PENGGUNAAN SPSS
26
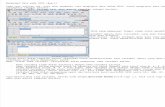
SPSS SPSS SPSS (Statistical Package for the Social Science) pada awalnya merupakan program komputer statistik untuk ilmu-ilmu sosial- dibuat pertama kali oleh tiga mahasiswa Stanford University yaitu Norman H. Nie; C Hadlai Hull dan Dale H Bent pada tahun 1968- yang dijalankan dengan komputer mainframe. Pada tahun 1984 versi PC SPSS muncul dengan nama SPSS/PC+ dan pada tahun 1992 mengeluarkan SPSS versi Windows. Seiring dengan perkembangan pelayanan jenis user –untuk proses produksi, riset ilmu sains dan lainnya- SPSS telah berkembang tidak hanya Statistical Package for the Social Science tetapi telah menjadi Statistical Product and Service Solution. SPSS versi 12 (2004) untuk statistik berisi : □ Descriptive Statistics: Crosstabulations, Frequencies, Descriptives, Explore, Descriptive Ration statistics □ Bivariate Statistics: Means, t-test, ANOVA, Correlation - bivariate, partial, dan distance- non- parametric test □ Prediction for numerical outcomes: linear regression □ Prediction for indentifying group: factor analysis, two-step cluster analysis; K-mean cluster analysis, hierarchical cluster analysis, discriminat Semua proses perhitungan denga menggunakan SPSS mengikuti alur ditunjukkan Bagan 1. Data yang akan digunakan untuk perhitungan dimasukkan (inputing) melalui menu DATA EDITOR yang secara otomotis muncul di layar monitor sesaat program SPSS dijalankan. Setelah data dimasukkan, proses pengolahan data juga melalui DATA EDITOR dan hasilnya ditampilkan dalam layar VIEWER. Hasil perhitungan tersebut dapat berupa teks, tabel maupun grafik. Bagan 1. Proses Perhitungan SPSS 1. MEMPERSIAPKAN DATA Statistik merupakan ilmu yang berkaitan dengan kegiatan pengoleksian, pengorganisasian, presentasi, analisis, dan interpretasi data numerik (kuantitatif) untuk membantu pembuatan keputusan lebih efektif (Douglas 2005). Pada hakekatnya, statistik dibagi menjadi dua yaitu: statistik PROSES DENGAN DATA EDITOR Input Data: Data Editor Output Data: Viewer Raw data Info rmas i 1
-
Upload
dhe-moelyana-asy-syabani-nobilis -
Category
Documents
-
view
263 -
download
4
description
sss
Transcript of PENGGUNAAN SPSS
PENGGUNAAN SPSS:
SPSS
SPSS SPSS (Statistical Package for the Social Science) pada awalnya merupakan program komputer statistik untuk ilmu-ilmu sosial- dibuat pertama kali oleh tiga mahasiswa Stanford University yaitu Norman H. Nie; C Hadlai Hull dan Dale H Bent pada tahun 1968- yang dijalankan dengan komputer mainframe. Pada tahun 1984 versi PC SPSS muncul dengan nama SPSS/PC+ dan pada tahun 1992 mengeluarkan SPSS versi Windows. Seiring dengan perkembangan pelayanan jenis user untuk proses produksi, riset ilmu sains dan lainnya- SPSS telah berkembang tidak hanya Statistical Package for the Social Science tetapi telah menjadi Statistical Product and Service Solution.SPSS versi 12 (2004) untuk statistik berisi :
Descriptive Statistics: Crosstabulations, Frequencies, Descriptives, Explore, Descriptive Ration statistics Bivariate Statistics: Means, t-test, ANOVA, Correlation - bivariate, partial, dan distance- non-parametric test Prediction for numerical outcomes: linear regression Prediction for indentifying group: factor analysis, two-step cluster analysis; K-mean cluster analysis, hierarchical cluster analysis, discriminatSemua proses perhitungan denga menggunakan SPSS mengikuti alur ditunjukkan Bagan 1. Data yang akan digunakan untuk perhitungan dimasukkan (inputing) melalui menu DATA EDITOR yang secara otomotis muncul di layar monitor sesaat program SPSS dijalankan. Setelah data dimasukkan, proses pengolahan data juga melalui DATA EDITOR dan hasilnya ditampilkan dalam layar VIEWER. Hasil perhitungan tersebut dapat berupa teks, tabel maupun grafik.
