
Who to follow recommendation in large-scale online development communities
13
Who to follow recommendation in large-scale online development communities Daniel Schall ⇑ Siemens Corporate Technology, Siemensstrasse 90, 1211 Vienna, Austria article info Article history: Available online 15 December 2013 Keywords: Online communities Software development GitHub Knowledge management Who-to-follow recommendation Social resilience abstract Context: Open source development allows a large number of people to reuse and contribute source code to the community. Social networking features open opportunities for information discovery, social collab- orations, and improved recommendations of potential collaborators. Objective: Online community and development platforms rely on social network features to increase awareness and attention among community members for improved collaborations. The objective of this work is to introduce an approach for recommending relevant users to follow. Follower networks provide means for informal information propagation. The efficiency and effectiveness of such information flows is impacted by the network structure. Here, we aim to understand the resilience of networks against ran- dom or strategic node removal. Method: Social network features of online software development communities present a new opportu- nity to enhance online collaboration. Our approach is based on the automatic analysis of user behavior and network structure. The proposed ‘who to follow’ recommendation algorithm can be parametrized for specific contexts. Link-analysis techniques such as PageRank/HITS provide the basis for a novel ‘who to follow’ recommendation model. Results: We tested the approach using a GitHub-based dataset. Currently, users follow popular commu- nity members to get updates regarding their activities instead of maintaining personal relations. Thus, social network features require further improvements to increase reciprocity. The application of our ‘who to follow’ recommendation model using the GitHub dataset shows excellent results with respect to context-sensitive following recommendations. The sensitivity of GitHub’s follower network to random node removal is comparable with other social networks but more sensitive to follower authority based node removal. Conclusion: Link-based algorithm can be used for context-sensitive ‘who to follow’ recommendations. GitHub is highly sensitive to authority based node removal. Information flow established through fol- lower relations will be strongly impacted if many authorities are removed from the network. This under- pins the importance of ‘central’ users and the validity of focusing the ‘who to follow’ recommendations on those users. Ó 2013 Elsevier B.V. All rights reserved. 1. Introduction Social networks have become a central part for many people in their everyday activities. The type of network used for different activities often varies depending on the desired purpose. Profes- sional networks such as LinkedIn are used to stay in touch with colleagues and coworkers. Personal social networks including the popular Facebook platform enable people to engage with their friends and to follow their news updates. News media and social network services such as Twitter allow people to follow short news updates (tweets) of celebrities and friends. Recently, another type of social network has become highly popular attracting millions of users: online social collaboration networks. These networks enable people to collectively work on projects. An example of such a social collaboration platform is Github [1]. GitHub was launched in 2008 and enables people to work on public (open source) or private pro- jects. Indeed, open source development has a long history (e.g., see [2]) and dates back to the 1950s and 1960s when IBM released software sources of its operating systems and other programs [3]. A novel aspect of recent online social collaboration platforms on the World Wide Web such as GitHub is that they provide improved support for social networking features such as followers/followings or news feeds based on the users’ social network. These online col- laboration platforms enable users to discover interesting projects and repositories more quickly and let people collaborate almost 0950-5849/$ - see front matter Ó 2013 Elsevier B.V. All rights reserved. http://dx.doi.org/10.1016/j.infsof.2013.12.003 ⇑ Tel.: +43 6802049749. E-mail address: [email protected] Information and Software Technology 56 (2014) 1543–1555 Contents lists available at ScienceDirect Information and Software Technology journal homepage: www.elsevier.com/locate/infsof
Transcript of Who to follow recommendation in large-scale online development communities

Information and Software Technology 56 (2014) 1543–1555
Contents lists available at ScienceDirect
Information and Software Technology
journal homepage: www.elsevier .com/locate / infsof
Who to follow recommendation in large-scale online developmentcommunities
0950-5849/$ - see front matter � 2013 Elsevier B.V. All rights reserved.http://dx.doi.org/10.1016/j.infsof.2013.12.003
⇑ Tel.: +43 6802049749.E-mail address: [email protected]
Daniel Schall ⇑Siemens Corporate Technology, Siemensstrasse 90, 1211 Vienna, Austria
a r t i c l e i n f o
Article history:Available online 15 December 2013
Keywords:Online communitiesSoftware developmentGitHubKnowledge managementWho-to-follow recommendationSocial resilience
a b s t r a c t
Context: Open source development allows a large number of people to reuse and contribute source codeto the community. Social networking features open opportunities for information discovery, social collab-orations, and improved recommendations of potential collaborators.Objective: Online community and development platforms rely on social network features to increaseawareness and attention among community members for improved collaborations. The objective of thiswork is to introduce an approach for recommending relevant users to follow. Follower networks providemeans for informal information propagation. The efficiency and effectiveness of such information flows isimpacted by the network structure. Here, we aim to understand the resilience of networks against ran-dom or strategic node removal.Method: Social network features of online software development communities present a new opportu-nity to enhance online collaboration. Our approach is based on the automatic analysis of user behaviorand network structure. The proposed ‘who to follow’ recommendation algorithm can be parametrizedfor specific contexts. Link-analysis techniques such as PageRank/HITS provide the basis for a novel‘who to follow’ recommendation model.Results: We tested the approach using a GitHub-based dataset. Currently, users follow popular commu-nity members to get updates regarding their activities instead of maintaining personal relations. Thus,social network features require further improvements to increase reciprocity. The application of our‘who to follow’ recommendation model using the GitHub dataset shows excellent results with respectto context-sensitive following recommendations. The sensitivity of GitHub’s follower network to randomnode removal is comparable with other social networks but more sensitive to follower authority basednode removal.Conclusion: Link-based algorithm can be used for context-sensitive ‘who to follow’ recommendations.GitHub is highly sensitive to authority based node removal. Information flow established through fol-lower relations will be strongly impacted if many authorities are removed from the network. This under-pins the importance of ‘central’ users and the validity of focusing the ‘who to follow’ recommendations onthose users.
� 2013 Elsevier B.V. All rights reserved.
1. Introduction
Social networks have become a central part for many people intheir everyday activities. The type of network used for differentactivities often varies depending on the desired purpose. Profes-sional networks such as LinkedIn are used to stay in touch withcolleagues and coworkers. Personal social networks including thepopular Facebook platform enable people to engage with theirfriends and to follow their news updates. News media and socialnetwork services such as Twitter allow people to follow short newsupdates (tweets) of celebrities and friends. Recently, another type
of social network has become highly popular attracting millions ofusers: online social collaboration networks. These networks enablepeople to collectively work on projects. An example of such a socialcollaboration platform is Github [1]. GitHub was launched in 2008and enables people to work on public (open source) or private pro-jects. Indeed, open source development has a long history (e.g., see[2]) and dates back to the 1950s and 1960s when IBM releasedsoftware sources of its operating systems and other programs [3].
A novel aspect of recent online social collaboration platforms onthe World Wide Web such as GitHub is that they provide improvedsupport for social networking features such as followers/followingsor news feeds based on the users’ social network. These online col-laboration platforms enable users to discover interesting projectsand repositories more quickly and let people collaborate almost

1544 D. Schall / Information and Software Technology 56 (2014) 1543–1555
instantaneously. An intriguing hypothesis was postulated by [4]arguing that GitHub will be the next big social network driven bywhat people do instead of who people know. In professional net-works such as LinkedIn people are mainly connected because theyknow each other from, for example, past work experience.
In networks such as LinkedIn or Facebook friendship is repre-sented as reciprocated links in an undirected graph. Services suchas Twitter and recently GitHub are based on a directed networkapproach. A directed network approach allows users to followother users based on their interest without requiring them toreciprocate the relationship. In traditional social networks, someusers may be followed by many people without following manypeers themselves (‘stars’ or ‘celebrities’). Is this also the case foronline social collaboration networks such as GitHub? People inGitHub are mostly followed because they work on interestingprojects. Thus, this difference between conventional social net-works and online social collaboration networks requires a novel‘who to follow’ recommendation approach. One important aspectin knowledge-intensive disciplines such as software engineeringis to promote the effective dissemination of knowledge [5]. Theauthors in [6] found that formal routines should be supplementedby collaborative and social processes to promote awareness andlearning. In our opinion, follower networks provide excellentmeans to address the need for effective dissemination of knowl-edge through informal relations and information interest. Follow-ing the right person is essential to get information updates fromthe community leaders and ‘gurus’. ‘Who to follow’ recommenda-tions aim to solve the problem of selecting the right person tofollow.
Follower networks, information flows through re-tweets, and‘who to follow’ recommendations have been analyzed in great de-tail for platform such as Twitter [7–9] or in enterprise social medianetworks such as WaterCooler [10]. To our best knowledge, there isno existing work that proposed context-sensitive following recom-mendations in online development networks.
In this research we present the following key contributions:
� Who to follow recommendation. Here we propose a methodand algorithm for ‘who to follow’ recommendations. ‘Who tofollow’ recommendations can be based on behavior, network,or similarity. Our approach is based on network analysis tech-niques. User relevance with respect to following recommenda-tions is based on a novel authority metric. Authority in thiswork means being an expert or guru in a specific area (e.g.,expert/guru in ‘javascript’ programming). The approach is spe-cifically targeted at online software development communitiesbut may be applied to other types of collaboration networksas well.� Social network metrics and evaluation. We analyze our
approach by using social network (follower network) and activ-ity data from GitHub. We introduce the used dataset and calcu-late various metrics such as reciprocity to support ourhypothesis that people in GitHub are mostly followed becausethey work on interesting projects. The proposed authority-based ‘who to follow’ recommendation approach is evaluatedby using the GitHub dataset.� Social network resilience. The main purpose of follower net-
works such as the feature in GitHub is to get informationupdates and to potentially forward information (analogous totweets and re-tweets). To understand social network robustnessand resilience, we gradually remove nodes from the networkand analyze metrics such as average path length. How manyhopes on average must be passed to disseminate an item ofinformation? We use datasets of other popular social networkssuch as Facebook, Twitter and Google Plus and compare themwith GitHub.
This paper is structured as follows: Section 2 discusses relevantrelated work. Section 3 introduces our ‘who to follow’ recommen-dation approach. Section 4 introduces social network metrics andour evaluation. The paper is concluded in Section 5 with an outlookon future research.
