
The journal of the Symmetrion SYMMETRIES IN GENETIC INFORMATION AND ALGEBRAIC BIOLOGY CONTENTS
23
Transcript of The journal of the Symmetrion SYMMETRIES IN GENETIC INFORMATION AND ALGEBRAIC BIOLOGY CONTENTS


Symmetry: Founding editors: G. Darvas and D. Nagy The journal of the Symmetrion
Editor: György Darvas
Volume 23, Numbers 3-4,225-448, 2012
SYMMETRIES IN GENETIC INFORMATION AND ALGEBRAIC BIOLOGY
CONTENTS
ANNOUNCEMENT Symmetry Festival 2013, 2-7 August, Delft, The Netherlands 228
EDITORIAL, Sergey Petoukhov 229
SYMMETRY IN SCIENCE AND ART Genome symmetries, Paul Dan Cristea 233 Symmetry of mitochondrial DNA. The case of COXn genes in primates
and carnivores, Teodora Popovici and Paul Dan Cristea 255 Symmetries of the genetic code, hypercomplex numbers and
genetic matrices with internal complementarities, Sergey V. Petoukhov 275 Fractal genetic nets and symmetry principles in long nucleotide
sequences, S.V. Petoukhov, V.I. Svirin 303 A Markov information source for the syntactic characterization of amino
acid substitutions in protein evolution, Miguel A. Jiménez-Montaño 323 Symmetries in molecular-genetic systems and musical harmony,
G. Darvas, A.A. Koblyakov, S.V.Petoukhov, I.V.Stepanian 343 Modeling “cognition” with nonlinear dynamic systems, Yuri V. Andreyev,
Alexander S. Dmitriev 377 The irregular (integer) tetrahedron as a warehouse of biological
information, Tidjani Négadi 403 Theory of topological coding of proteins and nature of antisymmetry
of the amino acids canonical set, Vladimir A. Karasev 427

SYMMETRY: CULTURE AND SCIENCE is the journal of and is published by the Symmetrion, http://symmetry.hu/. Edition is backed by the Executive Board and the Advisory Board (http://symmetry.hu/isa_leadership.html) of the International Symmetry Association. The views expressed are those of individual authors, and not necessarily shared by the boards and the editor.
Editor: György Darvas
Any correspondence should be addressed to the
Symmetrion Mailing address: Symmetrion c/o G. Darvas, 29 Eötvös St., Budapest, H-1067 Hungary Phone: 36-1-302-6965 E-mail: [email protected] http://symmetry.hu/
Annual subscription:
Normal € 120.00, Members of ISA € 90.00, Student Members of ISA € 60.00, Benefactors € 900.00, Institutional Members please contact the Symmetrion.
Make checks payable to the Symmetrion and mail to the above address, or transfer to the following account: Symmetrology Foundation, IBAN: HU24 1040 5004 5048 5557 4953 1021,
SWIFT: OKHBHUHB, K&H Bank, 20 Arany J. St., Budapest, H-1051.
© Symmetrion. No part of this publication may be reproduced without written permission from the publisher.
ISSN 0865-4824 – print version
ISSN 2226-1877 – electronic version
Cover layout: Günter Schmitz; Image on the front cover: Matjuska Teja Krasek: Star(s) for Donald, 2000, (tribute to H.S.M. Coxeter);
Images on the back cover: Matjuska Teja Krasek: Twinstar and Octapent; Ambigram on the back cover: Douglas R. Hofstadter.

Symmetry: Culture and Science Vol. 23, Nos. 3-4, 323-342, 2012
A MARKOV INFORMATION SOURCE FOR THE SYNTACTIC CHARACTERIZATION OF AMINO ACID
SUBSTITUTIONS IN PROTEIN EVOLUTION
Miguel A. Jiménez-Montaño
BioPhysicist, (b. México, D.F., MEXICO, 1941).
Address: Faculty of Physics and Artificial Intelligence, University of Veracruz, Sebastián Camacho # 5, Col. Centro, C.P. 91000, Xalapa, Ver., México. E-mail: [email protected].
Fields of interest: The structure of the genetic code, technological evolution and informational measures and algorithmic complexity of sequences of symbols and nerve signals.
Awards: Research Award, 1989; Dean Award, 2004; both from Universidad Veracruzana. Fulbright Fellow, 1982. First Prize National Contest on Scientific Non-technical Essay, 1990.
Publications: Ebeling W., Jiménez-Montaño M. A. (1980)*. On Grammars, Complexity, and Information Measures of Biological Macromolecules. Mathematical Biosciences Vol. 52:53-71. Jiménez-Montaño M. A. (1984). On the Syntactic Structure of Protein Sequences, and Concept of Grammar Complexity. Bulletin of Mathematical Biology, Vol.46:641-660. Jiménez-Montaño M.A., de la Mora-Basáñez R., Pöschel T. (1996)*. The Hypercube Structure of the Genetic Code Explains Conservative and Non-Conservartive Aminoacid Substitutions in Vivo and in Vitro. BioSystems Vol. 39: 117-125. Jiménez-Montaño M.A (1999)* Protein Evolution Drives the Evolution of the Genetic Code and Vice Versa. BioSystems Vol. 54: 47-64. Weiss O., Jiménez-Montaño M.A, Herzel H. (2000) Information content of protein sequences. J. Theor. Biol., Vol 206: 379-386. . Jiménez-Montaño M. A. (2004). Applications of Hyper Genetic Code to Bioinformatics. Journal of Biological Systems. Vol. 12: 5-20. .Jiménez-Montaño M. A. (2009)*. The fourfold way of the genetic code. BioSystems, Vol. 98 (2), 105-114.
Abstract: We introduce a theoretical model, which consists of a Markov Information
Source that generates codon sequences, and from them amino acid sequences, that
maintain the same or very similar functions and structures, as a direct consequence of
the structure of the genetic code, and general physical chemical constraints. With the
help of the model, we propose a codon dendrogram to describe a hierarchy of codon
categorizations, which explain the pattern of frequent amino acid substitutions in short-
term evolution.
Keywords: Markov source, genetic code, codon, amino acid, protein evolution.

