
UNIVERSIDADE FEDERAL DO OESTE DO PARÁ -PROF
33
UNIVERSIDADE FEDERAL DO OESTE DO PARÁ - PROF. RODRIGO MEDEIROS. 1. A Estatística A Estatística é um ramo da Matemática Aplicada que fornece métodos para a coleta, organização, análise e interpretação de dados e a sua respectiva utilização na tomada de decisões. A Estatística Descritiva (ou dedutiva) se encarrega da coleta, organização e descrição dos dados, enquanto que a Estatística Inferencial (ou indutiva) se encarrega da análise e interpretação dos dados. O método estatístico se dá em diferentes fases: coleta dos dados, crítica dos dados, apuração dos dados, exposição dos dados e análise dos dados. Coleta dos dados: A coleta dos dados deve ocorrer após um planejamento criterioso e a devida determinação das características mensuráveis do fenômeno que se quer estudar. Crítica dos dados: Durante a coleta dos dados, diversos tipos de erros ou falhas podem ocorrer. Essas falhas podem surgir tanto por parte do informante (por distração ou má interpretação das perguntas que lhe foram feitas), ou ainda, por possíveis falhas internas, como erros de digitação ou arredondamento, por exemplo. A crítica dos dados é de grande importância no processo, pois possíveis erros nos dados podem influir grosseiramente nos resultados, adulterando toda a pesquisa. Apuração dos dados: É a soma e o processamento dos dados obtidos e a disposição mediante critérios de classificação. Pode ser manual ou eletrônica. Exposição ou apresentação dos dados: Para que se possa estudar adequadamente um conjunto de dados é comum resumir e simplificar estes dados, a fim de apresentá-los de forma mais adequada (tabelas, gráficos, medidas típicas, etc.), tornando mais fácil o entendimento, a análise e a interpretação do objeto de estudo. Análise dos resultados: A análise dos resultados pode se dar a partir da Estatística Descritiva, que tem objeto descrever e analisar determinada população, sem pretender tirar conclusões de caráter mais genérico. Entretanto, o objetivo último da Estatística é tirar conclusões sobre o todo (População) a partir de informações fornecidas por uma parte representativa do todo (Amostra), objeto da Estatística Inferencial. 1
Transcript of UNIVERSIDADE FEDERAL DO OESTE DO PARÁ -PROF

UNIVERSIDADE FEDERAL DO OESTE DO PARÁ - PROF. RODRIGO MEDEIROS.
1. A Estatística A Estatística é um ramo da Matemática Aplicada que fornece métodos para a coleta, organização, análise e interpretação de dados e a sua respectiva utilização na tomada de decisões. A Estatística Descritiva (ou dedutiva) se encarrega da coleta, organização e descrição dos dados, enquanto que a Estatística Inferencial (ou indutiva) se encarrega da análise e interpretação dos dados. O método estatístico se dá em diferentes fases: coleta dos dados, crítica dos dados, apuração dos dados, exposição dos dados e análise dos dados. Coleta dos dados: A coleta dos dados deve ocorrer após um planejamento criterioso e a devida determinação das características mensuráveis do fenômeno que se quer estudar. Crítica dos dados: Durante a coleta dos dados, diversos tipos de erros ou falhas podem ocorrer. Essas falhas podem surgir tanto por parte do informante (por distração ou má interpretação das perguntas que lhe foram feitas), ou ainda, por possíveis falhas internas, como erros de digitação ou arredondamento, por exemplo. A crítica dos dados é de grande importância no processo, pois possíveis erros nos dados podem influir grosseiramente nos resultados, adulterando toda a pesquisa. Apuração dos dados: É a soma e o processamento dos dados obtidos e a disposição mediante critérios de classificação. Pode ser manual ou eletrônica.
Exposição ou apresentação dos dados: Para que se possa estudar adequadamente um conjunto de dados é comum resumir e simplificar estes dados, a fim de apresentá-los de forma mais adequada (tabelas, gráficos, medidas típicas, etc.), tornando mais fácil o entendimento, a análise e a interpretação do objeto de estudo.
Análise dos resultados: A análise dos resultados pode se dar a partir da Estatística Descritiva, que tem objeto descrever e analisar determinada população, sem pretender tirar conclusões de caráter mais genérico. Entretanto, o objetivo último da Estatística é tirar conclusões sobre o todo (População) a partir de informações fornecidas por uma parte representativa do todo (Amostra), objeto da Estatística Inferencial.
1

2. Conceitos Fundamentais
2.1. Variável: é o conjunto de resultados possíveis de um fenômeno.
Exemplos:
- Para o fenômeno “número de filhos” há um número de resultados possíveis expressos por números naturais: 0, 1, 2, 3, 4, ..., n;
- Para o fenômeno “estatura” há um número infinito de valores numéricos dentro de um determinado intervalo;
- Para o fenômeno “Sexo” são apenas dois os resultados possíveis: masculino ou feminino.
Obs: Quando uma variável admite apenas dois resultados possíveis, diz-se que ela é dicotômica.
Uma variável pode ser de dois tipos:
a) Qualitativa : é toda variável expressa por atributos.
Exemplos: Sexo (masculino ou feminino), profissão (professor, engenheiro, etc.), cor da pele (branca, parda, etc.).
b) Quantitativa : é toda variável expressa por números.
Exemplos: Idade, número de filhos, salário, etc.
Uma variável quantitativa pode ser ainda de dois tipos: contínua e discreta.
Variável contínua: é toda variável quantitativa que pode assumir, teoricamente, qualquer valor entre dois limites. Diz-se ainda que é “tudo aquilo que pode ser medido”.
Variável discreta: é toda variável quantitativa que só pode assumir valores pertencentes a um conjunto enumerável, ou seja, que só assume valores inteiros. Diz-se ainda que é “tudo aquilo que pode ser contado”.
Exemplos: Número de alunos em uma escola: variável discreta; Salário de professores da rede pública de ensino: variável contínua; Notas na 1ª avaliação de Literatura: variável contínua; Número de professores com pós-graduação: variável discreta.
2.2. População: é o conjunto de entes portadores de, pelo menos, uma característica comum.
2.3. Amostra: é um subconjunto finito da população.
2.4. Amostragem: técnica utilizada para recolher amostras. 2

