3.3. Through-out the review, we focus on the individual contributions of different authors, but try togroup them based on their specific goals and their adopted interpretation of uncertainty.
3.1 Overview of definitions and proposed interpretationsof concepts related to uncertainty
Over the years, linguists have classified phenomena related to uncertainty in text andin speech using a range of different terms. During the 1970s, concepts such as hedg-ing and epistemic modality were introduced and studied. Such concepts are closelylinked to phenomena of textual uncertainty and have been discussed and analysed indifferent fields. Uncertainty has also been identified as an element of conveying partialignorance 1 in Smithson’s taxonomy of ignorance [Smi12] and as an element of vague-ness by Powell [Pow85]. Subsequently, it was identified as a dimension of factuality[SP07]. It is important to note that even at the time of those early attempts to define
1 According to Voorbraack “a decision problem under partial ignorance can be expressed by “Whatto do when you know something concerning the relevant probabilities, but not enough?” We assumethat if you know the probabilities of possible outcomes of your actions, and the utilities of the possibleoutcomes, then you know what to do, namely to maximize your expected utility” [Voo97]

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 81
uncertainty, the proposed definitions overlapped, complemented and sometimes contra-dicted each other. For example, for Powell, uncertainty is an element of vagueness,whereas Smithson identifies vagueness as a sub-class of uncertainty (along with prob-ability and ambiguity) in his proposed taxonomy for expressions indicating some formof ignorance. Smithson’s taxonomy, which is illustrated in Figure 3.1, is one of the firstattempts to systematically classify such phenomena in a hierarchical manner.
Figure 3.1: Redrawn diagram of Smithson’s taxonomy of ignorance.
Overall, we can identify different perspectives relating to the interpretation of textualuncertainty and the properties attributed to it. The two main distinctions, often repeatedin different classification schemes and uncertainty-related concepts, are between uncer-tainty about the inherent truth of an event (the author knows with certainty that the eventmight not be valid under all conditions) and uncertainty of the author/speaker about thatevent (the event is true, but the author is unsure or ignorant about it). Note, that asHyland pointed out, these two dimensions are not always easy to distinguish in text,and the boundaries are quite fuzzy [Hyl98b]. In addition, in some interpretations, theemphasis is placed on complementary aspects, related to the type of evidence and theperception of the readers.
Generally, some uncertainty-related concepts, such as evidentiality or veracity, re-volve around a single perspective (evidence type and truth of the concept, respectively),

82 CHAPTER 3. DEFINITION AND CLASSIFICATION
while in other cases such as hedging or epistemic modality, there is work covering morethan one aspect (e.g., as we discuss further down, in his classification of hedging, Hy-land considers both the truth of the event and the attitude of the author). The diagramof Figure 3.2 illustrates this fuzziness of the boundaries between perspectives and def-initions and presents a mapping of uncertainty related concepts to the aforementionedperspectives.
Understanding the definition, coverage and similarities of concepts related to uncer-tainty is crucial if we are to comprehend the role of uncertainty in natural language andthe linguistic patterns that characterise it. In the sections that follow, we present thedefinitions for the three main uncertainty related-concepts, namely hedging, epistemicmodality and factuality. We discuss the main contributions to the interpretation andanalysis of each concept, the adopted perspectives and the connections between them.We summarise this information with the help of mind-maps at the beginning of each ofthe following sections, while the time line at the end of the chapter provides an overviewof the discussed work.

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 83
Figu
re3.
2:M
ind-
map
ofun
cert
aint
y:R
elat
edco
ncep
ts(r
ight
)and
thei
rcov
erag
eap
proa
chto
unce
rtai
nty
(lef
t).

84 CHAPTER 3. DEFINITION AND CLASSIFICATION
3.1.1 Hedging
One of the first terms to be used to describe phenomena of uncertainty in language ishedging. By hedging, we refer to the use of a mitigating word or multi-word expres-sion that lessens the impact of a statement. The term was introduced to the linguisticliterature by Lakoff [Lak75]. Lakoff proposed that statements expressed in natural lan-guage can be partially true (“true or false to some extent”) contrary to the dominanttruth conditional semantics paradigm of that time. He was primarily concerned withhow specific expressions can alter the meaning of sentences to make them either fuzzieror more precise.
The concept was studied further in the following years. Hubler [Hub83] suggestedthat hedging is a sub-category of understatement expressions – in other words, expres-sions that lower the validity of an otherwise absolute statement. Prince [Pri82] identi-fied two cases of hedging: the first, called propositional hedging, involves propositionalcontent and affects the truth condition of the conveyed proposition, while the second,conversational hedging, concerns the commitment of a speaker to the truth of the com-municated propositional content. 2. In attempting to define and classify the concept ofhedging, Prince is one of the first scholars to make the distinction between the perspec-tives that were mentioned earlier, i.e., the uncertainty of the speaker regarding the truthof a statement, and the inherent uncertainty of a situation (e.g., conditional on time,space etc.).
3.1.1.1 Hedging as an element of vagueness and imprecision
Powell [Pow85] classified hedges and imprecise quantification expressions as indica-tions of purposive vagueness. Channell [Cha94] also used the term “vagueness” to cap-ture argumentation that involves fuzziness of information. A significant part of Chan-nell’s work focused on vagueness as part of conversational strategies [Cha85] and later,on vague expressions specifically in the field of economics (albeit still limited to writtenlanguage) [Cha90]. While focusing on slightly different fields, both Powell and Chan-nell point out the impact of vague expressions on the certainty of statements, even inthose cases where the actual statement contains precise (often numerical) information.
2Propositional hedging has also been referred to as relational hedging in more recent literature (seethe work of Hirschberg and her colleagues [PH14, UBH18])

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 85
The issue of imprecision in communicated information that concerns numerical orquantifiable statements –and the way it is interpreted by the readers– has also attractedconsiderable attention. It is particularly relevant for various scientific fields such aseconomics, psychology and medicine, as well as forecasting, security, and intelligenceanalysis. Druzdel [Dru89, DVDG95, Dru96] further elaborates on the issue of impre-cision in communicated information that concerns numerical statements, by analysingthe use of non-precise expressions in place of exact numerical ones. He claims thatpeople show a preference for verbal expressions over numeric ones and thus attemptsto investigate whether verbal uncertainty expressions can be mapped to probabilities.To this end he classified 178 expressions into different certainty classes: comparativeexpressions (“more likely”), expectations (“great chances”), frequency-based (“almostalways”), logical (“inconsistent with”) and what he called utility considerations (“bestbet”). One of his major conclusions, is that there is “high between subject variability”,i.e., individual readers perceive the strength of uncertainty expressions differently. Asdiscussed later on, Rubin [Rub07] also comes to the same conclusion when focusing onnews articles. Furthermore, we demonstrate that the same condition seems to hold inthe biomedical domain (see Section 5.4.2).
The issue of quantifying vagueness and hedging in the form of probabilities wasalso addressed by Teigen and Brun [BT88] who tried to understand how people per-ceive verbal expressions as opposed to numeric percentages by conducting user sur-veys. While the study concluded that words cannot accurately represent numbers, theauthors point out that verbal expressions can better capture the distinction between pos-itive and negative directionality (likelihood vs. doubt). Thus, they can prove useful interms of communicating and understanding results as well as decision-making basedupon them. There were further attempts at the time, mostly based on user surveys, toquantify textual expressions of probability and to understand the parameters that causedifferent people (subjects) to rate such expressions as having different levels of un-certainty [O’B89, BN80, BM82]. Toogood [Too80] specifically focused on frequencyexpressions, evaluating them in terms of their impact on the perceived probability that agiven statement is true, from the perspective of the reader. Kong [KBMY86] and Mapes[Map79] attempted to tackle the same issue by conducting surveys that focused solelyon uncertainty expressions used in clinical and medical text.

86 CHAPTER 3. DEFINITION AND CLASSIFICATION
In an attempt to summarise the findings of those early attempts to interpret and for-malise uncertain expressions, Clark [Cla90] claims that while individuals are, to a largeextent, internally consistent in their use of verbal uncertainty expressions, there is lessconsistency in terms of agreement between different individuals, rendering it difficultto draw generalised conclusions on the quantifiability of fuzzy expressions. Clark alsopoints out that perception of uncertainty is influenced by the prior perceived probabil-ities of described events. With the rise of artificial intelligence (AI), Krause and Clarkturned their attention to the representation of uncertain knowledge and probabilities inAI systems [KC12]; this is further discussed in Chapters 5 and 7.
3.1.1.2 Hedging in discourse analysis
In discourse analysis, hedging expressions (which are not limited to verbal expressionsin contrast to the previous section ) are treated as meta-discourse indications that revealthe authors’ confidence towards the asserted statements and their intention towards thereader [Fra10, KMS10]. In this field, the work of Hyland and Myers is invaluable, as itlays the foundations for several approaches to automated uncertainty extraction whichhave subsequently been developed.
Myers [Mye89], focusing on scientific writing, suggests that hedging is often usedprimarily as a way to forestall a negative reaction from the readers by moderating thestrength of the statements, thus ensuring reader acceptance, and contextualises this ideaas “politeness”. In fact, Myers classifies hedging as a manifestation of negative polite-ness 3, i.e., an attempt to make a claim or any other statement seem provisional, pendingacceptance in the literature (and thus acceptance by the readers).
Hyland [Hyl96, Hyl98b] also focused on hedging and discourse in the academicand scientific domains, to show that contrary to common belief, scientific languagefrequently does not state absolute truths. While he acknowledged the case of politenessdescribed by Myers, Hyland took a broader view of hedging, and using statistical corpusanalysis, he tried to cover different aspects and strategies of hedging. He provides adetailed analysis of the surface features of hedging expressions in order to arrive at apragmatic classification of hedges (See Figure 3.3).
3The concept of politeness and negative politeness is introduced and discussed in length in the workof Levinson [LBLL87]

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 87
Figure 3.3: Diagram of Hyland’s classification of scientific statements, with emphasison hedged writing (what Hyland called “non-factive” statements). We provide simpli-fied sentence example relating to the biomedical domain for each of the “leaf” concepts.
In Hyland’s classification schema, hedges, which are generally identified as non-factive statements, are classified based on their purpose in the text. Hyland points outthat content-oriented hedging can either relate to the perceived accuracy of the state-ment (accuracy-oriented) or to the confidence of the author in terms of their knowledgeand expertise (writer-oriented). While this classification essentially re-iterates Prince’sseparation of the intention of the speaker and the inherent certainty level of a situation,Hyland provides a more thorough analysis of each category. He sought to describe thefunctions and features of each category, by analysing the most commonly used devices,based on a small corpus of 26 scientific articles. This was one of the first attempts topresent a more detailed categorisation of uncertainty based on specific expressions andtheir purpose in text, using statistical analysis.
Hyland concluded that that there exist different types of hedging, namely: referringto an experiment, questioning a methodology, and admitting lack of knowledge. More-over, he expanded the definition of hedging and claimed that it is not only limited tolexical signals (i.e. the use of specific words that down-tone a statement, such as “may”,“might”, etc.), but also includes grammatical patterns and more elaborate means of ex-pressing doubt regarding a particular statement, referred to as hedging strategies (e.g.,the use of passive voice and impersonal reference in writer-oriented hedging, or directquestions in reader-oriented hedging). In his work [Hyl98a], he provided a catalogueof hedging expressions including modal auxiliaries, epistemic lexical verbs, epistemic

88 CHAPTER 3. DEFINITION AND CLASSIFICATION
adjectives, adverbs and nouns, which was later used for the classification of scientificcitations [DMM04] and as the basis for many rule-based and distant supervision un-certainty identification systems [KB08a, CSH18]. We note here that such expressions,that are indicators of specific meta-knowledge dimensions, such as uncertainty, negationetc., are often referred to as cues. Henceforth, we will use the term cue to refer to suchindicative expressions.
Even though Hyland is mostly credited for his work on hedges, it is important tonote that he has significantly contributed to the understanding and analysis of expres-sions that have the opposite effect. His study also analysed expressions that aim toincrease the certainty of a statement and indicate the perceived confidence and expertiseof the author. While in earlier research, such expressions are treated in the same wayas hedges, Hyland makes a distinction and refers to such writing devices as boosters
(e.g., “it is certain”, “we prove that”) [Hyl98a]. He analysed a corpus of 330K words,performing one of the first annotation efforts in the field (inter-annotator agreement of0.87 kappa) and extracting the most frequent boosting and hedging expressions. Thisresulted in lists of cues found in the corpus, both for hedging (uncertainty) and boosting(certainty), which have been used widely as lexical resources ever since.
3.1.2 Epistemic modality
The concept of hedging, as presented in the previous section, is often defined as oneof the strategies used to convey epistemic modality. The term epistemic modality wascoined by Palmer [Pal77] to denote “the degree of commitment to the truth of a propo-sition”. Closely related to the concept of speaker (un)certainty, it has since been widelyused in linguistics and computational linguistics. Alternatively, as Kratzer [Kra77] andlater on Kiefer and Fintel phrased it [VFG11a, Kie87], epistemic modals act as quanti-fiers for possible states of the world in which a given proposition holds (see theory ofpossible world semantics4).
Different aspects of epistemic modality have been further researched and are still
4The theory of possible world semantics shows how possible worlds are incorporated into the semanticframework of a logic. Epistemic logics are usually formulated as normal modal logics using the semanticsdeveloped by Kripke [Kri63]. This logic is essentially classical propositional logic, extended by theaddition of two operators, namely necessarily and possibly. http://www.cs.ox.ac.uk/people/michael.wooldridge/pubs/ker95/subsection3_2_3.html.

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 89
discussed extensively [DH05, Pap06], especially in the scientific field [DWM12, Vol06].While it is generally recognised that the use of epistemic modality relates to the amountof certain/uncertain knowledge, there are various interpretations in terms of how epis-temic modals relate to the existence of evidence and to contextual certainty. Fintel[VFG07] attempted to frame different popular theories on epistemic modality using se-mantics and logic theory to evaluate their agreement and overlap. He proved that not allproposed theories are equal and he demonstrated that the assessment of the likelihoodof a statement (introduced by a modal) depends heavily on the context as well as theknowledge space of the interpreter.
Davis linked the amount and adequacy of presented evidence to epistemic modal-ity [DPS07] by highlighting the relation between the certainty of a statement and theamount and quality of the presented evidence related to it. Such a definition highlightsthe relation to other concepts such as factuality, which combines the notions of uncer-tainty and polarity [Sau17], veracity5 [FBW09] and evidentiality6 [Cor09, DPS07].
3.1.2.1 Epistemic modality and evidentiality
Evidentiality deals with the presence of evidence used to support a statement, and triesto identify, apart from the existence of evidence, its type and purpose. It has been studiedalongside epistemic modality, and often treated as a sub-category of it [Pal01]. Willetproposed a detailed taxonomy of evidentials based on the source type, as shown in Fig-ure 3.4. Frajzyngier [FM98] advocates the view that the notions of evidence source andepistemic modality are closely linked, and that the existence of one assumes the other:different manners of acquiring knowledge (sources of evidence) correspond to differentdegrees of certainty about the truth of the proposition (levels of epistemic modality).Drubig [Dru01] proposes that epistemic modals should be treated as evidentiality mark-ers. Fintel extends this suggestion, and considers epistemic modals to be markers ofindirect inference, which is a branch in Willet’s evidential taxonomy [VFG11b].
While acknowledging that the notions of both evidentiality and epistemic modalityrelate to evidence of information, Haan [DH99] claims that they differ in their seman-tics as well as in their resulting linguistic and syntactic traits. Evidential expressions
5conformity to truth or fact6a statement of epistemic modality that connotes the speaker’s assessment of the evidence for his or
her statement.

90 CHAPTER 3. DEFINITION AND CLASSIFICATION
Figure 3.4: Redrawn diagram of Willet’s taxonomy of evidentials.
assert the nature of the evidence and source of the information in the sentence, whileepistemic modals evaluate the speaker’s commitment to the statement made. Thus, ev-identiality is more concerned with the existence (or lack thereof) of evidence, whileepistemic modality concerns the level of confidence which, according to Haan, can beindependent of the evidence. In his work, he attempts to distinguish between the termsand linguistic aspects used for each notion, focusing on the tenses used, the lemmas,and their interpretation when negated.
3.1.3 Factuality
The extent to which a statement is factual, or else, an actual representation of an eventthat is true in the real world, is often referred to as “factuality”. In contrast to thepossible world semantics employed to explain epistemic modality, factuality seeks toidentify whether the statement is consistent with the reality of the existing world.
We consider this concept to be closer to the “truth of the event” perspective. How-ever, Almeida [Alm92], who used discourse analytic tools to interpret factuality in newstext, defines factuality based on the intention of the author/speaker. If the author in-tended to be understood as describing an actual situation, that alone can characterise thestatement as factual, regardless of its actual truth value. Thus, according to Almeida,factuality depends solely on the intention and expressed certainty of the speaker.

3.1. OVERVIEW OF DEFINITIONS AND INTERPRETATIONS 91
The perspective of Sauri, on the other hand, is closer to our interpretation. He ab-stracts the notion away from the speaker’s intentions and points out the need for infor-mation extraction systems to be sensitive to the implications of conveyed informationand distinguish between events mentioned in text that correspond to real world situa-tions and those that describe situations of uncertain status [SP07]. He defines this levelof information as event factuality. Sauri and Pustejovsky initially propose that factualitycan be analysed based on the dimensions of uncertainty and polarity, i.e. as a functionof whether a given event is described as actually taking place or not, and the perceivedcertainty of that assertion [SP12]. They suggest that polarity and uncertainty are twoindependent parameters, which can be viewed as orthogonal dimensions, when assess-ing the factuality of a statement/event (see Figure 3.5).This has important implicationswhen considering how different mentions of the same event can be combined, whichwe further discuss in Section 5.1.2. Subsequently, they introduce the concept of sourceorigin as an additional dimension in the process of determining factuality (thus relatingthe factuality to evidentiality) [Sau17].
Figure 3.5: Redrawn diagram of Sauri’s suggestion for the induction of factuality. It canbe seen how both polarity and uncertainty affect the final result.
It should be mentioned that, on some occasions, the terms veracity and veridicity

92 CHAPTER 3. DEFINITION AND CLASSIFICATION
are used almost interchangeably with factuality. For example, Karttunen and Zaenendiscuss the importance of verifying the truth value of extracted information, using theterm veridicity [KZ05]. On the other hand, in law-related speech and text analysis, weoften see the term veracity used in a similar context [AJ06, BFS08, FBW09]. Note that,in all cases, these concepts move a step beyond assessing the expressed certainty of theauthor or the perceived certainty of the reader, by focusing on identifying the actualtruth value of the statement in the real world.
Despite the varying degrees of differences in the definitions of the concepts describedin the sections above, they have all been linked to linguistic patterns used to conveyuncertainty about specific statements or described facts. In this work, we do not attemptto distinguish between the author’s attitude and the inherent truth of the event. Asfurther described in Chapter 5, Section 5.1, we perceive any mention of uncertainty bythe author as a valid indication of uncertainty about the truth of the event. However,we do attempt to take into account the perception of the readers (see experiments inSections 5.4.2.2 - 5.4.2.4 ).
Our study of the concepts described in the previous sections has provided us with acomprehensive understanding of the different factors affecting the uncertainty of state-ments. In addition, it has provided us with extensive lists of lexical cues and in-depthanalyses of linguistic and syntactic phenomena, which are valuable resources applicableto the automated identification of uncertainty. In particular, we have used the cues andhedging strategies identified by Hyland and Druzdel as guidelines for the compilationof uncertainty cue lists (see Chapter 5).
In the next section, we examine in detail some of the previously proposed categorisa-tions of uncertainty, from which we taken inspiration to frame uncertainty for the goalsof the present work.
3.2 Categorisation of uncertainty expressions
As explained in the previous section, categorising phenomena related to uncertaintyin a taxonomical manner has been a common practice since the time of the earliest

3.2. CATEGORISATION OF UNCERTAINTY EXPRESSIONS 93
studies. However, with the exception of the work of Hyland [Hyl98b] and Druzdel[Dru89], most of this work has revolved around describing and interpreting phenomenabased on examples, but without any detailed corpus analysis. Progressively, however,there has been a shift towards more comprehensive classifications of uncertainty, whichhas been enabled by the evolution of computational and statistical technologies andthe consequent evolution of computational linguistics. Indeed, the appearance of morefastidious definitions and categorisation schemes for uncertainty-related concepts hasaccordingly allowed the annotation of large collections of textual resources (corpora),and the subsequent development of methods that identify such categories in text in anautomated or semi-automated fashion.
We can identify two types of uncertainty classification: classification of expressionsof uncertainty into different sub-classes based on type and/or intensity; and classifica-tion of uncertainty as a concept along with other parameters that encode the manner inwhich a statement is communicated (which we also call meta-knowledge). We will referto the first type as uncertainty sub-classes and to the second as uncertainty super-classes.We present a mind-map of these classification schemes in Figure 3.6. The mind-map isorganised as follows: on the left-hand side, we present the super-classes for uncertainty,organised by publication and accompanied by the name of the relevant corpus (whereavailable). Note that the bottom two classification schemes do not focus on scientificliterature, but we mention them here for reasons of completeness. On the right-handside, we present the uncertainty subclasses, organised by publication and accompaniedby name of the relevant corpus (where available). The top three cases (green coloured),adopt a more quantitative approach, and classify uncertainty based on intensity. Thebottom three employ a more descriptive and qualitative approach, and classify uncer-tainty expressions based on the underlying semantics and the intention of the speaker(focusing on different aspects). Rubin’s work combines the two, accounting both for in-tensity (level) and other semantic aspects like perspective, focus and time. Note that thesame aspects that were identified by Rubin as sub-classes of uncertainty, are presentedby Wilbur as parallel dimensions of uncertainty (left side). This underlines the lack ofconsensus on the classification uncertainty and its dependence on other meta-knowledgeparameters.
We further elaborate on the work related to uncertainty classification below.
94 CHAPTER 3. DEFINITION AND CLASSIFICATION
Figure3.6:M
ind-map
ofuncertaintyclassification
schemes

3.2. CATEGORISATION OF UNCERTAINTY EXPRESSIONS 95
Light et al. [LQS04a] and later on Grabar and Hamon [GH09] studied uncertainty inbiomedical papers and classified expressions in a binary manner, as having high or low
certainty. Medlock [MB07a] proposed a more detailed categorisation that distinguishesbetween the cases of hedging, admission of lack of knowledge, relaying of hypotheses
from others, speculative questions and hypotheses.
Related research in the biomedical field continued, motivated by the need to iden-tify reliable facts and interactions. Wilbur et al. proposed a classification of biomedicalstatements along five different dimensions: focus, polarity, certainty, evidence, and di-rection/trend [WRS06]. As far as the certainty dimension was concerned, a statementcould be assigned a value between 0 and 3, with 0 indicating no certainty and 3 indi-cating absolute certainty. Focus is an attempt to distinguish between methodologicalstatements and scientific findings, while direction/trend captures the existence of quan-titative statements of high/low levels of a quantity/quality with respect to a specificphenomenon. Shatkay et al. use the same proposed annotation scheme to annotate acorpus of 10,000 sentences and sentence fragments selected from full-text articles froma variety of biomedical journals [SPRW08] (we refer to this as the WSR corpus). No-tably, the annotations of certainty were considerably skewed, with 97% of the instancesannotated as level 3 certainty. This was reflected in the performance of the SVM clas-sifier that they trained on the annotated corpus, which displayed a drop larger than 40%in recall when predicting the “less certain” classes.
Thompson et al. [TNMA11] also proposed a classification scheme over five (meta-knowledge) dimensions, focussing on how they affect events: Certainty, Polarity, Source,Knowledge Type and Manner. Certainty is classified in an intensity-based 3-level fash-ion, where L3 correspond to strong certainty and L1 to strong uncertainty. Sourceprovides some insight in the perspective, identifying whether there seems to be someattribution of a statement to an external source, or whether it is reported as a conclu-sion of the author. Knowledge type refers to the content of the event, distinguishingbetween observations, analyses, investigations, etc, while Manner, corresponds to whatWilbur identified as direction/trend. Thompson’s classification scheme was applied tothe annotation of the GENIA-MK corpus, which we chose for our experiments and ismore thoroughly discussed in Section 5.2.1. The same work also proposes that collec-tively these meta-knowledge dimensions can aid in the classification of assertions asNew knowledge or Hypothesis. Shardlow et al. [SBNT+18] took this idea a step further,

96 CHAPTER 3. DEFINITION AND CLASSIFICATION
annotating a small collection of documents with the aforementioned hyper-dimensionsand assessing the contribution of each of the five meta-knowledge parameters, in termsof their ability to identify hypothesis and new knowledge.
In the general text domain, Rubin et al. [RLK06, Rub10] proposed a theoreticalframework for classifying textual certainty information. They identified four main di-mensions of uncertainty: perspective, focus, timeline, and level. Each dimension hasits own sub-classes, which are considered to be independent of each other, but all con-tributing towards uncertainty to different degrees. While Hyland and Myers had alreadyidentified Tense as an aspect of hedging, Rubin was one of the first scholars to identifytime as an independent dimension of uncertainty. Time, in Rubin’s classification is notrelated to time-frequency expressions, but rather to the recency and timeliness of infor-mation. While their work is based on manual inspection, the resulting linguistic markersand patterns could be useful as seed terms or dictionary entries that support automateduncertainty identification.
Using Wikipedia articles as the basis for their study, Vincze and her colleagues[Vin13] attempt a different categorisation, focusing on discourse-level uncertainty; theyidentify three different types of uncertainty: weasels, hedges and peacocks. In definingweasels, they expand on older definitions (e.g. the one given by Medlock [MB07a] byclaiming that weaselling is a phenomenon not only restricted to cases where we havelack of citation/reference, but rather, it can cover any case where we are presented withan underspecified argument that would be relevant, but is not common knowledge (e.g.,“while A is not as strong inhibitor as other proteins”). It is interesting to also note theirapproach to peacock expressions, which they define as expressions that indicate subjec-tivity and often unproven or exaggerated opinions. They thus link uncertainty with thenotion of subjectivity, which we further explore in Chapter 6.
Szarvas et al. [SVF+12a] proposed a hierarchical categorisation which distinguishesbetween two main classes: hypothetical and epistemic uncertainty. They further cate-gorised hypothetical uncertainty into two categories; paradoxical uncertainty, whichrefers to either conditional declarations or statements mentioned under investigation,and non-epistemic modality. They point out that most annotation efforts focus mainlyon the epistemic type of uncertainty, overlooking the rest, and proceed to apply theircategorisation for the re-annotation of cues, in corpora across different domains, aimingto achieve a unified annotation with broader coverage than previous approaches, which

3.2. CATEGORISATION OF UNCERTAINTY EXPRESSIONS 97
can be applicable across domains.
Auger and Roy [AR08] tried to present a more inclusive taxonomy of uncertaintythat focuses more on the linguistic phenomena rather than the intensity or semanticclassification. It combines elements from early analyses by Smithson and Hyland withmore recent approaches such as Rubin’s [RLK06], Thompson’s [THM+05], etc.
Figure 3.7: Redrawn diagram of Roy’s broad classification of different phenomena ofuncertainty in linguistics.
Recently, Chen et al. [CSH18] revisited uncertainty in scientific writing and pro-posed a wider and more detailed definition, expanding on the definitions of Szarvas andThompson, that covers phenomena of citation distortion, contradictions, and claim in-consistencies. They distinguish between scientific and epistemic uncertainty, where by“scientific”, they refer to the type of uncertainty that stems from inconsistencies andcontradictions in scientific results. They point out that often this type of uncertainty de-rives from neither the uncertainty of the data nor from the uncertainty of the author, butrather from the opposing views of highly confident authors regarding the truth of theirdata. They suggest that this type of uncertainty can be identified by terms such as dis-
puted, ambiguous, etc. The two types of uncertainty can in fact occur simultaneously,and are thus treated as two independent dimensions.
In the following section, we introduce in detail classification efforts that led to theproduction of annotated corpora.

98 CHAPTER 3. DEFINITION AND CLASSIFICATION
3.2.1 Annotated corpora
In addition to studies that have classified and categorised uncertainty, advances in ma-chine learning and text mining methods have resulted in various attempts to automati-cally identify uncertainty. Research into this task has been greatly facilitated and moti-vated by efforts to annotate corpora, as well as by shared tasks that have focused on thisdomain.
In 2009, Sauri and Pustejovsky [SP09a] published FactBank, a small corpus con-sisting of texts from the newswire domain. It contains annotations of events that are ac-companied by their factuality value judged from the viewpoint of their sources. Some ofthe parameters that they consider as factuality indicators relate to semantic uncertainty(“possible” and “probable” statements, “underspecified” statements, and statements at-tributed to an external source (weaselling). The MPQA corpus published in 2003 byWilson [CWWL03] focuses on expressions indicating subjective opinion. The schemeemployed in this corpus classifies subjectivity strength as one of three different levels(low, medium, high) and, following Sauri’s factuality conceptualisation (see Figure 3.5)this is combined it with polarity markers to classify different opinions.
The LU corpus [DDL+09] has a greater focus more on the uncertainty aspect andcontains belief annotations for propositional heads in a heterogeneous collection ofnewswire and general text (nine (9) newswire documents, four (4) training manuals,two (2) correspondences and new (1) interview). It was produced by Diab et al. whoused a 3-way distinction of belief tags: Committed Belief (CB), where the author ex-presses a strong belief towards the proposition (e.g., use of hedging expressions such as“convinced”, “prove”, etc.), Non-committed belief (NCB), where the author specifies aweak belief in the proposition (e.g., use of hedging expressions such as “may”, “might”,etc.), and Non-attributable Belief (NA), where the author does not express their belieftowards the proposition (e.g., desires, questions etc.).
Note that for the corpora mentioned above the definition of event deviates from theone we have described in Chapter 2, since in these corpora only what would correspondto the event trigger is annotated. Thus, apart from the domain which differs from thedomain we focus on (biomedicine), the detail of the extracted information also deviatesfrom our target.

3.2. CATEGORISATION OF UNCERTAINTY EXPRESSIONS 99
Moving to more general text, the corpus produced by Vincze using Wikipedia ar-ticles (WikiWeasel), as mentioned earlier, contains annotations of uncertain text frag-ments classified as “weaselling”, “peacocks” and “hedging” [Vin13]. However, the an-notated uncertainty cues are not further linked to any specific event, or statement withinthe sentence.
Proceeding to scientific and biomedical text, a corpus that is very relevant to our re-search is the enrichment the events of the Genia corpus [KOTT03b] with meta-knowledge[TNMA11]. In this study, five different metaknowledge aspects were taken into consid-eration: Polarity, Manner, Knowledge Type, Source and Certainty level. Among those,Certainty level classes (“possible”, “doubtful”, and “certain”) as well as the “investiga-
tion” class of the Knowledge type aspect, are linked to the concept of uncertainty, ren-dering it an invaluable training resource. The BioScope corpus also classifies certaintyin similar biomedical document collection, but in this case using a cue-scope approach[VSF+08a]. The corpus consists of medical and biological texts annotated for negation,speculation and their linguistic scope. Both negation and speculation are annotated in abinary manner (negated vs non-negated and speculative vs non-speculative). It is com-posed of the Genia abstracts as well as nine (9) full papers from Flybase and BMCBioinformatics, and the radiology corpus used for the CMC challenge [PBM+07].
Shared tasks have also resulted in the annotation of significant resources, as wellas providing additional motivation for teams to develop software and solutions relatedto uncertainty identification. In the 2010 ConLL shared task [FVM+10], competingsystems were required to identify speculation / hedging cues and their scope in twodifferent domains. The first task focused on the general - newswire domain, and wasbased on annotated Wikipedia articles. The second focused on the biomedical domainand contained articles from the BioScope corpus [KOTT03b]. The annotated corpora forboth tasks were made publicly available and constitute a valuable resource for trainingand developing new systems and algorithms.
The pilot task for processing modality and negation, which was organised as part ofthe Question Answering for Machine Reading Evaluation Lab at CLEF 2012 [RPHP10],was also focused on annotation for negation and modality. The dataset included ar-ticles from different domains, namely Aids, climate change, music and society, andAlzheimer’s disease, all annotated with events 6. Each event could be assigned one ofthe following three labels: MOD if it was deemed uncertain, NEGMOD if it was both

100 CHAPTER 3. DEFINITION AND CLASSIFICATION
uncertain and negated or NEG if it was only negated.The BioNLP shared tasks [KOP+09b, KPO+11b, NBK+13b] have also contributed
to the development of uncertainty identification techniques for the biomedical domain,although their main tasks are not centred on uncertainty or speculation. Indeed, whilemost tracks focus on event extraction, many tracks (Genia, ID, EPI, CG and PC) includea sub-task that requires teams to identify negation and speculation attributes along witheach event 6. Negation and speculation are both annotated in a binary fashion that issimilar to the BioScope corpus, but centred on events. We provide further details aboutthe BioNLP tracks and corpora in Section 5.2.1.
In Table 3.1, we present an overview of the publicly available annotated corpora,comparing domains, document types, annotation units and size. Such annotation detailswere used to guide our choice of training corpora to be used for the evaluation of themethods discussed in Chapter 5, since we needed to identify corpora focusing on thebiomedical domain and having an adequate number of event annotations that are alsoannotated as uncertain.
6Events and event-centred uncertainty are described in Chapter 2.7Refers to the combined specifications for the following tracks: 2009: Genia track, 2011: Genia, EPI
and ID tracks, 2013: Genia, CG, and PC tracks

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 101
Table 3.1: Annotation specifications of available corpora annotated with uncertainty
Corpus Domain Annotationunit
Uncertaintyclassification
PassageType
Documentcount
Bioscope Biomedical cue-scope binary abstracts +full papers+ clinical
1273 + 9 +1954
FactBank General event 3 level newsarticles
208
MPQA Newswire state-frames
4 level newsarticles
70
GENIA-MK Biomedical cue-event 3 level abstracts 1000BioNLP-ST 7 Biomedical event binary abstracts +
full papers5955 + 45
Medlock et al. Biomedical sentence binary biomedicalsentences
300K
WikiWeasel Generic cue-scope binary wikipediaarticles
4530
Rubin et al. Newswire sentence 4 level newsarticles
32
WSR Biomedical sentence 4 level biomedicalsentences
10K
ACE-MK Newswire cue-event 4 level newsarticles
599
3.3 Automated identification of uncertainty
As expected, the analysis of different definitions and categorisation schemes has al-ready given rise to a wide range of methods that attempt to automate the identificationof uncertainty in text, varying from handcrafted rules to probabilistic, statistical and su-pervised machine learning approaches. This section provides an overview of methodsfor automated extraction of uncertainty from text, with a focus on scientific and, morespecifically, biomedical documents.
Strictly speaking, identification of uncertainty expressions could be cast as a namedentity recognition (NER) task, in which potential uncertainty cues are treated as namedentities; this is the approach taken in the recent work of Chen and colleagues [CSH18].However, the task is often broader than simply extracting the uncertainty expression

102 CHAPTER 3. DEFINITION AND CLASSIFICATION
and many related attempts seek to identify the exact piece of information that is affectedby the expressed uncertainty. The cue-scope approach is the generic term commonlyused for such cases, and it refers to the task of identifying an uncertainty expression ofinterest (what we have already defined as a “cue”), along with the word sequence (phraseor constituent) within the same sentence that is influenced by it. More recently, event-centred uncertainty identification has also been studied, where uncertainty is treated asone of the event attributes (see Chapter 2). Thus we can classify automated methods intothree level of granularity: (1) cue (and sentence) classification, (2) cue-scope approachand (3) event-centred approaches.
Figure 3.8 summarises the most important contributions8 to the automated iden-tification of uncertainty. The left-hand side, is organised by classification level, andsubsequently by domain and classification level (binary or multi-class), while we alsoindicate the concept used to frame uncertainty (e.g., hedging, speculation, etc.). On theright-hand side, we present different aspects of methodology, i.e., the rule-based andML approaches used, as well as the most commonly used feature types and externallexical resources (dictionaries etc.). Note that, often, methods are combined; typicallyfeatures and external resources are combined with learning methods, but there are casesthat combine either several different ML classifiers or rule-based approaches with MLsystems. In order to avoid a mind-map that is too fuzzy, we do not map authors to theirspecific approaches. However, we elaborate on the methods used by the main contribu-tors in each of the three classification cases in the following sections.
8Especially in the case of the shared tasks, there are many more approaches that we do not include,so as not to overcrowd the mind-map. For the same reason, we do not repeat the publication days forapproaches related to the shared tasks, where they can be inferred by the shared task date.
3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 103
Figu
re3.
8:M
ind-
map
ofau
tom
ated
unce
rtai
nty
clas
sific
atio
nta
sks
(lef
t)an
dm
etho
ds(r
ight
).

104 CHAPTER 3. DEFINITION AND CLASSIFICATION
3.3.1 Evaluation methods and metrics
Moving from the categorisation and definition of uncertainty to the automated identifi-cation and categorisation of uncertain phrases and/or events, there are various metricsused by the research community in seeking to report and compare results in terms ofperformance. In this section, we describe the most commonly used evaluation metricsused in relation to automated uncertainty classification, since these will be referred to insubsequent sections.
3.3.1.1 Main evaluation metrics:
• Accuracy: This is a description of systematic errors, a measure of statistical bias;these cause a difference between a result and a “true” value. It considers all classes(positive and negative) uniformly and the same is true for all errors. Essentiallyit is a measure of the proportion of correct classifications versus incorrect over atest sample. It is often deceptive, especially for classification tasks with skewedrepresentation of the positive and negative classes.
Accuracy =T P+T N
T P+T N +FN +FP(3.1)
• Precision:Precision =
T PT P+FP
(3.2)
• Recall:Recall =
T PT P+FN
(3.3)
• F-score: F-score measures consider both the precision and the recall on the testset to compute the score. The F1 score is the harmonic average of the precisionand recall, and it reaches its optimal value at 1 (perfect precision and recall) andits worst value at 0.
F1− score = 2 · Precision ·RecallPrecision+Recall
(3.4)
• Break-Even Point (BEP): While Break-even analysis is mostly used in businessand financial analytics, in some applications it is used to evaluate performance

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 105
of machine learning algorithms with varying parameters. Upon varying parame-ters of the algorithm or aspects such training-set size, feature-size etc., recall andprecision values change (usually in opposite directions). The Break-even pointrepresents the performance (F-score) for which both recall and precision have thesame value.
• Receiver operating characteristic (ROC) curve: This is a graphical plot thatillustrates the diagnostic ability of a binary classifier system as its discriminationthreshold is varied. The ROC curve is created by plotting the true positive rate(TPR) against the false positive rate (FPR) at various threshold settings. Thetrue positive rate essentially corresponds to recall while the false positive ratecorresponds to the fall-out (or probability of false alarm). Often, the area under thecurve (AUC) is used as a performance metric to assess the accuracy of a diagnostictest. Overall, for the test to be considered successful the area has to be larger than0.5, while an area of 1 would be the perfect score.
• Mean Absolute Error (MAE): This is a measure of the difference between twocontinuous variables X, Y.
MAE =∑
ni=1 |yi− xi|
n=
∑ni=1 |ei|
n(3.5)
In the case of text mining and uncertainty identification it represents the differ-ence between gold-standard uncertainty labels and system-attributed values. Ithas been used mostly in factuality evaluation.
• Pearson correlation coefficient (r): This is a measure of the linear correlationbetween two variables X and Y. It has a value between +1 and -1, where 1 is totalpositive linear correlation, 0 is no linear correlation, and -1 is total negative linearcorrelation. It is sometimes used as a measure of performance in factuality iden-tification approaches, comparing the gold-standard annotations and the systempredictions.
r =∑
ni=1(xi− x) · (yi− y)√
∑ni=1(xi− x)2 ·
√∑
ni=1(yi− y)2
(3.6)

106 CHAPTER 3. DEFINITION AND CLASSIFICATION
3.3.1.2 Other metrics and concepts
• Information Gain Ratio: Information gain (based on mutual information) is auseful metric that can be used instead of or along with ablation tests to assessthe contribution of specific features in classification tasks. It is employed largelyfor decision trees but it can be useful for evaluating features and attributes acrossvarying classification algorithms. It uses the entropy of each attribute with respectto the labels to be classified, in order to decide how informative the attribute canbe at a given classification stage. The word “informative” in this case, translatesto “efficient in distinguishing between the given labels correctly”.
Let Attr be the set of all attributes and Ex the set of all training examples, value(x,a)
with x∈ Ex defines the value of a specific example x for attribute a∈ Attr; H spec-ifies the entropy. The values(a) function denotes the set of all possible values ofattribute a ∈ Attr. The information gain for an attribute a ∈ Attr is defined asfollows:
IG(Ex,a) = H(Ex)−
∑v∈values(a)
|x ∈ Ex|value(x,a) = v||Ex|
· log2(|x ∈ Ex|value(x,a) = v|
|Ex|)
(3.7)
3.3.2 Cue and sentence classification
The first attempts at automating uncertainty identification focused on identifying poten-tial hedging expressions (henceforth referred to as cues) and accordingly labelling thesentences in which they were located as speculative or non-speculative. As we havealready mentioned in Section 3.2, Light and colleagues proposed a hedge classifica-tion approach to classify hedges (a) as a binary task and (b) as a 3-class task. Bothapproximate string matching (against a pre-complied list of cues) and SVM classifierswere used to automatically classify hedges, and it was found that the simpler, approxi-mate string matching approach slightly outperformed the SVM classifier, based on BEPscore [LQS04b]. Medlock and Briscoe [MB07b] proposed pairing a weakly super-vised approach that uses a probabilistic model to select training instances with an SVMclassifier. Applying their approach to a set of annotated documents from the fruit-fly

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 107
archive (full-text papers from the functional genomics literature relating to Drosophilamelanogaster) they managed to significantly improve the BEP from 0.60 (derived fromLight’s approximate matching method) to 0.76. Szarvas [Sza08] further improves on theaforementioned results by carrying out considerable improvements to the feature engi-neering and speculation conceptualisation aspects. Szarvas highlights the importanceof multi-word uncertainty expressions and thus proposes the use of bi- and trigrams toaccount for them; he also shows that the application of probabilistic feature selectionand keyword selection can raise the obtained BEP score to 0.79. Manual feature selec-tion and use of external dictionaries further improves the BEP score to 0.85. However,these latter improvements do not seem to be portable to other datasets, since when eval-uating on a different dataset, comprising BMC articles, the performance drops to 0.76.Finally, in the same work, Szarvas points out that there is significant difference in theuse of certain/uncertain expressions between different but related fields, by comparingbiomedical papers with radiology reports.
Kilicoglu et al. [KB08b] also used the fruit-fly archive and a BMC dataset to eval-uate and compare their methods. The authors used the hedging expressions and de-vices provided by Hyland [Hyl96] to generate a seed list of cues. The cue-list wasexpanded using WordNet [Mil95] to extract synonyms and the UMLS SPECIALISTLexicon[Bod04] to extract nominalisations. Subsequently, the authors manually ap-plied weights to each term using a rule-based system that was based on Hyland’s ob-servations concerning hedging strength. They compare this semi-automated weightingwith weighting based on information gain. They observe that the manual, rule-basedapproach outperforms the information gain weighting, achieving 0.85 BEP compared to0.80 on the fruit-fly dataset. Also, in contrast to the findings of Medlock and Szarvasmentioned above, they find that both methods are transferable to the BMC dataset with-out significant loss of performance.
More recently, Chen [CSH18] proposed a method based on word embeddings to ex-pand a small seed list of cues to generate rich resources for uncertainty identification.The generated cues cover not only hedging expressions as described by Hyland andused by previous authors, but also expand to a set of uncertainty cues indicating contra-diction and lack of consensus in result presentation, which the authors demonstrate tohave high strength in discriminating certain from uncertain statements. The authors thenuse two Word2Vec [MSC+13, MCCD13] models (one trained with word embeddings

108 CHAPTER 3. DEFINITION AND CLASSIFICATION
in the general domain (Google model 9 [MSC+13]) and one trained with embeddingsin the biomedical domain (PubMed model 10 [MA13d]) to further expand the initial listwith cues for certainty and uncertainty. A set of different machine learning approachesis then compared in terms of their ability to correctly classify the uncertainty cues 11.Among the RNN [Sch15], KNN [Alt92], Naive bayes [HY01], Random forest [Ho95]and SMO [Pla99] classifiers used, RNN seemed to significantly (p < 0.01) outperformall other classifiers in Accuracy (0.80), Precision (0.79) and Recall (0.79). For the eval-uation of the biomedical task, manually annotated cues from fifteen biomedical articlesdownloaded from the publicly available PubMedCentral database were used. Whiletheir work is not comparable to that of previous authors, since they did not attempt touse it for sentence classification and they used a broader definition of uncertainty, it isvaluable in providing a useful inventory of new uncertainty cues as well as providing ahelpful overview of potential machine learning classifiers and their predictive properties.Thus, it provides a solid basis for further experimentation and application in uncertaintyranking, especially in the biomedical field. Moreover, compared to other approaches,which were largely based on combinations of hand crafted features, dictionaries or rulesand which focused on supervised machine learning methods, this is the first attempt tomove towards semi-supervised approaches.
3.3.3 Cue-scope approaches
Shortly after the first attempts to classify hedges and their surrounding sentences ac-cordingly, research in the field turned to a more fine-grained task, i.e., that of detectinguncertainty-related cues along with their scope in a sentence, i.e. the exact sequence ofwords (most commonly a sub-phrase), that is influenced by them. The CoNLL 2010shared task [FVM+10] unequivocally played a critical role in defining the research di-rection towards this goal, since it provided the annotated resources and the opportu-nity for research teams to develop and test their systems in performing this task. Infact, CoNLL 2010 consisted of two tasks focusing on different fields, one centred on
9Accessible here: https://code.google.com/archive/p/word2vec/10Accessible here: http://bio.nlplab.org/11Note that in this case the evaluation is performed against a list of cues, rather than on the annotations
of corpus

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 109
Wikipedia articles and one on biomedical articles. The biomedical task had two sub-tasks, the first one of which focused on identifying uncertain sentences (task 1B) whilethe second focused on identifying cues and their scope (task 2). The Wikipedia task, onthe other hand, only focused on the first part, namely the hedge and sentence classifica-tion (Task 1W). For the Wikipedia task, sentences manually annotated with weasel cueswere used (WikiWeasel corpus), while for the biomedical task, a subset of the BioScopecorpus [VSF+08b] was used (including abstracts from the GENIA corpus, 5 full articlesfrom the functional genomics literature (related to the fruit fly) and 4 articles from theopen access BMC Bioinformatics website).
The published approaches to the task of cue-scope uncertainty identification (oftenreferred to as speculation or hedging identification) can be roughly classified into threecategories: those that employ purely machine learning techniques, those that use morelinguistically oriented rule-based systems, and finally, hybrid approaches that combineboth machine learning and rules to achieve improved performance.
For the purposes of the CONLL task, Kilicoglu and his colleagues extended theirprevious approach to account for the scope of cues, for which they employed dependency-based heuristic rules extracted from syntactic parse trees [KB10] to identify the scope.With the exception of Kilicoglu, the remainder of the submitted systems employed ma-chine learning rather than rule-based approaches for the hedge and sentence classifi-cation tasks. Algorithms used for hedge classification included various combinationsand configurations of Conditional Random Fields (CRF), Maximum entropy (Max-Ent), Support Vector Machines (SVM), Bayesian approaches and K-Nearest Neighbours(KNN) classifiers. There is no clear indication of which algorithm might be most suit-able for this task, since the methods employed by the top-scoring systems were quitedifferent. Moreover, the top-scoring systems for each domain (task) are from differentteams and use different methods. Overall, CRF systems seem to perform quite well,since some version of the CRF classifier was used by the majority of the top-scoringsystems, especially in the biomedical domain. MaxEnt classifiers, Bayesian approachesand SVMs were also quite successful. The feature selection and feature engineeringapproaches were also quite diverse; feature selection approaches included statistical orgreedy forwarding as well as a large number of manual and rule-based approaches,while common engineered features include Part Of Speech (POS) tags, dictionary fea-tures, orthographic and lemmatisation features as well as syntactic (dependency, chunk,

110 CHAPTER 3. DEFINITION AND CLASSIFICATION
constituent parsing) and semantic features (NEs, WordNet information). Other machinelearning approaches included dependency-based features paired with logistic regres-sion (LogReg) classifiers [VC10], SVM systems paired with Dependency Tree Kernels[MVAD10a] or MaxEnt approaches [ZDLC10].
While the methods employed differ in terms of performance, there is consistentlyhigher performance in the biomedical task, compared to the Wikipedia one. Top scoringsystems in the biomedical tasks outperform top scorers in the Wikipedia by at least 10points in the 0-100 scale for all evaluation metrics (Precision, Recall, F-score). Morespecifically, Tang et al. [TWW+10a] achieved a performance of 0.86 Precision, 0.88Recall and 0.86 F-score for the biomedical task using an ensemble of CRF classifiersthat were combined in a multi-stage cascading system, where in each stage the CRFclassifiers receive as their input features the output of the classifiers in the previousstage. In the Wikipedia task, the top scoring system [Geo10] achieved a score of 0.72Precision, 0.52 Recall and 0.60 F-score. Comparing the results for the two tasks, wecan see that most problems in the Wikipedia task concern Recall, which is consistentlymuch lower for all submitted systems than for the biomedical task. The differencesin the performance of uncertainty identification systems between the biomedical andthe generic/newswire domain is a very compelling topic that is further discussed andanalysed in Chapter 6.
Moving on to the cue-scope task (task 2), it is also noticeable that the top-performingsystems do not come from the same teams as those in task 1B. Moreover, when it comesto cue-scope extraction, the performance is significantly lower compared to task 1B,since the top-scoring system [MVAD10b]achieved only a score of 0.60 Precision, 0.55Recall and 0.57 F-score. More recently Jean [JHR+16] proposed a probabilistic model,showing a promising degree of improvement, especially for the biomedical field. Infact, on BioScope, the F-score was raised to 0.80; however, on WikiWeasel the bestperformance achieved was still 0.56 F-score, further highlighting the differences in thecomplexity of the task between the two domains.
Examining the employed approaches, CRF systems once again constitute the ma-jority of employed algorithms, since most teams treated the task as one of sequencelabelling, where the CRF classifier was trained to identify the first and last tokens of thescope of identified cues. Among the non-CRF systems, most treated the task as one oftoken classification (usually classifying tokens in using a First-Last-NONE (FL) token

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 111
classification to identify the boundaries of each cue’s scope). There were also somesystems that used a manual, rule-based approach for the scope identification, which insome cases proved quite efficient, since Rei’s team [RB10] achieved second place, us-ing a set of manual rules that were extracted from grammatical relation graphs for eachsentence, as input to a CRF classifier that fine-tuned the scope output. Overall, mostsystems employed some kind of dependency parsing or syntax analysis (e.g., syntactictrees and graphs), either as complimentary features or as a sentence pre-processing stepfor the extraction of rules. However, simple dependency relations and shallow syntacticparsing on their own do not seem sufficiently efficient enough to accurately predict thescope of a cue. Indeed, Zhou et al. [ZDLC10] approached the scope task as a simplifiedshallow syntactic parsing problem and, while their cue classifier is among the top scor-ers, they score only in the middle in terms of scope prediction, approximately 10 pointslower than the leading system.
The systems developed for the CoNLL 2010 task are in themselves a valuable con-tribution to the research community in terms of hedge/weasel identification, but perhapsthe most significant impact of the CoNLL 2010 shared task was the generation and dis-tribution of rich annotated resources and a wide range of tested approaches that could beused and compared against in the years that followed. Especially in the cue-scope task,there have been important contributions that have considerably improved the state-of-the-art performance. Moreover, the shared task inspired annotation of further resources,and the organisation of similar tasks in other domains. These include the SFU reviewcorpus [KDSD+12] that consists of 400 documents of movie, book and consumer prod-uct reviews, annotated for negation, speculation and their scope. Moreover, the SEM2012 shared task focused solely on the resolution of scope for negation cues [MB12],following a similar definition of scope to the one used in CoNLL 2010.
In terms of improvements and novel approaches that occurred after CoNLL task,proposed solutions continued to employ dependencies and syntax either as rules or asML features. Velldal [VØRO12] highlighted the critical role of syntax for scope res-olution and Apostolova et al. [ATDF11], opted for a rule-based approach, based onsemi-automated extraction of syntactic dependency patterns that they refer to as “rule-trees” in order to determine the scope of cues. They applied a linguistically motivatedheuristic to prune and thus generalise their trees, which yielded high performance onthe BioScope corpus (74-79% F-score) for scope identification.

112 CHAPTER 3. DEFINITION AND CLASSIFICATION
Taking the idea of exploiting dependencies a step further, some researchers opt fora hybrid approach, pairing machine learning with rule-based and heuristic methods. In-deed, Velldal proposed a MaxEnt system for cue identification, paired with dependency-based rules to identify scope [VOO10]. Yang [YRG+12] on the other hand, relies ona CRF classifier that is paired with dependency-based and other linguistically moti-vated heuristic rules, but in this case, the focus is on text related to natural languagerequirements. Zou et al. [ZZZ13] propose a novel approach to developing a tree kernel-based SVM classifier for scope detection, in which they use structured syntactic parseinformation. In addition, they propose an optimisation method for the feature selectionprocedure based on the identified POS of each token, since they show that there is im-balanced efficiency for scope classification depending on the POS of the cue. Zhou etal. [ZDHZ15] further improve the idea of a composite kernel to explore dependenciesin order to determine the scope boundaries, obtaining an F-score of 0.72 on BioScope,which constitutes the current state-of-the-art in non-rule-based systems.
A pitfall of the cue-scope approach, which was identified by Zhang et al. [ZZZL10]in their CoNLL 2010 submission, is the existence of multiple cues in a sentence, whichcan lead to potentially overlapping and interdependent scopes. Most systems submit-ted to CoNLL regarded multiple cues in a sentence as independent from each otherand consequently formed different classification instances from them. There were afew systems, however, which incorporated information about other hedge cues (e.g.their distance, their position) found in the sentence into the feature space [TWW+10a,LZWZ10]. Zhang and his colleagues constructed a cascaded system which directlyused the previously predicted scopes (handling cue phrases in order, from left to right)as part of the feature set to predict other scopes in the same sentence. Moncecchi alsoaddressed the issue of conflicting scopes [MMW14], and suggested that it can be solvedby employing syntactic rules derived from iterative error analysis. He showed that bystarting with the rule set presented by Morante [MD09a], and suggested that it can besolved by employing syntactic rules derived from iterative error analysis. He showedthat by starting with the rule set presented by Morante [MD09a], after five iterations ofcorrecting identified constituent tokens based on a set of rules applied to syntactic trees,they could improve the obtained F-score by approximately 10 points, to reach 0.83 .
Cruz et al. [CTM16] used a cue-scope approach for speculation and negation de-tection in order to improve opinion mining and sentiment analysis on the Simon Fraser

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 113
University Review corpus (SFU). They identify another complication regarding the useof supervised ML for uncertainty identification, which is the imbalanced representationof the certain/uncertain instances in the training set. In most texts, the certain instancessignificantly outweigh the uncertain ones, making it hard to achieve high recall withML. Cruz addresses this issue by applying Cost Sensitive Learning (CSL) on top oftheir SVM (RBF kernel) approach, which uses a combination of lexical, grammatical,positional and syntactical features, achieving a score of 0.78 Precision, 0.70 Recall and0.74 F-score, which is significantly higher than other proposed methods.
3.3.4 Event-centred approaches
The cue-scope approaches described in Section 3.3.3 constitute a significant improve-ment over sentence-based uncertainty classification, in terms of their ability to distin-guish between certain and uncertain spans within the same sentence, and thus to identifyuncertain information more accurately. However, according to the advances in event ex-traction, there has been a shift of interest towards identifying the influence of cues onspecific events (which do not normally constitute continuous text spans). As has alreadybeen mentioned in the Chapter 2, event structures can efficiently capture informationregarding a specific statement/claim by linking the trigger to the event arguments andomitting potentially intermittent text that might not be related.
Event extraction technology is being gradually introduced as an IE method in a rangeof different applications. For example, event extraction has proved useful in improvingsearch facilities for scientific literature databases [OTT+06],for updating databases withmolecular interactions and for updating (or creating) molecular networks or pathwaymodels [MYBHA14]. As event extraction performance improves, methods that canefficiently and accurately identify the uncertainty of events are becoming increasinglyimportant.
In a similar way to the CoNLL 2010 for the cue-scope approach, the BioNLP sharedtasks have played a critical role in the development of event-centred approaches to un-certainty identification. Along with the GENIA-MK corpus (see Section 3.2.1) the an-notated datasets developed for the BioNLP Shared tasks constitute the main annotated

114 CHAPTER 3. DEFINITION AND CLASSIFICATION
resources for training, evaluating and comparing performance of uncertainty (specula-tion) detection for biomedical events 12.
Looking at the performance scores reported for speculation classification by systemsparticipating in the BioNLP shared tasks, the results can seem rather demotivating: InBioNLP 2011, the best F-score performance reached for speculation classification was0.36%, which was achieved by UTurku system [BKS13] on the EPI task [OPT11]. Sim-ilarly, in BioNLP 2013, the best F-score reached for speculation detection was 0.30%that was achieved by EventMine of NaCTeM [MA13c] for the Cancer Genetics (CG)task [POA13].
Although these initial results could indicate that the technology for uncertainty de-tection is not mature enough for applications at the event rather than the sentence level,the results reported for later work following on from those tasks is much more promis-ing. Stenetorp et al. [SPO+12a] conducted a thorough study comparing the differencesbetween the generic cue-scope approach and the event-centred approach, and they iden-tified and addressed the conflicting characteristics in order to improve performance ofspeculation and negation detection. One of their core findings was related to the prop-agation of uncertainty in the case of complex events. They concluded that, in caseswhere a speculation cue affects a complex event, the certainty of the events that arenested within this event (in other words, the events that act as arguments to this event)should not be affected (i.e., should not be classified as uncertain). An illustrative ex-ample is given in Figure 3.9. Similarly, in the case of an uncertain nested event, theuncertainty should not be propagated to the top level event, although this case is signifi-cantly rarer in biomedical literature. Stenetorp ended up with a hybrid approach, whichcombined a heuristic rule-based component that decoupled the complex events to avoiderroneous propagation of uncertainty (in the example of Figure 3.9, that would removemetabolism and its arguments from the scope), and a machine learning component thatused an SVN classifier based on cue-scope and event-based features. Using this ap-proach, they demonstrated that they could achieve an F-score of 52% on the EPI task, aswell as improving upon the uncertainty identification results of the systems competingin the other BioNLP 2011 tasks by at least 4%.
The GENIA-MK corpus, which was focused on meta-knowledge identification, has
12The FactBank [SP09a] and ACE-MK [TNMA17] corpora are corresponding primary event annota-tion sources in the generic/newswire domain, further discussed in Chapter 6

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 115
Figure 3.9: Example of a sentence with an uncertainty cues, affecting only the top levelevent of the sentence (modulate) and not its nested event (metabolism), or the inhibitionevent (inhibits) that is found in the same sentence.
led to further research on the topic, with better performance reported recently, com-pared to the BioNLP-ST corpora. Indeed, Miwa et al. [MTM+12] presented a sys-tem that built upon EventMine, which was focused on meta-knowledge detection forevents. Using rich dependency and lexical features with an SVN classifier and train-ing the system on GENIA-MK, they were able to achieve F-scores of 0.67 and 0.74respectively for the two uncertain classes, L1 and L2. Kilicoglu et al. [KRCR15] alsofocused on uncertainty at the event level (referred to as event factuality in this case).Based on Szarvas’ classification of uncertainty [SVF+12b], they composed a dictionaryof “extra-propositional phenomena”, that contains information on embedding category,scope type, etc. They then applied semantic composition to the different categories ofthis dictionary in order to determine the certainty value for an event. They additionallyevaluate their results on the GENIA-MK corpus, achieving 0.66 and 0.68 respectivelyfor L1 and L2. In their latest work, Kilicoglu [KRR17] and his colleagues expand theirapproach to classify events according to a definition of uncertainty that is closer to thedefinition of factuality introduced by Sauri and Pustejovsky [SP12] using six differentclasses: fact, probable, possible, doubtful, counter-fact and uncommitted. They pro-pose an enhanced version of their compositional rule-based approach and show that,compared to other approaches, it is more efficient in capturing the non-factual classesthat are significantly under-represented and thus often wrongly predicted by other ap-proaches such as [MTM+12].
Although the factuality definition used in FactBank is not completely compatiblewith the proposed definition of uncertainty we intend to investigate, we provide anoverview of the most successful approaches proposed for automatically detecting event

116 CHAPTER 3. DEFINITION AND CLASSIFICATION
factuality. Early methods applied to the above corpora used lexical and syntactic fea-tures in combination with with CRF and SVM classifiers, as in the work of Pranhakaran[PRD10]. Later work saw a wider range of classifiers and elaborate syntax-based fea-tures; in [WPDR15] we see an increase of 14-19 points (compared to the results of Pran-hakaran) in F-score for the LU corpus and the overall results for FactBank and LU sur-pass 72.5 in F-score for both corpora. Stanovsky [SEKP+17] has also shown improvedon Pranhakaran’s results (a significant decrease in MAE and an increase Pearson’s rmetrics) by projecting a rule-based approach over generic dependency graphs extractedfor each sentence. Both Stanovsky and Lee [LACZ15] emphasise the important contri-bution of external knowledge towards accurate prediction of factuality. For MAE and rmetrics, current performance ranges in the low 40s and the high 70s, respectively (theperformance varies according to the corps used).
All of the recent efforts related to event-level uncertainty provide ample proof andmotivation for taking an event-centred approach towards the uncertainty identificationtask.
3.3.5 Confusions with existing annotations
Despite the many different attempts to classify phenomena related to textual uncertaintyand to produce corpora with uncertainty-related annotations, the work of Rubinstein[RHK+13] points out that there is no standard, commonly accepted categorisation ofuncertainty in text. Indeed, as seen in the previous section, different corpora focus ondifferent sub-categories of uncertainty. For example, the BioNLP shared tasks focuson speculation, disregarding the weaselling that is accounted for in WikiWeasel, or theKnowledge Type that accounts for investigations in GENIA-MK. This inconsistencyin the type of uncertainty that is annotated is sometimes motivated by the domain ofthe corpus (e.g., the BioNLP-ST focuses on biomedical scientific articles, while Wiki-Weasel is a collection of Wikipedia articles). However, this is not always the case:the BioNLP-ST and the GENIA-MK corpora are both concerned with the biomedicaldomain, but yet they still annotate different types of uncertainty.
The non-standardised classification of uncertainty inescapably leads to differentinterpretations and corpus annotations and subsequently, to decreased adaptability ofsupervised ML uncertainty classifiers. A characteristic case is described by Vincze

3.3. AUTOMATED IDENTIFICATION OF UNCERTAINTY 117
[VSM+11] who compared two corpora annotated for uncertainty and pointed out thatwhile in the Genia corpus [KOTT03b], there is consideration for cases such as inves-tigation, weaselling and speculation, based on cues relaying ability, in BioScope cor-pus [VSF+08a] such cases were ignored. Stenetorp et al. [SPO+12a] showed thatby combining the two corpora and bridging their mismatches, performance of spec-ulation detection can be greatly improved. It should also be noted that even whenanalysing the speculation annotations in the corpora used for the BioNLP shared tasks[KOP+09a, KPO+11a, NBK+13a]] there are observable differences among the sub-corpora, stemming from the evolution of the concept of uncertainty over the years 13.
Inconsistencies in annotation of uncertainty are not limited to differences in choiceof which meta-knowledge aspects should be annotated. Rather, such inconsistenciesextend to the annotation of intensity/strength of uncertainty expressions that are foundin text. Take, for example, the term “presume”, as analysed in the context of biomedicalarticles. Malhotra et al. [MYGHA13], in their analysis performed for HypothesisFinder,indicate “presume” as an indicator of weak speculation. On the other hand, Grabar andHamon [GH09] claim that “presume” an indicator of strong speculation.
The difficulty in distinguishing between expressions of high and low uncertaintyseems to be related to the inconsistent ways in which different readers perceive uncer-tainty. Apart from research into reader perception of uncertainty that we have alreadydiscussed in Section 5.4.2, this inconsistency is also reflected in the results presented byLight et al. [LQS04b]. They showed that although their classifiers were able to reliablyclassify sentences as uncertain or definitive, they were unable to achieve a good perfor-mance in the task of distinguishing between high and low levels of uncertainty. Alongthe same lines, Rubin [Rub07] showed that a fine-grained classification of uncertainty(five levels) resulted in unacceptably low levels of inter-annotator agreement, and thusargued in favour of a two level (binary) classification.
Notably, Kilicoglu et al. [KB08a] claimed that hedging cues could be gainfullyweighted to provide a measure of speculation in a sentence. However, while they pre-sented two different weighting approaches, they still evaluated their methods in a binaryfashion and did not conclude in favour of specific cue weights. Still, their methods arevaluable as a basis for improved uncertainty cue identification (see Section 3.3.2).
13The BioNLP shared task corpora are described in detail in section 5.2

118 CHAPTER 3. DEFINITION AND CLASSIFICATION
The difficulty of achieving a multi-class classification of uncertainty with high con-fidence was also obvious in our 5-level annotation experiments discussed in Chapter 5,Sections 5.4.2.3 and 5.4.2.4. While there is a general agreement between events withhigh certainty as opposed to events with low certainty, the perceived boundaries andquantification of uncertainty is highly subjective and thus complicated to frame.
3.4 Conclusions
In this chapter, we have provided an overview of a range of different classificationschemes and methods proposed for uncertainty. We separated our analysis into threedifferent sections, distinguishing between general concept interpretation, uncertaintyclassification and annotation schemes, and automated identification approaches. Thereis also an underlying time-line in this analysis, as most of the interpretation approachescorrespond to early linguistic work, which were followed by detailed classification ef-forts, which in turn gave rise to automated classification methods. However it shouldbe pointed out that there is no clear boundary between these three categories, as manyauthors have contributed to more than one of the aforementioned areas, or else haveinspired and aided advances in other areas. For example, the cues identified by Hy-land continue to be used as dictionary features in many automated uncertainty classi-fication methods [KB08a, CSH18], while Szarvas’ hierarchical classification inspiredKilicoglu’s automated uncertainty identification approach [KRCR15].
The time-line presented in Figure 3.10 captures this fluidity between approaches,by visualising the main contributions to the aforementioned areas. Note that to avoidovercrowding the timeline, we visualise only the earliest publication discussed in theprevious sections, in the case of researchers who authored multiple articles on the sametopic. Additionally, publications that are related to one of the shared tasks (visualised inlarger green bubbles) are not visualised. The size of the bubbles on the x axis, representthe amount of related work reported in each year of the time-line (thus, the bubblesaround the CoNLL and BioNLP shared tasks are much larger). The bubbles on themain part of the time-line are coloured as follows:
• red nodes: mostly interpretative analysis of uncertainty related phenomena in text

3.4. CONCLUSIONS 119
• orange nodes: interpretative analysis of uncertainty related phenomena, accom-panied by some hierarchical scheme or classification of cues.
• purple nodes: proposal of classification schema of uncertainty and annotation ofcorpora
• dark blue nodes: proposal of classification schema of uncertainty and annotationof corpora along with automated classification methods
• light blue nodes: focus on automated classification methods
• green nodes: Shared tasks
We discussed the main contributions in the biomedical but also the general domain,as well as discrepancies and shortcoming of different approaches. In the next chapter,we present our own approach towards the interpretation and classification of uncertainty,as well as the novel methods that we have developed for automated extraction identi-fication. We also evaluate our work, both in an intrinsic and extrinsic fashion, whichenables us not only to compare the performance of our methods against gold-standardcorpora, but also to assess the validity of our approach by biomedical scientists, whoare the end users of the envisioned applications of this work.

120 CHAPTER 3. DEFINITION AND CLASSIFICATION
Figure3.10:Tim
e-lineofuncertainty
classification.

Chapter 4
Implementation and evaluation detailsfor the uncertainty identificationmethods
In this chapter we do the following:
• Describe the different workflows implemented for uncertainty identification
– Specify the implementation details and clarify the main components devel-oped for the purposed of this work, as well as the ones re-purposed to addressthis task.
• Provide details on accessing, using and adapting those workflows and the relatedresources.
This work focuses on the task of automating the identification of the certainty levelof events, with the view of using such certainty values in order to inform the corre-sponding interactions in pathways and network models. To this purpose we build on thetheoretical interpretations and categorisations of uncertainty discussed in Chapter 3, toimplement uncertainty identification components for biomedical events. Consequently,
121

122 CHAPTER 4. IMPLEMENTATION AND EVALUATION
new events, along with their uncertainty values can be extracted from biomedical pa-pers and mapped to corresponding entries of interactions in pathways and interactionnetworks.
The process of addressing the above tasks and implement an end-to-end systemthat can parse a raw, non-annotated text and map the relevant parts (events) to existinginteraction networks, involves the use of a wide range of NLP and text-mining processesthat need to be applied on the raw text. Additionally, concerns related to computationalefficiency and processing speed also need to be addressed in order to be able to processa sufficient amount of biomedical articles to maximise the number of identified eventsthat map to a given interaction network.
In order to be able to streamline the parsing of biomedical papers, and to take advan-tage of separate components performing different NLP tasks, we take advantage of theArgo platform [RRBA12a, RBNR+13a, BNNS+17]. Argo is a Web-based, graphicalworkbench that facilitates the construction and execution of modular text-mining work-flows. Underpinning it is a library of diverse elementary NLP components implementedaccording to the Apache UIMA OASIS standard 1, each of which performs a specificNLP task. There is a wide array of inter-operable and configurable elementary compo-nents that are readily available to users and can be integrated into processing workflowsto build different customised text mining solutions. Moreover, users can develop theirown components using the UIMA standard and combine them with the already existingones. The use of Argo enabled us to combine and use already implemented componentsthat tackle different NLP tasks that are necessary in the pre-processing of raw paperssuch as sentence splitting, tokenisation, syntactic parsing and NER.
The following sections provide details on the implemented workflows, the task tack-led by each component, as well as the parameters that need to be tuned in order to obtainthe desired output. In the analysis of the workflows, we also specify the components thatwere fully developed for this work, as opposed to the ones that were used out-of-the-boxor with minimal adaptations. Where necessary, we also discuss our motivation for thedifferent choices of components and parameters as well as the distinction between Theimplemented workflows are publicly available to demonstrate the current work on Argoplatform (test server), that can be accessed here: http://argo.nactem.ac.uk/test2.
1https://uima.apache.org2Note that large parts of this chapter were initially published as Supplementary Material in our work

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 123
4.1 Demonstration of uncertainty related workflows
4.1.1 Description of end-to-end workflow for linking to pathwaymodels
In this section, we describe the components that are necessary for the implementationof an end-to-end workflow. As end-to-end, we refer to the workflow that would be ableto parse plain text documents, extract events and their uncertainty values and map themto a pathway or interaction network that is provided. Those components are used toannotate plain text sentences with events and uncertainty and then map them to modelinteractions and score the models. The workflow is available as a demo on Argo testserver (full path: http://argo.nactem.ac.uk/test/?workflow=16863). In Figure4.1 we present a conceptual schematic diagram of this workflow and its core processes.In the following sub-sections we elaborate on each conceptual block, discussing thecomponents and parameters that we used for the implementation.
Figure 4.1: Conceptual schematic diagram of Argo workflow used for experiments andend-to-end system. Tasks that appear as multiple blocks, signify the use of multiplelinked components in the actual workflow. The components that are in the green, dottedblock, were developed for this PhD work, while the rest were used/adapted from Argorepository.
for [ZBNDA17] and have been only minimally adapted for the purposes of this thesis.

124 CHAPTER 4. IMPLEMENTATION AND EVALUATION
4.1.1.1 Document Reading
The workflow begins with a document reader which loads a set of plain-text documents(usually from a remote server). In Argo there is a range of available document readers,that can parse different document formats, such as XML, XMI, TXT etc. For the pre-sented workflow we used a TXT reader (SFTP Document Reader component), whichreads one evidence passage per document, over an SFTP connection. This allows theparsing of large document collections without the need to pre-upload them to Argo.
The reader will convert the raw text to a generic document CAS 3, which is a UIMAspecific feature structure, allowing for it to be subsequently processed by UIMA-basedcomponents. The CAS object will be still identifiable by the original name of the .txt
document, but any additional meta-data will not be preserved by default.
The passages provided as evidence for the B-cell Acute Lymphoblastic Leukemia
Overview pathway of Pathway Studio are already uploaded on the NaCTeM server un-der the name leukemia files, as described in the beginning of the section. So are thesentences used for the Ras-Melanoma use-case, under the name ras melanoma files. Amore detailed description of the datasets is provided in Section 5.2.2.
In order to process new documents with the SFTP Document Reader, the .txt fileswould have to be uploaded to a server and the server details will have to be set accord-ingly in the parameter fields of the component, using the Argo interface.
The parameters to be set are the following:
• ServerURL: Server address
• RemoteDirectory: Path to the directory on the server
• Username: Username used to access the directory on the server
• Password: Password used to access the directory on the server
• Recurse: If set, implies recursive searching in the directory for files to read (notnecessary for the default use-case)
Alternative reading components are briefly described in Section 4.1.3.
3See the documentation of UIMA for more details: https://uima.apache.org/ .

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 125
4.1.1.2 Document Pre-processing
After reading plain documents, a set of pre-processing steps are necessary in order toprepare the text for core NLP tasks such as named entity recognition and event extrac-tion. Such pre-processing steps are typically used in order to separate the document tosmaller objects, such as paragraphs, sentences, words, etc. There is minimal configura-tion necessary for these components, but where necessary we describe it in the listingthat follows.
1. Paragraph splitting
(a) Regex Annotator: This is a generic component that can take regex expres-sions as input and apply them to text to annotate text spans accordingly.In this case it is used in the place of a paragraph splitter, and it identifiesend-of-line characters.
2. Sentence splitting
(a) LingPipe Sentence Splitter [Ai08]: LingPipe 4 is a general-domain NLPtoolkit designed for a wide range of NLP tasks, including sentence splitting.The Argo component contains only the sentence splitting models. LingPipecomes with a pre-trained sentence models on MEDLINE abstracts whichhas been used previously in the biomedical informatics literature for NER,among other tasks, and is the model of choice for all sentence splitting taskscarried out in this work. To use the Argo component in this biomedicalcontext the UseBiomedicalModel parameter should be set to “True”.
3. Chunking, tokenisation and POS tagging
(a) OSCAR4 Tokeniser [JAW+11]: The OSCAR4 library provides modular APIsfor different pre-processing tasks trained on medical and chemical datasets,and as such it was deemed suitable for our tasks.
(b) GENIA Tagger[TTK+05]: GENIA tagger is trained for NER tasks on biomed-ical text. As part of the NER task it contains pre-processing models, alsotrained on biomedical text. As such it is used at this point of the workflow,
4Accessible here: http://alias-i.com/lingpipe/ .

126 CHAPTER 4. IMPLEMENTATION AND EVALUATION
not only for NER but also for chunking as well as lemmatisation and part-of-speech (POS) tagging. The lemmas and POS tags produced are used inthe named entity recognition task as features.
4.1.1.3 Named Entity Recognition
The next step after document pre-processing and segmentation is Named Entity Recog-nition (NER). As this step is crucial for efficient event extraction and the subsequentuncertainty annotation, it is imperative to identify different named entities (proteins,drugs, cells) that participate in events with high accuracy. Thus a series of componentsare used in order to efficiently extract different NE types, as each component specialisesin certain entity type(s). An Annotation Remover component is used in certain casesafter NER components to filter annotations for particular entity types that are redundantor not needed in this application. Annotation Remover components are also used to re-move features that were generated for particular components and need not be used bythe components that follow. Essentially the Annotation Remover components are usedin any case when a specific type of CAS annotation needs to be removed. The type(s)of annotation to be removed can be chosen in the parameters.
The Genia Tagger component used for chunking also extracts the Cell Line entities.It produces some protein entity annotations as well, that are removed by the Anno-
tation Remover component that follows. Subsequently, Protein entities are extractedusing a NERsuite based model trained for protein identification (NERsuite Dictionary
Feature Generator and NERsuite Tagger components). The Annotation Remover thatfollows serves to remove the generated features. Next, the NERsuite Custom Tagger
uses a NERsuite model that uses dictionary features and is trained on BioCreative IIGM Track training corpus5 in order to identify Gene and Gene product entities. Thetwo Overlapping Annotation Removers merge the overlapping Gene and Protein an-notations to maintain only the Protein ones, using exact and relaxed string matchingrespectively. The overlapping annotations of Genes, Proteins and Protein Family an-notations are further disambiguated and resolved by the Gene/Protein Family Disam-
biguator component. The filtered annotations are then used as input for the Similar Text
Span Annotator components.
5http://www.biocreative.org

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 127
Having finished with protein and gene related annotations, the Chemical Entity
Recogniser, Type Mapper6 and Similar Text Span Annotator components that followare used to generate Chemical and Drug entity annotations.
The Concept Normaliser components provide grounding for the identified Protein
and Chemical entities to the UniProt7 and ChEBI8 database indexing respectively. TwoNERsuite Custom Tagger components follow with models trained on the BioNLP 2013Pathway Curation corpus [NBK+13a]. The former identifies protein complexes, whilethe latter identifies subcellular locations.
The components that follow perform mainly filtering and disambiguation tasks thatresolve overlaps and annotation conflicts, or correct annotation spans. More specifi-cally, the Function Word Annotator components extend already identified annotationspans for different entity types to include the term “inhibitor”. A series of Overlapping
Annotation Remover components resolve overlaps for different entity pairs (Chemical -Gene, Cell-line - Gene, Cell-line - Chemical, GeneOrProtein - Protein Family).
4.1.1.4 Dependency Parsing
Following NER, syntactic dependencies are extracted using two different componentslisted below.
1. Genia Dependency Parser 9:
2. Enju Dependency Parser [MT08a]: The Enju dependency parser comes withmodels pre-trained for different domains, among which the biomedical one, forthe training of which the GENIA corpus was used. The Argo component allowsfor the selection between the biomedical and the generic purpose (trained on theBrown corpus) component. For replication of the experiments, the parametersneed to be set as following:
• UseBiomedicalModel: Set to true, in order to use the GENIA trained model.
• UseHighSpeedParser: Set to false6 Type Mapper components are used throughout the workflow to map annotations among different
TypeSets used by different components7http://www.uniprot.org/8https://www.ebi.ac.uk/chebi/9Accesible here: http://people.ict.usc.edu/˜sagae/parser/gdep/ .

128 CHAPTER 4. IMPLEMENTATION AND EVALUATION
• DisableTokenisation: Set to false; Enju-generated tokens are used for fea-ture extraction
• DisablePOSTagging: Set to false; Enju-generated POS tags are used forfeature extraction
Both components generate annotations for dependencies that are used by the Event-
Mine component that follows. Moreover, the dependencies generated by Enju are alsoused by the negation and uncertainty identification components. Enju also producesPart-of-Speech (POS) and lemmatising annotations, that are used as features in the sub-sequent components (EventMine and Feature Generator components).
4.1.1.5 Event Extraction
Following the extraction of For the event extraction that follows we use EventMinetrained on multiple corpora using the wide coverage approach described by [MOR+13,MPOA13]. The corresponding Argo component used for this purpose is called Event-
Mine for BioNLP Shared Tasks. For the wide coverage approach to be used, the multi-
event value has to be chosen in the Model parameter. If the events are to be mapped tomodel interactions they can be further optimised at the last step of the workflow, towardsmatching the interactions of the pathway.
4.1.1.6 Negation Identification
Apart from uncertainty identification, it was deemed necessary to identify negation ofevents as a separate parameter. Negation is important not only for the proper contex-tualisation of the events, but also for the consolidation of certainty values of severalevent mentions which refer to the same pathway interaction, as explained in Chapter 7,Section 7.2.2.
The negation identification components are implemented on the basis of two nega-tion identification modules, one ML component similar to the one described in Chapter5, Section 5.3.3 and one rule based component similar to the one described in Chapter5, Section 5.3.1.3. The machine learning part is realised with Event Feature Gener-
ator and Negation Feature Generator in terms of the feature generation components.Then WEKA Classifier can be used with the negation model provided in resources. For

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 129
the correct configuration of the WEKA Classifier, the Target Feature option has to beset to attributeValue. The rule-based component is instantiated with the Negation Rule
Checker.
4.1.1.7 Uncertainty Identification
For the uncertainty identification task, we describe different configurations and modelsin chapter 5. Here we present some of the core uncertainty identification componentsthat were implemented for the experiments and made available on Argo. The work-flow presented in uses a random forest classifier implemented using the WEKA API[HFH+09]. In the demonstration workflow the incorporated components use an uncer-tainty cue list that was compiled based on GENIA-MK and BioNLP-ST annotations aswell as related work on uncertainty for scientific literature. A Rule Checker componentis also added in the workflow to combine rule-based and ML based methods. Below welist a series of available rule based and ML based components
1. Uncertainty Rule Checker components apply dependency-based rules as describedin Section 5.3.1.3 component applies dependency rules using lexical filters. It thusreceives as input a .txt file containing a list of rules with the following format:
• Length 1 dependencies:<word> D0 <dependency type>
• Length 2 dependencies:<word 1> <word 2> D1 <dependency type 1> <dependency type 2>
where the <word> part corresponds to the words being part of the pattern and the<dependency type > part can belong to one of the four core dependency types ofEnju Parser, namely [ARG1,ARG2,ARG3,ARG4,MOD]. 10
Both components will apply the rules to the events extracted in the previousstages. It can be combined in an incremental way with other components, andit will not alter events that have already been annotated as uncertain.
10ARG1 denotes a subject of a verb, a target of modification by modifiers, etc. ARG2 correspondsto object of verbs, prepositions, etc. ARG3 and ARG4 are objects and complements of verbs, etc. Fi-nally, MOD stands for participial constructions and denotes a clause modified by another clause, if thesubordinate clause has an ARG1.

