
Solving Sparse Least Squares Problems with Preconditioned Cgls Method on Parallel Distributed Memory...
18
Parallel Algorithms ami Applications, Vol. 13, pp. 289-305 Reprints available directly from the publisher Photocopying permitted by license only © 1999 OPA (Overseas Publishers Association) N.V. Published by license under the Gordon and Breach Science Publishers Imprint. Printed in Malaysia. SOLVING SPARSE LEAST SQUARES PROBLEMS WITH PRECONDITIONED CGLS METHOD ON PARALLEL DISTRIBUTED MEMORY COMPUTERS TIANRUO YANG"'* and H A I XIANG LIN'' " Department of Computer and Information Science, Linköping University, S-58183, Linköping, Sweden; ^Department of Technical Mathematics and Computer Science, TU Delft, P.O. Box 356, 2600 AJ Delft, The Netherlands In this paper we study the parallel aspects of PCGLS, a basic iterative method based on the conjugate gradient method with preconditioner apphed to normal equations and Incomplete Modified Gram-Schmidt (IMGS) preconditioner, for solving sparse least squares problems on massively parallel distributed memory computers. The performance of these methods on this kind of architecture is usually limited because of the global communication required for the inner products. We will describe the parallehzation of PCGLS and IMGS preconditioner by two ways of improvement. One is to accumulate the results of a number of inner products collectively and the other is to create situations where communication can be overlapped with computation. A theoretical model of computation and communication phases is presented which allows us to determine the optimal number of processors that minimizes the runtime. Several numerical experiments on the Parsytec GC/PowerPlus are presented. Keywords: Sparse least squares problems; PCGLS algorithm; Modified Gram-Schmidt preconditioner; Global communication and Parallel distributed memory computers 1 INTRODUCTION Many scientific and engineering applications such as linear programming [7], augmented Lagrangian method for computational fluid dynamics [15], and the natural factor method in structure engineering [3,17] give rise to the sparse least squares problems. Because the coefficient matrix is symmetric * Corresponding author. E-mail: [email protected]. (Received 11 March 1997: Revised 27 February 1998) 289
Transcript of Solving Sparse Least Squares Problems with Preconditioned Cgls Method on Parallel Distributed Memory...

Parallel Algorithms ami Applications, Vol. 13, pp. 289-305
Reprints available directly from the publisher
Photocopying permitted by license only
© 1999 O P A (Overseas Publishers Association) N.V.
Published by license under
the Gordon and Breach Science
Publishers Imprint.
Printed in Malaysia.
SOLVING SPARSE L E A S T SQUARES PROBLEMS WITH PRECONDITIONED C G L S
METHOD ON P A R A L L E L DISTRIBUTED M E M O R Y COMPUTERS
T I A N R U O Y A N G " ' * and H A I X I A N G L I N ' '
" Department of Computer and Information Science, Linköping University,
S-58183, Linköping, Sweden; ^Department of Technical Mathematics and
Computer Science, TU Delft, P.O. Box 356, 2600 AJ Delft, The Netherlands
In this paper we study the parallel aspects of PCGLS, a basic iterative method based on the conjugate gradient method with preconditioner apphed to normal equations and Incomplete Modified Gram-Schmidt (IMGS) preconditioner, for solving sparse least squares problems on massively parallel distributed memory computers. The performance of these methods on this kind of architecture is usually limited because of the global communication required for the inner products. We wil l describe the parallehzation of PCGLS and I M G S preconditioner by two ways of improvement. One is to accumulate the results of a number of inner products collectively and the other is to create situations where communication can be overlapped with computation. A theoretical model of computation and communication phases is presented which allows us to determine the optimal number of processors that minimizes the runtime. Several numerical experiments on the Parsytec GC/PowerPlus are presented.
Keywords: Sparse least squares problems; PCGLS algorithm; Modif ied Gram-Schmidt preconditioner; Global communication and Parallel distributed memory computers
1 I N T R O D U C T I O N
M a n y scientific and engineering applications such as linear p rogramming
[7], augmented Lagrangian method f o r computa t ional fluid dynamics [15],
and the natural factor method i n structure engineering [3,17] give rise to the
sparse least squares problems. Because the coefficient matr ix is symmetric
* Corresponding author. E-mail: [email protected].
(Received 11 March 1997: Revised 27 February 1998)
289