M. A. JIMÉNEZ-MONTAÑO 324
1. INTRODUCTION
Understanding protein evolution remains today a major challenge in molecular biology
as it was a decade ago (Dokholyan and Shakhnovich, 2001 and references therein),
despite the huge amount of data gathered from genes, protein sequences and structures
presently available. Our knowledge of the relation between the genotype (DNA coding
for a protein) and the phenotype (a protein’s structure and its pattern of specific traits
related to its biological function), which is central to the Theory of Evolution and all
biology, is still at a very primitive stage (Thorne and Goldman, 2001; Wagner, 2012).
While the mechanisms of mutations in DNA sequences that code for proteins are known
(Parkhomchuk et al., 2009 ; Skipper,et al., 2012) the contribution of the genetic code in
creating new information, against the part played by natural selection in its fixation in
the population, is not completely appreciated. According to Abel and Trevors, (2006),
“Genetic prescription of computation precedes and produces phenotypic realization.
And this prescription is “written in stone”. Only recently, it has been recognized in the
literature the full complexity of the genotype/phenotype map (Crutchfield and Schuster,
2003).
According to DePristo et al., (2005), “Taken as whole, recent findings from
biochemistry and evolutionary biology indicate that our understanding of protein
evolution is incomplete, if not fundamentally flawed”. They suggest joining the fields of
protein biophysics and molecular evolution by highlighting the shared questions. In the
same line of thought, Pàl et al., (2006) argue that an integrated view of this field should
embrace genomic, structural and population levels of description. In Fig.1 these
different levels are graphically displayed. However, the problem to achieve this aim is,
on the one hand, that these levels belong to fields of knowledge with radically different
conceptual frameworks; and, on the other, the degenerate relationship between physics
and biology. It is well known that many proteins with no apparent sequence similarity
display the same folds (Kleiger et al., 2000). Thus, the many-to-one map M (Ai / S),
depicted in Fig.1, gives the amino acid at position i of any of the sequences
corresponding to the given structure (fold) S. In the concise statement by Hietpas et al.,
(2011): “Biology is governed by physical interactions, but biological requirements can
have multiple physical solutions”.

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 325
Figure 1: The conceptual scheme for protein evolution. The connection between the domain of population genetics (where Darwinian selection operates and true evolution ocurrs) and the genome of an organism (where mutations, an essential ‘raw material’ of evolution, occur), is mediated by the physics and chemistry of proteins. The crucial point to appreciate the complexity implicit in this diagram comes from the degenerate relationship between physics and biology: Given a population, e.g. of virus quasi-species with frequencies {fi, i = 1, 2, …,n}and with corresponding phenotypes {ψi, i = 1, 2, …,n}, M (S/ ψi ) specifies the common structure (S) of a protein family (the set π of orthologous proteins, associated phenotype ψi ). Then, M (Ai/S) is the amino acid at position i of any of the sequences corresponding to the structure S. In the same way, M(Ci/Ai) gives one of the codons codifying the amino acid, according to the genetic code. Let Cm be the chosen codon, then M (C’m / Cm) represents the single-nucleotide mutation from codon Cm to codon C’m , obeying the structure of the genetic code. In turn, M (A’j / C’m) gives the mutated amino acid A’j , coded by C’m, and M (S’/A’j) maps A’j to the corresponding new structure S’ . This modified protein structure is mapped to a new phenotype ψ+ though M (ψ+ / S’), which through Darwinian selection starts the evolutionary cycle again. Notice that M (S’/A’j) maps A’j to the corresponding new structure S’, and M (ψ+ / S’), maps the new protein structure (fold) to the new phenotype ψ+. Certainly, there is no direct feedback from the old to the new structure. Proteins are concrete molecules that do not evolve.
The main purpose of the present work is to provide a theoretical model, built upon an
empirical codon substitution matrix (Schneider et al., 2005), which explains the pattern
of amino acid substitutions in proteins that maintain the same or very similar functions
and structures, as a direct consequence of the structure of the genetic code (Jiménez-
Montaño, 1994), which controls the possible amino acid changes from single
Environment
NaturalSelectionNeutralEvolution
VirusQuasi‐Speciesf1, f2…fn;ψ1, ψ2… ψn
(Concentrationspace)
DNAsequence space(Genotypes)
Translation apparatus
GeneticCode Space(Hypercube)MUTATIONS
X
M (f’/S’)
f
M(S/ψi)
M (S’/Aj’)
Cm
M(Cm’/Cm)
Population genetics(PHENOTYPE)
(Codonusage)
Molecular biology &Bioinformatics(GENOTYPE)
Protein structure(formSpace)
Protein sequence space(Coding of structure)
Aj’
M(Ai/S)M(Cj /Ai)
M(Ai’/C’m)
Biophysics&
Biochemistry(Thermodynamics)
S = 3‐d structure of the proteinAi = aa at site i of protein sequence Ci = codon at site i of protein fi= frequency of species iψi= phenotype of species i

M. A. JIMÉNEZ-MONTAÑO 326
nucleotide mutations, and general physical chemical constraints which are responsible
for the stability of the protein.
2. MODELS OF PROTEIN EVOLUTION
2.1 Amino acid models of protein evolution
Nonetheless the complexity of protein evolution, for a wide range of applications such
as database search, sequence alignment, protein family classification and phylogenetic
inference, among many others, the phenomenological approach to amino acid
substitutions in protein families, started with the empirical work of Margaret Dayhoff
and her colleagues (1978), is still widely used. Following Dayhoff’s footsteps, with the
help of large data bases available in subsequent years, various authors built several
amino acid substitution matrices based on observed mutation counts in protein
alignments (e.g. the updated Dayhoff matrices by Gonnet et al., 1992 or Jones et al.,
1992). This formalism operates in protein space (see below), thus completely ignores
the underlying mutational process that occurs at the DNA level. Dayhoff’s PAM
matrices describe the probabilities of amino acid substitutions, for a given period of
evolution. They are derived from a model in which amino acids mutate randomly and
independent of one another. Each substitution probability during some time interval
depends only on the identities of the initial and replacement residues. Mathematically
speaking, the dynamics of amino acid substitution resembles a time-homogenous first
order reversible Markov chain (Dayhoff et al., 1972, 1978; Gonnet et al., 1992; Jones et
al., 1992; Müller and Vingron, 2000).Of course, the above assumptions are not strictly
true, and various authors have pointed out that the dynamics of amino acid substitutions
is not Markovian, stationary, nor homogeneous (Crooks and Brenner, 2005).
Sequence space, the abstract space of all sequences drawn from an alphabet of k letters
and of length n, was first introduced in coding theory by Hamming (1950). It is a
metric space with respect to the Hamming distance, dH, (Hamming, 1950), which
represents the minimum number of changes that are required to convert one sequence
into another. Maynard Smith (1970) applied this concept to amino acid sequences
defining the concept of protein space (see also Kauffman, 1989 and references therein).
As recently described in a delightful paper by Frances Arnold (2011), in protein space
each sequence is surrounded by its one-mutant neighbors, that is, by all the proteins that
differ from it by a change in a single amino acid letter. As described in (Kauffman
1989), “The concept of protein space is a high-dimensional space in which each point