Exercícios Propostos 2.1. Classifique as variáveis em qualitativas ou quantitativas: a) Cor dos olhos. b) Face de cima de um dado após um lançamento. c) Diâmetro de uma roda de automóvel. d) Marca do automóvel. e) Renda anual. f) preço do Kg do feijão. g) Tipo de Hepatite. 2.2. Classifique as variáveis quantitativas em contínuas ou discretas:
a) Comprimento de parafusos produzidos por uma máquina. b) Número de pessoas mortas em acidentes aéreos. c) Número de defeitos por unidade de aparelhos produzidos em uma linha de montagem. d) Volume de bebida por garrafa em uma fábrica de refrigerantes. e) Notas na prova de estatística . f) Peso (Kg) . g) Número de alunos reprovados em História na turma de 1º ano da escola Charles Darwin. h) Número de livros em mau estado na biblioteca central da UFPA.
3. Tabulação
Um dos principais objetivos da Estatística é sintetizar os valores que uma ou mais variáveis podem assumir, para que tenhamos uma visão global da variação dessa ou dessas variáveis. Assim, uma vez realizada a coleta e apuração dos dados, devemos apresentá-los. Duas importantes ferramentas para tal são as Tabelas e os Gráficos.
A Tabela pode ser definida como um quadro que resume um conjunto de observações. Na construção de uma Tabela devemos sempre tentar obter um máximo de esclarecimentos com um mínimo de espaço e tempo, já que o objetivo principal é apresentar os dados de forma sucinta, coerente e organizada, para facilitar a compreensão e análise dos dados estudados.
Uma Tabela compõe-se de:
3.1. Cabeçalho: Conjunto de informações localizado no topo da Tabela. Estas informações são referentes a o quê a Tabela está procurando representar. Toda Tabela deve necessariamente responder a três perguntas: O QUÊ? ONDE? E QUANDO?
Exemplo:
Número de estudantes matriculados em escolas públicas no estado do Amapá no ano de 2003.
O quê? – Número de estudantes matriculados em escolas públicas.
Onde? – No estado do Amapá. 3
Quando? – No ano de 2003.
3.2. Corpo: é o conjunto de linhas e colunas que contém informações sobre a variável em estudo. Segundo o corpo, as Tabelas podem ser de entrada simples ou de dupla entrada.
Exemplo: Entrada Simples.
Faixa etária das vítimas de violência sexual atendidas no projeto Sentinela-Belém nos anos de 2002 a 2004.
Faixa Etária Freqüência Cabeçalho Título
Menor de 6 anos 71 De 6 a 11 anos 178 Corpo da Tabela De 12 a 18 anos 162
Total 411
Fonte: Projeto Sentinela – Belém, 2005
Rodapé
Exemplo: Entrada Dupla.
Terminais telefônicos em serviço no Brasil por região 1991-1993.
Regiões 1991 1992 1993
Norte 342.938 375.658 403.494 Nordeste 1.287.813 1.379.101 1.486.649 Sudeste 6.234.501 6.729.467 7.231.634 Sul 1.497.315 1.608.989 1.746.232 Centro-Oeste 713.357 778.925 884.822 Fonte: Ministério das Comunicações
3.3. Rodapé: é onde colocamos a legenda e todas as informações que venham esclarecer a interpretação da tabela. Geralmente é no rodapé que se coloca a fonte dos dados. Obs: Cuidado! Nunca devemos inserir unidades de medida ou outros símbolos nos dados da tabela. Comprimento fi fr Comprimento (cm) fi fr (% ) 10 cm 5 25% 10 5 25 15 cm 10 50% 15 10 50 20 cm 5 25% 20 5 25 Σ 20 100% Σ 20 100 ERRADO CERTO 4
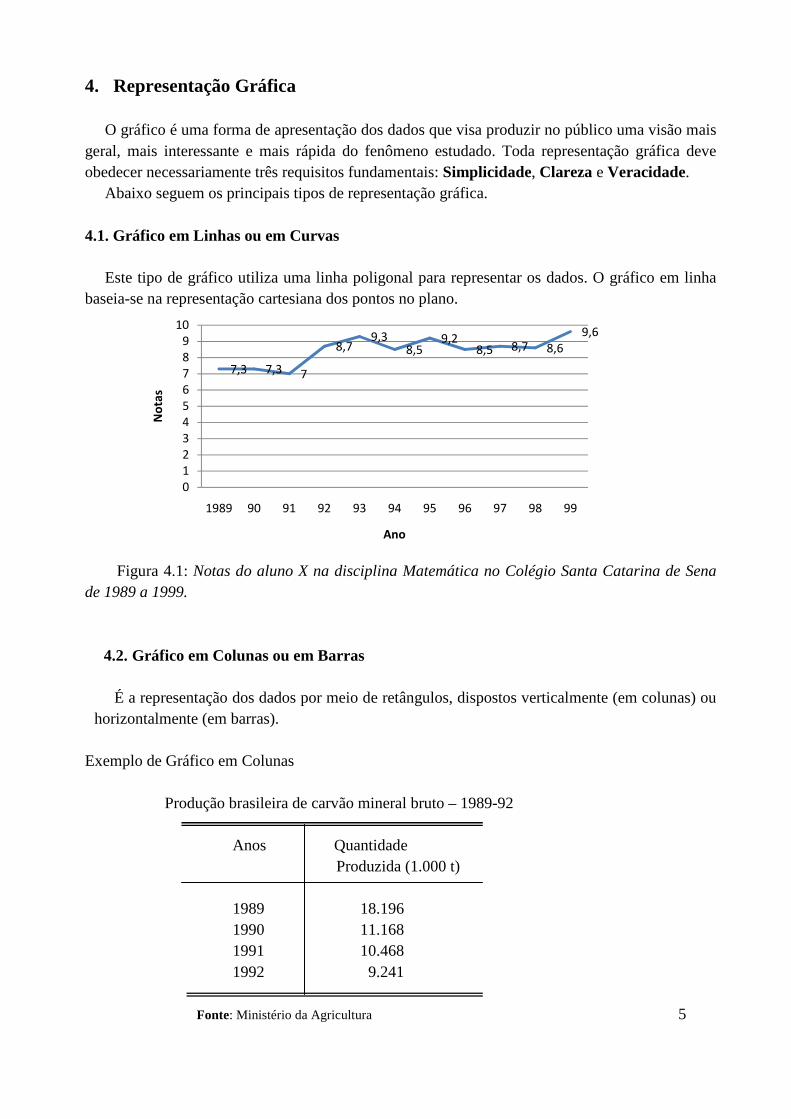
4. Representação Gráfica O gráfico é uma forma de apresentação dos dados que visa produzir no público uma visão mais geral, mais interessante e mais rápida do fenômeno estudado. Toda representação gráfica deve obedecer necessariamente três requisitos fundamentais: Simplicidade, Clareza e Veracidade. Abaixo seguem os principais tipos de representação gráfica. 4.1. Gráfico em Linhas ou em Curvas Este tipo de gráfico utiliza uma linha poligonal para representar os dados. O gráfico em linha baseia-se na representação cartesiana dos pontos no plano.
Figura 4.1: Notas do aluno X na disciplina Matemática no Colégio Santa Catarina de Sena de 1989 a 1999.
