
Antropologia średniowieczna i nowożytna Polski. Stan i perspektywy badań

White Paper Series
THE POLISHLANGUAGE IN
THE DIGITALAGE
Seria raportów
JĘZYK POLSKIW ERZECYFROWEJ
Marcin Miłkowski


White Paper Series
THE POLISHLANGUAGE IN
THE DIGITALAGE
Seria raportów
JĘZYK POLSKIW ERZECYFROWEJ
Marcin MiłkowskiInstytut Podstaw Informatyki PAN
Georg Rehm, Hans Uszkoreit(redakcja, editors)

WSTĘP PREFACE
Poniższy raport jest częścią serii wydawniczej, której is white paper is part of a series that promotescelem jest upowszechnianie wiedzy na temat techno- knowledge about language technology and its poten-logii językowych i ich możliwych zastosowań. tial. e availability and use of language technology inDostępność i wykorzystanie technologii językowych Europe varies between languages. Consequently, thew Europie są różne w zależności od języka. Dlatego też actions that are required to further support researchdziałania, którenależy podjąć, abyodpowiedniowspie- and development of language technologies also differ.rać badania i rozwój technologii dla danego języka, są e required actions depend on many factors, such asuzależnione od wielu czynników takich jak złożoność the complexity of a given language and the size of itsokreślonego systemu językowego i wielkość społeczno- community.ści posługującej się tym językiem. META-NET, a Network of Excellence funded by theCzłonkowie META-NET, Sieci Doskonałości współ- European Commission, has conducted an analysis offinansowanej przez Komisję Europejską, przeprowa- current language resources and technologies in thisdzili analizę bieżącego stanu zasobów i technologii ję- white paper series (p. 77). e analysis focused on thezykowych dla 23 europejskich języków urzędowych 23 official European languages as well as other impor-oraz innych ważnych języków narodowych i regional- tant national and regional languages in Europe. e re-nych w Europie (s. 77). Wyniki tej analizy sugerują, sults of this analysis suggest that there are tremendousże w przypadku każdego języka istnieje wiele istotnych deficits in technology support and significant researchbraków. Bardziej szczegółowa, specjalistyczna analiza gaps for each language. e given detailed expert anal-i ocena bieżącej sytuacji pozwoli na optymalne wyko- ysis and assessment of the current situation will helprzystanie dodatkowych badań. maximise the impact of additional research.Do sieci META-NET w listopadzie 2011 należały 54 As of November 2011, META-NET consists of 54ośrodki badawcze z 33 krajów, współpracujące z pod- research centres from 33 European countries (p. 73).miotami komercyjnymi, agencjami rządowymi, przed- META-NET is working with stakeholders from econ-stawicielami przemysłu, organizacjami badawczymi, omy (soware companies, technologyproviders, users),producentami oprogramowania, dostawcami techno- government agencies, research organisations, non-logii i uczelniami europejskimi (s. 73). Wszyscy człon- governmental organisations, language communitieskowie sieci tworzą wspólną wizję technologii języko- and European universities. Together with these com-wych i zajmują się opracowaniem planów strategicz- munities, META-NET is creating a common technol-nych, których realizacja pozwoli na uzupełnienie wy- ogy vision and strategic research agenda for multilin-krytych braków technologicznych do 2020 r. gual Europe 2020.
III

META-NET – [email protected] – http://www.meta-net.eu
Autor tego opracowania dziękuje autorom raportu dotyczą-cego języka niemieckiego za zgodę na wykorzystanie materia-łów niezależnych od języka [1].
Przekład na język polski: Anna Cichosz.
Opracowanie niniejszego raportu zostało sfinansowane w ra-
mach siódmego programu ramowego oraz programu na rzecz
wspierania polityki w zakresie technologii informacyjnych
i komunikacyjnych Komisji Europejskiej w ramach umów
T4ME (grant 249 119), CESAR (grant 271 022), META-
NET4U (grant 270 893) i META-NORD (grant 270 899).
e author of this document is grateful to the authors of theWhite Paper on German for permission to re-use selectedlanguage-independent materials from their document [1].
Polish translation: Anna Cichosz
e development of this white paper has been funded by the
Seventh Framework Programme and the ICT Policy Support
Programme of the European Commission under the contracts
T4ME (Grant Agreement 249 119), CESAR (Grant Agree-
ment 271 022), METANET4U (Grant Agreement 270 893)
and META-NORD (Grant Agreement 270 899).
IV

SPIS TREŚCI CONTENTS
JĘZYK POLSKI W ERZE CYFROWEJ
1 Streszczenie 1
2 Zagrożenie dla języków europejskich i wyzwanie dla technologii językowych 42.1 Bariery językowe utrudniają rozwój europejskiego społeczeństwa informacyjnego . . . . . . . . . 52.2 Nasze języki są zagrożone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Technologie językowe to klucz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4 Zastosowania technologii językowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5 Wyzwania stojące przed technologiami językowymi . . . . . . . . . . . . . . . . . . . . . . . . 82.6 Nabywanie języka przez ludzi i maszyny . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
3 Język polski w europejskim społeczeństwie informacyjnym 103.1 Informacje ogólne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2 Cechy szczególne języka polskiego . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.3 Najnowsze tendencje . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.4 Ochrona języka w Polsce . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.5 Język polski w Internecie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4 Technologie językowe dla języka polskiego 174.1 Technologie językowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.2 Architektury aplikacji technologii językowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.3 Główne obszary zastosowań . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.4 Projekty z zakresu technologii językowych . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.5 Badania i kształcenie w dziedzinie technologii językowych . . . . . . . . . . . . . . . . . . . . . 294.6 Dostępność narzędzi i zasobów . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 294.7 Porównanie języków . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 304.8 Wnioski . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
5 META-NET 35

THE POLISH LANGUAGE IN THE DIGITAL AGE
1 Executive Summary 37
2 Languages at Risk: a Challenge for Language Technology 402.1 Language Borders Hinder the European Information Society . . . . . . . . . . . . . . . . . . . . 412.2 Our Languages at Risk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 412.3 Language Technology is a Key Enabling Technology . . . . . . . . . . . . . . . . . . . . . . . . 422.4 Opportunities for Language Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 422.5 Challenges Facing Language Technology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 432.6 Language Acquisition in Humans and Machines . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3 The Polish Language in the European Information Society 453.1 General Facts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.2 Particularities of the Polish Language . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 453.3 Recent developments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 463.4 Language cultivation in Poland . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.5 Polish on the Internet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4 Language Technology Support for Polish 524.1 Application Architectures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 524.2 Core Application Areas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 534.3 Language Technology ‘behind the scenes’ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.4 LT Projects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 614.5 LT Research and Education . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 624.6 Availability of Tools and Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.7 Cross-language comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 634.8 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5 About META-NET 68
A Bibliografia -- References 69
B Członkowie sieci META-NET --- META-NET Members 73
C Seria raportów META-NET -- The META-NET White Paper Series 77

1
STRESZCZENIE
Informatyka zmienia nasze życie codzienne. Do pisaniai redagowania tekstów, liczenia i wyszukiwania informa-cji używamy zwykle komputerów. Coraz bardziej służąnam one także do czytania, słuchania muzyki, przeglą-dania zdjęć i oglądania filmów. W kieszeniach nosimymałe komputery, za pomocą których prowadzimy roz-mowy telefoniczne i piszemy e-maile. Są one źródłeminformacji i rozrywki w dowolnym miejscu na świecie.Jak digitalizacja informacji, wiedzy i codziennej komu-nikacji wpływa na język? Czy nasz język zmieni się lubnawet zaniknie?
Jakie szanse przetrwania ma polszczyzna?
Wszystkie nasze komputery łączą się ze sobą w gęstnie-jącej sieci globalnej o coraz większych możliwościach.Dziewczyna z Ipanemy, celnik w Dorohusku i inżynierwKatmandumogą rozmawiać ze znajomymi naFacebo-oku, ale prawdopodobnie nigdy nie spotykają się w spo-łecznościach internetowych i na forach. Gdy chcą po-radzić sobie z bólem ucha, wszyscy zajrzą do Wikipe-dii. Jednak nawet wtedy nie będą czytać tego samegoartykułu. Kiedy na forach i czatach sieciowi obywa-tele Europy dyskutują na temat wpływu awarii jądrowejw Fukushimie na europejską politykę energetyczną, ro-bią to w odseparowanych od siebie społecznościach ję-zykowych. Co łączy Internet, języki użytkowników na-dal rozdzielają. Czy zawsze tak będzie?Wiele spośród 6000 języków na świecie może nie prze-trwać w zglobalizowanym cyfrowym społeczeństwie in-formacyjnym. Szacuje się, że co najmniej 2000 języków
jest skazanych na wymarcie w nadchodzących dziesię-cioleciach. Inne nadal będą odgrywać pewną rolę w ro-dzinach i życiu codziennym, ale niew skali biznesu i śro-dowisk akademickich.
Język polski, którym mówi ponad 40 milionów osób,ma dosyć dobrą pozycję w porównaniu do wielu języ-ków. Istnieje duża liczba polskich kanałów telewizyj-nych. Większość zaś filmów zagranicznych wyświetlasię w wersjach z lektorem lub napisami w języku pol-skim. Wszystkie popularne pakiety oprogramowaniazostały przetłumaczone na język polski i mimo wszel-kich obaw o stopniową anglicyzację wydaje się, że w ży-ciu codziennym Polacy wolą używać własnego języka.Istnieje jednak niebezpieczeństwo jego kompletnegozniknięcia z głównych dziedzin naszego życia. Nie cho-dzi o naukę, lotnictwo i globalne rynki finansowe, którefaktycznie na całym świecie potrzebują lingua anca.Mamy na myśli wiele dziedzin życia, które są znacznieważniejsze dla obywateli niż dla partnerów międzyna-rodowych – chodzi na przykład o politykę wewnętrzną,procedury administracyjne, prawo, kulturę i zakupy.
Status języka zależy nie tylko od liczby mówiących nimosób czy dostępnych w nim książek, programów kom-puterowych, filmów i stacji telewizyjnych, ale także odobecności języka w cyfrowej przestrzeni. Tutaj równieżpolszczyzna jest w dosyć dobrej sytuacji. Polska Wiki-pedia jest jedną z największych na świecie, a domena .pl,mająca ponad 2 miliony zarejestrowanych poddomen,jest jedną z największych na świecie domen krajowych.(W USA bardzo niewiele stron internetowych faktycz-nie korzysta z domeny .us).
1

W dziedzinie technologii językowych polszczyzna dys-ponujewielomaproduktami, technologiami i zasobami.Istnieją aplikacje i narzędzia do syntezy mowy, jej roz-poznawania, korekty pisowni i gramatyki. Istnieje takżewiele aplikacji do automatycznego tłumaczenia języka,mimo że często nie dają językowo i idiomatycznie po-prawnych tłumaczeń, zwłaszcza gdy język polski jest ję-zykiem źródłowym. Wynika to głównie ze specyficz-nych cech języka polskiego.
Informatyka i komunikacja przygotowują się dokolejnej rewolucji.
Następna generacja techniki, po komputerach osobi-stych, sieci, miniaturyzacji, multimediach, urządze-niach przenośnych i przetwarzaniu „w chmurze”, tooprogramowanie rozumiejące nie tylko wypowiedzianelub zapisane litery i dźwięki, ale całe słowa i zdania,a także znacznie lepiej służące użytkownikom, gdyżmó-wiące ich językiem i go znające. Prekursorskie są tutaj ta-kie zjawiska, jak bezpłatne usługi internetowe TłumaczGoogle, które tłumacząmiędzy 57 językami, superkom-puter Watson firmy IBM, który zdołał pokonać amery-kańskiegomistrzaw teleturnieju „Jeopardy”, a także Siri,przenośny asystent firmy Apple, który potrafi reagowaćna polecenia głosowe i odpowiadać na pytania w językuangielskim, niemieckim, francuskim i japońskim. Alejuż nie w języku polskim.
Następna generacja informatyki opanuje ludzki językw takim stopniu, że przy użyciu techniki ludzie będąmogli komunikować sięwewłasnym języku. Urządzeniabędą w stanie automatycznie znajdować najważniejszewiadomości i informacje ze światowych zasobów wie-dzy w odpowiedzi na proste w użyciu polecenia gło-sowe. Technika znająca język będzie w stanie tłumaczyćautomatycznie lub pomagać tłumaczom, streszczać roz-mowy i dokumenty, a także pomagać w nauce.
Następna generacja technik informatycznych i komu-nikacyjnych umożliwi robotom przemysłowym i usłu-gowym (obecnie rozwijanym w laboratoriach badaw-czych) dobrze rozumieć, czego żądają ich użytkownicy,a następnie zdawać sprawę z realizacji tych żądań w ję-zyku naturalnym.
Ten poziomdziałania oznaczawyjście poza zestawy zna-ków i leksykony, korektory pisowni lub gramatyki orazzasady wymowy. Technika musi odejść od uproszczo-nych podejść i zacząć modelowanie języka w sposóbkompleksowy, biorąc pod uwagę składnię i semantykę,aby móc rozumieć kierunek pytań – a w ten sposób ge-nerować bogate i właściwe odpowiedzi.
Istnieje jednak coraz większa przepaść technologicznamiędzy językiem polskim i angielskim. Europa utra-ciła kilka bardzo obiecujących innowacji technicznychna rzecz USA, gdzie jest większa ciągłość w strategicz-nym planowaniu badań i większe wsparcie finansowedla wprowadzania nowej techniki na rynek. W wy-ścigu do innowacji technicznych dobry początek i wi-zjonerska koncepcja mogą zapewnić przewagę nad kon-kurencją tylko wtedy, jeśli rzeczywiście dotrze się na li-nięmety. Inaczej liczyćmożna co najwyżej na honorowąwzmiankę w Wikipedii.
Każdymiędzynarodowykonkurs technologiczny świad-czy o tym, że wyniki automatycznej analizy języka an-gielskiego są znacznie lepsze niż dla polskiego, mimo że(albo właśnie dlatego), że metody analizy są podobne,jeśli nie identyczne. Odnosi się to do ekstrakcji infor-macji z tekstów, korekty gramatycznej, tłumaczenia ma-szynowego i bardzo wielu innych zastosowań.
Wielu badaczy uznaje, że opóźnienia rozwojowe biorąsię stąd, iż od pięćdziesięciu lat metody i algorytmy lin-gwistyki komputerowej oraz badań nad aplikacjami ję-zykowymi skupiają się przede wszystkim na języku an-gielskim. Jednak inni sądzą, że język angielski z na-tury rzeczy lepiej nadaje się do przetwarzania kompu-terowego. Przy użyciu istniejących metod języki takie
2

jak hiszpański i francuski są znacznie łatwiejsze do prze-twarzania niż polszczyzna. Oznacza to, że potrzebaosobnych, zintegrowanych i długotrwałych prac badaw-czych, jeżeli chcemy korzystać z technologii informa-tycznych i komunikacyjnych następnej generacji w tychdziedzinach naszego prywatnego i zawodowego życia,w których żyjemy, mówimy i piszemy po polsku. Wtedydopiero będziemymogli powiedzieć, że dodaliśmy językpolski do ulubionych, jak głosi hasło kampanii Rady Ję-zyka Polskiego [2].
Myj tylko te zęby, które chcesz zachować.
Podsumowując, pomimo pesymistycznych proroctw ję-zyk polski nie jest zagrożony, nawet ze strony narzędziinformatycznych obsługujących język angielski. Sytu-acja może jednak ulec radykalnej zmianie, kiedy tech-nika następnej generacji naprawdę zacznie efektyw-nie opanowywać język naturalny. Dzięki coraz lep-szemu tłumaczeniu maszynowemu nowe techniki po-mogą w przełamywaniu barier językowych, ale tylkomiędzy tymi językami, które zdołały przetrwać w cyfro-wym świecie. Jeżeli będą istnieć odpowiednie techno-logie językowe, wówczas będzie można zapewnić prze-trwanie językom, którymi posługują się nawet bardzomałe społeczności. W przeciwnym razie nawet „więk-sze” języki będą pod ogromną presją.
Dentysta żartobliwie przestrzega: „Myj tylko te zęby,które chcesz zachować”. Dotyczy to również politykinaukowej. Jednak z jednymzastrzeżeniem. Możemyba-daćkażdy językpod słońcem, ale kosztowne technologiepowinniśmy rozwijać jedynie dla tych, które naprawdęchcemy utrzymać przy życiu.Seria raportów META-NET wskazuje, że istniejąogromne różnice między rozwojem technologicznymróżnych języków państw członkowskich. Mimo że pol-ski jest jednym z „większych” języków unijnych, należyprowadzić dalsze badania, aby dostępne dla tego językanarzędzia technologiczne były gotowe do codziennegoużycia.Długoterminowym celem META-NET jest opracowa-nie wysokiej jakości technologii językowych dla wszyst-kich języków, co pozwoli na zjednoczenie politycznei gospodarcze zachowujące różnorodność kulturową.Technologia pomoże nam przezwyciężyć istniejące ba-riery i zbudować pomost łączący języki europejskie. Tencel wymaga jednak wspólnego zaangażowania wszyst-kich stron: przedstawicieli świata polityki, nauki, biz-nesu i społeczeństwa.Seria raportów META-NET stanowi uzupełnienie in-nych działań strategicznych prowadzonych przez kon-sorcjum (patrz załącznik). Bieżące informacje, takie jakaktualna wersja wizji META-NET [3] lub Strategicz-nego Programu Badań (SPB), można znaleźć na stronieinternetowej META-NET: http://meta-net.eu.
3

2
ZAGROŻENIE DLA JĘZYKÓW EUROPEJSKICHI WYZWANIE DLA TECHNOLOGIIJĘZYKOWYCH
Jesteśmy świadkami cyfrowej rewolucji, która maogromny wpływ na komunikację i społeczeństwo. Roz-wój cyfrowej i sieciowej technologii komunikacyjnejporównuje się czasemdowynalezienia prasy drukarskiejprzez Gutenberga. Co ta analogia może powiedziećnam na temat przyszłości europejskiego społeczeństwainformacyjnego, a w szczególności na temat naszychjęzyków?
Jesteśmy świadkami cyfrowej rewolucjiporównywalnej z wynalezieniem druku przez
Gutenberga.
Wynalazek Gutenberga pociągnął za sobą przełomw komunikacji i przepływie wiedzy – warto wspomniećchoćby przekład Biblii autorstwa Lutra. Kolejne stule-cia przyniosły rozwój technik kulturowych umożliwia-jących bardziej efektywne przetwarzanie języka i wy-mianę wiedzy:
standaryzacja pisowni i gramatyki głównych języ-ków umożliwiła błyskawiczne rozpowszechnianienowych idei naukowych i intelektualnych;
wglobalnej przestrzeni gospodarczej i informacyjnejstykamy się z coraz większą liczbą języków i ich użyt-kowników oraz rosnącą ilością treści:
rozwój języków urzędowych pozwolił obywatelomporozumiewać się w ramach określonych (często po-litycznych) granic;
nauka języków i tłumaczenie ułatwiły komunikacjęponad barierami językowymi;
wypracowanie standardów redakcyjnych i bibliogra-ficznych poprawiło jakość oraz dostępność materia-łów drukowanych;
powstaniemediów takich jak gazety, radio, telewizjaczy książki zaspokoiło różnorodne potrzeby komu-nikacyjne.
W ciągu ostatnich dwudziestu lat technologia informa-cyjna pomogła zautomatyzować i usprawnić wiele pro-cesów:
oprogramowanie DTP (do komputerowego składutekstu) zastępuje maszyny do pisania i zecerów;
program Microso PowerPoint zastępuje folie dowykładów;
przesyłanie dokumentów pocztą elektroniczną jestczęsto szybsze niż za pomocą faksu;
komunikator Skype umożliwia prowadzenie inter-netowych rozmów i wirtualnych spotkań;
formaty kodowania audio i video ułatwiają wymianętreści multimedialnych;
wyszukiwarki zapewniają dostęp do stron interneto-wych po wpisaniu słów kluczowych;
4

serwisy internetowe, takie jak Google Translate, ofe-rują szybki dostęp do przybliżonych tłumaczeń tek-stu;
platformy społecznościowe, np. Facebook, Twitterczy Google+, ułatwiają współpracę i wymianę infor-macji.
Takie narzędzia i aplikacje są pomocne, ale czy mogąurzeczywistnić wizję zrównoważonego, wielojęzycz-nego społeczeństwa europejskiego gwarantującego swo-bodny przepływ informacji i towarów?
2.1 BARIERY JĘZYKOWEUTRUDNIAJĄ ROZWÓJEUROPEJSKIEGOSPOŁECZEŃSTWAINFORMACYJNEGONie wiemy dokładnie, jak będzie wyglądało społeczeń-stwo informacyjne przyszłości, ale rewolucja w techno-logiach komunikacyjnych może umożliwić nowe formykontaktumiędzy ludźmimówiącymi różnymi językami.To z kolei zmotywuje nas do nauki nowych językówi stworzy odpowiednie warunki do tworzenia nowychaplikacji umożliwiających wzajemne zrozumienie i do-stęp do wspólnej wiedzy.
Globalna przestrzeń informacyjna i gospodarczato także coraz więcej języków.
W globalnej przestrzeni gospodarczej i informacyjnejstykamy się z coraz większą liczbą języków i ich użyt-kowników oraz rosnącą ilością treści, i musimy sprawniewykorzystywać nowe rodzaje mediów. Popularność ser-wisów społecznościowych (Wikipedia, Facebook, Twit-ter i YouTube, a ostatnio również Google+) to tylkowierzchołek góry lodowej.
To, że możemy dziś przesyłać plik zawierający gigabajtytekstu z jednego końca świata na drugi, nie oznacza,że zniknęły bariery językowe uniemożliwiające zrozu-mienie zawartości tego pliku. Z ostatniego raportuwykonanego na zlecenie Komisji Europejskiej wynika,że 57 proc. internautów w Europie kupuje produktyi usługi w języku obcym (najczęstszym językiem jestangielski, za nim plasuje się język francuski, niemieckii hiszpański). 55 proc. użytkowników czyta w językuobcym, ale tylko 35 proc. używa języka obcego, piszącwiadomości e-mail lub dodając swoje komentarze w ser-wisach internetowych [4]. Kilka lat temu angielski byłlingua franca internetu – zdecydowana większość zaso-bów internetowych dostępna była w tym języku. Ta sy-tuacja zmieniła się diametralnie. Obserwujemy obecnieniezwykle gwałtowny wzrost ilości treści w innych języ-kach (szczególnie azjatyckich i arabskich).
Co ciekawe, wszechobecne podziały cyfrowe wynika-jące z granic pomiędzy językami rzadkowspomina się naforum publicznym. Nadal nie wiemy, które języki euro-pejskie będą się rozwijać i przetrwają w sieciowym spo-łeczeństwie informacyjnym opartym na wiedzy, a któresą skazane na wymarcie.
2.2 NASZE JĘZYKI SĄZAGROŻONEWynalezienie prasy drukarskiej miało ogromny wpływna rozwój wiedzy i wymianę informacji w Europie, alejednocześnie przyczyniło się dowymarciawielu językóweuropejskich. Teksty w językach lokalnych i mniejszo-ściowych drukowano rzadko. W konsekwencji wiele ję-zyków, takich jak kornwalijski czy dalmatyński, przeka-zywano wyłącznie w formie ustnej, co zmniejszyło ichznaczenie. Czy wynalezienie Internetu będzie mieć takisam wpływ na nasze języki?
Około 80 języków używanych w Europie to jeden z naj-ważniejszych zasobów kulturowych tego kontynentu.
5

Różnorodność językowa Europy przyczyniła się też dojej sukcesu społecznego [5].
Różnorodność językowa Europy jest jednymz najistotniejszych elementów jej dziedzictwa
kulturowego.
Podczas gdy języki szeroko rozpowszechnione, takie jakangielski czy hiszpański, z pewnością zachowają swą po-zycję w tworzącym się społeczeństwie cyfrowymoraz nacyfrowym rynku, wiele języków europejskichmożew tejnowej sytuacji stracić na znaczeniu – staną się niepo-trzebne dla społeczeństwa ery Internetu. Taki rozwójwypadków z pewnością byłby niekorzystny. Z jednejstrony, Europa zaprzepaściłaby niepowtarzalną szansę,co zaważyłoby na jej światowej pozycji. Z drugiej strony,stałoby to w sprzeczności z obowiązującą w Europie za-sadą równego uczestnictwa wszystkich obywateli w ży-ciu społecznym bez względu na język. Jak wynikaz raportu UNESCO na temat wielojęzyczności, językjest podstawowym środkiem zapewniającym korzysta-nie z fundamentalnych praw, takich jak prawo dowypo-wiadania opinii politycznych, kształcenia się czy uczest-nictwa w życiu społeczeństwa [6].
2.3 TECHNOLOGIE JĘZYKOWETO KLUCZDawniej inwestowano przede wszystkim w kształceniejęzykowe i przekład. Szacuje się na przykład, że war-tość europejskiego rynku tłumaczeń ustnych i pisem-nych, a także lokalizacji stron internetowych, w 2008wyniosła 8,4 miliarda euro. Oczekuje się, że wartość tabędzie rosnąć o10proc.w skali roku [7]. Istniejącemoż-liwości produkcyjne nie są jednak w stanie zaspokoićobecnych i przyszłych potrzeb w zakresie komunikacjimiędzy językami. Wydaje się, że najlepszym rozwiąza-niemmogącym zapewnić społeczeństwu Europy dostęp
do wszystkich języków jest odpowiednia technologia –w końcu to właśnie technologia pozwoliła nam rozwią-zać problemy z transportem czy energią lub też kwestiezwiązane z potrzebami osób niepełnosprawnych.
Technologie językowe wspierają współpracęmiędzy ludźmi, utrzymywanie kontaktów
biznesowych, wymianę wiedzy oraz poglądówspołecznych i politycznych w różnych językach.
Cyfrowe technologie językowe (obejmujące zarównomowę, jak i pismo) ułatwiają współpracę międzyludźmi, utrzymywanie kontaktów biznesowych, wy-mianę wiedzy oraz uczestnictwo w społecznych i poli-tycznych dyskusjach w różnych językach.
Często nie zdajemy sobie sprawy, że korzystamy z nich,kiedy:
wyszukujemy i tłumaczymy strony internetowe;
używamy funkcji sprawdzania pisowni i gramatykiw edytorze tekstu;
przeglądamypolecane produktyw sklepie interneto-wym;
słuchamy syntetycznego głosu płynącego z urządze-nia nawigacyjnego;
tłumaczymy strony internetowe online.
Na technologie językowe składa sięwiele podstawowychaplikacji, które umożliwiają realizację złożonych proce-sów. W raportach opracowanych przez META-NETprzedstawiona jest analiza stopnia zaawansowania klu-czowych technologii dla poszczególnych języków.
Europa potrzebuje wydajnych i niedrogichtechnologii językowych dla wszystkich języków
europejskich.
6

