
Parallel OLAP with the Sidera server
8
Future Generation Computer Systems 26 (2010) 259–266 Contents lists available at ScienceDirect Future Generation Computer Systems journal homepage: www.elsevier.com/locate/fgcs Parallel OLAP with the Sidera server Todd Eavis * , George Dimitrov, Ivan Dimitrov, David Cueva, Alex Lopez, Ahmad Taleb Concordia University, Montreal, Canada article info Article history: Received 16 May 2008 Received in revised form 26 September 2008 Accepted 5 October 2008 Available online 25 October 2008 Keywords: OLAP Cluster computing Parallel DBMS abstract Online Analytical Processing (OLAP) has become a primary component of today’s pervasive Decision Support systems. As the underlying databases grow into the multi-terabyte range, however, single CPU OLAP servers are being stretched beyond their limits. In this paper, we present a comprehensive model for a fully parallelized OLAP server. Our multi-node platform actually consists of a series of largely independent sibling servers that are ‘‘glued’’ together with a lightweight MPI-based Parallel Service Interface (PSI). Physically, we target the commodity-oriented, ‘‘shared nothing’’ Linux cluster, an architecture that provides an extremely cost effective alternative to the ‘‘shared everything’’ commercial platforms often used in high-end database environments. Experimental results demonstrate both the viability and robustness of the design. © 2008 Elsevier B.V. All rights reserved. 1. Introduction Contemporary data warehouses (DWs) now represent some of the world’s largest database systems, often stretching into the multi-terabyte range. Structurally, data warehouses are based upon a denormalized logical model known as the Star Schema. The ‘‘star’’ consists of a large fact table that houses the organization’s measurement records, coupled with a series of smaller dimension tables defining specific business entities (e.g., customer, product, store). Given the enormous size of the fact tables, however, it can be extremely expensive to query the raw data directly. Typically, we augment the basic Star Schema with compact, pre-computed aggregates (called group-bys or cuboids) that can be queried much more efficiently at run-time. We refer to this collection of aggregates as the data cube. Specifically, for a d-dimensional space, {A 1 , A 2 ,..., A d }, the cube defines the aggregation of the 2 d unique dimension combinations across one or more relevant measure attributes. In practice, the generation and manipulation of the data cube is often performed by a dedicated OLAP server that runs on top of the underlying relational data warehouse. In other words, it is the job of the OLAP server (at least in part) to pre-process the warehouse data. The sheer scale of the DWs, however, has recently led researchers to explore opportunities for parallelizing or distributing the OLAP workload across multiple CPUs/disks. While ‘‘shared everything’’ parallel models are relatively attractive for small to medium sized warehouses, they tend to have limited * Corresponding author. E-mail address: [email protected] (T. Eavis). scalability in terms of both the CPU count and the number of available disk heads. In this paper, we describe an architecture for a scalable OLAP server known as Sidera that targets the commodity-based Linux cluster. The platform consists of a network-accessible frontend server and a series of protected backend servers that each handle a portion of the user request. A key feature of the cluster design is that each backend server requires little knowledge of its siblings. In effect, each node functions independently and merely interacts with a Parallel Service Interface (PSI) that, in turn, coordinates communication between nodes of the sibling network. The various constituent elements of the server have been evaluated experimentally and demonstrate a combination of performance and scalability that is particularly attractive given the use of commodity hardware and open source software. The paper is organized as follows. In Section 2, we discuss related work. Section 3 presents a simple architectural overview, while Sections 4 and 5 describe the processing logic and system components for Sidera’s frontend and backend servers, respectively. Experimental results are presented in Section 6, with Section 7 offering concluding remarks. 2. Related work With respect to DBMS parallelism, early work focused on the exploitation of relatively exotic hardware in order to improve performance for transaction-based (OLTP) queries [1,2] By the 1990s, it had become clear that commodity-based ‘‘shared noth- ing’’ databases provided significant advantages over the earlier SMP architectures in terms of cost and scalability [3]. Subsequent research therefore focused on partitioning and replication models for the tables of the parallelized DBMS [4]. More recent research 0167-739X/$ – see front matter © 2008 Elsevier B.V. All rights reserved. doi:10.1016/j.future.2008.10.007
-
Upload
independent -
Category
Documents
-
view
4 -
download
0
Transcript of Parallel OLAP with the Sidera server

Future Generation Computer Systems 26 (2010) 259–266
Contents lists available at ScienceDirect
Future Generation Computer Systems
journal homepage: www.elsevier.com/locate/fgcs
Parallel OLAP with the Sidera serverTodd Eavis ∗, George Dimitrov, Ivan Dimitrov, David Cueva, Alex Lopez, Ahmad TalebConcordia University, Montreal, Canada
a r t i c l e i n f o
Article history:Received 16 May 2008Received in revised form26 September 2008Accepted 5 October 2008Available online 25 October 2008
Keywords:OLAPCluster computingParallel DBMS
a b s t r a c t
Online Analytical Processing (OLAP) has become a primary component of today’s pervasive DecisionSupport systems. As the underlying databases grow into the multi-terabyte range, however, singleCPU OLAP servers are being stretched beyond their limits. In this paper, we present a comprehensivemodel for a fully parallelized OLAP server. Our multi-node platform actually consists of a series oflargely independent sibling servers that are ‘‘glued’’ together with a lightweight MPI-based ParallelService Interface (PSI). Physically, we target the commodity-oriented, ‘‘shared nothing’’ Linux cluster, anarchitecture that provides an extremely cost effective alternative to the ‘‘shared everything’’ commercialplatforms often used in high-end database environments. Experimental results demonstrate both theviability and robustness of the design.
