
A practical approach to process support in health information systems
15
Clinical processes are characterized by a high degree of communication and cooperation among physicians, nurses, and other groups of personnel. An information system should support these processes by enabling a seamless information flow between different partici- pants and different locations. Because of rapidly changing and newly arising requirements, an appro- priate information system should be capable of incre- mentally evolving according to the users’ needs. 1 Yet current healthcare information systems stay far behind the expectations and rarely fulfil these requirements. 2–4 Failures of IT projects in healthcare are not uncom- mon. 2–6 The deeper reasons for these failures are still subject of interdisciplinary research, 5,6 but many core factors are already well known. Inaccurate under- standing of the end-users’ needs is a symptom which is most frequently mentioned. 5,7,8 This can be led back to various reasons, such as insufficient communica- tion, 8,9 and inability of users to express their require- ments and lack of common ground. 3,5,10 Projects also often fail because of missing or unsuitable manage- ment models for software engineering. 7,8 The wide- spread waterfall model, for example, is insufficient for health IT projects because important assumptions for the applicability of this model are not fulfilled in the healthcare domain [11] (e.g., systems are required to evolve over time, and functional requirements are subject to change). Iterative software engineering 7–9 is more suitable for IT projects in the healthcare domain because it is aimed at incrementally developing and improving software products step by step. Iterative software engineering is also particularly suitable to be combined with a participatory approach, as pos- tulated by many authors, 12 because it helps to encourage user feedback. 7 This effect is intensified if prototypes can be generated quickly without invest- ing too much encoding effort. Thus, the approach is ideally supported by using a CASE tool for rapid application development (RAD). 13 In healthcare environments, however, rapidly devel- oping isolated applications is not enough because new applications are required to be integrated with the overall healthcare information system. This arti- 571 Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002 Affiliations of the authors: Institute of Medical Informatics, Philipps-University, Marburg, Germany (RL, TE, KAK); GWI Research Council GmbH, Vienna, Austria (HS). Correspondence and reprints: Richard Lenz, DrIng, Institute of Medical Informatids, Philipps-University, Marburg, Bunsen- strasse 3, D-35037, Marburg, Germany; e-mail: <lenzr@mailer. uni-marburg.de> Received for publication: 9/17/01; accepted for publication: 6/6/02. Application of Information Technology ■ A Practical Approach to Process Support in Health Information Systems Abstract This article describes the design of a generator tool for rapid application develop- ment. The generator tool is an integral part of a healthcare information system, and newly devel- oped applications are embedded into the healthcare information system from the very beginning. The tool-generated applications are based on a document oriented user interaction paradigm. A sig- nificant feature is the support of intra- and interdepartmental clinical processes by means of pro- viding document flow between different user groups. For flexible storage of newly developed applications, a generic EAV-type (Entity-Attribute-Value) database schema is used. Important aspects of a consequent implementation, like database representation of structured documents, doc- ument flow, versioning, and synchronization are presented. Applications generated by this approach are in routine use in more than 200 hospitals in Germany. ■ J Am Med Inform Assoc. 2002;9:571–585. DOI 10.1197/jamia.M1016. RICHARD LENZ, DRING, THOMAS ELSTNER, DIPL.PHYS, HANNES SIEGELE, KLAUS A. KUHN, PROFDRMED
-
Upload
uni-erlangen -
Category
Documents
-
view
2 -
download
0
Transcript of A practical approach to process support in health information systems

Clinical processes are characterized by a high degreeof communication and cooperation among physicians,nurses, and other groups of personnel. An informationsystem should support these processes by enabling aseamless information flow between different partici-pants and different locations. Because of rapidlychanging and newly arising requirements, an appro-priate information system should be capable of incre-mentally evolving according to the users’ needs.1 Yetcurrent healthcare information systems stay far behindthe expectations and rarely fulfil these requirements.2–4
Failures of IT projects in healthcare are not uncom-mon.2–6 The deeper reasons for these failures are stillsubject of interdisciplinary research,5,6 but many corefactors are already well known. Inaccurate under-standing of the end-users’ needs is a symptom whichis most frequently mentioned.5,7,8 This can be led back
to various reasons, such as insufficient communica-tion,8,9 and inability of users to express their require-ments and lack of common ground.3,5,10 Projects alsooften fail because of missing or unsuitable manage-ment models for software engineering.7,8 The wide-spread waterfall model, for example, is insufficientfor health IT projects because important assumptionsfor the applicability of this model are not fulfilled inthe healthcare domain [11] (e.g., systems are requiredto evolve over time, and functional requirements aresubject to change). Iterative software engineering7–9 ismore suitable for IT projects in the healthcare domainbecause it is aimed at incrementally developing andimproving software products step by step. Iterativesoftware engineering is also particularly suitable tobe combined with a participatory approach, as pos-tulated by many authors,12 because it helps toencourage user feedback.7 This effect is intensified ifprototypes can be generated quickly without invest-ing too much encoding effort. Thus, the approach isideally supported by using a CASE tool for rapidapplication development (RAD).13
In healthcare environments, however, rapidly devel-oping isolated applications is not enough becausenew applications are required to be integrated withthe overall healthcare information system. This arti-
571Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002
Affiliations of the authors: Institute of Medical Informatics,Philipps-University, Marburg, Germany (RL, TE, KAK); GWIResearch Council GmbH, Vienna, Austria (HS).
Correspondence and reprints: Richard Lenz, DrIng, Institute ofMedical Informatids, Philipps-University, Marburg, Bunsen-strasse 3, D-35037, Marburg, Germany; e-mail: <[email protected]>
Received for publication: 9/17/01; accepted for publication:6/6/02.
Application of Information Technology ■
A Practical Approach toProcess Support in HealthInformation Systems
A b s t r a c t This article describes the design of a generator tool for rapid application develop-ment. The generator tool is an integral part of a healthcare information system, and newly devel-oped applications are embedded into the healthcare information system from the very beginning.The tool-generated applications are based on a document oriented user interaction paradigm. A sig-nificant feature is the support of intra- and interdepartmental clinical processes by means of pro-viding document flow between different user groups. For flexible storage of newly developedapplications, a generic EAV-type (Entity-Attribute-Value) database schema is used. Importantaspects of a consequent implementation, like database representation of structured documents, doc-ument flow, versioning, and synchronization are presented. Applications generated by thisapproach are in routine use in more than 200 hospitals in Germany.
■ J Am Med Inform Assoc. 2002;9:571–585. DOI 10.1197/jamia.M1016.