Jeżeli Europa ma zachować swoją przodującą pozycjęw zakresie innowacji, będziemy potrzebować dostęp-nych, niedrogich i zintegrowanych z kluczowymi pro-gramami technologii językowych dla wszystkich języ-ków europejskich. Bez odpowiedniej technologii sku-teczna interakcja użytkowników posługujących się róż-nymi językami w multimedialnym środowisku nie bę-dzie możliwa.
2.4 ZASTOSOWANIATECHNOLOGII JĘZYKOWYCHW świecie druku przełomem technologicznym byłamożliwość szybkiego powielenia obrazu tekstu (strony)za pomocą odpowiednio skonstruowanej prasy drukar-skiej. Mimo tej zmiany, to ludzie nadal odpowiadalizawyszukiwanie, odczytywanie, tłumaczenie i streszcza-nie informacji. Kilkaset lat później wynalazek Edisonaumożliwił nam nagrywanie mowy – jednak ta przeło-mowa technologia też pozwoliła nam jedynie na tworze-nie kopii.
Technologie językowe pomagają przezwyciężyćbariery wynikające z różnorodności językowej.
Technologie językowe umożliwiają automatyczne tłu-maczenie i tworzenie treści, przetwarzanie informa-cji i zarządzanie wiedzą we wszystkich językach euro-pejskich. Mogą też usprawnić tworzenie intuicyjnychinterfejsów językowych wykorzystywanych w urządze-niach domowych, maszynach, pojazdach, komputerachi robotach. Istnieją już prototypy takich urządzeń, choćrozwiązania komercyjne i przemysłowe nadal są w po-czątkowej fazie rozwoju. Obecne tempo badań pozwalajednak być dobrej myśli. Na przykład tłumaczenie ma-szynowe tekstów specjalistycznych jest już stosunkowodokładne, a dla wielu języków europejskich istnieją jużzaawansowane systemy zarządzania treścią.
Tak jak w przypadku większości nowych technologii,pierwsze aplikacje językowe, np. interfejsy głosowe orazsystemy dialogowe, były ściśle wyspecjalizowanymi na-rzędziami, a ich zastosowania były mocno ograniczone.Jednak sytuacja się zmieniła i obecnie technologie języ-kowemogą znaleźć szerokie zastosowaniawbranży edu-kacyjnej i rozrywkowej. Można je wykorzystywać przytworzeniu gier, projektowaniu infrastruktury dla ośrod-ków dziedzictwa kulturowego, w zabawkach edukacyj-nych, bibliotekach, symulatorach i programach szkole-niowych. Mobilne serwisy informacyjne, wspomaganekomputerowo oprogramowanie do nauki języka, środo-wiska e-learningowe, narzędzia do samodzielnej ocenyczy oprogramowanie do wykrywania plagiatów to tylkokilka kolejnych przykładów zastosowania technologiijęzykowych. Popularność serwisów społecznościowych,takich jak Twitter czy Facebook, pokazuje z kolei, że ist-nieje zapotrzebowanie na zaawansowane technologie ję-zykowe, które pozwolą monitorować i streszczać dysku-sje, wskazywać trendy, kategoryzować reakcje emocjo-nalne oraz wykrywać przypadki nadużyć oraz narusze-nia praw autorskich.
Technologie językowe są także ogromną szansą dla UniiEuropejskiej, ponieważ dzięki nim możemy zmierzyćsię ze złożonym problemem wielojęzyczności w Euro-pie. W europejskich przedsiębiorstwach, organizacjachi szkołach korzysta się równocześnie z wielu różnychjęzyków, lecz mieszkańcy Europy chcą się porozumie-wać ponad barierami językowymi, które nadal wystę-pują na Europejskim Wspólnym Rynku, a technolo-gie językowe mogą pomóc pokonać te bariery poprzezwspieranie swobodnego i nieograniczonego użycia ję-zyków. Co więcej, innowacyjne i wielojęzyczne tech-nologie językowe mogą pomóc porozumiewać się z na-szymi globalnymipartnerami i ichwielojęzycznymi spo-łecznościami. W tym rozumieniu technologie językowesą „protezą”, która pomaga nam przezwyciężyć „nie-pełnosprawność”wynikającą z różnorodności językowej
7

i w ten sposób ułatwia kontakt różnorodnym językowospołecznościom.Kolejną dziedziną badań jest zastosowanie technolo-gii językowych w systemach wspomagających opera-cje ratunkowe w rejonach klęsk żywiołowych, gdzie ja-kość działania systemu informatycznego może decydo-wać o życiu lub śmierci. W przyszłości inteligentne ro-botywyposażonewwielojęzyczne technologie językowebędą mogły ratować ludzkie życie.
2.5 WYZWANIA STOJĄCEPRZED TECHNOLOGIAMIJĘZYKOWYMITempo postępu technologicznego jest obecnie zbyt ni-skie, chociaż technologie językowe rozwinęły się znacz-nie w ciągu ostatnich kilku lat. Powszechnie używanetechnologie językowe, takie jak funkcje sprawdzaniagramatyki i pisowni w edytorach tekstu, są przeważniejednojęzyczne i dostępne dla niewielkiej liczby języków.
Obecne tempo postępu technologicznego jestzbyt niskie.
Internetowe serwisy tłumaczeniowe bardzo sprawnie ra-dzą sobie z wytwarzaniem przybliżonego przekładu, aleich efektywność pozostawia wiele do życzenia w sytu-acji, gdy potrzebne jest precyzyjne i wierne tłumaczenie.Ze względu na złożoność języka, projektowanie i testo-wanie systemów tłumaczenia maszynowego w rzeczy-wistych warunkach to długie i kosztowne przedsięwzię-cie, które wymaga systematycznego finansowania. Dla-tego też Europa musi zmierzyć się z wyzwaniem tech-nologicznym stojącym przed jej wielojęzycznym społe-czeństwem, opracowując nowe metody pozwalające nazwiększenie tempa rozwoju technologii w różnych re-gionach. Ten cel można osiągnąć zarówno poprzez roz-
wój technologii komputerowych, jak i techniki takie jakcrowdsourcing.
2.6 NABYWANIE JĘZYKA PRZEZLUDZI I MASZYNYAby pokazać, w jaki sposób komputery przetwarzają ję-zyk i dlaczegonabywanie języka jest procesemniezwyklezłożonym, przyjrzyjmy się procesowi nauki pierwszegoi drugiego języka u człowieka, aby następnie zarysowaćzasadę działania systemów przekładu maszynowego.Człowiek zdobywa umiejętności językowe na dwa spo-soby. Dziecko uczy się najpierw swojego języka ojczy-stego, przysłuchując się rozmowom rodziców, rodzeń-stwa i innych członków rodziny. Taki kontakt z języ-kiem umożliwia dziecku w wieku około dwóch lat wy-powiadanie pierwszych słów i krótkich fraz. Jest tomoż-liwe dzięki swoistym genetycznym uwarunkowaniomczłowieka umożliwiającym mu imitowanie i przetwa-rzanie słyszanych przez niego dźwięków.
Ludzie zdobywają umiejętności językowe na dwasposoby: ucząc się na przykładach i poznając
zasady rządzące językiem.
Nauka drugiego języka przeważnie wymaga o wiele wię-cejwysiłku, przedewszystkimdlatego, że dzieckoniemaciągłego kontaktu z użytkownikami nowego języka. Naetapie szkolnymnauka języka obcego odbywa się zazwy-czaj przez poznawanie struktur gramatycznych, słow-nictwa oraz pisowni na podstawie podręczników i ma-teriałów edukacyjnych opisujących język z wykorzysta-niem abstrakcyjnych reguł, tabel i przykładowych tek-stów.
Zasady działania systemów przetwarzaniajęzyka przypominają proces nabywania języka
przez ludzi.
8

Dwapodstawowe rodzaje systemów technologii języko-wych przyswajają kompetencje językowe podobnie jakczłowiek. Metody statystyczne otrzymują wiedzę ję-zykową z obszernych zbiorów przykładowych tekstówjednojęzycznych lub tekstów równoległych dostępnychw dwóch językach lub większej ich liczbie. Maszynowealgorytmy modelują określone umiejętności językowe,są w stanie wydobywaćwzorce poprawnego użycia słów,krótkich fraz oraz pełnych zdańw jednym języku lub ichtłumaczenia.Liczba zdań wykorzystywanych przy metodach staty-stycznych jest ogromna. Precyzja wyników zwiększa sięwraz z liczbą analizowanych tekstów. Często systemy tesą przygotowywane z wykorzystaniem zbiorów tekstówzawierających miliony zdań. Właśnie dlatego dostaw-com wyszukiwarek zależy na zebraniu jak największejilości materiałów w formie pisemnej. Narzędzia popra-wiania pisowniw edytorach tekstu, wyszukiwanie infor-macji online poprzez Google Search czy serwisy tłuma-czeniowe takie jak Google Translate są oparte na me-todach statystycznych. Ogromną zaletą metod statycz-nych jest to, że maszyna uczy się bardzo szybko dziękiciągłym cyklom treningowym, mimo że jakość genero-wanych w ten sposób tłumaczeń może być nierówna.Drugim podstawowym typem technologii językowych(a zwłaszcza tłumaczenia maszynowego) są systemyregułowe. Językoznawcy oraz informatycy modelująwarstwę analizy gramatycznej (reguły tłumaczeniowe)i tworzą bazy słownictwa (leksykony). Stworzenie sys-temu regułowego jest bardzo czasochłonne i wymaga
dużo pracy, a do ich opracowania potrzebni są też wyso-kiej klasy specjaliści. Prace nad niektórymi z najlepszychregułowych systemów tłumaczenia maszynowego pro-wadzone są od ponad dwudziestu lat. Zaletą takich sys-temów jest to, że ich twórcy mają większą kontrolę nadprocesem przetwarzania języka. Dzięki temu możliwejest systematyczne poprawianie błędów oprogramowa-nia i dostarczanie szczegółowych informacji użytkow-nikowi, szczególnie jeżeli systemy te wykorzystywane sądo nauki języka. Jednak ze względu na ograniczenianatury finansowej tego typu technologie językowe po-wstają tylko dla najpowszechniejszych języków.Ponieważ zalety i wady metod statystycznych i syste-mów regułowych się uzupełniają, bieżące badania kon-centrują się na modelach hybrydowych, które łączą obiete technologie. Mimo to na razie skuteczność tych me-tod w praktyce jest dużo niższa niż w warunkach labo-ratoryjnych.Podsumowując, wiele aplikacjiwykorzystywanychwna-szym społeczeństwie informacyjnym bazuje na techno-logiach językowych. Ma to szczególne znaczenie dla Eu-ropy zewzględu nawielojęzyczny charakter europejskiejprzestrzeni ekonomicznej i informacyjnej. Mimo żew ciągu ostatnich kilku lat technologie językowe znacz-nie się rozwinęły, jakość systemów przetwarzania ję-zyka można nadal znacząco usprawnić. W kolejnychczęściach raportu przedstawimy rolę języka polskiegow europejskim społeczeństwie informacyjnym i oce-nimy stan technologii językowych dostępnych dla ję-zyka polskiego.
9

3
JĘZYK POLSKI W EUROPEJSKIMSPOŁECZEŃSTWIE INFORMACYJNYM
3.1 INFORMACJE OGÓLNEJęzykiem polskim posługuje się od 40 do 48 milionówużytkowników rodzimych, co oznacza, iż jest to naj-częściej używany język zachodniosłowiański na świecie[8]. W Polsce językiem urzędowym jest polszczyzna,ale w kontaktach urzędowych używane są także językimniejszości: w zachodnich rejonach Polski jest to językniemiecki (22 gminy używają go jako języka pomocni-czego), na wschodzie – białoruski (3 gminy), kaszubski(2 gminy) oraz litewski (1 gmina) [9].
W Polsce polszczyzna jest językiem ojczystymzdecydowanej większości populacji.
Język polski jest dość jednorodny, pomimo pewnychróżnic regionalnych (gwara, podhalańska, śląska, po-znańska). Mniejszości narodowe to Niemcy (od 300do 400 tys.), Białorusini (od 250 do 300 tys.), Ukra-ińcy (300 tys.), Litwini (30 tys.), Rosjanie (20 tys.), Sło-wacy (15 tys.), Żydzi (5 tys.), Czesi (3 tys.) oraz Ormia-nie (1,5 tys.). Mniejszości etniczne to Rusini (50 tys.),Romowie (20 tys.), Tatarzy (2 tys.), a także Karaimi(150). Jedyną uznawaną grupą regionalną są Kaszubi(od 250 do 300 tys.) posiadający własny język regio-nalny. Do mniejszości regionalnych lub narodowościo-wychnależy łącznie 1,2miliona osób, chociaż z przepro-wadzonego w roku 2002 spisu ludności uwzględniają-cego grupy etniczne i narodowościowe wynika, iż liczba
ta wynosi tylko 417 tys., w tymm.in. 147 tys. Niemców,48 tys. Białorusinów, 34 tys. Ukraińców i 2 tys. Słowa-ków. Największe skupiska tych grup występują w wo-jewództwach warmińsko-mazurskim, podlaskim orazopolskim.
W ostatnich latach trwają spory, czy Ślązakównależy również uznawać za mniejszość narodową.W 2011 r. podczas polskiego Narodowego SpisuPowszechnego narodowość śląską zadeklarowało809 tys. osób [10].
3.2 CECHY SZCZEGÓLNEJĘZYKA POLSKIEGOJęzyk polski ma właściwości, które stanowią o jego bo-gactwie [11], ale jednocześnie są wyzwaniem dla syste-mów przetwarzania języka.
Swobodny szyk utrudnia przetwarzanie tekstuw języku polskim.
Właściwości te pozwalają użytkownikom wyrażać sięw rożny sposób. Po pierwsze, szyk wyrazów jest w ję-zyku polskim stosunkowo swobodny, może więc służyćpodkreśleniu znaczenia pewnych informacji. Weźmy naprzykład angielskie zdanie:
e woman gave the man an apple.
10

W angielskim szyk tego zdania można zmienić na dwasposoby:
e woman gave the man an apple.
An apple was given to the man by the woman.
W polskim mamy do wyboru przynajmniej dziewięćmożliwości (chociaż niektóre są mniej typowe):
Kobieta dała mężczyźnie jabłko.
Kobieta mężczyźnie dała jabłko.
Kobieta mężczyźnie jabłko dała.
Jabłko mężczyźnie dała kobieta.
Jabłko kobieta dała mężczyźnie.
Jabłko dała kobieta mężczyźnie.
Mężczyźnie jabłko dała kobieta.
Mężczyźnie jabłko kobieta dała.
Mężczyźnie kobieta dała jabłko.
Szyk wyrazów w powyższych zdaniach zależy od tego,które informacje zawarte w poszczególnych frazachosoba wypowiadająca dane zdanie uważa za nowe,a które za znane wcześniej.
Odmiana polskich wyrazów nastręcza trudnościnie tylko komputerom, ale i ludziom.
Po drugie, język polski odznacza się stosunkowo du-żym bogactwem morfologicznym, co oznacza, że dlaokoło 180 tys. form podstawowych istnieją 4 milionyform fleksyjnych. Wzorce odmiany są złożone i na-wet ustalenie ichdokładnej liczby jest sprawądyskusyjną(pojedyncze wyjątki można uznać za zaczątek nowegowzorca). Poprawna odmiana niektórych słów nastręczatrudności nawet rodzimym użytkownikom, a większo-ści osób posługujących się językiempolskim jako obcymnigdy nie udaje się w pełni opanować zawiłości systemufleksyjnego.
Obsługa polskich znaków nadal pozostawiawiele do życzenia.
Po trzecie, wiele programów komputerowych wykorzy-stuje alfabet angielski lub zachodnioeuropejski, przezco używanie polskich znaków diakrytycznych (np. „ą”,„ę”) może stać się problemem. Nie od dziś jednymz głównym problemów jest lokalizacja oprogramowa-nia dla języka polskiego. Obecnie dla języka polskiegopowszechnie wykorzystuje się przynajmniej trzy stronykodowe: Unicode (przeważnie UTF-8), standard ISOoraz strony kodowe Windows (1250). Dlatego też star-sze dane mogą łatwo ulec uszkodzeniu przez niewła-ściwe kodowanie. Odzyskiwanie odpowiednich zna-ków diakrytycznych nie jest sprawą łatwą: przy zamia-nie niektórych polskich literw znaki diakrytycznemogąpowstać inne słowa (na przykład słowo „glosy”może byćpoprawną formą dopełniacza liczby pojedynczej rze-czownika „glosa” lub liczbą mnogą rzeczownika „głos”,jeżeli „l” zostanie zastąpione przez „ł”).
Inną specyficzną cechą języka polskiego utrudniającąjego automatyczne przetwarzanie są dość długie i wielo-krotnie złożone zdania. Brak przedimków sprawia po-nadto, że identyfikacja fraz rzeczownikowych staje sięstosunkowo trudna, ponieważmożna je rozpoznać jedy-nie w świetle informacji morfologicznych (przypadek,liczba, rodzaj), które nie są w polszczyźnie jednoznacz-nie wyrażane.
3.3 NAJNOWSZE TENDENCJEJęzyk angielski jest jednym z głównych źródeł zapoży-czeń oraz kalk językowych, szczególnie w dziedzinie na-uki czy techniki, i ma dużywpływnawspółczesną polsz-czyznę. Wprzypadku językapolskiego liczba słówzapo-życzonych z angielskiego jest mimo wszystko niższa niżw przypadku języka niderlandzkiego czy niemieckiego,
11

co związane jest z problemami fleksyjnymi oraz różni-cami w wymowie. W początkach lat 90. ubiegłego stu-lecia, po przełomie politycznym, część firm używała an-gielsko brzmiących nazw. Nawet w szyldzie sklepu spo-żywczego można było znaleźć angielskie „Your shop”.Dzisiaj duża grupa użytkowników języka uznałaby takąnazwę za komiczną. Mimo to kalki z języka angiel-skiego, takie jak „dokładnie” („exactly”) czy „wydawaćsię być” („seem to be”) są powszechne.
Na współczesną polszczyznę w istotnym stopniuwpływa język angielski.
Innym przykładem wpływu języka angielskiego są co-raz bardziej bezpośrednie formy adresatywne, szczegól-nie w języku reklamy [12]. Polski zaimek „ty” staje siępowszechniejszy, choć kiedyś w analogicznych kontek-stach uznawany był za niegrzeczny. Można zaryzykowaćstwierdzenie, że zjawisko to wynika z błędnego tłuma-czenia angielskich zaimków na język polski. Podobnetrendy obserwujemy w interpunkcji. Użytkownicy ję-zyka polskiego coraz częściej kopiują angielskie zasady,szczególnie stosując przecinek po frazie wprowadzają-cej na początku zdania, co według tradycyjnych zasadpolskiej interpunkcji jest niepoprawne. Z języka an-gielskiego zapożyczane są także niektóre znaki typogra-ficzne (na przykład „&”).Wcześniejsze źródła zmian języka, takie jak sowieckapropaganda, obecnie mają znikome znaczenie. Więk-szy wpływ na rejestr oficjalny polszczyzny ma obecnielegislacja Unii Europejskiej. Pomimo iż widoczna jestnowa tendencja do tworzenia wyrazów złożonych w ro-dzaju „speckomisji” czy „Rywingate”, które pobrzmie-wają dawną radziecką nowomową, zmiana ta zdaje sięniezależna od historycznego wpływu języka rosyjskiegoi jest bardziej związana z oddziaływaniem języka angiel-skiego, chociaż na przykład akronimy w polszczyźniewystępują znacznie rzadziej niż w języku angielskim.
Widoczna jest nowa tendencja do tworzeniawyrazów złożonych w rodzaju „speckomisji” czy
„Rywingate”.
Jednym z najnowszych trendów w języku polskim jestużycie żeńskich form nazywających zawody, choć nadalpozostają one na marginesie stylu oficjalnego. Popraw-ność polityczna uwidacznia się z kolei w nowych for-mach odnoszących się do obcych narodowości oraz imi-grantów z Afryki (słowo „Murzyn”, kiedyś uznawane zaneutralne, dziś jest niedopuszczalne na łamach prasy).
Jednym z odwiecznych zarzutów w odniesieniu do roz-woju języka polskiego jest mnożenie się wulgaryzmówi brutalizowanie mowy kolokwialnej. Należy jednak za-znaczyć, że opinie te nie są oparte na korpusowych ana-lizach historycznych.
Niektóre typy odmiany zostają uproszczone (na przy-kład powszechniejsza jest forma „mieliłem” niż zale-cany przez językoznawców wariant „mełłem”), a częśćform przestaje praktycznie występować w mowie co-dziennej. Dobrym przykładem jest tu wołacz w po-tocznej polszczyźnie. Jednocześnie należy podkreślić,żewielką popularnością cieszą się internetowe poradnie,w której językoznawcy odpowiadają na pytania użyt-kowników języka polskiego (np. poradniawydawnictwaPWN [13]).
Słowa są też upraszczane dla uzyskania efektu humo-rystycznego w języku potocznym, na przykład słowo„impreza” jest zastępowane przez „imprę”, „klima” za-stępuje „klimatyzację”, a „kolo” to uproszczona wersjasłowa „kolega”. Wzorce fleksyjne pozostają jednak na-dal bardzo złożone i nie można mówić o jednoznacznejtendencji do ich upraszczania.
Dalsze i dokładniejsze omówienie zmian we współcze-snej polszczyźnie podają pozycje bibliograficzne [14, 15,16, 17, 18].
12

3.4 OCHRONA JĘZYKAW POLSCEStatus prawny języka polskiego na terytorium Rzeczy-pospolitej Polskiej określa Ustawa z dnia 7 paździer-nika 1999 z późniejszymi zmianami (z lat 2000, 2003,2004 i 2005) [9]. Przedmiotem tej ustawy jest „ochronajęzyka polskiego” i jego użycia w życiu publicznym,w handlu oraz działalności podlegającej prawu pracyna obszarze Rzeczypospolitej Polskiej. Ochrona językapolskiego polega w głównej mierze na:
dbałości o poprawność użycia języka i wytwarzaniuwarunków dla właściwego rozwoju języka jako na-rzędzia komunikacji;
przeciwdziałaniu wulgaryzacji języka;
rozpowszechnianiu wiedzy o języku i jego roli kultu-rowej;
wpajaniu szacunku dla regionalnych odmian językai dialektów, co ma zapobiec ich wymarciu;
promowaniu języka polskiego na świecie i wspiera-niu procesu nauczania języka polskiego w Polsce i zagranicą.
Jednostki funkcjonujące na terytorium Rzeczypospoli-tej Polskiej prowadzą działalność gospodarczą i składająoświadczenia woli w języku polskim, o ile przepisy niestanowią inaczej. Powyższy przepis dotyczy oświadczeńwoli, podań i innych formularzy przedkładanych oficjal-nym organom państwa (art. 5).Jeśli chodzi o działalność gospodarczą, zgodnie z art. 7w transakcjach z udziałem konsumenta oraz w sprawachpodlegających prawu pracy, język polski powinien byćużywany, jeśli konsument lub pracownik mieszka na te-rytoriumRzeczypospolitej Polskiej wmomencie zawar-cia umowy, a umowa ma zostać wykonana na obszarzeRzeczypospolitej Polskiej. W przypadku działalnościhandlowej bez udziału konsumentów język polski wi-nien być używany, tylko jeżeli działalność ta jest pro-
wadzona przez jednostki podlegające organom Państwalub państwowym władzom lokalnym.Obowiązek używania języka polskiego przy prowa-dzeniu działalności z udziałem konsumentów dotyczyprzede wszystkim nazw towarów, usług, ofert, warun-ków gwarancji, faktur, rachunków, paragonów, ostrze-żeń oraz informacji konsumenckich wymaganych namocy odrębnych przepisów, instrukcji obsługi oraz in-formacji o towarach i usługach.
Wymóg używania języka polskiego przypodawaniu informacji o właściwościach towarów
i usług obowiązuje także w reklamie.
Obcojęzyczne opisy towarów i usług, oferty, ostrzeże-nia oraz informacje konsumenckie wymagane na mocyodrębnych przepisów muszą być jednocześnie udostęp-nione w języku polskim. Opisy w języku polskim nie sąwymagane, jeśli ostrzeżenia, informacje konsumenckie,instrukcje obsługi oraz informacje o właściwościach to-warów i usług są wyrażone za pomocą powszechnie ro-zumianych rysunków; jeżeli formie graficznej towarzy-szą opisy tekstowe, należy je udostępnić w języku pol-skim.Osoby lub firmy, które nie przestrzegają tych przepisów,podlegają karze. Naruszenie przepisów grozi grzywną.Nadzór nad użyciem języka polskiego sprawuje PrezesUrzędu Ochrony Konkurencji i Konsumentów, Inspek-cja Handlowa, rzecznik praw konsumenta oraz Pań-stwowa Inspekcja Pracy.Zgodnie z art. 8 dokumenty, ze szczególnym uwzględ-nieniem umów konsumenckich oraz z zakresu prawapracy, winny być sporządzane w języku polskim. Do-kumenty te mogą być dodatkowo sporządzone w jednejlub kilku wersjach językowych. O ile strony nie zdecy-dują inaczej, dokumenty tego typu są interpretowane napodstawie wersji polskojęzycznej. Umowa o pracę lubinny dokument z zakresu prawa pracy, a także umowa,
13

której stroną jest konsument, mogą zostać sporządzonew języku obcym na żądanie strony wykonującej pracęlub konsumenta będącego obywatelem kraju członkow-skiegoUnii Europejskiej innego niż Rzeczpospolita Pol-ska, który został uprzednio powiadomiony o prawie dosporządzenia umowyw języku polskim. Umowa o pracęlub inny dokument z zakresu prawa pracy może zostaćsporządzonyw języku obcymna żądanie zleceniobiorcy,który nie jest obywatelem Polski, a także w przypadku,gdy zleceniodawca jest obywatelem lub mieszkańcemkraju członkowskiego Unii Europejskiej.Język polski jest używany w nauczaniu, podczas eg-zaminów i w pracach dyplomowych w państwowychi prywatnych szkołachwszelkiego typu, w państwowychi prywatnych szkołach wyższych, w jednostkach kształ-cenia i innych instytucjach edukacyjnych, o ile przepisynie stanowią inaczej (warto w tym miejscu zauważyć, żecoraz większa liczba uczelni oferuje zajęcia w języku an-gielskim). Zgodnie z rozporządzeniem Ministra Edu-kacji Narodowej i Sportu z dnia 15 października 2003,Państwowa Komisja Poświadczania Znajomości JęzykaPolskiego jako Obcego jest nadrzędnym organem nad-zorującymprzebieg egzaminów iwydającym certyfikatypotwierdzające znajomość języka polskiego na trzechpoziomach. Obcokrajowiec lub obywatel Polski miesz-kający za granicą otrzymuje oficjalny certyfikat znajo-mości języka polskiego po zdaniu egzaminu przed pań-stwową komisją egzaminacyjną.Przepisy Ustawy o Języku Polskim nie dotyczą:
nazw własnych, zagranicznych gazet, periodyków,książek i programów komputerowych (z wyjątkiemich opisu i instrukcji),
działalności dydaktycznej i naukowej szkół wyż-szych, szkół i klas obcojęzycznych lub dwujęzycz-nych, kolegiów dla nauczycieli języków obcych,
nauczania innych przedmiotów, jeżeli nie narusza toszczegółowych przepisów,
twórczości naukowej i kulturalnej,
zwyczajowej terminologii naukowej i technicznej,
znaków towarowych, nazw firmowych oraz infor-macji o pochodzeniu towarów i usług oraz
normwprowadzanychw języku źródłowym zgodniez przepisami o standaryzacji.
Instytucją upoważnioną do wydawania opinii i udzie-lania porad na temat użycia języka polskiego jest RadaJęzyka Polskiego, funkcjonująca jako komitet PolskiejAkademii Nauk. Co dwa lata prezentuje ona raport natemat ochrony języka polskiego w polskim parlamencie.Na wniosek Ministra Kultury i Dziedzictwa Narodo-wego, Ministra Edukacji, Ministra Szkolnictwa Wyż-szego, Prezesa Urzędu Ochrony Konkurencji i Konsu-mentów, Głównego Inspektora Inspekcji Handlowej,Prezesa Polskiej Akademii Nauk lub z własnej inicja-tywy Rada wydaje opinię na temat użycia języka pol-skiego w życiu publicznym oraz w handlu na terenieRzeczypospolitej Polskiej z udziałem konsumentów lubprzy wykonywaniu przepisów prawa pracy, i określa za-sady ortografii oraz interpunkcji języka polskiego.Towarzystwa naukowe, stowarzyszenia autorów orazszkoły wyższe mogą kierować do Rady wszelkie sprawyzwiązane z użyciem języka polskiego. W przypadkupoważnych wątpliwości dotyczących użycia języka pol-skiego wynikłych w toku prowadzenia działalnościkażdy organ państwowy lub samorządowy może zwró-cić się do Rady z prośbą o wydanie opinii. Producenci,importerzy oraz dystrybutorzy towarów i usług nie-posiadających odpowiedniej nazwy w języku polskimtakże mogą zwrócić się do Rady.Poza Radą Języka Polskiego istnieją inne instytucje pań-stwowe, których działalność statutowa obejmuje pielę-gnowanie, chronienie i promowanie języka polskiego.Poprawka do ustawy o języku polskim (z dnia 11 kwiet-nia 2003) stworzyła podstawy prawne dla oficjalnegopoświadczania znajomości języka polskiego jako ob-cego. Dwa rozporządzenia Ministerstwa Edukacji Na-rodowej i Sportu z dnia 15 października 2003 upraw-
14