130 CHAPTER 4. IMPLEMENTATION AND EVALUATION
2. Feature Generator components: These generate features to be used with an MLclassifier (ML classifiers are available in the WEKA classifier component de-scribed below).
(a) Event Feature Generator: It is used to extract mostly semantic features re-lated to event type, argument roles, event complexity level etc. This compo-nent is not affected by the cue selection and does not need any parameters tobe set.
(b) Uncertainty Feature Generator: It extracts the rest of the lexical, syntacticand position features for the ML classifier as described in Section 5.3.3.1.Uncertainty Feature Generator ACE (multiword): An alternative to Uncer-
tainty Feature Generator component, but it accounts for multi-word cues.This component takes as input a .txt file with a list of (potentially multiword)cues (i.e. ACE based list) as the cueList parameter (see Section 4.1.4). Un-
certainty Feature Generator Broad: This component is used for the rest ofthe features that are related to uncertainty cues, but in this case it needs asinput a dependency pattern list and automatically generates the cues from it.In order to avoid noisy cue generation it requires a list of stop -words to beprovided in the stopWord parameter, and the set of rules to be provided inthe ruleList parameter (see Section 4.1.4). It can be used as an alternativeto the Uncertainty Feature Generator.
(c) Rule Feature Generator : The dependency patterns 11 need to be set in theRuleFile parameter (see Section 4.1.4). The patterns can be provided inna simple .txt file and the format will be the same as the one needed forthe Uncertainty Rule Checker. Rule Feature Generator ACE (multiword)
component necessary for the enriched dependency n-gram features. It canaccount for multi word cues. It can be used as an alternative to the Rule
Feature Generator.
(d) EDNG Feature Generator: They serve the same purpose, generating en-riched dependency n-gram features, as described in Section 5.3.1.3, withoutfiltering. It can be used as an alternative to the Rule Feature Generator.
11We used patterns filtered using the pre-compiled uncertainty cue list and the Lift measure, but pro-vided that the format is correct, any rules can be used as input

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 131
(e) DNG Feature Generator: Generates simple dependency n-gram features andis not included in the final workflow. It was used for experiments and com-parisons. It can be used as an alternative to the Rule Feature Generator.
3. WEKA Classifier: It applies a trained classification model to the combination offeatures generated by the previous components. It is necessary that the selectedmodel was trained on the same combination of feature generator components (i.e.,if the Event Feature Generator was used for model training it should be used forclassification testing), in order to classify instances properly. However, the orderin which the feature generator components are placed in the workflow will notaffect the result in any way. There is a range of parameters that need to be set forthe classifier:
(a) ModelFile: The full path to the file containing the trained model.
(b) TargetFeature: Should be set to read “attributeValue”, indicating whichannotation type should be changed in the text.
Note that for the generation of models, the WEKA Trainer component was used. Itimplements different classification algorithms available via the WEKA API [HFH+09].It concatenates all the features generated by previous components, and uses them to trainthe selected model. There is a range of parameters that need to be set for the training:
1. Algorithm: The classifier algorithm to be used.
2. ModelFile: The full path to the model to be created. For example : “My Docu-ments/models/modelName.mdl”. Click on Select in order to choose the appropri-ate path, and enter the desired model name in the white dialog box.
3. ParameterString: Here the training parameters for the WEKA trainer can beset. For example for the RF classifier it allows to set parameters like number ofiterations, depth of tree, minimum variance for split etc. The full list of optionscan be accessed here: http://weka.sourceforge.net/doc.dev/weka/clas
sifiers/trees/RandomForest.html. For most of the experiments describedin this work we use the RF classifier set for 100 iterations, no random attributes,default “1” for the random generator and no parallelism. This is written as: “-I100 -K 0 -S 1 -num-slots 1” in the ParameterString.

132 CHAPTER 4. IMPLEMENTATION AND EVALUATION
The order of the feature generator components will not affect the training of a modelor the output of a classifier.
4.1.1.8 Linking to the model
The component to be used in order to link evidence passages and associated evidence toa pathway or interaction network, depends on the standard used for the encoding/formatof the network. Currently there are two components available that support two differentformats, namely Pathway Studio data in TSV and BioPAX data in JSON format.
• Uncertainty On Pathway Models (PS version): This model supports Pathway Stu-dio data [NEDM03] extracted in TSV format and was used for the Leukemiamodel use-case presented in the main manuscript, Sections 5.2.2.1 5.4.2.2, 5.4.2.3of the main manuscript. This component:
1. Checks each interaction of the pathway against the extracted events fromthe literature (also optimising the extracted events to match the pathwayinteractions using the approach discussed in Section 2.3.2.2).
2. Calculates the score of the interaction based on the uncertainty of the relatedevents as indicated in the formulas of Equation 7.16 and 7.17 in Section7.4.2 of the main manuscript.
It requires setting the following parameters:
– InputFile: Path to the uploaded Pathway Studio .csv file.Default file: leukemia.csv. Pathway files can be downloaded from PathwayStudio using the export option.
– OutputFile: Path to the output Pathway Studio .csv file, that will includethe uncertainty values and scores. It will append two columns at the end ofthe initial csv file: Uncertainty Score and Uncertain Event Percentage. Theformer represents the score as described in the main paper, and the latter thepercentage of identified uncertain events over the total of events mapped tothe interaction. Default value: leukemia uncertain.csv

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 133
– DepDepth: The threshold value for the dependency depth in order to linkmissed arguments. Default value: 3
– RelationMatch: Set to true for a strict matching of relation types. Defaultvalue: false12
– alpha: Allows setting the alpha value (see Equation 4 and 5 in the mainmanuscript). The default is 0.5
• Evidence Linking to Pathways (BioPAX): This model supports BioPAX models inJSON format and was used for the Ras-Melanoma use case described in Sections5.2.2.2 and 7.6.2.2. This component:
1. Checks each node (interaction and entities) of the pathway against the ex-tracted events from the literature.
2. Calculates the score of the interaction based on the uncertainty of the relatedevents as indicated in the formulas of Equation 7.16 and 7.17 in Section7.4.2.
It requires setting the following parameters:
– InputFile: Path to the initial BioPAX model encoded in JSON format.Ras.json in resources/ras models fits this description.
– OutputFile: Path to the output JSON file, that will include the linked sen-tences, uncertainty values and scores in the JSON format. Sample output:Ras-melanoma.json.
– alpha: Allows setting the alpha value (see Equations 4 and 5 in the mainmanuscript). The default is 0.5
– strict match: Set to true for a strict matching of relation types. Defaultvalue: false13
12This is the option corresponding to the mappings of Figure 7.7.13This is the option corresponding to the mappings of Figure 7.8.

134 CHAPTER 4. IMPLEMENTATION AND EVALUATION
4.1.1.9 Other outputs
Instead of linking to the model, the annotated sentences, can be visualised using theManual Annotation Editor component or written to files and stored on a server usingan SFTP XMI Writer component. In the case of the Manual Annotation Editor, theannotation types to be visualised have to be set in the parameter settings of the compo-nent (tick the corresponding boxes on the Parameters tab). By default we have enabled:CancerMechanisms, BioNLP-ST-Typesystem.
Alternatively the processed files can also be written on a server in XMI format, usingthe SFTP XMI Writer. In this case the following parameters have to be set:
• Server: Server address
• RemoteDirectory: Full path to the directory on the server used to output files
• Username: Username used to access the directory on the server
• Password: Password used to access the directory on the server
• Port: Set to 22 by default
• RecorderEnabled: Set to False by default
Finally, the output files can also be written in BioNLP standoff format (see Section4.1.2.1 and Figure 4.4 for details on the format) and visualised on Brat [SPT+12]. TheBioNLP ST Data Writer can be used for this reason, but the files will have to be storedon the Argo server. The user will have to create a folder in the Documents tab and thenselect the name of the folder in the settings (OutputFolder). The BioNLP ST Data Writer
component is not added in the public workflow, but it is available as a Consumer-typecomponent on the Editing panel, and can be added to the workflow by the user (seeSection 4.1.1.10 that follows for instructions on how to edit a workflow).
4.1.1.10 Full workflow and access instructions
The full workflow as viewed when editing the “DEMO of end-to-end linking textual
uncertainty to pathway interactions” public workflow is presented in Figure 4.2.

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 135
To access the workflow 14 visit http://argo.nactem.ac.uk/test/, select thisworkflow and select Edit or Run among the options that appear above the workflowlist. In order to make changes to any of the parameters and components, it is neces-sary to make a new copy of the workflow. This can be achieved by selecting Edit andsubsequently selecting More > Save as Copy.
For most of the work described in the main manuscript to be carried out, signifi-cant processing of the plain text documents is involved. Indeed building an end-to-endsystem that is able to parse full-text papers, relate them to interactions described in apathway model, and rank those interactions according to the (un)certainty of the in-teraction mentions in the related evidence, is a multifaceted task consisting of severalnatural language processing (NLP) subtasks, ranging from the annotation of sentenceswith named entities, events and uncertainty to the matching of events to a pathway in-teraction. To combine the different NLP tools in a pipelined manner, we used the Argoplatform [RRBA12b, BNNS+17].
For best results, please access the platform and workflows on Firefox web browser.A constantly updated version of this Appendix, titled Demonstration of uncertainty
related workflows is available at:https://docs.google.com/document/d/1b0YBllgic-f750_t63nyjMQLsOVHkB8OIm
rQi1Wh5bc/edit?usp=sharing
where it is maintained and updated on a regular basis, to account for changes in the argoplatform, new user requests, etc.
14Full path to the exact workflow :http://argo.nactem.ac.uk/test/?workflow=16863

136 CHAPTER 4. IMPLEMENTATION AND EVALUATION
Figure4.2:E
nd-to-endA
rgow
orkflowused
forexperiments
onlinking
evidenceto
apathw
aym
odelusinguncertainty
asa
scoringcriterion.

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 137
4.1.2 Description of workflow processing large corpora with binaryuncertainty
In this section we provide the description of a workflow that can process corpora anno-tated with stand-off annotations for events and named-entities, in order to identify eventuncertainty, as described in the main manuscript. We also provide details for additionalcomponents that can prove useful for training and testing purposes. The conceptual dia-gram of a standard uncertainty identification workflow for such corpora is illustrated inFigure 4.3.
Figure 4.3: Conceptual schematic diagram of Argo workflow used for experiments ongold-standard corpora. Tools that appear as multiple blocks, signify the use of multiplelinked components in the actual workflow. he components that are in the green, dottedblock, were developed for this PhD work, while the rest were used/adapted from Argorepository.
4.1.2.1 Document Reading
For the experiments with pre-annotated corpora with events, it is necessary to use oneof the BioNLP document readers. We have used the SFTP BioNLP Shared Task Data
Provider that allows users to read files over an SFTP connection. Files have to followspecific standoff format; annotations are stored in two files file (.a1, .a2) separately fromthe annotated document text that is stored in one .txt file. All three files must be iden-tically named. The annotation files have to follow the structure depicted in Figure 4.4.Annotations referring to the entities are stored in .a1 files while annotations referring tothe events, stored in the .a2 files15. The GENIA-MK and BioNLP-ST annotations arealready uploaded on the NaCTeM server as explained in the beginning of Section 4.1.
15For further details on the annotation structure see: http://2011.bionlp-st.org/home/file-formats

138 CHAPTER 4. IMPLEMENTATION AND EVALUATION
Any other files, will have to be uploaded to the same server or some other and the serverdetails will have to be set in the parameters. Alternatively, the SFTP BioNLP Shared
Task Data Provider can be swapped for SFTP BioNLP ST Data Reader and the files canbe uploaded on the Argo server.
Figure 4.4: Standoff annotation example: T# denotes entities, and E# events. The typeof the entity follows in the same line separated with a tab, and followed by the offsetsof the corresponding terms in the sentence. Then the exact text extract follows alsoseparated by a tab. Note that event triggers are also annotated as entities. For events,there is a tab separated entry indicating Event trigger and arguments with their roles.All triggers and arguments must be annotated in the sentence.
4.1.2.2 Document pre-processing and Dependency parsing
The pre-processing part starts with text being segmented into sentences. For all our ex-periments, we used LingPipe Sentence Splitter [Ai08]. The sentences are then decom-posed into chunks and then tokens. For this purpose, we used the OSCAR4 Tokeniser
and GENIA Tagger [TTK+05] components. Then syntactic dependencies are extractedusing Enju dependency parser [MT08a], which also performs lemmatisation and part-of-speech tagging. The lemmas and POS tags are used subsequently by the featureextracting components for uncertainty identification. Overall, the pre-processing anddependency parsing components are identical to the ones used in the end-to-end work-flow presented in the previous section (4.1.1).

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 139
4.1.2.3 Uncertainty Identification
For the uncertainty identification task, we used an RF classifier implemented using theWEKA API as we did for the workflow described in Section 4.1.1. The provided modelhas been trained using rule, event and cue based features described in the main docu-ment. Event based features are extracted using the “Event Feature Generator” compo-nent, the rule based features are extracted using the “Rule Feature Generator” one, andthe rest of the features that are related to uncertainty cues, are extracted by the use of“Uncertainty Feature Generator”. The “WEKA Classifier” component [HFH+09] willthen use the extracted features and the trained model (assigned in the ModelFile param-eter). It should be noted that different combinations of the feature generator componentscan be used to tailore them to different experiments; the descriptions of the componentsin Section 4.1.1.7 can be used to guide this choice.
4.1.2.4 Saving/displaying results
The produced uncertainty annotations, can either be viewed using the Manual Anntoa-
tion Editor component or written to a .tsv file using the Event Listing component. The.tsv file has the following fields: Event ID, Event type, Covered text (by trigger), Paper
ID, sentence (full sentence text), Certainty level (for GENIA), KT (for GENIA), Spec-
ulation, Uncertainty (value attributed by our tool). For this component the followingparameters have to be set:
• OutputFile: The name of the file to list the events and uncertainty information inthe output
• KT : If using on GENIA-MK and not on BioNLP-ST data, setting KT to true,will also output the original, knowledge type (KT) annotations for comparisonreasons.
Alternatively annotated files can also be written on a server in XMI format, usingthe SFTP XMI Writer. In this case the following parameters have to be set:
• Server: Server address
• RemoteDirectory: Full path to the directory on the server used to output files

140 CHAPTER 4. IMPLEMENTATION AND EVALUATION
Figure 4.5: End-to-end Argo workflow used for experiments on annotating large corporawith binary uncertainty values.
• Username: Username used to access the directory on the server
• Password: Password used to access the directory on the server
• Port: Set to 22 by default
• recorderEnabled: Set to false by default, since there is no reason for writingrecording in this case.
Finally, as in the workflow presented in Section 4.1.1 results can be written inBioNLP standoff format and visualised on Brat [SPT+12]. The BioNLP ST Data Writer
can be used for this reason, but the files will have to be stored on the Argo server. Theuser will have to create a folder and then select the name of the folder in the settings(OutputFolder). The BioNLP ST Data Writer component is not added in the publicworkflow, but it is available as a Consumer-type component on the Editing panel, andcan be added to the workflow by the user (see Section 4.1.2.5 that follows for instruc-tions on how to edit a workflow).
4.1.2.5 Full workflow and access instructions
The full workflow as viewed when editing the “DEMO Uncertainty tagging on eventannotated corpora” public workflow is presented in Figure 4.5.

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 141
The process of accessing the workflow is similar to the one described in Section4.1.1.10. To access the workflow visit http://argo.nactem.ac.uk/test/ (Full path:http://argo.nactem.ac.uk/test/?workflow=16878), select this workflow and se-lect Edit or Run among the options that appear above the workflow list. In order to makechanges to any of the parameters and components, it is necessary to make a new copy ofthe workflow. This can be achieved by selecting Edit and subsequently selecting More
and then Save as Copy.
4.1.3 Description of additional related components
In this section we describe components available on Argo platform that do not partic-ipate in the previously described workflows, but are crucial for training models andextracting rules.
Document Reading
There is a selection of components that can be used as alternative to the SFTP Document
Reader:
• The Document Reader component can be used in order to read .txt documentsuploaded on the Argo server.
• The SFTP XML Reader can be used to parse .xml documents over an sftp connec-tion.
• The SFTP XMI Reader can be used to parse .xmi documents over an sftp connec-tion.
WEKA Trainer component
All models described in Section 1.1 have been trained using WEKA Trainer component.For a model to be trained, a set of Feature Extractor components have to precede it inthe workflow. The same feature extractor components need to be used when using themodel with the WEKA Classifier component in order to properly classify the instancesthat need to be annotated. The order of the Feature Extractor components will notinfluence the results.

142 CHAPTER 4. IMPLEMENTATION AND EVALUATION
We describe below the parameter configurations for this component:
• Algorithm: The classifier algorithm to be used.
• ModelFile: The full path to the model to be created. For example : “My Docu-ments/models/modelName.mdl”. Click on Select in order to choose the appropri-ate path, and enter the desired model name in the white dialog box.
• ParameterString: Here the training parameters for the WEKA trainer can be set.Allows to set parameters like number of iterations, depth of tree, minimum vari-ance for split etc. The full list of options can be accessed here: http://weka.sourceforge.net/doc.dev/weka/classifiers/trees/RandomForest.html. Forthe the experiments described in this work we use the RF classifier and : “-I 100-K 0 -S 1 -num-slots 1”.
In order to use the WEKA Trainer component to train model for uncertainty iden-tification on events, the presence of a corpus with uncertainty annotated events is nec-essary. Also, pre-processing the corpus with NLP procedures such as tokenisation anddependency parsing is necessary for most of the Feature Generator components. As-suming existence of an event and uncertainty annotated corpus like the GENIA-MK orthe BioNLP-ST, a sample component sequence for a model training workflow would be:SFTP BioNLP Shared Task Data Provider > LingPipe Sentence Splitter > OSCAR 4
Tokeniser > Enju Parser > Event Feature Generator > Uncertainty Feature Generator
> WEKA Trainer.
WEKA Cross Validator component
This component can be used to perform cross-validation for ML tasks related to text-mining and document based tasks. It applies the “non-biased” approach described inSection 5.4.1. It will ensure that instances from the same document will always end upin the same fold, since the random fold generation is document-based and not instance-based. It assumes one or more Feature Generator components to generate the inputfeatures, and the gold-standard annotations to be provided in the Reader component.
We describe below the parameter configurations for this component:
• Algorithm: The classifier algorithm to be used.

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 143
• ParameterString: Here the training parameters for the WEKA trainer can be set.Allows to set parameters like number of iterations, depth of tree, minimum vari-ance for split etc. The full list of options can be accessed here: http://weka.sourceforge.net/doc.dev/weka/classifiers/trees/RandomForest.html. Forthe the experiments described in this work we use the RF classifier and : “-I 100-K 0 -S 1 -num-slots 1”.
• TargetFeature: The string “attributeValue” needs to be given as input for thisparameter, in all uncertainty and negation identification tasks (it is a default valueindicating how to access the gold-standard annotations for metaknowledge, asthey are annotated in GENIA-MK and BioNLP-ST corpora.)
• ModelDirectory: The path to the direcory where the models will be saved. Thedirectory needs to be created prior to running the workflow.
• ResultDirectory: The path to the direcory where the results will be saved. Thedirectory needs to be created prior to running the workflow.
• Folds: Input the number of folds to be created.
WEKA Evaluator component
This component performs the instance-based cross validation, as provided by the WEKAAPI. It assumes one or more Feature Generator components to generate the input fea-tures, and the gold-standard annotations to be provided in the Reader component.
We describe below the parameter configurations for this component:
• Classifier Name: The classifier algorithm to be used.
• ParameterString: Here the training parameters for the WEKA trainer can be set.Allows to set parameters like number of iterations, depth of tree, minimum vari-ance for split etc. The full list of options can be accessed here: http://weka.sourceforge.net/doc.dev/weka/classifiers/trees/RandomForest.html. Forthe experiments described in this work we use the RF classifier and : “-I 100 -K0 -S 1 -num-slots 1”.
• Number of Folds: Input the number of folds to be created.

144 CHAPTER 4. IMPLEMENTATION AND EVALUATION
• ResultDirectory: The path to the file where the results will be saved. Result filewill be generated and saved in the top level user directory.
Uncertainty Rule Key Selection components
Uncertainty Rule Key Selection components are used to extract dependency patternsused by the Rule Checker and the Rule Feature Generator components. Below wedescribe the different types of Rule Key Extraction components that are available onArgo test server.
• Uncertainty Rule Key Selection: It is the simplest among the rule-pattern extrac-tion components presented in this document. It takes a list of (ideally single word)cues as input for the CueFile parameter. The list has to be in .txt format, with onecue per line.
• Uncertainty Rule Key Selection Multiword: This component has the same func-tionalities as the simple Uncertainty Rule Key Selection, but can better accom-modate multi-word cues, when searching for dependency paths. This componentwas used for the experiments using cues from the ACE-MK corpus [TNMA17],since the list of cues annotated for this corpus contained multi-word expressionsof uncertainty.
• Uncertainty Rule Key Selection Broad (no cues): This component allows for rulepattern extraction without the need of a cue list to guide the pattern generation.It will generate all potential length 1 and length 2 dependency patterns arounduncertain events and then filter them according to the thresholds given for one ormore of the following parameters: LiftFilter, LeverageFilter, JaccardFilter, Jmea-
sureFilter. Each parameter corresponds to the Equations 5.7 – 5.10 described inSection 5.3.2.
The generated rule patterns will be of the following format:
• Length 1 dependencies:<word> D0 <dependency type>
• Length 2 dependencies:<word 1> <word 2> D1 <dependency type 1> <dependency type 2>

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 145
where the <word> part corresponds to the words being part of the pattern and the<dependency type > part can belong to one of the four core dependency types of Enju
Parser, namely [ARG1,ARG2,ARG3,ARG4,MOD]. ARG1 denotes a subject of a verb,a target of modification by modifiers, etc. ARG2 corresponds to object of verbs, prepo-sitions, etc. ARG3 and ARG4 are objects and complements of verbs, etc. Finally, MODstands for participial constructions and denotes a clause modified by another clause, ifthe subordinate clause has an ARG1.
For cases were multi-word cues are used for filtering rule generation, the notationconvention is altered using the + symbol for the first cue (what is described as TS) inthe main document, Section 5.3.1.1. Thus it would look like :
• Length 1 dependencies:<+multiword-cue+word> D0 <dependency type>
• Length 2 dependencies:<+multiword-cue+word> <word 2> D1 <dependency type 1> <dependencytype 2>
All Rule Key Selection components assume presence of uncertainty annotated events,in order for the rule extraction procedure to function properly. Also, since it rule ex-traction is based on dependency patterns, Enju Parser should also be used. Assumingan event and uncertainty annotated corpus like the GENIA-MK or the BioNLP-ST, atypical/minimal component sequence for a rule extraction workflow would be: SFTP
BioNLP Shared Task Data Provider > LingPipe Sentence Splitter > OSCAR 4 Tokeniser
> Enju Parser > Uncertainty Rule Key Selection .
4.1.4 Access to necessary resources
All the related files are available on a NaCTeM server, nactem10.mib.man.ac.uk. Anaccount has been created that can be accessed over SSH File Transfer Protocol (SFTP)connections using the following credentials:
• Username: workflow tester
• Password: ul+raRiver47

146 CHAPTER 4. IMPLEMENTATION AND EVALUATION
• Home directory: /data/sftp/workflow tester
Note that users have write access only under the uploads folder. By default, thefollowing data is uploaded on the folder:
1. leukemia files: Set of passages related as evidence to the interactions describedin B-cell Acute Lymphoblastic Leukemia Overview pathway of Pathway Studio(see the main manuscript, Section 5.2.2.1).
2. ras melanoma files: Set of sentences extracted from full-text PubMed papersfocussing on Melanoma disease and mapped to the nodes of the Ras 2-hop neigh-borhood network (see the main manuscript, Section 5.2.2.2).
3. leukemia.csv: File containing tabulated information for the interactions of theB-cell Acute Lymphoblastic Leukemia Overview pathway of Pathway Studio
4. GENIA-MK: The GENIA-MK corpus files in standoff annotation
5. All BioNLP: The merging of the BioNLP-ST corpora in standoff annotation
6. ras models: Directory that contains JSON snaphots of the normalised Ras modelthat was assembled the Big Mechanism project and was used for our Ras-Melanomause case described in the main manuscript, Section 5.2.2.2. It contains:
• Ras.json: Normalised JSON version of the 2-hop neighbourhood of theRas gene. The model was originally generated in BioPAX (owl) format,by querying the Pathway Commons API. The query used for the networkgeneration is: http://www.pathwaycommons.org/pc2/graph?source=P01112&source=P01116&source=P01111&kind=neighborhood
• Ras-melanoma.json: Ras.json model, enhanced with sentences extractedfrom full-text PubMed papers focussing on Melanoma disease and mappedto the nodes of the original model. In this version, each interaction is accom-panied with related evidence sentences (if any) along with uncertainty valuesfor each event/sentence and the fused confidence value for the interaction asa whole.
7. model resources: Contains pre-trained models to be used in the workflow.

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 147
• Negation.model: model trained on GENIA-MK to identify negated events.Needed for WEKA Classifier (negation) component. It needs to be used withboth the the Event Feature Generator and the Uncertainty Feature Genera-
tor Broad components in the same workflow.
• protein.model: model for Protein named entity recognition. Needed forNERsuite Tagger component.
• genia.all.model: model trained on GENIA-MK to identify uncertain events.Needed for WEKA Classifier (uncertainty) component. It is trained using thepreselected biomedical uncertainty cue list, which should be used with theRule Feature Generator component in the same workflow. It also requiresthe Event Feature Generator and Uncertainty Feature Generator compo-nents to be used before the classifier.
• bio.all.model: model trained on BioNLP-ST to identify uncertain events.Needed for WEKA Classifier (uncertainty) component. It is trained usingthe preselected biomedical uncertainty cue list, which should be used withthe Rule Feature Generator component in the same workflow. It also re-quires the Event Feature Generator and the Uncertainty Feature Generator
components to be used before the classifier.
• combined.all.model: model trained on the combination of GENIA-MK andBioNLP-ST to identify uncertain events. Needed for WEKA Classifier (un-
certainty) component. It is trained using the preselected biomedical uncer-tainty cue list, which should be used with the Rule Feature Generator com-ponent in the same workflow. It also requires the Event Feature Generator
and the Uncertainty Feature Generator components to be used before theclassifier.
• genia.all.ace.model: model trained on GENIA-MK to identify uncertainevents. Needed for WEKA Classifier (uncertainty) component. It is trainedusing the ACE-MK derived [TNMA17] cue list, which should be used withthe Rule Feature Generator ACE, Event Feature Generator and Uncertainty
Feature Generator ACE components in the same workflow.
• bio.all.ace.model: model trained on BioNLP-ST to identify uncertain events.Needed for WEKA Classifier (uncertainty) component. It is trained using

148 CHAPTER 4. IMPLEMENTATION AND EVALUATION
the ACE-MK derived [TNMA17] uncertainty cue list, which should be usedwith both the Rule Feature Generator ACE, Event Feature Generator andUncertainty Feature Generator ACE components in the same workflow.
• combined.all.ace.model: model trained on the combination of GENIA-MK and BioNLP-ST to identify uncertain events. Needed for WEKA Clas-
sifier (uncertainty) component. It is trained using the ACE-MK derived[TNMA17] uncertainty cue list, which should be used with the Rule Feature
Generator ACE, Event Feature Generator and Uncertainty Feature Genera-
tor ACE components in the same workflow.
• genia.all.nc.model: model trained on GENIA-MK to identify uncertain events.Needed for WEKA Classifier (uncertainty) component. It is trained usingenriched dependency n-grams (see ML+EDNG approach in Section 5.4.1)automatically extracted from GENIA-MK using the lift formula to filter themeaningful rules (see Eq 5.7). The resulting uncertainty cue list, can befound in the rule resources directory and should be used with the Rule Fea-
ture Generator Broad, Event Feature Generator and Uncertainty Feature
Generator Broad components in the same workflow.
• bio.all.nc.model: model trained on BioNLP-ST to identify uncertain events.Needed for WEKA Classifier (uncertainty) component. It is trained usingenriched dependency n-grams (see ML+EDNG approach in Section 5.4.1)automatically extracted from BioNLP-ST using the lift formula to filter themeaningful rules (see Eq 5.7). The resulting uncertainty cue list, can befound in the rule resources directory and should be used with the Rule Fea-
ture Generator Broad, Event Feature Generator and Uncertainty Feature
Generator Broad components in the same workflow.
• combined.all.nc.model: model trained on both GENIA-MK and BioNLP-ST to identify uncertain events. Needed for WEKA Classifier (uncertainty)
component. It is trained using enriched dependency n-grams (see ML+EDNGapproach in Section 5.4.1) automatically extracted from GENIA-MK andBioNLP-ST using the lift formula to filter the meaningful rules (see Eq 5.7).The resulting uncertainty cue list, can be found in the rule resources di-rectory and should be used with the Rule Feature Generator Broad, Event

4.1. DEMONSTRATION OF UNCERTAINTY RELATED WORKFLOWS 149
Feature Generator and Uncertainty Feature Generator Broad componentsin the same workflow.
• news.model: model trained on ACE-MK to identify uncertain events fornews. The model was trained on the MGS uncertainty configuration asdescribed in Section 6.2.2. It can be used with WEKA Classifier (uncer-
tainty) component. It is trained using enriched dependency n-grams (seeML+EDNG approach in Section 5.4.1) automatically extracted from ACE-MK using the lift formula to filter the meaningful enriched dependency n-grams (see Eq 5.7). The resulting uncertainty cue list, can be found in therule resources directory and should be used with the Rule Feature Generator
ACE, Event Feature Generator and Uncertainty Feature Generator Broad
components in the same workflow.
8. rule-cue resources:
• cues.all.txt: List of cues compiled based on GENIA-MK, BioNLP-ST andrelated literature, oriented to uncertainty in biomedical scientific publica-tions.
• rules.all.txt: Rules (enriched dependency n-grams) extracted using the pre-selected biomedical list cues.all.txt using the Uncertainty Rule Key Selection
component.
• cues.ace.txt: ACE-MK based [TNMA17] uncertainty cue-list.
• rules.ace.txt: Rules (enriched dependency n-grams) extracted using the pre-selected ACE-based list cues.ace.txt using the Uncertainty Rule Key Selec-
tion Multiword component.
• rules.genia.nc.txt: Rules (enriched dependency n-grams) extracted usingUncertainty Rule Key Selection Broad (no cues) component, by the GENIA-MK corpus.
• rules.bio.nc.txt: Rules (enriched dependency n-grams) extracted using Un-
certainty Rule Key Selection Broad (no cues) component, by the BioNLP-STcorpus.

150 CHAPTER 4. IMPLEMENTATION AND EVALUATION
• rules.combined.nc.txt: Rules (enriched dependency n-grams) extracted us-ing Uncertainty Rule Key Selection Broad (no cues) component, by the com-bination of GENIA-MK and BioNLP-ST corpora.
9. DemoXMIout: Empty directory to store XMI files written by the workflows
PLEASE NOTE:We advice the users to create their own directories and copy the files they need, espe-cially if they intend to create/edit their own workflows on Argo or elsewhere. They arekindly requested not to remove any files. This way files will remain intact to be used byfuture potential users.

Chapter 5
Automated identification of uncertainty
In this chapter we do the following:
• Propose a classification of uncertainty for the biomedical domain
• Investigate methods for automated uncertainty identification. We explore andevaluate the use of a novel feature representation, enriched dependency n-grams.(addressing RQ1 and H1 )
• Evaluate the performance of our methods in two ways:
1. Using gold-standard corpora and;
2. Validating of the output of our methods on evidence linked to pathways, byresearchers in the field of bio-medicine
– Compare the agreement of researchers when annotating uncertainty for5 different intensity levels (addressing RQ2 and H2 )
In the previous chapter, we provided a detailed discussion of the different defini-tions and classification schemes for uncertainty that have been previously proposed.Motivated by this existing work, as well as by the inconsistencies identified in previousannotation efforts, we propose a new classification scheme for uncertainty, focusing onthe biomedical domain (see Section 5.1). We subsequently explain how this relates to
151

152 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
existing annotations, with an emphasis on the event annotated corpora that we intend touse. The gold-standard annotated corpora and the other datasets that we use for trainingand testing our methods are described in Section 5.2.
We then proceed to detail our proposed methods to tackle the issue of uncertaintyidentification for (biomedical) events (Section 5.3). The proposed approach further ex-plores and takes advantage of the potential of dependency parsing both as a part ofrule-based systems and in the context of machine learning features. We describe ourdependency extraction approach and our proposed enriched dependency n-grams. Wediscuss the performance of our proposed approach in Section 5.4. For the evaluation ofour methods, we firstly assess the performance in terms of precision, recall and F-scoreon gold-standard annotated corpora (Section 5.4.1). Subsequently, we seek to validateour methods against the judgement of researchers in biomedicine. We assess the mannerin which they perceive uncertainty and evaluate the consistency of their judgements inbinary and multi-level uncertainty classification tasks, in order to address H2. We alsouse their judgements to validate our methods from a biomedical perspective, confirmingtheir suitability in terms of our overarching goal (i.e., using textual uncertainty to enrichbiomedical pathways).
5.1 A proposal for uncertainty classification
As previously mentioned in Section 3.1, our approach does not differentiate betweenthe inherent truth of an event and the uncertainty of the author. Instead, we treat anymention of uncertainty by the author as an indication of uncertainty about the truth ofthe event.
Moreover, following the observations of Rubin [Rub07] and Druzdel [Dru89], weopted for a binary classification of uncertainty, with the intention of reducing inaccura-cies and inconsistencies that have been demonstrated to occur in multi-class schemes (aswas discussed in Section 3.3.5). Hence, an event can be characterised either as certain
or as uncertain. We further validate the choice of binary versus multi-level classificationbased on the judgement of researchers in biomedicine in Section 5.4.2.1.
While we do not differentiate between multiple levels of uncertainty intensity, wedo specify the types of textual expressions that we consider to be uncertainty indicators.In reviewing the various definitions of uncertainty and related concepts across a wide

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 153
range of document types and fields, it became apparent that there is no consensus on aunified definition of uncertainty, even within specific fields (e.g., biomedicine).
Elaborating on what constitutes an uncertain event, we adopted a definition that isas broad as possible, encompassing different categories of uncertainty as described inthe literature. The definition is oriented towards uncertainty as expressed and perceivedin the scientific writing, and was influenced by the classification schemes proposed byMedlock [Med08], Thompson [TNMA11] and Malhotra [MYGHA13].
We identify the following categories as constituting uncertainty:
1. Speculation: Claims where the author uses expressions of hedging or hesitation,which decrease the reader’s confidence towards the truth of the introduced state-ment. This can be further broken down into:
(a) Strong speculation: Words such as may, might, perhaps, that clearly nega-tively affect the confidence in the truth of a statement.
(b) Weak Speculation: words such as suggest, indicate, etc., which, while theyare not as strong as those exemplified in (a), are still vague in terms of theexact degree of uncertainty conveyed. The perception of the conveyed un-certainty of such terms seems to depend largely on the interpretation of thereader. It has been suggested that in many cases, such terms are used to ex-press politeness rather than a decreased confidence in the results, in order toavoid antagonising readers. However, when these are compared to expres-sions such as prove, show, etc., it is clear that the latter are much strongerin terms of conveying certainty and confidence. Hence, all such expressionsthat could leave room for doubt as to the truth of a statement, are seen asindicators of uncertainty.
2. Investigation: Expressions that indicate that the statement in question is men-tioned in the context of an investigation, and hence constitutes a hypothesis to betested or a case not yet verified. Common ways to express investigation includeexpressions like “we examined whether”, “we experimented with”, as well as hy-pothetical clauses (if, whether). It should be noted that not all statements (events)mentioned in the context of an experiment are characterised as investigative. If

154 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
the event describes part of the experimental procedure as opposed to the questionsand hypotheses of the experiment, it can still be considered as factual.
3. Weaselling: In the case of scientific articles, we define weaselling as unsupportedrelays of external expertise. More specifically, it refers to cases where the au-thor mentions something as a well-known fact that is, however, not derived fromthe author’s work, and where there is an absence of a clearly indicated source.Weaselling under such conditions is often asserted with the use of expressionssuch as: is believed to be, it is known, etc. that are not accompanied by a cita-tion1.
4. Admission of limited knowledge (AoLK): Cases where the author acknowledgesthat an event is as yet unknown or only partially known, and/or where they ad-mit limited expertise that affects their confidence in the truth of the statement.AoLK is typically introduced by expressions such as “is out of the scope”, “is yet
unknown”, etc.
5. Time and frequency limitations: Cases where the event seems to occur withlimited frequency, as indicated by expressions such as usually, sometimes, etc.Such frequency limitations imply that the event in question is not always true.
Figure 5.1 illustrates the most representative single and multi-word uncertainty cuesthat denote each of the uncertainty categories that we have introduced above. The un-certainty cues shown were drawn from existing annotations in biomedical corpora, andhence are representative of the concept of uncertainty in scientific and biomedical writ-ing.
5.1.1 Excluded categories
There are a number of additional categories which, although their relation to uncertaintyhas been well documented in literature, we have chosen to exclude from our own defini-tion of uncertainty. A brief description of each of these notions, along with our reasonsfor excluding them from the current work, is provided below:
1There is no feature used for source/citation identification used in our methods. Nawaz proposed a RFclassifier to identify the Source of events on GENIA-MK in [NTA13b].

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 155
Figure 5.1: Uncertainty cues considered in our experiments, grouped according to cat-egory (Strong/Weak speculation, frequency, Admission of lack of knowledge (AoLK),Weaselling). Word clouds were generated using the relative frequencies of cues in theBioNLP-ST and GENIA-MK corpora.
1. Peacocks: The term “peacocks” was coined by Wikipedia editors to signify ex-pressions that convey exaggerations or qualifications that are not proven. It isadopted by Vincze [Vin13], who notes the relation of the term to subjectivity,as peacocks are usually expressed as positive or negative subjective judgements.Peacock terms, according to Vincze, include terms such as brilliant, excellent andbest-known. While peacocks and more generally biased, subjective opinions doaffect the trustworthiness of the author, and hence the truth and credibility of aclaim, we consider that this uncertainty category is more relevant in the generaland newswire domains (see Chapter 6).
Wiebe et al. [WWB+04, WR05] elaborate on the concept of subjectivity, itsappearance in text, and its automated identification in sentences. However, theanalysis concerns newswire and general domain text, and it is pointed out that acase judged as subjective in the context of news articles could be considered asobjective in a scientific article [WWC05]. In fact, scientific articles have an inher-ently subjective aspect, as their aim is to communicate the opinion and findings

156 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
of the author to the community. Even so, due to the formal expression of lan-guage assumed in the writing of scientific articles, expressions that convey strongjudgement or bias are usually avoided.
Nevertheless, we could not claim that there is complete absence of subjectivejudgement in scientific articles. On the contrary, Teufel et al. [TST09], in a thor-ough analysis of citation context, highlight cases where authors politely express anegative opinion towards the work of others. For example, in the sentence “How-
ever, <author name> himself understood that his initial implementation had sig-
nificant limitations in handling non-concatenative morphotactic processes”, theauthor passes a judgement on the work of the cited author without presenting sup-porting evidence for the judgement (at least not at that point in the document).Such cases could correspond to a scientific article-appropriate version of “pea-cocks” as described by Vincze, or to subjectivity in general as described by Wiebe.Nonetheless, such cases are relatively isolated and, to the best of our knowledge,there is no work that investigates the usage of subjective expressions in scientificarticles that are not related to the judgement of a claim proposed by some other(cited) author. Based on this fact, and the lack of extensive annotated resourceson subjectivity in the scientific field, subjectivity was excluded from the categori-sation of the uncertainty cases for the scientific domain that are considered inthis work. However, assessing its influence on the credibility of scientific claimsremains a very interesting, open question for future work.
2. Irony and sarcasm: Use of expressions that express irony and sarcasm and theirimpact on the credibility of statements, as well as on the trust of the readers,has been studied in various fields ranging from psychology and linguistics tocomputer science and, in particular, text mining. Myers is one of the first toacknowledge its presence in text and pointedly notes the apparent lack of work inanalysing it as a phenomenon by stating “Irony is a little bit like the weather: weall know it’s there, but so far nobody has done much about it” [Mye77]. Sincethen, various attempts at analysing irony and modelling its properties have beenproposed by linguists and psychologists alike [Uts96, DW99, LM91]. More re-cently, there has been increased interest in the automated detection of irony andsarcasm in speech [AEHP03], newswire and web content [Fil12] and social media

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 157
[Wan13, GIMW11, DTR10]. However, for reasons similar to the case of “pea-cocks”, the appearance of ironic and sarcastic statements is considerably sparserin the case of scientific articles. Hence, while research into irony and sarcasm iscrucial for text mining and uncertainty identification in the context of other do-mains such as online reviews and Twitter comments, it is considered outside thescope of this work.
3. Conditional statements: Many scientific findings, statements and claims are men-tioned in the context of very specific parameters, and often it is clearly stated thatthey hold only under specific conditions. To better understand such cases, we canconsider the following examples:
- It was confirmed that p53 binds to Ras when the quantities of MEK in the
same cell-line are sufficiently high.
- The US president confirmed the removal of their armed forces from Iraq
only after the agreement was signed by both sides.
As seen in the examples, conditioning a statement on another statement will re-duce its credibility when we consider a generic, unconditioned case. However,efficiently examining the universal, unconditional validity of a statement basedon its context would require more involved processes such as discourse analysisand identification of causality. Hence, this aspect of uncertainty is not consideredin this work, and unless otherwise hedged or doubted, statements such as the onespresented in the examples above are considered to be certain.
4. Tense: Arguably, the tense of the verbal expressions used to express an eventcan influence its perceived certainty. Rubin linked tense with the timeline of theevent and argues that events located in the past or the future should have differentcertainty levels attributed to them, compared to those presented as happening inthe present.
In our categorisation, expressions that place an event in the future, introducedwith the terms “will” and “would” are treated as part of the weak speculation
category and hence are considered to be cases of uncertainty. In contrast, thereis no distinction in the proposed categorisation between events expressed with

158 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
verbal expressions that use the past or present tense. This decision was motivatedby the fact that in scientific and academic writing, while some guidelines exist[WRS06], the use of present or past tense is considerably dependent on the writingstyle and choices of the author, rendering the drawing of credible conclusionsregarding its relation to certainty particularly tricky.
5. Experimental qualifiers: Specifically for the field of bio-medicine, it has beenshown that the experimental support, or in other words the perceived validityand accuracy of the described experimental methods, can considerably influencethe reliability of the derived results. As Krallinger shows [Kra10], along withnegation information, the experimental methods (and the confidence level associ-ated with each) can significantly influence the credibility of information extractedfrom biomedical literature. There already exist some resources (in the form ofdatabases and ontologies) with such experimental qualifiers, such as the Molecu-lar Interaction (PSI-MI) ontology [OK10], the Evidence Codes of Gene Ontology(GO) [RBH09] or the Open REGulatory ANNOtation (ORegAnno) database Evi-dence Types [GMB+07]. Furthermore, the detection of novel protein interactionsthat have been experimentally characterised in the biomedical literature was oneof the shared tasks in the BioCreative challenge [Smi12]. In addition, scientificterm repositories such as BioLexicon [TMM+11] have been published, as well aslists of cue terms that introduce experimental evidence. However, to date, therehas been no effort that has annotated such qualifiers with some level of confidenceor certainty. As a result, while there are a number of more or less commonly ac-knowledged standards (e.g., in-vitro experiments being less reliable than in-vivoones) the lack of annotated resources and supportive evidence regarding the accu-racy of different methods makes it problematic to include experimental qualifiersin our definition of uncertainty.
5.1.1.1 Cases of certainty
As mentioned above, we have decided upon a binary classification of events as eithercertain or uncertain. Thus, any event that does not fall into one of the uncertainty cate-gories introduced above will be categorised as “certain”. Since certainty is the default
class in the absence of any uncertainty indicator, we do not intend to propose a detailed

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 159
classification of certainty. However for the sake of clarity and completeness, we brieflyenumerate the most common indicators of certainty in a sentence.
1. Presence of an expression indicating high certainty, usually referred to as a booster[Hyl98a]:
• Time and frequency expressions: Terms such as “always” or phrases suchas “in all cases”.
• Assertive, high confidence expressions: Terms such as “certainly”, “prove”or phrases such as “based on the fact that”.
2. Presence of negated uncertainty expression: As further explained in Section 5.1.2,expressions in text that introduce negative polarity and which negate an uncer-tainty expression would render the event certain if and only if the negative polarityexpression applies to the uncertainty cue and not to the event itself.
3. Absence of any expression indicating uncertainty: This is the default case: evenin the absence of boosters or negated uncertainty expressions, the lack of a clearindication of uncertainty means that the event is classified as certain.
5.1.2 The role of negation
For reasons of completeness, alongside uncertainty, it is important to consider anothertextual parameter that can significantly affect the perceived credibility of an event,namely, negation. Negation refers to the textual modifiers that can affect the semanticinterpretation of statements or events and change the implied meaning from an affirma-tive statement/event that is true/happening to a negated one, i.e. one that is either falseor not taking place [Jor98]. In this sense, negation is an indicator of the polarity of astatement or event. Polarity represents precisely this property, which characterises anevent or statement as true or false.
While its definition might seem quite intuitive, negation is a complex phenomenonthat has been studied extensively in the fields of psychology [FRE25], linguistics [Hor89,VdW02, Zan91], and text-mining [MD09a, AY10, MDN01]. In fact negation detectionis still considered an unsolved task for text mining [WMM+14].

160 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Horn, in his seminal work on negation [Hor89, Hor10a] describes in detail the phe-nomenon, which he suggests to be an exclusive characteristic of humans. He has studiedextensively the means of conveying negation, both on the linguistic and the semanticlevel. While affirmative statements do not need to be introduced by specific words,negation has to be indicated by one or more words (never, deny, not) or affixes (un-, in-,
-n’t). In other words, readers perceive any statement as having positive polarity unlessthere is an explicit statement to the contrary in the text. However, the words indicatingnegation can vary greatly based on the context in which they occur, ranging from typicalnegative expressions to colloquial, negatively charged slang [DC11].
According to Huddleston and Pollum [PH02] there are four main ways to categorisenegation based on its properties:
1. Verbal vs. Non-verbal: Verbal if the marker of negation is grammatically associ-ated with the verb (e.g., I did not see anything at all); non-verbal if it is associatedwith a dependent of the verb (e.g., I saw nothing at all).
2. Analytic vs. Synthetic: Analytic if the negation is marked by words whose solesyntactic function is to mark negation (e.g. Bill did not go ); synthetic if the wordshave some other function in addition to negation (e.g., Nobody went to the meet-
ing). In the latter example, “Nobody” marks the negation but also syntacticallyplays the role of the agent.
3. Clausal vs. Sub-clausal: Clausal if the negation is based on a negative clause( e.g., She didn’t have a large income ); sub-clausal otherwise ( She had a not
inconsiderable income )
4. Ordinary vs. Meta-linguistic: A negation is ordinary if it indicates that somethingis not the case, e.g., She didn’t have lunch with your old man: he couldn’t make it .On the other hand, a negation is meta-linguistic if it does not dispute the truth, butrather reformulates a statement, e.g., She didn’t have lunch with your ‘old man’:
she had lunch with your father . Note that in the former example the lunch nevertook place, whereas in the latter, a lunch did take place and the existing negationdoes not interfere with the factuality of the event.
Horn points out another intricacy in terms of negation, namely the issue of multiple

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 161
negation (existence of more than one negation marker in the same sentence, syntacti-cally related negative statements, etc.) [Hor10b]. Two cases are distinguished:
1. Duplex negatio affirmat (DNA): Also termed logical double negation, in this casethe occurrence of double negation results in emphasised affirmation, such as inthe sentence:There has been no case of unpredictable behaviour
where the two negation related terms cancel each other and the sentence can besimplified to: All behaviour was predictable. This case of negation follows therules of logic about negation (and is hence also called logical).
2. Duplex negatio negat (DNN): Also called hyper-negation, it refers to those casesthat actually break the logic negation rules; the existence of double negation seemsto simply emphasise the negation of the action. See for example the sentence:We didn’t see no changes
In this case the phrase is equivalent with the emphatic single negation:We didn’t see any changes
It is thus important to handle the phenomenon of negation and multiple negationwhen it refers both to biomedical events and to uncertainty modifiers of such events.
In order to address such issues in their formalisation of factuality of an event, Sauriand Pustejovsky consider multiple context levels. They consider the immediate contextof the event, which includes the modality particle that is closest to it from a syntacticperspective, and in turn they consider the context of this modality particle, which theydefine as “the level of scope most immediately embedding it”. This allows them todefine the final modality value as the sequential combination of polarity and modalityvalues over different contextual levels [SP12].
To make this clearer, we demonstrate the aforementioned approach on two differentexamples.
1. Koenig denies [context:CT− that Freidin may have left the country].
2. Koenig suspects [context:PR+ that Freidin may have left the country].
In both cases, the word may is in the immediate context of the event of interest(“Freidin have left the country”) and its use in that phrase denotes uncertainty. However,

162 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
in the first case, the event sub-phrase, and hence the word may, is used in the contextof negative polarity and absolute certainty set by deny, whereas in the second case, it isused in a context of positive polarity and probable modality (uncertainty) set by suspect.The impact of the outermost context on may changes the overall factuality of the eventin question. As a result, in the first example, the event is deemed as a counter-factaccording to Koenig (signified by CT-), but as a possibility in the second (signified byPR+) 2.
In the scientific domain, the compositional approach to factuality would also hold ina similar fashion. This is illustrated in following modified examples:
1. Results failed to show any [context:CT− potential interaction between p53 andRas].
2. Results suggest there is some [context:PR+ potential interaction between p53and Ras].
Note that, in both cases, the assessment of negation is closer to the rules of logic,which does not cover the DNN case.
In this work, it would be impossible to disregard the role of the polarity dimensionand the impact of polarity markers on the credibility of an event. The importance ofsyntax in efficiently capturing the interaction between polarity and uncertainty markershas already been highlighted in the aforementioned work, as well as in FactBank [SP12].In fact, Sauri and Pustejovsky point out in their error analysis that the vast majority oferrors are related to the insufficient syntactic coverage of their approach [Sau17].
In our approach we account for negation on two levels:
1. For the prediction of uncertainty: We do not apply any rules for explicitly cap-turing “negated context” of uncertainty expressions. However, with the use ofour proposed enriched-dependency n-grams, which are explained in Chapter 5,Section 5.3.1.3, our classifiers can capture and distinguish between positive andnegative uncertainty, i.e., distinguish between “we confirm that A may activate B”and “we deny that A may activate B”.
2. For the prediction of overall confidence of an event: We consider both polarity anduncertainty, using the subjective logic presented in Chapter 7. For the automated
2Note that this example was taken from [SP12]

5.1. A PROPOSAL FOR UNCERTAINTY CLASSIFICATION 163
identification of textual polarity we adapt our methods that were presented foruncertainty detection, based on [NTA13a, MS12].
5.1.3 Relation to existing annotations
As discussed in Section 3.2.1, there is a range of publicly available annotated corpora,containing annotations related to uncertainty, often referred to using different terms,such as modality, speculation, hedging and factuality. However, the annotation level,i.e. the units of text annotated, varies from whole sentences to events, as we haveseen in Table 3.1 of Section 3.2.1, where we presented an overview of the differentcorpus annotations, comparing domains, document types, annotation units and corpussize. Such annotation details were used to guide our choice of training and testingcorpora for our automated uncertainty identification methods. We needed to identifycorpora focusing on the biomedical domain, which have an adequate number of eventannotations that are also uncertain (due to our problem description we had to excludecorpora with cue-scope or simple cue annotations for uncertainty). Moreover, we aimedto identify corpora with annotations that individually or in combination would satisfy asmuch as possible the uncertainty definition that we presented earlier. Simultaneously,the availability of corpora with event and uncertainty-type annotations also constrainedour definition of uncertainty in terms of the uncertainty categories covered (see Figure5.2).
We compared the uncertainty types covered by different corpora, based on our def-inition of uncertainty. This comparison aids in identifying potentially sparse or non-covered areas of the definition, and is useful for analysing the performance and in-terpretations of errors when evaluating our methods. A comparative overview of thecoverage of different types of uncertainty in different corpora is presented in Table 5.1.
In order to contextualise our work within the biomedical field, Figure 5.2 sum-marises the coverage of the uncertainty categorisation used in this work, its relationto other biomedical corpora, and to the types of uncertainty that have been excludedfrom the current study.
3Annotated as part of the Knowledge Type dimension of GENIA-MK.4Refers to the combined specifications for the following tracks: 2009: Genia track, 2011: Genia, EPI
and ID tracks, 2013: Genia, CG, and PC tracks
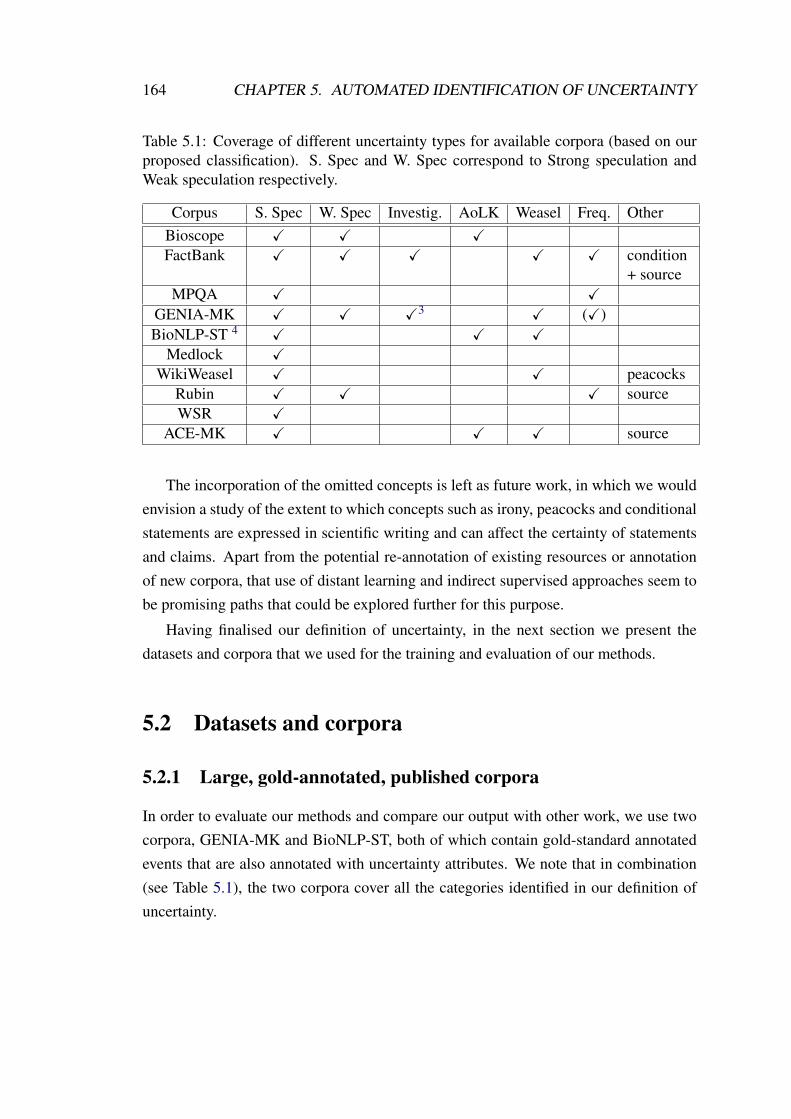
164 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Table 5.1: Coverage of different uncertainty types for available corpora (based on ourproposed classification). S. Spec and W. Spec correspond to Strong speculation andWeak speculation respectively.
Corpus S. Spec W. Spec Investig. AoLK Weasel Freq. OtherBioscope X X XFactBank X X X X X condition
+ sourceMPQA X X
GENIA-MK X X X3 X (X)BioNLP-ST 4 X X X
Medlock XWikiWeasel X X peacocks
Rubin X X X sourceWSR X
ACE-MK X X X source
The incorporation of the omitted concepts is left as future work, in which we wouldenvision a study of the extent to which concepts such as irony, peacocks and conditionalstatements are expressed in scientific writing and can affect the certainty of statementsand claims. Apart from the potential re-annotation of existing resources or annotationof new corpora, that use of distant learning and indirect supervised approaches seem tobe promising paths that could be explored further for this purpose.
Having finalised our definition of uncertainty, in the next section we present thedatasets and corpora that we used for the training and evaluation of our methods.
5.2 Datasets and corpora
5.2.1 Large, gold-annotated, published corpora
In order to evaluate our methods and compare our output with other work, we use twocorpora, GENIA-MK and BioNLP-ST, both of which contain gold-standard annotatedevents that are also annotated with uncertainty attributes. We note that in combination(see Table 5.1), the two corpora cover all the categories identified in our definition ofuncertainty.

5.2. DATASETS AND CORPORA 165
Figure 5.2: Coverage of uncertainty categories in biomedical text and corpora. Theapproach in the current work is entitled “UnMine”.
5.2.1.1 GENIA-MK corpus
GENIA-MK is an expanded version of the original Genia corpus [KOTT03a]. It consistsof 1000 biomedical abstracts from PubMed articles (selected from the search resultswith keywords (MeSH terms) Human, Blood Cells and Transcription Factors) and isannotated with bio-events. Its annotations constitute a total of 36,858 events and 56,248entities. All events are biomedical, describing molecular interactions and biomedicalprocesses. Events can be simple or complex, allowing for nested events. The maximumlevel of nested events identified in the corpus is three (3).
In GENIA-MK, each event has been annotated with additional high-level informa-tion (or meta-knowledge, as this type of annotation that is related to the contextualaspects of an event is often referred to [NTMA10, EF11]). The meta-knowledge anno-tations focus on 5 separate dimensions:

166 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
• Certainty Level: A 3 class distinction to characterise the certainty of events basedon the textual context. The classes are separated as follows: L1 (“considerablyspeculative”), L2 (“somewhat speculative”) and L3 (“non-speculative”).
• Knowledge Type (KT): A 6 class attribute that captures the general informationcontent of the event, as indicated by the sentence-based context and without con-sideration given to the actual zone/section of the article in which the event islocated. Classes are defined as follows:
– Investigation: refers to events that are describing planned or already con-ducted experiments or investigations, usually introduced by terms such asexamined, tested, studied.
– Observation: refers to events that are direct observations, sometimes repre-sented by lexical cues like found, observed and report, or event triggers setin the past tense.
– Analysis: refers to events that are part of inferences, interpretations, spec-ulations or other types of cognitive analysis, that must be accompanied bylexical cues such as suggest, indicate, therefore and conclude, etc.
– Method: events that refer to or describe experimental methods. Denoted bytrigger words such as stimulate, addition.
– Fact: descriptions and mentions of general facts and well-established knowl-edge, typically denoted by events that describe biological processes, andpossibly accompanied by lexical cues such as known.
– Other: this is the default category, assigned to events that do not fit into anyof the above categories.
• Polarity: A binary classification scheme to capture the truth value of the assertionrepresented by the event, i.e. to identify whether the interaction represented bythe event is negated or not. Classes are defined as follows:
– Positive: Default class, when there is no indication of negation referring tothe event.

5.2. DATASETS AND CORPORA 167
– Negative: Explicit mention of negated event, i.e. event describing a processthat does not take place or the absence of an entity or interaction. Usuallyindicated by terms such as no, not, fail, lack, etc.
• Manner: A 3 class annotation that identifies the rate, level, strength or intensityof the event (in biological terms). Classes are defined as follows:
– High: Explicit indication that the event occurs at a high rate, level, strengthor intensity. Cues are typically adjectives or adverbs such as high, strongly,rapidly, potent, etc.
– Low: Explicit indication that the event occurs at a low rate, level, strengthor intensity. Cues are typically adjectives and adverbs such as slightly, par-
tially, small, etc.
– Neutral: The default category. Assigned when there is no explicit indicationof either high or low nature, but also in the rare cases when neutral manneris explicitly indicated, using cue words such as normal or medium, etc.
• Source: A binary classification of the origin of the knowledge expressed by theevent. In this dimension, events can belong to one of the following two classes:
– Other: The event is attributed to a previous study. In this case, explicitclues are normally present, which can correspond either to cue words suchas previously, recent studies, etc. or by the presence of citations.
– Current: The event makes an assertion that can be attributed to the currentstudy. This is the default category, and is assigned in the absence of explicitlexical or contextual clues, although explicit cues such as the present study,
in this work, etc. may be encountered.
Note that all the above meta-knowledge dimensions are annotated based on infor-mation occurring in the same sentence as the event. Wherever feasible, cues for eachdimension are also annotated, following a scope-maximising approach (capturing themaximum number of continuous words perceived to be a cue).
Of the aforementioned dimensions, we identify CL and KT as dimensions that con-tain information falling under the definition of uncertainty that we introduced in Section

168 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
5.1. Specifically, we consider the cases annotated as L1, L2 in terms of CL and Inves-tigation in terms of KT to overlap with our definition of uncertainty, so we use them togenerate instances of uncertain events for training and testing purposes. Based on thisdefinition, 8.1% of the total number of events in GENIA-MK are classified as uncertain.
5.2.1.2 BioNLP-ST corpus
This corpus represents the combination of the available corpora from three consecu-tive BioNLP shared tasks, i.e., BioNLP 2009 [KOP+09a], BioNLP 2011 [KPO+11a]and BioNLP 2013 [NBK+13a]. In all of these shared tasks, a wide range of tracks in-cluded bio-events that were annotated with binary speculation values. The tracks withspeculation attributes are as follows:
• BioNLP 2009:
GE’09 Genia corpus: Collection of abstracts with bio-event annotations. It containsa total of 11,670 events, of which 567 are annotated as speculative.
• BioNLP 2011:
GE’11 Genia corpus: The 2009 Genia corpus, enhanced with five PMC full-textarticles included in each of the training, development, and test sets (15 ar-ticles in total). Updated total number of events is 13,560, of which 865 areannotated as speculative.
EPI Epigenetics and Post-translational Modifications: This task focuses on eventsrelating to epigenetic change, including DNA methylation and histone mod-ification, as well as other common post-translational protein modifications.The training and test datasets are drawn from a total of 800 relevant PubMedabstracts, with additional training data derived from evidence sentences ofrelevant databases such as PIR [BGM+99] and PubMeth [OVNDM+07].The corpus consists of a total of 2,453 events, of which 103 are annotated asspeculative.
ID Infectious Diseases: This task focuses on the bio-molecular mechanismsof infectious diseases. The training and test datasets are drawn from full-text PMC open access documents constituting representative publications

5.2. DATASETS AND CORPORA 169
on two-component regulatory systems.The corpus consists of a total of 2,779events, of which only 44 are annotated as speculative.
• BioNLP 2013:
GE’13 Genia: This task is based on the previous Genia tasks, but the associated cor-pus includes annotations of more recent PubMed articles, along with a com-plete re-evaluation and re-annotation of negation and speculation attributesfor events. The updated event count amounts to 6,016 events, of which 653are annotated as speculative.
CG Cancer Genetics: This task focuses on the biological processes relating tothe development and progression of cancer. The dataset consists of abstracts(including the titles) of publications from the PubMed literature database,selected on the basis of their relevance to cancer genetics. The annotatedevents in the corpus amount to a total of 11,718, of which 413 are annotatedas speculative.
PC Pathway Curation: This task aims to improve curation, evaluation and main-tenance of biomolecular pathway models. In this task, the extraction targetsand their semantics are defined with reference to physical entity and reactiontypes applied in pathway model standardisation efforts and to relevant on-tologies such as the Systems Biology Ontology (SBO). The corpus texts areselected on the basis of relevance to a selection of pathway models from Pan-ther Pathway DB [MT09] and BioModels [LNBB+06], covering both sig-nalling and metabolic pathways. The texts consist of both PubMed publica-tion abstracts and extracts from full-text articles obtained from the PubMedCentral open access database. The total number of annotated events is 8,121,of which only 67 are annotated as speculative.
Based on our definition of uncertainty presented in Section 5.1, all events in thecorpora associated with the aforementioned tasks that are annotated as speculative areconsidered to be uncertain, and are treated as such for all experiments. For the purposeof our experiments, we took the union of the datasets provided for the BioNLP tracksabove, which we collectively refer to in this work as the BioNLP-ST corpus. The totalnumber of events in the BioNLP-ST corpus amounts to 58,103, of which 3,005 are

170 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
annotated as speculative (uncertain). Thus, the uncertain events barely surpass 5% ofthe whole event set, highlighting the fact that uncertainty identification from a machinelearning point of view is a significantly skewed classification problem, and the classof uncertain events is under-represented. In other words, most events in biomedicalsentences are stated in a factual and/or certain manner.
For both GENIA-MK and BioNLP-ST, we evaluate the performance of our methodsusing 10-fold cross validation, calculating precision, recall, and F-score in each case.
5.2.2 Pathway related datasets
Evaluating performance on gold-standard corpus annotations is particularly importantto allow our methods to be compared with existing work. However, gold-standard cor-pora, particularly when annotated by linguistic communities, do not always capture theperception, needs and behaviour of researchers working in the field of biomedicine,who usually read such documents and then use the interactions mentioned in the text inorder to design new experiments, to curate pathways or to make new hypotheses. Thepotential of using events extracted from biomedical literature in combination with theiruncertainty information to facilitate the curation, correction or expansion of biomedi-cal pathways has further motivated our interest in evaluating our uncertainty definitionand our automated identification of uncertainty from the point of view of researchers inbiomedicine, who are familiar with the use of biomedical interactions in pathways.
Hence, we selected two use cases extracted from different pathway curation re-sources (developed on two different standards, namely, PathwayStudio [NEDM03] andBioPAX [DCP+10a]). Each use case focuses on a different sub-field (disease), althoughboth are significantly related to cancer diseases. For each of the two pathways describedin the following sections, we extracted a set of sentences that relate to the interactionsdescribed in the pathway. More details relating to the process of mapping interactionsto pathways are described in Chapter 7.

5.2. DATASETS AND CORPORA 171
5.2.2.1 Leukemia pathway and dataset
For this use-case, we focus on acute lymphoblastic leukemia, considering both relatedpublications and pathways. As the pathway resource, we use a manually curated path-way model from the Pathway Studio’s disease collections 5. Pathway Studio is currentlya proprietary software package that provides pathway curation tools as well as means forlinking interactions with evidence in the literature [NEDM03]. Along with facilities foruploading and management of one’s own pathways, it also provides a set of curated andvalidated pathways that are accompanied by evidence from literature. We used one ofthe curated/validated pathways named B-cell Acute Lymphoblastic Leukemia Overview.This pathway model contains 103 biomedical entities and 179 interactions, where eachinteraction is accompanied by related evidence (short passages) from published articles,manually selected by curators. The evidence passages provided as supporting evidenceconsist of one or more consecutive full sentences and constitute “raw text”, since thereare no annotations or highlighted text spans to indicate the exact part of the passage thatcorresponds to the interaction. Thus, it is necessary to further process them to iden-tify the exact event mention within each passage that matches the interaction that it isexpected to corroborate.
We collected and processed all such passages using a pipeline of text processingsteps (sentence splitting, tokenisation, syntax parsing) and then extracted all entitieswith a set of pre-trained NE taggers (i.e., Genia tagger and some customised CRF tag-gers as was explained in more details in Chapter 4) as well as all events using EventMine[MA13b, MPOA13]. Subsequently, we applied the label-relaxing heuristic approach asdescribed in Chapter 2, Section 2.3 and in [ZA15] to increase the number of argumentsthat are identified, and thus increase the number of extracted events that can be mappedto the pathway. Note that we were able to use the “informed” approach, as described inSection 2.3.2.2, using in each case the entities participating in the interaction related tothe analysed passage in order to guide the event extraction. In this way we managed toincrease the number of mapped events. The details of how identified events are mappedto the pathway interactions are described and discussed in detail in Chapter 7, Section7.5.
5https://mammal.pathwaystudio.com/#nav-5

172 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
After extracting events and mapping them to interactions, all passages were in-spected manually in order to remove any noisy events or incorrect mappings. Afterremoving noisy events, as well as events linked to interactions that had less than twosupporting passages, the gathered collection of interactions and passages contained atotal of 72 interactions and 300 sentences with matching events. The number of sup-porting sentences for each interaction ranges between 2 and 20. The uncertainty iden-tification methods that are described in Sections 5.3 were then applied to events in thelinked sentences, to classify mapped events as either certain or uncertain, and to scorethe related interactions in terms of textual (un)certainty.
We will henceforth refer to the pathway model described above as the LeukemiaModel and the accompanying evidence passages as the Leukemia corpus. An overviewimage of the model can be seen in Figure 5.3.
Figure 5.3: B-cell Acute Lymphoblastic Leukemia Overview : validated and curatedpathway, visualised in PathwayStudio.
The identified events were subsequently annotated for uncertainty by two groups ofresearchers. Group #1, consisting of 7 researchers, was instructed to annotate eventsonly for binary uncertainty. Group #2, consisting of 5 researchers, was instructed to

5.2. DATASETS AND CORPORA 173
annotate events on a 5-class scale of uncertainty, where 1 corresponds to the highlyuncertain and 5 to the highly certain events. In both cases, they were asked to basetheir annotations only on the information conveyed in the sentence and to refrain fromusing any related background knowledge to influence their decisions. Group #2 wassubsequently additionally asked to evaluate the certainty of the interaction of the path-way to which the evidence passages were mapped, based on the combined informationconveyed in the passages.
In all evaluation efforts, annotators were firstly presented with a separate set of 10interactions and associated passages in order to familiarise them with the task. Thesepassages and interactions were not included in the final datasets and were not usedto compare against the output of our system. The exact annotation guidelines that wereprovided to the annotators are available online (https://tinyurl.com/y7776ztl)Theannotated evidence passages that were used for evaluation can be accessed on the Bratannotation tool [SPT+12] following this link: http://nactem10.mib.man.ac.uk/bratv1.3/#/Pathway_Annotations/.
5.2.2.2 Melanoma pathway and dataset
The previously described Leukemia model was a very useful initial test-case, especiallybecause of the availability of pre-selected evidence passages. However, in order to beable to verify the generalisability and applicability of our methods, when applied todifferent pathways and interaction networks, we opted to extend our testing with anadditional use case. In this second use case, we also intended to address some of thelimitations of the Leukemia pathway use case. The Leukemia pathway is extracted froma proprietary resource. Thus, despite being a well described, detailed pathway, it is notopenly accessible. Moreover, the definitions of the interactions, entities etc. pertainto the classification and hierarchy of the software, meaning that it requires a dedicatedand non-generalisable definition of mappings between textual event types and path-way interaction types in order to be compared and matched to commonly used namingconventions for biomedical entities and reactions. Furthermore, it is a relatively smallpathway resource, focusing on the mechanisms of a very specific case.
In order to address these limitations, we selected a larger interaction network modelfor the second use case, namely, the 2-hop neighbourhood interaction network of the

174 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Ras gene, which was generated and distributed in the context of the Big Mechanismproject [Coh15]. The Ras gene has been identified as one of the crucial genes that re-late to various types of cancer [FMS11] such as breast cancer [FVC+87], melanoma[ANM+89, NSW+10] etc. and had a central role in the efforts to automate pathway cu-ration in the project. The model was generated using the API of the PathwayCommonsdatabase [CGD+10], in two steps. In the first step, all the interactions stored in thedatabase that have some form of the Ras gene (KRas, HRas, or NRas) as one of theirparticipants were added to the network. In the second step, the network was expandedusing the new entities, which were added to the network in the first step, by includingall interactions that had at least one of those entities as a participant. In this way, the socalled 2-hop neighbourhood interaction model for Ras was generated, in BioPAX stan-dard format [DCP+10b]. Note that the version of the network used for the experimentswas generated using the December 2015 version of the PathwayCommons database.
The model comes with grounding identifiers for all described interactions and enti-ties, which link them to external databases, but no supporting evidence passages. Forthis reason, we selected a large repository of full text documents from which we at-tempted to extract related events. Specifically, a collection of 16,000 full-text articleswas extracted from PubMed, focusing on the melanoma disease. In order to select doc-uments of interest, we collaborated with researchers from the field, in order to compile aquery that would allow us to retrieve related articles from PubMed. The query includedsynonyms and terms related to melanoma, as extracted from UMLS lexica, a selectionof 2 cell-lines of interest, as well as the constraint of selecting only open-source doc-uments. We present the collection query in Figure 5.4 for reasons of reproducibility.Since the query was run on a 2016 PubMed snapshot, the melanoma document collec-tion includes only documents published up until June 2016. Henceforth, we will referto this as the Melanoma corpus.
Following the document selection, all articles were processed to identify events, us-ing the combination of EventMine [MA13b, MPOA13] and the event post-processingapproach described in Chapter 2, Section 2.3. Following this, sentences that containedevents that could be mapped to interactions in the Ras model were grouped and mappedto their corresponding interaction in the network. Similarly to the Leukemia pathwaymodel, the details of the event-to-interaction mapping are discussed in detail in Chapter

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 175
(BODY:”melanoma” OR BODY: ”sarcoma” OR BODY: ”melanoblastoma”OR BODY: ”melanocarcinoma” OR BODY: ”skin cancer” OR BODY: ”neo-plasm” OR BODY: ”melanotic cancer” OR BODY:”melanoid carcinoma” ORBODY:”malignant cell melanoma” OR BODY: ”malignant melanoma” OR BODY:”malignant neoplasm” OR BODY: ”Hutchinson’s Melanotic Freckle” OR BODY:”Lentigo Maligna ” OR BODY: ”Melanotic Freckle” OR BODY: ”Lentigo, Malig-nant ” OR BODY: ”Melanotic Freckle” OR BODY: ”Melanoma, Amelanotic ” ORBODY: ”unpigmented malignant melanoma” OR BODY: ”anaplastic melanoma”OR BODY: ”skin neoplasm” OR BODY: ”malignant tumor, skin” )AND (BODY:”T47D” OR BODY:”T-47D” OR BODY:”MDMBA231” ORBODY:” MDM-BA-231” OR BODY:” MCF7” OR BODY:”MCF-7”)AND OPEN ACCESS:Y
Figure 5.4: Document collection query for the Melanoma corpus
7, Section 7.5. Uncertainty identification methods were then applied to the linked sen-tences, to classify the mapped events within them as certain/uncertain and to score therelated interactions in terms of textual (un)certainty.
5.3 A novel proposal for uncertainty identification
In this section we elaborate our approach to textual uncertainty identification for events.Our methods aim to combine the strengths of both machine learning and dependency-based rule induction approaches. In line with RH1 and RQ1, we explore the combinationof dependencies along with a wide range of other features in order to evaluate the im-pact of different feature categories on the performance of the classifier, as well as onthe resulting adaptability and flexibility to allow application to other domains (see alsoChapter 6). The emphasis in this work is placed on examining the potential, suitabil-ity and limitations of supervised and feature engineering-oriented approaches for sucha task. Along the same lines, we also aimed to compare rule-based approaches withsupervised ML methods.
In the majority of experiments, the proposed methods are tested on binary classifi-cation tasks for determining the uncertainty of extracted events. Overall, we show thatincorporation of enriched dependency n-grams in a supervised, ML classifier yielded the

176 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
best results, confirming our initial hypothesis (H1 and RQ1) and surpassing the perfor-mance of other approaches. Details of the implementation are described in the followingsections (5.3.1-5.3.3). In Section 5.4, we discuss the results of applying the methods toboth the gold annotated datasets (Section 5.4.1) and on the biomedical pathways (Sec-tion 5.4.2).
We note that all the methods described in this section assume that the events tobe classified for (un)certainty are already annotated in the text provided. The eventannotations are obtained either from gold-standard annotated corpora (see Genia-MKand BioNLP-ST described in Section 5.2.1) or by the application of the EventMinecomponent on raw datasets described in Section 5.2.2. Specifically, our methods assumeexisting annotations foe the event triggers and the event arguments in each sentence aswell as the event type/role. The uncertainty identification is performed with regardsto the event trigger that is considered to be the representative part of the event, but allthe other event information is used to provide additional features described in section5.3.3.1.
5.3.1 Modelling dependencies between uncertainty cues and events
As stated earlier, the task of textual uncertainty identification for events largely de-pends on (a) identifying textual expressions that signify uncertainty and (b) identifyingwhether such expressions actually impact upon the certainty of the event in question.In order to explore point (b), it is important to capture the existence and structure ofsyntactic dependencies between uncertainty cues and events.
Information about syntax has frequently been used to generate feature representa-tions in tasks related to uncertainty identification. However, we notice that often deepsyntactic trees are preferred (see the work of [KB10, MVAD10b, ZZZ13] mentioned inChapter 3), especially for cue-scope problems. Indeed, syntactic trees can be used toefficiently identify the sub-phrase that falls under the command of a specific uncertaintycue, but as we explain later on (see Figure 5.7), it might be the case that more thanone events fall within the scope of a cue, while not all of them are rendered uncertainbecause of it. We thus wanted to explore a more shallow structure, such as the predicate-argument structures, that can still capture dependencies between tokens in a sentence,but in a more direct way. Shallow syntactic dependencies have been used before as well,

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 177
but in restricted representations [SVS+12, ZDLC10].
Hence, in this section we aim to explore the potential of using dependencies to gen-erate rich feature structures that could capture dependency sequences between identifieduncertainty cues and events as well as role/type information of dependencies. We pro-pose the use of this feature structure (we refer to it as enriched dependency n-grams) toextract rules or machine learning features that support automated uncertainty identifica-tion, thus addressing O1.
5.3.1.1 Definition of dependency
Dependency parsing aims to identify and describe the grammatical and syntactic rela-tions between pairs of words in a sentence. In computational linguistics, dependencyparsing is applied to tokenised sentences, in which each word or symbol in a sentenceis treated separately as a minimal information unit called a token 6. Hence, dependencyparsing identifies relations between tokens in a sentence. The traditional linguistic no-tion of grammatical relations provides the basis for the binary relations that constitutethe dependency structures (dependencies for short). The arguments to these relationsconsist of a head and a dependent. In addition to specifying the head-dependent pairs,dependency grammars allow us to further classify the types of grammatical relations, orgrammatical functions, in terms of the role that the dependent plays with respect to itshead [JM14].
Given that dependencies are binary relations that link pairs of tokens in a sentence,and that every token will be an argument of at least one such dependency, we can con-sider the set of dependencies within a sentence to be a dependency graph. In depen-dency graphs, the tokens correspond to nodes, and the dependencies correspond to di-rected edges between the nodes. Further constraints can be applied to these dependencygraphs, which are specific to the underlying grammatical theory or formalism. Amongthe more frequent restrictions are that the graph must be connected, have a designatedroot node, and be acyclic (no directed edge path can start and end at the same token)or planar (it can be drawn on the plane in such a way that its edges intersect only attheir endpoints). Of the greatest relevance to the parsing approach discussed in thischapter is the common, computationally motivated, restriction to rooted trees. That is,
6A lexical token or simply token is a string with an assigned and thus identified meaning [UAS18].

178 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
a dependency tree is a directed graph that satisfies the following constraints:
1. There is a single designated root node that has no incoming arcs.
2. With the exception of the root node, each node has exactly one incoming arc.
3. There is a unique path from the root node to each other node in the graph.
Taken together, these constraints ensure that each word has a single head, that thedependency structure is connected, and that there is a single root node from which onecan follow a unique directed path to each of the words in the sentence. By definition,this dependency tree will also be acyclic and planar.
An example of a dependency graph over a sentence taken from a biomedical articleis presented in Figures 5.5 and 5.6-bottom-. As illustrated in these figures, the graphsgenerated by dependency parsing are shallow and easier to traverse compared to othertypes of syntactic graphs such as the typical deeper structures of phrase structure treesand provide a flatter but nonetheless comprehensive representation of relations betweenthe words of a sentence. Compared to such tree structures the dependency graphs ab-stract away from the phrase structure and constituents, and as such they are not optimalfor the identification of the scope of a specific modifier cue. Since in this work we aim tofocus mainly on uncertainty identification for events, rather than the cue-scope approachof uncertainty identification, we deem the dependency graphs to be more suitable, com-pared to the syntactic trees. Still, as detailed in Section 5.3.3.1, we use the syntactictrees to extract additional features (grouped under the constituency feature category).
In the next sub-section we provide details on the Enju dependency parser [MT08a]which was the main component used to generate dependency edges and graphs, thatwere subsequently utilised to generate features and rules for the uncertainty identifica-tion methods.
5.3.1.2 Enju dependency parser
For the extraction of dependency graphs as well as simplified dependency edges andtheir functions, we used the Enju dependency parser [MT08a]. Enju is a probabilistic
7The dependencies were generated by Enju parser. The original Enju output identifies the noun, detand adj dependencies inverted, which violates condition 2. Condition 3 holds only for the shortest non-directed path between root and target token; there can be more than one paths of varying lengths betweenroot and each token.