© 2008 Elsevier B.V. All rights reserved.
1. Introduction
Contemporary data warehouses (DWs) now represent someof the world’s largest database systems, often stretching intothe multi-terabyte range. Structurally, data warehouses are basedupon a denormalized logical model known as the Star Schema. The‘‘star’’ consists of a large fact table that houses the organization’smeasurement records, coupled with a series of smaller dimensiontables defining specific business entities (e.g., customer, product,store). Given the enormous size of the fact tables, however, it canbe extremely expensive to query the raw data directly. Typically,we augment the basic Star Schema with compact, pre-computedaggregates (called group-bys or cuboids) that can be queriedmuch more efficiently at run-time. We refer to this collectionof aggregates as the data cube. Specifically, for a d-dimensionalspace, {A1, A2, . . . , Ad}, the cube defines the aggregation of the2d unique dimension combinations across one or more relevantmeasure attributes.In practice, the generation and manipulation of the data cube
is often performed by a dedicated OLAP server that runs on topof the underlying relational data warehouse. In other words, itis the job of the OLAP server (at least in part) to pre-processthe warehouse data. The sheer scale of the DWs, however, hasrecently led researchers to explore opportunities for parallelizingor distributing the OLAP workload across multiple CPUs/disks.While ‘‘shared everything’’ parallel models are relatively attractivefor small to medium sized warehouses, they tend to have limited
∗ Corresponding author.E-mail address: [email protected] (T. Eavis).
0167-739X/$ – see front matter© 2008 Elsevier B.V. All rights reserved.doi:10.1016/j.future.2008.10.007
scalability in terms of both the CPU count and the number ofavailable disk heads.In this paper, we describe an architecture for a scalable OLAP
server known as Sidera that targets the commodity-based Linuxcluster. The platform consists of a network-accessible frontendserver and a series of protected backend servers that each handlea portion of the user request. A key feature of the clusterdesign is that each backend server requires little knowledge ofits siblings. In effect, each node functions independently andmerely interacts with a Parallel Service Interface (PSI) that, inturn, coordinates communication between nodes of the siblingnetwork. The various constituent elements of the server havebeen evaluated experimentally and demonstrate a combination ofperformance and scalability that is particularly attractive given theuse of commodity hardware and open source software.The paper is organized as follows. In Section 2, we discuss
related work. Section 3 presents a simple architectural overview,while Sections 4 and 5 describe the processing logic andsystem components for Sidera’s frontend and backend servers,respectively. Experimental results are presented in Section 6, withSection 7 offering concluding remarks.
2. Related work
With respect to DBMS parallelism, early work focused on theexploitation of relatively exotic hardware in order to improveperformance for transaction-based (OLTP) queries [1,2] By the1990s, it had become clear that commodity-based ‘‘shared noth-ing’’ databases provided significant advantages over the earlierSMP architectures in terms of cost and scalability [3]. Subsequentresearch therefore focused on partitioning and replication modelsfor the tables of the parallelized DBMS [4]. More recent research

260 T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266
Fig. 1. The core architecture of the parallel Sidera OLAP server.
in parallel systems has generally been smaller in scope and hastargeted issues such as static versus dynamic locking in parallelcontexts [5], as well as parallel file systems for transparent RAIDstorage [6]. Finally, the Grid has also emerged as a novel target fordistributed processing, and a number of papers have explored thedesign of protocols for scalable, Internet-based data managementsystems [25].Commercially, of course, a number of vendors have pursued
parallel implementations. Traditionally, such systems have tar-geted tightly coupled SMP hardware. More recently, vendors havebegun to exploit more cost effective CPU and storage frameworks.IBM, for example, is actively exploring cluster implementations [7],while Oracle currently exploits a shared disk backend [8]. Such sys-tems, however, are, by definition, proprietary and DBMS-specific.In terms of OLAP/data cube research, a large number of papers
have been published since Gray et al. delivered the seminaldata cube paper in 1996 [9]. Initially, work focused on efficientalgorithms for the computation of the exponential number ofviews in the complete data cube [10,11]. More recent methodshavemade an effort to support cubes that are bothmore expressiveand more space efficient. The CURE cube, for example, supportsthe representation of dimension hierarchies and relatively compacttable storage [12]. In fact, we note that OLAP-specific datastructures, algorithms, indexing, and storage have consistentlybeen shown to provide significant performance improvementsrelative to the facilities traditionally offered by relational databasemanagement systems. Stonebraker et al., for example, suggeststhat an order of magnitude improvement can be achieved viathe design and optimization of domain specific DBMS systems(e.g., dedicated DW/OLAP servers) [24].Finally, we have recently seen preliminary attempts to inte-
grate parallelism and data warehousing/OLAP. On the one hand, anumber of researchers have describedmethods for the paralleliza-tion of state-of-the-art sequential data cube generation methods[13,14]. On the other, fact table partitioning methods for clusterimplementations have been explored. Perhaps the most interest-ing approach is one that proposes the virtualization of partial frag-ments over physically replicated tables [15]. We note, however,that in none of these cases do we see a comprehensive, ‘‘end-to-end’’ proposal for OLAP parallelism.
