
REGRESIÓN NO LINEAL
15
1 REGRESIÓN NO LINEAL Índice 1. ¿CUÁNDO EXISTE REGRESIÓN? .............................................................................................................. 1 2. TIPOS DE REGRESIÓN ............................................................................................................................... 2 3. REPRESENTATIVIDAD DE LA CURVA DE REGRESIÓN .......................................................................... 3 3.1. Poder explicativo del modelo...................................................................................................................... 3 3.2. Poder explicativo frente a poder predictivo ................................................................................................ 3 3.3. Causalidad .................................................................................................................................................. 4 3.4. Extrapolación .............................................................................................................................................. 4 4. REGRESIÓN NO LINEAL E INFERENCIA ................................................................................................... 4 5. LINEALIZACIÓN............................................................................................................................................ 5 6. MÍNIMOS CUADRADOS ORDINARIOS Y PONDERADOS......................................................................... 5 7. ESTIMACIÓN DE LOS PARÁMETROS CON EL MÉTODO MONTE CARLO............................................. 5 8. ALGORITMO DE GAUSS–NEWTON ........................................................................................................... 5 8.1. El problema................................................................................................................................................. 6 8.2. El algoritmo ................................................................................................................................................. 6 8.3. Otros algoritmos ......................................................................................................................................... 6 9. REGRESIÓN NO LINEAL ............................................................................................................................. 7 9.1. Parábola de regresión ................................................................................................................................ 7 9.2. Regresión hiperbólica ................................................................................................................................. 8 9.3. Función exponencial, potencial, y logarítmica............................................................................................ 8 10. EJEMPLOS DE REGRESIÓN NO LINEAL ............................................................................................... 10 10.1. Ajuste de una función parabólica: Y * = a + b X + c X 2 ............................................................................. 10 10.2. Ajuste de una función potencial: Y * = a X b .............................................................................................. 11 10.3. Ajuste de una función exponencial: Y * = a b X ......................................................................................... 12 11. RELACIÓN NO LINEAL Y NO LINEALIZABLE......................................................................................... 12 12. BIBLIOGRAFÍA.......................................................................................................................................... 15 1. ¿Cuándo existe regresión? De una forma general, lo primero que suele hacerse para ver si dos variables aleatorias están relacionadas o no (de ahora en adelante se denominarán X e Y , siendo Y la variable dependiente, y X la variable independiente o regresora), consiste en tomar una muestra aleatoria. Sobre cada individuo de la muestra se analizan las dos características en estudio, de modo que para cada individuo se tenga un par de valores ( ) ( ) , 1,2, , i i x y i n = … . Seguidamente, se representan dichos valores en unos ejes cartesianos, dando lugar a un diagrama de dispersión o nube de puntos. Así, cada individuo vendrá representado por un punto en el gráfico, de coordenadas ( ) , i i x y . De esa forma, se podrá obtener una primera idea acerca de la forma y de la dispersión de la nube de puntos. Al dibujar la nube de puntos, se encontrará, entre otros, casos como los que hace referencia la figura 1. En primer lugar deberá distinguirse entre dependencia funcional y dependencia estocástica. En el primer caso la relación es perfecta: ( ) Y f X = (figura 1d y 1e); es decir, los puntos del diagrama de dispersión correspondiente aparecen sobre la función ( ) Y f X = . Por ejemplo, en 1d sería Y a bX = + . Sin embargo, suele ocurrir que no existe una dependencia funcional perfecta, sino otra dependencia o relación menos rigurosa o dependencia estocástica (figura 1b y 1c). Entonces, la relación entre X e Y , se escribiría (en el caso de la figura 1b) de la forma Y a bX e = + + , donde e es un error (o residual), debido por ejemplo, a no incluir variables en el modelo que sean importantes a la hora de explicar el
-
Upload
independent -
Category
Documents
-
view
5 -
download
0
Transcript of REGRESIÓN NO LINEAL

1
REGRESIÓN NO LINEALÍndice
1. ¿CUÁNDO EXISTE REGRESIÓN? .............................................................................................................. 12. TIPOS DE REGRESIÓN ............................................................................................................................... 23. REPRESENTATIVIDAD DE LA CURVA DE REGRESIÓN .......................................................................... 33.1. Poder explicativo del modelo...................................................................................................................... 33.2. Poder explicativo frente a poder predictivo ................................................................................................ 33.3. Causalidad.................................................................................................................................................. 43.4. Extrapolación .............................................................................................................................................. 44. REGRESIÓN NO LINEAL E INFERENCIA................................................................................................... 45. LINEALIZACIÓN............................................................................................................................................ 56. MÍNIMOS CUADRADOS ORDINARIOS Y PONDERADOS......................................................................... 57. ESTIMACIÓN DE LOS PARÁMETROS CON EL MÉTODO MONTE CARLO............................................. 58. ALGORITMO DE GAUSS–NEWTON ........................................................................................................... 58.1. El problema................................................................................................................................................. 68.2. El algoritmo................................................................................................................................................. 68.3. Otros algoritmos ......................................................................................................................................... 69. REGRESIÓN NO LINEAL ............................................................................................................................. 79.1. Parábola de regresión ................................................................................................................................ 79.2. Regresión hiperbólica................................................................................................................................. 89.3. Función exponencial, potencial, y logarítmica............................................................................................ 810. EJEMPLOS DE REGRESIÓN NO LINEAL............................................................................................... 1010.1. Ajuste de una función parabólica: Y* = a + b X + c X2............................................................................. 1010.2. Ajuste de una función potencial: Y* = a Xb .............................................................................................. 1110.3. Ajuste de una función exponencial: Y* = a bX ......................................................................................... 1211. RELACIÓN NO LINEAL Y NO LINEALIZABLE......................................................................................... 1212. BIBLIOGRAFÍA.......................................................................................................................................... 15
1. ¿Cuándo existe regresión?De una forma general, lo primero que suele hacerse para ver si dos variables aleatorias están relacionadaso no (de ahora en adelante se denominarán X e Y , siendo Y la variable dependiente, y X la variableindependiente o regresora), consiste en tomar una muestra aleatoria. Sobre cada individuo de la muestra seanalizan las dos características en estudio, de modo que para cada individuo se tenga un par de valores
( )( ), 1, 2, ,i ix y i n= … .
