
A Block Projection Method for Sparse Matrices
24
SIAM J. ScI. STAT. COMPUT. Vol. 13, No. 1, pp. 47-70, January 1992 () 1992 Society for Industrial and Applied Mathematics 003 A BLOCK PROJECTION METHOD FOR SPARSE MATRICES* MARIO ARIOLIt, IAIN DUFF:, JOSEPH NOAILLES, AND DANIEL RUIZ Abstract. A block version of Cimmino’s algorithm for solving general sets of consistent sparse linear equations is described. The case of matrices in block tridiagonal form is emphasized because it is assumed that the general case can be reduced to this form by permutations. It is shown how the basic method can be accelerated by using the conjugate gradient (CG) algorithm. This acceleration is very dependent on a partitioning of the original system and several possible partitionings are discussed. Underdetermined systems corresponding to the subproblems of the partitioned system are solved using the Harwell sparse symmetric indefinite solver MA27 on an augmented system. These systems are independent and can be solved in parallel. An analysis of the iteration matrix for the conjugate gradient acceleration leads to the consideration of rather unusual and novel scalings of the matrix that alter the spectrum of the iteration matrix to reduce the number of CG iterations. The various aspects of this algorithm have been tested by runs on an eight-processor Alliant FX/80 on four block tridiagonal systems, two from fluid dynamics simulations and two from the literature. The effect of partitioning and scaling on the number of iterations and overall elapsed time for solution is studied. In all cases, an accurate solution with rapid convergence can be obtained. Key words, sparse matrices, block iterative methods, projection methods, partitioning, augmented systems, parallel processing, block Cimmino method, conjugate gradient preconditioning AMS(MOS) subject classifications. 65F50, 65F10, 65F20, 65Y05 1. Introduction. Consider the solution of the system (1.1) Ax=b where A is an m n sparse matrix, x is an n-vector, and b is an m-vector. Although the experiments will examine the case when m is equal to n, the method is applicable for any m and n. The analysis will be principally concerned with the case m =< n where the system is consistent, that is, there exists a vector x satisfying (1.1). In the following, we assume for simplicity that A has full row rank, that is, dim(A)= m. The general solution to (1.1) can be expressed as the sum (1.2) :+r/ where : is in the range of AT and r/ is in the nullspace of A. Thus and, from (1.1), we have so that is given by := ATz AATz b (1.3) A(AA)-lb * Received by the editors December 11, 1989; accepted for publication (in revised form) November 12, 1990. t Istituto di Elaborazione dell’Informazione, Consiglio Nazionale delle Ricerche, via S. Maria 46, 56100 Pisa, Italy. $ Rutherford Appleton Laboratory, Didcot, Oxon OXll 0QX, England. Ecole Nationale Sup6rieure d’Electrotechnique, d’Electronique, d’Informatique, et d’Hydraulique de Toulouse, Institut de Recherche en Informatique de Toulouse, 2 rue Camichel, 31071 Toulouse Cedex, France. Centre Europ6en de Recherche et de Formation Avanc6e en Calcul Scientifique, 42 av. G. Coriolis, 31057 Toulouse Cedex, France. 47
-
Upload
independent -
Category
Documents
-
view
2 -
download
0
Transcript of A Block Projection Method for Sparse Matrices

SIAM J. ScI. STAT. COMPUT.Vol. 13, No. 1, pp. 47-70, January 1992
() 1992 Society for Industrial and Applied Mathematics
003
A BLOCK PROJECTION METHOD FOR SPARSE MATRICES*
MARIO ARIOLIt, IAIN DUFF:, JOSEPH NOAILLES, AND DANIEL RUIZ
Abstract. A block version of Cimmino’s algorithm for solving general sets of consistent sparse linearequations is described. The case of matrices in block tridiagonal form is emphasized because it is assumedthat the general case can be reduced to this form by permutations. It is shown how the basic method canbe accelerated by using the conjugate gradient (CG) algorithm. This acceleration is very dependent on apartitioning of the original system and several possible partitionings are discussed. Underdetermined systemscorresponding to the subproblems of the partitioned system are solved using the Harwell sparse symmetricindefinite solver MA27 on an augmented system. These systems are independent and can be solved inparallel. An analysis of the iteration matrix for the conjugate gradient acceleration leads to the considerationof rather unusual and novel scalings of the matrix that alter the spectrum of the iteration matrix to reducethe number of CG iterations.
The various aspects of this algorithm have been tested by runs on an eight-processor Alliant FX/80 on
four block tridiagonal systems, two from fluid dynamics simulations and two from the literature. The effectof partitioning and scaling on the number of iterations and overall elapsed time for solution is studied. Inall cases, an accurate solution with rapid convergence can be obtained.
Key words, sparse matrices, block iterative methods, projection methods, partitioning, augmentedsystems, parallel processing, block Cimmino method, conjugate gradient preconditioning
AMS(MOS) subject classifications. 65F50, 65F10, 65F20, 65Y05
1. Introduction. Consider the solution of the system
(1.1) Ax=b
where A is an m n sparse matrix, x is an n-vector, and b is an m-vector. Althoughthe experiments will examine the case when m is equal to n, the method is applicablefor any m and n. The analysis will be principally concerned with the case m =< n wherethe system is consistent, that is, there exists a vector x satisfying (1.1). In the following,we assume for simplicity that A has full row rank, that is, dim(A)= m.
The general solution to (1.1) can be expressed as the sum
(1.2) :+r/
where : is in the range of AT and r/ is in the nullspace of A. Thus
and, from (1.1), we have
so that is given by
:= ATz
AATz b
(1.3) A(AA)-lb
* Received by the editors December 11, 1989; accepted for publication (in revised form) November 12,1990.
t Istituto di Elaborazione dell’Informazione, Consiglio Nazionale delle Ricerche, via S. Maria 46, 56100Pisa, Italy.
$ Rutherford Appleton Laboratory, Didcot, Oxon OXll 0QX, England.Ecole Nationale Sup6rieure d’Electrotechnique, d’Electronique, d’Informatique, et d’Hydraulique de
Toulouse, Institut de Recherche en Informatique de Toulouse, 2 rue Camichel, 31071 Toulouse Cedex, France.Centre Europ6en de Recherche et de Formation Avanc6e en Calcul Scientifique, 42 av. G. Coriolis,
31057 Toulouse Cedex, France.
47

48 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
or
A+b
where A+ is the Moore-Penrose pseudoinverse of A. Because, usually, the solution to(1.1) of minimum norm is required, the component r/is taken to be zero, so the solutionof (1.1) is given by (1.3).
Sometimes the solution needed is the one closest to a vector y, that is, an xsatisfying (1.1) such that
(1.4)
is minimized. This is given by
x P(A)Y + A+b
where Par(A) is the orthogonal projector onto the nullspace of A given by
where P(Ar), the orthogonal projector on the range of AT, is given by
p(AT) A+A.
In this paper we will analyse parallel implementations of block iterative methodsfor solving (1.1) and (1.4). We describe the general framework in 2, the extensionto norms other than the Euclidean norm (1.4) in 3. In 4 we identify the iterationmatrix associated with the algorithm and introduce in 5 and 6 conjugate gradientacceleration and the augmented system, which is used in the implementation of thealgorithm.
In 7 the numerical properties of this algorithm will be studied, illustrating itsperformance on block tridiagonal matrices. We introduce in 8 the block SSOR methodof Kamath and Sameh (1988) and Bramley and Sameh (1990), which can be seen asan alternative to the block Cimmino algorithm. In 9 some ellipsoidal norms, whichwill be used to improve the performance on some of our test problems, are introducedfor block tridiagonal matrices.
In 10 we then describe some numerical experiments performed on the AlliantFX/80, and we present some concluding remarks in 11.
2. Block iterative methods. The method which will be introduced can be consideredas a generalization of the method of Cimmino (see Sloboda (1988)), and will thereforebe called the block Cimmino method.
The blocks are obtained by partitioning the system (1.1) as
(2.1)
A b
A bX’--
where 1 -<_ p -< m.If we define by Pt(AiT) the projector onto the range of Ai7", and the pseudoinverse
of A as Ai+, the block Cimmino algorithm can be described in the following way.