RICHARD LENZ, DRING, THOMAS ELSTNER, DIPL.PHYS, HANNES SIEGELE,KLAUS A. KUHN, PROFDRMED

cle describes such a CASE tool (generator tool or formsgenerator), which is an integral part of a commerciallyavailable hospital information system and which isparticularly designed for generating workflow-enabled clinical applications that are integrated withthe overall system. This generator tool is based on adocument oriented user interaction paradigm. Usersinteract with the system by filling paper-like elec-tronic documents, which serve as containers forinformation distribution (e.g., a discharge report) or a“laboratory order.” The generator tool allows to rap-idly develop new document types (templates). Werefer to such a template as an “electronic form.” Inother words, an electronic document is an instance ofan electronic form. Workflow is supported by estab-lishing a flow of electronic documents between dif-ferent parties involved in the health care process (e.g.,physicians in different departments, nurses, medical-technical assistants, secretaries). The concept and itsimplementation are explained in detail in the mainsection of the article. In particular, we describe theunderlying generic database schema.
This approach is being used in our university hospi-tal, where the tool has been continuously improvedduring the past two years. Although the currentimplementation has certain limitations, the approachhas proven practicable, and we consider the designideas based on our experiences helpful for systemarchitects and for implementers.
Background
Supporting clinical processes with information tech-nology requires workflow specification (i.e., the identi-fication of tasks, procedural steps, input and outputinformation, people and departments involved, andthe management of information flow according to thisspecification). Different approaches for process supportin health information systems are currently under dis-cussion. The most comprehensive approach for processsupport is offered by dedicated WorkflowManagement Systems (WfMS).14,15 General purposeWfMSs try to provide a complete environment inwhich to define, execute, and monitor businessprocesses. Existing applications are linked togetherinto global processes that are controlled by an externalworkflow engine. The WfMS approach is conceptuallymature and successful in many application areas. Well-structured business processes are increasingly sup-ported by WfMSs. However, the approach does not yetplay a significant role in health information systems.16
One reason might be that existing clinical applications
often come with built-in workflow functionality, whichis not conform to standards for interoperating work-flow engines as proposed by the WorkflowManagement Coalition (WfMC).17 More important,however, is that integrating autonomous, independ-ently developed applications in healthcare takes a higheffort, no matter which integration approach is used.Independently developed applications tend to be tech-nically and semantically incompatible.18 Thus, gettingup a WfMS in the extremely complex healthcare envi-ronment is risky (integration efforts are often underes-timated), costly, and time-consuming.
Architectural flexibility in health information sys-tems could be achieved by component-based systemswith exchangeable plug and play components.Emerging component technologies, such as CORBA,DCOM or EJB, are often considered the key to inte-gration of heterogeneous and autonomous compo-nents. Consistently combining domain-specific “bestof breed” components into a comprehensive inte-grated whole seems to be within reach. This, how-ever, is still not the case. Object middleware stan-dards such as CORBA provide a framework for thedevelopment of distributed applications, enablingthe programmer to concentrate on application logicinstead of distribution issues such as remote access ordistributed transaction management. Developingdistributed applications on top of such a framework,however, still requires conformance of different com-ponents involved with a common application frame-work. The essence of component technology is tobuild well-structured systems out of independentlyunderstandable and reusable building blocks.19 Tomake a component reusable by other components, aprecise specification of syntax and semantics of thecomponents’ interfaces is required. If the interfaces ofindependently developed components do not matchsemantically, components will not cooperate—even ifthey are implemented in the same component tech-nology. To achieve a truly integrated component-based system, component developers need to buildtheir components on the basis of a common context.This common context, in particular, includes a func-tional decomposition of the application domain.Moreover, common ontological and terminologicalfoundations of the application domain are requiredto achieve a common understanding of basic domainspecific concepts. This problem is well known, andthere is already a clear trend toward domain-specificmiddleware in healthcare.20–23 Yet standardizationefforts have not yet resulted in a complete applicationframework generally accepted and used for health-care information systems. System evolution by
LENZ, ET AL., Process Support in Health Information Systems572

adding plug-and-play components in a “best-of-breed” strategy is still difficult.
We report on a generator-tool approach that supports adifferent strategy for incremental system evolution. Thegenerator tool is an integral part of a holistic healthinformation system, and it is used to rapidly developnew functionality for this system employing an itera-tive and participatory software engineering process.Instead of trying to link independently developedapplications together, the generator tool provides ameans for developing new system components, whichare embedded into the overall system from the verybeginning. As it is still not realistic to provide the com-plete spectrum of clinical functionality by the use ofsuch a tool, conventional ways of connecting subsys-tems are also needed. In our hospital (and in other hos-pitals using software based on the generator approach),typical standard HL7 interfaces and an interface engineare used to connect separate subsystems. The numberof separate subsystems tends to be limited, however. Asan example, our laboratory system is connected viaHL7, whereas the radiology information system hasalready been built with the generator tool.
Design Objectives
The objectives of the generator tool approach are toimprove the quality of software components by bring-ing software development closer to the end-user. Thetool is intended to ease the apposition of new func-tions into a running health information system andthereby to shorten development cycles and increaseadaptation to the end-users needs. To achieve thesegoals, development of a new form should not be over-loaded with routine technical programming tasks thatare not directly related to the application logic (e.g.,mapping of different data formats). With thisapproach, software development is no longer a two-stage process in which some programmer implementsthe requirements of the end-user. Instead, an addi-tional distinction is needed between the system devel-oper and the application developer:
■ The system developer (system architect) isresponsible for developing and improving theoverall system architecture including the genera-tor tool and its functionality. With respect to theimplementation of the generator tool, the architectis not so much interested in the concrete require-ments of some clinical department but merely inmore general abstract requirements concerning thedesign of clinical applications. The system archi-
tect receives feedback primarily from applicationdevelopers, not from end-users.
■ The application developer (application designer)uses the generator tool for developing new appli-cations employing a participatory and iterativesoftware engineering process. He or she gets feed-back from the end-user. The generator tool shouldhelp the developer to rapidly implement proto-types according to the end-users’ requirementswithout investing too much encoding effort (e.g.,the application designer does not need to worryabout physical database schema design). This roleis closely related to knowledge engineering. Theapplication developer captures and formalizesdomain knowledge. In the light of the fundamen-tal works of Musen on Protégé, a central task of theapplication developer is extraction of a domainontology.24,25 Thus, the term knowledge engineermay be used from this perspective.
■ The end-user (e.g., physician, nurse) is the personwho works with the resulting applications (tool-generated applications). To optimize the adapta-tion of the software to the clinical work practice,the end-user is intensively involved in the softwareengineering process. Prototypes illustrating thedesign of forms and of information flow are avail-able early, and they allow a continuous feed backfrom the end user to the application developer.
