
Un modelo para medir la calidad en el servicio en una empresa local de pizza en Los Mochis, Sinaloa

UNIVERSIDAD AUTÓNOMA DE SINALOA
ESCUELA DE FILOSOFÍA Y LETRAS
MAESTRÍA EN ENSEÑANZA DE LA LENGUA Y LA LITERATURA
ANÁLISIS DE LÉXICO DISPONIBLE EN HABLANTES ESCOLARES DE
CULIACÁN, SINALOA
TESIS
QUE COMO REQUISITO PARA OBTENER EL GRADO DE
MAESTRO EN ENSEÑANZA DE LA LENGUA Y LA
LITERATURA
PRESENTA:
JOSÉ DE JESÚS VELARDE INZUNZA
DIRECTOR DE TESIS:
DR. EVERARDO MENDOZA GUERRERO
Culiacán, Sinaloa. Diciembre de 2014.

Agradecimientos
Un trabajo de esta magnitud obedece a múltiples inquietudes: personales,
intelectuales y profesionales. Sin embargo, el detonante principal está dado por el
genuino interés de dejar una huella en quienes me rodean.
Pretendo con la cristalización de este texto dar forma a todo el cúmulo de
propósitos que fueron evolucionando desde hace varios años hasta el momento
presente.
Durante ese periodo de desarrollo hubo distintas personas que entablaron
vínculo conmigo de diversas formas. En primer término agradezco de manera amplia
a mi maestro y, puedo expresar, mi amigo, el Dr. Everardo Mendoza Guerrero, pues
mantuvo en todo momento la confianza en que su alumno podría alcanzar la
culminación de este desafío académico. Así me lo hizo sentir siempre.
Debo agradecer de manera particular a mi familia: mis hijas y mi esposa, ya
que son el motor que impulsa mis acciones, tanto cotidianas como las extraordinarias.
Aun cuando no están presentes materialmente, manifiesto mi gratitud plena a
mi padre y a mi madre, pues sus figuras y consejos perduran en mi memoria y en mi
ser.
A mis alumnos les debo la iniciativa de nunca rendirme y de mantener una
actitud de franco optimismo.
A Dios, pues desde mis convicciones y fe, es el ímpetu que me sustenta. En
cada instante vaya mi intensa muestra de agradecimiento.

Índice Introducción ............................................................................................................4
Objetivos…………………………………………………………………………………..9
Antecedentes históricos..........................................................................................12
Marco teórico .........................................................................................................17
Metodología ...........................................................................................................34
Análisis de los datos ..............................................................................................44
Conclusiones .........................................................................................................83
Bibliografía .............................................................................................................87
Anexos ...................................................................................................................92

4
Introducción El estudio del léxico y de su influencia en la estructuración y organización de la
realidad representada en universos comprensibles a través de la lengua ha
permitido que diferentes investigadores, desde distintas disciplinas y ámbitos
científicos, hayan configurado asideros teóricos que otorgan sentido y
coherencia a trabajos de investigación recientes.
Particularmente dentro de la lexicología, la sociolingüística, la semántica
pragmática, la psicolingüística y otras disciplinas que abordan el análisis del
léxico han surgido teorías que intentan revelar los mecanismos y los hechos
más controversiales, que tienen que ver con el desarrollo lingüístico, la
constitución del léxico en la mente y su relación con las experiencias de
aprendizaje.
Cabe enfatizar que los estudios y los trabajos de análisis de la lengua
han configurado esquemas y modelos teóricos que la segmentan, se han
creado jerarquías y dimensiones estructurales y organizativas tendientes a
explicar diáfanamente todos los fenómenos lingüísticos. Ésta ha sido la
finalidad central: proporcionar paradigmas explicativos de la lengua con notable
claridad y sentido.
Tras esto, debo referir que parto en la investigación de las visiones del
léxico dadas en las diferentes nociones que se han generado de él a través del
tiempo. Algunas de estas formulaciones pasadas y recientes muestran una
simplificación o una restricción conceptual. El Diccionario de la Real Academia
(2001: 928) presenta en su segunda acepción que el léxico es el “diccionario de
una lengua”. En una tercera acepción identifica al léxico con el “vocabulario,
conjunto de las palabras de un idioma, o de las que pertenecen al uso de una
región, a una actividad determinada, a un campo semántico dado, etc.” De
igual manera lo han establecido otros lexicógrafos como Greimas y Courtés.
Investigadores como Juan López Chávez (2008:7-9) se orientan hacia un
entendimiento de mayor amplitud: el léxico presenta distintas aristas, una de
ellas es de orden psicológico o mental; otra más está dada por la estructuración
u organización social de los hablantes. Esta perspectiva ofrece una concepción
orientada a la incorporación de otros aspectos, por lo tanto, las consideraciones
que se hagan del léxico y que conduzcan a conocer cómo los hablantes lo

5
organizan cognitivamente, o bien, de qué forma lo configuran socialmente y lo
producen, tendrán sentido en una teoría más acabada sobre el mismo.
También Luis Fernando Lara (2006:143) afirma que “el léxico se nos
manifiesta como un fenómeno de la memoria de cada individuo”. Pero esto se
da gracias a un proceso de apropiación lingüística en el que cada hablante
recibe de su comunidad un caudal de voces y expresiones que son parte de un
acervo mayor heredado históricamente.
En este nuevo orden de concepciones se hace evidente la situación
referida en líneas anteriores: la producción lingüística es un complejo
entramado de hechos que van de lo individual a lo social y que no podrán ser
juzgados de una forma única o parcial sino que deberá adoptarse una óptica de
amplio espectro para lograr una visión cada vez más acabada. Pedro Payán
(1983:16-17) ha expresado en relación con el lenguaje la siguiente idea: “[…]
debe ser mirado como espejo fiel de la vida humana en su polivalente
complejidad y grandeza”.
De ahí que el interés primordial de esta investigación sea percibir al
lenguaje, y en especial al léxico, como una entidad multiforme, con relaciones y
nexos con todas las demás dimensiones de la lengua y no como una masa
amorfa, alejada del acontecer social. Éste es otro elemento de carácter
neurálgico en la perspectiva que abordo. La comprensión nodal mediante la
que establezco a la lengua como una entidad de origen social. Por tales
motivos, el estudio y análisis del léxico deben generarse dentro del contexto
social.
Aunado a esto puedo expresar que, en relación con la enseñanza de la
lengua, nuestro sistema de educación nacional ha promovido reformas en los
currícula tendientes a lograr un desarrollo óptimo del dominio lingüístico de los
alumnos en cualquier fase de formación académica. Mas es preciso manifestar
que los proyectos de planeación de enseñanza del léxico no han existido de
manera formal, aun en las nuevas acciones reformistas. Esto incrementa las
inadecuaciones y las ópticas erróneas al aplicar modelos y reformas educativas
en el plano de la lengua.
López Chávez y Arjona Iglesias (2001:28) refieren, acerca de lo anterior,
lo siguiente:

6
En general en México la enseñanza de la lengua materna ha aprovechado poco los fundamentos científicos que los estudios lingüísticos brindan. De esta manera, la elaboración de los textos desde la escuela primaria hasta la enseñanza media superior han carecido del sustento adecuado, pero sobre todo han dejado de beneficiarse del orden y la continuidad que una planificación cuidadosa hubiera podido ofrecerles. Esto, desde luego, se acentúa conforme se va ascendiendo en los niveles escolares, de modo que la situación se torna crítica en los años previos al ingreso a la universidad, como lo demuestra claramente la poca destreza de los estudiantes que ingresan a la enseñanza superior para expresarse por escrito y para comprender adecuadamente los textos que leen.
En consonancia con esto, Hernández Solís1 afirma que se ha confundido
formalmente la enseñanza de la lengua con la enseñanza de la teoría sobre la
lengua, lo cual ha conducido a obtener resultados inadecuados al desarrollar la
competencia lingüística en los educandos.
Considero pertinente señalar que ante esta situación es necesario
emplear los instrumentos y recursos que ofrecen las disciplinas lingüísticas
para fortalecer ampliamente las nuevas perspectivas y prácticas educativas.
Para ello se requiere conocer la realidad específica de los hablantes en
los entornos regionales. De aquí que la obtención de corpus sea tan valiosa,
pues sólo mediante el conocimiento tanto de las particularidades como de los
hechos generales que afectan a la lengua se ofrecerán referentes de la
realidad léxica y se podrá elaborar un análisis cuidadoso y detallado de los
fenómenos que están incidiendo y afectando a la enseñanza.
En especial, el análisis de aquello que se entiende como disponibilidad
léxica permite obtener información toral para comprender la conformación del
corpus léxico de una comunidad de hablantes. Es decir, el léxico disponible,
referido básicamente como el caudal de voces utilizadas por un hablante en
situaciones comunicativas determinadas (López Morales, 1999: 11), sí
configura notoriamente una noción básica en la comprensión del lexicón y de
los procesos que inciden directa e indirectamente en el aprendizaje de la
lengua.
1 Su tesis doctoral (2006) plantea un modelo para planificación de la enseñanza del vocabulario con fundamento en el léxico disponible de estudiantes universitarios de Zacatecas, México.

7
Por otra parte, alcanzar la certidumbre que arrojaría conocer el léxico
disponible de una comunidad de habla depende ampliamente de obtener, por
un lado, una serie de resultados numéricos que establecen una relación entre
la frecuencia de los vocablos referidos por los hablantes y el orden de aparición
de esos vocablos en una serie de encuestas que se aplican. Adicionalmente, y
de mayor trascendencia, está el análisis riguroso de los datos, lo cual requiere
de un entendimiento y una comprensión integral del fenómeno y de la
problemática de la enseñanza del léxico.
Debo mencionar que actualmente los estudios de disponibilidad léxica
(DL en lo sucesivo) siguen distintos derroteros y en nuestro país están
cobrando una vigencia cada vez mayor. Aunque es conveniente expresar que
en ciertos ámbitos hispánicos los estudios de DL se están orientando
solamente a la descripción de la norma léxica y en virtud de esto emplean una
metodología que ha seguido ciertos lineamientos, que posteriormente explicaré
con exhaustividad. Sin embargo, es plausible la diversificación de los estudios
que toman como entidad crítica a la DL.
También debo referir que el trabajo de investigación que he realizado
rebasa el somero levantamiento de datos que previamente desarrolló en la
región, hacia 1992, Ana Isabel Meraz Espinosa, quien llevó a cabo la aplicación
de las encuestas de DL con una muestra de alumnos de 4°, 5° y 6° de
primaria, ya que pretendo conformar un análisis cuantitativo y aproximarme a
otro de orden cualitativo con los resultados obtenidos.
Por otro lado, el objetivo central de mi labor de investigación es estudiar
el léxico disponible de adolescentes que cursan la educación secundaria (en
concreto el tercer grado de tal nivel educativo) en la ciudad de Culiacán,
Sinaloa, México.
Este análisis de disponibilidad léxica se enriquece con el escrutinio de
las siguientes variables a considerar: el sexo, el grado escolar y la pertenencia
de los informantes a un centro educativo privado o público. Una decisión
importante ha sido la de tomar como sujetos de investigación a los
adolescentes que cursan la fase final de la educación básica, es decir, la
secundaria, ya que he determinado que la valoración del léxico de tales
hablantes proporcionará datos cuantificables para estimar el desarrollo léxico
que presentan y buscar en futuras investigaciones, en la medida que otros

8
proyectos lo permitan, medios y herramientas didácticas pertinentes para
mejorar aquello que se requiriera.
Cabe precisar también que, aun cuando los estudios realizados
actualmente en la mayor parte del mundo hispánico se han hecho con una
metodología que respeta los lineamientos esenciales dados por los
investigadores franceses que a principios de los 50 iniciaron con tales labores,
un grupo mayoritario de estudiosos ha asumido que el máximo de respuesta
que deberán emplear los informantes para ofrecer las palabras en su encuesta
será de dos minutos. Ante esto, Juan López Chávez (2003: 40) ha insistido que
debe emplearse otro límite de tiempo, pues considera que el lapso de dos
minutos es demasiado “corto para que la memoria pueda traer a la luz un
número adecuado de vocablos”.
Por tal razón, he considerado pertinente que mi investigación permita
generar una comparación empleando los dos lapsos referidos y con los
resultados establecer si existen diferencias significativas en cuanto a esto.
Finalmente, reitero, los resultados que sean arrojados por este proceso
de investigación contribuirán de manera plena al conocimiento de una parcela
de la realidad léxica y lingüística de nuestra región. Sin embargo, el propósito
último será allanar el camino hacia la configuración y bosquejo de una
planeación de la enseñanza del léxico y por ende de la producción lingüística.

9
Objetivos En función de las ideas anteriormente expuestas, es posible definir con
propiedad los objetivos que orientan y determinan el quehacer total de la
investigación.
El primer objetivo general es conocer de manera precisa y detallada el
léxico disponible de adolescentes que cursan el tercer grado de educación
secundaria en la ciudad de Culiacán, Sinaloa, México.
El elemento de mayor trascendencia está focalizado en la obtención de
la cuantificación del léxico disponible mediante los vocablos que emiten
adolescentes que están próximos a egresar de secundaria, no sólo por las
implicaciones teóricas sino por la amplia gama de posibilidades prácticas.
Entiendo además que este trabajo puede convertirse posteriormente en una
herramienta útil para investigar la norma léxica de la región, al conjuntarse
posiblemente con resultados de otros grupos etarios y poblacionales y
constituir así un asidero que privilegie el estudio de las variaciones geográficas
y sociolingüísticas de nuestra lengua materna. Además, podrá ser un medio
que permitirá generar una base cuantitativa sólida sobre la que se pueda
realizar la selección de vocablos que se contemplen para una enseñanza
planeada en cuanto al léxico en ese nivel de estudios. Es necesario referir que
el conocimiento cuidadoso del léxico disponible de nuestra comunidad, aunado
también a una descripción formal del léxico básico, permitiría generar una idea
más clara del léxico fundamental que presenta tal comunidad. Esto en efecto
podría orientar el rumbo que debería darse a las tendencias educativas en
relación con la planificación lingüística en esta región del país.
Gracias a esto último, otro interés manifiesto es el de propiciar en un
momento ulterior la generación de procesos y estructuras pedagógicas que
sean útiles en la enseñanza del léxico. Sin embargo, por la envergadura y
tiempo que requiere una tarea de tal magnitud sólo puedo ceñirme a las
condiciones presentes para lograr los objetivos antes planteados.
Por otro lado, cabe mencionar que un primer objetivo específico de la
investigación tiene que ver con la posibilidad de establecer una comparación
entre los resultados que surjan de los informantes contemplando dos tiempos
límite para la emisión de palabras en cada encuesta, pues actualmente los

10
estudios de DL en el mundo panhispánico mantienen como tope de tiempo dos
minutos y la línea adoptada por Juan López Chávez en México ha sido la de
establecer tres minutos. Mi interés es mantener esta última línea metodológica,
ya que en trabajos preliminares que realicé en la localidad observé que el
tercer minuto sí permitía rescatar más vocablos, sin embargo, no pude estimar
con acierto esta proporción y consideré prudente establecer una comparación
con datos concretos.
Los resultados arrojados permitirán corroborar si hay variaciones y a su
vez conocer si las mismas determinan una significación relevante o
intrascendente.
Aunado a estos objetivos que validarían la pertinencia de la
investigación, está un hecho que considero importante: más allá del quehacer
de descripción que está implícito en la obtención de léxicos disponibles, está el
deseo de generar un entendimiento más amplio acerca de las estructuras,
ligazones y posibles organizaciones que hay en el léxicon mental. Juan López
Chávez (2003:35) ha expresado que la finalidad de sus trabajos tiene que ver
con esta idea y que le ha interesado sentar las bases para que se hagan más
indagaciones en torno a este asunto.
En relación con estos objetivos, puedo derivar un segundo objetivo específico: el de comparar dos hechos o variables que se relacionan con la
disponibilidad léxica de los adolescentes contrastando a quienes estudian en
centros educativos privados y públicos, así como hombres y mujeres.
Un tercer objetivo específico que también establezco tiene que ver con
la adición de un centro de interés, el cual toma como tópico la computación y el
internet. Lo anterior determina que se tengan en la encuesta un total de 17
centros de interés, ya que en la metodología original diseñada por los
franceses se emplearon 16. Esta añadidura la ofrezco debido a la situación
actual en la que las referencias a estos conceptos de la informática cobran un
auge, según entiendo, en la realidad de las personas y particularmente de los
adolescentes.
Sin embargo, considero que las posibilidades de aplicación de la
información resultante no se ceñirán a estos objetivos planteados
exclusivamente sino que es mi interés dilucidar y explotar, en la medida que
sea posible, otras aristas y apartados que ofrezcan más caminos para el

11
establecimiento de acciones orientadas a acrecentar el estudio del léxico y de
la lengua en general. Esta inquietud delimita un segundo objetivo general. Para finalizar, añado un cuarto objetivo específico: comparar los
primeros veinte vocablos de cada centro de interés, en función de los tres
minutos, con los resultados de las investigaciones de dos regiones distintas:
Navarra, España y Zacatecas, México. Del primero se tomó porque es fruto de
una investigación de 2013 y contempla convergencias amplias con los centros
de interés de la metodología y adiciona también uno relacionado con la
informática y recursos tecnológicos, tal investigación fue generada por Felipe
Jiménez Berrio. La de Zacatecas es fruto de un trabajo muy amplio que
desarrolló Juan López Chávez y ofrece características similares a las de esta
investigación.

12
Antecedentes históricos Dentro de las labores pasadas de la lexicología se encuentra el establecimiento
de líneas de investigación que permitan ofrecer una comprensión cada vez más
integral de múltiples fenómenos lingüísticos que se han analizado desde hace
algunas décadas en Europa y más recientemente en Hispanoamérica. En tal
corpus de investigación está el tema de la disponibilidad léxica.
Los estudios que propiciaron el análisis de tal fenómeno se dieron en
Francia hacia mediados del siglo XX. Un trabajo medular y notable fue el que
permitió la realización de la obra denominada Français élémentaire, publicada
en 1954. El organismo impulsor de este proyecto que intentaba formular un
medio formal para la enseñanza del francés a extranjeros fue el Centre national
de documentation pédagogique. Para su preparación se establecieron dos
encuestas: una encuesta estadística de la lengua hablada, que se sustentaba
en la frecuencia; se consideraba que los vocablos más frecuentes debían ser
los más representativos y útiles. Otra encuesta se preparó con centros de
interés.
Sin embargo, durante el transcurso de las investigaciones surgieron
palabras que eran muy conocidas y empleadas por los franceses y no
aparecían en los registros de vocabulario frecuente. Esto motivó que ya no se
entendieran como sinónimos los términos frecuente, común y usual dentro de
tales estudios léxicos.
La anterior situación permitió apreciar a los estudiosos que aquellos
vocablos que sólo se actualizan en el discurso si el tema del mismo lo requiere
necesitan un tratamiento distinto para ser obtenidos por parte de los hablantes,
ya que los vocabularios de frecuencia recogían palabras con mayor incidencia
estadística, pero dejaban al margen otras. Este hecho motivó que a la
metodología empleada se le considerara como impropia para registrar y valorar
adecuadamente ciertas unidades léxicas.
Otros trabajos fueron realizados por el francés René Michéa, quien leyó
a un grupo de alumnos un fragmento del texto “Tonnelier de Nuremberg” de
Hoffmann (de dos páginas y media, con aproximadamente 800 palabras).
Posteriormente, les pidió que escribieran una lista con aquellos vocablos que
les hubiesen llamado la atención. Después realizó otra prueba en la que pedía

13
a los alumnos que pensaran en la realización de un viaje en tren desde el
momento de llegar a la estación y que escribieran las 20 palabras que primero
se les ocurrieran.
De éste, y otros trabajos elaborados por Gustave Gougenheim, surgió la
idea de trabajar con pruebas asociativas. René Michéa fue el primero en
establecer la dicotomía de ‘palabras frecuentes’ vs. ‘palabras disponibles’. La
disponibilidad léxica se definió como el caudal léxico utilizable en una situación
comunicativa determinada.
Es preciso mencionar que Michéa generó un constructo de vital
importancia para desarrollar sus trabajos de investigación, éste es el centro de
interés, el cual constituyó un recurso teórico-metodológico que funciona como
el estímulo que permite al hablante desencadenar sus procesos de
recuperación léxica en la memoria para hacer emerger los vocablos que en su
mente encuentran conexión lógica con el tema que se presentaba.
Cabe mencionar que aún en la actualidad se utilizan los centros de
interés que René Michéa estableció. Lo cual, en juicio de Juan López Chávez
(2003: 31), es signo de la pertinencia de los mismos.
Los centros de interés son los siguientes:
1. Las partes del cuerpo
2. La ropa: vestido y calzado
3. La casa: el interior y sus partes
4. Muebles y enseres domésticos
5. Alimentos: comidas y bebidas
6. Objetos colocados sobre la mesa
7. La cocina y sus utensilios
8. La escuela: muebles y útiles
9. Electricidad y aire acondicionado
10. La ciudad
11. La naturaleza
12. Medios de transporte
13. Trabajos de campo y jardín
14. Los animales
15. Diversiones y deportes
16. Profesiones y oficios

14
Es necesario aclarar que, aun cuando los estudios iniciales referidos
anteriormente ya pretendían elaborar una distinción más nítida entre frecuencia
y disponibilidad de los vocablos, no se diseñaron los medios o artificios
pertinentes que lograran dar cuenta de tales diferencias.
Fueron precisamente las fórmulas de Roberto Lorán y Humberto López
Morales hacia 1982 y, particularmente, la de Juan López Chávez y Carlos
Strassburger Frías hacia fines de la década de los ochenta las que logran
conjuntar de manera viable los factores antes señalados: frecuencia y
’espontaneidad’ (disponibilidad). Es decir, desarrollaron artificios matemáticos
que además de considerar la frecuencia obtenida por cada vocablo también
expresaban el lugar de aparición de los mismos en las listas, ya que aquellos
vocablos que son recuperados inicialmente por la memoria ante el estímulo
dado a través de los centros de interés poseen un mayor grado de
disponibilidad.
Este grado específico que atiende tanto a la frecuencia de aparición de
los vocablos como a la posición en la que aparecen permite discriminar por
rangos a las unidades léxicas que son registradas por los informantes en las
encuestas.
El índice de disponibilidad se obtiene mediante la fórmula siguiente:
n
D(Pj) = Σ e -2.3 (i-1/n-1) (fji/I1)
i= 1
en la que n es la máxima posición alcanzada [en la lista], i es el número de
posición, j es el índice de la palabra, fji es la frecuencia absoluta de la palabra j
en la posición i, I1 es el número de informantes que participaron en la encuesta,
e o constante de Napier (Juan López Chávez recomienda emplear el siguiente
valor: 2.718181818459045) y D(Pj) es la disponibilidad de la palabra j (López
Chávez-Strassburger, 1987). Esta fórmula reunió de manera muy satisfactoria
la frecuencia y el orden, elementos nodales que logran constituir una expresión
sólida de la disponibilidad léxica en términos matemáticos.
Ya López Chávez y Strassburger Frías se han encargado de dilucidar
con acierto la exactitud de su fórmula en un artículo publicado en el año 2000
en el Anuario de Letras.

15
Todo lo anterior destaca el hecho de que la DL ha captado el interés de
diversos estudiosos e investigadores en nuestro país y con ello se promueve la
necesidad de orientar el entendimiento de la realidad lingüística para lograr
conformar cuerpos de trabajo que coadyuven en la planificación de la
enseñanza de la lengua.
Cabe expresar que en el ámbito panhispánico los estudios de DL
también han tenido ecos importantes. Humberto López Morales ha sido el
propulsor de estos estudios. Él ha logrado convocar a distintos especialistas de
la península ibérica y han constituido núcleos de investigación con una
orientación formal, ya que han concretado acuerdos para definir una ruta
metodológica común (un mismo tipo de encuesta para recopilar los materiales,
los centros de interés que se toman en cuenta, los criterios de edición y el
tratamiento matemático de los datos). Los alcances que pretenden son
diversos e impactan en distintas dimensiones de la lengua. Este grupo de
investigadores creó una página web en el año 2000
(http://www3.usal.es/dispolex ) y a través de ella brinda distintos servicios
relacionados con la DL. Tal página fue elaborada en la Universidad de
Salamanca por José Antonio Bartol.2
Precisando aún más acerca de los núcleos de investigación que se
derivaron de esta propuesta es posible referir que se iniciaron trabajos en las
siguientes regiones: Puerto Rico, con los esfuerzos del mismo Humberto López
Morales; República Dominicana, quien ha tenido a la cabeza de las
investigaciones a Orlando Alba; Uruguay, contando con el liderazgo de Carlos
Jones Gaye. En la península los esfuerzos se han multiplicado en distintas
diatopías: Madrid, con la dirección de P. Benítez Pérez; Canarias, con la
conducción de José Antonio Samper Padilla y C. E. Hernández Cabrera; País
Vasco, con los aportes de M. Etxebarria; Castilla y León, con los quehaceres
de J. A. Bartol, J. Borrego, C. Fernández Juncal, Ma. V. Galloso y F. J. de
Santiago Guervós; Asturias, con las orientaciones de A. Carcedo. También
debo referir que ha habido estudios en Aragón, Galicia y Cataluña.
Enfatizo, pues, afirmando que los estudios de DL han cobrado vitalidad
en diferentes regiones del mundo panhispánico especialmente y las
2 Esto es expuesto por Raúl Ávila, et al. (2003:27-28)

16
orientaciones básicas en cuanto a la metodología respetan en gran manera los
rudimentos dados por los franceses. Sin embargo, los sentidos de aplicación
están variando, ya que los resultados que se obtienen permiten ampliar el
espectro de significaciones que se otorga al léxico.
Otros estudios en México
En especial en México ha habido una serie de trabajos que han procurado
conocer el léxico disponible de diversos grupos de hablantes, así como
aspectos valiosos en relación con éste.
Menciono en primer lugar un trabajo que hacia 1989 se registró en la Dir.
Gral. de Asuntos del Personal Académico de la UNAM, el proyecto fue
denominado Determinación del léxico disponible y fundamental. Búsqueda de
estructuras y reglas de adquisición del léxico: desarrollos teóricos, descriptivos
y aplicaciones en la enseñanza de la lengua. Duró hasta 1992 y con él se
realizaron muchos acercamientos al tema, este trabajo se dio con la
conducción del Dr. Juan López Chávez.
A continuación referiré otros trabajos que se han realizado, los cuales
han tenido la característica de estar relacionados con la enseñanza y el léxico
disponible, pues en esencia es un rasgo de mi investigación al tener como
informantes a hablantes en edad escolar, menciono solamente al autor o
autores y el título del trabajo, pues no ha sido posible conocer los resultados y
pormenores de tales investigaciones: Juan López Chávez, Sobre el estudio de
disponibilidad léxica y la enseñanza del español, 1990; Martha Julián Peña,
Disponibilidad léxica en escolares de 4º y 5º años de escuela primaria
particular, 1991; Ana Isabel Meraz, El léxico disponible de alumnos de 4º, 5º y
6º grados de primarias representativas en el ciclo escolar 89-90 de la ciudad de
Culiacán, Sinaloa, 1992; Juan López Chávez y Rosalía Bolfeta Montes de Oca,
Léxico disponible de tercer grado de primaria, 1993; Juan López Chávez,
Crecimiento lexical en la escuela básica mexicana, 1995; Aída Araceli Sánchez
Álvaro, Identificación del léxico disponible en estudiantes terminales de la
enseñenza media-superior, 1996; Marina Arjona Iglesias, Sobre el léxico
disponible de escolares mexicanos, 1997; Ana Marcela Castellanos Guzmán,
Presencia del léxico escolar disponible en los diccionarios del español de

17
México, 1998; María Matilde Beatriz Hernández Solís, Disponibilidad léxica de
estudiantes de primaria de la ciudad de Zacatecas, 2000.
Un trabajo posterior que publicó Juan López Chávez hacia 2003,
denominado ¿Qué te viene a la memoria? La disponibilidad léxica: teoría,
métodos y aplicaciones reúne de manera clara tanto conceptos como recursos,
al igual que datos cuantitativos y cualitativos sobre la DL en escolares de
primaria de todo el estado de Zacatecas; debido a que es una primera
investigación que se genera con toda una entidad del país, resulta valiosa su
referencia, pues da pautas para el acercamiento en otras regiones para
generar un conocimiento más acabado en relación con los procesos de
enseñanza que puedan desarrollarse.

18
Marco teórico Nociones medulares: frecuencia y disponibilidad
Al hacer un análisis en un recorrido desde el origen de los estudios
relacionados con la disponibilidad léxica hasta el presente, es posible advertir
la serie de conceptos y de sentidos significativos que sustentan de manera
palmaria la visión del lenguaje y del léxico.
Como he referido en líneas anteriores, el surgimiento de la noción de la
disponibilidad léxica se da en el marco de un conjunto de esfuerzos realizados
en Francia a principios de los años cincuenta cuya finalidad era enseñar la
lengua francesa a personas que en ese periodo histórico vivían en los
territorios de lo que se denominaba Unión Francesa.
Debido a que se estableció en la propuesta del programa didáctico que
el nivel básico o elemental otorgaría un peso específico al vocabulario que
deberían aprender los extranjeros, ello demandó la selección de un corpus
léxico. Atendiendo a los recursos léxico-estadísticos de la época, el factor que
permitió elegir las palabras que habían de enseñarse fue el de la frecuencia. En
palabras de Gómez Devís (2004:28): “El índice de frecuencia representa el
número de veces que aparece una misma palabra o unidad léxica en el
recuento de un corpus”.
Sin embargo, me permito emplear en este apartado las ideas que sobre
frecuencia y familiaridad muestran Paul Fraisse, Georges Noizet y Claude
Flament (1977:179-190). Sobre la frecuencia denotan que “se haya en estrecha
relación con fenómenos de orden psicológico, como la rapidez y la exactitud
de la percepción de las palabras y el tiempo de reacción verbal”.
En cuanto a la familiaridad destacan que:
“Sin duda, hay que partir de la naturaleza de las palabras, que son
signos cuya función estriba en designar las cosas. Entre el sistema de la
lengua, socialmente codificado, y el mundo de los objetos manipulados o de
las situaciones vividas se establece un tejido de relaciones de índole funcional.
Entonces se presenta la hipótesis de un dato psicológico intermedio, al mismo
tiempo reflejo y encarnación de la frecuencia, que de alguna manera sería el
puente entre el plano lingüístico y el plano psicológico. Este dato nos ha
parecido cercano a lo que se llama familiaridad de las palabras”.

19
Y es que tal y como lo rescatan López Morales (1999:10) y Gómez Devís
(2004:28), los listados de las unidades léxicas recabadas por los investigadores
franceses en aquellos trabajos iniciales citados mostraban una realidad no
cabal: sí era posible encontrar palabras gramaticales, sustantivos de carácter
general, pero verbos y adjetivos, contradictoriamente no aparecían, o bien, con
una frecuencia menor, así como otras palabras con contenidos o sentidos
concretos que sí eran conocidas y empleadas por los hablantes del francés (cfr.
Gougenheim 1963: 5-11, 1967: 137-144).
Fue precisamente René Michéa (1953:338-344) quien, después de
realizar algunos ejercicios con alumnos de primaria y solicitarles que
registraran palabras relacionadas con una actividad dada, encuentra que sí
aparece una gran cantidad de sustantivos, acompañados de otros pocos
verbos de significado muy general. Es decir, la no frecuencia de algunas
palabras se debía a que su emisión estaba propiciada por el tema tratado en
los textos de los que se recogían. Es este investigador, insisto, quien opuso
entonces palabras frecuentes a palabras disponibles. Con esta oposición se
destaca que en la mente de los hablantes hay una serie de palabras que no se
actualizan o emergen a través de la memoria sino hasta que existe una
demanda comunicativa que lo precisa en un determinado momento. Por lo
tanto, un estudio basado en la frecuencia resultaba inoperante para rescatar
unidades léxicas potenciales.
Michéa (1953:340) conceptualiza la disponibilidad como:
“Un mot disponible est un mot qui, sans être particulièrement fréquent,
est cependant toujours prêt a être employé et se presente inmédiatement et
naturellement à lʾesprit au moment où lʾon en a besoin. Cʾest un mot qui,
faisant partie dʾassociations dʾidées usuelles, existe en puissance chez le sujet
parlant, dès que ces associations entrent en jeu”.
Estas reflexiones determinaron un viraje posterior hacia una
reformulación conceptual importante en relación con el léxico y sus tipologías.
Fue necesario diferenciar palabras frecuentes y palabras usuales, ya que voces
que se entendían como comunes no se encontraban en los listados de
frecuencias. Esto implicaba que no eran, pues, palabras frecuentes.

20
Conjugando estas informaciones, es preciso denotar que para los
investigadores franceses aquellas palabras que surgían cuando el tema del
discurso lo promovía se entendieron como temáticas. Por otro lado, las
palabras que surgieron en casi todos los contextos discursivos sin importar el
tema específico se concibieron como atemáticas. Se da entonces una relación
estrecha entre el léxico frecuente y este tipo de palabras. De todo esto se
dedujo que era necesario contar con recursos distintos para encontrar las
palabras temáticas.
La comprensión de la competencia léxica y sus componentes: sustrato para la
determinación de las relaciones entre las palabras
Diego Marconi (2000) ya ha planteado que aquello que se entiende
como competencia léxica es la capacidad que poseen los hablantes para usar
las palabras de una lengua. Dentro de tal uso identificó dos subcomponentes:
- la competencia inferencial, dada por el acceso a la red de
conexiones que una palabra tiene con el resto de las palabras.
- La competencia referencial, determinada por la capacidad del
hablante para proyectar las palabras en el mundo real, es decir,
ser capaz de nombrar objetos y aplicar dichas palabras a sus
referentes.
Adicionalmente, tal autor italiano ha referido que existen dos tipos de
léxico: uno semántico, que incorpora la información conceptual sobre las voces
y un léxico de educto, el cual conserva las representaciones fonéticas y
gráficas de las palabras. En ambos se presentan los componentes de lo
inferencial y lo referencial.
Frente a estos constructos, es posible discurrir lo siguiente: aquellas
destrezas puestas en juego cuando un hablante atiende a la tarea de enunciar
palabras que se evocan a partir de otra noción denotan habilidades
inferenciales, es decir, tal tarea detona conexiones o vínculos semánticos y de
categorización entre palabras.
Hernández Muñoz (2006:32), en relación con esto, ha declarado lo
siguiente: “la competencia inferencial no ha de concebirse como un ejercicio
simple de establecer relaciones entre palabras, sino de un complejo sistema de
rutas a través del léxico semántico combinado con el léxico de educto”.

21
Ante esto advierto que aun cuando un hablante que se enfrenta a la
demanda de registrar palabras que relaciona con un centro de interés no
demuestra una eficacia en el uso de las mismas en una circunstancia
comunicativa de la cotidianidad, sí es factible la consideración de que existen
en todo hablante conocimientos sobre esas unidades que le indican vínculos
dados por cargas y rasgos semánticos que conducen también a una adjunción
en grupos caracterizados de diversas formas.
Fundamentos derivados de la psicología
Incorporo a continuación un apartado en el que concentro los
principales sustentos psicológicos que considero nodales para la comprensión
del fenómeno del léxico disponible. Ulteriormente retomaré las formas que
permitieron registrar tal tipo de léxico.
Coincido con López Chávez (2003:21) en que en la disponibilidad léxica
subyace un fenómeno epistémico que se explica a través del asociacionismo
psicológico. Empleo para esto la referencia que el investigador citado refiere:
“A la pregunta epistemológica ´´¿cómo conocemos?´´, los filósofos
empiristas responden ´´por medio de los sentidos´´ […] ´´Entonces, ¿de
dónde vienen las ideas complejas, que no son directamente sentidas? ´´
La respuesta a esta segunda pregunta nos proporciona el primer
principio de la asociación: “Las ideas complejas provienen de la
asociación de otras más simples”.
Tras este dato es posible entender que los procedimientos de asociación
controlada que crearon los investigadores franceses para lograr en los
hablantes la evocación de las unidades léxicas en función de un estímulo, al
que llamaron centro de interés, cobraron pleno sentido.
No es la pretensión de este trabajo ahondar en los procesos de
almacenamiento y recuperación que intervienen en la estructuración del léxico
en la mente ya que el propósitono es tal, pero sí denoto que su análisis permite
un entendimiento que aclara el fenómeno de la DL y para ello las teorías
psicológicas y cognitivas que refiero constituyen un recurso sólido.
William K. Estes (1979:35-60) expresa que:

22
“Habitualmente se habla de la memoria como si fuese un almacén en el
que las cosas a recordar son guardadas con cierto orden, como las
mercaderías en los anaqueles de un depósito. Pero sabemos que la memoria,
en realidad, no es una entidad de este tipo; en verdad, no tiene nada que ver
con una entidad, sino más bien con un aspecto del funcionamiento de un
complejo sistema de procesamiento de información”.
Vinculo esto con la referencia de Luis Fernando Lara (2006:143) acerca
de que el léxico “se manifiesta cuando se piensa en las unidades verbales
denominadas palabras y la memoria permite recordar muchas de ellas.
Cuando, por ejemplo, pensamos en el vocablo gato y vienen a nuestra mente
otros con los que hablamos de los animales domésticos, como perro, caballo,
burro, gallina, cabra, etc., ese conjunto forma un léxico”. Sin mantener una
perspectiva reduccionista, esto representaría el principio de asociación
señalado anteriormente, sin embargo, también se debe postular que las
diversas relaciones que se dan entre esos vocablos escapan a un único
encadenamiento lógico-semántico. Como lo advierte López Chávez (2003:24)
cuando sostiene que “una palabra no trae consigo necesariamente a otra, es
decir, que no siempre decir `lápiz lleva´ al informante a decir `cuaderno´”.
Sobre esto en particular, parafraseo a Estes (1979:43) quien manifiesta
que las investigaciones derivadas de la teoría asociacionista se refirieron al
aprendizaje de pares asociados, al aprendizaje de listas o de otros ítems en
orden serial y que se interpretó de tales aprendizajes de ítems de vocabulario
que se formaba en el sistema de la memoria una asociación direccional
orientada de la representación del estímulo a la representación de la respuesta.
Por extensión se interpretaba también la memorización de una lista de ítems en
términos de esas asociaciones direccionales entre los ítems sucesivos. Mas
para explicar que la memoria de una lista no se desintegra totalmente si un
ítem es omitido durante el recuerdo, los investigadores admitieron que sí
existen asociaciones remotas entre ítems no adyacentes.
También este investigador explica que en diversos experimentos las
listas de palabras para evocar son seleccionadas a partir de categorías
semánticas familiares, aun en aquellos casos en que una lista no ha sido
clasificada según el investigador, cae dentro de categorías-grupos de palabras

23
desde el punto de vista de los sujetos, debido a su experiencia idiosincrática
previa y a sus actividades de repaso durante la entrada de la lista.
Otra declaración que enuncia William Estes (1979) que da significación
clara a los medios cognitivos que permiten la disponibilidad léxica es la que
señala que “los datos del recuerdo sugieren que la estructura de la memoria
que es responsable del libre recuerdo no adopta la forma de asociaciones en
cadena entre los ítems individuales, como tampoco la de asociaciones
múltiples independientes, sino más bien la de una estructura jerárquica en la
que los ítems relacionados son asociados con el rótulo de una categoría
común, y los nombres categoriales son asociados con un interrogante común
para la lista”.
Además de esto, Hernández Solís (2006:17) encuentra en su
investigación que los presupuestos derivados de la teoría generalizada de los
campos semánticos (cfr. Collins y Quillian, 1969: 240-248) no son compatibles
con los resultados arrojados en su investigación sobre léxico disponible, ya que
las clásicas relaciones de hiperonimia e hiponimia no se manifiestan en las
producciones de los hablantes de la forma esperada. Es decir, esta especialista
encuentra que en ciertos listados, con registros de voces emitidas por
informantes de Zacatecas, existen palabras que siendo hiperónimos se ubican
en posiciones posteriores a otros hipónimos referidos inicialmente por los
informantes y sin guardar estrechas relaciones de este orden.
En cuanto a propuestas decantadas de la psicolingüística, sólo me
referiré a ciertos modelos de acceso léxico que explican cómo son percibidas y
activadas las palabras durante las actividades lingüísticas. Berko y Bernstein
(1999:185-197) muestran dos grandes tipos: el primero se configura a través
del modelo de búsqueda serial. Éste postula que un hablante al percibir una
palabra revisa una lista léxica para establecer si tal ítem es o no una palabra y
posteriormente se recupera la información necesaria sobre la misma. La
búsqueda es serial en tanto que el proceso se da mediante el examen
secuencial, palabra a palabra, de cada entrada léxica.
En especial dentro de este tipo de modelo de búsqueda serial el
paradigma autónomo propuesto por Forster (1976:257-287) es el más
reconocido y se caracteriza por ofrecer el léxico y unos archivos de acceso que

24
seleccionan los subconjuntos apropiados de entradas léxicas sobre la base de
atributos perceptivos.
Por otro lado está el modelo de acceso en paralelo. En él, el input
perceptivo de una palabra puede activar directamente el ítem léxico, y múltiples
entradas léxicas se activan de manera paralela. Lo anterior implica que de
manera simultánea se activa un número de candidatos potenciales, y la palabra
almacenada que comparta más rasgos con la palabra percibida es
seleccionada. Dentro de este modelo, la propuesta de Morton (1969) del
logogén es el punto de partida para todos los modelos de activación. Según
Morton la entrada de cada palabra corresponde a una unidad en el léxico
mental, el logogén. Tal logogén está caracterizado por un umbral que
especifica la cantidad de información necesaria para que la unidad dé una
respuesta.
A estas nociones sólo agregaré otra visión formulada por Collins y
Quillian (1970:304-314), pues permite observar procesos que definen
notoriamente el desarrollo de la producción léxica. Logran reconceptualizar su
propuesta y formulan un modelo reticular de propagación de la activación.
Sostienen que el funcionamiento léxico se da a través de redes jerárquicas, en
las que las entradas léxicas constituyen nodos y los conceptos asociados
están interconectados. Mas los rasgos y elementos caracterizadores de los
conceptos también representan nodos funcionales y actúan a su vez como
otros conceptos. En todo momento se aprecia aún que el modelo mantiene su
naturaleza asociativa, mas la organización no es rígida o unidireccional sino
que asume la forma de una estructura compleja de entrecruzamientos.
Advierten también que existiría un principio de propagación de la activación.
Ejemplifico a continuación: si se activa un concepto como “canario”, este input
desencadena efectos en todos los conceptos asociados a él a través de los
distintos nodos vinculados y “ave”, “amarillo”, “aire” y otros alcanzan un
determinado umbral de activación. La fuerza asociativa dependerá de diversos
elementos psicolingüísticos que ordenan y dan estructura a los vínculos. En
aquellas tareas en las que un hablante debe decidir la elección de una palabra
debería utilizarse menos tiempo para reconocerla si está precedida por otra
categorizada o vinculada por nodos específicos (Berko y Bernstein, 1999:223).

25
Un representación que ilustra el modelo de propagación de la activación
propuesto por Collins y Loftus (1975:407-428) es la siguiente (cada línea
(vínculo) representa el grado de asociación entre conceptos):
Figura 1. Representación del modelo de propagación de la activación de Collins
Todo lo anterior me permite esbozar que el léxico alojado en la memoria
humana está dado por una serie de imbricadas redes y cúmulos relacionados
en los que las adjunciones de las palabras se dan no sólo de manera
unidireccional sino multidireccional, en una red polímita compleja. Es decir,
percibo que el modelo en paralelo y la visión de Collins en sí conducen a una
calle vehículo
coche
camión
ambulancia
autobús
coche de bomberos
naranja
amarillo
verde
rojo
fuego
casa
violetas
flores
rosas
cerezas
peras
manzanas
amaneceres nubes
puestas de sol

26
visión no propiamente de almacenamiento y de reconocimiento de vocablos en
la memoria sino a una concepción que muestra un tejido en el que las cargas
semánticas encuentran asociaciones diversas con posibilidades muy amplias
de conexión. Pero ciertamente aún no se dilucida la naturaleza de esta
conexión de manera plena.
A esta aseveración sumo un esquema que Hernández Solís (2006)
(figura 2) generó para su investigación de DL de Zacatecas. Ella ordena los
resultados que obtiene en relación con el centro de interés denominado “las
partes del cuerpo” y construye una representación de este tipo:
Figura 2. Representación de las relaciones léxicas según Hernández
Solís Solís.

27
Hernández Solís elabora un esquema visual en el que asocia los
vocablos emitidos por los informantes en relación con la categoría temática del
cuerpo humano. En su documento describe y emplea una terminología
específica para solventar las ideas de estas estructuras léxicas: refiere como
núcleos a las unidades léxicas básicas que se vinculan conceptualmente y
aparecen en las primeras posiciones de los listados y establecen determinadas
relaciones lógicas. Los núcleos primarios para el cuerpo son: ojo, cabeza,
mano, pie, corazón, cuello y hueso. Éstos en conjunto conforman un cúmulo
léxico. En conexión con estas unidades aparecen otros vocablos que
mantienen una relación también lógica y significativa, la cual la investigadora
desprende e interpreta gracias al orden subsecuente de aparición de las voces
en los listados y de los índices de disponibilidad léxica que obtuvieron tales
vocablos.
Estimo necesario afirmar que las posibles relaciones y vínculos que
subyacen en las interconexiones referidas por Hernández Solís devienen por
procesos no sólo de orden psicolingüístico o neurológico como tal sino que
obedecen a su vez a fenómenos del acontecer social y cultural en el que los
individuos se desenvuelven. En la referencia gráfica de esta investigadora los
vocablos que se anclan primariamente y aparecen en las primeras posiciones
de los listados son voces que denotan elementos externos del cuerpo humano
y que por lo general se aprenden en el nivel educativo básico, atendiendo a un
constructo académico dado por el currículum. Es decir, la organización léxica
en este caso es resultado de influencias socio-educativas y que adquieren peso
específico en las interacciones de los individuos en el seno de la sociedad.
Resulta pertinente conjuntar la posible organización dada en los modelos
previos que explican la génesis léxica en los hablantes y estas aproximaciones
que formulo, ya que hay convergencias que entiendo como válidas y que sería
necesario afinar para consolidar una perspectiva teórica en relación con la DL.
Más aún percibo que la problemática cognitiva y epistémica que encierra
la comprensión del léxico en la memoria y en la mente humana se debe
enfrentar mediante el abordaje de distintas teorías y concepciones, en especial
la teoría psicolingüística y las teorías del procesamiento de la información.
El fenómeno de la DL que se presenta en los individuos de cualquier
comunidad de habla obedece a estos procesos de percepción y reconocimiento

28
de estímulos que se dan, en el caso de la metodología empleada, a través de
los denominados centros de interés, los cuales actúan como detonantes o
impulsores, ya que constituyen categorías nocionales en las que se organizan
las experiencias humanas, logrando así la activación y el recuerdo de las
unidades léxicas contenidas en la memoria y que guardan una serie de
asociaciones o vínculos semánticos, conceptuales y culturales con esos
ámbitos.
Sin embargo, aclaro que a pesar de todas las disquisiciones derivadas
de los diversos ámbitos intelectuales y científicos no se tienen explicaciones
que describan de manera cabal los distintos elementos y mecanismos que
configuran la génesis léxica en la mente humana.
Tras esto, retomo el hecho de que la metodología creada por los
franceses sufrió una reformulación importante: el yugoeslavo Dimitrijévic (1969)
realiza una investigación en Escocia tomando exclusivamente once centros de
interés, pero a diferencia de las listas cerradas de los franceses, en las que
sólo demandaban una cantidad de veinte palabras, éste requirió listas abiertas
y determinó un tiempo fijo para que los informantes registraran las palabras.
En una sintopía distinta, Canadá, William F. Mackey (1971) realizó
investigaciones, particularmente en la parte francófona, para comparar el léxico
disponible de tal región con el de Francia, con el propósito de contrastar en
términos lingüísticos y culturales los resultados. Sus trabajos lo conducen a
ofrecer una serie de ideas que resultan significativas en cuanto al léxico:
sostiene que los influjos y condiciones del medio socio-cultural en que se
desenvuelven los hablantes generan efectos sobre las distintas asociaciones
léxicas que sí son relevantes. También hace ver que las pruebas generadas
por la metodología francesa logran descubrir en la organización y configuración
léxica de los hablantes de una comunidad las realidades circundantes de una
manera sencilla y en especial en ciertas dimensiones o aspectos, de ahí la
pertinencia de los dieciséis centros de interés. Aunque en relación con éstos
diverge de lo planteado por las pautas francesas y considera que, dependiendo
de agentes sociales, culturales, educativos y otros, los estímulos dados por
tales centros de interés pueden relativizarse debido a los contextos distintos en
los que los sujetos se desarrollan y por tal razón decidió adicionar otros seis
centros.