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 49
ALGORITHM 2.1 (block Cimmino method).Choose x(), set k 0repeat until convergence
begindo in parallel i-- 1,...,p
i(k) Ai+bi p(AiT)x(k)
(2.2)A’+(b’- A’x(k))
end parallelp
x(k+I) X(k) 4- to
i(k)
i=1
set k k 4- 1end
This gives rise to a general purpose iterative solver well suited for both sharedmemory and distributed memory computers. If we take p m, which means that eachmanifold from (2.1) is a hyperplane defined by one equation in (1.1), then Algorithm2.1 becomes the algorithm of Cimmino (see Sloboda (1988)).
The iterative scheme (2.2) will converge for any pseudoinverse ofA (see Campbelland Meyer (1979)) and, in particular, does not require A to be full rank. However,with the use of the explicit formulation of A i+ introduced in (1.3), the partitioning ofthe system has to be chosen so that the rows in each A are linearly independent. Thisis possible even if A is not full rank.
A general study of this block-row method has been performed by Elfving (1980).In this paper, he calls this the "block-row Jacobi" method. He shows the effect of rowand column partitioning, makes some comparisons with block SOR methods, andstudies the effect of the parameter to on the convergence of these methods.
First let us recall some results from Elfving (1980). Using the notation:p p
ERj-- E P(A’r) Air(A’A)-1A,i=1 i=1
QRJ--I-toER, for the iteration matrix,
(2.3) p(ER) =the spectral radius of ERj,
/Xmax the largest nonzero eigenvalue of ER,
/Xmin the smallest nonzero eigenvalue of ER,
we have the following:(1) Suppose be (A) and x()(Ar), then the block-row method converges
towards the minimum norm solution if and only if 0< to < min (2, (2/p(ER))).(2) The giving the optimal asymptotic rate ofconvergence is 2/(max+ min)-
3. The use of other norms. The solution of (1.1), (1.4) can be determined in anyellipsoidal norm defined by
(3.l) IIxll x Gxwhere G is an n x n symmetric positive definite (SPD) matrix.
When doing this, the arguments in 1 still hold, except that a generalized pseudo-inverse (see Rao and Mitra (1971))
(3.2) A- G-Ar(AG-Ar)-,

50 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
must be defined in addition to corresponding oblique projectors
(G) =I (G)a(G-I(G)1AT) A;--1A and aW’(A) --" (G- A
The solution to
min Ily-xll such that x {x
is then given by
(G)(3.3) x r(A)y+ A-lb.
The block Cimmino algorithm in 2 can be defined in terms of this general norm.We will now show that the use of G # I can be viewed as a right-hand side
preconditioning of the matrix A.From (3.1), (3.2), and (3.3), and knowing that any SPD matrix G can be decom-
posed as G1/2G1/2, with G1/2 SPD, it follows that:
(3.4)
Then the iteration matrix becomes:
where
QRG] I-- o)E(G)Rjp
I- o)G-1/2 P((AiG-1/2)T)G1/2
i=1
G-1/2QRjG1/2
p
(3.6) Q*j I- toE* I- w Z P((AiG-1/2)r)i=1
Thus the iteration matrix associated with the matrix A and using the ellipsoidalnorm, and the one associated with the matrix AG-/2 and using the two-norm, aresimilar. However, in the case of the G-norm, all the convergence properties (whichare determined only by the spectrum of the iteration matrix) can be written in a similarway to the previous ones (2.3), where block-rows AiG-1/2 are considered instead ofblock-rows Ai.
So from now on, to simplify notation and formulae, we will, as in 1 and 2,usually consider G I, knowing that other choices for G can easily be incorporated.
4. The iteration matrix. Let the QR decomposition of the blocks Air be given by
A/r: QiRi, i= 1,’’’, p where A is an mi x n matrix of full row rank,
Qi n mi, QiTQi= ImimR m x mi, R nonsingular ,,.rper triangular matrix;

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 51
then"
(4.1)
p
E A (AiAi)-IAi=1
PiRi Qi 1RiTQ (RiTQir Ri) Q
i=1
Py Q’R’(R’TRi)-IRiTQiT
i=1
P
QiQiT
i=l
__(Q1... Qp)(Q1...Qp)T.
But from the theory of the singular value decomposition (see Golub and Kahan(1965) and Golub and Van Loan (1989)), the nonzero eigenvalues of (Q1... Qp)(Q1... Qp)7- are also the nonzero eigenvalues of (Q1... QP)T(Q... Qp).
Thus the spectrum of the matrix ERj is the same as that of the matrix
(4.2)
I,,m, QIQ2 QIQt’
Q2Q1 im2xm2 Q2rQ3 Q2QpQpQ Impxm,
where the Q QJ are matrices whose singular values represent the cosines of theprincipal angles between the subspaces (Ai) and (AT) (see Bjbrck and Golub(1973)). This implies that a preconditioner, to be successful, should modify the principalangles between the subspaces t(Ai), in order to make these subspaces as muchorthogonal between each other as possible.
Another implication ofthe previous discussion concerns the choice ofthe partition-ing (2.1). As stated in Bramley and Sameh (1990), an ill-conditioned matrix A hassome linear combination of rows almost equal to the zero vector. After row partitioning,these may occur within the blocks or across the blocks. If, in the block Cimminoalgorithm, we assume that we compute the projections on the subspaces exactly, therate of convergence of the method will depend only on the conditioning across theblocks. However, if the method used for solving the subproblems is sensitive toill-conditioning within the blocks, we can quickly converge to the wrong solution.Thus, for a robust algorithm, we must use the most stable algorithm for computingthe projections combined with a partitioning that minimizes the ill-conditioning acrossthe blocks.
5. Conjugate gradient acceleration. Even when using the optimal w introduced
before, the convergence can still be slow. Thus it is natural to try to accelerate the
iterative scheme.The equalities in (4.1) show that (I-QRj)=wER is symmetric positive semi-
definite for any o > 0, and is definite if and only if A is square and of full rank. Now,in the case of ellipsoidal norms as defined in 3, (3.5) and (3.6) ensure that the matrix
G1/(I Q))G-/2 will have these properties. Thus G/2 can be seen as a symmetrizationmatrix for the block Cimmino method (see Hageman and Young (1981)), and so the
CG acceleration procedure can be applied to the preconditioned case in the followingmanner"

52 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
ALGORITHM 5.1 (conjugate gradient acceleration).x() is arbitrary, p(o)= 8(o),and 6(k is the pseudoresidual vector defined, for k 0, 1,- ., by
pk) QR)X’)- xk)+ tO Ai-C-,bi
i=1
for k 1, 2,..-, until convergence do"
X(k) X(k-l) + Ak_p(k-)
p(k) (k) + ak(k-1),(G/, G/:)
ak (G/2(k_), G/2(k-1))
1), G
(-,, (-Q)-,)G
where (.,.) denotes the dot product in the G norm viz.
(x, x) xGx.
The two main reasons for our choice of CG acceleration are:(1) It can be seen from the above equations that the CG acceleration is independent
of the choice of the relaxation parameter to, in the sense that the sequence of iteratesxck) is the same for any nonzero to (provided the starting point x) is the same). Thisis the reason why we did not emphasize the use of to too much in the previous sections.
(2) It is very simple to use ellipsoidal norms in the CG acceleration, because theonly requirement is the ability to compute the matrix-vector product relevant to workingwith the dot product in the G norm. The matrix G can thus be generated implicitly orstored in any appropriate way.
6. Use of augmented systems in solving subproblems. When solving the subproblems(2.2), the use of the augmented system approach has been chosen for two main reasons.First, it is more stable than the normal equations approach (see Arioli, Duff, andde Rijk (1989)) because it avoids building and storing the normal equations for eachblock row Ai. This can be useful for two reasons. It is less sensitive to ill-conditioningwithin the blocks caused by partitionings where rows within a block are nearly linearlydependent. Also, the kind of preconditioners (ellipsoidal norms) that will be used inthe experiments introduce some ill-conditioning within the blocks. Second, the use ofellipsoidal norms and the computation of the corresponding oblique projectors canbe trivially accommodated, as we will see in the following.

