
Análisis de abilidad mediante un modelo de regresión logística
70
-
Upload
khangminh22 -
Category
Documents
-
view
6 -
download
0
Transcript of Análisis de abilidad mediante un modelo de regresión logística

Máster en Estadística Aplicada
Universidad de Granada
Análisis de �abilidad mediante unmodelo de regresión logística
Alumna: Juliana Troyano Dueñas
Tutora: María Luz Gámiz Pérez

2

Índice general
1. Análisis de estructuras 5
1.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2. Conceptos básicos . . . . . . . . . . . . . . . . . . . . . . . . . 81.3. Fiabilidad de sistemas . . . . . . . . . . . . . . . . . . . . . . 13
1.3.1. Fiabilidad de sistemas de componentes independientes 141.3.2. Cotas de �abilidad . . . . . . . . . . . . . . . . . . . . 15
1.4. Medidas de importancia de una componente . . . . . . . . . . 171.4.1. Medida de importancia estructural (Birnbaum) . . . . 171.4.2. Medida de importancia de Birnbaum sobre la �abilidad 19
1.5. Redundancia . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2. Regresión Logística (RL) 23
2.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.2. Modelo de regresión con respuesta binaria . . . . . . . . . . . 24
2.2.1. Interpretación de los coe�cientes . . . . . . . . . . . . . 272.2.2. Estimación de los parámetros del modelo . . . . . . . . 28
2.3. Evaluación del modelo . . . . . . . . . . . . . . . . . . . . . . 292.3.1. Estudio de la bondad de ajuste . . . . . . . . . . . . . 292.3.2. Tests de signi�cación de los coe�cientes . . . . . . . . . 322.3.3. Análisis de la capacidad predictiva del modelo . . . . . 34
2.4. Regresión logística múltiple . . . . . . . . . . . . . . . . . . . 352.4.1. Interpretación de los coe�cientes . . . . . . . . . . . . . 362.4.2. Contrastes de signi�cación del modelo . . . . . . . . . 38
3. Análisis de estructuras mediante RL 41
3.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 413.2. Modelo de RL basado en una variable latente . . . . . . . . . 443.3. RL monótona para estimar la �abilidad . . . . . . . . . . . . . 463.4. Medida de importancia de Birnbaum (IB) . . . . . . . . . . . 493.5. Simulaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
3

4 ÍNDICE GENERAL
4. Modelo de regresión logística local 614.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . 614.2. Modelo de Probabilidad Local . . . . . . . . . . . . . . . . . . 614.3. RL local de la función de �abilidad de un sistema continuo . . 65

Capítulo 1
Análisis de estructuras
1.1. Introducción
En un mundo donde la tecnología avanza a pasos agigantados y don-
de nuestra vida cotidiana depende en gran medida y, día a día más, del
buen funcionamiento de mecanismos que se encargan de realizar determina-
das operaciones imprescindibles para nuestro bienestar, resulta fundamental
un conocimiento previo de la "�abilidad"de tales mecanismos.
Este hecho hace que paralelo al desarrollo tecnológico se produzca el desa-
rrollo de una ciencia que se encarga de cuanti�car los efectos que tendrá en
el futuro la incertidumbre en cuanto al éxito del funcionamiento de un me-
canismo o, en general del desarrollo de una operación. Así, se ha ido creando
una base teórica sobre fundamentos probabilísticos y estadísticos a la que
nos referimos como Teoría de Fiabilidad (ver Barlow y Proschan (1975) y
Modarres, M., Kaminskiy, M. and Krivtsov, V. (2010)).
La Teoría de la Fiabilidad experimentó un avance muy importante en la
Segunda Guerra Mundial. Desde entonces, ninguna otra rama de la ciencia
de ingeniería, a excepción de la tecnología informática y la ingeniería ambien-
tal, ha desarrollado y avanzado tan rápido como la ingeniería de �abilidad.
Este área se ha desarrollado para satisfacer las necesidades de la tecnología
moderna, particularmente en electrónica, comunicación, redes informáticas y
de transporte, sistemas de control, aviación, tecnología espacial entre otros.
El desarrollo tecnológico en estas áreas ha dado como resultado la creación
5

6 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
de una enorme variedad de dispositivos complejos, so�sticados y automati-
zados. La mayoría de estos dispositivos no son baratos, y nuestra con�anza
en ellos es cada vez mayor. Por lo tanto, existe una creciente necesidad de
dispositivos de alta �abilidad, particularmente en áreas en las que los costes
de sustitución son excesivamente altos. Cuando el fallo de un dispositivo au-
menta el coste y/o amenaza seriamente la seguridad pública, el usuario exige
determinado grado de con�anza de que el dispositivo que utiliza sea e�ciente.
En particular, los sistemas de alto riesgo, como las centrales nucleares y algu-
nas plantas químicas, requieren una seguridad operacional de primer orden.
Pero incluso los productores de objetos cotidianos como electrodomésticos o
teléfonos móviles tienen que tener en cuenta aspectos de �abilidad y calidad
del producto, o no tendrán una salida comercial adecuada.
Es por eso que en cualquier diseño de ingeniería, la �abilidad es un factor
clave. En todas las normas internacionales, la �abilidad de un mecanismo se
de�ne esencialmente como su idoneidad para llevar a cabo adecuadamente
su propósito de�nido en condiciones de funcionamiento especi�cadas durante
un intervalo de tiempo determinado. La teoría de �abilidad se entiende por
tanto como la ciencia de predecir y estimar la probabilidad de supervivencia,
la vida media, o, en general, la distribución del tiempo de vida de un sistema.
Desafortunadamente, este concepto de �abilidad de un sistema no es fá-
cilmente cuanti�cable. Usualmente se describe en términos de la probabilidad
de supervivencia del sistema, es decir, la probabilidad de que el sistema sea
capaz de hacer su trabajo cuando sea necesario.
El problema de determinar la �abilidad de un sistema complejo (más de
500 componentes) a partir de las �abilidades de sus componentes pertenece
desde el punto de vista computacional a los problemas más difíciles (Mteza,
2014). Con un número creciente de componentes, el tiempo de cálculo para
determinar la �abilidad del sistema a partir de la �abilidad de sus compo-
nentes generalmente aumenta exponencialmente. Por lo tanto, los algoritmos
para determinar �abilidad exacta del sistema pueden requerir un cómputo
sustancial incluso con la ayuda del ordenador más actualizado.

1.1. INTRODUCCIÓN 7
En esta memoria, entendemos por sistema una con�guración dada, des-
tinada a cumplir determinada misión, es decir una serie de bloques interco-
nectados de tal forma que desempeñan un conjunto de funciones requeridas.
Nuestro objetivo consiste en indicar cómo derivar modelos analíticos para el
funcionamiento de un sistema.
En primer lugar aclaramos que por sistema o estructura entendemos una
colección de elementos, llamados componentes, ordenados según un diseño
especí�co con el objetivo de cumplir determinadas funciones.
Se dice que la �abilidad de un sistema es la capacidad de dicho sistema
para llevar a cabo una determinada función, bajo unas condiciones experi-
mentales dadas y durante un cierto período de tiempo.
Debemos tener presente que la Teoría de la Fiabilidad pretende calcular
las medidas del rendimiento de un sistema, procedimiento para el que resulta
esencial tener clara la descomposición en unidades más simples del sistema
que estamos considerando.
Por tanto, el principal objetivo de este primer capítulo será calcular la
función de estructura, que determina el estado del sistema como una función
de los estados de sus componentes. En los siguientes apartados construire-
mos modelos que representen el funcionamiento de un sistema basado en el
funcionamiento de sus componentes.
En cuanto al número de unidades que componen el sistema, dependerá
de la información disponible acerca del sistema, pero también debemos te-
ner en cuenta que considerar un gran número de componentes aumentará la
complejidad de la función de estructura.
Otro aspecto elemental son las relaciones lógicas entre las componentes
del sistema y con el sistema. En principio suponemos que las componentes
funcionan de forma independiente. Además, la repercusión de cada unidad

8 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
en el sistema dependerá de cada estructura, y queda plasmada en la función
de estructura.
Para llevar a cabo el análisis consideramos un sistema en un instante
de tiempo �jo t, es decir, el estado actual del sistema viene dado por los
estados actuales de sus componentes, sin tener en cuenta la evolución de las
componentes, y por tanto del sistema, en el tiempo.
1.2. Conceptos básicos
Empezamos considerando lo que vamos a llamar sistemas y componentes
binarias, es decir, tanto para el sistema como para sus componentes distingui-
mos entre estado de funcionamiento y estado de fallo. Para indicar el estado
de la i-ésima componente del sistema, utilizamos la variable xi
xi =
{0 si la componente i-ésima falla1 si la componente i-ésima funciona
para i = 1, 2, ..., n, siendo n el número de componentes, al que llamaremos
orden del sistema. Así, el vector estado del sistema es x = (x1, x2, ..., xm) y
el número de posibilidades para este vector es 2m.
De forma análoga, asignamos la variable φ para indicar el estado del
sistema
φ =
{0 si el sistema falla1 si el sistema funciona
La función φ depende del vector estado del sistema, φ = φ(x), y se denomina
función de estructura del sistema.
Ejemplo. Sistema en serie
Sea un sistema de orden 2, diremos que está en serie en el caso de que
funcione si las dos componentes funcionan. Veamos los posibles estados de
las componentes y el valor de la función estructura en cada suceso

1.2. CONCEPTOS BÁSICOS 9
x1 x2 φ(x1, x2)0 0 00 1 01 0 01 1 1
Por tanto, la función de estructura, cuya expresión algeraica no es única, se
puede expresar como
φ(x) = min{x1, x2}
o equivalentemente, como los únicos valores posibles para el vector estado
son 0 y 1,
φ(x) = x1 · x2
Si generalizamos este resultado para un sistema con m componentes, la fun-
ción de estructura vendría dada por la siguiente expresión
φ(x) = min{x1, x2, .., xm}
o
φ(x) =m∏i=1
xi
Ejemplo. Sistema en paralelo
Si consideramos un sistema con dos componentes, diremos que está en
paralelo si funciona siempre que alguna de las dos componentes funcione. Así,
los posibles estados de las componentes y el valor de la función de estructura
en cada caso son los siguientes
φ(x) = max{x1, x2}
o equivalentemente, como la variable xi puede tomar únicamente los valores
0 y 1
φ(x) = 1− (1− x1)(1− x2)

10 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
x1 x2 φ(x1, x2)0 0 00 1 11 0 11 1 1
Generalizando para un sistema de orden m, se tiene la siguiente expresión de
la función de estructura
φ(x) = max{x1, x2, ..., xm}
o
φ(x) = 1−m∏i=1
(1− xi) =m∐i=1
xi
Ejemplo. Sistema k/m
Un sistema k/m es aquel que funciona siempre que funcionen al menos
k componentes, con 1 ≤ k ≤ m. La función de estructura de este sistema se
puede expresar de la forma
φ(x) =
{0 si x · 1 < k1 si x · 1 ≥ k
donde 1 = (1, 1, ..., 1)′ ∈ Rm.
Cabe destacar dos casos particulares, un sistema m/m es un sistema en
serie, y un sistema 1/m es un sistema en paralelo.
De�nición. Componente irrelevante
Una componente i se dice irrelevante al sistema si la función de estructura
es constante en xi, es decir, el sistema funciona o falla independientemente
del estado de la componente i-ésima. En otro caso, la componente será rele-
vante.

1.2. CONCEPTOS BÁSICOS 11
De�nición. Sistema monótono
Se dice que un sistema es monótono si se veri�ca que:
i. φ(0, ..., 0) = 0 y φ(1, ..., 1) = 1
ii. φ(x) ≤ φ(y) para x < y
De forma que un sistema monótono funciona si todas sus componentes están
operativas y falla si todas sus componentes han fallado. Además, en este tipo
de sistemas, si alguna de las componentes ha sido mejorada, el estado del
sistema no puede empeorar.
De�nición. Sistema coherente
Un sistema se denomina coherente si es monótono y no tiene componentes
irrelevantes.
Los sistema en serie, los sistemas en paralelo y los sistemas k/n son ejemplos
de sistemas coherentes.
De�nición. Sistema dual
Sea un sistema con función de estructura φ, se de�ne su dual como el
sistema que tiene la siguiente función de estructura
φD(x) = 1− φ(1− x)
Ejemplos de estructuras duales son los sistemas en serie y los sistemas en
paralelo.
De�nición. Módulo de un sistema
Se denominan módulos a los subsistemas en los que se puede dividir un
sistema para hacer más sencillo el análisis de su �abilidad. Cada módulo se
comporta como una componente y la función de estructura del sistema se
puede obtener como sigue.

