
Zipf's Law as a necessary condition for mitigating the scaling problem in rule-based agents
82
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bieedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6* x 9” black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. Bell & Howell Information and Learning 300 North Zeeb Road, Ann Arbor, Ml 48106-1346 USA 800-521-0600 Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
Transcript of Zipf's Law as a necessary condition for mitigating the scaling problem in rule-based agents

INFORMATION TO USERS
This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer.
The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bieedthrough, substandard margins, and improper
alignment can adversely affect reproduction.
In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion.
Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overlaps.
Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6* x 9” black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order.
Bell & Howell Information and Learning 300 North Zeeb Road, Ann Arbor, Ml 48106-1346 USA
800-521-0600
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

ZIPFS LAW AS A NECESSARY CONDITION FOR MITIGATING THE SCALING PROBLEM IN RULE-BASED AGENTS
by
Scott Serich
A dissertation submitted in partial fulfillment of the requirements for the degree of
Doctor of Philosophy (Business Administration)
in The University of Michigan 1999
Doctoral Committee:
Associate Professor David C. Blair, Chair Professor John Holland Professor Will Mitchell Assistant Professor Rick Riolo Professor Tom Schriber
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

UMI Number 9959857
Copyright 1999 by Serich, Scott Thomas
All rights reserved.
UMI*UMI Microform9959857
Copyright 2000 by Bell & Howell Information and Learning Company. All rights reserved. This microform edition is protected against
unauthorized copying under Title 17, United States Code.
Bell & Howell Information and Learning Company 300 North Zeeb Road
P.O. Box 1346 Ann Arbor, Ml 48106-1346
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

Scott Serich All Rights Reserved
1999
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

DEDICATION
Dedicated to Those who afforded me the privilege of embarking on this amazing journey and supported me patiently through to its end.
ii
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

ACKNOWLEDGMENTS
Special thanks go to David Blair, my dissertation advisor for his many long
months of support.
iii
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

TABLE OF CONTENTS
DEDICATION_________________________________________________________ii
ACKNOWLEDGEMENTS_____________________________________________ iii
LIST OF FIGURES_____________________________________________________v
LIST OF APPENDICES________________________________________________ vi
CHAPTER
I. OVERVIEW__________________________________________________1
II. BACKGROUND_____________________________________________ 18III. METHOD___________________________________________________28
IV. PROOF_____________________________________________________33V. CONTRIBUTIONS AND FUTURE DIRECTIONS________________ 42
APPENDICES________________________________________________________ 54
BIBLIOGRAPHY_____________________________________________________ 69
iv
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

LIST OF FIGURES
Figure
Figure 1.1 Pareto Histogram and Log-Log Transformation for Zipf s Law......................3
Figure 1.2 Zipfs Law: 5 Experiments, 3 Outcomes................................................... 4
Figure 1.3 Zipfs Law: 10 Experiments, 5 Outcomes.........................................................4
Figure 1.4 Zipfs Law: 27 Experiments, 10 Outcomes....................................................... 5
Figure 1.5 Zipfs Law: 87 Experiments, 25 Outcomes.......................................................5
Figure 1.6 The Classifier System Model.......................................................................... 13
Figure 1.7 Premature Utilization of Distant Rules............................................................15
Figure 1.8 Over-Utilization of Nearby Rules....................................................................16
Figure 1.9 Under-Utilization of Mid-Range Rules............................................................16
Figure 1.10 Over-Utilization of Mid-Range Rules............................................................17
Figure 3.1 The Classifier System Model..........................................................................29
Figure 4.1 Least-Action Histogram after Three Steps...................................................... 37
Figure 4.2 Zipfs Law after n Steps.................................................................................. 38
Figure 5.1 Necessary and Limiting Conditions................................................................43
Figure B.l The Standard Classifier System Model.......................................................... 58
Figure B.2 Homomorphisms........................................................................................... 62
Figure B.3 Q-Morphisms................................................................................................. 63
v
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

LIST OF APPENDICES
Appendix
A. The Energy Utilization Cost of Fetching Bits.............................................55
B. A Walking Tour of the Classifier System.................................................... 58
vi
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

CHAPTER I
OVERVIEW
What causes the scaling problem in information-processing agents and how can it
be mitigated?
The scaling problem arises when linear growth in some agent feature demands
faster-than-linear growth in the consumption of a scarce input.
The works of Simon, Bla:r and others have laid a foundation showing that the
input “time required of the manager” is one of the scarcest and most fundamental
resources leading to the scaling problem1.
This dissertation broadens the foundation of inquiry into scarce, fundamental
management resources. In the spirit of the work of George Zipf2, it borrows the Principle
o f Least Action from Physics and shows that the scaling problem arises inevitably from
the energy-utilization demands of a certain class of growing information-processing
agents. More formally, it shows that as particular types of information-processing agents,
those with fixed-length, fixed-position, constant-specificity rules, and under constant,
conservative external physical force, grow linearly in the number of rules they employ,
1 Simon 1981 p. 167; Blair and Maron 198S; Blair 1990; Blair 1993; Blair 1996.
2 The bulk of Zipfs work is referenced in Zipf (1949). The approach used here is consistent with Zipfs in that it seeks to explain human phenomena using a physical model. What Zipf did, however, was to conduct copious empirical research in the human domain and then develop plausibility arguments for the theoretical counterpart. The current inquiry imports the theory directly from the physical domain, converting it from a continuous to a discrete mathematical formulation.
1
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

2
their energy utilization will necessarily grow faster than linear. Thus the scaling problem
is inevitable for such any agent that is growing and subject to an energy constraint.
Physical systems mitigate energy scarcity by minimizing dissipation in converting
between different energy forms under the Principle of Least Action. When applied to the
rule-based information-processing agents modeled here, the Principle of Least Action
causes the hyperbolic Pareto histogram known as Zipfs Law.
Zipfs Law
While the main focus of this inquiry is upon the scaling problem, an interesting
by-product is the development of a deterministic model for generating Zipfs Law1. This
law2 has been shown (Zipf 1949) to arise from a wide variety of human phenomena, all
of which can be modeled as a sequence of experiments with discrete outcomes in
competition for a scarce resource. It posits that such a series of experiments will generate
a Pareto frequency histogram3 that approximates a hyperbolic function, i.e., a function of
the form f[x] = 1/x.
1 Mandelbrot (1982) developed a stochastic model for generating a corollary to Zipfs Law. Details are provided in a later chapter.
2 It is so pervasive that it is commonly referred to as Zipfs Law, though Zipf failed to ground it in a rigorous theoretical model. Hopefully the model described in this dissertation will provide the proper grounding.
3 The Pareto histogram is named after Vilfredo Pareto (1897), who showed that roughly 80% of wealth tends to be concentrated in 20% of the population (better known as the “80/20 Rule”).This work preceded Zipfs and served as an early indicator of the ubiquitous nature of Zipf s Law.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

3
A log-log transformation of a Pareto histogram was the most common visual Zipf
used to display his copious empirical findings. A diagram illustrating both hyperbolic
and log-log transformed representations appears below.Rank * frequency
constant
Event Frequency Rank
.on a log-log scale:
Figure 1.1 Pareto Histogram and Log-Log Transformation for Zipfs Law
Instances of Z ipfs Law for ideal cases are depicted below. The underlying data
have been intentionally selected to generate Zipfs Law perfectly, as is reflected in the
successively-higher fidelity of the histograms to the perfect hyperbolic function.
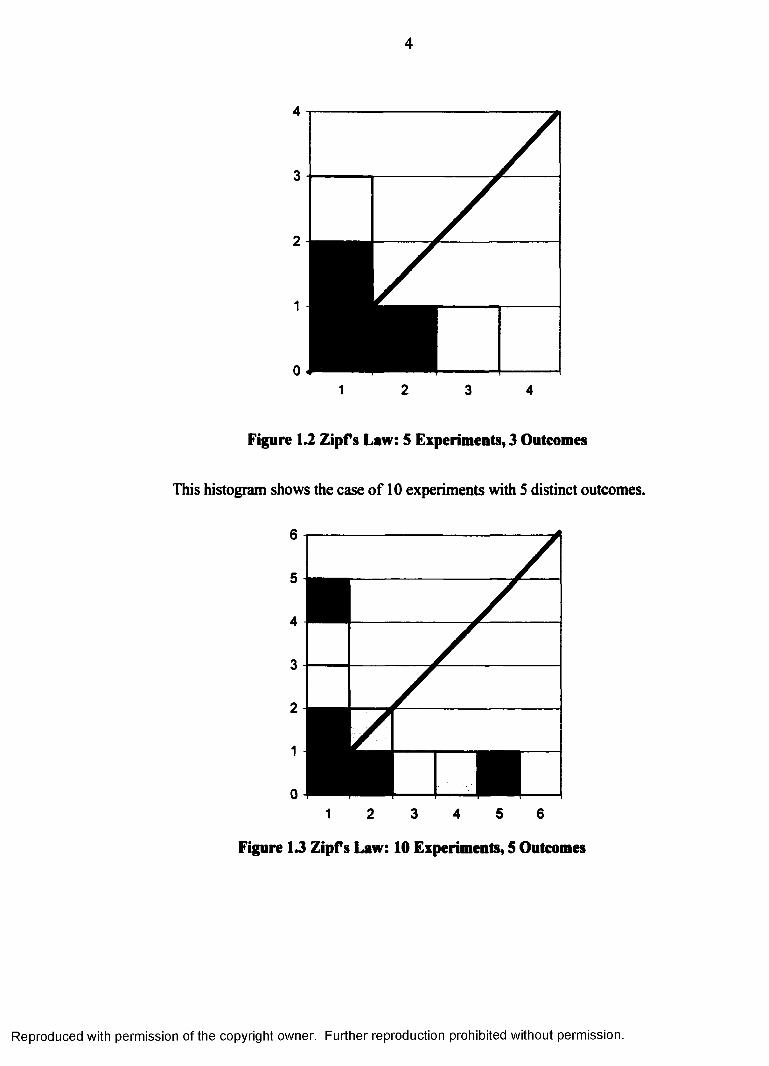
In the first case, five experiments were conducted. In three experiments, the
highest-ranking outcome occurred, and in the other two, each of the remaining two
outcomes occurred. Note that histogram is symmetrical about the 45° line, which has
been superimposed on the graph1. Note also that the third outcome could not have been
selected a second time until the second outcome has undergone its second selection2.
1 Zipf referred to this symmetry as formal-semantic balance. The current inquiry shows that such balance is consistent with the Principle of Least Action, in which the conversion of energy from one form is exactly balanced by the conversion to the second form, resulting in zero dissipation.
2 Otherwise the third outcome would have had a higher frequency, causing it to appear second in the Pareto histogram.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
4
4
3
2
1
01 2 3 4
Figure 1.2 Zipfs Law: 5 Experiments, 3 Outcomes
This histogram shows the case of 10 experiments with S distinct outcomes.
6
5
4
3
2
1
01 2 3 4 5 6
Figure 13 Zipfs Law: 10 Experiments, S Outcomes
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
5
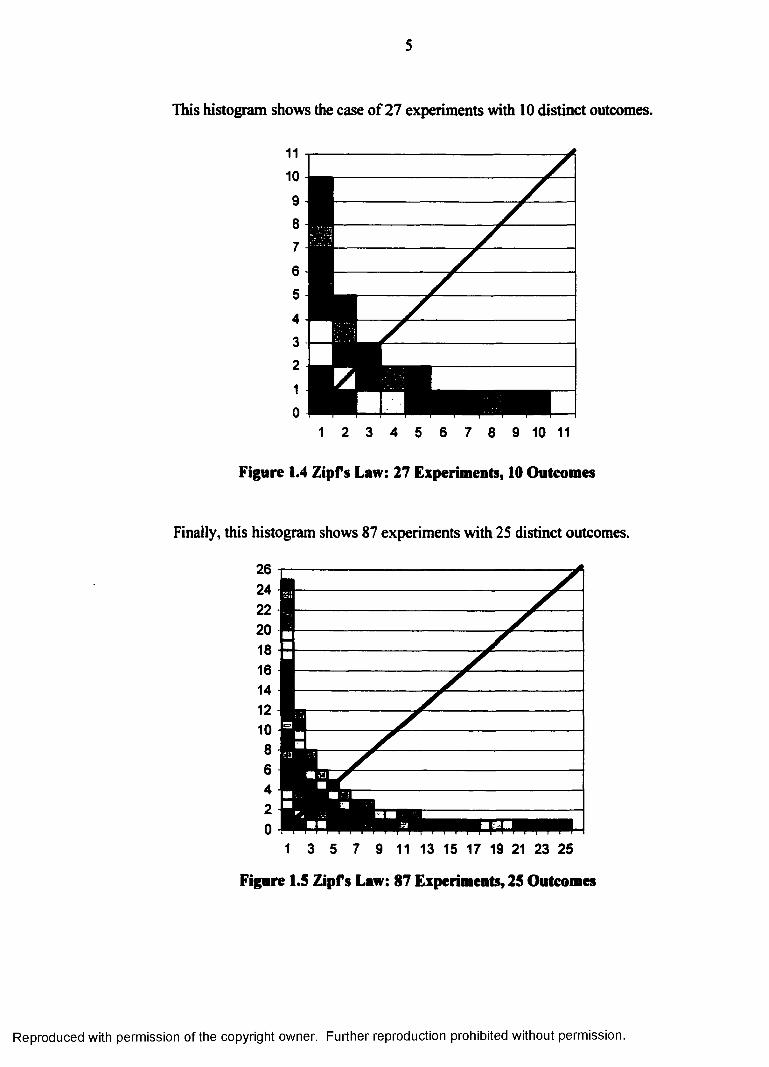
This histogram shows the case of 27 experiments with 10 distinct outcomes.
1 2 3 4 5 6 7 8 9 10 11
Figure 1.4 Zipfs Law: 27 Experiments, 10 Outcomes
Finally, this histogram shows 87 experiments with 25 distinct outcomes.
1 3 5 7 9 11 13 15 17 19 21 23 25
Figure 1.5 Zipfs Law: 87 Experiments, 25 Outcomes
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