Seguidamente, se representan dichos valores en unos ejes cartesianos, dando lugar a un diagrama dedispersión o nube de puntos. Así, cada individuo vendrá representado por un punto en el gráfico, decoordenadas ( ),i ix y . De esa forma, se podrá obtener una primera idea acerca de la forma y de la
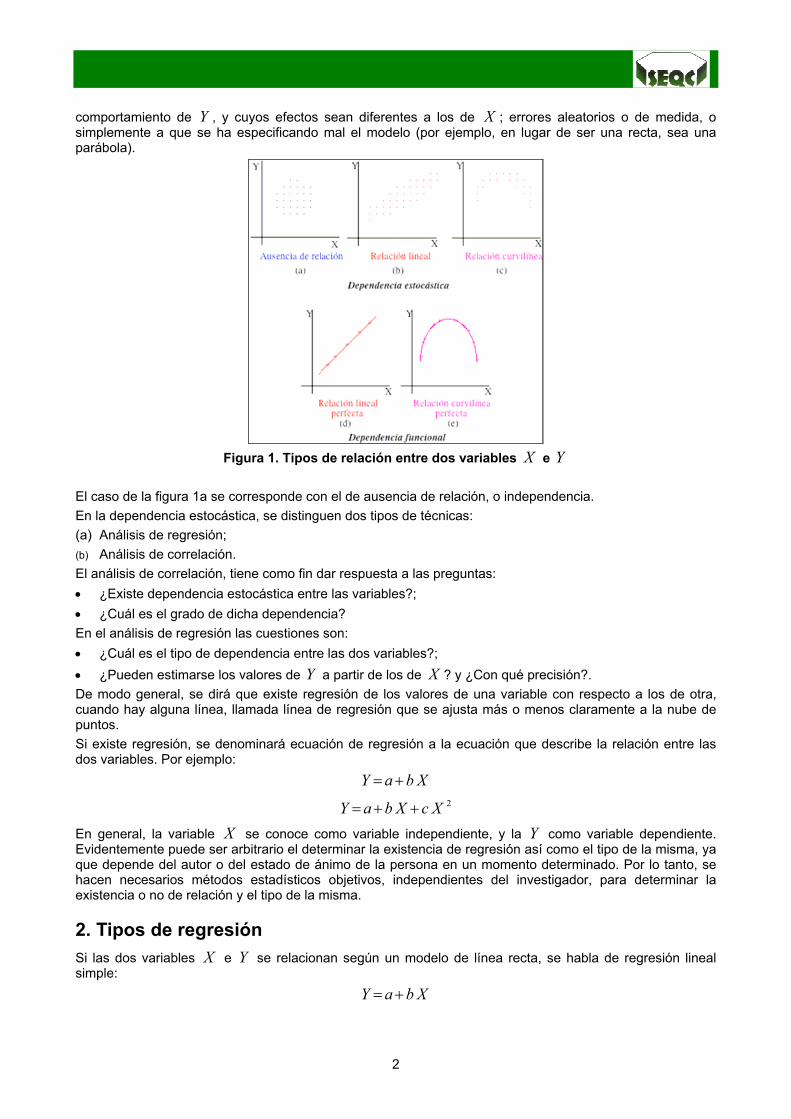
dispersión de la nube de puntos. Al dibujar la nube de puntos, se encontrará, entre otros, casos como losque hace referencia la figura 1.En primer lugar deberá distinguirse entre dependencia funcional y dependencia estocástica. En el primercaso la relación es perfecta: ( )Y f X= (figura 1d y 1e); es decir, los puntos del diagrama de dispersión
correspondiente aparecen sobre la función ( )Y f X= . Por ejemplo, en 1d sería Y a b X= + .
Sin embargo, suele ocurrir que no existe una dependencia funcional perfecta, sino otra dependencia orelación menos rigurosa o dependencia estocástica (figura 1b y 1c). Entonces, la relación entre X e Y , seescribiría (en el caso de la figura 1b) de la forma Y a b X e= + + , donde e es un error (o residual), debidopor ejemplo, a no incluir variables en el modelo que sean importantes a la hora de explicar el
2
comportamiento de Y , y cuyos efectos sean diferentes a los de X ; errores aleatorios o de medida, osimplemente a que se ha especificando mal el modelo (por ejemplo, en lugar de ser una recta, sea unaparábola).
Figura 1. Tipos de relación entre dos variables X e Y
El caso de la figura 1a se corresponde con el de ausencia de relación, o independencia.En la dependencia estocástica, se distinguen dos tipos de técnicas:(a) Análisis de regresión;(b) Análisis de correlación.El análisis de correlación, tiene como fin dar respuesta a las preguntas:• ¿Existe dependencia estocástica entre las variables?;• ¿Cuál es el grado de dicha dependencia?En el análisis de regresión las cuestiones son:• ¿Cuál es el tipo de dependencia entre las dos variables?;• ¿Pueden estimarse los valores de Y a partir de los de X ? y ¿Con qué precisión?.De modo general, se dirá que existe regresión de los valores de una variable con respecto a los de otra,cuando hay alguna línea, llamada línea de regresión que se ajusta más o menos claramente a la nube depuntos.Si existe regresión, se denominará ecuación de regresión a la ecuación que describe la relación entre lasdos variables. Por ejemplo:
Y a b X= +2Y a b X c X= + +
En general, la variable X se conoce como variable independiente, y la Y como variable dependiente.Evidentemente puede ser arbitrario el determinar la existencia de regresión así como el tipo de la misma, yaque depende del autor o del estado de ánimo de la persona en un momento determinado. Por lo tanto, sehacen necesarios métodos estadísticos objetivos, independientes del investigador, para determinar laexistencia o no de relación y el tipo de la misma.
