
Unfolding a Face: from Singular to Manifold
11
Unfolding a Face: from Singular to Manifold Ognjen Arandjelovi´ c Trinity College, University of Cambridge Cambridge CB2 1TQ United Kingdom [email protected] Abstract. Face recognition from a single image remains an important task in many practical applications and a significant research challenge. Some of the challenges are inherent to the problem, for example due to changing lighting conditions. Others, no less significant, are of a practical nature – face recogni- tion algorithms cannot be assumed to operate on perfect data, but rather often on data that has already been subject to pre-processing errors (e.g. localization and registration errors). This paper introduces a novel method for face recognition that is both trained and queried using only a single image per subject. The key concept, motivated by abundant prior work on face appearance manifolds, is that of face part manifolds – it is shown that the appearance seen through a sliding window overlaid over an image of a face, traces a trajectory over a 2D manifold embedded in the image space. We present a theoretical argument for the use of this representation and demonstrate how it can be effectively exploited in the sin- gle image based recognition. It is shown that while inheriting the advantages of local feature methods, it also implicitly captures the geometric relationship be- tween discriminative facial features and is naturally robust to face localization errors. Our theoretical arguments are verified in an experimental evaluation on the Yale Face Database. 1 Introduction Much recent face recognition work has concentrated on recognition using video se- quences as input for training and querying the algorithm. This trend has largely been driven by the inherent advantages of acquiring and exploiting for recognition as much data as possible, as well as the increased availability of low-cost cameras and storage devices. A concept that has gained particular prominence in this body of research, and one that is of interest in this paper, is that of face manifolds [1]. The key observation is that images of faces are (approximately) constrained to lie on a non-linear manifold, of a low dimensionality compared to the image space it is embedded in. This is a consequence of textural and geometric smoothness of faces and the manner in which light is reflected off them – a small change in imaging parameters, such as the head pose or illumination direction, thus produces a small change in the observed appearance, as illustrated in Fig. 1. In this paper, however, we are interested in recognition from individual images – a single, near frontal facial image per person is used both to train the algorithm, as well
-
Upload
st-andrews -
Category
Documents
-
view
0 -
download
0
Transcript of Unfolding a Face: from Singular to Manifold

Unfolding a Face: from Singular to Manifold
Ognjen Arandjelovic
Trinity College, University of CambridgeCambridge CB2 1TQ
United [email protected]
Abstract. Face recognition from a single image remains an important task inmany practical applications and a significant research challenge. Some of thechallenges are inherent to the problem, for example due to changing lightingconditions. Others, no less significant, are of a practical nature – face recogni-tion algorithms cannot be assumed to operate on perfect data, but rather often ondata that has already been subject to pre-processing errors (e.g. localization andregistration errors). This paper introduces a novel method for face recognitionthat is both trained and queried using only a single image per subject. The keyconcept, motivated by abundant prior work on face appearance manifolds, is thatof face part manifolds– it is shown that the appearance seen through a slidingwindow overlaid over an image of a face, traces a trajectory over a 2D manifoldembedded in the image space. We present a theoretical argument for the use ofthis representation and demonstrate how it can be effectively exploited in the sin-gle image based recognition. It is shown that while inheriting the advantages oflocal feature methods, it also implicitly captures the geometric relationship be-tween discriminative facial features and is naturally robust to face localizationerrors. Our theoretical arguments are verified in an experimental evaluation onthe Yale Face Database.
1 Introduction
Much recent face recognition work has concentrated on recognition using video se-quences as input for training and querying the algorithm. This trend has largely beendriven by the inherent advantages of acquiring and exploiting for recognition as muchdata as possible, as well as the increased availability of low-cost cameras and storagedevices.
A concept that has gained particular prominence in this body of research, and onethat is of interest in this paper, is that offace manifolds[1]. The key observation is thatimages of faces are (approximately) constrained to lie on a non-linear manifold, of a lowdimensionality compared to the image space it is embedded in. This is a consequenceof textural and geometric smoothness of faces and the manner in which light is reflectedoff them – a small change in imaging parameters, such as the head pose or illuminationdirection, thus produces a small change in the observed appearance, as illustrated inFig. 1.
