
Serial Combination of Multiple Experts: A Unified Evaluation
20
Pattern Analysis & Applications (1999)2:292–311 1999 Springer-Verlag London Limited Serial Combination of Multiple Experts: A Unified Evaluation A. F. R. Rahman and M. C. Fairhurst Electronic Engineering Laboratory, University of Kent, Canterbury, Kent, UK Abstract: Multiple expert decision combination has received much attention in recent years. This is a multi-disciplinary branch of pattern recognition which has extensive applications in numerous fields including robotic vision, artificial intelligence, document processing, office automation, human-computer interfaces, data acquisition, storage and retrieval, etc. In recent years, this application area has been extended to forensic science, including the identification of individuals using measures depending on biometrics, security and other applications. In this paper, a generalised multi-expert multi-level decision combination strategy, the serial combination approach, has been investigated from the dual viewpoints of theoretical analysis and practical implementation. Different researchers have implicitly utilised various approaches based on this concept over the years in a wide spectrum of application domains, but a comprehensive, coherent and generalised presentation of this approach from both theoretical and implementation viewpoints has not been attempted. While presenting here a unified framework for serial multiple expert decision combination, it is shown that many multi-expert approaches reported in the literature can be easily represented within the proposed framework. Detailed theoretical and practical discussions of the various performance results with these combinations, analysis of the internal processing of this approach, a case study for testing the theoretical framework, issues relating to processing overheads associated with the implementation of this approach, general comments on its applicability to various task domains and the generality of the approach in terms of reevaluating previous research have also been incorporated. Keywords: Character recognition; Generic serial framework; Multiple expert configurations 1. INTRODUCTION In the field of pattern classifier design, it is now accepted that the application of more than one classifier (expert) in a framework which allows their combination in such a way as to emphasise the strengths of the cooperating experts and counter-balance their deficiencies and weaknesses can be a very powerful approach in implementing robust and more efficient systems. There are numerous ways in which multiple experts can be combined to bring about recognition enhancement, but a topic that remains to be addressed in this context is the matter of deciding on an optimum combination for implementing a system for a particular task domain [1]. In early work on multiple expert combination techniques, the main topic of debate was the conflict between ‘multiple-expert versus multiple-level’ [2–4] con- figurations. More recently, a broader view has emerged, and many combination frameworks to categorise the various Received: 9 October 1998 Received in revised form: 5 March 1999 Accepted: 29 April 1999 approaches have been proposed (see, for example, Rahman and Fairhurst [5], Xu et al [6], Powalka et al [7], Kittler and Hatef [8], etc.). All of these frameworks attempt to present a unified and comprehensive view of the way in which multiple expert decision combination works, in order to enrich and enhance the quality of the combined decision with respect to the individual decisions of the participat- ing experts. In this paper, one particular multiple expert multiple level decision combination strategy, the serial combination approach, is investigated. No comprehensive, coherent and generalised presentation of this approach from both a theor- etical and implementation perspective has been attempted to date, yet this approach has been implicitly exploited in many different application domains. 2. GENERALISED MULTI-LEVEL MULTI- EXPERT APPROACHES Before examining the serial multiple expert decision combi- nation approach in detail, a brief introduction to the differ-
-
Upload
independent -
Category
Documents
-
view
0 -
download
0
Transcript of Serial Combination of Multiple Experts: A Unified Evaluation

Pattern Analysis & Applications (1999)2:292–311 1999 Springer-Verlag London Limited
Serial Combination of Multiple Experts:A Unified Evaluation
A. F. R. Rahman and M. C. FairhurstElectronic Engineering Laboratory, University of Kent, Canterbury, Kent, UK
Abstract: Multiple expert decision combination has received much attention in recent years. This is a multi-disciplinary branch of patternrecognition which has extensive applications in numerous fields including robotic vision, artificial intelligence, document processing, officeautomation, human-computer interfaces, data acquisition, storage and retrieval, etc. In recent years, this application area has been extendedto forensic science, including the identification of individuals using measures depending on biometrics, security and other applications. Inthis paper, a generalised multi-expert multi-level decision combination strategy, the serial combination approach, has been investigatedfrom the dual viewpoints of theoretical analysis and practical implementation. Different researchers have implicitly utilised variousapproaches based on this concept over the years in a wide spectrum of application domains, but a comprehensive, coherent and generalisedpresentation of this approach from both theoretical and implementation viewpoints has not been attempted. While presenting here aunified framework for serial multiple expert decision combination, it is shown that many multi-expert approaches reported in the literaturecan be easily represented within the proposed framework. Detailed theoretical and practical discussions of the various performance resultswith these combinations, analysis of the internal processing of this approach, a case study for testing the theoretical framework, issuesrelating to processing overheads associated with the implementation of this approach, general comments on its applicability to varioustask domains and the generality of the approach in terms of reevaluating previous research have also been incorporated.
Keywords: Character recognition; Generic serial framework; Multiple expert configurations
1. INTRODUCTION
In the field of pattern classifier design, it is now acceptedthat the application of more than one classifier (expert) ina framework which allows their combination in such a wayas to emphasise the strengths of the cooperating experts andcounter-balance their deficiencies and weaknesses can be avery powerful approach in implementing robust and moreefficient systems. There are numerous ways in which multipleexperts can be combined to bring about recognitionenhancement, but a topic that remains to be addressed inthis context is the matter of deciding on an optimumcombination for implementing a system for a particular taskdomain [1]. In early work on multiple expert combinationtechniques, the main topic of debate was the conflictbetween ‘multiple-expert versus multiple-level’ [2–4] con-figurations. More recently, a broader view has emerged, andmany combination frameworks to categorise the various
Received: 9 October 1998Received in revised form: 5 March 1999Accepted: 29 April 1999
approaches have been proposed (see, for example, Rahmanand Fairhurst [5], Xu et al [6], Powalka et al [7], Kittlerand Hatef [8], etc.). All of these frameworks attempt topresent a unified and comprehensive view of the way inwhich multiple expert decision combination works, in orderto enrich and enhance the quality of the combined decisionwith respect to the individual decisions of the participat-ing experts.
In this paper, one particular multiple expert multiplelevel decision combination strategy, the serial combinationapproach, is investigated. No comprehensive, coherent andgeneralised presentation of this approach from both a theor-etical and implementation perspective has been attemptedto date, yet this approach has been implicitly exploited inmany different application domains.
2. GENERALISED MULTI-LEVEL MULTI-EXPERT APPROACHES
Before examining the serial multiple expert decision combi-nation approach in detail, a brief introduction to the differ-

293Serial Combination of Multiple Experts: A Unified Evaluation
ent types of generalised multi-level multi-expert approachesis presented. The main attraction of multi-level multi-expertapproaches to decision combination is that these configur-ations implement a step-wise decision-making procedure.After the first global decisions are taken at the preliminarylevel in the decision hierarchy, the final decision is reachedthrough a step-wise refinement procedure. As the decisiontree is traversed in the forward direction, the decisionsbecome more and more refined, and the confidence associa-ted with the decision increases.
Many different approaches for implementing these hier-archical configurations can be visualised. The first is thedecision tree classifier. A decision tree classifier configurationconsists of a root-node, a number of nonterminal nodes anda number of terminal nodes. Associated with the root nodeis the entire set of classes into which a pattern may beclassified. A non-terminal node represents an intermediatedecision and its immediate descendant nodes represent thedecisions originating from that particular node. The decisionmaking process terminates at a terminal node and thepattern can be classified to belong to the class associatedwith that particular terminal node. The schematic of asystem incorporating these ideas is presented in Fig. 1. Themain attraction of this configuration is the way in whichthe number of alternatives to a possible identification for apattern is reduced, which allows the corresponding appli-cation of more focused algorithms to refine ambiguousdecisions. It is possible to design the configuration in a waythat enables only the most suitable features to be used intraining the decision making process associated with eachnode, thereby maximising the information usage of thecorresponding feature space. The important parameters inthese tree classifiers include the specific tree structure, theidentification of specific sub-feature space to be associatedwith each node and the decision rule to be implementedat each node.
Developing these principles further, it is also possible to
Fig. 1. A decision tree classifier configuration using multiple experts.
design a configuration where the decision process is itselfdistributed into several levels. These classifiers are knownas distributed decision tree classifiers. In this approach, thedecision tree is reconfigured in such a way that the inter-mediate nodes are now capable of becoming terminal nodes,based on satisfying some rule of termination in the overalldecision logic. So instead of having the constraint that eachpattern to be classified has to move through a specific paththrough the tree structure, it is possible to design decisiontree structures incorporating conditional terminal nodeswhich can be flexible enough to adapt to the recognitionrequirements of an individual unknown sample pattern. Theschematic of a system incorporating these ideas is presentedin Fig. 2. In such a generalised system, there are as manydiscriminators at each level as there are classes, K, and thedecision process is constructed by the logical intersection ofthe subset of classes accepted by the discriminators at eachsth level with the results of the intersection at the (s − 1)thlevel. The decision process stops at the sth level if theintersection at this level contains one class only, therebyrecognising the pattern. If the intersection contains no validclass, the pattern is rejected. Otherwise, if the intersectioncontains more than one accepted class, then the decisionprocess continues and the (s + 1)th level is activated. Obvi-ously, as the final level is reached the pattern is eitheridentified successfully or rejected as unrecognisable. Under-standably, such a generalised n level classifier configuration,incorporating Kxn discriminators, usually implies a highdegree of complexity.
There is considerable redundancy in the configuration justdescribed, and a logical step forward is to simplify thedesign. In a multi-class problem, only a subset of classes islikely to be similar, and a significant simplification can beachieved if it is possible to eliminate some of the unlikelyclasses. The design of such a simplified configuration canbe realised if a multi-layer serial classifier combination isvisualised. In such a configuration, the main objective is to
Fig. 2. A distributed decision tree classifier configuration using mul-tiple experts.

