
cf-cuadra_ll.pdf - Repositorio Académico - Universidad de Chile
113
UNIVERSIDAD DE CHILE FACULTAD DE CIENCIAS F ´ ISICAS Y MATEM ´ ATICAS DEPARTAMENTO DE INGENIER ´ IA INDUSTRIAL METODOLOG ´ IA DE B ´ USQUEDA DE SUB-COMUNIDADES MEDIANTE AN ´ ALISIS DE REDES SOCIALES Y MINER ´ IA DE DATOS TESIS PARA OPTAR AL GRADO DE MAGISTER EN GESTI ´ ON DE OPERACIONES MEMORIA PARA OPTAR AL T ´ ITULO DE INGENIERO CIVIL INDUSTRIAL LAUTARO BARTOLOM ´ E CUADRA LOBOS PROFESOR GU ´ IA: SEBASTI ´ AN ALEJANDRO R ´ IOS P ´ EREZ MIEMBROS DE LA COMISI ´ ON: GAST ´ ON ANDR ´ ES L’HUILLIER CHAPARRO FELIPE IGNACIO AGUILERA VALENZUELA MARCELO GABRIEL MENDOZA ROCHA SANTIAGO, CHILE ENERO 2012
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of cf-cuadra_ll.pdf - Repositorio Académico - Universidad de Chile

UNIVERSIDAD DE CHILE
FACULTAD DE CIENCIAS FISICAS Y MATEMATICAS
DEPARTAMENTO DE INGENIERIA INDUSTRIAL
METODOLOGIA DE BUSQUEDA DE SUB-COMUNIDADES MEDIANTE ANALISISDE REDES SOCIALES Y MINERIA DE DATOS
TESIS PARA OPTAR AL GRADO DE MAGISTER EN GESTION DEOPERACIONES
MEMORIA PARA OPTAR AL TITULO DE INGENIERO CIVIL INDUSTRIAL
LAUTARO BARTOLOME CUADRA LOBOS
PROFESOR GUIA:SEBASTIAN ALEJANDRO RIOS PEREZ
MIEMBROS DE LA COMISION:GASTON ANDRES L’HUILLIER CHAPARROFELIPE IGNACIO AGUILERA VALENZUELA
MARCELO GABRIEL MENDOZA ROCHA
SANTIAGO, CHILEENERO 2012

Agradecimientos
Esta tesis pone fin a una de las etapas de mayor aprendizaje y satisfacciones vividas, y a lavez, marca el comienzo de otra, donde habra otros grandes desafıos que enfrentar. En este cortopero intenso periodo de trabajo son muchas las personas que directa o indirectamente contribuyerona mi desarrollo profesional y quisiera agradecerles:
En primer lugar agradecer a mi familia, que durante todos estos anos me ha brindado apoyo,comprension, carino y me ha entregado las herramientas para poder enfrentar cualquier desafıo. Enespecial agradecer a mis padres, Veronica por sus carinosas correcciones, a Ernesto por las palabrasde aliento en los momentos difıciles, a mis hermanas, Victoria, Libertad y Esperanza, y a mis tıos,tıas, abuelas, abuelo y primos, quienes tambien han marcado su presencia en mi formacion.
En segundo lugar agradecer a Tamara por la paciencia, los remezones, las correcciones y elafecto entregado durante todo este periodo.
En tercer lugar agradecer al profesor Sebastian Rıos, quien me guio durante todo el procesode trabajo, entregando sus conocimientos y lineamientos en todos los ambitos para el correctodesarrollo de esta tesis. Tambien agradecer a Gaston L’Huillier por su disposicion, ayuda en laspublicaciones y apoyo en los aspectos tecnicos de mi tesis. A Felipe Aguilera y Marcelo Mendozapor sus comentarios y su disposicion para formar parte de la comision revisora de este trabajo.
A continuacion quisiera agradecer a mis amigos de toda la vida, Rodrigo, Jose, Pavel ylos amigos del Barrio. Agradecer a los companeros de la universidad. Javier, Rodrigo, Santiago,Maximiliano, Jorge, Gonzalo, Francisco, Pablo, Solsire, Rosa, Angelica, Miguel, Clemente, Olivia,Jose, Claudia y Ricardo con quienes compartı grandes momentos y de quienes aprendı mucho.
Finalmente quisiera agradecer a las personas que hacen posible el funcionamiento del Magisteren Gestion de Operaciones, en especial a Julie Lagos y Fernanda Melis.
Lautaro B. Cuadra LobosEnero, 2012
I

RESUMEN DE LA TESIS
PARA OPTAR AL TITULO DEINGENIERO CIVIL INDUSTRIALPOR: LAUTARO CUADRA L.FECHA: 12/01/2012
PROF. SEBASTIAN A. RIOS
METODOLOGIA DE BUSQUEDA DE SUB-COMUNIDADES MEDIANTE ANALISIS DEREDES SOCIALES Y MINERIA DE DATOS
Las redes sociales virtuales posibilitan que participantes de todo el mundo compartan expe-riencias, opiniones e ideas con otros usuarios de intereses comunes, formando ası grandes comunida-des. Uno de estos tipos de comunidad son las comunidades virtuales de practica (VCoP), en dondesus miembros generan conocimiento en base al traspaso de experiencias sobre las mejores practicasen relacion a algun tema en particular. En general los miembros comparten solo con algunos usua-rios especıficos de la red formando ası sub-comunidades. Identificar y caracterizar adecuadamenteestas sub-estructuras es de vital importancia, pues son en ellas donde se generan las interaccionesnecesarias para la creacion y desarrollo del conocimiento de la comunidad.
El objetivo principal de este trabajo es desarrollar e implementar una metodologıa paramejorar el proceso de busqueda de sub-comunidades mediante el uso de Social Network Analysis(SNA) y Text Mining, con el fin de apoyar el proceso de administracion en una VCoP.
Para ello se propone una metodologıa que combina dos procesos Knowledge Discovery inDatabases (KDD) y SNA y fue aplicada sobre una VCoP real llamada Plexilandia. En la etapade KDD se efectuo la seleccion, limpieza, y transformacion de los post de los usuarios, para luegoaplicar estrategias de reduccion de contenido basadas en Text Mining, en particular Latent DirichletAllocation (LDA) y Concept Based Text Mining (CB), que permiten describir cada post en terminosde topicos o conceptos. En la etapa de SNA se construyeron grafos o redes que son filtradas utilizandola informacion obtenida en la etapa anterior. A continuacion se utilizaron algoritmos basados enla modularity y algunas mejoras desarrolladas en esta tesis de estos metodos para encontrar lassub-comunidades.
Los resultados de los experimentos muestran que las redes filtradas, en general, poseen es-tructuras de comunidad mas fuertes que las redes sin filtrar, un 5 % mas estables en terminos decomunidades encontradas frente a diferentes algoritmos, de una composicion, en promedio un 30 %diferente a las comunidades encontradas en las redes sin filtrar, y que entre los miembros de lascomunidades encontradas se comparte un mayor porcentaje de temas comunes, un 8 % mayor paralas redes sobre LDA y un 30 % mayor para las redes sobre CB en comparacion con los grupos en-contrados sobre las redes sin filtrar, lo que permite obtener nueva y mejor informacion acerca de lassub-comunidades en la red. Adicionalmente el uso de estas herramientas basadas en el contenidopermite caracterizar a las comunidades encontradas en funcion de un grupo reducido de topicos oconceptos, tarea que con los metodos tradicionales no se puede lograr.
II

Indice general
Agradecimientos I
Resumen II
Indice general III
Indice de cuadros VI
Indice de figuras VII
1 Introduccion 1
1.1 El problema de la busqueda de sub-comunidades . . . . . . . . . . . . . . . . . . . . 1
1.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.1 Objetivo General . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2.2 Objetivos Especıficos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Resultados Esperados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Metodologıa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5 Estructura de la Tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Revision de Antecedentes 7
2.1 Comunidades virtuales de practica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Analisis de Redes Sociales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2.1 Representacion de una red usando grafos . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Medidas utilizadas en SNA . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2.3 Aplicaciones Minerıa de Datos para SNA . . . . . . . . . . . . . . . . . . . . 12
III

INDICE GENERAL
2.3 Estrategias de text mining para reducir la base de contenido . . . . . . . . . . . . . . 13
2.4 Metodos para busqueda de Sub comunidades . . . . . . . . . . . . . . . . . . . . . . 14
2.4.1 Comunidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.2 Metodos Tradicionales para la Busqueda de Comunidades . . . . . . . . . . . 16
2.4.3 Metodos basados en Modularity . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.4.4 sub-comunidades superpuestas . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5 Aplicaciones de SNA con Minerıa de texto . . . . . . . . . . . . . . . . . . . . . . . . 24
3 Metodologıa propuesta para la busqueda de sub comunidades 26
3.1 Seleccion, limpieza y trasformacion de los datos . . . . . . . . . . . . . . . . . . . . . 28
3.2 Procesamiento del texto en base a la Minerıa de Textos . . . . . . . . . . . . . . . . 29
3.2.1 Representacion de los datos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.2.2 Concept Based Text Mining . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.3 Latent Dirichlet Allocation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.3 Desarrollo de las redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3.1 Tipos de redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.3.2 Filtros basados en las estrategias de reduccion de contenido . . . . . . . . . . 36
3.3.3 Construccion de las redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.3.4 Construccion de redes topicas . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.3.5 Transformacion de redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4 Busqueda de sub-comunidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.4.1 Louvain modularity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.4.2 Max-Min Modularity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.4.3 Max-Min Modularity con Pesos . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.4.4 Comunidades superpuestas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.5 Analisis y evaluacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4 Resultados sobre una VCoP real 55
4.1 Una real comunidad de practica. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2 Aplicacion de la metodologıa propuesta . . . . . . . . . . . . . . . . . . . . . . . . . 57
IV

INDICE GENERAL
4.2.1 Seleccion y limpieza de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2.2 Minerıa de textos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.3 Construccion y Configuracion de las Redes . . . . . . . . . . . . . . . . . . . . . . . . 60
4.4 Comunidades encontradas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
4.4.1 Resultados con la Modularity de Louvain . . . . . . . . . . . . . . . . . . . . 64
4.4.2 Max-Min Modularity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
4.4.3 Max-Min Modularity con pesos . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.4.4 Mejoras de las redes con Metodos de superposicion . . . . . . . . . . . . . . . 72
4.5 Comparacion de los distintos metodos segun su composicion . . . . . . . . . . . . . . 74
4.5.1 Particiones entre metodos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
4.5.2 Informacion Estructural . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.6 Caracterısticas de los grupos encontrados . . . . . . . . . . . . . . . . . . . . . . . . 79
4.7 Comparacion de las comunidades segun su contenido . . . . . . . . . . . . . . . . . . 81
5 Conclusiones y Trabajo Futuro 84
5.1 Uso de la metodologıa para busqueda de sub-comunidades . . . . . . . . . . . . . . . 85
5.2 Uso de filtros semanticos basados en la minerıa de textos . . . . . . . . . . . . . . . . 86
5.3 Busqueda de sub-comunidades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5.4 Trabajo Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.4.1 Construccion de redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.4.2 Algoritmos de busqueda de sub-comunidades . . . . . . . . . . . . . . . . . . 89
5.4.3 Estudio de la evolucion de las comunidades y sus intereses . . . . . . . . . . . 90
5.4.4 Caracterizacion mediante relaciones . . . . . . . . . . . . . . . . . . . . . . . 90
REFERENCIAS 92
Apendice A Resultados de la Metodologıa de Busqueda de Sub-comunidades 101
A.1 Detalles de los Topicos Encontrados . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
A.2 Sub-comunidades Encontradas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
V

Indice de cuadros
Cuadro 3.1 Lista de conceptos y valores de pertenencia de un post hipotetico . . . . . . . 33
Cuadro 4.1 Actividad del foro de Plexilandia . . . . . . . . . . . . . . . . . . . . . . . . . 56
Cuadro 4.2 Seleccion de Topicos encontrados e interpretados . . . . . . . . . . . . . . . . 59
Cuadro 4.3 Ejemplos de Topicos encontrados . . . . . . . . . . . . . . . . . . . . . . . . . 60
Cuadro 4.4 Tipos de redes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Cuadro 4.5 Comunidades encontradas por el metodo de Louvain . . . . . . . . . . . . . . 66
Cuadro 4.6 Comunidades encontradas por el metodo Max-Min Modularity . . . . . . . . 68
Cuadro 4.7 Comunidades encontradas por el metodo Max-Min Modularity con pesos . . 70
Cuadro 4.8 Resultados de las comunidades y su similitud de contenido . . . . . . . . . . 82
Cuadro A.1 Topicos encontrados e interpretados 1-20 . . . . . . . . . . . . . . . . . . . . 101
Cuadro A.2 Topicos encontrados e interpretados 21-50 . . . . . . . . . . . . . . . . . . . . 102
Cuadro A.3 Resultados Comunidades encontradas . . . . . . . . . . . . . . . . . . . . . . 103
VI

Indice de figuras
Figura 1.1 Metodologıa para la busqueda de sub-comunidades . . . . . . . . . . . . . . . 5
Figura 2.1 Tipos de grafos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
Figura 2.2 Representacion de un grafo en una matriz . . . . . . . . . . . . . . . . . . . . 11
Figura 2.3 Problema de la busqueda local de comunidades. . . . . . . . . . . . . . . . . . 15
Figura 2.4 Ejemplo de Particion de Grafos en dos grupos . . . . . . . . . . . . . . . . . . 17
Figura 2.5 Comunidades Superpuestas que comparten nodos . . . . . . . . . . . . . . . . 22
Figura 3.1 Proceso SNA-KDD para busqueda de Sub-comunidades . . . . . . . . . . . . . 27
Figura 3.2 Estructura de un foro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
Figura 3.3 Orientacion de una red . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Figura 3.4 Heurıstica de Louvain de dos etapas . . . . . . . . . . . . . . . . . . . . . . . . 43
Figura 4.1 Seleccion de la base de Plexilandia . . . . . . . . . . . . . . . . . . . . . . . . 57
Figura 4.2 Densidad de la red V/S parametros γ y θ . . . . . . . . . . . . . . . . . . . . 61
Figura 4.3 Densidades de las redes sin peso por periodos . . . . . . . . . . . . . . . . . . 62
Figura 4.4 Grado promedio de los nodos en cada periodo . . . . . . . . . . . . . . . . . . 62
Figura 4.5 Grafos de las redes orientadas al creado . . . . . . . . . . . . . . . . . . . . . . 63
Figura 4.6 Grafos de las redes orientadas a todos los anteriores . . . . . . . . . . . . . . . 63
Figura 4.7 Modularity de Louvain promedio de 1000 iteraciones . . . . . . . . . . . . . . 65
Figura 4.8 Modularity de Louvain Maxima de 1000 iteraciones . . . . . . . . . . . . . . . 65
Figura 4.9 Numero de miembros de cada comunidad . . . . . . . . . . . . . . . . . . . . . 67
Figura 4.10 Resultados de Max-Min Modularity . . . . . . . . . . . . . . . . . . . . . . . . 68
Figura 4.11 Resultados de Max-Min Modularity con pesos . . . . . . . . . . . . . . . . . . 69
VII

INDICE DE FIGURAS
Figura 4.12 Max-Min Modularity con pesos con mayores parametros de corte . . . . . . . 71
Figura 4.13 Max-Min Modularity con pesos Versus Max-Min Modularity . . . . . . . . . . 71
Figura 4.14 Modularity para redes superpuestas al creador . . . . . . . . . . . . . . . . . . 73
Figura 4.15 Modularity para redes superpuestas a todos los anteriores . . . . . . . . . . . 73
Figura 4.16 Numero de superposiciones por red . . . . . . . . . . . . . . . . . . . . . . . . 74
Figura 4.17 Similitud de las particiones Louvain versus Min-Max Modularity . . . . . . . 75
Figura 4.18 Similitud de las particiones Louvain versus Min-Max Modularity con pesos . . 76
Figura 4.19 Similitud de las particiones Min-Max Modularity versus Min-Max Modularity
con pesos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Figura 4.20 Grado de informacion estructural por el metodo de Louvain . . . . . . . . . . 78
Figura 4.21 Grado de informacion estructural por el metodo Max-Min Modularity . . . . . 78
Figura 4.22 Grado de informacion estructural por el metodo Max-Min Modularity con pesos 79
Figura 4.23 Caracterizacion de comunidades por Concept Based . . . . . . . . . . . . . . . 80
Figura 4.24 Caracterizacion de comunidades por LDA . . . . . . . . . . . . . . . . . . . . 80
Figura 4.25 Caracterizacion de comunidades por LDA en forma reducida . . . . . . . . . . 81
VIII

Indice de Algoritmos
3.3.1 Red basada en Topicos Orientada al Creador . . . . . . . . . . . . . . . . . . . . . . 38
3.3.2 Red basada en topicos orientada a todos los anteriores . . . . . . . . . . . . . . . . . 39
3.4.1 Algoritmo Jerarquico de Clustering HMaxMin . . . . . . . . . . . . . . . . . . . . . . 46
3.4.2 Algoritmo de busqueda de sub-comunidades superpuestas basada en los arcos . . . . . 50
IX

Capıtulo 1
Introduccion
En este capıtulo se realizara una revision de los problemas generales respecto a la busqueda desub-comunidades y la importancia del conocimiento aportado por ellas, seguido de la presentacionde los objetivos generales y especıficos de esta tesis. A continuacion se presentara la metodologıautilizada para el desarrollo de la investigacion, y finalmente se describiran, brevemente, cada unode los capıtulos de esta tesis.
1.1. El problema de la busqueda de sub-comunidades
Con el desarrollo de las tecnologıas y las facilidades de acceso ellas, son cada dıa mas laspersonas que ingresan a navegar en la Internet. Asimismo, con el crecimiento de dicha red nacieronnumerosas companıas e individuos dispuestos a entregar servicios web y aplicaciones para satisfacerdiferentes necesidades de los navegantes. Hoy en dıa existen, por ejemplo, sitios de correo electronico(Hotmail1 , Gmail2), de comercio electronico (Amazon3, Mercado Libre4), aplicaciones de mensajerıainstantanea (MSN5, Yahoo Messenger 6), y por supuesto, sitios dedicados a las redes sociales on-line definidos como servicios basados en web que permiten a los individuos “Construir un perfilpublico o semi-publico dentro de un sistema limitado, articular una lista de otros usuarios con losque comparten una conexion, y explorarla, y finalmente recorrer su lista de las conexiones y lashechas por otros dentro del sistema” [17]. Algunos ejemplos de estos sitios son facebook7, twitter8,
1http://www.hotmail.com [Fecha de Acceso 29 de Septiembre de 2011]2http://www.gmail.com [Fecha de Acceso 29 de Septiembre de 2011]3http://www.amazon.com [Fecha de Acceso 29 de Septiembre de 2011]4http://www.mercadolibre.com [Fecha de Acceso 29 de Septiembre de 2011]5http://www.msn.com [Fecha de Acceso 29 de Septiembre de 2011]6http://messenger.yahoo.com[Fecha de Acceso 29 de Septiembre de 2011]7http://www.facebook.com [Fecha de Acceso 29 de Septiembre de 2011]8http://www.twitter.com [Fecha de Acceso 29 de Septiembre de 2011]
1

Capıtulo 1. Introduccion
Taringa! 9, entre otros.
Al interior de estas redes sociales, las interacciones entre los miembros pueden fortalecersecompartiendo experiencias, opiniones, intereses y persiguiendo objetivos comunes. De esta formalos usuarios asumen roles y desarrollan un sentido de pertenencia a este grupo de individuos deintereses comunes conformando una comunidad. Las comunidades pueden ser clasificadas segun suscaracterısticas, por ejemplo, en comunidades de interes, comunidades de proposito y comunidadesde practica como senalan Leve y Wenger [59]. Estas ultimas han sido ampliamente estudiadaspor Wenger et al.[101] que define a una comunidad de practica (en adelante, CoP por sus siglas eningles Community of Practice) como un “un grupo de personas que comparten una preocupacion, unconjunto de problemas, o una pasion sobre un tema, y que desean profundizar en sus conocimientosy experiencia, en esta area, mediante una interaccion continua entre miembros”. Si bien, estascomunidades requerıan de un espacio fısico para interactuar, con el surgimiento de la Internet ellugar dejo de ser un impedimento para su desarrollo y con esto surgieron las comunidades virtualesde practica (en adelante, VCoP por sus siglas en ingles Virtual Community of Practice). Estascomunidades establecen relaciones sociales a traves de las herramientas de la Internet, desarrollandouna identidad de comunidad y una manera comun de observar el mundo[90].
En general, en estos sitios de redes sociales los individuos pueden comunicarse y compartirexperiencias, ideas, hacer nuevas amistades, organizar eventos y formar comunidades. Debido a lasdiversas posibilidades que brindan, estos sitios son frecuentados por millones de usuarios en todo elmundo, superando incluso los setecientos cincuenta millones de usuarios en el caso de Facebook10,lo que a nivel mundial equivaldrıa al tercer paıs mas grande en terminos de poblacion. Debido aesto son cada dıa mas las empresas dispuestas a invertir en publicidad a traves de redes sociales,por ejemplo, solo en EE.UU. se estima que para el ano 2011 las empresas invertiran mas de dos milmillones de dolares especıficamente en publicidad en redes sociales11.
No obstante, el gran alcance economico que han alcanzado las redes sociales, tambien implicanciertas responsabilidades, primero con los usuarios y la privacidad de la informacion aportada porellos y por otro lado con los organismos reguladores de cada paıs. En Espana, por ejemplo, un sitiofue sancionado y obligo a sus administradores a pagar una multa de seis mil euros por comentariosexpresados por sus usuarios. Otro ejemplo, que tuvo lugar en Sudamerica, es el caso de Taringa!,donde los hermanos Botbol fueron procesados como “partıcipes necesarios”del delito de violaciona la propiedad intelectual por permitir que, en Taringa!, algunos usuarios compartieran links conmaterial protegido por Ley12.
Frente estos hechos se hace necesaria la administracion de acuerdo a las regulaciones localesde los sitios en donde el numero de usuarios se incrementa de manera constante y, por otro lado,trasformar en informacion la gran cantidad de datos almacenados en estos sitios de redes sociales.
9http://www.taringa.net [Fecha de Acceso 29 de Septiembre de 2011]10http://www.facebook.com/press/info.php?statistics [Fecha de Acceso 29 de Septiembre de 2011]11“The rise of Social Networking AD Spending”- www.flowtown.com [Fecha de Acceso 29 de Septiembre de 2011]12http://www.revistaenie.clarin.com/ideas/tecnologia-comunicacion/Caso-Taringa-debate-culturales-digital_
0_491951058.html [Fecha de Acceso 29 de Septiembre de 2011]
2

Capıtulo 1. Introduccion
Para poder analizar adecuadamente los datos existen diferentes enfoques, por ejemplo, el Analisisde Redes Sociales (en adelante, SNA por sus siglas en ingles Social Network Analysis) descritas porWasserman y Faust [99] el cual entiende a la red social como conjunto finito de actores y la relaciono las relaciones definidas sobre ellos. SNA aborda un numero reducido de aspectos sociales, como loson la busqueda de metricas e indicadores para describir una red, por ejemplo: densidad, centralidad,busqueda de sub-comunidades, visualizacion de las comunidades, entre otras propiedades relevantes.
Por otro lado, se tienen herramientas basadas en minerıa de textos (TM, de sus siglas en inglesText Mining) las cuales estan basadas en la minerıa de datos, para poder obtener informacion de losdocumentos aportados por los usuarios y ası encontrar los topicos mas hablados, que permiten entreotras aplicaciones, categorizar a los usuarios segun la informacion aportada. Ası, por un lado SNAaporta con los indicadores y medidas para analizar las interacciones de una red social y por otro lado,la minerıa de textos aporta con el analisis de los contenidos subyacentes en la red, lo que permitecaracterizar a los usuarios y fortalecer los enlaces entre ellos. Ambos enfoques son complementariospara obtener un entendimiento global de la red social y poder ası extraer informacion relevante afin de poder administrar de mejor manera un sitio web.
Uno de los principales desafıos a los cuales se enfrentan los administradores es el encontrarlas diferentes sub-comunidades que coexisten dentro de estas redes sociales y caracterizarlas adecua-damente, pues, las comunidades juegan un rol vital para entender como se crea, como se representay como se transfiere el conocimiento a traves de las personas [85]. Segun Fortunato [41], actualmenteno existe una definicion de comunidad en terminos cuantitativos universalmente aceptada y dependedel sistema que se tenga a mano o de la aplicacion que se tenga en mente la definicion a utilizar.Ası mismo Chen [21] senala que una comunidad puede ser definida como un grupo de entidades quecomparten propiedades similares o se conectan entre ellos mediante un tipo de relacion especıfica,ademas menciona, que identificar estas conexiones y localizar estas entidades en diferentes comu-nidades es el objetivo principal de las investigaciones en la busqueda de sub-comunidades. Se debetener en cuenta que los actuales metodos de busqueda de sub-comunidades solo permiten identificarestructuras de grupos cuando el numero de relaciones entre sus miembros es del orden del numerode usuarios [41] por lo que utilizar las herramientas de minerıa de textos es de gran utilidad paradeterminar quienes estan realmente relacionados en terminos semanticos y quienes no.
1.2. Objetivos
1.2.1. Objetivo General
El objetivo general de esta tesis es desarrollar e implementar una metodologıa para mejorarel proceso de busqueda de sub-comunidades mediante el uso de SNA y Text Mining, con el fin deapoyar el proceso de administracion en una VCoP.
3

Capıtulo 1. Introduccion
1.2.2. Objetivos Especıficos
1. Mejorar las actuales representaciones de grafos para el uso de SNA en una VCoP median-te el uso de Concept-Based Text Mining (CB), Latent Dirichlet Allocation (LDA) y otrasherramientas de text mining.
2. Comparar y adaptar algoritmos de busqueda de sub-comunidades sobre las mejoras en lasrepresentaciones de los grafos y validar estas mejoras.
3. Evaluar las mejoras del uso de la metodologıa de busqueda de sub-comunidades utilizandoText Mining y SNA sobre una VCoP real.
4. Caracterizar a las sub-comunidades encontradas mediante el uso de Text Mining.
1.3. Resultados Esperados
Algunos de los resultados esperados en esta tesis son:
1. Aplicar a la representacion de grafos la reduccion de la densidad, mediante el uso de los filtrosCB y LDA en los post.
2. Identificar sub-comunidades por topicos y/o conceptos en la comunidad de Plexilandia.
3. Comparar de los resultados de SNA clasico con SNA sobre los grafos filtrados.
4. Adecuar los algoritmos clasicos de busqueda de sub-comunidades de manera de mejorar larepresentacion de estas.
5. Evaluar los algoritmos propuestos y los resultados obtenidos.
1.4. Metodologıa
La metodologıa de trabajo se basa en el proceso Knowledge Discovery in Data Bases (enadelante, KDD) [34] combinado con SNA. Se trabajaran con los datos obtenidos desde una VCoPreal. Para el desarrollo de esta tesis se utilizaran datos previamente seleccionados, limpiados y pre-procesados, los cuales son resultado de los trabajos previos de busqueda de miembros claves enuna VCoP efectuados por Alvarez [1, 2]. Posteriormente se construiran las representaciones de lared en grafos utilizando los datos anteriormente senalados y estrategias de minerıa de textos. Acontinuacion se utilizaran herramientas de SNA para encontrar sub-comunidades en estos grafos yfinalmente se procedera a caracterizar las sub-comunidades encontradas, como senala la Figura 1.1.
4

Capıtulo 1. Introduccion
Figura 1.1: Metodologıa para la busqueda de sub-comunidades
La metodologıa usada para el desarrollo de esta tesis se realiza en los siguientes pasos:
1. Avances previos en el area y Busqueda de sub-comunidades
Para el desarrollo de este trabajo de tesis se realizara una breve introduccion de las aplicacionesde SNA, describiendo sus ambitos de estudio. Posteriormente se realizara una revision de losdiferentes metodos que abordan la problematica de busqueda de comunidades basados en SNAy algunos de los ultimos avances en el area. Ademas se revisaran algunos metodos que buscancombinar la minerıa de textos, en particular, que utilicen modelos de topicos o conceptos paraencontrar comunidades en redes.
2. Representaciones en grafos
Las representaciones de las redes sociales pueden ser diferentes dependiendo de las carac-terısticas del problema de SNA a abordar. Es por ello que es necesario utilizar estrategiasque permitan construir grafos que capturen toda la informacion contenida en una red socialy permitan el posterior analisis con herramientas de SNA, en particular, con las que abordanel problema de la busqueda de sub-comunidades.
3. Seleccion de algoritmos
El problema de la busqueda de sub-comunidades sera abordado seleccionando algoritmos quecumplan al menos con tres criterios fundamentales. En primer lugar, que sean aplicables sobregrafos; en segundo lugar, que esten a la vanguardia de la investigacionen el area; y en tercerlugar algoritmos que permitan usar y comparar las mejoras obtenidas utilizando minerıa detextos. En general, las comunidades se pueden clasificar en tres tipos segun su definicion[41]:locales, globales y basadas en la similitud entre nodos. Para cada definicion existen diferentesmetodos de solucion al problema y sera parte de esta tesis seleccionar y/o modificar losalgoritmos que mas se adecuen a las caracterısticas del problema.
4. Aplicacion de la metodologıa propuesta
Tanto los algoritmos de busqueda de sub-comunidades como los metodos de minerıa de textospara la obtencion de topicos y conceptos seran utilizados sobre una VCoP real. Primero yutilizando los datos obtenidos del trabajo realizado por Alvarez et. al.[1] se realizaran las
5

Capıtulo 1. Introduccion
configuraciones adecuadas para la construccion de los grafos, a continuacion se aplicaran losalgoritmos de busqueda de sub-comunidades seleccionados para, finalmente, caracterizar lascomunidades descubiertas.
5. Analisis de los resultados y conclusiones
Una vez implementada la metodologıa propuesta se evaluara la misma y los resultados ob-tenidos tras de la aplicacion de los distintos metodos de busqueda de sub-comunidades. Laevaluacion comparara los distintos metodos en redes generadas con y sin la utilizacion deminerıa de textos en particular los metodos Concept Based TextMining(CB)[90] y Latent Di-richlet Allocation (LDA)[14, 15]. Finalmente se presentaran las conclusiones de cada una delas etapas anteriormente descritas.
1.5. Estructura de la Tesis
En el siguiente capıtulo se presentara una revision de la bibliografıa mas relevante paraSNA, se abordaran los distintos metodos de minerıa de textos y sus aplicaciones sobre una VCoP,adicionalmente se realizara una revision de los metodos mas representativos para la busqueda desub-comunidades en las redes, y finalmente, se describiran algunos enfoques que combinen minerıade textos con SNA.
En el capıtulo 3 se presentara la metodologıa utilizada para la busqueda de sub-comunidadesutilizando como base el proceso KDD[34] y combinandolo con SNA. Se presentaran los algorit-mos de text mining y busqueda de comunidades utilizados para el desarrollo de esta tesis y susmodificaciones.
Luego en el capıtulo 4 se describira una VCoP real, posteriormente se presentaran los resul-tados de la aplicacion de la metodologıa propuesta en el capıtulo anterior sobre esta comunidad.
Finalmente, en el capıtulo 5 se comentaran las principales conclusiones del trabajo de te-sis, que incluyen tanto las contribuciones principales, como las siguientes lıneas de investigacion ytrabajo futuro.
6

Capıtulo 2
Revision de Antecedentes
En este capıtulo, se revisara la bibliografıa mas relevante respecto a los metodos y algoritmosutilizados en esta tesis. En primer lugar se describira brevemente lo referido a las comunidadesvirtuales de practica, luego se describiran los ambitos de estudio del analisis de redes sociales, acontinuacion se introducira el tema de la minerıa de textos y algunos de los metodos en el area, yfinalmente se revisaran los metodos tradicionales y de vanguardia de la busqueda de comunidades.
2.1. Comunidades virtuales de practica
Antes de definir las VCoP se introducira el concepto de las comunidades de practica (CoP),y la pregunta natural que nace es ¿Que son y para que sirven las CoP? Segun Wenger [101] lascomunidades de practica (CoP) pueden definirse como “Grupos de personas que comparten unapreocupacion, un conjunto de problemas, o una pasion sobre un tema, y que desean profundizar ensus conocimientos y experiencia, en esta area, mediante una interaccion continua entre miembros”.El concepto fundamental que separa a las comunidades de practica del resto de las comunidadestiene que ver con su objetivo. En el caso de las comunidades de practica, el deseo subyacentede generar consciente o inconscientemente conocimiento de forma colectiva. Las comunidades depractica sirven, por lo tanto, para que sus integrantes puedan aprender sobre un tema y compartirsus experiencias a traves de la interaccion, permitiendo generar conocimiento, que un individuo porsu cuenta no podrıa generar o tardarıa mucho tiempo en adquirir. Si bien, existen diversas formasque adoptan las CoP, Wenger senala que al menos comparten tres elementos fundamentales:
1. El dominio o el ambito permite establecer una base comun para la interaccion y un sentidode pertenencia e identidad a la comunidad. Un dominio de aprendizaje bien definido legitimaa la comunidad, reafirmando el proposito de esta y permite a sus miembros valorarse frente alos demas participantes.
7

