
3D Human Face Recognition Using Sift Descriptors of Face’s Feature Regions
Upload
terengganuCategory
view
1download
0
Content-Based Image Retrieval using SIFT for Binary and Greyscale Images
Suraya Abu Bakar, Muhammad Suzuri Hitam, Wan Nural Jawahir Hj Wan Yussof Department of Computer Science
Faculty of Science and Technology University of Malaysia Terengganu 21030 Kuala Terengganu, Malaysia
[email protected] [email protected]
Abstract—This paper presents an alternative approach for Content Based Image Retrieval (CBIR) using Scale Invariant Feature Transform (SIFT) algorithm for binary and gray scale images. The motivation to use SIFT algorithm for CBIR is due to the fact that SIFT is invariant to scale, rotation and translation as well as partially invariant to affine distortion and illumination changes. Inspired by these facts, this paper investigates the fundamental properties of SIFT for robust CBIR by using MPEG-7, COIL-20 and ZuBuD image databases. Our approach uses detected keypoints and its descriptors to match between the query images and images from the database. Our experimental results show that the proposed CBIR using SIFT algorithm producing excellent retrieval result for images with many corners as compared to retrieving image with less corners.
I. INTRODUCTION With the availability of internet technology, the number of
shared digital images has increased tremendously. Thus, an automated and efficient Content-based Image Retrieval (CBIR) system that can efficiently retrieve and rank similar images according to user request is a necessity. This CBIR system will not only be able to simplify and improve image retrieval but also make the image retrieval process automatic since the traditional manual image retrieval is almost impossible to deal with this task. CBIR system [1] extracts image information that is used to retrieve relevant images from image database that best match query image. In this process, several distinct image features such as colour, texture and shape or any other information that are derived from the images. CBIR has since been widely used to describe the process of retrieving desired images from a large collection of images on the basis of features that can be automatically extracted from the images themselves. Since its first introduction, CBIR has becomes an important research topic for academic and industrial practitioners [2]-[4].
CBIR systems are essential in searching for specific images, or for a member of a desired category of images from a digital image databases. There are many types of digital images to be considered such as binary, greyscale, colour and indexed image. In general, binary image is often appropriate if the image being studied is of type contour. This paper presents a method to extract the topological structure of a given binary image. Typically, a binary image is composed of two colours;
black and white. For a CBIR system, the use of a binary image leads to many advantages as compared to using real-valued bit-wise operations. These advantageous includes easy manipulation, cheap to store and also very fast to process. Several researchers [5], [6] used binary image in their CBIR system and their proposed techniques are based on binary coding of feature vectors. Binary histogram had also been proposed [6] that can be used for image classification and retrieval without image segmentation which provides good retrieval performances but only works on gray level images.
Generally, image features can be categorized into two categories; global features and local features. Global features are global image properties such as intensity histogram, mean and standard deviation values of pixel distribution, and on the contrary, local image features are specific image properties of local image region such as edges, corners, lines and curves. In some applications, a global image features is sufficient and could provide quite powerful image descriptors to represent global features of the images [7]–[9], however these global image features may not be able to cope with other specific application requirements such as varying object's sizes, cluttered objects, viewpoint differences of objects where object details are required. In general, global features were employed due to their low computational cost and acceptable effectiveness to validate their use. Despite its successfulness in representing image features, such CBIR systems could not capture some local image properties for representing the details of the object. Many benefits of using local features includes it is possible to detect objects under occlusions and it is invariant to scale as well as rotation changes. Scale Invariant Features Transform or widely known as SIFT [10] is one of the techniques that has been successfully used for local interest point detector and its descriptors.
A typical SIFT descriptors are computed on image patches and uses 8 orientation planes. At each orientation, gradient image is sampled over a 4x4 grid, thus producing what is known as keypoint descriptors of feature vector containing 128 elements. The descriptors are distinctive and at the same time robust to changes in viewing conditions as well as to errors of the point detector. SIFT is not just scale invariant but also invariant to rotation and translation and partially
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
83

invariant to illumination and viewpoint changes. Some other popular keypoint extraction techniques are Gabor [11], SURF [12] and Harris [13] corner detector.
