
The rules of spelling errors
13
THE RULES OF SPELLING ERRORS E. J. YANNAKOUDAKIS and D. FAWTHRO~ Postgraduate School of Computing, University of Bradford, Bradford, BD7 IDP, England (Receioed for publicution IS June 1982) Abstract-This paper demonstrates that the vast majority of spelling errors follow specific rules which are based on phonological and sequential considerations. It introduces and describes three categories of spelling errors (consonantal, vowel and sequential) and presents the results of the analysis of 1377 spelling error forms. I. INTRODUCTION The literature on spelling error correction is diverse and varied. Many different methods have been suggested and tested with varying measures of success. Although much work has been performed on the spelling errors of children very little work has been carried out to determine the nature of spelling errors as made by adults. This paper presents the results of the analysis phase of an automatic spelling error correction project. It is envisaged that this would be operationalised within a word processing environment. The paper demonstrates that the majority of spelling errors are highly predictable when a set of predefined rules are followed algorithmically. Some facts on the nature of spelling errors have been known from the early days of information storage technology. Examples of these are: (i) many errors are made in the use of vowels; (ii) many errors are made in the use of the letters “W”, “Y” and “H”; (iii) doubling and singling of any letter is common; (iv) few errors are made in the first character of a word; (v) transposition of any two adjacent characters is common; (vi) missing or adding a single character is common; (vii) certain consonants are more frequentfy interchanged than others. However two important questions remain to be answered: (i) Do spelling errors made by adults follow specific rules or patterns more complex than those presented above, and if so what proportion follows each rule? (ii) Can heuristic rules be developed which will identify those words in the dictionary which are unlikely to be the word intended? If satisfactory answers to these questions are obtained then the reverse should also be true. If an unknown word in the text differs from a dictionary word by one or two of these rules then it may be a misspelling of that dictionary word. Also if more than one word in the dictionary may be the word intended then it should be possible to rank the words using some measure of probability. A corpus of 1377 spelling error forms was collected from existing literature and from badly spelt text produced by adults. Existing literature sources are dated between 1927and 1964and a number of changes in spelling have taken place during this period. Therefore certain error forms quoted may now be acceptable forms of spelling. For example RESTAURATEUR may now be spelt RESTAURANTEUR. Similarly ARCHAEOLOGICAL may also be spelt ARCHEOLOGICAL. The methodology adopted here is to use the computer to compare the correct and misspelt forms of errors in order to develop and test certain hypotheses on the nature of spelling errors. The method involved the following steps: (i) divide the error form and its dictionary form into vowel and consonant elements; (ii) compare the two sets of elements to find element errors; (iii) compare the words in character form to find sequential errors; (iv) print all errors found and the rules they obey. The above method was used iteratively in the sense that all new error forms detected were inserted in the computer program and the process was repeated. All results established therefore are empirical and define the nature of spelling errors algorithmically.
Transcript of The rules of spelling errors

THE RULES OF SPELLING ERRORS
E. J. YANNAKOUDAKIS and D. FAWTHRO~ Postgraduate School of Computing, University of Bradford, Bradford, BD7 IDP, England
(Receioed for publicution IS June 1982)
Abstract-This paper demonstrates that the vast majority of spelling errors follow specific rules which are based on phonological and sequential considerations. It introduces and describes three categories of spelling errors (consonantal, vowel and sequential) and presents the results of the analysis of 1377 spelling error forms.
I. INTRODUCTION The literature on spelling error correction is diverse and varied. Many different methods have been suggested and tested with varying measures of success. Although much work has been performed on the spelling errors of children very little work has been carried out to determine the nature of spelling errors as made by adults.
This paper presents the results of the analysis phase of an automatic spelling error correction project. It is envisaged that this would be operationalised within a word processing environment.
The paper demonstrates that the majority of spelling errors are highly predictable when a set of predefined rules are followed algorithmically.
Some facts on the nature of spelling errors have been known from the early days of information storage technology. Examples of these are: (i) many errors are made in the use of vowels; (ii) many errors are made in the use of the letters “W”, “Y” and “H”; (iii) doubling and singling of any letter is common; (iv) few errors are made in the first character of a word; (v) transposition of any two adjacent characters is common; (vi) missing or adding a single character is common; (vii) certain consonants are more frequentfy interchanged than others.
However two important questions remain to be answered: (i) Do spelling errors made by adults follow specific rules or patterns more complex than those
presented above, and if so what proportion follows each rule? (ii) Can heuristic rules be developed which will identify those words in the dictionary which
are unlikely to be the word intended? If satisfactory answers to these questions are obtained then the reverse should also be true.
If an unknown word in the text differs from a dictionary word by one or two of these rules then it may be a misspelling of that dictionary word. Also if more than one word in the dictionary may be the word intended then it should be possible to rank the words using some measure of probability.
A corpus of 1377 spelling error forms was collected from existing literature and from badly spelt text produced by adults. Existing literature sources are dated between 1927 and 1964 and a number of changes in spelling have taken place during this period. Therefore certain error forms quoted may now be acceptable forms of spelling. For example RESTAURATEUR may now be spelt RESTAURANTEUR. Similarly ARCHAEOLOGICAL may also be spelt ARCHEOLOGICAL.
The methodology adopted here is to use the computer to compare the correct and misspelt forms of errors in order to develop and test certain hypotheses on the nature of spelling errors. The method involved the following steps: (i) divide the error form and its dictionary form into vowel and consonant elements; (ii) compare the two sets of elements to find element errors; (iii) compare the words in character form to find sequential errors; (iv) print all errors found and the rules they obey.
The above method was used iteratively in the sense that all new error forms detected were inserted in the computer program and the process was repeated. All results established therefore are empirical and define the nature of spelling errors algorithmically.

xx E. J. Y~NNAKOLDAKIS and D. FAWTHROP
2. DEFINITIONS AND TERMINOLOGY
Several conventions are used throughout this paper. (i) An “error form” is an example of a misspelled or misstyped word and it is counted only
once however many times it is encountered. (ii) A “dictionary form” is a word which appears in a dictionary. Both. American and
English dictionaries are considered to be relevant for words which are written in the ap- propriate dialect.
(iii) “Dialect” is defined in the normal way but both standard English and standard American are considered to be dialects of English.
(iv) An “error” is a difference between an error form and a dictionary form. One or more errors may be contained in an error form.
(v) An “element” is a string of characters as discussed in Section 4. A dictionary form and an error form may both be divided into elements to facilitate spelling error correction (e.g. A-CQU-IE-SC-E misspelled A-QU-IE-SC-E). An element is represented in this paper either as a character string (see (viii) below) or as a field of 4 characters. Unused characters are packed with an ‘*‘, and a space indicates the end of a word (e.g. A***, OUGH, ES *).
(vi) An “element error” is an error which changes one element in a dictionary form to another element in an error form, or misses an element from or adds an element to a dictionary form. A change element error is shown as ‘OR’ 9 ‘ER’ i.e. the element ‘OR’ in the dictionary form is changed to ‘ER’ in the error form.
(vii) “Phonemes” are represented between slashes (e.g. /ER/. /B/) and are defined as the most elementary units of sound in speech. A complete list of phonemes used is presented in Table 1.
(viii) Character strings and elements are shown in single quotes (e.g. ‘OUCH’, ‘AE’, ‘QU’). (ix) A “Grapheme” is a string of characters which may represent a phoneme. A grapheme
may be an element, but not all elements are graphemes. (x) An “element error form” is an element error defined without reference to a specific error
form. it is often shown in the paper with the number of occurrences found in the corpus (e.g. A*** 9 E***(32)).