294 A. F. R. Rahman and M. C. Fairhurst
achieve decision refinement by allowing constituent layersof the hierarchy to progressively reduce the target size whichcontains the class indices of the possible classes to which apattern might belong. A classifier based on these ideas canbe designated a modified distributed decision tree classifier,and a general block diagram of such a hierarchical systemis presented in Fig. 3. The system is designed with n cascadedlayers of specific classifiers. The ith layer has the input(X,Si−1) and generates the output set Si, where X representsthe current pattern and Si represents the set of classes towhich the ith layer believes the pattern X might belongand Si is a subset of Si−1 (Sn , Sn−1. . ., S1 , S0). Duringthe classification process, if the ith layer outputs a singleelement, then the decision has been reached, and the processterminates with the pattern identified with the class associa-ted with this single element of Si. Similarly, if the finallayer, n, outputs a subset Sn which has more than oneelement in its list, then the process has failed to identifythe pattern uniquely, and the pattern is rejected.
It is evident that the modified distributed tree classifieroffers significant advantages in modelling the multi-expertmulti-level decision combination as it incorporates explicita priori information about the relationship of participatingindividual experts, their inter-dependence and interactionwith the target application domain in the system design, andalso because the complexity associated with such schemes isminimal. In this paper, a comprehensive evaluation of thisserial multiple expert multiple level decision combinationstrategy is presented that includes a complete theoreticalanalysis, discussions about the structural design parameters,implementation of case studies to investigate the validity ofthe proposed theoretical model and comments about theadvantages and disadvantages of such decision combination
Fig. 3. A modified distributed decision tree classifier configurationusing multiple experts.
schemes. Although the serial decision combination approachis completely generalised, and can be applied to manydifferent task domains, the investigation presented in thispaper is illustrated in the context of recognising machineprinted and handwritten characters, principally because ofthe ready availability of large quantities of training andtesting data.
3. REVIEW OF THE SERIAL APPROACHTO CHARACTER RECOGNITION
Researchers have, over the years, explored the technique ofserial multi-expert multi-level decision combination strategyto enhance the robustness of the combined decision. Someof these investigations are concerned with the theoreticalanalysis of multi-level structures, some are designed asempirical solutions to particular problems, and some arepseudo-analytical approaches to incorporate multi-level pro-cessing in task domains having higher degrees of difficulty.All of these approaches offer significant insight into theproblem of multi-level structures in individual cases, butnone provides a comprehensive and coherent overalldiscussion.
Pudil et al [9] have reported the idea of constructing amulti-stage serial pattern classification system with a rejectoption. They derived the conditions of a successful decisioncombination in terms of upper bounds of the cost of higherstage measurements for a multi-stage classifier to give lowerdecision risk than a single-stage classifier. They have alsodemonstrated that a multi-stage pattern recognition systemwith a reject option in all the stages except the final onecan yield a lower average decision risk than the commonlyused single-stage pattern classification systems. Fairhurst andMattaso Maia [10] have presented a comparative pseudo-analytical study of the functionality of bi-level pattern recog-nition architectures, describing the principal design factorsof significance in such architectures, and commenting onthe flexibility of such configurations in terms of operationalcharacteristics. They have also emphasised flexibility interms of performance and implementation characteristicsobtainable when a hierarchical multi-level structure isadopted for the design of memory network pattern classifiersin place of a conventional single-level structure.
Some researchers have sought to define optimal stages fora multi-stage classification system and the determinationof optimal recognition algorithms in multi-level systems.Kurzynski [11] derived the decision rules of a multi-stageclassification configuration based on a decision tree scheme.Two optimal Bayes strategies for performing the classificationat each non-terminal node have been derived. The firstoptimal strategy uses features connected with particularnodes of a tree, whereas the second strategy takes intoaccount all the measured features. Fairhurst and AbdelWahab [12] have also investigated various serial multi-levelstructures for character recognition. They presented a multi-expert multi-level architecture, where the allocation ofdecision-making between different layers in the overall con-

295Serial Combination of Multiple Experts: A Unified Evaluation
figuration has generally been such that the classificationcomputation is divided into clearly disjoint operations par-titioned among the processing layers. They demonstrate howintroducing a degree of interaction between the compu-tational layers can enhance error-rate performance and offerincreased structural flexibility. Fairhurst and Mattaso Maia[13] introduced a novel multiple level system architecturewhich allows an improved performance index when com-pared with a conventional single level classifier structure.The authors point out that, although memory-based patternclassification systems can be very attractive in terms ofstructural simplicity, flexibility of application and potentialoperating speed, most practical applications involve a trade-off between attainable performance and storage required forimplementation, which can be considerable. Fairhurst andMattaso Maia [14] have also carried out investigations intodifferent strategies for storage allocation in a multi-levelmemory pattern classifier, with specific reference to decisionrefinement between processing levels.
Bubnicki [15] introduced the problem of optimisation ofa two-level classifier as opposed to the relatively commonsingle-level classifier combinations. The idea of pattern rec-ognition in the two-level system depends on executing therecognition taking into account not only the directly meas-ured features, but also features which have been previouslytransformed during identification or recognition procedures.Jozefczyk [16] investigated a specific two-level system, anddiscussed the application of linear decision functions to thedetermination of the optimal recognition algorithms in theframework of a multi-stage classification configuration.
There have also been attempts to formalise the multi-level multi-expert serial approach from a completely theor-etical point of view. Tang et al [17] proposed a novelapproach to systematically analyse the changes in entropywhich occur in the different stages of a pattern recogniser.It models the entire pattern recognition system as a MultipleLevel Information Source (MLIS). For a typical recognitionsystem, there are four levels in this information source, IS1to IS4, and they can be divided into two categories: entropy-reduced and entropy-increased. By examining the internalstructures of a pattern recognition system, it is possible touse MLIS to address all the different factors which increasethe entropy at the different levels of the entire system. Atheoretical analysis of the entropy distribution in the MLISindicates that, to improve the performance of a patternrecognition system, the entropy of the MLIS must bereduced in all the different levels. Elsewhere, Wang andSuen [18] have analysed the general decision tree classifierwith overlap based on a recursive process of reducingentropy. They show that when the number of pattern classesis very large, a theoretical analysis can reveal both theadvantages of tree classifiers and the main difficulties in theirimplementation. Argentiero et al [19] have also analysed anautomated technique for effective decision tree design whichrelies only on a priori statistics. They have utilised canonicaltransforms and Bayes look-up decision rules, and produceda procedure for computing the global probability of correctclassification.
4. GENERALISED SERIAL APPROACHTO CLASSIFIER COMBINATION
The Modified Distributed Tree Classifier introduced in Sec-tion 2 forms the basis of the generalised serial approach toclassifier combination to be evaluated in this paper. It isimportant to clarify some points here before a formal evalu-ation is attempted as to the nature and configuration ofsuch a classifier combination approach. Figure 4 presents thegeneralised physical configuration of such approaches. Theprincipal feature of this configuration is that the individualexperts are applied sequentially. Hence, at each stage (layer)there is only one classifier (expert) operating and processingthe patterns. No feedback loop can exist in such a configur-ation. Depending on the principle that is employed informulating the decision combination algorithm, there canbe two basic approaches to this generalised serial decisioncombination configuration:
I Class set reduction approach: the underlying principle isto make certain that the number of possible target classesis reduced continuously as the series configuration is tra-versed.
I Reevaluation approach: the underlying principle is toincorporate a scheme that ensures reevaluation of thosepatterns which are either rejected or recognised withvery low confidence at any layer by experts appearing atsubsequent layers.
The following sections evaluate these two variations of thegeneralised serial decision combination approach from botha theoretical and implementation point of view.
4.1. Class Set Reduction Approach
In this case, the character (pattern) to be recognised is firstpresented to the first expert in the configuration. The firstexpert generates a list of possible recognition indices, indi-cating the class to which it is predicted that the currentcharacter might belong, the indicated list being a subset ofthe total number of classes under consideration. The nextexpert then limits further investigation to the domain ofthe classes handed down by the primary expert. It thengenerates, for itself, another ordered list indicating the poss-ible class indices, and this process continues until the finalexpert picks up the ultimate class index. The followingpresentation elaborates on how this configuration can helpin combining decisions taken by multiple experts.
The philosophy behind the series combination is to designa classification configuration, where multiple algorithms areapplied in increasing order of complexity and performance[20]. As the experts appearing later in the hierarchy gener-ally have more weight attached to their decisions, it is
Fig. 4. Serial combination of multiple experts.

296 A. F. R. Rahman and M. C. Fairhurst
important to make sure that more powerful experts appearlate in the configuration. Another important issue is that,since the experts appearing later in the hierarchy need tosearch a smaller solution space in the search for a recog-nition solution, this sequential ordering leads to configur-ations having a very high throughput. It is therefore requiredto control the overall recognition process in an orderedway, where a certain number of possibilities are consideredat a certain stage, ensuring that the decision about the finalidentity is influenced by all the experts, although in anincreasing order of importance. The whole structure isoptimised to generate the highest overall performance.
To optimise the flow of the number of choices as all thepossibilities are exhausted, it is ensured that an optimisedset of patterns is processed by the different layers. Figure 5presents a schematic of the series combination of multipleexperts. The first expert in the hierarchy receives a list ofpossible classes which might be expressed as S0 = 0, 1,2,. . .,m, where m is the total number of classes present inthe problem domain. It extracts the necessary features per-taining to its classification strategy, and compares the charac-ter to the m prototypes built during a training phase. Fromthe responses obtained, it generates a candidate list wherethe possible candidate identifiers for the pattern in questionare listed in decreasing order of probability. The top pchoices are handed down to the second expert, where p , m.
Fig. 5. Serial combination of multiple experts: class set reductionapproach.
If #Sn denotes the number of members in set S pertainingto the nth layer, then #S0 = m and #S1 = p. The secondexpert receives the input pattern, along with the candidatelist handed down by the first expert. It then goes on togenerate its own features pertaining to its classificationstrategy and compares the responses from the p prototypesof the candidate list, rather than considering all the mprototypes. It then generates its own candidate list, andhands it down to the next expert, and so on. The lastexpert makes the final decision by selecting the top choicefrom its own candidate list as the class to which the inputpattern should be assigned.
In general, an expert appearing at the nth layer generateskn responses, and kn , kn−1, where kn represents the numberof class possibilities considered at this layer, and kn−1 is thenumber of classes that were considered at the previous layer.It is also noted that the set of class indices zn consideredat the nth layer is a subset of zn−1 considered at the previouslayer. zn , zn−1 automatically implies that the class indicesdropped by the the (n − 1)th layer are not considered atthe nth layer. The structure also suggests that once a classindex is dropped from the list of possible candidates, it isno longer considered at any subsequent layers. Hence, ingeneral, the actions taken by the nth layer are as follows:
I Generate kn responses, where kn , kn−1.I Sort the kn responses.I Pass on the top kn+1 responses to the (n + 1)th layer,
where kn+1 , kn.
4.1.1. Theoretical Analysis of the Class Set ReductionApproach. The operation of the serial classifier combi-nation scheme based on the class set reduction approachrequires that the experts at any layer generate a subset ofclass indices from the original set of class indices receivedfrom the previous layer. There are two sources of informationfor any expert, the first being the current input patternitself, and the other being the list of class indices passedon by the expert appearing immediately before it. The setof class indices is an ordered list of indices that reflects thechoice of the previous expert in identifying the current testpattern. Thus, the ith expert in the hierarchy needs toproduce a subset Si of its own preferences as a function ofthe current pattern X.
It is desirable that the subset Si should be as small aspossible in order to assist the next decision-making processin the hierarchy, yet at the same time this subset must havea very high probability of containing the true class indexcorresponding to the pattern X. Obviously, the extent towhich these pre-conditions are satisfied at any point in thedecision hierarchy depends upon the experts employed atthat particular layer. The subset Si and the decision processd(X,Si) employed at the current layer i characterise theperformance at that particular point. Assuming:
v(X) the original class associated with the current patternX,
Pei the probability that Si does not contain the true class,i.e. Pei = P[v(X) ∋ Si],