6
The Principle of Least Action
Zipfs explanation for these results was that the Principle ofLeast Effort governs
human phenomena in much the same way that the Principle of Least Action governs
physical phenomena. Under these principles, energy-converting systems minimize
dissipation during conversion.
The Principle of Least Action is one of the most pervasive principles in Physics,
capable of explaining phenomena as diverse as classical Newtonian Mechanics and
modem Quantum Electrodynamics.
A necessary condition for the principle to hold is that the first-order change in the
magnitude of the action, the time integral of the total energy across the entire path1, is
zero, i.e., showing the least change, under small changes in the path2. Thus this integral
is sometimes referred to as a path integral3.
Switching to mathematical notation, the least action principle will cause the
system to follow a path such that the following integral will remain constant under small
changes in the path (note that the path is a function of time, the variable of integration):-T
Action = J [Kinetic Energy(t) - Potential Energy(t)]*dt.
1 A path is just another name for the behavior of the system at all points along the way between its initial and final states. At any particular point in time a system is said to be in a particular state, such as particle positions and momenta for mechanical systems, or rule composition, frequency and location for rule-based information-processing agents. More formally, a path is any sequence of allowable states.
2 For differentiable functions of a variable, this is simply another way of saying that the first derivative of the function is zero. Since we’re dealing with an entire path here (sometimes called a functional), not just a simple function, we can’t use differentiation. Instead we must revert back to first principles and build up from there.
3 Another name, which has fallen out of use is Hamilton’s first principalJunction. Another name for the integrand of this integral is the Lagrangian.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

7
Note that the change in action must not only be zero for the designated path, it
must also be zero for every sub-path along the way. Otherwise the initial path for which
the action was not minimal could be appended to the least-action path from that point
forward, leading to an overall least-action path that incurs a higher cost than the assumed
minimum value1.
The following example illustrates how the Principle of Least Action can be used
to derive Newton’s Second Law of motion and the First Law of Thermodynamics.
The Principle of Least Action in Mechanics
Consider a mechanical system consisting of the earth, taken to be the fixed frame
of reference, and a point mass near the earth’s surface and free to move in 1 dimension.
In moving between any 2 points in 1-dimensional space, energy is converted between
potential and kinetic forms, and thus the point mass must follow a path that minimizes
dissipation and action. In other words, the following integral must remain constant under
small changes in the path:T T
Action = J [Kinetic Energy(t) - Potential Energy(t)]*dt= J (Jmv2-V)*dt.
where height h is a function of time, v = dh/dt represents velocity, the time rate of change
of height h, V represents potential energy as a function of height h, m represents mass,
and T represents the time interval over which the definite integral is evaluated.
What path must the particle follow?
1 Put another way, the system’s state data contains no record of the path it took to reach that state.So any sub-path between two points that deviates from the least action path between those same two points has necessarily dissipated energy that can’t be recovered. For mechanical systems, the primitives are the positions and momenta of the particles comprising the system. For a rule-based information-processing agent, the primitives include rule composition, length, location and frequency.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

8
Let h'(t) represent the optimal path as a function of time and A(t) any small
variation1 from the optimal path2. Under the least-action principle, any small variation in
the path must result in zero variation in the action. Otherwise, the original path would
not have been optimal: if the action variation were negative, the variational path would be
better than the assumed optimum, and if the action variation were positive, a move in the
opposite direction of the variational path would be better than the assumed optimum.3
This variational path that the particle follows can be represented by h(t) = lT(t) +
A(t). Substituting this in the action integral and taking advantage of the fact that
differentiation is a linear operator yields
J T(W -V [h ])* d t = J T(im[dh7dt + dA/dt]2 - V[h'+A])*dt
Multiplying out the left term in the integrand, we get
kn[dh7dt + dA/dt]2= 5m[dh7dt]2 + Jm[2*dh7dt*dA/dt] + im[dA/dt]2.
The first term in the expansion is the kinetic energy on the optimal path. The
cross product term in the middle will be retained. The third term is second-order in the
small variation A, and can thus be dropped from further consideration.
For the right term in the integrand, we must use a Taylor series expansion:
V[h+A] = V[h'] + A*dV[h']/dh + *A2*d2V[h']/dh2 + {higher-order terms}
1 Another name for this method is the “Calculus of Variations”.
2 Note that A(t) will be zero at both the beginning and the end of the path. Also note that A(t) can be any small function, where a “small” function is one for which the higher-order terms for it and its derivatives converge to zero more rapidly than the lower order terms.
3 A degenerate version of this principle is that a necessary condition to obtain an optimal value of a continuous function on a closed interval is that the first derivative of that function be equal to zero at the optimum point. In the case of path integrals, the “variable” over which the optimum is being sought is itself a function, and the “function” being optimized is called a functional.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

9
The first term in the expansion is the potential energy on the optimal path. The
second term is first-order in A and will be retained. All subsequent terms are second-
order or higher in A and can be dropped from further consideration1.
Dropping all terms of 2nd-order or higher and designating optimal path kinetic and
potential energy, respectively, as KE' and PE', the action integral becomes:
J T(K E '- PE' + m*dh'/dt*dA/dt - A*dV[h']/dh)*dt
= Action' + J T(m*dh 7dt*dA/dt - A*dV[h']/dh)*dt
Thus the variational action, or the difference between the action on the variational path
and the optimal path is:
Action - Action' = J (m*dh'/dt*dA/dt - A*dV[h']/dh)*dt
It is this quantity that must be zero in order to ensure that h'(t) does, in fact, represent the
least-action, dissipation-minimizing path.
The rule of integration by parts from the Calculus tells us that the derivative of a
product is equal to the first product term times the derivative of the second plus the
derivative of the first product term times the second. Performing some simple algebra, an
alternative statement of this rule is that the first product term times the derivative of the
second is equal to derivative of the product minus the derivative of the first product term
times the second. In symbols, and applying the rule to the left-hand side of the action
variation integral above:
d/dt([m*dh 7dt] * A) = m*dh'/dt*dA/dt + [m*d2h'/dt2]*A
1 A more rigorous derivation would actually carry the higher-order terms through the entire calculation until it was confirmed that the lower-order terms didn’t cancel each other out. This formality was avoided in favor of creating a more readable proof. As the reader will see later, the first-order terms do not cancel out, and so the decision not to carry the higher-order terms will beborne out.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

10
or, performing some algebra,
m*dh'/dt*dA/dt = d/dt([m*dh7dt]*A) - [m*d2h7dt2]*A.
Plugging the result into the integral yields
Action - Actionr =
/ {d/dt([m*dh7dt]*A)-[m*d2h7dt2]*A-A*dV[h']/dh}*dt =
J Td/dt(m*dh7dt*A)*dt - J T(m*d2h7dt2*A + A*dV[h']/dh)*dt
m*dh7dt*A | J T(m*d2h7dt2*A + A*dV[h']/dh)*dt
where the Fundamental Theorem of Calculus was used in the last step.
The two endpoints of the path are fixed, so the path variation A(t) must identically
be zero at either end. Thus the first of the three terms in the action variation above
disappears to zero. This leaves the variational action equal to
Action-Actionr =
- J T(m*d2h7dt2*A + A*dV[h']/dh)*dt
- J TA(t)*(m*d2h7dt2 + dV[h']/dh)*dt
As discussed above, this quantity must necessarily be equal to zero in order for
the assumed optimal path to actually be an optimum. Also, since A(t) can be any small
function, the variational action must be zero no matter what function is chosen for A(t).
The only way to guarantee this outcome is to force the sum within parentheses to
identically be zero at all times within the interval T. In symbols,
- m*d2h7dt2 - dV[h']/dh = 0, or
dV[h']/dh=-m *d2h7dt2.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

11
In other words, force, the rate of change of energy with distance, equals mass
times acceleration. This is just the constant-mass form of Newton’s Second Law, more
typically written “F=ma”.
Assuming force F and mass m are constant, acceleration is also constant.
Velocity v, the time integral of acceleration, is a linear function of time, and thus kinetic
energy Imv2 is a 2nd-order function of time. Position h, the time integral of velocity, is
also a 2nd-order function of time, and thus so too is potential energy V(h).
Thus kinetic and potential energy both go as the square of time, and their sum is
constant over the entire time interval. This is the First Law of Thermodynamics,
otherwise known as the Principle of Conservation of Energy.
From the Principle of Least Action to the Principle of Least Effort
What we take away from the proof above is that if we can describe a system’s
total energy as a continuously-differentiable function over time, we can use the action
integral and integration by parts to derive equations representing necessary conditions for
the system’s behavior1.
The obstacle Zipf faced in trying to import the Principle of Least Action into
human domains was that his empirical studies involved the counting of discrete
outcomes. For example, Zipf (1949) showed how words competing for space in
documents yielded a hyperbolic Pareto histogram of word occurrences for the following
instances:
• James Joyce’s Uiysses
1 Note that this is not guaranteed to be an easy task. This approach did, however, help RichardFeynman earn a Nobel Prize in 1965.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

12
• Four Latin plays of Plautus
• The Iliad (in Greek)
• Beowulf (in Old English)
• Combined samples from American newspapers (drawn from Eldridge 1911)
• Native American Nootka (drawn from Sapir 1939).
The hyperbolic Pareto histogram was found by Zipfs contemporaries in Sociology,
where cities compete for population and the nations containing those cities try to balance
the efficiencies of co-location against knowledge gained from having citizens located at
the nation’s frontiers. It was also found in Economics, where producers compete for
income and the economy tries to balance the efficiencies of repetitive activity against the
knowledge gained from experimenting with new endeavors.
The ubiquitous nature of the hyperbolic Pareto histogram in Zipfs empirical work
led to the convention of referring to the associated phenomenon as Zipfs Law.
In each of these cases, the population being sampled, whether composed of
words, people or dollars, can be modeled as a pool of energy seeking to find a sequence
of outcomes, or path, that allows the most efficient conversion of its energy. Given a
method by which to characterize energy conversion on these paths, we could import the
least-action principle and determine the “equations of motion” for these types of systems
also.
What Zipf needed was a way to find the least-action path without having to use
the continuous mathematics used previously.
This dissertation inquiry provides that method, putting Zipfs Principle of Least
Effort on a rigorous, formal foundation grounded in discrete mathematics. It places the
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

13
sampling experiment on a host information-processing model called a classifier system1.
Before we can answer questions about energy-conversion characteristics on alternative
paths, we need to develop a model of space, mass, force and energy corresponding to like
notions in the physical model. The classifier system’s rule table will provide that
foundation, with details described later.
Figure 1.6 The Classifier System Model
The diagram above2 illustrates the major features of a classifier system. In brief, a
classifier system is a computer program that interacts with its environment and receives a
payoff based on the sequence of messages it chooses to send. Many of the functions of
the standard classifier system have been disabled for this dissertation, however, in order
to conduct the proof. For example, the system’s rule table is pre-loaded with rules
comprised of a series of 0’s followed by a series of I ’s and ordered by increasing number
of ul” bits. The message board is not used, and the environment is ignored. The Genetic
1 Holland (1986b), Holland et al. (1989)
2 Adapted from Holland et al. (1989).
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