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 179
Figure 5.5: Example of dependency graph over a sentence. Arrows signify the depen-dent and not the head. The token “and” is the root of the graph. We can observe that theedges do not intersect and there is a path to any node 7.
parser based on head-driven phrase structure grammar (HPSG), which is an extensionof dependency grammars, including rules and lexicon entries [MT08b].
The Enju parser has been made available along with two models pre-trained on dif-ferent domains. The Genia model is trained on the Genia corpus [KOTT03a] and thusis tailored to the biomedical domain and is deemed suitable for our experiments on de-tecting uncertainty of biomedical events. The Brown model is trained on the Wall StreetJournal (WSJ) collection of documents [HJ82]], consisting of primarily newswire andliterature-related text. The Brown model is considered generic enough to be domain-independent, although comparative studies have shown a performance loss when appliedto the biomedical domain [MSS+08]. Thus in our experiments with biomedical events,we use the Genia model of Enju, without further re-training.
In terms of output, the Enju parser provides two different output modes:
1. Phrase-based syntactic graph: Tree structures that depict how words are com-bined to form phrases and clauses, by capturing head-phrase dependencies. It isa directed graph, where edges point from the head to the dependent phrase. Suchsub-phrases that are dependent on a head term are called constituents.
2. Dependency relations: A set of predicate-argument structures (PAS) that capturethe semantic relations among words in an input sentence by simplifying its deepsyntactic structure representation. Despite the flattened structure, PAS still in-clude the (grammatical) dependencies between tokens.

180 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
In Figure 5.6 we provide an example of the two different outputs for the same sen-tence, comparing the semantics captured in each case.
Each PAS is attributed a type by the Enju parser (we use the simplified PAS typesthat are similar to the output notation of many dependency parsers and abstract fromthe POS of the token). We present the PAS types below. Henceforth, we refer to thosedependency types as dependency roles.
• ARG1: Subject of a verb, a target of modification by modifier words, etc.
• ARG2: Object of verbs, prepositions, etc.
• ARG3*: Objects and complements of verbs that take multiple arguments, etc.
• ARG4*: Objects and complements of verbs that take multiple arguments, etc.
• MOD: Assigned to a modified term of VP modifiers (e.g. a matrix clause of par-ticipial construction). For complementary terms and determiners, their dependentphrases/clauses will be “ARG1”.
*ARG3 and ARG4 have the same definition. In a parsed sentence, argumentsARG3/ARG4 are assigned in a left-to-right order.
In addition to the aforementioned labels, a predicate type is also assigned to each ofthe predicate-argument relations. Enju differentiates between 52 predicate types 8.
Finally, Enju assigns a set of additional attributes to each token in a sentence tokens,along with their surface forms. Table 5.2 lists these additional attributes, which pro-vide additional linguistic and semantic information about the role of each token in thesentence. Thus, we also took advantage of them in our feature engineering. In the MLexperiments presented in Section 5.3.3, these attributes are used as nominal features forverb tokens.
8The 52 predicate types are: [noun arg0, noun arg1, noun arg2, noun arg12, it arg1, there arg0,quote arg2, quote arg12, quote arg23, quote arg123, poss arg2, poss arg12, aux arg12, aux mod arg12,verb arg1, verb arg12, verb arg123, verb arg1234, verb mod arg1, verb mod arg12, verb mod arg123,verb mod arg1234, adj arg1, adj arg12, adj mod arg1, adj mod arg12, conj arg1, conj arg12,conj arg123, coord arg12, det arg1, prep arg12, prep arg123, prep mod arg12, prep mod arg123,lgs arg2, dtv arg2, punct arg1, app arg12, lparen arg123, rparen arg0, comp arg1, comp arg12,comp mod arg1, relative arg1, relative arg12]
9Enju can use its own POS tagging methods, or use POS tags from other components as input.
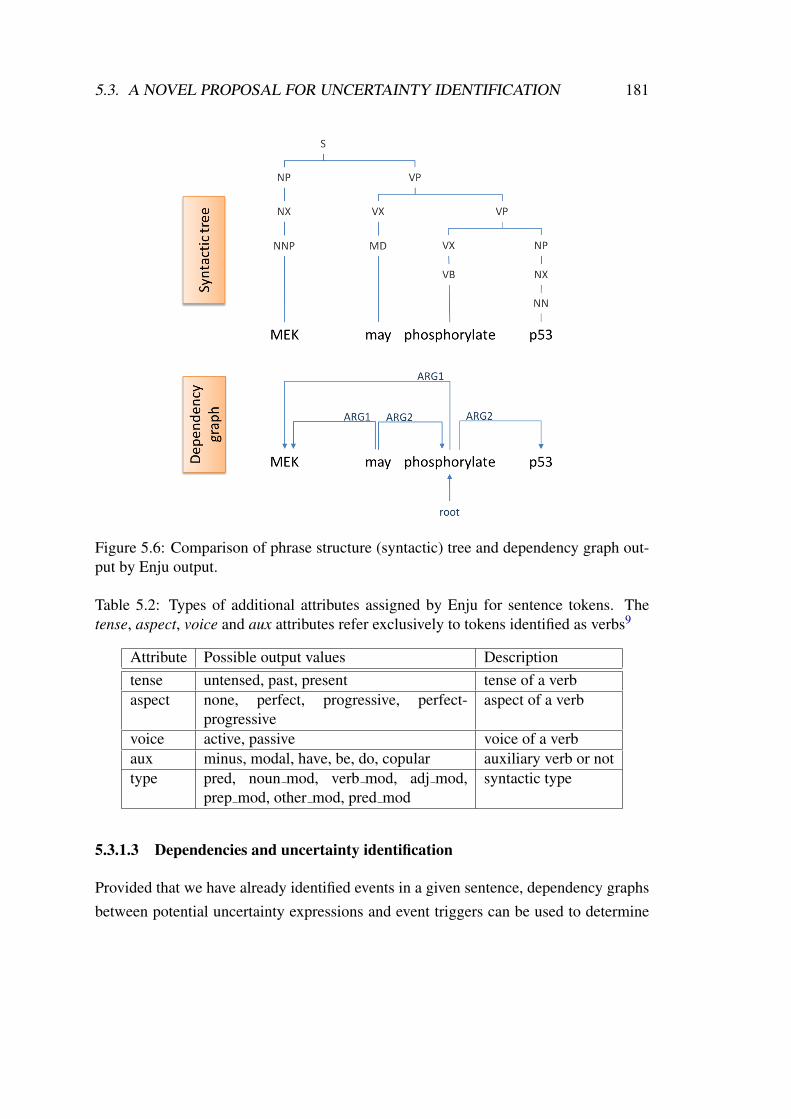
5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 181
Figure 5.6: Comparison of phrase structure (syntactic) tree and dependency graph out-put by Enju output.
Table 5.2: Types of additional attributes assigned by Enju for sentence tokens. Thetense, aspect, voice and aux attributes refer exclusively to tokens identified as verbs9
Attribute Possible output values Descriptiontense untensed, past, present tense of a verbaspect none, perfect, progressive, perfect-
progressiveaspect of a verb
voice active, passive voice of a verbaux minus, modal, have, be, do, copular auxiliary verb or nottype pred, noun mod, verb mod, adj mod,
prep mod, other mod, pred modsyntactic type
5.3.1.3 Dependencies and uncertainty identification
Provided that we have already identified events in a given sentence, dependency graphsbetween potential uncertainty expressions and event triggers can be used to determine

182 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
whether an uncertainty expression influences the event of interest. This is especially im-portant in long sentences with many sub-phrases and in sentences that contain multipleevents and/or nested events.
Indeed, the existence of an uncertainty cue such as possibly or suggest in a sentencewill not necessarily render any event in the same sentence uncertain, as illustrated inFigure 5.7, where the only uncertain event is the one that has the word modulate as itstrigger. The event with metabolism as a trigger, while syntactically within the scope ofmay, is not within the scope of the uncertainty. Similarly, inhibition of COX-2 is notaffected by the presence of may, and in this case it is not even within the scope of may.
The output of dependency parsing (marked with arrows above the sentence in Figure5.7), can help to identify which event triggers are directly dependent on the uncertaintycue. Thus, dependency parsing can provide useful insights into the way a cue affectsthe trigger of each event in a sentence.
Figure 5.7: Relation between the influence of uncertainty cues on event triggers and thesyntactic dependencies between them. Figure re-iterated from Chapter 2.
In Figure 5.7, the trigger of the uncertain event is directly dependent on may. Inmany cases, event (un)certainty can be determined from the dependency path between acue and the event trigger. The dependency path is the shortest path between two tokensof the undirected graph. Upon inspection of the example in Figure 5.7, we can seethat compared to the other event triggers in the sentence, the dependency path betweenmay and modulate is the shortest one, as there is a direct dependency identified betweenthe two verbs. Apart from the length of the dependencies, the role of the dependencyrelation can also affect the influence of the uncertainty cue on the event. For example,in Figure 5.8, we can observe that both event triggers phosphorylation and inhibit arelinked to the uncertainty cue may with a single dependency edge. However, only theevent with inhibit as a trigger is influenced by may in terms of uncertainty. In thiscase, the Arg2 dependency role can be used to distinguish the event with the uncertaininterpretation.

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 183
Figure 5.8: Example of case where two events in the sentence are both linked to theuncertainty cue may with a direct dependency. However, it is not the case that bothevents are uncertain. The type of dependency as indicated above the dependency edgescan help in differentiating between the two cases, i.e., events should only be consideredas uncertain if they are linked to may via an Arg2 dependency.
However, even dependency roles might not be sufficient to identify whether an un-certainty cue influences an event trigger in a manner that renders the event uncertain.Indeed, as illustrated in the example of Figure 5.9, the intermediate words in the de-pendency path between a cue and a trigger, can also affect (and change) the conveyedmeaning, and thus the perceived uncertainty of the event. This is due to the fact that dif-ferent terms (e.g. verbs), display different grammatical patterns and argument structuresbased on their context and their role in text [Lev93]. Thus, in dependency-annotatedsentences, they relate to other tokens via different attributes and argument roles.
Figure 5.9: Example of two sentences where the same uncertainty cue is linked to thetrigger through a dependency path with the same edge pattern, i.e. examine in bothcases is linked to the event trigger via two consecutive Arg2 edges. However, only inthe example of the top sentence is the event is actually uncertain, since in the bottomsentence, what is examined is the mechanism of regulation rather than the existence ofregulation itself. Thus, we can conclude that in dependency paths between cues andtriggers that are longer than a single edge, the intermediate words/nodes in the path canaffect the uncertainty of the event.
We propose a dependency pattern induction mechanism that can capture detailedinformation about the dependency path between an uncertainty cue and a potentially

184 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
uncertain event trigger, i.e. the length, the dependency roles and the intermediate to-kens/terms. The induced patterns can be used either as rules for use in a rule-baseduncertainty identification system, or as features for a machine learning classifier. Themethod proposed for dependency pattern induction can be applied to the output of anydependency parser, provided that the set of the parsers’ possible outputs for dependencyroles is known 10. In the current work we use the Enju parser and its PAS structureoutput, as described in Section 5.3.1.2.
In order to formalise the dependency pattern induction, we treat extracted dependen-cies between two tokens as directed edges from the source token TS (dependency head)to the target token (dependent) TT . Hence, we can define a dependency function whoseoutput is the dependency role whose possible values constitute a closed set of labels thatare defined by the parser, as shown in Equation 5.1.
dep(TS,TT ) = d,d ∈ [ARG1,ARG2,ARG3,ARG4,MOD, /0] (5.1)
where ARG1,ARG2,ARG3,ARG4 and MOD are the possible output values of the Enjudependency server, while /0 refers to the case where Enju (or any other dependencyparser used) did not identify any possible outputs.
Note that the output of the dep() function includes the null value to represent caseswhere there is no dependency identified between the two tokens. Based on the definitionof Equation 5.1, we can also define “dependency paths” as sequences of consecutivedependency edges that create a path between a source TS and a target TT token (seeEquation 5.2). If a sentence contains a non-empty path(TS,TT ), where TS corresponds toan (un)certainty cue (from a cue vocabulary C) and TT to an event trigger, then it is con-sidered as a valid dependency pattern and thus, a dependency rule candidate, formulatedas Equation 5.3.
10Note that the number of the dependency roles identifiable by the parser could influence the perfor-mance, and unless there is a correspondence between the dependency roles of different parsers, re-trainingand tuning of the methods would be necessary when considering the output of a new parser.

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 185
path(TS,TT )=
dep(TS,TT ), i f dep(TS,TT ) 6= /0
path(TS,w) ·w · path(w,TT ) i f∃w : path(TS,w) 6= /0, path(w,TT ) 6= /0
/0, else(5.2)
Rulei = TS · path(TS,Ttrigger), for TS ∈C (5.3)
In Figure 5.11 (top) we see an example of rule extraction from a sentence. Notethat the last term on the path (promotes), which corresponds to the event trigger, isremoved, so that that rule is sufficiently general for application to any other event trigger.This rule or dependency pattern, when unfolded as shown in the figure, corresponds toan “enriched” version of dependency n-grams for varying window lengths. N-grams
correspond to a continuous sequence of n tokens, and in NLP tasks they are often usedto represent a word in a sentence by capturing its n closest tokens. Dependency n-grams consist of n tokens which correspond to continuous nodes in a dependency path.Sidorov et al. [SVS+12] explored the use of dependency and syntactic n-grams anddemonstrated their effectiveness as machine learning features for NLP. While Sidorovet al. experimented with different versions of dependency n-grams (e.g., using lemmas,surface forms, POS tags etc.), there has been no experiment that has integrated thedependency role in the dependency n-grams [SVS+14]. We refer to the integration ofthe dependency role in the sequence of dependency n-grams (represented by the surfaceform of the tokens) as an enriched dependency n-gram. Treating the extracted rules asenriched dependency n-grams, it is possible to use them as features in ML classifiers,and combine them with additional features that capture lexical, semantic and syntacticaspects in the event context (see Section 5.3.3.1).
In some cases, especially those related to nominalised uncertainty cues, dependencypaths that “violate” the directionality of the graph are needed. As shown in the examplein Figure 5.10, the way in which dependency directions are represented when involvingprepositions (“of ”), means that it is important to consider counter directionality of paths.We use the following notation (
←−Arg) above dependency roles to identify such cases. For
the example shown in the figure, the resulting rule would be: indication ·←−−Arg1 ·o f ·Arg2

186 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.10: Example of dependency rule that “breaks” the directionality of the depen-dency graph. To distinguish from cases where the dependencies between tokens followone direction towards the trigger we use a left arrow over the corresponding dependencyrole: indication ·←−−Arg1 ·o f ·Arg2
As well as using the enriched dependency n-grams as features in ML classifiers,using Equation 5.3 we can use dependency patterns more directly for rule-based uncer-tainty identification. Indeed, we can use such patterns as rules that can be applied onsentences with event annotations to determine whether an event is affected by an uncer-tainty cue or not 11. We present in Figure 5.11 example of a step-by-step applicationof Equations 5.1-5.3 to a dependency-parsed sentence in order to derive a rule, and weillustrate the application of the same rule to a new sentence. In the top sentence, weobserve that dependency relations are firstly extracted. Subsequently, the ARG2 depen-dency between examine and how and the ARG1 dependency between how and promotes
are combined into a path(TS,TT ) relation, where TS is the cue examine and TT the eventtrigger promote. Since promote is an event trigger, we obtain a new rule for the cueexamine. The rule can then be applied to any sentence where the same dependency pathexists between the cue examine and any event trigger.
In Section 5.4 we compare the performance of the rule-based and machine learningbased approaches, and discuss why the best performance is achieved when the enricheddependency n-gram features are used in a Random Forest [LW02] classifier yields.
Furthermore, we note that simply applying the rule induction without further pro-cessing would normally generate noisy rule-sets, which would not be very effective in
11As explained l ater (see Section 5.3.2) these rules would still need to be filtered or constrained usingcue-lists, lexica, or supervised me
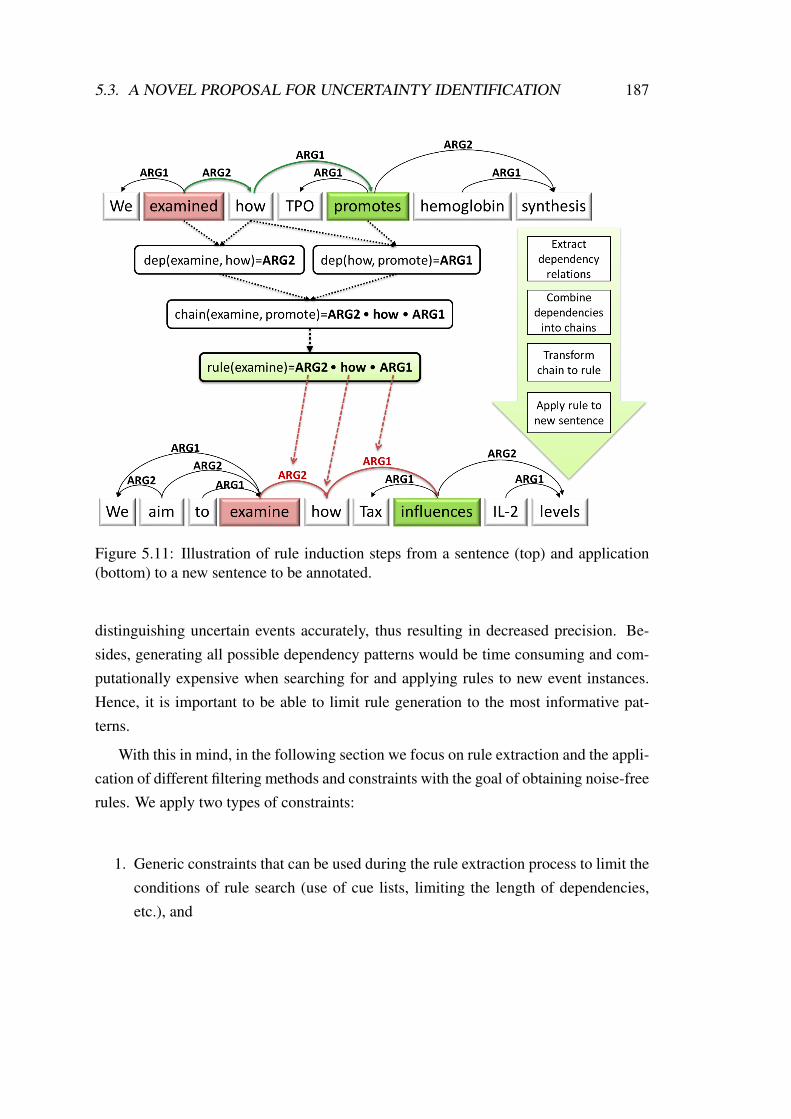
5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 187
Figure 5.11: Illustration of rule induction steps from a sentence (top) and application(bottom) to a new sentence to be annotated.
distinguishing uncertain events accurately, thus resulting in decreased precision. Be-sides, generating all possible dependency patterns would be time consuming and com-putationally expensive when searching for and applying rules to new event instances.Hence, it is important to be able to limit rule generation to the most informative pat-terns.
With this in mind, in the following section we focus on rule extraction and the appli-cation of different filtering methods and constraints with the goal of obtaining noise-freerules. We apply two types of constraints:
1. Generic constraints that can be used during the rule extraction process to limit theconditions of rule search (use of cue lists, limiting the length of dependencies,etc.), and

188 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
2. Informativeness filters that are applied as a [post-processing step to the raw ex-tracted dependency patterns in order to retain only the most meaningful ones asvalid rules.
5.3.2 Constraints and filters for the rule-based approach
As stated previously, in the rule-based approach, it is important to constrain the gener-ation of dependency patterns in order to the search space for rules. At the same time itis necessary to obtain a rule-set with a wide coverage of uncertainty while maintainingthe most meaningful and relevant rules and thus to boost recall without compromisingprecision.
These targets can be difficult to satisfy simultaneously. On the one hand, over-constraining the generation of the rules might imply the omission of useful rules, whichwill reduce recall. On the other hand, unconstrained rule extraction, especially whencues are not available in a sentence, would lead to the generation of many noisy rules,which would decrease precision. The latter is particularly important in cases that donot use uncertainty cues to guide rule pattern generation, but instead use the uncertaintyvalue of an event as an indicator. In such cases, the assumption is that since the event isuncertain, there has to be a rule pattern which can be identified by the dependency pathsthat terminate on the uncertain event trigger. Hence, all such dependency paths in thesentence would be extracted as candidate rules. The resulting problem is that some ofthose candidate rules will not generalise well to other sentences. Figure 5.12 presentsan example of a case where rule extraction, while guided by the uncertainty annotationof the event trigger, fails to generalise to other sentences.
Thus, filtering rules using measures of informativeness is necessary to avoid thegeneration of an overly large and noisy set of rules. Note that limiting and filtering arule set can also prove a useful practice for the machine learning approach to reducefeature dimensions. Below, we separately describe the employed methods to constrainthe search space for rules (Section 5.3.2.1) and to filter the generated rules to avoid noisyinputs (Section 5.3.2.2).

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 189
Figure 5.12: Example of a noisy rule pattern that does not generalise well to othersentences. In the top sentence, the event with trigger regulating is uncertain and mayis the uncertainty cue. However, if all potential paths to the trigger are considered, theintermediate path starting at the token role will also be extracted as (role ·Arg1 · in ·Arg2). We can see that if that candidate rule is applied to a new sentence, it will lead toa false positive result (bottom).
5.3.2.1 Constraints for search space
As indicated in Equations 5.1-5.3, rule patterns used to identify uncertain events areessentially dependency paths (or dependency n-grams), which capture dependency re-lations between uncertainty cues and event trigger words. During the rule pattern ex-traction process, the search space and computational complexity constitute an importantconcern affecting to the robustness of the system.
We identify three potential ways to limit the search space for dependency patterns,namely:
1. Limit the maximum path length.
2. Limit the valid surface forms of TS (which is the start token of a dependencypath as indicated in Equation 5.2), to a list of pre-defined dictionary cues foruncertainty.
3. Terminate pattern generation when another event trigger is encountered in thedependency path.

190 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
5.3.2.1.1 Limiting maximum path length
The maximum dependency path length corresponds to the maximum number of con-secutive dependency edges allowed in an extracted dependency path. Since the searchspace does not increase linearly as we increase the searched path length, it is importantto impose a limit. We estimate the size of the generated pattern set based on the maxi-mum length of the dependency path, by considering the parameters on which it depends.We assume the following notation:
• the maximum allowed path length (# of dependency edges) is n,
• the tokens which are nodes in the dependency path are noted as w,
• the potential surface forms for the tokens, w, originate from a dictionary of size|D|, and
• the number of possible dependency roles is S.
Expressing this as a combinatorics problem, we need to calculate the number of patternsthat we would need to search as a result of all potential word combinations and all thepotential dependency role combinations, for different maximum path lengths n. Theupper bound on the generated number of patterns can then be calculated using multisetcoefficients, as shown in Equation 5.4. Note that this is a relaxed upper bound, since itoverlooks the dependencies between the dependency roles and the word sequence, andthus is “overshooting” the calculated size of generated patterns.
|PatternSet|=n
∑k=0
(S+ k−1)! ·D!k! · (S−1)! · (D− k)!
(5.4)
We know that for the Enju parser, there are five potential dependency roles (seeEquation 5.1) and thus S can be considered to have a constant of size of five (S = 5,excluding the null value). The size of the dictionary |D| is a parameter that is moredifficult to constrain, although realistically, since we are applying the rule inductionprocess to single sentences, |D| is dependent on the sentence length. For example, forthe GENIA-MK corpus the maximum sentence length is 164, which is the upper boundof |D| for this corpus. However the average sentence length on the same corpus is 26,which is a more realistic estimation of |D|. Focusing on the only other parameter that

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 191
we can control, n, we estimate the coverage of uncertainty dependency rules accordingto length using the annotated cues in GENIA-MK and BioNLP-ST. By considering theshortest path between annotated cues and corresponding event triggers as a valid path,we estimated that we can retrieve around 95% of the valid dependency paths if weconstrain the path length to be n < 3 for GENIA-MK and BioNLP-ST corpora 12. Onlya small percentage of valid paths was of a larger size. It should be noted that for eventshaving more than one cue linked to them, as well as in the case of multi-word cues(such as “to the best of our knowledge”), only the shortest dependency path extractedwas taken into account. Also, in sentences that contained more than one uncertaintyexpressions, we considered only the one which resulted in the shortest dependency path.The results of the dependency length analysis are presented in Figure 5.13. Based onthese results we decided to limit maximum path length to n = 2.
Figure 5.13: Percentage of identified patterns for increasing n (chain length) on GENIA-MK and BioNLP-ST. We can observe that the percentage converges to 0 for n > 2.
12Since BioNLP-ST does not include uncertainty cue annotations, we use pre-compiled lists of uncer-tainty cues in order to identify and calculate the length of dependency paths.

192 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
5.3.2.1.2 Limiting permitted TS tokens
While |D| is difficult to control, it is possible to introduce a constraint for at least one ofthe tokens in the dependency paths, in order to restrict our rule search to those patternsthat contain at least one token that is expected to be an uncertainty cue. This approachassumes the existence of a list of uncertainty cues. Corpora annotated with uncertaintycues (CoNLL datasets, GENIA-MK, BioScope etc.) can serve as sources for the gen-eration of such lists, or alternatively, lists can be compiled based on existing literature(for example, Druzdel [Dru89], Hyland [Hyl96] and Malhotra [MYBHA14] all identi-fied lists of cues related to uncertainty). Thus, cue lists can be used to further limit thegenerated rule set, by assuming that only those dependency paths that occur between atoken in the cue list and an event trigger are valid paths. We compare the advantagesand disadvantages of the cue constraint and the unconstrained rule generation in Section5.4.
5.3.2.1.3 Halting pattern generation when encountering an event in the depen-dency path
When identifying uncertainty for events, it is important to consider the presence ofcomplex and nested events 13. In sentences that contain complex events (i.e., events thathave other nested events as arguments), and where there is an uncertainty expressionmodifying the certainty of either the top-level or the nested events, it is important todecide whether the other event(s) should also be considered as uncertain.
Rubin [Rub07] specifically identifies the case of nested events as an ambiguoustask in terms of certainty annotation. Stenetorp [SPO+12a], showed that by decouplingtop-level and nested events, he was able to improve the performance of uncertaintyscope identification. Moreover, in their guidelines for meta-knowledge for bio-eventannotations 14 Thompson et al. clearly state that “most meta-knowledge information
expressed in the sentence will apply to the primary event”, where “primary event” refersto what we refer to as top-level event.
13We discussed complex events and nested events in Chapter 214“Meta-Knowledge Annotation of Bio-Events Annotation Guidelines”, Thompson, Nawaz, Mc-
Naught and Ananiadou: http://www.nactem.ac.uk/meta-knowledge/Annotation_Guidelines.pdf

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 193
Overall, uncertainty expressions (and meta-knowledge modifiers in general) are con-sidered to relate primarily to the main, top-level event, as opposed to its nested events.We choose to follow an approach similar to the one adopted by Thompson et al., sinceit has been used for GENIA-MK annotations [TNMA11]. The only exception we con-sider, is that for a given uncertainty cue u, if there is a dependency path between thetrigger of the nested event and u, which is shorter in comparison to the path between thetop-level event trigger and u, then we consider only the nested event to be uncertain.
We generalise this statement, and assume that given a potential uncertainty cue TS,any dependency path starting from TS should not extend further than the first most di-rectly affected event trigger in the path. Hence if we are trying to identify rules for eventEi and there exists a path(TS,TEi) = TS ·ARG2 ·E j ·ARG2 ·Ei, then since E j is more di-rectly related to TS the rule pattern is invalid for Ei. We illustrate this constraint on anexample taken from literature in Figure 5.14 (a). Note that, as shown in Figure 5.14 (b),this limitation does not affect events that are linked by conjunctions or similar terms (ifthey are not nested).
We apply this constraint in all experiments and corpora and, when searching fordependency rules between a potential (un)certainty cue token TS and an event triggerTT pair (see Equations 5.1-5.3), if the dependency path extraction process encounteranother event trigger as an intermediate term w,then the search for rules between TS andTT is terminated.
5.3.2.2 Filtering rules based on informativeness
Figures 5.11 and 5.12 illustrate how the rule extraction process can result in both validand invalid rules. In this context, the term invalid refers to a rule that results in a falsepositive when applied to a new (unseen) sentence. Some rules have very high preci-sion and are able to consistently predict uncertain events with a high degree of accu-racy. However, often a rule will not be applicable in all cases, especially if it has beenextracted without any cue list restrictions, as was shown in the noisy rule extractionexample of Figure 5.12. Nevertheless, restricting the rules to a limited set of highly ac-curate rules would compromise the recall of uncertain events. Thus, a key issue for therule-based approach is determining a set of dependency rules that will balance precisionagainst recall and optimise performance. We have already presented the option of using

194 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.14: Example of rule pattern filtered out when an intermediate term is an event(a). When searching for dependency rules between may and transcription, the discoveryof the dependency edge between may and regulate (i.e., another event trigger), meansthat only path between may and regulate is extracted as a valid rule; the longer pathbetween may and transcription is discarded. In (b) we can observe that when multipleevents are linked by conjunctions, rule extraction can account for this, since regulateand inhibit do not intercept the path to each other.
a compiled cue list to limit rule generation. The availability of corpora whose eventsare annotated with uncertainty can allow additional filtering approaches to be applied.An uncertainty-annotated corpus allows us to extract all paths around an uncertain eventtrigger as potential rules.
Subsequently, we would need to rank those rules based on their estimated validity.A simple approach would be to use frequency filtering and select only the rules thatappear frequently in text as the most valid ones. However, this approach does not placemuch consideration on the ability of a rule to distinguish between certain and uncertainevents [KK05].
To address this issue, and in line with Kim’s observations about the suitability of as-sociation rule-based filters versus frequency-based ones [KK05], we decided to experi-ment with methods inspired from association rule mining (ARM). Variations of associa-tion rule mining have been used as informativeness filters for a wide range of rule-basedapproaches in NLP and text mining, ranging from predicting PPIs [PRG+09] to miningstressful events [YCLL11], or to ensure the semantic “meaningfulness” of sentences[LSW+15].

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 195
We use simplified association rules (AR) of the form X ⇒ Y , where X is the rulepattern and Y is the uncertainty value [AIS93]. Note that we consider only a simplifiedversion of ARM, since the item set X will always be of size one; in other words, we donot consider rule combinations. Even so, ARM measures for informativeness, especiallythose based on the support-confidence framework presented in Equations 5.5 and 5.6,can prove quite efficient for our task. Support, essentially provides the proportion of aspecific rule X in the corpus, and thus it is used as a measure of significance (importance)for it. Confidence is defined as the probability of seeing the rule’s consequent Y (whichin our case is the uncertainty annotation) if the rule was met in the sentence.
supp(X ⇒ Y ) = supp(X ∪Y ) = P(X ∧Y ) (5.5)
con f (X ⇒ Y ) =supp(X ⇒ Y )
supp(X)=
supp(X ∪Y )supp(X)
=P(X ∧Y )
P(X)= P(Y |X) (5.6)
Using the definitions of confidence and support, we can define various measuresthat take into account both of these aspects, and thus account both for the frequency andthe effectiveness of a rule X in predicting the target Y. We carry out experiments usingfour different informativeness measures with different properties, namely: Interest (alsocalled Lift) [BMUT97a], Leverage [PS91], Jaccard similarity [VR86, TKS04, BCJ10]and J-measure [GS91], as presented in Equations 5.7 - 5.10.
• Lift or Interest measures how many times more often X and Y occur together thanexpected if they were statistically independent. Ranges from 0 to infinity (inf).
interest(X ⇒ Y ) =con f (X ⇒ Y )
supp(Y )=
P(X ∧Y )P(X) ·P(Y )
(5.7)
• Leverage calculates the difference between the co-occurrence of X and Y (the ruleand the uncertainty) and the predicted co-occurrence if X and Y were statisticallydependent. Ranges from -1 to 1.
leverage(X⇒Y ) = supp(X⇒Y )−supp(X) ·supp(Y ) = P(X∧Y )−P(X) ·P(Y )(5.8)

196 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
• Jaccard’s coefficient measures the similarity between asymmetric information,commonly used for binary variables. Like the cosine similarity, it captures thecorrelation between two concepts, and can identify both negative and positivecorrelation (as well as independence). Ranges from -1 to 1.
jaccard(X⇒Y )=supp(X ∪Y )
supp(X)+ supp(Y )− supp(X ∪Y )=
P(X ∧Y )P(X)+P(Y )−P(X ∧Y )
(5.9)
• J-measure estimates the cross-entropy between the distributions of the rule and theevent uncertainty. The greater the value of J-measure the greater the correlation ofthe two distributions, and thus the greater the informativeness of the rule. Rangesfrom 0 to 1.
J−measure(X ⇒ Y ) = P(X ∧Y ) · log(P(Y |X)
P(Y )+P(X ∧ Y ) · log(
P(Y |X)
P(Y )(5.10)
We use two different tests to evaluate the efficiency of the informativeness measures.The first one is performance oriented, evaluating the performance of different measuresin terms of Precision, Recall and F-score, while the second one, is rather qualitative,allowing us to gain insights into the type of rules selected by each measure.
For the first test, we apply each filter to the GENIA-MK and BioNLP-ST corporaand evaluate the performance in terms of precision, recall and F-score. We compareperformance by varying the size of the final selected rule-set from 500 rules to 10 rules.We also compare the performance against a random and a frequency-based selection ofrules. The performance is calculated using 10-fold cross-validation.
The result of this comparison is presented in Figures 5.15 and 5.16. We can see thatall methods outperform the random and frequency-based baselines, with the exceptionof the J-measure, which seems ill-suited to the task, as its discriminative strength isoutperformed by the frequency baseline, especially for small rule-sets. Overall, Lift
seems to be the measure that is best able to discriminate between certain and uncertainevents on both corpora, consistently maintaining high precision, even for larger sets ofrules.
For the second, “qualitative” evaluation of the efficiency of each measure, which

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 197
(a) Random rule selection (b) Frequency-based rule selection
(c) Lift-based rule selection (d) Leverage-based rule selection
(e) Jaccard-based rule selection (f) J-measure-based rule selection
Figure 5.15: Rule selection performance when applying different measures for a varyingsizes of rule-sets. Applied to and evaluated on GENIA-MK corpus for precision, recalland F-score. We focus on the F-score performance as the main criterion. The red boxindicates the measure the achieves the best performance for the majority of rule-set sizes(i.e., Lift).

198 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
(a) Random rule selection (b) Frequency-based rule selection
(c) Lift-based rule selection (d) Leverage-based rule selection
(e) Jaccard-based rule selection (f) J-measure-based rule selection
Figure 5.16: Rule selection performance when applying different measures for a varyingsizes of rulesets. Applied to and evaluated on BioNLP-ST corpus for precision, recalland F-score. We focus on the F-score performance as the main criterion. The red boxindicates the measure the achieves the best performance for the majority of rule-set sizes(i.e., Lift).

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 199
is intended to provide us with more interpretable insights into their discrimination po-tential, we design an experiment where we identify the type of rules predicted by eachmeasure presented in Equations 5.7 - 5.10. For this task, we initially extracted a non-filtered rule-set from the combination of GENIA-MK and BioNLP-ST corpora. Thisrule-set was generated by considering all potential rules that can be extracted for eventsannotated as uncertain without applying any further limitations in terms of uncertaintycues. The assumption here is that if the event is uncertain, there must be an uncertaintycue in the same sentence that the rules are trying to capture. We still apply the rulelimitation of length < 3, where length corresponds to the number of edges (relations) inthe path between the event trigger and the starting word (TS) of the rule. Subsequently,we randomly selected a subset of that ruleset amounting to 500 rules and we manuallyclassified each extracted rule into one of five categories: Certain, Dubious, Irrelevant,Stopword, Uncertain. We defined each category as:
• Certain: Rule that contains at least one term that is an indicator of certainty (e.g.,cues such as “prove”, “confirm” etc.)Example : without ·ARG2 ·doubt ·ARG2·< Event >
• Dubious: Rule that has a cue that could be related to uncertainty under someconditions but due to lack of additional context it is hard to classify it accurately,such as “particularly”, “how” etc.Example: or ·ARG2 · exemplify ·ARG1·< Event >
• Stopwords: Rule that contains solely stopwords (The stopword list was compiledbased on http://www.ranks.nl/stopwords)Example: the ·ARG1 ·and ·ARG2·< Event >
• Uncertain: Rule that contains at least one term that is an indicator of uncertainty(eg. cues such as “may”, “likely” etc.)Example: poorly ·ARG2 ·understand ·ARG1·< Event >
• Irrelevant: Rule that does not fall under any of the above categories. Usually thesecontain biomedical terms that are found in the vicinity of event triggers, but donot form not part of them, such as “synergistic”, “angiogenic” etc.Example: intracellular ·ARG1·< Event >
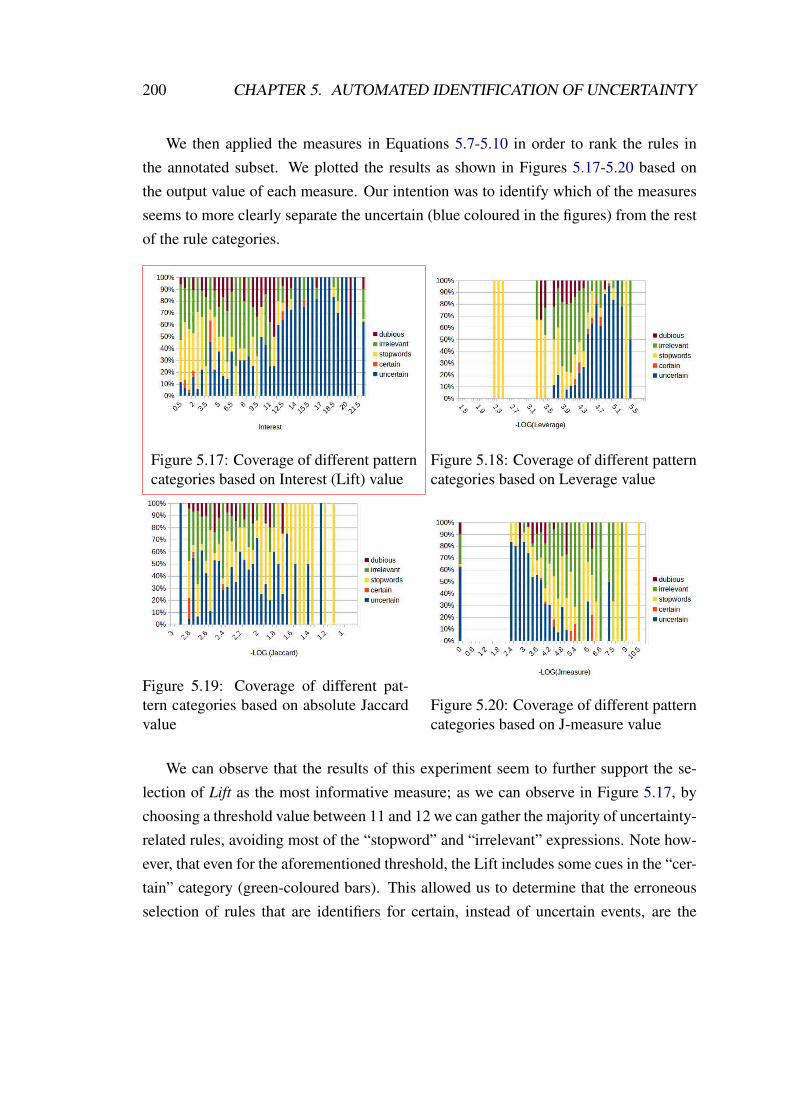
200 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
We then applied the measures in Equations 5.7-5.10 in order to rank the rules inthe annotated subset. We plotted the results as shown in Figures 5.17-5.20 based onthe output value of each measure. Our intention was to identify which of the measuresseems to more clearly separate the uncertain (blue coloured in the figures) from the restof the rule categories.
Figure 5.17: Coverage of different patterncategories based on Interest (Lift) value
Figure 5.18: Coverage of different patterncategories based on Leverage value
Figure 5.19: Coverage of different pat-tern categories based on absolute Jaccardvalue
Figure 5.20: Coverage of different patterncategories based on J-measure value
We can observe that the results of this experiment seem to further support the se-lection of Lift as the most informative measure; as we can observe in Figure 5.17, bychoosing a threshold value between 11 and 12 we can gather the majority of uncertainty-related rules, avoiding most of the “stopword” and “irrelevant” expressions. Note how-ever, that even for the aforementioned threshold, the Lift includes some cues in the “cer-tain” category (green-coloured bars). This allowed us to determine that the erroneousselection of rules that are identifiers for certain, instead of uncertain events, are the

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 201
major causes for precision loss (false positives) that occur in the rule based-approach.
We also considered combinations of measures, but no combination of thresholdsseemed to better discriminate uncertain rules from the rest . Based on Figures 5.17–5.20 we decided that the use of Lift (or Interest) was sufficiently discriminatory as afilter for our experiments.
5.3.3 Machine learning approach
We will now examine how machine learning and feature optimisation can be of benefitto our approach. Using a machine learning classifier, we examine whether the extracteddependency patterns described in the previous section can be used as features that canboost performance (enriched dependency n-gram features). Moreover, we experimentwith the use of additional contextual features covering lexical, syntactic and semanticaspects within a sentence. We compare the results obtained via the machine learningapproach to those obtained by rule application, as well as to other approaches in litera-ture.
As discussed earlier, the main focus of this work is to explore the efficiency of differ-ent feature structures, and especially dependency ones. Yet, some consideration needsto be given to the selected ML classification algorithms. We have seen in Section 3.3.3that variations on the SVM and CRF classifiers seem to be the preferred approachesfor the cue-scope approach on uncertainty classification, especially in the CoNLL task[FVM+10]. However, since then it has been shown that significant improvement canbe gained by the use of other statistical methods and algorithms, such as Jean et al.[JHR+16] who employed a Bayesian model.
We cast the uncertainty identification for events as an instance classification prob-lem, rather than sequence labelling, which was the case for the cue-scope approach.Moreover most of the features are categorical so we need to consider algorithms thatcan deal with categorical or binary data 15. As such we direct our attention towardsensemble methods.
As the main algorithm for the experiments, we choose a random forest classifier.Random forests, along with boosting and Bayesian neural networks have been shownto perform best in classification tasks with regards to the test set error rate [BDL08].
15all categorical features can be binarised

202 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Moreover, RF algorithms have shown to be the most robust and efficient when tested ona wide range of classification tasks against other classifiers [FDCBA14]. More impor-tantly, random forests require minimal parameter tuning compared to other ensemblealgorithms (eg. gradient boosting) and as such they are deemed more suitable for ourmain goal [JWHT13, BS16]. We expect that with a relatively large number of trees andtree size, we will be able to achieve optimal performance and avoid over-fitting.
Setting of hyper-parameters was decided based on related literature and fine-tuningexperiments, as follows.
• Maximum tree size was set to infinite. It has been shown that a allowing forlarger trees has a positive impact on performance, but can compromise the size ofthe resulting models. Our experiments showed that even when using the GENIA-MK and BioNLP-ST documents together for training, the resulting models did notsurpass 80 MB in size, which was easily manageable by Argo platform withoutsignificantly impacting the execution and annotation time.
• Number of features randomly evaluated at each node (K) was set to K =
log2(M)+1, where M is the dimensionality of the feature space. The choice wasbased on the experiments performed by Breiman in [Bre01, Bre04] and Bernardet al. in [BAH07]. Recently, the use of K =
√M has been proposed as a valid
alternative, but experimenting with this parameter is reserved for future work[BHA09].
• Number of trees in the forest was set to 300 in our experiments, yet, we didn’tobtain a statistically significant difference 16 when varying this number between100 and 500. Thus and to optimise the model in terms of size and running time,we propose the use of 100 trees.
• Number of iterations was set to 500 epochs
* Other parameters were left to the default value used in the WEKA implementationfor the RF classifier. Such parameters are:
– The minimum numeric class variance proportion of train variance for split,that is pre-set to 1e−3,
16 p < 0.8

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 203
– The minimum number of instances per leaf, that is pre-set to 1
For the machine learning approach we employed a Random Forest classifier [LW02]using the WEKA API17.In Chapter 4 we provide additional details on how to input thedesired parameters in the WEKA components.
While the main aim is to experiment with the performance, properties and robust-ness of different feature combinations, for reasons of completeness, we performed acomparison of performance with other classifiers, also implemented in the WEKA APIin order to validate the suitability of our classifier choice.
All of the components necessary for the evaluation, from the sentence pre-processingto the dependency parsing (Enju) and the WEKA classifiers were implemented as stan-dalone components in Argo [BNNS+17], and used in pipelined workflows as describedin Chapter 4.
5.3.3.1 Additional features
As discussed earlier, the dependency patterns can be used as features for machine learn-ing in the form of enriched dependency n-grams. We thus incorporate them in the MLmodule, using the search space constraints described in the previous sections. How-ever, especially with the addition of filtering and limiting conditions, such features aresometimes insufficient in terms of their ability to discriminate certain from uncertainevents and are prone to be over-fitted to specific examples, and as such, they may failto account adequately for the semantic context that renders an event uncertain. Hence,we have chosen to complement them with additional features covering further seman-tic, lexical and syntactic aspects. We wanted to explore the potential effect of differentfeature types on performance, and thus we selected a wide range of features coveringdifferent textual aspects, namely lexical, syntactic, grammatical and semantic.
To cover lexical and grammatical aspects, we use surface forms, lemmas and partsof speech (POS) tags. For verbs, we extend the features to include additional grammat-ical details such as tense, aspect, and mode. In additional to the lexical features, weaccount for semantic and event-related aspects, we include the event type, the triggersurface form and lemma (as a more elaborate representation of the event type), as well
17http://weka.sourceforge.net/doc.stable/

204 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
as the complexity level of the event (i.e., either nested or top level). We also use a com-piled dictionary-type list of uncertainty cues based on the annotations of GENIA-MK,BioNLP-ST and related literature [KRCR15, MYGHA13].
We also further extend the dependency-based features with features accounting forthe length of the dependency path and whether there is a direct dependency betweenevents and uncertainty cues. Capturing the dependency path length is an indirect way toaccount for longer dependency patterns that are excluded by the length filters applied tothe dependency n-gram generation (see Section 5.3.2.1.1).
To enrich the syntax-related traits, we use a series of constituency-related features,where we use the definition of constituent as a clause element. Then, based on theconstituency graph of the sentence, we analyse the command of identified uncertaintycues over the different structural elements of an event (trigger, arguments, etc). Theconcept of a command relation was first introduced by Langacker [Lan69] as a meansof identifying the nodes affected by a given element in the constituency parse tree of asentence. He defined an S-command relation as follows: ‘a node X commands a nodeY if neither X nor Y dominates the other and the S (sentence) node most immediatelydominating X also dominates Y’. In general, constituency parsing has been explored indifferent ways for the identification of the scope and coverage of uncertainty or negationcues [NTA13a, SN10, QLZ+16, ZPL13]. We focused our constituent feature generationon searching for S-, VP- and NP-command relations between the identified uncertaintycue and the event-trigger and/or event-argument.
To generate the dependency trees, POS tags, lemmas and, in general, syntacticaland grammatical information supporting the feature generation, we use the output ofthe Enju parser for each sentence. In Table 5.3 we present a summary of all featuresalong with a short description, and their output format to facilitate reproduction of ex-periments.
18Command of a word a over word b, signifies that in the syntactic tree a is the head of a branch thatcontains b

5.3. A NOVEL PROPOSAL FOR UNCERTAINTY IDENTIFICATION 205
Table 5.3: Features used for uncertainty identification with the RF classifier. The outputcolumn shows the type of the generated feature; Nom. denotes nominal features, Bin.denotes binary features and Num. denotes numeric features.
Cat. Sub-cat. Feature Output
Event
LexicalEvent trigger surface form Nom.
POS tags Nom.
SemanticEvent type Nom.
Argument type Nom.Argument role Nom.
Complexity Complex/simple Bin.
Cue LexicalExistence of cue (dictionary mapping) Bin.
Cue surface form Nom.POS tag of the cue Nom.
Event&Cue
Relativeposition
# of words between cue and event trigger Num.Position of cue on the left/right of the event trigger Bin.
DependencyDirect dependency between cue and trigger Bin.
Shortest dependency path length Num.Existence of dependency path rule Bin.
Dependency path rule Nom.Constituency(syntactic)
Command18of cue over trigger Bin.Command of cue over arguments Bin.

206 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
5.4 Evaluation and results
In this section, we compare the performance of our methods on different corpora andcompare the impact of using different feature and training configurations. We aim toidentify the strongest features as well as the limitations of the proposed machine learningapproach. Hence, in the following sections we discuss and compare performance ongold-standard corpora as well as on the pathway models described in Section 5.2.2.
5.4.1 Experiments on gold corpora
We evaluated our approach on the GENIA-MK corpus and the BioNLP-ST corpora, asdescribed in Section 5.2.
We firstly applied the rule-based approach. As described in Section 5.3.1.3, wetested various approaches to rule generation. After identifying the Lift measure as thebest discriminatory formula for rule informativeness, we paired it with predefined un-certainty cue lexica (cue-lists). We further experimented with a constrained set of cuesbased on the pre-compiled cue list19 (indicated as CombF in Table 5.4). The lexicon-bound rule generation was compared to the Lift-guided one as well as to the combinedresult. In Table 5.4, we show that filtering using the Lift information measure is more ef-ficient. However, the combination of the two filtering methods does not seem to furtherimprove the results.
We then compared the results with the performance of the random forest (RF) clas-sifier as well as its combination with the rule-based approach. To combine the twoapproaches, we explore two possibilities: (1) a sequential combination of two indepen-dent classifiers, the rule-based one and the RF one, where the ML componenent doesnot include the enriched dependency n-gram features; and (2) the incorporation of therule patterns as enriched dependency n-gram features along with the rest of the featuresof the RF classifier. For the sequential combination we use the union of the uncertainannotations for each event. Thus, assuming URF is the uncertainty decision of the RFclassifier and URB the uncertainty decision of the rule-based one, the final uncertaintydecision by the sequentially combined system UComb will be:
19Access to files containing the cues-lists used in various experiments is provided in Section 4.1.4.

5.4. EVALUATION AND RESULTS 207
UComb =
1, i f URF +URB > 0
0, else(5.11)
This means that if either classifier has determined that the event is uncertain, thenthe “uncertain” value will be assigned.
In Table 5.4, we compare the performance of the rule-based and machine learningbased combinations. Rule-based approaches are indicated by RB and machine learningby ML. For RB configurations, the baseline corresponds to the performance of randomrule selection (for a rule-set size of 200), while LexF signifies lexical filtering and Li f tF
the Lift-based filter (a ruleset size of 200 was also used, based on the optimal perfor-mance derived for the Lift filter as presented in Figures 5.15c and 5.16c). Moreover, forthe ML approach we present the incorporation of the enriched dependency n-grams asfeatures (noted as EDNG) and we also compare them with simple dependency n-grams(noted as DNG) which do not include the dependency role, but only the surface form ofthe tokens in the dependency path. Note that the the search space constraints were alsoapplied for the DNG case.
All the results have been calculated using 10-fold cross validation. For the imple-mentation of the 10-fold cross-validation we did not use the default random fold gener-ation of the WEKA API, as that would bias the system. The traditional fold generationapproach that randomly selects event instances to be represented in each fold allows fortwo events taken from the same sentence to be attributed to different folds. However,since many features use information from the same sentence, this means that it is possi-ble that the model will have been trained on the same sentence in which an instance inthe test set occurs. Indeed, when using the default 10-fold cross-validation approach, theresults that we obtained exhibited a performance increase of around 8%-11%. For thisreason, for all reported results we implement document-based fold generation, wheredocuments instead of classification instances are randomly attributed to one of the 10folds. As such, we attempt to avoid the common problem of presenting unrealisticallyoptimistic classification performance.
The best results are obtained by incorporating the enriched dependency n-gram fea-tures within the RF classifier. We note that the performance on the GENIA-MK corpusis consistently higher for all combinations of settings. We attribute this to the fact that

208 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Table 5.4: Comparative evaluation of uncertainty classification approaches on GENIA-MK and BioNLP-ST corpora. RB corresponds to rule-based methods while ML tomachine learning ones. Rule filters are noted as: LexF for lexical (cue-list) constraints,LiftF for the lift-based filtering and CombF for the sequential combination of the twofilters. DNG and EDNG correspond to the dependency and enriched dependency n-grams respectively. Best results for each performance metric and corpus are noted withbold.
Corpus System Precision Recall F-score
GENIA-MK
RB baseline 0.53 0.39 0.45RB LexF 0.81 0.52 0.63RB LiftF 0.92 0.71 0.80
RB CombF 0.91 0.52 0.66ML plain 0.79 0.67 0.72
ML + RB (UComb) 0.76 0.77 0.77ML + DNG 0.82 0.70 0.76
ML + EDNG 0.94 0.83 0.88
BioNLP-ST
RB baseline 0.49 0.63 0.55RB LexF 0.42 1.0 0.59RB LiftF 0.80 0.73 0.76
RB CombF 0.80 0.72 0.76ML plain 0.82 0.64 0.73
ML + RB (UComb) 0.35 0.77 0.48ML + DNG 0.80 0.48 0.60
ML + EDNG 0.87 0.68 0.76
the BioNLP-ST corpus consists of a number of different corpora, with differences intheir annotation procedures. For example, we found that events introduced with theword “suggest” in the sentence were consistently annotated as uncertain in the BioNLP2013 tasks, but not in the BioNLP 2011.
It is also noticeable that in the case of the BioNLP-ST corpus, the rule-based ap-proaches achieve a better balance between precision and recall, obtaining the same F-score with the ML+EDNG approach when using the combined filters (RB CombF).Further investigation would be necessary to identify the exact reasons for this behaviour.In general, it seems to be the case that the ML methods are more “conservative”, result-ing in fewer uncertainty predictions and thus lower recall. In contrast, the RB methodsare more greedy, determining more events to be uncertain and thus achieving better

5.4. EVALUATION AND RESULTS 209
recall, but compromising precision.
In both the BioNLP-ST and GENIA-MK corpora, we confirm our hypothesis H1
and show that enriched dependency n-gram features can provide a significant20 boostto the performance of uncertainty identification, compared to simple dependency n-grams. In the following sections we further discuss and analyse the performance in theuncertainty identification task, focusing on the ML+EDNG system, which obtained thebest performance.
5.4.1.1 Comparison with existing work on the same corpora
We do not directly compare our work with other existing approaches that have beentested on the same corpora, as they did not use the same configurations of the corpusannotations. Nonetheless, to put our results into perspective, we report the most rel-evant previously reported results, i.e., approaches that have achieved the top reportedperformance on the same corpora. For the BioNLP-ST corpus, the best performancein terms of uncertainty identification is reported by Stenetorp [SPO+12b] who obtainedan F-score of 0.52 for the EPI track, 0.40 for the Genia track and 0.37 for the ID trackof BioNLP 2011. In contrast, we obtain an F-score of 0.64 for the EPI track, 0.70 forthe Genia track and 0.48 for the ID track. Note that for the aforementioned results, weheld back the corpus that constitutes the test set for the track, and trained the model onthe remainder of the BioNLP-ST corpora. Hence, the comparison with the results byStenetorp is approximate.
On GENIA-MK, the best results are reported by Kilicoglu [KRCR15] and Miwa[MTM+12]. However, this work concerned the 3-level classification problem ratherthan the binary one. For comparison reasons, we re-purposed the machine learningclassifier by re-training it on the GENIA-MK with the original 3-level labels: L1 (highlyuncertain), L2 (somehow uncertain), L3 (highly certain). We present the results in Table4.5, where we can observe that while our system achieves better accuracy, and better F-score for L3 and L1, Kilicoglu and Miwa 21 are able to identify L2 and with significantlyhigher F-score. We speculate that the linguistic patterns related with L2 were harderto capture with our dependency and lexical features. However, further research and
20 p < 0.001 for t-test21We used the 10-fold cross validation results of Miwa et al. for comparison.

210 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
error analysis would be required in order to draw some more insightful conclusions andfurther improve performance.
Note however, that for this comparison, the parameters and features of our methodswere not re-purposed or further tuned for the 3-level classification system. Also, notethat the results of Kilicoglu are not a product of 10-fold cross-validation but of the ap-plication of their rule-based system on the whole GENIA-MK corpus. Thus, we believethat these initial results are quite encouraging and we expect that the performance onthe 3-level classification problem could be further improved with more task-orientedfeature engineering. While this would be an interesting challenge on its own, we choseto focus on the binary classification problem, for the reasons discussed in Sections 3.3.5and 5.1.
Table 5.5: Performance comparison against Miwa et al. and Kilicoglu et al. on the3-level classification problem applied to GENIA-MK corpus. Best results for each per-formance metric and uncertainty class are noted with bold.
Kilicoglu Miwa Our SystemClass Prec Rec F-sc Acc. F-sc Prec Rec F-sc AccL3 97.3 97.7 97.5 97.8 96.9 99.6 98.2L2 73.1 61.6 66.6 73.0 90.6 50.8 65.1L1 61.4 76.2 68.1 78.6 86.6 82.9 84.7CL 95.1 - 96.4
5.4.1.2 Additional experiments on feature engineering
We further explored the impact of enriched dependency n-grams and investigate theircontribution to the performance of the classifier, compared to features. To this end, weseparated features into specific classes based on their type: Lexical (L), Constituency(C), Dependency (D), Event-based (E) and finally the enriched dependency n-grams(EDNG). We investigated the contribution of these feature classes in two ways: (1)by performing ablation tests where we test the efficiency of different combinations ofthe aforementioned feature types and (2) by calculating the information gain for eachfeature, ordering features by informativeness, and then looking at the representation ofeach class in the top ranking features. Since the results on the GENIA-MK corpus werebetter in terms of F-score and more consistent, this corpus was chosen for the feature
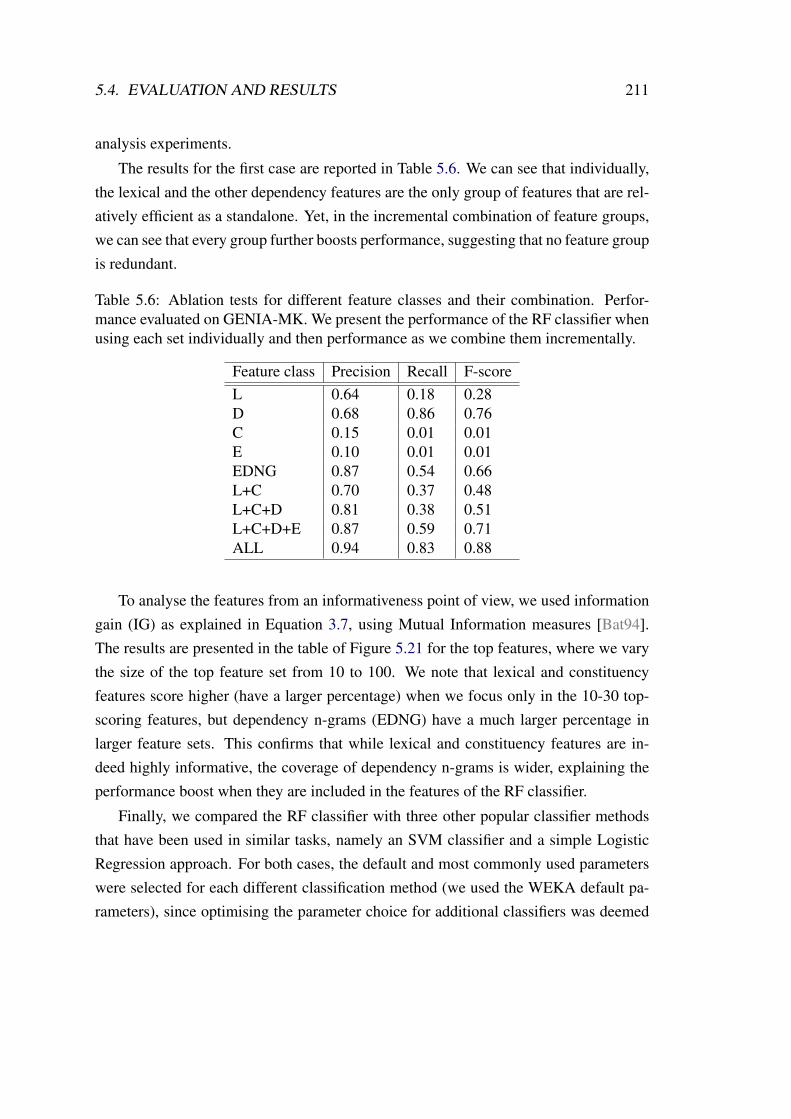
5.4. EVALUATION AND RESULTS 211
analysis experiments.
The results for the first case are reported in Table 5.6. We can see that individually,the lexical and the other dependency features are the only group of features that are rel-atively efficient as a standalone. Yet, in the incremental combination of feature groups,we can see that every group further boosts performance, suggesting that no feature groupis redundant.
Table 5.6: Ablation tests for different feature classes and their combination. Perfor-mance evaluated on GENIA-MK. We present the performance of the RF classifier whenusing each set individually and then performance as we combine them incrementally.
Feature class Precision Recall F-scoreL 0.64 0.18 0.28D 0.68 0.86 0.76C 0.15 0.01 0.01E 0.10 0.01 0.01EDNG 0.87 0.54 0.66L+C 0.70 0.37 0.48L+C+D 0.81 0.38 0.51L+C+D+E 0.87 0.59 0.71ALL 0.94 0.83 0.88
To analyse the features from an informativeness point of view, we used informationgain (IG) as explained in Equation 3.7, using Mutual Information measures [Bat94].The results are presented in the table of Figure 5.21 for the top features, where we varythe size of the top feature set from 10 to 100. We note that lexical and constituencyfeatures score higher (have a larger percentage) when we focus only in the 10-30 top-scoring features, but dependency n-grams (EDNG) have a much larger percentage inlarger feature sets. This confirms that while lexical and constituency features are in-deed highly informative, the coverage of dependency n-grams is wider, explaining theperformance boost when they are included in the features of the RF classifier.
Finally, we compared the RF classifier with three other popular classifier methodsthat have been used in similar tasks, namely an SVM classifier and a simple LogisticRegression approach. For both cases, the default and most commonly used parameterswere selected for each different classification method (we used the WEKA default pa-rameters), since optimising the parameter choice for additional classifiers was deemed
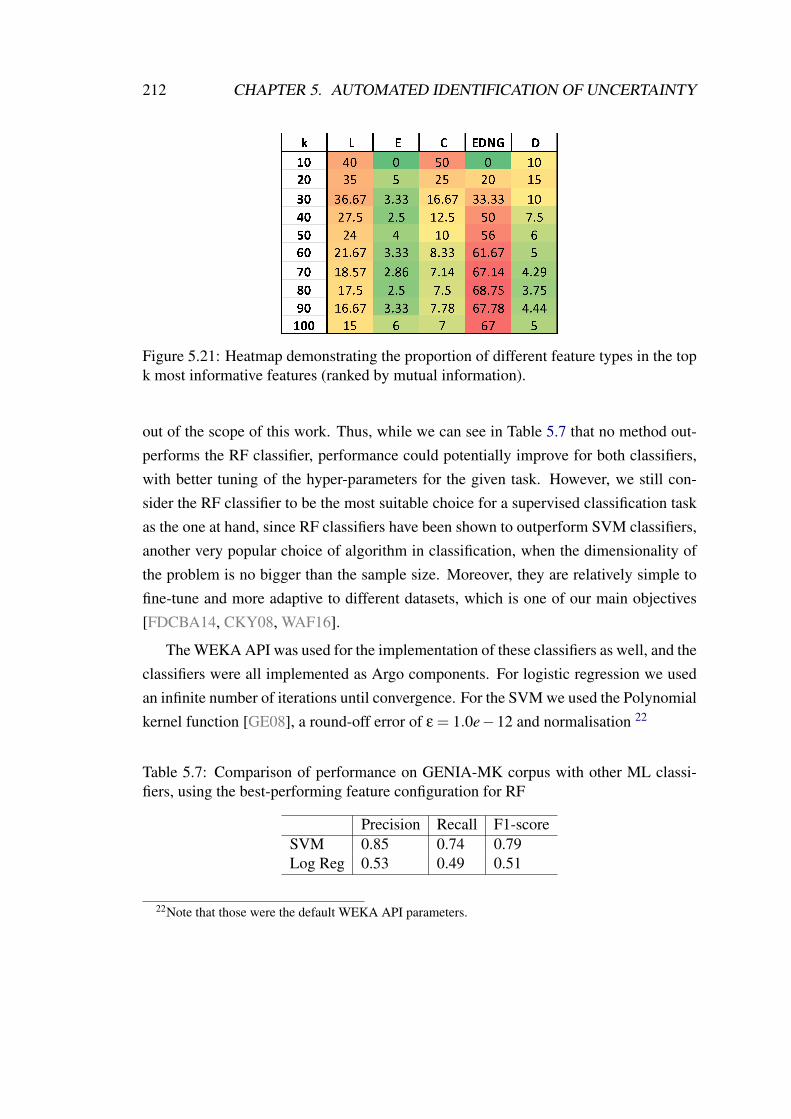
212 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.21: Heatmap demonstrating the proportion of different feature types in the topk most informative features (ranked by mutual information).
out of the scope of this work. Thus, while we can see in Table 5.7 that no method out-performs the RF classifier, performance could potentially improve for both classifiers,with better tuning of the hyper-parameters for the given task. However, we still con-sider the RF classifier to be the most suitable choice for a supervised classification taskas the one at hand, since RF classifiers have been shown to outperform SVM classifiers,another very popular choice of algorithm in classification, when the dimensionality ofthe problem is no bigger than the sample size. Moreover, they are relatively simple tofine-tune and more adaptive to different datasets, which is one of our main objectives[FDCBA14, CKY08, WAF16].
The WEKA API was used for the implementation of these classifiers as well, and theclassifiers were all implemented as Argo components. For logistic regression we usedan infinite number of iterations until convergence. For the SVM we used the Polynomialkernel function [GE08], a round-off error of ε = 1.0e−12 and normalisation 22
Table 5.7: Comparison of performance on GENIA-MK corpus with other ML classi-fiers, using the best-performing feature configuration for RF
Precision Recall F1-scoreSVM 0.85 0.74 0.79Log Reg 0.53 0.49 0.51
22Note that those were the default WEKA API parameters.

5.4. EVALUATION AND RESULTS 213
The lexical features (Section 5.3.3.1), which rely heavily on a pre-compiled dictio-nary cue list or existing cue annotations, showed high scores in the feature analysis, andboost precision. However, since this could bias the performance, and could affect thegeneralisation and adaptation of our system to other domains and datasets, we carriedout two additional experiments, presented in Table 5.8, to assess the extent to which theselection of the initial cue list affects performance.
Firstly, we chose to swap the cue list with one automatically derived from the anno-tations of the ACE 2005 corpus [TNMA17], i.e., a newswire corpus, recently annotatedwith meta-knowledge. This dictionary swap also allows us to assess whether the uncer-tainty identification task is domain-specific. Interestingly, while intuitively we assumethat expressions of uncertainty are domain-independent, it turned out that the range ofexpressions in the general/newswire domain is wider and the cues are more complicated(often multi-word expressions), leading to significantly decreased performance for bothcorpora, and especially for BioNLP-ST.
Secondly, since we have a corpus annotated for uncertainty (GENIA-MK), we em-ployed the enriched dependency n-grams and the Lift [BMUT97b] informativeness mea-sure in order to indirectly infer potential uncertainty cues. Specifically, we used therule-based approach to extract rules, and the Lift measure to rank them as described inSection 5.3.2.2. Rule patterns were then sorted according to Lift [BMUT97b], and weassumed that most of the tokens found as heads (TS) within these rules would constituteuncertainty cues. Hence, the cue list was automatically compiled from those patterns,removing stopwords and retaining only the top 150 cue candidates (almost double thesize of the original cue list and thus more noisy).
Interestingly, while the performance dropped on both corpora, it still produced rea-sonable results, and the precision remained high (drop by one point). Indeed, the com-promise in this case was mainly in terms of recall, since some of the correct cues andrule patterns are lost during filtering. However, in the case of the BioNLP-ST corpus,which is substantially larger than GENIA-MK, the drop in recall is considerably smaller.This result seems promising, and paves the way for further experiments towards semi-supervised uncertainty identification.

