
Web service workflow selection using system and network QoS constraints
21
114 Int. J. Web Engineering and Technology, Vol. 4, No. 1, 2008 Web service workflow selection using system and network QoS constraints Yannis Panagis, Konstantinos Papakonstantinou, Evangelos Sakkopoulos* and Athanasios Tsakalidis Department of Computer Engineering and Informatics University of Patras Campus, 26504, Patras, Greece and Research Academic Computer Technology Institute N. Kazantzaki str., Campus, 26504, Patras, Greece Fax: +30 261 0960322 E-mail: [email protected] E-mail: [email protected] E-mail: [email protected] E-mail: [email protected] *Corresponding author Abstract: Web services serve as a leading technology platform for web-based data-centric environments providing flexibility of loose coupling, message-based communication. Interest in more efficient web services selection strategies is rather requisite especially from the business process workflow perspective. We present several strategies to efficiently select a set of web services performing a workflow, fulfilling quality specifications at all workflow steps. The focus is on finding the best performing web service given a history of the execution times and current measured variation in operating system and network resource consumption. To assess their efficiency, we experimentally evaluate them and present comparative results, which strongly indicate that they can effectively reduce the overall workflow execution time in a web service-based workflow with QoS constraints. Approaches are presented for a number of workflows depending on their particular characteristics. Keywords: web service selection; web service workflows; Quality of Web Service; QoWS. Reference to this paper should be made as follows: Panagis, Y., Papakonstantinou, K., Sakkopoulos, E. and Tsakalidis, A. (2008) ‘Web service workflow selection using system and network QoS constraints’, Int. J. Web Engineering and Technology, Vol. 4, No. 1, pp.114–134. Biographical notes: Yannis Panagis holds a PhD from the Computer Engineering and Informatics Department, University of Patras and is a member of the Research Academic Computer Technology Institute (RACTI). Pannagis holds an MSc from the same department, where he completed his undergraduate studies. His interests span the areas of data structures, string processing algorithms and web engineering, where he has published papers in international journals and conferences. He has also co-authored two book chapters. Copyright © 2008 Inderscience Enterprises Ltd. Π14 1/21
Transcript of Web service workflow selection using system and network QoS constraints

114 Int. J. Web Engineering and Technology, Vol. 4, No. 1, 2008
Web service workflow selection using system and network QoS constraints
Yannis Panagis, Konstantinos Papakonstantinou, Evangelos Sakkopoulos* and Athanasios Tsakalidis Department of Computer Engineering and Informatics University of Patras Campus, 26504, Patras, Greece and Research Academic Computer Technology Institute N. Kazantzaki str., Campus, 26504, Patras, Greece Fax: +30 261 0960322 E-mail: [email protected] E-mail: [email protected] E-mail: [email protected] E-mail: [email protected] *Corresponding author
Abstract: Web services serve as a leading technology platform for web-based data-centric environments providing flexibility of loose coupling, message-based communication. Interest in more efficient web services selection strategies is rather requisite especially from the business process workflow perspective. We present several strategies to efficiently select a set of web services performing a workflow, fulfilling quality specifications at all workflow steps. The focus is on finding the best performing web service given a history of the execution times and current measured variation in operating system and network resource consumption. To assess their efficiency, we experimentally evaluate them and present comparative results, which strongly indicate that they can effectively reduce the overall workflow execution time in a web service-based workflow with QoS constraints. Approaches are presented for a number of workflows depending on their particular characteristics.
Keywords: web service selection; web service workflows; Quality of Web Service; QoWS.
Reference to this paper should be made as follows: Panagis, Y., Papakonstantinou, K., Sakkopoulos, E. and Tsakalidis, A. (2008) ‘Web service workflow selection using system and network QoS constraints’, Int. J. Web Engineering and Technology, Vol. 4, No. 1, pp.114–134.
Biographical notes: Yannis Panagis holds a PhD from the Computer Engineering and Informatics Department, University of Patras and is a member of the Research Academic Computer Technology Institute (RACTI). Pannagis holds an MSc from the same department, where he completed his undergraduate studies. His interests span the areas of data structures, string processing algorithms and web engineering, where he has published papers in international journals and conferences. He has also co-authored two book chapters.
Copyright © 2008 Inderscience Enterprises Ltd.
Π14
1/21

Web service workflow selection using system and network QoS constraints 115
Konstantinos Papakonstantinou graduated from the Computer Engineering and Informatics Department of the University of Patras in 2005. Since 2006, he has been a postgraduate student in the Technology Education and Digital Systems Department of the University of Piraeus. From November 2005 till October 2006, he worked as a Software Engineer for Actiglobe S.A and since October 2006, he has been working for Exodus S.A., Athens as a software engineer. His interests include web technologies, software design and database systems.
Evangelos Sakkopoulos holds a PhD from the Computer Engineering and Informatics Department, University of Patras, Greece and is a member of the Research Academic Computer Technology Institute (RACTI). He received his MSc degree with honours and his diploma in Computer Engineering and Informatics at the same institution. His research interests include web services, web engineering, web searching, large data set handling, data mining, web usage mining, web-based education and intranets. He has more than 30 publications in international journals and conferences in these areas.
Athanasios Tsakalidis obtained his Diploma in Mathematics from the University of Thessaloniki, Greece (1973), his Diploma in Computer Science (1981) and his PhD (1983) from the University of Saarland, Saarbuecken, Germany. He is currently a Full Professor in the Department of Computer Engineering and Informatics, University of Patras and the R&D Coordinator of the Research Academic Computer Technology Institute (RACTI). His research interests include data structures, graph algorithms, computational geometry, expert systems, medical informatics, databases, multimedia, information retrieval and bioinformatics. He has published several research papers in national and international journals and conferences and is the co-author of the Handbook of Theoretical Computer Science and other book chapters.
1 Introduction
Web service (WS) technologies have been widely accepted (Sholler et al., 2006; Adam, 2005) by both the industry and academia as the prevailing solution for web-based data-centric services integration. Their success was based on the adoption of popular XML-based standards, which as a result maximise compatibility, portability and scalability in the provided solutions – given of course comprehensive design and subsequent careful implementation. Nevertheless, web services need to be further enhanced in order to become a ubiquitous platform for application integration. However, current trends show (Sholler et al., 2006; Adam, 2005) that web services lead quickly towards becoming the standard for future web-based distributed solutions. As a result, the request for web service consumption is expected to rise rapidly and so is the need to indicate and provide efficient and effective web service selection mechanisms.
At the moment, the selection process is based mainly on the conceptual and technical description matching the standardised UDDI registry (UDDI Spec Technical Committee, 2003). According to UDDI specifications, the discovery utilises a query process that returns a list of possible WSs that meet requested functional specifications. However, the specification does not include Quality of Service (QoS) as part of its publication or inquiry APIs. QoS is a broad term, often encompassing policies and service-level agreements. A business is typically concerned with more than a simple performance for a service invocation, including authorisation and access security enforcement, transactional
Π14
2/21

