
A semantic learning for content-based image retrieval using analytical hierarchy process
11
A semantic learning for content-based image retrieval using analytical hierarchy process Shyi-Chyi Cheng a, * , Tzu-Chuan Chou b , Chao-Lung Yang a , Hung-Yi Chang a a Department of Computer and Communication Engineering, National Kaohsiung First University of Science and Technology, 1 University Road, Yenchao, Kaohsiung 824, Taiwan, ROC b Department of Information Management, National Kaohsiung First University of Science and Technology, 1 University Road, Yenchao, Kaohsiung 824, Taiwan, ROC Abstract In this paper, a new semantic learning method for content-based image retrieval using the analytic hierarchical process (AHP) is proposed. AHP proposed by Satty used a systematical way to solve multi-criteria preference problems involving qualitative data and was widely applied to a great diversity of areas. In general, the interpretations of an image are multiple and hard to describe in terms of low-level features due to the lack of a complete image understanding model. The AHP provides a good way to evaluate the fitness of a semantic description used to interpret an image. According to a predefined concept hierarchy, a semantic vector, consisting of the fitness values of semantic descriptions of a given image, is used to represent the semantic content of the image. Based on the semantic vectors, the database images are clustered. For each semantic cluster, the weightings of the low-level features (i.e. color, shape, and texture) used to represent the content of the images are calculated by analyzing the homogeneity of the class. In this paper, the values of weightings setting to the three low-level feature types are diverse in different semantic clusters for retrieval. The proposed semantic learning scheme provides a way to bridge the gap between the high-level semantic concept and the low-level features for content-based image retrieval. Experimental results show that the performance of the proposed method is excellent when compared with that of the traditional text-based semantic retrieval techniques and content-based image retrieval methods. q 2005 Elsevier Ltd. All rights reserved. Keywords: Decision making; AHP; Semantic access; Content-based image retrieval; Relevance feedback 1. Introduction With the rapidly increasing use of the Internet, the demands for storing multimedia information (such as text, image, audio, and video) have increased. Along with such databases comes the need for a richer set of search facilities that include keywords, sounds, examples, shape, color, texture, spatial structure and motion. Traditionally, textual features such as filenames, captions, and keywords have been used to annotate and retrieve images. As they are applied to a large database, the use of keywords becomes not only cumbersome but also inadequate to represent the image content. Many content-based image retrieval systems have been proposed in the literature (Flickner et. al., 1995; Jain & Vailaya, 1996; Rui, Huang, & Chang, 1999; Smeulders, Worring, Gupta, & Jain, 2000; Wang, Chi, & Feng, 2000). To access images according to their content, low-level features such as colors, textures, and shapes of objects are widely used as indexing features for image retrieval. Although content-based image retrieval (CBIR) is extremely desirable in many applications, it must overcome several challenges including image segmentation, extracting fea- tures from the images that capture the user’s notion, and matching the images in a database with a query image according to the extracted features. Owing to these difficulties, an isolated image content-based retrieval method can neither achieve very good results, nor will it replace the traditional text-based retrievals in the near future. 0957-4174/$ - see front matter q 2005 Elsevier Ltd. All rights reserved. doi:10.1016/j.eswa.2004.12.011 Expert Systems with Applications 28 (2005) 495–505 www.elsevier.com/locate/eswa * Corresponding author. Tel.: C886 7 6011000x2025; fax: C886 7 6011012. E-mail address: [email protected] (S.-C. Cheng).
Transcript of A semantic learning for content-based image retrieval using analytical hierarchy process

A semantic learning for content-based image retrieval using analytical
hierarchy process
Shyi-Chyi Chenga,*, Tzu-Chuan Choub, Chao-Lung Yanga, Hung-Yi Changa
aDepartment of Computer and Communication Engineering, National Kaohsiung First University of Science and Technology,
1 University Road, Yenchao, Kaohsiung 824, Taiwan, ROCbDepartment of Information Management, National Kaohsiung First University of Science and Technology,
1 University Road, Yenchao, Kaohsiung 824, Taiwan, ROC
Abstract
In this paper, a new semantic learning method for content-based image retrieval using the analytic hierarchical process (AHP) is proposed.
AHP proposed by Satty used a systematical way to solve multi-criteria preference problems involving qualitative data and was widely
applied to a great diversity of areas. In general, the interpretations of an image are multiple and hard to describe in terms of low-level features
due to the lack of a complete image understanding model. The AHP provides a good way to evaluate the fitness of a semantic description used
to interpret an image.
According to a predefined concept hierarchy, a semantic vector, consisting of the fitness values of semantic descriptions of a given image,
is used to represent the semantic content of the image. Based on the semantic vectors, the database images are clustered. For each semantic
cluster, the weightings of the low-level features (i.e. color, shape, and texture) used to represent the content of the images are calculated by
analyzing the homogeneity of the class. In this paper, the values of weightings setting to the three low-level feature types are diverse in
different semantic clusters for retrieval. The proposed semantic learning scheme provides a way to bridge the gap between the high-level
semantic concept and the low-level features for content-based image retrieval. Experimental results show that the performance of the
proposed method is excellent when compared with that of the traditional text-based semantic retrieval techniques and content-based image
retrieval methods.
q 2005 Elsevier Ltd. All rights reserved.