Bagan 1. Proses Perhitungan SPSS1. MEMPERSIAPKAN DATA
Statistik merupakan ilmu yang berkaitan dengan kegiatan pengoleksian, pengorganisasian, presentasi, analisis, dan interpretasi data numerik (kuantitatif) untuk membantu pembuatan keputusan lebih efektif (Douglas 2005). Pada hakekatnya, statistik dibagi menjadi dua yaitu: statistik deskriptif dan statistik inferensi. Statistik deskriptif adalah statistik yang berkiatan dengan metode mengorganisasikan, perangkuman dan presentasi data ke dalam suatu bentuk yang informatif. Sedangkan inferensi terkait dengan kegitan pembuatan keputusan, estimasi, prediksi atau generalisasi tentang populasi berdasarkan perhitungan sampel. Data harus dipersiapkan terlebih dahulu mengenai format, jenis dan aturan-aturan tertentu. Variabel adalah sesuatu yang nilainya dapat bervariasi. Variabel dibedakan menjadi dua yaitu variabel kuantitatif dan variabel kualitatif. Contoh variabel kuantitatif adalah suku bunga, pendapatan, penjualan dan lain-lain. Contoh variabel kualitatif adalah agama, warna kulit, asal kelahiran. Kadang-kadang kita sering bisa mengkuantifikasikan variabel kualitatif. Statistik terkait dengan variabel kuantitatif. Variabel kuantitatif dibagi menjadi dua macam yaitu diskrit (menunjuk angka tertentu) dan kontinyu (menunjuk rentang yang jumlah angkanya tak terhingga). Terdapat 4 tingkatan data, yaitu:
Nominal: data diklasifikasikan ke dalam kategori dan tidak dapat disusu dalam urutan tertentu. Sebagai contoh: varibel jenis kelamin: pria=1; wanita=2. Pemberian nilai tersebut terserah individu.
Ordinal: data disusun ke dalam urutan tetapi perbedaan nilai data tidak dapat ditentukan atau tidak memiliki arti. Contoh pembuatan ranking untuk minuman soft drink yang disukai.
Interval: data disusun dalam interval tertentu dan tidak terdapat nilai nol
Rasio
Bagan 2. Macam DataBeberapa hal yang perlu diperhatikan ketika kita akan memasukan data (inputing):
- Struktur Data: - baris/case
- kolom/heading/variabel: numeric, comma, dot, scientific, notation, date, dollar, custom currency, string
- Format data: - fixed (tertentu)
- freefield (bebas)
- Missing Value = data yang hilang atau tidak lengkap
2. MEMULAI SPSS
Untuk memulai program SPSS: icon SPSS
Bagan 3. Memulai SPSS
Buka Windows
1. Klik grup icon SPSS
2. Klik SPSSmuncul logo SPSS, kemudian hilang dan muncul: Output Windows dan SPSS Editor yang siap dioperasikan. Istilah: Penunjuk Sel, Nomor Case, Edit Line, Heading Kolom, Sel.
SPSS menyediakan beberapa Windows:
- Data Editor. Window ini terbuka secara otomatis ketika program SPSS dijalankan dan berfungsi untuk input data ke SPSS.
Membersihkan data editor: klik File, New, Data
Membuka File (ekstensi .sav): klik File, Open, Data
- Viewer. Window ini merupakan media tampilan proses yang dilakukan SPSS. Dapat disimpan melalui perintah Save SPSS Output (ekstensi .lst). Untuk membuka file output: klik File, Open, SPSS output
-Syntax Editor. untuk menuliskan susunan perintah/program--teks editor
Dapat disimpan lewat perintah Save SPSS Syntax pada menu file. Untuk membuka file syntax (ekstensi .sps): klik File, Open, Syntax
-Script Editor: digunakan untuk melakukan berbagai pengerjaan SPSS secara otomatis, seperti membuka dan menutup file, mengekspor grafik menyesuaikan bentuk output.
