Distribution, phylogeography and hybridization between two ...

Continuous Optimization Based on a Hybridization of
Differential Evolution with K-means
Luz-Marina Sierra, Carlos Cobos, Juan-Carlos Corrales
Universidad del Cauca, Popayán, Colombia
{lsierra, ccobos, jcorral}@unicauca.edu.co
Abstract. This paper presents a hybrid algorithm between Differential Evolu-
tion (DE) and K-means for continuous optimization. This algorithm includes
the same operators of the original version of DE but works over groups previ-
ously created by the k-means algorithm, which helps to obtain more diversity in
the population and skip local optimum values. Results over a large set of test
functions were compared with results of the original version of Differential
Evolution (DE/rand/1/bin strategy) and the Particle Swarm Optimization algo-
rithm. The results shows that the average performance of the proposed algo-
rithm is better than the other algorithms in terms of the minimum fitness func-
tion value reached and the average number of fitness function evaluations re-
quired to reach the optimal value. These results are supported by Friedman and
Wilcoxon signed test, with a 95% significance.
Keywords: continuous optimization, differential evolution, particle swarm op-
timization, K-means.
1 Introduction
The word “metaheuristic” is broadly used to refer to a stochastic algorithm that guide
the search process toward finding solutions very close to the optimum [1]. There are
many algorithms for carrying out this type of task - for example, Random Search,
Tabu Search, Simulated Annealing, Harmony Search, and Differential Evolution,
among others [1, 2]. In this paper we center on Differential Evolution, which showed
good performance in solving many theoretic and real optimization problems.
Differential Evolution was proposed by Rainer Storn and Kenneth Price [2] in
1997. Many implementations and changes have since been proposed. In [3] a hybrid
particle swarm differential evolution (HPSDE) is presented, this algorithm outper-
forms both DE and PSO algorithms. In [4], the authors propose two hybrids with
PSO: one uses DE operator to replace the standard PSO method for updating a parti-
cle’s position; and the other integrates both the DE operator and a simple local search;
these perform well in quickly finding global solutions. In [5] a hybrid algorithm
named CDEPSO is proposed, which combines PSO with DE and a new chaotic local
search. The study in [6] presents a performance comparison and analysis of fourteen
variants of DE and Multiple Trial Vectors DE algorithms to solve unconstrained

global optimization problems. In [7] a new DE is empowered with a clustering tech-
nique to improve its efficiency over multimodal landscapes (25 test functions were
used), the population is initialized randomly and divided into a specific number of
clusters (a minimum and maximum number of clusters is defined), after much itera-
tions each cluster exchanges information (in each cluster a best local solution is
searched for and the global solution determined), the number of clusters is self-
adaptive (when the algorithm is performing well, the cluster number is decreased;
otherwise it is increased), a rule is defined for the number of exploiters based on the
fitness of each vector solution in each cluster. In [8] the ACDE-k-means algorithm is
proposed, which improves the performance of the DE algorithm using a more bal-
anced evolution process through automatic adjustment of the parameter F [0.5; 1] and
a dynamic number of clusters between 2 and
√𝑁𝑃𝑜𝑝. In [9], the SaCoCDE algorithm improves the efficiency of DE by means of:
1) the cluster neighborhood mutation operator, through the auto-adaptation of Cr and
F parameters; 2) the overall mutation operator, which uses the centers of each cluster
to generate three test vectors using equations presented there, and selects from these
three generated vectors the new vector solution for the next generation.
The main contributions of this paper are: 1) a new version of the DE algorithm that
improves results of optimal values founded on 50 test functions against original ver-
sion of DE and PSO. 2) Feasible way of hybridizing DE with k-means in order to
provide a new operator to escape from the local optimum. 3) The definition of a new
selection strategy that combines the original operator of DE with the results of the k-
means algorithm (groups of solutions), providing more diversity and also increasing
the ability of the algorithm to work with multimodal test functions.
In section 2 that now follows, DE and K-means algorithms are briefly described.
The proposed hybrid algorithm is then presented in section 3. Later in section 4, the
results of the experiments are presented and analyzed. Finally, section 5 presents con-
clusions, remarks and future work.
