
Challenges and methodology for indexing the computerized patient record
26
Challenges and methodology for indexing the computerized patient record Frédéric Ehrler KIM Lab, 2007
Transcript of Challenges and methodology for indexing the computerized patient record

Challenges and methodology for indexing the computerized patient record
Frédéric Ehrler
KIM Lab, 2007

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Plan
• Problems• Information retrieval
• Indexing• Retrieval• Evaluation
• Retrieval in patient records• Specificity of our task• Acquiring required resources
• Documents collection• Queries and relevance assessments
• Results• Indexing efficiency• Retrieval efficiency and effectiveness

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Problematic
Improvement of the care providers efficiency
• Fact• Patient records contain most crucial documents for managing the
treatments and healthcare of patients in the hospital
• Problem• Care providers waste precious time searching and browsing the
patient record to collect all information pertinent to the actual situation
• Proposed solution• Indexing the patient record to retrieve efficiently and effectively
relevant information from patient documents Information retrieval

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Information Retrieval: Introduction
• Selecting from a relatively large collection of documents a manageable number of documents that is likely to satisfy an expressed need for information (Query)
• Two type of input• The document collection asynchronous processing • The queries real time processing

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Information Retrieval: Indexing
• Indexing• Creation of inverted files to improve the retrieval
speed• Inverted files
• Contains all the words of the collection• Link each word with the list of documents that contain it

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Information Retrieval: Retrieval
• Retrieval• The user perform a query• Comparison between every document and the query
in the vector space • Text represented by a vector of terms• Cosine distance
• The system return the documents that are the most similar to the query
• The documents returned contain the important terms of the query

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Information Retrieval: Key Techniques
• Weighting schema• Not all the words have the same significance level
• Words occurring with high frequency in a document are better discriminators than words of low frequency
• Words occurring in many documents of a corpus are less discriminative than rare words
• Two metrics reflect these intuitions• TF: frequency of the word in the document• IDF: frequency of the word in the corpus
• Text normalization• Stemming techniques
• Suffixes transformation rules• Reduction of the language variation
• Query extension• Synonym
• Improve the coverage

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Information Retrieval: Evaluation
• Two key metrics: precision and recall• Precision: measures the proportion of retrieved
documents which are relevant • Recall: measures the proportion of relevant
documents retrieved
• Typical balance between recall and precision• F-measure

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Retrieval in Patient Records
• Information retrieval technologies reply to our needs
• Applying IR in patient records• Specificity of our task• Acquiring required resources
• Documents collection• Queries and relevance assessments
• Results• Indexing efficiency• Retrieval efficiency and effectiveness

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Specificity of our Task
• Usually in common IR task • All the documents are stored in a unique and large
corpus• Indexing is asynchronous
• Our task• Numerous small corpora must be indexed
independently • The indexing efficiency is crucial• The data must be always up to date

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Test Collection Construction
• OSHUMED corpus share important common properties with patient record corpus
• Prediction of the behavior of our system on the patient records by looking at the results obtained on the OHSUMED corpus
• Rue to his Homogeneity, OSHUMED facilitate measures and reliability
• Documents share similar properties like length, word distribution, and word frequency
• Avoids biasing the experiments and allows focusing only on the quality of retrieval
• The final application is dedicated to run on the patient records however, the documents used in the experiment are selected from the OHSUMED corpus

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Documents Collection
• Composed of three parts• The collection of documents
• Must reflect the specificity of the patient record corpus• Organized in a two level structure
• The documents are spited in groups that represent a patient records
• The number of group vary in order two study the consequence of the structure on the retrieval process
• The retrieval is performed only at the group level
• The queries• Automatically built
• The relevance assessments

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Structure of the Patient Record Corpus
• Few large patient records• 3% of the records contain more than 100 documents• Returning a small subset of documents containing the
answer could be sufficient• Reducing the possible research space brings a
significant gain of time for the care providers
• Many small patient records• 50% of the records have less
than 7 documents• Little interest in using a tool
not returning the exact answer

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Document Collection Structure
• Structure of the experimental corpus• Study the impact of the corpus structure on the
performance • Variation of the number of groups • Keeping a constant number of documents
• Each increase in groups is accompanied by a proportional decrease in the number of documents per group
• Variation of 1 to 2048 groups for 8192 documents

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Queries and Relevance Assessments
• Usual situation• Experts construct relevant and interesting queries for
specific domains
• Chosen approach• Automatic generation of the queries and their related
relevance assessments by considering “known-item-search”
• Queries build randomly from documents• Must retrieve only the unique document that has been used
to build the query• Simulates a user seeking for a particular, partially
remembered document in the collection