14
Algorithm, typically a classifier system’s most prominent feature, must actually be turned
off in order for the proof to work.1
Using the simplified classifier system as the model of an information-processing
agent, the proof serves to provide a rigorous theoretical counterpart to Zipfs empirical
work. It shows that when particular types of information-processing agents follow a
local strategy to minimize the product of rank and frequency of the rule it chooses at any
point along the path, both the Principle of Least Action and Zipfs Law emerge as global
outcomes.
This finding is the major contribution of the dissertation. A side benefit is that
any future research in which an organization is modeled as an information-processing
agent will now have at least one formal means by which constrained energy utilization
can be analyzed and assessed. What remains, however, is to determine what these
findings have to say about the original research question regarding what causes the
scaling problem and how it can be mitigated.
The cause of the scaling problem is that energy utilization grows faster than
linear as the agent’s rule table grows linearly.
To mitigate the scaling problem, what energy-converting systems do is minimize
dissipation during the conversion process, and this is accomplished by following a least-
action path. In rule-based information-processing systems, this strategy causes Zipfs
Law to emerge. Thus any strategy that violates Zipfs Law will necessarily be
aggravating the scaling problem by dissipating energy at some point in its path and
incurring an unrecoverable loss of the opportunity to utilize that energy.
1 Clearly, a fruitful path for future research in this area will be to determine how the re-enabling of various classifier system features impact the system’s ability to preserve the least-action principle.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
15
Different Ways that Zipfs Law Can Be Violated
To round out and provide a visual representation of this inquiry, four different
ways of violating Zipfs Law are depicted below. The four violations are:
1. Premature utilization of distant rules;
2. Over-utilization of nearby rules;
3. Under-utilization of mid-range rules; and
4. Over-utilization of mid-range rules.
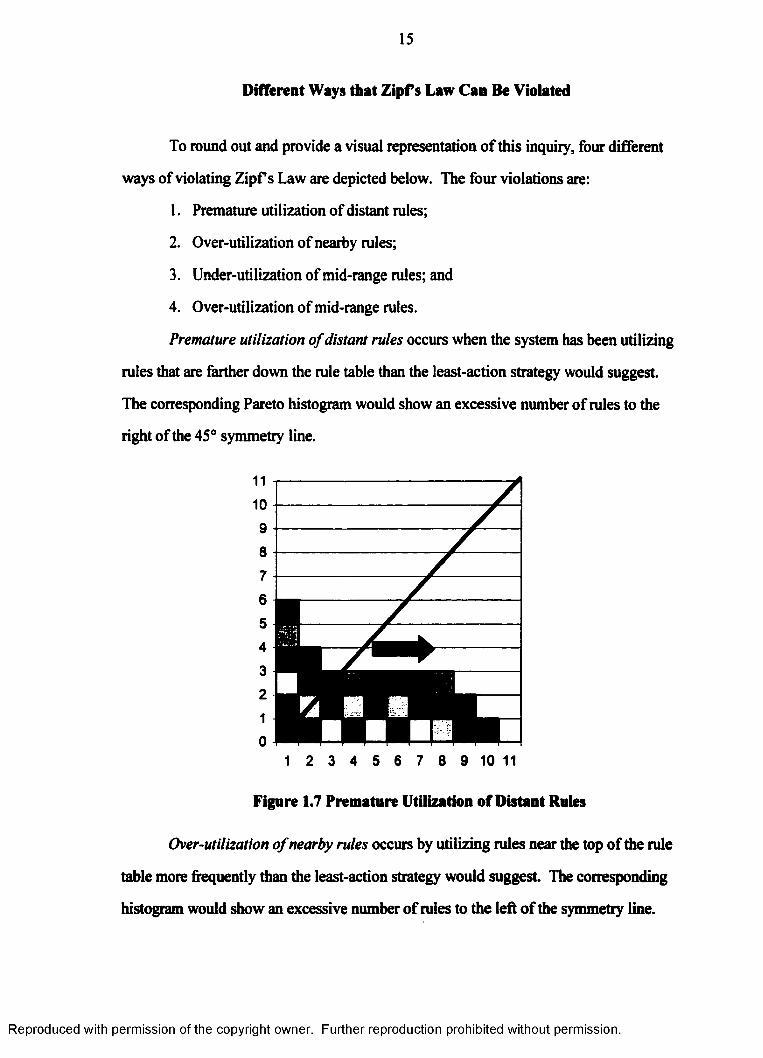
Premature utilization o f distant rules occurs when the system has been utilizing
rules that are farther down the rule table than the least-action strategy would suggest.
The corresponding Pareto histogram would show an excessive number of rules to the
right of the 45° symmetry line.
1 2 3 4 5 6 7 8 9 10 11
Figure 1.7 Premature Utilization of Distant Rules
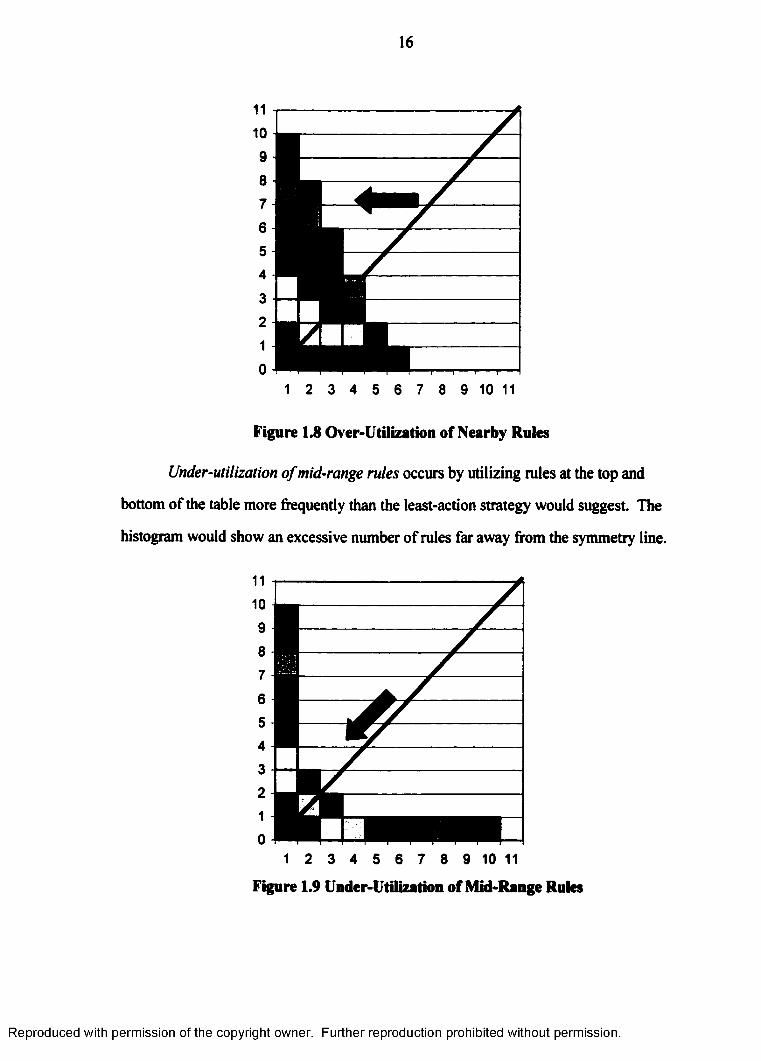
Over-utilization o f nearby rules occurs by utilizing rules near the top of the rule
table more frequently than the least-action strategy would suggest The corresponding
histogram would show an excessive number of rules to the left of the symmetry line.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
16
1 2 3 4 5 6 7 8 9 10 11
Figure 1.8 Over-Utilization of Nearby Rules
Under-utilization o f mid-range rules occurs by utilizing rules at the top and
bottom of the table more frequently than the least-action strategy would suggest. The
histogram would show an excessive number of rules far away from the symmetry line.
1 2 3 4 5 6 7 8 9 10 11
Figure 1.9 Under-Utilization of Mid-Range Rules
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

17
Finally, over-utilization o f mid-range rules occurs by utilizing rules in the middle
of the table more frequently than the least-action strategy would suggest. The histogram
would show an excessive number of rules near the symmetry line.
11
10 9 8 7 6 5 4
3 2 1
01 2 3 4 5 6 7 8 9 10 11
Figure 1.10 Over-Utilization of Mid-Range Rules
Zipf (1949) provides an extensive discussion of the potential sources of these
pathologies. For purposes of the dissertation inquiry, we only need note that they all
represent violations of the least-action strategy.
Remaining sections of this dissertation provide motivation for the research
question itself and flesh out details of both the model and the proof.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

CHAPTER II
BACKGROUND
What causes the scaling problem in information-processing agents and how can it
be mitigated?
This research question was inspired by a combination of observations and
recommendations from David Blair’s book (Blair 1990) assessing the STAIRS study in
Information Retrieval (IR). The STAIRS system retrieved documents by having a
searcher guess the exact words and phrases that would occur in the desired documents but
would not occur in the documents not desired1.
The study performed an evaluation of how well a large-scale, operational
document retrieval system could retrieve documents described by a set of searchers. The
system being used to store and retrieve documents was the IBM STAIRS software
program2.
The managers participating in the study were actually attorneys defending a
$237,000,000 lawsuit on behalf of a corporate client. The suit’s magnitude alone
qualified it as meriting the attention of any manager or corporate attorney who might
someday face such an unpleasant prospect.
Blair’s (1990) book provided a deeper discussion of the evaluation methods used
in the STAIRS study.
1 See Blair and Maron 1985 or Blair 1996 for a description of the study itself.
2 The STAIRS acronym was formed from STorage And /nformation Retrieval System.
18
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

19
Even more importantly, it detailed the unexpectedly poor IR system performance
witnessed in the study and explained why such performance shouldn’t have come as such
a surprise. Performance in this case referred to what percentage o f relevant documents
the attorneys estimated they were retrieving in response to specific requests, on average,
as compared to the actual percentage contained in the system’s collection.
Blair’s argument could be summarized as follows: the process of placing
documents into STAIRS removed them too far from their context, both of creation and of
anticipated usage, to be effectively retrieved without re-establishing some portion of that
context.1
In other words, as document descriptions were entered into STAIRS, content
information remained intact, while context information suffered a significant attrition.
Since search requests were formed from user expectations about the meanings of terms
within their dialect, and these meanings were dependent upon the context in which the
terms were embedded, the loss of context information decreased the efficacy of STAIRS
in delivering language-indexed documents.
For example, the term “program” to a lawmaker might refer to a legislative item
for which funding has been approved. The same term to a computer scientist, however,
1 Blair made three specific recommendations intended to help alleviate the problems seen in the STAIRS study (Blair 1990 p.l78). First, we should create “leamable” retrieval systems; i.e., systems providing informative feedback about document descriptions and failed searches so users could learn which term combinations were likely to fetch which document sets. Second, we need to contextualize subject description; i.e., include information about the activities that produce and use documents. And third, we should encourage communication between inquirers and indexers, using the Zipf distribution to indicate the effectiveness of this communication; i.e., try to induce a particular distribution of keywords (used in both searching and indexing) reflecting Zipf s Law.In other words, the degree of fit between Zipf s Law and index term usage may be a general measure of IR system effectiveness. Blair (1990 Chapter S) extended this third recommendation to suggest the Genetic Algorithm as a mechanism for efficiently modifying keyword assignments in trying to attain the hyperbolic distribution underlying Zipf s Law. Looking from this perspective, this dissertation provides a variation on Blair’s third recommendation by suggesting an information-processing model of organizations with (the negative value of) energy dissipation as the payoff function.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

20
might refer to a software item. Widely-divergent expectations would accompany the use
of this term in queries by the two different user communities.
Subsequent research (Blair 1993, Blair 1988 Appendix C) showed that the
detrimental effect of the content-context imbalance tends worsen as the document
collection grows.
The Scaling Problem
This general worsening of system performance as information quantity grows has
been labeled the scaling problem. As defined earlier, the scaling problem arises when
linear growth in some agent feature demands faster-than-linear growth in the
consumption of a scarce input.
Treatment of the scaling problem arose in the original STAIRS paper under the
label “output overload”, which can be described as follows. Suppose that a particular IR
search query results in a set of document abstracts, 10% of which are relevant and 90%
irrelevant. In a system containing 100 items, the worst possible case would be that a
searcher would have to look through 90 irrelevant abstracts to fetch all the relevant ones.
If, instead, the system were to contain 10,000 items, the searcher would have to search
through 9,000 abstracts to retrieve the 1,000 relevant ones. Such a search would typically
be abandoned well before all the relevant documents had been retrieved.
Blair1 expanded upon this problem in borrowing C. S. Peirce’s notion of unlimited
semiosis. This is the notion that there are an enormous number of possible combinations
for describing any particular item of information. Bar-Hillel (1964) noted the problem in
mathematical descriptions. For example, the single number “4” can be described as
“2+2”, “10-6”, “the successor to 3”, “the square o f-2”, etc. The same kind of synonymy
1 See Blair (1990) pp. 136-137.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

21
exists in document representation: "records management" may be functionally equivalent
to "record mgmt", "file management", "management of records", "management, records"
and so forth. The problem of unlimited semiosis greatly reduces the probability that the
particular combination of terms a searcher uses to request an item will match the
combination used to index the item.
The problem was revisited (Blair 1993) under the rubric of the “revenge effect of
information technology”. Ironically, the problem in this case is caused by ongoing
advances in computer hardware technology. Increased storage capacity enables larger
collections of de-contextualized information to efficiently be kept in a single location.
Unfortunately, these advances only serve to aggravate the problems of output overload
and unlimited semiosis. The hardware cost of storing information is dropping much
faster than the corresponding human cost of deciding which information to retain and
which to discard (Blair 1984a, 1984b, 1998). As a result, document collections will tend
to grow with no apparent upper bound in sight.
Some of Blair’s later work (Blair 199S) re-examines the problem in comparing
the difference between data and document models of information1.
Under the data model, once a small prototype system has been validated, we can
be fairly confident that it will function just about as well on a much larger database.
Document systems, on the other hand, may encounter output overload or increasing
ambiguity of search terms as the collection size grows. Thus the battle is not won for
such systems just because they’ve survived a test on a scale-level prototype. All
resources, including those of the users, must scale up in unison for the system to be
functional.
1 This is an extension of Blair (1984a).
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

