
Soft Scan - OCR for Programmer
21
Final Year Project – Documentation Soft - Scan Final Year Project COMP – 400B Advisor Dr. Nazim Ashraf Team Members Ajay Sagar Parwani : 14 - 10920 Rana Mohsin Sabir : 14 - 10815 Forman Christian College (A Chartered University) 1
Transcript of Soft Scan - OCR for Programmer

Final Year Project – Documentation Soft - Scan
Final Year Project
COMP – 400B
AdvisorDr. Nazim Ashraf
Team Members Ajay Sagar Parwani : 14 - 10920 Rana Mohsin Sabir : 14 - 10815
Forman Christian College (A Chartered University) 1

Final Year Project – Documentation Soft - Scan
Table of Contents
1. Abstract ____________ 3
2. Problem Statement ____________ 3 3. Literature Review ____________ 4 - 12
3.1 Optical Character Recognition ____________ 4
3.2 An Introduction to the process of OCR ____________ 5 - 6
3.3 Various Techniques for OCR ____________ 7 - 8
3.4 Optical Character Recognition for Handheld based Devices ____________ 9 - 10
3.5 Improving OCR ____________11 – 12
3.6 New Binarization Approach Based on Text Block Extraction ___________ 13
4. Method Used ____________ 14
5. Experiment & Results ____________15 - 20
6. Main Module Code ____________21 - 24
Forman Christian College (A Chartered University) 2

Final Year Project – Documentation Soft - Scan
Abstract
At the present time, human intervention from industries and organization are replaced to computing machines. Applications to fulfill the demands of organization are in high demand. Soft-Scan is a replica of human reading which might be an android application (or possibly desktop), which will be used to scan and convert it to editable files from captured or already scanned picture. The method used by the OCR – based Soft-Scan application is to convert digitized image into machine – encoded text that can be processed on machine. Application will used to enhance the content, create editable file in respective given format. However, existing optical character recognition applications making trade off between speed and accuracy, making it less attractive for large quantities of documents. Also those application do not deal with graphical objects for processing.
Keywords: Computer Vision, OCR, Correlation, Neural Networks, Digitization, Thinning Thresholding, Dark Background Images.
Problem Statement
Our problem falls under the umbrella of Computer Vision that converts captured or scanned image into editable text file. There are already many algorithms devised that solve the problem, but some are slow but accurate and others are vice versa.
We are trying to convert the scanned or captured Image containing text and graphics object into editable given respective format file, but the algorithms like Thresholding, Noise Reduction are just converting the text and if the image containing graphics object, the results comes out totally different. So we need a simple accurate and reasonable efficient algorithm that solve our desired problem. Text Segmentation with combination of some different algorithm would produce reasonable accurate results.
Forman Christian College (A Chartered University) 3

Final Year Project – Documentation Soft - Scan
Literature ReviewPaper – I
Optical Character Recognition
Summary
The paper titled Optical Character Recognition by Shalin A. Chopra, Amit A. Ghadge, Onkar A. Padwal, Karan S. Punjabi and Professor Gandhali S. Gujjar from Department of Computer Engineering, Sinhgad Academy of Engineering, Pune, India had discussed simple and basic steps of image containing fix font size and style of printed or handwritten text converting into editable file.
The research papers explained efficient way of converting image containing simple text of same font size and style into editable file. The simple OCR system claimed to be efficient because it uses database for recognition of English alphabets.
Author claimed that the success rate of text recognition in OCR had exceeded 99% for printed text. He discussed 5 steps for converting image into editable which were Image Scanning that simply dealt with the image to be scanned or captured. Next was pre-processing which included converted of colored image or grayscale image into binary containing only 0s and 1s, so that in next stage which was character extraction in which single character was isolated for further processing in next Recognition stage where each character was matched with the characters stored in database. The final stage requires human intervention when some unrecognized characters were allowed to give meaning to achieve better accuracy and greater range of recognition.
Relevant to WorkThe research paper dealt with processes involved in OCR system and provided a road
map to achieve simple basic goal of OCR.
Critics
Author had made too much assumptions on text either printed or handwritten that this method would only process the images which had same font size and style. It can be assumed for printed text but for handwritten text, it can vary from person to person and from time to time even for a single person.
Forman Christian College (A Chartered University) 4

