
Modelado de datos empresariales en Oracle Analytics Cloud
278
Oracle ® Cloud Modelado de datos empresariales en Oracle Analytics Cloud F32715-09 Julio de 2022
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Modelado de datos empresariales en Oracle Analytics Cloud

Oracle® CloudModelado de datos empresariales en OracleAnalytics Cloud
F32715-09Julio de 2022

Oracle Cloud Modelado de datos empresariales en Oracle Analytics Cloud,
F32715-09
Copyright © 2020, 2022, Oracle y/o sus filiales.
Autor principal: Rosie Harvey
Autores colaboradores: Suzanne Gill, Pete Brownbridge, Stefanie Rhone, Hemala Vivek, Padma Rao
Colaboradores: Oracle Analytics development, product management, and quality assurance teams
This software and related documentation are provided under a license agreement containing restrictions onuse and disclosure and are protected by intellectual property laws. Except as expressly permitted in yourlicense agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license,transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverseengineering, disassembly, or decompilation of this software, unless required by law for interoperability, isprohibited.
The information contained herein is subject to change without notice and is not warranted to be error-free. Ifyou find any errors, please report them to us in writing.
If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it onbehalf of the U.S. Government, then the following notice is applicable:
U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software,any programs embedded, installed or activated on delivered hardware, and modifications of such programs)and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government endusers are "commercial computer software" or "commercial computer software documentation" pursuant to theapplicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use,reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/oradaptation of i) Oracle programs (including any operating system, integrated software, any programsembedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oraclecomputer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in thelicense contained in the applicable contract. The terms governing the U.S. Government’s use of Oracle cloudservices are defined by the applicable contract for such services. No other rights are granted to the U.S.Government.
This software or hardware is developed for general use in a variety of information management applications.It is not developed or intended for use in any inherently dangerous applications, including applications thatmay create a risk of personal injury. If you use this software or hardware in dangerous applications, then youshall be responsible to take all appropriate fail-safe, backup, redundancy, and other measures to ensure itssafe use. Oracle Corporation and its affiliates disclaim any liability for any damages caused by use of thissoftware or hardware in dangerous applications.
Oracle, Java, and MySQL are registered trademarks of Oracle and/or its affiliates. Other names may betrademarks of their respective owners.
Intel and Intel Inside are trademarks or registered trademarks of Intel Corporation. All SPARC trademarks areused under license and are trademarks or registered trademarks of SPARC International, Inc. AMD, Epyc,and the AMD logo are trademarks or registered trademarks of Advanced Micro Devices. UNIX is a registeredtrademark of The Open Group.
This software or hardware and documentation may provide access to or information about content, products,and services from third parties. Oracle Corporation and its affiliates are not responsible for and expresslydisclaim all warranties of any kind with respect to third-party content, products, and services unless otherwiseset forth in an applicable agreement between you and Oracle. Oracle Corporation and its affiliates will not beresponsible for any loss, costs, or damages incurred due to your access to or use of third-party content,products, or services, except as set forth in an applicable agreement between you and Oracle.

Tabla de contenidos
Prefacio
Destinatarios xiii
Accesibilidad a la documentación xiii
Diversidad e inclusión xiii
Documentos relacionados xiv
Convenciones xiv
Parte I Introducción al modelado de datos empresariales
1 Acerca del modelado de datos empresariales
Tipos de modelos 1-1
Herramientas de modelado de datos 1-1
Parte II Uso de Data Modeler para crear modelos semánticos
2 Introducción a Data Modeler
Flujo de trabajo típico para modelar datos 2-1
Apertura de Data Modeler 2-2
Tareas principales para Data Modeler 2-2
3 Descripción del modelado de datos
Acerca del modelado de datos con Data Modeler 3-1
Planificación de un modelo semántico 3-2
Descripción de los requisitos del modelo semántico 3-2
Componentes de un modelo semántico 3-3
Acerca del modelado de objetos de origen con relaciones de estrella 3-4
Acerca del modelado de objetos de origen con relaciones de copo de nieve 3-4
Acerca del modelado de orígenes desnormalizados 3-5
iii

Acerca del modelado de orígenes normalizados 3-5
4 Cómo empezar a crear el modelo semántico
Uso de Data Modeler 4-1
Creación de un modelo semántico 4-2
Uso del panel izquierdo de Data Modeler 4-2
Uso del panel derecho de Data Modeler 4-3
Uso de los menús de acción 4-4
Bloqueo de un modelo semántico 4-5
Validación de un modelo semántico 4-5
Refrescamiento y sincronización de objetos de origen y objetos de modelo semántico 4-5
Publicación de cambios en el modelo semántico 4-7
Borrado de datos almacenados en caché 4-8
Cambio de nombre de un modelo semántico 4-9
Conexión de un modelo a una base de datos distinta 4-9
Exportación de un modelo semántico 4-10
Importación de un modelo semántico 4-10
Supresión de un modelo semántico 4-11
Revisión de tablas y datos de origen 4-11
Visualización de objetos de origen 4-12
Vista previa de los datos en objetos de origen 4-12
Creación de vistas de origen 4-13
Acerca de las vistas de origen 4-13
Agregación de vistas de origen propias 4-14
Definición de filtros para vistas de origen 4-16
Adición de tablas de hechos y tablas de dimensiones a un modelo semántico 4-17
Acerca de las tablas de hechos y de dimensiones 4-17
Creación de tablas de hechos y dimensiones desde una vista o tabla única 4-17
Creación de tablas de hechos individuales 4-20
Creación de tablas de dimensiones individualmente 4-21
Edición de tablas de hechos y tablas de dimensiones 4-22
Adición de más columnas a tablas de hechos y de dimensiones 4-23
Adición de columnas de otro origen a una tabla de dimensiones 4-24
Unión de tablas en un modelo semántico 4-24
Acerca de las uniones 4-25
Unión de tablas de hechos y dimensiones 4-25
Creación de una dimensión de tiempo 4-25
Adición de medidas y atributos al modelo semántico 4-27
Edición de medidas y atributos 4-27
Especificación de agregación para medidas en tablas de hechos 4-29
iv

Creación de medidas calculadas 4-31
Acerca de la creación de medidas calculadas 4-32
Creación de atributos derivados 4-34
Creación de expresiones en el editor de expresiones 4-34
Acerca del editor de expresiones 4-34
Creación de una expresión 4-35
Copia de medidas y atributos 4-36
Copia de objetos del modelo 4-37
5 Definición de jerarquías y niveles para obtención de detalles yagregación
Flujo de trabajo típico para definir jerarquías y niveles 5-1
Acerca de las jerarquías y los niveles 5-1
Edición de jerarquías y niveles 5-2
Definición de propiedades de la tabla de dimensiones para jerarquías 5-3
Definición de niveles de agregación para medidas 5-3
Acerca de la definición de niveles de agregación para las medidas 5-4
6 Protección del modelo semántico
Flujo de trabajo típico para proteger datos de modelos 6-1
Creación de variables para su uso en expresiones 6-1
Acerca de las variables 6-2
Definición de variables 6-2
Protección del acceso a los objetos del modelo 6-3
Acerca de la herencia de permisos 6-4
Protección del acceso a los datos 6-5
Parte III Creación de modelos de datos para informes de visualizaciónperfecta
7 Introducción al modelado de datos para informes de visualizaciónperfecta
Flujo de trabajo típico para modelar datos para informes de visualización perfecta 7-1
Inicio del editor de modelo de datos 7-2
Principales tareas para el modelado de datos para informes de visualización perfecta 7-2
v

8 Uso del editor de modelo de datos
Componentes de un modelo de datos 8-1
Acerca de las opciones de origen de datos 8-2
Funciones del editor del modelo de datos 8-3
Acerca de la barra de herramientas del editor del modelo de datos 8-4
Acerca de la interfaz 8-5
Propiedades de modelo de datos 8-8
Opciones de salida XML 8-11
Fragmentación de datos XML 8-12
Adición de anexos al modelo de datos 8-13
Cómo adjuntar datos de ejemplo 8-13
Cómo adjuntar un esquema 8-13
Archivos de datos 8-13
Gestión de orígenes de datos privados 8-14
9 Creación de juegos de datos
Creación de un juego de datos 9-1
Creación de juegos de datos utilizando consultas SQL 9-1
Introducción de consultas SQL 9-2
Uso de SQL Query Builder 9-2
Visión general del generador de consultas 9-3
Creación de una consulta mediante Query Builder 9-3
Tipos de columna soportados 9-4
Adición de objetos al panel de diseño 9-4
Eliminación u ocultación de objetos en el panel de diseño 9-5
Condiciones de consulta 9-5
Creación de relaciones entre objetos 9-5
Guardar una consulta 9-7
Edición de una consulta guardada 9-7
Adición de una variable de enlace a una consulta 9-8
Adición de una variable de enlace mediante un editor de texto 9-8
Adición de referencias léxicas a consultas SQL 9-9
Acerca de la definición de consultas SQL de Oracle BI Server 9-11
Definición de consultas SQL de Oracle BI Server 9-12
Creación de un juego de datos con una consulta de MDX con respecto a un origen dedatos de OLAP 9-13
Creación de un juego de datos con una consulta de MDX 9-13
Uso del generador de consultas MDX 9-14
Descripción del proceso de generación de consultas MDX 9-14
Uso del cuadro de diálogo Seleccionar cubo 9-15
vi

Selección de dimensiones y medidas 9-15
Adición de miembros de dimensión en el eje Divisor/Punto de vista 9-16
Realización de acciones de consulta MDX 9-16
Aplicación de filtros de consulta MDX 9-17
Selección de opciones de consulta MDX y guardado de consultas MDX 9-17
Creación de un juego de datos mediante un análisis 9-18
Notas adicionales sobre juegos de datos de análisis 9-19
Uso de análisis de autoservicio 9-19
Creación de un juego de datos mediante un juego de datos de autoservicio 9-19
Creación de un juego de datos mediante un flujo de datos de autoservicio 9-20
Creación de un juego de datos mediante un servicio web 9-20
Opciones de origen de datos de servicio web 9-20
Creación de un juego de datos mediante un servicio web simple 9-21
Creación de un juego de datos mediante un servicio web complejo 9-21
Información adicional en los juegos de datos de servicio web 9-22
Creación de un juego de datos mediante un archivo XML 9-22
Acerca de los archivos XML soportados 9-22
Carga de un archivo XML almacenado localmente 9-22
Refrescamiento y supresión de un archivo XML cargado 9-23
Creación de un juego de datos mediante Content Server 9-23
Creación de un juego de datos con un archivo Microsoft Excel 9-24
Acerca de los archivos de Excel soportados 9-24
Acceso a varias tablas por hoja 9-25
Uso de un archivo Microsoft Excel almacenado en un origen de datos del directorio dearchivos 9-26
Carga de un archivo Microsoft Excel almacenado localmente 9-27
Refrescamiento y supresión de un archivo de Excel cargado 9-28
Creación de un juego de datos mediante un archivo CSV 9-29
Acerca de los archivos CSV soportados 9-29
Creación de un juego de datos a partir de un archivo CSV almacenado centralmente 9-30
Carga de un archivo CSV almacenado de forma local 9-31
Edición del tipo de dato 9-32
Refrescamiento y supresión de un archivo CSV cargado 9-32
Creación de un juego de datos a partir de una fuente XML HTTP 9-33
Creación de un juego de datos a partir de un juego de datos XML HTTP 9-33
Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelode datos 9-34
Cómo se devuelven los datos 9-35
Notas adicionales sobre los juegos de datos con datos de la columna CLOB 9-37
Gestión de datos XHTML almacenados en una columna CLOB 9-37
Recuperación de datos XHTML encapsulados en CDATA 9-37
Encapsulamiento de datos XHTML en CDATA en la consulta 9-38
vii

Prueba de modelos de datos y generación de datos de ejemplo 9-38
Editar un juego de datos existente 9-39
Inclusión de información de usuario almacenada en variables del sistema en los datos delinforme 9-40
Adición de las variables del sistema de usuario como elementos 9-41
Caso de uso de ejemplo: Límite del juego de datos devuelto por el ID de usuario 9-41
Creación de variables de enlace desde los valores de atributo de usuario de LDAP 9-42
10
Estructuración de datos
Trabajar con modelos de datos 10-1
Acerca de los juegos de datos no relacionados de varias partes 10-1
Acerca de los juegos de datos relacionados de varias partes 10-3
Directrices para trabajar con juegos de datos 10-5
Acerca de la interfaz 10-6
Crear enlaces entre juegos de datos. 10-9
Acerca de los enlaces de nivel de elemento 10-9
Creación de enlaces de nivel de elemento 10-10
Eliminación de enlaces de nivel de elemento 10-10
Suprimir enlaces de nivel de grupo 10-11
Creación de subgrupos 10-11
Movimiento de un elemento entre un grupo principal y un grupo secundario 10-12
Creación de elementos de agregado de nivel de grupo 10-13
Creación de filtros de grupo 10-18
Realización de funciones a nivel de elemento 10-19
Definición de propiedades de elementos 10-19
Ordenar datos 10-20
Realización de funciones de nivel de grupo 10-20
Menú de acciones de grupo 10-21
Edición de juegos de datos 10-21
Eliminación de elementos del grupo 10-21
Edición de propiedades de grupo 10-22
Realización de funciones de nivel global 10-22
Adición de una función de agregado de nivel global 10-23
Adición de un elemento de nivel de grupo o de nivel global por expresión 10-25
Adición de un elemento de nivel global por PL/SQL 10-26
Uso de la vista Estructura para editar la estructura de datos 10-27
Cambio de nombre de elementos 10-27
Adición de un valor para elementos nulos 10-28
Referencia de función 10-28
viii

11
Adición de parámetros y listas de valores
Acerca de los parámetros 11-1
Adición de un nuevo parámetro 11-3
Creación de un parámetro de texto 11-3
Creación de un parámetro de menú 11-4
Personalización de la visualización de parámetros de menús 11-5
Definición de un parámetro de fecha 11-6
Creación de un parámetro de punto de vista (POV) 11-7
Inclusión de un valor de parámetro de PDV en una consulta MDX 11-7
Creación de un parámetro de búsqueda 11-8
Acerca de las listas de valores 11-8
Adición de listas de valores 11-8
Creación de una lista a partir de una consulta SQL 11-9
Creación de una lista desde un juego de datos fijo 11-11
Creación de una lista a partir de una consulta MDX 11-11
Adición de parámetros de campos flexibles 11-12
Requisitos para la utilización de campos flexibles 11-12
Adición de un parámetro de campo flexible y de una lista de valores 11-13
Adición de lista de valores de campo flexible 11-13
Adición del parámetro de menú para la lista de valores de campo flexible 11-14
Uso del parámetro de campo flexible para transferir valores a un campo flexibledefinido en el modelo de datos 11-15
Referencia al campo flexible en la consulta SQL 11-16
Transferencia de un rango de valores 11-16
12
Adición de disparadores de eventos
Acerca de los disparadores 12-1
Adición de disparadores de datos Antes de datos y Después de datos 12-2
Orden de ejecución 12-3
Creación de disparadores de programación 12-3
13
Agregar campos flexibles
Acerca de los campos flexibles 13-1
Uso de campos flexibles en su modelo de datos 13-1
Adición de campos flexibles clave 13-2
Introducción de detalles de campo flexible 13-3
ix

14
Adición de definiciones de repartición
Acerca de la repartición 14-1
¿Qué es una definición de depuración? 14-2
Requisitos para agregar definiciones de repartición 14-2
Uso de una consulta SQL para agregar una definición de repartición al modelo de datos 14-2
Asociación de PDF a informes mediante el motor de repartición 14-3
Uso de un juego de datos visualizado para agregar una definición de repartición al modelode datos 14-4
Definición de la consulta para la entrega de un archivo XML 14-5
Transferencia de un parámetro a la consulta de repartición 14-9
Definición de los elementos Dividir por y Entregar por para un juego de datos CLOB/XML 14-10
Configuración de un informe para usar una definición de repartición 14-12
Consulta de repartición de ejemplo 14-12
Creación de una tabla para utilizarla como origen de datos de una entrega 14-13
15
Adición de metadatos personalizados para Oracle WebCenter ContentServer
Acerca de la asignación de metadatos personalizados 15-1
Requisitos 15-1
Asignación de campos de datos a campos de metadatos personalizados 15-1
Supresión de campos de metadatos no usados 15-4
16
Mejores prácticas de rendimiento
Información sobre la opción Timeout por defecto de Oracle WebLogic Server 16-1
Mejores prácticas para juegos de datos de SQL 16-1
Solo devuelva los datos que necesite 16-2
Uso de alias de columnas para acortar la longitud del archivo XML 16-2
Evite usar filtros de grupo mediante la mejora de la consulta 16-3
Cómo evitar llamadas PL/SQL en cláusulas WHERE 16-3
Evite usar la tabla dual del sistema 16-3
Cómo evitar llamadas PL/SQL en el nivel de elemento 16-3
Cómo evitar incluir varios juegos de datos 16-4
Evitar juegos de datos anidados 16-4
Evite las consultas en línea como columnas de resumen 16-5
Cómo evitar valores de enlace de parámetros excesivos 16-6
Consejos sobre los parámetros de varios valores 16-6
Agrupación de divisiones y ordenación de datos 16-7
Límite de las listas de valores 16-8
Trabajar con parámetros de fecha 16-9
x

Ejecución del informe en línea/fuera de línea (programación) 16-9
Definición de propiedades de modelo de datos para evitar errores de memoria 16-9
Timeout de consulta 16-10
Activar eliminación de SQL 16-10
Tamaño de recuperación de base de datos 16-10
Modo escalable 16-10
Ajuste de consultas SQL 16-11
Generación de la explicación del plan 16-11
Explicación del plan para una sola consulta 16-11
Explicación del plan para informes 16-11
Directrices para ajustar las consultas 16-12
Consejos para ajustar la base de datos 16-13
Validación de modelos de datos 16-13
Resultados de validación del modelo de datos 16-13
Parte IV Uso de modelos semánticos de Oracle BI Enterprise Edition
17
Carga de modelos semánticos desde Oracle BI Enterprise Edition
Acerca de la carga de modelos semánticos de Oracle BI Enterprise Edition en la nube 17-1
Preparación del archivo de modelo semántico 17-2
Carga de modelos semánticos desde un archivo .rpd mediante la consola 17-3
Acerca de la edición de modelos semánticos cargados desde Oracle BI Enterprise Edition 17-4
Descarga e instalación de Oracle Analytics Client Tools 17-5
Conexión a un modelo semántico en la nube 17-6
Edición de un modelo semántico en la nube 17-7
Carga de un modelo semántico en la nube 17-8
Conexión a un origen de datos utilizando una conexión definida mediante consola 17-8
Conexión de un modelo semántico a un origen de datos de Spark 17-9
Trabajo con la herramienta de administración de modelos 17-9
Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous DataWarehouse 17-10
Visión general de la conexión a las vistas analíticas 17-10
Creación y carga de un modelo semántico basado en una vista analítica 17-10
Conexión a vistas analíticas en Oracle Autonomous Data Warehouse 17-14
Parte V Referencia
xi

A Preguntas frecuentes
Preguntas más frecuentes sobre Data Modeler (modelos semánticos) A-1
Principales preguntas frecuentes para el editor de modelo de datos (informes de impresiónperfecta) A-3
B Solución de problemas
Solución de problemas con Data Modeler B-1
Solución de problemas con la herramienta de administración de modelos (Oracle AnalyticsClient Tools) B-3
C Referencia del editor de expresiones
Objetos de modelo semántico C-1
Operadores SQL C-1
Expresiones condicionales C-3
Funciones C-5
Funciones de agregación C-6
Funciones analíticas C-10
Funciones de fecha y hora C-11
Funciones de conversión C-13
Funciones de visualización C-14
Funciones de evaluación C-15
Funciones matemáticas C-16
Funciones de agregado de ejecución C-18
Funciones espaciales C-19
Funciones de cadena C-20
Funciones del sistema C-25
Funciones de serie temporal C-25
Constantes C-28
Tipos C-28
Variables C-28
xii

Prefacio
Descubra cómo modelar datos en Oracle Analytics Cloud.
Temas:
• Destinatarios
• Accesibilidad a la documentación
• Diversidad e inclusión
• Documentos relacionados
• Convenciones
DestinatariosModelado de datos empresariales en Oracle Analytics Cloud está pensado paraadministradores y analistas de inteligencia empresarial que utilicen Oracle Analytics Cloud:
• Los analistas modelan los datos empresariales y crean libros de trabajo, análisis,paneles de control e informes de pixelado perfecto para los consumidores. Los analistaspueden seleccionar visualizaciones interactivas y crear cálculos avanzados paraentender mejor los datos.
• Los administradores editan y cargan modelos de datos creados en Oracle BI EnterpriseEdition en Oracle Analytics Cloud. Los analistas usan los modelos de datos para crearlibros de trabajo, análisis, paneles de control e informes de pixelado perfecto.
Accesibilidad a la documentaciónOracle se compromete a facilitar la accesibilidad.
Para obtener más información sobre el compromiso de Oracle con la accesibilidad, visite elsitio web del Oracle Accessibility Program en http://www.oracle.com/pls/topic/lookup?ctx=acc&id=docacc.
Acceso a Oracle Support
Los clientes de Oracle que hayan adquirido servicios de soporte disponen de acceso asoporte electrónico a través de My Oracle Support. Para obtener más información, visite http://www.oracle.com/pls/topic/lookup?ctx=acc&id=info o, si tiene algunadiscapacidad auditiva, visite http://www.oracle.com/pls/topic/lookup?ctx=acc&id=trs.
Diversidad e inclusiónOracle asume un compromiso absoluto con la diversidad y la inclusión. Oracle respeta yvalora el hecho de contar con una fuerza laboral diversa que aumenta el liderazgo de
xiii

pensamiento y la innovación. Como parte de nuestra iniciativa para crear una culturamás inclusiva que tenga un impacto positivo en nuestros empleados, clientes ypartners, estamos trabajando para eliminar términos insensibles de nuestrosproductos y nuestra documentación. Además, somos conscientes de la necesidad demantener la compatibilidad con la tecnología existente de nuestros clientes y lanecesidad de garantizar la continuidad del servicio a medida que las ofertas y losestándares industriales de Oracle evolucionan. Debido a estas restricciones técnicas,nuestro esfuerzo para eliminar términos insensibles llevará tiempo y demandarácooperación externa.
Documentos relacionadosPara obtener una lista completa de guías, consulte el separador Libros en el centro deayuda de Oracle Analytics Cloud.
• http://docs.oracle.com/en/cloud/paas/analytics-cloud/books.html
ConvencionesEste documento utiliza las convenciones de texto e imagen de Oracle estándar.
Convenciones de texto
Convención Significado
negrita El formato de negrita indica elementos de la interfaz gráfica deusuario asociados a una acción, o bien términos definidos en eltexto o en el glosario.
cursiva El formato de cursiva indica títulos de libros, énfasis o variables dependientes de asignación para los que se proporcionan valoresconcretos.
espacio sencillo El formato de espacio sencillo indica comandos en un párrafo,direcciones URL, código en los ejemplos, texto que aparece en lapantalla o texto que se introduce.
Vídeos e imágenes
Las máscaras y los estilos personalizan el aspecto de Oracle Analytics Cloud, lospaneles de control, los informes y otros objetos. Puede que los vídeos y las imágenesque se utilizan en esta guía no tengan la misma máscara o el mismo estilo que estáutilizando, pero el comportamiento y las técnicas que se muestran son los mismos.
Prefacio
xiv