116 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
guarantees (data consistency despite failure), and non-repudiation. We adopt the notions of QoS introduced in the work of Liu et al. (2004); the significance of quality assurance in web services (QoWS) has been discussed, using among others measured variation in operating system and network resource consumption. A technique was given in order to combine multiple quality parameters into a single representation in order to rank a number of WS with similar functionality. Such parameters can be Latency, Availability, Throughput, Execution Cost, Reputation, Authentication, Encryption and more. Their approach in the presence of such QoWS requirements, utilises an intelligent algorithm to provide a list of possible web services that meet certain QoWS criteria. However, the QoWS parameters utilised in that approach are only statically stored in a knowledge database updated through user feedback. We further extend the notion of QoWS knowledge base and we verify the QoWS and produce execution cost prediction at the moment of the WS selection and/or consumption using measured variation in operating system and network resource consumption.
1.1 QoS based in WS workflows
In addition, the WS selection problem becomes more intensive in the case of a workflow of WS (Cardoso et al., 2002), because the selection process is performed repeatedly for many WS. In a typical WSs workflow scenario, a consumer process transparently invokes a process that is subdivided into subprocesses implemented by separate web services.
There are business process workflows that invoke asynchronous services in a long-running context, such as processing a purchase order or insurance claim. Such cases are usually implemented using asynchronous Message Exchange Patterns (MEP). In our case, we study and experiment request-response web services workflows that are implemented in several different business environments where an application has to communicate a time- and data-intensive transaction to another application of the same or other enterprise, business partner or end user. Banking, trading, commercial and telecommunication business scenarios include processes that mainly need such web services (e.g., telecommunication Customer/Call Data Record (CDR) transfers, electronic bill issuing).
1.2 Aims and algorithmic roadmap
In this work, the key aim is to present analytically several different approaches for the selection of web services in some WS workflow scenario where QoWS requirement are met. In the following, the proposed solutions support QoWS capabilities fulfilment, which are verified at the WS selection and/or consumption time.
In particular, we propose and study a number of algorithm variants for the WS selection process in a business workflow execution sequence. Experimental assessment of the algorithms is presented for the case of different workflow characteristics to evaluate the efficiency of the approaches according to different workloads.
To have a short algorithmic roadmap, the reader may bear in mind that in Sections 5.2 to 5.5, we describe algorithms that select the optimal execution sequence at the beginning and stick to that sequence throughout the service consumption process. Note that these algorithms decide the execution sequence even before the start of consumption of any web service belonging to the workflow.
Π14
3/21

Web service workflow selection using system and network QoS constraints 117
We have further experimented, in Section 5.6, on the case where the
execution-sensitive characteristics of the intermediate providers change during the execution. Towards the same direction, we examine algorithms that make each workflow step selection immediately after or during the previously selected web service. Section 6.6 presents an elaborated example of WS selection in an arbitrary workflow step. The intermediate selections are implemented by algorithm variants, which are discussed as preliminary information in Sections 3 and 4.
Overall, this work is organised as follows: Section 2 briefly presents previous and related techniques for the selection of web services. Section 3 describes the key concept of the single QoWS-based WS selection, serving as the necessary preliminary steps. Section 4 presents an overview of further algorithmic variants for single WS selection. Section 5 includes the description of the proposed algorithms. Section 6 discusses the experimental assessment that has been performed in order to evaluate the algorithms’ performance under different workloads and workflow characteristics. Section 7 summarises our contributions and provides future research directions.
2 Previous work
2.1 Pre-WS players
UNIX RPC, Common Object Request Broker Architecture (CORBA), Microsoft’s Distributed Component Object Model (DCOM), and Java Remote Method Invocation (Java RMI) are some of the well-known architectures besides WS that have supported distributed application development and net-centric environments. However, owing to the very complex requirements or lack of support of large software vendors and platform-specific dependencies, all these architectures have more or less failed to become widely accepted (Gisolfi, 2001). Web services technology has been designed (and it continuously evolves) to deal with most of the above drawbacks.
Although non-functional specifications have to be taken into consideration within the context of real-world, method invocation procedures, the WS matching procedure does not usually fulfil this requirement. Ran (2003) presented some desirable characteristics that define Quality of Web Service (QoWS). A robust theoretical approach in the QoS parameters during WS discovery has been presented in Liu et al. (2004), where the requester is able to prioritise and select the preferable quality criteria. However, the authors in Liu et al. (2004) do not provide results that involve typical functional discovery to support performance issues.
2.2 WS discovery and selection
A flexible query language was introduced in Zhuge and Liu (2004), which presented an SQL-like language to support the flexible services retrieval. In order for dynamic discovery to be feasible and imprecise, or for vague query terms during the WS discovery to be acceptable, a fuzzy matchmaking algorithm for web services was introduced by Chao et al. (2005). In Makris et al. (2005) a novel approach introducing improved performance in searching and managing WS in overlay networks is NIPPERS. One more relative peer-based approach is included in the work (Sioutas et al., 2007) that presented
Π14
4/21

118 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
the BDT-Grid WS discovery approach. However, as all these flexible retrieval solutions change according to the web service point-of-presence availability and resources, they did not deal with non-functional criteria during their selection process.
Different WS discovery approaches include the adoption of P2P-like overlay networks to facilitate discovery. In Schmidt and Parashar (2004), a single web service is considered as a multidimensional point that is transformed in higher dimensions to numbers, the service IDs, which are then distributed according to Chord principles.
A recent solution towards QoS inclusion in the selection process called QoS Broker for web services is presented in Yu and Lin (2005). However, in the case of web service workflow, sequencing more workflow-focused solutions have been proposed as one can see in the next section.
2.3 Web service flow
Since web services provide cross-platform support and transparent integration among service providers, they have been utilised widely to accommodate end-to-end business processes. As the nature of these processes becomes increasingly complex, modelling languages such as WSBPEL (2007) provide a framework to represent and control them. In Cardoso et al. (2002), the notion of workflow QoS is introduced. The authors outline research directions in order to develop efficient workflows using web services towards the following areas: specification, prediction algorithms and methods, monitoring tools and mechanisms to control the QoS. In this section, we present mechanisms that deliver sequencing WS intelligence.
In Ballinger (2003), it is acknowledged that efficient and dynamic handling of exceptions can be the means to achieve quality in WS workflows. The authors introduce a number of quality parameters and implement their specifications in web flow, by using rules to monitor and to handle exception automatically. The proposed system ensures the process workflow in several cases as the violation of quality constraints or service faults.
The reader may find an updated and extensive study of more web service discovery and selection algorithms in the survey work of Garofalakis et al. (2006). For several years now, much work has been done concerning web-based data-centric environments based on web services flexibility of loose coupling and message-based communication. In the following, the proposed solutions are a novel attempt for online QoWS-based selection procedure. We will proceed to the next section with preliminary details with regard to our proposed solution.
3 Online QoWS-based selection for a single web service
In this work we enhance, introduce and experimentally evaluate new WS workflow selection algorithms using the notions of the discovery process initially presented in Makris et al. (2006). We will first present a short overview of the single WS QoWS-based selection process to assist the readership. Next, we introduce and analyse our new algorithms for the case of WS workflow in the following subsections.
The key idea is to select among functionally similar web services the one with the minimum expected execution cost. The proposed approach consists of two steps, each one contributing to the final selection. The approach is outlined in Figure 1.
Π14
5/21