3. PHONEMIC AND GRAPHEMIC BASIS OF ENGLISH/AMERICAN
There is some evidence[2] which suggests that spelling errors are dependent on the dialect of the subject. It is therefore necessary to design a spelling error correction system for standard English and American with some allowances for Australian, Scottish, Irish, etc. It has been
suggested[9] that spelling error correction could be performed by converting words to a standard phonetic spelling which could be used to find similar sounding words in a dictionary. The weakness of this approach is evident when differences between various dialects are
encountered. as for example BATH may be pronounced B-A-TH in Northern England, and B-AR-TH or B-OR-TH in Southern England. The Soundex system[S] in fact performs this function rather crudely by retaining the first letter of each word and converting following
consonants into digits, each digit representing a set of characters which are pronounced with some phonetic similarities.
Much.work has been carried out on the relationships between phonemes and graphemes, see Wu~[ll], HANNA[~], VENEZKY[IO], HALL[~]. The authors referred to above use different phonetic alphabets to study different dialects and this makes it rather difficult to determine which of the differences are real and which are purely symbolic. Whereas these researchers distinguish between different phonemes used in different dialects for the same word, the present work uses a single “equivalent phoneme”. The objective of this approach is to group all graphemes which may represent a single phoneme in any dialect under a single heading. although in a given dialect not all representations of an equivalent phoneme would be pronounced using the same phoneme. This approach is felt necessary in order to ensure that a spelling error correction system can operate over a number of differing dialects.
WIJK[ 1 I] describes an “r-less” dialect where in many cases ‘ER’ and other similar phonemes represent a singie phoneme, whereas H-\NN.~[~] describes an “r-ed” dialect where in most cases the /R/ in each of the phonemes is sounded. This work treats both pronunciations as a single equivalent phoneme /ER/, with other strings ending in ‘R’ (e.g. ‘EAR’. ‘EER’) being treated

The rules of spelling errors
Table I. Comparative list of phoneme\
89
Equlvelent tianns Wi Jk Venezky HalI Phoneme c4 1 Cl01 c9 1 c3 1
I B l II3 I lb / lb l lb I
ICH I ID l
IF I
IG l
IH l
IJ I
IK I /KS I /KY / IL l
IM l
/N /
/NG I
IP I
10 I
IS I
ISH I
IT / ITH I
IV I
iv l
II l
11 I
IZH l
IA I
IA2 I
/AIR/
IAY I
ISH(YI
IF I
/El /
IF@ /
/FFQI
II I
112 I
IP I
IO2 I
IOT I
IO11 I
IO0 I
IOP I
IV I
IU2 I
ICHI
ID I
IF l
IG l
In I
IJ I
IK I
/KS/
lKk/
IL /
ILll
IN /
/Ill/
IN I
IN11
INGI
IP I
/R / 1s / ISH/ IT /
ITl/ I121
IV I
lk I
IHkI
IY I
I.? /
IIlil
IA l
IA31
/AZ/
/A51
,dl
It /
/t3/
/t5/ IIJZI
/EZ/ /I ! /I3/ /G I 1031
/OII
/OL/
/0t/
/Oil
Ii, I
IUZI
ItI I
Id I
If I
19 l
Ih I
idSi
lk I
lksl
IkWl
II l
lrr l
/n /
‘9 ’ IF l
/r I
Is I
lI 1 It I
lP 1 I1 l
iv I
I* I
Ihul
/.i I
IZ l
‘3 l
/PI/
13 1
IEd/ ia:! /a / /a: I /e / Ia: t
IF I
Id I
/f I
/D l
lh I
iI I
lk I
lksl ____
II I
/m I
/n I
‘cl 1 IP l
ir I
IS I
ii I
it I
le I
Ial
IV I
iu I
lhkl
Ii I IZ I
ii I
/e I
/z I __--
___-
/ai
II I It 1 __--
---- (ail II I /o I ____
Id1 /
/au/
,u / -_-_
l.lUl
IU I
IE I
Id / If I IO 1 Ih I
15 1
Ik / Iksl
/ku/
II I
lm I
In I
‘9 1 IP I Jr I
IS l
I: I
It I
le 1
1251
IV I
I* I
lhwl
/Y 1 /z I
Ii l
/e\/
lB / __--
la I
lb I
l,Yl
/e /
/a r /
__--
lay/
/I /
ic*i __--
/Oil
/a*/
iu*i
/o I
IYUhl
IU I
similarly. Also some dialects differentiate between /W/ as in WATER and /HW/ as in WHIP whereas others use the same phoneme in both cases. /W/ and /HW/ are considered here to be equivalent.
The International Phonetic Alphabet is not appropriate in our case because the equivalent phonemes used are not strictly speaking phonemes. Note that all references to “phonemes” hereafter are references to “equivalent phonemes”. The alphabet used is a variant of that used by HANNA [4] and it is deliberately made very coarse and ignores many fine phonetic distinctions concentrating on those phonemes which are obvious to “the man in the street” while being
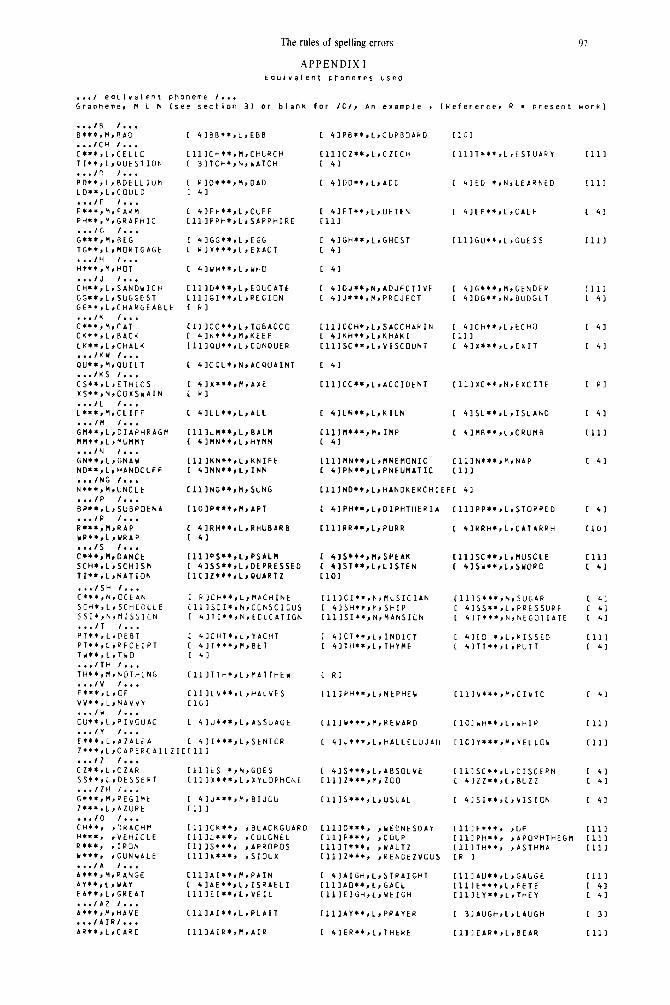
machine readable. Appendix I contains a list of the phonemes used together with their graphemic represen-
tations, examples of their use and the source. Table I contains a comparative list of phonemes used by different authors which are
considered to be equivalent within many contexts.
