
BAB III METODOLOGI PENELITIAN 3.1 Objek dan Subjek...
16
45 BAB III METODOLOGI PENELITIAN 3.1 Objek dan Subjek Penelitian Objek penelitian ini terdiri dari variabel bebas (independen) dan variabel terikat (dependen). Variabel independen terdiri dari pendapatan perkapita, populasi, nilai sektor industri, luas lahan perkebunan, dan investasi. Sedangkan variabel dependen yaitu rasio pajak pusat. Subjek penelitian ini yaitu 32 Provinsi di Indonesia dari tahun 2012 – 2016. 3.2 Metode Pengumpulan Data Data yang digunakan untuk penelitian ini sepenuhnya diperoleh melalui studi pustaka (library research) sebagai pengumpulan datanya. Studi pustaka merupakan teknik analisa untuk mendapatkan informasi melalui catatan, literatur, dokumentasi dan lain-lain yang masih relevan dengan penelitian (Nazir, 2003). 3.3 Metode Penelitian 3.3.1 Jenis Penelitian Jenis penelitian yang digunakan yaitu eksplanasi ( explanatory research). Dimana penelitian ini berusaha menjelaskan hubungan satu variabel dengan variabel yang lain yang digambarkan antara variable dependen dan variable independen, dengan menyoroti hubungan yang telah dirumuskan sebelumnya (Nazir, 2003).
Transcript of BAB III METODOLOGI PENELITIAN 3.1 Objek dan Subjek...

45
BAB III
METODOLOGI PENELITIAN
3.1 Objek dan Subjek Penelitian
Objek penelitian ini terdiri dari variabel bebas (independen) dan variabel
terikat (dependen). Variabel independen terdiri dari pendapatan perkapita,
populasi, nilai sektor industri, luas lahan perkebunan, dan investasi. Sedangkan
variabel dependen yaitu rasio pajak pusat. Subjek penelitian ini yaitu 32
Provinsi di Indonesia dari tahun 2012 – 2016.
3.2 Metode Pengumpulan Data
Data yang digunakan untuk penelitian ini sepenuhnya diperoleh melalui
studi pustaka (library research) sebagai pengumpulan datanya. Studi pustaka
merupakan teknik analisa untuk mendapatkan informasi melalui catatan,
literatur, dokumentasi dan lain-lain yang masih relevan dengan penelitian
(Nazir, 2003).
3.3 Metode Penelitian
3.3.1 Jenis Penelitian
Jenis penelitian yang digunakan yaitu eksplanasi (explanatory
research). Dimana penelitian ini berusaha menjelaskan hubungan satu
variabel dengan variabel yang lain yang digambarkan antara variable
dependen dan variable independen, dengan menyoroti hubungan yang
telah dirumuskan sebelumnya (Nazir, 2003).