CBIR implementations have received extensive attentions in recent years and a few reported researches were published on the use of SIFT for CBIR tasks [14]–[16]. In [14], the application of the SIFT for CBIR was developed and the results showed that the SIFT approach is invariant to colour channels and they found that there is a trade-off between the size of the feature vector and its description quality in order to produce good results. CBIR is the application to be solved in many fields including the area of medical, forensics and others. In forensics and law enforcement, CBIR system for tattoo images has great value in apprehending suspects and indentifying victims [15]. In this system, SIFT keypoint matching can reduce false retrievals and the experimental results on 1,000 queries against an operational database of 63,593 tattoo images show a rank-20 accuracy of 94.2%. The SIFT keypoints described in [16] enables the correct match for a keypoint to be selected from a large database of other keypoints. Multiple objects can be detected using SIFT keypoints. However, in this paper, we only focus on single binary object retrieval. Based on the improvement shown in CBIR tasks, this paper focuses on the design and developments of CBIR using SIFT on different image databases.
The paper is organized into four sections: Section I is the introduction, where the literature of CBIR and SIFT information were reviewed. The details of SIFT is describes in Section II. Section III describes the implementation detail, experimental results and discusses the experimental findings. Finally, conclusion and future work are discussed in Section IV.
II. SCALE INVARIANT FEATURE TRANSFORM (SIFT) Scale Invariant Feature Transform (SIFT) was proposed by
David Lowe [10] that is able to detect and describe local image features efficiently. The main SIFT algorithm consists of four major stages:
• Scale-space extrema detection • Keypoint localization • Orientation assignment • Keypoint descriptor
The following sub-section will describe each stage.
A. Scale-space extrema detection The first stage of SIFT is the detection of local interest
points called keypoint. In this stage, the algorithm must search the potential keypoints over all scales and image locations. It can be efficiently implemented by using a difference-of-Gaussian function that are invariant to scale and orientation. The scale space of an image is defined as a function L(x, y,σ), that is produced from the convolution of a variable-scale Gaussian G(x, y,σ), with an input image I(x, y) as shown in Eq.1 and Eq.2:
L(x, y,σ) = G(x, y,σ) ∗ I(x, y) (1)
where ∗ is the convolution operation in x and y and
G(x, y,σ) = / (2)
To effectively detect stable keypoint location in scale space,
Lowe [17] used scale space peaks in Difference of Gaussian (DoG) function convolved with the image D(x, y,σ) which can be computed from the difference of two nearby scaled images separated by a multiplicative factor k as in Eq. 3:
D(x, y,σ) = (G(x, y, kσ) - G(x, y,σ))∗ I(x, y)
= L(x, y, kσ) - L(x, y,σ) (3)
It is particularly efficient by using this function to compute a smoothed images L, need to be computed in any case for scale space feature description. Therefore, D can be computed by simple image subtraction.
Fig. 1 shows an example of blurred images at different scale. For each octave of scale space, the initial image is repeatedly convolved with Gaussian to produce the set of scale space images shown on the left. Adjacent Gaussian images are subtracted to produce the DoG images on the right. After each octave, the Gaussian image is down-sampled by a factor of 2, and the process repeated.
Fig. 1. Example blurred images at different scale [10].
Once a complete octave has been processed, the Gaussian image has twice the initial value of σ by taking every second pixel in each row and column.
B. Keypoint localization The next stage is to perform a detailed fit to the nearby data
for location, edge response and peak magnitude. A location in image scale space is identified that are invariant with respect to image rotation, translation and scaling. At each candidate location, a detailed model is fit to determine location, scale and contrast. Keypoints are selected based on measures of their stability.
Lowe [10] simply located keypoint at the location and scale of the central sample point. To characterize the image at each keypoint location, the smoothed image is processed to extract image gradient and orientations.
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
84

C. Orientation assignment One or more orientations are assigned to each keypoint
location based on local image properties. All future operations are performed relative to the assigned orientation, scale and location for each feature, providing invariance to these transformations.
The scale of the keypoint is used to select the Gaussian smoothed image L, with the closest scale, as all computations must be performed in a scale-invariant manner. For each image sample, Lx, y the gradient magnitude m, and orientation ө, is precomputed using pixel differences:
, , , , (4) , , / , , (5)
An orientation histogram is formed from the gradient
orientations at all sample points within a circular window around the keypoint.
D. Keypoint descriptor The local image gradients are measured at the selected
scale in the region around each keypoint and transformed into a representation that allows for local shape distortion and change in illumination. Figure 2 illustrates the computation of the keypoint descriptor as described in [10]. A Gaussian weighting function with σ equal to one half the width of the feature-vector window is used to assign a weight to the magnitude of each sample point as showed on the left side of Fig. 2.