In this paper, however, we are interested in recognition from individual images – asingle, near frontal facial image per person is used both to train the algorithm, as well

Person 1
Person 2−2000
−1000
0
1000
2000
3000
1000
2000
3000
4000
−1000
0
1000
−2
−1.5
−1
−0.5
0
0.5
1
−1.5
−1
−0.5
0
0.5
1
1.5
−2.5
−2
−1.5
−1
Person 1
Person 2
(a) Appearance (b) Face appearance manifold (c) Face part manifold
Fig. 1. (a) Textural and geometric smoothness of faces gives rise to appearance manifolds. (b)Motivated by previous research into face appearance manifolds, which as a representation demon-strated impressive results on the task of face recognition from video, in this paper we introduceface part manifolds (c).
as to query it. Although when available, recognition from video has distinct advantages,for practical reasons single image based recognition is preferred in a large number of ap-plications. In some cases video may be unavailable (e.g. when face recognition is usedfor browsing or organizing photographic collections); in others it may be impractical toobtain (e.g. for passports or national identification cards).
2 Unfolding a face
An observation frequently used by face recognition algorithms, is that not all parts ofa face are equally discriminative with respect to the person’s identity. For example,the appearance of the eye or mouth regions is often considered to carry more identi-fying information than, say, the cheek or forehead regions [2, 3]. Furthermore, due tothe smoothness of the face surface, local appearance is affected less with small headpose changes than holistic appearance and is more easily photometrically normalized.These are the key advantages oflocal-feature basedrecognition approaches (see e.g.[4–8]) over those which are holistic in nature. On the other hand, by effectively ignor-ing much of facial area, these methods do not fully utilize all the available appearanceinformation. The geometrical relationship between fiducial features is also often leftunexploited.
In this paper we demonstrate how the principles motivating the use of facial appear-ance manifolds, largely popularized by video based work, can be adapted to recognitionfrom single images. The resulting representation, a set of samples from a highly non-linear 2D manifold of face parts, inherits all of the aforementioned strengths of localfeature based approaches, without the associated drawbacks.

2.1 Manifold of face parts
The modelling of face appearance images as samples from a manifold embedded inimage space is founded on the observation that appearance changes slowly with vari-ation in imaging parameters. Depending on which parameters are considered in themodelling process, successful methods have been formulated that use video and personspecific appearance manifolds of pose (or, equivalently, motion) [9], person specificmanifolds of illumination and pose [10] or indeed the global face manifold of identity,illumination and pose [11, 12].
The assumption that face appearance is constrained to a manifold can be expressedas a mappingf from a lower dimensional face space to a high dimensional image spacef : Rd → RD, such that:
∀Θ1,Θ2 ∈ RD. ∃Θ3 ∈ RD :∥∥f(Θ1)− f(Θ3)∥∥ <
∥∥f(Θ1)− f(Θ2)∥∥ (1)
Strictly speaking, this condition does not actually hold. While mostly smooth, the facetexture does contain discontinuities and its geometry is such that self-occlusions occur.However, as an appropriate practical approximation and a conceptual tool, the idea hasproven very successful.
Low-level features.In this paper we define a face part to be any square portion of faceimage. We then represent the entirety of facial appearance by the set of all face parts ofa certain, predefined size. Formally, an imageI ∈ RW × RH produces set of samplesp ∈ Rs × Rs:
P (s) ={
p ≡ I(x + 1 : x + s, y + 1 : y + s)∣∣
x = 0 . . . W − s, y = 0 . . . H − s}
(2)
This is illustrated in Fig. 2 and can be thought of as appearance swept by a windowoverlaid on top of the face image and sliding across it.