22
Blair is not the only scholar to have recognized the revenge-effect variant of the
scaling problem. Simon posed it as a central problem for all of Management Information
Systems (Simon 1981 p.167):
“The first generation of management information systems installed in large American companies were largely judged to have failed because their designers aimed at providing more information to managers, instead of protecting managers from irrelevant distractions of their attention”.
In other words, as hardware research has marched ahead to provide cheaper, faster, more
capacious devices and ubiquitous, networked sources of data, MIS research has failed to
keep pace in helping managers deal with the concurrent growing glut of information.
Simon's Response to the Scaling Problem
Simon introduced the notion of satisficing to characterize how managers make
decisions in the face of their fundamental cognitive limitations. Satisficing purports that,
in gathering information and searching for solutions, managers reduce their aspiration
levels over time. Eventually, as available information increases and aspiration level
decreases, the two levels match and a decision is made.
Note how this scenario differs from the classical Management Science model.
Under the latter model, the decision maker gathers enough information to find an optimal
solution, whether via an algorithm such as the Simplex Method or by identifying enough
similarities between current and past decisions to simply re-utilize the past decisions.
The shortcoming of the classical decision model is that managers often lack
sufficient information to implement either of these strategies.
Simon went on to propose that the mechanism managers use to implement
satisficing is to maintain a set of heuristics, or rules, by which a limited set o f input
information can be converted into an output plan of action.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

23
The works of Simon and his colleagues1 in discovering and encoding such rules in
computer-based simulation models helped further the field of artificial intelligence', more
particularly in MIS, they contributed to the domain typically labeled expert systems.
Rationale for the Simplified Classifier System Model
After many years of advance in artificial intelligence, a particularly stubborn
bottleneck arose. While expert systems worked well in the narrow domains for which
they were designed, they required substantial human intervention when ported into other
domains2. In other words, they were having trouble learning.
The source of the problem was that if any pair of propositions in the system’s
database happened to contradict each other, the entire system could be rendered useless.
When such a system is presented with a new domain, many of the facts in its database are
no longer true. What it needed was a mechanism to gracefully adjudicate between the old
facts and the new.
Holland (1986a) called this hurdle to learning brittleness and addressed it by
proposing a new model called a classifier system. As with the expert system, it consists
of a table of rules which creates and responds to message-encoded stimuli. The advance
over expert systems is that classifier system rules are considered hypotheses rather than
facts. Each hypothesis can possess any of a range of values representing the strength of
the system’s belief in the truth of that hypothesis. Thus two contradictory rules can co
exist without destroying the behavior of the entire system.
1 This community is sometimes referred to as the “Carnegie School’ of Organization Theory and includes scholars such as Cyert, March and Williamson.
2 See Dreyfus & Dreyfus (1986) for a more general discussion of the limitations of computers as intelligent agents.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

24
With the introduction of classifier systems, the focus of attention switched from
entire rules to subsets of rules called schemata. These are building blocks, akin to genes
in DNA, which a system can re-use not only across multiple situations but also across
multiple rules. The approach to propagate these schemata into the system's future
generations is called the Genetic Algorithm or GA (Holland 1992). It allows systems
developed in one domain to better adapt to novel new domains.
The original intent of this dissertation was to model the emergence of Zipf s Law
on a classifier system substrate, including the GA to enable adaptation and rule strengths
to enable testing of hypotheses with graduated confidence levels.
In order to make the dissertation proof tractable, however, some classifier system
features had to be disabled. What remained was a simplified model that is well-
positioned to address the brittleness problem in the future.
Rationale for the Classifier System Environment
One rationale for leaving the model embedded in a classifier system is that it
provides a fertile and readily-accessible path by which future research in this area can
proceed. For example, the energy utilization calculations would enable us to introduce
the rule-strength feature back into the model and compare how costly it would be for an
agent to attack the brittleness problem in this fashion.
Note that the most important contribution of this dissertation is not to show how a
classifier system model can be applied in a new domain. Rather, it is to introduce a new
performance measure that systems can adopt when they first move into a new domain or
market niche and have little information about their new operating environment.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

25
Another rationale for retaining the classifier system model is that it represents a
much more intuitive information-processing model than the standard finite state
machine1.
Another of the original intentions of this dissertation was to model how a rule-
based system could survive being put at a severe disadvantage in a game of strategy
against its operating environment.
In the case of Simon’s satisficing managers, the disadvantage they faced was that
they were only boundedly-rational: they couldn’t afford the search time required to make
an optimal decision. Instead they used satisficing strategies such as heuristics.
The same disadvantage faced Blair’s information retrieval system user: they
lacked sufficient time to overcome the output overload that characterized results of their
queries.
In the case of Holland’s classifier system, the disadvantage was that the system
had to be able to handle a variety of operating environments, even those it had never seen
before2.
The original intent of this dissertation was to place the agent at an even more
severe disadvantage requiring it to face a hostile, omniscient, unrevealing, perpetually
novel environment.
An omniscient, unrevealing environment would have visibility into the agent’s
rule table (i.e., omniscient), but not vice-versa (i.e., unrevealing). A perpetually novel or
non-stationary environment would be one whose data-generating characteristics change
over time, so that the agent could never really draw a complete, lasting beat to help it
1 Forrest 1985 showed that a classifier system is sufficient to implement a finite-state machine, so the decision is a sound one in that respect.
2 An environment can, however, reveal some useful regularities or exploitable biases (Holland 1990) in its payoff function, allowing differentiation between better and worse schemata.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

26
predict the environment’s future behavior. Adaptation would have to continue
indefinitely, lest the agent be destroyed. A hostile environment would be one that sought
to force the agent to waste, through dissipation, as much energy as possible.1
After further consideration, the need for setting up such a complex environment
was obviated by assuming that the agent would just ignore such intricacies in its early
growth stages. Instead it focuses all attention on minimizing energy dissipation by
implementing the least-action principle. This information is embedded entirely in
knowledge of the path the agent has chosen to follow, the allowable future paths, and the
projected energy utilization associated with each of those paths. In some sense, the
agent’s environment is assumed to be so harsh that the agent will focus simply on
minimizing energy waste until it is more capable of dealing with its environment in an
advantageous fashion.
How to Make the Scaling Problem Worse
A very simple strategy that might merit consideration would be to have the agent
simply ingest as much information as possible. The agent would simply grow its rule
table as rapidly as its operating system would allow. The model assumes that rules
cannot be destroyed, so this strategy would be akin to simply accumulating as much
information as possible.
1 The very idea that an agent would stand the slightest chance of surviving in such a harsh environment might seem far-fetched. Current dogma in management circles, however, appears to be that business environments are changing so rapidly that managers cant keep up with them. Fuzzy, fluid market boundaries, constantly-advancing technologies, unpredictable consumer preferences, ambiguous government regulations and tax laws, and localized intellectual property norms in a global economy serve to defy any notion that the organization’s environment is any less daunting.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

27
The appeal of this information gluttony strategy is that if information has value in
the same fashion that physical economic assets such as commodities or manufactured
goods have value, then the more you have the better.
What this dissertation shows, however, is that an information gluttony strategy is
actually detrimental. It causes the agent to convert energy at much-too-rapid a rate,
leading to excessive dissipation and actually aggravating the scaling problem.
Before proving these claims, details of model and method will be provided.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

CHAPTER m
METHOD
What causes the scaling problem in information-processing agents and how can it
be mitigated? Recall that the scaling problem arises when linear growth in some agent
feature demands faster-than-linear growth in the consumption of a scarce input.
In answering these questions, this dissertation borrows the Principle of Least
Action from Physics and the classifier system from the work of John Holland. It shows
that the scaling problem arises inevitably from the energy-utilization demands of a
growing classifier system and is made more severe by any strategy from which a
hyperbolic Pareto histogram (Zipf s Law) fails to emerge in characterizing its rule
utilization.
Beth referent models, the Principle of Least Action and the classifier system, were
described in detail in a previous section1.
We noted earlier that under the Principle of Least Action, energy-converting
systems can minimize dissipation during conversion by following a path for which first-
order change in the magnitude of their action is minimized. Thus the model developed
here must contain a characterization o f energy. Or to be more precise, since we’re
searching for an optimal strategy, we need a characterization of energy sufficient to show
that any strategy other than the hypothesized optimum will induce a sub-optimal
dissipation rate.
1 See Appendix B for further elaboration on classifier systems.
28
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

29
We also noted earlier that the classifier system provides a discrete model into
which the continuous mathematics of the Principle of Least Action could be transformed
(a diagram is included below to help focus the discussion).
f c grr-.-r—Lem. MU' : tx c a r h r .- r
iwmm
Figure 3.1 The Classifier System Model
Each rule in the classifier system’s rule table can be characterized as a potential
outcome of an experiment in which the rules are competing for the opportunity to be
selected. The sequence of realized outcomes specifies a path over which energy is
utilized and variances are determined.
The Physics of Classifier System Rule Fetches
What corresponds to distance in the Principle of Least Action is the amount of
specificity that intervenes between rules in the table. It is assumed that access to the
topmost rule requires a distance equal to that rule’s specificity. Access to the second rule
requires a distance equal to the sum of the specificities of the first two rules. And so
forth, until the final rule in the table, whose access would occur at a distance equal to the
sum of the specificities of all rules.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

30
In the current model, the position of each rule in the table will be fixed, so that the
number of intervening rules between it and the top of the table will remain constant
throughout the analysis. The size and specificity of each rule will also remain fixed, as
will the ordering of the rules from most-frequently used at the top to least frequent at the
bottom.
What corresponds to mass in the Principle of Least Action is the amount of
specificity in the rule itself. The mass of each rule will be fixed to be equal to the rule
length1. Thus when calculating energy conversion differentials along different paths, the
masses of the particular rules being selected will have no bearing on the result since these
masses will all identical.
What corresponds to the conservative force under the Principle of Least Action is
represented by a constant value over the entire duration of the analysis2.
The amount of energy converted during one rule fetch is equal to force times
distance. Since force and mass are both constant, this energy will be proportional to the
distance the system must travel to fetch the rule. Since all rules are the same size, a
particular rule’s fetch distance will be proportional to its location or rank in the table.
These constraints on rule physics can and should be relaxed in future research
inquiries to find a more parsimonious theory. But they must remain fixed for now in
order to maintain the integrity of the proof.
1 In other words, there are no “don’t care” (#) symbols in any of the rales See Holland (1986b) or Holland (1992) for a discussion of don’t care symbols which, if present, would make no contribution to either rale specificity or intervening space.
2 Using the analogy to mechanics, since both force and mass are constant, force equals mass times acceleration, the system’s acceleration would also be constant Zipf (1949 pp. 59-60) uses the metaphor of a “demon” who is tasked with fetching bells spread out over a onedimensional storage container. Carrying the analogy one step further, his demon would be the rule-fetching body undergoing the constant acceleration.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

31
The rules are pre-arranged in the table in frequency order, from highest to lowest.
To assist in the discussion, the bits in each rule will be used to distinguish the rules in the
following fashion. Let L represent the length of each rule. The first rule will consist of
L-l zeros followed by a single one, represented symbolically as “000...0001”; the second
rule will consist of L-2 zeros followed by two ones, or “000. ..0011”; and so on to the last
rule in the table, which is all ones “111...1111”1.
Unlike the typical classifier system implementation, the bit values in these rules
could be pre-assigned in any arbitrary manner as long as their specificities remain
constant. Recall that the system is ignoring inputs from its environment2, and its payoff
function is strictly determined by the energy dissipation rate along its rule-fetching path.
What has been chosen here is to simply code the number of ones in each rule equal to that
rule’s fixed position in the table, which itself is the lone factor that differentiates the
amount of energy required to fetch that rule.
Game Tree Breadth
Note that even with the all constraints in place to simplify the classifier system
and enable a more tractable proof, there are still an enormous number of paths that the
system could choose in firing its rules. Suppose we refer to the sequence of experiments
during which the system chooses its path as a game. Then there are still many degrees of
freedom in path selection. In fact, at any point in time during the game the system will
always have at least two choices: to select the most frequent rule or to select the next new
rule in the sequence. So if n represents the number of experiments in the sequence since
1 As mentioned earlier, the GA has been disabled and the content of each rule is fixed.
2 It is also ignoring message from its own internal message board. We are assuming that no energy is utilized in posting messages, either to the environment or to the message board.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

32
the start of the game, there are a minimum of 2" different paths through the game tree1.
The breadth of the game tree grows at least exponentially with depth into the game.
The foundation has now been laid to conduct the formal proof, which is presented
in the following chapter.
1 And unless the system chooses a degenerate strategy such as always firing the most-frequent rule or always selecting a brand-new rule, the actual number of possible paths will be potentially much greater than 2".
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

CHAPTER IV
PROOF
What causes the scaling problem in information-processing agents and how can it
be mitigated? The scaling problem arises when linear growth in some agent feature
demands faster-than-linear growth in the consumption of a scarce input
The goal now is to implement the Principle of Least Action by finding a local rule
selection strategy that minimizes energy dissipation and action, and to prove that this
strategy causes Zipf s Law.
In order to do this, we must first answer the question of how much energy it takes
for the agent to fetch a rule.
Calculating Energy Utilization
Physics gives us the answer that energy is equal to the integral of the force over
the distance traveled; in symbols:.distance
Energy = J F(distance)*d(distance)
Since we’re dealing with the discrete case, we can translate this into:
Energy = Enforce at step i in the path]*[distance traveled to perform i111 rule fetch]
where the summation is performed over all outcomes in the path. Since force is assumed
to be constant, we get:
Energy = [constant force] * £i[distance traveled to perform i* rule fetch]
Gathering together all fetches of the same rule, we can re-write this as:
Energy = [constant force] * Sruies[frequency * distance],
where this summation is performed over all rules rather than all outcomes.
33
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