2. Related work
We structure related work into relevant topics including analy-sis of online development communities, social network analysis,and social resilience.
2.1. Online development communities
An online social network is a communication and collaborationmedium that connects a large number of people. People within thesocial network stay together if their interaction dynamics leads tothe emergent property that is called ‘community’. Here we focuson online development communities consisting of people develop-ing collaboratively open source projects. A topological analysis ofthe SourceForge community was presented in [11]. The focus ofthe work was on role detection of users and cluster analysis. In[12], metrics with regards to open versus private software develop-ment were analyzed with the focus on source code aspects. Mea-sures to investigate the social–technical congruence in softwaredevelopment projects were established in [13]. The interplay be-tween network metrics, software failures and software evolutionwas investigated in, for example [14–16]. Collaboration and influ-ence on GitHub was analyzed in [17] with the central focus onvisualization techniques. Interesting directions with regards tothe analysis of GitHub were presented in [18]. The authors [18]showed evidence for social collaboration on GitHub and proposedalgorithms addressing the team formation problem. Our authority-based recommendation approach can well be used to create exper-tise profiles that can be used to assist in the formation of expertteams [19,20]. From a technical point of view, the basic structureof the GitHub API and the event schema was described in [21].
In this work, we analyze the GitHub online development com-munity but focus on follower/following recommendations.
2.2. Social network analysis
Social network analysis techniques offer a rich set of theories(e.g., social network theory, small world phenomenon, power-laws,self-organization, and graph theory) and tools to analyze the topo-logical features and human behavior in online communities [7,22–27].
In many systems, including large-scale enterprises, mostlysearchable directories or databases that include descriptions ofthe employees’ knowledge and experience are used to locate ex-perts. The problem with this approach is that social networksand also big companies are in a constant state of flux and change[28,29]. In large-scale online communities and dynamic organiza-tions, it becomes infeasible to constantly review and update theprofile information of often rapidly changing experience, skills,and rolls of experts. Specifically with respect to software engineer-ing, the authors in [30] found that a person with the most modifi-cations to the code may be an expert within a community, and thatexpertise depends on the area of the code that is being modified.Furthermore, the ‘degree of knowledge model’ [31], showed howthat expertise decays with subsequent changes by other authors.
We apply well-grounded theories and algorithms to the analy-sis of large scale software development communities. Well knownranking algorithms to calculate importance in linked environmentsinclude the HITS algorithm [32] and PageRank [33]. Personalization

D. Schall / Information and Software Technology 56 (2014) 1543–1555 1545
techniques such as topic-sensitive PageRank [34,35] enable con-text-sensitive importance ranking. Link analysis algorithms havebeen successfully applied to estimate actor importance in socialand collaborative networks [27,36–38] as well as to online massproduction systems such as emerging crowdsourcing environ-ments [39]. The authors in [37] proposed link analysis techniquessuch as PageRank for expertise mining in online communities.However, no personalization with regards to expertise areas hasbeen performed by prior work. In our previous work [27] we pro-posed context-sensitive link analysis algorithms for expertise min-ing, but did not consider contributions of people to onlinecommunities (e.g., contributing source code to online repositories).
We propose a network-based metric to capture authority for‘who to follow’ recommendations. The proposed authority metricmeasures the relative community standing (i.e., reputation) of acommunity member. The metric is based on how much a personcontributes to the community (e.g., repository commits) and onhow many existing follower relations a person has.
2.3. Social resilience
The online social network and its users form a socio-technicalsystem in which the persistence of the community depends onboth the social interaction between users, and the implementationand design of the social network platform [40]. In this context, thesocial resilience [41] of an online community is defined as ‘The abil-ity of the community to withstand external stresses and disturbancesas a result of environmental changes’. Specifically, the underlyingtechnology platform of the social network can positively or nega-tively change the environment of the users. As an example,changes of platform features such as the user interface can posea general risk for user engagement in social network [40]. Animportant property of many social networks is the presence ofinfluencers (i.e., community leaders). Decisions regarding partici-pating or leaving the network are determined by a large extendby the number of one’s friends and their own engagement [42].Hence, users leaving a community have negative indirect effectson their friends [43]. As a result, this may trigger cascades ofdeparting users, which may ultimately endanger the wholecommunity.
3. Who to follow recommendation
3.1. Recommendation types
Following/follower recommendations can be performed accord-ing to different strategies. The authors in [10] suggested three cat-egories: behavioral, similarity, and network. We structurerecommendation types for online software development commu-nities in a similar manner but provide more strategies for networkbased recommendations. The following ‘who to follow’ recommen-dation types can be distinguished:
� Behavioral. This recommendation type is based on alreadyobserved interaction between two people. For example, a per-son may have commented on code checked in by some otherperson or a person may have replied to a question (e.g., usageof library, report of bug, etc.) posted by someone in a discussionforum. Thus, based on the interaction between two people a fol-low recommendation can be made.� Similarity. As often observed in real life, people tend to have
friends with similar characteristics and interests [45]. This phe-nomenon is called homophily. Homophily is the principle that acontact between similar people occurs at a higher rate than
among dissimilar people [46]. Shared characteristics includefollower degree and shared interests include watched reposito-ries or interest in programming language.� Network. The network based recommendation type can be
based on various techniques.Collaborative filtering [47] is a technique for recommending con-tent to users based on other users with similar interest. Collab-orative filtering techniques are commonly seen on e-commercesites. Applied to our problem domain, if A watches the samesoftware repositories as B, than A might be interested in follow-ing B because both share similar interests.Triadic closure [46] is another concept for network based recom-mendation. Suppose three community members A, B, and C andsocial ties between A–C and B–C. As suggested by Granovetter,in most of these social structures, a triadic closure occurs suchthat A and B are likely to become friends (or connected to eachother) the more they associate with C [46].Network centrality of various types of vertices in a graph can becomputed to determine the relative importance of vertices (e.g.,methods such as PageRank [33] and HITS [32]). In social net-works, network centrality techniques can be used to estimatethe importance of users [27]. The application is, for example,expert recommendation.
In the scope of this work, we focus on the network based recom-mendation type. The first type (behavioral) and the second type(similarity) are not within the scope of this work. With regardsto network based recommendation, we focus on a centrality basedapproach.
3.2. Authority-based recommendation model
The central concept in this work is user authority. Here we fol-low a social network analysis approach that is based on well estab-lished techniques including HITS [32] and PageRank [33]. In thiswork, somebody is considered to be an authority if s/he has knowl-edge in a given area and is recognized by the community. Thesetwo factors are combined in a novel authority metric. The pre-sented techniques and algorithms build upon our previous work[27,39]. Our previous work introduced a social network miningframework and context-sensitive expertise ranking algorithms.Here we introduce new metrics suitable for online developmentcommunities such as GitHub. Here, the basic ‘who to follow’ rec-ommendation model is established upon a user-repository graphmodel (in contrast to our previous work in [27]).
To illustrate the basic idea of our ‘who to follow’ approach,without going into details, we show the most fundamental stepsin Algorithm 1.
Algorithm 1. High level ‘who to follow’ recommendationalgorithm.
1: input: Person P for whom recommendations should becomputed.
2: output: Top-k list of recommended people.3: Q createQueryFromProfileðPÞ4: D getPrincipleInterestDomainsðPÞ5: for each User u 2 U do6: if matchesðu;DÞ then7: AðuÞ computeAuthorityScoreðu;QÞ8: end if9: end for10: return sortAndFilterðAÞ

1546 D. Schall / Information and Software Technology 56 (2014) 1543–1555
The input of the algorithm is a person P for whom ‘who to fol-low’ recommendations shall be computed. Thus, a personalizationprocedure to compute recommendations is needed. The output ofthe algorithm is a top-k list of people to follow. The threshold kcan be dynamically adjusted. As a first step, a query Q is createdfrom the person P’s profile (function createQueryFromProfileðÞ inline 3). As an example, if person P is interested in ‘javascript’ and‘closure’, then s/he may want to follow people who work with suchlanguages. The query would therefore consist of the keywordsQ ¼ f‘javascript0; ‘closure0g. The detailed mechanisms for extractingthe query Q from P’s user profile is not detailed in this work.
The next step is to extract principle interest domains for personP. Principle interest domains are, for example, ‘web engineering’,‘automation’, ‘embedded systems development’, ‘physics simula-tions’. A person with background web engineering and interest injavascript-based web frameworks for e-commerce may or maynot be interested in following a person with background ‘automa-tion’ who is working in javascript-based industry monitoringframeworks. The application domains can be very versatile and itmay also strongly depend on the person’s interest to follow some-body from another domain. Here, we highlight the fact that suchfiltering (see matchesðu;DÞ in line 6 which evaluates to true orfalse) may be needed to improve recommendations. However, itwould be beyond the scope of this work to elaborate on filteringby principle interest domains in detail.
The core focus of this work is depicted by the functioncomputeAuthorityScoreðÞ. Here the authority scores are computedthat are used to perform a ranking of recommended users to fol-low. The function sortAndFilterðÞ truncates the list (if desired) andreturns a sorted list of people (sorted by highest to lowest author-ity score).
Models to compute authority such as the popular hubs andauthority approach [32] are rooted in the link analysis domain torank Web pages. Here we apply link analysis mechanisms to eval-uate user authority with respect to community contributions.Detecting authoritative users is not only important for ‘who to fol-low’ recommendations but also for identifying key players in thecommunity. These users have strong impact with regards to com-munity cohesion and evolution. The following sections details thecontext-sensitive authority ranking model.
3.3. Personalized context-sensitive authority ranking
Here we define the ‘who to follow’ recommendation model thatis based on link analysis techniques. The basic idea is to computeuser authority based on performed repository actions (e.g., codingactivities, bug fixing, etc.). The concepts are depicted by Fig. 1.