297Serial Combination of Multiple Experts: A Unified Evaluation
Pci the probability that Si contains the true class, i.e.Pci = P[v(X) P Si],
Pe(i+1) the probability that the expert at the (i + 1)th layerassigns X to the wrong class, although the true classindex was included in Si, i.e. Pe(i+1) =P[(d(X,Si) ± v(X))/(v(X) P Si)],
Pc(i+1) the probability that the expert at the (i + 1)th layerassigns X to the correct class provided the true classindex was included in Si, i.e. (Pc(i+1) = P[(d(X,Si) =v(X))/(v(X) P Si)],
then the overall correct classification probability PcT of then-layer serial network is
PcT = Pc1.Pc2. . .Pcn (1)
Accordingly, the overall error rate probability PeT of the n-layer serial network is
PeT = (Pe2 + Pe1.Pc2) + (Pe3 + Pc1.Pe2.Pc3) (2)+. . .+ (Pen + Pc1.Pc2.Pc3. . .Pe(n−1).Pcn)
The rejection capacity of the system must also be considered.In dealing with individual experts at each layer, it has beenassumed that no expert appearing in any layer except thefinal layer, will have a rejection capacity, yet it is clear thatif each expert is allowed to reject a number of patterns,then this will have an effect on the overall performance.In general, as rejection capacity is incorporated, the errorrate falls at the cost of rejections, but as a result, theabsolute recognition rate also falls. This is well known, butthe phenomenon is explained in detail in, for example,Rahman and Fairhurst [21]. Although the purity of therecognition increases, on the whole fewer patterns are cor-rectly classified. This opposes the requirement of an individ-ual expert, since at each level the ability to include thecorrect class index within the class index list passed on tothe next expert is more important than the absolute recog-nition rate, and hence the rejection capacity was not usedwhile implementing serial configurations.
However, from a theoretical point of view, it is interestingto analyse the behaviour of the configuration if at least thefinal stage expert has a rejection capability. Assuming
Prn the probability that the final expert appearing at thefinal layer n rejects the current pattern X, whetheror not Sn−1 contains the correct class index in theindex list,
the overall reject probability PrT of the n-layer configurationcan be expressed as
PrT = Prn (3)
On the other hand, the overall error probability of theconfiguration is now affected by the rejection capabilityof the configuration. The overall error probability of theconfiguration can now be expressed as
PeT = Pe1 + Pe2 +. . .+ Pe(n−1) + (Pen.Pc(n−1) − Pe(n−1).Prn)(4)
It is interesting to note that the experts appearing at the
first and the final layers have some additional characteristics.In the case of the first expert, the input to the expert is acomplete set of target class indices, and its behaviour is notaffected by any of the subsequent experts coming later inthe configuration. On the other hand, the expert appearingin the final nth layer has to pick up only one element fromthe subset Sn−1. The main component in the overall errorof the configuration is the error contributed by this finalstage, in addition to the error propagated through the hier-archy. Hence the error probability of this final expert shouldbe very low to ensure significant performance enhancementwith respect to the performance of its cooperating experts.
This set of error expressions characterises a multiple expertserial decision combination configuration. Later in thispaper, it will be shown how it is possible to analyse theseconfigurations using these expressions.
4.2. Reevaluation Approach
In this case, the character (pattern) to be recognised is firstpresented to the first expert in the configuration. Instead ofgenerating a list of possible recognition indices indicatingthe class to which the current character might belong, thefirst expert generates a confidence value corresponding tothe strength of its decision. Based on this confidence threedifferent scenarios might arise:
I The confidence is higher than a threshold and thedecision is accepted, rendering subsequent reevaluationunnecessary.
I The confidence is such that it falls within the rangedefined by the first and a second threshold, indicating adegree of uncertainty in the decision.
I The confidence is lower than the second threshold, andthe decision is rejected. In this case, a reevaluation isnecessary.
These three categories indicate that in the first case, noreevaluation is carried out, and in the third case, a reevalu-ation is necessary. What is done in the intermediate caseis normally decided on local configuration restrictions. Incases where a reevaluation is necessary, the subsequentexpert does not limit further investigation to the domain ofthe classes handed down by the primary expert, but searchesfor a solution in the complete class domain. It then generatesfor itself another confidence value indicating the possibleclass identity, and this process continues until a decisionwith high enough confidence is found by an expert, or thefinal expert, picks up the ultimate class index.
Figure 6 presents a schematic of the series combinationof multiple experts based on the reevaluation approach. Thefirst expert in the hierarchy receives a list of possible classeswhich might be expressed as S0 = 0, 1, 2,. . ., m, where mis the total number of classes present in the problem domain.It extracts the necessary features pertaining to its classi-fication strategy, and compares the character to the mprototypes built during a training phase. From the responsesobtained, it generates a candidate list where the possiblecandidate identifiers for the pattern in question are listed

298 A. F. R. Rahman and M. C. Fairhurst
Fig. 6. Serial combination of multiple experts: reevaluation approach.
in decreasing order of probability, although only the topchoice from this candidate list is of interest in such con-figurations. This probability can be calculated from thesample confidence values for each test pattern. The sampleconfidence values (a), to be associated with every testsample, denote the confidence of the expert in question inclassifying the pattern to a particular class. As the magni-tudes of the responses of different experts vary, differentnormalisation approaches are adopted. In general, everyparticipating expert assigns a confidence value for everysample it evaluates from every class. aijk therefore denotesthe sample confidence value assigned by the ith expert tothe kth sample coming from the jth class in the test set.Details of how to estimate these confidence values in prac-tice can be found in Rahman and Fairhurst [21].
At any layer, therefore, a pattern is classified with anassociated sample confidence value and compared with athreshold value. Depending on this comparison, the patternis either recognised with a high or low confidence, orrejected. If it is rejected, or it is classified with a lowconfidence, then the next expert in the hierarchy goes onto generate its own features pertaining to its classificationstrategy, and compares the responses from all the m proto-types which describes the original solution space. It thengenerates its own candidate list and decides whether toaccept or reject it, and this process goes on until a classi-fication with a higher confidence is found.
In general, an expert appearing at the nth layer generateskn responses, and kn−1 = kn = kn+1, where kn represents thenumber of class possibilities considered at this layer, kn−1 isthe number of classes that were considered at the previouslayer, and kn+1 is the number of classes that were consideredat the next layer. Hence, in general, the actions taken bythe nth layer are as follows:
I Generate kn responses, where kn−1 = kn = kn+1.I Sort the kn responses.I Pick the top response.
– The decision associated with the sample confidencevalue a is accepted as the final decision, provided thesample confidence value is greater than or equal to athreshold value, so that,
auwt $ cc (5)
where u is the expert appearing at the nth layer, w isthe class under consideration, t is the sample in ques-tion and cc is the first threshold.
– The decision associated with the sample confidencevalue a is recognised with low confidence, providedthe sample confidence value is less than the first thres-hold value but greater than or equal to a secondthreshold value, so that,
cc . auwt $ uc (6)
where uc is the second threshold.– The decision associated with the sample confidence
value a is rejected provided the sample confidencevalue is less than the second threshold value, so that,
auwt , uc (7)
4.2.1. Theoretical Analysis of the ReevaluationApproach. The operation of the serial classifier combi-nation scheme based on the reevaluation approach requiresthat the experts at any layer generate a candidate list fromthe original set of class indices describing the original sol-ution space. There are, again, two sources of informationfor any expert, the first being the current input patternitself, and the other a set of two threshold values associatedwith the expert at that layer. The ith expert in the hierarchytherefore needs to produce a classification decision as afunction of the current pattern X and the list of its thresholdvalues Ti = {cc,uc}.
Defining a decision process d(X,Ti) employed at the cur-rent layer i characterises the performance at that particularpoint. Assuming:
v(X) the original class associated with the current patternPei the probability that v(X) does not contain the true
class, i.e. Pei = P[d(X,Ti) = v(X)/(v(X) ± X)],Pci the probability that v(X) contains the true class, i.e.
Pci = P[d(X,Ti) = v(X)/(v(X) = X)],
then the error probability at the ith layer (Pei) dependsupon the following criteria:

299Serial Combination of Multiple Experts: A Unified Evaluation
I When the class index associated with highest confidenceis erroneous, provided the sample confidence index ishigher than the first threshold value. The error probabilityPei (a) due to this case can be expressed as
Pei(a) = P[(d(X,Ti} ± X)/(atop $ cc)] (8)
I When the class index associated with the highest confi-dence is erroneous, provided the sample confidence indexis lower than the first threshold value, but higher orequal to the second confidence value. The error prob-ability Pei(b) due to this case can be expressed as
Pei(b) = P[(d(X,Ti) ± X)/((atop , cc)(atop $ uc))](9)
I When the class index associated with the highest confi-dence is correct, provided the sample confidence index islower than the second threshold value. The error prob-ability Pei(c) due to this case can be expressed as
Pei(c) = P[(d(X,Ti) = X)/(atop , uc)] (10)
The overall error at any layer i can then be expressed as
Pei = Pe(a) + Pe(b) + Pe(c) (11)
The overall correct classification probability PcT of the n-layer serial network based on the reevaluation approach is
PcT = Pc1.Pc2. . .Pcn (12)
Accordingly, the overall error rate probability PeT of the n-layer serial network based on the reevaluation approach is
PeT = 1 − PcT (13)
The rejection capacity of the system must also be considered.Unlike the case of the class set reduction approach, therejection capacity of each expert appearing at each layer(Pei(c)) is now explicitly incorporated into the errorexpressions.
This set of error expressions characterises a multiple expertserial decision combination configuration based on thereevaluation approach. Subsequent sections of this paperwill concentrate on analysing various multiple expertapproaches as evaluated within the proposed generalisedframework.
5. IMPLEMENTATION ANDPERFORMANCE
5.1. Selection of Individual Experts
To compare the performances of different multiple expertconfigurations, it is important to have a group of expertswhich have comparable inter-expert performance indices,but which, at the same time, use different types of featuresand classification criteria. The following experts were chosenfor an experimental study:
I Binary Weighted Scheme (BWS), employing a technique
Fig. 7. Some typical examples from the reference handwritten Data-base A.
Fig. 8. Some typical examples from the reference handwritten Data-base B.
based on n-tuple sampling or memory network pro-cessing [22].
I Frequency Weighted Scheme (FWS), similar to the BWS,but in this case the memory elements estimate the prob-ability distribution of the group of points or n-tuples [10].
I Multi-layer Perceptron Network (MLP), employing the stan-dard error backpropagation algorithm [23].
I Moment-based Pattern Classifiers (MPC), using nth ordermathematical moments derived from the binarised pat-terns [24].
Further details can be found in Rahman and Fairhurst [21].
5.2. Selection of Databases
Three databases are used in the experiments described, twocontaining handwritten characters and the third consistingof machine printed characters. The first handwritten data-base was compiled at the University of Essex, UK (DatabaseA), and some typical examples from this database arepresented in Fig. 7 [25]. The second database (Database B)is compiled by the U.S. National Institute of Standards andTechnology (NIST), and is well known [26]. Some typicalexamples from this database are presented in Fig. 8. Thethird is compiled at the University of Kent at Canterbury,UK (Database C), and some typical examples from thisdatabase are presented in Fig. 9 [27]. This is a compilation of
Fig. 9. Some typical examples from the reference machine-printedDatabase C.