Bagan 5. Window SPSS
3. MENANGANI FILE DATA
Buka SPSS: clik icon SPSS, maka akan ditampilkan di monitor sebagai berikut:
Bagan 6. Data Editor
masukkan data pada kolom pertama. Untuk memberikan nama Nilai tekan Variable View yang ada di kiri bawah kemudian ketikkan nilai pada Name. Variable View ini digunakan untuk mengedit semua yang berkaitan dengan variabel. Kemudian masukkan data berikut ini:
NamaSexProgramStatMKPKManajWesel
susi WanitaMSi658080250
susan WanitaMEP709898450
memed laki-lakiMSi9089100150
bambang laki-lakiMEP658740200
duri WanitaMM7878103340
nurul WanitaMSi987897500
ali laki-lakiMEP767689400
nika WanitaMSi909790230
gogon laki-lakiMM879170590
bolot laki-lakiMM6998120430
handi WanitaMSi787549120
unik WanitaMEP987859210
kali laki-lakiMSi6765200340
budi laki-lakiMEP897684560
santoso laki-lakiMM976056430
bukoli WanitaMEP6769179700
boy laki-lakiMM807878230
sici WanitaMSi8987180450
kutut laki-lakiMM656859650
kile WanitaMSi679868230
Dapat memberikan nama variabel dan format (type, label, missing value dan format kolom). Type untuk menentukan type variabel, jumlah angka dibelakang koma, lebar variabel. Labels untuk menentukan label variabel dan harga dari label tersebut. Missing Value untuk mementukan harga-harga dari suatu variabel yang akan dideklarasikan sebagai missing value. Format Kolom untuk menentukan jenis perataannya.
Bagan 7. Jenis Data
KETRAMPILAN DASAR:
FILE
- Membuka file yang sudah ada: File/Open- Menyimpan data: File/Save; File/Save As- Mencetak data: File/Print
- Keluar dari SPSS: File/Exit
DATA
- Menghapus data:
- Mencopy data
- Menyisipkan data
- Mengurutkan data
- Seleksi kasus
- Menyimpan File Data:
>klik File, Save Data
>Beri Nama: pada kotak dialog Newdata:Save Data As ......sav
>Enter
-Menyunting Data:
Menghapus isi sel: >Klik sel, tekan Delete
Menghapus isi sel satu kolom (Variable): >Klik heading kolom , tekan Delete
Menghapus satu baris(case): >Klik baris, tekan Delete-Mengkopi Data
Mengkopi isi sel:>pilih sel, Ctrl-C, arahkan sel, Ctrl-V
Mengkopi satu kolom:>pilih Heading kolom, Ctrl-C, arahkan heading, Ctrl-V
Mengkopi baris (case):>pilih case,Ctrl-C, arahkan baris, Ctrl-V
- Menyisipkan Data:
Menyisipkan kolom:>pilih kolom yang akan disisipi, klik Data, Insert Variable
Menyisipkan baris:> pilih baris yang akan disisipi, klik Data, Insert Case
-Tranpose Data: yaitu merubah baris menjadi kolom dan kolom menjadi baris. Maka menghasilkan data baru:
>buka file
>klik Data, Transpose >pindahkan satu atau beberapa variabel >Enter
-Pengurutan
>Data, Sort Cases >pindahkan variabel ke kotak, pilih ascending atau descending
- Agregate: untuk mengkombinasikan grup-grup dari case-case ke dalam case-case summari tunggal
- Split File: untuk memecah split file data ke dalam subgrup-subgrup sehingga nantinya dalam analisis maupun dalam pembuatan chart didasarkan pada tiap-tiap subgrup tersebut (analisis terpisah)
- Seleksi Case: untuk memilih, menentukan case yang akan diikutsertakan dalam analisis selanjutnya
- Pembobotan: untuk memberikan pembobotan yang berbeda pada case-case tertentu.
4. TRANSFORMASI DATA- Transformasi data
- hitung (compute)
- runtun waktu- COMPUTE - untuk melakukan perhitungan terhadap value yang sudah ada. Kita dapat membuat variabel baru berdasarkan atas variabel yang sudah ada.
- COUNT - untuk menghitung jumlah cacah value dari seluruh variabel yang didaftar yang memenuhi syarat value yang telah didefinisikan, pada tiap-tiap case.
- RECODE dan AUTOMATIC RECODE untuk memodifikasi atau mengganti value-value dari variabel-variabelyang didaftar menjadi value-value dengan harga baru.
- RANK CASES - untuk menyusun ranking, score normal, score rangking yang sejenis untuk semua case dari variabel numerik yang didaftar
- CREATE TIMES SERIES - untuk membuat varibel time series.