2 Strategies
This section gives a brief description of the Differential Evolution algorithm, the K-
means algorithm, and the rank selection strategy used in genetic algorithms (the strat-
egy used in the proposed algorithm).
2.1 Differential Evolution
Differential Evolution (DE) is an algorithm that works for optimization problems with
non-linear and non-differentiable continuous functions [1]. DE looks to optimize
functions from a set of randomly generated solutions using specific operators of re-
combination, selection and replacement. Broadly speaking, the steps of the algorithm
are [10]:
Step 1: An initial random population is generated taking into account the limits of
each test function.

Step 2: The objective function value for all solution vectors (𝑋𝑖,𝐺 ) of the initial
population is calculated.
Step 3: Three vectors solution are randomly selected from the current population,
in this research the DE/rand/1/bin strategy was used. Then the mutation operator is
applied to each of these vectors in order to generate a disturbed vector, using the
Equation (1) [2], where i=1,…,PopulationSize, r1,r2,r3∈ {1,…,PopulationSize},
r1≠r2≠r3≠i; F ∈ [0,1] is a parameter to control the amplitude of the differential varia-
tion at the time of disturbing the vector [1].
𝐷𝐸|𝑟𝑎𝑛𝑑|1: 𝑉𝑖,𝐺+1 = 𝑋𝑟1,𝐺 + 𝐹 ∗ (𝑋𝑟2,𝐺 − 𝑋𝑟3,𝐺 ) (1)
Step 4: The process of crossover starts, so each vector solution in the population is
recombined using the Equation (2) [2], where j=1…Dimension, Crossover rate [1],
Cr, is a parameter to control the crossover operation and has to be determined by
the user, rnbr(i) is chosen randomly at the time of the crossover process [1], and
rand is the jth evaluation of a uniform random number generator with outcome ∈
[0; 1].
𝑈𝑗,𝑖,𝐺+1 = {𝑉𝑗,𝑖,𝐺+1 𝑖𝑓 𝑟𝑎𝑛𝑑 ≤ 𝐶𝑟 𝑜𝑟 𝑗 = 𝑟𝑛𝑏𝑟(𝑖)
𝑋𝑗,𝑖,𝐺 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒} (2)
Step 5: Is related to the selection operator. This operation includes a vector in the
new population of DE, in order to decide which the best is. DE compares the fit-
ness of the vector resulting from the crossover operation with the fitness of the vec-
tor target in the current population. Equation (3) [2] summarizes the operation.
𝑋𝑖,𝐺+1 = {𝑈𝑖,𝐺+1 𝑖𝑓 𝑓(𝑈𝑖,𝐺+1) ≤ 𝑓(𝑋,𝑖,𝐺)
𝑋𝑖,𝐺 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒} (3)
Step 6: steps 3-5 are repeated for each element of the current population. The algo-
rithm stop based on a specific number of generations defined by user. Fig. 1 sum-
marizes the algorithm.
01 Generate the initial population
02 Calculate the fitness value for each element of the population
03 Repeat
04 For each agent Xi,G in the population do
05 Select parents vectors (Xr1,G, Xr2,G and Xr3,G where r1≠r2≠r3≠i)
06 Generate the perturbed vector (Vi,G+1, using the equation (1)).
07 Build the Crossover vector (Ui,G+1, using the equation (2))
08 Get a new element for the population (Xi,G+1, using the equation (3))
09 End for each
10 Until (Stop conditions are reached)
Fig. 1. Pseudo code of Differential Evolution

Authors of DE algorithm [2] present three simple rules for setting DE parameters:
“1) NP (Population size) is between 5*D and 10*D but NP must be at least 4 to en-
sure that DE will have enough mutually different vectors with which to work. 2) F =
0.5 is usually a good initial choice, but if the population converges prematurely, then
F and/or NP should be increased. 3) A large Cr often speeds convergence, to first try
Cr = 0.9 or Cr = 1.0 is appropriate”. For this work, the Cr and F values were taken
from those used in other experiments in order to have reference values to use for
comparison and the analysis of the algorithm performance.
