
9th International Conference on Big Data Analytics (BDA 2021)
43
9 th International Conference on Big Data Analytics Program Booklet BDA 2021
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of 9th International Conference on Big Data Analytics (BDA 2021)

9th International Conference on Big Data Analytics
Program Booklet
BDA 2021

2
Welcome
to 9th International Conference
on Big Data Analytics
(BDA 2021)
December 15 – 18, 2021
Organized in online mode
By
Indian Institute of Information Technology Allahabad,
Prayagraj, Uttar Pradesh, India
Web site: https://bda2021.org/

3
Contents
BDA 2021 Organising Committee .................................................................................... 4
Program Schedule BDA 2021 ........................................................................................... 5
Details about BDA 2021 Programs .................................................................................. 7
Brief Details of Research Session..................................................................................... 8
Details of Keynote talks BDA 2021 ................................................................................ 10
Details of Invited talks BDA 2021 .................................................................................. 14
Details of Research Sessions BDA 2021 ......................................................................... 19
Details about BDA 2021 Workshops .............................................................................. 29
Details about BDA 2021 Tutorials .................................................................................. 33
Details of Panel Discussion ............................................................................................ 41

4
BDA 2021 Organising Committee
Steering Committee Chair
• P. Krishna Reddy, IIIT Hyderabad, India Honorary Chair
• P. Nagabhushan, Director, IIIT Allahabad, India
General Chair • Sonali Agarwal, IIIT Allahabad, India
Program Committee Chairs
• Satish Narayana Srirama, University of Hyderabad, India • Jerry Chun-Wei Lin, Western Norway University of Applied Sciences, Bergen, Norway • Raj Bhatnagar, University of Cincinnati, USA
Proceeding Chair
• Sanjay Chaudhary, Ahmedabad University, India
Workshop Chairs • Partha Pratim Roy, IIT Roorkee, India • Joao Gama, University of Porto, Portugal • Pradeep Kumar, IIM, Lucknow, India
Tutorial Chairs
• Mukesh Prasad, University of Technology Sydney, Australia • Anirban Mondal, Asoka University, India • Pragya Dwivedi, MNNIT Allahabad, India
Panel Chairs
• Rajeev Gupta, Microsoft • Sanjay Kumar Madria, Missouri University of Science and Technology, USA
Publicity Chairs
• M Tanveer, IIT Indore, India • Deepak Gupta, NIT Arunachal Pradesh, India • Navjot Singh, IIIT Allahabad, India

5
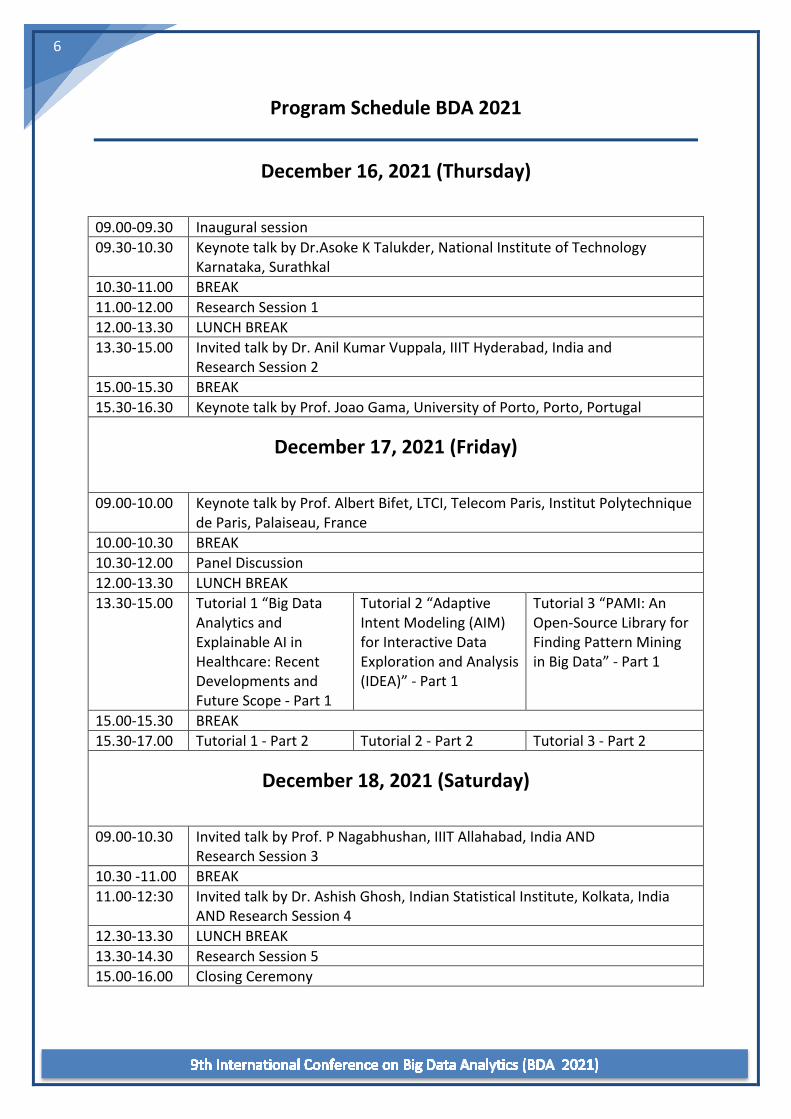
Program Schedule BDA 2021
December 15, 2021 (Wednesday)
Workshop 1: Data Challenges in Assessing Air Quality (DACAAQ 2021) Organizers: Anirban Mondal, Girish Agrawal, Jai Ganesh
December 15, 2021 (Wednesday) 09.00-09.15 Welcome and Introduction to Workshop 09.15-10.15 Keynote 1, by Dr. Sarath Guttikunda, Founder/ Director, Urban
Emsissions 10.15-11.00 Theme 1: Paper presentations ×3 11.00-11.15 Break 11.15-12.15 Theme 2: Paper presentations × 3 12.15-13.15 Keynote 2, by Dr. Anant Maringanti, Director, Hyderabad Urban
Labs 13.15-14.15 Lunch Break 14.15-15.45 Panel Discussion 15.45-16.00 Closing Remarks
Workshop 2: Data Science for Agriculture and Natural Resource Management (DSANRM2021) with Special Focus on Precision Agriculture Organizers: Srikrishnan Divakaran, Rutvij Jhaveri and Deepak Jaiswal
December 15, 2021 (Wednesday) 09.00-09.15 Registration
09.15-09.25 Welcome by Workshop co-chairs 09.30-10.25 Inaugural Address by Prof. Wei Guo,
Institute of Sustainable Agro-ecosystem Services, Graduate School of Agriculture and Life Sciences, The University of Tokyo.
10.30-11.25 Keynote Address by Dr. Anu Swatantran, Corteva Laureate and Principal Investigator, Remote Sensing Data Science
11.30-12.30 Tutorials- I (Introduction to R, Spatial and Temporal Data Analysis with R)
12.35-13.00 Research Paper Presentation-I 13.05-13.30 Research Presentation-II 13.30-14.00 Lunch Break 14.00-14.25 Research Presentation-III 14.30-14.55 Research Presentation-IV 15.00-16.00 Tutorials- II (Simulating impact of climate change on plants using R
package BioCro) 16.00-17.00 Panel Discussion
6
Program Schedule BDA 2021
December 16, 2021 (Thursday)
09.00-09.30 Inaugural session 09.30-10.30 Keynote talk by Dr.Asoke K Talukder, National Institute of Technology
Karnataka, Surathkal 10.30-11.00 BREAK 11.00-12.00 Research Session 1 12.00-13.30 LUNCH BREAK 13.30-15.00 Invited talk by Dr. Anil Kumar Vuppala, IIIT Hyderabad, India and
Research Session 2 15.00-15.30 BREAK 15.30-16.30 Keynote talk by Prof. Joao Gama, University of Porto, Porto, Portugal
December 17, 2021 (Friday)
09.00-10.00 Keynote talk by Prof. Albert Bifet, LTCI, Telecom Paris, Institut Polytechnique de Paris, Palaiseau, France
10.00-10.30 BREAK 10.30-12.00 Panel Discussion 12.00-13.30 LUNCH BREAK 13.30-15.00 Tutorial 1 “Big Data
Analytics and Explainable AI in Healthcare: Recent Developments and Future Scope - Part 1
Tutorial 2 “Adaptive Intent Modeling (AIM) for Interactive Data Exploration and Analysis (IDEA)” - Part 1
Tutorial 3 “PAMI: An Open-Source Library for Finding Pattern Mining in Big Data” - Part 1
15.00-15.30 BREAK 15.30-17.00 Tutorial 1 - Part 2 Tutorial 2 - Part 2 Tutorial 3 - Part 2
December 18, 2021 (Saturday)
09.00-10.30 Invited talk by Prof. P Nagabhushan, IIIT Allahabad, India AND Research Session 3
10.30 -11.00 BREAK 11.00-12:30 Invited talk by Dr. Ashish Ghosh, Indian Statistical Institute, Kolkata, India
AND Research Session 4 12.30-13.30 LUNCH BREAK 13.30-14.30 Research Session 5 15.00-16.00 Closing Ceremony