12 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
Sea S = {1, 2, ...,m} un sistema de orden m, consideramos una partición:
S =r⋃i=1
Mi, con Mi ∩Mj = ∅, para i 6= j. Sea φi(xMi) una función binaria
monótona de�nida sobre xMi = (xj; j ∈Mi), que vale 0 si el módulo Mi falla
y 1 si funciona. La función de estructura del sistema queda como
φ(x) = s(φ1(xM1), φ2(x
M2), ..., φr(xMr))
donde s es la función organizadora de la estructura del sistema.
Un ejemplo es el siguiente sistema
Cuya función de estructura es
φ(x) = max {x5,min {x1, x4,max {x2, x3}}}
De�nición. Vector camino
Se dice que un vector estado x es un vector camino si su conformación
conlleva el funcionamiento del sistema, es decir, si φ(x) = 1. El conjunto
de componentes activas en un vector camino se denomina conjunto camino,
A(x). Si φ(y) = 0 para todo y < x, x es un vector camino minimal y A(x),
llamado conjunto camino minimal, simboliza el menor conjunto de compo-
nentes cuyo funcionamiento garantiza que el sistema funcione.

1.3. FIABILIDAD DE SISTEMAS 13
Según esto, cualquier sistema coherente binario se puede representar me-
diante un conjunto de sistemas en serie, cada uno formado por un conjunto
camino minimal, dispuestos en paralelo. Esto es,
φ(x) =m∐j=1
∏i∈Aj
xi
donde Aj con j = 1, ...,m son los conjuntos camino minimales del sistema.
De�nición. Vector de corte
Se dice que un vector estado x es un vector de corte si su conformación
implica que el sistema falle, es decir, si φ(x) = 0. El conjunto de componen-
tes inactivas en un vector de corte se denomina conjunto de corte, C(x). Si
φ(y) = 1 para todo y > x, x es un vector de corte minimal y C(x), llamado
conjunto de corte minimal, simboliza el menor conjunto de elementos cuyo
fallo provoca que el sistema falle.
Por tanto, cualquier sistema coherente binario se puede representar me-
diante un conjunto de sistemas en paralelo, cada uno formado por un conjunto
de corte minimal, dispuestos en serie. Esto es,
φ(x) =r∏
k=1
∐l∈Ck
xl
donde Ck con k = 1, ..., r son los conjuntos de corte minimales del sistema.
1.3. Fiabilidad de sistemas
En esta sección suponemos que el estado de cada componente es una
variable aleatoria X, binaria que describiremos más adelante. Así, vincula-
remos la �abilidad de un sistema con la �abilidad de las componentes que
lo forman. Para los casos que sea posible analizaremos procedimientos para
obtener la �abilidad del sistema de forma exacta, pero en ocasiones ésto re-
sulta imposible. Para calcular la �abilidad de estos sistemas se suelen buscar
cotas en términos de los caminos y cortes minimales.

14 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
1.3.1. Fiabilidad de sistemas de componentes indepen-dientes
Sea Xi el estado de la i-ésima componente del sistema, esta variable to-
mará el valor 0 cuando dicha componente falle y el valor 1 cuando esté en
funcionamiento. Esto es, Xi B(pi)
Xi =
{0 con probabilidad 1− pi1 con probabilidad pi
donde pi es la �abilidad de la componente i-ésima.
De�nición. Fiabilidad del sistema, R
Sea un sistema con vector estado aleatorio X = (X1, ..., Xn) y función de
estructura φ(X) = φ(X1, ..., Xn), se de�ne la �abilidad del sistema, R, como
la probabilidad de que φ(X) = 1, es decir
R = P [φ(X) = 1] = E[φ(X)]
En el caso de que las componentes del sistema sean independientes, la �abi-
lidad estará totalmente determinada por las �abilidades de las componentes,
es decir
R = R(p1, ..., pn)
Ejemplo. Sistema en serie
Para calcular la función de �abilidad de un sistema en serie, consideramos
la esperanza de la función de estructura de dicho sistema, obteniendo la
siguiente expresión
R(p) = E
[m∏i=1
Xi
]=
m∏i=1
E[Xi] =m∏i=1
pi
Siendo R ≤ pi ya que pi ≤ 1 para todo i. Por tanto, la �abilidad de un
sistema en serie es siempre menor que la �abilidad de cada una de sus com-
ponentes.

1.3. FIABILIDAD DE SISTEMAS 15
Ejemplo. Sistema en paralelo
Procediendo de forma análoga al ejemplo anterior, pero en este caso con
la función de estructura de un sistema en paralelo, obtenemos que la función
de �abilidad de estos sistemas es de la forma
R(p) = E
[1−
m∏i=1
(1−Xi)
]= 1−
m∏i=1
E[1−Xi] = 1−m∏i=1
(1− pi)
Como pi ≤ 1, se tiene que, para todo i, R ≥ pi, por lo que la �abilidad de un
sistema dispuesto en paralelo es mayor que la �abilidad de sus componentes.
Ejemplo. Sistema k/m
Consideramos un sistema k/m con componentes idénticas, cuyas �abili-
dades son pi = p, para todo i. La función de �abilidad de este sistema tiene
la siguiente expresión
R(p) =m∑r=k
(m
r
)pr(1− p)m−r
De forma que cuanto más �ables sean las componentes de un sistema monó-
tono mayor es la �abilidad de dicho sistema.
Normalmente los sistemas no son tan sencillos. Es por ello que existen
distintas estrategias para simpli�car el cálculo de la función de �abilidad de
un sistema. Entre otras se puede emplear la descomposición pivotal o restrin-
gir el cálculo de la �abilidad del sistema a los vectores estado que sean camino.
1.3.2. Cotas de �abilidad
A pesar de contar con estrategias que nos facilitan el cálculo de la �abi-
lidad de un sistema, a veces esta labor resulta difícil en sistemas complejos.
Por una parte debemos encontrar todos los conjuntos de corte minimales, lo
cual podemos resolver utilizando el algoritmo del árbol de fallo. Por otra par-
te nos encontramos con el problema de representar la función de estructura

16 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
mediante la suma de productos de Xi, para así poder aplicar la esperanza a
cada sumando.
Suponemos que tenemos todos los conjuntos de corte minimales, entonces
sólo faltaría suprimir las repeticiones de las variables Xi para simpli�car la
expresión de la función de estructura y aplicar el operador esperanza. Pero
estos cálculos son complicados por lo que nos conformamos con aproxima-
ciones basadas en los conjuntos camino y de corte que acotan el valor de la
�abilidad del sistema.
Cota superior
Sean conocidos todos los conjuntos camino minimales, Ai, i = 1, ...,m,
el sistema es equivalente a una estructura en paralelo formada por sub-
sistemas en los que las componentes están dispuestas en serie y forman
un conjunto camino.
Así, la �abilidad del sistema queda acotada superiormente como sigue
R(p) ≤m∐j=1
∏i∈Aj
pi
Cota inferior
Análogamente, sean Ci, con i = 1, ..., r los conjuntos de corte del siste-
ma, éste es equivalente a una estructura en serie en la que cada elemento
es un subsistema formado por componentes de un conjunto de corte dis-
puestas en paralelo.
De esta forma, la cota inferior de la �abilidad viene dada por la siguiente
expresión
r∏h=1
∐q∈Ch
pq ≤ R(p)

1.4. MEDIDAS DE IMPORTANCIA DE UNA COMPONENTE 17
1.4. Medidas de importancia de una compo-
nente
En una estructura de �abilidad no todas las componentes son igual de
importantes a la hora de causar el fallo del sistema. Conocerla es importante
en ingeniería de �abilidad.
Podemos encontrar distintas formas de medir la importancia de una compo-
nente. Este aspecto depende de dos factores principalmente:
La ubicación de la componente en el sistema.
El valor de la �abilidad de la componente.
Sea un sistema conm componentes, pi la �abilidad de su componente i-ésima,
para todo i = 1, ..., n y sea R(p) = (p1, ..., pn) la función de �abilidad del
sistema, algunas medidas que aportan información sobre la importancia de
las componentes son
medida de importancia de Birnbaum;
medida de importancia crítica;
medida de capacidad de mejora;
La medida de importancia de Birnbaum y la de capacidad de mejora son las
más útiles si pretendemos localizar la componente que debería ser mejora-
da. Sin embargo, si nuestra intención es encontrar la componente con mayor
probabilidad de causar el fallo del sistema, debemos emplear la medida de
importancia crítica.
Nos centraremos en la medida de importancia de Birnbaum por su fácil
interpretabilidad práctica por encima de las otras dos. Podemos enfocar el
problema desde dos puntos de vista:
1.4.1. Medida de importancia estructural (Birnbaum)
Como hemos dicho previamente, en un sistema algunas componentes pue-
den jugar un papel más importante que otras. Es por ello que resulta de gran

18 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
interés conocer cómo cada componente contribuye al funcionamiento del sis-
tema. Birnbaum (1969) fue el primero en cuanti�car esta importancia.
Hay situaciones en las que sólo se conoce la función de estructura φ(x)
del sistema, pero no se tiene información acerca de las �abilidades de las
componentes. En estos casos la importancia relativa de varias componentes
se denomina importancia estructural.
De�nición. Importancia estructural
La importancia estructural de la componente con estado xi para el
funcionamiento del sistema viene dada por
I(B)i (φ, 1) = 2−m
∑x∈Vm
(1− xi)[φ(1i, x)− φ(0i, x)]
donde Vm representa el conjunto de estados: Vm = {x = (x1, ..., xn)} deforma que card(Vm) = 2m.
La importancia estructural de la componente con estado xi para el fallo
del sistema viene dada como
I(B)i (φ, 0) = 2−m
∑x∈Vm
xi[φ(1i, x)− φ(0i, x)]
La importancia estructural de la componente con estado xi para el
sistema viene dada por la siguiente expresión
I(B)i (φ) = I
(B)i (φ, 1) + I
(B)i (φ, 0) =
= 2−m∑x∈Vm
[φ(1i, x)− φ(0i, x)]
Teorema. Birnbaum (1969)
Para cualquier sistema coherente se veri�ca
I(B)i (φ, 1) = I
(B)i (φ, 0) =
1
2I(B)i (φ)

1.4. MEDIDAS DE IMPORTANCIA DE UNA COMPONENTE 19
Este teorema mani�esta que no resulta demasiado útil distinguir entre im-
portancia estructural para el funcionamiento y para el fallo del sistema. No
ocurre lo mismo para la importancia sobre la �abilidad, como veremos en la
siguiente sección.
1.4.2. Medida de importancia de Birnbaum sobre la �a-bilidad
En las situaciones en las que tanto la función de estructura φ(x) del siste-
ma como las �abilidades pi de las componentes son conocidas, la importancia
de las componentes se denomina importancia sobre la �abilidad.
De�nición. Importancia sobre la �abilidad
La importancia sobre la �abilidad de la componente xi para el funcio-
namiento del sistema es
RI(B)i (φ, 1, p) = P [φ(x) = 1|xi = 1]− P [φ(x) = 1]
La importancia sobre la �abilidad de la componente xi para el fallo del
sistema es
RI(B)i (φ, 0, p) = P [φ(x) = 0|xi = 0]− P [φ(x) = 0]
La importancia sobre la �abilidad de la componente xi para el sistema
es
RI(B)i (φ, p) = RI
(B)i (φ, 1, p) +RI
(B)i (φ, 0, p)
Cuanto mayor sea el valor de la importancia de la �abilidad de un compo-
nente, más peso tendrá la componente en dicho sistema.
Corolario 1. Birnbaum (1969)
Para cualquier función de estructura se veri�ca
cov[xi, φ(x)] = piqiE[φ(1i, x)− φ(0i, x)]

20 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS
Corolario 2. Birnbaum (1969)
Las siguientes identidades son siempre ciertas
RI(B)i (φ, 1, p) = qiE[φ(1i, x)− φ(0i, x)] = qi
∂R(p)
∂pi
RI(B)i (φ, 0, p) = piE[φ(1i, x)− φ(0i, x)] = pi
∂R(p)
∂pi
RI(B)i (φ, p) = E[φ(1i, x)− φ(0i, x)] =
∂R(p)
∂pi
Ejemplo. Sistema en serie
Sea la función de �abilidad de un sistema en serie
R(p) =n∏k=1
pk
La medida de importancia sobre la �abilidad de Birnbaum viene dada por
RI(B)i (φ, p) =
∂R(p)
∂pi=
n∏k=1,k 6=i
pk
De forma que la componente con menor �abilidad es la que tiene mayor im-
portancia.
Ejemplo. Sistema en paralelo
Sea la función de �abilidad de un sistema en paralelo
R(p) = 1−n∏k=1
(1− pk)
La medida de importancia sobre la �abilidad de Birnbaum viene dada por
RI(B)i (φ, p) =
∂R(p)
∂pi=
n∏k=1,k 6=i
(1− pk)
Esto es, la componente con máxima �abilidad es la que tiene mayor impor-
tancia.

