
Synchronized tag clouds for exploring semi-structured clinical trial data
15
Synchronized Tag Clouds for Exploring Semi-Structured Clinical Trial Data Maria-Elena Hernandez 1 , Sean M. Falconer 1 , Margaret-Anne Storey 1 , Simona Carini 2 , Ida Sim 2 1 University of Victoria, BC, Canada {maleh2, seanf, mstorey}@uvic.ca 2 University of Calif. San Francisco, CA, USA {ida.sim, simona.carini}@ucsf.edu Abstract Searching and comparing information from semi-structured repositories is an important, but cognitively complex activity for internet users. The typical web interface displays a list of results as a textual list which is limited in helping the user compare or gain an overview of the results from a series of iterative queries. In this paper, we propose a new interactive, lightweight technique that uses multiple syn- chronized tag clouds to support iterative vi- sual analysis and filtering of query results. Al- though tag clouds are frequently available in web interfaces, they are typically used for pro- viding an overview of key terms in a set of results, but thus far have not been used for presenting semi-structured information to sup- port iterative queries. We evaluated our pro- posed design in a user study that presents typ- ical search and comparison scenarios to users trying to understand heterogeneous clinical tri- als from a leading repository of scientific infor- mation. The study gave us valuable insights regarding the challenges that semi-structured data collections pose, and indicated that our design may ease cognitively demanding brows- ing activities of semi-structured information. Copyright c 2008 Maria-Elena Hernandez, Sean M. Falconer, Margaret-Anne Storey, Simona Carini, Ida Sim, the University of Victoria, and the University of California San Francisco. Permission to copy is hereby granted provided the original copyright notice is repro- duced in copies made. 1 Introduction The web is fast becoming a de facto mechanism for accessing controlled and semi-structured in- formation resources. In our research, we have been investigating how to improve web inter- faces for accessing and searching biomedical and clinical data repositories. In particular, we have been focusing our efforts on improving in- terfaces to access semi-structured information related to clinical trials. A semi-structured re- source consists of free text or data partially an- notated with some specific keywords or meta- data from a controlled terminology. ClinicalTrials.gov provides an interface for people with varying degrees of computer and domain expertise, such as researchers, clini- cians, patients, and family members, to browse and explore clinical trials. For example, the conditions treated in the trials, the interven- tions used and the outcomes from the trials are annotated with predefined terms from con- trolled medical terminologies. Other informa- tion on the trial can be searched as free text. In our investigations with clinical researchers, we have noted that current searching and brows- ing tools do not sufficiently aid a user in the complex process of seeking useful information (query specification, browsing results, under- standing and summarizing results) from a digi- tal collection of documents. Most often, a user starts with a vague idea of how to find useful in- formation and formulates an initial query that is, in most cases, refined as he or she better un- derstands the information domain. Typically, 1
Transcript of Synchronized tag clouds for exploring semi-structured clinical trial data

Synchronized Tag Clouds for Exploring Semi-Structured
Clinical Trial Data
Maria-Elena Hernandez1, Sean M. Falconer1, Margaret-Anne Storey1,Simona Carini2, Ida Sim2
1University of Victoria, BC, Canada {maleh2, seanf, mstorey}@uvic.ca2University of Calif. San Francisco, CA, USA {ida.sim, simona.carini}@ucsf.edu
Abstract
Searching and comparing information fromsemi-structured repositories is an important,but cognitively complex activity for internetusers. The typical web interface displays a listof results as a textual list which is limited inhelping the user compare or gain an overviewof the results from a series of iterative queries.In this paper, we propose a new interactive,lightweight technique that uses multiple syn-chronized tag clouds to support iterative vi-sual analysis and filtering of query results. Al-though tag clouds are frequently available inweb interfaces, they are typically used for pro-viding an overview of key terms in a set ofresults, but thus far have not been used forpresenting semi-structured information to sup-port iterative queries. We evaluated our pro-posed design in a user study that presents typ-ical search and comparison scenarios to userstrying to understand heterogeneous clinical tri-als from a leading repository of scientific infor-mation. The study gave us valuable insightsregarding the challenges that semi-structureddata collections pose, and indicated that ourdesign may ease cognitively demanding brows-ing activities of semi-structured information.
Copyright c© 2008 Maria-Elena Hernandez, SeanM. Falconer, Margaret-Anne Storey, Simona Carini, IdaSim, the University of Victoria, and the University ofCalifornia San Francisco. Permission to copy is herebygranted provided the original copyright notice is repro-duced in copies made.
1 Introduction
The web is fast becoming a de facto mechanismfor accessing controlled and semi-structured in-formation resources. In our research, we havebeen investigating how to improve web inter-faces for accessing and searching biomedicaland clinical data repositories. In particular, wehave been focusing our efforts on improving in-terfaces to access semi-structured informationrelated to clinical trials. A semi-structured re-source consists of free text or data partially an-notated with some specific keywords or meta-data from a controlled terminology.
ClinicalTrials.gov provides an interface forpeople with varying degrees of computer anddomain expertise, such as researchers, clini-cians, patients, and family members, to browseand explore clinical trials. For example, theconditions treated in the trials, the interven-tions used and the outcomes from the trialsare annotated with predefined terms from con-trolled medical terminologies. Other informa-tion on the trial can be searched as free text. Inour investigations with clinical researchers, wehave noted that current searching and brows-ing tools do not sufficiently aid a user in thecomplex process of seeking useful information(query specification, browsing results, under-standing and summarizing results) from a digi-tal collection of documents. Most often, a userstarts with a vague idea of how to find useful in-formation and formulates an initial query thatis, in most cases, refined as he or she better un-derstands the information domain. Typically,
1

results appear as a large, text-based, list thatmay have some structured information in eachindividual result. Unfortunately, due to a gapbetween the user’s and publisher’s terminolo-gies and due to the large amount of relevantdocuments that may satisfy the query, it maybe difficult for the user to gain an overall un-derstanding of the query results.
