
SEMANTIC INFORMATION RETRIEVAL USING ONTOLOGY IN UNIVERSITY DOMAIN
Upload
independentCategory
view
0download
0
information retrieval

Overview
� Sampai pertemuan yang lalu, kita sudah tahu cara pembangunan index yang dapat menyelesaikan boolean query.
� Hanya ada dua kemungkinan dokumen:• Dokumen relevan atau tidak.
� boolean bagus untuk expert user dengan pemahaman yang baik terhadap korpus dan information needs mereka.

Overview
� Dalam korpus yang besar, sebuah boolean query mampu mengembalikan hasil yang besar pula.
� Andaikan hasil boolean retrieval mengembalikan 10.000 dokumen, manakah yang benar-benar cocok untuk kita?• Apakah akan tetap grepping setiap dokumen satu per
satu sampai habis?
� Bagaimana pula dengan user yang kurang memiliki pengetahuan yang bagus dalam boolean query?

Overview
� Permasalahan:Kita butuh mengurutkan dokumen hasil retrieval disesuaikan dengan query yang kita masukkan.
� Pemecahan: Pemberian score/nilai untuk setiap dokumen dalam korpus terhadap query kita. (untuk dirangkingkan)

Scoring
� Yang sudah kita pelajari tentang scoring/nilai adalah score 1 untuk dokumen yang relevan dengan query dan score 0 untuk dokumen yang tidak relevan.
� Kita akan masuk ke tahap berikutnya:• dokumen yang memiliki token query lebih banyak
didalamnya, akan memiliki score yang lebih tinggi.
• query berupa free text (tanpa operator)
� Pemahaman score ini berubah menjadi nilai relevansi antara dokumen dengan query.

Overlap Measure [1]
� Ide perangkingan yang sederhana adalah overlap measure (Manning, 2008)
� Sebagai contoh, kita lihat kasus kemarin.

Overlap Measure [2]
� Misalkan contoh query-nya adalah:Brutus Mercy Antony.
� Maka dokumen “Antony and Cleopatra” memiliki score 3 (Karena ketiga token dalam query dimiliki semua oleh dokumen tersebut).
� Dokumen “Julius Caesar” dan “Macbeth” memiliki score 2.
� Nah, dengan begitu, dokumen “Antony and Cleopatra” menempati rangking pertama.

Overlap Measure [3]
� Tapi, apakah masih ditemui kelemahan dari penghitungan overlap measure?
� Bagaimana kalau query hanya satu kata/token saja?
� Overlap measure tidak:• Mempertimbangkan jumlah suatu token dalam suatu
dokumen.
• Mempertimbangkan scarcity dari tiap token
• Tidak memperhitungkan jumlah korpus dan jumlah token dalam query.

Overlap Measure [4]
� Ide selanjutnya adalah menemukan metode scoring yang lebih baik.
� Scoring juga tetap dapat dilakukan meski hanya ada satu token dalam query.
� Dokumen akan semakin relevan jika memuat token yang semakin banyak.
� Ini semua menuju ke ide berikutnya term weighting.

Term Frequency & Weighting [1]
� Untuk bisa mendapat score tadi, pertama-tama kita perlu memberikan bobot tiap token dalam tiap dokumen.Ex: bobot token “Negara” di dokumen 1.
� Bobot token ditentukan dari jumlah kemunculan token tersebut di dalam dokumen. ( term frequency – tf )
� term frequency dinotasikan dengan tf(t,d), dimana t token, dan d dokumen