4.2. Gráfico em Colunas ou em Barras
É a representação dos dados por meio de retângulos, dispostos verticalmente (em colunas) ou horizontalmente (em barras).
Exemplo de Gráfico em Colunas Produção brasileira de carvão mineral bruto – 1989-92 Anos Quantidade Produzida (1.000 t) 1989 18.196 1990 11.168 1991 10.468 1992 9.241 Fonte: Ministério da Agricultura 5
7,3 7,3 7
8,79,3
8,59,2
8,5 8,7 8,6
9,6
0
1
2
3
4
5
6
7
8
9
10
1989 90 91 92 93 94 95 96 97 98 99
No
tas
Ano
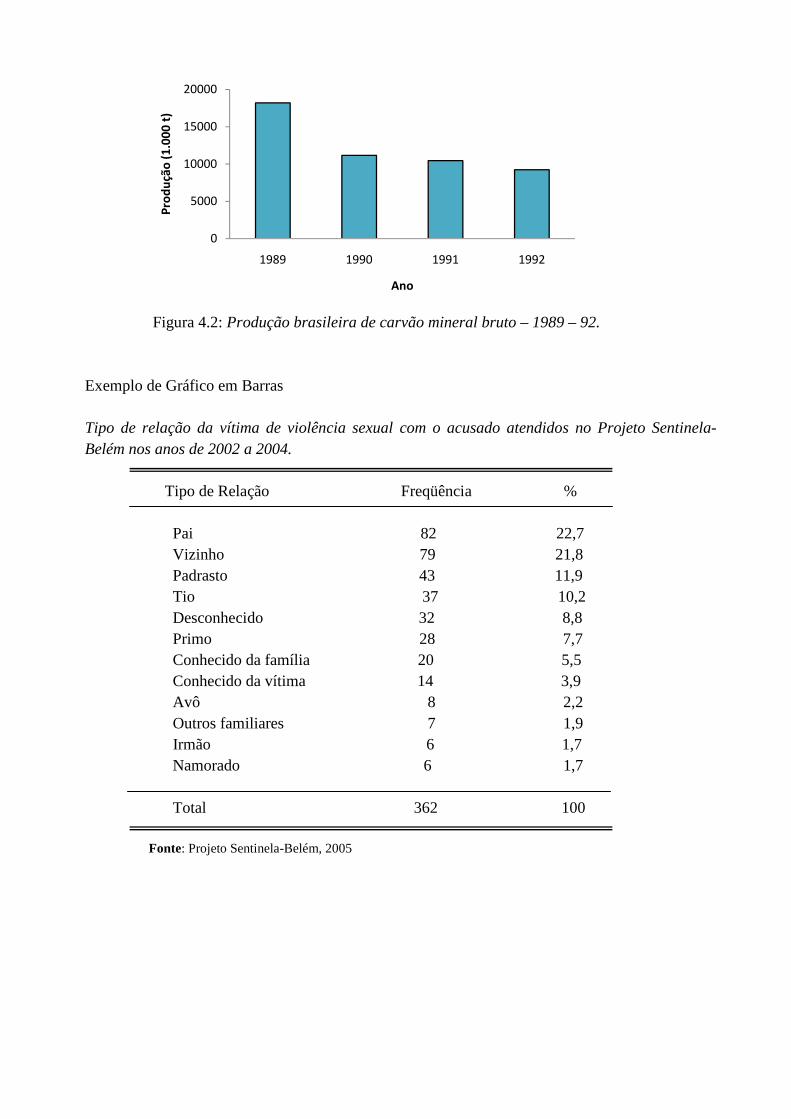
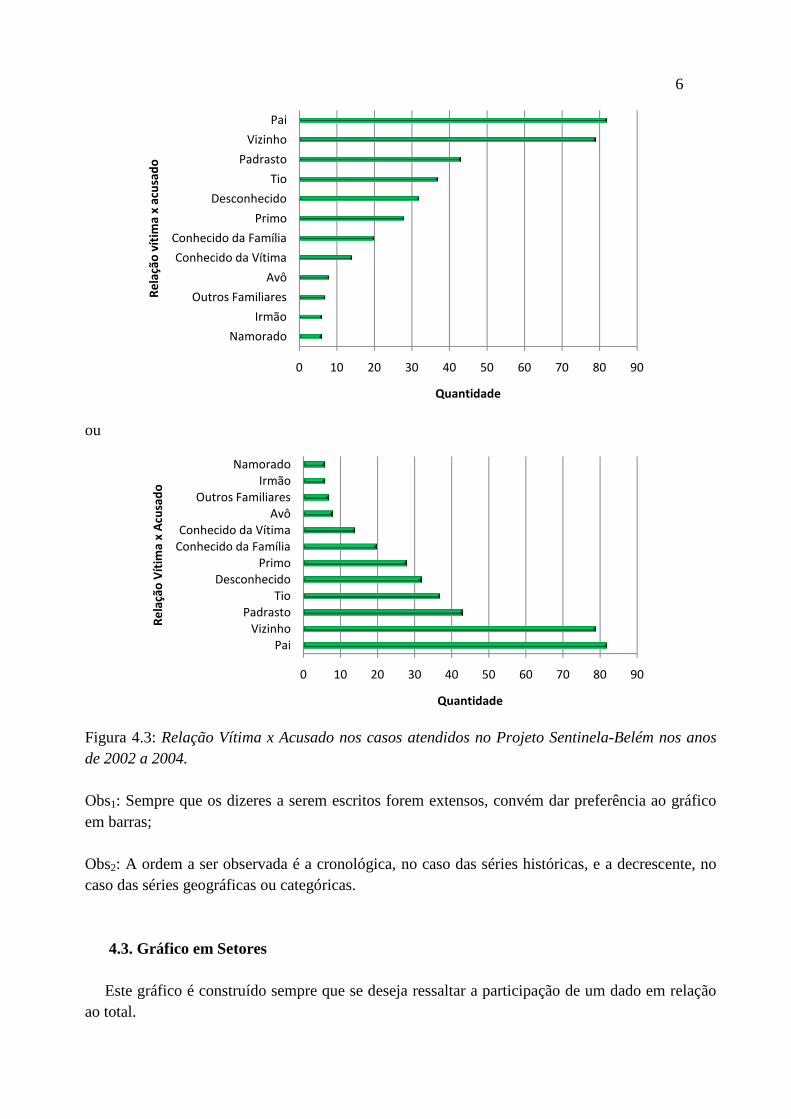
Figura 4.2: Produção brasileira de carvão mineral bruto – 1989 – 92. Exemplo de Gráfico em Barras Tipo de relação da vítima de violência sexual com o acusado atendidos no Projeto Sentinela-Belém nos anos de 2002 a 2004. Tipo de Relação Freqüência % Pai 82 22,7 Vizinho 79 21,8 Padrasto 43 11,9 Tio 37 10,2 Desconhecido 32 8,8 Primo 28 7,7 Conhecido da família 20 5,5 Conhecido da vítima 14 3,9 Avô 8 2,2 Outros familiares 7 1,9 Irmão 6 1,7 Namorado 6 1,7 Total 362 100 Fonte: Projeto Sentinela-Belém, 2005
0
5000
10000
15000
20000
1989 1990 1991 1992
Pro
du
ção
(1
.00
0 t
)
Ano
ou
Figura 4.3: Relação Vítima x Acusado nos casos atendidos no Projeto Sentinelade 2002 a 2004. Obs1: Sempre que os dizeres a serem escritos forem extensos, convém dar preferência aoem barras; Obs2: A ordem a ser observada é a cronológica, no caso das séries históricas, e a decrescente, no caso das séries geográficas ou categóricas.
4.3. Gráfico em Setores Este gráfico é construído sempre que se deseja ressaltar a participação de um dado em relação ao total.
Namorado
Irmão
Outros Familiares
Avô
Conhecido da Vítima
Conhecido da Família
Primo
Desconhecido
Tio
Padrasto
Vizinho
Pai
Re
laçã
o v
ítim
a x
acu
sad
o
Pai
Vizinho
Padrasto
Tio
Desconhecido
Primo
Conhecido da Família
Conhecido da Vítima
Avô
Outros Familiares
Irmão
Namorado
Re
laçã
o V
ítim
a x
Acu
sad
o
Relação Vítima x Acusado nos casos atendidos no Projeto Sentinela
: Sempre que os dizeres a serem escritos forem extensos, convém dar preferência ao
: A ordem a ser observada é a cronológica, no caso das séries históricas, e a decrescente, no caso das séries geográficas ou categóricas.
Este gráfico é construído sempre que se deseja ressaltar a participação de um dado em relação
0 10 20 30 40 50 60 70
Namorado
Irmão
Outros Familiares
Avô
Conhecido da Vítima
Conhecido da Família
Primo
Desconhecido
Tio
Padrasto
Vizinho
Pai
Quantidade
0 10 20 30 40 50 60 70
Pai
Vizinho
Padrasto
Tio
Desconhecido
Primo
Conhecido da Família
Conhecido da Vítima
Avô
Outros Familiares
Irmão
Namorado
Quantidade
6
Relação Vítima x Acusado nos casos atendidos no Projeto Sentinela-Belém nos anos
: Sempre que os dizeres a serem escritos forem extensos, convém dar preferência ao gráfico
: A ordem a ser observada é a cronológica, no caso das séries históricas, e a decrescente, no
Este gráfico é construído sempre que se deseja ressaltar a participação de um dado em relação
80 90
80 90
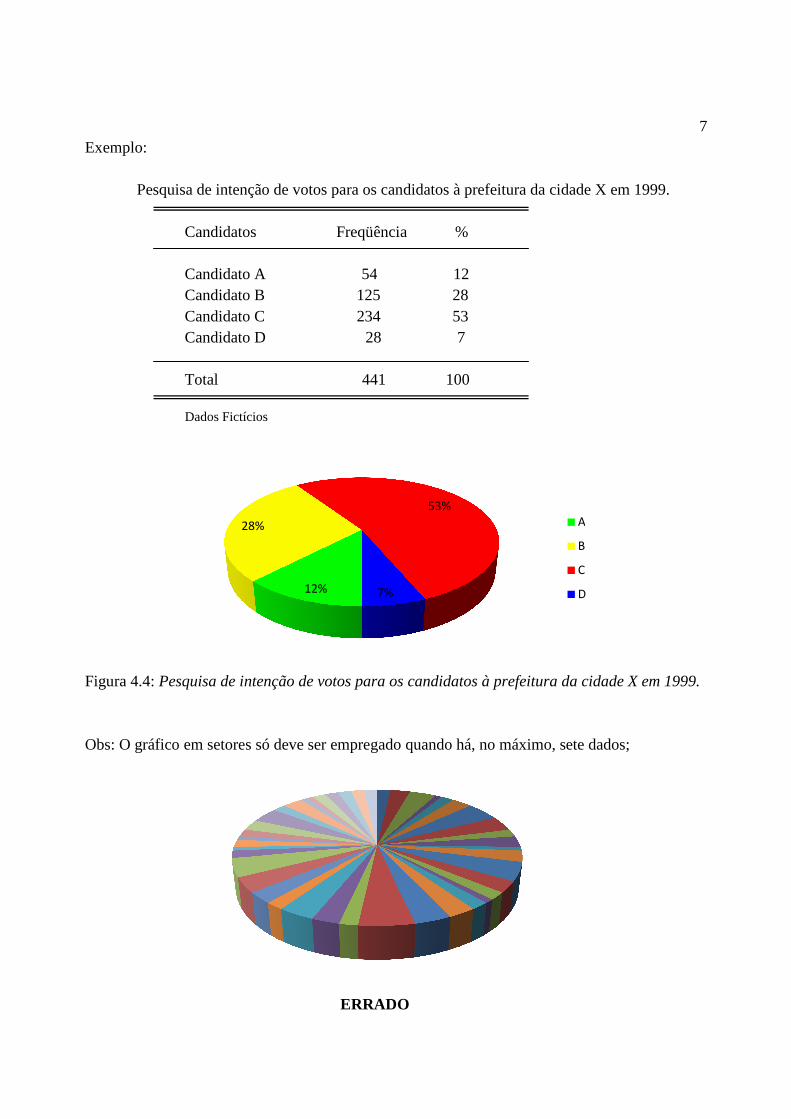
Exemplo: Pesquisa de intenção de votos para os candidatos à prefeitura da cidade X Candidatos Freqüência Candidato A 54 Candidato B 125 Candidato C 234 Candidato D 28 Total Dados Fictícios
Figura 4.4: Pesquisa de intenção Obs: O gráfico em setores só deve ser empregado quando há, no máximo, sete dados;
28%
Pesquisa de intenção de votos para os candidatos à prefeitura da cidade X
Candidatos Freqüência %
Candidato A 54 12 Candidato B 125 28 Candidato C 234 53
ato D 28 7
441 100
de intenção de votos para os candidatos à prefeitura da cidade X em 1999.
: O gráfico em setores só deve ser empregado quando há, no máximo, sete dados;
ERRADO
12%
53%
7%
7
Pesquisa de intenção de votos para os candidatos à prefeitura da cidade X em 1999.
de votos para os candidatos à prefeitura da cidade X em 1999.
: O gráfico em setores só deve ser empregado quando há, no máximo, sete dados;
A
B
C
D