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 53
In the augmented system approach, the system
A _Aix
whose solution is
V _(AiG-1AiT)-lr
U G-Air (AiG-1Air)-ri,is considered.
We solve the augmented systems with the sparse symmetric linear solver MA27from the Harwell Subroutine Library (see Duff and Reid (1983)). The solver MA27computes the LDLT decomposition of a permutation of the augmented matrix, usinga mixture of lx I or 2x2 pivots chosen during the numerical factorization. Theresulting L and D factors are then used to solve the augmented systems by forwardand backward substitution in the usual way.
It must be emphasized that the method (2.2) is totally independent of the choiceof the solvers for the underdetermined subproblems. For instance, in some problemsit may be preferable to use a solver adapted to the structure of the block A. In specialcases, several different solvers might be used, one for each different kind of block Ai.
7. Effect of the partitioning. We will now focus on some particular partitioningsof the system (1.1), and show how the algorithm can exploit them.
7.1. Two-block partitioning. Assume that the matrix A is partitioned in two blocks
where and have rn and rn rows, respectively. Assume, without loss of generality,that ml >- m:. With such a partitioning, the iteration matrix Qm can be considered asI- to(P1 + P2), where P1 P(Alr) and P2 P(A2T) So, as in 4, the matrix ERj PI.J+ P2can be reduced to (Q1Q2)(Q1Q2)r, and from (4.2), the spectrum of the iteration matrixQRJ is the same as that of the matrix
(7.1)(1 to)I,,-toQ2TQ (1 to)Im2m/"
Since we know from 5 that the block Cimmino algorithm with conjugate gradientacceleration is independent of to, we can take to- 1, and matrix (7.1) becomes
QIQ(7.2, (.__0 m2m2
)Then, looking at the shape of the rectangular submatrix QlQ2, which has rrl rOWS
and in columns (ml >_--in2) and therefore a rank not greater than rex, it follows thatthere are at most 2m2 nonzero eigenvalues.
The finite termination property of the conjugate gradient algorithm suggests thatthe block Cimmino algorithm with CG acceleration generally works better for smallm2, and in exact arithmetic takes not more than 2m2 steps for convergence. This isanother reason for the choice of the conjugate gradient acceleration.
7.2. Block tridiagonal structures. We now concentrate on block tridiagonalmatrices, which are quite general patterns very common in partial differential equation

54 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
discretization, and are obtainable from general systems as a byproduct of bandwidthreduction (see, for example, Duff, Erisman, and Reid (1986, pp. 153-157)). For suchstructures, a partitioning equivalent to the two-block one can be introduced and usedefficiently for obtaining fast convergence.
Consider, for instance, a block tridiagonal matrix A with blocks of size l l,partitioned as follows:
A
A4
A.
where A has ki x rows, ki >= 2, 1, 2, , 5. Then (AiT) and (Ai+2T), 1, 2, 3,represent orthogonal subspaces, so that
P(AT) + P(Ai+2T) P(AiT))(Ai+2T).
On the one hand, matrices of this form can therefore be easily partitioned insufficient blocks to utilize all the processors of the target machine (provided the matrixA is large enough in comparison with the size of the tridiagonal substructure). On theother hand, the problem being solved is equivalent, after permutation of the rows ofthe matrix A, to the one defined by taking only two blocks B and B2, where
thus
A
B2 A
A4

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 55
Then the nice property of the two-block partitioning discussed in the previous sectionis maintained while a good degree of parallelism is obtained.
If ml and me denote the number of rows of B and B2, respectively, we observethat it is easy to vary the number of zero eigenvalues in the iteration matrix, setting itclose to zero by taking the same size for the A in B as for the A in B2 (ml---m),or setting it as big as possible (ml >> m2) by taking large blocks A in B, and definingsmall interface blocks in B- of size 2 (the minimum required for making the A inB structurally orthogonal).
A good partitioning strategy must compromise between reducing the size of theinterface block B, with the aim of reducing the number of CG iterations, andmaintaining the degree of parallelism of the method. The degree of parallelism involvestwo things" first, the number of blocks in the partitioning compared to the number ofprocessors of the target machine, and second, the size of these blocks compared tothe amount of work the different processors will have to perform, which affectsgranularity and load balancing.
We remember from 3 that we can easily incorporate ellipsoidal norms, replacingorthogonal projectors by oblique ones. But in this case, when looking for partitioningsleading to a two-block partitioning, we must ensure that the right-hand side precon-ditioning matrix G-1/2 (see 3) preserves the orthogonality between the subspaces(AT) in each of the two blocks B and BE of the given two-block partitioning.
8. Block SSOR method. Kamath and Sameh (1988) use a block SSOR iterativescheme with a two-block partitioning for block tridiagonal structures. They consider,however, only the partitioning defined by taking equal-sized blocks of the smallestpossible size for a matrix partitioned into two blocks (twice the number of rows ofone block in the block tridiagonal structure). This leads to a high degree of parallelism,but also to the largest number of nonzero eigenvalues in the iteration matrix.
The block SSOR algorithm with two-block partitioning (as described in 7.2) canbe written in the following way:
ALGORITHM 8.1 (block SSOR method).Choose x(), set k 0repeat until convergence
beginZ X(k)
z z + toB1/(b Bz)Forward sweep B2+(b2
Z Z2 "31- (.0 B2z2)
Z Z + toB2+(b2 B2z3)Reverse sweep z5 z4 + toBl/(b Blz4)
x(g+l) z5, set k k + 1end
where the current iterate is projected in sequence onto the different subspaces usingthe updated value each time.
The iteration matrix for this algorithm can be expressed as a product of projectorsinstead of a sum as in the block Cimmino algorithm, viz.,
QRS (I- toa(Br))(l toP(B2r))2(l toa(ar))where one projection in the central part of the algorithm can be avoided, because ofthe idempotency of projectors.