300 A. F. R. Rahman and M. C. Fairhurst
printed characters extracted from machine printed postcodessupplied by the British Post Office. All these databasescontain samples of alpha-numeric characters (the numerals0 to 9 and upper case letters A to Z, with no distinctionmade between the characters ‘1/I’ and ‘0/O’).
5.3. Performance of Individual Experts
Before an attempt is made to combine multiple expertsusing the serial approach under consideration, it is importantthat the performances of the individual experts on theselected databases are evaluated. Table 1 presents the per-formance of the various individual experts on the variousdatabases, where the figures are clearly self-explanatory.
5.4. Performance Adopting Classifier Combination
Implementation of a series combination of multiple expertsinvolves realising a cascaded structure having multiple layers,the implementation of each of which is based on a singlestandalone expert. The results reported here are for a serialcombination based on the class set reduction approach.Discussions about the decision combination approachesbased on the reevaluation approach are reported inSection 6.6.
In this case, the earlier layers are used to generate anordered list of the possible class identifiers, while the laterlayers make the final decisions about the identity of theparticular character. The principal variable feature whichmust be considered is the size of the subset that is to bepassed on to the next expert in the processing layer, andin a specific implementation the optimum subset size isgenerally evaluated by experimentation.
The basis on which different experts are assigned to thedifferent layers depends upon their relative efficiencies anddegree of complexity. In general, the experts need to be
Table 1. Performance comparison of the different experts ondifferent databases
Database Type of Optimum recognition rateexpert
Digit classes Digit + Uppercase letters
BWS 98.24 95.70FWS 98.48 97.25C MPC 96.80 94.08MLP 98.34 96.25
BWS 88.18 72.05FWS 92.36 79.39A MPC 90.50 80.00MLP 92.17 81.07
BWS 73.57 66.27FWS 79.49 72.34B MPC 86.29 73.95MLP 84.86 72.86
placed in increasing order of computational complexity andefficiency. If there are n experts, zi, where 0 # i # n, andthe efficiency of each expert is expressed in terms of itsestimated error rate, Pei, (0 # i # n), then it is possible toestimate the order in which the experts should appear inthe serial hierarchy to be z0,z1,. . .,zn, wherePe0 . Pe1 .. . ..Pen. This approach puts the overall designemphasis on maximising the overall recognitionperformance, without considering issues concerning systemthroughput. Obviously the fastest combined configurationcorresponds to that in which the experts appear in the orderof decreasing throughput. Although such a combinationensures the highest overall throughput of the combinedsystem, it does not ensure the maximum performanceenhancement of the overall system with respect to theperformance of the cooperating experts working alone. Allthe configurations discussed here adopt this approach, allo-cating individual experts in increasing order of recognitionperformance.
Another important aspect of system design relates to thenumber of possible combinations that can be implementedfrom a pool of individual experts in various cases, wherethe total number of experts is already fixed. If there are mexperts available to be used in a hierarchy of n experts,then the total number of combinations that can be realisedis mCn. For example, when there are four available expertsand a two-level system is envisaged, then six combinationscan be implemented. On the other hand, if three expertsare used from the same pool of four experts, then four validcombinations can be implemented, and so on. The otherimportant issue in realising effective serial multiple expertcombination configurations is the training of the differentexperts appearing at the different layers in the hierarchy. Toachieve overall optimisation, the individual experts are trainedseparately, each expert being optimised with respect to its owncritical parameters and using a common training set.
Fig. 10. Performance of the two layer configurations on DatabaseC: Numeral cases only.