290 T. Y A N G A N D H.X. L I N
and positive definite, the no rma l equations o f the min imiza t ion p rob lem
can of ten be solved eff ic ient ly using the conjugate gradient method. The
resulting method is used as the basic iterative method to solve the least
squares problems. I n theory, i t is a s t ra ightforward extension o f the stan
dard conjugate gradient method. However, many variants o f these methods
appear to be numerical unstable. A comprehensive comparison o f d i f ferent
implementations can be f o u n d i n [6]. I n this paper we use the most accurate
version C G L S I as standard C G L S which w i l l be introduced later on.
Precondit ioning techniques that accelerate the convergence, such as col
u m n scahng and SSOR preconditionings [5], incomplete Cholesky factor
izat ion [20], po lynomia l precondi t ioning [1] and incomplete or thogonal
fac tor iza t ion [19,23] have received extensive at tention i n the literature. W e
consider i n this paper the Incomplete M o d i f i e d G r a m - S c h m i d t ( I M G S )
method as the preconditioner.
O n massively parallel computers, the basic t ime-consuming computa
t iona l kernels o f the iterative schemes are usually: inner products, vector
updates, ma t r ix -vec to r products, and precondit ioning. I n many situations,
especially when mat r ix operations are well structured, these operations are
suitable f o r implementat ion o n vector and shared memory parallel compu
ters [13]. But f o r parallel distr ibuted memory machines, the matrices and
vectors are distr ibuted over the processors, so that even when the ma t r ix
operations can be implemented efficiently by parallel operations, we cannot
avoid the global communica t ion required f o r inner product computations.
The detailed discussions o n the communica t ion problem o n distr ibuted
memory systems can be f o u n d i n [10,22]. I n other words, these global com
munica t ion costs become relatively more and more impor tan t when the
number o f the parallel processors is increased and thus they have the poten
t ia l to affect the scalability o f the a lgor i thm i n a negative way [9,10]. This
aspect has received much at tent ion and several approaches have been sug
gested to improve the parallel performance [2,10].
We also consider preconditioners because the precondi t ioning part is
o f t en the most problematic par t i n a parallel environment. These precondi
tioners should preferably have a good convergence rate, only a moderate
communica t ion cost, a h igh degree o f paralleUsm, and al low f o r a relatively
simple implementat ion.
I n this paper we focus on the I M G S preconditioner, because o f its exis
tence is guaranteed [24] theoretically and its special properties that can be
eff ic ient ly exploited to reduce the global communicat ion costs i n practice.
I n the present study we apply the techniques f o r reducing the global com
munica t ion overhead o f the inner products suggested by de Sturler and

CGLS M E T H O D O N P A R A L L E L COMPUTERS 291
van der Vors t [11]. I n our approach we ident i fy operations that can be
executed while communica t ion takes place ( for overlapping), and combine the
messages f o r several inner products. F o r P C G L S the first goal o f over
lapping is achieved by rescheduling the operations, w i t h o u t changing the
numerical stabiHty o f the method [12]. F o r I M G S precondi t ioning bo th
goals are achieved by re formula t ing the I M G S or thogonal izat ion procedure.
Several numerical experiments are carried out on the Parsytec G C /
PowerPlus at the N a t i o n a l Supercomputing Center, L i n k ö p i n g Universi ty.
These experimental results are compared to the results f r o m our theoretical
analysis.
I n Section 2, we describe short ly about P C G L S a lgor i thm w i t h the
I M G S preconditioner. Then we present the communica t ion model to be
used i n the theoretical analysis o f t ime complexity and a simple model f o r
computa t ion time and communica t ion costs f o r P C G L S and I M G S pre
condi t ioning i n Sections 3 and 4, respectively. I n Section 5, comparisons
between the sequential and the parallel performance are made th rough
bo th theoretical complexi ty analysis and experimentai observations.
2 P C G L S W I T H I M G S P R E C O N D I T I O N E R
Basically the linear least squares problem can be described as fo l lows:
m i n \\b — Ax\\2,
where A e R ' " ^ ", r a n k ( ^ ) = «, is a given matr ix .
I t is wel l k n o w n that x is a least squares solut ion i f and only i f the resi
dual vector r = b-Ax±TZ(A), or equivalently when A^(b - Ax) = 0. The
resulting system o f no rma l equations
A'^Ax = A^b
is always consistent.
The conjugate gradient method (CG) , developed i n the early 1950s by
Hestenes and Stiefel [18]. Because i n exact ari thmetic i t converges i n
at most n steps i t was first considered as a direct method. However, the finite
te rminat ion does not ho ld w i t h roundof f , and the method came in to wide
use first i n the mid-1970s, when i t was realized that i t should be regarded as
an iterative method. N o w i t has become a basic t oo l f o r solving large sparse
linear systems and linear least squares problems.

292 T. Y A N G A N D H . X . L I N
There are many different ways, a l l mathematically equivalent, to imple
ment the conjugate gradient method as described i n [6,25]. I n exact ar i th
metic they w i l l a l l generate the same sequence o f approximations, but i n
finite precision the achieved accuracy may d i f fe r substantially.
E l f v i n g [14] compared several implementations o f the conjugate gradient
method, and f o u n d C G L S l to be the most accurate. A small var ia t ion o f
C G L S l is obtained instead o f r = b-Ax, the residual to the no rma l equa
tions s = A^{b - Ax) is recurred, namely C G L S 2 which is bad w i t h regard
to numerical stabihty. Besides these two versions o f C G L S , Paige and
Saunders [21] developed algorithms based on the Lanczos bidiagonalizat ion
method o f G o l u b and K a h a n [16]. There are two fo rms o f this bidiagonah-
zat ion procedure, B id i ag l and Bidiag2, which result i n two algorithms w i t h
d i f ferent numerical properties. The comprehensive comparison o f these di f
ferent implementations has been done by B j ö r c k et al. [6]. They d id a
detailed analysis f o r the fai lure o f C G L S 2 and LSQR2 .
I n this paper, we choose the version o f C G L S l , namely the standard
C G L S , throughout the rest o f the paper as the basic method f o r solving the
least squares problems. The P C G L S which is the C G L S w i t h a precondi
tioner M can be sketched as fo l lows:
A L G O R I T H M P C G L S
Let X Q be an in i t i a l approximat ion and set
i'o = b - Axo, so=po = R ^{A^ro), 70 = {so,so),
f o r /c = 1 ,2 , . . . compute
qk = Atk;
Oik = ikl{qk,qk);
Xk+\ Xk + aktkl
i'k+\ = I'k - akqk',
Ok+\ = A^rk+\;
Sk+\ = R'^^Ok+w
ik+\ = {sk+\,sk+\);
lik = ik+\hk;
Pk+l =Sk+\ + PkPk'y

