
BAB I STATISTIKA
33
BAB I STATISTIKA A. Pengertian Statistika Statistika adalah suatu ilmu pemecahan masalah dan penarikan kesimpulan dengan cara mengumpulkan dan menganalisa data. Berdasarkan kebutuhan terhadap pengelolaan data, statistika dibagi menjadi: 1. Statistika deskriptif, yaitu segala informasi yang bias menggambarkan data yang diperoleh. 2. Statistika inferensi, yaitu statistika yang diperoleh dari data yang ada dan digunakan untuk menarik kesimpulan tentang populasi objek yang lebih besar. Dalam statistic, data menurut jenisnya dapat dibagi menjadi dua yaitu data kuantitatif dan data kualitatif: 1. Data Kuantitatif, adalah data yang diperoleh dari hasil mengukur atau menghitung. 2. Data Kualitatif, adalah data yang menyatakan keadaan atau karakkteristik yang dimiliki objek yang diteliti. Data ini juga biasa disebut sebagai data kategori. B. Penyajian Data 1. Penyajian Data dalam Bentuk Tabel (Daftar) a. Distribusi frekuensi tunggal
-
Upload
universitasnegerimakassar -
Category
Documents
-
view
7 -
download
0
Transcript of BAB I STATISTIKA

BAB I
STATISTIKA
A. Pengertian Statistika
Statistika adalah suatu ilmu pemecahan masalah
dan penarikan kesimpulan dengan cara mengumpulkan
dan menganalisa data. Berdasarkan kebutuhan terhadap
pengelolaan data, statistika dibagi menjadi:
1. Statistika deskriptif, yaitu segala informasi yang
bias menggambarkan data yang diperoleh.
2. Statistika inferensi, yaitu statistika yang
diperoleh dari data yang ada dan digunakan untuk
menarik kesimpulan tentang populasi objek yang
lebih besar.
Dalam statistic, data menurut jenisnya dapat
dibagi menjadi dua yaitu data kuantitatif dan data
kualitatif:
1. Data Kuantitatif, adalah data yang diperoleh dari
hasil mengukur atau menghitung.
2. Data Kualitatif, adalah data yang menyatakan
keadaan atau karakkteristik yang dimiliki objek
yang diteliti. Data ini juga biasa disebut sebagai
data kategori.
B. Penyajian Data
1. Penyajian Data dalam Bentuk Tabel (Daftar)
a. Distribusi frekuensi tunggal

Data tunggal seringkali dinyatakan dalam bentuk
daftar bilangan, namun kadangkala dinyatakan
dalam bentuk tabel distribusi frekuensi. Tabel
distribusi frekuensi tunggal merupakan cara
untuk menyusun data yang relatif sedikit.
Perhatikan contoh data berikut.
5, 4, 6, 7, 8, 8, 6, 4, 8, 6, 4, 6, 6, 7, 5, 5,
3, 4, 6, 6
8, 7, 8, 7, 5, 4, 9, 10, 5, 6, 7, 6, 4, 5, 7,
7, 4, 8, 7, 6Dari data di atas tidak tampak adanya pola yang
tertentu maka agar mudah dianalisis data tersebut
disajikan dalam tabel seperti di bawah ini
b. Distribusi frekuensi berkelompokTabel distribusi frekuensi bergolong biasa
digunakan untuk menyusun data yang memiliki
kuantitas yang besar dengan mengelompokkan ke dalam
interval-interval kelas yang sama panjang.
Perhatikan contoh data hasil nilai pengerjaan tugas
Matematika dari 40 siswa kelas XI berikut ini:

Tabel distribusi frekuensi bergolong dengan
langkah-langkah sebagai berikut:
1. Mengelompokkan ke dalam interval-interval kelas
yang sama panjang. Cara untuk menentukan
banyaknya kelas yaakni dengan aturan sturgess:
k=1+1,33lognDimana, k adalah banyaknya kelas dan n adalah
ukuran data.
2. Membuat turus (tally), untuk menentukan sebuah
nilai termasuk ke dalam kelas yang mana.
3. Menghitung banyaknya turus pada setiap kelas,
kemudian menuliskan banyaknya turus pada setiap
kelas sebagai frekuensi data kelas tersebut.
4. Ketiga langkah di atas direpresentasikan pada
tabel berikut ini:
2. Penyajian Data dalam Bentuk Diagram
a. Diagram Garis
Untuk menyajikan perkembangan data yang
kontinu, paling baik dengan menggunakan diagram
garis. Pada diagram garis sumbu X (sumbu