56 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
A detailed study of the block SSOR algorithm and of its iteration matrix isperformed by Bramley (1989) and by Bramley and Sameh (1990). They show that,even when conjugate gradient acceleration is used, the first projection can also beavoided, provided that to 1 and that x is such that Blx=b. Therefore, with thetwo-block partitioning, one iteration of block SSOR has the same cost in number offlops as one iteration of block Cimmino.
It was shown by Elfving (1980) that, with to 1, and the same kind of partitioning,the spectrum of the iteration matrices for the two algorithms are:
/k +COS I3’k, k 1,. ,for block Cimmino: /k --COS l’k_m:z, k m2 + 1, , 2m2,
/k --0, k 2m+ 1,. ., n;
Ak COS2 I3’k, k 1, , m,
for block SSOR:hk =0, k rn2+ 1,. , n
where {k} are the principal angles between (BT) and (B2T).Thus, with two-block partitioning, the block SSOR algorithm with CG acceleration
should converge in about half the number of iterations as the block Cimmino algorithmwith CG acceleration.
Similar comparisons between block Cimmino and block SSOR can also be foundin Bramley (1989) and in Bramley and Sameh (1990). They show that, in general, theblock SSOR iteration matrix has more eigenvalues collapsed to zero than that of blockCimmino, which will benefit the convergence of block SSOR. But we must not forgetthat the degree of parallelism in the block Cimmino method is higher because all theprojections can be performed in parallel. This is not the case for the block SSORmethod where information must be updated from one subproblem to the next so thatthe subspaces must be orthogonal to permit parallelism.
However, when using two-block partitioning on shared memory machines, wehave found experimentally that block SSOR is still faster because memory bank conflictsprevent block Cimmino from attaining twice the speedup of block SSOR. At any rate,in the following, results and comments on various two-block partitionings will be givenfor the CG accelerated block Cimmino scheme only, because the aim here is not tocompare the two methods in terms of efficiency, but to emphasize our approach to theimplementation of row projection methods, using block Cimmino by way of illustration.Different techniques have been introduced in the previous sections, e.g., the augmentedsystem, the ellipsoidal norms that can easily be incorporated in the augmented systemapproach, and the varying of the relative sizes of the blocks in the two-block partition-ings. The experiments are designed to emphasize these novel aspects.
The main reason why we have chosen block Cimmino is that its degree ofparallelism depends only on the partitioning and not on special properties of structuralorthogonality between sets of equations. Thus block Cimmino provides more degreesof freedom for the choice of any ellipsoidal norm as a preconditioner because it is notnecessary to preserve the structure of the original matrix to maintain the degree ofparallelism.
9. Use of ellipsoidal norms. In this section we introduce a particular kind ofellipsoidal norm associated with two-block partitioning. This will be used to improvethe convergence on some of the test problems.
Consider a two-block partitioning as shown in Fig. 9.1. The aim is to make thetwo subspaces, generated by the two sets of rows, nearly orthogonal so that the

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 57
Preconditioning
II
FIG. 9.1
eigenvalues of the iteration matrix (which are the cosines of the principal anglesbetween the two subspaces, as shown in 8) will all be small. The solution would thenbe obtained rapidly.
The simplest way to make two sets of rows in a matrix orthogonal is to multiplytheir overlapping part by zero. But obviously, if we do this, the resulting system canbe rank deficient. In order to avoid this, we instead divide them by a large number a,as shown in Fig. 9.1. This leads to a diagonal matrix G with a 2 in positions correspondingto the overlapping columns and 1 elsewhere, remembering from 3 that it is G-1/2
which preconditions the matrix A.Of course, with such a preconditioner, some numerical instability in the factoriz-
ation of the augmented systems can be expected if a very large value of a is used. Wewill see in 10.4 that a value of c 10 gives the best compromise for our test problemsand that much larger values for c introduce numerical instabilities without improvingthe rate of convergence. Also, the overlapping part must not involve all the columnsof the matrix, because in that case the preconditioning would be equivalent to a scalingof the complete matrix, which would not modify the principal angles between the twospaces at all.
We note that this scaling preserves the block structure of the partitionings, asrequired in 7.2, and thus can also be used with the block SSOR method of Kamathand Sameh (1988). However, it cannot be applied with their particular partitioning,because it involves a complete overlapping of the two blocks.

58 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
10. Numerical experiments. In this section we present some numerical experimentsfor testing the behaviour of our CG accelerated block Cimmino method. We firstdescribe three different test problems and the particular points we wish to clarify bymeans of these tests. Then we analyse the results obtained on the eight-processorAlliant FX/80 at CERFACS, varying the two-block partitionings. Afterwards, wepresent results obtained using preconditioners of the kind discussed in 9 and showhow they decrease the number of iterations and the elapsed time for some of our testproblems. Finally, we introduce a fourth test problem derived from Bramley (1989)and describe the results obtained using different kinds ofpartitioning from the two-blockones. These supplementary runs permit the comparison of our approach with the oneof Bramley (1989) and Bramley and Sameh (1990) and an illustration of theirdifferences.
10.1. The test problems. We will introduce the first three test problems. All aresquare problems, although we note that our algorithm does not require this. The firsttwo problems come from simulation models of real flows developed at CERFACS inthe fluid dynamics team.
The first model, developed by Petrel, concerns the study of a body entering theatmosphere at a high mach number. It is based on a finite-volume discretisation of theNavier-Stokes equations coupled with chemistry. For our test, we consider a two-dimensional problem which leads to three variables per mesh point (energy and twovelocities), plus two species in the chemistry which lead to two density variables permesh point, making a total of five variables. The discretization is performed using animplicit scheme on a curvilinear mesh of 69 60 points. This leads to block tridiagonalmatrices of order 60 x 69 x 5 20,700. The off-diagonal blocks are block diagonal with69 blocks of 5 5 elements. The diagonal blocks have a block tridiagonal structure.The test problem solved is taken from the first time step in this time-dependent problem.The matrix is unsymmetric and nondiagonally dominant. The right-hand side is verylarge because the initial guess of the parameters is far from the steady-state solution.Therefore, a large correction to this guess is expected, and in this case, the solutionneed not be very accurate.
The second model, developed by Weinerfelt, is from the study of a two-dimensionalwing profile at transonic flow (with no chemistry effects). It is still based on finite-volumediscretisation, but this time, of the Euler equations. We are also looking for thesteady-state solution, and the discretisation is performed using an upwind and implicitscheme on a curvilinear mesh of80 x 32 points. This leads to unsymmetric but diagonallydominant block tridiagonal matrices of order 32xS0x3=7,680. The off-diagonalblocks are block diagonal with 80 blocks of 3 x 3 elements. The diagonal blocks areof the same order and have the following block triangular circulant structure:
80x3
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 59
This time the test problem solved is close to the steady-state solution, and a veryaccurate solution is required.
The other test problem comes from the paper by Kamath and Sameh (1988). Itis obtained by application of the finite-difference method to a two-dimensional partialdifferential equation. The right-hand side is computed using a given solution
PROBLEM 3 (Kamath and Sameh (1988)).
Ux Uyy "-{- 1000exYl,lx 1000exytly g, u x + y,
on a 64 x 64 grid. We have selected this problem for the following reasons. First, aswill be shown, it converges very slowly, but we will try to improve the situation usingellipsoidal norms. Second, this problem is the particular one for which Kamath andSameh show that their block SSOR method converges while the iterative solver GMRESfrom the Yale package PCGPACK does not. By means of this test, we want to indicatethat our method belongs to the same class of robust iterative solvers as the block SSORmethod of Kamath and Sameh. This is also shown by Bramley and Sameh (1990),who compare different accelerated row projection methods, including the blockCimmino method with CG acceleration, with other iterative methods such as GMRESfrom PCGPACK, CG on the normal equations, and preconditioned versions of thesetwo. They also use the previous equation and several other problems on three-dimensional grids.
10.2. Different partitionings. We now introduce the partitionings by which wehope to influence the number of iterations as indicated in the discussion in 7. Sincethe tests are performed on an eight-processor Alliant, we consider the five followingpartitionings.
(1) A single block to provide a comparison with the direct solution of theaugmented system on the overall matrix.
(2) Eight equal-sized blocks, in an attempt to balance the work on the eightprocessors of the Alliant FX/80. For this partitioning, however, the sizes of the twoblocks in the equivalent two-block partitioning (after reordering the rows) are equal,so that the number of nonzero eigenvalues in the iteration matrix is expected to bemaximum.
(3) Five large blocks in B and four minimum-sized blocks in B2. This partitioningshould minimize the number of iterations, but gives a poor balancing of the work. Itis then interesting to see if the gain in elapsed time due to the expected decrease inthe number of iterations can overcome the loss of parallelism in the partitioning.
(4) A compromise between the size of the interface block and the degree ofparallelism. For instance, if we consider a block tridiagonal structure with 32 32blocks (which is the case for the problem given by Weinerfelt), we can partition byblocks of rows according to
4 4 4 4 4 1 (AiinB1)1 2 2 2 2 2 (A in B2)
where we give in sequence the number of block-rows for each partition. Here the sizeof the interface B is 11 block-rows, and the work is well balanced, with five processorshandling blocks of size 4 (in number ofblock-rows) and the three remaining processors,each handling two blocks of size 2, or one block of size 2 plus two blocks of size 1.Of course, the number of rows in each block is only a rough heuristic for calculatingthe amount of work that will be performed by MA27 in the corresponding augmentedsystems. However, as we will see from the results, it gives a good estimate.