Final Year Project – Documentation Soft - Scan
Paper – II
An Introduction to the Process of Optical Character Recognition
Summary
The paper titled An Introduction to the Process of Optical Character Recognition by Umal Patel from L.D College of Engineering, Gujarat Technology University, Gujarat, India had discussed the types, applications, problems and processes involved in OCR.
The research papers first explained different types of OCR based system, which can be offline or online systems. He further classified the areas falls in these categories that offline systems deals with captured or scanned image while online systems deals with the digital devices only.
The paper also discussed various applications of OCR based systems used by many organizations and multi-national companies which includes text recognition, writer recognition, signature verification, language identification and many more. Author had also discussed major problems in OCR systems which includes character fonts and noise present can affect the result that the processed character/text comes out totally different from actual character/text present in document.
Furthermore, the paper also dealt with the 7 phases involved in OCR process implemented in top-down approach. Author identified the first phase as Data Acquisition which required the image containing the data. Preprocessing, the second phase which was the most important component used for reducing noise and eliminating unnecessary data, for which the author discussed different solutions like noise reduction, thresholding, skew correction, stroke width normalization, thinning, filtering and noise modeling. Third phase, he identified was segmentation which separated every single character from noised free processed image. Normalization, as the fourth phase which reduced every single character to specific size depending on method used. Then next phase was Feature Extraction which minimizes the pattern variability based on 3 types of feature which were statistical, structural and global transformation into feature vectors. Classification as sixth phase which was used to train the neural net using feature vectors based on different methods. E.g.: K-Nearest Neighbour (k-NN), Neural Network (NN), Bayes Classifier, Support Vector Machine, etc. The last and the final stage was Post-Processing which was used for incorporation of context and shape information.
Forman Christian College (A Chartered University) 5

Final Year Project – Documentation Soft - Scan
Relevant to WorkThe research paper dealt with processes involved in OCR system what we are exactly
trying to accomplish in our application. Author had discussed some techniques of each process, which would be helpful in our work. Secondly it also deals with some problem while working on OCR system which would definitely provide help and guidance in our work possibly to improve or make some assumptions.
Critics
First. author had include some irrelevant information in the process involved in OCR systems. Secondly, he had only pointed out some techniques of pre-processing which are not discussed, even he had not provided a minor detail about those techniques.
Forman Christian College (A Chartered University) 6

Final Year Project – Documentation Soft - Scan
Paper – III
A Review on Various Techniques used for Optical Character Recognition
Summary
The paper titled A Review on Various Techniques used for Optical Character Recognition by Pranob K Charles, V.Harish, M.Swathi and CH. Deepthi from Department of Electronics and Communication, K. L. University. The paper discusses two major various techniques used for OCR and three major processes in each technique.
The research paper first explained three processes involved in OCR based systems which were document scanning that dealt with hardware used for scanning printed or handwritten text. Next he discussed recognition process which was core part of OCR system that includes complex algorithms for recognition of text and last verifying process which can be done randomly or chronologically by human intervention. In the document scanning process, author had pointed out a major issue of hardware that it should be of high quality and speed that is desirable for best results.
The paper also dealt with two major techniques used for OCR which are Correlation method which involved three stages that were pre-processing which dealt with the image itself not the content for noise reduction using technique of Digitization in which image was converted into binary image containing only 1 and 0 pixel value. Next step was segmentation in which the character from the image is found and cropped to size available in template, and last stage was recognition which matches the segmented character with character present in template. He also discussed this method for continuous character recognition which was exactly the same as for single character. The only difference was that the whole document was divided into lines and furthermore each line was divided in single character.
Second technique was Artificial Neural Network in which author discussed that it learns to identify through example. First the network should be trained through different examples and then later on it started to identify the characters. He also discussed two types of learning that were supervised learning in which network was started to learn through examples and the second was unsupervised learning which was difficult to implement.
Author also suggested that training should be done with and without noise in order for best and proper recognition, because text vary in font and even from person to person in case of handwritten text.
Forman Christian College (A Chartered University) 7

Final Year Project – Documentation Soft - Scan
Relevant to WorkThe research paper deals with different techniques used for OCR systems based
applications. It also provides a basic framework for beginner to start. The best thing of author was that he classifies each step and provide relevant information regarding implementation for Correlation method.
CriticsFirst, author had only focused on Correlation method, he had not discussed the Artificial
Neural Network for OCR in detail or even not provide basic information regarding this.
Forman Christian College (A Chartered University) 8