29
Sobre esto último cabe una reflexión que, aunque ya otros
investigadores se han planteado, resulta válida para los fines que me interesan
en este trabajo: los centros de interés elegidos por los franceses intentaron
concentrar de manera fehaciente los diversos ámbitos o parcelas de la realidad
y del quehacer humano, pero considerando además el transcurrir del tiempo y
los cambios y contextos en las distintas sociedades, es necesario aceptar que
dieciséis centros de interés no pueden agotar todo el espectro y la gama de
dimensiones existentes en la realidad que circunda a los hablantes. De aquí
que sea comprensible que las investigaciones de DL que han surgido
consideraron otras áreas temáticas que resultaron significativas y coherentes
con los medios y factores que envuelven a los hablantes de cada región.
Medios y artificios para el análisis cuantitativo del léxico disponible
Después de hacer la revisión de aquellos conceptos que construyen la
comprensión de la DL, es necesario dar cuenta de los recursos que han
surgido para cuantificar el léxico que se entiende como disponible en una
comunidad de habla.
Los investigadores franceses citados previamente mantuvieron que el
índice de DL era igual a la frecuencia que presentaban las palabras vertidas
por los informantes. Sin embargo, esto no permitía tener una definición
cuantitativa que discriminara claramente los rangos de aparición de los
vocablos, pues sucedía que una palabra que aparecía n cantidad de veces en
los registros y otra que presentaba igual cantidad obtenían el mismo índice de
frecuencia sin importar el lugar o posición que ocuparan al ser evocados por los
informantes, a pesar de que los investigadores consideraban que el grado de
disponibilidad correspondía a la presencia más o menos inmediata de las
palabras en la memoria. Charles Müller (1973: 354-355) afirmó que en los
análisis debía atenderse el lugar de aparición de las palabras en los listados y
denomina que esto sería el índice de espontaneidad y hacer ver que es
necesario para considerar la disponibilidad tanto la frecuencia de los vocablos
como la espontaneidad de la aparición de los mismos.
Sin embargo, no fue sino hasta principio de los ochenta cuando
Humberto López Morales (Lorán y López Morales, 1983) diseñó fórmulas que
lograron incluir ambos elementos. Mas estos primeros artificios matemáticos no

30
lograron cubrir satisfactoriamente la necesidad de discriminación para los
vocablos que aparecían en los corpora debido a imprecisiones en
determinados factores de ponderación que se emplearon.
Fueron posteriormente Juan López Chávez y Carlos Strassburger Frías
(1987)3, en México, quienes pudieron hacer los ajustes adecuados en las
formulaciones y generar un artificio que considerara la frecuencia de los
vocablos y la posición de los mismos en los listados. La descripción de la
fórmula la he mostrado anteriormente. No estimo necesario dilucidar este
proceso de reformulación del artificio matemático, pues ya ha quedado
comprobado por diversos especialistas, entre ellos Humberto López Morales y
otros, que la eficacia de la fórmula de López Chávez y Strassburger es
contundente.
Sobre las aplicaciones de los estudios de DL
Un fruto primordial de los estudios de DL en las distintas sintopías ha
sido de orden pedagógico, pues desde los estudios en Francia a mediados del
siglo pasado hasta los más recientes, la necesidad de conocer el léxico de una
comunidad de habla ha permitido la descripción, por un lado, de las estructuras
léxicas en términos colectivos y, por otro, de aquello que requieren los
hablantes en distintos niveles educativos durante su formación académica para
acrecentar su caudal léxico, ya sea en lengua materna o en lengua extranjera.
Sostiene López Morales (1999: 20) que “el vocabulario fundamental de
una comunidad dada está constituido por el léxico básico y el disponible. Su
identificación es un ejercicio imprescindible para emprender cualquier tipo de
planificación relacionada con el léxico”. Esto debe orientar una visión rectora en
cuanto al aprendizaje del léxico, pues considerando la concepción de Dubois et
al. (1998:203) sobre léxico disponible quien destaca que “se denomina
vocabulario disponible al conjunto de palabras con una frecuencia baja y poco
estable, pero usuales y útiles, que están a disposición del locutor”, se torna
esencial el que los hablantes no sólo tengan noción fidedigna de las palabras
frecuentes de su lengua, las cuales son empleadas en las diferentes
3 Posteriormente a este artículo publicaron en 2000 otro texto en el que describen de manera exhaustiva las diferentes características de la fórmula de la DL con los ajustes hechos para que determine exactamente los índices.

31
situaciones de comunicación de la vida cotidiana, sino de todas aquellas que
son disponibles y que son evocadas por la memoria dependiendo de la
demanda comunicativa y en relación con la temática abordada.
Como interés formal de mi investigación, puedo mencionar que el
obtener los índices de DL de vocablos emitidos por adolescentes que cursan el
último grado de educación secundaria posibilitará tener un conocimiento cierto
acerca del léxico que poseen y corroborar las características del mismo. Ello
también creará la oportunidad para reflexionar y estimar posteriormente
posibles rutas para el enriquecimiento léxico de alumnos en este periodo, ya
que en México constituye el término del nivel básico según el currículum oficial.
Ante esto es pertinente reflexionar en torno de lo que hacen las
comunidades de habla para instaurar y desarrollar el léxico en sus miembros, a
través de distintas instancias y entidades, siendo una de ellas la educativa.
Refieren Cassany, Luna y Sanz (2007: 378) que los aprendizajes y el
conocimiento del vocabulario son decisivos para poder efectuar la
comunicación. Por ello resulta comprensible el hecho de que toda sociedad
promueva y detone la adquisición y aprendizaje formal de los distintos recursos
lingüísticos de los individuos. Además, afirman estos autores que el vocabulario
que se fija en nuestra memoria es el que hemos necesitado y usado y el que
más oímos y leemos.
Ante esto, también es posible reiterar que en cada individuo existen
complejos procesos de cognición y de génesis del lenguaje que inciden tanto
en el aprendizaje formal del léxico, como en la adición y activación del mismo.
Sin embargo, existen un cúmulo de experiencias en los sujetos que los llevan a
diversos encuentros con la realidad y los entornos en que se desenvuelven,
siendo éstos muy significativos para el desarrollo léxico.
Estas ideas permiten entender que la noción de aprendizaje de léxico no
puede ceñirse exclusivamente a la generación de un corpus o un listado de
palabras evocados en la mente de los hablantes, pues el bagaje o caudal léxico
de una persona está asociado indisolublemente a una serie de conocimientos,
ideas, fenómenos, características y funciones de ese vocabulario. Cada
palabra que un hablante conoce y entiende posee valor lingüístico, discursivo,
pragmático y referencial.

32
Dentro de los esfuerzos plausibles que se han dado en América debo
mencionar el trabajo de Max Echeverría 4 , quien diseñó un programa
informático denominado “Vocabulario disponible”, el cual permite a los alumnos
conocer el rendimiento léxico en aquellos centros de interés que elija.
Específicamente es una autoevaluación que da al alumno un conocimiento del
avance de su proceso de aprendizaje léxico y a su vez le ofrece una
comparación con los promedios nacionales.
4 Cfr. http://www.c5.cl/ieinvestiga/actas/tise99/html/papers/metacognicion

33
Precisiones terminológicas
Dentro del marco nocional que he generado incorporo a continuación
una serie de precisiones en relación con términos que en lo sucesivo tomarán
los sentidos que elucidaré y que son convenientes para lograr las descripciones
del fenómeno de la disponibilidad léxica.
Luis Fernando Lara( 2006:18) ha formulado una perspectiva de
aproximación conceptual sobre la noción de palabra y formula una interrogante:
“¿a qué se debe que la unidad palabra parece ser tan evidente para
muchísimas personas, tan válida psicológicamente hablando y, sin embargo,
de tan difícil explicación lingüística?” Posteriormente afirma:
“Hemos podido reunir las tres condiciones para determinar la
existencia de unidades palabra en cada lengua: sus características
fonológicas (estructura silábica y existencia de funciones demarcativas
de algunos fonemas o de algún rasgo suprasegmental), su característica
semántica de unidad de denominación y sus características
morfológicas, determinadas con ayuda de varios procedimientos. Juntas,
las tres condiciones se vuelven suficientes.
Hemos agregado a estas tres condiciones, a la vez, una extensión
de la concepción palabra, cuya procedencia es perceptual y económica,
aun cuando la lingüística no se haya preocupado, hasta la fecha, por
someter a experimentación esas propiedades de la unidad palabra.”
(Lara 2006:81-82)
Esto me conduce a afirmar llanamente que la palabra constituye una
unidad que se puede identificar, abstraer y contar fácilmente aun por cualquier
hablante común. Sin embargo, las necesidades propias de la investigación de
léxico imponen medios demarcativos para precisar formalmente la organización
de los hallazgos y clarificar las descripciones en torno del fenómeno.
Lo anterior ha promovido que quienes ya han realizado previamente
trabajos sobre DL adopten el uso de vocablo para referirse a toda forma del
contenido que se comporte como representante de un paradigma completo de
flexión, de conjugación o de derivación correspondiente a una unidad de
denominación (Lara 2006: 138).

34
Precisa aún más Lara afirmando que cada aparición de una palabra en
un texto será una ocurrencia. Un tipo o vocablo será cada palabra encontrada,
pero eliminando sus repeticiones. Adicionalmente sobre el vocablo puedo
referir:
“Está formado por un lexema y el conjunto de paradigmas de morfemas
ligados con que se manifiesta en el uso. El vocablo, por lo tanto, es una forma
léxica abstracta, de naturaleza social y elaborada a lo largo de la historia de la
comunidad lingüística. Su abstracción consiste en el hecho de que se ha
construido como esquema o como representación de un conjunto de formas
léxicas que ocurren en el habla como palabras. Así, por ejemplo, en español
formas como correr, amar o subir son vocablos que representan más de un
ciento de palabras, correspondiente a todas sus conjugaciones”. (Lara
1997:119-120).
Por todo esto, coincido en esta afirmación de Lara que consuma la idea
fundamental de este subapartado: “palabra será ahora un término de
observación y descripción, correspondiente a un fenómeno real de las lenguas;
vocablo será un término de descripción y primera teorización, que sirve como
instrumento abstracto de la investigación lingüística”. (Lara 2006:138-139)
De igual manera, considero al vocablo como una unidad léxica, pues
entiendo que esta noción también se describe como “la unidad conceptual base
en el aprendizaje del vocabulario. Implica la unión de una forma léxica, que
contenga al menos una palabra, con un significado unitario” (Cervero y
Pichardo, 2000:192) o “con un valor semántico identificable (Haensch,
1997:38)” (Gómez Devís, 2004: 42)

35
Metodología En apartados anteriores he referido los orígenes de la metodología y los
presupuestos teóricos que han determinado la obtención de corpus de léxico
disponible, por tal razón no ahondaré más en éstos.
Centraré la atención en los distintos rubros que definen este
planteamiento metodológico y que en efecto dan respuesta a los objetivos
adoptados. Tales rubros también se siguen en las investigaciones que se
enmarcan dentro del proyecto panhispánico, tal y como lo advierten distintos
estudiosos, entre ellos Ma. Begoña Gómez Devís (2004:62):
- selección de la muestra: centros educativos y variables sociológicas
- técnica de obtención de datos. Trabajo de campo.
- Criterios de edición de los materiales
- Procesamiento de los datos.
Selección de la muestra
El proceso de selección de la muestra se hizo entre alumnos de nivel
secundaria, exclusivamente de aquéllos que cursaran el tercer grado, es decir,
el último de los años de la educación básica en México. Lo anterior se dio así
porque en efecto un interés especial ha sido conocer el corpus léxico de esta
población de hablantes con la finalidad ulterior de permitir otras investigaciones
que se desarrollen en torno de medios y recursos que favorezcan el
aprendizaje y la enseñanza del léxico.
En efecto, la cantidad de encuestas en un primer momento,
considerando la representatividad y el universo de dicha población, apuntaba a
una muestra de tamaño amplio. Sin embargo, hubo dificultades para obtener la
aprobación de las autoridades educativas en el proceso de aplicación de
encuestas dentro de las escuelas. Por lo tanto, y atendiendo a los objetivos
esenciales de la investigación que eran tener una comparación y una primera
aproximación al léxico disponible, sólo tomé un total de 48 informantes para
efectuar los análisis. No es necesario aclarar que el grado de representatividad
con esta cantidad de informantes es discutible, sin embargo, permite tener ya
un acercamiento que de manera pertinente permite conocer una realidad léxica
en un conjunto de hablantes.

36
Los centros educativos fueron elegidos sujetándome a las posibilidades
de ingreso en los mismos, pues no se contó con el apoyo de las instancias
administrativas escolares y esto dificultó el acercamiento a los alumnos.
Finalmente se logró la aprobación en dos escuelas secundarias, una privada y
una pública; el ciclo escolar fue el 2007-2008.
Es necesario referir que la mayoría de los estudios de léxico disponible
se han realizado con muestras integradas por informantes en edad escolar,
particularmente niños o adolescentes.
Los dos centros educativos se encuentran ubicados en zonas urbanas y
en áreas del norte y del noroeste de Culiacán, Sinaloa, única ciudad en la que
se aplicaron las encuestas.
La técnica de muestreo empleó también una determinación proporcional
y se tomaron en cuenta las variables de sexo y tipo de institución educativa
(privada o pública), la edad de los alumnos estuvo comprendida entre los 14 y
los 15 años.
Dentro de las características de la población seleccionada es notorio
destacar que al elegir informantes que cursan el último grado de estudios de la
educación básica se hace posible conocer el caudal léxico que esta formación
esencial posibilita en tales personas.
Precisamente los documentos oficiales, entre ellos el programa de
estudios de Español, emanado del Plan de Estudios de Educ. Básica 2011,
elucidan que al término de la educación básica una persona es capaz de
desenvolverse en los contextos del acontecer social de manera franca y con las
competencias apropiadas para una comunicación eficiente. De ahí la relevancia
de esta característica en la muestra, que permite tener una aproximación a la
formación educativa para valorar el posible impacto en la construcción del
léxico.
En cuanto al sexo, sobra destacar que ya los estudios de la
sociolingüística han procurado determinar si los comportamientos lingüísticos
entre hombres y mujeres son distintos. También entiendo que no es apropiado
delimitar posibles distinciones en términos estrictamente biológicos sino a partir
de los elementos que denotan el comportamiento social de éstos y de aquéllas,
reflejada tal conducta en los usos léxicos, que emanan de los roles y papeles

37
socio-culturales que son adquiridos por ambos en el seno de las comunidades.
Para tal efecto, la cantidad de hombres fue igual a la de mujeres: 24.
En relación con el tipo de centros educativos: privado / público, cabe
mencionar que en el país es obligatoria la educación básica y por ende existen
una cantidad mayor de centros públicos, pero en la última década ha
aumentado la cantidad de centros privados, especialmente de aquéllos que
atienden a los alumnos en edades de cursar la educación básica. Sólo debo
reafirmar que logré aplicar las encuestas en dos centros: uno privado y uno
público, éste último con alumnos provenientes de estratos económicos bajos o
medios, esto en función del conocimiento de los centros poblacionales en los
que viven y que fueron confirmados por las autoridades de esos centros de
estudios. Así, aunque no incorporé la variable de nivel sociocultural sí fue
posible encontrar indicios que establecen connotaciones de esta naturaleza, ya
que el centro educativo privado contaba en su mayoría con alumnos
provenientes de familias con niveles de estudios, profesiones o ingresos
salariales mayores que las de aquellos alumnos que estudiaban en el centro
público. Esto lo constaté con preguntas que oralmente hice a los jóvenes para
saber las profesiones y oficios de sus padres, así como de los sueldos
estimados que tenían los progenitores.

38
Obtención de los datos
Atendiendo a la metodología decantada de los primeros estudios de DL, así
como de posteriores, esta investigación ha empleado una prueba asociativa
como instrumento para recoger las unidades léxicas evocadas por los
informantes, las cuales no cuentan habitualmente con una estabilidad
estadística. El recurso de la encuesta utilizada, a la que designo como
encuesta de disponibilidad léxica, constituye una técnica en la que los
hablantes responden de manera voluntaria y por escrito. El documento consta
de una sección en la que los informantes registraron los datos socioculturales:
edad, sexo, grado escolar cursado, tipo de escuela: privada o pública, y
adicionalmente solicitaba el oficio u ocupación de ambos padres. Estos
elementos permitían la post-estratificación social. En la primera página se
incluyó también un apartado con instrucciones escritas pertinentes para el
llenado de la encuesta.
Se incorporaron además cinco hojas en las que aparecían los centros de
interés numerados en columnas (tres por página, excepto la última que
presentaba dos) y con una serie de líneas debajo de cada estímulo (para el que
se empleó el nombre sugerido desde los estudios iniciales) con el fin de facilitar
el registro de las palabras. Los centros de interés quedaron repartidos de la
siguiente manera: página uno: CI 1 Las partes del cuerpo, CI 2 La ropa: vestido
y calzado, CI 3 La casa: el interior y sus partes; página dos: CI 4 Muebles y
enseres domésticos, CI5 Alimentos: comidas y bebidas, CI 6 Objetos colocados
sobre la mesa; página tres: CI 7 La cocina y sus utensilios, CI 8 La escuela:
muebles y útiles, CI 9 Electricidad y aire acondicionado; página cuatro: CI 10 La
ciudad, CI 11 La naturaleza, CI 12 Medios de transporte; página cinco: CI 13
Trabajos de campo y jardín, CI 14 Los animales, CI 15 Diversiones y deportes;
página seis: CI 16 Profesiones y oficiones y CI 17 Computación e internet. En
el apartado de anexos incluyo el formato empleado.
La elección de mantener los centros de interés originales obedece al
propósito de lograr correspondencia metodológica y congruencia con el
conjunto de investigaciones hechas, tanto con las realizadas dentro del
proyecto panhispánico, cuyo liderazgo mantiene Humberto López Morales,
como con otras que se han realizado en distintas sintopías que han procurado

39
esta igualdad. Sin embargo, uno de los cuestionamientos que también
sostengo se relaciona con el hecho de si con sólo dieciséis centros de interés
se da cabida al amplio espectro y panorama léxico que condensa la realidad
humana en sus múltiples posibilidades de concreción comunicativa. Considero,
al igual que quienes anteriormente han tenido esta interrogante, y a riesgo de
mostrar un hecho que puede entenderse como obvio, que no es así. Por tal
razón, y debido al tiempo que tenía para desarrollar la investigación, sólo me
permití adicionar otro centro de interés que vinculara a los informantes
adolescentes con el universo de la computación y el internet, como un posible
bastión de experiencias y oportunidades que en nuestra contemporaneidad
ofrecen distintas posibilidades léxicas. En otras investigaciones se han
agregado centros de interés relacionados con dimensiones abstractas como los
defectos y cualidades (Canizal Arévalo, 1987), las artes, mundo espiritual
(Vargas, 1991) o ciencia y tecnología (Valencia, 2000). Entiendo, por
consiguiente, que sí será posible realizar posteriormente otros trabajos que den
cuenta de nuevos centros de interés para conocer con más detenimiento el
fenómeno.
Además debo agregar que el procedimiento empleado en la aplicación
de las encuestas contempló un tiempo límite de reacción por parte de los
informantes. El tiempo asignado en el proyecto panhispánico es de dos
minutos. Es en tal lapso en el que los sujetos responden registrando en las
columnas las palabras evocadas al momento de recibir el estímulo. Tales
listados son abiertos, pues no se define una cantidad específica de voces a
anotar. Debido a esto cada informante registraría todas aquellas palabras que
recordase en el tiempo señalado.
Sin embargo, para fines de esta investigación, dentro de los que he
referido el hacer una comparación de la cantidad de palabras emitidas
empleando los dos minutos y utilizando tres minutos como tiempo límite de
reacción, al momento de aplicar la encuesta se dio la indicación a los alumnos
que en el instante que el aplicador expresara “dos minutos” registrara un
asterisco al lado de la palabra escrita y que continuara anotando las palabras
hasta que se diera el término de los tres minutos, al concluirse el tiempo el
aplicador manifestaría oralmente la palabra “fin”. Como indicación adicional, las
instrucciones escritas dadas al informante referían: “Anota todas las palabras

40
que vengan a tu mente” relacionadas con el centro de interés planteado. No se
otorgaron mayores precisiones ni más elementos de identificación para cada
uno de los centros de interés, salvo aquellas referencias nocionales para
quienes por alguna razón se habían mostrado dispersos al momento de leer
tanto las instrucciones como los nombres de cada centro de interés.
Ahondaré a continuación en la decisión de ofrecer un lapso de tres
minutos como tiempo límite para la producción de voces en cada uno de los
centros de interés. Juan López Chávez (2003:40) sostiene, como lo he
mostrado en líneas anteriores, que el tiempo de dos minutos es insuficiente
para permitir que el proceso de evocación mediante la memoria logre que el
hablante recupere aquellas unidades léxicas asociadas con el estímulo dado a
través del centro de interés y que un tercer minuto ofrece un lapso que sí
detona una producción léxica mayor. Por tal razón, he decidido hacer la
comparación y determinar las cantidades de palabras emitidas en el minuto
tres.
Criterios de edición de los materiales
Un aspecto que es necesario precisar al realizar trabajos de obtención
de corpus con voces emitidas por un conjunto de hablantes es el relacionado
con el tratamiento que se dará a ese conjunto para determinar qué voces
permanecerán en él. En efecto, dependerá de los objetivos que traza el
investigador la posterior definición y estandarización de los datos obtenidos.
En los procesos estadísticos relacionados con el léxico es el lema la unidad
funcional y suele emplearse como sinónimo de vocablo (Gómez Devís, ídem).
Por tanto, el proceso de lematización consiste en conjuntar las diversas formas
de un mismo vocablo, así como por otro lado está separar las expresiones
homógrafas que denotan vocablos distintos.
Sin embargo, he procurado mantener una edición no estricta con el fin
de mantener prácticamente todas aquellas formas emitidas por los informantes
tras el afán de resguardar una fidelidad al corpus dado por los informantes,
debido especialmente a que sí hay posibilidades de distinción en el dialecto
regional que ofrecen matices de significación variados para palabras que
pudieran agruparse en un vocablo y con ello se sesgaría una gama de
designación y de comprensión de la realidad.

41
Cabe destacar que se ha realizado en una primera edición una
corrección ortográfica, se respetaron en su mayoría las distintas designaciones
usadas en expresiones que proceden particularmente del inglés, así como
distintas entradas evocadas por los hablantes, como ha sido el uso de ciertos
diminutivos para casos en los que éstos ofrecen una distinción de sentido. Pero
no se han mantenido otros casos de palabras diferentes que denotan el mismo
significado (ejemplo: TV, televisión, televisor, tele). De todo lo anterior resulta
que el corpus mostrado en este trabajo corresponde a la edición definitiva.
Algunas de estas resoluciones sí obedecen a la inquietud de indagar cuántas
designaciones aparecen en los registros que ofrecen los hablantes y que
denotan referentes iguales.
Los lineamientos básicos utilizados en la edición los concreto de la
siguiente manera:
- Omisión de formas repetidas. Aquellas palabras repetidas en un mismo
centro de interés se eliminan y se mantiene la que aparece en un primer
momento en el listado.
- Ortografía. Debido a que los informantes en edad escolar aún mantienen
importantes vicios y errores de naturaleza gráfica se hace necesaria la
corrección ortográfica.
- En los casos de neologismos o extranjerismos, se ha optado por las
formas adoptadas por el DRAE o por el DEM de manera preferencial.
Ante aquellos casos no registrados en tales fuentes se registran las
formas dadas por los informantes.
- Ha sido una decisión en la investigación dar entrada a las voces tanto
extranjeras como a las correspondientes españolas para estimar los
usos privilegiados por los hablantes.
- Marcas comerciales. No todas las referidas por los hablantes se
mantienen en el corpus, sin embargo, aquéllas que sí aparecen se
anotaron con iniciales minúsculas. Algunos investigadores han referido
que sólo deberían aceptarse las voces que estén plenamente
lexicalizadas. Mas no resulta claro valorar cuándo una voz adquiere este
status o la lexicalización sí existe. Por lo tanto, mi determinación ha sido
incluirlas si la designación ofrecida constituye una voz usual, difundida
y/o extendida en la comunidad de habla, en diferentes contextos y

42
registros. Considero que, como lo han señalado otros estudiosos, la
investigación de la DL abre las puertas para estimar los usos y las
formas en que los informantes, en este caso particular los adolescentes,
optan por las marcas comerciales para designar productos o realidades
concretas.
- Neutralización de variantes propiamente flexivas. Las variantes
morfológicas de un vocablo se reducen a formas no marcadas del
paradigma. Los sustantivos se registran en singular, así como los
adjetivos, y si presentan variación de género, en masculino. Sin
embargo, hay excepciones que se dan debido a usos que denotan
variaciones concretas que orientan a sentidos diversos (ejemplo:
gorditas, voz que se emplea en la región, y en otras más, para designar
un tipo de alimento al que no se le designa como gorda o gordas).
Tras lo anterior, sí es prudente manifestar que todo este proceso de edición
ha llevado a una toma de decisiones para determinar si un vocablo se registra
tal cual o si habría necesidad de modificarlo sin que ello implique
transformaciones de otra índole. Esto se acentúa más si se entiende que en el
momento en el que un informante evoca un vocablo durante la aplicación de la
encuesta se desconocen los contextos desde los que se produce. Esta
problemática no está del todo resuelta, sin embargo, entiendo que llevará
posteriormente a afinar los procesos metodológicos con el propósito de
articular otras perspectivas que denoten un alcance mayor en el análisis y
obtención de resultados.
En relación con esto, ya ha afirmado Luis Fernando Lara (1990:98), en
particular sobre la metodología aplicada para la obtención del Corpus del
Español Mexicano Contemporáneo, que lo cuantificado “son significantes y no
la compleja relación que hay entre éstos y los sememas que vehiculan en
cuanto signos polisémicos”. En la investigación de LD sucede un hecho
análogo, los vocablos emitidos por los informantes no tienen tras de sí, en los
registros de las encuestas, aquellos significados dados y por ello al realizar una
cuantificación y posterior análisis he procurado una visión de notoria objetividad
para racionalizar los sentidos que por el uso social le otorga un hablante a toda
voz y que depende, reitero, de los procesos mismos de significación
elaborados gracias a la intercomprensión presente en el conjunto de discursos

43
probados y generados en el seno del grupo social, que en otros términos se ha
entendido como el consenso socio-lingüístico, sujeto a tiempos y espacios
concretos de producción.
Es pertinente señalar que cada uno de los centros de interés posibilita
un espectro distinto de la realidad que vive cada persona en los diferentes
entornos en los que se desenvuelve y todo ello arroja que los vocablos emitidos
se expresen de acuerdo con decisiones que cada informante toma en breves
instantes y que dejan visualizar los registros y estilos que adopta toda persona,
éstos van desde la total espontaneidad al optar por palabras que proceden de
registros familiares, coloquiales y populares hasta el máximo cuidado el referir
voces que proceden de registros especializados o cultos. Ejemplo de esto es el
uso de la palabra huevos que algunos hablantes emplearon para designar los
testículos en el centro de interés de las partes del cuerpo y otros registraron la
voz testículos, derivada de formas especializadas o cultas. También es posible
apreciar las elecciones que dialectalmente toma un hablante al emplear voces
que proceden de usos regionales, o bien, en caso contrario emplea unidades
cuya difusión y dispersión son amplias en todo el país.
Todos estos elementos otorgan matices que son complejos de registrar y
denotar mediante un tratamiento de selección para la obtención de un corpus.
Por tal razón, la premisa esencial ha sido salvaguardar la fidelidad y atenuar la
estandarización que pudiera decantarse en una pérdida de riqueza y
diferenciación que léxicamente tuviera sentido.

44
Procesamiento informático de los datos
Una labor crucial para la obtención de información que explique lo que
se aprecia en el corpus y las relaciones que existen con los hablantes es la
tarea de cuantificación de los vocablos a través de procesos que se llevan a
cabo mediante el uso de instrumentos informáticos diversos. En particular he
hecho uso de la herramienta de Excel para registrar y manipular las bases de
datos capturadas en sistemas de cómputo. Además he empleado el programa
de cómputo denominado IDL 2007, cuyo diseño y concreción fue obra de Juan
López Chávez y Daniel Acosta Escareño, ambos de la Universidad Autónoma
de Zacatecas. Tal programa permite obtener tablas de frecuencias de los
vocablos, así como los índices de disponibilidad léxica (IDL) de cada uno de
ellos.
Esta tarea requirió de otros subprocesos específicos, entre ellos: la
captura de todas las encuestas en archivos de Excel. Después el programa IDL
es alimentado con esa base de datos y con ello se permite el cálculo del índice
de DL de cada vocablo concentrado en los diecisiete centros de interés.
El recuento numérico de las palabras y vocablos, que son estrictamente
las variables dependientes, así como la identificación codificada de la serie de
variables extralingüísticas, que constituyen las variables independientes, es el
quehacer medular de todo el procesamiento informático, al igual que el cálculo
formal del IDL.

45
Análisis de los datos Análisis cuantitativo
En este apartado se muestran los resultados de las cuantificaciones realizadas.
Los mismos permitirán apreciar con detenimiento una serie de relaciones y
vínculos que en términos conceptuales será preciso elucidar para lograr la
aprehensión del fenómeno de la DL en la sintopía analizada.
Refiero en primer término, mediante una tabla comparativa (tabla 1), los
totales de palabras que el conjunto de los informantes ofreció en los
cuestionarios, tanto en el tiempo de dos minutos como en el de tres, así como
las cantidades de palabras según el sexo de los informantes. En la fila final de
la tabla siguiente aparecen los promedios de palabras en ambos tiempos (estos
promedios están en relación con el total de palabras en cada tiempo y el total
de informantes de la muestra -48 sujetos-).
Tabla 1. Comparativo de palabras totales de hombres y mujeres.
Además presento los promedios de palabras según el sexo de los
informantes (tabla 2).
Tabla 2. Comparativo de promedio de palabras de hombres y mujeres.
DOS MINUTOS TRES MINUTOS
MUJERES 9,171 12,431
HOMBRES 8,520 11,373
TOTAL DE PALABRAS 17,691 23,804
PROMEDIO DE PALABRAS 368.56 495.92
DOS MINUTOS TRES MINUTOS
Promedios de palabras de
mujeres 382.13 517.96
Promedios de palabras de
hombres 355 473.88

46
La diferencia en la cantidad de palabras producidas en el tiempo límite
de tres minutos en relación con el total de palabras emitidas en el tiempo de
dos minutos es de seis mil ciento trece. Por otro lado, cabe denotar que las
informantes femeninas presentan promedios de palabras mayores a los de los
informantes masculinos en ambos tiempos.
En cuanto a los promedios de palabras de acuerdo con el tipo de
institución educativa, los datos son los siguientes:
Tabla 3. Comparación de promedios de palabras de los hombres de
escuela privada y pública. HOMBRES
PROMEDIOS DE PALABRAS TOTALES DE PALABRAS
DOS MINUTOS TRES MINUTOS DOS MINUTOS TRES MINUTOS
ESCUELA
PRIVADA 415 571 4,980 6,849
ESCUELA
PÚBLICA 295 377 3,540 4,524
GRAN TOTAL 8,520 11,373
Tabla 4. Comparación de promedios de palabras de las mujeres de escuela
privada y pública. MUJERES
PROMEDIOS DE PALABRAS TOTALES DE PALABRAS
DOS MINUTOS TRES MINUTOS DOS MINUTOS TRES MINUTOS
ESCUELA
PRIVADA 449 614 5,388 7,369
ESCUELA
PÚBLICA 315 421 3,783 5,062
GRAN TOTAL 9,171 12,431
Como es posible apreciar, son informantes de institución privada quienes
alcanzan una mayor producción, tanto del sexo femenino como del masculino,
en ambos tiempos. Pero al ponderar la cantidad de palabras producidas por las
mujeres tanto en la escuela privada como en la pública, son éstas quienes
alcanzan las mayores cantidades.

47
A continuación empleo una gráfica para ilustrar lo que previamente he
mencionado.
Gráfica 1. Comparación de palabras emitidas por hombres y mujeres de centro
educativo privado y público.
Es preciso advertir que hay una constante en la mayor producción de
ocurrencias emitidas por las mujeres de ambos centros educativos, esto mismo
sucede en el caso de los hombres en los dos tipos de centros educativos. En el
caso de las mujeres de centro público sólo alcanzan un 69% de la producción
alcanzada por las mujeres de centro privado. En el caso de los hombres, los
pertenecientes a centro público alcanzan apenas el 66% de la producción de
los pertenecientes a centro privado.
Los datos previos atienden a las palabras generadas por los
informantes. En tal estatus se considerará como palabra toda voz producida
por los hablantes independientemente de sus repeticiones en el corpus. A
continuación refiero los datos de los vocablos.
La tabla 5 compara las cantidades totales de vocablos emitidos por los
informantes en los tiempos límite que se dieron durante las encuestas: dos y
tres minutos.
Tabla 5. Comparación de cantidades totales de vocablos emitidos en dos
y tres minutos. DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 4,230 5,428
7369
5062
6849
4524
0
1000
2000
3000
4000
5000
6000
7000
8000
0 0.5 1 1.5 2 2.5
MUJERES
HOMBRES

48
Además enlisto en tablas similares las cantidades de vocablos emitidos
para cada uno de los centros de interés:
Tabla 6. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Partes del cuerpo. CENTRO DE INTERÉS 1 (PARTES DEL CUERPO)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 156 189
Tabla 7. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La ropa: vestido y calzado. CENTRO DE INTERÉS 2 (LA ROPA: VESTIDO Y CALZADO)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 157 199
Tabla 8. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La casa: el interior y sus partes.
CENTRO DE INTERÉS 3 (LA CASA: EL INTERIOR Y SUS PARTES)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 216 273
Tabla 9. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Muebles y enseres domésticos.
CENTRO DE INTERÉS 4 (MUEBLES Y ENSERES DOMÉSTICOS)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 251 354
Tabla 10. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Alimentos: comidas y bebidas.
CENTRO DE INTERÉS 5 (ALIMENTOS: COMIDAS Y BEBIDAS)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 303 385

49
Tabla 11. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Objetos colocados sobre la mesa. CENTRO DE INTERÉS 6 (OBJETOS COLOCADOS SOBRE LA MESA)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 294 374
Tabla 12. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La cocina y sus utensilios. CENTRO DE INTERÉS 7 (LA COCINA Y SUS UTENSILIOS)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 246 303
Tabla 13. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La escuela: muebles y útiles.
CENTRO DE INTERÉS 8 (LA ESCUELA: MUEBLES Y ÚTILES)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 330 419
Tabla 14. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Electricidad y aire acondicionado.
CENTRO DE INTERÉS 9 (ELECTRICIDAD Y AIRE ACONDICIONADO)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 217 296
Tabla 15. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La ciudad.
CENTRO DE INTERÉS 10 (LA CIUDAD)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 363 495

50
Tabla 16. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés La naturaleza. CENTRO DE INTERÉS 11 (LA NATURALEZA)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 360 447
Tabla 17. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Medios de transporte.
CENTRO DE INTERÉS 12 (MEDIOS DE TRANSPORTE)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 129 164
Tabla 18. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Trabajos de campo y de jardín.
CENTRO DE INTERÉS 13 (TRABAJOS DE CAMPO Y JARDÍN)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 310 410
Tabla 19. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Los animales.
CENTRO DE INTERÉS 14 (LOS ANIMALES)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 214 244
Tabla 20. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Diversiones y deportes.
CENTRO DE INTERÉS 15 (DIVERSIONES Y DEPORTES)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 298 393

51
Tabla 21. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Profesiones y oficios. CENTRO DE INTERÉS 16 (PROFESIONES Y OFICIOS)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 246 298
Tabla 22. Comparación de cantidades de vocablos en dos y tres minutos
para el centro de interés Computación e internet. CENTRO DE INTERÉS 17 (COMPUTACIÓN E INTERNET)
DOS MINUTOS TRES MINUTOS
CANTIDAD DE VOCABLOS 140 185
A continuación se muestra una gráfica de barras (gráfica 2) que
concentra los datos relacionados con las cantidades de vocablos emitidos en el
tiempo límite de dos minutos.
Gráfica 2. Producción de vocablos emitidos en el tiempo de dos minutos en
cada centro de interés.
Como se aprecia en la gráfica, es el centro de interés la ciudad, con
363, el que presenta la mayor cantidad de vocablos y el de menor cantidad es
el de medios de transporte, con 129.
156 157 216
251 303 294
246
330
217
363 360
129
310
214
298 246
140
0 50 100 150 200 250 300 350 400
Cantidad de vocablos
Cantidades de vocablos en dos minutos
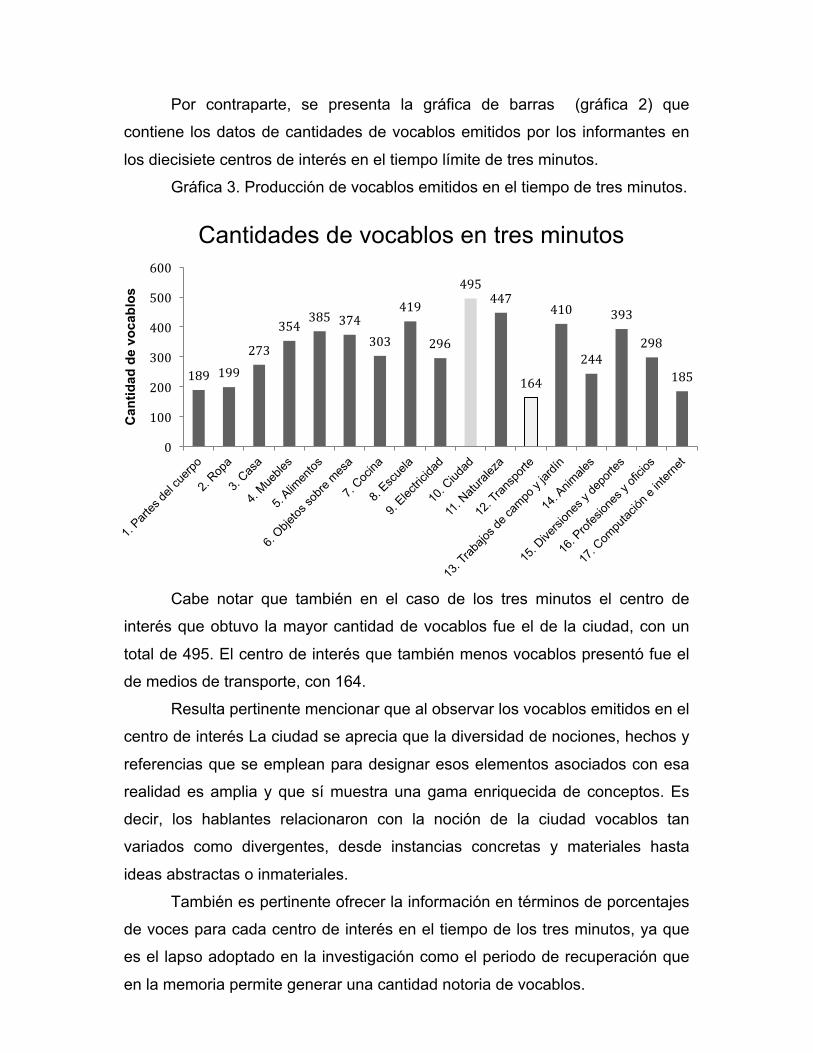
52
Por contraparte, se presenta la gráfica de barras (gráfica 2) que
contiene los datos de cantidades de vocablos emitidos por los informantes en
los diecisiete centros de interés en el tiempo límite de tres minutos.
Gráfica 3. Producción de vocablos emitidos en el tiempo de tres minutos.
Cabe notar que también en el caso de los tres minutos el centro de
interés que obtuvo la mayor cantidad de vocablos fue el de la ciudad, con un
total de 495. El centro de interés que también menos vocablos presentó fue el
de medios de transporte, con 164.
Resulta pertinente mencionar que al observar los vocablos emitidos en el
centro de interés La ciudad se aprecia que la diversidad de nociones, hechos y
referencias que se emplean para designar esos elementos asociados con esa
realidad es amplia y que sí muestra una gama enriquecida de conceptos. Es
decir, los hablantes relacionaron con la noción de la ciudad vocablos tan
variados como divergentes, desde instancias concretas y materiales hasta
ideas abstractas o inmateriales.
También es pertinente ofrecer la información en términos de porcentajes
de voces para cada centro de interés en el tiempo de los tres minutos, ya que
es el lapso adoptado en la investigación como el periodo de recuperación que
en la memoria permite generar una cantidad notoria de vocablos.
189 199 273
354 385 374
303
419
296
495 447
164
410
244
393
298
185
0
100
200
300
400
500
600
Can
tidad
de
voca
blos
Cantidades de vocablos en tres minutos

53
Gráfica 4. Porcentajes de vocablos para cada centro de interés en el
lapso de tres minutos.
Como se aprecia en esta gráfica (gráfica 3), y en consonancia con las
gráficas previas, es el centro de interés de la ciudad el que presenta el mayor
porcentaje de vocablos, 9%, y a éste le sigue el de la naturaleza y la escuela,
así como el de los trabajos de campo y jardín con un 8%. Es posible afirmar
que estos centros de interés ofrecen a los hablantes una serie de posibilidades
léxicas dadas por el contexto tanto en términos culturales y sociales, como
económicos, pues el hecho de que la localidad mantenga una actividad
económica sustentada en el agricultura, así como la ganadería y otros
similares, permite que las experiencias próximas de estos hablantes estén
nutridas de diferentes recursos de designación para esta dimensión de la
realidad, asociada especialmente con el centro de interés denominado
Partes del cuerpo 3%
Ropa 4% Casa
5%
Muebles 7%
Alimentos 7%
Objetos sobre mesa 7%
Cocina 6%
Escuela 8%
Electricidad 5%
CIUDAD 9%
Naturaleza 8%
Transporte 3%
Trabajos de campo y jardín
8%
Animales 4%
Diversiones y deportes
7%
Profesiones y oficios
5%
Computación e internet
3%
PORCENTAJE DE VOCABLOS TRES MINUTOS

54
Trabajos de campo y jardín. Con mayor razón lo anterior sucede con el centro
de interés de la escuela, debido a que la totalidad de los hablantes
encuestados son estudiantes de secundaria y la aplicación misma del
instrumento de la encuesta se realizó precisamente dentro de las aulas de las
instituciones educativas. Esto genera que tales hablantes mantengan en su
memoria reciente nociones, hechos y otros vocablos vinculados directamente
con la dimensión de lo escolar.
Con el propósito de dilucidar las relaciones que cuantitativamente se
presentan con los datos previos, muestro una gráfica que reúne las cantidades
de vocablos emitidos tanto en los dos como en los tres minutos concedidos a
los informantes.
Gráfica 5. Comparación de cantidades de vocablos en ambos lapsos.
Acompañando a la información anterior también es posible destacar las
diferencias en cantidades de vocablos para cada centro de interés. El siguiente
listado (tabla 23) concentra tales datos.
Tabla 23. Diferencias en cantidades de vocablos por cada centro de
interés, en función de los lapsos de dos y tres minutos.
0 50 100 150 200 250 300 350 400 450 500
156 157 216
251 303 294
246
330
217
363 360
129
310
214
298 246
140 189 199
273 354 385 374
303
419
296
495 447
164
410
244
393
298
185
Comparación en producción de vocablos en dos y tres minutos
Dos minutos
Tres minutos

55
CENTRO DE INTERÉS
CANTIDAD DE
VOCABLOS (DOS
MINUTOS)
CANTIDAD DE
VOCABLOS (TRES
MINUTOS
DIFERENCIA
1. Partes del cuerpo 156 189 33 2. Ropa 157 199 42 3. Casa 216 273 57 4. Muebles 251 354 103 5. Alimentos 303 385 82 6. Objetos sobre mesa 294 374 80 7. Cocina 246 303 57 8. Escuela 330 419 89 9. Electricidad 217 296 79 10. Ciudad 363 495 132 11. Naturaleza 360 447 87 12. Transporte 129 164 35 13. Trabajos de campo y jardín 310 410 100 14. Animales 214 244 30 15. Diversiones y deportes 298 393 95 16. Profesiones y oficios 246 298 52 17. Computación e internet 140 185 45
TOTALES 4,230 5,428 1,198
Se debe advertir que el tercer minuto ha permitido la recuperación en la
memoria de los hablantes de un total de mil ciento noventa y ocho vocablos, lo
cual constituye un 28.32% de crecimiento en el corpus léxico en comparación
con el resultado de los dos minutos. Esto representa casi un tercio más de
vocablos generados durante el lapso añadido. Aunque cabe mencionar que el
comportamiento dado en el crecimiento en cada uno de los centros de interés
es muy variado, pues en el de los animales hubo un incremento de 30
vocablos y en el de las partes del cuerpo ascendió a 33. Por contraparte, el
centro que registró un aumento mayor fue el de la ciudad, con 132, así como
otros dos centros: el de los muebles, con 103 voces y el de los trabajos de
campo y jardín, con 100 voces más.
El hecho de que no se mantenga un crecimiento homogéneo o similar en
todos los centros de interés lo explico a partir de las divergencias conceptuales
o nocionales que ofrece cada uno de ellos y las posibles experiencias socio-
culturales que sustentan el sistema léxico de los hablantes; tales experiencias
se derivan de todas las vivencias y las acciones en las que se desenvuelven

56
los hablantes en sus comunidades de habla. Estimo pertinente referir que hará
falta un estudio que permita encontrar la producción de vocablos en hablantes
no alfabetizados para realizar las comparaciones con hablantes alfabetizados
y así dilucidar con mayor certidumbre si el aporte que otorga la escuela como
entidad de formación lingüística es determinante.
Análisis cuantitativo en función de las variables de sexo y tipo de centro
educativo en el lapso de tres minutos
Añado otra tabla comparativa en la que se aprecian las distinciones
entre las cantidades de vocablos atendiendo al sexo de los informantes, en el
lapso de tres minutos para cada uno de los diecisiete centros de interés (tabla
24).
Tabla 24. Diferencias en cantidades de vocablos por cada centro de
interés, en función del sexo, en el lapso de tres minutos.
CENTRO DE INTERÉS MUJERES HOMBRES DIFERENCIA 1. Partes del cuerpo 135 142 7 2. Ropa 140 135 5 3. Casa 175 197 22 4. Muebles 248 234 14 5. Alimentos 280 275 5 6. Objetos sobre mesa 269 250 19 7. Cocina 222 206 16 8. Escuela 309 273 36 9. Electricidad 203 197 6 10. Ciudad 354 290 64 11. Naturaleza 307 315 8 12. Transporte 123 121 2 13. Trabajos de campo y jardín 290 244 46 14. Animales 199 189 10 15. Diversiones y deportes 259 265 6 16. Profesiones y oficios 228 218 10 17. Computación e internet 132 121 11
TOTALES 3873 3672 201
Añado otra gráfica en la que se muestra la comparativa de las
cantidades de vocablos generados por hombres y mujeres.