Term Frequency & Weighting [2]
� Kita ambil contoh 5.1 dengan dokumen (Grossman,1997):
� Mari kita buat sama-sama lexicon dan tf(t,d) dari
ketiga dokumen di atas.
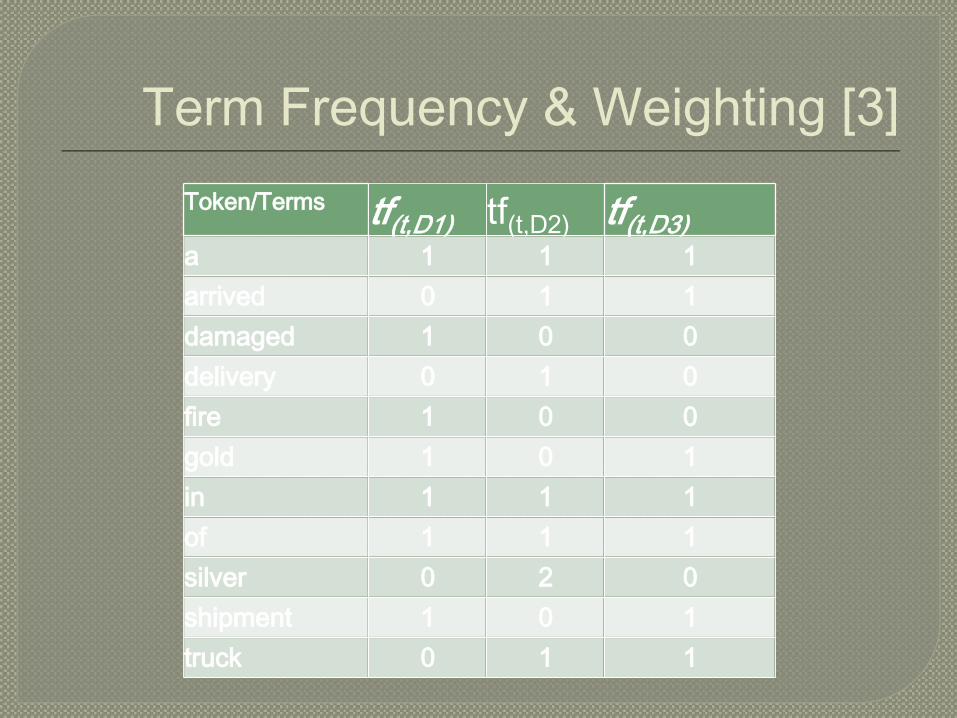
Term Frequency & Weighting [3]
Token/Terms tf(t,D1) tf(t,D3)a 1 1 1arrived 0 1 1damaged 1 0 0delivery 0 1 0fire 1 0 0gold 1 0 1in 1 1 1of 1 1 1silver 0 2 0shipment 1 0 1truck 0 1 1

Term Frequency & Weighting [4]
� Dalam memberi bobot tf, perlu kita pikirkan bahwa yang perlu kita beri bobot, adalah token/terms yang penting saja. (Fungsi dari stopword)
� Kita recall lagi definisi dari stopwords token-token yang tidak kita index karena tidak berkonstribusi dalam proses retrieval dan tidak mempengaruhi isi dokumen.
Untuk contoh kita di kuliah ini, kita tidak akan buat
stopword-nya. ^^

Term Frequency & Weighting [5]� Penghitungan bobot sebuah token terhadap
dokumen dapat dihitung dengan rumus: wf(t,d) = 0 jika tf(t,d) = 0,atauwf(t,d) = 1 + log tf(t,d)
� Kemudian score dari dokumen dihitung dengan
rumus:
∑ ∈=
qt dtwf ,

Term Frequency & Weighting [6]
� Contoh: Untuk query “gold silver truck”
D1 = wf(gold,D1) + wf(silver,D1) + wf(truck,D1)
= (1+log 1) + 0 + 0 = 1 � Jadi score untuk dokumen D1
terhadap query adalah 1.

Term Frequency & Weighting [7]
� Contoh: Untuk query “gold silver truck”
D2 = wf(gold,D2) + wf(silver,D2) + wf(truck,D2)
= 0 + (1+log 2) + (1+log 1) = 0 + 1.301 + 1 = 2.301
� Jadi score untuk dokumen D2 terhadap query adalah 2.301

Term Frequency & Weighting [8]
� Contoh: Untuk query “gold silver truck”
D3 = wf(gold,D3) + wf(silver,D3) + wf(truck,D3)
= (1+log 1) + 0+ (1+log 1) = 1 + 0 + 1 = 2
� Jadi score untuk dokumen D3 terhadap query adalah 2

Term Frequency & Weighting [9]
� Dari perhitungan tersebut, kita tahu bahwa dari korpus data sbb:
� Query user: gold silver truck� Maka urutan relevansinya adalah dokumen
D2,D3,D1 dengan score 2.301, 2, dan 1

Term Frequency & Weighting [10]
� Apakah term frequency (tf) sudah mampu menentukan tingkat relevansi sebuah dokumen terhadap query yang dimasukkan oleh user?

