







Bahasa
Halaman
Hukum


5-5U t-| ^ % Îd T H E S E
% â °\ P R E S E N T E E
A L ’EC O L E DES G R A D U E S
DE L ’U N I V E R S I T E L A V A L
P O U R L ' O B T E N T I O N
DU G R A D E DE M A I T R E ES A R T S (M.A.)
PA R
FACULTE DES SCIENCES DE L'EDUCATION
S Y L V I E M O R E L
B A C H E L I E R E ES AR TS
DE L ' U N I V E R S I T E L A V A L
LA R E G R E S S I O N L O G I S T I Q U E : C O M P A R A I S O N A V E C L''ANALYSE
P R O B I T A L ' A I D E DE LA M E T H O D E M O N T E C A R L O
S E P T E M B R E 1986

RESUME
Cette recherche effectue une comparaison, à l ’aide de la méthode
Monte Carlo, entre les méthodes d'analyse de régression logistique et
d'analyse probit dans le contexte de la prédiction d'une variable dé
pendante binaire. Ces simulations s'inscrivent dans un devis expéri
mental impliquant trois intensités d 'interrelations ( p = 0, .3, .7)
entre les trois variables indépendantes et des échantillons de trois
tailles différentes (n= 30, 50, 100). Les principaux résultats indi
quent que la méthode probit est plus efficace que la méthode de régres
sion logistique lorsque les interrelations s 'intensifient et la taille
de l'échantillon augmente.
François A. Dupuis Ph.D.
Directeur de recherche
Sylvie Morel Etudiante

REMERCIEMENTS
Je r e m e r c i e m o n d i r e c t e u r de r e c h e r c h e M o n s i e u r F r a n ç o i s
A. D u p u i s , p r o f e s s e u r a u d é p a r t e m e n t de M e s u r e et E v a l u a t i o n de
l ' U n i v e r s i t é L a v a l p o u r la q u a l i t é de la s u p e r v i s i o n .
J e t i e n s é g a l e m e n t à s o u l i g n e r la c o l l a b o r a t i o n de M o n
s i e u r D e n i s S a v a r d l o r s de m o n e x p é r i m e n t a t i o n . Je ne v o u d r a i s
p a s n o n p l u s o u b l i e r m e s a m i ( e ) s q u i m ' o n t c o n s t a m m e n t e n c o u r a
gée et a i n s i p e r m i s de m e n e r à b i e n c e t t e r e c h e r c h e .

RESUME
C e t t e t h è s e e f f e c t u e d ' a b o r d u n s u r v o l d e s p r o b l è m e s
r e l i é s à l ' e m p l o i de la r é g r e s s i o n m u l t i p l e ( b a s é e su r la m i n i
m i s a t i o n de la s o m m e des c a r r é s de 1 1 e r r e u r -m o i n d r e s c a r r é s ) ,
p o u r e x p l i q u e r o u p r é d i r e u n e v a r i a b l e d é p e n d a n t e b i n a i r e .
P a r m i les s o l u t i o n s p r o p o s é e s j u s q u ' à ce j o u r , il s e m b l e q u e ce
s o i t le r e c o u r s à u n m o d è l e r e p o s a n t s u r u n e f o n c t i o n de r é p a r
t i t i o n de f o r m e c u r v i l i n é a i r e q u i p a r v i e n n e le m i e u x à c o n t o u r
n e r les d i f f i c u l t é s i n h é r e n t e s au m o d è l e de r é g r e s s i o n l i n é a i r e
c l a s s i q u e a i n s i q u e c e l l e s p e r s i s t a n t a u x t e n t a t i v e s d ' a d a p
t a t i o n de ce d e r n i e r à ce t y p e de p r o b l è m e p a r t i c u l i e r .
L ' a n a l y s e de r é g r e s s i o n l o g i s t i q u e , o u a n a l y s e l o g i t ,
a i n s i q u e l ' a n a l y s e p r o b i t s o n t d e u x m é t h o d e s s t a t i s t i q u e s
s ' a p p u y a n t s u r u n t e l l e f o n c t i o n et s o n t d ' a i l l e u r s a p p a r u e s
c o m m e é t a n t le s p l u s u t i l i s é e s d a n s le c o n t e x t e q u i n o u s i n t é
r e s s e .
L e p r e m i e r o b j e c t i f de c e t t e r e c h e r c h e se r e s t r e i n t à
l ' é t u d e de la n a t u r e et de s p r o p r i é t é s d ' u n e de ces d e u x m é t h o
des, s o i t l ' a n a l y s e de r é g r e s s i o n l o g i s t i q u e , d a n s la s i t u a t i o n
p a r t i c u l i è r e o ù au m o i n s u n e des v a r i a b l e s i n d é p e n d a n t e s c o n s i
d é r é e s e s t de n a t u r e c o n t i n u e .

iv
plus présentées pour servir l'atteinte du second objectif de la
recherche qui consiste à évaluer la performance relative, en
termes de valeur prédictive, de ces deux méthodes d'analyse
sous des conditions bien précises.
Pour ce faire, des échantillons de données ont été géné
rées a l é a t o i r e m e n t selon la méthode Monte Carlo de façon à
étudier l'influence de deux facteurs: la taille des échantil
lons (n= 30, 50, 100) et le niveau des interre1ations entre les
variables indépendantes ( = 0, .3, .7) dont le nombre fut fixé
à trois. Les deux méthodes furent appliquées à des données
issues d'une distribution logistique d'une part et à des don
nées associées à une distribution normale standardisée (probit)
d'autre part pour ainsi donner une chance égale à chacune des
méthodes de manifester son efficacité.
Les principaux résultats de ces simulations nous amènent
à conclure que dans l'ensemble la méthode probit devient supé
rieure à la régression logistique, quant à la précision de ses
prédictions, lorsque la taille de l'échantillon et l'intensité
des inter r e 1 a tions entre les variables indépendantes augmen-
tent .
François A. Dupuis Ph.D. Directeur de la recherche
Sylvie Morel. Etudiante

VTABLE DES MATIERES
PAGE
1 . 0 INTRODUCTION ......................................... 1
1.1 L'ANALYSE DE LA REGRESSION ........................ 3
1.1.1 Le modèle de régression linéaire multiple et sesp o s tulats ..................................... 5
1.1.2 Types de variables considérées ........... 7
1.2 PREDICTION D'UNE VARIABLE DICHOTOMIQUE ......... 8
1.3 PROBABILITE PREDITE ................................. 11
1.4 PROBLEMES ASSOCIES A L ’EMPLOI D'UN MODELE LINEAIRE POUR PREDIRE UNEVARIABLE BINAIRE' ..................................... 13
1.4.1 Non normalité des termesd ' erreurs ..................................... 14
1.4.2 Variance d'erreur non constante .......... 16
1.4.3 Contrainte au niveau des valeurs prédites 18
1.5 MODIFICATIONS A LA SOLUTION DES MOINDRES CARRES 21
CHAPITRE I : SITUATION ET POSITION DU PROBLEME
1.5.1 Moindres carrés généralisés 21

vi
1.6 MODELES ALTERNATIFS A CEUX DES MOINDRES CARRES .. 27
1.6.1 L'analyse discriminante ..................... 27
1.6.2 Modèles basés sur les lois de probabilitélogistique et normale standardisée ....... 29
1.7 BUTS DE LA RECHERCHE ................................ 36
CHAPITRE II : LA REGRESSION LOGISTIQUE
2.0 INTRODUCTION ......................................... 38
2.1 SPECIFICATION DU MODELE DE REGRESSION LOGISTIQUE 39
2.2 ESTIMATION DES PARAMETRES DU MODELE DEREGRESSION LOGISTIQUE ............................... 48
2.2.1 Méthode des moindres carrés généralisés .. 48
2.2.2 Méthode du maximum de vraisemblance ..... 50
2.2.3 Propriétés des estimés du maximum devraisemblance ................................ 56
2.2.4 Tests d'hypothèses concernant lesparamètres ................................... 58
2.3 TESTS DE QUALITE DE L'AJUSTEMENT ................... 64
2.3.1 Le test de "Hosmer" ......................... 65
2.3.2 Le test de "Brown" ......................... 6 8
2.3.3 Autres approches ............................ 70
1 . 5 . 2 Contrainte au niveau de la solution ........ 25

vii
2.4 LES PROGRAMMES D'ORDINATEUR DISPONIBLES POUR LAREGRESSION LOGISTIQUE ............................... 71
2.4.1 Description du programme BMDPLR .......... 74
2.4.2 Description du programme PROBIT de SPSSX 78
2.4.3 Résultats obtenus via BMDPLR................ 81
2.4.4 Résultats obtenus via SPSSX ............... 85
2.4.5 Comparaison des coefficients logistiquesfournis par les deux logiciels ........... 87
CHAPITRE III : CADRE THEORIQUE ET METHODOLOGIQUE
3.0 INTRODUCTION ......................................... 92
3.1 L'ANALYSE PROBIT .................................... 93
3.1.1 Correspondance des paramètres des modèleslogit et probit ............................. 95
3.1.2 Interprétation des coefficients des modèleslogit et probit ............................. 97
3.2 CHOIX DES PROGICIELS ................................ 100
3.3 COMPARAISON DES RESULTATS D'ANALYSE LOGIT ETPROBIT POUR L'ETUDE DE DAGENAIS .................. 102
3.4 REVUE DE LA LITTERATURE ............................ 105
3.5 QUESTIONS ET HYPOTHESES DE RECHERCHE ............ 108

vili
3.6 DEVIS EXPERIMENTAL .................................. 114
3.6.1 Considérations générales .................. 114
3.6.2 Nombre d'échantillons ..................... 118
3.6.3 Création de la variable dépendante ..... 119
3.6.4 Sélection des valeurs des paramètres .... 121
3.6.5 Application des méthodes d'analyse logitet probit ..................................... 1 2 2
3.6.6 Mesures de la performance ................. 123
3.6.7 Réalisation de l'expérimentation ........ 128
3.7 ANALYSE DES RESULTATS ................................. 131
3.7.1 Présentation des résultats préliminaires .. 131
3.7.2 Stratégie d'analyse ......................... 132
3.7.3 Analyse des moyennes et écarts-types ...... 133
3.7.4 Vérification des hypothèses ............... 135
3.7.4.1 Première hypothèse ................ 139
3.7.4.2 Deuxième hypothèse ................ 141
3.7.4.3 Troisième hypothèse ............... 144
3.7.4.4 Quatrième hypothèse ............... 146
CHAPITRE IV : CONCLUSION
4.0 RESUME ................................................. 152
4.1 LIMITATIONS DE CETTE RECHERCHE .................... 156
4.2 SUGGESTIONS DE RECHERCHES FUTURES .................. 157

ix
BIBLIOGRAPHIE ................................................. 159ANNEXE A: Valeurs de critères pour chacune des méthodes
sous chacun des modèles pour les 1 0 0 échantillons de chacune des neuf situations expérimentales. 1 5 4

X
LISTE DES FIGURES
FIGURES PAGE
1.1 Comparaison des courbes logistique et normalestandardisée ...................................... 32
2.1 Représentation graphique de la fonctionlogistique ........................................ 44

xi
LISTE DES TABLEAUX
TABLEAUX PAGE
2.1 Exemple des commandes BMDPLR pour l'exécutiond'une analyse de régression logistique ...... 74
2.2 Exemple de commandes SPSSX pour l'exécution d'une analyse de régression logistique àl'aide du programme PROBIT ...................... 79
2.3 Résultats produits par l'analyse de régression logistique effectuée par le programme BMDPLRsur les données de Dagenais (1984) ............ 82
2.4 Résultats types produits par le programmePROBIT de SPSSX pour l'analyse de régression logistique effectuée sur les données de Dagenais 86
3.1 Comparaison des résultats de la régression logistique et de l'analyse probit appliquéesaux données de Dagenais (1984) ................. 104
3.2 Principales études ayant comparé les méthodesd'analyse logit et probit ....................... 106
3.3 Instructions informatiques associées aux principales étapes de l'expérimentation ........... 129
3.4 Moyennes et écarts-types des valeurs de critères 134
3.5 Résultats des comparaison entre les méthodes logit et probit sous chacun des modèles dedonnées ............................................. 137
3.6 Méthode d'analyse s'étant avérée supérieure dans chacune des situations expérimentales etgain net pour chaque critère ..................... 149

CHAPITRE I
SITUATION ET POSITION DU PROBLEME
1.0 INTRODUCTION
La science a pour principal but de décrire la réalité.
Elle tente donc de découvrir et d'expliquer les rapports
pouvant exister entre les faits pour finalement arriver à
prédire ou c ontrôler l'apparition de phénomènes. Dans la
p oursuite de cet objectif fondamental de la science, les
chercheurs u t i l i s e n t souvent des outils statistiques pour
résumer les informations obtenues à partir d'un échantillon
de données, vérifier certaines hypothèses et tirer des géné
ralisations de ces observations.
Il va sans dire que la validité de ces vérifications et
de ces généralisations dépend de la pertinence des méthodes
statistiques utilisées, car en plus d'être nombreuses et
variées ces méthodes postulent généralement un certain nombre
de conditions préalables. Il devient donc nécessaire, pour
l ' avancement de la science^ que l'on étudie avec soin les
méthodes disponibles.

Les études ayant un tel objectif sont souvent qualifiées
de rech e r c h e s m é t h o d o l o g i q u e s et prennent entre autres la
forme de comparaisons de méthodes considérées adéquates pour
analyser tel ou tel type de problème.
Le type de recherche m é t h o d o l o g i q u e que nous avons
privilégié pour la présente étude est associé aux études de
simulation, aussi appelées études Monte Carlo. A ce propos,
voici, tel qu'exposé par Goldstein et Dillon (1978), l'inté
rêt que ce type de recherche présente lorsque l'on cherche à
investiguer la supériorité d'une technique sur une autre:
"In particular, attempts at general conclusions regarding the superiority of one procedure over another are made by associating the underlying parametric structure in the two groups to the relative effectiveness of the procedures." (p.99)
"From a theoretical perspective, therefore, the use of Monte Carlo sampling experiments is propitious to the extent that it allows one to determine the relative effectiveness of a procedure,since specification of the underlying parametric structure in the two groups is possible." (p. 1 0 0 )

3
Parmi les chercheurs dont l'intérêt est de découvrir les
relations entre des variables, plusieurs semblent d'avis que
parmi les méthodes statistiques disponibles, les plus perti
nentes se trouvent du côté de la théorie de la régression.
Cohen et Cohen (1975) vont plus loin en notant:
"... it also became clear that multiple regression correlation was potentially a very general system for analyzing data in the behavioral sciences, one that could incorporate the analysis of variance and covariance as special cases." (p.xix)
Pour leur part, Kerlinger et Pedhazur (1973) soutien
nent que l'analyse de régression multiple est la méthode la
plus générale et la plus puissante et qu'elle permet de
s'attaquer à une grande variété de problèmes de recherche.
De plus, selon Draper et Smith (1981), cette méthode d'analy
se est l'outil statistique le plus largement utilisé pour
exprimer les relations existant entre les variables étudiées.
Pour bien saisir la portée de cette méthode, soulignons comme
l'ont fait Kerlinger et Pedhazur (1973) que:
1.1 L ’ANALYSE DE LA REGRESSION

4
" M u l t i p l e régr e s s i o n and its rational underlie most other multivariate methods. Once multiple régression is well understood other multivariate methods are easier to comprehend. "(p. V)
En recherche, on semble donc recourir fréquemment à
l'analyse de la r é g r e s s i o n linéaire lorsqu'on cherche à
expliquer ou à prédire une (ou plusieurs) variable dépendante
à partir des valeurs observées à d'autres variables dites
indépendantes ou explicatives.
Ces considérations expliquent en partie l'engouement
observé chez les chercheurs, aussi bien en sciences humaines
que dans les autres sciences en général, pour cette méthode
d'analyse. Nous croyons que l'attrait qu'elle exerce tient
également à son caractère "naturel". Quoi de plus fascinant,
en effet, que de pouvoir prédire (ou expliquer), à l'aide des
résultats d'un individu à un ensemble de variables, ce que
serait sa situation par rapport à une autre variable. Les
développ e m e n t s méthodologiques importants qu'elle a connus
ces dernières années, combinés à l'apparition de logiciels
permettant de considérer simultanément un nombre de plus en
plus grand de variables indépendantes, la rendent adaptée à
l'analyse d'une grande variété de problèmes où la valeur
attendue d'une variable dépendante est une combinaison (liné
aire ou non) de variables indépendantes.

5
1.1.1 Le modèle de régression linéaire multiple et ses postulats
Les n o m b r e u x avantages que laisse entrevoir ce type
d'analyse ne doivent cependant pas faire perdre de vue qu'en
s'appuyant sur un certain nombre de postulats, il possède
par le fait même des limites. Avant d'en énumérer les parti
cularités, rappelons que le modèle de régression linéaire
multiple "classique” avec k variables indépendantes s'exprime
comme suit :
Y i — B q + B i X i i + B 2 X 2 i . •+ ^ lc^ki + 'i ( 1 * 1 )
où i correspond à la I ième observation:i- 1 , 2 .....n ;
est la variable dépendante;
X^ , X 2 , . . . , Xjç sont des variables indépendantes nonaléatoires i.e. pouvant être fixées à
volonté ;
B q est la constante d'ajustement;
sont les coefficients de régression ou poids associés aux k variables indépendantes ;

6
E est le terme de l'erreur associé à laI ième observation, i.e. représentant
les effets dus aux variables indépendantes non contrôlées.
Quatre postulats ou hypothèses de base sont associés à
ce modèle (Baillargeon et Rainville, 1979):
i. Le terme d'erreur E^ est une variable aléatoire demoyenne nulle i.e. :
E(Ei) - 0 (1.2)
ii. Le terme d'erreur Ej[ est une variable aléatoire devariance constante et inconnue (postulat d'homoscé- dasticité) , i.e. :
VAR(Ei) = a2 (1.3)pour chaque i
iii. L'erreur associée à une observation est totalementindépendante de l'erreur rattachée aux autres observations (postulat d'indépendance), i.e. :
COV ( E i , E j ) = 0 , i / j (1.4)
iv. Le terme d'erreur E^ se distribue selon la loinormale (postulat de normalité). (1.5)
Notons que ces quatre postulats peuvent (en langage matri
ciel) se résumer comme suit:
E~Nn (0 ,a2l)

7
Pour des valeurs X^ données, suit donc une distribu
tion de moyenne égale à (en vertu des postulats (1 .2 ) et
(1.3)) :
E ( Yj_ ) - B0 + BX X 1± + B2 X 2i +...+ Bk Xki (1.6)
( i = l , 2 ......n)
Les estimés des paramètres B sont obtenus à l'aide
des valeurs observées dans un échantillon de n sujets en
faisant o r d i n a i r e m e n t appel à la méthode d'estimation des
moindres carrés. Celle-ci consiste à trouver des estimés
bQ , b ^ ,b 2 , . • . ,bk de B g ,B ^ ,B2 , . • . ,Bk respectivement tels que £(Y-Ÿ)2 sera minimisée, Y = bQ+b^X^+b 2 X 2+ ...+bkXk étant la
valeur prédite.
1.1.2 Types de variables considérées
Il est intéressant de constater qu'il n'existe aucune
restriction quant à la nature des variables indépendantes
considérées dans une analyse de régression linéaire. Elles
peuvent, en effet, être aussi bien quantitatives (de propor
tion ou à intervalles égaux) que qualitatives (à caractère
nominal ou ordinal); ce dernier type de variables nécessite

cependant la création de variables factices ("dummy varia
bles") .
Il faut cependant admettre qu'en ce qui concerne la
nature de la var i a b l e dépendante, la situation n'est pas
aussi accommodante car, en principe, le modèle de régression
linéaire n'est valide que lorsque la variable dépendante est
quantitative.
1.2 PREDICTION D'UNE VARIABLE DICHOTOMIQUE
Il existe de nombreuses situations de recherche où la
variable d é p e n d a n t e est qualitative, et plus précisément
dichotomique. Nous avons dit que lorsque les variables
explicatives sont qualitatives il convient de les représenter
par des variables factices. Il semble indiqué (Theil, 1971)
d'utiliser la même approche lorsqu'il s'agit d'une variable
dépendante dichotomique. Nous parlerons alors d'une variable
binaire; de plus, pour des raisons d'ordre pratique, on
associe la v a l e u r " 1 " à un succès ou à la présence d'une
caractéristique, et la valeur "0 " à un échec ou à l'absence
de la caractéri s t i q u e . A titre d'exemple, un sujet peut
fournir une réponse satisfaisante ou une réponse insatisfai
sante à une qu e s t i o n ou encore lors de l'exécution d'une
tâche; ces réponses seraient alors respectivement cotées 1 et

9
0. Notons en passant qu'une variable binaire peut être de
deux types: 1 ) nominale ou 2 ) foncièrement quantitative
mais artificiellement dichotomisée selon un critère quelcon
que. On peut ainsi établir une distinction entre une dicho
tomie naturelle comme le sexe et une dichotomie artificielle
comme le succès ou l'échec à un examen où il existe une note
minimum pour réussir.
Il est fréquent dans le domaine de l'éducation de
rencontrer des problèmes de recherche impliquant une variable
dépendante b i n a i r e . ’ Les chercheurs sont en effet souvent
intéressés à expliquer un comportement qui ne s'observe que
sous une forme dichotomique. Pensons, par exemple, à la
prédiction de la décision d'abandonner ou de poursuivre des
études ou à la prédiction du succès dans un programme d'étude
à l'aide de variables académiques et socio-économiques. De
même, un chercheur pourrait tenter d'expliquer ou de prédire
le choix ou non d'un cours optionnel ou d'un programme d'étu
de particulier. Ajoutons que dans le cadre de la théorie des
tests, plus p a r t i c u l i è r e m e n t en analyse d'items, il peut
s'avérer utile d'évaluer si le fait de répondre correctement
ou non à un item s'explique par les connaissances de l'indi
vidu qui y répond, par des habiletés préalables ou encore par
des caractéristiques de sa personnalité.

Dans cette veine, une étude effectuée récemment par
Dagenais (1984) de l'Ecole des Hautes Etudes Commerciales de
Montréal v isait à v alider les critères utilisés à cette
i n s t i t u t i o n pour sélect i o n n e r les meilleurs candidats au
B a c c a l a u r é a t en A d m i n i s t r a t i o n des Affaires. Nous nous
servirons d ' ailleurs des données de cette recherche aux
chapitres II et III. Il s'agissait d'y étudier la relation
entre le succès (ou l'échec) à la fin de la première année
d'étude au Baccalauréat et les critères utilisés aux fins de
sélection. Le succès y était mesuré par une variable dicho
tomique binaire: un individu admis en deuxième année d'étude
obtenait la cote " 1 " alors que celui ayant échoué ou abandon
né pendant sa première année obtenait la cote "0 ".
Bien que la façon de résumer la performance d'un étu
diant par un "1 " ou un "0 " peut sembler simpliste à l'extrê
me, elle p r ésente néanmoins un avantage. Ainsi, comme le
souligne l'auteure de cette étude, cette procédure permet de
considérer une fraction de la population étudiante, (celle
ayant abandonné ou échoué) qui autrement serait ignorée
malgré son pote n t i e l prédictif. Il s'avère en effet tout
aussi important, pour effectuer une sélection efficace, de
connaître les caractéristiques des étudiant/e/s ayant quitté
le programme en cours d'année que les particularités de ceux
et celles qui ont persisté.

11
Une autre étude entreprise en 1983 par le Groupe de
Recherche sur l'Apprentissage de la Lecture chez le Lecteur
Précoce (GRALLP) du département de Psychopédagogie de l'Uni
versité Laval fournit un autre exemple de recherche impli
quant une var i a b l e dépendante binaire. Cette recherche
comptait parmi ses objectifs celui d'identifier les caracté
ristiques distinguant les lecteurs précoces des non-lecteurs.
De prime abord, les p r é o c c u p a t i o n s de ces études
suggèrent de faire appel à l'analyse de la régression classi
que. Nous nous sommes demandée si le fait que la variable
dépendante soit binaire présente quelqu 1 inconvénient et, dans
l'affirmative, de quel ordre.
1.3 PROBABILITE PREDITE
Avant d ' e n t r e p r e n d r e cette investigation, il nous
semble opp o r t u n de démontrer que lorsqu'on considère un
modèle de r é g r e s s i o n linéaire où la variable dépendante,
notée Y, ne prend que les valeurs "1" et "0", l'espérance
m a t h é m a t i q u e (i.e. la moyenne) de cette dernière prend une
signification particulière (Neter, Wasserman et Kutner, 1983,
p. 354) .

12
Etudions de plus près cette situation en nous restrei
gnant, pour simplifier l'exposé, au cas où il n'y a qu'une
seule va r i a b l e indépendante. Nous obtenons alors le modèle
suivant, découlant directement de (1 .1 ):
= £0+ ¿iXi+ Ei (Yi-0,1) i-1,2..... n. (1.7)
Comme il est postulé, à l'intérieur de ce modèle, que
E(E.j_)-0, il en découle que:
E(Yi) - + fi1X i (1 ! 8)
puisqu'en moyenne l'erreur aura tendance à s'annuler. D'au
tre part, si nous considérons l'espérance mathématique d'une
variable discrète, on peut également écrire:
E(Yt ) - 1 . Pr(Yi-l) + 0 . Pr(Yi=0)
- PriYi-l) (1.9)
Il ressort clairement de (1.8) et (1.9) que, dans le
cas d'une variable dépendante binaire, la moyenne, pour une
valeur donnée de X, n'est nulle autre que la probabilité d'un
succès, Pr(Yj_=-l).

13
Il va sans dire que cette interprétation demeure juste
dans le cas où il y a plus d'une variable indépendante. Il
apparait donc logique, dans le contexte où la variable dépen
dante est dichotomique, que l'intérêt se déplace vers la
p r é d i c t i o n de la p r o b a b i l i t é qu'une des alternatives se
réalise et vers la façon dont cette probabilité varie en
fonction des valeurs associées aux variables explicatives.
1.4 PROBLEMES ASSOCIES A L ’EMPLOI D'UN MODELE LINEAIRE POUR PREDIRE UNE VARIABLE BINAIRE
Puisque P, la probabilité qu'un événement se produise,
est une v aleur restreinte à l'intervalle [0 ,1 ] nous devons
prendre soin de choisir un modèle tenant compte de cette
particularité. Dans cette optique, nous nous interrogerons
d'abord sur la pertinence d'utiliser un modèle linéaire, par
le biais de la régression, pour estimer la probabilité qu'a
un événement de se produire.
T e c hniquement, en effectuant l'analyse de régression
linéaire, nous obtenons toujours une solution même si la
variable d é pendante est de type binaire. Considérant les
valeurs entre 0 et 1 comme les résultats d'un événement
p r o b a b i 1 iste , nous pouvons même tenter d'interpréter ces

résultats en associant la valeur du coefficient de régression
B au changement au niveau de la probabilité de succès cor
respondant à une unité d'augmentation de la variable indépen
dante correspondante Nous verrons plus loin en quoi cette
approche n'est pas, de façon générale, appropriée. Pour
l'instant, disons seulement qu'à une augmentation constante
de la va r i a b l e indépendante ne correspond pas, comme nous
pourrions nous y attendre, une augmentation constante de P
mais plutôt un changement de probabilité moindre au fur et à
mesure que P s'approche de 0 ou de 1.
1.4.1 Non-normalité des termes d'erreurs
Le modèle de régression classique ne semble pas le plus
approprié pour prédire ou expliquer une variable dépendante
binaire à partir d'une ou plusieurs variables prédictrices et
ce p r i n c i p a l e m e n t à cause de la nature dichotomique de la
variable dépendante . (Cox, 1971; Hanushek et Jackson, 1977;
Buse, 1972; Judge, Hill, Griffiths et Lee, 1980).
Examinons donc ce qu'il advient des termes d'erreur.
Lorsque la variable dépendante est binaire, le terme d'erreur
E^ - - (Bq + B^X^) devient égal à

- (B0 + B X £) , lorsque Y t = 0 (1.10b)
1 - (Bq + B X^) lorsque Yj_ = 1 (1.10a)
et égal à
Comme il n'existe que deux valeurs possibles, il est
évident que les termes d'erreur ne se distribuent pas selon
la loi normale tel qu'il est postulé dans le cadre du modèle
classique de régression linéaire (postulat (1.5)).
Soulignons que même si les termes d'erreur ne suivent
pas la loi normale lorsque Y est dichotomique, la méthode des
moindres carrés fournit malgré tout des estimés de coeffi
cients non biaisés à la condition que la taille de l'échan
tillon soit suffisamment grande (Neter, Wasserman et Kutner,
1983; Am e m i y a , 1981).
Bien que la violation du postulat de normalité ne semble
pas avoir d'incidence directe sur les propriétés ou qualités
des estimés des coefficients, elle pose néanmoins un doute
sérieux sur la validité des tests statistiques (tests t) et
des intervalles de confiance qu'on pourrait vouloir calculer.
En fait, comme le résume Buse (1972) :

16
"... the conventional least squares estimators for the variances of the estimâtes are biased and inconsistent, in turn invalidating conventional tests of hypotheses."(p. 27)
1.4.2 Variance d'erreur non constante
Il semble que le caractère dichotomique de la variable
dépendante soit à l'origine d'un second problème. Cette
p a r t i c u l a r i t é implique en effet que les termes d'erreur
possèdent une variance égale à:
Var (E ¿ ) - (B0 + B X¿) (1 - B 0 - B X¿) (1.11a)
-Pi ( 1 - Pi) (1 .1 1 b)
où Pi correspond à la probabilité d'un succès à la variable
dépendante pour une valeur X i j i- 1 , 2 ... .
On constate donc que les variances des termes d'erreur
ne sont pas constantes mais directement fonction des valeurs
prises par la variable indépendante. Nous ne pouvons donc
pas assumer l'homogénéité de la variance telle que réclamée
par le postulat (1.3). L'essence du problème est très bien
rendue par les propos des auteurs Hanushek et Jackson (1977):

17
"Thus even if we observe P^, the true probability of a given choice for each different value of X, the deviation implied by the linear model vary systematically with X and preclude obtaining good estimates of the parameters of the distribution."(p. 184)
Notons que le p o stulat d'homogénéité permet, dans le
cadre de la méthode des moindres carrés, de s'assurer que les
estim a t e u r s ont la p r opriété de variance minimale (BLUE :
best linear unbiased estimator). Lorsque ce postulat n'est
pas respecté, les estimateurs demeurent non biaisés mais ils
ne possèdent plus la plus petite variance possible et ne sont
plus les meilleurs en termes de précision. Comme Buse (1972)
le conclut: " The heterosckedastic variance also imply that
ordinary least squares is inefficient." (p.7)
Tout cela a pour conséquence de fournir des estimés des
c o efficients dont les valeurs attendues dépendent des élé
ments de l'échantillon et des erreurs - types différentes de
celles calculées en tenant compte de l'hétéroscédasticité
(non constance) des variances. De toute façon, même si l'on
était assuré d'obtenir des estimés d 'erreurs - types non b i a i
sés, les tests de s i g n i f i c a t i o n h a b i t u e l l e m e n t utilisés
(tests t et F) ne sont valides qu ' asymptotiquement car les
termes d'erreurs ne se distribuent pas selon la loi normale.

Cox (1970) nuance cependant les conséquences de la
violation du postulat d'homogénéité de la variance:
18
"However, it is known that quite appreciable changesin Var(Y^) induce only a modest loss of efficiency. Further, at least in the range say, 0.2 < P < 0.8, the function P(l-P) changes relatively little.Therefore, within this range,there is unlikely to be a serious loss of efficiency arising from the changes in Var(Y¿)." (p.16)
1.4.3 Contraintes au niveau des valeurs prédites
Abordons maintenant ce qui, semble-t-il, constitue la
restriction la plus sérieuse quant à l'utilisation du modèle
(1.1) en présence d'une variable dépendante binaire. Rappe
lons d'abord que la valeur prédite par le modèle de régres
sion linéaire dans cette situation devrait (section 1.4) être
une probabilité. Comme une probabilité se définit en termes
de valeurs appartenant à l'intervalle [0 ,1 ], on souhaiterait
que les valeurs prédites à partir de l'équation (1 .6 ) aient
la même particularité, i.e.:
0 < Y < 1 (1.12)
Or, étant donné le type de relation postulé entre Y et
les var i a b l e s indépendantes, nous sommes ici susceptibles

d'obtenir des estimés de probabilités qui ne satisfont pas la
c o n d i t i o n (1.7) pour certaines observations, extrêmes, de
l ' é c h a n t i l l o n (Cox,1970). Comment alors interpréter des
valeurs prédites telles que 1.25 ou encore -.18? Il est évi
demment absurde de considérer ces valeurs comme étant des
probabilités .
Une sol u t i o n simpliste à ce problème consiste à
assigner la valeur "0 " aux probabilités prédites négatives et
la valeur 1 aux probabilités supérieures à "1". Cette solu
tion a posteriori corrige aisément le problème des valeurs
prédites hors-limites mais à quel prix! En y pensant bien,
cela implique, dans le cas d'une seule variable indépendante
X, que pour toutes les o b s ervations pour lesquelles nous
observons une valeur inférieure à un point disons "c" ou
supérieur à un point "d" pour X nous prédirions une probabi
lité de 1 d'avoir respectivement un échec et un succès. Il
nous semble irréaliste, sinon imprudent,d'effectuer un juge
ment aussi catég o r i q u e surtout lorsque des comportements
humains critiques sont en jeu et que ce jugement est suscep
tible d'être généralisé à un ensemble d'individus. De toute
façon, même si les probabilités prédites par le modèle de
r égr e s s i o n linéaire n'excèdent pas l'intervalle [0 ,1 ] pour
l' é c h a n t i l l o n en main, nous devons nous attendre à obtenir
des prédictions hors-limites pour de nouvelles valeurs de X

20
Soulignons qu'en plus d'engendrer des problèmes
d'interprétation, la présence de probabilités prédites néga
tives entraîne aussi une difficulté technique au niveau de
l'estimation de la variance d'erreur. En effet, cette der
nière sera également négative, chose bien entendue impossible
pour une v a r i a n c e (sauf, peut-être, dans certains travaux
d 1 étudiants !) .
Il ressort des considé r a t i o n s p r écédentes que la
forme linéaire du modèle classique et la nature dichotomique
de la variable dépendante sont incompatibles en ce sens que
le modèle ne permet pas dans un tel cas d'estimer correcte
ment la vraie probabilité de succès pour toutes les valeurs
de la variable indépendante.
En général, comme l ' expliquent Hanushek & Jackson
(1977), les modèles de probabilité linéaire, c'est-à-dire les
modèles linéaires qui relient la probabilité qu'à un événe
ment de se produire à un ensemble de facteurs explicatifs,
sont en général irréalistes. Comme le précise Dhrymes (1978)
un modèle linéaire:
e x c é d a n t c e l l e s o b s e r v é e s d a n s c e t é c h a n t i l l o n p a r t i c u l i e r .

21
" ... will yield 'reasonable' results only in highlyspecial circumstances, and with the data configuration one often encounters in empirical work it is likely to lead to very poorly fitting probability functions."(p.333)
1.5 MODIFICATIONS A LA SOLUTION DES MOINDRES CARRES
Nous avons vu, dans les sections précédentes, que l'uti
lisation de la régression multiple dans le cas où la variable
dépendante est binaire entraîne trois inconvénients poten
tiellement sérieux pour la validité de l'analyse: (1 ) viola
tion du postulat de normalité de la régression; (2 ) violation
du postulat d'homogénéité de la variance de l'erreur; et (3)
p o s s i b i l i t é d 'obtenir des valeurs (probabilités) prédites
inférieures à 0 ou supérieures à 1 .
Des corr e c t i f s à l'analyse de régression linéaire et
d'autres approches ont été proposés pour remédier aux incon
vénients m e n t i o n n é s ci-dessus dans le cas d'une variable
dépendante binaire. Nous les passons ici en revue.
1.5.1 Moindres carrés généralisés
A la section préc é d e n t e nous avons vu qu'en présence
d'une variable dépendante binaire, la variance d'erreur n'est

22
pas c o nstante mais qu'elle fluctue en fonction des valeurs
des v a r i a b l e s indépendantes, ce qui engendre des problèmes
d'estimation et d'interprétation. En effet, l'estimation de
1 'erreur-type par la méthode des moindres carré repose sur le
postulat de l'égalité des variances. Comme ces dernières v a
rient alors de façon appréciable, nous risquons une perte
importante d'information en utilisant les estimés des m oin
dres carrés ordinaires. Pour atténuer les problèmes liés à
1 1 hé téros cédasticité, Golberger (1964), Neter, Wasserman et
Kutner ( 1983 ) et Zellner et Lee (1965) suggèrent de faire
appel à la méthode des moindres carrés généralisés ("genera
lized least squares") qui a pour effet de mini m i s e r les
erreurs - types des coefficients et donc de fournir des estimés
efficaces lorsque les variances d'erreur sont inégales.
Cette approche utilise l'information disponible concer
nant les v a r i a n c e s d'erreur. Elle consiste , en effet, à
donner des p o n d é r a t i o n s inégales aux différentes observa
tions, accordant des poids plus élevés aux observations dont
les termes d'erreur ont une plus petite variance, donc plus
fiables, et des poids plus faibles aux observations dont les
termes d'erreur ont une variance plus importante.

Pour obtenir les estimés des moindres carrés généralisés
il s'agit d'effectuer une analyse de régression pondérée où
les poids sont simplement les inverses des variances. Les
estimés sont donc obtenus en minimisant la somme des carrés
de l'erreur "pondérés". Cette dernière peut être représentée
par :
l (Wi êi ) 2 (1.13a)
où: w t- 1______ (1.13b)Pi(l-Pi)
Cette m éthode ne peut pas s'appliquer directement
puisque les coeffi c i e n t s de régression B nécessaires pour
estimer ê^ nous sont inconnus. Nous pouvons alors, comme le
suggère Goldberger (1964), opérer en deux étapes. Il s'agit,
dans un premier temps, d'effectuer l'estimation des coeffi
cients de r é g r e s s i o n par la méthode des moindres carrés
ordinaire, puis, dans un deuxième temps, d'appliquer à n o u
veau cette méthode aux données pondérées par 1.13b.
Cette approche présente malheureusement elle aussi un
inconvénient (Judge, Hill, Griffiths et Lee, 1980): elle ne
peut être utilisée que dans la situation particulière où nous
possédons plusieurs observations à chacun des niveaux de la

24
variable indépendante i.e. lorsque les variables indépendan
tes sont catégorielles. Cette exigence est parfois très
difficile à remplir; il suffit de penser aux problèmes impli
quant p l usieurs variables indépendantes où il est rarement
possible d'effectuer des regroupements de façon à conserver
un nombre satisfaisant d'observations pour chaque cellule. De
plus, il n ' e x i s t e aucune garantie absolue que les valeurs
prédites, à partir desquelles seront calculés les poids,
n'excéderont pas l'intervalle [0,1]. Si ces valeurs prédites
ne sont pas contenues entre ces limites, les poids estimés
correspondants ne le seront pas non plus, rendant alors cette
méthode d'estimation inadéquate.
Une solution simple serait d'ajuster les valeurs hors-
limites prédites par l'équation de régression. Ainsi, cer
tains auteurs conseillent d'affecter la valeur .5 ou encore
.98 aux Pi lorsque p^il-p^) < 0 ; d'autres s'entendent pour
remplacer les p^ négatives ou plus grandes que 1 par les v a
leurs |Pî(l_Pi)| correspondantes. Cependant, si l'on consi
dère les résultats de l'étude Monte Carlo effectuée par Smith
et Cicchetti (1972) il semble que ces diverses stratégies
aient peu d'attraits. De son côté, Cox (1970) ne conseille
le recours à une pondération que lorsque les p^ sont infé
rieures à .20 et/ou supérieures à .80. Autrement, il semble

rait que l'amélioration par rapport à la solution des moin
dres carrés ordinaire soit négligeable (Neter, Wasserman et
K u t n e r , 19 8 3).
Finalement, bien que l'utilisation de l'analyse de
régression pondérée, surtout lorsque les poids sont obtenus
de façon itérative, a généralement pour effet de fournir des
estimés d ' e r r e u r -type inférieurs à ceux qu'on obtiendrait
par l ' e n t r e m i s e de l'approche classique, elle n'élimine
n u l l e m e n t cepe n d a n t la possibilité de prédire des valeurs
ininterprétables en termes de probabilités.
1.5.2 Contrainte au niveau de la solution
Aucune des méthodes m e ntionnées jusqu'ici ne permet
vraiment de s'assurer d'obtenir des valeurs de probabilités
restreintes à l'intervalle [0,1]. Par ailleurs, il existe
une autre avenue: celle de restreindre coûte que coûte les
résultats prédits aux valeurs de cet intervalle.
Une approche, nommée "inequality restricted least squa
res" (Judge, Griffiths, Hill et Lee, 1980), consiste à impo
ser mathématiquement une contrainte à la solution de façon à
obtenir des valeurs prédites acceptables. Cette méthode

plutôt complexe s'avère satisfaisante pour l'échantillon en
main mais, malheureusement, a peu de chance de l'être pour
des v aleurs extrêmes de la population. Cependant, si on
connaît l'étendue réelle des valeurs susceptibles d'être
prises par la variable indépendante, il est possible de tenir
compte de cette information pour imposer des contraintes plus
rigoureuses. Une limite sérieuse de cette variante est la
nécessité de disposer des informations concernant l'étendue
des valeurs de X dans la population. En commentant cette
méthode, Cox (1970) note de plus qu'au niveau des calculs, la
programmation mathématique y est considérablement plus com
plexe que pour les moindres carrés non modifiés.
Les solutions proposées jusqu'ici et qui font partie de
ce que l'on pourrait appeler la "famille des moindres car
rés", supposent l'adéquation du modèle linéaire pour exprimer
la relation entre une variable dépendante binaire et une ou
p lusieurs variables indépendantes ainsi que le respect des
postulats concernant les termes d'erreurs. Ces conditions,
nous l'avons vu, sont dans l'ensemble irréalisables; de plus,
les "correctifs" laissent plusieurs auteurs perplexes quant à
leur efficacité réelle. Heureusement, d'autres méthodes ont
été proposées et nous allons nous empresser de les examiner.

27
1.6 MODELES ALTERNATIFS A CEUX DES MOINDRES CARRES
1.6.1 L'analyse discriminante
D'autres méthodes ont en effet été utilisées pour analy
ser des problèmes impliquant une variable dépendante binaire.
On peut d'abord souligner l'analyse discriminante canonique-*-
(Tatsuoka, 1971) dont l'objectif est de trouver une combi
naison linéaire des variables indépendantes, appelée fonction
discriminante, i.e.:
Y-iL^X^ + &2X2 "*■••• T-^k^-k •
(où X]_ , X 2 , . . . Xk représentent les variables indépendantes
et £]_, £ 2 , . . . , sont les poids ou coefficients de discrimina
tion) telle que les Y calculés dans les groupes de sujets
seront les plus différents possibles en termes de leur moyen
ne .
Bien qu'assez populaire, cette approche présente selon
nous certaines restrictions:
^Comme cas p a r t i c u l i e r de la c o r r é l a t i o n canonique et en contraste avec l'analyse discriminante de classification (Green, 1979).

28
(1) Elle est basée sur plusieurs postulats difficiles à
satisfaire en pratique, notamment:
- la normalité des variables indépendantes, ce qui
implique entre autres que l'on ne peut pas y
considérer des variables indépendantes qualitati
ve s ;
- l'égalité des deux matrices de variances-
covariances (ou de dispersion).
(2) Les comparaisons empiriques dont elle a fait
l'objet avec d'autres méthodes ne se sont généra
lement pas soldées à son avantage, surtout lorsque
les variables indépendantes ne respectaient pas le
p o s t u l a t de normalité (Byth et McLachlan, 1980;
Press et Wilson, 1978; Efron, 1975). Maddala
(1983) présente une critique de ces comparaisons.
Pour ces raisons, voyons d'autres approches qui ont été
proposées pour étudier la relation entre une variable
dépendante binaire et des variables indépendantes, aussi bien
qualitatives que continues.

29
1.6.2 Modèles basés sur les lois de probabilité logistique et normale standardisée
Si nous considérons la possibilité qu'un événement se
réalise, il s'avère commode d'un point de vue mathématique de
définir une variable aléatoire Y dichotomique en termes des
valeurs " 1 " si l'événement se produit et "0 " s'il ne se
produit pas. Nous assumons que sa probabilité d'occurrence
dépend d'un ve c t e u r de v a riables indépendantes X et d'un
vecteur de paramètres inconnus &. Il est à noter que dans la
suite de ce texte, nous ferons souvent appel au langage de
l'algèbre matricielle en supposant que le lecteur est déjà
familier avec celui-ci. En utilisant l'indice i pour référer
à la i ième observation de l'échantillon nous pouvons écrire
le modèle général de cette relation comme suit:
- Prob (Y^ = l) - F (Xi ' £) i=l,2,...,n. (1.14)
où X^' £ = £ qX q +fi^Xi +. . . +£kXk , X q = 1 et F(X^'£) est la
fonction de répartition qui décrit comment les probabilités
sont reliées aux variables prédictrices.
Nous ne pouvons envisager d'estimer cette probabilité à
l'aide d'un modèle linéaire puisqu'un tel modèle, nous l'a

30
vons expliqué, s'avère généralement inadéquat. Parmi les
problèmes associés à la prédiction d'une variable binaire par
les modèles de r é g r e s s i o n linéaire classique ou pondérés,
celui qui constitue apparemment la plus sérieuse restriction,
concerne le c o m p o r t e m e n t des probab i l i t é s prédites. En
effet, qu'il soit possible de prédire des probabilités néga
tives ou supérieures à l'unité constitue une situation p r o
blématique qui met en doute la linéarité de la relation qui
est postulée. Les approches utilisées pour contraindre les
p r o b a b i l i t é s prédites à l'intervalle [0 ,1 ] impliquent à
toutes fins pratiques que la nouvelle fonction soit discon
tinue à ses limites.
Pour des considérations d'ordre aussi bien théorique que
pratique, il s'avère (Buse, 1972; Hanushek et Jackson, 1977;
Neter, Wasserman et Kutner, 1980) qu'un type de fonctions non
linéaire mais ayant pour asymptotes 0 et 1 et la forme d'un S
incliné i.e. curvilinéaire, soit plus approprié pour repré
senter la relation entre la probabilité d'obtenir un succès
et une c o m b i n a i s o n de facteurs explicatifs. Ce type de
fonctions implique notamment qu'un changement de probabilité
donné est plus difficile à obtenir au fur et à mesure que P
se rapproche des limites.

31
Plus d'une fonction de répartition répondent à ces
sp é c i f i c a t i o n s et pour r a i e n t être utilisées. Nous nous
sommes cependant limitée aux deux fonctions les plus fréquem
ment u t i l i s é e s jusqu'à nos jours pour représenter la rela
tion entre la probabilité de succès et les prédicteurs . Il
s'agit des fonctions de répartition logistique et normale
standardisée intégrée (Fig. 1.1), la première définissant la
classe des modèles dits "logit ou logistique" et la seconde,
la classe des modèles "probit".
La fonction logistique fut apparemment utilisée dès 1838
par le m a t h é m a t i c i e n belge Ve r h u l s t (1804-1849) dans des
études d é m o g r a p h i q u e s (Batschelet, 1979). Concernant la
distribution normale, sans en faire l'historique, soulignons
seulement qu'une des premières utilisations de cette distri
b ution dans le cadre de l'analyse de variables dépendantes
binaires remonte au moins aux expériences psychophysiques de
Fechner en 1860 sur la sensibilité humaine à divers stimuli
(Finney, 1971).

32
Figure 1.1 Comparaison des courbes logistique et normale standardisée (adapté de Hanushek et Jackson, 1977) .
Les p r i n c i p a u x champs d ' a p p l i c a t i o n de ces modèles
semblent être la biologie et l'économique. Les biométriciens
utilisent ces modèles pour étudier, par exemple, l'effet du
dosage d'un insecticide sur la survie d'insectes. L'applica
tion qu'ils en font est habituellement la plus simple, i.e.
restreinte à des problèmes n'impliquant qu'une seule variable
indépendante (souvent une dose) et où la variable dépendante

33
binaire est désignée par le vocable "variable quantale".
C'est d'ailleurs dans le cadre de telles études que l'analyse
probit connut un regain de popularité au début des années
1930, peu avant de prendre, grâce à R.A. Fisher en 1935, la
forme qu'on lui connaît maintenant. Chez les économétri-
c iens, qui travaillent souvent avec des variables naturelle
ment ou artificiellement discrètes, ces modèles sont appli
qués à des problèmes plus complexes, entre autres au niveau
du nombre de variables explicatives. Ils ont été utilisés
notamment pour étudier le choix des modes de transport, les
c omp o r t e mem t s des consommateurs et la participation de la
main-d'o euvre.
Ces deux modèles paraissent également populaires en r e
cherche médicale dans le cadre d'études sur l'effet de dro
gues sur la guérison ou non d'un patient et en psychophysi
que. Plus près de nous, en théorie des tests, l'"item res-
ponse theory", la théorie la plus sophistiquée présentement
disponible, s'appuie sur ces fonctions pour prédire le succès
à un item à partir de l'habilité latente de l'individu (Fin-
n e y , 1944; Lord et N ovick,1968).
Le modèle que nous avons choisi de privilégier dans
cette étude est le modèle logit ou de régression logistique

34
P(Y-l) = ___________________ (1.15)X'£
1 + e
où X'£ est tel que déjà défini en (1.14).
Selon H a n u s h e k et Ja c k s o n (1977), la distri b u t i o n
logistique, qui est la plus souvent postulée, tient sa popu
larité à la fois de sa forme et de ses propriétés mathéma
tiques. Comme le souligne aussi Cox (1970): "It is the most
useful analogue for binary response data of the linear model
for normally distributed data. " (p. 19)
Ce choix fut aussi motivé par la similitude qui existe
entre ce modèle et le modèle classique de régression linéai
re, tel que nous le verrons au prochain chapitre, et par la
q u a s i -absenee de référence pertinente et détaillée sur ce
type d'analyse dans la littérature en Education. Nous sommes
convaincue que cette approche est susceptible de trouver de
n ombreux champs d'application en Education, les chercheurs
dans ce domaine étant souvent confrontés à des variables
dépendantes qui sont naturellement discrètes ou mesurées de
façon discrète. Elle nous apparaît d'autant plus intéressan
q u i s ' e x p r i m e c o m m e s uit:
X'£e

te que les supports informatiques nécessaires à l'estimation
des paramètres de ce modèle ne sont disponibles que depuis
quelques années. De plus, il s'agit d'un domaine nouveau
où il reste, semble-t-il, des avenues à explorer.
Voyons m a i n t e n a n t b r i è v e m e n t ce qui caractérise le
modèle probit. Celui-ci est basé sur l'ogive normale ou
courbe normale cumulée ("Integrated normal response curve")
qui est une fonction monotone s'élevant de 0 jusqu'à 1 avec
un point d'inflexion correspondant à la moyenne. La probabi
lité d'un succès y est définie de la façon suivante:
e d v (1.16)
i- 1 > 2 .....n .
où X'£ = + ^1^1 + • • • + ^k^k et v est une variablealéatoire se distribuant selon la loi normale i.e.
v ~ N ( 0 , 1 ) .
L'idée est que la probabilité d'obtenir un succès,
étant donné les valeurs observées aux variables indépendan
tes, c o r r e s p o n d à la p r o babilité qu'une variable normale
standardisée soit inférieure à X'É ou encore que la probabi
lité de succès, Prob(Yi= 1), est l'aire sous la courbe
■Prob (Y. = 1 )1V 2 tt L

36
probit nous fournit donc des estimés de probabilités qui
correspondent à de "vraies" probabilités i.e. à des valeurs
contenues dans l'intervalle requis. Il va de soi que plus la
valeur de X'£ est grande, plus le succès est susceptible de
se manifester. C'est la nature probabiliste des valeurs
prédites par cette technique qui aurait conduit au choix du
qualificatif "probit", ce dernier étant une abréviation pour
"probability unit" (Aldrich et Cnuddle, 1975).
1.7 BUTS DE LA RECHERCHE
Jusqu'ici, le présent chapitre a tenté de brosser un
tableau des p r oblèmes associés à l'utilisation de modèles
linéaires lorsque la variable dépendante est binaire et plus
précisément à l'estimation de la probabilité de "succès". A
cet effet, un rappel des p r i ncipales caractéristiques du
modèle de régression linéaire "classique" fut effectué et ses
limites pour prédire une variable binaire furent rapidement
identifiées. Par la suite, nous avons examinés des correc
tifs possibles ainsi que trois modèles alternatifs proposés
dans la littérature. Parmi ces derniers, nous avons décidé
de jeter notre dévolu sur le modèle de régression logistique
(ou logit).
n o r m a l e s t a n d a r d i s é e se t r o u v a n t e n t r e et X'£. L'analyse

Le premier objectif de cette recherche consistait donc à
étudier en p r o f o n d e u r ce modèle en p r écisant la méthode
d'estimation la plus appropriée pour les situations, fréquen
tes en recherche en éducation, où les variables indépendantes
peuvent être aussi bien continues que qualitatives. Nous
nous sommes également intéressée aux propriétés des estima
teurs, aux principaux tests d'hypothèses et aux mesures de
précision de la prédiction de la probabilité de succès. En un
deuxième temps, nous avons effectué une étude comparative, à
l'aide de la méthode de Monte Carlo, de la régression logis
tique ou méthode logit avec ce qui nous est apparu comme son
principal compétiteur, tant au plan théorique que pratique,
soit l'analyse probit. En résumé, les deux objectifs de
cette recherche étaient les suivants:
(1) Faire une présentation la plus claire et la
plus exhaustive possible de la r é gression
logistique (chapitre II);
(2) Effectuer une comparaison de l'analyse de la
régression logistique versus l'analyse probit à
l'aide de la méthode Monte Carlo, en vue de d é
terminer la méthode d'analyse la plus efficace
en termes de capacité à bien prédire la proba
bilité d'un succès (chapitre III).