301Serial Combination of Multiple Experts: A Unified Evaluation
The first group of results discussed here is based on ahierarchy of two processing layers. Figure 10 presents theresults compiled for the two-layer networks BWS-FWS,BWS-MLP, MLP-FWS, MPC-BWS, MPC-FWS and MPC-MLP, investigated using the database of machine printednumerals from Database C. It is observed that the perform-ance of the combined configuration is directly dependenton the choice of the subset size. It is seen that in all thecombinations, the lower the subset size, the higher is thefinal performance, except in the case when the subset sizebecomes too small, typically less than three. Obviously, thesmallest value of the subset size corresponds to the scenariowhen the correct class index begins to be discarded fromthe list of possible solutions. This optimum subset size isdependent on the individual experts chosen at each layer,and on the dataset on which the combination is applied.Figure 11 presents the results on Database C using thecomplete alpha-numeric set. The same observations canagain be made about the behaviour of the combined con-
Fig. 11. Performance of the two layer configurations on DatabaseC: Alpha-numeric cases only.
Fig. 12. Performance of the two layer configurations on DatabaseA: Numeral cases only.
Fig. 13. Performance of the two layer configurations on DatabaseA: Alpha-numeric cases only.
figurations in terms of varying subset size. In general, thelower the subset size, the better was the overall performance.It is interesting to note the behaviour of the configurationswhen the subset size was greater than 15. Beyond that point,the performance remained more or less unchanged. This isnot surprising, because in most of the cases, the correctclass indices of the various patterns should occur within afew top choices in the output of the first expert, and noadditional advantage is gained by taking into account veryunlikely classes.
Figure 12 presents the results compiled for the two-layernetworks BWS-FWS, BWS-MLP, BWS-MPC, MLP-FWS,MPC-FWS and MPC-MLP, respectively, using Database Awith the target character set of the digit classes only.Here again a smaller subset size was generally found to beadvantageous for enhancing the overall performance of thecombined configurations. However, it is noted that there isa tendency for these combinations to reach the optimumstate at a slightly higher subset size than was the case with
Fig. 14. Performance of the two layer configurations on DatabaseB: Numeral cases only.
302 A. F. R. Rahman and M. C. Fairhurst
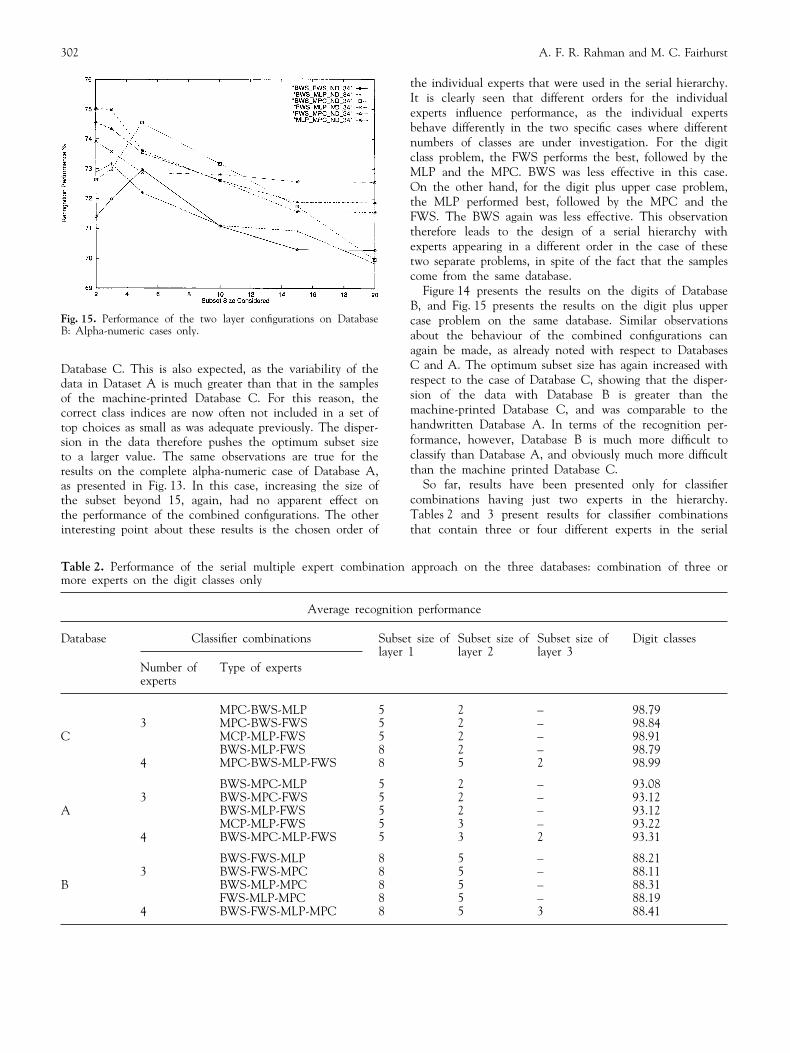
Fig. 15. Performance of the two layer configurations on DatabaseB: Alpha-numeric cases only.
Database C. This is also expected, as the variability of thedata in Dataset A is much greater than that in the samplesof the machine-printed Database C. For this reason, thecorrect class indices are now often not included in a set oftop choices as small as was adequate previously. The disper-sion in the data therefore pushes the optimum subset sizeto a larger value. The same observations are true for theresults on the complete alpha-numeric case of Database A,as presented in Fig. 13. In this case, increasing the size ofthe subset beyond 15, again, had no apparent effect onthe performance of the combined configurations. The otherinteresting point about these results is the chosen order of
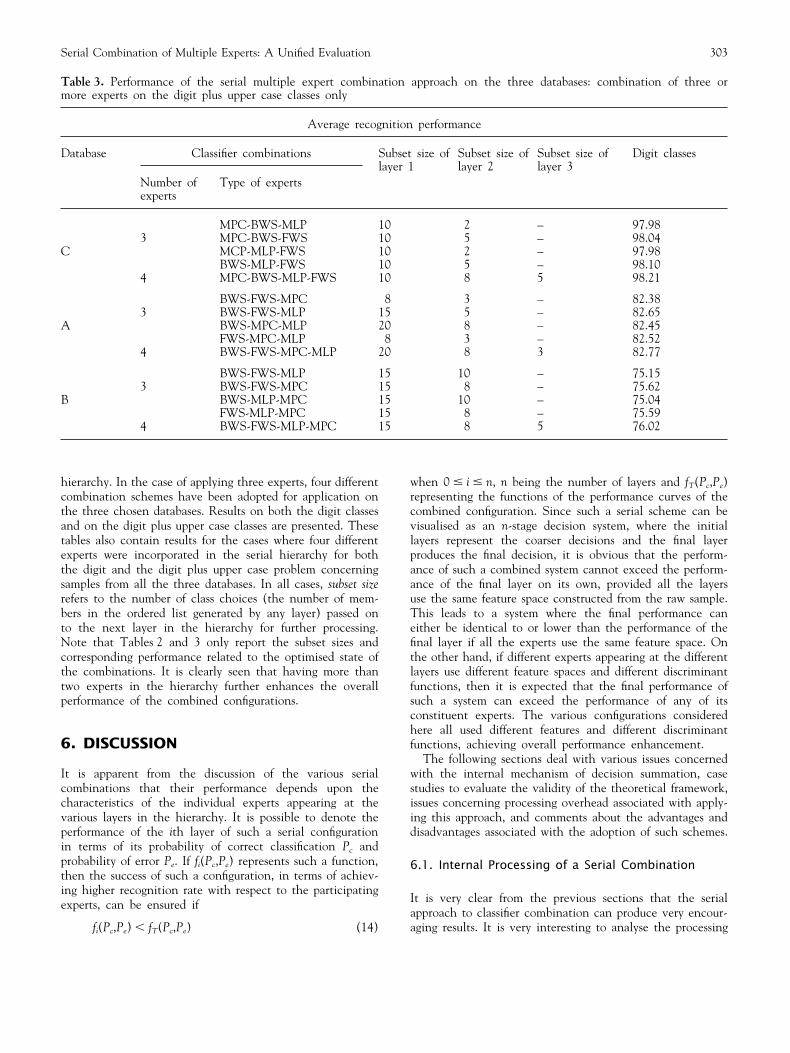
Table 2. Performance of the serial multiple expert combination approach on the three databases: combination of three ormore experts on the digit classes only
Average recognition performance
Database Classifier combinations Subset size of Subset size of Subset size of Digit classeslayer 1 layer 2 layer 3
Number of Type of expertsexperts
MPC-BWS-MLP 5 2 – 98.793 MPC-BWS-FWS 5 2 – 98.84
C MCP-MLP-FWS 5 2 – 98.91BWS-MLP-FWS 8 2 – 98.79
4 MPC-BWS-MLP-FWS 8 5 2 98.99
BWS-MPC-MLP 5 2 – 93.083 BWS-MPC-FWS 5 2 – 93.12
A BWS-MLP-FWS 5 2 – 93.12MCP-MLP-FWS 5 3 – 93.22
4 BWS-MPC-MLP-FWS 5 3 2 93.31
BWS-FWS-MLP 8 5 – 88.213 BWS-FWS-MPC 8 5 – 88.11
B BWS-MLP-MPC 8 5 – 88.31FWS-MLP-MPC 8 5 – 88.19
4 BWS-FWS-MLP-MPC 8 5 3 88.41
the individual experts that were used in the serial hierarchy.It is clearly seen that different orders for the individualexperts influence performance, as the individual expertsbehave differently in the two specific cases where differentnumbers of classes are under investigation. For the digitclass problem, the FWS performs the best, followed by theMLP and the MPC. BWS was less effective in this case.On the other hand, for the digit plus upper case problem,the MLP performed best, followed by the MPC and theFWS. The BWS again was less effective. This observationtherefore leads to the design of a serial hierarchy withexperts appearing in a different order in the case of thesetwo separate problems, in spite of the fact that the samplescome from the same database.
Figure 14 presents the results on the digits of DatabaseB, and Fig. 15 presents the results on the digit plus uppercase problem on the same database. Similar observationsabout the behaviour of the combined configurations canagain be made, as already noted with respect to DatabasesC and A. The optimum subset size has again increased withrespect to the case of Database C, showing that the disper-sion of the data with Database B is greater than themachine-printed Database C, and was comparable to thehandwritten Database A. In terms of the recognition per-formance, however, Database B is much more difficult toclassify than Database A, and obviously much more difficultthan the machine printed Database C.
So far, results have been presented only for classifiercombinations having just two experts in the hierarchy.Tables 2 and 3 present results for classifier combinationsthat contain three or four different experts in the serial
303Serial Combination of Multiple Experts: A Unified Evaluation
Table 3. Performance of the serial multiple expert combination approach on the three databases: combination of three ormore experts on the digit plus upper case classes only
Average recognition performance
Database Classifier combinations Subset size of Subset size of Subset size of Digit classeslayer 1 layer 2 layer 3
Number of Type of expertsexperts
MPC-BWS-MLP 10 2 – 97.983 MPC-BWS-FWS 10 5 – 98.04
C MCP-MLP-FWS 10 2 – 97.98BWS-MLP-FWS 10 5 – 98.10
4 MPC-BWS-MLP-FWS 10 8 5 98.21
BWS-FWS-MPC 8 3 – 82.383 BWS-FWS-MLP 15 5 – 82.65
A BWS-MPC-MLP 20 8 – 82.45FWS-MPC-MLP 8 3 – 82.52
4 BWS-FWS-MPC-MLP 20 8 3 82.77
BWS-FWS-MLP 15 10 – 75.153 BWS-FWS-MPC 15 8 – 75.62
B BWS-MLP-MPC 15 10 – 75.04FWS-MLP-MPC 15 8 – 75.59
4 BWS-FWS-MLP-MPC 15 8 5 76.02
hierarchy. In the case of applying three experts, four differentcombination schemes have been adopted for application onthe three chosen databases. Results on both the digit classesand on the digit plus upper case classes are presented. Thesetables also contain results for the cases where four differentexperts were incorporated in the serial hierarchy for boththe digit and the digit plus upper case problem concerningsamples from all the three databases. In all cases, subset sizerefers to the number of class choices (the number of mem-bers in the ordered list generated by any layer) passed onto the next layer in the hierarchy for further processing.Note that Tables 2 and 3 only report the subset sizes andcorresponding performance related to the optimised state ofthe combinations. It is clearly seen that having more thantwo experts in the hierarchy further enhances the overallperformance of the combined configurations.
6. DISCUSSION
It is apparent from the discussion of the various serialcombinations that their performance depends upon thecharacteristics of the individual experts appearing at thevarious layers in the hierarchy. It is possible to denote theperformance of the ith layer of such a serial configurationin terms of its probability of correct classification Pc andprobability of error Pe. If fi(Pc,Pe) represents such a function,then the success of such a configuration, in terms of achiev-ing higher recognition rate with respect to the participatingexperts, can be ensured if
fi(Pc,Pe) , fT(Pc,Pe) (14)
when 0 # i # n, n being the number of layers and fT(Pc,Pe)representing the functions of the performance curves of thecombined configuration. Since such a serial scheme can bevisualised as an n-stage decision system, where the initiallayers represent the coarser decisions and the final layerproduces the final decision, it is obvious that the perform-ance of such a combined system cannot exceed the perform-ance of the final layer on its own, provided all the layersuse the same feature space constructed from the raw sample.This leads to a system where the final performance caneither be identical to or lower than the performance of thefinal layer if all the experts use the same feature space. Onthe other hand, if different experts appearing at the differentlayers use different feature spaces and different discriminantfunctions, then it is expected that the final performance ofsuch a system can exceed the performance of any of itsconstituent experts. The various configurations consideredhere all used different features and different discriminantfunctions, achieving overall performance enhancement.
The following sections deal with various issues concernedwith the internal mechanism of decision summation, casestudies to evaluate the validity of the theoretical framework,issues concerning processing overhead associated with apply-ing this approach, and comments about the advantages anddisadvantages associated with the adoption of such schemes.
6.1. Internal Processing of a Serial Combination
It is very clear from the previous sections that the serialapproach to classifier combination can produce very encour-aging results. It is very interesting to analyse the processing

304 A. F. R. Rahman and M. C. Fairhurst
mechanism of such systems, to clarify some of the conceptsbehind their successful implementation. In this section, aspecific case is analysed in detail to give an insight into theinternal operation of serial classifier combination techniques.
The case study to be considered here is that of a two-layer serial configuration BWS-MPC, applied in classifyingthe characters in the handwritten Database A. It has alreadybeen observed that this particular classifier combination isable to achieve improved overall recognition performancewith respect to its constituent classifiers. The behaviour ofthe system can be explained by considering a specific classand describing how the classifier combination handles therandom occurrence of the samples belonging to that parti-cular class. For this purpose, the class chosen is the numeralclass 3. Figure 16 shows how the cooperating classifiers(experts) work in terms of successfully identifying thesamples belonging to class 3. It is seen that the MPC, onits own, is capable of identifying 80% of the unseen testsamples as its top choice after it is properly trained. Onthe other hand, the BWS expert is capable of successfullyidentifying 76% of the test samples as its own top choice.The interesting point to be noted here is that as more andmore choices are taken into account, the BWS expert nowoutperforms the MPC expert. For example, if the top twochoices are considered, then the BWS expert can correctlyidentify 94% of the test samples, whereas the MPC classifiercan only correctly identify 91% of the test samples. For thetop four choices, the BWS is capable of guaranteeing theinclusion of the correct class indices, while the MPC expertcan include only 97% of the correct class indices. Thisbehaviour is the key to the success of applying more thanone expert in a serial fashion. Figure 16 also shows theoptimum performance of the combined BWS-MPC scheme.The combination is clearly seen to outperform individualconstituent experts functioning alone.
Further analysis of the behaviour of the combined BWS-MPC configuration is presented in Fig. 17, which illustratesthe internal functioning of the combined configuration byshowing how the changing of the subset size passed fromthe first to the second expert influences the performance of
Fig. 16. Dispersion of the identified class indices.
Fig. 17. Comparison of behaviour of an expert (MPC) appliedindividually and in a combined configuration.
the second expert. It is demonstrated that as the numberof subsets is reduced, the performance curves shift towardsthe left in the area of the graph defined by the subset sizeand percentage recognition performance (Fig. 17), implyingmore success by the second classifier in correctly includingthe true class indices in the top choices. This correspondsto more accurate performance while considering a smallernumber of subsets corresponding to a particular case. As thesubset size is reduced to 2, the top choice of the secondaryexpert becomes more accurate than the top choice successrate of the same (the second classifier in this case) when itwas functioning on its own. This is shown clearly in Fig. 17,where the performance of the MPC expert is also plottedfor comparison with the combined behaviour, demonstratingvery successfully why a serial combination of two or moreclassifiers has the potential to outperform all of thecooperating experts incorporated within that particularframework.
Although this paper deals with performance of the expertsin terms of their accuracy in correctly identifying the trueclass index as their top-most choice, in many practicalapplications the behaviour in terms of class dispersion of aparticular dataset in relation to a particular expert is ofparamount interest, where class dispersion denotes the abilityof a particular expert in including the correct class indexin a preference list of particular length. The serial classifiercombination technique can offer significant advantages inparticular applications where the inclusion of the correctclass in the classifier output is more important that theabsolute recognition as a top choice candidate for a parti-cular recognition task [28,29]. It can be seen from Fig. 16that the combined BWS-MPC configuration now has thepotential to achieve greater than an 82% correct recognitionrate with respect to its top choice, and a 100% correctrecognition rate if the top two choices are considered.