Suppose the community consists of the set of users U ¼ fa; b; cgand the set of software repositories R ¼ fe; f ; gg. The
Fig. 1. User-repository graph model.
user-repository graph can be modeled as a directed bipartite graphGBðVU ;VR; EBÞwhere VU represents the set of users and VR the set ofrepositories. An edge ðu; rÞ 2 EB is established from u to r iff u per-forms an action in r. An edge between u and r is weighted by wur
based on performed actions. Each repository is associated with aprogramming language. In Fig. 1, e and f are associated with java-script and g is associated with java. A user gains experience in aprogramming language if the user performs actions in language-re-lated repositories. The programming languages denote the contextfor our personalized authority ranking approach.
The set of users fa; bg has gained experience in javascript be-cause they have performed actions in the repositories e and fwhose language is javascript. The user b is experienced in javascriptand java because b has performed actions in fe; f ; gg. The users aand c are only experience in javascript and java, respectively.
A quite natural and intuitive approach to rank users and repos-itories in GB is to model importance using the notion of hubs andauthorities1 as introduced in [32]:
AðuÞ ¼Xðu;rÞ2EB
HðrÞ HðrÞ ¼Xðv;rÞ2EB
AðvÞ ð1Þ
A user u 2 VU has high authority if u contributes to importantrepositories. The authority of u is depicted by the authority scoreAðuÞ. A repository r 2 VR is important if authoritative users contrib-ute to it. The repository importance is depicted by the hub scoreHðrÞ. Thus, an important ‘hub’ attracts many authoritative users.This recursive definition of user and repository importance pro-vides the basis for our ranking approach. Other centrality metricssuch as PageRank [33] cannot discriminate between two types ofscores. However, when compared with PageRank, HITS is less sta-ble to small perturbations [48]. Thus, a combined model wouldbring the advantage that one can compute two scores (propertyof HITS) and that the algorithm is rank stable (property of Page-Rank). Here we follow the randomized HITS approach as proposedin [48]:
AðuÞ ¼ ð1� kaÞpðuÞ þ ka
Xðu;rÞ2EB
HðrÞ ð2Þ
HðrÞ ¼ ð1� khÞpðrÞ þ kh
Xðv;rÞ2EB
AðvÞ ð3Þ
Eqs. (2) and (3) show a natural way of designing a random-walkbased algorithm following the HITS model. However, the random-ized HITS approach is, like PageRank, stable to small perturbations[48]. The symbols pðuÞ and pðrÞ depict personalization vectors thatmay be assigned uniformly for each node such that pðuÞ ¼ 1
jVU jand
pðrÞ ¼ 1jVR j
.Non-uniform personalization vectors result in personalized
rankings (cf. personalized PageRank [33]). The parameters ka andkh with 0 6 k 6 1 allow for balancing between authority/hubweights and personalization weights. A typical value for k is 0.85[33]. Assigning lower values to k means that higher importanceis given to the personalization weights; thereby reducing the ‘net-work effect’ of the ranking algorithm.
The idea of our personalized authority ranking approach is tocompute ranking scores with respect to certain interest areas. Thedemanded areas of interest are passed via the keyword basedquery Q ¼ fq1; q2; . . . ; qng to the ranking algorithm. Each querykeyword qn corresponds to a desired area of interest. An interestarea is identified via the name of a programming language (forexample, Q ¼ f‘javascript’; ‘java’g). A query returns a ranked listof people based on the demanded set of interest areas.
1 The algorithm introduced by Kleinberg [32] to compute the scores is calledHyperlink Induced Topic Search (HITS).

D. Schall / Information and Software Technology 56 (2014) 1543–1555 1547
Based on the discussion on personalization techniques and thedepicted graph model in Fig. 1, we refine the hubs and authoritiesapproach as follows:
Aðu; QÞ ¼ ð1� kaÞpðu; QÞ þ ka
Xðu;rÞ2EB
wurHðr; QÞ ð4Þ
Hðr; QÞ ¼ ð1� khÞpðr; QÞ þ kh
Xðv;rÞ2EB
wvrAðv ; QÞ ð5Þ
Using this model, the authority of user u is computed withrespect to a specific context that is given by query Q. A central rolein this model plays the personalization vector pðu; QÞ. Notice,also the importance (‘hubness’ depicted by Hðr; QÞ) of a repositoryr is computed with respect to Q. However, since Aðu; QÞ ispersonalized by assigning non-uniform weights to pðu; QÞ alsoHðr; QÞ will be influenced by pðu; QÞ. Thus, with kh ¼ 1 we defineHðr; QÞ as:
Hðr; QÞ ¼Xðv;rÞ2EB
wvrAðv; QÞ ð6Þ
We substitute Hðr; QÞ in Eq. (4) and have:
Aðu; QÞ ¼ ð1� kÞpðu; QÞ þ kXðu;rÞ2EB
Xðv;rÞ2EB
wurwvrAðv; QÞ ð7Þ
The next step is to decompose the query Q as follows:
Aðu; QÞ ¼ ð1� kÞXq2Q
wqpðu; qÞ
þ kXðu;rÞ2EB
Xðv;rÞ2EB
Xq2Q
wurwvrwqAðv; qÞ ð8Þ
The weight wq is associated with a particular keyword q withwq ¼ 1
jQ j for uniform weights andP
qwq ¼ 1. In the next steps we
apply some of the ideas of the PageRank linearity theorem to ourproposed ranking model in Eq. (8). This is possible because Eq.(8) has a PageRank-like structure. The PageRank linearity theoremhas been originally introduced by [34] to create topic-sensitiveimportance scores for Web-pages, but has not been applied in‘who to follow’ recommendations.
For constant k we show that authority can be computed asAðu; QÞ ¼
Pq2Q wqAðu; qÞ. We restructure Eq. (8) to first iterate over
each q 2 Q:
Aðu; QÞ ¼Xq2Q
wqð1� kÞpðu; qÞ
þXq2Q
wqkXðu;rÞ2EB
Xðv;rÞ2EB
wurwvrAðv; qÞ ð9Þ
The final step is shown in Eq. (10):
Aðu; QÞ ¼Xq2Q
wq ð1� kÞpðu; qÞ þ kXðu;rÞ2EB
Xðv;rÞ2EB
wurwvrAðv ; qÞ" #
¼Xq2Q
wq½Aðu; qÞ� ð10Þ
The model as depicted by Eq. (10) brings the following impor-tant benefits:
� Ranking scores for individual interest areas can be precomputedand saved in a database. This is typically done periodically in anoffline manner.� At query time, the precomputed ranking scores are retrieved
and aggregated to a composite score. This step is performedonline at low computational cost.
The proposed model computes user authority with respect to acertain interest area by using personalization techniques. This is a
different mechanism than (1) performing matching of users basedon interest areas and then (2) computing authority without usingpersonalization techniques. In our approach, authority of users iscomputed by considering all repositories the user has performed ac-tions and giving preference to those repositories by using interestspecific personalization weights. This mechanism better capturescommunity-wide reputation by not only computing authoritybased on a small portion of the user-repository graph but insteadusing the entire user-repository graph. Thus, our approach followsa PageRank-like model.
In addition, our proposed model is important due to the compu-tational complexity and the inability to compute personalizedrankings in an online manner only. For large social networks andcollaborative platforms such as the GitHub, the computation ofranking scores may take a long time depending on available hard-ware and resources.
3.4. Weights and personalization metrics
The edge weight wur , which is not personalized or ‘context’dependent (cf. also Fig. 1 and related discussions), is calculatedas follows:
wur ¼P
t2T f ðu; r; tÞPz2RðuÞ
Pt2T f ðu; z; tÞ ð11Þ
The set T denotes event types (i.e., the type of user action). Theset RðuÞ depicts all repositories u is connected to in GB (u’s neigh-bors). The function f ðu; r; tÞ retrieves the event count of user u inrepository r of event type t.
As mentioned before, personalization is done for individualinterest areas and ranking scores are precomputed offline. Assumea is an interest area and pðu;aÞ is the corresponding personaliza-tion vector for users. Generally, we assign to pðu;aÞ an interest areaspecific weight and non-interest area specific weight. For brevity,let Rðu;aÞ ¼ matchðu;aÞ be the set of u’s repositories matchingthe interest area a. Eq. (12) defines the personalization vectorpðu;aÞ:
pðu;aÞ ¼ w1
Xr2Rðu;aÞ
wur þw2kinðu; GÞ=Xv2VU
kinðv ; GÞ ð12Þ
with w1 þw2 ¼ 1. The first partP
r2Rðu;aÞwur assigns interest areaspecific weights to pðu;aÞ. If a given user performs many actionsin interest area related repositories (i.e., Rðu;aÞ) then also the areaspecific weight will be higher. The interest area related weight willbe more important than the other part and thus w1 > w2. The sec-ond part kinðu; GÞ=
Pv2VU
kinðv; GÞ is the non-interest area specificweight where kinðu; GÞ depicts u’s indegree (follower count) in thefollower graph G. This weight increases the likelihood that userswith high reputation in terms of follower count are ranked higherthan users that are not followed. However, because higher impor-tance is given to the interest area specific weight, we ensure thatusers have primarily relevant experience and not only manyfollowers.
3.5. Social resilience and authority
In previous sections, we proposed network-based metrics (i.e.,user authority) to determine community leaders and influencers.Follower networks provide means for informal information propa-gation. In this work, we argue that the efficiency and effectivenessof such information flows is impacted by the network structure.Metrics to measure the impact of such users leaving the social net-work include the average path length or the average number of so-cial contacts (e.g., number of followers/followings). A practicalexample where a community could be endangered are changes

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 170%
20%
40%
60%
80%EventsDistinct UsersDistinct Repositories
Fig. 2. Basic event statistics by type.
1548 D. Schall / Information and Software Technology 56 (2014) 1543–1555
in the technology platform such as the user interface of the socialnetwork or tools to commit or review source code.
Bucket testing is a practice that is widely used by online siteswith large audiences to test new platform features. A methodologycould be, for example, to expose a new feature to a small fraction ofthe total number of users and measuring its effect on this exposedgroup [44]. For traditional uses of this technique, uniform indepen-dent sampling of the social network users is often enough to pro-duce an exposed group that can serve as a statistical significantrepresentation for the full user population. However, in many so-cial network applications, one often wishes to perform a morecomplex test by evaluating a new platform feature that will onlyproduce an effect if certain users are exposed. To avoid negative ef-fects on the community by introducing new platform features, itmay be more beneficial to select a group of users that would havehigh impact on the community if those users were leaving thecommunity. Therefore, understanding social resilience and factorsthat have strong impact has practical applications in testing of newfeatures. First, a strategy has to be determined to select users (e.g.,either randomly or based on their authority). Second, the resilienceof the network can be tested by measuring network propertiessuch as average path length if those users were leaving the com-munity. Third, if it has been confirmed that those selected usershave high impact (e.g., the structure of the follower network) stra-tegic testing can be performed thereby avoiding dissatisfaction ofcommunity leaders and influencers.