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 327
represents one protein, and is next to 19 N points representing all the 1-mutant
neighbors of that protein. The protein space therefore simultaneously represents the
entire ensemble of 20N proteins and keeps track of which proteins are 1-mutant
neighbors of each other”.
However, the autonomous description of protein evolution in protein (sequence) space
is misleading, because it violates the Central Dogma of molecular biology. In nature
amino acids do not interchange among themselves during evolution. The space of
possibilities is at the DNA level, where the meaningful unit is a base triplet or codon.
Therefore, the relevant space to describe codon substitutions is a genetic code space
(Fig. 1), where codon mutations occur (Swanson, 1984; Jiménez-Montaño et al., 1996;
Petoukhov, 1999; Stambuk, 2000; Jiménez-Montaño, 2004; Jiménez-Montaño and He,
2009). Thus, by single-nucleotide mutations many of the 19 amino acids are out of
reach from the original amino acid, and thus they have null probability of appearance.
This is the first place where the symmetry associated to the concept of random
mutations is broken. The single-nucleotide mutations among the four bases are indeed
random (although not necessarily equally probable), but the corresponding amino acid
substitution probabilities cannot be equal, due to the structure of the genetic code. The
dynamics of amino acid substitutions refers to an aggregate level (see below).
2.2 Codon models of protein evolution
Goldman and Yang (1994) and, independently, Muse and Gaut (1994) introduced the
first models of a Markovian dynamics at the DNA (codon) level. In these models all
substitution rates are derived from parameters. We will not discuss parametric codon
models here; instead, we are going to employ an adaptation for short-term evolution of
the empirical codon substitution model proposed by Gaston Gonnet and his group
(Schneider et al., 2005). In this case, all substitution rates were estimated from a large
data set of aligned vertebrate coding sequences and then fixed.
Assuming a Markovian dynamics at the DNA (codon) level, the dynamics of amino acid
substitutions is defined by an aggregation (grouping) of codon states. However,
Görnerup and Jacobi (2010) pointed out that in general the dynamics on the aggregated
level is not closed, since the partition of the original space introduces memory on the
aggregated level. Only in the special case when the aggregated dynamics indeed is
closed, the stochastic process over the partitions constitutes a Markov chain with the
same order as the original process. Employing the same empirical codon substitution
matrix (Schneider et al., 2005) as we do, they showed that the substitution process

M. A. JIMÉNEZ-MONTAÑO 328
hierarchically operates on multiple levels, from nucleotides to codons, to groups of
codons, associated with amino acids, and to amino acid groups which form “reduced
alphabets”. Since each level approximately has its own closed dynamics, the original
dynamics and the partition of the state space then define a new stochastic process on the
coarser level. These theoretical aspects of molecular evolution were corroborated by our
computer simulations.
Recently, Kosiol and Goldman (2011) proposed a closely related approach in terms of
aggregated Markov processes (AMPs), to model protein evolution as time-
homogeneous Markovian at the DNA (codon) level but observed (via the genetic code)
only at the amino acid level. They showed that this approach leads to time-dependent
and non-Markovian observations of amino acid sequence evolution. The main
difference between their work and the paper by Görnerup and Jacobi (2010) and our
model is that Kosiol and Goldman employed a parametric codon substitution matrix.
Nonetheless, our model is consistent with their assertion that the genetic code and
amino acids' physiochemical properties “influence the average substitution patterns
observed over collections of proteins at all evolutionary distances in the same way”.
That is, we assert that is not exact that the influence of the genetic dominates in the
short-term, and physiochemical properties in the long-term, as supposed by Benner et
al. (1994).
3. THE MARKOVIAN CODON-SUBSTITUTION MODEL
Markov processes/ chains/ models were first developed by Andrei A. Markov. Their
first use was for a linguistic purpose, modeling the letter sequences in works of Russian
literature (Markov, 1913). Later on, Markov models were developed as a general
statistical tool and applied to problems in the study of natural language processing
(Christopher and Schutze, 2003) and in computational biology (Nielsen, 2005; Ewens
et al., 2001; Yang, 2006), among many other applications.
3.1 The Markov Information Source
Probabilistic finite state automata, PFA, as hidden Markov models, HMM, are widely
used in computational linguistics, machine learning, time series analysis, computational
biology, and speech recognition among other fields of research. Their definition, given
in (Vidal et al., 2005), is equivalent to the definition of a stochastic regular grammar.
PFA are built to deal with the problem of probabilizing a structured space by adding

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 329
probabilities to structure. This is precisely what we want to do: To bring in codon
transition probabilities into the structure of the genetic code.
This is necessary because in our model, as in the parametric models by Goldman and
Yang (1994), and by Halpern and Bruno (1998), the state-space for the Markov process
corresponds to the standard genetic code (or its variants). In the model of Goldman and
Yang, “The states of the Markov process are the 61 sense codons. The three nonsense
(stop) codons are not considered in the model, as mutations to or from stop codons can
be assumed to affect drastically the structure and function of the protein and therefore
will rarely survive”. But, except for sharing the same abstract space, our approach is not
related with the mentioned models. Rather, its formulation and interpretation is closer to
that of informational and linguistic models. Therefore, we interpret the genetic code as a
Markov information source, exactly as this expression is understood in information
theory (Ash, 1965, p 172). That is, a finite Markov chain, together with a function f
whose domain is the set of states S and whose range is a finite set Γ called the alphabet
of the source. In our case, Γ = {A, G, S, T,…, Y, W} is the amino acid alphabet. The
PFA can be displayed graphically as a six-dimensional Boolean hypercube (Jiménez-
Montaño et al., 1996; Petoukhov, 1999; Stambuk, 2000; Jiménez-Montaño, 2004;
Sánchez et al., 2004; Karasev and Soronkin, 1997). In a forthcoming paper (Jiménez-
Montaño and Ramos-Fernández, 2013) we describe an implementation of the PFA with
the help of software tool GSEQUENCE that we developed specially to simulate the
generation of codon sequences, and from them amino acid sequences, in protein
evolution.
As Shannon (1948) did not mean that his statistical description of human language, with
a Markov information source, is the actual manner in which human discourse is
generated, it is clear that we are not suggesting that Nature really produces proteins with
the help of a Markov information source at the codon level. This is only a mathematical
device to describe the correlations among the amino acid substitutions along the
evolutionary process.
As mentioned above, for our model we have adapted for short term evolution (i.e., for
single-nucleotide changes) the 61 x 61 codon matrix introduced in (Schneider et al.,
2005), for which all substitution rates have been estimated from a set of 17,502
alignments of orthologous genetic sequences from five vertebrate genomes. The codon
transition probabilities are fixed, and correspond to protein divergence between 25 and
60 accepted point mutations per 100 amino acids (PAMs). Besides the influence of the
genetic code, this as any other empirical codon substitution matrix includes variable

M. A. JIMÉNEZ-MONTAÑO 330
factors such as codon usage, transition/transversion bias and selective pressures.
Inversions and duplications are not considered in this paper.
Out of the 190 possible interchanges among the 20 amino acids, we consider only 75
that can be obtained by single-base substitutions. Therefore, we employ a reduced
empirical matrix (REM), making zero all entries corresponding to more than one
nucleotide change in the original matrix and normalizing the resulting matrix; see
(Jiménez-Montaño and He, 2009) for more details. In this way, we take into account the
local structure of the genetic code around each codon. In one step, a codon can change
in nine different ways and generally can have from zero to three synonymous changes
and from six to nine non-synonymous changes, except in the cases of six-fold
degeneracy such as serine, leucine and arginine. We consider all possible one-step
changes for all 61 codons disregarding the three stop codons.
The important contribution of the genetic code to protein evolution has recently been
underlined by Hietpas et al., (2011), who found that the genetic code is highly
optimized (+2.4σ) to favor single-base substitutions between codons with WT-like
fitness compared with randomly generated codes. Thus, the genetic code generally
permits single-base substitution pathways between codons with WT-like fitness.
4. SELECTIVE CONSTRAINTS
The functions and structure of individual proteins impose different constraints on their
evolution. Irrespective of their dispensability, most proteins require a suitable three
dimensional structure to function. Therefore, any polypeptide having a well defined
globular structure must be the subject of a strong selection and its sequence is, from this
point of view, nearly optimal in terms of stability (Sánchez et al., 2006). Therefore, a
majority of positions in a protein globular domain are selected for stability. The
fundamental role of selection for thermodynamic stability in shaping molecular
evolution has been demonstrated by studies that simulated sequence evolution under
structural constraints (Parisi and Echave, 2001). The amino acid substitution
probabilities derived from the REM matrix are highly anti-correlated with the values
taken from the amino acid substitution matrix suggested long ago by Miyata et al.,
(1979) (Table 2). Therefore, the selective constraints are approximately captured by the
amino acid properties of hydrophobicity and volume.