305Serial Combination of Multiple Experts: A Unified Evaluation
6.2. A Case Study: Testing the TheoreticalFramework
The theoretical framework previously introduced predictsthat the final error probability of a serial multiple expertconfiguration depends upon the error rates of all the preced-ing layers in addition to the error probability of the finallayer. It is noted that the form of the discriminant functiondi(·): i = 1, 2,. . .,K, where K is the total number of classesunder consideration, plays a very important role in estab-lishing the overall behaviour of the combined configuration.In all the simulations reported here, the choice of thediscriminant function consists of including in Si all thoseclass indices associated with the H highest scores producedby the function di(·), where H is an arbitrarily choseninteger and 0 , H , K.
In this section a specific case study is considered, and asimple two-layer network is chosen for this demonstration.The first layer of the network is a BWS expert and thesecond an MPC network. The performance of such a clas-sifier combination will depend upon the subset S1 producedby the first layer, and on the type of classifier employed inthe second layer, as seen from Eqs (1)–(4). The probabilitythat the true class is not included in the subset Si, Pe1, isa monotonically decreasing function of the number ofelements in Si, which corresponds to H in this case. Thisfunction is not dependent on any of the characteristics ofthe second expert. On the other hand, the probability oferror by the second classifier is affected by the performanceof the first expert, as the elements of Si directly dependupon its own performance, the number of elements in thesubset Si, H, and the discriminant function of the secondexpert. It is therefore clear that as more and more elementsare included in the subset Si, it becomes increasingly moredifficult for the second expert to pick up the correct classindex, and in the final limit, when H → K, the first expertbecomes redundant and the overall recognition rate of theconfiguration becomes identical to the case where the secondclassifier is functioning alone.
The BWS-MPC combined configuration was applied tothe task of recognising the digit classes from Database A.The probabilities of error of the first and second layers havebeen evaluated separately in the case of this BWS-MPCconfiguration, and can be compared to the overall probabilityof error by the combined configuration. Figure 18 shows theerror probability of the expert at the first layer, the BWSclassifier. It is clearly seen that the error probability functionPe1 is a rapidly decreasing monotonic function of the chosensubset size. In this case, this error probability reflects theerror of this expert in including the correct class index inthe generated subset list. It is not surprising, therefore, tofind that the error rate drops to zero after the first fourchoices are considered.
The probability of error induced by the expert appearingat the second layer is presented in Fig. 19. It is seen thatthe error probability increases as more and more subsetelements are passed on to the second layer. Figure 18 showsthat all the correct class indices are included in the firstfour choices, and it is easy to see that as more and more
Fig. 18. Error probability of the BWS-MPC configuration due tothe first layer only, Pe1.
Fig. 19. Error probability of the BWS-MPC configuration due tothe second layer only, Pe2.
class choices are passed on, the more difficult it becomesfor the MPC expert to identify the correct class index.Figure 19, on the other hand, presents the error probabilityof the same MPC expert, provided all ten class indices aresupplied to the MPC and it is asked to pick up the correctclass index from that list. It is seen that, in this case, theMPC is able to pick up the correct class index if the topsix choices are picked up from its own preference list. Thisis exactly the same behaviour as has been seen from theBWS expert placed in the first layer. This demonstrates thepotential of this type of classifier combination technique inachieving higher recognition performance using more thanone expert in the hierarchy. Figure 20 demonstrates the finalerror rates that characterise the overall performance of theconfiguration. It is clearly seen that at the optimised subsetsize of 3, the combined configuration easily outperforms theconstituent experts operating alone.
From Figs 18–20, it is clear that these graphs match thepredictions of the theoretical model. Since, in this case

306 A. F. R. Rahman and M. C. Fairhurst
Fig. 20. Error probability of the combined BWS-MPC configur-ation, PeT.
study, a zero rejection rate by the final expert in thehierarchy is assumed,
PrT = Pr2 = 0 (15)
and accordingly Eq. (4) can be rewritten as
PeT = Pe1 + Pe2.Pc1 (16)
The first term of Eq. (16) corresponds to the graph inFig. 18, and the second part corresponds to Fig. 19. If thesetwo graphs are added, the third graph in Fig. 20 is obtained.This shows perfect correspondence between the theoreticalprediction and practical performance in this particular case.
6.3. Issues Concerning Processing Overhead
An important issue relating to performance evaluation con-cerns achievable processing speed. The primary emphasis ofthe present study is on the relative performance enhance-ment achievable by adopting serial decision combinationstrategies, and little effort is made to optimise the variouscombined configurations with respect to pattern throughput.Nevertheless, it is important to consider briefly the pro-cessing speed implications when implementing this decisioncombination approach.
Table 4 presents the system overhead incurred as the
Table 4. Design overhead: processing time
Type of Type of Different Processingconfiguration algorithm versions speed
BWS – 2174 cpsFWS – 2128 cpsSingle expert MPC – 542 cpsMLP – 10 cps
Multiple Serial BWS-MPC- 32 cpsexpert MLP-FWS
result of adopting a multiple expert approach in place ofthe traditional single expert approach. The figures presentedhere are the average throughput achieved by these configur-ations in recognising the test characters (resolution of16 × 24 pixels), but excluding the time for file handling.Although it is clear that the serial multiple expert configur-ation has a relatively reduced throughput with respect tothe individual experts, there are instances where the com-bined serial structure is faster than the experts workingalone. This is especially true for the case of the neuralnetwork expert (MLP), which has an extremely low through-put. This is possible because of the unique way in whichthe data is distributed into smaller subgroups due to thesub-set reduction effect of the serial design, where progress-ively fewer classes are evaluated by successive experts appear-ing in the serial hierarchy. This controlled data-flow ensuresthat the data is properly split up into smaller groups beforebeing processed by various experts, enabling each expert inthe hierarchy to successively evaluate the class membershipof only a fraction of the total input classes, making theoverall processing faster.
There are some further points that should be noted here.The throughput cited for the serial multiple experts isrelated to the subset size corresponding to the best overallperformance, since the throughput values are naturally differ-ent for different subset sizes. For example, in the case ofthe serial BWS-MPC-MLP-FWS classifier, the subset sizefrom the first to the second layer corresponding to the bestperformance was 5, from the second to the third layer 3,and from the third to the fourth layer 2. The throughputvalues cited here obviously correspond to this particularconfiguration. Other configurations in which the expertsappear in a different order or in which the subset sizes aredifferent will naturally have a different throughput. Thethroughput values cited here are related to implementationsbased on C programming language running on a SPARCIPX hardware platform.
Accepting the fact that multiple expert configurationswould involve additional processing costs, it is interestingto compare the relative costs incurred by the serial decisioncombination approach with respect to that incurred by othermore traditional decision combination approaches, such asthe Majority Voting Scheme [8]. Table 5 presents thethroughput of these two approaches. Also, when comparingissues relating to speed, it is important that comparisons aremade among configurations having the same number ofcooperating experts combined in such configurations. Anillustrative case is presented here, where four independentexperts are unified in a single framework using two differentdecision combination strategies. This demonstrates that theserial approach has a much higher throughput with respectto the more traditional Majority Voting Scheme. Obviously,for this illustration, a serial computer implementation (atraditional single processor system) has been considered. Aparallel implementation (having multiple processors),although less traditional, would undoubtedly tilt the balanceconsiderably in favour of the Majority Voting Scheme, wheredecision combination takes place in a ‘flat’ single stage [30].

307Serial Combination of Multiple Experts: A Unified Evaluation
Table 5. Process time requirements: a simple comparison
Type of configuration Type of algorithm Different versions Processing speed
Multiple Serial BWS-MPC-MLP-FWS 32 cpsexpert Majority voting BWS-FWS-MPC-MLP 8 cps
6.4. General Comments on the Applicability ofthe Approach
The inherent structure of the serial configuration suggeststhat, within the series hierarchy, the performance of sub-sequent experts depends upon the performance of the pre-vious experts. Hence, the order in which the experts occurin the hierarchical configuration is very important. If anexpert at any previous stage within the overall configurationfails to include the correct target class in its list of possi-bilities, the subsequent experts become redundant, makingthe worst case scenario potentially very unattractive. How-ever, it is noted that if two or more experts are to becompared, the overall performance index is not necessarilyan adequate index for describing the performances on indi-vidual classes [31]. Since the experts positioned later in thisconfiguration are required to classify among the members ofthe reduced candidate list, a greatly decreased computationaloverhead is incurred, which intuitively suggests the possi-bility of a faster implementation. This scenario also impliesa greater accuracy in the final combined performance.
On the other hand, it is also very important to employthe optimum number of experts in a serial hierarchy, sincethe incremental enhancement that is achievable from theseconfigurations diminishes as more experts are combined.Table 6 lists the configurations that produced the best resultson the three databases to demonstrate the truth of thisstatement. This observation suggests that, for practical pur-poses, a two-layer system would be most attractive from the
Table 6. Best performance of the serial multiple expert combination approach on the three databases: the digit classes only
Average recognition performance
Database Classifier combinations Subset size of Subset size of Subset size of Digit classeslayer 1 layer 2 layer 3
Number of Type of expertsexperts
2 MPC-FWS 3 – – 98.75C 3 MPC-MLP-FWS 5 2 – 98.91
4 MPC-BWS-MLP-FWS 8 5 2 98.99
2 MPC-FWS 3 – – 92.93A 3 MPC-MLP-FWS 5 3 – 93.22
4 BWS-MPC-MLP-FWS 5 3 2 93.31
2 MLP-MPC 2 – – 87.98B 3 BWS-MLP-MPC 8 5 – 88.31
4 BWS-FWS-MLP-MPC 8 5 3 88.41
viewpoint of its simplicity in design and lower complexity.The low operational costs in terms of higher throughputassociated with such configurations is also a very importantissue in adopting such schemes, and this is why serialapproaches can be an extremely attractive choice when thepriority of the system is high throughput in addition to highperformance, especially in those cases where the systemdemands multiple top choices from the recogniser, so thatsubsequent stages might exploit this information by pro-cessing it further. Examples of such applications mightinclude bank cheque processing [32], printed and handwrit-ten document [33] or word recognition [34], signature enrol-ment and validation [35], on-line handwriting recognition[36], isolating abnormalities in medical images (e.g. digitalmammographs [37]), and so on.
6.5. Optimisation of the Serial DecisionCombination Configuration
Optimisation of serial decision combination strategies isdifficult as there are various parameters which need to beadjusted. It is apparent that, to optimise the overall perform-ance of such a framework, it is required to optimise threesets of variables, as follows:
I Number of experts: at least in a general sense, thenumber of experts in the overall framework is animportant parameter that should be optimised.
I Order of experts: it is required to select the particular

