
Application of Multiobjective Evolutionary Algorithms for Dose Optimization Problems in...
13
E. Zitzler et al. (Eds.): EMO 2001, LNCS 1993, pp. 416-428, 2001. © Springer-Verlag Berlin Heidelberg 2001 A Hybrid Evolutionary Approach for Multicriteria Optimization Problems: Application to the Flow Shop El-Ghazali Talbi 2 , Malek Rahoual 1 , Mohamed Hakim Mabed 1 , and Clarisse Dhaenens 2 1 Institut d’Informatique / Université des Sciences et de Technologie Houari Boumèdienne, BP 32 El Alia, Bab Ezzouar / ALGER. [email protected], [email protected] 2 LIFL, Université de Lille1, Bât.M3 59655 Villeneuve d’Ascq Cedex FRANCE. {talbi, dhaenens}@lifl.fr Abstract. The resolution of workshop problems such as the Flow Shop or the Job Shop has a great importance in many industrial areas. The criteria to optimize are generally the minimization of the makespan or the tardiness. However, few are the resolution approaches that take into account those different criteria simultaneously. This paper presents an approach based on hybrid genetic algorithms adapted to the multicriteria case. Several strategies of selection and diversity maintaining are presented. Their performances are evaluated and compared using different benchmarks. A parallel model is also proposed and implemented for the hybrid metaheuristic. It allows to increase the population size and the number of generations, and then leads to better results. Keywords: Genetic Algorithm, Multicriteria optimization, Flow Shop, Hybrid Metaheuristic, Local Search, Parallel Metaheuristic. 1 Introduction The Flow Shop problem has received a great attention [6][16] since its importance in many industrial areas [13]. The proposed methods to its resolution vary between exact methods such as the branch & bound algorithm [3], specific heuristics [7][12][16] and metaheuristics [10][11]. However, the majority of these works study the problem in its single criterion form and aim mainly to minimize the makespan. Population based algorithms such as genetic algorithms (GAs) have turned out to be of great efficiency to deal with multicriteria combinatorial optimization problems. The difficulty of the multicriteria case lies in the absence of a total order relation that links solutions of the problem. Considering the GAs, this insufficiency appears in the difficulty in designing a selection operator that assigns selection probabilities proportional to the desirability degree of the individuals in the population. Another difficulty is related to the balance between the exploration of the search space and the exploitation of the obtained Pareto frontier. Advanced mechanisms have been proposed to deal with this issue, such as combined sharing in the objective and the
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Application of Multiobjective Evolutionary Algorithms for Dose Optimization Problems in...

E. Zitzler et al. (Eds.): EMO 2001, LNCS 1993, pp. 416-428, 2001.© Springer-Verlag Berlin Heidelberg 2001
A Hybrid Evolutionary Approach for MulticriteriaOptimization Problems: Application to the Flow Shop
El-Ghazali Talbi2, Malek Rahoual1, Mohamed Hakim Mabed1, andClarisse Dhaenens2
1Institut d’Informatique / Université des Sciences et de Technologie Houari Boumèdienne,BP 32 El Alia, Bab Ezzouar / ALGER.
[email protected], [email protected]
2 LIFL, Université de Lille1, Bât.M3 59655 Villeneuve d’Ascq Cedex FRANCE.{talbi, dhaenens}@lifl.fr
Abstract. The resolution of workshop problems such as the Flow Shop or theJob Shop has a great importance in many industrial areas. The criteria tooptimize are generally the minimization of the makespan or the tardiness.However, few are the resolution approaches that take into account thosedifferent criteria simultaneously. This paper presents an approach based onhybrid genetic algorithms adapted to the multicriteria case. Several strategies ofselection and diversity maintaining are presented. Their performances areevaluated and compared using different benchmarks. A parallel model is alsoproposed and implemented for the hybrid metaheuristic. It allows to increasethe population size and the number of generations, and then leads to betterresults.
Keywords: Genetic Algorithm, Multicriteria optimization, Flow Shop, HybridMetaheuristic, Local Search, Parallel Metaheuristic.
1 Introduction
The Flow Shop problem has received a great attention [6][16] since its importance inmany industrial areas [13]. The proposed methods to its resolution vary between exactmethods such as the branch & bound algorithm [3], specific heuristics [7][12][16] andmetaheuristics [10][11]. However, the majority of these works study the problem inits single criterion form and aim mainly to minimize the makespan.