34
In other words, the amount of converted energy is proportional to the sum over all
rules of the product of utilization frequency and distance.
As discussed earlier, each rule is assumed to be of fixed length, and the distance
required to fetch a rule is proportional to its position in the table, which is equal to its
rank in the Pareto histogram. Thus the amount of converted energy is proportional to the
sum over all rules of the product of frequency and rank.
What we need to do now is find a rule-selection strategy that minimizes
dissipation. A necessary condition is the least-action principle: that the first order change
in the action, the sum over time of the differences between energy forms, remain as small
as possible under small variations in path.
The Least-Action Strategy
The hypothesized least-action strategy is achieved by selecting, at each step along
the path, a rule whose contribution, measured in terms of its rank-frequency product, to
the energy conversion total will be minimal. More formally, the rule-selection strategy
can be described as follows:
1. At each step in the path, identify the set of allowable rules as those that can be
selected without violating the requirement of monotonic decrease required of
all Pareto histograms1.
2. Add 1 to the utilization frequency of each allowable rule and multiply the
result by the rule’s distance (which is equal to its rank). This calculation
yields the value of that rule’s contribution to the total action against which
variational actions are to be compared.
1 Technical note: it’s permissible for two consecutively-selected rules to have equal frequencies.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

35
3. Select any rule for which this product is minimal. Note that that the selected
rank-frequency product will be a monotonically-increasing function of time:
its value at any particular step will always be less than or equal to the its value
at all subsequent steps.
4. Cycle back to step 1.
Proof by Induction and Contradiction
The proof will proceed using the method of contradiction embedded within an
inductive framework. While only the first step of the induction is absolutely necessary,
several steps in the induction sequence will be provided to demonstrate the strategy’s
efficacy when faced with a more interesting set of path choices.
At time zero, the Pareto histogram is empty and the set of allowable rules contains
only one rule, that having rank one. Thus the rule selection strategy is irrelevant for the
first step in the path. After selecting this rule, the Pareto histogram will contain a
frequency of one for the rule of rank one. And the first rule’s contribution to the action
will be 1*1 = 1.
The set of allowable rules for the second step contains two elements: the rule of
rank one and the rule of rank two. Under the proposed strategy, we add 1 to the
utilization frequency of each allowable rule and multiply by the rule’s rank. This yields
the action contribution for that rule, and the rule with the least action contribution is
selected.
For the first rule, the action contribution would be 2*1 = 2. Note that the
difference between action contributions for any two rule choices at any point along the
path is simply equal to what the difference in their rank-frequency products would be
after the choice had been made.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

36
For the second rule, the action contribution would be 1*2 = 2. So the difference
between the rates of contribution for the two rules is zero, and the strategy is thus
indifferent between the two options.
Had the second rule been chosen first instead of the first rule, the action
contribution difference would still have been zero.
Continuing on to the step 3, suppose we had chosen the first rule in step 2,
resulting in a Pareto histogram with frequency two at rank one and frequency zero at all
other ranks. We now have two options for the third step: the first rule (yet again), or the
second rule.
The action contribution from choosing the first rule would be 3* 1 = 3.
The action contribution from choosing the second rule would be 1 *2 = 2.
The selection strategy would choose the second rule.
Why is this the least-action choice? This is where the proof-by-contradiction
method comes into play.
Suppose we had chosen the first rule instead. We could achieve a small variation
in path by replacing the last choice of first rule with a substitute choice of the second rule.
The reduction in contribution to action from the first rule would not be offset by the
increase in contribution due to the second rule. Thus the magnitude of the action
variation due to the path variation would be non-zero, and the original path could not
have been the least action path1.
Likewise, if the second rule had been chosen in step 2, followed by the third rule
in step 3, the resulting action variation would also have been non-zero, showing that our
choice of the third rule in step 3 was sub-optimal.
1 The corresponding case in ordinary Calculus would be that the first derivative of the function being optimized was non-zero.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
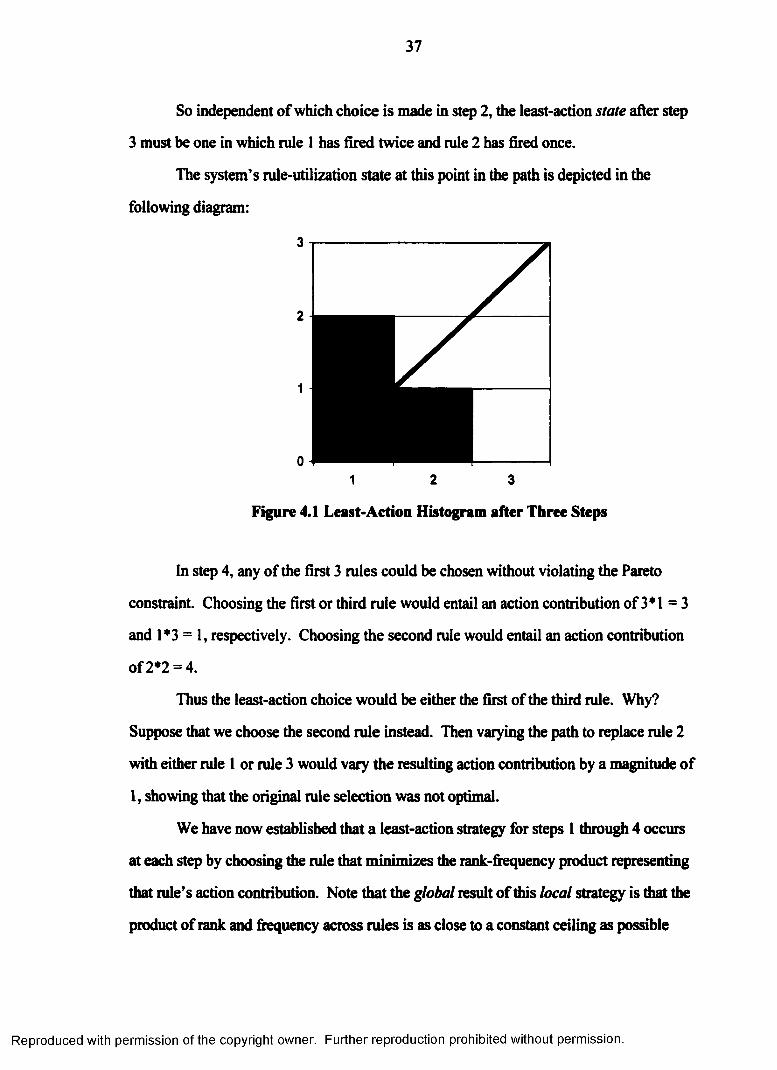
37
So independent of which choice is made in step 2, the least-action state after step
3 must be one in which rule 1 has fired twice and rule 2 has fired once.
The system’s rule-utilization state at this point in the path is depicted in the
following diagram:
3
2
1
01 2 3
Figure 4.1 Least-Action Histogram after Three Steps
In step 4, any of the first 3 rules could be chosen without violating the Pareto
constraint. Choosing the first or third rule would entail an action contribution of 3* 1 = 3
and 1*3 = 1, respectively. Choosing the second rule would entail an action contribution
of2*2 = 4.
Thus the least-action choice would be either the first of the third rule. Why?
Suppose that we choose the second rule instead. Then varying the path to replace rule 2
with either rule 1 or rule 3 would vary the resulting action contribution by a magnitude of
1, showing that the original rule selection was not optimal.
We have now established that a least-action strategy for steps 1 through 4 occurs
at each step by choosing the rule that minimizes the rank-frequency product representing
that rule’s action contribution. Note that the global result of this local strategy is that the
product of rank and frequency across rules is as close to a constant ceiling as possible
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
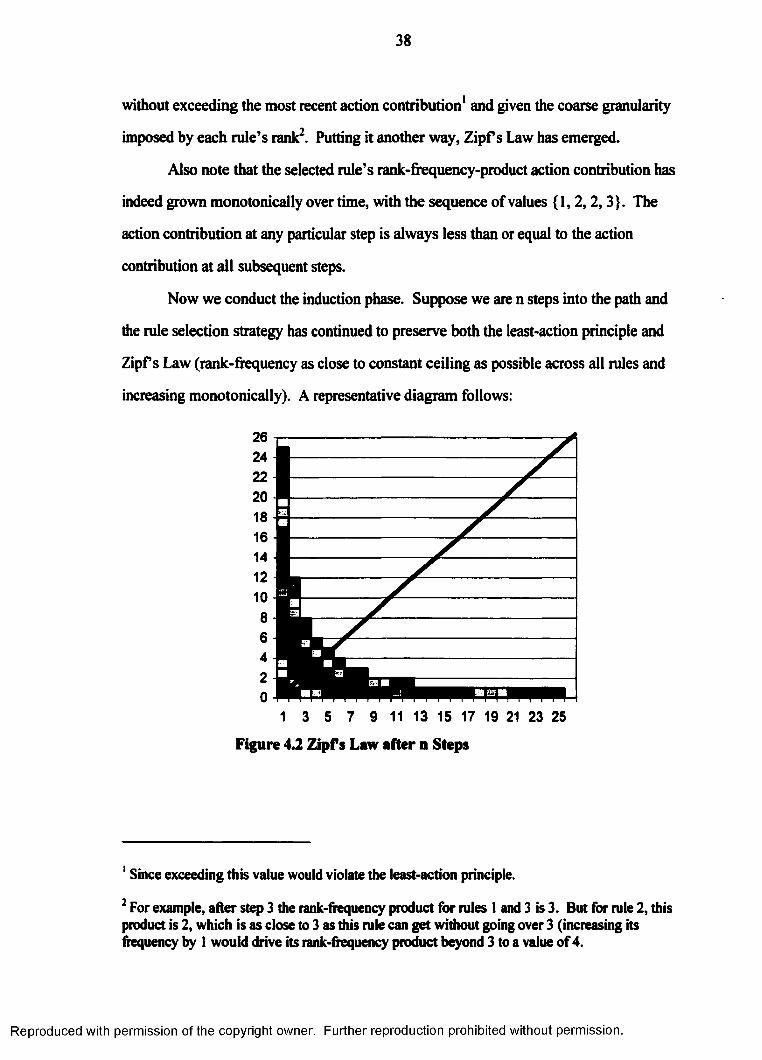
38
without exceeding the most recent action contribution1 and given the coarse granularity
imposed by each rule’s rank2. Putting it another way, Zipf s Law has emerged.
Also note that the selected rule’s rank-frequency-product action contribution has
indeed grown monotonically over time, with the sequence of values {1,2,2,3}. The
action contribution at any particular step is always less than or equal to the action
contribution at all subsequent steps.
Now we conduct the induction phase. Suppose we are n steps into the path and
the rule selection strategy has continued to preserve both the least-action principle and
Zipf s Law (rank-frequency as close to constant ceiling as possible across all rules and
increasing monotonically). A representative diagram follows:
1 3 5 7 9 11 13 15 17 19 21 23 25
Figure 4.2 Zipf s Law after n Steps
1 Since exceeding this value would violate the least-action principle.
2 For example, after step 3 the rank-frequency product for rules 1 and 3 is 3. But for rule 2, this product is 2, which is as close to 3 as this rule can get without going over 3 (increasing its frequency by 1 would drive its rank-frequency product beyond 3 to a value of 4.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

39
For step n+1, the rule-selection strategy requires selection of a rule for which
rank-frequency-product action contribution minimal. One of two cases will hold at this
point. If one is available, we can choose a rule whose action contribution is equal to that
of the most-recent rule. Otherwise we will have to choose a rule whose action
contribution is the smallest value beyond the most recent.
To help prevent confusion, we’U refer to the next rule as the “step-n+1 rule”, and
the previous rule as the “step-n rule”.
If the action contribution for the step-n+l rule is equal to that of the step-n rule,
then the least-action principle will not be violated because varying the path by
exchanging the order of these two rules will result in zero change in total action.
Also, Zipf s Law will be maintained because the rank-frequency product of the
step-n+1 rule will be no greater than that of the step-n rule, which itself was no greater
than the constant ceiling at step n. Thus this product across all rules will still be less than
the constant ceiling at step n+1. The monotonicity of this sequence actions will also be
maintained.
On the other hand, suppose the rank-frequency-product action contribution of the
step-n+1 rule were greater than that of the step-n rule.
If this action contribution were not minimal, then we could create a non-zero
variation in action by varying the path to select the rule for which it is minimal.
Choosing the rule whose action contribution was not minimal at this point in the
path would also violate Zipf s Law. Under Zipf s Law, all rank-frequency products are
as close as possible to the constant ceiling without exceeding it. But by choosing a step-
n+1 rule which didn’t have the minimal product among the allowable rules, rules for
which this product was minimal are no longer as close to the ceiling as possible. In fact,
the next time they are selected they will still be farther from the new step-n+1 ceiling
than the chosen step-n+1 rule.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