308 A. F. R. Rahman and M. C. Fairhurst
Table 7. Best performance of the serial multiple expert combination approach on the three databases. The digit plus uppercase classes only
Average recognition performance
Database Classifier combinations Subset size of Subset size of Subset size of Digit classeslayer 1 layer 2 layer 3
Number of Type of expertsexperts
2 MPC-FWS 3 – – 97.91C 3 BWS-MLP-FWS 10 5 – 98.10
4 MPC-BWS-MLP-FWS 10 8 5 98.21
2 BWS-MLP 5 – – 82.12A 3 FWS-MPC-MLP 8 3 – 82.52
4 BWS-FWS-MPC-MLP 20 8 3 82.77
2 MLP-MPC 2 – – 75.03B 3 BWS-FWS-MPC 15 8 – 75.62
4 BWS-FWS-MLP-MPC 15 8 5 76.02
type of expert to be placed at a specific position in thehierarchy. To fulfil this pre-requisite, it is required tohave a pool of pre-trained classifiers (experts) which canthen be used to determine which expert is best placedin which position.
I Subset size: the subset size is a very important parameter.This dictates the required search space for each expert.
In this paper, a genetic algorithm has been proposed tooptimise the overall framework. Initially proposed by Hol-land [38], genetic algorithms have been used extensively invarious search and optimisation problems. The basic advan-tage of this approach is that instead of beginning with asingle solution to a specific problem, genetic algorithmsbegin by assuming an initial set of solutions, termed theinitial ‘population’. The quality of these randomly generatedsolutions is then assessed by an objective function, and anumeric ‘fitness value’ is computed for each of the solutions.Depending on the fitness value, better solutions are selectedfor reproduction, and the less ‘fit’ solutions are discarded.Each solution is encoded as a bit-string, which is known asa ‘chromosome’.
6.5.1. Data Characteristics. In the current investigation,the optimisation problem is to select which type of expertshould be placed at which position in the hierarchy.Assuming only four positions are available, it is easily poss-ible to code this information using only two bits. Therefore,since we have four independent classifiers, eight bits arerequired to code the position information for all four possibleclassifiers. Since we have 34 classes, a further 6 bits arerequired to code the information of subset size for eachexpert. Assuming xi denotes a bit in this coding method,the values that each variable is able to contain is either 0or 1, i.e. xi P {0,1}.
6.5.2. Chromosome Structure. A classifier, either indi-vidually or in a multiple expert framework, can be viewed
as a machine obeying various production rules. A generalisedform of a rule can be expressed as
kclassifierl :: = kconditionl:kmessagel
The kconditionl part of the rule is a simple pattern matchingdevice. On the other hand, the kmessagel part of the rulefeeds back information to the system so that certain actionscan be taken based on a particular message. Specifically, thekmessagel part of the classifier is an index which denotesthe classification label assigned by the expert to a parti-cular pattern.
In the present investigation, however, the genetic algor-ithm is not applied as a classifier system, rather it is usedas an optimising tool. In this application, all that is requiredis the encoded identity of the various experts as they areassigned into different positions in the decision combinationframework and the subset size used by them.
6.5.3. Fitness Function. This is a very important aspectof the genetic algorithm design, as the quality of the overallsolution depends upon the appropriateness of the fitnessfunction to the problem in hand. In the current context,the fitness of a solution is conceptually very well defined.A solution is better than other competing solutions if thestructural configuration corresponding to that solution yieldsbetter recognition rate. (Obviously other fitness parameters,such as the throughput can also be used.) In terms of thefitness function, for every possible solution a set of testingpatterns was tested and the average recognition rate wasused as an indicator to the level of fitness of that particularsolution. The overall fitness function can therefore bedefined as
Fitness = Correct Patterns/Total Patterns
6.5.4. Genetic Operators. To make sure that enough vari-ations are introduced into new populations in addition tothe characteristics inherited from the parents, various genetic

309Serial Combination of Multiple Experts: A Unified Evaluation
operators were employed. There are three basic operators,as briefly described below:
I Reproduction: is a process in which individual strings arecopied according to their objective function values [39].This process ensures that solutions having higher fitnessscores have a higher probability of contributing moreoffspring in the next generation. In other words, thisoperator imitates the phenomenon of natural selection,the so-called ‘Darwinian survival of the fittest’. There arevarious alternatives for artificially producing this oper-ation, some of which are Weighted Roulette Wheel [39],Stochastic-Remainder Selection [40] and TournamentSelection [41]. In the current investigation, the WeightedRoulette Wheel selection method has been adopted.
I Crossover: is a process where the mating solutionsexchange part of their chromosome. After reproduction,an exact replica of the chromosome of the fitter solutionis sent to the mating pool. These solutions are thenrandomly mated with other competing solutions. Duringthis process, an integer position k along the chromosomeis selected at random between 1 and chromosome lengthless one, i.e. [1,l − 1], where l is the length of the originalchromosome. Two new offspring are created by swappingall the bits (called genes) between positions k + 1 and l,respectively. This genetic operator ensures that the newgeneration of solutions has new characteristics in additionto the inherited part.
I Mutation: crossover ensures that a new population hasconsiderable variation with respect to the old population.However, sometimes sporadic or random changes in thegene can contribute a rich source of innovation in thesolutions. This random change in a chromosome is calledmutation. Various types of mutation are available, themost common of which are the change of a single geneor a change of all the genes in the chromosome. In thisinvestigation, only single gene mutation was allowed.
The population size used in this investigation was 150. Theprobabilities of crossover was set at 0.95, and the probabilityof mutation was set at 0.05.
6.5.5. Performance. It is realised that there are numerousways in which to build the multiple expert configuration.A specific example is chosen here. All four experts wereallowed to be combined to recognise the numeral classesfrom Database C. The configuration and performance of aspecific implementation based on a trial and error methodis reported in Table 8. Table 9 presents the result of theoptimisation. It is seen that the same configuration as found
Table 8. Performance of the combined framework
Position Combinedperformance (%)
BWS FWS MPC MLP
2 4 1 3 98.99
by trial and error has also been selected by the geneticalgorithm. In this case, there were only four experts, but incases where more experts are required to be combined, theproposed method is likely to prove very powerful.
6.6. Generality of the Approach: ReevaluatingPrevious Research
The generalised serial approach to multiple expert decisioncombination has been implicitly employed by variousresearchers over the years in designing individual schemes.In spite of the fact that the experts chosen by variousresearchers in the individual approaches are entirely differ-ent, the way in which the recognition problem is split intosmaller sub-problems is unique in each case, and the holisticapproach to overall network configuration varies signifi-cantly, the underlying principle of the decision combinationcan easily be generalised with respect to the serial decisioncombination approach discussed in this paper.
Kimura and Shridhar [42] have combined two algorithmsfor unconstrained handwritten numeral recognition. The firstof their algorithms employs a modified quadratic discriminantfunction using direction-sensitive spatial features of thenumeral image. The other algorithm uses features derivedfrom the profile of the character in a structural configurationto recognise the numerals. This is the typical reevaluationapproach discussed in Section 4.2. A similar approach hasbeen adopted by Lam and Suen [43]. They described amultiple expert configuration that comprises a feature extrac-tor and two classifiers. The feature extractor decomposes theskeleton of a character into geometric primitives, and a fastclassifier, based on structural decision-tree techniques, isapplied that classifies a majority of the characters. A smallnumber of characters are processed by the secondary clas-sifier, which is based on a robust relaxation algorithm. Chiet al [44] described a recognition scheme based on Self-Organising Maps (SOMs) and fuzzy rules. A SOM is usedto determine prototypes from the training set during thelearning phase, but in the recognition phase, characters areclassified by a classifier built on the basis of fuzzy rules.There is an error recovery path where any uncertain decisioncan be re-classified by using a classifier based on the SOMs.Figure 21 demonstrates how it is possible to represent thesethree decision combination approaches in terms of the gen-eralised serial approach. These are further examples of thereevaluation approach discussed in Section 4.2. It is alsovery interesting to note that these approaches, althoughemploying very different algorithms, are inherently verysimilar and in the cases of the approaches proposed by Lamand Suen [43] and Chi et al [44], they are identical whenevaluated within the proposed generalised serial decisioncombination strategy discussed in this paper.
6.7. Final Comments
It has been demonstrated in this paper that the serialcombination approach can offer significant performanceenhancement, especially in the case of complex large classproblems (e.g. handwritten character recognition), in