1.5. REDUNDANCIA 21
De�nición. Equivalencia entre la importancia estructural y de
�abilidad de Birnbaum
La importancia estructural y de �abilidad de Birnbaum son equivalen-
tes en todos los sentidos si p1 = p2 = · · · = pn, es decir, ambas medidas
determinan de igual forma la importancia de las componentes del sistema.
1.5. Redundancia
Una forma de aumentar la �abilidad de un sistema es incluir redundancia
en los puestos críticos del sistema, esto es, introducir unidades de reserva.
Se dice que hay redundancia activa si la unidad principal es sustituida
por dos o más componentes dispuestas en paralelo. Además, las unidades
que están en reserva pueden permanecer en standby, esto es, se mantienen
inactivas hasta que la componente operativa falla. Diremos que en un sistema
se ha introducido redundancia pasiva si las unidades en reserva garantizan
el funcionamiento del sistema durante el período de inactividad. Finalmente,
hablamos de redundancia parcialmente cargada cuando hay posibilidad de
que el sistema falle durante el período de inactividad. No trataremos este
tipo de estructura (redundancia pasiva) en esta memoria.

22 CAPÍTULO 1. ANÁLISIS DE ESTRUCTURAS

Capítulo 2
Regresión Logística (RL)
2.1. Introducción
Como hemos explicado en el capítulo anterior, en teoría de �abilidad, el
estado del sistema se expresa por medio de la función de estructura a partir
de los estados de sus componentes. Esta función se considera usualmente
como una relación determinística, de modo que conocido el estado de las
componentes y conocida la estructura del sistema, se puede determinar con
certeza si el sistema está en funcionamiento o fallo.
Ya hemos visto en el capítulo anterior que determinar la función de es-
tructura de un sistema es una tarea difícil y la di�cultad crece debido al
incremento de la complejidad de los sistemas en ingeniería. A esto se une que
el hecho de que el comportamiento de todos los factores que in�uyen en el
rendimiento del sistema puede no estar bajo control de modo que el estado
del sistema puede no ser por tanto especi�cado teniendo en cuenta única-
mente el vector de estado (ver Gámiz et al. (2011)). En consecuencia, resulta
conveniente tener en cuenta una componente de perturbación aleatoria (no
controlada) que impide que el estado del sistema Y pueda determinarse con
certeza a partir de los estados de las componentes usando como enlace la
función de estructura tal como se ha explicado en el capítulo anterior.
Siguiendo esta línea, tiene sentido formular un modelo de regresión en
el que la respuesta Y , estado del sistema, puede considerarse una variable
aleatoria con distribución B(1, p), donde el parámetro es alguna función que
depende del vector estado. Más especí�camente, consideramos para analizar
23

24 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
el estado del sistema un modelo de regresión con respuesta binaria, en el
que Y , el estado del sistema es una función de X, el vector estado y una
perturbación aleatoria, ε, y en concreto nos permita expresar
E [Y |X = x ] = Pr {Y = 1 |X = x} = π(x)
con x = (x1, x2, . . . , xm) representa un valor del vector de estados de las
componentes del sistema y π es una función de�nida convenientemente.
El modelo más usual en esta situación es el modelo de regresión logística.
En este capítulo presentamos un resumen de las característica más impor-
tantes de este modelo que usaremos en el capítulo siguiente para analizar el
comportamiento del estado del sistema a partir del estado de sus componen-
tes en presencia de incertidumbre.
En concreto, en este capítulo estudiaremos un modelo clásico de regresión
lineal, que puede ser simple o múltiple, en el que la variable dependiente es
binaria o dicotómica. Esto es, toma sólo dos posibles valores: éxito (Y = 1)
o fracaso (Y = 0).
La regresión logística es un caso particular de regresión que se utiliza para
explicar y predecir una variable categórica binaria en función de una serie de
variables independientes cualitativas o cuantitativas. Es decir, esta estretegia
nos permite modelizar la probabilidad de que ocurra un determinado suceso
a partir de una serie de variables independientes.
En este capítulo recogemos conceptos y resultados generales del modelo
de regresión logística binaria para lo cual nos basamos en el texto de Hos-
mer y Lemeshow (2000). Usaremos el lenguaje y notación general y habitual
en el contexto de regresión logística. En el capítulo siguiente usaremos esta
herramienta general en el contexto particular de estructuras de �abilidad.
2.2. Modelo de regresión con respuesta binaria
Nos centramos en las situaciones en las que la variable respuesta, Y ,
re�eja la ocurrencia o no de un suceso. Esta variable es binaria y la podemos

2.2. MODELO DE REGRESIÓN CON RESPUESTA BINARIA 25
codi�car como sigue:
Y =
{1 si el suceso estudiado ocurre0 si el suceso estudiado no ocurre
Empezamos considerando el caso simple, en el que la ocurrencia o no del
suceso está determinada por una sola variable explicativa X. Únicamente
imponemos la hipótesis monotonía.
El paso siguiente es construir un modelo adecuado para Y de la forma que
se ha mencionado anteriormente, Y = f(X, ε). Como hemos explicado antes
el objetivo �nal es predecir la probabilidad de una respuesta 1. Se podría
plantear la idea de utilizar el modelo de regresión lineal para ontener la res-
puesta binaria, pero este modelo presenta importantes defectos estructurales
que le hacen inviable para explicar el comportamiento de las probabilidades
de respuesta, y que podemos enumerar como sigue.
1. Este modelo predice valores fuera del intervalo [0, 1] ya que las funciones
lineales de variables cuantitativas pueden tomar valores en toda la recta
real.
2. No se satisface la condición de homocedasticidad .
3. Como Y no tiene distribución normal no podemos usar las distribucio-
nes normales de los estimadores de mínimos cuadrados ordinarios para
hacer inferencia sobre el modelo.
4. Este modelo implica el cambio en probabilidad de respuesta por unidad
de cambio en la variable explicativa es constante.
Debido a estas di�cultades nos planteamos ajustar un modelo no lineal
que implique una relación entre X y Pr {Y = 1 |X } que sea curvilínea, mo-
nótona, y acotada entre cero y uno.
En resumen, si la media o probabilidad condicional E [Y |X ] = Pr {Y = 1 |X }se expresa como una ecuación lineal tenemos que es posible para esta función
tomar cualquier valor cuando X se mueve en toda la recta real. Con datos
binarios, la media condicional tiene que limitarse al intervalo [0, 1]. Además
en muchos casos, esta media se aproxima gradualmente a 0 y a 1, esto es, el

26 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
cambio en E [Y |X ] por unidad de cambio en X se va haciendo progresiva-
mente menor a medida que la media condicional se aproxima a 0 y 1. Las
funciones de distribución de variables continuas de�nidas sobre toda la recta
real podrían ser transformaciones adecuadas que cumplen estos objetivos.
La que usaremos aquí es la función de distribución de una variable logística,
principalmente por dos razones:
Desde un punto de vista algebraico es extremadamente �exible y fácil
de usar;
Se presta a interesantes interpretaciones desde el punto de vista prác-
tico.
El modelo de regresión logística tiene la siguiente expresión:
π(x) =eβ0+β1x
1 + eβ0+β1x
Al analizar dicho modelo, cobra especial importancia la transformación logit :
logit(x) = lnπ(x)
1− π(x)= β0 + β1x
dondeπ(x)
1− π(x)simboliza la relación entre la probabilidad de que tenga lu-
gar el acontecimiento estudiado y la probabilidad de que no suceda. Esta
cantidad se denomina odds. Por ejemplo, si π toma el valor 0,6 el odds es de
3 : 2, es decir, la ocurrencia del acontecimiento tiene una ventaja de 3 a 2
respecto a que no ocurra.
La regresión logística es un procedimiento cuyos dos principales objetivos
son
1. Medir la importancia de la relación que hay entre la variable depen-
diente y las distintas variables independientes.
2. Clasi�car individuos según la probabilidad que tengan de pertenecer a
la categoría presente o a la categoría ausente de la variable dependiente.

2.2. MODELO DE REGRESIÓN CON RESPUESTA BINARIA 27
2.2.1. Interpretación de los coe�cientes
Retomando la expresión obtenida tras realizar la transformación logit de
π
logit(X) = lnπ(X)
1− π(X)= β0 + β1X
Consideramos dos individuos con probabilidades π1 y π2 de poseer la propie-
dad estudiada, respectivamente. Para estos sujetos el modelo queda como
lnπ1
1− π1= β0 + β1X1 ; ln
π21− π2
= β0 + β1X2
siendo X1 el valor del primer individuo para la variable X y X2 el valor que
toma el segundo. Restando ambas cantidades
lnπ1
1− π1− ln
π21− π2
= (β0 + β1X1)− (β0 + β1X2) = β1(X1 −X2)
y aplicando las propiedades del logaritmo, obtenemos
ln
π1
1− π1π2
1− π2
= ln
[π1(1− π2)π2(1− π1)
]= β1(X1 −X2)
Pues bien, la cantidadπ1(1− π2)π2(1− π1)
se denomina odds ratio (OR), de forma
que podemos escribir
ln(OR) = β1(X1 −X2)
En el caso particular de que X1 = X2 + 1 tenemos que ln(OR) = β1, por
lo que el odds ratio es igual a eβ1 . Veamos distintos casos sobre el riesgo de
presentar la característica de interés en función del odds ratio:
Si OR > 1 (β1 > 0), el primer individuo tiene mayor riesgo de presentar
la propiedad en cuestión que el segundo.
Si OR < 1 (β1 < 0), el primer sujeto tiene menor probabilidad de tener
la caraterística de interés que el segundo.
Si OR = 1 (β1 = 0), ambos sujetos tienen el mismo riesgo de presentar
la característica de interés. Esto signi�ca que la variable independiente,
X, no está ligada a la probabilidad de que el suceso estudiado ocurra.