7
Details about BDA 2021 Programs
KEYNOTES Keynote 1 “Current Trends in Learning from Data Streams”, by Prof. Joao Gama, University of
Porto, Porto, Portugal Keynote 2 “Challenges of Machine Learning for Data Streams in the Banking Industry” by Prof. Albert
Bifet, LTCI, Telecom Paris, Institut Polytechnique de Paris, Palaiseau, France Keynote 3 “Bridging the Inferential Gaps in Healthcare” by Dr.Asoke K Talukder, National
Institute of Technology Karnataka, Surathkal
INVITED TALKS Invited Talk 1 “Towards machine learning to machine wisdom: A potential quest” by Prof. P
Nagabhushan, IIIT Allahabad, India Invited Talk 2 “Outcomes of Speech to Speech Translation for Broadcast Speeches and Crowd
Source Based Speech Data Collection Pilot Projects” by Dr. Anil Kumar Vuppala, IIIT Hyderabad, India
Invited Talk 3 “Multi-label classification”, by Dr. Ashish Ghosh, Indian Statistical Institute, Kolkata, India
TUTORIALS Tutorial 1 “Big Data Analytics and Explainable AI in Healthcare: Recent Developments and
Future Scope” by Prof. Mayuri Mehta, Sarvajanik College of Engineering and Technology, Surat, Gujarat, India
Tutorial 2 “Adaptive Intent Modeling (AIM) for Interactive Data Exploration and Analysis (IDEA)” by Prof. Vikram Singh, NIT Kurukshetra, India
Tutorial 3 “PAMI: An Open-Source Library for Finding Pattern Mining in Big Data” by Prof. Rage Uday Kiran, The University of Aizu, Japan
Panel Discussion: AI for healthcare Panellists: Prof. Praveen Rao, Prof. Deva Priyakumar, Dr. Sujoy Kar and Dr. Ashwini Mathur

8
Brief Details of Research Session
Research Session 1: Medical and Health Applications
1. Sachin Gupta, Narinder Singh Punn, Sanjay Kumar Sonbhadra and Sonali Agarwal.
MAG-Net: Multi-task attention guided network for brain tumor segmentation and classification
2. Rohini Basu, Meghana Madarkal and Asoke K Talukder. Smartphone Mammography for Breast Cancer Screening of Disadvantaged & Conservative Population.
3. Asoke K Talukder, Prantar Chakrabarti, Bhaskar Chaudhuri, Tavpritesh Sethi, Rakesh Lodha and Roland Haas. 2AI&7D Model of Resistomics to Counter the Medical Climate Crisis.
4. Shweta Dasharath Shirsat and Siby Abraham. Tooth Detection From Panoramic Radiographs Using Deep Learning.
Research Session 2: Machine/Deep Learning
5. Gaurav Rajput, Narinder Singh Punn, Sanjay Kumar Sonbhadra and Sonali Agarwal.
Hate speech detection using static BERT embeddings 6. Aditya Kumar and Satish N Srirama. Fog enabled distributed training architecture for
federated learning 7. Kusumat T and Ashwini K. Modular ST-MRF Environment for Moving Target
Detection and Tracking Under Adverse Local Conditions 8. Saurav Tewari, Pramod Pathak and Paul Stynes. A Novel Aspect-Based Deep Learning
Framework (ADLF) to improve Customer Experience
Research Session 3: IoTs, Sensors, and Networks
9. Akshet Patel, Shanmugapriya D, Gautam Srivastava and Jerry Chun-Wei Lin. Routing Protocol Security for Low-Power and Lossy Networks in the Internet of Things
10. Shanmugapriya D, Akshet Patel, Gautam Srivastava and Jerry Chun-Wei Lin. MQTT Protocol use cases in the Internet of Things
11. Chandresh Maurya, Seemandhar Jain and Vishal Thakre. Large-Scale Contact Tracing, Hotspot Detection,and Safe Route Recommendation
Research Session 4: Fundamentation
12. Akshara P, Shidharth S, Gokul S Krishnan and Sowmya Kamath S. Diagnostic Code Group Prediction by Integrating Structured & Unstructured Clinical Data
13. Neeraj Kollepara, Snehith K Chatakonda and Pawan Kumar. SCIMAT: Dataset of Problems in Science and Mathematics
14. Anusha Nalajala, Ragunathan T, Rathnamma Gopisetty and Vignesh Garrapally . Rank-Based Prefetching and Multi-level Caching Algorithms to Improve the Efficiency of Read Operations in Distributed File Systems

9
15. Minakshi Kaushik, Rahul Sharma, Dirk Draheim and Sijo Arakkal Peious. Impact-Driven Discretization of Numerical Factors: Case of Two- and Three-Partitioning
Research Session 5: Pattern Mining and data Analytics
16. B Dheeraj Chitara and Sanjeev B. S. Big Data over Cloud: Enabling Drug Design under Cellular Environment
17. Alok Negi, Krishan Kumar, Narendra S. Chaudhari, Navjot Singh and Prachi Chauhan. Predictive Analytics for Recognizing Human Activities using Residual Network and Fine-Tuning
18. Pawan Kumar. DXML: Distributed Extreme Multilabel Classification. 19. Preetham Reddy Sathineni, Srinivas A Reddy, Krishna Reddy P and Anirban Mondal.
An Efficient Distributed Coverage Pattern Mining Algorithm

10
Details of Keynote talks BDA 2021
Bridging the Inferential Gaps in Healthcare
Prof. Asoke K Talukder National Institute of Technology Karnataka, Surathkal Abstract: Inferential gaps are the combined effect of reading-to-cognition gaps as well as the knowledge-to-action gaps. Misdiagnoses, medical errors, prescription errors, surgical errors, under-treatments, over-treatments, unnecessary lab tests, etc. – are all caused by inferential gaps. Late diagnosis of cancer is also due to the inferential gaps at the primary care. Even the medical climate crisis caused by misuse, underuse, or overuse of antibiotics are the result of serious inferential gaps. Electronic health records (EHR) had some success in mitigating the wrong site, wrong side, wrong procedure, wrong person (WSWP) errors, and the general medical errors; however, these errors continue to be quite significant. In the last few decades the disease demography has changed from quick onset infectious diseases to slow onset non-communicable diseases (NCD). This changed the healthcare sector in terms of both training and practice. In 2020 the COVID-19 pandemic disrupted the entire healthcare system further with change in focus from NCD back to quick onset infectious disease. During COVID-19 pandemic misinformation in social media increased. In addition, COVID-19 made virtual healthcare a preferred mode of patient-physician encounter. Virtual healthcare requires higher level of audit, accuracy, and technology reliance. All these events in medical practice widened the inferential gaps further. In this position paper, we propose an architecture of digital health combined with artificial intelligence that can mitigate these challenges and increase patient safety in the post-COVID healthcare delivery. We propose this architecture in conjunction with diseasomics, patholomics, resistomics, oncolomics, allergomics, and drugomics machine interpretable knowledge graphs that will minimize the inferential gaps. Unless we pay our attention to this critical issue immediately, medical ecosystem crisis that includes medical errors, caregiver shortage, misinformation, and the inferential gaps will become the second, if not the first leading cause of death by 2050. Biography: Prof Dr Asoke Talukder is an educator, an innovator, and an entrepreneur. An adjunct faculty at National Institute of Technology Karnataka, Surathkal Dr Asoke founded Cybernetic Care, a company is healthcare transformation. He innovated and engineered many killer products and first in the world. He engineered the first 64 bit database in the world for Digital DEC

11
Alpha and Informix in 1993. He setup the first X.25 network with reverse emulator for the Department of Telecommunications, India. He engineered the Network Management System for Queen’s Award winning PDMX. He co-founded Cellnext in 2000 that defined the mobile Web and mobile Internet in India. He co-founded the first big-data genomics company InterpretOmics in India in 2008. He is recipient of many awards for innovation and professional excellence including Karnataka Bio-Excellence Award, ICIM Professional Excellence Award, ICL Services Trophy, ICL Excellence Award, IBM Solutions Excellence Award, Simagine GSMWorld Award, Atlas Club Excellence Award, All India Radio/Doordarshan Award etc. Asoke’s expertise ranges from compilers to cancer. He did M.Sc in Physics and Ph.D in Computer Science. He was the DaimlerChrysler Chair Professor at IIIT-Bangalore. Two of his books have been translated in Chinese Language. His current areas of interest are Knowledge Engineering and Medical AI.

12
Details of Keynote talks BDA 2021
Current Trends in Learning from Data Streams
Prof. João Gama Laboratory of Artificial Intelligence and Decision Support, and Faculty of Economics, University of Porto Porto, Portugal
Abstract: This article presents our recent work on the topic of learning from data streams. We focus on emerging topics, including fraud detection, learning from rare cases, and hyper parameter tuning for streaming data.
Biography: João Gama is a Full Professor at the School of Economics, University of Porto, Portugal. He received his Ph.D. in Computer Science from the University of Porto in 2000. He is EurIA Fellow, IEEE Fellow, and member of the board of directors of the LIAAD, a group belonging to INESC Porto. His h-index at Google Scholar is 58. He is an Editor of several top-level Machine Learning and Data Mining journals. He has been ACM Distinguish Speaker. He served as Program Chair of ECMLPKDD 2005, DS09, ADMA09, EPIA 2017, DSAA 2017, served as Conference Chair of IDA 2011, ECMLPKDD 2015, DSAA’2021, and a series of Workshops on KDDS and Knowledge Discovery from Sensor Data with ACM SIGKDD. His main research interests are in knowledge discovery from data streams, evolving data, probabilistic reasoning, and causality. He published more than 300 reviewed papers in journals and major conferences. He has an extensive list of publications in data stream learning.