In this work, the first step (user selection strategy) and the sec-ond step (resiliency measures of the network) are defined in detailand evaluated using a dataset from GitHub.
Table 1Top-20 watched languages.
Rank Language Watchers #
1 javascript 1,004,1372 ruby 401,6943 python 273,0704 objective-c 243,6155 php 212,6046 java 170,3597 c 128,3948 c++ 92,4709 shell 63,258
10 c# 49,93411 coffeescript 44,22612 viml 42,59513 scala 26,94814 perl 26,757
4. Evaluation and results
4.1. GitHub data collection
At a high level, GitHub provides information regarding entitiesand events through a REST-based API.2 Information regarding enti-ties are, for example, user details (followers, followings, personaluser details) or details regarding repositories (e.g., watchers). Thus,entity information captures the current state of users, repositories,and artifacts. GitHub also provides access to events that describethe dynamic view and state changes. Events are generally generatedby user actions. Technical details regarding the REST API interface aswell as the event structure can be found in [21] and online at [49].The GitHub archive [50] offers access to GitHub events. Events canbe downloaded in JSON format and inserted into a database forquery processing.
We collected GitHub data using the following two methods:
� We retrieved the entire follower/following graph using the Git-Hub API. The graph was obtained in December 2012.� We further downloaded all GitHub events between March 11,
2012 and December 12, 2012 from the GitHub archive [50]amounting for roughly 10 months of event data. When perform-ing this research, event data was available starting from March11, 2012.
Fig. 2 gives an overview of the different event types3 captured inthe 10-months time frame. The total number of events captured is36,094,501. The number of distinct users associated with theseevents is 1,052,916. The total number of distinct software
2 http://developer.github.com/v3/.3 Event Types: 1 PushEvent, 2 CreateEvent, 3 WatchEvent, 4 IssueCommentEvent, 5
IssuesEvent, 6 ForkEvent, 7 PullRequestEvent, 8 GistEvent, 9 FollowEvent, 10 GollumEvent,11 CommitCommentEvent, 12PullRequestReviewCommentEvent, 13 MemberEvent, 14DeleteEvent,15 DownloadEvent, 16 PublicEvent, 17 ForkApplyEvent.
repositories is 2,334,921. The most common event is the PushEventamounting for 46% of the overall number of events. A PushEvent isa commit on a repository. Second is the CreateEvent with 14% thatis triggered when an object (‘repository’, ‘branch’, or ‘tag’) was cre-ated. WatchEvent, IssueCommentEvent, IssuesEvent amount for 9%,8%, and 5% respectively.
Detailed descriptions regarding the semantics of event typescan be found online [49]. As expected, most events result from ac-tual contributions such as repository commits and the creation ofobjects.
Table 1 provides a list of most popular programming languagesbased on the count of users watching repositories on GitHub. Lan-guage popularity is certainly more biased towards the Linux com-munity where the base technology Git emerged from. However,this bias does not have impact on our ‘who to follow’ recommen-dation approach. On GitHub, javascript is the most popular lan-guage with most watchers. It has more than twice as manywatchers then the second ranked language.
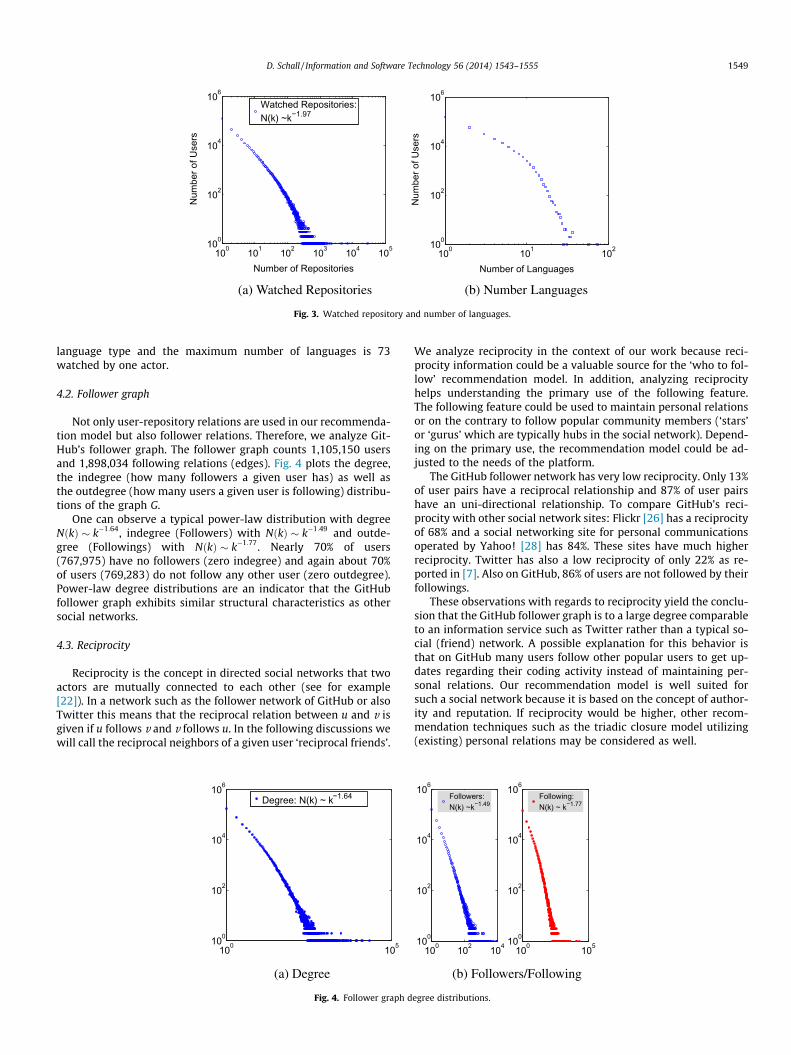
To understand repository popularity, Fig. 3 shows repositorywatch distributions. Note, all scatter plots in this paper have loga-rithmic scale on both the x-axis and y-axis. The actual distributionof the number of repositories shown against the number of users isdepicted by Fig. 3a. The number of languages watched by howmany users is shown by Fig. 3b. The depicted distribution inFig. 3a follows a power law with NðkÞ � k�1:97 with 132,446 userswatching one repository and one user watching 28,080 reposito-ries. In total 406,376 repositories are watched by 327,222 users.Fig. 3b the number of users over the number of watched languages.The basic characteristics are that 152,577 users watch exactly one
15 clojure 24,52516 go 20,77117 emacs lisp 13,94818 erlang 13,83419 actionscript 13,33920 haskell 11,378
100 101 102 103 104 105100
102
104
106
Number of Repositories
Num
ber o
f Use
rs
Watched Repositories:N(k) ~k−1.97
(a) Watched Repositories
100 101 102100
102
104
106
Number of Languages
Num
ber o
f Use
rs
(b) Number Languages
Fig. 3. Watched repository and number of languages.
D. Schall / Information and Software Technology 56 (2014) 1543–1555 1549
language type and the maximum number of languages is 73watched by one actor.
4.2. Follower graph
Not only user-repository relations are used in our recommenda-tion model but also follower relations. Therefore, we analyze Git-Hub’s follower graph. The follower graph counts 1,105,150 usersand 1,898,034 following relations (edges). Fig. 4 plots the degree,the indegree (how many followers a given user has) as well asthe outdegree (how many users a given user is following) distribu-tions of the graph G.
One can observe a typical power-law distribution with degreeNðkÞ � k�1:64, indegree (Followers) with NðkÞ � k�1:49 and outde-gree (Followings) with NðkÞ � k�1:77. Nearly 70% of users(767,975) have no followers (zero indegree) and again about 70%of users (769,283) do not follow any other user (zero outdegree).Power-law degree distributions are an indicator that the GitHubfollower graph exhibits similar structural characteristics as othersocial networks.
4.3. Reciprocity
Reciprocity is the concept in directed social networks that twoactors are mutually connected to each other (see for example[22]). In a network such as the follower network of GitHub or alsoTwitter this means that the reciprocal relation between u and v isgiven if u follows v and v follows u. In the following discussions wewill call the reciprocal neighbors of a given user ‘reciprocal friends’.
100 105100
102
104
106
Degree: N(k) ~ k−1.64
(a) Degree
Fig. 4. Follower graph d
We analyze reciprocity in the context of our work because reci-procity information could be a valuable source for the ‘who to fol-low’ recommendation model. In addition, analyzing reciprocityhelps understanding the primary use of the following feature.The following feature could be used to maintain personal relationsor on the contrary to follow popular community members (‘stars’or ‘gurus’ which are typically hubs in the social network). Depend-ing on the primary use, the recommendation model could be ad-justed to the needs of the platform.
The GitHub follower network has very low reciprocity. Only 13%of user pairs have a reciprocal relationship and 87% of user pairshave an uni-directional relationship. To compare GitHub’s reci-procity with other social network sites: Flickr [26] has a reciprocityof 68% and a social networking site for personal communicationsoperated by Yahoo! [28] has 84%. These sites have much higherreciprocity. Twitter has also a low reciprocity of only 22% as re-ported in [7]. Also on GitHub, 86% of users are not followed by theirfollowings.
These observations with regards to reciprocity yield the conclu-sion that the GitHub follower graph is to a large degree comparableto an information service such as Twitter rather than a typical so-cial (friend) network. A possible explanation for this behavior isthat on GitHub many users follow other popular users to get up-dates regarding their coding activity instead of maintaining per-sonal relations. Our recommendation model is well suited forsuch a social network because it is based on the concept of author-ity and reputation. If reciprocity would be higher, other recom-mendation techniques such as the triadic closure model utilizing(existing) personal relations may be considered as well.