46
TE = T
T/Y …………………………………….…………. (3.2)
Dimana :
TE = Upaya Perpajakan (Tax Effort)
T/Y = Pajak Hasil Estimasi (Taxable Capacity)
T = Pajak Aktual (Realisasi Penerimaan Pajak Daerah)
3.3.2 Model Penelitian
Model dalam penelitian ini merupakan pengembangan dari model
Richard M. Bird (2008) dan Tuan Minh Le (2012), modelnya dapat
dituliskan sebagai berikut:
T/Yit = α0 + α1LnYCAPit + α2LnPOPit + α3LnAREAit + α4LnINDUSTit
+ α5LnINVESit + ɛit
Keterangan:
T/Yit = Rasio Pajak (Tax Ratio) (TAX/GDPit)
YCAPit = Pendapatan per Kapita daerah ke-i tahun ke-t
POPit = Kepadatan Penduduk (population density)
AREAit = Luas Lahan Perkebunan (Land Area)
INDUSTit = Nilai Sektor Industri
INVESit = Penanaman Modal Total Bruto (Investation)
i = Provinsi
t = Tahun
𝛼0 , β0 = Intercept
𝛼1, 𝛼2, 𝛼3, 𝛼4, 𝛼5, 𝛼6, β1, β2, β3, β4, β5 = Koefisisen Regresi
Setelah menghitung kapasitas pajak dari hasil estimasi regersi masing-
masing Provinsi maka langkah selanjutnya adalah menhitung berapa
besar upaya pajak dari masing-masing Provinsi, dengan menggunakan
rumus sebagai berikut:
47
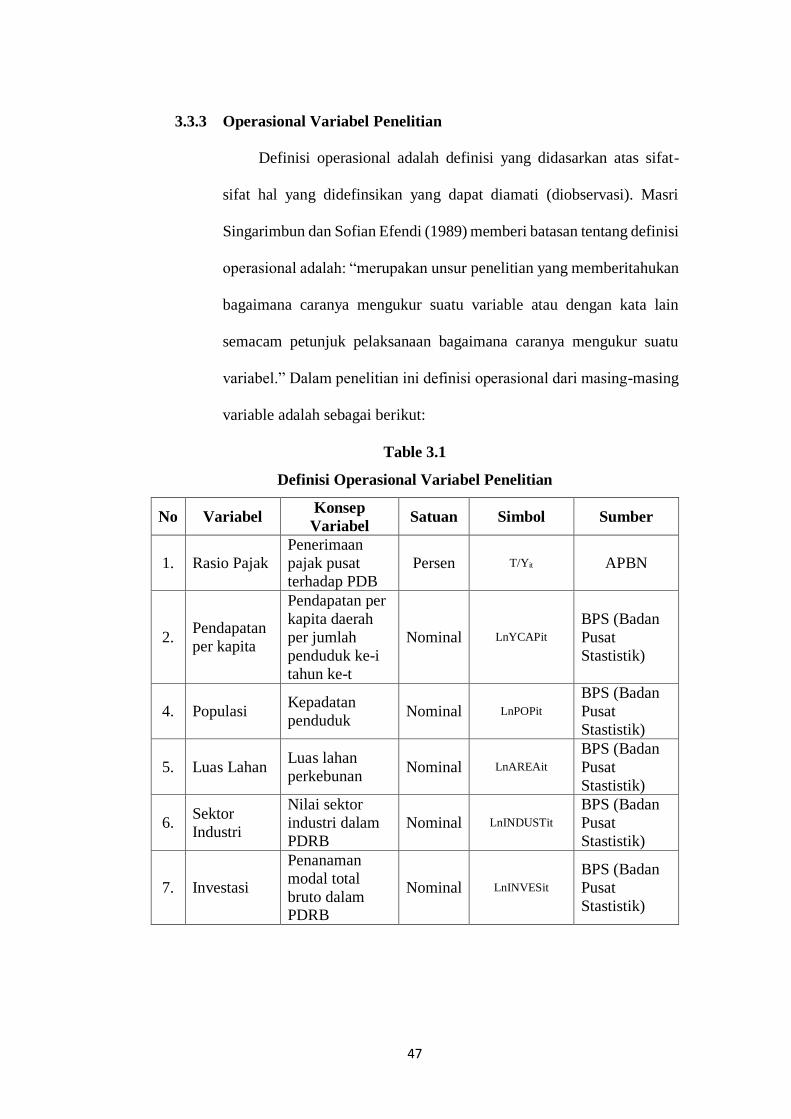
3.3.3 Operasional Variabel Penelitian
Definisi operasional adalah definisi yang didasarkan atas sifat-
sifat hal yang didefinsikan yang dapat diamati (diobservasi). Masri
Singarimbun dan Sofian Efendi (1989) memberi batasan tentang definisi
operasional adalah: “merupakan unsur penelitian yang memberitahukan
bagaimana caranya mengukur suatu variable atau dengan kata lain
semacam petunjuk pelaksanaan bagaimana caranya mengukur suatu
variabel.” Dalam penelitian ini definisi operasional dari masing-masing
variable adalah sebagai berikut:
Table 3.1
Definisi Operasional Variabel Penelitian
No Variabel Konsep
Variabel Satuan Simbol Sumber
1. Rasio Pajak
Penerimaan
pajak pusat
terhadap PDB
Persen T/Yit APBN
2. Pendapatan
per kapita
Pendapatan per
kapita daerah
per jumlah
penduduk ke-i
tahun ke-t
Nominal LnYCAPit BPS (Badan
Pusat
Stastistik)
4. Populasi Kepadatan
penduduk Nominal LnPOPit
BPS (Badan
Pusat
Stastistik)
5. Luas Lahan Luas lahan
perkebunan Nominal LnAREAit
BPS (Badan
Pusat
Stastistik)
6. Sektor
Industri
Nilai sektor
industri dalam
PDRB
Nominal LnINDUSTit BPS (Badan
Pusat
Stastistik)
7. Investasi
Penanaman
modal total
bruto dalam PDRB
Nominal LnINVESit BPS (Badan
Pusat
Stastistik)