Population based algorithms such as genetic algorithms (GAs) have turned out to beof great efficiency to deal with multicriteria combinatorial optimization problems.The difficulty of the multicriteria case lies in the absence of a total order relation thatlinks solutions of the problem. Considering the GAs, this insufficiency appears in thedifficulty in designing a selection operator that assigns selection probabilitiesproportional to the desirability degree of the individuals in the population. Anotherdifficulty is related to the balance between the exploration of the search space and theexploitation of the obtained Pareto frontier. Advanced mechanisms have beenproposed to deal with this issue, such as combined sharing in the objective and the

A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 417
decision space, hybrid GAs with local search, and parallel model and implementationof the algorithm.
The next section of this paper presents the multicriteria flow shop problem we areinterested in. We formulate the different objectives to optimize as well as theconstraints to satisfy. In the third section, we will describe the application of geneticalgorithms to the problem [16][17][18]. Different selection strategies are presentedand their performances compared. We present the implemented diversity maintainingmethods and their contribution in the quality of solutions. The fourth section isdevoted to the presentation of the hybridization of multicriteria GAs with local search,and its contribution is underlined. In the fifth section, we describe and evaluate aparallel model for the proposed metaheuristic.
2 A Multicriteria Flow Shop Problem
The flow shop problem can be presented as a set of N jobs {J1, J2, …JN} to scheduleon M machines. The machines are critical resources: one machine cannot be assignedto two jobs simultaneously. Each job is composed of M consecutive tasks Ji = {ti1,ti2,,.., tiM}, where tij represents the jth task of the job Ji requiring the machine mj.Following this description, jobs have the same processing sequence on the machines.To each task tij is associated a processing time pij and each job Ji must be achievedbefore the due date di.
Scheduling of tasks on different machines must optimize certain regular criteria[16]. These criteria vary according the specificity of the treated problem, andgenerally consist in the minimization of the following objectives [16] :Cmax : makespan (total completion time);
C : mean value of completion times of the jobs;Tmax : maximum tardiness; T : total tardiness;
U : number of jobs delayed with regard to their due date di;Fmax : maximum flow time; F : mean flow time.
The optimization criteria taken into account are resumed into two objectives:minimizing the makespan and the total tardiness.
We are interested in the study of the permutation flow shop problemF/permu,di/(Cmax,T), where jobs must be scheduled in the same order on all themachines.
f1 = Cmax = Max (siM + piM)
f2 = T = ∑ [max (0, siM + piM - d i)]

418 E.-G. Talbi et al.
3 GA and Multicriteria Flow Shop Problem
The application of GAs to a given problem needs, first, a chromosomal representationof a solution (in our case the schedule of jobs). The processing sequence of jobs onthe machines being identical, a schedule is then considered as a permutation definingthe processing order of the jobs in the machines. The used coding is a jobs array. Aposition of a job defines its sequencement order.
Once a sequence of jobs is defined, all tasks are scheduled as early as possible(respecting precedence constraints between tasks of a same job and preventing anymachine to be allocated to two tasks simultaneously). Then, starting time (sij) of eachtask of each job may be computed in a recursive manner, as follows, starting with thefirst job.
Where i’ represents the job that immediately precedes job i in the sequence. Thisformula expresses the fact that a task tij cannot be planned unless: the machine mj hasfinished to process the previous task ti’j and the previous task ti(j-1) of the same job isover.
Applying a GA method to a given problem requires also to define the geneticoperators. The mutation operator consists in choosing randomly two points of thechromosome, inserting the last job before point 2, just after point 1 and shifting to theright jobs scheduled between the two points. The crossover operator, also called twopoints crossover, consists in generating one offspring from 2 parents [10]. Two pointson Parent 1 are randomly chosen, defining two extremities that will constituteextremities of the Offspring. Then jobs that are not already selected in these twoextremities, are selected in the order they appear in Parent 2, to fill the rest of theoffspring.