60 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
(5) The partitioning of Kamath and Sameh (1988), defined by taking equal-sizedblocks of the smallest possible size for a matrix partitioned into two blocks (two timesthe number of rows in one block of the block tridiagonal structure). Although thispartitioning also leads to a large interface block and to good load balancing, it hasthe added advantage that it minimizes the overall fill-in in the factorization of thedifferent augmented systems because they are all of the smallest size. This leads to asmaller elapsed time for the factorization part, which can be of great benefit, especiallyin the case where the time for factorization is greater than the time for iterations.
10.3. Results. We will now present the results obtained on the Alliant FX/80. Allthe tests are performed in double precision (64 bit words) with machine precision2.2 10-16.
For each test problem we give two figures, each with a histogram and a graph. Inthe first figure the histogram gives, for each partitioning, the number of floating-pointoperations for the factorization of all the augmented systems and the number offloating-point operations for the iterative part (computation of the minimum normsolutions and CG acceleration), and the graph in the same figure shows the numberof iterations performed to reach the accuracy specified. With this histogram, we cansee whether the factorization or the iteration is the more costly and also the effect ofthe partitionings on the number of iterations. The histogram in the second figure gives,for each partitioning, the total elapsed time for the solution (divided into the elapsedtime for analysis and factorization of the augmented systems and the elapsed time forthe iterative part), and the graph in the same figure gives the speedup of the methodusing the eight processors of the Alliant FX/80. The speedup measure used is the ratiobetween the elapsed time for execution on one processor and the elapsed time forexecution on eight processors, using the same code. With this histogram, we can seewhich partitioning is the best, and also how well the work is balanced. We present, intabular form in the Appendix, the results used in generating these figures.
For the stopping criterion of convergence, we use the scaled residual tok definedby
IlAxk) -bll
For an assigned value of TOL, if, at step k, tok TOL, we stop the process. A smallvalue for Ok means that the algorithm is normwise backward stable (see Oettli andPrager (1964)) in the sense that the solution x(k) is the exact solution of a perturbedproblem where the max norm of the error matrix is less than or equal to tOg. The bound
][x(g)-xll--<tOk(n+ 1) [IAI[I[A-1[I + O(tO)
also holds, which gives an estimate of the normwise relative error of the solution.
10.3.1. Problem given by Perrel. In the problem from Perrel, the iterations werestopped when tOk TOL 10-9 because, as we said in 10.1, we do not need very highaccuracy for this problem. Results for partitioning (1) are not given because the directsolution of the single augmented system produces too much fill-in for the memory ofthe Alliant. We present the results in Figs. 10.3.1 and 10.3.2 and, in tabular form, inTable A.1 in the Appendix.
The first remark is that the algorithm converges very quickly for this problemconsidering that the matrix is of order 20,700 and is not diagonally dominant. Asexpected from the discussion in 10.2, the minimum number of iterations is attained