57
Gráfica 6. Comparación entre cantidades totales de vocablos producidos
por mujeres y hombres en el lapso de tres minutos.
En este caso, la producción de vocablos de los hombres alcanza casi el
95% de la que tuvieron las mujeres. Por tanto, no hay un margen amplio de
sobreproducción.
Es viable generar otra comparación de vocablos en función de los dos
tipos de centros educativos: público y privado (tabla 25).
Tabla 25. Diferencias en cantidades de vocablos por cada centro de
interés, en función del tipo de centro educativo, en el lapso de tres minutos.
CENTRO DE INTERÉS ESCUELA PÚBLICA
ESCUELA PRIVADA DIFERENCIA
1. Partes del cuerpo 107 169 62 2. Ropa 116 160 44 3. Casa 126 213 87 4. Muebles 183 272 89 5. Alimentos 230 292 62 6. Objetos sobre mesa 163 307 144 7. Cocina 173 237 64 8. Escuela 214 313 99 9. Electricidad 94 261 167 10. Ciudad 262 341 79 11. Naturaleza 178 364 186 12. Transporte 69 148 79 13. Trabajos de campo y jardín 146 335 189 14. Animales 140 223 83 15. Diversiones y deportes 164 305 141 16. Profesiones y oficios 158 256 98 17. Computación e internet 93 145 52
TOTALES 2616 4341 1725
3873
3672 3650
3700
3750
3800
3850
3900
0 0.5 1 1.5 2 2.5

58
Aunada a esta tabla, incorporo otra gráfica en la que también comparo
los vocablos totales generados por los informantes de los dos tipos de centros
educativos.
Gráfica 7. Comparación entre cantidades totales de vocablos producidos
por mujeres y hombres en el lapso de tres minutos.
Con esta gráfica, la comparativa muestra que la cantidad de vocablos
producidos por informantes de escuela pública sólo constituye el 60% de la
cantidad generada por los informantes de escuela privada.
Como se aprecia con estos datos, en la distinción en cuanto al género
éste cobra menor peso (según la cuantificación observada) en relación con la
condición de la pertenencia a centro educativo privado o público. La diferencia
de vocablos entre lo producido por hablantes de centro privado sobrepasa con
1725 a la producción de los hablantes de centro público. Por tanto, considero
pertinente expresar que las circunstancias dadas por la dimensión socio-
educativa adquieren un peso de mayor relevancia que el factor de tipo sexual,
aunque valdrá la pena ahondar en futuras investigaciones para conocer cuáles
son específicamente las posibles circunstancias que logran determinar tal
relevancia, como pueden ser: tipos de programas y currícula educativos,
distinta capacitación pedagógica y didáctica de los docentes en cada tipo de
centro, vivencias y experiencias diversificadas en relación con el desarrollo
lingüístico de los centros educativos (como pueden ser: realizaciones de ferias
y exposiciones sobre diversas temáticas, concursos y eventos en los que se
4341
2616
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 0.5 1 1.5 2 2.5

59
privilegia la producción escrita y oral, entre otras, que generalmente se
presentan más en los centros privados).
Índice de cohesión léxica
Un recurso que también permite añadir un aporte significativo dentro de
este estudio es el constructo cuantitativo que diseñó Max Echeverría (1991): el
índice de cohesión léxica. Éste se obtiene al dividir el promedio de palabras
dadas por los informantes de cada centro de interés entre el número de
vocablos del mismo. Los resultados que surgen estarán siempre en un rango
entre 0 y 1. En tanto el valor resultante se acerque más a la unidad, se
entenderá que las coincidencias en las respuestas son mayores y esto
determina un incremento en la cohesión y viceversa. Atendiendo a esta noción,
los resultados obtenidos para cada centro de interés permiten categorizarlos a
éstos en dos: abiertos o difusos y cerrados o compactos.
A continuación muestro el listado de los centros de interés con el índice
de cohesión léxica (ICL) correspondiente (tabla 26).
Tabla 26. Relación de centros de interés con el Índice de Cohesión
Léxica.
Centro de interés vocablos promedio de palabras ICL
1. Partes del cuerpo 189 31 0.164 2. Ropa 199 28.54 0.143 3. Casa 273 24.72 0.090 4. Muebles 354 31.68 0.089 5. Alimentos 385 39.04 0.101 6. Objetos sobre mesa 374 31.39 0.083 7. Cocina 303 29.89 0.098 8. Escuela 419 36.95 0.088 9. Electricidad 296 26.87 0.090 10. Ciudad 495 30.56 0.061 11. Naturaleza 447 31.14 0.069 12. Transporte 164 22.16 0.130 13. Trabajos de campo y jardín 410 22.50 0.054 14. Animales 244 38.70 0.158 15. Diversiones y deportes 393 26.54 0.067 16. Profesiones y oficios 298 28.20 0.094 17. Computación e internet 185 17.29 0.093

60
Como se aprecia, el centro de interés más compacto o cerrado es el del
cuerpo humano y el más abierto o difuso es el de los trabajos de campo y
jardín. Esto implica que en el primer centro de interés mencionado hay una
menor cantidad de voces diferentes, es decir, hay un mayor grado de
coincidencia en las respuestas emitidas por los informantes. Lo opuesto sucede
en el otro centro de interés con el más bajo ICL.
La valía conceptual de este índice, más allá de estos enunciados
cuantitativos, radica en las posibilidades de ponderar con otras perspectivas la
conformación de los centros de interés logrando una correlación con los datos
que han reflejado los informantes, aunque sería complejo establecer
determinaciones estrictas en cuanto a la naturaleza nocional de cada uno de
ellos. Esto es, confirmar por qué el centro de interés de Partes del cuerpo en
este caso presenta un mayor grado de coincidencias o una menor cantidad de
voces distintas obedece a una causa en particular, no es simple de dilucidar.
Ya Samper et al. han referido que este centro es apreciado dentro de una
categoría conceptual de validez universal y, a su vez, Hernández Muñoz
(2006: 155) destaca que en diferentes investigaciones ha obtenido índices por
encima de la media.

61
Análisis cualitativo
Después de haber elaborado una serie de razonamientos en relación
con las cuantificaciones de las voces dadas por los informantes, considero
necesario establecer otras descripciones y asertos en torno de los vocablos
que conforman el léxico disponible obtenido a partir de la muestra de
informantes.
Tales descripciones las hago en relación con los conjuntos de los
primeros veinte vocablos (con los respectivos índices de DL) para cada uno de
los centros de interés (CI en lo sucesivo), derivados de los tres minutos. Me
resulta pertinente tener este referente, ya que varios de los estudios realizados
tanto en México como en Hispanoamérica han otorgado tal información y la
comparación permitirá tener medios para encontrar divergencias,
convergencias y la relevancia de las mismas. Para tal efecto emplearé sólo dos
estudios, uno elaborado por Juan López Chávez y publicado en 2003 en el
texto denominado ¿Qué te viene a la memoria? La disponibilidad léxica: teoría,
métodos y aplicaciones, realizado con alumnos de primaria de Zacatecas,
aunque para la comparativa tomaré los resultados de los informantes de sexto
de primaria, alumnos más cercanos a los informantes de mi muestra.
El otro estudio que me permite efectuar estos contrastes es el de Felipe
Jiménez Berrio, investigador español que realiza un estudio con alumnos
inmigrantes en Navarra y, aunque difiere en varios centros de interés y en el
tiempo en el que los informantes generan el listado de palabras, me ofrece una
aproximación especialmente por la edad de los encuestados. El estudio de
Jiménez se publicó en 2013, en una versión digital bajo el título de Léxico
disponible de inmigrantes escolares no hispanohablantes.
Tabla 27. Vocablos con mayor índice de disponibilidad léxica del CI 1
Las partes del cuerpo
1 ojo 0.689145344 2 dedo 0.667680247 3 brazo 0.598563771 4 pie 0.587320558 5 oreja 0.575540909 6 mano 0.568620338 7 boca 0.562082035
62
8 pierna 0.556021229 9 nariz 0.555170921
10 cabeza 0.536979761 11 uña 0.500321854 12 ceja 0.379888612 13 rodilla 0.338287068 14 pestaña 0.317717361 15 codo 0.302521813 16 diente 0.298417454 17 pelo 0.290958447 18 estómago 0.282251221 19 corazón 0.270275621 20 cabello 0.242945195
En este primer centro de interés encuentro que los veinte vocablos
referidos son estrictamente sustantivos y lexías simples. En su mayoría
constituyen voces pertenecientes a una norma común y no especializada. Al
hacer la comparación con el estudio de López Chávez en México y Jiménez B.
encuentro una convergencia muy amplia. Para comprobación de lo anterior me
permito mencionar que en el estudio realizado por Felipe Jiménez Berrio
(2013), en Navarra, dentro de los primeros veinte vocablos que registra están
quince de los que aparecen en mi listado, a excepción de ceja, pestaña,
estómago, corazón y cabello, voces dadas por los informantes en Culiacán.
Esto constituye un 75% de igualdad.
Por otro lado, en contraste con el estudio de López Chávez, hay una
coincidencia de dieciséis vocablos, excepto: hueso, pulmón, cuello y oído que
no aparecen en los primeros veinte vocablos en Culiacán. En este caso, hay
una coincidencia del 80% de las voces registradas. Cabe precisar que este
centro de interés es de los que ha obtenido el mayor índice de cohesión léxica
y que la naturaleza nocional es casi de validez universal para los hablantes del
español.
Además es pertinente abundar en un hecho que, aunque ya se
destacado en otros análisis, permite desarrollar una óptica para la comprensión
del léxico dado en este centro de interés: las voces emitidas por los
informantes configuran una estructura que mantiene determinados ejes de
referencia explícitos, aquellos asociados con partes del cuerpo que son
externas y superiores y las que son inferiores e internas. Todas estas
designaciones son aprendidas por las personas desde su ingreso en preescolar

63
y se refuerzan a medida que se transita por el nivel básico, durante los seis
años de la educación primaria y tres años de la educación secundaria. Esto
implica que las designaciones dadas en este centro de interés siguen el orden
de un modelo taxonómico dado por el modelo educativo que así lo privilegia.
Es decir, la escuela sí modela una visión conceptual y nocional en aquello que
entendemos como las partes del cuerpo. Sin embargo, esto no implica que
aparezcan dentro de los primeros veinte vocablos, términos que procedan
formalmente de áreas especializadas del conocimiento, como son la anatomía
o la fisiología. Las voces que aparecen son parte de una norma común.
Tabla 28. Vocablos con mayor índice de disponibilidad léxica del CI 2
La ropa
1 camisa 0.634979895 2 pantalón 0.580943037 3 calzón 0.566585011 4 blusa 0.545894623 5 zapato 0.543081104 6 tenis 0.526318531 7 vestido 0.458500995 8 brasier 0.448132569 9 bóxer 0.403284077
10 calceta 0.382593374 11 falda 0.3519844 12 tanga 0.345475206 13 calcetín 0.327065974 14 camiseta 0.298649285 15 playera 0.295465045 16 short 0.282329627 17 huarache 0.272565831 18 pants 0.250581358 19 zapatilla 0.225919546 20 chamarra 0.218345717
En este segundo centro de interés todos los vocablos emitidos son
sustantivos y lexías simples. Sin embargo, hay una presencia de voces de
origen extranjero, como las siguientes: tenis, bóxer, short, pants, todos estos
procedentes del inglés; brasier, voz derivada del francés y tanga (según el
DRAE, voz procedente del tupí guaraní). A su vez, aparece huarache,
indigenismo originario del purépecha.

64
De lo anterior se desprende que un 35% de estos veinte vocablos es de
origen extranjero. Lo anterior se entiende pues estos vocablos designan
elementos de la realidad que se han incorporado a nuestra lengua con el uso
de prendas que los hablantes del español en México no tenían anteriormente
aun cuando hay voces en tal lengua que permiten tales designaciones.
Al hacer la comparación con los estudios referidos previamente, es
posible encontrar que en el estudio de Jiménez Berrio hay una coincidencia de
siete vocablos solamente, éstos son: camisa, pantalón, blusa, zapato, vestido,
calcetín y camiseta. Esto es, un 35% de convergencia. Cabe mencionar que en
algunos casos sí hay designaciones distintas para referentes similares, como
calzoncillo y zapatilla (de deporte), en las voces dadas por los informantes de
Jiménez; en el caso de los hablantes mexicanos emplearon bóxer y tenis,
respectivamente, (vocablos del inglés).
En relación con el estudio de López Chávez, las coincidencias fueron de
dieciséis voces: camisa, pantalón, calzón, blusa, zapato, tenis, vestido, brasier,
calceta, falda, calcetín, camiseta, playera, short, zapatilla y chamarra. Es decir,
el 80% de los primeros veintes vocablos son coincidentes. Esto permite
entender que constituyen un conjunto de vocablos pertenecientes a la variante
mexicana.
Tabla 29. Vocablos con mayor índice de disponibilidad léxica del CI 3
La casa
1 baño 0.61737687 2 cocina 0.564846638 3 ventana 0.484645021 4 pared 0.450832123 5 sala 0.450392076 6 puerta 0.427454543 7 cuarto 0.408724332 8 comedor 0.405769401 9 techo 0.359988359
10 patio 0.356658954 11 piso 0.317796015 12 repisa 0.306580264 13 cochera 0.303546121 14 escalera 0.26315737 15 recámara 0.225556663 16 clóset 0.224641631 17 sótano 0.152037386 18 balcón 0.151345093

65
19 ladrillo 0.145628299 20 terraza 0.136977364
En este centro, como es posible observar, los veinte vocablos son
sustantivos y lexías simples. En este caso aparece el préstamo clóset, del
inglés.
En cuanto a la comparación con el estudio de Felipe Jiménez B.,
encuentro las siguientes coincidencias: cocina, baño, ventana y puerta, lo que
representa un 20% de coincidencias. En el caso del estudio de J. López
Chávez las coincidencias son del 65%, con las siguientes voces: cocina, baño,
ventana, pared, sala, puerta, comedor, techo, patio, piso, cochera, escalera y
recámara, un total de 13 vocablos.
El conjunto de voces que aparece en este centro de interés refleja un
conocimiento compartido y heredado por la comunidad de hablantes y no está
determinado por patrones de tipo educativo o por modelos impuestos que se
crean desde los ámbitos escolares, pues es la experiencia que comúnmente
tienen los hablantes en sus propias condiciones de vida, al interior de las
viviendas que habitan, la que rige y configura las voces que aparecen en este
listado.
Tabla 30. Vocablos con mayor índice de disponibilidad léxica del CI 4
Muebles y enseres domésticos
1 silla 0.611206601 2 sillón 0.599771183 3 cama 0.54705993 4 cuchara 0.511673074 5 mesa 0.508875036 6 tenedor 0.47809455 7 cuchillo 0.421018558 8 refrigerador 0.393102794 9 televisión 0.390762747
10 estufa 0.368075974 11 comedor 0.348408781 12 escoba 0.305228595 13 trapeador 0.298541355 14 sofá 0.263407131 15 computadora 0.251850531 16 plato 0.229000291 17 licuadora 0.210012482

66
18 clóset 0.204829354 19 sartén 0.196031092 20 vaso 0.187395133
Los sustantivos que aparecen están constituidos por lexías simples. Del
total de vocablos, dos son de origen extranjero: computadora y clóset, ambas
tienen su origen en la lengua inglesa. En cuanto a la comparación con los
estudios mencionados encuentro lo siguiente: con el estudio de Jiménez Berrio,
hay cinco voces coincidentes, silla, cama, mesa, televisión y sofá. Lo anterior
representa un 20% de coincidencia. Hay dos vocablos que aunque designan el
mismo referente, muestran otro significante: ordenador (que corresponde a la
computadora en la norma mexicana) y frigorífico (que corresponde a
refrigerador).
En relación con el estudio de López Chávez advierto que hay una
coincidencia con once voces: silla, sillón, cama, mesa, refrigerador, televisión,
estufa, escoba, trapeador, sofá y clóset. Esto implica un 55% de voces iguales.
Es importante referir que la divergencia en este centro de interés es mayor que
en los casos anteriores y obedece, considero, a que nocionalmente posibilita
un espectro de la realidad que se alimenta de experiencias diversas para los
hablantes de estas sintopías y que no sigue patrones o paradigmas rigurosos y
compartidos con designadores validados para todos estos grupos de hablantes
tanto a uno como a otro lado del Atlántico. Aunque debo precisar que los
fenómenos que intervienen en estos procesos van mucho más allá de lo que
socialmente valida cada comunidad de habla.
Tabla 31. Vocablos con mayor índice de disponibilidad léxica del CI 5
Alimentos
1 pollo 0.366331396 2 pescado 0.352855805 3 pizza 0.346616176 4 hamburguesa 0.319587078 5 papa 0.315819718 6 sopa 0.304127513 7 sándwich 0.295846261 8 frijol 0.28304511 9 torta 0.279862211
10 carne 0.279545429

67
11 huevo 0.262756712 12 manzana 0.254370633 13 sushi 0.250312593 14 quesadilla 0.247757168 15 tortilla 0.243343079 16 tomate 0.243119107 17 refresco 0.239985861 18 agua 0.231779135 19 plátano 0.220013605 20 pera 0.21677221
En este quinto centro de interés sólo se encuentran sustantivos, que son
también lexías simples. En este caso aparecen extranjerismos como: pizza
(vocablo italiano), sándwich y hamburguesa (vocablos ingleses) y sushi (voz
japonesa). Cabe referir que estos cuatro vocablos emitidos designan comidas
de preparación rápida y que fueron incorporadas gracias a los procesos de
globalización cultural. Sin embargo, se percibe una serie de voces que refieren
elementos alimenticios propios del país, como la tortilla, la cual es esencial en
la alimentación y la cocina de México, y la quesadilla, que se elabora con
aquella.
Al comparar estos veinte vocablos con los emitidos en la investigación
de López Chávez es posible advertir que doce son coincidentes, éstos son:
pollo, pescado, papa, sopa, frijol, carne, huevo, manzana, tortilla, refresco,
agua y plátano. Varios de éstos vocablos designan alimentos que constituyen
recursos básicos en la comida y gastronomía mexicana de casi todos los
habitantes independientemente de su estrato o nivel socioeconómico, entre los
cuales destaco: frijol, huevo, tortilla, papa, sopa, carne y refresco,.
En cuanto a la comparativa con los resultados de Jiménez Berrio hay
coincidencia con cinco vocablos: carne, manzana, tomate, agua y plátano. Me
parece apropiado precisar que esta correspondencia se da con elementos que
resultan de notoria presencia en muchas gastronomías y que no refieren
alimentos elaborados o preparados. En particular mencionaré el vocablo
tomate, que siendo de origen indígena ya no constituiría un mexicanismo
debido a la generalización que presenta en las distintas variedades del
español. Adicionalmente, la presencia del vocablo agua es coincidente en los
tres listados estudiados y debo manifestar que es dado por la universalidad de
este líquido en los medios de alimentación de todos los grupos humanos.

68
Tabla 32. Vocablos con mayor índice de disponibilidad léxica del CI 6
Objetos colocados sobre la mesa
1 plato 0.69269514 2 vaso 0.646676985 3 cuchara 0.591588739 4 mantel 0.571686697 5 tenedor 0.569728621 6 servilleta 0.479181265 7 comida 0.469213276 8 cuchillo 0.466307666 9 sal 0.362091192
10 libro 0.33097187 11 lápiz 0.304047641 12 florero 0.247278428 13 jarra 0.237770513 14 borrador 0.213591237 15 refresco 0.205067861 16 pimienta 0.204166281 17 estuche 0.20202198 18 salero 0.195976344 19 mochila 0.188693214 20 salsa 0.169363231
En el sexto centro de interés todos los veinte primeros vocablos son
sustantivos y lexías simples. Se advierte que los vocablos pertenecen a la
lengua estándar, es decir, como lo describe Luis Fernando Lara (1996:22), son
aquellos que se utilizan en todo el país.
En el contraste con los vocablos referidos por los informantes de
Zacatecas, en el estudio de López C., encuentro que ocho son coincidentes:
plato, vaso, tenedor, cuchara, cuchillo, servilleta, florero y jarra. El porcentaje
de esta correspondencia es de 40%. También considero necesario expresar
que los veinte vocablos vertidos se relacionan primariamente con aquellos
objetos que en la mesa permiten el acto de comer, como he referido (plato,
vaso, cuchara, mantel, tenedor, servilleta, comida, cuchillo, sal, jarra, refresco,
pimienta, salero y salsa) y el resto de voces se vinculan con otra actividad que
los informantes adolescentes realizan en la mesa: efectuar tareas o
quehaceres de orden intelectual y escolar, como: libro, lápiz, borrador, estuche
y mochila. Sólo florero referiría a una entidad que se desvincula de estas dos
69
dimensiones y que se liga con un objeto de otra naturaleza, la de tipo
ornamental.
En el estudio de Jiménez B. no se utilizó este centro de interés.
Tabla 33. Vocablos con mayor índice de disponibilidad léxica del CI 7
La cocina
1 estufa 0.725300909 2 refrigerador 0.719346858 3 tenedor 0.682769115 4 cuchara 0.655650704 5 sartén 0.55110429 6 cuchillo 0.525716739 7 licuadora 0.490086652 8 plato 0.401847979 9 vaso 0.386266487
10 pelapapas 0.323754938 11 olla 0.282054836 12 tostador 0.275888973 13 horno 0.256569298 14 mesa 0.22891115 15 comida 0.226535011 16 alacena 0.205100606 17 horno de microondas 0.19994538 18 cajón 0.17665601 19 servilleta 0.167190994 20 exprimidor 0.165693344
En este caso, las veintes primeras voces son sustantivos y dieciocho son
lexías simples, a excepción de pelapapas, que es un compuesto verbonominal;
por otra parte está horno de microondas, locución nominal creada por la pauta
sintáctica sustantivo + de + sustantivo.
En cuanto al contraste con los estudios enunciados, en primer término
con el trabajo de López C., hay lo siguiente: una coincidencia con 16 vocablos,
los cuales son: estufa, refrigerador, tenedor, cuchara, sartén, cuchillo,
licuadora, plato, vaso, olla, tostador, horno, mesa, alacena, horno de
microondas y exprimidor. Cuantitativamente representa un 80% de
coincidencia.
En segundo término, con el trabajo de Jiménez B. estableceré una
correspondencia con el centro de interés que él denominó Muebles y
electrodomésticos, que para efectos de mantener en todo lo posible el proceso
70
de comparación, me resulta apropiado por la cercanía conceptual al ámbito de
la cocina. Hay una coincidencia de sólo dos vocablos: horno y mesa. Aunque
es preciso expresar que en el caso de refrigerador, voz empleada en México,
corresponde el vocablo frigorífico; con esto se aprecia una variación de índole
dialectal.
Tabla 34. Vocablos con mayor índice de disponibilidad léxica del CI 8
La escuela
1 pizarrón 0.589135309 2 lápiz 0.524116104 3 borrador 0.499361059 4 mesa 0.478480396 5 pluma 0.456399075 6 silla 0.454221682 7 libro 0.424771579 8 mochila 0.4237479 9 plumón 0.411531205
10 maestro 0.390406797 11 ventana 0.298237634 12 libreta 0.295091822 13 puerta 0.286619305 14 alumno 0.275370859 15 colores 0.267834753 16 salón 0.265226298 17 cuaderno 0.257890809 18 árbol 0.254339173 19 abanico 0.247458343 20 baño 0.243711703
En el análisis de este centro encuentro que los veinte vocablos son
sustantivos y lexías simples. Dieciocho del total designan objetos de la realidad
cotidiana del entorno escolar y dos denotan a las personas que intervienen en
el proceso de enseñanza-aprendizaje. A diferencia de los centros analizados
previamente, en éste aparecen personas, en los anteriores no es así. Esto
pone en relieve la configuración socio-interactiva que hay en los participantes o
protagonistas de la vida de la escuela y trasciende a la mención de los meros
objetos que en el resto de los centros se da.
En la comparativa con el estudio de Zacatecas se presenta una
coincidencia de 10 vocablos: pizarrón, lápiz, borrador, mesa, pluma, silla, libro,

71
mochila, colores y cuaderno. Esto representa un 50% de correspondencia en
los vocablos.
En cuanto al estudio de Navarra, hay coincidencia en siete vocablos:
mesa, silla, libro, ventana, puerta, alumno y cuaderno; esto representa un 35%.
Hay diferentes designaciones, como en: pizarrón, los informantes de Navarra
emplearon pizarra; pluma, los informantes de España registraron boli(grafo);
borrador, en el estudio de Jiménez aparece goma. De manera adicional
menciono el caso de maestro, pues aunque en Culiacán también los
informantes manifestaron profesor, éste apareció con un índice de DL menor,
en una posición inferior del listado. Y en el caso del estudio de Navarra
profesor sí está en los primeros veinte vocablos.
Sobre esto sí abundaré tomando en cuenta lo que refiere el Diccionario
del Español de México (referido en lo sucesivo como DEM). En él se manifiesta
que maestro es la persona que enseña en alguna escuela o da clases de
alguna materia y sobre profesor se ofrece el sentido de persona que enseña
una ciencia, un arte u otra actividad. Aunque hay algún matiz de distinción al
precisar en el primer caso que hay un ámbito específico de acción para quien
se desempeña en tal actividad o lleva a cabo la impartición de la enseñanza a
través de un modelo curricular y en el segundo se establece una especificación
dentro de ciertos ámbitos disciplinares como la ciencia, las artes y finalmente
otra actividad, comparto lo que Moreno de Alba (1992: 288) manifiesta en
relación con estas dos voces:
Así pues, en la Península Ibérica, comúnmente al que enseña, por
ejemplo en la Universidad, se le llama profesor, y maestro al que atiende el
nivel elemental. […]
Tengo la impresión de que esta oposición no existe en el español
mexicano. Aquí llamamos maestro tanto al que enseña en la primaria cuanto al
catedrático universitario, además de que esta voz sirve para otras varias
funciones, como por ejemplo para designar a las personas que ejercen un
oficio o a quienes han obtenido un grado universitario anterior al de doctorado.
El vocablo profesor, que también se usa, aunque creo que menos que maestro,
puede aludir al docente de cualquier nivel.

72
En función de los datos cuantitativos se reitera lo referido por Moreno, en
primer término aparece maestro y con un menor índice de DL profesor, pero
considero que ambos casos son usados sin oposición explícita.
Valdría la pena en un estudio posterior dilucidar o analizar con
detenimiento este fenómeno con el interés de lograr una descripción mucho
más reflexiva en cuanto al uso de estos dos vocablos.
Tabla 35. Vocablos con mayor índice de disponibilidad léxica del CI 9
Electricidad y aire acondicionado
1 televisión 0.632308973 2 cable 0.565431788 3 abanico 0.532886732 4 foco 0.526043094 5 computadora 0.505372781 6 lámpara 0.372210143 7 refrigerador 0.360325871 8 radio 0.311297674 9 frío 0.300796654
10 estéreo 0.283087998 11 celular 0.279365072 12 licuadora 0.276620758 13 luz 0.276366253 14 aire 0.241219212 15 estufa 0.239591859 16 DVD 0.235930196 17 teléfono 0.230388873 18 lavadora 0.219683621 19 grabadora 0.212582678 20 calor 0.199259755
En este centro la mayoría son igualmente sustantivos y lexías simples, a
excepción de DVD, que es un acrónimo dado por las voces inglesas Digital
Video Disc. Otra voz procedente del inglés es computadora. El caso de
estéreo, empleado aquí como sustantivo, es un acortamiento de la voz
estereofónico. En su mayoría, los vocablos designan objetos de la realidad
propia de los hogares o de los entornos de mayor familiaridad para los
informantes adolescentes que integran la muestra. Sólo frío, luz y calor
designan ya sea formas de energía o asociaciones con éstas.
El vocablo celular, del cual no aparece un artículo lexicográfico en el
DEM con el sentido de artículo electrónico usado para la comunicación, sí está

73
registrado en el Diccionario de americanismos editado por la Asociación de
Academias de la Lengua Española y sobre tal vocablo se establece que es el
teléfono portátil que se conecta a una central mediante ondas hercianas.
Presenta la marca de estratificación sociocultural de tipo popular. Aunque cabe
considerar que, como lo refiere Luis Fernando Lara 1996:23), tal marca “tiene
un carácter valorativo relativamente negativo. Pero hay que destacar que, por
un lado, la calificación de popular se refiere al uso de la lengua, no a un grupo
social ni mucho menos a personas determinadas. […] Por otro lado, hay que
reconocer que se trata de vocablos que todos usamos en determinadas
circunstancias y que nos identificamos como pueblo, precisamente, mediante
ellos”. Asumiendo esta perspectiva, me es posible enfatizar que por sobre las
valoraciones surgidas gracias a un tratamiento lexicográfico está el
entendimiento de que aquello que se percibe como lo popular es especialmente
un recurso de las posibilidades de expresión y de riqueza léxica de las
comunidades de habla.
En relación con la comparativa del estudio de López C. es posible
denotar que hay once vocablos que son plenamente coincidentes: televisión,
foco, computadora, lámpara, refrigerador, radio, licuadora, luz, teléfono,
lavadora y grabadora. Aparece en el listado de Zacatecas el vocablo ventilador,
el cual en el caso de las voces de Culiacán está designado con abanico. Puedo
afirmar que una coincidencia del 60%.
Respecto del estudio de la península, la coincidencia de vocablos es del
25%. Sólo los siguientes vocablos aparecen en ambos listados: abanico,
lámpara, frío, luz y calor. Es de interés observar que la correspondencia se da
especialmente con las nociones relacionadas con las formas de energía, es
decir, con conceptos que pueden demandar un tratamiento lógico de
abstracción posibilitado gracias a los entornos escolares, sin que se sostenga
por ello que sea el único medio para generarlos en los hablantes.
Tabla 36. Vocablos con mayor índice de disponibilidad léxica del CI 10
La ciudad
1 carro 0.657198176 2 casa 0.50064521 3 edificio 0.392332308 4 árbol 0.350298535
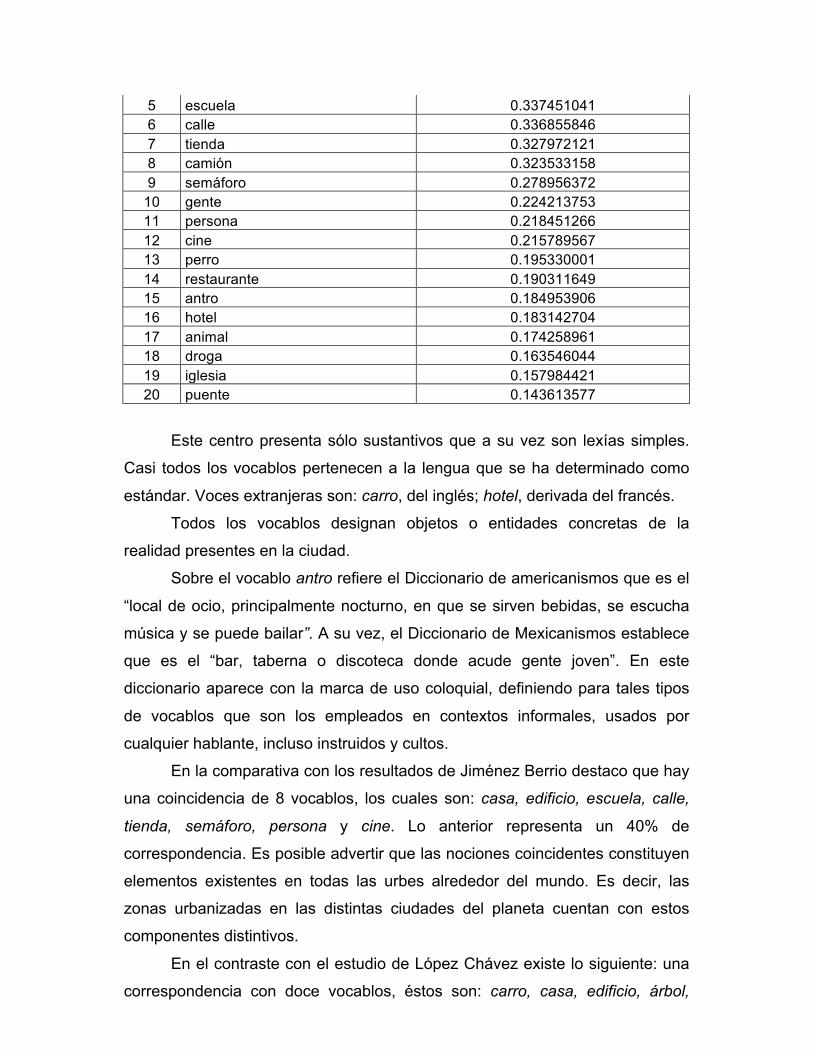
74
5 escuela 0.337451041 6 calle 0.336855846 7 tienda 0.327972121 8 camión 0.323533158 9 semáforo 0.278956372
10 gente 0.224213753 11 persona 0.218451266 12 cine 0.215789567 13 perro 0.195330001 14 restaurante 0.190311649 15 antro 0.184953906 16 hotel 0.183142704 17 animal 0.174258961 18 droga 0.163546044 19 iglesia 0.157984421 20 puente 0.143613577
Este centro presenta sólo sustantivos que a su vez son lexías simples.
Casi todos los vocablos pertenecen a la lengua que se ha determinado como
estándar. Voces extranjeras son: carro, del inglés; hotel, derivada del francés.
Todos los vocablos designan objetos o entidades concretas de la
realidad presentes en la ciudad.
Sobre el vocablo antro refiere el Diccionario de americanismos que es el
“local de ocio, principalmente nocturno, en que se sirven bebidas, se escucha
música y se puede bailar”. A su vez, el Diccionario de Mexicanismos establece
que es el “bar, taberna o discoteca donde acude gente joven”. En este
diccionario aparece con la marca de uso coloquial, definiendo para tales tipos
de vocablos que son los empleados en contextos informales, usados por
cualquier hablante, incluso instruidos y cultos.
En la comparativa con los resultados de Jiménez Berrio destaco que hay
una coincidencia de 8 vocablos, los cuales son: casa, edificio, escuela, calle,
tienda, semáforo, persona y cine. Lo anterior representa un 40% de
correspondencia. Es posible advertir que las nociones coincidentes constituyen
elementos existentes en todas las urbes alrededor del mundo. Es decir, las
zonas urbanizadas en las distintas ciudades del planeta cuentan con estos
componentes distintivos.
En el contraste con el estudio de López Chávez existe lo siguiente: una
correspondencia con doce vocablos, éstos son: carro, casa, edificio, árbol,

75
escuela, calle, tienda, camión, semáforo, gente, persona y restaurante.
Además, en algunos casos hubo similitud incluso en la posición alcanzada,
como en los vocablos casa, en la segunda posición en ambos estudios; árbol,
escuela, calle y tienda ocuparon respectivamente la cuarta, quinta, sexta y
séptima posición; restaurante aparece en la posición catorce. La coincidencia
asciende al 60%.
Tabla 37. Vocablos con mayor índice de disponibilidad léxica del CI 11
La naturaleza
1 árbol 0.771810855 2 flor 0.459790232 3 animal 0.429120566 4 agua 0.370711076 5 río 0.363159959 6 planta 0.345228939 7 tierra 0.282108111 8 montaña 0.246322745 9 lluvia 0.232332764
10 aire 0.204877038 11 hoja 0.202428689 12 sol 0.195003173 13 huracán 0.185799793 14 rosa 0.183798017 15 perro 0.183668061 16 girasol 0.17552115 17 mar 0.168652718 18 volcán 0.164171853 19 maíz 0.163125812 20 nube 0.160685106
En este centro de interés los vocablos son, al igual que en el resto,
lexías simples dadas por sustantivos.
En la comparación con los estudios a que hago referencia, se aprecia lo
siguiente: con los resultados de Jiménez Berrio hay una coincidencia de ocho
vocablos: árbol, flor, animal, río, sol, perro, mar y maíz. Esto equivale a un 40%
de similitud. En cuanto a los resultados de López Chávez, se advierte que hay
una correspondencia de doce vocablos: árbol, flor, animal, agua, río, planta,
tierra, montaña, hoja, perro, mar y nube. Hay una coincidencia del 60%.
Me permito enunciar que el primer vocablo de este centro (árbol) alcanza
un índice de 0.771810855, que en el conjunto global de los vocablos
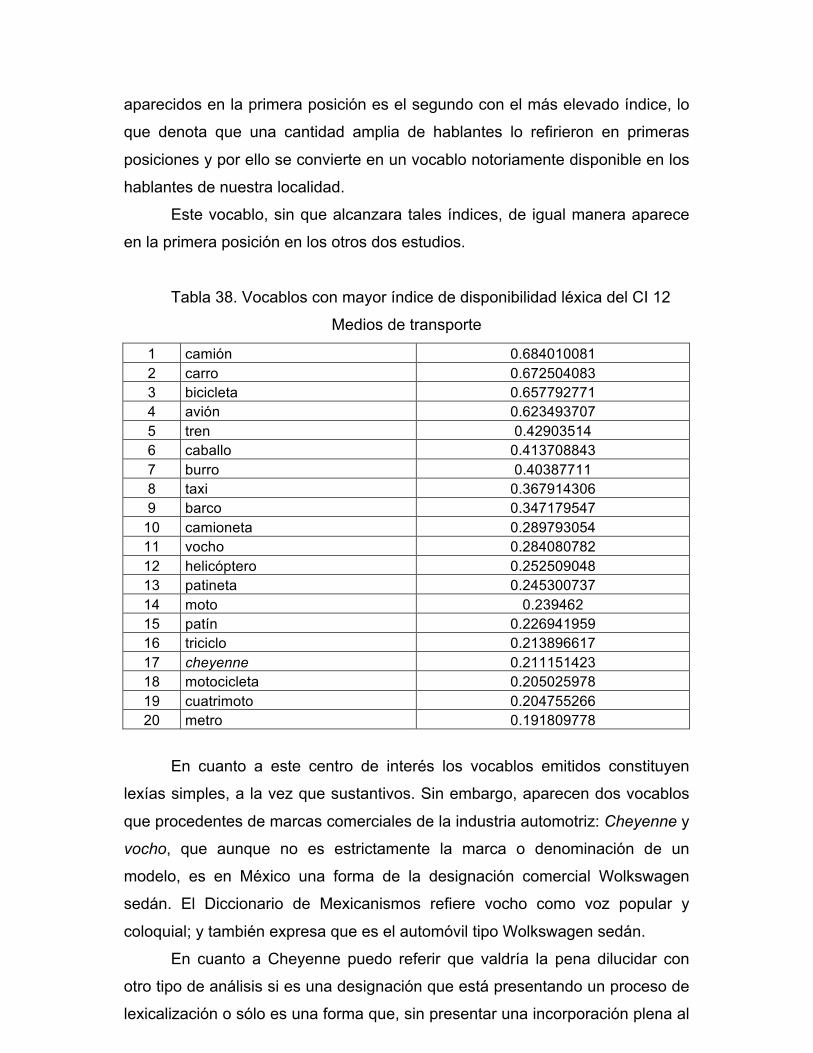
76
aparecidos en la primera posición es el segundo con el más elevado índice, lo
que denota que una cantidad amplia de hablantes lo refirieron en primeras
posiciones y por ello se convierte en un vocablo notoriamente disponible en los
hablantes de nuestra localidad.
Este vocablo, sin que alcanzara tales índices, de igual manera aparece
en la primera posición en los otros dos estudios.
Tabla 38. Vocablos con mayor índice de disponibilidad léxica del CI 12
Medios de transporte
1 camión 0.684010081 2 carro 0.672504083 3 bicicleta 0.657792771 4 avión 0.623493707 5 tren 0.42903514 6 caballo 0.413708843 7 burro 0.40387711 8 taxi 0.367914306 9 barco 0.347179547
10 camioneta 0.289793054 11 vocho 0.284080782 12 helicóptero 0.252509048 13 patineta 0.245300737 14 moto 0.239462 15 patín 0.226941959 16 triciclo 0.213896617 17 cheyenne 0.211151423 18 motocicleta 0.205025978 19 cuatrimoto 0.204755266 20 metro 0.191809778
En cuanto a este centro de interés los vocablos emitidos constituyen
lexías simples, a la vez que sustantivos. Sin embargo, aparecen dos vocablos
que procedentes de marcas comerciales de la industria automotriz: Cheyenne y
vocho, que aunque no es estrictamente la marca o denominación de un
modelo, es en México una forma de la designación comercial Wolkswagen
sedán. El Diccionario de Mexicanismos refiere vocho como voz popular y
coloquial; y también expresa que es el automóvil tipo Wolkswagen sedán.
En cuanto a Cheyenne puedo referir que valdría la pena dilucidar con
otro tipo de análisis si es una designación que está presentando un proceso de
lexicalización o sólo es una forma que, sin presentar una incorporación plena al

77
habla de nuestra región, muestra una vitalidad o uso en cierto distintos
sociolectos en nuestra comunidad de habla.
En relación con las comparaciones, en relación con el estudio de
Jiménez B. existe una coincidencia de ocho vocablos: camión, bicicleta, avión,
tren, taxi, barco, moto y metro, esto representa un 40% de correspondencia.
En el caso de los resultados de López C. existe una coincidencia con
doce vocablos: camión, carro, bicicleta, avión, tren, caballo, burro, taxi, barco,
helicóptero, patineta y moto. En este caso la correspondencia es del 60%.
Conviene precisar que en este listado mantuve la presencia del vocablo
motocicleta y de la forma moto, pues ambas estuvieron en los registros de los
hablantes y fue ésta última la que obtuvo un mayor índice. Sin embargo, no
existe una distinción en términos conceptuales. El DEM registra entradas para
ambos vocablos y considero que esto da cuenta del uso de los mismos.
Tabla 39. Vocablos con mayor índice de disponibilidad léxica del CI 13
Trabajos de campo y jardín
1 ganadería 0.626065702 2 agricultura 0.514723301 3 tractor 0.453334398 4 jardinero 0.413231383 5 agricultor 0.279443645 6 tijeras 0.255174923 7 pesca 0.244354375 8 vaca 0.181327278 9 caballo 0.178852185
10 tierra 0.176647876 11 flor 0.175564223 12 tomate 0.174363838 13 burro 0.163974306 14 árbol 0.160757602 15 ordeñar 0.159851817 16 pala 0.153839719 17 apicultura 0.151447387 18 podadora 0.148690987 19 planta 0.137541491 20 maíz 0.116664507
En este centro de interés sólo hubo un vocablo del tipo de los verbos, los
diecinueve restantes fueron sustantivos y todos son lexías simples.
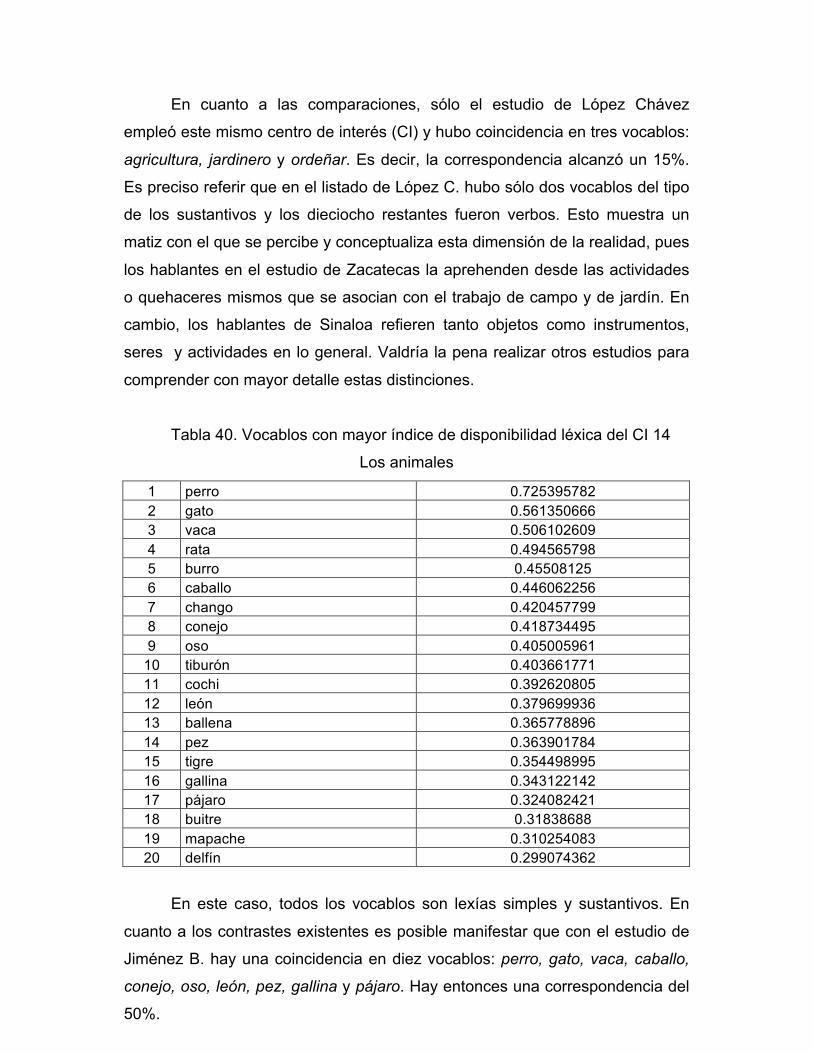
78
En cuanto a las comparaciones, sólo el estudio de López Chávez
empleó este mismo centro de interés (CI) y hubo coincidencia en tres vocablos:
agricultura, jardinero y ordeñar. Es decir, la correspondencia alcanzó un 15%.
Es preciso referir que en el listado de López C. hubo sólo dos vocablos del tipo
de los sustantivos y los dieciocho restantes fueron verbos. Esto muestra un
matiz con el que se percibe y conceptualiza esta dimensión de la realidad, pues
los hablantes en el estudio de Zacatecas la aprehenden desde las actividades
o quehaceres mismos que se asocian con el trabajo de campo y de jardín. En
cambio, los hablantes de Sinaloa refieren tanto objetos como instrumentos,
seres y actividades en lo general. Valdría la pena realizar otros estudios para
comprender con mayor detalle estas distinciones.
Tabla 40. Vocablos con mayor índice de disponibilidad léxica del CI 14
Los animales
1 perro 0.725395782 2 gato 0.561350666 3 vaca 0.506102609 4 rata 0.494565798 5 burro 0.45508125 6 caballo 0.446062256 7 chango 0.420457799 8 conejo 0.418734495 9 oso 0.405005961
10 tiburón 0.403661771 11 cochi 0.392620805 12 león 0.379699936 13 ballena 0.365778896 14 pez 0.363901784 15 tigre 0.354498995 16 gallina 0.343122142 17 pájaro 0.324082421 18 buitre 0.31838688 19 mapache 0.310254083 20 delfín 0.299074362
En este caso, todos los vocablos son lexías simples y sustantivos. En
cuanto a los contrastes existentes es posible manifestar que con el estudio de
Jiménez B. hay una coincidencia en diez vocablos: perro, gato, vaca, caballo,
conejo, oso, león, pez, gallina y pájaro. Hay entonces una correspondencia del
50%.