3.1 Selection Operators
In this study, we have implemented 6 multicriteria selection strategies. The maindifferences between those methods consist in the way individuals of the populationare ranked and the selection probabilities are calculated.
max (si(j-1) + pi(j-1), si’j + pi’j ) otherwise.
sij=
0 if Ji is the first job of the sequence and j =1.
si(j-1) + pi(j-1) if Ji is the first job of the sequence and j ≠ 1.
si’j + pi’j if Ji is not the first job of the sequence and j = 1

A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 419
3.1.1 Selection by Weighted Sum of Objectives
It was one of the first methods used for the multicriteria optimization (used in [10] forexample). Based on the transformation of the problem to a single criterion problem,this method consists in combining the different objective functions in one singlefunction, generally in a linear manner.
f(Si) = ∑ λk fk(Si) k ∈ [1..2]
The weights λk are taken in the interval [0..1] such as ∑ λk =1 (k=1..n). An individualSi has then a probability to be selected equal to :
π(Si)= f(Si) / ∑ f(Sj) where tp : population size j ∈[1..tp]
3.1.2 Parallel Selection
This selection approach has been used in the VEGA algorithm. Half of the selectedindividuals are selected with regard to their makespan. The remaining tp/2 individualsare selected with regard to their tardiness.
3.1.3 NSGA Selection
In the NSGA selection [14] (Non-dominated Sorted Genetic Algorithm), the ranks ofindividuals are calculated in a recursive manner, beginning with the non-dominatedindividuals of the population. A rank equal to 1 is associated to the non-dominated setof individuals E1 of the current population. Rank k is associated to the set ofindividuals Ek dominated only by individuals belonging to E1 ∪ E2 ∪ … ∪ Ek-1.
The selection probability of an individual Si of rank n in the population followsBaker expression [1][16]:
Where S represents the selection pressure and
Ri = 1+ |Ei| +2 * ∑ j∈ [1.. i-1] |Ej |
3.1.4 NDS Selection
In the NDS selection (Non-Dominated Sorting), the rank of an individual is equal tothe number of solutions dominating this individual plus one [4].
Rank (Si) = | Sj ∈ Population / Sj dominates Si| + 1
The selection probability is calculated by the same formula as for NSGA selection.
S(tp + 1 – Ri ) +Ri -2
tp(tp - 1 )π(Si )=

420 E.-G. Talbi et al.
3.1.5 WAR Selection
The weighted Average Ranking consists in calculating the rank of each individual ofthe population with regard to the different objectives separately [2]. The rank of anindividual is computed as the sum of ranks for each criterion. For this purpose, weorder the individuals by an increasing order of f1 and f2.
Rank(Si) = Rank_Makespan(Si) + Rank_Tardiness(Si)
The selection probabilities are calculated as for NSGA selection.
3.1.6 Elitist Selection
The elitist selection consists in maintaining an archive population PO* that willcontain the best non-dominated solutions encountered during all the stages of thesearch (fig. 1.). This population will participate to the selection and reproductionstages [14]. In this case, the selection probability of an individual Si of rank n(calculated with the NSGA technique) of the current population will correspond tothe following expression:
The selection leaves us a probability of A/tp to choose an individual from the Paretopopulation. Hence, the parameter “A” determines the expectation of the number ofindividuals selected from PO* set. Actually, all the selection methods keep an archivecontaining the best solutions encountered during the search (Pareto set). Theparticularity of the elitism is to let this population participate during the selectionphase.