As a first step in our research, we conducteda review and survey of existing tools and visu-alization approaches for summarizing, compar-ing, and refining query results. From our sur-vey, we concluded that no existing techniqueis suitable for our users’ needs. Most existingtechniques either support browsing and query-ing of either unstructured data or highly struc-tured data. We discuss the survey of relatedwork in Section 3 but first further elaborate onthe challenges of browsing semi-structured in-formation resources that are prevalent for rep-resenting clinical trial data in Section 2.
In Section 4, we propose a novel and intuitivetechnique for browsing and comparing resultsfrom a semi-structured information space. In-spired by the recent popularity of the tag cloudstechnique to represent collections of annota-tions (folksonomies) used in YouTube1, Flickr2,CiteULike3, etc. we developed a tool basedon the hypothesis that seeking and comparingclinical trial information can be improved bysynchronized tag clouds that afford dynamicfiltering of search results. Tag clouds are pop-ular for summarizing information on user de-fined keywords (usually called tags) on the web.Generally, a tag cloud lists keywords in alpha-betic order, where the size of the text is pro-portional to a metric such as frequency of use.The clouds often facilitate browsing by makingthe tag link to content matching the value ofthe tag. The traditional use of tag clouds canbe observed in CiteULike (see right side in Fig-ure 1), an online social bookmarking system foracademic bibliographies.
Our tool, called CTSearch, combines multi-ple synchronized tag clouds to improve the re-finement of queries and the comparison of re-sults from a clinical trials repository, Clinical-Trials.gov. We performed a preliminary eval-
1www.youtube.com2www.flickr.com3http://citeulike.org
uation of CTSearch by comparing it to base-line search tool and collect subjective data aswell as insights into how both tools support theusers’ preferred searching and browsing strate-gies. We describe the study in Section 5, andpresent the findings in Section 6.
This style of semi-structured information re-source is not unique and is very prevalent onthe web. Other examples of semi-structured in-formation spaces that are non-medical includepublication archives like CiteSeer and DBLP,online library systems, and online stores suchas Amazon.com. In this paper, we focus onsearching and browsing clinical trial data, butwe expect our results to be applicable to otherdomains. In Section 7, we discuss how the find-ings can be applicable to other domains, as wellas discuss the limitations of the study we con-ducted. Finally, we conclude the paper in Sec-tion 8.
2 Challenges browsing andquerying semi-structuredinformation repositories
The digital collections we are addressing in ourresearch are centralized repositories (e.g., Clin-icalTrials.gov 4, MedLine5, and CiteSeer6) thatstore large collections of semi-structured text-based documents (articles, books, journal pa-pers, and clinical trial protocols). These doc-uments are semi-structured because they areonly partially described according to a definedmodel or schema. Author, title, and journalname are typical examples of fields that de-scribe a document in CiteSeer, but not all ofthe content of a document is annotated bya defined field in the schema. Some digi-tal collections are annotated using controlledvocabularies to facilitate information-seeking.For example, ClinicalTrials.gov annotates itselectronic documents with the Unified Medi-cal Language System (UMLS), and MedLineindexes its database with the Medical SubjectHeadings (MeSH).
Information-seeking with this level of diver-
4http://clinicaltrials.gov5http://mbr.nlm.nih.gov6http://citeseer.ist.psu.edu
2

Figure 1: Tag clouds in CiteULike
sity and heterogeneity is cognitively demand-ing. Moreover, for these repositories, whenusers search for specific information, the re-sults are returned as lists where the user canonly access details of a resource one at a time.Thus, it is left to the user to mentally com-bine the information so that they can compareparticular aspects of the query results. Figure2 shows how the user can enter a query usingthe annotated information in the clinical trialdescription through an advanced search screen.However, the results shown in Figure 3 revealhow it is difficult to match the list of resultsto the specific query terms added without asignificant amount of manual scanning throughthe results. The current interface, and those ofother sites similar to ClinicalTrials.gov, unfor-tunately do not promote further iteration onthe preliminary query. To iterate, a user isforced to come up with new terms for a newquery. Furthermore, the context of their origi-nal results are now lost.
Another challenge is that the annotationsadded to the data often may have no unifor-mity; this is because different authors may usedifferent keywords (also referred to as tags)to describe the same concept (in other words,synonyms). For example, documents relatedto liver cancer may be tagged with any com-bination of terms such as “Liver carcinoma”,“HCC”, “Hepatocellular carcinoma”, “Livermetastases” etc. Additionally, sometimes, thedescriptions and annotations on the data areambiguous and incomplete (e.g., the real name
of a drug tested may not be mentioned bythe description or the document’s annotations).Again, the set of results as shown in Figure 2does not address this issue. For example, if auser enters “Liver cancer” as a search term inthe condition field, 541 results are returned, onthe other hand if they use “Hepatocellular car-cinoma” they get 384 results. There is no wayfor the user to know how these result sets in-tersect or how they may relate to one another.
It is these challenges that our proposed tooladdresses: support for iteratively exploring asemi-structured information space, and feed-back on overlapping results from varied but re-lated queries. In the next section we first de-scribe current approaches for query refinementand browsing results from information spaces,and conclude with a summary of why a newapproach is needed.