Web service workflow selection using system and network QoS constraints 119
Figure 1 Overview of the selection procedure
2. Adaptive Selection
History Log of QoWSOnline request of current QoWSQoWS matching to the expected WSexecution timeManagement of online actions andFinal Selection
1. Pruning Selection
Contour-based selection usinga) network distanceb) # of functionally related WS
In the pruning selection, a contour construction algorithm is activated, which uses two parameters initially. First, the network latency is the mean time required for the network communication between the client requester and the host offering the web service. The second parameter is the number of other distinct web services functionally related to the web service in question.
Contour-based pruning represents WS providers as 2d points and uses a heuristic to exclude some of those servers from further consideration. The heuristic helps excluding points-servers, which have both larger network distance and less number of available services than other available servers. The second parameter can also be substituted by the notion of reputation of brand impact that would depict the fidelity of the provider. The effectiveness and impact of contour selection step has been previously analysed theoretically and experimentally in Makris et al. (2006).
In the second step a selection logic is applied to select the service provider which can, at the moment of execution, guarantee the best possible total execution time (also accounting for network delays), by either matching stored profiles or querying providers at the moment of selection. This logic is called the Adaptive Selection process.
Adaptive selection process includes the following activities:
• QoWS ratings recording. This is the creation and logging of QoWS parameter values and the corresponding execution time of the web service. This information is stored into a history profile (hereafter called web service execution scheme). It is a statistical track of records including the time elapsed during the process of a request by a web service under specific QoWS ratings, as well as the ratings themselves. QoWS parameters are considered to be countable factors in the infrastructure, such as system and application performance counters or user-based feedback evaluation.
• The act of online request of the current QoWS ratings in the WS provider infrastructure. The intention is to retrieve the most recent QoWS ratings from the WS provider. Contrary to the solution proposed in Liu et al. (2004), here ‘live’ QoWS values are retrieved. This action can be implemented using an agent service that will return the current values of system/application countable factors selected as QoWS ratings for the infrastructure implementing a web service.
Π14
6/21

120 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
• Online computation of the expected web service execution time. The idea is to find the expected execution time from the history profile-based matching the current QoWS with some previous one. This action performs matching based on the Euclidean distance between the QoWS ratings and the web service execution scheme. The stored execution time of the record having the minimum Euclidean distance from the QoWS rating is supposed to be the expected execution time for the web service.
• Algorithmic management of the online actions and production of the final selection outcome.
The authors in Makris et al. (2006) also present an algorithm outline to tackle the selection problem for the compositions of web services, with no experimental results though. The kind of composition that is considered is linear composition or, in the terminology of Makris et al. (2006), ‘Execution Sequence’. The proposed methodology models the entire execution sequence and the intermediate choices for service selection as a single graph, and then proposes the execution of a shortest path algorithm to find the overall optimal solution.
4 Algorithmic variants for single service selection
The Adaptive Selection (Makris et al., 2006), depending on network traffic, does one of the following: (a) queries candidate servers one by one; (b) matches stored profiles of the candidate providers; or (c) a combination of (a) and (b). We call this strategy Online Questions Adaptive Selection (OQAS). We propose three more variations:
1 In Offline Preparation Adaptive Selection (OPAS), we store an execution history for each service–provider pair. This history is always consulted in order to obtain execution time estimates, without polling nodes at all.
2 Multicast Questions Adaptive Selection (MQAS) is the same as OQAS, only that we query candidate servers in parallel (multicast) and not one by one.
3 In Offline Preparation, Multicast Questions, Adaptive Selection (OPMQAS), we store profiles as in OQAS/OPAS but we may need to query candidates for their current workload in order to compute execution time estimates (in direct contrast to OQAS). This option arises if the minimum computed estimation is less than the maximum network delay.
5 WS selection in workflows
In this section, we discuss the different proposed solutions. We initially present the background information concerning the notations used. In the sequel, in Sections 5.2 to 5.5, we present novel algorithms that first select the optimal execution sequence and follow that sequence throughout the service consumption process. In particular, two workflow selection approaches are presented in subsections 5.2 and 5.3, which are further enhanced using a multicast mechanism (subsections 5.4 and 5.5 respectively).
Π14
7/21

Web service workflow selection using system and network QoS constraints 121
In Subsection 5.6, cases are discussed where step-by-step selection is performed on the workflow. Four more approaches are presented in this last section that select a WS for the next workflow step just after or during the consumption of the previously selected web service.
5.1 Notations
Before we further discuss our solutions, we provide some useful notation borrowed from Makris et al. (2006). Intuitively we postulate that web services are in general hosted in some network node. Nodes in that sense can possibly host more than one web service. The set of all network nodes is denoted as V. Moreover, we are interested in a service execution sequence W = {ws1, ws2, …, wsk}.
We also consider the execution graph ( , )WG V E of W. The elements of V are produced as follows: for each pair (vi, wsj), vi in set of network nodes V and wsj in set of web services WS(vi), we construct a new virtual node vi,j∈ .V We choose GW to be directed, thus an edge e(vi,j, vk,j+1) indicates that right after the execution of wsj in vi we choose node vk to execute wsj+1. We disallow edges between nodes vi j and vk j, i.e., nodes that serve the same web services. Furthermore, edges of the form e(vi,j, vk, j-1) are prohibited, since in the execution sequence, wsj is strictly followed by wsj+1. Edges are assigned costs from a cost function C: E +→ ℜ For an edge e(vi,j, vk,j+1)∈ ,E C(e) corresponds to the execution time of wsj+1 in vk plus the network latency to switch from vi to node vk, i.e.:
C(e) = ET(wsj+1, vk) + NL(vi, vk) (1)
Whenever an edge e∈ E connects two virtual nodes that are distinct entities of the same real-world computer, the latency term is zero. We complement GW with two more nodes, a source s and a drain t and with a set of extra edges from s to vi,1 for each appropriate i, as well as edges from every vi,k node to t. Edges from s to every distinct vi,1 have a cost equal to the cost of reaching vi,1 from s, whereas the edges leading to t have zero cost. This representation allows running some shortest path algorithm in order to locate the optimal execution sequence in terms of execution time.
5.2 Online Questions Workflow Selection – OQWS
In order to be able to judge the quality of the candidate web services, we can ask all nodes for their current workload and therefore compute new execution time estimations for every candidate web service before ever selecting any web service for the execution schedule. The execution time estimation for every web service is done as in single service selection by matching their hosts’ workload against stored profiles for each web service and setting estimated time according to the execution time of the nearest profile with respect to the Euclidean distance between the stored profiles and the current profile. The execution time estimates are stored in an array called r. In this way, the graph GW is constructed only once for a specific workflow and the shortest s–t path can be computed using any known algorithm for the shortest path finding (e.g., greedy algorithm, Dijkstra’s shortest path algorithm).
Π14
8/21