Initial Population PO*
elitist Selection
Intermediate Population
Reproduction
Fig. 1. Elitist selection strategy
(tp-A) S (tp + 1 –Rn ) +Rn-2
tp tp (tp - 1 )π(Si) =
A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 421
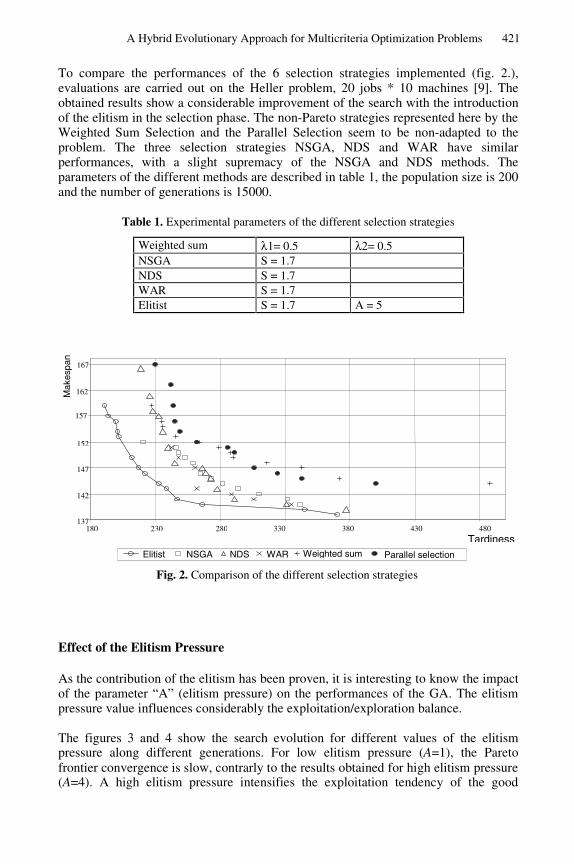
To compare the performances of the 6 selection strategies implemented (fig. 2.),evaluations are carried out on the Heller problem, 20 jobs * 10 machines [9]. Theobtained results show a considerable improvement of the search with the introductionof the elitism in the selection phase. The non-Pareto strategies represented here by theWeighted Sum Selection and the Parallel Selection seem to be non-adapted to theproblem. The three selection strategies NSGA, NDS and WAR have similarperformances, with a slight supremacy of the NSGA and NDS methods. Theparameters of the different methods are described in table 1, the population size is 200and the number of generations is 15000.
Table 1. Experimental parameters of the different selection strategies
Weighted sum λ1= 0.5 λ2= 0.5NSGA S = 1.7NDS S = 1.7WAR S = 1.7Elitist S = 1.7 A = 5
Effect of the Elitism Pressure
As the contribution of the elitism has been proven, it is interesting to know the impactof the parameter “A” (elitism pressure) on the performances of the GA. The elitismpressure value influences considerably the exploitation/exploration balance.
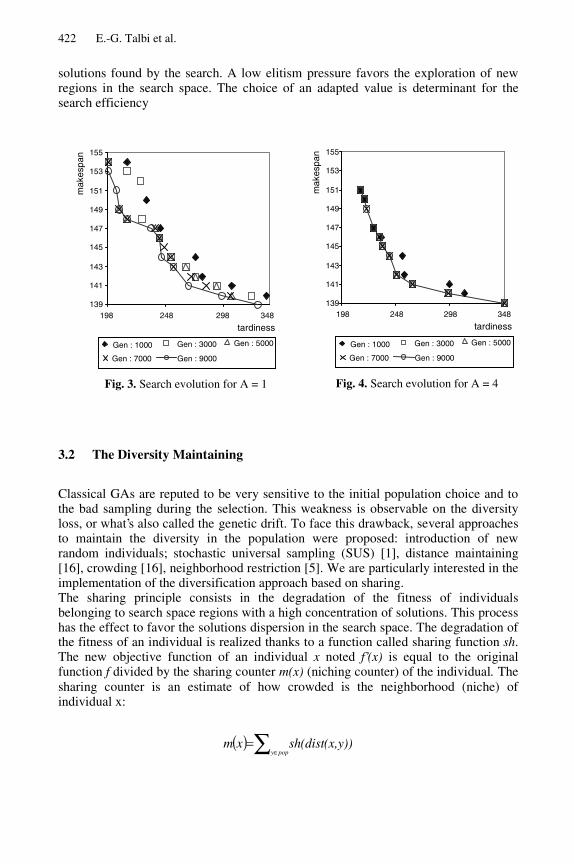
The figures 3 and 4 show the search evolution for different values of the elitismpressure along different generations. For low elitism pressure (A=1), the Paretofrontier convergence is slow, contrarly to the results obtained for high elitism pressure(A=4). A high elitism pressure intensifies the exploitation tendency of the good