Keywords: Decision making; AHP; Semantic access; Content-based image retrieval; Relevance feedback
1. Introduction
With the rapidly increasing use of the Internet, the
demands for storing multimedia information (such as text,
image, audio, and video) have increased. Along with such
databases comes the need for a richer set of search facilities
that include keywords, sounds, examples, shape, color,
texture, spatial structure and motion. Traditionally, textual
features such as filenames, captions, and keywords have
been used to annotate and retrieve images. As they are
applied to a large database, the use of keywords becomes not
only cumbersome but also inadequate to represent the image
0957-4174/$ - see front matter q 2005 Elsevier Ltd. All rights reserved.
doi:10.1016/j.eswa.2004.12.011
* Corresponding author. Tel.: C886 7 6011000x2025; fax: C886 7
6011012.
E-mail address: [email protected] (S.-C. Cheng).
content. Many content-based image retrieval systems have
been proposed in the literature (Flickner et. al., 1995; Jain &
Vailaya, 1996; Rui, Huang, & Chang, 1999; Smeulders,
Worring, Gupta, & Jain, 2000; Wang, Chi, & Feng, 2000).
To access images according to their content, low-level
features such as colors, textures, and shapes of objects are
widely used as indexing features for image retrieval.
Although content-based image retrieval (CBIR) is extremely
desirable in many applications, it must overcome several
challenges including image segmentation, extracting fea-
tures from the images that capture the user’s notion, and
matching the images in a database with a query image
according to the extracted features. Owing to these
difficulties, an isolated image content-based retrieval
method can neither achieve very good results, nor will it
replace the traditional text-based retrievals in the near future.
Expert Systems with Applications 28 (2005) 495–505
www.elsevier.com/locate/eswa

Fig. 1. Two images contain different levels of semantic uncertainty. (a) A
lion image, (b) an image with a personified cow.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505496
As the consequence of the wide applications, semantic
image retrieval is a topic of growing research interest and
remains as a challenge for content-based image retrieval.
The methods towards semantic image retrieval can be
roughly categorized into the following classes (Eakins,
2002; Wang, Li, & Wiederhold, 2001; Xiang & Huang,
2002): (a) automatic scene classification in whole images by
statistically based techniques; (b) methods for learning and
propagating labels assigned by human users; (c) automatic
object classification using the knowledge based techniques
or statistical techniques; (d) retrieval methods with
relevance feedback during a retrieval session. An indexing
algorithm may be a combination of two or more of the
above-mentioned classes. For example, one promising
approach is to first perform object segmentation and then
use appropriate object annotation techniques to construct
the knowledge framework for semantic image retrieval.
A detailed discussion of each category is out of the scope of
this paper and interested readers could refer to (Eakins,
2002) for further details.
Applying similar techniques used in the area of
information retrieval (Crestain, Lalmas, Rijsbergen, &
Campbell, 1998), text-based image retrieval systems
retrieve images by matching two images in which one is
from the database and the other is the query image
according to their annotation. The text annotation of an
image could be captured from the caption of the image by
parsing automatically the corresponding paragraphs in a
document or given by human assessment. One can further
extract keywords from the annotation and represent the
content of the associated image as a keyword vector of high
dimensionality.
Most existing systems for learning and propagating
labels assigned by human users using hidden annotation
either annotate all the objects (full annotation) in the
database, or annotate a subset of the database manually
selected (partial annotation). Full annotation is cumbersome
when the database becomes larger. Zhang and Chen (2002)
presented an active learning framework to guide hidden
annotation by partial annotation in order to trim down heavy
manual labors and improve retrieval performance.
A potential problem of partial annotation is that it is not
clear how much annotation is sufficient for a specific
database, and what the best subset of objects is.
One basic assumption being common to all the text-
based retrieval models is: retrieval is made according to
representations of queries and documents, not the queries
and documents themselves (Korfhang, 1999). Hence, the
key to success in developing an effective text-based
retrieval system is accurate content representation. How-
ever, the representation of images on the basis of keywords
is ‘uncertain.’ For example, most people would agree that
the object in Fig. 1(a) is a ‘lion’ according to its shape and
the caption of the image. Contrast to Fig. 1(a), the
interpretations of the object in Fig. 1(b) will be diverse:
one may describe it as a ‘child dressed in a suite of cow-like
clothes’; while others may treat it as a ‘personified cow’.
The extraction of semantic descriptions from an image
given by human assessment is a highly uncertain process.
As a consequence, the retrieval process becomes uncertain.
Contrast to the traditional content-based image retrieval,
semantic retrieval in general prefers to use some sort of
semantic description rather than specifying low-level visual
features. A good way to allow semantic access to databases
is by means of object-based queries (Stejic, Takama, &
Hirota, 2003). In this case, objects are used to search the
images in the database. The key issue of semantic retrieval
is that computers must semantically index images; other-
wise, they output mostly irrelevant images to us. There are
two difficult problems for semantic retrieval by computers:
(1) it is not a trivial job to segment meaningful objects from
images due to the lack of complete image-understanding
models; (2) the problem to recognize an object by any
existing object recognition technique is not totally solved.
Applying a human-in-the-loop technique to capture the
user’s notion for CBIR systems is therefore, essential for
semantic retrieval.
In this paper, a new semantic learning method for
content-based image retrieval using the analytic hierarchical
process (AHP) is proposed. AHP proposed by Satty (1980)
used a systematical way to solve multi-criteria preference
problems involving qualitative data and was widely applied
to a great diversity of areas (Jain, 1997; Min, 1994; Lai,
Trueblood, and Wong, 1999). Pairwise comparisons are
used in this decision-making process to form a reciprocal
matrix by transforming qualitative data to crisp ratios, and
this makes the process simple and easy to handle. The
reciprocal matrix is then solved by a weighting finding
method for determining the criteria importance and
alternative performance. The rationale of choosing AHP,
despite its controversy of rigidity, is that the problem to
assign the semantic descriptions to the objects of an image
can be formulated as a multi-criteria preference problem. As
shown in Fig.1, the interpretations of an image object are
multiple and depend heavily on the features used to interpret
it. The AHP provides a good way to evaluate the fitness of a
semantic description used to represent an image object.