The same smoothness properties of faces that gave rise to the concept of face ap-pearance manifolds allow the set of face part appearancesP (s) to be treated as beingconstrained to aface part manifold. This manifold is 2-dimensional, with the two di-mensions corresponding to the sliding window scanning the image in horizontal andvertical directions. The required smoothness condition of (1) is qualitatively illustratedin Fig. 2 and quantitatively in Fig. 3
2.2 Photometric normalization
Local appearance based representations have important advantages for recognition.Specifically, in a more spatially constrained region, the variation in both the surfacegeometry and the corresponding texture will be smaller than across the entire face. Thisuniformity allows for simpler correction of lighting. Furthermore, thedistributednatureof our representation also allows for increased robustness to troublesome face regions,which may not get normalized correctly.
We process each face part in four steps, as follows:
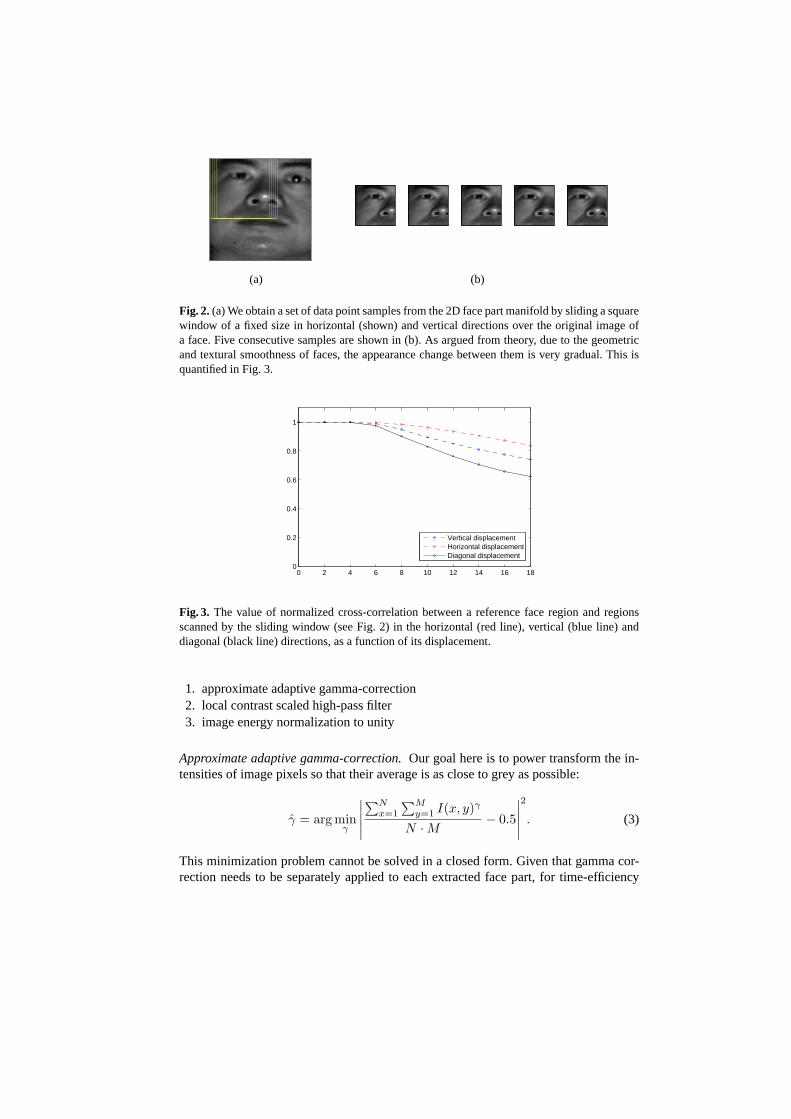
(a) (b)
Fig. 2.(a) We obtain a set of data point samples from the 2D face part manifold by sliding a squarewindow of a fixed size in horizontal (shown) and vertical directions over the original image ofa face. Five consecutive samples are shown in (b). As argued from theory, due to the geometricand textural smoothness of faces, the appearance change between them is very gradual. This isquantified in Fig. 3.