C G L S M E T H O D O N P A R A L L E L C O M P U T E R S 293
A l l the operations o f the P C G L S method, except f o r the update o f x,
must be computed i n sequence. Therefore attempts to p e r f o r m some o f
these statements i n P C G L S simultaneously are bound to f a i l . A better way
to paralleHze the P C G L S method is to exploit geometric parallelism. This
means that the data w i l l be distr ibuted over the processors i n such a way
that every processor is responsible f o r the computations on its local data.
I M G S is a mod i f i ed version o f Incomplete G r a m - S c h m i d t orthogonaH-
zation to obtain an incomplete or thogonal fac tor izadon precondit ioner
M = R, where A = QR + £" is an approx imaf ion o f a QR fac tor izat ion, Q
is a mat r ix and R is upper tr iangular mat r ix , respectively. A detailed
descripfion can be f o u n d i n [25].
Let P „ = {( / , ; • ) I i ^ J , 1 < iJ < «} and assume that the matr ix A has f u l l
rank. Suppose we are given a set o f index pairs P such that P G P„ and
{iJ)eP implies that i < j <n. The set P determines which elements o f the
mat r ix R w i l l be dropped i n the approximate factor izat ion, i.e., P is the
drop set. Given these assumptions, the I M G S precondit ioning technique
can be described as fo l lows:
A L G O R I T H M I M G S
Here a drop tolerance f o r elements P in R suggested by Jennings and
A j i z [19] is used, where the magnitude o f each off-diagonal element r,y is
compared against a drop tolerance r scaled by the n o r m o f the correspond
ing r o w \\aj\\2, i.e., \rkj\<Tdj, where T = 0.02 is recommended and
A = {ax,a2,ai,...,a„f, dj=\\aj\\2. (1)

294 T. Y A N G A N D H.X. L I N
I t can be shown that the choice o f P, not surprisingly, can be crucial no t
only to the quahty o f the preconditioner but also to the combined efficiency
o f the parallel implementat ion [24,25].
3 C O M M U N I C A T I O N M O D E L
We w i l l focus on the study o f the relative delaying effects o f global commu
nicat ion f o r P C G L S and I M G S precondi t ioning caused by the global com
munica t ion f o r the inner products.
The detailed description o f P C G L S and I M G S precondi t ioning can be
f o u n d i n [4]. Based on this mathematical background described i n Section 2,
we use the f o l l o w i n g assumptions described i n [11] f o r our communica t ion
model . Firs t , the processors are configured as 2-D gr id . Each processor
holds a suff icient ly large number o f successive rows o f the mat r ix , and the
corresponding sections o f the vectors involved. Tha t is, our problems have
a strong data locahty. Secondly, we can compute the inner products i n two
steps because the vectors are distr ibuted over the processor grids. A l l p ro
cessors start to compute the local inner product i n parallel. A n d after that,
the local inner products are accumulated on a central processor and broad
casted back to al l processors. The communica t ion time o f an accumulat ion
or a broadcast is o f the order o f the diameter o f the processor gr id . I n other
words, f o r an increasing number o f processors, the communica t ion t ime f o r
the inner products increases as wel l , and this is a potent ia l threat to the
scalabiUty o f our P C G L S and I M G S precondit ioning. I f the global commu
nicat ion f o r the inner products is no t overlapped, i t o f ten becomes a bott le
neck on large processor grids.
4 P A R A L L E L I M P L E M E N T A T I O N
I n this section we w i l l describe a simple performance model inc luding the
computa t ion time and communica t ion cost f o r the ma in kernels as we pre
sented before based on our assumptions. These two impor tan t terms in t ro
duced i n [11] are used i n our paper:
e Communication cost: The te rm to indicate al l the wall-clock time spent i n
communica t ion , that is not overlapped w i t h useful computa t ion .
e Commimication time: The term to refer to the wall-clock time o f the
whole communicat ion.

