
Amazon Redshift 最佳实践
46
AWS中国(北京)区域由光环新网运营 Amazon Redshift 最佳实践 基于SQL的列式数据仓库管理系统 韩思捷,AWS技术支持经理 Sijie Han, Technical Account Manager, Amazon Web Services
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Amazon Redshift 最佳实践

AWS中国(北京)区域由光环新网运营
Amazon Redshift 最佳实践基于SQL的列式数据仓库管理系统
韩思捷,AWS技术支持经理Sijie Han, Technical Account Manager, Amazon Web Services

AWS中国(北京)区域由光环新网运营
此在线研讨会的学习内容
• Amazon Redshift服务概述
• 客户示例
• 迁移到Amazon Redshift的最佳实践
• Amazon Redshift schema设计的最佳实践
• Amazon Redshift数据加载的最佳实践
• Amazon Redshift性能调优的最佳实践
• Q & A

AWS中国(北京)区域由光环新网运营
Amazon Redshift 服务概述

AWS中国(北京)区域由光环新网运营
关系型数据仓库
大规模并行处理; 基于PB级的扩容
完全托管
包含HDD和SSD两种平台
每年$1,000/TB; 从$0.25/小时开始计费
Amazon
Redshift
快速简单便宜

AWS中国(北京)区域由光环新网运营
使用Amazon Redshift 的部分客户清单

AWS中国(北京)区域由光环新网运营
Amazon Redshift 的系统架构
主节点• 执行SQL语句的入口
• 存放元数据
• 协调查询语句的执行
计算节点• 基于本地以及列式存储
• 并行执行查询
• 通过Amazon S3加载,备份和恢复数据;从Amazon DynamoDB,Amazon EMR或者SSH
进行数据加载。
两种硬件平台• 针对数据处理进行了优化
• DS2: HDD; 可以从2 TB扩展到2 PB
• DC1: SSD; 可以从160 GB扩展到326 TB
10 GigE
(HPC)
Ingestion
Backup
Restore
JDBC/ODBC

AWS中国(北京)区域由光环新网运营
计算节点架构
每个节点包含多个分片
• DS2 – XL上有2个分片, 8 XL上有16个
分片
• DC1 – L上有2个分片, 8 XL上有32个分
片
每个分片都会分配CPU并管理表数据
每个分片并行的处理部分工作负载
Leader Node

AWS中国(北京)区域由光环新网运营
Amazon Redshift 极大的减少了I/O
数据压缩
区域映射
ID Age State Amount
123 20 CA 500
345 25 WA 250
678 40 FL 125
957 37 WA 375
• 行式存储中计算SUM(Amount) :
– 需要扫描所有列的数据
– 不必要的I/O
ID Age State Amount

AWS中国(北京)区域由光环新网运营
Amazon Redshift 极大的减少了I/O
数据压缩
区域映射
ID Age State Amount
123 20 CA 500
345 25 WA 250
678 40 FL 125
957 37 WA 375
• 行式存储中计算SUM(Amount) :
– 只需要扫描必要的数据块
ID Age State Amount

AWS中国(北京)区域由光环新网运营
Amazon Redshift 极大的减少了I/O
列式存储
数据压缩
区域映射
• 基于列的压缩
– 高效
– 减少存储空间
– 减少I/O
ID Age State Amount
analyze compression orders;
Table | Column | Encoding--------+-------------+----------orders | id | mostly32 orders | age | mostly32 orders | state | lzo orders | amount | mostly32

AWS中国(北京)区域由光环新网运营
Amazon Redshift 极大的减少了I/O
列式存储
数据压缩
区域映射
• 位于内存里的数据块元数据• 记录了每个数据块里的最小值和最大值• 对于查询语句来说,有效的去除了不会包含请求数据的数据块
• 最小化不必要的I/O请求• 基于排序键继续宁过滤的时候最为高效
ID Age State Amount