CHAPITRE II LA REGRESSION LOGISTIQUE
2.0 INTRODUCTION
Au premier chapitre nous avons passé en revue les p r o
blèmes associés à l'emploi de l'analyse de régression linéai
re dans le cas d'une variable dépendante binaire ainsi que
les solutions proposées pour contourner ces difficultés en
attirant l ' a t t e n t i o n sur leurs avantages et inconvénients.
Ce c h e m i n e m e n t nous a amené à considérer d'autres modèles
qui semblent plus adaptés au contexte de prédiction d'une
variable binaire, en termes de la probabilité d'un "succès".
L'un d'eux a attiré davantage notre attention: il s'agit du
modèle basé sur la fonction logistique.
Afin de répondre au premier objectif de cette recherche,
voyons plus en détail les principales caractéristiques de ce
modèle que l'on désigne aussi par l'expression "régression
logistique".

39
Tel que mentionné au premier chapitre, dans le modèle
f o ndamental de la régr e s s i o n logistique avec k variables
indépendantes, on retrouve Y ^ , Y 2 , •••, Y n qui sont des
v a r i a b l e s aléatoires binaires indépendantes prenant les
valeurs 0 ou 1 , ayant une probabilité de prendre la valeur
"1 " égale à:
Xi'Se
Pr (Yi-1) - Pj. - ______________________ (2.1)Xi'fi
1 + e
où e - 2.7183... constante bien connue;
Xi* - [XQi XU X2i ... Xki] , i-1,2.... n
- [Ê0 &2 •••
et
X 0i - 1, valeur constante pour les n individus.
Le v ecteur Xi' représente les valeurs observées pour le
i ième individu aux k + 1 variables indépendantes (en comptant
X q comme variable) souvent considérées fixées, tandis que le
vecteur E contient les k + 1 p a ramètres ou coefficients de
régression logistique.
2.1 SPECIFICATION DU MODELE DE REGRESSION LOGISTIQUE

40
On remarque aussi que, par définition,
Xi'* = [X0 X i X 2 ... Xk ]
ß-
ß<
=fi0 x 0 i + Ê lx li + Ê 2 x 2 i + ••• + ^kxki
=fi0 + ¿lx li + fi2 x 2 i + ••• + fikxki (puisque Xgi = 1 ).
Substituant ce dernier résultat en (2.1) on obtient:
ß 0 + ßix ii+ ... +^kxki
1 + e ß 0 + ßlx li+ ••• +ßkxki( 2 . 2 )
forme fréquemment rencontrée dans la littérature.
D'autres formes équivalentes à (2.1) sont également
utilisées par différents auteurs. Ainsi, en partant du
membre de droite de (2 .1 ) on obtient:

41
X i ' f i
Xi’fi Xi 'fi
X< ' fi1 + e 1 + e
Xi'fi+ 1
X î 'fi Xi ' f i
i.e.
1 +Xi'J
(2.3)
Directement de cette dernière expression, on obtient:
1 +-Xi'fi
( 1 + e-Xi'fi
1 . e
-1Pi = [ 1 + exp (-Xi'fi)] (2.4)
ycar exp (y) = e , par définition.

42
Les expressions (2.1) à (2.4) inclusivement sont algé
briquement équivalentes et chacune présente un certain avan
tage. Ainsi, (2.2) permet de faire ressortir l'analogie qui
existe avec le modèle de régression multiple classique alors
que l'expression (2.4) est la plus succincte.
Quant à l'expression (2.3), son utilité peut d'abord
être considérée de la façon suivante. En partant de (2.1),
on peut écrire que la probabilité que Y prenne la valeur zéro
au lieu de un est égale à:
X'i*e
Pr(Yt - 0) - 1 __________________i £
1 + e
( 1 + eX'i*
1 + eX'i*
i.e. PrtYi - 0) - _________________ (2.5)
1 + eX ' i *

Comparant (2.5) et (2.3), on réalise que toutes deux
sont symétriques, seul le signe de l'exposant les distin
guant. C'est dire qu'en changeant tous les signes des coef
ficients, on obtient la p r o b a b i l i t é que (Y=0) au lieu de
(Y-l), i.e. la p r o b a b i l i t é de l'alternative. Ce résultat
implique également que la façon d'assigner les valeurs "1 " et
"0" aux deux niveaux de la variable dépendante Y n'a aucune
influence sur les valeurs absolues des coefficients de ré
gression logistique: en effet, seuls les signes de ces der
niers c h angent si l'on intervertit la définition des deux
niveaux. Nous verrons un peu plus loin un deuxième avantage
de recourir à l'expression (2.3).
Bien que les quatre expressions (2.1), (2.3), (2.4) et
(2.5) soient essentiellement équivalentes, nous ne nous ser
virons que de l'expression du modèle fondamental (2 .1 ) dans
la suite de ce texte. Revenant à cette dernière, nous cons
tatons que la r e lation décrite entre la probabilité d'un
succès et la (les) variable(s) i n d é p e n d a n t e (s) n'est pas
linéaire. De plus, l'examen de la représentation graphique
de ce modèle à la Figure 2.1 nous permet de réaliser que la
fonction logistique convient tout à fait à la prédiction
d'une probabilité. En effet, elle permet de prédire des
valeurs à l'intérieur des limites associées à des probabili
tés atteignant 0 pour X'£ = - 00 et 1 pour X'£ - 00 .

44
Figure 2.1 Représentation graphique de la fonction logistique
Bien sûr, le modèle (2.1) contient l'expression X'£ que
nous retrouvons dans le modèle de régression linéaire; mais
cela ne signifie pas pour autant qu'il soit linéaire, bien au
contraire, puisque X'£ est l'exposant de e. Par contre, une
propriété particulièrement intéressante de la fonction logis
tique est qu'elle peut facilement être rendue linéaire.

45
Considérons le rapport p^/il-p^), appelé "odds ratio",
et plus précisément le logarithme naturel de cet "odd ratio",
appelé "logit". Par définition:
Logit(pi) = log 1 (PiAl-Pi)) (2 .6 )
Ce dernier fut introduit par Berkson en 1944 qui lui
donna le nom de logit à cause de sa relation avec la fonction
logistique. Partant de l'expression (2.1) nous obtenons
d 'abord :
X'fi X ' *e / ( 1 + e )
P/(1-P) - ___________________________________ (2.7)X’ fi X' £
1 - [ e / ( 1 + e ) ]
Après simplification:
X' £p/(l-p) - e (2 .8 )
^Dans tout le texte, nous travaillerons avec le logarithme naturel, i.e. de base e=2.7183.... Aussi, pour simplifier les développements à venir, nous abandonnerons l'indice désignant une observation ou profil particulier.

46
d ' où
L =* Logit (p) = log (p/(l-p)) = log e - X'fi (2.9)X'£
et où, tout comme en régression linéaire,
Fait intéressant, une autre façon de parvenir à l'ex
pression (2.9) consiste à partir de l'expression (2.3) pour
r e p r é s e n t e r la rel a t i o n entre la probabilité que (Y=0) et
l'ensemble des variables explicatives. On obtient alors:
P r (Y = 0 ) - 1 - Pr(Y-l)
1- 1 - _________________
- X'fi1 + e
-X'£1 + e 1
-X'£ -X'£1 + e 1 + e
-X'£
_______________ ( 2 . 1 0 )-X'£
1 + e

47
d'où
L - log p(l-p) - log p - log (1-p)
-X'& -X’fi -X'£- -log ( 1 + e ) - riog (e ) - log ( 1 +e )]
- X'£
Enfin, on aura reconnu que cette dernière expression est
tout à fait linéaire. L'expression (2.3) présente donc aussi
l'avantage d'illustrer clairement le passage de la forme expo
nentielle à la forme linéaire qui constitue l'atout majeur
d'utiliser le modèle logistique. En résumé, nous pouvons dire
que grâce à la transformation logistique de P nous aboutissons
à une expression linéaire semblable à l'équation du modèle de
régression linéaire en (1 .1 ), mais où la variable prédite n'est
plus la probabilité P mais plutôt le logit de P.
Les logits sont donc des fonctions linéaires des varia
bles indépendantes alors que les probabilités ne le sont pas.
Il est aussi i n téressant de noter qu'alors que les valeurs
"odds ratio" (P/(l-P)) augmentent de zéro à l'infini, les
logits, i.e. les valeurs X'B, sont susceptibles de prendre
n'importe quelles valeurs entre - 00 e t + 00 et les valeurs

48
de P sont restreintes à l'intervalle [0,1] tel que souhaité.
De plus, lorsque la probabilité approche de 0 ou de 1, le
logit est sujet à des changements très grands puisque la
valeur de ce dernier n'est restreinte à aucun intervalle, de
sorte que X'£ peut prendre n'importe quelle valeur réelle
sans violer les limites auxquelles les P sont assujetties. Ce
dernier point représente, selon Theil(1971), un avantage
considérable du logit par rapport à la probabilité.
2.2 ESTIMATION DES PARAMETRES DU MODELE DE LA REGRESSIONLOGISTIQUE
2.2.1 Méthode des moindres carrés généralisés
Etant donnée la ressemblance qui existe entre la régres
sion logistique et la régression linéaire multiple, on pour
rait croire que la méthode des moindres carrés est la plus
adéquate pour estimer log (p/( 1 - p ) ) = X'£ à partir des données
d'un échantillon. En y regardant de plus près, on réalise
rapidement qu'il est impossible d'utiliser les observations
originales Y=»0 ou 1 pour représenter P, notamment parce que
la division par 0 est impossible.

Il demeure certes possible de partitionner l'axe des X
en catégories de façon à capturer suffisamment d'observations
dans chacune d'elles pour y observer des proportions plus
grandes que zéro et alors d'appliquer la solution des m oin
dres carrés généralisés (équivalente, ici, au critère du
chi-deux m i n i m u m proposé par Berkson (1955) et explicité
entre autres par Cox (1970). En fait, comme le souligne
H a n u s h e k & J a c k s o n ( 197 7 ) , les difficultés inhérentes à
l ' e s t i m a t i o n de modèles p r o b a b i 1 istes sont amoindries en
présence de données regroupées (ou répliquées) où la variable
dépendante est la proportion d'individus effectuant un choix
donné ou se trouvant dans une catégorie particulière plutôt
que la variable binaire observée au niveau individuel.
Cette approche possède cependant une limite sérieuse au
niveau du nombre très grand d'observations requis pour effec
tuer une estimation valable lorsqu'il y a plusieurs variables
indépendantes. Cette exigence est particulièrement suscepti
ble de ne pas être remplie en recherche en éducation, où les
unités d'observations sont généralement des individus et où
les variables explicatives sont souvent multiples. Le lec
teur intéressé à en savoir davantage sur cette méthode d'es
timation est invité à consulter l'ouvrage de Neter, Wasserman
& Kutner (1983) .

50
Nous nous concentrerons donc sur une méthode d'estima
tion plus souple, qui elle, dans le cadre de l'analyse de
r é g r e s s i o n logistique, permet de considérer des variables
in d é p e n d a n t e s aussi bien d i chotomiques par exemple, que
continues, de même que leurs interactions, et ce contraire
ment à la méthode du X 2 minimum qui n'est applicable qu'en
présence de plusieurs observations par cellule. Il s'agit de
la méthode d'estimation du maximum de vraisemblance. Celle-
ci, du moins en présence de variables indépendantes conti
nues, s'avère une meilleure voie pour estimer le modèle logit
puisqu'elle permet de traiter chaque observation séparément.
Elle ne n é c e s s i t e donc aucun regrou p e m e n t plus ou moins
artificiel des observations et évite de postuler, souvent de
façon irréaliste (Hanushek & J acks on , 19 7 7 ) , que des sujets
avec des caractéristiques différentes ont la même probabilité
de "succès" du fait qu'ils sont regroupés dans une même
cellule.
Pour décrire cette méthode, supposons un échantillon
aléatoire de n observations (Y^.X'^), i = l ,2,...,n. Si nous
considérons différentes valeurs de paramètres ...,
pour le modèle (2 .1 ), la vraisemblance d'obtenir l'échantil-
2 . 2 . 2 M é t h o d e d u m a x i m u m de v r a i s e m b l a n c e

51
Ion en m ain variera. Les valeurs pour lesquelles cette
vraisemblance est la plus élevée seront appelées les estimés
du maximum de vraisemblance. Le critère du maximum de v r a i
s emblance fournit donc les valeurs des paramètres les plus
suscep t i b l e s de produire les données observées, i.e. de
maximiser la vraisemblance de l'échantillon observé.
Supposons que l'on détermine la probabilité de succès
pour la première observation de notre échantillon. Si l'on
représente par la probabilité d'obtenir un succès (Yi=l),
on peut noter par 1-Pi la probabilité d'un échec (Yi=0). Ces
deux probabilités complémentaires peuvent être combinées en
une même formule permettant de trouver la probabilité d'obte
nir n'importe laquelle des 2 valeurs associées à Y]_, notée
p(Y^) (Wonnacott & W o n n a c o 1 1 ,1981) . Cette formule est la
suivante :
y ( l - y )p(Yx)- Pi (1-Pi) ( 2 . 11 )
Ainsi, on peut vérifier que dans le cas où Yi = l nous obte-
nons :
1Probabilité d'un succès™ Pi (1-Pi) ( 1 - 1 )

et de la même façon si nous substituons Y^ = 0 dans (2 .1 1 ),
nous aurons :
0 (1 -0 )Probabilité d'un échec= P-j_ (1-P^) = 1 - Pj_
Le calcul de p(Y^) peut par la suite être effectué pour
p (Y 2 ),...,p(Yn ) , de sorte que la probabilité pour l'échantil
lon total, si toutes les observations sont indépendantes, ce
qui est le cas pour un échan t i l l o n aléatoire, s'obtient en
calculant le produit des probabilités individuelles, i.e.:
P(Y 1 ,Y2 ----,Yn ) = p(Yx ) p (Y 2)... p(Yn ).
Cette valeur, appelée fonction de vraisemblance et notée
L(fi)1, prend l'allure générale:
n yi d-Yi)L(fi) = n ^ d-Pi) (2-12)
i- 1
Pour simplifier les opérations mathématiques, c'est
h a b i t u e l l e m e n t le logarithme naturel de la fonction (2 .1 2 )
que l'on vise à maximiser. En effet, en travaillant avec log
L(fi), le produit des probabilités que l'on retrouve dans
1 L : "likelihood"(fi): fonction des valeurs des paramètres fi
52

53
l'équation (2 .1 2 ) devient simplement la somme des logarithmes
des termes. Le logarithme de la fonction de vraisemblance
pour le modèle logistique correspond à:
log L(A) - i£ iYi log Pi + ? (1-Yi) log (1-Pi) (2.13)
Tentons de simplifier cette expression. Notant tout d'abord
qu'en vertu des propriétés des indices de sommation
( 1 - W t ) U i - J 1 ( U i - w t U j ) - i £ i Ut - . ^ W t Ut
et a p p l i q u a n t ce résultat au deuxième terme de droite de
(2.13) on obtient:
log L(*)- log Pi + S log (1-Pi) - S Yi log (1-Pi)(2.14)1 - 1 i=l i=l
Interchangeant les deux derniers termes de (2.14), nous
obtenons :
log L(*)- Yi log Pi - Z Yi log (1-Pi) + Z log (1-Pi) (2.15)1 - 1 i=l i=l
On sait également, en vertu d'une autre propriété des

l o g a r i t h m e s que:
log W - log U - log (W/U)
Appliquant cette propriété en (2.15) nous obtenons finale
ment :
log L(£)= ^ log [Pi/d-Pi)] + £ log (1-Pi) (2.16)i- 1 i=l
Mais on a vu en (2.3), (2.5) et (2.10) respectivement que
1
P i “ ------------------------X'£1 + e
11-Pi - -----------
X'£1 + e
et log [Pi/d-Pj)] - X'A
Substituant ces dernières valeurs en (2.16) on obtient:

55
n nl o g L (£) -.v Y t Xi'£ + r log [ 1 / (1+ e)]
l - l i = l
i.e.
n n X ± * £log L (£) = E Y t Xj 1 £ - £ log ( 1 + e i= 1 i=l ) (2.17)
En vue de trouver les estimés de £ qui maximiseront la
vraisemblance de l'échantillon, il s'agit en partant de
(2.16) ou (2 .1 2 ), de substituer les par l'expression (2 .1 )
ou un équivalent, de trouver les dérivées partielles pour
chacun des p a r a m è t r e s inconnus et d'égaler ces dérivées à
zéro .
L'application de cette procédure produit un système
d'équations non linéaires. Nous obtiendrons alors autant
d 'équations qu'il y a de paramètres à estimer (i.e. k + 1 ).
Ces équations ne peuvent être résolues en termes de formules
algébriques ordinaires mais grâce à des méthodes dites itéra
tives qui cons i s t e n t à essayer systématiquement différentes
valeurs de paramètres pour choisir celles qui satisferont le
mieux possible le système d'équations ci-dessus. Notons que
les calculs associés à cette approche étaient pratiquement

impossibles à réaliser avant l'apparition de l'ordinateur.
Aujourd'hui la solution d'un système d'équations non linéai
res peut être trouvée très rapidement et à un coût relative
ment bas. Parmi les techniques itératives les plus populai
res signalons l'expansion de Taylor, la méthode de Newton-
Raphson, celle des constantes ajustées ( Fienberg,198 0 ) et
celle de Gauss-Newton.
2.2.3 Propriétés des estimés
Il est reconnu (Fienberg (1980), Judge, Lee, Manski &
McFadden (1981)), que les estimés du maximum de vraisemblance
pour le modèle logistique p o ssèdent certaines propriétés
c o mparables à celles associées aux estimés des moindres
carrés en régression linéaire. La plupart de ces propriétés
découlent de la théorie des grands échantillons (asymptotic
theory) d'où le qualificatif "asymptotique" qui les accompa
gne souvent.
Trois de ces propriétés nous intéressent particulière
ment :
(1) Les estimés logistiques du m a x i m u m de v r a i s e m b l a n c e
sont c o nsistants i.e. qu'ils se rappr o c h e n t de plus

en plus de la valeur des paramètres quand n tend vers
1 'infini ;
57
(2) Ils tendent à se distribuer selon la loi normale lorsque
n tend vers l'infini;
(3) Ils sont asymptiquement efficaces i.e. qu'il est impossi
ble d ' o b t e n i r d'autres estimés ayant de plus petites
variances, lorsque n tend vers l'infini;
Pour un exposé des preuves de ces propriétés, le lecteur
est invité à consulter l'ouvrage de Ffeaetros Dhrymes (1978,
pp .336-338).
Il est à noter qu'en principe, ces propriétés ne s'appli
quent qu'aux estimés obtenus à partir de grands échantillons.
Il semble cependant qu'en pratique:
" Under many circumstances, maximum likelihood estimators have been found to have desirable properties even when applied to small samples." (Hanushek & Jackson, 1977, p. 203)
Les résultats d'une étude de simulation menée par O r
chard (1976) nuancent cette assertion. L'auteur y compare la
méthode d ' e s t i m a t i o n du m aximum de vraisemblance pour la

régression logistique avec des données non répliquées et deux
autres méthodes d'estimation approximatives. Les résultats
de cette étude indiquent qu'en présence de 2 0 observations et
plus la m é t h o d e du m a x i m u m de vraisemblance est stable et
converge r a p i d e m e n t vers une solution, lorsqu'elle existe,
mais qu'en deçà de ce nombre d'observations il s'avère qu'il
n'y aurait pas suffisamment d'informations, en présence de
données non répliquées, pour obtenir de bons estimés.
2.2.4 Tests d'hypothèses concernant les paramètres
Plusieurs s t atistiques sont destinées à vérifier la
qualité d'ajustement (goodness of fit) des modèles logisti
ques. Nous nous restreindrons cependant dans cet exposé aux
princ i p a l e s s t atistiques utilisées spécifiquement dans le
cadre d ' analyses impliquant une ou des variables indépen
dantes continues et nécessitant de ce fait le recours à la
méthode d'estimation du maximum de vraisemblance. Pour un
aperçu des tests d'hypothèses conçus’ pour les analyses n'im
pliquant que des variables indépendantes catégorielles ou des
variables continues dont les valeurs ont été regroupées en
catégories nous référons le lecteur à l'ouvrage d'Hanushek &
Jackson (1977, p. 196-200).

59
Notons d'abord qu'en plus de fournir des estimés de
paramètres possédant les propriétés énumérées ci-haut, l'ap
p l i c a t i o n de la méthode du maximum de vraisemblance permet
d'obtenir un estimé asymptotiquement consistant de la matrice
de v ar i anc e s - c o var i ance s des coefficients. Cette matrice,
que nous noterons (V), et qui correspond à la matrice "infor
mation" (I) de Fisher (Pun, 1981), peut être utilisée pour
calculer des intervalles de confiance et procéder aux tests
d'hypothèse conventionnels concernant les estimés des paramè
tres du modèle. Quant à ces estimés des paramètres £ du
modèle logistique, soulignons qu'ils suivent la loi multinor-
male avec moyenne S (i.e. estimés non-biaisés) et matrice de
variances - covariances (ou de dispersion) égale à l'inverse de
V. En d'autres termes,
-1b ~ N (fi,V )
où X' D XV - (2.18)
3 b^ 3 bj
et
D - diag (p. (1-p. ))i i

6 0
Un estimé de la matrice V peut être obtenu en évaluant
l'expression (2.17) à partir des estimés du maximum de v rai
semblance. Les e r r e u r s -types des coefficients logistiques,
correspondant à la racine carrée des éléments de la diagonale
de V, peuvent être utilisées pour effectuer un test statisti
que éprouvant l'hypothèse qu'un paramètre est égal à 0 i.e.:
Cette statistique est obtenue en divisant l'estimé du
paramètre visé par son erreur-type. Asymptotiquement , sous
l'hypothèse nulle, ce test statistique se distribue selon la
loi normale standardisée, i.e:
de sorte que la valeur critique pour rejeter Ho au seuil de
s i g i n i f i c a t i o n de .05 est 1.96, ou 2, valeur arrondie.
Certains auteurs préfèrent baser le test sur l'approximation
suivante :
Ho : fii - 0 versus Ha : fii / 0.
bk / s <b k) ' N(0,1) H o (2.19)
t>k / s(bk ) ^ cn-k> (2.20)
où tn _k correspond à la distribution du t de Student avec n-k

61
degrés de liberté. Cette statistique est alors appelée test t
asymptotique. Cependant, comme le souligne Amemyia (1981),
étant donné que n-k est généralement grand dans les modèles
où la variable dépendante est qualitative, il n'y a pratique
ment pas de différence entre N(0,1) et tn .jc pour déterminer
la v aleur critique. En fait, ces deux approximations sont
théoriquement correctes puisque tn .k ” N(0,1 ) 2 quand n -*• 00
(Hays,197 3).
L'hypothèse nulle est rejetée lorsque la valeur absolue
de la s t a t i s t i q u e est plus grande que la valeur tabulaire
correspondant à un niveau de signification déterminé. Nous
conclurons alors à la véracité de l'hypothèse alternative
i.e. que le coefficient est significativement différent de 0 ,
et que, par conséquent, la variable indépendante correspon
dante associée a un rôle à jouer dans la prédiction de la
probabilité d'obtenir un "succès", i.e. Y**l .
Une autre statistique communément utilisée en régression
logistique résulte de la comparaison des valeurs maximum des
vraisemblances obtenues pour différents modèles par le biais
de tests ch i - d e u x a s y mptotique s . Cette statistique est
parfois considérée comme équivalente au test F rencontré en
régression linéaire (Aldrich, Cnuddle, 1975). Ce test du

rapport de v r a i s e m b l a n c e (likelihood ratio test) pour les
h y p o t h è s e s c o ncernant des groupes de paramètres vérifie
l'effet combiné des variables indépendantes de l'équation de
régression logistique i.e.:
Ho : £ - 0 versus Ha: £ ^ 0
Ce test revient à calculer la valeur:
- 2 log X - - 2 [ log L(£) - log L(W) ]H" X2 (k-1)
où X est le rapport de vraisemblance pour Ho: £=0, L(£) est
la valeur de la fonction de vraisemblance évaluée en utili
sant les estimés du m a ximum de v r a i s e m b l a n c e et L (W) la
valeur de cette fonction sujette à la contrainte que le
vecteur £ égale zéro. Cette statistique est donc une compa
raison de la probabilité d'observer l'échantillon en main où
les estimés du maximum de vraisemblance ont été obtenus sans
contrainte versus la probabilité de la situation où tous les
coefficients faisant l'objet de l'hypothèse ont été mis égaux
à zéro.
Si l'hypothèse nulle est vraie, le test suivra asympto-
tiquement la distribution du chi carré avec (k- 1 ) degrés de
liberté (Judge & L e e , 1982). L ' hypothèse nulle sera donc

63
rejetée si la valeur de la statistique (qui n'est jamais
négative) excède la valeur du X 2 critique au seuil de signi
fication désiré.
Notons finalement que, malheureusement, aucun indice de
qualité d'ajustement facilement interprétable comme le coef
ficient de détermination R 2 > populaire en régression multiple
n'est disponible pour évaluer la valeur prédictrice de l'é
quation de régression logistique (Fienberg 1980).
Il existe cependant une mesure qui lui est apparentée
jusqu'à un certain point: il s'agit du Pseudo R 2 (likelihood
ratio index) (Judge, Griffiths, Hill & Lee, 1980; Amemiya,
1981). Cet indice s'obtient de la façon suivante:
ln L(£)Pseudo R 2 : 1 - _________ (2.21)
ln L (W)
où L(£) et L(W) ont la même signification que dans le cadre
du test du rapport de vraisemblance. La valeur pour ce test
varie entre 0 et 1 ; elle sera égale à 0 lorsque le vecteur
£-0 et 1 lorsque le modèle est un prédicteur parfait. Sous
cet aspect, certains auteurs considèrent cet indice comme
étant analogue au R 2 • Cependant, il ne partage pas la p r o

64
priété que possède ce dernier de nous renseigner sur l a
proportion de la variabilité de la variable dépendante "ex
pliquée" par les variables indépendantes.
2.3 Tests d'ajustement basés sur les probabilités prédites
Un certain nombre de méthodes ont récemment été propo
sées pour évaluer la qualité d'ajustement pour les modèles de
régression logistique multiple (Lemeshow & Hosmer, 1982). Il
va sans dire que de tels tests de la qualité d'ajustement
sont très importants car si les données analysées s'éloignent
du modèle logistique, avec sa courbe bien particulière (voir
Figure 2.1), les statistiques éventuellement calculées (par
exemple, les estimés des paramètres) risquent d'être biaisées
sinon totalement invalides (Brown, 1982).
Ces méthodes tirent profit de la possibilité qui existe,
une fois les coefficients de régression logistique estimés,
de calculer, pour chaque observation de l'échantillon, la
p roba b i l i t é de succès prédite en remplaçant en (2 .1 ) les
paramètres £ par leurs estimés. Plusieurs de ces tests font
appel au principe du test d'indépendance du chi-deux pour les
tableaux de contingence. Voyons en détail deux de ces tests.

65
Une statistique, Cg, proposée par Hosmer et Lemeshow
(1980), nous a semblé particulièrement intéressante; comme
nous le verrons d'ailleurs plus loin, elle fait partie des
renseignements fournis par la routine d'analyse de régression
logistique informatisée BMDPLR (Dixon, 1983). Cette statisti
que est calculée à partir d'un tableau de contingence 2 xg
constitué du croisement des valeurs observées à la variable
dépendante (0 ,1 ) et d'une variable catégorielle résultant du
partitionnement en g groupes des probabilités prédites ordon
nées .
Intuitivement, si le modèle logistique est adéquat, on
s'attendra à ce que les individus ayant obtenu un "succès"
(i.e. Y=l) possèdent des probabilités estimées élevées et se
retrouvent dans les groupes supérieurs, vice versa. Selon ce
raisonnement, il semble approprié d'étudier, pour chaque
catégorie de probabilités prédites, la proportion de succès
obtenue par les individus appartenant à cette catégorie. Il
s'agit donc de comparer, dans chaque catégorie, le nombre
d'observations pour lesquelles on observe un succès avec le
nombre d ' o b s e r v a t i o n s regroupées selon leur probabilités
prédites par le modèle.
2.3.1 Test de "Hosmer"

66
La stratégie utilisée pour regrouper les observations
est basée sur le vecteur ordonné des probabilités estimées
(p i , i - 1 ,2..... n) . Le nombre de groupes le plus fréquemment
utilisée est 5, i.e. g=5 . Pour déterminer les limites de ces
intervalles (Ik , k-l, 2 ,...g) pour chacun des g groupes, il
s'agit d'évaluer la condition suivante:
Ik “ [ i: (k- 1 )n/g < i < kn/g ] (2 .2 2 )où k=l, 2 ,...,g et i-l, 2 ,...n.
Ainsi, dans le cas où g-5 et n-50, nous retrouverons, dans
le 3e groupe, les 20e à 29e observations ordonnées selon
leurs probabilités prédites puisque suivant (2 .2 2 ):
I 3 - (3-1)50/5 < i < 3(50)/5
20 ^ i < 30
Après avoir réparti les n observations à l'intérieur
des g groupes, il faut, dans une deuxième étape, déterminer
les fréquences observées (Cjk) puis les fréquences attendues
ou théoriques (Cjk ) pour chacune des 2 xg cellules du tableau
de contingence i.e. et Cjk où j=l lorsque Y = 1 et j=2
lorsque Y - 0 alors que k = l ,2.... g.

67Ces fréquences sont fournies par les expressions suivan
te s :
clk " E *i ielk
C 2 k - 2 (1 -Yi)i«Ik
^lk ” 2 Pii£lk
C2k “ 2 d - P i )i«Ik
La statistique Cg est alors égale à:
2 g 2 .Cg - E E (Cjk - Cj k ) / Cjk (2.23)
j - 1 k - 1
Des études simulées, (Lemeshow,Hosmer, 1982) ont démon
tré que la distribution de la statistique Cg suit approxima
tivement la loi du avec (g-2 ) degrés de liberté lorsque le
modèle logistique est le modèle adéquat. C'est dire qu'une
trop grande valeur de la statistique Cg entraîne le rejet du
modèle logistique comme exprimant la relation entre la proba
bilité d'un succès et les variables indépendantes considérées .

68
Nous parlerons ici, sans toutefois entrer dans tous les
détails, étant donné la complexité des calculs qu'il impli
que, d'un autre test de la qualité d'ajustement: le test de
Brown. Ce test de la qualité de l'ajustement du modèle
logistique fut d'abord proposé par Prentice (1975) pour le
cas d'une seule variable indépendante puis il fut généralisé
par Brown (1982) au cas où plusieurs variables indépendantes
sont considérées.
Le principe du test de Brown est d'intégrer le modèle logistique dans une "famille" plus générale de modèles para
métriques, où les valeurs de deux paramètres , m^ et m 2
distinguent entre eux ces différents modèles. Par exemple,
dans le cas du modèle logistique, on a mi=*l et m 2 = l . Il
devient alors possible de développer un test en vue d'éprou
ver l'hypothèse nulle que le modèle de régression logistique
est adéquat versus l'hypothèse alternative que c'est plutôt
un des autres modèles de la famille qui convient le mieux
pour décrire la relation entre la variable dépendante binaire
et les v a r i a b l e s indépendantes considérées. Comme Brown
(1982) le souligne, la famille de modèles définie ci-dessus
(laquelle comprend, entre autres, le modèle probit, celui de
2.3.2 Le test de Brown

69
Cauchy et celui de la valeur extrême) est suffisamment vaste
pour couvrir un très grand nombre de relations entre une
variable dépendante binaire et des variables indépendantes.
Le test développé par Brown s'appuie sur la statistique
T, définie comme suit:
T - s' C ' 1 s (2.24)
où s'- (s^, s2) ” ( 9 1 9 1 ), et correspond3 m]_ 3m 2
au vecteur constitué des dérivées partielles du logarithme de la vraisemblance, 1 , i.e. du "log likelihood" (voir plus loin) de l'échantillon, par rapport aux paramètres m^ et m 2 définis ci-dessus;
C - la matrice des variances - covariances (de dimension 2 x 2 ) de la distribution des deux dérivées partielles conditionnelle à ce que les dérivées partielles du logarithme de la v r a i s e m b l a n c e par rapport à chacun des
paramètres Bq B^ ..., Bk du modèle logistique à estimer’solent égales à zero.
Brown (1982) a démontré que la statistique T suit, sous
l'hypothèse nulle à l'effet que le modèle logistique est le
"vrai" modèle, et lorsque n tend vers l'infini, la loi du
chi-deux, avec 2 degré de liberté, i.e.

T Xi (2.26)Ho z
Il va sans dire que le calcul des matrices s et C est
assez complexe, surtout dans le cas de plusieurs variables
indépendantes, et que le recours à l'informatique est inévi
table .
2.3.3 Autres approches
Récemment, d'autres travaux, dont ceux de Pregibon
(1981), Landwehr, Pregibon & Shoemaker (1984) ont porté sur
la généralisation ou la modification de méthodes graphiques
déjà utilisées dans le cadre des modèles de régression li
néaire pour évaluer l'ajustement des modèles de régression
logistique. Il s'agit de techniques informelles et explora
toires basées en partie sur la représentation graphique des
résidus. Une première approche ("local mean deviance plots")
vise à d étecter un manque d ' ajustement général entre les
données observées et les valeurs prédites. Une deuxième
méthode ("empirical probability plots") permet surtout d'i
dentifier des observations ayant des valeurs extrêmes
(outliers) tandis qu'une troisième a pour but de trouver les
causes spécifiques de mauvais ajustements. Le lecteur
702

71
intéressé à en connaître davantage sur ces méthodes pourra
consulter les auteurs mentionnés ci-dessus.
2.4 LES PROGRAMMES D'ORDINATEUR DISPONIBLES POUR LA REGRESSION LOGISTIQUE
Nous avons déjà justifié le choix de la méthode du
maximum de vraisemblance pour estimer les paramètres du
modèle de régression logistique lorsqu'une partie ou l'ensem
ble des v a r i a b l e s explicatives est de nature quantitative.
En pratique, dû entre autres à la complexité des équations à
résoudre, l'application de cette méthode est impensable sans
l'aide d'un programme informatisé.
Dans l'espoir que le contenu de cette thèse présente une
certaine utilité en recherche appliquée, nous avons cru bon
d'y inclure une d e s c r i p t i o n des deux programmes^ que nous
avons utilisés dans cette recherche, soit le programme PLR
du progiciel BMDP (BioMeDical computer Programs) (Dixon,1983)
et le programme PROBIT du progiciel SPSSX (Statistical Packa
ge for Social Sciences, version 1986, 2e édition). Cependant,
JA notre connaissance, le progiciel SAS n'offre pas de routine permettant d'effectuer une analyse de régression logistique avec variables indépendantes quantitatives.

72
pour restreindre cette partie essentiellement descriptive à
des dime n s i o n s raisonnables, notre disc u s s i o n de chaque
routine sera brève, se limitant aux renseignements pertinents
à la s i t u a t i o n où il y a au moins une variable continue
(données non regroupées). Le lecteur intéressé à obtenir une
d e s c r i p t i o n plus détaillée des possibilités ainsi que des
modalités d'utilisation de ces programmes est invité à con
sulter les manuels de ces deux progiciels.
L'exemple que nous utiliserons pour illustrer les carac
téristiques des deux progiciels est tiré de l'étude de
Dagenais (1984) que nous avons sommairement décrite au chapi
tre I. Résumons le contexte de cette étude. L'objectif de
l'auteure était esse n t i e l l e m e n t de prédire les chances de
succès, i.e. de réussir la première année du Baccalauréat à
partir de données concernant les étudiants admis au programme
d'administration des affaires de l'Ecole des H.E.C. de M o n
tréal au cours des années 1979 et 1980. Dans cette étude,
portant sur 824 sujets, trois variables ont été utilisées
pour prédire le succès futur dans le programme et par le fait
même étudier la validité du processus de sélection. Pour
atteindre cet objectif, Dagenais a recouru au modèle probit
(voir chapitre trois).

Grâce à la co l l a b o r a t i o n de l'auteure, nous avons eu
accès aux données complètes pour les 824 sujets de l'étude.
Ces données réelles, touchant un problème important du domai
ne de l'éducation, celui de la sélection de futurs étudiants,
nous ont servi à deux fins: ( 1 ) illustrer les résultats
fournis par deux programmes de régression logistique; (2 )
comparer ces résultats à ceux obtenus par Dagenais par la
méthode probit.
Voici la description des variables utilisées. La varia
ble dépendante SU60 prenait la valeur "1" si l'étudiant était
admis en deuxième année du programme et "0 " s'il y avait
abandon ou échec en 1ère année. Parmi les 3 variables indé
pendantes, deux étaient de nature continue: il s'agit du
résultat moyen au niveau collégial (SCZ), normalisé en fonc
tion de la m oyenne du groupe de référence, et du résultat
moyen obtenu par le candidat aux tests d'admission adminis
trés par l ' é t a b l i s s e m e n t (T). Finalement, on a considéré
l'année ( 197 9 ou 1980) où le candidat fut admis dans le
programme comme troisième variable indépendante, qualitative
cette fois (D), afin de tenir compte des différences pouvant
exister entre ces deux groupes d'étudiants.

742.4.1 Description du programme BMDPLR
Le programme PLR du progiciel BMDP permet de procéder à
une analyse de régression logistique avec une ou plusieurs
v a r i a b l e s indépen d a n t e s q u a ntitatives et/ou qualitatives
ainsi que leurs interactions. Nous n'analyserons pas une
p a r t i c u l a r i t é de ce p r ogramme consistant à effectuer une
sélection des "meilleures" variables indépendantes à l'aide d'une procédure hiérarchique (STEPWISE) similaire à celle que
l'on r e ncontre en régre s s i o n linéaire multiple. Dans le
cadre de cette thèse, nous nous sommes plutôt intéressé à
co nserver toutes les variables en les "forçant" à demeurer
dans l'analyse. Voici donc, au tableau 2.1, les commandes
BMDP pour analyser les données de Dagenais.
T ableau 2.1 Exemple des commandes BMDPLR pour l'exécution ________________d'une analyse de régression logistique.__________
PROGRAM CONTROL INFORMATION/:tÊ£kT YARTABLAS ARE 6. „FORMAT ÎS • (F3.0,6X,FZ.0,3X,/=5\0,4X,F4..0,7X,FL.0,6X,F2.0) 1
Un I T a o ./VARIABLE n a m e s ARE MT,D,SCZ,M0Yl,SU60,T./t ^ 5 s2 '3 '5 '6 '-
IF (D EQ 79) T H E N D =■ 1 .IF CD EQ 80) THEN 0 = 8 ./RE&RESS DEPENDANT = SUfeO,
INTERVAL - SCZ,T.CATE&ORICAL = D.M0DEL=£>,SCZ, T.START = Tw, tH, W .MOVË -0.0/0,/PRrwr CEULSrMODEL.S0RT=P0TH.

75
Quelques commentaires sur les commandes de ce tableau:
a) /INPUT spécifie le nombre et le format (i.e la
position) des variables ainsi que le
support où elles sont emmagasinées.
b) /VARIABLE les noms des variables y sont précisés. La
position qu'occupe chacune des variables
retenues dans cette analyse est précisée
grâce au sous-paragraphe USE=
c) /TRAN a pour objectif de transformer les variables
Ici, les valeurs 79 et 80 (i.e. 1979 et
1980) sont transformées en 0 et 1, redéfi
nissant ainsi la variable catégorielle D .
d) /REGRESS : permet d'identifier les variables dépendante
et indépendante(s ) ainsi que la nature de
ces dernières.
-L'énoncé DEPENDANT=SU60 indique que c'est la variable SU60
qui est la variable dépendante. SU60 valait "1" si l'étu-
diant(e) concerné(e) avait g r a d u é (e) en deuxième année
(succès) et "0" (échec) dans le cas contraire. Cet énoncé

7 6
a aussi pour rôle de p r éciser que le résultat à cette
variable est fourni, pour chaque observation et ne se
présente pas sous forme de fréquences (variables indépendantes catégorielles).
-Les énoncés INTERVAL— et CATEGORICAL— permettent d'identi
fier le type de v a riables indépendantes utilisées. Dans
cette analyse, les variables indépendantes SCZ et T étaient
de nature quantitative (ou INTERVAL) tandis que la variable
indépendante D est de nature qualitative ("CATEGORICAL"). Il
est à noter que pour chaque variable catégorielle, PLR
génère un ensemble de variables factices, une de moins que
le nombre de catégories de la variable. A l'intérieur de
cette procédure il est possible de choisir parmi trois types
de codage factice soit sous forme de contrastes marginaux
(utilisé par défaut), de contrastes partiels ou de contras
tes orthogonaux.
-L'énoncé MODEL= fournit la liste des variables indépendantes
que l'on veut considérer dans l'analyse.
-L'énoncé START= indique, lors de l'application de la procé
dure "stepwise", quelles variables indépendantes on désire
conserver dans tous les modèles. Ici, le IN devant chacune

de nos 3 var i a b l e s indépendantes indique que l'on désire
c o n s e r v e r chacune d'entre elles dans tout modèle investi
gué. En fait, on n'aura ici qu'un seul modèle, celui in
cluant toutes les variables indépendantes mentionnées ici.
-L'énoncé MOVE- est surtout utile lors de l'application de la
pro c é d u r e "stepwise" ; elle indique le nombre maximum de
fois qu'un terme du modèle peut y être inclus ou en être
exclu. Ainsi, la présence des trois "0" a pour effet d'an
nuler cette procédure "stepwise" qui autrement s'effectue
rait automatiquement.
e) /PRINT : permet de spécifier dans quel ordre les
résultats de l'analyse (probabilités prédi
tes, 1 o g odds etc...) a p p araîtront à la
fin de la sortie. Ainsi, CELL- MODEL signi
fie que des résultats seront fournis pour
chaque ensemble distinct des variables
indépendantes et S0RT=B0TH implique qu'ils
apparaîtront par ordre croissant de probabi
lité de succès et ensuite selon les valeurs
observées aux variables indépendantes.
Il est également p o ssible de c o nsidérer dans une analyse

toute interaction entre deux ou plusieurs variables (i.e. le
produit de ces variables). Ces interactions sont spécifiées
à l ' i n t é r i e u r de l'énonce MODEL= en reliant par un asté
risque (*) les variables impliquées. Il est également possi-
le de contrôler les calculs inhérents au processus itératif
de calcul des estimés du ma x i m u m de v r a i s e m b l a n c e (i.e.
nombre maximum d'itérations et valeur du critère de conver
gence, etc.).
2.4.2 Description du programme PROBIT de SPSSX
La p r o c é d u r e PROBIT, comme son nom l'indique, calcule
les estimés du maximum de vraisemblance des paramètres d'un
modèle probit. Elle peut également, en dépit de son nom,
effectuer une analyse similaire pour un modèle de régression
logistique et permet de considérer des variables explicati
ves aussi bien catégorielles que continues. Cependant, dans
ce dernier cas, la procédure est moins efficace qu'en p r é
sence de variables exclusivement catégorielles.
En effet, en présence de variables continues, les don
nées numériques sont fournies pour chaque observation alors
que le pro g r a m m e a été a priori conçu pour analyser des
données groupées, considérant les fréquences de succès obser-

vées pour différentes catégories de variables indépendantes.
Malgré cette incompatibilité, le programme estimera correc
tement les estimés des paramètres et leurs erreurs - types mais
fournira un averti s s e m e n t à l'effet que la valeur du test
d'ajustement (X^) est incorrecte dans cette situation. Voici
les commandes que nous avons utilisées lors de l'application
du programme PROBIT aux données de Dagenais.
Tableau 2.2 Exemple de commandes SPSSX pour l'exécution d'une analyse de r é g r e s s i o n logistique à l'aide du
______________ programme PROBIT________________________________________
DATA LIST FILE = FT08F001 F I XED/MAT , D ,SCZ,MOY1,SU60,TTT(F3.0,6X,F2.0,3X,F5.0,4X,F4.0,7X,Fl.0,fex,F2.0)RECODE D (79=1) (80=-l)COMPUTE SUJE T = 1PROBIT SU60 OF SUJET WITH SCZ T D/MODEL = LOGIT/L0G=N0NEBEGIN DATA END DATA FINISH /*//

Voyons maintenant la signification des principaux énoncés.
a) DATA LIST
b) RECODE
c) COMPUTE
d) PROBIT
: permet à l'usager de fournir la liste des
variables qu'il compte utiliser.
: sert ici à donner les nouvelles valeurs "0 "
et 1 à la variable D.
: est utilisé ici pour créer une nouvelle
v a riable spécifiant que les observations
doivent être considérées individuellement.
Cette spécification est nécessaire lorsque,
comme c'est parfois le cas en régression lo
gistique,les données ne sont pas regroupées.
: exige d'abord que l'utilisateur identifie la
var i a b l e dépendante et précise de quelle
façon ses valeurs seront fournies à l'ordi
nateur. Ainsi SU60 OF SUJET indique que la
v aleur pour la variable SU60 est fournie
pour chaque observation puisque l'on a p r é
cédemment assigné la valeur "1 " à la varia
ble SUJET. Il faut ensuite définir les v a
riables indépendantes qui doivent, si elles
sont continues, être précédées de WITH.

81
-La sous - commande MODEL= sert à spécifier la forme du modèle
u t ilisé pour prédire la variable dépendante binaire. Ici
BOTH signifie que les deux modèles disponibles, probit et
logit, seront utilisés successivement. Cependant, un seul
modèle ne peut être spécifié à l'intérieur d'une commande PROBIT.
-La s o u s -commande LOG-NONE indique qu'aucune transformation
logarithmique des variables prédictrices ne sera effectuée.
Cette spécification est essentielle si l'on désire effectuer
une analyse de régression logistique.
-La sous - commande PRINT-FREQ permet l'impression d'une table
des fréquences ou p r o babilités observées et prédites par
1 'équation.
Il est aussi possible de contrôler le nombre maximum d'itéra
tions et le critère de convergence pour cette procédure.
2.4.3 Résultats obtenus via BMDPLR
La sortie d ' o r d i n a t e u r obtenue grâce aux commandes
décrites précédemment pour la procédure BMDPLR est présentée au Tableau 2.3.

