Uji normalitas dan homogenitas
29
UJI NORMALITAS DAN HOMOGENITAS Nama Kelompok : Desty Rupalestari Arini Rizki Anita Uswati Khoiriah
-
Upload
desty-rupalestari -
Category
Education
-
view
594 -
download
8
Transcript of Uji normalitas dan homogenitas

UJI NORMALITAS DAN HOMOGENITAS
Nama Kelompok :Desty
RupalestariArini Rizki AnitaUswati Khoiriah

UJI NORMALITAS Uji normalitas berguna untuk menentukan data yang telah dikumpulkan berdistribusi normal atau diambil dari populasi normal. Metode klasik dalam pengujian normalitas suatu data tidak begitu rumit
Macam-macam metode : - Chi-Square - Kolmogorov Smirnov - Lilliefors - Shapiro Wilk.

A. CHI SQUARE (UJI GOODNESS OF FIT DISTRIBUSI NORMAL)
Keterangan :X2 = Nilai X2Ei = Nilai expected / harapan, luasan interval kelas berdasarkan tabel normal dikalikan N (total frekuensi) (pi x N)N = Banyaknya angka pada data (total frekuensi)
Metode Chi-Square atau X2 untuk Uji Goodness of fit Distribusi Normal menggunakan pendekatan penjumlahan penyimpangan data observasi tiap kelas dengan nilai yang diharapkan

Persyaratan Metode Chi Square (Uji Goodness of fit Distribusi Normal)a. Data tersusun berkelompok atau dikelompokkan dalam tabel distribus frekuensi.b. Cocok untuk data dengan banyaknya angka besar ( n> 30 )c. Setiap sel harus terisi, yang kurang dari 5 digabungkan.
Signifikansi:Signifikansi uji, nilai X2 hitung dibandingkan dengan X2 tabel (Chi-Square).Jika nilai X2 hitung < nilai X2 tabel, maka Ho diterima ; Ha ditolak.Jika nilai X2 hitung > nilai X2 tabel, maka maka Ho ditolak ; Ha diterima.

CONTOH :
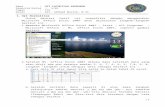
Diketahui data skor 32 siswa dalam menyelesaikan soal-soal matematika pada try out di suatu bimbingan belajar.
Ujilah normalitas dari data tersebut!
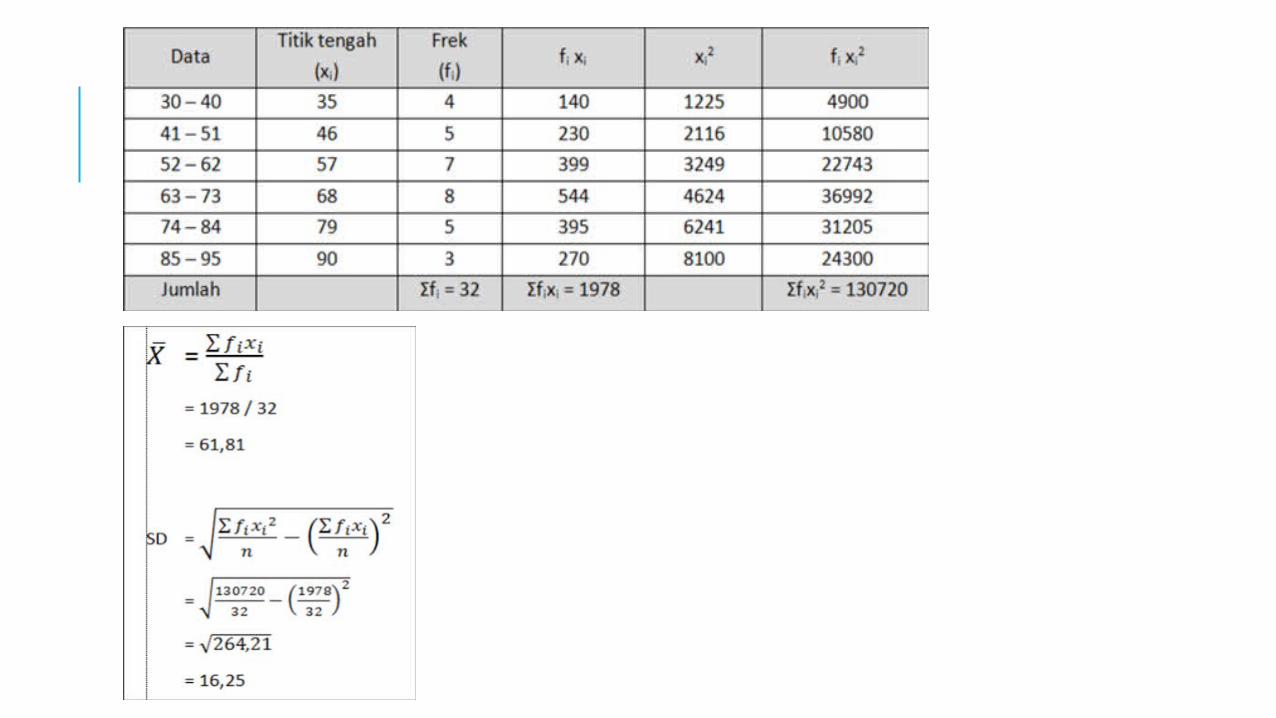