3 Visualizing results fromquery refinement andbrowsing activities
Query refinement techniques provide tools thatallow users to refine their queries and thus theset of results. While seeking information, usersgenerally formulate short queries (between oneand three words); look only at the first 10 re-sults; seldom modify their query; and rarelyuse advanced search features [1, 2]. Refinementsupport in mainstream search engines is begin-ning to surface with tools like Google Suggest,
3
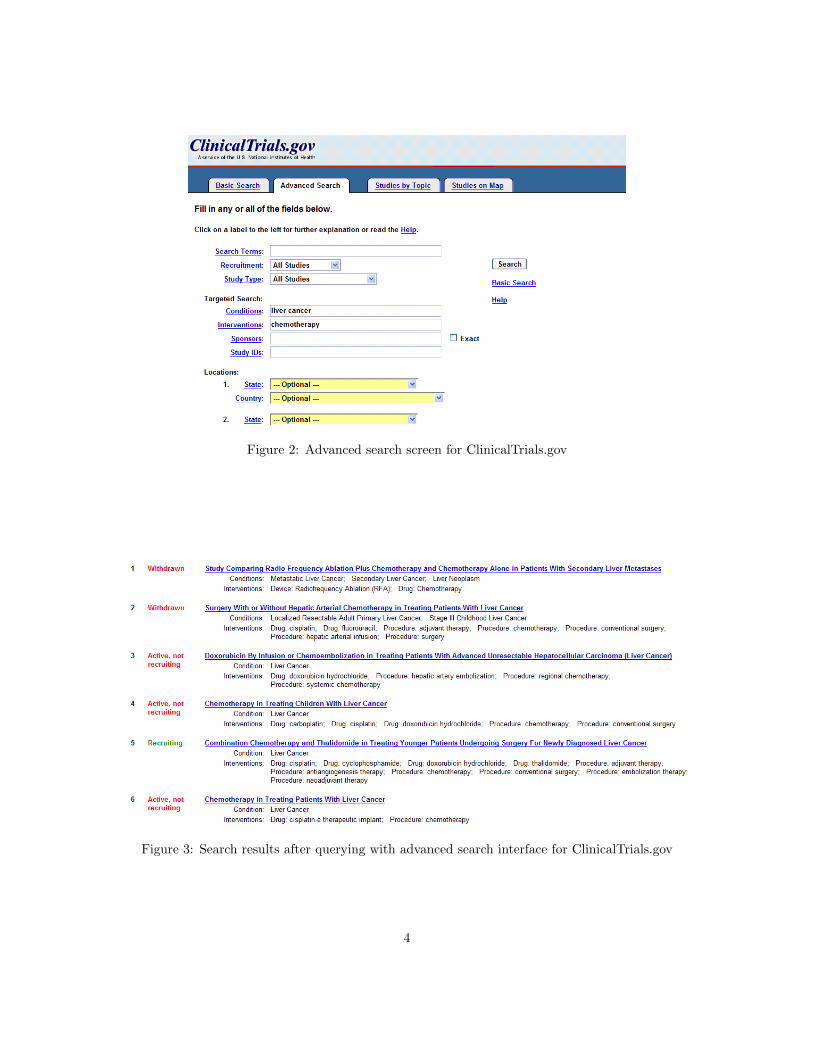
Figure 2: Advanced search screen for ClinicalTrials.gov
Figure 3: Search results after querying with advanced search interface for ClinicalTrials.gov
4

Google Refine, and the Yahoo! Search Assist.Google Suggest provides query refinement byguessing at what the user is typing and of-fering suggestions in real time. Google Refineprovides query refinement by listing facets as-sociated with the original query. The Yahoo!Search Assist expands on this idea by provid-ing a list of related topics as well as specificsuggested queries as a user types.
Although query refinement is reasonably newto mainstream search, researchers have ex-plored various techniques for over a decade,proposing several graph-based query refine-ment tools (see [3, 4]). These techniques al-low a user to design a query or refine searchresults via a graph, where nodes represent con-cepts and edges represent relationships betweenthose concepts. Although this approach ad-dresses specific issues in defining queries, it of-ten forces users to rely on reference terminolo-gies and to use a query interface that is morecomplex than natural language.
Another popular approach in query refine-ment is clustering, where results are groupedbased on some similarity measurement. Sev-eral search companies, including Clusty.com7
and Grokker8 have successfully used hierarchi-cal clustering. Clustering can be performedfully automatically and can sometimes discoverunexpected trends in data. However, clusteringalso suffers from a lack of predictability, diffi-culties with labeling, and sometimes inconsis-tent and un-intuitive sub-hierarchies [5].
Faceted search attempts to alleviate some ofthe difficulties of the graph-based and cluster-ing approaches. Faceted searches make use ofa set of hand-crafted categories. Each hier-archy of category represents a potential facet(feature) relevant to the data searched. Forexample, if the search domain was clinical tri-als, then the pre-defined facets include Condi-tions, Interventions, Outcomes, and Country.Faceted search combines browsing a referenceterminology with querying in the language ofthe user’s own terminology. Browsing refinesthe search results and allows exploration of spe-cific relationships in the data. Studies haveshown that users prefer faceted search inter-faces to traditional keyword-and-results inter-
7http://www.clusty.com8http://www.grokker.com
faces [5, 6]. As well, results have shown thatusers prefer categories to clustering [7].
A disadvantage to faceted search is that thecategories and facets must be pre-defined; thus,unexpected trends and relationships may re-main hidden. Moreover, faceted search inter-faces such as Flamenco [8] require highly struc-tured data, which may not always be available.The interface also does not permit explorationof multiple categories within the same facet.For example, in the “BioMedical Journal Ti-tles” demonstration of Flamenco9, in perform-ing a search for “cancer,” one of the avail-able facets is Medical Speciality. Within thisfacet, the display shows nine results withinthe Medicine category and two within Oncol-ogy category. What is not obvious is thatsome of the results from Oncology also occurwithin the Medicine category. Selecting ei-ther of these categories displays only their sub-categories and related facets. A user cannotsee the results common to both Medicine andOncology. Moreover, the disjunction of resultsbetween facets is difficult to discover.