AWS中国(北京)区域由光环新网运营
用户示例

AWS中国(北京)区域由光环新网运营
分析 Twitter 的数据

AWS中国(北京)区域由光环新网运营
分析 Twitter 的数据 Amazon
Redshift
Starts at
$0.25/hour
EC2
Starts at
$0.02/hour
S3
$0.030/GB-Mo
Amazon Glacier
$0.010/GB-Mo
Amazon Kinesis
$0.015/shard 1MB/s in; 2MB/out
$0.028/million puts

AWS中国(北京)区域由光环新网运营
分析 Twitter 的数据所需要的成本
500MM tweets/day = ~ 5,800 tweets/sec
2k/tweet is ~12MB/sec (~1TB/day)
$0.015/hour per shard, $0.028/million PUTS
Amazon Kinesis 的成本为 $0.765/hour
Amazon Redshift的成本为 $0.850/hour (使用2TB的计算节点)
S3的成本为 $1.28/hour (非压缩)
总共: $2.895/hour

AWS中国(北京)区域由光环新网运营
NTT Docomo – Mobile使用分析
很多手机基站会产生PB级别的数据
很难扩展,并且昂贵
需要一个安全的,可伸缩的系统,并且可以在本地数据中心里运行
Data
Source
ET
DirectConnect
Client
Forwarder
LoaderState
Management
SandboxRedshift
S3

AWS中国(北京)区域由光环新网运营
Sushiro –实时数据流分析
380 家门店的实时数据
近实时的处理库存量以及消费用量
预测门店的需求量,使得食物的浪费最少,并且提高效率
Amazon
使用Amazon Kinesis进行实时数据的捕获,并在Amazon
Redshift里进行分析

AWS中国(北京)区域由光环新网运营
euclid –零售和POS系统分析
- 每小时处理10TB的数据,而之前需要2星期
- 成本下降80-90%

AWS中国(北京)区域由光环新网运营
迁移到 Amazon Redshift 的最佳实践

AWS中国(北京)区域由光环新网运营
迁移到Amazon Redshift之前的重点考虑内容
• 并发查询进程数量应该控制在8-12个,最多为50个
• 表结构设计非常重要,不能使用索引• DISTKEY和SORTKEY对性能影响很大
• 可以使用PRIMARY KEY, FOREIGN KEY, UNIQUE这些约束注意: 这些约束并不是强制的
• 压缩可以提高查询性能

AWS中国(北京)区域由光环新网运营
迁移到Amazon Redshift之前的重点考虑内容
• 对于大的写操作进行优化
• 如果数据是基于时间进行生成,则对不同时间范围的数据创建不同的表,并通过UNION ALL视图进行合并查询

AWS中国(北京)区域由光环新网运营
Amazon Redshift schema 设计的最佳实践

AWS中国(北京)区域由光环新网运营
数据分布方式
• 均匀的分布数据,以便进行并行处理
• 在计算节点之间,最小化数据的传递
• 相邻分片之间的数据关联
• 在本地进行汇总计算
Distribution key All
Node 1
Slice 1 Slice 2
Node 2
Slice 3 Slice 4
Node 1
Slice 1 Slice 2
Node 2
Slice 3 Slice 4
在每个节点的第一个分片上都会有完整的表的数据相同的key值的数据放在同一个
分片上
Node 1
Slice 1 Slice 2
Node 2
Slice 3 Slice 4
Even轮询方式进行数据分布

AWS中国(北京)区域由光环新网运营
选择合适的分布方式
Key
• 大型的事实表
• 在关联中使用经常变化的表
• 在聚合运算中进行本地化操作的列
All
• 表的数据不太变化
• 相对较合理的大小尺寸 (比如几百万行但是不超过一亿条数据)
• 在关联操作中没有经常使用的关联字段
• 典型的使用场景: 对维度表进行关联,但是在关联中没有统一的关联列
Even
• 表不经常进行关联或汇总操作
• 大表同时其中的列不会用于where条件

AWS中国(北京)区域由光环新网运营
分布不均衡
表的定义
CREATE TABLE test (id INT, customer
CHAR(255) DISTKEY, createdate
TIMESTAMP );
当前状态
• 10亿条数据
• 90%的记录中customer字段的值为‘abc.com’
• 导致90%的数据都落在同一个节点上
• 该特定的分片会比其他节点上的分片都要忙
• 可能会导致OOM和Disk Full错误
如何解决
• 修改分布键,使其为一个分布更加均匀的字段或者数据分布方式修改为EVEN
• 重新分布 vs 数据分布不均匀