Xi = Batas tidak nyata interval kelasZ = Transformasi dari angka batas interval kelas ke notasi pada distribusi normalpi = Luas proporsi kurva normal tiap interval kelas berdasar tabel normalOi = Nilai observasiEi = Nilai expected / harapan, luasan interval kelas berdasarkan tabel normal dikalikan N (total frekuensi) (pi x N)
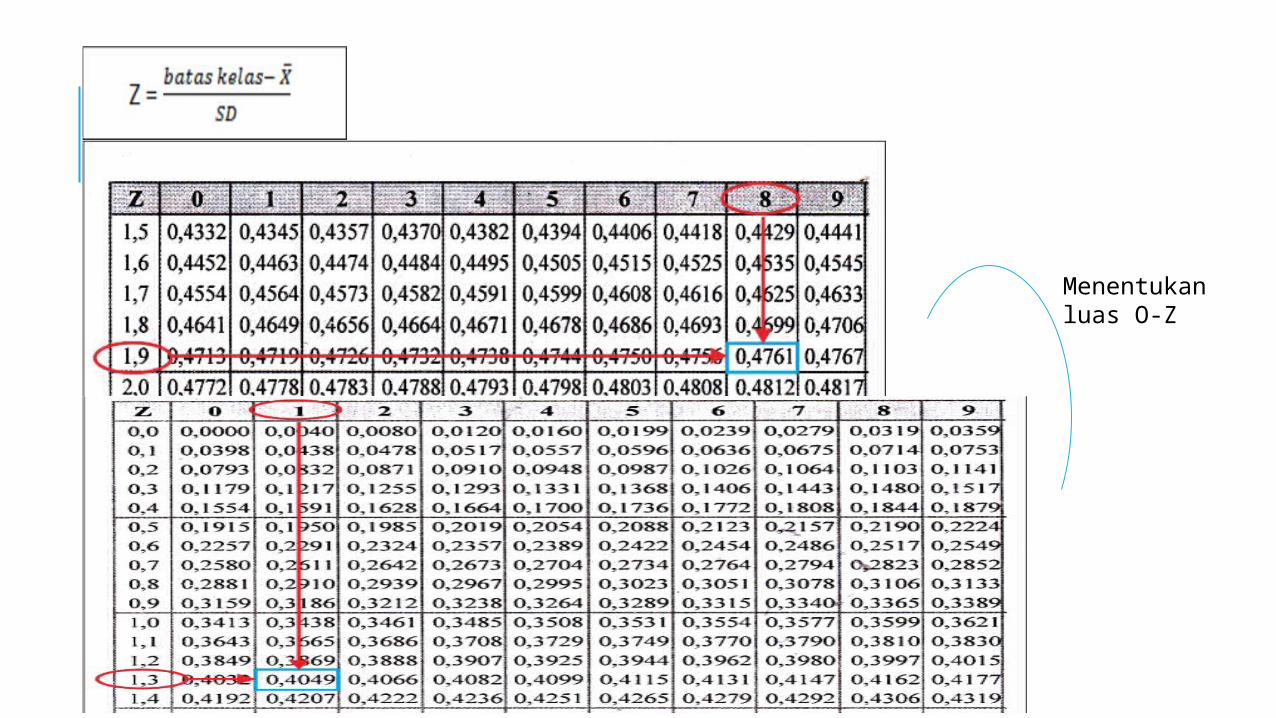
Menentukan luas O-Z

Menentukan taraf nyata :

Karena Ho diterima. Artinya, data skor siswa dalam menyelesaikan soal-soal try out matematika di suatu bimbingan belajar berdistribusi normal.

