
Cleavage of single-stranded DNA by plasmid pT 181-encoded RepC protein
Upload
independentCategory
view
0download
0
Plasmid P1 RepA Is Homologous to the F Plasmid RepEClass of Initiators*
Received for publication, October 3, 2003, and in revised form, November 20, 2003Published, JBC Papers in Press, November 21, 2003, DOI 10.1074/jbc.M310917200
Suveena Sharma‡, Bangalore K. Sathyanarayana‡, Jeremy G. Bird, Joel R. Hoskins,Byungkook Lee, and Sue Wickner§,
From the Laboratory of Molecular Biology, NCI, National Institutes of Health, Bethesda, Maryland 20892
DNA replication of plasmid P1 requires a plasmid-encoded origin DNA-binding protein, RepA. RepA is aninactive dimer and is converted by molecular chaper-ones into an active monomer that binds RepA bindingsites. Although the sequence of RepA is not homologousto that of F plasmid RepE, we found by using fold-rec-ognition programs that RepA shares structural homol-ogy with RepE and built a model based on the RepEcrystal structure. We constructed mutants in the twopredicted DNA binding domains to test the model. Asexpected, the mutants were defective in P1 DNA bind-ing. The model predicted that RepA binds the first halfof the binding site through interactions with the C-ter-minal DNA binding domain and the second half throughinteractions with the N-terminal domain. The experi-ments supported the prediction. The model was furthersupported by the observation that mutants defective indimerization map to the predicted subunit interface re-gion, based on the crystal structure of pPS10 RepA, aRepE family member. These results suggest P1 RepA isstructurally homologous to plasmid initiators, includingthose of F, R6K, pSC101, pCU1, pPS10, pFA3, pGSH500,Rts1, RepHI1B, RepFIB, and RSF1010.
A large class of circular double-stranded DNA plasmids con-tain multiple repeated sequences, iterons, in their origins ofreplication that specifically bind plasmid encoded replicationinitiator proteins (recently reviewed by del Solar et al., Ref. 1).Binding of the initiator protein to the plasmid origin is anessential step in the initiation of theta-type DNA replicationand triggers the assembly of a replication complex at the sitethrough interactions between the plasmid initiator, host pro-teins, and the plasmid origin DNA. Plasmid initiator proteinsare not only essential for DNA replication, but in most casesare also involved in the control of replication by autoregulatingtheir gene expression. Additionally, some plasmids also possessiterons located in separate copy control loci. Binding of theinitiator protein simultaneously to the control locus and theorigin regulates plasmid copy number by a mechanism involv-ing pairing of the control site and origin iterons.
In the work presented here we have studied the plasmid P1initiator protein, RepA. RepA binds to five direct repeats of a19-bp sequence in the P1 origin (2, 3). By binding to the origin
iterons, RepA also represses transcription from the repA pro-moter, located within the origin repeats and it regulates copynumber by binding a group of nine similar repeated sequencesin a copy control locus. The purified RepA protein exists as adimer in solution and is unable to bind DNA. The action ofDnaJ and DnaK in an ATP-dependent reaction converts theinactive dimer to active monomer that is capable of binding theP1 iteron with high affinity (4–6). GrpE is required underconditions where the reaction is limited by slow nucleotideexchange (7). The RepA monomer is the active form in vivo,since DnaK, DnaJ, and GrpE are required for the stable main-tenance of P1 plasmids and for repA promoter repression(8–10).
In vitro RepA can be activated for DNA binding by ClpA, amember of the Clp/Hsp100 family of ATP-dependent chaper-ones (11). In this case, activation is the conversion of inactivedimers to active monomers. Although both ClpA and the DnaKchaperone system convert RepA dimers to monomers, theyrecognize different regions of RepA (12, 13).
The initiator proteins of several other plasmids also exist asdimers yet bind to origin iterons as monomers. RepE, theinitiator protein of F plasmid, requires DnaJ, DnaK, and GrpEfor monomerization and activation of origin binding (14, 15).The initiator of plasmid RK2 is activated in vitro for DNAbinding by monomerization by either the DnaK chaperone sys-tem in combination with ClpB or by ClpX (16, 17). The chap-erone system used to activate the RK2 initiator in vivo has notbeen identified, suggesting the possibility that several chaper-one systems are able to carry out the reaction. Recent studieshave suggested that iteron DNA binding by RepA of pPS10facilitates the conversion of inactive dimers to active monomers(18). For RepA of pSC101, the monomer is active in iteron DNAbinding, but the monomer-dimer transition is independent ofmolecular chaperones (19, 20). Interestingly, the R6K initiatoris able to bind to its iteron as a dimer or monomer (21).
Structural studies of a monomeric mutant of RepE of Fplasmid in complex with the 19-bp iteron demonstrated thatRepE consists of topologically similar N- and C-terminal do-mains related to each other by internal pseudo 2-fold symme-try, despite the lack of amino acid similarity between the twodomains (22). The two domains bind to two consecutive majorgrooves on one face of the helix. Amino acid homology betweenRepE and the initiator proteins of R6K, pSC101, pCU1, pPS10,pFA3, and pGSH500 suggests that those proteins bind theirrespective iterons similarly (22).
P1 RepA does not share sequence homology with RepE andcould not initially be aligned with the other plasmid initiators.In this study we addressed the question of whether P1 RepAmight be structurally similar to the RepE class of plasmidinitiator proteins, to another class of initiator proteins, or to aknown class of DNA-binding proteins by fold prediction analy-
* The costs of publication of this article were defrayed in part by thepayment of page charges. This article must therefore be hereby marked“advertisement” in accordance with 18 U.S.C. Section 1734 solely toindicate this fact.
