Constructing linguistic versions for the multicriteria decision support systems preference ranking...
21
Constructing Linguistic Versions for the Multicriteria Decision Support Systems Preference Ranking Organization Method for Enrichment Evaluation I and II J. M. Martı´n, 1, * W. Fajardo, 1,† A. Blanco, 2,‡ I. Requena 1,§ 1 Department of Electronic Engineering of Computer and A.S., University of Huelva, 21071 Huelva, Spain 2 Department of Computer Science and A.I., University of Granada, 18071 Granada, Spain The environmental impact assessment (EIA) is a real problem of multicriteria decision making (MCDM) where information, as much quantitative as qualitative, coexists. The traditional methods of MCDM developed for the EIA discriminates in favor of quantitative information at the expense of qualitative information, because we are unable to integrate this latter information inside their procedure. In this study, we present two new multicriteria decision fuzzy methods called fuzzy in preference ranking organization method for enrichment evaluation (FPROMETHEE 2T ) I and II, which are able to integrate inside their procedure quantiative and qualitative information. This has been performed by applying a new linguistic representation model based on two tuples. These methods, although they have been developed for EIA problems, can be applied to all sorts of decision-making problems, with information of any nature. Therefore, the application of this method to real problems will lead to better results in MCDM. The main interest of our investigation group currently is to develop a set of different multicriteria decision fuzzy methods to be integrated inside a software program that works as a multicriteria decision aid. © 2003 Wiley Periodicals, Inc. 1. INTRODUCTION Decision-making problems are search processes that look for the best option among (a large number of) possible alternatives, which are given as the feasible solution to a certain problem. This situation is very common in real life, both in * Author to whom all correspondence should be addressed: e-mail: [email protected]. † e-mail: [email protected]. ‡ e-mail: [email protected]. § e-mail: [email protected]. INTERNATIONAL JOURNAL OF INTELLIGENT SYSTEMS, VOL. 18, 711–731 (2003) © 2003 Wiley Periodicals, Inc. Published online in Wiley InterScience (www.interscience.wiley.com). • DOI 10.1002/int.10112
-
Upload
pedagogica -
Category
Documents
-
view
4 -
download
0
Transcript of Constructing linguistic versions for the multicriteria decision support systems preference ranking...

Constructing Linguistic Versions for theMulticriteria Decision Support SystemsPreference Ranking Organization Methodfor Enrichment Evaluation I and IIJ. M. Martın,1,* W. Fajardo,1,† A. Blanco,2,‡ I. Requena1,§
1Department of Electronic Engineering of Computer and A.S.,University of Huelva, 21071 Huelva, Spain2Department of Computer Science and A.I., University of Granada,18071 Granada, Spain
The environmental impact assessment (EIA) is a real problem of multicriteria decision making(MCDM) where information, as much quantitative as qualitative, coexists. The traditionalmethods of MCDM developed for the EIA discriminates in favor of quantitative information atthe expense of qualitative information, because we are unable to integrate this latter informationinside their procedure. In this study, we present two new multicriteria decision fuzzy methodscalled fuzzy in preference ranking organization method for enrichment evaluation(FPROMETHEE2T) I and II, which are able to integrate inside their procedure quantiative andqualitative information. This has been performed by applying a new linguistic representationmodel based on two tuples. These methods, although they have been developed for EIAproblems, can be applied to all sorts of decision-making problems, with information of anynature. Therefore, the application of this method to real problems will lead to better results inMCDM. The main interest of our investigation group currently is to develop a set of differentmulticriteria decision fuzzy methods to be integrated inside a software program that works as amulticriteria decision aid. © 2003 Wiley Periodicals, Inc.
1. INTRODUCTION
Decision-making problems are search processes that look for the best optionamong (a large number of) possible alternatives, which are given as the feasiblesolution to a certain problem. This situation is very common in real life, both in
*Author to whom all correspondence should be addressed: e-mail: [email protected].†e-mail: [email protected].‡e-mail: [email protected].§e-mail: [email protected].
INTERNATIONAL JOURNAL OF INTELLIGENT SYSTEMS, VOL. 18, 711–731 (2003)© 2003 Wiley Periodicals, Inc. Published online in Wiley InterScience(www.interscience.wiley.com). • DOI 10.1002/int.10112

simple situations or in unimportant activities and also in more complex andimportant affairs with greater social and economic consequences.1–3 The process ofchoosing a restaurant to eat in is similar to that of establishing the most appropriatelayout for a freeway, but the social and economic significance of the second isobviously higher. The more important the choice, the greater the number ofvariables and factors that need to be taken into account in the decision-makingprocess. For this kind of problem, decision support systems are extremely usefulbecause they help decision makers deal with very complex problems.
Different methods to cope with multicriteria decision making (MCDM) prob-lems have been developed: preference ranking organization method for enrichmentevaluation (PROMETHE), ELECTRE, AHP, etc.4–6 All of these methods can onlyhandle quantitative information and therefore cannot be used when qualitativeinformation is present (as occurs in any real situation).5,7
To cope with this, these methods have been used in MCDM on environmentalimpact assessment (EIA) problems, in which qualitative information was tradition-ally transformed into numerical information using an ordinal scale.8,9 However, thedrawback of this was that it could cause major problems in projects of considerablescope in which a bad choice could lead to far-reaching economic, social, andcultural repercussions.
Because of the imprecision and subjectivity of the information associated withthese kind of problems, the crisp values are completely unsuitable for solvingcertain decision-making problems. A much more realistic approach would be touse linguistic estimators instead of numeric values, in other words, to use linguisticvariables in the processes of the different MCDM methods.
The application of the fuzzy set theory to the MCDA methods has resulted inthe appearance of different fuzzy methods able to manage both qualitative andquantitative information perfectly.10–12
In decision problems in which the different linguistic variables are composedof a finite set of linguistic terms, the final result maybe not correspond to any termsin the original term set of the linguistic variable.13 Therefore, a process of linguisticapproximation must be performed.
The linguistic approximation causes a loss of information, and, therefore, alack of precision in the final results of the decision problems. To avoid this newdrawback, we will use a new fuzzy model of linguistic representation withtwo-tuples. The application of the two-tuple model to the fuzzy MCDM methodsconsiderably improves the results obtained. This is caused by the recovery of theinformation that the fuzzy methods lost in their linguistic approximation.
Currently, our main interest lies in developing decision support systems thatare capable of handling both numerical and linguistic information in MCDMproblems. More specifically, we are interested in solving
1. The problem of adding linguistic information to discrete multicriteria decision meth-ods. For this, the theory of fuzzy sets14 will be used.
2. To avoid any loss of information (approximation process) with the linguistic approachby using the new two-tuple–based model to represent linguistic information.15–17
712 BLANCO ET AL.