100 102 104100
102
104
106
100 105100
102
104
106
Followers:N(k) ~k−1.49
Following:N(k) ~ k−1.77
(b) Followers/Following
egree distributions.

Table 2Top-10 ‘Who to Follow’ recommendations for ‘javascript’.
Rank User and top-5 repositories kout/kin Followers
1 fat 30 1597/twitter/bootstrap (js) 4/twitter/bower (js) 8/maker/ratchetjs 3/twitter/hogan.js (js) 3/twitter/recess (js) 2
2 caniszczyk 34 91/twitter/bootstrap (js) 4/twitter/bower (js) 8/twitter/ambrose (js) 4/twitter/twitter.github.com (js) 1/twitter/bootstrap-server (js) 3
3 mdo 6 879/twitter/bootstrap (js) 4/twitter/bootstrap-server (js) 3/mdo/github-buttons 1/mdo/code-guide 1/mdo/sublime-snippets 1
4 paulirish 61 5694/h5bp/html5-boilerplate (js) 8/twitter/bower (js) 8/yeoman/yeoman (js) 7/h5bp/mobile-boilerplate (js) 4/paulirish/infinite-scroll (js) 3
5 addyosmani 46 3110/addyosmani/todomvc (js) 3/twitter/bower (js) 8/addyosmani/backbone-fundamentals (js) 1/addyosmani/jquery-ui-bootstrap (js) 3/yeoman/yeoman (js) 7
6 visionmedia 299 3725/visionmedia/express (js) 1/visionmedia/jade (js) 1/visionmedia/mocha (js) 2/senchalabs/connect (js) 1/component/component (js) 2
7 jzaefferer 53 302/jquery/jquery (js) 10/jquery/jquery-mobile (js) 14/jquery/jquery-ui (js) 9/jzaefferer/jquery-validation (js) 2/jquery/qunit (js) 5
8 wycats 43 3259/jquery/jquery (js) 10/rails/rails (ruby) 21/emberjs/ember.js (ruby) 7/wycats/handlebars.js (js) 3/tildeio/rsvp.js (js) 3
9 scottgonzalez 47 261/jquery/jquery (js) 10/jquery/jquery-mobile (js) 14/jquery/jquery-ui (js) 9/jquery/qunit (js) 5/jquery/plugins.jquery.com (js) 3
10 mbostock 17 1477/mbostock/d3(js) 1/square/cubism (js) 1/square/crossfilter (js) 1/square/cube (js) 2/d3/d3-plugins (js) 6
1550 D. Schall / Information and Software Technology 56 (2014) 1543–1555
Based on the presented GitHub data, we performed variousranking experiments, which are shown next.
4.4. Who to follow recommendations
We perform ranking experiments to analyze the quality of the‘who to follow’ recommendation approach. We use the previouslydeveloped recommendation model as detailed Section 3. The goalof our evaluation is to understand the quality and impact of thepersonalization techniques. This is done by comparing the top-kresults of differently personalized rankings and their results. Sinceall data and user profiles are public available, we perform rankingand check the GitHub homepages and activities of the top-rankedusers. The results can also be easily verified by the reader.
For k we use a value of k ¼ 0:9 for all experiments. A usual valuefor k is within the range 0:8 6 k 6 0:9. The metric weights w1 andw2 are set to w1 ¼ 0:9 and w2 ¼ 0:1; thereby giving higher impor-tance to expertise area specific personalization weights. Theweights and personalizations are calculated based on the fre-quency of the various GitHub events.
4.4.1. Recommendations without personalizationThe first results are calculated without personalization (i.e., the
interest area-specific metrics and personalization weights are allzero). The top-10 results are shown by Table 3. The actual GitHubuser profile can be found online using the link: http://github.com/{User}.
The top-10 list in Table 3 gives a list of distinguished softwareengineers and community contributors. Users at rank 1 (mojom-bo), 3 (defunkt), 4 (schacon), and 7 (pjhyett) are GitHub staff mem-bers and, not surprisingly, rank among the top. The Linux fathertorvalds ranks at position 2. At positions 5 (paulirish) ranks afront-end developer and Google Chrome developer relations engi-neer. At 6 (jeresig) ranks the creator of the jQuery javascript li-brary. At 8 (ryanb) ranks a producer of ruby on rails screencastsand at 9 (android) ranks the ‘android’ user associated with the an-droid framework, kernel, and system core. At 10 (visionmedia)ranks a javascript contributor. The third column in Table 3 depictsthe outdegree kout in GB (i.e. the number of repositories the user isinvolved in). There is a correspondence between rank and numberof followers. It becomes already apparent that the top-10 rankedusers in Table 3 may have very diverse expertise areas with regardsto programming languages. We observe a mixture of ‘javascript’,‘c’, and ‘java’ experts.
4.4.2. Personalized recommendationsThus, as the next step we take full advantage of personalization
and perform ranking for the interest area ‘javascript’. Table 2shows the top-10 ranking results. The second column shows usersand repositories. For each user we provide the top-5 repositoriesby number of user contributions.
The repository language (if available) is provided in parenthesisnext to the repository name. The actual number of repository ac-tions has been omitted for privacy reasons. Furthermore, kout de-picts the outdegree of a user in GB (the number of repositories auser has been working on), kin depicts the repository indegree(the number of contributors), and the column Followers showingthe numbers of followers.
By looking at the results in Table 2, two aspects become imme-diately apparent:
1. The top-10 list is populated by users that contribute to popularjavascript repositories.
2. The list is no longer correlated in a strict order by the number offollowers.
Both observations demonstrate the intended behavior of ourranking algorithm. Not only high reputation in terms of numberof followers is a predominant factor, but also the number of
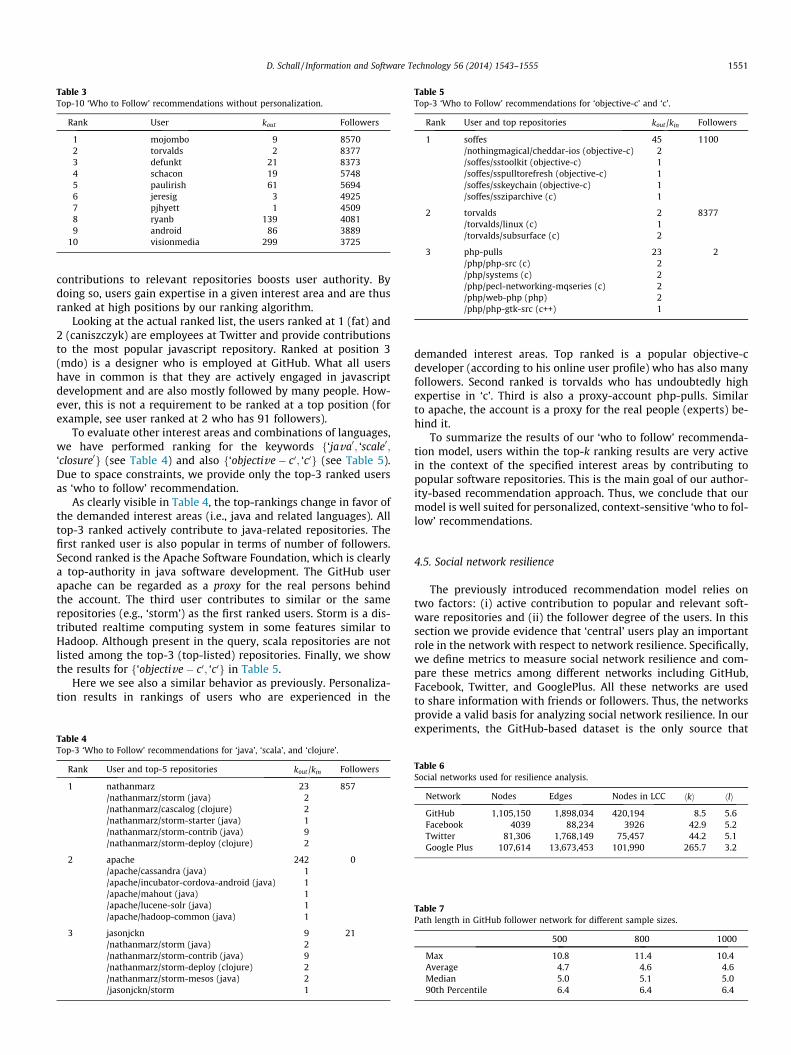
Table 3Top-10 ‘Who to Follow’ recommendations without personalization.
Rank User kout Followers
1 mojombo 9 85702 torvalds 2 83773 defunkt 21 83734 schacon 19 57485 paulirish 61 56946 jeresig 3 49257 pjhyett 1 45098 ryanb 139 40819 android 86 3889
10 visionmedia 299 3725
Table 5Top-3 ‘Who to Follow’ recommendations for ‘objective-c’ and ‘c’.
Rank User and top repositories kout/kin Followers
1 soffes 45 1100/nothingmagical/cheddar-ios (objective-c) 2/soffes/sstoolkit (objective-c) 1/soffes/sspulltorefresh (objective-c) 1/soffes/sskeychain (objective-c) 1/soffes/ssziparchive (c) 1
2 torvalds 2 8377/torvalds/linux (c) 1/torvalds/subsurface (c) 2
3 php-pulls 23 2/php/php-src (c) 2/php/systems (c) 2/php/pecl-networking-mqseries (c) 2/php/web-php (php) 2/php/php-gtk-src (c++) 1
D. Schall / Information and Software Technology 56 (2014) 1543–1555 1551
contributions to relevant repositories boosts user authority. Bydoing so, users gain expertise in a given interest area and are thusranked at high positions by our ranking algorithm.
Looking at the actual ranked list, the users ranked at 1 (fat) and2 (caniszczyk) are employees at Twitter and provide contributionsto the most popular javascript repository. Ranked at position 3(mdo) is a designer who is employed at GitHub. What all usershave in common is that they are actively engaged in javascriptdevelopment and are also mostly followed by many people. How-ever, this is not a requirement to be ranked at a top position (forexample, see user ranked at 2 who has 91 followers).