40
Finally, choosing the non-minimal rule would destroy the monotonicity of the
rank-frequency sequence, since we could go back afterward and select a rule with a
smaller rank-frequency product than the selected step-n+1 rule.
The inductive proof is now complete, showing that the rule selection strategy
described earlier preserves both the least-action principle and Zipf s Law at all steps
along the path as the agent grows.
What Causes the Scaling Problem?
Back to the original research question, the scaling problem materializes in the
case at hand because linear growth in the number of rules the agent employs demands
faster-than-linear growth in the consumption of energy.
Note that total energy consumption in this model is equal to the sum of the rank-
frequency products across all rules.
Since the rank-frequency product is nearly constant across all rules, this sum can
be approximated by the product of the largest rank and the largest frequency. And since
these factors are nearly identical1, their product is approximately equal to the square of
the rank2.
Thus the total energy consumption grows as the square o f the largest rank, which
is equivalent to the square of the number of active rules.
How Can the Scaling Problem Be Mitigated?
The strategy that physical energy-converting systems use to mitigate the scaling
problem is to waste or dissipate as little energy as possible during the conversion process.
1 Otherwise we could construct a path that violates the least-action principle.
2 Or equivalently, the product would also be equal to the square of the frequency.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

41
In fact, most (all?) physical systems dissipate no energy whatsoever when all the relevant
forces are accounted for, no matter how microscopic or complex they may be. The
strategy that physical energy-converting systems use to minimize energy waste is called
the Principle of Least Action.
When that mitigation strategy was applied to the agent in this inquiry, we found
that a necessary outcome was for the rule utilization Pareto histogram to approximate
Zipf s Law.
In other words, Zipf s Law is a necessary condition for an energy-converting,
rule-based information-processing agent to be minimizing energy dissipation during
conversion.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

CHAPTER V
CONTRIBUTIONS AND FUTURE DIRECTIONS
Major Contributions
This inquiry’s main contribution is in finding and proving an answer to the
original research question regarding the cause and mitigation of the scaling problem. To
summarize, it showed that the scaling problem arises inevitably from the energy-
utilization demands of a certain class of growing information-processing agents. More
formally, as agents with fixed-length, fixed-position, constant-specificity rules, and under
constant, conservative external physical force, grow linearly in the number of rules they
employ, their energy utilization will necessarily grow faster than linear. Thus the scaling
problem is inevitable for such any agent that is growing and subject to an energy
constraint.
This inquiry also showed that information-processing agents could mitigate
energy scarcity just as physical systems do: by minimizing dissipation in converting
between different energy forms under the Principle of Least Action. A by-product of this
local mitigation strategy is that rule-utilization displays a hyperbolic Pareto histogram
known as Zipf s Law at the global level.
As mentioned in an earlier chapter, Mandelbrot (1982) developed a stochastic
model for generating a corollary to Zipf s Law. This model was based on a fractal called
a lexicographic tree, containing a set of letters and one blank. It showed that word length
and frequency were inversely related when random draws were made from such a tree,
provided the tree’s fractal dimension is equal to one. In the more general case, the fractal
42
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

43
dimension d determines the exponent in the equation f[x] = l/xd. In contrast to
Mandelbrot’s approach, the model developed in this dissertation inquiry focuses on the
relationship between fetch distance (and the energy associated with such fetches) and
frequency, thus maintaining a higher fidelity to Zipf s Principle of Least Effort.
The following diagram depicts the relationship between this family of models.
Figure 5.1 Necessary and Limiting Conditions
The upper path in the diagram shows how the Principle of Least Action provides a
continuous model under which the least-action integral is a necessary condition to ensure
minimal energy dissipation in physical systems.
The lower path shows how Mandelbrot’s lexicographic fractal provided a
discrete, albeit stochastic, model under which Zipf s Law is a limiting condition in a
random sample from an exponential probability distribution.
The model used in this dissertation links these two previously-separate domains
as indicated by the middle path. On this path, the Principle o f Least Action provides a
deterministic, discrete model under which Zipf s Law is a necessary condition to ensure
minimal energy dissipation in information processing systems.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

44
Future Research
As discussed earlier, the classifier system model serving as the foundation for the
proof had to be stripped of many of its most powerful features in order to enable the
proof. While this was disconcerting for purposes of the current inquiry, it does provide a
clear path toward a wide variety of future research topics.
The class of research questions that have been enabled by the work in this inquiry
are of the form “What is the impact of adding a particular classifier system feature on an
agent's energy dissipation characteristics?”. A wide variety of such features, including
rule strengths, look-ahead, and the Genetic Algorithm, with its own varied set of different
adaptation strategies, can be enabled for the purpose of studying their energy-dissipation
effects on information-processing agents.
Another class of research questions that can be grounded in this research is that
which explores different payoff functions. Under the current inquiry, the payoff function
was the negative o f the amount of energy dissipated during rule-fetching operations.
Future inquiries could replace this with an alternative such as survival duration, or even
form a composite payoff formed out of a combination of energy dissipation and survival
duration.
Note that an interesting by-product of this research is that the payoff function has
been based on internal agent features rather than an external environment. Future
research could continue in this vein by exploring other means of linking performance to
internal, operating-system features.
One such feature would be the choice of data structure in which rules are stored.
The data structure for the current inquiry was a table containing rules of fixed-length,
fixed-position and constant-specificity. Each rule was assumed to be fetched from the
table, charged for energy utilization, and then returned back to its fixed position in the
table.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

45
An interesting variation on this theme would be to change the operating system so
that the rules are returned to the top of the table instead.
A second variation would be to have the rule specificities vary based on position
in the table. For example, rule specificity might be proportional to distance from the top
of the table. Generic rules would be stored near the top of the table; specific rules would
reside nearer to the bottom.
This change would impose a differential energy cost in fetching different rules.
Their masses would be different, causing the carrying mass of each rule to differ; and the
distance required to fetch the rule would differ, since this distance is proportional to the
specificity sum of all intervening rules.
Contributions to Management Theory
What do these findings about information-processing energy dissipation have to
say about the everyday management challenges facing the typical organization?
Just as information processing requires time, so it also requires energy. And to
the extent that energy is a constrained resource, any strategy to help organizations
minimize energy dissipation (i.e., waste) will help them become more efficient.
Secondly, most if not all organizations seek to grow and are thus likely to
encounter the scaling problem. These findings offer insights into the cause of the scaling
problem and what can be done to help mitigate it.
Thirdly, many organizations don’t possess or can’t afford to purchase reliable
demand and cost forecasts, and thus can’t determine which production levels would
maximize the difference between the forecasted values for total demand and total cost.
Consuming as little time and energy as possible in the use o f information represents a
possible alternative strategy for such organizations.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

46
This strategy is particularly salient for organizations that operate in information
intensive environments1. Some additional elaboration on how the model components
could be operationalized will help explain why2.
The agent’s rule table serves to provide an encoding of repeatable transformations
of input to output signals. In other words, it is a mathematical function that uses bit-
string inputs and outputs rather than numerical ones.
The notion of firms as rule-following agents is certainly not foreign to
management research. As alluded to earlier, this notion was central to the work of Simon
and his followers. Nelson and Winter’s (1982) concept of routines would be another
closely-related concept.
The ability to concatenate rules into a sequence in response to a series of
environmental stimuli would represent what some have referred to as a capability.
Businesses such as law firms, engineering contractors, management
consultancies, and software developers would be prime examples of firms as information
processing agents. They clearly use information and information-related assets to
differentiate their services and sustain their value4.
" Porter and Millar (1985) lay out the characteristics of such organizations, decomposing their information-processing intensities into product and process aspects.
2 How they should be operationalized is another open question that merits further research.
3 Amit and Schoemaker (1993) provide a survey discussion of capabilities.
4 There are two unusual properties of information assets that make analysis of their markets very difficult for traditional micro-economics approaches. The first is that when such an asset is sold, the seller doesn't lose possession of the asset. It is copied rather than moved, as would be the case with a physical asset. Thus the production-scale economies that are so important to the economics of physical assets play a much less important role for information assets. The second property is that it's possible for the buyer to gain value just from the description of the asset itself, without having to purchase it at all. For example, when a law firm advertises that it provides legal advice regarding a new tax law, buyers can use this information to know what law to look for in conducting their own personal tax research, and may not need to hire an attorney at all.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

47
Firms such as cement providers or pencil manufacturers, on the other hand, don’t
display such high information intensity in their processes or products (Porter and Millar
1985). Such firms might find the more traditional micro-economic approach more
applicable1. Likewise, a trustee engaged in passive oversight of the annuity from a
financial asset might find the traditional approach suitable.
The main contribution of this dissertation’s line of research to mainstream
management research, then, is that it provides an alternative performance measure for
growing firms facing unreliable demand and cost forecasts in information-intensive
industries. This measure is unique in that it is based upon the internal consumption of
energy rather than external, market-based forecasts. As described earlier, the firm’s goal
under this new performance measure would be to waste as little energy as possible.
One favorable by-product of such a performance measure is that all the
information required to calculate performance would be generated internally, which
could serve to reduce the agent’s data gathering burden.
A second favorable by-product of this measure is that any advantage the agent
gains based on this measure would become very difficult to imitate. The performance
metric is difficult to calculate without an intimate knowledge of the agent’s internal, rule-
fetching activities.
A third advantage is that the energy-dissipation-minimizing strategy would
provide a single operating principle that could be propagated throughout the entire firm.
This would help obviate the need to develop different strategies for different lines of
business.
1 Though if such firms did indeed choose to customize their products and seek to differentiate themselves based on the results, they might find information-processing models of their firms to be worth exploring.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

48
As alluded to above, this inquiry also provides an information-based definition of
a capability: the ability to concatenate rules into a related sequence in response to a series
of environmental stimuli. It further suggests a necessary condition for optimal energy
utilization in applying these capabilities.
Zipf (1949) showed how a language user could simultaneously maintain two
distinct rule tables, each moving individually toward an energy-dissipation optimum,
leading to the phenomenon called schizophrenia The source of the schism in this would
be that the agent were adapting to multiple superlatives. Instead of seeking a single
energy-dissipation optimum, the agent is instead attempting to maintain the efficiency of
two separate tables'.
Porting this notion over into the management domain, it could lay the foundation
for developing an early warning signal that such a schism might loom on the horizon for
an organization in an information-intensive industry. A firm possessing this schism
would be trying to optimize two distinct sets of capabilities simultaneously. In other
words, it would be failing to maintain a single core competence. Thus another
contribution from this inquiry is to suggest an information-based definition of core
competence.
Guidelines for Empirical Management Research
What does this inquiry have to say about the empirical side of management
research?
The theory developed here should be particularly useful for growing firms facing
unreliable demand and cost forecasts in information-intensive industries. In other words,
1 This pathology was referred to in an earlier chapter as “over-utilization of nearby rules” and is characterized by the over-use of high-frequency rules relative to low-frequency rules.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

49
it should be useful for firms likely to encounter the scaling problem and likely to benefit
most from being able to mitigate that problem.
A representative example of such a firm would be a growing developer of
customized software.
As mentioned earlier, a notion closely related to an information-processing
agent’s rule is that of a routine: “Our general term for all regular and predictable
behavioral patterns of firms is “routine”. We use this term to include characteristics of
firms that range from well-specified technical routines for producing things, through
procedures for hiring and firing, ordering new inventory, or stepping up production of
items in high demand, to policies regarding investment, research and development
(R&D), and overseas investment. In our evolutionary theory, these routines play the role
that genes play in biological evolutionary theory.”1
For many organizations, such routines may not be documented or, if they are
documented, they may be difficult to find. Software development organizations, and the
corresponding software engineering profession, appear to be taking steps that will help
ameliorate these difficulties, however.
On the product side of software development, two forms of product encoding
could be used to help identify routines.
The first is the product specification, in which the desired system functions are
described. One software engineering practice is to break the product specification down
into component parts called Junction points. There are several families o f function
points, including external inputs, external outputs, files, and interfaces to other software
programs.
1 Nelson and Winter (1982) page 14
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

50
The use of function points helps decompose the task of specifying software-based
systems into more manageable chunks. This is particularly important for firms that
develop software for sale to outside parties because the product specification is a binding
contract document. Measures such as function point analysis reduce the risk of mis-
specification and associated transaction costs.
A beneficial side effect accrues from function point analysis: once a particular
function point has been identified to help describe one system, it can be re-used in
subsequent systems without having to be created from scratch. In terms of routines, a
function point is a re-usable tool as part of the routine of creating a software system
specification. Organizations that maintain libraries of such re-usable assets could
conceivably track the utilization frequencies of various function points, thus providing
the desired data on routine-utilization frequency.
The second form in which routines are encoded on the product side of software
development is through objects. Objects are electronic files containing programs that
adhere to a strict set of usage rules designed to make them re-usable across multiple
systems.
Unlike function points, which describe the behavior of the system as it would look
and feel to its end user, objects capture the behavior of the system as it appears to the
programmers developing the system.
Like function points, however, they serve to decompose the system in manageable
chunks, thus reducing the likelihood of quality defects during development.
And like function points, they provide the beneficial side effect o f enabling re-use
in subsequent systems without having to be created from scratch.
In terms of routines, an object is a re-usable tool as part of the routine of creating
the software system itself. Organizations that maintain libraries of such re-usable assets
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