Final Year Project – Documentation Soft - Scan
Paper – IV
Design of Optical Character Recognition System for Camera-based Handheld Devices
Summary
The paper titled Design of Optical Character Recognition System for Camera-based Handheld Devices by Ayatullah Farukh Mollah, Nabamita Majumder, Subhadip Basu and Mita Nasipuri from India dealt with the OCR systems for Handheld devices processing images containing text embedded images/graphics.
The research paper discussed some disadvantages of using scanners compared to portable camera-based handheld device that they are slow and not portable, so for designing OCR systems for camera-based handheld devices would be beneficial and low cost effective.
Author also pointed some key issues when dealing with handheld digital devices that had low memory and processing power compared to desktop computes. So the OCR system should be simple, computationally efficient and light weight that could be executed easily on any handheld device which had a maximum processing power of 700MHz – 1GHz and memory of 128 – 256MB.
Author also discussed some researches made on handheld devices that were the first application designed for digital devices only focused on English captial letters, but was not accurate and satisfactory for real time applications. Second try was made by Motorola China Research Center which used in general correlation method for OCR that was designed as a two layer template based classifier. A similar system was presented for Chinese-English mixed script. Another work was done on Chinese script recognition for business card image.
Author suggested a method for converting color images to grayscale as camera-based handheld devices are capable of capturing color images containing three function in terms of red (i , j), green (i , j) and blue (i , j) respectively which can be converted to grayscale using grayscale(i , j) = 0.299 x red (i , j) + 0.587 x green (i , j) + 0.114 x blue (i , j)
Lastly, author suggested some algorithms could be best for using in handheld devices that were text – region extraction, binarization, skew correction and text region segmentation and showed their individual results.
Forman Christian College (A Chartered University) 9

Final Year Project – Documentation Soft - Scan
Relevant to WorkThe research paper deals with different techniques used for handheld device which is
more relevant with the next version of application that is handheld.
CriticsAuthor had only focused on processing of textual information.
Forman Christian College (A Chartered University) 10

Final Year Project – Documentation Soft - Scan
Paper – V
Improving Optical Character Recognition
Summary
The paper titled Improving Optical Character Recognition by AJ Palkovic from Villanova University, United States deals with accuracy and efficiency of OCR systems, and discussed five different algorithms falls in pre-processing stage discussed in previous papers. Author have suggested to implement these algorithms in GPU (Graphics Processing Unit) in order to achieve great accuracy and efficiency.
The research paper first discussed the process of Binarization that only need one bit to store the pixel value which is either 1 or 0. It had greatly reduced complexity of Image, if the image is colored which require 32 bits to store one pixel value. The image to be converted in binary, author had discussed 2 algorithms. Threshold Algorithm as first which is computationally fast but not accurate calculate an arbitrary color value T which is an average of whole image pixel value, so the pixel value decided for binary image was the value above T considered white and below considered black, but it created holes, when Threshold T value would be low and blurry, when Threshold T value would be high. To overcome, author suggested to apply local binarization which is accurate, but not computationally fast calculates by analyzing each pixel relative to pixels nearest in order to convert in either black and white, so the value T would be lower for darker text and higher for lighter text.
Next was Noise Reduction that can be applied on dirty, wrinkled and old documents which exist in two forms that were ON Noise in which black pixel should be white and OFF Noise in which white pixel should be black. So author discussed two algorithms for noise reduction that were Erosion for removing ON Noise and dilution for reducing ON Noise.
Thinning as the third algorithm that reduce the complexity of processing the image. It converts connected multiple black pixels in one row into one black pixel in middle, which reduces bold face letters into single thin pixel.
Next the author discussed was Skew Detection and suggested as good algorithm compared to others in terms of accuracy. The last algorithm was Text Segmentation which was used to isolate text from image containing different graphics objects.
The papers also discussed problems in first three algorithms that they are bit slow for large documents. Skew algorithm has two major problems that it does not working for the document which are skewed more than 45 degree and if the document contains graphics objects.
Forman Christian College (A Chartered University) 11