2.2 K-means Algorithm
K-means is a clustering algorithm that looks to find clusters among a set of individu-
als by calculating the distances between each individual and the centroid of the near-
est group (cluster) [11]. Fig. 2 summarizes the k-means algorithm [12]. Below, a list
of some specific considerations of the k-means algorithm for the proposed algorithm
is presented:
The data to be processed by the k-means algorithm are all vector solutions in the
population of DE.
The number of desired groups (k) is previously defined and constant during the
execution of the entire hybrid algorithm; in this case, this value is equal to the
greater integer of the population size divided by 4. Preliminary tests show that
higher values of this parameter allow obtaining better results.
The centroids of every cluster are initially randomly selected.
The Euclidean distance (see Equation (4)) is used for finding the similarities be-
tween vector solutions and centroids of each cluster (group), then the centroids are
re-calculate for each cluster.
𝑑(𝑥, 𝑦) = √∑ (𝑥𝑖 − 𝑦𝑖)2𝑛
𝑖=1 (4)
The set of data (vector solutions in population) is organized into the numbers of
clusters previously defined.
01 Define the number of clusters (groups)
02 Randomly select a set of initial centroids
03 Repeat
04 Assign every data in a specific cluster based on Euclidian distance
05 Re-Calculate the centroids of each cluster
06 Until (there no more changes in centroids or iterations max are achieved)
07 Return groups
Fig. 2. Pseudo code of the K-means algorithm
2.3 Rank Selection
Rank selection was initially proposed by Baker to eliminate the high convergence of
genetic algorithms when using proportional selection methods. This selection method

chooses a new vector solution from the population, based on a ranking table. This
table lists in order all the solutions based on the fitness function of solutions. Values
in the ranking table are calculated based on formula (5), where n is the total number
of vector solutions in the population (population size) and i (between 0 and n-1) is the
order number of each specific vector solution [13].
0.25−1.5∗(𝑖∗
1.0
𝑛−1)
𝑛 (5)
3 The Proposed Algorithm
In this section, the proposed hybrid algorithm is presented, called DEKmeans. DEK-
means is the result of combining the original version of Differential Evolution with K-
means. The main motivation for the development of this proposal is the change of the
selection operator in DE based on groups formed by the k-means algorithm, so that
the algorithm gets more exploration, in order to seek more diversity and skip the local
optimum.
This proposed algorithm includes some improvements, such as adapting a version
of k-means strategy to operate sometimes on the population in order to organize the
vector solutions in groups and then use the DE mutation operator (See Eq. 1) as a step
to create the new vector solution. In DEKmeans, the rand/1/bin strategy of the origi-
nal DE is also used. The computational steps of this hybrid algorithm are described as
follows:
The initial population is generated in the same way described above in the differen-
tial evolution section.
The fitness of every vector solution is calculated according to each function.
In the generation of the following populations, a variation was proposed that in-
cludes two ways to generate every new population:
─ The first way, given the PEOA - percentage of execution of the original algo-
rithm - parameter, involves using the method described above for differential
evolution 95% of the time (this parameter can be defined by the user,) when a
new population is generated.
─ The second way, the remaining 5% (1 - PEOA) of the time, the parent selection
operator uses a version that includes the adaptation of k-means algorithm. Par-
ents vectors are selected in a special way: first they are taken from the different
groups and special probabilities (Rank Selection, see Section 2.3) assigned to
them in order to increase the probability for selecting registers with best fitness
on each group.
─ Following application of the mutation, crossover, and replace operators, the al-
gorithm carries out a review of the elements of the new population, to avoid in-
cluding a vector solution that already exists in the new population generated. If
the resulting vector solution exits in the population a new randomly vector solu-
tion is generated. This approach avoids premature converged.