- REPLACE MISSING VALUE - untuk menghasilkan variabel baru berdasarkan variabel asal yang mengandung missing value, dimana value valid dari variabel asal akan dicopykan ke variabel baru, sedangkan value yang berharga missing diganti dengan harga rata-rata dari value valid atau diganti dengan salah satu dari beberapa fungsi time series.
5. FASILITAS STATISTIK
Semua fasilitas statistik diberikan pada menu AnalyzeStatistik:
- deskriptif
- induktif/inferensi:
* parametrik
* non parametrikDESCRIPTIVE STATISTICS
- FREQUENCIES - untuk membuat tabel frekuensi, yaitu berisikan cacah harga semua case dari variabel-variabel yang didaftar, cacah persentase terhadap semua case, cacah persentase valid (tanpa nilai missing), dan persentase kumulatif.
- DESCRIPTIVES - digunakan untuk menampilkan deskripsi stastik univariat dari variabel numerik yang didaftar.
- CROSSTABS - untuk menampilkan tabulasi silang (tabel kontingensi) yang menunjukan distribusi bersama, deskripsi bivariatnya dan berbagai pengujian dari 2 variabel atau lebih, khususnya variabel berbentuk katagori.
COMPARE MEANS
Perintah ini digunakan untuk membandingkan rata-rata dari dua populasi atau lebih
- MEANS - untuk menampilkan statisik mean, standar deviasi, count (cacah) dan statistik-statistik lainnya pada suatu variabel numerik yang case-casenya dibagi-bagi dalam grup-grup dengan mengelompokan berdasar case-case variabel lain.
- INDEPENDENT - SAMPLES T TEST - digunakan untuk menguji apakah dua sampel yang tidak bertalian (independen) berasal dari populasi yang mempunyai Mean (ekspektasi) yang sama.
- PAIRED -SAMPLE T TEST digunakan untuk menguji apakah dua sampel yang bertalian (dependen) atau sampel berpasangan berasal dari populasi yang mempunyai Mean yang sama (ekspektasi) yang sama
-ONE-WAY ANOVA (analysis of Variance) adalah alat statistik yang digunakan untuk menguji dua populasi atau lebih apakah mempunyai rata-rata yang bisa dianggap sama atau tidak.
Contoh:
1. MEANS - digunakan untuk menampilkan statistik Mean, Standar Deviasi, Count (cacah), dan statistik-statistik lainnya pada suatu variabel numerik yang case-casenya dibagi-bagi dalam grup dengan pengelompokan case-case variabel lain.
Dependent list - untuk variabel yang akan dianalisis statistiknya (variabel summari)
Independent list - untuk variabel-variabel dasar pengelompokan (variabel grup)
contoh:
statistics / compare means / means / dep.list:stat / indep.list: sex / OK
Options - untuk menampilkan statistik yang akan ditampilkan: mean, standar deviasi, varians, count, sum, tabel ANOVA & Eta, test of linierity.
2. INDEPENDENT-SAMPLES T TEST - digunakan untuk menguji apakah dua sampel yang tidak bertalian (independen) berasal dari populasi yang mempunyai Mean (ekspektasi) yang sama.
Test variabel(s) - untuk mendaftar satu atau beberapa variabel numerik yang akan diuji
Grouping Variable - untuk mendaftar variabel yang dijadikan variabel grup.
contoh:
statistics/compare means/indnt sample T test/dep.list:stat/indep.list:sex/ OK
Define groups - untuk mengelompokan variabel grup menjadi 2 kelompok independen .
Options - untuk menentukan besarnya interval confidency (selang kepercayaan), mengontrol keberadaan label variabel dan keberadaan missing value
3. PAIRED-SAMPLE T TEST - digunakan untuk menguji apakah dua sampel yang bertalian (dependen) atau sampel berpasangan berasal dari populasi yang mempunyai Mean (ekspektasi) yang sama. Contoh: nilai setelah tutorial dan sebelum tutorial.
Paired variables - digunakan untuk mendaftar pasangan variabel yang akan diuji (dibandingkan) Meannya.
Options - untuk menentukan besarnya interval confidensi (selang kepercayaan) dan untuk mengontrol keberadaan label variabel dan keberadaan missing value.
4. ONE-WAY ANOVA - ANOVA (Analysis of Variance) adalah alat statistik yang digunakan untuk menguji dua populasi atau lebih apakah mempunyai rata-rata yang dianggap sama atau tidak.