This article focuses on implementation aspects of sucha generator tool. Thus, we primarily take the view-point of the system developer, who has been develop-ing a tool suitable for rapidly implementing distrib-uted clinical applications that support clinicalprocesses including cross-departmental workflows.The generator tool should enable the applicationdesigner to concentrate on the application logicinstead of encoding problems. Most importantly, how-ever, the generator tool has to support the definition ofapplications that are integrated with the overall healthinformation system via a common database. Thus, themain objectives for the system designer are as follows:
■ Newly defined data items should be stored withinthe same central database, and newly defined appli-cations should be accessible via a common frame-work without any a posteriori integration effort.
■ Tool-generated applications should avoid redundantdata entry. Therefore, the tool must enable the appli-cation designer to refer to existing data elements thatare already stored in the central database to uploadthese data into newly designed applications.
573Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002

■ The tool should support developing distributed(interdepartmental or interinstitutional) applica-tions such as order entry/result reporting. There-fore, the tool must provide means for workflowspecification—i.e., means to specify how to deliverthe right information (what), at the right time(when), to the right people (who).
Perspectives of a Document BasedGenerator Tool
The concrete approach in this article is based on adocument-oriented user interaction paradigm, whichsubstantially determines the different perspectives ofend users, application developers and system devel-oper. For this article we use the terms related to thisparadigm as follows:
■ Electronic documents serve as a structured unit ofinformation and information flow.
■ Each electronic document is an instance of an elec-tronic form, which in turn is to be seen as type ortemplate for corresponding electronic documents.
■ A form contains different fields.
■ An entry is an instance of a field that belongs to aconcrete electronic document.
■ Reference lists contain references pointing to elec-tronic documents or to other reference lists. Theyare the point of ingress to electronic documentsand an important instrument for gainingoverview. A reference is represented by a shortdescription of the contents of the associated docu-ment (e.g., discharge letter for patient John Doefrom June 21st, 2001). Different types of referencelists can be distinguished as follows:
1. Patient-related lists contain references topatient related documents. Examples are thepatient history, in which all documents for a par-ticular patient are collected, departmental viewson a subset of the documents that belong to a par-ticular patient, and reference lists for openrequests for a particular patient.
2. Task-related reference lists are work lists thatare related to a specific task (e.g., discharge reportsthat are to be validated).
3. Meta-level reference lists contain references toother reference lists. Examples are departmentoverviews that contain references to patient spe-cific lists, and user specific lists that contain refer-
ences to different lists which are at the users dis-posal.
The generator tool is a means to rapidly develop newdocument-based applications. The generator tool andthe tool-generated applications are embedded into anapplication framework, which is based on a commoncentral database. The application framework mapsboth document data and necessary meta-data togeneric database tables. These generic tables are onepart of the overall database schema of the healthinformation system, which also contains conven-tional database tables with explicitly modeledsemantics. Administrative applications (e.g., patientdata management with ADT functionality, financialaccounting) operate on these conventional databasetables. To illustrate the basic idea, the overall systemarchitecture is shown in Figure 1.
The Perspective of the Application Developer
The development of tool-based applications must beseen in the broader context of an iterative and partic-ipatory software engineering process. The applica-tion designer closely cooperates with the end-users tocapture specific workflow requirements and to adaptthe application to the users’ needs. This is done byelaborating the required information flow and map-ping it to workflow enabled forms and reference lists.The generator tool supports the development of newforms and new reference lists.
Reference lists are also used to control access rights.The application developer assigns different Roles todifferent user groups. Each role is associated withaccess rights to certain reference lists. If a new form isto be developed, the application designer figures outwho is going to use this form (which user groups areinvolved) and which reference lists are needed asingress points for these users. If necessary, new refer-ence lists are to be defined. For each new form, theapplication designer defines the associated fields andtheir graphical layout. The application designer mayalso define a default value or a computation rule fora field. Access restrictions can be defined for certainfields (e.g., only a physician is allowed to validate adischarge letter). To specify document flow, differentstates are to be defined for each form. An electronicdocument has exactly one state at a time. The appli-cation designer specifies in which reference lists adocument appears in a certain state. For example, thereference list “new results for John Doe” presents anoverview of all documents containing results for thispatient (e.g., laboratory results, radiology results,
LENZ, ET AL., Process Support in Health Information Systems574

reports from consultants) that have not yet been seenby the ordering physician. Moreover, the applicationdesigner defines the triggering events that change thedocument status. Each user interaction (e.g., updat-ing a field) is an event that could be used. However,typically an explicitly defined button is used as a trig-gering event for a status change (e.g., a button “vali-date”). A trigger may also initiate an automaticupload of information from the central database. Interms of our initial characterization of workflowspecification, document based applications asdescribed cover all three workflow aspects:
■ “What” is covered by the definition of forms andtheir contents
■ “Who” is covered by assigning access rights to ref-erence lists as well as individual fields and buttons
■ “When” is covered by defining triggering eventsfor controlling document flow
To enhance software reuse, it is also possible to includerepeatable fields and sub forms within electronic forms.The application developer may, for example, define asub form for entering a diagnosis and reuse this subform in multiple “top-level forms.” Workflow, however,is only specified for top-level forms.
The Perspective of the End User
Each user enters the system via his personal userfolder, which provides access to the reference listsfor which the user is authorized. By openingdepartment- and patient-specific reference lists, theuser navigates into a specific context. For example,Dr. A views the departmental patient history ofCardiology for patient John Doe. If the user createsa new document by instantiating a form, this cur-rent context information is used to automaticallyupload context specific information into the docu-ment (e.g., a newly instantiated discharge letter is
575Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002
F i g u r e 1 Overall system architecture. Conventional administrative applications as well as document-based clinical appli-cations directly operate on a common central database. An application framework provides access to generic database tablesas well as conventional (explicitly modeled) database tables. A generator tool is used to incrementally add new clinical appli-cations to the system, which are based on a document-oriented user interaction paradigm.

automatically filled with the patients address andother context determined information). Once a doc-ument is open, the user typically interacts with thesystem by filling this document almost like an ordi-nary paper form, and by explicitly invoking events(e.g. clicking on a dedicated button) to send thisdocument to its destination. Electronic documentsare typically filled step by step at different locationsand by different users. A radiology report, forexample, traverses different steps before it is com-pleted and validated. Changes of validated docu-ments are not permitted. If modifications are neces-sary, a new version of this document can be createdwhile the old version is kept with an explicit inval-idation remark.
Technical View on Electronic Forms
Technically, a form is an event-driven program thatcollects information from multiple sites (differentlocations involved in a distributed health careprocess) and stores it persistently in the central data-base. This program is always executed in a certaincontext: When a user opens a discharge letter for JohnDoe, the corresponding program is executed, and thecurrent context information for John Doe and thedocument contents are uploaded into the local pro-gram variables. The program starts an event handler,which is simply a routine which registers events(such as user input) and performs predefined actions,accordingly. Each form has a closing event. If theevent handler registers the closing event, the docu-ment contents are written back into the central data-base and the program terminates.
