
Survey of Study Literature for Sign Language Synthesizer
21
Survey of Study Literature for Sign Language Synthesizer Haris Al Qodri Maarif 1) , Rini Akmeliawati 1) , Teddy Surya Gunawan 2) 1) Intelligent Mechatronics Research System Unit, Department of Mechatronics Engineering, Faculty of Engineering, International Islamic University Malaysia 2) Department of Electrical and Computer Engineering, Faculty of Engineering International Islamic University Malaysia Abstract Sign language synthesizer is a method to visualize the sign language movement from the spoken language. The sign language is not only hand movement but also the face expression. Those two elements have complimentary aspect each other. The hand movement will show the meaning of each signing and the face expression will show the emotion of a person. Generally, Sign language synthesizer will recognize the spoken language by using speech recognition, the grammatical process will involve context free grammar, and 3D synthesizer will take part by involving recorded avatar. This paper will analyze and compare the available method of sign language synthesizer.
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Survey of Study Literature for Sign Language Synthesizer

Survey of Study Literature for Sign LanguageSynthesizer
Haris Al Qodri Maarif1), Rini Akmeliawati1), Teddy Surya Gunawan2)
1) Intelligent Mechatronics Research System Unit, Department of Mechatronics Engineering, Faculty of Engineering,
International Islamic University Malaysia2) Department of Electrical and Computer Engineering, Faculty of
EngineeringInternational Islamic University Malaysia
Abstract
Sign language synthesizer is a method to visualize the sign
language movement from the spoken language. The sign language is
not only hand movement but also the face expression. Those two
elements have complimentary aspect each other. The hand movement
will show the meaning of each signing and the face expression
will show the emotion of a person. Generally, Sign language
synthesizer will recognize the spoken language by using speech
recognition, the grammatical process will involve context free
grammar, and 3D synthesizer will take part by involving recorded
avatar. This paper will analyze and compare the available method
of sign language synthesizer.

Introduction
The word of hearing/speech impaired (HSI) or deaf refers to the
person who has disability to hear voices and sounds. The sign
language (SL) is one of means used by HSI people to communicate
to normal people. But, unfortunately the number of people,
including the HSI people, who are familiar with sign language is
very limited. These cause difficulties in the communication
between the normal people and the HSI people.
There is no universal language of the sign language which is
proven by each country has their own sign language. For example,
Thai sign language (Werapan & Chotikakamthorn, 2004), British
sign language (Ohene-Djan & Naqvi, 2005), French sign language
(Lejeune, Braffort, & Desclés, 2002), and Chinese sign language
(Wang, Chen, & Gao, 2006). Malaysia has its own sign language,
known as Malaysia Sign Language (MSL) or Bahasa Isyarat Malaysia. As
described in (MFD, 2000), the MSL is derived from the American
Sign Language (ASL).
The technology to bridge the communication between HSI and
normal people is highly required. The means of the technology

which can help the HSI people are signing avatar, mobile TTYs,
Interactive Voice Response, Smart Internet Technology, and Video
Relay Service (Deaf, 2002). Those technologies help the
flexibility of the established systems, especially in terms of
mobility and durability.
To enhance the technology that helps the HSI people, the
attempt to provide technology that can result sign language
synthesizer is on the track. This is because the need of
communication in this era increases rapidly as people are more
mobile and flexible. It is no longer the era in which the HSI
person is treated as a minority group that has many limitations
in his/her life especially in communication, either direct
conversation would be tele-conversation with the
telecommunication tools. Therefore, a sign language synthesizer
is handy solution to this communication gap

Literature Review
The main idea of SL synthesizer depends on two main components,
i.e. speech recognition and signing avatar. Speech recognition is
analyzed by two common algorithms, i.e. lips reading and voice
recognition. Combination between two is an important part of the
SL synthesizer. The exact translation from spoken language will
be required to understand the meaning of the words. The following
process will be the signing avatar. The detail of both main
components will be explained in this section.
Speech Recognition
Speech recognition is the algorithm that allows recognition of
the speech and translates into some purposes. Speech recognition
is designed to translate voice into text. The research of speech
recognition is conducted by applying audio recognition and video
speech information process. From the oldest research (Petajan,
Brooke, Bischoff, & Bodoff, 1988) until the recent one (Daubias,
2002; Goecke, 2004), showed that the audio-video speech
recognition system is efficient in recognizing the voice from the
spoken language.