To do so, we have started with the crisp multicriteria decision PROMETHEEI and II methods,18–20 which belong to the family of outranking methods of theEuropean school of MCDM, generating two family fuzzy in methods known asFPROMETHEE and FPROMETHEE2T.
We have chosen the PROMETHEE methodology because (a) it seems to becompletely adequate for the applications we are interested in (see further remarksin Section 6) because it models preferences flexibly simply within its procedure,and (b) it is perfectly intelligible for decision makers because it is one of the mostintuitive multicriteria decision methods.
In this study, we will attempt to outline our progress in this research area.
2. PROMETHEE I AND II METHODS
PROMETHEE is an MCDM method developed by Brans and Vincke.18,19
This method starts from the decision matrix that comprises of a set of choicecriteria C � {c1, . . . , cj, . . . , cn}, a set of alternatives A � {A1, . . . , Ai, . . . ,Am} given as possible solutions to the multicriteria decision problem, and a set ofweights associated with the criteria W � {w1, . . . , wj, . . . , wn}, which reflectthe relative importance of the different criteria in the decision-making process.Each alternative Ai � {ai,1, . . . , ai, j, . . . , ai,m} is formed by a group ofvaluations ai, j and the set of all of them form the decision matrix, that is to say, ai, j
is the valuation given to the alternative i with regard to the criteria j.The PROMETHEE methodology belongs to the category of outranking rela-
tion–based methods5,18,21 that divide the decision-making process into two distinctphases:
1. Construction of the so-called “outranking relation” from the data contained in thedecision matrix
2. Exploitation of this outranking relation in order to obtain the best alternatives
The “outranking relation” in an MCDM problem, say �, is a real value so that foreach couple of feasible alternatives ( Ai, Ak) it assigns a value ( Ai, Ak) � �i,k �[0, 1] that approximately represents the credibility of the statement “the alternativeAi outranks or overcomes the alternative Ak.”
The outranking degree is calculated as
� : A � A 3 �0, 1�
��Ai, Ak� �¥j�1
n wj � Fj�Ai, Ak�
¥j�1n wj
where wj is the weight associated to each of the criteria, say ( gj( Ai) � ai, j), andFj is a group of preference functions Fj( Ai, Ak) � [0, 1]. These preferencefunctions are chosen or they can be built by the decision maker so that the jthpreference of Ai on Ak increases when the difference of values among the differentalternatives for the jth criterion gj( Ai) � gj( Ak) increases, i.e., the greater the
CONSTRUCTING LINGUISTIC VERSIONS 713

difference among the jth criterion values for two alternatives Ai and Ak, the higherthe value of the preference function Fj.
The index �( Ai, Ak) expresses the preference of the alternative Ai over thealternative Ak considering all criteria. The weighting factors express the relativeimportance of each criterion.
For each criterion, the decision maker can choose from a set of six differenttypes of functions, which we can see from Figures 1–6. These are not the onlyfunctions and the decision maker can design or choose others, but experience hasshown that this set of six preference functions is enough to model the decisionmaker’s preferences.
Once built, the outranking function is used to obtain three new functions onthe set of alternatives known as inflow (��), outflow (��), and net flow (�). Theinflow for an alternative Ai measures how many alternatives Ak outrank Ai, and iscalculated by
�� : A 3 �0, 1�
���Ai� �1
m � 1 �k�1,k�i
m
�k,i
�1
m � 1 �k�1,k�i
m
��Ak, Ai� @ Ai � A
The outflow for an alternative Ai measures how many alternatives Ak are outrankedby Ai and is calculated by
�� : A 3 �0, 1�
Figure 1. Strict immediate preference function.
Figure 2. Strict preference function with indifference threshold.
714 BLANCO ET AL.

���Ai� �1
m � 1 �k�1,k�i
m
�i,k
�1
m � 1 �k�1,k�i
m
��Ai, Ak� @ Ai � A
And the net flow is the difference between the outflow and the inflow:
��Ai� � ���Ai� � ���Ai� @ Ai � A
PROMETHEE I provides a preorder in the set of alternatives based on the inflowand outflow, and PROMETHEE II provides a preorder on the set of alternativesbased on the net flow.7
By using these two preorders, the PROMETHEE I method obtains a finalpreorder with the following meaning: “an alternative Ai overclassifies the alterna-tive Ak, S( Ai, Ak)” if one of the following conditions proves to be true:
���Ai� � ���Ak� ∧ ���Ai� � ���Ak�
���Ai� � ���Ak� ∧ ���Ai� � ���Ak�
���Ai� � ���Ak� ∧ ���Ai� � ���Ak�
Using the net flow, the PROMETHEE II method builds a final preorder from thealternatives with the following meaning: “an alternative Ai overclassifies thealternative Ak, S( Ai, Ak)” if the following proves to be true:
��Ai� � ��Ak�
Figure 3. Preference function with preference threshold.
Figure 4. Layered preference function between the indifference and preference thresholds.
CONSTRUCTING LINGUISTIC VERSIONS 715

In all other cases, we can say that the alternative Ai does not overclassify thealternative Ak.
The results of PROMETHEE methods can be represented graphically bymeans of outranking relation S. Given two alternatives Ai and Ak, if the alternativeAi is preferred to Ak, S( Ai, Ak), an arc leads from Ai to Ak. If two alternatives areincomparable, no arc exists between them.
The solution of both PROMETHEE methods depends on the different param-eters used to build the outranking relation, although it has been shown that thesemethods are very robust (much more so in fact than other methods) against possiblevariations of their parameters.
Although these methods have been designed to work on numerical values,they have been used to deal with EIA problems9 where qualitative values (linguis-tic terms) are present. To do so, an ordinal scale with discrete values is introducedto represent such qualitative values and then the procedure for both methods isdirectly applied. This may be observed in Ref. 8 where 12 of the 15 decisioncriteria are qualitative.
All results obtained with this ordinal scale have a very important loss ofinformation, but in recent years, several authors have worked on constructing truelinguistic versions of PROMETHEE,3,22–26 mainly by using the fuzzy sets theory(perhaps the most natural way to represent and handle linguistic information). Inthe following sections, such developments are presented, together with our ownapproaches.
3. FUZZY PROMETHEE I AND II
The fuzzy methods FPROMETHEE I and II3,22 use fuzzy sets to includeperfectly both quantitative and qualitative information in their procedure. In the
Figure 5. Linear preference function between the indifference and preference thresholds.
Figure 6. Preference functions with normal distribution.
716 BLANCO ET AL.