horizontal) biasanya digunakan untuk satuan
waktu, sedangkan sumbu Y digunakan untuk
frekuensi. Beberapa macam dari diagram garis
ialah:
a. Grafik Garis Berganda (Multiple Line Chart)
Grafik garis berganda adalah grafik yang
terdiri dari beberapa garis untuk
menggambarkan perkembangan beberapa hal atau
kejadian sekaligus.
b. Grafik Garis Komponen Berganda (Multiple
Component Line Chart)
Serupa dengan grafik berganda, akan tetapi
garis yang teratas atau terakhir
menggambarkan masing-masing komponen
c. Grafik Garis Persentase Komponen Berganda
(Multiple Percentage Component Line Chart)
Serupa dengan grafik garis komponen berganda,
hanya masing-masing komponen dinyatakan
sebagai persentase terhadap jumlah (total).
b. Diagram Lingkaran
Diagram lingkaran adalah penyajian data dengan
menggunakan sektor-sektor dalam suatu
lingkaran. Diagram ini sangat baik untuk
menunjukkan perbandingan antara objek yang satu
dengan objek yang lainnya serta terhadap
keseluruhan dalam suatu penyelidikan. Misalnya,
diagram lingkaran seperti Gambar 1.7
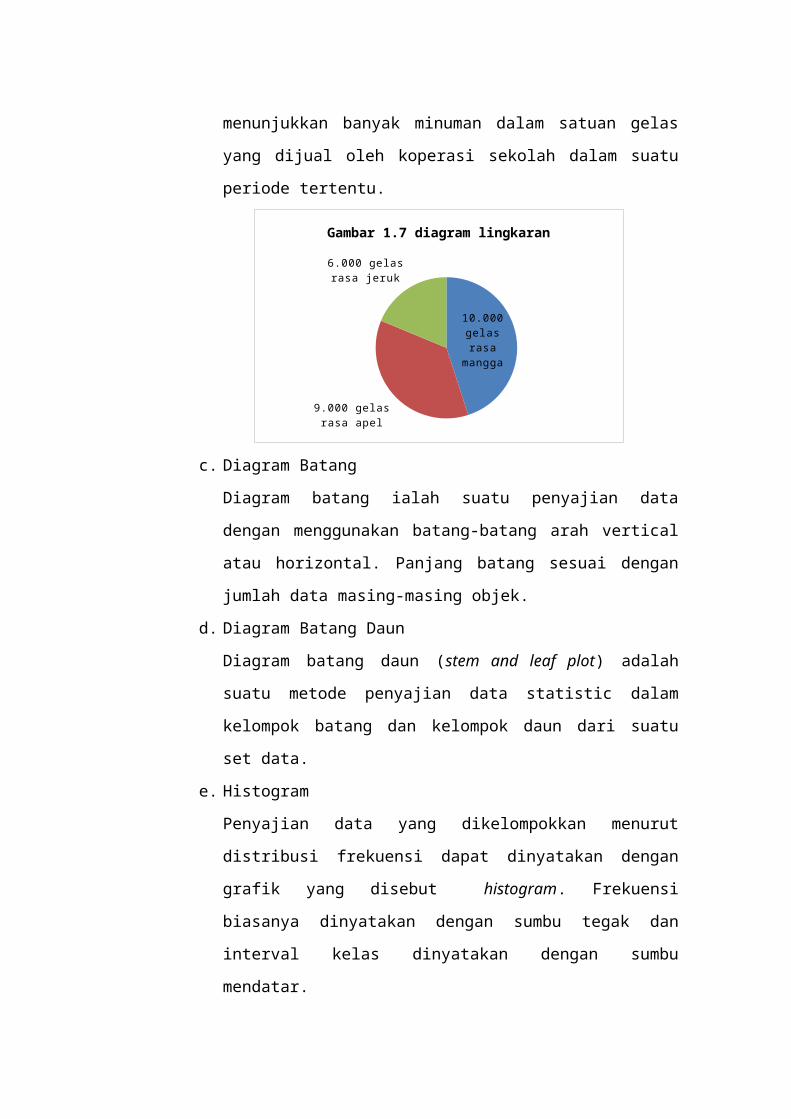
menunjukkan banyak minuman dalam satuan gelas
yang dijual oleh koperasi sekolah dalam suatu
periode tertentu.
10.000 gelas rasa
mangga
9.000 gelas rasa apel
6.000 gelas rasa jeruk
Gambar 1.7 diagram lingkaran
c. Diagram Batang
Diagram batang ialah suatu penyajian data
dengan menggunakan batang-batang arah vertical
atau horizontal. Panjang batang sesuai dengan
jumlah data masing-masing objek.
d. Diagram Batang Daun
Diagram batang daun (stem and leaf plot) adalah
suatu metode penyajian data statistic dalam
kelompok batang dan kelompok daun dari suatu
set data.
e. Histogram
Penyajian data yang dikelompokkan menurut
distribusi frekuensi dapat dinyatakan dengan
grafik yang disebut histogram. Frekuensi
biasanya dinyatakan dengan sumbu tegak dan
interval kelas dinyatakan dengan sumbu
mendatar.