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 61
2000
1800
1600
1400
1200
1000
800
600
400
200
03 4 5
Different partitionings
5O
4O
3O
2O
10
Iterations
Number of operations initerative part
Number of operations infactorization
Number of iterations
FIG. 10.3.1. Perrel’ test problem, to <= 10-9.
300
25O
200
150
100
5O
2 3 4 5
Different partitionings
8 Speedup
7Elapsed time for iterative
6 part
5 Elapsed time for
4 factorization
3 [ Elapsed time for analysis
2 - Total speed up of themethod (8 processors)
FIG. 10.3.2. Perrel" test problem. (,o <- 10-9.
by partitioning (3), and partitioning (4) gives a good compromise between the numberof iterations and the balancing of the work between factorization and iteration. In thisproblem, the fill-in in the direct solution of the subproblems is very significant and ismore so when the subproblems are larger. Thus a partitioning with the smallest blockspossible should be the best even if this causes an increase in the number of iterations.This is illustrated by the results of partitioning (5), which has the least elapsed timealthough it has the greatest number of iterations. For such partitionings, we will alsoattain a higher speedup because, with the smaller blocks, there will be less cacheconflict when solving the subsystems simultaneously on the different processors.
We also tried to obtain a more accurate solution with tOk 10-14. The results aresummarized in Table A.2 in the Appendix. All the partitionings achieved this accuracywith partitioning (5) again requiring the largest number of iterations but the leastelapsed time because, even if the gap between the number of iterations for the differentpartitionings is increased for such an accuracy (it becomes roughly double that forthe previous accuracy), the time and the amount of work performed during iterationsstill remains proportional to the fill-in produced during the factorization.
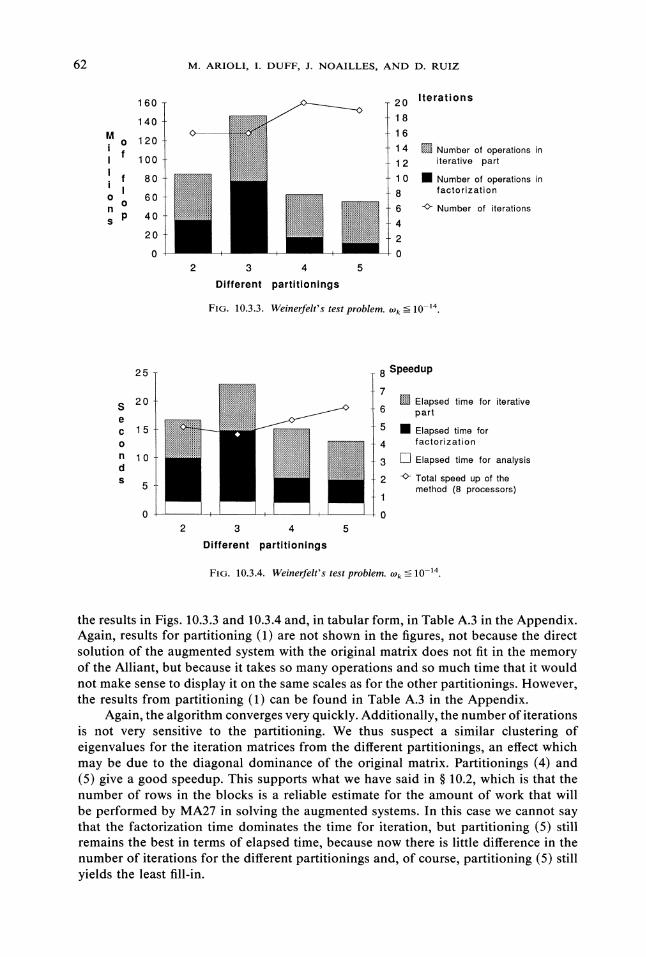
10.3.2. Problem given by Weinerfelt. In the problem from Weinerfelt, a very accur-ate solution is needed and so iterations are stopped when tOk TOL 10-14. We present
62 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
160
140
120
100
80
60
4O
20
03 4 5
Different partitionings
20
18
16
14
12
10
8
6
4
2
0
Iterations
Number of operations initerative part
Number of operations infactorization
Number of iterations
FIG. 10.3.3. Weinerfelt’s test problem. (o 10-14.
25
20Sec 15on 10ds
5
2 3 4 5
Different partitionings
8 Speedup
7Elapsed time for iterative
6 part
5 Elapsed time for
4 factorization
3 r-] Elapsed time for analysis
2 Total speed up of themethod (8 processors)
FIG. 10.3.4. Weinerfelt’ s test problem. (ok <= 10-14.
the results in Figs. 10.3.3 and 10.3.4 and, in tabular form, in Table A.3 in the Appendix.Again, results for partitioning (1) are not shown in the figures, not because the directsolution of the augmented system with the original matrix does not fit in the memoryof the Alliant, but because it takes so many operations and so much time that it wouldnot make sense to display it on the same scales as for the other partitionings. However,the results from partitioning (1) can be found in Table A.3 in the Appendix.
Again, the algorithm converges very quickly. Additionally, the number of iterationsis not very sensitive to the partitioning. We thus suspect a similar clustering ofeigenvalues for the iteration matrices from the different partitionings, an effect whichmay be due to the diagonal dominance of the original matrix. Partitionings (4) and(5) give a good speedup. This supports what we have said in 10.2, which is that thenumber of rows in the blocks is a reliable estimate for the amount of work that willbe performed by MA27 in solving the augmented systems. In this case we cannot saythat the factorization time dominates the time for iteration, but partitioning (5) stillremains the best in terms of elapsed time, because now there is little difference in thenumber of iterations for the different partitionings and, of course, partitioning (5) stillyields the least fill-in.
A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 63
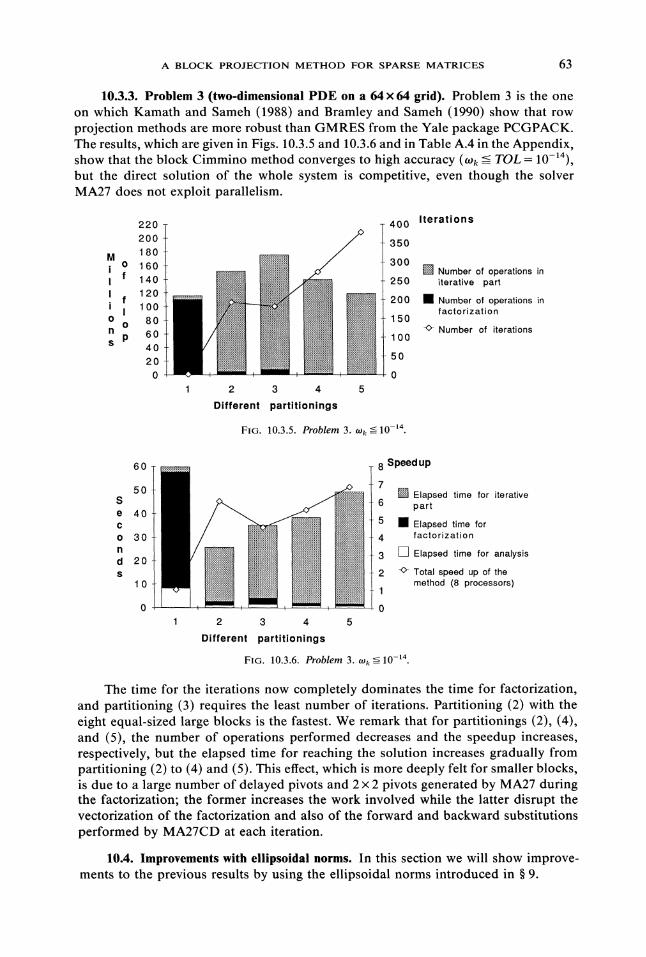
10.3.3. Problem 3 (two-dimensional PDE on a 64 x 64 grid). Problem 3 is the oneon which Kamath and Sameh (1988) and Bramley and Sameh (1990) show that rowprojection methods are more robust than GMRES from the Yale package PCGPACK.The results, which are given in Figs. 10.3.5 and 10.3.6 and in Table A.4 in the Appendix,show that the block Cimmino method converges to high accuracy (tOk <-- TOL 10-14),but the direct solution of the whole system is competitive, even though the solverMA27 does not exploit parallelism.
M
220 400200 350180160 300
140 250120
20010080 150
60 1004020 50
0 02 3 4 5
Different partitionings
Iterations
Number of operations initerative part
Number of operations infactorization
Number of iterations
FIG. 10.3.5. Problem 3. to 10-14.
6O
50Se 40co 30nd 20s
10-
8 Speedup
Elapsed time for iterativepart
Elapsed time forfactorization
Elapsed time for analysis
Total speed up of themethod (8 processors)
2 3 4 5
Different partitionings
FIG. 10.3.6. Problem 3. O) 10-14.
The time for the iterations now completely dominates the time for factorization,and partitioning (3) requires the least number of iterations. Partitioning (2) with theeight equal-sized large blocks is the fastest. We remark that for partitionings (2), (4),and (5), the number of operations performed decreases and the speedup increases,respectively, but the elapsed time for reaching the solution increases gradually frompartitioning (2) to (4) and (5). This effect, which is more deeply felt for smaller blocks,is due to a large number of delayed pivots and 2 x 2 pivots generated by MA27 duringthe factorization; the former increases the work involved while the latter disrupt thevectorization of the factorization and also of the forward and backward substitutionsperformed by MA27CD at each iteration.
10.4. Improvements with ellipsoidal norms. In this section we will show improve-ments to the previous results by using the ellipsoidal norms introduced in 9.

64 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
A wide range of values for the parameter a in the matrix G (see 9) were triedto improve the results on all of our test problems. This was not very helpful for thetwo problems coming from fluid dynamics simulations. For these, the convergence (asshown in 10.3) was already very fast without the ellipsoidal norm. Thus, on the onehand, the number of iterations could be decreased by a small amount only and, onthe other hand, more ill conditioned subsystems created more problems for thefactorization. For this reason results are not given in this section for the two problemsof Weinerfelt and Perrel. However, for the test coming from the set of Kamath andSameh problems, and for which the convergence was quite slow, the use of ellipsoidalnorms improved the results significantly.
For this test problem, better results, in terms of both accuracy and convergence,were obtained for all the partitionings on which we could apply this kind of ellipsoidalnorm. These were partitionings (2), (3), and (4). Partitioning (1) is only one block,and partitioning (5), as we said in 9, is one on which these ellipsoidal norms areequivalent to a complete scaling of the original matrix by a factor a.
Figure 10.4.1. shows, for Problem 3 with partitioning (4), the convergence fordifferent values of the parameter a. The tests showed that it was not worth taking avery large a, but that the best improvements in convergence were obtained for a oforder 10. Larger values for a introduce some oscillations in the convergence curve, ascan be seen in Fig. 10.4.1. This phenomenon is due to the ill-conditioning of thesubproblems when a increases. If iterative refinement (see Arioli, Duff, and de Rijk(1988)) is used in the computation on the subproblems, then the accuracy reached isthe same, and the convergence behaviour for large a approaches that for a of order10 but is never better than it.
PROBLEM 3 (N 4096) WITH ROW PARTITIONING 4
10i0-1 ..vRomomsa..H.a....1.o,
-o eo i l soo so oo oo
FIG. 10.4.1. Effect of ellipsoidal norms. Two-dimensional PDE Problem 3. Partitioning (4).
Table A.5 in the Appendix gives iteration counts, times, and flop counts obtainedusing ellipsoidal norms with a 10, on Problem 3 for partitionings (2), (3), and (4),and for a value of TOL equal to 10-14 in the stopping criterion.
The ratio between the number of flops for factorization before and after thepreconditioning varies with the different partitionings. For example, in Problem 3,these ratios are 1.54 (partitioning (2)), 1.4 (partitioning (3)), and 1.47 (partitioning (4)).