Exercícios Propostos 4.1. Represente os dados abaixo usando o gráfico em linha: Comércio exterior Brasil – 1984 - 93 Quantidade (1.000 t) Ano Exportação Importação 1984 141 90 1985 146 108 1986 133 120 1987 142 100 1988 169 139 1989 177 140 Fonte: Min. Indústria, comércio e turismo
4.2. Foi realizada uma pesquisa em uma escola para descobrir quais são os principais fatores causadores do baixo rendimento escolar entre os estudantes. O pesquisador obteve os seguintes dados: Problemas familiares: 56 alunos Problemas de saúde: 13 alunos Falta de interesse: 61 alunos Problemas com o professor: 25 alunos Falta de motivação: 30 alunos Conversa em sala de aula: 42 alunos Outros: 5 alunos O pesquisador deve utilizar o gráfico em barras ou o gráfico em colunas? Construa o gráfico. 4.3. Uma pesquisa vocacional foi realizada entre jovens que cursam o ensino médio em uma escola pública de Castanhal. Esta é a tabela com os dados percentuais: Área Freq. Relativa (%) Exatas 20 Humanas 30 Biológicas 40 Letras e artes 10
Total 100 Construa o gráfico em setores: 9

4.4. Um professor de língua Portuguesa registrou as médias anuais de uma turma durante 5 anos, como mostra a tabela a seguir:
Ano 2004 2005 2006 2007 2008 Média 7,0 5,25 8,60 9,0 6,5 Construa um gráfico em barras para a tabela acima.
5. Distribuição de Freqüências Vamos inicialmente considerar as notas de 30 alunos da escola Madre Celeste, em Ananindeua, em 2003. 3,0 5,0 1,0 8,0 8,0 6,0 5,0 7,0 9,0 9,0 9,0 2,0 3,0 0,0 2,0 4,0 5,0 6,0 6,0 4,0 9,0 5,0 3,0 3,0 4,0 7,0 4,0 6,0 4,0 8,0 Portanto, estamos lidando com a variável quantitativa Nota. Repare que os dados encontram-se desorganizados e é difícil tirar alguma conclusão a seu respeito. A distribuição de freqüência é uma tabela na qual indica-se o número de ocorrências (freqüência) de cada observação. Para construir uma distribuição de freqüências, é necessário compreender os seguintes conceitos:
1. Rol: Consiste na ordenação dos dados segundo algum critério de grandeza (crescente ou decrescente).
Rol: 0,0 1,0 2,0 2,0 3,0 3,0 3,0 3,0 4,0 4,0 4,0 4,0 4,0 5,0 5,0 5,0 5,0 6,0 6,0 6,0 6,0 7,0 7,0 8,0 8,0 8,0 9,0 9,0 9,0 9,0
2. Freqüência simples ou absoluta (f i): é um valor que representa o número de vezes que uma determinada observação aparece.
3. Freqüência relativa (fr): é a razão entre a freqüência simples e o total de observações.
4. Freqüência acumulada (fac): é o total das freqüências de todos os valores inferiores a uma dada observação. O último valor da fac sempre coincidirá com ∑ ��.
10