Parte IIntroducción al modelado de datosempresariales
Esta parte ofrece una introducción al modelado de datos en Oracle Analytics Cloud.
Capítulos:
• Acerca del modelado de datos empresariales

1Acerca del modelado de datos empresariales
Oracle Analytics Cloud ofrece varias herramientas para modelar sus datos empresariales.
Temas:
• Tipos de modelos
• Herramientas de modelado de datos
Tipos de modelosPuede crear varios modelos semánticos o modelos de datos con Oracle Analytics Cloud.
• Modelos semánticos para libros de trabajo de visualización, análisis y paneles de controlque cree usando Data Modeler.
Consulte Uso de Data Modeler para crear modelos semánticos.
• Modelos de datos para informes de impresión perfecta que cree con el editor de modelode datos
Consulte Creación de modelos de datos para informes de visualización perfecta.
• Archivos .rpd de modelo semántico de Oracle BI Enterprise Edition que carguedirectamente en Oracle Analytics Cloud o que edite y cargue con la herramienta deadministración de modelos.
Consulte Uso de modelos semánticos de Oracle BI Enterprise Edition.
Herramientas de modelado de datosOracle Analytics Cloud ofrece varias herramientas de modelado de datos.
1-1

Caso de uso Herramientas de modelado de datos
Visualizaciones de datosAnálisisPaneles de control
• Data ModelerModelador de datos basado en el explorador que esfácil de usar y que ofrece funciones de modeladosimples. Los modelos semánticos se muestran comoáreas temáticas que puede utilizar envisualizaciones, paneles de control y análisis.Data Modeler no soporta funciones de modeladocomplejas como la federación de varios orígenes o elredireccionamiento automático de consultas.
• Archivo .rpd de modelo semántico de Oracle BIEnterprise Edition– Herramienta de administración de modelosSi ha modelado previamente los datos de negociocon Oracle BI Enterprise Edition, no tiene queempezar desde cero con Data Modeler. Puede cargarun archivo .rpd de modelo semántico completo enOracle Analytics Cloud y empezar a utilizarinmediatamente las áreas temáticas en lasvisualizaciones, los paneles de control y los análisis.También puede utilizar la herramienta deadministración de modelos para descargar, editar ycargar los archivos .rpd de modelo semántico enOracle Analytics Cloud.
Informes de visualizaciónperfecta
• Editor del modelo de datosEl editor del modelo de datos le permite combinardatos de varios juegos de datos en una únicaestructura de datos XML para obtener informes devisualización perfecta.
Capítulo 1Herramientas de modelado de datos
1-2

Parte IIUso de Data Modeler para crear modelossemánticos
En esta parte se describe cómo diseñar, crear y proteger modelos semánticos con DataModeler.
Capítulos:
• Introducción a Data Modeler
• Descripción del modelado de datos
• Cómo empezar a crear el modelo semántico
• Definición de jerarquías y niveles para obtención de detalles y agregación
• Protección del modelo semántico

2Introducción a Data Modeler
En este tema se describe cómo puede acceder y empezar a trabajar con Data Modeler.
Temas:
• Flujo de trabajo típico para modelar datos
• Apertura de Data Modeler
• Tareas principales para Data Modeler
Flujo de trabajo típico para modelar datosA continuación se detallan las tareas comunes de modelado de datos con Data Modeler.
Tarea Descripción Más información
Consulte informaciónsobre Data Modeler
Familiarícese con Data Modeler,incluida la forma de refrescar losdatos, de publicar cambios y de buscarlos menús de acciones.
Uso de Data Modeler
Crear un nuevomodelo
Inicie un nuevo modelo y conéctelo alorigen de datos.
Creación de un modelosemántico
Examinar objetos deorigen
Revise las tablas de origen paradeterminar cómo estructurar elmodelo semántico.
Revisión de tablas y datos deorigen
Crear nuevas vistas enla base de datos segúnsea necesario
Cree vistas para dimensiones derepresentación de roles o paracombinar varias tablas en una únicavista, como en orígenes de copo denieve o normalizados.
Agregación de vistas de origenpropias
Agregar tablas dehechos y tablas dedimensiones
Cree tablas de hechos y tablas dedimensiones a partir de objetos deorigen.
Adición de tablas de hechos ytablas de dimensiones a unmodelo semántico
Unir tablas de hechosy dimensiones
Cree uniones entre una tabla dehechos y una de dimensiones.
Unión de tablas de hechos ydimensiones
Agregar unadimensión de tiempo
Cree una tabla de dimensiones detiempo y una tabla de origen de basede datos con datos de tiempo.
Creación de una dimensión detiempo
Agregar medidasagregadas y calculadas
Especifique la agregación paracolumnas y cree medidas calculadascon expresiones.
Adición de medidas y atributosal modelo semántico
Agregar atributosderivados
Especifique atributos personalizadospara tablas de dimensiones conexpresiones.
Creación de atributos derivados
2-1

Tarea Descripción Más información
Crear jerarquías yniveles
Defina jerarquías y niveles basados enlas relaciones entre grupos decolumnas de atributos.
Edición de jerarquías y niveles
Crear variables También puede crear variables quecalculen y almacenen valoresdinámicamente para su uso enexpresiones de columna y filtros dedatos
Definición de variables
Configurar permisosde objeto
Controlar quiénes pueden acceder atablas de hechos, tablas dedimensiones y columnas.
Protección del acceso a losobjetos del modelo
Configurar filtros deseguridad de datos
Defina filtros de seguridad de datos anivel de fila para tablas de hechos,tablas de dimensiones y columnas.
Protección del acceso a losdatos
Cargar un archivo .rpdde modelo semántico
Si ha modelado los datos de negociocon Oracle BI Enterprise Edition, enlugar de crear un modelo semánticodesde cero mediante Data Modeler,puede usar la consola para cargar yeditar el modelo semántico en la nube.
Carga de modelos semánticosdesde un archivo .rpd mediantela consola
Apertura de Data ModelerEl administrador le dará acceso a Data Modeler.
1. Conéctese a Oracle Analytics Cloud.
2. Haga clic en el menú Página en la página inicial, y seleccione Abrir DataModeler.
3. En la página Modelos, abra un modelo existente o cree uno nuevo.
Tareas principales para Data ModelerEn este tema se identifican las principales tareas para el modelado de datos con DataModeler.
• Creación de un modelo semántico
• Revisión de tablas y datos de origen
• Agregación de vistas de origen propias
• Creación de tablas de hechos y dimensiones desde una vista o tabla única
• Creación de tablas de hechos individuales
Capítulo 2Apertura de Data Modeler
2-2

• Creación de tablas de dimensiones individualmente
• Unión de tablas de hechos y dimensiones
• Creación de medidas calculadas
• Creación de atributos derivados
• Creación de una dimensión de tiempo
• Edición de jerarquías y niveles
• Protección del acceso a los objetos del modelo
• Publicación de cambios en el modelo de datos
Capítulo 2Tareas principales para Data Modeler
2-3

3Descripción del modelado de datos
Se crea un modelo de los datos de negocio para permitir a los analistas estructurar lasconsultas del mismo modo intuitivo que hacen preguntas de negocios.
Vídeo
Temas:
• Acerca del modelado de datos con Data Modeler
• Planificación de un modelo semántico
Acerca del modelado de datos con Data ModelerUn modelo semántico es un diseño que presenta datos de negocio para su análisis de talforma que refleja la estructura del negocio. Los modelos semánticos permiten a los analistasestructurar las consultas de la misma forma intuitiva en la que hacen preguntas de negocio.Los modelos bien diseñados son simples y enmascaran la complejidad de la estructura dedatos subyacente.
Con Data Modeler puede modelar datos de varios tipos de origen, como una estrella y uncopo de nieve, de distintas formas que tienen lógica para los usuarios de negocios. Debetener el rol Autor de modelo de datos de BI para utilizar Data Modeler.
Nota:
Si ha modelado los datos de negocio con Oracle BI Enterprise Edition, no tiene queempezar desde cero con Data Modeler. Puede usar la herramienta deadministración de modelos para cargar el archivo .rpd de modelo semántico en lanube. Consulte Carga de modelos semánticos desde Oracle BI Enterprise Edition.
Aunque no todos los objetos de origen tienen relaciones de estrella, Data Modeler presentalos datos como una estructura de estrella simple en el modelo semántico. Es decir, el modelosemántico representa los hechos que se pueden medir y que se ven en términos de distintosatributos dimensionales.
Al crear un modelo semántico con Data Modeler, realice las siguientes tareas:
• Conéctese a la base de datos que contiene sus datos de negocio.
• Agregue tablas o vistas de origen al modelo y clasifíquelas como tabla de hechos o tabalde dimensiones.
• Defina uniones entre una tabla de hechos y una de dimensiones
• Asegurarse de que cada tabla de dimensiones se asigna al menos a una tabla dehechos y de que cada tabla de hechos se asigna al menos a una tabla de dimensiones.
3-1

• Especificar reglas de agregación para diferentes columnas de hechos, crearmedidas derivadas basadas en expresiones, crear jerarquías de dimensionespara soportar el detalle y crear medidas basadas en nivel.
• Publicar el modelo semántico para guardar los cambios de forma permanente yhacer que los datos estén disponibles para usarlos en los análisis.
Después de publicar el modelo semántico, puede empezar a visualizar los datos en lapágina inicial de informes de empresa. El modelo semántico se muestra como un áreatemática que puede utilizar en visualizaciones, paneles de control y análisis. Elnombre del área temática coincide con el nombre del modelo semántico.
Cuando modela objetos de origen con varias relaciones de estrella, todos formanparte del mismo modelo semántico y están incluidos en la misma área temática.
¿Puedo utilizar mi archivo. rpd de modelo semántico con Data Modeler?
Sí. En este capítulo se describe cómo se crean modelos semánticos desde ceromediante Data Modeler. Si ha modelado los datos de negocio con Oracle BIEnterprise Edition, puede cargar el archivo .rpd de modelo semántico completo enOracle Analytics Cloud y empezar a utilizar inmediatamente las áreas temáticas en lasvisualizaciones, los paneles de control y los análisis. Consulte Carga de modelossemánticos desde Oracle BI Enterprise Edition.
Si carga un archivo de modelo semántico existente de esta manera:
• Se desactivará Data Modeler.Aparecerá el mensaje "Utilice la herramienta de administración de Oracle BI paragestionar su modelo".
• Puede usar la herramienta de administración de modelos para hacer cambios.Consulte Edición de un modelo semántico en la nube.
Planificación de un modelo semánticoAntes de empezar a modelar los datos, tómese su tiempo para pensar los requisitosde su negocio y comprender los conceptos del modelado de datos.
Temas:
• Descripción de los requisitos del modelo semántico
• Componentes de un modelo semántico
• Acerca del modelado de objetos de origen con relaciones de estrella
• Acerca del modelado de objetos de origen con relaciones de copo de nieve
• Acerca del modelado de orígenes desnormalizados
• Acerca del modelado de orígenes normalizados
Descripción de los requisitos del modelo semánticoAntes de poder empezar a modelar los datos, primero debe comprender los requisitosdel modelo semántico:
• ¿Qué tipos de preguntas de negocio va a intentar responder?
• ¿Cuáles son las medidas necesarias para comprender el rendimiento delnegocio?
Capítulo 3Planificación de un modelo semántico
3-2

• ¿Cuáles son todas las dimensiones con las que funciona el negocio? O, con otraspalabras, ¿cuáles son las dimensiones utilizadas para desglosar las medidas yproporcionar cabeceras para los informes?
• ¿Hay elementos jerárquicos en cada dimensión? Y, ¿qué tipos de relaciones definencada jerarquía?
Después de haber respondido estas preguntas, podrá identificar y definir los elementos delmodelo de negocio.
Componentes de un modelo semánticoLas tablas de hechos, las tablas de dimensiones, las uniones y las jerarquías son loscomponentes clave de un modelo semántico.
Componente Descripción
Tablas de hechos Las tablas de hechos contienen medidas (columnas) que tienenagregaciones incorporadas en sus definiciones.Las mediciones agregadas a partir de hechos se deben definir en unatabla de hechos. Las medidas suelen ser datos calculados como el valoren dólares o la cantidad vendida, y pueden especificarse en términos dejerarquías. Por ejemplo, puede que desee determinar la suma de dólarespara un producto específico en un mercado concreto a lo largo de unperíodo de tiempo determinado.Cada medida tiene su propia regla de agregación, como SUM, AVG, MIN oMAX. Puede que un negocio desee comparar valores de una medida ynecesite un cálculo para expresar la comparación.
Tablas dedimensiones
Un negocio utiliza hechos para medir el rendimiento mediantedimensiones correctamente establecidas, por ejemplo, por tiempo,producto y mercado. Cada dimensión tiene un juego de atributosdescriptivos. Las tablas de dimensiones contienen atributos quedescriben entidades de negocio (como Customer Name, Region, Addresso Country).Los atributos de las tablas de dimensiones proporcionan contexto a losdatos numéricos, como por ejemplo, poder categorizar solicitudes deservicio. Los atributos almacenados en esta dimensión podrían incluir:Service Request Owner, Area, Account o Priority.Las tablas de dimensiones en el modelo se agrupan. En otras palabras,incluso aunque haya tres instancias de origen distintas de una tablaCliente concreta, el modelo solo tiene una tabla. Para lograr esto, las tresinstancias de origen de Customer se combinan en una con las vistas debase de datos.
Uniones Las uniones indican relaciones entre tablas de hechos y tablas dedimensiones en el modelo. Al crear uniones, se especifica la tabla dehechos, la tabla de dimensiones, la columna de hechos y la columna dedimensiones que desea unir.Las uniones permiten que las consultas devuelvan filas en las que hay almenos una coincidencia en ambas tablas.Consejo: Los analistas pueden utilizar la opción Incluir valores nulos alcrear informes para devolver filas de una tabla cuando no hay filascoincidentes en otra tabla.
Capítulo 3Planificación de un modelo semántico
3-3

Componente Descripción
Jerarquías Las jerarquías son juegos de relaciones descendentes entre los atributosde la tabla de dimensiones.En las jerarquías, los niveles se acumulan desde los niveles más bajoshasta los niveles más altos. Por ejemplo, los meses pueden acumularseen un año. Estas acumulaciones se producen sobre los elementos dejerarquía y abarcan las relaciones empresariales naturales.
Acerca del modelado de objetos de origen con relaciones de estrellaLos orígenes de estrella están formados por una o varias tablas de hechos que hacenreferencia a cualquier número de tablas de dimensiones. Debido a que Data Modelerpresenta los datos en una estructura de estrella, trabajar con orígenes de estrella esel caso de modelado más simple. En orígenes de estrella, las dimensiones senormalizan con cada una de las dimensiones representadas por una sola tabla.
Por ejemplo, suponga que tiene distintos orígenes para Medidas de ingresos,Productos, Clientes y Pedidos. En este caso, carga los datos de cada origen en tablasde bases de datos distintas. A continuación, puede utilizar Data Modeler para crearuna tabla de hechos (Medidas de ingresos) y tablas de dimensiones (Productos,Clientes y Pedidos). Por último, crea uniones entre las tablas de dimensiones y latabla de hechos.
Al crear sus tablas de hechos y de dimensiones, puede arrastrar y soltar los objetosde origen en el modelo semántico o puede utilizar opciones de menú para crear lasdistintas tablas de hechos y de dimensiones individuales.
Consulte Guía básica de modelado de datos para obtener una lista completa detareas de modelado de datos.
Acerca del modelado de objetos de origen con relaciones de copo denieve
Los orígenes de copo de nieve son similares a los orígenes de estrella. En unaestructura de copo de nieve, sin embargo, las dimensiones se normalizan en variastablas relacionadas en lugar de en tablas de una sola dimensión.
Por ejemplo, suponga que tiene distintos orígenes para Medidas de ingresos,Productos, Clientes y Pedidos. Además, tiene distintos orígenes para Marcas (unidosa Productos) y Grupo de clientes (unidos a Clientes). Las tablas Marcas y Grupo declientes se consideran "divididas en copos de nieve" de las tablas de dimensionesbásicas Clientes y Productos.
En este caso, carga los datos de cada origen en tablas de bases de datos distintas. Acontinuación, crea vistas de base de datos que combinan las distintas tablas dedimensiones en una sola tabla. En este ejemplo, crea una vista que combinaProductos y Marca y otra vista que combina Cliente y Grupo de clientes.
A continuación, utilice Data Modeler para crear una tabla de hechos (Medidas deingresos) y tablas de dimensiones (vista Productos + Marca, vista Clientes + Grupo declientes y Pedidos). Por último, crea uniones entre las tablas de dimensiones y la tablade hechos.
Capítulo 3Planificación de un modelo semántico
3-4

Consulte Guía básica de modelado de datos para obtener una lista completa de tareas demodelado de datos.
Acerca del modelado de orígenes desnormalizadosLos orígenes desnormalizados combinan los hechos y las dimensiones como columnas enuna tabla (o archivo plano). Con un origen plano desnormalizado, se carga un archivo dedatos en una tabla. El archivo de datos consta de atributos de dimensión y columnas demedidas.
En algunos casos, el modelo semántico podría estar compuesto por un modelo híbrido queimplicara una combinación de orígenes de estrella, copo de nieve y desnormalizados. Porejemplo, un origen desnormalizado podría incluir información sobre medidas de ingresos,productos, clientes y pedidos, pero todo en un solo archivo, en lugar de en distintos archivosde origen.
En este caso, primero se carga el archivo desnormalizado como una sola tabla de base dedatos. A continuación, se utiliza el asistente de Agregar al modelo para particionar lascolumnas en varias tablas de hechos y dimensiones. En este ejemplo, se arrastran y sesueltan las columnas de medidas de ingresos para crear una tabla de hechos y, acontinuación, se arrastran y se sueltan las columnas para productos, clientes y pedidos paracrear tres tablas de dimensiones distintas. Por último, crea uniones entre las tablas dedimensiones y la tabla de hechos.
Consulte Guía básica de modelado de datos para obtener una lista completa de tareas demodelado de datos.
Acerca del modelado de orígenes normalizadosLos orígenes normalizados o transaccionales distribuyen los datos en varias tablas paraminimizar la redundancia de almacenamiento de datos y optimizar las actualizaciones dedatos. En un origen normalizado, tiene varios archivos de datos que corresponden a cadauna de las tablas transaccionales. Es probable que los datos de las aplicaciones de OracleCloud se particionen en un origen normalizado.
De forma similar a los orígenes de copo de nieve, el modelado de orígenes normalizadosimplica la creación de vistas de base de datos para combinar columnas de varias tablas deorigen en tablas de hechos y dimensiones individuales. Algunos orígenes normalizados sonmuy complejos y necesitan varias vistas de base de datos para organizar los datos en unmodelo de tipo estrella.
Por ejemplo, suponga que tiene archivos de origen para Products, Customers, Orders yOrder Items. Tanto Orders como Order Item contienen hechos.
En este caso, primero se cargan los archivos como tablas de bases de datosindependientes. A continuación, crea una vista de base de datos que combina variascolumnas de hechos en una única tabla. En este ejemplo, crea una vista que combinacolumnas de Orders y Order Items.
A continuación, utilice Data Modeler para crear una tabla de hechos (vista Orders + OrderItems) y tablas de dimensiones (Products y Customers). Por último, crea uniones entre lastablas de dimensiones y la tabla de hechos.
Consulte Guía básica de modelado de datos para obtener una lista completa de tareas demodelado de datos.
Capítulo 3Planificación de un modelo semántico
3-5

4Cómo empezar a crear el modelo semántico
En esta sección se proporciona información sobre cómo realizar los primeros pasos paracrear un modelo semántico, como agregar tablas de dimensiones, tablas de hechos yuniones.
Vídeo
Temas:
• Flujo de trabajo típico para modelar datos
• Uso de Data Modeler
• Revisión de tablas y datos de origen
• Agregación de vistas de origen propias
• Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
• Unión de tablas de hechos y dimensiones
• Creación de una dimensión de tiempo
• Adición de medidas y atributos al modelo semántico
• Copia de objetos del modelo
Uso de Data ModelerData Modeler permite modelar los datos necesarios para realizar informes.
Temas:
• Apertura de Data Modeler
• Creación de un modelo semántico
• Uso del panel izquierdo de Data Modeler
• Uso del panel derecho de Data Modeler
• Uso de los menús de acción
• Bloqueo de un modelo semántico
• Validación de un modelo semántico
• Refrescamiento y sincronización de objetos de origen y objetos de modelo semántico
• Publicación de cambios en el modelo semántico
• Borrado de datos almacenados en caché
• Cambio de nombre de un modelo semántico
• Conexión de un modelo a una base de datos distinta
• Exportación de un modelo semántico
4-1