The general audio-visual speech recognition is divided into
two parallel stages: the lips reading and the voice recognition.
Figure 1 shows general flow of the audio-visual speech
recognition. In this system, voice and image are divided, and
then they are processed separately. After passing all processes
in each part, integration block combines result of two inputs,
and it is finally processed into recognition part, in this
diagram; search block is the final process.
Figure 1: General Process of the Audio-Visual Speech Recognition
Audio-visual integration solutions can be classified in three
different groups: early integration, late integration and finally
hybrid integration (Potamianos, Gravier, & A. Garg, 2003). In all
of these approaches the Hidden Markov Models (HMM) can be used to
perform the recognition. In hybrid integration the state emission

probabilities from the HMM theory (Rabiner, 1989) are evaluated
independently for the visual and the acoustic channel. However,
the Viterbi decoding is performed only once. The integration is
made on the emission probabilities level. This kind of feature
combination is known as multistream (Dupont & Luettin, 2000).
Signing Avatar
The basic idea of signing avatar is based on the recorded signing
avatar (Verlinden, Tijsseling, & Frowein, 2002). It described
about the work involved in the realization of a Virtual Human
signing the weather forecast on an Internet page. It has an
objective to achieve semi-automatic translation from text to SL.
With the use of a computer, sentences in a written language are
analyzed and transposed to a sequence of signs. Then the signs
are displayed using computer animation of an avatar.
The signing avatar uses synthetic signing (Elliott, Glauert,
Kennaway, & Marshall, 2000; Kennaway, 2002), and recorded signing
(Bangham, Cox, Lincoln, Marshall, Tutt, & Wells, 2000). The
general process of signing avatar is the conversion from text to

SL; it involves the capturing and animation of signs, and
publishes the avatar in a web page.
Figure 2: Signer with motion tracking devices (Verlinden, et al.,2002)
The possible sign in signing avatar recorded (Verlinden, et al.,
2002). The recording process utilizes the input devices: an
optical system for tracking facial expression, a magnetic body
suit for posture, and data gloves for hand and finger shapes.
With these devices on the body, the signer makes the signs of the

word and sentences. The equipment was originally developed for
capturing global movements like running or dancing.
For signing, the quality requirements of the capturing are
much higher than for previous applications of these techniques.
In SL, even the slightest difference in speed, direction or
gesture has a bearing upon meaning. But with the latest version,
motions, posture, hand shapes and facial expressions are captured
at very high resolution. The signs can be easily recognized when
the recorded motion data are visualized on the computer. For
visualization an avatar program is fed with the recorded data
from the three tracking systems. The avatar then makes the same
movements as the live person made with the equipment on.
Motion Capture
Signing avatar will involve motion capture or motion vector
recording process which records motion information for signing
avatar. Motion capture process must involve the sensor device
which can send information about position and orientation of each
joint in human body. The motion vector information will be saved