Fig. 2. Comparison of the different selection strategies
137
142
147
152
157
162
167
180 230 280 330 380 430 480
Tardiness
Mak
espa
n
Elitist NSGA NDS WAR Weighted sum Parallel selection
422 E.-G. Talbi et al.
solutions found by the search. A low elitism pressure favors the exploration of newregions in the search space. The choice of an adapted value is determinant for thesearch efficiency
3.2 The Diversity Maintaining
Classical GAs are reputed to be very sensitive to the initial population choice and tothe bad sampling during the selection. This weakness is observable on the diversityloss, or what’s also called the genetic drift. To face this drawback, several approachesto maintain the diversity in the population were proposed: introduction of newrandom individuals; stochastic universal sampling (SUS) [1], distance maintaining[16], crowding [16], neighborhood restriction [5]. We are particularly interested in theimplementation of the diversification approach based on sharing.The sharing principle consists in the degradation of the fitness of individualsbelonging to search space regions with a high concentration of solutions. This processhas the effect to favor the solutions dispersion in the search space. The degradation ofthe fitness of an individual is realized thanks to a function called sharing function sh.The new objective function of an individual x noted f’(x) is equal to the originalfunction f divided by the sharing counter m(x) (niching counter) of the individual. Thesharing counter is an estimate of how crowded is the neighborhood (niche) ofindividual x:
( ) ∑ ∈=
popy))y,x(dist(shxm
Fig. 3. Search evolution for A = 1 Fig. 4. Search evolution for A = 4
139
141
143
145
147
149
151
153
155
198 248 298 348
tardinessm
akes
pan
139
141
143
145
147
149
151
153
155
198 248 298 348
tardiness
mak
espa
n
Gen : 1000 Gen : 3000 Gen : 5000
Gen : 7000 Gen : 9000
Gen : 1000 Gen : 3000 Gen : 5000
Gen : 7000 Gen : 9000

A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 423
The sharing function Sh calculates the similarity degree of an individual with theremaining individuals of the population. The sharing function Sh is defined asfollows:
( )( )
( )
<
−
=
otherwise 0
y)(x,dist1 if y,xdist
1
y,xdistsh
γα
γ
where the constant γ designates the non-similarity threshold (niche size), i.e, thedistance from which two individuals x and y are not considered as belonging to thesame niche any more. The constant α allow to control and regulate the form of thefunction sh. Depending on whether the distance between two individuals is calculatedin the decision space (the chromosomal representation of an individual) or in theobjective space (fitness of individuals), three approaches have been used:
3.2.1 Genotypic Sharing
In this approach the distance between individuals is calculated according to thedifference between chromosomes (decision space). Since a schedule is represented bya permutation, the distance between two schedules is then equal to:
dist1(x, y) = | {(i, j) ∈ J x J / i precedes j in the solution x and j precedes i in y}|
What means that the distance between two individuals x and y is equal to the numberof the order ruptures between x and y.
3.2.2 Phenotypic Sharing
The distance in this approach is taken as the difference between individuals in the objectivespace. f1 and f2 designate the two objectives functions "makespan" and "total tardiness".
( ) ( ) ( ) ( ) ( )y2fx2fy1fx1fy,x2dist −+−=
3.2.3 Combined Sharing
This approach represents the combination of the two first approaches cited above. Thecomputation of the distance refers to both, the genotype and the phenotype, distances.The function Sh, in this case, takes the following form:
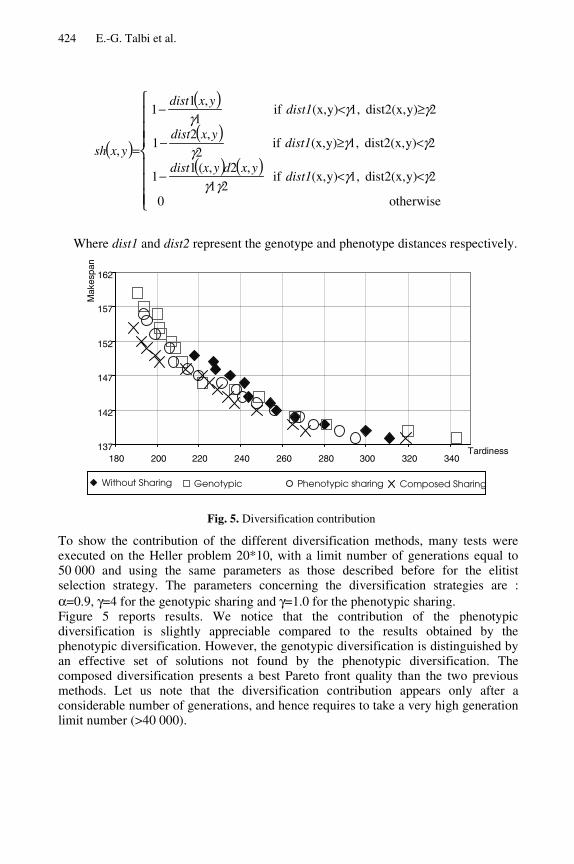
424 E.-G. Talbi et al.
( )
( )
( )
( ) ( )
<<−
<≥−
≥<−
=
otherwise 0
2y)dist2(x, ,1y)(x, if 21
,2,(11
2y)dist2(x, ,1y)(x, if 2
,21
2y)dist2(x, ,1y)(x, if 1
,11
,
γγγγ
γγγ
γγγ
dist1yxdyxdist
dist1yxdist
dist1yxdist
yxsh
Where dist1 and dist2 represent the genotype and phenotype distances respectively.