Dependent list - untuk variabel yang akan dianalisis statistiknya (variabel summari)
Factor - untuk mendaftar sebuah variabel numerik sebagai variabel faktor. Variabel ini akan mengelompokan value-value variabel yang akan diuji ke dalam bebrapa grup sampel independen. Tentu saja variabel ini adalah variabel yang berbentuk katagori.
Define Range - untuk menentukan harga terendah dan harga tertinggi dari katagori variabel factor.
contoh:
statistics / compare means / one-way anova / dep.list:stat/ factor:program/ define range / OK
Contrasts - untuk menentukan contrast a priori yang akan diuji dengan t statistik.
Post Hoc - untuk menampilkan uji-uji post-hoc sebagai perbandingan berganda antar mean.
Option - untuk menampilkan statistik-statistik tambahan, manampilkan label dan menentukan pilihan control terhadap keberadaan missing value.CORRELATE
- BIVARIATE CORRELATIOAN (PEARSON CORR) - digunakan untuk menghasilkan matrik korelasi product-moment Pearson dari pasangan dua variabel
- PARTIAL CORRELATIONS - digunakan untuk menghitung koefisien korelasi parsial yang mendiskripsikan hubungan antar dua variabel dengan efek kontrol untuk varabel lain dengan hasil yang ditampilkan dalam bentuk matriks
Contoh:
1. BIVARIATE CORRELATIOAN (PEARSON CORR) - digunakan untuk menghasilkan matrik korelasi product-moment Pearson dari pasangan dua variabel. Mengukur kekuatan ketergantungan linier antara dua variabel .
Variables - untuk mendaftar pasangan variabel yang akan dihitung korelasinya.
Correlation Coefficient: Pearson, Kendahlls tau-b (untuk non-parametrik), Spearman (non parametrik)
Test of Significance: two tailed (uji dua ekor), One tailed (uji dua ekor)
Options - untuk menampilkan statistik univariat bagi setiap variabel yang didaftar yakni Mean, Standar Deviasi, Deviasi Cross-product, dan Covarians dan untuk mengatur kebedaan missing Value
contoh:
statistics / correlate/ bivariate / Variables: stat,mkpk/ OK
2. PARTIAL CORRELATIONS - digunakan untuk menghitung koefisien korelasi parsial yang mendiskripsikan hubungan antar dua variabel dengan efek kontrol untuk varabel lain dengan hasil yang ditampilkan dalam bentuk matriks
Variables - untuk mendaftar pasangan variabel yang akan dihitung korelasinya.
Controlling for - untuk mendaftar satu atau beberapa variabel yang akan dikontrol efeknya dari korelasi variabel-variabel yang didaftar pada kotak variables
Test of Significance: two tailed (uji dua ekor), One tailed (uji dua ekor)
Options - untuk menampilkan statistik univariat bagi setiap variabel yang didaftar yakni Mean, Standar Deviasi serta untuk menampilkan koefisien korelasi bivariate
REGRESSION
LINIER REGRESSION - digunakan untuk menguji hubungan antara sebuah variabel dependen dengan himpunan variabel independen yang ditampilkan dalam bentuk persamaan regresi .
CURVE ESTIMATION - digunakan untuk menyusun beberapa type fungsi matematis dari data. Dapat menghasilkan diagram (plot) , tabel ANOVA, dan variabel residual, harga taksiran, dan interval taksiran
NONPARAMETRIC
- CHI-SQUARE TEST - digunakan untuk untuk uji hipotesis mengenai proporsi relatif dari sejumlah case yang dikelompokan dalam beberapa grup yamg saling asing (mutually exclusive)
- BINOMIAL TEST - digunakan untuk uji hipotesis bahwa suatu variabel berasal dari populasi binomial dengan probabilitas yang ditentukan dari peristiwa yang terjadi untuk katagori pertama dari dua katagori yang ditentukan.
- RUNS TEST - digunakan untuk menguji apakah dua harga dari variabel ekonoi terjadi dalam barisan random
- ONE-SAMPLE KOLMOGOROV-SMIRNOV TEST - digunakan untuk menguji apakah suatu sampel berasal dari populasi dengan distribusi teoritis tertentu, khususnya distribusi normal, uniform, dan Poison.
- TWO-INDEPENDENT-SAMPLE TESTS - digunakan untuk membandingkan distribusi variabel diantara dua grup independen
- TWO-RELATED-SAMPLES - digunakan untuk membandingkan distribusi dari dua variabel yang berhubungan .