Comparing our proposed algorithm (DEKmeans) with other work presented above:
1) In reference to [3, 4, 5, 6] our proposal introduces a new version of the DE algo-
rithm (DE/rand/1/bin strategy), which hybridizes to DE with the K-means algorithm
and uses Rank Selection, so that it not only generates a hybrid algorithm but a whole
strategy that improves its performance by helping it out of local optima, making it
more effective, comparing it with the original version of DE and PSO using 50 test
functions (which include a variety of problems), in contrast with the others that use
some aspects of DE or PSO for use within each. 2) In reference to [7, 8, 9], DEK-
means presents a simple and robust solution comparable with those that have a greater
complexity and also implement K-means, but applied from different points of view
and even redefining the operators of the DE algorithm, in contrast with DEKmeans
that retains the advantages of the original DE version but improving the evolution
process of DE in the selection of the vectors to be used in the mutation operator (see
Equation (1)) (applying Rank Selection to the groups obtained by the k-means algo-
rithm) and to improve in a simple way the process of selection of the population,
avoiding that the algorithm converges quickly and becomes trapped in local minima.
A summary of the proposed algorithm can be seen in Fig. 3. Lines 5, 8, 9, 14 and
15 are new; the other lines correspond to the original version of DE.
4 Experiments: DEKmeans vs DE and PSO
DEKmeans was compared against DE and Particle Swarm Optimization (PSO). To do
this, a set of fifty (50) test functions was used. This set of functions includes many
different kinds of problems - unimodal, multimodal, separable, regular, irregular, non-
separable and multidimensional. For every test function we ensured that the solution
vectors always are between the lower and upper limit in each dimension (D). Uncon-
strained problems were not taken into account in this proposal.
4.1 Settings
Test function: the definitions, parameters and ranges used for the implementation of
the test function are the same as described in [14], because this test functions are used
in several recent papers where new continuous optimization algorithms have been
proposed.
For the experiments, the values of the common parameters used in each algorithm
such as population size and total evaluation number were the same. Population size
(or swarm size in PSO) was set to 50 and the maximum evaluation number was set to
500.000 for all functions. The other specific algorithm parameters are summarized
below.
In DE, F is 0.5 and Cr is 0.9, similar to [10] [14].
In PSO, maximum speed (Vmax) is 5, minimum speed (Vmin) is -5, Cognitive and
social component varies between 0.5 and 1, and moment varies between 0.4 and 0.9,
Global Optimum in false is similar to [15], where the values of these parameters are
taken adaptively on each generation.

In DEKmeans, the execution frequency of the original DE operators against those
based on K-means is 95% of the time.
01 To generate an initial population
02 To calculate the fitness in every element of the population
03 Repeat
04 For each agent Xi,G in the population do
05 If (random is > PEOA) then
06 Select parents vectors (Xr1,G, Xr2,G and Xr3,G where r1≠r2≠r3≠i)
07 else
08 Cluster vector solutions in current population: Execute the K-means
procedure (See Fig. 2)
09 Select parents vectors from different groups of K-means (Xr1,G, Xr2,G
and Xr3,G belong a different groups in the population and using Rank
Selection method [13] for select the solution of each group, also
r1≠r2≠r3≠i).
10 end if
11 Generate the perturbed vector (Vi,G+1, using the equation (1)).
12 Build the Crossover vector (Ui,G+1, using the equation (2))
13 Get a new element for the population (Xi,G+1, using the equation (3)) but
14 If (Xi,G+1 already exists into the population) then
15 Xi,G+1 is randomly generated (as in initial population)
17 End for each
18 Until (Stopping criterion are reached)
Fig. 3. Hybrid algorithm Differential Evolution and K-means pseudo code
4.2 Results
All algorithms were executed 30 times for each test function and the average fitness
and standard deviation calculated. The average results obtained in the experiments are
summarized in Table 1.
DEKmeans reaches the optimum (minimum) value of thirty eight (38) functions
before completing the 500,000 evaluations of the fitness function, meanwhile DE
reaches thirty seven (37) and PSO only twenty seven (27).
Taking as a reference the PSO algorithm (baseline, line with value equal to cero),
Fig 4 shows that DE and DEKmeans required less evaluations of the fitness function
in order to reach the optimum, e.g. in test function 9 (Colville), PSO required on aver-
age 498081 evaluations, DE 124951 and DEKmeans only 30126, therefore, DE re-
quired on average 373130 evaluations less than PSO, and DEKmeans required on
average 467955 evaluations less than PSO.