0 2 4 6 8 10 12 14 16 180
0.2
0.4
0.6
0.8
1
Vertical displacementHorizontal displacementDiagonal displacement
Fig. 3. The value of normalized cross-correlation between a reference face region and regionsscanned by the sliding window (see Fig. 2) in the horizontal (red line), vertical (blue line) anddiagonal (black line) directions, as a function of its displacement.
1. approximate adaptive gamma-correction2. local contrast scaled high-pass filter3. image energy normalization to unity
Approximate adaptive gamma-correction.Our goal here is to power transform the in-tensities of image pixels so that their average is as close to grey as possible:
γ = arg minγ
∣∣∣∣∣
∑Nx=1
∑My=1 I(x, y)γ
N ·M − 0.5
∣∣∣∣∣
2
. (3)
This minimization problem cannot be solved in a closed form. Given that gamma cor-rection needs to be separately applied to each extracted face part, for time-efficiency

reasons we do not compute the optimal gammaγ exactly. Instead, we use its approxi-mate value:
γ∗ =0.5〈I〉 , (4)
where〈I〉 is the mean image patch intensity:
〈I〉 =
∑Nx=1
∑My=1 I(x, y)
N ·M . (5)
Local contrast scaled high-pass filter.In most cases, the highest inter- to intra- per-sonal information content in images of faces is contained in higher frequency compo-nents, low frequencies typically being dominated by ambient and directional illumina-tion effects [13]. We make use of this by applying a high-pass filter to gamma correctedpatches.
Il = I ∗Gσ=2 (6)
Ih = I − Il. (7)
An undesirable artefact of high-pass filtering is the sensitivity of the result to theoverall image contrast: the same facial feature illuminated more strongly will still pro-duce a higher contrast result, then when imaged in darker conditions. We adjust forthis by scaling the high-pass filter output by local image intensity, estimated using thelow-pass image:
I =Ih(x, y)Il(x, y)
. (8)
Image energy normalization to unity.The final step of our photometric adjustmentinvolves the normalization of the total image patch energy:
I(x, y) =I(x, y)√
E(I), (9)
whereE(I) is the original energy:
E(I) =∑x,y
I(x, y)2. (10)
The results of our photometric normalization cascade are illustrated on examples offace parts in Fig. 4.
2.3 Global representation
We have already argued that the face parts appearances extracted from a single imagecan be thought of as set of dense samples from the underlying face part manifold. Theanalogy between the relationships of face parts and this manifold and that of face images

Fig. 4. Examples of appearance of three facial regions before any processing (top row) and afterour photometric adjustment (bottom row). The effects of illumination are largely normalized,while the prominence of actual facial features is emphasized.
and the corresponding face appearance manifolds, is tempting but there is a number ofimportant differences between the two.
If the entire range of variation in the appearance of a person is considered, regard-less of the manner in which the face is illuminated or the camera angle, the appearanceshould never be the same as that of another person1. Although imaging parameters doaffect the discriminative power that an image has for recognition, this is far more pro-nounced in the case of face parts which inherently vary in information content [14]. Auniform region, such as may be observed in the cheek or forehead regions, after pho-tometric normalization described in the previous section, is nearly uniformly grey andvirtually void of person-specific information, see Fig. 5. Such parts will be clusteredin an apex from which all face part manifolds radiate, as illustrated on an example inFig. 1. It should be noted that these are non-informative only in isolation. In the con-text of other parts, they shape the face part manifold and by affecting the geodesicdistance between discriminative regions, implicitly capture geometric relationship be-tween them. Both observations highlight the need to represent and use extracted facepart manifold samples in a unified, holistic manner.