8 2
Ta b l e a u 2.3 Résultats produits par l'analyse de régression logistique effectuée par le programme BMDPLR sur les données de Dagenais (1984)
P A G F. 6 H M I M’Lr1
S T E P n u m b e r n
A P R I L 17, 1 Q H S 11 : n :3P
G 0 0 0 N E S S VF F I ! C H I - S U G O O D N E S S OF Fi l C U T - S O G O O D N E S S OF F I T CHl-.SU
T E R *
0sczTC O N S T A N T
L O G L I K E L I H O O D = ( 2 * 0 * 1 N (0/h ) ) =( P. M O S H E R ) = ( C . C . H R O w N ) =
C O E F F I C I E N T
C .2865'!0 . H 6 1 '110 . i t s s o- 3 . 0 3 8 8
-•■iso . 1 Ps •510.111
« . 6 7 3 3 . 2 6 6
s t a n d a r dE R R O R
0 . F r H i 6 D . F r «n . F : r ?
C O K F f / S . E .
v - v a l u F = n . n i ?p _ V A L l lE = 0 . 7 9 2P - V A L U F = 0 . 1 Q S
0 . 8 0 6 3 E - 0 1 3.s7<50 . 1 7 6 8 « . 8 7 20 . 2 0 9 0 F - 0 1 5 . 5 2 50 . 6 7 3 7 — a . s 1 1
C O R R E L A T I O N M A T R I X OF C O E F F I C I E N T S
S C ?
0sczTC O N S T A N T
1.000 0 . 0 5 6 0 . 0 3 «
- 0 . 0 3 2
1.0000 . 2 2 5
- 0 . 3 0 61.000
- 0 . 9 8 9
S T A T I S T I C S T O FNTEft U R R E M O V E T E R M S
T E R M F T O " D . F . D.F ,
00S C Zs c zTTC O N S T A N T
A P P R O X .F TO
ENTER
C O N S T A N T
1 . 0 0 0
A P P R O X .F TO D . F . D . F .
RE M O V F P - V A L U E
1 2 . 9 5 1 8 1 9 0 . 0 0 0 3IS IN M A Y Mil T BE RF M O V E D .
2 a . 01 1 H 1 9 0 . 0 0 0 0IS IN M A Y N O T BE R E 11V F 0 .
3 0 . 8 7 1 8 1 9 0 . 0 0 0 0IS IN M A Y M O T HF R E M O V E D .IS IN M A Y M O T BE RE M O V E D .
N O T E R M P A S S E S T H E R E M O V E A N D E N T E R L I M I T S ( 0 . 1 5 0 0 0 . 1 0 0 0 ) .
S U M M A R Y D E S C R I P T I O N OF C E L L S . C E L L S A R E F O R M E D B Y A L L P O S S I B L E C O M B I N A T I O N S OF V A L U E S OF V A R I A B L f
N U M B E RS U C C E S S
N U M B E Rf a i l
O B S E R V E D P R O P O R T I ON S U C C E S S
P R E D I C T E DP R O B . O FS U C C E S S
S , D . OF P R E D I C T E D
P R O H .
O B S - P R F O
s T d T r e s T
P R E D .L O G
O D D S D s c z 1
0 l 0 . 0 0 . « 7 6 7 0 . 0 5 2 2 - 0 . 9 5 9 8 - 0 . 0 9 3 0 . 0 - 0 . 6 7 3 3 . 0 01 0 1 . 0 0 0 0 0 . 5 9 7 0 0 . 0 5 2 9 0 . 826(4 0 . 3 9 3 0 . 0 - 0 . 6 « 3 7 . 0 00 l 0 . 0 o . a 5 9 ¿4 0 . 0 5 0 « - 0 . 9 2 6 5 - 0 . Ib3 0 . 0 - 0 . 6 2 5 2 . 0 01 0 1 . 0 0 0 0 0 , 6 0 « o 0 . 0 5 1 5 0 . 8 1 3 1 0 . « 25 0 . 0 - 0 . 6 0 3 7 . 0 01 0 1 . 0 0 0 0 0 . 5 5 1 7 0 . 0 « 9 8 0 . 9 0 5 g 0 . 2 0 8 0 . 0 - 0 . 5 9 3 5 . 0 01 0 1 . 0 0 0 0 0 . 5 8 2 « 0. 0 « 9 9 0 . 8 5 1 1 0 . 3 3 3 0 . 0 - 0 . 5 8 3 6 . 0 01 0 1 . 0 0 0 0 0 . 5 8 5 3 0 . 0 « 9 y 0 . 8 4 5 9 0 , 3 « 5 0 . 0 - 0 . 5 6 3o .000 1 0 . 0 0 . « 7 5 b 0 . 0 « 7 9 - 0 . 9 5 6 « - 0 . 0 9 7 0 . 0 - 0 . 5 « 3 2 . 0 01 0 1 . 0 0 0 0 0 . S b 6 b 0 . 0 « 7 2 0.878*, 0 . 2 6 8 0 . 0 - 0 . 5 2 3 5 . 0 01 0 1 . 0 0 0 0 0 . 5 6 7 2 0 . 0 « 7 1 0 .877<5 0 . 2 7 1 0 . 0 - 0 . 5 2 3 5 . 0 0

83
Examinons, dans l'ordre, les renseig n e m e n t s que fournit
dans le tableau.
1) Le l o garithme de la vraisemblance, i.e. le log de la
valeur maximum atteinte par la fonction de vraisemblance
et qui a détermine le choix des valeurs des estimés des
coefficients de régression logistique.
2) La valeur, le nombre de degrés de liberté et la significa
tion statistique associés à trois tests de qualité d'ajus
tement du modèle estimé. Il s'agit des tests de Hosmer et
de Brown décrits aux section 2.3.1 et 2.3.2, et d'un
troisième test faisant intervenir le rapport des fréquen
ces o b servées et des fréquences prédites pour chaque
cellule. Tel que souligné précédemment, la valeur calcu
lée pour ce dernier test constitue un résultat invalide
lorsque les fréquences observées sont plus petites que 5,
ce qui est généralement le cas en présence d'au moins une
v ariable indépendante continue. En ce qui concerne le
test d'Hosmer, il semble que la valeur calculée pour ce
test par le programme PLR ne soit pas très fiable. C'est
à la suite d'une vérification et d'un échange avec le Dr
David Hosmer, auteur du test, que nous avons pu confir

mer nos doutes. Il ne fut cependant pas possible de
d é t e r m i n e r s'il s'agit d'un biais systématique pouvant
être corrigé a postériori. L' u t i l i s a t e u r serait donc
avisé de ne prendre aucune décision sur la seule base du
résultat à ce test. Pour les données ci-dessus, comme les
tests d'Hosmer et de Brown ne sont pas significatifs, cela
indique que le modèle logistique paraît convenir.
3) Les coefficients de régression, leur erreur-type et leur
rapport constituant un test d'hypothèse (test t) sur la
nullité des p a ramètres correspondants. Ci-dessus, les
trois coefficients de régression logistique ainsi que la
constante sont tous significativement différents de zéro,
puisque toutes les valeurs des tests t excèdent 2 .
4) La matrice de corrélation asymptotique des coefficients de
régression. Ces valeurs sont rarement utiles sur le plan
pratique.
5) L ' i m p r e s s i o n des statistiques utilisées pour ajouter ou
exclure les termes du modèle lorsqu'on fait appel au
p rocessus de s é lection hiérarchique (stepwise), ce qui
n'est pas notre cas ici.
84

85
6 ) Un tableau des fréquences ou des proportions observées de
succès (Y-l) et d'échec (Y=0), On remarque ici qu'elles
sont r e s p e c t i v e m e n t de 1 et 0 puisque les observations
sont c o n s i d é r é e s individuellement, conséquemment à la
nature continue des variables SCZ et T. Ce tableau four
nit également la probabilité de succès prédite par l'équa
tion de régression logistique, les erreurs - types de ces
prédictions et le logit (log p/(l-p)) correspondant à
la p r o b a b i l i t é prédite pour chaque individu ou pour
chaque profil distinct issu du recoupement de variables
indépendantes catégorielles.
2.4.4 Résultats obtenus via SPSSX
Voici quelques c o mmentaires sur les renseignements
fournis au tableau 2.4 par le progiciel SPSSX, précisons que
ces résultats sont similaires à ceux fournis lorsqu'il s'agit
d'une analyse probit.
1) SPSSX fournit d'abord deux informations concernant le
processus de calculs itératifs utilisé pour estimer les
paramètres du modèle logit ou probit (selon la commande)
par la méthode du maximum de vraisemblance.

86
Tableau 2.4 Résultats types produits par le programme Probit de SPSSX pour l'analyse de régression logistique (ou l'analyse probit) effectuée sur les données de Dagenais (1984).
is Apr es ! 0 : 3 7 : a 8
S P S S - * R E L E A S E 2 . 0 F O R I B * O S U N I V E R S I T E L A V A L IBM « 3 8 1 M v S / S P OS
i t * * * * * * * * * * * * * * * * * * * * * * * p R Q f c l T A N A L
J t C O m ' v E R G E D AT I T E R A T I O N 7. TH E C O N V E R G E C R I T E R I O N = . 0 0 0 0 0
P A R A M E T E R E S T I M A T E S ( L O G I T M O D E L )
Y S I
R E G R E S S I O N C O F F E , S T A N D A R D E R R O R
3 C ZTTT
.28b 5«
. « 3 0 8 7 , 0 5 7 7 b
.08063 ,0 8 8 « 1 .0 10-45
COEFf ,/S.E.
3 . S 7 0 1 S « . P7 35 ' 5.S26Ϋ
I N T E R C E P T
3 . 3 3 5 8 1
S T A N D A R D E R R O R
, 3« 0 5 1>
G U O O N E S S - O F - F I T C H I S Q U A R E = 8 1 0 . 8 9 5
I N T E R C E P T / S . E .
9 . 7 9 5 1 a
DE = 8 2 0 P - .583
S I N C E G O O D N E S S - O F - F I T C « I S Q U A R E IS N O T S I G N I F I C A N T , n 0 HE T E R C G E NE I T Y F A C T O R 13 U S E D IN TH E C A L C U L A T I O N OF C O N F I D E N C E L I M I T s .
C O V A R I A N C E ( B E L O W ) A N O C O R R E L A T I O N ( A H O V E ) M A T R I C E S OF P a = a « e t E s E M T » ; T c :
n5 C 7TTT
.00650
. 0 0 0 « 0
. 0 0 0 0 3
scz. 0 5 5 6 9. 0 0 7 8 2. 0 0 0 2 1
TTT
,03«27 . ? ? « 7 3 . 0 0 0 1 1
OB SERVED AND E X PEC TED F R E QUE NCI ES
SCZ
- . « 1-.02• 02 .0«
•.02 09 .1“ ¡tfi ■133
- . 2 1 .09 . 1 0 ¡15.:il:18:*? 153
-.80 ■>2 -.39 • -02
TTT 0n u m b e r (IF SUBJECT S
riBSERvFDR E S P O N SFS
2«. 00 -1 .00 1.0 .022,00 1 .00 1.0 .022.00 1.00 1.0 1 .02 « . 00 1.00 1.0 .026,00 1.00 1.0 .02 « . 00 1.00 1.0 .023.00 -1.00 1.0 .023,00 -1 .00 1.0 .029.00 -1 .00 1.0 1 *227.00 -1.00 1.0 1.025.00 1 .00 1.0 1.025.00 -1 .00 1,0 •22«. 00 -1.00 1.0 .021.00 1 .00 1.0 ' *231.00 1.00 1.0 1 *225.00 -1.00 1.0 1 -225,00 -1.00 1.0 1 .023.00 1 .00 1.0 > *221,00 1 .00 1.0 •222,00 1.00 1.0 .032,00 1 .00 1.0 > *232.00 -1.00 1.0 .030.00 -1.00 1.0 .028.00 1 .00 1.0 .0
EXPECTEDt-^SPONSES RESIDUAI. PROB
.287 -.287 .28720
.««« -.««« .««375
.«53 ,5«7 .«5313,514 -.51« . 5 1 « 1 9.559 -.559 ,559y 0.525 -.525 ,52«95. 366 -.366 .36553.375 -.375 ,37« 7 7,U36 .56« .«3561.«03 .597 ,«0266.55« , « «6 . 55U50.«13 -.«13 .«130«.396 -.396 .39580.«9 1 .509 .«9068.578 .«22 .57806.«29 .571 .«2921, « 3« .566 .«3«50, 5 « 0 .«60 .5397«.533 -.533 ,53307.562 -.562 ,5621 1.563 .«37 .56330,«59 -.«59 .«5929,«50 -.«50 ,««965.615 -.615 .61«52

87
2) Les estimés des paramètres du modèle incluant la constante
d'ajustement. Les erreurs - types de ces coefficients
ainsi que la valeur du rapport de ces deux informations permettent d'effectuer des tests d'hypothèse.
3) Un test de qualité d'ajustement du modèle estimé. Rappe
lons qu'ici, c o n s équemment à la nature des variables
indépendantes, la valeur fournie est suspecte.
4) La matrice de covariances des estimés des paramètres est
fournie dès qu'il y a plus d'une variable prédictrice dans
le m o d è l e .
5) Une section nous renseignant sur les probabilités prédites
par le m o d è l e .
2.4.5 Comparaison des résultats produits par BMDP et SPSSX pour la régression logistique
Avant de p rocéder à la c o m p a r a i s o n systématique des
méthodes d'analyse logit et probit, qui fera l'objet du
p r ochain chapitre, nous avons cru bon de vérifier si les
outils informatiques dont nous disposions étaient fiables.

88
Nous avons donc appliqué la méthode de régression logis
tique aux données de Dagenais (1984) à l'aide des deux progi
ciels, SPSSX et BMDP, et nous avons comparé les résultats
produits par ces derniers.
Rappelons les principaux résultats fournis par SPSSX:
b Sb t
D .28859 .08063 3.57915
SCZ .43087 .08841 4 .87355
T .05776 .01045 5.52614
istante 3 . 33581 .34056 9.79514
et les résultats correspondants fournis par BMDP:
D
SCZ
T
b
.28854
.86141
.11550
constante -3.0388
Sb
08063
1768
0209
6737
t
3 .579
4 . 872
5 . 525
-4 . 511
Nous pouvons im m é d i a t e m e n t remarquer une disparité entre
certaines valeurs des coefficients (b) obtenues par les deux

progiciels. Il existe cependant un lien entre ces deux séries
de résultats qui nous permet de prouver qu'ils sont équivalents, en dépit des apparences.
Tout d'abord, avec BMDP, en présence de trois variables
indépendantes par exemple, les estimés bg, b]_, b 2 , bj sonttels que :
X'£e
P(Y-l) - P - ___________X'£
1 + e
C'est dire que les estimés de coefficients fournis par BMDP
sont ceux qui s'intégrent directement au modèle de base de la
régression logistique pour fournir l'estimé de probabilité
d'un succès. Bien entendu, si l'on considère l'expression
X ' £ en dehors du modèle ci-dessus, on a alors affaire au
logit de P, i.e,
LOGIT (p) = log p/(l-p) = bg + b^X^ + b 2 X 2 + b 3 X 3
La différence observée entre les deux progiciels s'ex
plique en ce que 1 'expression X'£ lorsque les estimés des
coefficients sont ceux fournis par SPSSX ne correspond pas à
LOGIT (p) mais à une transformation de ce dernier (SPSSX, 1986, p. 605):

90
i.e. Tr (p ) — ( bQ + b^X]_ + b 2 X 2 + b 3 X 3 ) /2 + 5
- (b0/2 + 5) + (bx/2) X X + (b2 /2) X 2 + (b3 /2) X 3
” Bq + B^X]_ + B 2 X 2 + B 3X 3
où Bg , B]_, B 2 , B 3 sont les coefficients produits par SPSSX,
c o m p a r a t i v e m e n t aux coefficients bg, b^, b 2 et b 3 produits par BMDP.
Remarquons aussi que de (2.15) ci-dessus, on obtient
LOGIT (P) - 2 [ T r (P ) -5 ]
- 2 [ Tr(P) ] - 10 (2.16)
Cela est une autre façon de faire ressortir le lien entre
les solutions des deux logiciels. Ainsi, étant donné la
solution Tr(p) fournie par SPSSX, il suffit, en principe,
de multiplier celle-ci par 2 et d'y retrancher 1 0 pour alors
obtenir la solution issue de BMDP.
La solution fournie par SPSSX pour les données de Dage-
nais étant la suivante:
Tr(p) - [LOGIT (p)] /2 + 5 (2.15)

91T r (P ) = 3.35581 + .28859 D + .43087 SCZ + .05776 T,
en vertu de (2.16) nous obtenons:
LOGIT (p) - 2 [3.35581 + .28859 D + .43087 SCZ + ,05776T]-10
- [ 6.67162 + .57718 D + .86174 SCZ + .11552 T]-10
- (6.67162 - 10 ) + .57718 D + .86174 SCZ + .11552T
-3.32838 + .57718 D + .86174 SCZ + .11552T
versus
-3.3273 + .57708 D + .86141 SCZ + .11550 T
pour BMDP. Les solutions sont maintenant équivalentes j u s
qu'à la troisième décimale. La raison justifiant cette trans
formation est selon toute apparence de faciliter l'établisse
ment des relations avec le modèle Probit auquel SPSSX fait
subir une transformation similaire. Cette transformation est
appliquée systématiquement de façon à ce que les valeurs X'fi
v a riant entre -3 et +3 dans 99.74% des cas, varient, après
l'ajout de cette constante 5, entre +2 et + 8 qui sont, à
toute fin pratique jamais négatives.

CHAPITRE III
.0 INTRODUCTION
Dans ce troisième chapitre, nous traitons du deuxième
objectif que nous nous étions fixé dans cette recherche, soit
la comparaison de l'analyse de régression logistique, objet
du chapitre précédent, et de l'analyse probit, méthode que
nous avons déjà abordée au premier chapitre et dont nous
p r é s e n t e r o n s le modèle dans les pages qui suivent. Pour
effectuer cette comparaison, nous avons procédé en deux
temps. Nous nous sommes d'abord servie de données réelles
issues du domaine de l'éducation, puis, pour introduire plus
de contrôle et de rigueur, nous avons décidé d'évaluer les
deux méthodes statistiques appliquées à des données possédant
des caractéristiques prédéterminées et simulées à l'aide de
l'ordinateur selon la méthode dite de Monte Carlo. Par ces
deux voies, nous avons tenté de déterminer quelle approche,
entre l'analyse probit et l'analyse de régression logistique,
produit ou estime avec le plus de précision les probabilités
d 'un succès.
COMPARAISON DES ANALYSES LOGISTIQUE ET PROBIT

93
Avant d'aborder les aspects techniques de ces comparai
sons, parlons plus en détail de l'analyse probit.
3.1 L'ANALYSE PROBIT
Rappelons que le modèle probit repose sur la fonction de
répar t i t i o n de la loi normale, de sorte que la probabilité
d'un succès est fournie par:
r x'* -v2/2Pi = Prob (Yi-1) - 1 / e d v (3.1)
i-1,2.... n.
OÙ
X'fi = £0X0 + + . . . + % X k
et v est une variable normale centrée réduite(ou standardisée), i.e. v ~ N(0,1).
Soulignons qu'à titre de fonction de répartition, le
champ de cette fonction est restreint à l'intervalle [0 ,1 ],
remplissant ainsi une importante condition de la représenta
tion de la relation entre une variable dépendante dichotomi
que et un ensemble de variables indépendantes.
La méthode d'estimation des paramètres du modèle (3.1)

94
utilisée en présence de données individuelles ou non-regrou-
pées est, tout comme dans le cas du modèle logit, celle du
m a x i m u m de vraisemblance. A ce propos Hanushek et Jackson
(1972) nous semblent très bien résumer la situation:
"The probit model with micro-data is also estimated by maximum likelihood techniques. The derivation of this estimator can be obtained in the same fashion that exactly parallels the ML logistic estimator. Starting with the likelihood function, the standard normal distribution for the P^ can be substituted instead of the logistic distribution..." (p.204)
Soulignons, en passant, que le terme "probit" correspon
dant à une probabilité donnée est souvent défini comme étant
la valeur d'abscisse (désignée ci-dessus par v) associée à
cette p r o b a b i l i t é dans une d i s t r i b u t i o n normale avec une
moyenne de 0 et une variance de 1 . L ' i n t e r p r é t a t i o n du
modèle probit est alors simple: la probabilité qu'un événe
ment se produise est la proportion de la surface sous la
courbe normale centrée réduite comprise entre -°° et X'ü,
ce dernier étant une valeur sur l'échelle v.
Nous tenons aussi à attirer l'attention sur le fait que
le terme "probit" a souvent été associé à celui de "normit"
(normal unit). En général on emploie les définitions
suivantes (Zellner & Lee, 1965):

95
Normit P^ =■
Probit P^ - + 5 .
Selon ces définitions, le normit est ce que nous avons
défini précédemment comme étant le "probit" et le probit est
cette variable normale standardisée à laquelle on a ajouté la
valeur 5, i.e. le normit plus 5. L'ajout de cette constante
avait originellement pour but d'éliminer les valeurs négati
ves. Cette procédure n'a plus tellement sa raison d'être
avec l'utilisation de l'ordinateur, mais elle est malgré tout
encore en usage dans certains logiciels. Il semble bien que,
malgré la confusion qui peut résulter de cette terminologie,
l'on préfère conserver le terme d'"analyse probit" déjà en
usage pour qualifier ce groupe de méthodes.
3.1.1 Correspondance entre les paramètres des modèles logit et probit
Comme on peut le remarquer en examinant la Figure 1.1,
page 3 2, les ogives logistique et probit sont toutes deux
monotones et ont à peu de choses près la même forme i.e celle
d'un S incliné. Elles possèdent également les mêmes asympto
tes: 0 et 1. Leur principale différence se situe aux extré
mités des distributions où on observe que la courbe normale

96
cumulée (probit) s'approche des axes plus rapidement. Une
seconde différence, non visible cependant, se situe au niveau
de leur variance, celle-çi étant égale à tt2 /3 pour la fonc
tion logistique et à 1 pour la distribution normale standardisée (Am e m y i a ,1981).
Malgré ces dissemblances existant entre les deux fonc
tions, on peut se demander quel lien devrait exister entre
les paramètres des deux modèles pour que les deux courbes de
la figure 3.1 soient les plus rapprochées possible.
On serait tenté de croire que la valeur tt /y/3 (celle de
l'écart-type de la distribution logistique) joue un rôle dans
un tel rapprochement (Amemiya, 1981), mais il n'en est rien.
C'est plutôt soit en utilisant la constante 1.7 approximati
vement (ou son inverse, .59) que nous pouvons rendre dans
l'ensemble les deux courbes les plus comparables. Ainsi, si
nous désignons par £ tout paramètre du modèle logistique et
par fi son é q u i v a l e n t dans le modèle probit, et que nous
posons
fi - 1 . 7 fi*
i . e . (3.2)

97
fi* - fi/1.7 = .59 fi
alors les deux courbes, logistique et probit, sont les plus
rapprochées possible, ne différant d'ailleurs jamais de plus
de .01 l'une de l ’autre quant à leur hauteur (Lord et Novick,
1968; Lord, 1980).
3.1.2 Interprétation des coefficients des modèles logit et probit
Une fois que les paramètres d'un modèle logit ou probit
ont été estimés, on cherche ordinairement à donner une signi
fication aux valeurs obtenues. Il faut alors éviter d'inter
préter ces coefficients comme s'il s'agissait de coefficients
de régression multiple. Dans ce dernier cas, on sait que la
valeur d'un coefficient indique la quantité de changement au
niveau de la variable dépendante correspondant à une unité de
changement au niveau d'une variable indépendante, les autres
variables indépendantes demeurant fixes. En ce qui concerne
les modèles étudiés ici, la valeur numérique de chaque coef
ficient n'est pas directement interprétable comme elle l'est
dans le cadre de l'analyse de régression linéaire. Ainsi,
comme l'expliquent Fomby et al (1984):

98
"Estimated coefficients do not indicate the increase in the probability of the event occurring given one unit increase in the corresponding independent variable. Rather, the coefficient reflect the effect of F _1 (Pi) for the probit model and upon (Pi/Cl-P^)) for the logit model."(p.348)
Les poids ou coefficients associés aux variables indé
pendantes ne sont donc pas d i rectement comparables d'un
modèle à l'autre, car chacun d'eux mesure quelque chose de
différent. En effet, dans le cadre d'un modèle logistique,
le c o e f f i c i e n t de régression représente le changement au
niveau du logarithme naturel des "odds ratio" ou logit, i.e.
log (p/(l-p)) associé à une unité de changement de la varia
ble indép e n d a n t e tandis que, pour le modèle probit, une
valeur de b correspond à un changement au niveau de l'écart
type d'une variable normale standardisée.
Ces interprétations sont, de toute évidence, plus
appropriées puisque ce sont les logits et les probits qui
sont des fonctions linéaires des variables indépendantes et
non les probabilités elles-mêmes.
En fait, pour évaluer la relation entre un changement de
probabilité et un changement au niveau d'une variable prédic-
dictrice il faut utiliser la dérivée partielle de P par

99
rapport port à cette variable. De façon générale, ces
dérivées partielles pour les deux modèles sont égales à:
5 Pj - /Ui'S) Bj (3.3)
où /(X'B) est la fonction ou densité de probabilité concer
née. De façon spécifique, pour le modèle logistique, elle est
égale à (Judge et Lee, 1982):
-Xi'B
-2
[ 1 + e-Xi'B
ou encore à (Hanushek et Jackson, 1972):
Bj (P (1 - P)) (3.4)
Pour le modèle probit, la valeur correspondante est, selon
Fomby et al. (1982):
1 exp (-1/2 X'iß) 2 B 4 (3.5)y/ 2 7T

Conformément à la formule générale (3.1), /(X'fi) correspond à
la valeur de la fonction de densité normale au point X'B.
Notons, avant de compléter cette section, que le signe
(+ ou -) associé au coefficient logistique ou probit indique
la direction du changement au niveau de la probabilité mais
que l'ordre de grandeur de ce changement dépend des valeurs
de X considérées. C'est donc, en dernière instance, la valeur
de X'fi qui détermine le degré d'inclinaison de la courbe à ce
point: plus la pente sera forte, plus l'impact d'un change
ment au niveau de la valeur d'une variable explicative sera
importante.
3.2 CHOIX DES PROGICIELS
Tel que mentionné au chapitre précédent, pour s'assurer
de pouvoir effectuer une comparaison entre les résultats des
analyses probit et logistique, nous avons cru bon de vérifier
si les outils informatiques dont nous disposions étaient
fiables. La concordance entre les résultats (après transfor
mations) fournis par les logiciels BMDP et SPSSX pour la
régression logistique nous a rassuré quant à la fiabilité de
ces logiciels en ce qui concerne cette méthode.

1 0 1
Logiquement, il nous a fallu aussi procéder à une
vérification des résultats fournis par SPSSX pour la méthode
probit. C'est ainsi que nous avons comparé les résultats de
Dagenais (1984) à ceux obtenus en appliquant la procédure
PROBIT de SPSSX aux mêmes données. La concordance de ces
résultats ainsi que le fait qu'ils furent corroborés ensuite
par un autre progiciel, SOUPAC, développé à l'Université
d'Illinois (1976), nous ont rassuré quant à la fiabilité de
la procédure PROBIT de SPSSX pour effectuer l'analyse probit.
C'est cette procédure que nous avons d'ailleurs retenue pour
effectuer notre expérimentation.
Nous tenons également à justifier le choix du progiciel
BMDP pour effectuer les analyses de régression logistique
requises pour notre étude. Au chapitre précédent, nous avons
appliqué la régression logistique aux données de Dagenais via
les deux progiciels BMDP et SPSSX. Ces deux programmes ont
produit les mêmes coefficients (après avoir cependant effec
tué les transformations appropriées à la solution fournie par
SPSSX) et, plus intéressant encore, les mêmes probabilités
prédites. Même s'il semble que l'on puisse utiliser indiffé
remment les deux progiciels pour fournir les résultats des
analyses de r é g r e s s i o n logistique, nous avons fixé notre
choix sur le progiciel BMDP en grande partie à cause du plus

grand nombre de renseignements fournis. Nous avons malheu
r e usement constaté u l t é r i e u r e m e n t que des renseignements
c o n c e r n a n t certains tests d'ajus t e m e n t étaient erronés;
toutefois, cette situation n'affecte en rien la validité des
autres informations disponibles.
3.3 COMPARAISON DES RESULTATS DES ANALYSES PROBIT ET LOGISTIQUE POUR L'ETUDE DE DAGENAIS
Examinons maintenant les coefficients probit estimés à
partir des données de Dagenais par la procédure PROBIT du
progiciel SPSSX, plus- précisément la valeur de X'b:
3.03149 + 0.34823 D +0 .51629 SCZ + 0.06862 T
et rappelons les valeurs correspondantes dans le cas de la
régression logistique obtenues via BMDP:
-3.03880 + 0.28854 D + 0.86141 SCZ + 0.11550 T
Comme il était à prévoir, les modèles sous-jacents à ces
approches étant différents (voir (2.1) et (3.1)), les estimés
des coefficients de la régression logistique sont différents
des estimés des coefficients probit. Ce qui est remarquable
cependant, c'est que la relation entre les paramètres des
1 0 2

103deux modèles trouvée en (3.2) ne tient plus au niveau de
leurs estimés.
Pour comparer la qualité d'ajustement du modèle de
régression logistique à celle du modèle probit, nous avons
conservé la stratégie de l'auteure qui, pour évaluer la
qualité d'ajustement de son modèle, compara les probabili
tés moyennes prédites" par l'équation (2 .1 ) (après y avoir
substitué les estimés des paramètres) aux probabilités
moyennes observées pour chacune des 25 cellules regroupant
les sujets selon le quintile observé aux variables SCZ
(résultat académique normalisé) et T (résultat au test
d'admission).
Suite à une analyse fort laborieuse des données, nous
avons réussi à identifier les limites originales des quinti
les des variables SCZ et T, de façon à retrouver les mêmes
effectifs que Dagenais dans chacune des cellules. Le tableau
(3.1) fournit les résultats suivants: les limites des quinti
les pour chacune des deux variables impliquées, et, pour
chacune des cellules issues du croisement des quintiles, le
nombre d'observations qu'elle regroupe, la probabilité moyen
ne de succès observée, la p r obabilité moyenne de succès
prédite par le modèle probit et la probabilité moyenne de
succès prédite par le modèle de régression logistique. A

104
l'exception de ces derniers, qui constituent notre contribution personnelle, tous les autres résultats étaient déjà fournis au tableau 3 de l'article de Dagenais (1984, p.673).
Tableau 3.1 Pour les 25 cellules du tableau 3 de Dagenais (1984), le nombre de sujets (n) , la probabilité observée de succès (PO) , la probabilité moyenne de succès prédite par le modèle PROBIT (PPP) et la probabilité moyenne de succès prédite par le modèle de régression LOGISTIQUE (PPL).
SCORE Z1/5 2/5 3/5 4/5 5/5
T <-Quintile 1
302 Z s .007)Quintile 2
(.008 < Z < .266)Quintile
(.271 £ Z .3522)
Quintile (.523 < Z .848)
Quintile (.850 < Z < 1
5857)
TOTAL
n PO PPP PPL n PO PPP PPL n PO PPP PPL n PO PPP PPL n PO PPP PPL n PO PPP PPL
Quintile 5 (35*iT-40)
5/5 46 .78 .73 .72 39 .74 .81 .81 25 .76 .82 .82 30 .87 .86 .85 49 .92 .92 .91 189 .82 .82 .82 (.84)
Quintile 4 (33;T<35*)
4/5 59 .59 .65 .66 39 .77 .73 .73 31 .74 .78 .78 29 .90 .81 .81 36 .78 .86 .85 194 .73 .75 .75
Quintile 3(3l£T<32)
3/5 37 .65 .61 .60 25 .56 .67 .67 24 .75 .71 .71 28 .82 .77 .77 33 .85 .83 .83 147 .73 .71 .71 (.72)
Quintile 2 (28*<Ti30)
2/5 17 .59 .57 .57 42 .62 .61 .61 33 .79 .67 .67 29 .69 .70 .70 25 .72 .78 .77 146 .68 .66 .66(.67)
Quintile 1 (21iTi28*)
1/5 5 .20 .47 .46 20 .50 .50 .49 52 .58 .58 .58 49 .59 .64 . 63 22 .77 .71 .70 148 .59 .60 .60 (.61)
TOTAL 164 .65 .65 .65 165 .66(.6869)
.68 165 .70 .69(.70)
.69 165 .75 .74(.75)
.74 165 .82 .83(.85)
.83
N.B. Les ncr-bres entre parenthèses sont ceux qui apparaissent dans le tableau de Dagenais

Selon les valeurs marginales, il n'y a pas de différence
entre la probabilité moyenne de succès prédite par le modèle
probit et celle prédite par le modèle de régression logisti
que au niveau des quintiles pour chacune des variables consi
dérée isolement. Il existe cependant des différences lorsque
nous comparons les probabilités prédites moyennes pour les
deux modèles pour chacune des cellules. Ces légères diffé
rences, qui ne sont jamais plus grandes que .0 1 , se manifes
tent pour 11 des 25 cellules et favorisent le modèle de
régression logistique 7 fois sur 11.
Il nous a semblé que les divergences observées étaient
trop minimes pour conclure à la supériorité d'une approche
sur l'autre. Il ne faut cependant pas oublier qu'il s'agit
d'un cas très particulier et que l'unique critère utilisé
pour la comparaison des deux méthodes est lui-même discuta
ble .
3.4 REVUE DE LA LITTERATURE
En vue de procéder à une expérimentation systématique
pour comparer les deux méthodes, nous avons passé en revue
les recherches déjà effectuées en ce sens. Cette tâche nous
a révélé que depuis les années soixante, la supériorité
105

106
relative des deux approches logit et probit a été débattue
dans la littérature spécialisée, aussi bien en statistique
"pure" que dans des domaines appliqués aussi variés que
l'économique (participation de la main d'oeuvre), les rela
tions industrielles, le marketing (préférence des consomma
teurs) et la biométrie. On peut retrouver au tableau 3.2 un
résumé, inspiré en bonne partie de l'article de Malhotra
(1984), des principales études comparatives.
Tableau 3.2 Principales études ayant comparé les méthodes d'analyse logit et probit.
rilJTLUj.i VARIABLES N CRITERES CONCLUSION
falvitie v19/2; Catégorielles 20 criteres de classification et cratères basée» sur les valeurs prédites.
Les deux procédures ont fourni des résultats comparables, l'approche logit ayant une légère avance.
wJer i icr . wlendl x nq c-t tfudde (1978)
Catégor i el 1es 25 75
250 500
biais, variance et carré moyen de 1 erreur des esti més.
L'analyse probit fut supérieure à 1 analyse logit.
Gur.dsrson (1930) cont i nues 1598 comparaison subjective de 1 effet d u n e unité de changement à une variable indépendante sur P 1.
Résultats très similaires pour les deux approches.
Mdihotr« ( 198; > cateaori e iles 27 54 81 108 135 162 \S9 21b
analyse conjointe et validité prédietive.
Le modèle looit performe mieux pour les échantillons de lûd obs. et plus.

Certaines de ces études^ (Chambers et Cox, 1967; Milicer et Szczotka, 1965; Gunderson, 1980) n'ont pas fait ressortir
de d i f f é r e n c e s marquées entre les estimés des coefficients
logistiques (ou logit) et les estimés probit. Ces résultats
vont dans le sens de ces propos de Finney (1971):
" These two are very similar indeed in all respects except for very small or very large P and extremely large e x periments would be needed to show one as a better fit than the other." (p.49)
Burrel et aj . (1961), utilisant des données similaires à
celles considérées dans ces études et de petits échantillons
conclurent que le modèle logit permettait un meilleur ajuste
ment que le modèle probit. En 1972, Talvitie effectua aussi
une étude c o m p a r a t i v e mais en présence d'échantillons de
petite taille u n i q u e m e n t ( n- 2 0 ); il obtint des résultats
c o mparables pour les deux approches sauf pour l'un de ses
critères de comparaison où il observa une légère supériorité
de l'analyse logit sur l'analyse probit.
Seule l'étude menée par Werner, Wendling et Budde en
1978, conclut en la supériorité de l'analyse probit pour
différentes tailles d'échantillons ( n=»2 5 , 7 5 , 2 5 0 , 5 00 ) . Plus
^•Souvent, en plus de la régression logistique et de l'analyse probit, d'autres méthodes étaient simultanément considérées dans ces études comparatives.
107

108
récemment, les résultats d'études empiriques et simulées
effectuées par M a l h o t r a (1983) qui considéra huit tailles
d ' é c h a n t i l l o n s variant entre 27 et 216 observations, l'ont
amené à conclure que les deux modèles avaient une performance
compa r a b l e pour des tailles d ' é chantillons inférieure ou
égales à 108. Pour les échantillons plus grands, la méthode
logit s'avéra la plus précise en termes de validité prédicti
ve telle que définie par Wittink et Cattin (1981, p. 103).
Plusieurs critiques pourraient être formulées concernant
la méthodologie utilisée dans ces recherches. Nous en
soulèverons quelques-unes dans la section traitant de notre
propre devis expérimental.
3.5 QUESTIONS ET HYPOTHESES DE RECHERCHE
Nous p r é s e n t e r o n s ici les questions auxquelles nous
avons tenté de répondre dans le cadre de cette recherche,
questions qui ont bien entendu guidé le choix des différentes
particularités de sa méthodologie.
Rappelons d'abord que l'interrogation de départ ayant
motivé cette étude simulée était de savoir laquelle de
l'analyse de régression logistique ou de l'analyse probit

109
est la plus efficace pour prédire la probabilité que la v aria
ble dépendante prenne la valeur "1 " lorsque cette dernière est
binaire. Nous avons décidé de traduire cette interrogation
générale sous la forme de quatre questions plus spécifiques.
Ainsi, une première question à laquelle nous avons tenté
de répondre était de savoir si la méthode correspondante au
modèle ayant été utilisé pour générer les échantillons traités
s'avère supérieure, en termes de valeur prédictive, à la métho
de concurrente. A cette question nous avons émis une hypothèse
suggérée par la simple logique, voulant que, sous chacun des
deux modèles considérés, la méthode correspondant à ce modèle
est supérieure à sa rivale en termes d'une meilleure prédiction
de la probabilité de succès.
Une seconde q u estion à laquelle cette étude souhaitait
répondre était de déterminer l'effet de l'augmentation de la
taille de l'échantillon sur la performance relative des deux
méthodes appliquées à des données générées sous chacun des deux
modèles. Cette fois, l'hypothèse émise s'inspira, en plus de
la logique, de l'avis de plusieurs auteurs dont Finney (1971),
Chambers et Cox (1977) et Amemiya (1981) pour n'en citer que
quelques-uns, à l'effet qu'étant donnée la grande similitude
existant entre les deux distributions il faille un grand nombre

d'observations pour distinguer statistiquement les deux méthodes .
Dans un troisième temps, nous nous sommes interrogée sur
l'effet, au niveau de la performance relative des deux méthodes
d'analyse sous chacun des modèles investigués, de la présence
de différents degrés d ' i n t e r r e 1 ations entre les variables
i n d épendantes lorsque ces i n t e r r e 1 ations sont fortes (ces
interrelations pouvant être considérées comme une facette d'un
phénomène plus général désigné par le terme "multicolinéarité").
La possibilité d'une telle influence est soulignée par Malhotra
(1983) citant lui-même d'autres auteurs. Compte tenu des
similitudes relevées dans la littérature entre les méthodes
logit et probit d'une part et des liens entre le modèle logis
tique et celui de la régression linéaire d'autre part, nous
avons cru que la présence de relations linéaires entre les
prédicteurs peut avoir sur l'efficacité relative des deux
méthodes des conséquences similaires à celles observées sur les
estimés des coeff i c i e n t s de régression linéaire. Il est en
effet reconnu (Mansfield et Helms, 1982) que le principal
problème causé par la multicolinéarité concerne les estimateurs
des coefficients des variables impliquées dans la dépendance
linéaire lesquels possèdent alors une grande variance. Cette
grande variance implique que les estimés eux-mêmes risquent
d'être sérieusement sous ou surestimés entraînant alors poten
1 1 0

1 1 1
t i ellement la prédiction de valeurs éloignées des vraies v a
leurs. Nous avons donc supposé que les probabilités prédites
par les méthodes logit et probit pourraient aussi être influen
cées par la présence de corrélations entre les prédicteurs de
sorte que la supér i o r i t é de chacune des méthodes sous son
propre modèle aurait tendance à devenir de moins en moins
probante lorsque le degré de multicolinéarité augmente.
La quatrième et dernière question à laquelle nous avons
voulu répondre dans cette étude se résume ainsi: peu importe le
modèle ayant été utilisé pour générer les observations, existe-
t-il une m éthode supérieure à l'autre en ce qui concerne sa
capacité de "bien" prédire les probabilités d'un succès ?
Quelques importantes mises au point s'imposent ici au
sujet des hypothèses que nous avons avancées. Précisons tout
d'abord que bien que dans le cadre de recherches de type métho
dologique on ne rencontre pour ainsi dire pas d'hypothèses de
recherche, nous avons cru souhaitable, à cause notamment du
nombre considérable de résultats que nous avions prévu devoir
analyser, d'en formuler, dans la mesure du possible, pour
chacune de nos questions de recherche. Constituant avant tout
des réponses provisoires à nos questions, leur ultime raison
d'être fut de focaliser notre attention lors de l'analyse des

nombreux résultats recueillis. Conséquemment , elles ne possè
dent pas le caractère formel des hypothèses que l'on émet dans
le cadre de recherches ex p é r i m e n t a l e s et que l'on traduit
g é n é r a l e m e n t en langage statistique; elles ne sauraient non
plus prétendre relever d'une théorie sous-jacente.
Avant de pré s e n t e r notre devis expérimental, il nous
apparaît utile de résumer formellement les questions auxquelles
cette recherche a tenté de répondre ainsi que les hypothèses
correspondantes qui ont guidé l'analyse des résultats.
Question 1
La régression logistique s 1 avère-1 -elle supérieure à l'analyse
probit sous le modèle logit et l'analyse probit s 'avère-1 -elle
supérieure à la régression logistique sous le modèle probit ?
Question 2
La supériorité d'une méthode sur sa concurrente sous un modèle
donné est-elle fonction de la taille d'échantillon ?
Question 3
La supériorité d'une méthode sous un modèle donné est-elle
fonction du niveau d'intensité des interrelations entre les
variables indépendantes ?

113
De façon générale, pour les situations expérimentales étudiées
(tailles d'échantillon combinées aux intensités des interrela
tions entre les variables indépendantes), une des méthodes
d'analyse s 'avère-1 -elle supérieure à l'autre, peu importe le modèle considéré ?
Hypothèse 1
La méthode de régression logistique sous le modèle logistique
prédit mieux la prébabilité d'un succès (Y=l) que ne le fait
l'analyse probit et de façon similaire, sous le modèle probit,
la méthode probit l'emporte sur sa concurrente.
Hypothèse 2
La méthode de la régression logistique sous le modèle logit et
la méthode d 'analyse probit sous le modèle probit ont une
valeur prédictive d'autant supérieure à la méthode concurrente
que la taille de l'échantillon augmente.
Hypothèse 3
L'analyse de la régression logistique sous le modèle logit et
l'analyse probit sous le modèle probit perdent de leur supério
rité au fur et à mesure que le niveau des interrelations entre
les prédicteurs s'inten s if i e .
Que s t i on 4

114
Indépendamment du modèle considéré et pour chacune des situa
tions e x p é r i m e n t a l e étudiées, la méthode de la régression
logistique est supérieure à la méthode d'analyse probit.
3.6 LE DEVIS EXPERIMENTAL
3.6.1 Considérations générales
L'examen des aspects méthodologiques des études effectuées
dans le passé pour comparer, entre autres, la performance de la
méthode de régression logistique (ou méthode logit) et celle de
la méthode probit nous a permis d'identifier certaines limites
et nous a amenée à cons i d é r e r un devis expérimental un peu
particulier afin de poursuivre notre recherche.
Il va sans dire qu'on ne saurait que difficilement se
prononcer sur la supériorité d'une des méthodes d'analyse sans
exercer au p r é a l a b l e un contrôle rigoureux des conditions
susceptibles de l'expliquer, notamment en ce qui concerne la
distribution statistique sous-jacente aux données recueillies.
L'approche Monte Carlo que nous avons privilégiée pour effec
tuer cette étude c o m parative possède j u stement l'avantage,
comme l'ont souligné Goldstein et Dillon (1978), de permettre
Hypothèse 4

ce type de contrôle. Dans ce type d'étude, où les données sont
générées par ordinateur, nous pouvons en effet déterminer
exactement la (ou les) distribution(s ) statistique(s ) à partir de laquelle ces données sont créées.
Ce dernier aspect constitue d'ailleurs un premier point en
faveur de notre étude car la très grande majorité des recher
ches empi r i q u e s dont nous avons discutée précédemment n'ont
pas v r a i m e n t contrôlé la d i s t r i b u t i o n de probabilité sous-
jacente aux données utilisées. Les chercheurs ont généralement
eu recours à des données réelles pour générer leurs échantil
lons, donc provenant de distributions inconnues. Nous avons
donc décidé, par le biais de simulations, de contrôler la
d i s t r i b u t i o n stati s t i q u e (modèle logistique ou probit) des
données analysées. De plus, nous avons mis en place un dispo
sitif n d ' auto - contrô le " si l'on peut dire, en permettant à
chacune des méthodes de faire ses preuves non seulement sous le
modèle concurrent mais également sous son propre modèle, i.e.
appliquée à des données générées par la fonction de probabilité
correspondante. Aucune des recherches que nous avons recensées
n'a procédé ainsi, de façon à fournir aux deux méthodes des
chances égales de se faire valoir. Nous verrons dans la sec
tion portant sur la réalisation de l'expérimentation, comment
une telle chose était techniquement possible.
115

116
Nous avons également tiré profit de ce que ce type d'expé
rimentation permet de faire varier systématiquement différentes
conditions susceptibles de faire ressortir la supériorité d'une
des procédures, si elle existe. Les deux autres conditions
que nous avons retenues, telles que l'ont d'ailleurs laissé
entrevoir nos questions de recherche et qui sont susceptibles
d'influencer la performance relative des méthodes étudiées sont
la taille de l'échantillon et l'intensité des interrelations
entre les variables indépendantes.
Selon la revue de littérature effectuée, il semble bien
qu'à l'exception de Werner, Wendling et Budde (1978) et
Malhotra (1983) les auteurs n'aient pas pris soin de vérifier
l'effet de la taille de l'échantillon sur la performance de ces
approches. De plus, à l'instar de Malhotra (1983) nous avons
donc décidé de nous concentrer sur de petits échantillons. Ces
deux types de considérations nous ont amené à fixer les tailles
d'échantillons à 30, 50 et 100 observations.
De même, à l'encontre de ces auteurs et malgré une remar
que faite à cet effet par Malhotra (1983), nous avons décidé
de contrôler l'effet possible des i n t e r r e 1 ations , ou d'une
manière plus gén.rale, de la multicolinéarité, entre les varia- t
bles indépendantes, et d 'investiguer ainsi l'impact possible

d'un tel facteur sur la p e rformance relative des méthodes
d'analyse logit et probit. Nous avons donc décidé de considé
rer trois niveaux d'intensité des relations entre les variables
indépendantes: corrélations nulles (P=0), faibles (p=.3) et
assez fortes ( P-.7). Il devient ainsi possible de comparer la
situation où les prédicteurs sont indépendants avec celles où
ils sont corrélés plus ou moins fortement.
Les combinaisons résultant de l'association des facteurs
"taille d'échantillon" (trois niveaux) et "intensité des inter
relations entre les variables indépendantes" (trois niveaux),
constituaient donc neuf cellules ou situations expérimentales
différentes. Pour chacune de ces neuf situations, les données
devaient être générées sous chacun des deux modèles, logit et
probit C'est à ces données que les deux méthodes comparées
furent appliquées.
Ces différentes étapes devaient nous permettre de simuler
un devis expérimental dont la structure de base prenait l'allu
re d'un schéma 3x3 où, à l'intérieur de chacune des neuf cellu
les on peut distinguer deux modèles sous-jacents aux données,
le modèle logit et le modèle probit. Nous avons choisi de
représenter la charpente de ce devis par un seul et même gra
phique de façon à pouvoir y intégrer tous nos résultats tel que
le lecteur peut le voir au tableau 3.4 de ce document.

118
A cette structure de base, il nous faut ajouter les dé
tails importants suivants.
3.6.2 Nombre d'échantillons
Pour chacune des neuf situations, nous avons décidé,
entre autres pour limiter les frais informatiques, de générer
cent é c h a n t i l l o n s d'observations associés à une distribution
logistique ou p o s s é d a n t le modèle logit (2 .1 ) comme modèle
sous-jacent aux données, et cent échantillons de données tirées
de la fonction de répartition normale standardisée associée au
modèle probit (3.1). Ce nombre d'échantillons, retenu notam
ment par Pun (1981), nous a semblé un nombre respectable pour
permettre de dé t e c t e r des différences, s'il en existe, au
niveau de la performance des méthodes comparées.
Comme une seule des études recensées avait considéré une
variable quantitative parmi les variables indépendantes utili
sées, nous avons choisi de considérer uniquement des variables
indépendantes continues. Le nombre de ces variables fut fixé à
trois parce qu'il s'agit, selon nous, d'un nombre suffisant et
semble-t-il souvent retenu pour permettre de généraliser les
résultats obtenus à des situations impliquant un plus grand

119
En vue de générer les dix-huit séries de cent échantillons
(deux pour chaque s i tuation expérimentale) il nous a fallu
choisir la loi de probabilité selon laquelle les trois varia
bles indépendantes seraient générées. Notre choix s'est arrêté
sur la loi normale (multinormale) qui, en plus d'être une loi
fréquemment utilisée dans ce genre de recherche, nous a permis
de c o ntrôler plus facilemnent le degré de relation linéaire
entre les variables , X 2 et X 3 .
3.6.3 Création de la variable dépendante
Pour que les données de base soient complètes, aux obser
vations pour les trois variables indépendantes devait s'ajouter
une valeur générée pour la variable dépendante, soit 1 ou 0 ,
tout en nous permettant de distinguer les échantillons associés
au modèle logistique de ceux générés du modèle probit. Cette
valeur, notée YL sous le modèle logistique, et YP sous le
modèle probit, était assignée à chacun des triplets X^ selon la
p r obabilité calculée en substituant les valeurs X ^ , X 2 , X 3
générées pour une o b s e r v a t i o n aux variables indépendantes à
l 'intérieur soit du modèle logit, soit du modèle probit. La
stratégie utilisée généralement pour ce faire consiste à préle
ver al é a t o i r e m e n t une valeur (U) d'une distribution ou loi
nombre de variables indépendantes.

1 2 0
uniforme définie sur le segment [0 , 1 ] et de comparer cette
valeur à la probabilité déterminée selon le modèle logit ou le
modèle probit.
Pour assigner les valeurs 1 et 0 à la variable dépendante
YL ou Y P , nous avons appliqué la règle suivante:
1, si U < PLYL=
0 , si U > PL
e t
1 , s i U < P PYP =
0 , si U > PP
Ainsi, à titre d'exemple, si P L ^ , la probabilité obtenue
sous le modèle logit pour la première observation (X^, X 2 et
X 3 ) d'un échantillon était égale à .8 , toute valeur, provenant
de la loi uniforme, plus petite ou égale à . 8 déterminait
l'attribution de la valeur 1 à la variable dépendante associée
au modèle logit pour cette observation. La logique de cette
procédure est que la p r o babilité de tirer au hasard, d'une
distribution uniforme d'intervalle [0 ,1 ], une valeur égale ou
plus petite que . 8 est exactement égale à .8 .

1 2 1
Bien entendu, avant d'utiliser les modèles (2.1) et (3.1)
pour générer les valeurs PL et PP et éventuellement les valeurs
( 1 ou 0 ) pour la variable dépendante, il nous a fallu détermi
ner les valeurs des paramètres impliqués. Les valeurs fig= 0,
-3, & 2 = et ^ 3 = -7 furent retenues tout d'abord parce qu'elles accordaient une importance inégale aux trois varia
bles, situation d'ailleurs tout à fait réaliste. De plus, il
s'avère qu'en faisant appel à une distri b u t i o n trinormale
standardisée, ces valeurs de paramètres produisent, dans le cas
du modèle logistique, une probabilité de succès de . 0 1 pour un
profil X^'= [-3 -3 -3], de .50 pour X^' = [0 0 0] et de .99 pour
X^'= [3 3 3], ce qui nous a également paru raisonnable. Bref,
bien qu'arbitraires, ces valeurs de paramètres nous ont semblé
réalistes.
Afin de rendre plus comparables les résultats obtenus sous
le modèle logit et ceux obtenus sous le modèle probit, nous
avons exploité la relation déjà présentée en (3.2) i.e.
&*= .59fi (ou plus précisément .5875Ê). Les valeurs des paramè
tres du modèle probit furent donc fixées à £ 9 = 0. &i= .17625,
fi2= .29375 et ¿ 3 = .41125.
3.6.4 Sélection des valeurs des paramètres.

C'est dire qu'à partir du modèle logistique (2.1), la
probabilité d'assigner la valeur "1 " à la variable dépendante YL devait être égale à:
0 + .3Xl + .5X2 + .7X3P- Pr (YL-1) = __e ( 3 . 8 )
0 + .3XX + .5X2 + .7 X 31 + e
De même, pour le modèle probit, cette probabilité correspond à:
C'est à partir du modèle logistique (3.8) ou probit (3.9)
que toutes les valeurs de Y ont été générées tout au long de
cette recherche.
3.6.5 Application des méthodes d'analyse logit et probit
Une fois terminé le processus de génération des échantil
lons d'observations aux trois variables indépendantes et à la
variable dépendante sous les deux modèles, nous avons appliqué
e (3.9)
où X'£ - 0 + .17625XX + ,29375X2 + .41125X3

les méthodes d'analyse logit et probit à chaque échantillon de
données associées au modèle logit d'une part puis à celles
associées au modèle probit d'autre part. Ainsi les deux métho
des furent appl i q u é e s aux observations (YL^, , %-2i> ^3i)dans le cas du modèle logit et aux observations (YP^, X ^ , X 2 ±,
X^±) dans le cas du modèle probit. A partir des résultats de
ces analyses, plus précisément des probabilités prédites, nous
avons calculé, pour chaque échantillon, les mesures de perfor
mance décrites dans la section suivante.
3.6.6 Mesures de la performance
Pour comparer la méthode de la régression logistique et la
méthode probit en ce qui concerne leur capacité respective à
bien prédire ou reproduire les probabilités vraies, il nous a
fallu décider comment mesurer le degré d'accord ou la perfor
mance de chaque méthode quant à la reproduction des vraies
probabilités. Autrement dit, il s'agissait de mesurer jusqu'à
quel point les probabilités prédites par une méthode se rap
prochaient des vraies probabilités déterminées par l'expression
(3.8) ou (3.9). Cette idée de comparer probabilités prédites
et probabilités vraies est appuyée par Amemiya (1981) lorsqu'il
souligne que :
123

124"When one wants to compare models with different probability functions, it is generally better to compare probabilities directly rather than comparing the estimates of the coefficients even after an appropriate conversion." (p.1488)
Cette approche nous a aussi semblé pertinente parce
qu'elle permet, compte tenu du type d'expérimentation que nous
avons mené, de prendre en considération une information dont
nous ne disposons jamais en pratique, soit les "vraies" proba
bilités générées par la simulation. Ces mesures de performance
peuvent donc être considérées comme des mesures de "goodness-
of-fit", c ' e s t - à - d i r e comme des statistiques sommaires nous
indiquant la justesse avec laquelle un type d'analyse reproduit
les vraies probabilités.
Plusieurs critères faisant appel aux probabilités prédites
ont été proposés (Amemiya, 1981; Buse, 1972; Hosmer et
Lemeshow, 1980). Naturellement, aucune de ces mesures n'est
parfaite ou totalement satisfaisante. En fait, comme nous le
fait remarquer Amemiya (1981, p. 1503),
"...we should not expect to find a single criterion which is optimal for every occasion ..."
Dans un tel contexte, le même auteur va même jusqu'à suggérer:
"A sensible strategy would be to select two or three criteria and compare the results." (ibidem)

125
Suivant ce conseil, nous avons choisi les trois critères qui suivent.
Biais absolu (BA)
Une p r e m i è r e mesure de la perfo r m a n c e que nous avons
retenue fait appel, comme prévu, aux probabilités "vraies". Il
s'agit du biais absolu (BA) qui fut calculé pour chaque échan
tillon en utilisant la formule suivante:
nS I PPi - Pv i IBA - i-1______________________ (3.10)
n
Ce critère repré s e n t e donc la moyenne des différences, en
valeur absolue, entre la probabilité prédite (pp) par la métho
de utilisée et la probabilité vraie (pv) telle que déterminée
par le modèle sous-jacent. En pratique, pour ce critère "natu
rel" et facile à obtenir, on souhaite, bien entendu, que la
valeur calculée pour un échantillon de grandeur n soit la plus
petite possible. C o n s é q u e m m e n t , lors de la comparaison des
deux méthodes, nous avons considéré une méthode d'autant plus
efficace ou performante que la valeur de son biais absolu était
petite, traduisant ainsi une bonne approximation des probabilités v r a i e s .