FPROMETHEE methods each criterion is introduced as a fuzzy number. Thiscomes from the fact that in most cases, the input information cannot be definedwithin a reasonable degree of accuracy. Fuzzy numbers are presented in the formx � (m, a, b)LR and the basic operations with fuzzy numbers, as presented byDubois and Prade.25,26
The procedure of the PROMETHEE methods described in the previoussection was followed step by step for the cases in which the performance ofalternative solutions can be determined only approximately and therefore is intro-duced into the calculations as a fuzzy number. Other parameters, expressing theopinion of the decision maker, such as the weighting factors and preferences areconsidered as regular information with precise numerical values and not as fuzzynumerical values.
The FPROMETHEE method needs all the information contained in the fuzzydecision matrix to be comparable in order to build the fuzzy outranking relation-ship. After constructing the fuzzy outranking relation, the approach is similar to thecrisp one to obtain FPROMETHEE I and II. In other words, in these methods, theperformance of alternative solutions are fuzzy and the preferences of the decisionmaker are not.
These methods have been applied successfully to decision-making problemsin areas such as the iron and steel industry3 or the exploitation of alternative energysources22 or nuclear waste management.2 In Refs. 3 and 22 the problem ofinformation loss is present within the process of linguistic aggregation.
4. A NEW VERSION OF FUZZY PROMETHEE I AND II USINGTHE TWO-TUPLE REPRESENTATION TO MODEL PREFERENCES
The linguistic aggregation process of the fuzzy multicriteria decision methods(computing with words), most of the time, produces a loss of information; there-fore, there is a lack of precision in the final results of the fusion of linguisticinformation. The two computational techniques of linguistic aggregation used inthe specialized literature present this common drawback in their processes. Thesecomputational techniques are
● The first one is based on the extension principle, which allows us to aggregate andcompare linguistic terms through computations on the associated membership functions.It is well known that the vagueness of the results increases step by step and the finalresults of these methods are fuzzy sets that do not correspond to any terms in the originalterm set.27
● The second one is the symbolic method, which acts by direct computations on the labelsonly taking into account the order and the properties of such linguistic assessments. Thismethod uses a process of approximation together with its computations to obtain theresults in the initial term set.28 An example can be seen in Figure 7, where we canobserve that the vagueness of the result increases in each linguistic aggregation.
In both approaches, the results usually do not exactly match any of the initiallinguistic terms; therefore, an approximation process must be developed to expressthe result in the source expression domain. This produces the consequent loss of
CONSTRUCTING LINGUISTIC VERSIONS 717
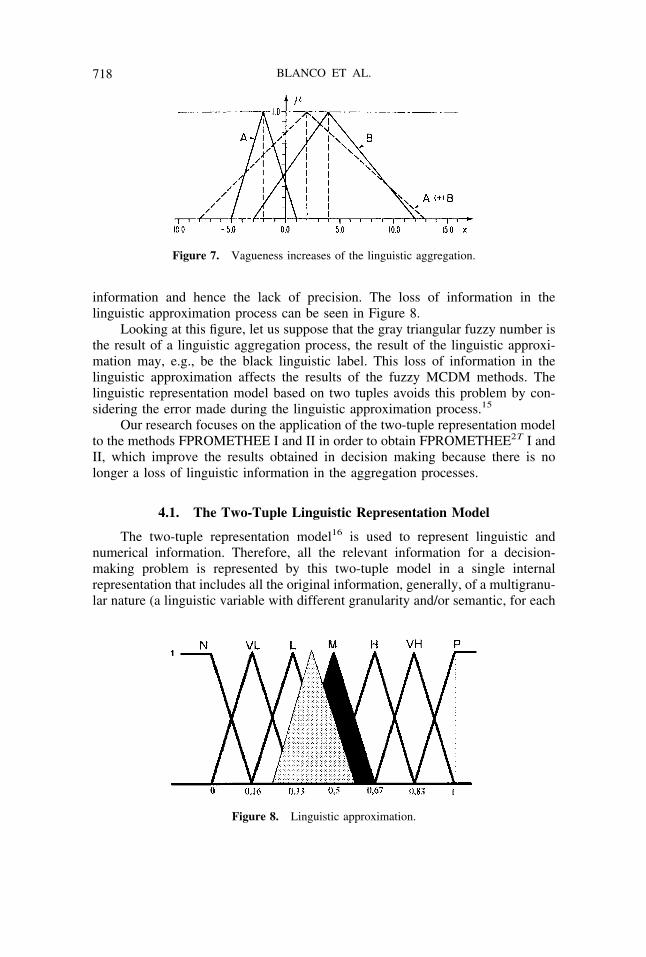
information and hence the lack of precision. The loss of information in thelinguistic approximation process can be seen in Figure 8.
Looking at this figure, let us suppose that the gray triangular fuzzy number isthe result of a linguistic aggregation process, the result of the linguistic approxi-mation may, e.g., be the black linguistic label. This loss of information in thelinguistic approximation affects the results of the fuzzy MCDM methods. Thelinguistic representation model based on two tuples avoids this problem by con-sidering the error made during the linguistic approximation process.15
Our research focuses on the application of the two-tuple representation modelto the methods FPROMETHEE I and II in order to obtain FPROMETHEE2T I andII, which improve the results obtained in decision making because there is nolonger a loss of linguistic information in the aggregation processes.
4.1. The Two-Tuple Linguistic Representation Model
The two-tuple representation model16 is used to represent linguistic andnumerical information. Therefore, all the relevant information for a decision-making problem is represented by this two-tuple model in a single internalrepresentation that includes all the original information, generally, of a multigranu-lar nature (a linguistic variable with different granularity and/or semantic, for each
Figure 7. Vagueness increases of the linguistic aggregation.
Figure 8. Linguistic approximation.
718 BLANCO ET AL.

fuzzy criterion). Then, this new representation of the information is introduced intothe selected decision method, either FPROMETHEE2T I or II, and once the resultshave been obtained, they are presented in the initial domain of the information(performing the inverse process if needed).
The two-tuple representation model is based on the concept of symbolictranslation.
DEFINITION 1. Let S � {s0, . . . , su} be a linguistic term set, and � [0, u] be avalue obtained by a symbolic method of linguistic aggregation. Each linguisticterm si is represented in the new model as (si, i), with si � S and i � [�0.5, 0.5),which represents the value of the distance from the original result to the indexof the closest linguistic label si in the set of linguistic terms S.This linguistic representation model defines a set of functions to make transfor-mations between linguistic terms, two tuples, and numerical values. These func-tions are defined as follows:
DEFINITION 2. Let S � {s0, . . . , su} be a linguistic term set and � [0, u] a valuethat represents the result of symbolic operation, and then the linguistic two tuple,which represents the information equivalent to : [0, u] 3 ST [�0.5, 0.5),verifying that () � (si, ), where si (i � round()) is the label with its indexclosest to , � � i ( � [�0.5, 0.5)) is the value of the symbolic translationand “round” is the usual rounding-off function.
PROPOSITION 1. Let S � {s0, . . . , su} be a BLTS and (si, ) be a linguistictwo-tuple; there is always a function �1, such that from a two-tuple it returns itsequivalent numerical value � [0, u]. The proof is trivial; we consider thefollowing function:
�1 : S � ��0.5, 0.5� 3 �0, u�
�1�si, � � i � �
Together with this linguistic representation model, a wide range of two-tupleaggregation operators have been developed extending classical aggregation oper-ators.15 Furthermore, comparison operators that are performed according to anordinary lexicographic order also have been defined. Let (sk, k) and (sl, l) betwo tuples, and then
● if k � l, then (sk, k) is smaller than (sl, l)● if k � l, then
if k � l, then (sk, k) and (sl, l) represents the same information,if k � l, then (sk, k) is smaller than (sl, l)if k � l, then (sk, k) is bigger than (sl, l),
4.2. General Application Synopsis of the Two-Tuple LinguisticRepresentation Model
The application of the two-tuple linguistic representation model17 to anyMCDM method contains the following steps:
CONSTRUCTING LINGUISTIC VERSIONS 719