Fig. 2. The computation of the keypoint descriptor [10]
A keypoint descriptor is created by first computing the
gradient magnitude and orientation at each image sample point in a region around the keypoint location, as shown on the left. These are weighted by a Gaussian window, indicated by the overlayed circle. These samples are then accumulated into orientation histograms summarizing the contents over 4x4 subregions, as shown on the right of the figure with the length of each arrow corresponding to the sum of the gradient magnitudes near that direction within the region. Fig. 2 shows a 2x2 descriptor array computed from an 8x8 set of samples, whereas the experiments in [10] use 4x4 descriptors computed from a 16x16 sample array.
III. IMPLEMENTATION AND EXPERIMENTAL RESULTS In this paper, SIFT is coded using MATLAB programming
language and implemented on a 2.00GHz CPU computer with 3.0GB RAM and Windows XP operating system. The dataset used in the experiment is the MPEG-7 Core Experiment Shape-1 Part B. It was created by the Motion Picture Expert Group (MPEG) committee which is a working group of ISO/IEC [18]. This image collection includes 1400 binary images grouped into 70 categories by their content and each category contains 20 image samples.
A. Feature Detection For efficient matching between the query image and
indexed images in the image database, firstly all images are represented as a set of SIFT features. Each SIFT feature represents a vector of local image measurements in a manner that is invariant to image translation, scaling, rotation and partially invariant to changes in illumination and local image deformations. The SIFT feature locations are efficiently detected by identifying maxima and minima of a DoG function in scale space as previously mentioned. A feature vector is formed by measuring the local image gradients in a region around each location at coordinates relative to the location, scale and orientation of the feature.
For clarity purpose of the experiments carried out in this paper, all detected maxima and minima of the DoG function are displayed as the keypoints. Fig. 3 illustrates examples of detected SIFT keypoints for MPEG-7 dataset images. The SIFT keypoints are shown as blue arrow lines with arrows overlaid indicating the locations, scales, and orientations of the key features. The length of the arrow lines correspond to the image regions used to construct the descriptor.
13 keypoints detected
19 keypoints detected
57 keypoints detected
62 keypoints detected
64 keypoints detected
87 keypoints detected
Fig. 3. Number of keypoints detected by SIFT.
In this example, it should be noted that more keypoints will be detected for image with a lot of corners. Hence, it can be assumed that the keypoints have already been detected as corners in scale-space namely local minima/maxima. All the detected keypoints of the dataset images have been saved in
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
85

the feature database to be used for indexpurposes. B. Feature Matching and Indexing
Keypoints from a query image can be from dataset images by the descriptor vEuclidean distance among all vectors froAccording to the Euclidean distance formbetween two points in the plane with coordib) is given as in Eq. 6:
Dist ((x, y), (a, b)) =
13
7m
5m
1m
In this experiment, SIFT features of eachmatches with the respective features idatabase and displays its results. The resinput images next to each other, with linmatching locations. The matches are identinearest neighbors of each keypoint fromamong those images in the database. As ilthe first row of hammer and octopus image13 and 62 keypoints, respectively. In the secand partially occluded hammer was matchewhile 22 matches are found for partially otentacles. For octopus image in the third romatched with the hammer image and matched with the octopus image. In the bkeypoint was matched between the hammimage whereas 4 matches are found for image.
xing and matching
matched to those vector with closest m dataset images. mula, the distance inates (x, y) and (a,
(6)
SIFT features use a charactekeypoint to form the similarity the SIFT keypoints need to be for indexing and similarity maquery. Fig. 4 shows a few sabetween the query image (on timages from the image databasimage shows in two columns hammer and the octopus imagyellow lines correspond to tmatched against the indexed im
3matches
62matches
matches
22matches
matches
10matches
matches
4matches
Fig. 4. Matching images by keypoint
h query image were in image features ult shows the two
nes connecting the ified by finding the
m the query image llustrated in Fig. 5, s are matched with cond row, a rotated ed with 7 keypoints occluded octopus's
ow, 5 keypoints are 10 keypoints are
bottom row, only 1 mer and the spoon
octopus and tree
C. Retrieval Results During the retrieval process
of the query are compared widatabase in order to rank each idistance to the query image. Tabimage retrieval ranking for images. In this table, only the twere showed. From these retriethat the octopus and tree imageas compared with the other thrsimilar category images are able10 ranking. The retrieval rankinall of the top 10 retrieval is anoctopus image correctly. This images have more corners asimages. For hammer, apple akeypoints are detected as co
eristics scale and orientation at matching. In the experiments,
stored (all dataset of images) atching keypoints from image amples of keypoint matching the right side) and the indexed se (on the left side). The query which in the first column the e in the second column. The the SIFT features that were ages.