79
Al comparar los resultados con los datos obtenidos por López C. se
encuentra una coincidencia con doce vocablos: perro, gato, vaca, burro,
caballo, chango, conejo, oso, león, pez, tigre y pájaro. La correspondencia es
del 60%.
Tabla 41. Vocablos con mayor índice de disponibilidad léxica del CI 15
Diversiones y deportes
1 futbol 0.822667242 2 basquetbol 0.747937948 3 volibol 0.616084034 4 beisbol 0.473685154 5 trompo 0.343441239 6 tenis 0.310548596 7 computadora 0.29704194 8 televisión 0.288221881 9 cine 0.281909977
10 canicas 0.252753164 11 natación 0.208139578 12 fiesta 0.206085129 13 atletismo 0.200772191 14 futbol americano 0.157320539 15 golf 0.151239353 16 tae kwon do 0.145697207 17 toro mecánico 0.144371058 18 karate 0.141129868 19 comer 0.138363362 20 correr 0.13761351
En esta dimensión de las diversiones y los deportes se aprecia que
diecisiete vocablos son lexías simples y sustantivos. Dos son vocablos
conformados por un sustantivo más adjetivo. El vocablo tae kwon do es un
extranjerismo oriental.
La naturaleza de las nociones citadas en este centro tiene que ver con
actividades deportivas, once de los vocablos se refieren a disciplinas de este
tipo. El resto se relacionan con hechos o actividades de distracción y
entretenimiento, como juegos o quehaceres en los que se emplean recursos
tecnológicos.
En la comparativa con el estudio de Jiménez Berrio se aprecia que sólo
hay coincidencia con cinco voces: futbol, volibol, tenis, televisión y correr. Esto
representa un 25% de correspondencia.
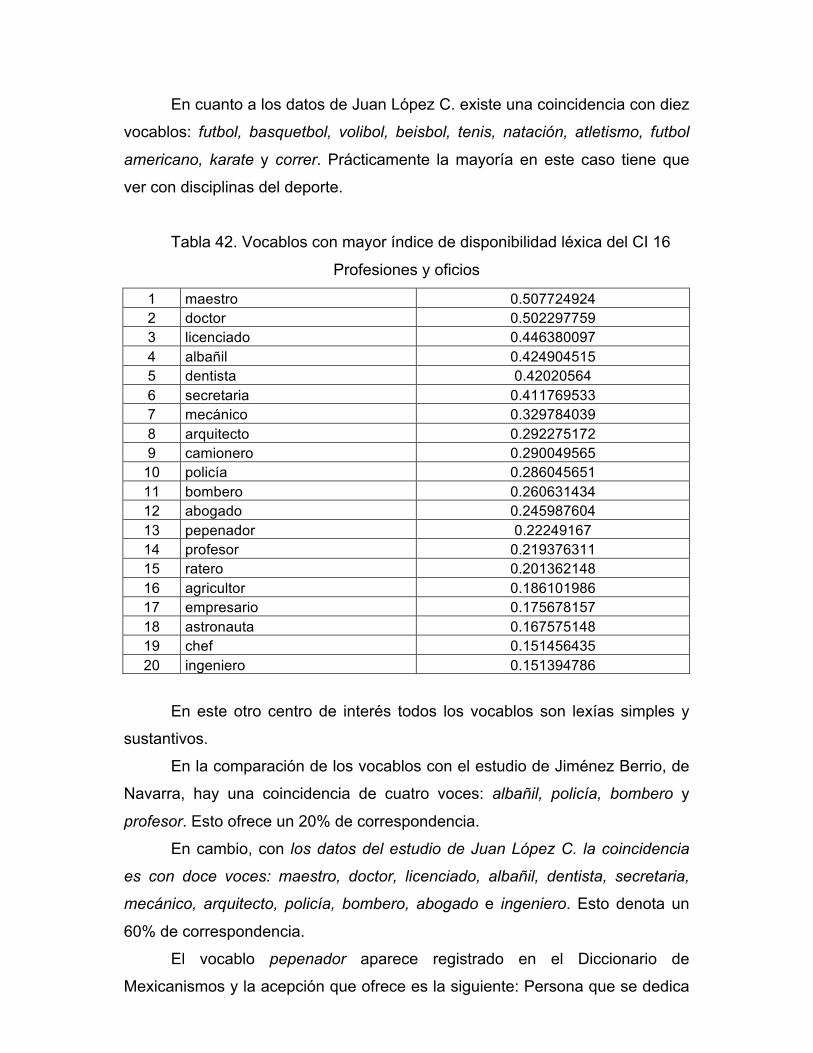
80
En cuanto a los datos de Juan López C. existe una coincidencia con diez
vocablos: futbol, basquetbol, volibol, beisbol, tenis, natación, atletismo, futbol
americano, karate y correr. Prácticamente la mayoría en este caso tiene que
ver con disciplinas del deporte.
Tabla 42. Vocablos con mayor índice de disponibilidad léxica del CI 16
Profesiones y oficios
1 maestro 0.507724924 2 doctor 0.502297759 3 licenciado 0.446380097 4 albañil 0.424904515 5 dentista 0.42020564 6 secretaria 0.411769533 7 mecánico 0.329784039 8 arquitecto 0.292275172 9 camionero 0.290049565
10 policía 0.286045651 11 bombero 0.260631434 12 abogado 0.245987604 13 pepenador 0.22249167 14 profesor 0.219376311 15 ratero 0.201362148 16 agricultor 0.186101986 17 empresario 0.175678157 18 astronauta 0.167575148 19 chef 0.151456435 20 ingeniero 0.151394786
En este otro centro de interés todos los vocablos son lexías simples y
sustantivos.
En la comparación de los vocablos con el estudio de Jiménez Berrio, de
Navarra, hay una coincidencia de cuatro voces: albañil, policía, bombero y
profesor. Esto ofrece un 20% de correspondencia.
En cambio, con los datos del estudio de Juan López C. la coincidencia
es con doce voces: maestro, doctor, licenciado, albañil, dentista, secretaria,
mecánico, arquitecto, policía, bombero, abogado e ingeniero. Esto denota un
60% de correspondencia.
El vocablo pepenador aparece registrado en el Diccionario de
Mexicanismos y la acepción que ofrece es la siguiente: Persona que se dedica

81
a pepenar (II buscar entre la basura). De igual manera, el DRAE lo refiere
como un vocablo usado en México.
El vocablo chef es un extranjerismo procedente del francés.
Tabla 43. Vocablos con mayor índice de disponibilidad léxica del CI 17
Computación e internet
1 teclado 0.41506504 2 CPU 0.408768661 3 computadora 0.368574935 4 google 0.363196499 5 mouse 0.356337281 6 impresora 0.350530085 7 facebook 0.340434887 8 wikipedia 0.280059156 9 música 0.268288304
10 bocina 0.253870282 11 monitor 0.243229855 12 disco duro 0.239573613 13 escáner 0.231706631 14 messenger 0.224437085 15 chat 0.191416914 16 internet 0.186261 17 página web 0.167890165 18 laptop 0.165477471 19 CD 0.163851016 20 pantalla 0.159432286
Un centro de interés que adicionalmente definí para la investigación es el
que se relaciona con la computación y el internet, pues pretendí encontrar las
voces disponibles en los hablantes que prácticamente concluyen la educación
secundaria.
Dentro de los primeros veinte vocablos aparecen en su mayoría lexías
simples y sustantivos, a excepción de los acrónimos CPU y CD; así como disco
duro, página web y laptop, que constituyen formas compuestas que ya son
usuales en nuestra región.
En este caso también es necesario destacar que opté por mantener las
designaciones de marcas o entidades cibernéticas, pues considero pertinente
validar con futuras investigaciones si estas voces logran una lexicalización en
nuestras comunidades de habla, tales vocablos son: google, facebook,

82
wikipedia, messenger e internet, según el orden del listado. Mantuve la
escritura sin la inicial mayúscula.
Adicionalmente es posible expresar que los siguientes vocablos son
procedentes de la lengua inglesa: computadora, mouse, monitor, escáner, chat,
laptop, página web, CD y CPU. Es decir, un 45% de estas primeras veinte
voces son extranjerismos. Y a éstas podemos sumar las marcas o
designaciones cibernéticas mencionadas anteriormente, pues proceden
también del inglés y el porcentaje asciende a 70. La prevalencia de voces
inglesas es innegable en este corpus.
Por otro lado, sólo hice la comparación con el estudio de Jiménez Berrio,
pues en el estudio de López Chávez no se incluyó un centro de este tipo. Las
coincidencias se dieron con los siguientes vocablos: teclado e internet. Esto
representa un 10% de correspondencia.
Es importante destacar que los hallazgos léxicos obtenidos con este
corpus podrán encontrar ecos en posteriores estudios con el fin de dar forma a
conocimientos formales de nuestra habla en esta región del país.

83
Conclusiones En franca consonancia con lo que han expuesto otros investigadores
durante las últimas dos décadas especialmente, admito que esta investigación
no da cuenta de distintos fenómenos que inciden en la dimensión del léxico y
su uso por parte de los hablantes particularmente en la región que he
estudiado. Sin embargo, sostengo que la valía de tal proceso de indagación sí
permite generar un basamento de reflexión que, sumado a los aportes de otros
estudiosos, permitirá generar un mosaico de entendimiento en torno del habla
en la región mucho más enriquecido.
A continuación me concentro en los hallazgos que dan cuenta de los
objetivos medulares de este trabajo. En primer término enuncio la comparación
de los vocablos cuantificados en los tiempos de dos y tres minutos, pues
interesaba conocer con exactitud la cantidad de voces que emitirían los
hablantes empleando los lapsos que se adoptaron tanto en la metodología del
proyecto panhispánico de léxico disponible, originado por Humberto López
Morales, que plantea dos minutos como periodo máximo para registrar los
vocablos, y el tiempo que determinó Juan López Chávez en México para
estimar si efectivamente el tercer minuto ofrece un espacio para una
producción léxica mayor. Los resultados confirman que el tercer minuto sí ha
permitido una producción de vocablos mayor, ya que en dos minutos la
cantidad de voces fue de cuatro mil doscientos treinta y en los tres minutos
ascendió a cinco mil cuatrocientos veintiocho, esto representa un 28.32% de
incremento, por tanto, sí considero útil, desde la comparación hecha con la
perspectiva metodológica empleada, el uso del tercer minuto para obtener los
corpora de léxico disponible. Aunque cabe precisar que en ulteriores estudios
propongo eliminar la mención del tiempo al llegar al minuto dos y que los
informantes tengan el periodo total de los tres minutos sin ninguna referencia
previa del lapso transcurrido.
Otro objetivo planteado para el análisis era comparar los resultados que
arrojaban los informantes de centro escolar privado y público, así como los de
hombres y mujeres en términos generales. Los datos demuestran que los
informantes de centro escolar privado superan a los del sistema público: cuatro
mil trescientos cuarenta y uno vocablos de los primeros contra dos mil

84
seiscientos dieciséis de los otros. Lo cual denota un 65% de incremento por
parte de centro privado.
Vale la pena mencionar que esta diferencia no sólo la circunscribo a la
circunstancia de lo que sucede en el entorno escolar, así también lo consideran
otros investigadores, entre ellos Juan López Chávez, y abundo refiriendo que
tal resultado obedece, entiendo, a distintas experiencias socio-culturales que
viven los hablantes que asisten a centro educativo privado y tienen que ver con
condiciones de naturaleza económica, social, tecnológica y cultural en términos
amplios, ya que estos hablantes están inmersos en contextos en los que el
factor económico y de desenvolvimiento social les favorecen, por tal razón, las
distintas experiencias a través de situaciones de comunicación conllevan a un
caudal léxico y lingüístico mayor.
Sin embargo, tal entendimiento obliga a que en los centros de educación
pública sí se dé una planificación cada vez más cuidadosa y elaborada de la
enseñanza tanto del léxico como de las otras dimensiones lingüísticas para
garantizar que exista una menor brecha tanto cuantitativa como cualitativa en
ambos grupos de hablantes.
En cuanto a la variable de género, las mujeres alcanzaron un total de
tres mil ochocientos setenta y tres voces contra tres mil seiscientos setenta y
dos de los hombres. Aun cuando la cifra no alcanza más que el 5% de
incremento, hay coincidencia de estos resultados con los encontrados en otras
investigaciones tanto de la península ibérica como de Hispanoamérica, en los
que la superioridad numérica no resulta cuantiosa tanto de hombres como de
mujeres.
Lo anterior valida que la condición del sexo de los informantes en este
caso no se presenta como determinante para una producción de notoria
trascendencia y de mayor relevancia. Sin embargo, cabe mantener la
perspectiva de inquirir posteriormente en esto y detallar con mayor
exhaustividad otros hechos asociados con tal variable.
Otro elemento que cobró sentido en la investigación fue el añadir un
centro de interés que permitiera indagar con detenimiento una dimensión
vigente de la realidad: la computación y el internet, pues al aplicar la encuesta
a informantes de secundaria, en especial de tercer grado, me propuse conocer
el léxico disponible en ese ámbito en especial. Los hallazgos permitieron

85
encontrar que la producción fue la segunda menos productiva con ciento
ochenta y cinco vocablos. En el análisis cualitativo de las primeras veinte voces
que alcanzaron una mayor frecuencia, se aprecia que son anglicismos, algunos
de los cuales son crudos, y otros son designaciones de marcas o entidades
cibernéticas. Esta falta de voces propias del español que designen elementos o
entidades se debe a que no pertenecen a nociones surgidas en el mosaico de
la lengua española y son recursos lingüísticos tomados de otros idiomas,
mecanismo neológico que permite el enriquecimiento de la lengua en la
mayoría de los casos.
Otro aspecto que también se definió en los objetivos de la investigación
era el de comparar los primeros veinte vocablos que tuvieran los más elevados
índices de disponibilidad léxica con los de dos investigaciones que para efectos
de tal comparación presentaban rasgos medianamente similares en cuanto a
las variables de sexo, rango de edad, tipo de centro escolar y la definición
equivalente de los centros de interés, una de ellas se realizó en España hacia
2013 por Felipe Jiménez Berrio y la otra fue publicada en Zacatecas por Juan
López Chávez hacia 2003. Las correspondencias o coincidencias de vocablos
se dieron en mayor cantidad con la muestra mexicana, en varios de los centros
de interés, hasta con un 60%. La presencia de elementos de tipo dialectal no
fue el elemento crucial para la no convergencia, aunque sí hubo distinciones
que obedecieron a este factor.
Adicionalmente considero pertinente manifestar que la metodología
empleada ha seguido los lineamientos que se mantienen en los diferentes
estudios alrededor del mundo, salvo el aspecto del tiempo de dos minutos que
prevalece en el proyecto panhispánico. Lo anterior permite una plausible
confiabilidad en los resultados obtenidos. Sin embargo, esto no debe admitirse
como condición absoluta, pues es necesario encontrar otros mecanismos que
permitan encontrar elementos léxicos distintos a las formas sustantivas que
aparecen en casi todos los corpora hasta el momento.
Por otra parte, en cuanto a las posibilidades de uso de este estudio para
efectos prácticos de enseñanza y aprendizaje del léxico considero que sí es
factible, pues ha permitido tener al alcance un corpus concreto con las voces
disponibles en los hablantes escolares de nivel secundaria, en un grado
terminal. Esto da cuenta de algunas voces que ya poseen tales informantes

86
para poder diseñar una planificación que tome lo que está presente y lo que
aún aparece como ausente. Aunque es necesario que en tal proceso de
planificación se integre la participación y voluntad no únicamente de lingüistas
sino de docentes y de otros especialistas en el hecho educativo. Ésta es una
condición sine qua non.
Sobre otras posibilidades de uso de este corpus para efectos de análisis
dialectológico, sociolingüístico o de índole similar, también entiendo que es
viable el empleo del mismo y que sólo será necesario efectuar una inmersión
en el caudal de voces con una visión crítica y juiciosa de la realidad lingüística
regional.

87
Bibliografía
- A.M. Collins y E.F. Loftus, 1975, A spreading activation theory of
semantic processing, Psychological Review, 82.
- Arjona Iglesias, Marina y López Chávez, Juan, 2001, Sobre la
enseñanza del español como lengua materna, Edere, México.
- Ávila, Raúl; Samper, José Antonio; Ueda, Hiroto, et al., 2003, Pautas y
pistas en el análisis del léxico hispano(americano), Iberoamericana,
Vervuert.
- Berko Gleason, Jean; Nan Bernstein Ratner, 1999, Psicolingüística,
Edit. Mc Graw Hill. España.
- Canizal Arévalo, Alma V., 1987, Disponibilidad léxica en escolares de
primaria terminada. Análisis de seis centros de interés (memoria de
licenciatura inédita), México, Universidad Autónoma de México.
- Cassany, Daniel, Marta Luna y Gloria Sanz, 2007, Enseñar lengua,
Barcelona, Graó.
- Cervero, Mª Jesús y Francisca Pichardo, 2000, Aprender y enseñar
vocabulario, Madrid, Edelsa.
- Collins, A. M. y Quillian M. R., 1969, Retrieval time from semantic
memory. Journal of verbal learning and verbal behavior, 8.
- Collins, A. M. y Quillian M. R., 1970, Facilitating retrieval from semantic
memory: The effect of repeating part of an inference. Acta Psychologia,
33.
- Dimitrijévic, Naum, 1969, Lexical Availability. Heidelberg, Julius Gross
Verlag.

88
- Dubois, Jean, Mathée Giacomo et alii, 1998, Diccionario de Lingüística.
Madrid, Alianza Editorial.
- Echeverría, Max, 1991, Crecimiento de la disponibilidad léxica en
estudiantes chilenos de nivel básico y medio, en H. López Morales (ed.),
La enseñanza del español como lengua materna, Actas del II Seminario
Internacional sobre Aportes de la lingüística a la enseñanza del español
como lengua materna, 61-78. Universidad de Puerto Rico.
- Estes, William K., 1979, Aspectos estructurales de los modelos
asociativos de la memoria, en Charles N. Cofer (ed.) Estructura de la
memoria humana, Ed. Omega, Barcelona.
- Fraisse, Paul, Georges Noizet y Claude Flament, 1977, Frecuencia y
familiaridad del vocabulario, en Jean Piaget et al., Introducción a la
psicolingüística, Nueva Visión, Buenos Aires.
- Forster, K.I., 1976, Accesing the mental lexicon, In F.J Wales & E.
Walker (Eds.) New approaches to language mechanisms.
- Gómez Devís, Ma. Begoña, 2004, La disponibilidad léxica de los
estudiantes preuniversitarios valencianos: reflexión metodológica,
análisis sociolingüístico y aplicaciones. Tesis doctoral. Universidad de
Valencia.
- Gougenheim, Georges, 1963, Les enseignements de la statistique du
vocabulaire, Études de Linguistique Appliquée, 2.
- Gougenheim, Georges, 1967, La statistique du vocabulaire et son
application dans l´enseignement des langues, Les Langues Modernes,
61.

89
- Haensch, Günther, 1997, Los diccionarios del español en el umbral del
siglo XXI. Salamanca, Ediciones Universidad de Salamanca.
- Hernández Muñoz, Natividad, 2006, Hacia una teoría cognitiva integrada
de la disponibilidad léxica: El léxico disponible de los estudiantes
castellano-manchegos, Salamanca, Ediciones Universidad de
Salamanca.
- Jiménez Berrio, Felipe, 2013, Léxico disponible de inmigrantes
escolares no hispanohablantes. Pamplona, Servicio de Publicaciones de
la Universidad de Navarra.
- Lara, Luis Fernando, 1990, Dimensiones de la lexicografía, México, El
Colegio de México.
- Lara, Luis Fernando, 2006, Curso de lexicología, México, D.F., El
Colegio de México.
- López Chávez, Juan y Carlos Strassburger , 1987, Otro cálculo del
índice de disponibilidad léxica, Presente y perspectiva de la
investigación computacional en México, Actas del IV Simposio de la
Asociación Mexicana de Lingüística Aplicada.
- López Chávez, J. y Carlos Strasburger Frías, 2000, El diseño de una
fórmula matemática para obtener un índice de disponibilidad léxica
confiable. Anuario de Letras, UNAM, pp. 227-251.
- López Chávez, Juan, 2003, ¿Qué te viene a la memoria? La
disponibilidad léxica: teoría, métodos y aplicaciones, Univ. Autónoma de
Zacatecas, Zacatecas.
- López Morales, Humberto, 1999, Léxico disponible de Puerto Rico, Arco
Libros, Madrid.

90
- Lorán, Roberto y Humberto López Morales, 1983, Nouveau calcul de
l´indice de disponibilité, MS.
- Mackey, William C., 1971, Le vocabulaire disponible du Francais, (2
vols.), París, Didier.
- Marconi, Diego, 2000, La competencia léxica, Madrid, Antonio Machado
Libros.
- Marx, Melvin H. y William A. Hillix, 1980, Sistemas y teorías psicológicos
contemporáneos, Edit. Paidós, Buenos Aires.
- Michéa, René, 1953, Mots fréquents et mots disponibles: un aspect
nouveau de la statistique du langage, Les Langues Modernes, 47.
- Morton, J., 1969, Interaction of information in word recognition,
Psychological Review, 76.
- Müller,Charles, 1973, Estadística lingüística. Madrid, Gredos.
- Payán Sotomayor, Pedro M., 1983, El habla de Cádiz, Quorum Libros
Editores, España.
- Valencia, Alba, 2000, Ciencia y tecnología. Análisis del léxico estudiantil,
Nueva Revista del Pacífico 45, 89-98.
- Vargas, Patricia, 1991, La disponibilidad léxica: un diagnóstico al
hablante medio de la V Región en seis centros de interés, Nueva Revista
del Pacífico, 33-36, 115-123.
Materiales de consulta

91
- Diccionario de americanismos / Asociación de Academias de la Lengua
Española, primera edición, 2010, Perú.
- Diccionario de mexicanismos / Academia Mexicana de la Lengua;
dirigido por Concepción Company Company, primera edición, 2010,
México, Siglo XXI.
- Diccionario de la lengua española / Real Academia Española, vigésima
segunda edición, 2001, Madrid.
- Diccionario del Español de México (DEM) http://dem.colmex.mx, El
Colegio de México, A.C., [consultado el 18 de abril de 2014]

92
Anexos Diccionario del léxico disponible de hablantes adolescentes de Culiacán, Sinaloa Centro de interés 1 – Las partes del cuerpo
VOCABLO IDL ojo 0.689145344 dedo 0.667680247 brazo 0.598563771 pie 0.587320558 oreja 0.575540909 mano 0.568620338 boca 0.562082035 pierna 0.556021229 nariz 0.555170921 cabeza 0.536979761 uña 0.500321854 ceja 0.379888612 rodilla 0.338287068 pestaña 0.317717361 codo 0.302521813 diente 0.298417454 pelo 0.290958447 estómago 0.282251221 corazón 0.270275621 cabello 0.242945195 lengua 0.230792757 hueso 0.205687105 cuello 0.200168883 muñeca 0.185803545 muslo 0.181043108 hígado 0.180423335 pulmón 0.17826381 tobillo 0.166965371 cara 0.166115404 espalda 0.163620399 pene 0.146431873 vagina 0.144749291 cadera 0.134413483 labio 0.129985681 cerebro 0.128798936 piel 0.120927094 ombligo 0.118558387 hombro 0.110719218 antebrazo 0.104859408 oído 0.094796429
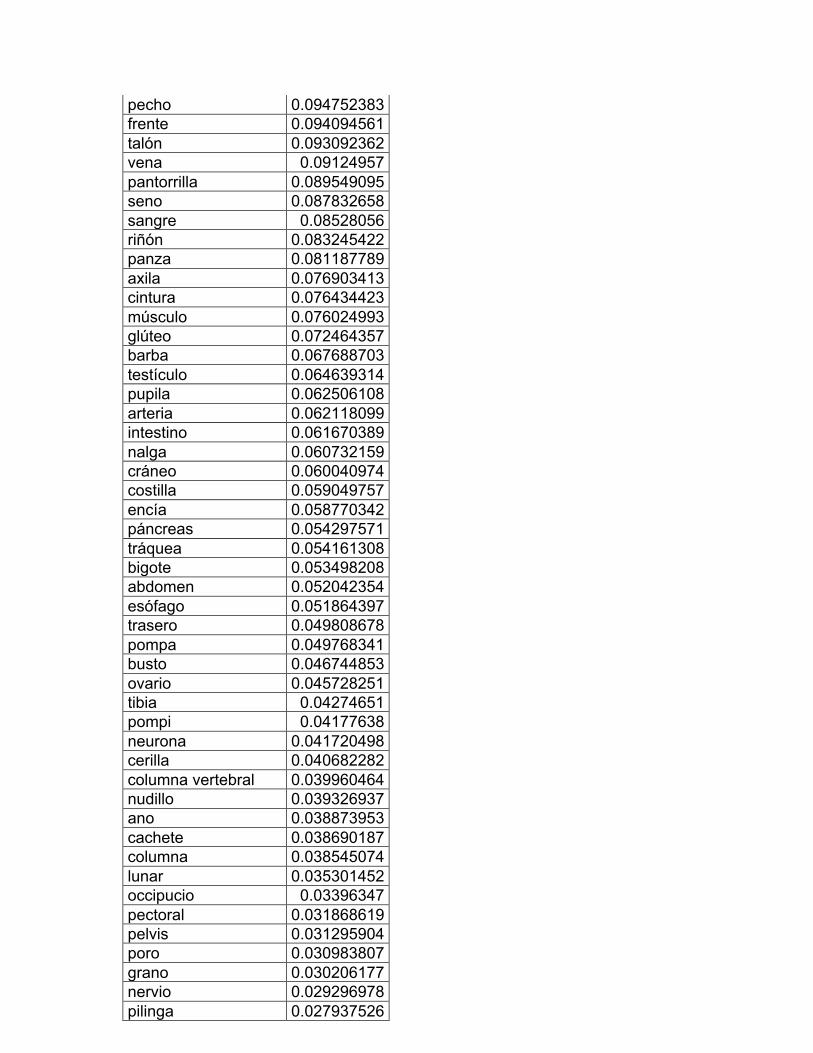
93
pecho 0.094752383 frente 0.094094561 talón 0.093092362 vena 0.09124957 pantorrilla 0.089549095 seno 0.087832658 sangre 0.08528056 riñón 0.083245422 panza 0.081187789 axila 0.076903413 cintura 0.076434423 músculo 0.076024993 glúteo 0.072464357 barba 0.067688703 testículo 0.064639314 pupila 0.062506108 arteria 0.062118099 intestino 0.061670389 nalga 0.060732159 cráneo 0.060040974 costilla 0.059049757 encía 0.058770342 páncreas 0.054297571 tráquea 0.054161308 bigote 0.053498208 abdomen 0.052042354 esófago 0.051864397 trasero 0.049808678 pompa 0.049768341 busto 0.046744853 ovario 0.045728251 tibia 0.04274651 pompi 0.04177638 neurona 0.041720498 cerilla 0.040682282 columna vertebral 0.039960464 nudillo 0.039326937 ano 0.038873953 cachete 0.038690187 columna 0.038545074 lunar 0.035301452 occipucio 0.03396347 pectoral 0.031868619 pelvis 0.031295904 poro 0.030983807 grano 0.030206177 nervio 0.029296978 pilinga 0.027937526
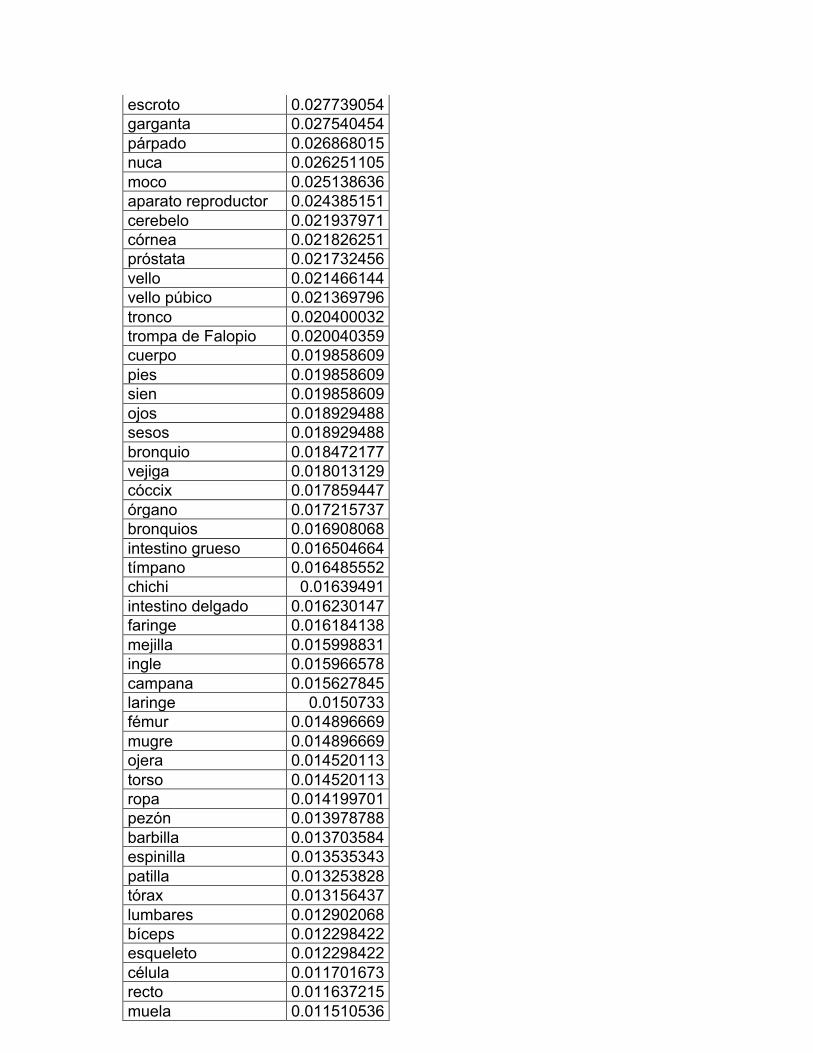
94
escroto 0.027739054 garganta 0.027540454 párpado 0.026868015 nuca 0.026251105 moco 0.025138636 aparato reproductor 0.024385151 cerebelo 0.021937971 córnea 0.021826251 próstata 0.021732456 vello 0.021466144 vello púbico 0.021369796 tronco 0.020400032 trompa de Falopio 0.020040359 cuerpo 0.019858609 pies 0.019858609 sien 0.019858609 ojos 0.018929488 sesos 0.018929488 bronquio 0.018472177 vejiga 0.018013129 cóccix 0.017859447 órgano 0.017215737 bronquios 0.016908068 intestino grueso 0.016504664 tímpano 0.016485552 chichi 0.01639491 intestino delgado 0.016230147 faringe 0.016184138 mejilla 0.015998831 ingle 0.015966578 campana 0.015627845 laringe 0.0150733 fémur 0.014896669 mugre 0.014896669 ojera 0.014520113 torso 0.014520113 ropa 0.014199701 pezón 0.013978788 barbilla 0.013703584 espinilla 0.013535343 patilla 0.013253828 tórax 0.013156437 lumbares 0.012902068 bíceps 0.012298422 esqueleto 0.012298422 célula 0.011701673 recto 0.011637215 muela 0.011510536

95
escafoides 0.011439806 matriz 0.010892068 bubis 0.010651715 mandíbula 0.010153356 fosa nasal 0.009678313 planta 0.009678313 colon 0.009433666 angina 0.009225496 epidídimo 0.009225496 orina 0.009225496 vesícula 0.009085364 boca del estómago 0.008793865 órgano reproductor 0.008382428 entrepierna 0.007616403 trompas de Falopio 0.007616403 vello intestinal 0.007616403 copete 0.006920382 glándula 0.006920382 glóbulos rojos 0.006920382 peroné 0.006920382 glóbulos blancos 0.006596599 útero 0.006596599 campanita 0.006287966 genitales 0.006287966 huesos 0.006287966 respirar 0.006287966 verruga 0.006287966 rabadilla 0.005993772 alveolo 0.005713343 apéndice 0.005713343 encéfalo 0.005713343 genital 0.005713343 páncreas 0.005713343 vellos 0.005713343 campanilla 0.005446034 huevos 0.005446034 paleta 0.005446034 peca 0.005446034 iris 0.005191231 testículos 0.005191231 vulva 0.005191231 sistema inmunológico 0.00494835 picadura 0.004716833 sistema nervioso 0.004716833 huevo 0.004496148 mujer 0.004496148 hombre 0.004285787 tetas 0.004085269
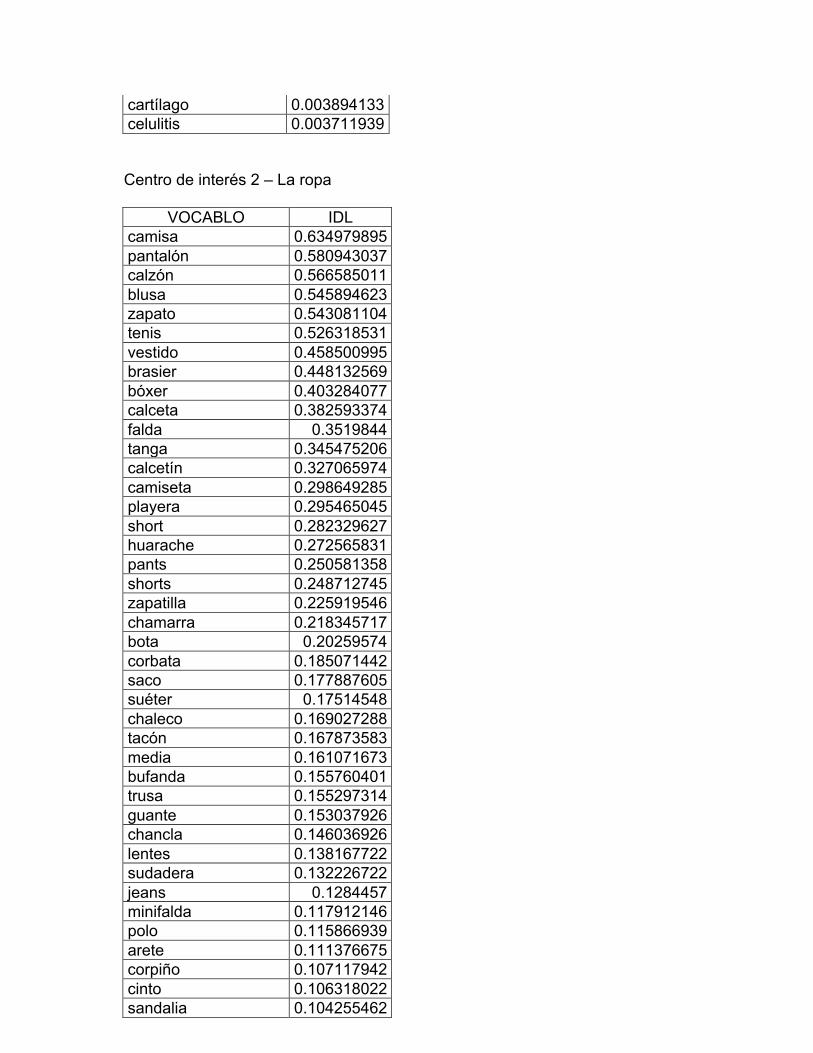
96
cartílago 0.003894133 celulitis 0.003711939 Centro de interés 2 – La ropa
VOCABLO IDL camisa 0.634979895 pantalón 0.580943037 calzón 0.566585011 blusa 0.545894623 zapato 0.543081104 tenis 0.526318531 vestido 0.458500995 brasier 0.448132569 bóxer 0.403284077 calceta 0.382593374 falda 0.3519844 tanga 0.345475206 calcetín 0.327065974 camiseta 0.298649285 playera 0.295465045 short 0.282329627 huarache 0.272565831 pants 0.250581358 shorts 0.248712745 zapatilla 0.225919546 chamarra 0.218345717 bota 0.20259574 corbata 0.185071442 saco 0.177887605 suéter 0.17514548 chaleco 0.169027288 tacón 0.167873583 media 0.161071673 bufanda 0.155760401 trusa 0.155297314 guante 0.153037926 chancla 0.146036926 lentes 0.138167722 sudadera 0.132226722 jeans 0.1284457 minifalda 0.117912146 polo 0.115866939 arete 0.111376675 corpiño 0.107117942 cinto 0.106318022 sandalia 0.104255462
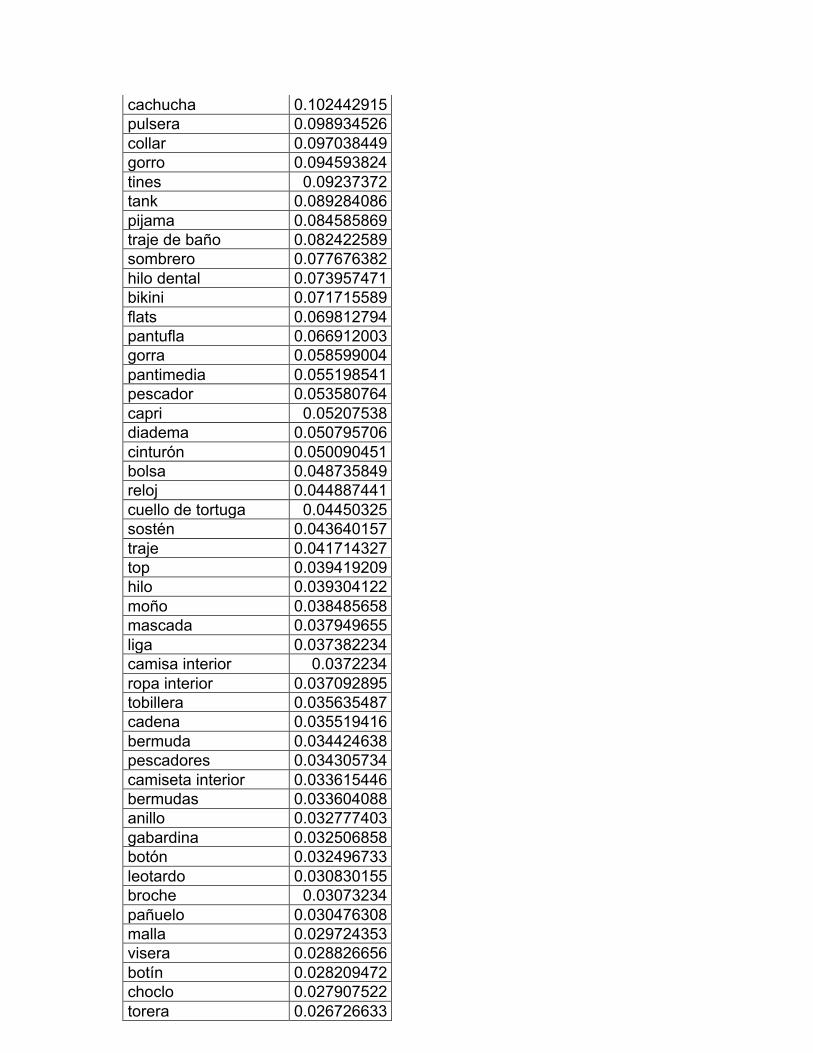
97
cachucha 0.102442915 pulsera 0.098934526 collar 0.097038449 gorro 0.094593824 tines 0.09237372 tank 0.089284086 pijama 0.084585869 traje de baño 0.082422589 sombrero 0.077676382 hilo dental 0.073957471 bikini 0.071715589 flats 0.069812794 pantufla 0.066912003 gorra 0.058599004 pantimedia 0.055198541 pescador 0.053580764 capri 0.05207538 diadema 0.050795706 cinturón 0.050090451 bolsa 0.048735849 reloj 0.044887441 cuello de tortuga 0.04450325 sostén 0.043640157 traje 0.041714327 top 0.039419209 hilo 0.039304122 moño 0.038485658 mascada 0.037949655 liga 0.037382234 camisa interior 0.0372234 ropa interior 0.037092895 tobillera 0.035635487 cadena 0.035519416 bermuda 0.034424638 pescadores 0.034305734 camiseta interior 0.033615446 bermudas 0.033604088 anillo 0.032777403 gabardina 0.032506858 botón 0.032496733 leotardo 0.030830155 broche 0.03073234 pañuelo 0.030476308 malla 0.029724353 visera 0.028826656 botín 0.028209472 choclo 0.027907522 torera 0.026726633

98
faja 0.02652367 jumper 0.025673398 pantalón de vestir 0.025613849 leguins 0.024247836 taquete 0.022185984 camisa de manga larga 0.021129925 orejeras 0.02105572 tirante 0.020833333 pantaloncillo corto 0.01974827 pentalón 0.01974827 tacos 0.01974827 celular 0.019040553 lentes de sol 0.018189888 falda larga 0.017934158 flip flop 0.01774474 corset 0.017037663 conjunto 0.01682054 calcetón 0.016346479 estraple 0.015944476 mallas 0.01590941 camiseta sin mangas 0.015114039 taquetenis 0.015114039 accesorio 0.014814291 cuello V 0.014326854 suela 0.014326854 escote 0.013862137 calzoncillo 0.013580668 pantalón de mezclilla 0.013580668 playera interior 0.013580668 alpargata 0.012873345 shorts bicicletero 0.012873345 tin 0.012418834 camisón 0.012202862 vestido largo 0.012202862 máscara 0.012193447 casco 0.011690776 calzón de hilo dental 0.0115673 huaraches 0.0115673 jersey 0.0115673 manga 0.0115673 lentes de contacto 0.011520682 (playera de) resaque 0.01096484 colgajes 0.01096484 falda short 0.01096484 listón 0.01071365 cartera 0.010686306 capucha 0.010393758

99
mocasín 0.010393758 mallón 0.009339276 blusón 0.008852858 cuerdas 0.008852858 smoking 0.008852858 flat 0.008603353 calcomanía 0.008391774 playera tipo polo 0.008391774 bata 0.008155265 mezclilla 0.007954705 plataforma 0.007954705 short de licra 0.007954705 blusa de tirantes 0.0075404 calcetines 0.0075404 lentes de cristal 0.0075404 nylon 0.0075404 pantimedias 0.0075404 piercing 0.0075404 licra 0.007147673 pantaleta 0.007147673 tiara 0.007005917 blusa estraple 0.0067754 camisola 0.0067754 chalina 0.0067754 lana 0.0067754 overol 0.0067754 pantuflas 0.0067754 sarape 0.0067754 zapato cerrado 0.0067754 banda 0.006422517 dona 0.006422517 polaina 0.006422517 skirt 0.006422517 tela 0.006422517 camisa de resaque 0.006088013 peluca 0.006088013 tanks 0.006088013 tienda 0.006088013 toreras 0.006088013 chaqueta 0.005770931 rodillera 0.005770931 saco sudadera 0.005770931 Converse 0.005470363 codera 0.005470363 mancuernilla 0.005470363 concha 0.00518545 camisa sin manga 0.004915376 medias 0.004915376
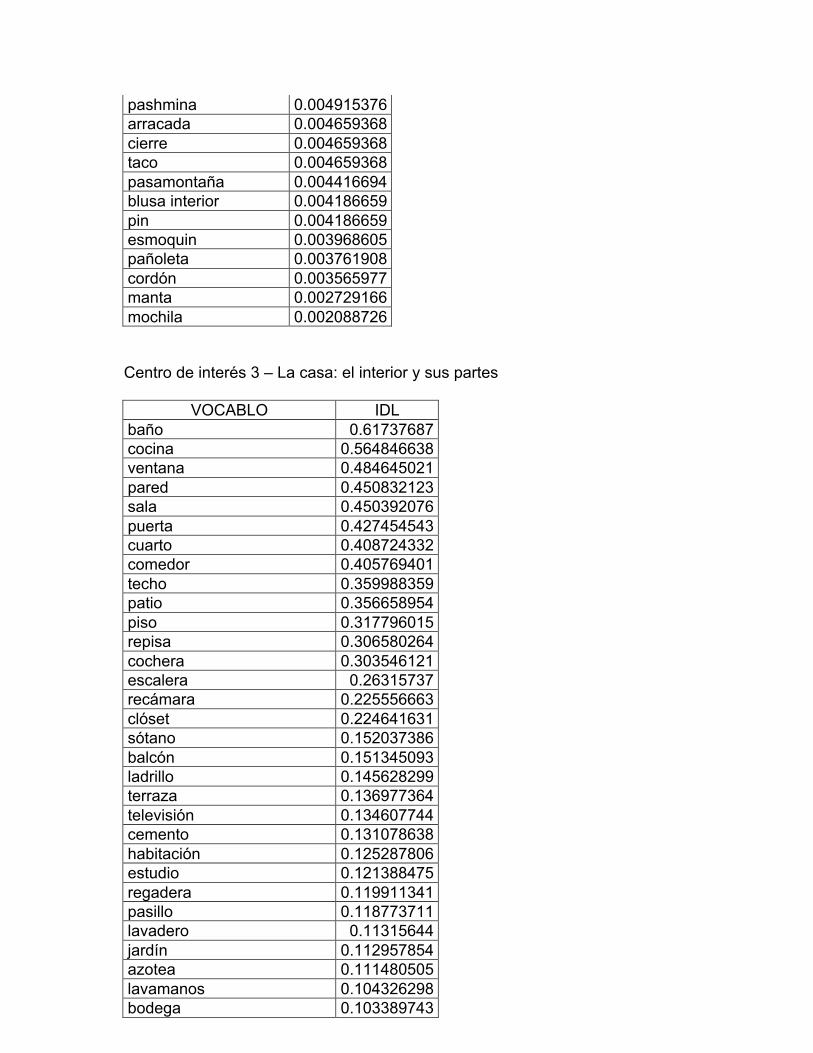
100
pashmina 0.004915376 arracada 0.004659368 cierre 0.004659368 taco 0.004659368 pasamontaña 0.004416694 blusa interior 0.004186659 pin 0.004186659 esmoquin 0.003968605 pañoleta 0.003761908 cordón 0.003565977 manta 0.002729166 mochila 0.002088726 Centro de interés 3 – La casa: el interior y sus partes
VOCABLO IDL baño 0.61737687 cocina 0.564846638 ventana 0.484645021 pared 0.450832123 sala 0.450392076 puerta 0.427454543 cuarto 0.408724332 comedor 0.405769401 techo 0.359988359 patio 0.356658954 piso 0.317796015 repisa 0.306580264 cochera 0.303546121 escalera 0.26315737 recámara 0.225556663 clóset 0.224641631 sótano 0.152037386 balcón 0.151345093 ladrillo 0.145628299 terraza 0.136977364 televisión 0.134607744 cemento 0.131078638 habitación 0.125287806 estudio 0.121388475 regadera 0.119911341 pasillo 0.118773711 lavadero 0.11315644 jardín 0.112957854 azotea 0.111480505 lavamanos 0.104326298 bodega 0.103389743
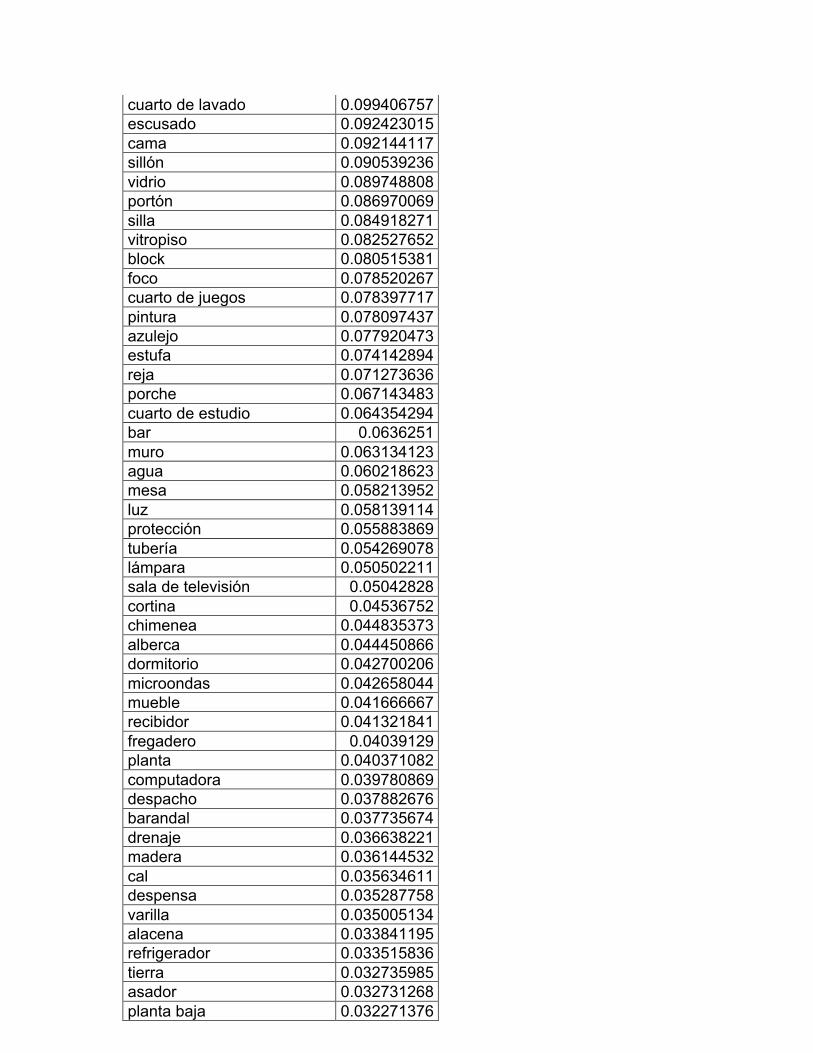
101
cuarto de lavado 0.099406757 escusado 0.092423015 cama 0.092144117 sillón 0.090539236 vidrio 0.089748808 portón 0.086970069 silla 0.084918271 vitropiso 0.082527652 block 0.080515381 foco 0.078520267 cuarto de juegos 0.078397717 pintura 0.078097437 azulejo 0.077920473 estufa 0.074142894 reja 0.071273636 porche 0.067143483 cuarto de estudio 0.064354294 bar 0.0636251 muro 0.063134123 agua 0.060218623 mesa 0.058213952 luz 0.058139114 protección 0.055883869 tubería 0.054269078 lámpara 0.050502211 sala de televisión 0.05042828 cortina 0.04536752 chimenea 0.044835373 alberca 0.044450866 dormitorio 0.042700206 microondas 0.042658044 mueble 0.041666667 recibidor 0.041321841 fregadero 0.04039129 planta 0.040371082 computadora 0.039780869 despacho 0.037882676 barandal 0.037735674 drenaje 0.036638221 madera 0.036144532 cal 0.035634611 despensa 0.035287758 varilla 0.035005134 alacena 0.033841195 refrigerador 0.033515836 tierra 0.032735985 asador 0.032731268 planta baja 0.032271376