To show the contribution of the different diversification methods, many tests wereexecuted on the Heller problem 20*10, with a limit number of generations equal to50 000 and using the same parameters as those described before for the elitistselection strategy. The parameters concerning the diversification strategies are :α=0.9, γ=4 for the genotypic sharing and γ=1.0 for the phenotypic sharing.Figure 5 reports results. We notice that the contribution of the phenotypicdiversification is slightly appreciable compared to the results obtained by thephenotypic diversification. However, the genotypic diversification is distinguished byan effective set of solutions not found by the phenotypic diversification. Thecomposed diversification presents a best Pareto front quality than the two previousmethods. Let us note that the diversification contribution appears only after aconsiderable number of generations, and hence requires to take a very high generationlimit number (>40 000).
Fig. 5. Diversification contribution
137
142
147
152
157
162
180 200 220 240 260 280 300 320 340Tardiness
Mak
espa
n
Without Sharing Genotypic Phenotypic sharing Composed Sharing

A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 425
4 Hybridization with Local Search
We are interested in the use of the Local Search (LS) as a mean of acceleration andrefinement of the Genetic Search. In this case, the idea is to run the GA first in orderto approach the Pareto solutions. The hybridization principle is very simple, once theGA is over (the limit generation number is reached), the Local Search is then run withthe previously obtained Pareto set as an entry (Figure 6).
The use of the Local search needs, first, to choose the manner to generate theneighborhood of a given solution. To construct a neighbor of a solution, a job ischosen, removed and put somewhere else in the sequence. Other jobs situatedbetween the two positions have to be shifted from one place to reconstruct thesequence.The hybridization process consists in generating, for each individual of the Paretopopulation, the neighborhood with the above described process. The non-dominatedneighbors, are inserted in the Pareto population. The solutions belonging to the Paretopopulation and dominated by the neighborhood of one solution are suppressed. Thisprocess is reiterated until no new non dominated neighbor is found. Figure 6 describesschematically this Local Search process.
The performance tests of the hybrid GA with the local search shows that hybridizationis of no interest for little size problems, notably Heller 20*10. However, thehybridization is able to improve solutions as soon as the size of the problem increases.The tests presented in figure 7 are realized on Heller problem with 100 jobs and 10machines.
Fig. 6. Local Search in action
516
518
520
522
524
526
528
530
500 600 700 800 900 1000 1100
non-hyrid Hybrid
Fig. 7. Local search contribution
Pareto
neighbors neighbors
Eliminate theneighborsdominated byPareto
Eliminate theneighborsdominatedby Pareto
New Pareto individuals
Updating of Pareto
Pareto
426 E.-G. Talbi et al.
5 A Parallel Model and Its Implementation
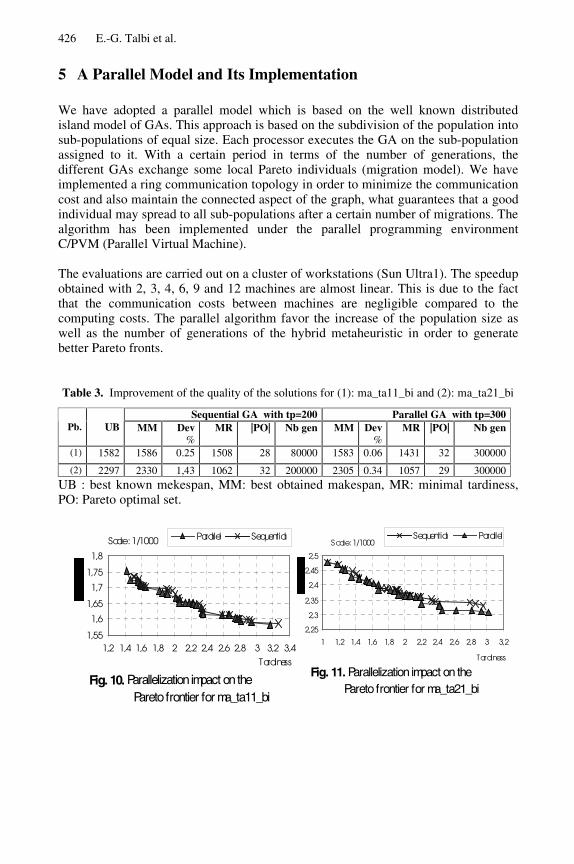
We have adopted a parallel model which is based on the well known distributedisland model of GAs. This approach is based on the subdivision of the population intosub-populations of equal size. Each processor executes the GA on the sub-populationassigned to it. With a certain period in terms of the number of generations, thedifferent GAs exchange some local Pareto individuals (migration model). We haveimplemented a ring communication topology in order to minimize the communicationcost and also maintain the connected aspect of the graph, what guarantees that a goodindividual may spread to all sub-populations after a certain number of migrations. Thealgorithm has been implemented under the parallel programming environmentC/PVM (Parallel Virtual Machine).