System Description
This section describes implementation aspects of thegenerator tool approach. In particular we describe theunderlying generic database schema, which coversboth the description of document-based applications aswell as the data on which these applications operate.
Generic Database Schema for Document-basedApplications
An extensible system, capable of dynamically han-dling newly defined forms and reference lists, requiresthe underlying database to be designed in a way thatallows introducing new concepts without modifica-tion of the existing database schema. The commonapproach is an entity-attribute-value (EAV) databaseschema, as described by Nadkarni et al.26 The basic
idea of EAV is to use a single database table for arbi-trary data items. The EAV table basically containsthree columns—one column to specify the entity, oneto specify the attribute, and one for the value of thespecified attribute. Data items with newly definedsemantics can be entered into the database without theneed for a schema modification. Necessarily, semanticcontrol on the database schema level is given up.Instead, semantic annotations are entered into explic-itly introduced tables for such metadata.
In our case, a modified and extended EAV schema isrequired which also contains generic tables for thedescription of dynamically defined document basedapplications. We need both type level tables fordescription of tool based applications (e.g., forms andfields) and instance level tables for storing electronicdocuments and their contents. Type level tables arefilled by the application developer via the generatortool. Instance level tables are filled at runtime by theend-user via the use of tool generated applications.The schema fragment shown in Figure 2 containstables for forms, fields, documents, and entries. Thetables Form and Field both describe the structural typeof electronic documents (e.g., the form “dischargereport” may contain fields for patient data, physicianaddress, date, and comments). The table Documentrepresents form instances. A document has particularentries (instances of fields). The table Entry is theequivalent of the classic EAV table that actually con-tains the user data to be stored. Instead of columns forentities and attributes, however, the table containscolumns for documents and fields, respectively.
This construct allows association of entries with doc-uments and fields, but it is too weak to identifysemantically interrelated fields in different forms. Forthis purpose an additional layer of metadata tablesfor semantic annotation of fields has been intro-duced. Following Chen’s E/R notation, we havenamed the corresponding tables Entity, Relationship,and Attribute. The comparable meta-data tables inNadkarni´s EAV/CR schema are named Classes,Class_Hierarchy, and Attributes, following an object-oriented notation.26
The concept supports reuse of subforms in multipletop-level forms. Subforms can be recursivelyincluded in other forms by allowing fields of the type“subform-reference.” If a form is modified, it is essen-tial to keep the old version of the form in order to stillbe able to interpret older documents. Additionaltables Form_Version and Layout are used to supportform versioning. They describe which field is used in
LENZ, ET AL., Process Support in Health Information Systems576

which form version and with which layout (e.g.,position, size, color). As a validated electronic docu-ment must not be modified, versioning is also neededon the instance level: An Entry is always associatedwith a document version (table Document_Version).
Generic database tables based on the EAV approachare used to be able to dynamically add new formsand fields to the system and thereby to extend thesystem’s functionality. Advantages and disadvan-tages of the EAV-approach are well known,26 and itmakes sense to use conventional database tables withexplicitly modeled attributes for major (static) partsof the schema, especially for patient administrationdata including the ADT-data. This conventional partof the database schema particularly contains data-base tables needed to describe the clinical contextinformation in which electronic documents are to be
embedded (e.g. an electronic document is generatedin a certain department and belongs to a patient anda case). The context of a document is expressed bydirectly referencing these tables: The table Documentactually contains foreign keys referencing conven-tional database tables such as Patient, Case, Episode,and Department.
Means to Support Data Integration
One of the main characteristics of the generator toolapproach is the ability of the tool to enable the appli-cation designer to include references to existing dataitems into newly defined forms. These may either bedata items stored in conventional database tables(e.g., ICD diagnoses) or even data items from theEAV table that belong to some other electronic docu-ment. This is an essential feature of the generator tool
577Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002
F i g u r e 2 Fragment of anEAV schema for storingforms and electronic docu-ments. Primary key (PK) andforeign key (FK) attributesare labeled. Mandatoryattributes are indicated bybold font. The tables Form,Form_Version, Layout andField are used to describe doc-ument types. The tablesDocument, Document_Versionand Entry are used to storedocument instances. Thetable Entry is the actual EAVtable, which is used to storeall kinds of data itemsregardless of their semantics.Semantic annotations arestored in the tables Entity,Attribute, and Relationship.Electronic documents (tableDocument) are embedded intoa clinical context by foreignkeys to conventional data-base tables Patient, Case,Episode and Department.

that enables the application designer to develop trulyintegrated applications from the very beginning.Subsequently, we refer to a field which is derivedfrom some other data item as a computed field. First,we concentrate on computed fields referring to datastored in conventional database tables. A possiblesolution would be to allow the application designerto specify SQL-statements that compute the desiredinformation for an electronic document. Direct SQL-access to the conventional database tables, however,is not a good idea because the definition of a formwould depend fully on the structure of these tables,and old forms might become unusable with a newsoftware release. Therefore, to be prepared forschema evolution, it is better to encapsulate conven-tional database tables into objects, which are used bythe application designer to refer to the associatedinformation. If the definition of a conventional data-base table is modified in this case, it is necessary toupdate only the encapsulating object appropriately toadapt computations for all documents accessing thistable. Another positive effect of this method is thatthe application developer is not confronted with thewhole complexity of the database schema. Instead,the developer can choose from a predefined set ofobjects which make sense in the current context.
After considering computed fields derived from con-ventional database tables, we should look at the sec-ond case: A computed field may also be derived fromanother field in some other form. A typical case isthat an entry from a completed and validated docu-ment is to be displayed in a newly created document.For example, findings from different examinationsare to be uploaded in a discharge report. The genera-tor tool offers a variety of options to upload contentsfrom other documents: The application designer caneither directly identify the document he refers to bycomputing its document ID (e.g., explicitly specify-ing an SQL query, which delivers the document ID),or chose from a set of predefined context dependentoptions (e.g., “last document of this case,” “last labo-ratory report for this patient”).
Different strategies of storing and updating entriesfor computed fields are to be distinguished. Oneoption is not to store the entries redundantly in theEAV table (table Entry). We refer to such a field as vir-tual field, and a corresponding entry is called virtualentry. A virtual entry is automatically computed anduploaded into local program variables when the doc-ument is created or opened, and it is written back tothe source database table when the document isclosed. There is no further synchronization with the
source database tables, unless the application devel-oper explicitly specifies trigger actions for repeatingthe upload or for writing back to the database. As thecontents of validated documents must not bechanged, virtual entries automatically imply the needfor versioning of conventional database tables. Anupdate of a data item in its source database tablemust not lead to an update in old and validated doc-uments referring to this data item. If the conventionaldatabase tables are not versioned, the applicationdeveloper must ensure that virtual data entries aresubstituted by redundant entries in the Entry table assoon as the document is validated. An alternativewith less redundancy is to delay explicit storage untilthe referenced data are modified.