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 331
More than thirty years ago, while analyzing the globin fold, Lesk and Chothia (1980)
reached already a similar conclusion. So long as some basic physical-chemical
constraints are satisfied, there is considerable latitude in primary structure (Axe, 2004).
About the same time, a related conclusion was reached by Sander and Schulz (1979) in
their study of the degeneracy of information contents of amino acid sequences from
overlaid genes. From the families of homologous protein know at that time, they
concluded that the information contained in a sequence is degenerate with respect to
function. They quantified this degeneracy on the basis of viral overlays and found that
five amino acid groups is the largest number of groups for which the assumption is
tenable that there exists one group sequence per protein function. Ever since, a great
number of reduced alphabets have been proposed, based on different amino acid
properties or observed substitutions (Miyata et al., 1979; Jiménez-Montaño, 1984;
Murphy et al., 2000; Solis and Rackovsky, 2000; Cannata et al., 2002; Li et al., 2003),
among many others. Here, following (Görnerup and Jacobi, 2010), we interpret reduced
amino acid alphabets simply as a result of the various codon sub dynamics, among
different groups of codons, which are neighbors according to the topology of the genetic
code space.
Recently, Chothia (Sasidharan and Chothia, 2007) returned to the problem from a
different perspective. For the divergence process in proteins that maintain the same or
very similar functions and structures, Sasidharan and Chothia reported very similar
overall patterns of divergence by counting observed amino acid substitutions in three
very different groups of orthologs. They interpret this result to mean that individual
responses of most proteins are variations on a common set of selective constraints
which govern the types of frequent mutations that are acceptable. In RESULTS we
show that the frequencies of amino acid pair substitutions deduced from our computer
simulations are in very good agreement with the mutation profile obtained in their
paper.
5. PROTEIN SYNTAX
Paraphrasing Prince and Smolensky (1997) in their attempt to relate the sciences of the
brain with the sciences of the mind, we can say in the present context that: “It is evident
that statistical thermodynamics and molecular biology are separated by many gulfs, not
the least of which lies between the formal methods appropriate for continuous
dynamical systems and those for discrete symbol structures”.

M. A. JIMÉNEZ-MONTAÑO 332
In order that an amino acid substitution is acceptable is necessary, first of all, that the
alteration it produces in the protein structure be as small as possible. Therefore, the
general Darwinian principle of “gradual change” is interpreted in the sense that the
destabilization of the structure should be as small as possible. Thus, thermodynamics
requires minimization of the Gibbs free energy change. However, this continuous
optimization is hampered by the discrete nature of the amino acid change. A rough
estimation of the effect produced by the substitution consists, for example, in
calculating the Miyata et al., distance (1979) between the original and the new amino
acid. However, this distance should not calculated between the original and any of the
other 19 amino acids; only between the original amino acid and the accessible amino
acids after a single-nucleotide mutation (that is, at most nine amino acids). In this way
the genetic code modulates acceptable mutations.
Following the parallelism between linguistics and a formal protein language (Jiménez-
Montaño, 1984), we recall that an important challenge of the first discipline is to
discover an architecture for grammars that both allows variation and limits its range to
what is actually possible in human language (Prince and Smolensky, 1997).
Furthermore, these authors remark that “… a central element in the architecture of
grammar is a formal means for managing the pervasive conflict between grammatical
constraints”. “The key observation is this: In a variety of clear cases where there is a
strength asymmetry between two conflicting constraints, no amount of success on the
weaker constraint can compensate for failure on the stronger one”. Finally, “….a
grammar consists entirely of constraints arranged in a strict domination hierarchy, in
which each constraint is strictly more important than-takes absolute priority over- all
constrains lower-ranked in the hierarchy. With this type of constraint interaction, it is
only the ranking of constraints in the hierarchy that matters for the determination of
optimally; no particular numerical strengths, for example, are necessary”.
Below we are going to show in which sense these concepts can be applied to the
characterization of amino acid substitutions. First, we need to say some words about
amino acid categorizations and the syntactic structure of proteins at the letter-unit level
which we discussed in detail in (Jiménez-Montaño, 1984).
We will call any classification of the 20 amino acid types in r groups (under different
criteria), an amino acid categorization. The set of symbols denoting the group names
will be called a reduced alphabet. When the reduced alphabet corresponds to a pattern
of substitutions according to an empirical matrix (Dayhoff et al., 1972, 1978; Gonnet et
al., 1992; Jones et al., 1992; etc.), the pattern is called a pattern of substitution classes.

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 333
If the categorization is based on physical-chemical properties (Grantham; 1964; Miyata
et al., 1979; etc.), the resulting patterns are called amino acid property sequences. In the
paper mentioned above, we approached the question of how we can select a fixed
number of categories which best mirror amino acid replacements. The mutational
categories should reflect the most frequent amino acid substitutions observed. In the
same way, if the selected physical chemical properties truly determine the protein´s
architecture, both patterns will be consistent. In other words, the reduced alphabets
obtained under different criteria will be almost equivalent. It is on this basis that is
reasonable to assume that the constraints responsible for a given fold are somehow
encoded in the pattern of substitution classes.
A hierarchy (inverted tree) of amino acid categorizations represents a syntactic structure
of proteins at the letter-unit level. We shall employ for our discussion the hierarchy
introduced in Fig. 1 of (Jiménez-Montaño, 1984). In the same paper we discussed two
more hierarchies, one from Sneath (1966) and the other from Lim (1974). Twelve more
hierarchies (also called dendrograms), associated with the same number of popular
amino acid substitution matrices are displayed in Fig. 4 of (Johnson and Overington,
1993). See also Fig. 1 in (Fan and Wang, 2003), and (Venkatarajan and Braun, 2001),
among many other proposals in the literature.
With this background, the interpretation of the above quotations from Optimality
Theory (Prince and Smolensky (1997) in the context of the present article is
straightforward. A hierarchy of amino acid categorizations encodes physical chemical
constraints arranged in a strict domination hierarchy. Thus, the dominant partition in the
dendrogram in Fig. 1 of (Jiménez Montaño, 1984) separates amino acids into non-
hydrophobic, represented by the group symbol a, and hydrophobic, represented by the
group symbol b. This constraint dominates over the lower constrains (for example size).
Therefore, we expect that an amino acid of a given class will be substituted with another
amino acid of the same class. In this case, we say that the substitution is syntactically
correct, and that the new sequence belongs to the language generated by the grammar.
Let us illustrate with an example how the grammar generates average amino acid
substitutions obeying general physical chemical constraints that preserve the stability of
the protein. If, in a given site of a protein sequence, we have aspartic acid (D) we expect
that it will be replaced by glutamic acid (E) because the node n in Fig. 1 of (Jiménez-
Montaño, 1984) is the smallest class that includes both amino acids. Next, we have node
e which includes two more amino acids, Q and N, that is, e = {D, E, N, Q}. Thus, the
category represented by the symbol n corresponds to the most conservative substitution,