122 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
Online Questions Workflow Selection – OQWS
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U and an array L storing the network latencies of servers in V. Output: An execution schedule ES 1. Ask all nodes in V for their current workload, compute new estimations for each candidate web service in U and store them to r. 2. Construct the graph GW based on values of r, L and W. 3. Find the shortest path of GW using a known algorithm 4. return the execution schedule ES corresponding to the shortest path of GW.
5.3 Online Questions Using Threshold Workflow Selection – OQUTWS
Instead of asking all nodes, we can use a time threshold beyond which, for web services belonging to unasked nodes, we take as their execution time estimates the averages of all their execution times recorded in the service profile. Such thresholds can be computed automatically as percentage of the minimum value of the averaged previous execution time of the WS involved in selection. We define a new set, A, holding servers of V that have not been asked so far. Array Execution Time (ET) is used to hold estimates for web services belonging to unasked nodes and r is used to hold estimates for web services belonging to asked nodes. Array NT stands for Network Time and holds durations owing to network distance.
Online Questions Using Threshold Workflow Selection – OQUTWS
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U, an array L storing the network latencies of servers in V and a time threshold T Output: An execution schedule ES 1. A ← V 2. while (elapsed time so far < T) 3. Let u be the next node in V, ask u for its current workload, compute the execution time
estimates for WS belonging to u based on this workload and store them to r. 4. A ← A – {u} 5. end-while 6. for each web service belonging to nodes of A, compute the average of all its execution times recorded in the service profile and store each average to the corresponding entry of ET; 7. construct the graph GW based on values of r, ET, L and W. 8. find the shortest path of GW using a known algorithm 9. return the execution schedule ES corresponding to the shortest path of GW.
5.4 Multicast Questions Using Threshold Workflow Selection – MQUTWS
We could modify the just previously presented algorithm in Section 5.3 by using multicast queries in order to ask all nodes for their current workload concurrently. We can also specify again a time threshold beyond which the algorithm stops waiting for node responses. For the web services belonging to nodes that had not responded before the time threshold was reached, we take as their execution time estimates the averages of all their execution times recorded in the service profile.
Π14
9/21

Web service workflow selection using system and network QoS constraints 123
Multicast Questions Using Threshold Workflow Selection – MQUTWS
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U, an array L storing the network latencies of servers in V and a time threshold T Output: An execution schedule ES 1. A ← V 2. ask all nodes for their current workload using a multicast mechanism; 3. while (elapsed time so far < T) 4. if (a node response has arrived) 5. Let u be this node; 6. compute the execution time estimates for WS belonging to u and store them to ET. 7. A ← A – {u}; 8. end-if 9. end-while 10. for each web services belonging to nodes of A compute the average of all its execution times recorded in the service profile and store each average to the corresponding entry of ET; 11. construct the graph GW based on values of ET, L and W. 12. find the shortest path of GW using a known algorithm 13. return the execution schedule ES corresponding to the shortest path of GW.
5.5 Multicast questions workflow selection
MQUTWS can be easily modified to a non-threshold-using algorithm:
Multicast Questions Workflow Selection – MQWS
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U, an array L storing the network latencies of servers in V and a time threshold T Output: An execution schedule ES 1. ask all nodes for their current workload using a multicast mechanism; 2. Construct the graph GW based on values of ET, L and W. 3. Find the shortest path of GW using a known algorithm 4. return the execution schedule ES corresponding to the shortest path of GW.
5.6 Workflow selection using step-by-step selection
In this section we present more algorithms on the case where the execution-sensitive characteristics of the intermediate providers change during the execution. The four (Sections 5.2 to 5.5) previously presented algorithms for workflow-selection problem make the assumption that the workloads of nodes do not change notably during the execution of the selected execution schedule. But this could not always be true especially when the execution times of the selected web services are relatively large. Thus, instead of asking all nodes initially, we can select the next web service of the execution schedule just after or during the consumption of the previously selected web service of the execution schedule.
The selection in each step of the workflow can be done using one of the several versions of online selection presented in Section 4. In this way, we can reduce the total time spent for the selection process.
Π14
10/21

124 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
5.6.1 Workflow selection using OQAS (WSOQAS)
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U and an array L storing the network latencies of servers in V.
1. Let k denote the number of web services constituting W;
2. while (i < k)
3. Let Ui denote the subset of U including all candidate services for the i-th step of the workflow.
4. Perform a web service selection for web services in Ui, using OQAS.
5. Consume the selected web service;
6. end-while
5.6.2 Workflow selection using OPAS (WSOPAS)
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U and an array L storing the network latencies of servers in V.
1. Let k denote the number of web services constituting W;
2. while (i < k)
3. Let Ui denote the subset of U including all candidate services for the i-th step of the workflow.
4. Perform a web service selection for web services in Ui, using OPAS.
5. Consume the selected web service;
6. end-while
5.6.3 Workflow selection using MQAS (WSMQAS)
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U and an array L storing the network latencies of servers in V.
1. Let k denote the number of web services constituting W;
2. while (i < k)
3. Let Ui denote the subset of U including all candidate services for the i-th step of the workflow.
4. Perform a web service selection for web services in Ui, using MQAS.
5. Consume the selected web service;
6. end-while
5.6.4 Workflow selection using OPMQAS (WSOPMQAS)
Input: A standard execution sequence W, a set of candidate web services U, a set of servers V hosting all services of U and an array L storing the network latencies of servers in V.
1. Let k denote the number of web services constituting W;
2. while (i < k)
3. Let Ui denote the subset of U including all candidate services for the i-th step of the workflow.
4. Perform a web service selection for web services in Ui, using OPMQAS.
5. Consume the selected web service;
6. end-while
Π14
11/21