AWS中国(北京)区域由光环新网运营
检查表是如何在分片里进行分布的
select trim(name) as table, stv_blocklist.slice, stv_tbl_perm.rows
from stv_blocklist,stv_tbl_perm
where stv_blocklist.tbl=stv_tbl_perm.id
and stv_tbl_perm.slice=stv_blocklist.slice
and stv_blocklist.id > 10000 and name not like '%#m%'
and name not like 'systable%'
group by name, stv_blocklist.slice, stv_tbl_perm.rows
order by 3 desc;

AWS中国(北京)区域由光环新网运营
数据排序
• 数据行在表的数据块里以有序方式进行保存
• 数据进入分片时,按照指定的排序键进行数据排序
• 表会同时包含排序的区域和非排序的区域
• 通过利用区域映射功能来跳过一些不需要扫描的数据块
• 对于经常用来过滤的字段定义排序键
• 如果未排序的区域不断增加,会导致性能下降
• 当数据加载到一个空的表的时候,会进行排序
• 定义SORTKEY的时候需要考虑:• 查询模式
• 数据格式
• 业务需求
• VACUUM [SORT ONLY]

AWS中国(北京)区域由光环新网运营
COMPOUND
• 最常见
• 定义良好的过滤条件
• 基于时间的数据
选择SORTKEY
INTERLEAVED
• 大表(超过10亿条记录)
• 没有固定的过滤条件
• 没有基于时间的数据
• 主要参考出现在where条件里的字段 (日期, ID, …)
• 或者, 选择一个经常用于聚合运算的字段
• 或者, 选择与分布键同样的字段

AWS中国(北京)区域由光环新网运营
Compound 类型的排序键
数据行保存在Amazon Redshift的数据块里
假设一个block里放了四条记录
对于一个特定的cust_id值的数据行,全都放在一个数据块里
不过对于一个特定的prod_id的数据行,则分布在四个数据块里
1
1
1
1
2
3
4
1
4
4
4
2
3
4
4
1
3
3
3
2
3
4
3
1
2
2
2
2
3
4
2
1
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
cust_id prod_id other columns blocks
Select sum(amt)
From big_tab
Where cust_id = (1234);
Select sum(amt)
From big_tab
Where prod_id = (5678);
AWS中国(北京)区域由光环新网运营
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
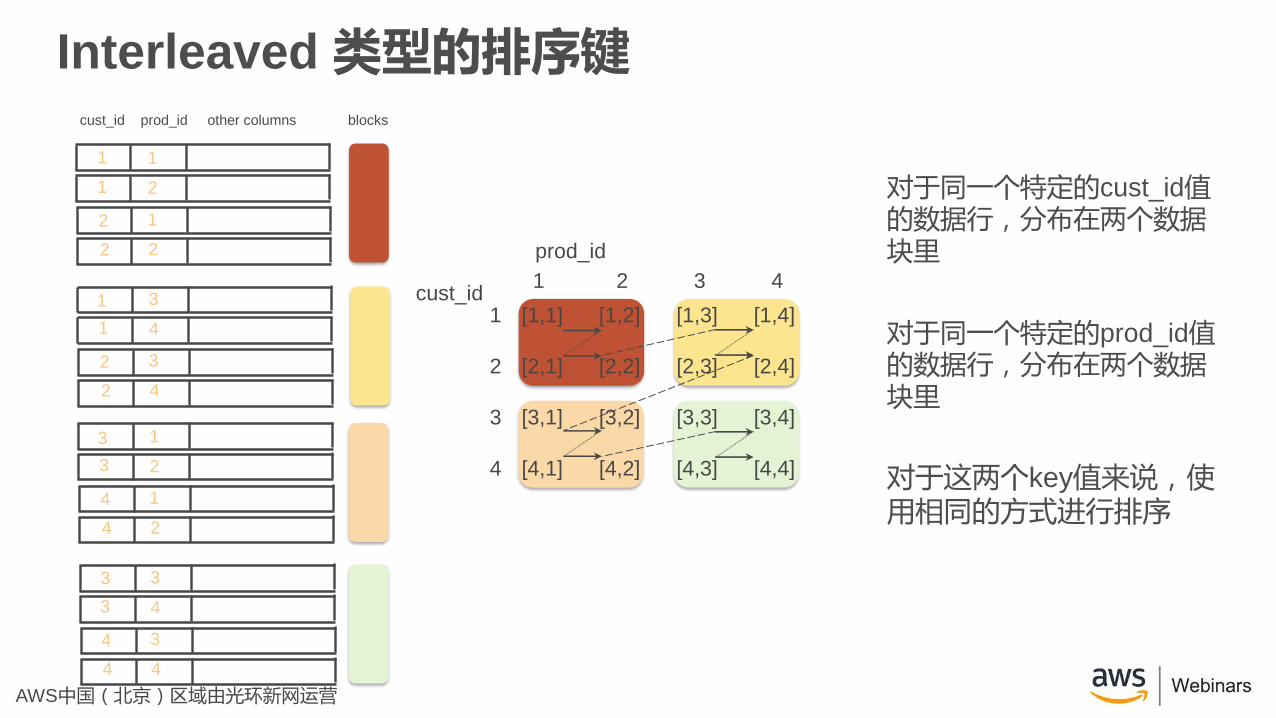
Interleaved 类型的排序键
对于同一个特定的cust_id值的数据行,分布在两个数据块里
对于同一个特定的prod_id值的数据行,分布在两个数据块里
对于这两个key值来说,使用相同的方式进行排序
1
1
2
2
2
1
2
3
3
4
4
4
3
4
3
1
3
4
4
2
1
2
3
3
1
2
2
4
3
4
1
1
cust_id prod_id other columns blocks