B. METODE LILLIEFORS (N KECIL DAN N BESAR) Metode Lilliefors menggunakan data dasar yang belum diolah dalam tabel distribusi frekuensi. Data ditransformasikan dalam nilai Z untuk dapat dihitung luasan kurva normal sebagai probabilitas komulatif normal. Probabilitas tersebut dicari bedanya dengan probabilitas kumulatif empiris. Beda terbesar dibanding dengan tabel Lilliefors.

PERSYARATAN a. Data berskala interval atau ratio (kuantitatif) b. Data tunggal / belum dikelompokkan pada tabel distribusi frekuensi c. Dapat untuk n besar maupun n kecil. SIGNIFIKANSI Signifikansi uji, nilai | F (x) - S (x) | terbesar dibandingkan dengan nilai tabel Lilliefors. Jika nilai | F (x) - S (x) | terbesar < nilai tabel Lilliefors, maka Ho diterima ; Ha ditolak. Jika nilai | F(x) - S(x) | terbesar > dari nilai tabel Lilliefors, maka Ho ditolak ; Ha diterima.

Contoh : Berdasarkan data ujian statistik dari 18 mahasiswa didapatkan data sebagai berikut ; 46, 57, 52, 63, 70, 48, 52, 52, 54, 46, 65, 45, 68, 71, 69, 61, 65, 68. Selidikilah dengan α = 5%, apakah data tersebut di atas diambil dari populasi yang berdistribusi normal ?
Penyelesaian : Hipotesis Ho : Populasi nilai ujian statistik berdistribusi normal
H1 : Populasi nilai ujian statistik tidak berdistribusi normal
Nilai α Nilai α = level signifikansi = 5% = 0,05 Statistik Penguji

Nilai | F(x) - S(x) | tertinggi sebagai angka penguji normalitas, yaitu 0,1469. Derajat Bebas Df tidak diperlukan Nilai tabel Nilai Kuantil Penguji Lilliefors, α = 0,05 ; N = 18 yaitu 0,2000. Tabel Lilliefors pada lampiran
Daerah penolakan Menggunakan rumus | 0,1469 | < | 0,2000| ; berarti Ho diterima, Ha ditolak Kesimpulan: Populasi nilai ujian statistik berdistribusi normal.

C. KOLMOGOROV SMIRNOFMetode Kolmogorov-Smirnov tidak jauh beda dengan metode Lilliefors.Langkah-langkah penyelesaian dan penggunaan rumus sama, namun pada signifikansi yang berbeda. Signifikansi metode Kolmogorov-Smirnov menggunakan tabel pembanding Kolmogorov-Smirnov, sedangkan metode Lilliefors menggunakan tabel pembanding metode Lilliefors.Keterangan :
Xi = Angka pada dataZ = Transformasi dari angka ke notasi pada distribusi normalFT = Probabilitas komulatif normalFS = Probabilitas komulatif empiris

PERSYARATAN a. Data berskala interval atau ratio (kuantitatif) b. Data tunggal / belum dikelompokkan pada tabel distribusi frekuensi c. Dapat untuk n besar maupun n kecil. SIGINIFIKANSI Signifikansi uji, nilai |FT – FS| terbesar dibandingkan dengan nilai tabel Kolmogorov Smirnov. Jika nilai |FT – FS| terbesar <nilai tabel Kolmogorov Smirnov, maka Ho diterima ; Ha ditolak. Jika nilai |FT – FS| terbesar > nilai tabel Kolmogorov Smirnov, maka Ho ditolak ; Ha diterima.