4. THE SPELLING ELEMENT
It is theoretically impossible to convert a given word into a phonetic code covering more than one dialect. It was therefore necessary to approach the problem from a different angle and to introduce a new concept of the “spelling element”. This concept was developed solely as an

90 E. J. YAUMKOIIIMKIS md D. F~\L IHKIIP
aid to spelling error correction by reference to the corpus of errors in such a way that most spelling errors appear as changes from one element to another rather than as a missed or added element. This approach has the advantage of improving the accuracy of description of an error by offering in effect an extended alphabet.
An element appears under one of two realms, (a) the consonant and (b) the vowel. Under (a) an element is either any graphemic representation of an equivalent consonantal
phoneme listed in Appendix I. or where groups of consonants may represent one or two consonantal phonemes as for example ‘CT’ a5 in .4CT or INDICT, or ‘PT. a\ in .4DAPTABLE or RECEIPT, the group is always a single element whether pronounced as one phoneme or two. The elements ‘Cl’, ‘TI’. ‘SI’, ‘SSI’, ‘SCI’, ‘GU’. ‘GI’, and ‘GE‘ only exist when they represent jSHi, iG/, fJ/, or iZH/. It is of course possible to divide certain words into elements in two different ways. This creates a conflict which can be resolved hy studying the pronunciation of the word. For example ACTION becomes A-C-TI-O-N rather than A-CT-IO-N.
Under (b) a vowel element is any string which starts with ‘A’. ‘E’, *I’. ‘0’, ‘U’ or ‘Y’ possibly followed by n occurrences of these or ‘W’ and which may end with the same characters or ‘R’. ‘RR’. ‘RH’, ‘RRH’ or ‘GH’. For example ‘A’, ‘OU’. ‘ER’ ‘ORRH’, ‘OUGH’. ‘AW’. The above definition would therefore not consider ‘WA’ as in WATER as a valid vowel element.
On the basis of the above two definitions regarding c~~ns~)n~~nt~~l and vouiel elements it wns possible to write programs to analyse the spelling errors contained in the test corpus, The total number of consonantal and vowel elements used in the present study was 96 and 171 respec- tively.
5. THE CORPUS OF SPELLING ERRORS USED
The error forms were transfered on to two computer files where each error form is accompanied by its dictionary form. The following is an extract from an actual file used:
ACCRUED ACCRUDE
ACQUIRE AQUIRE
co1,ossus COLLOSUS
EXERCISES EXCERCISES
GENIUS GENIOUS
The “typical” file contains 809 spelling errors collected from I. \\K) [7j. Table 1 of D~v~;K.~\I[ I] and all those words from KLIC.FRA[~] where the intended word could be clearly identified, and also those misspellings listed by M.\sTI.Ks[~] ;IC made by College ceniors 16th grade. The dialect of the misspellers in this list included various forms of American.
The “had” file contains spelling errors from some 60.000 words of continuous text written by three adults at the Liniversity of Bradford, each of them with a Northern English dialect; they all believed themselves to be very bad spellers. The ntlmber of occurrences of each error form
was also recorded. The list contains 568 error forms which occurred a total of 1095 times. The files were sorted and merged individually so that each error form occurred only once in a file.
6. THE ERRORS FOUND
Three types of errors are discussed: (I) sequential errors; (3) consonantal errors; and (3) vowel errors. The sequential errors were counted separately and the vowel and consonantal errors were counted together. Thus total double counting occurs between sequential and other errors.
Spelling errors typically follow several of the patterns detected. For instance PER- FORATION misspelled PREFORATION can be described in three ways: (i) short transposition of ‘E’ and ‘R‘: (ii) change ‘ER’ to ‘R’ and add ‘E’; (iii) add ‘R’ and change ‘ER’ to ‘E’. ,411 these are common errors in the corpus. All counting in this paper is thus subject to some value judgement by the authors and double counting is endemic. However in general a minimum count is given in all cases and errors are only classified under clearly defined headings.
The minimum number of errors which could fully describe each error form was established,
The rules of spelling errors 91
The typical list contained 77 error forms (9.5%) which contained 2 errors (e.g. SPECIFIC-A- LL-Y misspelled SPECIFIC-L-Y) and one form (.12%/c) containing three errors (O-CC-A-S-
IONA-LL-Y misspelled 0-C-A-SS-ION A-L-Y). The bad list included 76 (13%) error forms each containing 2 errors, 14 error forms (2.5%) which contained 3 errors, and one error form (0.18%) where 4 errors were clearly distinguishable (I-MM-E-DIAT-E-LL-Y misspelled I-M-I-DIAT-L- Y). None of the error forms containing two errors had a length of less than 4 characters and only 6 a length of less than 6 characters.
Both lists contained misspellings which could not be fully described by the rules in Sections 7, 8 and 9. The typical list contained 7 cases (.9%) (e.g. DELINQUENT misspelled DELI- GUENT, JEOPARDIZE misspelled JEPRODISE), and the bad list contained 20 cases (3.5%) (e.g. WEIGHTED misspelled WAGTED, SECRETARIES misspelled SECUTARIES, QUERIES misspelled QUIES).
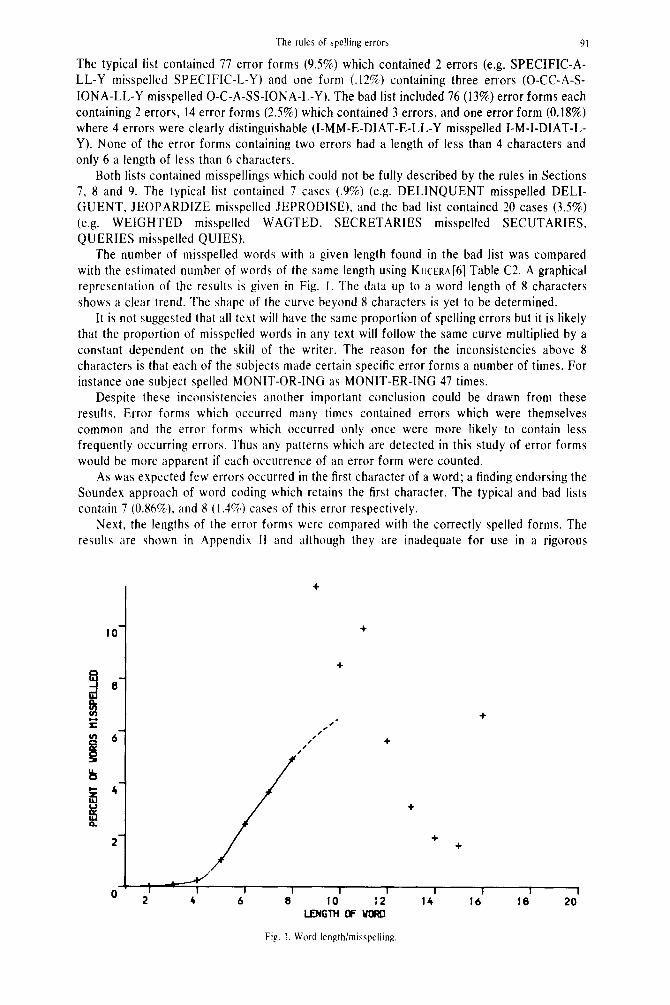
The number of misspelled words with a given length found in the bad list was compared with the estimated number of words of the same length using KUCERA[~] Table C2. A graphical representation of the results is given in Fig. I. The data up to a word length of 8 characters shows a clear trend. The shape of the curve beyond 8 characters is yet to be determined.