Final Year Project – Documentation Soft - Scan
Relevant to WorkThe research paper deals with different algorithms along with their respective
applications used in pre-processing phase. As we are also trying to find graphics objects in document like table, charts, etc so the Text Segmentation looks to be relevant for our work. Skew Detection would also be helpful in terms for improving the OCR system, if our document is skew to some amount.
CriticsAuthor had not discussed skew detection in details compared to other algorithms
discussed.
Forman Christian College (A Chartered University) 12

Final Year Project – Documentation Soft - Scan
Paper – VI
New Binarization Approach Based on Text Block Extraction
Summary
The paper titled New Binarization Approach based on Text Block Extraction by Ines Ben Messaoud, Hamid Amiri from Laboratoire des Syst` mes et Traitement de Signal (LSTS), Tunisia and Haikal El Abed, Volker Mrgner from Institute for Communications Technology (IfN) , Germany had discussed the reasons of noise present in image and how it affects the result and decrease the efficiency of system.
The research paper discussed different noise reduction methods to enhance the quality of grayscale image. The author proposed combination of preprocessing and localization method to find objects of interest. He suggested to integrate pre-binarization step that results creating better binary image. The methods were Shadding Correction that minimizes the multiplicative and additive components in image and or applying Weiner Filter to the neighbors of pixel p. Author performed some experiments on images having dirty background or shadows which create smooth and de-noised image. Localization was the next step to find objects of interest through Canny Edge Detection and Connected Components.
Author showed different combination of of noise reduction and localization methods used on images. The combination of Weiner filter and connected components create better results on images containing darker background.
Relevant to WorkThe research paper deals improving the result of images containing noise in order to find
accurate objects of interest.
CriticsAuthor had not provided detailed information about noise reduction method.
Forman Christian College (A Chartered University) 13