1. Uniform expression of the information. In this step, the BLTS must be chosen ST �{s0, . . . , su} on which the model will work. We select ST as BLTS, because of thefact that the conditions (a) ST is a fuzzy partition and (b) the membership functions ofits terms are triangular, i.e., si � (ai, bi, ci) are necessary and sufficient for thetransformation between values in [0, 1] and two tuples is performed without loss ofinformation.15 If ST does not satisfy the foregoing conditions, then we shall choose asBLTS a term set with a larger number of terms than the number of terms that a personis able to discriminate (normally, 11 or 13), satisfying the foregoing conditions. Wenormally choose the BLTS, with 15 terms symmetrically distributed, with the follow-ing semantics (Figure 9).
Remark 1. The authors of the two-tuple model should point out that the justifi-cation on this choice is based on the idea that the semantic is a parameter used bythe conversion process, and, thus, it has an effect on the final result. Furthermore,they decided to use a symmetrical term set with a granularity bigger than thenumber of terms that an expert or decision maker is able to discriminate (11 or 13;see Ref. 29).
2. Conversion of the numerical or linguistic decision-making problem information tofuzzy sets on the BLTS. The authors in Ref. 17 define a set of functions to translate anylinguistic or numerical information from the decision-making problem to the newinternal representation. To do this step, we should apply the multigranular transfor-mation functions �SST
: S 3 F(ST) and �vST : [0, 1] 3 F(ST) to all the informationof the decision-making problem, obtaining from each linguistic term in the initialdomain, a set of fuzzy sets (F(ST)) defined on ST.17
3. Conversion of the fuzzy sets defined on the BLTS ST in linguistic two tuples. Fromeach set defined on the BLTS ST, we obtain a two tuple that supports the sameinformation using the function : F(ST) 3 [0, u]. From the value obtained � [0,u], we can easily obtain the linguistic two tuple using the function .17
4. Two-tuple aggregation process. In the previous step, the information of the decision-making problem was represented by two tuples, and here it is aggregated, and using theconcept of symbolic translation allows us to transform the results of aggregation toa two-tuple and vice versa without any loss of information. This aggregation processwill depend on how the fuzzy multicriteria method must be used to obtain thealternative(s) to solve the decision-making problem, i.e., the aggregation operators arebased on numerical ones such as “extended arithmetic mean,” “extended weightedaverage,” etc.17 In our case, these are the fuzzy multicriteria methods FPROMETHEEI and II, which we will examine in the following section.
5. Backward process. This step consists of expressing the results obtained by themulticriteria decision method applied (in the previous step) expressed on a BLTS, in
Figure 9. A BLTS with 15 terms symmetrically distributed.
720 BLANCO ET AL.

any initial domain of the different sources of multigranular information of the decision-making problem. The backward process might be appropriate for improving thecomprehensiveness of the results of the multicriteria decision methods. To accomplishthis process, the model uses �1(si, i) � � [0, u] function that transforms a twotuple based on the symbolic translation into two tuples based on the degree ofmembership [0, 1] that supports the same counting of information. Each two tuple ((sh,1 � �) and (sh�1, �)) indicates the degree of membership of a counting ofinformation in its respective linguistic term, and from these two tuples, the modeldevelops a process to obtain an equivalent two tuple based on the symbolic translationexpressed in the initial expression domain (see Ref. 17).
4.3. The Fuzzy Methods PROMETHEE I and II (FPROMETHEE2T)
In this section, we will present the development of two new multicriteriadecision fuzzy methods called FPROMETHEE2T I and II using the new linguisticrepresentation model based on two tuples. These methods have been developed towork with quantitative and qualitative information; therefore, they can be used inreal EIA problems and any sort of multicriteria decision problems.
Let ST � {s0, s1, . . . , su} be a linguistic term set with a sufficiently highcardinality, e.g., u � 15, C � {C1, . . . , Cn} a set of n fuzzy criterion, and A �{A1, . . . , Am} a set of m fuzzy alternatives with Ai � {ai,1, ai,2, . . . , ai,m}where ai, j � (ai, j, i, j) � ST [�0.5, 0.5) and W � {w1, . . . , wn} with wj �(wj, j) � ST [�0.5, 0.5) a fuzzy set of weights that approximately representthe importance of each fuzzy criterion in the decision-making process.
The outranking relation �(2T) approximately represents the credibility of thestatement “the alternative Ai fuzzy outranking or it overcomes the alternative Ak.”This fuzzy outranking degree is calculated using the expression
� : A � A 3 ST � ��0.5, 0.5�
��Ai, Ak� �¥j�1
n wj � Fj�Ai, Ak�
¥j�1n wj
�¥j�1
n �wj, j� � Fj�Ai, Ak�
¥j�1n �wj, j�
�i,k � �¥j�1n �1�wj, j� � Fj�Ai, Ak�
¥j�1n �1�wj, j�
� u�� �¥j�1
n jw � Fj�Ai, Ak�
¥j�1n j
w � u�where wj � (wj, k) � ST [�0.5, 0.5), j
w � �1(wj, j) � [0, u], andFj(Ai, Ak) � [0, 1] is a preference function Fj : A A 3 [0, 1].
An example of the preference function is presented in Figure 10 with thefuzzy thresholds of indifference (qj) and preference ( pj), where gj(Ai) � ai, j, pj,qj � ST [�0.5, 0.5).
The fuzzy thresholds are included in the decision-making process as eitherlinguistic terms qj, pj � Ci or a number v � [0, 1], which in such cases is included
CONSTRUCTING LINGUISTIC VERSIONS 721

