
Naruto Uzumaki y su camino del ninja: un relato de formación, transformación y sanación
Upload
independentCategory
view
1download
0
The Ninja architecture for robust Internet-scale systems andservices
Steven D. Gribble *, Matt Welsh, Rob von Behren, Eric A. Brewer, David Culler,N. Borisov, S. Czerwinski, R. Gummadi, J. Hill, A. Joseph, R.H. Katz, Z.M. Mao,
S. Ross, B. Zhao
Computer Science Division, University of California, Berkeley, CA 94720-1776, USA
Abstract
The Ninja project seeks to enable the broad innovation of robust, scalable, distributed Internet services, and to
permit the emerging class of extremely heterogeneous devices to seamlessly access these services. Our architecture
consists of four basic elements: bases, which are powerful workstation cluster environments with a software platform
that simpli®es scalable service construction; units, which are the devices by which users access the services; active
proxies, which are transformational elements that are used for unit- or service-speci®c adaptation; and paths, which are
an abstraction through which units, services, and active proxies are composed. Ó 2001 Elsevier Science B.V. All rights
reserved.
Keywords: Distributed systems; Scalable services; Pervasive computing; Thin clients; Ninja architecture
1. Introduction
The emerging Internet landscape is populatedby rich services of immense scale that are o�ered toa diverse spectrum of clients. This presents excitingopportunities for innovation in the kinds of ser-vices that can be created, but also presents tre-mendous design and engineering challenges. Thetraditional suite of information stores, commercesites, network services, and search engines are be-ing combined in novel ways to provide new ser-vices that aggregate and transform many sources
of information. In addition, services are presentingthemselves in a multitude of forms to match theparticular capabilities of PCs, PDAs, Webphones,and other devices; this adaptation to diversityraises new notions of service composition andcontent transformation. Moreover, these new ser-vices may be utilized by millions of users.
In this opportunity for innovation and vastdelivery lies a deep engineering challenge: a suc-cessful service may need to scale to huge levels ofload over a short period and it must be continu-ously available. The Ninja project seeks to addressthese two goals ± enabling broad innovation ofservice design and easily constructing scalable,robust services ± through a distributed service ar-chitecture that deals with huge throughput de-mands and availability requirements in a genericfashion, while facilitating service composition.
Computer Networks 35 (2001) 473±497
www.elsevier.com/locate/comnet
* Corresponding author. Present address: Department of
Computer Science and Engineering, University of Washington,
114 Sieg Hall, Seattle, WA 98195-2350, USA. Tel.: +1-206-685-
1958.
E-mail address: [email protected] (S.D. Gribble).
1389-1286/01/$ - see front matter Ó 2001 Elsevier Science B.V. All rights reserved.
PII: S 1 3 8 9 - 1 2 8 6 ( 0 0 ) 0 0 1 7 9 - 1

The distributed service architecture tackles theproblem of ease of authoring scalable, robust ser-vices at several levels. At the network architecturelevel, structure is imposed on the Internet by apartitioning into three tiers (scalable service plat-forms, transformational intermediaries betweendevices and services, and the devices themselves) tofacilitate state management and consistency whileoperating in the presence of failures. Deep pro-cessing power and persistent storage are providedwithin the service platform through the use of well-engineered clusters on fast, dedicated networks,while soft state and functional transformations areprovided close to the devices. A service is renderedalong a path crossing all the tiers. These paths arethe natural unit of adaptation, optimization andmanagement.
At the language level, services are written in atype-safe language (Java) to reduce errors and tofacilitate composition at well-de®ned interfaces.Code mobility is harnessed to dynamically uploadservices into the platform. At the system level, aplatform provides a set of interfaces and dictates aprogramming discipline that yields e�cientlypipelined services that are robust to excessive load,replicated to achieve high absolute throughput,and tolerant of node failures. Services describethemselves to a service discovery service, whichitself must scale, so that they can be composedprogrammatically to yield new services. It is thestructure and careful design of the overall platformthat simpli®es the task of authoring services, be-cause they inherit the approach to scalability,availability, fault-tolerance, data consistency, andpersistence from the platform.
We begin in Section 2 with an overview of theentire Ninja platform architecture and an intro-duction of its basic terms and concepts. Section 3develops the core service platform, called a base,including the programming model for services, theexecution vehicle, and the approach to scalable,persistent state. Section 4 describes the character-istics of emerging devices, called units, whichfundamentally rely upon the infrastructure. Sec-tion 5 describes the role and function of thetransformational intermediaries, called activeproxies. Section 6 lays the foundation for servicecomposition, showing how services describe
themselves and locate other services in the widearea. Section 7 illustrates how services are com-posed across the platform tiers through the pathconcept. Section 8 puts these concepts together infour distinct services. The remaining sections dis-cuss related work and future directions.
2. Overview of the Ninja architecture
In Fig. 1, we provide a high-level illustration ofthe Ninja architecture, decomposing it into fourbasic elements: bases, which are the rich environ-ments that are engineered to support scalable androbust services, units, which are the numerous, het-erogeneous devices that we wish to support, active
proxies, which are transformational elements usedfor device- or service-speci®c adaptation, and paths,an abstraction used to compose the other elements.We motivate and explore each of these in turn.
2.1. Building robust services in bases
We de®ne a service as software embedded in theInternet infrastructure that exports a network-accessible, typed, programmatic interface, and thatprovides strong operational guarantees (such ashigh availability). The task of building and main-taining services is extremely challenging, since ifthey are to be depended upon, they must have theessential properties of scalability, availability,fault-tolerance, and data consistency and persis-tence, all in the face of voluminuous and potentiallygrowing tra�c demands. Unfortunately, there iscurrently a lack of suitable reusable building blocksand design methodologies for service construction.
We address this challenge in part by con-straining the execution environment of services: wemandate that the core of the service must run in awell-engineered cluster of workstations, which wecall a base. Clusters [3] are a natural platform forbuilding Internet services: each cluster node rep-resents an independent failure boundary, whichmeans that replication of computation and datacan be used to provide fault-tolerance. A clusterpermits incremental scalability as nodes canbe added to increase capacity. Coupled withhigh-performance system area networks, clusters
474 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

can deliver excellent performance for relativelylow cost. Modern cluster networks can achievegreater than 1 Gb/s throughput with 10±100 lslatency.
Designing software to run on clusters of work-stations is known to be di�cult [15]. To simplifythe task of authoring new services, we have con-structed a cluster-based software platform (calledvSpace) that allows service authors to concentrateon application-speci®c functionality, rather thanon details related to scalability, fault-tolerance,and composability. Services authored to run onthe vSpace platform inherit the essential serviceproperties from the platform, greatly reducing thesize and complexity of service code.
vSpace supports the dynamic uploading of newservices by trusted or untrusted third parties; webelieve this open infrastructure is an importantproperty necessary to sustain the distributed in-novation that has led to the current success of theInternet. Authors can construct their services lo-cally, but then upload their services into bases thatare externally maintained.
2.2. Device diversity
The spectrum of network-attached client de-vices is growing in diversity and scale. In addition
to PCs, laptops, and the now familiar class ofPDAs and mobile devices, networks of even moreresource-constrained tiny devices such as sensorsand actuators are being attached to the Internet.This large family of client devices, which we callunits, may have limited connectivity and low orintermittent bandwidth, poor computational abil-ities, and may be able to handle only a small set ofdata formats and network protocols. We believethat there will be a very large number of unitsattached to the network, reaching scales of hun-dreds of millions, and eventually, billions ofdevices.
Units, by nature, are typically not usefulwithout supporting infrastructure. We assumethat units can be easily lost or broken, implyingthat any state that they manage must be repli-cated in a durable environment, such as a servicerunning in a base, which can provide vast amountof highly available, durable storage. Inexpensiveor small units may not have enough computa-tional ability to handle the rich set of data typesand the growing set of protocols deployed in theInternet, implying that such units must rely onsurrogates that adapt content and protocols ontheir behalf.
Because some units are mobile, they may expe-rience regular periods of disconnected operation.
Internet
Active ActiveProxy
Bases
Activ
e
Proxies
Units
Path
e
Fig. 1. The Ninja platform architecture. The architecture consists of bases (services running on clusters of workstations), active proxies
(stateless or soft-state intermediaries between units and services), units (heterogeneous devices and sensors), and paths (a composition
chain across units, proxies, and services in bases).
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 475