1) Polygon FrekuensiBila titik-titik tengah dari tiap kotak di bagian
atas pada histogram saling dihubungkan, maka
akan diperoleh diagram yang bentuknya
menyerupai polygon (segibanyak), sehingga
diagram yang dihasilkan dinamakan polygon
frekuensi.
2) OgiveJika titik-titik yang membentuk polygon
frekuensi kumulatif kurang dari dihubungkan
dengan kurva mulus, maka terbentuk ogive positif.
Sedangkan jika titik-titik yang membentuk
polygon frekuensi kumulatif lebih dari
dihubungkan dengan kurva mulus, maka
terbentuk ogive negative.
C. Ukuran Pemusatan Kumpulan Data
Ukuran pemusatan serta penafsirannya suatu
rangkaian data adalah suatu nilai dalam rangkaian
data yang dapat mewakili rangkaian data tersebut.
Suatu rangkaian data biasanya mempunyai
kecenderungan untuk terkonsentrasi atau terpusat
pada nilai pemusatan ini. Ukuran statistik yang
dapat menjadi pusat dari rangkaian data dan memberi
gambaran singkat tentang data disebut ukuran pemusatan
data. Ukuran pemusatan data dapat digunakan untuk
menganalisis data lebih lanjut. Ukuran pemusatan

data terdiri dari tiga bagian, yaitu mean, median,
dan modus.
1. Rataan Hitung (Mean)
Rataan hitung seringkali disebut sebagai ukuran
pemusatan atau rata-rata hitung. Rataan hitung
juga dikenal dengan istilah mean dan diberi
lambangx .
a. Rataan Data Tunggal
Rataan dari sekumpulan data yang banyaknya n
adalah jumlah data dibagi dengan banyaknya
data. Rataan hitung (biasa disingkat dengan
rataan) data: x1,x2,x3,x4,…,xn didefinisikan
dengan:
x=x1+x2+x3+x4+…+xn
n
atau
x=∑i=1
nxi
n
b. Rataan dari data distribusi frekuensi
Apabila data disajikan dalam tabel distribusi
frekuensi maka rataan dirumuskan sebagai
berikut.
x=f1x1+f2x2+f3x3+…+fnxn
f1+f2+…+fn
atau

x=∑i=1
rfixi
∑i=1
rfi
Keterangan: fi = frekuensi untuk nilai xi
xi = data ke-i
c. Rataan Data Tunggal Dengan Rataan Sementara
Menghitung rataan suatu data kadang-kadang
tidak mudah dilakukan jika nilai datanya
merupakan bilangan-bilangan yang relatif rumit
seperti berikut.
23,424,525,626,526,727,828,229,932,3Untuk memudahkan perhitungan maka digunakanlah
rataan sementara yang merupakan dugaan kita.
Nilai dugaan tersebut sebaiknya yang terletak
di pusat data.
Rataan sebenarnya dinyatakan dengan rumus:
x=xs+∑i=1
n
(xi−xs )n =xs+
dn
Dimana xs= rataan sementara
xi=¿ data ke-i
n=¿ ukuran data
d. Rataan Data Berkelompok Dengan Menggunakan
Rataan Sementara
Dengan cara yang sama seperti menghitung rataan
dengan menggunakan rataan sementara pada data