Notas dos alunos do colégio Madre Celeste em Ananindeua no ano de 2003 Notas fi fac fr (%) 0,0 1 1 3,3 1,0 1 2 3,3 2,0 2 4 6,7 3,0 4 8 13,3 4,0 5 13 16,7 5,0 4 17 13,3 6,0 4 21 13,3 7,0 2 23 6,7 8,0 3 26 10,0 9,0 4 30 13,4 Total 30 100 Fonte: Colégio Madre Celeste
Muitas vezes, o processo de construir uma distribuição de freqüências pode se tornar inconveniente, já que pode tomar muito espaço e tornar a análise muito trabalhosa. Nestes casos convém dividir a amostra em intervalos de classe. Notas dos alunos do colégio Madre Celeste em Ananindeua no ano de 2003 Notas fi fac fr (%) 0,0 |---- 2,0 2 2 6,7 2,0 |---- 4,0 6 8 20,0 4,0 |---- 6,0 9 17 30,0 6,0 |---- 8,0 6 23 20,0 8,0 |---- 10,0 7 30 23,3 Total 30 100 Fonte: Colégio Madre Celeste.
5. Classe: é um intervalo de variação da variável. As classes são representadas simbolicamente por i, sendo i = 1, 2, 3, 4, ..., k (onde k é o número total de classes). Portanto, no exemplo apresentado temos k = 5 e o intervalo 4,0 |---- 6,0 define a terceira classe (i = 3). 6. Limites de classe: são os extremos de cada classe.
11

O menor número é o limite inferior de classe (l i) e o maior número, o limite superior de classe (Li).
Na quarta classe, por exemplo, temos l4 = 6,0 e L4 = 8,0.
7. Amplitude de um intervalo de classe (hi): é a medida do intervalo que define a classe e
pode ser obtida simplesmente pela diferença entre os limites superior e inferior dessa classe. hi = Li - li No caso da segunda classe, temos: h2 = L2 – l2 = 4,0 – 2,0 = 2.
8. Amplitude total da distribuição (AT) : é a diferença entre o limite superior da última classe e o limite inferior da primeira classe.
AT = L (max.) – l (min.) Em nosso exemplo: AT = 10,0 – 0,0 = 10.
9. Número de Classes:Uma das primeiras questões a enfrentar na hora de construir uma distribuição de freqüências com intervalos de classe é o número de classes e, conseqüentemente, a amplitude e os limites dos intervalos de classe.
A regra de Sturges fornece o número de classes (i) de uma distribuição: i ≈ 1 + 3,3 . log n onde: i é o número de classes; n é o número total de observações. Abaixo segue outra regra para o cálculo do número de classes (i) de uma distribuição: Se n < 25 => i = 5
Se n ≥ 25 => i = √� Resolvido o problema da determinação do número de classes, obtém-se a amplitude do intervalo de classe dividindo a amplitude total (AT) pelo número de classes:
h = ���
Exercícios Propostos 5.1. Construir uma distribuição de freqüência (sem intervalos de classe) para as medidas do diâmetro (mm) de uma barra de metal: 12

325 324 328 327 326 328 328 329 329 330 326 327 324 326 327 330 326 328 328 328 5.2. Dada a seguinte distribuição: Valores 2 5 6 8 10 �� 10 15 8 3 2 Encontrar:
a) n. b) Freqüência acumulada. c) Freqüência relativa. d) Freqüência acumulada relativa. e) Qual ó o percentual de valores menores ou iguais a 6?
5.3. Abaixo estão descritas as notas de 32 estudantes de uma classe: 6,0 0,0 2,0 6,5 5,0 3,5 4,0 7,0 8,0 7,0 8,5 6,0 4,5 0,0 6,5 6,0 2,0 5,0 5,5 5,0 7,0 1,5 5,0 5,0 4,0 4,5 4,0 1,0 5,5 3,5 2,5 4,5 Determinar:
a) O rol. b) A distribuição de freqüência com intervalos de classe (sugestão: iniciar por zero e intervalo
de classe de 1,5). c) A maior e a menor nota. d) A amplitude total. e) A freqüência acumulada. f) A freqüência relativa. g) Qual o percentual de alunos que tiraram nota menor que 4,5?
5.4. Os pesos (Kg) dos 40 alunos de uma classe estão abaixo descritos: 69 57 72 54 93 68 72 58 64 62 65 76 60 49 74 59 66 83 70 45 60 81 71 67 63 64 53 73 81 50 67 68 53 75 65 58 80 60 63 53 Determinar:
a) A distribuição de freqüência com intervalos de classe, utilizando a fórmula de Sturges (sugestão: iniciar com 45). Dado log 40 = 1,60.
b) A distribuição de freqüência acumulada. c) A distribuição de freqüência relativa. 13

5.5. Com os dados abaixo, fazer uma distribuição de freqüências com intervalos de classe (Sugestão: intervalos de 10, início com 40): 63 81 57 90 46 68 72 75 50 60 76 61 52 56 68 80 75 95 47 73 76 71 82 63 74 56 68 72 64 77 77 65 71 85 80 75 75 86 69 58 70 68 56 79 51 78 80 72 61 53
6. Medidas de Tendência Central Os dados observados em determinada distribuição tendem, em geral, a se agrupar em torno de valores centrais. Medidas representativas desses valores são chamadas medidas de tendência central. Dentre as principais medidas de tendência central, destacamos:
a) A média aritmética; b) A mediana; c) A moda.
6.1. Média Aritmética (�) A Média aritmética é definida como o quociente entre a soma dos valores da variável pelo número de observações.
= ∑ ������
Onde: é a média aritmética; � os valores da variável; � o número de observações. 6.1.1. Dados não-agrupados Para conhecer a média dos dados não-agrupados, determinamos a média aritmética simples. Exemplo: Sabendo-se que a produção diária de uma fábrica de iogurte, durante uma semana, foi de 90, 115, 105, 110, 95, 100 e 120 litros, temos que a produção média da semana foi:
= �������������������������� = 105
Nota-se que em alguns casos o valor da média pode ser diferente de todos os demais valores da amostra. Esse será o valor representativo dessa amostra, embora não esteja representado nos dados originais. Neste caso, dizemos que a média não tem existência concreta. 14

• Desvio em relação à média Denomina-se desvio em relação à média a diferença entre cada elemento de um conjunto de valores e a média aritmética. �� = � − Para o exemplo anterior, temos: �� = � − = 90 − 105 = −15 �� = � − = 95 − 105 = −10 �� = � − = 115 − 105 = 10 � = − = 100 − 105 = −5 �! = ! − = 105 − 105 = 0 �� = � − = 120 − 105 = 15 �# = # − = 110 − 105 = 5 Propriedade: A soma algébrica dos desvios em relação à média é igual a zero. ∑ �� = 0��$� No exemplo anterior, temos: ∑ �� = %−15& + 10 + 0 + 5 + %−10& + %−5& + 15��$� => ∑ �� = 0��$� 6.1.2. Dados Agrupados
• Sem intervalos de Classe Como, neste caso, as freqüências são números indicadores da intensidade de cada valor da variável, elas funcionam como fatores de ponderação. Portanto, devemos utilizar a média aritmética ponderada:
= ∑ �(�∑ (�
15

Exemplo: Número de filhos do sexo masculino em 34 famílias de quatro filhos � �� ��� 0 2 0 1 6 6 2 10 20 3 12 36 4 4 16 Σ 34 78 Dados fictícios
Assim: = ∑ �(�∑ (� => = �)!# = 2,29 => = 2,3 meninos.
Como interpretar o valor médio de 2,3 meninos?
• Com intervalos de Classe Aqui, convenciona-se que todos os valores incluídos em um determinado intervalo de classe coincidem com o seu ponto médio.
= ∑ �(�∑ (� ,
onde � é o ponto médio da classe. Exemplo: Estaturas (cm) de 40 alunos do curso de pedagogia – UFPA em 2007 i Estaturas (cm) �� � ��� 1 150 |--- 154 4 152 608 2 154 |--- 158 9 156 1404 3 158 |--- 162 11 160 1760 4 162 |--- 166 8 164 1312 5 166 |--- 170 5 168 840 6 170 |--- 174 3 172 516 Σ 40 6440 Dados fictícios
16