3. The Sidera architecture
Sidera has been designed from the ground up, to function as aparallel OLAP server. Node coordination is controlled by an MPI(Message Passing Interface) based Parallel Service Interface (PSI)that allows each node to participate in global sorting, merging, and
Fig. 2. Query processing cycle on the Sidera frontend.
aggregation operations. This ensures that the full computationalcapacity of the cluster is brought to bear on each and every query.Fig. 1 provides an illustration of the fundamental design. Note howthe frontend node serves as an access point for user queries. Queryreception and session management is performed at this point butthe frontend does not participate in query resolution, other thanto collect the final result from the backend instances and returnit to the user. In turn, the backend nodes are fully responsible forstorage, indexing, query planning, I/O, buffering, and meta datamanagement. In addition, each node houses a PSI component thatallows it to hook into the the global Parallel Service Interface.In the remainder of the paper,we present a succinct overviewof
the frontend and backend server components. Though the focus ison the physical architecture, we will present algorithmic elementswhere necessary in order to understand the full functionality of thesystem.
4. The Sidera frontend
The Sidera frontend, or head node, represents the server’spublic interface. Its core function is to receive user requests andto pass them along to the backend nodes for resolution. Fig. 2provides an illustration of the frontend architecture and processinglogic. Here, one can see that processing is essentially driven bya sequence of three FIFO queues: the Pending Queue (PQ), theDispatch Queue (DQ), and the Results Queue (RQ). Also, in keepingwith current trends in server design, server functionality is basedupon a lightweight, multi-threaded execution model. The threadsthemselves are based upon the POSIX pthread framework.In short, as queries arrive, they are placed into the Pending
Queue and subsequently retrieved by a set of persistent querythreads (organized into a pre-initialized thread pool). Once aquery thread is notified of a pending user query, it executes thesteps outlined in Fig. 2. Upon successful authentication, a basicsyntactical check of the query is performed to ensure that it shouldeven be passed to the backend for resolution. If so, the query isdeposited in the Dispatch Queue and a signal is sent to the sleepingDispatch Thread. The Query Thread then goes to sleep. Eventually,the final query results will return to the frontend and the sleepingQuery Thread will be notified that a result is waiting in the ResultQueue. The final result is simply returned to the user, the client-specific socket is closed, and the Query Thread ‘‘returns’’ to thethread pool to await the next user request.A key element of the frontend cycle is the work of the MPI
Dispatcher thread. The job of the dispatcher is to interface with thebackend query resolution nodes. Quite simply, once the thread issignaled that a new query is pending, it passes the query to each ofthe p nodes in the cluster and waits for the results to be depositedin a local buffer. Communication at this stage is implementedwith standard MPI Broadcast and Gather operations. We note that,since the final result of the query request is globally sorted by thebackend nodes (one of the functions of the Parallel Serve Interface)

T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266 261
before its return to the frontend, absolutely no merging or re-ordering of records is required in the local buffer. Finally, we addthat, in order to support concurrent query execution, the singleDispatcher Thread appends a unique tag or ID to each query atthe time it is initially broadcast. It is therefore possible to receivemultiple query results in arbitrary order, since the results can bedisambiguated on the basis of the MPI tag.
5. The Sidera backend
While the frontend provides the public interface, it is ofcourse the backend network that performs virtually all of thequery resolution. In this section, we will describe the backendarchitecture, both in terms of the constituent components onthe local nodes and the relationship between server instances.In particular, we will discuss the storage and distribution model,as well as the OLAP-specific functionality that each local nodeprovides.
5.1. Cube generation
Recall that the function of an OLAP server is to provideadvanced data cube processing support. Recent research inthe area of data warehouse parallelism has generally assumedthat query resolution is performed on top of partitioned facttables [15]. However, this is rarely the case in real worldOLAP settings, as the fact tables are simply too large tosupport acceptable real-time query performance. Instead, a subsetof heavily aggregated summary tables (i.e., cuboids) are pre-computed so as to dramatically improve response time.Sidera provides such functionality by virtue of parallel cube
generation algorithms that efficiently construct either full cubes(i.e., all 2d cuboids) or partial cubes (i.e., cuboid subsets). Methodsfor both shared disk [16] and fully distributed clusters [17]are available. In either case, the PSI is used extensively inthe generation process. Specifically, ordering and aggregationoperations are driven by a Parallel Sample Sort [18] that exploitsthe processing power of each of the p nodes in the backend. Thoughthe details of the complete algorithms are beyond the scope of thispaper, we note that at the conclusion of this process, each nodehouses a fragment of the primary fact table, as well as a fragmentof each of the O(2d) cuboids in the full or partial cube.
5.2. Table partitioning
While the cube generation algorithms produce cuboid frag-ments of approximately equivalent size, there is no guarantee thatarbitrary, parallelized queries will access an equivalent numberof records per node/fragment. Because the dominant OLAP queryform is a multi-dimensional range query, the clustering of spatiallyrelated records on each node becomes a crucial concern. Sidera ad-dresses this issue through the use of a Hilbert space filling curve.Briefly, a Hilbert curve is a non-differential curve enclosedwithin ad dimensional space of side width s. The curve traverses all sd pointsof the d-dimensional grid, making unit steps and turning only atright angles. We say that a d-dimensional space has order k if it hasa side length s = 2k. We use the notationHd
k to denote the k-th or-der approximation of a d-dimensional curve, for k ≥ 1 and d ≥ 2(typical values in OLAP environments are d ≤ 16 and k ≤ 20).If we think of themulti-field cuboid records as points in amulti-
dimensional space, then the Hilbert curve allows us to order therecords such that points close to one another in the space are nearone another on the curve. The end result is a linearization of thenative space thatmapsmuchmore directly to the one-dimensionalstructure of a physical storage device. The following two-phasemethod produces the final data distribution:
Fig. 3. The use of Hilbert partitioning to produce local node record clustering. Theovals represent disk blocks, while the dashed line delineates a range query.