CGLS M E T H O D O N P A R A L L E L COMPUTERS 295
I n the non-overlapped communicat ion , the communica t ion time and the
communica t ion cost are identical.
4.1 Computation Time
The P C G L S a lgor i thm contains three distinct computa t ional tasks per
i terat ion:
• Four ma t r i x -vec to r products, BT^Pk, At^, A^r^^ i and Br'^6k+ u
• T w o inner products, {qj,, q^) and {sk+\,Sk+1);
e Three vector updates, Xk+i, i\+ \ a n d P k + i -
F o r the fixed parameter selecting pat tern o f I M G S preconditioner,
besides the general computa t ion which we need \{T? + Sn) inner products at
most, here we also need to compute n inner products f o r the drop tolerance
parameter 4= W^jWi, and i f (i,j)€P, we even do not need to compute the
inner products. So combining w i t h the above considerations, we use the
average number o f them as the estimated number o f the inner products i n
I M G S precondi t ioning procedure. Hence the I M G S precondi t ioning
requires approximately | ( « ^ + Sn) inner products, \{n^ -\- n) vector updates,
and n ma t r i x -vec to r products. The complete (local) computa t ion time f o r
I M G S precondi t ioning procedure is approximately
« ^ = ( Q " ^ + ^ « ) + " ( 2 « z - l ) ) f ^ f l , (2)
where NjP is the number o f unknowns to be computed locally by a pro
cessor, /n is the (average) t ime f o r a double precision floating po in t opera
tion, «2 is the average number o f non-zero elements per r o w o f the matr ix .
Therefore, the to ta l (local) computa t ion time f o r the P C G L S is
re^o"n,r = (10 + 4 ( 2 « . - l ) ) ^ r f l . (3)
4.2 Communication Cost
Let /s denote communica t ion start-up time and let the transmission time
f r o m processor to processor associated w i t h a single inner product compu
ta t ion be ?w and the diameter = y/P f o r a processor gr id w i t h P=p^ p ro
cessors. Then the global accumulation and broadcast t ime f o r one inner
product is
= = 2;'d(?s + /w), (4)

296 T. Y A N G A N D H.X. L I N
while the global accumulation and broadcast t ime f o r k simultaneous inner
products are Ipaits + kt^^). F o r the I M G S precondi t ioning procedure the
communicat ion time is the f o l l o w i n g :
Tl^r^r!=ïi"' + 5n)Péih + h.). (5)
F o r the P C G L S procedure the communica t ion time f o r the two inner p rod
ucts per i terat ion is
T!oTrt'=^Péih + h.). (6)
4.3 Communication Reduction for I M G S
I n order to construct the preconditioner, f i rs t a basis f o r the K r y l o v sub-
space has to be generated. F o r that purpose we use an m-step G M R E S [8]
to generate a basis w i t h vectors Vi,Avi,... ,A"vi f r o m the K r y l o v subspace
f i rs t , and then we orthogonahze this basis.
A f t e r generating a suitable in i t i a l basis, we can adapt the approach p ro
posed i n [11] f o r the G M R E S method o f overlapping the communica t ion
w i t h computa t ion to the I M G S precondi t ioning procedure. Instead o f com
put ing all local inner products i n one block and accumulating these par t ia l
results only once f o r the whole block, we can divide v , + i , . . . , v,„+i and
the r o w n o r m o f A in to block 1 and block 2, respectively. The overlap o f
the communica t ion and computa t ion t ime can be achieved by pe r fo rming
the accumulation and broadcast o f the local inner products o f the first
b lock concurrently w i t h the computa t ion o f the local inner products o f the
second block and pe r fo rming the accumulat ion and broadcast o f the local
inner products o f the second block concurrently w i t h the vector updates o f
v,+i , then we set the vj+i as the or ig inal value i f \hij\ <0.02dj. Similar ly we
compute ||V;+i I I 2 and normalize vj+\. W e can consider this k i n d o f variant as
a parallel version o f I M G S . The a lgor i thm Par I M G S is depicted as fo l lows:
A L G O R I T H M P a r l M G S
F o r = 1 ,2 , . . . , n do
set v , + i = v / + i ;
place Vj+\,..., v,i+\ in to b lock 1
place aj,...,aj, in to block 2
compute the local inner products f o r block 1

CGLS M E T H O D O N P A R A L L E L COMPUTERS 297
begin /*pardo/
accumulate the local inner products i n b lock 1
compute the local inner products f o r block 2
end /*pardo/
begin /*pardo/
accumulate the local inner products in b lock 2
update the vector v,+i
end /*pardo/
i f \hij\ < 0.02||a,||2 update v,-+i = vj+j
spht Vj+i in to block 1, b lock 2
compute the local inner products f o r b lock 1
begin /*pardo/
accumulate the local inner products i n block 1
compute the local inner products f o r b lock 2
end /*pardo/
accumulate the local inner products i n b lock 2
normalize vj+\
End
I f we assume that sufficient computat ional w o r k is available, then the
communica t ion cost T^^l^ can be almost neglected. I t can be easily seen
that the communica t ion cost f o r neighbor connections, l ike local start-up
times, can be overlapped. So i n such a case the communica t ion cost decreases
f r o m Q{7fy/P) i n non-overlapped execution to 9 ( « ) . I n other words, the
con t r ibu t ion o f start-up times to the communica t ion cost is reduced f r o m
Q{rP-\/P) to 9 ( « ) by using parallel I M G S precondi t ioning. I n many situa
tions we w i l l not have sufficient w o r k i n the inner products to completely
overlap al l communica t ion t ime. I n that case the wal l -c lock time f o r the
inner products is determined by the global communica t ion time
7^com™°' = 2«W/s + K " ' + 5" )w/w. (7)
The parallel computa t ion o f the K r y l o v subspace basis requires m extra
daxpys operations. Since this has to be done only once before the iterations,
we w i l l ignore these addi t ional computat ional cost i n our fur ther t ime
complexity analysis.