It is not suggested that all text will have the same proportion of spelling errors but it is likely that the proportion of misspelled words in any text will follow the same curve multiplied by a constant dependent on the skill of the writer. The reason for the inconsistencies above 8 characters is that each of the subjects made certain specific error forms a number of times. For instance one subject spelled MONIT-OR-ING as MONIT-ER-ING 47 times.
Despite these inconsistencies another important conclusion could be drawn from these results. Error forms which occurred many times contained errors which were themselves common and the error forms which occurred only once were more likely to contain less frequently occurring errors. Thus any patterns which are detected in this study of error forms would be more apparent if each occurrence of an error form were counted.
As was expected few errors occurred in the first character of a word; a finding endorsing the Soundex approach of word coding which retains the first character. The typical and bad lists contain 7 (0.86%), and 8 (I .4%) cases of this error respectively.
Next, the lengths of the error forms were compared with the correctly spelled forms. The results are shown in Appendix II and although they are inadequate for use in a rigorous
+
+
+
+
+
+
+ +
Fig. I. Word length/misspelling.

92 E. .I. ~~~~~~~~~~~~~~~~ and D. F4Vi1HKW
statistical analysis they demonstrate the main patterns found. It is clear that if the length of the dictionary form is less than 6 characters, the length of the error form will differ from the dictionary form by not more than 1 character. If the length of a dictionary form is between 6 and IO characters then the length of the error form will differ from the dictionary form by not more than 2 characters. If the length of the dictionary form is more than IO characters then the
misspelled form will be between 3 characters less and 2 characters more than the dictionary form. It is also clear that the length of an error form is typically less than the dictionary form.
Both lists contained data from typed text and identi~able typing errors made by the original misspellers. A proportion of these clearly derived from hitting an adjacent key and others from hitting the required key and its neighbour on an electronic QWERTY keyboad. The layout of the QWERTY keyboard however makes detection of some typing errors impossible particularly when the letters ‘M’, ‘N’, ‘U’, ‘I’, and ‘0’ are involved. These are adjacent keys and their
interchange creates a known form of error. The total number of typing errors found was IO (e.g. AND misstyped ANF, ARE misstyped ARTE. See also Section 9).
7. CONSONANTAL, ERRORS FLUID
The number of consonantal errors found in the typical and bad lists was 391 and 262 respec- tively, while the number of element error forms was 104 and 77, and the merging of both lists gave a total of 130 unique element error forms. Because we could find no significant difference between the consonantal errors in the typical and bad lists they were analysed together. Examination of these errors revealed several patterns which led to the classification of the
consonantal graphemic forms into three groups: (i) (M) more frequently used forms: (ii) (I,) less frequently used forms; (iii) (N) natural forms; as shown in Appendix I.
While these classifications were derived from the errors found, some patterns can be seen without reference to the errors themselves. An (M) grapheme is an obvious representation of the corresponding phoneme and in general follows H4~~4[4] Tables 7 and 8. An (N) grapheme is a form which appears natural to the misspeller. For example ‘TCH’ is a (N) grapheme for /CH/ because of a tendency to sound /CH/ as IT, Cl-r/ as in BACHELOR. Similarly ‘CQU’ is a (N) form of /KW/ because of a tendency to sound /KW/ as /K, KW/ as in ACQUAINT. ‘TI’, ‘Cl’, XI’ etc. are designated as natural forms of /SH/ from the pattern of spelling errors found.
An (~5) form is any other form. Consonantal errors found in the present context followed nine rules some of which have a
phonetic basis: (I) Where a dictionary word contained an element representing a phoneme then the error
form often replaced that element with an (M) element which represented the same phoneme. Examples of this replacement are, A-CC-OMPLICE misspelled A-C-OMPLICE which is also an example of a singling error, ACQUIE-SC-ENCE misspelled ACQUIE-S-ENCE is a simple example of the use of an (M) element, ANTAR-CT-IC misspelled ANTAR-T-IC is a case where the ‘CT’ which may be pronounced /‘I/ is in this case normally considered to be
pronounced /K, Ti but the error indicates that the misspeller used the pr~~nunci~~tion of /T/. The total number of errors in both lists involving an (M) representation of a consonantal phoneme was 376.
(2) Where a dictionary word contained an element representing a phoneme which differed from an (N) element representing the same phoneme by one character added missed or changed. then the error form often contained the (N) element. Examples of this are BA- CH-ELOR misspelled BA-TCH-ELOR, COMMI-SSI-ON misspelled COMMI-SI-ON, PLA-QU- E misspelled PLA-CQU-E. The number of (N) element errors found was 58.
(3) A strange form of error was discovered involving the ‘.difficult” string ‘NT’ which was present in all four possible forms of insertion and deletion errors. Examples are, RESTAURA-T- EUR misspelled RESTAURA-NT-EUR, MERCHANTME-N misspelled MERCHANTME-NT, SUPER-IN-TENDENT misspelled SUPER-TENDENT, ACCOMPANIME-NT misspelled ACCOMPANIME-N. We do not suggest any phonetic reason for this, however the pattern appears in both lists a total of 10 times as follows: ‘N’ 3 ‘NT’(3), ‘NT’ % ‘N’(3), ‘NT’ % ‘T’(3), ‘T’ 9 ‘NT’( 1).
(4) If a dictionary word contains an element which is an (M) representation of a phoneme. then the error form may contain an element which is an (M) representation of a phonetically related phoneme (e.g. CANTALOU-P-E misspelled CANTALOU-B-E). The corpus contained

The rules of spelling errors 93
13 cases where the following transformation occurred: ‘B’ @ ‘P’(2), ‘J’ % ‘D’(l), ‘M’ % ‘N’(3),
‘N’ 9 ‘M’(3), ‘P’ % ‘B’(3), ‘T’ 9 ‘D’(1). These counts are considerably lower than predicted by the Soundex system[5]. We would expect that more related phonemes would be discovered if a larger sample of errors were studied.
(5) Doubling and singling of consonants which occur doubled in normal text was a common form of error. A total of 96 cases of this error were detected. These are the following: ‘B’ ti ‘BB’(4). ‘C’ % ‘CC’( 13) ‘D’ 9 ‘DD’( I), ‘F’ 9 ‘FF’(6), ‘G’ ti ‘GG’( I), ‘L’ 9 ‘LL’(31), ‘M’ % ‘MM’(3). ‘N’ + ‘NN’(8). ‘P’ ,> ‘PP’(8), ‘S’ 9 ‘SS’( 15), ‘T’ % ‘TT’(6)). There are 227 cases of
singling as follows: ‘BB’ % ‘B’(4), ‘CC’ % ‘C’(22), ‘DD’ ti ‘D’(2), ‘FF’ 9 ‘F’(6), ‘GG’ % ‘G’( I I), ‘LL’ % ‘L’(64), ‘MM’ 9 ‘M’(25), ‘NN’ ti ‘N’(20), ‘PP’ % ‘P’(30), ‘SS’ 9 ‘S’(32), ‘TT' s ‘T’(1 I).
Doubling and singling of ‘C’, ‘S’ and ‘K’ proved to be a special case because ‘C’ is pronounced as /K/ or as IS/. The errors found obeyed the following rules: (i) ‘C’ is equivalent to ‘S’ and ‘K’; (ii) doubling or singling of any character or equivalent character may occur; (iii) interchanging of equivalent characters my occur; (iv) an element containing ‘K’ may not interchange with an element containing ‘S’.