To evaluate other interest areas and combinations of languages,we have performed ranking for the keywords f‘java0; ‘scale0;‘closure0g (see Table 4) and also f‘objective� c0; ‘c0g (see Table 5).Due to space constraints, we provide only the top-3 ranked usersas ‘who to follow’ recommendation.
As clearly visible in Table 4, the top-rankings change in favor ofthe demanded interest areas (i.e., java and related languages). Alltop-3 ranked actively contribute to java-related repositories. Thefirst ranked user is also popular in terms of number of followers.Second ranked is the Apache Software Foundation, which is clearlya top-authority in java software development. The GitHub userapache can be regarded as a proxy for the real persons behindthe account. The third user contributes to similar or the samerepositories (e.g., ‘storm’) as the first ranked users. Storm is a dis-tributed realtime computing system in some features similar toHadoop. Although present in the query, scala repositories are notlisted among the top-3 (top-listed) repositories. Finally, we showthe results for f‘objective� c0; ‘c0g in Table 5.
Here we see also a similar behavior as previously. Personaliza-tion results in rankings of users who are experienced in the
Table 4Top-3 ‘Who to Follow’ recommendations for ‘java’, ‘scala’, and ‘clojure’.
Rank User and top-5 repositories kout/kin Followers
1 nathanmarz 23 857/nathanmarz/storm (java) 2/nathanmarz/cascalog (clojure) 2/nathanmarz/storm-starter (java) 1/nathanmarz/storm-contrib (java) 9/nathanmarz/storm-deploy (clojure) 2
2 apache 242 0/apache/cassandra (java) 1/apache/incubator-cordova-android (java) 1/apache/mahout (java) 1/apache/lucene-solr (java) 1/apache/hadoop-common (java) 1
3 jasonjckn 9 21/nathanmarz/storm (java) 2/nathanmarz/storm-contrib (java) 9/nathanmarz/storm-deploy (clojure) 2/nathanmarz/storm-mesos (java) 2/jasonjckn/storm 1
demanded interest areas. Top ranked is a popular objective-cdeveloper (according to his online user profile) who has also manyfollowers. Second ranked is torvalds who has undoubtedly highexpertise in ‘c’. Third is also a proxy-account php-pulls. Similarto apache, the account is a proxy for the real people (experts) be-hind it.
To summarize the results of our ‘who to follow’ recommenda-tion model, users within the top-k ranking results are very activein the context of the specified interest areas by contributing topopular software repositories. This is the main goal of our author-ity-based recommendation approach. Thus, we conclude that ourmodel is well suited for personalized, context-sensitive ‘who to fol-low’ recommendations.
4.5. Social network resilience
The previously introduced recommendation model relies ontwo factors: (i) active contribution to popular and relevant soft-ware repositories and (ii) the follower degree of the users. In thissection we provide evidence that ‘central’ users play an importantrole in the network with respect to network resilience. Specifically,we define metrics to measure social network resilience and com-pare these metrics among different networks including GitHub,Facebook, Twitter, and GooglePlus. All these networks are usedto share information with friends or followers. Thus, the networksprovide a valid basis for analyzing social network resilience. In ourexperiments, the GitHub-based dataset is the only source that
Table 6Social networks used for resilience analysis.
Network Nodes Edges Nodes in LCC hki hli
GitHub 1,105,150 1,898,034 420,194 8.5 5.6Facebook 4039 88,234 3926 42.9 5.2Twitter 81,306 1,768,149 75,457 44.2 5.1Google Plus 107,614 13,673,453 101,990 265.7 3.2
Table 7Path length in GitHub follower network for different sample sizes.
500 800 1000
Max 10.8 11.4 10.4Average 4.7 4.6 4.6Median 5.0 5.1 5.090th Percentile 6.4 6.4 6.4
0% 25% 50% 75% 100%0
2
4
6
8
10
Removed Nodes
Average DegreeAverage Path Length
(a) GitHub
0% 25% 50% 75% 100%0
10
20
30
40
50
Removed Nodes
Average DegreeAverage Path Length
(b) Facebook
0% 25% 50% 75% 100%0
10
20
30
40
50
Removed Nodes
Average DegreeAverage Path Length
(c) Twitter
0% 25% 50% 75% 100%0
100
200
300
0% 25% 50% 75% 100%0
2.5
5
Removed Nodes
Average DegreeAverage Path Length
Average Path Length
(d) GooglePlus
Fig. 5. Average degree and average path length for random strategy.
1552 D. Schall / Information and Software Technology 56 (2014) 1543–1555
exhibits user activity data such as software repository commits.Thus, the detailed authority model as proposed in Eq. (10) cannotbe directly applied in our social network resilience analysis.
Here, we use a simplified approximation of user authority basedon the users’ follower degree. Notice, however, the follower degreeis one essential parameter of our personalized authority model aspresented previously. Let us define the follower-based user author-ity AF as follows:
AFðuÞ ¼ kinðu; GÞ ð13Þ
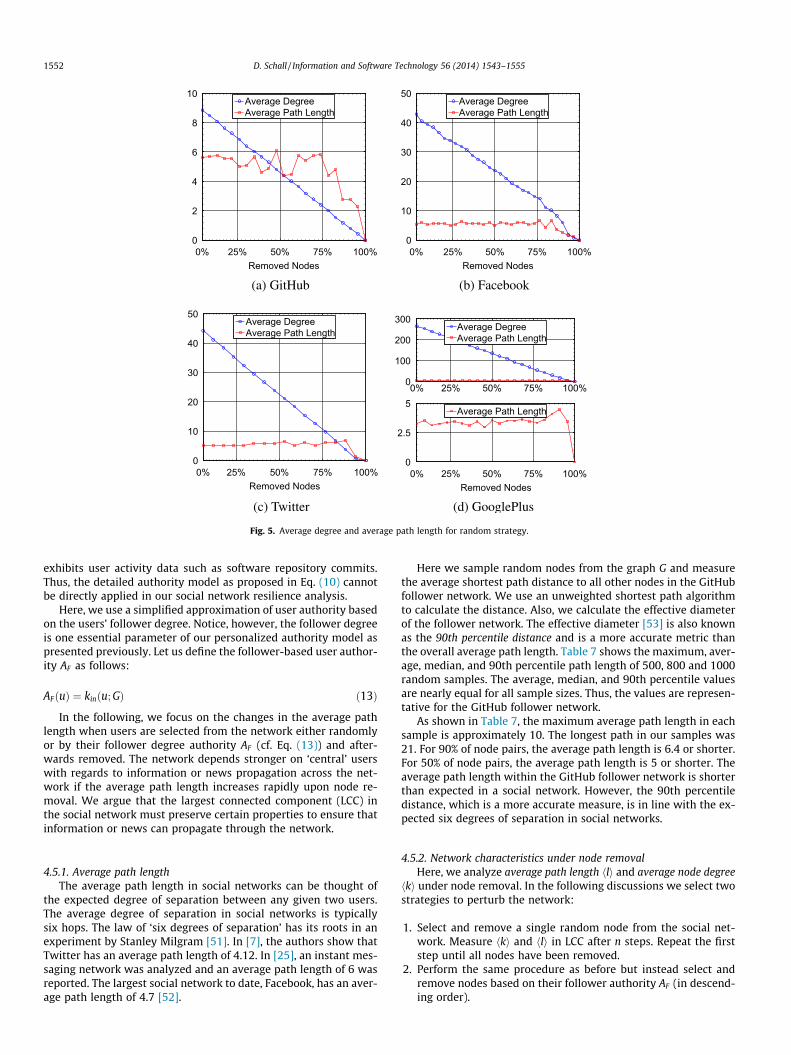
In the following, we focus on the changes in the average pathlength when users are selected from the network either randomlyor by their follower degree authority AF (cf. Eq. (13)) and after-wards removed. The network depends stronger on ‘central’ userswith regards to information or news propagation across the net-work if the average path length increases rapidly upon node re-moval. We argue that the largest connected component (LCC) inthe social network must preserve certain properties to ensure thatinformation or news can propagate through the network.
4.5.1. Average path lengthThe average path length in social networks can be thought of
the expected degree of separation between any given two users.The average degree of separation in social networks is typicallysix hops. The law of ‘six degrees of separation’ has its roots in anexperiment by Stanley Milgram [51]. In [7], the authors show thatTwitter has an average path length of 4.12. In [25], an instant mes-saging network was analyzed and an average path length of 6 wasreported. The largest social network to date, Facebook, has an aver-age path length of 4.7 [52].
Here we sample random nodes from the graph G and measurethe average shortest path distance to all other nodes in the GitHubfollower network. We use an unweighted shortest path algorithmto calculate the distance. Also, we calculate the effective diameterof the follower network. The effective diameter [53] is also knownas the 90th percentile distance and is a more accurate metric thanthe overall average path length. Table 7 shows the maximum, aver-age, median, and 90th percentile path length of 500, 800 and 1000random samples. The average, median, and 90th percentile valuesare nearly equal for all sample sizes. Thus, the values are represen-tative for the GitHub follower network.
As shown in Table 7, the maximum average path length in eachsample is approximately 10. The longest path in our samples was21. For 90% of node pairs, the average path length is 6.4 or shorter.For 50% of node pairs, the average path length is 5 or shorter. Theaverage path length within the GitHub follower network is shorterthan expected in a social network. However, the 90th percentiledistance, which is a more accurate measure, is in line with the ex-pected six degrees of separation in social networks.
4.5.2. Network characteristics under node removalHere, we analyze average path length hli and average node degree
hki under node removal. In the following discussions we select twostrategies to perturb the network:
1. Select and remove a single random node from the social net-work. Measure hki and hli in LCC after n steps. Repeat the firststep until all nodes have been removed.
2. Perform the same procedure as before but instead select andremove nodes based on their follower authority AF (in descend-ing order).
0% 25% 50% 75% 100%0
2
4
6
8
10
Removed Nodes
Average DegreeAverage Path Length
(a) GitHub
0% 25% 50% 75% 100%0
10
20
30
40
50
Removed Nodes
Average DegreeAverage Path Length
(b) Facebook
0% 25% 50% 75% 100%0
10
20
30
40
50
Removed Nodes
Average DegreeAverage Path Length
(c) Twitter
0% 25% 50% 75% 100%0
100
200
300
0% 25% 50% 75% 100%0
5
10
Removed Nodes
Average DegreeAverage Path Length
Average Path Length
(d) GooglePlus
Fig. 6. Average degree and average path length for authority AF based strategy.