Web service workflow selection using system and network QoS constraints 125
6 Experiments
6.1 Implementation details and experimental evaluation
In this section, first we present the implementation and case study details; we also evaluate the performance of the workflow selection heuristics by performing a series of experiments. Our work on QoWS has been initially motivated during the study and implementations for the billing, customer relations and reporting infrastructure of a private national telecommunication carrier since 2003.
For this work, all implementations and the experimental assessments were based on MS .NET framework version 1.1 using the C# programming language. The servers’ operating system was Windows 2003 standard or enterprise editions and the DBMSs were based on MS SQL Server 2000. The development platform was chosen solely because of the experience of the development team. Synthetic web service data were generated to test the proposed algorithms, together with random network and workload characteristics. The latter, although random, reflect cases of intraenterprise web services for billing, customer relations and reporting infrastructure in the corporate network of a large private telephony provider–carrier. All web services were considered in a single instance of the request–response exchange message pattern (the most commonly used scenario (Ballinger, 2003)). More details on data ranges in the following sections.
In the following, we discuss the impact of QoS fulfilment during WS discovery under all these different circumstances, including the case where the cost of online QoS processing is high (compared to the execution time).
Following we experimentally evaluated the performance of the previously presented algorithms. The common characteristics of the methodologies used for the performing of these experiments are presented below.
• Distinct QoWS characteristics are participating in the execution schemes. Without affecting generality as more QoWS parameters may be utilised, we assumed six QoWS parameters being recorded, namely, number of system processes running on the infrastructure, CPU utilisation, memory utilisation, number of threads running on the infrastructure, physical disk utilisation and processor queue length. All parameters were normalised to facilitate computations: QoWS [0,1].∈
• The same WS list was imported, each time we performed an experiment, into an implementation of the random workflow selection algorithm. This algorithm for each step of the workflow simply selects randomly a web service that will be consumed. The time consumed at each workflow step by this algorithm is simply the total execution time of the selected web service (network latency + execution time).
Overall, algorithms have been evaluated in two groups, evaluating different behaviours. The first group included algorithms presented in Sections 5.2 up to 5.5, i.e., algorithms that first select the optimal execution sequence and follow that sequence throughout the service consumption process. The second group included algorithms presented in Section 5.6, i.e., algorithms on the case where the execution-sensitive characteristics of the intermediate providers change during the execution (These algorithms’ name start with the letter W). Sections 6.2 and 6.3 evaluate the first group using different execution and network time and using versatile workflow characteristics, respectively, with the same synthetic data but on different parameters. Sections 6.4 and 6.5 perform the respective tests (the same test data sets are utilised in Sections 6.2 and 6.3) for the
Π14
12/21
126 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
evaluation of the second group of algorithms. Finally in Section 6.6, workflow exception cases are evaluated using a method for dealing with host workloads that are expected to change significantly after a certain step of the workflow.
6.2 Performance comparison using different execution and network time
The key aim of this experimentation is to evaluate the behaviour of algorithms OQWS, OQUTWS, MQUTWS and MQWS (algorithm details in Sections 5.2–5.5, respectively) when performing selection of candidate web services with different ranges of execution and network times on the same business workflow. We consider that each workflow is characterised by the number of steps that it involves and the range of web services that each step has to select from. To evaluate our algorithms we consider that each workflow finishes at the same number of steps for any of its available possible paths. In this case, we used a workflow consisting of five steps and the range for the candidate web services per step for all experiments of this group was set at 1 up to 5.