102
fuente 0.03198632 electricidad 0.030838621 cuarto de televisión 0.029805374 cuchara 0.029805374 aire acondicionado 0.0295164 gimnasio 0.029261713 tapete 0.02842308 viga 0.028179399 segundo piso 0.02737948 lavado 0.027105402 arena 0.025848532 tina 0.025848532 xbox 0.025236834 tostador 0.024926388 suelo 0.024673583 lavadora 0.024654383 piedra 0.024540155 patio trasero 0.024463151 colcha 0.024228701 barra 0.023347249 tejabán 0.023339794 cable 0.023260109 tendedero 0.023245508 ático 0.023046003 esquina 0.022469015 mármol 0.022383562 adorno 0.022282532 textura 0.020889876 barda 0.020833333 sofá 0.020833333 persiana 0.020765548 teja 0.020742349 arco 0.020583157 spa 0.020475832 batidora 0.02037947 estancia 0.019607664 marquesina 0.019478331 antecomedor 0.018622288 primer piso 0.018622288 traste 0.018622288 gravón 0.018415727 fierro 0.017989903 piscina 0.017989903 vitral 0.01789901 banqueta 0.017802549 fachada 0.017606384 perilla 0.017606384 sala de estar 0.017606384

103
tejado 0.017606384 teléfono 0.017606384 alfombra 0.017454035 vestidor 0.017076374 comida 0.017069832 campana 0.016645901 marco de puerta 0.016645901 sábana 0.016645901 escritorio 0.016242382 jacuzzi 0.015765062 cuarto de servicio 0.015737816 lobby 0.015737816 vaso 0.015737816 videocasetera 0.015737816 yeso 0.015737816 área de juegos 0.015737816 alcoba 0.015666588 secadora 0.015638027 champú 0.014879269 colchón 0.014879269 game cube 0.014879269 sala de entretenimiento 0.014879269 biblioteca 0.014141949 cuadro 0.014080031 abanico de techo 0.014067559 enjarre 0.014067559 garage 0.014067559 jabón 0.014067559 play station 0.014067559 taza 0.014067559 DVD 0.01330013 armario 0.01330013 barra de comer 0.01330013 cancel 0.01330013 cocina integral 0.01330013 entretenimiento 0.01330013 planta alta 0.01330013 elevador 0.013239934 estacionamiento 0.012848477 VHS 0.012574566 lavabo 0.012574566 raya 0.012574566 cilindro de gas 0.011888585 cobertizo 0.011888585 inodoro 0.011888585 animal 0.011734046 cuarto de tele 0.011240025 librero 0.011240025

104
patio de adelante 0.011240025 sala de juego 0.011240025 reloj 0.010909573 acondicionador 0.010626847 estéreo 0.010626847 medio baño 0.010626847 cañería 0.010047119 cornisa 0.010047119 cuarto de planchar 0.010047119 huerta 0.010047119 servilleta 0.010047119 tablarroca 0.010047119 cafetería 0.009499018 horno 0.009499018 papel 0.009499018 ventana de vidrio 0.009499018 aluminio 0.008980817 castillo 0.008980817 corredor 0.008980817 gamecube 0.008980817 gas 0.008980817 micropiso 0.008980817 servicio 0.008980817 abrecorchos 0.008785166 cuarto de masaje 0.008490885 maceta 0.008490885 tragaluz 0.008490885 wii 0.008490885 cenicero 0.008117123 escalón 0.008027681 gente 0.008027681 unicel 0.008027681 área verde 0.008027681 búnker 0.007589746 césped 0.007589746 estatua 0.007589746 grava 0.007589746 lap top 0.007589746 tejada 0.007589746 color 0.007175702 entrada 0.007175702 impermeable 0.007175702 llave 0.007175702 árbol 0.007175702 espejo 0.007019376 jacuzzi 0.007019376 buró 0.006784245 cantina 0.006784245

105
contacto 0.006784245 macetera 0.006784245 patio interior 0.006784245 sartén 0.006784245 techumbre 0.006784245 escaleras 0.006414144 juguete 0.006414144 marco 0.006414144 portal 0.006414144 cuarto de TV 0.006064232 cuarto de cómputo 0.006064232 baúl 0.005733409 hijos 0.005733409 pasillos 0.005733409 guardapán 0.005420634 oficina 0.005420634 padres 0.005420634 perchero 0.005124922 pluma 0.005124922 cuarto de máquinas 0.004845341 palapa 0.004845341 caminadora 0.004823412 bañera 0.004581013 bóiler 0.004581013 cobacha 0.004581013 columna 0.004581013 brasero 0.004331104 cuarto principal 0.004331104 bebida 0.004094829 música 0.004094829 piso superior 0.003871444 pasto 0.003660244 mantel 0.003271782 sala de estudio 0.003271782 trapeador 0.003271782 cuarto de servicio 0.003093296 escoba 0.003093296 plato 0.003093296 persona 0.002924547 toalla 0.002924547 costal 0.002765004 revista 0.002765004 periódico 0.002614164 pesa 0.002471554 vela 0.002471554 encendedor 0.002336723 máquina para hacer ejercicio 0.002336723

106
pesas 0.002088726 Centro de interés 4 – Muebles y enseres domésticos
VOCABLO IDL silla 0.611206601 sillón 0.599771183 cama 0.54705993 cuchara 0.511673074 mesa 0.508875036 tenedor 0.47809455 cuchillo 0.421018558 refrigerador 0.393102794 televisión 0.390762747 estufa 0.368075974 comedor 0.348408781 escoba 0.305228595 trapeador 0.298541355 sofá 0.263407131 computadora 0.251850531 plato 0.229000291 licuadora 0.210012482 clóset 0.204829354 sartén 0.196031092 vaso 0.187395133 lavadora 0.187158609 microondas 0.185094939 lámpara 0.182540112 buró 0.168474554 cajón 0.167046163 ropero 0.13313764 sala 0.128739759 taza 0.127776804 aire acondicionado 0.114820786 cuadro 0.11329462 foco 0.111459012 olla 0.110149474 plancha 0.109643328 tocador 0.109627812 espejo 0.107908638 secadora 0.10608668 escusado 0.105827071 DVD 0.102957988 jabón 0.098766339 alacena 0.097478584 regadera 0.097181753 abanico 0.096165392

107
colchón 0.090174243 estéreo 0.088050191 litera 0.087584873 pelapapas 0.086690738 puerta 0.08652972 recogedor 0.082528517 lavamanos 0.0811511 librero 0.076982836 escritorio 0.076857655 barra 0.076070778 sábana 0.07511755 ventana 0.070981779 horno de microondas 0.069427819 champú 0.068804451 vitrina 0.067514092 cocina 0.066817679 xbox 0.063352633 lavadero 0.062788289 tapete 0.062501597 almohada 0.061247217 cubeta 0.060812535 agua 0.059924568 tostador 0.057661102 vasija 0.057258841 cocina integral 0.056810804 jarra 0.055763231 alfombra 0.055733715 cepillo 0.055028542 cafetera 0.054198906 espátula 0.051363784 rastrillo 0.050650904 toalla 0.048892856 batidora 0.048578786 esquinero 0.047652873 maceta 0.047133217 basurero 0.044666039 ropa 0.043272765 exprimidor 0.043120831 nintendo 0.042411209 cucharón 0.042051874 cobija 0.041891693 tendedero 0.041408 radio 0.039420412 consoleta 0.038992736 desayunador 0.03866906 teléfono 0.038570267 repisa 0.038357756 horno 0.037495739

108
bote de basura 0.036752234 modular 0.035973459 pala 0.035395858 cojín 0.035156404 piso 0.034990607 mueble 0.03462911 garrafón 0.032033176 aspiradora 0.031145299 cazuela 0.030169174 cortina 0.030127764 campana 0.029306396 disco 0.028709039 cuna 0.028662303 jarrón 0.028336713 peine 0.028225766 papel 0.028146959 cómoda 0.027596231 lumbre 0.027561936 mecedora 0.026598369 bocina 0.026580472 cable 0.025931872 colcha 0.025699384 cajonera 0.025692452 cabecera 0.025675355 mantel 0.025427014 servilleta 0.024958597 comal 0.02493247 pecera 0.024784306 vela 0.024413162 juguetero 0.023971715 reloj 0.023825315 bolsa 0.022592655 cenicero 0.022305977 plumero 0.021633335 aire 0.021612948 banco 0.021369523 tina 0.02111134 destapacaño 0.020833333 minibar 0.020022483 puf 0.019838373 vidrio 0.019635874 extractor 0.019134722 flor 0.018679505 portagarrafón 0.018598423 juguete 0.018036221 PSP 0.017988736 caja 0.017988736 papel de baño 0.017988736

109
tazón 0.017988736 play station 0.017743338 alberca 0.01735069 comida 0.017169347 bebida 0.017129628 detergente 0.017129628 mesa comedor 0.017129628 árbol 0.016513103 llave 0.016462929 centro de entretenimiento 0.016436418 buró para ropa 0.01631155 mesa de centro 0.01631155 picahielo 0.01631155 tubería 0.01631155 armario 0.016089032 libro 0.016085116 portarretrato 0.015852306 cúler 0.015540759 carpeta 0.015532541 cocineta 0.015532541 sostén de TV 0.015532541 wii 0.015320651 mochila 0.015071111 encendedor 0.014852594 abrelatas 0.014790737 jarro 0.014790737 microcomponente 0.014790737 mini split 0.014790737 película 0.01444685 bandeja 0.014266121 carro 0.014266121 acondicionador 0.014084359 estante 0.013958695 asador 0.013926728 burro 0.013523569 base de cama 0.013411717 cepillo de dientes 0.013411717 cuchillo eléctrico 0.013411717 lavatrastes 0.013411717 mesa de noche 0.013411717 fregador 0.013387188 tubo 0.01320405 lap top 0.012889722 arbolito 0.012771199 despensa 0.012771199 karaoke 0.012771199 kótex 0.012771199 árbol de navidad 0.012771199
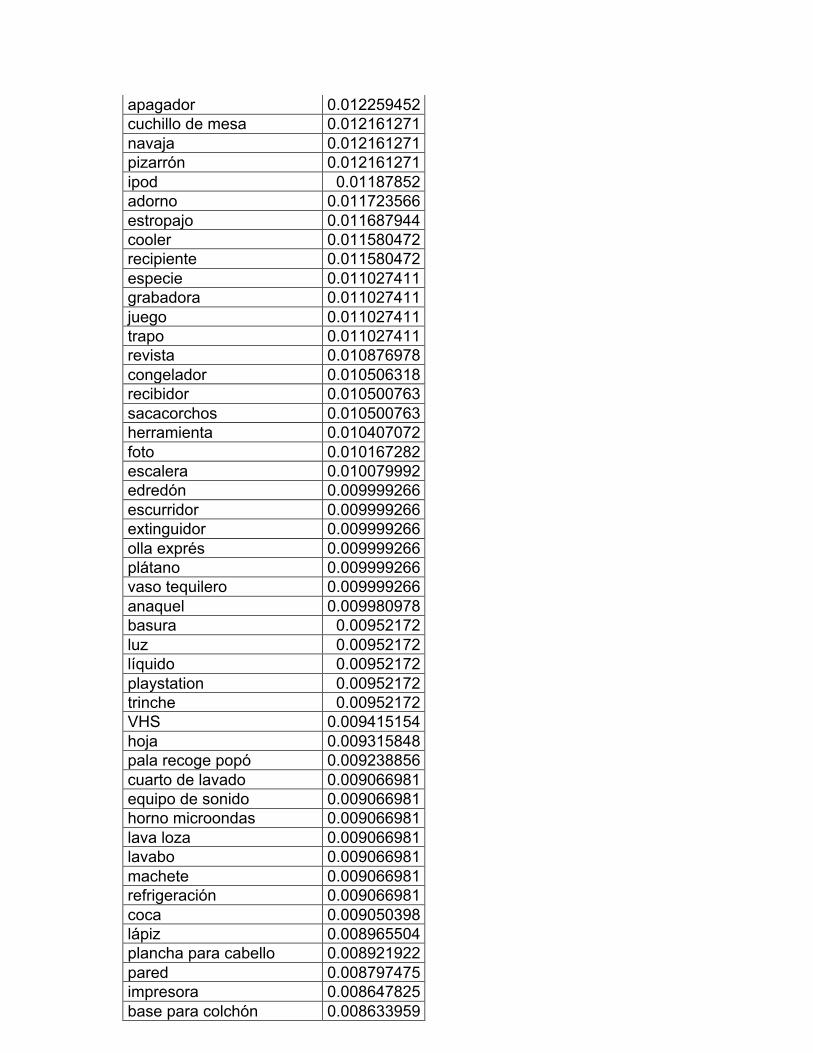
110
apagador 0.012259452 cuchillo de mesa 0.012161271 navaja 0.012161271 pizarrón 0.012161271 ipod 0.01187852 adorno 0.011723566 estropajo 0.011687944 cooler 0.011580472 recipiente 0.011580472 especie 0.011027411 grabadora 0.011027411 juego 0.011027411 trapo 0.011027411 revista 0.010876978 congelador 0.010506318 recibidor 0.010500763 sacacorchos 0.010500763 herramienta 0.010407072 foto 0.010167282 escalera 0.010079992 edredón 0.009999266 escurridor 0.009999266 extinguidor 0.009999266 olla exprés 0.009999266 plátano 0.009999266 vaso tequilero 0.009999266 anaquel 0.009980978 basura 0.00952172 luz 0.00952172 líquido 0.00952172 playstation 0.00952172 trinche 0.00952172 VHS 0.009415154 hoja 0.009315848 pala recoge popó 0.009238856 cuarto de lavado 0.009066981 equipo de sonido 0.009066981 horno microondas 0.009066981 lava loza 0.009066981 lavabo 0.009066981 machete 0.009066981 refrigeración 0.009066981 coca 0.009050398 lápiz 0.008965504 plancha para cabello 0.008921922 pared 0.008797475 impresora 0.008647825 base para colchón 0.008633959
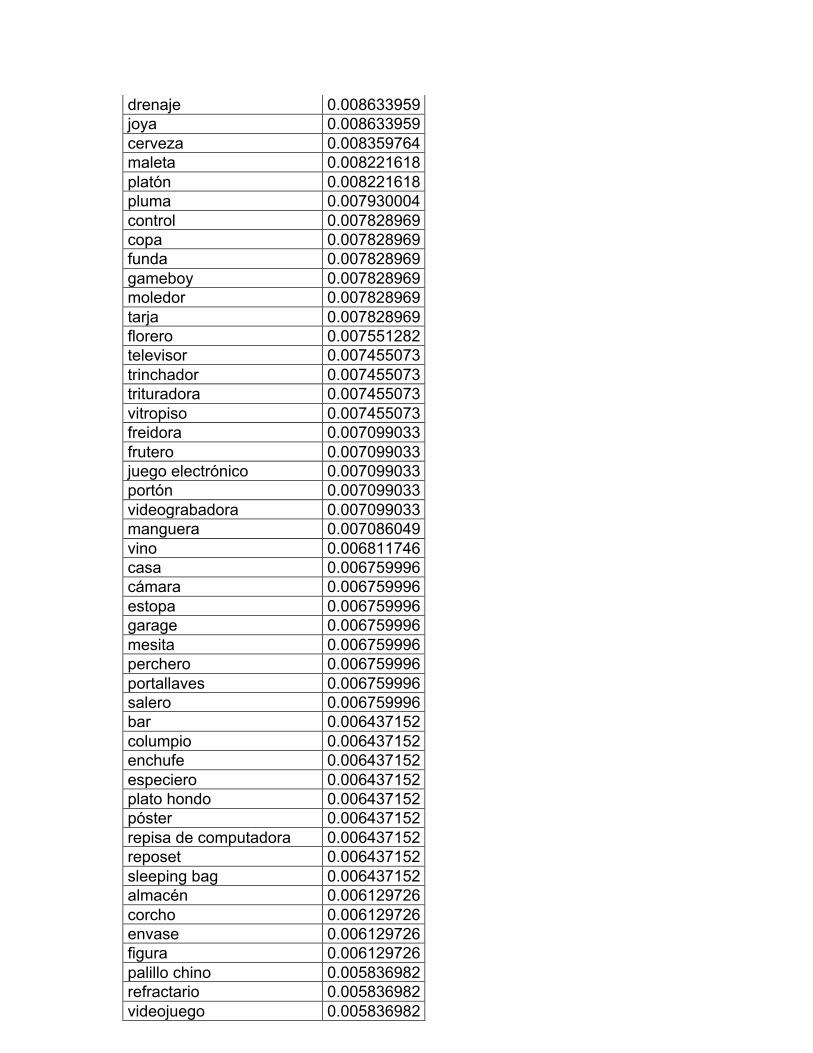
111
drenaje 0.008633959 joya 0.008633959 cerveza 0.008359764 maleta 0.008221618 platón 0.008221618 pluma 0.007930004 control 0.007828969 copa 0.007828969 funda 0.007828969 gameboy 0.007828969 moledor 0.007828969 tarja 0.007828969 florero 0.007551282 televisor 0.007455073 trinchador 0.007455073 trituradora 0.007455073 vitropiso 0.007455073 freidora 0.007099033 frutero 0.007099033 juego electrónico 0.007099033 portón 0.007099033 videograbadora 0.007099033 manguera 0.007086049 vino 0.006811746 casa 0.006759996 cámara 0.006759996 estopa 0.006759996 garage 0.006759996 mesita 0.006759996 perchero 0.006759996 portallaves 0.006759996 salero 0.006759996 bar 0.006437152 columpio 0.006437152 enchufe 0.006437152 especiero 0.006437152 plato hondo 0.006437152 póster 0.006437152 repisa de computadora 0.006437152 reposet 0.006437152 sleeping bag 0.006437152 almacén 0.006129726 corcho 0.006129726 envase 0.006129726 figura 0.006129726 palillo chino 0.005836982 refractario 0.005836982 videojuego 0.005836982

112
entrada 0.005558219 mantel individual 0.005558219 parrilla 0.005558219 silla de reposo 0.005558219 almohada 0.005292769 camilla 0.005292769 canasta 0.005292769 escáner 0.005292769 guante 0.005292769 podadora 0.005292769 tijeras 0.005292769 Braun 0.005039996 borrador 0.005039996 bote de ropa sucia 0.005039996 matraz 0.005039996 plumón 0.005039996 ron 0.005039996 sofá cama 0.005039996 sombrilla 0.005039996 aparato 0.004799296 bote de ropa de planchar 0.004799296 cochera 0.004799296 color 0.004799296 cuelgatoallas 0.004799296 enjuague 0.004799296 maquina de coser 0.004799296 pinza 0.004799296 reproductor de cintas 0.004799296 coche 0.00457009 cubrecama 0.00457009 esponja 0.00457009 lavaplatos 0.00457009 mouse 0.00457009 peluche 0.00457009 toallero 0.00457009 cartón de cerveza 0.004351832 mesa de juego 0.004351832 secadora para cabello 0.004351832 teclado 0.004351832 tortuga 0.004351832 bóiler 0.004143996 rodapié 0.004143996 bote de ropa 0.003946087 martillo 0.003946087 taza de baño 0.003946087 whisky 0.003946087 croqueta 0.00375763 destornillador 0.00375763

113
reproductor 0.00375763 puff 0.003578172 llavero 0.003407286 mesabanco 0.003407286 sacadora 0.003407286 sala de televisión 0.00324456 pintura 0.003089606 tele 0.003089606 cuaderno 0.002942052 gancho 0.002801546 lentes 0.002801546 burro de planchar 0.002667749 juego de video 0.002667749 crema 0.002540343 recámara 0.002303493 Centro de interés 5 – Alimentos: comidas y bebidas
VOCABLO IDL pollo 0.366331396 pescado 0.352855805 pizza 0.346616176 hamburguesa 0.319587078 papa 0.315819718 sopa 0.304127513 sándwich 0.295846261 frijol 0.28304511 torta 0.279862211 carne 0.279545429 huevo 0.262756712 manzana 0.254370633 sushi 0.250312593 quesadilla 0.247757168 tortilla 0.243343079 tomate 0.243119107 refresco 0.239985861 agua 0.231779135 plátano 0.220013605 pera 0.21677221 zanahoria 0.205997502 cebolla 0.198486592 salchicha 0.191639196 jamón 0.191130257 leche 0.19077878 jugo 0.183897611 enchilada 0.18128933 gorditas 0.180970847

114
queso 0.179059398 chilaquiles 0.176803416 limonada 0.173881226 pan 0.173413011 chile 0.171893578 tacos 0.171834639 camarón 0.164705818 pepino 0.163924741 tamal 0.15595793 tostadas 0.15438707 espagueti 0.151808202 hot dog 0.147701958 coca (cola) 0.141655351 melón 0.141553743 arroz 0.135205316 caldo 0.133346894 lechuga 0.12926188 galleta 0.127471622 cerveza 0.125422398 sandía 0.12397803 té 0.123366374 naranja 0.122748737 sabritas 0.121150444 mango 0.117403743 mole 0.11529645 pozole 0.114643162 chorizo 0.111525697 cereal 0.108956817 mollete 0.108947393 atún 0.108146355 papaya 0.106822608 cacahuate 0.103650965 brócoli 0.103624514 fresa 0.102969161 cochinita 0.098282847 ensalada 0.097886213 chamoy 0.097043432 limón 0.094527398 aguacate 0.092163667 paleta 0.091996517 burrito 0.088758014 pastel 0.08507192 aguachile 0.084410282 corbata 0.082900975 comida china 0.080292601 chilorio 0.077807009 ceviche 0.076604159 kiwi 0.074694651

115
taco 0.071762712 apio 0.068855022 lasaña 0.066096268 chocomilk 0.066079403 pulpo 0.063170602 chicle 0.062367877 durazno 0.061042067 menudo 0.059913163 enchiladas 0.059717258 salsa 0.058564159 whisky 0.05844136 chocolate 0.057842709 mayonesa 0.055959175 papitas 0.055652857 jamaica 0.055460894 res 0.05485096 corn flakes 0.053581626 cilantro 0.053504894 uva 0.05254127 entomatadas 0.052260442 coliflor 0.051196394 repollo 0.048314739 mandarina 0.048098501 jugo de naranja 0.047985159 machaca 0.046629434 horchata 0.046056079 frijoles puercos 0.045868361 carne asada 0.044135101 guacamole 0.043829853 chile relleno 0.042983818 barbacoa 0.041947766 dona 0.041147382 catsup 0.040290908 cazuela 0.040127151 tequila 0.03897099 dulce 0.038002496 elote 0.035537484 huevo ranchero 0.035372057 pepinillo 0.035312332 café 0.035072631 lichi 0.035030623 vino 0.034735683 almeja 0.034287465 pimienta 0.033605456 fresada 0.033449432 jitomate 0.032973401 milanesa 0.032434431 cebada 0.032203243

116
sal 0.032169915 tacos dorados 0.031812183 piña 0.031203169 agua de jamaica 0.031132878 taco al pastor 0.030990099 peperoni 0.030724444 vodka 0.030679727 caldo de pollo 0.030615917 papas fritas 0.030262226 soda 0.030237453 nieve 0.030190545 tostada 0.029978095 salami 0.029968536 sopa fría 0.029869572 raspado 0.029376973 mixta 0.029299943 pavo 0.029097211 salmón 0.028623039 verdura 0.028191164 pasta 0.028028495 buñuelo 0.026865129 piñada 0.026775114 cooler 0.02651075 caldo de papa 0.026440189 taco de carne asada 0.026303485 fruta 0.025622493 lentejas 0.02551102 ciruela 0.025473188 concha 0.025416602 agua de sabor 0.024958587 cereza 0.024955614 huevo estrellado 0.024647991 pollo asado 0.024318777 coctel 0.023785043 harina 0.023527554 mostaza 0.02339916 yoghurt 0.023171053 consomé 0.022956051 sardina 0.022664503 tamarindo 0.022329801 baguet 0.022070997 palomitas 0.022025321 pollo frito 0.021741891 betabel 0.020940132 powerade 0.020833333 albóndiga 0.020789658 agua fresca 0.020484459 maíz 0.020463477
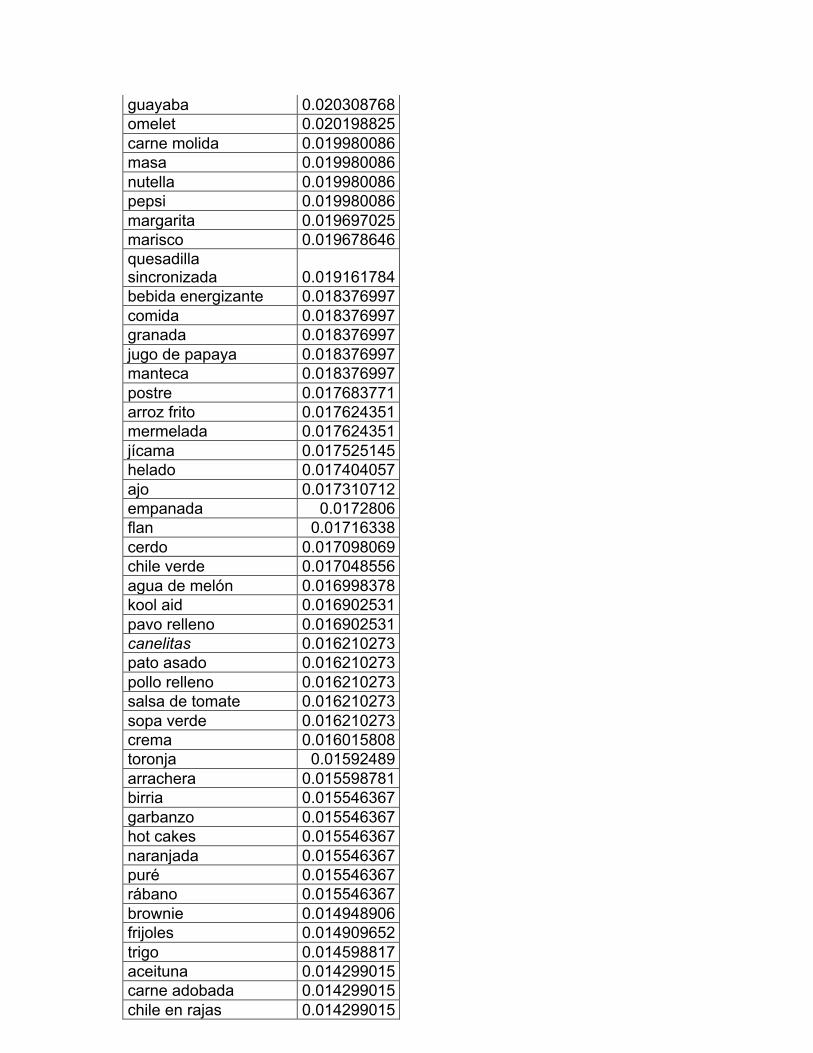
117
guayaba 0.020308768 omelet 0.020198825 carne molida 0.019980086 masa 0.019980086 nutella 0.019980086 pepsi 0.019980086 margarita 0.019697025 marisco 0.019678646 quesadilla sincronizada 0.019161784 bebida energizante 0.018376997 comida 0.018376997 granada 0.018376997 jugo de papaya 0.018376997 manteca 0.018376997 postre 0.017683771 arroz frito 0.017624351 mermelada 0.017624351 jícama 0.017525145 helado 0.017404057 ajo 0.017310712 empanada 0.0172806 flan 0.01716338 cerdo 0.017098069 chile verde 0.017048556 agua de melón 0.016998378 kool aid 0.016902531 pavo relleno 0.016902531 canelitas 0.016210273 pato asado 0.016210273 pollo relleno 0.016210273 salsa de tomate 0.016210273 sopa verde 0.016210273 crema 0.016015808 toronja 0.01592489 arrachera 0.015598781 birria 0.015546367 garbanzo 0.015546367 hot cakes 0.015546367 naranjada 0.015546367 puré 0.015546367 rábano 0.015546367 brownie 0.014948906 frijoles 0.014909652 trigo 0.014598817 aceituna 0.014299015 carne adobada 0.014299015 chile en rajas 0.014299015

118
energizante 0.014299015 flautas 0.014299015 maizoro 0.014299015 pollo en salsa 0.014299015 torta de cochinita 0.014299015 fritura 0.014267954 bollito 0.014096438 lenteja 0.014059564 calabaza 0.013831859 chile en crema 0.013713386 nectarina 0.013713386 sopa maruchan 0.013713386 champiñón 0.013305524 pay 0.013196083 agave 0.013151743 carne de cerdo 0.013151743 espárrago 0.013151743 miel 0.013151743 nachos 0.013151743 quequis 0.013151743 tajín 0.013151743 cuernito 0.013090945 bimbollo 0.012989006 asado 0.012931504 martini 0.012862214 callo 0.012809984 col de Bruselas 0.012613102 copa 0.012613102 dulces 0.012613102 albóndigas 0.012437172 avena 0.012158532 pollo en caldo 0.012158532 negrito 0.012144277 té negro 0.012137304 esquite 0.012096521 salsa guacamaya 0.012096521 bombón 0.01164021 berenjena 0.011601098 tocino 0.011601098 puré de papa 0.011359239 pitaya 0.011125965 tortilla de harina 0.011125965 té frío 0.011125965 calamar 0.010762474 col 0.010670291 pollo en salsa verde 0.010670291 agua de cebada 0.01023328 gomita 0.01023328

119
piña colada 0.01023328 pollo agridulce 0.01023328 mixtas 0.010053122 tamales 0.009847255 agua de piña 0.009814167 ejote 0.009814167 frapuchino 0.009814167 mariguana 0.009814167 pimiento 0.009814167 vino tinto 0.009814167 hielo 0.009598113 agua de lima 0.00941222 enchilada suiza 0.00941222 jalapeño 0.00941222 chile rojo 0.009026734 jugo de zanahoria 0.009026734 pollo en crema 0.009026734 salsa de soya 0.009026734 winky 0.009026734 agua de mango 0.008994577 gatorade 0.00877751 caldo de papas 0.008657036 papa asada 0.008657036 hot cake 0.008504628 cocido 0.00830248 gelatina 0.00830248 taco dorado 0.00830248 chayote 0.007962445 chicharrón 0.007962445 papa rellena 0.007962445 jocoque 0.007796444 botana 0.007636336 cocoa 0.007636336 lima 0.007636336 ron 0.007636336 caldo con albóndigas 0.007323583 caldo tlalpeño 0.007323583 caviar 0.007323583 cuerno 0.007323583 hierbabuena 0.007323583 marlin 0.007323583 queso crema 0.007323583 aceite 0.00702364 asadera 0.00702364 callo de hacha 0.00702364 legumbre 0.00702364 chambarete 0.006826788 aceite de oliva 0.00673598

120
huevo con chorizo 0.00673598 capuchino 0.006460102 falda de res 0.006460102 huevo con jamón 0.006460102 natas 0.006460102 vampiro 0.006460102 mantequilla 0.006219983 bistec 0.006195523 carne deshebrada 0.006195523 faja de res 0.006195523 habas 0.006195523 huevo con salchicha 0.006195523 paleta helada 0.006195523 papa en caldo 0.006195523 totopo 0.006195523 budín 0.00594178 canela 0.00594178 caldo de carne 0.00569843 caracol 0.00569843 deshebrada 0.00569843 jugo v8 0.00569843 mojarra 0.00569843 pollo crudo 0.00569843 frijoles fritos 0.005465046 nuggets 0.005465046 panqueque 0.005465046 chokis 0.00524122 frijoles rancheros 0.00524122 hojuela 0.00524122 licuado 0.00524122 orégano 0.00524122 cacao 0.005026561 chowmin 0.005026561 langosta 0.005026561 costilla 0.004820694 especias 0.004820694 lechera 0.004820694 pechuga 0.004820694 papas 0.004623258 torta ahogada 0.004623258 chop suey 0.004433909 rollo 0.004433909 pollo almendrado 0.004252314 quesadilla de camarón 0.004252314 agua de limón 0.004078157 fetuccini 0.004078157 pollo chino 0.004078157 agua de horchata 0.003911133

121
perejil 0.003911133 requesón 0.003911133 comino 0.003750949 azúcar 0.003597325 alcachofa 0.003449994 churro 0.003449994 queso amarillo 0.003449994 pasa 0.003308696 tomate verde 0.003308696 ajonjolí 0.003173186 hongo 0.003173186 almendra 0.003043225 emparedado 0.003043225 paleta de hielo 0.003043225 nuez 0.002918587 betún 0.002799054 agua de tamarindo 0.002684416 borrego 0.002684416 chuleta 0.002469034 Centro de interés 6 – Objetos colocados sobre la mesa
VOCABLO IDL plato 0.69269514 vaso 0.646676985 cuchara 0.591588739 mantel 0.571686697 tenedor 0.569728621 servilleta 0.479181265 comida 0.469213276 cuchillo 0.466307666 sal 0.362091192 libro 0.33097187 lápiz 0.304047641 florero 0.247278428 jarra 0.237770513 borrador 0.213591237 refresco 0.205067861 pimienta 0.204166281 estuche 0.20202198 salero 0.195976344 mochila 0.188693214 salsa 0.169363231 tortilla 0.166272032 cuaderno 0.163986909 libreta 0.163297503 televisión 0.163004128

122
papel 0.161303942 taza 0.154824958 mano 0.14898229 hoja 0.14095266 pluma 0.140011124 fruta 0.139834098 vela 0.137148752 polvo 0.124203019 azúcar 0.119382799 frutero 0.116462975 pan 0.113966556 adorno 0.113922831 computadora 0.110936894 charola 0.109922419 café 0.109306112 agua 0.10465263 sartén 0.102360533 portavasos 0.100861999 ropa 0.098732189 sacapuntas 0.09589332 reloj 0.095325143 colores 0.093531008 tapete 0.09037238 azucarera 0.089928049 flor 0.08402739 manzana 0.078756388 carpeta 0.076515407 coca (cola) 0.07482558 revista 0.072739368 silla 0.072419071 bebida 0.071167036 codo 0.071053509 servilletero 0.070759794 lapicero 0.069736044 examen 0.069331683 lámpara 0.067980255 olla 0.065377734 periódico 0.061729312 celular 0.060728298 jugo 0.059887645 plato hondo 0.058953878 jamaica 0.054760762 copa 0.054247168 cerveza 0.052645671 liga 0.052194632 naranja 0.050694116 lentes 0.047136854 pinza 0.046926149

123
pecera 0.046473023 DVD 0.046446344 hielo 0.046054596 foto 0.044826288 cabeza 0.043458681 persona 0.043059528 picadientes 0.04138118 vino 0.041137158 botana 0.039828123 plumón 0.039728568 tijeras 0.039291403 cartulina 0.039089309 tazón 0.039078614 guacamaya 0.039055755 mayonesa 0.038523124 perro 0.037781125 limonada 0.037553055 limón 0.037519644 cepillo 0.037490602 aderezo 0.037412916 vidrio 0.037260956 paleta 0.037077618 playstation 0.036955688 hielera 0.036655229 laptop 0.036131374 chile 0.035637216 dinero 0.035169195 verdura 0.034585203 pulsera 0.034553055 planta 0.03422978 regalo 0.034043845 teléfono 0.032742326 salsa guacamaya 0.032733861 tortillero 0.03079325 perfume 0.030764585 DVR 0.030714073 estéreo 0.030525416 cubierto 0.030269702 color 0.029860782 plátano 0.029658675 engrapadora 0.029430803 leche 0.029423349 espejo 0.02932543 retrato 0.029069081 condimento 0.028978192 liquid paper 0.028149751 tortillera 0.028036345 té 0.027753628

124
bebida alcohólica 0.027518744 cazuela 0.027326252 caja 0.026330971 llave 0.026031928 postre 0.025944635 ensalada 0.025412856 maquillaje 0.025347817 fresa 0.024736294 pintura 0.024610969 dulce 0.024197587 brazo 0.023620335 trapo 0.023155016 recipiente 0.022786493 horchata 0.022682919 jarrón 0.022151834 portarretrato 0.021875652 cadena 0.021601733 palillo 0.021208119 mostaza 0.021127415 platón 0.02105187 huevo 0.020565224 trasero 0.020301499 exprimidor 0.02022557 bandeja 0.020219319 juego 0.020216866 sandía 0.020216866 champú 0.020112179 película 0.02006977 mantelito 0.020009425 pera 0.020009425 papa 0.019851701 pastel 0.019535854 rastrillo 0.019318954 barra 0.019218099 vino tinto 0.019218099 ángel de porcelana 0.019218099 arete 0.019035198 pelota 0.018727498 radio 0.018538651 chuchara 0.018458069 jugo maggi 0.018458069 mesa 0.018458069 portapapeles 0.018458069 uva 0.018458069 bolsa 0.017931958 maqueta 0.017855883 goma 0.017728097 muñeca 0.017728097
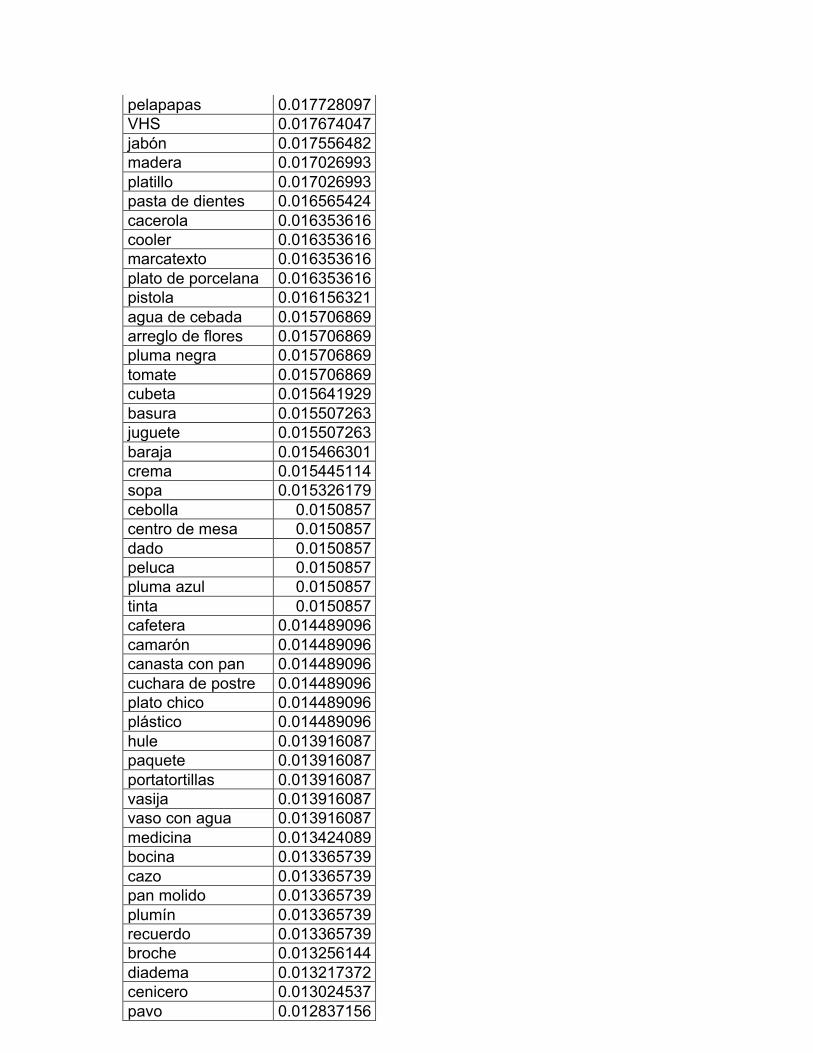
125
pelapapas 0.017728097 VHS 0.017674047 jabón 0.017556482 madera 0.017026993 platillo 0.017026993 pasta de dientes 0.016565424 cacerola 0.016353616 cooler 0.016353616 marcatexto 0.016353616 plato de porcelana 0.016353616 pistola 0.016156321 agua de cebada 0.015706869 arreglo de flores 0.015706869 pluma negra 0.015706869 tomate 0.015706869 cubeta 0.015641929 basura 0.015507263 juguete 0.015507263 baraja 0.015466301 crema 0.015445114 sopa 0.015326179 cebolla 0.0150857 centro de mesa 0.0150857 dado 0.0150857 peluca 0.0150857 pluma azul 0.0150857 tinta 0.0150857 cafetera 0.014489096 camarón 0.014489096 canasta con pan 0.014489096 cuchara de postre 0.014489096 plato chico 0.014489096 plástico 0.014489096 hule 0.013916087 paquete 0.013916087 portatortillas 0.013916087 vasija 0.013916087 vaso con agua 0.013916087 medicina 0.013424089 bocina 0.013365739 cazo 0.013365739 pan molido 0.013365739 plumín 0.013365739 recuerdo 0.013365739 broche 0.013256144 diadema 0.013217372 cenicero 0.013024537 pavo 0.012837156

126
porcelana 0.012837156 ángel 0.012837156 pañal 0.012471257 sabritas 0.012471257 ajedrez 0.01242846 plato giratorio 0.012400853 arreglo floral 0.012329477 desayuno 0.012329477 modular 0.012329477 portaservilletas 0.012329477 vegetal 0.012329477 agua fresca 0.011841875 alhaja 0.011841875 durazno 0.011841875 carne 0.011805772 chicle 0.011584725 desodorante 0.011539575 cena 0.011373557 chile en polvo 0.011373557 cucharón 0.011373557 lipstick 0.011373557 llavero 0.011373557 mango 0.011373557 tarea 0.011130518 gel 0.011038348 cofre 0.01092376 figura 0.01092376 jugo de zanahoria 0.01092376 patas 0.01092376 tabla de picar 0.01092376 vodka 0.01092376 collar 0.01056815 bote 0.010491751 caguama 0.010491751 gis 0.010491751 jugo de manzana 0.010491751 resistol 0.010491751 gato 0.010367671 zanahoria 0.010281952 juego de mesa 0.010192704 droga 0.010111172 botella 0.010076827 fruta decorativa 0.010076827 mantel individual 0.010076827 tequila 0.010076827 aceite de cocina 0.009295559 compás 0.009295559 foco 0.009295559

127
maceta 0.009295559 ropa doblada 0.009295559 ropa sucia 0.009295559 whisky 0.009295559 lotería 0.009219338 barbacoa 0.008927941 mandarina 0.008927941 manos 0.008927941 nintendo wii 0.008927941 pasador 0.008927941 pinturas 0.008927941 ropa amontonada 0.008927941 tutoreo 0.008927941 aceite 0.008814483 chamoy 0.008574863 codos 0.008574863 plastilina 0.008574863 tacos 0.008574863 calceta 0.00853941 nieve 0.008330453 aguachile 0.008235747 arcilla 0.008235747 bollito 0.008235747 salchicha 0.008235747 toalla 0.008235747 bimbollo 0.007910043 grabadora 0.007910043 huevos 0.007910043 jamón 0.007910043 pelo 0.007910043 plantas 0.007910043 carta 0.00759722 cerdo 0.00759722 ipod 0.00759722 panera 0.00759722 cabello 0.007296768 pizza 0.007296768 tamarindo 0.007296768 álbum 0.007296768 teclado 0.007064461 accesorio 0.007008198 dedo 0.007008198 galleta 0.007008198 hígado 0.007008198 zapato 0.006801647 cartera 0.00673104 cortauñas 0.00673104 dispensador 0.00673104