214 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Table 5.8: Comparative evaluation on GENIA-MK and BioNLP-ST corpora using dif-ferent approaches for rule extraction and cue identification
Corpus System Precision Recall F-score
GENIA-MKBio cues 0.94 0.83 0.88
ACE cues 0.82 0.86 0.84No cues 0.93 0.67 0.78
BioNLP-STBio cues 0.87 0.68 0.76
ACE cues 0.61 0.53 0.58No cues 0.86 0.66 0.74
5.4.2 Evaluation on pathway models
The evaluation against gold-standard corpora confirms both the potential to fine-tunethe proposed methods and confirms the effectiveness of the proposed approach for theidentification of uncertain events. However, since the goal of the proposed methods is tofacilitate literature processing for researchers in biomedicine to aid in building pathwaymodels, it was deemed necessary to evaluate the method on the two pathway datasets:the Leukemia pathway corpus and the Ras-melanoma corpus 5.2.2).
For this stage of the evaluation, we focused on the text of the evidence passagesthat were linked to the interactions. For both use cases we firstly applied EventMine[MPOA13] to identify events in text, and then applied our uncertainty identificationsystem to the identified events and generated a small test corpus with events annotatedas [CERTAIN, UNCERTAIN]. The automatically annotated events were then evaluatedby domain experts using the Brat annotation tool [SPT+12].
5.4.2.1 The Leukemia use-case
For this use case we decided to use two groups for evaluation with slightly differenttasks.
5.4.2.2 Binary evaluation on Leukemia pathway corpus
Group #1 consists of 7 annotators, working in the field of biomedicine and leukemia: 4PhD students, 2 post-doctoral researchers and 1 Professor in the field. They were askedto evaluate each event in a binary manner [CERTAIN, UNCERTAIN] using only the

5.4. EVALUATION AND RESULTS 215
information provided in the sentence in which the event was mentioned. Overall, 260evidence passages (ranging from 2 to 20 passages for each interaction) were evaluated,of which 12% were flagged as uncertain by our system. Each evaluator was presentedwith the decision of our system for each evidence sentence (bio-event) separately, aswell as the overall decision for each interaction, and was asked to state his/her agree-ment/disagreement for each. The results are presented in Table 5.9. The event washighlighted in the sentence along with its participating entities (arguments). The evalu-ation interface can be accessed on brat23 and the annotation guidelines are available athttps://tinyurl.com/y7776ztl.
A sample screenshot of the annotation procedure is illustrated in Figure 5.22.
Figure 5.22: Brat interface for binary evaluation of the uncertainty of events for theLeukemia pathway corpus.
We then evaluated our system’s predictions against the annotators. As well as cal-culating precision, recall and F-score values, we calculated the overall accuracy per
23http://nactem10.mib.man.ac.uk/bratv1.3/#/Pathway_Annotations/
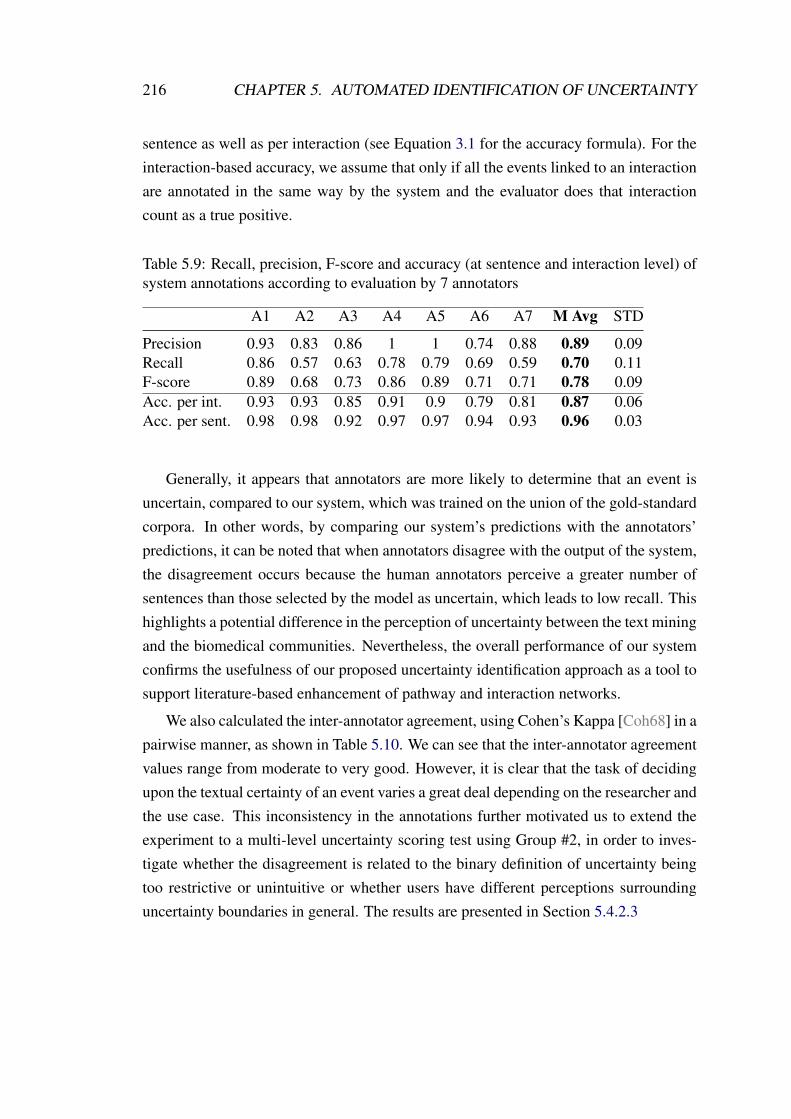
216 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
sentence as well as per interaction (see Equation 3.1 for the accuracy formula). For theinteraction-based accuracy, we assume that only if all the events linked to an interactionare annotated in the same way by the system and the evaluator does that interactioncount as a true positive.
Table 5.9: Recall, precision, F-score and accuracy (at sentence and interaction level) ofsystem annotations according to evaluation by 7 annotators
A1 A2 A3 A4 A5 A6 A7 M Avg STD
Precision 0.93 0.83 0.86 1 1 0.74 0.88 0.89 0.09Recall 0.86 0.57 0.63 0.78 0.79 0.69 0.59 0.70 0.11F-score 0.89 0.68 0.73 0.86 0.89 0.71 0.71 0.78 0.09Acc. per int. 0.93 0.93 0.85 0.91 0.9 0.79 0.81 0.87 0.06Acc. per sent. 0.98 0.98 0.92 0.97 0.97 0.94 0.93 0.96 0.03
Generally, it appears that annotators are more likely to determine that an event isuncertain, compared to our system, which was trained on the union of the gold-standardcorpora. In other words, by comparing our system’s predictions with the annotators’predictions, it can be noted that when annotators disagree with the output of the system,the disagreement occurs because the human annotators perceive a greater number ofsentences than those selected by the model as uncertain, which leads to low recall. Thishighlights a potential difference in the perception of uncertainty between the text miningand the biomedical communities. Nevertheless, the overall performance of our systemconfirms the usefulness of our proposed uncertainty identification approach as a tool tosupport literature-based enhancement of pathway and interaction networks.
We also calculated the inter-annotator agreement, using Cohen’s Kappa [Coh68] in apairwise manner, as shown in Table 5.10. We can see that the inter-annotator agreementvalues range from moderate to very good. However, it is clear that the task of decidingupon the textual certainty of an event varies a great deal depending on the researcher andthe use case. This inconsistency in the annotations further motivated us to extend theexperiment to a multi-level uncertainty scoring test using Group #2, in order to inves-tigate whether the disagreement is related to the binary definition of uncertainty beingtoo restrictive or unintuitive or whether users have different perceptions surroundinguncertainty boundaries in general. The results are presented in Section 5.4.2.3
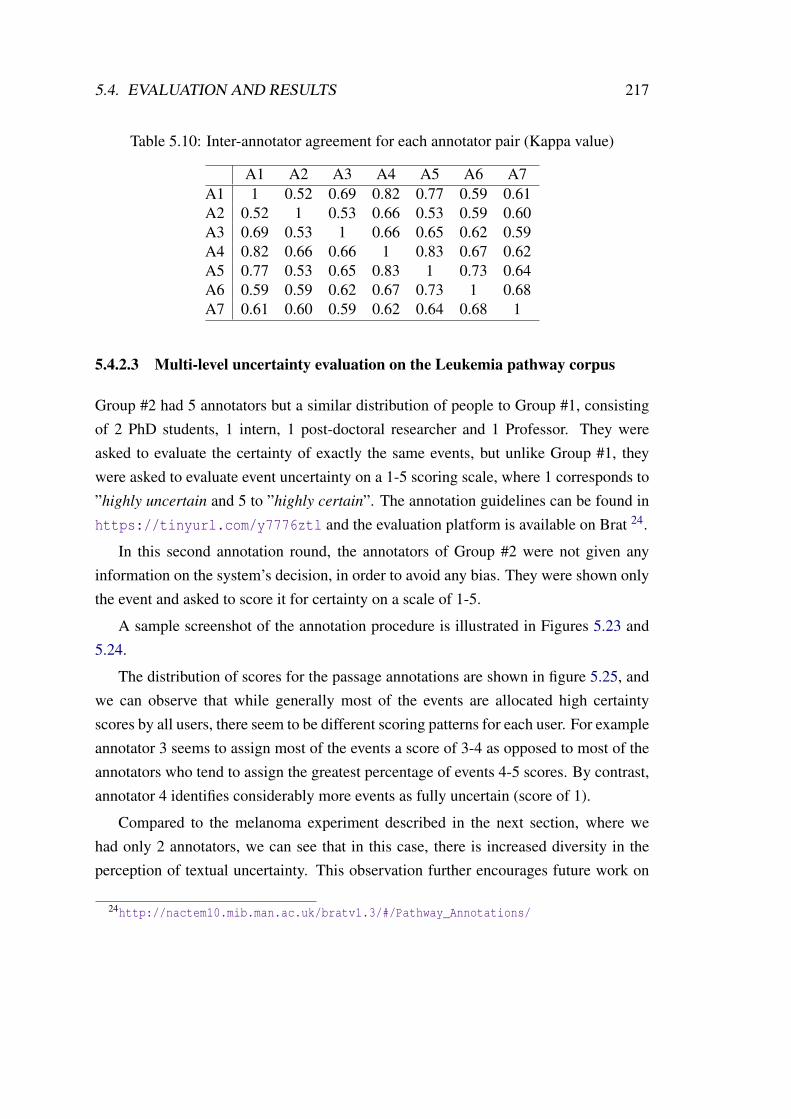
5.4. EVALUATION AND RESULTS 217
Table 5.10: Inter-annotator agreement for each annotator pair (Kappa value)
A1 A2 A3 A4 A5 A6 A7A1 1 0.52 0.69 0.82 0.77 0.59 0.61A2 0.52 1 0.53 0.66 0.53 0.59 0.60A3 0.69 0.53 1 0.66 0.65 0.62 0.59A4 0.82 0.66 0.66 1 0.83 0.67 0.62A5 0.77 0.53 0.65 0.83 1 0.73 0.64A6 0.59 0.59 0.62 0.67 0.73 1 0.68A7 0.61 0.60 0.59 0.62 0.64 0.68 1
5.4.2.3 Multi-level uncertainty evaluation on the Leukemia pathway corpus
Group #2 had 5 annotators but a similar distribution of people to Group #1, consistingof 2 PhD students, 1 intern, 1 post-doctoral researcher and 1 Professor. They wereasked to evaluate the certainty of exactly the same events, but unlike Group #1, theywere asked to evaluate event uncertainty on a 1-5 scoring scale, where 1 corresponds to”highly uncertain and 5 to ”highly certain”. The annotation guidelines can be found inhttps://tinyurl.com/y7776ztl and the evaluation platform is available on Brat 24.
In this second annotation round, the annotators of Group #2 were not given anyinformation on the system’s decision, in order to avoid any bias. They were shown onlythe event and asked to score it for certainty on a scale of 1-5.
A sample screenshot of the annotation procedure is illustrated in Figures 5.23 and5.24.
The distribution of scores for the passage annotations are shown in figure 5.25, andwe can observe that while generally most of the events are allocated high certaintyscores by all users, there seem to be different scoring patterns for each user. For exampleannotator 3 seems to assign most of the events a score of 3-4 as opposed to most of theannotators who tend to assign the greatest percentage of events 4-5 scores. By contrast,annotator 4 identifies considerably more events as fully uncertain (score of 1).
Compared to the melanoma experiment described in the next section, where wehad only 2 annotators, we can see that in this case, there is increased diversity in theperception of textual uncertainty. This observation further encourages future work on
24http://nactem10.mib.man.ac.uk/bratv1.3/#/Pathway_Annotations/

218 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.23: Brat interface for 5-level evaluation of uncertainty events of the Leukemiapathway corpus.
user-adaptive identification of uncertainty, but at the same time suggests that an ob-jective 5-level classification of uncertainty would be too risky to attempt. The resultsof this annotation round concur with the conclusions of Rubin [Rub07] who also con-ducted experiments to compare annotator agreement when annotating event uncertaintyon a binary versus a five-level scale. While Rubin’s experiments were conducted inthe general domain, our conclusions in the biomedical domain are similar, since a finergrained annotation of uncertainty seems to induce even larger discrepancies between theannotators.
The agreement percentages for each annotator pair are presented in Table 5.11. Wecan see that while the agreement percentage for each pair ranges from 55% (annotators1 & 5) to 24% (annotators 4 & 5), for most of the disagreements the scores differ by justone point along the grading scale. The percentage of disagreements that exceed 1 pointon the 1-5 scale is presented in 5.12 and ranges between 13% and 37%, while differencesgreater than 2 points on the scale account for only 1% to 13% of pairwise disagreement
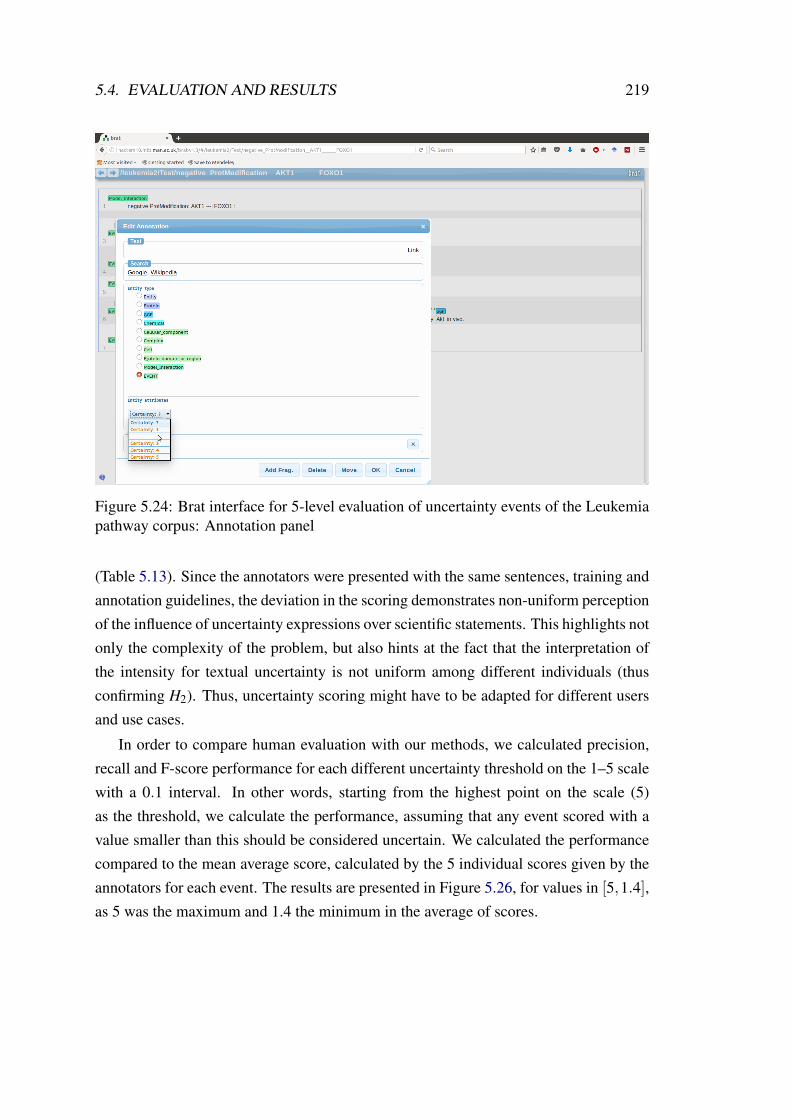
5.4. EVALUATION AND RESULTS 219
Figure 5.24: Brat interface for 5-level evaluation of uncertainty events of the Leukemiapathway corpus: Annotation panel
(Table 5.13). Since the annotators were presented with the same sentences, training andannotation guidelines, the deviation in the scoring demonstrates non-uniform perceptionof the influence of uncertainty expressions over scientific statements. This highlights notonly the complexity of the problem, but also hints at the fact that the interpretation ofthe intensity for textual uncertainty is not uniform among different individuals (thusconfirming H2). Thus, uncertainty scoring might have to be adapted for different usersand use cases.
In order to compare human evaluation with our methods, we calculated precision,recall and F-score performance for each different uncertainty threshold on the 1–5 scalewith a 0.1 interval. In other words, starting from the highest point on the scale (5)as the threshold, we calculate the performance, assuming that any event scored with avalue smaller than this should be considered uncertain. We calculated the performancecompared to the mean average score, calculated by the 5 individual scores given by theannotators for each event. The results are presented in Figure 5.26, for values in [5,1.4],as 5 was the maximum and 1.4 the minimum in the average of scores.
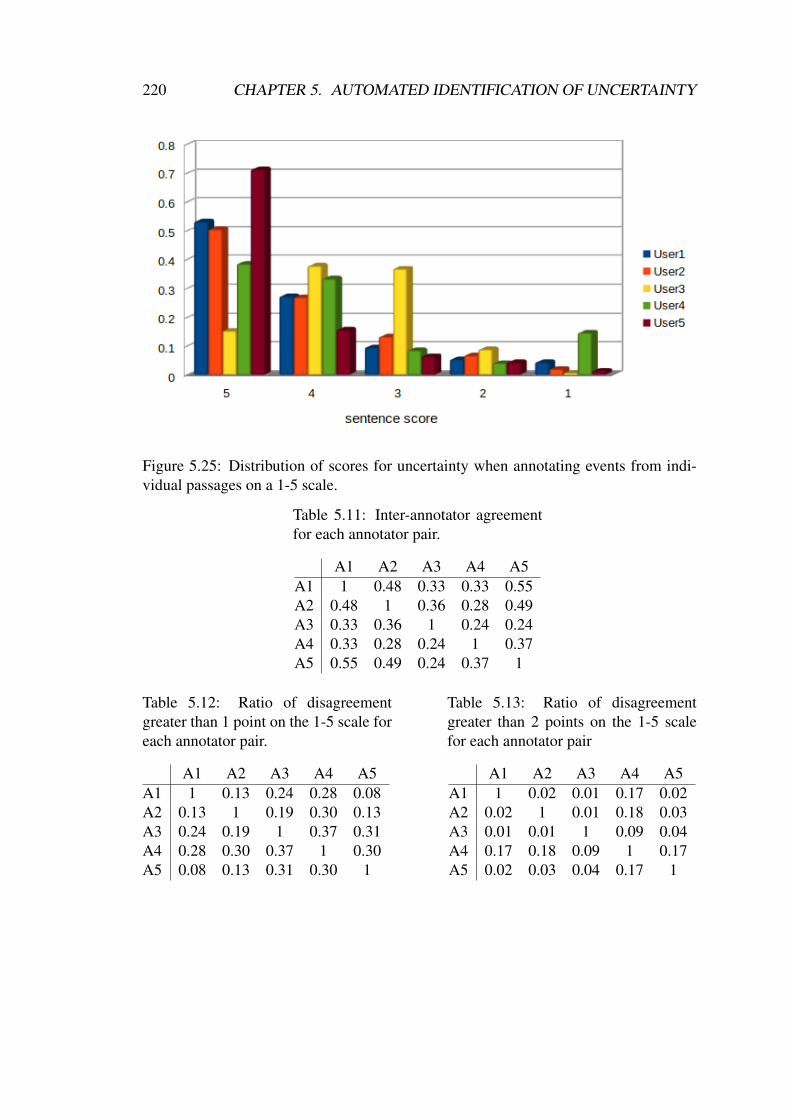
220 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.25: Distribution of scores for uncertainty when annotating events from indi-vidual passages on a 1-5 scale.
Table 5.11: Inter-annotator agreementfor each annotator pair.
A1 A2 A3 A4 A5A1 1 0.48 0.33 0.33 0.55A2 0.48 1 0.36 0.28 0.49A3 0.33 0.36 1 0.24 0.24A4 0.33 0.28 0.24 1 0.37A5 0.55 0.49 0.24 0.37 1
Table 5.12: Ratio of disagreementgreater than 1 point on the 1-5 scale foreach annotator pair.
A1 A2 A3 A4 A5A1 1 0.13 0.24 0.28 0.08A2 0.13 1 0.19 0.30 0.13A3 0.24 0.19 1 0.37 0.31A4 0.28 0.30 0.37 1 0.30A5 0.08 0.13 0.31 0.30 1
Table 5.13: Ratio of disagreementgreater than 2 points on the 1-5 scalefor each annotator pair
A1 A2 A3 A4 A5A1 1 0.02 0.01 0.17 0.02A2 0.02 1 0.01 0.18 0.03A3 0.01 0.01 1 0.09 0.04A4 0.17 0.18 0.09 1 0.17A5 0.02 0.03 0.04 0.17 1
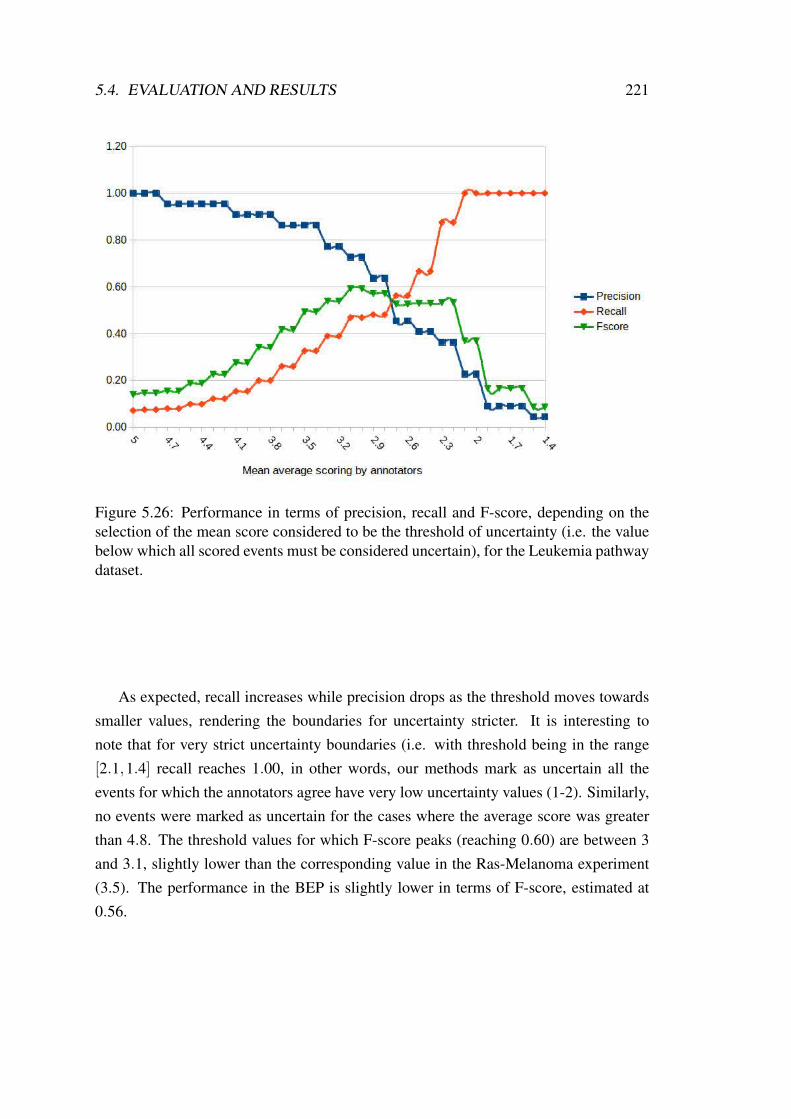
5.4. EVALUATION AND RESULTS 221
Figure 5.26: Performance in terms of precision, recall and F-score, depending on theselection of the mean score considered to be the threshold of uncertainty (i.e. the valuebelow which all scored events must be considered uncertain), for the Leukemia pathwaydataset.
As expected, recall increases while precision drops as the threshold moves towardssmaller values, rendering the boundaries for uncertainty stricter. It is interesting tonote that for very strict uncertainty boundaries (i.e. with threshold being in the range[2.1,1.4] recall reaches 1.00, in other words, our methods mark as uncertain all theevents for which the annotators agree have very low uncertainty values (1-2). Similarly,no events were marked as uncertain for the cases where the average score was greaterthan 4.8. The threshold values for which F-score peaks (reaching 0.60) are between 3and 3.1, slightly lower than the corresponding value in the Ras-Melanoma experiment(3.5). The performance in the BEP is slightly lower in terms of F-score, estimated at0.56.

222 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
5.4.2.4 The Ras-melanoma case
For the Ras-melanoma use case, we examined more closely the perception of uncer-tainty levels and the differences between two annotators. There were just two annota-tors, a post-doctoral researcher and a PhD student, both familiar with and working onRas modelling and networks.
For this annotation task, a subset of the Melanoma documents, amounting to a totalof 392 passages, was selected 25. Each passage contained at least one event that had tobe annotated for uncertainty. Events were extracted with EventMine [MPOA13] and an-notated with uncertainty using our RF classifier with the enriched dependency n-grams,trained on the combination of GENIA-MK and BioNLP-ST corpora. Each event wasclearly indicated in the text along with the participating entities (event-arguments), butthere were no other annotations indicating potential uncertainty markers; it was left upto the annotators to decide if uncertainty about the event was conveyed in the sentence.The system’s decision was also hidden, in order to avoid biasing their responses. Theywere given detailed guidelines, asking them to focus only on the information presentedin each sentence in terms of the certainty and confidence of the author, and discourag-ing them from using any existing background knowledge concerning the veracity of thepresented events. Moreover, they were asked to base their scoring on specific textualevidence. The detailed annotation guidelines that were provided to the annotators areavailable online (https://tinyurl.com/y7776ztl)
The annotators were asked to assess the certainty of the event in each sentence on ascale of 1-5, where 1 corresponds to ’most uncertain’ and 5 to ’most certain’. Annota-tions were also performed in Brat 26 in a similar fashion to the leukemia use-case.
The distribution of scores is presented in Figure 5.27. It is worth noting that whilethere is not total agreement, both annotators annotated the majority of sentences withhigh certainty (>= 4). However, it is clear that the perception of the uncertainty in-tensity varies since, for example, the scoring of annotator 1 is shifted towards highercertainty values. The overall agreement at the sentence level was 43%, but only in 8%
25There was at least one event in each passage mapping to an interaction of the Ras 2-hop neighborhoodmodel. This was done so that the same passages could be used for the evaluation presented in Chapter7, thus reducing the workload of the annotators. However, it does not affect the results or procedurepresented in this section.
26Accessible here: http://nactem10.mib.man.ac.uk/brat-v1.3/#/Melanoma/
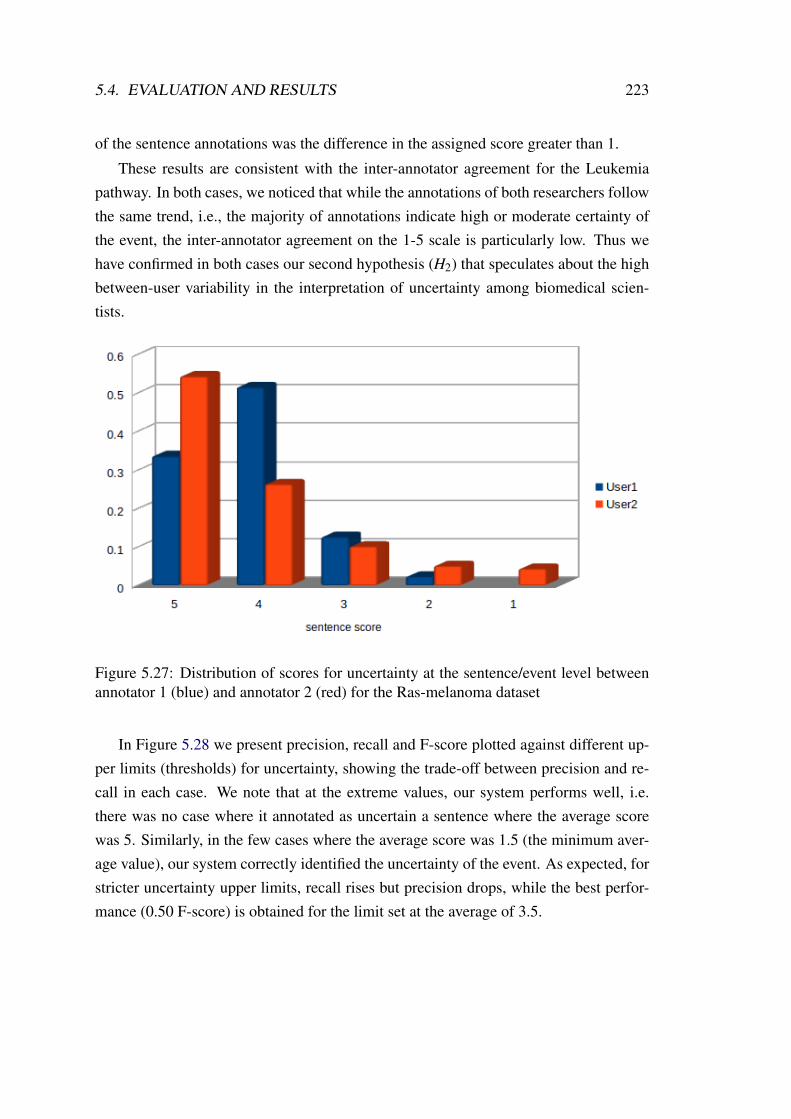
5.4. EVALUATION AND RESULTS 223
of the sentence annotations was the difference in the assigned score greater than 1.
These results are consistent with the inter-annotator agreement for the Leukemiapathway. In both cases, we noticed that while the annotations of both researchers followthe same trend, i.e., the majority of annotations indicate high or moderate certainty ofthe event, the inter-annotator agreement on the 1-5 scale is particularly low. Thus wehave confirmed in both cases our second hypothesis (H2) that speculates about the highbetween-user variability in the interpretation of uncertainty among biomedical scien-tists.
Figure 5.27: Distribution of scores for uncertainty at the sentence/event level betweenannotator 1 (blue) and annotator 2 (red) for the Ras-melanoma dataset
In Figure 5.28 we present precision, recall and F-score plotted against different up-per limits (thresholds) for uncertainty, showing the trade-off between precision and re-call in each case. We note that at the extreme values, our system performs well, i.e.there was no case where it annotated as uncertain a sentence where the average scorewas 5. Similarly, in the few cases where the average score was 1.5 (the minimum aver-age value), our system correctly identified the uncertainty of the event. As expected, forstricter uncertainty upper limits, recall rises but precision drops, while the best perfor-mance (0.50 F-score) is obtained for the limit set at the average of 3.5.
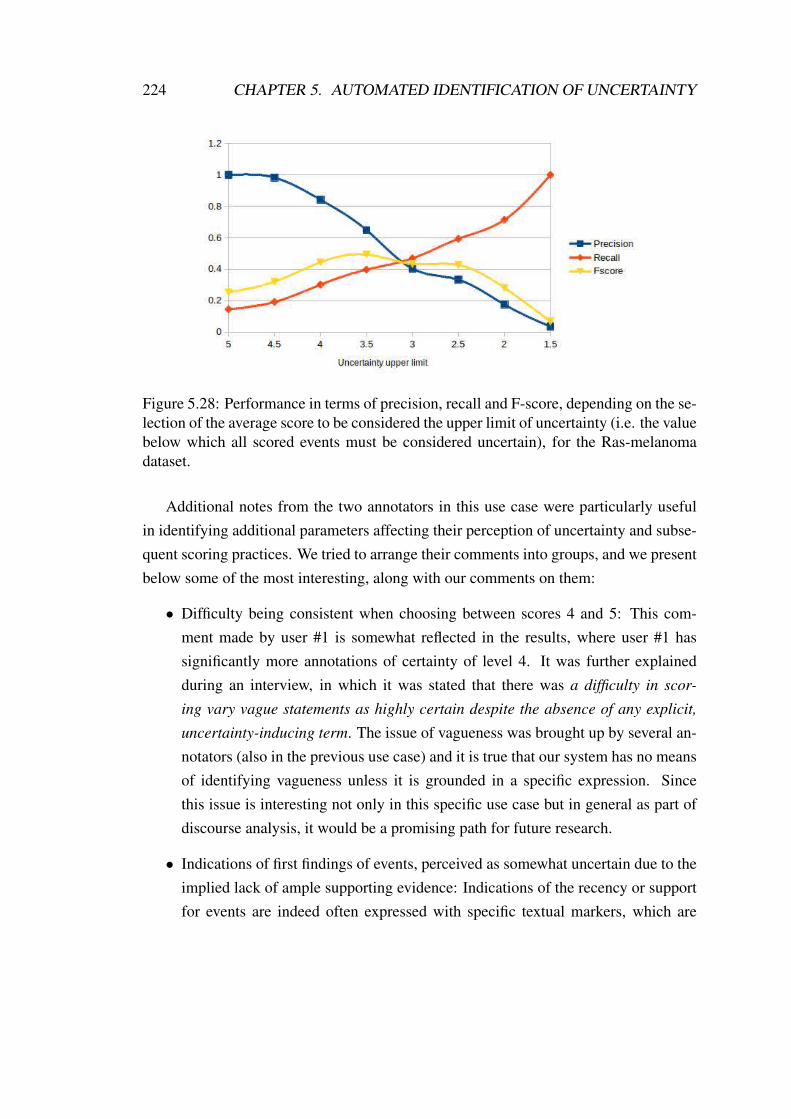
224 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
Figure 5.28: Performance in terms of precision, recall and F-score, depending on the se-lection of the average score to be considered the upper limit of uncertainty (i.e. the valuebelow which all scored events must be considered uncertain), for the Ras-melanomadataset.
Additional notes from the two annotators in this use case were particularly usefulin identifying additional parameters affecting their perception of uncertainty and subse-quent scoring practices. We tried to arrange their comments into groups, and we presentbelow some of the most interesting, along with our comments on them:
• Difficulty being consistent when choosing between scores 4 and 5: This com-ment made by user #1 is somewhat reflected in the results, where user #1 hassignificantly more annotations of certainty of level 4. It was further explainedduring an interview, in which it was stated that there was a difficulty in scor-
ing vary vague statements as highly certain despite the absence of any explicit,
uncertainty-inducing term. The issue of vagueness was brought up by several an-notators (also in the previous use case) and it is true that our system has no meansof identifying vagueness unless it is grounded in a specific expression. Sincethis issue is interesting not only in this specific use case but in general as part ofdiscourse analysis, it would be a promising path for future research.
• Indications of first findings of events, perceived as somewhat uncertain due to theimplied lack of ample supporting evidence: Indications of the recency or supportfor events are indeed often expressed with specific textual markers, which are

5.5. CHAPTER CONCLUSIONS 225
overlooked in existing uncertainty annotation schemes. Nevertheless, both anno-tators identified these as one of the parameters that would make a mention of aninteraction less trustworthy.
• Different opinions as to the uncertainty implications of terms relating to ability(was able to bind to, can inhibit ). Such terms were viewed as factual by user #1and uncertain by user #2.
• Lastly, both annotators pointed out that refraining from judging the correctnessand validity of the events, was a particularly counter-intuitive task. While thisdid not affect the outcome of the annotations, it was deemed necessary to men-tion it since it is an indication of the importance of pairing text mining methodswith external experimental or -omics resources as an additional measure of eventcorrectness.
These results further indicate that while the binary method performs more consis-tently, looking into a finer grained quantification of uncertainty in combination withuser-oriented and customisable methods such as active learning would be a worthwhilegoal for future work, since this appears to more closely mirror the perceptions of users.
5.5 Chapter conclusions
In this chapter, we presented our own definition of uncertainty in the biomedical domainand proposed novel methods for uncertainty identification of events extracted from thebiomedical literature.
By identifying the differences and inconsistencies between annotations of existingcorpora, we proposed a definition of uncertainty that achieves a broad coverage overdifferent textual phenomena and expressions that reduce the certainty of a statement,while still being able to take advantage of existing annotations of uncertainty (Section5.1).
Based on the aforementioned definition and analysis of the selected corpora, wedeveloped novel methods for automated uncertainty identification. We explored depen-dency graphs as a way to capture the potential influence of an uncertainty expression ona given event, and proposed the use of enriched dependency n-grams, as an expressive

226 CHAPTER 5. AUTOMATED IDENTIFICATION OF UNCERTAINTY
structure that can represent the relationship between an uncertainty cue and an eventtrigger. We showed that by replacing the “traditional” dependency n-gram representa-tion with our “enriched” representation, we were able to improve performance by 12and 16 points, in terms of F-score, for the GENIA-MK and the BioNLP corpus respec-tively. We thus addressed O1 and RQ1 and also confirmed our first hypothesis H1, andwe demonstrated that using our proposed enriched dependency n-grams along with awide range of other features, our RF classifier achieves state-of-the-art performance forthe binary classification of uncertainty. We also studied the potential utility of auto-mated methods that do not rely on external dictionary resources, but only on event-leveluncertainty annotations. We showed that using a combination of our dependency ruleinduction methods with Lift as a measure of informativeness, we were able to minimisethe drop in performance, especially in terms of precision, and replace the pre-compiledcue list with predictions of uncertainty cues in the feature generation procedure (seeTable 5.8).
Furthermore, we validated the classification of uncertainty and the predictions ofour methods against the perception of researchers in the field of biomedicine. To dothis, evaluated the predictions of our uncertainty identification approach on evidencepassages linked to pathway interactions. We observed that the best F-score achieved onthese pathway annotation tasks is still lower compared to the performance we achievedon the gold-standard corpora. However, we noted that even among the researchers whowork in this field, there was considerable disagreement about whether some events wereuncertain, which motivates our intention to revisit the problem and to consider user-adaptive and customisable uncertainty identification approaches as future work.
These researcher-led evaluation experiments gave us the opportunity to explore theuser agreement in the task of evaluating the intensity of textual uncertainty. We de-signed a 5-level uncertainty annotation experiment for this purpose. We confirmed, thaton both pathway datasets, the inter-annotator agreement for the 5-level annotation taskwas particularly low, showing high between-user variability in the perception of uncer-tainty. Our results confirm H2, and concur with the early findings of Druzdel [Dru89]and with the conclusions of Rubin [Rub07], who had similar findings in the newswiredomain. The resulting annotated datasets as well as the valuable comments made byannotators provide solid ground for future experimentation and expansion of the uncer-tainty definition. Moreover, while we confirmed that it is hard to achieve meaningful

5.5. CHAPTER CONCLUSIONS 227
multi-level classification of the intensity of different uncertainty expressions, it wouldbe interesting to examine whether there is still an underlying order in the perceived in-tensity of uncertain expressions, for which there is a higher inter-annotator agreementamong researchers in biomedicine.
In the next chapter, we examine the adaptation and generalisation properties of ouruncertainty identification method, comparing textual uncertainty between the biomedi-cal and the newswire domains.


Chapter 6
Adaptability to a new domain: Acase-study in newswire
In this chapter we do the following:
Investigate the potential of application of the methods we developed for uncertaintyidentification on biomedical text, to new domains (addressing RQ3 as well as H3.1 andH3.1) by:
• Focusing specifically on the newswire domain: news articles
• Comparing lexical properties and dependency patterns for uncertainty, betweenbiomedical and news articles.
While the focus of this thesis is mostly on scientific writing, we would also like toexamine the extent to which the concept of textual uncertainty is domain-specific. Intu-itively, it might seem that expressions indicating uncertainty are domain-independent. Inother words, we could assume that people express uncertainty in the same way, with lit-tle influence from the context and the target of the communication. Yet, when it comesto comparing the results of applying uncertainty identification systems to biomedicaltext and to general/newswire text, we notice that their performance is consistently lowerfor the latter; the results of the CoNLL 2010 [FVM+10] challenge, as well as follow up
229

230 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
work on the same corpora, highlight this difference. More than 10 point difference inF-score performance between the biomedical and the newswire domain can be observedfor tasks 1A (Wikipedia) and 1B (BioScope) of this challenge. Moreover, we have seenin the previous chapter (Section 5.4.1.2) that when using cue lists compiled from the an-notations of a newswire corpus (ACE-MK: [TNMA17]) instead of those compiled frombiomedical corpora, the performance of our method for detecting biomedical event un-certainty drops considerably. These outcomes motivated us to look more closely at thephenomena surrounding uncertainty in newswire text and explore the causes of suchdiscrepancies in performance.
News articles constitute another rapidly increasing source of digital text, with anexpansion pattern that is comparable to that of scientific publications. According to The
Atlantic in 2016 The Washington Post online newspaper published an average of 500digital articles daily 1. Moreover, in much the same way as for scientific articles, infor-mation conveyed in news is often non-factual: it contains speculation about events andtheir causes, opinionated articles expressing the subjective view of the journalist ratherthan a validated truth, along with exaggerations, metaphorical speech and hypotheti-cal scenarios. Thus, when it comes to automatically extracting information from newsarticles, it is important to develop systems that are aware of such phenomena and canaccount for uncertainty in news. The recent fake news fever further highlights the needfor certainty assessment in news, and it is already reflected in related initiatives in thefield of computational linguistics such as the recent fake news challenge tasks 2.
The detection of fake news is an involved process requiring in-depth discourse andstance analysis [RASR17, BSS+18, BSR17, FV16], along with other parameters such assource reputation or compatibility with external resources [CRC15] in order to properlydistinguish real from fake news. The aspects that affect the credibility and veracityof news information, which could lead to efficient automated fact-checking, are still atopic of active debate [Ber17, CCR15, VRA18] and proper identification of fake news isworthy of a dedicated PhD study in itself. However, identifying certainty is an importantstep towards the assessment of credibility of news events and we aim to explore it a littlefurther in this chapter.
1Original article accessible here: https://www.theatlantic.com/technology/archive/2016/05/how-many-stories-do-newspapers-publish-per-day/483845/ .
2Fake news challenge, FNC-I : http://www.fakenewschallenge.org/

6.1. UNCERTAINTY IN THE NEWSWIRE DOMAIN 231
More specifically, we intend to focus on the apparent performance gap between theuncertainty identification systems for newswire and biomedical text. We hypothesisethat the discrepancies are at least partly due to differences in the linguistic patterns andlexical properties of the expressions used to communicate uncertainty in each domain.Hence we study the application of our proposed methodology (see Chapter 5) to ACE-MK, a newswire corpus, and through comparison with GENIA-MK, we try to locate thelinguistic differences.
6.1 Uncertainty in the newswire domain
In Chapter 3 we provided an extensive overview of uncertainty and different theoriesrelated to it. In this section, we provide an overview of the work dedicated to the anal-ysis of news documents and the uncertainty (or related concepts) expressed in thosedocuments.
Rubin was one of the first authors to present a classification of uncertainty focus-ing specifically on news articles [RLK06]. She proposed a four-dimensional certaintycategorisation model, as presented in Figure 6.1. More importantly, she presented aquantitative analysis comparing 32 news stories and 28 editorial pieces based on thepresence and frequency of markers in the text belonging to any of the four dimensions:certainty level, perspective, focus and time. It was found that editorials contain signifi-cantly higher certainty level, but also that in terms of perspective they fall mostly in thewriter’s point of view category. On the contrary, news stories were mostly reported to beclassified as 3rd party point of view in terms of perspective as well as having a moderatelevel of certainty.
Along the same lines, Wan et al. [WZ14] also identify four dimensions of certaintymarkers in news: explicit certainty markers; subjectivity markers that indicate judge-ments and opinions; time markers indicating past or future references; and perspectivemarkers distinguishing between 1st and 3rd party perspective as well as involvementlevels. They show that detection of certainty information at the sentence level can beused in order to produce more certain and thus less confusing news summaries.
The ACE 2005 corpus [WSMM06] contains events from news texts that are anno-tated with meta-knowledge dimensions, including modality, which accounts for spec-ulated versus asserted events, and genericity which identifies the scope/broadness of a

232 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
Figure 6.1: Redrawn diagram of Rubin’s certainty categorisation, proposed for thenewswire / generic domain.
statement. Recently, the meta-knowledge annotations were extended to include amongothers the aspect of subjectivity [TNMA17]. This extended version of the ACE 2005corpus is known as the ACE-MK corpus.
There is also a range of factuality corpora, which contain annotations of uncertaintyrelated concepts and focus on events extracted from news articles. FactBank [Sau17],contains annotations that combine certainty and polarity for news events (see also Chap-ter 3). UW [LACZ15] contains factuality scores for each event, ranging from -3 to 3,and representing the likelihood that the event in question actually took place as de-scribed. Finally, MEANTIME [MSU+16], is a multi-lingual corpus containing eventlevel annotations including temporal information. Note, that while all factuality corporarefer to events, the concept of the event in this case is slightly different to the one weintroduced in Chapter 2: while the event trigger is identified in text, there is no explicitidentification of the participating arguments or their roles with respect to the event.
In contrast to the previously mentioned work, a considerable body of other work onnews articles studies uncertainty under the frame of subjectivity. Rubin et al. [RLK06]claims that subjectivity is inherently linked to certainty, while Wiebe et al. [WWB+04],who pioneered the study of subjectivity in computational linguistics, refers to it as “as-pects of language used to express opinions, evaluations, and speculations”. Wiebe uses

6.1. UNCERTAINTY IN THE NEWSWIRE DOMAIN 233
the term “private states” introduced by Quirk et al. [QGL8] as a blanket term for alllinguistic phenomena indicating subjective language and has produced annotations toidentify both subjective sentences as a whole as well as specific subjective expressionswithin sentences. Wiebe also showed that such expressions can be successfully learnedand used for automated classification of documents.
Building on Wiebe’s categorisation of subjectivity, Wilson et al. annotated theMPQA corpus [DW15] and showed that it can be used for the automatic recognitionof fine-grained subjectivity [WHS+05]. Wilson also pointed out that strong sentimentis highly correlated with subjectivity and indicates opinionated statements [WWH04].Along the same lines, Godbole et al. presented methods to classify subjective opinionsbased on their sentiment polarity and applied these methods to large-scale newswire andblog datasets [GSS07]. Vis also focused on subjectivity, and in a diachronic study ofnews text from the 1950s onwards, demonstrated that in recent years the use of “privatestates” in news text has dramatically increased [VSS12], thus highlighting the impor-tance of methods to identify the level of subjectivity in information extracted from news.
In terms of the performance of such systems, as we have already pointed out, therehave been relatively few attempts to automatically identify uncertainty in news text,apart from the classification of particular aspects that embody uncertainty, such as sub-jectivity [Wil08]. The most significant work is the Wikipedia-related task of CoNLL2010, which was concerned with weasel cue detection. The best-performing systemsat the time compared poorly to the results obtained in the biomedical field, but morerecently Jean et al. [JHR+16] proposed a probabilistic model that achieved an F-scoreof 55.7, showing a promising degree of improvement. Even more encouragingly, therehave recently been important efforts concerned with the classification of factuality val-ues based on FactBank and related factuality corpora (UW, MEANTIME), which showgreat improvements in their predictions [SEKP+17, LACZ15] compared to earlier at-tempts [PRD10]. Finally, Qian et al. [QLZ+18] recently presented a hybrid neuralnetwork model which combines Bidirectional Long Short-Term Memory (BiLSTM)networks and Convolutional Neural Networks (CNN) for event factuality identification.They show that their hybrid approach can outperform other methods on the FactBankcorpus. Such efforts have motivated our interest in studying the detection of uncertaintyin the newswire domain. In the following sections, we use ACE-MK to try to identifythe patterns influencing performance in the automated classification of uncertainty.

234 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
6.2 Experimental setup
6.2.1 Events in newswire
Since we aim to study the expression of uncertainty in news text, we choose the ACE-MK corpus, because it is already annotated with events that have a similar structureto the biomedical events described and used for the other experiments in this thesis.Indeed, events in ACE-MK follow the same principles of having a trigger and one ormore related arguments. The trigger determines the type of the event, and is usuallyone word (it can be verb, noun or adjective) that describes or characterises the event.Also similarly to biomedical events, the relation between the trigger and each argumentdetermines the argument’s role. Furthermore, events in news documents can be, likebiomedical events, either simple or complex. In Figure 6.2, we present examples ofevents taken from the GENIA-MK and ACE-MK corpora to facilitate their comparison.
Figure 6.2: Event examples taken from GENIA-MK (a-b) and ACE-MK (c-d). We cansee that in both domains, event triggers (green) can be verbs (a,c) or nominalisations(b,d), having potentially multiple arguments (blue). Overall, while the content and se-mantics change across domains, the structure remains the same.

6.2. EXPERIMENTAL SETUP 235
6.2.2 Datasets
As a comparative corpus in the field of biomedicine, we choose to use GENIA-MK,since it contains not only event and meta-knowledge information, but also, like ACE-MK, it includes annotations of cues for each of the meta-knowledge dimensions. De-tailed information about the GENIA-MK corpus has already been described in Chapter5, Section 5.2.1. We re-iterate here that it contains annotations for six meta-knowledgedimensions including Certainty Level (L1, L2, L3), Polarity (Positive, Negative), Man-
ner (High, Low and Neutral), Source (Current, Other) and Knowledge Type (Investiga-tion, Observation, Analysis, Method, Fact, Other). We use the same conceptualisationof uncertainty employed for GENIA-MK throughout this work - namely, we treat asuncertainty indicators annotations having Certainty Level (CL) values of L1 or L2, aswell as those events whose Knowledge Type (KT) value is Investigation.
The ACE corpus was originally annotated with named entities (NEs), events, aswell as some meta-knowledge information, and has been subsequently enriched withadditional meta-knowledge annotations [TNMA17]. We refer to the first version of thecorpus as the ACE corpus and to the enriched version as the ACE-MK corpus in orderto distinguish between the two.
The ACE-MK corpus comprises 600 news articles originating from various sources,and contains annotations for 5,349 events. Regarding event annotation, while nestednews events occur in other corpora, ACE 2005 contains only simple / flat and non-overlapping events. In this sense, the annotation complexity is reduced compared toGENIA-MK. ACE 2005 contains a significantly larger number of annotated entity typescompared to GENIA-MK (13 entity classes and 53 sub-classes). Similarly, the num-ber of potential argument role types as well as the number of potential arguments thatcan be attributed to a single event are also high (35 and 11 respectively). Miwa et al.[MTKA14] presented a detailed and in-depth comparison of the early versions of theACE 2005 and the Genia 2003 corpora. A summary is presented in Table 6.1, updatedto reflect the details of the ACE-MK and GENIA-MK corpora.
The meta-knowledge annotation scheme of the GENIA-MK corpus comprises sixmeta-knowledge dimensions, of which four were present already in the ACE corpusand the rest were introduced in the 2017 annotation enrichment effort that resulted inACE-MK. The newly added dimensions, as well as some newly added values for the
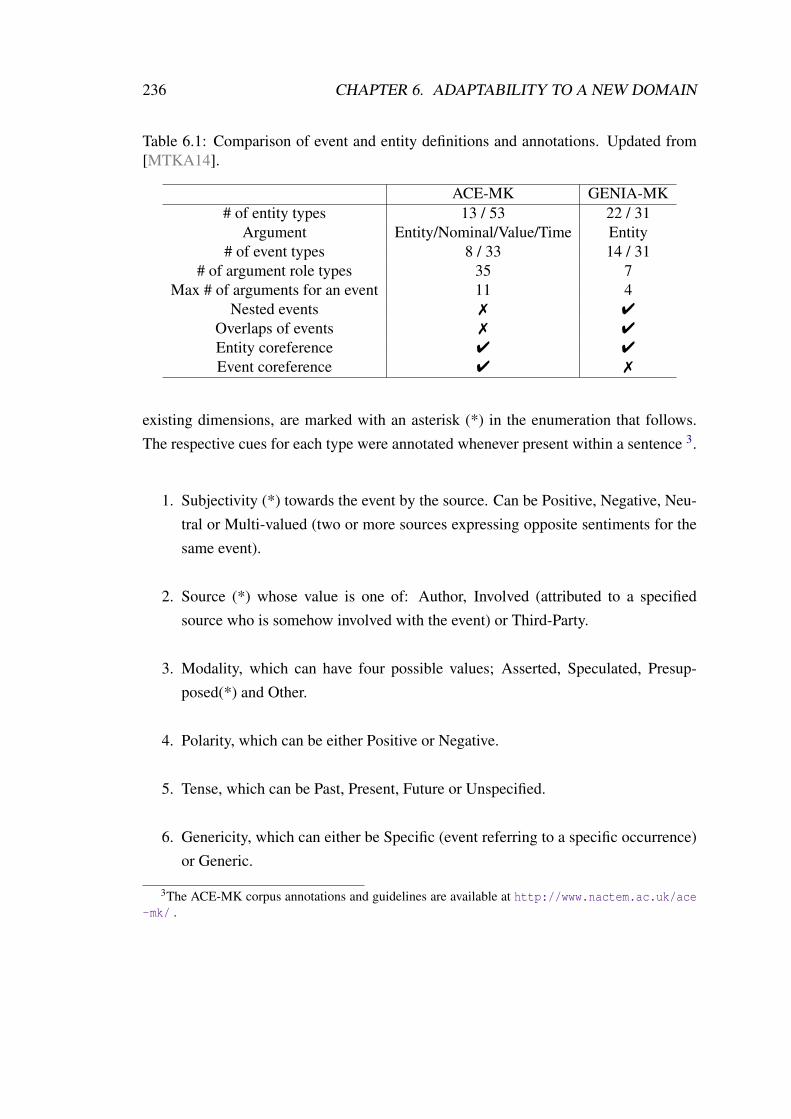
236 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
Table 6.1: Comparison of event and entity definitions and annotations. Updated from[MTKA14].
ACE-MK GENIA-MK# of entity types 13 / 53 22 / 31
Argument Entity/Nominal/Value/Time Entity# of event types 8 / 33 14 / 31
# of argument role types 35 7Max # of arguments for an event 11 4
Nested events 7 4
Overlaps of events 7 4
Entity coreference 4 4
Event coreference 4 7
existing dimensions, are marked with an asterisk (*) in the enumeration that follows.The respective cues for each type were annotated whenever present within a sentence 3.
1. Subjectivity (*) towards the event by the source. Can be Positive, Negative, Neu-tral or Multi-valued (two or more sources expressing opposite sentiments for thesame event).
2. Source (*) whose value is one of: Author, Involved (attributed to a specifiedsource who is somehow involved with the event) or Third-Party.
3. Modality, which can have four possible values; Asserted, Speculated, Presup-posed(*) and Other.
4. Polarity, which can be either Positive or Negative.
5. Tense, which can be Past, Present, Future or Unspecified.
6. Genericity, which can either be Specific (event referring to a specific occurrence)or Generic.
3The ACE-MK corpus annotations and guidelines are available at http://www.nactem.ac.uk/ace-mk/ .

6.3. AN APPROACH TO UNCERTAINTY DETECTION 237
6.3 An approach to uncertainty detection
In Chapter 5, Section 5.1 we proposed a scheme for uncertainty classification, orientedtowards the scientific, and more specifically, the biomedical, field. At the same time, inrelated literature, various concepts have been introduced, such as modality, subjectivity,genericity and timeliness, which have been linked to uncertainty in the newswire do-main. In fact, most of the aforementioned event attributes annotated in ACE-MK couldaffect event certainty. As there was no prior work on automated identification of eventuncertainty on the ACE-MK corpus, we experimented with different dimensions (andtheir combinations) that seem related to uncertainty and could be linked to our originaldefinition in Section 5.1. We focused on three dimensions: Modality, Genericity andSubjectivity.
It should be noted that Polarity has been identified as a dimension that is orthogonalto uncertainty [SP09b], and thus we choose not to include it in our investigation, eventhough both the GENIA-MK and ACE-MK corpora contain such annotations. As futurework, we would like to further investigate the combination and interaction of certaintyand polarity and perhaps expand our analysis to the FactBank corpus. It would alsobe interesting, as future work, to expand our experiments to investigate whether Tense
could also be used to account for the timeliness aspect, or whether Source could helpto identify weaselling phenomena, thus expanding the coverage of uncertainty. In orderto comprehensively accounting for these two dimensions in future work, we aim to takeinto account additional resources such as time-analysis corpora such as MEANTIME[MSU+16] and TimeBank [PHS+03] as well as build on previous work ([NTA13b]) forsource identification and citation analysis [TST09].
To facilitate comparison and obtain consistent results for the GENIA-MK and ACE-MK corpora, we maintain the binary approach to the uncertainty classification task. Assuch, for each of the dimensions considered, we determined which categories denotethat the associated events are certain, and which indicate uncertain events. This allowsus to maintain the same classification problems, i.e. one which determines whether anevent is certain or uncertain.
Considering these three different dimensions of Modality, Genericity and Subjectiv-
ity as well as their combinations as uncertainty indicators, we generate four differenttest-sets, each corresponding to a different uncertainty definition:

238 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
1. M: uncertainty corresponds only to Modality, and only Asserted events are con-sidered to be Certain. Based on descriptions in [BBD+14, SVF+12b].
2. G: uncertainty corresponds only to Genericity, and only Specific events are treatedas Certain. We thus claim that that generic, more vague events lack certainty,inspired by the distinction between abstract and specific statements in [Rub10].
3. S: uncertainty corresponds only to Subjectivity, and only Neutral events are treatedas to Certain. This decision is based on [WR05], which showed that positiveor negative bias can affect the certainty of an event. Multi-valued instances aretreated as Uncertain since contradictory assertions have also been linked to un-certainty [AS15, Ala16].
4. MGS : uncertainty corresponds to the union of the above uncertainty indicators;only an event that is Asserted, Neutral and Specific is considered Certain.
Our main motivation for experimenting with the different datasets –separately and incombination– is that we noticed a co-occurrence of more than one uncertainty indicators(M, G, S) in more than 40% of the uncertain events. As illustrated in Figure 6.3 Sub-
jectivity and Genericity uncertainty indicators often co-occur with Modality uncertaintyindicators (although Subjectivity and Genericity uncertainty indicators alone rarely co-occur together – instances of events with S+G uncertainty indicators only constituteonly to 1% of the total number of uncertain events). The apparent relation betweenthe three different uncertainty types motivated us to consider their union as a uniformuncertainty class. We thus wanted to examine whether we can use shared informationfrom the different uncertainty indications in order to more accurately predict uncertainevents.
In both ACE-MK and GENIA-MK, annotations are based on events. Additionally,evidence for each meta-knowledge annotation, if it can be attributed to one or morewords in the same sentence as the event, is annotated as a cue for the dimension an-notated, along with a link to the event(s) that it affects. Figure 6.4 (a-b) illustrates oneexample from each corpus where the cue affects only one of the events in a sentence. Inboth corpora, cues for most meta-knowledge dimensions constitute word sequences thatare distinct from the trigger of the event. However, for Subjectivity, which is annotatedin ACE-MK, there are cases where the trigger of the event also acts as a Subjectivity cue.
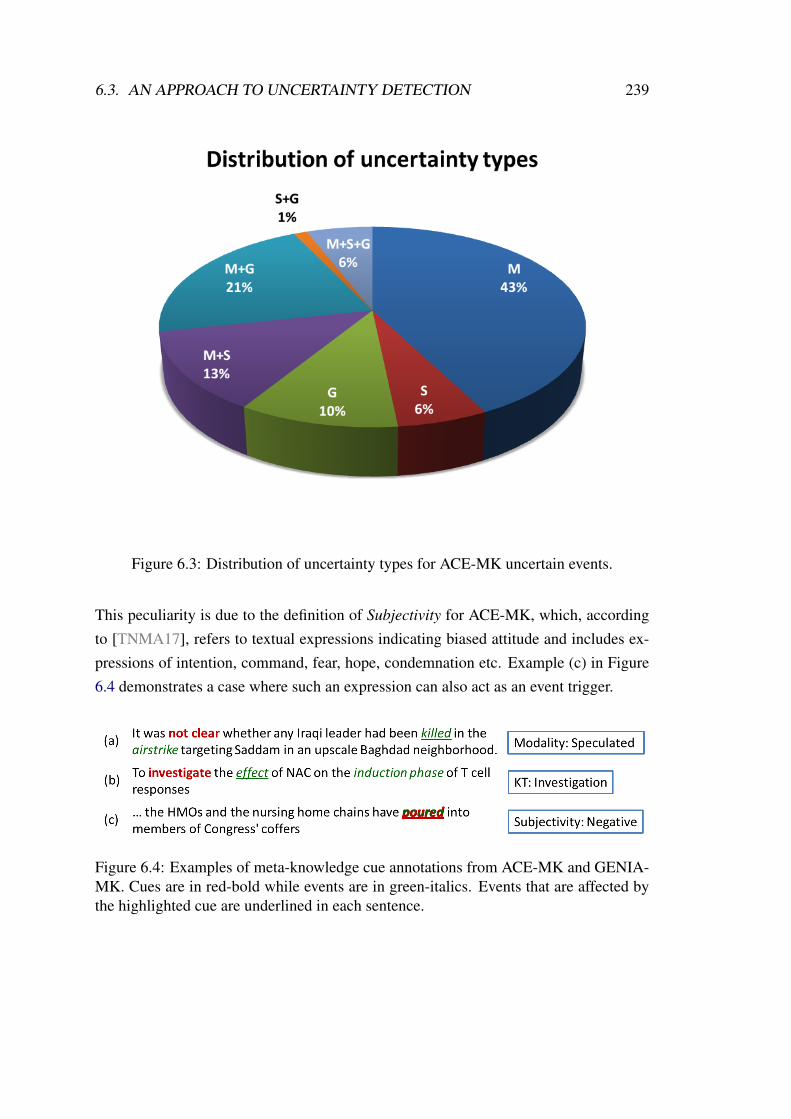
6.3. AN APPROACH TO UNCERTAINTY DETECTION 239
Figure 6.3: Distribution of uncertainty types for ACE-MK uncertain events.
This peculiarity is due to the definition of Subjectivity for ACE-MK, which, accordingto [TNMA17], refers to textual expressions indicating biased attitude and includes ex-pressions of intention, command, fear, hope, condemnation etc. Example (c) in Figure6.4 demonstrates a case where such an expression can also act as an event trigger.
Figure 6.4: Examples of meta-knowledge cue annotations from ACE-MK and GENIA-MK. Cues are in red-bold while events are in green-italics. Events that are affected bythe highlighted cue are underlined in each sentence.

240 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
To perform experiments using the above test-sets, we re-purposed the configura-tion of our uncertainty detection system that obtained the optimal performance on theGENIA-MK corpus (ML + EDNG in Table 5.4). We maintain the same set of fea-tures, but retrain the RF classifier on the ACE-MK corpus. Apart from changing thecue lists to those containing cues annotated in the ACE-MK corpus (for certain expre-riments), the workflows that processed the documents and extracted the features for theRF classifier were not modified. Similarly to other experiments, the ACE-MK corpuswas pre-processed using a series of NLP components implemented in the Argo platform[BNNS+17], as described in Chapter 4. Moreover, the same WEKA API configurationsand 10-fold cross validation methods are used, as described in the previous chapter.
6.4 Results
6.4.1 Automated classification of uncertainty
In our initial experiments, we employed the same cue list that was compiled from thebiomedical corpora and used in the previous experiments (Chapter 5). We then trainedand tested the RF classifier with all the features presented in Table 5.3 on each of the dif-ferent certainty test sets enumerated earlier (M, G, S, MGS). We then repeated the sameexperiment, but this time swapping the original cue list for one with cues compiled basedon news articles from ACE-MK annotations. As expected (Table 6.2), the classifiersthat were trained with biomedical cues perform significantly lower than those trainedand tested with the ACE-MK cues, for any of the uncertainty configurations. This resultis well aligned with the performance drop we noticed when using ACE-MK cues forbiomedical papers (see Table 5.8), which further reinforces the domain-dependence ofuncertainty expressions and highlights the need for domain-specific approaches.
When using ACE-MK cues, we can see that F-score increases significantly (p <
0.01) for all different test sets. The improvement is mostly due to the consistent boost inrecall for all test configurations, since in terms of precision, it is only in the case of theModality test set that the experiments with the ACE-MK cues outperform those usingthe GENIA-MK cues. This result suggests that across different domains, there are partlyoverlapping rather than competing definitions of uncertainty. In other words, there seemto be some cues that are shared across domains, and some that are domain-specific

6.4. RESULTS 241
Table 6.2: Performance for uncertainty identification on each separate meta-knowledgedimension using GENIA-MK (GEN) and ACE-MK (ACE) cues. Best results for eachperformance metric are noted with bold.
M G S MGS CuesPrecision 0.53 0.27 0.40 0.61
GENRecall 0.55 0.62 0.46 0.69F-score 0.54 0.38 0.34 0.65Precision 0.57 0.26 0.40 0.69
ACERecall 0.69 0.67 0.63 0.74F-score 0.62 0.37 0.49 0.71
and do not appear in the other domain(s). Thus, if cues from a different domain areused, recall drops without significantly affecting precision. We thus confirm hypothesisH3.1, stating that textual uncertainty expressions vary across domains, requiring domain-specific approaches and knowledge extraction. We elaborate on the lexical differencesbetween the two domains in Section 6.5.2.
More interestingly however, we notice that even using ACE-MK cues, the best per-formance that we obtain (using the MGS dataset) is significantly lower in comparison tothe performance obtained when the same method is applied to the GENIA-MK corpus(as presented in the previous chapter). Indeed as illustrated in Table 6.3, which showsthe performance of our method for uncertainty identification in GENIA-MK, signifi-cantly higher results are obtained for all metrics (i.e., Precision, recall and F-score),even when using cues extracted from ACE-MK.
Table 6.3: Performance for uncertainty identification on GENIA-MK corpus using dif-ferent cues.
GENIA-MK cues ACE-MK cuesPrecision 0.94 0.82Recall 0.83 0.86F-score 0.88 0.84
A closer examination of the performance on the individual test configurations (M,G, S) reveals that Genericity seems to be the attribute whose values are hardest to distin-guish, especially in terms of precision. This can be explained through an examination

242 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
of the training data, which reveals that there are very few Generic event instances thatare linked to a Genericity cue. Thus, while there is a sufficient number of training in-stances for Generic events and good representation of both Genericity classes (1132Generic events versus 4217 Specific events), Genericity cues were linked to only 1% ofthe Generic events. Hence, the feature vectors generated were not very representative.
The classifier also has difficulties in predicting Subjectivity, but for different reasons.Looking more closely at the results for Subjectivity, we discovered that one issue relatesto Multi-valued test cases, which are particularly complex since they often involve theexistence of several (> 1) Subjectivity cues linked to the same event. At the same time,the distribution for Multi-valued events is skewed since they are significantly under-sampled (18 instances). A further issue for the learning process is that Subjectivity cuesconsist of a greater number of nouns and longer, often colloquial expressions comparedto Modality or Genericity cues (see the example of Figure 6.6-b).
Further enhancement of the machine learning approach could address such issues,in order to better identify the Subjectivity and Genericity dimensions. A possible futuredirection would be to improve feature engineering and to generate feature vectors thatcan account for positive or negative bias of nouns, or borrow other methods from relatedwork on subjectivity identification to improve performance on uncertainty cases that arerelated to subjectivity. Coupled with a training corpus containing a greater number ofinstances for under-sampled cases, such methods could enable further conclusions to bedrawn.
In the last column of Table 6.2, we can observe the performance of the modelstrained on the combined uncertainty dimensions. By combining the meta-knowledgedimensions into one uncertainty identification task, we can see that we obtain improvedperformance, compared to the individual tasks. This further confirms the relation andinterplay between these different dimensions in the context of detecting uncertainty (asdiscussed in Figure 6.3).
However, as mentioned earlier, we notice that for all possible combinations, per-formance is lower compared to results reported for biomedical corpora using the samemachine learning approach4, even when we use domain-specific cues extracted fromthe ACE-MK corpus. This difference in performance, is noticeable even in the case of
4We used the same RF classifier and re-purposed the features to the task, so that our results would becomparable to the results on GENIA-MK.

6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 243
Modality (which is the dimension most closely associated with uncertainty). While itcould be partially attributed to less consistent annotation, this performance differenceconcurs with the results of Tang et al. [TWW+10b] for the CoNLL 2010 datasets andprovided motivation to look more closely into the differences between the means ofexpressing uncertainty in the two different domains.
Thus our results seem to reject hypothesis H3.2, indicating that automated uncer-tainty identification is a domain specific task and that domain adaptation is required inorder to identify uncertainty across domains. The experiments with different cue-listsshow that the expressions used to indicate uncertainty are different in the biomedicaland newswire domains. However, as discussed above, even with domain-specific cue-lists performance of the same methods in the newswire domain is significantly lower. Inthe next section, we further explore this difference in performance, interpreting it on thebasis of dependency relations and lexical properties which are associated with uncertainevents across domains.
6.5 Comparison of linguistic uncertainty patterns be-tween corpora
We identify two points of interest to be explored: (a) dependency relations betweenannotated cues and event triggers and (b) the lexical and semantic properties of the cuesthemselves. The goal is to see how these compare across both corpora and whetherwe can identify points of divergence that could explain the discrepancy in performancebetween the two different domains.
6.5.1 Dependency based comparison
As observed in Chapter 5, Section 5.3.1, the machine learning classifiers are heavilydependent on features related to the dependencies between potential uncertainty cuesand the triggers of events. More specifically, the enhanced dependency n-grams wereamong the most informative features, accounting for a boost in the performance of theRF classifier in the biomedical field.
In addition, the dependency paths between cues and triggers in both the GENIA-MK
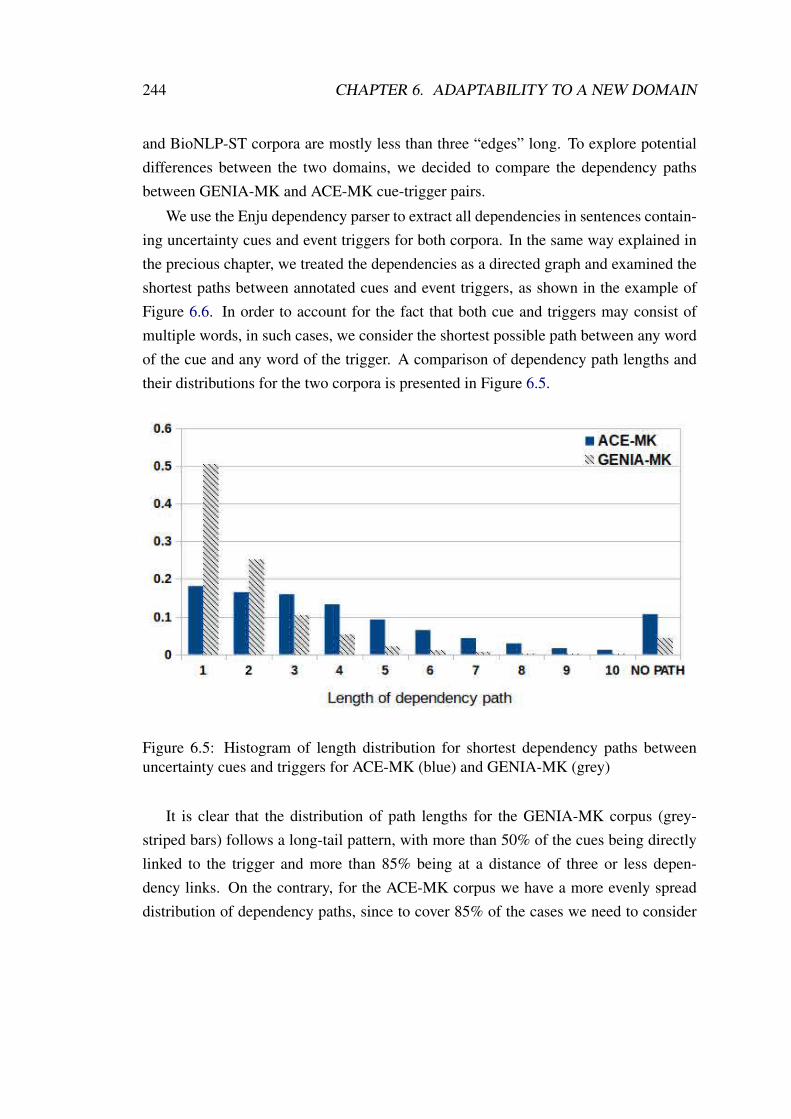
244 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
and BioNLP-ST corpora are mostly less than three “edges” long. To explore potentialdifferences between the two domains, we decided to compare the dependency pathsbetween GENIA-MK and ACE-MK cue-trigger pairs.
We use the Enju dependency parser to extract all dependencies in sentences contain-ing uncertainty cues and event triggers for both corpora. In the same way explained inthe precious chapter, we treated the dependencies as a directed graph and examined theshortest paths between annotated cues and event triggers, as shown in the example ofFigure 6.6. In order to account for the fact that both cue and triggers may consist ofmultiple words, in such cases, we consider the shortest possible path between any wordof the cue and any word of the trigger. A comparison of dependency path lengths andtheir distributions for the two corpora is presented in Figure 6.5.
Figure 6.5: Histogram of length distribution for shortest dependency paths betweenuncertainty cues and triggers for ACE-MK (blue) and GENIA-MK (grey)
It is clear that the distribution of path lengths for the GENIA-MK corpus (grey-striped bars) follows a long-tail pattern, with more than 50% of the cues being directlylinked to the trigger and more than 85% being at a distance of three or less depen-dency links. On the contrary, for the ACE-MK corpus we have a more evenly spreaddistribution of dependency paths, since to cover 85% of the cases we need to consider

6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 245
dependency paths up to length 7. In fact, more than 50% of the paths are longer thanthree edges. In addition, focusing on the last bar of the histogram (NO PATH), whichaccounts for cases where the path length is either larger than 10 or the path is non-existent 5, we observe that the percentage of such cases for ACE-MK is double of thatin GENIA-MK. Especially the latter is an indication of uncertainty expressions that aremore loosely linked to the actual event trigger, due perhaps to more complex sentences,figurative speech, etc. More specifically, in ACE-MK, event triggers are often nominal-isations or other nouns that are not in close proximity to the main verb (and surroundingmodals) of the sentence, or in more extreme cases, the cue that indicates uncertainty isto be found in a different phrase (see examples in Figure 6.6).
Figure 6.6: Dependency paths between cue (red-bold)and trigger (green-underlined)for ACE-MK. Arrows denote the edges of the dependency graph that participate in theshortest path between cue and trigger. In (a) could is a Modality cue, influencing aPersonel nominates event. In (b) we have a phrase that is annotated as a Subjectivitycue and the event is Personnel end position.
This difference in the dependency path distribution between the two domains, couldexplain why features based on dependency paths and dependency rules are not as effec-tive for newswire. To confirm this, we repeated the analysis of feature informativeness(using Mutual Information measures [Bat94]) for the two corpora. The results of thecomparison are presented in Figure 6.7.
We can see that while for the top 10 most informative features the distributions aresimilar for the two corpora, dependency-rule features (R-columns) play a progressively
5For the ACE-MK corpus this could include cases where the triger is also the cue
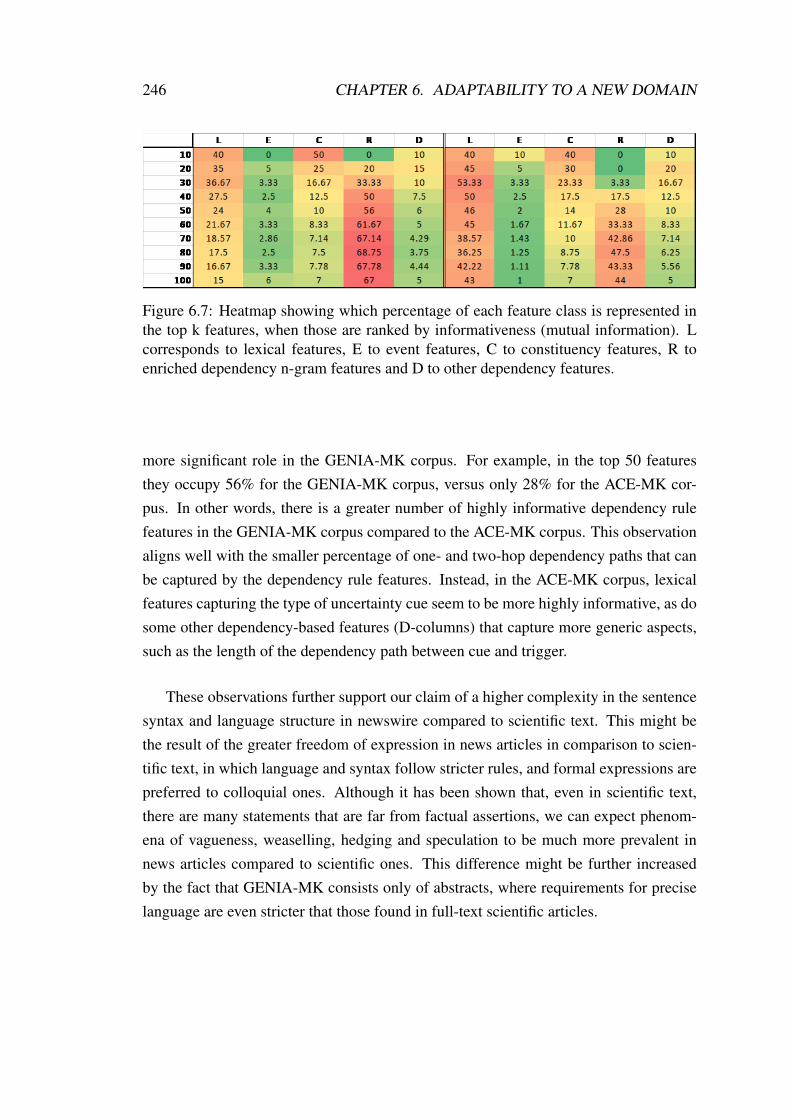
246 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
Figure 6.7: Heatmap showing which percentage of each feature class is represented inthe top k features, when those are ranked by informativeness (mutual information). Lcorresponds to lexical features, E to event features, C to constituency features, R toenriched dependency n-gram features and D to other dependency features.
more significant role in the GENIA-MK corpus. For example, in the top 50 featuresthey occupy 56% for the GENIA-MK corpus, versus only 28% for the ACE-MK cor-pus. In other words, there is a greater number of highly informative dependency rulefeatures in the GENIA-MK corpus compared to the ACE-MK corpus. This observationaligns well with the smaller percentage of one- and two-hop dependency paths that canbe captured by the dependency rule features. Instead, in the ACE-MK corpus, lexicalfeatures capturing the type of uncertainty cue seem to be more highly informative, as dosome other dependency-based features (D-columns) that capture more generic aspects,such as the length of the dependency path between cue and trigger.
These observations further support our claim of a higher complexity in the sentencesyntax and language structure in newswire compared to scientific text. This might bethe result of the greater freedom of expression in news articles in comparison to scien-tific text, in which language and syntax follow stricter rules, and formal expressions arepreferred to colloquial ones. Although it has been shown that, even in scientific text,there are many statements that are far from factual assertions, we can expect phenom-ena of vagueness, weaselling, hedging and speculation to be much more prevalent innews articles compared to scientific ones. This difference might be further increasedby the fact that GENIA-MK consists only of abstracts, where requirements for preciselanguage are even stricter that those found in full-text scientific articles.
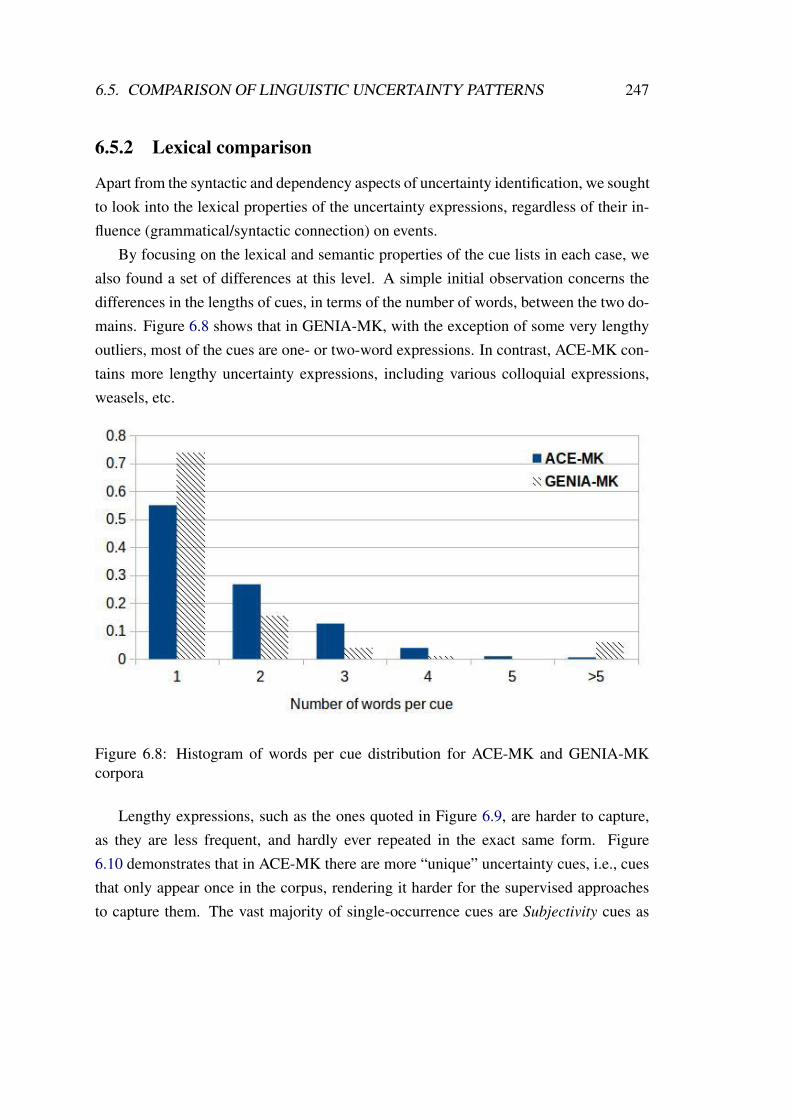
6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 247
6.5.2 Lexical comparison
Apart from the syntactic and dependency aspects of uncertainty identification, we soughtto look into the lexical properties of the uncertainty expressions, regardless of their in-fluence (grammatical/syntactic connection) on events.
By focusing on the lexical and semantic properties of the cue lists in each case, wealso found a set of differences at this level. A simple initial observation concerns thedifferences in the lengths of cues, in terms of the number of words, between the two do-mains. Figure 6.8 shows that in GENIA-MK, with the exception of some very lengthyoutliers, most of the cues are one- or two-word expressions. In contrast, ACE-MK con-tains more lengthy uncertainty expressions, including various colloquial expressions,weasels, etc.
Figure 6.8: Histogram of words per cue distribution for ACE-MK and GENIA-MKcorpora
Lengthy expressions, such as the ones quoted in Figure 6.9, are harder to capture,as they are less frequent, and hardly ever repeated in the exact same form. Figure6.10 demonstrates that in ACE-MK there are more “unique” uncertainty cues, i.e., cuesthat only appear once in the corpus, rendering it harder for the supervised approachesto capture them. The vast majority of single-occurrence cues are Subjectivity cues as

248 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
indicated in Figure 6.11.
Figure 6.9: Lengthy cue examples for Subjectivity: positive (green) and negative (red).
Figure 6.10: Distribution for the frequency of occurrence of annotated cues for theACE-MK and GENIA-MK corpora.
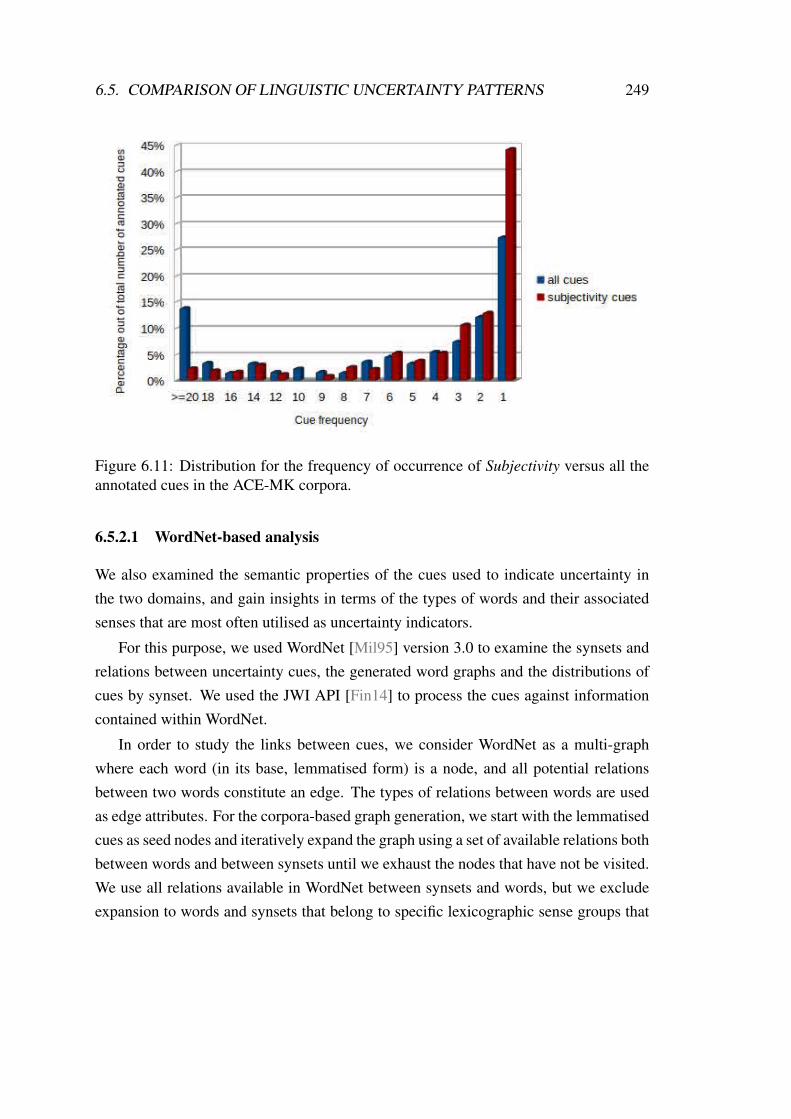
6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 249
Figure 6.11: Distribution for the frequency of occurrence of Subjectivity versus all theannotated cues in the ACE-MK corpora.
6.5.2.1 WordNet-based analysis
We also examined the semantic properties of the cues used to indicate uncertainty inthe two domains, and gain insights in terms of the types of words and their associatedsenses that are most often utilised as uncertainty indicators.
For this purpose, we used WordNet [Mil95] version 3.0 to examine the synsets andrelations between uncertainty cues, the generated word graphs and the distributions ofcues by synset. We used the JWI API [Fin14] to process the cues against informationcontained within WordNet.
In order to study the links between cues, we consider WordNet as a multi-graphwhere each word (in its base, lemmatised form) is a node, and all potential relationsbetween two words constitute an edge. The types of relations between words are usedas edge attributes. For the corpora-based graph generation, we start with the lemmatisedcues as seed nodes and iteratively expand the graph using a set of available relations bothbetween words and between synsets until we exhaust the nodes that have not be visited.We use all relations available in WordNet between synsets and words, but we excludeexpansion to words and synsets that belong to specific lexicographic sense groups that
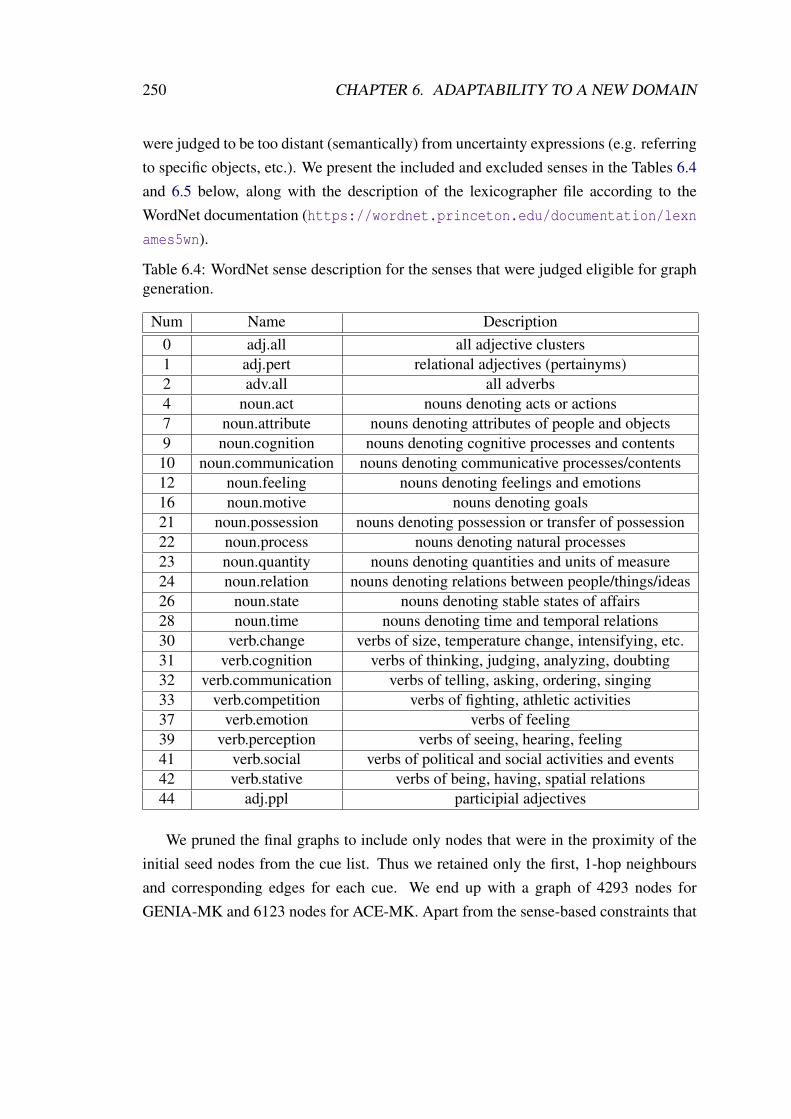
250 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
were judged to be too distant (semantically) from uncertainty expressions (e.g. referringto specific objects, etc.). We present the included and excluded senses in the Tables 6.4and 6.5 below, along with the description of the lexicographer file according to theWordNet documentation (https://wordnet.princeton.edu/documentation/lexnames5wn).
Table 6.4: WordNet sense description for the senses that were judged eligible for graphgeneration.
Num Name Description0 adj.all all adjective clusters1 adj.pert relational adjectives (pertainyms)2 adv.all all adverbs4 noun.act nouns denoting acts or actions7 noun.attribute nouns denoting attributes of people and objects9 noun.cognition nouns denoting cognitive processes and contents
10 noun.communication nouns denoting communicative processes/contents12 noun.feeling nouns denoting feelings and emotions16 noun.motive nouns denoting goals21 noun.possession nouns denoting possession or transfer of possession22 noun.process nouns denoting natural processes23 noun.quantity nouns denoting quantities and units of measure24 noun.relation nouns denoting relations between people/things/ideas26 noun.state nouns denoting stable states of affairs28 noun.time nouns denoting time and temporal relations30 verb.change verbs of size, temperature change, intensifying, etc.31 verb.cognition verbs of thinking, judging, analyzing, doubting32 verb.communication verbs of telling, asking, ordering, singing33 verb.competition verbs of fighting, athletic activities37 verb.emotion verbs of feeling39 verb.perception verbs of seeing, hearing, feeling41 verb.social verbs of political and social activities and events42 verb.stative verbs of being, having, spatial relations44 adj.ppl participial adjectives
We pruned the final graphs to include only nodes that were in the proximity of theinitial seed nodes from the cue list. Thus we retained only the first, 1-hop neighboursand corresponding edges for each cue. We end up with a graph of 4293 nodes forGENIA-MK and 6123 nodes for ACE-MK. Apart from the sense-based constraints that

6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 251
Table 6.5: WordNet sense description for the senses that were excluded graph genera-tion.
Num Name Description3 noun.Tops unique beginner for nouns5 noun.animal nouns denoting animals6 noun.artifact nouns denoting man-made objects8 noun.body nouns denoting body parts
11 noun.event nouns denoting natural events13 noun.food nouns denoting foods and drinks14 noun.group nouns denoting groupings of people or objects15 noun.location nouns denoting spatial position17 noun.object nouns denoting natural objects (not man-made)18 noun.person nouns denoting people19 noun.phenomenon nouns denoting natural phenomena20 noun.plant nouns denoting plants25 noun.shape nouns denoting two and three dimensional shapes27 noun.substance nouns denoting substances29 verb.body verbs of grooming, dressing and bodily care34 verb.consumption verbs of eating and drinking35 verb.contact verbs of touching, hitting, tying, digging36 verb.creation verbs of sewing, baking, painting, performing38 verb.motion verbs of walking, flying, swimming40 verb.possession verbs of buying, selling, owning43 verb.weather verbs of raining, snowing, thawing, thundering
were described in Tables 6.4 and 6.5, there was no further attempt to filter senses ofcues that corresponded to more than one synset. Instead, for each word, in each graphexpansion step, all possible synsets that corresponded to eligible senses were added tothe graph. At the end of the graph generation procedure, a total of 781 synsets wereincluded for the cues of GENIA-MK, compared to 1444 synsets for the ACE-MK cues.Hence, expressions identified as uncertainty cues in ACE-MK seem to have a far broadersemantic coverage, which we interpret as an indication of greater lexical variability,which in turn means that cues are harder to predict.
Looking at the connectivity properties of the two graphs and the number of fullyconnected components (subgraphs), we notice that the GENIA-MK graph has only two

252 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
fully connected subgraphs, versus fifteen (15) for ACE-MK. The difference in the num-ber of subgraphs is a further indication supporting the difference in the semantic rangesof cues for the two corpora. However, for both corpora, 85% of the nodes are containedin the largest subgraph.
We also investigated whether we could group word senses into “communities” (clus-ters), related to uncertainty for each corpus. We thus proceeded to carry out modularity-based community detection for the two graphs [New06] aiming to identify and visualisepatterns in the senses of each graph. We focused on the first 10 largest communities(size calculated on the basis of node count) and their central nodes. To identify centralnodes, we ranked nodes using three different centrality measures: betweenness, close-ness [Bra01] and eccentricity [HH95] and then used the intersection of the top rankednodes for each measure. The graphs for GENIA-MK and ACE-MK are illustrated inFigures 6.13 and 6.12, respectively. The analysis and visualisation of the graphs wasperformed using Gephi [BHJ+09].
In both graphs, we were able to identify communities that seem to be semanticallyrelated (i.e., the most representative terms seem close in terms of meaning and interpre-tation), and it is easy to see that in some communities, the central nodes are related touncertainty (likelihood, probability etc). Some of the communities revolve around simi-lar concepts, such as ability, probability, communication and investigation, although theconcepts are expressed using different terms.
We note that using only 1-hop expansion of the original cues gathered from the twocorpora, we were able to generate a graph with semantically meaningful communities.Hence, it would be interesting to further explore the use of WordNet and other semanticgraphs as an unsupervised way to expand cue lists and use them on previously unseendata. This could prove particularly useful for domains lacking annotated resources.
6.5. COMPARISON OF LINGUISTIC UNCERTAINTY PATTERNS 253
Figu
re6.
12:G
ener
ated
wor
dgr
aph
base
don
Wor
dNet
rela
tions
forA
CE
-MK
cues
.
254 CHAPTER 6. ADAPTABILITY TO A NEW DOMAIN
Figure6.13:G
eneratedw
ordgraph
basedon
WordN
etrelationsforG
EN
IA-M
Kcues.