tunggal, terlebih dahulu tentukan rataan yang
kita duga (rataan sementara).
Rataan sebenarnya dinyatakan dengan rumus:
x=xs+∑i=1
rfi.di
∑i=1
rfi
Keterangan:
x=¿ rataan
xi=¿ data ke-i
fi=¿ frekuensi dari xi
di=¿ xi - xs . (Simpangan data ke-i terhadap
rataan sementara)
∑i=1
rfi=n=¿ ukuran data
Adapun, sifat rataan sebagai tingkat kecenderungan
memusat ialah:
Kebaikan Kelemahan Mudah dihitung
Perhitungannya
melibatkan seluruh
data
Sangat peka terhadap
nilai data yang ekstrim
(terlalu besar atau
teralu kecil)
2. Modus
Modus dari suatu data adalah nilai (ukuran) yang
paling banyak muncul atau mempunyai frekuensi
tertinggi.

a. Modus Data Tunggal
Data yang mempunyai satu modus disebut unimodus,
yang mempunyai dua modus disebut bimodus, dan
yang mempunyai lebih dari dua modus disebut
multimodus.
b. Modus Data Berkelompok
Secara umum modus dapat ditentukan dengan rumus
berikut:
modus=L+c.d1
d1+d2Dimana L: tepi bawah kelas modusd1:selisih frekuensi kelas modus dengan
frekuensi kelas sebelumnya
d2: selisih frekuensi kelas modus dengan
frekuensi kelas sesudahnya
c:lebar kelasKebaikan dan kelemahan sifat modus sebagai suatu
ukuran kecenderungan memusat adalah sebagai
berikut:
Kebaikan Kelemahan Dapat memberi nilai data
yang paling sering
berulang atau muncul.
Mudah diketahui dari
data tanpa membuat
perhitungan.
Kadang kala
mempunyai lebih dari
satu modus.


3. Median
a. Median untuk data tunggal
Jika satu set data statistik disusun
berdasarkan urutannya, maka kita dapat
menentukan median atau nilai tengahnya. Median
membagi data menjadi dua bagian yang sama,
dimana 50% dari data mempunyai nilai sama atau
kurang dari median, sedangkan 50% lainnya
mempunyai nilai sama atau lebih dari median.
Simbol median Me. Untuk menentukan nilai Median
data tunggal dapat dilakukan dengan cara:
1) Mengurutkan data kemudian dicari nilai
tengah,
2) jika banyaknya data besar, setelah data
diurutkan, digunakan rumus:
Untuk n ganjil: Me=x12
(n+1)
Untuk n genap: Me=
xn2
+xn2
+1
2
Keterangan: xn2data pada urutan ke- n2 setelah
diurutkan.
b. Median untuk data bekelompok
Jika data yang tersedia merupakan data
berkelompok, artinya data itu dikelompokkan ke
dalam interval-interval kelas yang sama
panjang. Untuk mengetahui nilai mediannya dapat
ditentukan dengan rumus berikut ini:

Me=b2+c( 12 N−F
f )Keterangan: b2 = tepi bawah kelas median
c = lebar kelasN= banyaknya data
F= frekuensi kumulatif kurang dari
sebelum kelas median
f= frekuensi kelas median

D. Ukuran Letak Data
1. Kuartil
Kuartil merupakan datum yang membagi dua data
terurut menjadi seperempat-seperempat bagian.
Untuk membagi data menjadi empat bagian sama besar
memerlukan tiga sekat.
Q1 disebut kuartil pertama atau kuartil bawah.
Sebanyak 25% data bernilai lebih kecil atau
sama dengan Q1.
Q2 disebut kuartil kedua atau kuartil tengah.
Sebanyak 50% data bernilai lebih kecil atau
sama dengan Q2,
Q3 disebut kuartil ketiga atau kuartil atas.
Sebanyak 75% data bernilai lebih kecil atau
sama dengan Q3.
Selanjutnya, cara memperoleh kuartil untuk masing-
masing data, yakni:
a. Kuartil Data Tunggal
Kuartil pada data tunggal ditentukan setelah
data terurut dari data terkecil ke data
terbesar, mengikuti diagram kotak berikut:
Jangkauan antar kuartil
= Q3-Q1
MedianX1 Xn
Kuartil bawah Kuartil atasDiagram kotak ini sendiri sangat berguna untuk:

1) Untuk memastikan lokasi suau set data
berdasarkan median.
2) Untuk memastikan sebaran data berdasarkan
panjang kotak, yaitu jangkauan antarkuartil,
dan sebaran data berdasarkan panjang garis,
yaitu jangkauan data tanpa nilai ekstrim.
3) Untuk menentukan momen kemiringan suatu
histogram yaitu distribusi simetris,
negative, atau positif.
b. Kuartil Data Berkelompok

2. Jangkauan interkuartil dan semi kuartil
3. Desil
Desil adalah datum yang membagi data terurut
menjadi sepersepuluh-sepersepuluh bagian. Pesentil
adalah datum yang membagi data terurut menjadi
seperseratus bagian.

3) Desil untuk data berkelompok


E. Ukuran Penyebaran Kumpulan Data
Ukuran lokasi saja belum cukup untuk
menggambarkan karakteristik sebaran data, sebab
kebanyakan data mempunyai nilai yang bervariasi,
jadi tidak homogen. Untuk mengetahui tingkat variasi
sekelompok data diperlukan ukuran yang disebut
ukuran penyebaran atau ukuran variasi. Ukuran ini
memberikan gambaran tentang seberapa jauh suatu
nilai pusat dapat dijadikan ukuran yang
representatif dari kumpulan data tersebut.
1. Rentang Data
Rentang, rentang antar kuartil, dan simpangan
kuartil yang akan dibahas di sini adalah ukuran
penyebaran yang didefinisikan sebagai jarak atau
selisih antara dua nilai.
a. Rentang
Rentang (R) ataupun biasa disebut Jangkauan (J)
merupakan selisih antara nilai-nilai ekstrem
dari sekelompok data, atau selisih antara nilai
terbesar dengan nilai terkecil. Secara aljabar
dapat dituliskan :
J=xn−x1
Di mana, xn = Data terbesar
x1 = Data terkecil
b. Rentang Antar Kuartil
Rentang antar kuartil (RAK) ataupun biasa
disebut jangkauan antar kuartil (JK)

didefinisikan sebagai nilai Q3 dikurangi nilai
Q1. Secara aljabar, defini tersebut dapat
dituliskan sebagai berikut:
JK=Q3−Q1=P75−P25Di mana,
JK=JangkauanAntarKuartil Q1=Nilaikuartilke−1
Q3=Nilaikuartilke−3
P75=Nilaipersentilke−75,dan
P25=Nilaipersentilke−25.
c. Rentang semi antar kuartil
Rentang semi antar kuartil yang kadang-kadang
disebut simpangan kuartil, didefinisikan
sebagai setengah dari selisih antar Q3denganQ3.
Secara aljabar, definisi tersebut dituliskan
sebagai berikut :
SK=Q3−Q1
2
Di mana,
SK=jangkauansemiantarkuartil Q1=Nilaikuartilke−1
Q3=Nilaikuartilke−3
2. Simpangan
Kata simpangan mengacu kepada selisih nilai
setiap data dengan nilai reratanya. Jadi, rerata
simpangan, simpangan baku, dan variansi memberikan

rumus untuk menghitung ukuran variasi penyimpangan
nilai-nilai data dari nilai rerata.
a. Rerata Simpangan
rerata simpangan dapat didefinisikan sebagai
jumlah nilai mutlak dari selisih nilai data
dengan nilai rerata dibagi dengan banyaknya
data (n). Secara aljabar, definisi tersebut
dapat ditulis seperti pada rumus dibawah ini:
RS=∑i=1
n
|xi−x|n
Rerata simpangan data yang sudah disusun dalam
tabel sebaran frekuensi dihitung dengan
menggunakan rumus :
RS=∑i=1
kfi|xi−x|n
Di mana,
xi=tandakelasinterval
fi=frekuensiyangsesuaidenganxi
n=ukuransampel k=banyaknyakelasinterval.
b. Simpangan Baku