S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505 497
According to a predefined concept hierarchy, a semantic
vector consisting of the values of fitness of semantics of a
given image is used to represent the semantic content of the
image. A similarity measurement between two semantic
vectors is then proposed to cluster images. For each
semantic cluster, the weightings of the low-level features
for content-based image retrieval are calculated by analyz-
ing the homogeneity of the class. In this work, the weighting
values setting to the low-level features (i.e. color, shape, and
texture) are different in different semantic clusters.
Given a query image, traditional content-based image
retrieval techniques in terms of low-level features (color,
shape, and texture) are used to retrieve images. Further-
more, a similarity measure by integrating the high-level
semantic distance and the low-level visual feature distance
is proposed in this work. Experimental results show that the
performance of the proposed method is excellent when
compared with that of traditional text-based semantic
retrieval systems and the QBIC CBIR system (Flickner
et al., 1995).
The remainder of this paper is organized as follows.
Section 2 presents the use of the analytical hierarchy process
for representing images as semantic vectors. Section 3
discusses the proposed semantic learning method. Section 4
presents the proposed image retrieval strategy. Some
experimental tests for illustrating the effectiveness of the
proposed image retrieval method are discussed in Section 5.
Finally, a conclusion is drawn in Section 6.
2. Image semantic representation using AHP
2.1. A brief review of AHP
The AHP usually consists of three stages of problem-
solving: decomposition, comparative judgments, and
synthesis of priority. The decomposition stage aims at
the construction of a hierarchical network to represent a
decision problem, with the top level representing overall
objectives and the lower levels representing criteria,
subcriteria, and alternatives. With comparative judgments,
users are requested to set up a comparison matrix at each
hierarchy by comparing pairs of criteria or subcriteria.
A scale of values ranging from 1 (indifference) to 9
(extreme preference) is used to express the users
preference. Finally, in the synthesis of priority stage,
each comparison matrix is then solved by an eigenvector
method for determining the criteria importance and
alternative performance.
The following list provides a brief summary of all
processes involved in AHP applications:
1.
Specify a concept hierarchy of interrelated decisioncriteria to form the decision hierarchy.
2.
For each hierarchy, collect input data by performing apairwise comparison of the decision criteria.
3.
Estimate the relative weightings of decision criteria byusing an eigenvector method.
4.
Aggregate the relative weights up the hierarchy to obtaina composite weight which represents the relative
importance of each alternative according to the
decision-maker’s assessment.
One major advantage of AHP is that it is applicable to the
problem of group decision-making. In group decision
setting, each participant is required to set up the preference
of each alternative by following the AHP method and all the
views of the participants are used to obtain an average
weighting of each alternative.
2.2. Semantic image classification using AHP
We view an image as a compound object containing
multiple component objects which are then described by
several semantic descriptions according to a concept
hierarchy. The task to construct a concept hierarchy for
assigning the semantics to an image object is not a trivial
work because the domain-specific knowledge should be
included in the hierarchy. Fig. 2 shows the image
classification hierarchy (IPO, 1997) defined by the Intellec-
tual Property Office, Taiwan for censoring trademark
registration applications. According to the hierarchy, the
method for involving the semantic access to an image
database by AHP is proposed in this study. For the sake of
illustration convenience, the classification hierarchy is
abbreviated as IPO hierarchy.
There are 12 subjects in the top level of IPO hierarchy
and a two-digit code ranging from ‘01’ to ‘12’ is used to
specify the subjects to which an image object belongs. Each
top-level subject is then divided into several sub-subjects,
and each sub-subject is again decomposed into several Level
3 subjects. The codes to locate the Level 2 subjects and the
Level 3 subjects are ‘A’ to ‘Z’ and ‘01’ to ‘99’, respectively.
A composite path code is formed by aggregating the code of
each level for specifying a particular meaning to an object.
For example, if a path code ‘01A01’ is given to describe an
image object semantically, the content of the object would
include a man and an aircraft. Note that multiple path codes
can interpret an image object according to different aspects
of user notion.
The simplest way to retrieve images from a database on
the basis of path codes is to combine the path codes of a
query image into a Boolean query expression. Unfortu-
nately, we cannot distinguish the retrieved images according
to their content if the path codes of the retrieved images are
the same as those of the query image. Users are requested to
judge whether a retrieved database is really relevant to the
query image in such kind of systems. In the worst case, users
would browse all the retrievals to make sure that every
relevant database image is inspected, and this becomes too
cumbersome to use the system especially when the size of
database is large.

Fig. 2. The image classification hierarchy defined by Intellectual Property Office, Taiwan for censoring trademark registration applications.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505498
A question arises naturally: is the weight of each path
code of an image object equivalent? The answer to the
problem is of course no. Some path codes are obviously
more important than others for a specific image object. For
example, the semantic description ‘personified cow’ is more
important than the code with the semantic description ‘child
dressed in a suit of cow-like clothes’ for the image object in
Fig. 1(b) according to the authors’ opinion.
Fig. 3 shows the path code selection model using AHP.
At the highest level (Level 0) of the hierarchy is the
objective to fulfill for image classification. The objective
can be classified into 12 large classification codes, each of
which codes an image category. Each large classification
code is further classified into multiple Level 2 classification
codes, which measure the shape and texture differences
among the images of the same large classification code.