as pj � ( (�RSt( pj))) and qj � ( (�RS, (qj))) where pj, qj � R and R are the
linguistic variables where the decision maker takes linguistic terms to express hispersonal preferences.
In the procedure of FPROMETHEE2T I and II methods, the fuzzy inflow(��), fuzzy outflow (��), and net flow (�) are defined as
● �� : A 3 ST [�0.5, 0.5) defined as
���Ai� �1
m � 1 �k
��Ak, Ai� � � 1
m � 1� �1� �
k�1,k�i
m
�k,i��� � 1
m � 1� �1� �
k�1,k�i
m
��k,i, k,i���� � 1
m � 1� �
k�1,k�i
m
k,i� � @ Ai � A
with k,i� � �1(�k,i, k,i) and m is the cardinality of A.
● �� : A 3 ST [�0.5, 0.5) defined as
���Ai� � � 1
m � 1� �
k�1,k�i
m
i,k� � @ Ai � A
with i,k� � �1(�i,k, i,k).
Table I. Input information to FPROMETHEEE I andII methods.
NH RE CO VI
Type 3 3 3 3q — — — —p 100 VH H VHw H H M VLA0 50 H T MA1 10 VH L MA2 200 VH H HA3 90 L L LA4 30 L L VHA5 100 VH T MA6 20 L T M
Figure 10. Function to linear preference between the indifference and preference thresholds.
722 BLANCO ET AL.
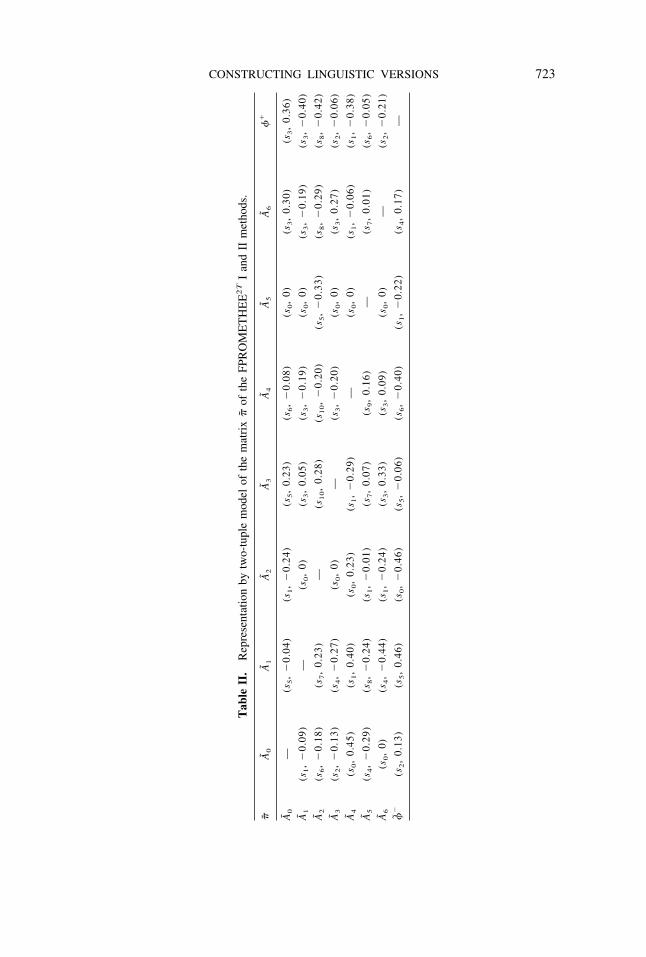
Tab
leII
.R
epre
sent
atio
nby
two-
tupl
em
odel
ofth
em
atri
x�
ofth
eFP
RO
ME
TH
EE
2T
Ian
dII
met
hods
.
�A
0A
1A
2A
3A
4A
5A
6�
�
A0
—(s
5,
�0.
04)
(s1,
�0.
24)
(s5,
0.23
)(s
6,
�0.
08)
(s0,
0)(s
3,
0.30
)(s
3,
0.36
)
A1
(s1,
�0.
09)
—(s
0,
0)(s
3,
0.05
)(s
3,
�0.
19)
(s0,
0)(s
3,
�0.
19)
(s3,
�0.
40)
A2
(s6,
�0.
18)
(s7,
0.23
)—
(s1
0,
0.28
)(s
10,
�0.
20)
(s5,
�0.
33)
(s8,
�0.
29)
(s8,
�0.
42)
A3
(s2,
�0.
13)
(s4,
�0.
27)
(s0,
0)—
(s3,
�0.
20)
(s0,
0)(s
3,
0.27
)(s
2,
�0.
06)
A4
(s0,
0.45
)(s
1,
0.40
)(s
0,
0.23
)(s
1,
�0.
29)
—(s
0,
0)(s
1,
�0.
06)
(s1,
�0.
38)
A5
(s4,
�0.
29)
(s8,
�0.
24)
(s1,
�0.
01)
(s7,
0.07
)(s
9,
0.16
)—
(s7,
0.01
)(s
6,
�0.
05)
A6
(s0,
0)(s
4,
�0.
44)
(s1,
�0.
24)
(s3,
0.33
)(s
3,
0.09
)(s
0,
0)—
(s2,
�0.
21)
��
(s2,
0.13
)(s
5,
0.46
)(s
0,
�0.
46)
(s5,
�0.
06)
(s6,
�0.
40)
(s1,
�0.
22)
(s4,
0.17
)—
CONSTRUCTING LINGUISTIC VERSIONS 723