Capıtulo 2. Revision de Antecedentes
2. La comunidad como la base social para el aprendizaje. Una comunidad fuerte fomenta a susmiembros a participar y a formar relaciones basadas en el respeto mutuo y la confianza.
3. La practica es la serie de ideas, herramientas, informacion, estilos, documentos, conocimientosy formas de hacer las cosas, que los miembros de la comunidad comparten, desarrollan ymantienen entre ellos.
En general compartir y fomentar una practica requiere de interaccion con una cierta regulari-dad entre los miembros de la comunidad, por ejemplo, una reunion mensual en donde los miembrosexpongan sus ideas y discutan cara a cara ciertas practicas desarrolladas. Sin embargo, la definicionanterior no restringe la interaccion a la necesidad de un espacio fısico. De esta forma las comu-nidades pueden utilizar como medio para la interaccion algun servicio de Internet (e-mail, foros,blog, redes sociales) trasformandose en Comunidades Virtuales (en adelante, VC por sus siglas eningles Virtual Communities) [100]. Las definiciones anteriores pueden ser aplicadas VC , y de estaforma utilizar el concepto de Comunidades Virtuales de Practica (VCoP), es decir, comunidades depractica que utilizan como medio de interaccion algun servicio Web.
El hecho de poder almacenar el conocimiento generado de las practicas permite a los ad-ministradores de las comunidades poder gestionar el conocimiento y resulta fundamental para elcorrecto funcionamiento de las CoP.
2.2. Analisis de Redes Sociales
Las VCoP pueden ser analizadas utilizando diferentes tecnicas entre ellas podemos encontrarEtnografıa y tecnicas asociadas, Cuestionarios, Experientos y Cuasi-experimentos, y Analisis deRedes sociales o Social Network Analisys (SNA) [90]. Esta ultima, como senalan, Wasserman y Faust[99], se basa en la importancia de las relaciones entre las diferentes unidades, donde una unidad puederepresentar personas, libros, paıses, instituciones, etc. lo que permite representar adecuadamente lasinteracciones en una VCoP. Dichas relaciones y unidades pueden ser representadas mediante redeslas cuales seran el centro del analisis para SNA.
Chen [21] senala que SNA nace en la decada de 1930 liderada por tres cientıficos: JacobMoreno, quien desarrollo la sociometrıa [72] y los “sociogramas”; Kurt Lewin, propuso la idea deque las propiedades estructurales del espacio social podıa ser investigado utilizando herramientasmatematicas como la topologıa y la teorıa de vectores [61]; y Fritz Heider, quien desarrollo lo quehoy se conoce como teorıa del balance entre individuos [53, 32]. Sin embargo, no fue hasta 1950donde por primera vez Barnes [7] introdujo el termino “Red Social”. Basados en su trabajo, y comosenala Cheng [22], Harrison C. White entre 1960 y 1970 desarrolla los aspectos matematicos detrasde SNA. Ası SNA nace de la actividad conjunta de diversas areas de investigacion con enfoquesdiferentes.
Wasserman y Faust [99] senalan que existen cuatro diferencias fundamentales de SNA frente
8

Capıtulo 2. Revision de Antecedentes
a otros focos de investigacion. En primer lugar, las unidades son vistas como inter-dependientes yno como independientes y autonomas, en segundo lugar las relaciones o vınculos entre los actoresrepresentan una transferencia o un flujo de recursos (material o no). En tercer lugar los modelosde red, que se centran en los individuos, ven el entorno de red estructural como proveedor deoportunidades a favor de la accion individual o como una limitacion de esta. Finalmente los modelosde redes conceptualizan las estructuras como patrones de relaciones duraderas entre actores.
Como senala Nooy [27], el objetivo principal del analisis de redes sociales es la deteccion einterpretacion de los patrones de las relaciones sociales entre los actores. Nooy, ademas, divide losambitos de investigacion de SNA en cuatro grandes areas:
Cohesion: Estudia las relaciones entre actores como la amistad y la afiliacion de estos a ungrupo determinado, buscando ver cuales miembros estan vinculados y quienes no. La principalhipotesis en esta area se relaciona con que las personas que coinciden en sus caracterısticassociales interactuaran mas intensamente y que las personas que regularmente interactuandesarrollaran una identidad comun.
Intermediacion: Pretende entender como la informacion se mueve dentro de la red social.Ve temas como quienes son los miembros centrales en una comunidad, quienes son los quegeneran la informacion, quienes sirven de enlace, y como se difunde la informacion en las redes.
Ranking: Busca estudiar el prestigio y la ubicacion de los actores en terminos de importanciadentro de una red.
Rol: Se preocupa de estudiar los roles de los participantes de una red. Se basa en la idea de queun miembro de grupo, un mediador, o un administrador tiene asociado un patron particularen sus relaciones.
2.2.1. Representacion de una red usando grafos
A continuacion se introduciran algunas ideas y conceptos para la representacion de una redsocial en un grafo. Una buena representacion permitira hacer mediciones con mayor precision paraexplicar los fenomenos detras de SNA.
2.2.1.1. El concepto de Relacion
Como menciona Chen [21] el concepto fundamental para el estudio de SNA es la “Relacion”.Asimismo Easley [32] senala que en el sentido mas basico, una red puede entenderse como cualquiercoleccion de objetos en que algunos pares de ellos estan conectados por un enlace. Senala, ademas,que este enlace puede ser un concepto sumamente flexible y que dependiendo de la configuracionde la red, diferentes tipos de relaciones se pueden utilizar para definir.
9

Capıtulo 2. Revision de Antecedentes
En palabras simples, Chen, define el concepto de relacion como sigue: Si se consideran dosset de actores, etiquetados como X e Y .“Una relacion entre X e Y es cada set de parejas ordenadasdonde el primer elemento pertenece a X, y el segundo elemento pertenece a Y ”. Wasserman [99]provee de una amplia descripcion de los tipos de relaciones posibles, que van desde relaciones binariashasta multiples relaciones entre set de actores. Con el objetivo de facilitar el analisis, en adelante setrabajara con una red donde solo se tiene un set de actores X y se estudian las relaciones binariasentre los actores pertenecientes a este set, sin embargo, para poder cuantificar estas relaciones serequiere de la teorıa de grafos.
2.2.1.2. Teorıa de grafos
Los conceptos de la teorıa de grafos pueden extenderse a multiples campos de estudio cientıfi-co. Los grafos pueden representar ciudades y las distancias entre ellas, relaciones sociales entre ac-tores, flujos entre fuentes y sumideros, entre otras tantas opciones. En particular, para el analisis deredes sociales, la teorıa de grafos es una herramienta de suma importancia, pues permite cuantificarlas propiedades de la red y representar el concepto de relacion.
Para entender el funcionamiento de los grafos se entregaran algunas definiciones:
Un grafo es una forma de especificar relaciones entre un conjunto de ıtems. la cual tiene doscomponentes fundamentales [32]:
Nodos: Los cuales pueden representar cualquier objeto de estudio. En particular en una redsocial representan miembros o conjuntos de miembros.
Arcos: Representa una relacion entre un par de nodos. Para el caso de las redes socialespuede representar un tipo de relacion como grado de amistad, parentesco, intereses, grado deinteraccion, entre otros.
Figura 2.1: Tipos de grafos
10

Capıtulo 2. Revision de Antecedentes
Un arco, como relacion binaria, puede ser definido como un arco dirigido en el caso de unarelacion como, por ejemplo “ser jefe de”, o como un arco no dirigido en el caso de una relacioncomo, por ejemplo “ir a la misma clase de”. Un arco no dirigido puede ser representado como lacombinacion de dos arcos dirigidos en sentidos opuestos. Ası, un grafo que tenga solo arcos dirigidosse define como grafo dirigido y del mismo modo, un grafo en el cual todos sus arcos son no dirigidosse define como grafo no dirigido(Figura 2.1).
En terminos formales, un grafo G, puede expresarse como G(N,A) donde N = (n1, . . . , nl)corresponde al conjunto de nodos y A = (a1, . . . , ak) al conjunto de arcos. Notemos que un grafoG se dice no dirigido si ak = (ni, nj) = (nj , ni) ∀ (ni, nj) ∈ A y dirigido si esta condicion no secumple. Algunas otras definiciones de utilidad son:
Nodos adyacentes: Un nodo ni se dice que es adyacente con el nodo nj si ∃ ak ∈A, tal que ak = (ni, nj), esto es, que existe un arco entre ellos.
Camino: Un camino es una secuencia de nodos en la cual, cada par de nodos consecutivosen la secuencia, son nodos adyacentes.
Trıada: Conjunto de tres nodos en que todos los nodos son adyacentes entre ellos.
Sub grafo: Se dice que G′ = (N′,A′) es un sub grafo de G = (N,A) si N′ ⊆ N y A′ ⊆ A.
Grafo completo: Se dice que un grafo es completo cuando todos sus nodos son adyacentesentre ellos. Un grafo completo de n nodos tiene exactamente n(n−1)
2 arcos.
Una manera util de representar un grafo G, para diferentes metodos, es por medio del uso dela matriz de adyacencias. Una matriz de adyacencias contiene tantas filas y columnas como actorestenga el grafo (Figura 2.2). Formalmente si tenemos un grafo G(N,A) la matriz de adyacencias sedefine como una matriz A de N ×N donde Ai,j = 1 si (i, j) ∈ A y Ai,j = 0 en caso contrario.
Figura 2.2: Representacion de un grafo en una matriz
11

Capıtulo 2. Revision de Antecedentes
2.2.2. Medidas utilizadas en SNA
A continuacion se presentaran algunas de las medidas utilizadas en SNA, utilizando la teorıade grafos, que seran de utilidad para esta tesis:
Grado de un nodo: Es una de las metricas mas simples y a la vez mas usadas para unsinnumero de metodos de SNA. Existen dos tipos de grados en un nodo nk el grado-entrante(in-degree) que es igual al numero de arcos incidentes en el nodo nk y se representa por diky el grado-saliente (out-degree) que es igual al numero de arcos que salen del nodo nk y serepresenta por dok. Resulta relevante notar que en un grafo no dirigido dik = dok = dk. Siasumimos que el numero de nodos en un grafo es n y el numero de arcos es m el gradopromedio de un grafo dirigido es di = do = m
n y en un grafo no dirigido d = 2mn .
Densidad: La densidad de un grafo refleja que tan entrelazada esta una red. Se mide contandoel numero de arcos en la red sobre todos los posibles arcos existentes. En un grafo dirigido semide como D = m
n(n−1) y en un grafo no dirigido se mide como D = 2mn(n−1) .
Vecindario: El vecindario de un nodo nk se define como el conjunto de nodos que se conectacon nk.
Clique: Un clique es el maximo sub grafo completo compuesto de al menos tres nodos. Unatrıada es el mınimo elemento que puede ser llamado clique.
Estos indicadores u otros, de acuerdo a las necesidades del problema de SNA a abordar sepueden encontrar en el resumen de Chakrabarti y Faloutsos [19] para minerıa en grafos y en eltrabajo desarrollado por Leskovec [60] para el estudio de la dinamica de grandes redes.
2.2.3. Aplicaciones Minerıa de Datos para SNA
Una de las areas de investigacion de la minerıa de datos se enfoca en la busqueda de patronesbasadose en los enlaces de ciertos objetos llamada “minerıa de enlaces”(Link mining) [43]. SNApersigue entender las propiedades de una red e identificar patrones para explicar los fenomenossociales, lo cual sugiere que sus objetivos se sobreponen y pueden utilizarse conjuntamente. Chen[21] introduce algunas aplicaciones de Link Mining que son categorizadas como aplicaciones paraSNA, enfocadas en los actores sociales, las relaciones y los grafos:
Deteccion de comunidades: El objetivo de la deteccion o busqueda de comunidades con-siste en agrupar los nodos de un grafo dentro de grupos o comunidades que compartan carac-terısticas similares. Existen un gran numero de metodos y enfoques que buscan resolver esteproblema. En la seccion 2.4 se abordara con mas detalle este tema.
12

Capıtulo 2. Revision de Antecedentes
Ranking de objetos relacionados: El objetivo consiste en aprovechar la estructura dela red para rankear a los diferentes actores de esta segun ciertas propiedades. Una de lasaplicaciones mas conocidas en terminos de ranking de sitios web es “Page Rank” [81] utilizadapor google para su buscador. En SNA, algunas de las medidas utilizadas para rankear usuarios,son Prestigio, Centralidad [42, 44, 73] y HITS [56], entre otros. Dentro de esta area tiene granimportancia la busqueda de los miembros claves de una comunidad (Key-members) [1, 3, 63]
Clasificacion de objetos relacionados: El objetivo consiste en encasillar a los miembrosde la red dentro de un numero finito de posibles categorıas. En general, al estar los elementosde la red relacionados entre sı las categorıas tambien lo estan. Es por ello que el desafıo esdesarrollar algoritmos que saquen provecho de dichas correlaciones y que ademas sean capacesde inferir los valores categoricos de los objetos en el grafo [20, 43].
Clasificacion de Entidades: En una red, diferentes nodos, pueden estar haciendo referenciaal mismo objeto en el mundo real. Ası el fin es identificar tanto las referencias como lasentidades que son referenciadas. Algunos ejemplos de este tipo de problemas son los quedeben resolverse en las bases de datos (duplicidad de la informacion, integracion de datos).En general esto se aborda resolviendo el problema de a pares (referente y referenciado), peroen las redes, cada nodo se encuentra relacionado con otros, por lo que igualmente debiesentomarse en cuenta estas relaciones para resolver el problema [13, 29].
Prediccion de Enlaces: El objetivo consiste en inferir la existencia de enlaces entre dosnodos utilizando para ello la informacion aportada por estos y los enlaces en la red. Algunosejemplos de este problema busca predecir amistad [80], relaciones semanticas, entre otros [64].
Busqueda de Subgrafos: Tal como lo se realiza en la minerıa de datos tradicional, el objetivoes encontrar estructuras con patrones de interes en un grafo para luego ser utilizados comoinputs para otras problematicas, por ejemplo, la busqueda de comunidades [43, 58].
2.3. Estrategias de text mining para reducir la base de contenido
Como se ha mencionado con anterioridad, las comunidades virtuales de practica establecenrelaciones sociales a traves de las herramientas de la Internet, como son los foros, e-mails, salas dechat, etc. Esto permite que los datos puedan ser almacenados y analizados a traves de herramientasde analisis de redes sociales [104]. En general, muchos de los algoritmos abordados para SNA, generanlas relaciones entre miembros de la comunidad sin explotar informacion semantica subyacente en lared. Si bien, en el caso de los e-mails es pertinente pensar que las relaciones existen en la medidaen que el e-mail sea enviado a un destinatario dado, en otros casos, como por ejemplo en un foro,el destinatario del post no es tan simple de determinar.
Por otro lado, y en particular para la busqueda de comunidades en un grafo, es posibleidentificar estructuras de grupos solo cuando el grafo es disperso, es decir, el numero de arcos esdel orden del numero de nodos [41], esto sugiere que serıa de gran utilidad contar con metodos que
13

Capıtulo 2. Revision de Antecedentes
permitan comparar y filtrar los arcos en un grafo que no tengan relacion semantica. Ası pues sesugiere el uso de herramientas de minerıa de textos que utilicen los datos subyacentes en la red paradeterminar adecuadamente quienes realmente establecen relaciones y quienes no.
Varios son los autores que proponen una definicion acerca de que es la minerıa de textosy que aspectos aborda. [52, 57]. Para esta investigacion se utilizara la definicion propuesta porFeldman [35], quien senala que el objetivo de la minerıa de textos es “extraer informacion util delas fuentes de datos a traves de la identificacion y exploracion de patrones relevantes en donde lasfuentes de datos corresponden a una coleccion o conjunto de documentos y los patrones relevantesse encuentran entre los datos no estructurados en las palabras de los documentos pertenecientes aesa coleccion”.
Dentro de las areas que abarca la minerıa de textos se encuentra la recuperacion de lainformacion (Information Retrieval) [6] que se preocupa, entre otros aspectos, de la reduccion delcontenido en terminos de dimensionalidad y categorizacion de una coleccion de textos. Muchasson las estrategias que permiten reducir el contenido de una coleccion de documentos [15, 54, 68,69, 70, 89], sin embargo, para esta tesis se utilizaran dos: Concept-based Text Mining [89](CB),que permite representar una serie de documentos en funcion de conceptos claves de la comunidad,previamente definidos, utilizando un modelo de razonamiento difuso para decidir que conceptos seencuentran y cuales no en los documentos de una coleccion. Asimismo, se usara Latent DirichletAllocation[14, 15] (LDA) que permite, dado un numero fijo de topicos, encontrar las probabilidadesde que cada palabra de la coleccion de documentos pertenezca a cada uno de los topicos, para luegodescribir los documentos en terminos de topicos. Ambos metodos para la reduccion del contenidoseran explicados en detalle en la seccion 3.2. Es importante destacar que gracias a la reduccion delcontenido se podran comparar elementos en una red y determinar la validez de los enlaces entre loselementos.
2.4. Metodos para busqueda de Sub comunidades
Dentro de los temas abordados para el analisis de redes sociales se encuentra el de la busquedade Sub-comunidades en grafos. En estos grafos, los miembros de una red social representan losnodos o vertices y las relaciones entre estos vertices son representadas por los arcos, ası, la idea dela busqueda de Sub-comunidades se basa en encontrar estructuras de comunidad ocultas en la red.Segun Chakrabarti [19] una comunidad es generalmente considerada como “un conjunto de nodosdonde cada uno de estos esta mas cerca de los otros nodos que componen la comunidad que de los queno la componen”. De igual manera Chen [21] se refiere a las comunidades en las redes sociales como“un conjunto de las entidades de una red social de tal manera que estas compartan rasgos comunes ouna proximidad, determinada por alguna similitud entre las entidades o una metrica relacional”. Enlo que sigue en la busqueda de Sub-comunidades se asumira que toda la informacion de la relacionentre nodos se condensa en la existencia y el valor del arco. Por lo tanto, los metodos que se veran acontinuacion buscaran encontrar comunidades dentro del grafo, utilizando para ello, exclusivamentela informacion aportada por la topologıa de este. Es importante senalar que solo se mencionaran
14

Capıtulo 2. Revision de Antecedentes
algunos de los metodos tradicionales y los mas relevantes para la presente investigacion. Para unarevision mas completa de la gran gama de metodos existentes se sugiere revisar el estudio realizadopor Santo Fortunato en relacion a la busqueda de comunidades en grafos [41].
2.4.1. Comunidades
Segun senala Fortunato [41], el primer problema de la busqueda de sub-comunidades o clus-tering del grafo es encontrar una definicion cuantitativa de comunidad. Sin embargo Fortunatosostiene que no existe una definicion universalmente aceptada, de hecho, la definicion generalmentedepende del sistema que se analice y/o de las aplicaciones que se requieran realizar. A continua-cion se presentara una breve descripcion de los tipos de problemas abordados en la busqueda decomunidades dependiendo de las caracterısticas del problema:
Figura 2.3: Problema de la busqueda local de comunidades.
Busqueda de Sub-comunidades con informacion Global: Una buena particion en co-munidades puede ser definida segun criterios o metricas globales, es decir, tomando en cuentalas interacciones de todas las entidades de la red. La idea central es que el hecho de que unnodo pertenezca o no a una comunidad afectara el resultado de las pertenencias de todoslos vecinos. Para abordar este tipo de problemas es necesario contar con toda la informacionde la red. En la secciones 2.4.2 y 2.4.3 se abordara en detalle algunos de los metodos masimportantes para resolver esta clase de problemas.
Busqueda de Sub-comunidades con informacion Local: En redes sociales muy grandeso en redes que varıan en cortos perıodos de tiempo, no es posible acceder a la informacionde toda la red. En estos casos se pretende descubrir comunidades con la informacion local, esdecir, conociendo solo un grupo de nodos, los vecinos y algunas relaciones entre ellos. Chen[21] se refiere a las comunidades locales como conjuntos de nodos con conexiones densas entre
15

Capıtulo 2. Revision de Antecedentes
los miembros, encontradas y evaluadas en base a informacion local y define el problema comosigue: Supongamos que existe una porcion de nodos D de la cual se conocen todos los vecinos.Dado que no se posee el conocimiento de toda la red existe un grupo S del cual solo se conocenlos nodos que son adyacentes a D pero no el resto de relaciones posibles. Ası la unica manerade conocer todos los vecinos de un nodo si perteneciente a S es visitandolo y adquiriendo lainformacion de sus enlaces. Al realizar este proceso integraremos este nodo al conjunto D.Este procedimiento se realiza iterativamente de manera de ir agregando nodos al conjuntoD y decidir cuales debiesen ser parte de la comunidad y cuales no. Para ello se definira unconjunto C ⊆ D el cual debe cumplir con una cierta metrica o ley de pertenencia y representala comunidad y un conjunto B de nodos que pertenecen a D y no cumplen con esta metrica. Unejemplo de esta ley de pertenencia es que para cada nodo ci ∈ C todos sus nodos adyacentespertenecen a D, de manera de que la comunidad sera compuesta solo por miembros de los quese tenga toda la informacion y de sus vecinos, como muestra la Figura 2.3. Algunos metodospara la busqueda de comunidades con informacion local son los propuestos por Clauset [23],Lou [66] en los cuales definen diferentes metricas para descubrir y evaluar las comunidades.
Busqueda de Sub-comunidades superpuestas: En general, los metodos tradicionalesde busqueda de comunidades asumen que un nodo puede pertenecer a una y solo a unacomunidad. Sin embargo, en las redes sociales un usuario puede tener mas de un grupo deamigos, por lo tanto, puede pertenecer a mas de una comunidad. En la seccion 2.4.4 seexaminaran algunos de los metodos actuales para abordar este tipo de problemas.
Sub-Comunidades Dinamicas: En general las redes sociales son dinamicas en el tiempo,es decir, los miembros de las comunidades pueden ir cambiando sus relaciones con los otros,modificando la estructura de la red y por lo tanto, variando las estructuras de las comunida-des. El problema de la busqueda de comunidades dinamicas ha sido estudiado por diversosautores [5, 11, 82, 96, 97]. La idea basica es estudiar los cambios de las relaciones suponiendoinicialmente un grafo G(N,A) donde n es el numero total de usuarios participantes en todoel periodo de estudio. Se tiene un conjunto de miembros de X = {x1, x2, . . . , xn} y una se-cuencia H =< P1, P2, . . . , PT > de observaciones donde cada Pi representa las particiones dela red del conjunto X. El estudio de las comunidades dinamicas permite responder preguntascomo cuales son las comunidades que perduran en el tiempo y cuales no, estudiar factoresinternos o externos que llevan a la desaparicion de una comunidad, quienes son los usuariosque conforman el core de una comunidad, y preguntas globales respecto a la evolucion delproposito de toda la comunidad [90], entre otras tantas interrogantes.
2.4.2. Metodos Tradicionales para la Busqueda de Comunidades
A continuacion se veran algunos de los metodos tradicionales para la busqueda de comunida-des en un grafo, divididas en dos grandes lıneas de investigacion: Los que buscan particiones comolos metodos de particion de grafos y metodos de clustering y los algoritmos basados en la busque-da de estructuras de comunidad como los metodos jerarquicos y metodos basados en modularity.Segun Chen [21] la gran diferencia entre estas dos lıneas de investigacion es que en los primeros,
16

Capıtulo 2. Revision de Antecedentes
usualmente, los investigadores conocen de antemano el numero y/o el tamano de los grupos denodos en la red a clasificar, mientras que en los metodos basados en la busqueda de estructuras decomunidad, suponen que la red se dividira naturalmente en sub-grupos los cuales son determinadospor la estructura propia de la red y no por los investigadores.
2.4.2.1. Particion de grafos
El problema de particion de grafos consiste en dividir los nodos de un grafo G(N ,A) en pgrupos de un tamano similar y predefinido, mientras se minimiza el numero de arcos entre los grupos[41]. En la figura 2.4 se muestra un clasico ejemplo donde p = 2. Los arcos entre los grupos se llaman“tamano del corte”. La mayorıa de estos tipos problemas son utilizados para computacion paralela,diseno y particion de circuitos, entre otros y son considerados problemas NP-Completo. Debido aesto un gran numero de heurısticas han sido propuestas[87], entre las primeras y las mas conocidasse encuentra el algoritmo de Kernighan-Lin [55] el cual busca mejorar una particion inicial, engeneral, buscada con otro metodo, optimizando la diferencia entre los arcos en las particiones yentre ellas. El metodo explora entre los vecinos buscando mejorar esta diferencia.
Figura 2.4: Ejemplo de Particion de Grafos en dos grupos
En general el algoritmo de Kernighan-Lin es usado con otras estrategias para optimizar losresultados de busqueda de particiones o grupos. Una conocida estrategia para encontrar particionesson los metodos de biseccion espectral [78, 88]. Estos buscan separar iterativamente la red en 2 subgrafos y luego repetir el procedimiento con cada sub grafo hasta completar el numero de grupossolicitado a priori. Para separar los vertices en cada iteracion se utilizan los vectores propios de lamatriz Laplaciana [21]. Otros enfoques se basan en el conocido teorema de maximo flujo-mınimocorte propuesto por Ford Fulkerson [39] que busca determinar cual es el maximo flujo entre cualquierpareja de nodos de la red, definiendo el primero como una fuente y el segundo como el sumidero, oinversamente, cual es el mınimo numero de arcos que se debe eliminar para que esta pareja de nodoseste desconectada. Por ejemplo, Flake et. al. [36, 37] han utilizado estos avances para identificar
17

Capıtulo 2. Revision de Antecedentes
comunidades web. Otros autores han desarrollado metodos que utilizan estas ideas, pero ademas,buscan resolver el problema del tamano de los grupos. Ya que, es posible que el numero de usuariosde un grupo no sea similar al de otro (en una comunidad pueden existir grupos masivos y grupospequenos conjuntamente), los metodos tradicionales de corte requieren como restriccion un numerode integrantes por grupo, pues si este parametro fuese libre, la solucion del problema serıa la soluciontrivial en que todos los nodos pertenecieran al mismo grupo. Un ejemplo de algoritmos que buscaresolver este inconveniente es el metodo desarrollado por Ding et al. llamado min-max cut [28].
El gran problema de estos metodos es que se debe entregar de antemano el numero de gruposy en general esto es una de las interrogantes del problema. Luego estas estrategias resultan no serdel todo adecuadas para la busqueda de comunidades.
2.4.2.2. Metodos de Clustering
Este tipo de metodos busca determinar como separar adecuadamente un conjunto de nodosrespecto a un numero predefinido de clusters o grupos. Para poder utilizar este tipo de metodos esnecesario embeber el grafo bajo una metrica espacial, de tal manera de que cada nodo se encuentrea una distancia respecto a cada uno del resto de nodos que componen el grafo. Esta distancia puedeser una medida de similitud o de disimilitud. Luego el problema consiste en, dado un numero kde clusters, colocar a cada uno de los nodos en uno de los k grupos maximizando o minimizandouna funcion de costos basados en la distancia de los nodos a ciertos centroides o puntos en elespacio que representan a estos k grupos. Existen diversas funciones que pueden ser utilizadas paraencontrar los clusters [103], entre ellas, las mas conocidas son k-means [67] y Fuzzy c-means [31]que si bien apuntan al mismo objetivo, se diferencian en que este ultimo otorga a cada nodo ungrado de pertenencia a cada cluster, pudiendo pertenecer, segun el nivel de corte exigido, a mas deuna comunidad al mismo tiempo, cosa que en k-means no es posible.
Sin embargo, al igual que los metodos de particion de grafos (Seccion 2.4.2.1) requierenque el numero de grupos o comunidades sea definido de antemano. Adicionalmente, el hecho deembeber el grafo sobre una metrica espacial puede resultar engorroso para grafos donde las cone-xiones representan relaciones como la amistad o grado de interaccion, pues no son necesariamenterecıprocas.
2.4.2.3. Metodos Jerarquicos
Este tipo de metodos tiene por objetivo buscar las divisiones naturales de la red en grupos,basados en la idea de que los grafos tiene una estructura jerarquica, es decir, pequenos grupos denodos que son parte de grupos medianos de nodos y que a su vez estos pertenezcan a grupos masgrandes y ası sucesivamente. Una de las tecnicas mas conocidas es la de Clustering jerarquico [51, 94].Para utilizar esta estrategia se requiere que se especifique una medida de similitud y calcularla paracada par de nodos (i, j) en la red. A continuacion se deben usar estas similitudes entre nodos
18

Capıtulo 2. Revision de Antecedentes
dependiendo de la clase de metodo jerarquico a utilizar, los cuales pueden ser del tipo aglomerativo,en el cual los clusters son iterativamente unidos si la similitud entre los nodos de cada cluster essuficientemente alta, partiendo desde un solo nodo y terminando cuando todos los nodos son partede la misma comunidad y del tipo divisivo en el cual, los clusters, son iterativamente separadosremoviendo los arcos con baja similitud, partiendo de la red completa hasta terminar en que todoslos nodos esten separados.
Uno de los mas recientes metodos en esta area es el propuesto por Girvan y Newman [44].Este metodo usa como medida la betweenness de un arco, la cual se define como la suma de todoslos caminos mınimos que existen entre todos los pares de nodos de la red que pasan por este arco.La finalidad es remover iterativamente los arcos con mayor betweenness hasta que no quede ningunarco o hasta que se cumpla un criterio de detencion adecuado para el problema en particular. Lagran desventaja de este algoritmo es que resulta poco eficiente, pues se hace necesario recalcular loscaminos mınimos entre los nodos que pasan por el arco retirado en cada iteracion.
Si bien los metodos jerarquicos poseen la ventaja de que no es necesario definir a prioriel numero de grupos, segun Chen [21], tienen ciertas desventajas: En primer lugar los metodosaglomerativos tienden solo a encontrar el core de las comunidades y a descuidar los nodos perifericosdebido a la forma en que operan. Por otro lado, los metodos divisivos si bien clasifican a los nodosperifericos tambien clasifican dentro de una comunidad a los nodos “outliers”.
Otro problema de los metodos jerarquicos es que no proveen de una medida que permitadeterminar cuales de las soluciones entregadas es mejor y dependera de la medida de similitudutilizada cual o cuales son las mejores soluciones. Para resolver esto Newman y Girvan proponen la“modularity”[76], un ındice que permite medir que tan buena es una cierta division del grafo. Lamodularity y sus alcances seran estudiados en profundidad en la seccion 2.4.3.
2.4.3. Metodos basados en Modularity
El termino Modularity fue introducido por Newman y Girvan[76] como medida para deter-minar que particiones de una red son mejores, al utilizar el algoritmo de Girvan y Newman [44]. Enterminos practicos busca medir la fraccion de los arcos que se conectan dentro de las comunidadesdel total de arcos, menos la fraccion esperada de los arcos que se conectarıan dentro de las comu-nidades si estos fueran puestos al azar. Consideremos una division de una red en k comunidades.Luego se define la matriz simetrica e de k × k elementos donde cada elemento ei,j es la fraccion detodos los arcos de la red que parten de un nodo en la comunidad i y llegan a la comunidad j. Luegola traza de la matriz e es Tr(e) =
∑i ei,i este termino representa la fraccion de los arcos que se co-
nectan dentro de las comunidades del total de arcos. Se observa que si bien, altos valores de la trazasignificarıan mejores particiones de la red, en el sentido que hay menos arcos entre-comunidadesque intra-comunidades, este valor, por sı solo, no es un buen indicador de la calidad de una divisionde la red, pues por ejemplo, si todos los elementos se encuentran en una misma comunidad la trazaTr(e) = 1. Por ello, ademas, se define la suma de las filas (o columnas) ai =
∑j ei,j que representan
la fraccion de los arcos que conectan con al menos uno de los nodos de la comunidad i. Si suponemos
19

Capıtulo 2. Revision de Antecedentes
que los arcos de la red son puestos al azar entre las comunidades y se quiere determinar la fraccionesperada de todos los arcos que parten de i y terminan en j de del total de arcos en la red, se tendrıaei,j = aiaj , luego a2i representa la fraccion esperada de los arcos que se conectarıan dentro de lascomunidades si estos arcos fueran puestos al azar [76]. Ası se puede definir la modularity como:
Q =∑i
(eij − a2i ) = Tr(e)−∥∥e2∥∥ (2.1)
Donde ∥X∥ representa la suma de los elementos de la matriz X. Segun senala Newman yGirvan si el numero de arcos en las comunidades no es mejor que el que se conseguirıa si los arcosfuesen puestos al azar, entonces Q = 0. Si los valores son cercanos a 1, que es el maximo posible,indica que hay una fuerte presencia de una estructura de comunidad en la red. Q en general seencuentra en las redes con valores que van desde los 0,3 a los 0,7, raramente se encuentran valoresmayores [76].
Segun senala Fortunato [41] la modularity representa uno de los primeros intentos por lograrentender los principios del problema de clustering, integrando en su funcion de calidad todos loselementos esenciales, desde la definicion de comunidad, pasando por la eleccion de un modelo nulo decomparacion, hasta la expresion de solidez o fortaleza de las comunidades y particiones encontradas.Desde ese momento muchos investigadores han tratado de extender esta definicion a otros metodospara abordar la problematica del descubrimiento de comunidades en una red.
Dado que la modularity representa una funcion que refleja que tan buena es una particionde una red, entendiendo que entre mayor sea el valor, mejor es la particion de la red encontrada,parece ser una buena estrategia buscar maximizar esta funcion. Sin embargo, se ha determinadoque, dado la gran cantidad de posibles particiones de una red, el problema de maximizar la mo-dularity es del tipo NP-Completo [18]. Ası resulta natural pensar en heurısticas para poder lograrvalores aproximados al optimo de modularity, en particular, tecnicas basadas en algoritmos voraces(greedy). Uno de los primeros intentos en esta area fue el metodo voraz de Newman [77], un metodoaglomerativo jerarquico, que parte con cada uno de los n nodos siendo el unico miembro de unacomunidad, es decir, en un principio hay n comunidades. Luego se van uniendo las comunidadesuna a una, escogiendo en cada iteracion la union que resulte en un mayor incremento (o menordisminucion) de la modularity global, hasta que no queden mas comunidades. Luego los resulta-dos son representados en un dendograma para tras ello, realizar cortes en diferentes niveles, con locual se obtienen distintas divisiones de la red. Finalmente, se escoge entre las distintas divisiones aaquella que entregue una mayor modularity. Posteriormente este algoritmo fue mejorado por Clau-set [24] quien realizo cambios en la manera en que era calculada la modularity entre los grupos,eliminando todas las operaciones innecesarias y mejorando la eleccion de la maxima modularity encada iteracion utilizando max-Heap. Diversos autores han propuesto modificaciones para mejorarlos resultados del algoritmo voraz de Clauset [26, 98], sin embargo, este sigue siendo uno de losalgoritmos comunmente usado para comparar y encontrar la maxima modularity en grandes grafos.Otro metodo voraz conocido es el propuesto por Blondel et al. [16]. Este metodo funciona en dosetapas: En la primera se busca encontrar la maxima modularity con una estrategia local y en la
20