niają obcokrajowców do otrzymywania certyfikatówokreślających ich poziom znajomości języka polskiego.Wyróżnia się trzy poziomy: podstawowy, średnio za-awansowany i zaawansowany. W niektórych krajach ję-zyk polski jest wysoko ceniony, ponieważ jego znajo-mość umożliwia dostęp do polskich uczelni i polskiegorynku pracy.
Polscy uczniowie plasują się zdecydowaniepowyżej średniej OECD pod względem
umiejętności czytania.
Jak wynika z przeprowadzonego w roku 2009 badaniaPISA (Programu Międzynarodowej Oceny Umiejętno-ści Uczniów), polscy uczniowie plasują się zdecydowa-nie powyżej średniej Organizacji Współpracy Gospo-darczej i Rozwoju pod względem umiejętności czytania(drugi wynik w Europie po Finlandii), zajmując ósmemiejsce [19]. Oznacza to, że nauczanie języka w Polscejest efektywne, chociaż nie bez znaczenia może być tudość duża językowa jednorodność społeczeństwa.
3.5 JĘZYK POLSKIW INTERNECIEWedług danych z wiosny 2011 r. prawie 55 proc. Po-laków było użytkownikami Internetu [20], w tym72 proc. korzystało z Internetu codziennie. Ta pro-porcja jest jeszcze wyższa wśród młodych ludzi. Istnie-nie aktywnej polskojęzycznej społeczności internetowejpotwierdza fakt, że polskaWikipedia, posiadająca około800 tysięcy haseł, jest jedną z największych – ustępujerozmiarami tylko angielskiej, niemieckiej i francuskiej(nie licząc wersji tłumaczonych automatycznie, jak Wi-kipedia tajska) i jest porównywalna zwersjąwłoską [21].
Ponad połowa Polaków korzysta z Internetu.
Głównapolska domenapl., którawmaju2011osiągnęłaliczbę około 2 milionów subdomen [22], jest jednymz najpowszechniejszych rozszerzeń na świecie [23]. Takwyraźna internetowa obecność wskazuje, że w sieci do-stępna jest duża ilość danychw języku polskim. Ponadtoniektóre wielojęzyczne zasoby, jak internetowy słownikling.pl [24], są dostępne bezpłatnie.
Rosnące znaczenie Internetu jest dla technologii języ-kowych istotne z dwóch powodów. Z jednej strony,duża ilość danych językowych dostępnych w formie cy-frowej stanowi bogate źródło do analiz użycia języka na-turalnego, ze szczególnym uwzględnieniem danych sta-tystycznych. Z drugiej strony, Internet jest miejscem,w którym szerokie zastosowanie znaleźć mogą techno-logie językowe.
Najczęściej używanymi aplikacjami wykorzystującymitechnologie przetwarzania języka są z pewnością wy-szukiwarki internetowe, wykorzystujące automatycznei wielopoziomowe przetwarzanie języka, co zostanieomówione bardziej szczegółowo w dalszej części ra-portu. Ich działanie opiera się na zaawansowanychtechnologiach językowych, różnych dla każdego języka.W przypadku języka polskiego istotne jest na przykładjednakowe traktowanie znaków „ę” i „e”, które polep-sza wyniki wyszukiwania tekstów pozbawionych zna-ków diakrytycznych. Co więcej, aby zwiększyć efek-tywność wyszukiwania, należy uwzględnić wszystkieformyfleksyjne słówzawartychwzapytaniu (a zatemnietylko „wziąłem”, ale także „wziąć”, „wzięłam”, „wziąłby”,„wziąwszy” itd.). Jednak użytkownicy Internetu orazautorzy treści WWW mogą też korzystać z technologiijęzykowychwmniej oczywisty sposób, na przykład przyautomatycznym tłumaczeniu zawartości stron. Przywy-sokich kosztach tradycyjnego tłumaczenia tych zaso-bów należy stwierdzić, że w stosunku do zapotrzebowa-nia powstaje stosunkowo niewiele użytecznych techno-logii językowych. Może to być związane ze złożonościąjęzyka polskiego oraz liczbą technologii wykorzystywa-
15

nych przy typowych zastosowaniach z zakresu techno-logii językowych.W następnym rozdziale omówione zostaną podstawytechnologii językowych oraz ich najważniejsze zastoso-
wania. Ponadto opisana zostanie obecna sytuacja tech-nologii językowych dostępnych dla języka polskiego.
16

4
TECHNOLOGIE JĘZYKOWE DLA JĘZYKAPOLSKIEGO
4.1 TECHNOLOGIE JĘZYKOWETechnologie językowe to dział informatyki zajmującysię przetwarzaniem języka naturalnego – dlatego teżczęsto nazywane są technologiami języka naturalnego.Język naturalny występuje w odmianie mówionej i pisa-nej. Podczas gdy mowa jest najstarszą i najbardziej na-turalną formą komunikacji, bardziej złożone informa-cje i większość ludzkiej wiedzy jest zapisana i przekazy-wana w formie pisemnej. Powyższym formom komu-nikacji odpowiadają technologie przetwarzania i gene-rowania mowy i tekstu pisanego. Język cechują jednakrównież aspekty wspólne dla obydwu jego postaci, ta-kie jak słowniki, znaczna część gramatyki oraz znaczeniezdań. Z tego względu wiele z technologii językowych(TJ) łączy w sobie obydwa aspekty i trudno je przypo-rządkować ściśle do technologii przetwarzania tekstulub mowy. Należą do nich technologie wiążące językz wiedzą. Rysunek 1 ukazuje główne typy technologiijęzykowych.
W codziennej komunikacji łączymy język z innymi spo-sobami porozumiewania się i środkami przekazywaniainformacji – mowa wzbogacana jest gestykulacją i wy-razem twarzy; słowu pisanemu mogą towarzyszyć in-formacje i dźwięk; w filmach może występować językw postaci mówionej i pisanej itd. Technologie przetwa-rzania tekstu i mowy mają więc wiele obszarów wspól-nych i mogą współpracować z wieloma innymi tech-nologiami ułatwiającymi przetwarzanie multimodalnejkomunikacji i multimedialnych dokumentów.
W tym podrozdziale omówiono najważniejsze obszaryzastosowań technologii językowych, tj. korektę języ-kową, wyszukiwarki WWW, interakcję głosową i tłu-maczenie maszynowe. Do tych zastosowań i podstawo-wych technologii zaliczają się:
korekta pisowni,
wspomaganie tworzenia dokumentacji,
nauczanie języków wspomagane komputerowo,
wyszukiwanie informacji,
ekstrakcja informacji,
streszczanie tekstu,
odpowiadanie na pytania,
rozpoznawanie mowy,
synteza mowy.
Technologie językowe to znana dyscyplina badań,w której istnieje obszerna literatura wprowadzająca. Za-interesowany czytelnik może sięgnąć do następującychpozycji bibliograficznych: [25, 26, 27, 28, 29]. Odno-śniki do wspomnianych niżej narzędzi i zasobów dla ję-zyka polskiego podaje portal Computational Linguisticsin Poland [30].
Zanim omówimy powyższe obszary zastosowań, krótkoscharakteryzujemy architekturę typowego systemu TJ.
17
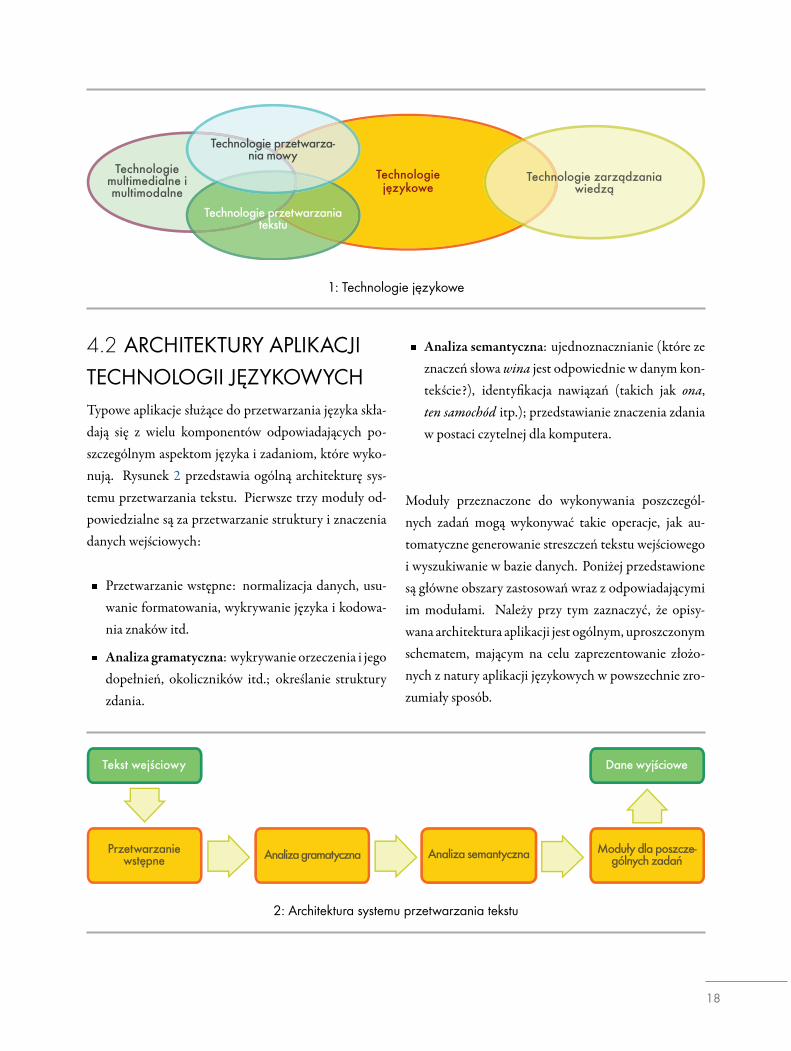
Technologie multimedialne i multimodalne
Technologie językowe
Technologie przetwarza-nia mowy
Technologie przetwarzania tekstu
Technologie zarządzania wiedzą
1: Technologie językowe
4.2 ARCHITEKTURY APLIKACJITECHNOLOGII JĘZYKOWYCHTypowe aplikacje służące do przetwarzania języka skła-dają się z wielu komponentów odpowiadających po-szczególnym aspektom języka i zadaniom, które wyko-nują. Rysunek 2 przedstawia ogólną architekturę sys-temu przetwarzania tekstu. Pierwsze trzy moduły od-powiedzialne są za przetwarzanie struktury i znaczeniadanych wejściowych:
Przetwarzanie wstępne: normalizacja danych, usu-wanie formatowania, wykrywanie języka i kodowa-nia znaków itd.
Analiza gramatyczna: wykrywanie orzeczenia i jegodopełnień, okoliczników itd.; określanie strukturyzdania.
Analiza semantyczna: ujednoznacznianie (które zeznaczeń słowawina jest odpowiednie w danym kon-tekście?), identyfikacja nawiązań (takich jak ona,ten samochód itp.); przedstawianie znaczenia zdaniaw postaci czytelnej dla komputera.
Moduły przeznaczone do wykonywania poszczegól-nych zadań mogą wykonywać takie operacje, jak au-tomatyczne generowanie streszczeń tekstu wejściowegoi wyszukiwanie w bazie danych. Poniżej przedstawionesą główne obszary zastosowań wraz z odpowiadającymiim modułami. Należy przy tym zaznaczyć, że opisy-wana architektura aplikacji jest ogólnym, uproszczonymschematem, mającym na celu zaprezentowanie złożo-nych z natury aplikacji językowych w powszechnie zro-zumiały sposób.
Tekst wejściowy
Przetwarzanie wstępne Analiza gramatyczna Analiza semantyczna Moduły dla poszcze-
gólnych zadań
Dane wyjściowe
2: Architektura systemu przetwarzania tekstu
18

Po zaprezentowaniu głównych obszarów zastosowańtechnologii językowych przedstawiony zostanie ogólnyobraz stanu badań i kształcenia w dziedzinie oraz prze-gląd (dotychczasowych) zasad finansowania. Podsumo-waniem niniejszego rozdziału jest przygotowane przezekspertów zestawienie najważniejszych narzędzi i zaso-bów i ich ocena na wielu płaszczyznach, takich jak do-stępność, stopień dopracowania lub jakość, dające rze-telny obraz stanu technologii językowychdla języka pol-skiego (patrz tabela 8). W tabeli podano wszystkie na-rzędzia i zasoby, które zostały wyróżnione drukiem po-grubionym w tekście. Technologie dostępne dla językapolskiego zostały także porównane z tym, co jest do-stępne dla innych języków omówionych w tej serii ra-portów.
4.3 GŁÓWNE OBSZARYZASTOSOWAŃ4.3.1 Korekta językowa
Moduły sprawdzania pisowni, wykrywające błędy orto-graficzne, są znane każdemu, kto kiedykolwiek używałedytora tekstu, takiego jakMicrosoWord. Wciągu 40lat, jakie upłynęły od pierwszego programu do korektypisowni, stworzonego przez Ralpha Gorrina, znaczniesię one rozwinęły. Dziś nie porównują już listy wyod-rębnionych z tekstu słów ze słownikiem zawierającympoprawne formy, lecz wykorzystują dostosowane do po-szczególnych języków algorytmy analizy gramatycznejprzetwarzające formy morfologiczne (np. formy liczbymnogiej), a niekiedy również i błędy składniowe, takiejak brakujące czasowniki lub błędną liczbę i rodzaj cza-sownika, np. w zdaniu „Ona *pisał list”. Jednak więk-szość korektorów pisowni nie wykryje błędów popeł-nionych specjalnie w wierszu Jerrolda H. Zara [31]:
Eye have a spelling chequer,It came with my Pea Sea.
It plane lee marks four my revueMiss Steaks I can knot sea.
Większość dostępnych algorytmów sprawdzania pi-sowni (w tymmoduł wbudowany w programMicrosoWord) nie wykryje w powyższym fragmencie błędów,ponieważ analizuje jedynie pojedyncze słowa. W wieluprzypadkachkonieczna jest analiza szerszegokontekstu;przykładem może być próba określenia, czy słowo „pol-ski” bądź „Polska” w poniższych przykładach należy za-pisać wielką, czy małą literą:
Ten tekst został przełożony na polski.
Czytał „Polskę Zbrojną”.
Przypadki takie wymagają sformułowania reguł grama-tycznych dla poszczególnych języków, co wiąże się z du-żymi nakładami pracy (lub zastosowania metod sztucz-nej inteligencji), lub użycia statystycznego modelu ję-zyka, obliczającego prawdopodobieństwo wystąpieniadanego słowa w konkretnym kontekście (np. poprzed-nich i następnych słów), zobacz Rysunek 3. Fraza „pol-ska książka” będzie na przykład znacznie bardziej praw-dopodobną konstrukcją niż „Polska książka”. Staty-styczny model języka może być stworzony automatycz-nie przy użyciu dużej ilości (poprawnych) danych języ-kowych (tzw. korpusu językowego).Większość prac w dziedzinie statystycznej korekty języ-kowej koncentrowała się na metodach i zasobach dla ję-zyka angielskiego, niekoniecznie przystających do pol-skiego, który charakteryzuje się swobodnym szykiemzdania i bogatą fleksją. Metody oparte na regułach zo-stały zaimplementowane w korektorze LanguageTool,zawierającym ponad tysiąc reguł dla polskiego (Langu-ageTool jest programem o otwartym kodzie źródłowymprzystosowanym do użycia w wielu edytorach tekstu,np. LibreOffice) [32, 33].W ostatnich latach znacznie zwiększyła się ilość wytwa-rzanej dokumentacji technicznej. Firmy, chcąc unik-nąć negatywnych opinii i odpowiedzialności prawnej
19

Tekst wejściowy Sprawdzenie pisowni Sprawdzenie gramatyki Propozycje zmian
Statystyczny model języka
3: Korekta (regułowa lub statystyczna)
wynikającej z niezrozumienia przez klientów instruk-cji i niewłaściwego użycia produktów, zaczęły corazbardziej zwracać uwagę na jakość dokumentacji tech-nicznej, nie zaniedbując przy tym rynku międzyna-rodowego. Rozwój technologii przetwarzania językanaturalnego zaowocował powstaniem oprogramowaniawspomagającego tworzenie dokumentacji technicznej,ułatwiającego jej twórcomużywanie słownictwa i struk-tur zdaniowych zgodnych z określonymi regułami i (we-wnętrznymi) przepisami regulującymi użycie termino-logii. Jako że polszczyzna rzadko jest językiem źródło-wym w takich zastosowaniach, nie istnieją jednak sys-temy opracowane specjalnie dla języka polskiego.
Moduły sprawdzania poprawności językowejmają zastosowanie nie tylko w edytorach tekstu,
ale również w systemach wspomagającychtworzenie dokumentacji.
Poza korektorami i wspomaganiem tworzenia doku-mentacji sprawdzanie poprawności językowej ma rów-nież znaczenie w dziedzinie nauczania wspomaga-nego komputerowo oraz jest stosowanie do autoko-rekty zapytań użytkownika w wyszukiwarkach WWW(np. podpowiedzi „Czy chodziło Ci o …” w wyszuki-warce Google).
4.3.2 Wyszukiwarki WWW
Wyszukiwarka Google, powstała w 1998 r., obsługujedziś ok. 80 proc. wszystkich zapytań [34]. Ani inter-
fejs wyszukiwania, ani sposób prezentacji wyników niezmieniły się zasadniczo w porównaniu z pierwszą wer-sją. ObecnieGoogle oferuje sugestie poprawnej pisownibłędnie wpisanych terminów; od 2009 r. algorytmywy-szukiwarki zawierają również podstawowy komponentwyszukiwania semantycznego [35], umożliwiający pod-niesienie jakości wyników wyszukiwania poprzez ana-lizę znaczenia wyszukiwanych terminów w kontekście.Sukces firmy Google pokazuje, że przy dostępności du-żej ilości danych i wydajnych mechanizmach ich indek-sowania podejście w dużej mierze statystyczne możeprzynieść satysfakcjonujące wyniki.
Następna generacja wyszukiwarek będziemusiała opierać się na znacznie bardziej
zaawansowanych technologiach językowych.
Zaspokojenie bardziej złożonych potrzeb informacyj-nychwymaga jednakwykorzystania większych zasobówwiedzy językowej. Prowadzone w laboratoriach badaw-czych eksperymenty wykorzystujące komputerowe te-zaurusy i zasoby ontologiczne (takie jak WordNet., lubjego polski odpowiednik, Słowosieć [36, 37]) przynio-sły poprawę wyników wyszukiwania przez zwracaniestron zawierających synonimy wyszukiwanego terminu(np. „energia atomowa”, „energia jądrowa”, „energia nu-klearna” itd.) lub terminy jeszcze luźniej powiązane.Jeśli wyszukiwana fraza nie jest listą słów kluczowych,lecz pytaniem lub innym typem zdania, wygenerowa-nie właściwych odpowiedzi wymaga analizy składnio-
20

Zapytanie użytkownika
Strony WWW
Przetwarzanie wstępne Analiza zapytania
Przetwarzanie wstępne Analiza semantyczna Indeksowanie
Dopasowywanie i obliczanie trafności
Wyniki wyszukiwania
4: Wyszukiwarka
wej i semantycznej podanego zdania, jak również istnie-nia indeksu umożliwiającego szybkie wyszukanie odpo-wiednich dokumentów. Wyobraźmy sobie, że użytkow-nik wpisuje zapytanie „Podaj mi listę firm przejętychprzez inne firmy w ciągu ostatnich pięciu lat”; wymagaono zastosowania analizy składniowej i semantycznej,aby móc zanalizować strukturę gramatyczną podanegozdania i określić, że użytkownik poszukuje firm, którezostały przejęte, a nie firm, które przejęły inne firmy.Należy również zanalizować wyrażenie ostatnie pięć lat,aby określić, do którego roku odnosi się zapytanie. Prze-twarzane zapytaniemusiwreszcie zostać dopasowanedodużej ilości nieuporządkowanych danych, aby odnaleźćinformację lub informacje, których poszukuje użytkow-nik. Wymaga to zaimplementowania systemu wyszu-kiwawczego oraz systemu klasyfikacji wyników. Two-rzenie listy firm wymaga dodatkowo wykrycia, że kon-kretny ciąg znaków odpowiada nazwie firmy; za tegotypu informacje odpowiadają systemy identyfikacji by-tów nazwanych.
Jeszcze większym wyzwaniem jest wyszukiwanie doku-mentów odpowiadających zapytaniu zadanemu w in-nym języku. W wyszukiwaniu wielojęzycznym zapy-tanie musi zostać automatycznie przetłumaczone nawszystkie możliwe języki źródłowe, a wyszukane infor-macje – z powrotem na język docelowy.
Rosnąca ilość danych zapisanych w formatach innychniż tekst tworzy zapotrzebowanie na usługi oferującewyszukiwanie multimedialne, tj. wyszukiwanie infor-macji w danych graficznych, dźwiękowych i wideo.W przypadku danych dźwiękowych i wideo wymaga tostworzenia modułu rozpoznawania mowy, przetwarza-jącego dane mówione na tekst lub ich reprezentację fo-netyczną, w których może zostać zrealizowane zapyta-nie użytkownika.
Polskie małe i średnie przedsiębiorstwa, takie jak po-znański Carrot Search, z powodzeniem rozwijają i im-plementują technologie wyszukiwania zwracające wy-niki wyszukiwania bardziej uporządkowane niż w stan-dardowych wyszukiwarkach (np. Google) dzięki zasto-sowaniu metod grupowania wyników dostosowanych
21

do poszczególnych języków. Znaczącymi polskimi wy-szukiwarkami są NetSprint oraz Szukacz, zintegrowanyz polskim tezaurusem i przeprowadzający normalizacjęmorfologiczną tekstu, co poprawia wyniki wyszukiwa-nia.
4.3.3 Interakcja głosowa
Technologie interakcji głosowej stanowią podstawę dlainterfejsów umożliwiających użytkownikom głosowąobsługę urządzeń (bez pomocy myszki, klawiatury czyekranu). Głosowe interfejsy użytkownika są obecniestosowanew częściowo lubwpełni zautomatyzowanychusługach świadczonych przez firmy telefonicznie klien-tom, pracownikom i partnerom biznesowym.
Interfejsy głosowe są często stosowanew sektorach takich jak bankowość, logistyka,
transport publiczny i telekomunikacja.
Technologia przetwarzania głosu stosowana jest takżew interfejsach do konkretnych urządzeń, np. w syste-mach nawigacji samochodowej i w graficznych interfej-sach użytkownika, np. w nowoczesnych telefonach ko-mórkowych (tzw. smartfonach).U podstaw interakcji głosowej leżą cztery technologie:
Automatyczne rozpoznawanie mowy umożliwiaautomatyczne przetworzenie ciągu głosek wypowia-danych przez użytkownika systemu na konkretnesłowa.
Analiza gramatyczna i analiza semantyczna odpo-wiadają za analizę struktury składniowej i znaczenio-wej wypowiedzi użytkownika na potrzeby danegosystemu.
Systemy dialogowe pozwalają zinterpretować żąda-nie użytkownika i podjąć odpowiednie działania.
Synteza mowy polega na przetworzeniu pisemnejpostaci wypowiedzi na postać dźwiękową.
Jednym z głównych wyzwań stojących przed automa-tycznym rozpoznawaniem mowy jest rozpoznanie słówwypowiedzianych przez użytkownika z maksymalnąmożliwą precyzją. Wymaga to ograniczenia zakresumożliwych wypowiedzi do zbioru wybranych słów klu-czowych lub ręcznego utworzenia modelu języka napodstawie korpusu języka mówionego, czyli ze zbio-rów plików dźwiękowych z nagraniami mowy wrazz ich tekstowymi transkrypcjami. Pierwsze z powyż-szych rozwiązań skutkuje ograniczoną elastycznościąpowstałego przy takich założeniach interfejsu głoso-wego imożepogorszyć ocenęproduktu, ale koszty stwo-rzenia, kalibracji i administrowania modeli językowychmogą być znaczne. Natomiast interfejsy używające mo-deli językowych i dające użytkownikom większą swo-bodę w wyrażaniu swoich potrzeb – na przykład po-przez zapytanie Jak mogę pomóc? – umożliwiają dużowiększe zautomatyzowanie systemu i w rezultacie sąznacznie wyżej oceniane przez użytkowników, a zatemmogą być uznawane za korzystniejsze niż bardziej ogra-niczone systemy oparte na dialogu kierowanym.
Większość stosowanych w praktyce systemów syn-tezy mowy bazuje na nagranych uprzednio wypowie-dziach. Takie rozwiązanie może w zupełności wystar-czać w przypadku wypowiedzi statycznych, niezależ-nych od konkretnego kontekstu użycia lub podanychprzez użytkownika danych. Im bardziej jednak dy-namiczna jest zawartość wypowiedzi, tym jakość sys-temu będzie niższa ze względu na mechaniczne łącze-nie przez system pojedynczych plików dźwiękowych,a co za tym idzie, nienaturalną intonację i akcent wyra-zowywypowiedzi. Wprzeciwieństwie do systemów sta-tycznych metody syntezy mowy umożliwiają osiągnię-cie dużowyższej jakości i wytworzenie naturalniej (choćciągle nie idealnie) brzmiących wypowiedzi.
W ciągu ostatnich dziesięciu lat na rynku technologiiinterakcji głosowej można było zaobserwować rosnącąstandaryzację interfejsów stosowanych w różnych kom-
22