Bases can assist such weakly connected units withthe consistency management of data shared acrossunits. Similarly, while a unit is disconnected, aservice running on a base can act as the unit'ssurrogate by responding to requests based on themost recent information in the service's persistentdata store.
2.3. Adaptation
The growing number of devices with Internetaccess capabilities presents a unique set of prob-lems to the designers of Internet-based services. Asthe demand for continuous access to content isincreasing, access to services is being demanded innew environments such as automobiles [26] andkiosks in airplane seats [25], and through newdevices such as Web-phones. Constructing a ser-vice that can be easily and securely used from thisdiversity of contexts and devices is daunting, be-cause of the huge variation in computationalpower, network connectivity, and interface capa-bilities of the devices. Additionally, the weakcomputational ability of small devices such aspagers and PDAs prevents them from usingcryptographic protocols such as SSL to access se-cure services. In today's Internet, this diversity inclient capabilities simply means that most servicesare inaccessible to clients other than standardhome PCs or o�ce workstations.
Rather than forcing services to adapt theircontent and access protocols to the abilities of allcurrent and future devices, we place transforma-tional intermediaries, called active proxies, be-tween devices and services to shield them fromeach other. An active proxy can transform datatypes through a process called distillation, adaptprotocols (e.g., by converting an SSL connectioninto a less expensive shared-key encrypted channelfor CPU constrained devices), or even adapt thevalue of content by removing sensitive informationbefore content is displayed on an untrusted accesspoint. Examples of active proxies include wirelessbasestations, network gateways, ®rewalls, cachingproxies, and transformational proxies. Devicesmay migrate to a new geographic or administrativedomain, and in the process may need to beginusing a new active proxy.
2.4. The composition of services
Instead of constructing a set of isolated, verti-cal services that can handle a ®xed set of devices,our architecture supports the dynamic composi-tion of horizontal services into a path, as well asadaptation along that path. A path is a ¯ow oftyped data through multiple services across thewide area, including the interposition of trans-formational operators to adapt the data into theform expected by the next service or device alongthe path. An essential feature of services that en-able path composition is programmatic access;services must export typed, programmatically ac-cessible interfaces, as opposed to the untyped,unstructured user interfaces common to servicestoday.
Since paths can be established dynamically,the path creation infrastructure can perform data¯ow optimization by examining many di�erentpotential paths before deciding on a particularone to use. During the course of this examina-tion, it can weigh the costs of the variouspaths, and choose a path that optimizes forquality of service, resource consumption, orsome other metric. By allowing the optimizationprocess to continue through the lifetime of agiven path, the infrastructure adapts the path tothe changing characteristics of the execution en-vironment. For example, if a network link be-comes overloaded while data are ¯owing throughthe path, this ¯ow may be redirected through adi�erent channel to improve the quality ofservice.
A necessary step in forming a path is being ableto locate services to place in that path. The Ninjaarchitecture includes a service discovery service
(SDS) that allows both human users and programsto locate appropriate services across the wide areabased on service attribute queries. All servicespublish descriptions of themselves to SDS in-stances running in their local base. These instancesare organized in a hierarchical structure, matchingthe administrative structure of the network. Sum-mary information about known services is ex-changed through this hierarchy; searches similarlypropagate through the hierarchy until matchinginformation is found.
476 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

3. Bases: scalable platforms for Internet services
We have constructed a software platform thatruns on cluster-of-workstation bases to help alle-viate the challenges of scalable, high-performanceservice construction. The platform consists of aprogramming model and I/O substrate gearedtowards obtaining high concurrency, and a cluster-based execution environment (vSpace) that pro-vides facilities for service component replication,load-balancing, and fault-tolerance. In addition,we provide services with a cluster-based, scalablestorage platform (distributed data structures, orDDSs) that exposes a coherent image of persistentdata across the physical nodes of a cluster. Wedescribe each of these three elements in turn.
3.1. A programming model and I/O substrate forhigh-concurrency services
Popular Internet services must be able to handlea very high throughput, perhaps even reachingtens of thousands of requests per second in theextreme case. A service must remain robust underthis extreme load, and it must also gracefullyhandle temporary bursts during which the o�eredload exceeds the capacity of the service. We call theprocess of achieving this robustness conditioningthe service. A necessary (but not su�cient) step inconditioning is selecting an appropriate program-ming model and concurrency strategy that allowsthe service author and the service's executionenvironment to observe and manage constrainedresources such as threads and client tasks.
Our programming model imposes a particularabstraction on services, illustrated in Fig. 2. Givena request from a wide-area client, the service pro-cesses that request through a sequence of logicallydistinct stages, each of which is separated by ahigh- or variable-latency operation. For example,a Web server might have three stages: reading andparsing an HTTP request from a browser, re-trieving the requested ®le from the ®le system, andreturning a formatted response to the browser. Weimpose the constraint that all data sharing betweenthese stages is done using pass-by-value semantics,for example, through the exchange of messagescontaining the data to be shared. This constraint
acts to decouple the stages, allowing them to beisolated from each other, and perhaps be physi-cally separated across address spaces or physicalmachine boundaries.
Given these separated stages, our programmingmodel o�ers four design patterns that authors andthe service infrastructure can apply to composeand condition these stages (Fig. 3):
Wrap. The wrap pattern places a queue in frontof a stage, and assigns some number of threads tothe stage in order to process tasks that arrive onthe queue. The queue conditions the stage to load;excess work that cannot be absorbed by the stage'sthreads is bu�ered in the queue. This queue alsoserves to expose scheduling and admission controlmechanisms to the stage: because the queue isapparent, the code in the stage can decide the or-der in which to process tasks, and it can alsochoose to drop tasks in the case of excessive orlong-lasting overload. Because threads are dedi-cated to the stage, applying the wrap pattern al-lows the stage to execute independently of otherstages.
Pipeline. The pipeline pattern takes a wrappedstage, and splits it into two pipelined, wrappedstages. Pipelining further decouples a stage, andallows for functional parallelism across processorsor cluster nodes. Pipelining permits optimizationssuch as having a single thread repeatedly executethe same code while processing many tasks from aqueue, thereby increasing instruction locality.
Combine. The combine pattern is the logicalinverse of the pipeline pattern. Given two previ-
Fig. 2. Splitting a service into stages. Our programming model
views a service as a sequence of stages, separated by high- or
variable-latency operations. Stages only share data using pass-
by-value semantics, for example, by exchanging messages.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 477

ously independent, wrapped stages, the combineoperator fuses the code of the two stages into asingle, wrapped stage. Combine permits resourcesharing and fate sharing between these previouslyindependent stages.
Replicate. Given a wrapped stage, the replicatepattern duplicates that stage on a number of in-dependent processors or cluster nodes. Replicationis used to eliminate bottlenecks; by replicating astage, the resources that can be applied to itsbottleneck are augmented, hopefully increasingthe throughput of the stage. Replication alsoduplicates the stage's functionality across multiplefailure boundaries, introducing the potential forfault-tolerance.
We have implemented a programming librarythat makes it simple for both service authors andthe service's execution environment to apply thesepatterns to pieces of code. All network communi-cation and disk I/O provided by this library arebuilt using a nonblocking, asynchronous event-driven style of programming. This event-drivenstyle nicely matches the task-driven composition ofstages, and also permits each note to scale to thepoint where it can handle many thousands ofconcurrent tasks, network connections, and diskinteractions.
3.1.1. Java-based I/O substrate implementationThe Ninja base architecture makes extensive use
of the Java [19] programming language, whichprovides strong typing, platform independence,code mobility, and automatic memory manage-ment. These language properties are greatly ben-e®cial for engineering robust Internet services,eliminating many common sources of bugs. Javaalso provides ¯exibility in terms of service de-
ployment across multiple architectures. We makeuse of optimizing Java compilers including Open-JIT [30] and the IBM JIT compiler [27].
Implementing the base platform in Java pre-sented two important challenges. The ®rst was thelack of nonblocking I/O mechanisms in the Javacore libraries. We overcame this by implementingour own nonblocking I/O library using native codewrappers to existing system calls, for example,nonblocking sockets and select. The second wasproviding e�cient access to specialized interfaces,such as user-level network interfaces to the clus-ter's system area network. The native code inter-face provided by Java is ill-suited for theseinterfaces, as they require fast access to hardwareresources and pinned I/O bu�ers outside of theJava heap. We have developed an extension to theJava environment, Jaguar [46], which performs acompile-time specialization of Java bytecode toperform low-level operations directly, whilemaintaining type safety and portability. We haveused Jaguar to implement a Java interface to theVIA [7,41] cluster network interface, which obtains80 ls round-trip latency and over 488 Mbit/sbandwidth over the Myrinet [32] system area net-work. This is equivalent to the performance ofVIA as accessed from C and is more than an orderof magnitude greater than that possible when us-ing Java's native code interface. Jaguar has alsobeen used to implement fast object serializationand memory-mapped ®le access.
3.2. The vspace execution platform
vSpace is an execution environment for scalableInternet services which operates on a cluster ofworkstations (see Fig. 4). vSpace services are
Fig. 3. The four design patterns. The four design patterns, wrap, pipeline, combine, and replicate, can be applied to stages of a service to
condition it against load, failures, and limited or bottleneck resources.
478 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