AWS中国(北京)区域由光环新网运营
压缩数据
• 在加载数据到一个空的表的时候,COPY命令会自动分析并压缩数据
• ANALYZE COMPRESSION命令检查已经存在的表,并未每个字段提供一个建议的压缩算法
• 如果修改了某个字段的压缩算法,则需要重建该表

AWS中国(北京)区域由光环新网运营
大部分情况下自动压缩都是一个推荐的做法
如果你在一个定期运行的ETL流程,并且你使用的是临时表或者暂存表,则关闭自动压缩:
• 使用ANALYZE COMPRESSION命令来确定正确的压缩方式
• 在你的DDL里添加这些压缩方式
• 使用CREATE TABLE … LIKE命令重建表
通过区域映射我们可以知道:
• 每个数据块包含的数据范围
• 在一个数据块里应该扫描哪些数据行

AWS中国(北京)区域由光环新网运营
测试压缩效率• 获得建议的压缩方式:
ANALYZE COMPRESSION <table_name>
• 使用建议的压缩方式创建表:
CREATE TABLE encodingcolumns ( columnraw varchar(100) encode raw, columnbytedict
varchar(100) encode bytedict, columnlzo varchar(100) encode lzo);
• 检查每个列所使用的数据块的个数:
select col, count(*)
from stv_blocklist, stv_tbl_perm
where stv_blocklist.tbl = stv_tbl_perm.id
and stv_blocklist.slice = stv_tbl_perm.slice
and stv_tbl_perm.name = 'your_table_name'
group by col
order by col;

AWS中国(北京)区域由光环新网运营
定义约束
• Amazon Redshift并不会强制约束
• 用来作为生成执行计划的时候的提示信息
• 比如查询执行器会在计算某些特定的统计信息的时候使用主键和外键约束
• 假定加载的数据都没有违反约束的要求
• 在加载数据到集群之前,要先对数据进行约束方面的检查,确保它们都没有违反约束的定义
• NOT NULL约束是强制的
注意: 如果加载到数据库的数据违反了约束的要求,则可能会导致错误的查询结果