Dźwiękowe dane wejściowe
Przetwarzanie sygnału
Dźwiękowe dane wyjściowe Synteza mowy Sprawdzenie wymowy
i zaplanowanie intonacjiAnaliza języka
naturalnego i wygenerowanie
odpowiedzi (dialog)Rozpoznawanie
5: Interakcja głosowa
ponentach oraz ujednolicenie zasad tworzenia poszcze-gólnych składników danej aplikacji. Nastąpiła równieżdaleko idąca konsolidacja rynku, szczególnie w zakresieautomatycznego rozpoznawania i syntezymowy– rynkilokalne krajów grupy G20 (tj. silnych gospodarczo kra-jów o znaczącej liczbie ludności) zostały zdominowaneprzez kilka globalnych firm; w Europie najważniejszymiz nich są Nuance i Loquendo.
Interakcja głosowa to podstawa interfejsówpozwalających użytkownikowi obsługę przy
użyciu języka mówionego.
Na polskim rynku syntezy mowy najważniejszym gra-czem jest Ivona, mająca w ofercie również produkty dlainnych języków. Sytuacja przedstawia się inaczej w przy-padku języków o mniejszej liczbie użytkowników – ko-mercyjne systemy rozpoznawania i syntezy mowy czę-sto są dla nich niedostępne. W przypadku technolo-gii i wiedzy eksperckiej z zakresu systemów dialogo-wych rynki sąwprzeważającej większości zdominowaneprzez lokalne, najczęściej małe i średnie przedsiębior-stwa. W Polsce głównymi graczami są obecnie Prime-Speech i Skrybot, których model biznesowy przewidujenie tylko sprzedaż licencji na oprogramowanie, ale teżdostarczanie kompleksowych rozwiązań wykorzystują-cych systemy rozpoznawania mowy. Trudno na raziemówić o rynku dla technologii analizy składniowej i se-mantycznej w zakresie interakcji głosowej.
Jeśli chodzi o faktyczne wykorzystanie interfejsów gło-sowych, popyt na nie znacząco wzrósł w Polsce w ciąguostatnich 5 lat. Główną przyczyną tego zjawiska byłorosnące zapotrzebowanie wśród użytkowników końco-wych na rozwiązania oferujące możliwość samoobsługi,jak również konieczność optymalizacji kosztów w przy-padku zautomatyzowanych usług telefonicznych orazwzrost akceptacji wśród klientów dla głosowej komuni-kacji z maszyną.
Wybiegając w przyszłość, można przewidzieć znaczącezmiany związane z coraz powszechniejszym użyciemsmartfonów, obok telefonu, Internetu i poczty elektro-nicznej, jako platformy komunikacji z klientem. Ten-dencja ta będzie miała wpływ również na stopień wyko-rzystania technologii interakcji głosowej. Po pierwsze,w perspektywie długoterminowej zapotrzebowanie nagłosowe interfejsy użytkownikaw telefoniiwzrośnie. Podrugie, coraz istotniejsze jest użycie języka mówionegojako łatwejwużytku formypracy z urządzeniami. Już te-razmożna zauważyć zwiększenie precyzji systemów roz-poznawaniamowy stosowanychw smartfonach, co stałosię możliwe głównie dzięki przeniesieniu funkcji rozpo-znawania mowy do zdalnych ośrodków przetwarzania.Z tych wszystkich względów zastosowanie technologiijęzykowych w przyszłości powinno znacznie zyskać naznaczeniu.
23

4.3.4 Tłumaczenie maszynowe
Idea wykorzystania maszyn cyfrowych do tłumaczeniajęzyka naturalnego została przedstawiona po raz pierw-szy przez A. D. Bootha w 1946 r. W latach 50. i na po-czątku lat 80. na badania w tej dziedzinie przeznaczonoznaczne środki. Niemniej jednak systemy tłumaczeniamaszynowego ciągle jeszcze nie spełniają oczekiwań, ja-kie rozbudziły w pierwszych latach swojego istnienia.
Najprostszą metodą przekładu jest tłumaczeniesłowo po słowie.
Na najbardziej podstawowym poziomie tłumaczeniemaszynowe polega na prostym zastąpieniu słów w jed-nym języku odpowiadającymi im słowami w innym.Algorytmy takie mogą mieć praktyczne zastosowaniew dziedzinach o bardzo ograniczonym, sformalizowa-nym języku, np. w prognozach pogody. Dobrej jako-ści tłumaczenie większych jednostek niekonwencjonal-nych typów tekstów wymaga jednak dopasowania tek-stu źródłowego do jego najbliższego odpowiednikaw ję-zyku docelowym na poziomie całych wyrażeń, zdań lubdłuższych fragmentów. Największa trudność wynika tuz wieloznaczności języka naturalnego, utrudniającej au-tomatyczne tłumaczenie na wielu poziomach; na pozio-mie leksykalnym występuje np. problem ujednoznacz-niania sensu wyrazów („jaguar” może oznaczać zwierzęlub samochód); na poziomie składniowym – przypisa-nia przyimków do właściwej części zdania, np.:
Policjant zauważył samochód w zaroślach.
Policjant zauważył samochód w okularach.
Jedna z obecnie stosowanych metod tłumaczenia ma-szynowego wykorzystuje algorytmy oparte na regułachjęzykowych. Dla blisko spokrewnionych ze sobą ję-zyków dosłowne tłumaczenie przypadków takich, jakprzedstawiony powyżej, może przynieść akceptowalne
efekty. Często jednak systemy oparte na regułach anali-zują tekst źródłowy i generują pośrednią, symbolicznąjego reprezentację, na podstawie której tworzony jesttekst docelowy. Efektywność powyższych metod w wy-sokim stopniu zależy od dostępności obszernych leksy-konów, zawierających informacje morfologiczne, skła-dniowe i semantyczne, oraz dużych zestawów reguł gra-matycznych opartych na wyspecjalizowanej wiedzy ję-zykoznawczej.
Począwszy od lat 80., wraz zewzrostemmożliwości obli-czeniowych komputerów, na znaczeniu zyskały modelestatystyczne służące do tłumaczeniamaszynowego, two-rzone na podstawie analizy dwujęzycznych, lub równo-ległych, korpusów tekstów (takich jak korpus równole-gły Europarl, zawierający protokoły z prac ParlamentuEuropejskiego w 21 językach UE). Przy wystarczającejilości danych tłumaczenie statystyczne jest często w sta-nie przedstawić przybliżone znaczenie tekstu. W prze-ciwieństwie jednak do systemów regułowych tłumacze-nie statystyczne (oparte na danych) często generuje tek-sty niegramatyczne. Natomiast przewagą systemów sta-tystycznych, poza niższym kosztem korekty gramatycz-nej w porównaniu z tłumaczeniem, jest to, iż mogą po-prawnie przetłumaczyć problematyczne fragmenty wy-nikające z indywidualnych cech danego języka, na przy-kład wyrażenia idiomatyczne.
Ponieważ omawiane tu typy systemów tłumaczenia ma-szynowego wzajemnie się uzupełniają, obecnie więk-szość badań prowadzona jest nad systemami hybrydo-wymi, łączącymi w sobie obydwie metodologie (zobaczRysunek 6). Można to osiągnąć na wiele sposobów.Jednym z nich jest wykorzystywanie zarówno systemuopartego na wiedzy, jak i na danych, i zaimplemento-wanie modułu dokonującego wyboru najlepszego tłu-maczenia. Dla dłuższych zdań jednak żaden z wynikównie będzie doskonały. Lepszym rozwiązaniem jest więcpołączenie tłumaczeń poszczególnych części zdania po-chodzących z różnych źródeł; może być to zadaniem
24

Statystyczne tłumaczenie maszynowe
Tekst źródłowy
Tekst docelowy
Analiza tekstu (formatowanie, morfologia, składnia, itd.)
Korekta (formatowanie, kontekst itd.)
Reguły tłumaczeniowe
6: Tłumaczenie maszynowe (statystyczne, regułowe)
dość złożonym, jako że zidentyfikowanie odpowiadają-cych sobie fragmentów w poszczególnych alternatyw-nych tłumaczeniach może być trudne.
W przypadku języka polskiego tłumaczeniemaszynowe jest zadaniem szczególnie trudnym.
Tłumaczenie maszynowe tekstu polskiego jest zada-niem wyjątkowo trudnym. Swobodny szyk zdaniautrudnia analizę, a bogata fleksja – generowanie po-prawnych form gramatycznych.Najważniejszym systemem tłumaczenia maszynowegow Polsce jest szeroko stosowana Translatica (rozwijanaprzez firmę Poleng [38]), powstająca we współpracyz PWN i wykorzystująca wydawane przez nie słowniki,w tympolsko-angielski słownikPWN-Oxford. Transla-tica jest systemem opartym na regułach, obsługującymjęzyk polski, angielski, niemiecki i rosyjski. Liczne pro-jekty badawczew zakresie systemów statystycznych i hy-brydowych nie zaowocowały na razie komercyjnie uda-nym produktem.Język polski obsługiwany jest również przez zwykłe sta-tystyczne systemy tłumaczenia maszynowego, takie jakGoogle Translate czy Bing, które sprawdzają się szcze-gólnie w tłumaczeniu tekstów polskich na język angiel-ski i angielskich na język polski. W przypadku innychjęzyków jakość tłumaczenia jest znacznie gorsza, a wy-niki często bywają niezrozumiałe lub wręcz absurdalne.
U podstaw takiego stanu rzeczy leży mała dostępnośćkorpusów równoległych, niezbędnych do uczenia syste-mów statystycznych.
Systemy tłumaczenia maszynowego umożliwiające wy-korzystanie wewnętrznej terminologii i integrację z sys-temami zarządzania projektem mogą znacznie zwięk-szyć wydajność pracy tłumaczy. Na rynku polskimfunkcjonują specjalne systemy wspomagające procestłumaczenia, np. TranslAide firmy Poleng czy TIGER,stworzony przez Studio Gambit; istnieją również two-rzone przez mniejsze MŚP narzędzia do tłumaczeniawspomaganego komputerowo, takie jakCafetran. Waż-nymnarzędziem jest również systemetos, tłumaczącypolski na język migowy.
Jakość systemów tłumaczenia maszynowego pozostawianadal bardzo wiele do życzenia. Nierozwiązane jesz-cze problemy obejmują możliwość adaptacji zasobówjęzykowych do poszczególnych dziedzin oraz integra-cję z istniejącymi systemami zarządzania tłumaczeniamioraz bazami terminologii i pamięciami tłumaczenio-wymi. Większość z obecnych systemów jest ponadtorozwijana głównie dla tłumaczeniamiędzy polskima an-gielskim; obsługa innych kombinacji językowych jestograniczona. Prowadzi to do zaburzenia i spowolnie-nia procesu tłumaczenia, np. zmuszając użytkownikówsystemów tłumaczenia maszynowego do przyswojeniasobie różnych schematów kodowania terminologii dlaróżnych systemów.
25

Kampanie na rzecz ewaluacji pomagają porównywać ja-kość systemów tłumaczeniamaszynowego, różne podej-ścia i stan tych systemów dla różnych par języków. Ta-bela 7 (s. 27), która została przygotowana w trakcie pro-jektu Euromatrix+, zawiera wyniki dla par uzyskane dla22 z 23 języków urzędowych UE (irlandzki nie był po-równywany). Wyniki są uszeregowane według wynikuBLEU, a wyższe wyniki oznaczają lepsze tłumaczenia[39]. Tłumacz będący człowiekiem zazwyczaj osiągawynik na poziomie około 80 punktów.
Najlepsze wyniki (w kolorze zielonym i niebieskim)mają języki korzystające z wyników skoordynowanychprogramów oraz mające wiele korpusów równoległych(np. angielski, francuski, niderlandzki, hiszpański i nie-miecki). Języki o gorszych wynikach przedstawionow kolorze czerwonym. W odniesieniu do nich nie matakich programów lub są one strukturalnie bardzo różneod innych języków (np. węgierski, maltański i fiński).
4.3.5 Zarządzanie wiedzą i technologiepomocnicze
Tworzenie aplikacji z zakresu technologii językowychobejmuje wiele etapów, których rezultaty nie zawsze sąbezpośrednio widoczne dla użytkownika, ale które od-grywają ważną rolę w systemie. Jako istotne zagadnieniabadawcze stały się odrębnymi dziedzinami językoznaw-stwa komputerowego.
Automatyczne odpowiadanie na pytania jest aktywnierozwijającym się obszarem badań, w którego ramachtworzone są anotowane korpusy i organizowane są kon-kursy. Celem takich systemów jest umożliwienie przej-ścia od wyszukiwania opartego na słowach kluczowych(na których podstawie wyszukiwarka generuje listy po-tencjalnie adekwatnych dokumentów) do systemów,które udzielają konkretnej odpowiedzi na pytanie, np.:
Ile latmiałNeilArmstrong, kiedy stanął naKsiężycu?
38.
Choć tego typu zastosowania są w oczywisty sposóbzwiązane z opisanym powyżej obszarem wyszukiwaniaw sieci, automatyczne odpowiadanie na pytania jestobecnie ogólnym terminem obejmującym takie zagad-nienia badawcze, jak rozróżnianie poszczególnych ty-pów pytań i odpowiedniej adaptacji zachowania sys-temu, metody analizy i porównywania zbiorów doku-mentów potencjalnie zawierających odpowiedź (w celupogodzenia sprzecznychodpowiedzi), algorytmyprecy-zyjnego wyszukiwania odpowiedzi w dokumencie przyuwzględnieniu kontekstu itd.Ostatnie z powyższych zagadnień bezpośrednio łączysię z obszarem ekstrakcji informacji niezwykle popular-nym w latach 90., gdy w językoznawstwie komputero-wym popularne stały się metody statystyczne. Wyszuki-wanie informacji ma na celu identyfikowanie konkret-nych informacji w określonych typach dokumentów –np. wykrywanie podmiotów najaktywniej przejmują-cych inne spółki na podstawie doniesień prasowych. In-nym z rozwijanych obecnie zastosowań jest przetwa-rzanie raportów o aktach terroru w celu wyodrębnie-nia z tekstu informacji o napastniku, celu, dacie i go-dzinie oraz miejscu zdarzenia, a także jego rezultatach.Poszukiwanie standardowych informacji dla konkret-nych dziedzin jest podstawową cechą tego obszaru ba-dawczego – stąd też stanowi on technologię „pomocni-czą”, która musi zostać zintegrowana z kompletnym sys-temem odpowiednim dla konkretnego zadania.
Technologie językowe często są stosowane zakulisami większych systemów oprogramowania
i zapewniają istotne funkcje.
Dwoma obszarami „granicznymi”, pełniącymi czasemrolę autonomicznych aplikacji, a czasem technologii na-rzędziowych, są systemy generowania streszczeń i gene-rowania tekstu. Systemy streszczania tekstu, wbudo-wane na przykład w program Microso Word, oparte
26

Język docelowy – Target languageEN BG DE CS DA EL ES ET FI FR HU IT LT LV MT NL PL PT RO SK SL SV
EN – 40.5 46.8 52.6 50.0 41.0 55.2 34.8 38.6 50.1 37.2 50.4 39.6 43.4 39.8 52.3 49.2 55.0 49.0 44.7 50.7 52.0BG 61.3 – 38.7 39.4 39.6 34.5 46.9 25.5 26.7 42.4 22.0 43.5 29.3 29.1 25.9 44.9 35.1 45.9 36.8 34.1 34.1 39.9DE 53.6 26.3 – 35.4 43.1 32.8 47.1 26.7 29.5 39.4 27.6 42.7 27.6 30.3 19.8 50.2 30.2 44.1 30.7 29.4 31.4 41.2CS 58.4 32.0 42.6 – 43.6 34.6 48.9 30.7 30.5 41.6 27.4 44.3 34.5 35.8 26.3 46.5 39.2 45.7 36.5 43.6 41.3 42.9DA 57.6 28.7 44.1 35.7 – 34.3 47.5 27.8 31.6 41.3 24.2 43.8 29.7 32.9 21.1 48.5 34.3 45.4 33.9 33.0 36.2 47.2EL 59.5 32.4 43.1 37.7 44.5 – 54.0 26.5 29.0 48.3 23.7 49.6 29.0 32.6 23.8 48.9 34.2 52.5 37.2 33.1 36.3 43.3ES 60.0 31.1 42.7 37.5 44.4 39.4 – 25.4 28.5 51.3 24.0 51.7 26.8 30.5 24.6 48.8 33.9 57.3 38.1 31.7 33.9 43.7ET 52.0 24.6 37.3 35.2 37.8 28.2 40.4 – 37.7 33.4 30.9 37.0 35.0 36.9 20.5 41.3 32.0 37.8 28.0 30.6 32.9 37.3FI 49.3 23.2 36.0 32.0 37.9 27.2 39.7 34.9 – 29.5 27.2 36.6 30.5 32.5 19.4 40.6 28.8 37.5 26.5 27.3 28.2 37.6FR 64.0 34.5 45.1 39.5 47.4 42.8 60.9 26.7 30.0 – 25.5 56.1 28.3 31.9 25.3 51.6 35.7 61.0 43.8 33.1 35.6 45.8HU 48.0 24.7 34.3 30.0 33.0 25.5 34.1 29.6 29.4 30.7 – 33.5 29.6 31.9 18.1 36.1 29.8 34.2 25.7 25.6 28.2 30.5IT 61.0 32.1 44.3 38.9 45.8 40.6 26.9 25.0 29.7 52.7 24.2 – 29.4 32.6 24.6 50.5 35.2 56.5 39.3 32.5 34.7 44.3LT 51.8 27.6 33.9 37.0 36.8 26.5 21.1 34.2 32.0 34.4 28.5 36.8 – 40.1 22.2 38.1 31.6 31.6 29.3 31.8 35.3 35.3LV 54.0 29.1 35.0 37.8 38.5 29.7 8.0 34.2 32.4 35.6 29.3 38.9 38.4 – 23.3 41.5 34.4 39.6 31.0 33.3 37.1 38.0MT 72.1 32.2 37.2 37.9 38.9 33.7 48.7 26.9 25.8 42.4 22.4 43.7 30.2 33.2 – 44.0 37.1 45.9 38.9 35.8 40.0 41.6NL 56.9 29.3 46.9 37.0 45.4 35.3 49.7 27.5 29.8 43.4 25.3 44.5 28.6 31.7 22.0 – 32.0 47.7 33.0 30.1 34.6 43.6PL 60.8 31.5 40.2 44.2 42.1 34.2 46.2 29.2 29.0 40.0 24.5 43.2 33.2 35.6 27.9 44.8 – 44.1 38.2 38.2 39.8 42.1PT 60.7 31.4 42.9 38.4 42.8 40.2 60.7 26.4 29.2 53.2 23.8 52.8 28.0 31.5 24.8 49.3 34.5 – 39.4 32.1 34.4 43.9RO 60.8 33.1 38.5 37.8 40.3 35.6 50.4 24.6 26.2 46.5 25.0 44.8 28.4 29.9 28.7 43.0 35.8 48.5 – 31.5 35.1 39.4SK 60.8 32.6 39.4 48.1 41.0 33.3 46.2 29.8 28.4 39.4 27.4 41.8 33.8 36.7 28.5 44.4 39.0 43.3 35.3 – 42.6 41.8SL 61.0 33.1 37.9 43.5 42.6 34.0 47.0 31.1 28.8 38.2 25.7 42.3 34.6 37.3 30.0 45.9 38.2 44.1 35.8 38.9 – 42.7SV 58.5 26.9 41.0 35.6 46.6 33.3 46.6 27.4 30.9 38.9 22.7 42.0 28.2 31.0 23.7 45.6 32.2 44.2 32.7 31.3 33.5 –
7: Tłumaczenie maszynowe między 22 językami europejskimi – Machine translation for 22 EU-languages [40]
są głównie na algorytmach statystycznych, identyfikują-cych w tekście „ważne” wyrazy (tj. wyrazy występującew tekście istotnie częściej niż w języku ogólnym) i za-wierające je zdania. Zdania te są następnie oznaczanei wyodrębniane z tekstu, tworząc streszczenie. Najczę-ściej więc w praktyce streszczenie tekstu oznacza spro-wadzenie go do podzbioru jego zdań: tak funkcjonująwszystkie dostępne rozwiązania komercyjne. Alterna-tywną metodą jest generowanie nowych zdań, tj. two-rzenie streszczenia ze zdań, które niemuszą występowaćw tekście źródłowym. Wymaga to głębszego zrozumie-nia tekstu, w związku z czym wyniki tej grupy metod sądużo mniej przewidywalne. W obu przypadkach jed-nak systemy generowania tekstu rzadko stanowią auto-nomiczne aplikacje, będąc najczęściej elementami więk-szych systemów (np. jako moduły generowania rapor-tów w medycznych systemach informacyjnych, groma-dzących i przetwarzających dane o pacjentach).
Narzędzia dla języka polskiego są w opisanychpowyżej obszarach rozwinięte znacznie gorzejniż ich odpowiedniki dla języka angielskiego.
Narzędzia dla języka polskiego są w opisanych powyżejobszarach rozwinięte znacznie gorzej niż ich odpowied-niki dla języka angielskiego, będące od lat 90. przed-miotem licznych konkursów naukowych, organizowa-nych przede wszystkim przez amerykańskie instytucjeDARPA/NIST. Choć konkursy te umożliwiły znacznyrozwój technologii, skupiały się głównie na języku an-gielskim; nawet gdy obejmowały sekcje wielojęzyczne,język polski nigdy nie był ważnym elementem tych ba-dań. Równie nieliczne są polskie korpusy anotowanei inne zasoby niezbędne do realizacji podobnych zadań.Systemy generowania streszczeń używające metod czy-sto statystycznych są w wielu przypadkach niezależneod języka, istnieje więc pewna liczba rozwiązań proto-
27

typowych. W przypadku generowania tekstu możliwedo wykorzystania moduły są zasadniczo ograniczonedo warstwy powierzchniowej („gramatyki generowaniatekstu”); tak jak w poprzednim przypadku większośćsystemów jest zaprojektowana dla języka angielskiego.Prototypowe implementacje systemu generowania tek-stu powstały podczas tworzenia wspomnianego wcze-śniej systemu tłumaczenia maszynowego dla języka mi-gowego etos.
Powyższe zestawienie nie wyczerpuje zastosowań tech-nologii językowych. Jednym z aktywnie rozwijanychobszarów jest wykrywanie plagiatów, u którego pod-staw leżą metody niezależne od języka, lecz które możebyć wzbogacone w opcje wyszukiwania prostych para-fraz tekstu źródłowego. Najpopularniejszym systememdla językapolskiego jest usługaplagiat.pl, używanaprzezwiększość uczelniwyższychdo sprawdzania oryginalno-ści prac magisterskich, jak również do identyfikowaniaprzypadków naruszenia praw autorskich w sieci [41].
4.4 PROJEKTY Z ZAKRESUTECHNOLOGII JĘZYKOWYCHJednym z najwcześniejszych polskich projektów z za-kresu technologii językowych był podjęty w 1967 r.wysiłek na rzecz stworzenia korpusu frekwencyjnegowspółczesnej polszczyzny o strukturze porównywalnejz anglojęzycznym korpusem Brown University. Zada-nie zrealizował interdyscyplinarny zespół naukowcówz Uniwersytetu Warszawskiego. Częściowe wyniki pro-jektu zostały opublikowane w latach 1972–77, a ukoń-czony korpus – w roku 1990. W kolejnych latach zo-stał on wzbogacony na wielu płaszczyznach, zarównopoprzez ręczną edycję, jak imetodami automatycznymi.
Spośród innych projektów realizowanychwewczesnychlatach rozwoju językoznawstwa komputerowego w Pol-sce wymienić należy próby utworzenia reprezentatyw-nego słownika morfologicznego polszczyzny. Jedną
z nich był projekt POLEX (1993–1996), realizowanyprzez Uniwersytet Adama Mickiewicza; kolejnym pro-jektembył SłownikGramatyczny Języka Polskiego [42],którego efektem jest najbardziej obecnie zaawansowanyanalizator morfologiczny języka polskiego, Morfeusz.W 2008 r. w Instytucie Informatyki Stosowanej Po-litechniki Wrocławskiej, we współpracy z Uniwersyte-tem Adama Mickiewicza (projekt POLNET) rozpo-częty został projekt plWordNet, mający na celu zbu-dowanie polskiej wersji bazy leksykalno-semantycznejWordNet [36, 37]. Powstała w jego wyniku baza, stwo-rzona przy użyciu licznych innowacyjnych półauto-matycznych metod wykrywania relacji semantycznychw korpusach językowych, jest jedną z największych naświecie (niektóre z kategorii są bogatsze niż w oryginal-nej wersji Princeton University).
Innym istotnym projektem korpusowym był korpus IPIPAN, tworzony w pierwszej dekadzie XXI wieku w In-stytucie Podstaw Informatyki Polskiej Akademii Nauk(IPI PAN) [43]. W tym samym okresie powstały rów-nież dwa inne korpusy języka polskiego – korpus PWN,używany do prac słownikowych, oraz korpus referen-cyjnyPELCRA, tworzonywZakładzie JęzykoznawstwaKomputerowego Uniwersytetu Łódzkiego. Ten ostatnizawiera sporą pulę autentycznych danych konwersacyj-nych. Kontynuacją powyższych projektów był rozpo-częty pod koniec 2008 r. przez wszystkie trzy instytu-cje oraz Instytut Języka Polskiego PAN projekt Naro-dowego Korpusu Języka Polskiego (NKJP) [44], zawie-rający część zasobów z korpusów IPI PAN, PWN orazPELCRA. Celem projektu było stworzenie najwięk-szego z dotychczas istniejących, ponadmiliardowegokorpusu języka polskiego oraz milionowego podkor-pusu anotowanego ręcznie na wielu poziomach, w za-myśle autorów będącego podstawą do tworzenia dal-szych zasobów językowych (jeden z wykorzystującychNKJP projektów stawia sobie za zadanie stworzeniepierwszego banku drzew składniowych dla języka pol-
28