, keypoints feature descriptors th those of the images in the indexed image according to its ble I shows sample of the SIFT randomly selected MPEG-7
top 10 of the retrieved images eval results, it can be observed give the best retrieval ranking ree images, where most of the e to be retrieved in the first top ng for octopus also shows that
n octopus and able to recall 17 result is due to the octopus
s compared to the other four and spoon query images, less
ompared to octopus and tree
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
86
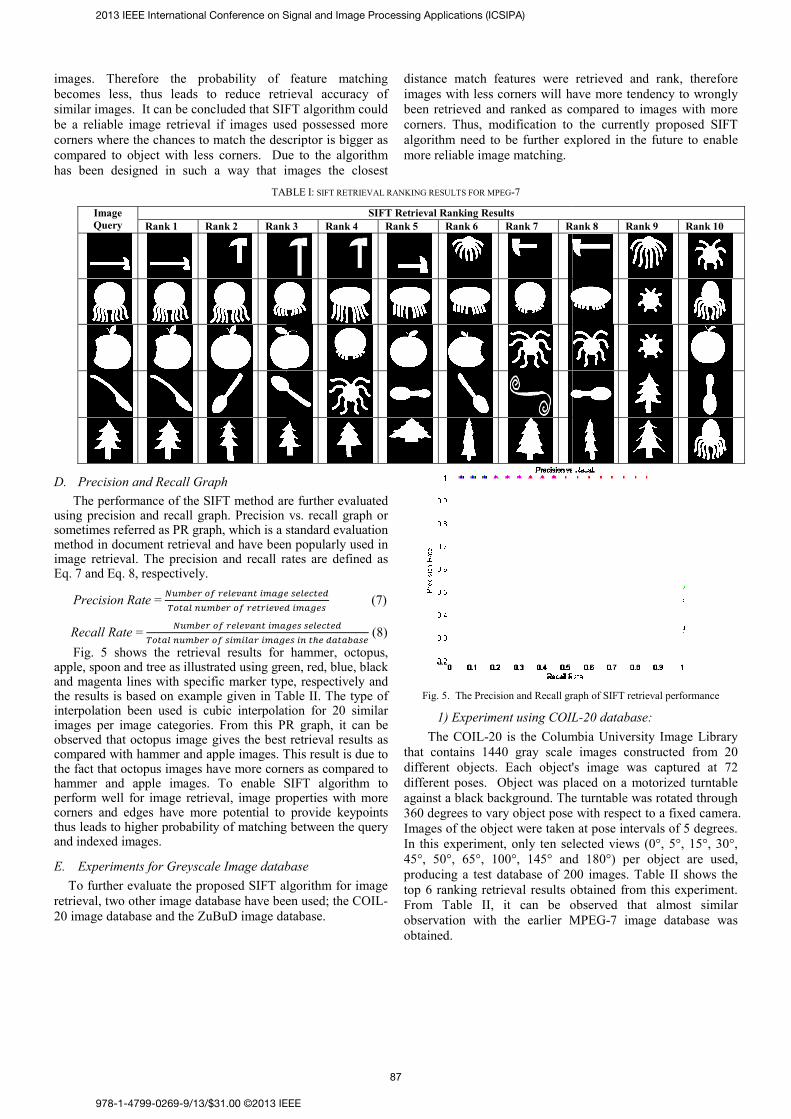
images. Therefore the probability of becomes less, thus leads to reduce retrsimilar images. It can be concluded that SIFbe a reliable image retrieval if images usecorners where the chances to match the descompared to object with less corners. Duhas been designed in such a way that i
TAB
Image Query Rank 1 Rank 2 Rank
D. Precision and Recall Graph
The performance of the SIFT method arusing precision and recall graph. Precision sometimes referred as PR graph, which is a method in document retrieval and have beenimage retrieval. The precision and recall raEq. 7 and Eq. 8, respectively.