- K-INDEPENDENT-SAMPLES TESTS - digunakan untuk membandingkan distribusi variabel di antara dua grup independen atau lebih .
- K-RELATED-SAMPLES TESTS - digunakan untuk membandingkan distribusi variabel di antara dua grup independen atau lebih.
6. ANALYSIS OF VARIANCE (ANOVA)- Hubungan antar distribusi: Normal, Normal standar, 2, F
- Langkah Standar Pengujian:
= Penentuan hipotesa
= Level of significant =..% berkaitan dengan nilai kritis/tabel
= Statistik hitung
= Kesimpulan membandingkan statistik hitung dan nilai kritis
Perkembangan terakhir dengan p-value, sig. Dll
- ANOVA dapat dipergunakan untuk menguji perbedaan lebih dari dua rata-rata
- Asumsi dalam ANOVA:
= kenormalan distribusi
= homogenitas dari varians
= independensi dari penyimpangan
ONE-WAY ANOVA (contoh data: umy_spss.sav)
1. Varian antar sampel:
--> -->
2. Varian dalam sampel:
maka F statistik dirumuskan:
~ Fk, k(n-1)
TWO-WAY ANOVA (contoh data: data_ukm.sav)
Dapat digunakan untuk menguji rata-rata populasi ketika kita memiliki dua faktor.
Disain
Misal membedakan penjualan berdasarkan lokasi dan pendidikan:
GLM/univariate/options/descriptive statistics
Uji HipotesaApakah hubungan penjualan dan lokasi usaha sama untuk lulusan sekolah.
Efek utama (main effects) adalah efek dari masing-masing faktor, dalam kasus kita lokasi dan pendidikan secara individual bagaimana efeknya terhadap penjualan
Interaksi faktor-faktor tersebut bersama-sama mempengaruhi.
Two-way ANOVAPerbedaan dengan one-way ANOVA adalah kita dapat menguji tiga hipotesis sekaligus:Efek utama dari lokasi
Efek utama dari lulusan
Interaksi antara lokasi dan lulusan
Menghilangkan Efek InteraksiGLM/Model/Custom/
7. REGRESI1. LINIER REGRESSION - digunakan untuk menguji hubungan antara sebuah variabel dependen dengan himpunan variabel independen yang ditampilkan dalam bentuk persamaan regresi .
Dependent - untuk sebuah variabel numerik yang akan dijadikan variabel dependen
Independent(s) - untuk mendaftar variabel-variabel numerik yang akan dijadikan variabel independent.
Method :- Enter , Remove (tidak berlaku untuk blok pertama), Stepwise (metode regresi reduksi bertahap), Backward (akan mengeluarkan variabel idividu sesuai dengan kriteria options), Forward (menambah variabel individu sesuai kriteria options)
WLS>> - untuk menghedaki ada variabel yang diboboti
Statistics - untuk menampilkan berbagai nilai statistik mengenai koefisien regresi, yaitu: taksiran, selang kepercayaan, matriks covarians, DW, diagnosa colinearitas
Plot - untuk menampilkan diagram pencar (scater plot) residual, histogram. diagram outlier, dan diagram probalitas normal.
Options - untuk menentukan kriteria yang akan digunakan dalam analisis yang menggunakan Stepwise, Backward dan Forward,untuk menentukan ditampilkan atau dihilangkannya konstanta dalam persamaan regresi yang dihasilkan, dan untuk mengontrol keberadan missing value.
2. CURVE ESTIMATIONS - digunakan untuk menyusun beberapa type fungsi matematis dari data, menghasilkan diagram (plot) kurve estimasi pada Chart Carousel, menghasilkan tabel ANOVA, menghasilkan variabel baru yang berisi residual, harga taksiran dan interval taksiran.
Dependents - untuk mendaftar satu atau beberapa variabel numerik yang akan dijadikan var. Dependent (sumbu vertikal)
Independent - untuk mendaftar sebuah vaiabel numerik yang akan dijadikan variabel independent. Variabel (untuk variabel yang dipilih), Time (untuk variabel independent: waktu)
Models - untuk menentukan model regresi untuk menyusun data (linier, Logarithic, Inverse, Quadratic, Cubic, Compound, Power, S, Ggrowth, Exponential, Logistic)
Include constant in equations - ingin memasukan konstanta dalam persamaan.