skiego przy wykorzystaniu anotacji gramatycznych kor-pusu).
W pierwszej dekadzie XXI wieku rozpoczęte zostałyrównież dwa projekty zajmujące się zbieraniem korpu-sów języka mówionego oraz rozwojem metod przetwa-rzania dyskursu – LUNA (IPI PAN) oraz POLINT-112-SMS (UAM).CelemprojektuLUNAbyło uspraw-nienie zautomatyzowanych systemów telefonicznychpoprzez umożliwienie spontanicznych i nieograniczo-nych interakcji człowiek-maszyna. Projekt POLINT-112-SMS zajmował się zarządzaniem informacjamiw sytuacjach krytycznych. Tworzony w nim system,oparty na danych tekstowych pochodzących z wiado-mości SMS,mawspomagać proces podejmowania decy-zji w centrach zarządzania kryzysowego. Jednym z ele-mentów projektowanego systemu jest moduł zarządza-nia dialogiem.
Polskie instytucje naukowe są ponadto zaangażowanew trwające obecnie projekty CLARIN, mające na celustworzenie infrastruktury technologicznej dla narzędzii zasobów językowych, oraz FLaReNet, ogólnoeuropej-skie forum ułatwiające interakcję między użytkowni-kami i twórcami zasobów językowych. Biorą one rów-nież aktywny udział w pracach projektu META-NET.
Obecnie prowadzone są ponadto co najmniej 2 dużeprojekty finansowane ze środków UE w ramach pro-gramu Innowacyjna Gospodarka – ATLAS i NEKST– oraz liczne programy badawcze z dziedziny technolo-gii językowych, w tym finansowane z Programu Ramo-wego.
Niemniej jednak zapewnienie odpowiedniego poziomuwsparcia dla projektów rozwijających zaawansowanetechnologie, korpusy i inne zasoby językowewymaga za-angażowania większych środków finansowych.
4.5 BADANIA I KSZTAŁCENIEW DZIEDZINIE TECHNOLOGIIJĘZYKOWYCHObecnie w Polsce wiele uniwersytetów i ośrodków na-ukowych – co najmniej 12 – aktywnie uczestniczyw pracach z zakresu technologii językowych i języko-znawstwa komputerowego. Wiele z nich oferuje kursyw tym zakresie [45].Poza uniwersytetami główne projekty badawcze prowa-dzone są w Zakładzie Inżynierii Lingwistycznej Insty-tutu Podstaw Informatyki PAN.Towarzystwami naukowymi aktywnymi w dziedzinietechnologii językowych są Polskie Towarzystwo Infor-matyczne i Polskie Towarzystwo Fonetyczne.Jako dziedzina badań technologie językowe stoją przednastępującymi wyzwaniami:
Osoby aktywne w dziedzinie technologii języko-wych należą do różnych społeczności naukowych,spotykają się na odrębnych konferencjach i należą doodrębnych towarzystw naukowych; brakuje wspól-nego forum, które mogłoby zgromadzić wszystkiezainteresowane strony.
Językoznawstwo komputerowe w dalszym ciągu jestpostrzegane jako dziedzina „egzotyczna”, o nieusta-lonym miejscu w systemie kształcenia, w związkuz czym rozproszona w różnych wydziałach (np. wy-działach informatyki lub filologiach).
Brak efektu synergii między podejmowanymi zagad-nieniami badawczymi.
4.6 DOSTĘPNOŚĆ NARZĘDZII ZASOBÓWW poniższej tabeli przedstawiony jest ogólny obraz bie-żącej sytuacji na polu technologii językowych w Pol-sce. Ocena (w skali 0–6) istniejących narzędzi i zaso-
29

bów oparta jest na eksperckim oszacowaniu na skali od0 (bardzo niska ocena) do 6 (bardzo wysoka).
Lista 8 przedstawia najważniejsze wnioski płynącez oceny stanu technologii językowych w Polsce. Do naj-ważniejszych problemów stojących na przeszkodzie dal-szemu rozwojowi metod automatycznego przetwarza-nia języka można zaliczyć:
Brak korpusów oraz zaawansowanych narzędzi doprzetwarzania języka mówionego dla języka pol-skiego. Ciągle trwają prace nad korpusamimultimo-dalnymi.
Wiele z dostępnych zasobów nie jest zgodnych zestandardami – nawet jeśli istnieją, zapewnienie ichtrwałości, czyli możliwości ich utrzymania w dłuż-szym okresie może być trudne lub niemożliwe. Ko-nieczne jest współpraca i wspólne inicjatywy standa-ryzujące dane i formaty ich zapisu.
Analiza semantyczna jest trudniejsza niż skła-dniowa; analiza semantyczna tekstu jest trudniejszaniż pojedynczych wyrazów lub zdań.
Im większy zakres analizy semantycznej dokonywa-nej przez narzędzie, tym trudniej jest uzyskać od-powiednie dane; niezbędne są bardziej intensywneprace nad głęboką analizą.
Istniejące standardy w zakresie semantyki i kodowa-nia wiedzy (RDF, OWL itd.) nie mogą w prostysposób zostać dostosowane do wymogów przetwa-rzania języka naturalnego.
Narzędzia i zasoby dla przetwarzania językamówio-nego, w szczególności syntezymowy, są obecnie bar-dziej rozwinięte niż technologie dla języka pisanego.
Dotychczasowe badania zaowocowały stworzeniempojedynczych narzędzi o wysokiej jakości, jednakw obecnych warunkach finansowych niemalże nie-możliwe jest stworzenie trwałego i zgodnego ze stan-dardami rozwiązania.
Brakuje dużych, zrównoważonych i ogólnodostęp-nych korpusów równoległych języka polskiego,w tym korpusów równoległych języków pokrew-nych (np. czeskiego).
Do wielu zastosowań niezbędne są dwu- i wieloję-zyczne słowniki zawierające nie tylko tłumaczenia,lecz również informacje o walencji. Jako że standar-dowe słowniki zazwyczaj pomijają ten rodzaj anota-cji, należy stworzyć odpowiednie zasoby.
Do wielu zastosowań niezbędne są duże, ogólno-dostępne zasoby ontologiczne dla języka polskiego.Obecnie dostępne ontologie są relatywnie małei oparte na ontologii OpenCyc lub polskiej wersji te-zaurusa Openesaurus. Polska wersja DBPedii jestw przygotowaniu.
4.7 PORÓWNANIE JĘZYKÓWObecny stan technologii językowych jest bardzo różnyw zależności od języka. Aby porównać sytuację mię-dzy różnymi językami, w tej części raportu zostanie za-prezentowana ocena opracowana na podstawie dwóchprzykładowych obszarów zastosowań (tłumaczenie ma-szynowe i przetwarzaniemowy) oraz jednej technologiibazowej (analiza tekstu) i podstawowych zasobów nie-zbędnych do tworzenia aplikacji w obszarze technologiijęzykowych.Języki skategoryzowano według pięciostopniowej skali:
doskonała jakość,
bardzo dobra jakość,
dobra jakość,
średnia jakość,
słaba lub zerowa jakość.
Jakość TJ wyznaczano zgodnie z następującymi kryte-riami:Przetwarzanie mowy: jakość istniejących technologiirozpoznawania mowy, jakość istniejących technologii
30

Licz
ba
Dos
tępn
ość
Jako
ść
Zakr
es
Dojrz
ałoś
ć
Trwałoś
ć
Elas
tycz
ność
Technologie językowe (narzędzia, technologie, aplikacje)
Rozpoznawanie mowy 1 2 3 4 3 2 4
Synteza mowy 4 3 6 5 4 4 3
Analiza gramatyczna 4 4,5 4,5 4,5 4 4 3
Analiza semantyczna 1 1 3 1 1 2 2
Generowanie tekstu 1 1 1 1 1 1 2
Tłumaczenie maszynowe 3 4 3 3 3 4 3
Zasoby językowe (zasoby, dane, bazy wiedzy)
Korpusy tekstów 3 2 4 4 5 5 3
Korpusy równoległe 3 1 4 4 5 5 5
Korpusy języka mówionego 1 0 3 3 2 2 2
Zasoby leksykalne 3 3 4 4 4 4 3
Gramatyki 3 2 4 4 3 2 2
8: Stan dostępnych technologii językowych dla języka polskiego
syntezy mowy, zakres dziedzinowy, liczba i wielkość ist-niejących korpusówmowy, ilość i różnorodność dostęp-nych aplikacji obsługujących mowę.
Tłumaczenie maszynowe: jakość istniejących techno-logii MT, ilość obsługiwanych par językowych, zakreszjawisk językowych i dziedzin, jakość i wielkość istnieją-cych korpusów równoległych, ilość i różnorodność do-stępnych aplikacji MT.
Analiza tekstu: jakość i zakres istniejących technologiianalizy tekstu (morfologia, składnia, semantyka), zakreszjawisk językowych i dziedzin, ilość i różnorodność do-stępnych aplikacji, jakość i rozmiar istniejących (anoto-wanych) korpusów tekstowych, jakość i zakres istnieją-cych zasobów leksykalnych (np. WordNet) i gramatyk.
Zasoby: jakość i wielkość istniejących korpusów teksto-wych, mowy i równoległych, jakość i zakres istniejącychzasobów leksykalnych i gramatyk.
4.8 WNIOSKIW serii raportów META-NET podjęliśmy ważną próbęoszacowania stanu technologii językowych dla 30 językóweuropejskich i porównania zaplecza technologicznego do-stępnego dla tych języków. Dzięki określeniu luk, potrzebi braków europejska społeczność specjalistów i podmio-tów zainteresowanych technologiami językowymi możeteraz nakreślić programbadań i rozwoju na szeroką skalę.W ten sposób będziemy w stanie stworzyć realne wsparcietechnologiczne dla wielojęzycznej Europy.
Raport pokazał, że istnieją ogromne różnice między ję-zykami Europy. Podczas gdy niektóre języki i obszaryzastosowań mogą korzystać z oprogramowania i zaso-bów dobrej jakości, inne (zwykle „mniejsze” języki) od-czuwają znaczące braki w tym zakresie. Dla wielu języ-ków nie opracowano nawet podstawowych technologiianalizy tekstu ani nie stworzono zasobów umożliwiają-
31

cych budowę tych technologii. Inne języki dysponująpodstawowymi narzędziami i zasobami, ale nie są w sta-nie inwestować w analizę semantyczną. Dlatego też ko-nieczne są dalsze intensywne działania, które pozwoląnam zrealizować nasz podstawowy cel: zapewnić wy-dajny system tłumaczenia maszynowego dla wszystkichjęzyków europejskich.Można również zauważyć brak ciągłości wfinansowaniubadań i rozwoju. Krótkoterminowe programy koordy-nacyjne przeplatają się z okresami ograniczonego finan-sowania lub braku jakichkolwiek funduszy. Dodatkowowidoczny jest brak koordynacji działań z programamiprowadzonymiw innych krajach unijnych i na poziomieKomisji Europejskiej.
Można zatem stwierdzić, że istnieje paląca potrzeba re-alizacji dużego, odpowiednio skoordynowanego pro-jektu mającego na celu zniwelowanie różnic w rozwojutechnologicznym wszystkich języków europejskich.Długoterminowym celem META-NET jest opracowa-nie wysokiej jakości technologii językowych dla wszyst-kich języków, co pozwoli na zjednoczenie politycznei gospodarcze zachowujące różnorodność kulturową.Technologia pomoże nam przezwyciężyć istniejące ba-riery i zbudować pomost łączący języki europejskie. Tencel wymaga jednak wspólnego zaangażowania wszyst-kich stron: przedstawicieli świata polityki, nauki, biz-nesu i społeczeństwa.
32

Doskonała Bardzo dobra Dobra Średnia Słaba/zerowadostępność dostępność dostępność dostępność dostępność
angielski czeskifińskifrancuskihiszpańskiniderlandzkiniemieckiportugalskiwłoski
baskijskibułgarskiduńskiestońskigalisyjskigreckiirlandzkikatalońskinorweskipolskiserbskisłowackisłoweńskiszwedzkiwęgierski
chorwackiislandzkiłotewskilitewskimaltańskirumuński
9: Przetwarzanie mowy: stan technologii językowych dostępnych dla 30 języków europejskich
Doskonała Bardzo dobra Dobra Średnia Słaba/zerowajakość jakość jakość jakość jakość
angielski francuskihiszpański
katalońskiniderlandzkiniemieckipolskirumuńskiwęgierskiwłoski
baskijskibułgarskichorwackiczeskiduńskiestońskifińskigalisyjskigreckiirlandzkiislandzkilitewskiłotewskimaltańskinorweskiportugalskiserbskisłowackisłoweńskiszwedzki
10: Tłumaczenie maszynowe: stan technologii językowych dostępnych dla 30 języków europejskich
33
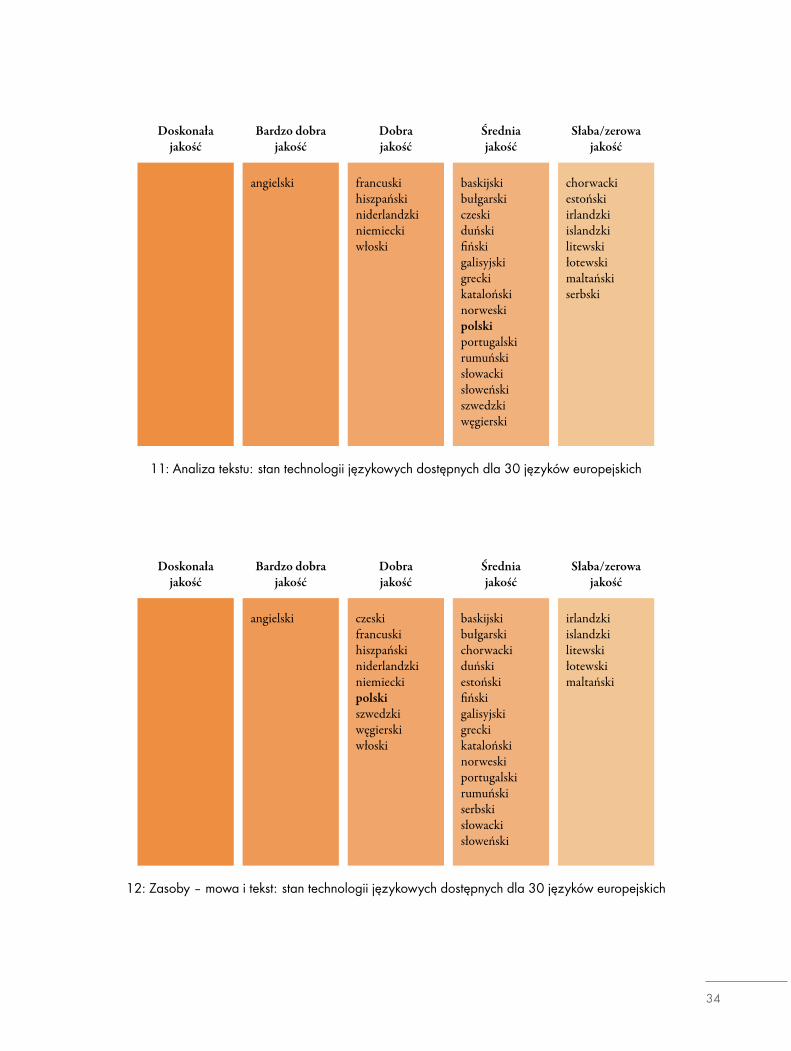
Doskonała Bardzo dobra Dobra Średnia Słaba/zerowajakość jakość jakość jakość jakość
angielski francuskihiszpańskiniderlandzkiniemieckiwłoski
baskijskibułgarskiczeskiduńskifińskigalisyjskigreckikatalońskinorweskipolskiportugalskirumuńskisłowackisłoweńskiszwedzkiwęgierski
chorwackiestońskiirlandzkiislandzkilitewskiłotewskimaltańskiserbski
11: Analiza tekstu: stan technologii językowych dostępnych dla 30 języków europejskich
Doskonała Bardzo dobra Dobra Średnia Słaba/zerowajakość jakość jakość jakość jakość
angielski czeskifrancuskihiszpańskiniderlandzkiniemieckipolskiszwedzkiwęgierskiwłoski
baskijskibułgarskichorwackiduńskiestońskifińskigalisyjskigreckikatalońskinorweskiportugalskirumuńskiserbskisłowackisłoweński
irlandzkiislandzkilitewskiłotewskimaltański
12: Zasoby – mowa i tekst: stan technologii językowych dostępnych dla 30 języków europejskich
34

5
META-NET
META-NET to Sieć Doskonałości finansowana przezKomisję Europejską. Obecnie do sieci należą 54 organi-zacje z 33 krajów europejskich [46]. META-NET two-rzy Technologiczne Konsorcjum Wielojęzycznej Eu-ropy (META), czyli rosnącą społeczność osób i organi-zacji zajmujących się językiem.Celem działania META-NET jest tworzenie technolo-gicznych podwalin wielojęzycznego społeczeństwa in-formacyjnego Europy. Dzięki tej inicjatywie:
możliwabędzie komunikacja iwspółpraca ponadba-rierami językowymi;
użytkownicy wszystkich języków będą mieć równydostęp do wiedzy i informacji;
obywatele Europy będą mogli korzystać z zaawanso-wanych i powszechnie dostępnych technologii języ-kowych.
Sieć wspiera Europę jednoczącą się jako jednolity ry-nek cyfrowy i przestrzeń informacyjną. Stymuluje roz-wój technologii dla wszystkich języków europejskich.Umożliwiają one przekład maszynowy, publikowanietreści, przetwarzanie informacji i zarządzanie wiedząwwielu dziedzinach i do różnych celów. Stanowią takżepodstawę językowych interfejsów w różnego rodzajuurządzeniach, od sprzętu AGD przez maszyny przemy-słowe po samochody, komputery i roboty.Sieć META-NET, która rozpoczęła działalność 1 lu-tego 2010, prowadzi działania na trzech płaszczy-znach: META-VISION, META-SHARE i META-RESEARCH.META-VISION wspiera powstanie dynamiczneji wpływowej społeczności skupionej wokółwspólnej wi-zji i strategii badawczej. Głównym celem tego kierunku
działań jest doprowadzenie do powstania spójnej euro-pejskiej społeczności technologii językowych poprzezstworzenie wspólnej platformy dla przedstawicieli róż-nych i zróżnicowanych grup. Ten raport przygotowanonie tylko w odniesieniu do języka polskiego, ale też 29innych języków. Wspólna wizja techniki rozwijana byław trzech grupach. Ustanowiono META TechnologyCouncil (Radę technologiczną META), która ma przy-gotować strategię w ścisłej współpracy z całym środowi-skiem związanym z technologiami językowymi.META-SHARE to otwarta platforma wymiany zaso-bów. Repozytorium będzie zawierać dane językowe,narzędzia i usługi internetowe udokumentowane przypomocy wysokiej jakości metadanych i zorganizowanew zestandaryzowanych kategoriach. Platforma będzieumożliwiać łatwy dostęp do zasobów i jednolite ich wy-szukiwanie. Dostępne w repozytorium zasoby będą za-wierać zarówno bezpłatne materiały typu open source,jak i płatne zasoby komercyjne o ograniczonej dostęp-ności.META-RESEARCH to tworzenie powiązań z pokrew-nymi technologiami. Ten kierunek działania wiąże sięz wykorzystywaniem postępu technologicznego w in-nych dziedzinach i wyszukiwaniu innowacyjnych ba-dań, które mogą wpłynąć na rozwój technologii języko-wych. W szczególności chodzi tutaj o najbardziej za-awansowane badania nad tłumaczeniem maszynowym,zbieranie danych, przygotowywanie zbiorów danychi organizację zasobów językowych w celu ich ewaluacji;tworzenie spisów narzędzi i metod; oraz organizowaniewarsztatów i kursów dla członków społeczności.
[email protected] – http://www.meta-net.eu
35

English
36

1
EXECUTIVE SUMMARY
Information technology changes our everyday lives. Wetypically use computers for writing, editing, calculating,and information searching, and increasingly for reading,listening tomusic, viewing photos andwatchingmovies.We carry small computers in our pockets and use themto make phone calls, write emails, get information andentertain ourselves, wherever we are. How does thismassive digitisation of information, knowledge and ev-eryday communication affect our language? Will ourlanguage change or even disappear?
All our computers are linked together into an increas-ingly dense and powerful global network. e girl inIpanema, the customs officer in Dorohusk and the en-gineer in Kathmandu can all chat with their friends onFacebook, but they are unlikely ever to meet one an-other in online communities and forums. If they areworried about how to treat earache, they will all checkWikipedia to find out all about it, but even then theywon’t read the same article. WhenEurope’s netizens dis-cuss the effects of the Fukushima nuclear accident onEuropean energy policy in forums and chat rooms, theydo so in cleanly-separated language communities. Whatthe internet connects is still divided by the languages ofits users. Will it always be like this?
Many of the world’s 6,000 languages will not survive ina globalized digital information society. It is estimatedthat at least 2,000 languages are doomed to extinctionin the decades ahead. Others will continue to play a rolein families and neighbourhoods, but not in the widerbusiness and academic world.
With almost 50 million speakers, the Polish languageis fairly well positioned compared to many languages.ere are a large number of television channels withPolish-language programmes. And most internationalmovies come with voice-over translation or closed cap-tions in Polish. All common soware packages are lo-calized into Polish and despite the worries of the grad-ual Anglicisation, it seems that Poles prefer to use theirown language in everyday lives. But there is a dangerof its complete disappearance from major areas of ourpersonal lives. Not science, aviation and the global fi-nancial markets, which actually need a world-wide lin-gua anca. We mean the many areas of life in which itis far more important to be close to a country’s citizensthan to international partners–domestic policies, for ex-ample, administrative procedures, the law, culture andshopping.e status of a language depends not only on the num-ber of speakers or books, computer programmes, filmsand TV stations that use it, but also on the presenceof the language in the digital information space andsoware applications. Here too, the Polish language isfairlywell-placed: the PolishWikipedia is the one of thelargest in the world, and withmore than 2million regis-tered domains, the top level domain .pl (“Polska”) is oneof the world’s largest country-specific top level domains.(In theUS only very fewwebsites actually use the .us toplevel domain.)
What are the Polish language’schances of survival?
37

In the field of language technology, the Polish languageis also well equipped with products, technologies andresources. ere are applications and tools for speechsynthesis, speech recognition, spelling correction, andgrammar checking. ere are alsomany applications forautomatically translating language, even though theseoen fail to produce linguistically and idiomatically cor-rect translations, especially when Polish is the sourcelanguage. is is mainly due to the specific linguisticcharacteristics of the Polish language.
Information and communication technology arenow preparing for the next revolution.
Aer personal computers, networks, miniaturisation,multimedia, mobile devices and cloud-computing, thenext generation of technology will feature sowarethat understands not just spoken or written letters andsounds but entire words and sentences, and supportsusers far better because it speaks, knows and under-stands their language. Forerunners of such develop-ments are the free online service Google Translate thattranslates between 57 languages, IBM’s supercomputerWatson that was able to defeat the US-champion in thegame of “Jeopardy”, and Apple’s mobile assistant Siri forthe iPhone that can react to voice commands and answerquestions inEnglish, German, French and Japanese. Butnot in Polish.e next generation of information technology willmaster human language to such an extent that humanusers will be able to communicate using the technologyin their own language. Devices will be able to automat-ically find the most important news and informationfrom the world’s digital knowledge store in reaction toeasy-to-use voice commands. Language-enabled tech-nology will be able to translate automatically or assistinterpreters; summarise conversations and documents;and support users in learning scenarios.
e next generation of information and communi-cation technologies will enable industrial and servicerobots (currently under development in research labs)to faithfully understand what their users want them todo and then proudly report on their achievements.
is level of performancemeans going way beyond sim-ple character sets and lexicons, spell checkers and pro-nunciation rules. e technology must move on fromsimplistic approaches and start modelling language inan all-encompassing way, taking syntax as well as seman-tics into account to understand the dri of questionsand generate rich and relevant answers,
However, there is a yawning technological gap betweenEnglish and Polish, and it is currently getting wider. Eu-rope lost several very promising high-tech innovationsto the US, where there is greater continuity in theirstrategic research planning and more financial backingfor bringing new technologies to themarket. In the racefor technology innovation, an early start with a vision-ary concept will only ensure a competitive advantage ifyou can actually make it over the finish line. Otherwiseall you get is an honorary mention in Wikipedia.
Every international technology competition tends toshow that results for the automatic analysis of Englishare far better than those for Polish, even though (orprecisely because) the methods of analysis are similar, ifnot identical. is holds true for extracting informationfrom texts, grammar checking, machine translation anda whole range of other applications.
Many researchers reckon that these setbacks are due tothe fact that, for fiy years now, the methods and algo-rithms of computational linguistics and language tech-nology application research have first and foremost fo-cused on English. However, other researchers believethat English is inherently better suited to computer pro-cessing. And languages such as Spanish and French arealso a lot easier to process than Polish using currentmethods. is means that we need a dedicated, consis-
38

tent, and sustainable research effort if we want to be usethe next generation of information and communicationtechnology in those areas of our private and work lifewhere we live, speak and write Polish. Only then can wesay that we added our native language to the favourites,as the slogan of the recent social campaign goes [2].Summing up, despite the prophets of doom the Polishlanguage is not in danger, even from the prowess of En-glish language computing. However, the whole situa-tion could change dramatically when a new generationof technologies really starts to master human languageseffectively. rough improvements in machine transla-tion, language technology will help in overcoming lan-guage barriers, but it will only be able to operate be-tween those languages that have managed to survive inthe digital world. If there is adequate language technol-ogy available, then it will be able to ensure the survivalof languages with very small populations of speakers. Ifnot, even ‘larger’ languages will come under severe pres-sure.e dentist jokingly warns: “Only brush the teeth youwant to keep”. e same principle also holds true for re-search support policies: You can study every languageunder the sun all you want, but if you really intend tokeep them alive, you also need to develop technologiesto support them.
As this series of white papers shows, there is a dramaticdifference between Europe’s member states in terms ofboth the maturity of the research and in the state ofreadiness with respect to language solutions. Yet eventhough Polish is one of the ‘bigger’ EU languages, itneeds further research before truly effective languagetechnology solutions are ready for everyday use.
Only brush the teeth you want to keep!
META-NET’s long-term goal is to introduce high-quality language technology for all languages in orderto achieve political and economic unity through cul-tural diversity. e technology will help tear down ex-isting barriers and build bridges between Europe’s lan-guages. is requires all stakeholders – in politics, re-search, business, and society – to unite their efforts forthe future.
is white paper series complements other strategic ac-tions taken by META-NET (see the appendix for anoverview). Up-to-date information such as the cur-rent version of the META-NET vision paper [3] or theStrategic Research Agenda (SRA) can be found on theMETA-NET web site: http://www.meta-net.eu.
39

2
LANGUAGES AT RISK: A CHALLENGE FORLANGUAGE TECHNOLOGY
We are witnesses to a digital revolution that is dramati-cally impacting communication and society. Recent de-velopments in information and communication tech-nology are sometimes compared to Gutenberg’s inven-tion of the printing press. What can this analogy tellus about the future of the European information soci-ety and our languages in particular?
The digital revolution is comparable toGutenberg’s invention of the printing press.
Aer Gutenberg’s invention, real breakthroughs incommunication were accomplished by efforts such asLuther’s translation of the Bible into vernacular lan-guage. In subsequent centuries, cultural techniques havebeen developed to better handle language processingand knowledge exchange:
the orthographic and grammatical standardisationof major languages enabled the rapid disseminationof new scientific and intellectual ideas;
the development of official languages made it possi-ble for citizens to communicate within certain (of-ten political) boundaries;
the teaching and translation of languages enabled ex-changes across languages;
the creationof editorial andbibliographic guidelinesassured the quality of printed material;
the creation of different media like newspapers, ra-dio, television, books, and other formats satisfieddifferent communication needs.
In the past twenty years, information technology hashelped to automate and facilitate many processes:
desktop publishing soware has replaced typewrit-ing and typesetting;
Microso PowerPoint has replaced overhead projec-tor transparencies;
e-mail allows documents to be sent and receivedmore quickly than using a fax machine;
Skype offers cheap Internet phone calls and hostsvirtual meetings;
audio and video encoding formatsmake it easy to ex-change multimedia content;
web search engines provide keyword-based access;
online services like Google Translate produce quick,approximate translations;
social media platforms such as Facebook, Twitterand Google+ facilitate communication, collabora-tion, and information sharing.
Although these tools and applications are helpful, theyare not yet capable of supporting a fully-sustainable,multilingual European society in which informationand goods can flow freely.
40