into animation file format after recorded by using camera or
particular sensor.
One of file formats which is widely used in motion capture
is .BVH, Biovision Hierarchy. The Biovision Hierarchy (BVH)
character animation file format was developed by Biovision, a
defunct motion capture services company, to give motion capture
data to customers. This format largely displaced an earlier
format Biovision providing skeleton hierarchy information as well
as motion data ("Biovision Hierarchy," 2012)
The other motion capture file formats are also possible to
be involved in 3D synthesizer. The variety of motion capture file
format is based on the development of gesture controllers, haptic
systems, motion capture systems, etc., on the one hand, and the
need of allowing virtual reality systems to inter-communicate
through control data, the question of gesture and motion takes
more and more importance.
Motion and gesture file formats are widely used today in
many applications that deal with motion and gesture signal. It is
the case in domains like motion capture, character animation,
gesture analysis, biomechanics, musical gesture interfaces,
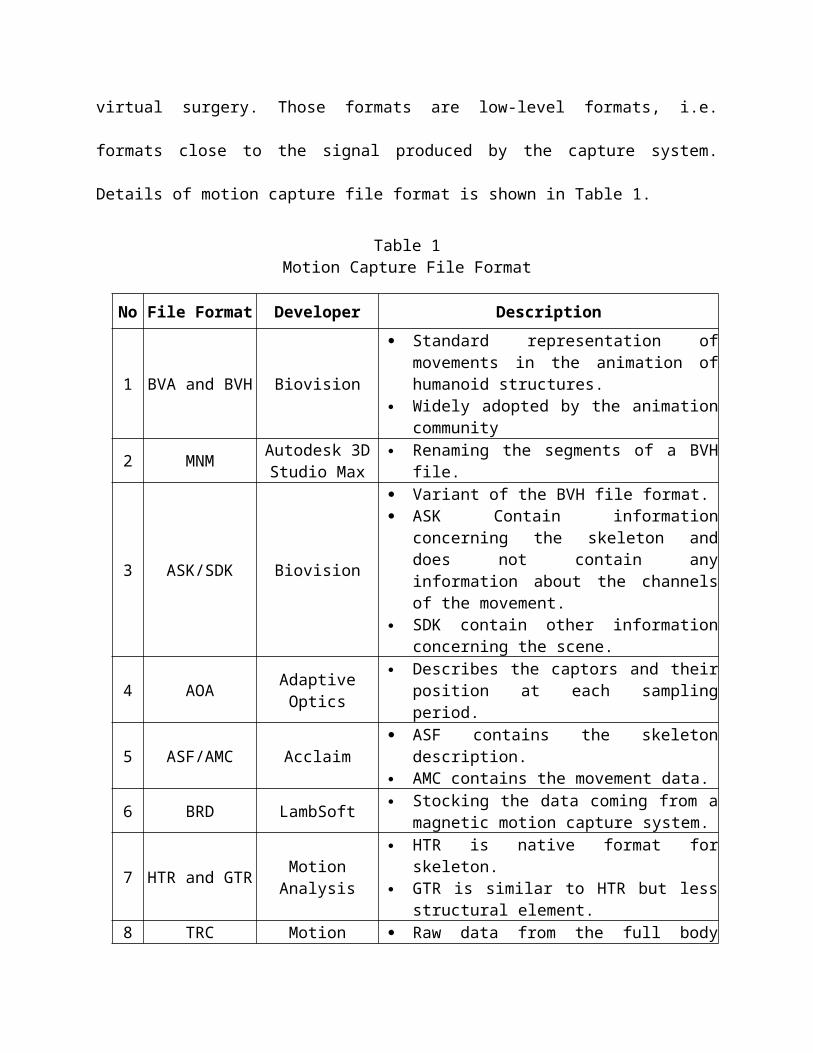
virtual surgery. Those formats are low-level formats, i.e.
formats close to the signal produced by the capture system.
Details of motion capture file format is shown in Table 1.
Table 1Motion Capture File Format
No File Format Developer Description
1 BVA and BVH Biovision
Standard representation ofmovements in the animation ofhumanoid structures.
Widely adopted by the animationcommunity
2 MNM Autodesk 3DStudio Max
Renaming the segments of a BVHfile.
3 ASK/SDK Biovision
Variant of the BVH file format. ASK Contain information
concerning the skeleton anddoes not contain anyinformation about the channelsof the movement.
SDK contain other informationconcerning the scene.
4 AOA AdaptiveOptics
Describes the captors and theirposition at each samplingperiod.
5 ASF/AMC Acclaim ASF contains the skeleton
description. AMC contains the movement data.
6 BRD LambSoft Stocking the data coming from amagnetic motion capture system.
7 HTR and GTR MotionAnalysis
HTR is native format forskeleton.
GTR is similar to HTR but lessstructural element.
8 TRC Motion Raw data from the full body

Analysismotion capture system.
Output data coming from facetracker
9 CSM CharacterStudio Importing marker data
10 V/VSK Vicon MotionSystem
Marker data. Global segment translation and
rotation data. Local rotation data (with root
translation data).
11 C3D
Binary file format. Stores 3D coordinate
information, analog data andassociated information used in3D motion data capture andsubsequent analysis operations.
12 GMS
Low-level data. Binary data. Minimal Size. Format for storing Gesture and
Motion Signals
13 HDF House ofMoves
includes all translationalmarker data as well as allrotational bone data in thescene and more.
3D Sign Language Synthesizer
The recorded motion vector (motion capture file) will be
transferred into 3D framework synthesizer. 3D framework
synthesizer will process the recorded motion capture file into
designated animation for signing avatar. Loading and retargeting