‡ These authors contributed equally to this work.§ To whom correspondence should be addressed: Bldg. 37, Rm. 5144,
NCI, National Institutes of Health, 37 Convent Dr. MSC37-4264,Bethesda, MD 20892-4264. Tel.: 301-496-2629; Fax: 301-402-1344;E-mail: [email protected].
THE JOURNAL OF BIOLOGICAL CHEMISTRY Vol. 279, No. 7, Issue of February 13, pp. 6027–6034, 2004Printed in U.S.A.
This paper is available on line at http://www.jbc.org 6027
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

sis and molecular modeling. We were able to align RepA with Fplasmid RepE and generate a model of a RepA monomer boundto DNA based on the crystal structure of monomeric RepE. Themodel was tested experimentally and our results indicate thatP1 RepA is structurally similar to the class of plasmid initiatorproteins to which RepE belongs.
EXPERIMENTAL PROCEDURES
Materials—ATP was obtained from Roche Applied Science. Restric-tion endonucleases were obtained from New England BioLabs andpolymerase chain reaction reagents were obtained from PerkinElmerLife Sciences. Oligonucleotides used in DNA binding experiments weresynthesized and PAGE purified by Sigma Genosys.
Plasmids—Site-directed mutants of wild-type RepA and RepA-His6
(13) were constructed using the QuickChange mutagenesis kit (Strat-agene). RepA His134 and Gly156 were converted to Asn and Val, respec-tively, generating point mutants RepA(H134N) and RepA(G156V).Lys88, Lys128, Arg130, Arg245, and Arg269 were converted to alanines,generating RepA(K88A), RepA(K128A), RepA(R130A), RepA(R245A),and RepA(R269A). To make RepA(3M), H134N, G156V, and N142Kwere introduced by megaprimer PCR. The sequences of all the mutantswere verified by DNA sequencing. [3H]oriP1 plasmid DNA (3590 cpm/fmol) was prepared as described (5).
Proteins—RepA and RepA mutants were purified as described (4).ClpA was isolated as reported (23). The purity of all proteins wasgreater than 95% as determined by SDS-PAGE. Protein concentrationsare expressed as molar amounts of RepA dimers and ClpA hexamers.Protein concentrations were determined by Bradford assay (Bio-Rad).Proteins were 3H-labeled in vitro using succinimidyl propionate, N-[pro-pionate-2,3-3H] as described (24).
RepA Activation and DNA Binding Assays—For measuring DNAbinding by nitrocellulose filter binding, reaction mixtures (20 �l) con-tained Buffer A (20 mM Tris-HCl, pH 7.5, 100 mM KCl, 5 mM dithio-threitol, 0.1 mM EDTA, 10% glycerol (v/v)), 10 mM MgOAc, 1 mM ATP,100 �g/ml bovine serum albumin, 0.005% Triton X-100 (v/v), 0.5 pmol ofClpA, and RepA or RepA mutant protein as indicated. Proteins werediluted in Buffer A containing 0.05% Triton X-100 (v/v). After 10 min at24 °C, calf thymus DNA (1 �g) and 10 fmol of [3H]oriP1 plasmid DNA(3590 cpm/fmol) were added. Following 5 min at 0 °C, the mixtures werefiltered through nitrocellulose filters, and the retained radioactivitywas measured.
For measuring DNA binding by gel retardation, reaction mixtures(20 �l) contained Buffer A, 10 mM MgOAc, 5 mM ATP, 100 �g/ml bovineserum albumin, 0.005% Triton X-100 (v/v), 0.64 pmol of ClpA, and RepAor RepA mutant protein as indicated. After 20 min at 24 °C, 2.5 pmol ofdouble-stranded oligonucleotide, prepared by annealing complemen-tary oligonucleotides, were added. After 10 min at 0 °C, the sampleswere electrophoresed in 8% polyacrylamide Tris borate/EDTA gels andstained with SYBR green (Molecular Probes). Band intensities werequantified using 300-nm transillumination and an Eagle Eye II (Strat-agene) image acquisition system.
Molecular Modeling of RepA—RepA was aligned to RepE using 2-foldrecognition programs, bioinbgu and 3D-PSSM (25, 26). The alignmentobtained was combined manually with the previously published multi-ple alignment of RepE and the initiator proteins of R6K, pSC101, pCU1,and pPS10 (22). The alignment was manually adjusted to eliminatebreaks or insertions in secondary structures compared with the x-raystructure of RepE. The final alignment was used to build a model of amonomer of RepA with reference to a monomer of RepE using theautomated homology modeling program, modeler, of the homology mod-eling option of the InsightII program (Accelrys, Inc.). In two regions ofthe x-ray structure where there were gaps, the modeler program in-serted the corresponding residues. The model was then superimposedon the RepE protein structure using the program Sheba (27). The rootmean-squared deviation between the two molecules is 1.1 Å over 191 of211 C� atoms of RepA. The superimposed proteins along with the RepEiteron DNA were displayed using InsightII on a SGI work station andthen the RepE protein structure was removed, generating a model ofRepA bound to a 23-bp oligonucleotide with the RepE iteron sequence.Modeling of the initiator proteins of R6K, pSC101, pCU1, and pSP10was carried out similarly using a protein alignment that was slightlymodified from the previously published alignment (22) and the crystalstructure of RepE as the template.
Illustrations of P1 RepA, F RepE, and R6K pi dimers were made bysuperimposing the models of P1 RepA and R6K pi monomers and thecrystal structure of the F RepE monomer on each of the protomers of the
pPS10 RepA dimer structure (28) using the program Sheba. The pro-gram Molscript was used to generate the ribbon diagrams.