Table 1. General Results (Mean ± Standard Deviation) of PSO, DE And DEKmeans Over Each
Test Function. D: Dimension, T: Type, U: Unimodal, M: Multimodal, S: Separable, N: Non-
Separable.
Id Function D Type PSO DE DEKMEANS
1 StepInt 5 US 0 ± 0 0 ± 0 0 ± 0
2 Step 30 US 0 ± 0 0.0333333 ± 0.1825742 0 ± 0
3 Sphere 30 US 0.00044 ± 0.0010574 0 ± 0 0 ± 0
4 SumSquares 30 US 0.00201 ± 0.0029216 0 ± 0 0 ± 0
5 Quartic 30 US 0.00642 ± 0.0026019 0.0016232 ± 0.0006038 0.0014402 ± 0.0005918
6 Beale 5 UN 0 ± 0 0 ± 0 0 ± 0
7 Easom 2 UN -1 ± 0 -1 ± 0 -1 ± 0
8 Matyas 2 UN 0 ± 0 0 ± 0 0 ± 0
9 Colville 4 UN 0 ± 0 0.1206508 ± 0.5217277 0 ± 0
10 Trid6 6 UN -50 ± 0 -50 ± 0 -50 ± 0
11 Trid10 10 UN -210 ± 0 -210 ± 0 -210 ± 0
12 Zakharov 24 UN 4.98533 ± 18.9722821 0 ± 0 0 ± 0
13 Powell 30 UN 56.26736 ± 75.19882 0.0000005 ± 0.0000004 0.0000004 ± 0.0000004
14 Schwefel2 30 UN 0.006425 ± 0.01428 0 ± 0 0 ± 0
15 Schwefel 30 UN 0.99335 ± 0.4182441 0 ± 0 0 ± 0
16 Rosenbrock 30 UN 51.596532 ± 34.24415 15.56863 ± 7.76282 15.5650881 ± 7.5419387
17 DixonPrice 30 UN 1.37192 ± 1.04845 0.6666667 ± 0 0.6666667 ± 0
18 Foxholes 2 MS 1.3958 ± 0.6167405 0.9983 ± 0.0004 0.9985195 ± 0.00058
19 Branin 2 MS 0.3979313 ± 0.00003 0.39794 ± 0.00003 0.3979349 ± 0.0000297
20 Bohachevsky1 2 MS -0.2690782 ± 0.2067532 0 ± 0 0 ± 0
21 Booth 2 MS 0 ± 0 0 ± 0 0 ± 0
22 Rastrigin 30 MS 127.06191 ± 64.4077 12.46682 ± 3.55653 9.48422 ± 3.5301
23 Generalized
Schwefel 30 MS -6373.901205 ± 697.3241 -10275.43814 ± 512.582 -11179.76933 ± 506.52748
24 Michalewicz2 2 MS -1.8013 ± 0 -1.801302 ± 0.0000009 -1.8013 ± 0
25 Michalewicz5 5 MS -4.67431 ± 0.03721 -4.6820898 ± 0.0144393 -4.6876582 ± 0
26 Michalewicz10 10 MS -9.34212 ± 0.43607 -9.6185266 ± 0.037151 -9.6525355 ± 0.0160679
27 Schaffer 2 MN 0 ± 0 0 ± 0 0 ± 0
28 Six-Hump
Camel-Back 2 MN -1.03163 ± 0 -1.0316285 ± 0 -1.0316285 ± 0
29 Bohachevsky2 2 MN 0 ± 0 0 ± 0 0 ± 0
30 Bohachevsky3 2 MN 0 ± 0 0 ± 0 0 ± 0
31 Shubert 2 MN -186.7309 ± 0 -186.7309 ± 0 -186.7309 ± 0
32 GoldsteinPrice 2 MN 3 ± 0 3 ± 0 3 ± 0
33 Kowalik 4 MN 0.00046 ± 0.00032 0.0005242 ± 0.0003738 0.0003075 ± 0
34 Shekel5 4 MN -10.05353 ± 0 -10.0535269 ± 0 -10.0535269 ± 0
35 Shekel7 4 MN -10.06371 ± 0 -10.0637085 ± 0 -10.0637085 ± 0
36 Shekel10 4 MN -10.07505 ± 0 -10.0750459 ± 0 -10.0750459 ± 0