Note that each image might consist of several sub-objects.
For example, a human being image object can be further
divided into several segments, such as head, body, and limb.
The small classification codes, the Level 3 codes, represent
the semantics of each part of an image object. Another
purpose of small classification codes is to specify the
semantics about the spatial composition of individual parts
of an image.
2.3. Object representation
Assume the path codes of the semantic classification
hierarchy are numbered from 1 to n. Given an image I, the
content of the image is represented by a semantic vector
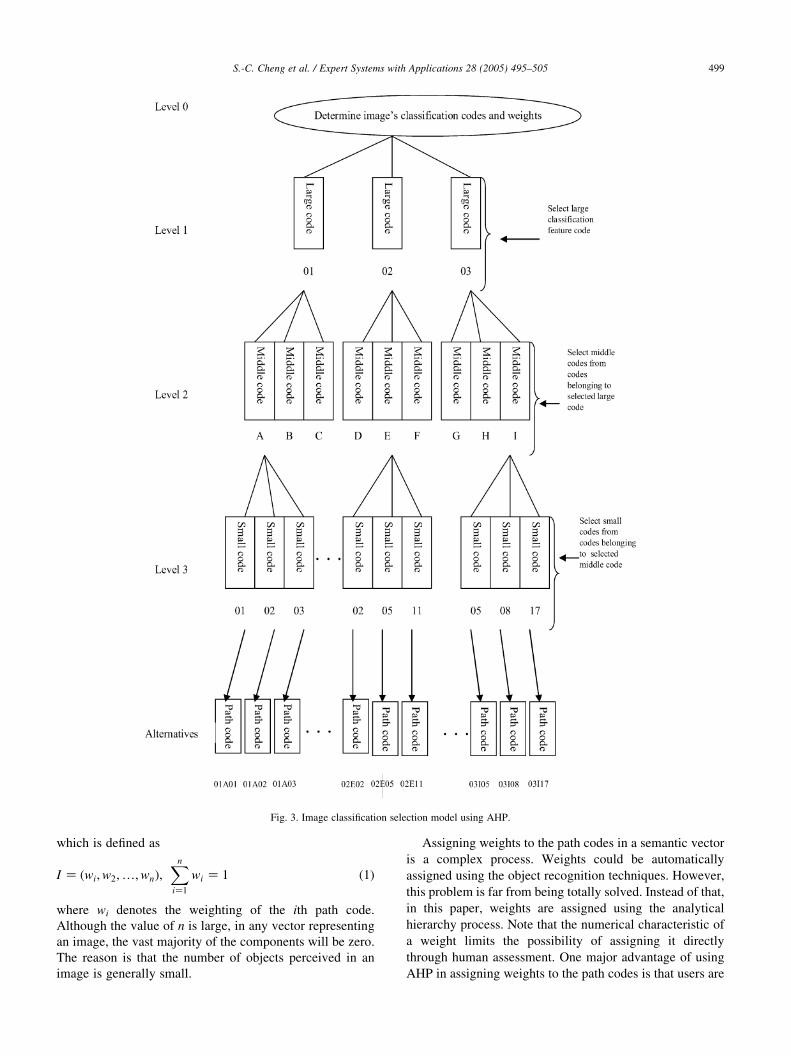
Fig. 3. Image classification selection model using AHP.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505 499
which is defined as
I Z ðwi;w2;.;wnÞ;Xn
iZ1
wi Z 1 (1)
where wi denotes the weighting of the ith path code.
Although the value of n is large, in any vector representing
an image, the vast majority of the components will be zero.
The reason is that the number of objects perceived in an
image is generally small.
Assigning weights to the path codes in a semantic vector
is a complex process. Weights could be automatically
assigned using the object recognition techniques. However,
this problem is far from being totally solved. Instead of that,
in this paper, weights are assigned using the analytical
hierarchy process. Note that the numerical characteristic of
a weight limits the possibility of assigning it directly
through human assessment. One major advantage of using
AHP in assigning weights to the path codes is that users are

Table 1
Pairwise comparison judgments between semantic descriptions A and B
Judgment Values
A is equally preferred to B 1
A is equally to moderately preferred over B 2
A is moderately preferred over B 3
A is moderately to strongly preferred over B 4
A is strongly preferred to B 5
A is strongly to very strongly preferred over B 6
A is very strongly preferred over B 7
A is very strongly to extremely preferred over B 8
A is extremely preferred to B 9
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505500
only required to set the relative importance of several pairs
of semantic descriptions, and then the values of weights are
automatically calculated.
The judgment of the importance of one semantic
description over another can be made subjectively and
converted into a numerical value using a scale of 1 to 9,
where 1 denotes equal importance and 9 denotes the highest
degree of favoritism. Table 1 lists the possible judgments
and their representative numerical values.
The numerical values representing the judgments of the
pairwise comparisons are arranged to form a reciprocal
matrix for further calculations. The main diagonal of the
matrix is always 1. Users are required to adopt a top-down
approach in their pairwise comparisons. Given an image, the
first step of the classification process using AHP is to choose
the large classification codes and evaluate their relative
importance by performing pairwise comparisons. For
example, Fig. 4(a) containing a man that is pulling a carriage
is the target of classification. In this case, three image objects,
which can be classified into three Level 1 image categories—
‘human beings’ H, ‘animals’ A, and ‘means of conveyance’
C. Fig. 4(b) is the corresponding Level 1 reciprocal
matrix M1 for judging the relative importance of the three
semantic descriptions. The entries of M1 can be denoted as
M1 Z
H A C
H
A
C
wH=wH wH=wA wH=wC
wA=wH wA=wA wA=wC
wC=wH wC=wA wC=wC
264
375 (2)
where wH, wA, and wC are the relative importance values
(defined in Table 1) for the three semantic descriptions H, A,
Fig. 4. An example image to be classified: (a) the image; (b) the corresponding reci
1 semantic descriptions in representing the image.
and, C, respectively. Level 1 weightings of the three
semantic descriptions are then obtained from M1.