All combinations of this case are tabulated below. A number shows the total number of occurrences found. A “y” shows that the rule is obeyed and we would expect the error to occur. An “n” shows that the rule is not obeyed and the error is unlikely to occur. Although this table is based on rather small samples of errors, the associations are intuitively correct and would be proved to be correct if a larger corpus of errors were to be analysed.
incorrect
C CC CK CS K S SC SS C 13 2 Y 18 6 6
c cc 22 Y : Y Y Y Y
o CK 2 y n y n n n
r CS y y n n Y Y Y r K Y Y 2 n n n n
e S 18 y n y n Y 15
c SC 2 Y n Y n 8 1
t SS y 1 n y n 32 y 2
(6) If a dictionary word contains an element which includes ‘H’ then the ‘H’ may be missed.
If a dictionary word contains an element which is part of an element containing ‘H’ then an error form may contain that element (e.g. A-GH-AST misspelled A-G-AST, S-U-CH misspelled SH-U-CH, TE-CH-NIQUES misspelled TE-C-NIQUES). A total of 28 ‘H’ errors were found as follows ‘CH’ % ‘C’(3). ‘GH’ b ‘G’(3), ‘P’ % ‘PH’(2), ‘PH’ B ‘P’(7), ‘RH’ B ‘R’(3). ‘S’ % ‘SH’( I). ‘SH’ ti ‘S’(l). ‘T’ B ‘TH’(2). ‘TH’ b ‘T’(3). ‘W’ 9 ‘WH’(2). ‘WH’ >> ‘W’(1).
(7) Some errors consisted of a missed element representing the silent phoneme /O/ (see
Appendix I). In the majority of these cases the element would not normally be considered as silent although it may be silent in certain dialects (e.g. RENDE-ZVOUS misspelled RENDE- VOUS, A-L-THOUGH misspelled A-THOUGH and P-R-IMARILY misspelled P-IMARILY). A total of 35 missed silent forms were found as follows: ‘H’(2), ‘L’(6), ‘R’(l4), ‘S’(8), ‘T’(4). ‘Z’(I).
(8) Missed elements representing a single non silent consonant occur very infrequently. A total of I4 cases occur in both lists as follows: ‘C’(l), ‘D’(2), ‘G’(3), ‘N’(6), ‘P’(2). An example is EN-C-Y-C-LOPEDIA misspelled EN-C-Y-LOPEDIA.
(9) Few cases of added elements representing a single consonant exist. A total of 12 cases some of which are related were found as follows: ‘D’(I), ‘G’(l), ‘K’(l), ‘L’(l), ‘N’(l), ‘R’(3), ‘S’(2), ‘T’(2).
8. VOWEL ERRORS FOUND
The number of vowel element errors found in the typical and bad lists was 481 and 390 respectively. The number of element error forms was 150 and 122, and the merging of both lists

94 E. J. Y~~NAKO: MKIS and I). F\x IHXIW
gave a total of 207 unique error forms. Because we could find no significant difference between
the errors in the two lists they were analysed together. The vowel errors found differed substantially from the consonantal errors. It was again
possible to classify vowel graphemes into (M) and (I.) forms by examination of the errors. The (N) form was not apparent with vowel graphemes.
Three patterns of vowel errors were evident and they all had some phonetic basis: (I} Where a dictionary word contained an element which was only a representation of one
phoneme then the misspelled word often contained an (M) represent~~tion of that phoneme (e.g. CLEV-ER misspelled CLEV-A where ‘A’ is an (M) representatit~n of ISHWI). A total of 413 (M) errors were found only 9 of which were not similar.
(2) Where a dictionary word contained any vowel element, the misspelled word often contained a “similar” element. “Similar” is defined as an element which differs from the dictionary element by one of the following: (i) mks any character or ‘GH’ (e.g. ARCH-AEO- LOGICALmisspelled ARCH-EO-L,OGIC,~t):(ii)add’A‘.‘E‘.’I’.’O‘.’U’.‘W’,‘Y’.‘GH’,’R’.or’H’
(e.g. CUR-IO-SITY misspelled CUR-IOU-SITY 1; (iii) interchange any two of ‘A’, ‘E’, ‘I’, ‘0’. ‘U’ and ‘Y’, or ‘U 9 ‘W‘ or ‘W’* ‘U‘ (e.g. ASSAD-U~U-S misspelled ASSAD-I~U-S); (iv) transpose any two adjacent characters (e.g. AMPl’f-EUR misspelled AMAT-UER). The resul- ting element will be a vowel element which occur< in normal English text. The following numbers were established: 850 cimilar errors (including the \ingle character vowel element error), 404 error forms containing only an (M) representation of the phoneme and 137 error forms containing only an (L) repreyent;\tion of the phoneme in the dictionary form.
(3) A total of 6 vowel errors were found which resembled the similar errors but contained two distinct errors: S-OR-ORITY misspelled S-ARR-ORITY, and ~NTERT-Ai-NED misspelled
ENTERT-EY-NED. This leads to an alternative definiti~)n of the similar error as, an error form
containing 2 errors one of which changes ‘I’:- ‘Y’. ‘Y’ 5, ‘I’, ‘RR’ -’ ‘R‘ or ‘R’ 3 ‘RR’ and the
other is as defined above. The following cases were found: ‘AI’ i, ‘EY’(l), ‘AR’> ‘URR’(l), ‘OR’ 9 ‘ARR’( I), ‘URR’ 9 ‘ER’(2). ‘Y’ 9 ‘IE’( 1).
The single character vowel element errors were analysed separately. All missed vowels were found and these were as follows: ‘A’(14), ‘E’(72), ‘I’(Z), ‘O’(4). ‘U’(I j, ‘Y’(2). All added vowels except added ‘5” were found, and these are: ‘A’(9). ‘E’(32), ‘I’(9). ‘O’(2). ‘U‘( I ). The following changes occurred: ‘A’ ZQ ‘E’(32). ‘A” ,> ‘I’( 15). ‘A’ 2’ ‘O’(5), ‘A’ 2, ‘U’(l), ‘E’ + ‘A?.(5), ‘E’ ,> ‘I’(35), ‘E’ $ ‘O’(l), ‘E’ b ‘U’(2j, ‘I’ B ‘A’(32). ‘1‘ + ‘E’f24). ‘I‘ *a ‘(j’(2), ‘I’ .>r ‘U’( I), ‘1’ > ‘Y’(h), ‘0 9 ‘A’(4), ‘0’ :, ‘E’(2), ‘0’ $. ‘I’( 1). ‘0’ i> ‘Y’(l), ‘II‘ I. ‘A’(3). ‘U’ .” ‘E’(3). ‘L:’ ._ ‘I’(3). ‘Y’ 2~ ‘I’(7), ‘Y’% ‘O’(2). The following error4 were not found: ‘,A’ ” ‘1”. ‘1:’ ;a ‘Y‘, ‘O’il> ‘U’. ‘II‘ * ‘0‘ ‘U’ & ‘Y’. ‘Y’ s ‘A’, ‘Y’ s ‘E’, “Y’ 9 ‘U’. It is believed that this pattern may he an artifact due to the limited linguistic background of the misspellers and that all single character change element errors except possibly those involving ‘Y’ would be found if a larger sample of misspellings was
used.