M. A. JIMÉNEZ-MONTAÑO 334
then follows the wider category e, and so on up to the category represented by the
symbol a, which embraces the non-hydrophobic amino acids.
The amino acid dendrograms we are considering were derived from a number of amino
acid substitution matrices, by several authors that employed different clustering
procedures which have a significant influence in the result. Besides, this approach in
protein space disregards the fact that two amino acids in the same group may be
separated by two or three nucleotide substitutions, thus unlikely to substitute one
another. As pointed out long ago by Miyata et al., (1979): “Amino acids separated by
two or three codon position differences are unlikely to interchange even if they are
chemically similar”. Recently, we discussed this problem (Jiménez-Montaño and He,
2009). For example, the category i = {F, Y, W} in Fig. 1 of (Jiménez-Montaño, 1984) ,
which includes the three large hydrophobic amino acids should be refined into two
groups:{F, Y} and {W}. This is so because to go from the codon of W to any of the
codons of the other two amino acids we need two nucleotide changes; thus, W
constitutes a separate group by itself. This splitting of W was already proposed, for
example, in (Murphy et al., 2000) but for a different reason (which is a consequence of
the above reason): The small number of substitutions observed between W and the other
two amino acids, as reflected in the empirical BLOSUM 50 matrix. Therefore, it is clear
that to improve over previous approaches it is necessary to have a syntactic structure at
the codon level.
6. RESULTS
The first result of this paper is the proposal of the codon dendrogram shown in Fig. 2. It
was obtained by applying the clustering algorithm UPGMA (unweighted pair-group
method using arithmetic averages) to the full codon substitution matrix introduced in
(Schneider et al., 2005). This classification of codons, inferred from an empirical
matrix, induces a corresponding arrangement for amino acids. We observe that the
codons for D and E share the same group, therefore, we expect these two amino acids
exchange frequently both because they are very similar and because they are neighbors
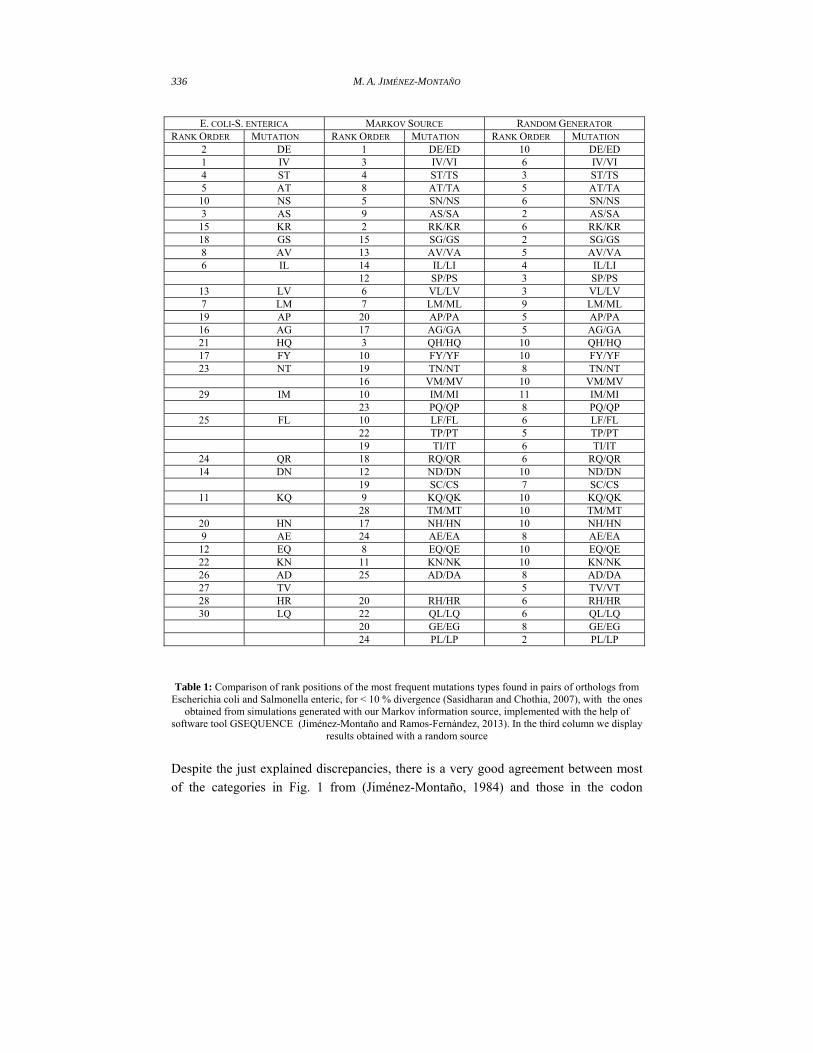
in codon space. They are ranked one in our simulations (Table 1) and in Human-
Chicken orthologs, and ranked two in Escherichia coli and Salmonella orthologs; both
from the observed data (Table 6 in supp. material from Sasidharan and Chothia, 2007).
However, the group e = {D, E, N, Q} does not occur in Fig.2; N and S2 (S with AGY
codons) form one category, and Q and H another. Therefore, the letters in category e are
not completely equivalent from the point of view of their substitutability. From the