128
listón 0.00673104 mameluco 0.00673104 mecate 0.00673104 catsup 0.006464844 lima 0.006464844 plancha 0.006464844 tarjeta 0.006464844 tierra 0.006464844 coctel 0.006209174 croqueta 0.006209174 sushi 0.006209174 utensilio dental 0.006209174 delineador 0.005963616 plancha para el pelo 0.005963616 tabla 0.005963616 blusa 0.00572777 mota 0.00572777 baqueta 0.00550125 ensaladera 0.00550125 regalo de navidad 0.00550125 disco 0.005344447 cereal 0.005283689 diccionario 0.005283689 gel de cuerpo 0.005283689 linterna 0.005283689 tela 0.005074731 trabajo 0.005074731 decoración 0.004874038 espuma 0.004874038 helado 0.004874038 pollo 0.004874038 acondicionador 0.004681281 churro 0.004681281 gel de afeitar 0.004681281 jeringa 0.004681281 loción 0.004681281 ruleta 0.004681281 crema de afeitar 0.004496148 herramienta 0.004496148 quesadilla 0.004496148 moneda 0.004318336 afeitador 0.004147556 gameboy 0.004147556 estuche de lentes 0.00398353 cerveza light 0.003825991 paleta payaso 0.003825991 rifle 0.003825991

129
bola de cristal 0.003674682 cosas navideñas 0.003529357 refresco light 0.003529357 almohada 0.003389779 cuadro 0.003389779 mugre 0.003255722 billetera 0.003126965 boca 0.003126965 lengua 0.003003301 chocolate 0.002884528 palomilla 0.002660887 cosas para el pelo 0.002454585 Centro de interés 7 – La cocina y sus utensilios
VOCABLO IDL estufa 0.725300909 refrigerador 0.719346858 tenedor 0.682769115 cuchara 0.655650704 sartén 0.55110429 cuchillo 0.525716739 licuadora 0.490086652 plato 0.401847979 vaso 0.386266487 pelapapas 0.323754938 olla 0.282054836 tostador 0.275888973 horno 0.256569298 mesa 0.22891115 comida 0.226535011 alacena 0.205100606 horno de microondas 0.19994538 cajón 0.17665601 servilleta 0.167190994 exprimidor 0.165693344 taza 0.165049536 agua 0.152373048 fregadero 0.147445092 aceite 0.146603188 batidora 0.145147212 sal 0.140157493 abrelatas 0.136330242 silla 0.131775462 lavamanos 0.1303547 cucaracha 0.130106136 rata 0.124009892

130
mantel 0.121789555 rallador 0.117537006 garrafón 0.114281596 cafetera 0.112595814 barra 0.10336556 congelador 0.10197032 comal 0.101133458 espátula 0.101073725 cucharón 0.101067778 tabla 0.096085628 fruta 0.09480728 azúcar 0.088279352 copa 0.08390774 verdura 0.083483436 lavaplatos 0.077810855 puerta 0.074665764 jarra 0.072759477 pinza 0.069259494 cazuela 0.067548756 piso 0.067015906 campana 0.065666016 colador 0.065256333 lavatrastes 0.062654586 braun 0.060574631 extractor 0.060377626 banco 0.059737667 café 0.059010069 escurridor 0.058699123 encendedor 0.051760758 sandwichera 0.051577065 manzana 0.051308865 cascanueces 0.05030954 jabón 0.049466663 cerillo 0.047040491 ventana 0.046970707 charola 0.046753492 despensa 0.046416253 pared 0.044743629 sacacorchos 0.044548638 mosca 0.043503716 picahielo 0.043404781 techo 0.042501832 pimienta 0.042159679 papa 0.04175682 esponja 0.04104859 asador 0.040245733 desayunador 0.040202683 cocina integral 0.039869833

131
foco 0.039734898 moledor 0.037304566 llave 0.036774052 televisión 0.036683674 machete 0.035591702 tortilla 0.035412379 vasija 0.034629525 vaporera 0.033645447 plato hondo 0.033374351 sopa 0.03285145 carne 0.032600368 cocina 0.032588144 semilla 0.031788774 refresco 0.031681536 cuchara sopera 0.03115113 traste 0.030826979 comedor 0.028219191 plancha 0.028219191 fuego 0.027621564 queso 0.026974831 abanico 0.026955341 batidor 0.026785093 jamón 0.026760194 basura 0.026643058 destapador 0.026115117 estilador 0.025903539 secador 0.024618218 tapón 0.023844157 tina 0.023740057 molcajete 0.023668687 popote 0.023592726 waflera 0.023561408 mueble 0.023274341 postre 0.023206758 palillo chino 0.023028028 hielo 0.022805476 tapete 0.022718152 cenicero 0.022672033 perro 0.022218632 tapa 0.022183427 pala 0.021795519 tijera 0.021548136 basurero 0.021271587 portavasos 0.021205221 atún 0.020833333 molino 0.020833333 trastero 0.020833333 dulce 0.020758757
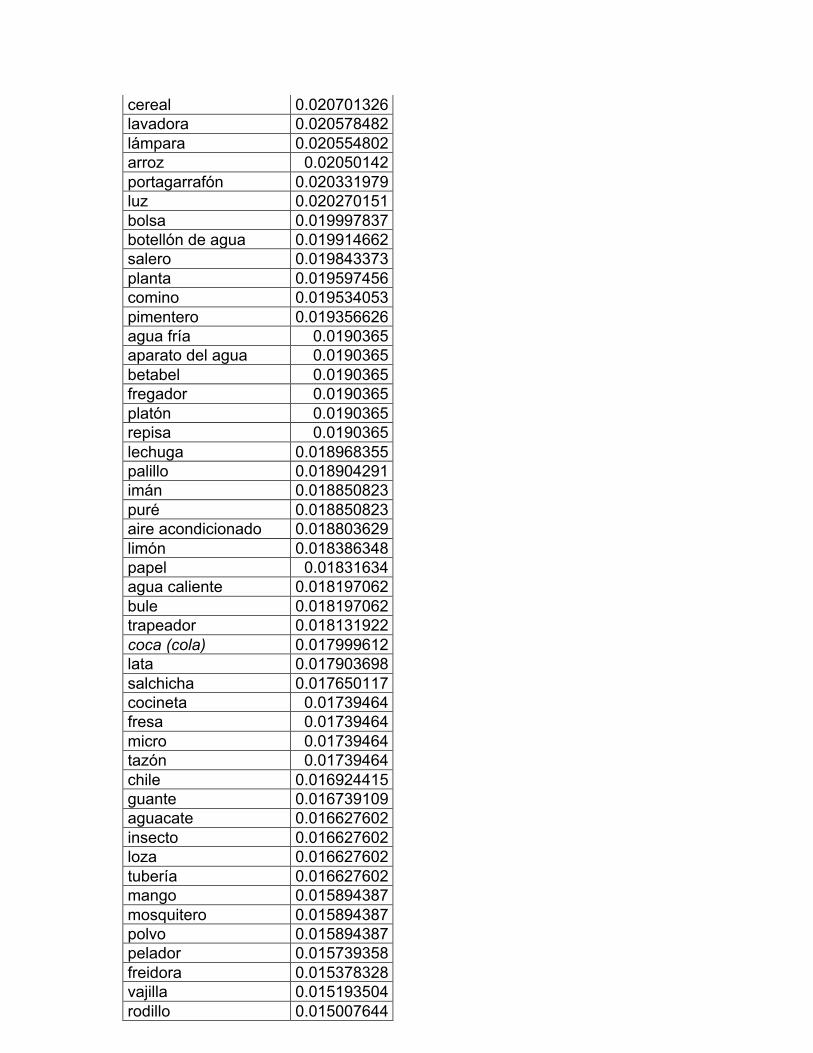
132
cereal 0.020701326 lavadora 0.020578482 lámpara 0.020554802 arroz 0.02050142 portagarrafón 0.020331979 luz 0.020270151 bolsa 0.019997837 botellón de agua 0.019914662 salero 0.019843373 planta 0.019597456 comino 0.019534053 pimentero 0.019356626 agua fría 0.0190365 aparato del agua 0.0190365 betabel 0.0190365 fregador 0.0190365 platón 0.0190365 repisa 0.0190365 lechuga 0.018968355 palillo 0.018904291 imán 0.018850823 puré 0.018850823 aire acondicionado 0.018803629 limón 0.018386348 papel 0.01831634 agua caliente 0.018197062 bule 0.018197062 trapeador 0.018131922 coca (cola) 0.017999612 lata 0.017903698 salchicha 0.017650117 cocineta 0.01739464 fresa 0.01739464 micro 0.01739464 tazón 0.01739464 chile 0.016924415 guante 0.016739109 aguacate 0.016627602 insecto 0.016627602 loza 0.016627602 tubería 0.016627602 mango 0.015894387 mosquitero 0.015894387 polvo 0.015894387 pelador 0.015739358 freidora 0.015378328 vajilla 0.015193504 rodillo 0.015007644

133
dinero 0.014530354 escoba 0.014530354 enfriador de vinos 0.014523528 lavabo 0.014523528 maruchan 0.014523528 metate 0.014523528 portaplatos 0.014523528 hormiga 0.014093117 vino 0.01398095 azulejo 0.013883095 petate 0.013883095 té 0.013588019 naranja 0.013357891 bote 0.013270903 cojín 0.013270903 conejo 0.013270903 maestro limpio 0.013270903 servilleta para tortillas 0.013270903 pan 0.013228357 gas 0.012949757 servilletero 0.012912154 cuchillo eléctrico 0.012768858 canasta para huevos 0.012685706 jugo 0.012685706 recipiente 0.012685706 toalla 0.012645036 frijol 0.012410656 bandeja 0.01222065 olla exprés 0.012189201 galleta 0.012126314 mandil 0.012126314 azucarera 0.011591589 cazo 0.011591589 tortillero 0.011591589 trapo 0.011450593 almacén 0.011080444 sacacorazones 0.011080444 tabla de picar 0.011080444 tostada 0.011080444 chocolate 0.010959222 cachora 0.010591838 huevos 0.010591838 plato de sopa 0.010591838 sal de ajo 0.010591838 tapa de cazuela 0.010591838 tomate 0.010591838 carbón 0.010124778 harina 0.010124778
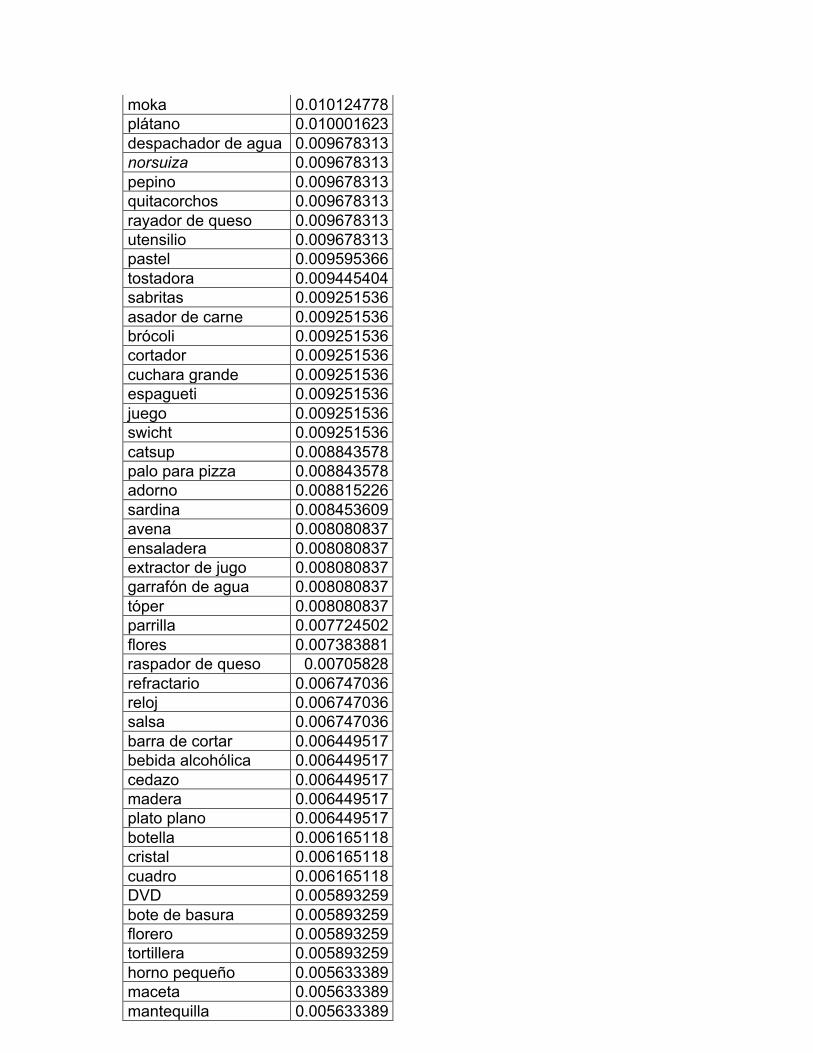
134
moka 0.010124778 plátano 0.010001623 despachador de agua 0.009678313 norsuiza 0.009678313 pepino 0.009678313 quitacorchos 0.009678313 rayador de queso 0.009678313 utensilio 0.009678313 pastel 0.009595366 tostadora 0.009445404 sabritas 0.009251536 asador de carne 0.009251536 brócoli 0.009251536 cortador 0.009251536 cuchara grande 0.009251536 espagueti 0.009251536 juego 0.009251536 swicht 0.009251536 catsup 0.008843578 palo para pizza 0.008843578 adorno 0.008815226 sardina 0.008453609 avena 0.008080837 ensaladera 0.008080837 extractor de jugo 0.008080837 garrafón de agua 0.008080837 tóper 0.008080837 parrilla 0.007724502 flores 0.007383881 raspador de queso 0.00705828 refractario 0.006747036 reloj 0.006747036 salsa 0.006747036 barra de cortar 0.006449517 bebida alcohólica 0.006449517 cedazo 0.006449517 madera 0.006449517 plato plano 0.006449517 botella 0.006165118 cristal 0.006165118 cuadro 0.006165118 DVD 0.005893259 bote de basura 0.005893259 florero 0.005893259 tortillera 0.005893259 horno pequeño 0.005633389 maceta 0.005633389 mantequilla 0.005633389
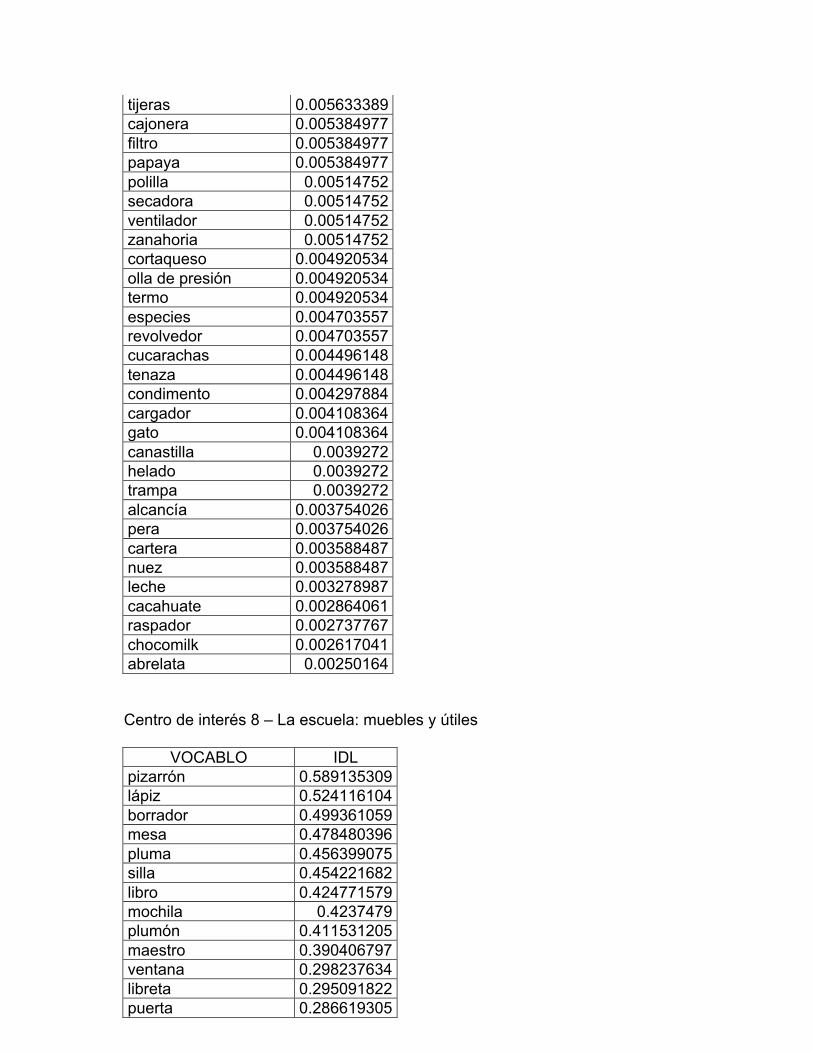
135
tijeras 0.005633389 cajonera 0.005384977 filtro 0.005384977 papaya 0.005384977 polilla 0.00514752 secadora 0.00514752 ventilador 0.00514752 zanahoria 0.00514752 cortaqueso 0.004920534 olla de presión 0.004920534 termo 0.004920534 especies 0.004703557 revolvedor 0.004703557 cucarachas 0.004496148 tenaza 0.004496148 condimento 0.004297884 cargador 0.004108364 gato 0.004108364 canastilla 0.0039272 helado 0.0039272 trampa 0.0039272 alcancía 0.003754026 pera 0.003754026 cartera 0.003588487 nuez 0.003588487 leche 0.003278987 cacahuate 0.002864061 raspador 0.002737767 chocomilk 0.002617041 abrelata 0.00250164 Centro de interés 8 – La escuela: muebles y útiles
VOCABLO IDL pizarrón 0.589135309 lápiz 0.524116104 borrador 0.499361059 mesa 0.478480396 pluma 0.456399075 silla 0.454221682 libro 0.424771579 mochila 0.4237479 plumón 0.411531205 maestro 0.390406797 ventana 0.298237634 libreta 0.295091822 puerta 0.286619305
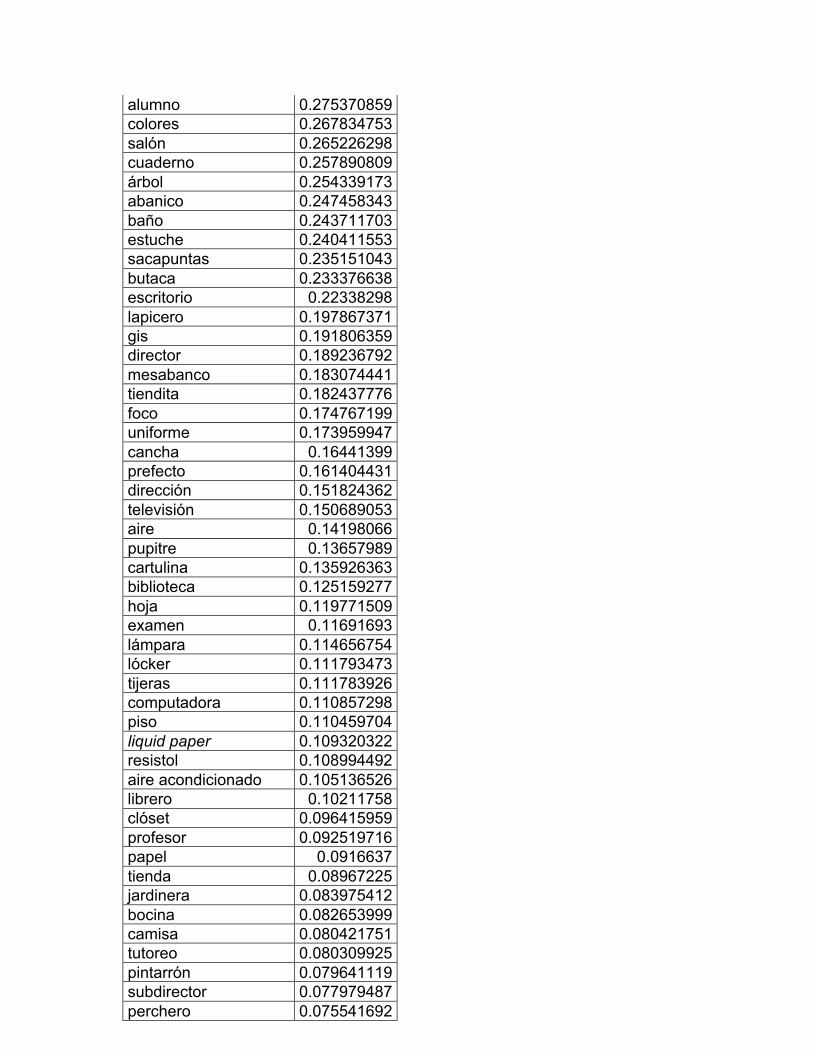
136
alumno 0.275370859 colores 0.267834753 salón 0.265226298 cuaderno 0.257890809 árbol 0.254339173 abanico 0.247458343 baño 0.243711703 estuche 0.240411553 sacapuntas 0.235151043 butaca 0.233376638 escritorio 0.22338298 lapicero 0.197867371 gis 0.191806359 director 0.189236792 mesabanco 0.183074441 tiendita 0.182437776 foco 0.174767199 uniforme 0.173959947 cancha 0.16441399 prefecto 0.161404431 dirección 0.151824362 televisión 0.150689053 aire 0.14198066 pupitre 0.13657989 cartulina 0.135926363 biblioteca 0.125159277 hoja 0.119771509 examen 0.11691693 lámpara 0.114656754 lócker 0.111793473 tijeras 0.111783926 computadora 0.110857298 piso 0.110459704 liquid paper 0.109320322 resistol 0.108994492 aire acondicionado 0.105136526 librero 0.10211758 clóset 0.096415959 profesor 0.092519716 papel 0.0916637 tienda 0.08967225 jardinera 0.083975412 bocina 0.082653999 camisa 0.080421751 tutoreo 0.080309925 pintarrón 0.079641119 subdirector 0.077979487 perchero 0.075541692

137
conserje 0.074238442 friso 0.069438907 puntilla 0.069371772 tarea 0.067980599 agenda 0.066934391 vidrio 0.066721202 violencia 0.066538674 secretaria 0.062419215 bote de basura 0.062136818 reloj 0.062056465 maltrato 0.062025536 boleta 0.061757578 niño 0.057548525 carpeta 0.056686562 marcador 0.055674452 abuso 0.054911276 regla 0.054511429 lentes 0.054275508 escalera 0.054258486 DVD 0.053547319 compañero 0.052881792 corrector 0.051982255 plumín 0.051977408 escoba 0.051472098 basura 0.050582452 amigo 0.049212333 vitropiso 0.049038463 tejabán 0.048640989 techo 0.047126128 agua 0.047091613 grabadora 0.046746955 zapato 0.046386189 luz 0.044177883 enfermería 0.043447778 tortura 0.043266005 explanada 0.042967205 estéreo 0.042874713 comida 0.041830976 calificación 0.041541466 planta 0.040905046 corbata 0.040203331 pegamento 0.039727778 pantalón 0.039328705 pared 0.039061779 chicle 0.03893666 balón 0.03886469 calculadora 0.038495736 aviso 0.038444581
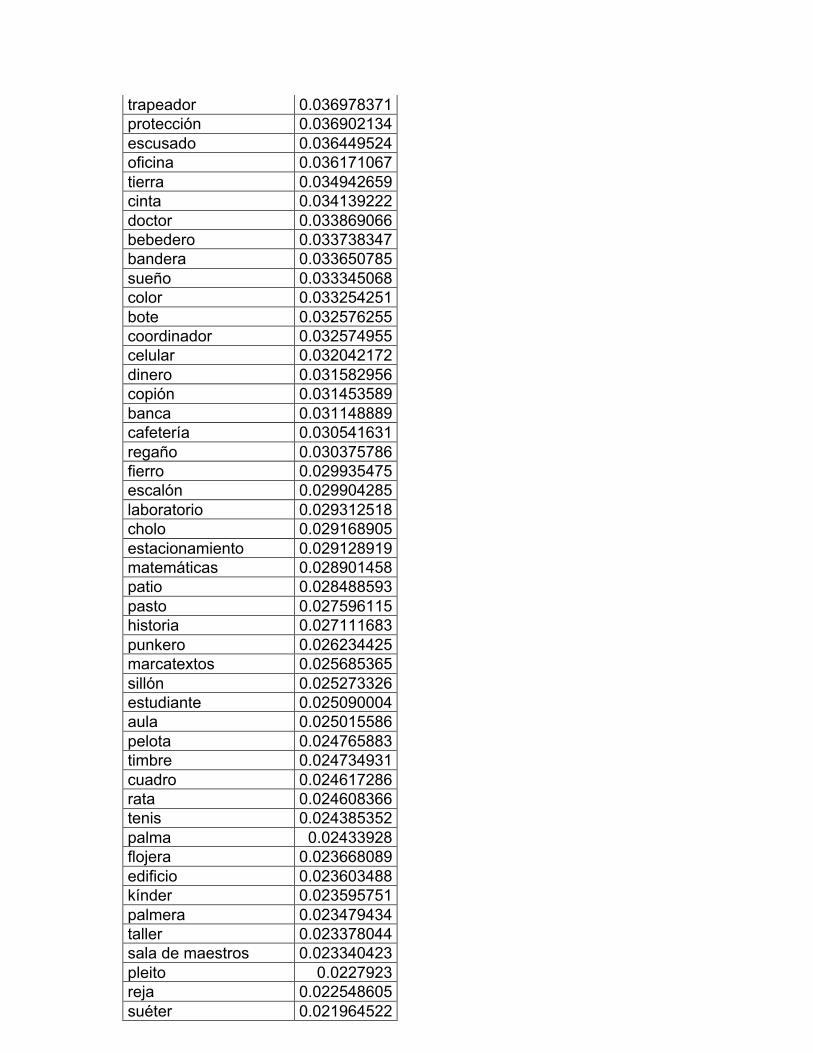
138
trapeador 0.036978371 protección 0.036902134 escusado 0.036449524 oficina 0.036171067 tierra 0.034942659 cinta 0.034139222 doctor 0.033869066 bebedero 0.033738347 bandera 0.033650785 sueño 0.033345068 color 0.033254251 bote 0.032576255 coordinador 0.032574955 celular 0.032042172 dinero 0.031582956 copión 0.031453589 banca 0.031148889 cafetería 0.030541631 regaño 0.030375786 fierro 0.029935475 escalón 0.029904285 laboratorio 0.029312518 cholo 0.029168905 estacionamiento 0.029128919 matemáticas 0.028901458 patio 0.028488593 pasto 0.027596115 historia 0.027111683 punkero 0.026234425 marcatextos 0.025685365 sillón 0.025273326 estudiante 0.025090004 aula 0.025015586 pelota 0.024765883 timbre 0.024734931 cuadro 0.024617286 rata 0.024608366 tenis 0.024385352 palma 0.02433928 flojera 0.023668089 edificio 0.023603488 kínder 0.023595751 palmera 0.023479434 taller 0.023378044 sala de maestros 0.023340423 pleito 0.0227923 reja 0.022548605 suéter 0.021964522

139
primaria 0.021881835 secundaria 0.021560416 mural 0.021368057 compás 0.021009132 odio 0.020833333 portón 0.020822347 física 0.020693884 maldad 0.020062439 animal 0.019657201 futbol 0.019629376 dulce 0.019537424 cinto 0.01932007 supervisor 0.01932007 tinaco 0.01932007 cobro 0.01926614 diccionario 0.019113975 nachos 0.019113975 velador 0.019082704 espejo 0.018899813 cancha deportiva 0.01860517 droga 0.01860517 estudio 0.01860517 periódico 0.01860517 calceta 0.018528804 enciclomedia 0.01837107 burro 0.018294073 té 0.018118291 teclado 0.018035522 bóiler 0.017916724 logotipo 0.017916724 mueble 0.017916724 hipócrita 0.017866712 intendente 0.017554827 conejo 0.017253753 peine 0.017253753 trabajo 0.017181162 robo 0.016977655 torta 0.016977655 gafete 0.016802239 español 0.016757293 deporte 0.016706833 ropa 0.016686725 short 0.016686725 urinario 0.016686725 ardilla 0.016615313 dentista 0.016615313 resistol de barra 0.016615313 tubo 0.016545409

140
castigo 0.016000498 maternal 0.016000498 pide pesos 0.016000498 resistol líquido 0.016000498 trabajadora social 0.016000498 videocasetera 0.016000498 química 0.01595153 asta 0.015871759 enciclopedia 0.015414451 cuarto 0.015408432 poste 0.015408432 reprobado 0.01496507 taza 0.014838275 papel china 0.014651572 geografía 0.014409793 banqueta 0.014289215 barrendero 0.014289215 manual 0.014289215 ágora 0.014289215 falda 0.014251594 jabón 0.014209707 juego geométrico 0.01407642 pizarrón eléctrico 0.013960876 macetera 0.013761055 cooperativa 0.013760472 sin dinero 0.013760472 zacate 0.013760472 cartel 0.013702579 barandal 0.013540275 entrada 0.013482527 banco 0.013251295 garrafón 0.013251295 jugo 0.013251295 pintor 0.013251295 pobre 0.013251295 sabritas 0.013251295 grapa 0.013216406 cemento 0.013090439 inglés 0.013028215 boli 0.012760958 cárcel 0.012760958 malas noticias 0.012760958 microbio 0.012760958 naco 0.012760958 paquetero 0.012760958 presión 0.012760958 basquetbol 0.012717643 beisbol 0.012546133

141
lavamanos 0.012289285 directivo 0.012288765 estrés 0.012288765 nido de rata 0.012288765 refrigerador 0.012288765 pesadilla 0.011952165 bolígrafo 0.011834044 campo deportivo 0.011834044 letra 0.011834044 paleta 0.011834044 pulsera 0.011834044 recreo 0.011776938 verdugo 0.011644674 bodega 0.011636167 cable 0.011576627 número 0.01139615 plumón de agua 0.01139615 llave 0.011345593 matraz 0.011097924 fresa 0.010974459 plaza cívica 0.010974459 plumón de aceite 0.010974459 monitor 0.010729909 escolta 0.010568819 barda 0.010568372 cancha de futbol 0.010568372 deuda 0.010568372 garrafón de agua 0.010568372 rico 0.010568372 sándwich 0.010568372 canasta 0.010523908 mouse 0.010332871 aburrimiento 0.010177311 cancha de basquetbol 0.010177311 gente 0.010177311 lustre 0.010177311 nice 0.010177311 pesado 0.010177311 pasillo 0.009884469 campo 0.009800721 dona 0.009800721 gordo 0.009800721 taza de baño 0.009800721 portería 0.009582325 bicho 0.009438065 flaco 0.009438065 regadera 0.009438065 tiza 0.009438065

142
engrapadora 0.009221196 abeja 0.009088829 calcetín 0.009088829 estúpido 0.009088829 letrina 0.009088829 pintero 0.009088829 tabla 0.008839878 clip 0.008752516 corcho 0.008752516 exposición 0.008752516 injusticia 0.008752516 micrófono 0.008752516 apagador 0.008428647 carrera 0.008428647 idiota 0.008428647 lechuga 0.008428647 letrero 0.008428647 música 0.008393186 campamento 0.008116762 crayola 0.008116762 cuento 0.008116762 dizque amigo 0.008116762 mapa 0.008116762 pintura 0.007882376 coca cola 0.007816418 constitución 0.007816418 papel cascarón 0.007816418 reporte 0.007816418 víbora 0.007816418 juego 0.007789886 barra 0.007527188 nieve 0.007527188 salón de danza 0.007527188 tornillo 0.007527188 fajado 0.00724866 máquina de escribir 0.00724866 equipo 0.006980438 escuadra 0.006980438 galleta 0.006980438 gancho 0.006980438 guitarra 0.006980438 basurero 0.006736463 aluminio 0.006722141 modular 0.006722141 recibo 0.006722141 voz 0.006722141 VHS 0.006473402 césped 0.006473402

143
estricto 0.006473402 gimnasio 0.006473402 maceta 0.006473402 separador 0.006473402 bat 0.006233867 material 0.006233867 radio 0.006233867 red 0.006233867 revista 0.006233867 liga 0.006003196 póster 0.006003196 abusón 0.00578106 cortina 0.00578106 lectura 0.00578106 raqueta 0.00578106 abanderada 0.005567144 blusa 0.005567144 cheque 0.005567144 chocolate 0.005567144 impresora 0.005567144 malla 0.005567144 metal 0.005567144 pájaro 0.005567144 paraguas 0.005361143 tarjeta 0.005361143 CPU 0.005162765 bolas 0.005162765 geometría 0.005162765 útil 0.005162765 alberca 0.004971728 apunte 0.004971728 banda de guerra 0.004971728 bibliotecaria 0.004971728 folder 0.004971728 gimnasia 0.004971728 pista 0.004971728 albañil 0.004787759 elote 0.004787759 formación cívica y ética 0.004787759 esquite 0.004610598 listón 0.004610598 ética 0.004610598 mal olor 0.004439992 matas 0.004439992 pepino 0.004439992 aprendizaje 0.004275699 listas 0.004275699

144
lavabo 0.004117486 CD 0.003965127 kleenex 0.003965127 muerte 0.003965127 biología 0.003818406 medicina 0.003818406 perilla 0.003818406 tae kwon do 0.003677113 documento 0.003541049 madera 0.003541049 materia 0.003541049 pino 0.003541049 rompehielo 0.003541049 carro 0.00341002 plastilina 0.002932627 raya 0.002932627 rombo 0.002719611 ladrillo 0.002618977 electricidad 0.002428743 enchufe 0.002338873 conexión 0.002252327 Centro de interés 9 – Electricidad y aire acondicionado
VOCABLO IDL televisión 0.632308973 cable 0.565431788 abanico 0.532886732 foco 0.526043094 computadora 0.505372781 lámpara 0.372210143 refrigerador 0.360325871 radio 0.311297674 frío 0.300796654 estéreo 0.283087998 celular 0.279365072 licuadora 0.276620758 luz 0.276366253 aire 0.241219212 estufa 0.239591859 DVD 0.235930196 teléfono 0.230388873 lavadora 0.219683621 grabadora 0.212582678 calor 0.199259755 (horno de) microondas 0.18727451 plancha 0.185131066

145
aire acondicionado 0.182944897 secadora 0.173685755 mini split 0.162713141 tostador 0.151468473 reloj 0.14065563 enchufe 0.135415303 electrón 0.127531687 temperatura 0.122241863 física 0.120393601 xbox 0.116965698 videocasetera 0.103267534 energía 0.09200398 cargador 0.091865833 iphone 0.088850805 protón 0.081687985 caliente 0.077826657 catión 0.077131528 botón 0.076537143 anión 0.075220988 ánodo 0.07337947 cátodo 0.071272525 bocina 0.064616393 batería 0.063545363 neutrón 0.061799769 modular 0.060210189 playstation 0.060036365 nintendo 0.058124114 laptop 0.055910102 VHS 0.054432067 alarma 0.052072432 cámara 0.050885293 electricidad 0.048244863 videojuego 0.047429301 agua 0.045584002 control 0.045508232 timbre 0.043261377 calculadora 0.04302156 batidora 0.042621589 gas 0.041666667 química 0.041037382 cafetera 0.040786133 rejilla 0.040253628 sóquet 0.039821974 sol 0.039553054 átomo 0.037653874 cobre 0.03749301 tornillo 0.036464461 viento 0.036389016

146
audífono 0.035740085 polvo 0.033833759 calavera 0.032858779 mp3 0.032428313 carro 0.031055675 despertador 0.030946132 congelador 0.028653708 extractor 0.028228035 clavija 0.027521138 cooler 0.027013314 teclado 0.026932968 CPU 0.026787015 corriente 0.025867393 tubo 0.025507797 poste 0.025444627 poste de luz 0.024709558 shock 0.02436094 tostadora 0.023785695 corriente eléctrica 0.023770163 regulador 0.023064911 impresora 0.022639521 equilibrio térmico 0.022454061 toque 0.021474527 copiadora 0.021265119 engrane 0.020833333 nivelador 0.020833333 walkman 0.020833333 calentador 0.01974827 eléctrica 0.01974827 locomotora 0.01974827 mufa 0.01974827 tuerca 0.01974827 contacto 0.019539164 gameboy 0.019350535 estufa eléctrica 0.019216115 pistola de silicón 0.018968848 rayo 0.018733151 clavo 0.01774474 sombra 0.01774474 tierra 0.01774474 plancha de pelo 0.01773105 escalera eléctrica 0.017705715 trabajo 0.017532713 auto 0.01682054 equipo de sonido 0.01682054 martillo 0.01682054 pizarrón eléctrico 0.01682054 reacción 0.01682054

147
regadera eléctrica 0.01682054 elevador 0.016783548 secador 0.016389522 switch 0.016114805 apagador 0.015944476 gasto 0.015944476 oxígeno 0.015944476 socket 0.015944476 monitor 0.015539447 trueno 0.015275375 blindado 0.015114039 gamecube 0.015114039 helado 0.015114039 invierno 0.015114039 linterna 0.015114039 planta de energía 0.015114039 termostato 0.015114039 tibio 0.015114039 bisagra 0.014326854 chamarra 0.014326854 comodidad 0.014326854 congelamiento 0.014326854 luz eléctrica 0.014326854 magnetismo 0.014326854 oscuridad 0.014326854 ventana 0.014326854 CD 0.013862137 GPS 0.013725635 chispa 0.013725635 filtro 0.013725635 video 0.013628412 carga positiva 0.013580668 cargador de teléfono 0.013580668 horno 0.013580668 sonido 0.013580668 juego 0.013269552 carbono 0.012873345 carga negativa 0.012873345 ión 0.012873345 micrófono 0.012873345 matemáticas 0.012418834 amplificador 0.012202862 electrocutar 0.012202862 molécula 0.012202862 subir 0.012202862 escáner 0.012193447 tecnología 0.011807041 bajar 0.0115673

148
electrodo 0.0115673 guitarra eléctrica 0.0115673 plástico 0.0115673 regadera 0.0115673 sacapuntas eléctrico 0.011302308 termología 0.011273463 ducto 0.01096484 hiperactivo 0.01096484 ipad 0.01096484 Farenheit 0.01096206 prender 0.010683871 braun 0.010393758 PSP 0.010393758 arriba 0.010393758 dinero 0.010393758 madera 0.010393758 pared 0.010393758 quemar 0.010393758 ventilación 0.010393758 Kelvin 0.010056618 apagar 0.009992683 abajo 0.009852419 ambiente 0.009852419 disolución 0.009852419 mini ipad 0.009852419 máquina 0.009574744 DVR 0.009339276 coulomb 0.009339276 pino 0.009339276 puerta eléctrica 0.009339276 salvación 0.009339276 wii 0.009339276 salón 0.009227683 rastrillo 0.009154055 electrolito 0.00915118 conducto 0.008852858 fax 0.008852858 waflera 0.008852858 aparato 0.008391774 canal 0.008391774 diablito 0.008391774 micro 0.008391774 música 0.008391774 sandwichera 0.008391774 temporizador 0.008391774 ciudad 0.008389646 compresor 0.007954705 pista eléctrica 0.007954705

149
relámpago 0.007954705 secadora de pelo 0.007954705 señal 0.007954705 cilindro 0.0075404 enchinador 0.0075404 grado Celsius 0.0075404 mingitorio 0.0075404 nintendo wii 0.0075404 anuncio 0.007147673 escalera 0.007147673 grado Farenheit 0.007147673 interfón 0.007147673 cuchara 0.0067754 decoración 0.0067754 internet 0.0067754 juego de video 0.0067754 lumbre 0.0067754 antena 0.006422517 enchinadora 0.006422517 escusado 0.006422517 fresco 0.006422517 hielo 0.006422517 lavadero 0.006422517 chip 0.006088013 no calor 0.006088013 reja eléctrica 0.006088013 rápido 0.006088013 controlador de temperatura 0.005770931 plancha de ropa 0.005770931 casetera 0.005470363 conector 0.005470363 conexión 0.005470363 electrónica 0.005470363 estática 0.005470363 gripa 0.005470363 toro mecánico 0.005470363 wafle 0.005470363 abrelatas 0.00518545 carga eléctrica 0.00518545 extensión 0.00518545 refrescar 0.00518545 enfriar 0.004915376 extinguidor 0.004915376 jacuzzi 0.004915376 termómetro 0.004915376 cera 0.004416694 gotear 0.004416694 sustancia electrolítica 0.004416694

150
bicicleta 0.004186659 depiladora 0.004186659 grado 0.004186659 moto 0.004186659 proceso de excitación 0.004186659 swicht 0.004186659 blue ray 0.003968605 pantalla 0.003968605 amarillo 0.003761908 electrolítico 0.003565977 avión 0.00338025 energía en tránsito 0.00338025 lluvia 0.00338025 motor 0.003204196 proyector 0.003204196 control remoto 0.003037312 eléctrico 0.003037312 pastilla 0.003037312 vida 0.003037312 jeep 0.002879119 on 0.002879119 sudar 0.002879119 temblar 0.002729166 mundo 0.002587023 off 0.002587023 cuerpo 0.002452283 circuito 0.002324561 escuela 0.002324561 Centro de interés 10 – La ciudad
VOCABLO IDL carro 0.657198176 casa 0.50064521 edificio 0.392332308 árbol 0.350298535 escuela 0.337451041 calle 0.336855846 tienda 0.327972121 camión 0.323533158 semáforo 0.278956372 gente 0.224213753 persona 0.218451266 cine 0.215789567 perro 0.195330001 restaurante 0.190311649 antro 0.184953906

151
hotel 0.183142704 animal 0.174258961 droga 0.163546044 iglesia 0.157984421 puente 0.143613577 río 0.143312311 hospital 0.139757862 taxi 0.136352182 narco 0.134517713 bicicleta 0.134514288 policía 0.124657528 contaminación 0.119379216 banqueta 0.107106908 taquería 0.105191454 basura 0.101276341 prostituta 0.099274208 ratero 0.096121599 plaza 0.093814489 abarrote 0.085766063 planta 0.084057298 bar 0.081562149 buchón 0.081132467 carretera 0.08035395 agua 0.078151147 niño 0.0772387 conejo 0.077234405 alcantarilla 0.074031866 cerveza 0.073895534 tráiler 0.072348428 tráfico 0.070413108 rancho 0.06943279 fiesta 0.067507231 centro 0.066701439 lámpara 0.064678233 banco 0.063922975 parque 0.062498971 feria 0.062206938 zoológico 0.062065564 centro comercial 0.061142677 preparatoria 0.060906808 poste 0.060269777 secundaria 0.060196938 kínder 0.059733809 súper 0.059353771 gato 0.057520841 cholo 0.056423651 gimnasio 0.056384987 rata 0.056108669
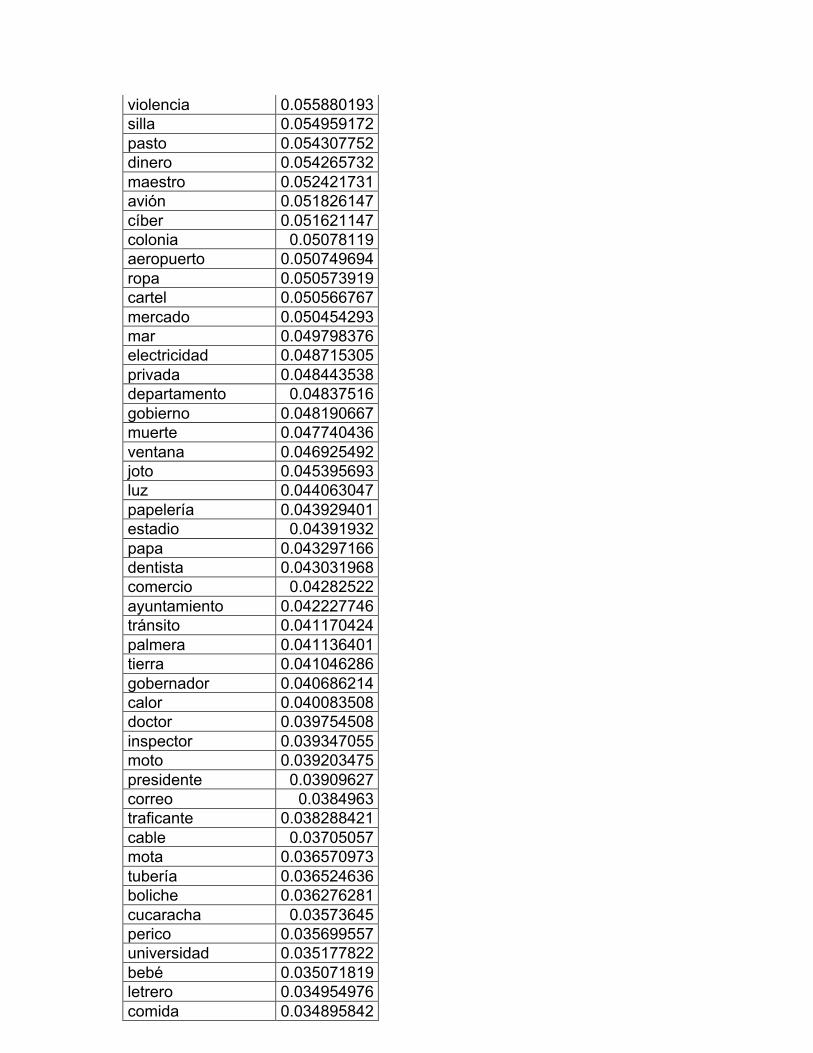
152
violencia 0.055880193 silla 0.054959172 pasto 0.054307752 dinero 0.054265732 maestro 0.052421731 avión 0.051826147 cíber 0.051621147 colonia 0.05078119 aeropuerto 0.050749694 ropa 0.050573919 cartel 0.050566767 mercado 0.050454293 mar 0.049798376 electricidad 0.048715305 privada 0.048443538 departamento 0.04837516 gobierno 0.048190667 muerte 0.047740436 ventana 0.046925492 joto 0.045395693 luz 0.044063047 papelería 0.043929401 estadio 0.04391932 papa 0.043297166 dentista 0.043031968 comercio 0.04282522 ayuntamiento 0.042227746 tránsito 0.041170424 palmera 0.041136401 tierra 0.041046286 gobernador 0.040686214 calor 0.040083508 doctor 0.039754508 inspector 0.039347055 moto 0.039203475 presidente 0.03909627 correo 0.0384963 traficante 0.038288421 cable 0.03705057 mota 0.036570973 tubería 0.036524636 boliche 0.036276281 cucaracha 0.03573645 perico 0.035699557 universidad 0.035177822 bebé 0.035071819 letrero 0.034954976 comida 0.034895842
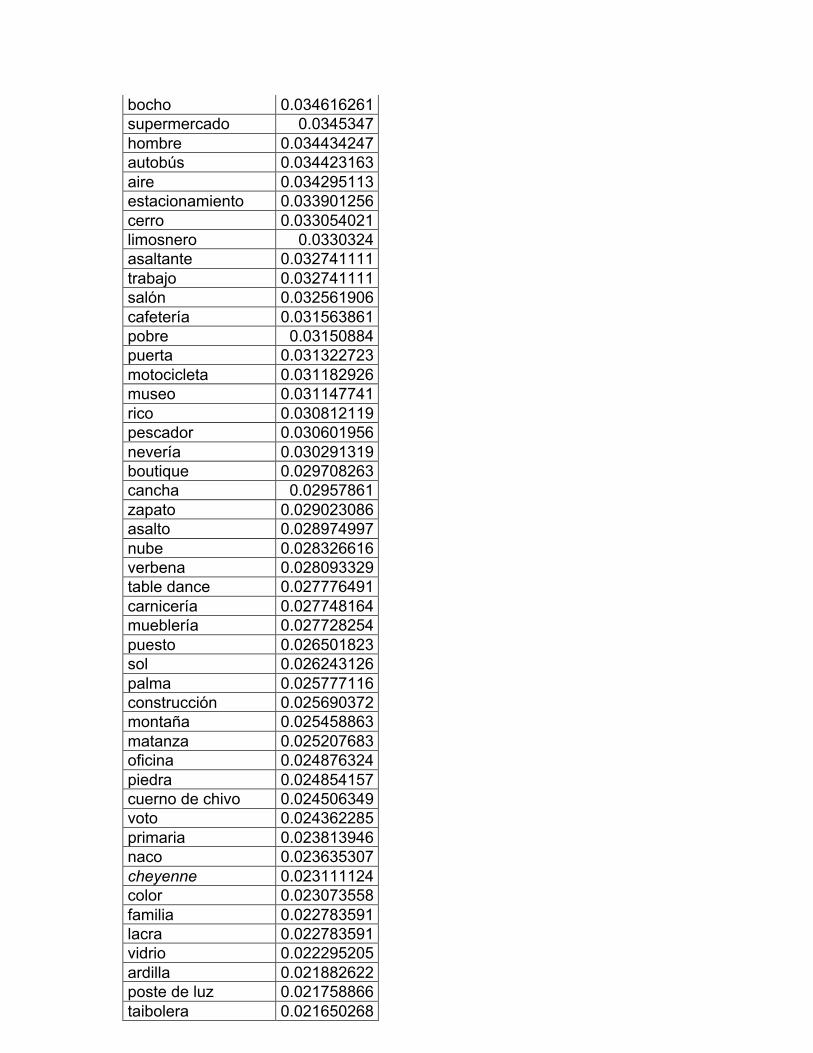
153
bocho 0.034616261 supermercado 0.0345347 hombre 0.034434247 autobús 0.034423163 aire 0.034295113 estacionamiento 0.033901256 cerro 0.033054021 limosnero 0.0330324 asaltante 0.032741111 trabajo 0.032741111 salón 0.032561906 cafetería 0.031563861 pobre 0.03150884 puerta 0.031322723 motocicleta 0.031182926 museo 0.031147741 rico 0.030812119 pescador 0.030601956 nevería 0.030291319 boutique 0.029708263 cancha 0.02957861 zapato 0.029023086 asalto 0.028974997 nube 0.028326616 verbena 0.028093329 table dance 0.027776491 carnicería 0.027748164 mueblería 0.027728254 puesto 0.026501823 sol 0.026243126 palma 0.025777116 construcción 0.025690372 montaña 0.025458863 matanza 0.025207683 oficina 0.024876324 piedra 0.024854157 cuerno de chivo 0.024506349 voto 0.024362285 primaria 0.023813946 naco 0.023635307 cheyenne 0.023111124 color 0.023073558 familia 0.022783591 lacra 0.022783591 vidrio 0.022295205 ardilla 0.021882622 poste de luz 0.021758866 taibolera 0.021650268