9. SEQUENTIAL ERRORS
Short transpositions, doubling and singling of characters have long been recognised as major forms of spelling errors, The present work extend\ this knowledge to include other forms of errors which appear to have a common baTis. That is the misspeller knows that certain characters are present in a word hut is uncertain of the sequence and/or the number of occurrences.
Sequential errors have been categorised under (a) simple sequential errors and (b) related sequential errors.
(a) Simple sequential errors (i) “Short transposition+” are simple reversals of two adjacent characters and occur at any
position in a word regardless of its phonetic structure (e.g. ANA-LY-SIS misspelled ANA-YL- SIS). They are very common but occur predominantly as a single error in a word. The typical list contained 68 cases where a short transposition was the only error in the word. The bad list had 31 cases where all but 2 were the only error in the word. This finding confirms the results of DAMER~u~~].
(ii) Doubling normally affects a character which occurs doubled in normal English text.

The rules of spelling errors 95
However, double errors occur infrequently in any character in the text and when a character is doubled (e.g. FO-X misspelled FO-XX and MATR-I-X misspelled MATR-III-X), it may be due to the repeat facility on electronic keyboards.
(iii) The “double long transposition” is the transposition of two characters which often have some phonetic similarity, over one or more intervening characters (e.g. E-N-E-M-Y misspelled E-M-E-N-Y, EQUIV-A-L-E-NT misspelled EQUIV-E-L-A-NT). The typical list contains I2 examples and the bad list only 3. The algorithm used here detected only a single case of this error which will probably occur as a single error in a word.
(iv) The “single long transposition” involves a single character transposed over one or more characters. This is not a common error and when detected the reason for its occurrence will be clear. Examples are: RHODOD-END-R-ON misspelled RHODOD-R-END-ON, PAM-PH-LET misspelled PH-AM-P-LET. The typical list contains 7 cases and the bad list only I. Similarly the algorithm detected only one case of this error and again it is expected that this will occur only as a single error in a word.
(v) The “vowel consonant transposition” is a short transposition of a vowel and a consonant where the vowel has also been changed. A typical case is PARTICIP-LE misspelled PARTI- CIP-AL but other types are not uncommon (e.g. FIGU-RE-S misspelled FIGU-AR-S). These again occur mainly as single errors in a word. Three single error cases were found in the typical list, and 12 cases (only I of which occurred with another error) were found in the bad list.
(b) Related sequential errors A group of errors designated “related” were found where the misspeller missed or added
characters probably because he knew that the characters existed in the word but was not sure how many. The evidence for the existence of this group of errors is strongest where two characters are missed. In order to demonstrate that related errors occur more frequently than would be expected if spelling errors were random, we are examining closely matched sets of real and random spelling errors.
(i) The “related double miss” occurs where two characters are missed, one a vowel and the other a consonant. The consonant occurs elsewhere in the dictionary form but neither of the characters is singled (e.g. AUTHOR-IT-A-T-IVE misspelled AUTHOR-A-T-IVE, QUAN-TI- TIES misspelled QUAN-TIES). This error again occurs mainly as a single error in a word and the first occurrence of this consonant in the dictionary form is usually omitted. The typical list contains 8 cases all as single errors in the word and only 1 where the second occurrence of the consonant is missed. The bad list contains 6 cases out of which 1 involves 2 errors in the word and 1 where the first occurrence of the consonant is ommitted It is interesting to note that in all cases the error form was at least 7 characters long.
(ii) The “related double add” occurs when two characters are added to a word one a vowel
and the other a consonant the latter occurring elsewhere in the dictionary form, but neither of the characters being doubled (e.g. HEART-R-END-ING misspelled HEART-R-END-ER-ING, PREVEN-T-IVE misspelled PREVEN-T-AT-IVE). This error appears as the only error in a word and it occurs three times in the typical list only.
(iii) The “related single miss” occurs when a single character is missed but then appears
elsewhere in the dictionary form without being singled (e.g. ADD-I-T-I-ON misspelled ADD-I- T-ON, APP-R:OPR-IATE misspelled APP-R-OP-IATE). These errors occur when the missed character is before or after the second occurrence of that character and in error forms with one or two errors. The typical list contains 109 of these errors and the bad list 78.
(iv) The “related single add” occurs where a character is added and the same character occurs elsewhere in the dictionary form but is not doubled (e.g. M-I-N-U-TES misspelled M-U-IN-U-TES). A well known statement in this case is “I know there is a ‘U’ in it somewhere”. This error again appears in error forms with one or two errors and as a character which is added before or after its occurrence in the dictionary word. The typical list contains 74 errors and the bad list 54.
IO. OTHER DIALECTS AND LANGUAGES
The consonantal structures of various dialects of the English/American language do not differ markedly. We would therefore expect that the consonantal structure used here will apply to the

Yh Il. J. Y IN~AKOLIIIWC and D. FAIVIHKOP
vast majority of dialects and that only minor changes will be necessary to cater for the rest.
Most differences occur in the vowels, but the fact that over 97% of vowel element errors
followed the similar rule defined in Section 8, indicates that if the misspeller speaks a different
dialect from those studied here, the present rules will describe more than 97% of his vowel
error{.
Some of the rules described will be directly transferable to other languages. For example
there is no reason lo suppose that sequential errors in French will differ from sequential errors
in English but vowel and consonantal errors may differ. There is some evidence which suggests
that medical. chemical and Latin/Greek based dialects should be treated as separate languages
for spelling correction. JowPH[.(] found that the Soundex codes for Spelling errors in medical
text\ differed from the Soundex codes used in standard English and also noted that the
frequency of occurrence of letters differed markedly from standard English. We also believe
that computer symbol tables with less than 32 characters should be treated as a separate
language twcauw the compression of variable names (e.g. 6 characters in FORTRAN) produces
strings which do not occur in English.
The present study involve\ a total of X7 elements and this is limited to those occurring in
normal English text. Thus the maximum number of element errors (E) involving changing one
element to another. mincing or adding an element is
E = N * N + N (N is the number of elements).
Clearly ;I large proportion of these will not occur. The errors likely to occur will be those which
follow one or more of the rules described.
Although only :I ~m111 proportion of all possible element errors have been found, (130
consonantal and 207 towel errors), rigorous application of these rules will produce a list which
will include the vast majority of element errors occurring in real text. Our present estimate of
the size of thi\ list is \omc 3500 element errors or approximately 3% of possible element errors.
The next stage of the research will utilise the knowledge gained from the present analysis as
the foundation of an “expert” spelling error correction program. Thus if an unknown token is
found then only ;I small proportion of ;I dictionary would be searched and any words which
differ from the unknown token by up to two or perhaps three known error forms would be
considered as possible version\ of the word intended by the misspeller. A choice would then be
made from the list of possible words on the hasis that more frequently occurring error forms
are more likely to indicate the intended word.
Thi\ expert program i\ currently being developed using the Shorter Oxford Dictionary and
results to date indicate that more than 80% of the errors in the bad list can be corrected and
more than c)O? of error\ in the typical list.