13
Details of Keynote talks BDA 2021
Challenges of Machine Learning for Data Streams in the Banking Industry Prof. Albert Bifet LTCI, Télécom Paris Data, Intelligence and Graphs Team 19 place Marguerite Perey 91120 Palaiseau, FRANCE
Abstract:
Banking Information Systems continuously generate large quantities of data as inter-connected streams (transactions, events logs, time series, metrics, graphs, process, etc.). Such data streams need to be processed online to deal with critical business applications such as real-time fraud detection, network security attack prevention or predictive maintenance on information system infrastructure. Many algorithms have been proposed for data stream learning, however, most of them do not deal with the important challenges and constraints imposed by real-world applications. In particular, when we need to train models incrementally from heterogeneous data mining and deployment them within complex big data architecture. Based on banking applications and lessons learned in production environments of BNP Paribas - a major international banking group and leader in the Eurozone - we identified the most important current challenges for mining IT data streams. Our goal is to highlight the key challenges faced by data scientists and data engineers within complex industry settings for building or deploying models for real word streaming applications. We provide future research directions on Stream Learning that will accelerate the adoption of online learning models for solving real-word problems. Therefore, bridging the gap between research and industry communities. Finally, we provide some recommendations to tackle some of these challenges.
Biography: Albert Bifet is the director of the AI Institute at University of Waikato, and professor at IP Paris. He is the co-author of a book on Machine Learning from Data Streams published at MIT Press. He is one of the leaders of MOA, scikit-multiflow and Apache SAMOA software environments for implementing algorithms and running experiments for online learning from evolving data streams. He was serving as Co-Chair of the Industrial track of IEEE MDM 2016, ECML PKDD 2015, and as Co-Chair of KDD BigMine (2019-2012), and ACM SAC Data Streams Track (2022-2012).

14
Details of Invited talks BDA 2021
Outcomes of Speech to Speech Translation for Broadcast Speeches and Crowd Source Based Speech Data Collection Pilot Projects? Dr. Anil Kumar Vuppala Associate Professor IIIT Hyderabad.
Abstract: Speech-to-Speech Machine Translation (SSMT) applications and services use a three-step process. Speech recognition is the first step to obtain transcriptions. This is followed by text-to-text language translation and, finally, synthesis into text-speech. As data availability and computing power improved, these individual steps evolved. How- ever, despite significant progress, there is always the error of the first stage in terms of speech recognition, accent, etc. Having traversed the speech recognition stage, the error becomes more prevalent and decreases very often. This chapter presents a complete pipeline for transferring speaker intent in SSMT involving humans in the loop. Initially, the SSMT pipeline has been discussed and analyzed for broadcast speeches and talks on a few sessions of Mann Ki Baat, where the source language is in Hindi, and the target language is in English and Telugu. To perform this task, industry-grade APIs from Google, Microsoft, CDAC, and IITM has been used for benchmarking. Later challenges faced while building the pipeline are discussed, and potential solutions have been introduced. Later this introduces a framework developed to collect a crowd-sourced speech database for the speech recognition task.
Biography: Anil Kumar Vuppala received his B.Tech. in Electronics and Communications Engineering from JNTU, Hyderabad, India, in 2005, M.Tech. in Electronics and Communications Engineering from NIT, Kurukshetra, in 2007, and PhD in signal processing from IIT Kharagpur, in 2012. From March 2012 to June 2019 he has worked as Assistant Professor at IIIT Hyderabad. From July 2019 onwards he is working as Associate Professor at IIIT Hyderabad. His research interests lie primarily in speech processing in mobile and practical environments. He has published 5 book chapters, 26 reputed journals, and 74 international conference papers. He is currently handling 2 sponsored projects and completed 7 funded projects. He is guiding 5 full-time PhD students (2 of them submitted the thesis) and 9 MS students. He successfully guided 4 PhD students and 2 MS students. He has given more than 75 invited talks in various workshops and conferences.

15
Details of Invited talks BDA 2021
Towards machine learning to machine wisdom: A potential quest Prof. P Nagabhushan Director, Indian Institute of Information Technology Allahabad Abstract: In the present era of artificial intelligence (AI) enabled solutions, the world is observing a tremendous influx in machine learning (ML) approaches across various application domains like healthcare, industry, document analysis, audio-video processing, etc. All existing machine learning approaches claim for intelligent solutions, but till date the learning is guided by the human wisdom i.e. all the proposed machine intelligence algorithms are data centric and infer knowledge without understanding the scenarios. The wisdom is an ability to take wise decisions based on the inferred knowledge to satisfy W5HH principle which outlines the series of answers to the questions such as why, what, who, when, where, how and how much, in a given context. This paper discusses the scope of machine wisdom (artificial wisdom) over conventional machine learning strategies along with its significance and how it can be achieved.
Biography: Brief Bio-Sketch: Prof. P. Nagabhushan, presently the Director of Indian Institute of Information Technology Allahabad, Prayagraj (An Institute of National Importance by the Act of Parliament), was earlier Chief Nodal Officer, Dean, and Chairman with various academic administrative responsibilities, and with academic reformation activities at University of Mysore, Mysore. Being the founder Professor of the Department of Studies in Computer Science, University of Mysore, he focused on moulding the department as a learning and research focused department. He was responsible for shaping the department as a centre of excellence in Computer Cognition and Recognition covering the areas of Pattern Recognition, Image Processing, Intelligence and Learning. Earlier to this, he was coordinator of M.Tech. program in SJ College of Engineering, Mysore. Prof. P. Nagabhushan remained enthusiastically active in implementing continuous learning, continuous assessment, and choice based credits earning since 2000 at department level and since 2010 at University of Mysore, and since 2017 at Indian Institute of Information Technology Allahabad, which are now being promoted by NEP2020. He has supervised 33 Ph.D. scholars and has authored more than 200 Journal papers totalling more than 500 research papers. He was an invited academician and researcher at USA, JAPAN, FRANCE, SUDAN. He was the Investigator of several research projects funded by UGC, MHRD, AICTE, ICMR, ISRO, IFCAR, DRDO and MHA. He has received

16
many awards for his academic roles, and he is the recipient of fellowships from Institute of Engineers (FIE), Institute of Electronics and Telecommunication Engineers (FIETE), and International Academy of Physical Sciences (FIAPS). His Google Scholar Citation is 2838 with H-Index 27 and i10-Index 81.

17
Details of Invited talks BDA 2021
Multi-label classification Dr. Ashish Ghosh Professor & former Head, Machine Intelligence Unit ISI Kolkata Abstract: Multi-label classification (MLC) is a generalization of the traditional single-label/multi-class classification. This lecture will be on the what, why and how of multi-label classification. To understand the basics, we will begin with "what" multi-label data classification is. Then, we will discuss "why" it is needed, focussing on some real-life application areas where it is used. Next, we will move on to "how" multi-label classification is performed, and highlight some popular ML classification models in the literature. Finally, some datasets, metrics relevant to ML classification will be discussed.
Biography: Starting as an electronic engineer (1983-'87), Prof. Ghosh moved to computer science during his master's (1987-'89), and finally to Artificial Intelligence (AI) during PhD (1993). Completing post-doctoral research in Japan (1995-'96), he joined as a faculty member at ISI (1997), now a full professor, and contributing immensely to the field of artificial intelligence, machine learning, image/video analysis and data science. He has already published about 300 research articles on these subjects; and has an h-index 47. His name is cited in the list of "world's top 2% scientists". For his pioneering contribution in computational intelligence and image analysis, he earned Young Scientist award from Indian Science Congress (1992), Young Scientist Medal from INSA (1995), and Young Associateship of Indian Academy of Sciences (1997). He is a Fellow of the West Bengal Academy of Science and Technology, The National Academy of Sciences, India (NASI), and the International Association for Pattern Recognition (IAPR). For his excellent service to IEEE, he received IEEE-GRSS Regional Leader Award, 2019. He visited various Universities/Academic Institutes in connection with conducting collaborative research/projects and deliver lectures in different countries including China, Germany, Hong Kong, Italy, Japan, Poland, Portugal, South Korea, Thailand, The Netherlands, UK and the USA. He is a member of the Governing Body of Asia Pacific Neural Network Society and a Global Coordinator of IEEE Geoscience and Remote Sensing Society Chapters. He served as plenary/keynote speakers in many international conferences in India and abroad. To upgrade and nurture the engineering community, he disseminated seminar lectures and conducted several workshops /short-term courses in different parts of India on upcoming topics of AI, machine learning, image & video analysis and data science. As PI and Co-PI, he completed eighteen projects of national and international importance, funded by Government of India, European Commission, Indo-Italy and Indo-US forum for science &

18
technology. He is a member of the founding team that established the National Center for Soft Computing Research at the Indian Statistical Institute, Kolkata in 2004 with funding from the Department of Science and Technology, Govt. of India. He acted as the In-charge of this Center for ten years that has been recognized as an Associate Institute of ISI. He also served as the Head of the well-known Machine Intelligence Unit of ISI during 2013- 2014 and serving for the next term 2019-2021. He is a member of the Research Advisory Committee of many Academic organizations, and SEBI (Mumbai, India), and is nominated to the Academic Council of Banasthali Vidyapith as an Eminent Educationist. He is currently leading the Data Science Research consortium project as the Theme Coordinator to manage a number of projects assigned to different reputed Indian Institutes under ICPS program of DST, and is the Project Director of the Technical Innovation Hub on Data Science established at Indian Statistical Institute, Kolkata with a funding of 100 crores. He is an Associate Editor of several International journals, like, IEEE JSTAR, IET Journal of Computer Vision, Springer Nature Computer Science, CAAI Transactions on Intelligence Technology (published from IET) and Sadhana, Journal of Banking and Financial Technology, and a Series Editor of Communications in Computer and Information Science (CCIS), Springer-Nature.