126Biais pondéré (BP)
Le deuxième critère que nous avons utilisé est appelé
"biais pondéré" et s'inspire directement de celui utilisé par
O'Hara et al . (1982). Il consiste à considérer l'écart entre
la p r o b a b i l i t é prédite et la probabilité vraie, pondérée par
cette même probabilité vraie. Plus précisément, pour un échan
tillon de taille n, le biais pondéré a été défini comme
Notons que le "pv" au dénominateur du numérateur joue un rôle
pondérateur similaire à celui de la fréquence théorique dans la
statistique classique du chi-deux.
Somme des carrés des résiduels pondérés (SCR)
La troisième mesure de performance que nous avons choisie
est basée sur un critère très en vogue en régression linéaire;
il s'agit de la "somme des carrés des résiduels pondérée" dont
la formule de calcul est la suivante:
n£ (ppi - Pvi ) / pV;L
BP = i-1_______________________ (3.11)n
n ( Y i - PPi ) 2SCR = £ -_____________
i- 1 PPi ( 1 - PPi)(3.12)

Notons que c'est en effet à partir du numérateur de (3.12)
qu'est calculée la valeur du coefficient de corrélation inulti-Opie , fort populaire en régression linéaire. Comme le souli
gne Pun (1981), la somme des carrés des résiduels 2 constitue un
critère p a r t i c u l i è r e m e n t intéressant lorsqu'il est appliqué
dans le contexte de la prédiction d'observations futures ayant
des c a r a c t é r i s t i q u e s similaires aux observations servant à
déterminer l'équation de prédiction. On souhaite alors que la
m i n i m i s a t i o n du carré moyen de l'erreur pour les données en
main contribue également à minimiser la valeur du critère pour
les o b s e r v a t i o n s futures. Concernant l ' u tilisation de ce
critère dans le cadre de modèles impliquant une variable dépen
dante qualitative, Amémiya (1981) montre une certaine réticen-
"However, its use in qualitive response models cannot be defended as strongly as in the standard régression model because a qualitative response model is essentially a heteroscedastic régression model." (p.1504)
Il serait donc légitime, et c'est d'ailleurs ce que p l u
sieurs auteurs, dont Efron (1978), ont fait, de pondérer le
carré de l'erreur par une valeur inversement proportionnelle à
la variance i.e. p ^ l - p ^ ) de façon à tenir compte de l'inéga
lité des variances. Il semble en effet raisonnable (Amemiya,
2 0 n entend ici par résiduel la différence entre la valeur observée et la valeur prédite.

1981) d'attacher une perte plus importante à l'erreur résultant
de la prédiction d'une variable possédant une petite variance
qu'à l'erreur issue de la prédiction d'une variable ayant une
plus grande variance, la première devant logiquement être plus
facile à prédire que la seconde.
Une autre raison- militant en faveur du choix de la somme
des carrés des résiduels pondérés en (3.11) découle du fait que
si nous c o n naissons les probabilités vraies et que nous les
utilisions à l ' intérieur du dénominateur de ce critère, la
minimisation de ce dernier fournirait un estimateur de & asymp-
totiquement plus efficace que celui obtenu de la minimisation
de la somme des carrés de l'erreur non pondérée.
3.6.7 Réalisation de l'expérimentation
Na t urellement, la p r o d u c t i o n de la grande quantité de
données qu'exige la nature de cette recherche a nécessité le
recours à l'ordinateur par l'intermédiaire de trois logiciels
différents. Nous avdns dispensé le lecteur de la description
détaillée de chacune des lignes constituant ce programme. Nous
avons cependant regroupé en 7 sections les principales ins
tructions informatiques, présentés au tableau 3.3, de façon
à permettre au» lecteur de les associer aux différentes étapes
de la réalisation de notre expérimentation.
128

Tableau 3.3 Instructions informatiques associées aux ----------------- Principales étapes de l'expérimentation.
/ / e x e c S A SHMDP
0 A T A A ;00 A = 1 TO 2<J0;
_ . R ! = R A NNOR ( 6 0 2 1 « ) !a ) R2= R a N N O R ( S S 9 0 0 ) i
R 5= r a n n ü R ( 2 3 S 0 1 ) i P R 0 0 = R A N U N I ( Ü 9 2 6 6 )I
Pl2-.it P 2 2 = , 9 5 3 9 39 ;P13=,3;P 2 3 = , ? 2 0 1 ü ;P 3 3 = . Q 2 A 1 9 1 ;
X 1 =R 1 JX 2 = P t ? * R t + P 2 2 * R 2 ; X 3 = P 1 3 * R 1 » P 2 3 * H 2 » P 3 3 * R 3 ;
r j P L = E X P C . 3 * X ! + . 5 « x 2 + . 7 * x î ) / ( ( l » £ X P ( , î « X l + , 5 * x 2 * . 7 * X î ) ) ) J ° ) PP = PR0HN0RM ( , 1 7 6 2 5 » x l * . 2 <j 3 7 5 * x 2 * . < l l l 2 5 * x i ) ;
YL = 0 ;
I F PL LE PROB THEM YL = 0 ;I F PL GT PROB THEM Y L = 1 ;
YP = 0 ;
I F PP LE PRUB T h e m YP = 0 ;I F PP GT PRUB ThEM Y P = l ;
t C H = 3 0 ;GROUPES I N T C ( A - l ) / E C H ) + l ;I s A - f ( G R O U P È - n * E C H ) ;OUTPUT ;
END :PROC S ORT; BY GROUPE;
PROC BMOP PROG=QHUPLR ;VAR I GROUPE x i x 2 x 3 y l ;BY GROUPE;p a r m C a r o S ;
I / I N P U T UN I T = 3 . C O U E r ' A ' , C ON T E N T = ' DATA ' . / R E GR ES S DEPENDANT = Y L .
I N T E R V A L = X 1 , X 2 , X 3 .D V A R s P A H T ,
M Û D E L = X 1 , X 2 , X 3 .S T A R T S I N , i n , i n ,MUVE = 0 , 0 / 0 ,I T E R = 2 0 .
/ P R I N T CE L L S = t " ODE L .SOPT=NONf c ,
/ END/ F I N I S H
PROC BMOP p r o g = b m u p l r :VAR I GROUPF X I X2 X 3 IP :BY GROUPE;p a r m c a r d S : ,/ I N P U T UN I T = 3 . CODE = ' A 1 , COi j T t M T = DAT A / RE GRES S DEPENDANT = Y P .
I N T E R V A L = X 1 , X 2 / X 3 ,D V A R s P A R T ,
MODEL = x 1 , X 2 , x 3 .S T A R T : I N , I N , I N ,MOVE = 0 , 0 , 0 .I T E R = 2 0 .
/ P R I N T C E L L S s M O O E L .SORT=MOME,
/ END / F I N I S H
D A T A XL l S T P S F I L t = I N F I x E D / G R O U P E X 1 , X 2 , X 3 , YL , YP (F 1 . 0 3 F A . U . 2 F 1 , 0 )
COMPUTE 0BS=1SORT CASES BY GROUPES P L I T F I L E BY GROUPEP R OB I T YL OF OBS * I T H X 1 , X 2 , X 3 /
L O G = N O N t /P R I N T = F R E O /
P ROB I T YP OF URS wI I H X l , X ? , X i /L OGs NONE /P R I N T = F R E Q
B EGI N OATA F NI) DATA F I N I S H

procéder à la génération au hasard des valeurs pour les trois
variables indépendantes, notées XI, X2 et X3 , nous avons fait
appel à la fo n c t i o n RANNOR (RANdom NORmal) du logiciel SAS
(1982) qui génère de façon aléatoire des observations (RI, R2
et R3) à partir d'une variable normale standardisée (de moyenne
0 et de variance 1). On pouvait ainsi s'attendre à ce que les
valeurs générées soient comprises entre -3 et 3 dans 99.7% des cas .
Quant aux différentes structures de corrélations entre les
trois variables indépendantes, elles furent mises en place par
l'intermédiaire de poids (section b) préalablement obtenus en
appliquant la technique de d é c o m p o s i t i o n de Cholesky à la
matrice des corrélations désirées (obligatoirement symétrique,
positive semi — définie) . Cette technique, qui s'appuie sur des
notions d'algèbre matri c i e l l e et des théorèmes statistiques
fait l'objet d'une fonction (HALF) du progiciel SAS accessible
à même la procédure PROC MATRIX. Ces poids, différents pour
chacune des structures de corrélations prévues, furent, comme
on peut également le voir à cette section (b), appliqués aux
valeurs RI, R2 et R3 selon un schéma déterminé. Ainsi, par
exemple, la valeur à la variable X2 résulte de la somme du
produit des deux premiers poids et des valeurs RI et R 2 .
A la section (a) des commandes, on remarque que pour

131
A la section (c) nous retrouvons les commandes nécessaires
au calcul des probabilités vraies associées au modèle logisti
que PL et au modèle probit PP (formules 3.8 et 3.9 respective
ment) tandis qu'à la section (d) nous procédions à la détermi
nation de la valeur de la variable dépendante générée par le
modèle logit, Y L , ou le modèle probit, Y P . Les sections (e) et
(f) visaient l'application de l'analyse de régression logisti
que (programme LR de BMDP) aux données générées à partir des
deux modèles alors que la section (g) commandait l'application
de l'analyse probit (programme PROBIT de SPSSX) aux mêmes
données.
3.7 ANALYSE DES RESULTATS
3.7.1 Présentation des résultats préliminaires
Les résultats de cette étude simulée, en termes des mesu
res de performance définies à la section 3.6.6, pour chacun des
échantillons générés aléatoirement par ordinateur, sont repro
duits en appendice A où on les retrouve pour chacune des neuf
situations expérimentales, dûment identifiées. Rappelons que
ces quelque 10,800 résultats sont en termes de biais absolu
(BALL, BALP, BAPL, BAPP), biais pondéré (BLL, BLP, BPL, BPP) et
somme des carrés des résiduels pondérée (SCRLL, SCRLP, SCRPL,

SCRPP). Le lecteur notera que deux lettres ont été ajoutées au
sigle se trouvant au haut des colonnes de résultats afin de
distinguer les quatre valeurs obtenues à un même critère. La
dernière de ces lettres identifie le modèle utilisé pour géné
rer les données alors que 1 1 avant - dernière lettre indique la
méthode employée pour analyser ces mêmes données. Ainsi, par
exemple, BALP c o r r e s p o n d au critère "biais absolu" calculé
entre autres à partir des probabilités prédites par la méthode
logit appliquée aux données générées par le modèle probit.
Parmi ces critères, rappelons que les deux premiers, BA et
BP, visent à mesurer l'écart entre les probabilités de succès
telles que prédites ou estimées par chacune des méthodes et les
probabilités vraies telles que générées initialement par l'un
des deux modèles, tandis que le troisième critère, SCR, évalue
l'écart entre la variable dépendante (YL ou YP), i.e. la valeur
"vraie" associée à chacun des modèles et la probabilité prédite
par une méthode donnée.
3 . 7 . 2 S t r a t é g i e d ' a n a l y s e
Vis-à-vis une telle quantité de données, nous avons opté
pour une stratégie d'analyse permettant de les réduire à des
dimensions plus abordables tout en nous offrant la possibilité
de vérifier les hypothèses de recherche efficacement. Dans un
132

133
premier temps, il nous est apparu intéressant de résumer ces
informations en termes de statistiques traditionnelles. C'est
ainsi que nous avons calculé la moyenne et l'écart-type pour
les cent valeurs disponibles sous chaque situation expérimenta
le pour chacun des trois critères et pour chacune des deux
méthodes appliquées sous chacun des modèles.
En un deuxième temps, nous avons voulu vérifier nos h ypo
thèses de recherche par le biais de la comparaison systématique
des deux séries de cent valeurs calculées, pour chaque critère,
suite à l ' a p p l i c a t i o n de chacune des méthodes d'analyse aux
mêmes échantillons correspondant à un modèle donné, à l'inté
rieur de chacune des neuf situations expérimentales. Nous ex
pliquerons plus loin les détails de cette partie de l'analyse.
3.7.3 Analyse des moyennes et écarts-types
En examinant les moyennes et les écarts-types des valeurs
de critères reproduits au tableau 3.4 et calculés sur les cent
échantillons analysés par les deux méthodes sous chacun des
deux modèles ayant servis à générer ces échantillons de don
nées, nous observons que l'écart entre les moyennes d'un même
critère sous un modèle apparaissent dans l'ensemble très m inimes .

Tableau 3.4 Moyennes et écarts-types des valeurs de crlteres.
n = 30 n = 50 n =100
MODELE LOGIT MODELE PROBIT MODELE
logit probit probit logit logit
B A 0.1314 0.1324 0.1328 0.1334 0.10530.06 0.06 0.06 0.06 0.04
1 BP -0.0045 0.0016 -0.0147 -0.0083 0.02550 0.19 0 . 2 1 0 . 2 0 0 . 2 1 0.181 S C R 28.4998 28;6803 28.4656 28.5823 49.6236
4.26 3.97 3.27 3.00 7.43
BA 0.1343 0.1355 0.1343 0.1356 0.09870.06 0.06 0.05 0.05 0.04
3 BP 0.0124 0.0187 -0 . 0 0 2 1 0.0039 0.01823 0 . 2 2 0 . 2 2 0 . 2 1 0.23 0.191 S C R 28.7708 28.6597 28.3599 28.3303 50.3810
_ 6.93 6.81 3.69 3.60 7.42
BA 0.1314 0.1319 0.1335 0.1343 0.09300.06 0.06 0.06 0.06 0.04
7 BP 0.0345 0.0466 0.0259 0.0351 -0.00877 0.27 0.31 0.28 0.31 0.171 S C R 28.3686 28.0987 27.4708 27.4034 51.0707— 9.84 9.75 5.73 5.59 18.45
LOGIT
probitMODELE
probitPROBIT
logitMODELE
logitLOGIT
probitMODELE
probitPROBIT
logit
0.1058 0.1054 0.1058 0.0704 0.0724 0.0699 0.07190.04 0.04 0.04 0 . 0 2 0.03 0 . 0 2 0.030.0291 0.0248 0.0283 0.0011 -0.0060 -0.0050 -0.00240.18 0.18 0.18 0.11 0.11 0.11 0.1148.9149 49.1942 48.6650 100.0808 99.9909 99.8722 99.71444.14 5.44 3.54 4.71 4.26 4.33 3.91
0.1005 0.0983 0.0998 0.0657 0.0665 0.0654 0.06610.04 0.04 0.04 0 . 0 2 0 . 0 2 0 . 0 2 0 . 0 20.0260 0.0171 0.0239 -0.0038 -0.0001 -0.0079 -0.00620.19 0.19 0.19 0 . 1 2 0.13 0 . 1 2 0.1349.9444 49.5554 49.2916 98.8013 98.2499 98.5638 98.00926.61 6.39 5.95 4.85 4.53 4. 77 4.49
0.0928 0.0933 0.0928 0.0626 0.0628 0.0624 0.06220.04 0.04 0.04 0 . 0 2 0 . 0 2 0 . 0 2 0 . 0 20.0035 -0.0134 -0.0032 -0.0066 0.0007 -0 . 0 1 0 1 -0.00840.18 0.17 0.18 0.13 0.14 0.14 0.1449.9882 49.7725 49.3028 100.4847 99.1301 101.0255 99.486812.28 11.24 8.74 14.70 12.33 16.04 13.07

Cette situation, surtout en l'absence d'un test statisti
que permettant d'évaluer la signification de cette différence,
limite notre analyse à la simple constatation de ces écarts
car il nous apparait difficile de se prononçer sur une quelcon
que supér i o r i t é d'une méthode sur sa concurrente à partir
d'informations aussi incertaines.
L ' e x a m e n des é c arts-types permet d'observer un effet
stabilisateur de l'augmentation de la taille de l'échantillon
sur la dispersion des valeurs des critères BA et BP. On remar
que en effet que ces dernières démontrent une variance moindre
au fur et à mesure qu'augmente le nombre d'observations. On
peut par ailleurs observer une variance accrue pour le critère
SCR lorsque les interrelations entre les variables indépendan
tes s 'intensifient.
Bref, les statistiques préliminaires présentées ci-dessus
laissent difficilement présager de la supériorité d'une méthode
sur 1 'a utre.
3.7.4 Vérification des hypothèses
Tel que souligné précédemment, nous avons procédé à la
v é r i f i c a t i o n de nos quatres hypothèses de recherche à partir
des 10,800 valeurs p r ésentées à l'appendice A. Il s'agit,
135

136
rappelons - l e , des valeurs observées aux trois critères (BA, BP
et SCR) pour chacune des deux méthodes, régression logistique
et analyse probit, comparées sous chacun des deux modèles,
logistique ou probit, et ce à l'intérieur de chacune des neuf
situations expérimentales résultant du croisement de la taille
de l'échantillon et de l'intensité des interrelations entre les
variables indépendantes.
Les quatre h y pothèses portant e s s e n t i e l l e m e n t sur la
c o m p a r a i s o n de deux méthodes d'analyse, il fallait que la
stratégie d'analyse des résultats soit basée sur les comparai
sons appropriées.
Nous avons donc procédé de la façon suivante. Pour chaque
situation expérimentale, sous un modèle donné et pour chacun
des trois critères, nous avons dénombré combien de fois (sur
les 1 0 0 échantillons) la méthode d'analyse correspondant au
modèle s'est avérée supérieure^ à sa concurrente. Nous avons
ainsi effectué 54 séries de comparaisons (impliquant toujours
deux colonnes adjacentes dans l'appendice A) dont nous présen
terons les résultats au tableau 3.5.
QJi.e. dont la valeur au critère était plus petite que celle de sa compétitrice.

Tableau 3.5 Résultats des comparaisons entre les méthodes logit et probit sous chacun des modèles de données.
n = 30 n = 50 n =100
MODELE LOGIT MODELE PROBIT MODELE LOGIT MODELE PROBIT MODELE LOGIT MODELE PROBIT
logit>probit probit>logit logit >probit probit>logit logit >probit probit>logit
BA 5 7 " (57.6) 45 98 (45.9) 54 (54.0) 46 (46.0) 45 9 7 (46.4) 519 6 (53.1)
1 0 1 BP 54 (54.0) 4 9 " (49.5) 60 (60.0) 43 (43.0) 4898 (49.0) 4 9 " (49.5)0 1 00 0 1 S C R 149 7 (14.4) 829 7 (84.5) 1 7 " (17.2) 7 4 " (74.7) 37 (37.0) 57 (57.0)
B A 5 4 " (54.5) 4 1 " (Al.4) 469 8 (46.9) 55 (55.0) 409 8 (40.8) 5 6 " (56.6)
1 . 3 . 3 BP 51 (51.0) 4 9 " (49.5) 56 (56.0) 46 (46.0) 5 7 " (57.6) 39 (39.0)3 1 . 33 . 3 1 S C R 1 2 9 6 (12.5) 859 6 (88.5) 1 2 " (1 2 .1 ) 9 0 " (90.9) 2998 (29.6) 7 1 " (71.7)
BA 48 (48.0) 5 1 " (51.5) 54 9 7 (55.7) 5 0 " (50.5) 469 6 (47.9) 569 “ (59.6)
1 . 7 . 7 BP 54 (54.0) 4 4 " (44.4) 45 (45.0) 54 (54.0) 59 (59.0) 41 (41.0)7 1 . 77 . 7 1 S C R 6 9 1 ( 6 .6 ) 8 8 9 2 (95.7) 79 ■* ( 7.4) 8 8 9 5 (92.6) 3 4 " (34.3) 6 5 " (65.7)
'-j

Qu elques e x plications concernant ce tableau s'imposent
avant de procéder à la vérification formelle des hypothèses de
recherche. Un premier point touche la signification des colon
nes. Ainsi, sous l'expression "LOGIT > PROBIT" se trouve le
nombre de fois où la méthode logit l'a emporté sur la méthode
probit. De même, sous l ' e x p r e s s i o n "PROBIT > LOGIT" a été
reporté le nombre de fois où la méthode probit l'a emporté sur
la m é thode logit. En fait, pour un modèle donné, nous nous
sommes toujours demandée combien de fois la méthode du même nom
l'emportait sur sa rivale. Ce sera-là un détail important à se
rappeler lors de l'analyse des résultats.
Le lecteur prendra également note que le résultat de la
comparaison des méthodes à un critère donné n'est pas toujours
issu de la comparaison des valeurs de cent échantillons comme
prévu. Certains échan t i l l o n s ont en effet été exclus des
comparaisons ainsi que du calcul des statistiques préliminaires
en raison de valeurs aberrantes qu'ils présentaient pour cer
tains critères. Ces valeurs ont alors été remplacées par un
point, tel qu'on peut le constater à l'appendice A. Il ne fut
malheureusement pas possible d'identifier la cause de ces
valeurs extrêmes; de toute façon, comme le lecteur pourra le
constater, ces valeurs sont peu nombreuses. Par ailleurs,
d'autres é c h a n t i l l o n s ont été exclus mais uniquement parce
qu'il y avait égalité entre les deux méthodes.
138

Comme le nombre total d'échantillons considérés pouvait
varier, nous avons indiqué ce nombre, lorsqu'il différait de
cent, en le pl a ç a n t comme exposant du nombre de fois qu'une
méthode s'était avérée supérieure à une autre. Par ailleurs,
ces variations au niveau du nombre total d'échantillons retenus
nous a éga l e m e n t inc i t é e à présenter, entre p a renthèses et
accolé au nombre de "supériorité", le pourcentage correspondant
de façon à rendre les résultats plus comparables d'une cellule
à l'autre.
A titre d'exemples sur la façon de lire les valeurs du
tableau 3.5, voyons d'abord la situation où les corrélations
entre les p r é d i c t e u r s sont nulles et où n=30. On note que
l'analyse de régression logistique appliquée aux échantillons
associés au modèle logit, s'est avérée, selon le critère B A ,
supérieure à la méthode d'analyse probit, 57 fois sur 99, soit
57.6%. De même, pour la situation expérimentale correspondant
à des interrelations de .3 et une taille d'échantillon égale à
50, sous le modèle logit et pour le critère BP, la méthode
logit (régression logistique) a été "meilleure" que l'analyse
probit 56 fois sur 100 (puisqu'il n'y a pas d'exposant), soit
56% des occasions.
Ce tableau 3.5, basé essentiellement sur les comparaisons
entre les deux méthodes d'analyse, nous servira lors de la
139

140
v é r i f i c a t i o n des trois premières hypothèses de recherche.
Quant à la quatrième hypothèse, elle pourra être vérifiée grâce
à un second tableau déduit directement du tableau 3.5.
Enfin, avant d'effectuer la vérification des hypothèses,
il nous a fallu définir une règle de décision concernant leur
a c c e p t a t i o n ou leur rejet. Ainsi, comme nous disposions de
trois critères, nous avons décidé qu'une h y pothèse serait
confirmée si au moins deux des trois critères allaient dans le
sens de l'hypothèse, avec certaines modalités particulières,
dépendant de la nature de l'hypothèse, comme nous le verrons
plus loin. Bien qu'arbitraire, cette règle nous est apparu
rai s onnable.
3.7.4.1 Vérification de la première hypothèse
Rappelons que notre première hypothèse prévoyait la supé
riorité de chacune des méthodes sur sa concurrente lorsqu'ap
pliquée aux données générées sous son propre modèle. La v é r i
fication de cette hypothèse doit donc se faire en deux volets,
c'est-à-dire sous chacun des deux modèles.
A noter qu'une méthode fut jugée supérieure, pour un
critère particulier et une situation expérimentale donnée, si

141
le p o u r c e n t a g e d ' é chantillons pour lesquels la valeur à ce
critère était l'indice d'un meilleur ajustement, était supérieur
à 50. Rappelons, de plus, que nous avons choisi de ne considérer
une hypothèse confirmée, que si au moins deux des trois critères
présentaient des résultats en ce sens (i.e. > 50%) et ce pour au
moins cinq des neuf cellules du devis.
Un examen attentif du tableau 3.5, fait d'abord ressortir
que sous le modèle logit, la méthode logit l'emporte sur sa
compétitrice au niveau de six des neuf cellules pour le critère
BP. Par contre, pour les critères BA et SCR c'est la méthode
probit qui l'emporte le plus souvent.
Selon la règle de décision définie plus haut, il s'avère
que l ' hypothèse 1 se trouve infirmée dans le cas du modèle
logit puisque, pour les critères BA et SCR, l'avantage est en
faveur de la méthode probit, soit dans le sens opposé de l'hy
pothèse .
Sous le modèle probit, en ce qui concerne le critère B A ,
la méthode probit se révèle supérieure à sa concurrente six
fois sur neuf. En ce qui à trait au critère SCR, il traduit,
avec des pourcentages relativement élevés, une supériorité de
l'analyse probit dans toutes les situations expérimentales
investiguées. Pour le troisième critère, BP, nous remarquons
que la méthode probit n'est supérieure à la méthode logit

142
première hypothèse sous le modèle probit.
En résumé, la première hypothèse a été infirmée dans le
cas du modèle logit et confirmée dans celui du modèle probit.
Avant de p o ursuivre au niveau de la v é r i f i c a t i o n des
hypothèses 2 et 3, nous tenons à apporter quelques précisions
sur la façon dont nous avons procède . Soulignons immédiate
ment que la règle de décision d'un minimum de deux critères sur
trois pour confirmer une hypothèse a été conservée. Nous avons
cependant c o ncentré notre attention sur l'identification de
tendances dans les résultats c'est-à-dire d'une augmentation
continue du pourcentage d'échantillons pour lesquels la méthode
c o r r e s p o n d a n t à un modèle donné s'avérait supérieure à la
méthode concurrente. Nous avons donc vérifié si de telles
tendances se dessinaient sous chacun des modèles et pour chacu
ne des trois mesures de' performance.
3.7.4.2 Vérification de la deuxième hypothèse
Rappelons que l'hypothèse co r r e s p o n d a n t à la deuxième
question de cette recherche avance que la "supériorité" d'une
méthode, lorsqu'app 1 iquée à des données associées au modèle sur'
lequel elle se base, est de plus en plus marquée au fur et à
qu'une seule fois. Nous concluons donc en la confirmation de la

143
Compte tenu de 1 1 i n firmation partielle de la première
hypothèse, il semble maintenant incongru de parler de la "supé
riorité" de la méthode de régression logistique sous le modèle
logit. Mais, si l'on considère que nous nous concentrions sur
la présence de tendances, cette deuxième hypothèse ainsi que la
suivante deme u r e n t selon nous vérifiables en dépit de cette
incongruité. En effet, même dans le cas où, par exemple, la
régression logistique serait inférieure à l'analyse probit pour
les trois tailles d'échan t i l l o n s i n v e s t i g u é e s , si cet état
d'infériorité diminue graduellement, nous parlerons alors quand
même de tendance mais concernant 1 ' efficacité (et non plus la
supériorité) de la méthode.
Passons donc à la vérification de la deuxième hypothèse
dans le cas du modèle logit. Dans le tableau 3.5, en l'absence
d 'interrelations entre les variables indépendantes, et pour le
critère B A , on relève bien une tendance mais, contrairement à
l'hypothèse 2 , l'efficacité relative de la méthode logit (ré
gression logistique) tend à diminuer avec l'accroissement de la
taille de l'échantillon, cette méthode devenant même moins
efficace que l'analyse probit dans le cas d'échantillons de taille égale à 1 0 0 .
mesure que le nombre d'observations croît.

La seule tendance allant dans le sens d'une supériorité
accrue en faveur de la méthode logit, se retrouve au critère
SCR, bien que pour les trois tailles d'échantillons investi- guées, elle demeure inférieure à la méthode probit.
Lorsque l'intensité des interrelations correspond à .3, le
critère BA amène une fois de plus des résultats étonnants: on y
observe une tendance à l'avantage de la méthode probit. La
seule tendance allant dans le sens de l'hypothèse qu'il soit
possible d'observer se manifeste pour le critère BP.
Enfin, lorsque l'intensité des interrelations est la plus
forte (.7), il n'y a qu'au niveau du critère SCR que nous
pouvons détecter une tendance dans le sens de l'hypothèse, mais
encore une fois, pour les trois tailles d'échantillons, la
méthode logistique est en position d'infériorité.
Passons m a i n t e n a n t au modèle probit. Tout d'abord, en
l'absence de corrélations entre les prédicteurs et au niveau du
critère B A , l'efficacité relative de la méthode probit augmente
avec la taille de l'échantillon alors qu'au niveau du critère
SCR sa supériorité diminue. Aucune tendance ne ressort quant
au critère BP.
144

Lorsque l'on considère le degré intermédiaire d'interrela
tions , aucune tendance ne ressort sur quelque critère. Il
s'avère donc que, sous le modèle probit, tout comme dans le cas
du modèle logit, la deuxième hypothèse n'est pas confirmée.
3.7.4.3 Vérification de la troisième hypothèse
Pour procéder à la vérification de l'hypothèse à l'effet
que l ' i n t e n s i f i c a t i o n des interrelations entre les variables
indépendantes atténue la supériorité (ou efficacité) relative
d'une méthode sous son propre modèle, nous avons une fois de
plus cherché à identifier des tendances en considérant, cette
fois, chacune des tailles d'échantillons isolément, c'est-à-
dire en travaillant sur le plan vertical du tableau 3.5.
A partir des résultats de ce tableau nous observons, sous
le modèle logit, lorsque n=30 et pour les critères BA et SCR,
que l'efficacité relative de la méthode logit s'atténue au fur
et à mesure que les interrelations s 'intensifient.
Lorsque la taille de l'échantillon est égale à 50, pour
ces critères BP et SCR, nous notons le même phénomène que
précédemment, c'est-à-dire une méthode logit de moins en moins
efficace sous son propre modèle.
145

146
Lorsque n = 1 0 0 , pour le critère BP, la méthode logit semble
devenir de plus en plus efficace alors que les corrélations
entre les v a r i a b l e s indépendantes prennent de l'importance.
Cela va, bien sûr, dans le sens contraire à notre hypothèse.
On ne relève par ailleurs aucune tendance en ce qui a trait aux
deux autres critères.
Si l'on effectue un bilan de ces derniers résultats nous
concluons que la troisième hypothèse, en ce qui concerne les
é c h antillons générés sous le modèle logit, est confirmée au
niveau des tailles d'échantillons n=30 et n=50.
Sous le modèle probit, lorsque n-30, les valeurs au critè
re SCR indiquent que la supériorité de la méthode du même nom
s'intensifie en même temps que la force des interrelations donc
dans le sens contraire de celui avancé par l'hypothèse. Aucune
tendance n'est observable dans le cas des deux autres critères.
Quand la taille des échantillons correspond à 50, les
résultats aux critères BP et SCR indiquent que l'efficacité de
la méthode probit s'améliore avec l'intensité des interrela
tion quoiqu'au niveau de BP, la méthode probit est inférieure
dans deux des cellules.

Lorsque l'on examine les résultats aux échantillons de
taille 100, nous notons qu'il n'y a qu'au niveau du critère BA
qu'une tendance est observable. Celle-ci va, contrairement à
l ' hypothèse 3, dans le sens d'une supériorité accrue de la méthode probit.
En somme, sous le modèle probit, l'hypothèse 3 n'a été
confirmée pour aucune des tailles d'échantillon investiguées.
3.7.4.4 Vérification de la quatrième hypothèse
Les trois hypothèses que nous avons vérifiées jusqu'ici
p o r t a i e n t sur la comparaison des méthodes d'analyse logit et
probit sous chacun des deux modèles concernés.
Comme nous l'avons déjà souligné, le devis ayant conduit à
ces vérifications avait la particularité qu'en générant, pour
chaque situation expérimentale, un même nombre d'échantillons
de données issues de chacun des modèles, logit et probit, il
'fournissait à chacune des méthodes des chances égales de se
faire valoir, de démontrer sa supériorité sur la méthode con
currente .
Pour vérifier la véracité de la quatrième hypothèse de
cette recherche voulant, qu'en faisant abstraction du modèle
147

ayant servi à générer les données, la méthode de la régression
logistique soit supérieure à la méthode d'analyse probit, nous
avons décidé de tirer profit de cette particularité pour combi
ner les résultats observés sous les deux modèles de façon à
pouvoir vérifier, indépendamment du modèle, laquelle des métho
des est supérieure à l'autre au niveau de chacune des neuf
situations expérimentales.
A noter que cette fusion des résultats obtenus sous les
deux modèles comportait certains avantages, le plus important
étant de rejoindre une situation beaucoup plus "réelle" que
précédemment étant donné qu'en pratique, justement, on ne sait
jamais lequel des deux modèles, logit ou probit, est le plus
approprié pour les données en main. Un second avantage était
que les analyses effectuées sur les résultats devenaient plus
fiables que p r é c é d e m m e n t puisqu'elles s'appuyaient désormais
sur 2 0 0 comparaisons au lieu de 1 0 0 .
Pour ces raisons nous considérons que cette quatrième
hypothèse est la plus importante de cette étude. Voyons m ain
tenant comment, à partir du tableau 3.5, on a pu en construire
un autre fournissant les informations nécessaires à sa vérifi
cation .
148

Pour bien saisir le principe de construction de ce n o u
veau tableau (3.6), servons-nous d'un exemple. Prenons le cas
de la sit u a t i o n ex p é r i m e n t a l e où le niveau d ' interrelations
c o r r e s p o n d à .3 et la taille d'échantillon est égale à 30.
Pour le critère B A , nous observons que, sous le modèle logit,
la méthode correspondante l'a emporté sur l'analyse probit au
niveau de 57 des 99 échantillons conservés, l'analyse probit ne
comptant donc que 42 victoires (“ 99-57). Sous le modèle p r o
bit, la méthode du même nom ne l'emportait sur sa concurrente
qu'au niveau de 45 des 98 échantillons conservés, nous pouvons
alors déduire par soustraction qu'il ne reste que 53 échantil
lons (=98-45) en faveur de la méthode logit.
A partir de ces informations, si nous additionnons le
nombre d'échantillons favorisant la méthode logit sous les deux
modèles, il ressort que celle-ci l'a emporté 110 fois (=57+53)
au total. En e f fectuant la même opération pour la méthode
probit, nous obtenons un total de 87 échantillons (=42+45) en
sa faveur. Ceci constitue un gain net de 2 3 (=1 10 - 87) en
faveur de la méthode logit.
Des calculs similaires ont été effectués pour les autres
critères de performance et les résultats reportés au tableau
3.6, sous chacune des neuf situations expérimentales.
149

Tableau 3.6 Méthode d'analyse s'étant avérée supérieure dans chacune des situations expérimentales et gain net pour chaque critère.
n
METHODE LOGIT
= 30
METHODE PROBIT
n
METHODE LOGIT
= 50
METHODE PROBIT
n = 1 0 0
METHODE LOGIT METHODE
BA 23* 16* 13*
I 0 0 BP 9* L 34* L P 1p = 0 1 0
0 0 1 S C R 136* 114* - 40*
BA 26* - - 19* 31*
1 . 3 . 3 BP 3* L 2 0 * P 37* Pp = . 3 1 . 3
. 3 . 3 1 S C R
'146* 156* 83*
BA - 17 1 0 - 2 2 *
1 . 7 . 7 BP 19* P - P 18* 36* Pp = . 7 1 . 7
. 7 . 7 1 S CR - 163* - 161* 62*
PROBIT
LnO

151
Comme règle de décision nous avons considéré qu'une métho
de d'analyse serait supérieure, pour une situation expérimen
tale, si elle l'emportait sur sa concurrente pour au moins deux
des trois critères (règle de départ) et qu'en plus au moins un
de ces deux critères soit accompagné d'un astérisque
signifiant qu'il ait fait ressortir la supériorité (i.e. plus
de 50% des gains) de la méthode concernée sous chacun des deux
m odèles.
La deuxième condition^, de cette règle de décision, bien
qu'arbitraire, nous a semblé raisonnable, compte tenu de l'ab
sence de test s t atistique formel applicable dans de telles
s ituations.
En examinant le tableau 3.6 on observe qu'indépendamment
du modèle considéré, la méthode probit l'emporte six fois sur
neuf selon notre règle de décision. Ce résultat est opposé à
celui prévu par notre hypothèse et nous amène à conclure que,
dans l'ensemble, la méthode probit est supérieure à la méthode
l ogit.
^En fait, sans cette condition, la décision aurait été la même pour chaque situation expérimentale.

De plus, nous pouvons observer que la supériorité relative
de la méthode probit s'accentue au fur et à mesure que la
taille de l'échantillon augmente jusqu'à démontrer une domina
tion totale lorsque n= 1 0 0 .
Dans la même veine, il ressort que l'avantage de la métho
de p robit sur sa rivale s'accroît quand les interrelations
entre les variables indépendantes s 'intensifient, cette supé
riorité étant complète lorsque les interrelations entre les
variables indépendantes sont égales à .7 .
152

CHAPITRE IV
CONCLUSION
4.0 RESUME
La régression multiple constitue, pour la recherche dans le
domaine de l'éducation, l'un des outils statistiques les plus
u t i l e s et puis s a n t s pour prédire ou expliquer une variable
dépendante à partir de plusieurs variables indépendantes.
Lorsqu'u t i1 isé en présence d'une variable dépendante binaire
le modèle de régression linéaire classique, basé sur la minimisa
tion de la somme des carrés de l'erreur (moindres carrés) pré
sente cependant trois problèmes que nous avons clairement iden
tifiés dans cette thèse: il s'agit de la violation du postulat
d ' h o m o g é n é i t é de la variance de l'erreur, de la violation du
p o stulat de n o r m a l i t é de celle-ci, ainsi que la possibilité
d'obtenir des valeurs (probabilités) prédites inférieures à 0 ou
supérieures à 1 .
Un survol des principales solutions qui ont été proposées
pour remédier à ces difficultés a permis de réaliser qu'elles
ne sont efficaces qu'en présence de conditions qui, dans l'en
semble, sont difficilement réalisables. De plus, les solutions

qui tentent d ' adapter le modèle de régression linéaire aux
situations où la variable dépendante est binaire, laissent en
général au moins un problème irrésolu, celui de restreindre les
valeurs prédites aux limites associées aux probabilités.
Heureusement, parmi les alternatives proposées à la r é
gression multiple dans le cas d'une variable dépendante binai
re, une solution semble plus appropriée que les autres. Cette
solution consiste à faire appel à un modèle basé sur une fonc
tion de répartition dont la forme est curvilinéaire. L'analyse
de la régression logistique et l'analyse probit, deux méthodes
ayant recours à des fonctions de ce type, sont considérées
c o n e e p t u e 1 1 ement et p r a t i q u e m e n t supérieures à l'analyse de
régression linéaire.
Le premier objectif de cette recherche était d'étudier en
profondeur une de ces deux méthodes, la régression logistique
lorsqu'une ou l'ensemble des variables indépendantes sont de
nature continue. C'est ainsi qu'au chapitre deux, nous nous
sommes penchée sur l'estimation des paramètres, les propriétés
des estimateurs, les principaux tests d'hypothèses ainsi que sur les mesures de précision de la prédiction.
Le second objectif visait à évaluer, à partir de données

générées aléatoirement selon la méthode Monte Carlo, la perfor
mance relative de ces deux méthodes d'analyse. Ces simulations
visaient également à explorer l'influence de deux facteurs, la
taille de l'échantillon et le niveau des interrelations entre
les vari a b l e s indépendantes. L ' é v a l u a t i o n de l'efficacité
relative des méthodes fut basée sur les probabilités estimées
par chacune d'elles plutôt que sur les estimés des coeffi
cients, comme c'est souvent le cas dans ce genre d'études.
Une première conclusion se dégageant de cette recherche,
est que lorsque l ’on tient compte du modèle ayant servi à
générer les données (soit le modèle logit, soit le modèle
probit) analysées par les deux méthodes, il semble que ce
dernier ne conditionne en rien l'efficacité de la méthode logit
sous son propre modèle. En fait, l'hypothèse 1 avançant qu'une
méthode est plus efficace que sa concurrente lorsqu'appliquée à
des données générées de son propre modèle ne fut confirmée que
par les résultats associés au modèle probit.
Nous avions également prévu (hypothèses 2 et 3) que les
résultats des comparaisons entre les deux méthodes sous chacun
des deux modèles seraient sensibles aux variations imposées au
n iveau de la taille des échantillons ainsi qu'au niveau des
degrés d 'interrelations entre les variables indépendantes. Les
résultats obtenus ne permettent d' identifier que quelques

156
tendances isolées en ce qui conserne l'influence de ces fac
teurs. De plus, ces tendances n'étaient généralement pas les
mêmes d'un modèle à l'autre.
Pour les situations expérimentales considérées dans cette
étude et si l'on fait abstraction du modèle sous-jacent aux
données (hypothèse 4), il est ressorti que l'utilisation de
la méthode d'analyse probit est plus efficace que la méthode
logit sauf pour de très petits échantillons et un faible niveau
d 'interrelations entre les variables indépendantes. C'est donc
dire qu'en général, la méthode logit (ou de régression logisti
que) a produit des estimés de probabilités plus éloignés des
vraies valeurs que les probabilités estimées par la méthode
d'analyse probit.
Il faut cependant souligner que le fait qu'au niveau de
certaines situations expérime n t a l e s les résultats se sont
avérés très rapprochés, rend nos conclusions mitigées.
Nous croyons que malgré que les comparaisons entre les
méthodes furent effectuées dans un contexte de simulations, il
semble raisonnable d'extrapoler les résultats à des situations
réelles si les chercheurs en éducation prennent soin de bien
considérer la structure des données qu'ils veulent analyser.

157
En dépit des qualités d'originalité et de solidité que
nous attribuons à notre devis expérimental, nous pouvons iden
tifier une pre m i è r e limite à cette étude. Celle-ci découle
d'un manque de rigueur associée à l'absence de tests statisti
ques portant sur les différences observées entre les méthodes
en ce qui à trait aux valeurs des critères choisis. Il est en
effet regrettable que la signification statistique de l'ampleur
de ces différences n'ait pu être évaluée.
Rappelons, de plus, que dans le cadre de toute étude de ce
type, les concl u s i o n s auxquelles nous sommes parvenue sont
confinées aux conditions investiguées , notamment celles d 'é
chantillons de petites tailles. Il est également légitime de
soulever un doute sur la valeur des généralisations suscepti
bles d'être dégagées de cette étude de simulation. En effet,
étant donné que ces résultats sont basés sur un nombre res
treint de r é p l i c a t i o n s sous chaque situation expérimentale,
nous nous demandons si un nombre supérieur à cent échantillons
fournirait des conclusions similaires.
4.1 LIMITATIONS DE CETTE RECHERCHE

158
Suite aux critiques que nous avons émises concernant les
résultats de cette recherche, nous pensons qu'il serait peut-
être opportun de reprendre l'étude en augmentant le nombre des
échantillons et surtout la taille de ces derniers, pour v é r i
fier si la domination apparente de l'analyse probit se poursuit
dans le cas de grands échantillons.
De plus, étant donné les résultats de cette recherche, il
nous semble qu'il serait intéressant d 'investiguer plus à fond
les caractéristiques de l'analyse probit que nous avons délais
sée quelque peu au profit de l'analyse logit.
Finalement, comme nous avons passé sous silence
les applications de ces deux méthodes d'analyse à des situa
tions où la va r i a b l e dépendante qualitative ne possède plus
deux mais p l usieurs catégories, il nous semblerait louable
d'effectuer des recherches dans cette voie.
4.2 SUGGESTIONS DE RECHERCHES FUTURES

159
BIBLIOGRAPHIE
Aldrich, J., C n u d d l e , C.F. (1975). Probing the bounds of conventional wisdom: A comparaison of regression, probit and discriminant analysis. American Journal of Political Sciences . XIX (3) , 571-608 .
Amemiya, T. (1981). Qualitative response models: A survey.Journal of Economic Literature. 9_, 1483-1536.
Baillargeon, G., Rainville, J. (1979). Tome 3. Statistique appliquée. Trois-Rivières, Québec: Les Editions S M G .
Batchelet, E. (1979). Introduction to mathematics for life scientist (3e ed. rev.). New York: Springer-Verlag.
Berkson, J. (1955). Maximum likelihood and minimum X 2 estimates of the logistic function. Journal of the American Statistical Association. 5 0 . 130-162.
Brown, C.C. (1982). On a goodness of fit test for the logistic model b ased on score statistics. U npublished. National Cancer Institute, NIH, Bethesda, Maryland.
Burrel, R.J.W., Healy, M.J.R., Tanner, J.M. (1961). Age at menarche of South African Bantu school girls living in theTranskei reserve. Human Biology. 3 3 . 250-261.
Buse, A. (1972). A tehcnical report on binary dependent v ariables as applied in the social sciences. Edmonton, Alberta: Human Resources Research Council.
Byth, K., McLachlan G.J. (1980). Logistic regression compared to normal discrimination for non-normal populations. Aus - tralian Journal of Statistics. 22 (2), 188 -196.
Chambers, E.A., Cox, D.R. (1967). D i s c r i m i n a t i o n be t w e e n alternative binary response models. Biométrika. 5 4 .573-578 .
Cicchetti, C.J., Smith, V.K. (1972). An analysis with dichoto- mous dependent variables. Paper presented at the third world congress of the Econometric Society. Toronto, Canada.
Cohen, J., Cohen, P. (1975). Applied multiple regression / C o r r e l a t i o n analysis for behavioral Sciences. New York: John Wiley and Sons.

160
Cox, D.R. (1966). Some procedures connected with the logistic quali t a t i v e response curve. In David, F.N. (ed) Research papers in statistics. New York: Wiley.
Cox, D.R. (1970). The analysis of binary d ata. London: Methuen.
Dagenais, D. (1984). The use of a probit model for the validation of selection procedures. Educational and Psychological measurement. 4 4 . 629-645.
Draper, N.R. , Smith, H. (1981). Applied regression analysis (2e ed. rev.). New York: John Wiley and Sons.
Dhrymes, P.J. ( 197 8 ). Introductory ecinometrics . New York: Springer-Verlag.
Dixon, W.J. (Ed.) (1981). Stepwise Logistique Regression, inBMDP Statistical Software. (pp.330 - 340) . Los Angeles: University of California Press.
Efron, B. (1975). The efficiency of logistic regression compared to normal discriminant analysis. Journal of the Ameri can Statistical Association. 70 (352), 892-898.
Efron, B. (19 ) . Regression and anova with zero-one data:M e asures of residual variation. Journal of the American
Statistical Association. 7 3 (361), 113-121.
Fienberg. S. (1980). The analysis of cross-classified categorical data (2e ed. rev.). Cambridge, Massachusetts: The MITPress .
Finney, D.J. (1944). The application of probit analysis to the results on mental tests. Psvchometrika. 9_, 31-39.
Finney, D.J. (1971). Probit analysis (3e ed. rev.). Cambridge: University Press.
Fomby, T.B., Hill, R.C., Johnson, S.R. (1984). Adveneed econometric me t h o d s . New York: Springer-Verlag.
Golberger, A.S. (1964). Econometric theory. New York: Wiley.
Goldstein, D., Dillon, W.R. (1978). Discrete discriminant analvsis. New York: John Wiley and Sons.
Green, B.F. (1979). The two kinds o'f linear discriminant functions and their relationship. Journal of Educational Statistics . 4, (3), 247-263.

161
Gunderson, M. (1980). Probit and logit estimates of labor-force participation. Industrial relations. 1 9 . 216-220
Hanushek, E.A., Jackson J.E. (1977). Statistical methods for social scientists. New York: Academic Press.
Hays, W.L. (1973), Statistics for the social sciences (2e ed. rev.). New York: Holt Rinehart and Winston.
Hosmer, D.W., Lemeshow, S (1980). Goodness of fit tests for the multiple logistic regression model. Communication in statistics - theory and methodology. a9 (10), 1043-1069.
Hosmer, D.W., Lemeshow, S (1982). A review of goodness of fit statistics for use in the development of logistic regression models. American Journal of Epidemiology. 1 1 5 . 92-106.
Judge, G.G., Lee, T.C. (1982). Introduction to the theory andpractice of econometrics. New York: Wiley.
Judge, G.G., Griffiths, W.E., Hill, R.C., Lee, T.C. (1980). The theory and practice of econometrics. New York: JohnWiley and S o n s .
Kerlinger, F.N. (1973). Foundations of behavioral research (2e ed. rev.). New York: Holt, Rinehart ans Winston.
Kerlinger, F.N., Pedhazur, E.J. (1973). Multiple regression in behavioral research. New York: Holt, Rinehart and Winston.
Kotz, S., Johnson, N.L., Read, C.B. (Ed) (1982). Encyclopedia of statistical sciences (volume 1). New York: John Wileyand S ons.
Landwehr, J.M., Pregibon, D., Shoemaker, A.C. (1984). Graphical m e t h o d s fpr assessing logistic regr e s s i o n models. Journal of the american statistical association. 7 9 (385),61-71 .
Lee, T.H., Zellner, A. (1965). Joint estimation of relationships involving discrete random variables. Econometrika.13, 382-394.
Lord, F.M., Novick, M.R. (1968). Statistical theories of mental tests. Reading, Mass.: Addison-Wesley.
Maddala, G.S. (1977). Econometrics. New York: McGraw-Hill.

162
Malhotra, N.K. (1983). A comparison of the predictive validity of procedures for analyzing binary data. Journal of b u s i ness & economic statistics. 1_, (4), 326-336.
M a n s k y , C.F., McFadden, D. (1981). Alternative estimators andsamples designs for discrete choice analysis. In C.F. Mansky et D. Mcfadden (Eds), Structural analysis of discrete data with econometruc applications. Cambridge: MIT Press.
Mansfield, E.R., Helms, B.P. (1982). detecting multico11inea- rity. The American Statistician. 36 (3), 158-160.
Milicer, H., Szczotka, F. (1966). Age at menarche in Warsaw girls in 1965. Human Biology. 3 8 . 199-203.
Neter, J., Wasserman, W., Kutner, M.H. (1983). Applied linear r e g r e s s i o n m o d e l s . Homewood, Illinois: Richard D. IrwinInc . .
O'Hara, T.F., Hosmer, D.W., Lemeshow, S., Hartz , S.C. (1982). A comparison of discriminant function and maximum likelihood estimates of logistic coefficients for categorical-scaled data. Journal of Statistical Comput. Simul.. 1 4 . 169-178.
Orchard (1976). Binary regr e s s i o n with unreplicated data. Biometrics. 3 2 . 935- 938.
Pregibon, D. (1981). Logistic regression diagnostics. Annals of Statistics . 9_, 61-71.
Prentice, R.L. (1976). A g e n e r a l i z a t i o n of the probit and logit methods for dose response curves. Biometrics . D e c . 761-768.
Press, J., Wilson S. (1978). Choosing between logistic regression and d i s c r i m i n a n t analysis. Journal of the American Statistical Association. 73 (364), 699-705.
Pun, F.C. (1981). Model b u i l d i n g by logistic regression. Dissertation Abstracts international. 4 3 . (01), 178-B.
Reynolds, H.T. (1977). The analysis of cross-classifications. New York: The Free Press.
SAS Institute Inc. (1982). SAS User's Guide: Basics, 1982edition. Cary, N.C.: SAS Institute Inc.
Soupac Program D e s c r i p t i o n I & II (1976). Computing Service Office: University of Illinois at Urbana-Champaign.