The atomic coordinates for the molecular model of the P1 RepAmonomer are deposited in the model data base (www.rcsb.org/pdb).Molecular models of P1 RepA with DNA, R6K pi, pSC101 RepA, pPS10RepA, and pCU1 will be provided upon request.
RESULTS
Molecular Modeling of P1 RepA Bound to DNA—When wequeried the protein data base with the P1 RepA amino acidsequence using blastp, the RepE family of initiator proteinswere not identified, as previously reported (22). However, aPfam search placed both RepA and RepE in the Rep3 family ofthe Pfam data base, indicating similarity between the twoproteins. We used 2-fold recognition programs, bioinbgu (25)and 3D-PSSM (26), to determine if the amino acid sequence ofRepA could be identified with any existing protein folds. Bothprograms predicted RepA to fold similarly to RepE of F plasmidwith medium to high confidence. Alignment of RepA with RepEobtained from the fold-recognition programs was combinedmanually with the multiple alignment of RepE and the initia-tor proteins of plasmids R6K, pSC101, pCU1, and pPS10,which were previously shown to be related to RepE (22). Man-ual adjustments of this alignment were done to avoid breaks orinsertions within the secondary structures of the model whencompared with the x-ray structure of RepE (Fig. 1). RepE andRepA align such that amino acid 71 of RepA aligns with thefirst amino acid of the RepE crystal structure, residue 15. Theadjusted alignment of the other initiators differs slightly fromthat of Komori et al. (22).
The final alignment was used to build a model of RepA withreference to RepE (Fig. 2, A and B). From the alignment andmodel of RepA it can be seen that RepA, like RepE, is composedof two domains that are structurally similar although they donot share amino acid homology. Each domain contains a HTHDNA binding motif (29). Using similar methods, we modeledthe initiator proteins of R6K, pSC101, pCU1, and pPS10 usingour refined alignment of the proteins and the crystal structureof RepE as the template (Fig. 2, C–F). RepA of pPS10 haspreviously been modeled (30) using the published alignment(22). The structural similarity of P1 RepA and F RepE with theother plasmid initiator proteins is apparent. The models pro-vide useful tools for designing site-directed mutants to eluci-date the protein-protein and protein-DNA interactions in-volved in the process of initiation of DNA replication.
Site-directed RepA Mutants Defective in DNA Binding—Wenext wanted to test the validity of the model experimentally.One prediction is that RepA binds to one face of the DNA. Thiswas confirmed by previous DNA footprinting experimentsshowing that RepA binds exclusively to one face of the DNA,through two consecutive major groove interactions (31, 32).
The model predicts that RepA should contact the majorgroove of the DNA binding site through a N-terminal and aC-terminal HTH motif. To test the model, we constructed site-directed mutations in RepA, two in the predicted N-terminalrecognition helix, RepA(K128A) and RepA(R130A), and one inthe predicted C-terminal recognition helix, RepA(R245A) (in-dicated in Figs. 1 and 2A). We purified the proteins and meas-ured DNA binding both by a gel shift assay using a 33-bpdouble-stranded oligonucleotide containing the RepA consen-sus binding site and by nitrocellulose filter binding assay usingplasmid DNA containing the P1 origin of replication. As acontrol, and as previously seen, RepA bound specifically to theconsensus iteron in a reaction requiring chaperone activation,either ClpA (Ref. 11 and Fig. 3) or DnaJ and DnaK (5). Whenthe mutant proteins were tested for DNA binding,RepA(R130A) and RepA(R245A) bound P1 iteron DNA withabout 10% the affinity of wild type following activation by ClpA
Homology between P1 RepA and F RepE6028
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

(Fig. 3A). These results strongly suggest that Arg130 and Arg245
participate in RepA-DNA interactions. RepA(K128A) boundoriP1 DNA with about 60% the affinity of wild type afteractivation (Fig. 3B). Although Lys128 is predicted to be in theDNA recognition helix of RepA, the biochemical results indi-cate that it is not as involved in DNA binding as Arg130.
The model predicts that RepA should make contacts with thephosphate backbone of the DNA outside of the recognitionhelices in the N-terminal region of �2 (residues 87–89), theN-terminal region of �2� (residues 204–206), between �3 and�4 (residues 170–173), and between �3� and �4� (residues266–269). We constructed and tested mutants in two of theseregions. RepA(K88A) was tested because it aligns with anarginine of RepE that contacts the phosphate backbone, R33(shown in Figs. 1 and 2). We found that it bound oriP1 DNAwith about 60% lower affinity than the wild type (Fig. 3B).RepA(R269A) was also tested and found to bind oriP1 DNAwith about 25% lower affinity than wild type (Fig. 3C). Both ofthese results are consistent with these regions being in closeproximity to the DNA.
The observations that the mutant proteins bound P1 iteroncontaining DNA, albeit poorly in some cases, and requiredClpA for activation suggested that the proteins folded in con-formations similar to wild type. Thus these results support thevalidity of the model and the importance of residues in bothDNA binding recognition helices, �4 and �4�. They also suggestthat the residues in the N-terminal region of �2 and between�3� and �4� are important for DNA binding.