c. Ragam atau varians

BAB II
PELUANG
A. Kaidah Pencacahan
Kaidah pencacahan adalah suatu cara/aturan
untuk menghitung semua kemungkinan yang terjadi
dalam suatu percobaan tertentu. Ada tiga metode
pencacahan, yaitu metode aturan pengisian tempat,
metode permutasi, dan metode kombinasi.
Adapun makna dari pencacahan itu sendiri yakni
Jadi, apabila suatu himpunan A memuat r elemen dan
himpunan B memuat s elemen, maka A x B adalah suatu
himpunan yang memuat rs elemen, dimana rs adalah
banyaknya pasangan berurutan (a, b) dengan a∈A danb∈B.
Misalnya dalam pelemparan sebuah dadu dan
sekeping uang logam A={1,2,3,4,5,6 } dan B={G,A }
maka xB=¿ { (1,G ), (1,A ), (2,G ), (2,A ), (3,G), (3,A ),(4,G ), (4,A ), (5,G ), (5,A ), (6,G),(6,,A)}. n(A)
= 3, n(B) = 2, n(A x B) = 3 X 2 = 6.
Dengan demikian, jika suatu peristiwa dapat
terjadi dalam m cara yang berbeda, dan setelah salah
satu peristiwa itu terjadi dan peristiwa lain dapat
terjadi dalam n cara yang berbeda, maka kedua
peristiwa tersebut dalam urutan itu dapat terjadi
dalam m x n cara yang berbeda.

B. Aturan Pengisian Tempat
Dalam aturan pengisian tempat, dilakukan dengan
cara mendaftar semua kemungkinan hasil secara
manual. Ada beberpa cara dalam aturan ini, yakni:
1. Diagram pohon
Dari percobaan pelemparan sebuah dadu dan sekeping
logam di atas dapat di buat dalam diagram pohon
yakni sebagai berikut:
2. Tabel silang
Misalkan peristiwa di atas disajikan dalam table
silang maka terlebih dahulu komponen pertama (mata
dadu) di pasangkan pada bagian kolom dan komponen
kedua (mata uang logam) dipasangkan pada bagian
baris. Pasangan (kolom,baris) menunjukkan hasil
yang mungkin terjadi.
1 2 3 4 5 6G (1,G) (2,G) (3,G) (4,G) (5,G) (6,G)A (1,A) (2,A) (3,A) (4,A) (5,A) (6,A)
3. Pasangan terurut
Cara pasangan terurut adalah yang paling
sederhana dan yang paling memerlukan sedikit
tempat. Untuk kasus di atas dimana
1 GA 2 G
A 3 GA
4 GA 5 G
A 6 GA

A={1,2,3,4,5,6} dan B={G,A } maka xB=¿
{ (1,G ), (1,A ), (2,G ), (2,A ), (3,G), (3,A ),(4,G ), (4,A ), (5,G ), (5,A ), (6,G),(6,,A)}. n(A) = 3,
n(B) = 2, n(A x B) = 3 x 2 = 6. Hal ini
bersesuaian dengan kaidah penjumlahan dan
perkalian sebagai berikut:
Kaidah Penjumlahan
Misalkan suatu peristiwa dapat terjadi dengan n
cara yang berlainan (saling asing). Dalam cara
pertama p1 kemungkinan hasil yang berbeda, cara
kedua memberikan p2 kemungkinan yang berbeda,
dan seterusnya sampai cara ke-n memberikan pn
kemungkinan berbeda, maka total banyaknya
kemungkinan kejadian dalam peristiwa tersebut
adalah p1 + p2 + … + p n cara.
Kaidah Perkalian
Misalkan suatu peristiwa terdiri dari n tahap
kejadian yang berurutan dimana tahap pertama
terjadi dalam q1 cara yang berbeda, tahap kedua
dengan q2 cara yang berbeda, dan seterusnya
sampai tahap ke-n dapat terjadi qn cara yang
berbeda, maka total banyaknya cara peristiwa
tersebut dapat terjadi adalah q1 x q2 x … x qn.
C. Permutasi
Permutasi ialah susunan yang berbeda yang dapat
dibentuk dari n unsur atau sebagian unsur
1. Notasi factorial