We tried four different web services sets, which are combinations of execution and network times. These sets are based on case study services. Details of the set combinations of execution and network times are presented in Table 1. On the basis of our experience from the industry, we experimented on formulating four different sets of execution and network times for web services.
Table 1 Description of tested web services sets
Result set ID Execution time(s) Network time(s)
WS Set 1 10 up to 60 1 up to 30
WS Set 2 30 up to 320 1 up to 30
WS Set 3 60 up to 600 1 up to 30
WS Set 4 180 up to 3600 10 up to 60
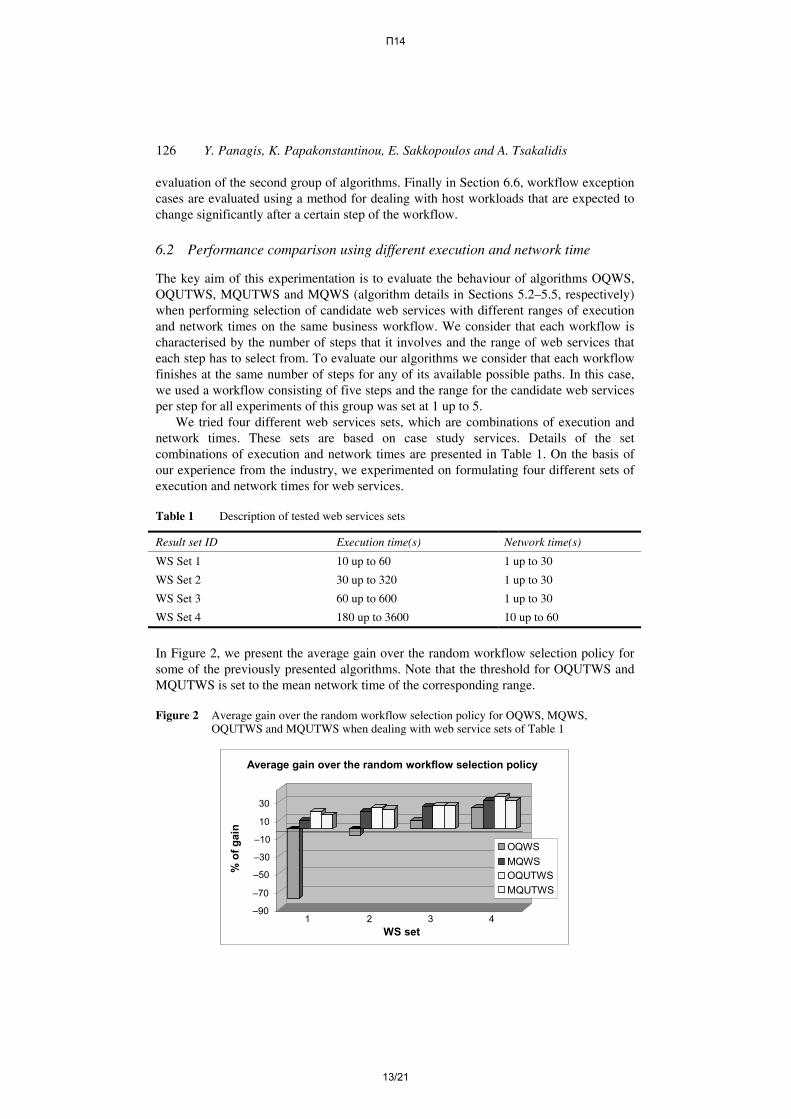
In Figure 2, we present the average gain over the random workflow selection policy for some of the previously presented algorithms. Note that the threshold for OQUTWS and MQUTWS is set to the mean network time of the corresponding range.
Figure 2 Average gain over the random workflow selection policy for OQWS, MQWS, OQUTWS and MQUTWS when dealing with web service sets of Table 1
–90
–70
–50
–30
–10
10
30
% o
f gai
n
1 2 3 4WS set
Average gain over the random workflow selection policy
OQWSMQWSOQUTWSMQUTWS
Π14
13/21
Web service workflow selection using system and network QoS constraints 127
As we see in Figure 2, the average gain of all algorithms is larger when execution times are relatively large compared to network times. We can also see that the performance of OQWS is rather bad in the first two sets, which contain web services with execution times that range close to the network times. Note that OQWS algorithm works efficiently for long execution times with respect to network latencies because it queries all web service nodes. This behaviour is expected as OQWS is practically the direct transformation of the adaptive algorithm presented in Makris et al. (2006) for the case of workflows. In these cases, the use of one of the other presented algorithms would be preferable. Moreover, algorithms using multicast questions have better performance than algorithms using normal online questions only when threshold is not used, as OQUTWS seems to have a better performance than MQUTWS in all tested sets. We could also note that the use of threshold helped all algorithms to achieve better average gains on all tested sets.
6.3 Comparison results using versatile workflow characteristics
To further evaluate the proposed algorithms, we experimented with OQWS, OQUTWS, MQUTWS and MQWS (algorithm details in Sections 5.2–5.5, respectively) w.r.t. different workloads and versatile workflow characteristics, including the range of possible choices per workflow step as well as the length of workflow. To be able to see the impact on performance by taking only these two parameters into account, we stabilised the web service execution time range (10 to 60) and the network time range (1 to 30). For the parameters referred before, we used several combinations of possible choices per workflow step and workflow length.
These combinations are presented in Table 2.
Table 2 Test set characteristics
Set ID Workflow steps-length Candidate web services per workflow step
1 5 1 up to 2
2 5 2 up to 5
3 5 3 up to 8
4 5 8 up to 10
5 10 1 up to 2
6 10 2 up to 5
7 10 3 up to 8
8 10 8 up to 10
9 15 1 up to 2
10 15 2 up to 5
11 15 3 up to 8
12 15 8 up to 10
13 20 1 up to 2
14 20 2 up to 5
15 20 3 up to 8
16 20 8 up to 10
Π14
14/21
128 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
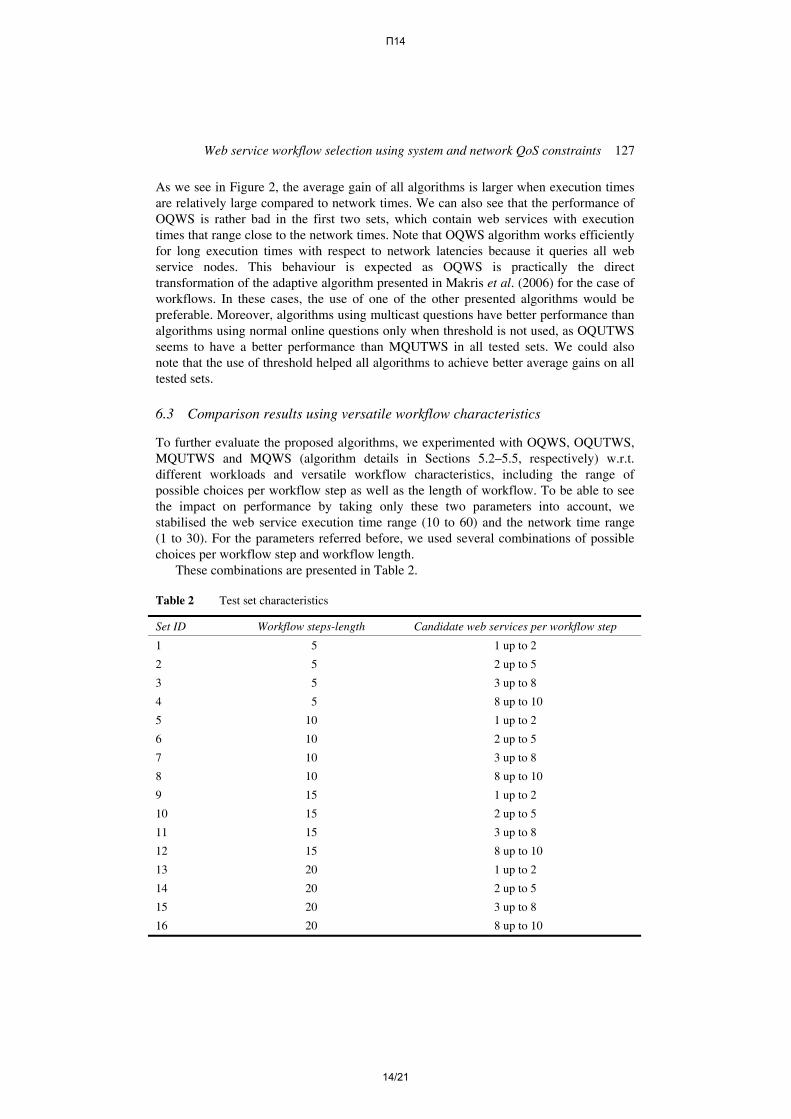
In Figure 3, we present the average gain over the random selection policy for MQWS, OQUTWS, MQUTWS. Once again for OQUTWS and MQUTWS the threshold is set to the mean network time of the corresponding network time range.
Figure 3 Average gain over the random workflow selection policy for MQWS, OQUTWS and MQUTWS when dealing with web service sets of Table 2
Average gain over the random workflow selection policy
–10
–5
0
5
10
15
20
25
30
35
40
45
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Set ID
% o
f gai
n
MQWSOQUTWSMQUTWS
As we can observe, MQWS performance increases as either the average number of web services per step or the workflow length increases. The same happens with MQUTWS using a threshold value equal to the mean of network time range, albeit this algorithm seems to achieve a better average gain than MQWS when dealing with the same workload. From the above experiment, it seems that both a large number of web services per step and a long workflow are desirable in order to achieve larger average gain. Nevertheless, in case of the algorithms using normal online questions, this advantage is lost because of the long time required to ask all hosts for their current workload.
In Figure 4, we present the performance of MQWS according to the workflow length and the average number of web services per workflow step.
Figure 4 MQWS performance according to workflow length and average number of web services per step
Π14
15/21