constructed using the programming model de-scribed in the previous section; services are con-structed as a graph of workers, each of whichconsists of a ®xed-size thread pool, an incomingevent queue, and a set of methods that implementthe worker's logic. A vSpace service is described bya formal service de®nition, which precisely speci®esthe set of workers in the service, their code, andresource requirements. The act of service publica-
tion resolves intra-service dependencies and e�ec-tively ``freezes'' the code used by this particularversion of the service. This allows the entire serviceto be treated as a versioned, immutable entitywhich is ready for deployment and compositionwith other services. Further modi®cations to theservice code result in a new version of the service,and do not a�ect previously published versions.
Workers correspond directly to stages, as de-scribed in the previous section. Workers commu-nicate by asynchronously pushing typed messagesonto other workers' queues. Worker instances andworkers of di�erent types are pipelined, executingin parallel on the multiple CPUs and physicalnodes in the cluster. vSpace uses the replicate de-sign pattern to instantiate copies of workers acrossmultiple cluster nodes; each worker instance,called a clone, uses the same code base and sharesglobal persistent state through a distributed datastructure (described below). A set of worker clones
of the same type are called a clone group. vSpaceautomatically spawns and destroys clones in re-sponse to observed system load; workers' queuelengths and worker execution times are both usedto determine the current load. Scalability andfault-tolerance are obtained by replicating clonesacross multiple physical resources (such as thenodes of the cluster), and by providing a mecha-nism for failure detection and clone restart.
A worker may send one or more outgoing tasksto a named clone group, in which case the out-going tasks are load-balanced across the clones inthat group. Optionally, the sender may specify aparticular clone as the destination for a task. Thisis used as a locality optimization to allow the resultof a previous task dispatch to return to the originalsender.
3.3. Distributed data structures
A distributed data structure (DDS) [20] is a self-managing storage layer designed to run on a clusterof workstations at the scale required by Internetservice workloads. A DDS has all of the previouslymentioned service properties: high throughput,high concurrency, availability, incremental scala-bility, and strict consistency of its data, but pro-vides a narrow data structure interface. Serviceauthors see the DDS as a conventional data
Fig. 4. Software architecture of a base. A base consists of a cluster, the nodes of which run the vSpace execution environment. Services
are implemented as a graph of workers which communicate through a typed task dispatch mechanism. vSpace load balances tasks
across workers based on information from a cluster load monitor. Workers are replicated across nodes for scalability and availability,
and share global state through a consistent, scalable storage platform (distributed data structures, or DDS).
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 479
structure, such as a hash table, a tree, or a log.Behind this interface, the DDS platform hides allof the mechanisms used to access, partition, repli-cate, scale, and recover the data in the DDS (il-lustrated in Fig. 5). The DDS greatly simpli®esservice construction by hiding the complexity ofrobustly managing scalable persistent state that ispartitioned and replicated across the cluster.
We have implemented a distributed hash tableas an example of DDS. All operations on elementsinside this distributed hash table are atomic, inthat any operation completes entirely, or not at all.The hash table has one-copy equivalence, so al-though data elements in the hash table are repli-cated across multiple hash table nodes (or bricks),workers that use the hash table see a single, logicaldata item. Two-phase commit is used to keep allreplicas coherent. We have not yet implementedtransactions across multiple elements or opera-
tions, but we believe that the atomic consistencyprovided by our current distributed hash table isalready strong enough to support a large class ofinteresting services.
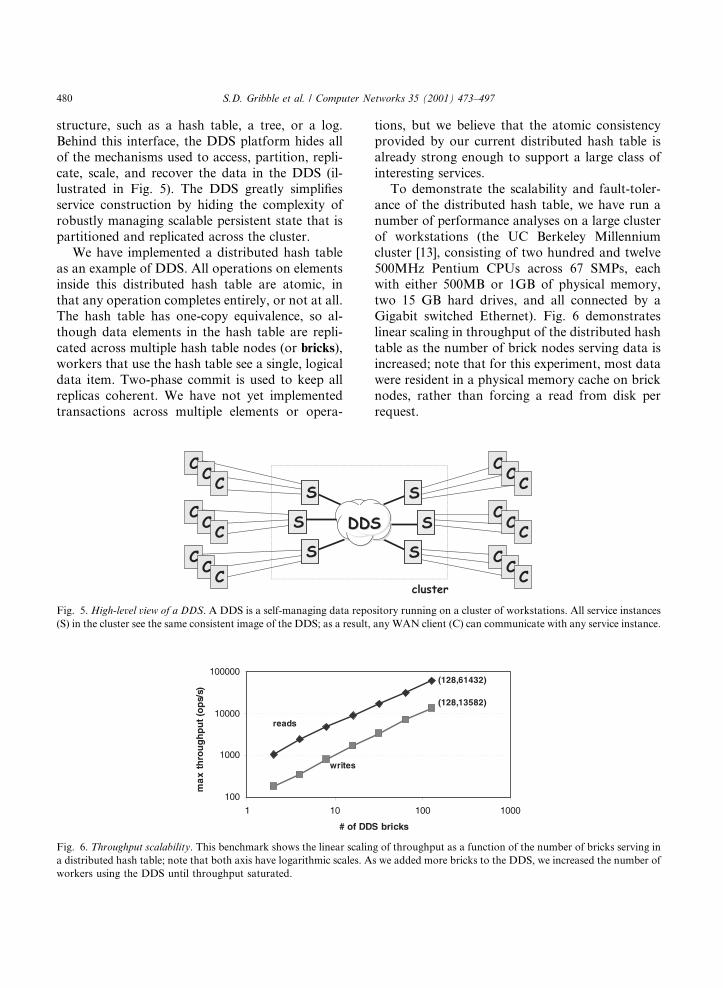
To demonstrate the scalability and fault-toler-ance of the distributed hash table, we have run anumber of performance analyses on a large clusterof workstations (the UC Berkeley Millenniumcluster [13], consisting of two hundred and twelve500MHz Pentium CPUs across 67 SMPs, eachwith either 500MB or 1GB of physical memory,two 15 GB hard drives, and all connected by aGigabit switched Ethernet). Fig. 6 demonstrateslinear scaling in throughput of the distributed hashtable as the number of brick nodes serving data isincreased; note that for this experiment, most datawere resident in a physical memory cache on bricknodes, rather than forcing a read from disk perrequest.
Fig. 5. High-level view of a DDS. A DDS is a self-managing data repository running on a cluster of workstations. All service instances
(S) in the cluster see the same consistent image of the DDS; as a result, any WAN client (C) can communicate with any service instance.
Fig. 6. Throughput scalability. This benchmark shows the linear scaling of throughput as a function of the number of bricks serving in
a distributed hash table; note that both axis have logarithmic scales. As we added more bricks to the DDS, we increased the number of
workers using the DDS until throughput saturated.
480 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

In Fig. 7, we show the read throughput of athree-node distributed hash table as a fault is de-liberately induced in one node, and as that failednode undergoes recovery. This ®gure shows thatthe read throughput of this hash table degrades to2/3rds of its initial throughput as one of the threenodes crashes, but quickly resumes to its fullthroughput as the crashed node completes its re-covery.
We have also experimented with scaling thecapacity of a distributed hash table by creatingand populating a single hash table with over 1 TBof data spread over 128 CPUs and 128 disks. This1 TB hash table took 1.5 h to populate, achieving awrite throughput of 256 MB/s (2 MB/s per disk).The disk write performance was seek limited, asrandom keys were inserted into the hash table forthis experiment.
Our DDS implementation makes use of theexposed queues and events (as described in Section3.1) to implement e�cient internal task scheduling.Exposing the queues to the DDS code makes it ispossible for each DDS brick to ``peek'' into itsqueue of incoming requests and schedule thembased on resource availability. For example, in-coming read requests for which data are present inthe bu�er cache can be scheduled before thoserequiring disk access. This technique leads tohigher throughput, as head-of-line blocking is re-duced. The use of event queues also makes itpossible to reorder disk accesses for greater local-ity and to perform prefetching, similar to optimi-zations used in ®lesystems and database storagemanagers.
4. Units
The space of units is extremely diverse withlarge variations in CPU, memory, and storagecapabilities, communication bandwidths and la-tencies, and user interfaces. In this section, webrie¯y circumscribe this space by describing arepresentative set of units. We then focus on aparticularly interesting new class of units, net-worked sensors that are the most constrained interms of capabilities and resources.
PCs and laptops are examples of extremely ca-pable units, in that they have liberal amounts ofCPU and memory resources, persistent storage,and sophisticated display capabilities. However,laptops still must be capable of dealing with mo-bility, disconnected operation, and low bandwidthor unreliable communication over wireless net-works.
PDAs represent a class of device with limitedcomputation, displays, user interfaces, and persis-tent storage. Cell phones are currently distinctfrom PDAs in that they have much more limitedcomputational abilities and they are essentiallycontinuously connected to the network. There is,however, a strong trend towards the convergenceof PDA and cell phone capabilities, yielding a classof units that has the minimal graphical user in-terface, storage, and programmability of a PDA,but with the continuous connectivity of a cellphone.
The most limited form of units that we considerare networked sensors and actuators. Thesedevices have extremely limited computational
Fig. 7. Availability and recovery. This benchmark shows the read throughput of a three-node hash table as a deliberate single-node
fault is induced, and afterwards as recovery is performed.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 481

resources, almost no storage capabilities and nohuman interface. In addition to limited commu-nication bandwidth, communication is extremelyexpensive for these devices, since power is theirmost critical resource and communication con-sume signi®cant power. As an example of net-worked sensors, we have developed a device, calleda mote that contains a microcontroller, a radio,and photo and light sensors. This device (which isslightly larger than a quarter) can be placed in theenvironment or carried by an individual, and re-ports information collected from its sensors toservices for analysis. We report further on ourexperiences with this device below.
4.1. Characteristics of networked sensors
The characteristics of networked sensors re-quire a design methodology focused on extremee�ciency, both in terms of computation andpower. As an example of networked sensor, wehave assembled a ``mote'' that includes an AT-MEL 8535 4 MHz microcontroller with 512 B ofSRAM and 8 KB of ¯ash memory, an RF radiowith 10 kbps throughput, a light and temperaturesensor, and three LEDs for visual feedback ofinformation (Fig. 8).
Somewhat surprisingly, the programmingmodel that we have designed for these tiny devicesis very similar to that of high-throughput servicesin vSpace, although we use this model for the sakeof power and computational e�ciency, rather thanthroughput and load conditioning. Power is themost precious resource on these devices, andcommunication is the most expensive operation in
terms of power consumption. Given this, theability to put hardware components into a standbystate can save signi®cant amounts of power. Tomaximize the opportunity for putting the device'sCPU into standby, we have developed an event-driven software architecture for our operatingsystems and applications. The presence of blockingoperations could limit the system's ability toswitch into a low-power mode, especially if hard-ware polling is used to complete a blocking oper-ation. In contrast, with an event-driven system, allprocessing occur in response to hardware events.This allows the processor to enter standby modebetween events, as no computation needs to bedone there until the next hardware event occurs.
We have also observed that our network sen-sors must be able to handle signi®cant amountsof concurrency. Sensors are typically I/O centric,and must be capable of supporting multiple, si-multaneous ¯ows of information. Flows can belocal to a sensor (e.g., the interaction between aCPU and the physical sensor devices or the radioused for communication), or they may spanacross multiple sensors in a sensor network. Forexample, networked sensors may cooperate topropagate each other's data towards a centralcollection point. In this case, the microcontrol-ler's interaction with its sensors must be over-lapped with its operation of the radio andexecution of networking protocols. To exacerbatethe situation, on many microcontrollers, the CPUmust directly interact with the radio (comparedwith PCs which typically have dedicated NICs toservice the communications device), introducingreal-time constraints.
To address these challenges, we have developedthe TinyOS operating environment for networkedsensors. TinyOS has a component-based architec-ture in which each hardware and software com-ponent exports an interface that contains the set ofcommands that it accepts as well the set of eventsthat it ®res (Fig. 9). Internally, a software com-ponent is given a statically allocated storage frame.While handling a command, a component can emittasks that TinyOS's scheduler must execute. Tasksare similar to vSpace workers, but they share thestate of the component that created them ratherthan sharing state through the passing of typed
Fig. 8. A TinyOS-based mote. This ``mote'' includes a 4 MHz
microcontroller, a software-driven radio, and an application
that coordinates with neighboring motes to discover an ad hoc
sensor network routing topology.
482 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