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 335
results in Table 1, the substitutions DN, and EQ are in ranks between 12 and
14, while NQ and EN, are ranked 44 and 45, respectively, in (Table 6 in supp.
Material from Sasidharan and Chothia, 2007). In the first case the amino acids have
neighboring codons; in the second case the corresponding codons differ by two bases.
Figure 2: Dendrogram (Codon rooted tree) obtained from the full empirical codon-substitution matrix (Schneider et al., 2005), employing the UPGMA method.
M. A. JIMÉNEZ-MONTAÑO 336
E. COLI-S. ENTERICA MARKOV SOURCE RANDOM GENERATOR
RANK ORDER MUTATION RANK ORDER MUTATION RANK ORDER MUTATION 2 DE 1 DE/ED 10 DE/ED 1 IV 3 IV/VI 6 IV/VI 4 ST 4 ST/TS 3 ST/TS 5 AT 8 AT/TA 5 AT/TA 10 NS 5 SN/NS 6 SN/NS 3 AS 9 AS/SA 2 AS/SA 15 KR 2 RK/KR 6 RK/KR 18 GS 15 SG/GS 2 SG/GS 8 AV 13 AV/VA 5 AV/VA 6 IL 14 IL/LI 4 IL/LI 12 SP/PS 3 SP/PS
13 LV 6 VL/LV 3 VL/LV 7 LM 7 LM/ML 9 LM/ML 19 AP 20 AP/PA 5 AP/PA 16 AG 17 AG/GA 5 AG/GA 21 HQ 3 QH/HQ 10 QH/HQ 17 FY 10 FY/YF 10 FY/YF 23 NT 19 TN/NT 8 TN/NT 16 VM/MV 10 VM/MV
29 IM 10 IM/MI 11 IM/MI 23 PQ/QP 8 PQ/QP
25 FL 10 LF/FL 6 LF/FL 22 TP/PT 5 TP/PT 19 TI/IT 6 TI/IT
24 QR 18 RQ/QR 6 RQ/QR 14 DN 12 ND/DN 10 ND/DN 19 SC/CS 7 SC/CS
11 KQ 9 KQ/QK 10 KQ/QK 28 TM/MT 10 TM/MT
20 HN 17 NH/HN 10 NH/HN 9 AE 24 AE/EA 8 AE/EA 12 EQ 8 EQ/QE 10 EQ/QE 22 KN 11 KN/NK 10 KN/NK 26 AD 25 AD/DA 8 AD/DA 27 TV 5 TV/VT 28 HR 20 RH/HR 6 RH/HR 30 LQ 22 QL/LQ 6 QL/LQ 20 GE/EG 8 GE/EG 24 PL/LP 2 PL/LP
Table 1: Comparison of rank positions of the most frequent mutations types found in pairs of orthologs from
Escherichia coli and Salmonella enteric, for < 10 % divergence (Sasidharan and Chothia, 2007), with the ones obtained from simulations generated with our Markov information source, implemented with the help of
software tool GSEQUENCE (Jiménez-Montaño and Ramos-Fernández, 2013). In the third column we display results obtained with a random source
Despite the just explained discrepancies, there is a very good agreement between most
of the categories in Fig. 1 from (Jiménez-Montaño, 1984) and those in the codon

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 337
dendrogram (Fig. 2). For example, the important category h = {L, I, V, M} of aliphatic
amino acids in our hierarchy of amino acid categorizations, coincides with the category
d in Fig.2. The same is true for the small neutral amino acids in group c = {P, A, G, S,
T}, except for glycine (G), which in Fig. 2 belongs class b = {N, S2, G, D, E}. There are
other coincidences and differences that the reader can easily find. An important
difference worth mention is the following: while in the grouping based on amino acid
properties I and L are in the same category q, in the codon dendrogram I joins V to form
a group; even though there are proofreading process in protein synthesis to correct
translation errors, the substitutions VI are ranked three and the substitutions
LI are ranked fourteen in our simulations; and are ranked one and six, respectively,
in pairs of orthologs from Escherichia coli and Salmonella enterica (See our Table 1
and Table 6 in supp. Material from Sasidharan and Chothia, 2007).
The amino acid substitution pairs from our codon dendrogram, (D,E),(K,R),(I,V),
(Y,F),(M,L),(N, S2 ) (Q, H) and (A,S) are consistent to the ones reported in the
dendrogram displayed in Fig. 3 of (Görnerup and Jacobi, 2010), except for minor
differences. These are in the two last groups; in their paper (which employs a
completely different agglomeration procedure), Q and H form separate groups, and A
pairs with T instead of S. However, the higher categorizations are completely different
in both dendrograms. The separation of hydrophobic and hydrophilic amino acids in our
dendrogram (Fig. 2) is consistent with that in Fig. 1 of (Jiménez-Montaño, 1984). The
only difference comes from the small neutral amino acids, which are in the non-
hydrophobic group in our former publication, and are grouped with the hydrophobic
amino acids in the codon dendrogram.
The second but not less important result is that six of the ten more frequent amino acid
substitutions pairs, obtained from simulations generated with our Markov information
source, implemented with the help of software tool GSEQUENCE (Jiménez-Montaño
and Ramos-Fernández, 2013), agree with the pairs in the three sets of orthologs from E.
coli – S. enterica, Human-Mouse and Human-Chicken, respectively, from Table 6 in
supp. material from (Sasidharan and Chothia, 2007). These pairs are: DE, IV, ST, NS,
AT, AS. The pair KR agrees with two of the three sets of orthologs. Additionally, we
have in descending order the pairs VL, LM and FY which are ranked twelve, thirteen
and seventeen, respectively, in the same source. Seven of these amino acid substitution
pairs agree with the codon pairs in the Codon Dendrogram (Fig. 2), they are: DE, IV,
NS, AS, KR, LM, FY. These results are consistent with the most frequent amino acid
exchanges found in (Schmitt et al., 2007). In our simulations, the corresponding codons

M. A. JIMÉNEZ-MONTAÑO 338
outline approximately closed dynamics, as discussed in (Görnerup and Jacobi, 2010).
Therefore, these cycles of the codon dynamics produce amino acid substitutions which
are fixed in the population because of the similarity of the corresponding amino acids.
These outcomes take us to the third and last result of this paper.
AA/CODON CORR COEF AA/CODON CORR COEF AA/CODON CORR COEF
K AAA -0.8791 I ATA -0.5617 D GAC -0.7193 K AAG -0.9266 I ATC -0.5668 D GAT -0.7201 N AAC -0.6477 I ATT -0.5791 A GCA -0.3349 N AAT -0.7568 M ATG -0.6726 A GCC -0.3815 T ACA -0.6894 Q CAA -0.7166 A GCG 0.7656 T ACC -0.4522 Q CAG -0.5851 A GCT -0.4195 T ACG 0.4707 H CAC -0.6559 G GGA -0.4947 T ACT -0.4727 H CAT -0.6578 G GGC -0.8047 R AGA -0.8543 P CCA -0.8373 G GGG -0.2542 R AGG -0.8397 P CCC -0.8056 G GGT -0.7988 R CGA -0.8787 P CCG 0.3259 V GTA -0.4626 R CGC -0.9202 P CCT -0.7635 V GTC -0.6288 R CGG -0.9238 L CTA -0.6903 V GTG -0.8257 R CGT -0.9403 L CTC -0.964 V GTT -0.6141 S2 AGC -0.7744 L CTG -0.9467 Y TAC -0.9487 S2 AGT -0.6739 L CTT -0.9273 Y TAT -0.9621 S TCA -0.9765 L TTA -0.5547 C TGC -0.788 S TCC -0.8915 L TTG -0.7221 C TGT -0.7812 S TCG -0.7629 E GAA -0.6831 W TGG -0.7817 S TCT -0.9292 E GAG -0.8145 F TTC -0.4676
F TTT -0.4737
Table 2: Anti-correlation between the substitution probabilities from the reduced empirical matrix, REM (Jiménez-Montaño and He, 2009), and the physical-chemical dissimilarity index (distance) from (Miyata et
al., 1979). For a given codon, e.g. AAA (K), I calculated the correlation between the list of values of substitution probabilities with its neighbors (AGA (R), GAA (E), etc, and the list of values of the index of the
associated amino acids (in parenthesis)
In Table 2 we display the anti-correlation between the substitution probabilities from the
reduced empirical matrix, REM (Jiménez-Montaño and He, 2009), and the dissimilarity
physical-chemical index (distance) from (Miyata et al., 1979), which is based on
hydrophobicity and volume of amino acids. As expected, amino acid pairs which have
codons that substitute frequently have small values of the dissimilarity index and vice
versa. So, this well-known result from comparisons of amino acid substitution matrices,
is corroborated at the codon level.
7. CONCLUSIONS
After presenting a general conceptual framework for the analysis of protein evolution,
we introduced a theoretical model, which consists of a Markov Information Source that
generates codon sequences, and from them amino acid sequences, that maintain the
same or very similar functions and structures. This invariance is a consequence not only