2. Tipos de regresiónSi las dos variables X e Y se relacionan según un modelo de línea recta, se habla de regresión linealsimple:
Y a b X= +

3
Cuando las variables X e Y se relacionan según una línea curva, se habla de regresión no lineal ocurvilínea. Aquí se puede distinguir entre regresión parabólica, exponencial, potencial, etc.
Cuando hay más de una variable independiente ( )1 2, , , nX X X… , y una sola variable dependienteY , se
habla de regresión múltiple. Las variables iX se denominan, regresoras, predictoras o independientes.
3. Representatividad de la curva de regresión
3.1. Poder explicativo del modelo
La curva de regresión, tiene carácter de línea media que trata de resumir o sintetizar la informaciónsuministrada por los datos. Si tiene carácter de línea media (de promedio, en definitiva), deberá iracompañada siempre de una medida que exprese su representatividad, es decir, de lo buena que es lacurva, ya que el haber obtenido la mejor de todas no da garantías de que sea buena. Se necesita, por tanto,una medida de dispersión, que tenga en cuenta la dispersión de cada observación con respecto a la curva,es decir, lo alejado que se encuentra cada punto de la curva. Es decir, se debe evaluar esas distanciasverticales a la curva, es decir, los errores o residuales.Si las dispersiones son pequeñas, la curva será un buen representante de la nube de puntos, o lo que es lomismo, la bondad de ajuste del modelo será alta. Si la dispersión es grande, la bondad de ajuste será baja.Una forma de medir dicha bondad de ajuste es precisamente evaluando la suma de los cuadrados de loserrores. Por tanto, se llamará varianza residual a la expresión:
( ) 2*
12
n
i ii
e
y yS
n=
−=∑
Si la varianza residual es grande, el modelo será malo, es decir, la curva no explicará el comportamientogeneral de la nube.La cota máxima de la varianza residual es la varianza que se trata de explicar mediante el modelo deregresión, es decir, la varianza de la variable dependiente. Por tanto, sin más que hacer relativa la varianzaresidual respecto de su máximo valor, y multiplicando por 100, se obtiene el porcentaje de variación noexplicado por el modelo:
2
2% 100e
y
Sde variaciones sin explicar
s=
En el que es fácil obtener una medida 2R o coeficiente de determinación que indique el porcentaje devariación controlada o explicada mediante el modelo. Expresado en tantos por 1, será:
22
21 e
y
SR
s= −
Como puede observarse, a partir de la expresión anterior: 20 1R< < . Por tanto:
• Si 2 1R = no hay residuos: habrá una dependencia funcional. Cuanto más se acerque dicho valor a launidad, mayor poder explicativo tendrá el modelo de regresión. Cuanto más cercano a 0 esté dichovalor, menor poder explicativo;
• Si 2 0R = entonces X no explica en absoluto ninguna de las variaciones de la variable Y , de modoque o bien el modelo es inadecuado, o bien las variables son independientes.
3.2. Poder explicativo frente a poder predictivo
Un modelo de regresión con un alto porcentaje de variaciones explicado, puede no ser bueno para predecir,ya que el que la mayoría de los puntos se encuentren cercanos a la recta de regresión, no implica que todos

4
lo estén, y puede ocurrir, que justamente para aquel rango de valores en el que el investigador estáinteresado, se alejen de la recta, y por tanto, el valor predictivo puede alejarse mucho de la realidad.La única forma de poder evaluar el poder predictivo del modelo es tras la observación y el análisis de losgráficos de residuales, es decir, de diagramas de dispersión, en los que en el eje de ordenadas se colocanlos residuales, y en el eje de abscisas se colocan o bien X , Y , o *Y .Sólo si la banda de residuales es homogénea, y se encuentran todos los puntos no demasiado alejados del0 (aunque depende de la escala de medida), diremos, que un modelo con un alto poder explicativo, tambiénes bueno para predecir.
3.3. Causalidad
Es muy importante resaltar el hecho, de que un modelo sea capaz de explicar de manera adecuada lasvariaciones de la variable dependiente en función de la independiente, no implica que la primera sea causade la segunda.Es un error muy común confundir causalidad con casualidad. El hecho de que las variables esténrelacionadas no implica que una sea causa de la otra, ya que puede ocurrir el hecho de que se esté dandouna variación concomitante, por el simple hecho de que las dos son causa de una tercera. Por ejemplo, sise realiza un estudio en el que se analiza el número de canas ( )X y la presión arterial ( )Y podríaencontrarse una relación lineal casi perfecta. Eso no significa que el tener canas aumente la presión arterial,lo que verdaderamente está ocurriendo es que es la edad, la causante, de que se tengan más canas y unatendencia a tener más alta la presión arterial.
3.4. Extrapolación
Es importante resaltar el hecho de que al hacer predicciones, no deben extrapolarse los resultados más alládel rango de la variable X utilizado para ajustar el modelo, ya que más allá de ese rango se desconocequé puede estar ocurriendo.De todos es conocido que las plantas necesitan abono para poder crecer y que hay que abonarlas, de modoque en principio, cuanto más abono se les suministre más crecerán. Pero ¿qué ocurriría si se abonasedemasiado el suelo? Obviamente, moriría la planta. Esto se traduce en que conforme aumenta la cantidadde abono, el crecimiento es más notable, pero a partir de un punto, la planta deja de crecer y muere, comorefleja la figura 2 que ilustra el peligro de extrapolar los resultados.
Figura 2: Comparación de una posible verdadera relación entre cantidad de abono y crecimiento deuna planta, con los resultados de una recta de regresión obtenida mediante el estudio de un rango
limitado de valores de abono.