298 T . Y A N G A N D H . X . L I N
4.4 Communication Reduction for P C G L S
A l l the operations o f the P C G L S method, except f o r the update o f x, must
be computed i n sequence. Therefore implementat ion o f P C G L S by
at tempting to pe r fo rm some o f these statements simultaneously is bound to
f a i l . A better way to parallelize the P C G L S method is to exploit geometric
parallelism (e.g., th rough domain decomposition). This means that the data
w i l l be distr ibuted over the processor i n such a way that every processor is
responsible f o r the computations on its local data.
I n order to reduce the communica t ion overhead f o r P C G L S we adapt
the approach suggested in [12]. I n that approach the operations are
rescheduled to create more opportunit ies to overlap w i t h communicat ion.
The m a i n idea here is that postponing the update o f x, one i tera t ion does
not affect the numerical stability o f the a lgor i thm. This leads to the possibi
l i t y to corripute the update o f x while the processors are communicat ing
w i t h each other f o r the inner products. The parallel version o f P C G L S , the
a lgor i thm ParPCGLS, is depicted as fo l lows:
A L G O R I T H M Pa rPCGLS
1-0 = b - AXQ, SO=PO= M~'^{A'^ro), 70 = (^o,•^o)
f o r /c = 1 ,2 , . . . compute
Pk = Sk + Pk-\Pk-\\ (8)
tk = M~^pk; (9)
qk = Atk; (10)
Sk = {qk,qk)\ (11)
Xk = Xk-\ - f ak-\tk-{] (12)
Oik = Ik/Sk', (13)
rk+i = rk - akqk; (14)
dk+\ = A^fk+i; (15)
sk+i =M~'^0k+]; (16)
7k+l = {Sk+\,Sk+l); (17)
i f 7/t < t o l then (18)
Xk+\ = Xk + aktkl (19)
qui t
Pk = Ik+i/lk, (20)

CGLS M E T H O D O N P A R A L L E L COMPUTERS 299
The P C G L S can be eff icient ly parallelized as fo l lows:
• Only operations ( 9 ) - ( l l ) and (15)- (17) require communicat ion;
• The communica t ion required f o r the reduct ion o f the inner product (i.e.,
accumulation o f al l local inner products) i n (11) can be overlapped w i t h
the update f o r i n (12);
• Steps ( 8 ) - ( l l ) can be combined: the computa t ion o f a segment o f pk can
be fo l lowed immediately by the computa t ion o f a segment o f tk i n (9).
N e x t the computa t ion a segment o f qk i n (10) fo l lows, and finally the
computa t ion o f a par t o f the inner product i n (11) which can be per
fo rmed locally on a processor fo l lows . This saves on load operations f o r
segments o f pk, tk and qk\
o Pk can be computed as soon as the computa t ion i n (17) has been com
pleted. Whi le at the same time, the computa t ion f o r (8) can be started
since the required parts o f Sk have already been completed;
• The computa t ion o f segments o f Yk+i i n (14) can be fo l lowed by opera
t i on depending on the structure o f M i n (15) and (16), wh ich can be
fo l lowed by the computa t ion o f parts o f inner product i n (17).
By overlapping the communica t ion w i t h the computa t ion , the communica
t i o n cost f o r the inner products i n an i terat ion o f ParPCGLS can be signi
ficantly reduced especially on a large ensemble o f processors.
5 P A R A L L E L P E R F O R M A N C E
5.1 Theoretical Complexity Analysis
I n this section we w i l l first focus on the theoretical analysis on the perfor
mance o f P a r l M G S precondi t ioning and I M G S precondit ioning, then on
the performance o f t h e ParPCGLS and P C G L S algorithms.
The to ta l runt ime f o r I M G S is (Section 4)
T I I M G S _ T I I M G S I -T-IMGS P comp ' comm
= | " ^ + ^ " + " ( 2 « z - l ) ) ^ / n + ^(??^ + 5n)(?s + ? w ) \ / P . (21)
This equation shows that as P increases the second term, which corre
sponds to the communicat ion time, w i l l also increase. For suff icient ly large
P the communica t ion time can even dominate the to ta l runt ime.