(i) Sort the local fragmented cuboids in Hilbert order.(ii) Stripe the data across all processors in a round robin fashionsuch that successive records are sent to the next processorin the sequence. For a network with p processors, a dataset of n records, and 1 ≤ i ≤ p, processor Pi receivesrecords Ri, Rp+i, R2p+i, . . . Rbn/pcp+i as a single partial set. Whenn mod p 6= 0, a subset of processors receives one additionalrecord.
Essentially, we arrange the records of the local nodes in Hilbertspace order and then use the PSI and a Round Robin stripingpattern to send every p-th record of a given cuboid to the nextsibling server in the sequence. Fig. 3 illustrates how the RoundRobin Hilbert striping is used to partition a single logical pointspace into a pair of partial Hilbert spaces. Within each of the newHilbert cuboid fragments, we can see how spatially related pointsare collected within common physical disk blocks. A subsequentmulti-dimensional range query — indicated in the figure by thedashed rectangle — can now be represented as a pair of identicalsibling queries, each accessing an essentially equivalent number ofclustered records.
5.3. Sidera indexing
Despite the fact that records have now been partitioned andclustered, it is important to remember that the partitions of boththe fact table and the high dimension cuboids may still be verylarge. As such, efficient multi-dimensional indexing is necessaryin order to ensure optimal performance. In practice, only a fewsuch indexing models have demonstrated significant success inpractical environments, with the R-tree being one of the mostrobust. Recall that the R-tree is a hierarchical, d-dimensional tree-based index that organizes the query space as a collection ofnested, possibly overlapping hyper-rectangles [19]. The tree isbalanced and has a heightH = dlogM ne, whereM is themaximumbranching factor and n is equivalent to the number of points in thedata set.While R-trees can by constructed dynamically, it has been
observed that in relatively static settings — such as that found inOLAP environments — significant storage and performance gainscan be obtained by pre-packing the tree. In fact, the Hilbert curvehas been shown to be one of the most effective techniques inthis regard. Sidera builds upon this observation by constructing adistributed forest of R-trees for the cuboids in the system [20]. Foreach cuboid fragment, the basic process is as follows:

262 T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266
Fig. 4. A simpleH23 curve showing (a) The ordinal mapping (b) Basic differentials
(c) Leading ‘‘zero bits’’ removed.
(i) Based upon the Hilbert sort order, associate each of the npoints with m pages of size d nM e. The page size/branchingfactor is chosen so as to be a multiple of the disk’s physicalblock size.
(ii) Associate each of them leaf node pages with an ID that will beused as a file offset by parent bounding boxes.
(iii) Construct the remainder of the index by recursively packingthe bounding boxes of lower levels until the root node isreached.
The end result is a partial Hilbert-packed R-tree index for eachfragment in the system (excluding very small fragments). Becausethe disk blocks cluster related points as per the progression of thecurve, the total number of blocks accessed for an arbitrary request— typically the most expensive element of the query — can bedramatically reduced. We can therefore conclude that the use ofthe Hilbert ordering technique improves the characteristics of bothload balancing and local access.
5.3.1. CompressionDue to the size of the larger cuboids, even in partitioned form,
it is desirable to provide effective, page-level table compressionmethods. Again, Sidera exploits the underlying Hilbert curve toprovide such functionality. Specifically, we note that the sd-lengthHilbert curve represents a unique, strictly increasing order onthe sd point positions, such that CurveHilbert : {1, . . . , sd} →{1, . . . , s}d. We refer to each such position as a Hilbert ordinal.The result is a two-way mapping between d-dimensional tuplesand their associated ordinals in Hilbert space. Fig. 4(a) provides asimple illustration of the 16 unique point positions inH2
2 . Here, forexample, we would have CurveHilbert(2, 2) = 3.Given the ordinal representation, we may now exploit a tech-
nique called differential coding to dramatically reduce the stor-age footprint of the tables. Specifically, rather than representinga multi-dimensional record in its tuple form, our Hilbert SpaceCompression method stores the value as the integer difference be-tween successive ordinal positions along the curve [21]. In Fig. 4(b)and (c), for example, we see the effect of Hilbert differential cod-ing. Storage required (with leading zero bits removed) is now justρ = 9 − 6 = 310, or 112 in binary form. This is 62 bits less thanthe default encoding for a two dimensional value (assuming 32-bitintegers). We note, as well, that Hilbert differential coding is appli-cable to both data and the associated indexes.