4. Regresión no lineal e inferenciaEn estadística, la regresión no lineal es un problema de inferencia para un modelo tipo:
( ),y f x θ ε= +

5
basado en datos multidimensionales ,x y , donde f es alguna función no lineal respecto a algunosparámetros desconocidos θ . Como mínimo, se pretende obtener los valores de los parámetros asociadoscon la mejor curva de ajuste (habitualmente, con el método de los mínimos cuadrados). Con el fin dedeterminar si el modelo es adecuado, puede ser necesario utilizar conceptos de inferencia estadística talescomo intervalos de confianza para los parámetros así como pruebas de bondad de ajuste.
5. LinealizaciónAlgunos problemas de regresión no lineal pueden linealizarse mediante una transformación en laformulación del modelo. Por ejemplo, considérese el problema de regresión no lineal (ignorando el términode error):
( )expy a b x=
Aplicando logaritmos a ambos lados de la ecuación, se obtiene:
( ) ( )ln lny a b x= +
lo cual sugiere una estimación de los parámetros desconocidos a través de un modelo de regresión lineal de( )ln y con respecto a x , un cálculo que no requiere procedimientos de optimización iterativa. De todas
formas, la linealización debe usarse con cuidado ya que la influencia de los datos en el modelo cambia, asícomo la estructura del error del modelo y la interpretación e inferencia de los resultados, cosa que puedeser un inconvenientes.Hay que distinguir entre la "linealización" usada en los párrafos anteriores y la "linealización local" que seadopta para algoritmos clásicos como el de Gauss-Newton.
6. Mínimos cuadrados ordinarios y ponderadosSe considera la mejor curva de ajuste aquella que minimiza la suma de las desviaciones (residuales) alcuadrado (SRC). Esta es la aproximación por el método de mínimos cuadrados (MMC). Sin embargo, enaquellos casos donde se tienen diferentes varianzas de error para diferentes errores, es necesariominimizar la suma de los residuales al cuadrado ponderados (SRCP) (método de mínimos cuadradosponderados). En la practica, la varianza puede depender del valor promedio ajustado. Así que lasponderaciones son recalculadas para cada iteración en un algoritmo de mínimos cuadrados ponderadositerativo.En general, no hay una expresión de forma cerrada para los parámetros de mejor ajuste, como sucede en elcaso de la regresión lineal. Métodos numéricos de optimización son aplicados con el fin de determinar losparámetros de mejor ajuste. Otra vez, en contraste con la regresión lineal, podría haber varios máximoslocales de la función a ser optimizada. En la práctica se suponen algunos valores iniciales los cuales juntocon el algoritmo de optimización conducen a encontrar el máximo global.
7. Estimación de los parámetros con el método Monte CarloSi el error de cada observación es conocido, entonces la precisión y confiabilidad de los parámetros puedeser estimada mediante simulación Monte Carlo. Cada observación es aleatorizada de acuerdo a su media ysu desviación estándar. Con el nuevo conjunto de datos, una nueva curva es ajustada y las estimaciones delos parámetros registradas. Las observaciones son entonces aleatorizadas y nuevos valores de losparámetros son obtenidos. Al final, se generan varios conjuntos de parámetros y pueden ser calculadas lamedia y desviación típica.
8. Algoritmo de Gauss–NewtonEn matemáticas, el algoritmo de Gauss–Newton se utiliza para resolver problemas no lineales de mínimoscuadrados. Es una modificación debida a CF Gauss del método de optimización de Newton que no usasegundas derivadas.

6
8.1. El problema
Dadas m funciones 1 2, , , mf f f… de n parámetros 1 2, , , np p p… con m n≥ , se desea minimizar lasuma:
( ) ( )( ) 21
n
ii
S p f p=
= ∑
donde p se refiere al vector ( )1 2, , , np p p… .
8.2. El algoritmo
El algoritmo de Gauss–Newton es un procedimiento iterativo. Esto significa que se debe proporcionar unaestimación inicial del parámetro vector denominado 0p .
Estimaciones posteriores kp para el vector parámetro son producidas por la relación recurrente:
( ) ( ) ( ) ( )1
1k k k k k kf f fp p J p J p J p f p
−+ ′ ′= −
donde ( )1 2, , , mf f f f= … y ( )fJ p es el Jacobiano de f en p (nótese que no es necesario que
fJ sea cuadrada).
En la práctica nunca se computa explícitamente la matriz inversa, en su lugar se utiliza:1k k kp p δ+ = +
y se computa la actualización de kδ resolviendo el sistema lineal:
( ) ( ) ( ) ( )k k k k kf f fJ p J p J p f pδ′ ′= −
Una buena implementación del algoritmo de Gauss-Newton utiliza también un algoritmo de búsqueda lineal:en lugar de la fórmula anterior para 1kp + , se utiliza:
1k k k kp p α δ+ = +
donde kα es de algún modo un número óptimo.
8.3. Otros algoritmos
La relación de recurrencia del método de Newton para minimizar la función S es:
( )( )( ) ( )11k k k kSp p H S p J p
−+ = −
donde SJ y ( )H S son respectivamente el Jacobiano y Hessiano de S .
Utilizando el método de Newton para la función:
( ) ( )( ) 21
m
ii
S p f p=
= ∑se obtiene la relación recurrente:
( ) ( ) ( ) ( )( ) ( ) ( )1
1
1
mk k
f f i i fi
p p J p J p f p H f p J p f p−
+
=
′ ′= − +
∑
7
Se puede concluir que el método de Gauss–Newton es el mismo que el método de Newton ignorando eltérmino ( )f H f∑ .