300 T. Y A N G A N D H.X. L I N
Let Pn,ax denote the number o f processors that minimizes the to ta l r un
time f o r I M G S precondi t ioning. M i n i m i z a t i o n o f (21) gives
2(3«2 + 7 « ) 4 / 7 ( 2 « z - 1) Ntn
2/3
(22)
The percentage o f the computa t ion time to the to ta l runt ime Ep=Ti/Tp
f o r Pmax processors is given: Ep^^^ = 5 , where Ti = T^^^. This means that
5 o f the to ta l runt ime Tp^^^ is spent i n communicat ion!
F o r the P a r l M G S , the performance is improved because o f the created
overlap possibihties and reduced start-up times. Let PQVI as the number o f
processors f o r wh ich al l communica t ion can be precisely overlapped w i t h
computa t ion . I n other words, the communica t ion time T^o^^'^^ is equal to
the overlapping computa t ion time
N
I t can be easily derived that
Povl = («2 + 5n)tnN
4nts + {fi^ + 5n)ty,\
2/3
(23)
Based on these theoretical results, we distinguish three di f ferent situa
tions: i f P < Povi, there is no significant communicat ion visible. I f P > Povi,
then the overlap is not complete and the runt ime is determined by Tj^^^
plus a part o f the communica t ion . I f P = Povi, the communica t ion is com
pletely overlapped w i t h the computat ion. I f ts dominates the communica
t ion , then Povi > Pmax and f o r P < Pmax we can overlap al l communica t ion
after the reduction o f start-ups. A n d since | o f the time is spent i n com
munica t ion i n the or ig inal I M G S algor i thm, this means that w i t h the
P a r l M G S a lgor i thm we can reduce the runt ime almost by a factor o f three.
I f ts does not dominate the communicat ion, f o r example ts ~ tw and n is
large enough, we k n o w that the time is reduced by a factor o f almost two .
F o r the other cases, PQVI < Pmax> and when P = Pmax the runt ime can be
easily given.
Similarly, f o r P C G L S the communica t ion time dominates the to ta l r un
time f o r large P and a t ime o f | Tp^^.^^ is spent i n communica t ion where Pmax
is the number o f processors that gives the min ima l runt ime.
F o r the Pa rCGLS, we define Povi as the number o f processors f o r which
all communica t ion can be exactly overlapped w i t h computa t ion . O f course,
i t is the ideal si tuation. I t means that we have the to ta l communica t ion t ime

CGLS M E T H O D O N P A R A L L E L COMPUTERS 301
^cornrn^^^^ equal to the computa t ion time AlsxNjP, wh ich gives
Povl =
.2/3
F o r any number o f processors P , i f P < Povi, the communica t ion vanishes,
which gives a reduct ion by a factor o f e ( % / P ) . I f P > P o v i , the communica
t i on cost is given by
4(/s + / w ) \ / P - 4 ? n | .
I t can be easily shown that i n general i t yields Povi < P n
5.2 Numerical Experiments
I n the f o l l o w i n g we discuss the numerical experiments o n the parallel per
formance o f I M G S and P a r l M G S f i r s t on the Parsytec GC/PowerPlus mas
sively parallel system, then focus on the parallel performance o f P C G L S
and ParPCGLS. Since we are only interested i n the delaying effects relative
to the computat ional t ime, we w i l l only consider the time o f one i terat ion
o f each a lgor i thm.
As the test p roblem we use the d i f fu s ion equations discretized by f in i te
volumes in to a 100 x 100 gr id , resulting i n a symmetric definite penta-diag-
onal mat r ix corresponding to the 5-point star. The corresponding param
eter values are
Hz = 5, ta= 3.00 \x&, h = 5.30 us, = 4.80 ^is.
The theoretical results about P^^^ and Povi o f I M G S are Pn,ax = 700,
Povi = 330. The measured runtimes, efficiencies and speed-ups f o r I M G S
and P a r l M G S are given i n Table I .
T A B L E I Measured runtime, efficiencies and speed-ups for I M G S and ParlMGS
Processor grid IMGS ParlMGS Reduction (%) Processor grid
Tp is) Ep(Vo) Sp r^(s) Ep{%) Sp
Reduction (%)
10 X 10 0.703 69.\ 86.1 0.520 88.6 90.9 35.2 14x 14 0.656 49.0 98.5 0.483 70.4 177.6 35.9 18 X 18 0.607 38.5 117.5 0.364 59.8 308.5 65.2 2 2 x 2 2 0.618 29.8 120.8 0.332 51.2 328.6 85.7 2 6 x 2 6 0.634 21.2 114.6 0.320 43.4 336.3 97.8