5.4. Hierarchical representation
The primary purpose of a dedicated OLAP server is to provideadvanced functionality that would not be available within a
standard relational database. As noted, this is one of the maindrawbacks of building upon commodity DBMS systems in clusterenvironments. In particular, RDBMS platforms lack a nativeunderstanding of the cube model and are quite limited in theirability to support the slicing and dicing operations at the heartof OLAP analysis. Moreover, such operations rely heavily uponthe notion of dimension hierarchies. Briefly, we may describe ahierarchy as a set of binary relationships between the variousaggregation levels of a dimension. A simple example might be aCategory→ Brand→ Skew product hierarchy.Sidera natively supports hierarchical queries by building upon
the notion of hierarchy linearity. We say that a hierarchy is linearif for all direct descendants A(j) of A(i) there are |A(j)| + 1 values,x1 < x2 . . . < x|A(j)|, in the range {1 . . . |A(i)|} such that A(j)[k] =∑xk+1l=xkA(i)[l], where the array index notation [ ] indicates a specific
value within a given hierarchy level. Informally, we can say that,if a hierarchy is linear, there is a contiguous range of values R(j) onA(j) that may be aggregated into a contiguous range R(i) on A(i).Sidera uses a sorting technique to establish linearity for
each dimension hierarchy, with data subsequently being storedat the finest level of granularity. It then uses a compact, in-memory data structure called mapGraph to support efficient real-time transformations between arbitrary levels of the dimensionhierarchy [22]. While a number of commercial products andseveral research papers do support hierarchical processing forsimple hierarchies — those that can be represented as a balancedtree — mapGraph is unique in that it can enforce linearity onunbalanced hierarchies (optional nodes), as well as hierarchiesdefined by many-to-many parent/child relationships. The endresult is that users may intuitively manipulate complex cubes atarbitrary granularity levels and can invoke drill down and rollup operations at will. While a full description of mapGraph isbeyond the scope of this paper, Fig. 5(a) provides an illustrationof the hMap structure that is used for the simplest hierarchyforms (structures for unbalanced and many-to-many hierarchiesare considerably more complex).
5.5. Approximate query answering
Because the largest data warehouses are terabytes in size,certain complex queries may still require considerable resourcesand time. Often, it is not necessary to have an exact answerto the query; an approximate solution will suffice. Traditionally,approximate query answering, and the related problem ofselectivity estimation, has been performed using histogramtechniques. However, extensions to multiple dimensions haveproven to be somewhat less reliable (i.e., accurate).Sidera utilizes a new technique called rK-Hist that is designed
for the construction of skew-sensitive multi-dimensional his-tograms [23]. Because the success of such histograms essentiallydepends upon the quality of their space partitioning, we are able toexploit Sidera’s native Hilbert packed R-trees for this very purpose.Specifically, during R-tree construction, sequences of physical diskblocks are coalesced into a small number of histogram buckets.The underlying space filling curve ensures, of course, that spatiallyrelated points are associated with the same, or perhaps contigu-ous, buckets. However, this process alone does not ensure thatestimates extrapolated from the density measure of intersectedbuckets — calculated as bucketcount
bucketvolume— are optimal. Specifically, the
distribution of actual points within a bucket region may not beeven, as conventional techniques assume. Consequently, rK-Histrestructures the initial buckets so as to improve estimation accu-racy. It does so using a new technique known as k-uniformity. Inshort, the kU metric uses a k-d-tree space decomposition to par-tition the buckets into sub-regions, each housing a single point.

T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266 263
Fig. 5. (a) The hMap component of mapGraph. Granularity delineation points —defined in terms of the finest granularity level — are housed within the embeddedarrays. Bi-directional translations can be performed without scanning the sub-arrays. (b) kU-based rk-Hist space partitioning (the red blocks are clusters of 2-dpoints in a 50k× 50k space). (For interpretation of the references to colour in thisfigure legend, the reader is referred to the web version of this article.)
The standard deviation of the sub-region volumes is then used as aprecise measure of bucket uniformity so that unacceptable initialbuckets may be re-structured. The final result is a compact, effi-cient tool for the accurate estimation ofmassivemulti-dimensionalqueries. An illustration of rK-Hist space decomposition is providedin Fig. 5(a). Notice how rK-Hist avoids representing ‘‘dead’’ areas ofthe space.
5.6. Backend processing logic
The Sidera server actually consists of a pair of executables,one for the frontend and one for each of the backend nodes.In other words, each of the p nodes of the backend invokesthe same binary. Because of the exploitation of MPI’s collectivecommunication model, it is not necessary to embed any form ofnode-specific functionality within the local nodes. Network metadata is created and maintained by the common MPI initializationroutines. Consequently, each node executes exactly the sameapplication code and is completely oblivious to the specifics of thebackend network architecture, as well as to the actual node count.A simple illustration of the basic processing loop is illustrated in
Fig. 6. At startup, the local instance first initializes the mapGraphhierarchy manager, with meta data describing the multi-leveldimension hierarchies, and then scans the local disk to analyzethe structure of the local cube fragments. Because full cubematerialization is both expensive and often unnecessary, a subsetof the 2d possible cuboids is generally constructed. The ViewManager can therefore be used to identify a surrogate target — the
Fig. 6. The Sidera Backend Node.
smallest viewhousing a superset of the required dimensions— thatcan satisfy the actual user request.The main server thread will then invoke the query engine
module to process the query received from the frontend server.Typically, the user’s query is re-written as per (i) the availablemetadata, and (ii) the physical materialization of the current data. Ifcached results are available, they will be utilized. Otherwise, rawdata comes from the disk via the Hilbert packed r-tree indexes(de-compression is performed transparently). Once the base datais available, various post-processing operations (e.g., selection,projection, re-ordering, aggregation, drill down, roll up) may haveto be performed. However, such operations are not guaranteedto be constrained to the local node. For example, large duplicatecounts may be generated during common aggregation operations.As such, the nodes of the backend utilize the PSI to obtain fullyparallelized sorting and aggregation operations. At the conclusionof this phase, each node houses a segment of the final result.Moreover, the n records of the final result are partitioning acrossthe p nodes of the network such that for records {i, j}, 1 ≤ i ≤ j ≤n, andwith locations {i(m), j(n)}, 1 ≤ m, n ≤ p, we are guaranteedm ≤ n. In other words, the final result is sorted in network order asper the initial user request. All that is required is to merely returnthe results to the frontend buffers using a PSI/MPI Gather operationand to cache the local values if necessary.