19
Details of Research Sessions BDA 2021
Research Session 1: Medical and Health Applications
Piper Title: MAG-Net: Multi-task attention guided network for brain tumor segmentation and classification Authors: Sachin Gupta, Narinder Singh Punn, Sanjay Sonbhadra and Sonali Agarwal Abstract: Brain tumor is the most common and deadliest disease that can be found in all age groups. Generally, MRI modality is adopted for identifying and diagnosing tumors by the radiologists. The correct identification of tumor regions and its type can aid to diagnose tumors with the followup treatment plans. However, for any radiologist analysing such scans is a complex and time-consuming task. Motivated by the deep learning based computer-aided-diagnosis systems, this paper proposes multi-task attention guided encoder-decoder network (MAG-Net) to classify and segment the brain tumor regions using MRI images. The MAG-Net is trained and evaluated on the Figshare dataset that includes coronal, axial, and sagittal views with 3 types of tumors meningioma, glioma, and pituitary tumor. With exhaustive experimental trials the model achieved promising results as compared to existing state-of-the-art models, while having least number of training parameters among other state-of-the-art models.
Piper Title: Smartphone Mammography for Breast Cancer Screening of Disadvantaged & Conservative Population Authors: Rohini Basu, Meghana Madarkal and Asoke K Talukder Abstract: In 2020 alone approximately 2.3 million women were diagnosed with breast cancer which caused over 685,000 deaths worldwide. Breast cancer affects women in developing countries more severely than in developed country such that over 60% of deaths due to breast cancer occur in developing countries. Deaths due to breast cancer can be reduced significantly if it is diagnosed at an early stage. However, in developing countries cancer is often diagnosed when it is in the advanced stage due to limited medical resources available to women, lack of awareness, financial constraints as well as cultural stigma associated with traditional screening methods. Our paper aims to provide an alternative to women that is easily available to them, affordable, safe, non-invasive and can be self-administered. We propose the use of a smartphone’s inbuilt camera and inbuilt flashlight for breast cancer screening before any signs or symptoms begin to appear. This is a novel approach as there is presently no device that can be used by women themselves without any supervision from a medical professional and uses a smartphone without any additional external devices for breast cancer screening. The theory of the system is that when visible light penetrates through the skin into the breast tissue, it reflects back differently in normal breast tissue as compared to tissue with

20
anomalies. A phantom breast model, which mimics real human breast tissue, is used to develop the modality. We make use of computer vision and image processing techniques to analyze the difference between an image taken of a normal breast and that of one with irregularities in order to detect lumps in the breast tissue and also make some diagnosis on its size, density and the location.
Piper Title: 2AI&7D Model of Resistomics to Counter the Medical Climate Crisis Authors: Asoke K Talukder, Prantar Chakrabarti, Bhaskar Chaudhuri, Tavpritesh Sethi, Rakesh Lodha and Roland Haas Abstract: The antimicrobial resistance (AMR) crisis is referred to as ‘Medical Climate Crisis’. Inappropriate use of antimicrobial drugs is driving the resistance evolution in pathogenic microorganisms. The miracle drug that once saved many lives and helped safe surgery is becoming ineffective with an increase in morbidity and mortality. In 2014 it was estimated that by 2050 more people will die due to antimicrobial resistance compared to cancer. It was estimated to cause a reduction of 2% to 3.5% in Gross Domestic Product (GDP) and cost the world up to 100 trillion USD. However, the COVID-19 pandemic made this worse – indiscriminate use of antibiotics for COVID-19 patients has accelerated the resistance rate. COVID-19 reduced the window of opportunity for the fight against AMR. This man-made crisis can only be averted through accurate antibiotic knowledge, usage, and a knowledge driven Resistomics. In this paper, we present the 2AI (Artificial Intelligence and Augmented Intelligence) and 7D (right Diagnosis, right Disease-causing-agent, right Drug, right Dose, right Duration, right Documentation, and De-escalation) model of antibiotic stewardship. The resistance related integrated knowledge of resistomics is stored as a knowledge graph in a Neo4j properties graph database for 24x7 access. This knowledge is made available through smartphones and the Web as a Progressive Web Applications (PWA). The 2AI&7D Model delivers the right knowledge at the right time to the specialists and non-specialist alike at the point-of-action (Stewardship committee, Smart Clinic, and Smart Hospital) and then delivers the actionable accurate knowledge to the healthcare provider at the point-of-care in realtime.
Piper Title: Tooth Detection From Panoramic Radiographs Using Deep Learning Authors: Shweta Dasharath Shirsat and Siby Abraham Abstract: The proposed work aims at implementing a Deep Convolutional Neural Network algorithm specialized in object detection. It was trained to perform tooth detection, segmentation, classification and labelling on panoramic dental radiographs. A dataset of dental panoramic radiographs was annotated according to the FDI tooth numbering system. Mask R-CNN Inception ResNet V2 object detection algorithm was able to give excellent results in terms of tooth segmentation and numbering. The experimental results were validated using standard performance metrics. The method could not only give comparable results to that of similar works but could detect even missing teeth, unlike similar works.

21
Research Session 2: Machine/Deep Learning
Piper Title: Hate speech detection using static BERT embeddings Authors: Gaurav Rajput, Narinder Singh Punn, Sanjay Sonbhadra and Sonali Agarwal Abstract: With increasing popularity of social media platforms hate speech is emerging as a major concern, where it expresses abusive speech that targets specific group characteristics, such as gender, religion or ethnicity to spread violence. Earlier people use to verbally deliver hate speeches but now with the expansion of technology, some people are deliberately using social media platforms to spread hate by posting, sharing, commenting, etc. Whether it is Christchurch mosque shootings or hate crimes against Asians in west, it has been observed that the convicts are very much influenced from hate text present online. Even though AI systems are in place to flag such text but one of the key challenges is to reduce the false positive rate (marking non hate as hate), so that these systems can detect hate speech without undermining the freedom of expression. In this paper, we use ETHOS hate speech detection dataset and analyze the performance of hate speech detection classifier by replacing or integrating the word embeddings (fastText (FT), GloVe (GV) or FT + GV) with static BERT embeddings (BE). With the extensive experimental trails it is observed that the neural network performed better with static BE compared to using FT, GV or FT + GV as word embeddings. In comparison to fine-tuned BERT, one metric that significantly improved is specificity.
Piper Title: Fog enabled distributed training architecture for federated learning Authors: Aditya Kumar and Satish N Srirama Abstract: The amount of data being produced at every epoch of second is increasing every moment. Various sensors, cameras and smart gadgets produce continuous data throughout its installation. Processing and analyzing raw data at a cloud server faces several challenges such as bandwidth, congestion, latency, privacy and security. Fog computing brings computational resources closer to IoT that addresses some of these issues. These IoT devices have low computational capability, which is insufficient to train machine learning. Mining hidden patterns and inferential rules from continuously growing data is crucial for various applications. Due to growing privacy concerns, privacy preserving machine learning is another aspect that needs to be inculcated. In this paper, we have proposed a fog enabled distributed training architecture for machine learning tasks using resources constrained devices. The proposed architecture trains machine learning model on rapidly changing data using online learning. The network is inlined with privacy preserving federated learning training. Further, the learning capability of architecture is tested on a real world IIoT use case. We trained a neural network model for human position detection in IIoT setup on rapidly changing data.

22
Piper Title: Modular ST-MRF Environment for Moving Target Detection and Tracking Under Adverse Local Conditions Authors: Kusumat T and Ashwini K Abstract: The amount of data being produced at every epoch of second is increasing every moment. Various sensors, cameras and smart gadgets produce continuous data throughout its installation. Processing and analyzing raw data at a cloud server faces several challenges such as bandwidth, congestion, latency, privacy and security. Fog computing brings computational resources closer to IoT that addresses some of these issues. These IoT devices have low computational capability, which is insufficient to train machine learning. Mining hidden patterns and inferential rules from continuously growing data is crucial for various applications. Due to growing privacy concerns, privacy preserving machine learning is another aspect that needs to be inculcated. In this paper, we have proposed a fog enabled distributed training architecture for machine learning tasks using resources constrained devices. The proposed architecture trains machine learning model on rapidly changing data using online learning. The network is inlined with privacy preserving federated learning training. Further, the learning capability of architecture is tested on a real world IIoT use case. We trained a neural network model for human position detection in IIoT setup on rapidly changing data.
Piper Title: A Novel Aspect-Based Deep Learning Framework (ADLF) to improve Customer Experience Authors: Saurav Tewari, Pramod Pathak and Paul Stynes Abstract: Restaurateurs manage the customer experience of a restaurant through the overall rating of reviews on platforms such as Yelp, Google, and TripAdvisor. The challenge is to identify aspects of the restaurant to improve based on a deeper analysis of restaurant reviews. This research proposes a Novel Aspect-Based Deep Learning Framework (ADLF) to improve the customer experience of restaurants based on the value of Key Performance Indicators (KPIs) derived from the sentiment of restaurant reviews. The proposed framework combines an information retrieval algorithm, Okapi BM25 and a deep learning model, word2vec-cnn. The model is trained on the Yelp dataset that consists of 600,000 reviews. Key Performance Indicator’s (KPIs) are identified to help a restaurateur improve customer experience based on the sentiment of restaurant reviews. Five predetermined aspects namely flavor, cost, ambience, hygiene, and service are used to create the KPIs. Results demonstrate that diners express positive sentiment about “service” and negative sentiment about “cost”. The proposed framework achieved an accuracy of 94% and AUROC of 0.98. This novel framework, ADLF, shows promise for providing restaurateurs with a way to mine the unstructured textual opinion of their customers into KPIs that allows them to improve the customer experience of a restaurant.