Without lose of generality, let l, m, and n be the number
of Level 1 semantic descriptions, the number of Level 2
semantic descriptions for each Level 1 description, the
number of Level 3 semantic description for each Level 2
description, respectively. For each row of Level 1 reciprocal
matrix M1, we can define a weighting measurement as
r1i Z
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffia1
i
a11
$a1
i
a12
$.$a1
i
a1l
l
s; i Z 1;.; l (3)
where a1i is the relative important value of the ith Level 1
semantic description. Then the Level 1 weightings are
determined by
w1i Z a1
i
Xl
jZ1
a1j ; i Z 1;.; l: (4)
Similarly, we can compute the Level 2 weightings w2i;j, jZ
1,.,m for the ith Level 1 semantic description and the
Level 3 weightings w3i;j;k, kZ1,.,n for the ith Level 1
semantic description and the jth Level 2 semantic descrip-
tion. Finally, the entry p of the semantic vector defined in
Eq. (1) is computed as
wpZðiK1Þ$lCðjK1Þ$mCk Z w1i $w2
i;j$w3i;j;k: (5)
Note that the number of reciprocal matrixes for the image is
l$m$n and it is actually equal to the number of path codes
used to describe the image. It would be too cumbersome to
classify an image using AHP if the value of l$m$n is very
large. Fortunately, this problem would not occur because
most of the images do not have a large amount of path codes
to describe them. Most of them have at most 4–10 path
codes according to our experience.
3. The proposed semantic learning for image retrieval
3.1. Similarity function
As mentioned above, in the learning phrase, all the
database sample images are represented as semantic vectors
by AHP. When the vector model is used, the value of
similarity can be measured either with the idea of distance,
procal matrix with respect to (a) for calculating the local weightings of Level

S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505 501
following the philosophy that images close together in the
vector space are likely to be highly similar, or with an
angular measure, according to the idea that images in the
same direction are closely related (Korfhang, 1999).
In this study, we use the widely used cosine measure for
vector-based clustering. The cosine measure is not a
distance measure, but rather it is developed from the cosine
of the angle between the vectors representing two images.
Its definition is
dðD1;D2Þ Z
Piðw
D1
i $wD2
i ÞffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiPiðw
D1
i Þ2q
$ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiP
iðwD2
i Þ2q (6)
where wD1
i and wD2
i are the weightings of the ith path
code of the sample images D1 and D2, respectively. The
cosine measure transforms the angular measure into a
measure ranging from 1 for the highest similarity to 0 for
the lowest.
The cosine measure does not consider the distance of
each image from the origin, but only the direction. Hence,
two images that lie along the same vector from the origin
will be judged identically, despite the fact that they may be
far apart in the image space. Among the metrics that
consider the distance of each image from the origin are the
Lp metrics. They are defined by the equation
LpðD1;D2Þ ZX
i
jwD1
i KwD2
i jp
" #1=p
: (7)
Commonly used values for p include pZ1 (city block
distance), pZ2 (Euclidean distance), and pZN (maximal
direction distance). Euclidean distance is the best known of
these, corresponding to ordinary straight-line distance.
Using Euclidean distance, we can define the similarity
measurement as
dðD1;D2Þ Z 1 KL2ðD1;D2Þ
Maxk½L2ðDk;D1Þ�(8)
These two similarity measurements are implemented in our
system and yield almost the same performance.
3.2. Semantic learning by clustering
The K-means clustering algorithm is widely used and
proved to be optimal. For the sake of easy reference, the
semantic clustering using the K-means algorithm is
described below.
Step 1
For each semantic cluster Sk, kZ1,.,K, randominitial semantic vectors are chosen for the cluster
representatives �Ik.
Step 2
For every semantic vector I, the difference isevaluated between I and �Ik, kZ1,.,K. If dðI; �IiÞ!dðI; �IkÞ for all ksi, I is assigned to cluster Si.
Step 3
According to the new classification, �Ik is recalcu-lated. If Mk elements are assigned to Sk then
�Ik Z1
Mk
XMk
mZ1
Im (9)
where Im, mZ1,.,Mk are the semantic vectors belonging to
cluster Sk.
Step 4
If the new �Ik is equal to the old one then stop, elseStep 2.
The value of K indicates the number of clusters that
the database images will be clustered. It is difficult to
determine its value in theory. In this paper, the value of
K is set equal to the average number of path codes for
describing an image. Note that the number of clusters is
obviously far smaller than the total path codes defined in
the concept hierarchy.
Once the semantic clusters are obtained, three types of
low-level features, i.e. color, shape, and texture are
extracted from the content of each database image.
According to the QBIC method (Flickner et. al., 1995),
the three low-level features are the color histogram, digital
central moments, and the triple (contrast, coarseness,
directionality) for color feature, shape feature, and texture
feature, respectively. In the QBIC system, the three features
are used independently. Users are required to set the
weighting of each feature type in order to retrieve
semantically relevant images. Unfortunately, the low-level
features and the high-level semantic concepts do not have an
intuitive relationship, and hence, the problem of weighting
setting is not a trivial job to solve. This limits the retrieval
accuracy of the QBIC-like systems. In this paper, we
propose a method for determining automatically the
weightings of the three low-level feature types for each
semantic cluster.