Dokumen sebagai vector
� Kita dapat menggambarkan hasil perhitungan bobot token pada contoh di atas sebagai sebuah matriks dengan ukuran t x N• t = Jumlah lexicon
• N = Jumlah dokumen dalam korpus
� Dari contoh 5.1 didapat:
d1 d2 d3arrived (t1) 0 1 1
silver(t2) 0 2 0
truck (t3) 0 1 1

Dokumen sebagai vector
� Matriks tersebut dikenal dengan istilah Document vector.
� Dari vector inilah kita dapat mulai menghitung score untuk tiap dokumen yang ada.
� Salah satunya dengan metode Vector Space Model (Salton, 1975)

Vector Space Model [1]
� Idenya adalah dokumen dipandang sebagi sebuah vektor yang memiliki magnitude (jarak) dan direction (arah)
� Vector space model adalah model yang pertama menggunakan tf-idf weighting sebagai dasar penentuan score dokumen.

Vector Space Model [2]
� Kita akan melihat classic vector space model yang belum memakai tf-idf untuk penghitungannya.
� classic vector space model sering disebut dengan term count model (TCM)

Term Count Model [3]
� Contoh 5.3: Misal kita memiliki 3 buah dokumen dan memiliki lexicon dan tf sebagai berikut:
� Gambaran vectornya
Collection QueryLexicon D1 D2 D3 auto 3 1 2 0car 1 2 3 0insurance 3 4 0 1Coordinate (3,1,3) (1,2,4) (2,3,0) (0,0,1)Magnitude |D1| |D2| |D3| |Q|

Term Count Model [4]
� Rumus dasarnya adalah:

Term Count Model [5]
� Dari rumus-rumus di atas, kita tahu bahwa ada persamaan lain yang bisa didapat. Persamaan-persamaan tersebut adalah:

Term Count Model [6]
� Dari rumus-rumus tersebut, pertama-tama kita perlu menghitung dot product (Q . Di) dari tiap dokumen.
� Contoh perhitungan menggunakan contoh 5.3:
� Q.D1 = (0 0 1)(3 1 3) = 0*3 + 0*1 + 1*3 = 3� Q.D2 = (0 0 1)(1 2 4) = 0*1 + 0*2 + 1*4 = 4� Q.D3 = (0 0 1)(2 3 0) = 0*2 + 0*3 + 1*0 = 0

Term Count Model [7]
� Yang kedua, kita perlu menghitung |Di| dan |Q|(magnitude) yang sudah kita lihat pada contoh vector.
� Contoh perhitungan menggunakan contoh 5.3:

Term Count Model [8]
� Setelah itu, kita tinggal menghitung nilai cosine dari tiap dokumen. Contoh perhitungannya:

Term Count Model [9]
� Berarti kita dapatkan score dan rangking untuk dokumen yang ada dalam korpus.� Rank 1 : D2 (0.8729)� Rank 2 : D1 (0.6882)� Rank 3 : D3 (0)
� Jadi, untuk query: “insurance”, Dokumen D2 paling relevan.

Term Count Model [10]
� Mari coba perhitungan Classic VSM untuk contoh 5.1:

Term Count Model [11]
Token/Terms tf(t,D1) tf(t,D3) Query
a 1 1 1 0arrived 0 1 1 0damaged 1 0 0 0delivery 0 1 0 0fire 1 0 0 0gold 1 0 1 1in 1 1 1 0of 1 1 1 0silver 0 2 0 1shipment 1 0 1 0truck 0 1 1 1

Any Questions??
Copyright © 2022 FDOKUMEN




