154
jardín botánico 0.021615857 barrendero 0.020996779 sexo 0.020833333 teléfono 0.020833333 alberca 0.020608011 ovni 0.020324538 libreta 0.020251196 corrupción 0.020114518 corrido 0.019931941 letra 0.019931941 tecnología 0.019931941 tienda de ropa 0.019931941 pordiosero 0.01981732 estatua 0.019697683 personas fresas 0.019663345 motel 0.019644126 birriería 0.019424618 anuncio 0.019069548 centro nocturno 0.019069548 muerto 0.019069548 presa 0.019069548 jardín 0.018929752 gasolinera 0.018845426 mafia 0.018812574 basurero 0.018336584 bebida 0.018319617 arrancón 0.018244469 avenida 0.018244469 carro del año 0.018244469 cuarto 0.018244469 discoteca 0.018244469 tumulto 0.018244469 anciano 0.017564481 ave 0.017455088 coche 0.017455088 humo 0.017455088 secuestro 0.017455088 tela 0.017455088 pescadería 0.017354711 camioneta 0.017270394 tacos 0.016929741 cemento 0.016782022 caos 0.016699861 negocio 0.016699861 pistola 0.016699861 rodeo 0.016699861 siembra 0.016699861 servicio 0.016577437
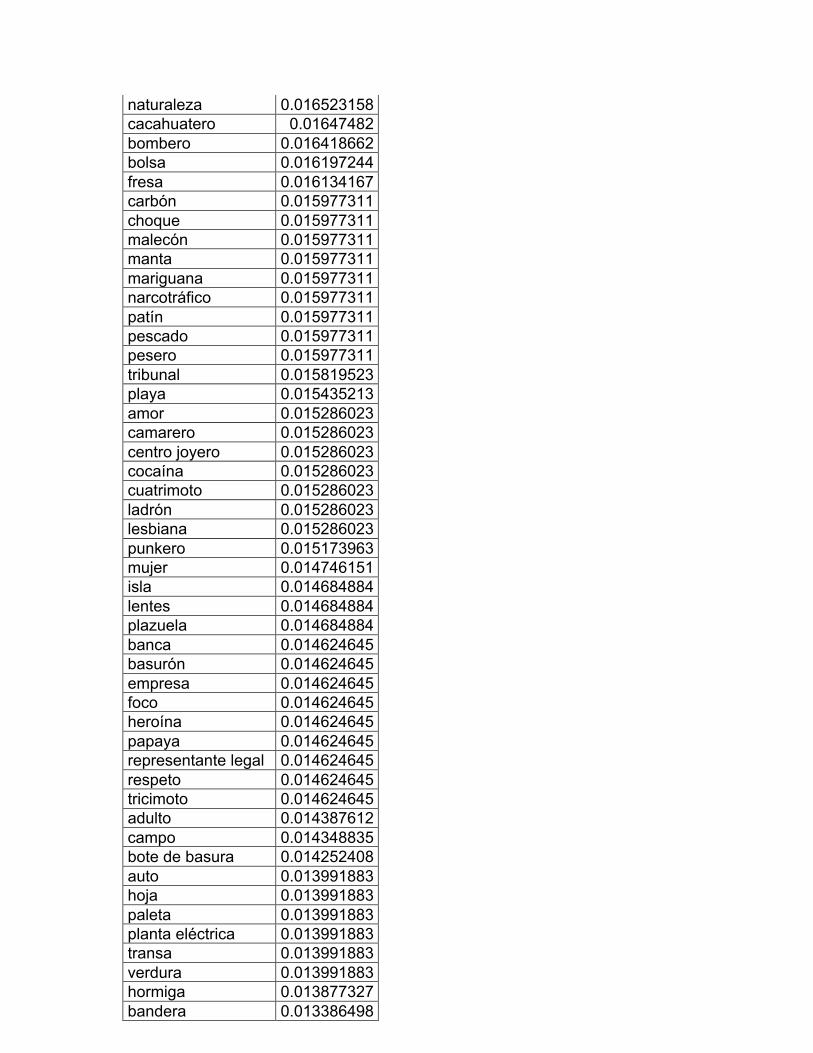
155
naturaleza 0.016523158 cacahuatero 0.01647482 bombero 0.016418662 bolsa 0.016197244 fresa 0.016134167 carbón 0.015977311 choque 0.015977311 malecón 0.015977311 manta 0.015977311 mariguana 0.015977311 narcotráfico 0.015977311 patín 0.015977311 pescado 0.015977311 pesero 0.015977311 tribunal 0.015819523 playa 0.015435213 amor 0.015286023 camarero 0.015286023 centro joyero 0.015286023 cocaína 0.015286023 cuatrimoto 0.015286023 ladrón 0.015286023 lesbiana 0.015286023 punkero 0.015173963 mujer 0.014746151 isla 0.014684884 lentes 0.014684884 plazuela 0.014684884 banca 0.014624645 basurón 0.014624645 empresa 0.014624645 foco 0.014624645 heroína 0.014624645 papaya 0.014624645 representante legal 0.014624645 respeto 0.014624645 tricimoto 0.014624645 adulto 0.014387612 campo 0.014348835 bote de basura 0.014252408 auto 0.013991883 hoja 0.013991883 paleta 0.013991883 planta eléctrica 0.013991883 transa 0.013991883 verdura 0.013991883 hormiga 0.013877327 bandera 0.013386498

156
caballo 0.013386498 chicle 0.013386498 crucero 0.013386498 metal 0.013386498 operación 0.013386498 zorro 0.013386498 drenaje 0.01337858 abanico 0.012840177 campestre 0.012820438 beisbol 0.012807306 drogadicto 0.012807306 farmacia 0.012807306 inmigrante 0.012807306 pelea 0.012807306 tabla 0.012807306 tortillería 0.012807306 vaca 0.012807306 flor 0.012724266 morro 0.012671791 cárcel 0.012397903 blusa 0.012253174 cajero 0.012253174 diente 0.012253174 director 0.012253174 futbol 0.012253174 fábrica 0.012253174 local 0.012253174 recurso económico 0.012253174 trabajador 0.012253174 artista 0.011723018 bala 0.011723018 campana 0.011723018 cigarro 0.011723018 diversidad ecológica 0.011723018 galería 0.011723018 kiosko 0.011723018 padre 0.011723018 pantalón 0.011723018 paseo 0.011723018 sushi 0.011598975 alcohol 0.0112158 calzón 0.0112158 curandera 0.0112158 hoyo 0.0112158 industria 0.0112158 maromero 0.0112158 pájaro 0.0112158

157
motor 0.011026944 brasier 0.010730528 clima 0.010730528 cuenca 0.010730528 fraccionamiento 0.010730528 matón 0.010730528 pavimento 0.010730528 póster 0.010730528 canal 0.010266251 corpiño 0.010266251 monumento 0.010266251 travesti 0.010266251 barco 0.010207214 barrio 0.009822063 chica 0.009822063 chiclero 0.009822063 chilango 0.009822063 cortauñas 0.009822063 emo 0.009822063 jeep 0.009822063 profesor 0.009822063 pastelería 0.009656675 contrabando 0.009397093 estudio 0.009397093 laboratorio 0.009397093 médico 0.009397093 navidad 0.009397093 puesto de comida 0.009397093 trovador 0.009397093 acuario 0.008990511 colegio 0.008990511 consultorio 0.008990511 estética 0.008990511 futbolista 0.008990511 insecto 0.008990511 marisquería 0.008990511 polvo 0.008990511 prieto 0.008990511 uso de energía 0.008990511 agricultura 0.00860152 cantante 0.00860152 centro de ciencias 0.00860152 deporte 0.00860152 lacras 0.00860152 mal gobierno 0.00860152 morro guapo 0.00860152 vagabundo 0.00860152 vestido 0.00860152

158
mochila 0.008510506 caseta 0.008229359 gel 0.008229359 lavacarros 0.008229359 modo de vida 0.008229359 negros 0.008229359 seminario 0.008229359 taller 0.008229359 tamalería 0.008229359 arma 0.0078733 bicho 0.0078733 café 0.0078733 callejón 0.0078733 carro de súper 0.0078733 casino 0.0078733 cañería 0.0078733 centro religioso 0.0078733 computadora 0.0078733 disco 0.0078733 faro 0.0078733 hacienda 0.0078733 shopping 0.0078733 spray 0.0078733 convento 0.007532648 ferrocarril 0.007532648 mecánico 0.007532648 vendedor 0.007532648 alegría 0.007206734 autoservicio 0.007206734 cofre 0.007206734 estudiante 0.007206734 indio 0.007206734 mesa 0.007206734 teatro 0.007206734 zapatería 0.007206734 lápiz 0.007109618 amigo 0.006894921 baño 0.006894921 césped 0.006894921 delincuente 0.006894921 extraterrestre 0.006894921 feo 0.006894921 jarro 0.006894921 lavado de carros 0.006894921 miedo 0.006894921 tecnológico 0.006894921 transporte 0.006894921 bueno 0.006596599

159
encajuelado 0.006596599 libertad 0.006596599 llantera 0.006596599 moneda 0.006596599 palacio de gobierno 0.006596599 proletariado 0.006596599 pueblo 0.006596599 sillón 0.006596599 chamarra 0.006311185 incertidumbre 0.006311185 joven 0.006311185 lavado 0.006311185 limusina 0.006311185 océano 0.006311185 religión 0.006311185 zorra 0.006311185 cachora 0.00603812 gas 0.00603812 lago 0.00603812 laguna 0.00603812 pan 0.00603812 puta 0.00603812 tenedor 0.00603812 tren 0.00603812 catecismo 0.00577687 cuchara 0.00577687 gasolinería 0.00577687 guardería 0.00577687 masaje 0.00577687 pez 0.00577687 suelo 0.00577687 agencia 0.005526923 boulevard 0.005526923 chofer 0.005526923 bosque 0.00528779 librería 0.00528779 papel 0.00528779 pared 0.00528779 reloj 0.00528779 vela 0.00528779 costumbre 0.005059004 dulcero 0.005059004 escalera 0.005059004 liga 0.005059004 llanta 0.005059004 seguridad 0.005059004 camellón 0.004840117 club 0.004840117

160
jefe 0.004840117 moño 0.004840117 patines 0.004840117 paz 0.004840117 tradición 0.004840117 apartamento 0.0046307 automóvil 0.0046307 diadema 0.0046307 electricista 0.0046307 panteón 0.0046307 partido 0.0046307 hijo 0.004430344 tiara 0.004430344 tumba 0.004430344 cinto 0.004238657 señorita 0.004238657 aire acondicionado 0.004055264 alfombra 0.004055264 cajera 0.004055264 secretaria 0.004055264 secretario 0.004055264 sirviente 0.004055264 calceta 0.003879806 estufa 0.003879806 felicidad 0.003879806 mosca 0.003879806 soldado 0.003879806 refrigerador 0.003711939 zapatero 0.003711939 municipio 0.003551335 pluma 0.003551335 raspado 0.003551335 borrador 0.00339768 sindicatura 0.00339768 alcalde 0.003250673 patrulla 0.003250673 político 0.003250673 pulsera 0.003250673 arete 0.003110026 diputado 0.003110026 fierro 0.003110026 pintura 0.002975465 gente mala 0.002846726 palabra 0.002846726 gente buena 0.002723557 ciudadano 0.002605718

161
Centro de interés 11 – La naturaleza
VOCABLO IDL árbol 0.771810855 flor 0.459790232 animal 0.429120566 agua 0.370711076 río 0.363159959 planta 0.345228939 tierra 0.282108111 montaña 0.246322745 lluvia 0.232332764 aire 0.204877038 hoja 0.202428689 sol 0.195003173 huracán 0.185799793 rosa 0.183798017 perro 0.183668061 girasol 0.17552115 mar 0.168652718 volcán 0.164171853 maíz 0.163125812 nube 0.160685106 semilla 0.158041241 pasto 0.144604409 lago 0.144483129 luna 0.138499258 papa 0.129435863 tsunami 0.12461268 manzana 0.123988776 zacate 0.123710395 piedra 0.120093897 terremoto 0.115508191 oxígeno 0.114103724 rata 0.113555329 vaca 0.112869194 tulipán 0.112517905 gato 0.107906527 papaya 0.103967898 pez 0.103687496 arbusto 0.103014541 contaminación 0.100176518 zanahoria 0.099840641 tormenta 0.098455663 pino 0.097631015 bosque 0.097256633 margarita 0.093721171 fruta 0.093359512

162
palmera 0.089754178 trigo 0.088915102 selva 0.088747074 cielo 0.086922615 humano 0.08533831 nieve 0.08440362 castor 0.083445699 ciclón 0.083040077 naranja 0.083026741 césped 0.082000178 arena 0.080308646 verdura 0.079433542 palma 0.079089631 guayabo 0.078882728 pájaro 0.078360615 tomate 0.076877498 tigre 0.076373007 raíz 0.074202436 océano 0.074195586 remolino 0.07387324 madera 0.070152252 fuego 0.066083946 plátano 0.064997409 cerro 0.06391579 topo 0.06340508 gusano 0.062999849 basura 0.0625 hurón 0.061965401 caballo 0.058389049 laguna 0.057975756 burro 0.057017826 campo 0.05665341 orquídea 0.055163133 estrella 0.05451409 cascada 0.054211818 león 0.054078461 mineral 0.051656235 violeta 0.05084505 pepino 0.049955644 calor 0.049555174 ardilla 0.048284091 viento 0.046567565 cempasúchil 0.046029578 mariposa 0.044336991 cachora 0.043146243 frío 0.042478072 cuerpo 0.042333974 pera 0.042304559

163
comadreja 0.041832766 vida 0.041531832 tronco 0.04147096 jazmín 0.041224403 mariguana 0.04081342 sexo 0.04060015 inundación 0.039968434 manantial 0.039422138 playa 0.039289262 mango 0.03922075 chango 0.038748563 persona 0.037894366 mota 0.037735864 granizo 0.037181041 tornado 0.037040817 ratón 0.036257255 verde 0.035526453 manzano 0.035248703 limón 0.035158097 desierto 0.034420096 conejo 0.034279101 rana 0.033636201 hormiga 0.033589255 algodón 0.033578998 ser humano 0.033286649 silla 0.032875171 hortaliza 0.031992644 planeta 0.03163085 fotosíntesis 0.031503625 camarón 0.031483955 tiburón 0.031275008 nochebuena 0.031052055 lirio 0.030615917 cerote 0.03045602 lombriz 0.030135832 elefante 0.03007124 toronja 0.030061729 tacha 0.030054273 delfín 0.029118604 corteza 0.028759591 pipí 0.028623039 popó 0.028598029 biología 0.028495415 inútil 0.028286748 presa 0.027999505 tallo 0.027522754 canal 0.027450757 chile 0.027227161

164
núcleo 0.027147465 lodo 0.027065036 ciruelo 0.026912116 bicho 0.026542613 fresa 0.026440189 cactus 0.026340807 sierra 0.025779648 vegetal 0.025622493 hipopótamo 0.025559567 jardín 0.025221306 gente 0.024958587 serpiente 0.024864976 ahuehuete 0.024559472 matorral 0.024532295 ozono 0.024512753 desecho 0.024203404 física 0.023731035 jamaica 0.023697619 arroyo 0.023202195 jirafa 0.022846382 química 0.02275911 alcatraz 0.02274012 porno 0.022727062 sismo 0.022025321 abeja 0.021702508 mundo 0.021639836 sal 0.021507342 rayo 0.021369755 cerdo 0.02119283 evaporación 0.021155443 hippie 0.020833333 reproducción 0.020833333 tundra 0.020695394 eucalipto 0.020329695 condensación 0.020289003 mandarina 0.020258134 cloración 0.019980086 ballena 0.019807598 calabaza 0.019697025 frijol 0.0196455 iguana 0.019420104 gorila 0.019343561 dios 0.019226387 gallina 0.019167775 cocaína 0.019161784 cuenca 0.019161784 rosal 0.019161784 alpiste 0.018924681

165
lechuga 0.018890317 suelo 0.01853576 café 0.018376997 guayaba 0.018376997 heroína 0.018376997 lili 0.018376997 parque 0.018376997 pupitre 0.018376997 smog 0.018376997 ganso 0.017861945 petróleo 0.017776612 anfetamina 0.017624351 naturaleza 0.017624351 venado 0.017607711 zapato 0.017556863 cebolla 0.017406272 maremoto 0.017406272 polvo 0.01723636 ejote 0.016989179 sandía 0.016959516 cueva 0.016932091 dióxido de carbono 0.016902531 garza 0.016902531 tranquilidad 0.016902531 vidrio 0.016902531 éxtasis 0.016902531 fruto 0.016693383 águila 0.016677963 chubasco 0.016210273 clavel 0.016210273 elemento químico 0.016210273 energía 0.016210273 monte 0.016210273 pingüica 0.016210273 polen 0.016210273 tachas 0.016210273 oso 0.016050374 pozo 0.016050374 nevar 0.016009691 cambio climático 0.015546367 mata 0.015546367 riviera 0.015546367 hielo 0.015067078 cambio atmosférico 0.014909652 erupción 0.014909652 hombre 0.014909652 lindo 0.014909652 lápiz 0.014909652

166
naranjo 0.014909652 orina 0.014909652 zoológico 0.014909652 manzanilla 0.014667189 enredadera 0.014659976 nopal 0.014402739 ecosistema 0.014299015 hermoso 0.014299015 mosca 0.014299015 mujer 0.014299015 vapor 0.014299015 pato 0.013831859 agua negra 0.013713386 lechuza 0.013713386 maceta 0.013713386 papayo 0.013713386 paz 0.013713386 pingüino 0.013713386 rama 0.013713386 reptil 0.013713386 vómito 0.013713386 sabana 0.013392337 barro 0.013151743 cama 0.013151743 coladera 0.013151743 limonero 0.013151743 árbol de mandarina 0.013151743 paisaje 0.012749678 asiento 0.012613102 belleza 0.012613102 mosquito 0.012613102 puente 0.012613102 sapo 0.012613102 árbol de limón 0.012613102 koala 0.012158532 bobito 0.012096521 cangrejo 0.012096521 cuidar 0.012096521 mueble 0.012096521 periférico 0.012096521 pradera 0.012096521 galaxia 0.012070245 lava 0.011893953 coco 0.011601098 continente 0.011601098 culebra 0.011601098 dinosaurio 0.011601098 patines 0.011601098

167
reciclar 0.011601098 sexo oral 0.011601098 sillón 0.011601098 metal 0.011412439 virus 0.011135631 caimán 0.011125965 comedor 0.011125965 fuente 0.011125965 meseta 0.011125965 perico 0.011125965 uva 0.011125965 rancho 0.010988295 araña 0.010670291 arroz 0.010670291 depresión 0.010670291 sembradío 0.010670291 temperatura 0.010647113 apareamiento 0.01023328 ciempiés 0.01023328 cocodrilo 0.01023328 geografía 0.01023328 lengua 0.01023328 miel 0.01023328 picadientes 0.01023328 universo 0.01023328 oro 0.01021081 ciclo del agua 0.009814167 día 0.009814167 fenómeno 0.009814167 hierba 0.009814167 insecto 0.009814167 mercado 0.009814167 televisor 0.009814167 plata 0.009792617 polo 0.00971736 coral 0.009645517 luz 0.009609562 alimento 0.00941222 betabel 0.00941222 murciélago 0.00941222 tala de árboles 0.00941222 asteroide 0.009250477 calentamiento global 0.009026734 cultivo 0.009026734 dieta 0.009026734 dátil 0.009026734 huevo 0.009026734 leopardo 0.009026734

168
paja 0.009026734 vida humana 0.009026734 agua subterránea 0.008657036 chícharo 0.008657036 hongo 0.008657036 lince 0.008657036 moco 0.008657036 mora 0.008657036 pastizal 0.008512066 avena 0.00830248 ciruela 0.00830248 cítrico 0.00830248 liebre 0.00830248 loro 0.00830248 satélite natural 0.00830248 seda 0.00830248 lagartija 0.007962445 mina 0.007962445 tamarindo 0.007962445 atardecer 0.007636336 cedro 0.007636336 lichi 0.007636336 mapache 0.007636336 país 0.007636336 bosque tropical 0.0074255 cochi 0.007323583 jaguar 0.007323583 minerales 0.007323583 ornitorrinco 0.007323583 perejil 0.007323583 pulpo 0.007084318 albahaca 0.00702364 alpaca 0.00702364 azul 0.00702364 chancla 0.00702364 demonio de Tazmania 0.00702364 durazno 0.00702364 exploración 0.00702364 sed 0.00702364 sólido 0.00702364 valle 0.00702364 estepa 0.006954358 amarillo 0.00673598 borrego 0.00673598 canguro 0.00673598 escurrimiento 0.00673598 gas 0.00673598
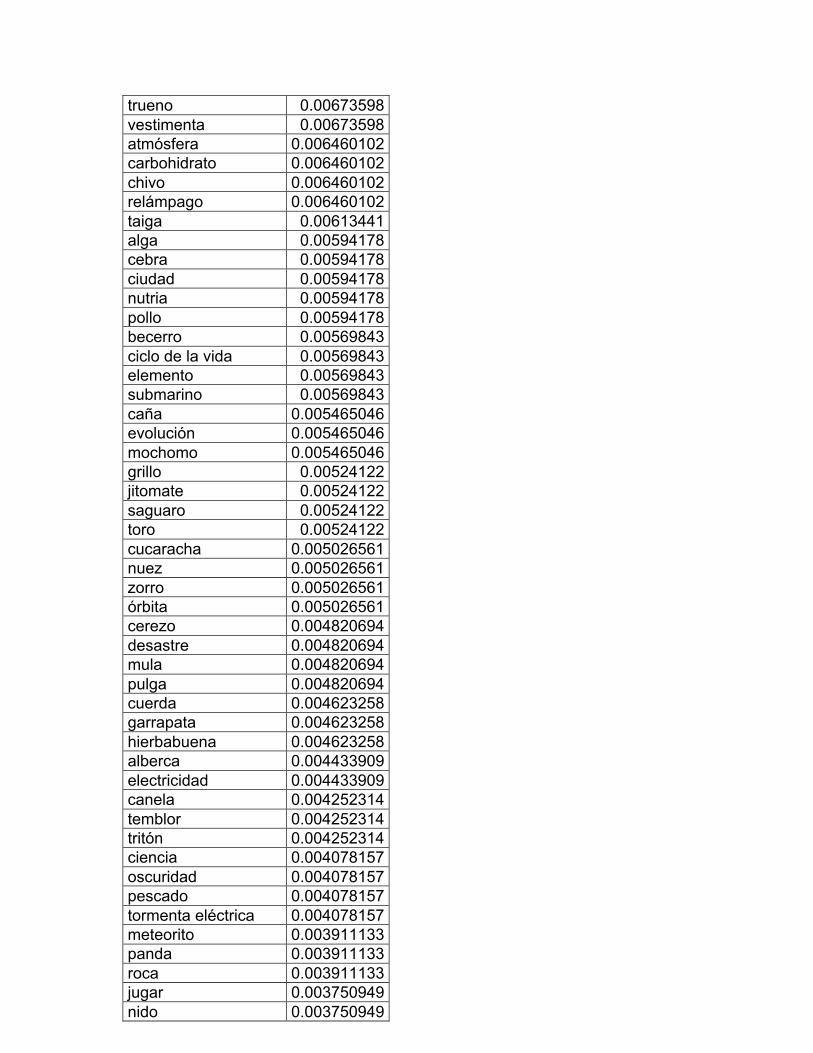
169
trueno 0.00673598 vestimenta 0.00673598 atmósfera 0.006460102 carbohidrato 0.006460102 chivo 0.006460102 relámpago 0.006460102 taiga 0.00613441 alga 0.00594178 cebra 0.00594178 ciudad 0.00594178 nutria 0.00594178 pollo 0.00594178 becerro 0.00569843 ciclo de la vida 0.00569843 elemento 0.00569843 submarino 0.00569843 caña 0.005465046 evolución 0.005465046 mochomo 0.005465046 grillo 0.00524122 jitomate 0.00524122 saguaro 0.00524122 toro 0.00524122 cucaracha 0.005026561 nuez 0.005026561 zorro 0.005026561 órbita 0.005026561 cerezo 0.004820694 desastre 0.004820694 mula 0.004820694 pulga 0.004820694 cuerda 0.004623258 garrapata 0.004623258 hierbabuena 0.004623258 alberca 0.004433909 electricidad 0.004433909 canela 0.004252314 temblor 0.004252314 tritón 0.004252314 ciencia 0.004078157 oscuridad 0.004078157 pescado 0.004078157 tormenta eléctrica 0.004078157 meteorito 0.003911133 panda 0.003911133 roca 0.003911133 jugar 0.003750949 nido 0.003750949
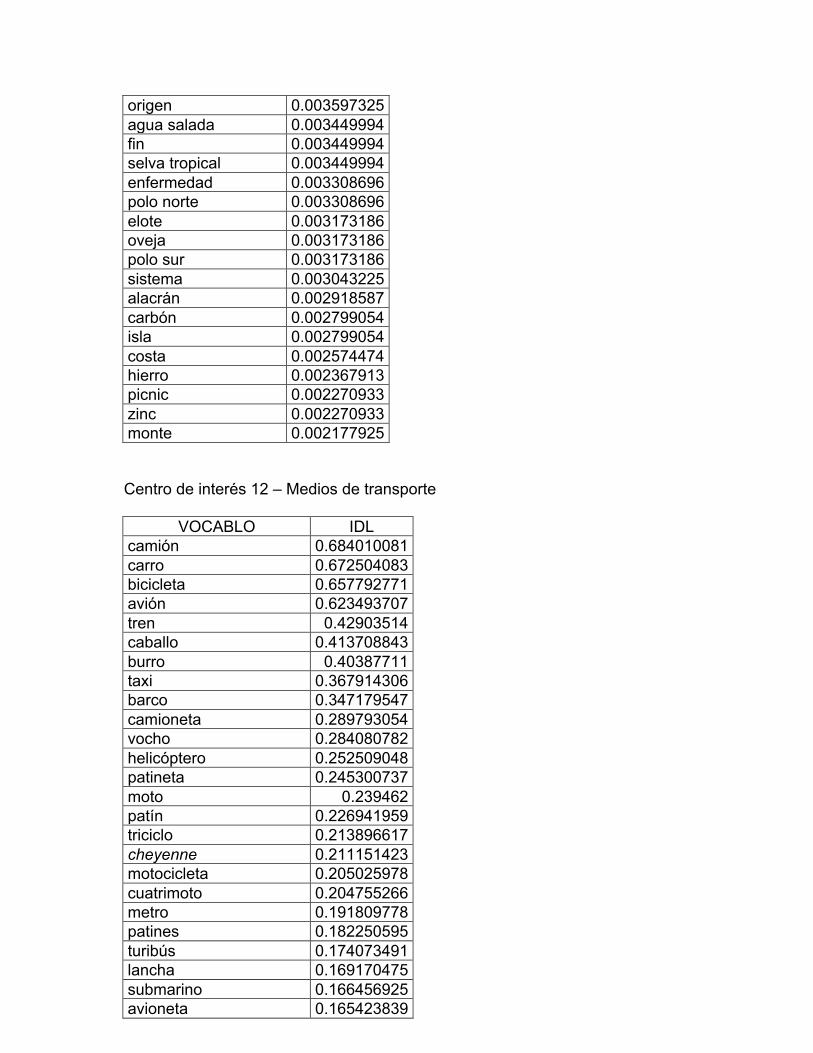
170
origen 0.003597325 agua salada 0.003449994 fin 0.003449994 selva tropical 0.003449994 enfermedad 0.003308696 polo norte 0.003308696 elote 0.003173186 oveja 0.003173186 polo sur 0.003173186 sistema 0.003043225 alacrán 0.002918587 carbón 0.002799054 isla 0.002799054 costa 0.002574474 hierro 0.002367913 picnic 0.002270933 zinc 0.002270933 monte 0.002177925 Centro de interés 12 – Medios de transporte
VOCABLO IDL camión 0.684010081 carro 0.672504083 bicicleta 0.657792771 avión 0.623493707 tren 0.42903514 caballo 0.413708843 burro 0.40387711 taxi 0.367914306 barco 0.347179547 camioneta 0.289793054 vocho 0.284080782 helicóptero 0.252509048 patineta 0.245300737 moto 0.239462 patín 0.226941959 triciclo 0.213896617 cheyenne 0.211151423 motocicleta 0.205025978 cuatrimoto 0.204755266 metro 0.191809778 patines 0.182250595 turibús 0.174073491 lancha 0.169170475 submarino 0.166456925 avioneta 0.165423839

171
tráiler 0.132030754 jet 0.131995917 autobús 0.130612836 limusina 0.125523144 ferrocarril 0.1090314 kayak 0.106978031 jet esquí 0.092314558 camello 0.089060589 teleférico 0.080501226 vaca 0.071914592 microbús 0.071181738 cohete 0.065436579 pulmonía 0.057768838 jeep 0.055191354 crucero 0.055035306 trineo 0.052379209 convertible 0.05139006 carreta 0.049752363 trolebús 0.048122238 pie 0.047004646 elefante 0.046210483 pierna 0.043750491 aeroplano 0.041832645 gasolina 0.040377276 pesero 0.040377276 periférico 0.040337986 subterráneo 0.037835306 ferri 0.03624628 bogie 0.035623185 esquí 0.035579596 yate 0.035315235 volante 0.034275248 patín del diablo 0.032604546 tricimoto 0.032602691 a pie 0.030803502 velero 0.030774735 tranvía 0.030375595 globo 0.030294855 tren subterráneo 0.027858145 carroza 0.026521183 nave espacial 0.0236377 carrito del súper 0.023304676 llanta 0.023279016 jet privado 0.022632231 carretera 0.02246133 balsa 0.021994943 rueda 0.019995142 auto 0.019543942

172
catedral 0.019543942 mecánico 0.019543942 volkswagen 0.019543942 maxipista 0.019396144 canoa 0.019379617 globo aerostático 0.019209315 góndola 0.018731688 elevador 0.018334353 carruaje 0.017528348 motoneta 0.017484446 carcancha 0.017199625 carro de carreras 0.017185802 tractor 0.016367644 banqueta 0.016135127 micro 0.016135127 transporte 0.016135127 minibús 0.016111118 barca 0.015980482 pick up 0.015136512 pipa 0.015136512 transbordador espacial 0.015136512 bote 0.014871579 camión de carga 0.014199701 camión eléctrico 0.014199701 mano 0.014188289 monociclo 0.014092318 calle 0.013575462 avión supersónico 0.013320871 motor 0.013320871 tour 0.013320871 trasbordador 0.013320871 moto de nieve 0.013193199 araña 0.012496432 asiento 0.012496432 carretilla 0.012496432 torre de control 0.011723018 ave 0.011452549 autopista 0.010997471 panga 0.010997471 patín eléctrico 0.010997471 andadera 0.010977923 caminar 0.010316829 flotador 0.010316829 carro de gas 0.009678313 nave 0.009079315 monorriel 0.008928238 avión jumbo 0.008517389 buey 0.008517389

173
camionero 0.008517389 partes de auto 0.008517389 patín de motor 0.008059464 blanco 0.007990241 cañón 0.007990241 lechero 0.007495719 pata 0.007495719 esquís 0.007031803 tabla 0.007031803 zepelin 0.007031803 carreola 0.006331197 partybus 0.006188331 globo de aire 0.00580533 demoledora 0.005446034 paracaídas 0.005446034 silla de ruedas 0.005446034 asfalto 0.005108975 carrocero 0.005108975 motocicleta todo terreno 0.005108975 mula 0.005108975 silla eléctrica 0.005108975 ferry 0.004792776 trilladora 0.00461873 nadando 0.004496148 rino 0.004496148 tun-tún 0.004496148 ambulancia 0.004217878 carrera 0.004217878 cielo 0.004217878 raite 0.004217878 aeropuerto 0.00395683 aire 0.00395683 aventón 0.00395683 garage 0.003711939 trasatlántico 0.003711939 cochera 0.003482204 remolque 0.003482204 delfín 0.003266688 empujón 0.00306451 dona 0.002696918 cuerpo 0.00237342 perro 0.002226527 Centro de interés 13 – Trabajos de campo y jardín
VOCABLO IDL ganadería 0.626065702

174
agricultura 0.514723301 tractor 0.453334398 jardinero 0.413231383 agricultor 0.279443645 tijeras 0.255174923 pesca 0.244354375 vaca 0.181327278 caballo 0.178852185 tierra 0.176647876 flor 0.175564223 tomate 0.174363838 burro 0.163974306 árbol 0.160757602 ordeñar 0.159851817 pala 0.153839719 apicultura 0.151447387 podadora 0.148690987 planta 0.137541491 maíz 0.116664507 semilla 0.113275286 jimador 0.110025747 pasto 0.108978966 campesino 0.108381612 sembrador 0.105242926 botánica 0.099143239 recolector 0.092242571 siembra 0.09169972 agua 0.089224633 biólogo 0.087333497 sembrar 0.086072775 frijol 0.085391096 jornalero 0.082612069 granjero 0.080090749 regar 0.076871362 trigo 0.076657706 hacienda 0.075433718 podar 0.073049273 sembradío 0.071011622 ordeñador 0.070978904 rosa 0.065199429 gallina 0.062336159 podador 0.059997027 cochi 0.059950541 trilladora 0.058502103 martillo 0.057826329 zanahoria 0.057794634 animal 0.053968771 papa 0.053785328

175
riego 0.051850313 forraje 0.051077031 granja 0.050154194 coa 0.049440641 charro 0.048593663 césped 0.048392776 rancho 0.047704787 terraza 0.046209867 cortar elotes 0.046207029 excavar 0.04534112 elote 0.044711004 vaquero 0.044378649 hoja 0.044310373 recogedor 0.042813574 pato 0.041591923 leche 0.041403091 escoba 0.041032547 gallinero 0.040915475 chile 0.040663649 recolección 0.040437481 maceta 0.040346504 jardinería 0.039444358 abeja 0.039218753 campestre 0.039052363 pescador 0.038823857 agave 0.03846409 calabaza 0.038451867 agrícola 0.038176409 narco 0.038139096 chinampa 0.037775128 cultivo 0.037387029 traficante 0.037314017 lechuga 0.036975585 velador 0.036535767 cucharón 0.036524636 invernadero 0.03594829 cosechar 0.03576941 biología 0.035413644 plantador 0.035046859 toro 0.034404515 minería 0.034355571 manzana 0.03422178 hombre 0.03415495 machete 0.03364064 granja de camarón 0.033530492 camión 0.032964957 pepino 0.032718545 verdura 0.032714369

176
fertilizante 0.032561457 fuente 0.032456046 extraer trigo 0.031954622 margarita 0.031617331 jinete 0.031070481 pastor 0.030858149 arquitecto 0.030691744 camioneta 0.030572046 rata 0.030473266 cerdo 0.0303049 capataz 0.02967918 cosechador 0.0293358 patrón 0.02870036 manguera 0.028662301 médico 0.028616527 abono 0.028197838 botánico 0.027700329 ganadero 0.027277151 trillador 0.027253686 cortar tomate 0.026877819 calor 0.026311958 limpiar 0.026117769 jardín 0.025690372 güingo 0.025301381 macetera 0.025060481 motocicleta 0.024994888 avena 0.024920594 insecticida 0.024890896 máquina 0.02472241 zacate 0.024648021 rama 0.023906595 buey 0.023887543 caballería 0.023446036 tulipán 0.023231958 tortilla 0.022774395 mariguana 0.022476731 campo 0.022304878 trabajo 0.022046945 regador 0.021758866 torero 0.021650268 cebolla 0.021427724 pastizal 0.021022706 sierra 0.020996779 hippie 0.019952377 pescadería 0.019931941 pizcar 0.019931941 traición 0.019931941 veterinario 0.019931941
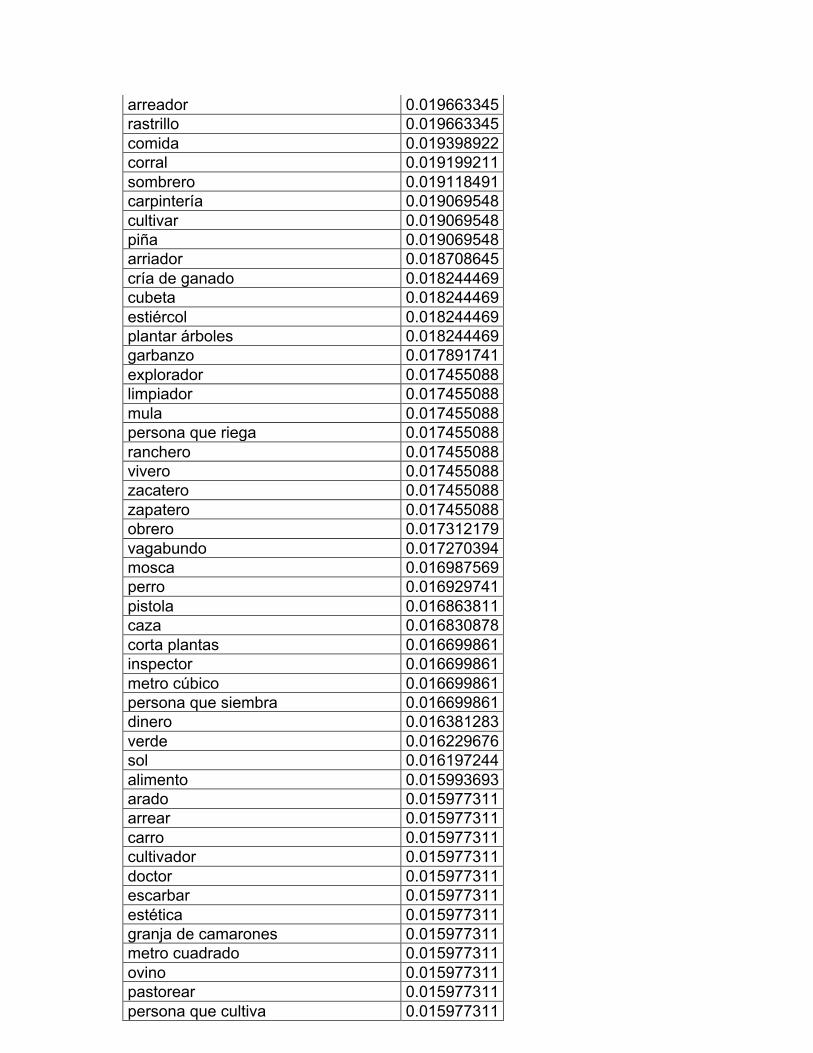
177
arreador 0.019663345 rastrillo 0.019663345 comida 0.019398922 corral 0.019199211 sombrero 0.019118491 carpintería 0.019069548 cultivar 0.019069548 piña 0.019069548 arriador 0.018708645 cría de ganado 0.018244469 cubeta 0.018244469 estiércol 0.018244469 plantar árboles 0.018244469 garbanzo 0.017891741 explorador 0.017455088 limpiador 0.017455088 mula 0.017455088 persona que riega 0.017455088 ranchero 0.017455088 vivero 0.017455088 zacatero 0.017455088 zapatero 0.017455088 obrero 0.017312179 vagabundo 0.017270394 mosca 0.016987569 perro 0.016929741 pistola 0.016863811 caza 0.016830878 corta plantas 0.016699861 inspector 0.016699861 metro cúbico 0.016699861 persona que siembra 0.016699861 dinero 0.016381283 verde 0.016229676 sol 0.016197244 alimento 0.015993693 arado 0.015977311 arrear 0.015977311 carro 0.015977311 cultivador 0.015977311 doctor 0.015977311 escarbar 0.015977311 estética 0.015977311 granja de camarones 0.015977311 metro cuadrado 0.015977311 ovino 0.015977311 pastorear 0.015977311 persona que cultiva 0.015977311

178
punta 0.015977311 girasol 0.015793174 cajero 0.015286023 cereza 0.015286023 cortar semilla 0.015286023 metro 0.015286023 persona que corta 0.015286023 pico 0.015286023 plantar flores 0.015286023 probador de material 0.015286023 avicultura 0.014624645 charco 0.014624645 construir patio 0.014624645 cosecha 0.014624645 fotosíntesis 0.014624645 hectómetro 0.014624645 océano 0.014624645 puerco 0.014624645 químico 0.014624645 bicicleta 0.014267479 abonador 0.013991883 administración 0.013991883 atole 0.013991883 biólogo marino 0.013991883 cavar 0.013991883 cortar pepino 0.013991883 cortar zacate 0.013991883 ficus 0.013991883 hectómetro cuadrado 0.013991883 mar 0.013991883 rastrear 0.013991883 fruta 0.013843833 trabajador 0.01349152 agro 0.013386498 cortar rosales 0.013386498 flora 0.013386498 florero 0.013386498 geólogo 0.013386498 hectómetro cúbico 0.013386498 mantenimiento 0.013386498 motosierra 0.013386498 regar las plantas 0.013386498 río 0.013386498 terreno 0.013386498 alberca 0.012807306 apicultor 0.012807306 cortar el césped 0.012807306 fertilizar 0.012807306

179
ganado equino 0.012807306 kilómetro 0.012807306 nutriólogo 0.012807306 persona que da comida a los animales 0.012807306 pintar 0.012807306 sustancia 0.012807306 zancudo 0.012807306 costal 0.012481325 aire 0.012253174 cercar 0.012253174 cortar calabaza 0.012253174 hacha 0.012253174 kilómetro cuadrado 0.012253174 nogal 0.012253174 pastoreo 0.012253174 pinza 0.012253174 recortar 0.012253174 trovador 0.012253174 té 0.012253174 cereal 0.012227091 cortador 0.011723018 cortar ejote 0.011723018 cortar sandía 0.011723018 kilómetro cúbico 0.011723018 mecate 0.011723018 minero 0.011723018 proveedor 0.011723018 quemar 0.011723018 recogedor de basura 0.011723018 amarillo 0.01132591 hierba 0.0112273 barredor 0.0112158 decorador 0.0112158 decámetro 0.0112158 explotación 0.0112158 fertilizador 0.0112158 lodo 0.0112158 pintor 0.0112158 plantar 0.0112158 regar las flores 0.0112158 tequilero 0.0112158 decámetro cuadrado 0.010730528 dátil 0.010730528 limpiar el jardín 0.010730528 tamal 0.010730528 cemento 0.010266251 cortar 0.010266251