Let IC, IS, and IT denote the feature vectors of the image I
for color, shape, and texture, respectively. For the semantic
cluster Sk, we compute its representative feature vectors �ICk ,
�ISk , and �IT
k by
�ICk
�ISk
�ITk
2664
3775 Z
1
Mk
XMk
mZ1
ICm
1
Mk
XMk
mZ1
ISm
1
Mk
XMk
mZ1
ITm
26666666664
37777777775
(10)
where Ifm, mZ1,.,Mk are the f-type feature vectors
belonging to cluster Sk.

Fig. 5. Average precision versus number of retrieved images using the
trademark database.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505502
A generalized distance of an image I from its cluster
representative is defined as follows:
DðI; �IkÞ ZlC
s2C
jjIC K �ICk jjC
lS
s2S
jjIS K �ISkjjC
lT
s2T
jjIT K ITk jj
(11)
where jjIK �Ikjj is the Euclidean distance, sC, sS, sT are the
standard deviations of color, shape, and texture distance,
respectively, and lC, lS, lT are regulation parameters. To
keep the clustering results consistent in terms of high-level
semantic concepts and low-level features, the following
energy function should be minimized:
EðSk; ÐlÞ ZXI2Sk
ÐlTDLFðI; �IkÞ (12)
where
Ðl Z
lC
s2C
lS
s2S
lT
s2T
26666664
37777775; DLFðI; �IkÞ Z
jjIC K �ICk jj
jjIS K �ISkjj
jjIT K �ITk jj
2664
3775:
Clearly, the energy function in (12) depends on the
regularization parameter Ðl. In our case, setting lC[lS
emphasizes the importance of color feature; by contrast,
setting lS[lC means that the shapes of the image objects
belonging to Sk are very similar. The weight factor Ðl must be
constrained, because otherwise, as Ðl increases without limit,
so does the energy EðSk; ÐlÞ. Thus, we set
jjÐljj Z 1:
This parameter may be chosen heuristically or by using a
priori knowledge. Alternatively, the min–max criterion (Lai
& Chin, 1995) can be used for evaluating automatically the
optimal Ðl. This criterion assumes that in situations with
conflicting alternatives, the most rational strategy is the one
aiming to minimize the maximum possible losses. Thus, the
function is minimized over all possible combinations of
weight values and the min–max criterion selects the
combination producing the maximum of these minima. In
this case, the application of the min–max criterion gives
EðSk; Ðl�ÞREðSk; ÐlÞ; if jjÐljj Z 1; Ðl
�sÐl: (13)
The resulting min–max criterion yields very satisfactory
results for determining the weighting factors of the low-
level features in a semantic cluster.
An approximation method for determining the weighting
factor Ðl is also proposed to speed up the execution of the
learning algorithm. Note that all the semantic clusters
obtained from clustering the semantic vectors by K-means
algorithm need to determine their weighting factors for the
low-level features. This is time-consuming if K is large
when using the min–max criterion. Hence, in this paper,
the weighting factor for each cluster is simply determined
by
Ðl Z l1; l2; l3
� �
Z1
2
s2S Cs2
T
s2C Cs2
S Cs2T
;s2
C Cs2T
s2C Cs2
S Cs2T
;s2
C Cs2S
s2C Cs2
S Cs2T
� �:
(14)
The greedy method yields very satisfactory results accord-
ing to the experimental results.
4. Image retrieval strategies
The semantic learning needs to be integrated into the
retrieval system in order to provide better retrieval
performance. In previous work, semantic access to an
image database was often through a Boolean vector. In our
system, each image has a semantic vector, including the
query image the user provides using the AHP. If the query is
chosen from the database, we already have this semantic
vector. This is the normal case as AHP is largely for
improving the performance of inside-database queries. If the
query is selected from the outside of the database, we can
estimate its semantic vector as in Section 2.3 as well. The
semantic vector is a complete description of all the semantic
descriptions we have in the concept hierarchy and is
associated with high-level semantics. We can treat this
semantic vector as a feature vector, similar to low-level
features such as color, texture, and shape. The semantic
distance d(S) between a query image with the semantic
vector IqZ ðwðqÞ1 ;w
ðqÞ2 ;.;w
ðqÞN Þ and a database image Ik Z
ðwðkÞ1 ;wðkÞ
2 ;.;wðkÞN Þ belonging to the semantic cluster Sk,