DNA Binding by RepA to the 19-bp Binding Site and to theHalf-Sites—The model predicts that RepA should contact bothhalves of the iteron. The structure data shows that the C-terminal DNA binding domain of RepE makes stronger pro-tein-DNA contacts with the first half of the iteron than theN-terminal domain makes with the second half of the iteron(22). The two halves of the iterons were referred to as “first”and “second” before the structure of RepE demonstrated thatthe C-terminal domain of RepE binds to the first half-site and
the N-terminal domain binds to the second half-site (22). In theN-terminal recognition helix of RepE, �4, only two residuescontact the second half of the iteron directly while in theC-terminal recognition helix, �4�, four residues contact the firsthalf of the iteron (22). We wanted to test whether or not P1RepA binds to the separate halves of the P1 iteron and whetherRepA has a higher affinity for the first half of the site than thesecond. We compared DNA binding to 33-bp double-strandedoligonucleotides containing either the 19-bp consensus RepAbinding site, the first half of the site, or the second half of thesite (shown in Fig. 4). When DNA binding to the consensus sitewas measured using RepA activated by ClpA, 50% retardationwas seen with 80 nM RepA and 125 nM DNA fragment (Fig. 5A).When we measured RepA binding to the first half of the iteron,we found that RepA bound, but the apparent affinity was about60-fold lower than that for the full site (Fig. 5B). DNA bindingwas specific and required activation by ClpA. In contrast wewere unable to detect binding of activated RepA to the secondhalf of the iteron, suggesting that the affinity was at least300-fold lower than that for the full site (Fig. 5C). DNA bindingwas also not detected when we used an oligonucleotide contain-ing the second half-site plus the T that is located in the middleof the 19 bp iteron (data not shown). The observation that RepAbinds with higher affinity to the first half of the site than thesecond further suggests similarity between RepE and RepA.
The model predicts that the C-terminal DNA binding domainof RepA interacts with the first half of the iteron. To test thiswe reasoned in the following way. Since RepA binds, althoughwith lower affinity, to the first half of the iteron, mutants in theN-terminal DNA binding domain might bind the first half-sitethrough interactions involving their wild-type C-terminal DNAbinding domain with similar affinity as wild-type RepA. DNAbinding studies confirmed this (Fig. 6). Both RepA(R130A) andwild-type RepA bound the first half-site with similar relativeaffinity, suggesting that they were both binding to the firsthalf-site through interactions with their C-terminal DNA bind-ing domain. Moreover the RepA(R130A) bound the first half-
FIG. 1. Sequence alignment of plasmid initiator proteins showing secondary structure alignment. P1 RepA was aligned as describedunder “Experimental Procedures” with F plasmid RepE and other plasmid initiator proteins, including those of F, R6K, pSC101, pCU1, and pPS10.The two DNA binding helices are shown in red. The structurally homologous N- and C-terminal domains are aligned one above the other, coloredblue and yellow, respectively. Amino acid positions of the mutants used in these studies that alter DNA binding or monomer dimer ratio areindicated in green and red, respectively.
Homology between P1 RepA and F RepE 6029
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

site DNA with similar affinity as it bound the full iteron (Fig.3), suggesting that the defect in DNA binding to the full sitereflects a defect in interaction of the second half-site with theN-terminal domain of RepA. In addition, the model predictedthat RepA(R245A) would have weaker binding to the firsthalf-site than wild-type RepA. When DNA binding was tested,there was no detectable binding by RepA(R245A) to the firsthalf-site (Fig. 6). These results also support the validity of themolecular model.
The dimeric forms of the initiators of plasmids F, pSC101,R6K, and pSP10 are known to bind as dimers to the promotersof the initiator genes and repress transcription (1). For theseplasmids the operator site is in a separate location from theorigin of replication and consists of the first half of the iteronfollowed by an inverted first half-site. The two inverted repeatsequences are separated by roughly one turn of the helix, 9 bp.
Although the promoter for the repA gene of P1 is embeddedwithin the origin iterons and repression of repA expressionresults from the binding of monomers to the origin iterons, itremained possible that RepA might bind to inverted half-sitesas a dimer, by analogy with RepE, and perhaps function else-where in the P1 genome. We used an oligonucleotide in whichthe first half-site was followed by an inverted first half-site andthe two half-sites were separated by 9 bp (Fig. 4). When wemeasured DNA binding by dimeric RepA, there was no detect-able binding (data not shown). After chaperone activation,RepA bound the DNA with about the same affinity as the firsthalf-site (data not shown). Although it remains possible thatRepA might bind to an inverted repeat of the first half-site if adifferent spacer were used, the results suggest that dimericRepA does not possess the same ability as some other plasmidinitiators to act as a dimeric repressor. This difference may be
FIG. 2. Models of initiator proteins bound to DNA. A, model of a P1 RepA monomer bound to DNA. B, crystal structure of a RepE monomerbound to DNA (22). C–F, models of the initiator proteins of pSC101, pCU1, R6K, and pPS10 bound to DNA, respectively. The N- and C-terminaldomains are blue and yellow, respectively. The DNA binding helices, �4 and �4�, are red. The site-directed P1 RepA DNA binding mutants usedin these studies are shown as balls.
Homology between P1 RepA and F RepE6030
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

because it contains a N-terminal domain of 70 amino acids notpresent in the other initiators.
RepA Mutants with Increased Monomer/Dimer Ratios—Thecrystal structure of a dimer of the N-terminal domain of RepAof plasmid pPS10 was solved recently (28) (shown in Fig. 7A).The structure demonstrates that the conformation of the N-terminal domain in the dimer protomers is similar to that inthe monomer. The dimerization interface is between �2b of oneprotomer and �3 of the other, forming a five-stranded antipa-rallel pleated sheet of �2-�4-�3 from one protomer and �2b-�2afrom the other, using the secondary structure nomenclatureused in Fig. 1 and by Komori et al. (Ref. 22 and shown in Fig.7A). Because pPS10 RepA is a member of the RepE family ofinitiator proteins, the other members of the family are expectedto have similar dimeric structures.