Capıtulo 2. Revision de Antecedentes
segunda, para mejorar los resultados, se itera de la misma manera pero embebiendo las comunidadesen un solo nodo. El metodo en detalle sera explicado en la seccion 3.4.1.
El algoritmo voraz de Blondel, tambien conocido como algoritmo de Louvain, tiene mejoresresultados en terminos de modularity maxima encontrada que el algoritmo de Clauset y sus me-joras. Aun ası, el resultado obtenido con este metodo depende significativamente del orden de losnodos escogidos. Una variacion del metodo de Louvain, que incluye la eleccion de un nodo al azarpara mejorar el resultado, fue implementada por McSweeney [8] para el software Gephi, el cualsera utilizado en este trabajo de tesis.
Entre otras estrategias, para la optimizacion de la modularity, se encuentran el uso de simu-lated annealing como el propuesto por Guimera[50], optimizacion extrema como el propuesto porDuch y Arenas[30] y de optimizacion espectral en combinacion con un algortimos voraz como elpresentado por Ruand y Zhang [91] entre otros tantos descritos en detalle en el trabajo realizadopor Fortunato [41]. Cabe destacar, como senala Fortunato, que aun cuando los metodos voraces hansufrido refinamientos a traves de los anos, tienen un peor desempeno en terminos de modularitymaxima encontrada, comparado con estas otras estrategias de optimizacion. Sin embargo, la mayorıade estas otras estrategias son lentas respecto a los algoritmos voraces puros, lo cual puede ser ungrave problema en grandes redes.
2.4.3.1. Lımites de la modularity
Si bien la modularity parece ser una de las mejores funciones para comparar divisiones dentrode la red, tiene ciertas limitaciones y problemas que deben ser discutidos. Uno de los mas importantespuntos en discusion es la capacidad de la modularity para encontrar buenas particiones [40]. Enterminos simples, senala que si existen dos comunidades lo suficientemente pequenas medidas segunel numero de arcos con respecto al total de arcos de la red y ademas, estas comunidades estuviesenunidas debilmente a traves de algun arco, al aplicar un algoritmo basado en la modularity estetenderıa a unir a estas dos comunidades en una sola. Lo anterior se debe a que, en este caso particular,la fraccion esperada de arcos al unir las comunidades es demasiado pequena para contrarrestar elbeneficio de unirlas, aun cuando no debiesen estar unidas. Si bien, se requiere que las comunidadessean pequenas en terminos de arcos, basta que las comunidades sean comparativamente pequenascon el resto de la red para que este fenomeno ocurra. Chen [21] senala que las posibles soluciones aeste problema se encuentren en la aplicacion de algoritmos recursivos para optimizar la modularitypropuestos por Ruan [92]. Ademas senala que otro problema de la modularity es que si bien, computala existencia de arcos entre las comunidades, no mide explıcitamente la ausencia de estos arcos. Enterminos simples, la modularity no penaliza el hecho de que en la misma comunidad se encuentrendos nodos que no tienen arcos en comun. Chen propone una variacion de la modularity, llamadaMax-Min Modularity [22] que segun una ley de penalizaciones, resuelve lo anterior. Este algoritmose vera en detalle en la seccion 3.4.2.
Finalmente Fortunato [41] senala que otra dificultad que se presenta al utilizar la modularity,y quizas la mas grave, tiene que ver con los resultados planteados por Good et al. [45]. Ellos
21

Capıtulo 2. Revision de Antecedentes
descubrieron que puede existir un numero exponencial de posibles estados/divisiones de la red, enla cual la modularity es cercana al maximo global. Esto explica el por que de las buenas solucionesentregadas por diferentes heurısticas, sin embargo, senala que llegar al optimo global por mediode estas es virtualmente imposible. Adicionalmente, indica que las divisiones de la red con altosvalores de modularity no son necesariamente iguales, aun cuando tengan valores muy cercanos. Porultimo menciona que al no estar aun resuelto el problema de la agregacion de comunidades que nodebiesen estar juntas, el maximo global no refleja necesariamente el optimo topologico de la red, esdecir, el que realmente debiese tener, y dado que las soluciones tienen valores cercanos al optimoglobal, se confundirıa el optimo topologico con el gran numero de soluciones cercanas al maximoglobal. Good et al.[45] terminan senalando en su investigacion que solo en los casos en que la red searelativamente pequena, que existan estructuras no jerarquicas y no superpuestas, la degeneracionserıa menos severa y los metodos maximizacion de modularity tendrıan un buen desempeno, y en lasque no, como sucede en mayorıa de las redes reales, los resultados obtenidos solo permiten obtenerun buen bosquejo de algunas partes modulares de la red. Motivado por lo anterior y basado en elalgoritmo Max-Min Modularity que se presentara en la seccion 3.4.2, se introduce una variacion deeste algoritmo para trabajar con redes con pesos que se expondra en la seccion 3.4.3 y de esta formaencontrar comunidades con mayor precision.
2.4.4. sub-comunidades superpuestas
Figura 2.5: Comunidades Superpuestas que comparten nodos
En general los metodos anteriormente explicados dividen la red en grupos donde cada nodopuede pertenecer a una y solo a una comunidad. En la vida real las personas, representadas pornodos, pueden pertenecer a varias comunidades. Es ası que nacen los metodos de superposicion quetienen por objetivo identificar las comunidades dentro de la red, en las cuales los grupos puedancompartir a uno o a muchos individuos a la vez como muestra la figura 2.5.
Un metodo para enfrentar este problema consiste en obtener una division de la red y luegolocalmente buscar nodos que puedan pertenecer a mas de una comunidad, obteniendo ası comunida-
22

Capıtulo 2. Revision de Antecedentes
des superpuestas. Una de las aproximaciones de este estilo de solucion del problema es el propuestopor Baumes et al. [9] el que consiste en dos etapas, donde la primera busca el nucleo de las comuni-dades usando un algoritmo para remover nodos segun un ranking, llamado RaRe y la segunda etapabusca encontrar las comunidades finales explorando los nodos perifericos a los nucleos por medio delalgoritmo de Escaneo Iterativo (IS). Posteriormente Baumes et al. [10] mejoraron la busqueda delos nucleos de las comunidades con un metodo llamado Agregacion de Enlaces (Link Aggregate) y enla segunda etapa mejoro IS para disminuir su tiempo de ejecucion en base a algunas observacionesy bautizando este nuevo metodo como IS2.
Otra idea, para buscar comunidades superpuestas, es la propuesta por Zhang et al. [105] quecombina Fuzzy C-means [31] y modularity, bajo el supuesto de que cada uno de los n nodos tiene unapertenencia, entre 0 y 1, a cada una de las k comunidades (uj,k el grado de pertenencia del nodo j ala comunidad k) y la suma de las pertenencias sobre todas las comunidades es 1. El algoritmo tienetres fases, en la primera, se embeben todos los nodos en un espacio euclidiano a traves de un mapeoespectral. A continuacion, se agrupan los nodos en la k comunidades utilizando Fuzzy C-means,para finalmente, maximizar una version mejorada de modularity que incluye las pertenencias decada nodo a cada comunidad encontrada en la fase anterior. Nepusz et al. [75] utilizan la idea delas pertenencias de los nodos en las k comunidades explicadas en el algoritmo de Zhang para definiruna medida de similitud entre los nodos como s =
∑k ui,kuj,k. Estas similitudes son minimizadas
como un problema de optimizacion no lineal con restricciones, utilizando un metodo iterativo deoptimizacion basado en el gradiente, de manera de mantener conectados a los nodos similares ydesconectar a los que no. Sin embargo, requiere como parametro el numero de comunidades paraefectuar el proceso. Otra estrategia similar es la presentada por Nicosia et al. [79] quienes utilizan laidea de pertenencia de los nodos a las comunidades sobre una variacion de la modularity y proponenresolver el problema de optimizacion a traves algoritmo genetico, sin embargo, la definicion de lamodularity utilizada por Nicosia requiere de la definicion de una funcion de pertenencia, lo queinfluye en los resultados obtenidos y por lo demas tiene un alto grado de complejidad O(|C|n2),donde |C| es el numero de comunidades y n el numero de nodos en la red, lo que la hace difıcil deaplicar sobre comunidades de gran tamano. Basados en la idea de las pertenencias y la busquedalocal, se propondra una heurıstica simple que permita encontrar comunidades superpuestas a partirde los resultados de division global de la red, la cual sera explicada en detalle en la seccion 3.4.4
Una de las tecnicas mas populares para identificar comunidades superpuestas es la expuestapor Palla et al. [83] llamada metodo de percolacion de clique (CPM). Un clique, como se explico enla seccion 2.2.2 es el mınimo subgrafo en el cual todos sus nodos estan conectados entre sı. Estealgoritmo se basa en que es muy probable que los arcos internos de una comunidad formen cliquesdebido a que las comunidades son densas en arcos internamente. Por otro lado, es probable queentre comunidades no se formen cliques debido a que no debiesen existir muchos arcos entre ellas.Palla et al. utilizan el termino k-clique para referirse a un subgrafo de k elementos que forma unclique, luego define el termino de adyacencia entre dos k-clique senalando que son adyacentes si entreellos comparten k-1 nodos. Luego define una cadena de k-clique como la union de dichos elementosadyacentes. A continuacion senala que dos k-clique estaran conectados si ambos son parte de unamisma cadena de k-clique. Ası finalmente, Palla define a una comunidad de k-clique como el subgrafocon el mayor numero de estos conectados. Luego se deben buscar, a traves de una heurıstica, los
23

Capıtulo 2. Revision de Antecedentes
diferentes k-clique de la red para ir armando las comunidades segun las definiciones anteriores. Sibien el metodo CPM inicial solo servıa para redes no dirigidas y sin peso, Palla et al. extendieronsu uso para ser utilizado sobre redes dirigidas [84], y Farkas para la utilizacion de pesos [33]. Elmetodo CPM y sus mejoras estan disponibles en el software CFinder1.
En otra lınea de investigacion, Gregory propone el algoritmo de Newman y Girvan paracomunidades superpuestas (CONGA)[47] basada en la betweenness definida por Girvan y Newman[44]. Implica que luego de encontrar las comunidades de la division de la red, se evaluen nodospara ser divididos (o clonados) para pertenecer a mas de una comunidad a la vez. Es ası que seindividualiza a cada nodo y se mide su betweenness de nodo si este valor es mayor al de la maximabetweenness de la red, entonces este nodo debe ser dividido. Posteriormente Gregory mejoro elmetodo para disminuir su tiempo de ejecucion, bautizando esta nueva heurıstica como CONGO[48].Adicionalmente agrego un parametro h que refleja la region local de nodos que debe ser consideradosal decidir como este debe ser dividido y con esto mejoran de manera significativa el tiempo deejecucion del algoritmo [21].
2.5. Aplicaciones de SNA con Minerıa de texto
La aparicion de los modelos de topicos, permitio que muchos investigadores comenzaran aexplorar y analizar grandes grupos de documentos relacionados, etiquetandolos, agrupandolos ydescubriendo las tematicas ocultas en estos documentos. Otra de las ventajas de los modelos detopicos es que permiten comparar el contenido de estos documentos y determinar si uno o masson similares en terminos de contenido y ası validar la existencia de una relacion real entre ellos.A continuacion se presentaran algunos metodos que buscan relacionar analisis de redes sociales enconjunto con el uso de modelos de topicos.
McCallum et al. [68, 69] presentan dos metodos que combinan LDA con el algoritmo deTopicos-Autor (AT)[95]. El Modelo de Topicos Autor-Destinatario (ART) que busca determinar lostopicos de discusion de una red social basada en documentos, es este caso e-mails y el Modelo detopico de Rol-Autor-Destinatario (RART) que intenta determinar los multiples roles de las personasde la red, basados en el envıo y la recepcion de mensajes. Posteriormente Pathak [85] propuso unaextension del ART para la busqueda de comunidades llamada el modelo de Topicos de ComunidadesAutor-Destinatario (CART). Este modelo asume que en una comunidad los autores se comunicansobre temas o topicos de interes mutuo, y los topicos de la comunicacion, a su vez, determinan lascomunidades. Pathak sostiene que su metodo permite, por un lado, identificar comunidades super-puestas, utilizando tanto los enlaces como el contenido disponible en la red y por otro, caracterizarlas comunidades a traves de los topicos. Sin embargo, el numero de comunidades debe ser entregadocomo un dato de entrada.
Rıos et al. [90] presentan un estudio sobre la evolucion del proposito de una comunidad virtual
1http://www.cfinder.org [Fecha de Acceso 29 de Septiembre de 2011]
24

Capıtulo 2. Revision de Antecedentes
de practica, en donde proponen que las herramientas de SNA por sı solas no son suficientes para elestudio de una VCoP y se requieren tecnicas de la minerıa de datos para afrontar este problema. Rıoset al. proponen para ello el uso de Concept Based Text Mining (CB) para identificar como evolucionael proposito de la comunidad a traves del tiempo. Posteriormente Alvarez et al. [1] utilizaron CBpara mejorar la representacion de una VCoP en un grafo, para luego, buscar los miembros clave dela red utilizando el algoritmo HITS [56]. De esta forma se combinaron exitosamente, elementos deSNA con Minerıa de textos. Recientemente, y en la misma lınea de Alvarez, L’Huillier et al. [63]propusieron el uso de Latent Dirichlet Allocation (LDA) para la construccion de una red basada enun foro de la “Dark Web”, filtrando segun topicos de interes, para buscar los miembros que tenganuna vinculacion con el terrorismo, utilizando HITS sobre las comunidades filtradas.
25

Capıtulo 3
Metodologıa propuesta para labusqueda de sub comunidades
En el presente capıtulo se presentaran las principales contribuciones de esta tesis. La meto-dologıa para la busqueda de sub-comunidades sera descrita aplicando un enfoque basado en KDDy SNA, que incluye la seleccion, pre procesamiento y limpieza de datos empleando la minerıa detextos basado en el uso de LDA[15] y Concept-Based [89], la construccion de los grafos utilizandolas interacciones y la semantica de la red, la busqueda de comunidades mediante metodos basadosen la modularity [76], la caracterizacion de las comunidades encontradas, basados en los metodosde minerıa de textos anteriormente senalados y, finalmente, la evaluacion del proceso.
Como se explico en la seccion 2.4 una comunidad es “un conjunto de las entidades de una redsocial de tal manera que las entidades dentro de una comunidad compartan rasgos comunes o unaproximidad, determinada por alguna similitud entre las entidades o una metrica relacional” [21].En general, los metodos de trabajo en grafos presentados en esta tesis, buscan resolver el problemade la busqueda de comunidades centrados en la idea de que en la existencia del arco se concentratoda la informacion respecto a la similitud entre nodos. Estos arcos, en general, son creados a travesde las interacciones simples entre usuarios, sin utilizar la informacion semantica detras de la red[1].Estos metodos que buscan resolver el problema desde la creacion de la red, tienen la ventaja de queal utilizar una metrica, como la modularity, pueden determinar la cantidad y los integrantes de losgrupos utilizando solo la informacion entregada por la topologıa de la red. Existen algunos metodosque combinan la informacion semantica con las interacciones simples de los usuarios de la red para labusqueda de comunidades, por ejemplo, el modelo de Topicos de Comunidades Autor-Destinatario(CART)[85]. Este modelo asume que en una comunidad los autores se comunican sobre temas otopicos de interes mutuo, y los topicos de la comunicacion, a su vez, determinan las comunidades.Esto permite identificar los temas acerca de los cuales se comunican los usuarios dentro de unacomunidad. Sin embargo, estos metodos resuelven todo el problema de forma unificada a traves demodelos bayesianos o extensiones de modelos de topicos, como LDA. Para ello requieren el numerode comunidades como dato de entrada, lo que en general es uno de los parametros a estimar.
26

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Ası, el proposito de esta metodologıa es utilizar las ventajas de los metodos que explotanenlaces de la red para identificar a las comunidades y la informacion que entregan los metodos detopico para, por un lado, fortalecer los enlaces entre las redes usando la informacion semantica de lared y por otro lado, caracterizar segun los topicos a las comunidades encontradas. Adicionalmente,al ser un metodo que funciona en etapas permite cambiar, a medida que evolucione la tecnologıa,los metodos de topicos o los metodos de busqueda de comunidades utilizados.
La metodologıa combina dos enfoques para la resolucion de problemas, Descubrimiento deConocimiento en Bases de Datos (KDD)[34] y SNA [99] formando un hıbrido nombrado por Alvarezy Merlo [2, 71] como SNA-KDD. Esta fusion de metodologıas de estudio tiene como base los pasosde KDD e incorpora algunas de las aplicaciones de SNA, en el caso de esta tesis, la busqueda desub-comunidades. Los pasos de esta metodologıa modificada de forma resumida son: Seleccion dedatos para el estudio de la red social, seguido de la limpieza y transformacion de esta seleccion, acontinuacion se realiza el proceso de Minerıa de Textos (TM) para identificar los topicos y conceptosprincipales de la red social y clasificar los documentos en base a estos resultados, luego se evaluanlos topicos y conceptos encontrados. A continuacion se utiliza SNA para la construccion de losgrafos utilizando la informacion semantica propia de la red y los resultados del proceso anterior, acontinuacion se deben buscar y caracterizar a las comunidades, y finalmente, la evaluacion de losresultados obtenidos para ir mejorando iterativamente el proceso, como muestra la figura 3.1.
Figura 3.1: Proceso SNA-KDD para busqueda de Sub-comunidades
El presente trabajo de tesis se enmarca en la continuacion de la metodologıa propuesta
27

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
por Alvarez [2] del cual se utilizan los procesos de seleccion y pre-procesamiento de datos porel realizados. Por lo tanto, se centra en los procesos de construccion de grafos, la busqueda ycaracterizacion de comunidades. A continuacion se explicaran en detalle los pasos de SNA-KDD ylos metodos utilizados en cada uno de ellos.
3.1. Seleccion, limpieza y trasformacion de los datos
Existen diversas formas de obtener los datos desde las redes sociales. En general, depen-dera del problema a abordar el metodo adecuado para este proceso. Culotta[25] presenta una meto-dologıa para obtener datos de una red social desde los e-mail y Alvarez [2] presenta los pasos basicospara la extraccion de datos desde una VCoP, las cuales usualmente basan su funcionamiento, ensistemas de foros como VBuletin1, MyBB2 y phpBB3 entre otros. Un foro, en el contexto de laWeb, se refiere a un lugar virtual en el ciberespacio donde los miembros interactuan, discuten ideas,comparten y generan conocimiento. En general, los temas dentro de un foro son ordenados en formajerarquica, con distintas categorıas segun el interes de los miembros que lo frecuentan. En el casode las VCoP las categorıas estan directamente relacionadas con el proposito de la comunidad. Cadaconversacion en el foro, dentro de las categorıas, es denominada threads o temas de discusion y enellas los miembros plantean sus opiniones y discuten en torno a una idea central. Cada uno de losmensajes entre miembros efectuados dentro de un threads se llama post, el cual es la unidad basicadentro de un foro. Un tema de discusion se inicia por un post de algun usuario en la comunidad,que en general, contiene una pregunta o la presentacion de una idea que se quiere discutir. Luegolos diferentes miembros de una VCoP, afines con el usuario o con el tema de discusion, efectuan suspost para ir debatiendo y generando ası conocimiento en torno al tema central de la comunidad.
Cada post se compone de algunos elementos basicos como el identificador del usuario (ID)el cual permite conocer que miembros de la comunidad estan interactuando en la discusion, elcontenido del post, el cual dependiendo del foro puede ser texto, imagenes, enlaces a otras paginas,videos, etc. y la informacion propia del sistema de foro, como la fecha de creacion del post, el threadsy la categorıa a la cual pertenece, entre otros. De acuerdo a la metodologıa expuesta por Alvarez[2], se seleccionaran como datos los elementos basicos recien mencionados y el contenido solo enformato de texto disponible en el foro.
Para la limpieza de los datos, Alvarez [2] senala que el primer filtro debe hacerse respectoa las replicas (quotes) de otros post. En un foro, un usuario, puede replicar otro post, creando unnuevo mensaje con la copia del post citado mas el texto adicional expuesto por este nuevo usuario.Por lo tanto, es necesario eliminar del nuevo post la parte replicada y solo almacenar el aporte detexto nuevo.
Luego se deben trasformar los acronimos o abreviaturas, eliminar los errores de ortografıa
1https://www.vbulletin.com [Fecha de Acceso 29 de Septiembre de 2011]2http://www.mybb.com [Fecha de Acceso 29 de Septiembre de 2011]3http://www.phpbb.com [Fecha de Acceso 29 de Septiembre de 2011]
28

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
y todos los elementos de los post que hacen que estos no puedan ser comparables. Este proceso selleva a cabo mediante dos metodos: El primero es un proceso llamado stemming el cual implica latransformacion de cada palabra a su raız, la modificacion de las palabras plurales en singulares yel cambio de todas las frases o palabras que no representan una contribucion a los datos del texto,asignandole un termino representativo como “inservibles” o “miscelaneos” y el segundo metodollamado filtro de stopwords es donde se eliminan todas las palabras que no aportan informacion ala red, como los artıculos, pronombres, las palabras “inservibles” en un proceso.
El objetivo de los metodos antes mencionados es por un lado, hacer comparables los postpara evaluar si ambos hablan de lo mismo y por otro, reducir la cantidad de palabras utilizadaspara realizar la comparacion. Sin embargo, la cantidad de palabras resultantes podrıa ser demasiadogrande para relacionar los post solo en base a palabras utiles. Para reducir el contenido del voca-bulario empleado en la red y poder comparar adecuadamente cada post se utilizaran los metodosde procesamiento de textos.
3.2. Procesamiento del texto en base a la Minerıa de Textos
Luego de la seleccion, limpieza y trasformacion de los datos, es necesario reducir el grannumero de palabras existentes en el foro para realizar una comparacion exitosa del contenido dela red. Sin embargo, no se puede realizar cualquier estrategia de reduccion del contenido, se debenutilizar metodos que permitan extraer las ideas centrales de cada post. Una manera de realizarloes definir una serie de conceptos, topicos, o categorıas y clasificar cada mensaje segun su cercanıa acada una de las categorıas. Al realizar este proceso adecuadamente, los post podrıan ser descritospor un numero reducido de conceptos, lo que resultarıa de suma utilidad para realizar comparacionesentre ellos. El problema es que, las diferentes categorıas a formar, dependeran de la estructura delforo, el objetivo que persigue y los temas tratados en el. Para solucionar lo anterior se propone eluso de los Modelos de Topicos o de Conceptos como estrategia para la reduccion del contenido dela red.
Los modelos de topicos y de conceptos permiten descubrir el contenido tematico de docu-mentos sin una clasificacion previa[4], sin embargo, es necesario representar los datos obtenidos enla etapa anterior de una manera que permita su aplicacion. A continuacion se presentara la no-tacion y la representacion de los datos para implementar los modelos de topicos, seguido de dosestrategias para la reduccion de contenido y clasificacion de post con su aplicacion practica paraesta metodologıa.
3.2.1. Representacion de los datos
Cada uno de los mensajes obtenidos en la etapa 3.1 contiene una serie de palabras quecaracterizan al post. Si se toman todas la palabras distintas de todos los mensajes, entonces se
29

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
obtendra el vocabulario completo que utiliza la red.
Sea V el vector de tamano |V| en el cual cada fila representa una palabra distinta utilizada enla red. Sea vi la palabra i del vector V. Es posible representar al post pj como una secuencia de unconjunto de Sj palabras de V, con Sj = |pj |, donde j ∈ {1, . . . , |P|} y P corresponde al conjunto depost en la red. Un “corpus” se define como una coleccion de P post C = {p1, . . . , p|P|}. En terminosde composicion podemos definir la matrizW de |P|×|V| donde cada elemento de la matriz de definecomo:
wi,j = numero de veces que vi aparece en pj (3.1)
Luego∑|V|
i=1wi,j = Sj . De igual manera se puede definir∑|P|
j=1wi,j = Ti que representa elnumero total de apariciones del termino vi en un corpus.
Un corpus se puede representar a traves de la medida de la frecuencia de un termino por lainversa de la frecuencia del documento (TF-IDF)[93]. Se define la matriz tf-idf que representa alcorpus C como M de |P| × |V| donde cada mi,j se determina como:
mi,j =wi,j
Ti× log
[|P|
1 + ni
](3.2)
Donde ni corresponde al numero de post pertenecientes al corpus en que la palabra i aparece.El termino IDF presentado en 3.2 corresponde a una correccion habitual respecto al termino IDF
original log[|P|ni
]debido a que, luego de la limpieza y seleccion de datos, algunos post pueden no
contener palabras provocando que este termino estuviese indefinido.
3.2.2. Concept Based Text Mining
Concept-Based Text Mining propuesta por Rıos [89] es una tecnica que combina informacionobtenida de los administradores o un grupo de expertos con herramientas de minerıa de datos, enparticular con logica difusa, para mejorar el entendimiento de sitios Web, la cual posteriormentefue adaptada por Rıos et al. [90] para ser aplicada sobre las VCoP y utilizada por Alvarez para labusqueda de miembros clave en una VCoP[1].
En la primera etapa del metodo, es necesario realizar encuestas y entrevistas a los admi-nistradores y expertos de una VCoP para definir los conceptos que representan los objetivos de lacomunidad. Esta definicion puede ser extendida a cualquier grupo de conceptos relevantes que sequieran explorar e investigar dentro de una comunidad. En la segunda etapa del metodo se clasi-ficara cada uno de los post en funcion de la cercanıa que tengan a los conceptos, por medio de lalogica difusa. A continuacion se explicara el metodo en detalle.
30

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Las Variables Linguısticas (en adelante, LV) en la logica difusa, no representan numeros,sino palabras o sentencias en lenguaje comun. Son mas complejas y a la vez menos precisas. Sea uuna LV, se puede extraer un set de terminos T (u) que cubre su universo de discurso U, por ejemploT (gusto) = {dulce, salado, acido, amargo, agridulce}.
Una Relacion Difusa (×) es una representacion del valor de pertenencia entre espacios deobjetos. Sea A = {a1, . . . , an} y B = {b1, . . . , bn} dos set de objetos. Se define una relacion difusacomo :
µ : A×B −→ µi,j ∈ [0, 1] (3.3)
Donde el valor de pertenencia entre ai y bi es representado como ai× bj = µi,j y µ representala funcion de pertenencia de la relacion.
Una Composicion Difusa (⊗) es una regla para realizar una composicion de relaciones difusas.Sean A, B y C set de objetos, Q(A,B) y Q(B,C) dos relaciones difusas que comparten un set Bde objetos, y µQ(a, b) con a ∈ A ∧ b ∈ B y µR(b, c) con b ∈ B ∧ c ∈ C las funciones de pertenenciaambas relaciones difusas. Se define una composicion difusa como:
µ[A×B]⊗[B×C] = µQ◦R(a, c) =∨{µQ(a, b) ∧ µR(b, c)} (3.4)
Donde ◦ representa la composicion difusa entre funciones difusas y∨
y ∧ representan lasreglas de composicion.
Para utilizar las LV para clasificar los conceptos se asumira que un post puede ser represen-tado por una relacion difusa [Conceptos×Post] la cual es una matriz en donde cada fila representaun concepto y cada columna un post. Esta matriz puede re-escribirse de una manera convenienteutilizando la composicion de relaciones difusas representada a continuacion:
[Conceptos× Post] = [Conceptos× T erminos]⊗ [T erminos× Post] (3.5)
Como se definio en 3.2.1, sea |P| el numero total de post en la VCoP, |V| el numero depalabras o terminos diferentes en todos los post y |C| el numero de conceptos definidos por losadministradores de la VCoP, entonces se puede caracterizar la matriz [Conceptos × Post] por su
31

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
funcion de pertenencia como sigue:
µ[C×P ](a, c) =
µ1,1 µ1,2 · · · µ1,|P|µ2,1 µ2,2 · · · µ2,|P|
......
. . ....
µ|C|,1 µ|C|,2 · · · µ|C|,|P|
(3.6)
Donde µ[C×P ] = µ[C×T ] ⊗ µ[T×P ] representa la funcion de pertenencia de la composiciondifusa en la ecuacion 3.5 y cada elemento µc,p con c ∈ C y p ∈ P un valor de pertenencia entre[0, 1] que refleja cuanto un post de P pertenece a un concepto de K.
Luego, se utilizara la composicion difusa de Nakanishi [74]. La justificacion dada por Lohet al. [65] es que para que un post refleje un concepto, no es necesario que todas las palabras delconcepto sean nombradas, sino que basta con un sub conjunto, luego, si algunos terminos no estanpresentes en el post, el grado con el cual ese post refleja un concepto no deberıa sufrir alteraciones.Ası, la regla de composicion difusa resultante se presenta a continuacion:
µ[C×T ]⊗[T×P ] = µQ◦R(c, p) = {1, µQ(c, t) ∗ µR(t, p)} (3.7)
Donde ∗ es el producto algebraico, Q(C, T ) y Q(T, P ) las relaciones difusas sobre[Conceptos × T erminos] y [T erminos × Post] respectivamente, µQ(c, t) con c ∈ C ∧ t ∈ T yµR(t, p) con t ∈ T ∧ p ∈ P .
A continuacion se deben formalizar las matrices [Conceptos×T erminos] y [T erminos×Post].
Para la matriz [T erminos × Post] se utiliza la matriz traspuesta Mt tf-idf definida por laecuacion 3.2 que representa la participacion de cada termino en cada post. Para formar la matriz[Conceptos×T erminos], en primer lugar se deben identificar los conceptos relevantes para el procesode reduccion. Este proceso se realiza en conjunto con los administradores y expertos de la comunidadquienes seleccionan los conceptos y palabras afines. Luego se utilizan diccionarios para expandir lalista de palabras que representa un concepto del total de palabras disponibles en el corpus de lospost, para luego, asignar valores entre [0, 1] a cada palabra segun su cercanıa al concepto. Esteproceso se realiza para cada concepto para formar ası la matriz requerida.
Ası, finalmente, aplicando la ecuacion 3.7 se obtiene la matriz de relaciones difusas[Conceptos × Post] que permite conocer la participacion de cada uno de los conceptos en cadauno de los post efectuados en la comunidad. En el cuadro 3.1 se presentan los resultados de un posthipotetico en base a 5 conceptos.
Se observa que el post esta fuertemente relacionado con los conceptos 1, 3 y 5 pero noesta relacionado con los conceptos 2 y 4.
32

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Cuadro 3.1: Lista de conceptos y valores de pertenencia de un post hipotetico
Conceptos µC×P
Concepto 1 0.71Concepto 2 0Concepto 3 0.92Concepto 4 0.1Concepto 5 0.81
3.2.3. Latent Dirichlet Allocation
A continuacion se presentara el proceso de reduccion de contenido por medio del uso de unmodelo de topicos, basado en trabajo realizado por Alvarez [2] y L’Hullier[62].
Latent Dirichlet Allocation (LDA) [15, 14] es un modelo bayesiano donde los topicos o temaslatentes en los documentos son inferidos a traves de la estimacion de distribuciones sobre un conjuntode datos de entrenamiento. El proposito es que cada topico sea modelado como una distribucionde probabilidad sobre un conjunto de palabras representadas por el vocabulario (w ∈ V), y cadadocumento como una distribucion de probabilidad sobre un conjunto de topicos (T ). El muestreode estas distribuciones se realiza con distribuciones multinomiales de Dirichlet.
La ventaja de este metodo, respecto al enfoque de Concept Based, es que el proceso se realizade forma automatizada y solo se necesita etiquetar cada topico descubierto por el algoritmo con laayuda de los expertos de la comunidad.
Sea V el vector de tamano |V| que representa cada palabra del vocabulario a utilizar. Unapalabra se considera la unidad basica de datos discretos con indices entre {1, . . . , |V|}. El mensajecontenido en un post puede representarse como una secuencia de tamano S de palabras definidocomo W = (w1, ..., wS), donde ws representa la sth palabra en el post. Finalmente se define un“corpus” como una coleccion de |P| post descrita como C = (W1, ...,W|P|).
A continuacion se describe el proceso generativo para el modelo LDA ideado por Blei [15].
Para cada post p del corpus:
1. Escoger un numero S de multinomiales (S ∼ Poisson(ξ)) que representan la cantidad depalabras en el post.
2. Escoger θ ∼ Dir(α).
3. Para cada ws ∈ w.
a) Escoger un topico zs ∼ Multinomial(θ).
33

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
b) Escoger una palabra ws de p(ws|zs, β), que es una probabilidad condicional multinomialsobre el topico zs.
Para LDA, teniendo en cuenta los parametros de suavizamiento β ∈ RR+ y α ∈ R
Q+, y
la distribucion conjunta de una combinacion de topicos θ, se debe determinar la distribucion deprobabilidad para generar a partir de un set de T topicos z, un post compuesto por un conjunto deS palabras de W .
p(θ, z,W |α, β) = p(θ|α)
T∏n=1
p(zn|θ)p(wn|zn, β) (3.8)
Donde p(zn|θ) puede ser representada por una variable aleatoria θi, que representa el ith
valor de ese topico zn que esta presente en el documento i (zin = 1). La expresion final puede serdeducida integrando la ecuacion 3.8 sobre la variable aleatoria θ y sumando sobre todos los topicosz. Dado esto, la distribucion marginal de los post puede ser definida como sigue:
p(W |α, β) =
∫p(θ|α)
(T∏
n=1
∑zn
p(zn|θ)p(wn|zn, β)
)dθ (3.9)
El objetivo final que persigue LDA es estimar la distribucion previamente senalada paraconstruir un modelo generativo para el corpus de los post. Existe un gran numero de metodosdesarrollados para realizar la inferencia sobre esta distribucion de probabilidad como, por ejemplo,variational expectation-maximization [15], o una aproximacion variacional discreta de la ecuacion 3.9de forma empırica por Xing[102] y a traves de un muestreo de Gibbs (Modelo de Monte Carlo basadoen cadenas de Markov) [49] el cual ha sido eficientemente implementado y aplicado por Phang yNguyen[86].
De acuerdo a la metodologıa de Alvarez [2], el siguiente paso para la formacion de la matriz[T opicos× Post], es similar a lo efectuado para la construccion la matriz [Conceptos× Post] vistaen la seccion 3.2.2 para Concept-Based. Esta matriz entregara una reduccion del contenido delos post. Se utilizara el metodo desarrollado por Phang y Nguyen[86] el cual requiere una serieparametros de entrada, como numero de iteraciones, hiper parametros α, β, numero de topicosrequeridos T , el numero n de palabras por topico que debiese guardar, los post del corpus, entreotros. El metodo devolvera como salida las distribuciones de las palabras sobre los topicos, el deestos sobre el documento, k topicos con las n palabras mas importantes que representan al topico ysus correspondientes probabilidades de pertenecer a este, entre otras cosas. En particular, con los ktopicos y sus n ⊆ V palabras o terminos representativos se pueden formar vectores de tamano |V|completando con ceros en las |V| − n palabras no representativas. Con estos vectores se formara lamatriz semantica (SM) [T opicos×T erminos], luego esta matriz se operara con la matriz traspuestaMt tf-idf definida por la ecuacion 3.2 que representa la participacion de cada termino en cada post,
34