Otros algoritmos utilizados para resolver el problema de los mínimos cuadrados incluyen el algoritmo deLevenberg–Marquardt y el de descenso de gradiente
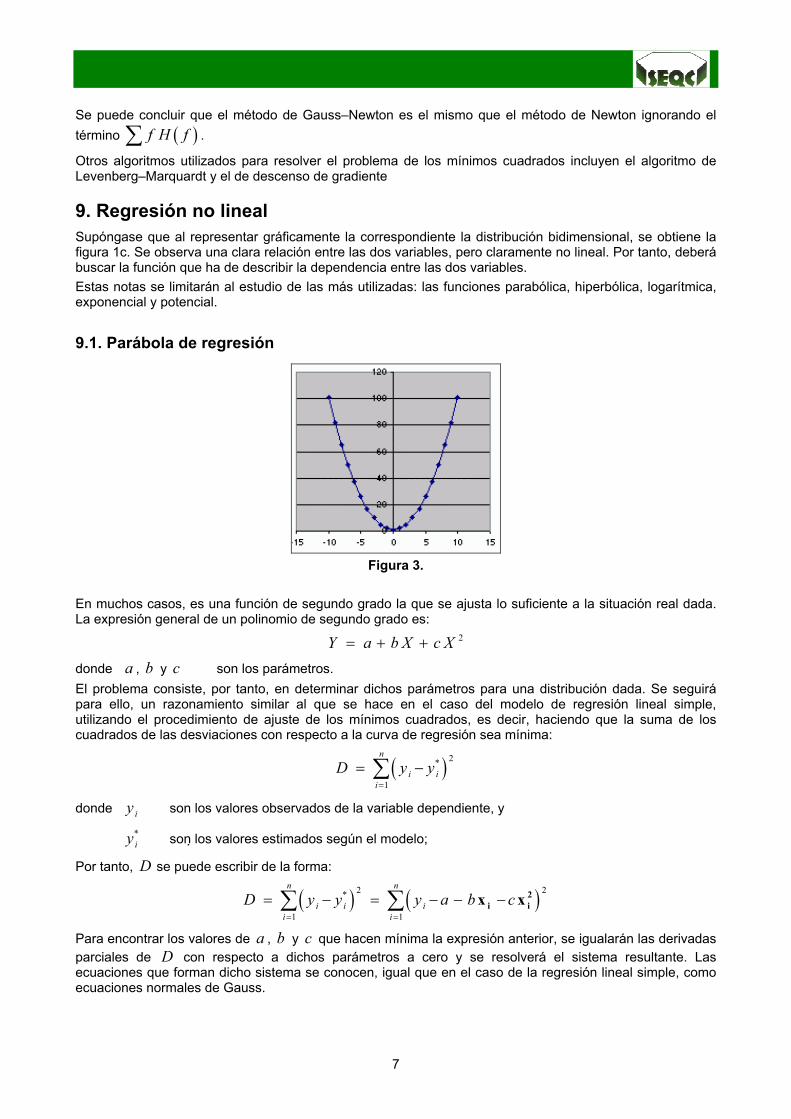
9. Regresión no linealSupóngase que al representar gráficamente la correspondiente la distribución bidimensional, se obtiene lafigura 1c. Se observa una clara relación entre las dos variables, pero claramente no lineal. Por tanto, deberábuscar la función que ha de describir la dependencia entre las dos variables.Estas notas se limitarán al estudio de las más utilizadas: las funciones parabólica, hiperbólica, logarítmica,exponencial y potencial.
9.1. Parábola de regresión
Figura 3.
En muchos casos, es una función de segundo grado la que se ajusta lo suficiente a la situación real dada.La expresión general de un polinomio de segundo grado es:
2Y a b X c X= + +
donde a , b y c son los parámetros.El problema consiste, por tanto, en determinar dichos parámetros para una distribución dada. Se seguirápara ello, un razonamiento similar al que se hace en el caso del modelo de regresión lineal simple,utilizando el procedimiento de ajuste de los mínimos cuadrados, es decir, haciendo que la suma de loscuadrados de las desviaciones con respecto a la curva de regresión sea mínima:
( ) 2*
1
n
i ii
D y y=
= −∑donde iy son los valores observados de la variable dependiente, y
*iy son los valores estimados según el modelo;
Por tanto, D se puede escribir de la forma:
( ) ( )2 2*
1 1
n n
i i ii i
D y y y a b c= =
= − = − − −∑ ∑ 2i ix x
Para encontrar los valores de a , b y c que hacen mínima la expresión anterior, se igualarán las derivadasparciales de D con respecto a dichos parámetros a cero y se resolverá el sistema resultante. Lasecuaciones que forman dicho sistema se conocen, igual que en el caso de la regresión lineal simple, comoecuaciones normales de Gauss.

8
2
1 1 1
2 3
1 1 1 1
2 2 3 4
1 1 1 1
n n n
i i ii i i
n n n n
i i i i ii i i i
n n n n
i i i i ii i i i
y n a b x c x
x y a x b x c x
x y a x b x c x
= = =
= = = =
= = = =
= + +
= + +
= + +
∑ ∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑
9.2. Regresión hiperbólica
Cuando la dependencia entre las variables X e Y es de forma hiperbólica, interesa ajustar a la nube depuntos una función del tipo:
by ax
= +
La función a minimizar será:
( ) 22,
, 1 , 1
ˆn n
i j ji j i j
M d y y= =
= = −∑ ∑
donde ˆ ii
by ax
= +
por tanto,2
, 1
n
ji j i
bM a yx=
= + −
∑
Para minimizar la expresión, se calculan las derivadas parciales respecto a los parámetros a y b ,igualando a cero:
, 1
, 1
2 0
12 0
n
ji j i
n
ji j i i
M ba ya x
M ba yb x x
=
=
∂= + − = ∂
∂
= + − = ∂
∑
∑En consecuencia, las ecuaciones normales serán:
, 1 1 1
21 1 , 1, 1
10
1 11 0
n n n
j ji j i ji i
n n nn j
ji i i ji i ii j i i
ba y a N b yx x
yb a ba y x x xx x
= = =
= = ==
+ − = + = ⇔ + = + − =
∑ ∑ ∑
∑ ∑ ∑∑
9.3. Función exponencial, potencial, y logarítmica
El problema de ajustar un modelo potencial, de la forma bY A X= y uno exponencial XY A B= sereduce al de la función lineal, con solo tomar logaritmos.
9
Figura 4.