Visualization techniques have been usedto support query formulation in information-seeking. Boolean queries are supported in toolssuch as VQuery [9] and InfoCrystal based onVenn diagrams [10]; the filter-flow model basedon a pipeline metaphor [11]; and the magiclenses interface [12]. However, research has re-peatedly shown that users find Boolean queriesconfusing and difficult to specify, in part due tothe differences between the meaning of Booleanoperators and the meanings of “and,” and “or”in natural language [13].
The Cat-a-Cone interface is a visualizationapproach that integrates query formulation andbrowsing query results. This approach sup-ports browsing of large hierarchies of termswith their corresponding text collections. Cat-a-Cone represents the hierarchy of terms as adynamic, three-dimensional tree where the se-lection of multiple terms forms a query. Cat-a-Cone was used to search and display resultsfrom MedLine, a repository of biomedical jour-nal publications. Nonetheless, research hasshown that graph-based depictions of textualinformation are unhelpful to the user, regard-
9http://orange.sims.berkeley.edu/cgi-bin/flamenco.cgi/medicine-automated/Flamenco
5

less of their attractive appearance [14].TileBars is a tool and approach for visual
summarization of query results. The TileBarstool represents query results as a list of hor-izontal bars, each bar representing one elec-tronic document. Each bar is divided into rowscorresponding to terms within the query [15].Squares along the rows represent the part ofthe document containing the pertinent terms,while color is used to represent the frequencyof terms. This approach seems promising forsearching for a few specific terms but does notseem appropriate to discover relevant informa-tion related to the formulated query. For exam-ple, TileBars may effectively display documentsthat contain “liver cancer” but will not list thedocuments that contain “Hepatocellular carci-noma” or “HCC”, although they are referringto the same medical condition.
The most recent visualization approach ap-plicable to information-seeking is the use of tagclouds. Tag clouds are compact visual rep-resentations of tags or annotations that de-scribe text-based information. The annota-tions can be individually or socially generated(folksonomies). Annotations consist typicallyof single words. A tag cloud is displayed in aparagraph format, typically with terms alpha-betically arranged. Font size and color repre-sent the frequency and age of a tag, respec-tively. Each tag has a hyperlink to a collectionof data resources correspondingly annotated.
The traditional use of tag clouds can be ob-served in CiteULike 10, an online social book-marking system for academic bibliographies.The user can query based on tags and re-ceive a list of citations of corresponding arti-cles, books, or other sources of information thatmatch the given tag. Note that query resultsrest on the union of tags. For example, query-ing for “hepatocellular carcinoma” (a type ofliver cancer) will bring all the resources taggedas “hepatocellular,” “carcinoma,” or “hepa-tocellular carcinoma.” Consequently, “breastcarcinoma” will be in the list of results eventhough “breast carcinoma” is not related to“hepatocellular carcinoma.” In CiteULike, atag cloud shows related tags from which theuser may select in further queries; unfortu-
10http://citeulike.org
nately, the current query is not subject to re-finement by selecting terms from the offeredtag cloud. A user can also search and filterthe tags in the cloud; for example, filtering on“ca” displays “cancer,” “classification,” “com-munication,” and “education.” However, thisfiltering does not affect the currently displayedlist of results.
The above techniques, although useful forspecific kinds of querying and browsing tasks,do not address the challenges of a user iter-atively browsing and comparing results froma semi-structured information space. Whatis needed is a technique that combines anoverview of the structured aspect of the results(i.e. the meta-data or facets) with an overviewof the unstructured data. The technique alsoneeds to support the user in iteratively refiningtheir queries, in a lightweight manner, provid-ing feedback on the refinements made and theimpact of the refinement on the results set. Inthe next section we discuss a technique whichprovides this user support.
4 Multiple synchronizedtag clouds for searchingclinical trials
Supporting a user in finding meaningful infor-mation in large collections of semi-structureddocuments demands a more flexible approach.We propose the use of multiple synchronizedtag clouds to summarize search results andto compare results along different dimensions(i.e. facets). With a summarization, a usercan further refine queries and narrow resultsto a more relevant set of documents. Whenthe user refines a query by selecting tags fromone facet, all the facets are updated due tothe synchronization of the tag clouds. Ourapproach is similar to faceted search in thatit combines browsing with result refinement;however, it does not rely on highly structureddata. Our approach relies on predefined cat-egories to group non-predefined terms (termsfreely assigned by the author of the electronicdocument) and supports multiple selections ofterms within each dimension (a feature unavail-able in faceted search.)
6

We designed and tested the tool CTSearchto query ClinicalTrials.gov and construct tagcloud representations of the results in combi-nation with traditional list-based results. SeeFigure 4 for a depiction of CTSearch. The userbegins with an initial query (at A) and thesystem provides the query results summarizedand grouped by meaningful categories, repre-sented as tag clouds (at B). Each tag cloudcorresponds to one dimension (or facet) of aclinical trial, for example, conditions, interven-tions, study design, and phases. Each tag cloudshows a view of the prevalent terms for eachfacet. Larger fonts are used for more frequentlyoccurring terms in the result set. The tra-ditional list of documents is displayed on theright side of the screen (at C). The user receivesfeedback regarding the number of results andthe query formulated at D.