Precision Rate = Recall Rate =
Fig. 5 shows the retrieval results for apple, spoon and tree as illustrated using greand magenta lines with specific marker typthe results is based on example given in Tainterpolation been used is cubic interpolatimages per image categories. From this PRobserved that octopus image gives the best compared with hammer and apple images. Tthe fact that octopus images have more cornhammer and apple images. To enable Sperform well for image retrieval, image prcorners and edges have more potential to thus leads to higher probability of matchingand indexed images.
E. Experiments for Greyscale Image databTo further evaluate the proposed SIFT a
retrieval, two other image database have bee20 image database and the ZuBuD image da
feature matching rieval accuracy of FT algorithm could ed possessed more scriptor is bigger as ue to the algorithm images the closest
distance match features were images with less corners will hbeen retrieved and ranked as ccorners. Thus, modification toalgorithm need to be further exmore reliable image matching.
BLE I: SIFT RETRIEVAL RANKING RESULTS FOR MPEG-7
SIFT Retrieval Ranking Results k 3 Rank 4 Rank 5 Rank 6 Rank 7 R
re further evaluated vs. recall graph or
standard evaluation n popularly used in ates are defined as
(7) (8) hammer, octopus,
een, red, blue, black pe, respectively and able II. The type of tion for 20 similar R graph, it can be retrieval results as
This result is due to ners as compared to SIFT algorithm to roperties with more
provide keypoints g between the query
base lgorithm for image en used; the COIL-atabase.
Fig. 5. The Precision and Recall gr
1) Experiment using COILThe COIL-20 is the Colum
that contains 1440 gray scale different objects. Each object'different poses. Object was plagainst a black background. The360 degrees to vary object poseImages of the object were takenIn this experiment, only ten se45°, 50°, 65°, 100°, 145° anproducing a test database of 20top 6 ranking retrieval results oFrom Table II, it can be oobservation with the earlier Mobtained.
retrieved and rank, therefore have more tendency to wrongly compared to images with more o the currently proposed SIFT xplored in the future to enable
Rank 8 Rank 9 Rank 10
raph of SIFT retrieval performance
IL-20 database: mbia University Image Library images constructed from 20 's image was captured at 72 laced on a motorized turntable e turntable was rotated through
e with respect to a fixed camera. n at pose intervals of 5 degrees. lected views (0°, 5°, 15°, 30°, d 180°) per object are used, 00 images. Table II shows the obtained from this experiment. observed that almost similar MPEG-7 image database was
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
87

TABLE II SIFT RETRIEVAL RANKING RESULTS FOR COIL 20 I
Query SIFT Retrieval Ranking R1 2 3 4
2) Experiment using ZuBuD databaseThe ZuBuD image database is the
Image Database that has been developed aSwiss Federal Institute of Technology in Zdata set consists of 1,005 colour imageswhere each building was captured 5 timviewpoints and some of them are also takweather conditions and with two differesimplify the experiment in this paper, all oconverted to gray scale images. The imagusing the proposed SIFT algorithm are show
TABLE III SIFT RETRIEVAL RANKING RESULTS FOR ZUBUD IM
Query SIFT Retrieval Ranking 1 2 3
From the results shown in Table III, it ca
the proposed SIFT algorithm could accuratefirst top 5 buildings irrespective of differerotation changes as well as scale changes. the superiority of proposed SIFT algoritsimilar look images from image databasobtained due to the buildings have many with different buildings possess different nucorners with each others. Thus, it is quite accurately differentiate between differecompared to the single object as elaboexperiments.
IV. CONCLUSION This paper has presented an alternativ
retrieval by using SIFT algorithm. SIFT k
IMAGE DATABASE.
Results 5 6
e: Zurich Buildings
and created by the Zurich. The ZuBuD s of 201 buildings mes from different ken under different ent cameras. To of the images were ge retrieval results wn in Table III.
MAGE DATABASE.
Results 4 5
an be observed that ely retrieved all the ent viewing angles, This results show thm for retrieving se. This result is edges and corners
umber of edges and simple for SIFT to ent buildings as
orated in previous
ve way of image keypoints described
in this paper are particularly usewhich enables the correct matchfrom a set of large image databfeatures will be detected for iedges which make the retrievalhas lesser corners. Future worparameterization of feature methods for better retrieval perf
ACKNOWL
The first author would likscholarship provided by MiMalaysia that makes this study i
REFERE[1] K. Hirata, K., Kato, T., “Query b
retrieval” in Third InternationalTechnology, 1992, pp. 56–71.