Modelo potencialSi en la expresión de la función potencial se toman logaritmos, se obtiene:
log log logY A b X= +
que es la ecuación de una recta Y a b X= + , donde ahora loga A= . El problema se reduce a transformarY en logY y X en log X y ajustar una recta a los valores transformados. El parámetro b del modelopotencial coincide con el coeficiente de regresión de la recta ajustada a los datos transformados y A seobtiene mediante ( )antilog a .
Modelo exponencialEn determinados experimentos, en su mayoría biológicos, la dependencia entre las variables X e Y es deforma exponencial, en cuyo caso interesa ajustar a la nube de puntos una función del tipo:
( )expy a b x= + . Mediante una transformación lineal, tomando logaritmos neperianos, se convierte elproblema en una cuestión de regresión lineal. Es decir, tomando logaritmos neperianos:
ln y a b x= +
Y llamando lnY y= se tiene Y a b x= + (regresión lineal).
Para simplificar, descartando multiplicidades y suponiendo que cada par se repite una sola vez, lasecuaciones normales serán:
1 1
2
1 1 1
ln
ln
n n
i ii i
n n n
i i i ii i i
a N b x y
a x b x x y
= =
= = =
+ = + =
∑ ∑
∑ ∑ ∑
Calculando los parámetros a y b se tiene la ecuación de la función exponencial: ( )expy a b x= + .

10
Modelo logarítmico
Figura 5.
La curva logarítmica logY a b X= + es también una recta, pero en lugar de estar referida a las variablesoriginales X e Y , está referida a log X y a Y .
10. Ejemplos de regresión no lineal
10.1. Ajuste de una función parabólica: Y* = a + b X + c X2
X Y X2 X3 X4 XY X2Y Y* e=Y-Y* e2
1 1,25 1 1 1 1,25 1,25 1,18 0,07 0,00492 5 4 8 16 10 20 5,11 -0,11 0,01213 11,25 9 27 81 33,75 101,5 11,32 -0,07 0,00494 20 16 64 256 80 320 19,81 0,19 0,03615 30,5 25 125 625 152,5 762,5 30,58 -0,08 0,0064
Σ 15 68 55 225 979 277,5 1205 68 0 0,0644
1/5 Σ 3 13,6 11 55,5 13,6 0 0,0128
Aplicando el método de los mínimos cuadrados se obtiene el siguiente sistema de ecuaciones:
2
1 1 1
2 3
1 1 1 1
2 2 3 4
1 1 1 1
68 5 15 55277,5 15 55 2251205 55 225 979
n n n
i i i
n n n n
i i i i
n n n n
i i i i
Y N a b X c Xa b c
X Y a X b X c X a b ca b c
X Y a X b X c X
= = =
= = = =
= = = =
= + +
= + + = + + ⇒ = + + = + +
= + +
∑ ∑ ∑
∑ ∑ ∑ ∑
∑ ∑ ∑ ∑Resolviendo este sistema se obtiene:
* 2
0, 470,511,140,47 0,51 1,14
abcY X X
= −==
= − + +

11
Bondad del ajusteCoeficiente de determinación:
*2 2
22 2
0,012881 1 0,9998111,715
Y e
Y Y
S SR
S S= = − = − =
2
122 0,01288
N
ie
eS ECM
N== = =∑
10.2. Ajuste de una función potencial: Y* = a Xb
Linealizando:* *ln ln lnY a b X V A bU= + ⇒ = +…
X Y U=lnX V=lnY U2 UV Y* e=Y-Y* e2
1 1,25 0 0,2231 0 0 1,2557 -0,0057 0,00002 5 0,6931 1,6094 0,4803 1,1156 4,9888 0,0112 0,00013 11,25 1,0986 2,4203 1,2069 2,6590 11,18 0,0697 0,00494 20 1,3863 2,9957 1,9215 4,1530 19,82 0,1799 0,03245 30,5 1,6094 3,4177 2,5901 5,5006 30,901 -0,4012 0,1610
Σ 15 68 4,7875 10,666 6,1988 13,428 68,146 -0,1461 0,1984
1/5 Σ 3 13,6 0,9575 2,1332 1,2397 2,6856 13,629 -0,0292 0,0397
0e ≠∑
12 2
2 2
1
15 2,6856 0,9575 2,1332 1,9902
1,2397 0,957515
n
U V in
U
i
U V U VS
bS U U
=
=
−− ×
= = = =−−
∑
∑
2,1332 1,9902 0,9575 0,2277A V bU= − = − × =Se deshace el cambio efectuado:
ln ln 0,2277 1,2557a anti A anti= = =De modo que el ajuste efectuado es:
* 1,99021, 2557Y X=
Bondad del ajuste
2
13 0,0397
N
ii
eECM
N== =∑
Nótese que al haber transformado la variable dependiente ya no se minimiza 2e∑ sino
( ) 2*ln lnY Y−∑ de ahí que 0e ≠∑ .

12
10.3. Ajuste de una función exponencial: Y* = a bX
Linealizando:* *ln ln lnY a X b V A B X= + ⇒ = +…
X Y V=lnY X2 XV Y* e=Y-Y* e2
1 1,25 0,2231 1 0,2231 1,7794 -0,529 0,27982 5 1,6094 4 3,2188 3,86 1,138 1,29503 11,25 2,4203 9 7,2609 8,37 2,88 8,29444 20 2,9957 16 11,983 18,18 1,82 3,31245 30,5 3,4177 25 17,088 39,45 -8,95 80,102
Σ 15 68 10,666 55 39,774 71,64 -3,641 95,8031/5 Σ 3 13,6 2,1332 11 7,9548 14,328 -0,728 19,16
0e ≠∑
12 2
2 2
1
15 7,9548 2,1332 3 0,7776
11 315
n
X V in
X
i
X V X VS
BS X X
=
=
−− ×
= = = =−−
∑
∑
2,1332 0,7776 3 0,1996A V b X= − = − × = −Deshaciendo los cambios efectuados:
ln ln 0,1996 0,819ln ln 0,7776 2,176
a anti A antib anti B anti= = == = =
Por lo que el ajuste efectuado es:* 0,819 2,176 XY =
Bondad del ajuste
2
14 19,16
N
ii
eECM
N== =∑
La comparación de la bondad de modelos de regresión mediante el coeficiente de determinación sólo escorrecta cuando la variable dependiente no ha sido sometida a transformaciones no lineales (por ejemplo,una transformación logarítmica). En este ejercicio, mediante 2R sólo se puede comparar la regresión linealy la parabólica. Por eso, para comparar los cuatro ajustes efectuados se utiliza el error cuadrático medio(ECM). El mejor ajuste resulta ser el parabólico puesto que presenta el menor valor para el ECM.