Java objects. Unlike general purpose threads, Ti-nyOS tasks execute to completion and are atomicwith respect to each other. TinyOS includes atwo-level scheduling mechanism that allows high-priority events to preempt low-priority tasks.Real-time constraints (e.g., servicing the radio) aremet by using high-priority events, while less criticaloperations (such as gathering data from a tem-perature sensor) are serviced with the remaininglow-priority CPU time.
The use of the TinyOS component model andscheduler greatly simpli®es the composition ofmultiple components on a sensor. To demonstratethis, we have built an application in which ourmotes self-assemble in an ad hoc network, andcommunicate their routing information to a stati-cally con®gured active proxy node. This routingdiscovery application, as well as the particularoperating system tuned for this hardware, arecomposed of several TinyOS components. Thecomponents are composed together using a CADtool (which represents commands and events withCAD symbols), and structural VHDL is exportedby the CAD tool. This VHDL is used at compiletime to assemble the system image that is down-loaded into the device's ¯ash memory. A particu-
larly interesting feature of these devices is theability to wirelessly reprogram them by sendingsystem images over the sensor network.
5. Active proxies
Active proxies in the Ninja architecture servethe purpose of performing ``impedance matching''between client devices and services by adaptingdata and access protocols to the devices' and ser-vices' needs. Because active proxies can execute inan environment local to devices, active proxies canperform context-aware optimizations and trans-formations on behalf of devices. We believe thatactive proxies bring three essential properties tothe Ninja architecture: dynamic service adapta-tion, secure access to information, and the fusionof multiple devices. We describe each of these inturn.
5.1. Dynamic service adaptation
In the Ninja architecture, active proxies assumethe responsibility for mitigating the heterogeneityof units by translating both network protocols anddata formats between clients and services. At thenetwork protocol level, active proxies can com-municate with clients through protocols speciallydesigned for low-computation, low-power, orpoorly connected devices. This is important sincecommon service communication protocols such asJava RMI, Ninja RPC, and Jini assume that cli-ents are well connected and computationallypowerful. Similarly, active proxies can be used tohelp establish connections between clients andservices by performing more complicated tasksassociated with cryptographic handshakes [16].
Additionally, active proxies can distill servicecontent into a format more suitable for smalldevices [17]. Content presentation can be tailoredfor small screen layouts, and image resolution andbit-depth reduced both for limited display andnetwork capabilities of these devices [15,17]. Forexample, a HTML representation of the contentcan be rendered as WML for a WAP [44]-enabledphone, a custom application format, or even asvoice. Active proxies may perform this ®ltering at
Fig. 9. A TinyOS software component. Each TinyOS software
component accepts and emits commands and events. Com-
mands ¯ow from higher level layers to lower levels, and events
¯ow from lower level layers to higher levels.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 483

the application level (e.g., by selectively droppingMPEG frames in a video stream), or at the pro-tocol level (e.g., by delaying or compressing datato increase actual or perceived throughput, basedon knowledge of the network conditions that thedevice is currently experiencing).
5.2. Secure service access from diverse clients
Current security models of infrastructure ser-vices assume that both the user's access device andthe software running on it can be trusted not tointercept or send private information elsewhere.Unfortunately, this is not the case for many accesspoints, including public kiosks. A subverted kioskis able to record all keystrokes (such as typedpasswords), monitor network tra�c to extractpersonal information such as account numbers ormailing addresses, or perform active attacks byhijacking connections, even if the network trans-mission is encrypted. To avoid such attacks,trusted active proxies can perform context-awaretransformations on data before it arrives at a kioskto reduce the content value. Proxies can also in-troduce alternative authentication mechanisms(such as one-time passwords) so that users will notneed to divulge passwords or other personal in-formation to untrusted infrastructure. In Section8.2, we describe in detail an example frameworkthat has this functionality.
PDAs are problematic because they are gen-erally power-constrained, computationally limit-ed devices with little memory and poornetworking capabilities. To perform the industry-standard SSL handshake phase on one suchdevice (a Palm Pilot) requires 5±10 s. Thislatency imposes an intolerable delay for con-nection setup, which is particularly undesirable ifnetwork connectivity is intermittent. An SSLimplementation that uses elliptic curve cryptog-raphy [8] is feasible on a Palm Pilot V, but fewInternet services support that option. Activeproxies can be used to adapt the securityrequirements of services to the capabilities of thedevice. Trusted active proxies can present unitswith power and computation e�cient securityprotocols, while communicating with end servicesthrough standard protocols.
5.3. Multiple device fusion
In addition to enabling basic access, activeproxies can be used to combine the capabilities ofseveral devices. This is useful for both content andsecurity adaptation. For example, the limited GUIof a PDA can be supplemented by the richer,larger display of a public kiosk, by placing most ofthe application on the kiosk while displaying andentering sensitive personal information on thePDA. Entering form data using a pen-based in-terface is tedious at best and even more cumber-some using number pads on devices such ascellular telephones. Active proxies can split thetrust between the PDA and the public terminal byfusing the devices together to provide one logicalchannel with secure access to the end service. Thisdevice fusion can only be done because the activeproxy is aware of the context in which the devicesare being used, and thus serves as another exampleof context-aware adaptation.
6. Service location across the wide area
The service discovery service (SDS) [10] servestwo important, and complementary roles: it pro-vides a mechanism by which services can announcetheir presence to the infrastructure, and it providesa mechanism by which both human users andprograms can locate these announced servicesacross the wide area. While designing the SDS, wefocused on providing a fully secure, semanticallyrich service location system that would successfullyscale to the wide area. The SDS is a scalable, fault-tolerant, and secure information repository, pro-viding clients with directory-style access to allavailable services. Services describe themselves tolocal SDS instances; these descriptions are pub-
lished and aggregated across a wide-area hierar-chy, and clients can query this hierarchy of SDSinstances in order to locate services.
In addition to serving as a location mechanism,the SDS also plays an important role in helpingclients determine the trustworthiness of services,and vice versa. This role is critical in an openenvironment, where there are many opportunitiesfor misuse, both from fraudulent services and
484 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

misbehaving clients. To address security concerns,the SDS controls the set of agents that has theability to discover services, allowing capability-based access control, i.e., to hide the existence ofservices rather than (or in addition to) disallowingaccess to a located service.
As a globally distributed, wide-area service, theSDS must surmount challenges that are not facedby services that operate solely inside a base. Theglobal SDS service must be robust against networkpartitions and component failures, it must addressthe potential bandwidth limitations between re-mote SDS entities, and it must arrange its indi-vidual SDS instance components into a hierarchyto distribute the query workload (implying queriesmust be routed across this hierarchy).
6.1. Design
The SDS system (see Fig. 10) is composed ofthree main components: clients, services, and SDSservers. Clients want to discover the services thatare running in the network. SDS servers solicitinformation from the services and then use it toful®ll client queries. To provide scalability in bothnumber of services and volume of client requests,SDS servers are organized into a hierarchicalstructure. Services and requests are associated withSDS servers according to each server's domain, thenetwork extent that it covers.
To propagate information across potentiallyheterogeneous service architectures, we use an
``announce/listen'' model of data propagation.Servers cache data contained in periodic multicastmessages. Component failures are toleratedthrough the course of normal operation, removingthe need for a separate recovery procedure: re-covery is enabled simply by listening to channelannouncements [2].
To provide both ¯exibility and simplicity in theservice query mechanism, the SDS uses XML toencode both service descriptions and queries.XML allows the encoding of arbitrary structuresof hierarchical named values, and supports vali-dating service descriptions against well-de®nedschemas (document type de®nitions). This mech-anism gives SDS servers functionality to validateselect service descriptions while allowing evolutionof existing service description schemas.
SDS servers are responsible for sending au-thenticated messages to the well-known globalSDS multicast channel, including announcingmulticast addresses to be used for service an-nouncements, the rate at which announcementsshould be repeated, and contact information forthe certi®cate authority and the capability man-ager. On each channel, a measurement-based pe-riodicity estimation algorithm determines theoptimal send rate for messages that produce thedesired trade-o� between update latency andbandwidth utilization. Each server can spawn achild server in order to hand o� a portion of itsload. Parents monitor child servers throughheartbeat packets, and will restart a crashed child
Fig. 10. Components of the Berkeley SDS. Dashed lines correspond to periodic multicast communication between components, while
solid lines correspond to one-time transport connections.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 485