Final Year Project – Documentation Soft - Scan
Method Used
There are multiple methods for designing OCR systems like Correlation and Neural Network. All the methods having same stages, they only differ in recognition phase where they use different algorithms for character extraction and recognition.
The method we have used is Correlation method, because it require reasonable processing and storage resources. In Pre-Processing stage, we have converted an image into binary using general thresholding and using connected components for Segmentation phase.
Experiments and Results
To achieve the objective, we performed some experiments on pre-processing stage to convert either grayscale or colored image into binary image. We chose to starting working on MatLab and used their APIs. Initially we used built-in functions in MatLab. Later on for better results, we designed our own functions and used different techniques. Here are sample pictures.
Figure 1 Figure 2
Figure 3
Forman Christian College (A Chartered University) 14
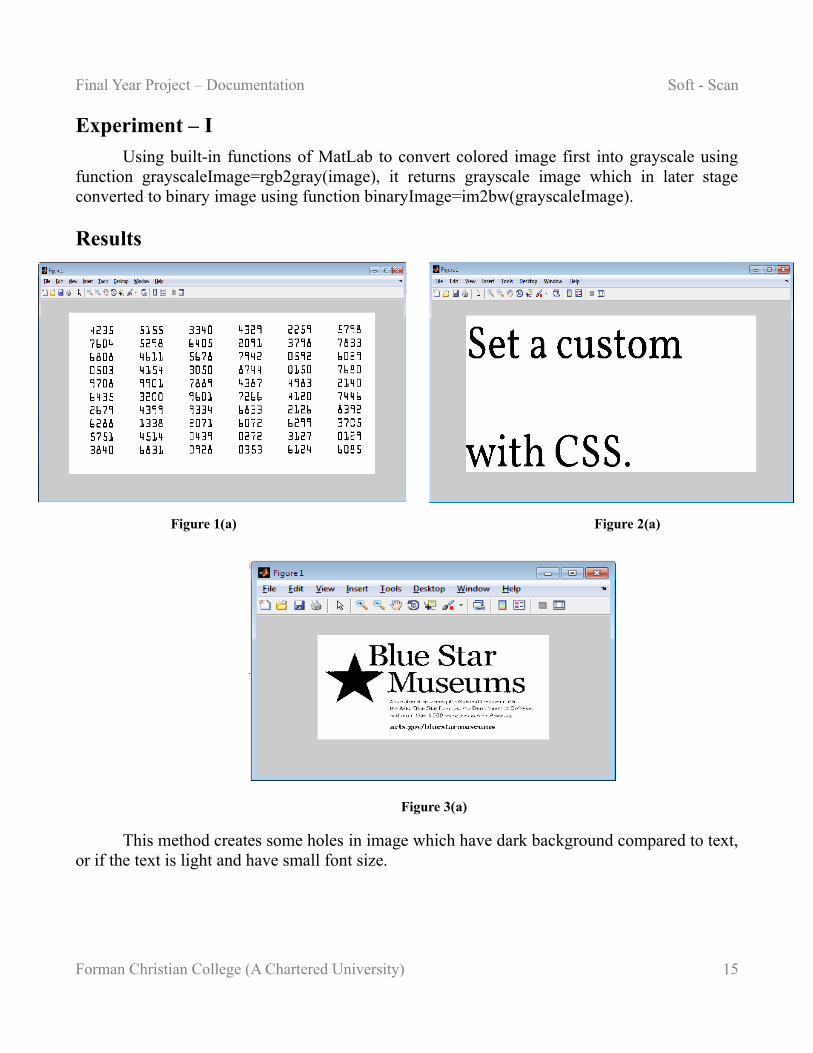
Final Year Project – Documentation Soft - Scan
Experiment – I
Using built-in functions of MatLab to convert colored image first into grayscale using function grayscaleImage=rgb2gray(image), it returns grayscale image which in later stage converted to binary image using function binaryImage=im2bw(grayscaleImage).
Results
Figure 1(a) Figure 2(a)
Figure 3(a)
This method creates some holes in image which have dark background compared to text, or if the text is light and have small font size.
Forman Christian College (A Chartered University) 15
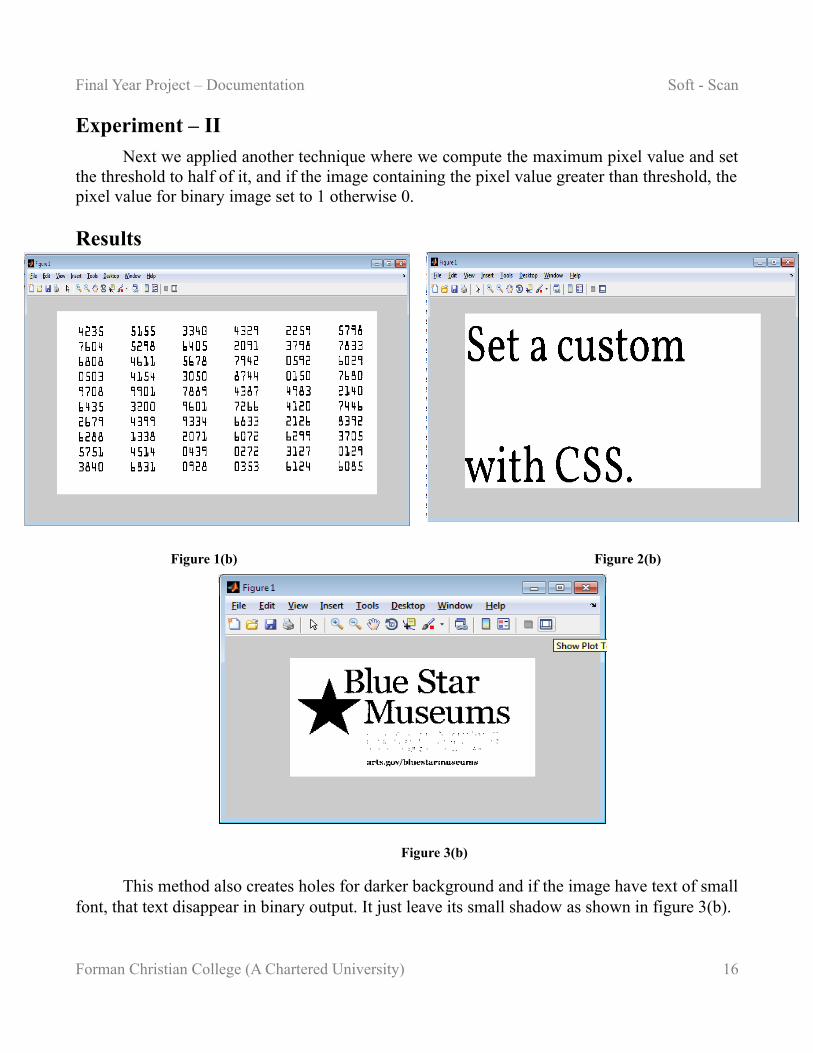
Final Year Project – Documentation Soft - Scan
Experiment – II
Next we applied another technique where we compute the maximum pixel value and set the threshold to half of it, and if the image containing the pixel value greater than threshold, the pixel value for binary image set to 1 otherwise 0.
Results
Figure 1(b) Figure 2(b)
Figure 3(b)
This method also creates holes for darker background and if the image have text of small font, that text disappear in binary output. It just leave its small shadow as shown in figure 3(b).
Forman Christian College (A Chartered University) 16