We have illustrated the P1 RepA dimer by superimposing themodeled monomer structure of RepA on each of the protomersof the pPS10 RepA dimer structure (28) as described under“Experimental Procedures” (Fig. 7B). In the figure the dimer-ization interface of P1 RepA is very similar to that of pPS10RepA, involving the �2b- and �3-sheets in the N-terminal do-main. The monomer form of P1 RepA and the other plasmidinitiator proteins differ from the x-ray crystallographic dimerstructure of the N-terminal domain of pPS10 RepA in that themonomer has a �-sheet at the N terminus where the dimer hasa long �-helix, and the monomer has a much shorter �5-helixthan the dimer (Fig. 7, A–D). In addition, the antiparallel�2a-�2b-sheet is bent inwards in the monomer compared withthe dimer. The C-terminal domain of the RepA monomer modelis included in the illustration, although its location relative tothe N-terminal domain is not known.
Previously, mutations in P1 RepA were isolated that resulted
FIG. 3. DNA binding by RepA mutants predicted to be DNAbinding defective. A, RepA (diamonds), RepA(R130A) (squares), orRepA(R245A) (triangles), at the concentrations indicated, was incu-bated with ClpA in the presence (closed symbols) or absence (opensymbols) of ATP and DNA binding was measured using gel shift assayas described in “Experimental Procedures.” B, RepA (diamonds),RepA(K128A) (squares), or RepA(K88A) (circles) was incubated withClpA (filled symbols) or without ClpA (open symbols), and DNA bindingwas measured using nitrocellulose filter binding assay as describedunder “Experimental Procedures.” C, RepA (diamonds) orRepA(R269A) (triangles) was incubated with ClpA (filled symbols) orwithout ClpA (open symbols), and DNA binding was measured usingnitrocellulose filter binding assay as in Fig. 3B.
FIG. 4. Double-stranded DNA oligonucleotides used. The firstand second half-site oligonucleotides were made by replacing the otherhalf-site sequence with a random sequence of nine bp.
FIG. 5. RepA binds to the consensus RepA binding site and tothe first half-site. RepA at the concentrations indicated was incubatedwith ClpA with and without ATP. Then a 33-bp double-stranded oligo-nucleotide containing the full RepA binding site, (A), the first half of thebinding site (B), or the second half of the binding site (C), was added,and RepA-DNA complexes were detected by gel shift assay as describedunder “Experimental Procedures.”
Homology between P1 RepA and F RepE 6031
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

in a high copy phenotype and some of these were shown to bechaperone independent in vivo, suggesting that they may bedimerization defective (33–35). The region on the P1 RepAmodel that contains the known high copy mutations is coloredin yellow. Importantly, it is the region predicted to be involvedin dimerization (Fig. 7B).
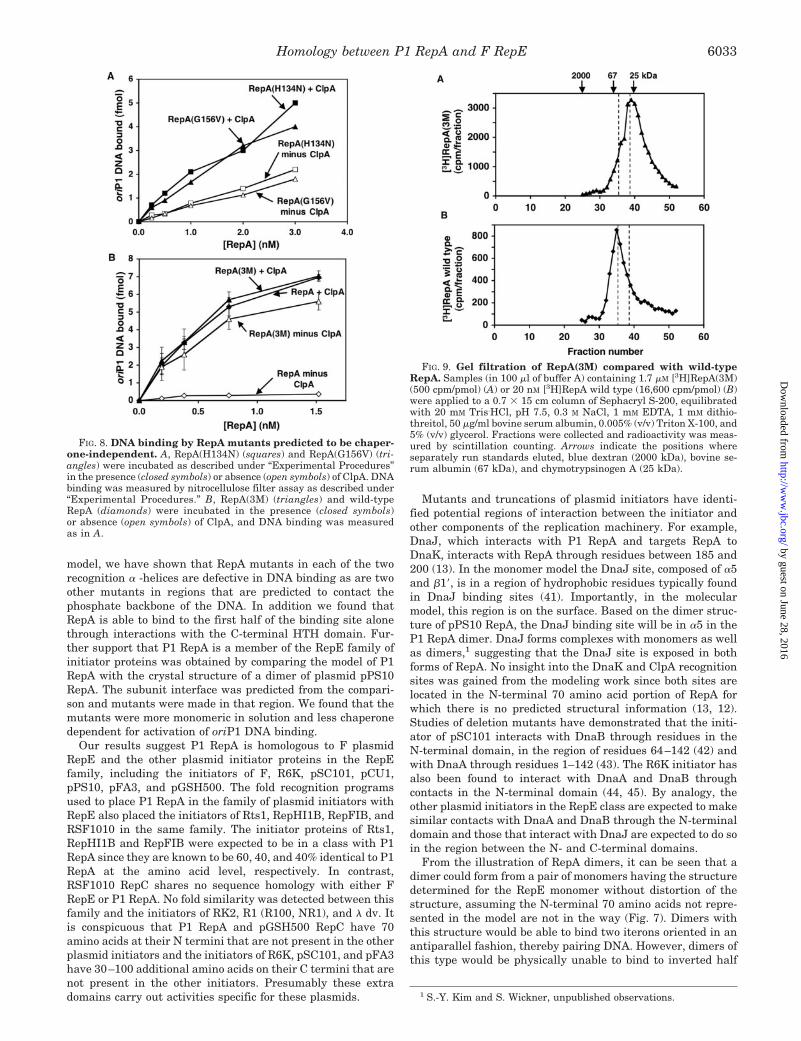
As a further test that P1 RepA is structurally related to theother plasmid initiators, we tested two previously isolated highcopy RepA mutants, RepA(H134N) and RepA(G156V) (Refs. 33and 34 shown in Figs. 1 and 7B), for their ability to bind DNAin the absence of chaperones. The mutant proteins bound oriP1DNA well in the absence of chaperones (Fig. 8A), although bothwere further activated about 2-fold by ClpA (Fig. 8A) and by theDnaK chaperone system (data not shown). By gel filtrationanalysis, the mutant proteins existed predominantly as mono-
mers in the low nanomolar range and existed as mixtures ofmonomers and dimers in the low micromolar range (data notshown). To obtain a RepA mutant with a higher monomer/dimer ratio we constructed a multiple mutant, RepA(3M), con-taining both H134N and G156V substitutions and N142K, an-other substitution that results in a high copy phenotype (Ref.36 shown in Figs. 1 and 7B). RepA(3M) bound oriP1 DNA wellwithout activation by chaperones and was not significantlyfurther activated by chaperones (Fig. 8B). By gel filtrationanalysis RepA3M existed mainly as a monomer at concentra-tions as high as 1.7 �M (Fig. 9A). At concentrations below 0.8�M, the dimer shoulder was not present. In contrast, RepA wildtype existed as a dimer at 20 nM, the lowest concentration thatcould be measured (Fig. 9B). The observation that mutantspredicted to be in the subunit interface region are defective indimerization further supports the validity of the alignment ofRepA with the RepE family of initiators.