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 65
10.5. Memory requirements. In this section we give the memory (integer and real)required by MA27 when solving the subproblems. These numbers do not take intoaccount the arrays needed in the algorithm to perform all the other stages of thecomputations (conjugate gradient acceleration, etc.). These missing numbers can,however, be directly determined knowing the size of the original matrix and thepartitioning in use.
It can be seen from Table 10.5.1 that the memory required decreases as the sizeof the blocks in the partitionings decreases.
TABLE 10.5.1Memory requirements in thousands ofwordsfor handling the LUfactors
of the different blocks.
Problem Problem 2 Problem 3N 20,700 N 7,680 N 4,096NZ 511,050 NZ 113,760 NZ 20,224
Part. Int. Real Int. Real Int. Real
123 4,328 65 6972 368 4,881 171 611 50 1673 400 6,328 142 907 55 2074 430 3,539 187 429 48 1035 676 1,067 172 375 60 56
We do not want, however, to focus too much on these numbers because the versionof MA27 we are using does not perform well on augmented systems since the analysisphase assumes that the diagonal of the matrix is full. For instance, the ratio betweenthe estimated amount of real storage (given by the analysis) and the actual amount ofreal storage used, can be as high as 2.5 for Problem 1 with partitioning (3) (the onewith the largest blocks). A new version of MA27 that recognizes and exploits the zeroson the diagonal and behaves much better in terms of fill-in is being developed now atRutherford Appleton Laboratory (Duff et al. (1991)).
Table 10.5.2 shows the memory required with and without the preconditioner,with a 10, for Problem 3. We see the bad effect on the fill-in due to the ill-conditioningthat our scaling introduces in the augmented systems. In particular, partitioning (3)gives the least increase in memory requirement when going from the unpreconditioned
TABLE 10.5.2Memory requirements in thousands of words for handling
the LU factors with and without preconditioning.
Problem 3N 4,096 NZ 20,224
Unpreconditioned Preconditioned
Part. Int. Real ce Int. Real
2 65 167 10 53 2123 55 207 10 56 2474 48 103 10 48 125

66 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
case to the preconditioned one (19 percent more). In this partitioning, the size of theinterface is minimized; therefore, the size of the overlapping part (see 9) is minimizedand the augmented systems are not strongly affected by the scaling.
10.6. More experiments. Bramley (1989) and Bramley and Sameh (1990) describeimplementations of the block Cimmino and block SSOR algorithms that are differentfrom the ones illustrated here. They test the robustness of these row projection methodson a set of linear systems coming from the discretization of three-dimensional partialdifferential equations by the seven-point formula.
We will now present more tests related to one of their test problems in order toillustrate the difference between our approach and theirs. Consider the followingthree-dimensional partial differential equation defined on the unit cube
Uxx + blyy "JI- blzz + 100xuz -yUy + ZUz nt-100(x + y + z)u
xyz
where the right-hand side F is computed using the solution
u exp (xyz) sin (Trx) sin (Try) sin (Trz).
=F
The test problem is obtained by discretizing the previous equation by the seven-pointfinite-difference formula on a 24 x 24 x 24 mesh. This problem is Problem 3 in Bramleyand Sameh (1990) and Problem 5 in Bramley (1989).
Bramley and Sameh implement block Cimmino and block SSOR using the normalequations approach for computing the projections instead of the augmented systemapproach described in 6. According to this choice, they analyse the most suitablerow partitioning strategies, considering other partitionings than the two-block one. Infact, taking advantage of the nested level of tridiagonal structures in the seven-pointfinite-difference operator matrices, we can define the following row partitionings:
(1) A two-block partitioning of the kind (5) described in 10.2, with 12 blocksof 2 24 x 24 rows each.
(2) A three-block partitioning (see Kamath and Sameh (1988)) with 24 blocks of24 24 rows each.
(3) A six-block partitioning, with 24 x 8 blocks of 3 24 rows each.(4) A nine-block partitioning, with 24 x 24 blocks of 24 rows each.
Partitioning (4) is reported by Bramley and Sameh (1990) as the one giving the bestaverage performance.
In the runs, the value of TOL in the stopping criterion has been set to TOL 10-1
because it was the value giving results similar to those provided in Bramley (1989,p. 158) and in Bramley and Sameh (1990) in terms of the residual ([[Axk)-bll) andthe error (llxk)-x[l). For ease of comparison, we give in Table 10.6.1 the values for
TABLE 10.6.1Behaviour of the block Cimmino method on an Alliant FX/80 (eight processors). Three-
dimensional partial differential equation, tOg <-10-.
Part. No. iter.Elapsed time (seconds)
Analysis Factorization Iterations IlAxk-bll Ilx<k)-xll
128 6.6 13.8 103.9 1.34E- 5 9.57E- 42 127 4.7 6.7 83.8 1.25E 5 8.37E- 43 383 7.9 17.3 548.8 1.35E- 5 1.85E- 34 205 14.1 20.5 705.4 1.27E 5 7.90E -4

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 67
the errors and the residuals reached in the tests. However, it must be observed thatthe value of tOk does not decrease much after it has been reduced to 10-11.
The experiments show that the behaviour of the number of iterations as a functionof the partitioning is quite irregular. Moreover, for this problem and with the partition-ing (4), Bramley and Sameh (1990) report that the block Cimmino algorithm convergesin 572 iterations when the block SSOR algorithm converges in 666, with a final valuefor the residual of 10-5. The considerable difference from our number of iterations of205 for the block Cimmino algorithm can be explained by the difference in the twostopping criteria.
The augmented system approach performs very poorly in term of efficiency withblocks having a small number of rows, as illustrated in the elapsed time of partitioning(4). However, with bigger blocks, as for partitionings (1) and (2), it takes care ofill-conditioning within the subproblems and yields the fastest convergence. In par-ticular, for the augmented system approach, partitioning (2) is the most efficient,whereas Bramley (1989, p. 69) rejects the same partitioning because of instabilityproblems in solving the normal equations.
Finally, the elapsed times shown in Table 10.6.1 might be not very attractivecompared to those shown in Bramley (1989, p. 158) where convergence is obtained in76 seconds. However, the elapsed time obtained using partitioning (2) is only 1.3 timesgreater, and significant improvement can be expected from the use of a new versionof MA27 specially tuned for augmented systems.
11. Conclusions. In this paper, we have introduced a method for the solution oflarge sparse linear systems. There are many different components to this method, mostof which we have explored here, but some of which warrant further study. The maincomponents are: the partitioning, the choice of the method for solving the subproblems,the iterative scheme used, and the scaling (ellipsoidal norm) employed. We have shownthat we can, for block tridiagonal matrices, partition the system cleverly in order toreduce the number of conjugate gradient iterations, while maintaining a good degreeof parallelism.
Our numerical experiments reinforce what we expect from the theory, showingthat we can vary the number of iterations and tune the speedup, using simple heuristicslike the size of the subblocks in the two-block partitioning.
There are, however, some problems still requiring further work or investigation.First, the method is very dependent on the behaviour of MA27, which can generatemuch fill-in, as in Problem 1, or induce many 2x2 pivots and delayed pivots andperform poorly, as in Problem 3. This is because MA27 considers all diagonal entriesas nonzero, which is not the case for the augmented systems. It then picks a poor pivotorder at the beginning and corrects it during the factorization. This situation is beingimproved at the moment at Rutherford Appleton Laboratory by Duff et al. (1991). Wealso need to study the phenomenon of clustering of the eigenvalues, which can bequite pronounced for some matrices (see Problem 2) and seems to be linked to thepartitioning. We effectively saw in all our tests that partitioning (2) with eight equal-sizedlarge blocks generally requires the least number of iterations, although the size of theinterface block for this partitioning is the largest.
The results show that the block Cimmino method with conjugate gradient acceler-ation can be considered a robust iterative solver similar to the conjugate gradientaccelerated block SSOR method of Kamath and Sameh (1988). In fact, since we useconjugate gradient acceleration, we know that we must converge in exact arithmeticwithin at most n iterations, n being the size of the system. Moreover, we know that