28 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
2.2.2. Estimación de los parámetros del modelo
Supongamos que observamos una muestra {(Xi, Yi) ; i = 1, 2 . . . , n} de ta-maño n. Las técnicas de regresión lineal simple requieren de observaciones
del logit, de las cuales no disponemos puesto que π (Xi) son cantidades des-
conocidas. Es por ello que, para estimar los parámetros del modelo de�nido
por logiti = β0 + β1Xi, emplearemos el método de máxima verosimilitud.
Este método nos proporciona los valores de los parámetros que maximizan
la probabilidad de obtener el conjunto de datos examinado. En primer lugar,
construimos la función de verosimilitud, la cual expresa la probabilidad de la
muestra como función de los parámetros desconocidos. En el caso de regresión
logística, como la variable dependiente Y es binaria, se tiene
π(x) = P (Y = 1|x)
y
1− π(x) = P (Y = 0|x)
De este modo, la contribución a la función de verosimilitud de pares de la
forma (Xi, Yi) con i = 1, ..., n tales que Yi = 1 es π(Xi) =eβ0+β1Xi
1− eβ0+β1Xi,
mientras que en aquellos pares tales que Yi = 0 la contribución es 1− π(Xi).
Así, la contribución del par (Xi, Yi) a la función de verosimilitud viene dada
por la siguiente expresión
Li = π(Xi)Yi [1− π(Xi)]
1−Yi
Suponiendo que las observaciones son independientes, obtenemos que la fun-
ción de verosimilitud es:
L(β0, β1) =n∏i=1
Li (2.1)
La �nalidad es obtener los valores de los parámetros β0 y β1 que maximizan
la ecuación (1). Para ello, en primer lugar tomamos logaritmos
l(β0, β1) =n∑i=1
[Yi ln(π(Xi)) + (1− Yi) ln(1− π(Xi))]

2.3. EVALUACIÓN DEL MODELO 29
A continuación, diferenciamos respecto a los parámetros e igualamos a cero,
obteniendo las siguientes ecuaciones de verosimilitud:n∑i=1
[Yi − π(Xi)] = 0 (2.2)
n∑i=1
Xi[Yi − π(Xi)] = 0 (2.3)
La resolución de estas ecuaciones requiere métodos iterativos que incorpo-
ran herramientas de regresión logística. Una forma usual de resolverlas es
mediante el método de Newton-Raphson.
2.3. Evaluación del modelo
2.3.1. Estudio de la bondad de ajuste
En esta sección se presentan algunos métodos que nos permiten estudiar
la bondad del ajuste para el caso simple. No obstante, son también aplicables
a los casos de regresión logística múltiple, es decir, con más de una variable
explicativa.
Coe�ciente R2
Para determinar la bondad de ajuste en un modelo de regresión lineal
analizamos el coe�ciente de determinación R2, pero en el caso de la regresión
logística este coe�ciente puede aportar información errónea. Sin embargo,
encontramos varias formas para calcular el coe�ciente R2 para el model lo-
gístico binomial. Maddala (1983) y Magee (1990) propusieron el siguiente
coe�ciente
R2 = 1−
[L(0)
L(β0, β1)
] 2n
donde L(0) es la verosimilitud del modelo nulo, esto es, sin regresores, y
L(β0, β1) la función de verosimilitud evaluada en el estimador máximo vero-
símil.

30 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
Por una parte, se tiene que L(0) = pn11 (1 − p1)n−n1 ya que en el modelo
logístico nulo se estima π0 = p1 =n1
n, con n1 =
∑Yi el total de 1 en los datos.
Por otro lado, L(β0, β1) es un producto de probabilidades, lo que signi�ca
que el valor máximo que puede tomar es 1. Así, el máximo valor que puede
tomar R2 es
R2 ≤ 1− (L(0))2n = 1− (pn1
1 (1− p1)n−n1)2n =
= 1− (pp1n1 (1− p1)n−p1n)2n = 1− (pp11 (1− p1)1−p1)2
lo que implica que los valores entre los que está el coe�ciente R2 depen-
derán del problema. Para evitar esta coyuntura podemos medir la bondad
del ajuste utilizando el coe�ciente dado por Nagelkerke (1991): R2= R2
max(R2).
Además, se tiene que el coe�ciente es siempre positivo porque ln(L(0)) ≤ln(L(β0, β1)).
Test de razón de verosimilitudes
En regresión logística, la comparación entre los valores observados y los
predichos por el modelo se realiza mediante la función de verosimilitud pre-
sentada en (2,1), basándonos en la expresión
D = −2lnn∑i=1
[Yiln
(πiYi
)+ (1− Yi)ln
(1− πi1− Yi
)]donde πi = π(Xi) simboliza el valor i predicho por el modelo. La expresión
de D se obtiene como menos dos veces el logaritmo de la razón de verosi-
militudes, la cual se calcula como el cociente de la función de verosimilitud
del modelo actual y la del modelo saturado (modelo en el que el número de
parámetros coincide con el número de datos). El estadístico D se denomina
deviance y es equivalente a la suma de residuos al cuadrado en regresión
lineal.
Para evaluar la bondad del ajuste comparamos el valor de D incluyendo
y sin incluir la variable en la ecuación, obteniendo
G = D(modelo sin la covariable)−D(modelo con la covariable)

2.3. EVALUACIÓN DEL MODELO 31
y como el modelo saturado es común para los dos valores de D anteriores,
podemos reescribir G como
G = −2ln[función de verosimilitud del modelo sin covariablefunción de verosimilitud del modelo con covariable
]Cabe destacar que, debido a la presencia de una sola varible independiente,
la estimación de la bondad del ajuste equivale a evaluar el grado de signi�-
cación de dicha variable, tal y como se mostrará en la sección (2.3.2.)
En el modelo sin covariable o nulo únicamente consideramos el parámetro
β0. El estimador máximo verosímil se obtiene como ln(n1
n0
), con n0 =
∑(1−
Yi), n1 =∑Yi y valor predicho π0
i =n1
n0+n1= n1
nconstante. De esta manera
se obtiene
G = −2ln
(n1
n
)n1(n0
n
)n0
n∏i=1
πYii (1− πi)1−Yi
En el caso univariante, el estadístico G se emplea para resolver el siguiente
contraste de hipótesis: {H0 : β1 = 0H1 : β1 6= 0
De forma que, bajo la hipótesis nula, G tiene una distribución χ2(1).
Test de Hosmer-Lemeshow
Para realizar este test debemos seguir los siguientes pasos:
1. Calculamos π1 = π(X1), ..., πn = π(Xn), una vez que el modelo esté
ajustado.
2. Ordenamos los n valores de menor a mayor.
3. Agrupamos los valores calculados en cuartiles, deciles o alguna distri-
bución semejante. O bien formamos el primer grupo con los sujetos
para los que Pi < 0,1, el segundo grupo con los individuos tales que

32 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
0,1 < Pi < 0,2, etc.
Sean n1, ..., n10 las respectivas frecuencias,
4. Sumamos los valores de πi en cada uno de los grupos, obteniendo los
valores esperados, denotados por E1, ..., E10.
5. En cada grupo contamos el número de sujetos para los que Y = 1,
obteniendo los valores observados, denotados por O1, ..., O10.
Finalmente, calculamos el estadístico de Hosmer-Lemeshow:
χ2 =10∑i=1
(Oi − Ei)2
Ei+
10∑i=1
(O∗i − E∗i )2
E∗i
donde E∗i = ni − Ei y O∗i = ni −Oi.
Según Hosmer y Lemeshow este estadístico se distribuye como una χ2 con
8 grados de libertad.
2.3.2. Tests de signi�cación de los coe�cientes
Una vez que el modelo está ajustado, procedemos a valorar la signi�ca-
ción de las variables del modelo. Los contrastes de hipótesis nos servirán para
determinar si las variables independientes están relacionadas de forma sig-
ni�cativa con la variable respuesta. Este proceso se basa en la comparación
de los valores observados de la variable respuesta con los valores obtenidos
a partir de los modelos con y sin la variable cuya signi�cación estemos es-
tudiando. Veamos algunos estadísticos útiles para evaluar la signi�cación de
una determinada variable a la hora de explicar la variable respuesta.
Test de Wald
Para j = 0, 1 se consideran los siguientes contrastes de hipótesis:{H0 : βj = 0H1 : βj 6= 0

2.3. EVALUACIÓN DEL MODELO 33
El contraste para β1 es el mismo que planteábamos para el test de razón de
verosimilitudes en la sección 2.3.1.
Otro método para resolver el contraste anterior es el test de Wald, el cual
se calcula comparando el estimador de máxima verosimilitud de βj con una
estimación de su error estándar. Sea H la matriz hessiana de orden 2 dada
por
Huj =∂2l(β0, β1)
∂βu∂βj
con u, j = 0, 1. Al evaluarla en los estimadores máximo verosímiles de los
parámetros, para muestras grandes, obtenemos la matriz de covarianzas de
los coe�cientes de regresión, es decir,∑(β0, β1) = −(H(β0, β1))
−1
siendo las raíces cuadradas de los elementos de la diagonal los errores están-
dar, esto es, los coe�cientes de regresión seβj , para j = 0, 1.
Así, el estadístico de Wald para el contraste de signi�cación de�nido es
W =βjseβj
Y se distribuye según una distribución Normal estándar, bajo la hipótesis
nula.
Prueba Score
Tanto el test de razón de verosimilitudes como el test de Wald requie-
ren calcular el estimador máximo verosímil para β1. En el caso de muestras
grandes el coste computacional puede ser elevado. Para evitar esta situación
podemos utilizar la prueba Score, test de signi�cación basado en la distribu-
ción condicional de la derivada dada en la ecuación (3) dada la derivada de
la ecuación (2).

34 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
Veamos la expresión para la prueba Score en el caso univariante. Para
ello usamos el valor de la ecuación (3) calculado usando que β0 = ln(n1
n0) y
β1 = 0. Los valores predichos con estos parámetros son πi =n1
n= Y . De
forma que la ecuación (3) queda como sigue
n∑i=1
Xi(Yi − Y ) = 0
Siendo la varianza estimada: Y (1− Y )n∑i=1
(Xi −X)2.
Finalmente, el estadístico para la prueba Score viene dado por la siguiente
expresión
ST =
n∑i=1
Xi(Yi − Y )√Y (1− Y )
n∑i=1
(Xi −X)2
Este estadístico sigue una distribución Normal estándar.
2.3.3. Análisis de la capacidad predictiva del modelo
Resulta de gran utilidad presentar los resultados de un modelo logístico
ajustado en una tabla de clasi�cación. Este método consiste en construir una
tabla 2 x 2 cruzando los valores de la variable respuesta y una variable di-
cotómica cuyos valores se obtienen a partir de las probabilidades logísticas
estimadas.
Para de�nir la variable dicotómica tenemos que elegir un punto c de corte,
y a continuación comparar cada probabilidad estimada con ese valor. Si la
probabilidad estimada supera al valor c, la nueva variable tomará el valor 1,
en otro caso, se le asignará el valor 0. Lo más frecuente es considerar c = 0,5.
El objetivo es determinar si el modelo logístico estimado clasi�ca adecua-
damente a los individuos de acuerdo con los valores de la variable respuesta,
pero no siempre se obtienen conclusiones acertadas. Sin embargo, la tabla
de clasi�cación nos proporciona interesantes conclusiones sobre el ajuste del
modelo a los datos.

2.4. REGRESIÓN LOGÍSTICA MÚLTIPLE 35
2.4. Regresión logística múltiple
En este punto consideramos más de una variable explicativa (categóricas
o continuas), de forma que el modelo se expresa como
P (Y = 1) =eβ0+β1X1+···+βpXp
1 + eβ0+β1X1+···+βpXp
Para estimar los parámetros se suele utilizar el método de máxima verosimi-
litud, al igual que en el modelo simple. Supongamos que contamos con una
muestra de n observaciones {(Xi, Yi) ; i = 1, 2, . . . , n}, donde ahora Xi es un
vector que contiene la información de las variables explicativas respecto al
i-ésimo individuo de la muestra.
Sean
X =
1 X11 · · · X1p
1 X21 · · · X2p... . . .
. . ....
1 Xn1 · · · Xnp
;Y =
Y1Y2...Yn
; π =
π1π2...πn
con πi = π(Xi1, Xi2, ..., Xip), la función de verosimilitud viene dada por
ln(L(β)) =n∑i=1
[Yilnπi + (1− Yi)ln(1− πi)]
y las ecuaciones de verosimilitud quedan como
∂l(β)
∂β0=
n∑i=1
(Yi − πi) = 0
∂l(β)
∂βj=
n∑i=1
(Yi − πi)Xij = 0
con j = 1, ..., p. Matricialmente
X ′(Y − π) = 0
Para resolver estas ecuaciones empleamos el método de Newton-Raphson,
llegando a π(Xi1, Xi2, ..., Xip). Derivando dos veces la función de verosimilitud
obtenemos la matriz de información de Fisher
I(β) = −(∂2l(β)
∂βj∂βu
)