Figure 5 shows how the user can further re-fine the query by manipulating the tag clouds.For instance, the user can see the relationshipbetween concepts within one dimension (i.e. asingle tag cloud) and across different dimen-sions by selecting tags (see Figure 4). For ex-ample, by selecting “hepatocellular” and “car-cinoma” in the “Conditions” tag cloud, all thenon-related tags become “greyed-out” acrossall tag clouds (see A). The tags “hepatocellu-lar” and “carcinoma” are also highlighted inthe list of results (darker tags in B). The userreceives feedback on the terms selected fromthe tag clouds at C. The number of resultsand the number of filtered documents are bothupdated at D. When the user selects multipletags, the query will consist of the intersectionor conjunction of the selected tags and originalquery, shown at C. Multiple selection of tagscan also occur within one tag cloud. Finally,the tag clouds are collapsible as shown at E inFigure 5 (the study design and phase tag cloudsare collapsed).
The last feature of CTSearch is that it willhighlight relevant tags for a given documentwhen the user hovers over a search result. Asdepicted in Figure 6, the user is hovering on thefirst result of the query “hepatocellular carci-noma in los angeles” to highlight correspond-ing terms that were extracted from this trial toform the different tag clouds (underlined andshown in light grey at A). This feature provides
feedback to the user about how the tag cloudswere constructed allowing them to recognizeterms associated with their current query tohelp facilitate further querying and refinement.
4.1 CTSearch architecture
CTSearch was developed completely in Java us-ing the Google Web Toolkit (GWT) 11 andExt GWT 12 for compilation and construc-tion of the front-end Javascript and HTMLcode. For performance reasons, offline, wedownloaded results from ClinicalTrials.gov andcreated a copy of their searchable document in-dex using Lucene 13. We modeled our clinicaltrial domain objects using the Eclipse Model-ing Framework (EMF) 14 and stored the in-dexed Java objects in a MySQL database usingthe Teneo/Hibernate framework 15. During in-dexing, we also perform the parsing to extractrelevant tags from all the searchable facets.
When a user executes a query with CT-Search, the query text is sent to our Java searchservlet asynchronously. The servlet executesthe query on the Lucene index and converts theresults into client-side Plain Old Java Objects(POJOs). The first ten results are packagedtogether, along with all the relevant facets andtheir corresponding tags, and the total numberof results found. For performance and read-ability, only the top 100 most frequent tags foreach facet are returned.
Selecting a tag in the interface results ina request being sent asynchronously to theJava search servlet (i.e. an AJAX approach).The original query text, along with any se-lected tags is used to construct an aggregateLucene query. For example, assuming the origi-nal search text was “hepatocellular carcinoma”and the condition tag “cancer” was selected,then the following query will be generated andexecuted on the server: hepatocellular carci-noma AND condition:cancer. Once this queryis performed, the same packaging of results iscarried out as the original search, and the clientside user interface updates in place and auto-matically (no page refreshing).
11http://code.google.com/webtoolkit12http://code.google.com/p/gwt-ext13http://lucene.apache.org14http://eclipse.org/emf15http://www.elver.org
7

Figure 4: Main results view of the CTSearch
Figure 5: Additional features of the results view
8

Figure 6: Highlighting terms
By mining the clinical trial data offline, re-stricting the number of tags per facet and byonly reporting a maximum of 10 results perpage, the performance of the system is fast andthe user to interface interaction has little to nodelay.
4.2 Summary
CTSearch provides a powerful and simple in-terface to aid the user in composing complexqueries as well as understanding the relation-ships between terms in their search results.The tag cloud approach draws the user’s at-tention to highly relevant terms, while the fil-tering draws their attention to how the data re-lates to the given query. By supporting queryconstruction through this dynamic visualiza-tion and aiding the user in their understandingof the data, we hope to facilitate query refine-ment and ultimately speed up the process ofdisseminating clinical trial search data.
In the next section, we discuss the designand results of the user study. In this pre-liminary study, we were interested in evalu-ating how easy the interface is to learn anduse, and whether the iterative query mecha-nism helps foster a more in depth understand-
ing of the semi-structured information spacethat promotes further exploration.
5 User study design
To evaluate CTSearch, we conducted a prelim-inary user study. The design of the study is asfollows:
Users: To gain insights on the use of CT-Search, we recruited 9 participants ranging inage from 25 to 60, from various occupationsand with various educational backgrounds. Wespecifically chose to recruit from a generic usergroup as one of the main populations reposi-tories such as ClinicalTrials.gov is targeting isthe general public, both for recruitment intotrials and for use by families of those involvedin trials.
Tools: In the study, we asked participants toperform search tasks using two different toolsfor searching clinical trial data. The tools usedwere the CTSearch tool and a Baseline toolthat provides the same look and feel as CT-Search, but only provides a paged list of resultswith no tag clouds. Thus, the only differencebetween the two tools is the availability of thesynchronized tag clouds.
9

Research Questions: Our goal in this pre-liminary study was to seek feedback on the fol-lowing three research questions:
1. Are multiple synchronized tag clouds use-ful for searching, browsing and performingquery refinement on clinical trial data?
2. What is the level of learnability, confi-dence, and user satisfaction while usingCTSearch and the Baseline tool?
3. What kinds of other features could behelpful in supporting users perform searchtasks of semi-structured data?
As this is the first evaluation of the CTSearchtool and the use of synchronized tag clouds,our research questions are conservative and theresults from this study will be used to designfuture studies as we refine the tool.
Tasks: We asked the participants to carry aset of 7 randomly pre-selected search tasks (fortraining) and one open-ended task (see Task#8 below) using CTSearch and the Baselinetool for searching clinical trial data. The orderof use for each tool was randomized. The tasksare as follows:
Task #1: Name three popular drugs thatwere used in trials to treat lung cancer.