37 Perm 4 MN 0.00291 ± 0.0020308 0.05509 ± 0.1436 0.0002862 ± 0.0004535
38 PowerSum 4 MN 0.00781 ± 0.0053186 0.00012 ± 0.000133 0.0001066 ± 0.0001298
39 Hartman3 3 MN -3.90511 ± 0.0232529 -3.89989 ± 0.0248041 -3.8978425 ± 0.0240514
40 Hartman 6 MN -3.1916115 ± 0.0725006 -3.23495 ± 0.0536161 -3.3183945 ± 0.021764
41 Griewank 30 MN 0.0000324 ± 0.0000783 0.00156 ± 0.0036878 0.0004927 ± 0.0026984
42 Ackley 30 MN 0.0106014 ± 0.0129442 0 ± 0 0 ± 0
43 Penalized 30 MN 0 ± 0 0 ± 0 0 ± 0
44 Penalized2 30 MN 8.00602 ± 43.85012 0.0030181 ± 0.0165308 0 ± 0
45 Langerman2 2 MN -1.08052 ± 0.00022 -1.080499 ± 0.0002486 -1.0805055 ± 0.0002397
46 Langerman5 5 MN -1.83903 ± 0.13651 -1.9217559 ± 0.0734335 -1.9372483 ± 0.0687818
47 Langerman10 10 MN -2.44412 ± 0.22349 -2.5296588 ± 0.0407439 -2.5354428 ± 0.0320827
48 FletcherPowell2 2 MN 129.16175 ± 262.73961 0 ± 0 0 ± 0
49 FletcherPowell5 5 MN 432.89501 ± 616.72146 321.88845 ± 668.95475 0 ± 0
50 FletcherPowell10 10 MN 1385.35261 ± 1676.62682 869.99811 ± 2320.78567 179.35054 ± 220.58321
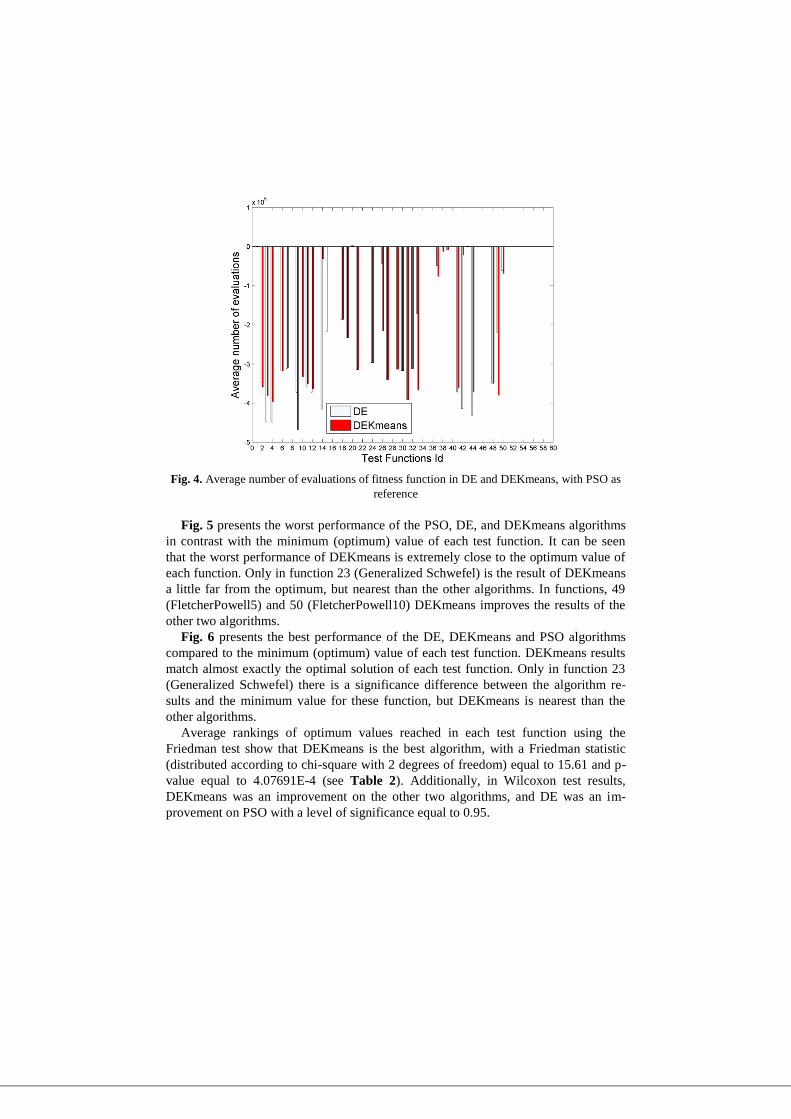
Fig. 4. Average number of evaluations of fitness function in DE and DEKmeans, with PSO as
reference
Fig. 5 presents the worst performance of the PSO, DE, and DEKmeans algorithms
in contrast with the minimum (optimum) value of each test function. It can be seen
that the worst performance of DEKmeans is extremely close to the optimum value of
each function. Only in function 23 (Generalized Schwefel) is the result of DEKmeans
a little far from the optimum, but nearest than the other algorithms. In functions, 49
(FletcherPowell5) and 50 (FletcherPowell10) DEKmeans improves the results of the
other two algorithms.
Fig. 6 presents the best performance of the DE, DEKmeans and PSO algorithms
compared to the minimum (optimum) value of each test function. DEKmeans results
match almost exactly the optimal solution of each test function. Only in function 23
(Generalized Schwefel) there is a significance difference between the algorithm re-
sults and the minimum value for these function, but DEKmeans is nearest than the
other algorithms.
Average rankings of optimum values reached in each test function using the
Friedman test show that DEKmeans is the best algorithm, with a Friedman statistic