163
SPSSX (1983). SPSSX User's Guide. New York: McGraw-Hill.
Talvitie, A. (1972). Comparison of probabilistic modal-choice model: e s t i m a t i o n methods and system inputs. highwayResearch R e c o r d . 3 9 2 . 111-120.
Tatsuoka, M.M. (1971). Multivariate analysis: techniques fore d u c a t i o n a l and p s y c h o l o g i c a l r e s e a r c h . New York: JohnWiley and S o n s .
Theil, H. (1970). On the estimation of relationships involving quali t a t i v e variables. American Journal of Sociology. 7 6 (1), 103-154.
Theil, H. (1971). Principles of e c o n o m e t r i c s . New York: Wiley.
Wannacott, R . J . , Wannacott, T.H. (1981). Regression: a secondin statistics. New York: Wiley.
Werner, J., Wendling, W., B udde, N. (1978). A comparison of probit, logit, discriminant and O L S : The physicians locationchoice problem. A m e r i c a n Statistical A s s o c i a t i o n 1978 Proceedings of the Social Statistics Section. 260-265.
Wittink, D.R., Cattin, P. (1981). A l t e r n a t i v e e s t i m a t i o n methods for conjoint analysis: A Monte Carlo study. Journal of marketing Research. 1 7 . 101-106.

ANNEXE A

P=O n=30 ETH AALI. RAPI_ '~Ll F~PL SCf?l L. SCRPL. BALP Rl\PP RLP rwr sr.RI p scqpp
1 n.1130 0.1120 -o~l61h -0:1111 ?0~7hh0 ?0~3R7h 0.11A7 0.1?1Q -0.?25'i -0.23Q'i ?7.ROhO ?7.7,QA ? o.nR4?. O.OAh'i -O.IQA3 -0.2121 ?Q.1Rh7 ?Q.l?SA n.OA'i9 o.OAR? -o.t9A? -0.2111 2Q.tA67 2Q.125A ' n.1oc;o 0.1031 -0.1103 -0.1663 30.43~7 'o .. ~'iH~ o.101a 0.105? -o.1760 -o.111q 30.Q307 3n.?'i83 11 o • 1 3 ? o n • 1 3 ll 1 o • 1 ? !' h n .. t 1 q tJ ? 7 • o 1 •1 c; ?. 7 .. b 7 q 5 o • 1 3 ?. 4 o • t 3 tJ c; o .. 1 t 5 t o .. 1 1 3 7 2 7 • q 1 « 5 ? 7 • h 7 9 5 5 n.1?n? n.t??5 o.??.55 0.2350 ?9.,45' ?Q.,O?h 0.1176 o.11q9 o.?.13? o.??.?.6 ~o.345' ?Q.3026 h () • 0 1\ Q ? 0 • 0 /\ 7 p. 0 .. 1 3 1 ô 0 .. l ? A ? 2 q • li 1 1 1 ?. q • R 1 6 b n • 0 ~ q l 0 • 0 H 7 Q 0 • 1 ?. 2 h 0 • 1 1 q ? ;> q • q 1 l 1 ? Q • A 1 b h 7 o.oR3h o.nR56 -O.l,17 -0.13Rf.. 2Q.~QH5 ?9.6304 o.07RQ o.0781 -0.0390 -O.OQO'ï ?9.APQA ?9.A9h0 A o.1lln5 o.1a1n o.~?4o o .. 3175 ?A.16?7 ?R.1637 o.1402 o.1ao1 o.3162 o.3096 ?R.1627 ?R.1637 q n.0650 0.06~3 0.0046 0.011'ï 20.34H7 ?Q.0643 o.066h 0.067? -o.OOB3 -0.0015 ?Q.3Q87 ?Q.0643
tn 0.1216 0.1120 o.o?&A 0.01&7 3LJ.Roto 33.0003 o.t265 o.1169 o.o?.55 o.0152 34.A619 33.oao3 11 0.1?56 0.1?83 o.?aQt o.2so5 ?9.9?71 ?.Q-"797 n.t165 0.1110 o.231q n.2?q3 21.&qtn ?7.&o3A 1 ? o • ;> 7 ? 9 o • 2 7 4 ? - o • 1 o 8 n - o .. t o b o ? a • c; 7 a n ? a • 1 o q a o • 2 1 3 o o • 2 7 a tJ - o • t 1 5 o - o • 1 1 2 6 2 11 • 5 7 8 o ? 11 • 1 h 9 li 1 3 o • ? 4 n '' o • 2 a o A o • ? 1 4 A o • 2 1 ?. 2 ? 3 • 6 6 5 o ? 3 • t c; 3 o o • ? LJ o 5 o • 21.1 1 tJ o • ? h 2 6 o • ?. h o 11 2 3 • 6 h 5 o ? 3 • l r:; 'q 1LJ o.13A6 o.t3H1 -n .. 0033 -o .. nona ?Q._qhoA ?9~qc;nq n.t364 o.t358 -o.013q -0.0110 ?Q.9hOR ?q.qc;oq 15 0.0079 0.011A -0.0034 -0.0045 ?Q.?.91fl ?q.2736 o.0317 O.O?Q?. -0.062Q -0.0h?A. 29.o642 29.619~ 16 0.1067 O.l05A 0.1h35 . 0.1515 ?A.7t;h2 ?B.5055 n.tOAl 0.107? n.15QO o.1a11 28.756? 2R.5455 11 o.o4Q3 o.naaq -0~1165 -o .. 100A 30.?3S1 3o~n7Aq o.ouq3 o.oa5? -0.1210 -0.11 tll 3o.?3St 3n.n7AQ 1H o.?o7R o.?n8n -0.2051 -o.211qq ?Q.3?32 ?Q.327? 0.2047 o.2oaA -o.2sto -n.?547 29.323? ?.Q.3?.7?. 1q n.o4?3 o.o45LJ 0.0737 o.013c; ?A.S?O? ?B.s2c;1 n.nA01 o.0A2n o.1q44 o.19c;3 ?R.&Q5Q ?A.73b7 ?n n.1A?Q n.l7QR -n.3757 -0.366h ?7.ti&bn ?.7.0315 n.1R33 o.1H03 -o.3741 -0.3hilR 27.hhhO ?7.03t5 21 o.1Rno o.11q4 o.oc;q1 0.0111 27.3~Hh ?b.5Rao n.1esa o.1R77 0.1&17 o.lh91 2h.070h ?5.7793 ?? 0.0806 o.o7t1h o.oht7 0.0527 30.«3R3 30 .. oc;2& n.oAat o.n776 o.osa? 0.0451 3n.43H3 3n.o5?6 ?3 o.19AS 0.2020 o.on1t1 -n.o096 ?0.1530 19.667Q n.202q o.?064 n.ooo? -o.010LJ ?o.1c;30 19.6679 ?4 n.~309 O.ll?QO 0.30A1 -O.Q~Q6 A.6123 • n.3436 0.4?90 o.30h~ -0.40?4 R.h1?3 • 2 5 n • 1 3 5 o n .. 1 ? q 7 - o • o 7 ~ q - o .. o h 4 A 3 o • b ' ) 6 ti 3 n • 1 c; 3 h n • 1 1 o o o • t o 5 A - o .. 1 3 q 11 - o • 1 3 2 q 3 o • o 7 6 7 ?. q • H 9 3 tJ ?6 n.nH64 n.nA?3 o.31Rh o.319h 3ll.1Qht 33.?046 o.123LJ 0.1?10 o.4972 o.s101 35.6554 3Q.t?4q ?7 0.1532 o.1s35 o.47QQ n.QRtl 30.056~ 3o.n433 n.1R28 o.1R32 o.5707 o.s12n 3n.n77o 3n.oc:;70 ?R o.nsoti n .. n«q~ o.oq1R 0 .. 0736 2A.55HR ?A~aqo5 n.0788 0.0111 o.3Qt7 o.3nqo ?q.1160 ?Q.13?1 ?9 0.1549 o.156Q -o.o7?a -o.0723 ?o.~3on ;>q_3a50 o.t5?A o.t54A -o.oA4' -o.OA4? ?.Q.3300 ?Q.3450 ~o n.1095 n.tOA9 o.0146 o.0313 ?9.A?Sh ?q.3qq3 n.1110 0.1,03 o.096LJ o.11oa ?Q.711a ?9.3,QA 31 o.n6t6 n.nh«U -o.1n57 -0~1166 31.555R 30~9775 n.0622 n.o6ao -o.105q -n.116Q 31.55~A 30.Q775 3? 0.1308 n.1371 -o.?O?l -n.2167 ?S.6?3Q ~s.aAoh n.1346 n.136Q -o.202q -n.?17? ?S.h?39 ?5.4A06 33 n.1416 n.1010 -n.2s11 -0.253? 30.345? ?9.qc;7q o.nH7LJ o.0845 -0.1616 -o.thOt 31.1100 31.ot?Q 3q n.10?Q 0.10h0 -o.1R97 -O.tQ70 ?Q.7A4A ?Q.77&Q o.101a n.1047 -o.1q25 -0.1QQ7 ?9.7A4A ?9.77h9 35 n.0844 O.OQ17 0.1?58 0.1?&0 28.161? ?H.11Q3 o.0855 o.OQ?A o.tt5Q 0.1164 2R.th1? ?H.1 tQ3 ~6 o.1b50 o .. 1oq? o.t?71 o.OAQ9 1q_q?b7 • o.16Q? n.?03Q n.1?A6 o.oq?1· 1Q.Q?h7 • 3 7 o • 1 5 A 3 o • 1 5 A 1 o • 5 s 11 o o • 5 5 7 ?. ' <' • 1 6 Cl c; 3 o • 1 n A 5 o • 1 q t LI o • 1 q t 3 o • 6 6 o 1 o • b h 1 q 3 o • n 'l. 7 1 3 0 • o n n q 3A 0.1021 0.101? -o.tQ63 -o.1q25 30.1A114 30.nA?7 n.10?6 n.1011 -o.2osa -n.2015 30.1R«4 3n.oR27 3Q o.13R5 0.134R -0.1?47 -0.13Hh 35.h777 33.54?A n.1JQR 0.13QQ -0.1303 -0.14Q5 35.h777 33.542A li 0 0 • n H A () 0 • n H 9 0 - 0 • 1 c:; 3 7 - 0 • 1 b 6 3 ? 0 • 7 0 0 1 ? A • ) 3 A 0 n • n Q ? 2 0 • 0 Q 3 ? - 0 • 1 5 s 3 - 0 • 1 6 7 A ? R • 7 0 0 1 7 A • 3 3 p, n 01 n.106a 0.10&7 -o.??oo -0.2125 30.7?2h ~0.3665 o.1h27 n.t631 -o.223q -n.??76 2Q.4QA5 ?Q.Sltih 4? n.1AbO n.1AAO 0.077? n .. OAlQ 18.57?.4 18.1015 o.tRQO O.lQ10 0.07h1 n.0AOQ 1A.S7?4 lR.1015 q3 o.?006 0.2010 -n.3404 -o.3?25 31.0bijo 30.7?QR o.?31H o.?,?4 -o.3771 -o.3c:;35 31.13Q7 3n.73A5 44 0.0745 0.0784 -0.1377 -0.1551 ?5.7016 ?5.hhQ3 n.n775 O.OA15 -o.1~q4 -11.1569 ?5.7Q]h ?S.6603 ac; o.?2R9 n.230Q -o.oR7n -0 .. 1105 27.70?6 ?7.Q5ao n.??hR 0 .. 2?.R? -o.oq37 -n.t1b7 ?7.70?6 ?7.asao 46 0.1606 0.171' 0.2?R3 0.2241 ?<l.3QOO ?9.4464 n.1&Sh o.th70 o.?.043 n.?OO? 2Q.3QOO ;>Q.4064 111 o.1Q?R n.l9?A -0.3160 -O.~OQh ?4.4613 ?3.3035 n.1795 0.174~ -0.346? -0.3343 '0.039? ?H.h43l 4 A o • 1 1 A 7 o. 1 ? 3' o. 1 q q 3 o. 2 1 t 3 ~ o • 9 1 114 ~o. on 7 6 n • 1 151 n • 1 ? o 1 o • t H 7 3 o • t q q o 3 o • q 1 tJ 11 'n • ho 7 6 uq o.o9o;> 0.1031 -o.001n 0.0055 ?H.St76 ?A.3Q4? n.tonq 0.1044 -0.0076 -n.001? ?R.G176 ?R.3942 so o.119q o .. tlH? -o.33th -n.1~&4 ?b.477h ?&.1R1c; n.ttA5 o.t\&A -0.'3"' -n.334A ?h.4776 ?6.1R35 St n.?177 n.?1R1 0.37114 n.357A ?2.Q7Qn ?2.40?Cj n.?tRA 0.219? o.,fi50 0.34QR ?2.Q7QO ?2.4025 c;? n • n 1111 2 o • o A 1> h o. o? R 3 o • n? fl A ? R • Q o 11 1 ?. C). o 1 n q o • o A :-r,? o • n Ac; 7 n • o? b 7 n • o? 7 1 ? A • q o 11 t ? q • n 1 o 9 53 n.0C)12 o.0R7h o.1n1q o.1c;1A 30.Q46Q 30.?343 n.ORQO n.oR~a o.13RQ n.1a21 3o.4n&o 30.?3u3 ~a n.1071> n.104R -n.nc:;;>7 -n.Ohh5 ?q.74q3 ?q.~q'q n.nhA4 o.o&6R 0.0113 n.0650 ?9.6AOh ?9.5312 5 r::; 0 • n q h (i n • 0 Q 7 a - 0 • 1 c; ') 7 - () • 1 5 /J C) ? H • () 1 6 R è 1\ • 5 q s /I n • (1 q R 6 0 • t 0 0 0 - 0 • t h 3 ? - n • l h 2 ,, ? R • b l h R ? H • c; q 5 Il ...... 5h o.19c;o n.??nt o.nsnA -1'.0046 1e.h1b1 • n.1453 n.145? o.onH7 -0.0096 27.Qt:;&? • ~

i <>. i?H7 - o . ^ n p s - o . ? o o n p m . M i so« ? 7 l « ? H7 'M H i o . i ? 9 3 - o . ? o /j ? - n . ? o i f > ? 7 . h ?87
166
o r" ~
ircir c^a cx^ccc «o ir •-i\j ;r o
d 3,K'—
orvir ~ a — rvx x
ircrvr- rv i-- ~ — ir
rorio' a
axN"ia—irxx«-<Lro km
c — x t-'-! x
x r. ©rv r-cir K'r-a a
ir rva xrvf'ixx — x o
s-3jc(? r^c=jcc —
r^ira Narrx — x x x —irx —
ca x x — a x-xr''—
cierva ir x
c —o- xK^r^,sccc irf'' x
— ccc—< — c x o xftjcn rvc —
ir oír ir rvrv—x -cr^ic? rv x
•
•«
••
• •
• •
•« •
»•
••
••
••
(!
•»
• •
••
••
••
••
••
•
• •
«•••
3-
sí
ic
c
— cr x
ai
rx
xx
aa
ao
xo
aa
í-
cc
r-
íc
-o
oa
c c
ir
c?
i x
ir f''r'“rv
rvrvp
''rvjrv
-rvrv
rvrv rvrv rvir'"’^ rvrv r^'r'-r'- rvrv rvi*~N" rvK
' rv rv rv r'-rvr'’ r>. rv rv o» rv rv
o x —
a r*
-x — c
a x
inr
xx
irr
'-xx
rv
c o-
n_ rvx
rvr^
-rvm
rxx
xirx
rv lt rv —
x —
cr x— ■—
ccirít íc -'rKisairir^xcc^c-xr^c o-“'
í\iXst£so -i£csc-ccrvt
-------rvir x
xc
rv
r-
ir
3t
c^
^c
-i
nf
f'-
M/
-cx
> s
i'r'irr-- x —
a x
ir ir ox
o —
ir —o
xa
i'- xx
r^
ex
a r-~
xir —
p~-r-.r— ir
ca
^.t
cs
cu
.rv
y'c
ir^
iru
'fn
rv
cf
v'j'y
x x
er
ve
■o —•
xx
xo
ax
r-' —
a x
a x
x a
rv a a
cc
cc
o-c
x —
— a
— ir a
a c
a —
cir
ca
o x
£
*■ k- rv rv rv rv rv —
rv rv rv rv rv rv rv x rv rv k
- r'- f'- rv rv rv r*
rv rv rv rv r*- rv
rv rv r<~ rv rv rv rv*»
lt
cc
«-x r'* r<~ x
xx
x a
is
ir
ce
x-
¿<
cr
v-
o r
v^
x x
ir>--r-r^
LrL
rxp
'''irrvo
—r~- —
— r --
x xrvr~ ca- ,cocirf'~aí'~x x
rvrv a x — c-xr'-r
—cctra o r- r
rv — — a xir r
-irc
ir
x^
as
c-
ff
ex
—a
xk-x —
ir o — o
a x
x-
xc
^i
ra
c c
cc
-r
v rvir ir x
— x
o
c —
c —
— rv
c 0
5c
c^
r\
jcc
f\
jc'-c
i\.0
-r\
jcc
cc
0^
c-
cc
cc
^-
(\
,^
c^
rv
';
cc
oc
cc
ec
oc
oo
co
cc
c O
OC
CC
OO
OC
OC
CO
C-
CC
CO
CC
C o
c o
es
• I
II
li
li
lí
I
II
I I
I • I I I I
I
ií
ct
ri
rc
xk
cc
i^
oij'C
' 3
rva
xx
ex
— a
a
x rvrv'irt'~irr'~ x
-ct
cc
cs
rv
rv—
a
Xir ir o
rvir
x rvt^ —
—x
«^
(flf
rc
ira
tj
cc
nc
it
^x;^
r^c
rvc
'- — x
— —
cir
c
r-ir ir x
x r'-x
—x
c a
r~- — x
irx
co
rv
a x
ir — x
— rv
ir rvx
c3
^c
r\
.'-ir x
x^
-ir co
— o
— —
rv cc
cc
c-
rv
cc
rv
/c
-c
tv
c-
rv
oc
cc
c-
c-
cc
cc
—r
.-
cK
w• •tea«****«*. ••••••••«•••• ••••••••#••»••••••
00
00
oc
oo
oo
oo
oo
oc
co
00
0c
co
cc
oc
cc
oc
oc
co
co
oo
co
oII
II
I I
I I I I I
I II
I I
I I I I I I
I
x —
Xf'-
a —
ok
x —
rvr-~
XN
'rv r^
rv. —
x x
— x
— -
ex
ea
— a
irr
vx
irir
rv
rv
t-''x
ir x
a f^
-ir 1*0 x c
c i^
x o
cr
vi^
imir
r- cK
".r~K
- —x
i*' ir
rva
a
xc
iro
c
nc
j'.~ —
— x
3s
x
xx
cM
c-
íx
cf
na
-^
^i
xx
x x
--
^ir
^-
-c
ff
sí
e^
a x
r^
rv
x rv
x x
x o
x
0 —
0 —
— o
—r\j —
—i —
*rv¡—
rv—
o —
— —1 —
—1 —
® —
— c
oc
o —
oo
co
nj
——
o—
— —
rv
o o
c c
oc
cc
co
cc
co
oc
co
cc
cc
cc
cc
oc
co
cc
cc
co
oc
cc
cc
c
x c
a x
Lr=rr-r-~
x c
o-c
cc
^c
ir-c
ícir
iir .c
a,/' a
'v
-c
^a
o-3
5r
\jx
ír\
:(v-c
r
rv — x
c x
x ir
ff
N^
í\.X
5ff>
cc
iN
(\
.,jO' H
~rvf^ ^~ir x
a irr^ í
i\
cc
c x
a a
—o
¡ve
r~- x
x c
ní
xf^
inx
crv
jrv—
,xr-c
xrA
xx
~-í'''.x
——
xc
r-x
r-~
xc
-ernr^ x —
x
x c
ir o
— o
— —
— o
—rv
— —
— rv —
rv'——
— —
— —
— —
c —
— c
—c
c —
c —
cc
rv
——
o-
— —
rv
cc
oe
eo
cc
cc
cc
co
cc
cc
cc
ce
cc
ec
cc
cc
cc
cc
co
cc
oc
ec
c
ar
^x
ir
c—
cx
xx
xr
^c
x x
ir—
rv x o
ir x c?rv—
cc
ir
^r
a—
Lr
xc
ir —
rv
r^
rv
r'-—
u r^
rJ'o
co
-iTN
'C'C
Lrx
x—
xo
r^"'^
'—x
N'o
a-f^
'.a'v
—rv
crp
^r^
arv
ir—c
rirrvf^
'xx
—x
o—
~
c c
ir
ro
í x
-r^
ir—
n rvr^- x
—e
ro x
—i
rx
—f-^c 3
3-
c^
c^
r^
c^
a x
r^ir x
o
—c
c^
cn
x-i
PF
'X —
c- ex
— —
-o —
xa
^j
td
c —
ire
irx
rv
— —
rv — c
.^x
c "v
x
5 —
x x
x —
o-r
^d
— r
xa
cc
Kí
aa
rc
s c
ko
x —
o a
— =: x
a c
j-
?i
ro
c-
cx
ir
r“ w
-rvrvrvr>r rvrv
—rvrv rvrv —
rvrvp^ rvrvrvr^i^ r^
-rvr^
rvK
K rvr^r^rvrvK
-rvr^ rvrv
K rvrvrvrv
a x
—a
1—lt —
ca
xir ir
-ox
irN
Xx
no
c^
rvr^
x rv —
rvK
irxf^
^x
-rjrvirrv
—
xs
*-------cc
^x
xo
r^
—x
^r^
rvin
r=T
XX
^rr^
— x
r-~
ca
cr
vx
t^
xo
r^
x —
rvx
r^a
c —
rvx
— — rvir cr\.crvcirctc^ — o — xxa rvr~ ircxNS^KirNN-irxMrcxc-'-x- c
iO'N
cín
^c
i'?iv
xir
sr
^“'s
jicc
jLr
x "
cx
rv
.o-^
ir^
iru
'rr
'—c
in
r^
.xx
cr
v-
■C —x
íX
"(í ?
c-r
cic
s!
0'(\
ijO'o
-3 0
(n
x —
—a
— ir>
xa
ca
— ín
ro
aa
xx
^
-^rv rvrvr^“ rvrv — rvrvr^rvrv rvrv ^r r
vr
vr
^-.r
vr
v rvr^r^-rvN
'rvrvrvK'rvf^ rvrv ^~ rvrv rvrv
aa
? ^
-¡
r x
- c
^r
^ rv
rvc
irx
cK
cr
ojr
vir
^i^
~x
sN
rv
xr
^a
—irN
fr.*/>-
-a
c
iN
XS
io
;i
r\
ícf
f'X
X"
—x
x s
cc
cc
Nr
íi
^c
^ x
cr
x—
ira^
r-^c
rvix
a —
X5
— rrx
^iirrv
c:—
—
a —
aa
fv
i/c
cj—
—c
c a
— a
sir
t' 3
ría a
r^rv
ee
rvir ir x "
ira
o —
o —
— —
co
co
o—
rvic
on
jo —
cr
vo
—.r
vr
vc
cc
c —
o —
rv
o—
c-ro —
A, —
oi^
rv^
oc
cc
cc
oc
cc
oc
co
oc
oo
oc
cc
oo
cc
cc
cc
cc
co
co
cc
cc
oo
o■
II
I I
I I
I I
I I
I I
I I I I I I
•
ir
^ir
—r
^x
c—
^a
xr
-x
ar
vx
—x
x —
xo
K-a
a rv
írrvrv
r^x
xr'ir—
ir ci
rx
x^
r-r
v
x —
ir x o
'^a
xs
c'v
rv
írir
air
o'r
vix
xív
ri c
ax
— —
cr
^x
ir-ir xir
oír
x —
—
^ cr
o x
x ~
xr^
t^rv
rvrv
a —
a c
c x
~ r'“ 0
0 rv
a a
crv
r'iri^'írrv
x —
r-r rv — c
—ir~
xo
xc
o
— o
— —
— o
cí
í 00
— rv —
er\
jc —
or
ve
— rvjrvc c
cc
. — c
— n
jo—
crv
— rv —
c--N~rvi’'
t 1 • t
1 1 1
1 1
1 t * 1 1
1 » • 1 i • f
1 1 » »
1 • 1 *
1 1
1 • 1 • *
1 1
1 ■ ■ f 1
oo
oo
co
oo
oc
cc
cc
co
oo
cc
cc
cc
cc
cc
cc
oo
co
oc
oc
oo
oc
cI
II
I lili
I I
II
lililí
o x
c —
x
—i
ri
rx
ai
rc
—r~
c —
^c
x^
o x
x—
r^a
r^—
r^—
x^
r-r
^x
i^^
c x
r^i^
i
^x
c-^
i^
x^
——
j~a
a —
a
rvr^
x —
rvx
a c
^c
rvir^
r^p
^r^
rva
rr — .r o
x —
xx
x c
x —
c
cN
í3
cj
xc
rv
(V
7í
ít
x3
ro
or
^x
——
Lra
f^irf^
-—a
ir
^ —
3—
xx
^c
-i
o
— c
— —
— c
—rv
——
— rv —
rv — o
— —
— c
— —
o —
— 0
00
c —
— o
co
rv
— —
c------—
rv
cc
cc
co
co
oo
cc
oo
co
cc
co
oc
cc
cc
cc
cc
cc
co
cc
cc
cc
cc
c
^ x
i^a
cri^1 cr xir
x x
x rv
x r- ~
a rv ^
— x
r^ ir r^
ir ac
ir -c
A.!
tr
ci
rc
^-i;ir
x’
^o
cr^r^a x
~xxxcxf^3c.*^r-r'r^x — ir^T'Xc — xr^airorv3í3X—xaL^acrc
c s'X a r'i^crr^xxcrvrvir^'xaxt^'erc? — r^x— — xar^c^-oci''a' —
'^•xxee?
c —
cc
— —
c —
rv — —
— rv —
rv — o
— —
— o
— —
c —
— o
cc
c —
— —
cc
rv
^ —
0«------—
rv
oc
cc
cc
cc
cc
cc
cc
cc
oc
cc
cc
cc
cc
co
cc
cc
cc
cc
-c
rc
co
cc
c.
r^
xa
c—
rvr^ — i/
xr
^x
ac
— r
vr
'air
xr
'xc
c
— rv
c ./
x: r- x o o
— r>.K- —
j- x r~~ x
c —
x ir ir x
x x
cx
xx
xx
c r- r»
r- i^-r- x x
x x
x x
x x
x x
u e
a .? a
a a
ar
e c.

167
me
rxa
i/i>oa r~-to—
ox
xro
roe
rero
'a o
oi
t-O
"^
ro — =r o
ruc
xin
xa
xx
rox
=r sj oí
ot
cìr
o-ip
no
a rv
=7 cr « —
xr-~ rv ro
ax
ìm-ir
oo
oi/
'wr
vjc
oo
^o
' rvx
LP
f^x
x —
r-f'-tra x
ro ej rv x
—'-•
or^
if\jo
if\jL
''cQ.
roir —
eja
of‘~
xx
xr
vc
xx
—to
rva x
-xr
oo
ro
—r
^r
vc
ac
—L
no
xL
rrvro
oiV
JjK'r^
Lrrv
irroo.
cc
íNío
rv
, a
©=3 —
xr
ux
x ©
u-'X
roirx
rvtra
» o -
cs
^ r-~ lp x
tv r\j ex errore -cirro
aro
—x
ivo
aro
rox
iT
et ............ ..
...................................................................
..(_'
tcco
-cc©
r~
ir
xr
^a
—xero-
oo
^a
ON
0'K
-C
0'0
'ox
-0
'rt
0'C
00
'-0
C!C
0'C
NK
iir
'<r
'S3
0'r
v,-
xr
'a(V
,C'
co ;?
ir er er ir
ey lo
5K
ii
ri
rc
ir
3i
r-
oi
rc
e3
?3
3C
3i
ra
'ip
ci
r'0
3^
3L
ii
3c
?5
- c
ir
ch
i
ir-£>r-~r~-cr—ro
rsixx
r-- or^
cc
iTo
iro<
o^
iriTro
—x
xrv
rvc
ox
x—
in x tv e
x ì
cn
oc
- cira
<0
3r,'7
CM
ri^iir
a. s
a,i^
NK
ì^)>
OK
ico
Nr\
jo-h
-Nc
co
iriir'rv<
ON
ao
r\jo
sff x
p-lt —
ertv
civ
xrv
ca
x—
eTX
X(V
G(v©
eJf■
^l^.ae
^ _l
CM
nirin
—i^
oo
f^
Ki-«
ax
eT
inx
tv
irc
r'-^
ax
ej-«
ccN
O'a
ac
-*N
?>
cro
gcc
otM
tc
3-o
j:--cr'O
oi£
crr
-r- C;
ro©i'~-r-~-x©
— ©
©m
irria—
XlP
roir —
roo
xrv
roc
rx o
^d
Xi/
'r' XiP
ir. Xr-rO
Lrx
r-r-»xa
rOiV
©x
:r' —ir ro
a =7
u
•co
x—
ax
cm
^o
-s
o-
rv
it
t^
o-
—«
c^
NS
'Nf
'O'f
f' ©
x —
a rv
ac
co
-c
cic
o'g
h.r
oir
Kis
Na
03
— a
sí
-r
va
ej-
iTia
ejip
en
rfo
eT
fo
erin
oin
eT
irxin
ireT
erix
eT
iyiT
eT
Lrerir
eT
trer
D. a
xa
xir
—a
© —
xrvjx
r'-in —
ej(V
jNs
c^
c^
tj'CM
rK
i^ip
o-K
'^íc
as
oa
aN
a x
xx
— a
cc
xc
tv
t1- —
a.
xo
irr
or
vx
xx
errorv —1 ro
cca —
<ro—m
—,0
—<^*
;jru—
torve
Toro
rvon
jirir'-roa
me
T or^
cc
o—
^ —
o- a rvr^ —
r-x
x
in=
íar'-x
xa
iva
xrv
53
-(vx
x©
x:3
r~=
yi''" —
irr-xe
r er tvej —c- >
co
^^
o^
r^
cir
^c
®N
ia-tc
c-^
^^
inK
,c
oe
x©
oo
— ©
—(V
ro©
——
rv
o;r
-©©
——
© —
©o
—©
—ro
©e
r©o
rorv
——
c©
— —
©r\
j©©
-ru©
—K
iro — o
c
oo
oc
oo
oo
oo
oo
oo
oo
oo
oo
oo
oc
oo
co
oc
oo
oo
oo
oo
oo
oo
oo
oo
co
oc
co
oc
I I I
I I I I I
I I
III
I I I I
I I
I I
I III
o_ — —O'^O
'—oa—t^r^r^xarv^c—cmco-x
n-®o3-"^r/''0 7
r^^sa-0—a ar'-rvxxxir(vr-~r'''©x<vr'~x
_i a
rox
r~.'v
eTin
(va
afs'r'-:3
'a©
—ir —
xrv
roa
-©o
oro
xr--©
rofo
iri;3-irin
——
© —
—L
rr'-o©
©L
Pir—
roo
xrv
ir1
ip
cc
xa
tcc
©x
:rrvr\
j tox
ica
©ro^o —
roe
xa
x=
j er — ;? —
ox
o —
x—
to ere
irroro
x ^
<c
irr^o
5c
r\;c
^c
©;r
©e
© —
o —
ruro©
— —
(vororvj ©
c -
—©
-©
©—
© —
ro ©
ir ©
©ro
rv
——
~ ©
— —
©¡v
©©
—iv
——
roro
— o
c
oo
oo
oo
oo
oo
oo
co
co
oo
co
co
co
oo
oo
oo
co
oo
oo
oo
oo
oo
oo
oo
oo
oc
oc
o©
I I I
I I I I I
I I
III
I I I I
I I
» I
III
rorv
ivx
xtv
x©
F'~
©x
xr'-a
=T
—ro —
er<vr-~cT©ejrvr~-a ©
t'- o —
©0
—t"
-rvx
xx
o ©
—ro
eo
o-e
ca
iii^a
— x
u
q. —
irr-a
cr—
—•
xx
— ro
ru
ipx
ro
xin
ro
rin
xe
rx
xaro
— x
lP
ìvx
iv©
a»
£o
irs
r\,r
-N ic
cc
iri/'.f
f'c
jxro
j' c_
ei (va
—x
rvin
rvtv
xtv
a s
r'ir
vif
f'^
ioa
irc
a =
7©
(v-n
jf'-x —
inir—
x m
irar'*
rva
rox
r—c
crv
r^x
— x
ro^
<
©
—©
— ©
— o
ru —
— ©
©©
——
—©
——
—©
c —
©—
— —
——
©—
—©
— —
©o
-©
© —
© —
©c
— —
— ©
——
o—
<0
CD ...............................................................................................................................................................................................................................................................................................
oo
oo
oo
oo
oo
oo
oo
oo
oo
oc
oo
oo
co
00
00
00
oc
oo
oc
co
co
oc
oo
oo
oo
c o
oc
i^roira ©xoxinox-a oxxiiMuiaitNN«?!)' <vx—x=r ir ferver rv© o
a x axmxirx erxin —
>x a xir
c. a x ir a
a xxr^r'-xivr'‘'r
xtVLrtvxeTror'-;j er —a ro—
rox ro—.ruc a
irxrvxirrororor^r^x —ir tv o
—xr^a r-
2 _j
rorva—x—ir. orvipr\jaxei(Vx©ro>cGairo©eT©r\j-r\jr-C'—
mir —XLrinar'-rvaror'~r--- —
©roxx —x<vx
Il <1
o—© — c—©rv——eoe-— — ——— — cc —
——— ———o——o — — oc —©©—o — ©© ———©——©—©
cX
CC
OO
CO
OC
Tr
'^O
CC
CC
CC
CO
OO
OC
CC
OC
CC
CC
OO
OO
CO
CO
CO
OC
OO
OC
OC
OC
OC
C
irr
ox
air
xa
1
ro — o
31'- er ro ;r a
a a
© x
ir x —
ir o—
cr © tv
ro © x
a x
x -o o
=7
;i©x
e~
-xirrv
— irx
o=
jrv
o
cio
a^
cs
rv
: M
O‘X
o(\
)N-o
ox
irK
ir\
j?c
cx
jir\
jxiT
M£
xir
xs
i/'a
af
'a c
rv
jcc
-so
r^
sr
vo
xM
Po
li _j
rv
jcc
cir
i —
roir —
ir —a
© x
x rv
tvc
x x
—ro
tvx
x —
xro
cr'':y
ej rv©
a —
—tv ©
xir (V
X er (V
or^
r-Lr ru
irjo
o. c
oa
r^
x©
oj
ae
eT
iro
ro
xx
©o
xr
oip
xr
vir
ax
c—
©h
~—
r-roa
rvrv
oe
rro—
xiriro
aro
—x
—o
ato
rox
j-. o:
• ...t«...
i_> x
— a
xo
Mr
i x
r-~a
r--a<
va
©©
-ax
r'-o
t"-x
aa
©x
—a
—a
xx
xo
xo
cr
x ro
m —
r- x c
a a
—x
r~- a rv
o
co a
ire
3iT
7iT
' íiro
cíir:c
rmd
irxL
ríio-íJíT
=T
íT3
íjLP
5n
r3L
roíi~
;rir;r
_j x
—c
or
^x
x—
lt—
xl
t—
ax
x—
ro^
o(v
xx
eT
©r''x
r^a
r'-xx
— r*
ac
(ve
r a o
a x
rve
ia o
ki
cn
©irr~
ir©e
r _j
ao
xir
—ro
crv
roro
—i--ro
xir x
rv
^o
s o
a x
u —
xr
- a =? a
© —
©c
rxro
erx
xirx
xiT
X©
—ì
om
oc
cì
xs
q:
r^©
—r-'-x ©
— ©
oirir o
a e
ririnro
ir —^
.xx
rvjro
ax
© —
ci xir.r^-K'.r^ir x
^t^
irix r^
r~x
a l
tiv
© —
r*-—ir ro
a =7
u
..
..
..
..
1
..
..
. ......................
............................................
..........................
co x
—o
x©
r~x
<v
ar^
a—
©~
a —
— —
cx
r^a
r-r-a
a o
x —
a rva
xa
x ©
x a
crx
ro
ir^
oa
©a
— a
r-a
rva
“irtre
TireTirro
dro
er x
ir-m ín
nx
irinc
jeTe
Tere
jeie
íine
riniyire
j'ej'íje
Tine
reTO
d—
erin
de
roiro
inc
reTiTe
rer
_j x
rve
ra ©
rv'x
sip
c —
<v
x —
— x
rvrv
irr'~a
a K
isx
rvjN
NX
O1 iv
a iv
a ru
r'-r^a c
ax
ow
Ln
rv
xt
r^
-cx
a rv
x
a_ xe
rt'-r-- ©ro
erro
rv—©
rvx
xir x
tva
tv©
xr--ire
Tx
t^ire
rar^
in;v
a x
er «vir- ivo
a ro
x r- r^ro
rviva irro
tvx
o —
x
x
ifKi-c
o'a
ac
ox
rv
ax
LT
—e
x©
x^
^'-in
Ne
rr-'-r*'—
ir—©
r'-eT
ox
otv
a©
Gro
roa
xo
ir.XL
ron
jr''~e
r:e?
c
or
o©
©©
—©
—r
or
o©
©©
(v
oc
r —
©©
——
© —
©c
© ©
—iro
©ir©
orv
jrv —
ro
o'v
—>
©r\j©
© —
rv
©—
roro
^-©
©
..
..
..
. .
..
..
..
. «
..
i.
. .
..
..
. .
..
..
. .
..
..
. «.«•■
« .
..
..
..
..
©©
©©
©©
©©
©©
©©
©c
oc
o©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
©©
I I I
I I I I I
III
I I I
I I I I
I I
I I
I III
_i
r>~ —'X
fv =T ro
sjr- s
ir-»ro
mi^
-ro©
roa
roi'r'r\jrv
jfoa
o- L
Tro
foro
—r~
~a
©«
Vira
xr
~x
x o
xr
~ rv
rox
a x
(Vr^
a —
r^rv
ir _
j x
—ir>
— c
—ro
ior^
>o
LP
X o
r^r^
-x w
oír
roo
x =
rar~
iriLP
©rv
jr^o
o ©
lp
u —
'LP
rorv
© e
ra x
i'O —
xir
xr
^r
vx
LO
^a
x
x
irr
vx
©a
xr
^a
er
(V
(^
©x
—a
cr
vr
^—
<p^ —
xx
ejr
-f
o-
x —
—r
^L
rr
^x
— rv
a ©
— r«'" rv
a ir>
a ir
r^
x e
r — —
aro
.ro©
ro
©©
——
1©©
ruro
© ©
—iv
or
or
v©
©—
•—•©
—0
0©
©—
*ro©
LP
©o
r\jf\j——
roo
ro —
i©(
v©
© —
(V©
—to
ro —
© ©
■ •..•ti*...!...«.. ......... ..................... ......
oo
cc
oc
oo
oo
©©
©©
©©
©©
©©
©o
c o
©o
© ©
©©
©©
©©
©©
© ©
o©
©©
© ©
© ©
oc
©©
eo
e©
I I I
I I I I I
III
III
I I I I
II
I
I III
ro
xx
— ro —
©e
jLrx
xL
nro
ir.r-— ro
x—
foi/iiv—s
aa
eix
xx
— ©
ar
^x
cx
— err^ .c
iviv
arv
io—
n.1 — L
rrvx
xx
_i
rvro
rvx
rvc
ao
xr-x
errv
j—i^
irerr^
© x
x^
xir
ro
x x
xs
s:—
ox
Lr(v
erin
eTro
©=
jx;/
'—r-.©
oa
— L
r'xx
xx
ex
er — ©
— x
(V errorviir — a
ar~
ivx
a —
Nc
airic
airu
trxj —
rvr-x
— f\jx —
x~j t^
ax
rva
ro
na
co
cx
x- x
rvx
<j
©—
—i —
© —
©n
j—*—
co
© —
- —
<©
— —
—«
©©
—0
—0
— —
— ©
—>—
©^
—<
0©
— ©
© —
© —
©c
— —
©©
— —
©—
ox-
©©
©©
c©
©©
©o
c©
©c
©©
©©
©©
o©
ce
©©
©c
c©
©c
oo
©o
©©
o©
©c
©c
c©
oc
©©
cc
©©
r'-i'-i/'ro
xL
r'ax
roirx
rox
©rv
a e
roro
xx
inx
sjx
rvr'in
aa
Lr'in
xe
rca
xx
ao
'irr— a
oo
xir
x ©
xa
ox
rv
_i o
^-X
sO
Nc
xr
'3N
©c
ox
5-A
ir'3
M<
',3x
roa
ir> ao
xc
xir
ro
ra
irx
^ —
sj — (v
xa
ip©
i'rx
<v
— rv
xe
j —
_i ej —
© —
x —
ino
rviri —o
a x
(VX
©r
vx
ca
ipc
air
xo
j— ro
r-a—
njx
— x
erro
ax
rva ro
c-a
—©
ltx
x —
xrv
r^ «1
c—
— —
c —
©rv
——
© —
© —
— —
— —
— —
e©
— c
—c
— —
—©
— —
©—
— ©
© —
©©
—©
—c
o —
— ©
©—
— o
—©
x
...............................................
©©
©C
C©
©©
©C
©©
©G
©©
e©
C©
C©
0©
©O
OC
©©
©©
©©
©©
O©
©©
©©
©©
CG
CC
G©
©0
C©
x
— (\ii,
5ir<
XN
xa
o-rv
rog
-ir-^c
r^-x
ao
— n
jroe
rinx
r^x
a ©
—rvi^e
yir xr^
xa
©-•
rviK
'cirX
Nx
a ©
— rvK
'er O
—
— —
— —
— —
——
— rvru
rvnjrv rvrvivrvrvro
foro
roro
e«'. K'r^'io
r^id'o
oc
sre
jejo
'ero
LrL
rLO
irir

[fH HhU HAPI. nll HPL SCPLL SCRPL
SS 0.1100 O.ltOh (). 2 lJ q li 0. 2lJ11 () 47_7qq3 ll7.73ll5 Sh o.1rq o.lh~Q o.oHrd O.UH27 sc.;.1321 ss.1Jw;;H r:,7 n.1 ·rn4 0.13?1 -o.1h7? -0.1560 4 r.. • 0 7 7 5 11 7 • t ? h Cj ') R n.M~oo o.oH:7iLI O.lb'>O 0 • t 7 A t so. ':ihLJh so. ~q•J n c)q <'.12c;ll O.l?lj3 -o.111H -o.176? 11 l/ • 2 q 1 A Il 9 • 3 S 7 0 IJ 0 0 • 1 l! 0 b 0 • l 2 0 1 0 • 0 li 1 0 0 • 0 IJ? ) lJ H • b 0 4 0 Il A • ~) 0 5 1 hl 0 0 (lhhO 0.0673 -0.0513 -O.OiJ36 Sl.617h Sl.3463 h2 n.1370 0.1321 -o.2sQo -o.253q aq.0121 47.A?oo b3 o.1&Q~ o.1657 o.o3RA o.0~2s LILJ.4333 43.34Qh 6 li 0 • 1 2 7 0 0 • l ? q 5 - 0 • 0 0 3 3 - 0 • 0 0 li ? IJ 4 • b ~ 3 0 li lJ • (l ~Il 7 bS o.ob63 o.01ns -o.1365 -0.1486 so.02BA ll9.n?2A b6 0.1914 0 0 1R9R -0.2330 •0.2021 47 0 6217 47.?S4t 67 0.1160 0.1?00 -0.0?1A •0.02~? 43.6533 43.S157 oA 0.1110 0.1111 o.1456 o.138Q 51.7426 st.5534 hq o.oao6 o.0405 -o.0960 -o.102H 48.04R5 Gn.u12s 70 0 0 0b2A o.0614 o.2149 o.210H 4a.3275 49.3976 71 0.1734 0.17?5 -0.2193 -0.2?4h llh.43Q4 44.8721 7? o.12q1 o.1318 -0.3410 -0.3502 ll4.h227 43.R466 1~ 0.1021 0.1034 n.2s10 0.2535 49.09QO 4Q.0769 74 o.12H9 n.130h -0.0301 -0.0323 41.lOSb 41.0547 7 s o • n H R 7 o • o H iJ 0 o • o ? 6 A o • o ? 1 3 s o • 3 11 1 7 11 q • 1 3 q h 7h n.n9H3 o.o9Rh o.o4oS o.o55H 5(1.2296 4".7293 77 n.0902 o.oR87 -O.?ORI -0.201~ 4Q.6534 49.hl49 7R o.n936 0.0941 o.04?b 0.0616 sn.2103 ~9.h7&7 1q n.10Q3 o.1oq? o.24Rb o.2483 4~.68Q4 4R.6740 Rn 0.1599 o.1SRO 0.370? 0.3609 4H.8313 4H.9?42 R 1 0 • 1 ? Q H 0 • l 2 9 h 0 • l ? H 5 0 • l 2 S 7 li li • 0 1 li A IJ 7 • 9 Q 7 q fl? o • 1 -~ n t o • 13 l q o • os 7 o o • o 5 7 9 114 • o 4 7 "3 1rn • <? q 1 4 Il) 0 • 1 ? q? 0 • 1 ? 4 Il - n • 0 7 R R - n • 0 7 q 3 s <' • 0 Il 5 5 i::; 0 • () 0 ') IJ I l IJ 0 • n 9 lJ 0 () • (l q _) n - 0 • 1 0 H 1\ - 0 • 1 1 q 3 l.J q • 1 9 2 5 Il q • 1 'I 7 7 H c; 0 • {) 3 1\ LJ 0 • 0 3 9 6 () • 0 h 1 1 0 • 0 c; 7 1 Il /; • 4 S () A Il H • ~ H Q 5 R6 0.12?0 n.1211 n.è.?A3 0.2337 4 li • 7 1 31 4 li. bb58 r.1 o.obU-. O.OSR4 -0.0?2b ·O.O?B7 4Q.603fl lJ9.C)0"39 AR 0.0922 n.0947 o.OOb3 0.0114 4c:,.1110 44.9101 HQ o.13CJB 0.142? -O.OQ21 -0.101~ 37.1A74 1h.7463 QO n.n539 o.oi::;3? -o.o9tt -o.o~qn a4.2695 aA.94QS 91 n.nh?l o,06?R o.1S95 0.16?9 so.s211 sn.~1r1 9? o.n76H o.01q7 o.1oa6 0.10&0 4b.2QRt llb.2~9o 9 "°S 0 • 0 3 Q ?. 0 • 0 Il () H - 0 • C) 3 1 3 • 0 • (1 3 Il 3 li b • q 2 6 9 Il 6 • l) R 9 1 qu o.oA53 n.0867 -0.0131 -o.o?o9 1JCJ.q1a;> aQ.H771 rJc; 0.0418 n.0936 -o.14sc; -n.tllo9 so.B?11~ sn.soHA q h 0 • (l 4 (1 2 Ll • 0 R H 7 0 • 2 3 q 2 1) • ?. ? 0 R 11 Il • 1 9 C:, 4 Il H • 2 ·3 ? 9 q7 0.0933 o.o9H.o -o.ono? o.016? c:,2.1c;13 c;1.1.1398 9 1~ n • n 11 c; s o • o ~ ? b - n • 1 2 o 3 - o • t n H ? 5 i:.., • 7 i\7 o c:, ? • 7 5 5 3 O q 0 • Of\ 11 IJ 0 • (\A'; h 0 • è 3 2 9 0 • 2) 4 9 Ill\ • 7 0 t~ IJ IJH • 7 Il ,..l h
1 o n o • r. 2 s n n • o ?. n tJ - o • o 1.1 1.1 6 - o • ~> c; 9 t> 1J q • 9 7 o ? ~ q • l '1 H H
BALP RAPP HLP RPP SC f?l P SCRPP
0.1105 0.111? o.2412 o.23b1 47.7Q93 ll7.73ll5 o.th03 o.lSbiJ o.Ollb7 n.o4S? 4Q.bhbl ll9.7lll8 0.1332 0.1353 -0.1111 -0.160? 48.0775 47.1265 o.01q4 o.OR25 o.t5Rll 0.110? ~o.5646 so.2tj40 o.1302 o.12q3 -o.o94A -0.09H2 49.6479 a9.6A9t 0.1?09 0.1?01 0.0332 0.0345 4~.6040 48.5051 0 • 0 6 4 7 0 • 0 6 5 5 - 0 • 0 S 7 J - 0 • 0 Il 9 7 5 1 • b l 7 6 S l • 3 /~ b 3 n.13Q5 o.13Qa -0.2605 -n.2555 4Q.072t 47.8260 0.1716 0.1075 0.0391 o.0330 44.1.1333 43.3LJ96 0.1311 o.133S -o.oos? -0.0060 44.h3~o all.0347 0.0692 0.073? -0.1392 -0.1514 so.o?HR 49,0228 o.t444 o.1LJ17 -0.10?6 -o.OQ7A 51.0650 so.8534 o.1197 o.1?40 -0.0219 -o.o?aq 43.6533 43.5157 o.11qo 0.1133 o.1L103 0.1335 51.74?6 s1.ss34 o.o4?0 0.0418 -0.0974 -o.10L16 4R,0485 48.0125 n.ORtb o.o7Q9 o.t54H 0.1502 49,ll640 49.SORQ 0 0 1768 0.1760 -0.2144 -0.224A 46.4394 44.8721 0.1174 0,1?05 -0.?775 -0.2A79 44.4814 43.Q114 0.1021 0.1033 0.2472 0.2496 49.0990 4Q,076Q 0.1337 o.1351 -0.0301 -0.032? 41,30S6 41.0547 o.OQ?7 o.ORHO 0.0292 o.0?33 S0.3417 49.1396 0,09Q5 0.0~9" 0.0338 O.OQHH 50.??Q6 49.7?93 o.n7R? 0.0763 -0.1518 -o.1so1 49.7677 49.5931 n.0971~ o.o97A o.o3R1 n.OShh so.2103 49.6767 o.oAQ3 0.0901 o.?.012 0.2013 48.2237 4A.26Q3 o.tS9?. 0.1573 0.3619 o.~S?h llR.R313 4R.9?42 o.llAC/ 0.11A7 0.156A o.1c;q3 49.0301 49.0SQR o.t2R3 0.1~00 o.OIJ87 O.Oll96 IJ9,0473 48,9914 0.1211 0.1212 -n.oHbh -0.0~11 50.04S5 so.0054 0 • 0 9 ê' 7 0 • 0 q 1 h - 0 • 1 1 1 H - () • 1 ? 2 li 4 q • 1 r1 2 5 IJ q • l Il 7 7 n.0343 o.oaoa 0.0572 o.os21 IJH.4SOR 48.3A95 O • 1 ? 3 0 0 • 1 ? 8 ? O • ?. ? 6 11 o • 2 3 1 9 li li • 7 1 3 l 4 4 • 6 6 5 R 0,0?98 0.0263 0.0438 0,037R 49 0 2714 ll9,2845 o.oqs2 o.o97R 0.0012 o.oo&s 45.1110 4ll.9101 o.1a43 o.t4b4 -o.0874 -0.0970 37.1874 36.74h3 n.oSRl 0.0572 -0.04Q8 -n.0926 lJ4.?69S llH.9495 o.n5RR n.0606 0.1065 o.1101J so.2A7? so.tA17 n.oRS9 o.oA81 0,0771 0.0770 46.6543 46.540A 0.0468 o.o47o -0.0696 -0.0108 lJ7.?9h4 a7.337LJ o.oq37 o.094A 0.0380 o.o3?3 sn.14RR 50.0472 o.0911 0.0926 -0.1515 -0.14/0 50.R?74 50,50A8 o.tOll5 n.1032 0.3432 o.3?31 LJR.SS03 llA.6176 0.0914 o.09hO -0.0053 n.0111 52.1513 st.439R n,OA4R o.oA1R -0.1234 -0.1116 52.7870 52.7SS3 0 • 0 fi 1 S 0 • 0 A 2 9 l) • 2 1 5 6 Cl • ?. t 7 6 Il 8 • 7 0 4 4 Il H • 7 4 ') 6 o.o~3B 0.0354 o.02a4 0.0160 4Q.~671 49.51A7
...... °' CX>