51
could track the utilization frequencies of various objects, thus providing the desired data
on routine-utilization frequency.
The process side of the software development industry is also undergoing changes
that should help enable empirical research.
A widely-accepted model of organizational software development capabilities
called the Capability Maturity Model (CMM)1 has become the standard to which
software development organizations strive. It describes the principles and practices
underlying an organization’s process maturity and is intended to help software
organizations proceed up an evolutionary path from ad hoc, chaotic processes to mature,
disciplined software development practices.
The CMM is organized into five maturity levels. The initial level is characterized
by ad hoc, and occasionally even chaotic, procedures where success depends on
individual effort and heroics. In the repeatable level, basic project management
processes are established to track cost, schedule, and functionality. The goal is to repeat
earlier successes on projects with similar applications. At this level, the organization’s
memory is sufficient to allow software development routines to be re-used over time.
At the defined level, the software process for both management and engineering
activities is documented, standardized, and integrated into a standard software process for
the organization. All projects use an approved, tailored version of the organization's
standard software process for developing and maintaining software.
The remaining two levels, managed and optimized represent successively more
efficient and predictable levels of re-using the organization’s defined development
routines.
1 This model was developed at the Software Engineering Institute at Carnegie Mellon University under funding from the U.S. Department of Defense.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

52
As is the case with function points and objects on the product side of software
development, the CMM documented software process provides a standard approach to
decompose the development effort into manageable chunks and to re-use those chunks in
the future.
The CMM focus on software development process provides a more faithful
operationalization of Nelson and Winter’s description of a routine than do the product-
oriented notions of function points and objects. This is because the latter constructs focus
more on the artifacts produced by routines rather than the routines themselves.
What does the theory developed in this dissertation inquiry suggest about the
behavior of organizations whose routine-utilization frequencies are measured by one or
more of the measures suggested above?
It suggests that to the extent that the selected set of measures are representative of
the entirety of the organization’s rule-based activities, the organization will be wasting
the least amount of energy in utilizing those routines when the corresponding Pareto
Histogram follows Zipf s Law. The more rule-based activities that escape these
measures, the weaker the correlation will be between the Pareto Histogram and actual
energy dissipation.
And in the absence of reliable forecasts of financial performance, optimal
physical performance may be the best that can be expected.
How can we measure energy utilization and dissipation in a software development
organization?
In the physical world, energy consumption is typically measured by monitoring
the utilization of a single source of fuel. Finding the fuel tank in a software development
organization appears to present even more of a challenge than finding the routines that
make up their “DNA”.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

53
Instead of trying to find a direct measure of fuel consumption, it would be more
fruitful to use a proxy measure such as overtime labor hours.
Software development projects typically tend to consume labor at the highest rate
at the end of the development cycles, when customer requirements have become
understood most fully, and the probability of any further scope changes is reduced due to
the impending product delivery deadline.
Restating the theory in these terms, the thesis suggests that a software
development organization will be wasting the least amount of overtime labor in utilizing
its routines when the corresponding Pareto Histogram follows Zipf s Law.
In other words, an organization whose rule utilization follows Zipf s Law more
closely should be expected, all else being equal, to consume less overtime labor than one
whose utilization follows the law less closely.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

APPENDICES
54
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

55
APPENDIX A
THE ENERGY UTILIZATION COST OF FETCHING BITS
A critical assumption underlying the dissertation model is that a rule-based
information-processing agent will incur an energy cost in fetching its rules for use. The
larger a rule's specificity, the higher will be its fetch cost. Similarly, the further down the
table the rule is located (i.e., the lower its relative utilization frequency), the higher this
cost will be.
The following discussion walks through several considerations, grounded in
Information Physics, showing why energy is actually required in the physical world to
fetch strings of bits.
The field of Information Physics is lies at the intersection of Statistical Physics1
and Information Theory2. It represents an exciting field for all of the information
sciences because it helps put physical bounds on how information can be utilized3.
The Cost of Erasing Bits
One important finding dealing with energy and information is due to Bennett and
Landauer (1985). It states that an agent must incur a thermodynamic entropy cost in
order to carry out the irreversible process of erasing one bit of information.
1 ...which itself lies at the intersection of Quantum Physics and Thermodynamics.
2 The seminal work in the field of Information Theory is due to Shannon (1948), though others (Szilard, Nyquist, Hartley, Morse, Wiener, Kolmogoroff) also made important contributions during its nascent stages.
3 The Proceedings Volume on the 1989 Santa Fe Institute Workshop on Complexity, Entropy and the Physics of Information (Zurek 1990) covers much of this territory of Information Physics in more detail.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

56
In the dissertation model, erasing a bit would correspond to changing it from a 0
or 1 to a don't-care symbol. In the standard classifier system, such a change would occur
during operation of the Genetic Algorithm as the agent were adapting its rule table.
Zipf (1949 p.61) called the phenomenon of erasing information from the agent's
rule table the "Principle of the Abbreviation of Mass" and used it to help explain why the
most frequently used words in a language tend to also be the shortest.
The dissertation model doesn’t utilize this classifier system feature, so we need
not concern ourselves with the associated energy costs for now.
The Cost of Fetching Rules
The dissertation model does, however, presume that the agent must search for and
move bit strings in order to fetch and utilize a rule. The following analysis, while not
being as rigorous as the typical theoretical argument in Physics, will at least offer some
plausibility for why energy is required at all.
The specificity of the rule being fetched corresponds to what is modeled as mass
in Physics, and the sum of specificities of intervening rules corresponds to distance.
For a bit to be stored at all, it must have some physical substrate on which to be
encoded. The encoded bit is said to be bound in the complexion of the physical system
(Brillouin 1962). Complexions in a physical system correspond to the total number of
possible states a bit string can take on in an information processing system.
The Uncertainty Principle of Quantum Physics tells us that the limits in our ability
to detect a physical property of any system is governed by the inequality AP*AR > h,
where AP represents the precision limit of our knowledge of the momentum, AR the limit
for the position, and h is Planck's constant.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

57
Dividing both sides by AP, we get the result that there is a lower bound on the
precision with which we can measure position in the physical system in which the bit is
stored.
Thus for a string of, say, n bits to be encoded on a physical substrate, a distance of
no less than n*h/AP must be utilized or the values of neighboring bits won't be
distinguishable.
Using a similar argument, a momentum differential of no less than h/AR must
separate the physical states representing the bits "0" and "1" or they won't be
distinguishable.
Thus the physical substrate must carry some mass in order to provide these
momentum differences.
As suggested above, this simple argument is by no means rigorous enough to
carry any weight in the field of Physics itself.
It does, however, lay the groundwork required to support the claim that stored bits
do indeed require space and mass, and thus their movement will entail some energy cost.
Also note that the current inquiry does not depend upon a metric describing how
much information is utilized. It only depends only upon being able to create an ordering
on the set of all strategies available to the agent. And this ordering was provided by
comparing only relative energy utilizations, independent of any measure of absolute
energy utilizations.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

58
APPENDIX B
A WALKING TOUR OF THE CLASSIFIER SYSTEM
The classifier system (CS) is an adaptive rule-based system that models its
environment by activating appropriate clusters of rules. The following diagram shows
the major features of the standard classifier system':
inputmessages
Rult
matchTHEN
payoff —
post
Output liEffector*
Credit
Figure B.1 The Standard Classifier System Model
The payoff function and two message interfaces make up the agent’s
environment. The internal features include a message list, a rule table and an operating
system. The standard CS copies signals, presented by the environment in the form of bit
strings, to its input interface and compares them against the conditions in the rule table.
Messages are then sent to the message list and the output interface. The
environment returns a payoff value, which the agent uses to modify its behavior. The
1 Adapted from Holland (1992 p.173)
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

59
payoff function is typically interpreted as being outside the agent’s boundary, though the
dissertation model interprets it as being inside.
The rules that led to the payoff receive credit using an algorithm called the Bucket
Brigade. The agent searches for new rules or learns using the Genetic Algorithm (GA).
The Genetic Algorithm
The GA is a mechanism used to search for advantages in a parameter space
containing exploitable biases and symmetries.
Advantage, in the case of the GA, accrues to building blocks called schema
(Holland 1992), which can be defined as any combination of bits and don 't-care symbols
in a string no longer than the current length of the agent’s classifier rules.
An exploitable bias is an advantage that can be sustained from one time period to
the next via a schema.
A symmetry is an advantage that can be sustained in a schema from one period to
the next independent of what changes may occur in those bits which are not part of that
schema.
One advantage the GA provides over other search methods is that it can test many
schema simultaneously. A classifier of length L can test 2L distinct schema in one cycle
of the GA. This feature is called implicit parallelism}
Comparing the Dissertation Model and the GA
Unlike the standard GA, the dissertation model doesn’t allow any adaptation. The
agent is concerned strictly with choosing a rule-utilization path that minimizes energy
dissipation.
1 See Holland (1992) p. 69f. and Holland (1995) p. 65f. for further details.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

60
Beyond this obvious difference, however, we can also identify a subtle difference
in emphasis between the two approaches.
The dissertation model focuses upon developing an advantage for a single agent,
whose identity has been established from the start in its fixed rule table. The agent itself
provides the single focal point which is seeking an optimum over the agent’s entire
existence. The boundary allows a distinction to be formed between internal and external
performance measures.
The GA, on the other hand, is typically targeted toward exploiting biases in a
population’s environment. No such singular identity or focal point exists. The patterns
contained in the population’s structures at any point in time may contain no thread of
resemblance back to the initial population as it adapts to what may be a perpetually-novel
environment.
The population periodically receives quantitative feedback regarding its
performance. One of the major findings surrounding the GA is the Schema Theorem. It
states that building blocks called schema will, according to how far the average
performance of their owning structures are above or below the population average,
receive proportionately higher or lower consideration in becoming part of the
population’s next generation.
Holland (1992) cautions against trying to use the GA to focus exclusively upon
optimization. Instead, it may be more prudent, particularly in perpetually-novel
environments, to utilize the GA to search for repeated local improvements versus
neighboring competitors.
The dissertation model takes a different approach in response to its environment
Instead of searching for repeated improvement versus neighboring competitors, it seeks
to optimize an internally-calculated payoff function.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

61
Lookahead
One advanced CS feature that may prove useful in future research in this area is
called tag-mediated lookahead (Holland 1990). In order to describe this feature, we must
first construct a model of how the classifier system agent interacts with its environment.
The formal structure describing the operation of a CS in its environment is a q-
morphism. Q-morphism is an abbreviation for quasi-homomorphism and represents an
extension of the notion of homomorphism from abstract algebra. A homomorphism is a
function defined on algebraic structures1 in which the operations in one set, the range,
mirror those same operations in the second set, or domain.
We can use the diagram below to illustrate a homomorphism. Ignoring the
diagonal arrow for the moment, the horizontal arrows correspond to operations being
performed within each of the algebraic structures. The vertical arrows correspond to the
mapping from each element of the top structure to an element in the bottom structure.
The mapping represents a homomorphism if the diagram commutes’, that is, if the
element picked out by doing an operation within the top structure followed by an
application of the homomorphism is identical to the element picked out by applying the
homomorphism first and then the operation corresponding to the bottom structure.
1 These structures are typically groupoids and their various subset structures. Further details can be found in textbooks on abstract algebra or group theory.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

62
Operation within Domain structure
►
Homomorphism: mapping from
Domain element to Range element
Homomorphism: mapping from
Domain element to Range element
►Operation within Range structure
Figure B.2 Homomorphisms
Applying this to the CS, the top arrow corresponds to state transitions in the
environment over time. The homomorphism maps each state of the environment into an
input message. The Classifier acts on the input message, creating an output message
(represented by the diagonal arrow pointing up horn the lower left comer to the top
arrow), and a transition of its message list to a new state.
Under a homomorphism, the next input message received from the environment
would pick out exactly the same state that was anticipated in this new message list.
Using control-theoretic terminology, when the agent is fully certain about the
states of its environment, that environment is termed completely observable. Likewise,
when an agent can drive its environment into any desired state in a finite amount of time,
the environment is termed completely controllable.
The vast majority of problems in management are only partially observable and
controllable. Agents must try to estimate what’s occurring in their environments and how
their actions impact those activities.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.
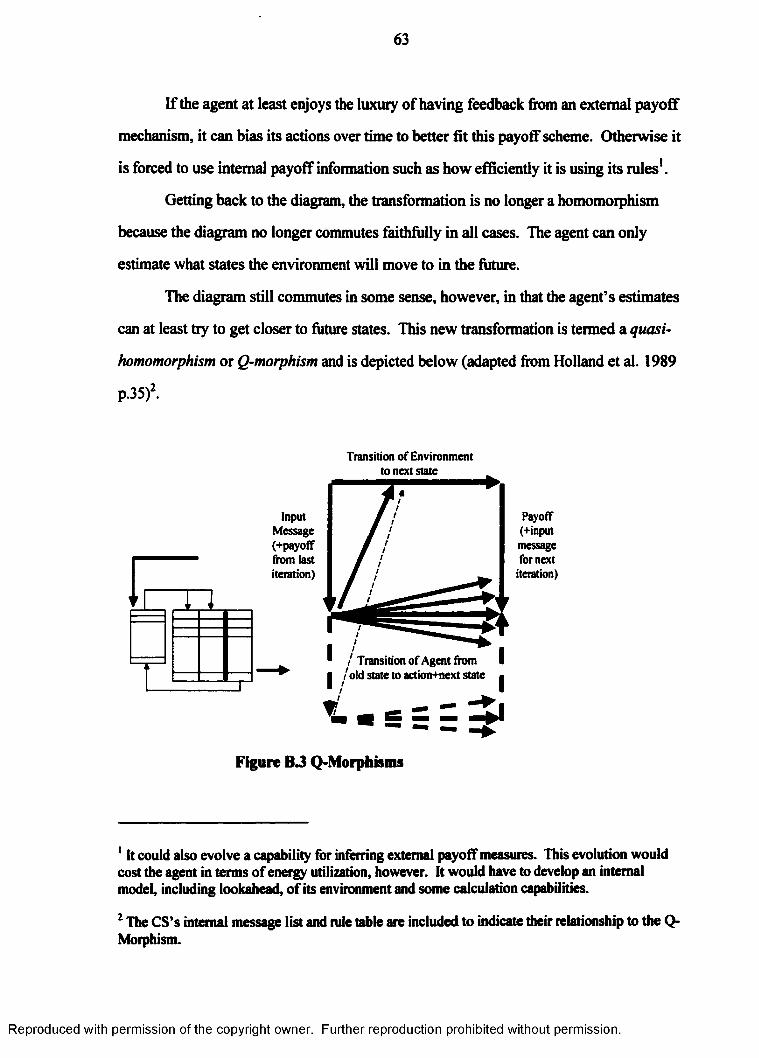
63
If the agent at least enjoys the luxury of having feedback from an external payoff
mechanism, it can bias its actions over time to better fit this payoff scheme. Otherwise it
is forced to use internal payoff information such as how efficiently it is using its rules1.
Getting back to the diagram, the transformation is no longer a homomorphism
because the diagram no longer commutes faithfully in all cases. The agent can only
estimate what states the environment will move to in the future.
The diagram still commutes in some sense, however, in that the agent’s estimates
can at least try to get closer to future states. This new transformation is termed a quasi
homomorphism or Q-morphism and is depicted below (adapted from Holland et al. 1989
p.35)2.
Input Message (+payoff from last iteration)
Transition of Environment to next state
/ Transition of Agent from I / old state to action+next state ■
Payoff (+input message for next iteration)
Figure B J Q-Morphisms
1 It could also evolve a capability for inferring external payoff measures. This evolution would cost the agent in terms of energy utilization, however. It would have to develop an internal model, including lookahead, of its environment and some calculation capabilities.
2 The CS’s internal message list and rule table are included to indicate their relationship to the Q- Morphism.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