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 339
of natural selection (that preserves the sequences that obey general physical chemical
constraints, which are responsible of the stability of the protein), but also of the
structure of the genetic code, which controls the possible amino acid changes, from
single nucleotide mutations. With the help of the model, we introduced a syntactic
formulation (codon dendrogram) to describe a hierarchy of codon categorizations which
explain the pattern of frequent amino acid substitutions in short-term evolution. From
our computer simulations (Jiménez-Montaño and Ramos-Fernández, 2013) we
interpreted the reduced amino acid alphabets simply as a result of the various codon
sub dynamics, among different clusters of codons, which are neighbors according to the
topology of the genetic code space.
Acknowledgements: I wrote this paper while commissioned at Dirección General de
Investigaciones de la Universidad Veracruzana. I want to thank director César I.
Beristain-Guevara for his support. I also thank Q.F.B. Antero Ramos-Fernández for his
help in doing some calculations and preparing the tables and figures. I thank David Abel
for suggestions to make clearer the manuscript and some references. I express thanks to
Sistema Nacional de Investigadores, México, for partial support. Finally, I thank my
wife, Ma. Eta. Castellanos G. for her patience and understanding.
REFERENCES
Abel, D.L. and Trevors, J.T. (2006) More than Metaphor: Genomes are Objective Sign Systems, Journal of BioSemiotics, 1 253-267.
Arnold, F.H. (2011) The Library of Maynard-Smith: My Search for Meaning in the Protein Universe. Microbe, ASM News 6(7) 316-318.
Ash, R. (1965) Information Theory, New York: Interscience Publishers, 339pp.
Axe D.D. (2004) Estimating the Prevalence of Protein Sequences Adopting Functional Enzyme Folds. Journal of Molecular Biology, 341 1295-1315.
Benner S.A. Cohen M.A. Gonnet G.H. (1994). Amino acid substitution during functionally constrained divergent evolution of protein sequences. Protein Engineering, 7 1323–1332.
Cannata,N., Toppo, S., Romualdi, C. and Valle, G. (2002) Simplifying amino acid alphabets by means of a branch and bound algorithm and substitution matrices. Bioinformatics 18 1102-1108.
Crooks, G.E. and Brenner, S.E. (2005) An alternative model of amino acid replacement. Bioinformatics 21 975–980.
Crutchfield, J.P. and Schuster, P. (2003) Evolutionary Dynamics–Exploring the Interplay of Accident, Selection, Neutrality, and Function, Oxford University Press, New York, 452pp.
Dayhoff, M.O., Eck, R.V. and Park, C.M. (1972) A model of evolutionary change in proteins. In: Dayhoff M, ed. Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, Washington, D.C., 5 89–99pp.
Dayhoff, M.O., Schwartz, R.M. and Orcutt, B.C. (1978) A model of evolutionary change in proteins. In: Dayhoff M, ed. Atlas of Protein Sequence and Structure, National Biomedical Research Foun- dation, Washington, D.C. 5(3) 345–352pp.

M. A. JIMÉNEZ-MONTAÑO 340
DePristo, M.A., Weinreich, D.M. and Hartl, D.L. (2005) Missense meanderings in sequence space: a biophysical view of protein evolution. Nature Reviews Genetics 6 678-687.
Dokholyan, N.V. and Shakhnovich, E.I. (2001) Understanding hierarchical protein evolution from first principles. Journal of Molecular Biology 312 289–307.
Ewens, W.J. and Grant, G.R. (2001) Statistical Methods in Bioinformatics: An Introduction, Springer- Verlag, New York, 476pp.
Fan, K. and Wang, W. (2003) What is the Minimum Number of Letters Required to Fold a Protein? Journal of Molecular Biology 328 921–926.
Goldman, N. and Yang, Z. (1994) A Codon-based Model of Nucleotide Substitution for Protein-coding DNA Sequences. Molecular Biology and Evolution 11 725-736.
Gonnet, G.H., Cohen, M.A. and Benner, S.A. (1992) Exhaustive matching of the entire protein sequence database. Science 256 1443-1445.
Görnerup, O. and Jacobi, M.N. (2010) A model-independent approach to infer hierarchical codon substitution dynamics. BMC Bioinformatics 11 201
Grantham, R. (1974) Amino acid difference formula to help explain protein evolution. Science 185 862-864.
Halpern, A.L. and Bruno, W.J. (1998) Evolutionary Distances for Protein-Coding Sequences: Modeling Site- Specific Residue Frequencies. Molecular Biology and Evolution 15 910–917.
Hamming, R.W. (1950) Error detecting and error correcting codes. Bell System Technical Journal 29 147-160.
Hietpas, R.T., Jensen, J.D. and Bolon, D.N.A. (2011) Experimental illumination of a fitness landscape. Proceedings of the National Academy of Sciences 108 7896–7901.
Jiménez-Montaño, M.A. (1984) On the syntactic structure of protein sequences and the concept of grammar complexity. Bulletin of Mathematical Biology 46 641-659.
Jiménez Montaño M. A. (1994) On the Syntactic Structure and Redundancy Distribution of the Genetic Code. BioSystems, 32 11-23.
Jiménez-Montaño, M.A. (2004) Applications of Hyper Genetic Code to Bioinformatics. Journal of Biological Systems 12 5-20.
Jiménez-Montaño, M.A. and He, M. (2009) Irreplaceable Amino Acids and Reduced Alphabets in Short-term and Directed Protein Evolution. In Bioinformatics Research and Applications. Mandoiu, Ion; Narasimhan, Giri; Zhang, Yanquing (Eds.). Springer-Verlag Berlin Heidelberg, 297–309pp.
Jiménez-Montaño, M.A. and Ramos-Fernández, A. (2013) Simulation of protein evolution with a Markovian empirical codon-substitution model. Manuscript in preparation.
Jiménez-Montaño, M.A., de la Mora-Basáñez, R. and Pöschel, T. (1996) The Hypercube Structure of the Genetic Code Explains Conservative and Non-Conservartive Aminoacid Substitutions in Vivo and in Vitro. BioSystems 39 117-125.
Johnson, M.S. and Overington, J.P. (1993) A structural basis for sequence comparisons—an evaluation of scoring methodologies. Journal of Molecular Biology 233 716–738
Jones, D.T., Taylor, W.R. and Thornton, J.M. (1992) The rapid generation of mutation data matrices from protein sequences. Computer Applications in the Biosciences 8 275–282.
Karasev, V.A. and Soronkin, S.G. (1997) Topological structure of the genetic code, Russian Journal of Genetics 33 622–628.
Kauffman, S. (1989) Adaptation on Rugged Fitness Landscapes. In Lectures in the Sciences of Complexity. Stein, D.L., Editor.Addison-Wesley Publishing Company, Redwood City, California, 527- 618pp.
Kleiger, G., Beamer, L.J., Grothe, R., Mallick, P., and Eisenberg, D. (2000) The 1.7 Å Crystal Structure of BPI: A Study of How Two Dissimilar Amino Acid Sequences can Adopt the Same Fold, Journal of Molecular Biology 299 1019-1034.
Kosiol, C. and Goldman, N. (2011) Markovian and Non-Markovian Protein Sequence Evolution: Aggregated Markov Process Models, Journal of Molecular Biology 411 910–923.