302 T. Y A N G A N D H.X. L I N
I t can be observed that the runt ime o f the I M G S is about 35% more
than that o f the P a r l M G S on a 10 x 10 processor gr id and approximately
36% larger on a 14 x 14 processor gr id . However , on a 18 x 18 processor
gr id the runt ime o f the I M G S is already 65% larger than that o f the
P a r l M G S . F r o m then on the increase i n relative reduct ion o f runt ime
becomes more gradual and approaches to a m a x i m u m o f about a factor o f
two f o r P close to Pmax- Thcsc results are very much i n agreement w i t h the
theoretical expectations described i n Section 5.1.
The runt ime f o r I M G S is reduced by 7 % and 14% when increasing the
number o f processors f r o m 10 x 10 to 14 x 14 and 10 x 10 to 18 x 18,
respectively. W h e n the number o f processors is fu r ther increased the run
time only changes shghtly which is i n agreement w i t h our previous results.
This can be explained by the fact that a l though the computa t ion time is
reduced by using more processors, the communica t ion t ime increases as
more processors are used. Compar ing the runt ime o f P a r l M G S , i t can be
seen that the reduction is about 7% when increasing f r o m 10 x 10 pro
cessor gr id to 14 X 14 processor gr id and reduct ion is about 30% f r o m
l O x 10 to 1 8 x 18 processor gr id whi le the theoretical upper bound is 32%.
This superb speed-up is expected because we have P<Pos\ so that any
increase i n the communica t ion o f the inner product is completely annihi
lated th rough the overlapping w i t h computations. The reduction is
approximately 36% when increasing f r o m a 1 0 x 1 0 processor gr id to a
22 X 22 processor gr id which is less eff icient than before because the over
lap is no longer complete. I f we continue to increase the size o f the pro
cessor gr id , the efficiency decreases because f o r a fixed problem size the
communica t ion time increases and the overlap decreases due to the
decreased computa t ion time.
F o r P C G L S and ParPCGLS, the measured runt ime, efficiencies and
speed-ups f o r one i terat ion step are given i n Table I I . The theoretical
results about P^ax and Povi o f P C G L S are P n , a x = 1682 and Povi = 208.
T A B L E I I Measured runtime, efficiencies and speed-ups for PCGLS and ParPCGLS
Processor grid PCGLS ParPCGLS Reduction (%)
Tp (ms) Ep(%) Sp r^(ms) Ep(%) Sp
10 X 10 14.6 77.3 80.1 14.0 81.2 94.4 4.11
14x 14 11.4 62.1 116.2 9.22 76.0 174.2 19.12
18 X 18 9.61 48.8 132.4 8.91 55.2 185.5 7.28
2 2 x 2 2 8.82 40.2 148.6 8.20 46.4 192.3 7.03
2 6 x 2 6 7.96 31.1 154.7 7.23 35.7 199.5 6.70
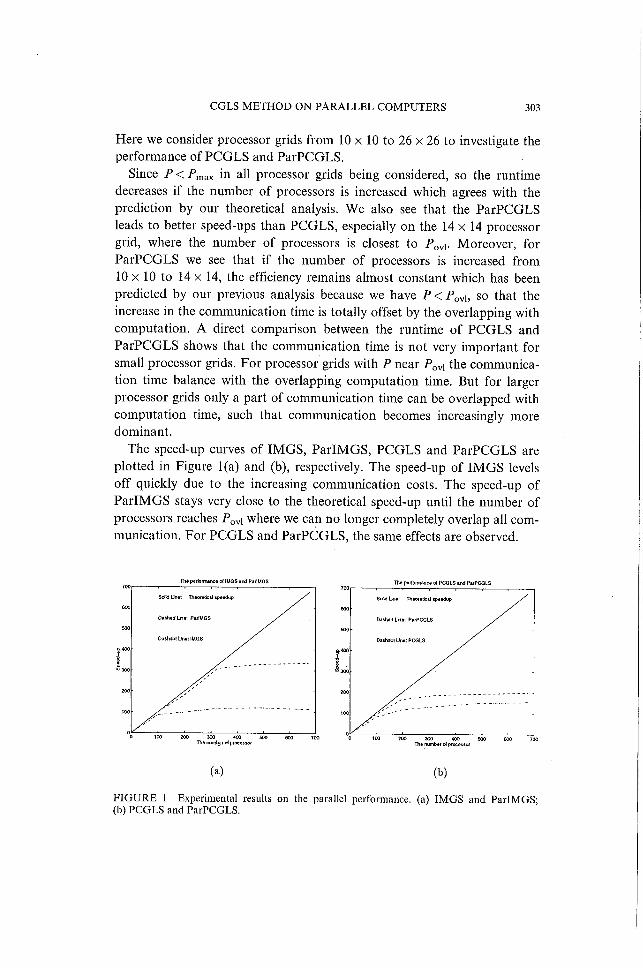
CGLS M E T H O D O N P A R A L L E L COMPUTERS 303
Here we consider processor grids f r o m 10 x 10 to 26 x 26 to investigate the
performance o f P C G L S and ParPCGLS.
Since P<Pmax i n a l l processor grids being considered, so the runt ime
decreases i f the number o f processors is increased which agrees w i t h the
predict ion by our theoretical analysis. W e also see that the Pa rPCGLS
leads to better speed-ups than P C G L S , especially on the 14 x 14 processor
gr id , where the number o f processors is closest to Povi. Moreover , f o r
Pa rPCGLS we see that i f the number o f processors is increased f r o m
10 X 10 to 14 X 14, the efficiency remains almost constant which has been
predicted by our previous analysis because we have P < Povi> so that the
increase i n the communicat ion time is to ta l ly offset by the overlapping w i t h
computa t ion . A direct comparison between the runt ime o f P C G L S and
Pa rPCGLS shows that the communica t ion time is no t very impor tan t f o r
small processor grids. F o r processor grids w i t h P near P Q V I the communica
t i on t ime balance w i t h the overlapping computa t ion time. But f o r larger
processor grids only a par t o f communica t ion time can be overlapped w i t h
computa t ion t ime, such that communica t ion becomes increasingly more
dominant .
The speed-up curves o f I M G S , P a r l M G S , P C G L S and ParPCGLS are
p lo t ted i n Figure 1(a) and (b), respectively. The speed-up o f I M G S levels
o f f quickly due to the increasing communica t ion costs. The speed-up o f
P a r l M G S stays very close to the theoretical speed-up u n t i l the number o f
processors reaches P Q V I where we can no longer completely overlap al l com
munica t ion . For P C G L S and ParPCGLS, the same effects are observed.
F I G U R E I Experimental results on the parallel performance, (a) IMGS and ParlMGS; (b) PCGLS and ParPCGLS.