If a computed entry is explicitly stored in the Entrytable, it is up to the application developer to decidehow to synchronize this entry with the source datafrom which it is derived. If the computation is usedonly to set a default value for this field, furtherupdates or synchronization with the source databasetables are not necessary (we refer to this case as anunsynchronized computed field). If the field, however, issemantically redundant with the source databasetable, the application designer must take steps to pre-vent diverging instances of redundant data. The gen-erator tool has to support this goal by providingmeans to specify an appropriate replication protocol.In its current version, the generator tool only pro-vides asynchronous mechanisms for update propa-gation between redundant entries. For computedfields referring to conventional database tables, theapplication programmer typically chooses a primarycopy approach, in which the data item in the conven-tional database tables is the primary copy (master)and all redundant entries in the EAV table are the sec-ondary copies (slaves). This approach avoids diverg-ing instances of the same data since updates arealways performed on the master copy. Bernstein etal.27 provide a more detailed discussion of the under-lying synchronization issues.
As shown in Figure 2, the table Field may contain sev-eral flags to describe the storage and update charac-teristics of a particular field:
■ Field_Computed: is true if corresponding entries arecomputed from conventional database tables.
■ Field_Virtual: is true if corresponding entries arecomputed but not redundantly stored in the tableEntry.
■ Field_Modifiable: is true if the user is allowed toexplicitly update the field.
LENZ, ET AL., Process Support in Health Information Systems578

■ Field_Synchronized: is true if the field is computedand modifiable and updates on the field are to besynchronized with the original conventional data-base tables.
Another important attribute to characterize a field isField_Visible, which is true if the value of the corre-sponding data entry is actually displayed on the elec-tronic document. Invisible fields are typically definedfor additional document-related status informationthat is not interesting for the user of the documentbut that is used by the application designer for inter-nal document control.
The attributes described in this section and in Figure2 clarify the concept, but they are not sufficient for aconcrete implementation of a generator tool:Additional tables and attributes are required; e.g., forspecifying whether a field is updated continuously(immediate asynchronous propagation) or not.Furthermore, to describe delayed updates, specifica-tion and storage of triggering events are needed, butnot covered by the schema fragment in this article.
Handling Dynamic Aspects of ElectronicDocuments
To support document flow, the generator tool mustprovide means to specify when a document appearsin which reference list. For each form, a status vari-able has to be defined and initialized, trigger eventsfor state changes have to be specified, and referencelist assignments have to be made according to thecurrent status. In the current implementation of thegenerator tool, all this is done explicitly by the appli-cation developer:
■ The developer explicitly defines an invisible fieldinterpreted as the document status.
■ The developer specifies trigger events that initiatemodifications of the status field.
■ For each relevant reference list, the developerdefines how references for this form and this listare represented. The developer also defines a con-dition indicating when a document of this typeappears in this reference list. A typical conditionwould check whether the status field has a certainvalue (e.g., $status == “validated”); arbitrary con-ditions are possible, however.
As a consequence of this method, document defini-tion and workflow definition are closely intertwinedand implementation of document flow is cumber-some. The application designer must explicitly inter-
pret the individually defined status variable anddefine trigger actions for state changes and referencelist assignment. Once processes are implemented andhidden in the definition of forms, they are difficult tounderstand and to modify.
Current developments are directed towards a morecomfortable way of specifying document flow. Forthis purpose, specification of document flow andspecification of form contents are separated.Workflow specification via the generator tool can beeased by the use of graphical elements (e.g., by usingsimple directed graphs that are annotated with attrib-utes for workflow definition). A graph containsnodes and directed edges. A directed edge connects asource node and a destination node. Nodes representworkflow states and are associated with reference listtypes. A directed edge indicates a possible state tran-sition. “Empty forms” that already include triggeringevents and reference list assignments can then beautomatically generated from such a graphicaldescription of workflow. Within these empty formsthe application designer can already refer to work-flow states in order to use them for document inter-nal control (e.g., depending on the state, the applica-tion designer might want to decide whether a certainfield is modifiable or not). Besides ease of program-ming and advanced maintainability, another advan-tage of this approach is that the workflow specifica-tion is automatically documented.
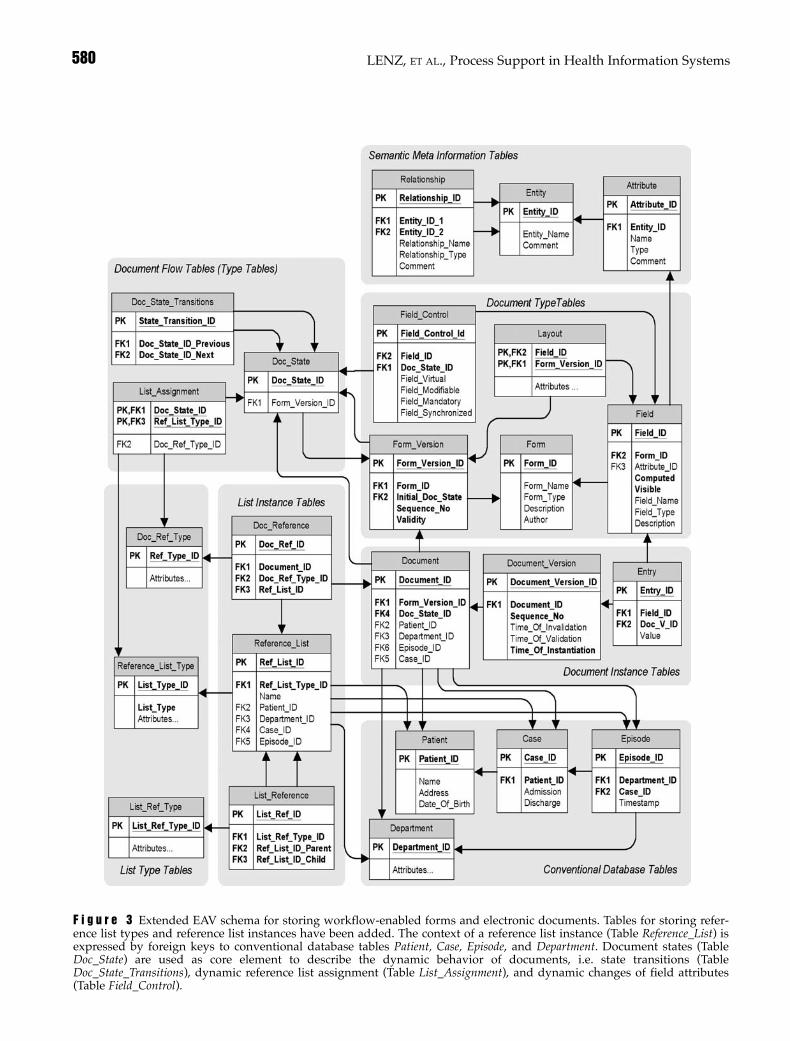
The relational database schema described so far cov-ers the contents of forms and documents only (the“what” in the workflow specification). Additionaltables are required to store reference lists, references,and document states. These extensions are describedin Figure 3. The characteristics of a reference listare described by a reference list type (tableReference_List_Type). Concrete reference lists areinstances of a reference list type and are stored in thetable Reference_List. Like electronic documents, refer-ence lists can be related to a concrete clinical context.A reference list type “patient history,” for example,has concrete instances for each patient.