P=O n=100
FCH Il fil . L RAPL l~Ll RPL SC I~ L L SCRPL RAL.P BAPP HLP BPP SCRLP SCF~PP ~
1 0 • 0 Il 7 ~ 0 • 0 3 A q - 0 • I ;.> IJ .? - () • 1 1 3 7 1 () q • 6 li I\ 1 0 q • q H ') 0 • 0 5 0 5 0 • 0 LI 1 1 • 0 • 1 2 Il 0 - 0 o 1 1 3 h 1 0 q • 6 /J H 1 0 q • 9 8 5 ? 0.1n?7 0.1040 n.?S'i' o.2SHR ~H.4~6 48.343 o.09hh 0.0973 o.?30q 0,2327 9A.5b8 98.Sb9 3 r..o,Q?. o.OLIO? -O.Oh'il -0.0707 9R.7fll\ 9R,Qbl O,Oll6b O,Ollbt:- -0,0381 -0.001.lO 98.931 99,112 4 n,o'172 o.1lSbO -0.1037 -0.1114 QO,L170 QR,921 ~.05A6 0,0593 -0.1175 -0,126? 97.950 97 612 5 o.11R1 o.tt5A n,th4h o.1sao 100.1?9 tn0.25~ n.t2b7 0.1239 0,189b o,1A2b too.579 100:696 6 o.oQOS n.0887 -0.0710 -0,0654 94,739 9A.757 O,OQS3 0,0Q33 -0,073& -o.OhH3 99,739 QA,737 1 n.0104 o.O&hQ o.1544 o.15oq 103.~hll to3.Ll7t 0,0103 o,0664 o,14l.I? 0.1001 103,064 103,471 R 0.0575 o.05~3 -0,1?.3? -0.1?70 101.40? 101.553 O,ObQ4 0.0704 -0,1407 -0.1441 100,133 100.193 Q 0 • o ll 1 5 0 • O 3 Il 9 n • 0 3 S 4 0 • 0 <. 0 7 1 o 1 • 0 il q 1 O 1 • 1 li b O • O 4 6 3 0 , 0 li 3 ~ 0 , 0 3 2 q 0 , 0 2 A l 1 0 1 , 0 '' 9 1 0 1 , t 4 6
10 n.oH?6 o.OH16 -o.os13 -O.OS7R 100.773 100,hl.!6 0,0769 0,0771 -0,0SLIO -0,0&07 101,105 100,598 11 n.oRRQ o.nRQO O,Ol~H 0,0\0Q \O?,Q41 \Oll,LIH8 0,0708 0,0730 -0,0369 -0,0420 99,326 99,ll2ll 12 o.ns7o n.o -~'.5? -n.o?.39 -o.o?25 100,'Jlll 100,H9h n.03q5 0,0374 -0.0210 -o.o?'ï7 100,541 100,896 t~ n.n4hl o.oa1n o.?~so 0.2~~8 97.24q Q7,?S9 o.n9&~ 0.0970 n.22111 o.2278 97,2Ll9 97,259 14 0,0h4S o.n63? 0.04?4 n.Oll43 qq.311s 9Q,279 J,Oh5R 0.0646 0,0411 O,OLl29 99,3ll5 99,279 1s o.os10 o.nsc;q 11.ons9 o.002Q 100,Q5u 100.AS5 0,0578 o.os&5 o,oooa -0.0025 l00,954 100.ess th n.0362 0.03ba o.o,7? o.oa14 QR·G'3 9~.R70 o.o~Ll7 o,03llR 0,0294 o.03LIO 9H.933 9H,870 1 7 0 • O ?. 11 'I o • 0 2 5 5 0 • 0 1 1 h 0 • Il 0 3 h q ~ • Q 2 3 q 9 • ?. 2 1 0 • 0 2 7 H 0 • 0 2 7 7 0 , 0 3 5 3 0 • 0 2 7 9 9 H , 9 3 6 9 9 , 2 5 1 tR n.0533 o.os~A -o.oQ&l -o.oa2q 94.177 9ll.37R o,0497 0,0513 -o.o5hq -0,0549 95.004 95,20? 1 q 0 • O c., t 7 () • CJ ':' 2 7 - 0 • t U H <, - 0 • l <; 3 b q h • ) 5 ? 9 b • tJ LI 1 0 • Il 'i li b 0 • 0 5 5 b - 0 • 1 'ï 0 7 - 0 , 1 5 h 0 9 6 • 3 5 2 9 6 , LI li 1 ?n n.nh43 n.0636 o.l4A7 o.t441 tnt.3b7 101.1AS o,Ob7S 0,0666 o.112A o.1687 101.130 101.518 ?.l n.0904 o.0900 o.tAT5 o.1R~() UH,7bb OH.Rl7 o.n9~7 o.09AI o.213~ o.2103 QA,523 98,626 ?? n.oQ9t> o.oGQO o.oc.,41 o.o~39 10?.287 101,3tLI 0.1003 0.0993 o,o5o3 o,0499 102,?H7 101.314 2 3 r. • n ~ 3 fl 0 • 0 f~ ':) l - 0 • 0 q 2 LI - 1) • 0 A 7 h 1 0 ? • o 11 3 1 O 1 • 6 4 ?. 0 • 0 9 3 7 0 , 0 9 4 LI - 0 • 1 l 0 4 - 0 • l 0 7 5 1 0 1 , 1 7 7 l 0 0 , 9 A l ? LJ o • n 11 q 2 o • o LJ 6? - <' • l ? ? n - n • \ 1 11 h 4 q • ;.}(17 q ci • o 1 o o • o 1~ q o o • o 4 5 9 - o • 1 ? o 5 - o • t ? 1 3 9 9 • ~ 9 7 q 9 • o t o ? 5 () • 0 H 311 0 • () R s c:, (\ • 0 9 t b (/ • 0 q h 3 1 0 () • h Il q l () n • :'. q 3 0 • 0 H 7 .S 0 • 0 H <J LI 0 • 1 1 8? 0 • 1 ? t 2 9 q • 9 A 5 9 9 • 8 q 2 2 b O • o q 911 n • Il 9 o 9 1) • J a O o O • t 11111 1 3 1.1 • '-i?.? 1 -~ o • 7 11 P O , 1 0 fi?. 0 • l 0 0 LI O , ?. 2 0 2 0 , 2 1 H 0 l 2 A , 8 3 8 l 2 5 , 3 0 7 ?7 0.0102 0.0108 -0.0100 -o.013h qh.?3a Qh.5o7 o.o&Ab o,06Qb o,0245 0,0240 9o,770 9h,9AO ?H o.o7?S 0.0120 0.0~2~ 0.on~ti 97.7~h Q7,524 o.01n2 0,0755 o.0769 o.oAoo 97,756 97,524 29 n.ohllll n.oc:,51 o.o<.5? o.n32H 104.?17 1u1.qL1& o,obRl 0,0593 o.o3t7 0.0288 109,?17 107.446 30 o.nblq o.ohn4 -o.o4H4 -o.oc;11H 100.q10 tno.746 o,Ob79 0,0670 -O.Ob22 -0,0652 to0,492 100,llHl 31 o.10Gn n.106f1 n.0,11.1 o.o ·~oh 101.qc.;o tot.21111 n.10Q3 0.1066 0.0310 o.02ll2 101,qso 101.?..65 .3? n. 0 9 LI 2 0. 0 q s 7 - 0. 0 !llj 9 - \). 0 li 3 Q q 1\ • 1 H q q A.? 7 1 n. 0 9 c; li 0. 0 9 6 c; - 0. 0 b 4 5 - 0. 0 b 3 6 9 A. 5 3 8 9 8. h 2 1 33 o.nSb4 o.nS77 o.O\AQ o.0344 10Q.OOQ 106,499 0,057LI 0.0576 O,Ol~ll o.0305 109,009 106.llQ9 3ll n.ollOQ 0.0<.93 o.n77~ 0.0770 104.S9.3 103.H~7 0.0509 n.0090 0,093LI 0,0922 10Q,79b tOll,087 3c; 0,1$76 0.1.367 -O.OLI04 -0,047Q qc.;.c.;ns 94.79H 0,14?2 o.1422 -0.0357 -O.Oll28 95,A78 95.371 3h o.oust o.Oll43 o.osoq o.oS97 99.'ïü7 99,674 0.0399 0,0390 0,0527 0.0526 99,5h7 99,67ll '7 0.0100 0.011' -o.10Hc.; -o.1?a 11 92.190 q2.001 n.0718 0,01~2 -0,109LI -o,1261.l 92,190 92.007 3B n.ob7? o.066? o.naH7 o.o4Y~ Y9,7lt Q9,7~? n,oHo7 0,01~1 o,0?1t1 o.0226 100,213 l00.?54 39 n.nb~7 o,Oh23 -o.os10 -o.ost6 1nll 0 b10 103,466 n.n6A7 o,0651 -o,0543 -o.osso 10ll,6t9 103,466 4 n " • 0 61~ 6 o • o 1 11 o - o • o c.., c; t - o • o h 11 n q t1 • 1 1 t> q 4 • o s? " • o h 8 7 o • o 7 o 1 - o • o 5 R b - o • o 7 1 6 Y a • t t 6 q LI , o 5 2 41 o.oH1.3 o.OR07 0,04~6 1).04\4 99.?h3 QQ,,~Q O,OA42 0,0835 o.0708 0,0687 99.286 99,3~? 11 ? o • o 1 7 o o • o 7 7 o - 0 • o 1 ., r.. - ll • o 1 11 o 1 n o • t 11 1 t r, o • ~ 1 n n • n 7 7 7 o • o 7 7 5 - o • o 1 7 h - o • o t LI 1 l n o , 1 4 1 1 o o , 8 t o 43 n,nbQ2 o.o69Q -n.o~~~ -0.0977> ~b.7~t 9h.S15 n,075Q 0.0112 -0.1210 -o.1?91 95,674 <15,526 au n,nijrR n.olln7 0.0012 o.u111 1on.o?P 100.12? o.o,bo o.o35H o.oooR 0.0052 100,028 100.122 11 c; o • o a 11 n o • 11 a Rh o • t 1 <) 11 u • i 1 ,, ,~ <) q • ' 1 q q 9 • <. ·s o o • o '~a o o • o 11 3 q o • t 1 A tt o • i t 1 A 9 9 • 3 1 q q q • 3 3 6 11 r. o • o 2 7 h n • n? <:> q o • o 11 r," o • Ill! '>? 1 on • c.., q n 1 o o • ac., 1, n • o 3 1 q o • o 2 9 B o • o o o H o • on o 7 1 o o • 5 9 o 1 o o , li 5 6 47 n.n~l.S o.!1777 ll.O',,'I n.oVl7 10?.?C:)/\ 101.l>Oh o.OH?9 0.0792 O,OIH,9 o.03 11ll \0?.258 101,606 4 H 0 • 0 3 Q Il Cl • o \ q ? - ll • 0 S .i 0 - n • 0 6 '~ ') <) H • 7 :' H a H • h H fi n • 0 3 l q 0 • 0 3 3 5 - 0 • 0 6 9 q - 0 • 0 7 7 6 q A , 7 LI R 9 A • 7 0 7 1~ q 0 • 0 7 7 t 0 • li 7 t- q 0 • U l, I 7 1) • 0 3 1 7 \ (1 0 • 1 Il 7 t (1 0 • t 0 0 0 • 0 7 4 2 0 , 0 7 LI 0 0 • 0 ? 5 3 0 • 0 ? 5 3 l 0 0 , 1 4 7 l 0 0 , 1 0 0 c.; n o • 1 o ? q n • t o 4 n o • ? ti 1.1 h o • 2 h '' t1 t o n • ' " 11 1 o n • ? q 7 o • 1 o l t o • t o t q o • ? 3 8 5 o • ? 3 7 A 9 9 • 9 b q q 9 • 9 b q c., 1 n • n 11 7 ?. o • o 4 t ~ -i - Cl • t n ,, o - " • t o q 9 t o t • l R c; t o? • ''ho n • o tt q 8 o • o li 9? - o • t 1 l 3 - o • l 1 tH l o 1 • 1 H 9 l o 2 • li b o '1? n • 1 n 7 n r, • \ n ) <1 - n • 1 1 ;, 1 - n • t o H 1 \ o? • c' l c.; 1 0?. • 1 11 7 n • 1 o 6 fi 11 • 1 O -~ 7 - O • t t Ab -1) • 1 t :~ 6 t O 2 • ? 7 5 1 O? • \ o 7 '1) 11.nb~\ o.ohqn n.o?~7 o.n??~ 1no,4Q~ 100.~t>O o,ob05 0,0651 o.01Rb o,0174 100,ll93 to0,360 5 4 o • 1 ~ 0 ~1 o • 1 ? ti q u • 2 o o <> o • ? 1J ~ q .., <1 • o ~ ·1 q R • i::, 2 q n • t 3 A A o • 1 3 4 5 o • 2 q ·15 o • 2 A 5 8 1 o o • q 5 3 q 9 , Q 5 5
1-'
°' \0
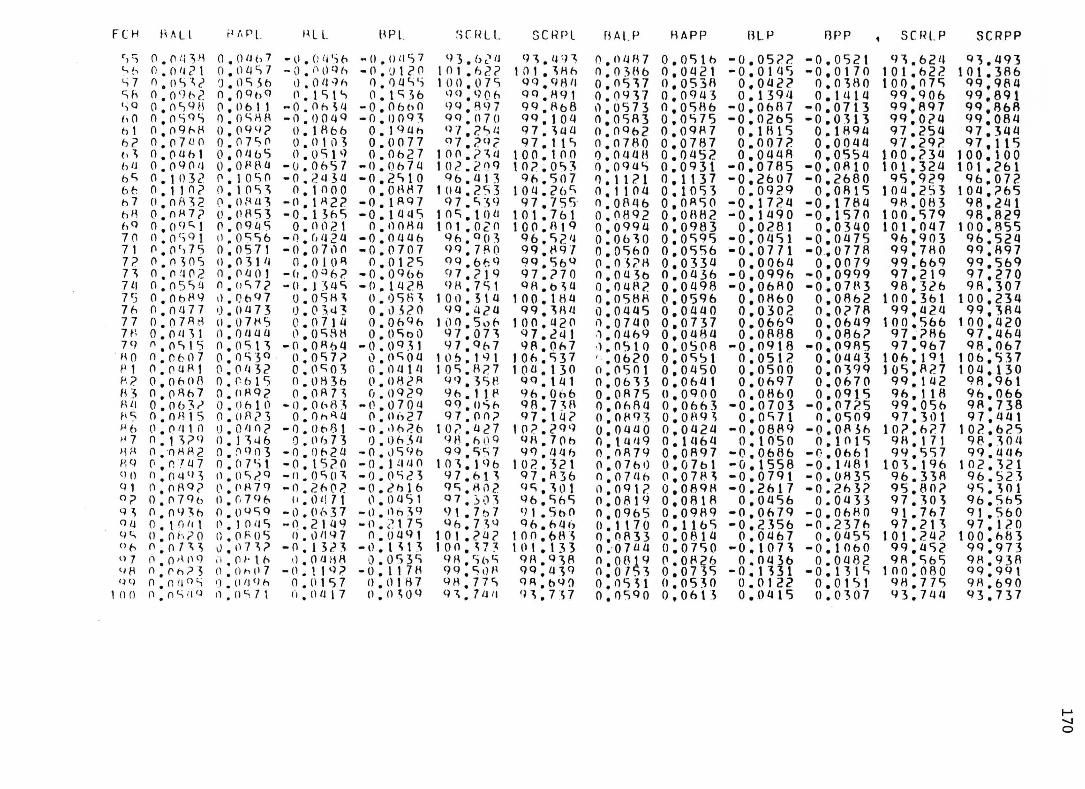
f(H HALL ri r. r l. HLL t~ pl. r ~
) ') (1 0 (1 1.i~H O.OIJ(>7 - 0 • (: l i ':i h -0.011')7 L, !"> 0 .01121 o .n11s1 - 0 . i' llqh -o. u 1?0 r.;, 7 n.os ·~,: '.J .ll'ï5o \). 011-1 h 0.0llS') C:, h 0. (1 9 h2 0
00QhQ n.1c:;1i... o.1c;36
i.;o Cl.nSQB 0.06\1 - (l • () h ~ /~ - 0. 0 b () 0 11 () o.n'-iqc; 0. O~HI~ -il. O 040 -0. O 09 ~ h 1 O. ()9/'IH O,(lC/9? O.lH66 O.JOIHi b? 0.(171!0 o. n1s0 0.010) 0.0077 ( l ' 0•()Uh1 O. o 11 oS 0.051-> 0.0627 /J /j (l • () q 0 11 o.01q~o -ü.0657 -0.0674 hC:.. 0.1 0 32 r.1oso -0.2Ll3ll -o. 2c., l 0 bb 0.110.? 0.10'1~ 0.1000 O.OHH7 r.7 (l • () h 3 2 0 .0~11~ -o.tH2? -o.P~q7 h I~ o.n~7? o.OH53 -o.t3h5 -o.101.1s Il q o.ncic:.1 0.(l91J5 0.0021 o.noHt~ 7 (l () • 0 ') q 1 \l. 0 c:;c:;b - () , (1 IJ 2 li -o. 0 li llh 71 ().(l'i 75 0.0571 -0.07110 -0.0101 7? n.1HOC, () • 0 3 1 /j o. o 1 o~ 0,0125 7, 0.0 1102 n.n1~n1 - (J • !) q 6 ? - 0 • 0 q {> 6 711 o.n S C)!.I (). (1 c:., 7? - () • J :s lJ c; - (l • 1 IJ 2 13 7 'j 0,0bAq \) • f) b q 7 u.osH' o. OS o l, 7h o.0 L177 1_l,Oll73 o.o; .. n O. lJ .~20 77 o.o7A ~1 o.o7~r; 0.071lJ o.Oh9o n : o.o Ll)J () • () 11 IJ li l'. OC.RH O,OSt>O 7 <) l'
00C.,l'j o.osn -o.o~64 -0.()Q _,,
Il 0 n.o b 07 o.ns30 . o.os7? 0,(lt;OQ p 1 o.o4Al 0 . 0 1132 o.t,c:;o3 0 • () IJ l li f , ? 0 • OhOA O.C6l') n.oH36 0,0f:lèR fl 3 0,()f\h7 n.oRQ?. 0 •OR 7' (j. 09è9 H li o.o&3? o .ntilO - o • o <' H ·.~ - l' • 0 7 0 1.1 w:; 0. 0 Il 1 5 o.of1?3 O. Oh~ li 0. 062 7 Fo (l • (l 11 1 () 0 .01.10? -0.otif.11 -0.•)h?.b 11 7 n.1,;>ci n.J~46 0.0673 t) • i) h :~ / j >\H o.oHH2 0. 0<103 -O,Oh2lJ -o. dt:;9o l', q r·.r. 1 47 0 • (l 7 ':i t -0.1 5 ?.0 - 0. 1!11-l0 CJ (l () • 0 (j q ) 11.0C)?.Q -o.OSO\ -o.0'123 q 1 n.(lflQ? 0 0 0R7<) •0.2h0?. -0.2olh O? 0. () 7<?6 () • 0 7 q h. ( 1 • ()I l 7 1 0 , 0 IJ 5 1 q ~ o.o93h 0. (l4C,Q - l). 0 ô 3 7 - () • Il(,.) 9 () lJ o • t n '' t n. 1 n 11 c:; -0.2149 -n. ? t7') (/ t;, 0. Oh ? 0 () , 0 F. () 5 C) • l) fi 4 7 0 • 0 li q 1 () h () • 0 7 l, ' 0.111~? -0.1323 -o.t~t3 0 7 (\ • () ,\ (\ q , 1 • fi 1· l fi 1 l • 0 tJ iH:\ o .or;3r, "fl n.rM?3 n .nhP7 -0.119? -0.117H qq n.n 11ot; ') • (l 11 q h 0.0157 0,0187
1 (l () " • () '-) !I (~ n.n s 11 (1 • (l IJ l 7 n.n~oq
'.H~ fn L SCRPL
93.b t"IJ cq .1ni; \Ot.h2? 101 0 ,Hh 100.07'ï QQ. 90 Il
'1'1,9(.)h QQ 0 H91 9Q. 8 97 9q. t~bB QQ.1170 9Q.10ll q ., • ?. r, /~ 97.~lllJ q7. ?.qè 97.ltC.,
l()ll 0 ?~IJ 1 0 0 • 1 0 0 102.C'OCJ t O?. 01:)3
Q(>,ll\3 9o.507 10ll,253 10li.26c;
q 7. c, V~ q 7. 7 55· 1oc;.1ot1 101.761 101,0èll 100.1119 qh.003 q 6. c:; 2 '~ qq 0 7RO 99.~91 qq.6~q 9Q.56Q 97.?19 97.?70 9H.7St QA.o'll
100,314 100.tHll 9Q.4èll 9 9, 3H IJ
1 \l 0 • 5 ,, h 100. 1.120 q -, • 0 7 3 Q 7. èi.11 97,Q{.7 9R.Oh7
tll~.191 10h.t:;37 1 QC:,.H?.7 10ll.130
49 0 3Stl QQ,\l.11 9h.11~ 9h,06b qq. o-;i- QA.73H 97.on? cn.111?
10?,427 to.;>.?q9 4 B. h 1) q QH.7(lo 9q.c;c;7 q <) • /j /.j,,
10 ·~.lClb 102. ·s21 q7,hl' 97 0 836 qc:; .1rn2 c,c;. ~o 1 cn. ) 0:n 96.c:;hc; 91,7b7 91 .5bO Qh. p,q Q6. n '-' ,,
101,?4? I00 0 6fn 1 OO• q ~ tnt.t33
9H 0 '1b'1 qH.Q38 9 q. c, 1) /1 qq.113q QA. 7 7C., QA. bl.)0 q l, • 7 /J , , '~ ' • 7 :~ 7
BAU~ HAPP BLP OPP • o.n4H7 o.o5th -o.o5?? -o.o52t n.o3Hb o.ol.121 -0.014~ -0,0110 o.n5~7 o,o53H o,Oll22 o.01Ro o.0917 o,09ll3 o.139~ o.l~lll 0 0 0573 0,05Hb -0,0687 -0.0713 n.o5A3 o,o,75 -0.0265 -o,0313 n.OQ62 o.o9A7 o.1H15 o.189ll o.n780 0.0787 0.007?. O,OOllll O.OllllH o.Ol.152 o.OllllA 0,055ll o.o9u~ o.0931 -0.0785 -o.0A10 0.11?1 0,1137 -0,2607 -0.2680 o.11oq 0.1053 o.092q o,0A15 n.oAll6 o.oA50 -0,17?.ll -o.t78ll 0.0892 0,0882 -0,1490 -0,1570 o,o99ll 0,0983 o.02e1 o.03llO 0,06~0 0,0595 •0,0451 ·O,Oll75 o.o5ho 0.0556 ~0.0111 -o.o77R 0.01?H o.o33ll O,OOhll 0,0079 O,Oll3o O,Oll36 -o.099h -0,0999 O,OllA?. 0,0098 •0,0680 -0,07H3 O,OSHA 0,0596 0,0860 0,0862 o.Ollll5 O,OllllO 0,0302 o.0?7R n.o7llo 0,0737 o.06&Q o.Ooll9 ~.Ollb9 O,Oll84 O.OA88 0,086? 0.nsto o.osoe -0.0918 -o.o9R5 " ,Ob?O o,oc:;~1 0,0512 O,OLJ43 0,0501 0,0450 0,0500 0,0399 0,0613 o.Ohllt O,Oh97 o.0670 o.oH75 o,oqoo o,oH60 o.o9t5 n.nhAll 0,0063 -0.0103 -o.o7?5 o.0~93 0,0R4~ O,OS71 0 0 0509 o.OllOO o.042ll -o,o~Aq -o.OA3h o,14~9 o.146ll 0.1050 0.1015 n.nR79 O,OA97 -0,0686 -0,0hbl n.07hO o.07bt -0.1558 -o.1481 n.o7«h o.07H' -0.0791 -O.OH35 n.09\2 0,089H -0.2617 -0.2h3? o.0819 0,0818 O,Oll5& O.Ol.133 0 0 0965 0,09H9 •0,0679 -O.OhHO 0.1170 O,llb'ï -0,2356 -0.237h 0,0833 0,081ll o.Ollh7 0,0115, Oi074ll 0.0750 •0 0 1073 -0.1060 O,Ol\lQ 0,0A26 O.Oll~ô O.Oll82 0.0153 0,0735 -0.11 1 -0.111~ 0. ilS H 0.0530 0.0122 0.0151 0 0 05QO 0 •Oh L~ 0.0415 0,0307
SC JH. P
en. 6211 101.h22 1OO,O7'ï 99.90h 99,A97 99,0?ll 97,25Q 9"/. 29?.
100,?311 l01,32ll 95,929
tOll,253 qA.,OH3
100.579 l01,0ll7 96,903 99,780 99,669 97,2lq 9B,3i?h
l00.3bl 99,ll2Q
100,566 97,-?86 97,967
l0h,1Ql 1oc;,827 9q. 1 ll2 9h,11A 99,056 97,301
1 O? • h?. 7 98. 1 71 94,557
103.196 96.338 95 0 AO? 97.303 91.767 97,213
101.2L12 99. li')? 9A.5bS
100.080 98.775 9 3 0 7 4 Il
SCRPP Q1.ll93
101.386 Q9,9All 99.891 99,86A 99,084 97.3llll 97,115
100.100 101,261 96.072
tOll,?65 98,241 9B,B29
100,855 CJ6.52ll q<],897 99,569 cn,210 9R,307
100. 23ll 99,3RQ
100,ll20 97,llhll 98,067
1Ob,53 7 tOll.130
9A 0 96t 9h.Obb 9A,738 q7,L141
l O?., 6?.5 98.30ll 99. 1-l li b
102,321 q6.523 qc:;. ,01 9b.5h5 91,560 97,l?.O
l00,htt3 99.973 9H,93fl Q9.99\ 9fl.690 q3.737
....... '1 0
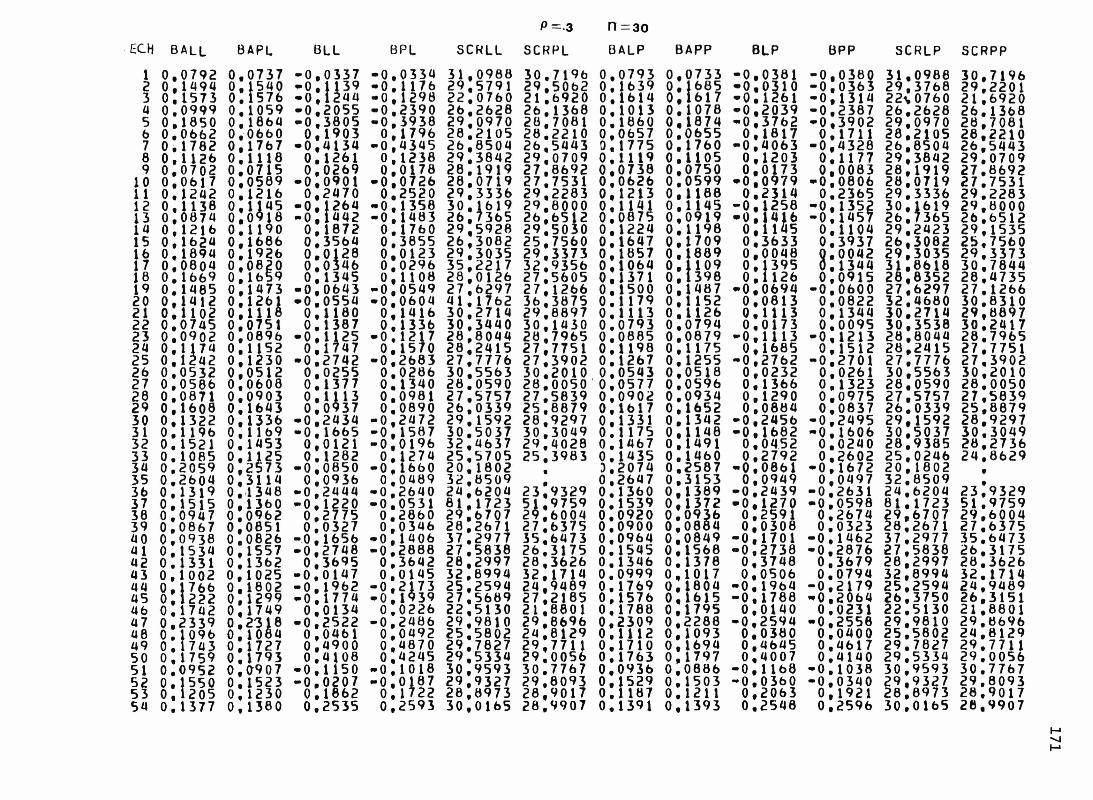
£CH BALL BAPL BLL BPL
P = 3 n =30SCKLL SCRPL BALP
1 0 0792 0 0737 -0 0337 -0 0334 31 0988 30 7196 0 0793 0 0733 -0 0301 -0 0380 31 09802 0 1494 0 1540
1576-0 nn -0 1176 29 5791 29 5062 0 1639 0 605 • 0 0310 -0 0363 29 3760
3 0 1573 0 -0 -0 1290 22 0760 21 6920 0 1614 0 617 -0 1261 -0 1314 221.07604 0 0999 0 1059 -0 2055 -0 2390 26 2628 26 1368 0 1013 0 1070 -0 2039 -0 2387 26 26205 0 1050 0 1064 -0 3005 -0 3938 29 0970 28 7081 0 1060 0 1874 -0 3762 *0 3902 29 09706 0 0662 0 0660 0 1903 0 1796 28 2105 28 2210 0 0657 0 0655 0 1017 0 1711 28 21057 0 1702 0 1767 -0 4134 -0 4345 26 0504 26 5443 0 1775 0 1760 -0 4063 -0 4328 26 05040 0 1126 0 1 110 0 1261 0 1230 29 3042 29 0709 0 1119 0 1105 0 1203 0 1177 29 38429 0 0702 0 0715 0 0269 0 0170 28 1919 27 8692 0 0738 0 0750 0 0173 0 0083 20 1919
10 0 0617 0 0509 -0 0901 -0 0726 28 0719 27 7531 0 0626 0 0599 • 0 0979 •0 0806 20 07191 1 0 1242 0 1216 0 2470 0 2520 29 3336 29 2283 0 1213 0 1100 0 2314 0 2365 29 333612 0 1 130 0 Mil -0 1264 •0 1350 30 1619 29 8000 0 1141
00750 1 145 -0 1250 -0 1352 30 1619
736513 0 0074 0 ■0 1442 -0 1403 26 7365 26 6512 0 0 0919 -0 14161145
-0 1457 2614 0 1216 0 1190 0 1072 0 1760 29 5928 29 5030 0 1224 0 1190 0 0 1104 29 242315 0 1624 0 1606 0 3564 0 3055 26 3082 25 7560 0 1647 0 1709 0 3633 0 3937 26 308216 0 1094 0 1926 0 0128 0 0123 29 3035 29 3373 0 1057 0 1809 0 0040 0 0042 29 303517 0 0004 0 0820
16590 0346 0 0296 35 2217 32 9356 0 1064 0 L1 09 0 1395 0 1344 31 8610
10 0 1669 0 0 1345 0 1 108 28 0126 27 5605 0 1371 0 398 0 1 126 0 0915 20 035219 0 1485 0 1473 -0 0643 -0 0549 27 6297 27 1266 0 1500 0 1407 •0 0694 -0 0600 27 629720 0 1412 0 1261
1116*0 0554 -0 0604 41 1762 36 3075 0 1 179 0 1 152 0 0013 0 0822 32 4600
21 0 1 102 0 0 1100 0 1416 30 2714 29 0097 0 1113 0 1126 0 1113 0 1344 30 271422 0 0745 0 0751 0 1387 0 1336 30 3440 30 1430 0 0793 0 0794 0 0173 0 0095 30 353623 0 0902 0 0896 -0 li25 -0 1217 28 8044 20 7965 0 0085 0 0079 -0 1113 -0 1213 20 804424 0 1 174 0 1152 0 1747 0 1570 28 2415 27 7751 0 1 190 0 1 175 0 1605 0 1512 20 241525 0 1242 0 1230 -0 2742 -0 2603 27 7776 27 3902 0 1267 0 1255 -0 2762 -0 2701 27 777626 0 0532 0 0512 0 0255 0 0206 30 5563 30 2010 0 0543 0 0510 0 0232 0 0261 30 556327 0 0506 0 0608 0 1377 0 1340 28 0590 28 0050 0 0577 0 0596 0 1366 0 1323 20 059028 0 0871 0 0903 0
0^370 0901 27 5757 27 5039 0 0902 0 0934 0 1290 0 0975 27 5757
29 0 1608 0 1643 0 0 0090 26 0339 25 0879 0 1617 0 1652 0 0604 0 0837 26 033930 0 1322 0 1336 -0 2434 -0 2472 29 1592 28 9297 0 1331 0 1342 -0 2456 -0 2495 29 159231 0 1 196 0 1 169 -0 1665 -0 1587 30 5037 30 3049 0 1175 0 1148
1491-0 1602 *0 1606 30 5037
32 0 1521 0 1453 0 0121 -0 0196 32 4637 29 4028 0 1467 0 0 0452 0 0240 20 938533 0 1005 0 1125 0 1202 0 1274 25 5705 25 3983 0 1435 0 1460 0 2792 0 2602 25 024634 0 2059 0 2573 • 0 0050 -0 1660 20 1802 D 2074 0 2587 "0 0061 -0 1672 20 100235 0 2604 0 3114 0 0936 0 0489 32 8509 0 2647 0 3153 0 0949 0 0497 32 050936 0 1319 0 1348 -0 2444 -0 2640 24 6204 23 9329 0 1360 0 1389 -0 2439 -0 2631 24 620437 0 1515 0 1360 -0 1220 -0 0531 81 1723 51 9759 0 1539 0 1372 -0 1270 •0 0598 01 172330 0 0947 0 0962 0 2775 0 2060 29 6707 29 6004 0 0920 0 0936 0 2591 0 2674 29 670739 0 0867 0 0051 0 0327 0 0346 28 2671 27 6375 0 0900 0 0804 0 0300 0 0323 20 267140 0 0938 0 0026 -0 1656 -0 1406 37 2977 35 6473 0 0964 0 0049 -0 1701 -0 1462 37 29774 1 0 1534 0 1557 -0 2748 -0 2888 27 5838 26 3175 0 1545 0 1560 “0 2730 -0 2076 27 503842 0 1331 0 1362 0 3695 0 3642 28 2997 28 3626 0 1346 0 378 0 3748 0 3679 20 299743 0 1002 0 1025 -0 0147 0 0145 32 8994 32 1714
94890 0999 0 017 0 0506 0 0794 32 0994
44 0 1511 0 1802 -0 1962 -0 2A 73193925 2594 24 0 1769 0 604 -0 1964 -0 2179 25 2594
45 0 0 1299 -0 1774 -0 27 5689 27 2185 0 1576 0 615 -0 1786 "0 2064 26 375046 0 1742 0 1749 0 0134 0 0226 22 5130 21 8001 0 1700 0 795 0 0140 0 0231 22 513047 0 2339 0 îîiî -0 2522 -0 2486 29 9810 29 8696 0 2309 0 Í288 -0 2594 •0 2556 29 901048 0 1096 0 0 0461 0 0492 25 5802 24 8129 0 1112 0 1093 0 0300 0 0400 25 500249 0 1743 0 1727 0 4900 0 4870 29 7827 29 771 1 0 1710 0 1694 0 4645 0 4617 29 702750 0 1759 0 1793 0 4108 0 4245 29 5334 29 0056 0 1763 0 1797 0 4007 0 4140 29 533451 0 0952 0 09 0 7 -0 1150 « 0 1018 30 9593 30 7767 0 0936 0 0006 -0 1 168 •0 1030 30 959352 0 1550
12050 1523 -0 0207 -0 0187 29 9327 29 8093 0 1529 0 1503 -0 0360 -0 0340 29 9327
53 0 0 1230 0 1662 0 1722 28 8973 28 9017 0 1 107 0 1211 0 2063 0 1921 20 097354 0 1377 0 1380 0 2535 0 2593 30 0165 28 9907 0 1391 0 1393 0 2548 0 2596 30 0165
BAPP BLP BPP SCRLP SCRPP
30,7196 29,2201 21,6920 26,1368 28,7081 26,2210 26,5443 29.0709 27,8692 27,7531 29.2283 29,8000 26.6512 29,1535 25,7560 29,3373 30,7844 20,4735 27,1266 30,0310 29,0097 30,2417 20,7965 27,7751 27,3902 30,2010 20,0050 27,5839 25,0079 20,9297 30,3049 20,2736 24,0629
23,9329 51.9759 29,6004 27,6375 35.6473 26,3175 20,3626 32,1 7 1 <1 24,9409 26,3151 21,8801 29.8696 24.0129 29.7711 29.0056 30.7767 29.8093 28.9017 26,9907
171

E~~ HALL BAPL BLL BPL SCRLL SCRPL ss o.1s11 o.t56A o.~969 o.2os1 29,0569 28,8952 Sb o.1763 o.11u o. t4b o,5039 28.3525 26.2337 57 o,2287 0.2294 o,5429 o,5378 26,3909 26.1739 58 0.1109 0.1005 •0.0728 •0,0635 38,9401 34.b290 59 0,0929 0.0933 -0,0029 -0.02~1 29,2b07 29.2395 60 0,0790 0,0776 0,2029 0,2026 30,9497 30,7515 bl 0.1282 0,1256 o.0066 •0.0008 26,2121 25,6669 62 o tbs; o 1667 o oo3o 0,0069 24,0330 23 132b b3 0:121 0:1292 -0:0596 -o,obo9 2s,1911 24:9299 b4 0,1435 0,1435 0,5208 0,5204 29,7814 29,8008 65 0,1270 0,1253 -0,3741 •0,3843 26,1400 25,7023 66 0,1187 0.1220 •0,0776 •0,0809 2799410 27,9511 b7 O.l6qb 0,1714 0,0108 0,0181 2b,6390 26,3653 68 0,1528 0,1477 0,3829 0,3574 29,1637 28,6885 69 0,1018 0,1021 0,1911 0,1791 29,8572 29,75}3 70 0 1149 0 1176 0 1551 0 1623 29,5733 29,44 2 11 0:2oa2 0:2101 0:1a15 0:1922 29,4801 29,4920 12 o,0654 o.o6b2 -0.1791 -0,1880 27,9305 27,8996 73 0.1005 0,1~91 -o.201b -0,2122 24,3601 24,0850 74 0,0940 0,0 38 •0,2378 •0,2452 28,0068 27,6062 75 0,1292 0,1288 0.0907 0,1072 2b,7505 26,3481 76 0,062b 0,0818 0,14bl 0,1427 29,6315 29,5246 77 0,0266 0,0290 •0,0494 ·0.0506 28.8306 28,7227 78 0,1767 0,2531 0,0910 •0,0337 18,0203 • 79 0,1401 0,1369 •0,3lb9 •0,3066 32,1734 31,7520 80 0,1356 0,1391 0,1834 0,1851 28,2687 28,0232 81 0,0656 0,0669 0,0323 0.0007 24,8668 24,6133 82 0,1507 0,1512 0,3578 0,3554 26,6068 28,6627 83 o,oo~S O,Ob~O 0,0590 0,0563 29,4874 29,5046 84 0,07 7 0 06 3 0 1020 0 09bq 27,485b 27,366q 85 o,0654 o:oq22 0:1808 0:2001 29,5089 29,0777 bb 0,1354 0,1411 •0,297b •0,3124 26.3061 26,1757 87 0,1325 0,1355 •0,1775 -0,1442 35,5049 30,5779 68 o,1585 o,1636 -0,3699 -o.3866 24,2128 24,0065 89 0,1903 0,1884 0.4131 0,4007 33,4753 31,30b9 90 0,2114 0.2094 0,0137 0,0077 19,7713 19,0240 91 0,1043 0,1077 •0,2643 •0,2751 27,4606 27,3608 92 O 5700 o.3695 0,3079 •O,b480 0,0029 , 93 0:1617 0,1565 o,1608 o,1513 30,6045 30,432b 94 0,1216 0,1197 0,0561 0,0495 23,3793 22,9094 95 O,lb64 0,1643 •0,3127 •0,2957 27,4886 24 1 0111 9b 0,1475 0,1425 0,0302 o.Ot60 29,5277 2b,6742 q7 0,1644 0,1656 -0,2873 •0,2969 26.8736 28.9269 98 0,1494 0,1545 •0,3119 •0,3234 30,2006 29,7992 99 o,139~ 0,1472 •0,3521 -o.37b~ 25,2519 24,9474
100 0,112 0.1085 •0,1676 •0,189 33,3838 31,7091
BALP BAPP BLP BPP SCRLP SCRPP o.1504 o,1547 o,1897 o,1qs9 zq,0569 26,6952 o. 749 0.1131 o,4957 o,4851 28 3525 28,2337 0.2206 0.2294 o.s123 o.5274 20~3909 20.1739 0.1143 0,1092 •0,0767 •O,Ob82 38.9401 34.6290 o.o9o~ o,o90b -0,0097 -o,o3o3 29.2607 29,2395 0.1294 o.1296 o.3247 o.3257 30,1403 30.1016 0,1322 0,1295 0,0068 •0,0066 26,2121 25,6669 o,1504 o,lSb~ 3.1359 o.1385 ~3.529~ 23,07~4 0,1307 o. 32 - ,0655 •0,0665 5,197 24,92 9 0,1415 0,1415 0,5009 0,5005 29,7814 29,8008 0.0923 0,0900 -0,2472 -0,2566 28,7666 28,4280 0,1196 0,1226 •0,0782 -0,0818 27,9410 27,9511 0.1103 0,1121 0,0121 0,0201 26,6390 2b,3b53 0,1512 0,1461 0,3747 0,3493 29,1637 26,8885 0,0993 0,0996 0,2194 0,2065 29,8572 29,7513 0.1145 o,1175 o.1480 0,1551 29,5733 29,4472 0,204b 0,2065 0,1808 0,1855 29,4801 29,4920 0.0606 o.0694 -0.1795 -0.1669 21.q3os 21,a9q6 0.1102 0,1128 -o.~008 -0.2115 24,3601 24,0650 O 0964 0.09bl •0 1 360 •0,2435 28,00b8 27,6082 0:1~29 0,1324 0,0908 0,1071 26.7505 26,3481 o.o 41 o,0826 o,1399 0,1301 29,6315 29,5246 0,0200 o.0294 •0,0536 -0,0547 26,6366 26,1221 0,1765 0,2547 0,0913 •0,0339 18,0203 • o,1401 o.1369 -o.3163 •0,3062 32,1734 31,7520 0,1359 0,1394 0,1740 0,1756 28,2687 28,0232 0,0670 O,Ob80 0,0240 ·0,0013 24,8668 24,b133 0,1510 0,1513 0,3429 0,3405 28,6066 26,6627 0.0575 O,OSbO 0,0567 0 1 0541 29,4874 29,5046 0,0808 0,0659 0,0904 0,0654 27,4856 27,3669 0,0859 0,0927 0,1803 0,1983 29,5089 29,0777 0.1335 o,1391 -o,2965 •0,3112 26,3061 26,1757 0,1350 0,1336 -0,2164 -0,1875 36,7724 32,2524 0,1963 0,2035 •0,4405 •0,4601 23,1101 22,7677 0.1094 o,1875 o,3934 o,3809 33.4753 31,3069 0.2144 0.2125 0,0154 0,0094 19,7713 19.024o 0,1036 0.1010 •0,2643 -0,2749 27.4606 27,3608 0 5b6b 0,3716 0,2917 -0.6452 0,0029 • 0:1003 0,1551 0,1631 0,1533 30,8045 30,4326 0 1239 0,1215 0,045b 0,0393 23,3793 22,9094 0'1132 0,1112 -0,3102 •0,2934 27,4886 24.6111 0:1515 o,1464 0,0265 0,0125 29,5277 2b,b742 o lb33 o.1646 -o,2895 -o,2968 ~6,8738 26,9209 0'1501 o.1558 •0,3179 •0,3293 0,2006 29,7992 0:1010 0,1083 •0,0577 •O,Obb7 29,7209 29,~471 0,1145 0,1095 •0,1718 -0,1939 33,3638 31,7091
..... -...J t-.)

P:.3 n=so ECl-I llALL RAPL RLL HPL SC!~LL SCHPL BALP t~ APP Bl.P RPP SCRI P SCRPP
1 n OAbA o.OR64 0.1?32 0.1160 48.9619 48.8066 n.OH74 o.0867 0.1191 0.1\20 4H.9ht9 4H.H06b 2 0°oQ15 o.OQ09 -0.0531 -0.04AO 45.9?42 45.6042 n.nHH6 o.oA75 -O.OA53 -0.0~10 4b.Qb25 46.1990 ' o:oQ49 0.095& -0;1051 -o.0Ro2 53.993b 51.709b o.05bO 0.0590 o.o3~2 o.04R6 so.2402 49.7894 4 0.12>3 0.11'5 o.1605 o.151?. 64.2373 5~.2&57 n 0 1 ?. b 5 0 • 1 1 5 9 (1 • 1 c; 4 0 0 • 1 lJ li 'i fi 4 • 2 .~ 7 ' 5 H. 2 b 5 7 s n n657 o.o&AB n.13A4 o.1407 4b.724A 4&.5955 o.oA99 o.oq20 n.2042 o.211Q 1n 0 9Q?' 4&.H7Ab ~ o:n4h5 o.o4QO -o.1?53 -0.1,11 47.6507 47.523~ (\ • 0 b 7 0 0 • 0 6 l3 0 - ù • 1 5 0 3 - 0 0 1 b 0 4 4 1\ • A 2 2 9 1~ A • A t 7 1 1 0.1113 o.1197 0.2,88 o.2555 53.b07o 52.7,>1 n.t24' 0.12&1 o.?.99' 0 0 )152 53.SH3A ~2.H199 A 0.1446 o.1440 o.1793 o.111q 51.aoAs 50.9424 o.t41J o.1405 0.1135 n.1h58 51.4085 50.9424 q n.t593 0.1&20 -o.3783 -o.3020 47.1200 46.9517 0.1&0~ o.1631 -o.,7QO -o.3826 47.7?00 4&.Q517
10 n.o7Q2 0.0732 -0.2550 -0.2?6) 62.557A 5A.705A 0 0 0822 0 0 0755 -0.2562 -0.2?91 h? 0 557A 5H 0 705A 11 n.?OHl 0.2111 -0.0471 -o.oa22 41.0755 40.6029 0.19R2 0 0 2000 -0.1099 -O.lQ'' J6.74?7 '5.A9A1 1? 0.0924 0.093?. o.0421 0.0425 51.4241 5l.09lb 0.1093 0.1100 0.1743 0.1755 5t.3h'h ~1.1314 13 0.0618 o.0659 o.t,b3 o.t43h 52.6041 51.9668 0.0615 O.ObQ5 0.1414 0 0 1473 52.6041 ~t.9668 14 o.oB87 0.0936 o.1254 o.1245 n5.0496 44.qt25 o.o87b o.oq25 o.1th5 n.11sa as.o49n 44.Qt25 1~ 0 0 0940 0 0 0970 •0.0938 -O.Oh9t 5R.1124 56.9Q70 o.oQ?7 0.095' -o.o9Q8 -0.0160 5A.1t?Q sn.9970 th o.o45Q o.ua75 -0.0002 -0.0035 aa.aoe7 48.7564 o.0477 .0.04Q] -n.0048 -O.OOHO QR.8087 µA.75b4 11 n.onas o.o85h o.ot&7 o.o?85 51.A498 51.2555 O.ORQR 0 0 0856 ù.0159 0.0?70 5t.A4QA ~l.2535 1A n.o45A o.o4H3 -0.0190 -o.o?.90 49.7303 49.7045 o.04?5 0.0450 -o.02oq -0.0111 49.7~n~ 49 0 7045 1q o.10A2 0.1100 o.3874 n.3965 49.6250 49.5496 n.099?. o.099h n.35qq n.36~7 49.7~5' 4q.1~30 20 0.0846 0 0 0778 -0.0131 -0.006A 53.h754 52.Q61h o.o7Q5 o.0743 -n.oa2q -o.o,qs ~2.0001 s1.R"a4 21 n.10ht o.1073 -O.Ob?6 -0.0672 4A.82b9 48.8663 n.1305 n.131h n.0024 -n.0034 4H.7n'i5 aA.7567 ?? o.nh,6 o.o&34 o.1654 o.1nso 49.7904 49.Al?.A o.ono5 o.ob03 0.158? n.t577 49.7Qn~ 44.H1?A · ?~ o.nAh4 O,OR64 -0.0343 -0.0519 48.88QA 48.AS57 0 • 1 2 2 () 0 • 1 2 l 0 \) • 2 5 4 A 0 • 2 4 IJ ?. lj q • h ~AS Il 9 • h 7 7 q ?4 o.n573 o.0567 -o.1124 -0.1090 50.7582 50.4331 0.0~11 0.05ho -n.tlhQ -o.tt37 5n.1sn2 50.4351 2s 0.0417 0.0472 -0.0549 -0.0757 49.2?.75 49.0407 n.012a o.o7~o -0.0150 -n.r~57 4Q.21o1 44.1707 26 0 t~lb 0.1431 O.OltA 0.0049 49 0 6307 QQ.5286 n.112R o.1140 0.0101 n.0032 4Q.h~07 44.S?Ao ~7 n:o 74 o.o 46 n.1769 o.1&84 49.8401 49.bRO? o • t o o 3 o • o q 6 2 o • 1 q 4 2 o • lf:l 11 3 5 o • 2 ?. o 1 5 o • o 5 7 4 2A n.n474 o.o4&t -o.1ttA -0.1025 54.4Aoc; 53.23?7 o.Ol.JQO o.04n5 -n.11Ro -o.IOQ? s~.4H05 C:.,3.?3?7 2q 0.1715 0.17S1 -0.2660 -0.2642 40.8564 40.473? n.172h 0.1762 -n.2bh5 -0.264R 40.RShQ 40.4732 30 0.1555 o.1557 0.1.1106 o.411? 49.?34?. 4q_3or,3 n.1474 o.147R o.35Qa n.360H t.JQ.35R' 49.4214 31 o.12&q o.t247 0.0115 0.0131 52.5605 51.Q073 0.121~ 0.1255 0.0751 o.o7t3 ~2.560~ s1.qo7' 3? 0.1021 0.1014 -o.2655 -0.2112 56.2206 56.1486 n.!Ohû 0.10~3 -C.2635· -0.21~& 5o.2?0h 'i6.14~h 33 o.n7&6 o.076A -0.0011 -o.0365 51.a355 51.2013 n • n 7 c;; '' o • 1) 7 5?. - o • n 5 a 3 - n • n 4 3 5 c., t • 11 3 c:., 5 c; 1 • 2 o 1 3 34 o.o7R5 0.0793 0.1022 O.l02q 47.4A66 47.5361 n.oR&2 0.0846 o.nb97 n.0140 47 0 QS97 47.9631 35 o.nA46 o.oA?A -0.079? -o.05qq 5R.4115 55.97?5 o.OAbl u.OA32 -o.ORC.,1 -0.0609 SR.4115 5~.9725 36 n.ob76 0.0100 o.1327 o.1323 qQ_qo3a 4Q.7149 n • n h c:; c; n • o b 7 7 n • 1 3 1 1~ n • t 3 0 c; 4 q • ci o 3 11 11 9 • 7 1 4 q 37 0.1336 o.1?98 -o.0Q23 -0.1043 so.Hh83 qQ.76?2 o.1319 o.t2A3 -n.o~3H -0.0970 c;r.~hr3 49.76?? ~H o os1a 0.0478 -o.on33 -o.oAAQ 49.2435 4A.7n3Q o.o5'1 o.049h -o.nH36 -n.nH97 4q.?.43S 4A.76~Y ~q 0:1t44 0.1140 o.o5t4 o.0422 43.341& a2.1000 0 0 0Q62 0.0967 0.0200 ll.0103 44.tOlS 43 0 74QO 40 n.t5bO o.1551 n.54bb o.5436 so.4134 'i0.3027 0.1&?3 0.1612 n.5561 n.5St5 50.nQ~O 50.3656 111 o.oHo6 o.n7R7 n.1335 n.1396 49.9470 49.110·4 o.OR?.5 n.oAo~ o.1?c;o 0 • 1 ) 0 A Il q • Q l.J 7 0 4 q • 1 1 0 li u? 0.0773 o.o7q? o.1933 0.2055 50.561? 50.3291 n.oot•:J O,OA32 O. 06 n A n • n c; 3 c; 1.1 7 • ·' 3 o i;; 11 7 • 2 1 5 1 "' o.nq12 o.oA99 -o.1qqc; -0.205& aQ.4325 a9.2Q51 0 • 0 q 1 Q 0 • 0 9 0? • () • 1 Q 5 0 - 0 • 2 0 S 0 Il Q • 4 ~ 2 c) Il q • 2 Q c; 1 44 n.n694 o.o6H? -o.057t -o.0741 47.4302 47.t«?.7 0 0 0730 0.07?? -0.0591 -0.076? 47 0 4~0? a7.1Q27 45 0.1377 n.1371 -o.o38R -o.o~aq 43.8770 4~.3087 o. 1 IH 3 o • i:rn?. - o. o e 3 o - n • o 1 H ~ 'Ji;;.<? o 1 11 a 4 • s h 1 s 4h o.oRas o.oA37 o.o4?0 0.0375 46.0147 45.7514 0 • 0 A At 0 • 0 H 7 5 0 • 0 3 7 5 0 • 0 '? b Il h • 0 t Q 7 Il C). 7 S 1 li 47 n.1010 0.1009 -o.t34b -0.1211 c;1.3245 51.0~2? n • n Q ~ q ll • Il q A A - 'l • 1 IJ 1 1 - () • 1 -~ ~ A c; 1 • -~ ? 11 5 c; l • (l n 2 ?. aA n.1369 o.t?7h -o.1ç2c:; -o.1&65 &7.1557 69.9175 n.t372 o.1?7b -ù.14A7 -0.11~4 h7.t5S7 n4.4175 4q o.o9Q& o.o9Q6 o.24BO o.2462 50.3471 so.2q7c:; o.\OQ\ 0.10Q2 0.3200 n.319~ SD.5SHO so.5024 50 o.nAht o.OA39 -0.1h49 -0.1741 49.0,26 48.H374 n.OH50 0.0H2?. -0.1S36 -O.lh75 qQ.0)2b 4H.K§74 51 n.t14H o.1117 -O.Ob3A -0.0547 55.12sq 51.1111 o.1lhb n.1133 -n.ob54 -n.n5o5 53.l?R9~1.1113 5? n.oH.1H o.0865 0.2205 0.235? 49.14RO llR.llbOb 0 • n A 2 c; 0 • 0 8 7 1 0 • ? 1 1 Q () • ? ?. li 0 4 q • 1 /J A 0 Il A • Ah n 6 5 ~ 0 • 1 0 0 IJ n • 1 0 3 A 0 • t q H 0 (1 • ? 0 2 6 lJ R • 4 3 3 7 4 H • Il Il 4 5 o • O q -~ n 0 • D q?. 1 0 • ?. ? 7 B o • 2 2 7 6 5 0 • 0 0 J q 11 </ • ri SS Il so n.1son o.1s1R -o.1524 -o.1soo 1R.nAc;3 37.2173 n • 1 4 7 n o • t 4 R 5 - n • 1 o oh - n • 1 ·1 t ? li o • 4 11 :111 •~ q • ? ? n?
...... -...J w