[2] A. Pentland, R. Picard and S. manipulation of image databaseImage and Video databases, 1994
[3] M. Flickner et. al., “Query bysystem”, IEEE Computer, 1995,
[4] Z. Lei, L. Fuzong and Z. Bo, “Afeature”, in Proceedings of the IE1, pp. 166-169
[5] Mario A. Nascimento and Viretrieval using binary signaturesSymposium on Applied Computi
[6] I. Kunttu, L. Lepisto, J. Rauhamimage classification for retrieval11th International Conference in CVisualization and Computer Visi
[7] R. O. Stehling, M. A. Nascimentefficient image retrieval approclassification,” in Proc. Int’l Management,2002, pp. 102–109.
[8] N. Arica and F. T. Y. Vural, “BAon the beam angle statistics,” Pa9–10, pp. 1627–1639, 2003.
[9] R. S. Torres, E. M. Picado, A. Ximage retrieval by shape salComputer Graphics and Image P
[10] D. G. Lowe, “Distinctive imkeypoints,” in International Journo. 2, pp. 91–110.
[11] Jun Qin and Zhong-Shi He,”A SGabor-featured key points”, in Pron Machine Learning and Cybern
[12] H. Bay, T. Tuytelaars, and L. Vfeatures”, in ECCV, 2006.
[13] Harris, C. G., Stephens, M., “A c4th Alvey Vision Conference, M
[14] J. Almeida, R. S. Torres and SCBIR”, in Revista de Sistemas d48.
[15] A. K. Jain, J-E. Lee, R. Jin aRetrieval: An Application toInternational Conference on Ima
[16] S. Kumar, S. Singhal and A. ShCBIR for SIFT Features”, in Research in Computer Science anissue 4.
[17] D.G. Lowe, “Object recognition International Conference on Copp. 1150-1157.
[18] The Moving Picture http://www.chiariglione.org/mpe
eful due to their distinctiveness, h for a keypoint to be selected base. More keypoints of SIFT images that have corners and l results better than image that rk will look at more efficient
descriptors and alternative formance.
LEDGMENT ke to acknowledge the Ph.D inistry of Higher Education is possible.
ENCES by visual example-content-based image l Conference on Extending Database
Sclaroff, “Photobook: Content-based es”, in SPIE Storage and retrieval for 4, vol. 2, no. 2185
y image and video content: the qbic vol. 28, no. 9, pp. 23-32
A CBIR method based on color-spatial EEE Region 10 Conference, 1999, vol.
ishal Chitkara, “Color based image s”, in Proceedings of the 2002 ACM ing, Madrid, Spain, 2002, pp. 687-692.
maa and A. Visa, “Binary histogram in l purposes”, in Journal of WSCG, The Central Europe on Computer Graphics, ion, 2003, pp. 269-273. to, and A. X. Falc˜ao, “A compact and oach based on border/interior pixel
Conf. Information and Knowledge .
AS: a perceptual shape descriptor based attern Recognition Letters, vol. 24, no.
X. Falc˜ao, and L. F. Costa, “Effective liences,” in Proc. Brazilian Symp.
Processing, 2003, pp. 167–174. mage features from scale-invariant rnal on Computer Vision, 2004, vol. 60,
VM face recognition method based on roceedings of International Conference netics, 2005. Van Gool, “SURF: Speeded up robust
combined corner and edge detector”, in anchester, 1988, pp. 147-151. Siome Goldenstein, “SIFT applied to de Informacao da FSMA, 2009, pp. 41-
and N. Gregg, “Content-based Image o Tattoo images”, in 16th IEEE
age Processing (ICIP), 2009. harma, “Radial Basis Function used in
International Journal of Advanced nd Software Engineering, 2012, vol. 2,
from local scale-invariant features”, In omputer Vision, Corfu, Greece, 1999,
Experts Group (MPEG), eg, 2012.03.01
978-1-4799-0269-9/13/$31.00 ©2013 IEEE
2013 IEEE International Conference on Signal and Image Processing Applications (ICSIPA)
88
Copyright © 2022 FDOKUMEN




