AMINO ACID SUBSTITUTIONS IN PROTEIN EVOLUTION 341
Lesk, A.M. and Chothia, C. (1980) How different amino acid sequences determine similar protein structures: The structure and evolutionary dynamics of the globins, Journal of Molecular Biology 136 225-270.
Li, T., Fan, K., Wang, J. and Wang, W. (2003) Reduction of protein sequence complexity by residue grouping, Protein Engineering 16 323-330.
Lim, V.I. (1974) Algorithms for prediction of alpha-helical and beta-structural regions in globular proteins, Journal of Molecular Biology 88 873-94.
Markov, A.A. (1913) Primer statisticheskogo issledovanija and tekstom `Evgenija Onegina' illjustrirujuschij svjaz' ispytanij v tsep (An example of statistical study on the text of `Eugene Onegin' illustrating the linking of events to a chain). Izvestija Imp, Akademii nauk, serija VI, 3 153-162.
Miyata,.T., Miyazawa, S. and Yasunaga,.T. (1979) Two types of amino acid substitutions in protein evolution, Journal of Molecular Evolution 12 219-236.
Müller, T. and Vingron, M. (2000) Modeling amino acid replacement, Journal of Computational Biology 7 761–776.
Murphy,L.R., Wallqvist, A. and Levy, R.M. (2000) Simplified amino acid alphabets for protein fold recognition and implications for folding, Protein Engineering 13 149-152.
Muse, S.V. and Gaut, B.S. (1994) A Likelihood Approach for Comparing Synonymous and Nonsynonymous Nucleotide Substitution Rates, with Application to the Chloroplast Genome, Molecular Biology and Evolution 11 715-724.
Manning, C.D. and Schutze, H. (1999) Foundations of Statistical Natural Language Processing, Cambridge, Massachusetts, MIT Press, 680pp. Reprint: Cambridge, Massachusetts, MIT Press 2003.
Nielsen, R. (2005) Statistical Methods in Molecular Evolution, Springer Verlag, New York, 508pp.
Pál, C., Papp, B. and Lercher, M.J. (2006) An integrated view of protein evolution, Nature Reviews Genetics 7 337-348.
Parisi, G. and Echave, J. (2001) Structural constraints and emergence of sequence patterns in protein evolution, Molecular Biology and Evolution 18 750–756.
Parkhomchuk D., Amstislavskiy,V. , Soldatov A. and Ogryzko V. (2009) Use of high throughput sequencing to observe genome dynamics at a single cell level, Proceedings of the National Academy of Sciences 106 20830-20835.
Petoukhov, S.V. (1999) Genetic code and the ancient Chinese book of changes, Symmetry: Culture and Science 10 211-226.
Prince, A. and Smolensky, P. (1997) Optimality: From Neural Networks to Universal Grammar, Science 275 1604-1610.
Sanchez, I.E., Tejero, J., Gomez-Moreno, C., Medina, M. and Serrano, L. (2006) Point Mutations in Protein Globular Domains: Contributions from Function, Stability and Misfolding, Journal of Molecular Biology 363 422–432.
Sánchez, R., Morgado, E. and Grau, R. (2004) The Genetic Code Boolean Lattice, Communications in Mathematical and in Computer Chemistry 52 29-46.
Sander, C. and Schulz, G.E. (1979) Degeneracy of the information contained in amino acid sequences: Evidence from overlaid genes, Journal of Molecular Evolution 13 245-252.
Sasidharan, R. and Chothia, C. (2007) The selection of acceptable protein mutations, Proceedings of the National Academy of Sciences 104 10080–10085.
Schmitt A. O., Schuchhardt, J., Ludwig A., Brockmann G. A. (2007) Protein evolution within and between species, Journal of Theoretical Biology 249 376–383.
Schneider, A., Cannarozzi, G.M. and Gonnet, G.H. (2005) Empirical codon substitution matrix, BMC Bioinformatics 6 134.
Shannon C. (1948). A Mathematical Theory of Communication, The Bell System Technical Journal 27 379–423, 623–656, July, October.

M. A. JIMÉNEZ-MONTAÑO 342
Skipper M., Dhand R., Campbell P. (2012) Nature/Encode. 2001 Will always be remembered as the year of the human genome, Nature 489: 45. The ENCODE Project Consortium (2012). An integrated encyclopedia of DNA elements in the human genome. Nature 489: 57–74. http://www.nature.com/encode/
Smith, J.M. (1970) Natural Selection and the Concept of a Protein Space, Nature 225 563–564.
Sneath, P.H.A. (1966) Relations between chemical structure and biological activity in peptides, Journal of Theoretical Biology 12 157-195.
Solis, A.D. and Rackovsky, S. (2000) Optimized representations and maximal information in proteins, Proteins: Structure, Function, and Bioinformatics 38 149-164.
Stambuk, N. (2000) Universal metric properties of the genetic code, Croatica Chemica Acta 73 1123-1139.
Swanson, R. (1984) A unifying concept for the amino acid code, Bulletin of Mathematical Biology 46 187-203.
Thorne, J.L. and Goldman, N. (2001) Probabilistic models for the study of protein evolution. Balding, D.J., Bishop, M., Cannings, C. (Eds.), Handbook of Statistical Genetics. John Wiley, Chichester, UK, 67-82pp.
Venkatarajan, M.S. and Braun, W. (2001) New quantitative descriptors of amino acids based on multidimensional scaling of a large number of physical–chemical properties, Journal of Molecular Modeling 7 445–453.
Vidal, E., Thollard, F., de la Higuera, C., Casacuberta, F. and Carrasco, R.C. (2005) Probabilistic finite-state machines-Part I, IEEE Trans, Pattern Analysis and Machine Intelligence 27 1013-1025.
Yang, Z. (2006) Computational molecular evolution, Oxford: Oxford University Press 374 pp.
Wagner A. (2012). The Role of Randomness in Darwinian Evolution, Philosophy of Science 79 95-119.




