With the database schema in Figure 3 we present thecurrent developments toward a more stringent inter-pretation of the document-based approach. Defini-tion of document flow is supported explicitly, and itis separated from the definition of form contents.Each form (table Form_Version) is assigned to a num-ber of workflow states (table Doc_State). The tableDocument receives an additional foreign key on thetable Doc_State, indicating the current state of the
579Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002
LENZ, ET AL., Process Support in Health Information Systems580
F i g u r e 3 Extended EAV schema for storing workflow-enabled forms and electronic documents. Tables for storing refer-ence list types and reference list instances have been added. The context of a reference list instance (Table Reference_List) isexpressed by foreign keys to conventional database tables Patient, Case, Episode, and Department. Document states (TableDoc_State) are used as core element to describe the dynamic behavior of documents, i.e. state transitions (TableDoc_State_Transitions), dynamic reference list assignment (Table List_Assignment), and dynamic changes of field attributes(Table Field_Control).

document. The document flow for a certain form isdescribed by defining the potential successor statesfor each document state (table Doc_State_Transitions).When a document is used at runtime, trigger buttonsare displayed for each successor of the current stateof this document. For each document state, it is nec-essary to define in which reference lists a correspon-ding document is to be displayed (tableList_Assignment). The table List_Assignment refers to adocument state and a reference list type (e.g., patienthistory); the concrete reference list instance for a con-crete document is determined by the context of thatparticular document (e.g., if the document belongs topatient John Doe, it will appear in the patient historyfor John Doe). Task-related work list types typicallyhave only one instance. Reference types are used tospecify how a document is referenced within a par-ticular reference list (table Doc_Ref_Type); for exam-ple, a validated discharge report may be referencedby displaying the document type, the patients nameand the date of validation. A concrete reference is aninstance of this type (e.g., “discharge letter for patientJohn Doe from June 21, 2001”). A list assignment con-tains an additional foreign key to the TableDoc_Ref_Type to determine which reference type is tobe used for a document in a certain state and in a cer-tain reference list. The table Doc_Reference is used forconcrete document references (e.g., document Aappears in reference list B using the document refer-ence type C). Meta-level reference lists contain listreferences instead of document references. The typeof such a list reference is described in the tableList_Ref_Type. Concrete list references are thendescribed in the table List_Reference (e.g., list Aappears in list B using reference type C).
Now that document states are explicitly stored in thedatabase, they can be used to control dynamic fieldattributes: For example, a field may be modifiable untilthe document is validated and not modifiable fromthen on. The table Field_Control is used to store the def-inition of this state dependent dynamic behavior.
Practical Aspects of Implementation
The relational database tables presented in this articleare intended to explain the concept of a document-based generator tool. As already mentioned, they donot represent a complete database schema, which isneeded for a concrete implementation. Additionaltables for event handling are needed, additionalattributes for layout and field positioning and the likeare needed, and the conventional database tables are
indicated only by rudimentary table fragments.Moreover, in order to achieve an acceptable perform-ance further considerations are necessary. For exam-ple, interpreting forms solely from their descriptionin relational database tables will result in unaccept-able response times. Therefore, it is necessary to pro-vide measures to increase performance, e.g. redun-dant storage of pre-generated forms as blobs.
Status Report
From the vendor’s perspective, the generator tool isthe fundamental strategy by which all new clinicalapplications are developed. The tool can be used indifferent scenarios. The application developer caneither be a member of the hospital’s IT staff or one ofthe vendor’s specialists. A further perspective mightbe to hand the tool to the end-user to let him or herdesign his or her own forms; a modified (simplified)version of the tool is being discussed for this purpose.While tool-generated applications are in use in morethan 200 hospitals in Germany, only a few hospitalsare developing their own tool-based applications.Instead, the vendor company employs both a(smaller) group of system developers and a (larger)group of application designers.
In our university hospital, the tool has been in usesince December 1999. Major components of the hos-pital information system, such as clinical applica-tions for wards and ambulatory care settings aswell as ancillary systems (radiology, pathology,endoscopy and others), are based on the generatortool approach. Several of the generator-based dis-tributed applications have been implemented byour hospital IT-staff.28 Generator-based applica-tions are currently being used at all wards through-out the hospital (approximately 180 clinical work-stations at 90 wards). Additional generator-basedapplications are used at approximately 100 work-stations (radiology, 40; nuclear medicine, 20;pathology, 25; dermatohistology, 5; endoscopy, 5;sonography, 4). Applications for several ambula-tory care settings are being introduced. All ICD-diagnoses are captured via synchronized electronicforms and are directly written into conventionaldatabase tables. Documentation of procedures isalso increasingly covered by electronic forms.Approximately 11,500 examination reports permonth are produced by means of electronic docu-ments (e.g., in August 2001: radiology, 8,162;pathology, 1,793; nuclear medicine, 993; dermato-histology, 230; endoscopy, 322). Currently, 10 of 30
581Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002

departments use generator-based discharge reports(approximately 1,800 reports per month). Orderentry for radiology has been implemented viaworkflow enabled forms, which include electronicscheduling. The introduction time was about 4months for all wards (90) of the hospital. The cen-tral EAV table currently (Dec 2001) contains morethan 42 million entries and is growing at an increas-ing rate of currently 2.2 million entries per month.From our experiences, neither the tool-generatedcode nor the EAV storage technique affected the sys-tem performance negatively. There were negativeperformance effects, but these resulted from theholistic system with dependencies on administrativemodules (and long running administrative statisticsprograms); they were not caused by the generatorapproach.
The current implementation of the generator tool haslimitations. As already mentioned, specification ofdocument flow is not yet represented in the database.Instead, the application designer is forced to useinvisible fields as status variables. This approach isunsatisfying because definition of document contentsand workflow are intertwined and there is no possi-bility to easily obtain any workflow-related informa-tion from an existing generator-based application.Because definition and interpretation of status vari-ables are up to the application developer, dynamicbehavior of fields is also hidden in the program code.The generator tool is currently being re-implementedto separate workflow specification from the specifica-tion of document contents. This re-implementationalso considers more general workflow issues, such asdependencies among different forms. Another goal ofthe re-implementation is to enhance reuse of soft-ware-components (e.g., subforms). To reach thesegoals, the application developer should be able torefer to standardized sub form interfaces within theworkflow specification (e.g., an electronic documentshould allow external access to its states in order toenable a workflow engine to modify these states).