D. Schall / Information and Software Technology 56 (2014) 1543–1555 1553
We performed this study using the social networks as listed inTable 6. For GitHub, we have the full social network available inform of the follower graph. For the other networks, only partialinformation is available. The social networks for Facebook (undi-rected), Twitter (directed), and Google Plus (directed) were ob-tained from the Stanford large network dataset collection4 (see[54] for details).
However, we believe that this is sufficient for comparing the ba-sic network characteristics under node removal. As stated before,we calculated hki and hli in LCC after n steps. Depending on the net-work size, we adjusted the rate at which we collect these measure-ments: GitHub at a batch rate of 50,000 nodes, for the smallFacebook graph we collected at a batch of 100, and for Twitter aswell as Google Plus at a batch size of 5000. The average path lengthhli was calculated at each batch for 20 nodes.
All networks exhibit linear decay for hki. In Google Plus hki isvery high compared with hli. Thus, we provide subplots to showthe graph for hli in better detail. In GitHub (Fig. 5a) hli decays rap-idly at 81%, in Facebook (Fig. 5b) at 83% and in Twitter (Fig. 5c) at91%. Although, GitHub has lower hki than Facebook, both networksare comparable with regards to the threshold where hli decay be-gins. Google Plus (Fig. 5d) has short hli of only 3.2, which doesnot considerably drop until 98% nodes have been removed. Thismakes Google Plus more comparable to Twitter rather than GitHubor Facebook.
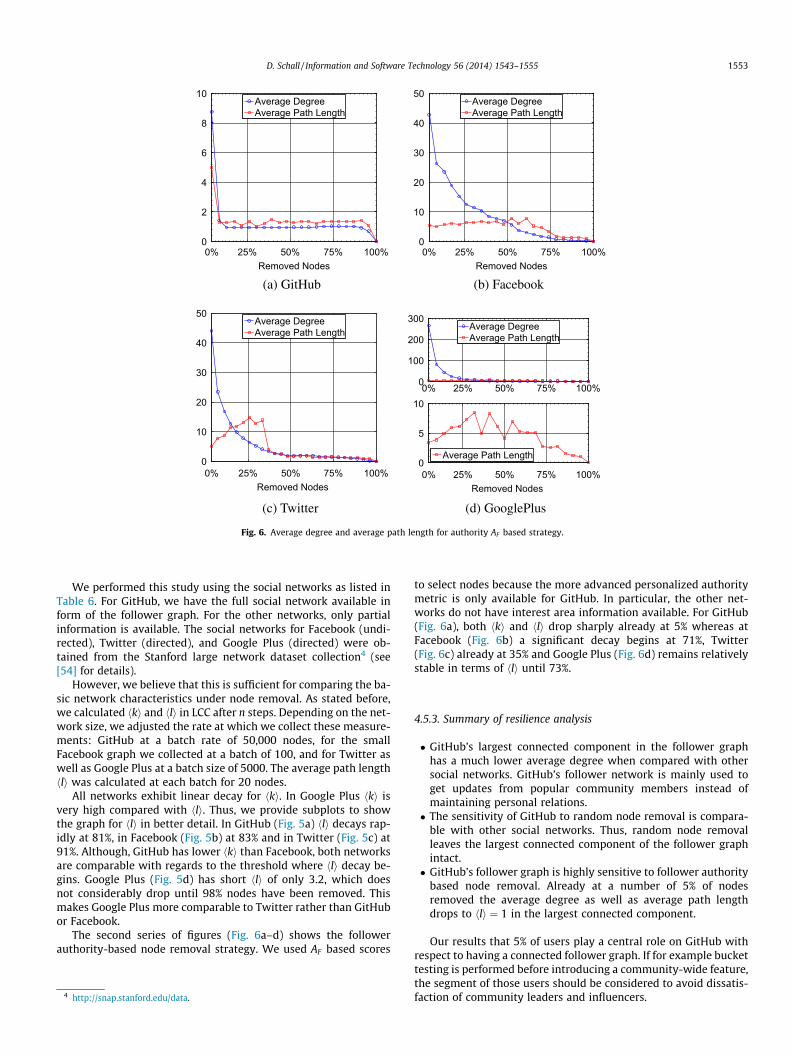
The second series of figures (Fig. 6a–d) shows the followerauthority-based node removal strategy. We used AF based scores
4 http://snap.stanford.edu/data.
to select nodes because the more advanced personalized authoritymetric is only available for GitHub. In particular, the other net-works do not have interest area information available. For GitHub(Fig. 6a), both hki and hli drop sharply already at 5% whereas atFacebook (Fig. 6b) a significant decay begins at 71%, Twitter(Fig. 6c) already at 35% and Google Plus (Fig. 6d) remains relativelystable in terms of hli until 73%.
4.5.3. Summary of resilience analysis
� GitHub’s largest connected component in the follower graphhas a much lower average degree when compared with othersocial networks. GitHub’s follower network is mainly used toget updates from popular community members instead ofmaintaining personal relations.� The sensitivity of GitHub to random node removal is compara-
ble with other social networks. Thus, random node removalleaves the largest connected component of the follower graphintact.� GitHub’s follower graph is highly sensitive to follower authority
based node removal. Already at a number of 5% of nodesremoved the average degree as well as average path lengthdrops to hli ¼ 1 in the largest connected component.
Our results that 5% of users play a central role on GitHub withrespect to having a connected follower graph. If for example buckettesting is performed before introducing a community-wide feature,the segment of those users should be considered to avoid dissatis-faction of community leaders and influencers.

1554 D. Schall / Information and Software Technology 56 (2014) 1543–1555
5. Conclusions
Online software development has taken a new path where so-cial networking features can be used to discover users and reposi-tories. These features help users to stay up-to-date regarding newdevelopment efforts and community activities. Here we proposed anovel ‘who to follow’ recommendation approach that is based onthe concept of user authority. Instead of simply matching usersby static skill profiles, we proposed a network-centric approachtaking a user’s community engagement as well as social metricsinto account. We have systematically derived a mathematicallysound model to measure user authority based on activity (e.g.,repository commits) and community reputation (follower degree).
The presented concepts have been evaluated using a real worlddataset. To date, GitHub is the most popular platform offering col-laboration features, Wikis, development related tools (e.g., issuetracking) and social networking features such as following. Wehave obtained a GitHub-based dataset including the follower graphand relevant user actions. Based on the dataset, we have performeda number of experiments to test the proposed recommendationapproach. Results show that our personalized ‘who to follow’ rec-ommendation approach delivers better recommendations thannon-personalized recommendations.
Finally, to show the importance of ‘central’ users, we studiednetwork resilience with respect to random and authority-basednode removal. Our analysis shows that GitHub is more sensitiveto authority-based node removal than other social networks. Thelargest connected component of GitHub’s follower graph disap-pears if only 5% of nodes (those having a high degree) leave thenetwork. Information flow established through follower relationswill be strongly impacted if many users whose authority is highare removed from the network. This underpins the importance of‘central’ users and the validity of focusing the ‘who to follow’ rec-ommendations on those users. In addition, applications such asbucket-based testing would benefit from the proposed approachby selecting high authority user for feature testing. At this stage,we have compared the social network resilience among GitHub, adeveloper community with social network features, and other so-cial networks including Facebook, Twitter, and GooglePlus. Allthese platforms have in common that they use follower networksenabling information sharing among users.
In our future work, we will compare the social network resil-ience of GitHub and the resilience of other network-based devel-oper communities (for example, SourceForge). In addition, wewill study more fine grained repository actions for follower recom-mendations. This includes analyzing the detailed location ofchanges in the source code as well as details regarding criticalityof bugs fixes. Finally, we are working on a ‘time-aware’ authorityranking model that takes temporal properties of user actions andcollaborations into account.
References
[1] Github.com, Github Website <http://www.github.com> (last access: August2013).
[2] G. Madey, V. Freeh, R. Tynan, The open source software developmentphenomenon: an analysis based on social network theory, in: AmericasConference on Information Systems (AMCIS2002), 2002, pp. 1806–1813.
[3] F.M. Fisher, R.B. Mancke, J.W. McKie, IBM and the US Data Processing Industry:An Economic History, Praeger, New York, NY, USA, 1983.
[4] A.W. Kosner, Github is the Next Big Social Network, Powered By What You Do,Not Who You Know <http://onforb.es/PX02oJ> (July 2012).
[5] F.O. Bjørnson, T. Dingsøyr, Knowledge management in software engineering: asystematic review of studied concepts, findings and research methods used,Inf. Softw. Technol. 50 (11) (2008) 1055–1068.
[6] R. Conradi, T. Dybå, An empirical study on the utility of formal routines totransfer knowledge and experience, SIGSOFT Softw. Eng. Notes 26 (5) (2001)268–276, http://dx.doi.org/10.1145/503271.503246. <http://doi.acm.org/10.1145/503271.503246>.
[7] H. Kwak, C. Lee, H. Park, S. Moon, What is twitter, a social network or a newsmedia?, in: Proceedings of the 19th International Conference on World WideWeb, WWW ’10, ACM, New York, NY, USA, 2010, pp 591–600.
[8] J. Weng, E.-P. Lim, J. Jiang, Q. He, Twitterrank: finding topic-sensitiveinfluential twitterers, in: Proceedings of the Third ACM InternationalConference on Web Search and Data Mining, WSDM ’10, ACM, New York,NY, USA, 2010, pp. 261–270.
[9] P. Gupta, A. Goel, J. Lin, A. Sharma, D. Wang, R. Zadeh, Wtf: the who to followservice at twitter, in: Proceedings of the 22nd International Conference onWorld Wide Web, WWW ’13, 2013, pp. 505–514.
[10] M.J. Brzozowski, D.M. Romero, Who Should I Follow? Recommending Peoplein Directed Social Networks, Tech. rep., HP Labs, 2011.