36 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
para u ≥ 1, p ≥ j y con
Hjj =∂2l(β)
∂β2j
= −n∑i=1
X2ijπi(Yi − πi) = 0
Huj =∂2l(β)
∂βj∂βu= −
n∑i=1
XijXiuπi(Yi − πi) = 0
notando, cuando j = 0, Xi0 = 1 para todo i = 1, ..., n.
La matriz de varianzas-covarianzas se obtiene como∑
(β) = I−1(β) y,
evaluando en el estimador de máxima verosimilitud, conseguimos una estima-
ción de la matriz de varianzas:∑
(β) = I−1(β). Los elementos de la diagonal
aportan estimaciones de las varianzas de las componentes de β, de forma que
podemos considerar se(βj) como una estimación del error estándar.
2.4.1. Interpretación de los coe�cientes
El coe�ciente β0 simboliza el logaritmo del odds de presentar la carac-
terística de interés cuando todas las variables independientes valen 0. El
coe�ciente βj representa el cambio producido en el logaritmo del odds cuan-
do Xj aumenta en una unidad y el resto de variables se mantienen iguales.
Veamos a continuación un ejemplo para ilustrar lo anterior que hemos
tomado del texto de Silva y Barroso (2004), pg. 58.
Ejemplo. Se quiere estudiar la aparición de cierta enfermedad
coronaria en varones no menores de 50 años durante un período
de observación de 10 años. Para ello se consideran 3 variables cuya
in�uencia sobre el desarrollo de la enfermedad se sospecha. De
forma que la variable Y registra la aparición o no de la enfermedad,
tomando el valor 1 si ésta se desarrolla y el valor 0 en caso contrario,
esto es,
Y =
{1 si la enfermedad se desarrolla0 si la enfermedad no se desarrolla

2.4. REGRESIÓN LOGÍSTICA MÚLTIPLE 37
Las tres variables medidas al principio del período son
X1 = edad del sujeto
X2 = hábito de fumar =
{1 si fuma0 en otro caso
X3 = tensión arterial sistólica
A partir de una muestra de individuos se han estimado los pará-
metros por máxima verosimilitud, obteniendo
β0 = −6,614β1 = 0,075
β2 = 0,312
β3 = 0,018
A partir de ellos es posible estimar la probabilidad de que un sujeto
padezca la enfermedad según los valores que tomen las tres cova-
riables. Por ejemplo, el modelo asigna una probabilidad de 0.679
de desarrollar la enfermedad a un individuo de 58 años, fumador y
con una tensión de 150 mm.
Si consideramos los per�les de dos individuos: X11 , X
12 , ..., X
1k y
X21 , X
22 , ..., X
2k , denotamos O(X1) y O(X2) a los respectivos odds de
desarrollar la enfermedad frente a no hacerlo para cada uno de los
sujetos. Haciendo el cociente entre los odds obtenemos la siguiente
expresión
O(X1)
O(X2)= e
k∑i=1
βi(X1i −X2
i )
la cual proporciona una medida relativa del riesgo que tiene el per�l
1 de presentar la enfermedad respecto al per�l 2. Por ejemplo, si
consideramos dos individuos de la misma edad y presión sistólica,
siendo el primero fumador y el segundo no, tenemos
O(X1)
O(X2)= 1,37

38 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)
lo que signi�ca que ser fumador aumenta la probabilidad de padecer
la enfermedad coronaria un 37%. Si ahora comparamos el riesgo
cuando la edad aumenta en 10 años y el resto de variables son
iguales, obtenemos
O(X1(40años))
O(X2(30años))= 10β2 = 0,75
2.4.2. Contrastes de signi�cación del modelo
Desviación del modelo
El test de bondad de ajuste para la signi�cación del modelo
es equivalente al del caso univariante. Ahora tenemos el siguiente
contrate de hipótesis:{H0 : β1 = β2 = · · · = βp = 0H1 : ∃βj 6= 0
Para contrastar la signi�cación del modelo se utiliza un test de ra-
zón de verosimilitudes basado en el estadístico G de�nido para el
caso univariante. La diferencia es que ahora los valores ajustados,
π, bajo el modelo se basan en un vector β que contiene p+ 1 pará-
metros.
Bajo la hipótesis nula, G sigue una distribución χ2 con p grados
de libertad.
Pruebas de hipótesis sobre subconjuntos de parámetros
Los contrastes individuales{H0 : βj = 0H1 : βj 6= 0
para todo j = 0, 1, ..., p, se resuelven mediante el estadístico de Wald:
Wj =βjseβj

2.4. REGRESIÓN LOGÍSTICA MÚLTIPLE 39
Este estadístico tiene una distribución Normal estándar.
Puede resultar interesante resolver contrastes de signi�cación
de subconjuntos de covariables. Para ello partimos del vector de
parámetros β = (β(1), β(2)), cuyo primer vector tiene dimensión r < p
y el segundo p− r. En este caso el contraste queda como{H0 : β(1) = 0H1 : β(1) 6= 0
y para resolverlo empleamos una vez más el test de razón de vero-
similitudes:
G = −2[l(modelo bajoH0)− l(modelo bajoH1)],
este estadístico sigue una distribución χ2 con p− r grados de liber-tad.

40 CAPÍTULO 2. REGRESIÓN LOGÍSTICA (RL)

Capítulo 3
Análisis de estructuras medianteRL
3.1. Introducción
La mayoría de los modelos en �abilidad se han concentrado tra-
dicionalmente en una formulación binaria del comportamiento de
los sistemas, esto es, los modelos consideran sólo dos niveles de fun-
cionamiento para un sistema y sus componentes: funcionamiento
perfecto y fallo completo. Sin embargo, en la práctica, muchos sis-
temas pueden experimentar una degradación continua de tal modo
que pueden exhibir diferentes niveles de desarrollo entre los dos ex-
tremos de funcionamiento completo y fallo fatal. Un ejemplo típico
es un sistema sujeto a desgaste, el cual se va degradando continua-
mente en el tiempo, de modo que sus propiedades de rendimiento
decrecen progresivamente y, en consecuencia, es necesario conside-
rar una más amplia especi�cación del espacio de estados con el �n
de obtener una descripción más precisa y apropiada del comporta-
miento del sistema en cada momento.
Baxter (1984) introdujo los modelos continuos para la �abilidad
de sistemas, y desde entonces, una amplia variedad de medidas de
rendimiento han sido de�nidas y calculadas siendo válidas para sis-
temas binarios, multi-estados y continuos (ver Brunelle y Kapur
(1998) para un detallado resumen). En particular, la función de
41

42 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
estructura del sistema, que representa la función de enlace entre
el estado del sistema y sus componentes, ha sido un tema de in-
terés principal en el campo de la �abilidad de sistemas. Dado que
la evaluación de la �abilidad puede ser un problema complejo en
la práctica, incluso para sistemas parece razonable que contar con
un procedimiento para modelizar la relación entre el estado del
sistema y sus componentes puede ayudar de modo e�ciente en la
evaluación de la �abilidad de sistemas complejos.
Para sistemas binarios, la función de estructura puede determi-
narse cuando o bien los caminos minimales o los cortes minima-
les son conocidos (ver capítulo 1). Diversos procedimientos se han
desarrollado para generalizar el concepto de estructura coherente
binaria a una con�guración multi-estado, y así, la función de es-
tructura puede especi�carse por medio de un conjunto �nito de
puntos frontera. Aven (1993) justi�ca la introducción de modelos
multi-estado por la necesidad en algunas áreas de aplicación, en
Ingeniería, tales como producción de gas/oil y sistemas de trans-
portes, donde un enfoque binario daría una representación pobre
del mundo real. Este autor investiga el problema del cálculo de de-
terminadas medidas del rendimiento de un sistema monótono con
múltiples estados y presenta estudios de comparación sobre la pre-
cisión de sus cálculos mediante un estudio de simulación de Monte
Carlo.
En la literatura reciente sobre el análisis posterior del problema
se ha puesto de mani�esto que la evaluación de la �abilidad de un
sistema es una tarea difícil desde un punto de vista práctico, inclu-
so en sistemas no excesivamente complejos.
En el caso de un sistema continuo, si la función de estructura no
puede ser determinada basada en características cualitativas, por
ejemplo, estructuras en serie y/o paralelo) o mediante análisis de
puntos frontera, se requieren métodos de aproximación. Para tal

3.1. INTRODUCCIÓN 43
�n, Lisnianski (2001) desarrolla diversos tratamientos del proble-
ma e investiga una aproximación basada en la técnica de la función
generatriz universal.
El método consiste en una aproximación discreta del rendimien-
to del sistema con conjunto de estados continuo mediante un siste-
ma multi-estado �nito y el propósito es construir cotas superiores
e inferiores para las medidas de �abilidad del sistema continuo.
En vista de la gran di�cultad inherente en la evaluación analítica
del rendimiento de un sistema continuo, nuevos enfoques basados
en métodos empíricos han surgido recientemente. Brunelle y Ka-
pur (1998) propusieron un método de interpolación multivariante
mediante el cual puede construirse la función de estructura del sis-
tema continuo partiendo de una nube de puntos que representa el
valor del estado del sistema dados determinados valores de los esta-
dos de sus componentes. Por otro lado, Gámiz y Martínez-Miranda
(2010) han propuesto una nueva técnica que asume un modelo de
regresión para la función de estructura de un sistema continuo. El
principal �n es construir la función de estructura del sistema dado
un conjunto observado de estados del sistema y sus componentes.
La idea principal se basa en el uso de técnicas de regresión mo-
nótona no paramétrica, dado que la naturaleza del problema exige
que la función de regresión debe ser monótona en cada variable
explicativa. El método de ajuste se desarrolla teniendo en cuenta
dos etapas, en primer lugar usando técnicas de regresión local se
construye la super�cie que mejor se ajusta a los datos y a conti-
nuación se considera un método numérico de isotonización de la
respuesta. El método considerado es el algoritmo PAVA (Pool Ad-
jacent Violators Algorithm) que fue introducido para resolver el
caso uni-dimensional, con una sóla variable explicativa y posterior-
mente ha sido generalizado para problemas de mayor dimensión,
ver Burdakow et al. (2004).

44 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
En este capítulo consideramos también el caso de sistemas conti-
nuos pero usamos un enfoque diferente. Nuestro objetivo se centra
más en construir una expresión para la función de �abilidad del
sistema más que para la función de estructura.
Proponemos estimar la probabilidad de que el sistema se en-
cuentre en funcionamiento dada una con�guración particular del
conjunto de sus componentes mediante un modelo de regresión con
respuesta binaria que explicamos en la siguiente sección. Queremos
hacer notar que nuestra propuesta también supone un enfoque di-
ferente al análisis tradicional de �abilidad, donde, por un lado, el
estado del sistema se analiza usualmente en función de los estados
de las componentes a través de la función de estructura, y, por otro
lado, la �abilidad del sistema se determina a partir de las �abilida-
des de sus componentes mediante la misma función enlace que para
los estados (ver capítulo 1). Dado el carácter continuo de los es-
tados de las componentes, proponemos analizar la probabilidad de
que el sistema esté en funcionamiento (�abilidad del sistema) direc-
tamente partir de los estados de las componentes. La razón es que
el procedimiento que proponemos es un procedimiento empírico
basado en la observación de una muestra de sistemas y entende-
mos que el estado de una componente es directamente observable
y/o controlable mientras que su �abilidad puede no serlo.
3.2. Modelo de RL basado en una variable la-
tente
Sin pérdida de generalidad, consideramos en esta sección que el
estado de l i-ésima componente del sistema es una variable xi (i =
1, 2, . . . ,m) directamente observable que toma valores en el intervalo
[0, 1]. Dada una con�guración particular de las componentes, se
tendrá que el estado del sistema y∗ es una variable aleatoria que
puede responder a un modelo como el siguiente
y∗ = ψ (x1, x2, . . . , xm) + u