64
Under a Q-Morphism, the agent is no longer certain about what action to take as it
would have been in the case of a pure homomorphism. The CS addresses the problem by
entertaining competing hypotheses about which current actions will engender the best
expected performance in the future. These competing hypotheses are represented by the
four gray arrows accompanying the agent’s chosen response, represented by the black
arrow.
An agent in an environment that’s only partially observable and controllable may
receive surprises.
If such a surprise is correlated with a very unusual and specific combination of
properties detected at its input interface, then its rule discovery mechanism, the GA, may
create a rule to take a different set of actions the next time these properties are detected.
This new variation is represented by the dashed arrows at the bottom of the
diagram.
The CS is designed, all else being equal, to give more credence to rules that
respond to specific conditions. Thus, over time, a default hierarchy emerges whereby
specific conditions can generate responses to potential surprises, and when such specific
conditions aren’t present, more general rules at higher levels in the hierarchy are chosen.
Properties of the environment are embedded within the input messages the CS
receives over time. Many subsets of these properties can be formed.
Suppose some subset of properties residing closely in time tends to be correlated
with substantially better-than-average performance.
Better performance leads to stronger rules via the Bucket Brigade Algorithm, the
system’s credit assignment procedure. Stronger rules lead to more variations on those
rules via the GA, the system’s rule discovery algorithm.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

65
As more rules are generated by the GA, the system occasionally discovers an
open time window with a few unused bits that can serve as a tag to label this subset of
properties. Such a subset will be termed a concept or category.
In the context of the CS, a tag is a set of bits within a rule that serves to identify
the address of that rule. In other words, a tag is a label1.
Once a concept has emerged within a CS, the presence o f one of the properties
associated with that concept can then use the tag to activate all the other rules related to
that concept.
Now suppose the same scenario with the exception that the properties comprising
the subset are spread out over a long period of time. In other words, several properties
are presented to the system, activating corresponding rules.
A period of time then passes so that those rules fall inactive.
Then a correlated set of properties are received, followed by a better-than-average
payoff.
Tags can emerge to manage this process as well. Instead of being called a
concept or category, however, in this case the cluster of rules is called a procedure.
When the triggering property is received from environment, it activates the rule
that will manage the procedure. This rule, in turn, is re-activated by all the other rules
which carry out the actual work of the procedure. When the above-average payoff is
received, this rule shares in the payoff.
The managing rule is called a bridging rule because it stays active throughout the
execution of all the rules making up the procedure. In other words, it bridges its activity
1 Tags are not just conveniences introduced as an afterthought in agent behavior. For firms and managers in particular, tags such as “audit”, “lawsuit”, “profit”, “strike”, and “crash” can serve as signals to instigate significant changes in agent behavior before the actual activities surrounding these tags are ever initiated.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

66
from the first rule all the way through to the last rule, when the ultimate payoff is
received. In doing so, it ensures that early acting rules share in the payoff1.
The CS can use tags to enable higher-level features to emerge; for example, they
can be used to indicate whether a message
• is coming from the agent’s input interface, thus representing external
information, or is coming from one of its own internal rules;
• is activating a cluster of rules representing a single concept or category;
• is activating a bridging rule to distribute payoff to early-acting rule in a
procedure; and
• is participating in an internal model to help the agent anticipate future
contingencies.
Another name for this internal modeling capability within a CS is lookahead.
Just as an agent can use tags to distinguish internal from external messages, so too
can it use tags to distinguish virtual from actual activity.
Actual activity is that which interacts directly with the environment. It either
comes from the agent’s input interface or gets sent to the agent’s output interface.
Virtual activity is that which the agent uses to model the behavior of its
environment in order to anticipate future events.
Lookahead uses virtual activity along with two additional rule strength registers to
keep track of how well various rules are predicting future states.
A virtual strength register tracks how well the rule is performing in the agent’s
current context as opposed to its average historical context. Often a rule will set the stage
for a later rule to gain a reward, yet the stage-setting rule doesn’t get any direct reward.
The virtual strength register allows such rules to predict the utilization of a future rule
1 Technically, this payoff sharing doesn’t occur until the next iteration of the procedure.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

67
that has received a large payoff in the past and take virtual credit for this prediction.
Thus these stage-setting rule can compete with other historically-stronger rules until the
bucket brigade algorithm has a chance to work the large payoff backward in the chain to
the earlier stage-setting rules.
A prediction strength register tracks how well the rule is predicting future
environmental states. Like the virtual strength register, this one provides a means by
which a rule can compete with stronger rules until a large payoff has been given a chance
to make its way back down a long chain of rules. Instead of being based on the
prediction of stronger rules later in a chain, however, prediction strength is drawn from
the correct prediction of environmental states.
Both of these strength registers allow potential stage-setting rules to increase their
bidding power in local contexts without having to risk too much of their historical
bidding strength. If they later turn out to indeed be setting the stage for larger payoffs
down the road, the bucket brigade algorithm will be provided sufficient time to propagate
the payoff bucket back to their standard historical strength registers1.
Associated with the long chains of rules described above, a bridging rule may
evolve to remain active over the duration of the chain, thus making this rule collection a
procedure. The tag activating the bridging rule would represent the name of the
procedure.
As discussed earlier, a default hierarchy of rules, spanning a spectrum of
specificities, could be activated by a single set of environmental attributes or a single tag.
Likewise, procedures can also be aggregated into hierarchies. A procedure at a
generic level can contain a rule that activates another procedure at a more specific level.
Holland (1990 p. 199) refers to such a structure as an epoch hierarchy. The rule in the
1 Riolo (1990) and Holland (1990) both provide more detailed descriptions of the mechanics behind the lookahead procedure.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

68
more general procedure activates an entire procedure at the more specific level. The
duration over which the specific procedure is active is termed an epoch.
Like actual activity, virtual activity will incur specificity movement costs that will
play into the agent’s overall performance.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

BIBLIOGRAPHY
69
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

70
BIBLIOGRAPHY
Bar-Hillel, Y. 1964 "Theoretical Aspects of the Mechanization of Literature Searching”, Chapter 19 in Language and Information: Selected Essays on Their Theory and Application, Addison-Wesley, London
Bennett, C. H. and Landauer, R. 1985 "The Fundamental Physical Limits of Computation" Scientific American, 242:48-56
Blair, D. C. 1984a “The Data-Document Distinction in Information Retrieval”, Communications o f the ACM, 27:4, 369-374
Blair, D. C. 1984b “The Management of Information: Basic Distinctions”, Sloan Management Review, 26:1,13-23
Blair, D. C. 1986 “Indeterminacy in the Subject Access to Documents”, Information- processing and Management, 22:2,229-241
Blair, D. C. 1988 “An Extended Relational Document Retrieval Model”, Information- processing and Management, 24:3, 349-371
Blair, D. C. 1990 Language and Representation in Information Retrieval, Elsevier
Blair, D. C. 1993 “The Challenge of Document Retrieval: Major Issues and a Framework Based on Search Exhaustivity and Data Base Size”, Working Paper, University of Michigan, Ann Arbor
Blair, D. C. 1995 “The Revolution in Document Management: Corporate Memory or Information Landfill”, Working Paper, University of Michigan, Ann Arbor
Blair, D. C. 1996 “STAIRS Redux: Thoughts on the STAIRS Evaluation, Ten Years After”, Journal ofthe American Society fo r Information Science, 47:1,4-22
Blair, D. C. and Maron, M. E. 1985 “An Evaluation of Retrieval Effectiveness for a Full- Text Document Retrieval System”, Communications o f the ACM, 28:3,289-297
Brillouin, L. 1962 Science and Information Theory, Academic Press, New York
Dreyfus, H. and Dreyfus, S. 1986 Mind Over Machine: The Power o f Human Intuition and Expertise in the Era o f the Computer, Free Press, New York
Eldridge, R. C. 1911 Six Thousand Common English Words, The Clement Press, Buffalo, NewYork
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

71
Feynman, Richard P., Leighton, Robert B. and Sands, Matthew 1964 “The Principle of Least Action”, in The Feynman Lectures on Physics, Addison-Wesley, Reading, MA
Forrest, Stephanie 198S A Study o f Parallelism in the Classifier System and ItsApplication to Classification in KL-ONE Semantic Networks, PhD Dissertation, The University of Michigan
Hamel, G. and Prahalad, C. K. 1994 Competing for the Future, Harvard Business School Press: Cambridge, MA
Holland, John H. 1986a “Escaping Brittleness: The Possibilities of General-Purpose Learning Algorithms Applied to Parallel Rule-Based Systems”, in Machine Learning: An Artificial Intelligence Approach, Vol. 2, Morgan Kaufmann, San Mateo, CA
Holland, John H. 1986b “A Mathematical Framework for Studying Learning in Classifier Systems” Physica D, 22:307-317
Holland, John H. 1990 “Concerning the Emergence of Tag-Mediated Lookahead in Classifier Systems” Physica D, 42:188-201
Holland, John H. 1992 Adaptation in Natural and Artificial Systems, MIT Press edition (revision of 1975 edition)
Holland, John H. 1995 Hidden Order: How Adaptation Builds Complexity, Helix Books, Addison Wesley
Holland, John H., Holyoak, K., Nisbett, R., and Thagard P. 1989 Induction: Processes o f Inference, Learning and Discovery, Paperback Edition, MIT Press, Cambridge, MA
Mandelbrot, Benoit 1983 The Fractal Geometry o f Nature, (3rd Ed.) W. H. Freeman and Co., New York
Nelson, R., and Winter, S. 1982 An Evolutionary Theory o f Economic Change, Belknap Press of Harvard University Press: Cambridge, MA
Neumann, J. von and Morgenstem, 0 . 1953 Theory o f Games and Economic Behavior, Third Edition (original published 1944), Princeton University Press, Princeton, NJ
Pareto, Vilfredo 1897 Cours d'economie politique, Rouge, Lausanne et Paris
Porter, M. and Millar, V. 1985 “How Information Gives You Competitive Advantage”, Harvard Business Review, July-August, 149-160
Prahalad, C. K. and Hamel, G. 1990 “The Core Competence of the Corporation”, Harvard Business Review, May-June, 79-91
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.

72
Sapir, Edward 1939 Nootka Texts, University of Pennsylvania Press (Linguistic Society of America), Philadelphia, PA
Schriber, T. J. 1990 An Introduction to Simulation, John Wiley & Sons, New York
Shannon, C. E. 1948 “A Mathematical Theory of Communication”, Bell Systems Technical Journal, 27:379-423
Simon, H. 1996 The Sciences o f the Artificial, Third Edition, MIT Press, Cambridge, MA (first edition 1969)
Tversky, A. and Kahneman, D. 1974 “Judgment under Uncertainty: Heuristics and Biases” Science 185:1124-1131
Zipf, George. K. 1949 Human Behavior and the Principle o f Least Effort, Addison- Wesley, Cambridge MA
Zurek, Wojciech H. 1990 Complexity, Entropy & the Physics o f Information, Addison- Wesley Longman, Inc.
Reproduced with permission of the copyright owner. Further reproduction prohibited without permission.




