23
Research Session 3: IoTs, Sensors, and Networks
Piper Title: Routing Protocol Security for Low-Power and Lossy Networks in the Internet of Things Authors: Akshet Patel, Shanmugapriya D, Gautam Srivastava and Jerry Chun-Wei Lin Abstract: The Internet of Things (IoT) is a two-decade-old technology that allows the inter-connection of various cyber-physical objects located anywhere in the world over the internet. A cyber-physical object is an inanimate object with the ability to connect itself to the internet and communicate with other similar objects. This communication is enabled by communication protocols that bridge the gap between hardware devices and the user by ensuring secure communication with optimum efficiency. As the number of IoT devices is increasing exponentially every year with the current estimation of more than 35 billion IoT devices according to a study conducted by findstack.com, there is a need for a lightweight and highly secure communication protocol for IoT devices. This creates a need for handling all the dynamic data exchanges in real-time. Hence, Big Data and IoT technologies are often proposed together for processing and analyzing data streams. Incorporating Big Data analytics in IoT applications enables real-time information transfer, data monitoring and processing easily. To facilitate efficient communication in IoT networks, the Routing Protocol for Low-Power and Lossy Networks (RPL) comes into the picture which is a low power consuming routing protocol that operates on IEEE 802.15. This paper aims to encrypt the RPL Protocol using cryptographic algorithms and compare the results with a non-encrypted RPL Protocol using Cooja Simulator so that the data is securely communicated for Big Data analysis. The (Secure Hash Algorithm) SHA3 algorithm had been used to encrypt the sink nodes of the RPL protocol and the parameters such as average power consumption, network graph, latency is analyzed and compared. The results of this experiment show a considerable drop in latency and power consumption after deploying.
Piper Title: MQTT Protocol use cases in the Internet of Things Authors: Shanmugapriya D, Akshet Patel, Gautam Srivastava and Jerry Chun-Wei Lin Abstract: In the imminent generations, the Internet of Things (IoT) will have a vital role in ‘Networking’. There are a lot of subscribing/publish protocols used in IoT like MQTT, AMQP, XMPP, HTTP etc., but every protocol used here will not have the same features required for the Internet of Things. This paper helps you to find which is the best and efficient protocol through the use cases and the Big Data analysis used in IoT. To choose the best protocol, it should be used in the real-world application and analyzed through some statistical measurements, as like in this study two use cases are taken to experiment with the protocol. Light-weight MQTT (Message queuing telemetry transport) protocol is vastly used in IoT, So MQTT protocol is used to subscribe/publish in these use cases, using the use cases measurements (speed of the transmission of messages and throughput of the message transmission) are measured and the security systems are either explained. Mainly for the use

24
cases like home automation and vehicular network, there are a huge number of resources like sensors are used, these sensors collect massive data, so for storing these massive data big data is used. This paper majorly focuses on the use cases of MQTT protocol in IoT, the advantages of using MQTT protocol and big data analytics used in IoT.
Piper Title: Large-Scale Contact Tracing, Hotspot Detection,and Safe Route Recommendation Authors: Chandresh Maurya, Seemandhar Jain and Vishal Thakre Abstract: The COVID-19 pandemic created a worldwide emergency as it is estimated that such a large number of infections are due to human-to-human transmission. As a necessity, there is a need to track users who came in contact with users having travel history,asymptomatic and not yet symptomatic, but they can be in the future. To solve this problem, we propose a solution for contact tracing based on assisted GPS and cloud computing technologies. An application is developed to collect each user’s assisted GPS coordinates once all the users install this application. This application periodically sends assisted GPS data to the cloud. To determine which devices are within the permissible limit of 5m, we perform clustering over assisted GPS coordinates and track the clusters for about t mins (tunable parameter) to allow the measure of spread. We assume that it takes around 3-5 mins to get the virus from an infected object. For clustering, the proposed M-way like tree data structure stores the assisted GPS coordinates in degree, minute, and second(DMS) format. Thus, every user is mapped to a leaf node of the tree. The crux of the solution lies at the leaf node. We split the ”seconds” partof the assisted GPS location into m equal parts (a tunable parameter), which amount to d meter in latitude/longitude. Hence, two users who are within d meter range will map to the same leaf node. Thus, by mapping assisted GPS locations every t mins (usually t = 2.5 mins), we can find out how many users came in contact with a particular user for at least t mins. Our work’s salient feature is that it runs in O(n) for n users in the static case, i.e., when users are not moving. We also propose a variant of our solution to handle the dynamic case, that is, when users are moving. Besides, the proposed solution offers potential hotspot detection and safe-route recommendation as an additional feature, and proof-of-concept is presented through experiments on simulated data of 2/4/6/8/10M users.

25
Research Session 4: Fundamentation
Piper Title: Diagnostic Code Group Prediction by Integrating Structured & Unstructured Clinical Data Authors: Akshara P, Shidharth S, Gokul S Krishnan and Sowmya Kamath S Abstract: Diagnostic coding is a process by which written, verbal and other patient-case related documentation are used for enabling disease prediction, accurate documentation, and insurance settlements. It is a prevalently manual process even in countries that have successfully adopted Electronic Health Record (EHR) systems. The problem is exacerbated in developing countries where widespread adoption of EHR systems is still not at par with Western counterparts. EHRs contain a wealth of patient information embedded in numerical, text, and image formats. A disease prediction model that exploits all this information, enabling accurate and faster diagnosis would be quite beneficial. We address this challenging task by proposing mixed ensemble models consisting of boosting and deep learning architectures for the task of diagnostic code group prediction. The models are trained on a dataset created by integrating features from structured (lab test reports) as well as unstructured (clinical text) data. We analyze the proposed model's performance on MIMIC-III, an open dataset of clinical data using standard multi-label metrics. Empirical evaluations underscored the significant performance of our approach for this task, compared to state-of-the-art works which rely on a single data source. Our novelty lies in effectively integrating relevant information from both data sources thereby ensuring larger ICD-9 code coverage, handling the inherent class imbalance, and adopting a novel approach to form the ensemble models.
Piper Title: SCIMAT: Dataset of Problems in Science and Mathematics Authors: Neeraj Kollepara, Snehith K Chatakonda and Pawan Kumar Abstract: Datasets play an important role in driving innovation in algorithms and architectures for supervised deep learning tasks. Numerous datasets exist for images, language translation, etc. One of the interesting challenge problem for deep learning is to solve high school problems in mathematics and sciences. To this end, a comprehensive set of dataset containing 100s of millions of samples, and the generation modules is required that can propel research for these problems. In this paper, a large set of datasets covering mathematics and science problems is proposed, and the data set generation codes are proposed. Test results on the proposed datasets for character-to-character transformer architecture shows promising results with test accuracy above 95\%, however, for some datasets it shows test accuracy of below 30\%. Dataset will be available at: www.github.com/misterpawan/scimat2

26
Piper Title: Rank-Based Prefetching and Multi-level Caching Algorithms to Improve the Efficiency of Read Operations in Distributed File Systems Authors: Anusha Nalajala, Ragunathan T, Rathnamma Gopisetty and Vignesh Garrapally Abstract: In the era of big data, web-based applications deployed in cloud computing systems have to store and process large data generated by the users of such applications. Distributed file systems are used as the back end storage component in the cloud computing systems and they are used for storing large data efficiently.Improving the read performance of the distributed file system is the important research problem as most of the web-based applications deployed in the cloud computing systems carry out read operations more frequently. Prefetching and caching are the two important techniques used for improving the performance of the read operations in the distributed file system. In this paper, we have proposed novel rank-based prefetching, multi-level caching and rank-based replacement algorithms for the effective caching process. Our simulation results reveal that the proposed algorithms improve the performance of the read operations carried out in the distributed file systems better than the algorithms proposed in the literature.
Piper Title: Impact-Driven Discretization of Numerical Factors: Case of Two- and Three-Partitioning Authors: Minakshi Kaushik, Rahul Sharma, Dirk Draheim and Sijo Arakkal Peious Abstract: Many real-world data sets contain a mix of various types of data, i.e., binary, numerical, and categorical; however, many data mining and machine learning (ML) algorithms work merely with discrete values, e.g., association rule mining. Therefore, the discretization process plays an essential role in data mining and ML. In state-of-the-art data mining and ML, different discretization techniques are used to convert numerical attributes into discrete attributes. However, existing discretization techniques do not reflect best the impact of the independent numerical factor onto the dependent numerical target factor. This paper proposes and compares two novel measures for order-preserving partitioning of numerical factors that we call Least Squared Ordinate-Directed Impact Measure and Least Absolute-Difference Ordinate-Directed Impact Measure. The main aim of these measures is to optimally reflect the impact of a numerical factor onto another numerical target factor. We implement the proposed measures for two-partitions and three-partitions. We evaluate the performance of the proposed measures by comparison with human-perceived cut points. We use twelve synthetic data sets and one real-world data set for the evaluation, i.e., school teacher salaries from New Jersey (NJ). As a result, we find that the proposed measures are useful in finding the best cut-points perceived by humans.

27
Research Session 5: Pattern Mining and data Analytics
Piper Title: Big Data over Cloud: Enabling Drug Design under Cellular Environment Authors: Dheeraj Chitara and Sanjeev B. S. Abstract: Molecular Dynamics (MD) simulations mimic the motion of atoms. While simulations often require weeks to complete, the terabytes of data generated in the process also present a challenge for analysis. Recent studies discovered drug-receptor interactions with the cellular environment. Comprising of hundreds of small and large molecules seen in cells, such complex studies are necessary for improving drug design. Current resources and techniques do not provide, in reasonable time, necessary insights into such systems. In this study, we developed an algorithm to identify molecules interacting with drug-receptor complexes. Using first ever application of big data framework to MD studies, we demonstrate that our approach enables rapid analysis of MD data. Finally, we propose a cloud-based, Spark-enabled, self-tuning, scalable and responsive framework to accomplish optimal MD studies for drug-development within available resources.
Piper Title: Predictive Analytics for Recognizing Human Activities using Residual Network and Fine-Tuning Authors: Alok Negi, Krishan Kumar, Narendra S. Chaudhari, Navjot Singh and Prachi Chauhan Abstract: Human Action Recognition (HAR) is a rapidly growing study area in computer vision due to its wide applicability. Because of their varied appearance and the broad range of stances that they can assume, detecting individuals in images is a difficult undertaking. Due to its superior performance over existing machine learning methods and high universality over raw inputs, deep learning is now widely used in a range of study fields. For many visual recognition tasks, the depth of representations is critical. For better model robustness and performance, more complex features can represent using deep neural networks but the training of these model are hard due to vanishing gradients problem. The use of skip connections in residual networks (ResNet) helps to address this problem and easy to learn identity function by residual block. So, ResNet overcomes the performance degradation issue with deep networks. This paper proposes an intelligent human action recognition system using residual learning-based framework “ResNet-50” with transfer learning which can automatically recognize daily human activities. The proposed work presents extensive empirical evidence demonstrating that residual networks are simpler to optimize and can gain accuracy from significantly higher depth. The experiments are performed using the UTKinect Action-3D public dataset of human daily activities. According to the experimental results, the proposed system outperforms other state-of-the-art methods and recorded high recognition accuracy of 98.25 percent with a 0.11 loss score in 200 epochs.