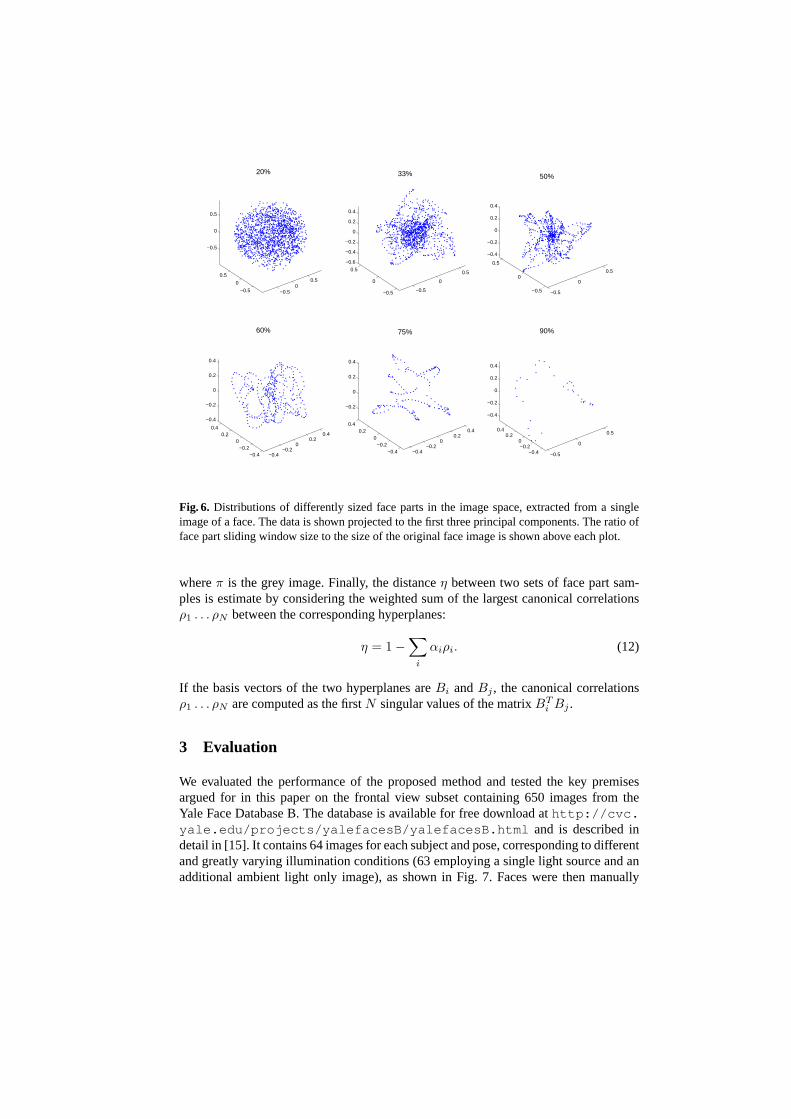
Manifold structure, modelling and discrimination.The shape that face part manifoldstake in image space is greatly dependent on the sliding window size. This is illustratedin Fig. 6. For very small part sizes, of the order of 10% of face image size, the infor-mation content of any patch is so small that the corresponding manifold is so highlycurved and self-intersecting, that its structure is entirely lost in the sampling process. In
1 Exceptions such as in the case of twins are not of relevance to the issue at hand.

Non−discriminative
Discriminative
Fig. 5. One of the difficulties introduced by employing a dense, local representation of a face iscaused by a large number of non-discriminative local appearance patches (top row). Such, similarlooking regions can result from images of faces of different individuals, in contrast to informationcontaining, person specific ones (bottom row). The algorithm used to compare two sets of patches(one corresponding to a known, database individual and one to a novel, query image) must takethis observation into account.
contrast, large parts, with dimensions comparable to that of the original image, producemanifolds with a far simpler structure.
Irrespective of the chosen part size, all face part manifolds will have a common originat the cluster of nearly uniform, non-informative parts. While many parts will fall withinor near this region of image space, it can be observed that manifolds correspondingto individuals with different identities can be discriminated between by looking thedirection they extend in from it. This is illustrated in Fig. 1(b). An important corollary ofthis observation is that for recognition, it is not necessary to accurately model the exactshapes of part manifolds. Rather, it is sufficient to discriminate between the minimalhyperplanes they are embedded in.