The evaluations are carried out on a cluster of workstations (Sun Ultra1). The speedupobtained with 2, 3, 4, 6, 9 and 12 machines are almost linear. This is due to the factthat the communication costs between machines are negligible compared to thecomputing costs. The parallel algorithm favor the increase of the population size aswell as the number of generations of the hybrid metaheuristic in order to generatebetter Pareto fronts.
Table 3. Improvement of the quality of the solutions for (1): ma_ta11_bi and (2): ma_ta21_bi
Sequential GA with tp=200 Parallel GA with tp=300Pb. UB MM Dev
%MR |PO| Nb gen MM Dev
%MR |PO| Nb gen
(1) 1582 1586 0.25 1508 28 80000 1583 0.06 1431 32 300000
(2) 2297 2330 1,43 1062 32 200000 2305 0.34 1057 29 300000UB : best known mekespan, MM: best obtained makespan, MR: minimal tardiness,PO: Pareto optimal set.
Fig. 11. Parallelization impact on the Pareto frontier for ma_ta21_bi
2,25
2,3
2,35
2,4
2,45
2,5
1 1,2 1,4 1,6 1,8 2 2,2 2,4 2,6 2,8 3 3,2
Scale : 1/1000
Tardiness
Sequential Parallel
Fig. 10. Parallelization impact on the Pareto frontier for ma_ta11_bi
1,55
1,6
1,65
1,7
1,75
1,8
1,2 1,4 1,6 1,8 2 2,2 2,4 2,6 2,8 3 3,2 3,4
Scale : 1/1000
Tardiness
Parallel Sequential

A Hybrid Evolutionary Approach for Multicriteria Optimization Problems 427
As shown in figures 10 and 11, the use of large populations distributed on differentGAs and the increase of the number of generations improve the quality of the Paretofrontiers.
6 Conclusion and Perspectives
In this work, we have tried to construct our approach by a progressive introduction ofconcepts such as selection, diversity maintaining, hybridization and parallelization. Ateach stage we have shown the contribution of the introduced mechanisms, that’s whatallows us to formulate the following conclusions.Pareto selection strategies (NSGA, NDS, WAR) seem to be well adapted to themulticriteria flow shop problem. The efficiency of such methods is improved with theintroduction of elitism during the selection phase. The elitism may lead to prematuresearch convergence though and then, parameters A (elitist pressure) and Q (selectionpressure) have to be adequately chosen. However, the risk of a genetic drift is alwayspresent. The diversification strategies seem to be the privileged mean to prevent suchproblems. Three variants of the method, based on the sharing, were developed. Thephenotypic sharing (diversification in the objective space) appears to be the mostinteresting. This interest is related to the fact that a larger and better dispersed Paretofrontier is desirable. However, the genotypic diversification may yield good resultsalso. The combination of both concepts improves considerably the search.
Combining GAs with local search was used in order to refine the search. The idea isto run the GA first in order to get a first approximation of the Pareto frontier. Thelocal search has the merit to improve the solutions (find the local optima of the searchregions). The contribution of hybridization appears for problem of important sizeonly.