6.6. CONCLUSIONS 255
6.6 Conclusions
In this chapter we examined the adaptation of our uncertainty identification techniquesto the newswire domain. We have shown that it is possible to transfer methods similarto those employed in the biomedical domain, although we established that regardlessof whether detecting uncertainty is restricted to individual meta-knowledge dimensions(M, G, S), or is treated as a combined task, the performance is significantly lower thanthe performance obtained by applying the same methods to biomedical articles.
We identified the linguistic properties of uncertainty expressions as a candidatecause of this discrepancy and to verify this, we analysed the syntactic and lexical proper-ties of textual uncertainty in the newswire domain. Our analysis highlighted the role oflonger dependencies between cues and events as one of the main issues that complicatethe task in newswire articles, along with lengthy cues that exhbit increased semanticvariability. We concluded that uncertainty is expressed differently across domains, andrequires domain -specific approaches, thus answering RQ2 and confirming H2.
We consider this work a promising first step towards a more detailed and fine-tunedapproach to uncertainty identification in the newswire domain. As future work, we aimto take advantage of our findings regarding the syntactic and lexical properties that werehighlighted above, in order to build more robust classifiers. Moreover, we would liketo expand our analysis of uncertainty in the newswire domain using word-embeddingsand potentially expand the uncertainty definition in a similar fashion to the work ofChen that we discussed in Chapter 3 [CSH18]. To support this goal, we also intend toexperiment with further corpora in the newswire domain.
In the next chapter, we move from the “local” uncertainty of individual event men-tions towards ways of combining uncertainty values from several event mentions (eachreferring to the same interaction) into one consolidated confidence score.


Chapter 7
Consolidating uncertainty
In this chapter we do the following:
Focus on the consolidation of uncertainty based on several events describing a commoninteraction (addressing RQ4 and H4) .
• Discuss how we can map event mentions to interaction models in pathways
• Propose the use of subjective logic theory in order to model event certainty
• Demonstrate how using subjective logic we can fuse uncertainty values of mul-tiple individual events describing the same interaction to obtain a consolidatedscore
• Present user evaluation experiments to show that our fusion method can producecertainty scores that are a good approximation of the scores attributed by users
7.1 Normalisation of event mentions
In the previous chapters, we addressed textual uncertainty and its influence on the mean-ing of an extracted statement or event. We have shown that it is feasible to automate
257

258 CHAPTER 7. CONSOLIDATING UNCERTAINTY
the identification of uncertain events (using a binary classification of uncertainty) withhigh accuracy. This is an important step towards the use of better informed methods forinformation extraction that can provide enriched statements, and allow users to searchfor anaysed information more easily, e.g.by filtering on certainty.
However, as Vailaya accurately points out, extraction of information from text is notan end in itself [VBK+04]. Rather, scientists need to relate the extracted informationwith other sources of information, such as experimental data or diagrammatic biologicalmodels. Hence, events annotated with uncertainty and polarity values need to be furtherprocessed and integrated with existing knowledge bases and interaction networks to ob-tain full value from them. In fact, as further explained in Section 7.2.1, event extractionalongside uncertainty identification has enabled researchers to automatically generatenetworks from scratch [MYBHA14]. In addition to the generation of new networks andpathways, event extraction allows the enrichment and automated updating of existingdatabases.
However, such endeavours to automate pathway curation usually have to deal withtwo challenges. The first relates to the extraction framework and the procedures ofmapping newly discovered events to existing networks of interactions. In this case, thegranularity of annotations for events and entities can significantly influence the per-ceived mapping between two entries. A typical example highlighting the entity anno-tation issues concerns the mapping of interactions between genes and gene families.Similar issues arise with event types, or with the number/role of their arguments. Fig-ure 7.1 illustrates some of the aforementioned issues that occur trying to map eventsextracted from text to pathway interactions. More specifically, while all phrases essen-tially refer to the same core interaction, i.e., the regulation of an src kinase by Shp2,there are small variations. For example sentences 1,2 and 4 refer to a specific mem-ber of the src family of kinases (Fyn), while in 3 the mention is more generic. On theother hand, while in sentences 2 and 3, the general term regulates is used to describethe event, the exact nature of regulation is more specifically mentioned in sentences 1and 4 (activates). In addition, sentence 4 specifies that the activation takes place at sites
of the receptor, which could be considered as an extra participant of the interaction,specifying the interaction site. A mapping system would have to decide which (if any)of these variations can be disregarded in order to merge the events as referring to thesame interaction concept and which (if any) of the variations have characteristics that

7.1. NORMALISATION OF EVENT MENTIONS 259
distinguish them sufficiently distinguish to extract them as separate interactions.
Figure 7.1: Examples of entity and event mapping challenges, which require specific de-cisions and modelling to allow mapping between genes and gene families (1,3), genericand specific event triggers (1,2), and events with additional arguments (1,4).
The second challenge concerns the existence of multiple potential sources of infor-mation, which can result in multiple statements about the same interaction. In realisticscenarios, whether the target is news or biomedical events, it is highly likely that thesame event will be mentioned by several different documents, and quite often multipletimes in different parts of a single document. Even if the mentions are otherwise identi-cal (avoiding the problems described earlier) it is highly unlikely that their surroundingcontext will also be identical. Thus, not all the mentions will have the same certaintyvalue. This makes it necessary to develop some sort of certainty combination strategy,to allow an overall certainty value to be determined for the combined mentions. Thepotential existence of mentions with different polarities (positive or negative) for thesame event further complicates the task of how multiple mentions can be combined intoa single representation. Figure 7.2 presents a typical example from the biomedical field,which illustrates multiple occurrence of the same event in different textual contexts,resulting in different uncertainty and polarity values in each case.
Figure 7.2: Examples of mapping challenges in terms of uncertainty and polarity value.In the sentences (1)-(4) the event and its participants are identical but the uncertaintyand polarity context (marked with bold-italic-red font) varies in each case.

260 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Such contextual differences between otherwise identical mentions of the same eventposes a significant challenge when it is required to use such event mentions for auto-mated curation of databases. As revealed by the BioGRID effort [SBCA+10, CAOB+17],direct comparisons between text mining and exhaustive manual curation reveal substan-tial false positive and false negative error rates [LMK+10]. To handle this discrepancy,BioGRID [SBCA+10, CAOB+17], as well as more focused databases such as miR-Cancer [XDHW13], TarBase [VVA+11] combine the automated approach with manualanalysis. While most such biomedical databases resort to requiring curators to manuallyannotate the text mining output, we aim to facilitate the process by estimating the over-all uncertainty of each event (based on multiple mentions) and using it to automaticallyrank events to be added to knowledge bases or interaction networks, thus bridging thegap between text mining and expert knowledge.
As expected, when attempting to consolidate uncertainty information over a poten-tially wide range of different mentions of an event, the binary uncertainty values usedpreviously are no longer practical. Thus, it is necessary to develop methods that canaccount for a range of different uncertainty and polarity values, and combine them intoa single confidence value that will represent an accurate estimate of the overall certaintyof the event. As an additional requirement, our aim is for the derived value to success-fully approximate the reasoning process of a potential user, in order to provide userswith realistic and interpretable information.
In Section 7.2 we provide an overview of related work in three different area: (1) ap-proaches to integrating text mining results into interaction networks or knowledge bases,(2) methods to combine uncertainty or other meta-knowledge values of extracted eventsor other information units and (3) an overview of research in terms of user perceptionand integration of knowledge from multiple documents. We then proceed to introduceour proposed approach for integrating multiple uncertainty values, which is based insubjective logic theory as proposed by Josang [Jøs97, JHP06] in Section 7.3,and ourapproach to mapping event mentions to pathways and interaction networks in Section7.5. Finally, in Section 7.6 we present and discuss the application of our proposedmethods to the integration of extracted events into different pathways (extending on thepathway-related experiments discussed in Chapter 5, Section 5.4.2) and the evaluationagainst user judgements of uncertainty scores.

7.2. RELATED WORK 261
7.2 Related work
7.2.1 Text-mining for database curation and interaction networkgeneration
With the exponential increase in the amount of available literature relating to bio-molecularinteractions, it is virtually impossible to achieve comprehensive curation and updatingof biomedical databases and interaction networks or pathways. Hence, various studieshave proposed the use of text mining to support biomedical network construction andpathway curation [HKA+05, SF03], which have been adopted in a series of differentknowledge bases and models. Inferring a biomedical network from textual resources isa complicated task, typically requiring the combination of several text mining processes.[CS14] analyse the process of constructing protein-protein interaction (PPI) networksand specify the necessary components for a text mining pipeline to achieve this.
In [OKO+08b], Oda presents methods for linking events to pathways while high-lighting the challenges involved in such a complicated task. They present three mainchallenges, namely (1) the identification of the mapping position of a specific entityor reaction in a given pathway, (2) the recognition of the causal relationships amongmultiple reactions and (3) the formulation and implementation of the required infer-ences based on biological domain knowledge. As part of the first challenge, they alsohighlight the intricacies involved in the attempt to map and integrate multiple textualfragments into the same pathway node, which is particularly relevant to our work. Infact, in this work, we focus on enhancing existing interaction networks and pathwaymodels with confidence-ranked interactions, but we do not aspire to draw conclusionsfrom the updated pathways, leaving the task of inference to the users. Moreover, asdiscussed in Section 7.5, we adopt a rather simplified, incremental approach in terms ofthe perceived causal relations between newly discovered interactions. Thus, our focusis mostly on the implied sub-tasks related to the first challenge, since a central aspectof our approach is a method to combine snippets of information with different levels ofcertainty, and to determine their impact on the confidence of an interaction.
Looking into applications of text-mining for network generation, Li and colleagues[LWZ06] applied a combined literature mining and micro-array analysis (LMMA) ap-proach to construct a target network for angiogenesis. In their approach, they used text

262 CHAPTER 7. CONSOLIDATING UNCERTAINTY
mining to extract co-occurring genes as potential interactions and create a literature-based interaction network. The literature-based angiogenesis network was filtered us-ing gene expression profiles retrieved from the Stanford Microarray Database (SMD)through a multivariate selection procedure, based on the hypothesis that gene pairs co-cited in the literature will indeed interact with each other if they are co-upregulated orco-downregulated. Chassey [DCNT+08] also worked on filtering and refining literature-based networks, but used a set of experimental results and existing databases for this pur-pose. They demonstrated the successful generation of a Hepatitis C virus (HCV) infec-tion protein target network by integrating yeast two-hybrid screening and literature min-ing with eight curated interaction knowledge bases, including BIND, BioGRID, DIP,GeneRIF, HPRD, IntAct, MINT and Reactome. Malhotra [MYGHA13] also workedon literature-based network generation and extracted hypothesis statements (overlap-ping with uncertain statements) from text to build hypothetical stage-specific diseasenetworks. While they acknowledge and describe different degrees of uncertainty for theextracted statements, they do not use this information to rank interactions in the net-works. Rather, they use a binary approach in which any hypothetical interaction is avalid candidate for integration into the hypothesis network. Along the same lines, Sub-ramani [SKMN15] extracts potential protein relations from text, and uses two curateddatabases, HPRD and KEGG, to validate them. Subsequently, using a pathway-miningsearch tool, they map extracted interactions to pathways and visualise the results. Notethat the above processes are significantly dependent on information contained withinthe databases, and they do not providing the additional confidence measures that wouldallow users to judge the trustworthiness of the obtained interactions.
In contrast, Soliman in [SNC16] presents the construction of an interaction net-work from text mining results, while specifically using reference interaction databasesto classify the extracted relations in terms of validity and knowledge novelty. Finally, al-though not related to networks, [JGMJ08] use speculation markers to classify –in termsof confidence– statements from biomedical papers relating to the apolipoprotein E gene.The STRING database [FSF+13] scores interaction networks based on co-occurrencestatistics of the participating entities (along with experimental assay scoring). Don-aldson [DMDB+03] also proposes a text mining approach to support PPI curation andprovides a confidence score based on the co-occurrence of protein mentions. However,in this work, textual uncertainty expressed in the evidence passages was not considered,

7.2. RELATED WORK 263
and there was no distinction between certain and uncertain statements.
PathText [KMM+10] uses text mining tools (KLEIO, FACTA and MEDIE) to linkdocuments that mention specific interactions in a pathway, thus allowing researchersto inspect and update pathways in an easier manner. PathText2 [MOR+13] uses anupdated approach to linking documents, by using event extraction to identify matches tointeractions in the pathway. Moreover, in PathText2, the identified evidence documentsare ranked according to confidence scoring, based on the estimated relevance of thedocument to the targeted pathway.
These past efforts have contributed to the automation of pathway curation and en-hancement of biomedical networks, and help to illustrate potential uses of textual un-certainty for biomedical purposes. However, the scope of each application is limitedand textual uncertainty is rarely considered as an indication of confidence when linkingevidence to pathways. In addition, in efforts to extract uncertainty from biomedical cor-pora, there has often been a notable lack of experimental evaluation or validation of anapplication by domain experts.
7.2.2 Representation and fusion of uncertainty values
While there has been limited work on integrating uncertainty values of multiple eventsextracted from literature, there are various areas concerned with similar issues. Theproblem of representing uncertainty over an object and incorporating uncertain valuesinto calculations and logic operations or modelling uncertainty as a probability is rele-vant for many different problems in science. The Ellsberg paradox presents the outcomeof an experiment in which people are asked to place consecutive bets on expected eventsfor which they have only partial knowledge (expected colour of balls taken out of a box).Ellsberg reports that human betting behaviour diverges from the principles of traditionalprobability theory [Ell61]. Indeed, traditional probability theory does not express de-grees of vagueness and uncertainty and thus it could not explain the prevalent mappingstrategies of the users. Instead, models using uncertain probabilities have been shown tobe better predictors in the Ellsberg paradox problem [CS01, Jos16]. The Ellsberg para-dox is just one example where traditional probability theory falls short; especially inartificial intelligence, the need to model vague or uncertain values has led to the devel-opment of a series of logic theories that expand the properties of Bayesian and Boolean

264 CHAPTER 7. CONSOLIDATING UNCERTAINTY
logic or other frameworks that can account for vagueness in information. Such meth-ods have proved particularly useful in the fields of decision making and informationretrieval as well as text mining. We present below core theories and frameworks thathave proposed ways to account for operations with different degrees of uncertainty.
Information theory [Sha01] provides a formalism that allows us to model first-orderuncertainty and use it to predict the outcome of random events based on their probabilitydistributions. By defining entropy as the amount of information pertaining to a givenevent that is associated with a random variable, it is possible to assess the degree towhich a given variable can be used to predict the event outcome (the lower the entropyvalue, the more accurate the prediction). The amount of information associated with agiven outcome is called surprisal (see Equation 7.1), and corresponds to the log-inverseof the probability of a given event.
surprisal(X) =1
P(X)(7.1)
The Dempster-Shafer Belief Theory [Sha92], also known as evidence theory, mod-els expression of beliefs using the term ‘frame of discernment’, to denote the set ofmutually exclusive possible states. It defines three basic functions that are important tothe understanding and application of the theory to partially-uncertain data: (1) the basicbelief mass function, (2) the belief function and (3) the plausibility function.
1. Belief mass function: This specifies the belief mass distribution, m, over allpossible sub-sets of a frame of discernment, T heta. Note that for a given sub-setA, the mass m(A) corresponds to the proportion of all evidence that supports A.The value of m(A) pertains only to the set A and makes no additional claims aboutany further subsets of A, each of which will have their own mass.
2. Belief function: This is similar to the probability distribution function of Bayesianprobability logic with one core difference: apart from individual states, it can beassigned to any subset of the frame, including the whole frame itself. Then thebelief function over a set of elements A of frame Θ can be defined as the totalbelief one has based on the sum of evidence, i.e., the sum of all the belief massesassigned to elements of A. Unlike probability theory, Bel(A) = 0 represents a lackof evidence about A, while P(A) = 0 represents the impossibility of A. However,

7.2. RELATED WORK 265
both P(A) = 1 and Bel(A) = 1 represent certainty.
3. Plausibility function: In a set A of a frame Ω consisting of a mutually exclusiveand exhaustive set of elements, plausibility represents the maximum possibilitythat A is true given all the evidence. Mathematically, it is equal to the sum of thebelief masses over all the subsets of A that have non-zero intersection with the setA.
The main idea behind evidence theory is to abandon the additivity principle of prob-ability theory, i.e., that the sum of probabilities on all pairwise exclusive possibilitiesmust add up to one. Thus the lack of evidence to support any specific probability (un-certainty about probabilities) can be explicitly expressed by assigning belief mass to thewhole frame.
Using Dempster’s rule, it is possible to combine two independent sets of probabilitymass assignments in specific situations. Specifically, the combination (called the jointmass) is calculated from the two sets of masses m1 and m2 in the following manner:
m1,2(A) = (m1⊕m2)(A) =1
1−K ∑B∩C=A 6= /0
m1(B)m2(C) (7.2)
whereK = ∑
B∩C= /0
m1(B)m2(C). (7.3)
K is a measure of the amount of conflict between the two mass sets. The normali-sation factor above, 1−K, has the effect of completely ignoring conflict and attributingany mass associated with conflict to the null set. This combination rule for evidence cantherefore produce counter-intuitive results, which is one of the main criticisms of thetheory. Generally, while it is more expressive than probability theory, Dempster’s ruleof combination has been criticised as misleading on many occasions and incapable offusing dependent or unconstrained beliefs [KR90, DWT12, Jos16]. Regardless of this,the Dempster-Shafer theory is still used as a basis for many modern decision-makingand belief-modelling approaches [Sch11]. More relevant to our problem, Merigo andcolleagues have proposed a model of aggregation of linguistic expressions of certaintyand probability on the basis of Dempster-Shafer theory [MCM10].

266 CHAPTER 7. CONSOLIDATING UNCERTAINTY
The Imprecise Dirichlet Model (IDM) [Ber05] for multinomial variables was pro-posed as a method for determining upper and lower probability bounds produced bysetting the minimum and maximum base rates in the Dirichled probability density func-tion (PDF) for each possible value in the domain. The expected probability resultingfrom assigning the maximum base rate (i.e. equal to one) to the probability of a valuein the domain produces the upper probability, and the expected probability resultingfrom assigning a zero base rate to a value in the domain produces the lower probability.The upper and lower probabilities are interpreted as the upper and lower bounds for therelative frequency of the outcome.
The use of fuzzy logics and fuzzy set theory is also very popular for combininguncertain beliefs in decision making or even fuzzy relational databases. Fuzzy set theorywas proposed by Zadeh [Zad76] as a means to deal with objects that have a continuumof grades of membership for the categories of a given classification problem. Handlingthis fuzziness in classification, a membership function is used to attribute to each objecta grade of membership ranging between zero and one. Then, notions of inclusion, union,intersection, complement, relation, convexity, etc. are defined for fuzzy sets, allowingfor operations that are possible in probability or Boolean logic.
Later, Dubois [DP88] demonstrated how fuzzy set theory can be used to address oneof the issues with Dempster-Shafer theory, namely the inability to accurately combineuncertainty values from multiple sources. It must be noted that fuzzy set logic generallyassumes that vagueness as expressed by the membership functions is an inherent char-acteristic of the objects of interest. It has been adopted and adapted several times sincethen in different problem settings, e.g., to combine information from sensors, images,textual information, etc. Focusing on textual information extraction tasks, fuzzy set the-ory evolved to account for three important uncertainty-bearing cases (closely related toeach other), as described in [DP12]:
• Gradualness: This is the concept that is closer to the original fuzzy set paper byZadeh, mentioned earlier ([Zad76]). It encompasses the idea that many categoriesin natural language are a matter of degree, and thus concepts related to truth,validity, certainty, specificity etc., are better expressed as a value on a scale. Fuzzysets allow the transition between membership and non-membership to become, inthe words of its inventor, “gradual rather than abrupt”.

7.2. RELATED WORK 267
• Epistemic uncertainty: Closely related to the issue of evidentiality discussed inSection 3.1.2.1, this refers to the idea of partial or incomplete information, lead-ing to uncertainty about the classification or membership of the information inquestion. In the field of information extraction this would imply the existence ofa set of possible values (qualitative or quantitative) for the element of interest,one of which is the right one. This view leads to possibility theory and possibleworlds semantics [GC06, Cop02].
• Bipolarity: This aspect refers to the idea that information can be described bydistinguishing between positive and negative sides, which are possibly handledseparately. In the case of information extraction, this can expand to negated oreven controversial statements and the resulting need to combine opposing polarityvalues for the same object.
Fuzzy logic has been used to combine vague information in different text miningtasks. Suanmali and colleagues used it in order to combine sentence features for textsummarisation [SSB09, SBS09]. Focusing on information processing for decision mak-ing, Herrera and Martinez [HM00] propose a method that classifies linguistic markers ofuncertainty into tuples representing fuzzy probability intervals. They then propose a setof theorems and operators, showing that it is possible to use such tuples in combinationwith numerical values in order to perform probabilistic calculations in a multi-attributedecision-making problem. While their method assumes a mapping of linguistic mark-ers to fuzzy probabilities and can only handle linguistic markers independently (onemarker at a time), the idea of handling linguistic uncertainty with the use of fuzzy logicis still prevalent in decision-making systems. In more recent work, the hesitant fuzzylinguistic term set (HFLTS) has been proposed and used widely for decision support[RMH12, LXZM15]. While HFLTS is able to handle multiple uncertainty expressionsusing context-free grammars, it is still heavily dependent on rules for context-free gram-mars, which can then be translated to HFLTS.
Another category of uncertainty-aware logic theories comprises the n-valued logictheories. Starting from the three-valued logic systems of Kleene [Kle68] and Priest[Pri79], n-valued logics propose the existence of multiple truth values. In the case ofthree-valued logics the truth values are simplified to true, false and a third “unknown”indeterminate state whose properties depend on the logic framework. In the case of

268 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Kleene’s logic, this unknown state is defined as neither true nor false, while in Priest’slogic it is both true and false. In other three-valued logics such as that of Lukasiewicz,the indeterminate value is simply the in-between (1/2) of true and false (0 and 1), definedas the probability of truth [Gil76]. The definition of the indeterminate states determinesthe expected outcome of operations performed with those logics, since they affect thedefinition of tautologies. For example, while in Kleene’s logic, the only designated truthvalue is true, in Priest’s logic the designated truth values are both true and unknown. Inboth cases, standard operators (6=,AND,OR,MIN,MAX etc ) can be defined, and theoutcome of pairwise application is usually presented in truth tables.
The concept has been further extended in the form of four-valued logics [Bel77],six-valued logics [FM93, GM90] and many-valued logics [Res68], where the principlesare the same but there are further constraints and assumptions describing the role ofeach in-between value in the transition between true and false. In fact, the fuzzy setlogic described earlier can be considered an abstraction of a multi-value logic systemwhere there can be an indefinite number of in-between values [Mal07]. Note that, espe-cially for finite-valued logics (e.g. three- and four-valued logics), while binomial fusionoperations are easy to define and produce consistent results, multinomial fusion wouldgenerate inconsistencies and cannot be generalised well.
Jankowski and Skowron [JS08] demonstrate that many-valued logics that can ac-count for uncertainty can contribute to problem solving in different hierarchical stages ofartificial intelligence such as database technologies, information technology and knowl-edge management to encompass what is framed as ‘wisdom technology’. Many-valuedlogics have been used extensively in decision-making applications, and have also beenshown to be efficient for text mining cases including language understanding [Hoa02]and text classification [JO04, GP03]. More specifically for the biomedical domain,Elkin and colleagues showed that by introducing uncertainty modelling through multi-valued logic they could achieve improved results in the task of identification of pneu-monia cases from free-text radiological reports [EFWR+08].
Concerns about combining information and assessing uncertainty values were ex-pressed early on in the field of information retrieval. Belkin pointed out that it is im-perative not to treat two different points of view as mutually exclusive and stressed theimportance of being able to integrate observations that appear to be different or con-troversial [Bel80]. He proposed the Anomalous state of Knowledge (ASK) theory in

7.2. RELATED WORK 269
order to acknowledge and account for incomplete information, uncertainty and impre-cise specifications that are part of the user’s knowledge state and which contribute to theformulation of the user’s information need. While the task that ASK addresses (infor-mation retrieval) is substantially different from our task, it captures both the importanceof representing uncertain and incomplete knowledge (Belkin stresses that it can helpto identify interesting topics for research) and the need for interaction with the user,along with an approximation to the user’s representation of knowledge. More specifi-cally, Belkin, Oddy and Brooks believed that by deriving and resolving the user’s ASK,which was identifiable and possible to represent, instead of the user’s information need,which was not identifiable or representable, a properly designed IR system could servethe user seeking information with an unknown information need in a more “natural man-ner” than current systems [DBB85]. Wilson and his colleagues subsequently built onthat initial idea to further stress the use of uncertainty in information retrieval (or infor-mation seeking) [WFE+02]. The issue being able to account for multiple evidence anduncertainty values remains a crucial issue in information retrieval as well as in decision-making systems. While the methods in information retrieval have evolved greatly sincethe ASK framework was proposed, the premises of ASK are still relevant and con-tinue to be used to identify user needs beyond those directly expressed by the user inmore recent information retrieval systems, challenging the traditional system-orientedinformation retrieval theories which are built upon assumptions regarding expressed in-formation need [Liu17, ISHH17, SKA18].
At a high level, our task is also related to the problem of integrating knowledgefrom various sources into a single knowledge base. Knowledge Vault [DGH+14] is alarge knowledge base assembled by mining relation triples from the web and bootstrap-ping them using existing databases as prior knowledge. While in this case, linguisticuncertainty is not accounted for, the authors acknowledge that the reliability of eachnewly added triple depends largely on the accuracy of the triple extractor tools, as wellas on the reliability of the sources. They train a boosted decision stump classifier thattakes features related to each different extraction procedure as well as the number ofsources and show that it can provide good estimates of credibility. They re-apply thesame method to fuse prior knowledge information extracted from existing databases,and show that fusing both prior and extracted scores can help to maximise the AUCscore.

270 CHAPTER 7. CONSOLIDATING UNCERTAINTY
In the biomedical field, as discussed in Section 7.2.1, most knowledge bases or as-sembled interaction networks do not present users with confidence scores, but insteadinvolve a manual curation step to avoid noisy or uncertain data inputs. The STRINGand STITCH databases [SMC+16, SSvM+16] are among the few wide coverage inter-action databases that include, among other things, text-mining driven probability scor-ing. While their proposed text mining based scoring does not correspond to linguisticuncertainty, but rather to term co-occurrence statistics, both databases provide a range ofother scores for each interaction (derived from other databases, large scale experiments,co-expression statistics, etc.), and then scores are combined to infer an overall scoring.The combined score is computed under the assumption of independence of the varioussources, in a naıve Bayes fashion, as shown in Equation 7.4. Notably, this simplified ap-proach considers each metric to be equally trustworthy, and as shown in the equation, inthe presence of multiple different scores, it would result in an increased overall scoring[VMJS+05].
S = ∏i(1−Si) (7.4)
PreBIND and Textomy [DMDB+03] constitute another example of a text miningsystem (Textomy) employed to populate a biomedical database (PreBIND and BIND)and where scoring is used to represent the credibility of each captured association. Theproposed system uses an SVM-based classifier in two steps: firstly in order to identifyscientific abstracts containing bio-molecular interactions and secondly in to identify co-occurring pairs that represent interaction mentions in the previously selected abstracts.The prediction scores from both rounds of using the SVM classifier are stored in thePreBIND database and allow users to filter interactions based on scoring. More impor-tantly, the SVM classifiers are updated in an online learning fashion [TL03] using theresults produced by users and curators, who manually assess which of the automaticallyidentified Pre-BIND interactions should become validated BIND entries.
7.2.3 User perception of knowledge and uncertainty
While it is not directly related to the computational approach of combining evidenceand uncertainty values, it is relevant to mention research into the ways in which human

7.2. RELATED WORK 271
readers process information, which is derived from different sources which may containcontradictory statements. There are two strands of work that are of interest in this case:(1) work focused on researchers and active members of the scientific community whoread and process scientific articles and (2) extensive studies on the ways in which readersprocess and understand information about a topic originating from multiple sources 1.While the first case seems more closely related to our main focus, there is a considerablylarger and more comprehensive body of work for the second case, providing us withuseful insights into the role of prior beliefs, the processing of contradictory information,etc. Considering the conclusions of the work carried out on both the aforementionedcases can prove particularly useful, since our proposed automated procedures aim to beapplied to real-world use cases where the end users are humans. Thus, as we furtherstress in Section 7.6, our proposed methods endeavour to approximate the way humanreaders would process and evaluate textual information in terms of uncertainty, in orderto provide them with meaningful results and to facilitate processing of such information.
More specifically, research concerned with both the expert (scientists) and non-expert (other readers) groups has been primarily concerned with the integration of knowl-edge. Early research showed that field experts will put significantly more emphasis onprovenance and of the use of source details as important information, in comparison tonovices [Win91]. More recently, Rouet confirmed these findings and has shown thatexperts will use such information when interpreting statements in a document [Rou06].However, Braaten and Stromso showed that nonetheless, when evaluating trustworthi-ness of a document, the content and contextual information play the most significantrole [BSS11]. Moreover, it has often been claimed that the mere existence of multi-ple sources of information for the same topic can hamper instead of boost the accurateintegration of knowledge [SBB10]. Finally, it has been shown that the perceived trust-worthiness of a given document is significantly dependent on the prior knowledge ofthe reader [BSS11] as well as the reader’s epistemic beliefs (beliefs about the inherentcertainty of knowledge, etc.). This last statement is particularly important, because ithighlights the relativity inherent in the perception of knowledge certainty and thus theneed for knowledge models 2 that can learn and adapt their confidence scoring to userpreferences.
1So far this strand of research focuses largely on school students.2or in our specific case interaction network models

272 CHAPTER 7. CONSOLIDATING UNCERTAINTY
The need for user-adaptive knowledge and information systems has been also recog-nised and addressed —up to a point— in the field of biomedicine. Palakal et al. [PMM02]proposed an intelligent information management system to sift through vast volumesof heterogeneous data. Their tool, BioSifter, automatically retrieves relevant text docu-ments from biological literature based on a user’s interest profile. The tool acts as a filterby significantly reducing the size of the information space. The filtered data obtainedthrough BioSifter is significantly more concise (smaller and more relevant) comparedto the initially retrieved data, thus reducing search space and time that users have tospend on reviewing the retrieved documents. Vailaya also placed an emphasis on theuser interaction element in their proposed architecture [VBK+04]. They propose theuse of user-defined lexicons to generate a user context, and the subsequent selection andranking of documents and interactions is based on these “context files”. Moreover, theyallow implicit user annotation of undiscovered interactions (or correction of erroneousones) in text, in order to improve curation in a collaborative semi-automated manner.
7.3 Adapting subjective logic to uncertainty quantifica-tion
In an attempt to identify the most suitable method to integrate and combine differentuncertainty values for the same event in a meaningful way, we concentrate on the prob-lem description and its similarities with other areas of research. Ideally, the consolidatedscoring should represent both the uncertainty and the polarity dimensions for each eventmention. This criterion derives from the fact that in existing databases and interactionnetworks, only the positive caption of an interaction is represented. As a result, anynegated mentions of an interaction in a pathway would still need to be mapped to thepositive version. Thus, an efficient way to integrate a negative mention without losingsemantics and functionality would be to integrate the negated aspect within the confi-dence score. In other words, the intuition when comparing an interaction i1 which hastwo certain and positive mentions in literature with interaction i2 which has one certainand positive and one certain and negative mention in the literature would be to design ascoring function that would attribute a lower confidence score to i2.
Moreover, the chosen approach should preferably be able to accommodate different

7.4. SUBJECTIVE LOGIC THEORY 273
potential weighting and classification schemes for uncertainty. As discussed in Chapter3, there is no consensus on a “correct” uncertainty scheme, and as such, there is a widerange of proposed uncertainty classifications, often depending on the targeted usagecase. While we have settled on the use of a simplified binary approach, we envision aconsolidation function that should be easily adaptable to other schemes.
The ability to account for the amount of linked evidence is also important for sucha scoring function. Put simply, this implies that the discovery and inclusion of a new(positive and certain) event mention that can be mapped to an existing interaction shouldincrease the confidence of the interaction.
In order to maximise usability and interpretability, the proposed confidence scoringshould efficiently approximate the user perception of uncertainty. To this end, we eval-uate our approach against user ratings, as presented in Section 7.6.2, and choose thefunction that is closest to user scores. While this is not an arduous demand, for reasonsof interpretability and to facilitate comparison with other approaches, we also aim todefine a function that can be projected and used as a probability estimate.
Finally, it is our intention as future work, to source and citation information willbe integrated into the scoring function. Thus, we focus our attention on solutions thatcan account for propagation of uncertainty via citation links, and can also incorporatedifferent trust values depending on the source of the statement (external vs internaluncertainty).
Based on the above specifications and demands, we have decided to adapt solu-tions proposed for data fusion systems and trust networks, as described in Section 7.2.2.We propose the adaptation and use of subjective logic theory as introduced by Josang[Jøs01] and model our problem as a case of fusing beliefs regarding independent facts.We briefly present subjective logic theory as described by Josang and then explain indetail how we adapt it to the task at hand.
7.4 Subjective Logic theory
Subjective logic theory was proposed by Josang as early as 1997 and, along with othertypes of “uncertainty-modelling” logics discussed earlier (Section 7.2.2), aims to pro-vide a solution to artificial intelligence problems, where uncertainty about the truth of

274 CHAPTER 7. CONSOLIDATING UNCERTAINTY
statements prohibits the use of standard Boolean or Bayesian logic. We deem subjec-tive logic particularly relevant to our problem setting, because of the proposed framingof the solution, which explicitly takes uncertainty and belief ownership into accountand models objects as distinct opinions, accounting for parameters representing belief,disbelief and ignorance.
Josan proposes to achieve this using the opinion model, which states that althougha proposition about an aspect of the world will be either true or false, due to our im-perfect knowledge, it is impossible to know its truth value with certainty, and hencewe can only have an opinion about it, which translates into degrees of belief or disbe-lief. Moreover, there is a need to represent degrees of ignorance or indecisiveness as aseparate parameter that accounts for the lack of belief or disbelief. Note that the param-eter called ignorance in the first proposal of subjective logic in 1997 was subsequentlyre-designated as uncertainty, yet its meaning has remained the same [Jøs97, JHP06].Moreover, a few years later, the concept of a base rate or prior probability of α was intro-duced into the model (also called relative atomicity function in early versions [JG03]).More precisely, the base rate determines how uncertainty contributes to the probabilityexpectation value. In the absence of any specific evidence about a given party, the baserate determines the default trust in the proposition [JB08].
Thus the opinion model of subjective logic proposes that if x is a proposition, abinomial opinion about the truth of x is the ordered quadruple ωx = (b,d,u,α) where:
• b: belief is the belief that the specified proposition is true.
• d: disbelief is the belief that the specified proposition is false.
• u: uncertainty is the amount of uncommitted belief.
• α: base rate is the a priori probability in the absence of evidence.
Subjective logic theory does not dispute the binary true or false state of things inthe world. Rather, it claims that while the state of world is binary and certain, ourknowledge about it is usually incomplete and uncertain and thus that it is important tomodel this uncertainty. In fact, subjective logic is based on Dempster-Shafer evidencetheory and thus operates on a frame of discernment (denoted by Θ) which containsthe set of possible system states, only one of which represents the actual system state.

7.4. SUBJECTIVE LOGIC THEORY 275
However, Josang re-models the belief mass assignment using the opinion model, andthe belief, disbelief and uncertainty definitions. Thus for a proposition x we have:
b(x), ∑y⊆x
mΘ(y), where x,y ∈ 2Θ (7.5)
d(x), ∑y∩x 6= /0
mΘ(y), where x,y ∈ 2Θ (7.6)
u(x), ∑y∩x 6= /0
y*x
mΘ(y), where x,y ∈ 2Θ (7.7)
a(x/y),|x∩ y|
ywhere x,y ∈ 2Θ (7.8)
From the definitions in equations 7.5-7.7 we can infer that b(x), d(x) and u(x) ∈[0,1]. Also, for a single opinion about x, the condition in Equation 7.9 must always besatisfied and thus it is always possible to infer one of the variables based on the othertwo.
b+d +u = 1, ∀b,d,u,α ∈ [0,1] (7.9)
The opinion space can then be mapped onto the interior of an equilateral triangle, asillustrated in Figure 7.3 where the three parameters b, d and u determine the position ofthe opinion point within the triangle, with ω(x) = (0.5,0.1,0.4,0.5) as an example.
Based on the above, the probability expectation value (E(x)) of an opinion is definedin Equation 7.10.
E(x) = b(x)+α(x) ·u(x) (7.10)
The probability estimate of x actually taking place (E(x)) is thus distinguished fromthe confidence/uncertainty of knowledge about x, that is represented by (u(x)).
7.4.1 Adaptation to uncertainty for events
The definition and properties of subjective logic are easily adaptable to our problemstatement, and as explained below, the adapted version of subjective logic satisfies all

276 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Figure 7.3: Subjective logic representation of the opinion model.
the requirements set earlier. Each evidence sentence that contains an event e j thatrefers to an interaction i j (where i j is contained in a pathway or interaction network)can be considered as the subjective opinion of the author regarding the interaction i j.Thus, the event uncertainty and negation values can be used to determine the ω(e j) =
(b(e j),d(e j),u(e j),α) about the event. Considering how to map author opinions to theopinion model variables, we make the following assumptions:
1. We assume a state of discernment Θ, where the possible states for an interactioni j are limited to two: the interaction is either valid or invalid (binomial case) 3.
2. If an event is negated then b(e j)> 0
3. If an event is uncertain then u(e j)> 0
4. For each event we expect that the author can express either belief or disbeliefregarding the truth of an event. In other words: i f b(e j)> 0, then d(e j) = 0and i f d(e j) > 0, then b(e j) = 0. Then we can transform the equation 7.9
3In the future we would like to refine this approach and consider more refined multinomial caseswhere an interaction can have several state.

7.4. SUBJECTIVE LOGIC THEORY 277
as follows:
u(e j) = 1−b(e j)−d(e j) =
1−d(e j), if event is negated
1 = b(e j), otherwise(7.11)
5. For the binary classification scheme presented earlier there are four potential opin-ion states:
(a) If event e j is uncertain and negated: b(e j) = 0,d(e j) = 0.5,u(e j) = 0.5
(b) If event e j is uncertain and not negated: b(e j) = 0.5,d(e j) = 0,u(e j) = 0.5
(c) If event e j is not uncertain and negated: b(e j) = 0,d(e j) = 1,u(e j) = 0
(d) If event e j is not uncertain and not negated: b(e j) = 1,d(e j) = 0,u(e j) = 0
6. Unless experimental results are available, α = 0.5
7. Any interaction in a pathway of interest will also have a corresponding ω(i j)
tuple.
• For interactions i j in a pathway for which there is no evidence found in text,u(i j) = 1
• For any interaction i j that has at least one event mention e j mapped to it,there is a fused opinion tuple, ω(i j) = (b(e j),d(e j),u(e j),α), where signifies the fused values for each variable. We discuss the calculation ofthe fused values below.
7.4.2 Fusion of opinions using subjective logic
Subjective logic defines the methods for fusing multiple opinions about the same propo-sition x, which is our target, since we aim to combine multiple mentions of the sameinteraction. Assuming we have several different opinion sources (authors) referring tothe same proposition (interaction) with different levels of certainty, we can fuse theiropinions based on subjective logic. Depending on the assumptions about the indepen-dence of each event mention, different fusion formulas can be applied. Focusing on

278 CHAPTER 7. CONSOLIDATING UNCERTAINTY
the simplified case of fusing just two event mentions, ω(eAj ) and ω(eB
j ) we can explorepotential fusion methods, namely cumulative and averaging fusion.
Assuming that the two event mentions correspond to independent statements, thecumulative fused opinion would be : ω(i j) = ωAB(e j) = (bAB,dAB,uAB,αAB). Thevariables of the opinion model can be expressed as follows:
• If uAj 6= 0 OR uB
j 6= 0 bAB
j =bA
j ·uBj +bB
j ·uAj
uAj +uB
j−uAj ·uB
j
uABj =
uAj ·uB
j
uAj +uB
j−uAj ·uB
j
(7.12)
• If uAj = 0 AND uB
j = 0bAB
j = γ ·bAj +(1− γ) ·bB
j
uABj = 0, where γ = lim
uAj→0
uBj→0
uBj
uAj +uB
j(7.13)
The formulas are derived and explained in [Jos09] based on the addition of Dirich-let parameters, the bijective mapping between multinomial opinions, and the Dirich-let distribution. In the case of the binary uncertainty of events used in this work,the calculation of bAB
j in the case described in equation 7.13 can be simplified tob = bAB
j = bAj = bB
j = 1.
According to Josang, it is provable that the averaging fusion operator is commuta-tive (changing the order of the operands does not change the outcome), idempotent (theoperator can be applied multiple times without changing the outcome beyond the ini-tial application) and associative (if we apply the operator sequentially to three or morevalues, the order in which the operations are performed will not change the outcome).
However, not all event mentions are independent. We could consider event depen-dencies on different levels. For example, the same event can be mentioned in the samedocument multiple times, or the same author might write about the same event in sev-eral different publications (articles). Moreover, the same event can be mentioned by anauthor citing the work of someone else, and thus implying influence (dependency) by

7.4. SUBJECTIVE LOGIC THEORY 279
the opinions of some other author. Note that the degree of dependency is different in theaforementioned cases, since there is a higher possibility of different authors disagreeingwith each other, or an author changing their opinion between publications of differentpapers, while the dependency of event mentions within the same paper is expected to bestronger.
For dependent opinions over the same proposition x, Josang defines the averagingfusion. Assuming that the two event mentions are written by the same author, the av-eraging fused opinion would be : ω(i j) = ωAB(e j) = (bAB,dAB,uAB,αAB). Thevariables of the opinion model can be expressed as follows:
• If uAj 6= 0 OR uB
j 6= 0 bAB
j =bA
j ·uBj +bB
j ·uAj
uAj +uB
j−uAj ·uB
j
uABj =
uAj ·uB
j
uAj +uB
j−uAj ·uB
j
(7.14)
• If uA(e j) = 0 AND uBj = 0
bABj = γ ·bA
j +(1− γ) ·bBj
uABj = 0, where γ = lim
uAj→0
uBj→0
uBj
uAj +uB
j(7.15)
Again, in the case of binary uncertainty of events used in this work, the calculation ofbAB
j in the case described in equation 7.15 can be simplified to b= bABj = bA
j = bBj = 1.
Note also that in all cases, d is derived from equation 7.9 as d = 1−α · u− b. Gener-ally, the averaging fusion operator is equivalent to averaging the evidence of Dirichletdistributions. According to Josang, it is provable that the averaging fusion operator iscommutative (changing the order of the operands does not change the outcome) andidempotent (the operator can be applied multiple times without changing the outcomebeyond the initial application), but not associative. This means that if we apply the av-eraging operator sequentially to three or more values, the order in which the operationsare performed will influence the outcome.
Fusion of two opinions can expand to multi-opinion fusion both for the cumulative

280 CHAPTER 7. CONSOLIDATING UNCERTAINTY
and averaging operators. We present below the derived formulas. To generalise theformulas, let us assume that each evidence sentence is a separate opinion source C. Wecan then combine belief bC
X(x) and uncertainty uCX from each source (C ∈ C) to derive
the fused belief b(C)X and uncertainty u(C)X that will allow us to calculate the overall
probability expectation value E = b(C)X +α ·u(C)X .For cumulative fusion we have:
• If ∃C ∈ C such that uCX 6= 0
b(C)X =
∑C∈C
(bCX(x) · ∏
C j 6=CuC j
X )
∑C∈C
∏C j 6=C
uC jX − (N−1) ·∏
C∈CuC
X
u(C)X =
∏C∈C
uCX
∑C∈C
∏C j 6=C
uC jX − (N−1) ·∏
C∈CuC
X
(7.16)
• If ∀C ∈ C uCX = 0
b(C)X = ∑C∈C
γCX ·bC
X(x)
u(C)X = 0 where γCX = lim
uCX
uCX
∑C j∈C
uC jX
(7.17)
While for averaging fusion we have:
• If ∃C ∈ C such that uCX 6= 0
b(C)X =
∑C∈C
(bCX(x) · ∏
C j 6=CuC j
X )
∑C∈C
( ∏C j 6=C
uC jX )
u(C)X =
N ·∏C∈C
uCX
∑C∈C
( ∏C j 6=C
uC jX )
(7.18)

7.4. SUBJECTIVE LOGIC THEORY 281
• If ∀C ∈ C uCX = 0
b(C)X = ∑C∈C
γCX ·bC
X(x)
u(C)X = 0 where γCX = lim
uCX
uCX
∑C j∈C
uC jX
(7.19)
Note that the application of the formulas for the two different fusion operators willimpact the integration of an additional event differently. For cumulative fusion, in-troduction of a new opinion ωn(e j) will boost the fused belief (b(e j)), based on theassumption that the introduction of a new independent opinion (even if it contains un-certainty) constitutes supporting evidence. In averaging fusion, the assumption is thatthere is some dependence between opinions, so the boost in belief is conditional to thelevel of uncertainty. Hence in the formulas, when comparing the calculation of belief incumulative and averaging multi-source fusion respectively, we can observe that the de-nominator will necessarily correspond to a larger value for cases of non-zero uncertainty(Equations 7.16 and 7.18). In the example of Figure 7.4 we illustrate the difference be-tween averaging and cumulative fusion when applied on three opinion quadruples usingEquations 7.16 and 7.18.
The property of cumulative fusion to boost belief upon the introduction of additionalevidence implies that the greater the number of mentions of events that we try to fuse,the higher the overall confidence score for the corresponding interaction will be. Thisis well-aligned with the pre-requisite for the desired metric, which has to be able toaccount for the frequency of mentions of an interaction as an indication of increasedconfidence in the interaction.
However, cumulative fusion, as explained before, makes the “naive” assumptionthat all event mentions are independent. Ideally, we would like to consider a hybridfusion, where the certainties of potentially dependent events (e.g., events extracted fromthe same article, written by the same author, or extracted from articles linked with acitation) are fused with the averaging fusion formulas, and then the fused values wouldbe forwarded to the cumulative fusion formulas to be merged with the certainties ofother events, that are perceived as independent.
However, such an approach would require us to define dependency relations between

282 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Figure 7.4: Cumulative and averaging fusion comparison for three opinion tuples. Wecan observe that with cumulative fusion, the belief is boosted and uncertainty decreasescompared to averaging fusion.
events and scientific articles, and then evaluate them independently before applyingthem in the merging procedure. This constitutes a rather complicated procedure. Forexample, even when considering events within the same document, additional discourseand argumentation mining methods would be required in order to decide the degree ofdependence between the different mentions of the same event. For example, it is typicalfor an event to be mentioned in the introduction as part of a hypothesis to be tested, andlater on for the same event to be confirmed or rejected as a result of an experiment. As

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 283
a matter of fact, the same event could be tested in several experimental settings withdifferent outcomes (and resulting certainty values for the event). While one could claimthat there is dependency between the hypothesised event and the event that is stated asa result of an experiment, it is unclear what is the nature of the underlying dependencybetween the events that are mentioned as results of independent experiments within thesame paper. As an example we present a number of statements referring to the regulationof p53 by Mdm2 4. These include an investigative statement in (1) and two mentions ofthe same event (with different certainty) mentioned in the result section (2,3).
1. We intend to investigate the extent to which p53 is regulated by Mdm2.
2. Mdm2 is shown to inhibit p53 cell-cycle arrest and apoptic functions.
3. We show here that interaction with Mdm2 may also result in a large reduction inp53 protein levels through enhanced proteasome-dependent degradation.
Due to the high complexity of the task in terms of defining dependencies and thelack of available datasets, further elaboration of this topic was determined be outsidethe scope of this work. Thus in our evaluation we do not use any dependency informa-tion (thus simplifying the evaluation task for the annotators) and we compare uniformapplication of averaging and cumulative fusion to all events.
Future work will revolve around investigating dependencies between integrated eventmentions and analysing potential ways to model them in line with subjective fusion. In[JMP06], there is a substantial body of theory on combining dependent or partly de-pendent opinions as well as on propagation of opinions within networks and attributingdifferent certainty to different sources, which we intend to study in the future.
7.5 Mapping event mentions to existing knowledge mod-els
As discussed in the previous section, subjective logic is used to combine different opin-ions regarding the truth of a specific event. The ultimate goal behind the efforts to con-solidate certainty values of different mentions of the same event is the propagation of a
4Examples taken and adapted from [KJV97]

284 CHAPTER 7. CONSOLIDATING UNCERTAINTY
consolidated confidence value to the corresponding interaction in an existing knowledgebase, interaction network or pathway model. While this task may seem straightforward,it can be quite challenging, as errors can be introduced at various stages when mappingtextual information (e.g., erroneous matching of protein names, misidentification of theinteraction type or directionality, etc.). We provide details of the event-to-interactionmapping task, the main challenges and the final approach in the sections that follow.
7.5.1 Related work and challenges in integrating text-mined inter-actions to existing knowledge models
The major challenges of mapping text-mined events to interactions can be divided intotwo main categories: (1) Errors related to correctly identifying the entities involved inthe event and (2) Errors related to correctly identifying the type of the interaction thatholds between them (if any). The latter is particularly important when trying to mapnew evidence to existing interactions in a database. A further challenge, recently intro-duced by Muller and colleagues [MVALS18] in the context of the Textpresso Centralsystem, is the need to verify the correct placement of a new interaction in a database, inan automated manner, to ensure the coherence and consistency of the database. Text-presso Central uses a verification system based on validation token exchange betweenthe database and Textpresso. While this aspect is also important, we choose to focus onthe first two categories in this work.
7.5.1.1 Entity mapping
After having identified a mention of a biomedical entity in text (e.g. chemicals, genes,proteins etc.) it is important to disambiguate it and map it to an entry in one or moreexisting databases. This task is often referred to as grounding or normalisation andconstitutes a general problem in many different information extraction task, rangingfrom general newswire concept grounding (often called ‘wikification’) and geo-spatialinformation grounding [LSW03] to grounding of biomedical entities.
In the biomedical field, the BioCreAtIve challenges of 2004 and 2005 [HCMY05]included a task dedicated to the issue of grounding of genes. More specifically, partici-pating systems were required to produce the correct list of unique gene identifiers for the

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 285
genes and gene products mentioned in sets of abstracts relating to three model organ-isms (Yeast, Fly and Mouse). While the task was relatively lenient, in that it concernedonly abstracts, and evaluated only the final produced lists rather than the exact matchingof each gene mention to its NCBI ID, it nevertheless highlighted the importance of thegrounding phase for biomedical applications and motivated research in this direction.
While the task may seem straightforward, it is a rather involved problem, due to anumber of factors, such as a lack of proper naming conventions, which leads to ambigu-ous and non-defined terms and abbreviations. For example the cell signalling proteinTumor necrosis factor alpha can be mentioned many different ways in the literature,e.g., TNFA, TNF-alpha, tnf alpha, TNFalpha or even cachexin and cachectin. Similarly,Mitogen-activated protein kinase 1 (MAPK1) is also known as extracellular signal-
regulated kinase 2 (ERK2) and has an extended list of aliases (Mitogen-activated ProteinKinase 2, MAPK 2, MAPK2, Extracellular Signal-regulated Kinase 2, ERK2, ERK-2,ERK, ERT1, MAP Kinase Isoform p42, Mitogen-activated Protein Kinase 1, MAP Ki-nase 1, MAPK 1, Mapk1, Mapk, p42mapk, p42-MAPK, Prkm1) but is different fromERK1. The task is further complicated by the extensive use of acronyms such as ALTfor alanine aminotransferase and ambiguous symbols such as mAB, which can stand for‘monoclonal antibody’ or ‘male abnormal’ gene.
Thus, although techniques that match terms in text either exactly or approximatelyagainst dictionaries such as BLAST [KRMF00] can achieve high accuracy entity iden-tification tasks (e.g., simply identifying that a string in text refers to a protein or achemical), they are not optimal for grounding tasks as they result in reduced ground-ing accuracy due to mismatches. Instead, most recent approaches consist of severalintegrated filtering steps. A normalisation step, in which entity mentions are simplifiedin order to better facilitate grounding, is common practice, and often includes removalof non-alphanumeric characters, removal of capitalisation, and normalisation of specificprefixes and suffixes that have standardised role in entity naming (e.g., “p” is added atthe end of proteins to signify phosphorylated molecules). Subsequently, a variety ofapproaches have been proposed in the literature in order to resolve synonym and ab-breviation issues, most of them relying on external knowledge sources, databases andsynonym lexica or semantic technologies, such as ontologies and reasoners.
Wang et al. [WZL+14] propose a combination of rules and machine learning. Theycompile a rich lexicon by combining organism names from two dictionaries: the NCBI

286 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Taxonomy and the UniProt Controlled Vocabulary of taxa. Gene mentions are thenmapped to species IDs using a mixture of heuristic rules, supervised classification witha maximum entropy model and custom parsers. TaxonGrab [KSM05] also uses a com-bined lexicon consisting of a combination of WordNet and the SPECIALIST UMLSlexicon enriched with the terms from NCBI Taxonomy, the Integrated Taxonomic Infor-mation System and the German Collection of Microorganisms and Cell Cultures. Theycomplement the lexicon with regular expression custom rules in order to account fornon-identified multi-word expressions. uBioRSS [LRN+07], a Web service, indexestaxonomic names using pattern-matching expressions and a lexicon of English words,providing a confidence score for resultant names and IDs. Apart from uBioRSS, a num-ber of gazetteer-based Web services are available for entity recognition and normali-sation, such as Whatizit [RSAG+07]. has demonstrated good performance in taggingspecies names in biomedical texts using a gazetteer (species dictionary) combined withpost-processing techniques for disambiguation, acronym resolution and filtering. Funkand his colleagues [FCHV16] demonstrated how a combination of different rules (de-compositional and derivational rules) derived from GO can aid in synonym mappingand boost the performance in concept recognition.
For entities that are mapped to more than one entry in the lexica or databases, mostsystems use further processing and sets of heuristic rules to disambiguate them. Witteet al. [WKB07] resolve ambiguous entities based on the closest non-abbreviated formappearing in the document that matches the genus. In the OrganismTagger, Naderi etal. [NKBW11] further expand this approach with additional context-based heuristicrules to resolve entity mentions that could match more than one NCBI entry. Morespecifically, they propose the use of species mentioned in the same document to guideID disambiguation for ambiguous common species names such as “mice”. Kaljurand[KRKS09] takes a similar approach, claiming that interacting proteins are usually fromthe same species, and, assuming that co-occurrence of entities implies potential interac-tion, they propose the following generalised strategy: for every protein mention, removeevery ID that references a species that is not among the species referenced by the IDs ofthe neighbouring protein mentions.
Note that such strategies could result in more than one ID being assigned to theentry in the final set. However, such lenient, high recall approaches are common in thegrounding task. In fact, Naderi demonstrates that if heuristic rules fail to disambiguate

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 287
an entity, a greedy approach where all potential NCBI IDs are assigned to the entries ispreferable in terms of the final accuracy.
Recently, ConsensusPathDB [HHLK16] published extensive and comprehensive iden-tifier maps generated by combining and processing the contents of 11 genomic, pro-teomic and metabolite databases including Ensembl, Uniprot and PubChem. Usingthese maps, the database integrates interaction and pathway information from 32 differ-ent online sources and allows users to map their preferred namespace encoding to thegrounded entities.
Notably, some proposed approaches in the BioCreAtIve tasks [HCMY05] reliedsolely on supervised machine learning approaches for the final disambiguation and fil-tering step. BioTagger [L+04] used features derived from rich lexical resources to cre-ate feature vectors used for word sense disambiguation. Crim et al. [CMP05] combinedtheir high recall pattern matching system with a maximum entropy classifier trained todistinguish correct matches from erroneous matches. Hachey [HNN+04] used informa-tion retrieval techniques to associate candidate gene identifiers with term frequencies ina document. More recently, Tsai and Roth [TR16] proposed a system that uses mul-tiple knowledge bases to generate grounding candidates after which they an approachwhich they term “indirect supervision”, which uses the common information among thecandidate IDs to disambiguate protein names. They show that in this way it is possibleto generate suitable training instances and to train a competent SVM classifier to rankcandidate IDs.
7.5.1.2 Interaction mapping
Automatically determining that two grounded entities are mentioned as participants inthe same interaction (or event in our case) and correctly mapping this interaction to anexisting entry in the knowledge base is also rather error prone. Potential error sourcesare not limited to the difficulties in identifying the type of interaction (event trigger)but also relate to the correct identification of the directionality of the interaction, (orin other words, distinguishing the subject from the object), identification of additionalarguments (e.g., interaction site) and correct identification of the polarity (e.g., is the
regulation positive or negative?). Handling apposition, i.e. correctly identifying whenit is appropriate to generalise the described relation in order to map it to an existing

288 CHAPTER 7. CONSOLIDATING UNCERTAINTY
interaction, is another crucial question. For example, should mentions of activation in-teractions be merged with positive regulation ones? Should the latter be further mergedwith negative regulation as generic regulation interactions? Admittedly, there is no uni-formly optimal answer to the above questions, since they are largely dependent on theapplication and the interaction definitions and conventions adopted by the knowledgebase(s) that is the target of the mapping.
Many approaches assume that co-occurrence of entities in close proximity, oftenwithin sentence or phrase boundaries, implies that an interaction exists between them[BSSM+10, FSF+13]. Indeed, Naderi found that only 2% of co-occurring proteinnames were not involved in interactions with each other [NKBW11], thus justifying theapproach of treating co-occurrence as evidence of an interaction. Jenssen and colleaguesagree with this, and propose PubGene, a set of tools to extract biomedical networks.However, such approaches lack accuracy in terms of the directionality and the type ofinteraction. PPI Finder [HWL09] uses information from databases such as NCBI EntrezGene Data to bootstrap the extraction of co-occurring entities and ranks them accord-ingly. Contrary to Naderi, in the evaluation they found that only 28% of the co-occurringpairs in PubMed abstracts appeared in any of the commonly used human PPI databases(HPRD, BioGRID and BIND). When comparing against the DIP [SMS+04] database,Blaschke and Valencia [BV01], demonstrated a similar overlap with the database ofonly 30% (when looking at PPIs extracted using co-occurrence methods).
OpenDMAP [HLF+08] uses a predicate-object structure to capture interactions fromtext and uses Protege to encode them. In this way, using logical programming theyencode constraints for roles and type of arguments, as well as the hierarchy of permit-ted interactions. They make use of the Gene Ontology (GO) and the OBO FoundryRelationship Ontology to define potential interactions. Thus, they define interactiontemplates that they try to populate using text mining and they show that they are quiteexpressive. The performance of this approach varies significantly between interactiontypes, with transport interactions exhibiting the best performance (F-score of 0.59) de-spite the increased argument complexity. The large number of incomplete interactions(non-fully filled templates) has a significantly negative effect on the performance. Ifeven incomplete transport interactions are considered correct, then the F-score rises to0.71. Templates have also been used for interaction mapping by other systems, such asthe RLIMS-P, which focused only on phosphorylation [TAL+15].

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 289
Chen and Sharp [CS04] propose a combined approach that uses a hierarchical struc-ture to define different interaction granularity levels, from fine-grained interactive (in-hibitory, stimulatory, etc.) interactions, to simple co-occurrence. For the interactiveinteractions, the exact terms from the text (what would correspond to our event triggers)that map to them are defined, and the classification is then performed in a rule-basedfashion. More recently, Abacha also applied a rule-based method for interaction map-ping [AZ11]. BioRAT [CBLJ04] also uses templates to map information from textand, in this case, a manually assembled gazetteer guides the interaction mapping, i.e.,the types of interaction (“bind”, “phospohorylate” etc) are mapped to each user query.In IMID [BMC+12], three different types of interaction mined from text are recog-nised: (i) PPIs including physical, regulatory and genetic interactions; (ii) protein–smallmolecule interactions; and (iii) associations of interactions with other bio-entities suchas pathways, species, diseases or GO terms. Interactions are extracted using a Bayesiannetwork approach that also provides probability scoring, and are combined with exist-ing databases (Reactome and Pathways). PCorral [LJYA+13] uses a similar approachwith two categories: chemical modification and regulation. For each interaction cate-gory, a set of manually compiled lists of terms defines the interaction triggers that canbe mapped to them (eg “acetylate” denotes a chemical modification while “associate”denotes a regulation event). Natarajan and colleagues show that by filtering patternsaccording to the frequency of the identified interaction type (term), it is possible to gen-erate meaningful networks using full-text articles. They demonstrate the efficiency oftheir approach by studying the effects of Sp1 on angiogenesis [NBD+06].
In addition to co-occurrence and templates, some systems use formal grammars andmostly syntactic parsing to identify nested structures in a sentence and extract eventsor event-like structures (often triplets) that can be mapped to an interaction [TG03].Among such systems, GeneWays [RIK+04] uses GENIES [FKY+01], a biomedicalNLP system, to extract relations between entities and then applies a rule-based systemto generate interactions that will populate the Knowledge Base. Essentially, in Ge-neWays the extracted relations are flattened to binary format, maintaining right-to-leftdirectionality, and then classified based on interaction type, similar to those used byPCorral etc. FACTA+ [TMH+11] uses the event type conventions specified in the Ge-nia corpus and the BioNLP Shared tasks, using EventMine for the event extraction. It

290 CHAPTER 7. CONSOLIDATING UNCERTAINTY
does not map against any external database, but rather against user queries. They per-formed a small-scale experiment, asking researchers to verify the correct classificationattributed to the interactions to demonstrate the validity of their results. Chowdharyand colleagues make special reference to the issue of directionality in the PIMiner im-plementation [CZT+13] (also in previous work: [BCL+11]). They separate terms intodirection-invoking (e.g., regulation) and non-direction-invoking (e.g., binding) ones andthen train a Bayesian model to predict right-to-left or left-to-right directionality in thetriplet. The CPNM system [CTZ+12] builds on PIMiner and provides functionality forboth co-occurrence mining and interaction triplet mining. To map interactions to thenetwork, it also uses a list of predefined terms for each interaction class and approxi-mate string matching to classify the type of interaction, and provides confidence scoresfor the selected interactions in terms of relevance to the user query.
Overall, we can see that mapping interaction types in an automated, network-agnosticmanner is rather complicated, and most systems approach it in either a relaxed manner,where every interaction with matching entities will be mapped to the corresponding in-teraction in the database, or using a rule-based approach, where a set of rules or listswill define the mapping of the relation term identified in text to the predefined inter-action types. However, Tari and colleagues present a system using a reasoner as apost-processing step after the interaction type classification that guides the assemblyof interactions towards network generation [TAL+10]. Also, in order to integrate in-formation from multiple databases, Bayesian models have been proposed to identifypotential interaction mappings across databases [MSB08, XDH06].
7.5.2 Proposed approach
For the entity mapping, we follow the commonly used approach of “enhanced” multi-step string matching. More specifically, we compiled synonym lists from UMLS [Bod04],GeneOntology [Con04], Panther database [MT09], ChemSpider [PW10] and CHEBI[DDME+07], in order to map protein, gene and chemical names we identified in text.We then applied approximate string matching between the text-mined candidate entity,the synonym list and the pathway entities, as shown in Figure 7.5. For the approximatestring matching, we remove any capitalisation as well as any non-alphanumeric charac-ters. We then obtain the lemma of the remaining entities and apply string matching to

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 291
try to find a match against the synonym lists.
Figure 7.5: Entity mapping procedure.
For interaction mapping, since we focus on events as the representative informationunit corresponding to a potential interaction, it is necessary to define a mapping strat-egy between events and potential interaction databases, pathways and networks. Westrive to achieve a balance between recall and precision, thus we opted not to imposean overly strict mapping between interaction types, but rather to allow some degree ofgeneralisation while preserving core classification and directionality constraints, as de-tailed below. Moreover, while directionality and polarity constraints can be consideredvalid across a range of knowledge bases using different standards and conventions, itwas impossible to define fine-grained mappings and generalisation rules for event typesglobally, since different pathway models, interaction networks and databases use differ-ent naming conventions. As diverse representation standards (e.g., SBML [HFS+03],BioPAX [DCP+10a], KGML [KGF+09], etc.) have been adopted by the systems bi-ology community in encoding pathway models, it was necessary to define mappingsbetween the types recognised by EventMine and those contained in a given model. InSection 7.6.1 we present the mapping conventions that we have defined for two different

292 CHAPTER 7. CONSOLIDATING UNCERTAINTY
pathways (described in the datasets, Section 5.2.2).Overall we converge on the following conventions:
• Negation: Unless the network interactions have specific attributes for negation(as is the case of Pathway Studio [NEDM03] in which case we try to match nega-tion as well), we extract negation as a meta-knowledge dimension that is countedtowards the calculation of confidence. However, it does not affect the interactionmapping any further.
• Directionality: Following the approach of Chowdhary [CTZ+12] we considertwo different types of identified interactions: directional and non-directional. Al-though the directionality categorisation is different for each attempted network,the following rough distinctions are made:
– Binding events are considered non-directional and thus the order of entitiesdoes not matter. (See example (a) in Figure 7.6)
– Protein/gene processes such as Regulation, phosphorylation, expression, pro-tein catabolism, etc. are considered directional, with specified positions fordifferent argument roles. For example, the direction is typically from Cause
arguments to Theme arguments. (See example (b) in Figure 7.6)
– Chemical reactions like: Acetylation, methylation, sulfation etc., are consid-ered directional, with specified positions for different argument roles. Sim-ilarly to the previous case, the direction is typically from Cause argumentsto Theme arguments. (See example (c) in Figure 7.6)
– Localisation and translocation are considered directional (from the protein/-gene to the location). Translocation is treated as a special case – events ofthis type need to be simplified to allow them to be added to binary networks,since the events sometime have three different arguments. Typically the sim-plification process breaks the event into two linked events. (See example (d)in Figure 7.6)
• Generalisation: We tried to define some generic, hierarchy-based generalisa-tion rules for the mapping of interaction types (through consultation with re-searchers from the field of biomedicine and using PathwayCommons [CGD+10]as a guide):

7.5. MAPPING EVENT MENTIONS TO EXISTING KNOWLEDGE MODELS 293
– Non-polarised regulation can be mapped to both positive and negative inter-action types.
– Positive/negative regulation can be mapped either to regulation of the samepolarity or to non-polarised regulation.
– Phosphorylation, expression and protein catabolism can be mapped to regu-lation in networks that do not distinguish between these interactions.
– Location-related interactions that are directional (transport, translocation,localization) can be mapped to the same interaction concept.
Figure 7.6: Examples of different directionality handling according to event type.
More specific rules are defined for each pathway as explained in section 7.6.1. Build-ing upon the work of Ohta [OPR+13, AOR13], we defined mappings between thetypes specified by two different standards (i.e. BioPAX [DCP+10b] and PathwayStudio[NEDM03]) and the EventMine types in order to address each use case described inSection 5.2.2.

294 CHAPTER 7. CONSOLIDATING UNCERTAINTY
7.6 Application to biomedical events and pathways
7.6.1 Implementation
We test the subjective logic adaptation and event mapping on the two different pathwaymodels described in section 5.2.2. In both cases, the process consisted of the followingsteps:
1. Selection of relevant documents. In the case of the leukemia pathway this pro-cess implied collecting all the evidence passages that were manually attributed bypathway curators as supporting evidence for each interaction. For the Ras neigh-borhood network, the document selection was guided by the evaluating scientistsand was a collection of articles focusing on Melanoma-type cancers.
2. Document pre-processing and event extraction. All the NLP operations necessaryfor document pre-processing as well as event and uncertainty extraction were car-ried out using Argo workflows [BNNS+17] as described in more detail in Chapter4. Events were extracted using EventMine models [MA13b] trained with the widecoverage approach [MPOA13]. Subsequently, the events were further processedusing the post-processing approach described in Chapter 2 to improve mappingrecall.
3. Negation and uncertainty identification methods are applied as described in Chap-ter 5.
4. Events are mapped to the interactions. The generic conventions described in Sec-tion 7.5.2 are applied. We list below the exact conventions applied to facilitateinteraction type mapping for each of the two different pathways.
• Leukemia Pathway: see Figure 7.7.
• Ras neighborhood network: see Figure 7.8.
5. For each event, the uncertainty and negation binary values are translated to opin-ion tuples as described in Section 7.4.1, point 4. In the absence of experimental
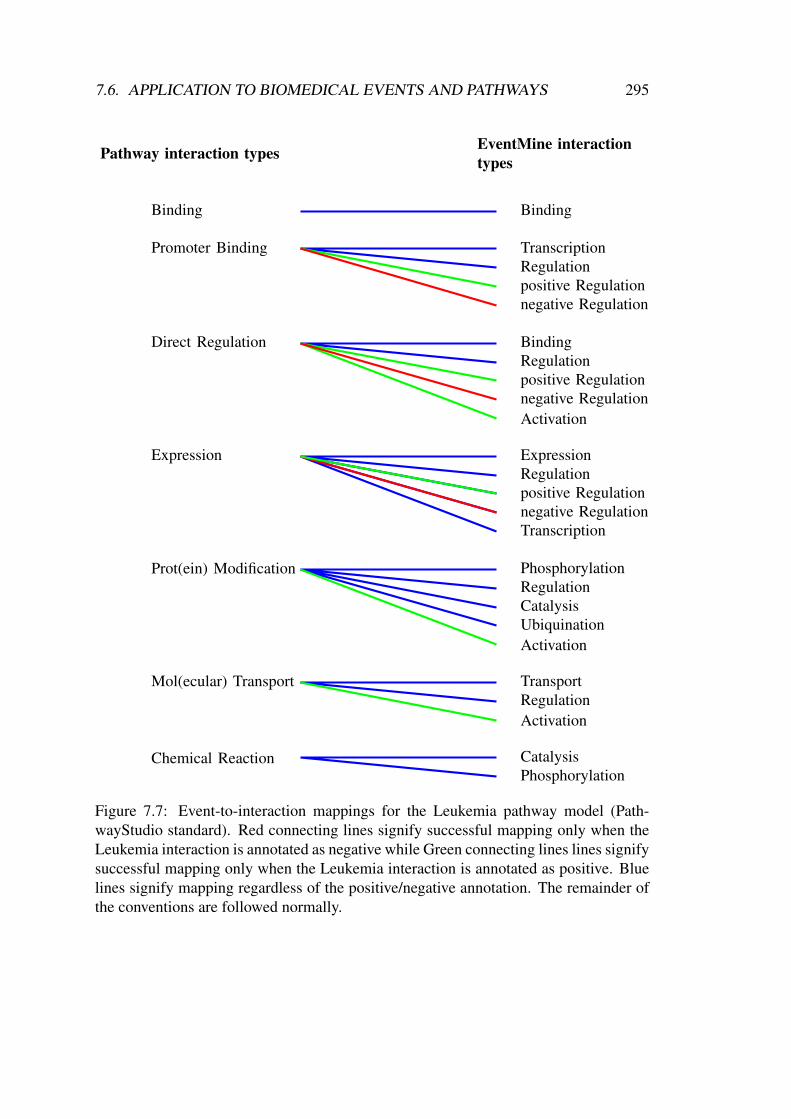
7.6. APPLICATION TO BIOMEDICAL EVENTS AND PATHWAYS 295
Binding Binding
Promoter Binding TranscriptionRegulationpositive Regulationnegative Regulation
Direct Regulation BindingRegulationpositive Regulationnegative RegulationActivation
Expression ExpressionRegulationpositive Regulationnegative RegulationTranscription
Prot(ein) Modification PhosphorylationRegulationCatalysisUbiquinationActivation
Mol(ecular) Transport TransportRegulationActivation
Chemical Reaction CatalysisPhosphorylation
Pathway interaction types EventMine interactiontypes
Figure 7.7: Event-to-interaction mappings for the Leukemia pathway model (Path-wayStudio standard). Red connecting lines signify successful mapping only when theLeukemia interaction is annotated as negative while Green connecting lines lines signifysuccessful mapping only when the Leukemia interaction is annotated as positive. Bluelines signify mapping regardless of the positive/negative annotation. The remainder ofthe conventions are followed normally.

296 CHAPTER 7. CONSOLIDATING UNCERTAINTY
Catalysis
Modulation
Template Reac-tion Regulation
Control
ActivationBindingProtein CatabolismTranscriptionRegulationpositive Regulationnegative RegulationGene ExpressionPhosphorylationProtein processingBreakdownMetabolismChemical Reactions
Biochemical Re-action
BindingProtein Catabolismpositive Regulationnegative RegulationRegulationPhosphorylationTranslationChemical ReactionsLocalization
Transport with Bio-chemical Reaction
Transport
Degradation
BindingGene ExpressionLocalizationProtein Catabolismpositive Regulationnegative RegulationRegulationPhosphorylationBreakdownMetabolismChemical ReactionsTranslationMethylationTranscription
Complex Assembly
Pathway interaction types EventMine interactiontypes
Figure 7.8: Event-to-interaction mappings for the Ras 2-hop neighborhood network(BioPAX standard). Red connecting lines signify successful mapping only when the in-teraction is annotated as negative while Green connecting lines lines signify successfulmapping only when the interaction is annotated as positive. Blue lines signify map-ping regardless of the positive/negative annotation. Dashed lines signify mapping to arange of chemical reactions as described below. The remainder of the conventions arefollowed normally.

7.6. APPLICATION TO BIOMEDICAL EVENTS AND PATHWAYS 297
data for the validity of events we set α to 0.5 for all experiments presented in thefollowing sections.
6. Uncertainty values for events mapped to the same interaction are fused as indi-cated in Equations 7.16 and 7.17.
7. Estimated probabilities are calculated for each interaction based on the fusedopinions of the related events, based on Equation 7.10.
7.6.2 Evaluation and results
As there is no similar annotated resource for this task, the evaluation was extrinsic, basedon user evaluation. For both pathway model datasets we extended the user evaluationpresented in Chapter 5, Section 5.4.2 and asked users to score each interaction in termsof certainty. In all evaluation groups, annotators were instructed to provide the certaintyscoring based on all sentences that contained the events mapped to each interaction.While not explicitly mentioned to the annotators, our assumption was that they woulduse the certainty of the different event mentions to infer the overall certainty level of theinteraction.
Similarly to the previous evaluation tasks, users were asked to avoid using any ex-isting background knowledge in determining the certainty of the interactions, since thegoal was to infer the certainty based only on the provided text. Moreover, with the ex-ception of the initial “training” round, users were discouraged from communicating andcollaborating with each other during the interaction scoring. The output of the traininground is not included in the evaluation results since its contents were used to familiariseusers with the task and give them the chance to identify potential issues and questions.
We present the details of the evaluation process for each pathway dataset in thefollowing sections.
7.6.2.1 The Leukemia pathway use-case
Using our event mapping methods, detailed in Section 7.5, a total of 278 events wereextracted and mapped to one of the 108 interactions of the leukemia pathway. Aftermanual inspection, 15 events and the accompanying evidence passages were removedas they were judged to be erroneous or incomplete. This event removal was performed

298 CHAPTER 7. CONSOLIDATING UNCERTAINTY
as part of the data cleaning and preparation for the annotation task. Thus, it providesonly an approximate and not an exact estimation of the error rate of our mapping ap-proach. For a better estimation, additional resources as well as multiple external anno-tators would be required.
The resulting dataset consists of 72 interactions, each having 2-20 events mappedto them. In total, 263 events mapped to the pathway interactions were presented to theannotators for evaluation along with the 72 interactions. In the evaluation procedure,each interaction is presented with a list of passages 5 containing the mapped events.
Once the interaction and event data were prepared, 5 annotators (Group #2 from theprevious annotation task in Section 5.4.2.3) were asked to score the certainty of eachinteraction. This interaction uncertainty evaluation task was performed following thepreviously described task (see Section 5.4.2.3) in which annotators were asked to scoreeach individual event mapped to a given interaction using a certainty scale of 1−5. Afterthis, annotators were asked to evaluate the general level of certainty of the interaction,based on the mapped evidence provided, using the Brat annotation interface [SPT+12].Again, this was done using a certainty scale of 1− 5, where 1 corresponds to “highlyuncertain” and 5 to “highly certain”. The annotators were specifically requested notto evaluate the perceived correctness of the mapping, but rather to use only the textualinformation and certainty of each evidence passage.
The uncertainty score distribution over the Leukemia pathway interactions for eachannotator is presented in Figure 7.9a. To facilitate comparison, we present again theevent-centred certainty scoring in Figure 7.9b (presented initially in Figure 5.25) along-side the interaction-based scoring. It is clear that for each user, the perception of un-certainty related to the model interactions follows a similar pattern to the perception ofuncertainty over the events extracted from the related evidence passages. For example,User #3 demonstrates the same tendency towards a preference for middle values (foursand threes) both for interactions and events. Likewise, User #5 classifies the majority ofevents ( 72%) and interactions ( 68%) as “highly certain”.
We then proceeded to evaluate the effectiveness of the subjective logic fusion interms of predicting the user-provided interaction uncertainty scores based on the event
5The passages correspond to no more than a few (usually just one) sentences. Even in multi-sentencecases only one event per passage is highlighted. The reason that more than one sentence is allowed is thatthe passages were manually mapped to the interactions during manual curation (see Section 5.2.2)
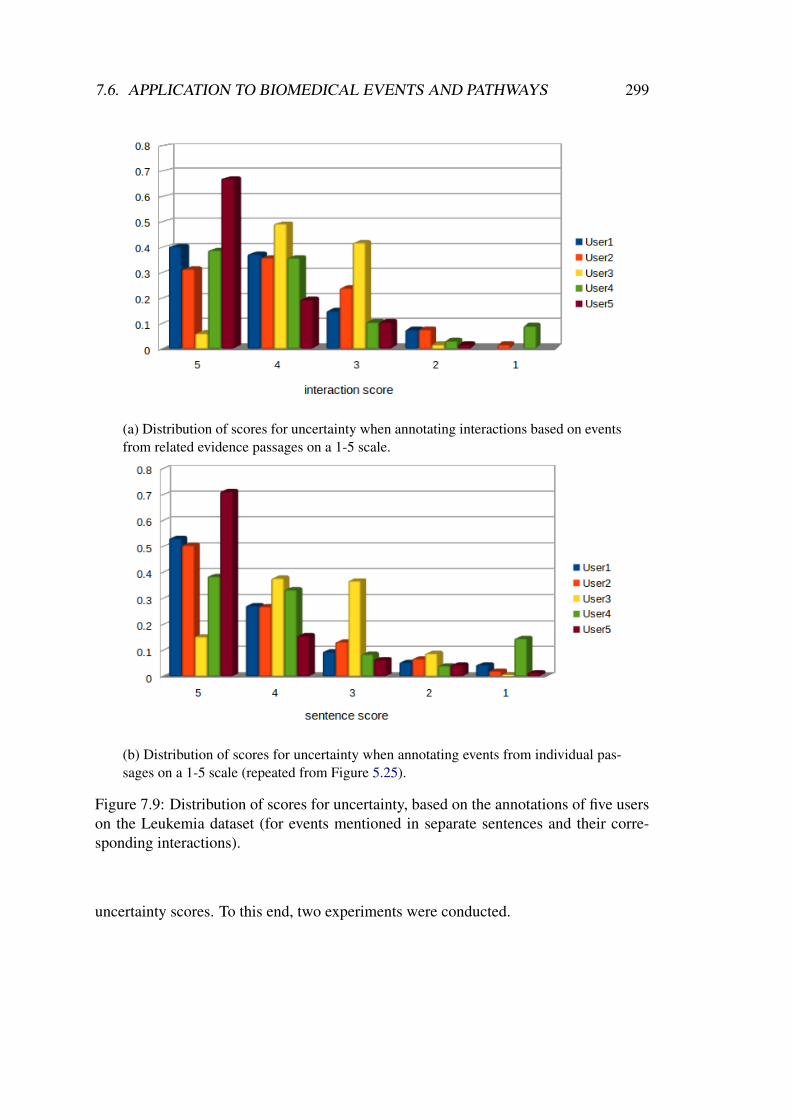
7.6. APPLICATION TO BIOMEDICAL EVENTS AND PATHWAYS 299
(a) Distribution of scores for uncertainty when annotating interactions based on eventsfrom related evidence passages on a 1-5 scale.
(b) Distribution of scores for uncertainty when annotating events from individual pas-sages on a 1-5 scale (repeated from Figure 5.25).
Figure 7.9: Distribution of scores for uncertainty, based on the annotations of five userson the Leukemia dataset (for events mentioned in separate sentences and their corre-sponding interactions).
uncertainty scores. To this end, two experiments were conducted.