RepE mutants that are defective in dimerization have alsobeen reported, one of which was used in the crystallizationstudies (15, 22, 37). These mutations map to a region of RepEwhere high copy mutations map (38, 39). We have representedF plasmid RepE as a dimer using the method used for the P1RepA dimer and indicated the region of the known high copymutants. It can be seen that the mutants are in the predictedsubunit interface region (Fig. 7C). We have similarly repre-sented R6K pi protein as a dimer and colored the region thatcontains high copy mutations (Fig. 7D). These also are locatedin the dimerization region, although none reported to date arein the �-sheets expected to be involved directly in subunitinteractions (21, 40).
DISCUSSION
By using fold recognition programs we are able to align P1RepA with the F plasmid RepE family of initiator proteins andconstruct a molecular model of a monomer bound to DNA. Allmembers of the class contain N- and C-terminal domains re-lated to each other by 2-fold structural symmetry and eachdomain contains an HTH DNA binding motif. To verify the
FIG. 6. RepA(R130A) binds to the first half-site of the RepAbinding site, but RepA(R245A) does not. RepA(R130A) (closedsquares), RepA(R245A) (closed triangles), or wild-type RepA (closeddiamonds) was incubated with ClpA in the presence of ATP. A 33-bpdouble-stranded oligonucleotide containing the first half of the RepAbinding site was added, and DNA binding was detected by gel shiftassay as described under “Experimental Procedures.” In the absence ofATP, no DNA binding was detected by either the wild-type or mutantproteins (data not shown).
FIG. 7. Dimer models of initiatorproteins. A, crystal structure of the N-terminal domain of dimeric pPS10 RepA(18). The �-strands involved in formingthe antiparallel pleated �-sheet are la-beled according to the nomenclature usedin Fig. 1 and by Komori et al. (22). B,illustration of a P1 RepA dimer generatedas described under “Experimental Proce-dures.” The region containing high copymutants is colored yellow. The N-terminaldomain (residues 71–188) is colored red.The C-terminal domain is gray. The highcopy P1 RepA mutants used in the exper-iments shown in Figs. 8 and 9 are shownas balls. C and D, illustrations of F RepEand R6K pi dimers showing regions ofhigh copy number mutants, using thecolor coding as in 7B. The dotted lines in FRepE indicate loop regions of RepE thatwere disordered in the structure.
Homology between P1 RepA and F RepE6032
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from
model, we have shown that RepA mutants in each of the tworecognition � -helices are defective in DNA binding as are twoother mutants in regions that are predicted to contact thephosphate backbone of the DNA. In addition we found thatRepA is able to bind to the first half of the binding site alonethrough interactions with the C-terminal HTH domain. Fur-ther support that P1 RepA is a member of the RepE family ofinitiator proteins was obtained by comparing the model of P1RepA with the crystal structure of a dimer of plasmid pPS10RepA. The subunit interface was predicted from the compari-son and mutants were made in that region. We found that themutants were more monomeric in solution and less chaperonedependent for activation of oriP1 DNA binding.
Our results suggest P1 RepA is homologous to F plasmidRepE and the other plasmid initiator proteins in the RepEfamily, including the initiators of F, R6K, pSC101, pCU1,pPS10, pFA3, and pGSH500. The fold recognition programsused to place P1 RepA in the family of plasmid initiators withRepE also placed the initiators of Rts1, RepHI1B, RepFIB, andRSF1010 in the same family. The initiator proteins of Rts1,RepHI1B and RepFIB were expected to be in a class with P1RepA since they are known to be 60, 40, and 40% identical to P1RepA at the amino acid level, respectively. In contrast,RSF1010 RepC shares no sequence homology with either FRepE or P1 RepA. No fold similarity was detected between thisfamily and the initiators of RK2, R1 (R100, NR1), and � dv. Itis conspicuous that P1 RepA and pGSH500 RepC have 70amino acids at their N termini that are not present in the otherplasmid initiators and the initiators of R6K, pSC101, and pFA3have 30–100 additional amino acids on their C termini that arenot present in the other initiators. Presumably these extradomains carry out activities specific for these plasmids.