2.1 LANGUAGE BORDERSHINDER THE EUROPEANINFORMATION SOCIETYWe cannot predict exactly what the future informationsociety will look like. However, there is a strong like-lihood that the revolution in communication technol-ogy is bringing together people who speak different lan-guages in new ways. is is putting pressure both on in-dividuals to learnnew languages and especially ondevel-opers to create new technology applications to ensuremutual understanding and access to shareable knowl-edge. In the global economic and information space,there is increasing interaction between different lan-guages, speakers and content thanks to new types ofme-dia. e current popularity of social media (Wikipedia,Facebook, Twitter, YouTube, and, recently, Google+) isonly the tip of the iceberg.
The global economy and information spaceconfronts us with different languages, speakers
and content.
Today, we can transmit gigabytes of text around theworld in a few seconds before we recognise that it is ina language that we do not understand. According toa recent report from the EuropeanCommission, 57% ofInternet users in Europe purchase goods and services innon-native languages; English is the most common for-eign language followed byFrench,German andSpanish.55% of users read content in a foreign language while35% use another language to write e-mails or post com-ments on the Web [4]. A few years ago, English mighthave been the lingua anca of the Web – the vast ma-jority of content on the Web was in English – but thesituation has now drastically changed. e amount ofonline content in other European (as well as Asian andMiddle Eastern) languages has exploded. Surprisingly,
this ubiquitous digital linguistic divide has not gainedmuch public attention; yet, it raises a very pressing ques-tion: Which European languages will thrive in the net-worked information and knowledge society, and whichare doomed to disappear?
2.2 OUR LANGUAGES AT RISK
While the printing press helped step up the exchange ofinformation in Europe, it also led to the extinction ofmany European languages. Regional and minority lan-guages were rarely printed and languages such as Cor-nish and Dalmatian were limited to oral forms of trans-mission, which in turn restricted their scope of use. Willthe Internet have the same impact on our modern lan-guages? Europe’s approximately 80 languages are oneof our richest and most important cultural assets, anda vital part of this unique social model [5]. While lan-guages such as English and Spanish are likely to sur-vive in the emerging digital marketplace, many Euro-pean languages could become irrelevant in a networkedsociety. is would weaken Europe’s global standing,and run counter to the strategic goal of ensuring equalparticipation for every European citizen regardless oflanguage.
According to a UNESCO report on multilingualism,languages are an essential medium for the enjoyment offundamental rights, such as political expression, educa-tion and participation in society [6].
The variety of languages in Europe is one of itsrichest and most important cultural assets.
41

2.3 LANGUAGE TECHNOLOGYIS A KEY ENABLINGTECHNOLOGYIn the past, investments in language preservation fo-cussed primarily on language education and transla-tion. According to one estimate, the European mar-ket for translation, interpretation, soware localisationand website globalisation was €8.4 billion in 2008 andis expected to grow by 10% per annum [7]. Yet this fig-ure covers just a small proportion of current and futureneeds in communicating between languages. e mostcompelling solution for ensuring the breadth and depthof language usage in Europe tomorrow is to use appro-priate technology, just as we use technology to solve ourtransport and energy needs among others.Language technology targeting all forms of written textand spoken discourse can help people to collaborate,conduct business, share knowledge and participate insocial and political debate regardless of language barri-ers and computer skills. It oen operates invisibly insidecomplex soware systems to help us already today to:
find information with a search engine;
check spelling and grammar in a word processor;
view product recommendations in an online shop;
follow the spoken directions of a navigation system;
translate web pages via an online service.
Language technology consists of a number of core ap-plications that enable processes within a larger applica-tion framework. e purpose of the META-NET lan-guage white papers is to focus on how ready these coreenabling technologies are for each European language.
Europe needs robust and affordable languagetechnology for all European languages.
Tomaintain our position in the frontline of global inno-vation, Europe will need language technology, tailoredto all European languages, that is robust and affordableand can be tightly integrated within key soware envi-ronments. Without language technology, we will notbe able to achieve a really effective interactive, multime-dia and multilingual user experience in the near future.
2.4 OPPORTUNITIES FORLANGUAGE TECHNOLOGYIn the world of print, the technology breakthrough wasthe rapid duplication of an image of a text using a suit-ably powered printing press. Human beings had to dothe hard work of looking up, assessing, translating, andsummarising knowledge. We had to wait until Edisonto record spoken language – and again his technologysimply made analogue copies.
Language technology can now simplify and automatethe processes of translation, content production, andknowledge management for all European languages. Itcan also empower intuitive speech-based interfaces forhousehold electronics, machinery, vehicles, computersand robots. Real-world commercial and industrial ap-plications are still in the early stages of development,yet R&D achievements are creating a genuine windowof opportunity. For example, machine translation is al-ready reasonably accurate in specific domains, and ex-perimental applications provide multilingual informa-tion and knowledge management, as well as contentproduction, in many European languages.
As with most technologies, the first language applica-tions such as voice-based user interfaces and dialoguesystems were developed for specialised domains, and of-ten exhibit limited performance. However, there arehuge market opportunities in the education and enter-tainment industries for integrating language technolo-gies into games, edutainment packages, libraries, simu-
42

lation environments and training programmes. Mobileinformation services, computer-assisted language learn-ing soware, eLearning environments, self-assessmenttools and plagiarism detection soware are just someof the application areas in which language technologycan play an important role. e popularity of socialmedia applications like Twitter and Facebook suggesta need for sophisticated language technologies that canmonitor posts, summarise discussions, suggest opiniontrends, detect emotional responses, identify copyrightinfringements or track misuse.
Language technology helps overcome the“disability” of linguistic diversity.
Language technology represents a tremendous oppor-tunity for the European Union. It can help to addressthe complex issue ofmultilingualism inEurope–the factthat different languages coexist naturally in Europeanbusinesses, organisations and schools. However, citi-zens need to communicate across the language bordersof the European Common Market, and language tech-nology can help overcome this final barrier, while sup-porting the free and open use of individual languages.Looking even further ahead, innovative European mul-tilingual language technology will provide a benchmarkfor our global partners when they begin to supporttheir own multilingual communities. Language tech-nology can be seen as a form of “assistive” technologythat helps overcome the “disability” of linguistic diver-sity andmakes language communitiesmore accessible toeach other. Finally, one active field of research is the useof language technology for rescue operations in disas-ter areas, where performance can be a matter of life anddeath: Future intelligent robots with cross-lingual lan-guage capabilities have the potential to save lives.
2.5 CHALLENGES FACINGLANGUAGE TECHNOLOGYAlthough language technology has made considerableprogress in the last few years, the current pace of tech-nological progress and product innovation is too slow.Widely-used technologies such as the spelling and gram-mar correctors in word processors are typically mono-lingual, and are only available for a handful of languages.
Technological progress needs to be accelerated.
Onlinemachine translation services, althoughuseful forquickly generating a reasonable approximation of a doc-ument’s contents, are fraught with difficulties whenhighly accurate and complete translations are required.Due to the complexity of human language, modellingour tongues in soware and testing them in the realworld is a long, costly business that requires sustainedfunding commitments. Europe must therefore main-tain its pioneering role in facing the technological chal-lenges of a multiple-language community by inventingnewmethods to accelerate development right across themap. ese could include both computational advancesand techniques such as crowdsourcing.
2.6 LANGUAGE ACQUISITIONIN HUMANS AND MACHINESTo illustrate how computers handle language andwhy itis difficult to program them toprocess different tongues,let’s look briefly at the way humans acquire first and sec-ond languages, and then see how language technologysystems work.Humans acquire language skills in two different ways.Babies acquire a language by listening to the real inter-actions between their parents, siblings and other familymembers. From the age of about two, children produce
43

their first words and short phrases. is is only possi-ble because humans have a genetic disposition to imitateand then rationalise what they hear.Learning a second language at an older age requiresmore cognitive effort, largely because the child is not im-mersed in a language community of native speakers. Atschool, foreign languages are usually acquired by learn-ing grammatical structure, vocabulary and spelling usingdrills that describe linguistic knowledge in terms of ab-stract rules, tables and examples.
Humans acquire language skills in two differentways: learning from examples and learning the
underlying language rules.
Moving to language technology, the two main types ofsystems “acquire” language capabilities in a similar man-ner. Statistical (or “data-driven”) approaches obtain lin-guistic knowledge from vast collections of concrete ex-ample texts. While it is sufficient to use text in a singlelanguage for training, e. g., a spell checker, parallel textsin two (ormore) languages have to be available for train-ing a machine translation system. e machine learn-ing algorithm then “learns” patterns of howwords, shortphrases and complete sentences are translated.is statistical approach usually requiresmillions of sen-tences to boost performance quality. is is one rea-son why search engine providers are eager to collect asmuch written material as possible. Spelling correctionin word processors, and services such as Google Searchand Google Translate, all rely on statistical approaches.e great advantage of statistics is that the machinelearns quickly in a continuous series of training cycles,even though quality can vary randomly.e second approach to language technology, and tomachine translation in particular, is to build rule-based
systems. Experts in the fields of linguistics, computa-tional linguistics and computer science first have to en-code grammatical analyses (translation rules) and com-pile vocabulary lists (lexicons). is is very time con-suming and labour intensive. Some of the leading rule-basedmachine translation systems have been under con-stant development for more than 20 years. e greatadvantage of rule-based systems is that the experts havemore detailed control over the language processing.is makes it possible to systematically correct mistakesin the soware and give detailed feedback to the user, es-pecially when rule-based systems are used for languagelearning. However, due to the high cost of this work,rule-based language technology has so far only been de-veloped for a few major languages.
The two main types of language technologysystems acquire language in a similar manner.
As the strengths and weaknesses of statistical and rule-based systems tend to be complementary, current re-search focusses on hybrid approaches that combine thetwomethodologies. However, these approaches have sofar been less successful in industrial applications than inthe research lab.As we have seen in this chapter, many applicationswidely used in today’s information society rely heavilyon language technology, particularly in Europe’s eco-nomic and information space. Although this technol-ogy hasmade considerable progress in the last few years,there is still huge potential to improve the quality of lan-guage technology systems. In the next section, we de-scribe the role of Polish in European information soci-ety and assess the current state of language technologyfor the Polish language.
44

3
THE POLISH LANGUAGE IN THEEUROPEAN INFORMATION SOCIETY
3.1 GENERAL FACTSWith about 40–48 million native speakers, Polish is themost spoken West Slavic language around the world. Itis the official language of Poland [8]. e auxiliary mi-nority languages that can be used in legal contexts are:German in the west areas of Poland (22 communes us-ing it as auxiliary language), andBelarusian in the east (3communes), Kashubian (2 communes) and Lithuanian(1 commune) [9].
In Poland, the Polish language is the commonspoken and written language and the native
language of the vast majority of the population.
e Polish language is quite homogenous, while thedifferences between its dialects (góralski, from Pod-hale region, Silesian in Silesia, and the dialect ofPoznań) are fairly small. e minority nationalsare the Germans (according to the minority speak-ers: 300,000 to 400,000), Belarusians (250,000 to300,000), Ukrainians (300,000), Lithuanians (30,000),Russians (20,000), Slovaks (15,000), Czechs (3,000),Jews (5,000) and Armenians (1,500). e ethnicminorities are the Ruthenians (50,000), the Roma(20,000), the Tatars (2,000) and the Karaites (150).e only regional group recognised is the Kashubians(250,000 to300,000), with their own regional language.In total, 1,200,000 people belong to regional and na-tional minorities, even though the latest census statis-
tics from 2002 on ethnicity and nationality only note417,000, including theGermans (147,000), Belarusians(48,000), Ukrainians (34,000), Slovaks (2,000). estrongest concentrations of minority nationals can befound in the provinces of Warmia-Masuria, Podlachiaand Opole.Recently, it was debated if Silesians are to be considereda national minority. In 2011 during the census the Sile-sian nationality was declared by 809,000 people [10].
3.2 PARTICULARITIES OF THEPOLISH LANGUAGEPolish exhibits some specific characteristics, which con-tribute to the richness of the language [11] but arechallenges for computational processing of natural lan-guage.
Free word order is a major problemfor language technologies.
Some of these characteristics allow the speakers to ex-press ideas in a wide variety of ways. First, word order isrelatively free in Polish sentences, and it is used to stressthe importance of information rather than simply fol-low from the rules of grammar. Consider, e. g., the En-glish sentence:
e woman gave the man an apple.
45

In English, there are two more ways to express the sameidea, namely:
e woman gave an apple to the man.
An apple was given to the man by the woman.
In Polish, there exist at least nine possible ways (eventhough some of them are less likely to be used):
Kobieta dała mężczyźnie jabłko.
Kobieta mężczyźnie dała jabłko.
Kobieta mężczyźnie jabłko dała.
Jabłko mężczyźnie dała kobieta.
Jabłko kobieta dała mężczyźnie.
Jabłko dała kobieta mężczyźnie.
Mężczyźnie jabłko dała kobieta.
Mężczyźnie jabłko kobieta dała.
Mężczyźnie kobieta dała jabłko.
e meaning of these sentences, though grammaticallyequivalent, varies, as the word order shows which part isthe new information in the sentence, andwhat is alreadyknown.
The number of inflections in Polish is troublesomeboth for language users and computers.
Second, Polish is relatively morphologically rich, whichmeans that for roughly 180 thousand base forms ofwords, almost 4 million inflected word forms exist. einflection paradigms are complex, and even their exactnumber is a matter of a dispute (single exceptionsmightbe thought to create a new paradigm). Even nativespeakers have problems with properly inflecting manywords, andmost speakers of Polish as a second languagenever completely master the complexities of the inflec-tional system.
ird, many computer applications assume either En-glish orWestern-European alphabets, and that may leadto problems with typing Polish diacritical characters(“ą”, “ę” etc.). Historically, it was one of the biggestproblems to get international soware toworkwithPol-ish, and therewere numerousways to encode these char-acters. Even now, there are at least three popular codepages used for Polish: Unicode (mostly UTF-8), ISOstandard and Windows code page (1250). For this rea-son, older data might easily be corrupted with incorrectencoding. Restoring the proper diacritical characters isnot a trivial problem: there are many words that couldbe created by changing some of the characters to Polishdiacritics (for example, “glosy” may be a correct singulargenitive form of “glosa” or plural nominative of “głos”that has “l” instead of “ł”).
Polish diacritic characters are still not sufficientlysupported.
Other specific characteristics of Polish that make auto-matic processing of language difficult are the tendencyto use comparably long and nested sentences. In addi-tion, the lack of articlesmakes detection of nounphrasesrelatively hard, as the only way to detect them is to relyon morphological information (case, number, gender),which is far from unambiguous.
3.3 RECENT DEVELOPMENTSe English language is one of the biggest sources ofloan words and calques, in particular in science andtechnology, and it exerts a considerable influence oncontemporary Polish. e number of words loanedfrom English into Polish is however much lower thanin Dutch or German because of the problems with in-flecting some words and differences in pronunciationsystems. In early 1990s, just aer the major political
46

changes, companies used brands that sounded “Englishlike”. Even a grocery shop could bear an English sign-board “Your shop”. Today, such a name would be con-sidered ridiculous by a much larger group of speakers.But calques from English, such as “dokładnie” (exactly)or “wydawać się być ” (seem to be), are numerous andpopular.
The major influence on today’s Polish is theEnglish language.
Another influence of English is the appearance of moredirect forms of address, especially in advertising [12].While in the past, using the Polish pronoun “ty” (“you”singular) would have been considered rude, it is quitepopular these days. Arguably, this influence stems fromincorrect, non-professional translations from English,yet it is a stable phenomenon. Similarly, Polish speak-ers are now more likely to follow English punctuationpatterns, especially a comma aer introductory phrase,which is, according to traditional Polish punctuationrules, incorrect. Even some typographical characters(such as “&”), never used in Polish before, are borrowedfrom English.
There is a new tendency towards creating wordcompounds such as “speckomisja” (special
committee) or “Rywingate”.
e previous sources of linguistic influence, such as So-viet propaganda and doublespeak, are now of almost noimportance. e official register is nowmore connectedwith the bureaucracy of the EU. ough one can finda new tendency towards creating word compounds suchas “speckomisja” (special committee) or “Rywingate”,which remindof the older Soviet newspeak compounds,the development seems to be independent from the his-torical influence of Russian and is connected with En-
glish instead, though acronyms are a considerably rarerphenomenon in Polish than in English.
One of the current developments in Polish is that fem-inine forms for professions are nowadays more fre-quently used, though they still remain somewhat out-side of the official register. Political correctness is alsovisible in new forms used to refer to foreign nation-als, and immigrants from Africa (the word “Murzyn”[negro], previously considered neutral, is now all butbanned in newspapers).
One of the traditional complaints about the develop-ment of Polish is the proliferation of obscene languageand brutality in colloquial speech. It must be stressed,however, that these claims are not based on corpus-based historical research.
Some of the traditional inflection patterns seem to un-dergo a process of simplification (for example, speakersare more likely to say “mieliłem” than “mełłem”, whichwould be the standard form), and some of the forms be-come almost extinct in everyday speech. is is espe-cially true of the vocative case in colloquial Polish. Atthe same time, the official linguistic counselling websiteare especially popular among Polish speakers, for exam-ple the one run by the scientific publisher PWN [13].
Some of the words are also specially simplified to hu-morous effect in colloquial speech, e. g., instead of thefull word “impreza” (party) one could hear “impra”,“klima” instead of “klimatyzacja” (air-condition), or“kolo” instead of kolega (mate). is said, inflectionpatterns are still highly complex and no simple trend to-wards simplifying them is discernible.
Much more detailed information about changes in thecontemporary Polish language are to be found in the fol-lowing reference works: [14, 15, 16, 17, 18].
47

3.4 LANGUAGE CULTIVATIONIN POLANDe legal status of the Polish language within the terri-tory of the Republic of Poland is defined more preciselyby the Law of 7 October 1999 on the Polish language,with its subsequent amendments (in 2000, 2003, 2004and 2005) [9]. e regulations of this Act relate to “theprotection of the Polish language” and to the use thereofin the pursuit of public tasks, in trade and in the fulfil-ment of labour-law regulations within the territory ofthe Republic of Poland. e protection of the Polishlanguage shall consist especially:
in concern for the correct usage of language and theestablishment of conditions for the proper develop-ment of language as an instrument of human com-munication;
in counteracting the vulgarisation of the language;
in the dissemination of knowledge about languageand its role in culture;
in the promotion of respect for regional languagevariations and dialects and the prevention of theirextinction;
in the promotion of the Polish language in theworldand in support for the teaching of Polish in Polandand abroad.
Entities carrying out public tasks within the territory ofthe Republic of Poland transact all official business andsubmit statements of intent in the Polish language, un-less specific regulations state otherwise. is applies tostatements of intent, applications and other forms sub-mitted to official organs of the state (Article 5).As regards commercial activities, according to Article7, in commercial dealings involving the participation ofconsumers and in the fulfilment of labour-law regula-tions, the Polish language is to be used if the consumeror employee have their place of domicile in the territory
of the Republic of Poland at the time an agreement wasconcluded and this agreement is to be carried out in theterritory of the Republic of Poland. In commercial deal-ings not involving the participation of consumers, thePolish language is to be used only if this trade is car-ried out by the entities subordinated to the organs of theState or to the regional public authorities.e obligation to use the Polish language in commer-cial dealings involving the participation of consumersapplies especially to the names of goods, services, offers,guarantee terms, invoices, bills and receipts as well aswarnings and consumer information required by sepa-rate regulations, operating instructions and informationabout the properties of goods and services. e obliga-tion to use the Polish language in information on theproperties of goods and services also applies to advertis-ing.
The obligation to use the Polish language alsoapplies to advertising.
Foreign-language descriptions of goods and services aswell as foreign-language offers, warnings and consumerinformation required on the basis of other regulationsmust be simultaneously made available in a Polish-language version. Descriptions in the Polish languageare not required as regards warnings and consumer in-formation, user manuals and information on the prop-erties of goods if they are expressed in universally com-prehensible graphic form; if the graphic form is accom-panied by a description, it should be drawn up in thePolish language.Action may be taken against individuals or businessesthat donot respect these requirements. Fines are charge-able for infractions.Supervision of the use of the Polish language is exer-cised within the scope of their tasks by the President ofthe Office of Competition and Consumer Protection,
48

theTrade Inspectorate and the district (municipal) con-sumer spokesman and the State Labour Inspectorate.
According to Article 8, documents, including in par-ticular agreements involving consumers and labour-lawagreements, are to be drawn up in the Polish language.e documents may be simultaneously drawn up in oneor more language versions. Unless parties decide other-wise, the basis for the interpretation of such documentsis their Polish-language version. A job agreement orother document arising out of labour-law regulations,as well as an agreement to which a consumer is a party,may be drawn up in a foreign language at the request ofa job-performing party or consumer who is a citizen ofa EuropeanUnionmember-state other than the Repub-lic of Poland and has previously been informed of theright to draw up an agreement in the Polish language.A job agreement or other labour-law document may bedrawn up in a foreign language at the request of the job-performing party who is not a Polish citizen, and also inthe event the employer is a citizen of a European Unionmember-state or is based in that state.
Polish is the language of teaching, examinations anddiploma dissertations in public and non-public schoolsof all types, in higher state and non-state schools, in ed-ucational establishments and other educational institu-tions, unless specific regulations state otherwise (a grow-ing number of universities offer programmes in English,though). According to the ordinance of the Minister ofNational Education and Sport of 15 October 2003, theState Commission for the Certification of Proficiencyin Polish as a Foreign Language is the supreme bodywhich supervises administration of examinations andissues certificates of the Polish language proficiency atthree levels. e foreigner or the Polish citizen, resid-ing abroad, receives an official certificate of proficiencyin Polish aer examination before the state examinationcommission.
e regulations of the Act on the Polish Language donot pertain to:
proper names, foreign daily newspapers, periodicals,books or computer programs with the exception oftheir description or instructions;
the teaching and research activities of schools ofhigher education, schools and classes with a for-eign language of instruction or bilingual instruc-tion, foreign-language teachers’ colleges and also theteaching of other subjects, if it is in accordance withdetailed regulations;
scientific and cultural creativity;
customarily used scientific and technical terminol-ogy;
trade-marks, brand names and indications of the ori-gin of goods and services;
norms introduced in the original language in accor-dance with standardisation regulations.
e authoritative institution that expresses opinionsand gives advice on issues concerning the use of thePolish language is the Polish Language Council (RadaJęzyka Polskiego), acting as a committee of the PolishAcademy of Sciences. Every second year, it presents a re-port on the protection of the Polish language to the Par-liament of the Republic of Poland.eCouncil, upon amotion by theminister in charge ofculture and the protection of national heritage, themin-ister in charge of education and training and the minis-ter in charge of higher education, the President of theOffice of Competition and Consumer Protection, theChief Inspector of the Trade Inspectorate or the Pres-ident of the Polish Academy of Sciences, or at its owninitiative, expresses by means of a resolution its opin-ion on the use of the Polish language in public activi-ties and in trade within the territory of the Republic ofPoland involving consumers or the execution in the Re-public of Poland of labour-law regulations, and estab-
49

lishes the principles of the Polish language’s orthogra-phy and punctuation.Learned societies, associations of authors and higherschools (i. e., tertiary schools or universities) may referany issues on the use of the Polish language to theCoun-cil. In the event of significant doubts arising in its offi-cial business concerning Polish-language usage any stateor local government authorities may seek the opinionof the Council. Producers, importers and distributorsof goods or services which do not have an appropriatename in Polish may request the Council for an opinionconcerning appropriate terms for the said goods or ser-vices.Besides the Polish Language Council, some other na-tional institutions are engaged (according to theirstatutes) in the cultivation, protection and/or promo-tion of the Polish language.e law which amended the law on the Polish language(11 April 2003) created a legal foundation for officiallycertifying knowledge of Polish as a foreign language.Two depositions from the Ministry of National Educa-tion and Sports dated 15 October 2003 allow foreignnationals to receive certificates confirming their level ofknowledge of the Polish language. ere are three lev-els: elementary, intermediate, and advanced. In somecountries, the Polish language is prized as giving accessto Polish universities and the Polish job market.
Polish students performed well above OECDaverage with respect to reading literacy.
e PISA study, conducted in 2009, shows that Polishstudents performed well above OECD average with re-spect to reading literacy (a second European country af-ter Finland), the eight best place [19]. is means thatlanguage teaching is successful in Poland, though it is ar-guable that relative linguistic homogeneity contributesto this result.
3.5 POLISH ON THE INTERNETIn spring 2011, almost 55% of the Poles were Internetusers [20]. 72% of them said they were online everyday. Among young people, the proportion of users iseven higher. e existence of an active Polish-speakingweb community is alsomirrored by the fact that the Pol-ishWikipedia, with around 800 thousand entries, is oneof the largest Wikipedias aer English, German, andFrench (not counting automatically translated versionssuch as the ai Wikipedia), and is comparable to theItalian version [21].
Over a half of Poles uses the Web.
With about 2 million Internet domains in May 2011[22], Poland’s top-level country domain .pl is one of thetop country extensions in the world [23]. is domi-nant Internet presence suggests that there is a consid-erable amount of Polish language data available on theweb. In addition, some multi-lingual resources like theonline dictionary mash-up ling.pl [24] are freely avail-able.For language technology, the growing importance ofthe Internet is important for two reasons. On the onehand, the large amount of digitally available languagedata represents a rich source for analysing the usage ofnatural language, in particular by collecting statisticalinformation. On the other hand, the Internet offersa wide range of application areas for language technol-ogy.e most commonly used web application is certainlyweb search, which involves the automatic processing oflanguage on multiple levels, as we will see in more de-tail the second part of this paper. It involves sophisti-cated language technology, differing for each language.For Polish, this comprisesmatching “ę” and “e” tomatchtexts written without diacritic characters; moreover, allinflected versions of query words should also be found
50

to enhance the search (so not only „wziąłem”, but also„wziąć”, „wzięłam”, „wziąłby”, „wziąwszy…”). But inter-net users and providers of web content can also profitfrom language technology in less obvious ways, e. g., if itis used to automatically translate web contents from onelanguage into another. Considering the high costs as-sociated with manually translating these contents, com-paratively little usable language technology is built com-
pared to the anticipated need. is might be due to thecomplexity of the Polish language and the number oftechnologies involved in typical LT applications.In the next chapter, we will present an introduction tolanguage technology and its core application areas aswell as an evaluation of the current situation of LT sup-port for Polish.
51

4
LANGUAGE TECHNOLOGY SUPPORTFOR POLISH
Language technology is used to develop soware sys-tems designed to handle human language and are there-fore oen called “human language technology”. Humanlanguage comes in spoken and written forms. Whilespeech is the oldest and in terms of human evolution themost natural form of language communication, com-plex information and most human knowledge is storedand transmitted through the written word. Speechand text technologies process or produce these differ-ent forms of language, using dictionaries, rules of gram-mar, and semantics. is means that language technol-ogy (LT) links language to various forms of knowledge,independently of the media (speech or text) in which itis expressed. Figure 1 illustrates the LT landscape.When we communicate, we combine language withother modes of communication and information media– for example speaking can involve gestures and facialexpressions. Digital texts link to pictures and sounds.Movies may contain language in spoken and writtenform. Inotherwords, speech and text technologies over-lap and interact with other multimodal communicationand multimedia technologies.In this section, we will discuss the main applicationareas of language technology, i. e., language checking,web search, speech interaction, and machine transla-tion. ese applications and basic technologies include:
spelling correction;
authoring support;
computer-assisted language learning;
information retrieval;
information extraction;
text summarisation;
question answering;
speech recognition;
speech synthesis.
Language technology is an established area of researchwith an extensive set of introductory literature. e in-terested reader is referred to the following references:[25, 26, 27, 28, 29]. Links to tools and resources for Pol-ish, which will be mentioned below, are available on thewebsite Computational Linguistics in Poland [30].Before discussing the above application areas, we willbriefly describe the architecture of a typical LT system.
4.1 APPLICATIONARCHITECTURESSoware applications for language processing typicallyconsist of several components that mirror different as-pects of language. While such applications tend to bevery complex, figure 2 shows a highly simplified archi-tecture of a typical text processing system. efirst threemodules handle the structure and meaning of the textinput:
1. Pre-processing: cleans the data, analyses or removesformatting, detects the input languages, and so on.
52