• Importación de un modelo semántico
• Supresión de un modelo semántico
Creación de un modelo semánticoCree un nuevo modelo semántico desde cero en Data Modeler.
Vídeo
1. Abra Data Modeler.
2. Haga clic en Crear modelo.
3. Introduzca un nombre y una descripción para el modelo semántico.
El área temática asociada a este modelo recibe el mismo nombre.
4. Conecte el modelo a una base de datos.
Si la base de datos que desea no aparece en la lista, solicite al administrador queconfigure la conexión en su lugar.
Uso del panel izquierdo de Data ModelerHay disponibles varios menús de modelado de datos en el panel izquierdo de DataModeler.
• Base de datos : muestra los objetos de origen como tablas y vistas de base dedatos
• Modelo de datos: muestra objetos de modelo como tablas de hechos, tablas dedimensiones, jerarquías, columnas de hechos y columnas de dimensiones
• Variables : muestra variables para su uso en filtros de seguridad de datos y enexpresiones de columna
• Roles : muestra roles que puede utilizar al definir permisos de objetos y filtros deseguridad de datos
Filtre una lista para encontrar exactamente lo que desea.
1. En Data Modeler, en el panel izquierdo, abra el menú Base de datos, Modelo dedatos, Variables o Roles.
2. Haga clic en el icono Filtrar a la derecha del menú seleccionado.
Capítulo 4Uso de Data Modeler
4-2
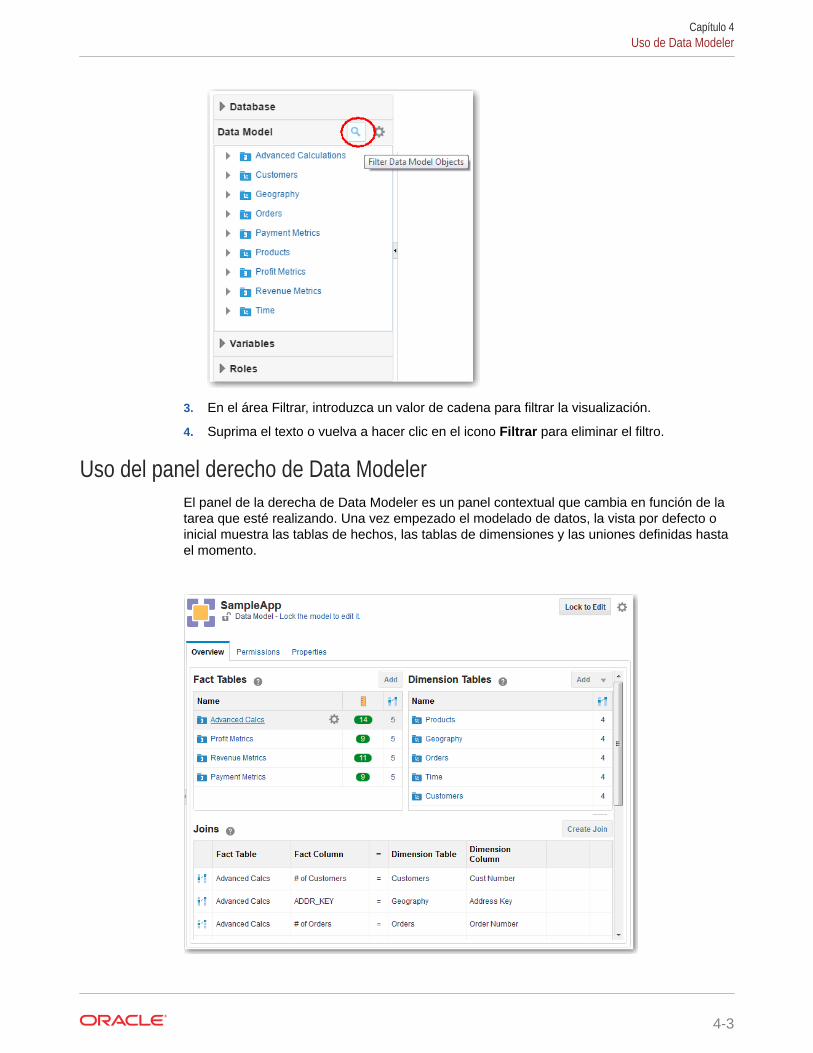
3. En el área Filtrar, introduzca un valor de cadena para filtrar la visualización.
4. Suprima el texto o vuelva a hacer clic en el icono Filtrar para eliminar el filtro.
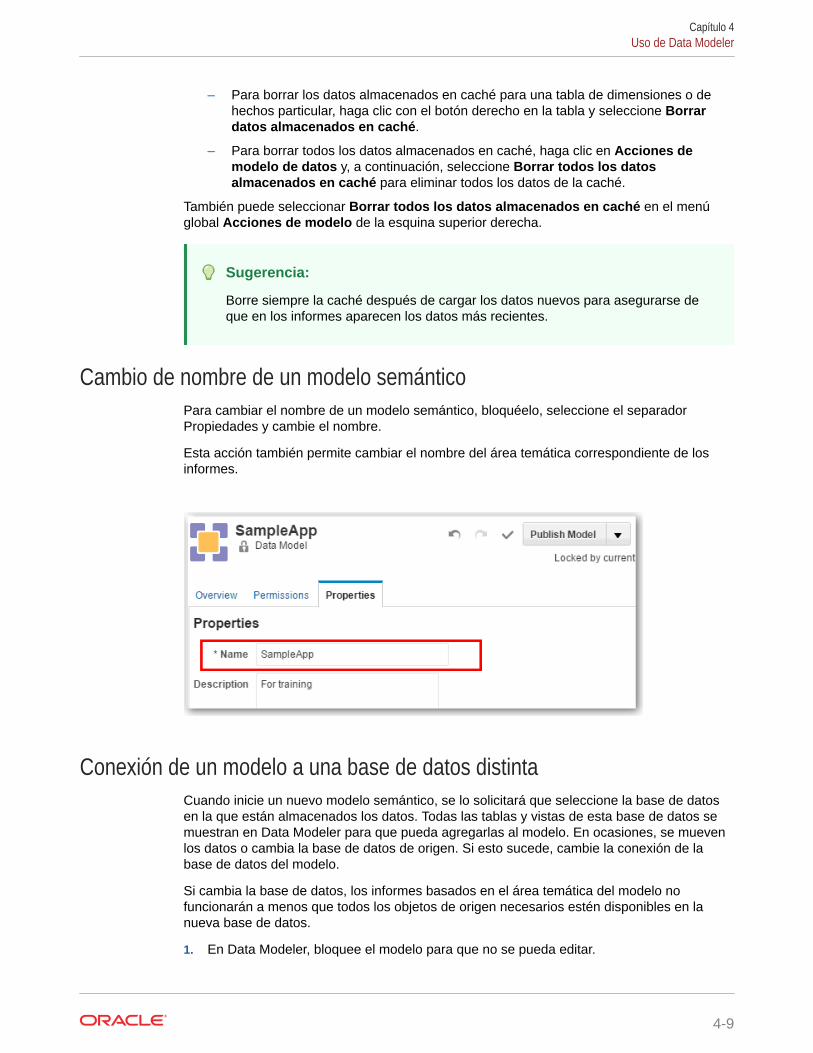
Uso del panel derecho de Data ModelerEl panel de la derecha de Data Modeler es un panel contextual que cambia en función de latarea que esté realizando. Una vez empezado el modelado de datos, la vista por defecto oinicial muestra las tablas de hechos, las tablas de dimensiones y las uniones definidas hastael momento.
Capítulo 4Uso de Data Modeler
4-3

• En el área de las tablas de hechos y las tablas de dimensiones, puede ver elnúmero de uniones de cada tabla de hechos y de dimensiones, así como elnúmero de medidas en cada tabla de hechos.
• Las uniones se muestran bajo las tablas de hechos y de dimensiones. Haga clicen la flecha arriba o abajo de cada cabecera de columna para ordenar.
• Al hacer clic en un objeto para abrir su editor, el editor aparece en el panelderecho. Por ejemplo, al hacer clic en el nombre de una tabla de dimensiones delmenú Modelo de datos del panel izquierdo, se abre el editor de tablas dedimensiones en el panel derecho.
• Abra el separador Permiso para controlar quién tiene acceso al modelo y quiénpuede crear informes desde el área temática asociada.
• Abra el separador Propiedades para renombrar el modelo, o bien para conectarloa una base de datos diferente.
Uso de los menús de acciónData Modeler proporciona menús de acción para la mayoría de los objetos. Alseleccionar un objeto, aparecerá un icono de engranaje que muestra el menú ( ).
El menú global Acciones de modelo de la esquina superior derecha le permiteborrar, cerrar, refrescar o desbloquear el modelo.
También puede utilizar los menús de acciones para suprimir objetos individuales quehaya bloqueado.
• Puede suprimir vistas de origen, pero no se pueden suprimir tablas de origen.Utilice el Taller de SQL para borrar tablas de la base de datos de origen.
• No se pueden suprimir objetos de modelo de los que dependan otros objetos.
Capítulo 4Uso de Data Modeler
4-4

Bloqueo de un modelo semánticoDebe bloquear el modelo semántico antes de realizar algún cambio. Haga clic en Bloquearpara editar para bloquear el modelo semántico.
Consejos:
• Publique los cambios regularmente (en los exploradores se produce un timeout despuésde 20 minutos de inactividad).
• Publique los cambios antes de cerrar el explorador para asegurarse de que se libera elbloqueo.
• Bloquee el modelo antes de cambiar las vistas.
• Si tiene privilegios administrativos, puede sustituir los bloqueos definidos por otrosusuarios.
Validación de un modelo semánticoPuede utilizar el icono de marca de control global Validar en la esquina superior izquierdapara comprobar si el modelo semántico es válido.
El modelo semántico también se valida automáticamente al publicar cambios. Los errores devalidación se muestran en la parte inferior del panel derecho.
Utilice el menú Acciones de mensajes para personalizar los tipos de mensajes que semuestran (errores, advertencias e información).
Algunas tareas se validan cuando se realizan. Por ejemplo, no puede guardar una vista deorigen, a menos que su consulta SQL sea válida. Las expresiones para las medidascalculadas y las columnas derivadas deben ser válidas para poder guardarlas. Los mensajesde validación que se muestran conforme está realizando tareas proporcionan másinformación sobre cualquier error de validación.
Refrescamiento y sincronización de objetos de origen y objetos de modelosemántico
Data Modeler proporciona tres formas de refrescar los datos para garantizar que consulta lainformación más actualizada. Puede refrescar los objetos de origen, refrescar el modelo
Capítulo 4Uso de Data Modeler
4-5

semántico o sincronizar el modelo semántico con las definiciones del objeto de origenen la base de datos.
Refrescamiento de objetos de origen
Puede refrescar el panel Base de datos para garantizar que la lista de objetos deorigen refleja los objetos más recientes en la base de datos. Por ejemplo, puederefrescar la lista de objetos de origen para incluir cualquier tabla de base de datosnueva que se haya agregado. La lista de objetos de origen no se refrescaautomáticamente una vez que se cargan los nuevos objetos en la base de datos.
Para refrescar objetos de origen, seleccione Refrescar en el menú Acciones debase de datos del panel izquierdo.
Refrescamiento del modelo semántico
En algunos casos, otros usuarios de Data Modeler pueden haber bloqueado elmodelo y haber realizado cambios. Puede refrescar el modelo semántico paragarantizar que Data Modeler muestra la versión más reciente del modelo.
Para refrescar el modelo semántico, seleccione Refrescar en el menú Acciones demodelo de datos del panel izquierdo.
También puede seleccionar Refrescar modelo en el menú con el icono de engranajeAcciones de modelo junto al botón Bloquear para editar.
Sincronización con la base de datos
Puede sincronizar el modelo semántico con objetos de origen en la base de datos. Lasincronización identifica los objetos en el modelo que se han suprimido en la base dedatos, así como las tablas y columnas que son nuevas. También identifica otrasdiscrepancias como los tipos de datos de columna que no coinciden.
Para sincronizar todos los objetos de modelo y los objetos de origen con la base dedatos, seleccione Sincronizar con base de datos en el menú Acciones de modeloglobal en la esquina superior derecha.
Para sincronizar tablas de hechos o tablas de dimensiones individuales, seleccioneSincronizar con base de datos en el menú Acciones de la tabla de hechos o tablade dimensiones determinada en la lista de objetos de modelo de datos del panelizquierdo. A continuación, haga clic en Aceptar.
Debe bloquear el modelo semántico para sincronizar con la base de datos.
Capítulo 4Uso de Data Modeler
4-6

Las discrepancias de sincronización se muestran en un cuadro de mensajes en la parteinferior del panel derecho. Utilice el menú Acciones de mensajes para personalizar los tiposde mensajes mostrados (errores, advertencias e información), seleccione o anule laselección de todos los mensajes y realice acciones de sincronización en los mensajesseleccionados. Por ejemplo, puede seleccionar todas las advertencias de tipos de datos queno coinciden y, a continuación, seleccionar Sincronización seleccionada en el menúAcciones para realizar los cambios de sincronización correspondientes.
Publicación de cambios en el modelo semánticoAl actualizar un modelo semántico, se realizan cambios que puede guardar o desechar.Publique un modelo para guardar los cambios permanentemente y que los datos esténdisponibles para su uso en informes. El modelo semántico publicado se muestra como unárea temática.
Sugerencia:
Aunque los cambios en el modelo semántico se guardan como el trabajo delusuario, solo se guardan en la sesión del explorador. Los cambios no se guardanrealmente hasta que se publica el modelo.
Cuando se publica un modelo semántico, se valida automáticamente. Cualquier error devalidación aparecerá en la parte inferior del panel derecho. Si ve errores de validación,soluciónelos y vuelva a intentar publicar el modelo semántico de nuevo.
Capítulo 4Uso de Data Modeler
4-7

Después de realizar cambios en el modelo semántico, puede realizar estas accionesmediante los menús de la esquina superior derecha:
• Publicar y desbloquear: verifica que el modelo es válido, guarda los cambios ypublica el modelo para su uso en informes. El modelo está desbloqueado paraotros usuarios.
• Publicar y mantener bloqueo: verifica que el modelo es válido, guarda loscambios y publica el modelo para su uso en informes. Se mantiene el bloqueopara posteriores ediciones.
• Desbloquear : elimina el bloqueo del modelo, de forma que otros usuarios lopuedan actualizar. Los cambios no publicados realizados en el modelo sedesechan.
• Revertir : devuelve el modelo a su estado de publicación anterior. Los cambios nopublicados realizados en el modelo se desechan, pero el modelo permanecebloqueado.
• Borrar: suprime permanentemente todos los objetos del modelo y los elimina detodos los informes basados en el área temático del modelo.
También puede hacer clic en Deshacer y Rehacer en la esquina superior derechapara revertir o volver a aplicar los cambios individuales.
Sugerencia:
No es necesario publicar el modelo para guardar los cambios en la base dedatos. Los cambios realizados en las vistas de la base de datos y otrosobjetos de base de datos de origen se guardan en la base de datos alrealizar la acción, no en el modelo semántico. Para cambios de base dedatos, no están disponibles Deshacer y Rehacer.
Después de publicar el modelo, espere unos dos minutos para que los cambiosrealizados en el modelo semántico se reflejen en los informes y paneles de control.Para ver los cambios inmediatamente, abra el informe y haga clic en Refrescar y, acontinuación, en Recargar metadatos del servidor.
Oracle Analytics Cloud realiza una instantánea cuando usted o alguna otra personapublican cambios en el modelo semántico. Si está teniendo algún problema con elúltimo modelo semántico, puede pedirle al administrador que restaure una versiónanterior.
Borrado de datos almacenados en cachéOracle Analytics Cloud almacena en caché los datos para maximizar el rendimiento.Esto significa que es posible que las actualizaciones de datos no se reflejen de formainmediata en los informes y Data Modeler.
Después de cargar datos nuevos en las tablas, puede que desee borrar la caché paraver los datos más recientes.
• Para ver los datos nuevos en Data Modeler, seleccione el menú Refrescarmodelo.
• Para ver los datos nuevos en los informes, borre manualmente la caché del menúModelo de datos del panel izquierdo
Capítulo 4Uso de Data Modeler
4-8
– Para borrar los datos almacenados en caché para una tabla de dimensiones o dehechos particular, haga clic con el botón derecho en la tabla y seleccione Borrardatos almacenados en caché.
– Para borrar todos los datos almacenados en caché, haga clic en Acciones demodelo de datos y, a continuación, seleccione Borrar todos los datosalmacenados en caché para eliminar todos los datos de la caché.
También puede seleccionar Borrar todos los datos almacenados en caché en el menúglobal Acciones de modelo de la esquina superior derecha.
Sugerencia:
Borre siempre la caché después de cargar los datos nuevos para asegurarse deque en los informes aparecen los datos más recientes.
Cambio de nombre de un modelo semánticoPara cambiar el nombre de un modelo semántico, bloquéelo, seleccione el separadorPropiedades y cambie el nombre.
Esta acción también permite cambiar el nombre del área temática correspondiente de losinformes.
Conexión de un modelo a una base de datos distintaCuando inicie un nuevo modelo semántico, se lo solicitará que seleccione la base de datosen la que están almacenados los datos. Todas las tablas y vistas de esta base de datos semuestran en Data Modeler para que pueda agregarlas al modelo. En ocasiones, se muevenlos datos o cambia la base de datos de origen. Si esto sucede, cambie la conexión de labase de datos del modelo.
Si cambia la base de datos, los informes basados en el área temática del modelo nofuncionarán a menos que todos los objetos de origen necesarios estén disponibles en lanueva base de datos.
1. En Data Modeler, bloquee el modelo para que no se pueda editar.
Capítulo 4Uso de Data Modeler
4-9

2. Haga clic en el separador Propiedades.
3. Seleccione la base de datos.
Si la lista no muestra la base de datos que busca, pídale al administrador que leconfigure una conexión.
4. Sincronice el modelo semántico con la nueva base de datos. SeleccioneSincronizar con base de datos en el menú Acciones de modelo.
Exportación de un modelo semánticoLos modelos semánticos individuales se pueden exportar a un archivo JSON y lainformación se puede importar a otro servicio. Si desea implantar pequeños cambiosen el modelo, puede editar el archivo JSON antes de importarlo. Por ejemplo, puedeque desee cambiar el nombre del modelo (modelDisplayName) o la conexión de basede datos (connectionName).
1. Abra Data Modeler.
2. En la página Modelos, haga clic en el icono Acciones de modelo para el modeloque desea exportar y seleccione Exportar.
3. Guarde el archivo JSON. El nombre por defecto es model.json.
Importación de un modelo semánticoLos modelos semánticos individuales se pueden exportar a un archivo JSON y lainformación se puede importar a otro servicio. Si desea implantar pequeños cambiosen el modelo, puede editar el archivo JSON antes de importarlo. Por ejemplo, puedeque desee cambiar el nombre del modelo (modelDisplayName) o la conexión de basede datos (connectionName).
Para que un modelo semántico funcione correctamente, debe disponer de acceso alas tablas de bases de datos asociadas. Antes de importar el modelo semántico,asegúrese de que Data Modeler puede conectarse a la base de datos indicada. Si noes así, solicite a su administrador que configure la conexión.
Capítulo 4Uso de Data Modeler
4-10

1. Abra Data Modeler.
2. Haga clic en Importar modelo.
3. Acceda al archivo JSON que contiene el modelo semántico que desea importar.
4. Haga clic en Aceptar.
5. Opcional: Seleccione una conexión de base de datos para el modelo.
Si Data Modeler no reconoce el nombre de conexión del archivo JSON, se le pedirá queseleccione una conexión de base de datos. Si la conexión que busca no aparece en lalista, solicite al administrador que la configure e inténtelo de nuevo.
6. Opcional: Indique si desea sustituir un modelo semántico con el mismo nombre. Hagaclic en Sí para sobrescribir el modelo, o en No para cancelar la acción.
Esto ocurre cuando el modelo mencionado en el archivo JSON entra en conflicto conotro modelo en Data Modeler. Si no desea sustituir el modelo existente, cambie elatributo modelDisplayName en el archivo JSON e inténtelo de nuevo.
Supresión de un modelo semánticoPuede suprimir todos los objetos del modelo semántico si desea borrar el modelo y empezarde nuevo. O puede suprimir un modelo completo junto con su área temática.
• Borrado de contenido de modelo: Bloquee el modelo y seleccione Borrar modelo delmenú Acciones de modelo global en la esquina superior derecha.
Esta acción elimina permanentemente todos los objetos en el modelo semántico ytambién los elimina de cualquier informe que se base en el área temática del modelo.
• Supresión de un modelo: Haga clic en Data Modeler y, a continuación, en el menúAcciones de modelo del modelo que no desee y seleccione Suprimir.
Esta acción elimina de forma permanente el modelo semántico y su área temática.
Antes de borrar o suprimir un modelo, se recomienda que el usuario o el administradorrealicen una instantánea del modelo como copia de seguridad
Revisión de tablas y datos de origenEn este tema se describe cómo puede obtener más información sobre los objetos de la basede datos de origen que están disponibles para su modelo semántico.
Temas:
• Visualización de objetos de origen
• Vista previa de los datos en objetos de origen
Capítulo 4Revisión de tablas y datos de origen
4-11

Visualización de objetos de origenPuede ver una lista de tablas y vistas de origen en el menú Base de datos en el panelizquierdo. Haga clic en una tabla o vista para ver sus propiedades.
El separador Visión general de las tablas y vistas de origen muestra información decolumna, como el nombre de la columna, el tipo de dato, si es única y si aceptavalores nulos.
Vista previa de los datos en objetos de origenPuede obtener una vista previa de las primeras 25 filas de datos de las vistas y tablasde la base de datos. Al revisar las filas iniciales, puede obtener ideas para modelar lasvistas y tablas de base de datos como tablas de dimensiones o como tablas dehechos.
1. Abra Data Modeler.
2. En el menú Base de datos del panel izquierdo, haga clic en una vista o tabla debase de datos para abrirla.
3. Haga clic en el separador Datos.
4. Revise las primeras 25 filas de datos de la tabla o vista. Si es necesario, puedeajustar el tamaño de las columnas en la tabla de visualización.
Capítulo 4Revisión de tablas y datos de origen
4-12

5. Haga clic en Obtener recuento de filas para recuperar un recuento de filas completo dela tabla o vista. Esta operación puede tardar en completarse si la tabla es grande.
6. Haga clic en Listo.
Creación de vistas de origenCree vistas de origen como base para los objetos del modelo si cree que va a realizarcambios posteriores.
Temas:
• Acerca de las vistas de origen
• Agregación de vistas de origen propias
• Definición de filtros para vistas de origen
Acerca de las vistas de origenLas vistas de origen son consultas de datos guardadas en la base de datos. Puedeconsiderar que una vista de origen es como una "tabla virtual".
Puede crear vistas de origen cuando utilice una sola tabla como origen para más de unatabla de dimensiones. Por ejemplo, puede crear vistas de origen que utilizan la tabla deorigen Employee como origen de las tablas de dimensiones Employee y Manager.
También se crean vistas de origen al crear una tabla de dimensiones que se basa en variastablas de origen, como en un origen de copo de nieve. Por ejemplo, puede crear una vista deorigen que combine columnas de tablas de origen Customer y Customer Group para crearuna sola tabla de dimensiones Customers.
También puede realizar cálculos de agregación previa en una vista de origen. Por ejemplo,para crear una columna Average Revenue que sea una agregación previa calculada, puedeincluir el cálculo en la consulta SQL para la vista:
SELECT "BICS_REVENUE_FT1"."UNITS", "BICS_REVENUE_FT1"."ORDER_KEY", "BICS_REVENUE_FT1"."REVENUE", "BICS_REVENUE_FT1"."PROD_KEY", "BICS_REVENUE_FT1"."REVENUE"/"BICS_REVENUE_FT1"."UNITS" AS AVERAGE_REVENUEFROM "BICS_REVENUE_FT1"
En general, cree vistas de origen como base para objetos de modelo cuando piense quepuede desear realizar cambios posteriores. La creación de un modelo semántico basado envistas de origen proporciona una mayor flexibilidad que el uso de tablas de origendirectamente. Por ejemplo, el uso de vistas de origen facilita en gran medida la ampliaciónde objetos de modelo, la creación de filtros y la adición de cálculos agregados previamente.
Capítulo 4Creación de vistas de origen
4-13