48
3.3.4 Jenis dan Sumber Data
Jenis data yang digunakan dalam penelitian ini adalah data
sekunder. Data sekunder merupakan data yang sudah tersedia di
berbagai lembaga atau instansi terkait. Sumber datanya berasal dari
APBN (Anggaran Pendapatan Belanja Negara), BPS (Badan Pusat
Statistik), dan DJPK (Direktorat Jenderal Perimbangan Keuangan). Data
yang akan dipergunakan adalah data panel (panel/pooled data) yang
terdiri dari 2provinsi di Indonesia dari tahun 2012-2016. Sebagai
pendukung dalam penelitian ini digunakan pula berbagai sumber lain
seperti jurnal, buku, publikasi laporan per daerah yang terkait dengan
penelitian ini.
3.3.5 Teknik Analisis
Untuk menganalisis data yang telah dikumpulkan akan digunakan
model ekonometrika. Metode analisis yang digunakan adalah analisis
regresi berganda (multiple regression analysis) yang digunakan untuk
menganalisis pengaruh variabel independen terhadap variabel
dependen. Alat yang digunakan untuk mengolah datanya yaitu Eviews.
Menurut (Gujarati, 2009) dalam melakukan regresi dengan data
panel maka ada tiga metode analisis yang dapat digunakan yaitu:
1. Metode OLS atau dikenal juga sebagai metode common effect atau
koefisien tetap antar waktu dan individu. Dalam pendekatan ini
tidak memperlihatkan dimensi individu maupun waktu.
Diasumsikan bahwa perilaku data sama dalam berbagai kurun

49
waktu. Ini adalah teknik paling sederhana untuk mengestimasi
data panel.
2. Metode fixed effect atau slope konstan tetapi intersept berbeda
antara individu, menempatkan bahwa eit merupakan kelompok
spesifik atau berbeda dalam constant term pada model regresi.
Bentuk model tersebut biasanya disebut model Least Square
Dummy Variable (LSDV). Berbeda dengan OLS yang
mengasumsikan bahwa tidak adanya dimensi individu maupun
waktu, pengertian fixed effect ini diasarkan adanya perbedaan
intersept antara daerah namun intersepnya sama antar waktu (time
inavariant).
3. Metode random effect merupakan eit sebagai gangguan spesifik
kelompok identik dengan eit, kecuali terhadap masing-masing
kelompok. Namun, gambaran tunggal yang memasukan regresi
identik untuk setiap periode. Model ini lebih dikenal sebagai
model Generalized Least Squares (GLS).
Untuk dapat menentukan metode terbaik yang dapat digunakan
untuk mengestimasi model regresi dengan jenis data yaitu data panel,
maka yang harus dilakukan adalah membandingkan hasil regresi ketiga
metode tersebut melalui beberapa tahapn berikut, yaitu:
Pertama, uji yang harus dilakukan adalah Uji Chow. UJi Chow ini
bertujuan untuk membandingkan antara model fixed effect dan model
common effect yang baik untuk digunakan. Hipotesis dalam uji Chow
ini adalah sebagai berikut:

50
H0 = Metode Common Effect
Ha = Metode Fixed Effect
Hipotesis diatas dasar penggunaan nya yaitu dengan
membandingkan perhitungan antara Fstatistik dan Ftabel. Adapun uji Fstatistik
nya adalah sebagai berikut:
𝐹 =
(𝑅𝑆𝑆1 − 𝑅𝑆𝑆2)𝑚
𝑅𝑆𝑆2𝑛 − 𝑘
Keterangan:
RSS1= Residual Sum of Square Teknik tanpa variabel dummy
RSS2= Residual Sum of Square dengan variabel dummy
m = Jumlah resriksi di dalam model tanpa variabel dummy
Hasilnya apabila Fhitung > Ftabel maka hipotesis H0 ditolak, maka
estimasi yang tepat digunkan untuk model regresi data panel adalah
metode Fixed effect dan sebaliknya, jika Ftabel > Fhitung maka Ha ditolak,
artinya estimasi yang tepat digunakan untuk model regresi data panel
adalah Common effect.
Kedua, yaitu melakukan uji Hausman. Uji Hausman bertujuan
untuk melihat diantara model Fixed effect dan model Random effect
yang terbaik untuk digunakan. Hipotesis dari uji Hausman adalah
sebagai berikut:
H0 = Metode Random Effect
Ha = Metode Fixed Effect
Statistik uji Hausman ini mengikuti distribusi statistik Chi Squares
dengan degree of freedom sebanyak k dimana k adalah jumlah variabel
independen. Adapun ketentuan dari uji Hausman adalah jika nilai

51
statistik Hausman lebih besar dari nilai kritisnya maka model yang tepat
adalah model fixed effect, sedangkan jika nilai statistik Hausman lebih
kecil dari nilai kritisnya, maka model yang tepat adalah model Random
effect. (Rohmana, 2013)
Ketiga, yaitu melakukan uji Lagrange Multiplier (LM). Uji
Lagrange Multiplier bertujuan untuk melihat model mana yang cocok
antara random effect dan OLS yang baik untuk digunakan. Hipotesis
dalam uji Lagrange Multiplier adalah sebagai berikut:
H0 = Metode Common Effect
Ha = Metode Randoms Effect
Nilai statistik Lagrage Multiplier dapat dihitung sebagai berikut:
𝐿𝑀 =𝑛𝑇
2(𝑇−)|∑ |∑ �̂�𝑖𝑡𝑇
𝑡=1 |2𝑛𝑖=1
∑ ∑ �̂�2𝑖𝑡𝑇𝑡=1
𝑛𝑖=1
− 1|
2
=𝑛𝑇
2(𝑇−)|
∑ (𝑇 �̂�𝑖)2𝑛𝑖=1
∑ ∑ �̂�2𝑖𝑡𝑇𝑡=1
𝑛𝑖=1
− 1|
2
Keterangan:
n = Jumlah individu
T = Jumlah periode waktu
e = Residual Metode OLS
Kriteria dari LM test ini yaitu jika nilai LM statistik > daripada
nilai kritis statistik chi-squares maka H0 ditolak itu berarti estimasi yang
tepat untuk model regresi data panel adalah metode random effect dan
sebaliknya jika LM statstik < daripada nilai kritis statistik chi-squares
maka Ha ditolak itu berarti metode OLS yang tepat digunakan adalah
common effect.

52
3.3.6 Uji Asumsi Klasik
Metode Ordinary Least Squares (OLS) merupakan model yang
berusaha untuk meminimalkan penyimpangan hasil perhitungan
(regresi) terhadap kondisi aktual. Dibandingkan dengan metode lain,
Ordinary Least Squares merupakan metode sederhana yang dapat
digunakan untuk melakukan regresi linear terhadap sebuah model.
Sebagai estimator, Ordinary Least Squares merupakan metode regresi
dengan keunggulan sebagai estimator linear terbaik yang tidak bias.
BLUE (Best Linear Unbiased Estimator), sehingga hasil perhitungan
Ordinary Least Squares dapat dijadikan sebagai dasar pengambilan
kebijakan. Namun untuk menjadi sebuah estimator yang baik dan tidak
bias, terdapat beberapa uji asumsi klasik yang harus dipenuhi.
Perhitungan data dengan menggunakan program Microsoft Excell
dan pengolahan data dalam penelitian ini menggunakan program
Eviews. Gujarati (1993) menyebutkan bahwa kesepuluh asumsi yang
harus dipenuhi. Pertama, model persamaan berupa linear. Kedua, nilai
variable independen tetap meskipun dalam pengambilan sampel yang
berulang. Ketiga nilai rata-rata penyimpangan sama dengan nol.
Keempat, homocedasticity. Kelima tidak ada autokorelasi antara
variabel. Keenam, nilai covariance sama dengan nol. Ketujuh, jumlah
observasi harus lebih besar daripada jumlah parameter yang diestimasi.
Kedelapan, nilai variabel independen yang bervariasi. Kesembilan,
model regresi harus memiliki bentuk yang jelas. Kespuluh adalah tidak
adanya multicolinearity antar variabel independen. Terpenuhinya