The work presented here deals with a bi-criteria problem. However, the methodproposed is able to be extended very easily to multi-criteria problems. Therefore, wenow need to test the strength of the method for flow-shop problems with more thantwo criteria. A graphic comparison is impossible in this case, and more elaboratedtests of performances methods must be used, such as the contribution notion [16] andentropy [16]. The extension of the method to the general flow-shop problem (not onlypermutation flow-shop) and to the job shop problems is also to be studied. Otherhybridization schemes must be evaluated. Indeed, combining GAs with moreadvanced local search techniques such as tabu search may give better results.
The proposed hybrid metaheuristic is still very slow due to the advancedmechanisms introduced. A parallel model has been proposed and implemented for thealgorithm to overcome this drawback. The obtained speedup favor the use of largepopulations and the increase of the number of generations, which improves the qualityof the obtained Pareto frontier.

428 E.-G. Talbi et al.
References
1. Baker, J.E. Adaptive selection methods for Genetic Algorithms. Proceeding ofinternational conference on Genetic Algorithms and their application, Page 101, 1985.
2. Bentley, P.J., Wakefield, J.P. Find an acceptable Pareto-optimal solutions usingmultiobjective Genetic Algorithms. Springer Verlag, London, page 231, June 1997.
3. Brah, S.B., Hunsucker, J.L. Branch & Bound algorithm for the flow-shop with multipleprocessors. European Journal of Operational Research, Vol 51, page 88, 1991.
4. Fonseca, C. M., Fleming, P.J. Multiobjective genetic algorithms made easy: selection,sharing and mating restrictions. In IEEE Int. Conf On Genetic Algorithms in EngineeringSystem: Innovations and Applications, Page 45, Sheffield, UK, 1995.
5. Fujita, K., Hirokawa, N., Akagi, S., Kimatura, S., Yokohata, H. Multi-objective optimaldesign of automotive engine using genetic algorithm. In Proceedings of DETC’98 - ASMEDesign Engineering Technical Conferences, page 11, 1998.
6. Gonzalez, T., Sahni, S. Flowshop and Job-shop Schedules : Complexity andApproximation. Operational Research, Vol 26, N°1, page 36, 1978.
7. Gupta, N.D. An improved Combinatorial Algorithm For The Flowshop-SchedulingProblem. Operational Research, Vol 19, page 1753, 1969.
8. Hajela, P., Lin, C.Y. Genetic search strategies in multicriterion optimal design. StructuralOptimisation, (4) Page 99, 1992.
9. Heller, J. Some Numerical Experiments For a MxJ Flow Shop And Its DecisionTheoretical Aspects. Operational Research, Vol 8, page 178, 1960.
10. Murata, T., Ishibuchi, H. A Multi-objectives Genetic Local Search Algorithm and ItsApplication Flow-shop Scheduling. IEEE Transaction System. Vol 28, N°3, pp 392, 1998.
11. Nowicki, E. The permutation Flow shop with buffers : A tabu search approach. EuropeanJournal of Operational Research, Vol 116, page 205, 1999.
12. Rajendran, C., Chaudhuri, D. An efficient heuristic approach to the scheduling of jobs inflow-shop. European Journal Of Operational Research, Vol 61, page 318, 1991.
13. Simon French, F., Phil, D. Sequencing and scheduling: An introduction to the mathematicof the Job-Shop. Department of Decision Theory, University of Manchester. John Wiley &Sons Edition, 1982.
14. Srinivas, N., Deb, K. Multiobjective optimisation using non-dominated sorting in geneticalgorithms. Evolutionary Computation 2(8), page 221, 1995.
15. Taillard, E. Benchmarks for basic scheduling problems. European Journal of OperationalResearch, Vol 64, Page 278, 1993.
16. Talbi, E-G. Métaheuristiques pour l'optimisation combinatoire multi-objectifs: Etat del'art. Rapport interne, Université de sciences et Technologies de Lille, France, Jun 1999.
17. Van Veldhuizen, D.A., Lamount, G.B. Multiobjective Evolutionary Algorithm Research :A History and Analysis.Technical Report 98-03, Department of Electrical and ComputerEngineering, Air Force Institute of Technology, USA, Dec 1998.
18. Zitzler, E. Evolutionary Algorithms for Multiobjective Optimization : Methods andApplication. Dissertation submitted to the Swiss Federal Institute of Technology Zurich fora degree of Doctor of technical science, Nov 1999.




