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
obteniendo ası la matriz [T opicos×Post]. Esta matriz permite conocer la composicion de un post enterminos de los diferentes topicos encontrados. Esta matriz sera de gran utilidad para la construccionde las redes.
3.3. Desarrollo de las redes
A continuacion se presentara el proceso de creacion de las diferentes redes sobre las cuales seefectuara la busqueda de sub-comunidades. Se debe tener en cuenta que el grado de las interaccionesentre los diferentes miembros de una red se mide a traves de la participacion en el foro de la VCoP,y la participacion, a su vez, se mide respecto a la cantidad de post publicados en el foro. Ası, enlas redes, los nodos representaran a los usuarios de la VCoP y los arcos representaran el gradode interaccion entre miembros. Sin embargo, se deben hacer algunas consideraciones adicionalespara representar adecuadamente las redes, pues la cantidad de post no asegura que exista una realinteraccion entre miembros. Los mensajes en los post deben, al menos, tener un cierto nivel desimilitud para que la interaccion sea realista.
3.3.1. Tipos de redes
La figura 3.2 muestra la configuracion habitual de un foro, donde las elipses representan alos usuarios que realizan los post. Se observa que el post 1 representa al creador de un tema delforo. Cada una de estas estructuras representa un tema de discusion dentro del foro.
Figura 3.2: Una tıpica estructura de un foro
La estructura del foro permite interpretar los post de respuesta segun distintas orientaciones,para el presente trabajo se utilizaran dos orientaciones de respuesta entre los usuarios en las redes:
35

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Redes orientadas al creador: En estas redes cada usuario orienta su post de respuestadirectamente con el creador del thread. Esta orientacion para la formacion de redes es la queproduce las redes menos densas.
Redes orientadas a todos los anteriores: Cada respuesta de un post sera orientada acada uno de los miembros de la comunidad que anteriormente haya realizado una respuestaen este mismo thread. Esta orientacion produce las redes mas densas.
Figura 3.3: Redes creadas con orientacion al creador y a todos los anteriores
En la figura 3.3 se visualizan los tipos de orientaciones de la red basados en la estructura deforo presentado en la figura 3.2. Cada usuario es representado por un nodo y cada respuesta de unpost es representado con un arco. Las redes que se crean son del tipo “dirigidas”, pero de requerirse,la trasformacion es directa trasformando cada arco en dos. Este proceso se lleva a cabo con cadauno de los temas de discusion de la comunidad. En los enfoques tradicionales es posible construir lared solo con el conteo simple de la existencia de un post en cada uno de los thread, formando unared dirigida con pesos. A este tipo de redes construidas solo con el conteo de las respuestas segunla orientacion se le llaman Redes por conteo y seran utilizadas a modo de comparacion de las redesfiltradas.
3.3.2. Filtros basados en las estrategias de reduccion de contenido
Los enfoques tradicionales para la formacion de las redes, representadas por grafos, utilizancomo medida del grado de interaccion solo el conteo de los post entre los usuarios. Sin embargo,muchas de estas interacciones pueden no tener sentido si se comparan los mensajes dentro de cadapost. Para mejorar la representacion de las redes, deben filtrarse aquellas interacciones entre post enlas cuales su contenido no tiene ningun grado de relacion. Por otro lado, las estrategias de reduccionde contenido permiten representar a los post por un numero de conceptos o topicos mucho menor
36

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
al vocabulario del corpus y ademas, permiten comparar a los post respecto a su pertenencia encategorıas, ası, si dos post contienen diferentes palabras, pero se refieren al mismo tema se podrıaninterpretar como post similares. Este es el proposito de los filtros basados en estrategias de reducciondel contenido que buscan eliminar, de las redes, los enlaces que producen ruido o interferencias, pormedio de la comparacion semantica de los post.[90]
La comparacion semantica de los post se realiza por medio de la distancia euclidiana entreellos. Sin embargo, la interpretacion de la cercanıa opuesta. Si la distancia es baja no significaque entre los post exista una interaccion, sino todo lo contrario. Se considerara que existe unainteraccion entre dos post si la distancia euclidiana es mayor a un valor de corte (threshold) θ.De esta manera, se eliminaran aquellos enlaces irrelevantes para el estudio. En la ecuacion 3.10se puede ver la formula de distancia euclidiana de post Pi con i el numero del post y un post derespuesta Pj efectuado por los usuarios x e y respectivamente, donde los post estan representadospor K diferentes conceptos (o topicos). Se asume que el identificador del post i es unico y permitedeterminar el usuario x que efectuo el post.
dm(Pi, Pj) =
∑Kk=1 gikgjk√∑K
k=1 g2ik
∑k g
2jk
(3.10)
Donde gik es el valor del concepto (o topico) k en el post i del usuario x. Se debe senalarque la distancia solo existe si Pj es una respuesta para el post Pi. Por otro lado, es factible que dospost tengan un alto valor en la ecuacion 3.10 y no representen por sı solos un aporte significativoal conocimiento de la red. Por ejemplo, dos nodos que contengan solo la misma palabra, tendranun alto valor de la distancia pero no establecen una relacion que represente una interaccion en baseal conocimiento de la red, por lo que tambien deberan ser filtradas. Luego, otra condicion para laexistencia del enlace, es que la suma de todos los conceptos (o topicos) de cada post sea mayor aun segundo valor de corte γ como muestra la ecuacion 3.11.
Cm(Pi, Pj) = min
(K∑k=1
gik,
K∑k=1
gjk
)(3.11)
Luego se deben sumar todos los arcos para calcular el peso del arco ax,y como senala laecuacion 3.12.
ax,y =∑
i∈x,j∈ydm(Pi,Pj)≥θCm(Pi,Pj)≥γ
d(Pi, Pj) (3.12)
La ecuacion 3.12 puede variarse segun las necesidades del problema. Por ejemplo, si se quiere
37

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
computar el peso que tendrıa la red al sumar todas las contribuciones de las distancias entre postsujeto a que se cumpla la condicion presentada en la ecuacion 3.11 y los pesos sean proporcionalesa θ, se tendrıa la ecuacion 3.13:
ax,y =
∑
i∈x,j∈yCm(Pi,Pj)≥γ
d(Pi, Pj)
θ
(3.13)
Donde ⌊X⌋ corresponde a la funcion cajon inferior de X.
3.3.3. Construccion de las redes
El proceso descrito en 3.3.2 se realiza para cada par de usuarios x e y que representan losN nodos de la red. Se usaran pesos de la ecuacion 3.12 para armar las dos redes anteriormentemencionadas: orientadas al creador y orientadas a todos los anteriores, para luego aplicar algunade las estrategias de busqueda de sub-comunidades existentes. Para la creacion de las redes seasume la existencia de la matriz de [Conceptos × Post] obtenida en la seccion 3.2.2 y la matriz[T opicos× Post] obtenida como resultado de la seccion 3.2.3.
El algoritmo 3.3.1 muestra el pseudo-codigo para formar el grafo Gc = (N ,A) construidousando la orientacion al creador mediante la ecuacion 3.12 para el caso LDA, el metodo en el casode CB es el mismo.
Algoritmo 3.3.1: Red basada en Topicos Orientada al Creador
Data: La matriz [T opicos× Post] de |P| post y K topicos y los parametros de corte γ y θResult: Gc = (N ,A)Inicializar N = {},A = {};1
foreach i ∈ P do2
Identificar al usuario x creador del post i;3
N ← N ∪ x;4
foreach thread t ∈ P do5
Identificar al usuario x creador del post i que formo el thread t;6
foreach post j ∈ t, i = j do7
Identificar al usuario y que responde a traves del post j;8
if dm(Pi, Pj) ≥ θ y Cm(Pi, Pj)γ then9
ax,y ← ax,y + 1 ;10
A ← A∪ ax,y;11
return Gc = (N ,A) ;12
38

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
El algoritmo 3.3.1 utiliza la matriz [T opicos × Post] y los parametros de corte θ y γ paraformar el grafo. El algoritmo cambia al usar la ecuacion 3.13 o en su defecto para la creacion de lasredes por conteo, donde no se utilizan las restricciones relacionadas con los parametros de corte.
El algoritmo 3.3.2 se presenta a continuacion para la creacion de las redes orientadas a todoslos anteriores.
Algoritmo 3.3.2: Red basada en topicos orientada a todos los anteriores
Data: La matriz [T opicos× Post] de |P| post y K topicos y los parametros de corte γ y θResult: Gr = (N ,A)Inicializar N = {},A = {};1
foreach Post i ∈ P do2
Identificar al usuario x creador del post i;3
N ← N ∪ x;4
foreach thread t ∈ P do5
foreach post i ∈ t ordenados por fecha do6
Identificar al usuario x craedor del post i que formo el thread t;7
foreach post j ∈ t, i < j ordenados por fecha do8
Identificar al usuario y que responde a traves del post j;9
if dm(Pi, Pj) ≥ θ y Cm(Pi, Pj) ≥ γ then10
ax,y ← ax,y + 1 ;11
A ← A∪ ax,y;12
return Gr = (N ,A) ;13
El algoritmo 3.3.2 permite determinar la red orientada a todas las respuestas. Los arcos sonconstruidos comparando todas las interacciones dentro de un thread t, el cual esta ordenado segunlas fechas en que fueron efectuados los post. Ası se compara por medio de la ecuacion 3.12, cada unode los post efectuados en un mismo threads con los que fueron efectuados en una fecha posterior.
3.3.4. Construccion de redes topicas
Una de las grandes ventajas de la metodologıa propuesta es que permite la construccionde redes especializadas en ciertos conceptos o topicos. Por ejemplo, una empresa especializada enmarketing, podrıa estar interesada en conocer la red social de usuarios que discutieran acerca deproductos tecnologicos y en identificar los grupos y los miembros claves, para ofrecerles ofertasde nuevos productos que saldran al mercado. En general, estos procedimientos no son posiblesde realizar utilizando los metodos tradicionales pues los vınculos se encuentran embebidos en unsolo arco que representa la relacion. Sin embargo, es posible modificar la ecuacion de distanciaeuclidiana 3.10 para este fin. Se define el vector RC de tamano igual al numero de conceptos y RLde tamano igual al numero de topicos, sea k generico para alguno de estos dos vectores. A modo de
39

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
ejemplo se selecciona el caso para LDA y se emplea el vector RL donde RLk sera igual a 1 en lostopicos que se quieran mantener y 0 en aquellos que no. Luego se puede re-definir la ecuacion dedistancia como:
dm(Pi, Pj) =
∑Kk=1(gik ×RLk)× (gjk ×RLk)√∑Kk=1(gik ×RLk)2
∑k(gjk ×RLk)2
(3.14)
El resto del proceso para construir las redes topicas es el mismo descrito en la seccion 3.3.3.
3.3.5. Transformacion de redes
Si bien, las redes desarrolladas hasta el momento son redes dirigidas y con pesos, muchasveces las redes que utilizan los metodos presentados en la seccion 2.4, para la busqueda de sub-comunidades, necesitan recibir como entrada una red no dirigida y en algunos casos sin pesos. Parasolucionar esto se proponen dos estrategias para modificar las redes: Para la trasformacion a redesno dirigidas (ND) se modifican los arcos definiendo:
aNDi,j = aND
j,i = (aDi,j + aDj,i) (3.15)
Donde aNDi,j corresponde al arco entre el nodo i y el nodo j de la red no dirigida y aDi,j al arco de la
red dirigida. Para una trasformacion a redes no dirigidas y sin pesos (NDSP) se modifican los arcosdefiniendo:
aNDSPi,j =
{1 Si (aDi,j + aDj,i) ≥ 1
0 En caso contrario(3.16)
Se pueden mejorar estos resultados, si se utiliza en la creacion de las redes la ecuacion 3.13aumentando el valor de corte θ, pero esta variacion no sera efectuada en este trabajo.
3.4. Busqueda de sub-comunidades
Con los grafos construidos segun los pasos presentados en la seccion 3.3 es posible aplicarlas tecnicas de SNA presentadas en la seccion 2.2, en particular los metodos de busqueda de sub-comunidades presentados en la seccion 2.4. A continuacion se presentaran los metodos que utilizancomo funcion de la calidad de una particion de la red a la modularity y que seran aplicados parael desarrollo este trabajo. Se debe destacar que la modularity no se ve afectada por la presencia delos nodos aislados en la red, por lo tanto, resulta ser una funcion adecuada para analizar redes quehan sido previamente filtradas.
40

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Antes de presentar los metodos basados en la modularity se debe transformar esta funcionde su forma original presentada en la ecuacion 2.1 que tiene como unidad basica a las comunidadesa una ecuacion enfocada en los nodos. Dado un grafo G = (N ,A) con |N | = n y |A| = m. Sea,ademas, Aij la matriz de adyacencias del grafo G:
Aij =
{1 Si los nodos i y j estan conectados0 En otro caso
(3.17)
Se puede asumir sin perdida de generalidad que existen k comunidades en la red y que elnodo i pertenece a la comunidad Ci, luego la fraccion de arcos que existen entre la comunidad x yla comunidad y es:
exy =1
2m
∑i,j
Aijδ(Ci, x)δ(Cj , y) (3.18)
Donde δ(i, j) es una funcion que toma valor 1 si i y j corresponden a las mismas comunidadesy 0 si no. Se define el grado de un nodo i como κi =
∑j Ai,j , luego la fraccion de arcos que tienen
al menos un arco en la comunidad x se puede escribir como:
ax =1
2m
∑i,j
Aijδ(Ci, x) (3.19)
=1
2m
∑i
κiδ(Ci, x) (3.20)
Luego reemplazando ambas expresiones en la funcion de modularity:
Q =∑x
(eii − a2i ) (3.21)
Q =∑x
1
2m
∑i,j
Aijδ(Ci, x)δ(Cj , x)− (1
2m
∑i
κiδ(Ci, x))(1
2m
∑j
κjδ(Cj , x))
(3.22)
=1
2m
∑i,j
([Aij −
κiκj2m
]∑x
δ(Ci, x)δ(Cj , x)
)(3.23)
Se observa que la expresion δ(Ci, x)δ(Cj , x) tendra valor 1 solo cuando Ci y Cj coincidan enla misma comunidad x, luego si sumamos sobre todas las comunidades
∑x δ(Ci, x)δ(Cj , x) la nueva
41

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
expresion tomara el valor 1 solo cuando Ci y Cj coincidan en la misma comunidad. Ası la expresionse puede escribir:
∑x
δ(Ci, x)δ(Cj , x) = δ(Ci, Cj) (3.24)
Ası, finalmente se obtiene la expresion:
Q =1
2m
∑i,j
[Aij −
κiκj2m
]δ(Ci, Cj) (3.25)
Donde Aij corresponde al elemento de la fila i y columna j de la matriz de adyacencias deun grafo G = (N ,A), κi =
∑j Aij es el grado del nodo i ∈ N , m = 1
2
∑i,j Aij es el numero de
arcos en la red, y δ (ci, cj) es una funcion que toma valor 1 si los nodos i y j pertenecen a la mismacomunidad y 0 si no pertenecen.
A continuacion se veran las heurısticas que se utilizaran para la busqueda de sub-comunidades
3.4.1. Louvain modularity
Este metodo heurıstico desarrollado por Blondel et al.[16] se basa en la optimizacion de lamodularity. Es extremadamente rapido, con mejores resultados en terminos de modularity que elmetodo propuesto por Clauset et al.[24] y el de Wakita y Tusurumi[98] y permite ser aplicado sobreredes con peso.
La heurıstica se divide en dos etapas las cuales son aplicadas iterativamente. En primer lugarse asigna a cada nodo i ∈ N a una comunidad distinta. Ası, inicialmente se tiene |N | comunidadesdistintas. Luego se considera, para cada nodo i su vecindario compuesto por j ∈ V(i) ⊆ N . Acontinuacion se evalua la ganancia de modularity de sacar al nodo i de su comunidad y colocarlo enla comunidad de j. El nodo i se une a la comunidad que entregue la maxima ganancia de modularitycon valor positivo, de manera que si este no lo es, el nodo i continua en la comunidad actual. Seobserva que de los nodos aislados nunca seran unidos a alguna comunidad, luego no afectan elresultado del proceso. Este proceso es aplicado iterativa y secuencialmente hasta que no se puedanhacer mas mejoras locales a la red. Blondel senala que un mismo nodo puede ser considerado variasveces en este proceso, ademas menciona, que aunque el proceso varıa segun el orden de los nodosseleccionados, los test realizados senalan que esta variacion no es muy significativa en terminos demodularity, pero sı en los tiempos de ejecucion del algoritmo.
La ganancia de modularity para un nodo aislado y una comunidad C puede ser computada
42

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
segun la ecuacion 3.26.
∆Q =
[∑in +κi,in
2m−(∑
tot +κi2m
)2]−
[∑in
2m−(∑
tot
2m
)2
−( κi
2m
)2](3.26)
Donde∑
in es la suma de los arcos en C,∑
in es la suma de los arcos que inciden en losnodos de C, κi es el grado del nodo i, κi,in la suma de los arcos que parten en i y terminan en algunnodo de C y m = 1
2
∑i,j Aij . Para el caso en que el nodo i pertenezca a otra comunidad, se debe
evaluar el costo de remover i de la comunidad, a traves de una expresion similar, mas la gananciaal utilizar la ecuacion 3.26. La segunda fase consiste en construir una nueva red en cual los nuevosnodos representan a las comunidades encontradas en la etapa anterior. A continuacion se construyenlos nuevos arcos como la suma de los arcos entre las comunidades embebidas. Adicionalmente, seguardan los arcos dentro de una misma comunidad como un arco circular desde la comunidad i ala comunidad i. Una vez que esta fase esta completa se repite la fase uno del proceso descrito sobreesta nueva red. El autor, llama al proceso donde se utilizan estas dos fases como una “pasada”. Laspasadas son realizadas iterativamente hasta que no exista ninguna ganancia de modularity en lafase uno. En la figura 3.4 se grafica el proceso.
Figura 3.4: Heurıstica de Louvain de dos etapas[16]
Para el presente trabajo se utilizara la implementacion de esta heurıstica disponible en elsoftware Gephi[8]. Si bien, el metodo permite el uso de redes con pesos, la implementacion no losutiliza al momento de ingresar los datos para la construccion de comunidades. Luego se deberanutilizar redes no dirigidas y sin pesos como las senaladas en la seccion 3.3.5.
43

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
3.4.2. Max-Min Modularity
Este metodo es una variacion de la modularity que fue desarrollado por Chen et al.[22] conel fin de incluir en la funcion de calidad de las comunidades encontradas, un termino que penalizarasi dentro de las comunidades, conviven nodos no relacionados.
Chen senala que las comunidades pueden ser definidas como grupos densamente conectados,lo que sugiere que en las comunidades todos los nodos debiesen estar relacionados. Sin embargo, ladefinicion tradicional de la modularity no considera la medicion de la ausencia de enlaces entre losmiembros de la comunidad, es decir, solo mide si los nodos en una comunidad estan conectados,pero no ası cuantos de estos estan desconectados. Intuitivamente, en las redes sociales, los gruposse forman porque comparten ciertas afinidades, pero tambien los mismos grupos se diferencian delos demas porque no comparten las mismas ideas, por ejemplo, integrantes de barras de equiposde futbol rivales. La diferenciacion permite acentuar la pertenencia a los grupos. Luego una buenamedida para la calidad de las comunidades encontradas en las redes debiese no solo premiar cuandolos nodos conectados pertenecen a la misma comunidad, sino que debiese penalizar cuando dentrode una misma comunidad exista un gran numero de nodos desconectados. No obstante, en una reddos nodos desconectados pueden estar debilmente conectados en base a la “Hipotesis del EnlaceDebil”[46]. Esta hipotesis senala que si dos nodos A y B estan fuertemente conectados a un tercernodo C, es muy probable que A y B esten conectados tambien. Esto sucede con regularidad enlas redes sociales donde si dos miembros de una comunidad estan muy relacionados con un tercerintegrante, es muy probable que entre ellos exista algun grado de relacion.
Para evitar este problema Chen divide a los nodos desconectados en dos grandes grupos: Losconjuntos de pares relacionados que son aquellos que posiblemente esten relacionados y el conjuntode pares no relacionados que son los pares de nodos que no lo estan. La metrica propuesta solopenalizara a los pares de de nodos desconectados que pertenezcan al grupo de pares no relacionados.
De esta manera es posible definir la Max-Min Modularity que busca particiones, en la redtal que el numero de arcos dentro de los grupos sea mayor al esperado, pero que a la vez, el numerode arcos no relacionados sea menor al esperado. Esto permite entre otras cosas, disminuir uno delos problemas conocidos como lımite de la modularity. El uso de penalizadores permite reducir laprobabilidad de que dos comunidades pequenas en relacion con el resto de la red sean combinadascuando no deberıan estarlo.
Antes de formalizar la funcion Max-Min Modularity es necesario definir la red de los nodosno relacionados en funcion de la hipotesis de enlace debil.
Sea el grafo no dirigido y con arcos sin pesos G = (N ,A) con |N | = n y |A| = m. Sea, ademas,Aij la matriz de adyacencias del grafo G. Se define el grafo complemento de G como G = (N ,A)
44

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
donde |A| = m y Aij se define como:
Aij =
{1 Si Aij = 00 Aij > 0
(3.27)
A continuacion se deben retirar a las parejas de nodos que desconectados pero que pertenecenal conjunto de parejas de nodos relacionados. Para facilitar esta labor, se define el ponderador θ(i, j)que mide si dos nodos son vecinos como sigue:
θ(i, j) =
{1 Si
∑k AikAjk > 0
0 En caso contrario(3.28)
Luego se define el grafo G′ = (N ,A′) donde |A′| = m′ y A′ij se define como:
A′ij =
{1 Si Aij × θ(i, j) = 10 En caso contrario
(3.29)
Finalmente Chen[22], define la funcion de Max-Min Modularity como se muestra en la ecua-cion 3.30:
QMax−Min = QMax −QMin =
1
2m
∑i,j
[Aij −
κiκj2m
]− 1
2m′
∑i,j
[A′
ij −κ′iκ
′j
2m′
] δ(Ci, Cj) (3.30)
Chen, ademas, provee de una heurıstica que combina elementos de las heurısticas de Clasety Louvain con esta nueva funcion para medir la calidad de una particion de la red. El metodoheurıstico utiliza un Max Heap y arboles binarios balanceados para acelerar el proceso. El algoritmorequiere como entrada el conjunto de parejas de nodos que estando desconectados, tienen algun tipode relacion, pudiendo ser cualquier regla definida a priori diferente de la antes mencionada. Paraeste caso particular se utilizara la “Hipotesis del Enlace Debil” como regla para definir los nodosrelacionados. Si bien, el metodo fue construido para soportar el uso de redes con pesos, la reglautilizada y la manera de actualizar la matriz ∆Q soporta solo el uso de redes ellos, aun mas, eluso de una red con pesos requiere de una nueva definicion de pares de nodos relacionados que losinvolucre. Al igual que el metodo de Louvain solo agrega a las comunidades los nodos que impliquenun aumento en la Max Min modularity, luego los nodos aislados no son considerados y no afectanel resultado del proceso. El algoritmo 3.4.1 resume los pasos para optimizar Max-Min Modularitypara redes sin pesos. En la seccion 3.4.3 se explicaran las modificaciones necesarias para el uso de
45

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
pesos.
Algoritmo 3.4.1: Algoritmo Jerarquico de Clustering HMaxMin
Data: El grafo G = (N ,A), y un criterio U para la definicion de nodos relacionadosResult: La division de N : (C1, C2, . . . , Ck)Se asume que cada nodo pertenece a una sola comunidad, luego existen n comunidades. Se1
construye la matriz S, con Sij igual al numero de nodos relacionados entre la comunidad i yla comunidad j ;foreach Par de nodos x, y conectados en G do2
Computar ∆Qx,y = 12m(1− κiκj
2m )− 12m′ (0−
κ′iκ
′j
2m′ ) solo para los nodos conectados;3
Guardar cada columna x de la matriz Q como un arbol binario balanceado tx y como un4
MaxHeap hx;Guardar el elemento mas grande de cada columna como un MaxHeap HMax;5
foreach Nodo x do6
Computar ax = κx2m , a′x = κ′
x2m′ ;7
while PopHeap(HMax) > 0 do8
Seleccionar el mayor elemento de HMax y sus correspondientes x e y;9
Actualizar la matriz ∆Q uniendo la fila (columna) y con la fila (columna) x como sigue;10
foreach comunidad z de ∆Q.,z do11
if si la comunidad z conecta a x y a y en el grafo G then12
∆Qx,z = ∆Qx,z + ∆Qy,z ;13
if si la comunidad z solo conecta a x en G y a y en G′ then14
∆Qx,z = ∆Qx,z + 2a′ya′z − 2ayaz − 2|y||z|
m′ +2Syz
m′ ;15
if si la comunidad z solo conecta a y en G y a x en G′ then16
∆Qx,z = 2a′xa′z − 2axaz − 2|x||z|
m′ + 2Sxzm′ + ∆Qy,z;17
Se marca la fila (columna) y en ∆Q y S como unida ;18
Se actualiza S sumando la fila (columna) y a la fila (columna) x;19
Se Actualiza new.ax = ax + ay, new.a′x = a′x + a′y, tx, hx y HMax ;20
Se guardan los nodos de una fila no marcada en la misma comunidad como (C1, C2, . . . , Ck);21
return (C1, C2, . . . , Ck) ;22
3.4.3. Max-Min Modularity con Pesos
Para sacar el maximo provecho a la topologıa, de la red se debieran utilizar los pesos enlas redes que reflejen un mayor o menor grado de cercanıa o afinidad entre los integrantes de lacomunidad. Ası mismo estos pesos permitirıan definir adecuadamente el grado de rivalidad entredos integrantes que no estan relacionados. A continuacion se presentaran los cambios realizados alalgoritmo 3.4.1 para el soporte de redes con pesos.
46

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
En primer lugar se debe revisar la funcion de Max-Min Modularity 3.30. La trasformacionpara su uso con pesos es directa. El numero de arcos m y m′ de G y G′ respectivamente seranremplazados por el valor del peso del arco, luego 2m =
∑ij Aij = W y 2m′ =
∑ij A
′ij = W ′, el
grado de los nodos se mantendra con su formula tradicional de κi =∑
k Aik y κ′i =∑
k A′ik al igual
que la funcion δ. Ası la nueva expresion de Min-Max Modularity con pesos sera:
QMax−Min = QMax −QMin =
1
W
∑i,j
[Aij −
κiκjW
]− 1
W ′
∑i,j
[A′
ij −κ′iκ
′j
W ′
] δ(Ci, Cj) (3.31)
Parte importante de las mejoras del algoritmo presentado en 3.4.1 tiene relacion con unaadecuada definicion del conjunto de pares de nodos relacionados. En una red sin pesos la “Hipotesisdel Enlace Debil”[46] resulta adecuada, pues la cercanıa entre un nodo y sus vecinos es la misma. Sinembargo, en una red con pesos pueden surgir casos, que los cercanos de los vecinos muy relacionadoscon un nodo i tengan mas relacion con este nodo que un vecino directo. Luego debiera considerarseuna hipotesis de enlace debil que contemplara los niveles de cercanıa entre nodos. Se puede re-interpretar la hipotesis de enlace debil para las redes sin pesos como un problema de caminosmınimos. Dado un grafo G = (N ,A) se define la matriz de caminos entre nodos como C de [|N |×|N |]como:
Cij =
1 Si Aij ≥ 1 y j = i
Dcota Si Aij < 1 y j = i0 Si j = i
(3.32)
Con Dcota =∑
ij Aij + 1. Ası, la relacion basada en la hipotesis del enlace debil, puedeinterpretarse como la existencia de un camino mınimo de largo igual a 2 entre un nodo i y el restode los nodos de la red.
Del mismo modo, dado un grafo con pesos G = (N ,A) se define la matriz de caminos entrenodos como C de [|N | × |N |] como:
Cij =
[maxi,j(Aij) + 1]−Aij Si Aij ≥ 1 y j = i
Dcota Si Aij < 1 y j = i0 Si j = i
(3.33)
Con Dcota = m×maxi,j(Aij). Luego se define como medida de relacion entre pares de nodos,la existencia de un camino mınimo de largo variable definido como:
α× Cm (3.34)
47

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Donde α es un valor entre [0, 1] y Cm representa el largo promedio de los caminos mınimos delos nodos conectados en la red. Se observa que la definicion en 3.34 no requiere de un conocimientoa priori de la red, permitiendo ajustarse a las caracterısticas propias de la topologıa de esta.
Luego de definir el conjunto de nodos relacionados en funcion del parametro α se debedeterminar la matriz de complementos y, por supuesto, la matriz de caminos mınimos.
Se define el grafo complemento de G como G = (N ,A) donde Aij se define como:
Aij =
{maxi,j(Aij)−Aij Si Aij ≥ 12×maxi,j(C
minij ) Si Aij < 1
(3.35)
Para la creacion de la matriz de caminos mınimos se utilizara el metodo de Floyd-Warshall (Sec-cion 3.4.3.1) que entregara como resultado la matriz Cmin donde cada uno de sus Cmin
ij elementos
representa el camino mınimo entre el nodo i y el nodo j. Ası, el termino Cm se obtiene como:
Cm =
(∑i,j
Cminij <Dcota
Cminij
)∑ i,j
Cminij <Dcota
i =j
1
(3.36)
Finalmente, se define el grafo G′ = (N ,A′) donde A′ij se define como:
A′ij =
{Aij Si Cmin
ij ≥ (α× Cm)
0 Si no(3.37)
Para realizar la busqueda de sub-comunidades basados en esta nueva medida de la calidad delas particiones de la red, se utilizara el algoritmo 3.4.1 con algunas modificaciones, especıficamenteen el proceso de actualizacion de nodos de manera tal que soporte el uso de redes con pesos. Setomara como ejemplo la actualizacion de ∆Qxz donde la comunidad z solo conecta a x en G y a yen G′. Se puede descomponer la actualizacion en el aporte a la ∆Qmax
zx y ∆Qminzx como:
∆Qxz = ∆Qx,z + 2a′ya′z − 2ayaz −
4|y||z|2m′ +
4Syz
2m′
= ∆Qmaxx,z −∆Qmin
x,z + 2×[
1
2m
(0− κyκz
2m
)]− 2×
[1
2m′
(2 [|y||z| − Syz]−
κ′yκ′z
2m′
)]
48

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Dado que ningun elemento de z esta conectado a y y todos los arcos tienen valor 1 el termino 2|y||z|]equivale a todos los posibles arcos ((i, j) y (j, i)) entre la comunidad y y la comunidad z, luego sedeben eliminar los arcos relacionados entre ambas comunidades, utilizando el valor 2Syz, pues lamatriz S es simetrica, luego el valor 2[|y||z| − Syz] equivale al valor de la suma de todos los arcosentre las comunidades z e y en el grafo G′. Ası, para el uso de redes con pesos, se debe modificareste valor por la suma de todos los arcos entre z e y como:
∑i,j
i∈z y j∈y
A′ij (3.38)
Ademas los terminos 2m y 2m′ deben reemplazarse por∑
ij Aij = W y∑
ij A′ij = W ′
respectivamente y la matriz S pierde utilidad. Se debe realizar el mismo procedimiento para cambiarla condicion en que z solo conecta a y en G y a x en G′. De esta manera se puede computar el valorde las redes con pesos por medio de este algoritmo.
3.4.3.1. Algoritmo de Floyd-Warshall
El algoritmo de Floyd-Warshall[38] es un metodo disenado para la busqueda de caminosmınimos entre multiples orıgenes y multiples destinos. Para que el algoritmo funcione correctamenterequiere que no exista ningun camino mınimo con valor negativo. El metodo funciona sobre un grafoG = (N ,A) y se inicializa con la condicion[12]:
D0ij =
{Aij Si (i, j) ∈ A∞ Si no
(3.39)
y genera por cada k = 0, 1, . . . , |N | − 1, y los nodos i y j,
Dk+1ij =
{min
(Dk
ij , Dki(k+1) + Dk
(k+1)j
)Si j = i
∞ Si no(3.40)
Donde para la implementacion de este metodo basta que ∞ sea m×maxijAij + 1 con m elnumero de arcos de la matriz de incidencias. Finalmente el metodo entregara, luego de las |N | − 1
iteraciones, la matriz de caminos mınimos Cmin donde cada elemento Cminij = D
|N |−1ij .
3.4.4. Comunidades superpuestas
En la seccion 2.4.4 se describieron diferentes metodos para la busqueda de comunidadessuperpuestas, en donde un nodo puede pertenecer a mas de una comunidad a la vez. Algunos de
49

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
estos metodos buscan construir las comunidades superpuestas a partir de particiones encontradascon otros metodos, estas particiones son exploradas localmente para identificar los nodos que puedanpertenecer a mas de una comunidad. En base a esta idea, se presentara una estrategia simple a partirde las comunidades encontradas, utilizando alguno de los metodos de busqueda de sub-comunidadesantes presentados.
Dado el grafo G = (N ,A) y |C| comunidades encontradas en la red donde cada i ∈ Npertenece solo y a uno solo de los conjuntos C1, C2, . . . , C|C|. Se define C(i) ∈ C1, C2, . . . , C|C| comola comunidad a la cual pertenece un nodo i. Luego define el factor de pertenencia de un nodo i a lacomunidad Ck como:
Fp(i, Ck) =
∑j∈Ck
Aij∑j∈C(i)Aij
(3.41)
En terminos practicos el factor de pertenencia permite encontrar los nodos candidatos apertenecer a mas de una comunidad al mismo tiempo. Si este valor es cercano a 1 para algunacomunidad distinta a la que pertenece, entonces se puede interpretar que el nodo esta muy unidocon esta comunidad por lo que debiese pertenecer a esta tambien. Este termino es la base para laformacion del algoritmo 3.4.2.
Algoritmo 3.4.2: Algoritmo de busqueda de sub-comunidades superpuestas basada en losarcosData: El grafo G = (N ,A), las comunidades (C1, C2, . . . , Ck) y un valor de corte θ ∈ [0, 1]Result: (C1, C2, . . . , Ck) comunidades superpuestasSe inicializa la matriz Fp de tamano [n× k] con ceros;1
foreach nodo i ∈ N y cada comunidad Ct do2
Calcular Fp(i, Ct) segun 3.41 para Ct = C(i) ;3
Guardar cada fila i de la matriz FT como un MaxHeap hi;4
Guardar el elemento mas grande de cada fila como un MaxHeap HMax;5
while PopHeap(HMax) > θ do6
Seleccionar el mayor elemento de HMax y sus correspondientes i y Ct;7
Ct ← Ct ∪ i;8
if HMax¿1 then9
foreach Ck do10
Actualizo Fp(i, Ck);11
foreach nodo j vecino al nodo i do12
if Fp(j, Ck) > 0 then13
Actualizo Fp(j, Ck);14
Rehacer los n MaxHeap hi y el MaxHeap HMax ;15
return (C1, C2, . . . , Ck) ;16
50