304 T. Y A N G A N D H.X . L I N
6 C O N C L U S I O N S
We have studied the parallel implementat ion o f I M G S and P C G L S o n
massively distr ibuted memory systems. The experiments show how the
global communica t ion caused by the inner products degrades the perfor
mance on large processor grids. W e have considered alternative algori thms
f o r I M G S and P C G L S i n which the actual cost f o r global communica t ion
is decreased by reducing synchronization and start-up times, and over
lapping communica t ion w i t h computa t ion . The experiments show that this
is a very efficient approach.
References
[ I ] S. Ashby. Polynomial preconditioning for conjugate gradient methods. Ph.D. thesis, Department of Computer Science, University of Illinois at Urbana-Champaign, 1987.
[2] Z. Bai, D . H u and L . Reichel. A Newton basis GMRES implementation. Technical Report 91-03, University of Kentucky, 1991.
[3] M . W . Berry and R.J. Plemmons. Algorithms and experiments for structural mechanics on high performance architecture. Computer Methods in Applied Meclianics and Engineering, 64: 487-507, 1987.
[4] A. Björck. Numerical Methods for Least Squares Problems. S I A M , Philadelphia, PA, 1995.
[5] A . Björck and T. Elfving. Accelerated projection methods for computing pseudoinverse solutions of systems of linear equations. BIT, 19: 145-163, 1979.
[6] A . Björck, T. Elfving and Z. Strakos. Stabihty of conjugate gradient-type methods for linear least squares problems. Technical Report LiTH-MAT-R-1995-26, Department of Mathematics, Linköping University, 1994.
[7] I.e. Chio, C L . Monma and D.F. Shanno. Further development of a primal-dual interior point method. ORSA Journal on computing, 2(4): 304-311, 1990.
[8] A .T . Chronopoulos and S.K. K i m . i-Step O T H E R O M I N and GMRES implemented on parallel computers. Technical Report 90-R-43, Supercomputer Institute, University of Minnesota, 1990.
[9] L.G.C. Crone and H.A. van der Vorst. Communication aspects of the conjugate gradient method on distributed memory mechines. Supercomputer, X(6): 4-9, 1993.
[10] E. de Sturler. A parallel variant of the GMRES(f)i). I n Proceedings ofthe I3th IMACS World Congress on Computational and Applied Mathematics. IMACS, Criterion Press, 1991.
[ I I ] E. de Sturler and H.A. van der Vorst. Reducing the effect of the global communication in GMRES(;)0 and CG on parallel distributed memory computers. Technical Report 832, Mathematical Institute, University of Utrecht, Utrecht, The Netherlands, 1994.
[12] J.W. Demmal, M . T . Heath and H.A. van der Vorst. Parallel numerical algebra. Acta Numerica, Cambridge Press, New York, 1993.
[13] J.J. Dongarra, I.S. Duff , D.C. Sorensen and H.A. van der Vorst. Solving Linear Systems on Vector and Shared Memory Computers. S I A M , Philadelphia, PA, 1991.
[14] T. Elfving. On the conjugate gradient method for solving linear least squares problems. Technical Report LiTH-MAT-R-78-3, Department of Mathematics, Linköping University, 1978.
[15] M . Fortin and R. Glowinski. Augmented Lagrangian Methods: Application to the Numerical Solution of Boundary-value Problems. N H , 1983.
[16] G.H. Golub and W. Kahan. Calculating the singular values and pseudo-inverse of a matrix. SIAM Journal on Numerical Analysis, 2: 205-224, 1965.

CGLS M E T H O D O N P A R A L L E L COMPUTERS 305
[17] M . T . Heath, R.J. Plemmons and R.C. Ward. Sparse orthogonal schemes for structure optimization using the force method. SIAM Journal on Scientific and Statistical Computing, 5(3): 514-532, 1984.
[18] M.R . Hestenes and E. Stiefel. Methods of conjugate gradients for solving Hnear system. / . Res. Nat. Bur. Stds. B, 49: 409-436, 1952.
[19] A. Jennings and M . A . Ajiz. Incomplete methods for solving A^Ax = b. SIAM Journal on Scientific and Statistical Computing, 5: 978-987, 1984.
[20] J.A. Meijerink and H .A. van der Vorst. A n iterative solution method for linear system of which the coefficient matrix is a symmetric Af-matrix. Mathematics of Computation 31(137): 148-162, 1977.
[21] C.C. Paige and M . A . Saunders. LSQR: A n algorithm for sparse linear equations and sparse least squares. ACM Transactions on Mathematical Software, 8: 43-71, 1982.
[22] C. Pommerell. Solution of large unsymmetric systems of linear equations. Ph.D. thesis, E T H , 1992.
[23] X . Wang. Incomplete factorization preconditioning for linear least squares problems. Ph.D. thesis, Department of Computer Science, University of Illinois at Urbana-Champaign, 1993.
[24] T. Yang. Error analysis for incomplete modified Gram-Schmidt preconditioner. I n Proceedings of Prague Mathematical Conference (PMC-96), July 1996. Mathematical Institute of Academy Sciences, Zitza 25, CZ-115 67 Praha, Czech Republic.
[25] T. Yang. Iterative methods for least squares and total least squares problems. Licentiate Thesis LiU-TEK-LIC-1996:25, 1996. Linköping University, 581 83, Linköping, Sweden.





