server. Because servers keep a cache of an-nouncement service descriptions, a restarted serverrestores its data by listening to the channel.
To provide authentication, privacy, and accesscontrol, SDS servers work with a certi®cate au-thority (CA) and a capability manager (CM) usingsecure communication protocols. The CA is atrusted source which provides proof of the bindingbetween a principal and its public and encryptionkeys, in the form of a certi®cate. The CM managesindividual access control lists (ACLs) on behalf ofeach authenticated service. Communication be-tween SDS components utilize appropriate secu-rity measures while minimizing the performancepenalty. SDS server announcements need authen-tication, and are therefore signed, including anembedded timestamp. Service providers encrypttheir description broadcasts with a symmetric key,which accompanies the message as a data blockencrypted by the server's public key. This allowscaching of the symmetric key in the common case,and simple recovery of the symmetric key duringfailure recovery. Communication among serversand clients relies on a separate authenticatedtransport channel.
A client queries its SDS server over an au-thenticated channel to pass in an XML servicetemplate and its access rights in the form of ca-pabilities. The server uses an internal XML dat-abase (called XSet [51]), to ®nd services accessibleto the client which satisfy the query, and returnsthem to the client.
In order to make their services known, serviceproviders listen on the global multicast channel toroutinely determine their current responsible SDSserver. Providers periodically broadcast servicedescriptions to a multicast channel, using the ad-dress and broadcast rate de®ned by the serverannouncement messages. Providers are also re-sponsible for contacting a capability manager andde®ning access control information for its services.
6.2. Wide-area operation
The SDS wide-area hierarchy is designed toscale-up in both query volume and number ofavailable services, while adapting to changes in theunderlying entities. The primary goal is to allow
queries from all clients to reach services on all SDSservers. In our approach, servers dynamically ar-range themselves into a multi-level hierarchy,summary information is propagated up to parentservers, and queries are partitioned among andforwarded to the relevant servers.
The actual organization of the hierarchy can bedependent on many criteria, such as administrativedomains or network topology. We believe that themechanism should support the existence of multi-ple hierarchies, and actual usage should be basedon policy. Individual servers can choose to par-ticipate in more than one hierarchy by keepingmultiple routing tables, one for each hierarchy.
To prevent upper-level servers in the hierarchyfrom being overwhelmed by update or querytra�c, the SDS architecture ®lters informationwhile it propagates upward. In particular, the in-formation is summarized in a way that allowsqueries to determine which, if any, branch containspotential matches.
To accomplish this lossy aggregation, we usehash summarization, where information is sum-marized using a unique N-to-M mapping of datavalues. Complicating this procedure is the SDS'use of the subset query model, where matchingdocuments can be identi®ed by a partial list ofservice characteristics. Our solution is to hash alimited number of tag subsets, each subset con-taining a single tag or a cross-product of two tags.This limits computation required for summariza-tion. To address the issue of storage space forsummarizations, we use Bloom ®lters [5]. Bloom®lters collapse hashed summarizations into a ®xed-size table, accepting greater possibility of falsepositives in return for less storage requirements.
In summary, SDS servers dynamically organizethemselves into potentially multiple hierarchies fordata partitioning and query routing. Each serveruses multiple hash functions on various subsets oftags in service announcements, and uses the resultsto set bits in a bit vector. Servers which are internalnodes in the hierarchy combine bit vectors fromitself and its children servers, and associates theresult with this branch at its parent node. Afterreceiving a query, each server checks its own bitvector for a match, and failing that checks its chil-dren vectors to determine which branch to forward
486 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

the query to. A server resolves a query against thevector by multiply hashing it and checking if all thematching bits are set in the bit-vector. A missing bitguarantees a true miss, while a match could signaleither a false positive or a true hit.
The distribution of data across the wide areaexposes a trade-o� between consistency and per-formance. Strict consistency is di�cult to achievein the face of frequent updates, given the widearea's constraints on network bandwidth, trans-mission latency, and the greater possibility ofnetwork partitions. Therefore, the SDS systemprovides loose consistency guarantees about ser-vice location information across the wide area.
6.3. Performance
We have measured the performance of a singleSDS server on an Intel Pentium II 350 Mhz with128 MB RAM, running on Linux 2.0.36 using theBlackdown JDK 1.1.7 and the TYA JIT compiler.The results are presented in Table 1. This tableshows that the primary sources of latency are theauthenticated transport connections and capabilitychecking using the Cryptix Java security library.We expect both of these components will decreasesigni®cantly as a result of ongoing research. Fur-thermore, the XML query processing is shown toscale logarithmically with the size of the data set[51]. Finally, using these performance numbers, weestimate that a single SDS server (using o�-the-shelf components) can handle a user community ofabout 500 clients sending queries at a rate of ofone query per minute per client.
7. Paths: composition of services across the wide-
area
The primary goal of paths is to facilitate thecomposition of services. To be most useful, theinfrastructure should attempt to automate asmany parts of the path creation process as possi-ble. In our design, an automatic path creation(APC) facility automates the task of ®nding pathsbetween system components, creating the networkconnections between components, ®ne tuning theperformance of the data ¯ow, and handling errorconditions. Whenever possible, the APC facilityprotects users from the failure of individual pathcomponents or communication links. The idealsituation would be to provide the illusion that theuser is accessing a single robust service providingthe composed functionality. Because the APC fa-cility handles large numbers of concurrent users,we designed its path construction algorithms toscale well as the number of components increases,even though the number of possible paths maygrow exponentially as components are added.
A path comprises of a sequence of operators
that perform computations on data and connectors
that provide protocol translations between opera-tors. A connector is a channel through which op-erators can pass application data units (ADUs).The connector hides potential di�erences in net-work protocols from the operators, and allowsthem to communicate as long as the output datatype of the downstream operator matches the in-put data type of the upstream operator. Eachconnector is characterized by a speci®c transportprotocol.
Operators perform computation on data ¯ow-ing along the path. Operators are strongly typed:they have a clear de®nition of the input they acceptand the outputs they produce. Operators havevarious attributes such as supported communica-tion protocols, computational requirements, orrequired external data (e.g., a remote database). Inaddition, operators have associated cost metrics,which describe the run-time performance of theoperator and are used for optimization duringpath creation. The type and attributes for eachoperator are combined to form an XML descrip-tion of the operator. These descriptions are used to
Table 1
Secure query latency breakdown
Description Latency (ms)
Query encryption (client-side) 5.3
Query decryption (server-side) 5.2
Authenticated transport overhead 18.3
Query XML processing 9.8
Capability checking 18.0
Query result encryption (server-side) 5.6
Query result decryption (client-side) 5.4
Query unaccounted overhead 14.4
Total (secure XML query) 82.0
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 487

determine which combinations of operators couldmake a valid path.
The Ninja architecture provides two classes ofoperators: long-lived and dynamically created.Long-lived operators are standard Ninja services,and hence support both the data persistence andfault-tolerance properties previously discussed forservices. These are registered with and locatedthrough the service discovery service (SDS). Dy-namically created operators are light-weight,short-lived transformation elements created by theAPC facility as required. These operators, whichrun in active proxies, have only soft-state andhence can be simply restarted if the active proxyfails.
While the reliability of both long-lived and dy-namic operators helps to guarantee that a path canbe reconstructed when a failure occurs, this doesnot safeguard against the loss of data that wasalready in the path when the failure occurred.Hence, applications that use paths must providetheir own mechanisms for guaranteed or in-orderdata delivery if this is required.
7.1. An example of a path
As a motivating example, consider a map ser-vice that provides driving directions in response toa user-speci®ed address. This example illustratesthe composition of two operators with a service,and shows how active proxies that are selected bythe path creation process are used to performprotocol and data format translations betweenclients and services. To allow access to the overallaudio driving direction service from a cell phone,the APC facility might create a path as follows:1. The user initiates a call from a cellular phone.
The user speaks the address to which she wishesto get driving directions. An RTP-based audioconnector is used to send this audio to the ®rstoperator in the path.
2. A speech-to-text operator, running in an activeproxy, is used to convert the spoken audio intostructured text using a grammar speci®callychosen for this context (address input). Thestructured text emitted from this operator ispassed along a TCP-based reliable bytestreamconnector to a map service.
3. A map service, running in a base, receives theaddress, and returns structured text represent-ing driving directions to the speci®ed address.These directions are passed along a TCP-basedreliable bytestream connector to the next oper-ator in the path.
4. A text-to-speech translator, running in the sameactive proxy as the speech-to-text operator,transforms the textual driving directions intoaudio. An RTP-based audio connector is usedto send this audio to the user's cell phone.
5. The user hears the driving directions beingspoken to her over her phone.
7.2. Path construction
To create a Ninja path, a user provides the APCfacility a speci®cation of the endpoints of therequired path, a partially ordered list of operatorsthat must be included in the path, and an accept-able range of costs for the path in terms of latency,computation or memory requirements. This in-formation is used to construct an optimal path forthe user's speci®c requirements. The path con-struction process consists of four steps. As shownin Fig. 11, path construction is a process of con-tinuous feedback and optimization. The details ofeach step are described below.
Step 1: Logical path creation. A logical pathconsists of an ordered sequence of operators that
Fig. 11. Path construction process. Path execution is an iterative
process of optimization. The Ninja APC facility guarantees the
availability and fault-tolerance of a constructed path by re-
building its physical or logical path.
488 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