Agregación de vistas de origen propiasPuede agregar vistas a la base de datos origen desde Data Modeler. Por ejemplo,puede crear una vista de origen que combine las tablas de origen Brands y Productspara crear un origen único para la tabla de dimensiones.
Cree vistas de origen como base para los objetos del modelo si cree que va a realizarcambios posteriores. Puede crear una nueva vista y agregar cualquier columna quedesee de otras tablas y vistas de la base de datos. También puede crear una vistamediante la copia de una tabla de origen existente u otra vista de origen.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el menú Base de datos del panel izquierdo, haga clic en Acciones y, acontinuación, en Crear vista.
Inicialmente, la vista está vacía. Puede agregar cualquier columna que desee deotras tablas y vistas de la base de datos.
Sugerencia:
Para crear una vista a partir de una vista o tabla de origen existente,vaya al objeto de base de datos que desea copiar, haga clic enAcciones y, a continuación, en Duplicar.
3. En el editor de vistas, especifique un nombre y descripción para la vista. Tambiénpuede anular la selección de Eliminar filas duplicadas si desea incluir las filasduplicadas en la vista.
4. Agregue columnas a la vista de base de datos arrastrando y soltando tablas ovistas del menú Base de datos en el área Columnas del editor de vista.
También puede hacer clic en Agregar columnas, seleccionar una vista o tabla debase de datos de origen y, a continuación, hacer clic en Agregar.
Capítulo 4Creación de vistas de origen
4-14

5. Si es necesario, defina alias para las columnas. También puede mover filas hacia arribao hacia abajo con el menú Acción para una fila específica.
6. En el separador Uniones, puede definir uniones para la vista. Haga clic en Crear unión yespecifique la tabla de la izquierda, la tabla de la derecha, las columnas y el tipo deunión. Debe incluir más de una tabla de origen en la vista para crear uniones.
7. En el separador Filtros, puede definir filtros para la vista.
8. En el separador Consulta SQL, revise el código para la consulta SQL de la vista deorigen.
Puede editar el código SQL para la consulta aquí, pero hágalo solo si está familiarizadocon él. La introducción de código SQL no válido puede producir resultados inesperados.
Si edita la consulta SQL directamente, las actualizaciones simples se reflejarán en losseparadores Visión general, Unión y Filtros y puede utilizar estos separadores paraeditar la vista posteriormente. Por ejemplo, puede incluir:
• Una cláusula SELECT simple con alias y la palabra clave DISTINCT
• Cláusula FROM con uniones
• Cláusula WHERE con condiciones de filtro combinadas con la palabra clave AND
Si utiliza el separador Consulta SQL para realizar cambios de código avanzados, nopuede utilizar los separadores Visión general, Uniones o Filtros para editar la vistaposteriormente. Por ejemplo, si incluye:
• Funciones de agregación SQL, cláusula GROUP BY, cláusula HAVING
Capítulo 4Creación de vistas de origen
4-15

• Cláusula ORDER BY
• Palabra clave OR en la cláusula WHERE
9. Opcional: Haga clic en el separador Datos para obtener una vista previa de lasprimeras 25 filas de datos. También puede obtener un recuento de filas completo.Es mejor ver los datos después de definir uniones entre todas las tablas paraobtener un mejor rendimiento.
10. Haga clic en Guardar y cerrar.
Definición de filtros para vistas de origenUn filtro especifica los criterios que se aplican a las columnas para limitar losresultados que se devuelven. En otras palabras, un filtro es la cláusula WHERE para lasentencia VIEW. Por ejemplo, puede definir un filtro donde País de cliente sea igual aEstados Unidos.
1. Cree una vista.
2. Haga clic en el separador Filtros.
3. Haga clic en Crear filtro.
4. En la fila WHERE, seleccione en primer lugar la columna para el filtro. Acontinuación, seleccione la condición, como "es distinto de" o "es mayor que".
Por último, especifique el valor del filtro. Puede especificar una variable si esnecesario.
5. Opcional: Haga clic en Crear filtro para agregar una fila "y" al filtro. Especifique lacolumna, la condición y el valor. Repita esta operación según sea necesario.
6. Para eliminar una fila, haga clic en Acciones y, a continuación, seleccioneSuprimir.
7. Haga clic en Guardar.
Capítulo 4Creación de vistas de origen
4-16

Adición de tablas de hechos y tablas de dimensiones a unmodelo semántico
Utilice tablas de hechos y tablas de dimensiones para representar aspectos del negocio quedesea comprender mejor.
Temas:
• Acerca de las tablas de hechos y de dimensiones
• Creación de tablas de hechos y dimensiones desde una vista o tabla única
• Creación de tablas de hechos individuales
• Creación de tablas de dimensiones individualmente
• Edición de tablas de hechos y tablas de dimensiones
• Adición de más columnas a tablas de hechos y de dimensiones
Acerca de las tablas de hechos y de dimensionesLas tablas de hechos y de dimensiones contienen las columnas que almacenan los datospara el modelo:
• Las tablas de hechos contienen medidas, que son columnas con agregacionesincorporadas en sus definiciones. Por ejemplo, Revenue y Units son columnas demedidas.
• Las tablas de dimensiones contienen atributos que describen las entidades de negocio.Por ejemplo, Customer Name, Region y Address son columnas de atributos.
Las tablas de hechos y de dimensiones representan los aspectos del negocio que deseaentender mejor. Consulte Componentes de los modelos de datos.
Antes de empezar el modelado de tablas de hechos y de dimensiones, asegúrese de que losdatos que necesita modelar están disponibles en la lista de tablas de origen. Asegúresetambién de que ha creado las vistas de origen en las que se deben basar los objetos demodelo.
Si cree que la lista de objetos de origen de la base de datos ha cambiado desde que abrióData Modeler, puede hacer clic en Refrescar en el menú Acciones de base de datos. Silos datos que necesita no se han cargado aún en la base datos, puede cargarlos.
Creación de tablas de hechos y dimensiones desde una vista o tabla únicaAlgunas tablas de origen contienen tanto hechos como dimensiones. Para estas tablas deorigen, Data Modeler proporciona un asistente que le ayudará a particionar las columnas dehechos y dimensiones en tablas de hechos y de dimensiones.
Vídeo
Por ejemplo, puede darse el caso de que tenga un origen que contenga atributos deproducto y de cliente, así como medidas de ingresos. Utilice el asistente para crear las tablasde hechos y de dimensiones correspondientes.
1. En Data Modeler, bloquee el modelo para editarlo.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-17

2. En el menú Base de datos del panel izquierdo, haga clic con el botón derecho enla tabla de origen que contiene los datos de hechos y dimensionales que deseamodelar y seleccione Agregar al modelo y, a continuación, Agregar comotablas de hechos y dimensiones.
3. Para permitir que Data Modeler sugiera algunas tablas de hechos, tablas dedimensiones y uniones para la tabla de origen, seleccione Permitir a DataModeler realizar recomendaciones y haga clic en Aceptar. Puede revisar lassugerencias en el paso 4.
Si prefiere elegir tablas de hechos y de dimensiones usted mismo desde cero:
a. Anule la selección Permitir a Data Modeler realizar recomendaciones yhaga clic en Aceptar.
b. Arrastre medidas desde la tabla de origen hasta la tabla de hechos.
Sugerencia:
También puede hacer clic en el icono Más del área de la cabecerade columna para seleccionar una columna para incluirla en la tablade hechos.
c. Introduzca un nombre para la tabla de hechos, como Costos o Medidas.
d. Agregue una tabla de dimensiones para cada grupo de atributos relacionadose introduzca un nombre significativo, como Productos. Arrastre y suelte lascolumnas relacionadas desde la tabla de origen hasta la tabla de dimensionesadecuada.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-18
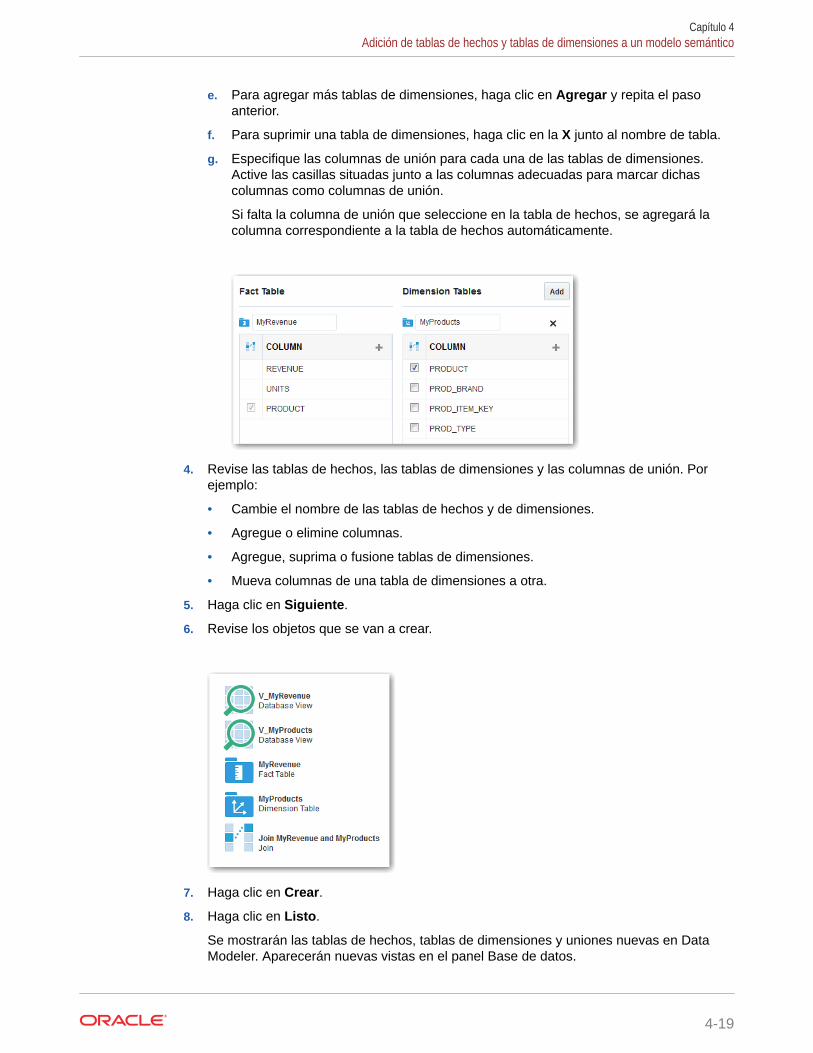
e. Para agregar más tablas de dimensiones, haga clic en Agregar y repita el pasoanterior.
f. Para suprimir una tabla de dimensiones, haga clic en la X junto al nombre de tabla.
g. Especifique las columnas de unión para cada una de las tablas de dimensiones.Active las casillas situadas junto a las columnas adecuadas para marcar dichascolumnas como columnas de unión.
Si falta la columna de unión que seleccione en la tabla de hechos, se agregará lacolumna correspondiente a la tabla de hechos automáticamente.
4. Revise las tablas de hechos, las tablas de dimensiones y las columnas de unión. Porejemplo:
• Cambie el nombre de las tablas de hechos y de dimensiones.
• Agregue o elimine columnas.
• Agregue, suprima o fusione tablas de dimensiones.
• Mueva columnas de una tabla de dimensiones a otra.
5. Haga clic en Siguiente.
6. Revise los objetos que se van a crear.
7. Haga clic en Crear.
8. Haga clic en Listo.
Se mostrarán las tablas de hechos, tablas de dimensiones y uniones nuevas en DataModeler. Aparecerán nuevas vistas en el panel Base de datos.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-19

Creación de tablas de hechos individualesPuede agregar tablas de origen individuales que contengan datos de hechos almodelo semántico.
Si tiene distintas tablas de origen con datos de hechos, como en un origen de estrella,puede agregarlas al modelo semántico individualmente. Por ejemplo, si tiene unatabla de origen que solo contiene medidas de ingresos, puede utilizar este métodopara crear la tabla de hechos correspondiente.
También puede tener orígenes con información de hechos distribuida en varias tablas,como orígenes transaccionales normalizados. En este caso, cree primero vistas deorigen para combinar tablas de forma que se parezca a un modelo en estrella. Paraobtener más información sobre la creación de vistas, consulte Agregación de vistas deorigen propias. Para obtener más información sobre el modelado de los diferentestipos de vistas, consulte Planificación de un modelo semántico.
Sugerencia:
Cree vistas de origen como base para el modelado de objetos si cree que vaa realizar cambios posteriores como la ampliación del modelo de objetos, lacreación de filtros y la adición de cálculos anteriores a la agregación. Lacreación de una tabla de hechos basada en vistas de origen proporcionamayor flexibilidad que el uso de tablas de origen directamente.
Cuando utilice este método para crear tablas de hechos individuales, todas lascolumnas de la tabla o vista de origen se asignarán a una sola tabla de hechos y, si elorigen tiene relaciones con otras tablas o vistas, se le ofrecerá la posibilidad deagregarlas al modelo.
Después de bloquear el modelo, realice una de las siguientes acciones para creartablas de hechos de forma individual:
• Arrastre la tabla o vista de origen del menú Base de datos del panel izquierdo alárea Tablas de hechos del modelo semántico.
• En el menú Base de datos del panel izquierdo, haga clic con el botón derecho enla tabla o vista y, a continuación, haga clic en Agregar al modelo y en Agregarcomo tabla de hechos.
• En el menú Base de datos del panel izquierdo, haga clic en Acciones de tabla oAcciones de vista y, a continuación, haga clic en Agregar al modelo y despuésen Agregar como tabla de hechos.
• En el editor de tablas o vistas de base de datos para una tabla o vista de origenconcreta, haga clic en Agregar al modelo y, a continuación, en Agregar comotabla de hechos.
• En el panel derecho, haga clic en Agregar en el área Tablas de hechos delmodelo semántico. A continuación, seleccione una o varias tablas y vistas deorigen de la lista Objetos de base de datos y haga clic en Aceptar.
• Para copiar una tabla de hechos existente, haga clic en Acciones de tablas dehechos para la tabla de hechos que desea copiar y, a continuación, haga clic enDuplicar.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-20

Después de agregar la vista o tabla de origen al modelo, puede editar la tabla de hechos.
Creación de tablas de dimensiones individualmentePuede agregar tablas de origen individuales que contengan datos de dimensión al modelosemántico.
Si tiene tablas de origen dimensional diferentes, como en un origen de estrella, puedeagregarlas al modelo semántico individualmente. Por ejemplo, si tiene una tabla de origenque solo contiene atributos de cliente, puede utilizar este método para crear la tabla dedimensiones correspondiente.
Opcionalmente, para orígenes de copo de nieve o normalizados (transaccionales), puedecrear vistas de origen para combinar objetos de origen de forma que parezca un modelo enestrella. Para obtener más información sobre la creación de vistas, consulte Agregación devistas de origen propias. Para obtener más información sobre el modelado de los diferentestipos de vistas, consulte Planificación de un modelo semántico.
Sugerencia:
Cree vistas de origen como base para el modelado de objetos si cree que va arealizar cambios posteriores como la ampliación del modelo de objetos, la creaciónde filtros y la adición de cálculos anteriores a la agregación. La creación de unatabla de dimensiones basada en vistas de origen proporciona mayor flexibilidadque el uso de tablas de origen directamente.
Cuando utilice este método para crear tablas de dimensiones individuales, todas lascolumnas de la tabla o vista de origen se asignarán a una única tabla de dimensiones y si elorigen tiene relaciones con otras vistas o tablas, le proporcionaremos la opción deagregarlas a su modelo.
Tras bloquear el modelo, realice una de las siguientes acciones para crear tablas dedimensiones individualmente:
• Arrastre la tabla o vista del menú Base de datos del panel izquierdo al área Tablas dedimensiones del modelo de datos.
• En el menú Base de datos del panel izquierdo, haga clic con el botón derecho en latabla, después en Agregar al modelo y, a continuación, en Agregar como tabla dedimensiones.
• En el menú Base de datos del panel izquierdo, haga clic en Acciones de tabla o en Veracciones para una tabla o vista, haga clic en Agregar al modelo y, a continuación, enAgregar como tabla de dimensiones.
• Haga clic en Agregar en el área Tablas de dimensiones y, a continuación, seleccioneAgregar a tablas de bases de datos. En la lista Objetos de base de datos, seleccioneuno o más orígenes, y haga clic en Aceptar.
• En el Editor de vistas o en la Tabla de la base de datos de una vista o tabla de origenconcreta, haga clic en Agregar al modelo y, a continuación, en Agregar como tabla dedimensiones.
• Para copiar una tabla de dimensiones existente, haga clic en Acciones de tablas dedimensiones para la tabla de dimensiones que desea copiar y, a continuación, haga clicen Duplicar.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-21

Después de agregar la vista o tabla de origen al modelo, puede editar la tabla dedimensiones.
Edición de tablas de hechos y tablas de dimensionesPuede editar las propiedades de las tablas de hechos y de dimensiones en el modelosemántico y obtener una vista previa de los datos de origen.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Haga clic en la tabla de hechos o en la tabla de dimensiones que desea editar.
3. Cambie la configuración en el separador Visión general según sea necesario.
• Dimensión de tiempo: solo para tablas de dimensiones. Especifica que lasjerarquías para esta tabla de dimensiones soportan una dimensión de tiempo.
• Activar niveles omitidos y Activar jerarquías desequilibradas: solo paratablas de dimensiones. Defina las propiedades para las jerarquías asociadasa esta tabla de dimensiones.
• Lista de columnas: haga clic en el enlace de una columna para editar esacolumna en el editor de columnas. O bien, haga clic con el botón derecho enla fila de la columna y haga clic en Editar.
• Agregación: solo para tablas de hechos. Haga clic para seleccionar un tipode agregación para la columna en una lista, o seleccione Definir agregaciónen el menú Acciones de columna. Entre los tipos de agregación se incluyen:
• Solo para tablas de hechos. Haga clic para seleccionar un tipo de agregaciónpara la columna en una lista, o seleccione Definir agregación en el menúAcciones de columna. Entre los tipos de agregación se incluyen:
Ninguna: no se aplica ninguna agregación.
Suma: calcula la suma agregando todos los valores.
Media: calcula el valor medio.
Mediana: calcula el valor intermedio.
Recuento: calcula el número de filas que no son nulas.
Recuento de los valores distintos: calcula el número de filas que no sonnulas. Cada incidencia distinta de una fila se cuenta una sola vez.
Máximo: calcula el valor numérico máximo.
Mínimo: calcula el valor numérico mínimo.
Primera: selecciona la primera incidencia del elemento.
Última: selecciona la última incidencia del elemento.
Desviación estándar: calcula la desviación estándar para mostrar el nivel devariación respecto a la media.
Desviación estándar (todos los valores): calcula la desviación estándar conla fórmula de la varianza de la población y la desviación estándar.
Consejo: algunas medidas calculadas muestran Agregado previamente parala agregación. Estas medidas tienen cálculos que implican medidas que yatienen aplicada una agregación. Para editar un cálculo que contenga medidasagregadas previamente, haga clic en el nombre de la columna.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-22

• Disponible: haga clic para marcar una columna como Disponible o No disponiblepara seleccionar si esa columna se va a mostrar en los análisis que se crean.También puede seleccionar Marcar como No disponible o Marcar comoDisponible en el menú Acciones de columna.
• Editar todo: puede hacer clic para editar las propiedades de columnas individualesen la tabla, o seleccionar Editar todo para editar todas las filas a la vez.
• Agregar columna : haga clic en Agregar columna para mostrar el editor decolumnas y crear una nueva columna.
4. En el separador Datos de origen, puede obtener una vista previa de las primeras 25 filasde los datos de origen para la tabla. Cambie el tamaño de las columnas en la tablamostrada si es necesario. Haga clic en Obtener recuento de filas para recuperar unrecuento de filas completo de la tabla o vista.
5. Solo para tablas de dimensiones: en el separador Jerarquías, edite las jerarquías yniveles para la tabla.
6. En el separador Permisos, especifique los permisos de objeto.
7. En el separador Filtros de datos, puede definir los filtros de datos que proporcionanfiltrado a nivel de fila para los objetos del modelo semántico. Consulte Protección delacceso a los datos.
8. Haga clic en Listo para volver al modelo semántico.
Adición de más columnas a tablas de hechos y de dimensionesHay distintas formas de agregar más columnas de origen a tablas de hechos y dedimensiones en su modelo.
• Si se agregan nuevas columnas a una tabla de origen y desea incluirlas en tablas dehechos y de dimensiones en su modelo, sincronice la tabla de hechos o de dimensionescon la base de datos. La sincronización identifica cualquier columna nueva y la agrega ala tabla de hechos o de dimensiones. Consulte Refrescamiento y sincronización deobjetos de origen y objetos de modelo semántico.
• Las tablas de dimensiones pueden combinar columnas de varios orígenes. Consulte Adición de columnas de otro origen a una tabla de dimensiones.
Capítulo 4Adición de tablas de hechos y tablas de dimensiones a un modelo semántico
4-23

Adición de columnas de otro origen a una tabla de dimensionesPuede agregar las columnas de otra tabla de origen o vista a una tabla dedimensiones existente. Por ejemplo, puede que desee incluir atributos de una tablaProduct Category en la tabla de dimensiones Products.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Seleccione la tabla de dimensiones que desea editar para que se muestre elseparador Visión general.
3. Arrastre y suelte la tabla de origen o la vista que contiene las columnas que deseaagregar del panel Base de datos a la tabla de dimensiones (área de columnas).
También puede hace clic con el botón derecho en la tabla de dimensiones quedesea editar, hacer clic en Agregar columnas y, a continuación, seleccionar latabla de origen o vista que contenga las columnas que desea agregar.
4. Seleccione las columnas de unión correspondientes y haga clic en Aceptar.
Visualice la tabla de dimensiones para ver las columnas adicionales. La propiedadOrigen muestra que la tabla de dimensiones está basada en una nueva vista de labase de datos. Data Modeler crea una nueva vista de la base de datos cuandoagregue columnas desde otro origen.
Unión de tablas en un modelo semánticoEn el modelo, una unión indica una relación entre una tabla de hechos y una tabla dedimensiones.
Vídeo
Temas:
• Acerca de las uniones
• Unión de tablas de hechos y dimensiones
Capítulo 4Unión de tablas en un modelo semántico
4-24