53
kesepuluh asumsi di atas menjadikan hasil regresi memiliki derajat
kepercayaan yang tinggi.
3.3.6.1 Multikolinearitas
Istilah multikolinearitas pada mulanya berarti adanya hubungan
linear yang“sempurna”, atau pasti, diantara beberapa atau semua
variabel yang menjelaskan dari model regresi (Gujarati, 2012).
Multikolinearitas itu merupakan kondisi adanya hubungan linear antar
variabel independen.. Multikolinearitas dapat disebabkan oleh beberapa
hal diantaranya (Ariefianto M. D., 2012) yaitu pertama, tergantung dari
cara pengambilan data atau kecilnya ukuran sampel; Kedua, pembatas
pada model atau populasi yang disampel; Ketiga, spesifikasi model dari
penelitian tersebut; Keempat, model yang overdetermined artinya jika
model dimaksud memiliki lebih banyak variabel dibandingkan jumlah
sampelnya yang biasanya terjadi pada penelitian medis dan yang
terakhir; kelima, yaitu common trend terutama jika menggunakan data
time series, banyak variabel seperti GDP, konsumsi agregat, PMA dan
sebagainya bergerak searah berdasarkan waktu.
Ada beberapa cara untuk mendeteksi multikolinearitas
(Rohmana, 2013) yaitu:
a. Nilai R2 tinggi tetapi hanya sedikit variabel independen yang
signifikan. Apabila nilai R2 tinggi, ini berarti bahwa uji F melalui
analisis varian, pada umumnya akan menolak hipotesis nol yang
mengatakan bahwa secara simultan, bersama-sama, seluruh
koefisien regresi parsial nilainya nol.

54
b. Korelasi parsial antar variabel independen. Dengan menghitung
koefisien korelasi antar variabel independen. Apabila koefisiennya
rendah, maka tidak terdapat multikolinearitas, sebaliknya jika
koefisien antarvariabel independen (X) itu koefisiennya tinggi (0,8
– 1,0) maka diduga terdapat multikolinearitas.
c. Regresi Auxiliary. Regresi jenis ini dapat digunakan untuk
mengetahui hubungan antara dua atau lebih variabel independen
yang secara bersama-sama (misalnya X2 dan X3). Kita harus
menjalankan beberapa regresi, masing-masing dengan
memberlakukan satu variabel independen (misalkan X1) sebagai
variabel dependen dan variabel independen lainnya tetap
diperlakukan sebagai variabel independen.
Setelah kita mengetahui adanya multikolinearitas maka ada
beberapa tindakan perbaikan apabila terjadi multikolinearitas. Tindakan
perbaikan yang harus dilakukan ketika terjadi multikolinearitas dalam
(Gujarati, 2012) yaitu:
a. Informasi Apriori
Informasi apriori ini dapat didapatkan baik dari teori ekonomi atau
dari penelitian empiris sebelumnya, dimana masalah kolinearitas
ternyata kurang serius.
b. Menghubungkan data cross-sectional dan data time-series. Suatu
varians yang tidak ada hubungannya atau disebut juga informasi
apriori merupakan gabungan dari cross sectional dan time series
yang dikenal dengan penggabungan data (pooling the data).