3.2. MODELO DE RL BASADO EN UNA VARIABLE LATENTE 45
donde ψ es una función apropiada, que usualmente se asume lineal,
es decir ψ (x1, x2, . . . , xm) = β0 + β1x1 + β2x2 + . . . + βmxm; y, U es una
variable aleatoria para la que asumimos E[u] = 0. Hay que destacar
que la función ψ no es literalmente la función de estructura del
sistema, tal como se de�ne en el capítulo 1.
En muchos casos prácticos la información que queremos extraer
no es el nivel exacto de rendimiento del sistema, es decir, no in-
teresa tanto el valor exacto de la variable y∗ que se obtiene sino que
es su�ciente con saber simplemente si el sistema está desarrollando
satisfactoriamente la operación para la que ha sido diseñado, o no.
Es decir, entendemos que la propiedad que nos interesa a nivel de
sistema es el resultado de una variable binaria y que toma valor 1 si
el sistema funciona y 0 en otro caso. El objetivo es caracterizar esta
variable en términos de los valores de las variables que denotan el
estado de cada componente. Para estimar la probabilidad de que
un sistema funcione proponemos un modelo de regresión basado
en una variable latente, que no es observada por el investigador, la
cual depende linealmente de xi, y que enunciamos como sigue
Modelo:
y∗i = x′iβ + ui , E (ui) = 0
La variable latente y∗i se puede interpretar como la diferencia de uti-
lidad entre el funcionamiento (yi = 1) y el fallo del sistema (yi = 0).
Se dice que es un modelo de utilidad aleatoria.
El investigador únicamente observa la variable yi. Se de�ne yi = 1
si la variable latente toma valor por encima de un umbral (y0)
�jado de antemano y que representa el límite por encima del cual
se considera que el sistema funciona satisfactoriamente, y yi = 0 en
otro caso. En resumen la variable observada se de�ne como
yi =
{1 si y∗i > y00 si y∗i ≤ y0
Además, suponemos que las observaciones individuales (xi,yi) son

46 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
independientes e idénticamente distribuidas, y que el modelo es
homocedástico, es decir, V ar (ui|xi) = σ2.
La probabilidad de que la con�guración i, es decir xi produzca un
buen funcionamiento del sistema, yi = 1, puede ser ahora obtenida
a partir de la variable latente y la regla de decisión, por ejemplo
P [yi = 1|xi] = P [y∗i > y0|xi] = P [x′iβ +Ui > y0|xi] = P [Ui > y0 − x′iβ|xi] =
= 1− φ (−x′iβ∗/σ) = φ (x′iβ∗/σ) ,
donde hemos llamado β∗ al vector de coe�cientes β∗0 = β0 − y0 y
β∗k = βk, para k = 1, . . . ,m.
Por otro lado la función φ denota la función de distribución de
la variable U estandarizada, que suponemos es simétrica con res-
pecto a 0. En esta memoria suponemos que φ(z) = Flogis(z) = ez
1+ez
con z ∈ R es la función de distribución de una variable logística.
Nótese que no es posible identi�car de forma separada los pa-
rámetros y0, β yσ, y que se estimará el cociente β∗/σ.
3.3. RL monótona para estimar la �abilidad
Teniendo en cuenta el apartado anterior, sea Y la variable alea-
toria que denota el estado de un sistema (funcionamiento o fallo)
con m componentes y sea x = (x1, ...,xm) el vector estado de dichas
componentes, suponemos que Y y x están relacionados mediante el
modelo de regresión logística de forma que Y sigue una distribución
binomial
Y =
{1 si el sistema funciona0 si el sistema falla
donde
P [Y = 1|x1, ..., xm] =eβ0+β1x1+···+βmxm
1 + eβ0+β1x1+···+βmxm= R(x1, ..., Rm)
es la �abilidad del sistema.
Denotamos como β = (β0, β1, ..., βm)′ al vector de los parámetros de

3.3. RL MONÓTONA PARA ESTIMAR LA FIABILIDAD 47
regresión, el cual queremos estimar a partir de los datos.
Para un conjunto de datos observados dados {(xi;yi) ∈ [0,1]m ×[0,1]; i = 1, ...,n} usamos el método de máxima verosimilitud para
estimar un valor apropiado del vector β, el cual nos proporcionará
una estimación de la �abilidad del sistema. En otras palabras, para
un determinado vector estado x = (x1, ...,xm) formulamos el modelo
de regresión, como es habitual, como sigue
π(x) = R(x) =eβ0+β1x1+···+βmxm
1 + eβ0+β1x1+···+βmxm
Dado nuestro contexto de esta memoria, utilizaremos la nota-
ción R(x) usual en el análisis de �abilidad de sistemas, para re-
ferirnos a esta probabilidad. De este modo, podemos reescribir el
modelo como
lnR(x)
1−R(x)= β0 + β1x1 + · · ·+ βmxm
Como vimos en el capítulo 2 de este documento, la cantidad R(x)1−R(x)
se denomina odds de la �abilidad R(x). De forma que el modelo es-
tablece que el logaritmo del odds, denominado logit, es una función
lineal del vector estado de las componentes del sistema considerado.
Ahora, dados dos vectores x1 y x2, esto es, dos con�guraciones
distintas de las componentes del sistema, se de�ne la medida de
asociación odds ratio como la proporción entre el odds de x1 y el
odds de x2 y viene dado por la siguiente ecuación
OR =
R(x1)
1−R(x1)
R(x2)
1−R(x2)
= ψ(x1, x2)
Y el logaritmo del odds ratio es entonces la diferencia de los loga-
ritmos de los odds de x1 y x2 como se muestra a continuación
ln OR = lnR(x1)
1−R(x1)− ln R(x2)
1−R(x2)= logit(x1)− logit(x2)

48 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
Si los vectores x1 y x2 sólo di�eren en el estado de la componente
j, por ejemplo, suponemos que en el primer vector la componente
j funciona al más alto nivel, x1,j = 1, mientras que en el segundo
vector esta componente está en fallo total, x2,j = 0, entonces el
logaritmo del odds ratio es
ln ψ(x1,x2) = βj
A continuación, para estimar los parámetros del modelo de�nido
anteriormente usamos métodos de máxima verosimilitud. Para ello
consideramos el siguiente problema de optimización
β = arg maxβ {ln L(β)} =
= arg maxβ
{n∑i=1
Yiln(R(xi))(1− Yi)(1− ln(R(xi)))
}
Para mantener la coherencia del sistema, necesitamos que la esti-
mación sea no decreciente en cada argumento, es decir, se requiere
que ∂R(x)∂xj
sea positiva para j = 1, ...,m. Si resolvemos la derivada
obtenemos, para j = 1, ...,m
∂R(x)
∂xj=
eβx
(1 + eβx)2βj > 0
Por consiguiente, el signo de la j-ésima derivada parcial viene de-
terminada por el signo del coe�ciente βj. Esto nos lleva a introducir
ciertas restriciones en el probema de optimización, de forma que
el problema de optimización queda formulado como sigue
ln L(β) =n∑i=1
Yi ln(R(xi))(1− Yi)(1− ln(R(xi)))
con las restricciones
βj > 0 ; j ∈ {1, ...,m}
En otras palabras, debe ocurrir que β0 < 0 para que se manten-
ga la condición de extremos propios, esto es, R(0) = 0. En nuestro

3.4. MEDIDA DE IMPORTANCIA DE BIRNBAUM (IB) 49
modelo, para un nivel nulo de �abilidad, R(0) = eβ0
1+eβ0debe ser su�-
cientemente pequeño para a�rmar que el sistema falla para p = 0.
De esta forma podemos introducir una nueva restricción en el pro-
blema de optimización anterior, al tener en cuenta que el parámetro
β0 debe ser negativo.
3.4. Medida de importancia de Birnbaum (IB)
La principal �nalidad de las medidas de importancia en �abi-
lidad es ordenar las componentes del sistema con el objetivo de
detectar aquellas componentes que por su localización o por sus
características particulares tienen una mayor probabilidad de cau-
sar el fallo del sistema. Como vimos en el capítulo 1, hay varias
formas de medir la importancia de las componentes, siendo la más
usada en la práctica la medida de importancia de Birnbaum, intro-
ducida por Birnbaum (1969).
Sea la siguiente cantidad
R(x|xj = 1)−R(x|xj = 0)
donde R(x|xj = a) denota la �abilidad del sistema cuando la compo-
nente j está en el estado a, siendo x = (x1, ..., xm) ∈ [0, 1]m el vector
de las estado de las componentes. Si el enfoque a nivel de compo-
nentes es binario, es decir sólo se consideran dos estados (0, fallo;
1, funcionamiento) la cantidad considerada arriba mide el efecto
(incremento) que causa en la �abilidad del sistema el hecho de que
la componente j-ésima pase de estado fallo a funcionamiento. Es-
ta medida podría considerarse una mezcla entre las medidas de
importancia estructural (I(B)j ) e importancia en �abilidad (RI
(B)j )
de�nidas en el capítulo 1, las cuales proporcionan desde diferentes
enfoques una cuanti�cación de la importancia de las componentes
en un sistema, la primera atendiendo exclusivamente a la localiza-
ción de la componente dentro del sistema y la segunda teniendo
en cuenta la calidad de la componente representada mediante la

50 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
�abilidad de la misma. Dado que en los sistemas continuos el esta-
do de las componentes puede tomar un rango de valores continuo
(asumimos el intervalo [0, 1]), introducimos la siguiente medida de
imporancia que surge de manera natural teniendo en cuenta los
dos conceptos anteriores de importancia estructural e importancia
en �abilidad.
De�nición. Medida de importancia de Birnbaum para sistemas
continuos, IBjSea S un sistema coherente formado por m componentes, y sea
R (x1, x2, . . . , xm) = P [”Y = 1” = Sistema funciona |x1, x2, . . . , xm ], se de-
�ne la medida de importancia de la componente j-ésima como
IBj =∂R (x1, ..., xm)
∂xj
Esta medida ordena las componentes de acuerdo con el efecto que
un cambio gradual en el estado de dichas componentes tiene sobre
la �abilidad del sistema.
Basándonos en el modelo de regresión logística de�nido en la
sección 3.2, podemos estimar la función de �abilidad mediante R,
de modo que proponemos estimar la medida de importancia de
Birnbaum para la componente j mediante
IBj =∂R (x1, ..., xm)
∂xj=
eβx
(1 + eβx)2βj
Teniendo en cuenta que Y es una variable con distribución B (R(x)),
podemos escribir
IBj = V (Y )βj,
de donde se deduce que, bajo el modelo logístico, las componentes
del sistema pueden ordenarse según el valor del coe�ciente β esti-
mado, o equivalentemente, según el valor del odds ratio, ORj = eβj ,
que habitualmente es el coe�ciente central en el software estadístico
para ajustar el modelo de regresión logística.

3.5. SIMULACIONES 51
3.5. Simulaciones
Siguiendo el procedimiento descrito anteriormente hemos reali-
zado una serie de simulaciones con la ayuda del software R. Para
ello hemos construido las siguientes funciones auxiliares: Una pri-
mera función se encarga de generar la muestra. Esta función nos
proporciona una matriz con tantas �las como simulaciones indique-
mos y con una columna más que componentes tenga el sistema: las
primeras columnas representan los estados de las componentes del
sistema y la última es de 1 y 0 en función de si el sistema funciona o
no. Las muestras son generadas a partir de un �chero de semillas. A
continuación, para emplear los métodos de máxima verosimilitud,
implementamos una función de verosimilitud y la función gradien-
te. Finalmente, construimos una función que nos permite hacer las
predicciones.
La siguiente función empleada elige una muestra del tamaño
indicado para cada simulación usando la primera función. Seguida-
mente, ajusta el modelo logístico usando las funciones de verosi-
militud y gradiente, así como la función constrOptim del paquete
MASS. Cabe destacar que este ajuste se lleva a cabo con ciertas
restricciones sobre el signo de los parámetros: los β deben ser todos
positivos a excepción de β0 que debe ser negativo. A continuación,
calcula predicciones usando el β estimado y lleva a cabo un estudio
de la bondad del ajuste mediante una tabla de clasi�cación. Para
ello compara los datos observados (simulados en nuestro caso) con
el modelo ajustado, de forma que si la probabilidad estimada es
menor que 0,5 entenderemos que el sistema falla y si se estima una
probabilidad superior el sistema funciona. Para cada muestra, esta
función crea un vector con la siguiente información: betas, esta-
dísticos deviance del modelo nulo y el modelo estimado, p-valor
asociado al test LR de bondad de ajuste y CPM (estadístico capa-
cidad predictiva del modelo). Cada vez que se genera una muestra,
se añade una �la al vector. Dicho vector es guardado en un �chero
de texto.