stage will involve in designing signing avatar ("Mocap: Load And
Retarget BVH," 2012).
There are couple software’s which can be utilized to process
the motion capture files. The open source and commercial
software’s are available. For instance, 3D Max and Blender
represent commercial and open source software, respectively
("Animation Export and Motion Transfer," 2012).
The Available Sign Language (SL) Synthesizers
The project of generating the SL in term of 3D animation has been
done. There are nine projects of SL synthesizer that can create
the sign animation from the text (Pyfers, 2011). The available SL
synthesizer is applied in Italy for Italian Sign Language (Atlas,
2011), Australia for Australian Sign Language-AUSLAN (Wong,
2004), United States of America for American Sign Language
(Wolfe, McDonald, & Schnepp, 2011),
Each of the available systems provides a method to perform
3D animation process. ATLAS for Italian SL uses three main
components to perform 3D animation, i.e. The Planner, Executor,
and Animation engine. Each of the components provides support to

show the animation process. Specifically, in Animation engine, it
relies on stored data repository which was recorded by using
Motion Capture or hand animated.
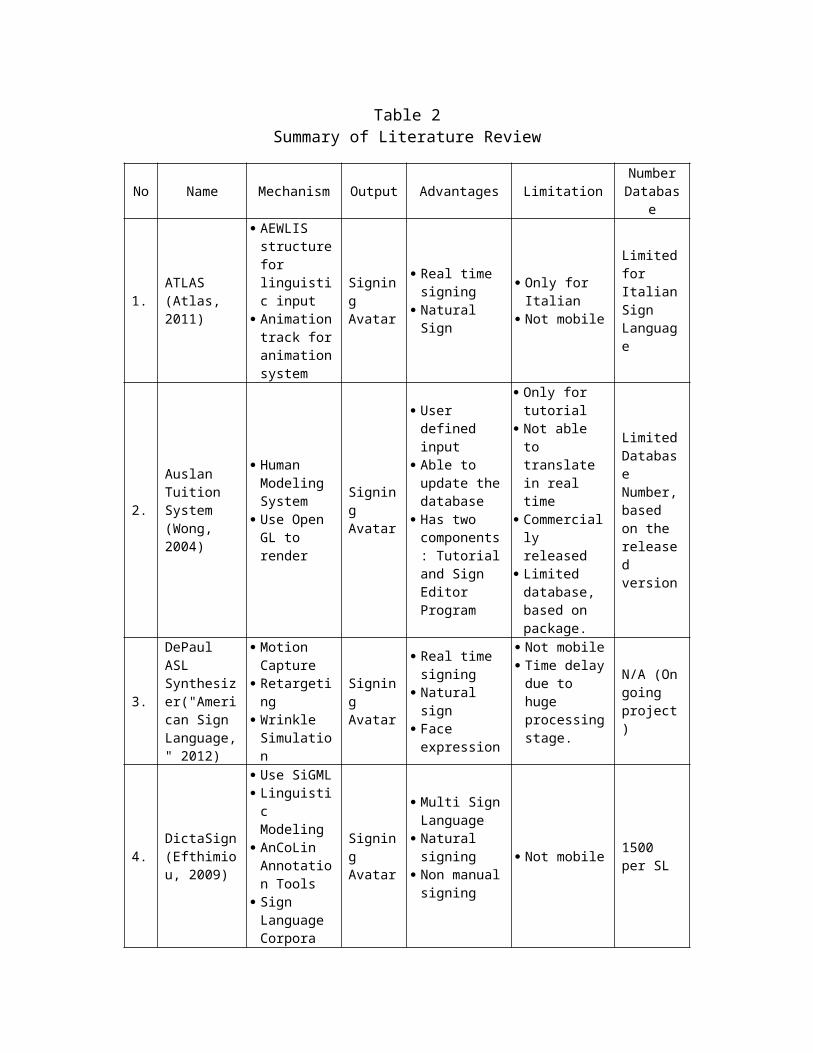
Table 2Summary of Literature Review
No Name Mechanism Output Advantages LimitationNumberDatabas
e
1.ATLAS(Atlas, 2011)
AEWLIS structurefor linguistic input
Animationtrack foranimationsystem
Signing Avatar
Real time signing
Natural Sign
Only for Italian
Not mobile
Limitedfor ItalianSign Language
2.
Auslan Tuition System(Wong, 2004)
Human Modeling System
Use Open GL to render
Signing Avatar
User defined input
Able to update thedatabase
Has two components: Tutorialand Sign Editor Program
Only for tutorial
Not able to translate in real time
Commercially released
Limited database, based on package.
LimitedDatabase Number,based on the released version
3.
DePaul ASL Synthesizer("American Sign Language," 2012)
Motion Capture
Retargeting
Wrinkle Simulation
Signing Avatar
Real time signing
Natural sign
Face expression
Not mobile Time delaydue to huge processingstage.
N/A (Ongoing project)
4.DictaSign(Efthimiou, 2009)
Use SiGML Linguistic Modeling
AnCoLin Annotation Tools
Sign Language Corpora
Signing Avatar
Multi SignLanguage
Natural signing
Non manualsigning
Not mobile 1500 per SL