28
Piper Title: DXML: Distributed Extreme Multilabel Classification Authors: Pawan Kumar Abstract: As a big data application, extreme multilabel classification has emerged as an important research topic with applications in ranking and recommendation of products and items. A scalable hybrid distributed and shared memory implementation of extreme classification for large scale ranking and recommendation is proposed. In particular, the implementation is a mix of message passing using MPI across nodes and using multithreading on the nodes using OpenMP. The expression for communication latency and communication volume is derived. Parallelism using work-span model is derived for shared memory architecture. This throws light on the expected scalability of similar extreme classification methods. Experiments show that the implementation is relatively faster to train and test on some large datasets. In some cases, model size is relatively small. Code is here: \url{https://github.com/annonymous24/parallelxml}
Piper Title: An Efficient Distributed Coverage Pattern Mining Algorithm Authors: Preetham Reddy Sathineni, Srinivas A Reddy, Krishna Reddy P and Anirban Mondal Abstract: Mining of coverage patterns from transactional databases is one of the data mining tasks. It has applications in banner advertising, search engine advertising and visibility computation. In general, most real-world transactional databases are typically large. Mining of coverage patterns from large transactional databases such as query log transactions on a single computer is challenging and time-consuming. In this paper, we propose Distributed Coverage Pattern Mining ({\em DCPM}) approach. In this approach, we employ a notion of the summarized form of Inverse Transactional Database (ITD) and replicate it at every node. We also employ an efficient clustering-based method to distribute the computational load of extracting coverage patterns among the worker nodes. We performed extensive experiments using two real-world datasets and one synthetic dataset. The results show that the proposed approach significantly improves the performance over the state-of-the-art approaches in terms of execution time and data shuffled.

29
Details about BDA 2021 Workshops
Workshop 1: Data Challenges in Assessing Air Quality (DACAAQ 2021) Organizers: Anirban Mondal, Girish Agrawal, Jai Ganesh About the Workshop: More than one and a half million deaths occur every year in India as a result of exposure to ambient air pollution - Global Burden of Disease study 2019. This workshop focuses on data challenges in assessing air quality, and marks the initiation of the first academia-industry partnership focused on air quality in India. The workshop is structured around ongoing research efforts in air quality analytics and assessment to develop an easy-to-use platform. Such a platform will be a visual tool to provide real-time, local information about outdoor air quality, along with the measured/estimated values of various air quality parameters, and one which can provide a simple assessment of the health impact of hyperlocal outdoor air quality. The workshop will also bring together researchers and practitioners in urban studies and data analytics who are interested in air quality and related issues of urban morphology and energy demand. About the Program: The DACAAQ 2021 program includes keynote talks by Dr. Sarath Guttikunda, Founder & Director, Urban Emissions (India) and Dr. Anant Maringanti, Executive Director, Hyderabad Urban Lab. It also includes the presentations by Prof. Girish Agrawal, OP Jindal Global University, Dr Anirban Mondal, Ashoka University and a panel discussion ( Panel title: Collaboration across a range of STEM and social sciences disciplines towards air quality improvement).
December 15, 2021 (Wednesday) 09.00-09.15 Welcome and Introduction to Workshop 09.15-10.15 Keynote 1, by Dr. Sarath Guttikunda, Founder/ Director, Urban
Emsissions 10.15-11.00 Theme 1: Paper presentations ×3 11.00-11.15 Break 11.15-12.15 Theme 2: Paper presentations × 3 12.15-13.15 Keynote 2, by Dr. Anant Maringanti, Director, Hyderabad Urban
Labs 13.15-14.15 Lunch Break 14.15-15.45 Panel Discussion 15.45-16.00 Closing Remarks
DR. SARATH GUTTIKUNDA, Founder & Director, Urban Emissions (India): Dr. Sarath Guttikunda is a chemical engineer, atmospheric scientist, TED fellow, and founder of Urban Emissions (India). His main research interest is air quality analysis and finding ways to bridge the gap between science and policy. He is the developer of the SIM-air family of tools used for air pollution knowledge assessments (APnA) city program showcasing emissions, pollution, and source contribution information for 50 airsheds in India. In 2016, Dr. Guttikunda was part of the team that launched the only air quality forecast platform for all of

30
India. He was a member of India's AQI formulation committee (2014) and WHO's air quality guidelines development group (2016-2020). He has a PhD in Chemical Engineering and Environmental Policy from the University of Iowa and a BTech (Hons) from IIT Kharagpur. DR. ANANT MARINGANTI, Executive Director, Hyderabad Urban Lab: Dr. Anant Maringanti is executive director of Hyderabad Urban Lab, a multi-disciplinary research programme. A geographer with a PhD from the University of Minnesota, he has taught graduate and undergraduate courses at the National University of Singapore, University of Hyderabad and the National Academy of Legal Studies and Research, Hyderabad. His research and teaching interests centre on questions of urban innovations, big data, and globalization from the South Asian vantage point. He is widely published in international academic journals on these subjects. As an evolving experiment in urban research, design and pedagogy, Hyderabad Urban Lab collaborates with media professionals, planners, technologists, academic researchers and legal professionals to develop innovative solutions. Institutionally, its mandate is to create safe spaces to explore and develop responses to the challenges of contemporary cities namely mobility, housing and waste.

31
Details about BDA 2021 Workshops
Workshop 2: Data Science for Agriculture and Natural Resource Management (DSANRM2021) with Special Focus on Precision Agriculture Organizers: Srikrishnan Divakaran, Rutvij Jhaveri and Deepak Jaiswal About DSANRM: DSANRM-2021 addresses challenges and issues related to Data Science in Agriculture and Natural Resource Management with special focus on Precision Agriculture. This workshop is in conjunction with Big Data Analytics 2021 and it aims to bring together experts in in Data Science and Agriculture in Academia, Government and Industry to share their expertise and insights with researchers and graduate students about
• Frameworks and Tools for Modelling, Simulation and performing Data Analytics. • Some exciting research opportunities/challenges in the application of Data Science in
Precision Agriculture, in particular problems of ensuring food security while mitigating global climate change and minimizing energy footprints.
• Current trends in Agriculture and Natural Resource Management from an Industry Perspective.
In addition, to keep the workshop relevant and focused, our theme for this workshop will be centered on “Data Analytic Tools and Technologies in Precision Agriculture”. Ahmedabad University, Pandit Deendayal Energy University and Indian Institute of Technology Palakkad are organizing this virtual workshop. For Whom: Researchers, Scientists, Professionals, Academicians, Students (PhD, MS, MTech), Government officials, Industry personnel Topics: Prospective authors are invited to submit research papers that are either their original research work or a survey of the key challenges and research trends in any one of the following areas but not limited to:
• Agricultural Data Model including sensing and reliability in precision agriculture; • Big data analytics, and cloud computing for agriculture • Data science and Data mining techniques for analysis of spatial agriculture data • Data science-based decision support systems for natural resource management • Data science in high performance plant breeding • Data science in Water Resource Management in Precision Agriculture • Innovations in agriculture and sensing devices used in smart precision farming • Precision Agriculture for smart farming solutions • Geo-Big Data platforms and solutions for smart agriculture • Visualization and analytics of agriculture data
Participating Organisations: Ahmedabad University Ahmedabad University is a private, non-profit institution established in 2009. It offers

32
a range of diverse, rigorous academic programs to enable students to grow into well- rounded leaders. Ahmedabad University is dedicated to foster continuous progress of self and society. It aspires to become an exemplar in the transformation of higher education and research in India. The programs include undergraduate, graduate and doctoral studies in areas such as engineering, life sciences, management, arts, and computer science. Pandit Deendayal Energy University Pandit Deendayal Energy University has been promoted by Government, Industry and Energy & Petrochemical Department to create a world class University in energy education and research with special focus on the oil and gas sector. The University addresses the need for trained and specialized human resource in the domains of engineering, management and humanities through a number of specialized and well-planned undergraduate and post-graduate education programs and intensive research initiatives. Indian Institute of Technology Palakkad Established in 2015, the Indian Institute of Technology Palakkad is dedicated to creating an environment that enables students and faculty to engage in the pursuit of knowledge, to dream, think and innovate thereby becoming a change agent for a better world. IIT Palakkad targets to become a multi-disciplinary institution and recognizes collective growth, in collaboration with industry and other academic institutions. IIT Palakkad embraces a vision to be a leader in cross-disciplinary inquiries which is embodied in the tagline of the institute “Nurturing minds for a better world”.
December 15, 2021 (Wednesday) 09.00-09.15 Registration
09.15-09.25 Welcome by Workshop co-chairs 09.30-10.25 Inaugural Address by Prof. Wei Guo,
Institute of Sustainable Agro-ecosystem Services, Graduate School of Agriculture and Life Sciences, The University of Tokyo.
10.30-11.25 Keynote Address by Dr. Anu Swatantran, Corteva Laureate and Principal Investigator, Remote Sensing Data Science
11.30-12.30 Tutorials- I (Introduction to R, Spatial and Temporal Data Analysis with R)
12.35-13.00 Research Paper Presentation-I 13.05-13.30 Research Presentation-II 13.30-14.00 Lunch Break 14.00-14.25 Research Presentation-III 14.30-14.55 Research Presentation-IV 15.00-16.00 Tutorials- II (Simulating impact of climate change on plants using R
package BioCro) 16.00-17.00 Panel Discussion