Acerca de las unionesEn el modelo, una unión indica una relación entre una tabla de hechos y una tabla dedimensiones. Si utiliza el asistente de Agregar al modelo para modelar los datos, el asistentecrea uniones automáticamente entre una tabla de hechos y cada una de sus tablas dedimensiones correspondientes.
Al modelar tablas de hechos y de dimensiones de forma individual, se creanautomáticamente uniones entre ellas si las referencias a estas uniones existen en las tablasde origen.
También puede crear uniones de forma manual en el modelo semántico. Para ello, arrastre ysuelte una tabla de dimensiones o una tabla de hechos, o haga clic en Crear unión en elárea Uniones.
Al definir una unión entre una tabla de hechos y una tabla de dimensiones, debe seleccionaruna columna de unión de cada tabla. Puede crear una unión en más de una columna.
Unión de tablas de hechos y dimensionesDefina uniones entre tablas de hechos y tablas de dimensiones para permitir la consulta dedatos relacionados. Por ejemplo, puede definir una unión entre la tabla de hechos ProfitMetrics y la tabla de dimensiones Products.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de dimensiones arrastre y suelte una tabla de dimensiones en el áreaTablas de hechos. O bien, en el área Uniones, haga clic en Crear unión.
3. En el área Uniones, especifique la tabla de hechos, columna de hechos, tabla dedimensiones y columna de dimensiones adecuada que desea utilizar para la unión.
Por ejemplo, puede especificar una columna de fecha de facturación y otra de fecha decalendario.
4. Haga clic en el icono de marca de control para guardar los cambios realizados en launión.
Si desea eliminar los cambios, haga clic en el icono X. Si comienza a crear una nuevaunión y hace clic en X, la nueva fila de la unión se elimina de la tabla Uniones.
Después de crear las uniones, podrá ver las jerarquías y los niveles por defecto al hacer clicen el separador Jerarquías de la tabla de dimensiones especificada.
Creación de una dimensión de tiempoLas funciones de serie temporal permiten comparar el rendimiento del negocio con períodosde tiempo anteriores, lo que permite analizar datos que abarcan varios períodos de tiempo.Por ejemplo, las funciones de serie temporal permiten realizar comparaciones entre las
Capítulo 4Creación de una dimensión de tiempo
4-25

ventas actuales y las ventas de hace un año, hace un mes, etc. Para utilizar lasfunciones de serie temporal, el modelo semántico debe incluir una dimensión detiempo
Vídeo
Al crear una dimensión de tiempo, el asistente Crear dimensión de tiempo crea unatabla en la base de datos, la rellena con datos de tiempo, crea una tabla dedimensiones de tiempo correspondiente en el modelo semántico y crea una jerarquíade tiempo.
El asistente de Crear dimensión de tiempo rellena la tabla de origen con datos detiempo del 1 de enero de 1970 al 31 de diciembre de 2020.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de dimensión, haga clic en Agregar y, a continuación, en Creardimensión de tiempo.
3. En el asistente de Crear dimensión de tiempo, especifique los nombres para latabla de base de datos, la tabla de dimensiones y la jerarquía.
4. En Niveles de jerarquía, especifique los niveles que desea incluir, como Año,Trimestre y Mes.
5. Haga clic en Siguiente.
6. En la siguiente página, revise las tareas que realizará el asistente para crear ladimensión de tiempo.
7. Haga clic en Crear para activar el asistente para crear la dimensión.
Capítulo 4Creación de una dimensión de tiempo
4-26

El asistente agrega una dimensión de tiempo con datos a la base de datos y crea unadimensión correspondiente en el modelo semántico. Esta acción puede tardar hasta 30segundos.
8. Haga clic en Listo.
9. Para crear uniones entre las columnas de la tabla de hechos y las columnas de la tablade dimensiones de tiempo, haga clic en Crear unión en el modelo semántico.
La dimensión de tiempo tiene dos columnas únicas. La columna DAY_TS tiene el tipoTIMESTAMP y la columna DATE_ID tiene el tipo NUMBER. Al crear una unión,especifique la columna con el formato de registro de hora o con el formato numérico (enfunción de si la columna de la tabla de hechos tiene un tipo de fecha o de número).
10. En el área Uniones de la nueva definición, seleccione la columna de hechos adecuada y,a continuación, seleccione la columna de registro de hora o numérica adecuada de ladimensión de tiempo.
Después de crear las uniones, puede visualizar el separador Jerarquías en el editorDimensión de tiempo para ver las jerarquías y los niveles por defecto.
11. Edite las tablas del modelo.
12. Haga clic en Listo para volver al modelo semántico.
Adición de medidas y atributos al modelo semánticoEn este tema se describe cómo agregar medidas y atributos al modelo semántico.
Vídeo
Temas:
• Edición de medidas y atributos
• Especificación de agregación para medidas en tablas de hechos
• Creación de medidas calculadas
• Creación de atributos derivados
• Creación de expresiones en el editor de expresiones
• Copia de medidas y atributos
Edición de medidas y atributosUtilice el editor de tablas para agregar, editar y suprimir medidas y atributos en el modelosemántico.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Haga clic en la tabla de hechos o en la tabla de dimensiones que contiene la media o elatributo que desea editar.
3. Para editar todas las columnas directamente en el editor de tablas, seleccione Editartodo.
Para editar, copiar o suprimir una selección de columnas al mismo tiempo, pulse Mayúso Ctrl y haga clic al mismo tiempo en las filas que desee.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-27
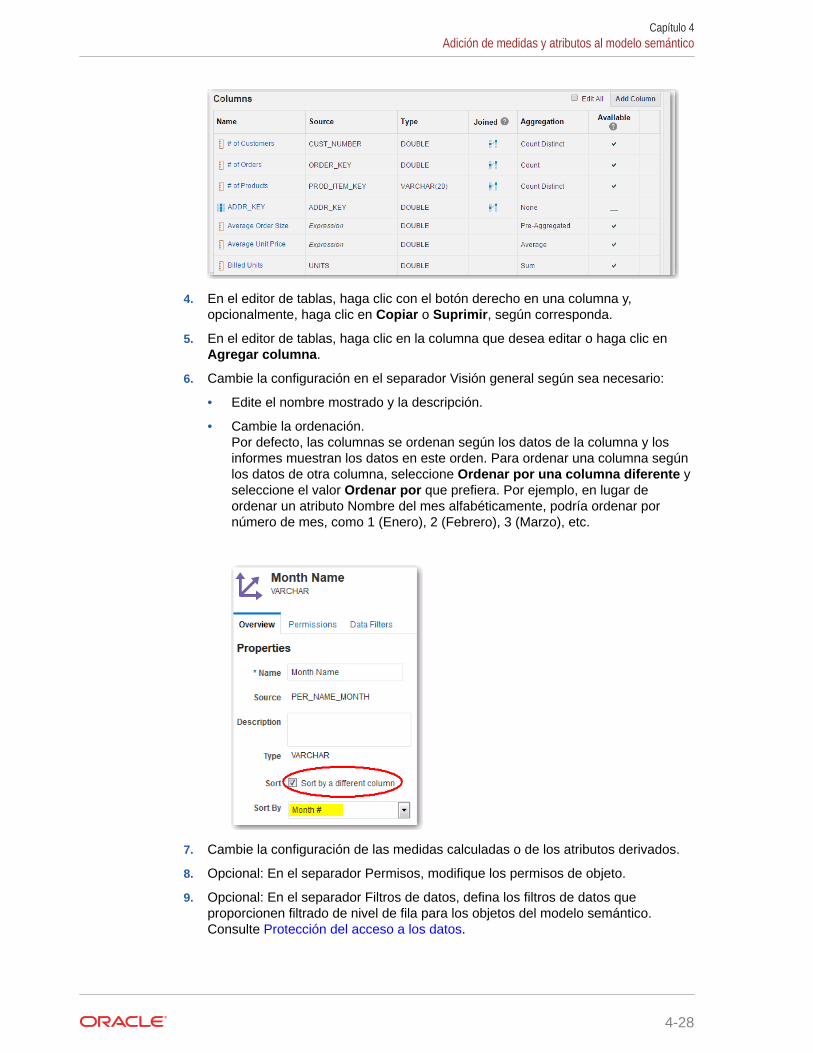
4. En el editor de tablas, haga clic con el botón derecho en una columna y,opcionalmente, haga clic en Copiar o Suprimir, según corresponda.
5. En el editor de tablas, haga clic en la columna que desea editar o haga clic enAgregar columna.
6. Cambie la configuración en el separador Visión general según sea necesario:
• Edite el nombre mostrado y la descripción.
• Cambie la ordenación.Por defecto, las columnas se ordenan según los datos de la columna y losinformes muestran los datos en este orden. Para ordenar una columna segúnlos datos de otra columna, seleccione Ordenar por una columna diferente yseleccione el valor Ordenar por que prefiera. Por ejemplo, en lugar deordenar un atributo Nombre del mes alfabéticamente, podría ordenar pornúmero de mes, como 1 (Enero), 2 (Febrero), 3 (Marzo), etc.
7. Cambie la configuración de las medidas calculadas o de los atributos derivados.
8. Opcional: En el separador Permisos, modifique los permisos de objeto.
9. Opcional: En el separador Filtros de datos, defina los filtros de datos queproporcionen filtrado de nivel de fila para los objetos del modelo semántico.Consulte Protección del acceso a los datos.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-28

10. Opcional: En el separador Niveles para las columnas de una tabla de hechos, cree unamedida basada en niveles. Consulte Definición de niveles de agregación para medidas.
11. Haga clic en Listo para volver al editor de tablas.
Especificación de agregación para medidas en tablas de hechosPuede especificar la agregación para una medida en una tabla de hechos. Por ejemplo,puede definir la regla de agregación para una columna Ingresos en Suma.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de hechos, haga clic en la tabla de hechos para la que desea crearmedidas.
3. En la lista Columnas, cambie la regla de agregación para las columnas correspondientespara especificar que son medidas.
Para aplicar la misma regla de agregación a varias columnas, pulse Mayús y haga clic oCtrl y haga clic en las columnas correspondientes.
Entre las opciones de agregación se incluyen:
Ninguna: Ninguna agregación.
Suma: calcula la suma agregando todos los valores.
Media: calcula el valor medio.
Mediana: calcula el valor intermedio.
Recuento: calcula el número de filas que no son nulas.
Recuento de los valores distintos: calcula el número de filas que no son nulas. Cadaincidencia distinta de una fila se cuenta una sola vez.
Máximo: calcula el valor numérico máximo.
Mínimo: calcula el valor numérico mínimo.
Primera: selecciona la primera incidencia del elemento.
Última: selecciona la última incidencia del elemento.
Desviación estándar: calcula la desviación estándar para mostrar el nivel de variaciónrespecto a la media.
Desviación estándar (todos los valores): calcula la desviación estándar con la fórmulade la varianza de la población y la desviación estándar.
Sugerencia:
Algunas medidas calculadas se han agregado previamente. Estas medidastienen cálculos que implican medidas que ya tienen aplicada una agregación.Para editar un cálculo que contenga medidas agregadas previamente, hagaclic en el nombre de la columna.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-29

En la mayoría de las medidas, se aplica la misma regla de agregación a cadadimensión; pero, en el caso de algunas medidas, querrá especificar reglas deagregación diferentes para distintas dimensiones.
Normalmente, las dimensiones de tiempo suelen requerir reglas de agregacióndiferentes. Por ejemplo, Recuento (medida calculada) normalmente se agregacomo SUMA en las dimensiones de organización y geografía, pero SUMA no seaplica a una dimensión de tiempo. La agregación de la dimensión de tiempo debeser ÚLTIMO, para que se pueda ver el recuento en la última semana o el últimodía del año.
4. Para sustituir la agregación para dimensiones específicas:
a. Haga clic en el nombre de la columna de medida.
b. Anule la selección de la opción Misma para todas las dimensiones.
c. Haga clic en Agregar sustitución.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-30

d. Seleccione la dimensión que desea agregar de forma diferente, por ejemplo, Tiempo.
e. Seleccione una regla de agregación para la dimensión.
f. Si es necesario, sustituya la agregación por otra dimensión.
g. Haga clic en Listo.
Si se han definido reglas de agregación específicas a dimensiones para una medida,aparecerá un asterisco * junto a la regla de agregación de la tabla Columnas. Porejemplo, Suma*.
5. Por defecto, todas las columnas de la tabla de hechos aparecerán en informes. Anule laselección del cuadro Disponible de cualquier columna que no desee mostrar. Puedeutilizar Mayús+ clic o Ctrl + clic para seleccionar varias filas.
6. Haga clic en Cancelar para cancelar cualquiera de los cambios.
7. Haga clic en Listo para volver al editor de tablas.
Creación de medidas calculadasEn una tabla de hechos no se incluyen todas las medidas que necesita, por lo que puedecrear medidas calculadas. Por ejemplo, puede crear una medida calculada denominadaAverage Order Size con la fórmula Revenue/Number of Orders.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de hechos, haga clic en la tabla de hechos para la que desea crearmedidas.
3. En el área Columnas, haga clic en Agregar columna.
4. En el editor de Nueva columna, introduzca un nombre y una descripción para lacolumna.
A continuación, introduzca una expresión directamente en el cuadro Expresión, o hagaclic en Editor completo para mostrar el editor de expresiones.
5. Las expresiones pueden contener medidas que ya se han agregado, así como medidasen las que no se ha aplicado ninguna agregación. Puede:
• Definir Agregación en Antes del cálculo, si la expresión incluye medidas que ya sehan agregado o la agregación no es necesaria.
• Definir Agregación en Después del cálculo y seleccionar una regla de agregación,como Sum, Average o Count para aplicar la agregación después de calcular laexpresión.
6. Haga clic en Listo para volver al editor de tablas.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-31
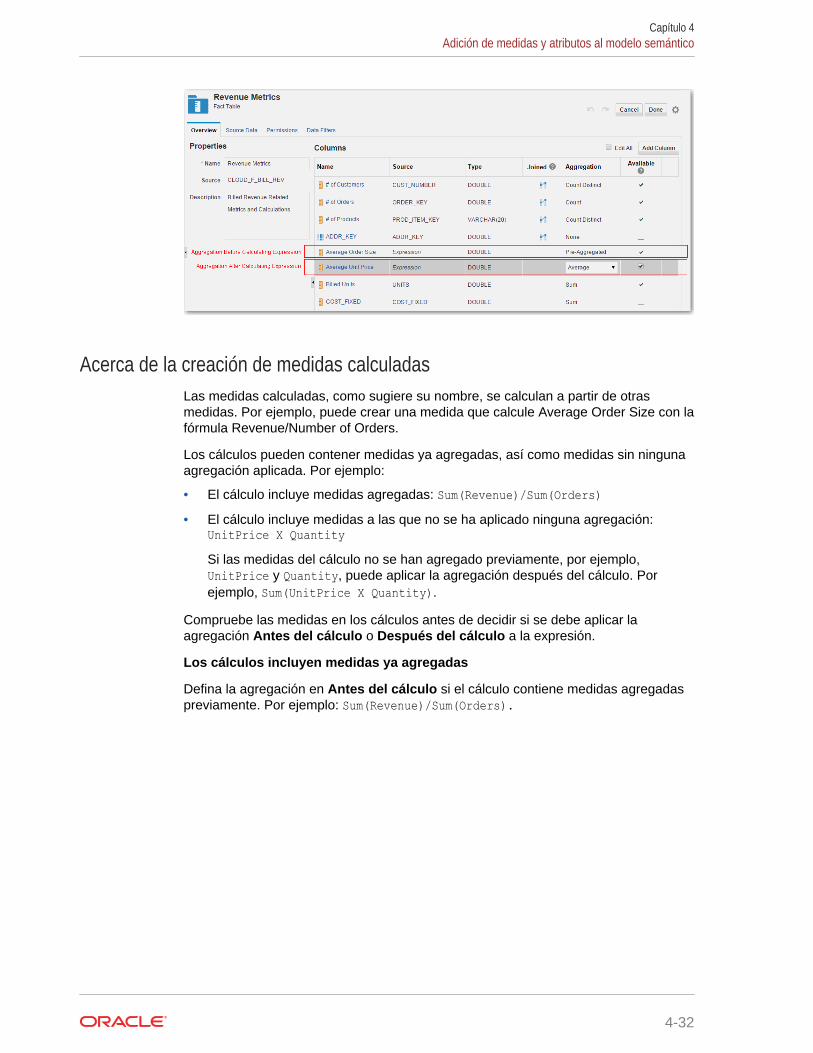
Acerca de la creación de medidas calculadasLas medidas calculadas, como sugiere su nombre, se calculan a partir de otrasmedidas. Por ejemplo, puede crear una medida que calcule Average Order Size con lafórmula Revenue/Number of Orders.
Los cálculos pueden contener medidas ya agregadas, así como medidas sin ningunaagregación aplicada. Por ejemplo:
• El cálculo incluye medidas agregadas: Sum(Revenue)/Sum(Orders)• El cálculo incluye medidas a las que no se ha aplicado ninguna agregación:
UnitPrice X QuantitySi las medidas del cálculo no se han agregado previamente, por ejemplo,UnitPrice y Quantity, puede aplicar la agregación después del cálculo. Porejemplo, Sum(UnitPrice X Quantity).
Compruebe las medidas en los cálculos antes de decidir si se debe aplicar laagregación Antes del cálculo o Después del cálculo a la expresión.
Los cálculos incluyen medidas ya agregadas
Defina la agregación en Antes del cálculo si el cálculo contiene medidas agregadaspreviamente. Por ejemplo: Sum(Revenue)/Sum(Orders).
Capítulo 4Adición de medidas y atributos al modelo semántico
4-32

Los cálculos incluyen medidas no agregadas
Opcionalmente, puede aplicar la agregación después del cálculo. Defina la agregación enDespués del cálculo y, a continuación, seleccione una regla de agregación de la lista. Porejemplo, Sum, Average, Count, etc.
No incluya columnas de expresión en el cálculo. Si incluye columnas agregadas en elcálculo, se ignora la agregación de las columnas.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-33

Creación de atributos derivadosPuede crear atributos personalizados o derivados para tablas de dimensiones queestén basadas en una expresión. Por ejemplo, puede utilizar una expresión paraconcatenar varias columnas de dirección en una sola columna Full Address.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de dimensiones, haga clic en la tabla de dimensiones para laque desea crear atributos derivados.
3. En el área Columnas, haga clic en Agregar columna.
4. En el editor de Nueva columna, introduzca un nombre y una descripción para lacolumna. A continuación, introduzca una expresión directamente en el cuadroExpresión, o haga clic en Editor completo para mostrar el editor de expresiones.
Puede utilizar una variable en una expresión de columna.
5. Haga clic en Listo para volver al editor de tablas.
Creación de expresiones en el editor de expresionesPuede utilizar el editor de expresiones para crear restricciones, agregaciones y otrastransformaciones en las columnas.
Temas:
• Acerca del editor de expresiones
• Creación de una expresión
Acerca del editor de expresionesAl modelar datos, puede utilizar el editor de expresiones para crear restricciones,agregaciones y otras transformaciones en columnas. Por ejemplo, puede utilizar eleditor de expresiones para cambiar el tipo de dato de una columna de fecha acarácter. También puede utilizar el editor de expresiones para crear expresiones parafiltros de datos.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-34

El editor de expresiones contiene las siguientes secciones:
• El cuadro Expresión del lado izquierdo permite editar la expresión actual.
• La barra de herramientas de la parte inferior contiene operadores de expresiones de usofrecuente, como un signo más, un signo igual o una coma para separar elementos.
• La sección Elementos de expresión del lado derecho proporciona bloques integrantesque puede utilizar en la expresión. Entre los ejemplos de elementos se encuentrantablas, columnas, funciones y tipos.
La sección Elementos de expresión solo incluye elementos que sean relevantes para latarea. Por ejemplo, si abre el editor de expresiones para definir una medida calculada, lasección Elementos de expresión solo incluye la tabla de hechos actual, cualquier tablade dimensiones unida a esa tabla, más cualquier tabla de hechos unida indirectamente através de una tabla de dimensiones. Del mismo modo, al definir un atributo derivado, vela tabla de dimensiones actual, cualquier tabla de hechos unida a esa tabla y cualquiertabla de dimensiones unida esas tablas de hechos.
Otro ejemplo es que las jerarquías de tiempo solo se incluyen si la tabla de hechos detiempo está unida a la tabla actual.
Consulte Referencia del editor de expresiones.
Creación de una expresiónPuede utilizar el editor de expresiones para crear restricciones, agregaciones y otrastransformaciones en las columnas.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-35

1. Agregue o edite una columna desde el editor de tablas.
2. Introduzca una expresión en el cuadro Expresión y haga clic en Listo. O bien,haga clic en Editor completo para iniciar el editor de expresiones.
3. Utilice los menús de Elementos de expresión para buscar los bloques de creaciónque desea utilizar para crear la expresión.
Arrastre y suelte un elemento para agregarlo a la expresión. También puede hacerdoble clic en un elemento para insertarlo, o bien seleccionar el elemento y hacerclic en el icono de flecha.
Al agregar una función, los corchetes indican el texto que se debe sustituir.Seleccione el texto y, a continuación, escriba o utilice los menús de Elementos deexpresión para agregar el elemento adecuado.
Consulte Referencia del editor de expresiones.
4. Haga clic en Filtro y, a continuación, introduzca el texto en el campo de búsquedapara filtrar los elementos disponibles. Elimine el texto para volver a la listacompleta de elementos.
5. Haga clic en Acciones para mostrar u ocultar menús de Elementos de expresiónpara ampliar o reducir todos los menús.
6. Haga clic en un elemento de la barra de herramientas para insertar un operador.
7. Haga clic en Deshacer o Rehacer según sea necesario cuando cree la expresión.
8. Haga clic en Validar para comprobar el trabajo realizado.
9. Haga clic en Guardar cuando haya terminado.
Copia de medidas y atributosPuede copiar medidas y atributos y pegarlos en el modelo semántico.
• En el menú Modelo de datos del panel izquierdo, haga clic con el botón derechoen la columna que desea copiar y seleccione Copiar.
Para copiar varias columnas, haga clic mientras pulsa Mayús o haga clic en todaslas filas que desee mientras pulsa Ctrl y, a continuación, haga clic con el botónderecho para seleccionar Copiar.
• En el menú Modelo de datos del panel izquierdo, haga clic en Acciones decolumna en la columna que desea copiar y seleccione Copiar.
La copia aparece con un número agregado al nombre.
Capítulo 4Adición de medidas y atributos al modelo semántico
4-36

Copia de objetos del modeloEn ocasiones es más sencillo copiar objetos que empezar desde cero.
En Data Modeler, puede copiar tablas de hechos, tablas de dimensiones, tablas de bases dedatos y vistas de bases de datos:
• Tablas de hechos
Para copiar una tabla de hechos existente, seleccione Duplicar en el menú Accionesde tablas de hechos. Al copiar una tabla de hechos, Data Modeler incluye uniones pordefecto. Consulte Creación de tablas de hechos individuales.
No se copia la configuración de nivel de agregación para medidas, ya que, en la mayoríade los casos, la configuración de nivel de la tabla de hechos original y de la versióncopiada difieren. Después de copiar una tabla de hechos, revise y defina los niveles deagregación necesarios para las medidas.
• Tablas de dimensiones
Para copiar una tabla de dimensiones existente, seleccione Duplicar en el menúAcciones de tablas de dimensiones. Al copiar una tabla de dimensiones, Data Modelerexcluye las uniones por defecto. Consulte Creación de tablas de dimensionesindividualmente.
• Tablas de base de datos y vistas
Para copiar un objeto de base de datos existente, seleccione Duplicar en el menúAcciones. Al copiar una tabla o una vista, Data Modeler crea una vista basada en latabla o vista que haya copiado. Consulte Agregación de vistas de origen propias.
Capítulo 4Copia de objetos del modelo
4-37