respectively is defined as
dðSÞ ZXN
iZ1
½wðqÞi ð1 KwðkÞ
i ÞCwðkÞi ð1 Kw
ðqÞi Þ� (15)
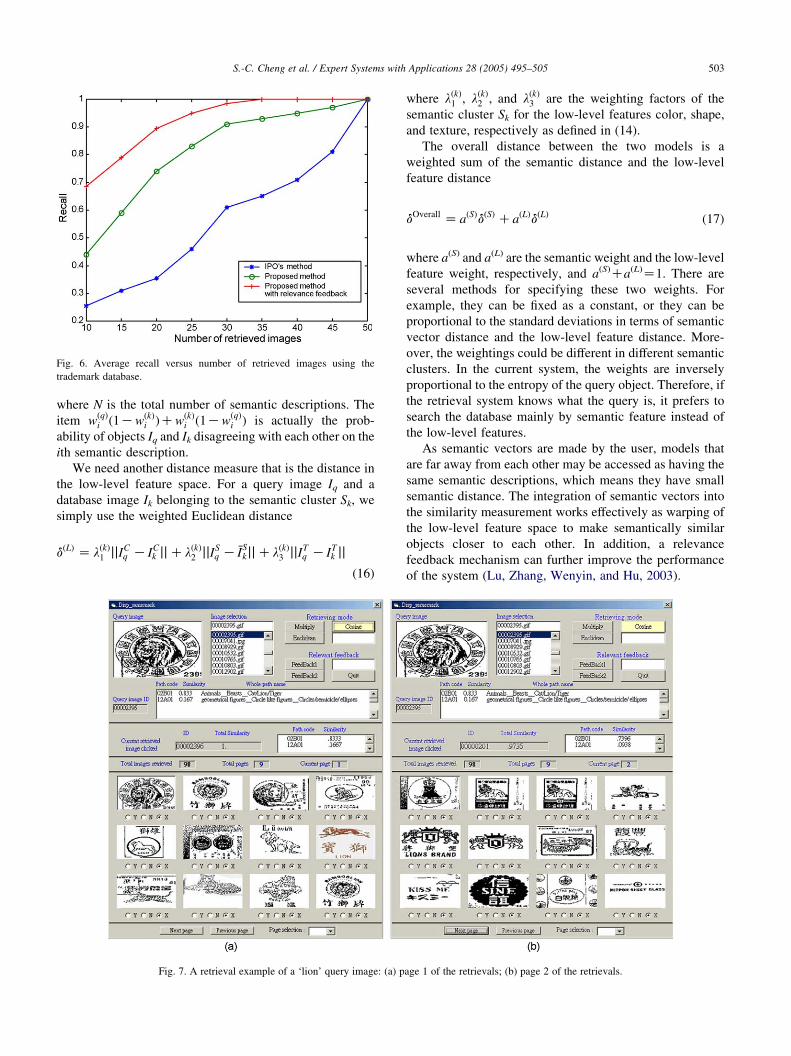
Fig. 6. Average recall versus number of retrieved images using the
trademark database.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505 503
where N is the total number of semantic descriptions. The
item wðqÞi ð1KwðkÞ
i ÞCwðkÞi ð1Kw
ðqÞi Þ is actually the prob-
ability of objects Iq and Ik disagreeing with each other on the
ith semantic description.
We need another distance measure that is the distance in
the low-level feature space. For a query image Iq and a
database image Ik belonging to the semantic cluster Sk, we
simply use the weighted Euclidean distance
dðLÞ Z lðkÞ1 jjIC
q K ICk jjCl
ðkÞ2 jjIS
q K �ISkjjCl
ðkÞ3 jjIT
q K ITk jj
(16)
Fig. 7. A retrieval example of a ‘lion’ query image: (a) p
where lðkÞ1 , l
ðkÞ2 , and l
ðkÞ3 are the weighting factors of the
semantic cluster Sk for the low-level features color, shape,
and texture, respectively as defined in (14).
The overall distance between the two models is a
weighted sum of the semantic distance and the low-level
feature distance
dOverall Z aðSÞdðSÞ CaðLÞdðLÞ (17)
where a(S) and a(L) are the semantic weight and the low-level
feature weight, respectively, and a(S)Ca(L)Z1. There are
several methods for specifying these two weights. For
example, they can be fixed as a constant, or they can be
proportional to the standard deviations in terms of semantic
vector distance and the low-level feature distance. More-
over, the weightings could be different in different semantic
clusters. In the current system, the weights are inversely
proportional to the entropy of the query object. Therefore, if
the retrieval system knows what the query is, it prefers to
search the database mainly by semantic feature instead of
the low-level features.
As semantic vectors are made by the user, models that
are far away from each other may be accessed as having the
same semantic descriptions, which means they have small
semantic distance. The integration of semantic vectors into
the similarity measurement works effectively as warping of
the low-level feature space to make semantically similar
objects closer to each other. In addition, a relevance
feedback mechanism can further improve the performance
of the system (Lu, Zhang, Wenyin, and Hu, 2003).
age 1 of the retrievals; (b) page 2 of the retrievals.

Fig. 9. Average recall versus number of retrieved images using the natural
scene database.
S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505504
5. Experimental results
In order to evaluate the proposed approach, a series of
experiments was conducted on an Intel PENTIUM-IV
1.5GMhz PC, and a trademark image database of 2045
trademark images and a real database of 1048 natural scene
images were used. Each image in the databases is first
analyzed by the AHP for testing the retrieval approach.
Query images are randomly extracted from these images.
The retrieval technique using Boolean queries proposed
by the Intellectual Property Office, Taiwan was also used for
performance comparison. Before the evaluation, human
assessment was done to determine the relevant matches
in the databases of the query images. The top 100
retrievals from both the system of the Intellectual Property
Office (IPO), Taiwan and the proposed approach were
marked to decide whether they were indeed visually similar
in color, shape, and texture. The retrieval accuracy was
measured by precision and recall
PrecisionðKÞ Z CK =K and RecallðKÞ Z CK =M (18)
where K is the number of retrievals, CK is the number of
relevant matches among all the K retrievals, and M is the
total number of relevant matches in the database obtained
through human assessment. The average precision and
recall curves are plotted in Figs. 5 and 6. It can be seen that
the proposed method achieves good results in terms of
retrieval accuracy compared with the method of IPO. This
shows the effectiveness of the proposed method that puts
successfully the related images in response to a query at the
front of the retrieval list.
Fig. 7 shows a retrieval example of a ‘lion’ query image.