Thus, we adopt the following approach. Given a set of extracted face partsP (i) ={p(i)
1 , p(i)2 . . .}, we first shift the image space origin to the non-informative, uniformly
grey image. The adjusted face part appearance variation is represented by the hyper-plane defined by the eigenvectors associated with the largest eigenvalues of the datacovariance matrix:
C(i) =∑
j
(p(i)j − π)(p(i)
j − π)T
, (11)
−0.50
0.5
−0.5
0
0.5
−0.5
0
0.5
20%
−0.5
0
0.5
−0.5
0
0.5
−0.6
−0.4
−0.2
0
0.2
0.4
33%
−0.5
0
0.5
−0.5
0
0.5
−0.4
−0.2
0
0.2
0.4
50%
−0.4−0.2
00.2
0.4
−0.4−0.2
00.2
0.4
−0.4
−0.2
0
0.2
0.4
60%
−0.4−0.2
00.2
0.4
−0.4−0.2
00.2
0.4
−0.2
0
0.2
0.4
75%
−0.5
0
0.5
−0.4−0.20
0.20.4
−0.4
−0.2
0
0.2
0.4
90%
Fig. 6. Distributions of differently sized face parts in the image space, extracted from a singleimage of a face. The data is shown projected to the first three principal components. The ratio offace part sliding window size to the size of the original face image is shown above each plot.
whereπ is the grey image. Finally, the distanceη between two sets of face part sam-ples is estimate by considering the weighted sum of the largest canonical correlationsρ1 . . . ρN between the corresponding hyperplanes:
η = 1−∑
i
αiρi. (12)
If the basis vectors of the two hyperplanes areBi andBj , the canonical correlationsρ1 . . . ρN are computed as the firstN singular values of the matrixBT
i Bj .
3 Evaluation
We evaluated the performance of the proposed method and tested the key premisesargued for in this paper on the frontal view subset containing 650 images from theYale Face Database B. The database is available for free download athttp://cvc.yale.edu/projects/yalefacesB/yalefacesB.html and is described indetail in [15]. It contains 64 images for each subject and pose, corresponding to differentand greatly varying illumination conditions (63 employing a single light source and anadditional ambient light only image), as shown in Fig. 7. Faces were then manually

registered (to allow the effects of localization errors to be systematically evaluated),cropped and rescaled to50× 50 pixels.
Fig. 7. A cross-section through the range of appearance variation due to illumination changes,present in the Yale Face Database B data set.
Holistic representation and normalization.One of the ideas underlying the proposedmethod is the case for face representation using some form of local representation. Con-sequently, our first set of experiments evaluated the performance of holistic matching,using the same basic representation for face appearance as we later use for face parts.The results are summarized in Fig. 8(a).
The extreme variability in illumination conditions present in our data set is evi-dent by the no better than random performance of unprocessed appearance (green). Asexpected, high-pass filtering produces a dramatic improvement (red), which is furtherincreased with gamma correction and image energy normalization (blue), resulting inthe equal error rate of 8.5%.
Proposed method and influence of face part size.The second set of experiments weconducted was aimed at evaluating the overall performance of the proposed algorithmand examining how it is affected by the choice of face part scale. This set of resultsis summarized in Fig. 8(b). For the optimal choice of the sliding window size, whichis roughly 70% of the size of the cropped face, our method significantly outperformsall of the holistic matching methods. The observed deterioration in performance withdecreased part size is interesting. We believe that this is not a reflection of inherentlyreduced discriminative power of the representations based on smaller part sizes, butrather of our linear model used to represent appearance variation within a set.
Sensitivity to face localization errors.Our final experiment tested how holistic andthe proposed local, dense representation of face appearance perform in the presence offace localization errors. Having manually performed face registration, we were able tosystematically introduce small translational errors between faces which are matched,thus obtaining a family of ROC curves for different error magnitudes. These are shownin Fig. 9. The superiority of our method over holistic recognition is very apparent; whilethe recognition success of the latter starts to rapidly degrade even with an alignmentdisparity of only one pixel and performing no better than random at six pixels, ourmethod shows impressive robustness and only a very slight dip in performance.