E C H
555657585960616?6364656667686970717?73m757677787980818?83P 48586878889909192939£J9596979899100
HALL RAPL BLL BPL SCRLL SCRPL
0 1022 0 1036 0.2919 0 .2917 50 1324 50 .0 7 800 1071 0 1073 0.1618 0 .1753 50 7720 5 0.23440 1 088 0 1003 - 0 . 2 5 1 9 - 0 . 2 4 5 9 64 0232 59 .3 0 370 1 040 0 1 057 0 .3150 0 .3 17 3 51 0095 5 0 . 5 21 50 1 466 0 1477 - 0 . 2 5 0 1 - 0 . 2 5 6 2 33 6727 3 2.95280 1171 0 1153 0.0596 0 .0532 46 4626 45 .9 4350 0867 0 0918 - 0 . 1 9 7 0 - 0 . 1 9 8 1 82 0833 72 .0 3970 1 046 0 1064 0.0613 0 .0534 44 2158 43.09610 1431 0 1429 0.2129 0 .2 11 6 49 8696 4 9 . 00 980 1 471 0 1462 - 0 . 2 4 3 4 - 0 . 2 4 7 1 46 7727 46 .4 3590 0848 0 0831 - 0 . 1 3 9 3 - 0 . 1 4 5 1 4 7 9367 48 .0 4090 1552 0 1567 0.6482 0.6501 50 3513 5 0 . 2 51 50 1 100 0 1034 - 0 . 0 9 4 8 - 0 . 0 9 9 8 68 9812 6 3 . 27 130 1 546 0 1497 0.1069 0. 1 145 47 7459 45 .88300 1425 0 1419 - 0 . 0 1 7 2 - 0 . 0 3 1 1 48 8494 4 8 . 92 020 0713 0 0607 - 0 . 0 8 9 5 - 0 . 0 6 7 2 63 6965 6 0 . 9 59 50 0532 0 0539 0.1503 0 .1537 49 6353 49 .62340 0806 0 0817 0 .2195 0 .2155 47 7858 47 .7 4730 0531 0 0530 - 0 . 0 6 9 1 - 0 . 0 8 5 7 40 2729 47 .98070 0611 0 0606 - 0 . 1 4 1 0 - 0 . 1 4 6 0 48 2357 4 8 . 09 860 1 1 30 0 1 1 04 0 .3188 0 .3064 48 1046 47 .66700 0601 0 0574 - 0 . 1 3 8 6 - 0 . 1 3 8 8 48 5683 48 .24200 0241 0 0227 - 0 . 0 6 7 1 - 0 . 0 6 8 6 47 4 161 4 7 . 29 030 1702 0 1720 - 0 . 0 0 3 2 - 0 . 0 0 9 5 39 7881 39 .4 2980 1 153 0 1 107 - 0 . 0 8 7 3 - 0 . 0 9 5 7 40 2493 47 .6 8890 0290 0 0336 0.0247 0.0331 52 6645 52 .0 2 590 1 358 0 1297 - 0 . 1 9 8 5 - 0 . 2 1 5 1 50 4172 49 .5 1860 0769 0 0753 0.0358 0 . 04 22 48 4624 4 8.06170 1001 0 1021 - 0 . 1 5 3 7 - 0 . 1 7 3 8 41 5998 40.58540 0893 0 0867 - 0 . 2 1 4 7 - 0 . 2 1 1 4 47 6595 47 .12520 0385 0 0359 0 .0212 0 .0179 60 34 16 56 .0 3 350 1241 0 1240 0.3018 0 .3829 4 9 M968 4 9 .8 2 950 0912 0 088? - 0 . 0 3 1 9 - 0 . 0 1 5 6 52 6660 51 .5 4890 1038 0 1057 - 0 . 0 9 1 0 - 0 . 0 8 4 7 45 4312 45 .18570 1 367 0 1339 - 0 . 0 8 0 6 - 0 . 1 0 0 9 42 2255 39 .80450 0 8 6 6 0 0881 - 0 . 1 2 4 3 - 0 . 1 3 9 0 44 3258 4 4 . 1 06 70 1 057 0 1063 0 .3706 0 .3619 4 8 7865 48 .75790 1 705 0 1688 0 .0790 0 .0716 32 0307 31 .99130 0546 0 0564 0 .0333 0 .0419 51 0092 50 .5 7320 0723 0 0752 - 0 . 0 1 3 8 - 0 . 0 2 9 2 50 2448 50.06410 1216 0 1246 0.1218 0.1237 45 0447 44 .83980 1401 0 1504 - 0 . 0 4 4 6 - 0 . 0 8 3 9 48 0636 «0 0414 0 0389 - 0 . 0 0 9 7 - 0 . 0 2 2 3 49 7268 49 .2 8520 0717 0 0535 - 0 . 1 0 6 3 - 0 . 0 7 1 0 84 4364 76 .51820 0881 0 0920 - 0 . 2 3 4 8 - 0 . 2 5 6 3 49 4055 48 .72050 1 023 0 1015 0.3417 0 .3347 49 34 16 49 .4344
BALP BAPP BL.P BPP SCRLP0 1014 0 1 027 0 . 29 52 0 .2 94 9 50. 1 3240 1 053 0 1 055 0 .1556 0. 1681 50 .77200 1 043 0 0980 - 0 . 1 9 5 2 - 0 . 1962 5 ^ . 2 2 4 30 1718 0 1719 0 .5417 0 .5402 4 9 .89100 1516 0 1525 - 0 . 2 4 8 8 - 0 . 2 5 4 7 33.67270 1 180 0 1161 0 .0 60 2 0 .0515 4 6.46260 0806 0 0854 - 0 . 1691 - 0 . 1 6 7 1 64 .18470 1071 0 1 087 0 .0604 0 .0519 44 ,21580 1389 0 t 388 0 .1947 0 .1934 49 .86960 1 490 0 1480 - 0 . 2 4 2 9 - 0 . 2 4 7 3 46 .77270 0861 0 0846 - 0 . 1457 - 0 . 1 5 1 1 47 .93670 1510 0 1522 0 . 63 3 5 0 . 63 53 50 .3 5130 1091 0 1024 - 0 . 0 9 9 4 - 0 . 1 0 4 8 68 .9 8120 1583 0 1531 0 . 10 26 0. 1098 47 ,7 4590 1620 0 1593 - 0 . 1 0 3 5 - 0 . 1 1 7 7 4 9.09040 0753 0 0679 - 0 . 0 4 0 9 - 0 . 0 2 3 9 58 .7 7430 05 22 0 0529 0 .1480 0 .1512 49 .63530 0796 0 0807 0.251 1 0 .2409 4 7.78580 0562 0 0561 - 0 . 0 7 4 0 - 0 . 0 9 0 ? 4 8.27290 0624 0 0618 - 0 . 1 4 55 - 0 . 1509 48 ,23570 1 124 0 1095 0 . 30 52 0 .29?9 48 .1 0460 0599 0 0571 - 0 . 1 3 9 4 - 0 . 1 4 0 5 48 ,5 6830 0255 0 0233 - 0 . 0 6 7 6 - 0 . 0 7 0 1 47,41610 1721 0 1 739 - 0 . 0 0 7 5 - 0 . 0 1 3 6 39, 78810 1131 0 1089 - 0 . 0 3 4 2 - 0 . 0 4 5 9 48 ,15650 0280 0 0319 0 .0194 0 . 02 75 5 2 , 66 450 1265 0 1 195 - 0 . 1282 - 0 . 1441 5 0 ,48690 0770 0 0752 0 . 02 8 3 0 .0344 48 .46240 1045 0 1064 - 0 . 1 5 1 0 - 0 . 1 7 1 2 4 1 .59980 00 i 4 0 0783 - 0 . 2 4 3 0 - 0 . 2 4 0 6 48 .46950 0361 0 0407 - 0 . 0 1 0 6 - 0 . 0 1 6 9 5 3.500/10 1142 0 I 1 ? 9 0.3751 0 .3778 51 .59430 0908 0 0077 - 0 . 0 2 9 2 - 0 . 0 1 8 0 5 2.66600 1 081 0 1 096 - 0 . 0 9 6 0 - 0 . 0 8 9 7 45 .43120 1405 0 1375 - 0 , 0 8 0 3 - 0 . 1007 4 2 . 22 550 09 1 8 0 0930 - 0 . 1 2 4 0 - 0 . 1 4 0 1 4 4 .32580 1 051 0 1 056 0 .3906 0 .3767 48.7H6S0 1 735 0 1718 0 .0750 0 . 06 77 32 ,83870 0448 0 0470 0 .0 9 23 0 . 099« 50 ,62 4 10 0659 0 0647 0 .0478 0 . 02 69 4 7 .80470 1236 0 1 263 0 . 11 42 0 . 11 58 4 5.04/170 1 436 0 1542 - 0 . 0 4 7 0 - 0 . 0 8 6 4 48 .0 6460 0428 0 0397 - 0 . 0 1 1 3 - 0 . 0 2 4 1 49 .7 2680 0766 0 05R0 - 0 . 1 0 3 1 - 0 . 0 7 0 5 8 4 .43640 09 7 4 0 10 33 - 0 . 2 7 7 1 - 0 . 2 9 7 6 4 6 . 48 460 1017 0 t 0 I 0 0.3451 0 . 33 72 4 9 .3 41 6

175
oom
(VIO ÍOO>i\j te n
o
r- n tuer
® ®
x m
tn ru c* ® <tnj «c-
Oí
fUffl®
»«
••
••
r~ — m
c m
x
cfftPO
'O'ir
aamaenaa<tna<aaa.otn
¡<fcr a
ir IO
Í O“
o
m —
m
o o o o • • • • ooao lW
V- \D *t
eiT
Cia
o
ca
in
c o
a o
• • • • o
oo
o
n n
mcr
—
ffl ffl \D
ion
N
o o
o o
• . é .
oo
oo
(\JCT« ai CD CF f'~ CC
NlflO
N
OO
OO
•
• • • 0
00
0
O —
X
(VI— o o< tn ® a xr^r» —
o <t
c —
o 0
0 —
•
»•
••
•0
00
00
01
r 1 1 1<» —
con «
a
<í K5 cv r CT e
m in h» —
o «
C —
O O
O —
• •
••
••
00
00
00
1 f
■ I
I
® o
í- ® x
ru— rvi rvj lo ®
“i i/i a
> k m
tu r>* 0
00
00
0
4cm
ÍMT
'o
c o
t • •d
ru®
c cr sr•4I-t<
t X
í«
«
4 n
«» -*0
01 > » •
00
0 l
«t ® X
«í <\i —
<* <t « -f 0
0
*00
0
! 1
NO
icv
ir>c
an
(\iiDffln
sí'»
cirfftc
x «r. —
lír
ica
® «
<r cr »0 ruco
r»«i\itr. rutvur. rvor^xru
c'——
««loir. «
ca
trín
«—
®>o~.r)
xin
T^
^c
r-'—c
rcrinin
r--vn-4
inf\j(\¡ —
^o
oc
rxr^
f~r-—
r~r^'o
r¡(\i CO
SÍ
Oí
O"
-
CN
X
e CV (O
»rviO'h
-cvflrj'^r)« » » • •
• • « *—® r*
x—x—xojoaa'ro’ofvir-c'x'oo'o—
r'-®r'--»xo«rviom ocr c
c c
o o
cr oc
'eic
co
ioo
'c'c
'or.o
i'c-rff 0
00
0*0
00
■ccjocr o
ocr c
craj oc
<\j —
a o
«
in
001
Xvflin <t «
m
— !T C
<V O
iTffl c
e
oc
o
• • •0
00
1(*)0v <tin
a <v »
oc®
00
0
do
ün
C'n
«
® o
a o> x
—
n o
oo
n
00
on
j o o
00
00
00
vCvcrji^n
xíMO
Ajr^
uic
r-—
o0
0 ¿1 "N
•'O
ií —
o —
— nj —
— o
— c
• • • *
o w
tn or^<o m
r- 10O
o
oof
cr> x
n —
ffl X
OO
00
01o» <t a-
o*® r~
m ¿>in
00
0 — — o n ir ru tfirí lCí~ —
cr fln
ffon
n
oo
om
oo
•
••
••
•0
00
00
0
— IO (M
NiílO
h
N®-fi«
10•« «
n o
incr
00
0—
00
oo
ao
»
r, 1o
croc
«í <v <* tf. (yir liiff o
o-ic
.
•0
00
01
l¡ II
<t in ocr —
—r» ru
x x
o r«-
oo
oo
00
00
00
It
it
i
— ® «TN O
®
tff «t ffl r- o
m o
? <t
a; — —
00
c
■«
«•
••
o
o o
o o
o
Il
ic
i
m «s- a> cr !T r\i
® o — — oj — ci —
o®
r* rvj o
——
00
0
sitr. <t nj r> r> —
<3 x f»
a't\ih-o<t<r»ovnino'o o
rr
¿o
NC
"x
n m
o
o—
oo
—o
—o
o—
• •
••
••
••
••
*o
co
oo
oo
oo
oo
r
i 11
1 ii
— X O- «
tCTOOX—OCT
Ou
rjiCO
iClC
OiiD
«!*) o
c—
oc
—c 0
00
—
• ••
••
••
••
••
oo
oo
oo
oo
oo
o
r i
11
11
n «
ot
ca
-íifiM')
- (\l«í—
<t®fu
r-<íO
J2
>D x<\istn
xcrx<í<*fflt' o
oo
oo
oo
oo
oo
®NO
NO
!íi£«
rj
Í'JCO
'CÍJO
'C'C
—
—
i
5'«nm<j‘c»cr-c» rsoriG'f^^ar-x nfflrue-no^in —
0
0 —
00
0 o
on
j0
00
00
00
00
l
I
X ocr «vi oofur* <» cc r. cr «fi-r.iv
OC
-CC
CC
Cft
• •
••
•»
••
«
00
00
00
00
0
I I
x«ina'crxrvi — x io
oin
eiM
iMo
n
rvxxr
~—.no«®
00
00
00
00
0—
w
^
-w
—
■ —
- —
—
--
— --
—
—
▼
—
—
—
—
—
—
—
00
00
00
O0
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
ro « x ¡n .m ® —
— ir
<t®(M
E(7>C3'B
XfO
ntn
xp
' — «íin-tta.
00
00
00
00
0
<» oím n®0'
^ tr> n
x tr t\í
in c r~ m
rvir
00
00
00
Injeo> — r» ru
tílf^rj p
o —
1 l
•.mfflainofOP'íM^ni««»^—cr«—^ir<<»®«—'O'voino«fr«v0<r. Urn«X®OvOXO®in — OÍNif í — lf>
<tTfflOin«Dtn<*<r<#oino'®>nffli
c7'—o®r
f\ii/ifuffitnxo'<i><í'*)®rn
-•oo
oo
oo
oo
— o
oo
oo
oo
— —
oo
co
oo
co
oo
oo
oo
o
• »•
••
•»
••
•
»•
••
♦■
•*
••
••
••
••
*•
•
••
••
•O
OO
OO
OO
O'
—
—
—
—
-
—
—
—
—
—
—
—
—
—
OO
OO
OO
OC
CO
OO
CO
OO
CO
OO
OO
OO
OO
OO
OC
OO
OO
OO
OO
OO
OO
OO
CO
OO
OC
rviffl<í'Xf«or
®(\nfla’f\iC'r'-fUíCO‘?':xofviB®o<*-f-ir. f" — — ooúímsiíixí acn^NX»- ru®ir)Mvru«
ry x ruó * o
sr> n? ® « n
fvj—n
—oj c? lo "3 c> n
"O o
<r — n- 10—
® «t- n
o
J5 o
n in ir> —
o in cr ®
n o
a ru ®
m a
o c
r^n
o —
®r^inC
T'f'\0fflin
®0'C'r»r^rj®s0®rv»n
®r^uiffl—
r^— ®®<
»?^r^
— o
on
joo
'fuin
^®«
— ru—
rvjor^n
cru
OiO
® io
ins
iTiO
tn —
r- or^
xx
— o
rox
ojw
c'C
'r^rv
j —r* e
xí-riru
— c
r~0‘®
««
ox
<í,C
T'<
r®r'O
(Mo
ox
«r'j
fuoc-c'c'crocro'c'po'c' oc'oc' oooc'oo'o'o'o'fl'oo'tr coo' oirrc'poooo'orppo'oooorro
_io:utn
r~——
®®
x xm
inoj —
or^njo'xr-, x
x®
f\jx
®’o
r^ru<ro
i^a'xxir. - ^
no
or
vj®
a»
;^x
ox
cx
— oír, x
— —
ruo
f^<
»o
'®<
íf\j«-fflfflN
r^o
of\i'«
rvíC
' — f«
,j)f\jor'tn
(\jC',o —
<s- — n
-jiN^
njc
ín«
M')n
íOM
.'i>C
£3
-is
(MXX
"0—o®<v®®o®xfflL0fflf
c'®iríC'C7'Lntnir>'—
Loxfvi —ruoor^r. «
o — — oirv;—
rux»ruir.tn«x®ronmo'tnsr-
-.inx
irxo(
Mf^o
®xx — omorv.'fflc'o'norjr'o'xir. n
roo^
c-h-n
x-x
xo<
í®f
^oc
roc
7'x
<jr
u
(Mccir-c' o'o'pc'rarpioa'co'ooco'oo'trpa'ír'oo'o'c cporpc'c'oooc'ooc'po'oc’oeic'j'o
_¡ ao jíc cooíiinifinoruiOMJi- mrvifu —
NNNN«-i/íNOOcoirnjNN£o- íO'iMOír or^aitT'inomíMX
c. in
— r^c,
0'o
<rK;L
oru
a'C't\ir*r^
<t4-<
í-ofu
tnh
- ® —
— —
c cr —
lo oc* b
o.r íi £
j c
-f) orj -
sk
? ?
r- p
í (\i
c o
x<
r —
— o<í<*r')<rx<i-(\JO
®nfO
ir—o
<ro
xir<
on
—’'>oa'tr)on
t'-f\jr\jr-~3-«<j-<í<rr-)r«-or'.'')f'-xxr\i
00
00
0 —
00
0 —
— 0
0—
——
oo
oo
or
uo
o —
o —
— (\J—
— 0
00
00
— 0
0 —
o —
00
— 0
0 —
00
00
0 rj
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
0 o
oo
oo
oo
oo
oo
oo
oo
oo
co
oo
oo
lililí
lll
1 i
1 1 i 1
1 1
11
11
11
II
_l-IC’
00
>No
so
-0
00
0« • • *
oo
oo1
0 <f c
0_l
® tn <
r~)
alo m
<? ®<
00
0c
a
••••
O O
OO
LOO
N <í
_jh- r: ru
_iV0 tT> *
5)<
OO
OO
Q• • * •
OO
OO
I—
CVÍ 'O *3Uu
1 l
1 1
l1
1I
l
11
1 1
11
1
11
1/1 rv¡ n r- <í cr* o
x f~ in « "010 o
in o ® in ®
a — pniC - x ru cr
® <?' r~ »0
x x *0 x
m ro ru ¿i m
<r ®
00
oo
ao
— 0
00
00
00
0 —
oo
oo
oo
o —
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00
00

176
2s,l *6b¿¿6*06¿«C0*0-V920 * 0-0620 * 02620*0000 • CO tVV9* VO 1¿060*0-1 eoo * 0-6 l S 0 * 09VS0* 0060* 101SI 0 * 20 I2990*0SO90 * 0V 5 V 0 * 09CV0* 0
“0 0 5 * / Bt 09•¿026IC * 0®2/62*0-9660 * 0C06O* 009 I * SbC 02 * G6V C ¿ 0 * 0 -Z290 * 0-000 0 * 0Z/flO* U90/ * 6bOOi * 662210*0/V l 0 * 02 ¿ 9 0 * 02090* 02si•LbL I 2 * ¿66210*00220 * 02020 * 0V C 2 0* 00C6* 00 Trro * 20166C 1 * 02021*09000*0C'b/o* 06 0 0 * L 62 2 9 * / 66bl2*0C022 * 0VObO * 01600* 00 I 0 * t,66<i I * SbV t 0 l * 0-V l 60 * 0-9990 * 090 9 0* 0i c 9 * o o I2 11*10 15002*0-2902*0-0901 *0200 t* 0
“9 ¿ 9 * 6COE. *176'¿ VVO * 0V 9 V 0 * 0S2V0 * 026C0* 02 I 6 * Sb1 VO * 9bSOO l * 0V¿l l *0C 0 ¿ 0 * 01090* 0S 9 L * S bC ¿ 9 * S 699 0 0*0l VOO * 0/vso * 0COSO* 092«; * I 0 IS9V * I 0 I162 l * 00/21 * 09 0 S 0 * 09f> VO* 0991*001¿25*00 16911*0/02I * 00 0 V 0 * 00050*0biS'tUI6 I V * V 0 I118 1*0«5V0 1 * 0-V 0 0 0 * 0S060* 0OCb *C6S 0 0 * V bC9 I 0 * 050VO* 0oivo * o02 VO* 0¿¿2* ¿ bV 9 C * ¿69bl0 * 0-9 V l 0 * 0 -l1/0*002/0* 0
“SC /“* ¿6 ~L 0 V~* 96“ "9290*0-1*50*0-V 2 C 0 * 0V2C0* 06bt? * 00 IOC/* 00 10520*0-0b20 * 0-2290 * 02C90* 0CI2*S6092*56C900 * 0-/l¿0 * 0-66/0 * 06000* 0606 * CO II 0 / * C 0 I(>¿01 * 06V60 * 0C 9 v 0 * 0l SVO* 0LlC*20t¿92*20 I0//0*0-2V/0 * 0-V 0 C 0 * 09620* 0217b * L b¿VO * 062990 * 0l ¿90 * 00220 * 00120* 00/V* 101¿02*00 1C V 9 0 * 0 -SOVO * 0-e 9 s o * o2 VSO*00 /. 4 * 9 bV6S * 960522 * 0-tb 12*0-VVOO * 05500* c
“552 * rot““Z82*20l■16/1*0«6/9 t * 0-rOBO * o1000*0990 * V60 52 * 9b0Vb t * 0-5091*0-SI /0*0Ov/O* 029V * 006S¿ * 009190*00b90 * 0620 I *C020 1* 0¿20* Lb¿20 * ¿69 V C l * 00/V l * 02250*0V VSO* 0LSS* ¿99/6* ¿9S901 * 0-005 1*0-6V90 * 0V 290*0212*66S69 * 0 0 XS292* 0«6092 * 0-VOO! *00201* 0l SS * 9092/* ¿06662 * 0«S062 * 0 —OCC 1 * 01CC1*06S0 * 6b¿96 * Ob/ C 0 l * 02C0 t*00/90*09690* 0
“BO 9*96—“06^3 * 9696 V1*0“*59V1*0—’V590 * 09990* 09b6 * BbSCO * 0615V0*0-22v0*0-seco * 06CC0* 00 C 0 * 8 61 S 0 * 0 66061 *06S02 * 0Sl90 * 00 V90* 0S V V * I U tV¿¿* 10 IOSOO * 00220 * 0V I s 0 * 0¿550*09 t T * 0 6000*060V2C * 0»¿CC*0/VgO * 0/ 5 00* 0I VO * ¿b006 * 9b00CO * 0«0Z20 * 0-96 90 * 0IO/O* 0/SC*I 0 IS66* 00 I/lCO * 0«ClVO * 0~C 2 C 0 * 0ZC CO* 0C T 9 * 0 6¿99* Ofe0662*0¿962 * 00CO l * 02C01*0
-9C2*S6~“¿62*56“0/21*0“1C21*0-6260*09690*0VO V * bbS VC * 66299l* 02SZ1 *0SS90 * 0C ¿ 9 0* 00 I <7 * Sbb 0 2 * S 669/0*0-0O¿O * 0-C 0 / 0 * 069Z0* 0
ddtOSdltnsdiiSdindclVUdivo
C 9 6 * 0 626S * 069CC0 * 0-9 9 2 0*0-C6l0 * 0V 6 t 0 * 000 looo * co tVVq * vO lC/00 * 0-6 1 0 0 * 0 -9 0 S 0 * 06250 * 066060*101510*201r9/0 * 0V 0 / 0 * 005VO * 05 r V 0 * 006VCO'OIt¿20*9010622* 0-V 0 2 2 * 0 -0/00*05 0 fi 0 * 0¿6V 0 0 * V 610 0*560 2 0 1*0-0 16 0*0-o r 6 o * o6 2 6 0 * 09 6b Z 9 * 6 6b 60*66CZ90 * 0V 9 9 0 * 0o r v o * o‘»etiU • o5625 l * ¿6/ I 2 * / 695 I 0 * 0I V20 * 00220 • 0952 0*00 6201’*0019CC * 2l l2CO0 * 05 V 5 0 * 05 59 0*06 5 9 0*0C6600* ¿6229*/6V 5 2 2 * 05522 * 05IbO * 010 6 0*02655C* 960 V y * 9 6r f. o i * o -000 1*0-5090*0¿1/0*0l 61 OV * 00lv 2 C * 0 0 1C 0 6 I * 0 -6C61 * 0-CC l l * 06 v I i * 00 6V90 * VG/1I * SbZ 6 0 0 * 010 10*06 / C 0 * 0cero * o602l6 * SbIVO* 96/ 6 Z 0 * 00 0 0 0*0Z o / 0 * 0r 8 9 o * o0 0ii'U * 56C L 9 * 5 60i/60*0CI60 * 09 C 5 0 * 0C 6 V 0 * 0/ 051/ 0 * S 0 lC 2 l * S 0 l6260 * 0¿500*00 5 V 0 * 0l 5 V 0 * 090591*001/2r, *ooi252t *00021 * 09 6 v 0 * 0f I 5 0 * 050H9¿ * VOlV26 * V0 lSOCl * 0-¿2VI * 0-0 5/0*0S¿/0 * 0V00 C 6 * C 65 0 0 * V 60510*029C0 * 0C l VO *00 C V 0 * 0COZ / 2 * / 6V 9C */62C10*0-VOOO * 0-9 1/0*02C/0 * 0205V5 * 962CC*/66201*0-2V60 * fl-6 9 r 0 * 025C0 * 01 056C* 06250 *6656 0 0*0-lC l 0 * 0 -OC/O * 02C/0 * 000C I 2 * 5 b0 92*965 I 00 * 0-9990 * 0-09/0 * 01 / / 0 * 06/65C‘VOI222*VOI2/21 ‘ 00211*06 6 V 0 * 0C / V 0 • 00/l 09 * CO IV29 * COl6050 * 0-C6V0 * 0-0C20 * 0z r 2 o * oLL2 V6 */6/VO * 8b22/0 * 0Z^¿0*06520 * 00S20 * 09 Zi z. * irti0/9*00 12960 * 0-2V90 * 0-0 0 90*05/50*05/0/9*96V 6 9 * 9 60222* 0-VZ 12*0-ZC0O * 09VOO * 0V/552* l 0 I/02*2016//l*0-0/91 * 0-6 0 Z 0 * 0{'0/0*0C /205*00106V * 20l9191*0-265l * 0-O 9 z 0 * 0/ 1 0 0 * 02/9CS* 002C6 * 00VVCO * 00 0 C 0 * 00660 * 00 06 0 * 0I //20* Z6Z 2 0 * / 60 / C 1 * 0005 t * 02550 * 02/50 * 0oz0V2* 00Z l 9 * 0 0Z C9l*0-('1*1*0-29Z0 * 0I 9 / 0 * 0b 9212*66569*0010092*0-C6S2 * 0 —V 0 6 0 * 0066 0 * 009t 55 * 9092z */06662 * 0-90b2 * 0-6 0 C ! * 0i in *0Z 9650*66Z96 * 06V 5 W l * 0ZVO1 * 0V 2 / 0 * 01V/0*09 9009*96069*9620 Vl*0-6VVI * 0-Z 590 * 00990*0590b6 * 06S t' 0 * 0 6CGCO * 0-9 5 C 0 • 0 —csro *o9 S f 0 * 0V 9OCB * 06150*06166 I * 06C l 2 * 0V590 * 00090 * 0C95 V V * I 0 lV//•10 tC 2 t 0 * 02620 * 0I (SVO * 02C50 * 029911*060 0 0*0692 1 C * 0Z22C * 00900 * 01/00*019l VO * Z6006*96/reo * o-1220*0-I b 9 0 * 09 b 9 0 * 00 9Z 5 C*10 1566*00 10 5 2 0*0-Z5C0 * 0-C 6 2 0 * 02oro • o6 50 v 0 * 0 60 V 0 * 0 6l f / 2 * 02 1/2*000bO* 0C 6 0 0 * 0os9r2*5bZ 6 2 * 5 b6C2 T *0-0 0 21*0-1260*00 000*0¿5»OV * 665 V $' * b 611/1*090Z l * 02990 * 06 Z 9 0 * 0950 l v • S 6602*56C9/0 * 0-CO/0 * 0-0//O•095/0 * 0SS
idtnsmiDs“IdUT101(1 V unvoHD3
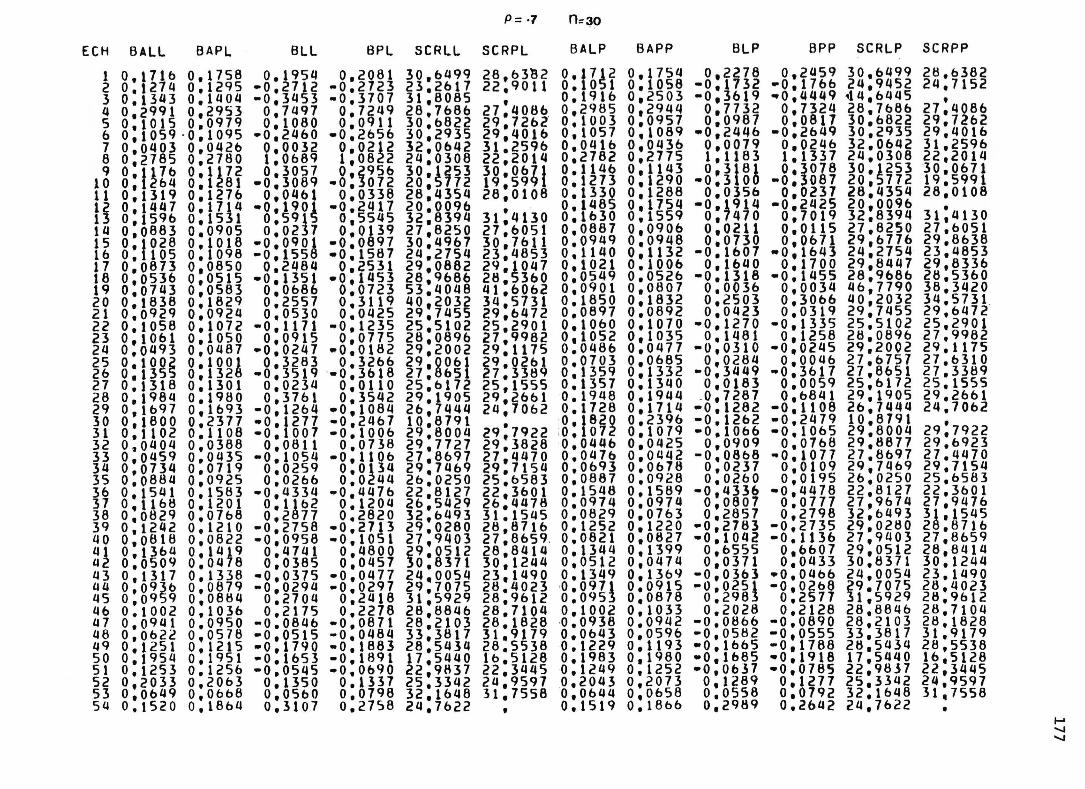
P= ·1 n=~O
ECH BALL BAPL BLL BPL SCRLL SCRPL BALP BAPP BLP BPP SCRLP SCRPP 1 0 171b 0 1758 0.1954 0 2081 30 b499 28 b3~2 0.17~2 0,1754 0,2~78 0,2U59 30,b499 28.b362 2 0:1214 0:12q5 ·0.2112 -0:2123 23:2617 22:qo11 0.10 1 o,1ose -0,1 32 •0,17bb 24,9452 24,7152 3 0.1343 0,1404 -o,3453 -0.1101 31 8085 o.1916 0,2503 -o,3619 ~o,4449 ~4,b445 • 4 0,2991 o,2953 o,7497 o.7249 28:7b6b 21:4086 o,2985 o,2q44 0,1112 o,7324 28,7b6b 27,4086 s o 101s 0.0979 o 1080 o 0911 3o 0622 29 12b2· 0.1003 0,0957 o,0987 o,oe11 30,b822 29,72b2 b 0:1059 ·0,1095 •0:24b0 -0:205b 10:2935 29:4016 0,1057 0,1089 •0,2446 •0,2b49 30,2935 29,401b 7 0.0403 0,042b 0,0032 0,02~2 32,0b42 31.259b 0,0416 0,0436 0,0079 0,024b 32.0642 31,259b 8 0,2105 0.2180 1.oba9 1,oa 2 24,o3o8 22,201a 0,2782 0,2115 1,1183 1,1311 24.o3oa 22,2014 9 o 1~7o o 1~12 o 3051 o ~95b 30 ~~53 30 Ob~I o.1146 o,1143 o 318A o,io78 30,~253 ·30,0b71 10 o: &4 0:1 81 -o:3o69 -o: 012 20: 12 19:59 0.1273 0,1290 -0:1 o -o. 087 20, 112 19.5991
11 0,1319 0,121& o,04b1 0,0338 28,4354 28,0100 o.133~ 0,1200 o.o3Sb o,0237 28,4354 2a,01oe 12 o 1447 o 17!4 -o 190~ -o 2417 20 009& o,148 o 1754 -o.~914 -o 2425 20 ooqb • 11 0:159b 0:1s 1 0:59! 0:5545 32:8394 31:4130 o,lb30 0:1559 o, 470 0:1019 32:8394 11,4130 14 0,0863 0,0905 0,02 7 0,0139 27 8250 27 b051 0,0887 0,090b 0,0211 0,0115 27,6250 27,b051 1s 0,1020 0,1018 -o,oqoA -o.o 97 30:4967 10:1&11 0.0949 o,0948 0.0730 o,0671 29,6776 29,8638 lb o. 105 0.1098 -o,155 •0,1587 24,2754 23,4853 o,1140 0,1112 -0.1&01 •0,1&43 24,2754 23,4853 17 0,0673 0 0850 0 2484 0 2531 29 0882 29 ~047 0 1021 0,1006 O,lb40 0 1700 29 8447 29 833& 18 o,o53b 0:0515 -0:115i .0:1453 2a:9bBo 2s: 360 o:os49 o.o52b -o,1318 -0:1455 2a:9b86 2s!53bO 19 0,0743 0 0563 O,Ob8 0,0723 53,4048 41 6062 0,0901 0,0807 0.0036 0,0034 4b,7790 36.3420 20 o,t838 0:1029 o.2557 o,3119 40,2032 34:5731 0.1850 0,1032 0,2503 o,30b6 40,2032 34,5731. 21 0,0929 0.0924 o,o53o 0,0425 29,7455 29,b472 0.0097 o,oB92 0,0423 0,0319 29,7455 29,b472 22 0.1058 0,1072 -0,1171 •0,1235 25,5102 25,2901 0,1060 0,1070 •0,1270 •0,1335 25,5102 25,290~ 23 0 lObl 0,1050 0 0915 0 0775 28 0896 27 9982 0 1052 0,1035 0,1481 0 1258 28,0896 27,996 24 0:0493 o,o4B7 -0:0241 -0:0182 29:2002 29:1115 o:o4Bb 0,0477 -0,0310 -0:0245 29,2002 29,1175 25 o lOg§ o 100! o i2B3 o 32&& 29 go&l ~9 02b~ o 0101 o 0685 o 0284 o 0046 21 6757 21 b310 26 0:11 0:132 -o: 519 -o:3&18 21: b5 1:338 0:1359 0:1312 -0:3449 -0:3617 21:aos1 21:1389 21 o.13tB 0.1101 o,0234 0,0110 25.6172 25 1555 o,1357 o,1340 o,01e3 0,0059 25,6172 25,1555 20 0,1984 o.1980 o,37bl o,3542 29,1905 29!2b61 o.1948 o,1944 .o,7287 0,0841 29,1905 29,2bb1 29 0,1b97 O,lb93 •0,12b4 •0,1084 2b,7444 24,7062 0.1726 0,1714 •0,1282 •0,1108 26,7444 24.7062 10 0,1000 o,2377 -0.1211 -o 24o7 10 8791 :o 1s2g o,2396 -0.1262 -0.2479 10,6791 31 0,1102 0.1106 •O, 007 •O:lOOb 29:8004 29:7922 :o: 07 0,1079 •0.1066 •0,1065 29,8004 29:7q22 32 o~o404 0.0100 0,0011 0.0738 29,7727 29 3828 0,0446 0,0425 o,o9o9 o.o7b8 29,8877 29.b923 33 0,0459 0,0435 •0,1054 •O,llOb 27,6697 27:4470 0,0476 0,0442 ·0,0808 •0,1077 27,8697 27.4470 34 0,0734 0,0119 o,0259 o,o~34 29,7469 29,7154 o,0693 0.0678 0,0211 0,0109 29,74bq 29,7154 35 0.0684 0,0925 0.02&& o.o 44 26,0250 25,6583 0.0081 o.oq26 0,0260 o,0195 26,0250 25,6583 3& 0,1541 0,1583 -o,a334 -0,447& 22,a121 22,1601 o.1548 0.1589 -o,4336 -o,4476 22.8121 22.3601 37 o,1À&8 0,1201 o,l!b2 0.1204 2b,5429 2&,4478 o.oq74 0,0974 0,0607 0.0111 27,9&74 27,947b 38 o,o 29 0,0768 0,2 11 0.2020 32 &493 31.15a5 0,0829 o,07b3 o,2657 o 2798 32 6493 3! A545 39 0,1242 0.1210 •0,2758 •0,27~3 29:0280 28,8716 0,1252 0,1220 •0,2781 -0:2735 29:0280 2 : 71b ao o,o8te 0,0822 -0,0958 -0,10 t 27,9403 27,6&59. 0.0621 0,0821 •0,1042 -0.111& 27,9403 27,8&59 a~ 0,13&4 o,14}9 o.4741 o,4600 ~9.3512 26,8414 o.1344 o,1399 o,&555 o,&&07 29,0512 26,6414 4 0,0509 0.04 6 0,0365 0,0457 O, 371 30,1244 0,0512 0,0474 0 1 0371 0,0433 30,8371 30,1244 43 0,1317 0,1338 •0,0375 •0,0477 24,0054 23,1490 0,1349 0,1369 -0,03b3 •0.04ob 24,0054 23.1490 44 o,o9~o 0,0679 -0,0294 -0.0297 29.7075 28.4023 ·0,097! o.o9t5 -o,02s! -o,o2b6 ~9,7075 26,4023 45 o.o9 9 0,0864 o.2704 o,2418 31,5929 28.9612 0.095 o,0878 o.296 o.2s11 1,5929 28.9&12 4& 0.1002 o,103b 0,2115 0,2210 2s 884& 20.1104 0,1002 0.1033 0.2028 0.2120 28,864b 28.7104 47 0.0941 0.0950 -o.OB4b -0.0011 28:2103 28,1826 .0.0938 0.0942 -0.0800 -0.0890 26,2103 2e,1026 46 O,Ob22 0,0578 •0 1 0515 •0,0464 33,3817 31,9179 0,0643 0,0596 ·0,0582 •0,0555 33,3817 ll,917q 49 0,1251 0,1215 •0,1790 •0,1883 28,5434 28.5536 0.1229 o,1193 •0,1&b5 -o,1788 28,sa34 28 5536 50 o.1qs4 o,1951 ·O.lb53 -o,1691 17,5440 lb,5128 o,1983 0,1960 •0,1&65 •0,1918 17,5440 tb:s128 51 0.1253 0,125b ·0.0545 •0,0690 22,9837 22,3445 0,1249 0,1252 •O,Ob37 •0,0785 22,9837 22,3445 s2 0,2033 0.20&3 0.1350 o.1337 25.3342 24,9597 0,2043 0,2013 0,1289 0,1211 25,3342 24,9597 53 O,Ob49 0,0668 0,0560 0,0798 32,1646 31,7558 0,0644 O,Ob58 o.ossa 0,0792 32.1646 31,7556 54 0.1520 0,1Bô4 0,3107 o.2758 24,7622 , 0,1519 0.18b6 0,298q 0.2642 24,7b22 •
.....
....... .......

ECH UALL BAPL BLL BPL SCRLL SCRPL ~ALP BAPP BLP BPP SCRLP SCRPP
55 0,1284 o,1254 -o,1980 -0,2033 28,073 21,0168 0.0952 0,0955 •0,23Y7 -o,251b 21,11~ 27,7505 Sb 0,1879 o,1869 0.4812 0,4716 21,675 21,3043 0.1891 0,1900 0,4860 0,4752 21,67 21,3043 57 0,1877 0,1893 •0,3339 -0,3347 27,690 27,4385 0,1869 0,1884 •0,33b3 •0,3372 27,b90 27,4385 56 0,0553 0,0552 -0,0514 •0,0848 29,156 28,6806 0,0575 0,0562 •0,0510 -0,0874 29,156 26,6806 59 0,1495 0,1479 0,0734 0,0465 25,710 24,3928 0,1528 0,1511 0,0742 0,0486 25,710 24 3928 bO 0.1001 o,1ouo 0,0350 o,o3oa 31,001 30,4506 o.oa12 0,0525 -0,0922 -o,1141 25,636 2s:saq3 61 o 2222 0,2297 0,1471 0,1611 26,969 2ô,1179 0,2229 0,2302 O,l9b7 0,2160 2ô,969 26 1179 62 0:1395 0,1417 •0,0264 •0,0195 30,924 30,6175 0,1414 0,1428 •0,0011 0,0088 30,924 30:0175 b3 0,1284 o,1299 -0,0059 -0,0358 19,934 19,3975 0,1301 o,1323 0,0093 -o,0294 19,934 19,3975 64 0,1876 o,~843 -o,4312 •0,4206 20,20! 25,0101 o,1879 o,~646 "0,4304 -0,4256 26,201 25,0101 o5 0,2620 o, 789 o,6954 0,8595 29,71 20,9092 0,2013 o. 600 1,4737 1,4546 29 262 27,3164 66 0,1481 o,1434 -o,o3o3 •0,0531 27,652 20,6912 o,1494 0,1447 -o,0345 -0,0569 21:os2 20,6912 67 0,0790 0,0740 •0,0198 •0,0483 34,495 32,4563 0,0792 0,0727 •0,0282 •0,0567 34,495 32,4563 68 0,1086 o,1429 0,0204 -0,0150 20.151 , o,1oq4 o,1443 o,02q1 -0.0120 20.1s~ b9 o,14q9 o,1496 -0.0970 •0,0915 21,446 20,7753 o,22q5 0.2204 -o,1363 -0,1302 20,a1 19:b906 10 0,1754 o,1735 o,3338 o,3346 35,637 34,2554 0.17&5 o,1745 o,3320 o,3327 35,637 34,2554 71 0,1401 0,1412 0,1996 0,1816 27.035 26,7219 0,1398 0,1414 0,1685 0,1710 27,035 26,7219 72 0,1322 0,1315 0,0178 0,0029 20,998 19,8867 0,1336 0,1329 0,0182 0,0017 20,996 19,6667 73 0,1336 o,1330 0.0013 -0,0244 20,021 19,2192 o,1362 0,1356 o,oo5o -o,o2b2 20,e21 19,2192 74 0,1850 0,1763 0,0965 0,0942 31,042 29,7120 0,1&71 0,1ô3b 0,2646 0.2661 29,649 29,2943 75 0,0111 0,0123 0.0026 -0,0314 21,101 26,q245 0,0735 o,0747 0,0139 ~0.0315 21,101 26,9245 7ô 0,1760 0,1795 0,0414 0,0277 23,830 23,54b5 0,1762 0,1792 0,0389 0,0243 23.830 23.5465 77 0,tb23 O,lb98 0,3517 0,3598 31,039 29,7217 0,1607 0,1662 0,3433 0 1 3510 31,039 29,7217 78 0,2170 0,2368 •0,0260 -0,0791 18,127 • 0,2\80 0,2373 •0,02b6 •0,0784 18,127 ' 79 0,1584 0.1537 -o,01a1 •0,0524 30,556 20.a638 o,1saa o,1549 -0,0274 -0.0015 30,558 28,8638 80 0,1333 0,1616 •0,1285 •0,1624 27,820 , 0,1489 0,1755 O,OOb7 •0,0534 3~,930 , 61 o,1B30 o.18b2 •0,3913 -o.3997 15,265 14,7024 o,1861 0,1890 •0,3892 -o,3975 1 ,2&5 14,7024 s2 0,1231 o,1197 -o,3519 -o,3375 29,377 27,4bl4 0,1739 o,1744 -o,3876 -o,3792 26,355 25,6103 83 0,1542 0,1550 -0.1219 ·0,1435 29,501 29,3451 0,1536 0.1545 -0,1221 -o,1454 29,501 29,3451 84 0,0743 0,0670 0,1335 0,13b6 32,776 31,0345 0,0758 0,0685 0,1509 0,1534 32,776 31,0345 85 0,0859 o,083A -o,2586 -o,2829 19,758 18,5378 0.0876 0,0053 -0.2558 •0,2805 19,756 18.5376 86 o 1132 o,1189 -0.2055 •0,2968 22,799 22,5667 0,1123 0,1103 -o.2852 -0,2982 22.199 22 56&7 87 0:1055 0,1642 O,llo7 0,248b 107,854 62,4697 O,lo5b 0,1637 0,1097 0,2402 107,854 62:4697 88 0,1672 0,1662 O,ob25 0,6342 29.310 29,3128 0,1763 0,1745 0,7300 0,6972 29,352 29,3744 89 0,1401 0,1453 •0,2019 •0,2107 26,077 26,0488 0,1405 0,1460 •0,2043 •0,2128 26,077 26.0488 90 0,1938 0,1962 -0,2792 •0,2869 16,366 15,8690 0,1956 0,1980 •0,2813 •0,2886 lb,38b 15.8690 91 0,1440 0,1000 o.1282 o,09b2 zl,133 o,1432 o.1789 0,1300 0.0970 21,133 92 0,1350 0,1339 0,2599 0,2324 2 ,462 21:2201 0,1355 0,1344 0,2566 0,2215 27,462 21:2201 93 0,0707 0,0717 •0,0710 •0,0800 29,812 29.6883 0,0674 0,0684 •0,0533 •0,0654 29,812 29,6883 9« 0,0556 o,oso5 -0.0757 -0.0123 27.955 21,80}0 0,0578 0,0579 •0,0864 ~o,0833 27,955 27,8018 95 0,0945 0.0978 0,0983 0,0812 25.14& 24,85 9 · 0,0706 0,0809 0,0197 0,0052 25,282 25,1248 96 0,0990 0.0973 0,2111 0,2115 29,537 29,5634 ,0,0945 0,0928 0,2088 o.2b88 29,537 29,5634 97 o,1a11 0,1125 -o.103A -0,1384 4e,131 35,7934 o.181e o,111a -0.1028 -0.1393 4e.13l 35.7934 98 0,1405 o,1447 o.398 o,419« 21.115 21,0310 o,1387 0,1408 o,1474 0,1312 24.37 24.2148 qq o.3514 o.35o7 -o,5010 -o,5258 10.101 16,3700 o,3278 o,3307 •0,32o2 -o.3367 23,293 23,0012
100 0,0726 o,o7lb o.2918 o.2850 28.443 2e,so2« 0.0120 0,0108 o,2982 o,288b 28,443 26,5024
........ ....... OO