180
decámetro cúbico 0.010266251 dueño 0.010266251 guiar al ganado 0.010266251 motor 0.010266251 negro 0.010266251 paja 0.00991849 cal 0.009822063 huevo 0.009822063 ingeniero 0.009822063 maicero 0.009822063 naco 0.009822063 persona que anda en el tractor 0.009822063 química 0.009822063 rastreadora 0.009822063 sermón 0.009822063 tabaquería 0.009822063 cheyenne 0.009488808 cerco 0.009397093 cortapasto 0.009397093 fiar 0.009397093 fruto 0.009397093 licenciado 0.009397093 lluvia 0.009397093 mota 0.009397093 paloma 0.009397093 pájaro 0.009397093 sembradora 0.009397093 azadón 0.008990511 cielo 0.008990511 espantapájaros 0.008990511 indígena 0.008990511 pastura 0.008990511 pétalos 0.008990511 remodelar 0.008990511 cribadora 0.00860152 destilación 0.00860152 queso 0.00860152 silla de jardín 0.00860152 turista 0.00860152 melón 0.008502388 arbusto 0.008342639 cortador de pasto 0.008229359 polen 0.008229359 sombrilla 0.008229359 naranja 0.008110528 arroz 0.0078733 nopal 0.0078733 cortar el pasto 0.007532648
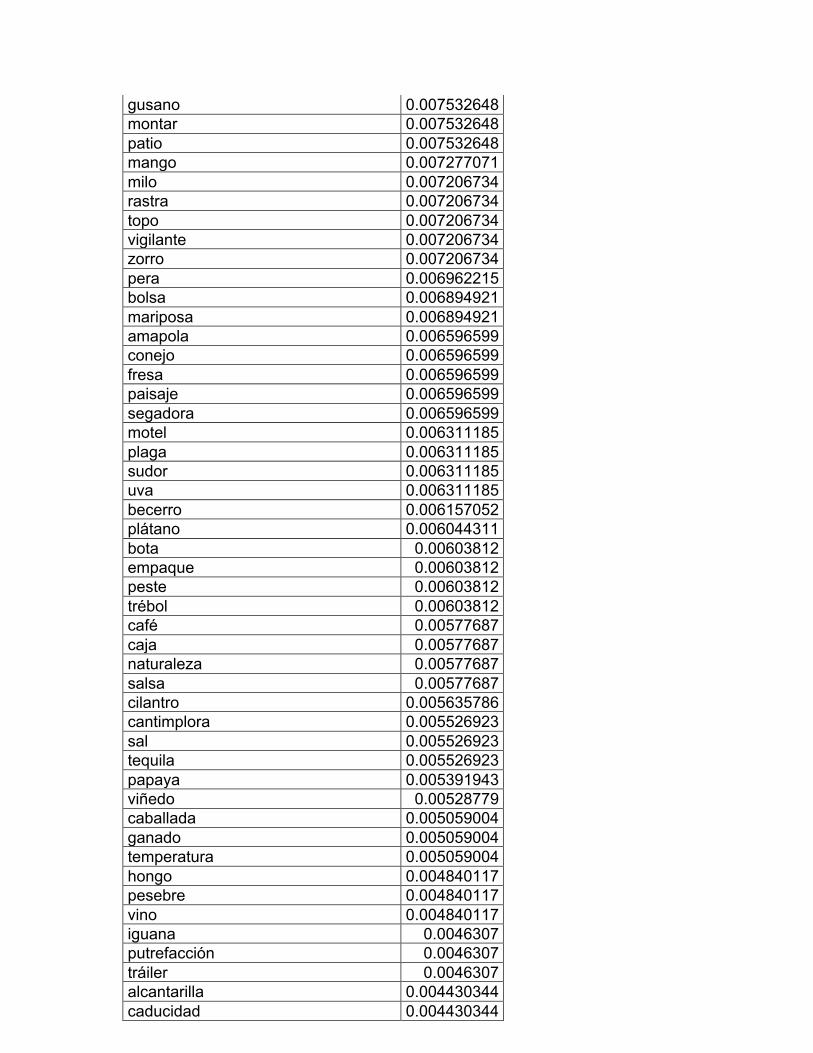
181
gusano 0.007532648 montar 0.007532648 patio 0.007532648 mango 0.007277071 milo 0.007206734 rastra 0.007206734 topo 0.007206734 vigilante 0.007206734 zorro 0.007206734 pera 0.006962215 bolsa 0.006894921 mariposa 0.006894921 amapola 0.006596599 conejo 0.006596599 fresa 0.006596599 paisaje 0.006596599 segadora 0.006596599 motel 0.006311185 plaga 0.006311185 sudor 0.006311185 uva 0.006311185 becerro 0.006157052 plátano 0.006044311 bota 0.00603812 empaque 0.00603812 peste 0.00603812 trébol 0.00603812 café 0.00577687 caja 0.00577687 naturaleza 0.00577687 salsa 0.00577687 cilantro 0.005635786 cantimplora 0.005526923 sal 0.005526923 tequila 0.005526923 papaya 0.005391943 viñedo 0.00528779 caballada 0.005059004 ganado 0.005059004 temperatura 0.005059004 hongo 0.004840117 pesebre 0.004840117 vino 0.004840117 iguana 0.0046307 putrefacción 0.0046307 tráiler 0.0046307 alcantarilla 0.004430344 caducidad 0.004430344

182
palo 0.004430344 producto 0.004238657 comercio 0.004055264 muestra 0.004055264 tren 0.004055264 pasto largo 0.003879806 venta 0.003879806 astilla 0.003711939 mandarina 0.003711939 negocio 0.003711939 camello 0.003551335 cuidado 0.003551335 casa 0.003250673 riega 0.003250673 tallo 0.003250673 mazorca 0.003110026 arena 0.002975465 comal 0.002975465 sandía 0.002846726 jugo 0.002723557 oveja 0.002723557 lechero 0.002385113 ordeña 0.002281917 pan 0.002281917 avioneta 0.002183185 oxígeno 0.002183185 Centro de interés 14 – Los animales
VOCABLO IDL perro 0.725395782 gato 0.561350666 vaca 0.506102609 rata 0.494565798 burro 0.45508125 caballo 0.446062256 chango 0.420457799 conejo 0.418734495 oso 0.405005961 tiburón 0.403661771 cochi 0.392620805 león 0.379699936 ballena 0.365778896 pez 0.363901784 tigre 0.354498995 gallina 0.343122142 pájaro 0.324082421

183
buitre 0.31838688 mapache 0.310254083 delfín 0.299074362 jirafa 0.272894481 gallo 0.24870063 cotorro 0.248575942 hipopótamo 0.242987288 rana 0.241931235 pavo real 0.21579196 elefante 0.20034249 cucaracha 0.199147567 cocodrilo 0.198144591 panda 0.195979598 águila 0.195188752 lagartija 0.192697178 perico 0.179787851 pato 0.172846949 serpiente 0.162317348 castor 0.161789777 cachora 0.160723576 garza 0.159137149 venado 0.157634104 cerdo 0.156626483 hormiga 0.14646607 mosca 0.137630465 tortuga 0.134027695 mono 0.128223279 lobo 0.127981546 hurón 0.126733633 camello 0.123884621 cuervo 0.121362632 cangrejo 0.121142152 topo 0.119840274 gorila 0.117374277 pollo 0.116430163 avestruz 0.115188889 guacamaya 0.11472944 pulpo 0.11291553 pescado 0.112739956 mariposa 0.112571072 coyote 0.10726698 grillo 0.103933342 foca 0.103697711 camarón 0.103546471 búho 0.100533755 mamut 0.097698246 ratón 0.096103997 sapo 0.096041031

184
toro 0.092747322 iguana 0.090769883 gusano 0.08971477 zorro 0.087954917 chanate 0.081735896 canguro 0.081097706 ardilla 0.078219953 tucán 0.076915947 lombriz 0.076516101 leopardo 0.07605096 comadreja 0.072577356 culebra 0.072359065 colibrí 0.070462022 oveja 0.068480893 paloma 0.068191843 chivo 0.067384928 oso hormiguero 0.065786687 pelícano 0.065018169 koala 0.063912126 araña 0.062899917 oso polar 0.058566303 alacrán 0.057552354 jaguar 0.055434765 humano 0.055135082 pingüino 0.054555381 lagarto 0.053840503 abeja 0.053355014 salamandra 0.053331965 urraca 0.05029475 chimpancé 0.046871892 orangután 0.045795084 víbora 0.045152761 liebre 0.04400524 dinosaurio 0.043653305 orca 0.042176768 mula 0.041728904 hámster 0.041350525 almeja 0.040854164 morsa 0.040789263 chapulín 0.040700109 medusa 0.040608674 oso panda 0.039477799 ganso 0.038758472 pavo 0.037929759 loro 0.037867685 lobo marino 0.037402776 gaviota 0.037363062 mosco 0.036782463

185
piojo 0.036179445 guajolote 0.03589044 puerco 0.035413435 ave 0.03454032 marrano 0.032231151 camaleón 0.030458054 piraña 0.030089775 langosta 0.029710594 rinoceronte 0.029361773 pez espada 0.029078743 buey 0.02877213 lechuza 0.028700443 jabalí 0.027883105 pez globo 0.027683828 cebra 0.026351636 abejorro 0.02607297 borrego 0.025585714 zopilote 0.025413203 perezoso 0.024365823 dromedario 0.024048205 armadillo 0.023179954 becerro 0.023131024 simio 0.022138721 dragón 0.022123676 puma 0.021973162 bicho 0.021645064 quemador 0.021323877 caballo de mar 0.02102661 pantera 0.02095354 atún 0.020201877 san bernardo 0.02002335 mosquito 0.019541374 huevo 0.01932513 oso grizzly 0.018514209 escorpión 0.018458677 lince 0.017633765 reptil 0.017086324 oso pardo 0.016789845 salmón 0.01652463 cardenal 0.016422022 tarántula 0.016295635 mantarraya 0.016245584 caimán 0.015783547 mono araña 0.015169895 marlin 0.015101243 pájaro carpintero 0.014580102 ciempiés 0.014302601 oso blanco 0.014013239

186
ornitorrinco 0.013481213 escarabajo 0.01314067 pez ángel 0.013037995 manatí 0.012985185 coral 0.012944775 frailecillo 0.012936728 hombre 0.011957777 sardina 0.011796415 pejelagarto 0.011492868 estrella de mar 0.011274126 reno 0.011046035 anaconda 0.010616574 ballena azul 0.010616574 langostino 0.010616574 lisa 0.010616574 pez vela 0.010502682 insecto 0.010487504 nutria 0.010473311 coralillo 0.01020381 raya 0.01020381 zancudo 0.01020381 dragón de Komodo 0.009807094 invertebrado 0.009807094 kiwi 0.009807094 pez payaso 0.009807094 roedor 0.009674754 cacatúa 0.009425802 chita 0.009425802 comida 0.009425802 dengue 0.009425802 halcón 0.009425802 liendre 0.009425802 murciélago 0.009425802 pichón 0.009425802 crustáceo 0.009059334 mochomo 0.009059334 vertebrado 0.009059334 calamar 0.008859911 caguama 0.008707115 guepardo 0.008707115 venado cimarrón 0.008368589 cabalgar 0.008043225 martillo 0.008043225 oso negro 0.008043225 ostra 0.008043225 quetzal 0.008043225 estrella 0.007730511 luciérnaga 0.007429955
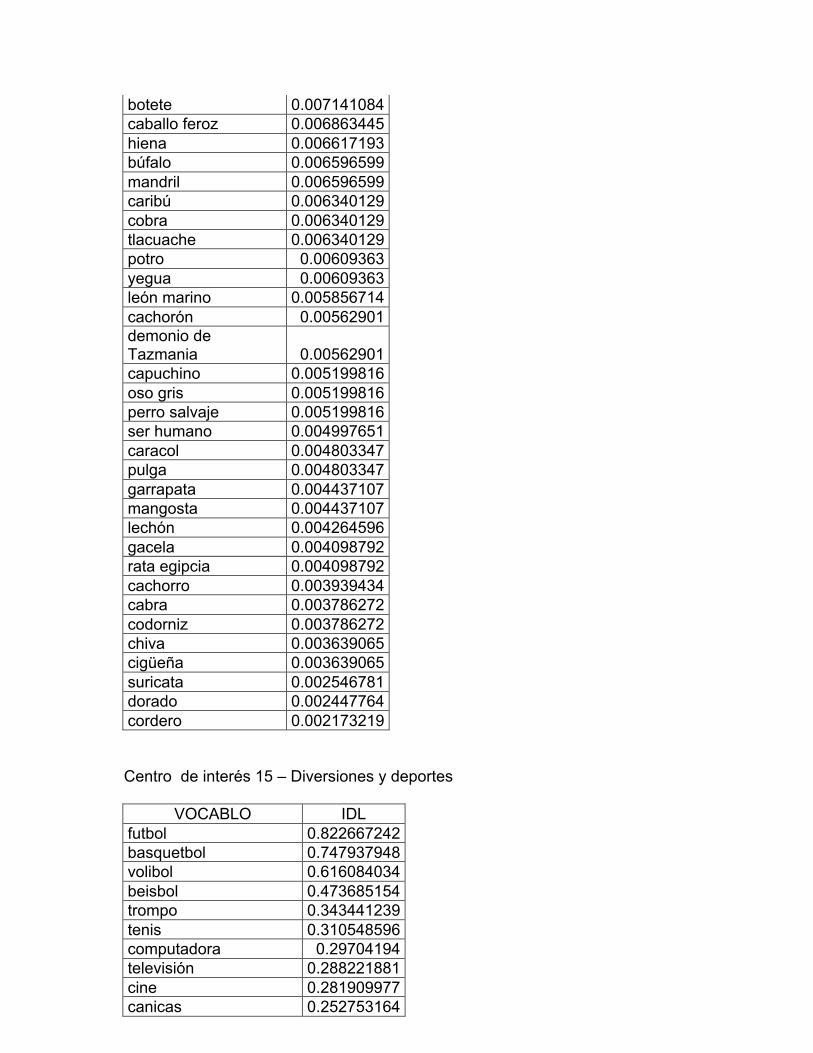
187
botete 0.007141084 caballo feroz 0.006863445 hiena 0.006617193 búfalo 0.006596599 mandril 0.006596599 caribú 0.006340129 cobra 0.006340129 tlacuache 0.006340129 potro 0.00609363 yegua 0.00609363 león marino 0.005856714 cachorón 0.00562901 demonio de Tazmania 0.00562901 capuchino 0.005199816 oso gris 0.005199816 perro salvaje 0.005199816 ser humano 0.004997651 caracol 0.004803347 pulga 0.004803347 garrapata 0.004437107 mangosta 0.004437107 lechón 0.004264596 gacela 0.004098792 rata egipcia 0.004098792 cachorro 0.003939434 cabra 0.003786272 codorniz 0.003786272 chiva 0.003639065 cigüeña 0.003639065 suricata 0.002546781 dorado 0.002447764 cordero 0.002173219 Centro de interés 15 – Diversiones y deportes
VOCABLO IDL futbol 0.822667242 basquetbol 0.747937948 volibol 0.616084034 beisbol 0.473685154 trompo 0.343441239 tenis 0.310548596 computadora 0.29704194 televisión 0.288221881 cine 0.281909977 canicas 0.252753164
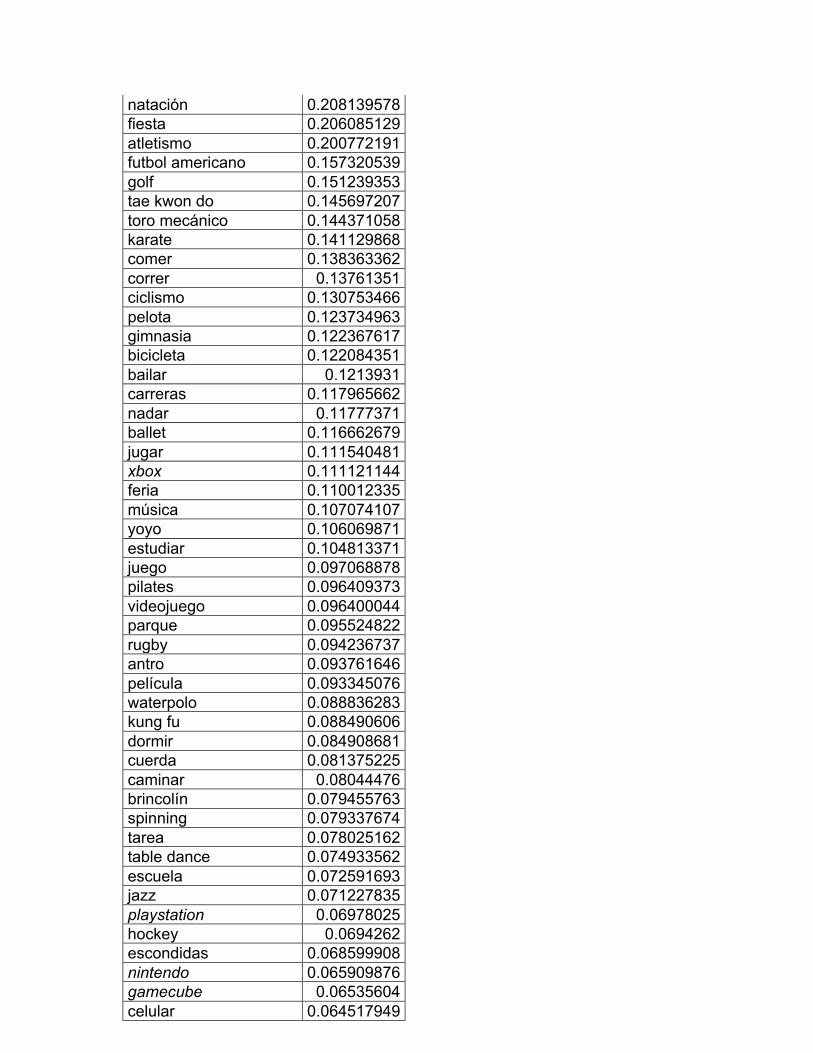
188
natación 0.208139578 fiesta 0.206085129 atletismo 0.200772191 futbol americano 0.157320539 golf 0.151239353 tae kwon do 0.145697207 toro mecánico 0.144371058 karate 0.141129868 comer 0.138363362 correr 0.13761351 ciclismo 0.130753466 pelota 0.123734963 gimnasia 0.122367617 bicicleta 0.122084351 bailar 0.1213931 carreras 0.117965662 nadar 0.11777371 ballet 0.116662679 jugar 0.111540481 xbox 0.111121144 feria 0.110012335 música 0.107074107 yoyo 0.106069871 estudiar 0.104813371 juego 0.097068878 pilates 0.096409373 videojuego 0.096400044 parque 0.095524822 rugby 0.094236737 antro 0.093761646 película 0.093345076 waterpolo 0.088836283 kung fu 0.088490606 dormir 0.084908681 cuerda 0.081375225 caminar 0.08044476 brincolín 0.079455763 spinning 0.079337674 tarea 0.078025162 table dance 0.074933562 escuela 0.072591693 jazz 0.071227835 playstation 0.06978025 hockey 0.0694262 escondidas 0.068599908 nintendo 0.065909876 gamecube 0.06535604 celular 0.064517949

189
cantar 0.064124811 Barbie 0.064110585 ver televisión 0.06399092 esquiar 0.06170193 esquí 0.061546992 montaña rusa 0.061089589 salsa 0.05689823 columpio 0.056880163 pistear 0.056393565 futbeis 0.054313617 ajedrez 0.053607003 patinaje 0.053545339 billar 0.053053448 sumo 0.050538413 chatear 0.047375876 maquinita 0.047202136 elástico 0.047130726 pasear 0.047110429 posada 0.046923177 polo 0.046708807 belly dance 0.046679462 resbaladilla 0.045123529 zumba 0.044863794 ping pong 0.044474588 boda 0.044358376 brincar 0.044136023 lucha libre 0.044082632 cíber 0.042710002 disco 0.041480707 bar 0.041056536 leer 0.039916212 sexo 0.039569776 amigo 0.038521557 lotería 0.038217855 divertido 0.038032959 box 0.037664597 quince años 0.037565518 sanguinario 0.037531894 platicar 0.037524474 yoga 0.037354793 reír 0.037304035 hip hop 0.037266924 tazos 0.037140256 equitación 0.036780562 oír música 0.035811011 brinca-brinca 0.035662291 verbena 0.035288028 juegos mecánicos 0.033985076

190
arquería 0.032530789 pelear 0.032357594 ipod 0.032277263 softbol 0.031954216 juego de mesa 0.031741863 tango 0.03151074 saltar 0.03125664 surf 0.031023487 patineta 0.030684858 tomar 0.030274785 patinar 0.030085754 oler 0.029616936 patines 0.029530865 viaje 0.02908201 baraja 0.028275801 cartas 0.028111393 escalar 0.028111393 ir de compras 0.028057468 dominó 0.027512288 enfadar 0.027431692 judo 0.027286044 juego de video 0.026380826 muñecas 0.026126759 baile 0.025780665 ligar 0.02573256 teléfono 0.025381343 centro comercial 0.025057544 alpinismo 0.02494782 kermés 0.024750831 lanzamiento de bala 0.024380151 super bowl 0.024068923 lanzamiento de jabalina 0.024009585 radio 0.023939273 aerobics 0.023904143 trampolín 0.023601244 dibujar 0.023487827 lanzamiento de disco 0.023463265 internet 0.023057071 salir 0.022830056 danza 0.022713651 kick boxing 0.022699875 manejar 0.02175899 carro 0.021621172 recreo 0.020960453 chat 0.020833333 danza del vientre 0.020833333 futbol sóccer 0.020833333 gimnasio 0.020833333
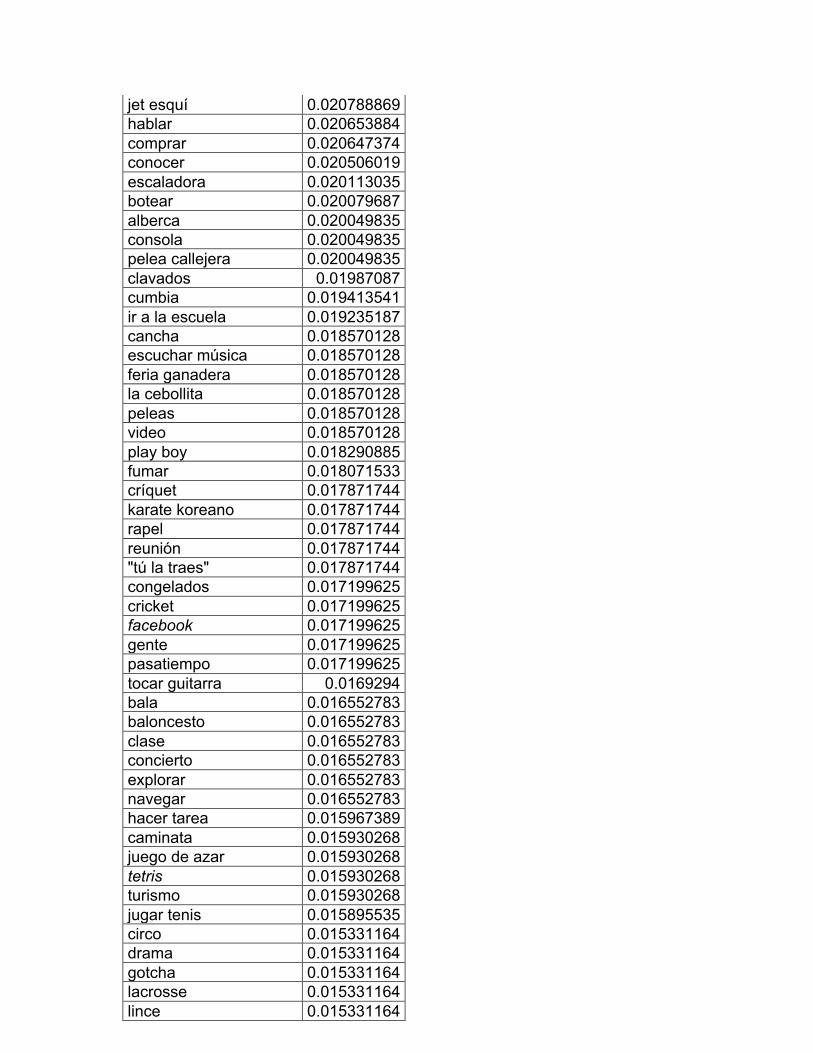
191
jet esquí 0.020788869 hablar 0.020653884 comprar 0.020647374 conocer 0.020506019 escaladora 0.020113035 botear 0.020079687 alberca 0.020049835 consola 0.020049835 pelea callejera 0.020049835 clavados 0.01987087 cumbia 0.019413541 ir a la escuela 0.019235187 cancha 0.018570128 escuchar música 0.018570128 feria ganadera 0.018570128 la cebollita 0.018570128 peleas 0.018570128 video 0.018570128 play boy 0.018290885 fumar 0.018071533 críquet 0.017871744 karate koreano 0.017871744 rapel 0.017871744 reunión 0.017871744 "tú la traes" 0.017871744 congelados 0.017199625 cricket 0.017199625 facebook 0.017199625 gente 0.017199625 pasatiempo 0.017199625 tocar guitarra 0.0169294 bala 0.016552783 baloncesto 0.016552783 clase 0.016552783 concierto 0.016552783 explorar 0.016552783 navegar 0.016552783 hacer tarea 0.015967389 caminata 0.015930268 juego de azar 0.015930268 tetris 0.015930268 turismo 0.015930268 jugar tenis 0.015895535 circo 0.015331164 drama 0.015331164 gotcha 0.015331164 lacrosse 0.015331164 lince 0.015331164

192
chiste 0.015091989 calcetín 0.014754591 discoteca 0.014754591 gameboy 0.014754591 vuelta 0.014754591 x box 0.014754591 fajar 0.014338756 navidad 0.014338756 cumpleaños 0.014337659 gritar 0.014254928 discovery 0.014199701 caricaturas 0.014199701 carritos 0.014199701 chistes 0.014199701 estudio 0.014199701 iphone 0.014199701 navegar en internet 0.014199701 novio 0.014199701 pop 0.014199701 deporte 0.01366568 novelas 0.01366568 ouija 0.01366568 patín 0.01366568 snowboard 0.01366568 bogies 0.013298766 anécdotas 0.013151743 balero 0.013151743 cagar 0.013151743 carreras de carros 0.013151743 carros 0.013151743 enfadar al perro 0.013151743 laptop 0.013151743 mp3 0.013151743 pasamanos 0.013151743 amigos 0.012657133 carreras de caballos 0.012657133 cocer 0.012657133 lucha grecorromana 0.012657133 skateboard 0.012657133 tocada 0.012657133 camión 0.012317298 agua 0.012181125 dardo 0.012181125 leer revistas 0.012181125 pesas 0.012181125 teatro 0.012181125 viajar 0.012181125 club 0.011723018

193
cuete 0.011723018 danza árabe 0.011723018 fin de semana 0.011723018 salir con amigas 0.011723018 jalar 0.011326019 belly dance 0.01128214 globo 0.01128214 golpear 0.01128214 ir al mar 0.01128214 peleaditas 0.01128214 viernes 0.01128214 alcohol 0.010857842 boxing 0.010857842 chismear 0.010857842 coger 0.010857842 contar chistes 0.010857842 estéreo 0.010857842 foto 0.010857842 picnic 0.010857842 sol y hielo 0.010857842 sube y baja 0.010857842 trineo 0.010857842 jugar nintendo 0.010449501 martillo 0.010449501 trotar 0.010449501 auto 0.010056518 banda 0.010056518 columpios 0.010056518 ir al campo 0.010056518 masturbarse 0.010056518 raquetbol 0.010056518 alegría 0.009678313 clavado 0.009678313 hacer ejercicio 0.009678313 limusina 0.009678313 patinaje sobre hielo 0.009678313 pornografía 0.009678313 reguetón 0.009678313 tapete 0.009678313 usar la computadora 0.009678313 futbolito 0.009314332 juego del pulpo 0.009314332 motocicleta 0.009314332 pedo 0.009314332 subir 0.009314332 tranca palanca 0.009314332 samba 0.009314332 ir al gimnasio 0.008964039

194
jiu jit su 0.008964039 kendo 0.008964039 mini soccer 0.008964039 patinaje en hielo 0.008964039 ratear 0.008964039 short 0.008964039 ver películas 0.008964039 besar 0.008939885 aprender 0.00862692 bañarse en la alberca 0.00862692 esgrima 0.00862692 mambo 0.00862692 personaje 0.00862692 playera 0.00862692 rock 0.00862692 tontería 0.00862692 descansar 0.00830248 payaso 0.00830248 risa 0.00830248 rock and roll 0.00830248 salir con amigos 0.00830248 tenis de mesa 0.00830248 tennis 0.00830248 tocar piano 0.00830248 amiga 0.007990241 jugar futbolito 0.007990241 kickbox 0.007990241 punk 0.007990241 recuerdo 0.007990241 tocar acordeón 0.007990241 tocar violín 0.007990241 bungee 0.007689745 chicle 0.007689745 doble salto 0.007689745 frontón 0.007689745 gritarle a las personas 0.007689745 hacer pesas 0.007689745 música norteña 0.007689745 ocio 0.007689745 verano 0.007689745 casino 0.00740055 cenar 0.00740055 pintar 0.00740055 salto de longitud 0.00740055 zoológico 0.00740055 contestar 0.00712223 felicidad 0.00712223 guerra 0.00712223

195
lucha 0.00712223 mensajear 0.00712223 restaurante 0.00712223 tocar teclado 0.00712223 volibol de playa 0.00712223 contar 0.006854378 emoción 0.006854378 nieve 0.006854378 pegar 0.006854378 kermesse 0.006596599 bautismo 0.006348515 hablar por teléfono 0.006348515 año nuevo 0.006109761 calle 0.006109761 fogata 0.006109761 libros 0.006109761 mirar 0.006109761 playa 0.006109761 observar 0.005879985 primera comunión 0.005879985 amar 0.005658851 bajar música 0.005658851 bola 0.005658851 levantamiento 0.005658851 planchar 0.005658851 balón 0.005446034 relaciones 0.005446034 tocar 0.005446034 cuidar 0.00524122 peda 0.00524122 quemados 0.00524122 aniversario 0.005044109 pinball 0.005044109 recordar 0.005044109 cuatrimoto 0.00485441 tatami 0.004671846 cojín 0.004496148 gritarle a la gente 0.004164325 taquete 0.004164325 vodka 0.004164325 artista 0.004007714 cama 0.00357234 colorear 0.003308696 personas 0.002530004 piñata 0.002170348 dulce 0.002088726
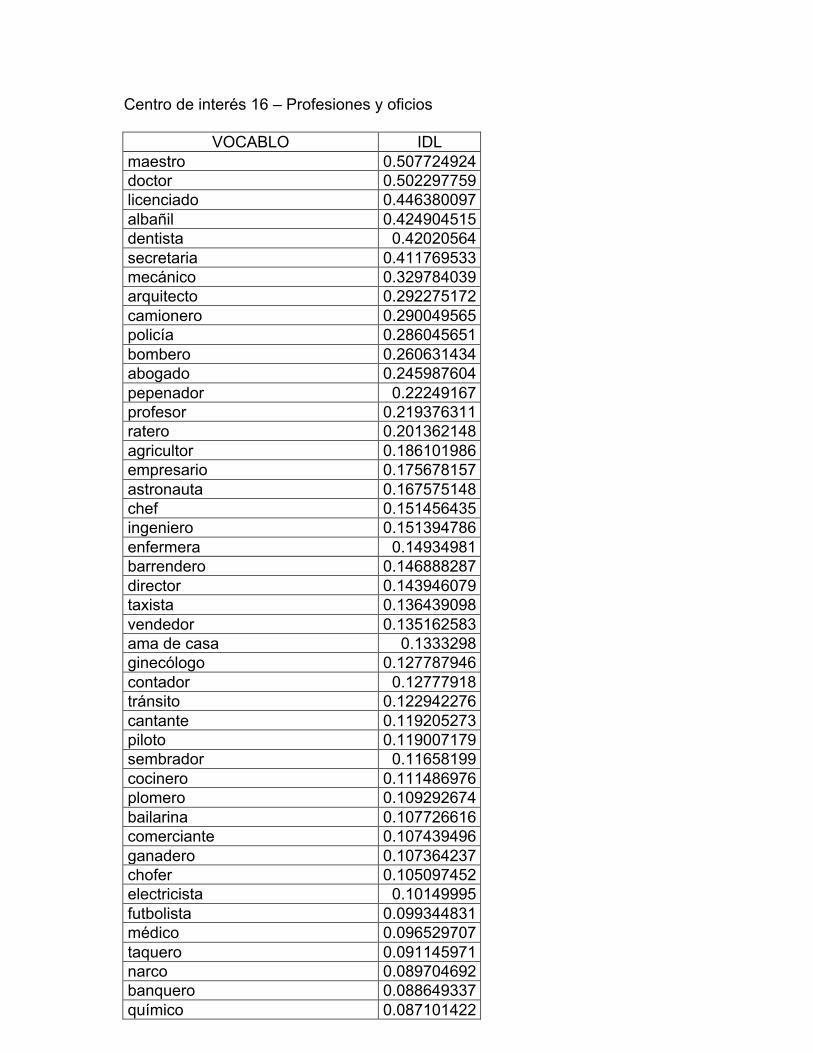
196
Centro de interés 16 – Profesiones y oficios
VOCABLO IDL maestro 0.507724924 doctor 0.502297759 licenciado 0.446380097 albañil 0.424904515 dentista 0.42020564 secretaria 0.411769533 mecánico 0.329784039 arquitecto 0.292275172 camionero 0.290049565 policía 0.286045651 bombero 0.260631434 abogado 0.245987604 pepenador 0.22249167 profesor 0.219376311 ratero 0.201362148 agricultor 0.186101986 empresario 0.175678157 astronauta 0.167575148 chef 0.151456435 ingeniero 0.151394786 enfermera 0.14934981 barrendero 0.146888287 director 0.143946079 taxista 0.136439098 vendedor 0.135162583 ama de casa 0.1333298 ginecólogo 0.127787946 contador 0.12777918 tránsito 0.122942276 cantante 0.119205273 piloto 0.119007179 sembrador 0.11658199 cocinero 0.111486976 plomero 0.109292674 bailarina 0.107726616 comerciante 0.107439496 ganadero 0.107364237 chofer 0.105097452 electricista 0.10149995 futbolista 0.099344831 médico 0.096529707 taquero 0.091145971 narco 0.089704692 banquero 0.088649337 químico 0.087101422

197
prostituta 0.08416691 tamalero 0.083611692 físico 0.08053356 gerente 0.079672361 velador 0.07904776 mayordomo 0.075396188 cajero 0.073421429 otorrinolaringólogo 0.071980061 mesero 0.070842233 taibolera 0.070526755 tortillera 0.069246633 biólogo 0.069151661 científico 0.066518549 luchador 0.065470051 pintor 0.063551007 jardinero 0.063120275 pediatra 0.06087261 conserje 0.060307312 cirujano 0.060245651 carpintero 0.058913233 herrero 0.058876915 niñera 0.054857012 paquetero 0.054622204 beisbolista 0.054309255 limpiavidrios 0.053290014 astrónomo 0.05299972 sirvienta 0.052930418 diputado 0.05022427 prefecto 0.050099007 bailarín 0.049902658 matemático 0.049898706 presidente 0.049653376 garbanzo 0.048447541 gobernador 0.047485668 psicólogo 0.04708521 maquillista 0.045920351 asesino 0.043817963 diseñador 0.042006331 músico 0.041987981 camotero 0.041799523 conductor 0.0397687 tortillero 0.039134962 deportista 0.039125113 trabajo 0.038705078 cerrajero 0.037565413 limosnero 0.036975068 educadora 0.03668068 paletero 0.036139678

198
campesino 0.035703753 dermatólogo 0.035013651 nutriólogo 0.034559616 farmacéutico 0.034114991 chacha 0.03343588 botánico 0.03340226 muchacha 0.033165204 cosmonauta 0.032925286 corrupción 0.031862282 peluquero 0.031077413 estilista 0.030748857 tecnológico 0.030702386 senador 0.030344243 criminalista 0.030177832 camarero 0.029854566 secretario 0.028994777 político 0.028680543 agrónomo 0.028674164 estudiante 0.028505104 secuestrador 0.028408677 cardiólogo 0.028318391 modelo 0.028041958 hotdoguero 0.027827596 constructor 0.027701236 capitán 0.027550638 coordinador 0.02699316 neurólogo 0.026349402 arqueólogo 0.026244764 boxeador 0.026174224 actor 0.025925304 robachicos 0.025849399 biólogo marino 0.025778978 aeromoza 0.025452621 panadero 0.025239091 actriz 0.02497144 payaso 0.02497144 juez 0.024370205 jefe 0.02414203 zapatero 0.023807692 dulcero 0.023729298 subgerente 0.023216418 cocinera 0.022830056 gigoló 0.022593759 abarrotero 0.022002126 internista 0.021961317 oculista 0.021903052 costurera 0.021536554 militar 0.021383883

199
cantinero 0.021334611 aviación 0.020833333 dinero 0.020833333 limpiacalles 0.020833333 traficante 0.020833333 tenista 0.020295306 veterinario 0.019920858 medicina 0.019795273 maromero 0.019381914 narcotraficante 0.019357486 derecho 0.018808935 economista 0.018808935 ejecutivo 0.018808935 financiero 0.018808935 licenciado en contabilidad pública 0.018808935 prostitución 0.018808935 taxidermista 0.018808935 ladrón 0.017871744 mantenimiento 0.017871744 obrero 0.017871744 basquetbolista 0.017712295 administrador 0.017498553 guardaespaldas 0.017150141 accionista 0.01698125 catador de vino 0.01698125 jugador 0.01698125 pedir dinero 0.01698125 sudor 0.01698125 vendedor de chicles 0.01698125 tendero 0.016615997 tamalera 0.016445665 odontólogo 0.016318303 escritor 0.016263985 agente de viajes 0.016135127 ama de llaves 0.016135127 chofer de camión 0.016135127 corredor 0.016135127 inventor 0.016135127 mucama 0.016135127 ordeñador 0.016067823 antropólogo 0.015593517 comercio internacional 0.015331164 ganadería 0.015331164 miss 0.015331164 narcotráfico 0.015331164 carcelero 0.014712141 domador 0.014656145 criada 0.014567259

200
curandero 0.014567259 minero 0.014567259 buzo 0.013889582 escolta 0.013841418 guardia 0.013841418 mafioso 0.013841418 promotor 0.013841418 químico-biólogo 0.013841418 padre 0.013725207 físico-matemático 0.013534703 buchón 0.013151743 ciencia 0.013151743 podador 0.013151743 sirviente 0.013151743 madrugar 0.012496432 vaquero 0.012496432 viene-viene 0.012496432 marino 0.012219521 filósofo 0.011873773 fisicoculturista 0.011873773 maquilladora 0.011873773 pastor 0.011873773 show 0.011873773 supervisor 0.011873773 boleador 0.011289667 nudista 0.01128214 publicista 0.01128214 eléctrico 0.011089827 artista 0.010737336 aguador 0.010719986 cerillito 0.010185842 granjero 0.010185842 licenciado en derecho 0.010185842 mecatrónica 0.010185842 psiquiatra 0.010185842 subdirector 0.010185842 vendedor de carros 0.010185842 gomero 0.009678313 hotelero 0.009678313 ingeniero civil 0.009678313 ingeniero industrial 0.009678313 soldado 0.009662322 oficial 0.009591964 monja 0.009460136 asistente 0.009196072 basurero 0.009196072 guarura 0.009196072 guionista 0.009196072
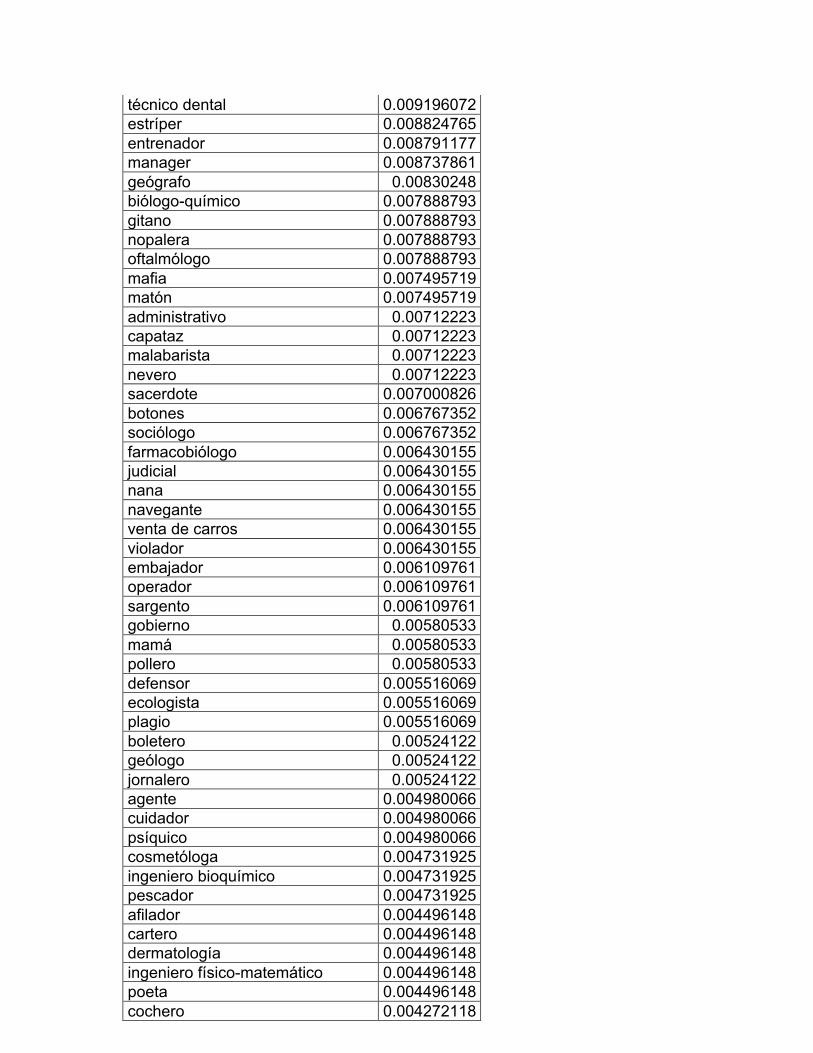
201
técnico dental 0.009196072 estríper 0.008824765 entrenador 0.008791177 manager 0.008737861 geógrafo 0.00830248 biólogo-químico 0.007888793 gitano 0.007888793 nopalera 0.007888793 oftalmólogo 0.007888793 mafia 0.007495719 matón 0.007495719 administrativo 0.00712223 capataz 0.00712223 malabarista 0.00712223 nevero 0.00712223 sacerdote 0.007000826 botones 0.006767352 sociólogo 0.006767352 farmacobiólogo 0.006430155 judicial 0.006430155 nana 0.006430155 navegante 0.006430155 venta de carros 0.006430155 violador 0.006430155 embajador 0.006109761 operador 0.006109761 sargento 0.006109761 gobierno 0.00580533 mamá 0.00580533 pollero 0.00580533 defensor 0.005516069 ecologista 0.005516069 plagio 0.005516069 boletero 0.00524122 geólogo 0.00524122 jornalero 0.00524122 agente 0.004980066 cuidador 0.004980066 psíquico 0.004980066 cosmetóloga 0.004731925 ingeniero bioquímico 0.004731925 pescador 0.004731925 afilador 0.004496148 cartero 0.004496148 dermatología 0.004496148 ingeniero físico-matemático 0.004496148 poeta 0.004496148 cochero 0.004272118

202
musa 0.004272118 cortador 0.004059252 pedicurista 0.004059252 bar tender 0.003856992 tutor 0.003856992 barman 0.00366481 intendencia 0.003482204 vigilante 0.003143834 DJ 0.002987187 agrícola 0.002838344 astrólogo 0.002838344 cadenero 0.002562539 vida galante 0.002313535 Centro de interés 17 – Computación e internet
VOCABLO IDL teclado 0.41506504 CPU 0.408768661 computadora 0.368574935 google 0.363196499 mouse 0.356337281 impresora 0.350530085 facebook 0.340434887 wikipedia 0.280059156 música 0.268288304 bocina 0.253870282 monitor 0.243229855 disco duro 0.239573613 escáner 0.231706631 messenger 0.224437085 chat 0.191416914 internet 0.186261 página web 0.167890165 laptop 0.165477471 CD 0.163851016 pantalla 0.159432286 juego 0.142727458 you tube 0.123466561 USB 0.121191798 word 0.118662392 video 0.114122098 yahoo 0.104830258 quemadora 0.099632639 cable 0.094726147 excel 0.08161251 memoria 0.081470088

203
hotmail 0.077484703 ratón 0.069020591 windows 0.062634941 power point 0.061578691 regulador 0.061037068 web 0.056789139 explorer 0.056683767 megared 0.056555221 virus 0.056460793 disquet 0.056199182 imagen 0.05571743 pornografía 0.05554142 información 0.053575745 microsoft 0.051122988 tecnología 0.047905018 disco 0.047878409 carpeta 0.046446737 documento 0.045259987 página 0.042877364 videojuego 0.042440719 megacable 0.042396927 front page 0.042262157 copiadora 0.041064158 chatear 0.039565265 red 0.038111704 software 0.037870339 hipervínculo 0.037553368 foto 0.037343095 bluetooth 0.033144145 tarea 0.032970407 ipod 0.032967574 DVD 0.032955007 chisme 0.029636355 reproductor 0.029477978 monografía 0.028554743 red inalámbrica 0.027693664 calculadora 0.027279456 cámara web 0.02697875 consola 0.026632335 escuela 0.025829227 ropa 0.02438236 foco 0.024381576 electricidad 0.02325366 e mail 0.02307858 noticia 0.02274012 acces 0.022699203 botón 0.021816886 dato 0.021607386

204
página de internet 0.020833333 secretaria 0.020833333 conversación 0.020803622 firefox 0.020645043 escritorio 0.020152699 iphone 0.020113735 escritor 0.01812261 marcador 0.01812261 wikiccionario 0.01812261 mail 0.017605393 computación 0.017470831 correo 0.017454194 memoria ram 0.017445756 audífono 0.016902531 celular 0.016902531 prodigy 0.016902531 sangría 0.016902531 investigación 0.016838044 protector de pantalla 0.016350317 módem 0.016318705 barra de inicio 0.015764592 gráfico 0.015764592 navegar 0.015764592 pantalla de plasma 0.015764592 solitario 0.014968514 PC 0.014703263 archivo 0.014703263 drama 0.014703263 internet explorer 0.014703263 rapidez 0.014703263 chip 0.014570376 office 0.014154117 eficacia 0.013713386 patineta 0.013713386 programa 0.013326134 dibujo 0.013265364 trabajo 0.01291517 estuche 0.012790152 infrarrojo 0.012790152 acceso 0.011929073 encarta 0.011929073 manual 0.011929073 marca 0.011929073 página xxx 0.011929073 cámara 0.011651227 diversión 0.011191371 flash 0.011125965 hardware 0.011125965

205
mesa 0.011125965 teclas 0.011125965 xxx 0.011125965 quemador 0.011083517 abecedario 0.010376925 reproductor de música 0.010376925 circuito 0.009678313 compra 0.009678313 linux 0.009678313 luz 0.009678313 tinta 0.009678313 virtual 0.009678313 windows vista 0.009678313 carpeta para compartir 0.009026734 fax 0.009026734 investigar 0.009026734 metro 0.009026734 tema 0.009026734 traductor 0.009026734 venta 0.009026734 windows xp 0.009026734 artista 0.008419022 drive 0.008419022 hard drive 0.008419022 película 0.008419022 servicio 0.008419022 actualización 0.007852223 amigo 0.007852223 correo electrónico 0.007852223 ipad 0.007852223 infinitum 0.007323583 memoria interna 0.007323583 cíber 0.006830533 dinero 0.006830533 librería 0.006830533 memoria externa 0.006830533 papelera de reciclaje 0.006830533 extensión 0.006370677 itunes 0.006370677 letra 0.006370677 micrófono 0.006370677 cable USB 0.00594178 cantante 0.00594178 dedo 0.00594178 encuesta 0.00594178 canción 0.005541758

206
imprimir 0.005541758 materia 0.005168667 álbum 0.005168667 estudio 0.004820694 fotografía 0.004820694 clase 0.004496148 enciclopedia 0.004496148 plática 0.004496148 borrador 0.004193451 medio tiempo 0.003911133 cine 0.003647821 moda 0.002959556 número 0.002401151
Copyright © 2022 FDOKUMEN




