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Indexing Strategies
• The specificity of the application • Numerous documents are daily added in the patient records and
queries can be performed immediately after• The generated data must be process in real time
• Possible indexation triggering strategies• Indexation performed at fixed, but short, intervals
• Lead to a lot of useless processing• Don’t ensure proper indexation when needed
• Indexation launched when a query is performed• Requires less indexation process• Induce a delayed answer when queries are performed• Severe impact on perceived performance
• Indexation triggered by a notification when a document is saved• Retrained strategy
©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
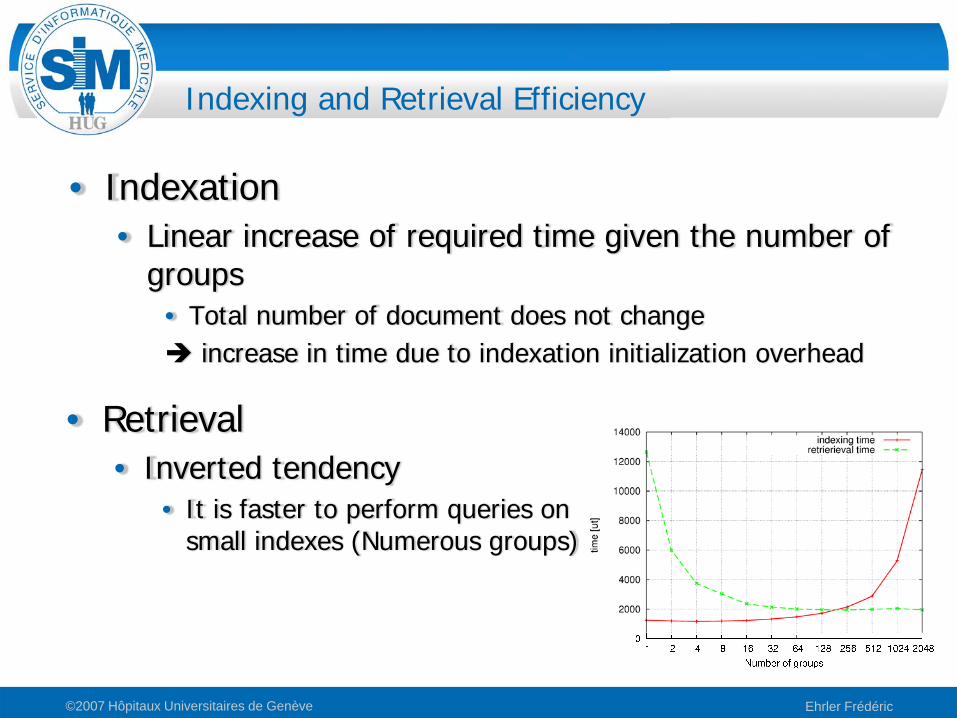
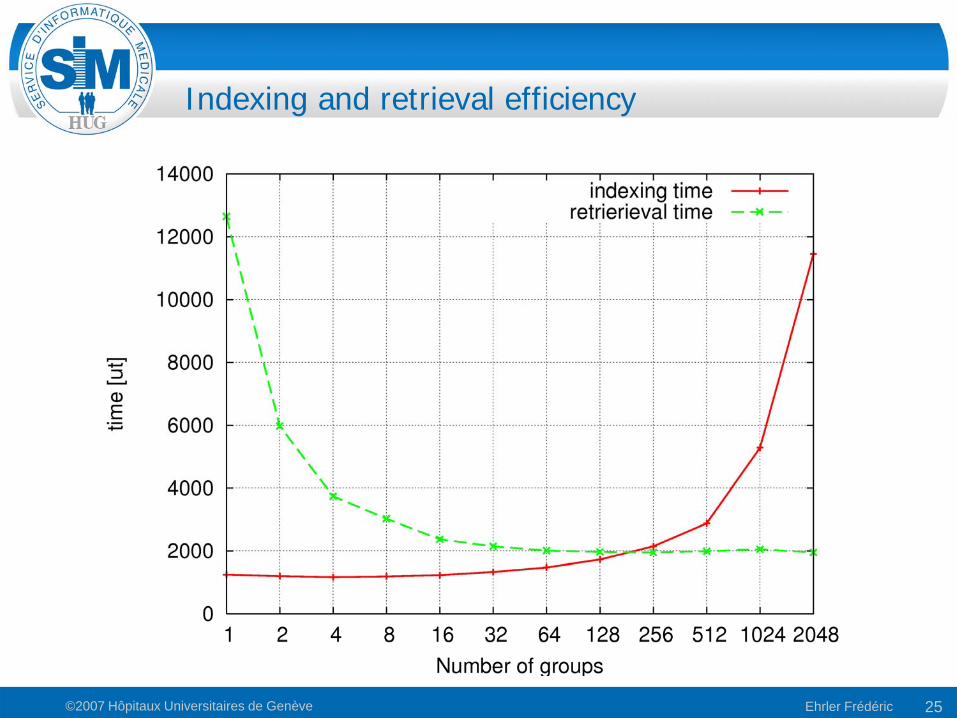
Indexing and Retrieval Efficiency
• Indexation• Linear increase of required time given the number of
groups• Total number of document does not change
increase in time due to indexation initialization overhead
• Retrieval• Inverted tendency
• It is faster to perform queries on small indexes (Numerous groups)
©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
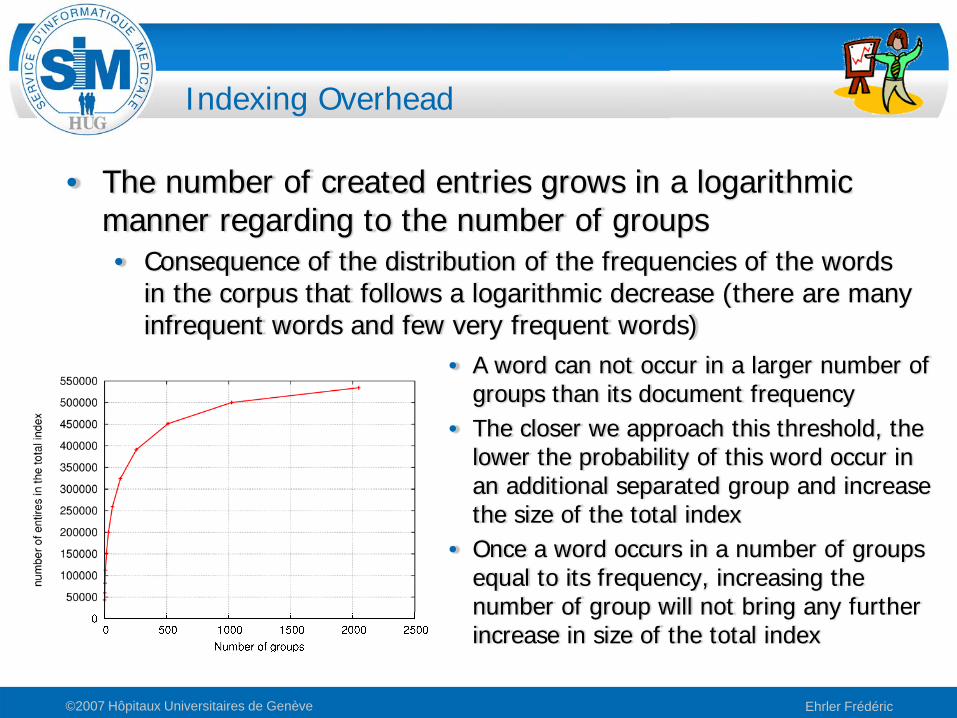
Indexing Overhead
• A word can not occur in a larger number of groups than its document frequency
• The closer we approach this threshold, the lower the probability of this word occur in an additional separated group and increase the size of the total index
• Once a word occurs in a number of groups equal to its frequency, increasing the number of group will not bring any further increase in size of the total index
• The number of created entries grows in a logarithmic manner regarding to the number of groups• Consequence of the distribution of the frequencies of the words
in the corpus that follows a logarithmic decrease (there are many infrequent words and few very frequent words)