are joined with connectors. During logical pathcreation, the APC facility searches through theXML descriptions of the operators, to ®nd validsequences that could perform the computationrequested by the user. The result of logical pathcreation is a list of possible operator sequences.Note that since some operators may be commu-tative (image format transcoders, for example), thespace of all possible logical paths is large. Hence,only a small number of logical paths are consid-ered initially.
Step 2: Physical path creation. A physical pathis a mapping of a particular logical path ontophysical nodes which execute the operators. Nodesfor long-lived operators are chosen from theknown services that provide the desired function-ality, as located using the SDS. Nodes for short-lived operators are chosen according to thecomputational capabilities of the node, and thecost of using that node in the path. The APC fa-cility constructs a physical path from a logical pathby ®nding the lowest cost nodes that meet theuser's requirements.
Step 3: Path instantiation, and execution. Oncethe nodes of the path have been selected, the APCfacility starts any required dynamic operators, andsets up appropriate connectors between the vari-ous operators. Once all nodes in the path are setup, data ¯ow is started. In addition, a controlchannel (used for reporting of error conditions andperformance information) is established betweenthe operator nodes and the APC facility. Duringthe lifetime of the path, the APC facility activelymonitors the operator nodes to make sure thatthey are functional. Operator nodes report prob-lems to the APC facility about their neighboringnodes in the path, so that the path is repaired whennecessary. The APC facility monitors the perfor-mance of the path, and reroutes the data ¯ow ifnew conditions make the original path suboptimal.The control path is used for exception handling,controlling parameters of path components,monitoring and analyzing path performance; thus,it needs to be independent of data paths and behighly robust.
Step 4: Path tear-down. When a path is nolonger needed, the user informs the APC facilitythat it should be removed. The APC facility then
stops the data ¯ow, removes connectors, and shutsdown any dynamic operators. As a performanceoptimization, the APC facility may cache com-monly used logical and physical paths for reuse ata later time.
7.3. APC implementation and evaluation
We have developed an initial prototype of theAPC facility that supports both long-lived anddynamic operators. In addition, we have a specialclass of dynamic operators that can be used towrap existing services. This allows the APC systemto make use of older services that cannot com-municate directly with our connectors.
Each operator has a reference to an output andinput connector that speaks a speci®c transportprotocol. All connectors implement a commonJava interface. To interact with previous andsubsequent operators in the operator chain, eachoperator invokes read and write methods of thisinterface to receive its input data and send itsoutput data. TCP, UDP, and RTP connectors aresupported in the current prototype.
Our current implementation encompasses thefull range of path creation described previously.Logical paths are created by searching the XMLdescriptions of the available operators to ®nd thesmallest number of operators that can perform thedesired data ¯ow. A physical path is then selectedby placing operators on the least loaded nodes ofthe network.
Machine failures are automatically detected bythe APC service, and running operators are re-started on other nodes. Fault detection is achievedby either time-out of a heartbeat beacon or bycatching an I/O exception when reading or writingdata from or to the failed machine. Our prototypedoes not presently exploit the possibilities forperformance tuning through dynamic reconstruc-tion of paths.
8. Example services
Having completed the description of the Ninjaarchitecture, in this section of the paper we de-scribe a number of interesting applications that we
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 489

have built on top of it. These applications dem-onstrate the capability of the Ninja architecture tofacilitate the simple construction of robust, scal-able services that are accessible by a diversity ofdevices. This illustrates the opportunity that ourarchitecture provides for the widespread innova-tion of both services and devices.
8.1. The Ninja Jukebox
The Ninja Jukebox [18] was an early applica-tion built using our architecture, and it demon-strates some of our platform's key features. TheJukebox allows a community of users to build adistributed repository of digital music, and pro-vides a collaborative ®ltering mechanism based onusers' music preferences. Cluster nodes are har-nessed to rip MP3 ®les from their local CD-ROMdrives, and to act as servers for streaming MP3 toclients. One node acts as the music directory, andmaintains a soft-state index of the songs publishedby each cluster node; the Jukebox client applica-tion contacts the directory to obtain a list of songs,and streams MP3 directly from the appropriatenode using HTTP.
The Ninja Jukebox is based on MultiSpace [21],an early design prototype of the base serviceplatform. MultiSpace nodes, each running a JVM,communicate through the use of NinjaRMI, anextensible variant of Java remote method invoca-tion [38]. Each component in the Jukebox appli-cation exports a NinjaRMI interface which isinvoked either internally to the cluster or exter-nally by the Jukebox client application (which alsomakes use of NinjaRMI). NinjaRMI providessupport for strong authentication and encryption,which is used to control access to the Jukeboxservice. Each song in the Jukebox can have anassociated ACL authorizing a particular set ofusers to listen to it.
Constructing this application as a set ofstrongly typed, distributed components greatlysimpli®ed service construction and facilitatedevolution, as new components could be added tothe service as needed. An example of service evo-lution was our addition of the Jukebox query en-gine [45], which allows users to search for music inthe Jukebox based on musical similarity between
songs. The user provides a query song and a set ofparameters to use for the search, as well as thenumber of results to return; the query engine re-turns the songs in the Jukebox which sound themost similar to the query song. The search isbased on a k-nearest-neighbor search in a multi-dimensional space of features previously extractedfrom each song. The query engine runs on thesame MultiSpace platform as the Jukebox itself,and its user interface is integrated into the Juke-box client.
8.2. An active proxy framework for accessingservices through untrusted devices
A more general service that we have imple-mented is an active proxy framework that pro-vides secure multi-modal access to Internetservices from units [23]. Consider the case of us-ers accessing their stock trading accounts frompublic access terminals. Instead of relying on theterminal to protect their secure information, theusers can direct private or sensitive informationsuch as portfolio values or account numbers totheir personal PDA, while using the rich GUIcapabilities of the public terminal to initiate re-quests and display generic stock information(e.g., stock price ¯uctuations and historicalgraphs). Users initiate trading operations throughthe untrusted public terminals, but then con®rmthem using their trusted portable devices. Net-work connections to the users' PDAs are pro-vided either by the environment, such as withkiosks with infrared network connections, or bythe devices themselves, for example, by directlyinitiating a connection from a wireless data en-abled PDA.
The proxy is implemented as a collection ofvSpace workers that abstract the functionality ofsecurity adaptation, service adaptation, and devicefusion. By combining generic content and securitytransformation functions with service-speci®crules, the proxy architecture decouples device ca-pabilities from service requirements and simpli®esthe addition of new devices and services. The ser-vice uses XML as a standard data representation;one vSpace worker transforms requests fromthe untrusted access device into an XML
490 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

representation. Another worker provides accesscontrol ®ltering on these requests, possibly inject-ing secure information into the request: for ex-ample, this worker may convert a one-timepassword provided by the user through the un-trusted terminal into a password that must besupplied to the service being accessed.
A third worker transforms the request from itsgeneric XML representation into whatever proto-col is necessary to access the service. For example,if the service is web-based, this worker will convertthe XML into a HTML form to be submitted tothe service's web server. This worker receives thecontent returned from the service, and transformsit back into XML. A fourth worker performs asequence of ®ltering operations on the data inorder to remove any sensitive information thatshould not be revealed to the untrusted device. A®nal worker is used to transform this ®ltered XMLinto whatever protocol and data format is neededto render the content on the untrusted terminal.This ®nal XML transformation is driven usingdevice-speci®c XSL style sheets.
The framework currently allows access to boththe Datek Online [12] and YahooContest [48] stocktrading services, and we are currently adding accessto a HTML-based mail service. Adding support fora new service merely requires authoring a script toconvert the service's content into an XML repre-sentation. For example, the YahooContest serviceconsists of half a dozen scripts each of which areapproximately 250 lines or less. Rendering contentfor di�erent client formats requires authoring theappropriate XSL style sheets. Our example stock
services consist of half a dozen style sheets for eachdevice format, each ranging from 50 to 300 lines inlength. Fig. 12 shows the output of the Yahoo-Contest service rendered as WML for a WAPbrowser running on a trusted Palm Pilot. In thisexample, because the device is trusted, sensitiveinformation such as the number of owned shareshas not been removed by the proxy. In Fig. 13, weshow the output of the Datek trading service ren-dered as HTML on an untrusted Web browsingkiosk; note in particular that sensitive informationsuch as account numbers and the number of pur-chased shares have been removed.
8.3. NinjaMail
Electronic mail was one of the ``killer apps'' ofthe early Internet, and even today, the number of
Fig. 12. WML for PDA. WML holdings page customized for
PDA display.
Fig. 13. Security ®ltered HTML. Stock holdings ®ltered for display on a public kiosk.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 491

users with e-mail access is growing exponentially.At the same time, these users are expecting morecomplex functionality such as embedded multi-media and anytime/anywhere access. These twotrends have implications on the requirements ofmodern e-mail servers. Hotmail alone has over 61million active users [33], and if they o�ered just50 MB worth of storage to each user, theirservers would have to handle over 3 petabytes ofdata.
The goal of the NinjaMail [42] project is tobuild a scalable and feature-rich e-mail service ontop of Ninja. NinjaMail was built to act as ageneral e-mail infrastructure which other applica-tions and services could use to provide more spe-ci®c functionality, as depicted in Fig. 14. Thisloose coupling of the separate components allowsfor more ¯exibility and extensibility than tradi-tional e-mail servers.
At NinjaMail's core, the MailStore modulehandles storage operations such as saving andretrieving messages, pushing out noti®cation ofe-mail events, updating message metadata, andperforming simple per-user message metadatasearches. A message's metadata represents itsmutable attributes which are used to record its¯ags and current folder. Access modules supportspeci®c communication methods between usersand NinjaMail, including an SMTP module forpushing messages into the MailStore and POP andHTML modules for user message access.
Each of the above modules is a separate workerrunning in the cluster, with scalability beingachieved by running multiple clones of the worker.We found that decomposing the NinjaMail system
into a set of workers to be a natural programmingmodel and the typed task dispatching allowed thecomponents to be easily composed. We also cre-ated an event mechanism that allowed extensionmodules to register with the MailStore service toreceive noti®cations when particular events occursuch as e-mail receipt. This allowed for very di-verse services to be built, such as an instant mes-saging noti®er of new e-mail.
8.4. Sanctio
Recently, there has been an ongoing contro-versy over access rights to proprietary instantmessaging networks, such as AOL's AIM network[1]. Many companies have tried to compose theirown services with these existing networks, how-ever, the owners of the proprietary networks haveattempted to prevent such composition, as itdiminishes their perceived market penetration.
We have built a service called Sanctio, which isan instant messaging gateway that provides pro-tocol translation between popular instant mes-saging protocols (such as Mirabilis' ICQ andAOL's AIM), conventional e-mail, and voicemessaging over cellular telephones. Sanctio obvi-ates this controversy by bridging together thesepreviously proprietary networks into an instantmessaging internetwork. Sanctio runs on a vSpacebase, and acts as a middleman between all of thesemessaging protocols, routing and translatingmessages between the networks (Fig. 15). In ad-dition to protocol translation, Sanctio also cantransform the content of messages. We have built a``Web scraper'' that allows us to compose Alta-Vista's BabelFish natural language translationservice with Sanctio, and thus the service canperform language translation (such as English toFrench) as well as protocol translation. A Spanishspeaking ICQ user can send a message to an En-glish speaking AIM user, with Sanctio providingboth language and protocol translations.
Users can take advantage of unmodi®ed com-mercial client application software in order to useSanctio, or they can use software that we haveconstructed for mobile devices such as Palm Pilots.This software interacts with the Sanctio servicethrough an active proxy. The proxy presents a very
Fig. 14. The NinjaMail architecture.
492 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