(distributed according to chi-square with 2 degrees of freedom) equal to 15.61 and p-
value equal to 4.07691E-4 (see Table 2). Additionally, in Wilcoxon test results,
DEKmeans was an improvement on the other two algorithms, and DE was an im-
provement on PSO with a level of significance equal to 0.95.

Fig. 5. Worst performance of DE, PSO and DEKmeans algorithms compared against the mini-
mum value for each test function
Table 2. Friedman Test Rankings.
Algorithm Optimum Value Reached
Ranking Position
DEKmeans 1.6 1
DE 2.01 2
PSO 2.39 3
Fig. 6. Best performance of DE, PSO and DEKmeans algorithms compared against the mini-
mum value for each test function

5 Conclusion and future work
Three metaheuristics for continuous optimization were compared, namely: 1) Differ-
ential Evolution (DE/rand/1/bin), 2) Particle Swarm Optimization, and 3) DEKmeans,
a hybrid algorithm between Differential Evolution and K-means. The three algorithms
were tested using 50 test functions of different types (Unimodal, Multimodal, Separa-
bles, and Non-Separables).
Performing thirty test runs of each algorithm in all test functions, DEKmeans
shows better results than the original DE and PSO algorithms. DEKmeans shows that:
It can achieve an optimal solution with far fewer iterations, as shown in Fig 4.
The best and worst performances of DEKmeans are better in some functions and
similar to the other algorithms, DE and PSO, but approximate very closely to the
optimal values of the test functions.
For these reasons, we can say that the DEKmeans algorithm has practical ad-
vantages for solving unimodal, multimodal, separable, and non-separables continuous
optimization problems.
As regards future work, it is hoped to compare DEKmeans with other metaheuris-
tics and make further improvements to this hybrid algorithm, for example some of the
algorithms presented in the introduction section of this paper. Adjustments are re-
quired to be made to the DE parameters in order get the best performance from the
proposed algorithm.
6 Acknowledgements
We are grateful to Universidad of Cauca and its research groups GTI and GIT of the
Computer Science and Telematics departments. We are especially grateful to Colin
McLachlan for suggestions relating to the English text.