∑ ��� = 6440; ∑ �� = 40
= ∑ �(�∑ (� = ##�#� = 161 => = 161 cm
6.3. Moda (Mo) Denomina-se moda o valor que ocorre com maior freqüência em uma série de valores.
6.3.1. Dados não-agrupados Quando lidamos com dados não-agrupados, reconhece-se a moda simplesmente como aquele valor que mais se repete na amostra. Exemplos: Amostra 1: 3, 4, 5, 5, 5, 6, 6, 7, 8 Mo = 5 Amostra 2: 0, 1, 3, 5, 9, 12 => Amodal (não apresenta moda); Amostra 3: 2, 3, 4, 4, 4, 4, 6, 7, 8, 8, 8, 8, 9 => Bimodal (apresenta duas modas: 4 e 8).
6.3.2. Dados Agrupados
• Sem intervalos de classe Para determinar a moda basta fixar o valor da variável com maior freqüência. Exemplo: Número de filhos do sexo masculino em 34 famílias de quatro filhos � �� 0 2 1 6 2 10 3 12 ← 4 4 Σ 34 Dados fictícios
No exemplo acima, à freqüência máxima corresponde o valor 3. Logo, Mo = 3. 17

• Com intervalos de classe A classe que apresenta a maior freqüência é denominada classe modal. A moda será obtida simplesmente calculando-se o ponto médio da classe modal.
/0 = 1∗�3∗� ,
onde: 4 ∗ é o limite inferior da classe modal; 5 ∗ é o limite superior da classe modal. Este valor recebe o nome de moda bruta. Existem ainda outros métodos mais elaborados para o cálculo da moda, como a fórmula de Czuber, por exemplo:
/0 = 4 ∗ + 6�6�789 × ℎ ∗
onde: 4 ∗ é o limite inferior da classe modal; ℎ ∗ é a amplitude da classe modal; <� = � ∗ −�%=�>&; <� = � ∗ −�%?0@>&, sendo: � ∗ a freqüência da classe modal; �%=�>& a freqüência da classe anterior à classe modal; �%?0@>& a freqüência da classe posterior à classe modal. Exemplo: Estaturas (cm) de 40 alunos do curso de pedagogia – UFPA em 2007 i Estaturas (cm) �� 1 150 |--- 154 4 2 154 |--- 158 9 3 158 |--- 162 11 ← Classe modal 4 162 |--- 166 8 5 166 |--- 170 5 6 170 |--- 174 3 Σ 40 Dados fictícios
Moda Bruta: /0 = 1∗�3∗� = � ����)� = !��� = 160
Logo: Mo = 160 cm
Pela fórmula de Czuber: /0 = 4 ∗ + 6�6�789 × ℎ ∗ 18

/0 = 158 + ���! × 4
/0 = 159,6 CD
6.4. Mediana A mediana pode ser definida como o valor central de um conjunto de valores ordenados segundo algum critério de grandeza.
6.4.1. Dados não-agrupados
Exemplo: Vamos considerar o conjunto de observações: 2, 5, 9, 3, 12, 6, 14 Vamos dar a este conjunto uma ordenação (que pode ser crescente ou decrescente): 2, 3, 5, 6, 9, 12, 14 ↑ Nota-se que a observação 6 representa o valor de posição central do conjunto quando este está organizado segundo um critério de grandeza. 6 é o valor central que divide o conjunto em questão ao meio. Portanto, temos Md = 6. No entanto, se o conjunto de valores dado tiver um número par de observações, a mediana será, por definição, qualquer número compreendido entre os dois valores centrais. Por convenção, geralmente utiliza-se o ponto médio. Por exemplo: 2 , 3, 5, 6, 9, 12, 14, 16 ↑ ↑
Md = ��� =7,5
Verificamos que, para um conjunto de dados com n elementos, a mediana será:
- o termo de ordem ���� , se n for ímpar;
- a média aritmética dos termos de ordem �� e
�� + 1, se n for par.
Obs1: O valor da mediana pode coincidir ou não com um termo da amostra. Quando o número de termos da amostra é ímpar, há coincidência, quando o número de termos da amostra é par, não há coincidência; Obs2: A mediana e a média aritmética não terão, necessariamente, o mesmo valor; 19

Obs3: A mediana depende unicamente da posição e não dos valores dos elementos da amostra. Por esta razão a mediana não se deixa influenciar facilmente por observações discrepantes, ao contrário da média, que toma todos os valores da amostra para o seu cálculo, sendo facilmente influenciada por observações discrepantes. Por conta disso diz-se que a mediana é mais resistente que a média; Obs4: Empregamos a mediana sempre que houver valores extremos (observações discrepantes ou outliers) afetando de uma maneira acentuada a média; Obs5: Utilizamos a mediana sempre que desejamos obter o ponto que divide a distribuição em partes iguais. 6.3.2. Dados Agrupados
• Sem intervalos de classe Identifica-se a freqüência acumulada imediatamente superior à metade da soma das freqüências. A mediana será aquele valor da variável que corresponde a tal freqüência acumulada. Exemplo: Número de filhos do sexo masculino em 34 famílias de quatro filhos � �� �FG 0 2 2 1 6 8 2 10 18 3 12 30 4 4 34 Σ 34 Dados fictícios
∑ (�� = !#� = 17
A menor freqüência acumulada que supera esse valor é 18, que corresponde ao valor 2, sendo este o valor mediano. Logo: Md = 2 meninos
Obs: Caso exista uma freqüência acumulada �FG, tal que: �FG = ∑ �I2 , a mediana será dada por:
20

/� = �� �7�� ,
ou seja, a mediana será a média aritmética entre o valor correspondente a essa freqüência acumulada e o seguinte.
• Com intervalos de classe Primeiramente devemos localizar a classe em que se encontra a mediana: a classe mediana. Tal
classe será aquela correspondente à freqüência acumulada imediatamente superior a ∑ (�� . E em
seguida empregamos a fórmula:
/� = 4 ∗ + J∑ K�9 L (MN%F�O&PQ∗(∗ ,
onde: 4 ∗ é o limite inferior da classe mediana; �FG%=�>& é a freqüência acumulada da classe anterior à classe mediana; � ∗ é a freqüência da classe mediana; ℎ ∗ é a amplitude do intervalo da classe mediana. Exemplo:
Estaturas (cm) de 40 alunos do curso de pedagogia – UFPA em 2007 i Estaturas (cm) �� �FG 1 150 |--- 154 4 4 2 154 |--- 158 9 13 3 158 |--- 162 11 24 ← Classe mediana 4 162 |--- 166 8 32 5 166 |--- 170 5 37 6 170 |--- 174 3 40 Σ 40 Dados fictícios
∑ (�� = #�� = 20
/� = 4 ∗ + J∑ K�9 L (MN%F�O&PQ∗(∗ = 158 + R��L�!S#�� = 160, 54
Logo: Md = 160,54 cm 21