5Definición de jerarquías y niveles paraobtención de detalles y agregación
Puede definir jerarquías y niveles en Data Modeler.
Temas:
• Flujo de trabajo típico para definir jerarquías y niveles
• Acerca de las jerarquías y los niveles
• Edición de jerarquías y niveles
• Definición de niveles de agregación para medidas
Flujo de trabajo típico para definir jerarquías y nivelesA continuación, se muestran las tareas comunes para agregar jerarquías y niveles al modelosemántico.
Tarea Descripción Más información
Agregar jerarquías yniveles
Crea jerarquías y niveles para lastablas de dimensiones
Edición de jerarquías y niveles
Definir niveles deagregación para medidas
Define niveles de agregaciónpersonalizados para medidas queson diferentes del nivel por defecto
Definición de niveles deagregación para medidas
Acerca de las jerarquías y los nivelesUna jerarquía muestra las relaciones entre grupos de columnas en una tabla dedimensiones. Por ejemplo, los trimestres contienen los meses y los meses contienen losdías. Las jerarquías permiten cambiar de nivel en los informes.
Una tabla de dimensiones puede contener una o más jerarquías. Una jerarquía sueleempezar por un nivel total, seguido de niveles secundarios, y descender hasta el nivel dedetalle inferior.
Todas las jerarquías de una determinada dimensión deben tener un nivel inferior común. Porejemplo, una dimensión de tiempo podría contener una jerarquía fiscal y una jerarquía decalendario, con Día como nivel inferior común. El día tiene dos niveles principales connombre denominados Año fiscal y Año natural, que son ambos secundarios del nivel raízTodo.
En todos los niveles, excepto en el nivel total, se debe especificar al menos una columnacomo columna clave o de visualización. Sin embargo, no es necesario asociar explícitamentetodas las columnas de una tabla a los niveles. Cualquier columna que no esté asociada a unnivel se asocia automáticamente al nivel inferior de la jerarquía que se corresponda con latabla de dimensiones.
5-1

No hay límite en el número de niveles que puede tener una jerarquía. El número totalde niveles no es, por sí mismo, un factor determinante para el rendimiento de laconsulta. Sin embargo, tenga en cuenta que, en el caso de consultasextremadamente complejas, incluso unos pocos niveles pueden afectar alrendimiento.
Edición de jerarquías y nivelesCuando se unen las tablas de hechos y las tablas de dimensiones, se crea unajerarquía por defecto, pero también se pueden agregar jerarquías y niveles a dichastablas. Por ejemplo, una jerarquía Geography puede incluir niveles para Country,State y City.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de dimensiones, haga clic en la tabla de dimensiones para laque desea agregar una jerarquía. La tabla de dimensiones debe tener al menosuna unión a una tabla de hechos.
3. En el editor de dimensiones, haga clic en el separador Jerarquías.
4. En el área Jerarquías, haga clic en Agregar nivel y seleccione las columnas dedimensión o los niveles compartidos que desea utilizar.
5. Arrastre y suelte los niveles en una posición diferente del orden, segúncorresponda. También puede hacer clic con el botón derecho en un nivel yseleccionar Mover a la izquierda o Mover a la derecha.
6. Haga clic en un nivel para acceder a un cuadro de diálogo en el que puedeespecificar el nombre de nivel, la columna de clave y la columna de visualizaciónpara el nivel.
7. Anule la selección de Disponible si no desea que la jerarquía esté visible en losanálisis.
8. Haga clic en Listo cuando termine.
Capítulo 5Edición de jerarquías y niveles
5-2

Definición de propiedades de la tabla de dimensiones para jerarquíasEn el separador Visión general de una tabla de dimensiones concreta, puede definirpropiedades que se apliquen a todas las jerarquías de esa tabla.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Haga clic en la tabla de dimensiones que desea editar.
3. Utilice el separador Visión general para definir las propiedades según sea necesario.
• Dimensión de tiempo: especifica que las jerarquías para esta tabla de dimensionessoportan una dimensión de tiempo. Las jerarquías para las dimensiones de tiempono pueden incluir niveles de salto ni estar desequilibradas.
• Activar niveles omitidos: especifica que esta tabla de dimensiones soportajerarquías con niveles omitidos. Una jerarquía de nivel de salto es una jerarquía en laque los miembros no tienen un valor para un nivel ascendiente concreto. Porejemplo, en una jerarquía País-Estado-Ciudad-Distrito, la ciudad "Washington, D.C."no pertenece a Estado. En este caso, puede aumentar detalle desde el nivel País(EE.UU.) hasta el nivel Ciudad (Washington, D.C.) y así sucesivamente.En una consulta, no se muestran los niveles saltados y no afectan a los cálculos.Cuando se ordenan jerárquicamente, los miembros aparecen bajo sus ascendientesmás cercanos.
• Activar jerarquías desequilibradas: especifica que esta tabla de dimensionessoporta jerarquías desequilibradas. Una jerarquía desequilibrada (o irregular) es unajerarquía en la que las hojas (miembros sin secundarios) no tienen necesariamentela misma profundidad. Por ejemplo, un sitio puede tener datos del mes actual en elnivel de día, datos del mes anterior en el nivel de mes y en el nivel de trimestre paralos datos de los últimos 5 años.
Definición de niveles de agregación para medidasSi se unen las tablas de hechos y las tablas de dimensiones, puede definir niveles deagregación personalizados para una medida.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el área Tablas de hechos, haga clic en la tabla de hechos en la que está ubicada lamedida.
3. Especifique la regla de agregación para la nueva columna que desea convertir en lamedida basada en nivel.
4. Haga clic en el nombre de columna y, a continuación, en Niveles.
5. En el separador Niveles, para una o más jerarquías, utilice la guía de desplazamientopara seleccionar el nivel de agregación para la medida.
Capítulo 5Definición de niveles de agregación para medidas
5-3
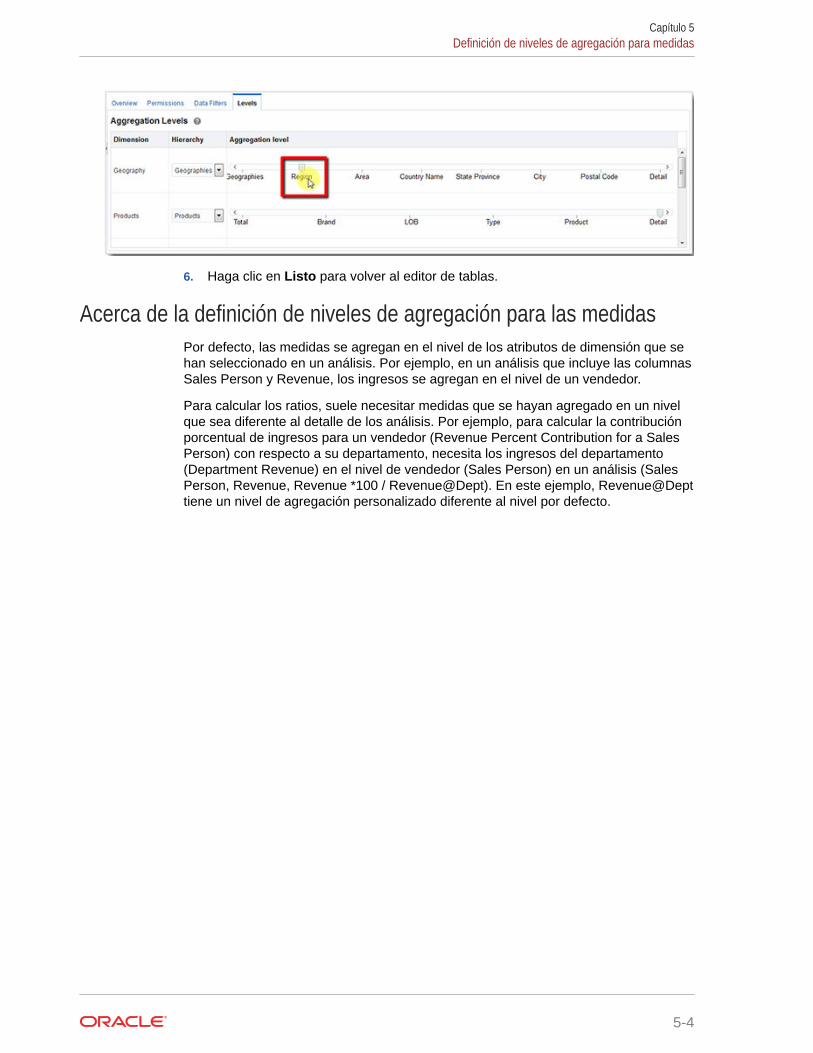
6. Haga clic en Listo para volver al editor de tablas.
Acerca de la definición de niveles de agregación para las medidasPor defecto, las medidas se agregan en el nivel de los atributos de dimensión que sehan seleccionado en un análisis. Por ejemplo, en un análisis que incluye las columnasSales Person y Revenue, los ingresos se agregan en el nivel de un vendedor.
Para calcular los ratios, suele necesitar medidas que se hayan agregado en un nivelque sea diferente al detalle de los análisis. Por ejemplo, para calcular la contribuciónporcentual de ingresos para un vendedor (Revenue Percent Contribution for a SalesPerson) con respecto a su departamento, necesita los ingresos del departamento(Department Revenue) en el nivel de vendedor (Sales Person) en un análisis (SalesPerson, Revenue, Revenue *100 / Revenue@Dept). En este ejemplo, Revenue@Depttiene un nivel de agregación personalizado diferente al nivel por defecto.
Capítulo 5Definición de niveles de agregación para medidas
5-4

6Protección del modelo semántico
Puede definir permisos a nivel de objeto y filtros de datos de seguridad a nivel de fila para elmodelo semántico.
Temas:
• Flujo de trabajo típico para proteger datos de modelos
• Creación de variables para su uso en expresiones
• Protección del acceso a los objetos del modelo
• Protección del acceso a los datos
Flujo de trabajo típico para proteger datos de modelosA continuación, se detallan las tareas comunes para proteger el modelo semántico.
Tarea Descripción Más información
Definir variables parafiltros de datos, si esnecesario
Opcionalmente, crea variables quecalculan y almacenan de formadinámica valores para utilizarlosen expresiones de columna y filtrosde datos.
Creación de variables para suuso en expresiones
Definición de permisos enobjetos de modelos
Los permisos de objetos controlanla visibilidad de todo su modelo ode tablas de hechos individuales,tablas de dimensiones y columnas.
Protección del acceso a losobjetos del modelo
Definir filtros de seguridada nivel de fila
Los filtros de datos limitan losresultados que se devuelven paratablas de hechos, tablas dedimensiones y columnas.
Protección del acceso a losdatos
Creación de variables para su uso en expresionesEn Data Modeler, puede definir variables que calculan y almacenan valores dinámicamentede forma que pueda utilizar dichos valores en expresiones de columna o filtros de datos.
Temas:
• Acerca de las variables
• Definición de variables
6-1

Acerca de las variablesLas variables calculan y almacenan valores dinámicamente de forma que puedautilizar dichos valores en expresiones. Puede utilizar variables en expresiones decolumna o en filtros de datos.
Por ejemplo, suponga que User1 pertenece a Department1 y User2 pertenece aDepartment2. Cada usuario debe acceder solo a los datos específicos de sudepartamento. Puede utilizar la variable DEPARTMENT_NUMBER para almacenar losvalores adecuados para User1 y User2. Puede utilizar esta variable en un filtro dedatos en el que los datos se filtran por Department2 para User1 y Department2 paraUser2. Es decir, las variables modifican de forma dinámica el contenido de metadatospara ajustarlo a un entorno de datos cambiante.
Los valores de las variables no son seguros, ya que los permisos de objeto no seaplican a las variables. Cualquier persona que conozca o pueda averiguar el nombrede la variable puede utilizarla en una expresión. Por este motivo, no incluya datosconfidenciales, como contraseñas, en las variables.
No puede utilizar una variable en una expresión que define otra variable.
Definición de variablesPuede crear una variable para su uso en expresiones de columna y filtros de datos.Por ejemplo, una variable denominada SalesRegion puede utilizar una consulta SQLpara recuperar el nombre de la región de ventas del usuario.
Sugerencia:
Haga referencia a los objetos de base de datos de origen solo en la consultaSQL para una variable. No incluya nombres de objetos de modelo semánticoen la consulta.
1. En Data Modeler, bloquee el modelo para editarlo.
2. En el menú Variables del panel izquierdo, haga clic en el icono Más.
3. Introduzca una consulta SQL para rellenar el valor de la variable:
a. Especifique si la variable devuelve Un único valor o Varios valores.
b. Introduzca una consulta SQL para rellenar el valor o los valores de la variable.Por ejemplo:
— Devolver un solo valor con la consulta como: SELECT prod-name FROMproducts— Devolver varios valores con una consulta como: SELECT 'MyVariable',prod-name FROM productsPara varios valores, utilice siempre el formato: SELECT ‘NombreVariable’,ValorVariable FROM Tabla
c. Proporcione un valor inicial por defecto si es necesario.
d. Haga clic en Probar para validar que la consulta devuelve un valor adecuado
Capítulo 6Creación de variables para su uso en expresiones
6-2

4. Para crear una variable que refresque su valor al inicio de cada sesión de usuario,seleccione Al iniciar sesión para Actualizar valor.
5. Para crear una variable que refresque su valor según la programación que haya definido,seleccione De manera programada para Actualizar valor.
En el área Ejecutar consulta SQL, seleccione la frecuencia y la fecha de inicio pararefrescar la variable.
6. Para crear una variable con un valor estático que nunca cambie, seleccione Nunca paraActualizar valor y proporcione un valor para la variable en el campo Valor.
7. Haga clic en Listo para volver al modelo semántico.
Sugerencia:
Para editar una variable existente, haga clic con el botón derecho en la listaVariables y seleccione Inspeccionar. Para suprimir una variable, haga clic conel botón derecho y seleccione Suprimir.
Después de definir una variable, puede utilizarla en un filtro de datos o en una expresión decolumna.
Protección del acceso a los objetos del modeloEs importante mantener la información confidencial segura. Todo el mundo tiene acceso alos datos del modelo por defecto. Para evitar la exposición de datos confidenciales, definapermisos de mostrar y ocultar para todo el modelo o para tablas de hechos, tablas dedimensiones y columnas individuales.
Por ejemplo, puede restringir el acceso a determinadas columnas Ingresos para asegurarsede que solo los usuarios autorizados puedan verlas. O bien puede restringir el acceso a todoel modelo para impedir que los usuarios abran el modelo o accedan a su área temática.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Para restringir el acceso a todo el modelo, seleccione el separador Permisos.
Capítulo 6Protección del acceso a los objetos del modelo
6-3
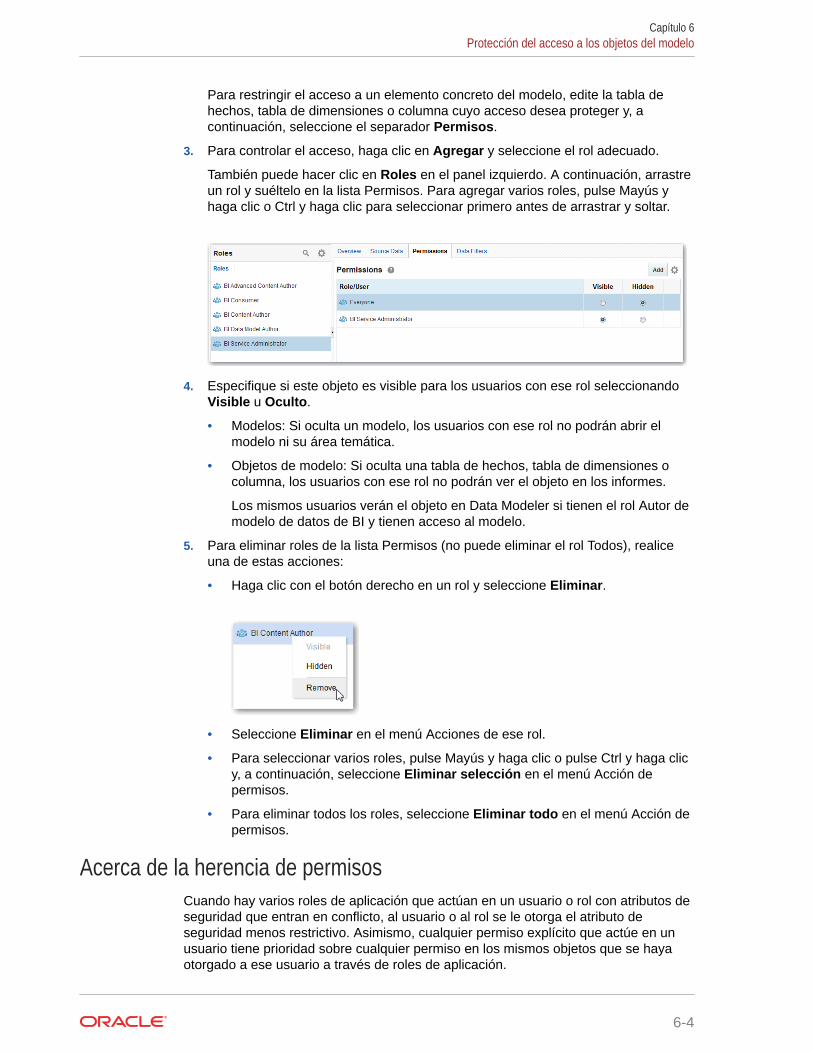
Para restringir el acceso a un elemento concreto del modelo, edite la tabla dehechos, tabla de dimensiones o columna cuyo acceso desea proteger y, acontinuación, seleccione el separador Permisos.
3. Para controlar el acceso, haga clic en Agregar y seleccione el rol adecuado.
También puede hacer clic en Roles en el panel izquierdo. A continuación, arrastreun rol y suéltelo en la lista Permisos. Para agregar varios roles, pulse Mayús yhaga clic o Ctrl y haga clic para seleccionar primero antes de arrastrar y soltar.
4. Especifique si este objeto es visible para los usuarios con ese rol seleccionandoVisible u Oculto.
• Modelos: Si oculta un modelo, los usuarios con ese rol no podrán abrir elmodelo ni su área temática.
• Objetos de modelo: Si oculta una tabla de hechos, tabla de dimensiones ocolumna, los usuarios con ese rol no podrán ver el objeto en los informes.
Los mismos usuarios verán el objeto en Data Modeler si tienen el rol Autor demodelo de datos de BI y tienen acceso al modelo.
5. Para eliminar roles de la lista Permisos (no puede eliminar el rol Todos), realiceuna de estas acciones:
• Haga clic con el botón derecho en un rol y seleccione Eliminar.
• Seleccione Eliminar en el menú Acciones de ese rol.
• Para seleccionar varios roles, pulse Mayús y haga clic o pulse Ctrl y haga clicy, a continuación, seleccione Eliminar selección en el menú Acción depermisos.
• Para eliminar todos los roles, seleccione Eliminar todo en el menú Acción depermisos.
Acerca de la herencia de permisosCuando hay varios roles de aplicación que actúan en un usuario o rol con atributos deseguridad que entran en conflicto, al usuario o al rol se le otorga el atributo deseguridad menos restrictivo. Asimismo, cualquier permiso explícito que actúe en unusuario tiene prioridad sobre cualquier permiso en los mismos objetos que se hayaotorgado a ese usuario a través de roles de aplicación.
Capítulo 6Protección del acceso a los objetos del modelo
6-4

Sugerencia:
Si deniega el acceso a una tabla, también se deniega implícitamente el acceso atodas las columnas de esa tabla.
Protección del acceso a los datosPuede definir filtros de datos para tablas de hechos, tablas de dimensiones y columnas queproporcionan una seguridad a nivel de fila para los objetos de modelo de datos. Por ejemplo,puede crear un filtro que restrinja el acceso a la tabla Products de forma que solo esténvisibles determinadas marcas para los usuarios asignados a un rol concreto.
1. En Data Modeler, bloquee el modelo para editarlo.
2. Edite la tabla de hechos, la tabla de dimensiones o la columna cuyo acceso deseeproteger.
3. Seleccione el separador Filtros de datos.
4. Agregue un rol a la lista Filtros de datos con una de las siguientes acciones:
• Haga clic en Agregar y seleccione el rol adecuado.
• En el panel izquierdo, haga clic en Roles. A continuación, arrastre y suelte un rol enla lista Filtros de datos.
5. Introduzca una expresión para especificar qué datos son accesibles para ese rol.Introduzca la expresión directamente o haga clic en Editor completo para mostrar eleditor de expresiones.
Puede utilizar una variable en una expresión de filtro de datos.
6. Seleccione Activar para especificar si el filtro está activado para ese rol.
7. Para eliminar filtros de la lista Filtros de datos, realice una de las siguientes acciones:
• Haga clic con el botón derecho en un filtro y seleccione Eliminar.
• Seleccione Eliminar en el menú Acciones de ese filtro.
• Seleccione varios filtros haciendo clic mientras pulsa Mayús o Ctrl y, a continuación,seleccione Eliminar selección en el menú Acción de filtro de datos.
Capítulo 6Protección del acceso a los datos
6-5

• Para eliminar todos los filtros, seleccione Eliminar todo en el menú Acción defiltro de datos.
8. Haga clic en Listo.
Capítulo 6Protección del acceso a los datos
6-6

Parte IIICreación de modelos de datos para informesde visualización perfecta
En esta parte se describe el proceso para crear y personalizar modelos de datos parainformes de impresión perfecta.
Capítulos:
• Introducción al modelado de datos para informes de visualización perfecta
• Uso del editor de modelo de datos
• Creación de juegos de datos
• Estructuración de datos
• Adición de parámetros y listas de valores
• Adición de disparadores de eventos
• Acerca de las opciones de origen de datos
• Agregar campos flexibles
• Adición de definiciones de repartición
• Adición de metadatos personalizados para Oracle WebCenter Content Server
• Mejores prácticas de rendimiento