33
Details about BDA 2021 Tutorials
Title of the tutorial: AIM for IDEA: Adaptive Intent Modeling (AIM) for Interactive Data Exploration and Analysis (IDEA)
Objectives and Scope:
The field of data science integrates various academic disciplines and practice-based perspectives mainly centered on "the collection, organization, storage, extraction/retrieval, interpretation, transformation, and utilization of stored data". The field of data science went through a significant paradigm-shift in recent years, changing focus from a merely data extraction to fetch matching data to enhanced orientation to facilitate a user-centric ‘dataplay’ (data exploration and analysis). The paradigm-shift emerged to design systems as new knowledge based ecologies that place peoples (user/community) and their interactions the different contexts in data play loop. More importantly, embracing user-interactions, situational/social relevance, contextual factors, community engagement, etc delivers interactive data exploration and analysis (IDEA). An adaptive intent model could achieve aimed IDEA objectives, as an instance of intent model replicates the user’s ‘current knowledge state’ and ‘futuristic data needs’.
The tutorial aims to outline the milestones: theoretical background, historical footprints, recent trends and developments, and demonstration of designed prototypes (IntentView, AIDE, and TEAM). The role of big data exploration using visual optimizations, models to capture user-interactions on visual elements and adaptive intent models (AIM) are the key takeaways of demonstrations phase of the tutorial. The two sessions are planned to showcase the several research findings, derived from the recently conducted research work. In this, three prototypes are to be demonstrated for the hands-on experience of the tutorial participants, and further feasibility analysis (in just-in-time).
Tutorial Objectives:
To revisit the paradigms of Data-Information-Knowledge Exploration.
The Fourth Paradigm: To explore different aspects on developing User-Centric Big Data Exploration and Analysis (IDEA), w.r.t. specific domains.
To understand, the modelling challenges and Issues: Role of exploitation-exploration trade-offs, Relevance aspects, and Machine Learning Techniques.
To discuss the contemporary Challenges & Issues: Interactive IR, Modelling Contextual Factors, Social Intelligence, etc.
Case Study on Potential equivalent system: uRank1, Hive2, Citeology3, etc.

34
To outline the proposed Conceptual Framework: Three-Context Theory (Pre-search, In-Search & Pro-search context).
To presents the conceptual schemes of Adaptive Intent Models (AIM) for IDEA.
To demonstration (designed prototypes): IntentView, AIDE, & TEAM. To present the Assessment Framework: User testing, Efficiency & Accuracy, etc. To assert future ahead: to highlight the outcomes for the futuristic research and
development of potential products (system/tool/algorithms).
Topics: Understanding Big Data Exploration, the Fourth Paradigm, Intent Modelling, Human Information/Data Behaviour (HIB), Human Information Interaction (HII), Context Modelling, Modelling & Delivery of Context Modelling for IDEA, Role of Data Visualization for IDEA, Visual Optimizations, Advancements in Bigdata Visual Exploration, Assessment of designed prototypes, Metrics and measures for Intent modelling-based IDEA.
Pedagogy: The developments and progression on theoretical frameworks will be will be shared via systematic study and milestones will be illustrated in graphical view. The case-studies on existing tool/techniques (Urank, BHive, etc.) will be used to trace the limitation inherent limitation of AIM for IDEA. The visual modeling diagrams are used to deliver the conceptual design of the proposed prototypes. The demonstrations is planned to showcase the prototype for IDEA.
Who can participate: Faculty Members, Industry Training Professionals, Research Scholar, etc.
Half Day Tutorial on 'AIM for IDEA’ Adaptive Intent Modeling(AIM) for Interactive Data Exploration and Analysis (IDEA)
Tutorial Schedule
Session 09:00 am-10:30 am 11:00 am-12:30 pm
Focus Area Theoretical Constructs & Background Demonstrations & Future Ahead
Theme
Fundamental notions of Data Exploration Theoretical Frameworks of Big Data
Exploration The Fourth Paradigm and Data
Exploration State-of-Art [systematic view on
Evolutions] o developments in Big Data Exploration o trends of Data Visualization o progression on Co-relating areas Research & Design Challenges/Issues
Conceptual Scheme & Models o ‘Three-Search Context’ Theory o Adaptive Intent Models (AIM) Demos:
IntentView, AIDE, and TEAM Feasibility Analysis & Assessment
framework Future Ahead: Outcomes & Research
Deliverables

35
Institute (page): https://www.nitkkr.ac.in/comp_faculty_details.php?idd=93
Tutorial Presenter Dr. Vikram Singh Assistant Professor Computer Engg Dept., NIT Kurukshetra, India Email: [email protected] Mob no.: 88160 86589

36
Details about BDA 2021 Tutorials
Title of the Tutorial: Big Data Analytics and Explainable AI in Healthcare: Recent Developments and Future Scope Presenter: Mayuri Mehta, PhD (NIT Surat) Professor Department of Computer Engineering, Sarvajanik College of Engineering and Technology, Surat, Gujarat, India. Email: [email protected], [email protected] M: 98255 55602 Brief Biography: Dr. Mayuri is a passionate learner, teacher and researcher. She received doctorate in Computer Engineering from NIT, Surat. Her areas of teaching and research include Data Science, Healthcare Informatics, Machine Learning/Deep Learning, Computer Algorithms and Python Programming. Her 21 years of professional experience includes several academic and research achievements along with administrative and organizational capabilities. She is the author of 30+ research papers and 2 book chapters. She has 3 granted International innovation patents and 2 filed patents in Healthcare. She has co-edited two books: (1) Tracking and Preventing Diseases with Artificial Intelligence and (2) Knowledge Modelling and Big Data Analytics in Healthcare with Springer and CRC Press respectively. Her AI-powered Healthcare project was approved for fund by the Multidisciplinary Research Unit of Surat Municipal Institute of Medical Education and Research (SMIMER). She has also received funds several times from Gujarat Council on Science and Technology (GUJCOST). She has also served in several International Conferences in different positions such as session chair, organizer of special session, member of advisory committee/technical program committee, etc. With the noble intention of applying her technical knowledge for societal impact, she is working on several AI-powered research projects in Healthcare in association with doctors doing private practice and doctors of Medical Colleges & their Local Research Units (LRU). Some of her recent healthcare projects are:
• Prediction of Next Move in Robot Assisted Minimally Invasive Surgery • Explainable Model to Diagnose Cholelithiasis using Ultrasound Images • Explainable Deep Model for Detection and Classification of Leukemia from Whole Slide
Image • A Deep Learning based Model for the Classification of Various Dermatological
Conditions using Whole Slide Imaging • Early Detection of Hypothyroidism in Infants (https://tinyurl.com/ymct535r) • TBUT based Dry Eye Disease Detection using CNN (https://tinyurl.com/fcehc5dm) • An Automated System to Measure Craniofacial Indices for Facial Reconstructive
Surgery (https://tinyurl.com/yb3nh2nj) • https://confengine.com/odsc-india-2020/proposal/14333/how-ai-is-transforming-
healthcare

37
Abstract: AI is seemingly inseparable today. Healthcare using AI is amongst the fastest growing research area across the globe. A massive amount of heterogeneous data generated in healthcare sector offers enormous opportunities for big data analytics using AI models. Such analysis transforms data into real and actionable insights to healthcare practices, thus provide new understanding and ways for better and quicker treatment, and improve overall individual and population health. Recent advancements in AI are proving beneficial in development of applications in various spheres of healthcare such as microbiological analysis, discovery of drug, disease diagnosis, genomics and proteomics, medical imaging and bioinformatics. Due to increasing availability of electronic healthcare data (structured as well as unstructured data) and rapid progress of data analytic techniques, a lot of research is being carried out in this area. Popular AI techniques include machine learning/deep learning for structured data and natural language processing for unstructured data. Guided by relevant clinical questions, automation using AI can unlock clinically relevant information hidden in the massive amount of structured/unstructured data, which in turn can assist clinical decision making. Healthcare offers unique challenges for AI techniques. Particularly, there is a challenge in the black box operation of decisions made by AI models which have resulted in a lack of accountability and trust in the decisions made. Explainable AI (XAI) is one of the answers to this problem to bring humans closer to machines. XAI enhances the trust of medical professionals. In future, XAI might be the pathway for many AI-recommended healthcare treatments to get approved. The first half of this tutorial will include need & significance of AI to process big healthcare data, major application areas of big data analytics & AI in healthcare, and discussion of AI-powered and big data-driven healthcare solutions (use cases). The discussion of each use case will include motivation, precise problem statement, proposed solution, dataset generated consulting doctors, experimental results and challenges faced. Subsequently, functioning of these healthcare solutions will be demonstrated. In second half of the tutorial, I will discuss why explanations are significant in healthcare domain and what is the future of Explainable AI in healthcare. This discussion will be extended with one XAI-powered healthcare application. Finally, challenges and future research opportunities will be discussed. Tutorial topic is emerging and demanding. Discussion on this topic is need of the hour. It connects four contemporary areas of research: Big Data Analytics, AI, XAI and Healthcare. It will help conference to attract a significant number of attendees from more than one sector such as Engineering & Technology, Medical, and Industry. Tutorial will provide attendees a collective update on developments in healthcare using AI & XAI, challenges, opportunities and future research directions. Outline of the Tutorial Duration: Half-day (3 Hrs)
• Significance of Big Data Analytics & AI in Healthcare (10 mins) • Application Areas of Big Data Analytics & AI in Healthcare (20 mins)
**Major application areas such as medical imaging, drug discovery, AI assisted robotic surgery, genetics & genomics, microbiological analysis and treatment design will be discussed
• Big Data-driven, AI-powered Healthcare Solutions (Use Cases) (1 hr)