Final Year Project – Documentation Soft - Scan
Experiment – III
A common and mostly used technique for binary conversion is general thresholding where the value Threshold T is computed as the average value of all available pixel in image, and if the pixel value is greater than T, the pixel value for binary image is set to 1 otherwise 0.
Results
Figure 1(c) Figure 2(c)
Figure 3(b)
This method works well almost for all images, but it requires additional overhead of using thinning algorithm to convert bold face letters into simple, and if the image containing darker background and light text, the text becomes white which also need to be converted to black.
Forman Christian College (A Chartered University) 17

Final Year Project – Documentation Soft - Scan
Experiment – IV
In previous experiment, some important data is missed out due to dark background noise present in an image, so some of the characters become invisible due to white pixels, so complementing the above result, we get:
Results
Figure 2(d) Figure 3(d)
Forman Christian College (A Chartered University) 18

Final Year Project – Documentation Soft - Scan
Experiment – V
To find the objects of interest using Connected Components for Figure 2 from experiment III and IV, we get:
Results
Figure 2(e) Figure 2(f)
Connected components return the four boundary pixel of each character as shown in figure. The connected components with 1 and 3. For figure 2(d), it returns one component for 1st and 3rd line.
Forman Christian College (A Chartered University) 19

Final Year Project – Documentation Soft - Scan
Experiment – VI
In previous experiment, again some data is skipped or missed, because of the background present in figure 2(f) which forces to be the part of text without background, so using the pre-binarization method before image to be converted into binary, we get:
Results
Figure 2(g) Figure 3(e)
From the above results, the connected components are returned as exactly each character separated having its own 4 boundary pixels. Thinning algorithms can also be applied now to reduce the boldness of character.
Recognition
For recognition of particular character, a large number of test data is stored. To achieve greater accuracy, each possible character of different size and font is stored to train the network. We have worked for just times new roman with size varying from 12 to 30.
Forman Christian College (A Chartered University) 20

Final Year Project – Documentation Soft - Scan
References
1. Shalin A. Chopra, Amit A. Ghadge, Onkar A. Padwal, Karan S. Punjabi, & Prof. Gandhali S. Gurjar. (2014). Optical Character Recognition. International Journal of Advanced Research in Computer and Communication Engineering, 3(1), 4956-4958.http://www.ijarcce.com/upload/2014/january/IJARCCE2G_a_shalin_chopra_Optical.pdf
2. Umal Patel. (2013). An Introduction to the Process of Optical Character Recognition. International Research of Science and Research India, 2(5), 155-158.http://www.ijsr.net/archive/v2i5/IJSRON20131005.pdf
3. Pranob K Charles, V.Harish, M.Swathi, & CH. Deepthi. (2012). A Review on Various Techniques used for Optical Character Recognition. International Journal of Engineering Research and Applications, 2(1), 659-662.http://www.ijera.com/papers/Vol2_issue1/DB21659662.pdf
4. Ayatullah Farukh Mollah, Nabamita Majumder, Subhadip Basu, & Mita Nasipuri. (2011). Design of an Optical Character Recognition for Camera-based Handheld Devices. International Journal of Computer Science, 8(4), 283-289.http://arxiv.org/pdf/1109.3317.pdf
5. AJ Palkovic. Improving Optical Character Recognition.http://www.csc.villanova.edu/~mdamian/Past/csc3990fa08/csrs2008/07-csrs2008-AJPalkovic.pdf
6. Ines Ben Messaoud, Hamid Amiri & Haikal El Abed, Volker Mrgner. (2011). New Binarization Approach Based on Text Block Extraction. International Conference on Document Analysis and Recognition, 1205-1209. http://www.bibsonomy.org/bibtex/2dec52553a71c7b557417504d05200893/dblp
Forman Christian College (A Chartered University) 21




