6. Experimental results
In this section,wehighlight a small number of key experimentalresults so as to demonstrate the efficiency of the platform.Withrespect to the general framework, we utilize a 17-node Linuxcluster (frontend+ 16 backend servers), with each node running astandard copy of the 2.6.x kernel. Individual nodes house 3.2 GHzdual CPU boards, with 1 GB of main memory and a 160 GB diskdrive operating at 7200 RPM. The cluster nodes are connectedby a Gigabit Ethernet switch. With the current tests, we utilizesynthetically generated data (similar results have been achievedwith a variety of real data sets) and employ a Zipfian skew valueof 1.0 to create clustering patterns. For query timings, we use thecommon approach of timing queries in batch mode, with resultsaveraged across five runs. Finally, when necessary, we use the dropcaches option available in the newer Linux kernels to delete the OSpage cache between runs.Fig. 7(a) shows parallel wall clock time for distributed query
resolution as a function of the number of processors used,while Fig. 7(b) presents the corresponding speedup. Tests wereconducted on arbitrary batches of 1000 queries and a fullymaterialized data cube. The cube was generated from an inputset of 1 million records, 10 dimensions, and mixed cardinalities of2–10,000, with the full cube representing over 200 million rows.We observe that, for parallel query resolution, the performancegain is close to linear. For example, on 16 processors, a speedupfactor of approximately 14 is achieved.
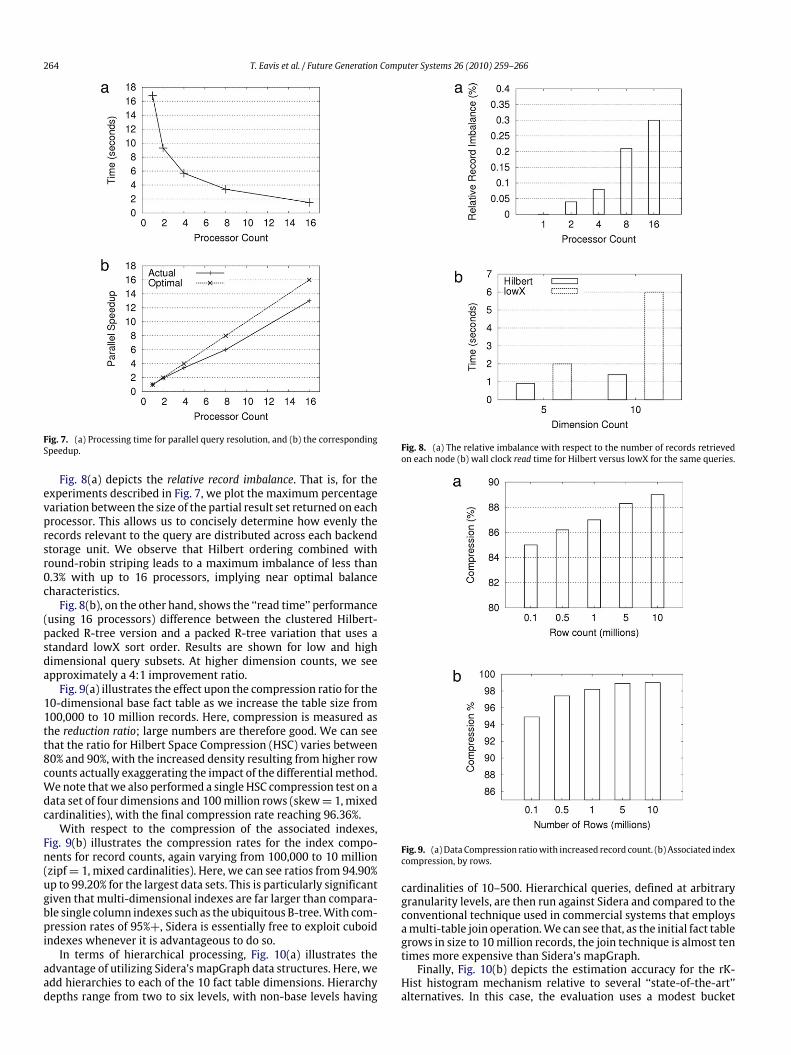
264 T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266
Fig. 7. (a) Processing time for parallel query resolution, and (b) the correspondingSpeedup.
Fig. 8(a) depicts the relative record imbalance. That is, for theexperiments described in Fig. 7, we plot the maximum percentagevariation between the size of the partial result set returned on eachprocessor. This allows us to concisely determine how evenly therecords relevant to the query are distributed across each backendstorage unit. We observe that Hilbert ordering combined withround-robin striping leads to a maximum imbalance of less than0.3% with up to 16 processors, implying near optimal balancecharacteristics.Fig. 8(b), on the other hand, shows the ‘‘read time’’ performance
(using 16 processors) difference between the clustered Hilbert-packed R-tree version and a packed R-tree variation that uses astandard lowX sort order. Results are shown for low and highdimensional query subsets. At higher dimension counts, we seeapproximately a 4:1 improvement ratio.Fig. 9(a) illustrates the effect upon the compression ratio for the
10-dimensional base fact table as we increase the table size from100,000 to 10 million records. Here, compression is measured asthe reduction ratio; large numbers are therefore good. We can seethat the ratio for Hilbert Space Compression (HSC) varies between80% and 90%, with the increased density resulting from higher rowcounts actually exaggerating the impact of the differential method.We note thatwe also performed a single HSC compression test on adata set of four dimensions and 100million rows (skew= 1,mixedcardinalities), with the final compression rate reaching 96.36%.With respect to the compression of the associated indexes,
Fig. 9(b) illustrates the compression rates for the index compo-nents for record counts, again varying from 100,000 to 10 million(zipf= 1, mixed cardinalities). Here, we can see ratios from 94.90%up to 99.20% for the largest data sets. This is particularly significantgiven that multi-dimensional indexes are far larger than compara-ble single column indexes such as the ubiquitous B-tree.With com-pression rates of 95%+, Sidera is essentially free to exploit cuboidindexes whenever it is advantageous to do so.In terms of hierarchical processing, Fig. 10(a) illustrates the
advantage of utilizing Sidera’s mapGraph data structures. Here, weadd hierarchies to each of the 10 fact table dimensions. Hierarchydepths range from two to six levels, with non-base levels having
Fig. 8. (a) The relative imbalance with respect to the number of records retrievedon each node (b) wall clock read time for Hilbert versus lowX for the same queries.