Pengertian notasi factorial dinyatakan dalam
definisi berikut:
Notasi Faktorial
Misalkan n adalah bilangan asli, maka
n!=n (n−1) (n−2 )…3.2.1 0!=1
2. Permutasi dengan semua unsur berbeda
Teorema
Jika ada n unsur yang berbeda diambil n unsur,
maka banyak susunan (permutasi) yang berbeda dari
n unsur tersebut adalah:
P (n,n)=n!Bukti
Misalkan diketahui n buah unsur akan disusun dalam
n tempat yang tidak melingkar. Maka, tempat
pertama diisi dengan n cara karena ada n unsur.
Tempat kedua diisi dengan (n -1) cara karena
sebuah unsur telah diisikan pada tempat pertama,
demikian seterusnya sampai tempat ke-( n-1) diisi
dengan 2 cara dan tempat ke- n diisi dengan 1
cara. Secara keseluruhn banyak cara untuk membuat
susunan (permutasi) yang berbeda adalah:
n (n−1 ) (n−2 )…3.2.1=n!3. Permutasi dengan sebagian unsur yang berbeda
Teorema
Banyak permutasi r unsur yang diambil dari n buah
unsur yang berbeda adalah:

P (n,r )= n!(n−r)!
Dimana r<nBukti
P (n,r )=n (n−1) (n−2)… (n−(r−1) )
P (n,r )=n (n−1 ) (n−2 )… (n−(r−1 )) (n−r ) (n−(r+1 ))…3.2.1
(n−r ) (n−(r+1) )…3.2.1
P (n,r )= n!(n−r )!
4. Permutasi dengan beberapa unsur yang sama
Jika terdapat n objek dengan n1 merupakan jenis
pertama, n2 merupakan jenis kedua, hingga nk
merupakan jenis ke-k; dengan adanya n objek maka
terdapat n! permutasi. Apabila P adalah banyaknya
permutasi yang berbeda, jenis pertama mempunyai
n1!, jenis kedua mmempunyai n2! Dan seterusnya.
Berdasarkan kaidah perkalian diperoleh permutasi:
P(n1!xn2!xn3!x…xnk!)
Karena banyaknya objek ada n unsur, maka:
P (n1!xn2!xn3!x…xnk!)=n!
Sehingga,
P=n!
n1!n2!…nk!⟺( n
n1.n2…nk)= n!n1!n2!…nk!
Dimana
Unsur yang sama tidak dibedakan n1+n2+n3+…+nk=n
5. Permutasi siklik

Permutasi siklik adalah permutasi yang cara
menyususnnya melingkar, sehingga banyaknya
menyusun n unsur yang berlainan dalam lingkarann
ditulis:
n!n
=n (n−1)¿¿
Atau
Psiklik=(n−1)!
D. Kombinasi
Kombinasi dari sekumpulan objek adalah
banyaknya susunan objek-objek tersebut tanpa
memperhatikan urutan objek dari objek-objek
tersebut.
1. Kombinasi dengan semua unsur berbeda
Misal objek-objek tersebut adalah n1,n2,n3,…,dannn
. Karena susunan tidak memperhatikan urutan, maka
susunan
n1,n2,n3,…,nn=nn,nn−1,nn−2,…,n1Sehingga,
C (n.n)=1
2. Kombinasi dengan sebagian unsur berbeda
Secara umum kombinasi r unsur dari n unsur yang
diketahu dimana r≤n adalah:
C (n,r )= n!r! (n−r )!
3. Binomial Newton

Penjabaran binomial newton merupakan bentuk
penjabaran dari bentuk pangkat atas 2 suku, yaitu
a dan b. Koefisien-koefisien yang dihasilkan pada
penjabaran bentuk pangkat ini tertuang dalam suatu
segitiga pascal. Adapun penjabaran binomnya yakni:
Jadi, teorema binomial newton dapat dituliskan
sebagai berikut:
E. Ruang Sampel
Sebuah percobaan dalan ilmu hitung peluang
adalah suatu tindakan atau kegiatan yang dapat
memberikan beberapa kemungkinan hasil. Himpunan
semua hasil yang mungkin dari percobaan disebut ruang
sampel. Dan setiap unsur dalam ruang sampel disebut
titik sampel. Sebarang himpunan bagian dalam ruang
sampel dinamakan kejadian (event).
F. Peluang