The second major drawback of the current implemen-tation is that semantic annotation of fields is not suffi-ciently elaborated yet; semantic meta-informationtables are missing. Usually electronic documents areaccessed as a whole via reference lists (e.g., patient his-tory, ward specific view, departmental view), which issufficient to support routine clinical work practice.Thus, semantic annotation of document contents hasnot been absolutely essential for the success of the gen-erator. Reasons for introducing semantic annotationsare well known, however,29,30 and the product is actu-
ally being developed into this direction. Although thetable Field may have an attribute for an informaldescription of a field, a more stringent method isneeded to be able to identify identical or related con-tents in different forms and for expressing semanticequivalence. The method of choice is an additionallayer of metadata tables (see Figure 2) in the databaseschema which is used to describe the semantics offorms and fields.26 These tables contain descriptions ofentities (medical concepts) and relationships betweenthese entities (see Figure 2). The semantics of a newlydefined field can be expressed by relating this field tothe associated medical concept.
The next step should be to use the contents of the meta-data tables for consistent semantic tagging of XML doc-uments, which can be generated if data are to beextracted and transferred to other systems. This step,however, requires semantic annotation of all fields.Moreover, if such an XML document is to be interpretedby some external system, it would be advantageous touse standardized XML tags. Ideally, the metadata tablesare to be filled with more or less standardized medicalconcepts (standard ontologies), so that the metadatatables finally provide a means for referencing a medicalentities dictionary or repository.29,30 Both semanticannotation of electronic documents as well as explicitworkflow support are currently under development.
Discussion
We have presented a generator tool for rapid proto-typing of document oriented and workflow-enabledapplications. Both the tool and the tool-generatedapplications are integral parts of a health informationsystem. The approach allows dynamic evolution ofthe information system by incrementally adding newapplications to the running system. The document-based generator tool approach has several advan-tages and drawbacks. Advantages of the approachcan be briefly summarized as follows:
■ Clinical documentation is supported in an intu-itive way by emulation of paper-like forms.
■ These forms are routinely used by different partiesinvolved in the care process, resulting in an effec-tive support of distributed clinical processes (e.g.,radiology order entry and result reporting fromthe wards could be realized in a surprisingly shorttime).
■ EAV storage of forms data results in flexibility andextensibility without the need for schema modifica-tions. New attributes, data types, and concepts can
LENZ, ET AL., Process Support in Health Information Systems582

be included dynamically into a running system.Moreover, EAV tables are space-efficient since unas-signed fields do not allocate any memory at all.26
■ The document- and reference list-based approachin combination with EAV has the advantage thatnew task related work lists can be dynamicallyincluded into a running system, which enablesdynamic extensibility of functionality.
■ Database integration of tool based applicationsavoids additional efforts for interfacing comparedwith independently designed applications.
■ The generator tool approach speeds up applica-tion development because the application devel-oper is not required to encode forms in a pro-gramming language. Templates (e.g., a predefineddischarge report) can be reused and adapted tospecific departmental needs.
■ The generator tool used in our hospital has shownthat the approach is workable.
Drawbacks of the approach are:
■ Typical disadvantages resulting from the EAVtechnique also affect the document orientedextended EAV approach. For example, databasemechanisms for integrity control cannot be used inthe usual way. A significant amount of programcode has to be generated by the generator tool tomaintain integrity, which is normally ensured bythe database system.
■ Querying data from documents stored in EAVtables is more complicated than querying conven-tional database tables.
■ Specification and synchronization of computedfields and redundantly stored data are essentiallyup to the application developer. He decides whento upload computed fields from conventionaldatabase tables into electronic documents. Thus,the application developer must carefully considerwhat he or she is doing in order to avoid unde-sired effects. Writing computed entries back intoconventional databases tables, for example, baresthe risk of potential inconsistencies because theconventional tables might have been updatedsince they were uploaded into the document,which would result in a lost update.
■ Using the generator tool for rapid development ofclinical applications involves the risk of inhomo-geneous forms. Style guides are needed to avoidthis. Moreover, to avoid unsynchronized semanti-
cally redundant forms, the tool should only beused in a controlled manner (i.e., different applica-tion developers working on semantically relatedforms should cooperate).
Future implementations of the approach might bemore flexible by using XML to store electronic doc-uments and appropriate DTDs (document-typedefinitions) to describe the contents of a docu-ment. This, however, is only a question of how toimplement the generator tool and which format isused to make the data persistent. The idea ofdeveloping distributed applications by definingwork lists and workflow-enabled documentsremains unaffected by this decision. For the long-term archiving of electronic documents, additionalmechanisms are needed to achieve authenticityand security in terms of availability, confidential-ity, and integrity. An electronic signature andmeans for redundant storage in a software-inde-pendent format (e.g., pdf) are currently beingintroduced in our implementation.
The generator tool described is essentially a tool forcomputer-aided software engineering. Software engi-neering and knowledge engineering are inherentlyrelated. A common goal is to make domain modelsand ontologies more explicit and thus improve themaintainability and flexibility of computer pro-grams.25 Musen’s work on Protégé has been funda-mental under this scientific perspective: Protégé is aset of tools and a methodology for building knowl-edge-based systems that support the clear separationof different system-building tasks such as explicitmodeling of domain ontologies and entry of contentknowledge.24,25 Although the approach in this articlecan also be seen as a contribution toward more tai-lorable and maintainable systems, the domain knowl-edge flowing into generator-based applications is notclearly separated yet. The semantic annotation of doc-ument contents and the representation of a domainontology are only rudimentarily supported, andinformation flow is still hidden in the declaration ofstatus variables. The current developments describedin the status report are indeed aimed at better consid-ering these knowledge engineering aspects.
Component technology is gaining importance asstandards for technical and semantic interoperabilityare evolving and increasingly adopted by healthcareIT vendors. Some examples have shown that effortsin integrating heterogeneous system components canbe successful if one can manage to map appropriatelythe constituents of the system to real world
583Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002

processes.31 However, healthcare information sys-tems are still far away from plug-and-play reuse ofautonomously developed generic components.Bridging incompatibilities between coarse grainedand functionally redundant subsystems is still stateof the art.
Projects such as RICHE and its successors, fromNUCLEUS to SynEx have aimed at the developmentof domain specific open systems architectures.21–23
They have significantly promoted standardizationefforts, but have not yet led to a commonly acceptedframework and widely available commercial prod-ucts. The concept of Act Management developed inthe RICHE project21 is an interesting approach to han-dling patient-related workflow issues in health infor-mation systems. Actually, the status of a medicalaction or act is related to the status of electronic doc-uments, which are used to support medical acts. Ourcurrent efforts to separate workflow definition fromdocument definition are going into the direction ofintelligent act management.