Fig. 9. (a) Data Compression ratiowith increased record count. (b) Associated indexcompression, by rows.
cardinalities of 10–500. Hierarchical queries, defined at arbitrarygranularity levels, are then run against Sidera and compared to theconventional technique used in commercial systems that employsamulti-table join operation.We can see that, as the initial fact tablegrows in size to 10million records, the join technique is almost tentimes more expensive than Sidera’s mapGraph.Finally, Fig. 10(b) depicts the estimation accuracy for the rK-
Hist histogram mechanism relative to several ‘‘state-of-the-art’’alternatives. In this case, the evaluation uses a modest bucket

T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266 265
Fig. 10. (a) mapGraph performance versus the conventional Sort-Merge Join. (b)Estimation error for 800 bucket histograms.
count of 800 and compares error rates against three of the leadinghistogram methods. In this test, queries were defined so as torepresent approximately 1% of the full space and were executedagainst the main fact table. For the Zipfian skewed data, rK-Hist isable to produce errors in the range of just 2%–4% (relative to theactual result) in two to three dimensions. This is extremely lowfor a multi-dimensional histogram. Moreover, none of the othermethods is even close to this range.
7. Conclusions
In this paper, we have presented the architectural design forthe Sidera platform, a robust parallel OLAP server designed forcluster applications. The server framework consists of a publiclyaccessible frontend and a collection of identical backend servers.The system is tightly coupled, using the Open MPI communicationlibraries as the basis of a powerful Parallel Service Interface, whileat the same time providing complete transparency for the backendserver instances. Unlike a number of other distributed datawarehousing applications that rely on standard RDBMS systems,Sidera provides extensive OLAP-specific functionality, includingbalanced partitioning, efficient Hilbert space R-tree indexing, datacompression, hierarchy-aware query resolution, and approximatequery answering. Experimental evaluation demonstrates theviability of the algorithms and the robustness of the platform. Toour knowledge, this combination of power and flexibility makesSidera the most comprehensive OLAP platform described in thecurrent research literature.
References
[1] D.J. DeWitt, S. Ghandeharizadeh, D.A. Schneider, A. Bricker, H.-I. Hsaio,R. Rasmussen, The Gamma database machine project, Transactions onKnowledge and Data Engineering 2 (1) (1990) 44–62.
[2] H. Boral, W. Alexander, L. Clay, G. Copeland, S. Danforth, M. Franklin, B. Hart,M. Smith, P. Valduriez, Prototyping bubba, a highly parallel database system,Transactions on Knowledge and Data Engineering 2 (1) (1990) 4–24.
[3] D. DeWitt, J. Gray, Parallel database systems: The future of high performancedatabase systems, Communications of the ACM 35 (6) (1992) 85–98.
[4] P. Scheuermann, G. Weikum, P. Zabback, Data partitioning and load balancingin parallel disk systems, The VLDB Journal 7 (1) (1998) 48–66.
[5] A. Mittal, S. Dandamudi, Dynamic versus static locking in real-time paralleldatabase systems, in: Parallel and Distributed Processing Symposium, 2004,pp. 32–42.
[6] F. Rauch, T. Stricker, OS support for a commodity database on pc clusters— distributed devices vs. distributed file systems, in: Australasian DatabaseConference, 2005, pp. 145–154.
[7] J. Rao, C. Zhang, N. Megiddo, G. Lohman, Automating physical database designin a parallel database, in: ACM SIGMOD, 2002, pp. 558–569.
[8] T. Cruanes, B. Dageville, B. Ghosh, Parallel sql execution in oracle 10g, in: ACMSIGMOD, 2004, pp. 850–854.
[9] J. Gray, A. Bosworth, A. Layman, H. Pirahesh, Data cube: A relationalaggregation operator generalizing group-by, cross-tab, and sub-totals, in:ICDE, 1996, pp. 152–159.
[10] K. Beyer, R. Ramakrishnan, Bottom-up computation of sparse and icebergcubes, in: ACM SIGMOD, 1999, pp. 359–370.
[11] Y. Zhao, P. Deshpande, J. Naughton, An array-based algorithm for simultaneousmulti-dimensional aggregates, in: ACM SIGMOD, 1997, pp. 159–170.
[12] K.Morfonios, Y. Ioannidis, CURE for cubes: Cubing using a ROLAP engine, VLDB(2006) 379–390.
[13] S. Goil, A. Choudhary, High performance multidimensional analysis of largedatasets, in: DOLAP, 1998, pp. 34–39.
[14] F. Dehne, T. Eavis, A. Rau-Chaplin, The cgmCUBE project: Optimizing paralleldata cube generation for ROLAP, Journal of Distributed and Parallel Databases19 (1) (2006) 29–62.