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Para efectuar una comparacion de la calidad de las redes encontradas se recurrira nuevamentea la modularity, sin embargo, la funcion tradicional de la modularity desarrollada por Newman [76]fue concebida con la idea de que un nodo puede pertenecer solamente a una comunidad, por loque es necesario utilizar una extension de esta funcion de la calidad de las particiones en la red.Nicosia et al. [79] proponen una extension de la modularity para redes superpuestas, que si bientiene una alta complejidad, como se senalo en la seccion 2.4.4, sera de utilidad a la hora de evaluarlas mejoras efectuadas por el algoritmo de busqueda de sub-comunidades superpuestas basado enlos arcos. La funcion esta inicialmente creada para redes dirigidas, pero es facilmente extensible pararedes no dirigidas utilizando la estrategia de trasformacion de redes senalada en la seccion 2.2.1.2.A continuacion se presenta la modularity para comunidades superpuestas. Sea el grafo G(N ,A) y|C| el conjunto de comunidades superpuestas donde cada c ∈ C es un subconjunto de nodos de N .Se define el vector de factores de pertenencia del nodo i a la comunidad c como [αi,1, αi,2, . . . , αi,|C|]donde cada αi,c cumpla con:
0 ≤ αi,c ≤ 1 ∀i ∈ N , ∀c ∈ C (3.42)
|C|∑c=1
αi,c = 1 (3.43)
Los autores senalan que estas condiciones solo afectan el rango de las pertenencias, pero no susignificado, donde un nodo puede pertenecer a mas de una comunidad a la vez, pero las pertenenciasde cada nodo a las comunidades es igual para todos los nodos de la red. A continuacion se definela pertenencia de un arco l = (i, j) a la comunidad c donde l representa un arco que parte en i ytermina en j segun la formula:
βl,c = F(αi,c, αj,c)
Con F(αi,c, αj,c) una funcion arbitraria a definir. Posteriormente los autores utilizan la modularitypara arcos dirigidos, similar a la senalada en la ecuacion 3.25 presentada a continuacion:
Qd =1
m
∑i,j
[Aijδ(Ci, Cj)−
κouti κinjm
δ(Ci, Cj)
](3.44)
Donde κouti =∑
j Ai,j y κinj =∑
iAi,j corresponde al grado out-degree e in-degree presentadosen la seccion 2.2.2. A continuacion, los autores reformulan la ecuacion reemplazando el terminoδ(Ci, Cj) por rij y sij como se muestra a continuacion:
Qov =1
m
∑i,j∈N
[rijAij − sij
κouti κinjm
](3.45)
Qov =1
m
∑c∈C
∑i,j∈N
[rijcAij − sijc
κouti κinjm
](3.46)
51

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
Donde rijc = βl(i,j),c = βl,c = F(αi,c, αj,c). La definicion de sijc es un poco mas compleja:
sijcκouti κinj
m=
βoutl(i,j),cκ
outi βin
l(i,j),cκinj
m(3.47)
Donde:
βoutl(i,j),c =
∑j∈N F(αi,c, αj,c)
|N |(3.48)
βinl(i,j),c =
∑i∈N F(αi,c, αj,c)
|N |(3.49)
En el caso de las redes no dirigidas se puede trasformar βoutl,c = βout
l,c = βl,c y κini = κouti = κi . Acontinuacion se presenta la ecuacion de la modularity para comunidades superpuestas en redes nodirigidas:
Qov =1
2m
∑c∈C
∑i,j∈N
[βl,cAij −
βl(i,j),cκiβl(ji),cκj
2m
](3.50)
Nicosia senala que esta funcion, independiente de la eleccion de F(αi,c, αj,c) cumple conlas dos propiedades fundamentales de la modularity: Tiene un valor igual a cero cuando todos losnodos pertenecen a la misma comunidad, es decir, cuando no es posible inferir la existencia de unaestructura de comunidad solo mediante la utilizacion de la informacion topologica de la red y ensegundo lugar que altos valores en la modularity indican la fuerte presencia de una estructura decomunidad.
3.5. Analisis y evaluacion
En los pasos previos de la metodologıa para la busqueda de sub-comunidades se presentaronlas etapas para la construccion de redes. En cada etapa se presentaron diferentes herramientas quedeben ser modificadas segun las caracterısticas propias de cada problema: En el caso de los modelosde reduccion del contenido 3.2.1, por ejemplo, si se utiliza CB se deberan senalar los conceptos clavesy crear un vocabulario adecuado. Este enfoque probablemente sea mas adecuado cuando se buscaestudiar la red con algun fin especıfico, como el uso de los usuarios de un producto en particular ouna cierta marca enfocado en marketing. En LDA, en cambio, se debe consultar a los expertos de lared respecto a como nombrar cada uno de los topicos. Este metodo probablemente sea mas efectivoen el caso que se quiera determinar los temas intrınsecos de la red con fines de administracion delcontenido o de investigacion.
En la construccion de redes 3.3.3 se debe determinar que tipo de estrategias son mas ade-cuadas para el problema y se debe realizar en conjunto con la eleccion de algun metodo para la
52

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
busqueda de sub-comunidades de los presentados en 3.4. En la construccion de redes se deben setearlos parametros de filtro, los cuales determinaran la cantidad de arcos que se eliminaran respecto auna red construida con los metodos tradicionales. Si el valor de corte es muy alto se encontrara el“core” de las comunidades, sin embargo, muchos nodos quedaran desconectados, por lo que nopodran ser clasificados dentro de alguna comunidad. Por otro, lado si el valor de corte es muy bajo,muchos de los arcos que solo provocan ruido, entraran a la red, provocando que aun cuando seresuelve el problema del gran numero de nodos desconectados, se encontraran comunidades que noreflejan lo que ocurre en la realidad.
En relacion a los metodos para la busqueda de sub-comunidades de los presentados en 3.4,se deben utilizar segun las caracterısticas de las redes encontradas, por ejemplo, el algoritmo deLouvain 3.4.1 segun sus autores, tiene complejidad lineal en redes poco densas, por lo tanto esextremadamente rapido y permite explorar redes de 2 millones de nodos y 5 millones de arcos en44 segundos[16]. Por otro lado Max-Min Modularity, si bien permite estudiar tanto la atraccioncomo la repulsion entre nodos con mejores resultados en la identificacion de comunidades, tieneun orden de complejidad de O(n log2n) [22] aun bajo el uso de una heurıstica simple. El metodoMax-Min Modularity con pesos, permite aprovechar aun mas las caracterısticas de las redes, sinembargo, el algoritmo de Floyd-Warshall para la busqueda de caminos mınimos, hace que el metodotenga orden de complejidad de O(n3), por lo que este metodo no resulta adecuado para el uso deredes masivas. Finalmente el metodo de busqueda de sub-comunidades superpuestas, propuesto eneste trabajo, permite operar sobres las particiones de las redes encontradas con cualquiera de losmetodos anteriores y mejorar los resultados para redes en las cuales un nodo pueda participar enmultiples comunidades, como ocurre con las redes sociales.
Una de las ventajas que produce el uso de los metodos de reduccion del contenido, es describirlos post de los usuarios en funcion de los topicos o conceptos, permitiendo que, una vez determinadaslas comunidades, se extienda el uso de los metodos de reduccion del contenido para describir alos usuarios y, por consiguiente, a las comunidades en terminos de los conceptos o topicos querepresentan. Por lo tanto, la metodologıa permite no solo encontrar a los usuarios que componen lascomunidades sino que tambien permite caracterizar en terminos de los conceptos, proporcionandoinformacion acerca de que tan alineados estan los grupos con estos, cuales mas, cuales menos.Por otro lado, con el uso de topicos, conocer los temas que se discuten dentro de cada una deestas comunidades y tambien determinar los perfiles de los distintos miembros. A continuacion, sedescribira brevemente el proceso para la caracterizacion de las comunidades.
Sea matriz TP de [T opicos× Post] obtenida como resultado de la seccion 3.2.3 (o la matrizCP de [Conceptos × Post] obtenida en la seccion 3.2.2) y el conjunto de usuarios N = n. Seanademas, (P1, P2, . . . , Pn) los conjuntos de post efectuados por cada usuario de la red en un periodode estudio. Se define la matriz UT de [Usuarios× T opicos] como:
UTi,j =∑w∈Pi
TPjw (3.51)
53

Capıtulo 3. Metodologıa propuesta para la busqueda de sub comunidades
De esta manera es posible caracterizar a cada usuario de la comunidad respecto a los topicos(o conceptos) contenidos en su post. En el caso de las redes topicas se debe multiplicar cada terminoTPjw por RLj el cual representa el vector de topicos utilizado en la ecuacion 3.14. Luego, dadaslas comunidades de (C1, C2, . . . , Ck) obtenidas de los metodos en 3.4 se define la matriz CT de[Comunidades× T opicos] como:
CTi,j =
∑v∈Ci
UPvj
|Ci|(3.52)
Donde el factor |Ci| permite que los valores entre comunidades sean comparables. De estamanera se puede caracterizar a cada comunidad en la red.
54

Capıtulo 4
Resultados sobre una VCoP real
En este capıtulo se aplicara la metodologıa propuesta en el capıtulo 3 para la busqueday caracterizacion de las sub-comunidades. En primer lugar se presentara y caracterizara a unacomunidad virtual de practica (VCoP) real. Luego se presentaran los resultados del trabajo previode Alvarez [2] en terminos de la aplicacion de minerıa de textos y algunas consideraciones efectuadas.A continuacion se expondran los resultados de los experimentos efectuados para la construccion delas redes y se discutira acerca de los parametros de configuracion. Posteriormente se exhibiranlos resultados de las comunidades encontradas y se realizara una comparacion respecto al uso deredes que no utilizan la informacion semantica inherente a esta. Luego, se caracterizaran los gruposencontrados a traves del uso de minerıa de textos, para finalizar con resultados sobre redes topicas.
4.1. Una real comunidad de practica.
Plexilandia1 es una comunidad virtual de practica formada por personas que buscan aprender,compartir sus conocimientos y experiencias acerca de la construccion de amplificadores, efectos desonido, lutherıa y elementos de audio profesional en general. Su nombre se debe a que en sus iniciosfue pensada para compartir la experiencia de la creacion de un Plexi, el nombre coloquial que se leda a los modelos de amplificadores de tubos (1958, 1986, 1987 y el JTM45) de la fabrica Marshall,los cuales eran construidos con una placa de Plexiglass (acrılico) dorado donde estan colocados loscontroles2. A contar del ano 2002, Plexilandia, implemento un foro en donde sus usuarios podıaninteractuar y compartir sus experiencias. Actualmente este foro cuenta con mas de 2.500 miembrosregistrados y mas de 80.000 post publicados repartidos en 6 categorıas.3.
Si bien, como senala Alvarez [2], en los inicios la comunidad tenia solo un administrador, la
1http://www.plexilandia.cl [Fecha de Acceso 29 de Septiembre de 2011]2http://www.plexilandia.cl/faq.html [Fecha de Acceso 29 de Septiembre de 2011]3http://www.plexilandia.cl/foro/index.php [Fecha de Acceso 29 de Septiembre de 2011]
55
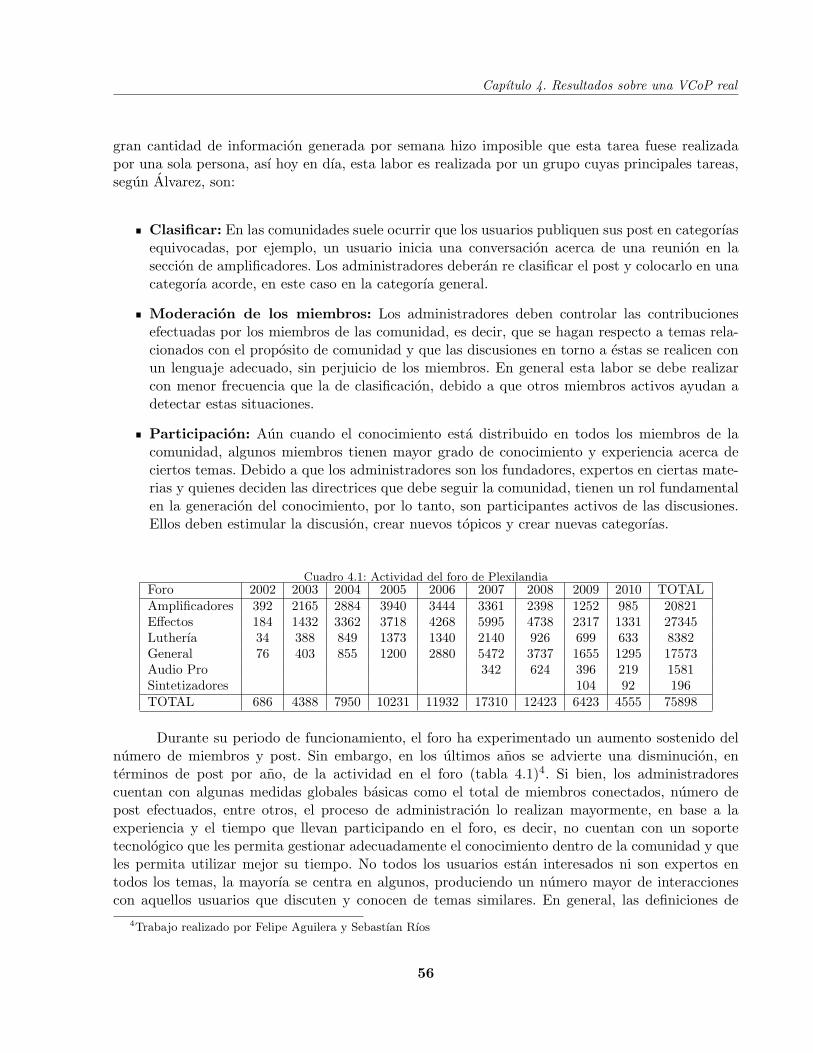
Capıtulo 4. Resultados sobre una VCoP real
gran cantidad de informacion generada por semana hizo imposible que esta tarea fuese realizadapor una sola persona, ası hoy en dıa, esta labor es realizada por un grupo cuyas principales tareas,segun Alvarez, son:
Clasificar: En las comunidades suele ocurrir que los usuarios publiquen sus post en categorıasequivocadas, por ejemplo, un usuario inicia una conversacion acerca de una reunion en laseccion de amplificadores. Los administradores deberan re clasificar el post y colocarlo en unacategorıa acorde, en este caso en la categorıa general.
Moderacion de los miembros: Los administradores deben controlar las contribucionesefectuadas por los miembros de las comunidad, es decir, que se hagan respecto a temas rela-cionados con el proposito de comunidad y que las discusiones en torno a estas se realicen conun lenguaje adecuado, sin perjuicio de los miembros. En general esta labor se debe realizarcon menor frecuencia que la de clasificacion, debido a que otros miembros activos ayudan adetectar estas situaciones.
Participacion: Aun cuando el conocimiento esta distribuido en todos los miembros de lacomunidad, algunos miembros tienen mayor grado de conocimiento y experiencia acerca deciertos temas. Debido a que los administradores son los fundadores, expertos en ciertas mate-rias y quienes deciden las directrices que debe seguir la comunidad, tienen un rol fundamentalen la generacion del conocimiento, por lo tanto, son participantes activos de las discusiones.Ellos deben estimular la discusion, crear nuevos topicos y crear nuevas categorıas.
Cuadro 4.1: Actividad del foro de PlexilandiaForo 2002 2003 2004 2005 2006 2007 2008 2009 2010 TOTALAmplificadores 392 2165 2884 3940 3444 3361 2398 1252 985 20821Effectos 184 1432 3362 3718 4268 5995 4738 2317 1331 27345Lutherıa 34 388 849 1373 1340 2140 926 699 633 8382General 76 403 855 1200 2880 5472 3737 1655 1295 17573Audio Pro 342 624 396 219 1581Sintetizadores 104 92 196TOTAL 686 4388 7950 10231 11932 17310 12423 6423 4555 75898
Durante su periodo de funcionamiento, el foro ha experimentado un aumento sostenido delnumero de miembros y post. Sin embargo, en los ultimos anos se advierte una disminucion, enterminos de post por ano, de la actividad en el foro (tabla 4.1)4. Si bien, los administradorescuentan con algunas medidas globales basicas como el total de miembros conectados, numero depost efectuados, entre otros, el proceso de administracion lo realizan mayormente, en base a laexperiencia y el tiempo que llevan participando en el foro, es decir, no cuentan con un soportetecnologico que les permita gestionar adecuadamente el conocimiento dentro de la comunidad y queles permita utilizar mejor su tiempo. No todos los usuarios estan interesados ni son expertos entodos los temas, la mayorıa se centra en algunos, produciendo un numero mayor de interaccionescon aquellos usuarios que discuten y conocen de temas similares. En general, las definiciones de
4Trabajo realizado por Felipe Aguilera y Sebastıan Rıos
56

Capıtulo 4. Resultados sobre una VCoP real
sub-comunidad se basan en buscar a estos grupos de personas que interactuan mas entre ellos quecon el resto de la red. Luego conocer estos grupos de personas es de suma importancia pues esa traves de estas interacciones contantes, en que los miembros exponen sus experiencias, errores ylogros, es que se crear nuevo conocimiento. Ası mismo, son estos grupos donde los nuevos usuarios sevan nutriendo de las experiencias que les transfieren los expertos para, posteriormente, convertirseen los nuevos expertos.
4.2. Aplicacion de la metodologıa propuesta
A continuacion se presentaran los resultados de la aplicacion de la metodologıa sobre lacomunidad virtual de practica Plexilandia. Este trabajo de tesis busca innovar sobre la configuracionde las redes, la busqueda de sub-comunidades y la caracterizacion de estas. Se hace hincapie en quela seleccion, limpieza de datos y aplicacion de minerıa de textos fue desarrollado por Alvarez [2] enun trabajo previo. En esta seccion se presentaran brevemente los principales resultados obtenidosen dicho trabajo.
4.2.1. Seleccion y limpieza de datos
Figura 4.1: Seleccion para la limpieza y aplicacion de minerıa de textos
Los datos se obtuvieron de la base de datos del foro de Plexilandia el cual es soportado por
57

Capıtulo 4. Resultados sobre una VCoP real
un sistema de foros phpBB y se trabajaron los datos sobre MySQL. En la figura 4.1 se presentauna seccion de la base de datos de la comunidad, la cual permitirıa obtener la informacion necesariapara efectuar la metodologıa.
En la tabla plxcl phpbb post text se encuentra el texto de cada uno de los post, mientras queel resto de la seleccion permite rescatar los usuarios y topicos que hacen la funcion de threads eneste caso. El periodo de estudio seleccionado corresponde a los post efectuados entre enero de 2009hasta agosto de 2010. El proceso de limpieza comienza justamente sobre el texto de cada uno de lospost utilizando la estrategia senalada en la seccion 3.1. Estos datos limpios son almacenados en unanueva base de datos, junto con la informacion de los usuarios que efectuaron los post y los threads(topicos). Adicionalmente, Alvarez senala que en esta nueva base de datos se tiene la informacionde los Conceptos que incluye una tabla con la descripcion de cada uno de ellos y una tabla con cadauna de las palabras que componen los conceptos.
4.2.2. Minerıa de textos
A continuacion de construye la matriz TF-IDF de [Post×T erminos] segun el metodo descritoen la seccion 3.2.1 utilizando los post en el periodo comprendido entre enero de 2009 y agosto de2010. Luego, se aplican las estrategias para reduccion de contenido, siendo directo en el caso deConcept Based 3.2.2 donde ya se cuenta con las palabras y los conceptos principales. Para el casode Plexilandia los Conceptos son 6 y se describen a continuacion5:
1. Generar una comunidad hispanoparlante con intereses comunes en torno a la construccionpropia (DIY Do It Yourself) de efectos, amplificadores y equipos musicales.
2. Constituir un repositorio de conocimientos en torno a la construccion de amplificadores atubo.
3. Constituir un repositorio de conocimiento en torno a la construccion de efectos.
4. Constituir un repositorio de conocimiento en torno a la construccion de instrumentos decuerda.
5. Ser un punto de partida y referencia para quienes se inician en el DIY relacionado con musicay audio.
6. Crear un repositorio de informacion en torno al audio profesional.
En funcion de estos 6 conceptos se construye la matriz de [Conceptos × Post] que se uti-lizara para la formacion de las redes. Esta matriz sera almacenada dentro de la base de datos deresumen de Plexilandia.
5Trabajo realizado por Felipe Aguilera y Sebastıan Rıos
58

Capıtulo 4. Resultados sobre una VCoP real
En el caso de LDA descrito en la seccion 3.2.3 se debe ejecutar el algoritmo sobre los post yalimpios. Se utilizo la implementacion de GibbsLDA++[86] el cual entrega las salidas con los topicos,las palabras y sus probabilidades. En la seccion 4.2.2.1 se analizaran los resultados obtenidos deeste metodo. Luego se construye la matriz de [T opicos × Post] la cual sera almacenada dentro dela base de datos de resumen de Plexilandia.
4.2.2.1. Topicos Encontrados
El metodo de LDA fue programado para encontrar 50 topicos y en cada uno de ellos se inclu-yeron las 100 palabras mas representativas con sus respectivas probabilidades6. Luego los resultadosde LDA fueron presentados a los administradores de Plexilandia para que puediesen interpretar cuales el significado de cada uno de los topicos. En el cuadro 4.2 se ven algunas de las etiquetas querepresentan el significado encontrado por los administradores, el cuadro completo se adjunta en elanexo A.1.
Cuadro 4.2: Seleccion de Topicos encontrados e interpretados
N◦ Topico Interpretacion Activo
Topico 01 Distorsion SiTopico 06 Tecnicas de soldado (de efectos y amplificadores) SiTopico 12 Felicitaciones varias NoTopico 13 Maderas para construccion de guitarras SiTopico 17 Componentes electronicos (enfasis en condensadores) SiTopico 18 Amplificadores a tubo SiTopico 22 No es util NoTopico 36 Normas y buena convivencia en Plexilandia NoTopico 49 Problema de acople en efectos de distorsion Si
Se observa que existen topicos que no tienen interpretacion posible, luego estos no son utilespara el analisis y no seran considerados. Ademas existen topicos como el numero 12, el cual no aportainformacion en el sentido de la generacion del conocimiento, por lo que tampoco seran consideradosen el analisis y al igual que el grupo anterior, no estaran activos a la hora de calcular las redes. Entotal se encontraron 8 topicos que no tienen interpretacion, 9 que no aportan a la generacion deconocimiento y 33 que son considerados activos en el analisis. El proceso en el cual se utilizan sololos topicos activos es similar al descrito en la seccion 3.3.4 para las redes topicas.
En el cuadro 4.3 se presentan a modo de ejemplo los topicos tecnicas de soldado, amplifica-dores a tubo y distintos efectos con las palabras mas relevantes encontradas y sus probabilidades.En general, las probabilidades de las palabras no son muy altas, pero la combinacion especıfica depalabras con estas probabilidades, permiten distinguir de forma semantica de que se habla dentrode un post. Se hace hincapie en que el proceso de interpretacion es de suma importancia para de-terminar el significado correcto de los topicos y debe ser realizado por los expertos de la comunidad
6Trabajo realizado por Gaston L’Huillier
59

Capıtulo 4. Resultados sobre una VCoP real
que conozcan los temas y palabras mas recurrentes en cada uno de estos y a la vez, puedan deter-minar cuales de estos topicos no tienen sentido, aun cuando representen distribuciones conjuntasde palabras muy recurrentes. Si este proceso se hace de forma incorrecta o no se toma en cuenta laopinion de los expertos, cualquier interpretacion posterior para entender de que se habla en cadacomunidad y las estrategias para fomentar este conocimiento sera erronea.
Cuadro 4.3: Ejemplos de Topicos encontrados
Tecnicas de soldado Amplificadores a Tubo Distintos efectos
Termino Probabilidad Termino Probabilidad Termino Probabilidad
cort 0,055175 tubo 0,215465 pedir 0,235931com 0,041549 pre 0,059177 com 0,066883pas 0,041345 power 0,055648 hac 0,034275cal 0,026497 par 0,045825 wah 0,028974
placa 0,026264 potencia 0,024267 efecto 0,017940par 0,024459 bia 0,019414 wha 0,014643
soldadura 0,021256 fender 0,018914 par 0,014550soldar 0,018985 sonar 0,017679 mod 0,013379pista 0,017646 rulz 0,015679 induc 0,009835qued 0,015725 preamp 0,015473 ocup 0,009711pun 0,014182 cambi 0,014738 simple 0,008417
cable 0,013716 clase 0,009650 clon 0,008386cautin 0,012085 cabezal 0,009356 tipo 0,008355poner 0,011183 inversor 0,008326 vox 0,007862cuid 0,009814 sac 0,007326 mxr 0,007246
. . . y 85 mas . . . y 85 mas . . . y 85 mas
4.3. Construccion y Configuracion de las Redes
Para la construccion de las redes se dividio el periodo comprendido entre enero de 2009 hastaagosto de 2010 en 5 cuatrimestres7 de manera de tener periodos representativos para la busquedade Sub-comunidades.
Se construyeron redes dirigidas y con pesos con un enfoque orientado al creador y con unenfoque orientado a todos los anteriores siguiendo las estrategias presentadas en la seccion 3.3.1 ysegun los tipos de filtrados: sin el uso de filtros (redes por conteo), filtros basados en Concept basedy filtros basados en LDA para cada uno de lo periodos. En el cuadro 4.4 se resumen las diferentesredes utilizadas.
El promedio de los usuarios por periodo es de 180. En el caso de los filtros topicos para lareduccion del contenido se deben setear los parametros θ y γ para determinar los niveles de corte
7Espacio de 4 meses
60

Capıtulo 4. Resultados sobre una VCoP real
Cuadro 4.4: Tipos de redes
Periodo Al creador A todos los anteriores (Anteriores)
Filtro LDA Creador CB Creador Cont Creador LDA Anteriores CB Anteriores Cont Anteriores
que se deben utilizar. En los graficos 4.2 se observa como influyen estos parametros para la redfiltrada utilizando LDA del primer cuatrimestre del 2010, primero dejando constante el parametroθ = 0, 3 y aumentando γ y luego dejando constante γ = 0, 01 y aumentando gradualmente θ.
Figura 4.2: Densidad de la red V/S parametros γ y θ
Se puede ver que existe una relacion directa entre el aumento de cada uno de estos parametrosy la disminucion de la densidad 2.2.2 en las redes sin pesos (la medida de densidad de una red solotiene sentido en las redes sin pesos). Se observa que el parametro γ produce una disminucion maspronunciada que el parametro θ y en ambos casos los valores altos de los filtros producen unaexcesiva disminucion de la densidad. Luego, dado que el objetivo de la reduccion de contenido, enel caso de la busqueda de sub-comunidades, es eliminar el ruido en la red y no los arcos que reflejanuna relacion aunque esta sea debil, se determino utilizar las redes con γ = 0, 01 y θ = 0, 3. El caso deCB es distinto, pues al ser un numero menor de conceptos y que involucran aspectos mas amplios,ocasiona que las puntuaciones de cada vector y de sus comparaciones sean mas altas. Sin embargo,reaccionan de la misma forma a los aumentos en los parametros de corte, luego realizando el mismotipo de analisis, se determino que un buen nivel de corte correspondıa a los valores mas bajos delas pruebas, es decir, con θ = 0, 5 γ = 0, 1.
Para evaluar la reduccion del contenido de las redes, se compararon los resultados de laaplicacion de los filtros tanto por CB como por LDA frente a una red de conteo construida con losmetodos tradicionales, es decir, solo verificando la existencia de un enlace, sin utilizar la informacionsemantica tras la red. Los resultados se presentan en los graficos 4.3 y consideran todo el periodode estudio. Para las redes filtradas se utilizaron los parametros de corte antes mencionados.
Se observa que en ambas estrategias para la construccion de las redes, la reduccion por mediode los filtros semanticos es considerable, por otro lado, los cortes de los filtros aunque son de valores
61
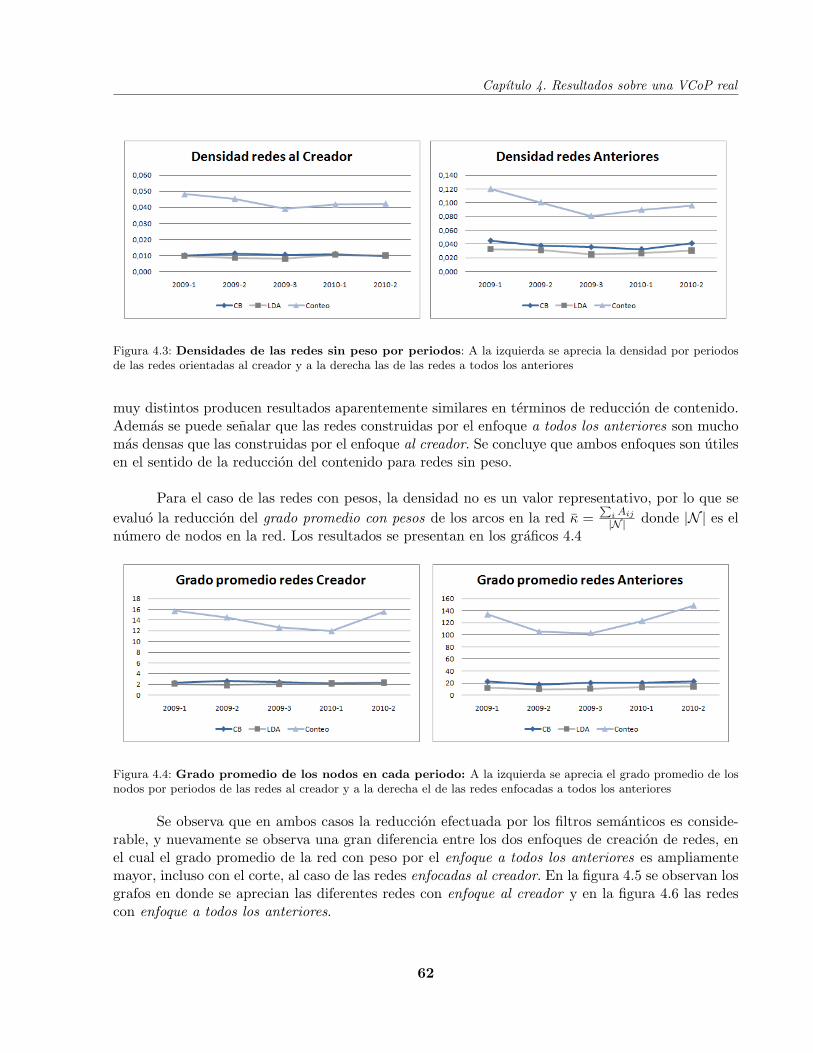
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.3: Densidades de las redes sin peso por periodos: A la izquierda se aprecia la densidad por periodosde las redes orientadas al creador y a la derecha las de las redes a todos los anteriores
muy distintos producen resultados aparentemente similares en terminos de reduccion de contenido.Ademas se puede senalar que las redes construidas por el enfoque a todos los anteriores son muchomas densas que las construidas por el enfoque al creador. Se concluye que ambos enfoques son utilesen el sentido de la reduccion del contenido para redes sin peso.
Para el caso de las redes con pesos, la densidad no es un valor representativo, por lo que se
evaluo la reduccion del grado promedio con pesos de los arcos en la red κ =∑
i Aij
|N | donde |N | es elnumero de nodos en la red. Los resultados se presentan en los graficos 4.4
Figura 4.4: Grado promedio de los nodos en cada periodo: A la izquierda se aprecia el grado promedio de losnodos por periodos de las redes al creador y a la derecha el de las redes enfocadas a todos los anteriores
Se observa que en ambos casos la reduccion efectuada por los filtros semanticos es conside-rable, y nuevamente se observa una gran diferencia entre los dos enfoques de creacion de redes, enel cual el grado promedio de la red con peso por el enfoque a todos los anteriores es ampliamentemayor, incluso con el corte, al caso de las redes enfocadas al creador. En la figura 4.5 se observan losgrafos en donde se aprecian las diferentes redes con enfoque al creador y en la figura 4.6 las redescon enfoque a todos los anteriores.
62
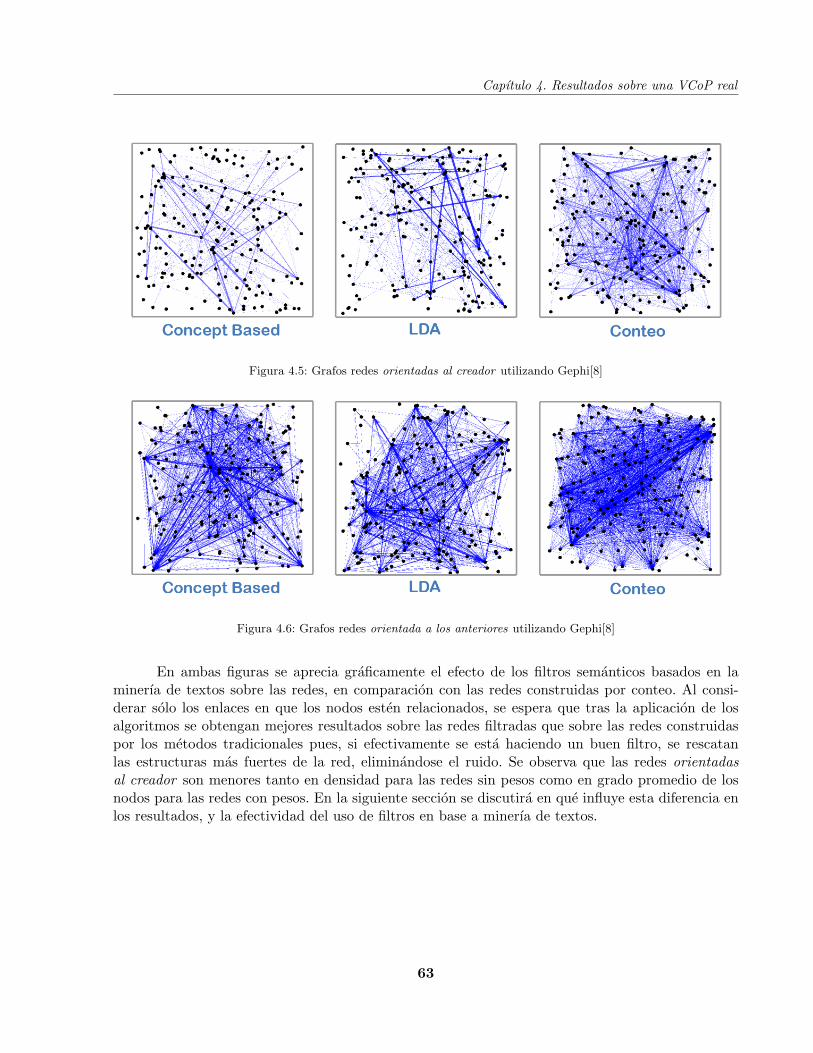
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.5: Grafos redes orientadas al creador utilizando Gephi[8]
Figura 4.6: Grafos redes orientada a los anteriores utilizando Gephi[8]
En ambas figuras se aprecia graficamente el efecto de los filtros semanticos basados en laminerıa de textos sobre las redes, en comparacion con las redes construidas por conteo. Al consi-derar solo los enlaces en que los nodos esten relacionados, se espera que tras la aplicacion de losalgoritmos se obtengan mejores resultados sobre las redes filtradas que sobre las redes construidaspor los metodos tradicionales pues, si efectivamente se esta haciendo un buen filtro, se rescatanlas estructuras mas fuertes de la red, eliminandose el ruido. Se observa que las redes orientadasal creador son menores tanto en densidad para las redes sin pesos como en grado promedio de losnodos para las redes con pesos. En la siguiente seccion se discutira en que influye esta diferencia enlos resultados, y la efectividad del uso de filtros en base a minerıa de textos.
63