38
** Discussion of each use case will include problem statement, proposed solution, dataset, results & analysis, and working demonstration of the proposed solution
i. Brain Tumor Detection and Localization using Fusion of MRI and MRSI ii. An Automated Approach to Detect Cholelithiasis using Ultrasound Images
iii. Early Detection of Hypothyroidism in Infants from Facial Images using CNN • Break (10 mins) • Role of Explainability in Creating Trustworthy AI for Healthcare (10 mins) • Explainable AI (XAI) for Healthcare: Methods and Models (25 mins) • Use Case: Explainable Deep Model for Leukemia Detection and Classification from
Whole • Slide Image (15 mins) • Current Challenges & Future Opportunities in Healthcare (20 mins) • Q & A (10 mins)
Target Audience Data Scientists, Machine Learning/Deep Learning Practitioners, Industry Professionals from Healthcare Sector, Researchers, Doctors, Students & Faculty Members from Engineering and Technology as well as Medical. Benefits to Audience After attending this tutorial, the participants will ...
• Get insights on how big data in healthcare and AI techniques can be utilized to automate diagnosis of unexplored or rarely focused diseases.
• understand how big data analytics and AI are useful to make faster, cheaper, and more • accurate disease diagnosis. • Be familiar with some big data-driven, AI-powered healthcare solutions. • Receive conceptual understanding of the role of Explainable AI (XAI) in healthcare and • medicine. • Be able to identify opportunities for big data analytics in healthcare sector. • Be familiar with future of AI in healthcare industry along with its risks and challenges.

39
Details about BDA 2021 Tutorials
PAMI: An Open-Source Library for Finding Pattern Mining in Big Data
PAttern Mining (PAM) is an open-source Python data mining library, specialized in pattern mining, offering implementations of more than 50 pattern mining algorithms. This library contains both traditional and state-of-the-art algorithms to discover different patterns (e.g., frequent patterns, periodic patterns, fuzzy patterns, uncertain patterns, and high utility patterns) in broad range of database types. The key features of this library are as follows: (i) PAMI can be used in other Python programs, (ii) PAMI can be integrated with other machine learning libraries, such as TensorFlow and Scikit, (iii) PAMI also offers a command line interface, and (iv) ease of installation, upgrade, and deletion using PYPI repository, (v) PAMI can be used as a benchmark to evaluate various algorithms, (vi) detailed manual on using PAMI, and (vii) bug tracking. This tutorial will be organized into four parts. We will first introduce existing open-source software’s, their limitations, and the need for developing PAMI. Second, we will introduce the architecture of PAMI, available algorithms, its installation and maintenance, and bug reporting. Third, we will describe different formats of databases (e.g., binary transactional database, binary temporal database, binary spatiotemporal database, non-binary transactional databases, no-binary temporal databases, uncertain transactional databases, and uncertain temporal databases), producers to call to create these databases from the well-known data frames, and how to discover the desired patterns. Fourth, we will discuss and demonstrate how PAMI can be utilized along with machine-learning libraries, such Tensor flow, Scikit, and PyTorch, to different patterns. This part is classified into two sub-parts. (i) In the first sub-part, we will apply machine learning libraries on the textual data to generate predicted data. Next, we use PAMI library to extract patterns from the predicted data. (ii) In the second sub-part, we will apply machine learning libraries on the imagery data to identify the objects and their probabilities in an image. Next, we describe the procedures to convert the generated data into both certain data and uncertain data. Finally, we describe the producers to discover hidden patterns from the generated data using PAMI library. In order to provide deeper understanding for applied researchers, the entire tutorial will be demonstrated using the data generated by real-world applications. Biographical sketch Prof. Rage Uday Kiran ([email protected]) He is working as an associate professor at The University of Aizu. He received his PhD degree in computer science from International Institute of Information Technology, Hyderabad, Telangana, India. His current research interests include data mining, parallel computation, air pollution data analytics, traffic congestion data analytics, recommender systems and ICTs for Agriculture. He has published over 50 papers in refereed journals and international conferences, such as International Conference on Extending Database Technology (EDBT), International Conference on Scientific and Statistical Database Management (SSDBM), The

40
Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Database Systems for Advanced Applications (DASFAA), International Conference on Database and Expert Systems Applications (DEXA), International Journal of Computational Science and Engineering (IJCSE), Journal of Intelligent Information Systems (JIIS), and Journal of Systems and Software (JSS).

41
Details of Panel Discussion
Panel discussion on “AI for Healthcare” : Panel Chairs:
• Rajeev Gupta, Microsoft • Sanjay Kumar Madria, Missouri University of Science and Technology, USA
Panelists:
• Prof. Praveen Rao • Prof. Deva Priyakumar • Dr. Sujoy Kar • Dr. Ashwini Mathur
Brief Biography of Panel Chairs and Panellists: Prof. Rajeev Gupta, Microsoft
Rajeev Gupta is Principal Applied Researcher at Microsoft. Prior to that, he was chief architect at IQLECT software and Senior Researcher at IBM Research. He has worked on various aspects of big data management, machine learning, data mining, distributed information extraction, processing and analytics, and distributed continuous query processing. Rajeev holds a B.Tech. from IIT-Kharagpur, M. Tech. from IIT-Delhi, and a Ph.D. (computer science) from IIT-Bombay. He is having specialties in the area of: Machine learning, Data management, Continuous query
processing over dynamic data, Analytics. Prof. Sanjay Kumar Madria, Missouri University of Science and Technology, USA
Sanjay K Madria is a Curators Distinguished Professor in the Department of Computer Science at the Missouri University of Science and Technology (formerly, University of Missouri-Rolla, USA. He has published over 285 Journal and conference papers in the areas of mobile and sensor computing, cloud and cybersecurity. He won five IEEE best paper awards from IEEE sponsored conferences. He has co-authored two books based on his research work, more recently being on Secure Sensor Cloud published by Morgan and Claypool. He has
served/serving in International conferences as a general co-chair, pc co-chair, and steering committee members, and presented several keynotes/invited at several venues. NSF, NIST, ARL, ARO, AFRL, DOE, Boeing, ORNL, Honeywell, and others have funded his research projects worth over $10M. He has been awarded JSPS (Japanese Society for Promotion of Science) invitational visiting eminent scientist fellowship and ASEE (American Society of Engineering Education) fellowship. In 2012 and 2018, he was awarded NRC Fellowship by National

42
Academies, US. He is ACM Distinguished Scientist, and served/serving as an ACM and IEEE Distinguished Speaker, and is an IEEE Senior Member as well as IEEE Golden Core Awardee. Prof. Praveen Rao, Associate Professor of Health Management & Informatics, Associate Professor of Electrical Engineering & Computer Science
Dr. Rao's research interests are in the areas of big data, data science, health informatics, and cybersecurity. Specifically, he focuses on developing scalable algorithms and software systems to extract meaningful insights from massive, diverse datasets. His research, teaching, and outreach activities have been supported by the National Science Foundation (NSF), Air Force Research Lab (AFRL), the University of Missouri System, University of Missouri Research Board, and companies. He is a Co-PI for the NSF IUCRC Center for Big Learning.
Prof. Deva Priyakumar, Professor, Ph.D (Pondicherry University)
Deva Priyakumar finished his PhD from Pondicherry University/Indian Institute of Chemical Technology in the area of computational chemistry. After a postdoctoral fellowship in the University of Maryland Baltimore in the area of biomolecular simulations and computer aided drug design, he joined as a faculty member in IIIT Hyderabad in 2008. He is currently an Associate Professor in CCNSB, IIIT Hyderabad and his research interests are in the application of molecular dynamics simulations, ab initio calculations and machine learning methods to
study chemical and biological processes. Some of the recognitions include the INSA young scientist medal, Innovative young biotechnologist award, JSPS visiting fellowship, and distinguished lectureship award of the Chemical Society of Japan. His research areas are: Computational chemistry to study chemical molecules and reaction mechanisms, biomolecular simulations to investigate DNA, RNA, proteins and protein interactions and computer aided drug design. Dr. Sujoy Kar, Vice-President and Chief Medical Information Officer, Apollo Hospitals
Dr Sujoy Kar is the Chief Medical Information Officer and the Vice-President of Apollo Hospitals, previously Medical Director of Apollo Gleneagles Hospitals, Kolkata. He is a Clinical Microbiologist by background with subsequent post graduations from Indian Statistical Institute and MIT Sloan School. He is an Adjunct Faculty for Healthcare Analytics and Management at IIM Calcutta and IIT Kharagpur. His current and ongoing research interests are in the development and
adoption of Artificial Intelligence in Healthcare and Digital Health Platforms

43
Dr. Ashwini Mathur, Head Clinical Technology and Innovation; Regional Head Ireland / UK GDD Hub
Dr. Ashwini Mathur have close to 25 years of experience in the area of clinical research. He taught for 4 years as an Adjunct Professor at Department of Radiology at University of California, San Francisco while doing work on Osteoporosis clinical trials. After that he has close to 20 years’ experience working in the pharmaceutical industry. He has more than 17 years in a management role and have built large teams supporting data science and analytics, clinical trial operations, statistics, statistical programming using SAS and R, data management,
data base programming and medical writing. He has worked for GSK in Philadelphia and Bangalore, for Novartis in Mumbai and Hyderabad. Currently He is based on Dublin working for Novartis Ireland. His specialties are in the area of: Data Science, Analytics, Statistical Design, Analyses and Reporting of Clinical trials, Clinical Trial Operations, Clinical Data Review.




