7Introducción al modelado de datos parainformes de visualización perfecta
En este tema se describe cómo puede acceder y empezar a trabajar con el modelado dedatos para obtener informes con una visualización perfecta.
Temas:
• Flujo de trabajo típico para modelar datos para informes de visualización perfecta
• Inicio del editor de modelo de datos
• Principales tareas para el modelado de datos para informes de visualización perfecta
Flujo de trabajo típico para modelar datos para informes devisualización perfecta
Un modelo de datos que se utiliza para los informes de visualización perfecta puede sersimple, con un juego de datos recuperado de un solo origen de datos (por ejemplo, los datosdevueltos de las columnas en la tabla de empleados); o puede ser complejo, conparámetros, disparadores y definiciones de repartición, y utilizando varios juegos de datos.
Tarea Usuario Más información
Iniciar el editor del modelo de datos. Modelador dedatos de informe
Inicio del editor de modelo de datos
Definir propiedades para el modelode datos. (Opcional)
Modelador dedatos de informe
Propiedades de modelo de datos
Crear los juegos de datos para elmodelo de datos.
Modelador dedatos de informe
Creación de juegos de datos
Definir la estructura de salida dedatos. (Opcional)
Modelador dedatos de informe
Estructuración de datos
Definir los parámetros que se van atransferir a la consulta y definirlistas de valores para que losusuarios seleccionen valores deparámetro. (Opcional)
Modelador dedatos de informe
Adición de parámetros y listas devalores
Definir disparadores de eventos.(Opcional)
Modelador dedatos de informe
Acerca de los disparadores
(Solo para Oracle Applications)Definir campos flexibles. (Opcional)
Modelador dedatos de informe
Agregar campos flexibles
Probar el modelo de datos y agregardatos de ejemplo.
Modelador dedatos de informe
Prueba de modelos de datos ygeneración de datos de ejemplo
Agregar una definición derepartición. (Opcional)
Modelador dedatos de informe
Adición de definiciones de repartición
7-1

Tarea Usuario Más información
Asignar metadatos personalizadospara documentos que se van aentregar en servidores de contenidosweb (opcional)
Modelador dedatos de informe
Adición de metadatos personalizadospara Oracle WebCenter Content Server
Inicio del editor de modelo de datosInicie el editor de modelo de datos desde la cabecera o desde la página inicial.
Para iniciar el editor de modelo de datos:
• Use uno de estos métodos:
– Haga clic en Nuevo y, a continuación, haga clic en Modelo de datos.
– En la región Crear, haga clic en Modelo de datos.
Principales tareas para el modelado de datos para informesde visualización perfecta
En este tema se identifican las principales tareas para el modelado de datos parainformes de visualización perfecta.
• Creación de un juego de datos
• Crear enlaces entre juegos de datos.
• Adición de parámetros y listas de valores
• Adición de disparadores de eventos
• Agregar campos flexibles
• Asignación de campos de datos a campos de metadatos personalizados
• Validación de modelos de datos
Capítulo 7Inicio del editor de modelo de datos
7-2

8Uso del editor de modelo de datos
En este tema se describen los componentes y las funciones que soporta el editor del modelode datos.
Temas:
• Componentes de un modelo de datos
• Acerca de las opciones de origen de datos
• Funciones del editor del modelo de datos
• Propiedades de modelo de datos
• Gestión de orígenes de datos privados
Componentes de un modelo de datosUn modelo de datos soporta los siguientes componentes:
• Juego de datos
Un juego de datos contiene la lógica para recuperar datos de un único origen de datos.Un juego de datos puede recuperar datos de distintos orígenes de datos (por ejemplo,una base de datos, un archivo de datos existente, una llamada de servicio web a otraaplicación, o una URL/URI a un proveedor de datos externo). Un modelo de datos puedetener varios juegos de datos de distintos orígenes.
• Disparadores de evento
Un disparador comprueba si se produce un evento. Cuando se produce el evento, eldisparador ejecuta el código PL/SQL asociado a este. El editor del modelo de datossoporta disparadores antes y después de los datos, así como disparadores deprogramación. Los disparadores antes y después de los datos constan de una llamadapara ejecutar un juego de funciones definidas en un paquete PL/SQL almacenado enuna base de datos Oracle. Un disparador de programación se ejecuta para los informesprogramados y prueba una condición que determina si se debe o no ejecutar un trabajode informe programado.
• Campos flexibles
Un campo flexible es una estructura específica de Oracle Applications. El editor demodelo de datos soporta la recuperación de datos desde estructuras de campo flexibledefinidas en las tablas de base de datos de Oracle Application.
• Listas de valores
Una lista de valores es un menú de valores en la que los consumidores del informepueden seleccionar valores de parámetro para transferirlos al informe.
• Parámetros
Un parámetro es una variable cuyo valor se puede definir en tiempo de ejecución. Eleditor del modelo de datos soporta varios tipos de parámetro.
8-1

• Definiciones de repartición
La repartición es un proceso de división de datos en bloques que generadocumentos para cada bloque de datos y entrega los documentos a uno o variosdestinos. Una única definición de repartición proporciona las instruccionesnecesarias para dividir los datos del informe, generando el documento yentregando la salida a los destinos especificados.
• Metadatos personalizados (para servidores de contenidos web)
Si ha configurado un servidor de contenidos web como un destino de entrega y haactivado los metadatos personalizados, el componente de metadatospersonalizados se muestra en el editor de modelo de datos. Utilice estecomponente para asignar campos de datos del modelo de datos a los campos demetadatos personalizados configurados para un juego de reglas definidas en unperfil de contenido.
Acerca de las opciones de origen de datosLos tipos de origen de datos soportados para crear juegos de datos se puedenclasificar en tres tipos generales.
Tipos de juego de datos que pueden utilizar el rango completo de funciones deleditor en el modelo de datos
Está soportado el rango completo de funciones del editor del modelo de datos paralos siguientes tipos de juego de datos:
• Consultas SQL ejecutadas en Oracle BI Server, una base de datos OracleDatabase u otras bases de datos soportadas. Publisher puede recuperar lainformación de metadatos de estas consultas SQL.
Consulte Creación de juegos de datos utilizando consultas SQL.
• Consultas multidimensionales (MDX) en el origen de datos de OLAP
Consulte Creación de un juego de datos con una consulta de MDX con respecto aun origen de datos de OLAP.
• Orígenes de datos de hoja de cálculo de Microsoft Excel
Puede almacenar la hoja de cálculo de Excel en un directorio de archivosconfigurado como origen de datos por el administrador, o bien cargarladirectamente desde un origen local en el modelo de datos. Consulte Creación deun juego de datos con un archivo Microsoft Excel.
• Orígenes de datos de archivo de datos XML
Puede almacenar el archivo XLM en un directorio de archivos configurado comoorigen de datos por el administrador, o bien cargarlo directamente desde unorigen local en el modelo de datos. Consulte Creación de un juego de datosmediante un archivo XML.
• Orígenes de datos de archivo CSV (valor separado por comas)
Puede almacenar el archivo CSV en un directorio de archivos configurado comoorigen de datos por el administrador, o bien cargarlo directamente desde unorigen local en el modelo de datos. Consulte Creación de un juego de datosmediante un archivo CSV.
Capítulo 8Acerca de las opciones de origen de datos
8-2

Tipos de juego de datos que pueden utilizar funciones parciales del editor en elmodelo de datos
Publisher puede recuperar los nombres de columna y la información de tipo de dato delorigen de datos de estos tipos de juego de datos, pero no puede procesar ni estructurar losdatos. Solo está soportado un subjuego del rango completo de funciones del editor delmodelo de datos para los siguientes tipos de juego de datos:
• Análisis
Consulte Creación de un juego de datos mediante un análisis.
• VisualizaciónConsulte Uso de análisis de autoservicio.
Tipos de juego de datos que no se pueden modificar en el editor del modelo de datos
Para los siguientes tipos de juego de datos, Publisher puede recuperar los datos generadosy estructurados en el origen. No puede aplicar modificaciones adicionales en el editor delmodelo de datos para los siguientes tipos de juego de datos:
• Fuentes XML HTTP fuera de la web
Consulte Creación de un juego de datos a partir de una fuente XML HTTP.
• Servicios web
Consulte Creación de un juego de datos mediante un servicio web.
Para utilizar un servicio web para devolver datos para el informe, proporcione el servicioweb WSDL a Publisher y, a continuación, defina los parámetros en Publisher.
Funciones del editor del modelo de datosEl editor del modelo de datos le permite combinar datos de varios juegos de datos en unaúnica estructura de datos XML.
Los juegos de datos de varios orígenes de datos se pueden fusionar como un XMLsecuencial o en el nivel de línea para crear un único XML jerárquico combinado. Mediante eleditor del modelo de datos, puede combinar de forma sencilla datos de los siguientes tiposde juegos de datos: consulta SQL, OLAP (consulta MDX), LDAP y Microsoft Excel.
El editor del modelo de datos está diseñado con un panel de componentes en el ladoizquierdo y un panel de trabajo en el lado derecho. La selección de un componente en elpanel de la izquierda inicia los campos adecuados para el componente en el área de trabajo.
El editor del modelo de datos soporta lo siguiente
• Agrupar datos: cree grupos para organizar las columnas del informe. Los grupospueden hacer dos cosas: separar los datos de una consulta en juegos y filtrar los datosde una consulta.
Cuando crea una consulta, el motor de datos crea un grupo que contiene las columnasseleccionadas por la consulta; puede crear grupos para modificar la jerarquía de losdatos que aparecen en un modelo de datos. Los grupos se utilizan principalmentecuando se desea tratar algunas columnas de forma diferente que otras. Por ejemplo,puede crear grupos para producir subtotales o crear divisiones.
• Enlazar datos: defina enlaces maestro -detalle entre juegos de datos para agrupar datosen varios niveles.
Capítulo 8Funciones del editor del modelo de datos
8-3

• Agregar datos: cree totales y subtotales de nivel de grupo.
• Transformar datos: modifique los datos de origen para que se ajusten a lostérminos de negocio y los requisitos de informes.
• Crear cálculos: calcule valores de datos necesarios para el informe que no esténdisponibles en los orígenes de datos subyacentes.
El editor del modelo de datos proporciona funciones en el nivel de elemento, el nivelde grupo y el nivel global. Tenga en cuenta que no todos los tipos de juegos de datossoportan todas las funciones. Consulte la sección Notas importantes que acompaña altipo de juego de datos para conocer las limitaciones. En la imagen que se muestra acontinuación se resaltan algunas de las funciones y acciones disponibles en el editordel modelo de datos.
Acerca de la barra de herramientas del editor del modelo de datosLa barra de herramientas del editor del modelo de datos en la parte superior leproporciona las opciones necesarias para gestionar orígenes de datos privados,visualizar datos, crear un informe y guardar el modelo de datos.
Opción Descripción
Validar Valida las consultas utilizadas para losjuegos de datos, las listas de valores y lasdefiniciones de repartición.
Gestionar orígenes de datos privados Conéctese a orígenes de datos privadospara su uso personal que no requieran laconfiguración de un administrador.
Ver datos Muestre el separador Datos, donde puedever y generar datos de ejemplo.
Capítulo 8Funciones del editor del modelo de datos
8-4

Opción Descripción
Crear informe Cree un nuevo informe con este modelo dedatos.
Guardar/Guardar como Seleccione Guardar para guardar eltrabajo en curso en el objeto de modelo dedatos existente, o seleccione Guardarcomo para guardar el modelo de datoscomo un nuevo objeto en el catálogo.Si crea un modelo de datos y, acontinuación, sale del editor del modelo dedatos sin guardarlo, puede que aparezcauna entrada de borrador o de modelo dedatos temporal en la sección Reciente de lapágina inicial. Estas entradas no se puedensuprimir manualmente, pero se suprimende forma automática después de 24 horas.
Ayuda Vea la Ayuda en Pantalla.
Acerca de la interfazPor defecto, los juegos de datos que ha creado se muestran en la Vista de diagrama comoobjetos independientes.
El generador de estructuras de juegos de datos tiene tres vistas:
• Vista de diagrama: la Vista de diagrama muestra juegos de datos y permite crearenlaces y filtros de forma gráfica, agregando elementos basados en expresiones,agregando funciones de agregado y funciones de nivel global, editando propiedades deelemento y suprimiendo elementos. La vista de diagrama es la vista que se utilizanormalmente para crear la estructura de datos.
Capítulo 8Funciones del editor del modelo de datos
8-5
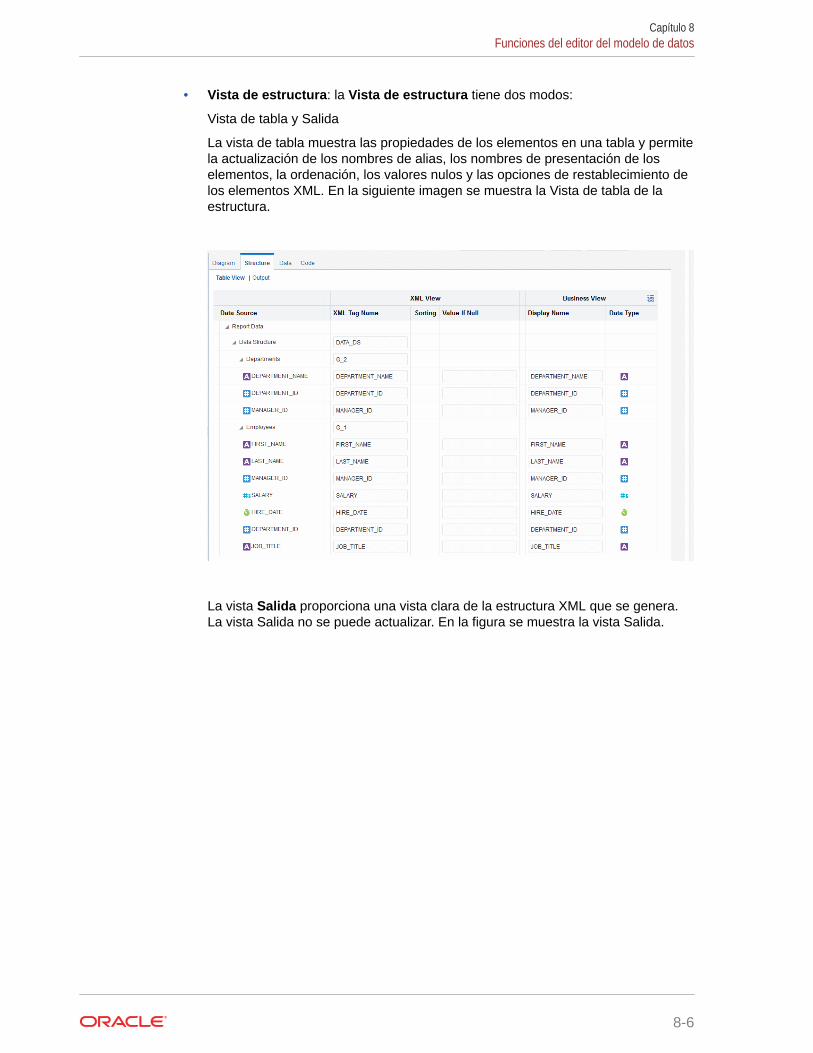
• Vista de estructura: la Vista de estructura tiene dos modos:
Vista de tabla y Salida
La vista de tabla muestra las propiedades de los elementos en una tabla y permitela actualización de los nombres de alias, los nombres de presentación de loselementos, la ordenación, los valores nulos y las opciones de restablecimiento delos elementos XML. En la siguiente imagen se muestra la Vista de tabla de laestructura.
La vista Salida proporciona una vista clara de la estructura XML que se genera.La vista Salida no se puede actualizar. En la figura se muestra la vista Salida.
Capítulo 8Funciones del editor del modelo de datos
8-6

• Vista de código: la Vista de código muestra el código de estructura de datos creadopor el generador de estructuras de datos que lee el motor de datos. Puede actualizar elcontenido en la vista de código. En la figura se muestra la vista de código.
Capítulo 8Funciones del editor del modelo de datos
8-7

Propiedades de modelo de datosPuede acceder a la página Propiedades del modelo de datos haciendo clic enPropiedades en el panel de componentes.
Introduzca las siguientes propiedades para el modelo de datos:
Propiedad Descripción
Descripción Introduzca una descripción para el modelo de datos.El catálogo muestra las descripciones de los modelosde datos. Esta descripción es traducible.
Origen de datos por defecto Seleccione el origen de datos en la lista. Los modelosde datos pueden incluir varios juegos de datos deuno o varios orígenes de datos. El origen de datospor defecto que seleccione aquí se presenta como elvalor por defecto de cada nuevo juego de datos SQLque defina. Seleccione Refrescar lista de orígenesde datos para ver todos los orígenes de datosnuevos agregados desde que se inició la sesión.
Paquete por defecto Oracle DB Introduzca un paquete PL/SQL por defecto para losmodelos de datos que incluyan disparadores deevento o un filtro de grupo PL/SQL. El paquete debeexistir en el origen de datos por defecto.Si define una consulta en una base de datos OracleDatabase, puede incluir disparadores antes odespués de los datos (disparadores de evento) en elmodelo de datos. Los disparadores de eventosutilizan paquetes PL/SQL para ejecutar funciones denivel del RDBMS.
Capítulo 8Propiedades de modelo de datos
8-8

Propiedad Descripción
Timeout de consulta Introduzca un límite de tiempo en segundos dentrodel cual la base de datos debe ejecutar sentenciasSQL. Esta propiedad se aplica a modelos de datosbasados en consultas SQL para informesprogramados. Si la consulta SQL se sigueprocesando cuando se cumple la condición del valorde timeout, se devuelve el error Fallo alrecuperar xml de datos. Introduzca un valoren segundos. Si no introduce un valor para estemodelo de datos, se utiliza el valor de propiedad delservidor.
Activar depuración de SQL Seleccione esta propiedad para mejorar el tiempo deprocesamiento y reducir el uso de memoria. Estapropiedad se aplica solo a las consultas de OracleDatabase que utilizan SQL estándar. Si la consultadevuelve muchas columnas, pero la plantilla deinforme solo utiliza un subjuego, la eliminación deSQL devuelve solo aquellas columnas que laplantilla necesita.Tenga en cuenta que Activar depuración de SQLtambién es una propiedad de nivel de servidor. Portanto, la propiedad de nivel de modelo de datos sedefine por defecto en el nivel de instancia paraheredar la configuración de nivel de instancia oservidor. Para activar o desactivar la depuraciónSQL para este modelo de datos en particular,seleccione Activar o Desactivar en la lista.La eliminación de SQL no se aplica a tipos deplantillas PDF, de Excel y de texto electrónico.
Omitir consulta de juegos dedatos no utilizados
Seleccione esta propiedad para omitir la ejecuciónde todos los juegos de datos no utilizados en eldiseño a fin de reducir el tiempo de procesamiento yel uso de memoria. Por defecto, se ejecutan todos losjuegos de datos de un modelo de datos si se requiereun juego de datos para la salida. Si un modelo dedatos contiene varios juegos de datos paradiferentes diseños, puede que no todos los diseñosrequieran todos los juegos de datos definidos en elmodelo de datos.Debe definir la propiedad Activar eliminación deSQL en Activar para utilizar la propiedad Omitirconsulta de juegos de datos no utilizados.
Capítulo 8Propiedades de modelo de datos
8-9

Propiedad Descripción
Activar rastreo de sesión SQL Seleccione esta propiedad para activar el rastreo dela sesión SQL. Para cada sentencia SQL, el rastreocontiene:• Recuentos de análisis, ejecuciones y
recuperaciones• Tiempo de CPU y tiempo transcurrido• Lecturas físicas y lógicas• Número de filas procesadas• Fallos de caché de biblioteca• Nombre de usuario para el que se ha producido
cada análisis• Cada confirmación y rollbackEsta propiedad se aplica a las consultas de OracleDatabase que utilizan SQL estándar.
Nombre de rastreo SQL Introduzca un nombre para el rastreo SQL.
Activar depuración de XML Seleccione Activado para eliminar juegos de datosXML con más de 2 GB.Si activa la depuración de datos XML, Publishereliminará los elementos de datos innecesarios ycreará la estructura XML utilizando solo los camposde datos asignados a los campos de diseño. Ladepuración de datos mejora el rendimiento,especialmente en extracciones de datosextremadamente grandes.Los consumidores de informes pueden configurar ladepuración de datos XML al programar un trabajo.La depuración de datos XML no está soportada parala plantilla XPT (diseño de Publisher).
Origen de datos de copiaseguridad
Seleccione la propiedad Activar conexión de copiade seguridad para utilizar el origen de datos decopia de seguridad.• Para utilizar el origen de datos de copia de
seguridad solo cuando el primario está inactivo,seleccione Cambiar a origen de datos de copiade seguridad si origen de datos primario nodisponible. Tenga en cuenta que cuando elorigen de datos primario está inactivo, el motorde datos debe esperar una respuesta antes decambiar a la copia de seguridad.
• Para utilizar siempre el origen de datos de copiade seguridad al ejecutar este modelo de datos,seleccione Usar solo origen datos de copiaseguridad. El uso de la base de datos de copiade seguridad puede mejorar el rendimiento.
Debe activar una copia de seguridad para el origende datos.
Activar salida de CSV Seleccione esta propiedad para generar la salida deinforme solo en un archivo CSV.
Capítulo 8Propiedades de modelo de datos
8-10

Propiedad Descripción
Optimizar ejecución deconsultas
Seleccione esta propiedad para permitir que elprocesador de datos optimice la ejecución deconsultas SQL de juegos de datos principales ysecundarios.Seleccione esta propiedad solo si el modelo de datosincluye una estructura jerárquica principal-secundario en un juego de datos SQL. No seleccioneesta opción para los juegos de datos noestructurados y los que no sean SQL.
Emplear varios threads para laejecución de consultas
Seleccione esta propiedad para crear variasconexiones de base de datos para consultar juegosde datos secundarios en paralelo. Si selecciona estapropiedad, aumenta el número de conexiones abase de datos por modelo de datos.Esta propiedad solo se activa si:• Optimizar ejecución de consultas está
definido en true.• El modelo de datos tiene más de un juego de
datos.• El modelo de datos tiene consultas de juegos de
datos secundarios paralelas asociadas al juegode datos principal.
• El modelo de datos utiliza el origen de datos pordefecto.
Esta propiedad no se puede utilizar si:• El modelo de datos utiliza disparadores de
eventos.• El modelo de datos tiene una consulta de juego
de datos asociada de forma lineal al juego dedatos principal.
• El modelo de datos utiliza varios orígenes dedatos.
Opciones de salida XMLEstas opciones definen las características de la estructura de datos XML. Todos los cambiosque se realicen en estas opciones pueden afectar a los diseños que se crean en el modelode datos.
• Incluir etiquetas de parámetros: si define parámetros para el modelo de datos,seleccione esta opción para incluir los valores de parámetro en el archivo de salida XML.Consulte Adición de parámetros y listas de valores para agregar parámetros al modelode datos. Active esta opción cuando desee utilizar el valor de parámetro en el informe.
• Incluir etiquetas vacías para elementos nulos: seleccione esta opción para incluirelementos con valores nulos en los datos XML de salida. Cuando incluye un elementonulo, un elemento solicitado que no contiene ningún dato en el origen de datos seincluye en la salida XML como una etiqueta XML vacía como se muestra a continuación:<ELEMENT_ID\>. Por ejemplo, si el elemento MANAGER_ID no tuviera ningún dato yeligiera incluir elementos nulos, aparecería en los datos de la siguiente forma:<MANAGER_ID />. Si no selecciona esta opción, no se muestra ninguna entrada paraMANAGER_ID.
Capítulo 8Propiedades de modelo de datos
8-11