Multimedia &MultimodalityTechnologies
LanguageTechnologies
Speech Technologies
Text Technologies
Knowledge Technologies
1: Language technologies
2. Grammatical analysis: finds the verb, its objects,modifiers and other sentence elements; detects thesentence structure.
3. Semantic analysis: performs disambiguation (i. e.,computes the appropriate meaning of words ina given context); resolves anaphora (i. e., which pro-nouns refer to which nouns in the sentence); rep-resents the meaning of the sentence in a machine-readable way.
Aer analysing the text, task-specific modules can per-form other operations, such as automatic summarisa-tion and database look-ups. Note that the architecturesof the applications are highly simplified and idealisedhere, to illustrate the complexity of language technol-ogy applications in a generally understandable way.Aer the introduction of the core application areas, wewill give a short overview of the situation in LT research
and education, concluding with an overview of (past)funding programs. In the end of this section, we willpresent an expert estimation on the situation regard-ing core LT tools and resources on a number of dimen-sions such as availability, maturity, or quality in figure 7(p. 64) at the end of this chapter. is table lists all toolsand resources that are boldfaced in the text. LT supportfor Polish is also compared to other languages that arepart of this series.
4.2 CORE APPLICATION AREAS
In this section, we focus on themost important LT toolsand resources, and provide an overview of LT activitiesin Poland.
Input Text
Pre-processing Grammatical Analysis Semantic Analysis Task-specific Modules
Output
2: A typical text processing architecture
53

Input Text Spelling Check Grammar Check Correction Proposals
Statistical Language Models
3: Language checking (top: statistical; bottom: rule-based)
4.2.1 Language Checking
Anyone who has used a word processor such as Mi-croso Word knows that it has a spell checker thathighlights spelling mistakes and proposes corrections.40 years aer the first spelling correction program byRalph Gorin, language checkers nowadays do not sim-ply compare the list of extracted words against a dic-tionary of correctly spelled words, but have become in-creasingly sophisticated. Today these programs are farmore sophisticated. Using language-dependent algo-rithms for grammatical analysis, they detect errors re-lated to morphology (e. g., plural formation) as well assyntax–related errors, such as a missing verb or a con-flict of verb-subject agreement (e. g., she *write a letter).However, most spell checkers will not find any errors inthe following text [31]:
I have a spelling checker,It came with my PC.It plane lee marks four my revueMiss steaks aye can knot sea.
Most available spell checkers (including MicrosoWord) will find no errors in this poem because theymostly look at words in isolation. However, analysis oflarger contexts is needed in many cases, e. g., for decid-ing if a word such as the “polski” / “Polska” needs to bewritten in upper case, as in:
Ten tekst został przełożony na polski. [is docu-ment was written in Polish.]
Czytał „Polskę Zbrojną”. [He read Polska Zbrojna.]
is either requires the formulation of language-specificgrammar rules, i. e., a high degree of expertise and man-ual labour, or the use of a so-called statistical languagemodel (alternatively, grammar rules might be inducedusing artificial intelligence methods). Such models cal-culate the probability of a particular word occurring ina specific environment (i. e., thepreceding and followingwords). For example, “polska książka” is a much moreprobable word sequence than “Polska książka”. A sta-tistical language model can be automatically derived us-ing a large amount of (correct) language data (i. e., a cor-pus). Up to now, these approaches havemostly been de-veloped and evaluated on English language data. How-ever, they do not necessarily transfer straightforwardlyto Polish with its flexible word order and richer inflec-tion. e rule-based methods have been used in theopen-source proof-reading tool LanguageTool that in-corporates over 1 thousand rules for Polish (the tool canbe used in various word processing systems, such as Li-breOffice) [32, 33].
Language checking is not limited to wordprocessors but also applies to authoring systems.
Accompanying the rising number of technical products,the amount of technical documentation has rapidly in-creased over the last decades. Fearing customer com-plaints about wrong usage and damage claims resulting
54

from bad or badly understood instructions, companieshave begun to focus increasingly on the quality of tech-nical documentation, at the same time targeting the in-ternational market. Advances in natural language pro-cessing lead to the development of authoring supportsoware, which assists the writer of technical documen-tation to use vocabulary and sentence structures consis-tent with certain rules and (corporate) terminology re-strictions. As Polish is rarely a source language in suchapplications, no generic authoring system has been builtespecially for Polish.
Besides spell checkers and authoring support, languagechecking is also important in the field of computer-assisted language learning and is applied to automati-cally correct queries sent to web search engines, e. g.,Google’s ‘Did you mean…’ suggestions.
4.2.2 Web Search
Searching theWeb, intranets or digital libraries is proba-bly themostwidely used yet largely underdeveloped lan-guage technology application today. e Google searchengine, which started in 1998, now handles about 80%of all search queries [34]. e search interface and re-sults page display has not significantly changed sincethe first version. In the current version, Google offersspelling correction for misspelled words and incorpo-rates basic semantic search capabilities that can improvesearch accuracy by analysing the meaning of terms ina search query context [35]. e Google success storyshows that a large volume of data and efficient indexingtechniques can deliver satisfactory results using a statis-tical approach to language processing.
However, for a more sophisticated request for infor-mation, integrating deeper linguistic knowledge is es-sential. In research labs, experiments using machine-readable thesauri and ontological language resourceslike WordNet (or the Polish equivalent, Słowosieć –[36, 37]) have shown improvements by allowing to find
a page on the basis of synonyms of the search terms(e. g., “energia atomowa”, “energia jądrowa”, “energianuklearna”, etc.) and even more loosely related terms.
The next generation of search engineswill have to include much more sophisticated
language technology.
e next generation of search engines will have to in-clude much more sophisticated language technology,especially to deal with queries consisting of a question orother sentence type rather than a list of keywords. Forthe query, Give me a list of all companies that were takenover by other companies in the last five years, a syntacticas well as semantic analysis is required. e system alsoneeds to provide an index to quickly retrieve relevantdocuments. A satisfactory answer will require syntacticparsing to analyse the grammatical structure of the sen-tence and determine that the user wants companies thathave been acquired, rather than companies that haveacquired other companies. For the expression last fiveyears, the system needs to determine the relevant rangeof years, taking into account the present year. e querythen needs to be matched against a huge amount of un-structured data to find the pieces of information thatare relevant to the user’s request. is process is calledinformation retrieval, and involves searching and rank-ing relevant documents. To generate a list of companies,the system also needs to recognise a particular string ofwords in a document represents a company name, usinga process called named entity recognition.A more demanding challenge is matching a query inone language with documents in another language.Cross-lingual information retrieval involves automati-cally translating the query into all possible source lan-guages and then translating the results back into theuser’s target language.Now that data is increasingly found in non-textual for-mats, there is a need for services that deliver multime-
55
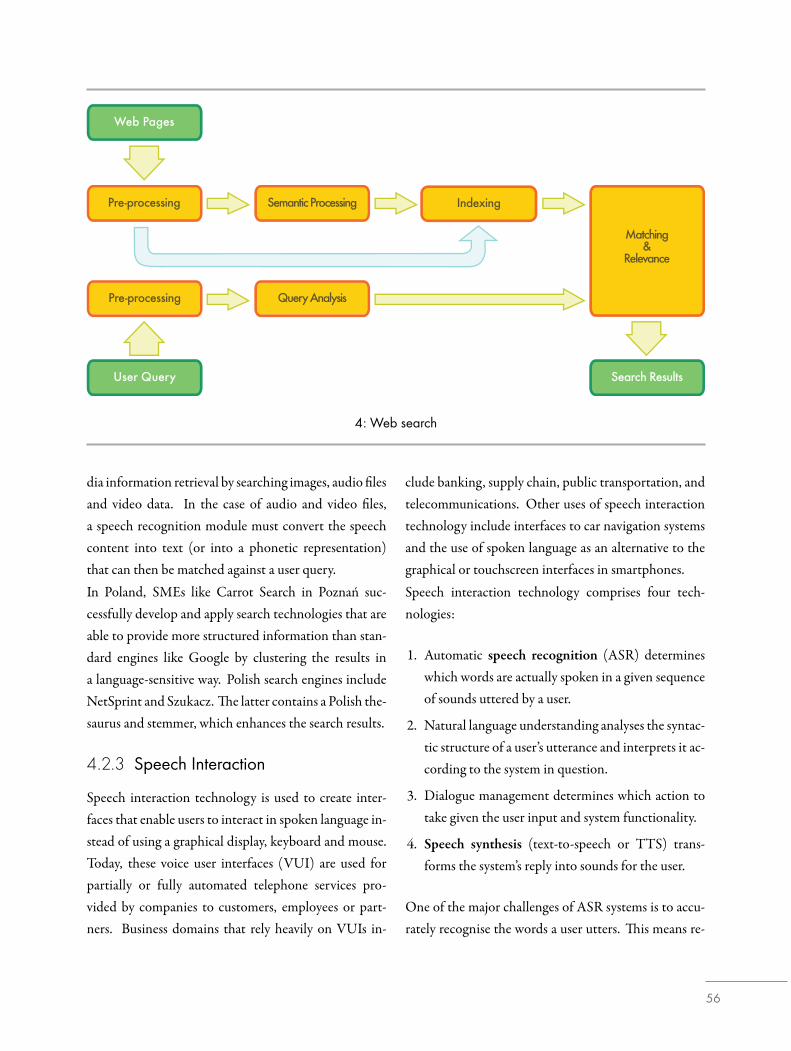
User Query
Web Pages
Pre-processing Query Analysis
Pre-processing Semantic Processing Indexing
Matching&
Relevance
Search Results
4: Web search
dia information retrieval by searching images, audio filesand video data. In the case of audio and video files,a speech recognition module must convert the speechcontent into text (or into a phonetic representation)that can then be matched against a user query.In Poland, SMEs like Carrot Search in Poznań suc-cessfully develop and apply search technologies that areable to provide more structured information than stan-dard engines like Google by clustering the results ina language-sensitive way. Polish search engines includeNetSprint and Szukacz. e latter contains a Polish the-saurus and stemmer, which enhances the search results.
4.2.3 Speech Interaction
Speech interaction technology is used to create inter-faces that enable users to interact in spoken language in-stead of using a graphical display, keyboard and mouse.Today, these voice user interfaces (VUI) are used forpartially or fully automated telephone services pro-vided by companies to customers, employees or part-ners. Business domains that rely heavily on VUIs in-
clude banking, supply chain, public transportation, andtelecommunications. Other uses of speech interactiontechnology include interfaces to car navigation systemsand the use of spoken language as an alternative to thegraphical or touchscreen interfaces in smartphones.Speech interaction technology comprises four tech-nologies:
1. Automatic speech recognition (ASR) determineswhich words are actually spoken in a given sequenceof sounds uttered by a user.
2. Natural language understanding analyses the syntac-tic structure of a user’s utterance and interprets it ac-cording to the system in question.
3. Dialogue management determines which action totake given the user input and system functionality.
4. Speech synthesis (text-to-speech or TTS) trans-forms the system’s reply into sounds for the user.
One of the major challenges of ASR systems is to accu-rately recognise the words a user utters. is means re-
56

Speech Input Signal Processing
Speech Output Speech Synthesis Phonetic Lookup & Intonation Planning
Natural Language Understanding &
Dialogue
Recognition
5: Speech-based dialogue system
stricting the range of possible user utterances to a lim-ited set of keywords, or manually creating languagemodels that cover a large range of natural language ut-terances. Using machine learning techniques, languagemodels can also be generated automatically from speechcorpora, i. e., large collections of speech audio files andtext transcriptions. Restricting utterances usually forcespeople to use the voice user interface in a rigid way andcan damage user acceptance; but the creation, tuningand maintenance of rich language models will signifi-cantly increase costs. VUIs that employ language mod-els and initially allow a user to express their intent moreflexibly – prompted by a How may I help you? greeting– tend to be automated and are better accepted.
For the output part of a VUI, companies tend to useutterances pre-recorded of professional – ideally corpo-rate – speakers a lot. For static utterances, in which thewording does not depend on the particular contexts ofuse or the personal data of the given user, this will re-sult in a rich user experience. However, the more dy-namic content an utterance needs to consider, the moreuser experience may suffer from a poor prosody result-ing from concatenating single audio files. In contrast,today’s TTS systems prove superior, though optimis-able, regarding the prosodic naturalness of dynamic ut-terances.
Regarding the market for speech interaction technol-ogy, the last decade underwent a strong standardisation
of the interfaces between the different technology com-ponents, as well as by standards for creating particularsoware artefacts for a given application. ere alsohas been strongmarket consolidationwithin the last tenyears, particularly in the field of ASR and TTS. Here,the national markets in the G20 countries – i. e., eco-nomically strong countries with a considerable popula-tion – are dominated by less than 5 players worldwide,with Nuance and Loquendo being the most prominentones in Europe.
Speech interaction is the basis for interfaces thatallow a user to interact with spoken language.
On the Polish TTS market, the most successful com-pany is Iona which offers products for other languagesas well. However, for languages with a smaller numberof speakers, commercially employable ASR and TTSproducts sometimes do not even exist. Regarding di-alogue management technology and know-how, mar-kets are strongly dominated by national players, whichare usually SMEs. Today’s key players in Poland arePrimeSpeech and Skrybot. Rather than exclusively re-lying on a product business based on soware licenses,these companies have positioned themselves mostly asfull-service providers that offer the creation of VUIs asa system integration service. Finally, within the domainof speech interaction, a genuine market for the linguis-
57

tic core technologies for syntactic and semantic analysisdoes not exist yet.
As for the actual employment of VUIs, demand inPoland has strongly increased within the last 5 years.is tendency has been driven by end customers’ in-creasing demand for customer self-service and the con-siderable cost optimisation aspect of automated tele-phone services, as well as by a significantly increasedacceptance of spoken language as a modality for man-machine interaction.
Looking beyond today’s state of technology, there willbe significant changes due to the spread of smartphonesas a new platform for managing customer relationships– in addition to the telephone, Internet, and email chan-nels. is tendency will also affect the employment oftechnology for speech interaction. On the one hand,demand for telephony-based VUIs will decrease, on thelong run. On the other hand, the usage of spoken lan-guage as a user-friendly inputmodality for smartphoneswill gain significant importance. is tendency is sup-ported by the observable improvement of speaker inde-pendent speech recognition accuracy for speech dicta-tion services that are already offered as centralised ser-vices to smartphone users. Given this ‘outsourcing’ ofthe recognition task to the infrastructure of applica-tions, the application-specific employment of linguisticcore technologieswill supposedly gain importance com-pared to the present situation.
4.2.4 Machine Translation
e idea of using digital computers for translation ofnatural languages came up in 1946 by A. D. Booth andwas followed by substantial funding for research in thisarea in the 1950s and beginning again in the 1980s. Yetmachine translation (MT) still cannot meet its initialpromise of across-the-board automated
e most basic approach to machine translation is theautomatic replacement of the words in a text written in
one natural language with the equivalent words of an-other language. is can be useful in subject domainsthat have a very restricted, formulaic language such asweather reports. translation.
At its basic level, Machine Translation simplysubstitutes words in one natural language with
words in another language.
However, in order to produce a good translation of lessrestricted texts, larger text units (phrases, sentences, oreven whole passages) need to be matched to their clos-est counterparts in the target language. e major diffi-culty is that human language is ambiguous. Ambiguitycreates challenges on multiple levels, such as word sensedisambiguation at the lexical level (a jaguar is a brand ofcar or an animal) or the assignment of case on the syn-tactic level, for example:
Policjant zauważył samochód w zaroślach. [e po-liceman observed the car in the bush.]
Policjant zauważył samochód w okularach. [e po-liceman observed the car through his glasses].
One way to build an MT system is to use linguis-tic rules. For translations between closely related lan-guages, a translation using direct substitution may befeasible in cases such as the above example. However,rule-based (or linguistic knowledge-driven) systems of-ten analyse the input text and create an intermediarysymbolic representation fromwhich the target languagetext can be generated. e success of these methods ishighly dependent on the availability of extensive lex-icons with morphological, syntactic, and semantic in-formation, and large sets of grammar rules carefully de-signed by skilled linguists. is is a very long and there-fore costly process.In the late 1980s when computational power increasedand became cheaper, interest in statistical models for
58

Statistical Machine
Translation
Source Text
Target Text
Text Analysis (Formatting, Morphology, Syntax, etc.)
Text Generation
Translation Rules
6: Machine translation (left: statistical; right: rule-based)
machine translation began to grow. Statistical modelsare derived from analysing bilingual text corpora, paral-lel corpora, such as the Europarl parallel corpus, whichcontains the proceedings of the European Parliament in21 European languages. Given enough data, statisticalMT works well enough to derive an approximate mean-ing of a foreign language text by processing parallel ver-sions and finding plausible patterns of words. Unlikeknowledge-driven systems, however, statistical (or data-driven) MT systems oen generate ungrammatical out-put. Data-driven MT is advantageous because less hu-man effort is required, and it can also cover special par-ticularities of the language (e. g., idiomatic expressions)that are oen ignored in knowledge-driven systems.
e strengths and weaknesses of knowledge-driven anddata-drivenmachine translation tend to be complemen-tary, so that nowadays researchers focus on hybrid ap-proaches that combine both methodologies. One suchapproach uses both knowledge-driven and data-drivensystems, together with a selection module that decideson the best output for each sentence. However, resultsfor sentences longer than, say, 12 words, will oen befar from perfect. A more effective solution is to com-bine the best parts of each sentence from multiple out-puts; this can be fairly complex, as corresponding partsof multiple alternatives are not always obvious and needto be aligned.
For Polish, machine translation is challenging. efree word order poses problems for analysis, and exten-sive inflection is a challenge for generating words withproper gender and case markings.
Machine Translation is particularly challengingfor the Polish language.
eleadingMTsystem forPolish isTranslatica (Poleng)and it is widely available. Poleng works with the PWNScientific Publishers and uses its extensive dictionaries,including the Oxford PWN English/Polish dictionary.Translatica is rule-based and supports Polish, English,German, and Russian. While there is significant re-search in this technology in national and internationalcontexts, data-driven and hybrid systems have been lesssuccessful in business than in research so far.However, generic statisticalMTsystems such asGoogleTranslate and Bing support Polish to a considerable de-gree, especially in translation from and into English.Nevertheless, for other language pairs the performanceis low and the results are far fromunderstandable, some-times even ridiculous. is is due to the scarcity of theparallel corpora that are used to train statistical MT.Provided good adaptation in terms of user-specific ter-minology and workflow integration, the use of MTcan increase productivity significantly. Special systemsfor interactive translation support were developed, e. g.,
59

at Poleng (TranslAide) and Studio Gambit (TIGER).ere are also smaller SMEs offering Computer-AidedTranslation (CAT) tools, such as Cafetran. A specialMT system, etos, was built to translate Polish intosign language for the hearing impaired.
e quality of MT systems is still considered to havehuge improvement potential. Challenges include theadaptability of the language resources to a given subjectdomain or user area and the integration into existingworkflows with term bases and translation memories.In addition, most of the current systems are English-centred and support only a few languages combinationsfromand intoPolish, which leads to frictions in the totaltranslationworkflow, and, e. g., forcesMTusers to learndifferent lexicon coding tools for different systems.
Evaluation campaigns help to compare the quality ofMT systems, the different approaches and the status ofthe systems for different language pairs. Figure 7 (p. 27),prepared by the Euromatrix+ project, shows the pair-wise performances obtained for 22 of the 23 EU lan-guages (Irish was not compared). e results are rankedaccording to a BLEU score, which indicates higherscores for better translations [39]. A human transla-tor would normally achieve a score of around 80 points.ebest results (in green andblue)were achievedby lan-guages that benefit froma considerable research effort incoordinated programmes and the existence ofmany par-allel corpora (e. g., English, French, Dutch, Spanish andGerman). e languages with poorer results are shownin red.ese languages either lack such development ef-forts or are structurally very different from other lan-guages (e. g., Hungarian, Maltese and Finnish).
4.3 LANGUAGE TECHNOLOGY‘BEHIND THE SCENES’Building language technology applications involvesa range of subtasks that do not always surface at the level
of interaction with the user, but they provide significantservice functionalities “behind the scenes” of the systemin question. ey all form important research issuesthat have now evolved into individual sub-disciplines ofcomputational linguistics.uestion answering, for example, is an active area of re-search for which annotated corpora have been built andscientific competitions have been initiated. e con-cept of question answering goes beyond keyword-basedsearches (in which the search engine responds by de-livering a collection of potentially relevant documents)and enables users to ask a concrete question towhich thesystem provides a single answer. For example:
Question: How old was Neil Armstrong when hestepped on the moon?
Answer: 38.
While question answering is obviously related to thecore area of web search, it is nowadays an umbrella termfor such research issues as which different types of ques-tions exist, and how they should be handled; how a setof documents that potentially contain the answer can beanalysed and compared (do they provide conflicting an-swers?); and how specific information (the answer) canbe reliably extracted from a document without ignoringthe context.uestion answering is in turn related to information ex-traction (IE), an area that was extremely popular andinfluential when computational linguistics took a sta-tistical turn in the early 1990s. IE aims to identify spe-cific pieces of information in specific classes of docu-ments, such as the key players in company takeovers asreported in newspaper stories. Another common sce-nario that has been studied is reports on terrorist in-cidents. e task here consists of mapping appropri-ate parts of the text to a template that specifies the per-petrator, target, time, location and results of the in-cident. Domain-specific template-filling is the central
60

characteristic of IE, which makes it another exampleof a “behind the scenes” technology that forms a well-demarcated research area, which in practice needs to beembedded into a suitable application environment.
Language technology applications often providesignificant service functionalities behind the
scenes of larger software systems.
Text summarisation and text generation are two bor-derline areas that can act either as standalone applica-tions or play a supporting role. Summarisation attemptsto give the essentials of a long text in a short form, andis one of the features available in Microso Word. Itmostly uses a statistical approach to identify the “im-portant” words in a text (i. e., words that occur very fre-quently in the text in question but less frequently in gen-eral language use) and determine which sentences con-tain the most of these “important” words. ese sen-tences are then extracted and put together to create thesummary. In this very common commercial scenario,summarisation is simply a form of sentence extraction,and the text is reduced to a subset of its sentences. Analternative approach, for which some research has beencarried out, is to generate brand new sentences that donot exist in the source text. is requires a certainamount of deeper understanding of the text and there-fore is much less robust. All in all, a text generator is inmost cases not a stand-alone application but is embed-ded into a larger soware environment, such as the clin-ical information system where patient data is collected,stored and processed, and report generation is just oneof many functionalities.
For the Polish language, research in most texttechnologies is much less developed than for the
English language.
For Polish, the situation in all these research areasis much less developed than it is for English, wheresince the 1990s QA, IE, and summarisation have beenthe subject of numerous open competitions, primarilythose organized byDARPA/NIST in theUnited States.ese have significantly improved the state of the art,but the focus has always been on English; some com-petitions have addedmultilingual tracks, but Polish wasnever prominent. Accordingly, there are hardly any an-notated corpora or other resources for these tasks. Sum-marisation systems, when using purely statistical meth-ods, are oen to a good extent language-independent,and thus some research prototypes are available. Fortext generation, reusable components have tradition-ally been limited to the surface realisation modules (the”generation grammars”); again, most of the availablesoware is designed for English. Prototype implemen-tations of text generation were created during the devel-opment of MT system that translated Polish into signlanguage.ere are other fields in which linguistic technologyis being applied. One of them is plagiarism detection,which uses language-independent technologies butmaybe enhanced with search for simple paraphrases of thetext. e most popular Polish application in this fieldis the web-based system plagiat.pl, used in most highereducation institutions to ensure originality of master’stheses, as well as to detect document copyright infringe-ment on the web.
4.4 LT PROJECTSOne of the earliest significant projects in computa-tional linguistics was the creation of the corpus of fre-quency dictionary of contemporary Polish by an inter-disciplinary team of researchers from the University ofWarsaw. e original purpose of the corpus was to cre-ate a general frequency dictionary of contemporary Pol-ish. e work started in 1967. Partial results were pub-
61

lished between 1972 and 1977, the completed dictio-nary in 1990. e corpuswas later augmented in variousrespects, both by manual editing and automated proce-dures. Its design is comparable to the Brown corpus ofEnglish.
e early efforts included projects that aimed at thecreation of a representative Polish morphological dic-tionary. One such project was POLEX (1993–1996)at Adam Mickiewicz University; another was SłownikGramatyczny Języka Polskiego [42] that is includedin the current state-of-the-art morphological analyserfor Polish, Morfeusz. In 2008, an important projectplWordNet coordinated by Wrocław University ofTechnology (Institute of Applied Informatics) [37, 36],with the cooperation of Adam Mickiewicz University(POLNET project), was started in order to build thefirst Polish wordnet. e resulting wordnet is one of thebiggest in the world (the coverage in some categories islarger than in Princeton WordNet), and numerous in-novative semi-automatic methods were used to discovermeaning relations on the basis of linguistic corpora.
Another important corpus projectwas the IPI PANcor-pus created in early 2000s at the Institute of ComputerScience of the Polish Academy of Sciences (ICS PAS).It was the first comprehensible corpus to be availableon the web for Polish [43]. At the same time, PWNscientific publishers developed their own corpus to beused for dictionary research, while at the University ofŁódź, a corpus was built in the Pelcra project. In thenext decade, a follow-up project, the National Corpusof Polish [44] was started by these three institutions andInstitute of Polish Language (Cracow) and it already in-cluded some data from their existing resources. e goalof the project is to create the biggest Polish compiledfrom a pool of over 1 billion words with a manually an-notated 1-million-word part (on several levels). eseannotations will make it possible to prepare other lin-guistic resources from it. For example, a project was
started to build the first Treebank for Polish using thegrammatical annotations from the NKJP corpus.
Twoprojects indiscourse processing, LUNA(ICSPAS)and POLINT-112-SMS (Adam Mickiewicz Univer-sity) were started in the first decade of 2000s, to gatherspoken language corpora and develop methods in dis-course processing for Polish. e vision of LUNA wasto improve automated telephone systems allowing easyhuman-machine interactions through spontaneous andunconstrained speech. POLINT-112-SMS is focusedon information management in emergency situations.e input data for the system are human-generated textmessages (SMS). ey are processed to support deci-sions in a crisis management centre. One of the partsof the project is a dialogue maintenance module.
Polish institutions are also involved in the ongoingCLARIN project and contribute to the efforts on thetechnological infrastructure for language resources andtools, and in FLaReNet, a European forum to facili-tate interaction among language resources stakeholders.ey are also active in META-NET project.
ere are also at least 2 large ongoing projects financedby the EU under the Innovative Economy Programme(ATLAS and NEKST), and numerous other researchprojects in language technology, including the ones inthe Framework Programme.
More financial means are necessary to support projectsaiming at developing more sophisticated LT, languagecorpora and other language resources.
4.5 LT RESEARCH ANDEDUCATIONPoland has a number of excellent centres active in thefield of language technology and computational linguis-tics. Currently, at least 12 Polish universities and re-search centres are active in the field. Many of them offercourses in the field of language technology [45].
62