Web service workflow selection using system and network QoS constraints 129
6.4 Performance comparison using different execution and network time for
algorithms with step-by-step selection
In the following paragraphs we attempt to evaluate the performance of WSOQAS, WSOPAS, WSMQAS and WSOPMQAS (algorithm details in Section 5.6) for candidate web services with different ranges of execution times and network times. This is the case where instead of asking all nodes initially, we select the next web service in the workflow just after or during the consumption of the previously selected one. We used a workflow of fixed length equal to 5 while the range of the candidate web services per step for all experiments of this group was set to 5.
We tried four different web service sets, using, combinations of execution and network times. These combinations are presented in Table 1.
In Figure 5, we present the average gain over the random workflow selection policy for algorithms using online selection.
As we see in Figure 5, algorithms for workflow selection that use online selection have, in general, a significantly better performance than algorithms not using it. Multicasting mechanisms can increase up to 81.7% the gain in the workflow WS selection process w.r.t. the first two techniques (WSOQAS, WSOPAS) when the network can support it.
Figure 5 Average gain over the random workflow selection policy for WSOQAS, WSOPAS, WSMQAS and WSOPMQAS when dealing with Table 1 web service sets
0102030405060708090
100
% o
f gai
n
1 2 3 4
WS ID
Average gain over the random workflow selection policy
WSOQAS
WSOPASWSMQAS
WSOPMQAS
6.5 Comparison results using versatile workflow characteristics for algorithms with step-by-step selection
Lastly, we try to evaluate the performance of WSOQAS, WSOPAS, WSMQAS and WSOPMQAS according to workload and workflow characteristics, including the range of possible choices per workflow step, as well as the length of workflow. In order to see the impact on performance by modifying only these two parameters, we stabilised the web service execution time range at 10 up to 60 and the network time range at 1 up to 30. For the aforementioned parameters, we used several combinations of possible choices per workflow step and lengths of workflow. These combinations are the same as those in Section 6.3 and are presented in Table 2.
Π14
16/21
130 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
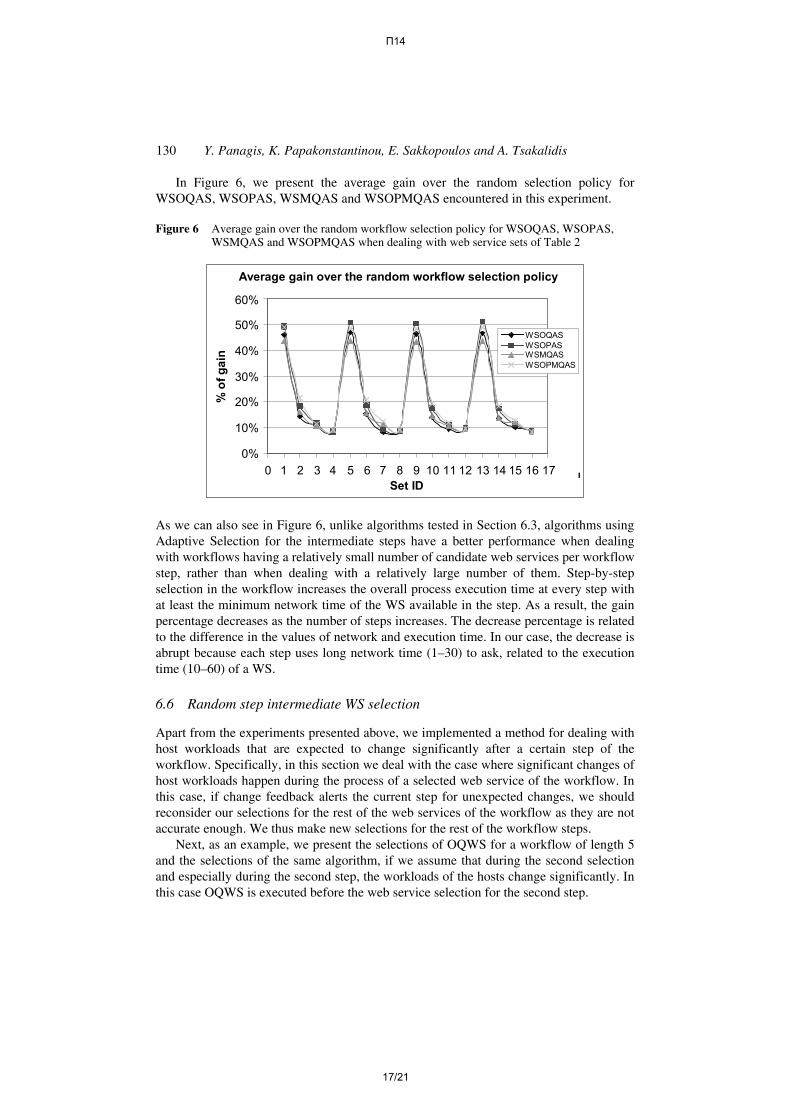
In Figure 6, we present the average gain over the random selection policy for WSOQAS, WSOPAS, WSMQAS and WSOPMQAS encountered in this experiment.
Figure 6 Average gain over the random workflow selection policy for WSOQAS, WSOPAS, WSMQAS and WSOPMQAS when dealing with web service sets of Table 2
Average gain over the random workflow selection policy
0%
10%
20%
30%
40%
50%
60%
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17Set ID
% o
f gai
n
WSOQASWSOPASWSMQASWSOPMQAS
As we can also see in Figure 6, unlike algorithms tested in Section 6.3, algorithms using Adaptive Selection for the intermediate steps have a better performance when dealing with workflows having a relatively small number of candidate web services per workflow step, rather than when dealing with a relatively large number of them. Step-by-step selection in the workflow increases the overall process execution time at every step with at least the minimum network time of the WS available in the step. As a result, the gain percentage decreases as the number of steps increases. The decrease percentage is related to the difference in the values of network and execution time. In our case, the decrease is abrupt because each step uses long network time (1–30) to ask, related to the execution time (10–60) of a WS.
6.6 Random step intermediate WS selection
Apart from the experiments presented above, we implemented a method for dealing with host workloads that are expected to change significantly after a certain step of the workflow. Specifically, in this section we deal with the case where significant changes of host workloads happen during the process of a selected web service of the workflow. In this case, if change feedback alerts the current step for unexpected changes, we should reconsider our selections for the rest of the web services of the workflow as they are not accurate enough. We thus make new selections for the rest of the workflow steps.
Next, as an example, we present the selections of OQWS for a workflow of length 5 and the selections of the same algorithm, if we assume that during the second selection and especially during the second step, the workloads of the hosts change significantly. In this case OQWS is executed before the web service selection for the second step.
Π14
17/21