55
Meskipun begitu, menghimpun data cross section dan time series
dengan cara yang disarankan dapat menciptakan masalah
interpretasi, karena secara implisit kita mengasumsikan bahwa
elastisitas pendapatan yang ditaksir dengan cara cross sectional
adalah elastisitas yang sama yang akan diperoleh dari time series
yang murni.
c. Mengeluarkan suatu variabel atau variabel-variabel dan bias
spesifikasi. Ketika dihadapkan dengan multikolinearitas yang
parah, satu cara yang paling sederhana untuk dilakukan adalah
mengeluaran satu dari variabel yang berkolinear. Tetapi, dalm
mengeluarkan suatu variabel dari model, kita mungkin melakukan
bias spesifikasi atau kesalahan spesifikasi. Bias spesifikasi timbul
dari spesifikasi yang tidak benar dari model yang digunakan dalam
analisis. Jadi, jika dalam teori ekonomi bahwa X1 dan X2 kedua-
duanya seharusnya dimasukan dalam model yang menjelaskan
variabel Y, maka dengan mengeluarkan variabel kekayaan akan
menimbulkan bias spesifikasi. Jadi, dari pembahasan diatas dapat
diketahui jika obatnya mungkin lebih buruk dari penyakitnya dalam
beberapa situasi, karena jika multikolinearitas mencegah
penaksiran yang efektif mengenai parameter model, mengabaikan
suatu variabel mungkin secara serius akan menyesatkan kita dari
parameter sebenarnya.
d. Transformasi Variabel. Misalkan kita mempunyai data time series
mengenai belanja konsumsi, pendapatan, dan kekayaan. Satu

56
alasan untuk multikolineartas yang tinggi antara pendapatan dan
kekayaan dalam data seperti itu adalah bahwa dengan berjalannya
waktu, kedua variabel cenderung untuk bergerak dalam arah yang
sama. Maka dari sini kita akan mengenal bentuk perbedaan utama
(first difference). Model regresi perbedaan utama ini sering
mengurangi kepelikan multikolinearitas meskipun tingkat X2 dan
X3 mungkin sangat berkorelasi, tidak ada alasan secara apriori
untuk percaya bahwa perbedaan juga sangat berkorelasi.
3.3.6.2 Heteroskedstisitas
Heteroskedastisitas terjadi ketika asumsi variasi faktor
gangguan yang seharusnya bersifat konstan tapi tidak terpenuhi. Jika itu
terjadi, maka penaksir OLS adalah unbiased. Jika unbiased maka varian
dari koefisien OLS akan salah dan penaksir OLS tidak efisien (Gujarati,
2012). Jadi, kesimpulannya dengan adanya heteroskedastisitas maka
estimator OLS tidak menghasilkan estimator yang Best Linear Unbiased
Estimator (BLUE) hanya mungkin baru sampai Linear Unbiased
Estimator (LUE) (Rohmana, 2013).
Ada beberapa metode yang digunakan untuk mendeteksi
heteroskedastisitas, yaitu metode informal (grafik), metode Park,
metode Glejser, metode korelasi Spearman, metode Goldfeld-Quandt
dan metode Breusch-Pagan-Godfrey. Sedangkan, untuk
penyembuhannya dapat dilakukan dengan metode WLS (Weighted
Least Square), metode White dan metode transformasi. Metode WLS
digunakan ketika varian dan residual diketahui sedangkan jika varian

57
tidak diketahui maka dapat menggunakan metode White atau metode
transformasi.
3.3.6.3 Autokolerasi
Autokorelasi dapat didefinisikan sebagai korelasi antara
anggota serangkaian observasi yang diurutkan menurut waktu (seperti
dalam data deretan waktu) atau ruang (seperti dalam data cross section).
Dalam konteks regresi, model regresi linear klasik mengasumsikan
bahwa autokorelasi seperti itu tidak terdapat dalam disturbansi atau
gangguan ui (Gujarati, 2012).
Akibat jika data yang kita analisis terkena autokorelasi yaitu
estimator metode kuadrat terkecil masih linear, masih tidak bias dan
tidak mempunyai varian yang minimum (no longer best) juga
menyebabkan estimator tidak BLUE. Cara mendeteksi autokorelasi
yaitu dengan uji Durbin Watson dan Breusch-Godfrey. Dalam uji
Durbin Watson (D-W test) autokorelasi dapat berbentuk autokorelasi
positif dan autokorelasi negatif. Hipotesisnya adalah :
H0 : tidak ada autokorelasi (r = 0)
H1 : ada autokorelasi (r ≠ 0)