[15] C. Furtado, A. Lima, E. Pacitti, P. Valduriez, M. Mattoso, Physical andvirtual partitioning in OLAP database clusters, in: Int. Symp. on ComputerArchitecture and High Performance Computing (SBAC), 2005, pp. 143–150.
[16] F. Dehne, T. Eavis, S. Hambrusch, A. Rau-Chaplin, Parallelizing the datacube,Journal of Distributed and Parallel Databases 11 (2) (2002) 181–201.
[17] Y. Chen, F. Dehne, T. Eavis, A. Rau-Chaplin, Parallel ROLAP datacubeconstruction on shared nothing multi-processors, Journal of Distributed andParallel Databases 15 (3) (2004) 219–236.
[18] H. Shi, J. Schaeffer, Parallel sorting by regular sampling, Journal of Parallel andDistributed Computing 14 (4) (1990) 361–372.
[19] A. Guttman, R-trees: A dynamic index structure for spatial searching, in: ACMSIGMOD, 1984, pp. 47–57.
[20] F. Dehne, T. Eavis, A. Rau-Chaplin, Rcube: Parallel multi-dimensional ROLAPindexing, Journal of Data Warehousing and Mining 4 (3) (2008) 1–14.
[21] T. Eavis, D. Cueva, A Hilbert space compression architecture for data ware-house environments, in: Conference on Data Warehousing and KnowledgeDiscovery, 2007, pp. 1–12.
[22] T. Eavis, A. Taleb, Mapgraph: Efficient methods for complex OLAP hierarchies,in: Conference on Information and Knowledge Management, CIKM, 2007,pp. 465–474.
[23] T. Eavis, A. Lopez, rk-hist: An r-tree based histogram formulti-dimensional se-lectivity estimation, in: Conference on Information and Knowledge Manage-ment, CIKM, 2007, pp. 475–484.
[24] M. Stonebraker, S. Madden, D. Abadi, S. Harizopoulos, N. Hachem, P. Helland,The end of an architectural era: (it’s time for a complete rewrite), VLDB (2007)1150–1160.
[25] A. Sánchez, M. Pérez, K. Karasavvas, P. Herrero, A. Pérez, MAPFS-DAI, anextension of OGSA-DAI based on a parallel file system, Future GenerationComputer Systems (The International Journal of Grid Computing: Theory,Methods and Application) 23 (1) (2007) 138–145.
Todd Eavis received his Ph.D. in Computer Sciencefrom the Faculty of Computer Science, Dalhousie Uni-versity, Halifax, Canada, in 2003. Since 2004, he hasbeen an Assistant Professor in the Department of Com-puter Science and Software Engineering, where he alsoholds a Tier II University Research Chair in Data Ware-housing. Prior to his current appointment, he wasan NSERC Postdoctoral fellow at Carleton Universityin Ottawa, Canada. His current research interests in-clude data warehousing architectures, hierarchical datacubes, multi-dimensional indexing, parallel algorithms,
and cluster computing.
George Dimitrov received a Bachelors degree withHonours in Computer Science in 2007 from ConcordiaUniversity in Montreal, Canada. In his honours project hedesigned and implemented an interface for a clustereddatabase server using a Message Passing Interface. Hisresearch interests include database management systems,computer networks and distributed systems. Georgecurrently works for Epicor, a leading provider of ERPsoftware and enterprise software solutions.

266 T. Eavis et al. / Future Generation Computer Systems 26 (2010) 259–266
Ivan Dimitrov received a Bachelors degree with Honoursin Computer Science in 2007 from Concordia Universityin Montreal, Canada. In his honours project he designedand implemented an interface for a clustered databaseserver using a Message Passing Interface. His research in-terests include database management systems, computernetworks anddistributed systems. George currentlyworksfor Epicor, a leading provider of ERP software and enter-prise software solutions.
David Cueva received a Masters degree in Computer Sci-ence in 2007 from Concordia University in Montreal,Canada. In his Masters thesis he investigated a data ware-house compression algorithm using an n-dimensionalHilbert curve. He had previously obtained an Engineer-ing in Informatics Systems from Escuela Politecnica Na-cional in Quito, Ecuador. His research interests includedata warehousing, database architecture and parallel al-gorithms. David currently works at SAP Labs Canada, anadvanced development facility of SAP AG.
Alex Lopez received aMasters in Computer Science degreein 2007 from Concordia University in Montreal, Canada. Inhis Masters thesis he presented an R-tree based histogramfor multi-dimensional selectivity estimation that uses ann-dimensional Hilbert curve. He had previously obtaineda BSc. in Computer Engineering from the University ofSan Buenaventura and a Graduate Diploma in DatabaseSystems from the University of Antioquia in Medellin,Colombia. His research interests include data warehous-ing, database architecture and parallel algorithms. Alexcurrentlyworks as a Business Intelligence Specialist at SNC
Lavalin in Montreal.
AhmadTaleb obtained a B.Sc. in Computer Science in 2004from Ajman University of Science and Technology in Aj-man, United Arab Emirates (UAE). In 2007, he received hisM. Comp. Sc. degree from Concordia Univeristy in Mon-treal, under the supervision of Dr. Todd Eavis. His researchfocus was the design of efficient software frameworks forthe manipulation of complex OLAP hierarchies. Currently,he is a Ph.D. candidate in Concordia University’s Depart-ment of Computer Science and Software Engineering, andis investigating the design and implementation of a multi-dimensional storage engine for Online Analytical Process-
ing (OLAP) servers.




