The retrievals are presented to the user in the page-by-page
style and it is easy to find that most of the related images are
located at the front pages. One can also begin the relevance
Fig. 8. Average precision versus number of retrieved images using the
natural scene database.
feedback cycles through the user interface of the system to
refine the retrieval results.
In the second experiment, we compare the performance
of the proposed system with that of the well-known IBM
QBIC retrieval system (Flickner et. al., 1995). Figs. 8 and 9
show the corresponding average precision and recall curves
for both methods. It can be seen that the proposed method
achieves good results in terms of retrieval accuracy
compared with the QBIC method. In addition, the
performance of the QBIC method is improved if we set
the weighting factor of the low-level features according to
the leaning results of the proposed semantic learning.
6. Conclusion
Although content-based image retrieval is extremely
desirable in many applications, it must overcome several
challenges including image segmentation, extracting fea-
tures from the images that capture the perceptual and
semantic meanings, and matching the images in a database
with a query image using the extracted features. Owing to
these difficulties, an isolated image content-based retrieval
method can neither achieve very good results, nor will it
replace the traditional text-based retrievals in the near
future.
The contributions of this paper include the following.
First, a new semantic image retrieval method using the
analytic hierarchical process (AHP) has been proposed in
this paper. The AHP proposed by Satty has been success-
fully used to improve the problem of multi-interpretation
characteristics of an image when we focus on different types
of features. Second, the method for ranking retrieved images
according to their similarity measurements is proposed by
integrating the high-level semantic distance and the low-
level feature distance semantic. Finally, a semantic learning

S.-C. Cheng et al. / Expert Systems with Applications 28 (2005) 495–505 505
mechanism for content-based image retrieval is proposed in
this study. Experimental results show that the performance
of the proposed method is excellent when compared with
traditional text-based and content-based retrieval
techniques.
To classify an image by human assessment is too
cumbersome. Future work will deal with shortening the gap
between the traditional content-based image retrieval
techniques and the high-level semantic access methods.
The method for enhancing the proposed learning algorithm
by applying AHP to the content-based image retrieval
systems is an on-going study of the authors.
References
Crestain, F., Lalmas, M., Rijsbergen, C. J. V., & Campbell, I. (1998). ‘Is
this document relevant?.Probably’: a survey of probabilistic models in
information retrieval. ACM Computing Surveys, 30(4), 527–552.
Eakins, J. P. (2002). Towards intelligent image retrieval. Pattern
Recognition, 1(35), 3–14.
Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang, Q., Dom, B.,
et al. (1995). Query by image and video content: the QBIC system.
IEEE Computer, 28(9), 23–32.
IPO (1997), Pictorial Trademark Retrieval System, Intellectual Property
Office, Taiwan, http://www.moeaipo.gov.tw/trademark/search_trade-
mark/search_trademark_simpicF.asp
Jain, R. (1997). Content-centric computing in visual systems. In
proceedings of 9th International conference on image analysis and
processing , 1–13.
Jain, A. K., & Vailaya, K. (1996). Image retrieval using color and shape.
Pattern Recognition, 29, 1233–1244.
Korfhang, R. R. (1999). Information storage and retrieval. New York:
Wiley.
Lai, K. F., & Chin, R. F. (1995). Deformable contours: Modeling and
extraction. IEEE Transactions on Pattern Analysis Machine Intelli-
gence, 17, 1084–1090.
Lai, V. S., Trueblood, R. P., & Wong, B. K. (1999). Software selection: a
case study of the application of the analytical hierarchy process to the
selection of multimedia authoring system. Information and Manage-
ment, 36, 221–232.
Lu, Y., Zhang, H., Wenyin, L., & Hu, C. (2003). Joint semantics and feature
based image retrieval using relevance feedback. IEEE Transactions on
Multimedia, 5(3), 339–347.
Min, H. (1994). Location analysis of international consolidation terminals
using the analytical hierarchy process. Journal of Business Logistics,
15(2), 25–44.
Rui, Y., Huang, T. S., & Chang, S.-F. (1999). Image retrieval: current
techniques, promising directions, and open Issues. Journal of Visual
Communication and Image Representation, 10, 39–62.
Saaty, T. L. (1980). The analytic hierarchy process. New York: McGraw-
Hill.
Smeulders, A. W. M., Worring, M., Gupta, A., & Jain, R. (2000).
Content-based image retrieval at the end of the early years. IEEE
Transactions on Pattern Analysis Machine Intelligence, 22(12),
1349–1380.
Stejic, Z., Takama, Y., & Hirota, K. (2003). Relevance feedback-based
image retrieval interface incorporating region and feature saliency
patterns as visualizable image similarity criteria. IEEE Transactions on
Industrial Electronics, 50(5), 839–852.
Wang, Z., Chi, Z., & Feng, D. (2000). Content-based image retrieval using
block-constrained fractal coding and nona-tree decomposition. IEE
Proceedings—Visual Image Signal Process, 147(1), 9–15.
Wang, J. Z., Li, J., & Wiederhold, G. (2001). Simplicity: semantics-
sensitive integrated for picture liberaries. IEEE Transactions on Pattern
Analysis Machine Intelligence, 23(9), 947–963.
Xiang, S., & Huang, T. S. (2002). Unifying keywords and visual
concepts in image retrieval. IEEE Transactions on Multimedia, 9(2),
23–33.
Zhang, C., & Chen, T. (2002). An active learning framework for content-
based information retrieval. IEEE Transactions on Multimedia, 4(2),
260–268.




