simple text-based messaging protocol to the PalmPilot, but interacts with Sanctio using the moresophisticated AIM or ICQ procotols.
Because a user of the service may be reached ona number of di�erent addresses (potentially onefor each of the networks that Sanctio can com-municate with), Sanctio must keep a large table ofbindings between users and their current transportaddresses on these networks. We used a distrib-uted hash table DDS for this purpose.
9. Related work
A number of projects share aspects of the Ninjavision of seamlessly interconnecting devices andInternet services. Related work can generally becharacterized as addressing speci®c aspects of thisproblem space (such as supporting scalable ser-vices or embedding intelligence in the network),rather than taking Ninja's vertical approach tobuilding a general-purpose Internet services plat-form. As the number of related projects in thisdomain is extremely large ± spanning operatingsystems, programming languages, networks, em-bedded systems, and distributed computing plat-forms ± we limit our discussion here to thoseprojects which have taken a particularly comple-mentary approach to the Ninja system design.
Flexible middleware systems, which supportdistributed computing across heterogeneous re-sources, are directly related to Ninja's goal oftying together Internet services with diverse small
devices. CORBA [40] and DCOM [14] provideplatform-independent, object-based networkcommunication, although both systems are de-signed for tightly coupled distributed applicationsand do not directly support composition andaggregation of components. Jini [39,43] takes aJava-centric view, exploiting bytecode mobility todeliver stub code which implements a privatecommunication protocol between client and ser-vice, stubs export a programming model based onremote method invocation (RMI) [38]. AlthoughJini's literature describes a holistic distributedcomputing model not unlike that of Ninja, thesystem has been developed mainly for use withina workgroup, and does not provide security orscalability for the wide area. eSpeak [22] isanother Java-based middleware system which in-tends to scale to the wide area, and to integratePKI into its nonstandard messaging layer. Nei-ther system addresses service scalability and fault-tolerance, or access from impoverished deviceswhich cannot run a Java-based communicationprotocol.
The goals of the Ninja Base environment arere¯ected by various application servers, includingIBM WebSphere [24] and BEA Weblogic [4].These systems strive to simplify the construction ofscalable, fault-tolerant Internet services, generallyrequiring that applications be constructed as a setof Java components using an interface such asEnterprise Java Beans (EJB) [37]. EJB componentsare expected to be stateless or to manage their ownstate persistence. EJB components usually interact
Fig. 15. Sanctio messaging proxy. The Sanctio messaging proxy service is composed of language translation and instant message
protocol translation workers in a base. Sanctio allows unmodi®ed instant messaging clients that speak di�erent protocols to com-
municate with each other; Sanctio can also perform natural language translation on the text of the messages.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 493

with a database to achieve the latter. vSpace di�ersfrom these application servers mainly by mandat-ing an event-driven programming style (whichfacilitates high concurrency) and through the useof the DDS layer for persistence. The Ninja Baseenvironment was inspired by earlier work onTACC [15] and SNS [9], both cluster-based In-ternet service platforms.
Harnessing intelligence in the network totransform and aggregate data across services hasbeen investigated by several projects. Active net-works [47] allow code to be injected into networkrouters to deploy new network protocols, imple-ment tra�c shaping, and perform packet ®ltering.An important distinction between these projectsand Ninja's active proxies is the level at which dataprocessing occurs; active networks operate at thetransport or packet level, while active proxies op-erate using higher level application semantics. Assuch, active proxies are not solely intended toimplement protocols or perform packet-level op-erations; rather, they are used to perform servicecomposition and aggregation, as well as soft-statetransformations (such as HTML ®ltering, asdemonstrated by the security proxy). While muchof the work on mobile agents [28] has focused onsupporting distributed arti®cial intelligence, activeproxies share many of the same systems-levelconcerns, such as code mobility, naming, security,and coordination.
Many projects have used transcoding to adaptservice content to better suit small devices[6,15,29,34±36,49,50]. Additionally, a number ofprojects have attempted to develop universal in-terfaces for large classes of devices, including therecent WAP protocol stack [44]. Instead of as-suming that a single standard will be adopted byall devices, the Ninja architecture allows multiplestandards to be bridged by using active proxies astransformational intermediaries.
There are several additional technologies thatwe would like to explore as interesting examples ofunits. For example, Java Rings [11] and smartcards allow minimal computation, communica-tion, and storage, but have no user interfaces.DIMM PC devices (matchbox-sized PCs on asingle chip) could be used as mobile, computa-tionally powerful devices that lack a user interface.
Additionally, we believe that universal Plug andPlay and Jini-based devices could be easily inte-grated into the Ninja architecture.
10. Discussion and future directions
If Ninja succeeds in enabling connectivity be-tween Internet services and arbitrarily small de-vices, a range of new research directions arise. TheNinja goal of moving intelligence into the networkinfrastructure, and opening up the infrastructureto allow anyone to push new components into it,raises questions about management, security, andservice composition.
The ®rst important concern is how to manageresources in a highly dynamic, decentralized net-work of active proxies. Operators should not beallowed to consume arbitrary amounts of networkbandwidth, CPU, or memory; however, such re-strictions cannot be made only on a per-site basis,as a given operator may consume many aggregateresources across many active proxies. Otherwise,malicious operators could be used to launch dis-tributed denial of service attacks against particularbases as well as the network itself. In the samevein, the infrastructure should prevent abuses ofits content delivery mechanisms for unsolicitedadvertising or ``spam'' ± already there are reportsof people receiving unwanted advertisements viatext paging to cellphones. If Ninja makes thisproblem worse, rather than better, the technologywill not be adopted in the wide scale, or the in-frastructure will remain closed.
New business models emerge in the world ofubiquitous network-based services. Today's modelof funding Websites through advertising revenue isinappropriate when services capture bits ratherthan eyeballs. Subscription and micropayment-based models are possible alternatives. In eithercase, retaining user privacy is an importantconcern as data and payments ¯ow across the in-frastructure. We envision a new ``service market-place'' where both individual operators as well asentire vertically integrated services are madeavailable on a per-use or subscription basis. An-other interesting model is that of a computationaleconomy [31], where active proxies, services, and
494 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

user agents participate in an automated market-place where the commodities are CPU cycles,memory, and bandwidth. Service authors earnrevenue by making their service available to oth-ers, and active proxies earn revenue by hostingservices on behalf of users. Apart from the busi-ness implications, computational economies canbe used to implement resource management, loadbalancing, and quality-of-service contracts.
Accessing powerful Internet services from smalldevices raises new challenges for user interfacedesign. Ideally, service-to-device integration willbe seamless. When failures do occur, however, theuser may need some way to inspect or control thepath of network components producing the fault.Exerting control over a network of active proxiesfrom a device as limited as a text pager is di�cultat best. Currently, networked devices are bound toa particular service; for example, a cellphone isused primarily for making phone calls. If the Ninjavision is realized, devices will become more ver-satile and the choices for using them more varied.Users will need some way to select between ser-vices and perhaps control a user pro®le used bythose services.
Perhaps the largest challenge to face is that ofautomatically composing service components tomeet the needs of particular devices. Expressingthe transformation, caching, or aggregationproperties of a Ninja operator in a type system issimple and potentially allows operators to beautomatically chained into a path. However, thetypes must be expressive enough to capture therelevant semantics of an operator. For example,an English-to-French translation operator maytake type English text as input, and French
text as output; however, this alone does notimply translation between the two, as the opera-tor might always output Je ne sais pas traduirecette texte. Apart from strict type-matching, op-erator selection also depends upon considerationof an operator's quality, performance, and cost.Automatic path creation becomes a problem ofbalancing user requirements with other systemdemands, such as resource availability. Perform-ing this operation e�ciently and in a decentral-ized manner suggests several avenues for futureresearch.
11. Conclusions
The Ninja architecture represents an important®rst step towards opening up the intrastructure ofscalable, robust, adaptive Internet services. Byopening the infrastructure, Ninja hopes to reclaimthe distributed innovation that was responsible forthe unprecedented success and widespread adop-tion of the Internet in the form of the world-wideweb. Unlike the today's web, the service landscapeenvisioned by Ninja is one of active services andextremely diverse, mobile devices.
In this paper, we described the essential ele-ments of this open architecture: robust serviceenvironments on clusters of workstations (bases),diverse devices (units), adaptive intermediaries toisolate services from units (active proxies), and anabstraction for the composition of these three el-ements (paths). In addition to describing our de-sign and implementation of these components, wepresented four innovative services that exploit thecapabilities o�ered by this open infrastructure.
Acknowledgements
This work is supported, in part, by the DefenseAdvanced Research Project Agency (grant DABT63-98-C-0038) and the National Science Founda-tion (grant RI EIA-9802069). Support is providedas well by Intel Corporation, Ericsson, Philips,Sun Microsystems, IBM, Nortel Networks, andCompaq.
References
[1] America Online, The AOL Instant Messaging (AIM)
Network. http://aim.aol.com/.
[2] E. Amir, S. McCanne, R. Katz, An active service frame-
work and its application to real-time multimedia transcod-
ing, in: Proceedings of ACM SIGCOMM '98, October
1998, pp. 178±189.
[3] T.E. Anderson, D.E. Culler, D. Patterson, A case for
NOW (networks of workstations), IEEE Micro. 12 (1)
(1995) 54±64.
[4] BEA Systems, BEA WebLogic Application Servers. http://
www.bea.com/products/weblogic/.
[5] B. Bloom, Space/time tradeo�s in hash coding with
allowable errors, Commun. ACM 13 (7) (1970) 422±426.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 495