The rules of spelling errors
APPENDIX I tquivalent ptloneaes bsea
. ..I eoulvalent Fhoneve /... Grapheme, U L h (see section 3) of blank for /O/k An example X [Reference, R = preseni
. ..I0 I... B***,M,RAD . ../CH /a.. C***tL.CELLO TI**rL,OUESlIOh . ../n /... PD**,L,8DELLIUM LD**,L,COULD
L 4lBB**,L,EBB L ClPB**,L,CuPROARD
LllICH**,fi,ChLRCH T 31TCH+,N,RATCH
CllICZ**,L,CZECH L 41
[ FlO***,M,DAD [ 41
L 4lOD**,L,ADG
110
Lll
L 4
L 4
T***,L,ESlUARY
ED *,N,LEbRNED
. ..IF /... F**t9MrFARM PH*+,M,GRAPHIC . ../G /... G***,M,REG TG**rL,MORTGAGE . ../H /... H**+,M,HOT . ..IJ /... CH*+,L,SANOYICh GG**,L,SUGGEST GE*+rL,CHARGEABLE . ../K /... C***rR,CAT CK**,L,BACK LK**,L,CHALK . ../KU /... QU**,MrPUILT . ../KS /... CS**,LkETHICS XS**,N,COXSYAIN . ../L /... L***,M,CLIFF . ../n I... GH+*,L,DIAPHRAGM MM**,L,flUMMY . ..IN /... GN**,L,GNAU ND**,L,HANDCuFF . ../NG /... N***rHrUNCLE . ../P /... BP**,L,SUBPOENA . ../Q /... R+**,M,RAP YP**,L,YRAP . ../s /... C***,M,DANCE SCH*,L,SCHISM TI+*,L,NATION
. ../SH /... C***kNkOCEAN SCH+,L,SChtDuLE SSI*,N,MISSION . ..I1 /... BT**,L*DEaT PT**,L,RFCtIPT Tu**,L.TuO . ../TH /... TH**rfl,NOThING . ../V /... F***,L,OF VV**,L,NAVVY . ../R /... OU**,L,RIVOUAC . ../Y /... F+**,L,AZALEA
[ LlFF**,L,CuFF LlllPPH*,L,SAPPHIRE
[ 41GG**XL,EGG [ ClX***,L,EkACT
C 41YH**,L,RhO
LlllD***,L,EDuCATt Ll1IGI**,L,REGION c PI
C11ICC**rL,lOBACCC C 4lK***,R,KEEP L11lDU**,L,CONOUER
[ 41CGu*,N,ACPUAINT
L 41X***ttltAkE c RI
L11lSC**,L,VISCOUN
c 41
CllICC**,L>ACCIDEN
C 41LL**,L,ALL C 41LN**,L,KILN
[lllLR**,L,BALM C ClMN*+,L,HYMN
ClllM***,M,IHP c 41
CllIKN**,L,KNIFE t 41NN**,L,INN
LlllMN**,L,MNEhONIC C 41PN**,L,PNEUMATIC
CllING*+,MrSuNG
ClOIP***,R,APT
t 41RH+*,L,RHuBARB c 41
CllIPS**,L,PSALM C 41SS**,L,DEPRESSED ClCIZ***,LAPUAR7Z
CllIND**,L,HANDKERCHIEFC 41
L 41PH**,L,DIPHTHERIA tllIPP+*,L,STOPPED
CllIPR++,L,PURR C 41RRH*,L,CATARRH
C 41S***,M,SPEAK C11ISC**,L,BUSCLE C 41ST**,L,LISTEN L 41SY**XLkSYORD Cl01
L PlCh**rL,MACHINt L11IscI*,N,ccNscIGus L 41TI**,N,ECLCATION
C CICHl*,L,YACHT [ 41T***,M,Btl L 41
L11lTIH+,L,MA1THER
LllILV**,L,HALWES L161
C 4lu***,L,ASSUAGE
[ 4lI***,L,SENICR
Cl1ICI**,h,MuSICIAN ClllS***XN,SUGAP L 41SH**,M,ShIP L 41SS**,L,PRESSURE tllISI**,N,MANSIOh L 41T***,h,NEGOlIATE
L 41CT**,L,INDICT L 41ED *,L,YISSED L 41TH**,L,ThVME I 41TT**,L,PUTT
L RI
LllIPH**,L,NEPHEh c11IV***,M,cIVIc
LlllU***,M,REUARD LlOIUH**,L,hHIP
L CIJ***rL,HALLELUJAH LlClY***.MrYELLOh
L 41S***rL,ABSOLVE LllISC*',L,DISCEPN Llll2***,M,200 C 41ZZ**,L,BUZZ
CllIS***,L,USLAL L 41SI**rL1VISION
LlllD**+, ,REDNESDAY ClllF+**. ,OF
2***,L,CAPERCAILZIETlll . ../2 /... CZ**,L,CZAR LIlltS *,N,GOES SS**,L,DESSEPT LllIX***,L,kYLOPHONE . ../ZH /... G**+,M.@EGIME L ~IJ***,M~BIJJLJ Z***tL,AZURE Llll . ..I0 /... cl+**, .nRAChM LlllcK**, #BLACKGUARD H***, ,b'EHICLE TlllL***, rCOLONEL F?***, ,IRON LlllS***, ,APROPOS Il***, XGUNRALE [111X***, ,SIOLJX . ../A /... A**+,H,RANGE CllIAI**,M,PAIN AY*+,L,YAY L 41AE**,L,ISPAELI FA**,L,GREAT L11IEI**kL,b'EIL . ../A2 /... A***,H,HAVE LlilAI**,L,RL4IT . ../AIP/... AR**,L,CARE ClllAIR*,N,AIP
E 41FT**,L,OFTFN Ill1
C 41GH**,L,GHOST c 41
L 41
C 41DJ**,N,AOJECTIVE C 41J***rM,PROJECT
L~~ICCH*,L,SACCHAR L 4TKH**,L,KhAKI
h
LF**,L.CALF
LllIGU**rL,GUESS
4 G***,M,LENDEP 4 DG**,N,BUDGtT
C 41CH**,L,tChO Llll L 41X***rL,EkIT
L11IkC*+,N,EXCITE
I 41SL**kL,ISLAND
C 41MB**sL,CRUflB
C11IN***,N,NAP Cl11
97
ROYRI
Cl11
Llll
L 41
Llll
r111 t 41
c 41
L 41
I RI
c 41
Cl11
c 41
T 41
Cl01
Cl11 c 41
c 4: L 41 L 41
Cl11 L 41
L 41
Llll
Llll
c 41 c 41
L 41
Llll clllP**+r ,CGUP LllIPH**, rAPOPHTHEGM Cl11 LlllT**+, ,YALTZ LlllTH**, ,ASTHMA Llll LlllZ***, ,RENDEZVOUS LR 1
L CIAIGH,L,STRAIGHT LlllAU**,L.GALGE Llll LllIAO**,L,GAOL LlllE***,L,FETE c 41 LlllEIGH,L,UEIGh CllIEY**,L,THEY c 41
LlllAY**rLIP~~~~~ L ~IAUG~XLXLAUGH L 31
L 41ER*+,L,ThERE CllIEAR*rL,BEAR Cl11
E. J. YANNAK~UDAKIS and D. FAWTHROP
EIR+,L,HEIR tIllEYR+,l,EYPIE
ClllAA**,l,BPP C 41AQ+*,H,ARtl c 31
C 41AI**,L,VILLAIN ClllEP**rL,SERGEANT t 41ER**rL,CONCERT t 43IR**,L,ELIXIR tllIOE**,L,DOES t 3lU***,H,DIFFIC'JLl
ci1lAY+*,L,auPY tlllEI**~L,CEILING C11IIE+*,L,CHIEF
Cl11
~~~IAU**,L,AUNT tllIER*+,L1DEQBY r111
t 4lE***,L,ENCORE C 41EAQ*,L,HEPRT c 41
. ../AR /... A*+*,L,CHAFF AH**,L,BAH. o***,LtHOT .,./SHY/... A*+*,M,PIQATE E**+,L,BARREL EOU*,L.COURAGEOUS IE**,L,ANCIENT OI**,L,PORPOISE OO+*,L,FLOOD . ..IE 1... AE+*,L,ANAEMIA EE**,M,NEEDLE I***,L,ANTIPbE
. ../EZ I... b***,L,nANY t**+rMrPETQOL IE**,L,FRIENC OE*+rL,FOETID . ../EQ /... AQ*?,L.CO~IARD IR**,L,BIRD UQ*+,L,RURN . ../EEQ/... ER**rL,PERIOD IEP*rL,PIER . ../I I... bI**,L,AISLE FY**,L,GtYSEQ GY**rLtCOYOTE . ../I2 I... A***,L,LUGGAGE FA**,L,GUINEb I***,f'rGIVE U***,L,RUSY . ..I0 /... AU**,L,CHAuFFEUR OA**.L,OAK OU**rL,SOUL . ../oz I... A**t.L,YAND EAU*,L,BUREAUCPAl . ..I01 I...