Mutants and truncations of plasmid initiators have identi-fied potential regions of interaction between the initiator andother components of the replication machinery. For example,DnaJ, which interacts with P1 RepA and targets RepA toDnaK, interacts with RepA through residues between 185 and200 (13). In the monomer model the DnaJ site, composed of �5and �1�, is in a region of hydrophobic residues typically foundin DnaJ binding sites (41). Importantly, in the molecularmodel, this region is on the surface. Based on the dimer struc-ture of pPS10 RepA, the DnaJ binding site will be in �5 in theP1 RepA dimer. DnaJ forms complexes with monomers as wellas dimers,1 suggesting that the DnaJ site is exposed in bothforms of RepA. No insight into the DnaK and ClpA recognitionsites was gained from the modeling work since both sites arelocated in the N-terminal 70 amino acid portion of RepA forwhich there is no predicted structural information (13, 12).Studies of deletion mutants have demonstrated that the initi-ator of pSC101 interacts with DnaB through residues in theN-terminal domain, in the region of residues 64–142 (42) andwith DnaA through residues 1–142 (43). The R6K initiator hasalso been found to interact with DnaA and DnaB throughcontacts in the N-terminal domain (44, 45). By analogy, theother plasmid initiators in the RepE class are expected to makesimilar contacts with DnaA and DnaB through the N-terminaldomain and those that interact with DnaJ are expected to do soin the region between the N- and C-terminal domains.
From the illustration of RepA dimers, it can be seen that adimer could form from a pair of monomers having the structuredetermined for the RepE monomer without distortion of thestructure, assuming the N-terminal 70 amino acids not repre-sented in the model are not in the way (Fig. 7). Dimers withthis structure would be able to bind two iterons oriented in anantiparallel fashion, thereby pairing DNA. However, dimers ofthis type would be physically unable to bind to inverted half
1 S.-Y. Kim and S. Wickner, unpublished observations.
FIG. 8. DNA binding by RepA mutants predicted to be chaper-one-independent. A, RepA(H134N) (squares) and RepA(G156V) (tri-angles) were incubated as described under “Experimental Procedures”in the presence (closed symbols) or absence (open symbols) of ClpA. DNAbinding was measured by nitrocellulose filter assay as described under“Experimental Procedures.” B, RepA(3M) (triangles) and wild-typeRepA (diamonds) were incubated in the presence (closed symbols)or absence (open symbols) of ClpA, and DNA binding was measuredas in A.
FIG. 9. Gel filtration of RepA(3M) compared with wild-typeRepA. Samples (in 100 �l of buffer A) containing 1.7 �M [3H]RepA(3M)(500 cpm/pmol) (A) or 20 nM [3H]RepA wild type (16,600 cpm/pmol) (B)were applied to a 0.7 � 15 cm column of Sephacryl S-200, equilibratedwith 20 mM Tris.HCl, pH 7.5, 0.3 M NaCl, 1 mM EDTA, 1 mM dithio-threitol, 50 �g/ml bovine serum albumin, 0.005% (v/v) Triton X-100, and5% (v/v) glycerol. Fractions were collected and radioactivity was meas-ured by scintillation counting. Arrows indicate the positions whereseparately run standards eluted, blue dextran (2000 kDa), bovine se-rum albumin (67 kDa), and chymotrypsinogen A (25 kDa).
Homology between P1 RepA and F RepE 6033
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

iterons and it is known that many plasmid initiator proteinsbind to such sites in the promoter regions of the initiator genesand repress gene expression. Thus the structure of the dimerwhen bound to inverted half iterons must be significantly dif-ferent than the known structure of the monomer bound to thefull iteron. It remains possible that there are two forms ofdimers, one that participates in handcuffing and another thatis involved in autoregulation.
In summary, we have presented evidence that P1 RepAresembles the other members of a large class of plasmid initi-ator proteins. Future studies aimed at understanding thestructure of the entire RepA monomer and the entire RepAdimer are needed to further our understanding of the confor-mational changes that the initiator proteins undergo in theirtransition from dimers to monomers and the mechanism ofaction of molecular chaperones in this process. Future work isalso needed to understand the architecture of initiation com-plexes, consisting of multiple initiator protein monomers boundto multiple iterons and replication factors recruited from thehost.
Acknowledgments—We thank Druba Chattoraj and Michael Yarmo-linsky for many helpful discussions and Chi Chae for helpful commentson the manuscript.
REFERENCES
1. del Solar, G., Giraldo, R., Ruiz-Echevarria, M. J., Espinosa, M., and Diaz-Orejas, R. (1998) Microbiol. Mol. Biol. Rev. 62, 434–464
2. Abeles, A. L., Snyder, K. M., and Chattoraj, D. K. (1984) J. Mol. Biol. 173,307–324
3. Chattoraj, D. K., and Schneider, T. D. (1997) Prog. Nucleic Acids Res. Mol.Biol. 57, 145–186
4. Wickner, S. H. (1990) Proc. Natl. Acad. Sci. U. S. A. 87, 2690–26945. Wickner, S., Hoskins, J., and McKenney, K. (1991) Nature 350, 165–1676. Wickner, S., Hoskins, J., and McKenney, K. (1991) Proc. Natl. Acad. Sci.
U. S. A. 88, 7903–79077. Skowyra, D., and Wickner, S. (1993) J. Biol. Chem. 268, 25296–253018. Bukau, B., and Walker, G. C. (1989) J. Bacteriol. 171, 6030–60389. Tilly, K., and Yarmolinsky, M. (1989) J. Bacteriol. 171, 6025–6029
10. Tilly, K., Sozhamannan, S., and Yarmolinsky, M. (1990) New Biol. 2, 812–81711. Wickner, S., Gottesman, S., Skowyra, D., Hoskins, J., McKenney, K., and
Maurizi, M. R. (1994) Proc. Natl. Acad. Sci. U. S. A. 91, 12218–1222212. Hoskins, J. R., Kim, S. Y., and Wickner, S. (2000) J. Biol. Chem. 275,
35361–3536713. Kim, S. Y., Sharma, S., Hoskins, J. R., and Wickner, S. (2002) J. Biol. Chem.