5.
SASL-MT(Zijl & Olivrin, 2008)
Graphicalsigning avatar
Linguistics aspects
Data building and data entry tools
H-Anim standard
Signing Avatar
Pluggable Avatar
Reusable Avatar
Not yet deployed
N/A (Ongoing project)
6.
SiSi – IBM(Murph, 2007)
Voice to Sign Translation
Signing Avatar
Real time translation
Not mobile Only for BSL
Commercially released
Unlimited

AUSLAN for Australian SL uses Human Modelling System. It
involves a parametric human animation technique to provide 3D
animation of human body. It consists of Human Modeling Module
which provides for input and output of XML definition describing
the hierarchical object being modeled, the Rendering Module
displays the position of joints of the above kinematic tree
graphical, while the while the Model Interpolation Module
provides for input, output and high-level control of animations
between a set of model key frames (Yeates, Holden, & Owens,
2003).
American Sign Language specified the SL synthesizer by
allowing animation to adapt visual or gesture language. The
adaptation is applied by using hand shape, hand position, palm
orientation, and non manual signal. The system utilizes motion
capture which captures the movement of humans in real-time and
the data would be saved in order to be used on the 3D animation.
Conclusion
The 3D animation used for Sign Language synthesizer involves
motion capture or recorder avatar. It is applied in order to

decrease time consuming and complexity. The achievement by
proposed systems have shown the usage of motion capture or
recorded avatar. It has been a part of 3D animation system for
sign language synthesizer.
Motion capture method avatar has shown the benefits of the
systems. Some of the advantages of using motion capture are
ranging from real time results until less of the amount of work.
Real time results can be obtained, since the recorded motion is
similar to the real motion from the model. Less amount of work is
always obtained with the complexity or length of the performance
to the same degree when using traditional techniques.
Unfortunately, motion capture technique is limited into some
disadvantages. Firstly, it uses specific hardware and software
which are necessary to be owned with some high cost. It can limit
into small 3D animation production. The capture system may have
specific requirements for the space it is operated in. When
problems occur it is sometime easier to reshoot the scene rather
than trying to manipulate the data. Only a few systems allow
real time viewing of the data to decide if the take needs to be
redone. Applying motion to quadruped characters can be difficult.

Based on advantages of motion capture, utilization of motion
capture method will be more required in the future. The
development of motion capture can be proposed in order to support
3D animation process in the future.