Capıtulo 4. Resultados sobre una VCoP real
4.4. Comunidades encontradas
Se realizaron comparaciones de los diferentes metodos (LDA, CB y Conteo) con las redesconstruidas con enfoque al creador y las construidas por el enfoque a todos los anteriores. Se uti-lizo como medida de la calidad de las comunidades encontradas la modularity y a cada uno delo algoritmos se le realizaron las modificaciones necesarias para su correcto funcionamiento. Lamodularity solo se ha utilizado como medida de comparacion entre algoritmos de busqueda de sub-comunidades para la misma red, esto ultimo porque el valor obtenido depende mucho de la topologıade la red, sin embargo, lo que se busca en este trabajo es encontrar mejores particiones dado que losarcos que permanecen en la red son los arcos que reflejan las relaciones mas fuertes, por lo que esesperable que las redes filtradas permitan encontrar estructuras de comunidad en la red mas fuertesy descubrir conocimiento que de otra manera serıa imposible.
Todos los algoritmos presentados a continuacion utilizan redes no dirigidas. El peso de cadaarco corresponde a la suma de los dos arcos dirigidos entre los nodos, es decir, arcoND(i, j) =arcoND(j, i) = arcoD(i, j) + arcoD(j, i). Esta adaptacion se puede realizar solo en ciertos tipos derelaciones. En el caso de esta red social, los lazos son dados por el grado de interaccion de susmiembros, si bien, para el caso de busqueda del rol o de los miembros clave dentro de la comunidad,es importante conocer quien genera la conversacion, quienes responden y cuales respuestas causanun mayor impacto en la actividad de la red, en el caso de las comunidades lo relevante es quienesse relacionan a traves del dialogo constante sobre los temas de interes de la comunidad. Bastaque, para el caso de las comunidades en el foro de Plexilandia, la relacion capture la existencia deuna conversacion en que los miembros expongan sus ideas bajo un mismo contexto sin importarla direccion de la conversacion. Por lo tanto, no se pierde informacion relevante, en este caso, alutilizar redes no dirigidas.
A continuacion se presentaran los resultados obtenidos con las diferentes estrategias para labusqueda de sub-comunidades.
4.4.1. Resultados con la Modularity de Louvain
Se utilizo la implementacion del software Gephi [8] del algoritmo de Louvain descrito en laseccion 3.4.1 para la busqueda sub-comunidades en base a la funcion de modularity. El softwareincluye una librerıa para java, disponible en la pagina oficial del programa8, con los metodos imple-mentados, tanto para las metricas, como para los modulos graficos. La implementacion de Gephi dela modularity de Louvain permite escoger que los nodos se ordenen al azar de tal forma de incre-mentar los resultados de la modularity obtenidos. Se determino efectuar 1000 iteraciones utilizandola librerıa de Gephi para cada uno de los periodos y se calculo el promedio como se muestra en losgraficos 4.7 tanto para las redes construidas con el enfoque al creador como a la con el enfoque atodos los anteriores.
8http://gephi.org/toolkit [Fecha de Acceso 29 de Septiembre de 2011]
64
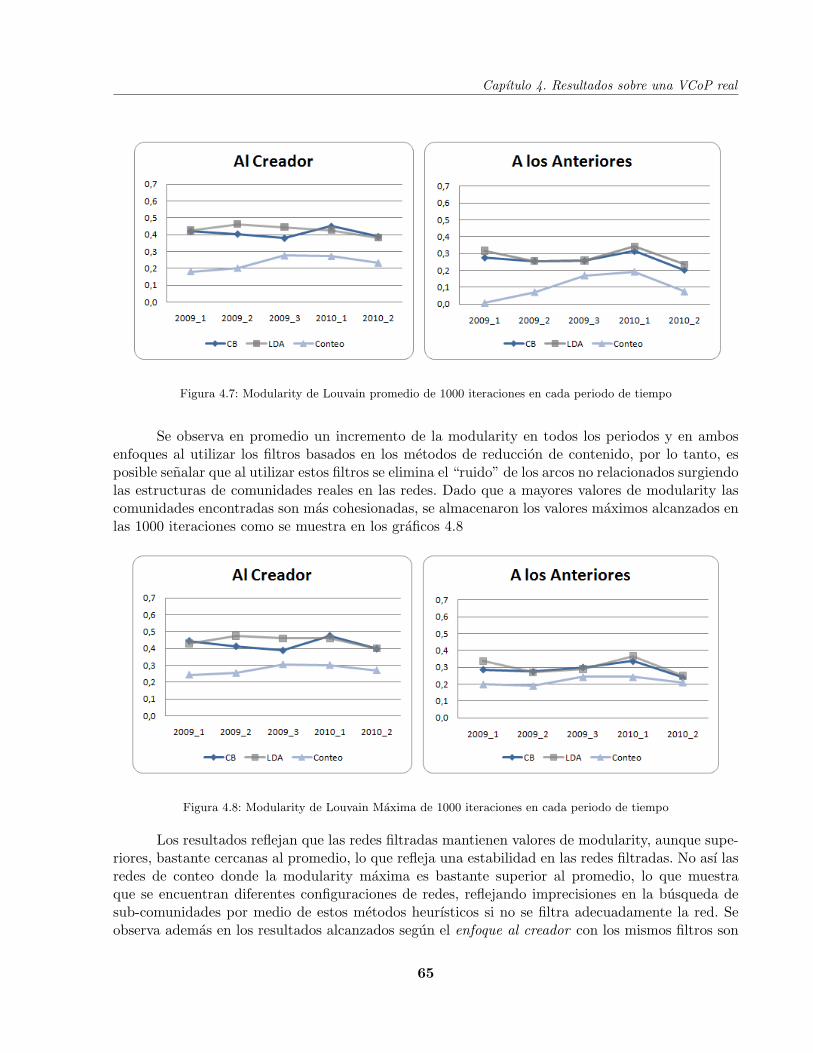
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.7: Modularity de Louvain promedio de 1000 iteraciones en cada periodo de tiempo
Se observa en promedio un incremento de la modularity en todos los periodos y en ambosenfoques al utilizar los filtros basados en los metodos de reduccion de contenido, por lo tanto, esposible senalar que al utilizar estos filtros se elimina el “ruido” de los arcos no relacionados surgiendolas estructuras de comunidades reales en las redes. Dado que a mayores valores de modularity lascomunidades encontradas son mas cohesionadas, se almacenaron los valores maximos alcanzados enlas 1000 iteraciones como se muestra en los graficos 4.8
Figura 4.8: Modularity de Louvain Maxima de 1000 iteraciones en cada periodo de tiempo
Los resultados reflejan que las redes filtradas mantienen valores de modularity, aunque supe-riores, bastante cercanas al promedio, lo que refleja una estabilidad en las redes filtradas. No ası lasredes de conteo donde la modularity maxima es bastante superior al promedio, lo que muestraque se encuentran diferentes configuraciones de redes, reflejando imprecisiones en la busqueda desub-comunidades por medio de estos metodos heurısticos si no se filtra adecuadamente la red. Seobserva ademas en los resultados alcanzados segun el enfoque al creador con los mismos filtros son
65

Capıtulo 4. Resultados sobre una VCoP real
mayores, sin embargo, este efecto tiene que ver con la topologıa de la red, en donde las comunidadesencontradas reflejaran la interaccion entre los miembros que inician o incitan las discusiones, encambio, en las comunidades creadas con el enfoque a todos los anteriores refleja las comunidadesformadas por la interaccion constante de sus miembros, luego como son redes que buscan explorardistintos ambitos de la red, los resultados de la modularity alcanzados en cada enfoque no son com-parables, asimismo las comunidades encontradas por ambos enfoques no tienen por que ser similaresen cuanto a los miembros encontrados. De esta forma la eleccion de la red a utilizar dependera delo que se desea buscar en la red.
Otro punto interesante de evaluar, es la existencia de estructuras de comunidad. Si bienlos filtros semanticos dejan en la red solo los arcos mas fuertes, no aseguran la existencia de unafuerte estructura de comunidad en esta. Es ası que los resultados no reflejan que la metodologıaincremente la modularity alcanzada, sino mas bien que en la red las relaciones fuertes entre losmiembros encontradas con la metodologıa, forman estructuras de comunidad con una alta cohesion,medida en terminos de modularity, y que, posiblemente, no son las mismas encontradas al aplicarla busqueda de comunidades sobre las redes sin filtrar. En el cuadro 4.5 se muestra el resumen delas comunidades encontradas:
Al creador A los Anteriores
Periodo CB LDA Conteo CB LDA Conteo
2009-1 107 - 24 112 - 27 25 - 13 61 - 8 61 - 10 21 - 92009-2 104 - 27 112 - 24 31 - 17 65 - 14 68 - 15 23 - 92009-3 113 - 25 118 - 25 27 - 17 68 - 6 76 - 14 22 - 122010-1 96 - 22 98 - 21 25 - 16 58 - 17 55 - 11 18 - 92010-2 120 - 23 118 - 26 32 - 9 73 - 9 75 - 13 29 - 6
Cuadro 4.5: Numero de comunidades encontradas utilizando el metodo de Louvain donde el primer termino correspondea las particiones realizadas y el segundo a las comunidades reales al restar a las particiones el numero de comunidadesde un solo integrante.
El primer termino corresponde al numero de particiones encontradas por el metodo y elsegundo al numero de comunidades reales de la red, es decir, el numero de particiones encontradascon mas de un miembro. En este metodo no existen usuarios que teniendo algun arco hacia otrootro esten aislado, por lo que el numero de comunidades formadas por un individuo correspondea los nodos aislados de la red. Se observa que en ambos enfoques de redes, los filtros producen unmayor numero de comunidades de dos o mas miembros que las redes por conteo. En el caso de lasredes enfocadas al creador el numero de particiones con un solo miembro son altas, lo que significaque el filtro elimino un gran numero de enlaces que solo producen ruido. En el caso de las redesenfocadas a todos los anteriores el resultado es similar pero en menor medida. Los resultados de lasparticiones encontradas, pueden verse en detalle en el anexo A.3.
A continuacion, en la figura 4.9 se presenta la composicion en terminos de numero de inte-grantes de las comunidades encontradas con el enfoque a todos los anteriores. Se observa que lasredes construidas por conteo tienen un mayor numero de comunidades con gran cantidad de inte-grantes en comparacion con los metodos basados en minerıa de textos. No se aprecia una marcada
66
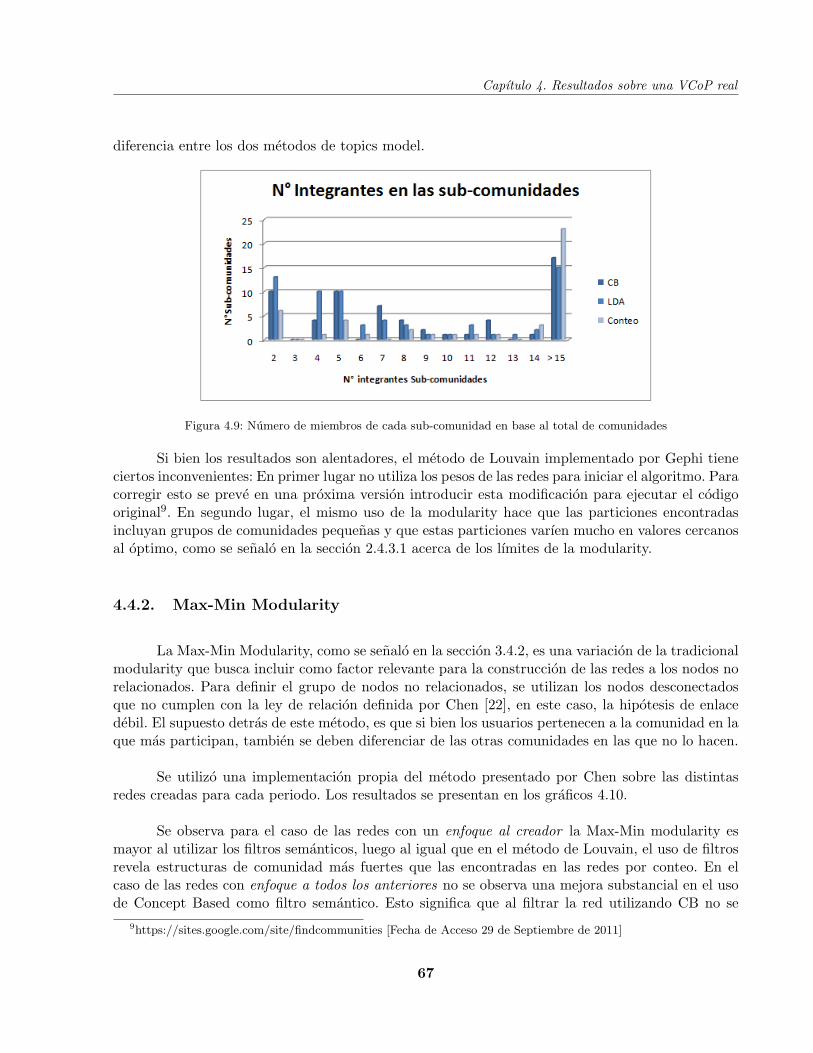
Capıtulo 4. Resultados sobre una VCoP real
diferencia entre los dos metodos de topics model.
Figura 4.9: Numero de miembros de cada sub-comunidad en base al total de comunidades
Si bien los resultados son alentadores, el metodo de Louvain implementado por Gephi tieneciertos inconvenientes: En primer lugar no utiliza los pesos de las redes para iniciar el algoritmo. Paracorregir esto se preve en una proxima version introducir esta modificacion para ejecutar el codigooriginal9. En segundo lugar, el mismo uso de la modularity hace que las particiones encontradasincluyan grupos de comunidades pequenas y que estas particiones varıen mucho en valores cercanosal optimo, como se senalo en la seccion 2.4.3.1 acerca de los lımites de la modularity.
4.4.2. Max-Min Modularity
La Max-Min Modularity, como se senalo en la seccion 3.4.2, es una variacion de la tradicionalmodularity que busca incluir como factor relevante para la construccion de las redes a los nodos norelacionados. Para definir el grupo de nodos no relacionados, se utilizan los nodos desconectadosque no cumplen con la ley de relacion definida por Chen [22], en este caso, la hipotesis de enlacedebil. El supuesto detras de este metodo, es que si bien los usuarios pertenecen a la comunidad en laque mas participan, tambien se deben diferenciar de las otras comunidades en las que no lo hacen.
Se utilizo una implementacion propia del metodo presentado por Chen sobre las distintasredes creadas para cada periodo. Los resultados se presentan en los graficos 4.10.
Se observa para el caso de las redes con un enfoque al creador la Max-Min modularity esmayor al utilizar los filtros semanticos, luego al igual que en el metodo de Louvain, el uso de filtrosrevela estructuras de comunidad mas fuertes que las encontradas en las redes por conteo. En elcaso de las redes con enfoque a todos los anteriores no se observa una mejora substancial en el usode Concept Based como filtro semantico. Esto significa que al filtrar la red utilizando CB no se
9https://sites.google.com/site/findcommunities [Fecha de Acceso 29 de Septiembre de 2011]
67
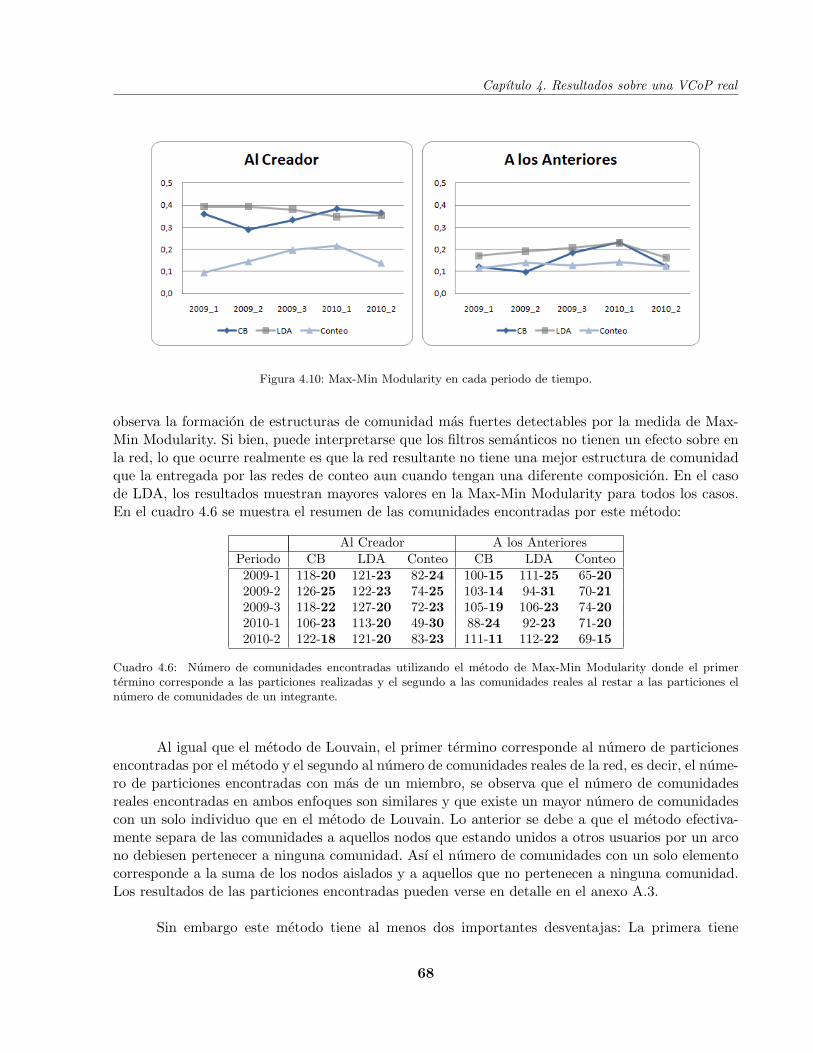
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.10: Max-Min Modularity en cada periodo de tiempo.
observa la formacion de estructuras de comunidad mas fuertes detectables por la medida de Max-Min Modularity. Si bien, puede interpretarse que los filtros semanticos no tienen un efecto sobre enla red, lo que ocurre realmente es que la red resultante no tiene una mejor estructura de comunidadque la entregada por las redes de conteo aun cuando tengan una diferente composicion. En el casode LDA, los resultados muestran mayores valores en la Max-Min Modularity para todos los casos.En el cuadro 4.6 se muestra el resumen de las comunidades encontradas por este metodo:
Al Creador A los AnterioresPeriodo CB LDA Conteo CB LDA Conteo2009-1 118-20 121-23 82-24 100-15 111-25 65-202009-2 126-25 122-23 74-25 103-14 94-31 70-212009-3 118-22 127-20 72-23 105-19 106-23 74-202010-1 106-23 113-20 49-30 88-24 92-23 71-202010-2 122-18 121-20 83-23 111-11 112-22 69-15
Cuadro 4.6: Numero de comunidades encontradas utilizando el metodo de Max-Min Modularity donde el primertermino corresponde a las particiones realizadas y el segundo a las comunidades reales al restar a las particiones elnumero de comunidades de un integrante.
Al igual que el metodo de Louvain, el primer termino corresponde al numero de particionesencontradas por el metodo y el segundo al numero de comunidades reales de la red, es decir, el nume-ro de particiones encontradas con mas de un miembro, se observa que el numero de comunidadesreales encontradas en ambos enfoques son similares y que existe un mayor numero de comunidadescon un solo individuo que en el metodo de Louvain. Lo anterior se debe a que el metodo efectiva-mente separa de las comunidades a aquellos nodos que estando unidos a otros usuarios por un arcono debiesen pertenecer a ninguna comunidad. Ası el numero de comunidades con un solo elementocorresponde a la suma de los nodos aislados y a aquellos que no pertenecen a ninguna comunidad.Los resultados de las particiones encontradas pueden verse en detalle en el anexo A.3.
Sin embargo este metodo tiene al menos dos importantes desventajas: La primera tiene
68
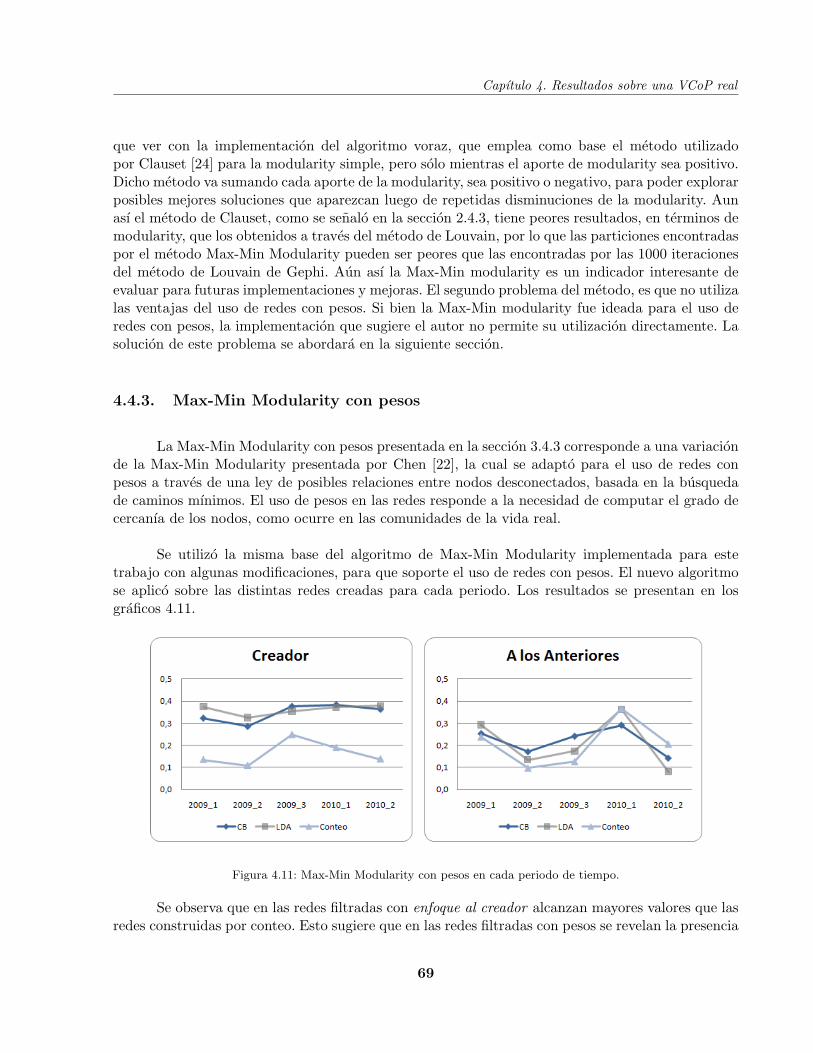
Capıtulo 4. Resultados sobre una VCoP real
que ver con la implementacion del algoritmo voraz, que emplea como base el metodo utilizadopor Clauset [24] para la modularity simple, pero solo mientras el aporte de modularity sea positivo.Dicho metodo va sumando cada aporte de la modularity, sea positivo o negativo, para poder explorarposibles mejores soluciones que aparezcan luego de repetidas disminuciones de la modularity. Aunası el metodo de Clauset, como se senalo en la seccion 2.4.3, tiene peores resultados, en terminos demodularity, que los obtenidos a traves del metodo de Louvain, por lo que las particiones encontradaspor el metodo Max-Min Modularity pueden ser peores que las encontradas por las 1000 iteracionesdel metodo de Louvain de Gephi. Aun ası la Max-Min modularity es un indicador interesante deevaluar para futuras implementaciones y mejoras. El segundo problema del metodo, es que no utilizalas ventajas del uso de redes con pesos. Si bien la Max-Min modularity fue ideada para el uso deredes con pesos, la implementacion que sugiere el autor no permite su utilizacion directamente. Lasolucion de este problema se abordara en la siguiente seccion.
4.4.3. Max-Min Modularity con pesos
La Max-Min Modularity con pesos presentada en la seccion 3.4.3 corresponde a una variacionde la Max-Min Modularity presentada por Chen [22], la cual se adapto para el uso de redes conpesos a traves de una ley de posibles relaciones entre nodos desconectados, basada en la busquedade caminos mınimos. El uso de pesos en las redes responde a la necesidad de computar el grado decercanıa de los nodos, como ocurre en las comunidades de la vida real.
Se utilizo la misma base del algoritmo de Max-Min Modularity implementada para estetrabajo con algunas modificaciones, para que soporte el uso de redes con pesos. El nuevo algoritmose aplico sobre las distintas redes creadas para cada periodo. Los resultados se presentan en losgraficos 4.11.
Figura 4.11: Max-Min Modularity con pesos en cada periodo de tiempo.
Se observa que en las redes filtradas con enfoque al creador alcanzan mayores valores que lasredes construidas por conteo. Esto sugiere que en las redes filtradas con pesos se revelan la presencia
69

Capıtulo 4. Resultados sobre una VCoP real
de una fuerte estructura de comunidad. En el caso de las redes construidas con el enfoque a todos losanteriores los valores alcanzados por las redes filtradas son similares a las redes por conteo, luegolas estructuras encontradas con este nivel de corte no reflejan la presencia de una mayor estructurade comunidad que las encontradas de forma tradicional, pero al modificar la red, se espera quelas comunidades no seran similares. En el cuadro 4.7 se muestra el resumen de las comunidadesencontradas mediante este metodo:
Al Creador A los AnterioresPeriodo CB LDA Conteo CB LDA Conteo2009-1 132-23 129-20 72-19 95-16 106-21 55-162009-2 129-23 134-24 81-17 105-17 108-19 63-142009-3 121-16 131-23 65-19 102-15 110-15 69-172010-1 110-19 113-15 63-17 87-18 98-16 57-122010-2 134-18 130-17 85-20 115-14 121-13 58-16
Cuadro 4.7: Numero de comunidades encontradas utilizando el metodo de Max-Min Modularity con pesos, donde elprimer termino corresponde a las particiones realizadas y el segundo a las comunidades reales al restar a las particionesel numero de comunidades de un integrante.
De acuerdo a lo expuesto en el cuadro 4.7, se observa que el numero de comunidades realesencontradas en ambos enfoques son en promedio similares, sin embargo, dado que el numero departiciones de un solo elemento en las redes con filtro es bastante mayor a lo encontrado en lasredes de conteo, es posible concluir que la composicion de las comunidades resultantes con el filtroes diferente a la encontrada en las redes de conteo, en el sentido de que las primeras tienen menosmiembros. Los resultados de las particiones encontradas pueden verse en detalle en el anexo A.3.
El efecto de los filtros semanticos es eliminar paulatinamente los arcos mas debiles de la redy ası ir aislando a los individuos que no son parte de los nucleos de las comunidades, los cualesestan formados solo por los usuarios que mas interactuan. Como se ha mencionado anteriormenteun buen filtro no asegura la existencia de estructuras de comunidad en la red, pero es esperable queal eliminar los arcos debiles, y por lo tanto aislar los nodos menos participativos, se logre encontrarestructuras de comunidad cada vez mas cohesionadas. Se calculo la Max-Min Modularity con pesospara un un nivel de corte de γ = 0, 02 y θ = 0, 5 para el caso de LDA y γ = 0, 2 y θ = 0, 7para el caso de Concept Based para las redes orientadasa todos los anteriores. En el grafico 4.12 sepresentan los resultados obtenidos:
Se observa que las redes filtradas a traves de LDA tienen estructuras de comunidades mascohesionadas, en tanto que CB logra niveles relativamente similares a los resultados encontradoscon las redes de conteo. Sin embargo, el mayor nivel de filtro genera un gran numero de nodosaislados que no podran ser asignados a ninguna comunidad. El filtro debe ser utilizado con bastantecuidado para lograr eliminar solo aquellos arcos que generen ruido y no a los que permitan conocerespecificamente a que comunidad pertenecen los miembros.
En la figura 4.13 se observa una comparacion entre las particiones encontradas por el metodode Max-Min Modularity con pesos y las entregadas por el metodo de Max-Min Modularity para el
70

Capıtulo 4. Resultados sobre una VCoP real
Figura 4.12: Max-Min Modularity con pesos para un un nivel de corte de γ = 0, 02 y θ = 0, 5 para el caso de LDA yγ = 0, 2 y θ = 0, 7 para el caso de Concept Based en cada periodo.
caso de las redes orientadas a todos los anteriores.
Figura 4.13: Comparacion entre las particiones encontradas Max-Min Modularity con pesos y Max-Min Modularity
Los resultados muestran que al comparar las particiones encontrados utilizando Max-MinModularity con pesos (QMMMW) se alcanzan mayores valores que las encontradas por el metodode Max-Min Modularity (QMMM) presentado en la seccion anterior. Esto es esperable pues seutiliza el mismo algoritmo bajo una nueva topologıa de la red.
Si bien, la Max-Min modularity con peso es un indicador interesante desde el punto de vistade estudio, su implementacion a traves de este algoritmo no permite aprovechar todas las mejorasque supone su uso. Se debe a futuro, combinar la funcion de calidad de las particiones de la redcon una estrategia de optimizacion mas efectiva, como la de Louvain, pues enfrentada con esta, nomuestra mejores resultados. Otro inconveniente importante, no solo de este metodo sino de todos losmetodos hasta ahora abordados, es que permiten encontrar solo particiones de la red y no conjuntosen los cuales sus individuos puedan participar en mas de una comunidad a la vez, como ocurre enla vida real.
71

Capıtulo 4. Resultados sobre una VCoP real
4.4.4. Mejoras de las redes con Metodos de superposicion
En esta seccion se presentan los resultados de la aplicacion el metodo de superposicionexhibidos en la seccion 3.4.4 sobre los resultados de las comunidades encontradas a traves de laaplicacion de los metodos de particion descritos en las secciones anteriores. El metodo se basa enque, en la vida real, los miembros de una red social pueden participar simultaneamente en mas deuna comunidad, segun sus diferentes intereses. Ası, el metodo permite identificar a estos miembrospor medio de un factor de pertenencia basado en el numero de arcos que un nodo comparte concada comunidad. El metodo requiere de un nivel de corte para el factor de pertenencia, el cual definecuando un usuario participa en mas de una comunidad a la vez.
Para evaluar los resultados del metodo se implemento una variacion de la modularity conel objetivo de encontrar comunidades superpuestas, de acuerdo a lo propuesto por Nicosia et al.[79]. La extension de la modularity propuesta por este autor requiere definir funcion F(αi,c, αj,c)que exprese cual es la pertenencia de una arco que va de i a j a la comunidad c donde αi,c y αj,c
corresponden a las pertenencias de los nodos i y j a la comunidad c respectivamente. El autorsenala que tras diferentes experimentos la funcion que presenta mejores resultados, a su juicio, esla funcion logıstica de dos dimensiones:
F(αi,c, αj,c) =1
(1 + e−f(αi,c))(1 + e−f(αj,c))(4.1)
Donde f(αi,c) es una funcion lineal de escalamiento:
f(x) = 2px− p, p ∈ R (4.2)
En este trabajo se selecciono para la funcion lineal de escalamiento p = 2.
Para evaluar las mejoras producidas por el metodo, se utilizaron los resultados de las parti-ciones obtenidas mediante la heurıstica de Louvain. Se compararon los resultados de la modularitypara comunidades superpuestas, obtenidos al mejorar las particiones del metodo de Louvain con elalgoritmo de comunidades superpuestas, frente a los resultados obtenidos al aplicar esta variacionde la modularity directamente sobre las particiones sin miembros superpuestos. Este proceso serealizo para cada periodo, tipo de enfoque de construccion de la red y ambos filtros semanticos.Como nivel de corte para evaluar el nivel de pertenencia de los nodos, se utilizo θ = 0,8 lo quesignifica que el factor de pertenencia de ese nodo a la nueva comunidad debe ser como mınimo0,8. Los resultados se presentan en los graficos 4.14, para el caso de las redes al creador, y en losgraficos 4.15 para el caso de las redes con enfoque a todos los anteriores.
Se observa que para todos los periodos y enfoques de construccion de las redes y filtrossemanticos el metodo para la superposicion de comunidades propuesto en este trabajo entrega me-
72