Task #2: Find two drugs tested in few clini-cal trials for lung cancer.
Task #3: Find the trials that have treated de-pression in patients with lung cancer. Howmany and what type of interventions wereused?
Task #4: Find the trials that tested tamox-ifen for breast cancer. How many trialsare there? What study design features aremore common in these trials?
Task #5: Find the three medical conditionsmore commonly treated with the drug“Docetaxel”.
Task #6: Find the most frequent medicalconditions associated with Fibromyalgiaconsidered in clinical trials.
Task #7: Give one example of a type of can-cer that is not treated with chemotherapyin clinical trials. How would you doublecheck the validity of your example?
Task #8: (For each tool) Try two or morequeries of your own interest about medi-cal research and please describe what youlearn doing these queries.
Data collection and analysis: After aninitial description of the tools, the users wereasked to use each of the two tools (in random-ized order) for the tasks as listed above. Weasked the users to do “think-aloud” as they per-formed the tasks and to write their answers.We videotaped the sessions for later analysis.We then asked the participants to complete ashort survey asking about their experiences us-ing the two tools, and for more input on howthe tools could be further improved. Since thegoal of this study was to refine our design andto provide feedback for future studies, we fo-cused our analysis on observing the strategiesthe participants employed using each of the twotools, as well as analyzing their subjective ex-periences and preferences, and gleaning ideasfor future tool refinements.
6 Findings
For each of our three research questions, we de-scribe the findings from this preliminary study.
Research Question #1: Are multi-ple synchronized tag clouds useful forsearching, browsing and performingquery refinement on clinical trial data?
Below, we organize the findings relating tothis question based on each tool. We includeresults from the Baseline tool here to providecontext for the results gleaned from CTSearch.
CTSearch tool: All users exercised queryrefinement by selecting terms in the tag cloudswhile doing the training tasks and during thefree query period. The number of times a usermade use of this feature ranked from two to12 times. Although three users did use thequery refinement only a few times (four timesor less), they were able to accomplish sometasks by hovering on terms and by scrolling
10

the tag clouds. The size of the font was prop-erly inferred to represent the frequency of howoften a term appeared in the results. Partic-ipants appeared to be confident in providinganswers based on “skimming” the tag cloudsand by observing and comparing the size ofterms. Interestingly, users did not dismiss thetraditional list of results as a source of infor-mation and frequently referred to the list todouble check their impressions and possible an-swers. For example, if the user searched for“tamoxifen” and then selected “breast cancer”from the conditions tag cloud, he/she wouldread the conditions field from the list of resultsto validate that each document would contain“breast cancer”.
Three users were observed to experience amild level of frustration while using this tool.In all of these cases, the users could not ver-balize the strategy needed to solve the corre-sponding task and decided to move on to thenext task.
The users were asked to formulate two ormore queries of their own interest using CT-Search. One out of nine users refused to elab-orate free queries arguing that he/she did nothave an interesting query to formulate. Oneuser did 10 queries and was asked to stop dueto time constraints. One user performed 5,4 and 2 queries each, and three users per-formed 1 query. Some interesting commentswere: “I find drug names I am not familiarwith”, “Wow, melatonin is used for prematurebirth brain damage, wow this is interesting,this is the most interesting thing I learned thisweek” and “actually, I want to look for a couplemore”.
Baseline tool: Five users vocalized thatthey experienced mild to a high level of frustra-tion during the training tasks. In some cases,the users refused to finish the tasks; although,they were able to describe the steps needed toaccomplish the tasks. Three out of nine usersassumed an order of relevancy in the list of re-sults that would accommodate their needs. Forexample, for task #5 ”find three medical condi-tions more commonly treated with Docetaxel”,if the user searched for the drug “Docetaxel”then he/she thought the results were given inorder of relevancy for conditions. This false as-sumption meant that the user would look at the
first few results and would extract the medicalconditions to answer the assigned task.
Five of nine users refused to do free queriesusing the Baseline tool arguing that they didnot have a query of interest to formulate. How-ever, this behavior may be a result of the usergetting tired after doing the pre-defined tasks.We attempted to mitigate this by alternatingthe order of the tools for each user. Four userswere willing to elaborate free queries, threeusers elaborated one or two queries, and oneuser formulated seven queries.
Based on these results, and the level of usersatisfaction with CTSearch (discussed below),it appears that the multiple synchronized tagclouds were useful for searching, browsing andperforming query refinements on clinical trialdata.
Research Question #2: What is the levelof learnability, confidence, and user sat-isfaction while using CTSearch/Baselinetool?
To answer this question, we posed several di-rect questions to our participants through thepost-task survey. The results from these ques-tions are summarized in Figures 7 through 10.The results predominantly favoured CTSearchover the Baseline tool in all questions. Al-though we recognize that there may be a biason the part of the users to “vote for” the moresophisticated tool, their responses are congru-ent with our observations on their ease of useand the level of frustration observable in thestudies.
Figure 7: Results - I found the CT-Search/Baseline very useful for finding inter-esting information.
11

We also asked our participants if they foundthe synchronization between the tag cloudshelpful for interpreting and understanding thedata. All but one of the users indicated thatthey found the synchronization very useful, forexample, one user commented “selecting othertags associated with your keyword search helpswith either finding more relevant trials or nar-rows your search to a more specific trial.” Oneparticipant also commented that they foundthe clouds useful for understanding the fre-quency for how often a term appears in thetrial set. Seven of the 9 users also indicatedthey were confident about the reliability of theresults found through the tag cloud queries.