References
. American Sign Language. (2012) Retrieved 23 March, 2012, fromhttp://asl.cs.depaul.edu/
. Animation Export and Motion Transfer. (2012) Retrieved 14December, 2012, from http://wiki.ipisoft.com/index.php?title=Animation_export_and_motion_transfer
Atlas. (2011). ATLAS - Automatic Translation into Sign LanguageRetrieved 23 March, 2012, fromhttp://www.atlas.polito.it/index.php
Bangham, J. A., Cox, S. J., Lincoln, M., Marshall, I., Tutt, M.,& Wells, M. (2000, April). Signing for the Deaf using Virtual Humans.Paper presented at the IEEE Seminar on Speech and LanguageProcessing for Disabled and Elderly People, London.
. Biovision Hierarchy. (2012) Retrieved 12 December 2012, 2012,from http://en.wikipedia.org/wiki/Biovision_Hierarchy
Daubias, P. (2002). Modèles A Posteriori De La Forme Et De L’apparence DesLèvres Pour La Reconnaissance Automatique De La Parole Audiovisuelle.l’Université de Maine France.
Deaf, A. A. o. t. (2002). Emerging Technologies : DiscussionPaper.
Dupont, S., & Luettin, J. (2000). Audio-Visual Speech Modelingfor Continuous Speech Recognition. IEEE Transaction on Multimedia,2(3).
Efthimiou, E. (2009). DictaSign Retrieved 23 March, 2012, fromhttp://www.dictasign.eu
Elliott, R., Glauert, J. R. W., Kennaway, J. R., & Marshall, I.(2000, November). The Development of Language Processing Support forthe ViSiCAST Project. Paper presented at the 4th International ACMSIGCAPH Conference on Assistive Technologies, Washington.
Goecke, R. (2004). A Stereo Vision Lip Tracking Algorithm and SubsequentStatistical Analyses of the Audio-Video Correlation in Australian English. TheAustralian National University Canberra.
Kennaway, R. (2002). Synthetic Animation of Deaf Signing GesturesLecture Notes in Artificial Intelligence (pp. 146-157).
Lejeune, F., Braffort, A., & Desclés, J.-P. (2002). Study onSemantic Representations of French Sign Language SentencesLecture Notes in Artificial Intelligence (pp. 197-201).

MFD. (2000). Bahasa Isyarat Malaysia (Vol. 1): Malaysian Federationof The Deaf.
. Mocap: Load And Retarget BVH. (2012) Retrieved 17 December,2012, from http://www.makehuman.org/node/286
Murph, D. (2007). IBM's SiSi virtually translates speech to signlanguage Retrieved 2 November, 2011, fromhttp://www.engadget.com/2007/09/13/ibms-sisi-virtually-translates-speech-to-sign-language/
Ohene-Djan, J., & Naqvi, S. (2005, July). An Adaptive WWW-BasedSystem to Teach British Sign Language. Paper presented at theConference on Advanced Learning Technologies (ICALT 2005).
Petajan, E. D., Brooke, N. M., Bischoff, B. J., & Bodoff, D. A.(1988). An Improved Automatic Lipreading System to Enhance SpeechRecognition. Paper presented at the Human Factors in ComputingSystem.
Potamianos, G., Gravier, C. N. G., & A. Garg. (2003). Recentadvances in the Automatic Recognition of Audio-VisualSpeech. IEEE, 91(9).
Pyfers, L. (2011). Open Sign from http://www.opensign.org/Rabiner, L. R. (1989). Tutorial on Hidden Markov Models and
Selected Applications in Speech Recognition. IEEE, 77(2), 257-286.
Verlinden, M., Tijsseling, C., & Frowein, H. (2002). A SigningAvatar on the WWW Lecture Notes in Artificial Intelligence (pp. 169-172).
Wang, C., Chen, X., & Gao, W. (2006, April). Expanding Training Set forChinese Sign Language recognition. Paper presented at theInternational Conference on Automatic Face and GestureRecognition.
Werapan, W., & Chotikakamthorn, N. (2004). Improved Dynamic GestureSegmentation for Thai Sign Language Translation. Paper presented atthe International Conference on Signal Processing (ICSP2004).
Wolfe, R., McDonald, J., & Schnepp, J. (2011, 10 - 11 Januari).An Avatar to Depict Sign Language: Building from Reusable Hand Animation.Paper presented at the International Workshop on SignLanguage Translation and Avatar Technology (SLTAT) FederalMinistry of Labour and Social Affairs, Berlin, Germany.

Wong, J. C. (2004, 25 March ). The Auslan Tuition SystemRetrieved 22 March, 2012, fromhttp://auslantuition.csse.uwa.edu.au/index.html
Yeates, S., Holden, E.-J., & Owens, R. (2003). An Animated AuslanTuition System. International Journal of Machine Graphics and Vision,12(2), 203-214.
Zijl, L. v., & Olivrin, G. (2008, April ). South African Sign LanguageAssistive Translation. Paper presented at the IASTED InternationalConference on Assistive Technologies, Baltimore, USA.




