52 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
Finalmente, hemos implementado una función encargada de leer
el �chero creado por la función anterior y presentar un resumen
con los resultados, guardándolos en un nuevo �chero.
Veamos los resultados obtenidos para algunos sistemas.
Caso 1. Sistema en serie
En primer lugar hemos considerado un sistema con 3 compo-
nentes dispuestas en serie.
La función de estructura de dicho sistema es de la forma
φ(x) = min(x1, x2, x3)
siendo x1, x2, x3 los estados de las respectivas componentes.
Esta función es introducida en la función auxiliar que genera la
muestra para calcular el estado del sistema en función de las com-
ponentes.
Por ejemplo, realizamos una prueba de tamaño 10 obteniendo
la siguiente matriz
x_1 x_2 x_3 y0
[1,] 0.5664804 0.5352917 0.7697899 0
[2,] 0.5072702 0.5025413 0.5062494 0
[3,] 0.5621357 0.7650100 0.5958715 0
[4,] 0.5647201 0.5903164 0.5338788 0
[5,] 0.6331171 0.6478231 0.6584968 1

3.5. SIMULACIONES 53
[6,] 0.5402228 0.6501890 0.7738738 0
[7,] 0.6171973 0.6206103 0.6185314 1
[8,] 0.6107947 0.7931248 0.6145577 1
[9,] 0.7006079 0.6074978 0.7902500 1
[10,] 0.7976330 0.6474982 0.7545984 1
A continuación se ajusta el modelo logístico utilizando las funciones
mencionadas previamente y se calculan predicciones usando el β
estimado, llevando a cabo un estudio de la bondad de ajuste. Para
la prueba anterior se obtiene el siguiente resumen de resultados
[[1]]
beta.0 beta.1 beta.2 beta.3
m.betas -28.40670 12.75563 12.58026 11.97476
se.betas 299.53371 56.80264 56.88887 55.64667
sd.betas 62.35762 71.47626 67.08149 66.72514
[[2]]
p.value CPM
summary 0.02251166 0.9506
En esta simulación la capacidad predictiva del modelo es muy bue-
na, pues supera ligeramente el 95%, siendo el p-valor 0.022.
Además, se observa que las tres componentes tienen una impor-
tancia similar, ya que la media de los coe�cientes β1 es 12.755, la
de los β2 12.580 y la de los β3 11.974. Este resultado es coherente
con la disposición de las componentes, ya que en el momento que
una de ellas falle, el sistema dejará de funcionar.
Caso 2. Sistema en paralelo
A continuación tenemos un sistema con 3 componentes en pa-
ralelo.

54 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
La función de estructura de este sistema se puede expresar como
φ(x) = max(x1, x2, x3)
donde x1, x2, x3 representan los estados de cada una de las tres com-
ponentes del sistema.
Si realizamos una prueba de tamaño 10 obtenemos la siguiente
matriz con los estados de las componentes y del sistema
x_1 x_2 x_3 y0
[1,] 0.18506510 0.10293477 0.72044665 1
[2,] 0.02914479 0.01669222 0.02645668 0
[3,] 0.17362403 0.70785978 0.26246155 1
[4,] 0.18042950 0.24783322 0.09921423 0
[5,] 0.36054163 0.39926737 0.42737489 0
[6,] 0.11592016 0.40549765 0.73120098 1
[7,] 0.31861965 0.32760723 0.32213279 0
[8,] 0.30175946 0.78189543 0.31166867 1
[9,] 0.53826744 0.29307755 0.77432495 1
[10,] 0.79376687 0.39841183 0.68044249 1
Procediendo de forma análoga al caso 1 obtenemos el siguiente
resumen de resultados
[[1]]
beta.0 beta.1 beta.2 beta.3
m.betas -12.64439 17.89610 18.38619 16.99085
se.betas 10.30345 18.01980 18.43604 17.66166

3.5. SIMULACIONES 55
sd.betas 31.68694 59.87154 66.39274 50.95524
[[2]]
p.value CPM
summary 0.0002505123 0.8802
En este caso la capacidad predictiva del modelo es bastante buena,
aunque algo inferior que la del sistema en serie, pues el modelo ex-
plica correctamente el 88% de las preicciones. El p-valor obtenido
en este ejemplo es de 0.00025.
Respecto a la importancia de las componentes, de nuevo las
tres tienen un peso similar en el funcionamiento del sistema. Este
resultado es lógico si tenemos en cuenta la disposición de las com-
ponentes, ya que mientras que una de ellas funcione, el sistema
funcionará.
Caso 3. Sistema en serie-paralelo
En este caso tenemos un sistema con 3 componentes, dos de ellas
dispuestas en paralelo y una terceera en serie respecto a éstas.
La función de estructura de este sistema se puede expresar como
φ(x) = min(max(x1, x2), x3)
donde x1, x2, x3 representan los respectivos estados de las compo-
nentes del sistema.

56 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
Si realizamos una prueba de tamaño 10 obtenemos la siguiente
matriz con los estados de las componentes y el estado del sistema
x_1 x_2 x_3 y0
[1,] 0.4329608 0.3705834 0.8395797 0
[2,] 0.3145403 0.3050827 0.3124987 0
[3,] 0.4242714 0.8300201 0.4917430 0
[4,] 0.4294401 0.4806328 0.3677576 0
[5,] 0.5662342 0.5956461 0.6169936 1
[6,] 0.3804457 0.6003780 0.8477476 1
[7,] 0.5343947 0.5412207 0.5370629 1
[8,] 0.5215895 0.8862497 0.5291154 1
[9,] 0.7012158 0.5149956 0.8805000 1
[10,] 0.8952660 0.5949963 0.8091968 1
Al igual que en los casos anteriores, ajustando el modelo logístico,
obtenemos el siguiente resumen de resultados
[[1]]
beta.0 beta.1 beta.2 beta.3
m.betas -15.529792 5.760361 5.745859 16.519198
se.betas 3.804046 2.036187 1.779591 5.413116
sd.betas 7.006675 2.840269 2.115077 24.164045
[[2]]
p.value CPM
summary 0.00100041 0.8871267
Para el sistema serie-paralelo la capacidad predictiva del modelo
es bastante buena, del 88%. El p-valor obtenido en este ejemplo es
de 0.001.
En esta simulación se re�eja que la componente 3, la cual se en-
cuentra en serie respecto a las otras dos componentes que forman
un módulo en paralelo, tiene una importancia mucho mayor en el
funcionamiento del sistema. Este hecho tiene sentido, ya que si la

3.5. SIMULACIONES 57
tercera componente falla, el sistema dejará de funcionar. Sin em-
bargo, si falla sólo la componente 1 o la componente 2, el sistema
continuará en funcionamiento.
Caso 4. Sistema en puente
En este ejemplo tenemos un sistema con 5 componentes dis-
puestas como se muestra a continuación
La función de estructura de este sistema se puede expresar como
φ(x) = max(min(x1, x4),min(x2, x5),min(x1, x3, x5),
min(x2, x3, x4))
donde x1, x2, x3, x4, x5 representan los estados de las cinco compo-
nentes del sistema.
Si realizamos una prueba de tamaño 10 obtenemos la siguiente
matriz con los estados de las componentes y el estado del sistema
x_ 1 x_ 2 x_ 3 x_ 4 x_ 5 y
[1,] 0.4329608 0.3705834 0.8395797 0.4203651 0.8763243 0
[2,] 0.3145403 0.3050827 0.3124987 0.8837189 0.7328086 0
[3,] 0.4242714 0.8300201 0.4917430 0.5814801 0.6433845 1
[4,] 0.4294401 0.4806328 0.3677576 0.8404032 0.4073213 0
[5,] 0.5662342 0.5956461 0.6169936 0.3026557 0.5368664 1
[6,] 0.3804457 0.6003780 0.8477476 0.8269504 0.4205405 1

58 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL
[7,] 0.5343947 0.5412207 0.5370629 0.7876191 0.7937319 1
[8,] 0.5215895 0.8862497 0.5291154 0.8651818 0.7070794 1
[9,] 0.7012158 0.5149956 0.8805000 0.4437783 0.4464304 0
[10,] 0.8952660 0.5949963 0.8091968 0.7530033 0.8597410 1
Al igual que en los casos anteriores, ajustando el modelo logístico,
obtenemos el siguiente resumen de resultados
[[1]]
beta.0 beta.1 beta.2 beta.3 beta.4 beta.5
m.betas -12.012323 5.549212 5.652446 1.841044 5.579165 5.576709
se.betas 3.114312 2.088085 2.011206 1.611218 2.151980 2.166964
sd.betas 4.162128 3.605022 5.326670 1.260466 2.847197 3.258897
[[2]]
p.value CPM
summary 0.00215754 0.8313787
Para el sistema puente la capacidad predictiva del modelo es de
0.83, es decir, explica correctamente más del 80% de las prediccio-
nes. El p-valor obtenido en esta simulación es de 0.002.
Si nos centramos en la importancia de las componentes, se ob-
serva que la componente 3 es la que menos peso tiene en el fun-
cionamiento del sistema, mientras que las otras cuatro tienen una
importancia muy parecida. Este resultado es totalmente coherente
con la disposición de las componentes.
Si nos �jamos en las matrices de los estados de las componentes
y del estado de los sistemas, observamos que el sistema en serie
funciona en muy pocos casos, mientras que el sistema en serie-
paralelo lo hace en un mayor número de pruebas. Los sistemas
cuyas componentes se disponen en paralelo, serie-paralelo y puen-
te, respectivamente son los que funcionan en más ocasiones. Este
suceso es totalmente coherente con la disposición de las compo-
nentes, pues el sistema en serie requiere que las tres componentes

3.5. SIMULACIONES 59
estén en funcionamiento para funcionar, mientras que el sistema
en paralelo por ejemplo funcionará siempre que, al menos, una de
las componentes esté funcionando.
Cabe destacar que en los cuatro tipos de sistemas se han consi-
derado componentes con un estado entre 0.01 y 0.9.
Finalmente, si nos �jamos en la segunda �la de los resultados
obtenidos, en cada uno de los casos vemos que, para cada sistema,
los errores para los coe�cientes son bastante similares.

60 CAPÍTULO 3. ANÁLISIS DE ESTRUCTURAS MEDIANTE RL

Capítulo 4
Modelo de regresión logística local
4.1. Introducción
Los modelos lineales generalizados (McCullagh y Nelder 1989)
proporcionan una extensión de la regresión lineal para modelos de
verosimilitud, por ejemplo, cuando las respuestas son binarias. En
este capítulo trabajaremos desde el punto de vista de la probabili-
dad local. Esta idea fue propuesta por primera vez por Brillinger
(1977) y estudiada en detalle por Tibshirani (1984), Tibshirani y
Hastie (1987) y Staniswalis (1989) entre otros. En la sección 4.2 se
describe el modelo de probabilidad local junto con una pequeña
discusión acerca de los ajustes con el paquete LOCFIT. En la sec-
ción 4.3 abordamos la estimación logística local de la función de
�abilidad en el caso de un sistema continuo.
4.2. Modelo de Probabilidad Local
En los capítulos anteriores, hemos asumido un modelo de regre-
sión con respuesta binaria (estado del sistema)
Yi ∼ B (R (x))
, donde hemos considerado en particular que la transformación logit
del parámetro R es una función lineal de los estados de las com-
ponentes. En muchas ocasiones prácticas este modelo paramétrico
61

62 CAPÍTULO 4. MODELO DE REGRESIÓN LOGÍSTICA LOCAL
podría resultar demasiado restrictivo. De modo que lo más apro-
piado sería asumir un modelo no paramétrico en el que el logit es
una función cuya forma no es especi�cada de antemano, en otras
palabras
R(x) =ef(x)
1+ ef(x).
Si admitimos que f es una función suave en el sentido de que existe
al menos la primera derivada, podemos considerar un desarollo en
serie de Taylor alrededor de un valor concreto x0, de la siguiente
forma
logit(x) = f (x0) +∇f (x0)′ (x− x0)
siendo esta aproximación válida en un entorno del punto x0; y, don-
de ∇f (x0) =(∂f∂x1, . . . , ∂f
∂xm
)|x0 es el vector gradiente de f evaluado
en el punto x0.
Si denotamos β0 = f (x0), y βj =∂f∂xj
(x0), podemos expresar el mo-
delo logístico no paramétrico para R(x) escrito arriba como un mo-
delo lineal localmente. Este modelo local ya no supone una forma
parámetrica para la función logit, pero ajusta un modelo lineal lo-
calmente dentro de una ventana de suavizado. La log-verosimilitud
polinomial local puede escribirse
`x0(β) =n∑i=1
wh(xi − x0) {Yi log (R0(xi)) + (1−Yi) (1− log (R0(xi)))} .
donde
R0(xi) =eβ
′(xi−x0)
1+ eβ′(xi−x0);
y donde wh(xi−x0) es una función núcleo que determina los pesos
asignados a las observaciones alrededor del punto x0, se consideran
así para asegurar que la aproximación lineal de la función f se
aplica en el entorno donde es válida. En este sentido, aunque otras
opciones más generales son admisibles, elegimos como función peso
la siguiente
wh(xi − x0) =m∏j=1
{K
(xij − x0j
h
)/h
}