310 A. F. R. Rahman and M. C. Fairhurst
Table 9. Optimised configuration and performance of the combined framework
Optimised parameters Combinedperformance (%)
BWS Subset size FWS Subset size MPC Subset size MLP Subset size
2 10 4 8 1 5 3 2 98.99
Fig. 21. Generalised representation of the decision combinationapproaches proposed by (a) Kimura and Shridhar, (b) Lam andSuen and (c) Chi et al.
addition to providing solutions which are easier toimplement and which ensure very high system throughput.It is also to be noted that these classifier combinations arevery easy to design on other platforms, and can be idealcandidates for parallel implementation [28,45–47]. Selectionof a particular combination strategy will naturally dependupon the specific task in hand, and is a difficult matter togeneralise. Optimum subset selection is also dependent onthe task domain, and it is therefore imperative that rigorousevaluation is made before adopting a particular combinationof experts for a particular task.
7. CONCLUSION
This paper has presented a comprehensive investigation ofa generalised serial approach to the combination of multipleexperts. Detailed theoretical and practical discussions ofthe various possible configurations, analysis of the internalprocessing mechanism inherent in this approach, a casestudy for testing the theoretical framework, issues concerningprocessing overheads associated with implementation of thisapproach, general comments on its applicability to varioustask domains, and generality of the approach in terms ofreevaluating previous research have been addressed. It hasbeen demonstrated that the generalised serial approach iscapable of representing and explaining many of the proposeddecision combination schemes in a unified way, and thiscan be very useful in analysing, implementing and improvingsuch schemes.
References
1. Fairhurst MC, Rahman AFR. A generalised approach to therecognition of structurally similar handwritten characters. IEEProc Vision, Image and Signal Process 1997; 144(1):15–22
2. Gluskman HA. Multicategory classification of patterns rep-resented by high-order vectors of multilevel measurements. IEEETrans Comput 1971; 20:1593–1598
3. Schueermann J, Doster W. A decision theoretic approach tohierarchical classifier design. Pattern Recognition 1983; 17(3):359–369
4. Mui JK, Fu KS. Automatic classification of nucleated bloodcells using a binary tree classifier. IEEE Trans Pattern Analysisand Machine Intelligence 1980; 2:429–443
5. Rahman AFR, Fairhurst MC. Introducing new multiple expertdecision combination topologies: a case study using recognitionof handwritten characters. Proc. 4th Int Conference on Docu-ment Analysis and Recognition (ICDAR97), volume 2, Ulm,Germany, 1997; 886–891
6. Xu L, Krzyzak A, Suen CY. Methods of combining multipleclassifiers and their applications to handwritten recognition.IEEE Trans Systems, Man and Cybernetics 1992; 23(3):418–435
7. Powalka RK, Sherkat N, Whitrow RJ. Multiple recognizer com-bination topologies. In Handwriting and Drawing Research:Basic and Applied Issues, ML Simner, CG Leedham, AJWMThomassen (eds). IOC Press, 1996; 329–342
8. Kittler J, Hatef M. Improving recognition rates by classifiercombination. Proc 5th Int Workshop on Frontiers of Hand-writing Recognition 1996; 81–102
9. Pudil P, Novovicova J, Blaha S. Multistage pattern recognitionwith reject option. Proc 11th IAPR ICPR 1992; 92–95.
10. Fairhurst MC, Mattaso Maia MAG. Performance comparison inhierarchical architectures for memory network pattern classifiers.Pattern Recognition Letters 1986; 4(2):121–124
11. Kurzynski MW. On the identity of optimal strategies for multi-stage classifiers. Pattern Recognition Letters 1989; 10(1):39–46
12. Fairhurst MC, Abdel Wahab HMS. An interactive two-levelarchitecture for a memory network pattern classifier. PatternRecognition Letters 1990; 11(8):537–540
13. Fairhurst MC, Mattaso Maia MAG. A two-layer memory net-work architecture for a pattern classifier. Pattern RecognitionLetters 1983; 1(4):267–271
14. Fairhurst MC, Mattaso Maia MAG. Configuration selection fortwo-layer memory network pattern classifiers. Electr Lett 1985;21(21):963–964
15. Bubnicki Z. Pattern recognition systems and their applications.Proc 2nd Int Conf on Systems Engineering, Conventry, UK,1982; 1–8
16. Jozefczyk J. Determination of optimal recognition algorithms inthe two-level system. Pattern Recognition Letters 1986;4(6):413–420
17. Tang YY, Qu YZ, Suen CY. Multiple-level information sourceand entropy-reduced transformation models. Pattern Recognition1991; 24(4):341–357

311Serial Combination of Multiple Experts: A Unified Evaluation
18. Wang QR, Suen CY. Analysis and design of a decision treebased on entropy reduction and its application to large characterset recognition. IEEE Trans Pattern Analysis and MachineIntelligence 1984; 6(4):406–414
19. Argentiero P, Chin R, Beaudet P. An automated approach tothe design of decision tree classifiers. IEEE Trans Pattern Analy-sis and Machine Intelligence 1982; 4(1):51–57
20. Rahman AFR, Fairhurst MC. A multiple-expert decision combi-nation strategy for handwritten character recognition. Proc IntConf on Computational Linguistics, Speech and Document Pro-cessing, Calcutta, India, February 18–20 1998;A23–A28
21. Rahman AFR, Fairhurst MC. An evaluation of multi-expertconfigurations for recognition of handwritten numerals. PatternRecognition 1998; 31(9):1255–1273
22. Fairhurst MC, Stonham TJ. A classification system for alphanu-meric characters based on learning network techniques. DigitalProcesses 1976; 2:321–339
23. Rumelhart DE, Hinton GE, Williams RJ. Learning internalrepresentations by error propagation. In Parallel DistributedProcessing, volume 1, DE Rumelhart, JL McClelland (eds). MITPress, Cambridge, MA, 1986; 318–362
24. Reiss TH. Recognizing Planer Objects using Invariant ImageFeatures. Springer-Verlag, 1993
25. Lucas S, Amiri A. Statistical syntactic methods for high-perform-ance OCR. IEE Proc Vision, Image and Signal Processing 1996;143(1):23–30
26. NIST Special Databases 1–3, 6–8, 19, 20, National Institute ofStandards and Technology, Gaithersburg, MD 200899, USA
27. Image Processing & Computer Vision, Electronic Engineering,University of Kent, Canterbury CT2 7NT, UK
28. Knerr S, Anisimov V, Baret O, Gorski N, Price D, Simon JC.The A2iA Intercheque System: Courtesy amount and legalamount recognition for French checks. Int J Patt Recognitionand Artif Intell 1997; 11(4):505–548
29. Leroux M, Lethelier E, Gilloux M, Lemarie B. Automaticreading of handwritten amounts on French checks. Int J PattRecognition and Artif Intell 1997; 11(4):619–638
30. Rahman AFR, Fairhurst MC, Lee P. Design considerations inreal-time implementation of multiple expert image classifierswithin a modular and flexible multiple-platform design environ-ment. Real Time Imaging Special Issue on Real-Time VisualMonitoring and Inspection 1998; 4:361–376
31. Rahman AFR, Fairhurst MC. A new hybrid approach in combin-ing multiple experts to recognise handwritten numerals. PatternRecongition Letters 1997; 18(8):781–790
32. Lethelier E, Leroux M, Gilloux M. An automatic reading systemfor handwritten numeral amounts on French checks. Proc 3rdInt Conference on Document Analysis and Recognition(ICDAR97) 1995; 92–97
33. Tang YY, Lee SW, Suen CY. Automatic document processing:A survey. Pattern Recognition 1996; 29:1931–1952
34. Saon G, Belaid A. Off-line handwritten word recognition usinga mixed HMM-MRF approach. Proc 4th Int Conference onDocument Analysis and Recognition (ICDAR97), volume 1,Ulm, Germany, 1997; 118–122
35. Dimauro G, Impedovo S, Pirlo G, Salzo A. A multi-expertsignature verification system for bankcheck processing. Int J PattRecognition and Artif Intell 1997; 11(5):827–844
36. Vuurpijl L, Schomaker L. Finding structures in diversity: Ahierarchical clustering method for categorization of allographsin handwriting. Proc 4th Int Conf on Document Analysisand Recognition (ICDAR97), volume 1, Ulm, Germany, 1997;387–393
37. Vyborny CJ, Giger ML. Computer vision and artificial intelli-gence in mammography. Am J Radiology 1994 (162):699–708
38. Holland JH. Adaption in Natural and Artificial Systems. Univer-sity of Michigan Press, 1975
39. Goldberg DE. Genetic Algorithms in Search, Optimization, andMachine Learning. Addison-Wesley, 1989
40. Booker LB. Intelligent behaviour as an adaptation to the taskenvironment. PhD thesis, University of Michigan, Ann Arbor,University Microfilms No. 8214966, 1982
41. Brindle A. Genetic algorithms for function optimization.Included in TCGA Tech. Report No. 91002, University ofAlabama, Tuscaloosa, AL 35487, USA. (Report authors: RESmith, DE Goldberg, JA Earickson)
42. Kimura F, Shridhar M. Handwritten numeral recognition basedon multiple algorithms. Pattern Recognition 1991;24(10):969–983
43. Lam L, Suen CY. Structural classification and relaxation match-ing of totally unconstrained handwritten zip-code numbers. Pat-tern Recognition 1988; 21(1):19–31
44. Chi Z, Wu J, Yan H. Handwritten numeral recognition usingself-organising maps and fuzzy rules. Pattern Recognition 1995;28(1):59–66
45. Fairhurst MC, Brittan P. An evaluation of parallel strategies forfeature vector construction in automatic signature verificationsystems. Int J Patt Recognition and Artif Intell 1994; 8(3):661–678
46. Heutte L, Barbosa-Pereira P, Bougeois O, Moreau JV, Plessis B,Courtellemont P, Lecourtier Y. Multi-bank check recognitionsystem: consideration on the numeral amount recognition mod-ule. Int J Patt Recognition and Artif Intell 11(4):595–618
47. Lee LL, Lizarraga MG, Gomes NR, Koerich AL. A prototypefor Brizilian bankcheck recognition. Int J Patt Recognition andArtif Intell 1997; 11(4): 549–569
Michael Fairhurst has been on the academic staff of the Electronic EngineeringLaboratory at the University of Kent since 1972. He has been actively involvedin various aspects of research in image analysis and computer vision, with aparticular interest in computational architectures for image analysis and theimplementation of high performance classification algorithms. Application areasof principal concern include handwritten text reading and document processing,security and biometrics and medical image analysis. Professor Fairhurst is a currentmember and past Chairman of the IEE Professional Group E4 on Image Processingand Vision, and has in the past been a member of the Professonal GroupCommittee for Biomedical Engineering. He has been Chairman of several of theIEE International Series of Conferences on Image Processing and Applications,including IPA 99 held in July 1999. He has been a member of many conferenceorganising and programme committees, including the most recent IWFHR Work-shop, and is a member of the British Machine Vision Association. He is amember of the IT and Computing College of the EPSRC. He has publishedsome 200 papers in the technical literature and has authored an undergraduatetextbook on computer vision.
A. F. R. Rahman is a member of the teaching staff in the Department ofComputer Science and Engineering at the Bangladesh Univerity of Engineeringand Technology (BUET). He has recently completed his PhD from the Depart-ment of Electronic Engineering at the University of Kent, UK, where he workedon image processing and handwriting recognition techniques. He obtained hisBSc in Electronic Engineering in 1992 from BUET, and his MSc in ComputerScience and Engineering in 1994 from the same university. At present he is apost-doctoral research fellow at the Department of Electronic Engineering at theUniversity of Kent, UK. He has published widely in scientific journals related toimage processing, pattern recognition and computer vision. His current researchinterests include image processing, pattern recognition and automatic documentprocessing.
Correspondence and offprint requests to: Professor M.C. Fairhurst, ElectronicEngineering Laboratory, University of Kent, Canterbury, Kent CT2 7NT, UK.






![The Rhododendron [serial] - Internet Archive](https://static.fdokumen.com/doc/165x107/63237b81117b4414ec0c57ee/the-rhododendron-serial-internet-archive.jpg)






![Yackety yack [serial]](https://static.fdokumen.com/doc/165x107/6328fdedcedd78c2b50e548e/yackety-yack-serial.jpg)