Obs: No caso de existir �FG = ∑ �I2 , a mediana será o limite superior da classe correspondente.
Exercícios Propostos 6.1. Para cada uma das séries de valores abaixo, calcule a média aritmética, a moda e a mediana:
a) 3, 4, 1, 6, 3, 6, 5, 6 b) 20, 9, 7, 2, 12, 7, 20, 15 c) 15, 18, 20, 13, 10, 16, 14
6.2. As notas de um aluno, em seis provas, foram: 8,4; 9,1; 7,2; 6,8; 8,7 e 7,2. Determine:
a) A nota média. b) A nota mediana. c) A nota modal
6.3. Em uma classe de 50 alunos, as notas obtidas formaram a seguinte distribuição: Notas 2 3 4 5 6 7 8 9 10 Nº de alunos 1 3 6 10 13 8 5 3 1 6.4. Calcule a média, a moda e a mediana para cada uma das distribuições de freqüência abaixo:
a) b) Notas fi Estaturas (cm) fi 0 |--- 2 5 150 |--- 158 5 2 |--- 4 8 158 |--- 166 12 4 |--- 6 14 166 |--- 174 18 6 |--- 8 10 174 |--- 182 27 8 |--- 10 7 182 |--- 190 8 Σ 44 Σ 70 22

c) Salários (R$) fi 500 |--- 700 18 700 |--- 900 31 900 |--- 1100 15 1100 |--- 1300 3 1300 |--- 1500 1 1500 |--- 1700 1 1700 |--- 1900 1 Σ 70
7. Separatrizes Vimos anteriormente que a mediana separa o conjunto de dados em dois grupos com mesmo número de valores. Além da mediana, existem outras medidas caracterizadas pela sua posição na série de dados. Essas medidas – os quartis, os percentis e os decis – são conhecidas pelo nome de separatrizes. 7.1. Quartis Os quartis são os valores de uma série que a dividem em quatro partes iguais. Portanto, podemos definir três quartis: - Primeiro quartil (Q 1): Valor situado na série de tal forma que uma quarta parte (25%) dos dados é menor que ele e as três quartas partes restantes (75%) são maiores; - Segundo quartil (Q2): Valor situado no centro da série de tal forma que a divide ao meio. O segundo quartil coincide com a mediana (Q2 = Md); - Terceiro quartil (Q 3): Valor situado na série de tal forma que as três quartas partes (75%) dos dados é menor que ele e uma quarta parte restante (25%) é maior. Para determinar os quartis utilizamos a mesma técnica do cálculo da mediana, substituindo ∑ (�� por
T ∑ (�# , onde k é o número de ordem do quartil. Assim:
U� = 4 ∗ + J∑ K�V L (MN%F�O&PQ∗(∗ ,
U� = 4 ∗ + J∑ K�9 L (MN%F�O&PQ∗(∗ = /�
23

U! = 4 ∗ + JW ∑ K�V L (MN%F�O&PQ∗(∗
Exemplo:
Estaturas (cm) de 40 alunos do curso de pedagogia – UFPA em 2007 i Estaturas (cm) �� �FG 1 150 |--- 154 4 4 2 154 |--- 158 9 13 ← (Q1) 3 158 |--- 162 11 24 4 162 |--- 166 8 32 ← (Q3) 5 166 |--- 170 5 37 6 170 |--- 174 3 40 Σ 40 Dados fictícios
Primeiro Quartil Terceiro Quartil ∑ (�# = #�# = 10
! ∑ (�# = !.#�# = 30
U� = 154 + R�� L#S#� = 156,66 U! = 162 + R!� L�#S#) = 165
Q1 = 156,7 cm Q3 = 165 cm
7.2. Percentis Percentis são os noventa e nove valores que separam uma série em 100 partes iguais. Para determinar os percentis utilizamos a mesma técnica do cálculo da mediana, substituindo ∑ (�� por
T ∑ (���� , onde k é o número de ordem do percentil.
Pela definição, fica evidente que: P25 = Q1 P50 = Q2 = Md P75 = Q3
24

Exercícios Propostos 7.1. Calcule o primeiro e o terceiro quartis das distribuições abaixo:
a) b) Notas fi Estaturas (cm) fi 0 |--- 2 5 150 |--- 158 5 2 |--- 4 8 158 |--- 166 12 4 |--- 6 14 166 |--- 174 18 6 |--- 8 10 174 |--- 182 27 8 |--- 10 7 182 |--- 190 8 Σ 44 Σ 70 c) Salários (R$) fi 500 |--- 700 18 700 |--- 900 31 900 |--- 1100 15 1100 |--- 1300 3 1300 |--- 1500 1 1500 |--- 1700 1 1700 |--- 1900 1 Σ 70
25

8. Medidas de Dispersão ou Variabilidade Vamos considerar os seguintes conjuntos de valores das variáveis x, y e z: x: 5, 5, 5, 5, 5 → = 5 y: 3, 4, 5, 6, 7 → Z[ = 5 z: 0, 1, 2, 10, 12 → \ = 5 Calculando as respectivas médias, verificamos que os três conjuntos de dados apresentam a mesma média aritmética: 5. Entretanto, é fácil notar que o conjunto x é o mais homogêneo que os demais, assim como o conjunto z é mais heterogêneo que os demais. Assim, verifica-se que conjuntos que apresentam a mesma média podem, ainda assim, ser bastante distintos entre si. Chegamos à conclusão de que a média não é um valor representativo suficiente para descrever determinado conjunto de dados. Para tal, seriam necessários ainda valores que dissessem algo a respeito da diversificação dos valores de determinada variável em torno de sua média representativa. Chamamos de dispersão ou variabilidade a maior ou menor diversificação dos valores de uma variável em torno de um valor de tendência central. Desta forma, podemos dizer do conjunto x do exemplo dado que possui variabilidade ou dispersão nula. Podemos dizer também que a variável z apresenta maior dispersão ou variabilidade que a variável y, que apresenta valores mais concentrados em torno da média 5. As principais medidas de dispersão ou variabilidade são: a amplitude total, a variância, o desvio padrão e o coeficiente de variação. 8.1. Amplitude Total A amplitude total é definida como a diferença entre o maior e o menor valor observado: ]^ = %Dá. & − %Dí�. & 8.1.1. Dados não-agrupados Exemplo: Para os valores: 30, 35, 46, 50, 63, 78, 80 AT = 80 – 30 = 50. Obs1: Quanto maior a amplitude total, maior a dispersão dos valores da variável; Obs2: A maior restrição em relação à utilização da amplitude total como medida de dispersão é o fato de que ela toma o maior e o menor valor da amostra para o seu cálculo, nada dizendo a respeito das observações que estão entre esses dois valores; Obs3: Faz-se uso da amplitude total quando se quer determinar a amplitude da temperatura em um dia ou no ano, como medida de cálculo rápido ou quando a compreensão popular é mais importante que a exatidão e a estabilidade. 26

8.1.2. Dados agrupados
• Sem intervalos de classe Neste caso ainda teremos: ]^ = %Dá. & − %Dí�. &
• Com intervalos de classe Neste caso, a amplitude total é tomada como a diferença entre o limite superior da última classe e o limite inferior da primeira classe. ]^ = 5%Dá. & − 4%Dí�. & 8.2. Variância e Desvio Padrão A variância e o desvio padrão fogem à falha a amplitude em considerar apenas o valores dos extremos de uma amostra. Tanto a variância como o desvio padrão levam em conta a totalidade dos dados, o que faz delas índices de variabilidade bastante estáveis e, por isso mesmo, os mais geralmente empregados. A variância baseia-se na soma dos desvios em relação à média tomados ao quadrado. Lembrando que a soma dos desvios em relação à média é sempre igual a zero. Por essa razão, esses desvios são tomados ao quadrado. Assim, a variância @� é dada por:
@� = ∑% �L &9∑ (�
ou, como ∑ �� = �
@� = ∑% �L &9� .
Obs: Quando nosso interesse não se restringe à descrição dos dados, mas, partindo da amostra, visamos tirar referências válidas para a população, convém utilizar o divisou n – 1 no lugar de n. Como a variância é calculada a partir dos quadrados dos desvios, ela acaba sendo um número em unidade quadrada em relação à variável em questão, o que, sob o ponto de vista prático, é um inconveniente. Por essa razão, foi pensada uma nova medida com utilidade e interpretação práticas, de nominada desvio padrão (s). O desvio padrão pode ser definido com a raiz quadrada da variância:
@ = √@� → @ = a∑%I−&2�
27