Setting up a health information system todayrequires a strategy for system evolution that is aimedat the convergence and integration of the systemscomponents. The approach presented in this paper isintended to support the development of new andintegrated components, and it is clearly based on adatabase centric system architecture, which is itsstrength and limitation at the same time.Implementing a comprehensive hospital informationsystem with a single central database is not a realisticscenario. For various reasons, heterogeneousautonomous subsystems still have to be integratedinto the overall system.32 Currently these subsystemsare to be integrated in the conventional way by usingstandard interfaces such as HL7 or DICOM and aninterface engine; imported data are typically con-verted into an appropriate format and stored in thecentral database. From there, these data may beuploaded into electronic documents.
Some important issues, such as data retrieval, syn-chronization and versioning of conventional data-base tables, are still somewhat difficult to handlewithin the current implementation of the generatortool. However, as plug-and-play components and anassociated component market are not yet available,this approach appears to be a workable step towardsan incrementally evolving and yet truly integratedhealthcare information system.
References ■
1. Kuhn KA, Lenz R, Blaser R. Building a hospital informationsystem: Design considerations based on the results from aEurope-wide vendor selection process. Proc AMIA Symp.1999; 834–8.
2. Dorenfest S. The decade of the ‘90s. Poor use of IT investmentcontributes to the growing healthcare crisis. Healthc Inform.2000;17(8):64–7.
3. Kuhn KA, Giuse DA. From hospital information systems tohealth information systems: Problems, challenges, perspec-tives. Methods Inf Med. 2001; 40: 275–87.
4. Institute of Medicine. Crossing the Quality Chasm: A NewHealth System for the 21st Century. Washington, DC, NationalAcademy Press, 2001.
5. Sauer C. Deciding the future for IS failures: Not the choice youmight think. In Currie W, Galliers R (eds). RethinkingManagement Information Systems. Oxford University Press,1999, pp 279–309.
6. Anderson JG, Aydin CE. Evaluating the impact of health careinformation systems. Int J Technol Assess Health Care 1997;13(2):380–93.
7. Kruchten P. The Rational Unified Process—An Introduction.2nd ed. Boston, Addison Wesley, 2000.
8. Verstegen G. Projektmanagement mit dem Rational UnifiedProcess. Heidelberg, Springer, 2000 [in German].
9. Beck K. Extreme Programming—Das Manifest. München,Addison Wesley, 2000 [in German].
10. Coiera E. When conversation is better than computation. J AmMed Inform Assoc. 2000;7(3):277–86.
11. Brender J. Methodology for constructive assessment of IT-based systems in an organisational. Int J Med Inf. 1999;56(1-3):67–86.
12. Timpka T, Sjoberg C, Hallberg N, et al. Participatory design ofcomputer-supported organizational learning in health care:methods and experiences. Proc Annu Symp Comput ApplMed Care. 1995;800–4.
13. University of California, Davis. Rapid ApplicationDevelopment. Available at URL: <http://sysdev.ucdavis.edu/WEBADM/ document/rad_toc.htm>. Accessed Decem-ber 20, 2001.
14. Georgakopoulous D, Hornick M, Sheth A. An overview ofworkflow management. Distrib Parallel Dat. 1995;3:119–53.
15. Alonso G, Mohan C. WFMS: the next generation of distributedprocessing tools. In: Jajodia S, Kerschberg L (eds): AdvancedTransaction Models and Architectures. Boston, KluwerAcademic Publishers, 1997.
16. Dadam P, Reichert M, Kuhn K. Clinical workflows—The killerapplication for process-oriented information systems?Proceedings of the Fourth International Conference onBusiness Information Systems, Posen, April 2000, pp 36–59.
17. Members of the Workflow Management Coalition. WfMCPub-lished Standards Documents. Available at URL: <http://www. wfmc.org/standards/docs.htm>. Accessed August 22,2001.
18. Lenz R, Kuhn KA. Intranet meets hospital information sys-tems—the solution to the integration problem? Methods InfMed. 2001; 40: 99–105.
19. Szyperski C. Component software. Harlow, England, AddisonWesley, 1998.
20. Spahni S, Scherrer JR, Sauquet D, Sottile PA. Towards spe-cialised middleware for healthcare information systems. Int JMed Inf. 1999;53:193–201.
LENZ, ET AL., Process Support in Health Information Systems584

21. Frandji B, Schot J, Joubert M, et al. The RICHE ReferenceArchitecture. Med Inform (Lond). 1994;19(1):1–11.
22. Kilsdonk AC, Frandji B, van der Werff A. The NUCLEUS inte-grated electronic patient dossier breakthrough and concepts ofan open solution. Int J Biomed Comput. 1996;42(1–2):79–89.
23. Xu Y, D’Alessio L, Jaulent MC, et al. Integrating medical appli-cations in an open architecture through generic and reusablecomponents. Medinfo. 2001;10(Pt 1):63–7.
24. Musen MA. Domain ontologies in software engineering: useof Protege with the EON architecture. Methods Inf Med. 1998;37(4–5):540–50.
25. Musen MA. Medical informatics: Searching for underlyingcomponents. Methods Inf Med. 2002;41(1):12–9.
26. Nadkarni PM, Marenco L, Chen R, et al. Organization of het-erogeneous scientific data using the EAV/CR representation. JAm Med Inform Assoc. 1999;6(6):478–93.
27. Bernstein PA, Hadzilacos V, Goodman N. ConcurrencyControl and Recovery in Database Systems. Reading, MA,
Addison-Wesley, 1987.28. Lenz R, Elstner T, Blaser R, Kuhn KA. Experiences with a
holistic health information system. Proc AMIA Symp. 2001:952.
29. Cimino JJ. From data to knowledge through concept-orientedterminologies: Experience with the Medical EntitiesDictionary. J Am Med Inform Assoc. 2000;7(3):288–97.
30. Zeng Q, Cimino JJ. A knowledge-based, concept-oriented viewgeneration system for clinical data. J Biomed Inform 2001;34(2):112–28.
31. Geissbühler A, Lovis C, Lamb A, Spahni S. Experience with anXML/HTTP-based federative approach to develop a hospital-side clinical information system. In Patel V, Rogers R, Haux R(eds): Medinfo 2001. Proceedings of the 10th World Congresson Medical Informatics. Amsterdam, IOS Press, 2001: 735–9.
32. McDonald CJ. The barriers to electronic medical record sys-tems and how to overcome them. J Am Med Inform Assoc.1997;4(3):213–21.
585Journal of the American Medical Informatics Association Volume 9 Number 6 Nov / Dec 2002




