300 CHAPTER 7. CONSOLIDATING UNCERTAINTY
In the first experiment, we were interested in predicting the interaction uncertaintyscoring for each user, based on the scores that the same user attributed to each of therelated events. We thus applied subjective logic fusion to the event uncertainty scoresas provided by the users, estimated Ex for each event based on Equation 7.10 and thencalculated the mean average error and standard deviation from each user’s scoring.
For the translation of user scores to the subjective logic opinion model, we projectedthe 1-5 scores to the [0,1] range in order to satisfy the condition that b(x),d(x),u(x) ∈[0,1]. There were no negation scores, so by default disbelief was set to 0. Then for eachpoint of the scale, event scores were mapped to opinion models as following:
• Score = 1→ ω(x) = 0.2,0.0,0.8,0.5
• Score = 2→ ω(x) = 0.4,0.0,0.6,0.5
• Score = 3→ ω(x) = 0.6,0.0,0.4,0.5
• Score = 4→ ω(x) = 0.8,0.0,0.2,0.5
• Score = 5→ ω(x) = 1.0,0.0,0.0,0.5
Interaction scores were also mapped to the [0,1] scale by dividing by 5.
Thus, assuming the used-provided interaction score for interaction i is IUi , and the
user-based opinion model for a related event ei is ω(ei) = b(ei),d(ei),u(ei),0.5, thenthe fused opinion model will be: ω(ei) = b(ei),d(ei),u(ei),0.5.
The predicted interaction score can be estimated as IPi = b(ei)+0.5 ·u(ei)
We can then calculate Errori = |IUi − IP
i | and calculate the mean average error(MAE) Error value over all interactions for each user.
The results are presented in Table 7.1, in which we compare the cumulative fusiondescribed in Equations 7.16 and 7.17 (identified as most suitable under the event in-dependence assumption discussed in Section 7.4) with the averaging fusion describedin Equations 7.18 and 7.19 as well as a simple score averaging baseline. The baselineaverage score is calculated as follows: the event uncertainty score assigned by each useris projected from the [1,5] to a [0,1] by dividing by 5. Then for each interaction, thescores of the related events are averaged (mean average) and this mean score is returnedas the interaction certainty prediction.
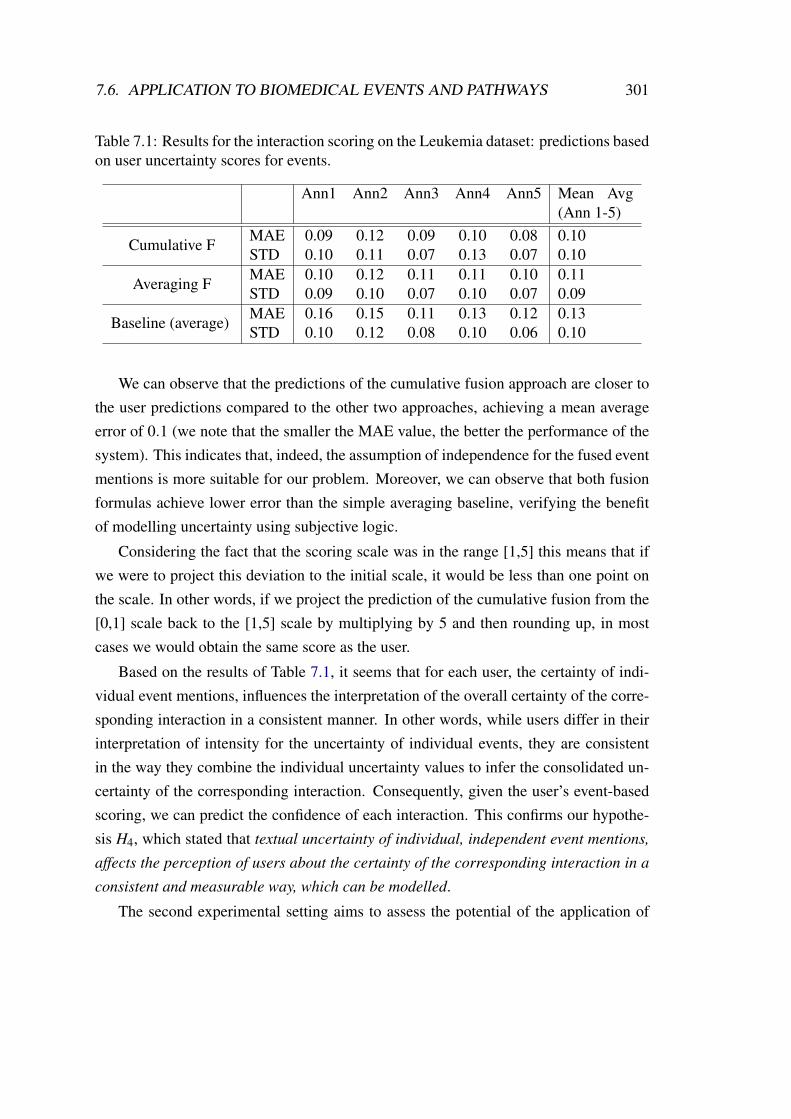
7.6. APPLICATION TO BIOMEDICAL EVENTS AND PATHWAYS 301
Table 7.1: Results for the interaction scoring on the Leukemia dataset: predictions basedon user uncertainty scores for events.
Ann1 Ann2 Ann3 Ann4 Ann5 Mean Avg(Ann 1-5)
Cumulative FMAE 0.09 0.12 0.09 0.10 0.08 0.10STD 0.10 0.11 0.07 0.13 0.07 0.10
Averaging FMAE 0.10 0.12 0.11 0.11 0.10 0.11STD 0.09 0.10 0.07 0.10 0.07 0.09
Baseline (average)MAE 0.16 0.15 0.11 0.13 0.12 0.13STD 0.10 0.12 0.08 0.10 0.06 0.10
We can observe that the predictions of the cumulative fusion approach are closer tothe user predictions compared to the other two approaches, achieving a mean averageerror of 0.1 (we note that the smaller the MAE value, the better the performance of thesystem). This indicates that, indeed, the assumption of independence for the fused eventmentions is more suitable for our problem. Moreover, we can observe that both fusionformulas achieve lower error than the simple averaging baseline, verifying the benefitof modelling uncertainty using subjective logic.
Considering the fact that the scoring scale was in the range [1,5] this means that ifwe were to project this deviation to the initial scale, it would be less than one point onthe scale. In other words, if we project the prediction of the cumulative fusion from the[0,1] scale back to the [1,5] scale by multiplying by 5 and then rounding up, in mostcases we would obtain the same score as the user.
Based on the results of Table 7.1, it seems that for each user, the certainty of indi-vidual event mentions, influences the interpretation of the overall certainty of the corre-sponding interaction in a consistent manner. In other words, while users differ in theirinterpretation of intensity for the uncertainty of individual events, they are consistentin the way they combine the individual uncertainty values to infer the consolidated un-certainty of the corresponding interaction. Consequently, given the user’s event-basedscoring, we can predict the confidence of each interaction. This confirms our hypothe-sis H4, which stated that textual uncertainty of individual, independent event mentions,
affects the perception of users about the certainty of the corresponding interaction in a
consistent and measurable way, which can be modelled.
The second experimental setting aims to assess the potential of the application of

302 CHAPTER 7. CONSOLIDATING UNCERTAINTY
cumulative fusion on the binary event uncertainty predictions of our uncertainty identi-fication system. We seek to compare the system-based prediction of interaction confi-dence to the average user score. For this purpose we infer the mean uncertainty score Ii
for each interaction i, based on all five user scores. Then we calculate an opinion modelfor each related event, based on the binary output of our system, as explained in Section7.4. In the same way as for the previous experimental setting, we calculate the fusedopinion model ω(ei) = b(ei),d(ei),u(ei),0.5 and subsequently the predicted in-teraction score can be estimated as IP
i = b(ei)+0.5 ·u(ei). In the results we comparecumulative and averaging fusion with the averaged score baseline, as shown in Table7.2.
Table 7.2: Results for interaction scoring on the Leukemia dataset: predictions based onsystem uncertainty scores for events.
MAE STDCumulative F 0.17 0.09Averaging F 0.16 0.12Baseline (average) 0.21 0.15
Quite intuitively, we can see that for the system-based predictions, cumulative fu-sion outperforms the other two methods. Compared to the user-based predictions, thesystem-based predictions deviate slightly more from the averaged interaction scoresgiven by the users. Even so, the mean difference is marginally less than 1 point if pro-jected back to the original 1−5 scale. This deviation is partly attributable to the limitedexpressive power of the binary classification system, compared to the 5-class task givento the annotators. However, it is encouraging that when assessing interactions for whichthere are multiple evidence passages, the output of the fusion on the binary system ap-proaches quite closely the user attributed interaction confidence.
7.6.2.2 The Ras-Melanoma use case
The annotation procedures and experiments conducted for the Ras-melanoma datasetare largely similar to those followed for the Leukemia use case. We provide below someadditional details regarding the initial selection and pre-processing of the interactions tobe annotated.

7.6. APPLICATION TO BIOMEDICAL EVENTS AND PATHWAYS 303
The whole Ras 2-hop neighbourhood network includes a total of 8802 interactions6.However, a relatively small proportion of these interactions is linked to a substantialamount of textual evidence (i.e., at least two events from different sentences) in theMelanoma document collection. Of the interactions with at least two supporting sen-tences, we randomly selected 100 interactions, along with the accompanying eventsand the sentences in which they were mentioned, to serve as supporting evidence. Allmappings were also manually verified as part of the annotation data cleaning and pre-processing. Subsequently, each interaction along with the supporting evidence sen-tences was presented to the annotators for evaluation using the Brat annotation interface[SPT+12].
The annotations were carried out by the same annotators who evaluated the event un-certainty as presented in Section 5.4.2. The annotation guidelines and procedure werevery similar to those followed in the leukemia pathway annotations. The interactionuncertainty evaluation task was performed after completing the annotation scoring foreach individual event mapped to a given interaction on a certainty scale of 1−5. Afterhaving scoring all individual events for a given interaction, annotators were asked toevaluate the certainty of the interaction itself, based on the mapped evidence available,again on a certainty scale of 1− 5, where 1 corresponds to “highly uncertain” and 5to “highly certain”. The annotators were specifically requested not to evaluate the per-ceived correctness of the mapping, but only to use the textual information and certaintyof each evidence passage to inform their decision.
The distribution of scores for the interactions is presented in Figure 7.10a. Thecorresponding distribution for the related events is re-iterated for comparison in Figure7.10b. Much like the leukemia case, the scoring of the interactions seems to be corre-lated with the event uncertainty scoring. The annotators’ differences in the perceptionof event uncertainty also seem to be reflected in the interaction uncertainty judgements.The overall agreement between the two annotators for the interaction scoring is 45%,but only for 8% of cases is the disagreement greater than 1 point on the scoring scale(compared to 43% and 8% respectively for the event scoring agreement).
We repeated the two experimental settings described for the leukemia use case inorder to assess the efficiency of predictions when relying both on the user-based and the
6some of these are interactions between identical entities, often mapping to exactly the same interac-tion grounded to a different database
304 CHAPTER 7. CONSOLIDATING UNCERTAINTY
(a) Distribution of scores for uncertainty when annotating interactions based on eventsfrom related evidence passages on a 1-5 scale.
(b) Distribution of scores for uncertainty when annotating events from individual pas-sages on a 1-5 scale (repeated from Figure 5.27).
Figure 7.10: Distribution of scores for uncertainty, based on the annotations of two users(User1 in blue and User2 in red) on the Ras-Melanoma dataset (for events mentioned inseparate sentences and their corresponding interactions).
system-based uncertainty scoring for events. We present the results in the Tables 7.3and 7.4.
Similarly to the Leukemia dataset, cumulative fusion outperforms other methodson the Ras-melanoma dataset. However, in the current use case, both subjective logic
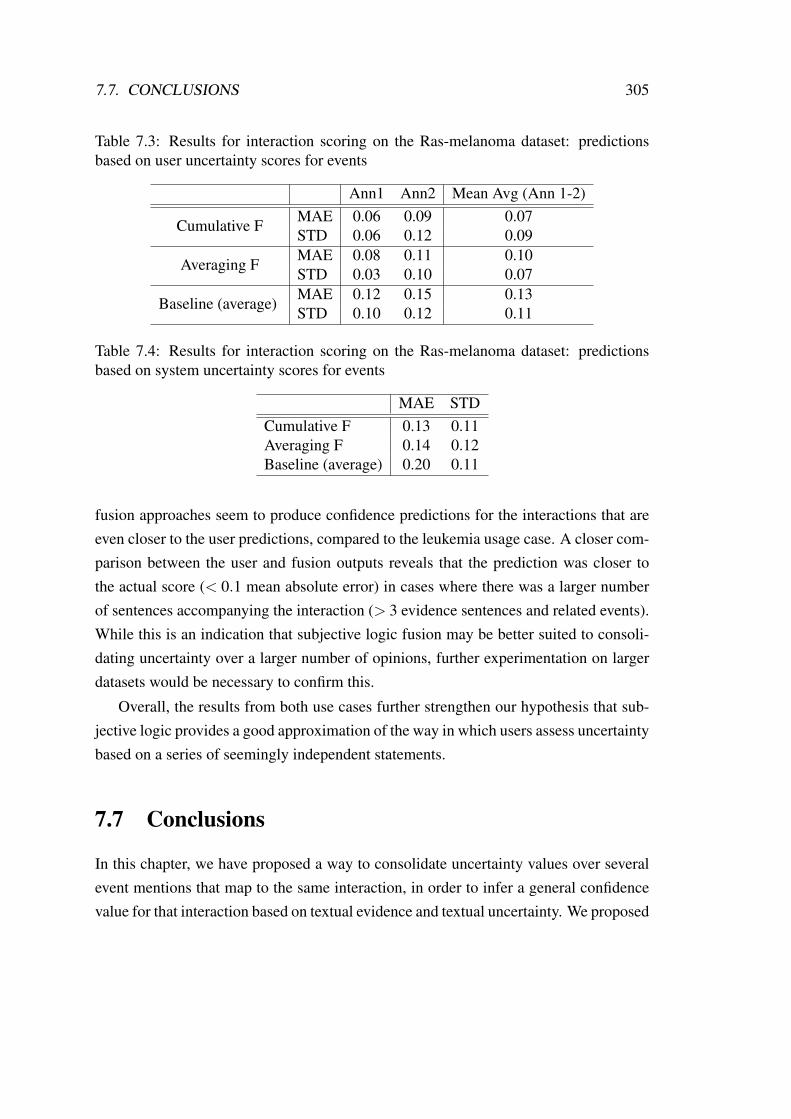
7.7. CONCLUSIONS 305
Table 7.3: Results for interaction scoring on the Ras-melanoma dataset: predictionsbased on user uncertainty scores for events
Ann1 Ann2 Mean Avg (Ann 1-2)
Cumulative FMAE 0.06 0.09 0.07STD 0.06 0.12 0.09
Averaging FMAE 0.08 0.11 0.10STD 0.03 0.10 0.07
Baseline (average)MAE 0.12 0.15 0.13STD 0.10 0.12 0.11
Table 7.4: Results for interaction scoring on the Ras-melanoma dataset: predictionsbased on system uncertainty scores for events
MAE STDCumulative F 0.13 0.11Averaging F 0.14 0.12Baseline (average) 0.20 0.11
fusion approaches seem to produce confidence predictions for the interactions that areeven closer to the user predictions, compared to the leukemia usage case. A closer com-parison between the user and fusion outputs reveals that the prediction was closer tothe actual score (< 0.1 mean absolute error) in cases where there was a larger numberof sentences accompanying the interaction (> 3 evidence sentences and related events).While this is an indication that subjective logic fusion may be better suited to consoli-dating uncertainty over a larger number of opinions, further experimentation on largerdatasets would be necessary to confirm this.
Overall, the results from both use cases further strengthen our hypothesis that sub-jective logic provides a good approximation of the way in which users assess uncertaintybased on a series of seemingly independent statements.
7.7 Conclusions
In this chapter, we have proposed a way to consolidate uncertainty values over severalevent mentions that map to the same interaction, in order to infer a general confidencevalue for that interaction based on textual evidence and textual uncertainty. We proposed

306 CHAPTER 7. CONSOLIDATING UNCERTAINTY
an adaptation of subjective logic theory in order to model the uncertainty of the authorabout a given event as an opinion tuple, and demonstrated that cumulative fusion is themost suitable approach to combining several such opinion tuples that are related to asingle interaction. We thus answered our fourth research question and correspondinghypothesis (RQ4 and H4).
We also demonstrated how events extracted from text can be mapped to existingpathway interactions in order to enhance these interactions with literature-based evi-dence. In contrast to the commonly used, but often less accurate [BV01] approachof employing entity co-occurrence to identify relations in text as a means to provideliterature-based support for pathway curation, we described in detail the event–to–interaction mapping process for two different pathway use cases. This allowed us todemonstrate that events, being richer and more precise representations of information intext, which capture not only the co-occurrence but also the precise relations between en-tities, can be used to provide effective supporting evidence for pathway interactions. Inthe next chapter, we describe how the mapping approach and uncertainty consolidationmethods have been integrated within a pathway visualisation and exploration tool.
There is still ample room for further experimentation on the issue of uncertaintycombination. As explained in Section 7.4, this work considers each event mention tobe independent, which ignores the fact that some statements can refer to informationstated in some other (usually cited) work. Additionally, the level of certainty of anevent mentioned multiple times within the same article can vary depending on the partof the article in which it is stated in (e.g. in the introduction as a hypothesis and thenin the conclusion as a confirmed result). As future work, we aim to enrich and extendthe modelling of uncertainty, and to study ways to translate the flow of arguments andevents within an article (exploring zoning [Lia10, LTS+10] or argumentation miningoptions [NCG16, LT16, SG14]) and the citation relations into belief and uncertaintyvalues in the opinion model.
Another parameter we would like to investigate during future work is time. This willallow us to treat event mentions in a more sequential manner and consider uncertaintypropagation over time. Apart from integrating the temporal aspect within the subjec-tive logic formulas, such a direction opens up the possibility of using a wide rangeof other approaches that we can experiment with and compare against, such as usingMarkov Chain to model transition probabilities as suggested by Welton in the field of

7.7. CONCLUSIONS 307
bio-medicine to model disease progression [WA05].


Chapter 8
Integrating textual uncertainty withother confidence metrics
In this chapter we do the following:
Focus on the integration of textual uncertainty along with other literature-based con-fidence measures, in a pathway browsing, interactive application (addressing our finalquestion: RQ5) .More specifically, we:
• Present the core visualisation aspects of this pilot application
• Discuss the aspects related to the integration of textual uncertainty
• Elaborate on the inter-dependency between textual uncertainty and otherliterature-based aspects, focusing on citation analysis
In Chapter 7, we focused on enriching pathway interactions with literature-basedevidence, as well as propagating textual uncertainty from evidence passages to pathwayinteractions. In this chapter, we examine how to rank pathway interactions accordingto confidence more broadly, by considering the issues of representing and integrating
309

310 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
confidence in pathway interactions and thus facilitating exploration of vast pathway in-teraction networks. As we have described previously, the evolution of computationaltechniques in the field of bioinformatics has made it possible to populate knowledgebases with interactions as well as to assemble interaction networks and pathway modelsin an automated or semi-automated way. Such models can support researchers from awide range of fields in designing and carrying out in silico experiments, which elucidatethe complex mechanisms that underpin several biological processes and their interac-tions. However, due to the automated means of assembling networks, and the need forconstant updates (which make it almost impossible for all such updates to be manu-ally verified by curators), automatically generated models are often neither completenor error-free [SKH+17, MGKK10]. The automated prediction of interactions, whetherachieved by application of high-throughput lab experiments, genomic context prediction[ENB+07], database merging [RHL+15, OAA+13], or literature-based predictions, willinevitably introduce some irrelevant or improbable interactions, or fail to identify somevalid and important ones. However, it has been shown that up to a certain degree, er-rors can be tolerated, and such large networks are still indispensable for researchers[AJB00]. Nevertheless, the vast increase in scientific literature implies that users wouldstill need to contrast and review large collections of research articles, which is a costlyand time-consuming task [BMKR+12]. Hence, in literature-based expansion, which isthe focus of this work, it is important not only to extract events in order to expand cur-rent interaction networks, but also to complement them with metrics that can guide theuser in terms of the confidence of each interaction.
In this context, textual uncertainty, i.e. uncertainty expressed by the author whendescribing a specific interaction of interest, is not the only parameter affecting eventconfidence. In this chapter, we discuss the use of the techniques for mapping events tointeractions that were introduced in the previous chapter to enhance a pathway, as wellas the integration of textual uncertainty about the interaction with other confidence-influencing parameters, such as the citability, the social media recognition and the yearof publication of the article mentioning the interaction of interest. A pilot user appli-cation, LitPathExplorer, makes it possible to demonstrate and visualise the impact ofcertainty parameters on pathway interactions and present different types of confidence-based filters and visualisations. This application constitutes an example of how differentuser perceptions of uncertainty can be accommodated and how the system can learn and

311
adapt to the user perceived certainty values. Using the Ras 2-hop neighbourhood net-work described in Section 5.2.2 and a breast cancer document collection, we explainhow a confidence-based literature enhancement can facilitate research.
LitPathExplorer was developed with four main objectives in mind [SZBNA17]:
1. Flexible search and exploration of bio-molecular pathway networks through theprovision of different views of the data, as well as various interactive functionali-ties
2. Provision of corroborating information in a given pathway model using evidencefrom the scientific literature
3. Facilitating the discovery of new interactions that are not yet part of a given model,and also quantifying the confidence of the events to be used or integrated withinthe model
4. Enabling curators and users to become active participants in the analytical pro-cess, in which they can explore, inspect and analyse the automatically extractedinformation.
This type of visual exploratory analysis, also known as visual text analytics [KMT10],shifts the focus towards the user, so that domain experts become a necessary element ofthe analytical process, rather than acting as mere consumers of the results generated bya statistical black box. It should be noted that this pilot application was a collaborativeproject resulting in a user interface application, available at http://nactem.ac.uk/LitPathExplorer_BI/, and a corresponding publication [SZBNA17]. As part of thiseffort, the visualisation software, as well as the model that handles the user input, wasfully implemented by Dr. Axel Soto. Thus, the visualisation development and the user-interaction details are not the focus of this chapter (although for better understanding ofthe application we do present the relevant visualisation functionalities in Figures 8.2-8.6). We describe our choices in terms of representing and integrating certainty metricsand their relation to each other.

312 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
8.1 Related Work: Pathway visualisation with confidencemetrics
There have been a number of methods proposed for applying text mining to generate[MYBHA14] or update pathways [VMJS+05]. Other efforts have been more concernedwith enhancing existing pathways with information extracted from literature. In thisarea, Czarnecki et al. [CNSS12] and PathText2 [MOR+13] extracted events and subse-quently linked them to metabolic and signalling pathway reactions, respectively. Severalof these efforts resulted in the implementation of user interfaces or add-ons that enablethe users to visualise uncertainty and filter interactions accordingly. Apart from methodsusing text mining to determine the certainty of interactions, there are approaches thatfocus on other methods to evaluate confidence, such as the output of high-throughputexperiments, omics data, etc., which we describe in Section 8.1.3.
8.1.1 Literature-based certainty in interaction networks
As discussed in previous chapters (see Chapter 5, Section 3.3.4 and Chapter 3, Section3.1.2) Malhotra proposed the use of uncertainty expressed in literature as an indicator ofhypothetical interactions that were used to generate new interaction networks to allowthe exploration of new hypotheses. He showcased the HypothesisFinder tool on anAlzheimer’s pathway that was generated completely from hypothetical statements inliterature [MYGHA13].
Ozgur et al. [OVER08] propose a different approach to infer confidence from lit-erature in identifying gene-disease associations for gene interaction networks. Theypropose the use of an SVM classifier paired with syntactic parsing features that iden-tify sentences containing interactions between entities. Subsequently, entities found inthose sentences are used to generate a gene interaction network. The network is thenprocessed using graph centrality metrics to infer the potency of genes with respect to adisease (their method was applied to a prostate cancer network). They achieve highlyaccurate results when using degree and Eigenvector metrics as a measure of potency forgenes. FACTA+ is another approach identifying indirect relations between chemicals,genes and diseases, although the information is not organised into networks [TMH+11].

8.1. RW: PATHWAY VISUALISATION WITH CONFIDENCE METRICS 313
8.1.2 Literature-based uncertainty visualisation
Some of the visualisation tools that provide literature-based evidence incorporate met-rics to score the confidence of interaction based on the provided evidence. While noneof the existing systems takes into account the textual uncertainty aspect discussed inthis PhD thesis, we present some of the core approaches, that mostly take into accountthe number of linked evidence passages, the co-occurrence statistics in the retrievedpassages, and measures of relatedness of the interaction mapping to the evidence.
For example, SIGNOR [LSCCP17] is a repository that is manually populated withwhat the authors refer to as “causal reactions”, which focus on signalling networks.The definition of causal reactions is very similar to our definition of events, identify-ing a regulator entity (cause) and a target entity (theme) as well as the mechanism thatunderpins their reaction (eg. down-regulation), which would correspond to the eventtrigger. The reactions are added to the repository accompanied by evidence sentencesfrom literature as well as confidence scores. These scores are not assigned based onthe evidence sentence, but rather, the co-occurrence statistics for the reacting entities inthe publication(s) from which the evidence sentence(s) were taken. A manually curatedapproach to linking evidence sentences is also adopted in PathwayStudio [NEDM03],which uses a 0-3 confidence scoring that represents the number of linked evidence pas-sages (0,1,2>3).
ARENA 3D [SPAS12] applies text mining to identify common and cooccurringterms and, subsequently, these term links are used to identify indirect connections be-tween entities. The connections are visualised in the ARENA3D networks with varyingedge width, depending on the weight of the connection. These weights can representsimilarity metrics, experimental probabilities, etc. (the exact weight generation mecha-nism is not described in detail in the related publications, as the focus is on the layoutand clustering aspects).
Other visualisation tools took a similar approach to ARENA 3D, assigning weightsto interactions based on entity co-occurrence and keyword frequency. CoPub appliedsuch methods to abstracts extracted from Pubmed in order to inform microarray dataanalysis [FHvB+08]. They later broadened both the scope of the analysis to cover ad-ditional biomedical interactions and the statistical analysis of co-occurrences employed[FVF+11]. The latest version of GenCLiP accounts for the fact that such approaches

314 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
are prone to overestimating interaction strength due to such co-occurring terms in ab-stracts, by proposing a solution that builds gene term profiles using keyword frequencyand the HUGO database. The interactive interface also allows users to control andchange the profiles to their liking [WZL+14]. Jelier et al. propose a profiling methodfor literature-aided interpretation of gene expression data [JGH+10], while Pubgene1
and Hanalyser also combine some co-occurrence statistics in their interaction weightcalculation [dLDHK+12, LTF+09].
ANDVisio [DIKI12] is one of the few tools that actually search the literature for fullinteraction mentions, rather than using only entity co-occurrences or profiling. Whilethey employ a large set of rules and dictionaries to achieve this, there is no confidence-based visualisation or filtering provided along with the evidence. GeneDive [PTW+18]is a gene interaction search and visualisation tool that is built on a set of interactionsextracted from PMC and PLOS articles using neural networks for information extraction[NZRS12]. They provide the evidence passages along with an accuracy probability foreach extracted interaction, and allow users to filter visualised interactions by probabilitystrength. The probability in this case refers to the accuracy of the interaction extractionrather than to the probability as expressed by the authors in the evidence passage.
Recently, Kondratova and colleagues proposed the NaviCell network visualisationapproach which builds on the Google Maps API framework [KSB+18]. By exploringsignalling network maps in a geographical map, navigation style so to speak, they takeadvantage of semantic zooming to facilitate exploration of large networks. They inte-grate two confidence scores. The first is a literature-based score, the reference score,which summarises the quantity and weight of publications found in the annotation ofa given reaction. The weight is calculated in a rule-based manner, and differentiatesbetween original publications and review articles (with the latter given a higher score).They also provide a second score, the functional proximity score, which is computedbased on the Human Protein Reference Database (HPRD) [KPGK+08] and captures theaverage distance in the PPI graph between all proteins participating in the reaction asreactants, products or regulators.
There are further visualisation tools that include literature-based evidence, althoughwithout explicitly providing a related confidence score. We present a summary of thecore properties and features of these visualisation tools in Tables 8.1 and 8.2. The
1https://www.pubgene.com

8.1. RW: PATHWAY VISUALISATION WITH CONFIDENCE METRICS 315
tables were initially published in the supplementary material of the LitPathExplorerpublication. However, the current versions of the tables have been updated with somerecent advances and tools in the field.
8.1.3 Integrating non-literature-based uncertainty parameters in vi-sualisation
Uncertainty related to textual evidence is not the only type of confidence scoring thatis typically used in visualisations of interaction networks. For example, MetaCore andMetaDrug pathway analysis tools are among the first platforms to allow users to visu-alise integrated interaction networks and analyse them with a variety of tools [EBB+06].They provided the means to analyse and prioritise high-throughput experimental data,using statistical methods to weight and filter interactions accordingly.
Patika [DBD+02] provides an environment for network visualisation, but with aparticular focus on cellular events. The environment provides a sophisticated searchfunctionality and a basic means for binary uncertainty visualisation, in which a questionmark is overlaid on reactions not verified by experts. In more recent work, WikiPath-ways [SKH+17], which is a popular crowd-sourced effort dedicated to the collaborativecuration of biological pathways, has adopted a set of so called “quality tags”. The qual-ity tags range from “work in progress” to “approved” or “featured”, and allow users tofilter their pathway searches based on the curation quality.
CABIN [SD07] provides confidence information determined from external experi-mental evidence. Kibinge [KOH+16] targets the integration of pathway-based transcrip-tion regulation networks and, more specifically, the interactions between transcriptionfactors and target genes. Along with processing pipelines, they propose a pathway vi-sualisation tool that allows users to filter interactions based on a normalised mutual
information score.
TheCellMap [UTW+17] is a recent visualisation effort focusing on genetic interac-tion networks and attempting to combine different types of confidence sources (althoughno literature-based ones) in order to provide a comprehensive confidence threshold filter
2As part of CellDesigner3Access to literature using the MetaCrop Plugin4Linking data from different databases

316 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
Table 8.1: List of features and properties for visualisation tools that support linkingnetwork information with textual evidence. Features marked with k signify limitedsupport for the property in question and features marked with •imply that the featureneeds to be specified by the user.
Path
way
crea
te/e
dit
Topo
logi
cal S
truc.
Inte
ract
ion
type
vis.
Entit
ies
Inte
ract
ions
Evid
ence
pass
ages
Lite
ratu
reco
nf.
Oth
erco
nf.
Vis
ual c
ues
onne
tB
yin
tera
ctio
nsB
yco
nfide
nce
Tool Name Network Search Scoring FilterANDVisio [DIKI12] k 7 4 4 4 4 7 7 7 4 7
Arena3D [SPAS12] 7 7 4 4 k 7 7 4 4 k 4
CellDesigner[MGKK10] 4 7 4 k 7 • 7 7 7 4 7
ChiBE [BDDS10] 4 7 7 4 4 • 7 7 7 4 7
CoPub [FVF+11] k 7 7 4 7 4 4 4 4 7 4
Cytoscape [SMDB14] 4 7 4 4 7 7 7 k k 7 k
GenClip [WZL+14] k 7 4 4 7 k 4 4 7 4 7
GeneDive [PTW+18] k 7 7 4 7 k k 4 7 7 7
GenMAPP [SHZ+07] 7 7 4 4 7 7 7 4 4 7 7
Hanalyzer [LTF+09] 4 4 4 4 4 4 4 4 4 4 4
iHOP [HV05] 7 7 k 4 k 4 4 4 7 7 7
LitPathExplorer[SZBNA17] 4 4 4 4 4 4 4 4 4 4 4
NaviCell [KSB+18] k2 4 4 4 7 4 4 4 7 7 7
NAViGaTOR[BOA+09] 4 7 7 4 4 k 7 7 7 4 4
PathVisio [KvIB+15] 4 4 4 4 7 • 7 4 4 7 7
PubGene [dLDHK+12] 7 4 4 4 7 4 4 4 7 4 4
Pathway Studio[NEDM03] 4 4 4 4 k 4 4 7 7 4 4
Signalink [FKT+13] &Autophagy [TFNF+15] 7 7 4 7 7 7 7 4 7 k 7
SIGNOR [LSCCP17] k 4 4 7 7 4 4 7 k 4 4
STITCH [SSvM+16]& STRING [SFW+14] 7 7 7 4 7 4 4 4 4 4 4
VANTED [RJH+12] 4 7 7 7 7 k3 7 4 4 4 7
WikiPathways[KRN+15] 4 4 4 4 7 • 7 7 7 7 7
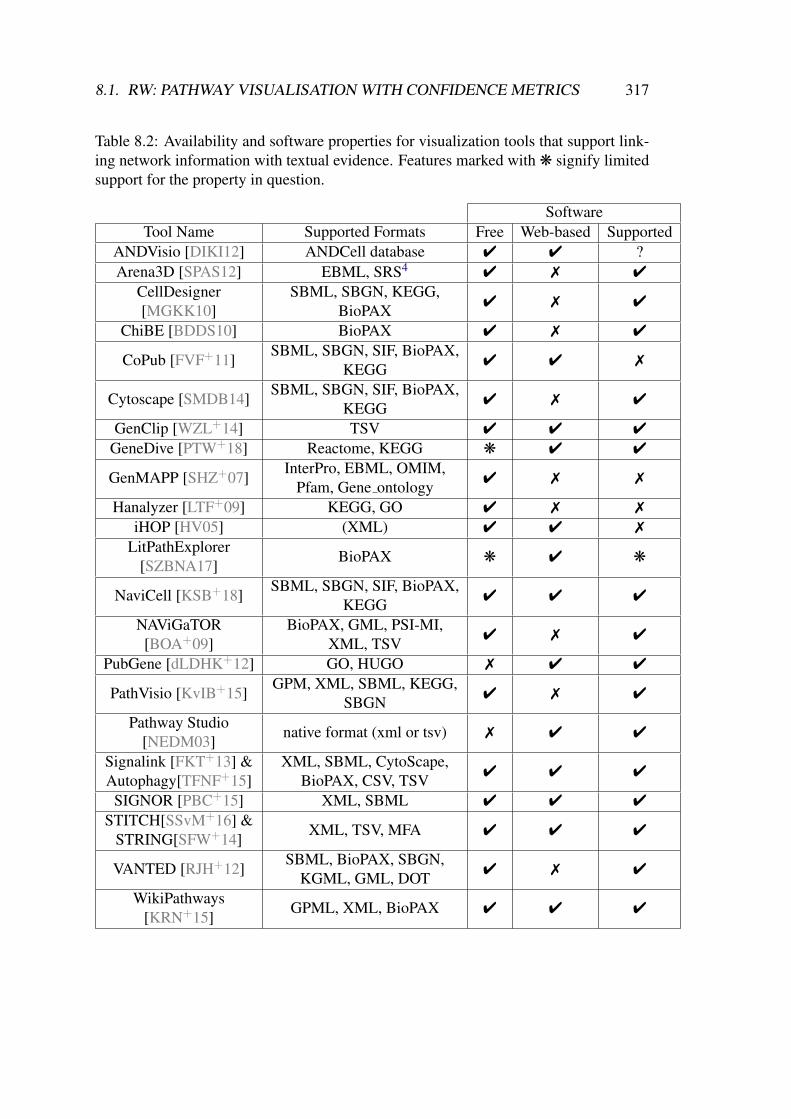
8.1. RW: PATHWAY VISUALISATION WITH CONFIDENCE METRICS 317
Table 8.2: Availability and software properties for visualization tools that support link-ing network information with textual evidence. Features marked with k signify limitedsupport for the property in question.
SoftwareTool Name Supported Formats Free Web-based Supported
ANDVisio [DIKI12] ANDCell database 4 4 ?Arena3D [SPAS12] EBML, SRS4 4 7 4
CellDesigner[MGKK10]
SBML, SBGN, KEGG,BioPAX 4 7 4
ChiBE [BDDS10] BioPAX 4 7 4
CoPub [FVF+11]SBML, SBGN, SIF, BioPAX,
KEGG 4 4 7
Cytoscape [SMDB14]SBML, SBGN, SIF, BioPAX,
KEGG 4 7 4
GenClip [WZL+14] TSV 4 4 4
GeneDive [PTW+18] Reactome, KEGG k 4 4
GenMAPP [SHZ+07]InterPro, EBML, OMIM,
Pfam, Gene ontology 4 7 7
Hanalyzer [LTF+09] KEGG, GO 4 7 7
iHOP [HV05] (XML) 4 4 7
LitPathExplorer[SZBNA17]
BioPAX k 4 k
NaviCell [KSB+18]SBML, SBGN, SIF, BioPAX,
KEGG 4 4 4
NAViGaTOR[BOA+09]
BioPAX, GML, PSI-MI,XML, TSV 4 7 4
PubGene [dLDHK+12] GO, HUGO 7 4 4
PathVisio [KvIB+15]GPM, XML, SBML, KEGG,
SBGN 4 7 4
Pathway Studio[NEDM03]
native format (xml or tsv) 7 4 4
Signalink [FKT+13] &Autophagy[TFNF+15]
XML, SBML, CytoScape,BioPAX, CSV, TSV 4 4 4
SIGNOR [PBC+15] XML, SBML 4 4 4
STITCH[SSvM+16] &STRING[SFW+14]
XML, TSV, MFA 4 4 4
VANTED [RJH+12]SBML, BioPAX, SBGN,
KGML, GML, DOT 4 7 4
WikiPathways[KRN+15]
GPML, XML, BioPAX 4 4 4
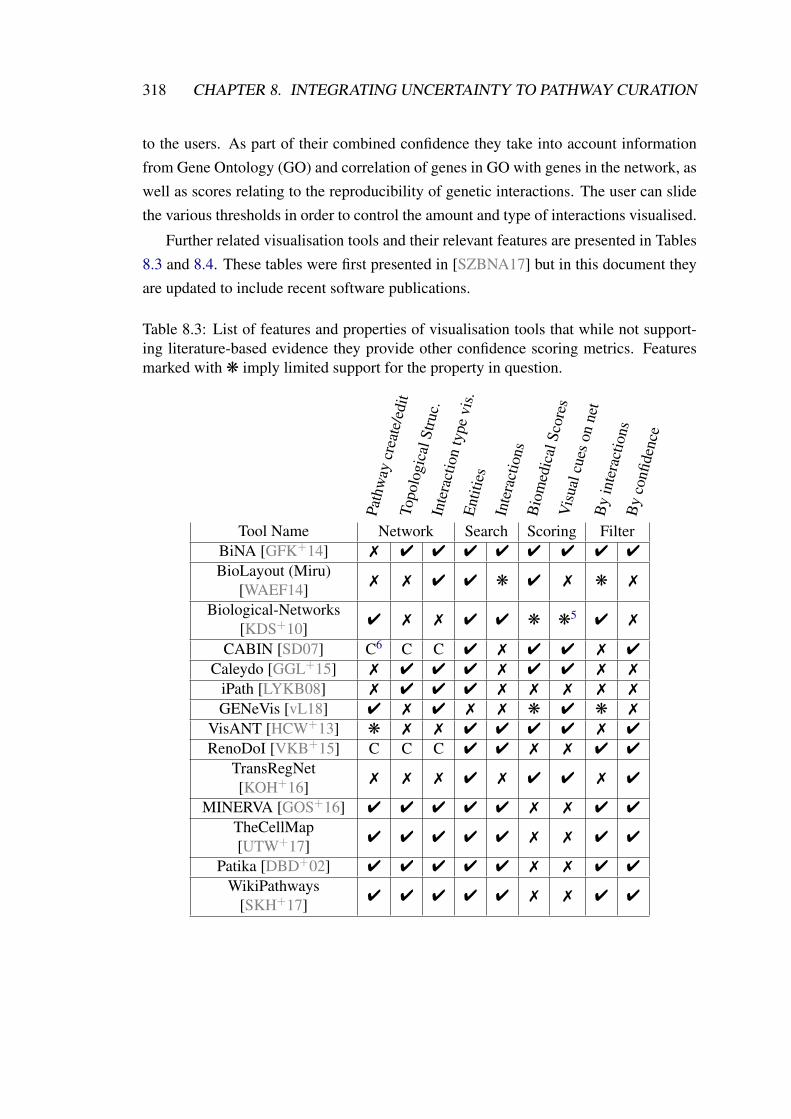
318 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
to the users. As part of their combined confidence they take into account informationfrom Gene Ontology (GO) and correlation of genes in GO with genes in the network, aswell as scores relating to the reproducibility of genetic interactions. The user can slidethe various thresholds in order to control the amount and type of interactions visualised.
Further related visualisation tools and their relevant features are presented in Tables8.3 and 8.4. These tables were first presented in [SZBNA17] but in this document theyare updated to include recent software publications.
Table 8.3: List of features and properties of visualisation tools that while not support-ing literature-based evidence they provide other confidence scoring metrics. Featuresmarked with k imply limited support for the property in question.
Path
way
crea
te/e
dit
Topo
logi
cal S
truc.
Inte
ract
ion
type
vis.
Entit
ies
Inte
ract
ions
Bio
med
ical
Scor
esV
isua
l cue
son
net
By
inte
ract
ions
By
confi
denc
e
Tool Name Network Search Scoring FilterBiNA [GFK+14] 7 4 4 4 4 4 4 4 4
BioLayout (Miru)[WAEF14] 7 7 4 4 k 4 7 k 7
Biological-Networks[KDS+10] 4 7 7 4 4 k k5 4 7
CABIN [SD07] C6 C C 4 7 4 4 7 4
Caleydo [GGL+15] 7 4 4 4 7 4 4 7 7
iPath [LYKB08] 7 4 4 4 7 7 7 7 7
GENeVis [vL18] 4 7 4 7 7 k 4 k 7
VisANT [HCW+13] k 7 7 4 4 4 4 7 4
RenoDoI [VKB+15] C C C 4 4 7 7 4 4
TransRegNet[KOH+16] 7 7 7 4 7 4 4 7 4
MINERVA [GOS+16] 4 4 4 4 4 7 7 4 4
TheCellMap[UTW+17] 4 4 4 4 4 7 7 4 4
Patika [DBD+02] 4 4 4 4 4 7 7 4 4
WikiPathways[SKH+17] 4 4 4 4 4 7 7 4 4
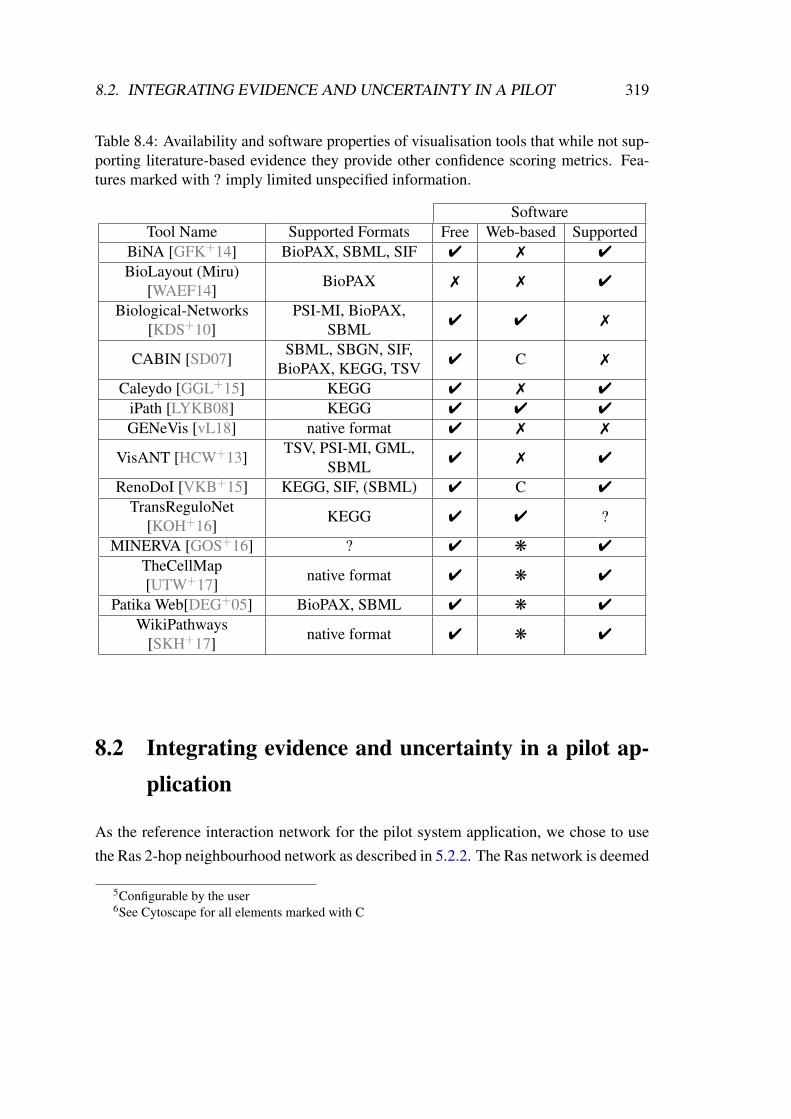
8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 319
Table 8.4: Availability and software properties of visualisation tools that while not sup-porting literature-based evidence they provide other confidence scoring metrics. Fea-tures marked with ? imply limited unspecified information.
SoftwareTool Name Supported Formats Free Web-based Supported
BiNA [GFK+14] BioPAX, SBML, SIF 4 7 4
BioLayout (Miru)[WAEF14]
BioPAX 7 7 4
Biological-Networks[KDS+10]
PSI-MI, BioPAX,SBML 4 4 7
CABIN [SD07]SBML, SBGN, SIF,
BioPAX, KEGG, TSV 4 C 7
Caleydo [GGL+15] KEGG 4 7 4
iPath [LYKB08] KEGG 4 4 4
GENeVis [vL18] native format 4 7 7
VisANT [HCW+13]TSV, PSI-MI, GML,
SBML 4 7 4
RenoDoI [VKB+15] KEGG, SIF, (SBML) 4 C 4
TransReguloNet[KOH+16]
KEGG 4 4 ?
MINERVA [GOS+16] ? 4 k 4
TheCellMap[UTW+17]
native format 4 k 4
Patika Web[DEG+05] BioPAX, SBML 4 k 4
WikiPathways[SKH+17]
native format 4 k 4
8.2 Integrating evidence and uncertainty in a pilot ap-plication
As the reference interaction network for the pilot system application, we chose to usethe Ras 2-hop neighbourhood network as described in 5.2.2. The Ras network is deemed
5Configurable by the user6See Cytoscape for all elements marked with C

320 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
suitable since it is large enough to support exploration of interactions for different ap-plications, pathways and cancer types. At the same time the central role of the Ras genein many different cancer types renders the usage case very relevant and important forscientists working in the field of cancer research.
The Ras network was paired not only with the Melanoma corpus (as described inChapter 5, Section 5.2.2 and Chapter 7, Section 7.6.2.2) but also with a document col-lection focused on Breast Cancer. The Breast cancer documents are full-text articlescollected from PubMed, dating from between 1995 and 2016. The documents weremined in a similar fashion to the Melanoma document collection. A query was com-plied using synonyms for Breast cancer obtained from UMLS Metathesaurus database.The query was filtered by constraining the cell lines mentioned in the papers to two celllines of interest and their aliases. We also added a constraint related to paper availabil-ity; in order to allow users to visualise and access not only the evidence passage butalso the full document from which this is extracted, it is necessary that the documentcollection consists only of open-access papers. The final query was used to collect pa-pers from the PubMed Central Open Access Restful Web-Service 7. We present the fullquery for the Breast Cancer documents in Figure 8.1.
The Ras network was visualised as an interactive node-link graph. Interactions(events) and entities are represented as nodes, while the type of relation between them,in other words the argument role, is represented as an edge. Note that events and enti-ties are treated as different node types, and thus have different visual representation andproperties that are displayed upon clicking on them. Additionally, different interactiontypes are visually discernible via different colours.
8.2.1 Integrating evidence
While mapping text-mined events against the Ras network has already been discussed(see Chapter 7, Section 7.5), for this application, we aimed to take the literature-basedenhancement a step further and suggest not only events that map to existing networkinteractions but also events that represent newly discovered interactions, yet are stillrelated to those of the initial network. This choice is dictated by the need for con-stant updates to networks, which can be a particularly involved and time consuming
7https://europepmc.org/RestfulWebService

8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 321
(BODY:”breast cancer” OR BODY:”breast cancer nos” OR BODY:”breast carci-noma” OR BODY:”breast cancer stage unspecified” OR BODY:”breast tumor ma-lignant” OR BODY:”breast tumour malignant” OR BODY:”breast, unspecified”OR BODY:”breast–cancer” OR BODY:”ca - breast cancer” OR BODY:”ca breast”OR BODY:”ca breast - nos” OR BODY:”cancer of breast” OR BODY:”cancer ofthe breast” OR BODY:”cancer, breast” OR BODY:”malignant breast neoplasm”OR BODY:”malignant breast tumor” OR BODY:”malignant neoplasm of breast”OR BODY:”malignant neoplasm of the breast” OR BODY:”malignant tumor ofbreast” OR BODY:”malignant tumor of the breast” OR BODY:”malignant breastneoplasm” OR BODY:”malignant neoplasm breast” OR BODY:”malignant neo-plasm of breast” OR BODY: ”malignant neoplasm/breast” OR BODY:”malignantneoplasms of breast (c50)” OR BODY: ”malignant tumor of breast” OR BODY:”malignant tumour of breast” OR BODY: ”mammary cancer” OR BODY: ”malig-nant neoplasm of breast” OR BODY: ”malignant neoplasm” OR BODY: ”malig-nant breast” OR BODY:”cancer of breast” OR BODY:”cancer of the breast” ORBODY: ”malignant breast neoplasm” OR BODY: ”malignant neoplasm of breast”OR BODY: ”malignant tumor of breast”)AND (BODY: ”T47D” OR BODY:”T-47D” OR BODY:”MDMBA231” OR BODY:”MDM-BA-231” OR BODY: ”MCF7” OR BODY: ”MCF-7”)AND OPEN ACCESS:Y
Figure 8.1: Document collection query for the Breast cancer corpus.
task, especially for large interaction networks. Indeed, the ever-expanding literatureon cancer-related topics implies that there are constantly new mentions of discoveredor hypothesised associations between genes, proteins and chemicals that are worthy offurther experimentation and consideration. Thus, we aim to identify possible networkextensions from the literature and expand the network accordingly, allowing for discov-ery of new interactions.
As a result, we distinguish between two types of evidence linked to the network:corroborating events and discovery events. Corroborating events follow the mappingrules and approach described in Chapter 7, Section 7.5, essentially requiring that theentity type, the interaction type and the directionality fully agree between the event can-didate and the interaction in the network. For discovery events, the mapping approachis different. The only applied constraint is that at least one of the entities participatingin the candidate event (regardless of the argument role), has to be part of the original

322 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
(non-extended) network and participate in at least one interaction in the original net-work. Being part of the original network in this case means that the identified entityhas to be an exact match to one of the entities in the original network. For the entitymapping, we use the same approach that we use for corroborating events, applying ap-proximate string matching between entity names as well as compiled lists of synonyms(see Chapter 7, Figure 7.5).
In the event-mapping approach and that of visualisation, both events and entities aretreated as network nodes with different properties. The edges represent the argumentsand their role, or in other words, the relation linking each event with the participatingentities. According to the requirement that the discovery events have at least one entityin the original network, we limit the discovery to 1-hop distance of interaction, in otherwords, we expand the original network once, without permitting further expansion onthe discovered events. As such, the shortest path between any entity and the Ras genewhich is the “central” node of the network will have a maximum length of six (or threeif we only count entity nodes).
Based on their needs, users are given the option to visualise only the original in-teractions or extend to the “discovery” view. Since no other “relevance” criterion wasapplied apart from the entity mapping, for some entities playing a key role in cancer re-search (and thus appearing in several publications as part of different interactions) thereis a large number of discovered events. An example of the expanded “discovery” viewcompared to the original can be seen in Figures 8.2 and 8.3.
To allow the user to evaluate the sources of the presented interactions, both the sen-tence from which the event was mined and the title, author and publication informationof the related paper are visualised for them to inspect. The full text of the paper is alsoaccessible by clicking on the related title. The evidence is organised on a per-paperbasis, meaning that for each interaction, evidence sentences are first grouped based onthe paper in which they appear, and presented under its title. A screenshot of this ispresented in Figure 8.4.
For each evidence sentence, uncertainty and polarity are calculated and then aggre-gated to calculate a combined paper confidence value. Different values are calculatedfor each paper that contains related evidence. Apart from the title and author informa-tion that are necessary to present the information about the paper to the users, additionalinformation is extracted to allow the calculation of additional values that can affect

8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 323
Figure 8.2: MEK related interactions be-fore addition of discovered events
Figure 8.3: MEK related interactions afteraddition of discovered events (greyed outinteractions linked with dotted edges)
overall confidence in the interactions. This information includes the publication date,the journal of publication and its corresponding impact factor, as well as a parameterthat estimates the social media and news acceptance of the paper, calculated based onits altmetric [TTH+15] score 8. These extracted values allow for the calculation of thefollowing confidence altering parameters for each evidenced interaction:
• Polarity: The average polarity of the mentions of this interaction in text.
• Language certainty: This is the value representing the combined textual uncer-tainty value over all the mentions of this interaction in text.
• Papers: The number of papers mentioning the interaction.
• Cites: The aggregated count of citations of all the papers mentioning the interac-tion (citation sum).
8The import and integration of the altmetric score and impact factor was implemented by Dr. AxelSoto.

324 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
Figure 8.4: Sample of evidence sentences for MEK and ERK binding, organised underthe related paper.
• Altmetrics: The sum of the altmetric score for each of the papers mentioning thisinteraction.
• IF: The mean average of the impact factors of the journals in which each papermentioning the interaction was published.
• Date: This date corresponds to the estimated date that the interaction was estab-lished in the scientific community.
All the values for the different confidence parameters are subsequently averaged,in order to provide an overall confidence value for the interaction. An example of thedisplay of the different parameters in the interface, as well as the overall confidence
value for an interaction, is presented in Figure 8.5.
In addition to the bar representation of confidence, the size of each interaction inthe network panel varies according to the confidence level. The user can also elect toorganise the layout of events based on their certainty value either in a sorted circle orin a sorted diagonal. More importantly, the user can choose to limit the events that arevisualised, according to those whose confidence falls within a given range, by movingtwo sliders along a confidence filter. An example visualisation with a diagonally sortedlayout, where the displayed interactions are organised and filtered by confidence, ispresented in Figure 8.6.
As different features have varying degrees of correlation with the actual likelihoodof the event taking place (e.g., the number of papers mentioning an event sometimesmay be more important than the language or wording used in those papers), a simple

8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 325
Figure 8.5: Example of different confidence parameters and the averaged confidencescore for the Phosphorylation of MEK by Raf (highlighed in red box).
average of these features may not be optimal when estimating confidence scores. To thisend, we developed an approach that is underpinned by a neural network (NN), whichlearns how to combine these features based on user input. Initially, the NN is trained toapproximate the initial average.
8.2.2 Integrating textual uncertainty values
When integrating aspects of textual uncertainty in a visualisation tool, there are variousaspects that need to be considered to facilitate user understanding and to maximise theaccessibility and usability of the tool.

326 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
Figure 8.6: Example of ascending confidence sorted diagonal layout.
Some choices in terms of presenting textual uncertainty and polarity information tothe user are partly influenced by the choices of evidence presentation and visualisationpresented in the previous section. Since evidence is organised in an article-centredfashion, and the article title and details are the first pieces of information seen by theuser, it was considered most appropriate to also organise textual uncertainty in a manner

8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 327
that distinguishes between article-level and global uncertainty.
Therefore, uncertainty is first summarised for each article, providing an article-baseduncertainty value, and subsequently, the article-based values are combined to calculatea global uncertainty value for the interaction in question. This decision may seem some-what incompatible with our analysis in Chapter 7, where we pointed out that, ideally,additional context would be used in order to decide on the relative weight of each eventmention within a paper. However, averaging the uncertainty values for each paper al-lows the user to easily inspect the distribution of certainty on a paper-by-paper basis,and quickly spot and inspect the articles that contain more controversial or more certaininformation, depending on the intended use.
Such an example, visualising the different combined certainty values for each paper,is illustrated in Figure 8.7.
Figure 8.7: Combined confidence values propagated from sentence level to paper level.
Moreover, visualising polarity information separately from uncertainty was deemednecessary in order to give users a more clear insight into the evidence context. Thus,while polarity is also considered during the calculation of the combined uncertainty val-ues, a global, averaged polarity value is presented to the user for each interaction, inorder to enable them to estimate whether or not an interaction is mentioned mostly in anegative context (i.e., they are not expected to take place). This feature is particularly

328 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
important to contextualise discovered interactions, as well as to identify potentially erro-neous interaction assertions in the original network. Such interactions, which are linkedto highly controversial or contradictory evidence, and which involve many negated andmany positive statements, are considered of particular interest for some of the applica-tions of the LitPathExplorer visualisation tool, since they can lead to the recognition oferroneous assertions or the identification of interactions that are key to further experi-mentation and hypothesis generation. Thus, an option to visualise and highlight con-tradictory interactions was included in the tool. Note that the polarity is also visualisedindependently for evidence passages in a similar way to uncertainty.
8.2.3 Interactive integration of certainty
The parameters that define the certainty level of an interaction, and the confidence auser can have in this certainty level, are significantly dependent on the intended use andapplication of the interaction network, as well as on the user’s perception of certainty asa concept. As already discussed in Chapter 7, interpretations of certainty vary greatly,even when based on the same single sentence (and judged using the same guidelines).Some researchers exhibit a more “strict” understanding of certainty, demanding veryprecise information in order to characterise an event from an evidence passage as highly
certain, while other researchers are more lenient. For example, some researchers willlook for explicit mentions of quality before they accept an event (statistical significance,experimental methods, validation by other researchers). The difference between thescores of users 1 and 2 who annotated the uncertainty for events and interactions for theRas-Melanoma dataset (in Chapter 7, Section 7.6.2.2) reflects this difference.
Furthermore, for use cases where the researchers are interested in compiling exe-cutable models (e.g. using a network to construct a Petrinet [Pet81] biological modelwhich can be executable) a strict interpretation of certainty is crucial to minimise errorsand construction time 9. In applications focusing on highly uncertain or controversialinteractions, being lenient and allowing for just a small number of uncertain interactionsmight be preferable.
9This was for example the case of one of our main test users, from the team who annotated the Ras-Melanoma sentences

8.2. INTEGRATING EVIDENCE AND UNCERTAINTY IN A PILOT 329
At the same time, many users consider the incorporation of personal scientific back-ground to be important in the final calculation of certainty. While this is an aspect thatwas difficult to take into account in the previous experiments (Chapters 5-7), it wasdecided to allow for personalisation and adaptation to user preferences within the visu-alisation tool. Thus, the users were able to change the uncertainty values at differentlevels of visualisation and aggregation. In this way, not only it is made possible for theuser to adapt the uncertainty and polarity calculation according to their judgement, butalso to move from the binary annotations of the tool (for the sentence/event level) tomore fine-grained annotations.
As such, apart from the overall uncertainty value for each interaction, which is calcu-lated independently and is fixed, uncertainty values at both the article level and sentencelevel are visualised with the use of sliding bars. For the sentence level, the initial posi-tion of the sliding bar is derived from the uncertainty predictions of our uncertainty andnegation identification systems. The uncertainty identification system is the ML+EDNGmodel as presented in Chapter 5 and trained on the combination of GENIA-MK andBioNLP-ST corpora. A similar polarity identification system is used to identify thenegation of the event (the polarity values can be either 1 for positive polarity or -1 fornegative). Then the polarity value is multiplied with the uncertainty value and repre-sented in the sentence confidence sliding bar. Initially the bar can take values from thefollowing set: −1,−0.5,0.5,1 If a user disagrees with any of the predictions, theycan modify by sliding the bar accordingly. The modification will propagate firstly to theaggregated paper-level confidence, subsequently to the overall aggregated calculation ofthe “Language certainty” value of the interaction, and finally it will affect accordinglythe overall confidence value.
At the paper level, the paper confidence bar can also be modified. Prior to modifi-cation, the paper confidence bar reflects the aggregated uncertainty and polarity valuesfor all relevant events in the paper. If the user chooses to modify the confidence valueat the paper level, all the individual sentence-level values will be modified accordingly.Additionally, the modification will propagate to the ”Language certainty” value of theinteraction, and ultimately it will accordingly affect the overall confidence value. Whilethe propagation of a change to upper levels implies recalculation of values based on theoriginal formulas, the backwards propagation of a change in uncertainty from paper-level confidence to the individual sentences within the paper is performed in a rather

330 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
simplistic way, in which all sentences are re-assigned an identical value (in other words,the modification is independent of the previously assigned values for each sentence).Thus, there is further room for experimentation and improvement in terms of the back-propagation of user-initiated changes, which could improve the user experience andmaintain the relative order of the sentence certainty ranking within a paper. However,this is reserved for future work and was not further studied within the present endeavour.
Note that when modifying any value using a sliding bar, the change in the overall
confidence value is also reflected through a corresponding change in the size of thecorresponding event node in the network. Moreover, the neural network that calculatesthe overall confidence value from the independent confidence parameters for each eventinstance will be updated accordingly. More specifically, the neural network will use thenewly assigned confidence value as a labelled instance, retrain the model and updateother event confidence values accordingly. The bars showing the breakdown of theconfidence value for a user-modified event are blurred to indicate that the value wasmanually assigned.
8.3 Textual uncertainty and citation patterns
As the pilot application was a first effort to bring together several different aspects thatcan affect the confidence of a text-mined interaction, there are various aspects of theconfidence parameter calculation for which a simplified approach was assumed. Theuse of the neural network that received a vector of normalised values for each parameter10 and predicted the overall confidence score was an efficient way to avoid makingany further assumptions about the potential dependencies between values, since theneural network would learn to attribute weights to each parameter according to the userchoices. However, there is ample room for further experimentation on the relationsbetween different parameters, as well as on the potential extension of the presentedparameters. By looking more closely at the interplay between different parameters, wehope to be able to define more elaborate confidence aggregation formulas and additionalconfidence features that will better assimilate the user’s preferences and uncertaintyperception.
10So that they all take values between 0 and 1.

8.3. TEXTUAL UNCERTAINTY AND CITATION PATTERNS 331
As a starting point for the above, this section examines somewhat more closely thecitation parameter and its relation, if any, to the textual uncertainty. For this reason,we aim to look beyond simple citation counts, and instead examine the exact waysin which citations referring to each paper are organised. For this purpose, we aim torevisit citations within the frame of a citation network. This complementary analysiswas performed using the Breast Cancer document collection as a basis.
For the extraction of the citation network, the Breast Cancer documents were usedas seeds. Then, the PubMed database was crawled iteratively until a so called “short-est path network” was generated. For the generation of the shortest path network, thenetwork is considered complete when each seed node is connected to the rest of thenetwork through the shortest path. This approach ensures network connectivity with-out risking over-expansion of the network 11. The resulting network consists of ˜27Mnodes (articles) and ˜410M edges (citations). A picture illustrating the henceforth calledBreast Cancer network can be seen in Figure 8.8
One of the most commonly used approaches in large network analysis is the useof different centrality measures to assess the importance of each node in the network.As the name reveals, centrality measures provide insights related to how central thenode is in a network. This is relevant to many different areas of network analysis, fromsocial [LFH10] to telecommunication [TLG10] networks. Overall, there is no consensusabout what constitutes a central node, as this can vary depending on the application andinterpretation of the task. For example, we could consider the most central node to bethe one to which the majority of nodes are directly linked, or else the node that is atthe centre of most paths between nodes. We can also examine whether incoming andoutgoing edges count equally, etc. As a result, there are many different algorithms andmeasures of centrality, focusing on capturing different elements in a network.
By calculating different graph centrality values over the network, it is possible toestimate the popularity and prominence of each paper as well as the trust attributed to itby the scientific community [BBH15, DJC15, AMOS18]. There is a wide range of al-gorithms proposed as a measure of the importance of specific nodes within a graph or anetwork. Some, like Google’s famous PageRank algorithm [PBMW99], were designed
11The network and the shortest path generation algorithm was provided by Dr. Mori’s team and thevaluable contribution of Dr. Masanao in the University of Tokyo.

332 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
Figure 8.8: Breast Cancer citation network visualised via LargeVis [TLZM16] andcoloured based on modularity index [New06].
specifically in relation to document (or, in this case, webpage) networks, while oth-ers, like the closeness [Sab66] and betweenness [Bar04] centrality measures are moregeneric. In this analysis, the following algorithms and metrics are employed to evaluateeach paper (node) of the network:
• Degree: Reflects the normalised sum of the incoming and outgoing edges for eachnode. It provides a balanced account of the relatedness of the node to the rest ofthe network. However, it is sometimes hard to interpret, as it draws no distinctionbetween incoming and outgoing edges.
• In-degree: The normalised sum of the incoming edges of each node. It providesa rough assessment of the document popularity, as well as its relatedness to otherwork in the network as perceived by other authors.

8.3. TEXTUAL UNCERTAINTY AND CITATION PATTERNS 333
• Out-degree: The normalised sum of the outgoing edges of each node. It providesa rough assessment of the document’s relatedness to other work in the network,as perceived by the author.
• Closeness centrality: It represents the reciprocal of the sum of the length of theshortest paths 12 between the node and all other nodes in the graph. Thus, it isa measure that estimates the centrality of the document (node) to the network.Documents with high closeness centrality values are assumed to be established,central papers to the main topic(s) of the network (in this case breast cancer). So,for a document node d, we have:
C(d) =N
∑t(min(d(t,d))(8.1)
where : d(u,v) is the distance between nodes v,u
• Betweenness centrality: This is another measure of centrality that is related toshortest paths 12. The betweenness centrality for each document (node) is thenumber of these shortest paths that pass through the node. It has been shownthat documents with high values for this metric are linked with higher “interdis-ciplinarity” of the document [Ley07]. So for a document node d we have:
B(d) = ∑s 6=t 6=d
σs,t(d)σs,t
(8.2)
where : σs,t(u) is the number of shortest paths between nodes s, t that go through u.
• Eigenvector centrality: This is a measure of the influence of a node over the restof the network nodes, calculated via the use of the graph adjacency matrix. Essen-tially, scores are assigned to each node, assuming that connections to high-scoringnodes contribute more to the score of the node in question than equal connectionsto low-scoring nodes. A high eigenvector centrality value signifies that a node isconnected to many nodes which themselves have high scores. For a document
12 In a connected graph, we define the shortest path as follows: for every pair of nodes in the graph,there exists at least one shortest path between those nodes such that either the number of edges that thepath passes through (for unweighted graphs) or the sum of the weights of the edges (for weighted graphs)is minimized.