Apart from the universities, major research projects arecarried out by the language technology group of the In-stitute of theComputer Sciences of the Polish Academyof Sciences (ICS PAS).Polish associations active in the field of language tech-nology are Polskie Towarzystwo Informatyczne andPolskie Towarzystwo Fonetyczne.LT as a field of research faces the following problems:
Since researchers are part of different communitiesthey meet in several separate conferences and havedifferent meetings and boards. Hence, there is nosingle conference at which one can meet all stake-holders.
Computational linguistics is still seen as an ‘exotic’topic, which has not acquired a fixed place in the fac-ulty system yet, and hence is located in different fac-ulties, e. g., the computer science faculties or in thehumanities.
Research topics dealt with are overlapping only par-tially.
4.6 AVAILABILITY OF TOOLSAND RESOURCESFigure 7 provides a rating for language technology sup-port for the Polish language. is rating of existing toolsand resources was generated by leading experts in thefield who provided estimates based on a scale from 0(very low) to 6 (very high) using seven criteria.e key results for Polish language technology can besummed up as follows:
For Polish, discourse corpora or advanced discourseprocessing are not widely available. Multimodal cor-pora are in preparation.
Manyof the resources lack standardization, i. e., evenif they exist, sustainability is not given; concerted
programs and initiatives are needed to standardisedata and interchange formats.
Semantics is more difficult to process than syntax;text semantics is more difficult to process than wordand sentence semantics.
e more semantics a tool takes into account, themore difficult it is to find the right data; more effortsfor supporting deep processing are needed.
Standards do exist for semantics in the sense ofworldknowledge (RDF, OWL, etc.); they are, however,not easily applicable to NLP tasks.
Speech processing, specially speech synthesis, is cur-rently more mature than NLP for written text.
Research was successful in designing particular highquality soware, but it is nearly impossible to comeupwith sustainable and standardized solutions giventhe current funding situations.
Polish lacks large, balanced andmore easily availableparallel corpora, including large parallel corpora forrelated languages such as Czech or Polish.
For many purposes, bilingual and multilingual dic-tionaries that include not only translations but alsovalency information seem indispensable. ese needto be built, as standard dictionaries usually omit thiskind of annotation.
Large and widely available ontological resources forPolish are needed for many applications. Currentlyavailable ontologies are relatively small, based onOpenCyc or on Polish Openesaurus. A Polishversion of DBPedia is in preparation.
4.7 CROSS-LANGUAGECOMPARISONecurrent state of LT support varies considerably fromone language community to another. In order to com-pare the situation between languages, this section will
63

ua
ntity
Availabi
lity
ua
lity
Cov
erag
e
Matur
ity
Sustaina
bilit
y
Ada
ptab
ility
Language Technology: Tools, Technologies and Applications
Speech Recognition 1 2 3 4 3 2 4
Speech Synthesis 4 3 6 5 4 4 3
Grammatical analysis 4 4,5 4,5 4,5 4 4 3
Semantic analysis 1 1 3 1 1 2 2
Text generation 1 1 1 1 1 1 2
Machine translation 3 4 3 3 3 4 3
Language Resources: Resources, Data and Knowledge Bases
Text corpora 3 2 4 4 5 5 3
Speech corpora 1 0 3 3 2 2 2
Parallel corpora 3 1 4 4 5 5 5
Lexical resources 3 3 4 4 4 4 3
Grammars 3 2 4 4 3 2 2
7: State of language technology support for Polish
present an evaluation based on two sample applica-tion areas (machine translation and speech processing)and one underlying technology (text analysis), as wellas basic resources needed for building LT applications.e languages were categorised using the following five-point scale:
1. Excellent support
2. Good support
3. Moderate support
4. Fragmentary support
5. Weak or no support
LTsupportwasmeasured according to the following cri-teria:Speech Processing: uality of existing speech recog-nition technologies, quality of existing speech synthesis
technologies, coverage of domains, number and size ofexisting speech corpora, amount and variety of availablespeech-based applications.
Machine Translation: uality of existing MT tech-nologies, number of language pairs covered, coverage oflinguistic phenomena and domains, quality and size ofexistingparallel corpora, amount andvariety of availableMT applications.
Text Analysis: uality and coverage of existing textanalysis technologies (morphology, syntax, semantics),coverage of linguistic phenomena and domains, amountand variety of available applications, quality and size of(annotated) text corpora, quality and coverage of lexicalresources (e. g., WordNet) and grammars.
Resources: uality and size of existing text corpora,speech corpora and parallel corpora, quality and cover-age of existing lexical resources and grammars.
64

4.8 CONCLUSIONSIn this series of white papers, we have made an impor-tant effort by assessing the language technology supportfor 30 European languages, and by providing a high-leel comparison across these languages. By identifyingthe gaps, needs and deficits, the European language tech-nology community and its related stakeholders are nowin a position to design a large scale research and develop-ment programme aimed at building a truly multilingual,technology-enabled communication across Europe.e results of this white paper series show that thereis a dramatic difference in language technology sup-port between the various European languages. Whilethere are good quality soware and resources availablefor some languages and application areas, others, usu-ally smaller languages, have substantial gaps. Many lan-guages lack basic technologies for text analysis and theessential resources. Others have basic tools and re-sources but the implementation of for example seman-tic methods is still far away. erefore a large-scale ef-fort is needed to attain the ambitious goal of providing
high-quality language technology support for all Euro-pean languages, for example through high quality ma-chine translation.
ere is also a lack of continuity in research and devel-opment funding. Short-term coordinated programmestend to alternate with periods of sparse or zero funding.In addition, there is an overall lack of coordination withprogrammes in other EU countries and at the EuropeanCommission level.
We can therefore conclude that there is a desperate needfor a large, coordinated initiative focused on overcom-ing the differences in language technology readiness forEuropean languages as a whole.
e long term goal of META-NET is to enable the cre-ation of high-quality language technology for all lan-guages. is requires all stakeholders – in politics, re-search, business, and society – to unite their efforts.e resulting technology will help tear down existingbarriers and build bridges between Europe’s languages,paving theway for political and economic unity throughcultural diversity.
65

Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English CzechDutchFinnishFrenchGermanItalianPortugueseSpanish
BasqueBulgarianCatalanDanishEstonianGalicianGreekHungarianIrishNorwegianPolishSerbianSlovakSloveneSwedish
CroatianIcelandicLatvianLithuanianMalteseRomanian
8: Speech processing: state of language technology support for 30 European languages
Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English FrenchSpanish
CatalanDutchGermanHungarianItalianPolishRomanian
BasqueBulgarianCroatianCzechDanishEstonianFinnishGalicianGreekIcelandicIrishLatvianLithuanianMalteseNorwegianPortugueseSerbianSlovakSloveneSwedish
9: Machine translation: state of language technology support for 30 European languages
66

Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English DutchFrenchGermanItalianSpanish
BasqueBulgarianCatalanCzechDanishFinnishGalicianGreekHungarianNorwegianPolishPortugueseRomanianSlovakSloveneSwedish
CroatianEstonianIcelandicIrishLatvianLithuanianMalteseSerbian
10: Text analysis: state of language technology support for 30 European languages
Excellent Good Moderate Fragmentary Weak/nosupport support support support support
English CzechDutchFrenchGermanHungarianItalianPolishSpanishSwedish
BasqueBulgarianCatalanCroatianDanishEstonianFinnishGalicianGreekNorwegianPortugueseRomanianSerbianSlovakSlovene
IcelandicIrishLatvianLithuanianMaltese
11: Speech and text resources: State of support for 30 European languages
67

5
ABOUT META-NET
META-NET is a Network of Excellence partiallyfunded by the European Commission. e networkcurrently consists of 54 research centres in 33 Europeancountries [46]. META-NET forges META, the Multi-lingual EuropeTechnologyAlliance, a growing commu-nity of language technology professionals and organisa-tions in Europe. META-NET fosters the technologicalfoundations for a truly multilingual European informa-tion society that:
makes communication and cooperation possibleacross languages;
grants all Europeans equal access to information andknowledge regardless of their language;
builds upon and advances functionalities of net-worked information technology.
e network supports a Europe that unites as a sin-gle digital market and information space. It stimulatesand promotes multilingual technologies for all Euro-pean languages. ese technologies support automatictranslation, content production, information process-ing and knowledge management for a wide variety ofsubject domains and applications. ey also enable in-tuitive language-based interfaces to technology rang-ing from household electronics, machinery and vehi-cles to computers and robots. Launched on 1 February2010,META-NEThas already conducted various activ-ities in its three lines of actionMETA-VISION,META-SHARE and META-RESEARCH.META-VISION fosters a dynamic and influentialstakeholder community that unites around a shared vi-sion and a common strategic research agenda (SRA).
e main focus of this activity is to build a coherentand cohesive LT community in Europe by bringing to-gether representatives from highly fragmented and di-verse groups of stakeholders. e present White Paperwas prepared together with volumes for 29 other lan-guages. e shared technology vision was developed inthree sectorial Vision Groups. e META TechnologyCouncil was established in order to discuss and to pre-pare the SRA based on the vision in close interactionwith the entire LT community.
META-SHARE creates an open, distributed facilityfor exchanging and sharing resources. e peer-to-peer network of repositories will contain language data,tools and web services that are documented with high-quality metadata and organised in standardised cate-gories. e resources can be readily accessed and uni-formly searched. e available resources include free,open sourcematerials as well as restricted, commerciallyavailable, fee-based items.
META-RESEARCH builds bridges to related tech-nology fields. is activity seeks to leverage advancesin other fields and to capitalise on innovative researchthat can benefit language technology. In particular, theaction line focuses on conducting leading-edge researchin machine translation, collecting data, preparing datasets and organising language resources for evaluationpurposes; compiling inventories of tools and methods;and organising workshops and training events formem-bers of the community.
[email protected] – http://www.meta-net.eu
68

A
BIBLIOGRAFIA REFERENCES
[1] Aljoscha Burchardt, Markus Egg, Kathrin Eichler, Brigitte Krenn, Jörn Kreutel, Annette Leßmöllmann,Georg Rehm, Manfred Stede, Hans Uszkoreit, and Martin Volk. Die Deutsche Sprache im Digitalen Zeital-ter – e German Language in the Digital Age. META-NET White Paper Series. Georg Rehm and HansUszkoreit (Series Editors). Springer, 2012.
[2] Rada Języka Polskiego. Kampania społeczna „Ojczysty – dodaj do ulubionych” (Council forPolish Language. Social campaign ”Native – add to Favorites!”). http://www.rjp.pan.pl/index.php?option=com_content&view=article&id=1329:ojczysty-dodaj-do-ulubionych&catid=82:przedsiwzicia-promujce-polszczyzn.
[3] Aljoscha Burchardt, Georg Rehm, and Felix Sasaki. e Future European Multilingual Information So-ciety – Vision Paper for a Strategic Research Agenda, 2011. http://www.meta-net.eu/vision/reports/meta-net-vision-paper.pdf.
[4] Directorate-General Information Society&Media of the EuropeanCommission. User Language PreferencesOnline, 2011. http://ec.europa.eu/public_opinion/flash/fl_313_en.pdf.
[5] European Commission. Multilingualism: an Asset for Europe and a Shared Commitment, 2008. http://ec.europa.eu/languages/pdf/comm2008_en.pdf.
[6] Directorate-General of the UNESCO. Intersectoral Mid-term Strategy on Languages and Multilingualism,2007. http://unesdoc.unesco.org/images/0015/001503/150335e.pdf.
[7] Directorate-General for Translation of the European Commission. Size of the Language Industry in the EU,2009. http://ec.europa.eu/dgs/translation/publications/studies.
[8] Translation Centre for the Bodies of the European Union. Our EU Languages. http://cdt.europa.eu/EN/whoweare/Pages/OurEUlanguages.aspx.
[9] EFNIL European Federation of National Institutions for Languages. Poland. Legal framework, 2009. http://www.efnil.org/documents/language-legislation-version-2007/poland/poland.
[10] Główny Urząd Statystyczny (Central Statistical Office). Wyniki Narodowego Spisu Powszechnego Ludnościi Mieszkań 2011. Podstawowe informacje o sytuacji demograficzno-społecznej ludności Polski oraz zasobachmieszkaniowych (e results of the Census 2011). Warszawa, 2012. http://www.stat.gov.pl/cps/rde/xbcr/gus/PUBL_lu_nps2011_wyniki_nsp2011_22032012.pdf.
69

[11] Walery Pisarek. e Polish Language. Rada Języka Polskiego przy Prezydium PAN, Warszawa, 2007. http://www.rjp.pan.pl/images/stories/pliki/broszury/jp_angielski.pdf.
[12] Władysław Chłopicki and Jerzy Świątek. Angielski w polskiej reklamie (English in Polish Advertising).Wydawnictwo Naukowe PWN, Warszawa, 2000.
[13] Poradnia językowa PWN (Linguistic counseling of the PWN publishers). http://poradnia.pwn.pl.
[14] Jerzy Bralczyk. Słowo o słowie (A word about words). Wydawnictwo Naukowe PWN, Warszawa, 2009.
[15] JanGrzenia. Komunikacja językowaw Internecie (LinguisticCommunication over the Internet). WydawnictwoNaukowe PWN, Warszawa, 2006.
[16] MarekŁaziński. Opanach i paniach (OnSirs andMadams). WydawnictwoNaukowePWN,Warszawa, 2006.
[17] Jan Mazur, editor. Słownictwo współczesnej polszczyzny w okresie przemian (Vocabulary of Polish during theTransformation Period). Lublin, 2000.
[18] Jerzy Bralczyk and Katarzyna Mosiołek-Kłosińska, editors. Zmiany w publicznych zwyczajach językowych(Changes in Public Linguistic Conentions). Rada Języka Polskiego przy Prezydium PAN, Warszawa, 2001.
[19] OECD. PISA2009Results: Overcoming Social Background–Equity inLearningOpportunities andOutcomes(Volume II). OECD, 2010. http://dx.doi.org/10.1787/9789264091504-en.
[20] Rzeczpospolita. 16,3miliona internautówwPolsce (16.3million users of the Internet in Poland), 19.04 2011.http://www.rp.pl/artykul/645517.html.
[21] List of Wikipedias. http://meta.wikimedia.org/wiki/List_of_Wikipedias.
[22] Krajowy Rejestr Domen, 2011. http://www.dns.pl/zonestats.html.
[23] eBrand Services. Updates to Country Code and Generic Top Level Domains. http://www.ebrandservices.com/welcome-to-e-brand-services,130.html.
[24] Ling.pl. http://ling.pl.
[25] Daniel Jurafsky and James H. Martin. Speech and Language Processing (2nd Edition). Prentice Hall, 2009.
[26] Christopher D. Manning and Hinrich Schütze. Foundations of Statistical Natural Language Processing. MITPress, 1999.
[27] Language Technology World (LT World). http://www.lt-world.org.
[28] Ronald Cole, Joseph Mariani, Hans Uszkoreit, Giovanni Battista Varile, Annie Zaenen, and Antonio Zam-polli, editors. Survey of the State of the Art in Human Language Technology (Studies in Natural LanguageProcessing). Cambridge University Press, 1998.
70

[29] Agnieszka Mykowiecka. Inżynieria lingwistyczna: komputerowe przetwarzanie tekstów w języku naturalnym(Linguistic Engineering: Computer Processing of Natural Language Texts). Wydawnictwo Polsko-JapońskiejWyższej Szkoły Technik Komputerowych, Warszawa, 2007.
[30] Computational Linguistics in Poland. http://clip.ipipan.waw.pl.
[31] Jerrold H. Zar. Candidate for a Pullet Surprise. Journal of Irreproducible Results, page 13, 1994.
[32] LanguageTool. Style and Grammar Checker. http://www.languagetool.org.
[33] Marcin Miłkowski. Developing an open-source, rule-based proofreading tool. Soware: Practice and Experi-ence, 40(7):543–566, 2010.
[34] Spiegel Online. Google zieht weiter davon (Google is still leaving everybody behind), 2009. http://www.spiegel.de/netzwelt/web/0,1518,619398,00.html.
[35] Juan Carlos Perez. Google Rolls out Semantic Search Capabilities, 2009. http://www.pcworld.com/businesscenter/article/161869/google_rolls_out_semantic_search_capabilities.html.
[36] Słowosieć. http://www.plwordnet.pwr.wroc.pl/main/.
[37] Maciej Piasecki, Stanisław Szpakowicz, and Bartosz Broda. A Wordnet om the Ground Up. OficynaWydawnicza Politechniki Wrocławskiej, Wrocław, 2009.
[38] Krzysztof Jassem. Przetwarzanie tekstów polskich w systemie tłumaczenia automatycznego POLENG (Process-ing of Polish Texts in the Machine Translation System POLENG). Wydawnictwo Naukowe UAM, Poznań,2006.
[39] Kishore Papineni, SalimRoukos, ToddWard, andWei-JingZhu. BLEU:AMethod forAutomatic Evaluationof Machine Translation. In Proceedings of the 40th Annual Meeting of ACL, Philadelphia, PA, 2002.
[40] Philipp Koehn, Alexandra Birch, and Ralf Steinberger. 462 Machine Translation Systems for Europe. InProceedings of MT Summit XII, 2009.
[41] Serwis plagiat.pl. http://plagiat.pl.
[42] Zygmunt Saloni; Włodzimierz Gruszczyński; Marcin Woliński and Robert Wołosz. Słownik gramatycznyje zyka polskiego: podstawy teoretyczne (Grammatical Dictionary of Polish). Wiedza Powszechna, Warszawa,2007.
[43] Korpus IPI (IPI Korpus). http://korpus.pl.
[44] Narodowy Korpus Języka Polskiego (National Corpus of Polish). http://www.nkjp.pl.
[45] Linguistic Engineering Research Centers in Poland. http://clip.ipipan.waw.pl/Centers.
[46] Georg Rehm and Hans Uszkoreit. Multilingual Europe: A challenge for language tech. MultiLingual,22(3):51–52, April/May 2011.
71


B
CZŁONKOWIESIECI META-NET
META-NETMEMBERS
Austria Austria Zentrum für Translationswissenscha, Universität Wien: Gerhard Budin
Belgia Belgium Computational Linguistics and Psycholinguistics Research Centre, Univ. ofAntwerp: Walter Daelemans
Centre for Processing Speech and Images, Univ. of Leuven: Dirk van Compernolle
Bułgaria Bulgaria Inst. for Bulgarian Language, Bulgarian Academy of Sciences: Svetla Koeva
Chorwacja Croatia Inst. of Linguistics, Faculty of Humanities and Social Science, Univ. of Zagreb:Marko Tadić
Cypr Cyprus Language Centre, School of Humanities: Jack Burston
Czechy Czech Republic Inst. of Formal and Applied Linguistics, Charles Univ. in Prague: Jan Hajič
Dania Denmark Centre for Language Technology, Univ. of Copenhagen:Bolette Sandford Pedersen, Bente Maegaard
Estonia Estonia Inst. of Computer Science, Univ. of Tartu: Tiit Roosmaa, Kadri Vider
Finlandia Finland Comp. Cognitive Systems Research Group, Aalto Univ.: Timo Honkela
Dept. of Modern Lang., Univ. of Helsinki: Kimmo Koskenniemi, Krister Lindén
Francja France Centre National de la Recherche Scientifique, Laboratoire d’Informatique pour laMécanique et les Sciences de l’Ingénieur and Institute for Multilingual and Multi-media Information: Joseph Mariani
Evaluations and Language Resources Distribution Agency: Khalid Choukri
Grecja Greece R. C. “Athena”, Inst. for Language and Speech Processing: Stelios Piperidis
Hiszpania Spain Barcelona Media: Toni Badia, Maite Melero
InstitutUniversitari de Lingüística Aplicada, Universitat Pompeu Fabra: Núria Bel
Aholab Signal Processing Laboratory, Univ. of the Basque Country:Inma Hernaez Rioja
Center for Language and Speech Technologies and Applications, UniversitatPolitècnica de Catalunya: Asunción Moreno
Dept. of Signal Processing and Communications, Univ. of Vigo:Carmen García Mateo
Holandia Netherlands Utrecht Inst. of Linguistics, Utrecht Univ.: Jan Odijk
73

Computational Linguistics, Univ. of Groningen: Gertjan van Noord
Irlandia Ireland School of Computing, Dublin City Univ.: Josef van Genabith
Islandia Iceland School of Humanities, Univ. of Iceland: Eiríkur Rögnvaldsson
Litwa Lithuania Inst. of the Lithuanian Language: Jolanta Zabarskaitė
Luksemburg Luxembourg Arax Ltd.: Vartkes Goetcherian
Łotwa Latvia Tilde: Andrejs Vasiļjevs
Inst. of Mathematics and Computer Science, Univ. of Latvia: Inguna Skadiņa
Malta Malta Dept. Intelligent Computer Systems, Univ. of Malta: Mike Rosner
Niemcy Germany Language Technology Lab, DFKI: Hans Uszkoreit, Georg Rehm
Human Language Technology and Pattern Recognition, RWTH Aachen Univ.:Hermann Ney
Dept. of Computational Linguistics, Saarland Univ.: Manfred Pinkal
Norwegia Norway Dept. of Ling., Literary and Aesthetic Studies, Univ. of Bergen:Koenraad De Smedt
Dept. of Informatics, Language Technology Group, Univ. of Oslo: StephanOepen
Polska Poland Inst. of Computer Science, Polish Academy of Sciences:Adam Przepiórkowski, Maciej Ogrodniczuk
Univ. of Łódź: Barbara Lewandowska-Tomaszczyk, Piotr Pęzik
Dept. of Computer Ling. and AI, Adam Mickiewicz Univ.: Zygmunt Vetulani
Portugalia Portugal Univ. of Lisbon: António Branco, Amália Mendes
Spoken Language Systems Laboratory, Inst. for Systems Engineering and Comput-ers: Isabel Trancoso
Rumunia Romania Research Inst. for AI, Romanian Academy of Sciences: Dan Tufiș
Faculty of Computer Science, Univ. Alexandru Ioan Cuza of Iași: Dan Cristea
Serbia Serbia Univ. of Belgrade, Faculty of Mathematics: Duško Vitas, Cvetana Krstev,Ivan Obradović
Pupin Institute: Sanja Vranes
Szwajcaria Switzerland Idiap Research Inst.: Hervé Bourlard
Szwecja Sweden Dept. of Swedish, Univ. of Gothenburg: Lars Borin
Słowacja Slovakia Ľudovít Štúr Inst. of Linguistics, Slovak Academy of Sciences: Radovan Garabík
Słowenia Slovenia Jožef Stefan Institute: Marko Grobelnik
Wielka Brytania UK School of Computer Science, Univ. of Manchester: Sophia Ananiadou
74

Inst. for Language, Cognition and Computation, Center for Speech TechnologyResearch, Univ. of Edinburgh: Steve Renals
Research Inst. of Informatics and Language Processing, Univ. of Wolverhampton:Ruslan Mitkov
Dept. of Computer Science, Univ. of Sheffield: Rob Gaizauskas
Węgry Hungary Research Inst. for Linguistics, Hungarian Academy of Sciences: Tamás Váradi
Dept. of Telecommunications and Media Informatics, Budapest Univ. of Technol-ogy and Economics: Géza Németh, Gábor Olaszy
Włochy Italy Consiglio Nazionale delle Ricerche, Istituto di Linguistica Computazionale“Antonio Zampolli”: Nicoletta Calzolari
Human Lang. Technology, Fondazione Bruno Kessler: Bernardo Magnini
Około 100 ekspertów ds. technologii językowych – przedstawicieli krajów i języków reprezentowanych w sieciMETA-NET – omawiało podstawowe rezultaty zawarte w raportach z serii META-NET, a także jego wydźwięk, naspotkaniu w Berlinie (Niemcy) w dniach 21–22 października 2011. – About 100 language technology experts –representatives of the countries and languages represented in META-NET – discussed and finalised the key resultsand messages of the White Paper Series at a meeting in Berlin, Germany, on October 21/22, 2011.
75


C
SERIA RAPORTÓWMETA-NET
THE META-NETWHITE PAPER SERIES
angielski English Englishbaskijski Basque euskarabułgarski Bulgarian българскиchorwacki Croatian hrvatskiczeski Czech češtinaduński Danish danskestoński Estonian eestifiński Finnish suomifrancuski French françaisgalisyjski Galician galegogrecki Greek εηνικάhiszpański Spanish espanolirlandzki Irish Gaeilgeislandzki Icelandic íslenskakataloński Catalan catalalitewski Lithuanian lietuvių kalbałotewski Latvian latviešu valodamaltański Maltese Maltiniderlandzki Dutch Nederlandsniemiecki German Deutschnorweski – bókmál Norwegian Bokmal bokmalnorweski – nynorsk Norwegian Nynorsk nynorskpolski Polish polskiportugalski Portuguese portuguesrumuński Romanian românăserbski Serbian српскиsłowacki Slovak slovenčinasłoweński Slovene slovenščinaszwedzki Swedish svenskawęgierski Hungarian magyarwłoski Italian italiano
77

www.meta-net.eu
La
ngua
ge Users Society Research Communities In
dustries
www.meta-net.eu
In everyday communication, Europe’s citizens, business part-
ners and politicians are inevitably confronted with language
barriers. Language technology has the potential to overcome
these barriers and to provide innovative interfaces to tech-
nologies and knowledge. This white paper presents the state
of language technology support for the Polish language. It
is part of a series that analyzes the available language re-
sources and technologies for 30 European languages. The
analysis was carried out by META-NET, a Network of Excel-
lence funded by the European Commission. META-NET con-
sists of 54 research centres in 33 countries, who cooperate
with stakeholders from economy, government agencies, re-
search organisations and others. META-NET’s vision is high-
quality language technology for all European languages.
W życiu codziennym europejscy obywatele, przedsię-
biorcy i politycy nieuchronnie napotykają bariery języ-
kowe. Technologie językowe dają możliwość pokona-
nia tych barier i mogą posłużyć do stworzenia innowa-
cyjnych interfejsów umożliwiających obsługę urządzeń i
dostęp do wiedzy. Niniejszy raport przedstawia poziom
technologii językowych w języku polskim. Należy do se-
rii, która analizuje dostępne zasoby językowe i technolo-
gie w 31 językach europejskich. Analiza ta została prze-
prowadzona przez META-NET, sieć doskonałości finanso-
waną przez Komisję Europejską. Na META-NET składają
się 54 ośrodki naukowe w 33 krajach, które współpracują
z podmiotami gospodarczymi, agencjami rządowymi, in-
stytucjami badawczymi i innymi. Wizją sieci META-NET
jest tworzenie wysokiej jakości technologii językowych
dla wszystkich języków europejskich.
“I consider the scientific challenges that linguistic engineering faces as extremely promising and intellectuallyattractive research area, where apparently different methodologies and tools of linguistics and computer sciencemeet. Language technologies, as a result of this research, will have a growing influence on capabilities andcommunication models of the contemporary world as well as on the way human natural languages, such asthe Polish language, take part in this process. The text data analysis, speech synthesis and speech recognition,machine translation and text summarisation are more and more present in our everyday life. For their presenceto be rational and functional, for it to serve the needs of the economy, as well as the social and cultural life well,further large-scale work in this area is needed.“— Prof. Michał Kleiber (President of the Polish Academy of Sciences)
Copyright © 2022 FDOKUMEN




