● � : A 3 [�u, u] is defined as��Ai� � �1����Ai�� � �1����Ai��
�1
m � 1� �
k�1,k�i
m
k,i� � i,k
� @ Ai � A
From these flows, we finally obtain a new outranking relation on the set ofalternatives, which is Ai outrank Ak, S(Ai, Ak) if and only if
● ��(Ai) � ��(Ak)∧��(Ai) � ��(Ak) for the FPROMETHEE2T I method● �(Ai) � �(Ak) for the FPROMETHEE2T II method
Finally, using the outranking relation S, we obtain a classification of thedifferent alternatives of the problem. The intermediate results and the final clas-sification can be obtained in the initial domain of the information using thebackward step defined in Section 4.2.
5. EXAMPLE
We shall apply the two-tuple representation in a decision-making problem. Inthis example we have included as much qualitative information as quantitativeinformation to show that this new multicriteria decision method integrates infor-mation perfectly and of a different nature.
Figure 11. Linguistic variable CO.
Figure 12. Linguistic variable w, RE and VI.
724 BLANCO ET AL.
A bus company wishes to build a bus station and it needs to decide which ofseven possible cities it will choose. To do so, it is necessary to rank the cities takinginto account their different needs according to the number of inhabitants (NH),requirements (RE) of the innercity bus, vicinity (VI), and connection (CO) withother access roads to adjacent towns. The type of preference function Fj, thresholdsof indifference qj and preference pj, weights wj, and alternatives Ai are shown inTable I. In Table II we have the same information but under the new linguistictwo-tuple representation model.
All the information of the decision-making problem is shown in Table I. Thepreference function Fj used in the decision-making problem corresponds to thepreference function with preference threshold, like we can see in Figure 3. Thefuzzy methods PROMETHEE2T I and II allow us to use the same or differentlinguistic variables for weights and criteria, but to simplify and make clearer theexample, we used the linguistic variables given in Figures 11 and 12.
Before applying the fuzzy multicriteria decision methods PROMETHEE2T Iand II, we must apply all the steps given in Section 4.2:
1. To make uniform the information, we choose a BLTS with 15 terms symmetricallydistributed as we can see in Figure 9.
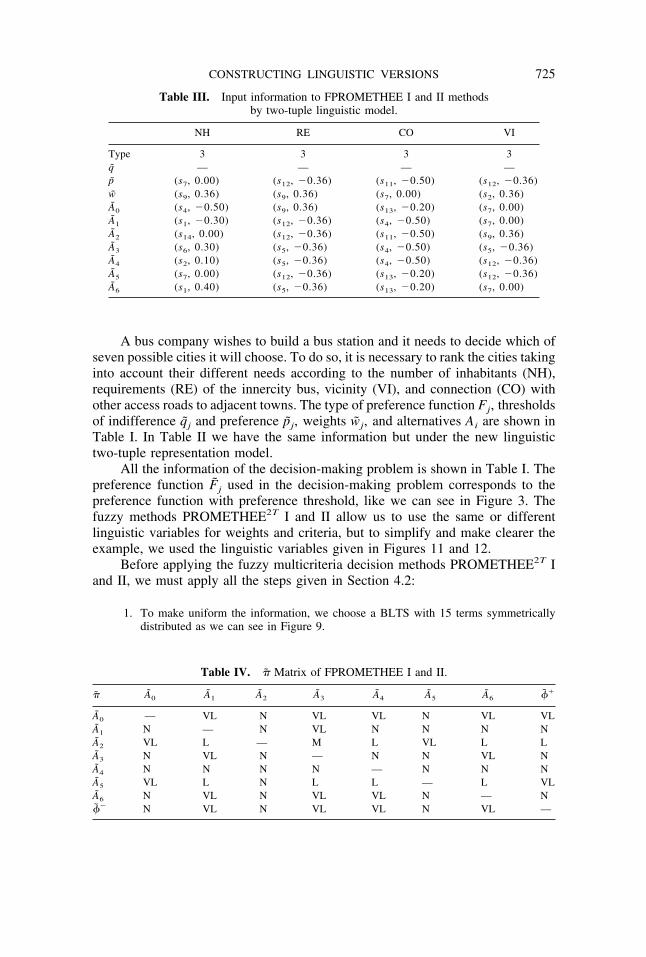
Table III. Input information to FPROMETHEE I and II methodsby two-tuple linguistic model.
NH RE CO VI
Type 3 3 3 3q — — — —p (s7, 0.00) (s12, �0.36) (s11, �0.50) (s12, �0.36)w (s9, 0.36) (s9, 0.36) (s7, 0.00) (s2, 0.36)A0 (s4, �0.50) (s9, 0.36) (s13, �0.20) (s7, 0.00)A1 (s1, �0.30) (s12, �0.36) (s4, �0.50) (s7, 0.00)A2 (s14, 0.00) (s12, �0.36) (s11, �0.50) (s9, 0.36)A3 (s6, 0.30) (s5, �0.36) (s4, �0.50) (s5, �0.36)A4 (s2, 0.10) (s5, �0.36) (s4, �0.50) (s12, �0.36)A5 (s7, 0.00) (s12, �0.36) (s13, �0.20) (s12, �0.36)A6 (s1, 0.40) (s5, �0.36) (s13, �0.20) (s7, 0.00)
Table IV. � Matrix of FPROMETHEE I and II.
� A0 A1 A2 A3 A4 A5 A6 ��
A0 — VL N VL VL N VL VLA1 N — N VL N N N NA2 VL L — M L VL L LA3 N VL N — N N VL NA4 N N N N — N N NA5 VL L N L L — L VLA6 N VL N VL VL N — N�� N VL N VL VL N VL —
CONSTRUCTING LINGUISTIC VERSIONS 725
2. To convert the information of the MCDM problem (Table I) to fuzzy sets defined onthe BLTS. Applying the � function obtains the following fuzzy sets:
�WST�w0� � �0, 0, 0, 0, 0, 0, 0, 0.30, 0.60, 0.90, 0.80, 0.50, 0.20, 0, 0�
�WST�w1� � �0, 0, 0, 0, 0, 0, 0, 0.30, 0.60, 0.90, 0.80, 0.50, 0.20, 0, 0�
�WST�w2� � �0, 0, 0, 0, 0.10, 0.40, 0.70, 1, 0.70, 0.40, 0.10, 0, 0, 0, 0�
�WST�w3� � �0.30, 0.60, 0.90, 0.80, 0.50, 0.20, 0, 0, 0, 0, 0, 0, 0, 0, 0�
�NHST�a0,0� � �0, 0, 0, 0.50, 0.50, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0�
�REST�a0,1� � �0, 0, 0, 0, 0, 0, 0, 0.30, 0.60, 0.90, 0.80, 0.50, 0.20, 0, 0�
�COST�a0,2� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.11, 0.33, 0.56, 0.78, 1�
�VIST�a0,3� � �0, 0, 0, 0, 0.10, 0.40, 0.70, 1, 0.70, 0.40, 0.10, 0, 0, 0, 0�
�NHST�a1,0� � �0.30, 0.70, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0�
�REST�a1,1� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�COST�a1,2� � �0.22, 0.44, 0.67, 0.89, 0.89, 0.67, 0.44, 0.22, 0, 0, 0, 0, 0, 0, 0�
�VIST�a1,3� � �0, 0, 0, 0, 0.10, 0.40, 0.70, 1, 0.70, 0.40, 0.10, 0, 0, 0, 0�
�NHST�a2,0� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1�
�REST�a2,1� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�COST�a2,2� � �0, 0, 0, 0, 0, 0, 0, 0.22, 0.44, 0.67, 0.89, 0.89, 0.67, 0.44, 0.22�
�VIST�a2,3� � �0, 0, 0, 0, 0, 0, 0, 0.30, 0.60, 0.90, 0.80, 0.50, 0.20, 0, 0�
�NHST�a3,0� � �0, 0, 0, 0, 0, 0, 0.70, 0.30, 0, 0, 0, 0, 0, 0, 0�
�REST�a3,1� � �0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30, 0, 0, 0, 0, 0, 0, 0�
�COST�a3,2� � �0.22, 0.44, 0.67, 0.89, 0.89, 0.67, 0.44, 0.22, 0, 0, 0, 0, 0, 0, 0�
Table V. Outranking relation of FPROMETHEE I method.
S A0 A1 A2 A3 A4 A5 A6
A0 — S — S S S SA1 — — — S S — SA2 S S — S S S SA3 — S — — S — SA4 — S — S — — SA5 S S — S S — SA6 — S — S S — —
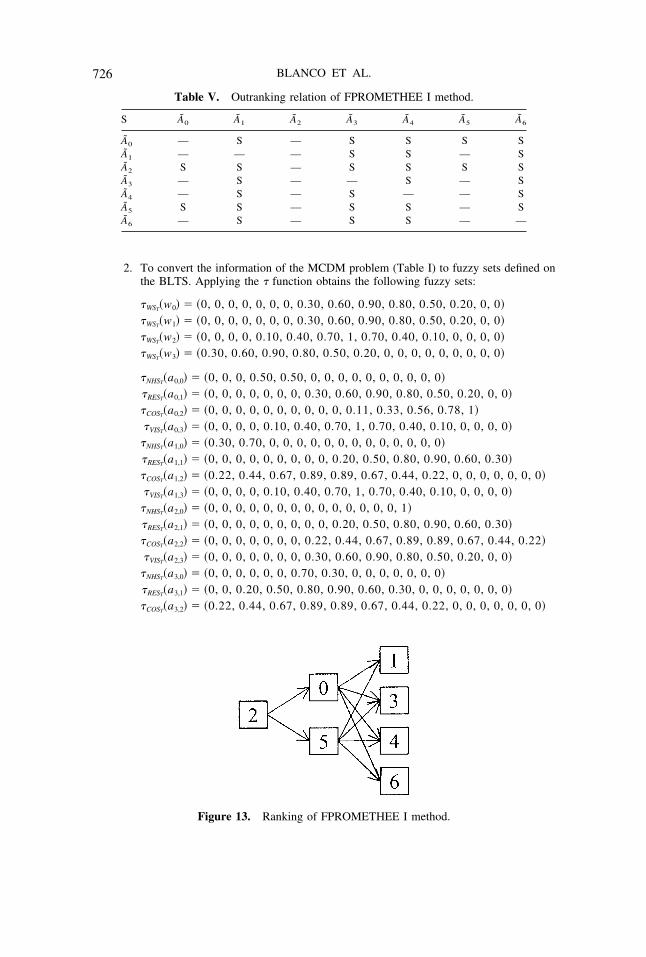
Figure 13. Ranking of FPROMETHEE I method.
726 BLANCO ET AL.