AWS中国(北京)区域由光环新网运营
Amazon Redshift 数据加载的最佳实践

AWS中国(北京)区域由光环新网运营
Amazon Redshift加载数据概述
AWS CloudCorporate data center
Amazon
DynamoDB
Amazon S3
Data
volume
Amazon EMR
Amazon
RDS
Amazon
Redshift
Amazon
Glacier
logs/files
Source DBs
VPN
Connection
AWS Direct
Connect
Amazon S3
Multipart Upload
AWS Import/
Export
Amazon EC2 or
on-premises
(using SSH)

AWS中国(北京)区域由光环新网运营
并行加载文件
每个分片一次可以加载一个文件:
• 流式解压
• 解析
• 分布
• 写入
如果只有一个文件需要被加载,
则说明只有一个分片在工作
这时只有6.25%的分片是活跃状态。
2 4 6 8 10 12 141 3 5 7 9 11 13 15

AWS中国(北京)区域由光环新网运营
使用多个文件来最大化吞吐量
确保需要加载的文件个数至少和集群里的分片个数一致
在具有16个加载文件的时候,所有的分片都在工作,因此你可以最大化吞吐量
随着你添加新的计算节点到集群里,在执行COPY命令的时候可以线性的扩展吞吐量
2 4 6 8 10 12 141 3 5 7 9 11 13 15

AWS中国(北京)区域由光环新网运营
Amazon Redshift 性能调优的最佳实践

AWS中国(北京)区域由光环新网运营
对查询进行优化
• 定期检查你的表的状态• 定期执行vacuum和analyze命令
• 检查SVV_TABLE_INFO表• 缺少统计信息• 表里的数据出现分布不均衡
• 检查skew_rows列, 该值表示不同的分片之间所包含的最多的数据行数除以最少的数据行数后得到的值。比如如果该字段的值为2.0,则表示一个分片里的数据包含的数据行数是另一个分片里的数据行数的2倍
• 要解决该问题,则需要使用另一个分布键来重建表,或者修改分布方式。• 未压缩的字段• 未排序的数据
• 检查你的集群的状态• WLM队列• 提交队列• 数据库锁

AWS中国(北京)区域由光环新网运营
缺失统计信息
• Amazon Redshift查询优化器会依赖于最新的统计信息
• 某个表上的统计信息只有在你访问这张表的时候才会被使用
• 对下面的字段的统计信息尤其重要:
• SORTKEY
• DISTKEY
• 在where条件里出现的字段
• 定期运行命令: analyze <tablename>
(col1, col2)

AWS中国(北京)区域由光环新网运营
表的数据分布不均匀
• 工作负载不均衡
• 只有当最慢的分片上的工作负载结束,整个查询才能结束
• 还可能导致出错:
• 临时数据保存在单个节点上,导致该节点的空间耗尽,从而导致查询失败
表维护和状态
未排序的数据
• 使用VACUUM或DEEP COPY
命令把表的数据进行排序
• 对于未排序的表进行扫描的时候,仍然可以通过区域映射来提高效率

AWS中国(北京)区域由光环新网运营
• 借助SVV_TABLE_INFO表
• 检查未排序的数据行占表的总记录数的百分比
• 这个百分比越高,则越需要运行VACUUM命令
• 通常在加载完数据以后建议运行VACUUM命令,除非被加载的数据已经按照排序键进行排序了,则不需要运行VACUUM命令
• 通过skew_sortkey1字段,检查排序键是否过度压缩:• 导致性能问题
• 只能通过Deep Copy进行调整
维护排序键

AWS中国(北京)区域由光环新网运营
WLM队列管理
确定短时间运行和长时间运行的查询并进行优先级排列
定义多个队列来让不同的查询语句使用
缺省的并发度为5
集群状态: 提交和WLM
提交队列
你的提交队列有多长?
• 确定不需要的事务
• 把相关的语句组织为一个事务
• 检查STL_COMMIT_STATS

AWS中国(北京)区域由光环新网运营
• 节点个数以及分片的个数
• 节点类型
• 数据分布方式
• 数据排序
• 数据集的大小尺寸
• 并发操作
• 查询语句
影响性能的各个因素

AWS中国(北京)区域由光环新网运营
Thank You!




