277, 44778–4478314. Kawasaki, Y., Wada, C., and Yura, T. (1990) Mol. Gen. Genet. 220, 277–28215. Ishiai, M., Wada, C., Kawasaki, Y., and Yura, T. (1994) Proc. Natl. Acad. Sci.
U. S. A. 91, 3839–384316. Konieczny, I., and Liberek, K. (2002) J. Biol. Chem. 277, 18483–1848817. Konieczny, I., and Helinski, D. R. (1997) Proc. Natl. Acad. Sci. U. S. A. 94,
14378–1438218. Diaz-Lopez, T., Lages-Gonzalo, M., Serrano-Lopez, A., Alfonso, C., Rivas, G.,
Diaz-Orejas, R., and Giraldo, R. (2003) J. Biol. Chem. 278, 18606–1861619. Manen, D., Upegui-Gonzalez, L. C., and Caro, L. (1992) Proc. Natl. Acad. Sci.
U. S. A. 89, 8923–892720. Ingmer, H., Fong, E. L., and Cohen, S. N. (1995) J. Mol. Biol. 250, 309–31421. Urh, M., Wu, J., Forest, K., Inman, R. B., and Filutowicz, M. (1998) J. Mol.
Biol. 283, 619–63122. Komori, H., Matsunaga, F., Higuchi, Y., Ishiai, M., Wada, C., and Miki, K.
(1999) EMBO J. 18, 4597–460723. Maurizi, M. R., Thompson, M. W., Singh, S. K., and Kim, S. H. (1994) Methods
Enzymol. 244, 314–33124. Hoskins, J. R., Pak, M., Maurizi, M. R., and Wickner, S. (1998) Proc. Natl.
Acad. Sci. U. S. A. 95, 12135–1214025. Fischer, D. (2000) in Pacific Symposium on Biocomputing (Altman, R. B.,
Dunker, A. K., Hunter, L., and Klein, T. E., eds), pp. 119–130, WorldScientific, Teaneck, NJ
26. Kelley, L. A., MacCallum, R. M., and Sternberg, M. J. (2000) J. Mol. Biol. 299,499–520
27. Jung, J., and Lee, B. (2000) Protein Eng. 13, 535–54328. Giraldo, R., Fernandez-Tornero, C., Evans, P. R., Diaz-Orejas, R., and Romero,
A. (2003) Nat. Struct. Biol. 10, 565–57129. Brennan, R. G., and Matthews, B. W. (1989) J. Biol. Chem. 264, 1903–190630. Maestro, B., Sanz, J. M., Diaz-Orejas, R., and Fernandez-Tresguerres, E.
(2003) J. Bacteriol. 185, 1367–137531. Abeles, A. L., Reaves, L. D., and Austin, S. J. (1989) J. Bacteriol. 171, 43–5232. Papp, P. P., and Chattoraj, D. K. (1994) Nucleic Acids Res. 22, 152–15733. Scott, J. R., Kropf, M. M., Padolsky, L., Goodspeed, J. K., Davis, R., and
Vapnek, D. (1982) J. Bacteriol. 150, 1329–133934. Baumstark, B. R., Lowery, K., and Scott, J. R. (1984) Mol. Gen. Genet. 194,
513–51635. Sozhamannan, S., and Chattoraj, D. K. (1993) J. Bacteriol. 175, 3546–355536. Froehlich, B. J., and Scott, J. R. (1988) Plasmid 19, 121–13337. Matsunaga, F., Ishiai, M., Kobayashi, G., Uga, H., Yura, T., and Wada, C.
(1997) J. Mol. Biol. 274, 27–3838. Ishiai, M., Wada, C., Kawasaki, Y., and Yura, T. (1992) J. Bacteriol. 174,
5597–560339. Kawasaki, Y., Wada, C., and Yura, T. (1991) J. Bacteriol. 173, 1064–107240. Filutowicz, M., and Rakowski, S. A. (1998) Gene (Amst.) 223, 195–20441. Rudiger, S., Schneider-Mergener, J., and Bukau, B. (2001) EMBO J. 20,
1042–105042. Datta, H. J., Khatri, G. S., and Bastia, D. (1999) Proc. Natl. Acad. Sci. U. S. A.
96, 73–7843. Sharma, R., Kachroo, A., and Bastia, D. (2001) EMBO J. 20, 4577–458744. Ratnakar, P. V., Mohanty, B. K., Lobert, M., and Bastia, D. (1996) Proc. Natl.
Acad. Sci. U. S. A. 93, 5522–552645. Lu, Y. B., Datta, H. J., and Bastia, D. (1998) EMBO J. 17, 5192–5200
Homology between P1 RepA and F RepE6034
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from

Byungkook Lee and Sue WicknerSuveena Sharma, Bangalore K. Sathyanarayana, Jeremy G. Bird, Joel R. Hoskins,Plasmid P1 RepA Is Homologous to the F Plasmid RepE Class of Initiators
doi: 10.1074/jbc.M310917200 originally published online November 21, 20032004, 279:6027-6034.J. Biol. Chem.
10.1074/jbc.M310917200Access the most updated version of this article at doi:
Alerts:
When a correction for this article is posted•
When this article is cited•
to choose from all of JBC's e-mail alertsClick here
http://www.jbc.org/content/279/7/6027.full.html#ref-list-1
This article cites 44 references, 30 of which can be accessed free at
by guest on June 28, 2016http://w
ww
.jbc.org/D
ownloaded from
Copyright © 2022 FDOKUMEN




