Obs: A variância é uma medida que tem pouca utilidade como estatística descritiva, porém é extremamente importante em inferência estatística. Em estatística descritiva, geralmente utiliza-se o desvio padrão. Para fins de computação, a fórmula dada para o cálculo do desvio padrão não é uma boa fórmula, pois quando a média aritmética () precisa ser arredondada, cada desvio fica afetado ligeiramente do erro, devido a esse arredondamento. Esse fato torna pouco prático o cálculo de ∑%� − &�. Por esta razão, é conveniente simplificar os cálculos fazendo uso da igualdade:
∑%� − &� = ∑ �� − %∑ �&9� .
E substituindo-a na fórmula do desvio padrão, temos:
@ = a∑ I2� − b∑ I� c2
Este método é não apenas mais prático, como também mais preciso. 8.2.1. Dados não-agrupados Vamos considerar como exemplo o conjunto de valores da variável x: x: 10, 12, 14, 16, 18, 20 � �� 10 100 12 144 14 196 16 256 18 324 20 400 ∑ � = 90 ∑ �� = 1420
Como n = 6, temos: @ = a∑ I2� − b∑ I� c2 = a14206 − b906 c2 = 3,42
8.2.2. Dados Agrupados Como aqui temos a presença de freqüências, devemos levá-las em consideração na hora do cálculo: 28

@ = d∑ �II2� − e∑ �II� f2
Exemplo: Estaturas (cm) de 40 alunos do curso de pedagogia – UFPA em 2007 i Estaturas (cm) �� � ��� ���� 1 150 |--- 154 4 152 608 92416 2 154 |--- 158 9 156 1404 219024 3 158 |--- 162 11 160 1760 281600 4 162 |--- 166 8 164 1312 215168 5 166 |--- 170 5 168 840 141120 6 170 |--- 174 3 172 516 88752 Σ 40 6440 1038080 Dados fictícios
@ = d∑ �II2� − e∑ �II� f2 = a103808040 − b644040 c2 = √31 = 5,567
@ = 5,57 CD 8.3. Coeficiente de Variação Como o desvio padrão é expresso na mesma unidade dos dados, seu emprego fica limitado quando desejamos comparar duas ou mais séries de valores, relativamente à sua variabilidade, quando expressas em unidades diferentes. Para contornar essas limitações, caracterizamos a variabilidade dos dados em termos relativos a seu valor médio, obtendo o coeficiente de variação (CV):
gh = ij[ × 100
No exemplo anterior, = 161 CD e @ = 5,57 CD . Portanto:
gh = �,��� � × 100 = 3,459 → gh = 3,5%
29

Exercícios Propostos 8.1. Dada a amostra 2, 3, 4, 5, 7, 10, 12. Calcule: a) A amplitude. b) A variância. c) O desvio padrão. 8.2. Num teste aplicado a 20 alunos, obteve-se a seguinte distribuição de pontos: Pontos 35 |--- 45 45 |--- 55 55 |--- 65 65 |--- 75 75 |--- 85 85 |--- 95 Nº de alunos 1 3 8 3 3 2
a) Calcular a variância. b) Calcular o desvio padrão. c) Calcular o coeficiente de variação.
8.3. Calcule o desvio padrão para cada uma das distribuições abaixo:
a) b)
Notas fi Estaturas (cm) fi 0 |--- 2 5 150 |--- 158 5 2 |--- 4 8 158 |--- 166 12 4 |--- 6 14 166 |--- 174 18 6 |--- 8 10 174 |--- 182 27 8 |--- 10 7 182 |--- 190 8 Σ 44 Σ 70 c) Salários (R$) fi 500 |--- 700 18 700 |--- 900 31 900 |--- 1100 15 1100 |--- 1300 3 1300 |--- 1500 1 1500 |--- 1700 1 1700 |--- 1900 1 Σ 70
30

8.4. Em um exame final de Matemática, a nota média de um grupo de 150 alunos foi 7,8 e o desvio padrão, 0,80. Em Estatística, entretanto, a nota média foi 7,3 e o desvio padrão, 0,76. Em que disciplina foi maior a dispersão?
9. Instrumental Matemático
9.1. Arredondamento de dados O arredondamento de dados consiste em suprimir unidades inferiores às de determinada ordem. O arredondamento é feito, na maioria da vezes, por uma questão de conveniência ou praticidade. O arredondamento é feito da seguinte maneira:
• Quando o primeiro algarismo a ser abandonado for 0, 1, 2, 3 ou 4, fica inalterado o último algarismo a permanecer.
Exemplos: 15, 543 = 15, 54 2, 94 = 2, 9
• Quando o primeiro algarismo a ser abandonado for 6, 7, 8 ou 9, aumenta-se de uma unidade o algarismo a permanecer.
Exemplos: 3, 87 = 3, 9 23, 918 = 23, 92 53, 99 = 54, 0
• Quando o primeiro algarismo a ser abandonado for 5, há duas soluções: a) Se ao 5 seguir em qualquer casa um algarismo diferente de zero, aumenta-se uma
unidade ao algarismo a permanecer. Exemplos: 6, 254 = 6, 3 24, 6501 = 24, 7 76, 250002 = 76, 3
b) Se o 5 for o último algarismo ou se ao 5 só seguirem zeros, o último algarismo a ser
conservado só será aumentado de uma unidade se for ímpar.
Exemplos: 24, 75 = 24, 8 24, 65 = 24, 6 24, 75000 = 24, 8 24, 6500 = 24, 6
Obs: Cuidado! Não devemos nunca fazer arredondamentos sucessivos. Exemplo: 3, 3452 = 3,35 = 3,4 Na verdade, 3,3452 = 3,3
31

9.2. Somatório
Usamos o símbolo Σ (letra grega, maiúscula: sigma), denominado somatório, para indicar a soma dos valores � de uma variável x, isto é, � + � + ⋯ + �. Assim: ∑ ���$� = � + � + ! + ⋯ + � Portanto, no caso em que n = 5:
∑ ���$� = � + � + ! + # + � Exemplo: ∈ %2, 5, 7&, tem-se: � = 2 � = 5 ! = 7 ∑ �!�$� = � + � + ! = 2 + 5 + 7 = 14
9.2.1. Propriedades do somatório
i) Sendo c uma constante: ∑ C��$� = � × C
ii) Sendo c uma constante e x uma variável:
∑ %C × ���$� & = C ∑ ���$�
iii) Sendo x e y duas variáveis: ∑ %���$� + Z�& = ∑ ���$� + ∑ Z���$� Obs: Cuidado. d∑ %�Z���$� & ≠ ∑ � × ∑ Z� ��$���$� d%∑ ���$� &� ≠ ∑ ����$� 32

Exercícios Propostos 9.1. Escreva sob a forma de somatório:
a) x1 + x2 + x3 + x4 = b) x4 + x5 + x6 + x7 =
9.3.Arredonde cada um dos números abaixo, deixando-os apenas com uma casa decimal:
a) 2,38 = b) 24,65 = c) 0,351 = d) 4,24 = e) 328,35 = f) 2,97 = g) 6,829 = h) 5,550 = i) 89,99 = j) 78,85 = k) 1,250001 =
33




