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Overhead in Indexing Process
1. Tokenization of the documents in order to build the vocabulary• No Overhead
• Task complexity is only dependent from the total number of words in the whole corpus
2. The term frequency and inverse document frequency values extraction • Required to compute the weights• Overhead
• Document frequency is dependant of the groups• Done once per entry
3. storing the indexes in the database• Overhead
• The size of the total index is bigger with a large number of groups

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Retrieval Effectiveness for 1024 Queries
Number of document per group recall at first retrieved document
8 96%
16 95%
32 94%
64 92%
128 88%
256 86%
512 82%
1’024 80%
2’048 74%
4’096 73%
8’192 69%

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Situation with Patient Records
• Given the structure of the patient records corpus • Indexing efficiency
• Suffer of a consequent overhead
• Retrieval efficiency• Very quick answer
• Retrieval effectiveness • Good effectiveness on most of the records• The 3% of the patient records containing more than 100
documents will be problematic
• Significant computational power will be required to offer acceptable efficiency

©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Conclusion
• Highly dedicated tools are needed to answers requirements for real-time and sensitivity
• Indexing in patient records is time-consuming, the finest tuning possible should be done in order to increase the efficiency

23©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Similarity OSHUMED and Patient Record Corpuses

24©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Record Size Distribution in Patient Records
25©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Indexing and retrieval efficiency

26©2007 Hôpitaux Universitaires de Genève Ehrler Frédéric
Indexing Overhead




