[6] C. Brooks, M.S. Mazer, S. Meeks, J. Miller, Application-
speci®c proxy servers as HTTP stream transducers, in:
Proceedings of the Fourth International World Wide Web
Conference, December 1995.
[7] P. Buonadonna, A. Geweke, D. Culler, An implementation
and analysis of the virtual interface architecture, in:
Proceedings of SC'98, November 1998.
[8] Certicom, Elliptic Curve Cryptography for Palm VII.
http://www.certicom.com/press/98/dec0298.htm, December
1998.
[9] Y. Chawathe, E.A. Brewer, System support for scalable
and fault tolerant Internet services, in: Proceedings of the
IFIP International Conference on Distributed Systems
Platforms and Open Distributed Processing (Middleware
'98), Lake District, UK, September 1998.
[10] S. Czerwinski, B.Y. Zhao, T. Hodes, A. Joseph, R. Katz,
An architecture for a secure service discovery service, in:
Proceedings of MobiCom '99, ACM, Seattle, WA, August
1999.
[11] Dallas Semiconductor Designs, The Java Ring. http://
www.ibutton.com/store/jringfacts.html.
[12] Datek Corporation. Datek Online Trading Service. http://
www.datek.com, January 2000.
[13] UC Berkeley CS Division, The Millennium Project (home
page), 1999. http://millennium.berkeley.edu.
[14] G. Eddon, H. Eddon, Inside Distributed COM, Microsoft
Press, Redmond, WA, 1998.
[15] A. Fox, S.D. Gribble, Y. Chawathe, E.A. Brewer, P.
Gauthier, Cluster-based scalable network services, in:
Proceedings of the 16th ACM Symposium on Operating
Systems Principles, St.-Malo, France, October 1997.
[16] A. Fox, S.D. Gribble, Security on the move: indirect
authentication using Kerberos, in: Proceedings of the
Second International Conference on Wireless Networking
and Mobile Computing (MobiCom '96), Rye, NY, No-
vember 1996.
[17] A. Fox, S.D. Gribble, E.A. Brewer, E. Amir, Adapting to
network and client variability via on-demand dynamic
distillation, in: Procedings of the Seventh International
Conference on Architectural Support for Programming
Languages and Operating Systems (ASPLOS-VII), Cam-
bridge, MA, October 1996.
[18] I. Goldberg, S.D. Gribble, D. Wagner, E.A. Brewer, The
Ninja Jukebox, in: Proceedings of the Second USENIX
Symposium on Internet Technologies and Systems, Boul-
der, CO, USA, October 1999.
[19] J. Gosling, B. Joy, G. Steele, The Java Language Speci-
®cation, Addison-Wesley, Reading, MA, 1996.
[20] S.D. Gribble, E.A. Brewer, J.M. Hellerstein, D. Culler,
Scalable, distributed data structures for Internet service
construction, in: Proceedings of the Fourth USENIX
Symposium on Operating System Design and Implemen-
tation (OSDI 2000), San Diego, CA, USA, October 2000.
[21] S.D. Gribble, M. Welsh, E.A. Brewer, D. Culler, The
MultiSpace: an evolutionary platform for infrastructural
services, in: Proceedings of the 1999 Usenix Annual
Technical Conference, Monterey, CA, USA, June 1999.
[22] Hewlett Packard, eSpeak: The Universal Language of E-
Services. http://www.e-speak.net/.
[23] J. Hill, S. Ross, D. Culler, A. Joseph, A security architec-
ture for the post-PC world. Available at http://
www.cs.berkeley.edu/�jhill/papers/SecPaper.ps.
[24] IBM Corporation, IBM WebSphere Application Server.
http://www-4.ibm.com/software/webservers/.
[25] InfoWorld, Boeing to Put Net in the Air. http://www.in-
foworld.com/articles/hn/xml/00/04/27/000427enboeing.xml,
April 2000.
[26] InfoWorld, E-cars take to the streets; wireless connections
link road warriors to the Net. http://www.infoworld.com/
articles/hn/xml/00/03/13/000313hnauto.xml, March 2000.
[27] Kazuaki Ishizaki, Motohiro Kawahito, Toshiaki Yasue,
Mikio Takeuchi, Takeshi Ogasawara, Toshio Suganuma,
Tamiya Onodera, Hideaki Komatsu, and Toshio Naka-
tani, Design, implementation, and evaluation of optimiza-
tions in a just-in-time compiler, in: Proceedings of the
ACM 1999 Java Grande Conference, June 1999.
[28] N. Jennings, K. Sycara, M. Wooldridge, A roadmap of
agent research and development, Autonomous Agents and
Multi-Agent Systems 1 (1) (1998) 7±38.
[29] M. Liljeberg et al., Enhanced services for World Wide Web
in mobile WAN environment, Technical Report C-1996-
28, University of Helsinki CS Department, April 1996.
[30] S. Matsuoka, H. Ogawa, K. Shimura, Y. Kimura, K.
Hotta, H. Takagi, OpenJIT: a re¯ective Java JIT compiler,
in: Proceedings of OOPSLA '98, Workshop on Re¯ective
Programming in C++ and Java, 1998. http://openjit.is.ti-
tech.ac.jp/.
[31] M.S. Miller, K. Eric Drexler, Markets and computation:
agorics open systems, in: B. Huberman (Ed.), The Ecology
of Computation, Elsevier, Amsterdam, 1998.
[32] Myricom Corporation, Myrinet: a gigabit per second local
area network, IEEE Micro, February 1995.
[33] PC World Communications, April 2000. http://
www.pcworld.com/pcwtoday/article/
0,1510,16045+1+0,00.html.
[34] Y. Sato, Dele Gate Server, March 1994. http://wall.etl.-
go.jp/delegate/.
[35] M.A. Schickler, M.S. Mazer, C. Brooks, Pan-browser
support for annotations and other meta-information on the
World Wide Web, in: Proceedings of the Fifth Interna-
tional World Wide Web Conference (WWW-5), May 1996.
[36] B. Schilit, T. Bickmore, Digestor: device-independent
access to the World Wide Web, in: Proceedings of the
Sixth International World Wide Web Conference (WWW-
6), Santa Clara, CA, April 1997.
[37] Sun Microsystems, Enterprise Java Beans Technology.
http://java.sun.com/products/ejb/.
[38] Sun Microsystems, Java Remote Method Invocation ±
Distributed Computing for Java. http://java.sun.com/.
[39] Sun Microsystems, Jini Connection Technology. http://
www.sun.com/jini/.
[40] The Object Management Group (OMG), The Common
Object Request Broker Architecture. http://www.cor-
ba.org.
496 S.D. Gribble et al. / Computer Networks 35 (2001) 473±497

[41] Virtual Interface Architecture Organization, Virtual Inter-
face Architecture Speci®cation version 1.0, December 1997.
http://www.viarch.org.
[42] J.R. von Behren, S. Czerwinski, A.D. Joseph, E.A. Brewer,
J. Kubiatowicz, NinjaMail: the design of a high-perfor-
mance clustered, distributed e-mail system, in: Proceedings
of the First International Workshop on Scalable Web
Services, Toronto, Canada, August 2000.
[43] J. Waldo, Jini Architecture Overview. Available at http://
java.sun.com/products/jini/whitepapers.
[44] WAP Forum, Wireless Application Protocol (WAP) Fo-
rum. http://www.wapforum.org.
[45] M. Welsh, N. Borisov, J. Hill, R. von Behren, A. Woo,
Querying large collections of music for similarity. Techni-
cal Report UCB/CSD-00-1096, U.C. Berkeley Computer
Science Division, November 1999.
[46] M. Welsh, D. Culler, Jaguar: enabling e�cient communi-
cation and I/O in Java, Concurrency: Practice and Expe-
rience, 2000, Java for High-Performance Network
Computing (special issue). http://www.cs.berkeley.edu/
�mdw/papers/jaguar-journal.ps.gz.
[47] D.J. Wetherall, J. Guttag, D.L. Tennenhouse, ANTS: a
toolkit for building and dynamically deploying network
protocols, in: Proceedings of IEEE OPENARCH'98, San
Francisco, CA, April 1998.
[48] Yahoo Finance, Yahoo Finance Investment Challenge,
2000. http://contest.®nance.yahoo.com/t1?u/.
[49] Ka-Ping Yee, Shoduoka Mediator Service, 1995. http://
www.shoduoka.com.
[50] Bruce Zenel, Dan Duchamp, A general purpose proxy
®ltering mechanism applied to the mobile environment, in:
Proceedings of the Third Annual ACM/IEEE Conference
on Mobile Computing and Networking (Mobicom '97),
ACM, New York, USA, 1997.
[51] B.Y. Zhao, A.D. Joseph, XSet: a lightweight database for
Internet applications, May 2000. http://www.cs.berke-
ley.edu/�ravenben/publications/saint.pdf.
S.D. Gribble et al. / Computer Networks 35 (2001) 473±497 497
Copyright © 2022 FDOKUMEN




