Display ANOVA table - menampilkan tabel ANOVA
Plot model - menghasilkan diagram (plot) pada Cart Carousel
Save - untuk membuat variabel-variabel baru pada file kerja (SPSS Data editor), yaitu variabel-variabel yang berisi harga taksiran, residual, interval taksiran, atau digunakan untuk menentukan pilihan yang berkenaan dengan taksiran case.
Misal model kita:
Keuntungan = a + b modal awal + c omzet + ui
PENYIMPANGAN KLASIK
1. Multicollinearity: hubungan antara variabel penjelas- jika hubungan sempurna maka estimasi tidak bisa dicari
- jika hubungan tinggi tetapi tidak sempurna
Meskipun BLUE tetapi variance (2) besar sehingga semua uji jadi tidak valid.
Deteksi: R2 tinggi tetapi banyak t yang tidak signifikan
Pengobatan: do nothing, do some rules of tumb 2. Heteroscedasticity: variance tidak konstan
------>
Digunakan GLS (genralized least square) yang pada hakekanya kita merubah model sehingga error termnya memenuhi varianse konstan dan kemudian mengaplikasikan OLS (ordinary least square). Contoh dengan membagai model dengan i, sehingga:
Adanya heteroskedastisitas menyebabkan varian tidak minimum.Deteksi: metode informal (sifat dari masalah, metode grafik); metode formal:
- Uji Park
jika signifikan maka ada hetero
- Uji Glejser
- dll: Spearmans rank, Goldfeld-Quandt test, Bruesh-Pagan-Godfrey test, Whites genral heteroscedasticity test
Pengobatan: jika i2 diketahui --> seperti diterangkan di atas jika i2 tidak diketahui --> kita gunakan asumsi-asumsi:
--> model dibagi dengan Xi
--> model dibagi dengan akar Xidst2. Autocorrelation: ui dan uj saling berkorelasi.
Adanya autokorelasi menyebabkan varian tidak minimum.
Deteksi: metode informal (metode grafik); metode DW
8. STATISTIK NON-PARAMETRIK
I. SATU SAMPEL
a. Binomial ( Untuk menguji sebuah sampel, apakah cirri tertentu dari sampel tersebut bisa dianggap sama dengan ciri populasinya Contoh: Ho: = 54 ; H1: 54 menggunakan tanda + jika di atas dan jika di bawah.
Obs Daya
155.4
254.6
357.8
458.9
548.6
644.5
749.7
857.2
b. Runs Test ( Untuk menguji apakah sampel yang mewakili populasi telah diambil secara acak/random Contoh: Ho: hasil acak
1bagus
2bagus
3bagus
4bagus
5bagus
6bagus
7jelek
8bagus
9bagus
10jelek
11bagus
12bagus
13bagus
14bagus
15jelek
16bagus
17bagus
18bagus
19bagus
20bagus
c. Uji Normalitas Kolmogorov Smirnov ( Untuk menguji apakah distribusi sampel adalah normal atau tidak normal
Obs Daya
155.4
254.6
357.8
458.9
548.6
644.5
749.7
857.2
c. Chi-square ( Untuk menguji homogenitas, indepensi, goodness of fit. Contoh: Konsumen sama-sama menyukai tiga warna: putih, hijau dan kuning yang ditunjukkan oleh jumlah responden yang sama (proporsi akan sama). Ho: p1=p2=p3=1/3
susi
putih
anddikai
hijau
bila
kuning
anton
kuning
juni
hijau
marlina
kuning
badu kuning
cica
kuning
cuki
putih
kena putih
andi hijau
reno hijau
II. DUA SAMPEL
A. DUA SAMPEL YANG INDEPENDEN
a. Mann-Whitney ( Untuk menguji apakah dua sampel berasal dari populasi yang sama Contoh: apakah terdapat perbedaan sikap konsumen roti sirkaya kota dan desa
Ttgl SikapTtgl Sikap
kotasangat suka
kotasuka
kotasuka
kotacukup suka
kotasangat suka
kotasuka
kotatidak suka
kotasangat suka
kotasuka
kotacukup suka
desasuka
desatidak suka
desatidak suka
desacukup suka
desatidak suka
desasuka
desatidak suka
desasangat suka
desasuka
desacukup suka