11. Relación no lineal y no linealizableSe ha visto que los modelos lineales son útiles en muchas situaciones y aunque la relación entre la variablerespuesta y las variables regresoras no sea lineal, en muchos casos la relación es “linealizable” en elsentido de que transformando (logaritmos, inversa,...) la variable respuesta y/o algunas variables regresorasla relación es lineal. Sin embargo, existen situaciones en que la relación no es lineal y tampoco eslinealizable. Por ejemplo, si el modelo de regresión es el siguiente:
( )21 2 3expi i i iy x xα α α ε= + +
13
la función de regresión ( ) ( )21 2 3, expm x x xα α α α= + no es lineal ni se puede transformar en
lineal, sería un modelo de regresión no lineal. La forma general de estos modelos es:
( ),i i iy m x α ε= +
donde m es una función que depende de un vector de parámetros α que es necesario estimar;
iε son los errores que se supone que verifican las mismas hipótesis que el modelo lineal.
El estudio de los modelos de regresión no lineal es muy extenso y complejo sobre el que existe una amplialiteratura sobre el tema. Textos de referencia son los de Bates y Watts (1988) y Seber y Wild (1989).La estimación del vector de parámetros α se realiza por el método de mínimos cuadrados. Esto es, secalcula el α que minimiza la función de la suma de residuos al cuadrado:
( ) ( )( ) 21
,n
i ii
y m xα α=
Ψ = −∑El algoritmo para minimizar esta función es un procedimiento iterativo que se basa en el método de Gauss–Newton o en algoritmos más complejos como el algoritmo de Levenberg–Marquard. Para aplicar estosprocedimientos se parte de unos valores iniciales 0α que permiten iniciar el algoritmo iterativo y en cada
etapa i se obtiene un nuevo estimador ( )iα hasta obtener la convergencia según un criterio de parada
predifinido.
Ejemplo 1Se ha diseñado un experimento para estudiar la resistencia de un material plástico que es sometido a unproceso de calentamiento constante durante un período de tiempo. Para ello se han realizado pruebas enlas que se ha sometido al material a una temperatura T constante durante t períodos de tiempopredeterminados. A continuación se somete el material a unas pruebas de resistencia que se miden segúnla variable Y . Los resultados de estas pruebas son los de la tabla adjunta.
t Y t Y t Y8 0'49
0'4920 0'42
0'420'43
32 0'410'40
10 0'480'470'480'47
22 0'410'410'40
34 0'40
12 0'460'460'450'43
24 0'420'400'40
36 0'410'38
14 0'450'430'43
26 0'410'400'41
38 0'400'40
16 0'440'430'43
28 0'410'40
40 0'39
18 0'460'45
30 0'400'400'38
42 0'39
14
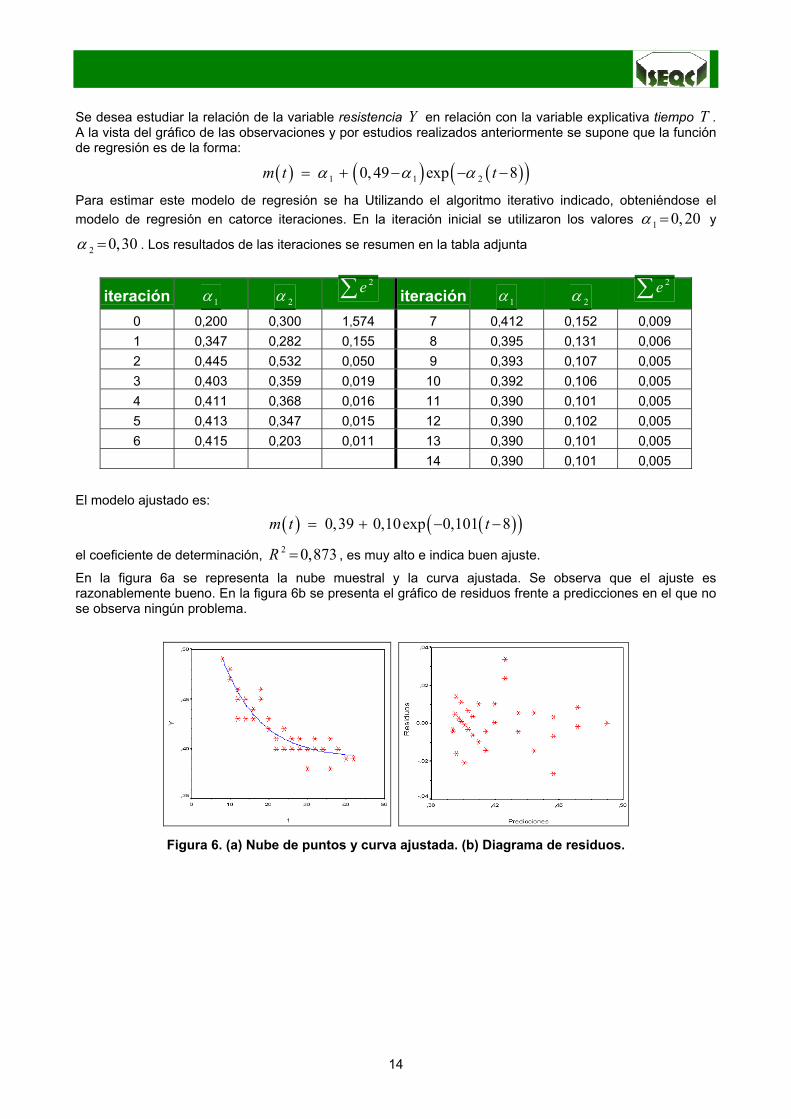
Se desea estudiar la relación de la variable resistencia Y en relación con la variable explicativa tiempo T .A la vista del gráfico de las observaciones y por estudios realizados anteriormente se supone que la funciónde regresión es de la forma:
( ) ( ) ( )( )1 1 20, 49 exp 8m t tα α α= + − − −
Para estimar este modelo de regresión se ha Utilizando el algoritmo iterativo indicado, obteniéndose elmodelo de regresión en catorce iteraciones. En la iteración inicial se utilizaron los valores 1 0, 20α = y
2 0,30α = . Los resultados de las iteraciones se resumen en la tabla adjunta
iteración 1α 2α2e∑ iteración 1α 2α
2e∑0 0,200 0,300 1,574 7 0,412 0,152 0,0091 0,347 0,282 0,155 8 0,395 0,131 0,0062 0,445 0,532 0,050 9 0,393 0,107 0,0053 0,403 0,359 0,019 10 0,392 0,106 0,0054 0,411 0,368 0,016 11 0,390 0,101 0,0055 0,413 0,347 0,015 12 0,390 0,102 0,0056 0,415 0,203 0,011 13 0,390 0,101 0,005
14 0,390 0,101 0,005