Capıtulo 4. Resultados sobre una VCoP real
Figura 4.14: Modularity para redes superpuestas con enfoque al creador.
Figura 4.15: Modularity para redes superpuestas con enfoque a todos los anteriores.
jores resultados en terminos de la modularity para redes superpuestas. Esto significa que el metodoidentifica correctamente a los nodos que participan en mas de una comunidad y mejora las comu-nidades existentes, permitiendo lograr un mayor grado de cohesion entre sus miembros. El metodoaunque sencillo, admite ser utilizado para mejorar cualquiera de las particiones conseguidas con losdiferentes algoritmos presentados.
En los graficos 4.16 se muestra el numero de superposiciones existentes en las diferentes redesestudiadas.
Se observa que en las redes por conteo existe, en general, un mayor numero de superposiciones.Esto, si bien se debe a que la red tiene una mayor densidad, tiene relacion con que la forma deconstruir las redes por conteo genera ruido y por lo tanto muchos arcos que no permiten determinaradecuadamente a cual o cuales comunidades pertenece efectivamente un nodo. Los resultados de lasparticiones encontradas, sobre el metodo de Louvain pueden verse en detalle en el anexo A.3.
Finalmente se debe mencionar que este metodo solo permite mejorar los resultados a partirde la existencia de las particiones iniciales, por lo que unicamente agrega valor en la medida que las
73
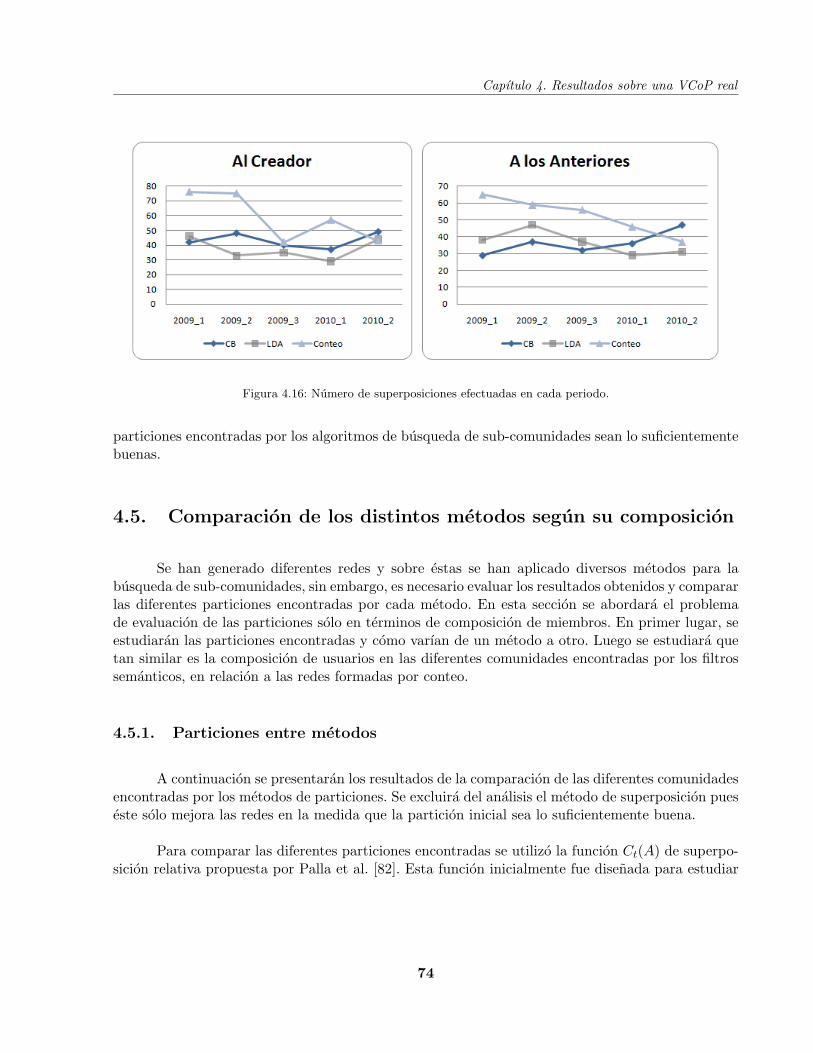
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.16: Numero de superposiciones efectuadas en cada periodo.
particiones encontradas por los algoritmos de busqueda de sub-comunidades sean lo suficientementebuenas.
4.5. Comparacion de los distintos metodos segun su composicion
Se han generado diferentes redes y sobre estas se han aplicado diversos metodos para labusqueda de sub-comunidades, sin embargo, es necesario evaluar los resultados obtenidos y compararlas diferentes particiones encontradas por cada metodo. En esta seccion se abordara el problemade evaluacion de las particiones solo en terminos de composicion de miembros. En primer lugar, seestudiaran las particiones encontradas y como varıan de un metodo a otro. Luego se estudiara quetan similar es la composicion de usuarios en las diferentes comunidades encontradas por los filtrossemanticos, en relacion a las redes formadas por conteo.
4.5.1. Particiones entre metodos
A continuacion se presentaran los resultados de la comparacion de las diferentes comunidadesencontradas por los metodos de particiones. Se excluira del analisis el metodo de superposicion pueseste solo mejora las redes en la medida que la particion inicial sea lo suficientemente buena.
Para comparar las diferentes particiones encontradas se utilizo la funcion Ct(A) de superpo-sicion relativa propuesta por Palla et al. [82]. Esta funcion inicialmente fue disenada para estudiar
74

Capıtulo 4. Resultados sobre una VCoP real
la evolucion de una comunidad A, en T diferentes periodos de tiempo, ası Ct(A) se define como:
Ct(A) =|A(t0) ∩A(t0 + t)||A(t0) ∪A(t0 + t)|
(4.3)
Donde A(t0) corresponde a la sub-comunidad A en el periodo t0 y A(t0 + t) a la misma comunidaden el periodo t0 + t. Fortunato [41] senala que esta medida puede ser adaptada para comparar dosparticiones, redefiniendo A(t0) como la comunidad Xi de la particion X y a A(t0 + t) como Yj quecorresponde a la misma comunidad pero en la particion Y, ası escribe la superposicion relativa sijcomo:
sij =|Xi ∩ Yj ||Xi ∪ Yj |
(4.4)
Para determinar la comunidad de la particion Y correspondiente a la comunidad Xi se buscaYj que maximice sij . Este indicador se promedia para las i particiones X para obtener tener unindicador global de la similitud de las particiones X e Y. Se deben eliminar del promedio los sij = 1tal que |Xi| = 1, pues significa que ambas particiones corresponden a nodos aislados y no aportaninformacion relevante al estudio. El indicador sera 1 si las redes poseen particiones iguales y tendera avalores pequenos en la medida que las particiones encontradas sean muy diferentes.
Se compararon las particiones del metodo de Louvain frente a las particiones encontradaspor Max-Min Modularity y Max-Min Modularity con pesos, para todos los periodos y para ambosenfoques de construccion de redes. Los resultados se presentan en los graficos 4.17 para el caso deLouvain - Max-Min Modularity y en los graficos 4.18 para el caso de Louvain - Max-Min Modularitycon pesos.
Figura 4.17: Similitud de las particiones encontradas por el metodo de Louvain frente a las encontradas por Min-MaxModularity para cada uno de los periodos, por ambos enfoques de construccion de las redes.
75
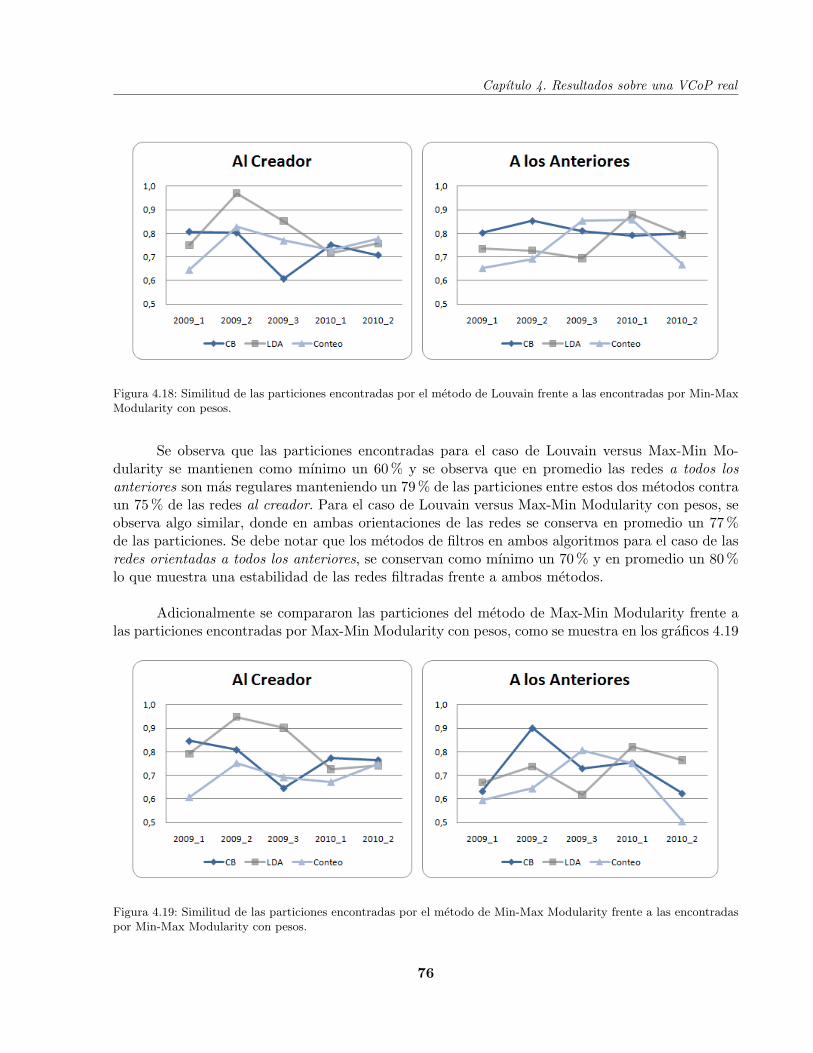
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.18: Similitud de las particiones encontradas por el metodo de Louvain frente a las encontradas por Min-MaxModularity con pesos.
Se observa que las particiones encontradas para el caso de Louvain versus Max-Min Mo-dularity se mantienen como mınimo un 60 % y se observa que en promedio las redes a todos losanteriores son mas regulares manteniendo un 79 % de las particiones entre estos dos metodos contraun 75 % de las redes al creador. Para el caso de Louvain versus Max-Min Modularity con pesos, seobserva algo similar, donde en ambas orientaciones de las redes se conserva en promedio un 77 %de las particiones. Se debe notar que los metodos de filtros en ambos algoritmos para el caso de lasredes orientadas a todos los anteriores, se conservan como mınimo un 70 % y en promedio un 80 %lo que muestra una estabilidad de las redes filtradas frente a ambos metodos.
Adicionalmente se compararon las particiones del metodo de Max-Min Modularity frente alas particiones encontradas por Max-Min Modularity con pesos, como se muestra en los graficos 4.19
Figura 4.19: Similitud de las particiones encontradas por el metodo de Min-Max Modularity frente a las encontradaspor Min-Max Modularity con pesos.
76

Capıtulo 4. Resultados sobre una VCoP real
Se advierte que en el caso de las redes orientadas al creador, en promedio, se mantiene un76 % de las particiones entre los metodos, sin embargo, las redes con filtros semanticos conservanun 80 % en promedio. En las redes orientadas a todos los anteriores se mantiene un 72,5 % de lasparticiones y si bien el promedio de las redes filtradas es levemente superior, se observa que solopara el tercer cuatrimestre de 2009 los resultados de las redes filtradas son menores que las redespor conteo.
En resumen, este indicador senala que se conserva un gran porcentaje de las particionesindependiente del metodo utilizado, de esta forma se puede senalar que existe un “nucleo” constanteentre los distintos metodos. Adicionalmente se observa que las particiones sobre las redes filtradasse mantienen en promedio con un mayor porcentaje en los distintos metodos utilizados.
4.5.2. Informacion Estructural
Una de las grandes interrogantes que surgen de este trabajo es si la utilizacion de los filtrossemanticos permite la obtencion de estructuras diferentes en terminos de usuarios, respecto a lasredes formadas por conteo. Si es ası, esto significarıa que efectivamente se esta descubriendo nuevainformacion en la red. La intencion inicial entonces, es utilizar el indicador de superposicion relativapresentado en la ecuacion 4.4. Sin embargo, los filtros semanticos producen un mayor numero denodos aislados en la red, luego, los resultados obtenidos bajo este indicador serıan enganosos pues,en general, se tendrıan comunidades reales de menor tamano que las encontradas en las redes porconteo. Ası, el indicador debiese medir cuanto de una comunidad i de las redes filtradas se puedeencontrar inserta en una sola comunidad j de las redes construidas por conteo. Para este proposito sepropone una variacion de la ecuacion 4.4 la cual permite evaluar cuanto de la informacion encontradapor los metodos en las redes filtradas ya se encontraba disponible por la aplicacion de los metodosen las estructuras de conteo. Se define la Informacion Estructural mantenida como:
IEij =|Xi ∩ Yj ||Xi|
(4.5)
Para determinar la comunidad de la particion Y correspondiente a la comunidad Xi se busca Yj quemaximice IEij . Para obtener el indicador global se promedian todos los IEij de la red. Al igual queel indicador de superposicion relativa, se deben eliminar las particiones de X de un solo usuario.Si el valor de este indicador es cercano a 1 significara que cada particion de las redes filtradas seencuentran contenidas casi completamente dentro de una particion de la red de conteo, luego losfiltros solo permiten mejorar la granularidad de la red encontrando comunidades mas pequenas. Encaso contrario, significara que la composicion de las nuevas comunidades es distinta a la encontradapor las redes filtradas, donde (1− IE)× 100 corresponde al porcentaje global de nodos clasificadosen comunidades distintas.
En los graficos 4.20 se presentan los resultados de la informacion estructural para las dife-rentes redes encontradas por el metodo de Louvain. Se observa que las redes filtradas al creador
77
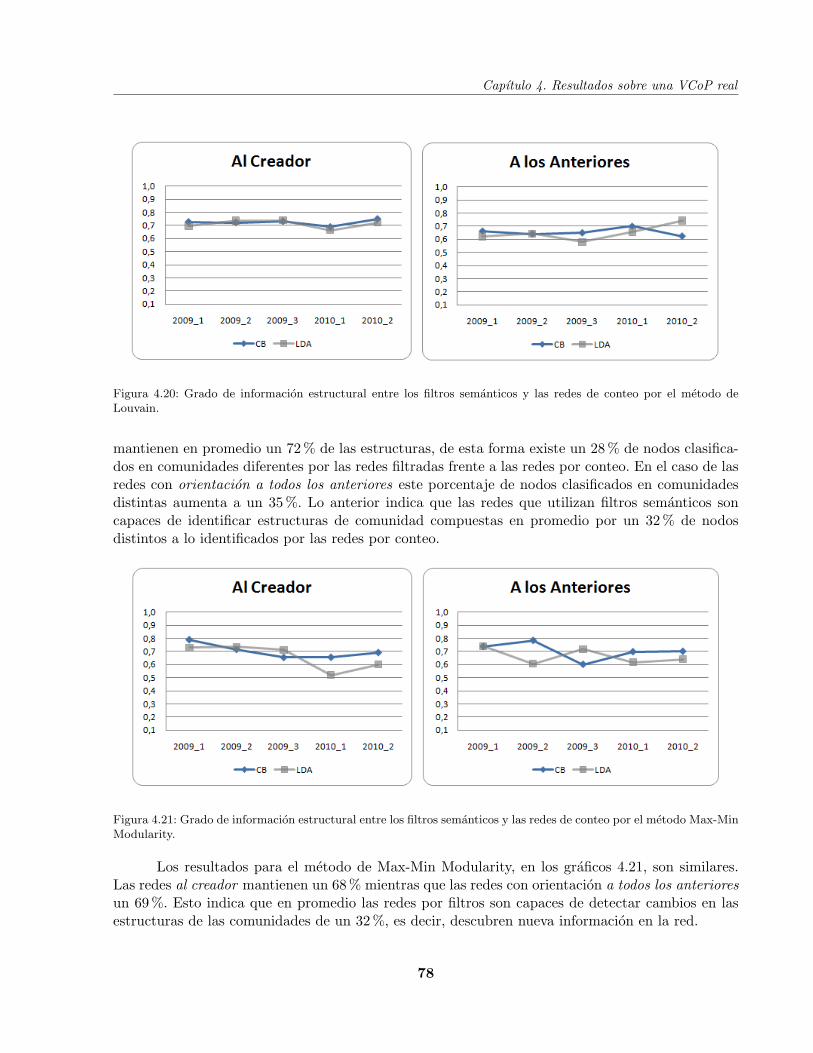
Capıtulo 4. Resultados sobre una VCoP real
Figura 4.20: Grado de informacion estructural entre los filtros semanticos y las redes de conteo por el metodo deLouvain.
mantienen en promedio un 72 % de las estructuras, de esta forma existe un 28 % de nodos clasifica-dos en comunidades diferentes por las redes filtradas frente a las redes por conteo. En el caso de lasredes con orientacion a todos los anteriores este porcentaje de nodos clasificados en comunidadesdistintas aumenta a un 35 %. Lo anterior indica que las redes que utilizan filtros semanticos soncapaces de identificar estructuras de comunidad compuestas en promedio por un 32 % de nodosdistintos a lo identificados por las redes por conteo.
Figura 4.21: Grado de informacion estructural entre los filtros semanticos y las redes de conteo por el metodo Max-MinModularity.
Los resultados para el metodo de Max-Min Modularity, en los graficos 4.21, son similares.Las redes al creador mantienen un 68 % mientras que las redes con orientacion a todos los anterioresun 69 %. Esto indica que en promedio las redes por filtros son capaces de detectar cambios en lasestructuras de las comunidades de un 32 %, es decir, descubren nueva informacion en la red.
78

Capıtulo 4. Resultados sobre una VCoP real
Figura 4.22: Grado de informacion estructural entre los filtros semanticos y las redes de conteo por el Max-MinModularity con pesos.
Se observa que, en terminos de informacion estructural, los valores en el metodo de Max-Min Modularity con pesos, presentados los graficos 4.22, son ligeramente mas altos que los casosanteriores, donde el promedio en las redes con orientacion al creador es de un 72 % mientra que enlas redes a todos los anteriores es de 78 % aun ası, las diferencias en promedio de nodos clasificadosen particiones distintas corresponde a un 25 %.
Se concluye que en todos los casos las redes por filtro son capaces de detectar nodos queno fueron clasificados juntos por los metodos aplicados a las redes tradicionales, ası las nuevasconfiguraciones entregadas por los filtros semanticos, efectivamente son capaces de descubrir nuevainformacion.
4.6. Caracterısticas de los grupos encontrados
Una vez encontradas las diferentes comunidades, se evaluo que es lo que se discute en cadacomunidad, cuales son los temas de interes y como estos hacen que la comunidad se diferencie delas otras. Para ello se utilizo la estrategia senalada en la seccion 3.5 la cual entrega el promedio dela suma de cada uno de los conceptos o topicos que habla cada usuario de la comunidad. Se debesenalar que la realizacion de este proceso solo es posible en la medida que se utilice la informacionsemantica de la red y los filtros de reduccion de contenido para definir los temas especıficos con loscuales se caracterizaran las comunidades. A continuacion se presentaran los resultados tanto paraLDA como CB para la red con enfoque a todos los anteriores del primer cuatrimestre del 2009.
En el Caso de CB el numero de conceptos presentados en la seccion 4.2.2 es de solo 6 conlo que facilmente se puede construir un grafico que refleje como cada comunidad representa a losconceptos. En en la figura 4.23 se presentan los graficos de 3 distintas comunidades:
79

Capıtulo 4. Resultados sobre una VCoP real
Figura 4.23: Caracterizacion de comunidades por Concept Based para el primer cuatrimestre del 2009 en una redconstruida por el enfoque a todos los anteriores.
Se observa un patron general similar para las distintas comunidades, donde en los dos pri-meros conceptos se encuentran en un alta proporcion pero en diferente magnitud. Los siguientesdifieren segun la comunidad y el ultimo es bajo en proporcion a los anteriores pero con diferentemagnitud.
En el caso de LDA el proceso es ligeramente distinto. El numero de topicos es de 50, porlo que se hace muy difıcil comparar el patron caracterıstico de las comunidades. La figura 4.24representa la comparacion entre los diferentes topicos validos de la red.
Figura 4.24: Caracterizacion de las comunidad 1, la comunidad 15 y la comunidad 25 encontradas por el metodosde Louvan utilizando una red filtrada por LDA para el primer cuatrimestre del 2009 con una orientacion a todos losanteriores.
Para mejorar la visualizacion de las comunidades se agruparon los conceptos similares dentrode 6 grupos topicos segun su grado de parentesco. Ası es posible comparar y entender de mejormanera las caracterısticas de las comunidades encontradas. Los topicos fueron agrupados comosigue:
80

Capıtulo 4. Resultados sobre una VCoP real
Grupo topico 1: Temas relacionados a los amplificadores.
Grupo topico 2: Construccion de implementos de audio y musica.
Grupo topico 3: Especializacion en efectos de distorsion.
Grupo topico 4: Efectos en general.
Grupo topico 5: Reparacion y arreglos en general.
Grupo topico 6: Compra y venta de artıculos.
En la figura 4.25 se presentan los graficos de las 3 comunidades presentadas en la figura 4.24.
Figura 4.25: Caracterizacion de comunidades por LDA con agrupacion de los topicos para el primer cuatrimestre del2009 en una red construida por el enfoque a todos los anteriores.
Con esta caracterizacion es posible determinar los intereses generales del grupo y en que temasse enfocan mas. Se observa que en la comunidad 1 se discuten temas relacionados con la construccionde implementos de audio y musica, con un enfoque a efectos en general. De la misma manera sepuede caracterizar a la comunidad 15 donde los temas de preferencia tiene relacion con el arreglo yreparacion en general con un fuerte enfoque a temas relacionados a los amplificadores. Finalmenteen la comunidad 25 se observa una marcada tendencia a temas relacionados con amplificadoresenfocados a la construccion de implementos de audio y musica y reparaciones en general.
4.7. Comparacion de las comunidades segun su contenido
Uno de los puntos mas difıciles de evaluar en este trabajo es si el uso de las redes semanticaspermite efectivamente encontrar comunidades mas cercanas en terminos de contenido respecto alas redes por conteo. Si bien, el uso de los metodos de text mining apuntan hacia esa direccion,no necesariamente los resultados obtenidos mostraran que en las comunidades sus integrantes serelacionen en torno a temas especıficos, aun cuando los experimentos presentados en la seccion 4.5
81

Capıtulo 4. Resultados sobre una VCoP real
demuestren que en composicion, las comunidades encontradas bajo las redes filtradas por topicos yconceptos, son distintas a las de conteo.
Para evaluar si los integrantes de las comunidades se relacionan en torno al mismo tema esnecesario realizar una comparacion manual de los post de los diferentes participantes que escribierondurante el periodo de estudio. Se deben comparar los post de cada miembros de la comunidad ydeterminar cualitativamente si los temas discutidos por ellos estan o no relacionados y ası determinarque porcentaje del contenido hablado es comun a todos los miembros de la comunidad. Dada unacomunidad C de U usuarios, el porcentaje de contenido comun hablado en C se obtiene como:
P c =
∑i,j∈ Ui =j
Ti,j
|U|2 − |U|(4.6)
Donde Ti,j se determina como,
Ti,j =
{1 Si los post de i son similares a los de j0 En caso contrario
(4.7)
De esta forma se obtiene el porcentaje de usuarios que estan relacionados por el contenidoen una comunidad sobre todas las relaciones posibles entre sus miembros.
Debido a la gran cantidad de datos existente se determino realizar este calculo seleccionandouna comunidad de cada tipo de red: por conteo, utilizando CB y utilizando LDA. Las redes fueronconstruidas bajo el enfoque a todos los anteriores para comunidades encontradas por el metodo deLouvain pertenecientes al primer cuatrimestre del ano 2010. En el cuadro 4.8 se presenta el resumende las comunidades y los resultados obtenidos:
Primer cuatrimestre ano 2010
Tipo de red N◦ de Miembros % de similitud de contenido
LDA 16 27,9 %CB 12 53 %
Conteo 30 19,7 %
Cuadro 4.8: Resultados de las comunidades y su similitud de contenido
Los resultados senalan que las redes filtradas forman comunidades en las cuales sus miembrosestan mas relacionados en terminos de similitud del contenido que aquellas redes formadas solopor conteo. Se observa que la comunidad encontrada en la red filtrada por CB tiene un 53 % desimilitud del contenido hablado por sus usuarios, esto significa que en promedio un miembro dela comunidad comenta sobre los mismos temas que el 53 % del resto de usuarios. De igual maneralas comunidades encontradas sobres las redes filtradas por LDA tienen en promedio un 27,9 % desimilitud de contenido, un 8 % mayor a la similitud semantica de las comunidades construidas sobreredes de conteo.
82

Capıtulo 4. Resultados sobre una VCoP real
En particular las comunidades tanto para el caso LDA como para CB fueron elegidas demanera que tuviesen el mayor numero de miembros intersectados con la comunidad elegida en lared de conteo. Esto sugiere que parte de los elementos no intersectados son los que tienen pocarelacion con el resto de la comunidad en terminos de contenido y que posiblemente esten sologenerando lazos incorrectos.
83

Capıtulo 5
Conclusiones y Trabajo Futuro
Las comunidades virtuales de practica permiten a sus integrantes aprender y compartir susexperiencias sobre un tema de interes a traves de la interaccion constante en un espacio virtual,permitiendo generar conocimiento, que un individuo por su cuenta, y sin la interaccion, no podrıao tardarıa mucho tiempo en generar. Esta interaccion constante hace que ciertos miembros se rela-cionen con mayor intensidad formando sub-comunidades. La busqueda de estas estructuras es unode los principales desafıos a los cuales se ven enfrentados los administradores a la hora de evaluar yentender como se crea, como se representa y como se trasfiere el conocimiento a traves de las per-sonas, pues es en estas comunidades donde las personas aprenden y ensenan a otros. Las tecnicasexistentes abordan este problema por medio de la representacion de las redes en grafos, describiendoa los usuarios como nodos y sus relaciones como arcos para, posteriormente, aplicar algoritmos paradeterminar las mejores estructuras de comunidad sobre los grafos. Sin embargo, en la formulacionde los arcos, en general, no se utiliza la informacion semantica existente en la red, por lo que apesar de que las tecnicas de busqueda de comunidades sean buenas, los resultados no reflejan lo queocurre en la realidad.
En esta lınea se determino que el objetivo central de esta tesis fuese desarrollar una me-todologıa para mejorar el proceso de busqueda de sub-comunidades incorporando el analisis delcontenido semantico de la red, a traves del uso de estrategias de reduccion del contenido basadosen minerıa de textos, en particular el uso de Concept-Based y LDA, para posteriormente, encontrarsub-comunidades con diferentes estrategias de optimizacion. Estas comunidades, finalmente, fueroncaracterizadas utilizando las mismas estrategias de reduccion de contenido antes mencionadas paramejorar la atencion a los miembros de la VCoP. De esta manera y como se presento en la seccion 4,el objetivo general de esta tesis y los objetivos especıficos presentados en 1.2 fueron logrados conexito. A continuacion se describe como esta tesis contribuye al cumplimiento de cada uno de ellos.
1. Con el objetivo de mejorar las actuales representaciones de las redes, se presentaron algunasestrategias para la reduccion del contenido en la seccion 3.2 las cuales, en conjunto con losmetodos para la creacion de redes presentados en la seccion 3.3.3, permitieron construir grafos
84

Capıtulo 5. Conclusiones y Trabajo Futuro
que reflejen con mayor veracidad las relaciones semanticas en la red.
2. En la seccion 3.4 se presentaron algunos algoritmos utilizados para la busqueda de sub-comunidades y adaptaciones a estos, como la Max-Min Modularity con pesos (seccion 3.4.3) yalgoritmos para la busqueda de sub-comunidades superpuestas (seccion 3.4.4). Los resultadosde las comunidades fueron expuestos en la seccion 4.4. Las mejoras de estos algoritmos sobrelas redes filtradas se presentaron en la seccion 4.5.
3. En la seccion 4.7 se presentaron los resultados de la comparacion de la metodologıa con redesfiltradas frente a redes sin filtrar.
4. Finalmente se presento en la seccion 3.5 una manera de caracterizar a las sub-comunidadesencontradas mediante el uso de Text Mining tanto para el caso de LDA como de CB y en laseccion 4.6 se exhibieron algunas de las comunidades como resultado de este proceso.
A continuacion se presentaran las principales conclusiones en cada una de las etapas deldesarrollo de esta tesis.
5.1. Uso de la metodologıa para busqueda de sub-comunidades
Se utilizo como base la metodologıa SNA-KDD propuesta por Alvarez y Merlo [2, 71] y seadapto para la busqueda de sub-comunidades(3), agregando en la etapa de analisis herramientaspara caracterizar las comunidades encontradas.
Una de las principales ventajas de la metodologıa es que permite mejorar cada una de lasetapas para la busqueda y caracterizacion de las redes en forma independiente. Lo anterior seconfigura en una virtud, pues otorga la posibilidad de que, a medida que surjan mejores modelospara la reduccion del contenido, configuraciones para la creacion de las redes, formulas para medirel peso de los arcos en la red u otras estrategias para la busqueda de sub-comunidades, estas puedenser aplicadas en la busqueda sin necesidad de cambiar el orden o las etapas para obtener resultados.
Sumado a lo anterior, la metodologıa permite adaptarse a las necesidades de busqueda quepresentan comunidades de diversos estilos sobre la red social. Para ejemplificarlo, se utilizaron dosorientaciones diferentes: Las orientadas al creador son utiles en la medida que se requiera encontrara las comunidades de los miembros que incentivan la participacion por medio de la proposicionde temas junto con quienes responden y participan de estos temas. Las redes orientadas a todoslos anteriores, en cambio, permiten descubrir grupos de miembros que discutan acerca de interesessimilares, lo que se acerca mas al problema de clustering clasico.
Finalmente la metodologıa posibilita, ademas de encontrar comunidades utilizando la in-formacion semantica latente de la red, entender los topicos mas relevantes de discusion entre losmiembros de dichas comunidades y de esta forma caracterizar a los grupos y adoptar estrategiaspara fomentar la participacion, segun sus temas de interes.
85

Capıtulo 5. Conclusiones y Trabajo Futuro
El uso de la metodologıa no solo permite comprender la formacion de comunidades con el finde mejorar la experiencia de la administracion de las redes, tambien permite extraer informacion deestas y sus miembros, lo que tal como en el inicio del estudio de las comunidades, brinda informacionde utilidad para diversas disciplinas (como la sociologıa, el marketing, la salud publica, la biologıa,entre otras) y sus aplicaciones.
5.2. Uso de filtros semanticos basados en la minerıa de textos
Como se presento en la la seccion 3.2 los filtros semanticos permiten reducir el contenido delos post de la red y hacerlos comparables para la formacion de los grafos. En este proceso los postentre usuarios son cotejados en funcion de la informacion semantica y solo se forman enlaces entreellos en la medida que el resultado indique un cierto grado de similitud y ası posibilitar la creacionde grafos se acerquen a lo que efectivamente ocurre en la realidad.
Para la construccion de estos grafos es necesario definir ciertos parametros de corte, de talmanera de eliminar los enlaces que producen ruido y no aquellos que siendo debiles reflejan ungrado de relacion. La variacion de la densidad de la red segun el valor de los parametros de corte sepresento en la seccion 4.3, en la cual se determino que un nivel adecuado para el estudio correspondıaa redes con parametros γ = 0, 01 y θ = 0, 3 para el caso de LDA y θ = 0, 5 γ = 0, 1 para CB. Sinembargo, se debe estudiar con mayor detalle el uso de estos filtros para la construccion de redesdependiendo del enfoque de la red a utilizar.
Como fue descrito en la seccion 3.5, el hecho de que los post sean descritos en terminos de unnumero reducido de topicos o conceptos permite describir y comparar a las comunidades encontradasen funcion de estas categorıas. Si bien lo anterior parece algo menor, propicia la obtencion deinformacion relevante de los intereses dentro del grupo, tarea que con los metodos tradicionales noes posible.
Si bien, ambos metodos permiten reducir el contenido y caracterizar la red, responden adiferentes necesidades, como se senalo en la seccion 3.5. Para el uso de CB es necesario desarrollar,en conjunto con los expertos, un vocabulario para describir a ciertos conceptos, los cuales puedenrepresentar, desde un producto concreto hasta una ideologıa. Por ejemplo, si una empresa de mar-keting desea conocer cuales son los usuarios que hablan e interactuan respecto a un producto enparticular, basta con definir los conceptos que representen a este producto y el vocabulario asociado.Los modelos de topicos como LDA, en cambio, utilizan el vocabulario semantico inherente de lared social, luego basta definir el numero de categorıas distintas para que el modelo busque la mejorseparacion del vocabulario de la red. Sin embargo, al igual que CB requiere la participacion de losexpertos, en este caso no para conformar el vocabulario, sino para interpretar los diferentes topicoso grupos de palabras altamente relacionadas que han sido encontradas. Este metodo favorece ladeterminacion de los temas intrınsecos de la red y es util para fines de administracion del contenidoo de investigacion.
86