Misalkan S adalah ruang sampel suatu percobaan
yang dilakukan n kali, dan A adalah suatu kejadian
dengan frekuensi munculnya A yaitu n(A) maka peluang
kejadian A adalah:
P (A )=limn→∞
n(A)n
Jika nilai n semakin besar, maka nilai n(A)n
konvergen ke suatu nilai sehingga limitnya disebut
sebagai peluang kejadian A.
Jika A adalah suatu kejadian yang terjadi padasuatu percobaan dengan ruang sampel S, di mana setiap
titik sampelnya mempunyai kemungkinan sama untuk muncul,
maka peluang dari suatu kejadian A ditulis sebagai:
P (A )=n(A)n(S)
Dimana P(A) = peluang kejadian A
N(A) = banyaknya anggota A
N(S) = banyaknya anggota ruang sampel S
Kisaran Nilai Peluang
Jika S adalah suatu ruang contoh dari suatu
percobaan, E adalah suatu kejadian, dan P adalah
suatu fungsi peluang, maka P(E) adalah peluang
kejadian E yang bernilai nyata jika memenuhi tiga
sifat berikut.
1. 0 ≤ P(E) ≤ 1, untuk setiap E.
2. P(S) = 1
3. P(E1 ∪ E2) = P(E1) + P (E2), untuk E1 dan E2 dan
kejadian yang saling lepas atau E1 ∩ E2 = ϕ.

G. Frekuensi Harapan
Frekuaensi harapan suatu kejadian pada percobaanyang dilakukan n kali adalah hasil kali peluang kejadian
tersebut dengan banyaknya percobaan, dirumuskan:
F (E )=P (E )xnH. Komplemen Suatu Kejadian
Komplemen suatu kejadian A ditulis AC atau A’
merupakan kejadian tidak terjadinya kejadian A.
Hubungan P(A) dan P(A’) dapat diturunkan sebagai
berikut:
P (A )+P (A')=n (A )n(S)
+n(S−A)n(S)
P (A )+P (A')= n (S )n(S)
=1
Jadi,
P (A )+P (A')=1 atau P (A' )=1−P(A')
I. Kejadian Majemuk
Beberapa kejadian dapat dikombinasikan untuk
menghasilkan suatu kejadian baru. Kejadian baru yang
dikonstruksi seperti ini disebut kejadian majemuk.
Ada dua notasi yang biasa digunakan untuk
mengkombinasikan dua kejadian atau lebih yakni:
Notasi ∩ disebut irisan, dalam logika matematikadisebut operasi “dan”
Notasi ∪ disebut gabungan, dalam logika matematikadisebut operasi “atau”

1. Dua kejadian saling lepas
Jika suatu kejadian A dan B tidak bersekutu maka
kita katakan dua kejadian tersebut adalah saling
lepas. Untuk kejadian yang saling lepas (saling
asing/saling eksklusif), maka P(A ∩ B) = P(∅) =
0, seperti ditunjukkan oleh diagram di bawah.
Apabila E1 dan E2 adalah kejadian-kejadian dalam
suatu percobaan dan jika :
(i) E1 ∩ E2 = maka E1 dan E2 disebut kejadian
yang saling lepas dan P(E1 E2 ) = P(E1) + P(E2);
(ii) E1 ∩ E2 ≠ maka E1 dan E2 disebut kejadian
yang tidak saling lepas dan P(E1 E2 ) = P(E1) + P(E2)
- P(E1 ∩ E2 )
2. Dua kejadian saling bebas
Dua kejadian saling bebas artinya kejadian yang
satu tidak mempengaruhi kejadian yang lain, atau
kejadian yang satu tidak bergantung dengan
kejadian yang lainnya,
Jika E1 dan E1 adalah dua kejadian dengan syarat
bahwa peluang bagi kejadian E1 tidak mempengaruhi
S
A B

kejadian E2, maka E1 dan E2 disebut sebagai
kejadian-kejadian saling bebas. Dan berlaku rumus:
P (E1∩E2 )=P (E1)∙P (E2 )Jika E1 dan E1 adalah dua kejadian dengan syarat
bahwa peluang bagi kejadian E1 akan mempengaruhi
kejadian E2, maka E1 dan E2 disebut sebagai kejadian
bersyarat tidak saling bebas. Dan berlaku rumus:
P (E1∩E2 )=P (E1)∙P (E2 ∕ E1 )P(E2/E1) dibaca peluang kejadian E2 dengan dari E1
telah terjadi atau peluang bersyarat kejadian E2
setelah diketahui kejadian E1.