�VIST�a3,3� � �0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30, 0, 0, 0, 0, 0, 0, 0�
�NHST�a4,0� � �0, 0, 0.90, 0.10, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0�
�REST�a4,1� � �0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30, 0, 0, 0, 0, 0, 0, 0�
�COST�a4,2� � �0.22, 0.44, 0.67, 0.89, 0.89, 0.67, 0.44, 0.22, 0, 0, 0, 0, 0, 0, 0�
�VIST�a4,3� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�NHST�a5,0� � �0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0�
�REST�a5,1� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�COST�a5,2� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.11, 0.33, 0.56, 0.78, 1�
�VIST�a5,3� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�NHST�a6,0� � �0, 0.60, 0.40, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0�
�REST�a6,1� � �0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30, 0, 0, 0, 0, 0, 0, 0�
�COST�a6,2� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0.11, 0.33, 0.56, 0.78, 1�
�VIST�a6,3� � �0, 0, 0, 0, 0.10, 0.40, 0.70, 1, 0.70, 0.40, 0.10, 0, 0, 0, 0�
�NHST� p0� � �0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0�
�REST� p1� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
�COST� p2� � �0, 0, 0, 0, 0, 0, 0, 0.22, 0.44, 0.67, 0.89, 0.89, 0.67, 0.44, 0.22�
�VIST� p3� � �0, 0, 0, 0, 0, 0, 0, 0, 0, 0.20, 0.50, 0.80, 0.90, 0.60, 0.30�
Then, we convert previous fuzzy set defined on BLTS to two tuples. Applying the function obtains the following two tuples:
� �w0�� � �s9, 0.36� � �w1�� � �s9, 0.36�� �w2�� � �s7, 0� � �w3�� � �s2, 0.36�
� � p0�� � �s7, 0� � � p1�� � �s12, �0.36�� � p2�� � �s11, �0.50� � � p3�� � �s12, �0.36�
Table VI. � Matrix of FPROMETHEE2T I and II.
� A0 A1 A2 A3 A4 A5 A6 ��
A0 — L N L M N VL VLA1 N — N VL VL N VL VLA2 L M — H H L M MA3 VL L N — VL N VL VLA4 N VL N N — N N NA5 L M N M H — M MA6 L L N VL VL N — VL�� VL L N L L N L —
Table VII. Outranking relation of FPROMETHEE2T I method.
� A0 A1 A2 A3 A4 A5 A6
A0 — S — S S — SA1 — — — — S — —A2 S S — S S S SA3 — — — — S — —A4 — — — — — — —A5 S S — S S — SA6 — S — — S — —
CONSTRUCTING LINGUISTIC VERSIONS 727

� �a0,0�� � �s4, �0.50� � �a0,1�� � �s9, 0.36�� �a1,0�� � �s1, �0.30� � �a1,1�� � �s12, �0.36�� �a2,0�� � �s14, 0.00� � �a2,1�� � �s12, �0.36�� �a3,0�� � �s6, 0.30� � �a3,1�� � �s5, �0.36�� �a4,0�� � �s2, 0.10� � �a4,1�� � �s5, �0.36�� �a5,0�� � �s7, 0� � �a5,1�� � �s12, �0.36�� �a6,0�� � �s1, 0.40� � �a6,1�� � �s5, �0.36�
� �a0,2�� � �s13, �0.20� � �a0,3�� � �s7, 0�� �a1,2�� � �s4, �0.50� � �a1,3�� � �s7, 0�� �a2,2�� � �s11, �0.50� � �a2,3�� � �s9, 0.36�� �a3,2�� � �s4, �0.50� � �a3,3�� � �s5, �0.36�� �a4,2�� � �s4, �0.50� � �a4,3�� � �s12, �0.36�� �a5,2�� � �s13, �0.20� � �a5,3�� � �s12, �0.36�� �a6,2�� � �s13, �0.20� � �a6,3�� � �s7, 0�
The final result of this step is shown in Table III.3. Applying the different multicriteria decision methods to the decision-making problem.
Table IV shows the result of applying FPROMETHEE I and II to the input data, theoutranking relationship appears in Table V and the ranking result is shown in Figure13 for FPROMETHEE I. We can see that the alternatives A0 and A5 are mutuallyincomparable. This happens when one alternative Ai is good on a set of criteria inwhich the second is weak and reciprocally the second alternative Ak is good on criteriain which the first is weak. In Tables VI and VII the results of the FPROMETHEE2T
I method are the ranking result in Figure 14. In Figure 15 we can see the ranking ofthe FPROMETHEE2T II. In this figure it is possible to see a great improvement in theresults.
4. To show the intermediate results of � matrix of the methods FPROMETHEE2T I andII in the initial domain of information, we must use the backward step. To do so, weuse VI linguistic variable as linguistic variable reference L. For the intermediate resultof � for the alternatives (A0, A1) � (s5, �0.04) the backward process (presented inSection 4.1) performs the following calculations:
��A0, A1� � �s5, �0.04����1��s5, �0.04��� � �s4, 0.04�, �s5, 0.96���STR�s4� � �r0, 0��r1, 0.50��r2, 0.80��r3, 0.10��r4, 0��r5, 0��r6, 0��
Figure 14. Ranking of FPROMETHEE2T I method.
Figure 15. Ranking of FPROMETHEE2T II method.
728 BLANCO ET AL.