Capıtulo 5. Conclusiones y Trabajo Futuro
5.3. Busqueda de sub-comunidades
En la seccion 3.4 se abordo el problema de la busqueda de sub-comunidades en el grafo. Elobjetivo era encontrar conjuntos de miembros en los cuales sus relaciones fueran intensas dentro delos grupos pero debiles entre ellos. Los resultados se exhibieron en la seccion 4.4 donde en general, labusqueda sobre redes filtradas arrojo mejores resultados. Esto sugerıa de la presencia de estructurasde comunidad mas fuertes que en los casos de las redes por conteo, bajo el uso de la modularity.
La modularity presentada en la seccion 2.4.3, es una de las funciones mas populares para labusqueda de sub-comunidades en los grafos. Busca medir la fraccion de los arcos que se conectandentro de las comunidades del total de arcos, menos la fraccion esperada de los arcos, que se conec-tarıan dentro de las comunidades si estos fueran puestos al azar. Esta funcion permite determinarque particiones son mejores dentro de la misma red y puede ser resuelto como un problema deoptimizacion el cual, por ser del tipo NP-Completo, solo puede ser abordado a traves de heurısticas.
Sin embargo, la modularity tiene ciertas limitaciones las cuales fueron discutidas en la sec-cion 2.4.3.1. Una de estas limitaciones tiene que ver con que si existen dos comunidades lo sufi-cientemente pequenas medidas segun el numero de arcos con respecto al total de arcos de la redy ademas, estas comunidades estuviesen unidas debilmente a traves de algun arco, al aplicar unalgoritmo basado en la modularity este tenderıa a unir a estas dos comunidades en una sola. Pa-ra resolver en parte estas limitaciones diversos autores han propuesto mejoras a la funcion comola Max-Min Modularity propuesta por Chen [22]. Esta funcion y una implementacion heurısticapropuesta por el autor fue presentada en la seccion 3.4.2 y adicionalmente, se realizo una adapta-cion de esta funcion para utilizar redes con pesos (seccion 3.4.3). Los resultados de la aplicacionde la Max-Min Modularity con pesos se presentaron en la seccion 4.4.3 donde se demuestra que,utilizando redes con pesos, las particiones encontradas bajo esta nueva funcion, son mejores quelas encontradas por el metodo Max-Min Modularity. Sin embargo, las heurısticas, propuestas porChen [22], usadas para maximizar esta funcion no permiten aprovechar todas las ventajas de estamodificacion, por lo que es necesario buscar nuevas estrategias de optimizacion que aprovechen estasventajas.
Otra de las limitaciones de estos metodos es que, en general, buscan determinar particionesde la red y olvidan el hecho de que en la vida real un individuo puede pertenecer a mas de unacomunidad a la vez. En la seccion 3.4.4 se propuso una heurıstica simple que permite aprovechar losresultados de las particiones anteriores y mejorarlas midiendo la pertenencia de cada miembro a unau otra comunidad mediante la cantidad de arcos que se enlazaran con estas, formando comunidadesde miembros superpuestos. Se compararon los resultados obtenidos de las particiones por el metodode Louvain y las comunidades superpuestas en la seccion 4.4.4 donde se concluye, utilizando comomedida una adaptacion de la modularity para este tipo de problemas, que se mejoran los resultadospara todas las redes, encontrando comunidades mas cohesionadas.
En la seccion 4.5.1 se estudio como afecta el metodo de busqueda de sub-comunidades enlas particiones encontradas en base a la ecuacion 4.4. Los resultados muestran que en general se
87

Capıtulo 5. Conclusiones y Trabajo Futuro
mantiene en promedio un 75, 6 % de las particiones encontradas entre los diferentes metodos paralas mismas redes. Esto senala que existe un nucleo de los grupos que se mantiene entre los metodos.Se aprecia que el valor promedio es mayor en las redes con filtro, en todos los casos, con un 77, 4 %frente a las redes por conteo que alcanzan en promedio un 72, 2 %. Esto senala que las comunidadesencontradas en las redes filtadas son, en promedio, mas regulares.
Para comparar las composiciones entre las distintas redes sobre un mismo algoritmo, seutilizo una variacion de la ecuacion 4.4 presentada en la seccion 4.5.2. El objetivo es verificar si lasredes filtradas solo permiten encontrar comunidades mas granulares, es decir, que formen parte ensu totalidad de otras comunidades mas grandes en las redes de conteo, o si existe un alto porcentajede los usuarios no importando la granularidad, que son clasificados en grupos diferentes, lo quesignificarıa que se esta descubriendo nueva informacion en la red. Los resultados senalan que enpromedio los metodos sobre las redes filtradas permiten encontrar un 30 % de nodos que pertenecena otras comunidades, lo que indica que efectivamente se descubre nueva informacion.
Para estudiar las diferencias del contenido semantico de las comunidades encontradas sobrelas distintas configuraciones de redes se comparo manualmente los post de los miembros de un grupode cada tipo de red utilizando la ecuacion 4.6 que permitio medir el porcentaje de temas comunes quetiene un miembro con el resto de los usuarios de la comunidad. Los resultados fueron presentados enla seccion 4.7 y senalan que los miembros de una comunidad sobre una red de conteo comparten enpromedio un 19, 7 % de similitud en el contenido de sus post, en tanto que una comunidad sobre lasredes filtradas poseen valores de un 27, 8 % para el caso de LDA y un 53 % para el caso de CB. Estoindica que las redes filtradas, para el caso de este experimento, permiten encontrar comunidadesmas cohesionadas en terminos de los temas compartidos en sus post. Sin embargo este estudio espreliminar y se requiere extenderlo a todas las comunidades de un periodo.
5.4. Trabajo Futuro
Este trabajo representa un punto de inicio para futuras investigaciones relacionadas con eluso de redes semanticas para la busqueda y caracterizacion de sub-grupos en las redes sociales. Enesta seccion se abordaran los diferentes extensiones posibles del trabajo realizado.
5.4.1. Construccion de redes
La formacion de las redes es un punto fundamental para la busqueda de sub-estructuras ydependera muchas veces de lo que se requiera, el tipo de red a usar o el parametro de corte utilizado.Si bien, se propusieron diferentes parametros de corte, es necesario estudiar en profundidad comoestos afectan el numero de nodos aislados que se producen, las comunidades encontradas, la densidadde la red, entre otros factores para mejorar los resultados obtenidos.
88

Capıtulo 5. Conclusiones y Trabajo Futuro
Adicionalmente se puede explorar en el uso de redes construidas aprovechando las ventajasde las comparaciones semanticas, por ejemplo, construir redes en que los enlaces refleje el maximo,el promedio, o alguna funcion que mida los niveles de discusion entre los miembros. Estas redes soloson posibles de crear a traves de los filtros semanticos. Siguiendo esta misma idea, para el estudiode ciertos aspectos de SNA se utilizan grafos en los cuales sus arcos solo reflejan relaciones binarias.En la ecuacion 3.13 se presento una variacion para la construccion de las redes en la cual se puedeaumentar el parametro θ de tal forma trasformar redes con pesos en redes binarias aprovechando lasventajas de las redes semanticas. Se debe investigar cual es el nivel optimo de corte para mantenerla informacion relevante en la red.
Si bien, en la seccion 3.3.4 se describio como construir redes enfocadas solo en algunos topicoso conceptos no se ahondo mayormente en la busqueda de comunidades con una tematica especıfica.En una futura investigacion se podrıa abordar este problema permitiendo agrupar miembros segunciertos intereses particulares de estudio. Finalmente la metodologıa permite utilizar diferentes estra-tegias para la reduccion del contenido en los post. En el futuro se podrıa agregar al analisis el uso,por ejemplo, de otras implementaciones de modelos topicos que permitan mejorar el entendimientosemantico de la red, o en el caso de LDA estudiar cual es el numero optimo de topicos para quecada uno de ellos tenga un significado y sea de utilidad para caracterizar adecuadamente la red. Sibien, en esta tesis se utilizo un numero fijo de conceptos, se puede investigar como en diferentesredes se consiguen mejores resultados variando el numero de estos.
5.4.2. Algoritmos de busqueda de sub-comunidades
En la seccion 3.4.3 se propuso una mejora de la funcion de Max-Min Modularity presentadoen la seccion 3.4.2 para su uso con pesos. Si bien, entre ambos metodos se pudo determinar mejorasen terminos de comunidades encontradas, no se pudo determinar una marcada diferencia frente alas encontradas por el metodo de Louvain. Esto se debe a que la heurıstica propuesta por Chen [22]para la Max-Min Modularity tiene comparativamente un peor desempeno optimizando la mismafuncion que la heurıstica de Louvain propuesta por Blondel et al.[16]. Para un futuro analisis debiesenutilizarse adaptaciones de los mejores metodos heurısticos o explorar en el uso de otras herramientasde optimizacion sobre esta nueva funcion.
En la seccion 3.4.4 se presento una heurıstica simple que permite mejorar las particionestransformandolas en comunidades superpuestas como ocurre en la vida real. Para esto utiliza unafuncion de pertenencia basada en los arcos existentes de cada usuario a las diferentes comunidades. Sibien, como se senala en la seccion 4.4.4 los resultados muestran la efectividad del metodo, se podrıaadaptar la funcion de pertenencias para que utilice la misma filosofıa que la Max-Min Modularity, esdecir, que la funcion de pertenencia penalice el hecho de que los nodos se encuentren desconectadosde un gran numero de usuarios dela comunidad candidata de pertenencia.
89

Capıtulo 5. Conclusiones y Trabajo Futuro
5.4.3. Estudio de la evolucion de las comunidades y sus intereses
En el trabajo realizado por Rıos et al.[90] se presenta un estudio de la evolucion del propositode la comunidad como un todo. Basados en esta misma idea se puede estudiar como evolucionan lassub-comunidades dentro de una red social mediante el uso de la funcion utilizada en la seccion 4.5para conocer cual es el nucleo de miembros del grupo que se mantiene, cuales ingresan y cuales salende cada uno o que comunidades se fusionan o dividen. Una vez determinada las comunidades sepuede estudiar como en cada una de ellas varıan los intereses con el tiempo y como estos influyen enel proceso de emigracion o entrada de nuevos miembros, a traves del uso de los topicos o conceptos.
5.4.4. Caracterizacion mediante relaciones
En la seccion 3.5 se presento una estrategia para la caracterizacion de las comunidades pormedio de la suma de los puntajes de los post efectuados por los usuarios que componen dicha comu-nidad. Los resultados fueron presentados en la seccion 4.6. Si bien, el metodo permite caracterizaradecuadamente a los individuos, y con esto, los temas de interes de las comunidades, el estudiose podrıa extender a la comprension de los temas especıficos hablados entre los miembros de lascomunidades eliminando los puntajes de los post realizados con usuarios de otras comunidades. Estopermite entender a la comunidad no como un conjunto de usuarios con intereses relacionados, sinomas bien como un conjunto de relaciones de interes. Esta forma de caracterizar a los grupos podrıaser de gran utilidad a la hora de describir y entender, por ejemplo, a las comunidades superpuestas.
90

Capıtulo 5. Conclusiones y Trabajo Futuro
Workshops
Los resultados de esta tesis fueron presentados con el apoyo de Fondecyt de Iniciacion “Se-mantic Web Mining Techniques to Study Enhancement of Virtual Communities” Cod: 11090188.Ademas este trabajo no podrıa haber sido posible sin Plexilandia, por lo tanto, quisiera agradecera la comunidad de Plexilandia. Especialmente a don Jose Ignacio Santa-Cruz, quien ha entrega-do siempre informacion fidedigna, y ademas, agradecer sus importantes observaciones respecto alfuncionamiento de una comunidad.
[1] Lautaro Cuadra, Sebastian A. Rıos, G. L’Huillier. “Enhancing Community Discovery andCharacterization in VCoP using Topic Models”. Proceedings of the Web Intelligence &Communities (WI&C) workshop on the links between Web Intelligence technologies and (virtual)communities. 2011 Lyon, France.
91

REFERENCIAS
[1] Hector Alvarez, Sebastian Rıos, Felipe Aguilera, Eduardo Merlo, and Luis Guerrero. En-hancing social network analysis with a concept-based text mining approach to discover keymembers on a virtual community of practice. In Rossitza Setchi, Ivan Jordanov, Robert How-lett, and Lakhmi Jain, editors, Knowledge-Based and Intelligent Information and EngineeringSystems, volume 6277 of Lecture Notes in Computer Science, pages 591–600. Springer Berlin/ Heidelberg, 2010.
[2] Hector Alvarez. Deteccion de miembros clave en una comunidad virtual de practica medianteanalisis de redes sociales y minerıa de datos avanzada. Master’s thesis, Universidad de Chile,2010.
[3] Xavier Amatriain, Neal Lathia, Josep M. Pujol, Haewoon Kwak, and Nuria Oliver. Thewisdom of the few: a collaborative filtering approach based on expert opinions from the web.In Proceedings of the 32nd international ACM SIGIR conference on Research and developmentin information retrieval, SIGIR ’09, pages 532–539, New York, NY, USA, 2009. ACM.
[4] Gary Anthes. Topic models vs. unstructured data. Communications of the ACM, 53(12):1618,December 2010.
[5] Lars Backstrom, Dan Huttenlocher, Jon Kleinberg, and Xiangyang Lan. Group formation inlarge social networks: membership, growth, and evolution. In Proceedings of the 12th ACMSIGKDD international conference on Knowledge discovery and data mining, KDD ’06, pages44–54, New York, NY, USA, 2006. ACM.
[6] Ricardo Baeza-Yates and Berthier Ribeiro-Neto. Modern Information Retrieval. AddisonWesley, 1st edition, May 1999.
[7] J. A. Barnes. Class and Committees in a Norwegian Island Parish. Human Relations, 7(1):39–58, February 1954.
[8] Mathieu Bastian, Sebastien Heymann, and Mathieu Jacomy. Gephi: An open source softwarefor exploring and manipulating networks. International AAAI Conference on Weblogs andSocial Media, 2009.
92

REFERENCIAS
[9] Jeffrey Baumes, Mark K. Goldberg, Mukkai S. Krishnamoorthy, Malik Magdon-Ismail, andNathan Preston. Finding communities by clustering a graph into overlapping subgraphs. InNuno Guimaraes and Pedro T. Isaıas, editors, IADIS AC, pages 97–104. IADIS, 2005.
[10] Jeffrey Baumes, Mark K. Goldberg, and Malik Magdon-Ismail. Efficient identification ofoverlapping communities. In Paul B. Kantor, Gheorghe Muresan, Fred Roberts, Daniel DajunZeng, Fei-Yue Wang, Hsinchun Chen, and Ralph C. Merkle, editors, ISI, volume 3495 ofLecture Notes in Computer Science, pages 27–36. Springer, 2005.
[11] Tanya Y. Berger-Wolf and Jared Saia. A framework for analysis of dynamic social networks.In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discoveryand data mining, KDD ’06, pages 523–528, New York, NY, USA, 2006. ACM.
[12] Dimitri P. Bertsekas. Network Optimization: Continuous and Discrete Models. Athena Scien-tific, 1998.
[13] Indrajit Bhattacharya and Lise Getoor. Collective entity resolution in relational data. ACMTrans. Knowl. Discov. Data, 1, March 2007.
[14] Istvan Bıro, David Siklosi, Jacint Szabo, and Andras A. Benczur. Linked latent dirichlet allo-cation in web spam filtering. In Proceedings of the 5th International Workshop on AdversarialInformation Retrieval on the Web, AIRWeb ’09, pages 37–40, New York, NY, USA, 2009.ACM.
[15] David M. Blei, Andrew Y. Ng, and Michael I. Jordan. Latent dirichlet allocation. Journal ofMachine Learning Research, 3:993–1022, January 2003.
[16] V.D. Blondel, J.L. Guillaume, R. Lambiotte, and E.L.J.S. Mech. Fast unfolding of communi-ties in large networks. J. Stat. Mech, page P10008, 2008.
[17] Danah Boyd and Nicole B. Ellison. Social network sites: Definition, history, and scholarship.Journal of Computer-Mediated Communication, 13(1-2), November 2007.
[18] Ulrik Brandes, Daniel Delling, Marco Gaertler, Robert Gorke, Martin Hoefer, Zoran Nikoloski,and Dorothea Wagner. On modularity – np-completeness and beyond, 2006.
[19] Deepayan Chakrabarti and Christos Faloutsos. Graph mining: Laws, generators, and algo-rithms. ACM Comput. Surv., 38(1), 2006.
[20] Soumen Chakrabarti, Byron Dom, and Piotr Indyk. Enhanced hypertext categorization usinghyperlinks. SIGMOD Rec., 27:307–318, June 1998.
[21] Jiyang Chen. Community Mining - Discovering Communities in Social Networks. Degree ofdoctor of philosophy, University of Alberta, 2010.
[22] Jiyang Chen, Osmar R. Zaıane, and Randy Goebel. Detecting communities in social networksusing max-min modularity. In SDM, pages 978–989. SIAM, 2009.
[23] Aaron Clauset. Finding local community structure in networks. Physical Review E (Statistical,Nonlinear, and Soft Matter Physics), 72(2):026132, 2005.
93

REFERENCIAS
[24] Aaron Clauset, M. E. J. Newman, , and Cristopher Moore. Finding community structure invery large networks. Physical Review E, pages 1– 6, 2004.
[25] A. Culotta, R. Bekkerman, and A.McCallum. Extracting social networks and contact infor-mation from email and the Web. In Proc. Conference on Email and Anti-Spam (CEAS),Mountain View, USA, July 2004.
[26] Leon Danon, Albert Dıaz-Guilera, and Alex Arenas. The effect of size heterogeneity on com-munity identification in complex networks. Journal of Statistical Mechanics, 2006(11):P11010,2006.
[27] Wouter de Nooy, Andrej Mrvar, and Vladimir Batagelj. Exploratory social network analysiswith pajek. pages 1–362, Aug 2005.
[28] Chris H. Q. Ding, Xiaofeng He, Hongyuan Zha, Ming Gu, and Horst D. Simon. A min-maxcut algorithm for graph partitioning and data clustering. In Proceedings of the 2001 IEEEInternational Conference on Data Mining, ICDM ’01, pages 107–114, Washington, DC, USA,2001. IEEE Computer Society.
[29] Xin Dong, Alon Halevy, and Jayant Madhavan. Reference reconciliation in complex informa-tion spaces. In Proceedings of the 2005 ACM SIGMOD international conference on Manage-ment of data, SIGMOD ’05, pages 85–96, New York, NY, USA, 2005. ACM.
[30] J. Duch and A. Arenas. Community detection in complex networks using extremal optimiza-tion. Physical Review E, 72:027104, 2005.
[31] J. C. Dunn. A fuzzy relative of the isodata process and its use in detecting compact well-separated clusters. Journal of Cybernetics, 3(3):32–57, 1973.
[32] David A. Easley and Jon M. Kleinberg. Networks, Crowds, and Markets - Reasoning About aHighly Connected World. Cambridge University Press, 2010.
[33] Illes Farkas, Daniel Abel1, Gergely Palla1, and Tamas Vicse. Weighted network modules. NewJournal of Physics, 9(6):180, 2007.
[34] Usama M. Fayyad, Gregory Piatetsky-Shapiro, and Padhraic Smyth. Advances in knowledgediscovery and data mining. chapter From data mining to knowledge discovery: an overview,pages 1–34. American Association for Artificial Intelligence, Menlo Park, CA, USA, 1996.
[35] Ronen Feldman and James Sanger. The Text Mining Handbook: Advanced Approaches inAnalyzing Unstructured Data. Cambridge University Press, 2007.
[36] Gary William Flake, Steve Lawrence, and C. Lee Giles. Efficient identification of web com-munities. In In Sixth ACM SIGKDD International Conference on Knowledge Discovery andData Mining, pages 150–160. ACM Press, 2000.
[37] GW Flake, S. Lawrence, CL Giles, and FM Coetzee. Self-organization and identification ofweb communities. Computer, 35(3):66–70, 2002.
94

REFERENCIAS
[38] Robert W. Floyd. Algorithm 97: Shortest path. Commun. ACM, 5:345–, June 1962.
[39] L. R. Ford and D. R. Fulkerson. Maximal flow through a network. Canadian Journal ofMathematics, 8:399–404, 1956.
[40] S. Fortunato and M. Barthelemy. Resolution limit in community detection. Proceedings ofthe National Academy of Sciences, 104(1):36, 2007.
[41] Santo Fortunato. Community detection in graphs. Physics Reports, 486:75–174, January 2010.
[42] N Friedkin. Theoretical foundations for centrality measures. The American Journal of Socio-logy, January 1991.
[43] Lise Getoor and Christopher P. Diehl. Link mining: a survey. SIGKDD Explor. Newsl.,7(2):3–12, 2005.
[44] M Girvan and M. E. J. Newman. Community structure in social and biological networks.Proc Natl Acad Sci USA, 99(12):7821–6, June 2002.
[45] Benjamin H. Good, Yves A. de Montjoye, and Aaron Clauset. Performance of modularitymaximization in practical contexts. Physical Review E, 81(4):046106+, April 2010.
[46] M.S. Granovetter. The strength of weak ties. The American Journal of Sociology, 78(6):1360–1380, 1973.
[47] Steve Gregory. An algorithm to find overlapping community structure in networks. In Pro-ceedings of the 11th European Conference on Principles and Practice of Knowledge Discoveryin Databases (PKDD 2007), pages 91–102. Springer-Verlag, 2007.
[48] Steve Gregory. A fast algorithm to find overlapping communities in networks. In Proceedingsof the 2008 European Conference on Machine Learning and Knowledge Discovery in Databases- Part I, ECML PKDD ’08, pages 408–423, Berlin, Heidelberg, 2008. Springer-Verlag.
[49] T Griffiths. Finding scientific topics. Number 101, pages 5228–5235, 2004.
[50] Roger Guimera, Marta Sales-Pardo, and Luis A. N. Amaral. Modularity from fluctuations inrandom graphs and complex networks. PHYS.REV.E, 70:025101, 2004.
[51] Trevor Hastie, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning.Springer Series in Statistics. Springer New York Inc., New York, NY, USA, 2001.
[52] Marti A. Hearst. Untangling text data mining. In Proceedings of the 37th annual meeting ofthe Association for Computational Linguistics on Computational Linguistics, ACL ’99, pages3–10, Stroudsburg, PA, USA, 1999. Association for Computational Linguistics.
[53] F. Heider. Attitudes and cognitive organization. Journal of Psychology, 21(2):107–112, 1946.
[54] Thomas Hofmann. Probabilistic latent semantic indexing. In Hearst [52], pages 50–57.
[55] B. W. Kernighan and Shen Lin. An efficient heuristic procedure for partitioning graphs. BellSystems Technical Journal, 49:291–307, 1970.
95

REFERENCIAS
[56] Jon M. Kleinberg. Authoritative sources in a hyperlinked environment. J. ACM, 46:604–632,September 1999.
[57] Jan H. Kroeze, Machdel C. Matthee, and Theo J. D. Bothma. Differentiating data- andtext-mining terminology. In Proceedings of the 2003 annual research conference of the SouthAfrican institute of computer scientists and information technologists on Enablement throughtechnology, SAICSIT ’03, pages 93–101, , Republic of South Africa, 2003. South African Ins-titute for Computer Scientists and Information Technologists.
[58] M Kuramochi and G. Karypis. Frequent subgraph discovery. In IEEE International Confe-rence on Data Mining, November 2001.
[59] J Lave and Etienne Wenger. Situated learning: Legitimate peripheral participation.books.google.com, Jan 1991.
[60] Jure Leskovec. Dynamics of large networks. PhD thesis, Pittsburgh, PA, USA, 2008.AAI3340652.
[61] Kurt Lewin. Principles of Topological Psychology. McGraw-Hill, 1936.
[62] Gaston L’Huillier. Clasificacion de phishing utilizando minerıa de datos adversarial y juegoscon informacion incompleta. Master’s thesis, Universidad de Chile, 2010.
[63] Gaston L’Huillier, Sebastian A. Rıos, Hector Alvarez, and Felipe Aguilera. Topic-based socialnetwork analysis for virtual communities of interests in the dark web. In ACM SIGKDDWorkshop on Intelligence and Security Informatics, ISI-KDD ’10, pages 9:1–9:9, New York,NY, USA, 2010. ACM.
[64] David Liben-Nowell and Jon Kleinberg. The link-prediction problem for social networks. J.Am. Soc. Inf. Sci. Technol., 58:1019–1031, May 2007.
[65] S Loh, J de Oliveira, and M Gameiro. Knowledge discovery in texts for constructing decisionsupport systems. Applied Intelligence, Dec 2003.
[66] Feng Luo, James Z. Wang, and Eric Promislow. Exploring local community structures in largenetworks. In Proceedings of the 2006 IEEE/WIC/ACM International Conference on WebIntelligence, WI ’06, pages 233–239, Washington, DC, USA, 2006. IEEE Computer Society.
[67] J. B. MacQueen. Some methods for classification and analysis of multivariate observations. InL. M. Le Cam and J. Neyman, editors, Proc. of the fifth Berkeley Symposium on MathematicalStatistics and Probability, volume 1, pages 281–297. University of California Press, 1967.
[68] A. McCallum, A. Corrada-Emmanuel, and X. Wang. Topic and role discovery in social net-works. In Proceedings of the 19th international joint conference on Artificial intelligence,pages 786–791. Citeseer, 2005.
[69] A McCallum, X Wang, and A Corrada-Emmanuel. Topic and role discovery in social networkswith experiments on enron and academic email. Journal of Artificial . . . , Jan 2007.
96

REFERENCIAS
[70] Qiaozhu Mei and ChengXiang Zhai. A mixture model for contextual text mining. In TinaEliassi-Rad, Lyle H. Ungar, Mark Craven, and Dimitrios Gunopulos, editors, SIGKDD, pages649–655. ACM, 2006.
[71] Eduardo Merlo. Identificacion de comunidades de copia en instituciones educacionales me-diante el analisis de redes sociales sobre documentos digitales, 2010.
[72] J.L. Moreno. Who shall survive? : a new approach to the problem of Human Interrelations,volume 58 of Nervous and mental disease monograph series. Nervous and Mental DiseasePubl., Washington, 1934.
[73] Katarzyna Musia l, PrzemysKazienko, and Piotr Brodka. User position measures in socialnetworks. In Proceedings of the 3rd Workshop on Social Network Mining and Analysis, SNA-KDD ’09, pages 6:1–6:9, New York, NY, USA, 2009. ACM.
[74] H. Nakanishi, I. B. Turksen, and M. Sugeno. A review and comparison of six reasoningmethods. Fuzzy Sets Syst., 57:257–294, August 1993.
[75] Tamas Nepusz, Andrea Petroczi, Laszlo Negyessy, and Fulop Bazso. Fuzzy communities andthe concept of bridgeness in complex networks. E-print, 2007.
[76] M. E. J. Newman and M. Girvan. Finding and evaluating community structure in networks.Physical Review E, 69(2):026113, February 2004. PT: J; PN: Part 2; PG: 15.
[77] M.E.J. Newman. Fast algorithm for detecting community structure in networks. PhysicalReview E, 69, September 2003.
[78] Andrew Y. Ng, Michael I. Jordan, and Yair Weiss. On spectral clustering: Analysis and analgorithm. In Advances in Neural Information Processing Systems 14, pages 849–856. MITPress, 2001.
[79] V. Nicosia, G. Mangioni, V. Carchiolo, and M. Malgeri. Extending the definition of modu-larity to directed graphs with overlapping communities. Journal of Statistical Mechanics,2009(3):P03024, 2009.
[80] Joshua O’Madadhain, Jon Hutchins, and Padhraic Smyth. Prediction and ranking algorithmsfor event-based network data. SIGKDD Explor. Newsl., 7(2):23–30, December 2005.
[81] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pagerank citationranking: Bringing order to the web. Technical Report 1999-66, Stanford InfoLab, November1999. Previous number = SIDL-WP-1999-0120.
[82] Gergely Palla, Albert-Laszlo Barabasi, and Tamas Vicsek. Quantifying social group evolution.Nature, 446(7136):664–667, April 2007.
[83] Gergely Palla, Imre Derenyi, Illes Farkas, and Tamas Vicsek. Uncovering the overlappingcommunity structure of complex networks in nature and society. Nature, 435(7043):814–818,June 2005.
97

REFERENCIAS
[84] Gergely Palla, Illes J Farkas, Peter Pollner, Imre Derenyi, and Tamas Vicsek. Directed networkmodules. New Journal of Physics, 9(6):186, 2007.
[85] Nishith Pathak, Colin Delong, Arindam Banerjee, and Kendrick Erickson. Social topic modelsfor community extraction. Aug 2008.
[86] X H Phang and CT Nguyen. Gibbslda++, 2008.
[87] Alex Pothen. Graph partitioning algorithms with applications to scientific computing. Tech-nical report, Norfolk, VA, USA, 1997.
[88] Alex Pothen, Horst D. Simon, and Kan-Pu Liou. Partitioning sparse matrices with eigenvec-tors of graphs. SIAM J. Matrix Anal. Appl., 11:430–452, May 1990.
[89] Sebastian A Rıos. A study on web mining techniques for off-line enhancements of web sites.Ph.D Thesis, page 231, Sep 2007.
[90] Sebastian A Rıos, F Aguilera, and L Guerrero. Virtual communities of practice’s purposeevolution analysis using a concept-based mining approach. Knowledge-Based and IntelligentInformation and Engineering Systems, 2:480–489, 2009.
[91] Jianhua Ruan and Weixiong Zhang. An efficient spectral algorithm for network communitydiscovery and its applications to biological and social networks. In Proceedings of the 2007Seventh IEEE International Conference on Data Mining, pages 643–648, Washington, DC,USA, 2007. IEEE Computer Society.
[92] Jianhua Ruan and Weixiong Zhang. Identifying network communities with a high resolution.Physical Review E, 77(016104):1–12, 2008.
[93] G. Salton, A. Wong, and C. S. Yang. A vector space model for automatic indexing. Commun.ACM, 18:613–620, November 1975.
[94] J. Scott. Social network analysis: A handbook. Sage, 2000.
[95] Mark Steyvers, Padhraic Smyth, Michal Rosen-Zvi, and Thomas Griffiths. Probabilisticauthor-topic models for information discovery. In Proceedings of the tenth ACM SIGKDDinternational conference on Knowledge discovery and data mining, KDD ’04, pages 306–315,New York, NY, USA, 2004. ACM.
[96] Jimeng Sun, Christos Faloutsos, Spiros Papadimitriou, and Philip S. Yu. Graphscope:parameter-free mining of large time-evolving graphs. In Proceedings of the 13th ACM SIGKDDinternational conference on Knowledge discovery and data mining, KDD ’07, pages 687–696,New York, NY, USA, 2007. ACM.
[97] Chayant Tantipathananandh, Tanya Berger-Wolf, and David Kempe. A framework for com-munity identification in dynamic social networks. In KDD ’07: Proceedings of the 13th ACMSIGKDD international conference on Knowledge discovery and data mining, pages 717–726,New York, NY, USA, 2007. ACM.
98

REFERENCIAS
[98] Ken Wakita and Toshiyuki Tsurumi. Finding community structure in mega-scale social net-works: [extended abstract]. In Proceedings of the 16th international conference on World WideWeb, WWW ’07, pages 1275–1276, New York, NY, USA, 2007. ACM.
[99] S Wasserman and K Faust. Social Network Analysis: Methods and Applications. Jan 1994.
[100] B. Wellman and M. Gulia. Virtual communities as communities: Net surfers don’trifide alone.Communities in cyberspace, pages 167–194, 1999.
[101] Etienne Wenger, R McDermott, and W Snyder. Cultivating communities of practice: A guideto managing knowledge. Harvard Business School Press, 2002.
[102] Dongshan Xing and Mark Girolami. Employing latent dirichlet allocation for fraud detectionin telecommunications. Pattern Recognition Letters, Vol. 28(13):1727–1734, 2007.
[103] Rui Xu and II Wunsch. Survey of clustering algorithms. Neural Networks, IEEE Transactionson, 16(3):645–678, 2005.
[104] K Yelupula and Srini Ramaswamy. Social network analysis for email classification. pages469–474, 2008.
[105] Shihua Zhang, Rui-Sheng Wang, and Xiang-Sun Zhang. Identification of overlapping com-munity structure in complex networks using fuzzy c-means clustering. Physica A: StatisticalMechanics and its Applications, 374(1):483–490, 2007.
99

Apendices
100

Apendice A
Resultados de la Metodologıa deBusqueda de Sub-comunidades
A.1. Detalles de los Topicos Encontrados
Cuadro A.1: Topicos encontrados e interpretados 1-20
N◦ Topico Interpretacion ¿Activo?
Topico 01 Distorsion SiTopico 02 No es util NoTopico 03 Impresion de Placas para efectos SiTopico 04 Preguntas clasicas usuarios nuevos NoTopico 05 Solicitudes de ayuda NoTopico 06 Tecnicas de soldado (de efectos y amplificadores) SiTopico 07 Conexion de cables/cableado SiTopico 08 Especıficamente: por favor redacten bien NoTopico 09 Conexion y construccion de cajas SiTopico 10 No es util NoTopico 11 Explicacion de fallas SiTopico 12 Felicitaciones varias NoTopico 13 Maderas para construccion de guitarras SiTopico 14 Tiendas de venta de insumos electronicos SiTopico 15 Referencias a libros y textos en ingles SiTopico 16 Modificaciones al Amplificador JCM Marshall modelo slash SiTopico 17 Componentes electronicos ( enfasis en condensadores) SiTopico 18 Amplificadores a tubo SiTopico 19 Conversacion en base a referencias de posts pasados NoTopico 20 No es util No
101

Appendix A.
Cuadro A.2: Topicos encontrados e interpretados 21-50
N◦ Topico Interpretacion ¿Activo?
Topico 21 Concepto de marcas de artesanos SiTopico 22 No es util NoTopico 23 Sitio web y foro plexilandia NoTopico 24 Imagenes y vıdeos del avance de lo que se construye. SiTopico 25 Efectos de modulacion SiTopico 26 Referencias de lugares donde comprar SiTopico 27 Diferencias de sonido dependiendo de diversos factores SiTopico 28 No es util NoTopico 29 Proceso de deteccion de fallas SiTopico 30 Ajuste de transistores SiTopico 31 Apreciacion del sonido de bandas SiTopico 32 Transformadores para amplificadores a tubo SiTopico 33 Rectificador en amplificadores a tubo SiTopico 34 No es util (Conversaciones) NoTopico 35 Muchas palabras mal escritas NoTopico 36 Normas y buena convivencia en plexilandia NoTopico 37 Cajas para efectos y chasis para amplificadores SiTopico 38 Esquemas de efectos SiTopico 39 Distintos efectos SiTopico 40 Interruptores para efectos SiTopico 41 No es util NoTopico 42 Plexijunta NoTopico 43 No es util NoTopico 44 Solicitudes de compra y venta de componentes SiTopico 45 Modelos y marcas de guitarras SiTopico 46 Etapas de distorsion SiTopico 47 Software y hardware para aplicaciones de sonido SiTopico 48 Opinion y recomendacion de marcas vs precio SiTopico 49 Problema de acople en efectos de distorsion SiTopico 50 Aislacion acustica Si
102

Appendix A.
A.2. Sub-comunidades Encontradas
Cuadro A.3: Resultados Comunidades encontradasSub-comunidades encontradas
Metodos Enlace
Louvain http://www.cec.uchile.cl/~lcuadra/Tesis/CsvUD.zip
Max-Min Modularity http://www.cec.uchile.cl/~lcuadra/Tesis/CsvQMMUD.zip
Max-Min Modularity con Pesos http://www.cec.uchile.cl/~lcuadra/Tesis/CsvQMMMWUD.zip
Superposicion sobre Louvain http://www.cec.uchile.cl/~lcuadra/Tesis/CsvOvUD.zip
103



![#@cf}+jflif{s k|ltj]bg @)&%–)&^](https://static.fdokumen.com/doc/165x107/6331ac16ba79697da50fe7f4/cfjflifs-kltjbg-.jpg)
