68 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
we can estimate the number of nonzero eigenvalues by considering the size of theinterface block. Then, knowing the influence of the spectrum of the iteration matrixon the conjugate gradient method, we can use this as an upper bound for the numberof iterations in order to stop the iterative process if it will not reach the requiredaccuracy.
It is also possible to interpret our method as a preconditioned conjugate gradientmethod, considering the block Cimmino scheme as an implicit preconditioner and theuse of ellipsoidal norms as an explicit preconditioner. From the experiments, the blockCimmino method appears to be a good preconditioner for the CG scheme (with respectto robustness) and, when the convergence would be otherwise slow, the ellipsoidalnorms appear to be good complementary preconditioners. From the behaviour ofthe method, we can, as a first conclusion, say that if the time for factorization is muchlarger than the time for the iterations, it is better to look for partitionings having smallblocks to minimize the fill-in and increase the speedup. But if the time for iterationsis the larger, then the use of ellipsoidal norms as preconditioners can help greatly. Westill need, however, to study and better understand the effect of these ellipsoidal normson the convergence of the method and, if possible, to determine when they work well.
Our iterative scheme appears to be reliable, at least for general block tridiagonalmatrices and is rather friendly, since it is easy to tune the speedup and the number ofiterations. For all the examples, we have separated the time for analysis and the timefor factorization because, in a time-dependent problem, for instance, we can avoid theanalysis after the first time step, setting the block tridiagonal structure and the partition-ing at the beginning and performing the analysis only once.
A particular strength of our approach is that it is not necessary to have disjointblocks in the partitions in order to exploit parallelism, thus widening the set ofapplicable partitions. We plan to investigate this further, extending the technique tomore general systems. With these other partitionings, we hope to decrease the ratio ofthe number of iterations between block Cimmino and block SSOR, enlarging the rangeof applicability of block Cimmino compared to block SSOR. We also need to considerother kinds of ellipsoidal norms, for instance, for partitionings that involve a completeoverlap of the columns.
Our final goal is to make the algorithm as complete and as friendly as possible,by designing heuristics for automatically choosing a good partitioning, a good ellip-soidal norm, or a combination of the two, and also a heuristic which can chooseautomatically between block Cimmino and block SSOR.
Appendix. Tables of results of numerical experiments.
TABLE A.1Behaviour of the block Cimmino method on an Alliant FX/80 (eight processors). Perrel’s test problem.
to 10-9.
No. operations (millions) Elapsed time (seconds)
Part. No. iter. Factorization Iterations Analysis Factorization Iterations Speedup
2 24 709 539 6.7 105.9 51.9 4.03 18 1345 519 8.9 234.0 54.9 2.94 24 405 405 7.3 64.0 40.0 4.55 33 30 214 7.2 12.9 34.4 6.1

A BLOCK PROJECTION METHOD FOR SPARSE MATRICES 69
TABLE A.2Behaviour of the block Cimmino method on an Alliant FX/80 (eight processors). Perrel’s test problem.
o) 10-14.
No. operations (millions) Elapsed time (seconds)
Part. No. iter. Factorization Iterations Analysis Factorization Iterations Speedup
2 48 709 1058 6.7 105.9 100.6 4.13 42 1345 1177 8.9 234.0 125.4 3.14 52 405 860 7.3 64.0 85.2 4.65 74 30 474 7.2 12.9 76.1 6.0
TABLE A.3Behaviour ofthe block Cimmino method on an Alliant FX/80 eight processors). Weinerfelt’s test problem.
tok 10-14"
No. operations (millions) Elapsed time (seconds)
Part. No. iter. Factorization Iterations Analysis Factorization Iterations Speedup
2257.2 35.3 14.7 773.6 10.7 1.02 16 35.3 49.3 2.2 7.7 6.7 4.93 16 76.9 69.4 2.3 12.5 8.2 4.54 17 17.1 45.6 2.1 4.3 8.8 5.45 19 10.8 44.2 2.0 4.1 7.0 6.1
TABLE A.4Behaviour of the block Cimmino method on an Alliant FX/80 (eight processors). Problem 3. tog _-< 10-14.
No. operations (millions) Elapsed time (seconds)
Part. No. iter. Factorization Iterations Analysis Factorization Iterations Speedup
110.1 5.7 8.3 49.2 2.3 1.02 193 4.4 147.3 1.0 1.6 23.1 6.03 182 7.4 168.1 1.5 2.5 31.3 4.64 274 1.8 138.0 0.9 1.1 36.5 5.65 379 0.4 118.3 0.8 0.9 47.6 6.8
TABLE A.5Results for Problem 3 with ellipsoidal norms, a 10. tok --<-- 10-14
No. operations (millions) Elapsed time (seconds)
Part. No. iter. Factorization Iterations Analysis Factorization Iterations
2 95 6.8 90.8 1.0 2.0 15.83 105 10.3 115.0 1.5 3.3 23.04 195 1.3 117.0 0.9 2.6 35.2

70 M. ARIOLI, I. DUFF, J. NOAILLES, AND D. RUIZ
REFERENCES
M. ARIOLI, I. S. DtJFF, AND P. P. M. DE RIJK (1989), On the augmented system approach to sparseleast-squares problems, Numer. Math., 55, pp. 667-684.
A. BJSRCK ANO G. H. GOLUB (1973), Numerical methods for computing angles between linear subspaces,Math. Comp., 27, pp. 579-594.
R. BRAMLEY (1989), Row projection methodsfor linear systems, Report No. 881, Center for SupercomputingResearch and Development, University of Illinois, Urbana, IL.
R. BRAMLEY AND A. SAMEH (1990), Row projection methods for large nonsymmetric linear systems, ReportNo. 957, Center for Supercomputing Research and Development, University of Illinois, Urbana, IL.
S. L. CAM’BE ANO C. D. ME, J,. (1979), Generalized Inverses of Linear Transformations, Pitman,London.
I. S. DuF ANO J. K. REIo (1983), The multifrontal solution of indefinite sparse linear systems, ACM Trans.Math. Software, 9, pp. 302-325.
I. S. DUFF, A. M. ERISMAN, AND J. K. REII (1986), Direct Methodsfor Sparse Matrices, Oxford UniversityPress, London.
I. S. DtJ, N. I. M. GoIO, J. K. Ro, J. A. Scow-r, ANO K. TtN (1991), Factorization of sparsesymmetric indefinite matrices, IMA J. Numer. Anal., 11, pp. 181-204.
T. ELlZVING (1980), Bloclc-iterative methods for consistent and inconsistent linear equations, Numer. Math.,35, pp. 1-12.
G. H. GOLUB AND W. KAHAN (1965), Calculating the singular values and pseudoinverse of a matrix, SIAMJ. Numer. Anal., 2, pp. 205-225.
G. H. GOLUB AND C. F. VAN LOAN (1989), Matrix Computations, Second Edition, The Johns HopkinsUniversity Press, Baltimore, MD.
L. A. HAGMAN AND D. M. YOUNG (1981), Applied Iterative Methods, Academic Press, New York, London.C. KAMATH AND A. SAMEH (1988), A projection method for solvin nonsymmetric linear systems on
multiprocessors, Parallel Comput., 9, pp. 291-312.W. OETTLI AND W. PRAGER (1964), Compatibility of approximate solution of linear equations with given
error bounds for coefficients and right-hand sides, Numer. Math., 6, pp. 405-409.C. R. RAO AND S. K. MITRA (1971), Generalized Inverse of Matrices and its Applications, John Wiley,
Chichester, New York, Brisbane, Toronto.F. SoOOA (1988), A projection method of the Cimmino type for linear algebraic systems, Tech. Report n.
16, Dipartimento di Matematica, University of Bergamo, Bergamo, Italy.
![[IN FIRST-ANGLE PROJECTION METHOD]](https://static.fdokumen.com/doc/165x107/6312eb38b1e0e0053b0e36b0/in-first-angle-projection-method.jpg)



