��STR�s4�� � 1.71�STR�s5� � �r0, 0��r1, 0.20��r2, 0.90��r3, 0.40��r4, 0��r5, 0��r6, 0��
��STR�s5�� � 2.13�1.71 � 0.04 � 2.13 � 0.96� � �r2, 0.12� � L
Other backward process examples for the intermediate result of � matrix may be��A0, A2� � �s1, �0.24����1��s1, �0.24��� � �s0, 0.24�, �s1, 0.76���STR�s0� � �r0, 1��r1, 0.30��r2, 0��r3, 0��r4, 0��r5, 0��r6, 0��
��STR�s0�� � 0.23�STR�s1� � �r0, 0.70��r1, 0.60��r2, 0��r3, 0��r4, 0��r5, 0��r6, 0��
��STR�s1�� � 0.46�0.23 � 0.24 � 0.46 � 0.76� � �r0, 0.41� � N
��A0, A3� � �s5, 0.23����1��s5, 0.23��� � �s5, 0.77�, �s6, 0.23���STR�s5� � �r0, 0��r1, 0.20��r2, 0.90��r3, 0.40��r4, 0��r5, 0��r6, 0��
��STR�s5�� � 2.13�STR�s6� � �r0, 0��r1, 0��r2, 0.60��r3, 0.70��r4, 0��r5, 0��r6, 0��
��STR�s6�� � 2.54�2.13 � 0.77 � 2.54 � 0.23� � �r2, 0.22� � L
��A0, A4� � �s6, �0.08����1��s6, 0.08��� � �s5, 0.08�, �s6, 0.92���STR�s5� � �r0, 0��r1, 0.20��r2, 0.90��r3, 0.40��r4, 0��r5, 0��r6, 0��
��STR�s5�� � 2.13�STR�s6� � �r0, 0��r1, 0��r2, 0.60��r3, 0.70��r4, 0��r5, 0��r6, 0��
��STR�s6�� � 2.54�2.13 � 0.08 � 2.54 � 0.92� � �r3, �0.49� � M
��A0, A5� � �s0, 0����1��s0, 0��� � �s0, 1�, �s1, 0���STR�s0� � �r0, 1��r1, 0.30��r2, 0��r3, 0��r4, 0��r5, 0��r6, 0��
��STR�s0�� � 0.23�STR�s1� � �r0, 0.70��r1, 0.60��r2, 0��r3, 0��r4, 0��r5, 0��r6, 0��
��STR�s1�� � 0.46�0.23 � 1 � 0.46 � 0� � �r0, 0.23� � N
��A0, A6� � �s3, 0.30����1��s3, 0.30��� � �s3, 0.70�, �s4, 0.30���STR�s3� � �r0, 0.10��r1, 0.80��r2, 0.50��r3, 0��r4, 0��r5, 0��r6, 0��
��STR�s3�� � 1.29�STR�s4� � �r0, 0��r1, 0.50��r2, 0.80��r3, 0.10��r4, 0��r5, 0��r6, 0��
��STR�s4�� � 1.71�1.29 � 0.70 � 1.71 � 0.30� � �r1, 0.41� � VL
CONSTRUCTING LINGUISTIC VERSIONS 729

6. ADDITIONAL REMARKS
The EIA is both a complex decision-making problem and a key step (toprovide essential information) for very difficult decision-making problems withfar-reaching social repercussions. The EIA itself handles a large amount of data,which can come from quantitative and qualitative sources alike and so it would beuseful to develop suitable decision support systems to facilitate the EIA task.Currently, our research group is developing a research project to develop softwaretools to support the EIA process and we are interested in developing new fuzzymethods like FPROMETHEE2T so that they may be used in the EIA.
AcknowledgmentsThis work has been developed under project TIC-99-0563.
References
1. Barba-Romero S, Pomerol JCh. Decisiones multicriterio, Coleccion de economıa. Alcala,Spain: University of Alcala; 1997.
2. Briggs Th, Vincke Ph, Mareschal B. Nuclear waste management: an application of themulticriteria PROMETHEE methods. Eur J Oper Res 1990;44:1–10.
3. Geldermann J, Spengler T, Rentz O. Fuzzy outranking for environmental assessment. Casestudy: iron and steel making industry. Fuzzy Sets Syst 2000;115:45–65.
4. Aragones P, Gomez-Senent E. Tecnicas de ayuda a la decision multicriterios. Valencia,Spain: University of Valencia; 1997.
5. Vincke Ph. Multicriteria decision aid. Chichester, England: John Wiley & Sons Publishers;1992.
6. Yves L, Pictet J, Simos J. Methodes multicriteres ELECTRE. Lausane, Suisse PressesPolytechniques et Universitaires Romandes; 1994.
7. Romero C. Teorıa de la decision multicriterio: conceptos, tecnicas y aplicaciones. Spain:Alianza Publishers; 1993.
8. Al-Rashdan D, Al-Kloub B, Dean A, Al-Shemmeri T. Environmental impact assessmentand ranking the environmental projects in Jordan. Eur J Oper Res 1999;118:30–45.
9. Conesa V. Instrumentos de la gestion ambiental en la empresa. Madrid/Barcelona/Mexico:Mundi-Prensa Ed; 1997.
10. Auke F. Fuzzy logic for planning and decision-making. Dordrecht/Boston/London: KluwerAcademic Publishers; 1997.
11. Fodor F, Roubens M. Fuzzy preference modelling and multicriteria decision support.Dordrecht: Kluwer Academic Publishers; 1994.
12. Meskens N, Roubens M. Advances in decision analysis. Dordrecht/Boston/London: Klu-wer Academic Publishers; 1999.
13. Zadeh LA. The concept of a linguistic variable and its application to approximatereasoning. Inform Sci 1975;8:199–249; 301–357; Inform Sci 9:43–80.
14. Zimmermann HJ. Fuzzy set theory and its applications. Boston/Dordrecht/Lancaster:Kluwer Academic Publishers; 1988.
15. Herrera F, Martınez L. A 2-tuple fuzzy linguistic representation model for computing withwords. IEEE Trans Fuzzy Syst 2000;8(6):746–752.
16. Herrera F, Herrera-Viedma E, Martınez L. A fusion approach for managing multigranu-larity linguistic term sets in decision making. Fuzzy Sets Syst 2000;114:43–58.
730 BLANCO ET AL.

17. Herrera F, Martınez L. An approach for combining numerical and linguistic informationbased on the 2-tuple fuzzy linguistic representation model in decision making. Int JUncertain Fuzz Knowledge Based Syst 2000;8(5):539–562.
18. Brans JP, Mareschal B, Vincke Ph. PROMETHEE: A new family of outranking methodsin multicriteria analysis. In: Brans JP, editors. Operational research ’84. Elsevier SciencePublishers. Amsterdam: North-Holland; 1984. pp 408–415.
19. Brans JP, Vincke Ph. A preference ranking organization method, the PROMETHEEmethod. Manag Sci 1985;31:647–656.
20. Brans JP, Vincke Ph, Mareschal B. How to select and how to rank projects: ThePROMETHEE method. Eur J Oper Res 1986;24:228–238.
21. Barba-Romero S, Pomerol JCh. Multicriterion decision in management: Principles andpractice. Dordrecht/Boston/London: Kluwer Academic Publishers; 2000.
22. Goumas M, Lygerou V. An extension of the PROMETHEE method for decision-makingin fuzzy environments: ranking of alternative energy exploitation projects. Eur J Oper Res2000;123:606–613.
23. Le Teno JF, Mareschal B. An interval version of PROMETHEE for the comparison ofbuilding products’ design with ill-defined data on environmental quality. Eur J Oper Res1998;109:522–529.
24. Meier K. Methods for decision making with cardinal numbers and additive aggregation.Fuzzy Sets Syst 1997;88:135–159.
25. Dubois D, Prade H. Operations on fuzzy numbers. Int J Syst Sci 1978;9:613–626.26. Dubois D, Prade H. Fuzzy real algebra: some results. Fuzzy Sets Syst 1979;2:327–348.27. Degani R, Bortolan G. The problem of linguistic approximation in clinical decision
making. Int J Approx Reason 1988;2:143–162.28. Delgado M, Verdegay JL, Vila MA. On aggregation operations of linguistic labels. Int
J Intell Syst 1993;8:351–370.29. Miller GA. The magical number seven or minus two: some limits on our capacity of
processing information. Psychol Rev 1956;63:81–97.
CONSTRUCTING LINGUISTIC VERSIONS 731