Web service workflow selection using system and network QoS constraints 131
As we can see in Figure 7, the minimum path selected in the second case differs
from the first case. Overall, the use of an asynchronous alerting mechanism at every WS candidate can help the workflow WS selection process to adapt in any random step with a recomputation of an intermediate WS selection following any of our presented approaches.
Figure 7 The effect of online modifications of execution time on the optimal selection path
0 51
58
45
33
67
2050
18
3125
37
1
1
2 3
4
4
4
5
(a) Original selection
0 51
58
45
33
21
36 4636
33 2739
1
1
2 3
44
4
5
(b) Modified selection
Note: In both cases bold arrows indicate shortest paths.
7 Discussion
In several combinations of algorithms and infrastructure attributes that we have tested, we have seen various interesting results on the behaviour of our algorithms. Firstly, on the algorithms of Sections 5.2 to 5.5, we have observed a considerable advantage of the multicast querying in comparison to sequential online polling. Notably the original adaptive selection does not performs so well compared to the rest of the heuristics. This result can be attributed to the rather long time to collect every online response.
Π14
18/21

132 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
When dealing with workflows with unstable characteristics, we have observed that when network times and execution times are unmodified and comparable, our algorithms perform virtually the same; and that as the number of available WSs per step increases, the gain over random selection increases, too. The latter is a consequence of the fact that our heuristics can gather all the necessary data faster and faster as the number of available services grows and that random selection has increased chances of selecting the slow-to-execute WS in larger candidate sets. Moreover, it seems that WSOPMQAS can very well adapt to the infrastructure conditions and thereby achieve the best gain.
8 Conclusion and future steps
In this work, we have presented several variations of the workflow selection problem, while meeting QoS constraints. Our work on QoWSs was initially motivated during the study and service implementations of a private national telecommunication carrier. It illustrates a mechanism for selecting web services from a group of services based on their performance criteria and an online feedback/prediction mechanism that allows selection of web services to be based on their relative performance.
We tried to provide a complete perspective and to assess different solutions for several cases of WS selection in a wide range of different QoS-based WS workflows using their characteristics as:
• number of WS execution steps involved
• number of WS candidates per step to choose from
• step-by-step QoWS evaluation in path selection
• overall workflow QoWS evaluation in path selection
• feedback-based QoWS evaluation in path selection.
In the experimental part we have conducted an extensive testing of the proposed methodologies for a wide variety of configurations.
During assessment, algorithms assuming stable QoWS attributes (during the whole workflow execution) for services comprising a workflow (e.g., algorithms of Sections 5.2 to 5.5) seem to perform well for the most workflow characteristics tested. Specially, the OQUTWS algorithm that implements online queries combining thresholds seems to obtain the highest overall average gain, topping with almost 36% gain. We have also tested heuristics for algorithms evaluating QoWS values either step by step or in arbitrary step (e.g., algorithms of Section 5.6 and case of Section 6.6). In this case, the WSOPMQAS can gracefully adapt to the changing characteristics and achieve a maximum of 95.9% gain over random selection at each step.
Moreover, the use of multicast mechanism in WS queries improves performance of WS workflow selection as expected. As we see in Figure 8, algorithms not using multicast queries achieve an average gain of 36.5% over random selection, while algorithms using multicast queries achieve an average gain of 46.27% over random selection. Use of timeout thresholds for online questions also seems to be an advantage, as algorithms using thresholds achieved an improvement of 20.92% in average gain over random selection.
Π14
19/21

Web service workflow selection using system and network QoS constraints 133
Figure 8 Comparison between algorithms using multicast queries and algorithms not using them
0%5%
10%15%20%25%30%35%40%45%50%
Ave
rage
gai
n ov
er th
e ra
ndom
sel
ectio
n po
licy
Algorithms NOT usingmulticast queries
Algorithms usingmulticast queries
As for future work directions, QoWS-aware service selection and QoWS provisioning especially in the case of workflows, provide a fertile ground for research by incorporating ideas from graph algorithms and multidimensional data structures. Towards this direction we consider the following steps as important:
• Test the applicability and efficiency of dynamic shortest path algorithms for the case of dynamically modified workflow.
• Extend the pruning first step presented in Figure 1 by computing a contour (layer of maxima) in more than two dimensions.
• As the semantic web strives to expand and more semantically annotated web services are available, the use of semantically enriched QoWS information can further refine the discovery process.
• Study the case of service compositions that form a service DAG to support all multiple flow sequences running in parallel.
References Adam, C. (2005) ‘From web services to SOA and everything in between: the journey begins’,
Webservices.org.
Ballinger, K. (2003) .NET Web Services: Architecture and Implementation with .NET, Addison-Wesley Professional.
Cardoso, J., Amit, S. and Miller, J.A. (2002) ‘Workflow Quality of Service’, in K. Kosanke, R. Jochem, J. Nell and A. Bas (Eds.) Enterprise Inter- and Intra-Organizational Integration – Building International Consensus, pp.303–312.
Chao, K.M., Younas, M., Lo, C.C. and Tan, T.H. (2005) ‘Fuzzy matchmaking for web services’, Proceedings of IEEE AINA Conference, pp.721–726.
Garofalakis, J., Panagis, Y., Sakkopoulos, E. and Tsakalidis, A. (2006) ‘Contemporary web service discovery mechanism’, Journal of Web Engineering, Vol. 5, No. 3, pp.265–290.
Gisolfi, D. (2001) ‘Is web services the reincarnation of CORBA?’, IBM jStart Emerging Technologies, http://www-128.ibm.com/developerworks/webservices/library/ws-arc3.
Π14
20/21

134 Y. Panagis, K. Papakonstantinou, E. Sakkopoulos and A. Tsakalidis
Liu, Y., Ngu, A.N.N. and Zeng, L. (2004) ‘QoS computation and policing in dynamic web service selection’, Proceedings of WWW 2004, USA, pp.66–73.
Makris, Ch., Panagis, Y., Sakkopoulos, E. and Tsakalidis, A. (2006) ‘Efficient and adaptive discovery techniques of web services handling large data sets’, J. Systems and Software, Elsevier Science, Vol. 79, No. 4, pp.480–495.
Makris, Ch., Sakkopoulos, E., Sioutas, S., Triantafillou, P., Tsakalidis, A. and Vassiliadis, B. (2005) ‘NIPPERS: network of InterPolated PeERS for Web Service Discovery’, Proceedings of the 2005 IEEE International Conference on Information Technology: Coding & Computing (IEEE ITCC 2005), Las Vegas, Vol. 2, pp.193–198.
Ran, S. (2003) ‘A model for web services discovery with qos’, ACM SIGecom Exch., Vol. 4, No. 1, pp.1–10.
Schmidt, C. and Parashar, M. (2004) ‘A peer-to-peer approach to Web Service Discovery’, World Wide Web, Springer, Vol. 7, No. 2, pp.211–229.
Sholler, D., et al. (2006) Hype Cycle for Web Services and Related Standards and Specifications.
Sioutas, S., Sakkopoulos, E., Drosos, L. and Sirmakessis, S. (2007) ‘Balanced distributed web service lookup system’, J. Network and Computer Applications, Elsevier Science, in press.
UDDI Spec Technical Committee (2003) ‘UDDI Version 3.0.2’, http://uddi.org/pubs/uddi_v3.htm.
WSBPEL 2.0 Specification (2007) ‘Web services business process execution language version 2.0’, http://docs.oasis-open.org/wsbpel/2.0/CS01/wsbpel-v2.0-CS01.html.
Yu, T. and Lin, K-J. (2005) ‘A broker-based framework for qos-aware web service composition’, 2005 IEEE International Conference on e-Technology, e- Commerce, and e-Services, Hong Kong, China, pp.22–29.
Zhuge, H. and Liu, J. (2004) ‘Flexible retrieval of web services’, J. Syst. Softw., Elsevier, Vol. 70, Nos. 1–2, pp.107–116.
Π14
21/21




