~~~~Z***,L,ENGZNE CllIOAR*,L,CUPBOARD t 31OU**,L,FAMOUS CllIUR**,L,AUBURN
C 41AU**#LsEPAULET C 41AR**rL,ANARCHIST Cl11
C 41EI+*rL~FORFEITURE C 41EO**#L,PIGEON c 41 C 41IA**,L,PARLIAflENT c 41 C11IO***,L,MELODY Cl11 tl1IOR**,L,COBFOQT Cl11 CllIYR**,L,ZEPHYQ
CllIEA**rM,BEAT CllIEY+*.L,KEY Cl11
t111
t 41 c 41
tlllAY**,L,SAYS t 41 tllIOE**,L,LEtPAPO t111 t 'ItE**,L,THPEtPtNCt t111
C 33E+**,M,CAtlELLIA t 41EO**rL#PEOPLE C 410E**,L,PHOENIX
L 41AI**,L.SPlD t 41EI**,L,LtISURE clllU***,L,B~PY
tlllAE**,L,AESTHETIC t11IEA**,L.HtPD CllIEY**;L,QtYNARG t 31
t 4ltR*+,fi,HtR tllIEAR*,L,tPQL ClllO***,LtCLLohEL ~~~IOQ+*,L,YCPLD C 41YR**,L,MYRTLE t 41
tlllEPR*,M,CLEAR c 41
t11lEuQ+,L,PHPTEUR tllIOuR*,L,GLA~OLR
c 41 L 41
Cl11
t 41 Cl11 t111
t111 I 41 t 41
t111 t 41 t 31
c 41
t111
t 41 t 41
t 41 c 41 Cl11
t 41 Cl11
t111
t 4ltEQ+,L,BEEP
tl1lAY**,L,KPYPK tllII*+*,tl,BLIND
C 4ltI+*,L,EIDER CllIIt**,L,DIED t 4lY***,L,BY
CllltIGH>L,HEIGHT CllIIGH*,L,HIGH I 4lYE**,L,DYE t 41UY**,L,eUY
tlllAI**,L,CAPTAIN C 4lEE**,L,BREECHES t11IIb**,L,HAPRIAGE t11IUI**,L,B~ILD
CllIEPL*,L,PLPTEPu tlllOt**rL,DOE C~~IOIJ~H,L,DOLJGH
C 4lAY**,L,YtSTEQDAY ClllEI**,L,FOREIGN t 4lIE**,L,SIEVE t 41Y+**rR,NYTH
tlllE~**,L,Stk t11IOH**,L,oHM t11IoY**1L1Bc~L
C 4lt***tL,BECOHt C 4lEY**rL,DOhKEY t1110***,L,hOMEN t 41
tlllO***,M,PATR0L c 4loo**,L,Dooa [1I1EO**,L,YEOMAN
ClllPU**,L,tltCAUSE Cl11
[lllO***tM,GONE tllIOU**,L,KNOLLEDGE
c 410Y**,N,lOY
CllIDU**,M,COLJCH
OI**,nlOIL . ../ou /...
t111
tlllO***,L,TOtlB t11IOUGH,L,THROUGH tllIUO**,L,BUOYANT
ClllAUGH,L,CPU6HT t11IOR**,M,NOQ C11100R*,L,DOOR
tllIEk+*,L,NEYS t 41UE*+,L,CUE t 31You*,L1You
[llIOR+*,L,~GRSTED t 41EE**,L,THQEEPENCE
AU**,L,GAUCHO . ../oo /... EU**,L#SLEUTh 00**r*,B00T UE**.L,BLUE . ../OR I... b**+,L,FPLL AH**,L.UTAH OUGH,L,BOUGHT . ..IU /...
t 410Y**rL,CO~
t 4lEr**,L,CQEY t 4lOU**,L,GROUP tllIUI**,L,BRLISE
C11IOE**,L,CAhOE C 41U***,h,TRLJTH t 41
tlllAU**,L,CAuSE t 3lO***,L1FQOST C 410AR*,L,OPR
t 4ltU'*rL,FtLD t 4lU***rtltFURY C 3lYEk+rL,YEk
t 4lPr**,L,LAY ClllOA**,L,BQOAD ~~~I~UQ*,L,GOURD
FAU*.L,BEPUTY IEY+.L.VIEn YU**;L,VULE . ../uz /... O***,L,COMFORT OY**,L,ROULOCK
t 41IEU*,L,LIEU tllIUI**,L,NUISANCE t 31
ClllOU*+,L.DoUBLE Cl11
APPENDIX II
cosoar lson Of lengths of dlctlonary forms with lengths of error forrs
TYPIcal 1Ist ---__-_-____
dlctlonary difference length -3 -2 -1 c. 1 2 3
D 0 0 0 0 0 0 0 0 C 0 0 O 0 0 0 0
0 0 c c 0 0 0 0 c 0 0 0
0 0 0 0 4 0 0 0 c 2 13 0 0 0 6 18 16 0 0 0 18 25 18 0 0 0 40 48 17 1 0 1 53 bt 19 1 0 2 53 71 20 1 0 1 50 55 19 1 0 6 23 27 15 1
; 3 4 5 6 7 8 9
10 11 12 0 6 21 18 9 2 13 0 414 7 1 0 14
: 2 3 0
15 3 10 16 0 0 c c 0 0 17 0 0 c L 0 0

The rules of spelling errors
dictionary lrnqth -3
1 u 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0
10 G 11 I 12 1 13 1 14 C 15 0 16 0 17 0
Bad tlst ________
cifference -2 -1 c 1 0 c 0 0 0 (r 10 0 15 2 0 0
4 It; 8 6 12
0 16 15 12 2 33 24 23 2 7
:: 31 17 32 9
5 49 24 10 b 26 7 4
2 1e 8 1 2 II 3 C 0 4 3 0 0 c (i 0 0 111 0 0 c 0
2 0 0 0 C 0 2 0 1 0 1 0 0 0 b 0 0 c,
99
3 0 0 0 0 0 0 0 0 0 0 0 0
L 0
0
0 0




