b. Kolmogorov-Smirnov ( Untuk menguji apakah dua sampel sama. Contoh: apakah rata-rata pengeluaran penduduk kota sama dengan penduduk desa
Ttgl PengeluaranTtgl Pengeluaran
kota200
kota400
kota680
kota470
kota254
kota678
kota356
kota725
kota354
kota543
desa234
desa345
desa234
desa546
desa356
desa235
desa423
desa345
desa234
desa123
c. Moses ( Untuk menguji apakah dua sampel sama memiliki variasi yang sama atau tidak. Contoh: apakah variasi pengeluaran penduduk kota sama dengan penduduk desa? H0: s1=s2
d. Wald-Wolfowitz ( Untuk menguji apakah dua sampel sama. Contoh: apakah rata-rata pengeluaran penduduk kota sama dengan penduduk desa
B. DUA SAMPEL YANG DEPENDEN
a. Wilcoxon ( Untuk menguji apakah dua sampel berpasangan memiliki ratarata yang sama. Contoh: penjualan salesman sebelum dan sesudah pelatihan adalah sama
Sales Sebelum Sesudah
15645
24767
38756
47887
59799
68083
74555
83438
96774
107656
b. Sign( Untuk menguji apakah dua sampel berpasangan memiliki ratarata yang sama. Contoh: penjualan salesman sebelum dan sesudah pelatihan adalah sama
c. NcNemar ( jika data yang digunakan adalah nominal (dikotomi) misal: ya, tidak. Contoh: sikap calon konsumen sebelum dan sesudah presentasi.
Nama Sblm Ssd
amdi suka
suka
budi tidak sukasuka
ciko tidak sukasuka
duni tidak sukasuka
feni tidak sukatidak suka
epi suka
tidak suka
kuma suka
suka
tina tidak sukasuka
yuki suka
suka
runi tidak sukatidak suka
c. multinominal ( jika data yang digunakan adalah multinominal: misal suka, sedang, sangat suka
cara: Descriptive statistics cross tab
III. N-SAMPEL
A. N SAMPEL INDEPENDEN
a. Kruskal-Wallis ( untuk menguji perbedaan rata-rata lebih dari dua sampel
Ho: 1= 2= 3
b. Median & Jocnkhere-Terpstra ( untuk menguji perbedaan median lebih dari dua sampel
Ho: Md1= Md2= Md3
B. N SAMPEL DEPENDEN
a. Friedman ( untuk menguji perbedaan rata-rata lebih dari dua sampel
Ho: 1= 2= 3
Misal data produktivitas (roti yang dihasilkan jika pada waktu bekerja diberi perlakuan: lampu, televisi, radio
b. Korkondasi Kendall ( untuk menguji keselarasan dari sekelompok obyek (orang) dalam menilai obyek tertentu. Ho: preferensi konsumen sama terhadap lima rasa roti perbedaan rata-rata lebih dari dua sampel ( data pengurutan
Contoh:
KonsumenCoklatNanasKacangDurianSusu
Dede54321
Andi34215
c. Cochran ( data nominal/dikotomi
KonsumenCoklatNanasKacangDurianSusu
DedeTidak SukaSukaTidak SukaSukaSuka
AndiSukaTidak SukaTidak SukaSukaSuka
---terimakasih---
PROSES DENGAN DATA EDITOR
Input Data:
Data Editor
Output Data: Viewer
Raw data
Informasi
EMBED Unknown
Standar Pengujian:
Hipotesis: H0: ......................
H1: .......................
Kaitannya dengan uji satu sisi atau dua sisi
Level of significance, degree of freedom
Kaitannya dengan nilai kritis/tabel
Statistik hitung
Kesimpulan: dengan membandingkan statistik hitung dan nilai kritis jatuh di Ho diterima atau ditolak
Langkah cepat (default komputer):
Hipotesis: H0: ......................
H1: .......................
Kaitannya dengan uji satu sisi atau dua sisi
Level of significance
Kesimpulan: sig > level of sig -- terima Ho
0
dL
du
2
4-du
4-dL
4
+
-
Ho diterima tidak ada auto
Ragu-ragu
Ragu-ragu
PAGE 1
_1139468605.unknown
_1139499004.unknown
_1139499373.unknown
_1139499862.unknown
_1139499741.unknown
_1139499356.unknown
_1139498702.unknown
_1139498923.unknown
_1139468726.unknown
_1139468492.unknown
_1139468548.unknown
_1139468422.unknown