334 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
node d and if xd is the expected score, we have:
xd =1λ
∑t∈M(d)
xt =1λ
∑t∈G
ad,t · xt = A ·x = λ ·x (8.3)
Thus transforming the notation to the eigenvector equation as indicated in Equa-tion 8.3.
• PageRank: This is a way to rank linked documents, initially suggested in orderto rank search results by Google. The idea behind it is that a page has a highrank if the sum of the ranks of its backlinks is high [PBMW99]. Backlinks inthis case correspond to incoming edges and this approach accounts both for thecases where a page has many backlinks and when a page has a few highly rankedbacklinks (similar to the eigenvector centrality intuition). This idea is directlytransferable to citation graphs and the intuition behind it is that a paper referredto by many papers is important; yet a paper referred to by many important papersis even more important. Various adaptations of PageRank have been proposedsince its first publication in 1999, some specifically tailored to citation evaluation[WXYM, DYFC09, MGZ08, MR08] and scientific paper ranking [SG09, DV12,JSC11, LNPC15]. In this preliminary study, we employ the original PageRankalgorithm. So, for a document node d we have:
PR(node) = ∑v∈Bd
PR(v)L(v)
, (8.4)
where : L(u) is the sum of the outgoing edges of node u.
• HITS (Hubs and Authorities): Much like PageRank, HITS (short for HyperlinkInduced Topic Search) is also a graph analysis algorithm initially designed to ratewebpages by Jon Kleinberg [KKR+99]. The idea behind Hubs and Authoritiesstemmed from a particular observation about the role of web pages: that certainweb pages, called hubs, serve as large directories that are not authoritative in termsof the information that they contain, but are used as reference points providing abroad catalogue of information and guiding users towards other, so-called author-itative pages. Thus, a good hub represents a page that points to many other pages,

8.3. TEXTUAL UNCERTAINTY AND CITATION PATTERNS 335
and a good authority represents a page that is linked to by many different hubs.Transferring this way of reasoning to citation networks, a document that wouldobtain a high value as a hub would most probably be a review paper, while docu-ments obtaining high values as authorities would be core, breakthrough papers ineach field. Calculating the hubs and authorities values is an iterative procedure,since the value of each metric depends on the other. For a document node d wehave:
Hub(d) = ∑i(Auth(i)) (8.5)
andAuth(d) = ∑
i(Hub(i)) (8.6)
where : i is any document linked to d
Thus, both metrics are calculated and normalised iteratively until convergence.
All the above metrics are calculated using the Snap software library, which allowsprocessing of large graphs. The algorithms described above are implemented in the Snapsoftware [LS16]. The code used to process the Breast Cancer network was written inC++.
Having calculated the aforementioned values, the goal is to examine potential re-lations (correlation or distributional relations) between the values and the expresseduncertainty of the document authors as communicated through textual uncertainty cues.In other words, we would like to establish whether the frequency of mention of uncer-tain events within a document influences the “citability” of that document, or whetherthe two concepts of textual uncertainty and citation confidence are independent.
In order to compare with textual uncertainty, it is imperative to consider the uncer-tainty scoring strategy. While one could simply infer a score aggregating all uncertaintyexpressions in a text, this approach is prone to erroneously considering as equal a) eventsthat are common background knowledge and are simply mentioned as part of a proce-dure or basis for a hypothesis and b) events that are central to the main narrative of apaper or its set of hypotheses.
To avoid this pitfall, we design a heuristic approach based on tf-idf theory [SM86].Tf-idf (term frequency - inverse document frequency) is often used in information re-trieval approaches to identify key terms in a document that distinguish it from the rest

336 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
of the documents. The reasoning behind this is that within a specific collection, someterms will have high frequency in all papers (such as stopwords or terms central to thegeneral topic of the collection) and thus they have low discriminating power. On theother hand, the terms that have high frequency exclusively in a specific document areboth highly representative of the document’s topic and highly discriminative within thecollection.
Tf-idf for a term t and a document d in a document collection D can be defined asshown in Equation 8.7:
T f − id f (t,D) = (1+ log ftd) · logN
|d ∈ D : t ∈ D|(8.7)
where ftd is the count of term t in document d, N is the total document count in D and|d ∈ D : t ∈ D| is the total number of documents in D where the term t appears.
We translate the tf-idf to the event space to infer a heuristic (Et f − Id f ) that willidentify the important events in each document, as shown in Equation 8.8 for an event e
and a document d in the Breast Cancer network G.
Et f − id f (d,G) = (1+ log fed) · logN
|d ∈ G : e ∈ G|(8.8)
where fed is the total number of mentions of event e in document d, N is the totaldocument count in G and |d ∈G : e∈G| is the total number of documents in G wherethe event e is mentioned.
While the definition is only slightly different from the original one, it is importantto note a point regarding the counting of event mentions. In Chapter 7, Section 7.5, weextensively discussed the implications of mapping event mentions to the same concept.As events (interactions) are not always expressed in the text using the same words, thereneeds to be a specific mapping strategy. In this case, we employ the approximate stringmatching technique, enhanced with dictionaries, that is illustrated in Figure 7.5 to mapentities among various event mentions. However, we drop any requirements relating tothe interaction type (or event trigger type), in order to increase mapping between eventmentions. Thus, two events whose entities can be mapped to each other and whosedirectionality is aligned (order of participating entities) will be considered to match tothe same interaction concept and will count towards the same event frequency. We use
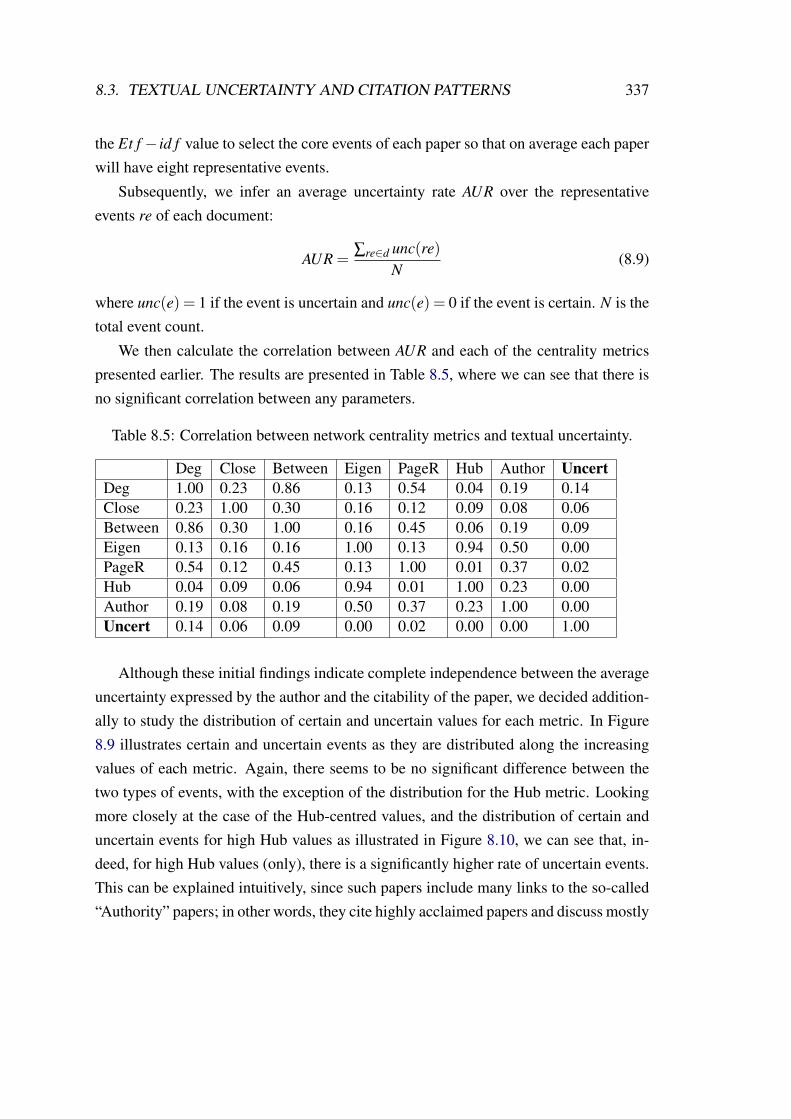
8.3. TEXTUAL UNCERTAINTY AND CITATION PATTERNS 337
the Et f − id f value to select the core events of each paper so that on average each paperwill have eight representative events.
Subsequently, we infer an average uncertainty rate AUR over the representativeevents re of each document:
AUR =∑re∈d unc(re)
N(8.9)
where unc(e) = 1 if the event is uncertain and unc(e) = 0 if the event is certain. N is thetotal event count.
We then calculate the correlation between AUR and each of the centrality metricspresented earlier. The results are presented in Table 8.5, where we can see that there isno significant correlation between any parameters.
Table 8.5: Correlation between network centrality metrics and textual uncertainty.
Deg Close Between Eigen PageR Hub Author UncertDeg 1.00 0.23 0.86 0.13 0.54 0.04 0.19 0.14Close 0.23 1.00 0.30 0.16 0.12 0.09 0.08 0.06Between 0.86 0.30 1.00 0.16 0.45 0.06 0.19 0.09Eigen 0.13 0.16 0.16 1.00 0.13 0.94 0.50 0.00PageR 0.54 0.12 0.45 0.13 1.00 0.01 0.37 0.02Hub 0.04 0.09 0.06 0.94 0.01 1.00 0.23 0.00Author 0.19 0.08 0.19 0.50 0.37 0.23 1.00 0.00Uncert 0.14 0.06 0.09 0.00 0.02 0.00 0.00 1.00
Although these initial findings indicate complete independence between the averageuncertainty expressed by the author and the citability of the paper, we decided addition-ally to study the distribution of certain and uncertain values for each metric. In Figure8.9 illustrates certain and uncertain events as they are distributed along the increasingvalues of each metric. Again, there seems to be no significant difference between thetwo types of events, with the exception of the distribution for the Hub metric. Lookingmore closely at the case of the Hub-centred values, and the distribution of certain anduncertain events for high Hub values as illustrated in Figure 8.10, we can see that, in-deed, for high Hub values (only), there is a significantly higher rate of uncertain events.This can be explained intuitively, since such papers include many links to the so-called“Authority” papers; in other words, they cite highly acclaimed papers and discuss mostly
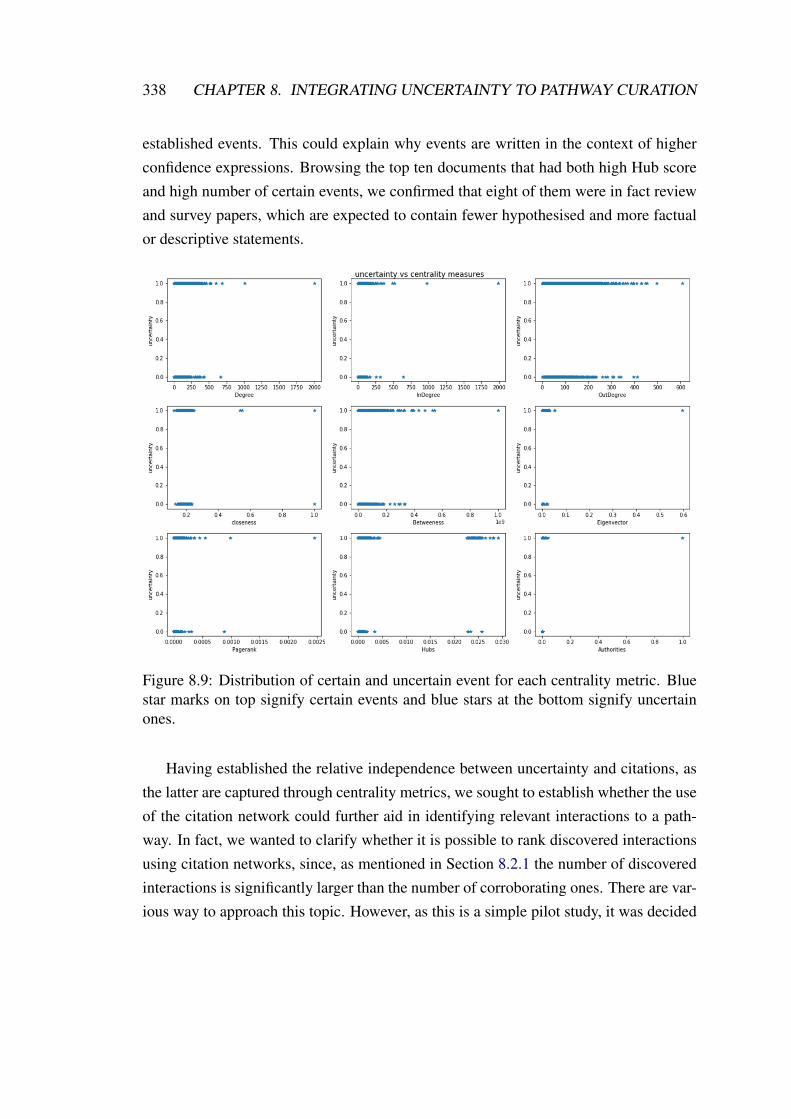
338 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
established events. This could explain why events are written in the context of higherconfidence expressions. Browsing the top ten documents that had both high Hub scoreand high number of certain events, we confirmed that eight of them were in fact reviewand survey papers, which are expected to contain fewer hypothesised and more factualor descriptive statements.
Figure 8.9: Distribution of certain and uncertain event for each centrality metric. Bluestar marks on top signify certain events and blue stars at the bottom signify uncertainones.
Having established the relative independence between uncertainty and citations, asthe latter are captured through centrality metrics, we sought to establish whether the useof the citation network could further aid in identifying relevant interactions to a path-way. In fact, we wanted to clarify whether it is possible to rank discovered interactionsusing citation networks, since, as mentioned in Section 8.2.1 the number of discoveredinteractions is significantly larger than the number of corroborating ones. There are var-ious way to approach this topic. However, as this is a simple pilot study, it was decided
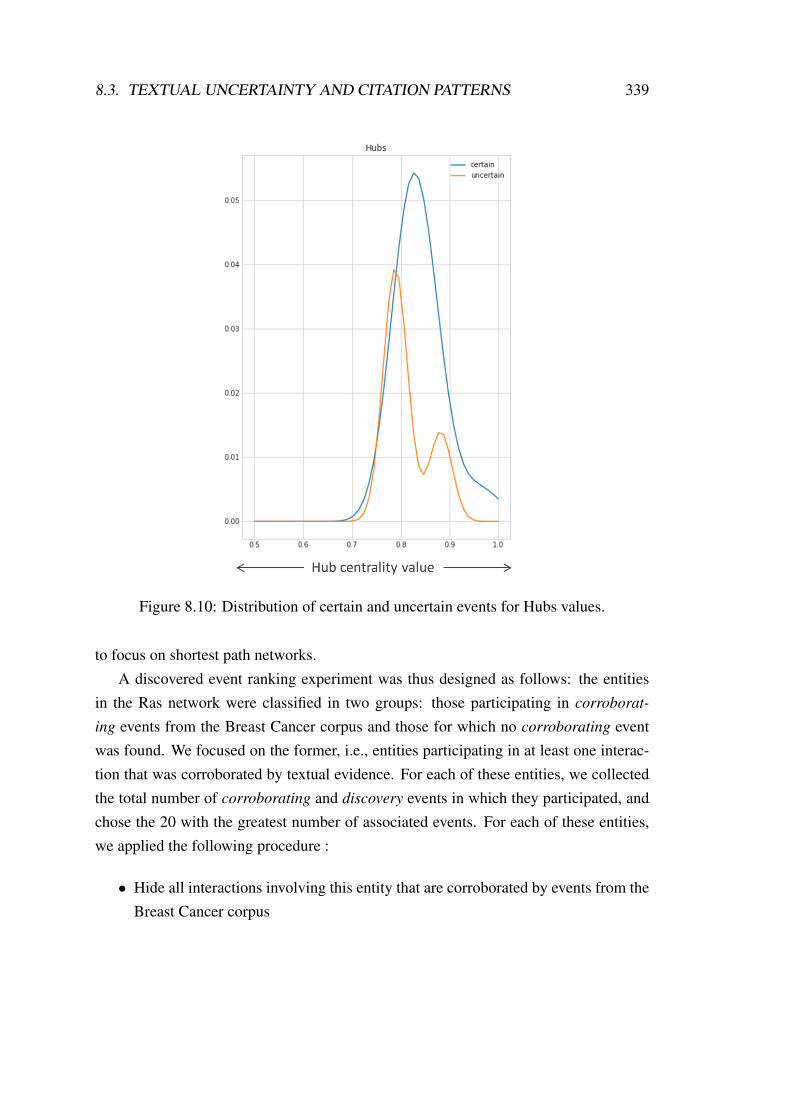
8.3. TEXTUAL UNCERTAINTY AND CITATION PATTERNS 339
Figure 8.10: Distribution of certain and uncertain events for Hubs values.
to focus on shortest path networks.
A discovered event ranking experiment was thus designed as follows: the entitiesin the Ras network were classified in two groups: those participating in corroborat-
ing events from the Breast Cancer corpus and those for which no corroborating eventwas found. We focused on the former, i.e., entities participating in at least one interac-tion that was corroborated by textual evidence. For each of these entities, we collectedthe total number of corroborating and discovery events in which they participated, andchose the 20 with the greatest number of associated events. For each of these entities,we applied the following procedure :
• Hide all interactions involving this entity that are corroborated by events from theBreast Cancer corpus

340 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
• Identify papers corroborating the rest of the interactions in the pathway
• Identify papers containing “discovered” events for that entity
• For each discovered event e corresponding to interaction i, calculate the relevancescore based on the average shortest path distance between the papers containingit and the pathway papers.
ASPscorei =1|D|· ∑
d∈D
∑t∈T min(distance(d, t))|T |
(8.10)
where D is the group of papers mentioning interaction i and T is the group ofpapers mentioning the rest of the pathway interactions.
• Rank all candidate interactions based on ASPscorei.
• Evaluate against the original pathway interactions. Our hypothesis is that theinteractions that were “hidden” at the beginning of the experiment (i.e. thosecorresponding to corroborating events) should be ranked highly, as they are moredefinitely related to the pathway.
The intuition behind this experiment is presented in Figure 8.11.
Using shortest path approach on the Breast Cancer pathway seems to yield goodranking results, for the cases where the number of candidate events is small. However,for larger sets of candidate events (> 20), simply ranking based on shortest paths isnot sufficient, since many events seem to end up in the same rank (same shortest pathdistances) and thus the measure is not good at discriminating event relevance. Figure8.12 demonstrates the mean average precision (MAP) performance for different sizes ofcandidate events.
These experiments aimed to explore in a heuristic way a) whether citation patternsand textual uncertainty are independent and b) whether citation patterns can capture therelevance of a paper to a given pathway model or interaction. The initial results areencouraging for both hypotheses. These preliminary findings render citation analysisa good candidate for relevance filtering, as well as for community trust estimation. InChapter 7, we have already discussed that our subjective logic adaptation does not ac-count for propagation of uncertainty across papers. Using citation networks it is possible

8.4. CONCLUSIONS 341
Figure 8.11: Intuition for ranking events experiments.
to address this issue by further adapting Josang’s theory for propagation of certainty intrust networks [JHP06]. Since we have proven their independence from textual uncer-tainty, citations can be treated as trust indicators and enriched with further informationregarding the attitude of the citing author towards the cited paper. (Usually, this type ofinformation is called citation function [TST06]). Moreover, the shortest path approachcould be further enriched with weights inspired by centrality metrics and used as anadditional filter for discovered events. Further experimentation and validation of theseproposals is reserved for future work.
8.4 Conclusions
In this chapter we have presented the details and decisions involved in the implementa-tion of a user-centric confidence visualisation tool designed for pathway curation. Webriefly presented other literature-based parameters that can affect the confidence of aninteraction (as estimated by the related evidence) and we have showed how textual un-certainty can be integrated and combined with such parameters. As this was a pilot
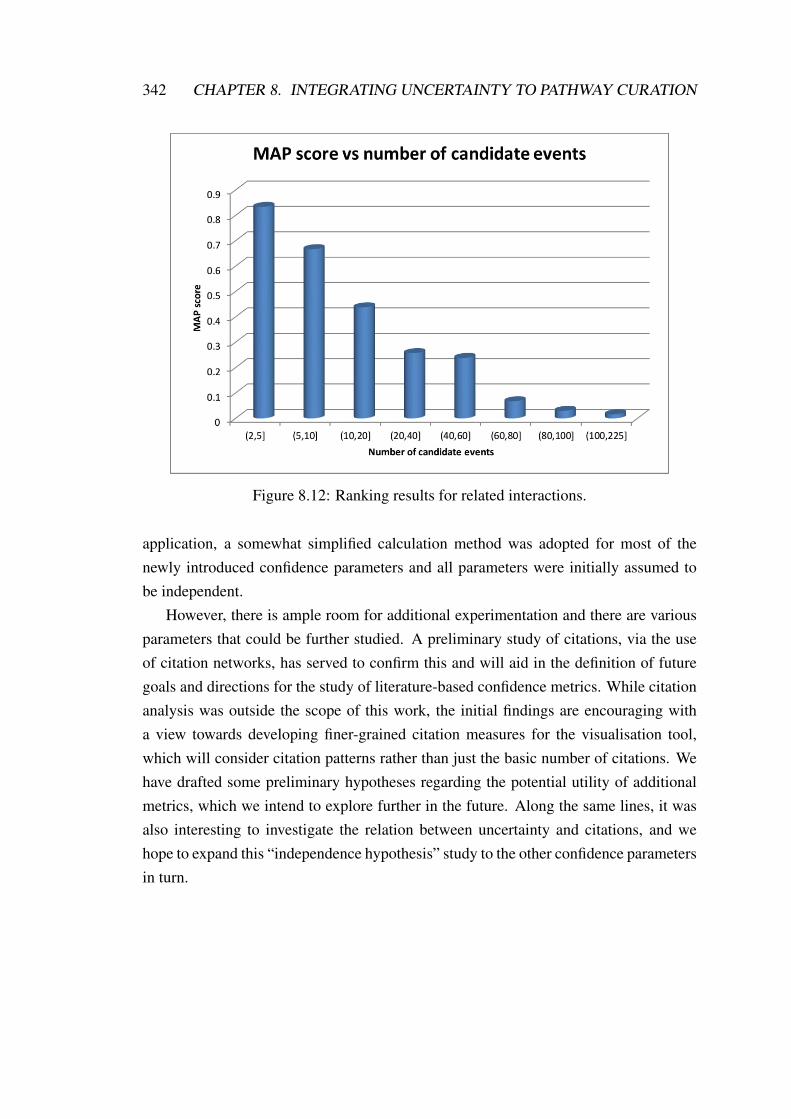
342 CHAPTER 8. INTEGRATING UNCERTAINTY TO PATHWAY CURATION
Figure 8.12: Ranking results for related interactions.
application, a somewhat simplified calculation method was adopted for most of thenewly introduced confidence parameters and all parameters were initially assumed tobe independent.
However, there is ample room for additional experimentation and there are variousparameters that could be further studied. A preliminary study of citations, via the useof citation networks, has served to confirm this and will aid in the definition of futuregoals and directions for the study of literature-based confidence metrics. While citationanalysis was outside the scope of this work, the initial findings are encouraging witha view towards developing finer-grained citation measures for the visualisation tool,which will consider citation patterns rather than just the basic number of citations. Wehave drafted some preliminary hypotheses regarding the potential utility of additionalmetrics, which we intend to explore further in the future. Along the same lines, it wasalso interesting to investigate the relation between uncertainty and citations, and wehope to expand this “independence hypothesis” study to the other confidence parametersin turn.

Chapter 9
Conclusions
This PhD work has concerned the concept of textual uncertainty, as it is communicatedin the context of scientific writing. We have focused on a specific scenario that guidedthe direction of the presented research: the potential use of uncertainty and its relation tomentions of interactions (events) in text as a means to integrate textual information andscore the confidence of interactions in external biomedical resources, such as databasesand interaction network models.
As stated in the introduction, our overarching goal was:
To integrate knowledge extracted from scientific, biomedical papers (in the form ofbiomedical events) to existing pathways and interaction networks, in an uncertainty-aware manner. In other words, to maintain information about the uncertainty expressedin the text over the event (and the interaction it refers to), and to incorporate this un-certainty related information in a way that is reflected in the confidence value of thecorresponding pathway interaction.
In the process of achieving the aforementioned goal, we first focused on optimis-ing the definition and identification methods of uncertainty in the biomedical domain.In terms of definition, we identified 5 categories of textual expressions that were allclassified as expressions of textual uncertainty, namely: speculation (further divided toexpressions of weak and strong speculation), investigation, weaselling, admission oflack of knowledge (AOLK) and time/frequency limitations.
343

344 CHAPTER 9. CONCLUSIONS
Further analysing sentences containing expressions of the aforementioned categories,we wanted to improve the feature structures used not only to identify such expressionsbut also to determine their influence on biomedical events. We hypothesised that featurestructures which could encode shallow dependency sequences between tokens would bea better fit the task description compared to deep syntactic trees that are preferred incue-scope tasks. We proposed the enriched dependency n-grams as a structure thatcould accurately capture the dependency path between an uncertainty cue and an eventtrigger, thus determining the uncertainty value of the event. Our experiments demon-strated that enriched dependency n-grams surpass the state-of-the-art performance ontwo corpora with gold standard annotations, namely GENIA-MK and BioNLP-ST. Wealso demonstrated that they provide a statistically significant improvement over the useof “traditional” dependency n-grams. Thus, we confirmed our first hypothesis H1 thatstated:
We hypothesise that by enriching dependency n-gram structures with with the cor-responding dependency types we can improve performance on automated uncertaintyidentification.
We demonstrated potential uses of our enriched dependency n-gram representation,both within the context of ML classifiers and as a rule induction structure for rule-basedmethods. The ML scenario produced the best performance achieving an F-score of 0.88on GENIA-MK and of 0.76 on BioNLP-ST for the identification of uncertain events.The ML version was thus incorporated in our final pipeline, but we demonstrated thatautomated rule induction can successfully account for semi-supervised scenarios. Ourexperiments also set the ground for the use of enriched dependency n-grams in otherrepresentations, such as deep neural networks as explained in the future work section9.1.1.
However, we have to note that the identified expressions of uncertainty as well as theproposed methods for identification of uncertain events, do not necessarily transfer wellto other domains. In a small spin-off of the main focus of this PhD, we have investigatedhow do our methods perform in the newswire domain, using the ACE-MK corpus as ourtest-case. We expected that expressions of uncertainty (uncertainty cues) would differ,but that when training on a corpus with annotated uncertainty in the newswire field, the

345
enriched dependency n-grams would be equally robust and efficient. As phrased in H3.1
and H3.2 respectively, we hypothesised that:
Textual uncertainty expressions vary across domains, requiring domain-specific ap-proaches and knowledge extraction.
and
Dependency based, ML methods that build on domain specific knowledge can beequally efficient across different domains.
Indeed, when comparing the GENIA-MK and ACE-MK corpora we observed thatthe use of cues from GENIA-MK as dictionaries in training classifiers on ACE-MK andvice-versa resulted in reduced performance on both corpora. We thus concluded that un-certainty is expressed differently across domains and that knowledge about uncertaintyexpressions is not fully transferable across domains, confirming H3.1. However, ourexperiments on the ACE-MK corpus revealed that, even when using uncertainty cuesextracted from the same corpus as dictionary features, and applying the same ML con-figuration that achieved optimal results for GENIA-MK, the performance of uncertaintyidentification on ACE-MK dropped significantly. Our results concur with other findings[FVM+10], and imply that even when using domain-specific knowledge, our ML meth-ods developed for scientific text are not fully transferable to the newswire domain, thusrejecting H3.2.
To further explore why this might be the case, we proceeded to identify the key dif-ferences between the syntactic and lexical properties of uncertain expressions in the twodifferent fields. Our analysis revealed a number of significant discrepancies between theexpression of uncertainty in the two different fields, which could be used as the basisfor the development of improved uncertainty identification methods for newswire text.There is a particularly important need for such methods since, at present, the perfor-mance of uncertainty identification methods in the newswire field is significantly lowerthan the biomedical domain. While this research path was not further pursued in thisthesis, it is a promising direction for future work and expansions of our system as de-scribed in Section 9.1.2.

346 CHAPTER 9. CONCLUSIONS
On the biomedical data, our ML methods, using the enriched dependency n-gramsalso showed promising results in the multi-level classification of uncertainty, whentested on the 3-level annotations of GENIA-MK. While the results were outperformthe other work for the two out of the three uncertainty classes, we decided not to delvefurther into optimisation for the multi-level uncertainty identification task, because ourin-house user evaluation experiments, showed that usually there is no consensus amongusers on the perceived intensity level of uncertainty.
More specifically, we wanted to evaluate the agreement of researchers in terms ofclassifying uncertainty in 5 intensity levels. We hypothesised that similarly to the find-ings of Rubin et al. [Rub07] for the newswire domain and those of Druzdel [Dru89]for generic text, researchers perceive the intensity of uncertainty differently, even whenreading the same sentence. As expressed in our second hypothesis, H2:
We hypothesise that among biomedical scientists there is a large degree of between-user variability in the interpretation of the uncertainty intensity in text.
We confirmed our hypothesis by asking two different research teams to look at sen-tences annotated with events and annotate each event with (un)certainty using a scaleof 1 to 5, where 1 corresponds to “most uncertain” and 5 to “most certain”. In bothuse cases, we observed low inter-annotator agreement, with the pairwise kappa valueranging from 0.55 to 0.24 and indicating high between user variability in the perceptionof uncertainty. However, we noticed that while there was low agreement on the exactscoring, the annotators seemed to agree in general on whether the event leaned towardscertainty (score >= 4) or uncertainty (score <= 3). Indeed, when we considered dis-agreement that was greater that two points on the annotation scale, the disagreementratio dropped to an average of 8%. We thus confirmed H2, as well as early findingsof Druzdel and Rubin who made similar observations and justified our preference for abinary classification of uncertainty, over a multi-level problem setting.
More importantly, we could then apply our trained models on the user annotationsto verify that the predictions generated by our methods were in accordance with theaveraged ratings of users. This helped to reinforce the validity of our approach andallowed us to address our subsequent aims, moving towards the integration of textualuncertainty in biomedical networks.

347
Having evaluated the performance of the uncertainty identification methods on theclassification of individual event mentions, we focused on the problem of combininguncertainty values of different mentions of the same event from different evidence pas-sages. We proposed an adaptation of subjective logic theory [Jos16] in order to frameeach event mention as an opinion model, capturing potentially varying values of uncer-tainty and negation for each mention. We showed that this adaptation of subjective logiccan account for and combine both uncertainty and negation, and is easily adaptable todifferent uncertainty classification schemes.
Moreover, we extended the user-based evaluation discussed for H2, in order to val-idate our methods for uncertainty consolidation. To do this, we presented researcherswith interactions paired with several evidence passages and asked them to score boththe passages themselves and the interactions in general in terms of their uncertainty.We demonstrated that by applying the cumulative fusion formula to the scores that re-searchers provided for the individual evidence passages, we were able to predict theconsolidated uncertainty value of the interaction with minimal error rate (0.10 and 0.07for the Leukemia and Melanoma research teams respectively). We thus confirmed ourfourth hypothesis H4 that stated:
We hypothesise that textual uncertainty of individual, independent event mentions,affects the perception of users about the certainty of the corresponding interaction in aconsistent and measurable way, which can be modelled. We can thus predict user scoresfor interactions, by their scores on uncertainty of related events.
The low MAE that was obtained with cumulative fusion for both teams demonstratesthat our methods can accurately approximate the way in which readers – and morespecifically biomedical researchers – combine information about the uncertainty of aninteraction from multiple sources. As described in Section 9.1.3, we aim to furtherexplore the potential of subjective logic in this context and see if we can also use it toaccount for the varying trust in a specific author, as indicated by the citation patterns.
The results described above, concerning the ability of our methods to successfullycombine uncertainty information from multiple evidence passages, demonstrate thatit is suitable to integrate these methods within applications that facilitate automated,literature-aided update of knowledge bases and biomedical interaction models. We thus

348 CHAPTER 9. CONCLUSIONS
address our final question, RQ5:
How can textual uncertainty be integrated with other literature-based confidencevalues to complement event-based evidence linking to biomedical interaction networksand pathway models?
In Chapter 7, we discussed our approach to mapping events to interaction networksand knowledge bases, focusing on our two pathway use cases. Subsequently in Chapter8, we present the potential of using these event mappings in the implementation of aliterature-aided, interactive pathway visualisation and navigation interface, namely, Lit-
PathExplorer. We discussed the method of integrating uncertainty in this application,and showed how it can facilitate interaction filtering and interpretation. We briefly pre-sented other literature-based parameters, such as citations, impact factor and altmetricscore, which can also affect the estimated impact of a given evidence passage on theoverall confidence of an interaction. We showed how different such parameters can becombined in one value and used in various usage scenarios by researchers in order to fa-cilitate their research and literature browsing. We specifically showed that citations canaid in identifying more relevant articles to a given interaction and initiated a discussionon how textual uncertainty can be integrated and combined with citations to providebetter informed confidence measures.
Overall, this work has shown that it is feasible, with high accuracy, to automat-ically identify expressions of uncertainty in a biomedical passage, to determine howand whether these expressions affect the interpretation of events that are described inthe same passage, and to present this information to readers in a manner that is bothintuitive and understandable. We have also demonstrated through quantitative and qual-itative user evaluation that by incorporating evidence and contextual knowledge in theform of evidence passages and confidence values, we can facilitate the browsing andcuration of interaction models and pathways. We believe that the work presented in thisPhD thesis lays the foundations for the meaningful integration of uncertainty as a con-fidence parameter in a variety of literature-aided applications, ranging from literature-based discovery of knowledge to the automated population of databases, interactionnetworks and other resources.

9.1. FUTURE WORK 349
9.1 Future work
Throughout this thesis, we have identified various interesting directions for future re-search. Although these would all be worthy of further investigation, they were deemedto be outside the scope of the current work. We outline below the main directions forfuture work.
9.1.1 Identification of textual uncertainty
We have demonstrated the effectiveness of our enriched dependency n-grams in the au-tomated identification of textual uncertainty. However, we found that performance isreduced when removing pre-compiled cue-lists (see Table 5.8). As future work, weintend to investigate potential combinations of our approach with the promising recentwork of Chen [CSH18], who used word embeddings to infer semantically equivalent cuewords that indicate uncertainty. Moreover, we would like to examine whether enricheddependency n-grams can be used for sentence representation in deep neural network ap-proaches. We envision adapting our approach to create an enriched form of dependencyembedding [LG14] which can be used as input to different neural network models, suchas Long Short Term Memory (LSTM), RNN and CNN models [SSN12, ZSLL15]. Weconsider that both of these ideas represent promising directions towards further improv-ing the performance of the uncertainty identification task.
On a different note, we have shown that readers, and more specifically researchers inbiomedicine who read related literature, have different, individual perceptions regardingthe intensity of textual uncertainty. This variability in the interpretation of uncertaintyamong individuals renders the task of multi-level uncertainty classification particularlycomplex to be achieved at a global level. Thus, it seems worthwhile to further investigateuser-adaptation methods and active learning techniques [LNA17, SGLZ14, PLM15],which will be able to account for user-specific representations of uncertainty. More-over, it would be interesting to further explore user agreement towards the intensity ofuncertainty, by transforming the classification task into a ranking task. Thus, we couldpotentially identify whether there is an underlying intensity order of uncertain expres-sions, which could achieve a higher agreement rate among researchers.

350 CHAPTER 9. CONCLUSIONS
9.1.2 Uncertainty in the newswire domain
While our main focus was biomedical literature, we have demonstrated that uncertaintyis expressed differently across domains. More specifically, it seems that the proposedconfiguration and constraints for the enriched dependency n-grams, which had an im-portant contribution towards the identification of uncertainty in the biomedical domain,proved to be a hindrance in terms of performance in the newswire domain. As futurework, we would like to focus more on the newswire domain and extend our featurerepresentation to include more complex dependencies in an attempt to improve perfor-mance on news articles. Moreover, we could explore the combination of our meth-ods with approaches used in closely related tasks that are popular in the newswire do-main. More specifically, the recent fake news challenge1 boosted research into stanceand sentiment detection in news articles, resulting both in new corpora annotations[FV16, TVCM18] and new methods [BSR17, BSS+18, RASR17] which we could useas the basis for revised classification and automated uncertainty identification methodsfor news events. Along the same lines, approaches used for factuality detection couldprovide valuable inspiration and resources to allow us to expand our definition of uncer-tainty to include other dimensions, such as tense, or source [Sau17, PHS+03, MSU+16].
9.1.3 Exploitation of citation networks
In the previous chapter (Chapter 8) we described the integration of textual uncertaintyalong with other literature-based confidence parameters into a pilot interface for path-way curation and visualisation. Moreover, we conducted a preliminary study into the re-lation and inter-dependence of textual uncertainty and citation analysis, which was usedas another confidence parameter in the application. While we only scratched the surfaceof this topic, we consider it to be a promising direction towards further improving theconsolidation of confidence values from different text passages. More specifically, wewould like to further exploit the properties of citation networks in order to identify thedependencies between events mentioned in different articles as well as the weighted sig-nificance and prominence of each paper. Paired with argumentation mining techniques,which could shed light on the dependencies of events within the same article, these
1http://www.fakenewschallenge.org/

9.1. FUTURE WORK 351
methods should enable us to account for varying degrees of event dependence. Thiswould allow us to further improve the modelling of event uncertainties and to use moreelaborate methods to calculate uncertainty fusion and uncertainty propagation over largedocument collections.


Bibliography
[AEHP03] Salvatore Attardo, Jodi Eisterhold, Jennifer Hay, and Isabella Poggi.Multimodal markers of irony and sarcasm. Humor, 16(2):243–260,2003.
[AGAV09] Enrique Amigo, Julio Gonzalo, Javier Artiles, and Felisa Verdejo. Acomparison of extrinsic clustering evaluation metrics based on formalconstraints. Information retrieval, 12(4):461–486, 2009.
[Ai08] Alias-i. Lingpipe 4.1.0. http://alias-i.com/lingpipe, 2008. (accessedNovember 2016).
[AIS93] R. Agrawal, T. Imielinski, and A. Swami. Mining association rules be-tween sets of items in large databases. In Proceedings of the ACM SIG-
MOD International Conference on Management of Data, pages 207–216, Washington D.C., May 1993.
[AJ06] Susan Adams and John P Jarvis. Indicators of veracity and deception:an analysis of written statements made to police. International Journal
of speech language and the law, 13(1):1, 2006.
[AJB00] Reka Albert, Hawoong Jeong, and Albert-Laszlo Barabasi. Error andattack tolerance of complex networks. nature, 406(6794):378, 2000.
[Ala16] Abdulaziz Alamri. The Detection of Contradictory Claims in Biomedi-
cal Abstracts. PhD thesis, University of Sheffield, 2016.
[Alm92] Eugenie P Almeida. A category system for the analysis of factualityin newspaper discourse. Text-Interdisciplinary Journal for the Study of
Discourse, 12(2):233–262, 1992.
353

354 BIBLIOGRAPHY
[Alt92] Naomi S Altman. An introduction to kernel and nearest-neighbornonparametric regression. The American Statistician, 46(3):175–185,1992.
[AMOS18] Kimitaka Asatani, Junichiro Mori, Masanao Ochi, and Ichiro Sakata.Detecting trends in academic research from a citation network usingnetwork representation learning. PloS one, 13(5):e0197260, 2018.
[ANM+89] AP Albino, DM Nanus, IR Mentle, C Cordon-Cardo, NS McNutt,J Bressler, and M Andreeff. Analysis of ras oncogenes in malignantmelanoma and precursor lesions: correlation of point mutations withdifferentiation phenotype. Oncogene, 4(11):1363–1374, 1989.
[AOR13] Sophia Ananiadou, Tomoko Ohta, and Martin K Rutter. Text miningsupporting search for knowledge discovery in diabetes. Current Car-
diovascular Risk Reports, 7(1):1–8, 2013.
[APTK10] Sophia Ananiadou, Sampo Pyysalo, Jun’ichi Tsujii, and Douglas BKell. Event extraction for systems biology by text mining the litera-ture. Trends in biotechnology, 28(7):381–390, 2010.
[AR08] Alain Auger and Jean Roy. Expression of uncertainty in linguistic data.In Information Fusion, 2008 11th International Conference on, pages1–8. IEEE, 2008.
[AS15] Abdulaziz Alamri and Mark Stevensony. Automatic identification ofpotentially contradictory claims to support systematic reviews. In 2015
IEEE International Conference on Bioinformatics and Biomedicine
(BIBM), pages 930–937. IEEE, 2015.
[AS16] Heike Adel and Hinrich Schutze. Exploring different dimensions ofattention for uncertainty detection. arXiv preprint arXiv:1612.06549,2016.
[ATDF11] Emilia Apostolova, Noriko Tomuro, and Dina Demner-Fushman. Au-tomatic extraction of lexico-syntactic patterns for detection of negationand speculation scopes. In Proceedings of the 49th Annual Meeting of

BIBLIOGRAPHY 355
the Association for Computational Linguistics: Human Language Tech-
nologies: Short Papers - Volume 2, HLT ’11, pages 283–287, Strouds-burg, PA, USA, 2011. Association for Computational Linguistics.
[AY10] Shashank Agarwal and Hong Yu. Detecting hedge cues and their scopein biomedical text with conditional random fields. Journal of biomedi-
cal informatics, 43(6):953–961, 2010.
[AZ11] Asma Ben Abacha and Pierre Zweigenbaum. Automatic extraction ofsemantic relations between medical entities: a rule based approach.Journal of biomedical semantics, 2(5):S4, 2011.
[BAH07] Simon Bernard, Sebastien Adam, and Laurent Heutte. Using randomforests for handwritten digit recognition. In Document Analysis and
Recognition, 2007. ICDAR 2007. Ninth International Conference on,volume 2, pages 1043–1047. IEEE, 2007.
[Bar04] Marc Barthelemy. Betweenness centrality in large complex networks.The European physical journal B, 38(2):163–168, 2004.
[Bat94] Roberto Battiti. Using mutual information for selecting features in su-pervised neural net learning. IEEE Transactions on neural networks,5(4):537–550, 1994.
[BBD+14] Kathryn Baker, Michael Bloodgood, Bonnie J Dorr, Nathaniel W Fi-lardo, Lori Levin, and Christine Piatko. A modality lexicon and its usein automatic tagging. arXiv preprint arXiv:1410.4868, 2014.
[BBH15] Jacopo A Baggio, Katrina Brown, and Denis Hellebrandt. Boundaryobject or bridging concept? a citation network analysis of resilience.Ecology and Society, 20(2), 2015.
[BCJ10] Waheed U Bajwa, Robert Calderbank, and Sina Jafarpour. Why ga-bor frames? two fundamental measures of coherence and their role inmodel selection. arXiv preprint arXiv:1006.0719, 2010.

356 BIBLIOGRAPHY
[BCL+11] Lindsey Bell, Rajesh Chowdhary, Jun S Liu, Xufeng Niu, and JinfengZhang. Integrated bio-entity network: a system for biological knowl-edge discovery. PloS one, 6(6):e21474, 2011.
[BCvMK13] Quoc-Chinh Bui, David Campos, Erik van Mulligen, and Jan Kors. Afast rule-based approach for biomedical event extraction. In proceed-
ings of the BioNLP shared task 2013 workshop, pages 104–108, 2013.
[BDDS10] Ozgun Babur, Ugur Dogrusoz, Emek Demir, and Chris Sander. ChiBE:interactive visualization and manipulation of BioPAX pathway models.Bioinformatics, 26(3):429–431, 2010.
[BDL08] Gerard Biau, Luc Devroye, and Gabor Lugosi. Consistency of randomforests and other averaging classifiers. Journal of Machine Learning
Research, 9(Sep):2015–2033, 2008.
[Bel77] Nuel D Belnap. A useful four-valued logic. In Modern uses of multiple-
valued logic, pages 5–37. Springer, 1977.
[Bel80] Nicholas J Belkin. Anomalous states of knowledge as a basis for infor-mation retrieval. Canadian journal of information science, 5(1):133–143, 1980.
[Ber05] Jean-Marc Bernard. An introduction to the imprecise dirichlet modelfor multinomial data. International Journal of Approximate Reasoning,39(2-3):123–150, 2005.
[Ber17] Hal Berghel. Lies, damn lies, and fake news. Computer, (2):80–85,2017.
[BFS08] Joan Bachenko, Eileen Fitzpatrick, and Michael Schonwetter. Verifi-cation and implementation of language-based deception indicators incivil and criminal narratives. In Proceedings of the 22nd International
Conference on Computational Linguistics-Volume 1, pages 41–48. As-sociation for Computational Linguistics, 2008.

BIBLIOGRAPHY 357
[BGM+99] Winona C Barker, John S Garavelli, Peter B McGarvey, Christo-pher R Marzec, Bruce C Orcutt, Geetha Y Srinivasarao, Lai-Su L Yeh,Robert S Ledley, Hans-Werner Mewes, Friedhelm Pfeiffer, et al. Thepir-international protein sequence database. Nucleic Acids Research,27(1):39–43, 1999.
[BGP+10] Jari Bjorne, Filip Ginter, Sampo Pyysalo, Jun’ichi Tsujii, and TapioSalakoski. Complex event extraction at pubmed scale. Bioinformatics,26(12):i382–i390, 2010.
[BH03] Gary D Bader and Christopher WV Hogue. An automated methodfor finding molecular complexes in large protein interaction networks.BMC bioinformatics, 4(1):2, 2003.
[BHA09] Simon Bernard, Laurent Heutte, and Sebastien Adam. Influence ofhyperparameters on random forest accuracy. In International Workshop
on Multiple Classifier Systems, pages 171–180. Springer, 2009.
[BHJ+09] Mathieu Bastian, Sebastien Heymann, Mathieu Jacomy, et al. Gephi:an open source software for exploring and manipulating networks.Icwsm, 8(2009):361–362, 2009.
[BKS13] Jari Bjorne, Suwisa Kaewphan, and Tapio Salakoski. Uturku: drugnamed entity recognition and drug-drug interaction extraction usingsvm classification and domain knowledge. In Proceedings of the 7th In-
ternational Workshop on Semantic Evaluation (SemEval 2013), pages651–659, 2013.
[BM82] Ruth Beyth-Marom. How probable is probable? a numerical translationof verbal probability expressions. Journal of forecasting, 1(3):257–269,1982.
[BMC+12] Sentil Balaji, Charles Mcclendon, Rajesh Chowdhary, Jun S Liu, andJinfeng Zhang. Imid: integrated molecular interaction database. Bioin-
formatics, 28(5):747–749, 2012.

358 BIBLIOGRAPHY
[BMKR+12] Fedor Bakalov, Marie-Jean Meurs, Birgitta Konig-Ries, Bahar Sateli,Rene Witte, Greg Butler, and Adrian Tsang. Personalized semanticassistance for the curation of biochemical literature. In Bioinformat-
ics and Biomedicine (BIBM), 2012 IEEE International Conference on,pages 1–4. IEEE, 2012.
[BMUT97a] Sergey Brin, Rajeev Motwani, Jeffrey D Ullman, and Shalom Tsur. Dy-namic itemset counting and implication rules for market basket data.Acm Sigmod Record, 26(2):255–264, 1997.
[BMUT97b] Sergey Brin, Rajeev Motwani, Jeffrey D. Ullman, and Shalom Tsur.Dynamic itemset counting and implication rules for market basket data.Proceedings of ACM SIGMOD International Conference on Manage-
ment of Data, pages 255–264, 1997.
[BN80] Geoffrey D Bryant and Geoffrey R Norman. Expressions of proba-bility: words and numbers. The New England Journal of Medicine,302(7):411–411, 1980.
[BNNS+17] Riza Batista-Navarro, Nhung TH Nguyen, Axel J Soto, William Ulate,and Sophia Ananiadou. Argo as a platform for integrating distinct bio-diversity analytics tools into workflows for building graph databases.Proceedings of TDWG, 1:e20067, 2017.
[BOA+09] Kevin R Brown, David Otasek, Muhammad Ali, Michael J McGuffin,Wing Xie, Baiju Devani, Ian Lawson van Toch, and Igor Jurisica. Nav-igator: network analysis, visualization and graphing toronto. Bioinfor-
matics, 25(24):3327–3329, 2009.
[Bod04] Olivier Bodenreider. The unified medical language system(umls): integrating biomedical terminology. Nucleic acids research,32(suppl 1):D267–D270, 2004.
[Bra01] Ulrik Brandes. A faster algorithm for betweenness centrality. Journal
of mathematical sociology, 25(2):163–177, 2001.
[Bre01] Leo Breiman. Random forests. Machine learning, 45(1):5–32, 2001.

BIBLIOGRAPHY 359
[Bre04] Leo Breiman. Statistics department university of california at berkeleyseptember 9, 2004. 2004.
[BS11] Jari Bjorne and Tapio Salakoski. Generalizing biomedical event extrac-tion. In Proceedings of the BioNLP Shared Task 2011 Workshop, pages183–191. Association for Computational Linguistics, 2011.
[BS13a] Jari Bjorne and Tapio Salakoski. Tees 2.1: Automated annotationscheme learning in the bionlp 2013 shared task. In Proceedings of the
BioNLP Shared Task 2013 Workshop, pages 16–25, 2013.
[BS13b] Jari Bjorne and Tapio Salakoski. TEES 2.1: Automated annotationscheme learning in the BioNLP 2013 shared task. Proceedings of the
BioNLP 2013, pages 16–25, 2013.
[BS15] Jari Bjorne and Tapio Salakoski. Tees 2.2: biomedical event extractionfor diverse corpora. BMC bioinformatics, 16(16):S4, 2015.
[BS16] Gerard Biau and Erwan Scornet. A random forest guided tour. Test,25(2):197–227, 2016.
[BSR17] Peter Bourgonje, Julian Moreno Schneider, and Georg Rehm. Fromclickbait to fake news detection: an approach based on detecting thestance of headlines to articles. In Proceedings of the 2017 EMNLP
Workshop: Natural Language Processing meets Journalism, pages 84–89, 2017.
[BSS11] Ivar Braten, Helge I Strømsø, and Ladislao Salmeron. Trust and mis-trust when students read multiple information sources about climatechange. Learning and Instruction, 21(2):180–192, 2011.
[BSS+18] Gaurav Bhatt, Aman Sharma, Shivam Sharma, Ankush Nagpal, Bala-subramanian Raman, and Ankush Mittal. Combining neural, statisticaland external features for fake news stance identification. In Companion
of the The Web Conference 2018 on The Web Conference 2018, pages1353–1357. International World Wide Web Conferences Steering Com-mittee, 2018.

360 BIBLIOGRAPHY
[BSSM+10] Adriano Barbosa-Silva, Theodoros G Soldatos, Ivan LF Magalhaes,Georgios A Pavlopoulos, Jean-Fred Fontaine, Miguel A Andrade-Navarro, Reinhard Schneider, and J Miguel Ortega. Laitor-literatureassistant for identification of terms co-occurrences and relationships.BMC bioinformatics, 11(1):70, 2010.
[BT88] Wibecke Brun and Karl Halvor Teigen. Verbal probabilities: ambigu-ous, context-dependent, or both? Organizational Behavior and Human
Decision Processes, 41(3):390–404, 1988.
[BV01] Christian Blaschke and Alfonso Valencia. The potential use of suisekias a protein interaction discovery tool. Genome Informatics, 12:123–134, 2001.
[CA18] Leshem Choshen and Omri Abend. Automatic metric validation forgrammatical error correction. arXiv preprint arXiv:1804.11225, 2018.
[CAOB+17] Andrew Chatr-Aryamontri, Rose Oughtred, Lorrie Boucher, JenniferRust, Christie Chang, Nadine K Kolas, Lara O’Donnell, Sara Oster,Chandra Theesfeld, Adnane Sellam, et al. The biogrid interactiondatabase: 2017 update. Nucleic acids research, 45(D1):D369–D379,2017.
[CBLJ04] David PA Corney, Bernard F Buxton, William B Langdon, and David TJones. Biorat: extracting biological information from full-length pa-pers. Bioinformatics, 20(17):3206–3213, 2004.
[CCR15] Yimin Chen, Niall J Conroy, and Victoria L Rubin. News in an onlineworld: The need for an “automatic crap detector”. Proceedings of the
Association for Information Science and Technology, 52(1):1–4, 2015.
[CGD+10] Ethan G Cerami, Benjamin E Gross, Emek Demir, Igor Rodchenkov,Ozgun Babur, Nadia Anwar, Nikolaus Schultz, Gary D Bader, and ChrisSander. Pathway commons, a web resource for biological pathway data.Nucleic acids research, 39(suppl 1):D685–D690, 2010.

BIBLIOGRAPHY 361
[CGM+10] Etienne Caron, Samik Ghosh, Yukiko Matsuoka, Dariel Ashton-Beaucage, Marc Therrien, Sebastien Lemieux, Claude Perreault,Philippe P Roux, and Hiroaki Kitano. A comprehensive map of themtor signaling network. Molecular systems biology, 6(1), 2010.
[Cha85] Joanna Channell. Vagueness as a conversational strategy. Nottingham
Linguistic Circular, 14:3–24, 1985.
[Cha90] Joanna Channell. Precise and vague quantities in writing on economics.The writing scholar: Studies in academic discourse, 3:95–117, 1990.
[Cha94] Joanna Channell. Vague language. 1994.
[CHR04] Hong-Woo Chun, Young-Sook Hwang, and Hae-Chang Rim. Unsuper-vised event extraction from biomedical literature using co-occurrenceinformation and basic patterns. In International Conference on Natural
Language Processing, pages 777–786. Springer, 2004.
[CKY08] Rich Caruana, Nikos Karampatziakis, and Ainur Yessenalina. An em-pirical evaluation of supervised learning in high dimensions. In Pro-
ceedings of the 25th international conference on Machine learning,pages 96–103. ACM, 2008.
[CL04] F. Ciravegnia and A. Lavelli. Learningpinocchio: adaptive informationextraction for real world applications. Natural Language Engineering,10:145–165, 6 2004.
[Cla90] Dominic A Clark. Verbal uncertainty expressions: A critical review oftwo decades of research. Current Psychology, 9(3):203–235, 1990.
[CML18] Arun Tejasvi Chaganty, Stephen Mussman, and Percy Liang. The priceof debiasing automatic metrics in natural language evaluation. arXiv
preprint arXiv:1807.02202, 2018.
[CMP05] Jeremiah Crim, Ryan McDonald, and Fernando Pereira. Automaticallyannotating documents with normalized gene lists. BMC bioinformatics,6(1):S13, 2005.

362 BIBLIOGRAPHY
[CNSS12] Jan Czarnecki, Irene Nobeli, Adrian M Smith, and Adrian J Shepherd.A text-mining system for extracting metabolic reactions from full-textarticles. BMC bioinformatics, 13(1):172, 2012.
[Coh68] Jacob Cohen. Weighted kappa: Nominal scale agreement provision forscaled disagreement or partial credit. Psychological bulletin, 70(4):213,1968.
[Coh14] Paul R. Cohen. Darpa’s big mechanism program. http://www.darp
a.mil/Our_Work/I2O/Programs/Big_Mechanism.aspx, 2014.
[Coh15] Paul R Cohen. Darpa’s big mechanism program. Physical biology,12(4), 2015.
[Con04] Gene Ontology Consortium. The gene ontology (go) database and in-formatics resource. Nucleic acids research, 32(suppl 1):D258–D261,2004.
[Cop02] B Jack Copeland. The genesis of possible worlds semantics. Journal of
Philosophical logic, 31(2):99–137, 2002.
[Cor09] Bert Cornillie. Evidentiality and epistemic modality: On the close re-lationship between two different categories. Functions of language,16(1):44–62, 2009.
[CRC15] Niall J Conroy, Victoria L Rubin, and Yimin Chen. Automatic de-ception detection: Methods for finding fake news. In Proceedings of
the 78th ASIS&T Annual Meeting: Information Science with Impact:
Research in and for the Community, page 82. American Society forInformation Science, 2015.
[CS01] Clare Chua Chow and Rakesh K Sarin. Comparative ignorance andthe ellsberg paradox. Journal of risk and Uncertainty, 22(2):129–139,2001.
[CS04] Hao Chen and Burt M Sharp. Content-rich biological network con-structed by mining pubmed abstracts. BMC bioinformatics, 5(1):147,2004.

BIBLIOGRAPHY 363
[CS14] Jan Czarnecki and Adrian J Shepherd. Mining biological networks fromfull-text articles. Methods in molecular biology, 1159:135–145, 2014.
[CSH18] Chaomei Chen, Min Song, and Go Eun Heo. A scalable and adaptivemethod for finding semantically equivalent cue words of uncertainty.Journal of Informetrics, 12(1):158–180, 2018.
[CTK+06] Hong-Woo Chun, Yoshimasa Tsuruoka, Jin-Dong Kim, Rie Shiba,Naoki Nagata, Teruyoshi Hishiki, and Jun’ichi Tsujii. Extraction ofgene-disease relations from medline using domain dictionaries and ma-chine learning. In Biocomputing 2006, pages 4–15. World Scientific,2006.
[CTM16] Noa P Cruz, Maite Taboada, and Ruslan Mitkov. A machine-learningapproach to negation and speculation detection for sentiment analysis.Journal of the Association for Information Science and Technology,67(9):2118–2136, 2016.
[CTZ+12] Rajesh Chowdhary, Sin Lam Tan, Jinfeng Zhang, Shreyas Karnik,Vladimir B Bajic, and Jun S Liu. Context-specific protein networkminer–an online system for exploring context-specific protein interac-tion networks from the literature. PLoS One, 7(4):e34480, 2012.
[CWB11] Minmin Chen, Kilian Q Weinberger, and John Blitzer. Co-training fordomain adaptation. In Advances in neural information processing sys-
tems, pages 2456–2464, 2011.
[CWWL03] Claire Cardie, Janyce Wiebe, Theresa Wilson, and Diane J Litman.Combining low-level and summary representations of opinions formulti-perspective question answering. In New directions in question
answering, pages 20–27, 2003.
[CXL+15] Yubo Chen, Liheng Xu, Kang Liu, Daojian Zeng, and Jun Zhao. Eventextraction via dynamic multi-pooling convolutional neural networks. In

364 BIBLIOGRAPHY
Proceedings of the 53rd Annual Meeting of the Association for Compu-
tational Linguistics and the 7th International Joint Conference on Nat-
ural Language Processing (Volume 1: Long Papers), volume 1, pages167–176, 2015.
[CZT+13] Rajesh Chowdhary, Jinfeng Zhang, Sin Lam Tan, Daniel E Osborne,Vladimir B Bajic, and Jun S Liu. Piminer: a web tool for extraction ofprotein interactions from biomedical literature. International journal of
data mining and bioinformatics, 7(4):450–462, 2013.
[DBB85] Penny J Daniels, Helen M Brooks, and Nicholas J Belkin. Using prob-lem structures for driving human-computer dialogues. In Recherche
d’Informations Assistee par Ordinateur, pages 645–660. LE CENTREDE HAUTES ETUDES INTERNATIONALES D’INFORMATIQUEDOCUMENTAIRE, 1985.
[DBC+16] Louise Deleger, Robert Bossy, Estelle Chaix, Mouhamadou Ba, ArnaudFerre, Philippe Bessieres, and Claire Nedellec. Overview of the bacte-ria biotope task at bionlp shared task 2016. In Proceedings of the 4th
BioNLP Shared Task Workshop, pages 12–22, 2016.
[DBD+02] Emek Demir, Ozgun Babur, U Dogrusoz, A Gursoy, Gurkan Nisanci,Renguel Cetin-Atalay, and Mehmet Ozturk. Patika: an integrated vi-sual environment for collaborative construction and analysis of cellularpathways. Bioinformatics, 18(7):996–1003, 2002.
[DC11] Karen De Clercq. Squat, zero and no/nothing: syntactic negation vs.semantic negation. Linguistics in the Netherlands, 28(1):14–24, 2011.
[DCNT+08] B De Chassey, V Navratil, Lionel Tafforeau, MS Hiet, A Aublin-Gex,S Agaugue, G Meiffren, F Pradezynski, BF Faria, T Chantier, et al.Hepatitis c virus infection protein network. Molecular systems biology,4(1):230, 2008.
[DCP+10a] Emek Demir, Michael P Cary, Suzanne Paley, Ken Fukuda, ChristianLemer, Imre Vastrik, Guanming Wu, Peter D’Eustachio, Carl Schaefer,

BIBLIOGRAPHY 365
Joanne Luciano, et al. The biopax community standard for pathwaydata sharing. Nature biotechnology, 28(9):935–942, 2010.
[DCP+10b] Emek Demir, Michael P Cary, Suzanne Paley, Ken Fukuda, ChristianLemer, Imre Vastrik, Guanming Wu, Peter D’eustachio, Carl Schaefer,Joanne Luciano, et al. The biopax community standard for pathwaydata sharing. Nature biotechnology, 28(9):935, 2010.
[DCR11] Quang Xuan Do, Yee Seng Chan, and Dan Roth. Minimally supervisedevent causality identification. In Proceedings of the Conference on Em-
pirical Methods in Natural Language Processing, pages 294–303. As-sociation for Computational Linguistics, 2011.
[DDL+09] Mona Diab, Bonnie Dorr, Lori Levin, Teruko Mitamura, Rebecca Pas-sonneau, Owen Rambow, and Lance Ramshaw. Language understand-ing annotation corpus. LDC, Philadelphia, 2009.
[DDME+07] Kirill Degtyarenko, Paula De Matos, Marcus Ennis, Janna Hastings,Martin Zbinden, Alan McNaught, Rafael Alcantara, Michael Darsow,Mickael Guedj, and Michael Ashburner. Chebi: a database and ontol-ogy for chemical entities of biological interest. Nucleic acids research,36(suppl 1):D344–D350, 2007.
[DEG+05] U Dogrusoz, EZ Erson, Erhan Giral, Emek Demir, Ozgun Babur, Ah-met Cetintas, and R Colak. Patika web: a web interface for analyz-ing biological pathways through advanced querying and visualization.Bioinformatics, 22(3):374–375, 2005.
[DGH+14] Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao,Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang.Knowledge vault: A web-scale approach to probabilistic knowledgefusion. In Proceedings of the 20th ACM SIGKDD international confer-
ence on Knowledge discovery and data mining, pages 601–610. ACM,2014.
[DH99] Ferdinand De Haan. Evidentiality and epistemic modality: Settingboundaries. Southwest journal of linguistics, 18(1):83–101, 1999.

366 BIBLIOGRAPHY
[DH05] Ferdinand De Haan. Encoding speaker perspective: Evidentials. Lin-
guistic diversity and language theories, 72:379–417, 2005.
[DI09] Hal Daume III. Frustratingly easy domain adaptation. arXiv preprint
arXiv:0907.1815, 2009.
[DIKI12] PS Demenkov, Timofey V Ivanisenko, Nikolay A Kolchanov, andVladimir A Ivanisenko. Andvisio: a new tool for graphic visualiza-tion and analysis of literature mined associative gene networks in theandsystem. In silico biology, 11(3, 4):149–161, 2012.
[DJC15] Yuxiao Dong, Reid A Johnson, and Nitesh V Chawla. Will this paperincrease your h-index?: Scientific impact prediction. In Proceedings
of the eighth ACM international conference on web search and data
mining, pages 149–158. ACM, 2015.
[dLDHK+12] Nicole de Leeuw, Trijnie Dijkhuizen, Jayne Y Hehir-Kwa, Nigel PCarter, Lars Feuk, Helen V Firth, Robert M Kuhn, David H Ledbetter,Christa Lese Martin, Conny MA van Ravenswaaij-Arts, et al. Diag-nostic interpretation of array data using public databases and internetsources. Human mutation, 33(6):930–940, 2012.
[DMDB+03] Ian Donaldson, Joel Martin, Berry De Bruijn, Cheryl Wolting, VickiLay, Brigitte Tuekam, Shudong Zhang, Berivan Baskin, Gary D Bader,Katerina Michalickova, et al. Prebind and textomy–mining the biomed-ical literature for protein-protein interactions using a support vector ma-chine. BMC bioinformatics, 4(1):11, 2003.
[DMM04] Chrysanne Di Marco and Robert E Mercer. Hedging in scientific arti-cles as a means of classifying citations. In Working Notes of the AAAI
Spring Symposium on Exploring Attitude and Affect in Text: Theories
and Applications, pages 50–54, 2004.
[DP88] Didler Dubois and Henri Prade. Representation and combination of un-certainty with belief functions and possibility measures. Computational
intelligence, 4(3):244–264, 1988.

BIBLIOGRAPHY 367
[DP12] Didier Dubois and Henri Prade. Gradualness, uncertainty and bipolar-ity: Making sense of fuzzy sets. Fuzzy Sets and Systems, 192:3–24,2012.
[DPS07] Christopher Davis, Christopher Potts, and Margaret Speas. The prag-matic values of evidential sentences. In Semantics and Linguistic The-
ory, volume 17, pages 71–88, 2007.
[Dru89] Marek J Druzdzel. Verbal uncertainty expressions: Literature review.Pittsburgh, PA: Carnegie Mellon University, Department of Engineer-
ing and Public Policy, 1989.
[Dru96] Marek J Druzdzel. Qualitiative verbal explanations in bayesian beliefnetworks. AISB QUARTERLY, pages 43–54, 1996.
[Dru01] Hans Bernhard Drubig. On the syntactic form of epistemic modality.ms., University of Tubingen, 2001.
[DTR10] Dmitry Davidov, Oren Tsur, and Ari Rappoport. Semi-supervisedrecognition of sarcastic sentences in twitter and amazon. In Proceed-
ings of the fourteenth conference on computational natural language
learning, pages 107–116. Association for Computational Linguistics,2010.
[DV12] Marcel Dunaiski and Willem Visser. Comparing paper ranking algo-rithms. In Proceedings of the South African Institute for Computer Sci-
entists and Information Technologists Conference, pages 21–30. ACM,2012.
[DVDG95] Marek J Druzdzel and Linda C Van Der Gaag. Elicitation of proba-bilities for belief networks: Combining qualitative and quantitative in-formation. In Proceedings of the Eleventh conference on Uncertainty
in artificial intelligence, pages 141–148. Morgan Kaufmann PublishersInc., 1995.

368 BIBLIOGRAPHY
[DW99] Shelly Dews and Ellen Winner. Obligatory processing of literaland nonliteral meanings in verbal irony. Journal of pragmatics,31(12):1579–1599, 1999.
[DW15] Lingjia Deng and Janyce Wiebe. Mpqa 3.0: An entity/event-level sen-timent corpus. In Proceedings of the 2015 Conference of the North
American Chapter of the Association for Computational Linguistics:
Human Language Technologies, pages 1323–1328, 2015.
[DWM12] Anita De Waard and Henk Pander Maat. Epistemic modality andknowledge attribution in scientific discourse: A taxonomy of types andoverview of features. In Proceedings of the Workshop on Detecting
Structure in Scholarly Discourse, pages 47–55. Association for Com-putational Linguistics, 2012.
[DWT12] Jean Dezert, Pei Wang, and Albena Tchamova. On the validity ofdempster-shafer theory. In Information Fusion (FUSION), 2012 15th
International Conference on, pages 655–660. IEEE, 2012.
[DYFC09] Ying Ding, Erjia Yan, Arthur Frazho, and James Caverlee. Pagerank forranking authors in co-citation networks. Journal of the American Soci-
ety for Information Science and Technology, 60(11):2229–2243, 2009.
[EBB+06] S Ekins, A Bugrim, L Brovold, E Kirillov, Y Nikolsky, E Rakhmat-ulin, S Sorokina, A Ryabov, T Serebryiskaya, A Melnikov, et al. Al-gorithms for network analysis in systems-adme/tox using the metacoreand metadrug platforms. Xenobiotica, 36(10-11):877–901, 2006.
[EF11] James A Evans and Jacob G Foster. Metaknowledge. Science,331(6018):721–725, 2011.
[EFWR+08] Peter L Elkin, David Froehling, Dietlind Wahner-Roedler, Brett Trusko,Gail Welsh, Haobo Ma, Armen X Asatryan, Jerome I Tokars, S TrentRosenbloom, and Steven H Brown. Nlp-based identification of pneu-monia cases from free-text radiological reports. In AMIA annual sym-
posium proceedings, volume 2008, page 172. American Medical Infor-matics Association, 2008.

BIBLIOGRAPHY 369
[Ell61] Daniel Ellsberg. Risk, ambiguity, and the savage axioms. The quarterly
journal of economics, pages 643–669, 1961.
[ENB+07] Sean Ekins, Yuri Nikolsky, Andrej Bugrim, Eugene Kirillov, and Ta-tiana Nikolskaya. Pathway mapping tools for analysis of high contentdata. In High Content Screening, pages 319–350. Springer, 2007.
[FBW09] Christie M Fuller, David P Biros, and Rick L Wilson. Decision supportfor determining veracity via linguistic-based cues. Decision Support
Systems, 46(3):695–703, 2009.
[FCH+08] Rong-En Fan, Kai-Wei Chang, Cho-Jui Hsieh, Xiang-Rui Wang, andChih-Jen Lin. Liblinear: A library for large linear classification. The
Journal of Machine Learning Research, 9:1871–1874, 2008.
[FCHV16] Christopher S Funk, K Bretonnel Cohen, Lawrence E Hunter, andKarin M Verspoor. Gene ontology synonym generation rules lead toincreased performance in biomedical concept recognition. Journal of
biomedical semantics, 7(1):52, 2016.
[FDCBA14] Manuel Fernandez-Delgado, Eva Cernadas, Senen Barro, and DinaniAmorim. Do we need hundreds of classifiers to solve real world clas-sification problems? The Journal of Machine Learning Research,15(1):3133–3181, 2014.
[FHvB+08] Raoul Frijters, Bart Heupers, Pieter van Beek, Maurice Bouwhuis, Renevan Schaik, Jacob de Vlieg, Jan Polman, and Wynand Alkema. Copub:a literature-based keyword enrichment tool for microarray data analy-sis. Nucleic acids research, 36(suppl 2):W406–W410, 2008.
[Fil12] Elena Filatova. Irony and sarcasm: Corpus generation and analysisusing crowdsourcing. In LREC, pages 392–398. Citeseer, 2012.
[Fin14] Mark Finlayson. Java libraries for accessing the princeton wordnet:Comparison and evaluation. In Proceedings of the Seventh Global
Wordnet Conference, pages 78–85, 2014.

370 BIBLIOGRAPHY
[FKT+13] David Fazekas, Mihaly Koltai, Denes Turei, Dezso Modos, Mate Palfy,Zoltan Dul, Lilian Zsakai, Mate Szalay-Beko, Katalin Lenti, Illes JFarkas, et al. Signalink 2–a signaling pathway resource with multi-layered regulatory networks. BMC systems biology, 7(1):7, 2013.
[FKY+01] Carol Friedman, Pauline Kra, Hong Yu, Michael Krauthammer, andAndrey Rzhetsky. Genies: a natural-language processing system forthe extraction of molecular pathways from journal articles. In ISMB
(supplement of bioinformatics), pages 74–82, 2001.
[FM93] Josep M Font and Massoud Moussavi. Note on a six-valued exten-sion of three-valued logic. Journal of Applied Non-Classical Logics,3(2):173–187, 1993.
[FM98] Zygmunt Frajzyngier and Jan Mycielski. On some fundamental con-cepts of mathematical linguistics: means and functional domains.STUDIES IN FUNCTIONAL AND STRUCTURAL LINGUISTICS,pages 295–310, 1998.
[FMS11] Alberto Fernandez-Medarde and Eugenio Santos. Ras in cancer anddevelopmental diseases. Genes & cancer, 2(3):344–358, 2011.
[Fra10] Bruce Fraser. Pragmatic competence: The case of hedging. New ap-
proaches to hedging, 1(1):15–34, 2010.
[FRE25] SIGMUNDND FREUD. Negation. The International Journal of
Psycho-Analysis, 6:367, 1925.
[FSF+13] Andrea Franceschini, Damian Szklarczyk, Sune Frankild, MichaelKuhn, Milan Simonovic, Alexander Roth, Jianyi Lin, Pablo Minguez,Peer Bork, Christian Von Mering, et al. String v9. 1: protein-proteininteraction networks, with increased coverage and integration. Nucleic
acids research, 41(D1):D808–D815, 2013.
[FV16] William Ferreira and Andreas Vlachos. Emergent: a novel data-setfor stance classification. In Proceedings of the 2016 conference of the

BIBLIOGRAPHY 371
North American chapter of the association for computational linguis-
tics: Human language technologies, pages 1163–1168, 2016.
[FVC+87] Frank B Fromowitz, Michael V Viola, Sylvia Chao, Sheila Oravez,Yousri Mishriki, Gerald Finkel, Roger Grimson, and Joel Lundy. Rasp21 expression in the progression of breast cancer. Human pathology,18(12):1268–1275, 1987.
[FVF+11] Wilco WM Fleuren, Stefan Verhoeven, Raoul Frijters, Bart Heupers,Jan Polman, Rene van Schaik, Jacob de Vlieg, and Wynand Alkema.Copub update: Copub 5.0 a text mining system to answer biologicalquestions. Nucleic acids research, 39(suppl 2):W450–W454, 2011.
[FVM+10] Richard Farkas, Veronika Vincze, Gyorgy Mora, Janos Csirik, andGyorgy Szarvas. The conll-2010 shared task: learning to detect hedgesand their scope in natural language text. In Proceedings of the Four-
teenth Conference on Computational Natural Language Learning—
Shared Task, pages 1–12. Association for Computational Linguistics,2010.
[GC06] Manuel Garcıa-Carpintero. Possible worlds semantics. Encyclopedia
of Cognitive Science, 2006.
[GE08] Yoav Goldberg and Michael Elhadad. splitsvm: fast, space-efficient,non-heuristic, polynomial kernel computation for nlp applications. InProceedings of the 46th Annual Meeting of the Association for Compu-
tational Linguistics on Human Language Technologies: Short Papers,pages 237–240. Association for Computational Linguistics, 2008.
[Geo10] Maria Georgescul. A hedgehop over a max-margin framework usinghedge cues. In Proceedings of the Fourteenth Conference on Computa-
tional Natural Language Learning — Shared Task, CoNLL ’10: SharedTask, pages 26–31, Stroudsburg, PA, USA, 2010. Association for Com-putational Linguistics.

372 BIBLIOGRAPHY
[GFK+14] Andreas Gerasch, Daniel Faber, Jan Kuntzer, Peter Niermann, OliverKohlbacher, Hans-Peter Lenhof, and Michael Kaufmann. Bina: a visualanalytics tool for biological network data. PloS one, 9(2):e87397, 2014.
[GGL+15] Samuel Gratzl, Nils Gehlenborg, Alexander Lex, Hendrik Strobelt,Christian Partl, and Marc Streit. Caleydo web: An integrated visualanalysis platform for biomedical data. In Poster Compendium of the
IEEE Conference on Information Visualization (InfoVis’ 15). IEEE,2015.
[GH09] Natalia Grabar and Thierry Hamon. Exploitation of speculation mark-ers to identify the structure of biomedical scientific writing. AMIA ...
Annual Symposium proceedings / AMIA Symposium. AMIA Symposium,2009:203–7, January 2009.
[Gil76] Robin Giles. Łukasiewicz logic and fuzzy set theory. International
Journal of Man-Machine Studies, 8(3):313–327, 1976.
[GIMW11] Roberto Gonzalez-Ibanez, Smaranda Muresan, and Nina Wacholder.Identifying sarcasm in twitter: a closer look. In Proceedings of the
49th Annual Meeting of the Association for Computational Linguistics:
Human Language Technologies: Short Papers-Volume 2, pages 581–586. Association for Computational Linguistics, 2011.
[GLR06] Claudio Giuliano, Alberto Lavelli, and Lorenza Romano. Exploitingshallow linguistic information for relation extraction from biomedicalliterature. In 11th Conference of the European Chapter of the Associa-
tion for Computational Linguistics, 2006.
[GM90] Oscar N Garcia and Massoud Moussavi. A six-valued logic for repre-senting incomplete knowledge. In Multiple-Valued Logic, 1990., Pro-
ceedings of the Twentieth International Symposium on, pages 110–114.IEEE, 1990.
[GMB+07] Obi L Griffith, Stephen B Montgomery, Bridget Bernier, Bryan Chu,Katayoon Kasaian, Stein Aerts, Shaun Mahony, Monica C Sleumer,

BIBLIOGRAPHY 373
Mikhail Bilenky, Maximilian Haeussler, et al. Oreganno: an open-access community-driven resource for regulatory annotation. Nucleic
acids research, 36(suppl 1):D107–D113, 2007.
[GOS+16] Piotr Gawron, Marek Ostaszewski, Venkata Satagopam, StephanGebel, Alexander Mazein, Michal Kuzma, Simone Zorzan, FintanMcGee, Benoıt Otjacques, Rudi Balling, et al. Minerva—a platformfor visualization and curation of molecular interaction networks. NPJ
systems biology and applications, 2:16020, 2016.
[GP03] Boris Galitsky and Rajesh Pampapathi. Deductive and inductive rea-soning for processing the claims of unsatisfied customers. In Interna-
tional Conference on Industrial, Engineering and Other Applications
of Applied Intelligent Systems, pages 21–30. Springer, 2003.
[GS91] Rodney M Goodman and P Smyth. Rule induction using informationtheory. G. Piatetsky, 1991.
[GSS07] Namrata Godbole, Manja Srinivasaiah, and Steven Skiena. Large-scalesentiment analysis for news and blogs. Icwsm, 7(21):219–222, 2007.
[HCMY05] Lynette Hirschman, Marc Colosimo, Alexander Morgan, and Alexan-der Yeh. Overview of biocreative task 1b: normalized gene lists. BMC
bioinformatics, 6(1):S11, 2005.
[HCW+13] Zhenjun Hu, Yi-Chien Chang, Yan Wang, Chia-Ling Huang, Yang Liu,Feng Tian, Brian Granger, and Charles DeLisi. VisANT 4.0: Integra-tive network platform to connect genes, drugs, diseases and therapies.Nucleic acids research, 41(W1):W225–W231, 2013.
[HFH+09] Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, PeterReutemann, and Ian H. Witten. The WEKA data mining software. ACM
SIGKDD Explorations Newsletter, 11(1):10, nov 2009.
[HFKDJ11] Frederik Hogenboom, Flavius Frasincar, Uzay Kaymak, and FranciskaDe Jong. An overview of event extraction from text. In Workshop on
Detection, Representation, and Exploitation of Events in the Semantic

374 BIBLIOGRAPHY
Web (DeRiVE 2011) at Tenth International Semantic Web Conference
(ISWC 2011), volume 779, pages 48–57. Citeseer, 2011.
[HFS+03] Michael Hucka, Andrew Finney, Herbert M Sauro, Hamid Bolouri,John C Doyle, Hiroaki Kitano, Adam P Arkin, Benjamin J Born-stein, Dennis Bray, Athel Cornish-Bowden, et al. The systems biologymarkup language (sbml): a medium for representation and exchange ofbiochemical network models. Bioinformatics, 19(4):524–531, 2003.
[HH95] Per Hage and Frank Harary. Eccentricity and centrality in networks.Social networks, 17(1):57–63, 1995.
[HHLK16] Ralf Herwig, Christopher Hardt, Matthias Lienhard, and Atanas Kam-burov. Analyzing and interpreting genome data at the network levelwith consensuspathdb. Nature protocols, 11(10):1889, 2016.
[HJ82] Knut Hofland and Stig Johansson. Word frequencies in british and
american english. Norwegian computing centre for the Humanities,1982.
[HKA+05] Robert Hoffmann, Martin Krallinger, Eduardo Andres, JavierTamames, Christian Blaschke, and Alfonso Valencia. Text mining formetabolic pathways, signaling cascades, and protein networks. Sci-
ence’s STKE, 283:1–21, 2005.
[HLF+08] Lawrence Hunter, Zhiyong Lu, James Firby, William A Baumgartner,Helen L Johnson, Philip V Ogren, and K Bretonnel Cohen. Opendmap:an open source, ontology-driven concept analysis engine, with appli-cations to capturing knowledge regarding protein transport, protein in-teractions and cell-type-specific gene expression. BMC bioinformatics,9(1):78, 2008.
[HM00] Francisco Herrera and Luis Martınez. A 2-tuple fuzzy linguistic repre-sentation model for computing with words. IEEE Transactions on fuzzy
systems, 8(6):746–752, 2000.

BIBLIOGRAPHY 375
[HNN+04] Ben Hachey, Huy Nguyen, Malvina Nissim, Bea Alex, and ClaireGrover. Grounding gene mentions with respect to gene database iden-tifiers. In BioCreAtIvE Workshop Handouts, 2004.
[Ho95] Tin Kam Ho. Random decision forests. In Document analysis and
recognition, 1995., proceedings of the third international conference
on, volume 1, pages 278–282. IEEE, 1995.
[Hoa02] James E Hoard. Language understanding and the emerging alignmentof linguistics and natural language processing. In Using Computers in
Linguistics, pages 213–246. Routledge, 2002.
[Hor89] Laurence Horn. A natural history of negation. 1989.
[Hor10a] Laurence R Horn. The expression of negation, volume 4. Walter deGruyter, 2010.
[Hor10b] Laurence R Horn. Multiple negation in english and other languages.The expression of negation, pages 111–148, 2010.
[Hub83] Axel Hubler. Understatements and hedges in English. John BenjaminsPublishing, 1983.
[HV05] Robert Hoffmann and Alfonso Valencia. Implementing the ihopconcept for navigation of biomedical literature. Bioinformatics,21(suppl 2):ii252–ii258, 2005.
[HWL09] Min He, Yi Wang, and Wei Li. Ppi finder: a mining tool for humanprotein-protein interactions. PloS one, 4(2):e4554, 2009.
[HY01] David J Hand and Keming Yu. Idiot’s bayes—not so stupid after all?International statistical review, 69(3):385–398, 2001.
[Hyl96] Ken Hyland. Writing without conviction? hedging in science researcharticles. Applied linguistics, 17(4):433–454, 1996.
[Hyl98a] Ken Hyland. Boosting, hedging and the negotiation of academicknowledge. Text-Interdisciplinary Journal for the Study of Discourse,18(3):349–382, 1998.

376 BIBLIOGRAPHY
[Hyl98b] Ken Hyland. Hedging in scientific research articles, volume 54. JohnBenjamins Publishing, 1998.
[ISHH17] Samuel Kelechukwu Ibenne, Boyka Simeonova, Janet Harrison, andMark Hepworth. An integrated model highlighting information literacyand knowledge formation in information behaviour. Aslib Journal of
Information Management, 69(3):316–334, 2017.
[JAW+11] David M Jessop, Sam E Adams, Egon L Willighagen, Lezan Hawizy,and Peter Murray-Rust. Oscar4: a flexible architecture for chemicaltext-mining. Journal of cheminformatics, 3:41–53, 2011.
[JB08] Audun Jøsang and Touhid Bhuiyan. Optimal trust network analysiswith subjective logic. In Emerging Security Information, Systems and
Technologies, 2008. SECURWARE’08. Second International Confer-
ence on, pages 179–184. IEEE, 2008.
[JG03] Audun Josang and Tyrone Grandison. Conditional inference in subjec-tive logic. In Proc. of the 6th International Conference on Information
Fusion, Cairns, pages 471–478, 2003.
[JG08] Heng Ji and Ralph Grishman. Refining event extraction through cross-document inference. Proceedings of ACL-08: HLT, pages 254–262,2008.
[JGCG09] Heng Ji, Ralph Grishman, Zheng Chen, and Prashant Gupta. Cross-document event extraction and tracking: Task, evaluation, techniquesand challenges. In Proceedings of the International Conference
RANLP-2009, pages 166–172, 2009.
[JGH+10] Rob Jelier, Jelle J Goeman, Kristina M Hettne, Martijn J Schuemie,Johan T den Dunnen, and Peter AC ’t Hoen. Literature-aided interpre-tation of gene expression data with the weighted global test. Briefings
in bioinformatics, 12(5):518–529, 2010.
[JGMJ08] Ines Jilani, Natalia Grabar, Pierre Meneton, and Marie-ChristineJaulent. Assessment of biomedical knowledge according to confidence

BIBLIOGRAPHY 377
criteria. Studies in health technology and informatics, 136:199–204,2008.
[JHP06] Audun Jøsang, Ross Hayward, and Simon Pope. Trust network analy-sis with subjective logic. In Proceedings of the 29th Australasian Com-
puter Science Conference-Volume 48, pages 85–94. Australian Com-puter Society, Inc., 2006.
[JHR+16] Pierre-Antoine Jean, Sebastien Harispe, Sylvie Ranwez, Patrice Bel-lot, and Jacky Montmain. Uncertainty detection in natural language: aprobabilistic model. In Proceedings of the 6th International Conference
on Web Intelligence, Mining and Semantics, page 10. ACM, 2016.
[JM14] Dan Jurafsky and James H Martin. Speech and language processing,volume 3. Pearson London:, 2014.
[JMP06] Audun Jøsang, Stephen Marsh, and Simon Pope. Exploring differenttypes of trust propagation. Proceedings of International Conference on
Trust Management, pages 179–192, 2006.
[JO04] Azam Jalali and Farhad Oroumchian. Rich document representa-tion for document clustering. In Coupling approaches, coupling me-
dia and coupling languages for information retrieval, pages 800–808. LE CENTRE DE HAUTES ETUDES INTERNATIONALESD’INFORMATIQUE DOCUMENTAIRE, 2004.
[Jor98] Michael P Jordan. The power of negation in english: Text, context andrelevance. Journal of Pragmatics, 29(6):705–752, 1998.
[Jøs97] Audun Jøsang. Artificial reasoning with subjective logic. In Proceed-
ings of the second Australian workshop on commonsense reasoning,volume 48, page 34. Citeseer, 1997.
[Jøs01] Audun Jøsang. A Logic for Uncertain Probabilities. International Jour-
nal of Uncertainty, Fuzziness and Knowledge-Based Systems, 09:279–311, 2001.

378 BIBLIOGRAPHY
[Jos09] Audun Josang. Fission of opinions in subjective logic. In Information
Fusion, 2009. FUSION’09. 12th International Conference on, pages1911–1918. IEEE, 2009.
[Jos16] Audun Josang. Subjective logic: A formalism for reasoning under un-certainty. 2016.
[JS08] Andrzej Jankowski and Andrzej Skowron. Logic for artificial intel-ligence: The rasiowa-pawlak school perspective. Andrzej Mostowski
and Foundational Studies, pages 106–143, 2008.
[JSC11] Pijitra Jomsri, Siripun Sanguansintukul, and Worasit Choochaiwattana.Citerank: combination similarity and static ranking with research papersearching. International Journal of Internet Technology and Secured
Transactions, 3(2):161–177, 2011.
[JWHT13] Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani.Tree-based methods. In An Introduction to Statistical Learning, pages303–335. Springer, 2013.
[KB08a] Halil Kilicoglu and Sabine Bergler. Recognizing speculative languagein biomedical research articles: a linguistically motivated perspective.BMC bioinformatics, 9(11):S10, 2008.
[KB08b] Halil Kilicoglu and Sabine Bergler. Recognizing speculative languagein biomedical research articles: a linguistically motivated perspective.BMC Bioinformatics, 9(11):1–10, 2008.
[KB10] Halil Kilicoglu and Sabine Bergler. A high-precision approach to de-tecting hedges and their scopes. In Proceedings of the Fourteenth Con-
ference on Computational Natural Language Learning—Shared Task,pages 70–77. Association for Computational Linguistics, 2010.
[KBMY86] Augustine Kong, GO Barnett, Frederick Mosteller, and Cleo Youtz.How medical professionals evaluate expressions of probability. The
New England Journal of Medicine, 1986.

BIBLIOGRAPHY 379
[KC12] Paul Krause and Dominic Clark. Representing uncertain knowledge: an
artificial intelligence approach. Springer Science & Business Media,2012.
[KDS+10] Sergey Kozhenkov, Yulia Dubinina, Mayya Sedova, Amarnath Gupta,Julia Ponomarenko, and Michael Baitaluk. Biologicalnetworks 2.0-an integrative view of genome biology data. BMC bioinformatics,11(1):610, 2010.
[KDSD+12] Natalia Konstantinova, Sheila CM De Sousa, Noa P Cruz Dıaz, ManuelJ Mana Lopez, Maite Taboada, and Ruslan Mitkov. A review corpusannotated for negation, speculation and their scope. In Lrec, pages3190–3195, 2012.
[KGF+09] Minoru Kanehisa, Susumu Goto, Miho Furumichi, Mao Tanabe, andMika Hirakawa. Kegg for representation and analysis of molecu-lar networks involving diseases and drugs. Nucleic acids research,38(suppl 1):D355–D360, 2009.
[Kie87] Ferenc Kiefer. On defining modality. Folia linguistica, 21(1):67–94,1987.
[KJV97] Michael HG Kubbutat, Stephen N Jones, and Karen H Vousden. Regu-lation of p53 stability by mdm2. Nature, 387(6630):299, 1997.
[KK05] Hyeoncheol Kim and Eun-Young Kwak. Information-based pruningfor interesting association rule mining in the item response dataset. InInternational Conference on Knowledge-Based and Intelligent Infor-
mation and Engineering Systems, pages 372–378. Springer, 2005.
[KKR+99] Jon M Kleinberg, Ravi Kumar, Prabhakar Raghavan, Sridhar Ra-jagopalan, and Andrew S Tomkins. The web as a graph: measurements,models, and methods. In International Computing and Combinatorics
Conference, pages 1–17. Springer, 1999.
[Kle68] Stephen Cole Kleene. Introduction to metamathematics. 1968.

380 BIBLIOGRAPHY
[KMM+10] Brian Kemper, Takuya Matsuzaki, Yukiko Matsuoka, Yoshimasa Tsu-ruoka, Hiroaki Kitano, Sophia Ananiadou, and Jun’ichi Tsujii. Path-Text: a text mining integrator for biological pathway visualizations.Bioinformatics, 26:374–381, 2010.
[KMS10] Gunther Kaltenbock, Wiltrud Mihatsch, and Stefan Schneider. New
approaches to hedging. BRILL, 2010.
[KMT10] Daniel A Keim, Florian Mansmann, and Jim Thomas. Visual analyt-ics: how much visualization and how much analytics? ACM SIGKDD
Explorations Newsletter, 11(2):5–8, 2010.
[KOH+16] Nelson Kibinge, Naoaki Ono, Masafumi Horie, Tetsuo Sato, TadaoSugiura, Md Altaf-Ul-Amin, Akira Saito, and Shigehiko Kanaya. Inte-grated pathway-based transcription regulation network mining and vi-sualization based on gene expression profiles. Journal of biomedical
informatics, 61:194–202, 2016.
[KOP+09a] Jin-Dong Kim, Tomoko Ohta, Sampo Pyysalo, Yoshinobu Kano, andJun’ichi Tsujii. Overview of BioNLP’09 shared task on event extrac-tion. Proceedings of BioNLP 2009, pages 1–6, 2009.
[KOP+09b] Jin-Dong Kim, Tomoko Ohta, Sampo Pyysalo, Yoshinobu Kano, andJun’ichi Tsujii. Overview of bionlp’09 shared task on event extraction.In Proceedings of the Workshop on Current Trends in Biomedical Nat-
ural Language Processing: Shared Task, pages 1–9. Association forComputational Linguistics, 2009.
[KOTT03a] J-D Kim, Tomoko Ohta, Yuka Tateisi, and Jun’ichi Tsujii. GENIAcorpus-a semantically annotated corpus for bio-textmining. Bioinfor-
matics, 19:180–182, 2003.
[KOTT03b] J-D Kim, Tomoko Ohta, Yuka Tateisi, and Jun’ichi Tsujii. Genia cor-pus—a semantically annotated corpus for bio-textmining. Bioinformat-
ics, 19(suppl 1):i180–i182, 2003.