0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Gamma corrected, scaledhigh−pass filter processed,image energy normalizedScaled high−pass filterprocessedUnprocessed
(a)
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Face part scale relativeto face image scale 70% 60% 50%
(b)
Fig. 8.Measured recognition performance, displayed in the form of Receiver-Operator Character-istic (ROC) curves, for (a) holistic appearance matching after different photometric normalizationtechniques, and for (b) the proposed method for different face part sizes.
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Displacement of 0 pixelsDisplacement of 1 pixelDisplacement of 2 pixelsDisplacement of 3 pixelsDisplacement of 4 pixelsDisplacement of 5 pixelsDisplacement of 6 pixels
(a)
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Displacement of 0 pixelsDisplacement of 2 pixelsDisplacement of 4 pixelsDisplacement of 6 pixels
(b)
Fig. 9.Performance degradation of the (a) best holistic and (b) the proposed method with relativedisplacement of compared images.

4 Conclusion
We introduced a novel method for face recognition from single images. Our algorithmis based on 2D manifold-like structures embedded in the image space and which wecall face part manifolds. Very much like the face appearance manifolds they were in-spired by, these are shown to be representations with significant discriminative power.What makes them particularly attractive is the observation that they naturally reconcilethe differences between local feature based and holistic recognition approaches. Theyinherit the simplicity of the basic element and the distributed nature of the former, whilemaking full use of available appearance and facial geometry information like the latter.A thorough theoretical analysis of the method is followed by its empirical verificationon the Yale Face Database.
References
1. Lui, Y.M., Beveridge, J.R.: Grassmann registration manifolds for face recognition.2 (2008)44–57
2. Mita, T., Kaneko, T., Stenger, B., Hori, O.: Discriminative feature co-occurrence selectionfor object detection.30(7) (2008) 1257–1269
3. Matas, J., Bilek, P., Hamouz, M., Kittler, J.: Discriminative regions for human face detection.(2002)
4. Sivic, J., Everingham, M., Zisserman, A.: Person spotting: video shot retrieval for face sets.(2005) 226–236
5. Arca, S., Campadelli, P., Lanzarotti, R.: A face recognition system based on local featureanalysis. Lecture Notes in Computer Science2688(2003) 182–189
6. Bolme, D.S.: Elastic bunch graph matching. Master’s thesis, Colorado State University(2003)
7. Heo, J., Abidi, B., Paik, J., Abidi, M.A.: Face recognition: Evaluation report for FaceItr. InProc. International Conference on Quality Control by Artificial Vision5132(2003) 551–558
8. Stergiou, A., Pnevmatikakis, A., Polymenakos, L.: EBGM vs. subspace projection for facerecognition. In Proc. International Conference on Computer Vision Theory and Applications(2006)
9. Lee, K., Kriegman, D.: Online learning of probabilistic appearance manifolds for video-based recognition and tracking.1 (2005) 852–859
10. Arandjelovic, O., Cipolla, R.: A pose-wise linear illumination manifold model for face recog-nition using video.113(2008)
11. Sim, T., Zhang, S.: Exploring face space. In Proc. IEEE Workshop on Face Processing inVideo (2004) 84
12. Arandjelovic, O., Cipolla, R.: Face recognition from video using the generic shape-illumination manifold.4 (2006) 27–40
13. Fitzgibbon, A., Zisserman, A.: On affine invariant clustering and automatic cast listing inmovies. (2002) 304–320
14. Gao, Y., Wang, Y., Feng, X., Zhou, X.: Face recognition using most discriminative local andglobal features.1 (2006) 351–354
15. Georghiades, A.S., Belhumeur, P.N., Kriegman, D.J.: From few to many: Illumination conemodels for face recognition under variable lighting and pose.23(6) (2001) 643–660




