In general, comments on the CTSearch toolwere quite favourable, for example when askedif they found the tool difficult to use, two usersanswered: “No difficulties” and “I would liketo use this tool for all my internet searches”.Most of the users (7 of 9) also stated that thelinking between tag clouds helped them to in-terpret and understand the data. Some com-ments provided included: “Yes, I found look-ing at the words related to topic helped me re-fine my search. Keywords related to topic nar-rowed my focus on topics”, “Yes, by selectingother tags associated with your keyword searchhelps with either more relevant trials or nar-rows your search to a more specific trial”, andfinally “GREAT! It got you where you wantedto go”.
Overall, there were more negative commentson the Baseline tool, e.g. “I found it very busywith information everywhere”, “I lost moretime” and “I needed to check a large number ofpossibilities in order to answer the question.”
Research Question #3: What other fea-tures should be supported by a querytool for clinical trials?
We asked several questions through the sur-vey to help us answer this question. We alsonoted comments from users during the studytasks that related to tool features.
One particularly strong theme that appearedduring the survey and study tasks related todisplaying results of a “negative” search. Par-ticipants had a difficult time understandinghow to use the CTSearch tag filtering to un-derstand terms not included in the search result
Figure 8: Results - I found my experience usingCTSearch/Baseline very satisfying.
Figure 9: Results - I imagine that most peoplewould need to use CTSearch/Baseline for longperiods of time in order to understand a set ofdocuments.
Figure 10: Results - I experienced frustrationwhile using CTSearch/Baseline.
12

set. Participants were also not able to formu-late a logical NOT in their queries. We suggestthat CTSearch could be enhanced by providingtooling for removing trials that contain specificterms in the clouds. Currently, tags can onlybe selected to help prune the results, there isnot a direct way for eliminating a term as aform of pruning.
We also had one user indicate that theywould like to know the specific frequency of howoften a given tag appears in the trials ratherthan just the font size indication. Finally, oneuser indicated that it would be nice for theclouds to hide the non-relevant tags from thedisplay, rather than just “greying-out” the cor-responding tags. We still believe there is utilityin not completely hiding the terms when tryingto understand the term relationships, however,perhaps a toggle could be introduced for com-pletely hiding the terms.
Another feature requested by three users wasto list the results using a priority scheme suchas alphabetical or relevancy. It was not clear tothe user if there were any semantics associatedwith the order of results. Two users also sug-gested adding spelling correction and phrasesearch. One user suggested adding the abilityto compare results side by side. And finally,there were some suggestions to make more useof color and bold fonts, for example to relatesearch terms to keywords in the results.
7 Limitations of the studyand discussion of findings
Although our user study was a preliminarystudy, the feedback we received was very en-couraging on the novel technique we proposefor exploring semi-structured data. We re-cruited users without a computer science back-ground, as computer scientists may already befamiliar with constructing advanced queries.Also, we intentionally recruited users lacking amedical background. This way we could assesswhat they could learn from browsing a semi-structured information space that is not thatfamiliar to them. The training tasks we setwere biased towards the CTSearch, as we wereinterested in a particular set of information-seeking tasks that CTSearch was designed to
aid. We had previously noted experts in themedical domain struggling with similar queriesusing ClinicalTrials.gov. Hence, in this studywe also included a Baseline tool to check thatour previous anecdotal observations on suchdifficulties would hold for these queries. Thetraining tasks may also have influenced theopen-ended queries the users specified.
We also recognize that the participants couldhave perhaps guessed that the CTSearch toolwith tag clouds was the interface of interest tous as computer science researchers, therefore,we realize that they may have felt more inclinedto be in favour of CTSearch over the Baselinetool. However, our observations of how theyused both tools are in line with the responsesthey gave through the surveys. The users hadconsiderably more difficulties using the Base-line tool than CTSearch. We were encouragedto see that the participants easily learned theCTSearch tool and understood how the mul-tiple synchronized tag clouds supported itera-tive queries. Although everyday users are veryefficient at using Google style simple queries,they seldom make use of more advanced queries[1, 2].
In this study, we focused the use of synchro-nized tag clouds for clinical trial data. Giventhe positive response to the tool, future workwill include exploring this idea for both expertand novice users in specific domains. The studyalso provided us with many insights on how toimprove the tool for browsing semi-structuredinformation resources. It may also be usefulto explore if the tag cloud approach has appli-cation for structured data sources, which arecurrently best explored using approaches likefaceted search [16].
8 Conclusions
In this paper we discussed the problems as-sociated with information-seeking over semi-structured repositories. We also discussed anumber of existing query refinement, brows-ing techniques, and search visualization ap-proaches. Although many techniques relatingto this problem have been presented in the lit-erature, we found that none of the approachesaddressed the specific types of tasks we were
13

interested in addressing for the domain of clin-ical trials. Due to this, we designed a new ap-proach using multiple synchronized tag clouds.Although a naive view is to consider this as atrivial extension to tag clouds, it is much morethan that, as it combines ideas from facetedsearch (for highly structured data) with vi-sual search approaches (tag clouds) throughunstructured informally annotated data. Theclouds provide an overview of the results re-turned, but also facilitate query refinement byallowing users to prune their results based onselected tags. The “greying-out” of unrelatedterms helps facilitate the user’s understand-ing about how the terms and data relates.In contrast to approaches like faceted searchthat must be strategically architectured up-front, our approach is mostly data-driven andlightweight.
We combined these ideas into a search toolfor ClinicalTrials.gov called CTSearch. Weevaluated this initial application with a pre-liminary user study. The study aided us in an-swering three specific research questions we hadwith regards to the approach and has also pro-vided valuable information about how to im-prove the tool and carry out subsequent eval-uations. Finally, we feel that the approach iswidely applicable to many search domains andwe plan to pursue this with further research.