58
Tabel 3.2
Pengambilan Keputusan Ada Tidaknya Autokorelasi
Cara mendeteksi autokorelasi yaitu dengan uji Durbin Watson
dan Breusch-Godfrey. Adapun pengujian menggunakan Durbin Watson
sebagai berikut:
Gambar 3.1
Stastik Durbin-Watson
3.3.7 Uji Signifikansi Koefisien
3.3.7.1 Uji t
Uji t dilakukan dengan tujuan untuk mengetahui masing-masing
pengaruh dari variabel indepeden terhadap variabel dependen
dan menjawab serta membuktikan hipotesis yang dibangun.
Menghitung nilai t statistik (t hitung) dan mencari nilai-nilai t
Hipotesis nol Keputusan Jika
Tidak ada autokorelasi
positif
Tolak 0 < d < dl
Tidak ada autokorelasi
positif
No decision dl ≤ d ≤ du
Tidak ada autokorelasi
negatif
Tolak 4-dl < d < 4
Tidak ada autokorelasi
negatif
No decision 4-du ≤ d ≤ 4-dl
Tidak ada autokorelasi
positif maupun negatif
Tidak ditolak du < d < 4-du

59
kritis dari tabel distribusi t pada α dan degree of freedom
tertentu.. Adapun nilai t hitung dapat dicari dengan formula
sebagai berikut:
𝑡ℎ𝑖𝑡𝑢𝑛𝑔 = 𝛽
𝑖− 𝛽
𝑖∗
𝑆𝐸(𝛽𝑖)
Keterangan:
ßi = Parameter yang diestimasi
ßi* = nilai hipotesis dari (H0: ßi*= 0)
Kriteria uji t adalah sebagai berikut:
1. Jika thitung > ttabel maka Ho ditolak dan Ha diterima,
artinya variabel bebas X berpengaruh signifikan terhadap
variabel bebas Y.
2. Jika thitung < ttabel maka Ho diterima dan Ha ditolak,
artinya variabel bebas X tidak berpengaruh signifikan
terhadap variabel terikat Y.
3.3.7.2 Uji F
Uji F digunakan untuk melihat pengaruh semua variabel
independen terhadap variabel dependen. Pengujian dilakukan
dengan membandingkan antara nilai Ftabel dengan Fhitung.. Rumus
Fhitung adalah sebagai berikut:
𝐹 =
𝑅2
(𝑘 − 1)
1 − 𝑅2
(𝑁 − 𝑘)
Keterangan:
k= Jumlah parameter yang diestimasi termasuk konstanta
N= Jumlah observasi
Kriteria uji F adalah sebagai berikut:

60
1. Jika Fhitung < Ftabel Ho diterima dan Ha ditolak
(keseluruhan variabel bebas X tidak berpengaruh pada
variabel terikat Y).
2. Jika Fhitung > Ftabel maka Ho ditolak dan Ha diterima
(keseluruhan variabel bebas X berpengaruh terhadap
variabel terikat Y).
3.3.7.3 Koefisien Determinasi
Koefisien determinasi (R2) merupakan ukuran yang
menunjukan seberapa besar proporsi variasi variabel independen
dalam menjelaskan semua variabel dependen yang terdapat di
dalam model. Dalam koefisien determinasi juga akan digunakan
koefisien determinasi untuk mengukur seberapa baik garis
regresi yang kita punya. Maka, untuk menghitung koefisien
determinasi (R2) formula yang digunakan adalah sebagai
berikut:
Adapun kriteria nya sebagai berikut:
1. Jika R2 semakin mendekati 1, maka hubungan antara
variabel bebas dengan variabel terikat semakin
erat/dekat, atau dengan kata lain model tersebut
dinilai baik.
2. Jika R2 semakin menjauhi angka 1, maka hubungan
antara variabel bebas dengan variabel terikat jauh
atau tidak erat, dengan kata lain model tersebut dapat
dinilai kurang baik.




