7 References
1. Brownlee, J.: Clever Algorithms Nature-Inspired Programming Recipes, Melbourne:
lulu.com (2011)
2. Storn, R., Price, K.: Differential Evolution – A Simple and Efficient Heuristic for Global
Optimization over Continuous Spaces. In Journal of Global Optimization, Netherlands
(1997)
3. Nwankwor, E., Nagar, A. K., Reid, D. C.: Hybrid differential evolution and particle swarm
optimization for optimal well placement. Computational Geosciences, vol. 17, no. 2, pp.
249-268, (2013)
4. Fu, W., Johnston, M., Zhang, M.: Hybrid Particle Swarm Optimisation Algorithms Based on
Differential Evolution and Local Search. In Advances in Artificial Intelligence Lecture
Notes in Computer Science, vol. 6464, pp. 313-322, Springer Berlin Heidelberg, (2011)

5. Tan, Y., Tan, G.-z., Deng, S.-g.: Hybrid Particle Swarm Optimization with Differential
Evolution and Chaotic Local Search to Solve Reliability-redundancy Allocation Problems.
In Journal of Central South University, vol. 20, no. 6, pp. 1572-1581 (2013)
6. Jeyakumar, G., Shunmuga, V., C.: A comparative Performance Analysis of Multiple Trial
Vectors Differential Evolution and Classical Differential Evolution Variants. In Rough Sets,
Fuzzy Sets, Data Mining and Granular Computing Lecture Notes in Computer Science, vol.
5908, pp. 470-477, Dehli, Springer Berlin Heidelberg (2009)
7. Maity, D., Halder, U., Dasgupta, P.: An Informative Differential Evolution with Self
Adaptive Re-clustering Technique. in Swarm, Evolutionary, and Memetic Computing.
Lecture Notes in Computer Science, vol. 7076, pp. 27-34, Visakhapatnam (2011)
8. Kuo, R.J., Suryani, E., Yasid, A.: Automatic Clustering Combinign Differenctial Evolution
Algorithm and K-means Algorithm. in Proceedings of the Institute of Industrial Engineers
Asian Conference 2013,pp. 1207-215 (2013)
9. Yang, X., Liu, G.: Self-adaptive Clustering-Based Differential Evolution with New
Composite Trial Vector Generation Strategies. in Proceedings of the 2011 2nd International
Congress on Computer Applications and Computational Sciences – Advances in Intelligent
and Soft Computing. Springer Berling Heidelberg, pp.261-267 (2012)
10. Ali, M., Pant, M., Abraham, A.: A simplex differential evolution algoritm: development
and applications. In Transactions of the Institute of Measurement and Control, vol. 34, no. 6,
pp. 691 - 704 (2012).
11. Hernández O., J., Ramírez Q., M. J., Ferri R., C.: Introducción a la Mineria de Datos.
Pearson - Prentice Hall, España (2004)
12. Zu-Feng, W., Xiao-Fan, M., Qiao, L., Zhi-guang, Q.: Logical Symmetry Based K-means
Algorithm with Self-adaptive distance metric. In Advances in Computer Science and Its
Application - Lecture notes in Electrical Engineering, vol. 279, pp. 929 – 936, Springer
Berlin Heidelberg (2014)
13. Jiang, H., Liu, Y., Zheng, L.: Design and Simulation of Simulated Annealing Algorithm
with Harmony Search. In Advances in Swarm Intelligence. Lecture Notes in Computer
Science, vol. 6146, pp. 454-460, Beijing, Springer Berlin Heidelberg (2010)
14. Karaboga, D., Akay, B.: A comparative study of Artificial Bee Colony algorithm. In
Applied Mathematics and Computation, vol. 214, no. 1, pp. 198-132 (2009)
15. Poli, R., Kennedy, J., Blackwell, T.: Particle swarm optimization. In Swarm Intelligence,
vol. 1, n°1, pp. 33-57 (2007)
16. Alcalá-Fdez, J., Sánchez, L., García, S., Del Jesus, M., Ventura, S., Garrell, J., Otero, J.,
Romero, C., Bacardit, J., Rivas, V., Fernández, C., Herrera, F.: KEEL: A Software Tool to
Assess Evolutionary Algorithms to Data Mining Problems. In Soft Computing, vol. 13, no.
3, pp. 307-318 (2009)
Copyright © 2022 FDOKUMEN