9 Acknowledgements
This work was supported by the National Cen-ter for Biomedical Ontology, under roadmap-initiative grant U54 HG004028 from the Na-tional Institutes of Health.
About the Authors
Maria-Elena Hernandez is a PhD Candidate inthe Department of Computer Science at theUniversity of Victoria, Canada. Ms.Hernandezis currently interested in: information visual-ization and retrieval of medical information; so-cial software; and teaching and learning toolsand strategies.
Sean Falconer is a PhD Candidate in the De-partment of Computer Science at the Univer-
sity of Victoria, Canada. Mr. Falconer is cur-rently interested in: information visualization,ontologies, algorithms, data structures, infor-mation retrieval, and data representation.
Dr. Margaret-Anne Storey is an associate pro-fessor of computer science at the University ofVictoria, a Visiting Scientist at the IBM Centrefor Advanced Studies in Toronto and a CanadaResearch Chair in Human Computer Interac-tion for Software Engineering. She is one ofthe principal investigators for CSER (Centrefor Software Engineering Research in Canada)and an investigator for the National Center forBiomedical Ontology, US. Her research goal isto understand how technology can help peopleexplore, understand and share complex infor-mation and knowledge.
Simona Carini is an analyst and programmer inDr. Sim’s medical informatics research groupat the University of California, San Francisco.Ms. Carini’s research interests include ontolo-gies for clinical research and eligibility crite-ria, automated information extraction of clin-ical trial features from published articles, andvisualization of clinical trial data.
Dr. Ida Sim is an associate professor of theDivision of General Internal Medicine, at theUniversity of California San Francisco UCSF.She is the director of the Center for Clinicaland Translational Informatics at UCSF and agraduate group member of the program in Bio-logical and Medical Informatics at UCSF. Herresearch interests are: informatics for clinicalresearch; clinical trial registration and publi-cation into structured knowledge bases; deci-sion support systems for evidence-based prac-tice; and economics of health information tech-nology.
References
[1] C. Silverstein, H. Marais, M. Henzinger,and M. Moricz, “Analysis of a very largeweb search engine query log,” SIGIR Fo-rum, vol. 33, no. 1, pp. 6–12, 1999.
[2] A. Spink, D. Wolfram, B. J. Jansen, andT. Saracevic, “Searching the web: The
14

public and their queries,” Journal of theAmerican Society for Information Scienceand Technology, vol. 5, no. 3, 2001.
[3] J. W. Cooper and R. J. Byrd, “Obiwan - avisual interface for prompted query refine-ment,” in HICSS ’98: Proceedings of theThirty-First Annual Hawaii InternationalConference on System Sciences-Volume 2,(Washington, DC, USA), p. 277, IEEEComputer Society, 1998.
[4] O. Hoeber, X.-D. Yang, and Y. Yao, “Vi-sualization support for interactive queryrefinement,” in IEEE/WIC/ACM Inter-national Conference on Web Intelligence,2005.
[5] M. A. Hearst, “Clustering versus facetedcategories for information exploration,”Commun. ACM, vol. 49, no. 4, pp. 59–61,2006.
[6] M. Kaki, “Findex: search result cate-gories help users when document rankingfails,” in CHI ’05, (New York, NY, USA),pp. 131–140, ACM, 2005.
[7] W. Pratt, M. A. Hearst, and L. M. Fa-gan, “A knowledge-based approach to or-ganizing retrieved documents,” in AAAI’99/IAAI ’99:, (Menlo Park, CA, USA),pp. 80–85, American Association for Arti-ficial Intelligence, 1999.
[8] M. A. Hearst, “Design recommendationsfor hierarchical faceted search interfaces,”in SIGIR 2006 Workshop on FacetedSearch, pp. 26–30, Aug. 2006.
[9] S. Jones, “Graphical query specificationand dynamic result previews for a digi-tal library,” in UIST ’98: Proceedings ofthe 11th annual ACM symposium on Userinterface software and technology, (NewYork, NY, USA), pp. 143–151, ACM,1998.
[10] A. Spoerri, “Infocrystal: a visual tool forinformation retrieval & management,” inCIKM ’93: Proceedings of the second in-ternational conference on Information andknowledge management, (New York, NY,USA), pp. 11–20, ACM, 1993.
[11] D. Young and B. Shneiderman, “A graph-ical filter/flow representation of booleanqueries: A prototype implementation andevaluation,” Journal of the American So-ciety of Information Science, vol. 44, no. 6,pp. 327–339, 1993.
[12] K. P. Fishkin and M. C. Stone, “Enhanceddynamic queries via movable filters,” inCHI, pp. 415–420, 1995.
[13] R. Baeza-Yates and B. Ribeiro-Neto, Mod-ern Information Retrieval. Addison Wes-ley, May 1999.
[14] M. A. Hearst and C. Karadi, “Cat-a-cone: an interactive interface for specify-ing searches and viewing retrieval resultsusing a large category hierarchy,” in SI-GIR ’97: Proceedings of the 20th annualinternational ACM SIGIR conference onResearch and development in informationretrieval, (New York, NY, USA), pp. 246–255, ACM, 1997.
[15] M. A. Hearst, “Tilebars: Visualization ofterm distribution information in full textinformation access,” in Proceedings of theConference on Human Factors in Comput-ing Systems, CHI’95, 1995.
[16] J. English, M. Hearst, R. Sinha,K. Swearingen, and K.-P. Yee, “Flexiblesearch and navigation using faceted meta-data,” 2002.
15




