BIBLIOGRAPHY 381
[KPGK+08] TS Keshava Prasad, Renu Goel, Kumaran Kandasamy, Shivaku-mar Keerthikumar, Sameer Kumar, Suresh Mathivanan, Deepthi Teli-kicherla, Rajesh Raju, Beema Shafreen, Abhilash Venugopal, et al. Hu-man protein reference database—2009 update. Nucleic acids research,37(suppl 1):D767–D772, 2008.
[KPO+11a] Jin-Dong Kim, Sampo Pyysalo, Tomoko Ohta, Robert Bossy, NganNguyen, and Jun’ichi Tsujii. Overview of BioNLP shared task 2011.Proceedings of BioNLP 2011, pages 1–6, 2011.
[KPO+11b] Jin-Dong Kim, Sampo Pyysalo, Tomoko Ohta, Robert Bossy, NganNguyen, and Jun’ichi Tsujii. Overview of bionlp shared task 2011.In Proceedings of the BioNLP Shared Task 2011 Workshop, pages 1–6.Association for Computational Linguistics, 2011.
[KR90] George J Klir and Arthur Ramer. Uncertainty in the dempster-shafertheory: a critical re-examination. International Journal of General Sys-
tem, 18(2):155–166, 1990.
[Kra77] Angelika Kratzer. What ‘must’and ‘can’must and can mean. Linguistics
and philosophy, 1(3):337–355, 1977.
[Kra10] Martin Krallinger. Importance of negations and experimental qualifiersin biomedical literature. In Proceedings of the Workshop on Negation
and Speculation in Natural Language Processing, pages 46–49. Asso-ciation for Computational Linguistics, 2010.
[KRCR15] Halil Kilicoglu, Graciela Rosemblat, Michael J Cairelli, and Thomas CRindflesch. A compositional interpretation of biomedical event factu-ality. ExProM 2015, page 22, 2015.
[Kri63] Saul A Kripke. Semantical analysis of modal logic i normal modalpropositional calculi. Mathematical Logic Quarterly, 9(5-6):67–96,1963.
[KRKS09] Kaarel Kaljurand, Fabio Rinaldi, Thomas Kappeler, and Gerold Schnei-der. Using existing biomedical resources to detect and ground terms

382 BIBLIOGRAPHY
in biomedical literature. In Conference on Artificial Intelligence in
Medicine in Europe, pages 225–234. Springer, 2009.
[KRMF00] Michael Krauthammer, Andrey Rzhetsky, Pavel Morozov, and CarolFriedman. Using blast for identifying gene and protein names in journalarticles. Gene, 259(1):245–252, 2000.
[KRN+15] Martina Kutmon, Anders Riutta, Nuno Nunes, Kristina Hanspers,Egon L Willighagen, Anwesha Bohler, Jonathan Melius, Andra Waag-meester, Sravanthi R Sinha, Ryan Miller, et al. WikiPathways: captur-ing the full diversity of pathway knowledge. Nucleic Acids Research,44(D1):D488, 2015.
[KRR17] Halil Kilicoglu, Graciela Rosemblat, and Thomas C Rindflesch. As-signing factuality values to semantic relations extracted from biomedi-cal research literature. PloS one, 12(7):e0179926, 2017.
[KSB+14] Ning Kang, Bharat Singh, Chinh Bui, Zubair Afzal, Erik M van Mul-ligen, and Jan A Kors. Knowledge-based extraction of adverse drugevents from biomedical text. BMC bioinformatics, 15(1):64, 2014.
[KSB+18] Maria Kondratova, Nicolas Sompairac, Emmanuel Barillot, Andrei Zi-novyev, and Inna Kuperstein. Signalling maps in cancer research: con-struction and data analysis. Database, 2018, 2018.
[KSD11] B. Kulis, K. Saenko, and T. Darrell. What you saw is not what youget: Domain adaptation using asymmetric kernel transforms. In Com-
puter Vision and Pattern Recognition (CVPR), 2011 IEEE Conference
on, pages 1785–1792, June 2011.
[KSM05] Drew Koning, Indra Neil Sarkar, and Thomas Moritz. Taxongrab: Ex-tracting taxonomic names from text. 2005.
[KvIB+15] Martina Kutmon, Martijn P van Iersel, Anwesha Bohler, ThomasKelder, Nuno Nunes, Alexander R Pico, and Chris T Evelo. PathVi-sio 3: an extendable pathway analysis toolbox. PLoS Comput Biol,11(2):e1004085, 2015.

BIBLIOGRAPHY 383
[KZ05] Lauri Karttunen and Annie Zaenen. Veridicity. In Dagstuhl Seminar
Proceedings. Schloss Dagstuhl-Leibniz-Zentrum fur Informatik, 2005.
[L+04] Hongfang Liu et al. Biotagger: a biological entity tagging system. InBioCreAtIvE Workshop Handouts. Citeseer, 2004.
[LACZ15] Kenton Lee, Yoav Artzi, Yejin Choi, and Luke Zettlemoyer. Eventdetection and factuality assessment with non-expert supervision. InProceedings of the 2015 Conference on Empirical Methods in Natural
Language Processing, pages 1643–1648, 2015.
[Lak75] George Lakoff. Hedges: A study in meaning criteria and the logic offuzzy concepts. In contemporary Research in Philosophical Logic and
Linguistic semantics, pages 221–271. Springer, 1975.
[Lan69] Ronald W Langacker. On pronominalization and the chain of com-mand. modern studies in english, ed. by da reibel and sa schane, 160-86,1969.
[LBLL87] Penelope Levinson, Penelope Brown, Stephen C Levinson, andStephen C Levinson. Politeness: Some universals in language usage,volume 4. Cambridge university press, 1987.
[Lev93] Beth Levin. English verb classes and alternations: A preliminary in-
vestigation. University of Chicago press, 1993.
[Ley07] Loet Leydesdorff. Betweenness centrality as an indicator of the inter-disciplinarity of scientific journals. Journal of the American Society for
Information Science and Technology, 58(9):1303–1319, 2007.
[LFH10] Andrea Landherr, Bettina Friedl, and Julia Heidemann. A critical re-view of centrality measures in social networks. Business & Information
Systems Engineering, 2(6):371–385, 2010.
[LG12] Ursula K Le Guin. The left hand of darkness. Hachette UK, 2012.

384 BIBLIOGRAPHY
[LG14] Omer Levy and Yoav Goldberg. Dependency-based word embeddings.In Proceedings of the 52nd Annual Meeting of the Association for Com-
putational Linguistics (Volume 2: Short Papers), volume 2, pages 302–308, 2014.
[Lia10] Maria Liakata. Zones of conceptualisation in scientific papers: a win-dow to negative and speculative statements. In Proceedings of the Work-
shop on Negation and Speculation in Natural Language Processing,pages 1–4. Association for Computational Linguistics, 2010.
[Liu17] Jiqun Liu. Toward a unified model of human information behavior:an equilibrium perspective. Journal of Documentation, 73(4):666–688,2017.
[LJYA+13] Chen Li, Antonio Jimeno-Yepes, Miguel Arregui, Harald Kirsch, andDietrich Rebholz-Schuhmann. Pcorral—interactive mining of proteininteractions from medline. Database, 2013, 2013.
[LM91] David C Littman and Jacob L Mey. The nature of irony: Toward acomputational model of irony. Journal of Pragmatics, 15(2):131–151,1991.
[LMK+10] Florian Leitner, Scott A Mardis, Martin Krallinger, Gianni Cesareni,Lynette A Hirschman, and Alfonso Valencia. An overview of biocre-ative ii. 5. IEEE/ACM Transactions on Computational Biology and
Bioinformatics (TCBB), 7(3):385–399, 2010.
[LNA17] Maolin Li, Nhung Nguyen, and Sophia Ananiadou. Proactive learningfor named entity recognition. BioNLP 2017, pages 117–125, 2017.
[LNBB+06] Nicolas Le Novere, Benjamin Bornstein, Alexander Broicher, MelanieCourtot, Marco Donizelli, Harish Dharuri, Lu Li, Herbert Sauro, MariaSchilstra, Bruce Shapiro, et al. Biomodels database: a free, centralizeddatabase of curated, published, quantitative kinetic models of biochem-ical and cellular systems. Nucleic acids research, 34(suppl 1):D689–D691, 2006.

BIBLIOGRAPHY 385
[LNPC15] Andras London, Tamas Nemeth, Andras Pluhar, and Tibor Csendes.A local pagerank algorithm for evaluating the importance of scientificarticles. In Annales Mathematicae et Informaticae, volume 44, pages131–141. szte, 2015.
[LQS04a] Marc Light, Xin Ying Qiu, and Padmini Srinivasan. The language ofbioscience: Facts, speculations, and statements in between. In Pro-
ceedings of BioLink 2004 workshop on linking biological literature,
ontologies and databases: tools for users, pages 17–24. Associationfor Computational Linguistics, 2004.
[LQS04b] Marc Light, Xin Ying Qiu, and Padmini Srinivasan. The language ofbioscience: Facts, speculations, and statements in between. In HLT-
NAACL 2004 Workshop: Linking Biological Literature, Ontologies and
Databases, 2004.
[LRN+07] Patrick R Leary, David P Remsen, Catherine N Norton, David J Patter-son, and Indra Neil Sarkar. ubiorss: tracking taxonomic literature usingrss. Bioinformatics, 23(11):1434–1436, 2007.
[LS16] Jure Leskovec and Rok Sosic. Snap: A general-purpose network analy-sis and graph-mining library. ACM Transactions on Intelligent Systems
and Technology (TIST), 8(1):1, 2016.
[LSCCP17] Prisca Lo Surdo, Alberto Calderone, Gianni Cesareni, and Livia Per-fetto. Signor: a database of causal relationships between biologicalentities—a short guide to searching and browsing. Current protocols in
bioinformatics, 58(1):8–23, 2017.
[LSL+15] Chen Li, Runqing Song, Maria Liakata, Andreas Vlachos, StephanieSeneff, and Xiangrong Zhang. Using word embedding for bio-eventextraction. ACL-IJCNLP 2015, page 121, 2015.
[LSW03] Jochen L Leidner, Gail Sinclair, and Bonnie Webber. Grounding spa-tial named entities for information extraction and question answering.

386 BIBLIOGRAPHY
In Proceedings of the HLT-NAACL 2003 workshop on Analysis of ge-
ographic references-Volume 1, pages 31–38. Association for Computa-tional Linguistics, 2003.
[LSW+15] Jialu Liu, Jingbo Shang, Chi Wang, Xiang Ren, and Jiawei Han. Min-ing quality phrases from massive text corpora. In Proceedings of
the 2015 ACM SIGMOD International Conference on Management of
Data, pages 1729–1744. ACM, 2015.
[LT16] Marco Lippi and Paolo Torroni. Argumentation mining: State of theart and emerging trends. ACM Transactions on Internet Technology
(TOIT), 16(2):10, 2016.
[LTF+09] Sonia M Leach, Hannah Tipney, Weiguo Feng, William A Baum-gartner Jr, Priyanka Kasliwal, Ronald P Schuyler, Trevor Williams,Richard A Spritz, and Lawrence Hunter. Biomedical discovery accel-eration, with applications to craniofacial development. PLoS computa-
tional biology, 5(3):e1000215, 2009.
[LTS+10] Maria Liakata, Simone Teufel, Advaith Siddharthan, Colin R Batchelor,et al. Corpora for the conceptualisation and zoning of scientific papers.In LREC. Citeseer, 2010.
[LW02] Andy Liaw and Matthew Wiener. Classification and regression by ran-domforest. R news, 2:18–22, 2002.
[LWZ06] Shao Li, Lijiang Wu, and Zhongqi Zhang. Constructing biological net-works through combined literature mining and microarray analysis: almma approach. Bioinformatics, 22(17):2143–2150, 2006.
[LXZM15] Huchang Liao, Zeshui Xu, Xiao-Jun Zeng, and Jose M Merigo. Qual-itative decision making with correlation coefficients of hesitant fuzzylinguistic term sets. Knowledge-Based Systems, 76:127–138, 2015.
[LYKB08] Ivica Letunic, Takuji Yamada, Minoru Kanehisa, and Peer Bork. ipath:interactive exploration of biochemical pathways and networks. Trends
in biochemical sciences, 33(3):101–103, 2008.

BIBLIOGRAPHY 387
[LZW+16] Lishuang Li, Jieqiong Zheng, Jia Wan, Degen Huang, and XiaohuiLin. Biomedical event extraction via long short term memory net-works along dynamic extended tree. In Bioinformatics and Biomedicine
(BIBM), 2016 IEEE International Conference on, pages 739–742.IEEE, 2016.
[LZWZ10] Junhui Li, Guodong Zhou, Hongling Wang, and Qiaoming Zhu. Learn-ing the scope of negation via shallow semantic parsing. In Proceed-
ings of the 23rd International Conference on Computational Linguis-
tics, pages 671–679. Association for Computational Linguistics, 2010.
[MA13a] Makoto Miwa and Sophia Ananiadou. Nactem eventmine for bionlp2013 cg and pc tasks. In Proceedings of BioNLP Shared Task 2013
Workshop, pages 94–98, 2013.
[MA13b] Makoto Miwa and Sophia Ananiadou. Nactem eventmine for bionlp2013 cg and pc tasks. In Proceedings of the BioNLP Shared Task 2013
Workshop, pages 94–98, 2013.
[MA13c] Makoto Miwa and Sophia Ananiadou. Nactem eventmine for bionlp2013 cg and pc tasks. In Proceedings of BioNLP Shared Task 2013
Workshop, pages 94–98, 2013.
[MA13d] SPFGH Moen and Tapio Salakoski2 Sophia Ananiadou. Distribu-tional semantics resources for biomedical text processing. In Proceed-
ings of the 5th International Symposium on Languages in Biology and
Medicine, Tokyo, Japan, pages 39–43, 2013.
[MA15] Makoto Miwa and Sophia Ananiadou. Adaptable, high recall, eventextraction system with minimal configuration. BMC bioinformatics,16(10):1, 2015.
[Mal07] Grzegorz Malinowski. Many-valued logic and its philosophy. The
Many Valued and Nonmonotonic Turn in Logic, 8:13–94, 2007.

388 BIBLIOGRAPHY
[Map79] Roy EA Mapes. Verbal and numerical estimates of probability in ther-apeutic contexts. Social Science & Medicine. Part A: Medical Psychol-
ogy & Medical Sociology, 13:277–282, 1979.
[MB07a] Ben Medlock and Ted Briscoe. Weakly supervised learning for hedgeclassification in scientific literature. In ACL, volume 2007, pages 992–999. Citeseer, 2007.
[MB07b] Ben Medlock and Ted Briscoe. Weakly supervised learning for hedgeclassification in scientific literature. In Proceedings of the 45th annual
meeting of the association of computational linguistics, pages 992–999,2007.
[MB12] Roser Morante and Eduardo Blanco. *sem 2012 shared task: Resolv-ing the scope and focus of negation. In Proceedings of the First Joint
Conference on Lexical and Computational Semantics - Volume 1: Pro-
ceedings of the Main Conference and the Shared Task, and Volume 2:
Proceedings of the Sixth International Workshop on Semantic Evalua-
tion, SemEval ’12, pages 265–274, Stroudsburg, PA, USA, 2012. As-sociation for Computational Linguistics.
[MBE+02] Kathleen R McKeown, Regina Barzilay, David Evans, Vasileios Hatzi-vassiloglou, Judith L Klavans, Ani Nenkova, Carl Sable, Barry Schiff-man, and Sergey Sigelman. Tracking and summarizing news on a dailybasis with columbia’s newsblaster. In Proceedings of the second inter-
national conference on Human Language Technology Research, pages280–285. Morgan Kaufmann Publishers Inc., 2002.
[MCCD13] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Effi-cient estimation of word representations in vector space. arXiv preprint
arXiv:1301.3781, 2013.
[MCM10] Jose M Merigo, Montserrat Casanovas, and L Martınez. Linguis-tic aggregation operators for linguistic decision making based on the

BIBLIOGRAPHY 389
dempster-shafer theory of evidence. International Journal of Un-
certainty, Fuzziness and Knowledge-Based Systems, 18(03):287–304,2010.
[MD09a] Roser Morante and Walter Daelemans. Learning the scope of hedgecues in biomedical texts. In Proceedings of the Workshop on Current
Trends in Biomedical Natural Language Processing, pages 28–36. As-sociation for Computational Linguistics, 2009.
[MD09b] Roser Morante and Walter Daelemans. Learning the scope of hedgecues in biomedical texts. In Proceedings of the Workshop on Cur-
rent Trends in Biomedical Natural Language Processing, BioNLP ’09,pages 28–36, Stroudsburg, PA, USA, 2009. Association for Computa-tional Linguistics.
[MDN01] Pradeep G Mutalik, Aniruddha Deshpande, and Prakash M Nadkarni.Use of general-purpose negation detection to augment concept indexingof medical documents: a quantitative study using the umls. Journal of
the American Medical Informatics Association, 8(6):598–609, 2001.
[Med08] Ben Medlock. Exploring hedge identification in biomedical literature.Journal of biomedical informatics, 41(4):636–654, 2008.
[MGKK10] Yukiko Matsuoka, Samik Ghosh, Norihiro Kikuchi, and Hiroaki Ki-tano. Payao: a community platform for SBML pathway model curation.Bioinformatics, 26(10):1381, 2010.
[MGZ08] Nan Ma, Jiancheng Guan, and Yi Zhao. Bringing pagerank to the cita-tion analysis. Information Processing & Management, 44(2):800–810,2008.
[Mil95] George A Miller. Wordnet: a lexical database for english. Communica-
tions of the ACM, 38(11):39–41, 1995.

390 BIBLIOGRAPHY
[MMW14] Guillermo Moncecchi, Jean-Luc Minel, and Dina Wonsever. The in-fluence of syntactic information on hedge scope detection. In Ibero-
American Conference on Artificial Intelligence, pages 83–94. Springer,2014.
[MOR+13] Makoto Miwa, Tomoko Ohta, Rafal Rak, Andrew Rowley, Douglas BKell, Sampo Pyysalo, and Sophia Ananiadou. A method for integratingand ranking the evidence for biochemical pathways by mining reactionsfrom text. Bioinformatics, 29(13):i44–i52, 2013.
[MPOA13] Makoto Miwa, Sampo Pyysalo, Tomoko Ohta, and Sophia Ananiadou.Wide coverage biomedical event extraction using multiple partiallyoverlapping corpora. BMC bioinformatics, 14(1):1, 2013.
[MR08] Sergei Maslov and Sidney Redner. Promise and pitfalls of extendinggoogle’s pagerank algorithm to citation networks. Journal of Neuro-
science, 28(44):11103–11105, 2008.
[MS12] Roser Morante and Caroline Sporleder. Modality and Negation: AnIntroduction to the Special Issue. Computational Linguistics, 38:223–260, 2012.
[MSB08] Mark D McDowall, Michelle S Scott, and Geoffrey J Barton. Pips:human protein–protein interaction prediction database. Nucleic acids
research, 37(suppl 1):D651–D656, 2008.
[MSC+13] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and JeffDean. Distributed representations of words and phrases and their com-positionality. In Advances in neural information processing systems,pages 3111–3119, 2013.
[MSKT10] Makoto Miwa, Rune Sætre, Jin-Dong Kim, and Jun’ichi Tsujii. Eventextraction with complex event classification using rich features. Journal
of bioinformatics and computational biology, 8(01):131–146, 2010.

BIBLIOGRAPHY 391
[MSM+08] Makoto Miwa, Rune Sætre, Yusuke Miyao, Tomoko Ohta, and Jun’ichiTsujii. Combining multiple layers of syntactic information for protein-protein interaction extraction. In Proceedings of the Third International
Symposium on Semantic Mining in Biomedicine, pages 101–108, 2008.
[MSS+08] Yusuke Miyao, Rune Sætre, Kenji Sagae, Takuya Matsuzaki, andJun’ichi Tsujii. Task-oriented evaluation of syntactic parsers and theirrepresentations. Proceedings of ACL-08: HLT, pages 46–54, 2008.
[MSU+16] A-L Minard, Manuela Speranza, Ruben Urizar, Begona Altuna, MGJvan Erp, AM Schoen, CM van Son, et al. Meantime, the newsreadermultilingual event and time corpus. 2016.
[MT08a] Takuya Matsuzaki and Jun’ichi Tsujii. Comparative parser performanceanalysis across grammar frameworks through automatic tree conversionusing synchronous grammars. In Proceedings of the 22nd International
Conference on Computational Linguistics-Volume 1, pages 545–552.Association for Computational Linguistics, 2008.
[MT08b] Yusuke Miyao and Jun’ichi Tsujii. Feature forest models for proba-bilistic hpsg parsing. Computational linguistics, 34(1):35–80, 2008.
[MT09] Huaiyu Mi and Paul Thomas. Panther pathway: an ontology-basedpathway database coupled with data analysis tools. In Protein Networks
and Pathway Analysis, pages 123–140. Springer, 2009.
[MT14] Paramita Mirza and Sara Tonelli. An analysis of causality betweenevents and its relation to temporal information. In Proceedings of COL-
ING 2014, the 25th International Conference on Computational Lin-
guistics: Technical Papers, pages 2097–2106, 2014.
[MTA12] Makoto Miwa, Paul Thompson, and Sophia Ananiadou. Boosting auto-matic event extraction from the literature using domain adaptation andcoreference resolution. Bioinformatics, 28(13):1759–1765, 2012.

392 BIBLIOGRAPHY
[MTKA14] Makoto Miwa, Paul Thompson, Ioannis Korkontzelos, and Sophia Ana-niadou. Comparable study of event extraction in newswire and biomed-ical domains. In Proceedings of COLING 2014, the 25th International
Conference on Computational Linguistics: Technical Papers, pages2270–2279, 2014.
[MTM+12] Makoto Miwa, Paul Thompson, John McNaught, Douglas B Kell,and Sophia Ananiadou. Extracting semantically enriched events frombiomedical literature. BMC bioinformatics, 13(1):1, 2012.
[MVAD10a] Roser Morante, Vincent Van Asch, and Walter Daelemans. Memory-based resolution of in-sentence scopes of hedge cues. In Proceedings of
the Fourteenth Conference on Computational Natural Language Learn-
ing — Shared Task, CoNLL ’10: Shared Task, pages 40–47, Strouds-burg, PA, USA, 2010. Association for Computational Linguistics.
[MVAD10b] Roser Morante, Vincent Van Asch, and Walter Daelemans. Memory-based resolution of in-sentence scopes of hedge cues. In Proceedings of
the Fourteenth Conference on Computational Natural Language Learn-
ing — Shared Task, CoNLL ’10: Shared Task, pages 40–47, Strouds-burg, PA, USA, 2010. Association for Computational Linguistics.
[MVALS18] H-M Muller, Kimberly M Van Auken, Yuling Li, and Paul W Stern-berg. Textpresso central: a customizable platform for searching, textmining, viewing, and curating biomedical literature. BMC bioinfor-
matics, 19(1):94, 2018.
[MYBHA14] Ashutosh Malhotra, Erfan Younesi, Shweta Bagewadi, and MartinHofmann-Apitius. Linking hypothetical knowledge patterns to diseasemolecular signatures for biomarker discovery in alzheimer’s disease.Genome medicine, 6(11):1, 2014.
[Mye77] Alice R Myers. Toward a definition of irony. Studies in language
variation: semantics, syntax, phonology, pragmatics, social situations,
ethnographic approaches, pages 171–183, 1977.

BIBLIOGRAPHY 393
[Mye89] Greg Myers. The pragmatics of politeness in scientific articles. Applied
linguistics, 10(1):1–35, 1989.
[MYGHA13] Ashutosh Malhotra, Erfan Younesi, Harsha Gurulingappa, and Mar-tin Hofmann-Apitius. ‘hypothesisfinder:’a strategy for the detection ofspeculative statements in scientific text. PLoS computational biology,9(7):e1003117, 2013.
[NBD+06] Jeyakumar Natarajan, Daniel Berrar, Werner Dubitzky, Catherine Hack,Yonghong Zhang, Catherine DeSesa, James R Van Brocklyn, andEric G Bremer. Text mining of full-text journal articles combined withgene expression analysis reveals a relationship between sphingosine-1-phosphate and invasiveness of a glioblastoma cell line. BMC bioinfor-
matics, 7(1):373, 2006.
[NBK+13a] Claire Nedellec, Robert Bossy, Jin-Dong Kim, Jung-Jae Kim, TomokoOhta, Sampo Pyysalo, and Pierre Zweigenbaum. Overview of BioNLPshared task 2013. Proceedings of BioNLP 2013, pages 1–7, 2013.
[NBK+13b] Claire Nedellec, Robert Bossy, Jin-Dong Kim, Jung-Jae Kim, TomokoOhta, Sampo Pyysalo, and Pierre Zweigenbaum. Overview of bionlpshared task 2013. In Proceedings of the BioNLP Shared Task 2013
Workshop, pages 1–7, 2013.
[NBK16] Claire Nedellec, Robert Bossy, and Jin-Dong Kim. Proceedings of the4th bionlp shared task workshop. In Proceedings of the 4th BioNLP
Shared Task Workshop, 2016.
[NCG16] Thien Huu Nguyen, Kyunghyun Cho, and Ralph Grishman. Joint eventextraction via recurrent neural networks. In Proceedings of the 2016
Conference of the North American Chapter of the Association for Com-
putational Linguistics: Human Language Technologies, pages 300–309, 2016.
[NEDM03] Alexander Nikitin, Sergei Egorov, Nikolai Daraselia, and Ilya Mazo.Pathway Studio–the analysis and navigation of molecular networks.Bioinformatics, 19(16):2155–2157, 2003.

394 BIBLIOGRAPHY
[New06] Mark EJ Newman. Modularity and community structure in networks.Proceedings of the national academy of sciences, 103(23):8577–8582,2006.
[NG15] Thien Huu Nguyen and Ralph Grishman. Event detection and domainadaptation with convolutional neural networks. In Proceedings of the
53rd Annual Meeting of the Association for Computational Linguistics
and the 7th International Joint Conference on Natural Language Pro-
cessing (Volume 2: Short Papers), volume 2, pages 365–371, 2015.
[NKBW11] Nona Naderi, Thomas Kappler, Christopher JO Baker, and Rene Witte.Organismtagger: detection, normalization and grounding of organismentities in biomedical documents. Bioinformatics, 27(19):2721–2729,2011.
[NSW+10] Ramin Nazarian, Hubing Shi, Qi Wang, Xiangju Kong, Richard CKoya, Hane Lee, Zugen Chen, Mi-Kyung Lee, Narsis Attar, HoomanSazegar, et al. Melanomas acquire resistance to b-raf (v600e) inhibitionby rtk or n-ras upregulation. Nature, 468(7326):973, 2010.
[NTA10] Raheel Nawaz, Paul Thompson, and Sophia Ananiadou. Evaluatinga meta-knowledge annotation scheme for bio-events. In Proceedings
of the Workshop on Negation and Speculation in Natural Language
Processing, pages 69–77. Association for Computational Linguistics,2010.
[NTA13a] Raheel Nawaz, Paul Thompson, and Sophia Ananiadou. Negated bio-events: analysis and identification. BMC bioinformatics, 14(1):14,2013.
[NTA13b] Raheel Nawaz, Paul Thompson, and Sophia Ananiadou. Somethingold, something new: identifying knowledge source in bio-events. In-
ternational Journal of Computational Linguistics and Applications,4(1):129–144, 2013.

BIBLIOGRAPHY 395
[NTMA10] Raheel Nawaz, Paul Thompson, John McNaught, and Sophia Anani-adou. Meta-knowledge annotation of bio-events. In LREC, pages 2498–2507, 2010.
[NZRS12] Feng Niu, Ce Zhang, Christopher Re, and Jude W Shavlik. Deepdive:Web-scale knowledge-base construction using statistical learning andinference. VLDS, 12:25–28, 2012.
[OAA+13] Sandra Orchard, Mais Ammari, Bruno Aranda, Lionel Breuza,Leonardo Briganti, Fiona Broackes-Carter, Nancy H Campbell, Gay-atri Chavali, Carol Chen, Noemi Del-Toro, et al. The mintactproject—intact as a common curation platform for 11 molecular inter-action databases. Nucleic acids research, 42(D1):D358–D363, 2013.
[O’B89] Bernie J O’Brien. Words or numbers? the evaluation of probabilityexpressions in general practice. British Journal of General Practice,39(320):98–100, 1989.
[OK10] Sandra Orchard and Samuel Kerrien. Molecular interactions and datastandardisation. In Proteome Bioinformatics, pages 309–318. Springer,2010.
[OKO+08a] Kanae Oda, Jin-Dong Kim, Tomoko Ohta, Daisuke Okanohara, TakuyaMatsuzaki, Yuka Tateisi, and Jun’ichi Tsujii. New challenges for textmining: mapping between text and manually curated pathways. In BMC
bioinformatics, volume 9, page S5. BioMed Central, 2008.
[OKO+08b] Kanae Oda, Jin-Dong Kim, Tomoko Ohta, Daisuke Okanohara, TakuyaMatsuzaki, Yuka Tateisi, and Jun’ichi Tsujii. New challenges for textmining: mapping between text and manually curated pathways. BMC
Bioinformatics, 9:1–14, 2008.
[OPMT11] Tomoko Ohta, Sampo Pyysalo, Makoto Miwa, and Jun’ichi Tsujii.Event extraction for dna methylation. J. Biomedical Semantics, 2(S-5):S2, 2011.

396 BIBLIOGRAPHY
[OPR+13] Tomoko Ohta, Sampo Pyysalo, Rafal Rak, Andrew Rowley, Hong-WooChun, Sung-Jae Jung, Sung-Pil Choi, Sophia Ananiadou, and Jun’ichiTsujii. Overview of the pathway curation (pc) task of bionlp sharedtask 2013. In Proceedings of the BioNLP Shared Task 2013 Workshop,pages 67–75, 2013.
[OPT11] Tomoko Ohta, Sampo Pyysalo, and Jun’ichi Tsujii. Overview of theepigenetics and post-translational modifications (epi) task of bionlpshared task 2011. In Proceedings of the BioNLP Shared Task 2011
Workshop, pages 16–25. Association for Computational Linguistics,2011.
[OTT+06] Tomoko Ohta, Yoshimasa Tsuruoka, Jumpei Takeuchi, Jin-Dong Kim,Yusuke Miyao, Akane Yakushiji, Kazuhiro Yoshida, Yuka Tateisi,Takashi Ninomiya, Katsuya Masuda, et al. An intelligent search en-gine and gui-based efficient medline search tool based on deep syntacticparsing. In Proceedings of the COLING/ACL on Interactive presenta-
tion sessions, pages 17–20. Association for Computational Linguistics,2006.
[OVER08] Arzucan Ozgur, Thuy Vu, Gunes Erkan, and Dragomir R Radev. Iden-tifying gene-disease associations using centrality on a literature minedgene-interaction network. Bioinformatics, 24(13):i277–i285, 2008.
[OVNDM+07] Mate Ongenaert, Leander Van Neste, Tim De Meyer, Gerben Men-schaert, Sofie Bekaert, and Wim Van Criekinge. Pubmeth: a can-cer methylation database combining text-mining and expert annotation.Nucleic acids research, 36(suppl 1):D842–D846, 2007.
[Pal77] Frank R Palmer. Modals and actuality. Journal of Linguistics, 13(1):01–23, 1977.
[Pal01] Frank Robert Palmer. Mood and modality. Cambridge University Press,2001.
[Pap06] Anna Papafragou. Epistemic modality and truth conditions. Lingua,116(10):1688–1702, 2006.

BIBLIOGRAPHY 397
[PBC+15] Livia Perfetto, Leonardo Briganti, Alberto Calderone, An-drea Cerquone Perpetuini, Marta Iannuccelli, Francesca Langone,Luana Licata, Milica Marinkovic, Anna Mattioni, Theodora Pavlidou,et al. SIGNOR: a database of causal relationships between biologicalentities. Nucleic acids research, page gkv1048, 2015.
[PBM+07] John P Pestian, Christopher Brew, Paweł Matykiewicz, Dj J Hover-male, Neil Johnson, K Bretonnel Cohen, and Włodzisław Duch. Ashared task involving multi-label classification of clinical free text. InProceedings of the Workshop on BioNLP 2007: Biological, Transla-
tional, and Clinical Language Processing, pages 97–104. Associationfor Computational Linguistics, 2007.
[PBMW99] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd.The pagerank citation ranking: Bringing order to the web. Technicalreport, Stanford InfoLab, 1999.
[Pet81] James L Peterson. Petri net theory and the modeling of systems. 1981.
[PGH+07] Sampo Pyysalo, Filip Ginter, Juho Heimonen, Jari Bjorne, JormaBoberg, Jouni Jarvinen, and Tapio Salakoski. Bioinfer: a corpus forinformation extraction in the biomedical domain. BMC bioinformatics,8(1):1, 2007.
[PH02] Geoffrey K Pullum and Rodney D Huddleston. Negation. 2002.
[PH14] Anna Prokofieva and Julia Hirschberg. Hedging and speaker commit-ment. In 5th Intl. Workshop on Emotion, Social Signals, Sentiment &
Linked Open Data, Reykjavik, Iceland, 2014.
[PHS+03] James Pustejovsky, Patrick Hanks, Roser Sauri, Andrew See, RobertGaizauskas, Andrea Setzer, Dragomir Radev, Beth Sundheim, DavidDay, Lisa Ferro, et al. The timebank corpus. In Corpus linguistics,volume 2003, page 40. Lancaster, UK., 2003.

398 BIBLIOGRAPHY
[PL17] Yifan Peng and Zhiyong Lu. Deep learning for extracting protein-protein interactions from biomedical literature. arXiv preprint
arXiv:1706.01556, 2017.
[Pla99] John C Platt. 12 fast training of support vector machines using sequen-tial minimal optimization. Advances in kernel methods, pages 185–208,1999.
[PLM15] Sungrae Park, Wonsung Lee, and Il-Chul Moon. Efficient extraction ofdomain specific sentiment lexicon with active learning. Pattern Recog-
nition Letters, 56:38–44, 2015.
[PMM02] Mathew Palakal, Snehasis Mukhopadhyay, and Javed Mostafa. An in-telligent biological information management system. In Proceedings
of the 2002 ACM symposium on Applied computing, pages 159–163.ACM, 2002.
[POA13] Sampo Pyysalo, Tomoko Ohta, and Sophia Ananiadou. Overview of thecancer genetics (cg) task of bionlp shared task 2013. In Proceedings of
the BioNLP Shared Task 2013 Workshop, pages 58–66. Citeseer, 2013.
[POM+12] Sampo Pyysalo, Tomoko Ohta, Makoto Miwa, Han-Cheol Cho,Jun’ichi Tsujii, and Sophia Ananiadou. Event extraction across multi-ple levels of biological organization. Bioinformatics, 28(18):i575–i581,2012.
[POMT11] Sampo Pyysalo, Tomoko Ohta, Makoto Miwa, and Jun’ichi Tsujii. To-wards exhaustive event extraction for protein modifications. In Pro-
ceedings of BioNLP 2011 Workshop, pages 114–123, 2011.
[POR+11] Sampo Pyysalo, Tomoko Ohta, Rafal Rak, Dan Sullivan, ChunhongMao, Chunxia Wang, Bruno Sobral, Jun’ichi Tsujii, and Sophia Ana-niadou. Overview of the infectious diseases (id) task of bionlp sharedtask 2011. In Proceedings of the BioNLP Shared Task 2011 Workshop,pages 26–35. Association for Computational Linguistics, 2011.

BIBLIOGRAPHY 399
[Pow85] Mava Jo Powell. Purposive vagueness: an evaluative dimension ofvague quantifying expressions. Journal of linguistics, 21(1):31–50,1985.
[PRD10] Vinodkumar Prabhakaran, Owen Rambow, and Mona Diab. Automaticcommitted belief tagging. In Proceedings of the 23rd International
Conference on Computational Linguistics: Posters, pages 1014–1022.Association for Computational Linguistics, 2010.
[PRG+09] Sung Hee Park, Jose A Reyes, David R Gilbert, Ji Woong Kim, andSangsoo Kim. Prediction of protein-protein interaction types usingassociation rule based classification. BMC bioinformatics, 10(1):36,2009.
[Pri79] Graham Priest. The logic of paradox. Journal of Philosophical logic,8(1):219–241, 1979.
[Pri82] E Prince. F., j, frader&c. bosk. on hedging in physician discourse. Lin-
guistics and the Professions, 1982.
[PS91] Gregory Piatetsky-Shapiro. Discovery, analysis, and presentation ofstrong rules. Knowledge discovery in databases, pages 229–238, 1991.
[PSR18] Nina Poerner, Hinrich Schutze, and Benjamin Roth. Evaluating neuralnetwork explanation methods using hybrid documents and morphosyn-tactic agreement. In Proceedings of the 56th Annual Meeting of the
Association for Computational Linguistics (Volume 1: Long Papers),volume 1, pages 340–350, 2018.
[PTKY11] Sinno Jialin Pan, I.W. Tsang, J.T. Kwok, and Qiang Yang. Domainadaptation via transfer component analysis. Neural Networks, IEEE
Transactions on, 22(2):199–210, Feb 2011.
[PTW+18] Paul Previde, Brook Thomas, Mike Wong, Emily K Mallory, DragutinPetkovic, Russ B Altman, and Anagha Kulkarni. Genedive: A gene in-teraction search and visualization tool to facilitate precision medicine.

400 BIBLIOGRAPHY
In Pacific Symposium on Biocomputing. Pacific Symposium on Biocom-
puting, volume 23, pages 590–601. World Scientific, 2018.
[PV10] Hoifung Poon and Lucy Vanderwende. Joint inference for knowledgeextraction from biomedical literature. In Human Language Technolo-
gies: The 2010 Annual Conference of the North American Chapter of
the Association for Computational Linguistics, pages 813–821. Associ-ation for Computational Linguistics, 2010.
[PW10] Harry E Pence and Antony Williams. Chemspider: an online chemicalinformation resource, 2010.
[QGL8] Randolph Quirk, Sidney Greenbaum, and Geoffrey Leech. G. andsvartvik, j. 1985. a comprehensive grammar of the english language.London and New York: Longman, 8.
[QLZ+16] Zhong Qian, Peifeng Li, Qiaoming Zhu, Guodong Zhou, ZhunchenLuo, and Wei Luo. Speculation and negation scope detection via con-volutional neural networks. In Proceedings of the 2016 Conference on
Empirical Methods in Natural Language Processing, pages 815–825,2016.
[QLZ+18] Zhong Qian, Peifeng Li, Yue Zhang, Guodong Zhou, and QiaomingZhu. Event factuality identification via generative adversarial networkswith auxiliary classification. In IJCAI, pages 4293–4300, 2018.
[QWR14] Changqin Quan, Meng Wang, and Fuji Ren. An unsupervised text min-ing method for relation extraction from biomedical literature. PloS one,9(7):e102039, 2014.
[RASR17] Benjamin Riedel, Isabelle Augenstein, Georgios P Spithourakis, andSebastian Riedel. A simple but tough-to-beat baseline for the fakenews challenge stance detection task. arXiv preprint arXiv:1707.03264,2017.

BIBLIOGRAPHY 401
[RB10] Marek Rei and Ted Briscoe. Combining manual rules and supervisedlearning for hedge cue and scope detection. In Proceedings of the Four-
teenth Conference on Computational Natural Language Learning—
Shared Task, pages 56–63. Association for Computational Linguistics,2010.
[RBH09] Mark F Rogers and Asa Ben-Hur. The use of gene ontology evi-dence codes in preventing classifier assessment bias. Bioinformatics,25(9):1173–1177, 2009.
[RBNR+13a] Rafal Rak, Riza Batista-Navarro, Andrew Rowley, Jacob Carter, andSophia Ananiadou. Customisable curation workflows in argo”. In Pro-
ceedings of the Fourth BioCreative Challenge Evaluation Workshop,volume 1, pages 270–278, 2013.
[RBNR+13b] Rafal Rak, Riza Batista-Navarro, Andrew Rowley, Makoto Miwa, Ja-cob Carter, and Sophia Ananiadou. Nactem’s bioc modules and re-sources for biocreative iv. In Proceedings of the Fourth BioCreative
Challenge Evaluation Workshop, volume 1, pages 61–67, 2013.
[RBNR+14] Rafal Rak, Riza Theresa Batista-Navarro, Andrew Rowley, JacobCarter, and Sophia Ananiadou. Text-mining-assisted biocuration work-flows in argo. Database, 2014, 2014.
[Res68] Nicholas Rescher. Many-valued logic. In Topics in Philosophical
Logic, pages 54–125. Springer, 1968.
[RHK+13] Aynat Rubinstein, Hillary Harner, Elizabeth Krawczyk, Daniel Simon-son, Graham Katz, and Paul Portner. Toward fine-grained annotationof modality in text. In Proceedings of IWCS 2013 Workshop on An-
notation of Modal Meanings in Natural Language (WAMM), Potsdam,
Germany, pages 38–46, 2013.
[RHL+15] Marylyn D Ritchie, Emily R Holzinger, Ruowang Li, Sarah A Pen-dergrass, and Dokyoon Kim. Methods of integrating data to uncovergenotype–phenotype interactions. Nature Reviews Genetics, 16(2):85,2015.

402 BIBLIOGRAPHY
[RIK+04] Andrey Rzhetsky, Ivan Iossifov, Tomohiro Koike, Michael Krautham-mer, Pauline Kra, Mitzi Morris, Hong Yu, Pablo Ariel Duboue, WubinWeng, W John Wilbur, et al. Geneways: a system for extracting, ana-lyzing, visualizing, and integrating molecular pathway data. Journal of
biomedical informatics, 37(1):43–53, 2004.
[RJH+12] Hendrik Rohn, Astrid Junker, Anja Hartmann, Eva Grafahrend-Belau,Hendrik Treutler, Matthias Klapperstuck, Tobias Czauderna, ChristianKlukas, and Falk Schreiber. VANTED v2: a framework for systemsbiology applications. BMC systems biology, 6(1):139, 2012.
[RLK06] Victoria L Rubin, Elizabeth D Liddy, and Noriko Kando. Certaintyidentification in texts: Categorization model and manual tagging re-sults. In Computing attitude and affect in text: Theory and applications,pages 61–76. Springer, 2006.
[RM11a] Sebastian Riedel and Andrew McCallum. Fast and robust joint mod-els for biomedical event extraction. In Proceedings of the Conference
on Empirical Methods in Natural Language Processing, pages 1–12.Association for Computational Linguistics, 2011.
[RM11b] Sebastian Riedel and Andrew McCallum. Fast and robust joint mod-els for biomedical event extraction. In Proceedings of the Conference
on Empirical Methods in Natural Language Processing, pages 1–12.Association for Computational Linguistics, 2011.
[RM11c] Sebastian Riedel and Andrew McCallum. Robust biomedical event ex-traction with dual decomposition and minimal domain adaptation. InProceedings of the BioNLP Shared Task 2011 Workshop, pages 46–50.Association for Computational Linguistics, 2011.
[RMH12] Rosa M Rodriguez, Luis Martinez, and Francisco Herrera. Hesitantfuzzy linguistic term sets for decision making. IEEE Transactions on
Fuzzy Systems, 20(1):109–119, 2012.
[RN09] Altaf Rahman and Vincent Ng. Supervised models for coreference res-olution. In Proceedings of the 2009 Conference on Empirical Methods

BIBLIOGRAPHY 403
in Natural Language Processing: Volume 2-Volume 2, pages 968–977.Association for Computational Linguistics, 2009.
[Rou06] Jean-Francois Rouet. The skills of document use: From text compre-
hension to Web-based learning. Psychology Press, 2006.
[RPHP10] Alvaro Rodrigo, Anselmo Penas, Eduard H Hovy, and Emanuele Pi-anta. Question answering for machine reading evaluation. In CLEF
(Notebook Papers/LABs/Workshops), 2010.
[RRBA12a] Rafal Rak, Andrew Rowley, William Black, and Sophia Ananiadou.Argo: an integrative, interactive, text mining-based workbench support-ing curation. Database, 2012:bas010, 2012.
[RRBA12b] Rafal Rak, Andrew Rowley, William Black, and Sophia Ananiadou.Argo: an integrative, interactive, text mining-based workbench support-ing curation. Database, pages 1–10, 2012.
[RSAG+07] Dietrich Rebholz-Schuhmann, Miguel Arregui, Sylvain Gaudan, Har-ald Kirsch, and Antonio Jimeno. Text processing through web services:calling whatizit. Bioinformatics, 24(2):296–298, 2007.
[Rub07] Victoria L Rubin. Stating with certainty or stating with doubt: Inter-coder reliability results for manual annotation of epistemically modal-ized statements. In Human Language Technologies 2007: The Confer-
ence of the North American Chapter of the Association for Computa-
tional Linguistics; Companion Volume, Short Papers, pages 141–144.Association for Computational Linguistics, 2007.
[Rub10] Victoria L Rubin. Epistemic modality: From uncertainty to certainty inthe context of information seeking as interactions with texts. Informa-
tion Processing & Management, 46(5):533–540, 2010.
[RVH+05] Jean-Francois Rual, Kavitha Venkatesan, Tong Hao, Tomoko Hirozane-Kishikawa, Amelie Dricot, Ning Li, Gabriel F Berriz, Francis D Gib-bons, Matija Dreze, Nono Ayivi-Guedehoussou, et al. Towards a

404 BIBLIOGRAPHY
proteome-scale map of the human protein–protein interaction network.Nature, 437(7062):1173, 2005.
[Sab66] Gert Sabidussi. The centrality index of a graph. Psychometrika,31(4):581–603, 1966.
[Sau17] Roser Saurı. Building factbank or how to annotate event factuality onestep at a time. In Handbook of Linguistic Annotation, pages 905–939.Springer, 2017.
[SBB10] Helge I Strømsø, Ivar Braten, and M Anne Britt. Reading multiple textsabout climate change: The relationship between memory for sourcesand text comprehension. Learning and Instruction, 20(3):192–204,2010.
[SBCA+10] Chris Stark, Bobby-Joe Breitkreutz, Andrew Chatr-Aryamontri, LorrieBoucher, Rose Oughtred, Michael S Livstone, Julie Nixon, KimberlyVan Auken, Xiaodong Wang, Xiaoqi Shi, et al. The biogrid interac-tion database: 2011 update. Nucleic acids research, 39(suppl 1):D698–D704, 2010.
[SBNT+18] Matthew Shardlow, Riza Batista-Navarro, Paul Thompson, RaheelNawaz, John McNaught, and Sophia Ananiadou. Identification of re-search hypotheses and new knowledge from scientific literature. BMC
medical informatics and decision making, 18(1):46, 2018.
[SBS09] Ladda Suanmali, Mohammed Salem Binwahlan, and Naomie Salim.Sentence features fusion for text summarization using fuzzy logic. InHybrid Intelligent Systems, 2009. HIS’09. Ninth International Confer-
ence on, volume 1, pages 142–146. IEEE, 2009.
[Sch11] Johan Schubert. Conflict management in dempster-shafer theory usingthe degree of falsity. International Journal of Approximate Reasoning,52(3):449–460, 2011.
[Sch15] Jurgen Schmidhuber. Deep learning in neural networks: An overview.Neural networks, 61:85–117, 2015.

BIBLIOGRAPHY 405
[SD07] Mudita Singhal and Kelly Domico. Cabin: collective analysis of bi-ological interaction networks. Computational Biology and Chemistry,31(3):222–225, 2007.
[SEKP+17] Gabriel Stanovsky, Judith Eckle-Kohler, Yevgeniy Puzikov, Ido Dagan,and Iryna Gurevych. Integrating deep linguistic features in factualityprediction over unified datasets. In Proceedings of the 55th Annual
Meeting of the Association for Computational Linguistics (Volume 2:
Short Papers), volume 2, pages 352–357, 2017.
[SF03] Hagit Shatkay and Ronen Feldman. Mining the Biomedical Literaturein the Genomic Era: An Overview. Journal of Computational Biology,10(6):821–855, dec 2003.
[SFW+14] Damian Szklarczyk, Andrea Franceschini, Stefan Wyder, Kristof-fer Forslund, Davide Heller, Jaime Huerta-Cepas, Milan Simonovic,Alexander Roth, Alberto Santos, Kalliopi P Tsafou, et al. STRINGv10: protein–protein interaction networks, integrated over the tree oflife. Nucleic acids research, page gku1003, 2014.
[SG09] Hassan Sayyadi and Lise Getoor. Futurerank: Ranking scientificarticles by predicting their future pagerank. In Proceedings of the
2009 SIAM International Conference on Data Mining, pages 533–544.SIAM, 2009.
[SG14] Christian Stab and Iryna Gurevych. Annotating argument componentsand relations in persuasive essays. In Proceedings of COLING 2014, the
25th International Conference on Computational Linguistics: Techni-
cal Papers, pages 1501–1510, 2014.
[SGLZ14] Jasmina Smailovic, Miha Grcar, Nada Lavrac, and Martin Znidarsic.Stream-based active learning for sentiment analysis in the financial do-main. Information sciences, 285:181–203, 2014.
[Sha92] Glenn Shafer. Dempster-shafer theory. Encyclopedia of artificial intel-
ligence, pages 330–331, 1992.

406 BIBLIOGRAPHY
[Sha01] Claude Elwood Shannon. A mathematical theory of communica-tion. ACM SIGMOBILE mobile computing and communications review,5(1):3–55, 2001.
[SHZ+07] Nathan Salomonis, Kristina Hanspers, Alexander C Zambon, KarenVranizan, Steven C Lawlor, Kam D Dahlquist, Scott W Doniger, JoshStuart, Bruce R Conklin, and Alexander R Pico. GenMAPP 2: newfeatures and resources for pathway analysis. BMC bioinformatics,8(1):217, 2007.
[SKA18] Reddy B Subhash, M Krishnamurthy, and Ashok Y Asundi. Informa-tion use, user, user needs and seeking behaviour: A review. DESIDOC
Journal of Library & Information Technology, 38(2):82, 2018.
[SKH+17] Denise N Slenter, Martina Kutmon, Kristina Hanspers, Anders Riutta,Jacob Windsor, Nuno Nunes, Jonathan Melius, Elisa Cirillo, Susan LCoort, Daniela Digles, et al. Wikipathways: a multifaceted pathwaydatabase bridging metabolomics to other omics research. Nucleic acids
research, 46(D1):D661–D667, 2017.
[SKMN15] Suresh Subramani, Raja Kalpana, Pankaj Moses Monickaraj, andJeyakumar Natarajan. HPIminer: A text mining system for building andvisualizing human protein interaction networks and pathways. Journal
of Biomedical Informatics, 54:121–131, apr 2015.
[SM86] Gerard Salton and Michael J McGill. Introduction to modern informa-tion retrieval. 1986.
[SMC+16] Damian Szklarczyk, John H Morris, Helen Cook, Michael Kuhn, Ste-fan Wyder, Milan Simonovic, Alberto Santos, Nadezhda T Doncheva,Alexander Roth, Peer Bork, et al. The string database in 2017: quality-controlled protein–protein association networks, made broadly accessi-ble. Nucleic acids research, page gkw937, 2016.
[SMDB14] Gang Su, John H Morris, Barry Demchak, and Gary D Bader. Bio-logical network exploration with Cytoscape 3. Current Protocols in
Bioinformatics, pages 8–13, 2014.

BIBLIOGRAPHY 407
[Smi12] Michael Smithson. Ignorance and uncertainty: emerging paradigms.Springer Science & Business Media, 2012.
[SMS+04] Lukasz Salwinski, Christopher S Miller, Adam J Smith, Frank K Pettit,James U Bowie, and David Eisenberg. The database of interacting pro-teins: 2004 update. Nucleic acids research, 32(suppl 1):D449–D451,2004.
[SN10] Farzaneh Sarafraz and Goran Nenadic. Using svms with the commandrelation features to identify negated events in biomedical literature. InProceedings of the Workshop on Negation and Speculation in Natu-
ral Language Processing, pages 78–85. Association for ComputationalLinguistics, 2010.
[SNC16] Maha Soliman, Olfa Nasraoui, and Nigel GF Cooper. Building a glau-coma interaction network using a text mining approach. BioData min-
ing, 9(1):17, 2016.
[SP07] Roser Saurı and James Pustejovsky. Determining modality and fac-tuality for text entailment. In International Conference on Semantic
Computing, pages 509–516, 2007.
[SP09a] Roser Saurı and James Pustejovsky. Factbank: A corpus annotated withevent factuality. Language resources and evaluation, 43(3):227–268,2009.
[SP09b] Roser Saurı and James Pustejovsky. Factbank: a corpus annotated withevent factuality. Language resources and evaluation, 43(3):227, 2009.
[SP12] Roser Saurı and James Pustejovsky. Are you sure that this happened?assessing the factuality degree of events in text. Computational Lin-
guistics, 38(2):261–299, 2012.
[SPAS12] Maria Secrier, Georgios A Pavlopoulos, Jan Aerts, and ReinhardSchneider. Arena3d: visualizing time-driven phenotypic differencesin biological systems. BMC bioinformatics, 13(1):45, 2012.

408 BIBLIOGRAPHY
[SPO+12a] Pontus Stenetorp, Sampo Pyysalo, Tomoko Ohta, Sophia Ananiadou,and Jun’ichi Tsujii. Bridging the gap between scope-based and event-based negation/speculation annotations: a bridge not too far. In Pro-
ceedings of the Workshop on Extra-Propositional Aspects of Meaning
in Computational Linguistics, pages 47–56. Association for Computa-tional Linguistics, 2012.
[SPO+12b] Pontus Stenetorp, Sampo Pyysalo, Tomoko Ohta, Sophia Ananiadou,and Jun’ichi Tsujii. Bridging the gap between scope-based and event-based negation/speculation annotations: a bridge not too far. Proceed-
ings of the Workshop on Extra-Propositional Aspects of Meaning in
Computational Linguistics, pages 47–56, 2012.
[SPRW08] Hagit Shatkay, Fengxia Pan, Andrey Rzhetsky, and W John Wilbur.Multi-dimensional classification of biomedical text: Toward auto-mated, practical provision of high-utility text to diverse users. Bioin-
formatics, 24(18):2086–2093, 2008.
[SPT+12] Pontus Stenetorp, Sampo Pyysalo, Goran Topic, Tomoko Ohta, SophiaAnaniadou, and Jun’ichi Tsujii. Brat: a web-based tool for nlp-assistedtext annotation. Proceedings of Demonstrations at 13th EACL, pages102–107, 2012.
[SS11] Kumutha Swampillai and Mark Stevenson. Extracting relations withinand across sentences. In Proceedings of the International Conference
Recent Advances in Natural Language Processing 2011, pages 25–32,2011.
[SSB09] Ladda Suanmali, Naomie Salim, and Mohammed Salem Binwahlan.Fuzzy logic based method for improving text summarization. arXiv
preprint arXiv:0906.4690, 2009.
[SSN12] Martin Sundermeyer, Ralf Schluter, and Hermann Ney. Lstm neuralnetworks for language modeling. In Thirteenth annual conference of
the international speech communication association, 2012.

BIBLIOGRAPHY 409
[SSvM+16] Damian Szklarczyk, Alberto Santos, Christian von Mering, Lars JuhlJensen, Peer Bork, and Michael Kuhn. STITCH 5: augmenting protein–chemical interaction networks with tissue and affinity data. Nucleic
acids research, 44(D1):D380–D384, 2016.
[SVF+12a] Gyorgy Szarvas, Veronika Vincze, Richard Farkas, Gyorgy Mora, andIryna Gurevych. Cross-genre and cross-domain detection of semanticuncertainty. Computational Linguistics, 38(2):335–367, 2012.
[SVF+12b] Gyorgy Szarvas, Veronika Vincze, Richard Farkas, Gyorgy Mora, andIryna Gurevych. Cross-genre and cross-domain detection of semanticuncertainty. Computational Linguistics, 38(2):335–367, 2012.
[SVS+12] Grigori Sidorov, Francisco Velasquez, Efstathios Stamatatos, Alexan-der Gelbukh, and Liliana Chanona-Hernandez. Syntactic dependency-based n-grams as classification features. In Mexican International Con-
ference on Artificial Intelligence, pages 1–11. Springer, 2012.
[SVS+14] Grigori Sidorov, Francisco Velasquez, Efstathios Stamatatos, Alexan-der Gelbukh, and Liliana Chanona-Hernandez. Syntactic n-grams asmachine learning features for natural language processing. Expert Sys-
tems with Applications, 41(3):853–860, 2014.
[SW49] Claude E Shannon and Warren Weaver. The mathematical theory ofinformation (urbana, il, 1949.
[Sza08] Gyorgy Szarvas. Hedge classification in biomedical texts with a weaklysupervised selection of keywords. Proceedings of ACL-08: HLT, pages281–289, 2008.
[SZBNA17] Axel J Soto, Chrysoula Zerva, Riza Batista-Navarro, and Sophia Ana-niadou. Litpathexplorer: a confidence-based visual text analyticstool for exploring literature-enriched pathway models. Bioinformatics,34(8):1389–1397, 2017.

410 BIBLIOGRAPHY
[TAL+10] Luis Tari, Saadat Anwar, Shanshan Liang, Jorg Hakenberg, and ChittaBaral. Synthesis of pharmacokinetic pathways through knowledge ac-quisition and automated reasoning. In Biocomputing 2010, pages 465–476. World Scientific, 2010.
[TAL+15] Manabu Torii, Cecilia N Arighi, Gang Li, Qinghua Wang, Cathy H Wu,and K Vijay-Shanker. Rlims-p 2.0: a generalizable rule-based informa-tion extraction system for literature mining of protein phosphorylationinformation. IEEE/ACM Transactions on Computational Biology and
Bioinformatics (TCBB), 12(1):17–29, 2015.
[TC11] Serhan Tatar and Ilyas Cicekli. Automatic rule learning exploiting mor-phological features for named entity recognition in turkish. Journal of
Information Science, 37(2):137–151, 2011.
[TFNF+15] Denes Turei, Laszlo Foldvari-Nagy, David Fazekas, Dezso Modos,Janos Kubisch, Tamas Kadlecsik, Amanda Demeter, Katalin Lenti,Peter Csermely, Tibor Vellai, et al. Autophagy Regulatory Network?Asystems-level bioinformatics resource for studying the mechanism andregulation of autophagy. Autophagy, 11(1):155–165, 2015.
[TG03] Joshua M Temkin and Mark R Gilder. Extraction of protein interac-tion information from unstructured text using a context-free grammar.Bioinformatics, 19(16):2046–2053, 2003.
[THM+05] Judi Thomson, Elizabeth Hetzler, Alan MacEachren, Mark Gahegan,and Misha Pavel. A typology for visualizing uncertainty. In Visual-
ization and Data Analysis 2005, volume 5669, pages 146–158. Interna-tional Society for Optics and Photonics, 2005.
[TIMA09] Paul Thompson, Syed A Iqbal, John McNaught, and Sophia Ananiadou.Construction of an annotated corpus to support biomedical informationextraction. BMC bioinformatics, 10(1):1, 2009.
[TKS04] Pang-Ning Tan, Vipin Kumar, and Jaideep Srivastava. Selecting theright objective measure for association analysis. Information Systems,29(4):293–313, 2004.

BIBLIOGRAPHY 411
[TL03] David MJ Tax and Pavel Laskov. Online svm learning: from classi-fication to data description and back. In Neural Networks for Signal
Processing, 2003. NNSP’03. 2003 IEEE 13th Workshop on, pages 499–508. IEEE, 2003.
[TLG10] Ali Tizghadam and Alberto Leon-Garcia. Betweenness centrality andresistance distance in communication networks. IEEE network, 24(6),2010.
[TLZM16] Jian Tang, Jingzhou Liu, Ming Zhang, and Qiaozhu Mei. Visualizinglarge-scale and high-dimensional data. In Proceedings of the 25th Inter-
national Conference on World Wide Web, pages 287–297. InternationalWorld Wide Web Conferences Steering Committee, 2016.
[TMH+11] Yoshimasa Tsuruoka, Makoto Miwa, Kaisei Hamamoto, Jun’ichi Tsu-jii, and Sophia Ananiadou. Discovering and visualizing indirect asso-ciations between biomedical concepts. Bioinformatics, 27(13):i111–i119, 2011.
[TMM+11] Paul Thompson, John McNaught, Simonetta Montemagni, NicolettaCalzolari, Riccardo Del Gratta, Vivian Lee, Simone Marchi, MonicaMonachini, Piotr Pezik, Valeria Quochi, et al. The biolexicon: a large-scale terminological resource for biomedical text mining. BMC bioin-
formatics, 12(1):397, 2011.
[TNMA11] Paul Thompson, Raheel Nawaz, John McNaught, and Sophia Anani-adou. Enriching a biomedical event corpus with meta-knowledge an-notation. BMC bioinformatics, 12(1):393, 2011.
[TNMA17] Paul Thompson, Raheel Nawaz, John McNaught, and Sophia Anani-adou. Enriching news events with meta-knowledge information. Lan-
guage Resources and Evaluation, 51(2):409–438, 2017.
[Too80] John H Toogood. What do we mean by” usually”? The Lancet,315(8177):1094, 1980.

412 BIBLIOGRAPHY
[TPA08] Hristo Tanev, Jakub Piskorski, and Martin Atkinson. Real-time newsevent extraction for global crisis monitoring. In International Confer-
ence on Application of Natural Language to Information Systems, pages207–218. Springer, 2008.
[TR16] Chen-Tse Tsai and Dan Roth. Concept grounding to multiple knowl-edge bases via indirect supervision. Transactions of the Association of
Computational Linguistics, 4(1):141–154, 2016.
[TST06] Simone Teufel, Advaith Siddharthan, and Dan Tidhar. Automatic clas-sification of citation function. In Proceedings of the 2006 conference
on empirical methods in natural language processing, pages 103–110.Association for Computational Linguistics, 2006.
[TST09] Simone Teufel, Advaith Siddharthan, and Dan Tidhar. An annotationscheme for citation function. In Proceedings of the 7th SIGdial Work-
shop on Discourse and Dialogue, pages 80–87. Association for Com-putational Linguistics, 2009.
[TTH+15] N Seth Trueger, Brent Thoma, Cindy H Hsu, Daniel Sullivan, Lind-say Peters, and Michelle Lin. The altmetric score: a new measure forarticle-level dissemination and impact. Annals of emergency medicine,66(5):549–553, 2015.
[TTK+05] Yoshimasa Tsuruoka, Yuka Tateishi, Jin-Dong Kim, Tomoko Ohta,John McNaught, Sophia Ananiadou, and Jun’ichi Tsujii. Developinga robust part-of-speech tagger for biomedical text. In Panhellenic Con-
ference on Informatics, pages 382–392. 2005.
[TVCM18] James Thorne, Andreas Vlachos, Christos Christodoulopoulos, andArpit Mittal. Fever: a large-scale dataset for fact extraction and ver-ification. arXiv preprint arXiv:1803.05355, 2018.
[TWW+10a] Buzhou Tang, Xiaolong Wang, Xuan Wang, Bo Yuan, and Shixi Fan.A cascade method for detecting hedges and their scope in natural lan-guage text. In Proceedings of the Fourteenth Conference on Computa-
tional Natural Language Learning — Shared Task, CoNLL ’10: Shared

BIBLIOGRAPHY 413
Task, pages 13–17, Stroudsburg, PA, USA, 2010. Association for Com-putational Linguistics.
[TWW+10b] Buzhou Tang, Xiaolong Wang, Xuan Wang, Bo Yuan, and Shixi Fan. Acascade method for detecting hedges and their scope in natural languagetext. In Proceedings of the Fourteenth Conference on Computational
Natural Language Learning—Shared Task, pages 13–17. Associationfor Computational Linguistics, 2010.
[UAS18] Jeffrey Ullman, Alfred V Aho, and Ravi Sethi. Compilers: Principles,techniques and tools, 2018.
[UBH18] Morgan Ulinski, Seth Benjamin, and Julia Hirschberg. Using hedgedetection to improve committed belief tagging. In Proceedings of the
Workshop on Computational Semantics beyond Events and Roles, pages1–5, 2018.
[Uts96] Akira Utsumi. A unified theory of irony and its computational for-malization. In Proceedings of the 16th conference on Computational
linguistics-Volume 2, pages 962–967. Association for ComputationalLinguistics, 1996.
[UTW+17] Matej Usaj, Yizhao Tan, Wen Wang, Benjamin VanderSluis, AlbertZou, Chad L Myers, Michael Costanzo, Brenda Andrews, and CharlesBoone. Thecellmap. org: A web-accessible database for visualizingand mining the global yeast genetic interaction network. G3: Genes,
Genomes, Genetics, pages g3–117, 2017.
[VBK+04] Aditya Vailaya, Peter Bluvas, Robert Kincaid, Allan Kuchinsky,Michael Creech, and Annette Adler. An architecture for biologicalinformation extraction and representation. Bioinformatics, 21(4):430–438, 2004.
[VBSB09] Andreas Vlachos, Paula Buttery, Diarmuid O Seaghdha, and Ted

414 BIBLIOGRAPHY
Briscoe. Biomedical event extraction without training data. In Proceed-
ings of the Workshop on Current Trends in Biomedical Natural Lan-
guage Processing: Shared Task, pages 37–40. Association for Compu-tational Linguistics, 2009.
[VC10] Andreas Vlachos and Mark Craven. Detecting speculative language us-ing syntactic dependencies and logistic regression. In Proceedings of
the Fourteenth Conference on Computational Natural Language Learn-
ing — Shared Task, CoNLL ’10: Shared Task, pages 18–25, Strouds-burg, PA, USA, 2010. Association for Computational Linguistics.
[VC12] Andreas Vlachos and Mark Craven. Biomedical event extraction fromabstracts and full papers using search-based structured prediction. InBMC bioinformatics, volume 13, page S5. BioMed Central, 2012.
[VdW02] Ton Van der Wouden. Negative contexts: Collocation, polarity and
multiple negation. Routledge, 2002.
[VEHPSH15] Marco A Valenzuela-Escarcega, Gus Hahn-Powell, Mihai Surdeanu,and Thomas Hicks. A domain-independent rule-based framework forevent extraction. Proceedings of ACL-IJCNLP 2015 System Demon-
strations, pages 127–132, 2015.
[VFG07] Kai Von Fintel and Anthony Gillies. An opinionated guide to epistemicmodality. Oxford studies in epistemology, 2:32–62, 2007.
[VFG11a] Kai Von Fintel and Anthony S Gillies. Might made right. Epistemic
modality, pages 108–130, 2011.
[VFG11b] Kai Von Fintel and Anthony S Gillies. Might made right. Epistemic
modality, pages 108–130, 2011.
[Vin13] Veronika Vincze. Weasels, hedges and peacocks: Discourse-level un-certainty in wikipedia articles. In IJCNLP, pages 383–391, 2013.
[VKB+15] Corinna Vehlow, David P Kao, Michael R Bristow, Lawrence E Hunter,Daniel Weiskopf, and Carsten Gorg. Visual analysis of biological data-knowledge networks. BMC bioinformatics, 16(1):135, 2015.

BIBLIOGRAPHY 415
[vL18] Casper van Leeuwen. Genevis-an interactive visualization tool forcombining cross-discipline datasets within genetics. arXiv preprint
arXiv:1805.02493, 2018.
[VMJS+05] Christian Von Mering, Lars J Jensen, Berend Snel, Sean D Hooper,Markus Krupp, Mathilde Foglierini, Nelly Jouffre, Martijn A Huynen,and Peer Bork. String: known and predicted protein–protein associ-ations, integrated and transferred across organisms. Nucleic acids re-
search, 33(suppl 1):D433–D437, 2005.
[VMKS+02] Christian Von Mering, Roland Krause, Berend Snel, Michael Cornell,Stephen G Oliver, Stanley Fields, and Peer Bork. Comparative assess-ment of large-scale data sets of protein–protein interactions. Nature,417(6887):399, 2002.
[Vol06] Eva Thue Vold. Epistemic modality markers in research articles: across-linguistic and cross-disciplinary study. International Journal of
Applied Linguistics, 16(1):61–87, 2006.
[Voo97] Frans Voorbraak. Deciding under partial ignorance. In Advanced Mo-
bile Robots, 1997. Proceedings., Second EUROMICRO workshop on,pages 66–72. IEEE, 1997.
[VOO10] Erik Velldal, Lilja Ovrelid, and Stephan Oepen. Resolving specula-tion: Maxent cue classification and dependency-based scope rules. InProceedings of the Fourteenth Conference on Computational Natural
Language Learning — Shared Task, CoNLL ’10: Shared Task, pages48–55, Stroudsburg, PA, USA, 2010. Association for ComputationalLinguistics.
[VØRO12] Erik Velldal, Lilja Øvrelid, Jonathon Read, and Stephan Oepen. Spec-ulation and negation: Rules, rankers, and the role of syntax. Computa-
tional linguistics, 38(2):369–410, 2012.
[VR86] Cornelis J Van Rijsbergen. A non-classical logic for information re-trieval. The computer journal, 29(6):481–485, 1986.

416 BIBLIOGRAPHY
[VRA18] Soroush Vosoughi, Deb Roy, and Sinan Aral. The spread of true andfalse news online. Science, 359(6380):1146–1151, 2018.
[VSF+08a] Veronika Vincze, Gyorgy Szarvas, Richard Farkas, Gyorgy Mora, andJanos Csirik. The bioscope corpus: biomedical texts annotated foruncertainty, negation and their scopes. BMC bioinformatics, 9(11):1,2008.
[VSF+08b] Veronika Vincze, Gyorgy Szarvas, Richard Farkas, Gyorgy Mora, andJanos Csirik. The BioScope corpus: biomedical texts annotated for un-certainty, negation and their scopes. BMC bioinformatics, 9:1–9, 2008.
[VSM+11] Veronika Vincze, Gyorgy Szarvas, Gyorgy Mora, Tomoko Ohta, andRichard Farkas. Linguistic scope-based and biological event-basedspeculation and negation annotations in the bioscope and genia eventcorpora. Journal of Biomedical Semantics, 2(5):1, 2011.
[VSS12] Kirsten Vis, Jose Sanders, and Wilbert Spooren. Diachronic changesin subjectivity and stance–a corpus linguistic study of dutch news texts.Discourse, Context & Media, 1(2-3):95–102, 2012.
[VVA+11] Thanasis Vergoulis, Ioannis S Vlachos, Panagiotis Alexiou, GeorgeGeorgakilas, Manolis Maragkakis, Martin Reczko, Stefanos Gerange-los, Nectarios Koziris, Theodore Dalamagas, and Artemis G Hatzige-orgiou. Tarbase 6.0: capturing the exponential growth of mirna tar-gets with experimental support. Nucleic acids research, 40(D1):D222–D229, 2011.
[WA05] Nicky J Welton and AE Ades. Estimation of markov chain transitionprobabilities and rates from fully and partially observed data: uncer-tainty propagation, evidence synthesis, and model calibration. Medical
Decision Making, 25(6):633–645, 2005.
[WAEF14] Derek W Wright, Tim Angus, Anton J Enright, and Tom C Free-man. Visualisation of BioPAX Networks using BioLayout Express 3D.F1000Research, 3:246, 2014.

BIBLIOGRAPHY 417
[WAF16] Michael Wainberg, Babak Alipanahi, and Brendan J. Frey. Are ran-dom forests truly the best classifiers? Journal of Machine Learning
Research, 17(110):1–5, 2016.
[Wan13] Po-Ya Angela Wang. # irony or# sarcasm—a quantitative and quali-tative study based on twitter. In Proceedings of the 27th Pacific Asia
Conference on Language, Information, and Computation (PACLIC 27),pages 349–356, 2013.
[WCWW18] Xin Wang, Wenhu Chen, Yuan-Fang Wang, and William Yang Wang.No metrics are perfect: Adversarial reward learning for visual story-telling. arXiv preprint arXiv:1804.09160, 2018.
[WFE+02] Thomas D Wilson, NIGEL J Ford, David Ellis, ALLEN E Foster, andAmanda Spink. Information seeking and mediated searching: Part 2.uncertainty and its correlates. Journal of the American society for In-
formation Science and Technology, 53(9):704–715, 2002.
[WHS+05] Theresa Wilson, Paul Hoffmann, Swapna Somasundaran, JasonKessler, Janyce Wiebe, Yejin Choi, Claire Cardie, Ellen Riloff, and Sid-dharth Patwardhan. Opinionfinder: A system for subjectivity analysis.In Proceedings of hlt/emnlp on interactive demonstrations, pages 34–35. Association for Computational Linguistics, 2005.
[WHS+11] Wei Wang, Krystl Haerian, Hojjat Salmasian, Rave Harpaz, HerbertChase, and Carol Friedman. A drug-adverse event extraction algo-rithm to support pharmacovigilance knowledge mining from pubmedcitations. In AMIA annual symposium proceedings, volume 2011, page1464. American Medical Informatics Association, 2011.
[Wil08] Theresa Ann Wilson. Fine-grained subjectivity and sentiment analysis:
recognizing the intensity, polarity, and attitudes of private states. PhDthesis, University of Pittsburgh, 2008.
[Win91] Samuel S Wineburg. Historical problem solving: A study of the cog-nitive processes used in the evaluation of documentary and pictorialevidence. Journal of educational Psychology, 83(1):73, 1991.

418 BIBLIOGRAPHY
[WKB07] Rene Witte, Thomas Kappler, and Christopher JO Baker. Enhancedsemantic access to the protein engineering literature using ontologiespopulated by text mining. International journal of bioinformatics re-
search and applications, 3(3):389–413, 2007.
[WMM+14] Stephen Wu, Timothy Miller, James Masanz, Matt Coarr, Scott Hal-grim, David Carrell, and Cheryl Clark. Negation’s not solved: gener-alizability versus optimizability in clinical natural language processing.PloS one, 9(11):e112774, 2014.
[Wol92] David H Wolpert. Stacked generalization. Neural networks, 5(2):241–259, 1992.
[WPDR15] Gregory Werner, Vinodkumar Prabhakaran, Mona Diab, and OwenRambow. Committed belief tagging on the factbank and lu corpora: Acomparative study. In Proceedings of the Second Workshop on Extra-
Propositional Aspects of Meaning in Computational Semantics (Ex-
ProM 2015), pages 32–40, 2015.
[WR05] Janyce Wiebe and Ellen Riloff. Creating subjective and objective sen-tence classifiers from unannotated texts. In International Conference
on Intelligent Text Processing and Computational Linguistics, pages486–497. Springer, 2005.
[WRS06] W John Wilbur, Andrey Rzhetsky, and Hagit Shatkay. New directionsin biomedical text annotation: definitions, guidelines and corpus con-struction. BMC bioinformatics, 7(1):356, 2006.
[WSMM06] Christopher Walker, Stephanie Strassel, Julie Medero, and KazuakiMaeda. Ace 2005 multilingual training corpus. Linguistic Data Con-
sortium, Philadelphia, 2006.
[WWB+04] Janyce Wiebe, Theresa Wilson, Rebecca Bruce, Matthew Bell, andMelanie Martin. Learning subjective language. Computational lin-
guistics, 30(3):277–308, 2004.

BIBLIOGRAPHY 419
[WWC05] Janyce Wiebe, Theresa Wilson, and Claire Cardie. Annotating expres-sions of opinions and emotions in language. Language resources and
evaluation, 39(2-3):165–210, 2005.
[WWH04] Theresa Wilson, Janyce Wiebe, and Rebecca Hwa. Just how mad areyou? finding strong and weak opinion clauses. In aaai, volume 4, pages761–769, 2004.
[WWL+17] Anran Wang, Jian Wang, Hongfei Lin, Jianhai Zhang, Zhihao Yang, andKan Xu. A multiple distributed representation method based on neuralnetwork for biomedical event extraction. BMC medical informatics and
decision making, 17(3):171, 2017.
[WXYM] Dylan Walker, Huafeng Xie, Koon-Kiu Yan, and Sergei Maslov. Citer-ank: A google-inspired ranking algorithm for citation networks.
[WZ14] Xiaojun Wan and Jianmin Zhang. Ctsum: extracting more certain sum-maries for news articles. In Proceedings of the 37th international ACM
SIGIR conference on Research & development in information retrieval,pages 787–796. ACM, 2014.
[WZL+14] Jia-Hong Wang, Ling-Feng Zhao, Pei Lin, Xiao-Rong Su, Shi-JunChen, Li-Qiang Huang, Hua-Feng Wang, Hai Zhang, Zhen-Fu Hu, Kai-Tai Yao, et al. Genclip 2.0: a web server for functional clusteringof genes and construction of molecular networks based on free terms.Bioinformatics, 30(17):2534–2536, 2014.
[XDH06] Kai Xia, Dong Dong, and Jing-Dong J Han. Intnetdb v1. 0: an in-tegrated protein-protein interaction network database generated by aprobabilistic model. BMC bioinformatics, 7(1):508, 2006.
[XDHW13] Boya Xie, Qin Ding, Hongjin Han, and Di Wu. mircancer: a microrna–cancer association database constructed by text mining on literature.Bioinformatics, 29(5):638–644, 2013.

420 BIBLIOGRAPHY
[XZHC13] Rui Xia, Chengqing Zong, Xuelei Hu, and E. Cambria. Feature ensem-ble plus sample selection: Domain adaptation for sentiment classifica-tion. Intelligent Systems, IEEE, 28(3):10–18, May 2013.
[YCLL11] Liang-Chih Yu, Chien-Lung Chan, Chao-Cheng Lin, and I-Chun Lin.Mining association language patterns using a distributional semanticmodel for negative life event classification. Journal of biomedical in-
formatics, 44(4):509–518, 2011.
[YM16] Bishan Yang and Tom Mitchell. Joint extraction of events and entitieswithin a document context. arXiv preprint arXiv:1609.03632, 2016.
[YRG+12] H. Yang, A. De Roeck, V. Gervasi, A. Willis, and B. Nuseibeh. Specu-lative requirements: Automatic detection of uncertainty in natural lan-guage requirements. In 2012 20th IEEE International Requirements
Engineering Conference (RE), pages 11–20, 2012.
[YTMT00] Akane Yakushiji, Yuka Tateisi, Yusuke Miyao, and Jun-ichi Tsujii.Event extraction from biomedical papers using a full parser. In Bio-
computing 2001, pages 408–419. World Scientific, 2000.
[ZA15] Chrysoula Zerva and Sophia Ananiadou. Event extraction in pieces:Tackling the partial event identification problem on unseen corpora.ACL-IJCNLP 2015, page 31, 2015.
[ZA18] Chrysoula Zerva and Sophia Ananiadou. Paths for uncertainty: Explor-ing the intricacies of uncertainty identification for news. In Proceedings
of the Workshop on Computational Semantics beyond Events and Roles,pages 6–20, 2018.
[Zad76] Lotfi A Zadeh. A fuzzy-algorithmic approach to the definition of com-plex or imprecise concepts. In Systems Theory in the Social Sciences,pages 202–282. Springer, 1976.
[Zan91] Raffaella Zanuttini. Syntactic properties of sentential negation. a com-parative study of romance languages. 1991.

BIBLIOGRAPHY 421
[ZBNDA17] Chrysoula Zerva, Riza Batista-Navarro, Philip Day, and Sophia Ana-niadou. Using uncertainty to link and rank evidence from biomedicalliterature for model curation. Bioinformatics, 33(23):3784–3792, 2017.
[ZDHZ15] Huiwei Zhou, Huijie Deng, Degen Huang, and Minling Zhu. HedgeScope Detection in Biomedical Texts: An Effective Dependency-BasedMethod. PLOS ONE, 10(7), jul 2015.
[ZDLC10] Yi Zheng, Qifeng Dai, Qiming Luo, and Enhong Chen. Hedge classi-fication with syntactic dependency features based on an ensemble clas-sifier. In Proceedings of the Fourteenth Conference on Computational
Natural Language Learning—Shared Task, pages 151–156. Associa-tion for Computational Linguistics, 2010.
[ZH08] Deyu Zhou and Yulan He. Extracting interactions between proteinsfrom the literature. Journal of biomedical informatics, 41(2):393–407,2008.
[ZPL13] Shkodran Zogaj, Christoph Peters, and Jan Marco Leimeister. Under-standing the principles of crowdsourcing in the light of the commons-based peer production model. 2013.
[ZS03] Guodong Zhou and Jian Su. System for recognising and classifyingnamed entities, December 31 2003. US Patent App. 10/585,235.
[ZSLL15] Chunting Zhou, Chonglin Sun, Zhiyuan Liu, and Francis Lau. A c-lstmneural network for text classification. arXiv preprint arXiv:1511.08630,2015.
[ZZZ13] Bowei Zou, Guodong Zhou, and Qiaoming Zhu. Tree kernel-basednegation and speculation scope detection with structured syntactic parsefeatures. In Proceedings of the 2013 conference on empirical methods
in natural language processing, pages 968–976, 2013.
[ZZZL10] Shaodian Zhang, Hai Zhao, Guodong Zhou, and Bao-Liang Lu. Hedge

422 BIBLIOGRAPHY
detection and scope finding by sequence labeling with normalized fea-ture selection. In Proceedings of the Fourteenth Conference on Compu-
tational Natural Language Learning—Shared Task, pages 92–99. As-sociation for Computational Linguistics, 2010.




