El modelo ajustado es:
( ) ( )( )0,39 0,10exp 0,101 8m t t= + − −
el coeficiente de determinación, 2 0,873R = , es muy alto e indica buen ajuste.
En la figura 6a se representa la nube muestral y la curva ajustada. Se observa que el ajuste esrazonablemente bueno. En la figura 6b se presenta el gráfico de residuos frente a predicciones en el que nose observa ningún problema.
Figura 6. (a) Nube de puntos y curva ajustada. (b) Diagrama de residuos.

15
12. Bibliografía1. Dette H., Melas VB, Pepelyshev A. Optimal designs for a class of nonlinear regression models. Ann Stats2004, 32: 2142–67.2. Yong Xu, Jong-Yu Yang, Jian-Feng Lu. An efficient kernel-based nonlinear regression method for tuo-class classification. Proceedings of the 4th International Conference on Machine Learning and Cybernetics,Guangzhou, 2005.3. Huet S, Bouvier A, Poursat MA, Jolivet E. Statistical tools for nonlinear regression A practical guide with S-Plus and R. Examples. Springer Verlag, 2003.4. Baran S. A consistent estimator for nonlinear regression models. Metrika 2005: 62: 1-15.5. Mirta B. Confidence regions and intervals in nonlinear regresión. Math Comm 1997, 2: 71-6.6. Matyska L, Kovai J. Comparison of several non-linear-regression methods for fitting the Michaelis-Mentenequation. Biochem J, 1985: 231; 171-7.7. Motulsky H, Brown RE. Detecting outliers when fitting data with nonlinear regression – a new methodbased on robust nonlinear regression and the false discovery rate. BMC Bioinformatics 2006, 7:123.8. Bielecki A,. Podolak IT, Bielecka M. A Neuronal algorithm of nonlinear regression. Schedae Informaticae2004; 13: 65-81.9. Motulsky HJ, Christopoulos A. Fitting models to biological data using linear and nonlinear regression. Apractical guide to curve fitting. San Diego CA: GraphPad Software, 2003. www.graphpad.com.10. Vidaurre G, Vasquez V R, Wallace B. Whiting robustness of nonlinear regression methods underuncertainty: applications in chemical kinetics models Ind Eng Chem Res, 2004: 43;1395-404.11. Peddada SD, Haseman JK. Analysis of nonlinear regression models: a cautionary note. Dose-Response2005; 3: 342–52.12. Seber GA, Wild CJ. Nonlinear regression. New York: Wiley, 1989.13- Bethea RM, Duran BS, Boullion TL. Statistical methods for engineers and scientists. New York: Dekker,1985.14. Motulsky HJ, Ransnas LA. Fitting curves to data using nonlinear regression. FASEB J, 1987: 1;365-74.15. McIntosh JEA, McIntosh RP. Mathematical modelling and computers in endocrinology. Berlin: Springer,1980; 71.16. eio.usc.es/eipc1/MATERIALES/311121873.pdf17. www.monografias.com/trabajos26/estadistica-inferencial/estadistica inferencial.shtml18. www.terra.es/personal/joseantm/Archiv%20pdf/96zoomc19. www.eui.upm.es/~plpuche/estadistica/2007%20 %202008/Tema%201/regrealumnos20. /www.unoweb-s.uji.es/A22/lista0/theList/TEMA%204.doc21. www.uam.es/personal_pdi/economicas/arantxa/No_linealidad.pdf22. www.ugr.es/~rruizb/cognosfera/sala_de_estudio/estadistica/regresion.ppt23. 155.210.58.160/asignaturas/15909/ficheros/Tema6_notas4.pdf –24. www.ugr.es/~ramongs/sociologia/regresionlogistica.pdf25. webs.um.es/mhcifre/apuntes/practicas_minitab.pdf26. www.uv.es/~yague/docencia/regresion.doc27. personal.us.es/jgam/API2005/2005_5_5.doc28. biplot.usal.es/ALUMNOS/BIOLOGIA/5BIOLOGIA/Regresionsimple.pdf29. www.stat.ufl.edu/~winner/sta6934/lognlreg.ppt30. hadm.sph.sc.edu/COURSES/J716/pdf/716-5%20Non linear%20regression.pdf31. www.uv.es/ceaces/base/regresion/REGRESIN.HTM




