[11] J. Xu, Y. Gao, S. Christley, G. Madey, A topological analysis of the open sourcesoftware development community, in: Proceedings of the 38th Annual HawaiiInternational Conference on System Sciences, 2005, HICSS ’05, 2005,p. 198a.
[12] J. Paulson, G. Succi, A. Eberlein, An empirical study of open-source and closed-source software products, IEEE Trans. Softw. Eng. 30 (4) (2004) 246–256.
[13] G. Valetto, M. Helander, K. Ehrlich, S. Chulani, M. Wegman, C. Williams, UsingSoftware Repositories to Investigate Socio-Technical Congruence inDevelopment Projects, MSR ’07, IEEE Computer Society, Washington, DC,USA, 2007, p. 25.
[14] M. Pinzger, N. Nagappan, B. Murphy, Can developer-module networks predictfailures?, in: Proceedings of the 16th ACM SIGSOFT International Symposiumon Foundations of Software Engineering, SIGSOFT ’08/FSE-16, ACM, New York,NY, USA, 2008, pp 2–12.
[15] T. Zimmermann, N. Nagappan, Predicting defects using network analysis ondependency graphs, in: Proceedings of the 30th International Conference onSoftware Engineering, ICSE ’08, ACM, New York, NY, USA, 2008, pp.531–540.
[16] P. Bhattacharya, M. Iliofotou, I. Neamtiu, M. Faloutsos, Graph-based analysisand prediction for software evolution, in: M. Glinz, G.C. Murphy, M. Pezzè(Eds.), ICSE, IEEE, 2012, pp. 419–429.
[17] B. Heller, E. Marschner, E. Rosenfeld, J. Heer, Visualizing collaboration andinfluence in the open-source software community, in: Proceedings of the 8thWorking Conference on Mining Software Repositories, MSR ’11, ACM, NewYork, NY, USA, 2011, pp. 223–226.
[18] A. Majumder, S. Datta, K. Naidu, Capacitated team formation problem on socialnetworks, in: Proceedings of the 18th ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, KDD ’12, ACM, New York, NY, USA,2012, pp. 1005–1013.
[19] T. Lappas, K. Liu, E. Terzi, Finding a team of experts in social networks, in:Proceedings of the 15th ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining, KDD ’09, ACM, New York, NY, USA, 2009, pp. 467–476.
[20] A. Anagnostopoulos, L. Becchetti, C. Castillo, A. Gionis, S. Leonardi, Online teamformation in social networks, in: Proceedings of the 21st InternationalConference on World Wide Web, WWW ’12, ACM, New York, NY, USA, 2012,pp. 839–848.
[21] G. Gousios, D. Spinellis, Ghtorrent: Github’s data from a firehose, in: M. Lanza,M.D. Penta, T. Xi (Eds.), MSR, IEEE, 2012, pp. 12–21.
[22] S. Wasserman, K. Faust, Social Network Analysis: Methods and Applications,Cambridge University Press, Cambridge, 1994.
[23] D.J. Watts, S.H. Strogatz, Collective dynamics of ’small-world’ networks, Nature393 (6684) (1998) 440–442.
[24] M.E.J. Newman, J. Park, Why social networks are different from other types ofnetworks, Phys. Rev. E 68 (2003) 036122.
[25] J. Leskovec, E. Horvitz, Planetary-scale views on a large instant-messagingnetwork, in: Proceedings of the 17th International Conference on World WideWeb, WWW ’08, ACM, New York, NY, USA, 2008, pp. 915–924.
[26] M. Cha, A. Mislove, K.P. Gummadi, A measurement-driven analysis ofinformation propagation in the Flickr social network, in: Proceedings of the18th International Conference on World wide Web, WWW ’09, ACM, NewYork, NY, USA, 2009, pp. 721–730. doi:http://dx.doi.org/10.1145/1526709.1526806.
[27] D. Schall, Expertise ranking using activity and contextual link measures, DataKnowl. Eng. 71 (1) (2012) 92–113.
[28] R. Kumar, J. Novak, A. Tomkins, Structure and evolution of online socialnetworks, in: Proceedings of the 12th ACM SIGKDD International Conferenceon Knowledge Discovery and Data Mining, KDD ’06, ACM, New York, NY, USA,2006, pp. 611–617. doi:http://dx.doi.org/10.1145/1150402.1150476.
[29] D. Nevo, I. Benbasat, Y. Wand, Who Knows What? <http://sloanreview.mit.edu/executive-adviser/2009-4/5147/who-knows-what/>(October 2009).
[30] A. Mockus, J.D. Herbsleb, Expertise browser: a quantitative approach toidentifying expertise, in: Proceedings of the 24th International Conference onSoftware Engineering, ICSE ’02, ACM, New York, NY, USA, 2002, pp. 503–512.doi:http://dx.doi.org/10.1145/581339.581401, <http://doi.acm.org/10.1145/581339.581401>.
[31] T. Fritz, J. Ou, G.C. Murphy, E. Murphy-Hill, A degree-of-knowledge model tocapture source code familiarity, Proceedings of the 32nd ACM/IEEEInternational Conference on Software Engineering, ICSE ’10, vol. 1, ACM,New York, NY, USA, 2010, pp. 385–394. doi:http://dx.doi.org/10.1145/1806799.1806856, <http://doi.acm.org/10.1145/1806799.1806856>.
[32] J.M. Kleinberg, Authoritative sources in a hyperlinked environment, J. ACM 46(5) (1999) 604–632.

D. Schall / Information and Software Technology 56 (2014) 1543–1555 1555
[33] L. Page, S. Brin, R. Motwani, T. Winograd, The Pagerank Citation Ranking:Bringing Order to the Web, Tech. rep., Stanford Digital Library TechnologiesProject, 1998.
[34] T.H. Haveliwala, Topic-sensitive pagerank, in: WWW ’02, ACM, New York, NY,USA, 2002, pp. 517–526.
[35] G. Jeh, J. Widom, Scaling personalized web search, in: WWW ’03, ACM, NewYork, NY, USA, 2003, pp. 271–279.
[36] D. Schall, Measuring contextual partner importance in scientific collaborationnetworks, J. Inform. 7 (3) (2013) 730–736. doi:http://dx.doi.org/10.1016/j.joi.2013.05.003, <http://www.sciencedirect.com/science/article/pii/S1751157713000461>.
[37] J. Zhang, M.S. Ackerman, L. Adamic, Expertise networks in onlinecommunities: structure and algorithms, in: Proceedings of the 16thInternational Conference on World Wide Web, WWW ’07, ACM, New York,NY, USA, 2007, pp. 221–230.
[38] L.A. Adamic, J. Zhang, E. Bakshy, M.S. Ackerman, Knowledge sharing and yahooanswers: everyone knows something, in: Proceedings of the 17th InternationalConference on World Wide Web, WWW ’08, ACM, New York, NY, USA, 2008,pp. 665–674.
[39] D. Schall, Service Oriented Crowdsourcing: Architecture, Protocols andAlgorithms, Springer Briefs in Computer Science, Springer, New York, NY,USA, 2012.
[40] D. Garcia, P. Mavrodiev, F. Schweitzer, Social Resilience in OnlineCommunities: The Autopsy of Friendster, Tech. rep., ETH Zurich, 2013.
[41] W.N. Adger, Social and ecological resilience: are they related?, Progr HumanGeography 24 (3) (2000) 347–364+.
[42] L. Backstrom, D. Huttenlocher, J. Kleinberg, X. Lan, Group formation in largesocial networks: membership, growth, and evolution, in: Proceedings of the12th ACM SIGKDD International Conference on Knowledge Discovery and DataMining, KDD ’06, ACM, New York, NY, USA, 2006, pp. 44–54. doi:http://dx.doi.org/10.1145/1150402.1150412, <http://doi.acm.org/10.1145/1150402.1150412>.
[43] S. Wu, A. Das Sarma, A. Fabrikant, S. Lattanzi, A. Tomkins, Arrival and departuredynamics in social networks, in: Proceedings of the Sixth ACM InternationalConference on Web Search and Data Mining, WSDM ’13, ACM, New York, NY,USA, 2013, pp. 233–242. doi:http://dx.doi.org/10.1145/2433396.2433425,<http://doi.acm.org/10.1145/2433396.2433425>.
[44] L. Backstrom, J.M. Kleinberg, Network bucket testing, in: Proceedings of the20th International Conference on World Wide Web, WWW 2011, 2011, pp.615–624.
[45] M. McPherson, L.S. Lovin, J.M. Cook, Birds of a feather: homophily in socialnetworks, Ann. Rev. Sociol. 27 (1) (2001) 415–444.
[46] M.S. Granovetter, The strength of weak ties, Am. J. Sociol. 78 (6) (1973) 1360–1380.
[47] D. Goldberg, D. Nichols, B.M. Oki, D. Terry, Using collaborative filtering toweave an information tapestry, Commun. ACM 35 (12) (1992) 61–70, http://dx.doi.org/10.1145/138859.138867. http://doi.acm.org/10.1145/138859.138867.
[48] A.Y. Ng, A.X. Zheng, M.I. Jordan, Stable algorithms for link analysis, in:Proceedings of the 24th Annual International ACM SIGIR Conference onResearch and Development in Information Retrieval, SIGIR ’01, ACM, NewYork, NY, USA, 2001, pp. 258–266.
[49] Github.com, Github Event Types <http://developer.github.com/v3/activity/events/types/>.
[50] I. Grigorik, Github Archive <http://www.githubarchive.org> (last access:August 2013).
[51] S. Milgram, The small world problem, Psychol. Today 2 (1967) 60–67.[52] J. Ugander, B. Karrer, L. Backstrom, C. Marlow, The Anatomy of the Facebook
Social Graph, CoRR abs/1111.4503.[53] J. Leskovec, J. Kleinberg, C. Faloutsos, Graphs over time: densification laws,
shrinking diameters and possible explanations, in: Proceedings of the EleventhACM SIGKDD International Conference on Knowledge Discovery in DataMining, KDD ’05, ACM, New York, NY, USA, 2005, pp. 177–187.
[54] J. McAuley, J. Leskovec, Learning to Discover Social Circles in Ego Networks,NIPS ’12, 2012.




