Contoh :Suatu penelitian tentang berat badan mahasiswa yang mengijkuti pelatihan kebugaran fisik/jasmani dengan sampel sebanyak 27 orang diambil secara random, didapatkan data sebagai berikut ; 78, 78, 95, 90, 78, 80, 82, 77, 72, 84, 68, 67, 87, 78, 77, 88, 97, 89, 97, 98, 70, 72, 70, 69, 67, 90, 97 kg. Selidikilah dengan α = 5%, apakah data tersebut di atas diambil dari populasi yang berdistribusi normal ?
Penyelesaian :•Hipotesis•Ho : Populasi berat badan mahasiswa berdistribusi normal•H1 : Populasi berat badan mahasiswa tidak berdistribusi normal•Nilai αNilai α = level signifikansi = 5% = 0,05•Statistik Penguji

Derajat bebas Df tidak diperlukan Nilai tabel Nilai Kuantil Penguji Kolmogorov, α = 0,05 ; N = 27 ; yaitu 0,254. Tabel Kolmogorov Smirnov.
Daerah penolakan Menggunakan rumus: | 0,1440 | < | 0,2540| ; berarti Ho diterima, Ha ditolak
Kesimpulan Populasi tinggi badan mahasiswa berdistribusi normal α = 0,05.

D. SAPHIRO WILKMetode Shapiro Wilk menggunakan data dasar yang belum diolah dalam tabel distribusi frekuensi. Data diurut, kemudian dibagi dalam dua kelompok untuk dikonversi dalam Shapiro Wilk. Dapat juga dilanjutkan transformasi dalam nilai Z untuk dapat dihitung luasan kurva normal.
Keterangan :D = Berdasarkan rumus di bawaha = Koefisient test Shapiro WilkX n-i+1 = Angka ke n – i + 1 pada dataX i = Angka ke i pada data

Keterangan :Xi = Angka ke i pada data yangX = Rata-rata data
Keterangan :G = Identik dengan nilai Z distribusi normalT3 = Berdasarkan rumus di atas bn, cn, dn = Konversi Statistik Shapiro-Wilk Pendekatan Distribusi Normal

PERSYARATAN a. Data berskala interval atau ratio (kuantitatif) b. Data tunggal / belum dikelompokkan pada tabel distribusi frekuensi c. Data dari sampel random
SIGNIFIKANSI Signifikansi dibandingkan dengan tabel Shapiro Wilk. Signifikansi uji nilai T3 dibandingkan dengan nilai tabel Shapiro Wilk, untuk dilihat posisi nilai probabilitasnya (p). Jika nilai p > 5%, maka Ho diterima ; Ha ditolak. Jika nilai p < 5%, maka Ho ditolak ; Ha diterima.
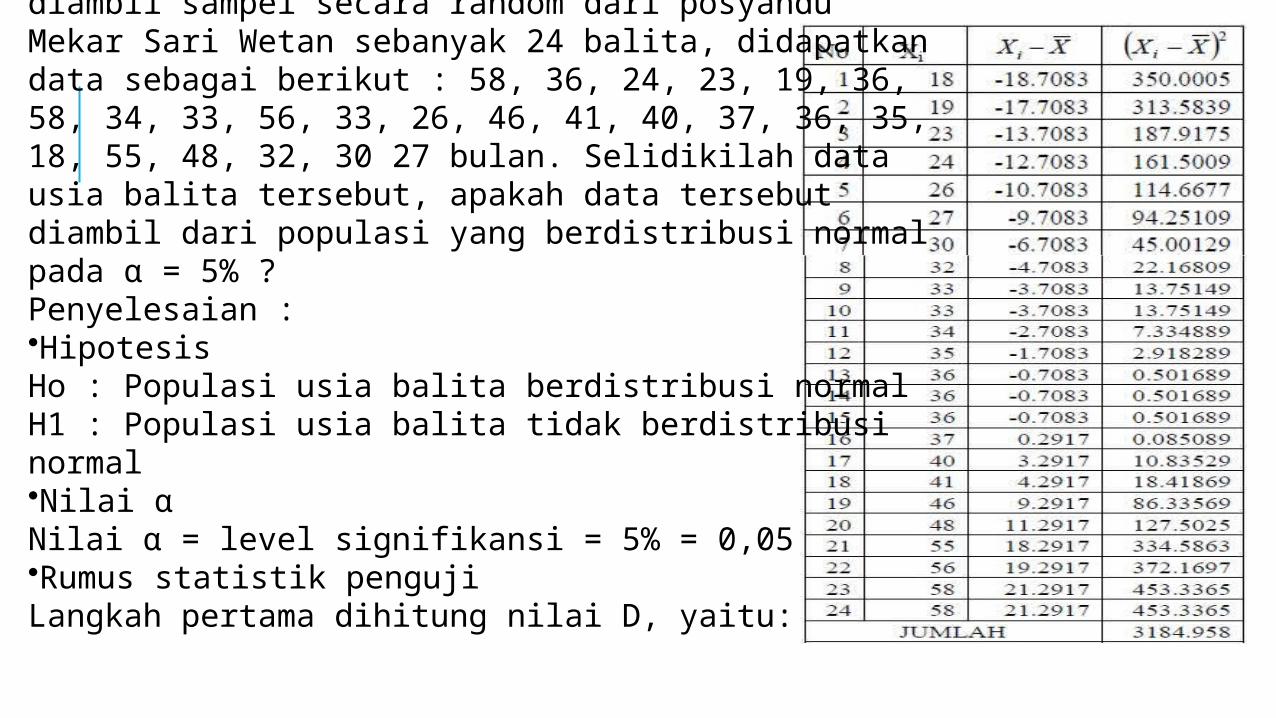
Contoh :Berdasarkan data usia sebagian balita yang diambil sampel secara random dari posyandu Mekar Sari Wetan sebanyak 24 balita, didapatkan data sebagai berikut : 58, 36, 24, 23, 19, 36, 58, 34, 33, 56, 33, 26, 46, 41, 40, 37, 36, 35, 18, 55, 48, 32, 30 27 bulan. Selidikilah data usia balita tersebut, apakah data tersebut diambil dari populasi yang berdistribusi normal pada α = 5% ?Penyelesaian :•HipotesisHo : Populasi usia balita berdistribusi normalH1 : Populasi usia balita tidak berdistribusi normal•Nilai αNilai α = level signifikansi = 5% = 0,05•Rumus statistik pengujiLangkah pertama dihitung nilai D, yaitu:

Langkah berikutnya hitung nilai T, yaitu:•Derajat bebasDb = n•Nilai tabelPada tabel Saphiro Wilk dapat dilihat, nilai α (0,10) = 0,930 ; nilai α (0,50) = 0,963•Daerah penolakanNilai T3 terletak diantara 0,930 dan 0,963, atau nilai p hitung terletak diantara 0,10 dan 0,50, yang diatas nilai α (0,05) berarti Ho diterima, Ha ditolak•KesimpulanSampel diambil dari populasi normal, pada α = 0,05. Cara lain setelah nilai T3 diketahui dapat menggunakan rumus G, yaitu :

Hasil nilai G merupakan nilai Z pada distribusi normal, yang selanjutnya dicari nilai proporsi (p) luasan pada tabel distribusi normal (lampiran). Berdasarkan nilai G = -1,2617, maka nilai proporsi luasan = 0,1038. Nilai p tersebut di atas nilai α = 0,05 berarti Ho diterima Ha ditolak. Data benar-benar diambil dari populasi yang berdistribusi normal.

HOMOGENITAS Uji homogenitas adalah pengujian mengenai sama tidaknya variansi variansi dua distribusi atau lebih.

LANGKAH LANGKAH MENGUJI HOMOGENITAS (UJI F) Mencari varians ( standar deviasi ) variabel x dan y
)1()( 22
2
nn
XXnSx
)1()( 22
2
nn
YYnSY

Mencari F hitung dari varians X dan Y
Membandingkan dan pada tabel distribusi FUntuk varians terbesar adalah dk pembilang n-1Untuk varians terkecil adalah dk penyebut n-1Jika < berarti kedua varians homogenJika > berarti kedua varians tidak homogen
kecil
besar
SSF
hitungF tabelF
hitungF tabelF

UJI BARTLETT uji Bartlett digunakan untuk menguji homogenitas varians lebih dari dua kelompok data
ln 10= 2,3026 varians data untuk setiap kelompok ke-idk = derajat kebebasanHipotesis pengujian
Ha : paling sedikit salah satu tanda tidak sama
}log)1(){10(ln 22isnBX
2log)( sdkB2
iS
223
22
21 ...: nHo

Jika maka Ho ditolak Jika maka Ho diterima dimana didapatkan dari tabel distribusi chi-kuadrat dengan peluang dan dk=k-1
2)1)(1(
2 kXX
2)1)(1(
2 kXX
2)1)(1( kX
)1(