4.2. MODELO DE PROBABILIDAD LOCAL 63
donde h es un parámetro ancho de banda que controla el tamaño
del entorno alrededor del punto x0 donde la aproximación local es
válida. La función K es una función núcleo que suele elegirse como
una función de densidad con soporte compacto, usualmente en el
intervalo [−1, 1].
Maximizando sobre el parámetro β obtenemos la estimación lo-
cal de la función f , de modo que el valor estimado de β0 proporciona
una estimación de f en el punto x0 y los demás valores estimados
del vector β proporcionan estimaciones de las derivadas parciales
de la función f evaluadas en el vector x0, es decir
β0 = f (x0)
βj =∂f
∂xj(x0) , j = 1, 2, . . . ,m.
Verosimilitud Local con LOCFIT
LOCFIT implementa la regresión local con una variedad de fa-
milias y funciones de enlace. En nuestro estudio nos interesa la
familia Binomial. Veamos un ejemplo.
Ejemplo En este ejemplo usaremos los datos de mortalidad de
Henderson y Sheppard (1919) para los que se conoce tanto el nú-
mero de muertes como el número de pacientes para cada edad. El
número de pruebas en cada edad es dado como el argumento pesos
en la función loc�t():
> fit<-locfit(deaths~age, weights=n,
+ family="binomial", data=morths, alpha=0.5)
> plot(fit, band="g", get.data=T)
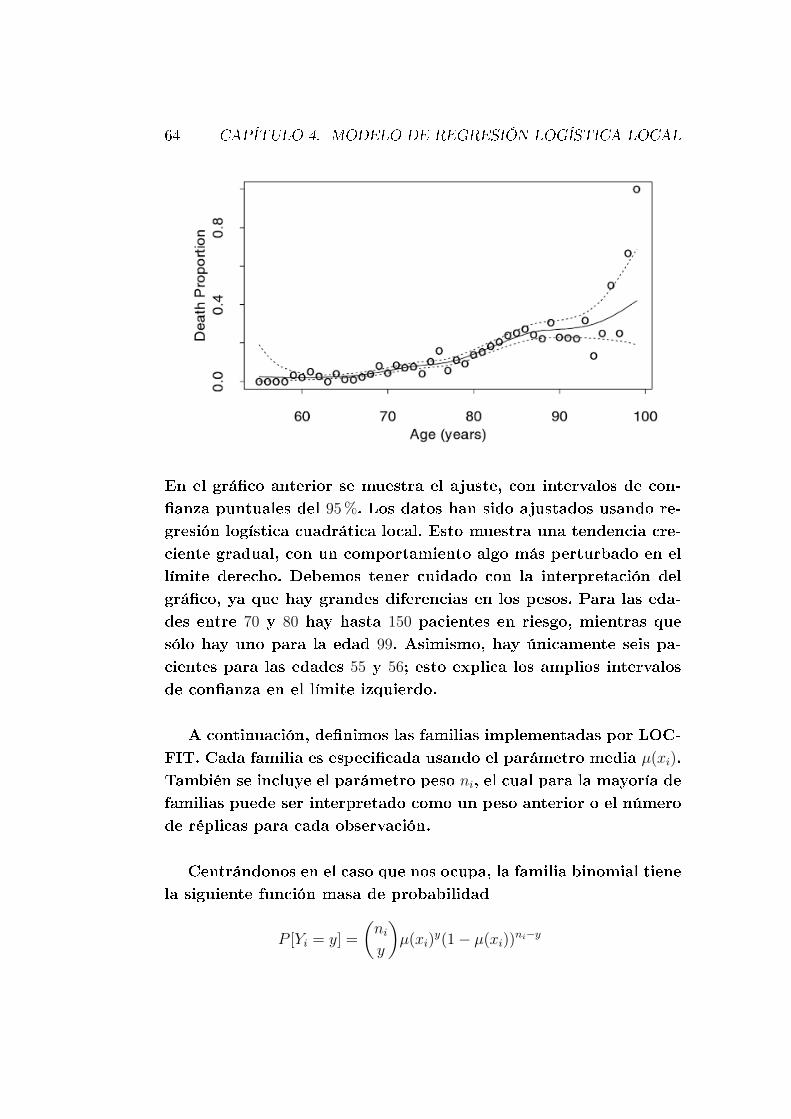
64 CAPÍTULO 4. MODELO DE REGRESIÓN LOGÍSTICA LOCAL
En el grá�co anterior se muestra el ajuste, con intervalos de con-
�anza puntuales del 95%. Los datos han sido ajustados usando re-
gresión logística cuadrática local. Esto muestra una tendencia cre-
ciente gradual, con un comportamiento algo más perturbado en el
límite derecho. Debemos tener cuidado con la interpretación del
grá�co, ya que hay grandes diferencias en los pesos. Para las eda-
des entre 70 y 80 hay hasta 150 pacientes en riesgo, mientras que
sólo hay uno para la edad 99. Asimismo, hay únicamente seis pa-
cientes para las edades 55 y 56; esto explica los amplios intervalos
de con�anza en el límite izquierdo.
A continuación, de�nimos las familias implementadas por LOC-
FIT. Cada familia es especi�cada usando el parámetro media µ(xi).
También se incluye el parámetro peso ni, el cual para la mayoría de
familias puede ser interpretado como un peso anterior o el número
de réplicas para cada observación.
Centrándonos en el caso que nos ocupa, la familia binomial tiene
la siguiente función masa de probabilidad
P [Yi = y] =
(niy
)µ(xi)
y(1− µ(xi))ni−y

4.3. RL LOCAL DE LA FUNCIÓN DE FIABILIDADDE UN SISTEMACONTINUO65
para y = 0, 1, ..., ni. La distribución de Bernoulli (ni = 1) representa
el resultado de un solo ensayo con probabilidad de éxito µ(xi). La
distribución binomial cuenta el número de éxitos en ni ensayos in-
dependientes.
4.3. RL local de la función de �abilidad de un
sistema continuo
Como sabemos la función de �abilidad de un sistema coherente
es una función no decreciente en cada argumento. Esta condición
no está asegurada por el procedimiento que hemos explicado en la
sección anterior, salvo que determinadas restricciones se impongan
en el proceso de estimación máximo verosímil local. En este caso,
no resolvemos el problema globalmente, sino que �jamos un punto
de estimación x0 y resolvemos un problema de estimación máximo
verosimímil y repetimos el procedimiento de modo que de alguna
manera podemos construir la función R en todo el espacio Vm =
[0, 1]m. Para que la estimación de la función R sea compatible con un
sistema coherente debemos asegurar de alguna manera que R (x1) ≤R (x2), siempre que x1 ≺ x2, donde ≺ es la relación de orden parcial
usual considerada en Vm = [0, 1]m.
Para asegurar esta situación proponemos un proceso de isotoni-
zación similar al empleado en Gámiz et al (2011) donde se generaliza
al caso multidimensional el problema de isotonización simple pro-
puesto por Ayer et al. (1955). El problema de isotonización simple
puede formularse como sigue:
"Sea {(xj, yj); j = 1, 2, . . . , n} un conjunto de datos bidimensio-
nal tal que los valores de xj están ordenados en orden crecien-
te. Se trata de encontrar {f(xj), j = 1, 2, . . . , n} tal que minimice
n−1∑n
j=1 (yj − f(xj))2 sujeto a la restricción f(x1) ≤ f(x2) ≤ . . . ≤
f(xn)".
Una solución puede ser obtenida mediante el algoritmo PA-
VA (Pool Adjacent Violators Algorithm) propuesto por Ayer et

66 CAPÍTULO 4. MODELO DE REGRESIÓN LOGÍSTICA LOCAL
al. (1955) y que puede resumirse en los siguientes pasos
Algoritmo PAVA
1o. Empezamos con y1. Nos movemos hacia la derecha y paramos
si el par (yj, yj+1) viola la condición de monotonía, esto es, si
yj > yj+1. En ese caso, yj y su adyacente yj+1 son reemplazados
por el valor promedio
y•j = y•j+1 =yj + yj+1
2
2o. A continuación, comprobamos que yj−1 ≤ yj. En otro caso sus-
tituimos yj−1, yj, yj+1 por el valor promedio. Nos movemos hacia
la izquierda hasta que la condición de monotonía se satisface.
Entonces procedemos de nuevo hacia la derecha.
La solución �nal es f(y1) ≤ f(y2) ≤ . . . ≤ f(yn).
Gámiz y Martínez-Miranda (2010) proponene una solución al
caso mulidimensional. En primer lugar se trata de de�nir una red
de d puntos en el intervalo [0, 1], es decir G = {l/d; l = 1, 2, . . . , d}, yconsideran Gm = G×G×. . .×G. Calculamos los valores del estimador
de R tal como se describe en la sección anterior en cada punto x de
la red. El problema de isotonización para el caso m-dimensional se
resuelve basándose en la solución del problema para el caso (m−1)-
dimensional. En otras palabras, �jamos una componente del punto
x, por ejemplo x1. Cada valor de x1 genera un problema de isotoni-
zación de orden m− 1. De modo que si el problema es resuelto en
una dimensión menor, se puede continuar. En la última etapa, te-
nemos un problema unidimensional de modo que podemos aplicar
el algoritmo PAVA.
Ejemplo. Sistema serie-paralelo
Hemos considerado un caso particular del sistema con tres com-
ponentes las dos primeras dispuestas en paralelo y en serie con la
tercera, como en la �gura de la página 52 especi�cado en el caso 3

4.3. RL LOCAL DE LA FUNCIÓN DE FIABILIDADDE UN SISTEMACONTINUO67
Figura 4.1: Estimación local de un sistema serie-paralelo
de la sección 3.5. Hemos simulado una muestra de tamaño n = 250
y hemos aplicado el procedimiento descrito arriba. El resultado
puede verse en la �gura a continuación para distintos niveles de
funcionamiento de la componente que está en serie.

68 CAPÍTULO 4. MODELO DE REGRESIÓN LOGÍSTICA LOCAL

Bibliografía
Aven T (1993) On performance measures for multistate
monotone systems. Reliab Eng Syst Safety 41:259�266
Barlow, R.E. and Proschan, F. (1975) Statistical theory of
Reliability and life testing, Holt, Rinehart and Winston, Inc.
Baxter, L.A. (1984). Continuum structures I. Journal of
Applied Probability, 21, 802-815
Birnbaum, Z.W. (1969). 'On the importance of di�erent
components in a multicomponent system', Multivariate
Analysis II (Academic Press, NY), pg 581-592.
Brunelle R.D., y Kapur, K.C. (1998). Continuous state system
reliability: an interpolation approach. IEEE Transactions on
Reliability, 31, 1171-1180.
Burdakow O, Grimwall A, Hussian M (2004) A generalised
PAV algorithm for monotonic regression in several variables.
COMPSTAT'2004 Symposium
Gamiz, M.L., Kulasekera, K.B., Limnios, N., y Lindqvist,
B.H. (2011), Applied nonparametric statistics in Reliability,
Springer.
Gámiz, M.L., Martínez-Miranda MD (2010) Regression
analysis of the structure function for reliability evaluation of
continuous-state system. Reliab Eng Syst 95(2):134�142
Hosmer, D.W. y Lemeshow, S. (2000), Applied logistic
regression, John Wiley and Sons.
Lisnianski A (2001) Estimation of boundary points for
continuum-state system reliability measures. Reliab Eng Syst
Safety 74:81�88
69

70 BIBLIOGRAFÍA
Modarres, M., Kaminskiy, M. and Krivtsov, V. (2010)
Reliability Engineering and Risk Analysis: A Practical guide,
Taylor and Francis Group.
Mteza, P.Y.: Bounds for the reliability of binary coherent
systems. Ph.D. thesis (2014)




