ECH HALL BAPL BLL RPL SCRLL SCRPL BAI.P RAPP RIP HPP SCRIP S C P P P
17
9
inr'xo^r^oc^rx— a- -g f-rv, x
r/'c?- ìjcctì i^crrvxaKi
— rvjr
rvoiri.xr-- —
o.'vr^ccro^pa’c^,i/''u''r^fvc.nj
xor^O
'Cxoo^
rxxr-'-o —ir X
X r v,r, rv. a.
c'''n~—r^r^LT^xr-cr c C"
rvju
-y'^
c x
f\j -cs
se
e fi-
c-
CN
iri
■? kix
s^
c i
c b
ac
ic
ci
—
r^-L
P^
x r^
x x
x <v o
rvB
iv^
c^
tic
irx
-ox
x a
— —
**■. xx
x
ai^
ìc
—a
¡r ruir x
o —
— o
e rv
x x
o <
vx
x
•cx
Ni-ffa
r\jc x cr in x'.r <\j tr lT
r\.r'OL
.oa--'a ^tK
'.rM
tNf'ir
xs-.a
.jXN
O'-K
'isit-ixc
circ
t?7“
3 ltlt
k-lt -
5cjc
3ir
^3
-ru
"ir
c3
irc
O-'iT
IT X
rv
i3
£iti i
^O
NC
lV
Ci-
O-
a rvrv.r~
. — XT —
X X
lT-O
iTC
—o
x?
~">
X rvjiv- c
iK
'i
^c
is
'v
a^
j —
£\'^
c\£
^c
xr
va
ox
xx
^x
x =7 rr-~ x er oxi-rvi^
iroff r^c-cccr rvcM
N-ir^N
^ / iN
Nfv
jr'rvci^
^^
xc^
K x
x c: -Si —
k"X xxircrr'~r\.hn.ci''-c:cc' X rvj'c'f^c.rv.r- —R
jf^c-ir x occ
cn
£-
-c
j a
1/ 0
-c
£iir
rv
LT
-cj;ir
r,'X
frL
''0'y
'ir[/
ix
rvc
xf'-O
'—•
"''x
r'-
xc
xx
x—
<~r
c ^
ir '.r -=r ;?■ c
irc
sir
cir
ir^
c?
“ 3-c ir ~ — lt ^ — -ra?
— klt --
^ciT
^cr
x lt -j ;r j- —
v” *“*
vcc^^rv-i/ir-r^r^circr- >c^n rvlr
ir^r^^xccccnj>c
-“a,a'c‘ or
>ro>cf
rcjr->cf\;
ro' cr^cx^
——
rvj Poro*- 0X
^^
iTX
rO—/-0 ^
x —xo.X r1X
X—
c cr
rvoro
xOjO.' X
cr xx
XX
X-CIT Oj X
__r*\K>r“c
^ X
lp rvj —
r^c Ocr 0
0 r^a
0 —
k' r.IPK'. —CC X
— a?
L—
r-xc
X—
0cr o
x c
— 0
0ocr cr «-X
O —
0c
oo
oro—
0-0 —0
croo
—Oj 0
—O
jc Oj —rv.—
0>oO
— 0
— Ha—
0O
rOC
y*.— —
0—
Oj 00.-0. —
—O
OC
cc:e 0
c-o0
00
0c
oc
oO 0
0c
oc
oC
O c
c. 0O
C:cc
0 0o
o3
OO
00
00
CC
c
• 0 ' u ■ 0
c1
Il
11
11
1 t
1 1l
11
1I
I1
1l
11 1
11
1 1
11
OO
c—
-x x K'cr
Xronjcr r**cr
X Xr^ÓjX C
NX
— rv •/'K
Ovjr ^ r-Cr.lPCT
^ir^r^XL
T^C
N_
rir
X'■r-
IT —X
OJ r\: r-
XN
.'\jrOr*K'rOX O
r\jx0IT
J- ^C
K'N
XO'X
Xr-X
K lTlTuT 0
r-0 —
c c
tP c o
x xLi
rorv.1 —rvr
t'K
'rvox
0: rv n.X—
X —
rv.1cr-
Tc —^cr
— X
—LP. c
ox
ox
XK
r-ojcO
CN
-Nr^rn^ruN
irx CLP0
—0
c coro
— f\jO
—0
0njcO
jO —
'V0
—* O: 0OJ —
rv ——
•sT-
rvc—
0.— O
0C
•—*—
OJ c0
— OJ —
Oc 0
00
00
cc 0
00
00
c0
0 c 0
oc
00
c0
00
00
00
c 00
0 0
CO
0c
0C
OC
O0 0 0
0 0
c 00
11
11
•1
1> t
11
1s
1r
11
11 1
»1
» 1
11
¿vcn
«. rc
cs
cfv
a —
x c- n
jir. x x
cc
lp
x r
irr^
a
^in
cr
c^
r Lr
ca
>ifia —
£ x
cm
p cr co
- oj-'* ^
— cr
ro
xiT
'ro
cr
v^
-r^
dr
Is-cr *
or
ox
o O
c n
j— c
irlT
-X^
cc
cr
v^
-ip x
rox
LP
JP
coir
—c
—«r- ip
ror- x
xiT
iNC
Lr
CN
C'^
x irc
r ^T
^a
:^«-c
cc
a cr c
lt x —
x c
xc
mtn
c —
ro rv c rv c
f“~ r*- cir
lp x
cr xr
- xc
r x z
<=. x —
o
o c
— o
o o
c —
> oo
c c
— o
— «
- ——
o o
co
cc
c^
-c
oc
o —
«——
— —
— —
oo
o —
oc
o-
oo
oo
— —
o —
cc
oc
oc
oc
co
oc
oo
oc
co
oc
oo
oo
oo
cc
oo
oo
oc
oo
co
oo
cc
oc
oc
oo
oc
co
cc
^^
cx
^^
xx
cn
C^
ol
tn
oit
— x
sK
^c
c-
^.
ci
r-
or
-
cc
r^
.cr
^a
-.'v
^^
^ir
^c
N^
gr^
cx
-^^
co
jirirrv-rv
iroc
rcr —
lp xc
ac
rva
>c
>c
^c
a c- c
lp o r«~ xn
jr^r^ xr*“ c r-
c^iT
sCfv
irxi^
c^x
h*
0'^N>co^K
'.ccf\.if\<c>0a :> x lp xi^xcirxL
Pr-C
-K'(\'C
Ojcr-r^LrLrLPxcr lo^
^cn
^o
>c^
CC
C—
CC
OO
—C
O—
C—
O—
——
—C
O O
C C
C O
— C
C C
C —
— —
— —
— —
C C
C —
CC
C —
C c
—« c
— —
c —
CC
CC
CC
CC
CO
CC
CC
CC
CC
CC
CC
CC
CC
CO
CC
OC
CC
CC
O^
CT
CC
CC
CC
C^
-C
CC
CC
CC
iTirXLTlTirO
OC
C XLTCT X
— f\J Xr
CT x
x-*
-*c
r r
-x
ro
c
r-
c lp
—r^
r\,or\
j n
jck
'cl
px
ojx
r- xc
r >c^
^c
nit
>d c
xro
njc
r co
ir>x
OnO
xO
'C-
^^
x
X X
C X
CL
P X
CT C
—r
oc
>O
C'C
C^
Cki\
;>C
Xr/'X
C^
XN
rOg
f\;N
f\.r\
JO
‘Xx
cN
a -
xo
cc
xe
s ^
^-
xx
a^
njX
f/'r^
r^
-ss
irx
>O
NO
' ox
nj
ck
'X^
^C
nCC
“ r^
^r
c^
a o
x x
r-r
vx
— k
'lp
c —
r-
irr
ox
njx
x x
— lp o.
rO r-o LP X
C" rO
C CT r-^ror-iT
» xrO
-^X
O —
<CT tTO
lPX
0*h
-C0
KI>
CsC
7>
C0
X
»or^
NN
oo
'CT
- oj c
xx
ir>x
r\jrvjir>
r^ir>
LP C C
C LP C
C C
C LP C
C C
r^ C C
LP
Cnjr- c
irx^a -*xr0aNf^Nr/'ir®N^ruc7,X
N0K-r0<c
Ncsx — x
n«c
lp c cr
cc
r
^ir
^^
c^
^ir
cic
c^
iPL
rc
cr
^
rcrsjiriro c >cx
^ —cr xr^r^ojoc—
lpct rvjrur- c c —xxiroir ro —
oxer rox rvrvjo xroxrooc cr ojojirrvjcx
aj^coxNXxojrNXXiTKix nO
ccr-xaooaa’inoo'^x —«
coa <vor\jr
j-\ror-cipc^KiiriP^iro- ^Nscipf\jox^f\.'a xxr^r^ x
r-rooo—xxor^xxxircr r-r'-rox r
ooca xcr incr r
cfVNrriO' Lr a
ca-ox ss^oo' njirr-x o
xronjirxx «OKicr/KirovriPirx.*
N r-rK* >ca x>orvjxxNa —<ro >c
nO'o
x -o
x —
o
ircc^iPircccircccKi^ciPCMncccrircNOinccipcccc^c rox» c
ccccinccccxipccinc
c^
xa
xir
irx
ox
co
'a x
^rv
ixr^
r'-njc
r c~
-r\jo
—r
vj.o
jLr
r-o
irc
xL
rx
irc
—*r^ —
f\.'r
\.'c
c^
>c
r^
NX
sx
a c
x
^r
oc
*ol
p~* x
cr —
xx
~^
^o
lp
lp
—«r-L
P*\
JX
c —n
jx x
cx
ho
^^
f-a
LP
roo
jrv rvj—^
cx
ol
pl
po
rvjio
cr l
p <^
c
ro
ro
cr
vo
c^
^v
Co
ca
x c
o^
c>
cc
ip
m^
-x
x —
«xc
r rvr'OL
prv—
ircr cr m
tx
xC
vC>
on
jx x
c c
cr x
— x
o
*H
O-
oo
oo
^.H
f\jo
oo
o^
of\
j — f\
.'o^
-»cr
\j^
f\j^
cr
^
— o
j—o
or
vo
^.-
^o
——
o o
Ow .oj oj —
—
oo
oo
oo
oo
o o
oo
oo
oo
oo
co
oo
c o
oo
oo
oo
oo
oo
oc
oo
cc
oo
cc
oo
o o
oo
oo
c o
I I » I
II I
I I
I I I I
I I I
III
I I
II I I I I I I
cr cr lp cr cr x
r^ >cir r\
j~*ir
>orucr r-r^
cr — n
jir c >
or- hjlt c
ruc
r c x
>o
crv
jLr-o
c7
r-cx
c n
. it rvj
^
r- >c f\- r\.' c
xx
f\j-
^^
x n
Oc
xk
^c
t rvjirc
r- ox
>o ~
*lt o
rvir^
c r- ro
roirn
j^ro
xc
r ro c rver-n
——
rvjx c
>o x c
>cr^
o —
-cr cr\.~
-rv.-—>
oo
r\j—
-r^ ^-x
ryjrvK'rvjr^
r- c c
c cr cr —
x ~-<r\jrvr-r^ o
x cr r
- r^trcr cr o
r^
xo
-o>
o —
r->c
x o
ir
o^ooo oooKi^f\jo^ocf\jorv—*-f\,o-^orvj^aj-^^ro-*^o nj^oorvjor^—«^o^njoo^njrvj-^^-o
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
cc
co
oo
oc
oc
oo
co
oo
oo
oc
oc
cc
co
c
Il
II
I I
I I
I I
I I
I I
II
I
I II
I I
I I
I I
era
—cr o
cr
vc
oc
r—
ror^
cro
or-rv
jr-cr cr r- c
rv
x —
c >
cro(x>c r\
jf\jx r^
x r^
x o
r-rvjir >orvjh
np^r^ rn
r^ ^n
c r^cr
rvjr- iprv
jo rvjh
OLP
c o >0 >c c
ruf^
rvj dir.ro
o —
r^n
jlPr*^
jnlt
>c x? xlp
x o
rvjcr x >
oo
rvjcr in >c —
• ro c c
iPX
Nc
rir
xr
^c
rc
cc
o'c
cx
ro
—o
crc
r cr cip
>o —x
c ^
(Tlp
n —
—rv
jrvo
njc
r-r'^irM
nirx
o-o
>c
cr cr >c x
c >c —
o
o c
co
oo
o«-<
oo
oc
——
o0
00
00
0 —
00
00
—c
00
—0
0 —
—0
00
0 —
— o
—
00
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oc
oo
oo
oo
00
00
00
0o
co
oo
oo
oo
oc
oc
o^
cr
TN
ox
=3ro
mr\jr\jr\jxX
Mn
>o
coo
rvjsoccr o
cr ocrx
rvjn
joco
cjcj-—crr^-crcr ^rorocr^ir^cr
njK
idp
rv
jro
cr
-ox
«o
oo
xin
ira
Sv
Ox
irc
>o
r^
*-S
Nc
irir
ox
cx
xr
^o
njx
r^xcr x
cr o^
x ccr —
cr lo
xn
c ir
xr
^o
c cccro
'CX
r-n>
--'Ox
xcrL
Pcx
—x
c x
x Lpr
——
rvjrvjoouc r-r^LPLPLPxer LP
xe
rox
xe
r xo
o
co
oo
co
o —
oo
oc
—c
——
— —
o o
co
co
c —
co
co
--
——
——
———
00
c —
00
0—
00
—c
—c
c —
00
00
00
00
00
00
00
00
00
00
00
00
00
00
0c
oc
oo
oo
oo
oo
oo
oo
oc
oo
oc
co
cc
—fX
jr^cL
T'X
r^xc
r o —
nj ro
c ir
'xs
x e
ro—
rv.ro cir
xr^
xa
o—
ryjr^
cL
rxr^
x cr o
—o
jroc
irxr-x
cr o
-rvr^
c
-*-1
rvjrvjrrvjrvnjrv-ixrumrorororor
rorororocccccccc ccltlTl'"ltlt>
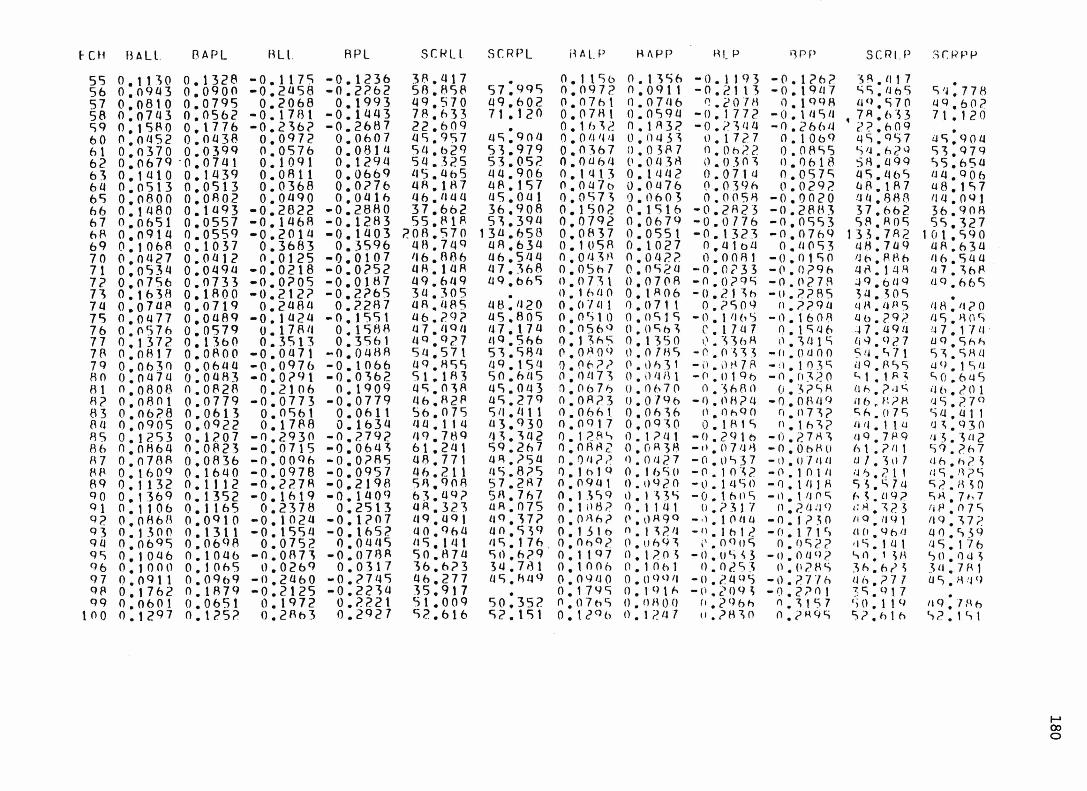
O .O
0-3
-2
-O
-O
-O O
O
OX
XX
XX
XX
XX
X—J—I—
I—1-4
—1—
J—
J-4
-4
0'0
'0'0
'0'0
'0'0
'0'0
' JIU
TO
l O
lUl
flo
-0x
-j0
'0í3
oj-x
— o
ox
'jo
'ois
ro
ix
— o
ox
-jo
'oi.t.w
x —
o-o
x—
íO
'Oii
.aix
— o
-o
x-jo
'oi
^
000 0 0000000 0 00000003 0 0000000000000000000000000
— o
— O
— —
. o —
O —
— —
— O
O —
OO
OO
OO
O—
OO
O —
OO
O —
O O
— O
O —
OO
O —
OO
O—
E»
ru
3'v
JÚ
OO
O'>
3:-
*^
>-3
'>iI
í\J
-O O
' X
X 3
0“ X
^J
I 3
—I0
'-4v/!.
30.0
3'.3xij
1.e
0'0
4.3
i_n
—JX
-O—
r~
OO
O*—
03
£0
3'0
0'W
0 3
3-J
10
^0
0v
i>j-
vlS
NlC
^.n
,vJ
ru
j'-J
iao
>->
’-'J
'JJ
15
!£-C
^
,—.r\j —
o0
'Olo
xC
'-0
X0
X3
04
0iœ
— X
3O
'~iX
0'—
4X
XO
-3
—ix
c—
00
04
0 Æ
orvjo
wo
wo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
• ••••••••••••••••*••«••••••••••••••••••«•«••*• CD
—»0
— 0
— —
O —
O —
— —
— O
O*—
OO
OO
OO
O»- O
OO
— O
OO
*-* 0
0—
00
— o
o o
— o
o o
»—
>
"uo' ï-ûooo'w o
—o*i—
o- x
xx oo"-4X30'XoJ0ic—i
x-4.c3ouiLn.3xoi3—joj
3—jo>-4.0
04 x
uvoi—io- O' fc o—— 0*
01 —cojxoix—-4fv>X3oc'-iX—ooj-o—
o^-noi
00—
04 3-00
4--lo'-oox
r~x — -c -o oic- x—
o o
ixxo O' o4—
jxoj -o awcoo -o
o^
cm —j -o—Jo4f\jo-i -o —
-ox O' xji o x
I I
I I
I I
I I
I I
I l
il
i
li
li
I
II
l
il
io
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
o•
..
#.
»•
••
••
••
••
••
••
••
••
••
••
••
••
••
••
••
••
••
••
••
•
Xx —
xx
o o
o —
— x
— x
o o
ox
—0
0x
00
00
4—
— ruru
ooow
M—
rvio
oo*-
oo
fv
-xx
—
r~so-cfxiavijio^iij-oo
\iiic jivici;—
Mí\j—O'ocacw3¡oji j-fi'-io c-
í-O' —
jxo* o*
—joij
ix —j—
—4-
4 o
—04
do- -j
o >c—
4-4—
xx
xx
o —
xx
—O'X
-o o-—
£>j
>i(3
-3!a
'ji->
i wru
uio
o^rvjc
caí lo
oyonoas->04 0' —
O' —
3
3xoix
oio
43
xxox—
>— o
~xx —
xxji
il
i ti
li
li
lí
i
il
l
• l
il
i
il
i
il
il
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
oo
................................
.......................................................................................................................................................
30ru
.M
fu
Mo
oo
i- »
*r
u'-
Mo
oo
\jk
*o
oi- o
—o
o4
——
xx
oo
oo
j —
•—x
oo
o—
oo
x—
— x
—
xo
xrv
-io
j-js
o-x
oi.c
—-o
xo
'-
jo'O
'-j
-o^
oi;
jio
io
ix
x—
x—
oic
rx
xc
xo
'x
xo
'o
'r
ro
xx
r-
xx.^
4 3
— jj —
oio
—0
-00
1x3
-00
4»—
so
aa
x^
cc j
ia
c-o
:a
io
^o
a:3
:i-‘-
siO
'-o>
-oo:i
:-c<
j'w
3
oí -
4 x
oi
x—
ioj
o 3
3-o a
i ,n-x
3 —
-o -
oru
o1
x —
x —
—io
i—4x
-40
'o4o4
o0
'0
'-0
33
—j—
iojo
jxo
-
xJV
0I0
43
»a40
I33
3 C
J1 J
lfiC
U-;
3 0
^3
3 0
l30
l33
33
04
33
3:3
0'0
l04
.33
30
l0'3
x—4
30
I04
x —
oio
- O' o
oio
o x
o4
xo*
x—
o 3
0- O
' oí —
oc
fl'
JO
'Sc
-oii
ss
ji'j
a-x
aic
cji
MX
iaa
</>
................................................
no
'o^
ox
o-x
—0
3o
j3 o
íx-4
x—
j — o
ïo
-x
ji
03
X3
04 0
' — x
-jo
ixo
's—
3oj
o' o
o-y
jix
c
x-
o-
>j'
u-
-j£
j' o
x o
o«—
xj
i'
j'
vo
ox
of
iú
xf
is
-o
'c
xa
' x
x o
í0^
4—jo
i—
r~o-
o>
i>il
íjc-
* 3
—
— —
oc
jix
sjj
ji-“
—4
3 x
oio
i -o
xo"
oo
xx
3—4
0101
-0—4
-oo4
ox
—i
'—
J\ O
lC
wJ
liC
t
EJ
1C
C J
lC
OlS
i ü
üc
cc
cw
jiw
ct
ca
ij'fi
—ic
ai
COx
oJ
IC
OJ
IO
0
XX
'-4
0’. x
-0
j4o
43
jl_n
0-0
^4
0-4
01 X
O—
lO
'X
t^
O'J
lX
C^
J'
— -
0-4
n X—
04
x-jy
-jijJ
os
fu
x\
ir
uji 0
3X
00
—■ jn
-_n—
X3
a^
aio
'o'w
-c
o-
^o
-o
o—
O' -0
JIL
flX
X a
io- -3 0
4—
—13 i
JIX
XS
OIM
XJ
-iW
LT
l J
0C
J1
0J
1>
JO
xo
or*
— X
o —
ox
jx
ai'j'jjic
-4
X0
— 0
04
01
3 i
xc
ji
oJ
lX
ec
ca
tX
-'IO
'X
Oi
ox
oi
O 3
00
00
00
00
0 0
00
30
00
00
00
00
0 0
00
30
00
00
00
00
00
00
00
oo
_—
0—
0—
— O
— O
— —
O —
OO
— O
OO
OO
OO
— 0
00
—0
00
—0
0—
00
— o
oo
— o
oo
—
:>x
-4—i -c
o —
o
x o
o*
-oo —
x,u
o O
' x
i? 3
o-
xj4
0i o
—; O
' —4 0
"¡3 c
x-—
¡010
13 3
3 o
j o
o' -
4—j -o
—
r-
oj
íú
oo
o—
jx
j’t
—-U
ÎX
-j-u
vo
i-u
ou
—.0
0-
4-
4—
o- -i
-H x
o-
-io
i x
v' /
'jio
x
x o
— o
.x
x o
—4 —
04O'
x o
o.
oo
— o
— —
j x —
4x*x
o 0
4 3
—4
3 x
— —
x o
00
00
00
0 3
00
00
00
00
00
00
00
00
00
00
00
00
00
0 0
00
00
00
00
00
• I
..
..
.
..
..
..
..
..
..
..
..
. .
..
..
..
.
J—
3 —
o —
— c
— —
------O
— O
O —
OO
OO
OO
O —
03
0 —
OO
O —
OO
— O
O —
OO
O —
OO
O—
>
’•V X
C O
O .X
I 3-
ï
->
£?
£
-N'jJ
-O
^
X3
0- —
o o
* o
-c x
-o 3
04 x
oí x
v4 3
—
— o
oiv
^p
uji
nj^
-»0
'-ii
i^ü
Di^
W'ú
¿—
oí
xo —
O O
O -4 X
— O
O'O
'O —
— -
TO
jiJ
l- O
' X
3X
-4 —
-C
O'^
O'IX
iX
'nIwW
.'VJÜO'—
O'
• • •
II lililí
I III
I III
III
II II
cr
oo
O —
OX
30
00
00
30
00
00
0 0
0-0
00
-0
00
00
00
00
0O
OO
OO
OO
OO
O*
..
.
..
..
..
. .
..
..
..
..
.
..
I.
..
..
—
OC
O —
— X
— —
— O
OX
— O
O O
'«' O
O O
«/-: —
— 'V
.p\
jOO
OC
- O
PV
JO
OO
OO
— .“V
— X
X —
'—
ïc
sc
.’Vîj
': o
j
o/
>iix
jx
i-
a
ji-^
^j
o-
wn
j j
o^
>i^
j s
^-
jo
—
x.aj o
' o
o o
' a-
~ —
3 —
oí _*¡
o4
3—
— o
x x
o
\(i\
j^'-
ivi/
-^
—1 O'
-i- o
j O
l '"U
3 —
• O' —. X
—4 i
3 -P
O 3
O O
' X
-a- X
—4 -
O-O
O O
Ì o
'—"
3 0
4 O
' o-* X
O' C
-aJ r\j
C X
i X
-aJ
* * »
II I I I I I I
I III
I I I I I I I I
I II II
° 3
OO
OO
OO
OO
OO
Ow
O O
OO
OO
OO
30
0-
^3
30
00
00
00
00
00
00
0 0
-0
00
.......•_...................................
J5'V
i-fjrV
J'V
;-----
ÌC —
Ai-
M-
co
^-
oO
^S
-O
/l—
>J
.\J
OO
OtO
O(U
OO
OO
O'—
r\J —
— —
—
T)I-
'J^
.’J
S^
N^
Èii
Os
iJ -
4J
C t
VIO
'UM
MM
- O
'-IJ
lXO
!\J
Jla
'XO
0'2
OÆ
’XJ-0
.PO
^:x
OX
—o-1
ii
o---
---3
O —
¿O
OX
>i-
OJ
1J13
-J1X
MÆ
vJ
- -T
C'O
'V'-
Oir
O-
-r-4
—O
-^-.
XX
-PO
-OJ
IXO
OO
jsIX
-VIO
TO
/O
J1?
-5C
'J1-
j:T
O^
£W
WO
AJ
J1»
J15
¿ÍI
>J
M
^X."'Í--- ” '
c O' — i: /I 3 3
'J'-'J1-''XO_TiO
— OiJJ J- - ûi ¿Nlî ÏI: 017 X
Ï-JiXJlXi;/I'AJj C Jli 03
••
••
•«
•
••
••
••
••
«.
•-
>«
.•
<•
••
•.
..
••
..
..
.,
.
..
..
..
.
flJ —
C\J -*-í ¿ vJ-
—O Í\í-X jn5í:f\i¿-0' —
ï>j>j IJ-X —ÛC7 00'0'«n33
3o X O "J— 3 3 X — -~4 X 3 7)01iX-0-OX033XC:XOO'XXC'
—~
— 3 — U~X
3 — — -OC
Ci\'Jl!\;X-4Ji OOJOOJO-JÌ--4
"O
-r—
tcic
ojiu
iicc
/jit
’ji
XO
J
lio
^o
i T
:iX
^J
O>
/(C
j;jo
CjJ
J
vlJ
lI
O
iO' X
— a
iO' Ä
X £
\J1^4 M
—
Or
n**
••••
••••
••••
••••
••••
••••
••••
••••
••••
##«#
«***
—
3-jJJlXJ'j4-00-û3'i)Æ
— O'
"CJ"
^
-Xtv
J>
v|«
4J J
,xX
7iW
-M
OC
JlI
3->
iO,'J
0'
0'30
j-c
r\j0
0j’
0'j
l~4 0
ÍV
IO-4
X
— O
’ -o
—
a~
ox
-P
-vi o
_r^
-ix
o—
o
— j
i 3
3
o'
3 s
io
ji?
cc
o>
ix
“>
i0'c
it
o
xx
081
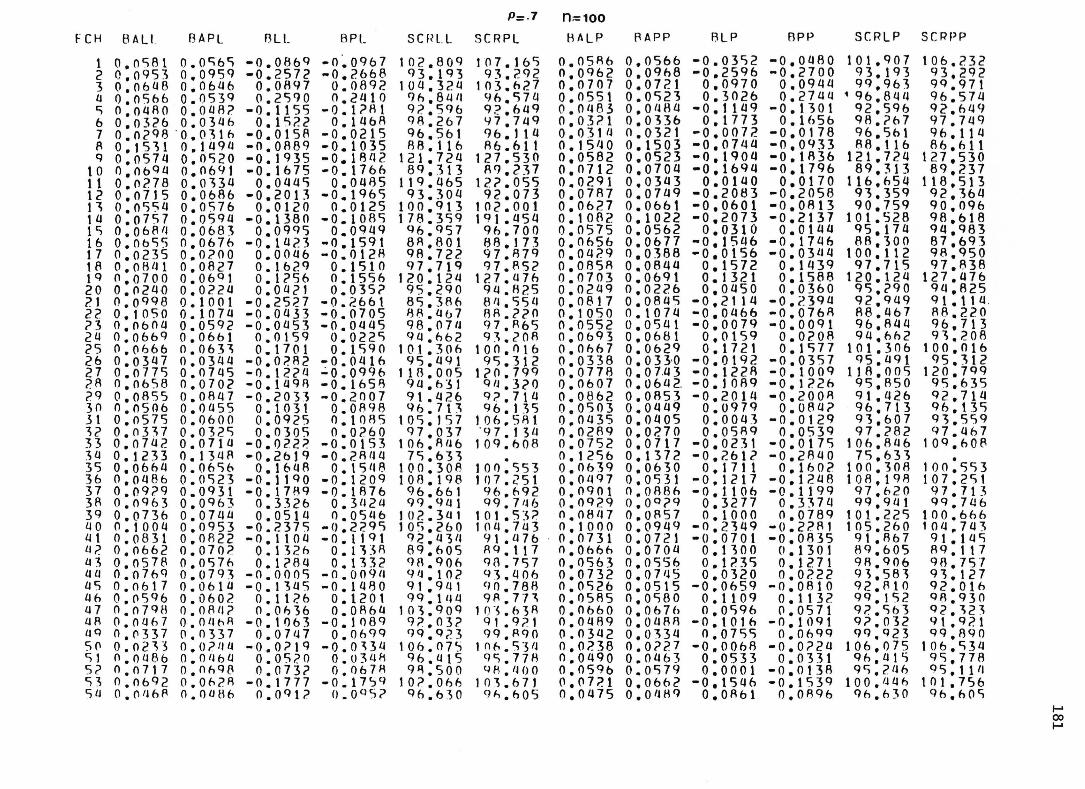
P= .7 n=100
FCH BALI f3 APL f3L L APL SCHL.l SCRPL HALP RAPP A.LP APP SCRLP SCRPP
1 0.0581 o.0565 -o.086Q -0~0967 102.809 107.tos 0.0586 0.0566 -0.0352 -0.0480 tot.907 106.232 2 0.0953 0.0959 -o.2572 -0.2668 93.1Q3 93.292 0 0 0962 0.0968 -o.2596 -0.2100 93.193 93 0 292 3 0.0648 0.0646 0.0897 0.0892 104.324 103.h27 0.0101 0.0121 0.0970 0.0944 99,963 9Q.971 o 0.0566 0.053Q o.2S90 0.2410 96 0 840 96.S74 o.o55t o.oc;23 o.3026 o.27Llo 1 96.801~ 96.574 5 0,04AO 0.04A?. -0.1155 -o.t?At 9?.,596 92,6Ll9 0.0483 0,0484 -0.1149 -0.1301 92.596 9?.649 6 0,0326 0.0346 0,15?.2 0 0 146A 9A.267 97 0 749 o.o3?t 0.0336 o,1773 o.1656 9H.?67 97.749 1 o.o2Q8 ·0.0316 -o.015A -o.021s 96,561 96.1 ttJ 0.0314 0,0321 -0,0072 -0.0178 96,5b1 96,114 A 0,1531 o.1494 -o.OA89 -0.1035 AB.116 A6.611 o.1540 o.1503 -0.0744 -o.0933 A8,116 8&,611 q 0.0574 o.os20 -o.1935 -o.1ao2 121.124 121.530 o.osa2 o.os23 -o.1qou -o.1A36 121,124 121.530
to 0.0094 0.0691 -o.1675 -o.t766 89.313 A9.237 0.0112 0.0104 -o.1694 -0.1796 89.313 89,237 11 o.o?.78 0.0334 o.044c; o.o4B5 119,465 12?.055 0.0291 0.0343 0.0140 0.0110 116.654 118,513 12 0.0115 o.o&A6 -0.2013 -0.1965 93.304 92,073 o.01a1 0.0749 -o.2oe3 -0.2058 93,359 92,364 11 o.oS54 0.0576 0.0120 0.0125 100.913 102.001 0.0627 0,0661 -0,0601 ·O.OA13 90 0 759 90.096 14 0,0757 0.059l.I -0.1380 -O.lOA5 178.359 1q1.454 0,10A2 0.1022 -0.2073 -0.2137 101.528 98.618 15 o.obAq o.0683 0,0995 o.o94Q Q6.Q57 96.700 0.0575 o.0562 0.0310 o.ot44 95.174 94.983 16 0,0b55 0.0676 -0.1423 -0.1591 8A,801 68.!73 0.0656 0.0677 -o.t546 -o.1746 88,300 87,693 17 0.0235 o.o?OO 0.0046 -o.Ot2H 98.722 G7.R79 o.0429 0.0388 -0.0156 -0.0344 too.112 98,950 1 A 0 • O H lt l 0 • 0 8 2 7 O.l62q 0.1510 97.719 '17.AS? 0,085A 0 0 0844 0 0 1572 0.1439 97,715 97.838 19 0,0700 0,0601 o.1?56 0.1556 120.124 1?.7.4 76 0.0103 0.0691 0.1321 o.1s0a 120.124 127,476 20 0,024-0 0,0224 0.0421 0.035? 95.290 94.f\25 0,0249 0,0226 o.Ol.150 0.0360 95,?90 94 0 825 ?1 0.0998 0.1001 -0.25~7 -0.2661 85,386 8 ,, • 5 5 ll 0,0817 0,0845 -0.2114 -0.2394 92.949 91.114 . 22 0,1050 O.l07lJ -0.0433 -0.0705 P,FJ..467 AA.??O 0,1050 0.1074 ·0.0466 •0.076R A8.4b7 R8,220 ?3 0,0604 0.0592 -O.Ol.153 -0.0445 9 8. 0 7 IJ 97,A65 0.0552 0,0541 ·0.0079 •0,0091 96,A44 96 0 713 24 0.0669 0,06b1 0.0159 0.0225 94.662 93 • .?0A 0.0693 0.0681 0.0159 0.0208 94.662 93,20A 25 0.0666 o.0633 0.1101 o.1590 101.306 1 o n • n t 6 0,0667 0.0629 0.1721 0.1577 101.306 100,016 26 0,0347 0.0344 -O.O?.A2 •0.0416 95,491 9S,312 0,0338 0,03~0 -0.0192 -0.0357 95,491 95,312 21 o.011s 0.0745 -o.12?4 ~0.0996 lll3,005 l?0.799 0.0778 o.o7~3 -o.122R -0.1009 tJA.oo5 120.799 ?A 0.0658 0.0702 -0.149A •O.l65A 9l.l,o31 Q /J. 3? 0 0.0607 0.064~ -0.1089 -0.1?26 95,ASO 95 0 635 ?9 0.0855 o.oA47 -0.2033 -0.2001 91.426 Q?,714 0 0 0862 0,0853 ·0.2014 ·0.200A 91 0 lJ26 92,71lJ 30 0.0506 0,0455 0.1031 O.OR98 96. 713 96,!35 0,0503 0.0449 0.0979 0.084? 96,713 96.t3C) 31 0.0575 0.0600 0.0925 0.1085 lOS.157 106.5131 0.0435 0,0405 0.0043 •0,0129 93 0 607 93.559 32 o.o3~7 0.0325 o.o3o5 o.o?60 rn.031 '97.134 n.o2A9 0.0210 o.o5A9 0.0539 97,282 Q7.467 33 0.0742 0.0114 -0.022? -o.ot53 1 0 6 • 8 /J 6 1 0 q • b 0 8 0.0752 0.0111 -0.0231 -0.0175 106,846 109,60A 3ll 0,1233 O,J3l.IA -0.26Jq •0.2A44 75,633 • 0.1256 0.1372 -o.2612 -o.2840 75,633 • 35 0 0 0664 0.0656 0.164A 0.\548 100.308 100,S53 0,0639 0,0630 0,1711 0 0 160? 100,30A l00.5S3 36 0,0486 0.0523 -0.11QO •0.120Q 108,198 107,251 0.0497 o.os31 -0.1211 -0.1248 loB,198 101.2s1 37 o.o9?9 0.0931 -o.11Rq -0.1A76 96,661 96.692 o.oqot o.oR86 -0.1106 -0.1199 97,620 97,713 3A 0.0963 0,0963 0.3326 0.3424 99.941 Q9.7Q6 o,0929 o.oo?q o.3277 o.3374 99,941 99.746 39 0.0736 0.0140 o.os14 0.0546 102.3Ll1 101.53?. 0.0847 o.oAS7 0.1000 0.0789 101.22s 100.666 40 0.1004 0.0953 -0.2375 -0.2295 105,260 104.743 n.1000 0.0949 -o,2349 -o.2?R1 105.260 104~743 41 o.oB31 o.oe22 -0.1104 -o.t191 92,434 91,476 0,0731 0.0721 ·0.0701 •0.0835 91.A67 91,145 42 0.0662 0.0702 0.1326 0.133A 89,605 RQ,117 0,06&6 0.0104 0.1300 0.1301 89,605 R9.1t7 43 0.0578 0.0576 0.1?84 0.1332 9R.90h 9n.157 0.0563 o.oc;s& o.l?.35 0.1211 9R.906 98,757 44 0.0769 0.0793 -0.0005 -0.0094 CJQ.102 Q].406 0.0132 o.0745 o,0320 0.0222 en. 58 3 93.127 45 0.0617 0.0614 -0.1345 -0.1480 91,941 Q0.788 0,0526 0,0515 -0.0659 -0.0810 92.RlO 92,016 4h 0,0596 0.0602 0.1126 0.1201 99 0 1Q4 9A.773 o.n5A5 o.o5ao 0. l 109 0,1132 99.152 Q8.930 47 o.o79H o.oA«? o.0636 o.OA64 103.909 10~.h3A 0,0660 O,Ob7h O,OS96 0,0571 9?.,563 92.323 4R 0.04h7 0.04~R -0.1063 -0.1089 9?.03? 91.9?1 o.04A9 o.04AR -0.1010 -0.1091 Q?.032 91 ,921 QQ 0,0337 0,0337 0.0747 0.0699 99,923 99,A90 0.0342 0.0334 0.0755 0.0699 99,923 99 0 890 so 0.0233 o.o?44 -o.o?t9 -0.0334 106.07':i 1nA.5 VJ o.o?.36 o.o?.27 -0.0068 -0.0224 106.075 106,534 51 0.0486 o,04b4 0.0520 o.u34H 96.415 95.77H n.0490 0.0463 0.0533 0.0331 9h,41'i 95,778 5? 0,0717 O,OhQA 0.073? 0.067A 9i\.500 CJH.'~OO 0,0596 0.0')79 0.0001 -o.o13A 95,21!6 9 5, 1 1 Il 53 o.ob92 o.Oh2A -o.t777 -0.17~9 10?,066 103.671 0,0721 0,0662 -0.1546 -0.1539 100,l~Qb 101,756 5 /J 0 • 0 IJ 6 A 0 • 0 /J H h o.0Q1?. O.OGS? 96.630 9'1.605 0,0475 0,04HQ 0,0A6l 0,0R96 96.630 96,h05
....... OO .......

18
2
o. —
c ecor--o- roccip
——
Lpcr —ir>cc —
r^p'io
cc
rvjrrr-- o- op
ox
xir
r^rvjx.C' a
. xir
— eco- =r ro
j'.ruro
Kico
cl o
xc
ki—
ruo-o
;—ocr^
i—rvjcr—
Kim
ojc c
rvjx
N-.fo
xru
ir—xorM
irxairo
o- c
^a^
^.a
cip
¡>- —
^rx
j3-^
-roir=
J'C
^o
-—i-'nO —
oc
cr\ia
>o
—’r'.o
fMC
'vD
ax
K'tc
f'jcc
cc
r'Lrx
LP
—i^cctcrvj —
**»***#*#*#••••••••••••••••••••*••*••••••• • • • •tn
f^-o*-<\ir>
- —m
ir iro
oirrv
jKic
cr- irirf-r^
o<
x or^
rve
rx =r «
cirx
irrvK
-prx
iir xir~
i'~K
'0' 3
3^
7
O'O
-oo
'O-'-O
'O'í'O
oo
'cc
rffa in
cr o-cr- —
co
xo
xe
-o-o
- era
c- cr cc
'ax
ao
'cc
ffao
'air
a
r^
ae
o-ía
ca
—a
ra
—rvir^ircr >
o>c*-ir —
x <
\j-cr'~
xr-r--x
i---íTX
oirir>
ccr
rvir r^—
ir =3_J
^lTf\¡f\.,C
31
/'3
W'-c
Co
rviO
'h.K
l ^M
ira
-CÍ
OÍ
O1 e
ro —
< P- Or~
— o- —
■ O'fV
OL
TO
'CT
r'-.Or^n
j—■-c
ce
cjo
o-
ox
-o
o—
Xirr~
irojr-'i'<
'p-C
' ^ix
i/ia
xi «a
íir.■c
o'in
n.s
-rvo
r- — ííc
ip^
nc
^iT
:
cn
r^>CíVt^P'OLP~CsOor\j^Tf\jCTr't^-xa'r'r-C'c;o'^'r-r'
fvx3^oirxLr^c: —
x x
c~ x rver o
ir^o
(j-3'C
0'p^
t)'0
'0'o
cff'C
0'0
'0-
i'^0
'?o
oc
cc
c0'0'0'C
'0'0'c
r0'C
íC'c
a0
'cc
c'(
?0
'3'tr
C'O
'O'cr
LTO'C
LT —
ec ucc
ir-c
<"v¿ir — o- —
=10
—
ir lp —p-- ~
Lr-r
-»- x —
‘Xrv fv
irx —
eo—,^.—
— —
ccoirp,''xc'—,x
xx—crxíTr'-Pri
xa irr^or^pnoK'.Lrxp^rvo—pxr'-r-r'
o. — C
'ocüi/
'trscK
c<ccxi\
3T
yi—
'CCM
r'urxr
r''K:(y
cca-o
a o
o rv. ir p'' íj nj ir o
o ir !V
c. oO-C«0 3(V03 0 0
C—
OCO-<'*-Cf\,«(VlCCÍ\.CCÍ\:'"OCf\iCOOOC;»"0 0-"0-
rr #••••••♦•••••••••#§•••••••••••••••••••••••••••
oo
co
oc
co
oc
oo
co
oo
co
oc
oo
oo
co
co
ce
cc
oo
oo
ec
oo
co
co
c©
t
I l
il
il
í
I I
I I I
I I I I I I I I
I Io_
—— —mr-
— xa C'frf''Xr~o'fvr<'r
'xxf'C-—
3'CirxírO'tr<MrrvjLr‘f\JC'Lri——r>o —
—a c-oo--
_1 — o.i'-K'.cTXC7'
-,cr-[~-'OX’X
rvjpri—•cmsr'3,iri
<CT'0' cir~*0'inp''r\,r'-Lr-x—-^xa —«o
o ir —*ruó-
e»—Gcj'f\joirf\jr'-r\jLrpr'p~c;Tir»—
irc —t^xK'ronj^'co'*-,o~íj*->0' í
c^cc^ircíS"-
crv
— o
— o
—(\jo=3 o
oo
—«c
c-o
—cr\
j--Mcc(\
joo\i-o
—o
cc
oc
-c
c—
c —
oo
oo
oo
oo
oo
co
oo
oo
oo
oo
cc
co
oo
oo
oo
oo
oc
oc
eo
oo
oc
oo
oc
ti
li
li
lí
I
I I
II
I I I I I
IIr~—
<vxco;r=TX>Pr'íTf\j«->«-'f\jOf\jr‘--XP/">cxx*-'0'p',op'iirf~-irf-r\jX
"Xxx=TXi'Vir\_ox:irr'- CL
ir <MririP — OIO—«X^rviOO-IMir O
LP OIT —
O —
rO ——<OXLT íTXr\jO~r'''Lr —
PCV*"! —
3" 3ÍOC
a
rfv;? x
xr
t'-xru
cc x
xx
ir x
trx =t
p'mta x
x x
xoxaxi\
¡irir<vir
p~-?vx
xl*-1 x
xr¿
xir r*- x
c
ceOOOOOOCOOOOOOO00-00CCOOCOOOOOOOOOCOOOCOOOOOO
OGOOGOOOOOOOOOOOOOOOOOGOOOOCGOOOOOOOOOOOOOOOOO
Lrr-cr oofvsc> »crvcr^^ocx c*—
*cr\jccojccirx ocr no
n>o>c*-
i or-nc*r-ncr•irr-rv«—
a. crvjK'.drcMrcr —
«ce cojc >C
nOO lt X'X —
— 'C>cr/"
r^cLPoc or-xx-'-^vCX o—- f\. ro >c ir
_,
'C'C'ONS^\jcC'C 'Cl'C'C'ClT'XC<\;l/'CkrcC 'ClTC>CC‘ >CfV-
ITAI^^ÍV'CX wr'>C
K'.'ChJ'C £
<
OOCGOOOCOOGCOCOGOO — CCGOOCOC
oo
co
og
oo
oo
co
co
gg
oc
g-
OOOOOOOO O O O O
GCOOGOOOCCGOCCOCOOGCOOOOOOOO G O O
OOO
-J —«X
irr^cr rvuLT—-O
O- —
i/’iorv
sroo
cc cvjrcr^c o^
c O
LTrorvjx rvjru—»K' —
cc~-c
O'K'iCCce
a. cccor^r^^rvia rvj-^-o o
c■*— rvicr rorO
LPrvjO" c
rvo -or-
ix c
c rvjr^rrir- >c ccr o
c rv;rv:r^oscc ir*
a.
cernir-*—
r\jc —r
ir»cesOK'.cr x*r>>o —
ocerxcj-
>erv.o>c--cerr>CM
r"OG
r^Lrr'sLP»-C‘ kx
c-
cj **********••••••••■••••••»•••••••••»••••«••••»
ce irir.iro
»-ir-rv.p^ ce x L
Tir.r^r-o
a o
o :vcr r^
ir-^^
ce
ircc
ss o íi/
'ca
>^
c
c —
c c
cr0
'oc
'0'-‘a>0
'ao
oa
oc
ra
a^
a cr cr «-«o* o
ao c ce o* O
O'O
O'C
-O'o
oa
- crck0'o
ca
'c'0
'a>0'
_■ o- ar\
jos >c
cr cc
— irro
—^)>c»-ir •-c
cf\
.or^
x*->
cx
xc
>o
f\j'c
ac
—«cr N
crr^
njc
cr^
-Nc
—
¡ n
jirr-r\.o
dr
cK
' — cr o
r\. cr «£■ cr cr
vir
c x
cr o o
ír o >c X
'Nrvjr--^-x
ore>
e >co:
roe
>c—c
x*o
o^
>o
crr'L
r.f\,r')L
rsc
' >c
x j“A
:>cn
cc
c
rvjcr o»-cr~*'-sin
x!tr><Vía’G
cn
ro
*
**
**
**
**
**
**
••
••
••
••
»*
••
••
••
••
••
••
••
••
••
•«
••
•^
cC'CfVf/'.N
CL/K>0
'Cc
cc
rvjc
cc
cc
'xc
sf^^
oo
*-K'?v
r^c
>e
'OX
Lr>x>
c*— ir-co- c
crv
io cir* c
c
cr cr o cr cr —
*cr O" cr oc
a- o
a e
ra r^c* cr a- o
oc
xc
cr
oc
ra-c
rcrc
r oo
oc
rx
cr
cr
co
oo
'o’ cr c-
'eLrr^->cccrr^K
'>ccr o o
rv cr xc
cr ^a
-cr
r^
cc
iro
c^
rv,cK>rv>c >e >c cr a
—* o
o cr
o c
xo
xr^'r^rvjLT
,j^cT'r^'co
r^r^ccr^',>ccrruxL
TvC
cr*--'XX
C'j^L
'r>;ru»-,r^o
cT
NC
co
xc
r\jLr'r\j---<cr «ocr ce c
—J o
nn
o>
o—
ar
- o cr
—o
^O
'Ki
oc
s^
cc
^nC
co
- cc
r^
ca
rv
i^
oK
'^
rj
&- C
OO
C^
OO
f\J
Cr/'0
00
»-'^O
OO
^^
^O
f\.*
Hf\
.CO
^C
Of\
J^
OO
'^0
0 0
00
^0
0—
H-
^
••••••••••*•*••«••«••••••••#••••••#•••••# (
• I f
O O
G O
O O
OO
O O
OO
OO
GG
OO
OO
OO
OO
OC
O O
OO
OO
O O
OO
C O
G'O
GC
CO
C O
1
1 »tiltil
I I I
I I I I I I I I I I
II—
' r
^'C
oa
rc
cx
xc
Lr
—LP
r-ro—r
^ir
co
x
co
n —
itc
mn
cc
t ^
-oc
?1 n ^
r\j——
j cr -n
x^
,>o
cir
>o
iPC
üa
G^
-oro
f^>
cc
—< r\j rv >c o c
on
cit
o' ^
i/^
njo
^jiro
c —
r^c
cr o
—g
íciro
cL
TA
íCr rv
jirrvsc
r oír
— fv o
— x
cr^
rv —
^;r\jO—
g^
t^
cn
vC
oc
oc
^-r
v—
lto rv
o *”* c
o —
«c —
«r\j o ro o
o o
—««o o
o *-«
•-* —»o
rv. rc
oo
rvj^
or\
j-, o—
cc
oo
o~
*o
o*
-««—• ■»-« ••••••• ••••
••••••••••#••%••••••••••••••••••»•
OO
OC
C O
OO
OC
OO
OO
OO
OO
OO
OO
CO
O C
OO
OC
OC
OO
OO
CC
CO
OO
OO
OO
11
I I I I
I I
I I
II I
I I
I I I I I
IIK-iXr
ccícc 3ca.itNMrN a ir rver-
x=j— rvrv — —
rv.'rr'X ojrux —
— rvjo- íí\.cí
—i "CCC JfVilT-CfV.Cr'ICl? £
£ir? r'"XXf\.i'ViC"-C" í i
ClriKl£C,l —
32-
s? p'' =3 íínn
cm
c x
•c>Girir'iT
LrK'.ir r^
^xr-- >c~~c~>C
í\jLri/'r\jir'tfv>cx j3
ük> -c^cu c
<Z O
OO
OO
OO
OO
OO
OO
OO
OC
O —
CO
OO
OO
OO
OO
OO
OC
'OO
OO
OO
OO
OO
OO
O
^ •••••••••••••••••«*•*•••••••#•••••••••••••••••
OO
OO
CO
OO
OO
OO
OO
CO
OO
OO
CO
OC
OO
CO
SC
OO
OO
OO
OO
OC
OC
OO
CC
.
rv.'Oircs.3 íí ír'it sx
occ
.í r
co'O- -3 it-Mnc-cs—ruoi^o^üas:“ír\jí-i/i-
_i o-r
ifvrv
cjc
xo —
orvrv-3
'r'LTc3
ir'XC'v0
io-r\.c'>crvf\.=3
c.o'irir.Lr'X
”cr—
r'X0'p
r'0-irciL
r —1
rs'rs
'-zr ííN
r's
rv
ff'C^
í inr
c £
3f\¡ird
trcc
£L
,'?c
c -c r^j^L
Tív ^
rv
ir x x
>c
irr^ ir. c
tr x<
C
CC
CC
CC
CO
CC
OC
CC
OC
O—
CC
CO
CC
-C
CC
OO
CO
CO
OO
C-O
CC
CO
CO
OC
*
**
**
**
**
**
**
*•
••
••
••
••
••
••
■•
■•
•*
»•
••
••
••
••
••
•O
OO
CO
OC
OC
OC
CO
CO
OC
OC
CO
CO
OO
CC
CO
OC
OC
OC
CO
OC
OC
OO
OO
C
X
ir ■osco-c
-rv,f''gi/
' •cf'- xo- o
— rvjK
cr ir -¿¿t^ x c
o —
rv. o
ír xi
-x.o
c —
ror
o ir -
oitf o
(_; lo
ir ir. ir ir 'ox-cx-r-cxvc-cxh'r'c'r^r^-r^r^p'r^r^-xxxxxxxxxxo'cj'o'o-a ero- C
'CJ'O
'OLl-

Top Related
Copyright © 2022 FDOKUMEN