• Incluir etiquetas de apertura y cierre: seleccione esta opción para incluiretiquetas de apertura y cierre en los datos XML de salida.
• Incluir etiqueta de lista de grupos: (esta propiedad es para la compatibilidadcon versiones anteriores a 10g y la migración de Oracle Report). Seleccione estaopción para incluir etiquetas de juego de filas en los datos XML de salida. Siincluye etiquetas de lista de grupos, la lista de grupos se muestra como otrajerarquía dentro de los datos.
• Excluir etiquetas para columnas LOB: seleccione esta propiedad para excluirlas etiquetas de elementos XML para columnas LOB. El modelo de datos debecontener un único juego de datos del tipo de consulta SQL y un único elemento dedatos de objeto grande de caracteres que contenga datos extraídos de un archivoXML. No puede usar funciones de nivel global, de resumen o de agregado,elementos basados en expresiones o filtros de grupo.
• Excluir salto de línea y retorno de carro para LOB: seleccione esta opción paraexcluir retornos de carro y saltos de línea en los datos.
• Etiqueta XML mostrada: seleccione este formato de visualización para generarlas etiquetas de datos XML en mayúsculas, en minúsculas, o para conservar ladefinición que ha suministrado en la estructura de datos.
Fragmentación de datos XMLLa fragmentación de datos XML soporta el procesamiento distribuido.
La fragmentación de datos XML es adecuada para informes grandes y de largaejecución. Si el administrador selecciona la propiedad de tiempo de ejecución Activarfragmentación de datos en el nivel de instancia, puede activar la fragmentación dedatos XML para los distintos modelos de datos, informes y trabajos programados.
En un modelo de datos, si hace clic en Fragmentación, selecciona Activarfragmentación y especifica un atributo en el campo Dividir por, el preprocesador delmodelo de datos utiliza la clave de división para dividir grandes cantidades de datosXML en varios fragmentos de datos de tamaño gestionable.
Antes de activar la fragmentación de datos XML, es necesario que comprenda suslimitaciones y recomendaciones de uso.
Fragmentación de datos XML:
• Es más adecuada para mostrar informes mediante una tabla y sin referenciascruzadas.
• Admite operaciones de ordenación, agrupación, agregación y de referenciascruzadas solo dentro de la salida fragmentada individual. La salida fusionada nosoporta estas operaciones de datos.
• Agrega números de página a las páginas PDF de la salida fusionada. En laplantilla de informe, elimine el elemento de numeración de página para evitarnúmeros de página duplicados o solapados en la salida PDF.
• Soporta el cálculo de totales y otras funciones solo en la salida fragmentadaindividual, y cada una se restablece con cada salida fragmentada.
• Soporta solo RTF, XPT y eText, y las plantillas XSL.
• Soporta solo los formato de salida PDF, XLSX y de texto.
Capítulo 8Propiedades de modelo de datos
8-12

• No soporta varios formatos de salida. Si selecciona la fragmentación de XML para untrabajo programado, no están permitidas varias salidas.
• No está soportada para los informes en línea.
Adición de anexos al modelo de datosEn la región Anexo de la página se muestran los archivos de datos que haya cargado oasociado al modelo de datos.
Cómo adjuntar datos de ejemploTras crear el modelo de datos, debe adjuntar un juego pequeño, pero representativo, de losdatos de ejemplo generados a partir del modelo de datos. Los datos de ejemplo se usan enlas herramientas de edición de diseño de Publisher. Si se usa un archivo de ejemplopequeño se mejorará el rendimiento durante la fase de diseño.
El editor del modelo de datos proporciona una opción para generar y adjuntar los datos deejemplo. Consulte Prueba de modelos de datos y generación de datos de ejemplo.
El administrador puede definir un límite para el tamaño del archivo de datos de ejemplo.
Cómo adjuntar un esquemaEl editor del modelo de datos le permite adjuntar un esquema de ejemplo a la definición delmodelo de datos.
Publisher no usa el archivo de esquema. Sin embargo, puede adjuntar el esquema comoreferencia para los desarrolladores. El editor del modelo de datos no soporta la generaciónde esquemas.
Archivos de datosSi carga un archivo CSV o XML local de Microsoft Excel como origen de datos para esteinforme, el archivo se muestra aquí.
Utilice el botón Refrescar para refrescar este archivo desde el origen local. Para obtenerinformación sobre la carga de archivos que usar como orígenes de datos, consulte Creaciónde juegos de datos.
En la figura siguiente se muestra la región Anexos con datos de ejemplo y archivos de datosadjuntos:
Capítulo 8Propiedades de modelo de datos
8-13

Gestión de orígenes de datos privadosLos desarrolladores de modelos de datos pueden crear y gestionar conexiones deorigen de datos HTTP, del servicio web, OLAP y JDBC privadas sin tener quedepender de un usuario administrador. No obstante, los usuarios administradorespueden seguir viendo, modificando y suprimiendo conexiones de origen de datosprivadas, si es necesario.
Las conexiones de origen de datos privadas se identifican mediante la palabra(Private) agregada al final del nombre del origen de datos. Por ejemplo, si crea unaconexión JDBC privada denominada My JDBC Connection, esta se muestra como MyJDBC Connection (Private) en las listas desplegables de orígenes de datos.
Si el usuario tiene el rol de administrador, solo puede crear orígenes de datos públicosincluso si crea el origen de datos en la página Gestionar orígenes de datos privados.
Para crear una conexión de origen de datos privada:
1. En la barra de herramientas del editor del modelo de datos, haga clic enGestionar orígenes de datos privados.
2. Seleccione el separador de tipo de conexión y haga clic en Agregar origen dedatos.
Si está conectado como administrador, el cuadro de diálogo muestra todas lasconexiones de origen de datos; sin embargo, en este cuadro de diálogo solopuede crear o modificar orígenes de datos JDBC, OLAP, HTTP y de servicio web.
3. Introduzca el nombre de conexión privada y la información de conexión.
4. Haga clic en Probar conexión. Se muestra una confirmación.
5. Haga clic en Aplicar. La conexión de origen de datos privada ya está disponiblepara su uso en los juegos de datos.
Capítulo 8Gestión de orígenes de datos privados
8-14

9Creación de juegos de datos
En este tema se describe la creación de juegos de datos, la prueba de modelos de datos y elalmacenamiento de datos de ejemplo.
Temas:
• Creación de un juego de datos
• Editar un juego de datos existente
• Creación de juegos de datos utilizando consultas SQL
• Creación de un juego de datos con una consulta de MDX con respecto a un origen dedatos de OLAP
• Uso del generador de consultas MDX
• Creación de un juego de datos mediante un análisis
• Uso de análisis de autoservicio
• Creación de un juego de datos mediante un servicio web
• Creación de un juego de datos mediante un archivo XML
• Creación de un juego de datos con un archivo Microsoft Excel
• Creación de un juego de datos mediante un archivo CSV
• Creación de un juego de datos a partir de una fuente XML HTTP
• Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelode datos
• Prueba de modelos de datos y generación de datos de ejemplo
• Inclusión de información de usuario almacenada en variables del sistema en los datosdel informe
Creación de un juego de datosPublisher puede recuperar datos de varios tipos de orígenes de datos.
Para crear un juego de datos:
1. En el panel de componentes del editor de modelo de datos, haga clic en Nuevo juegode datos y seleccione su tipo de juego de datos de origen.
2. Complete los campos requeridos. Consulte el tema de ayuda del tipo de juego de datosque desea crear.
Creación de juegos de datos utilizando consultas SQLEn estos temas se explica cómo crear juegos de datos con consultas SQL.
• Introducción de consultas SQL
9-1

• Uso de SQL Query Builder
• Adición de una variable de enlace a una consulta
• Adición de referencias léxicas a consultas SQL
• Definición de consultas SQL de Oracle BI Server
Introducción de consultas SQLUtilice estos pasos para introducir consultas SQL.
Para introducir consultas SQL:
1. Haga clic en Nuevo juego de datos y, a continuación, en Consulta SQL.
2. En el cuadro de diálogo para crear un nuevo juego de datos, introduzca unnombre para el juego de datos.
3. El origen de datos se define por defecto en el origen de datos por defecto que haseleccionado en la página Propiedades. Si no va a utilizar el origen de datos pordefecto para este juego de datos, seleccione el Origen de datos en la lista.
También puede utilizar las conexiones de origen de datos privadas como orígenesde datos para los juegos de datos de la consulta SQL.
4. Seleccione SQL estándar en la lista desplegable Tipo de SQL. El SQL estándarse utiliza para las sentencias SELECT normales interpretadas para comprender elesquema de base de datos.
5. Introduzca la consulta SQL o haga clic en Query Builder para iniciar la páginaQuery Builder.
6. Si va a utilizar campos flexibles, variables de enlace o algún otro procesamientoespecial en la consulta, edite el código SQL devuelto por Query Builder paraincluir las sentencias necesarias.
Si incluye referencias léxicas para el texto que embebe en una sentenciaSELECT, debe sustituir los valores para obtener una sentencia SQL válida.
7. Después de introducir la consulta, haga clic en Aceptar para guardarla. Para lasconsultas SQL estándar, el editor del modelo de datos valida la consulta.
Si la consulta incluye una variable de enlace, se le solicitará que cree elparámetro de enlace. Haga clic en Aceptar para que el modelo de datos cree elparámetro de enlace.
Uso de SQL Query BuilderUse el generador de consultas para crear consultas SQL sin codificación. Elgenerador de consultas le permite buscar y filtrar objetos de base de datos,seleccionar objetos y columnas, establecer relaciones entre objetos y ver resultadosde consulta con formato a pesar de tener un conocimiento mínimo acerca de SQL.
En esta sección se describe cómo usar el generador de consultas y contiene lossiguientes temas:
• Visión general del generador de consultas
• Creación de una consulta mediante Query Builder
• Tipos de columna soportados
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-2

• Adición de objetos al panel de diseño
• Eliminación u ocultación de objetos en el panel de diseño
• Condiciones de consulta
• Creación de relaciones entre objetos
• Guardar una consulta
• Edición de una consulta guardada
Visión general del generador de consultasLa página Generador de consultas se divide en un panel Selección de objetos y un panel dediseño y salida.
• El panel Selección de objetos contiene una lista de objetos desde la que puede crearconsultas. Solo se muestran los objetos del esquema actual.
• El panel de diseño y salida consta de cuatro separadores:
– Modelo: muestra los objetos seleccionados en el panel Selección de objetos.
– Condiciones: le permite aplicar condiciones a sus columnas seleccionadas.
– SQL: muestra la consulta.
– Resultados: muestra los resultados de la consulta.
Creación de una consulta mediante Query BuilderPuede crear una consulta mediante Query Builder.
Para crear una consulta mediante Query Builder:
1. Seleccione un esquema.
La lista Esquema muestra todos los esquemas disponibles en el origen de datos. Puedeque no tenga acceso a todos los esquemas de esta lista.
2. Agregue objetos al panel Diseño y seleccione columnas.
El panel Selección de objetos muestra las tablas, las vistas y las vistas materializadasdel esquema seleccionado. En una base de datos Oracle Database, el panel tambiénmuestra los sinónimos. Cuando selecciona un objeto en la lista, este se muestra en elpanel Diseño. Utilice el panel Diseño para especificar cómo se deben utilizar los objetosseleccionados en la consulta.
Puede que necesite utilizar el campo Buscar para introducir una cadena de búsqueda. Si el origen de datos incluye más de 100 tablas, utilice la función Buscar para buscar yseleccionar objetos.
3. Opcional: Establezca relaciones entre objetos.
4. Agregue un nombre de alias único para cualquier columna duplicada.
5. Opcional: Cree condiciones de consulta.
6. Ejecute la consulta y visualice los resultados.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-3

Tipos de columna soportadosTodos los tipos de columna se muestran como objetos en el panel Diseño. No puedeseleccionar más de 60 columnas para cada consulta.
Cuando utiliza el gateway de datos para conectarse a un origen de datos, lasconsultas SQL solo soportan los tipos de datos STRING, CHAR, VARCHAR, NCHAR,NVARCHAR, DATE, TIMESTAMP, NUMBER, INTEGER, FLOAT y DOUBLE. Si unaconsulta SQL para acceder a un origen de datos conectado a través del gateway dedatos contiene un tipo de dato no soportado, recibirá un mensaje de error.
Tipo de columna soportado Restricciones
VARCHAR2, CHAR NANUMBER NADATE, TIMESTAMP El tipo de dato TIMESTAMP WITH LOCAL
TIMEZONE no está soportado.
Objeto Binario Grande (BLOB) El BLOB puede ser una imagen, un texto odatos XML. Cuando ejecuta la consulta enQuery Builder, el BLOB no se muestra en elpanel Resultados; sin embargo, la consultase construye correctamente cuando seguarda en el editor del modelo de datos.Los datos BLOB no están soportados paraun origen de datos de Oracle BI EE debido alas limitaciones del controlador BIJDBC.Utilice una plantilla RTF si desea utilizaruna columna de datos BLOB con un tipo dedato de imagen.
Objeto grande de caracteres (CLOB) Publisher no soporta la consulta decolumnas CLOB en un origen de datos deOracle BI EE.
Adición de objetos al panel de diseñoSeleccione cada objeto que desee agregar al panel de diseño.
• Cuando agrega un objeto, aparece un icono que representa al tipo de dato junto acada nombre de columna.
• Cuando selecciona una columna, esta aparece en el separador Condiciones. Lacasilla de control Mostrar en el separador Condiciones controla si una columnaestá incluida en los resultados de la consulta. Por defecto, esta casilla de controlestá seleccionada.
• Para seleccionar las primeras veinte columnas, haga clic en el icono pequeño enla esquina superior izquierda del objeto y, a continuación, seleccione, Activartodo.
• También puede ejecutar una consulta pulsando las teclas CTRL + INTRO.
Para agregar objetos al panel de diseño:
1. Seleccione un objeto.
2. Seleccione la casilla de control de cada columna que desee incluir en la consulta.
3. Para ejecutar la consulta y ver los resultados, seleccione Resultados.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-4

Eliminación u ocultación de objetos en el panel de diseñoPuede eliminar u ocular los objetos en el panel Diseño.
Para eliminar un objeto:
1. Haga clic en Eliminar en la esquina superior derecha del objeto.
Para ocultar temporalmente las columnas de un objeto:
• Haga clic en Mostrar/Ocultar columnas.
Condiciones de consultaLas condiciones le permiten filtrar e identificar los datos con los que desea trabajar.
A medida que selecciona columnas dentro de un objeto, puede especificar condiciones en elseparador Condiciones. Puede modificar el alias de columna, aplicar condiciones decolumna, ordenar columnas o aplicar funciones.
Atributo Condición Descripción
Condición La condición modifica la cláusula WHERE de la consulta. Al especificaruna condición de columna, debe incluir el operador y el operandoadecuados. Todas las condiciones SQL estándar están soportadas. Porejemplo:>=10='VA'IN (SELECT dept_no FROM dept)BETWEEN SYSDATE AND SYSDATE + 15
Función Especifica las funciones. Las funciones de argumento disponiblesincluyen:• Columnas de número: COUNT, COUNT DISTINCT, AVG, MAXIMUM,
MINIMUM, SUM• Columnas VARCHAR2, CHAR: COUNT, COUNT DISTINCT, INITCAP,
LENGTH, LOWER, LTRIM, RTRIM, TRIM, UPPER• Columnas DATE, TIMESTAMP: COUNT, COUNT DISTINCT
Agrupar por Especifica las columnas que se van a utilizar para el agrupamientocuando se utilice una función de agregado. Solo se aplica para lascolumnas incluidas en la salida.
A medida que selecciona columnas y define condiciones, Query Builder escribe la sentenciaSQL. Para ver la sentencia SQL subyacente, seleccione el separador SQL.
Creación de relaciones entre objetosPuede crear relaciones entre objetos mediante la creación de una unión. Una unión identificauna relación entre dos o más tablas, vistas o vistas materializadas.
• Acerca de las condiciones de unión
• Unión objetos manualmente
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-5

Acerca de las condiciones de uniónCuando escribe una consulta de unión, especifica una condición que transmite unarelación entre dos objetos. Esta condición se denomina una condición de unión.
Una condición de unión especifica cómo se combinan las filas de un objeto con lasfilas de otro objeto.
El generador de consultas soporta uniones internas, externas, de izquierda y dederecha.
• Una unión interna, también denominada una unión simple, devuelve las filas quecumplen la condición de unión.
• Una unión externa amplía el resultado de una unión simple.
Una unión externa devuelve todas las filas que cumplen la condición de unión, ydevuelve además algunas o todas las filas de una tabla para las que ninguna delas filas de la otra cumple la condición de unión.
Unión objetos manualmenteCree una unión de forma manual mediante la selección de la columna de unión en elpanel Diseño.
Para unir objetos manualmente:
1. En el panel Selección de objetos, seleccione los objetos que desee unir.
2. Identifique las columnas que desee unir.
Puede crear una unión seleccionando la columna Unir situada junto al nombre decolumna. La columna Unir aparece a la derecha del tipo de dato. Cuando elcursos se sitúa en la posición adecuada, aparece el siguiente consejo de ayuda:
Haga clic aquí para seleccionar la columna que unir
3. Seleccione la columna Unir adecuada para el primer objeto.
Cuando se selecciona, la columna Unir se oscurece. Para anular la selección deuna columna Unir, solo tiene que volver a seleccionarla o pulsar ESC.
4. Seleccione la columna Unir adecuada para el segundo objeto.
Cuando se une, una línea conecta las dos columnas. A continuación aparece unejemplo.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-6

5. Seleccione las columnas que se van a incluir en la consulta. Puede ver la sentencia SQLque resulta de la unión colocando el cursor sobre la línea de unión.
6. Haga clic en Resultados para ejecutar la consulta.
Guardar una consultaGuarde consultas tras crearlas.
Una vez que haya creado una consulta, haga clic en Guardar para volver al editor delmodelo de datos. La consulta aparece en el cuadro Consulta SQL. Haga clic en Aceptarpara guardar el juego de datos.
Edición de una consulta guardadaCuando se guarda una consulta del generador de consultas en el editor del modelo de datos,también puede utilizar el generador de consultas para editar la consulta.
Si ha realizado modificaciones en la consulta o no ha utilizado el generador de consultaspara construirla, es posible que reciba un error al iniciar el generador de consultas paraeditar la consulta. Si el generador de consultas no puede analizar la consulta, puede editarlas sentencias directamente en el cuadro de texto.
No puede editar una consulta personalizada ni una avanzada con el generador de consultas.
Para editar una consulta guardada:
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-7

1. Seleccione el juego de datos SQL.
2. En la barra de herramientas, haga clic en Editar juego de datos seleccionadopara iniciar el cuadro de diálogo Editar juego de datos.
3. Haga clic en Generador de consultas para cargar la consulta en el generador deconsultas.
4. Edite la consulta y haga clic en Guardar.
Adición de una variable de enlace a una consultaDespués de crear una consulta, es posible que desee que los usuarios puedantransferir un parámetro a la consulta para limitar los resultados.
Para agregar una variable de enlace a una consulta:
1. En el generador de consultas, haga clic en el separador Condiciones.
2. Para la columna a la que desea agregar una variable de enlace, introduzca elnombre de parámetro con el siguiente formato:
in (:PARAMETER_NAME)Una vez que ha editado la consulta, el generador de consultas ya no puedeanalizarla. Debe realizar todas las ediciones adicionales manualmente.
Por ejemplo, en la lista de empleados, desea que los usuarios seleccionen undepartamento específico.
En la imagen se muestran las columnas de la tabla de departamento.
Adición de una variable de enlace mediante un editor de textoUtilice el editor del modelo de datos para actualizar una consulta SQL.
1. En el cuadro de texto Editar juego de datos, actualice la consulta SQL mediante laadición de lo siguiente después de la cláusula where en la consulta.
and "COLUMN_NAME" in (:PARAMETER_NAME)Por ejemplo:
and "DEPARTMENT_NAME" in (:P_DEPTNAME)donde P_DEPTNAME es el nombre que elija para el parámetro, como se muestra acontinuación.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-8

2. Haga clic en Guardar.
3. En el editor del modelo de datos, cree el parámetro que ha introducido con la sintaxis devariable de enlace como se muestra en la imagen.
4. Seleccione el parámetro y haga clic en Aceptar para que el editor del modelo de datoscree la entrada del parámetro.
Adición de referencias léxicas a consultas SQLPuede utilizar referencias léxicas para sustituir las cláusulas que aparecen después deSELECT, FROM, WHERE, GROUP BY, ORDER BY o HAVING.
Utilice una referencia léxica cuando desee que el parámetro sustituya varios valores entiempo de ejecución. También puede utilizar referencias léxicas para incluir campos flexibles
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-9

en la consulta. Las referencias léxicas solo están soportadas en las consultas deaplicaciones Oracle.
Cree una referencia léxica en la consulta SQL mediante la siguiente sintaxis:
¶metername1. Antes de crear la consulta, defina un parámetro en el paquete por defecto PL/SQL
para cada referencia léxica en la consulta. El motor de datos utiliza estos valorespara sustituir los parámetros léxicos.
2. En el editor del modelo de datos, en la página Propiedades, especifique elPaquete por defecto Oracle DB.
3. En el editor del modelo de datos, cree un disparador de eventos Antes de datospara llamar al paquete PL/SQL.
4. Cree una consulta SQL que contenga las referencias léxicas.
5. Al hacer clic en Aceptar para cerrar la consulta SQL, se le solicitará queintroduzca el parámetro.
Por ejemplo, cree un paquete denominado employee. En el paquete employee, definaun parámetro denominado where_clause:
Package employeeAS where_clause varchar2(1000); ..... Package body employee AS .....where_clause := 'where DEPARTMENT_ID=10';.....
Haga referencia al parámetro léxico de la consulta SQL donde desee que elparámetro se sustituya por el código definido en el paquete; por ejemplo:
select "EMPLOYEES"."EMPLOYEE_ID" as "EMPLOYEE_ID", "EMPLOYEES"."FIRST_NAME" as "FIRST_NAME", "EMPLOYEES"."LAST_NAME" as "LAST_NAME", "EMPLOYEES"."SALARY" as "SALARY", from "OE"."EMPLOYEES" "EMPLOYEES" &where_clause
Al hacer clic en Aceptar en el cuadro de diálogo Crear juego de datos SQL, el cuadrode diálogo de referencia léxica le solicita que introduzca un valor para las referenciasléxicas que ha introducido en la consulta SQL, como se muestra en la imagensiguiente. Introduzca el valor de la referencia léxica como está definido en el paquetePL/SQL.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-10

En tiempo de ejecución, el motor de datos sustituye &where_clause por el contenido dewhere_clause definido en el paquete.
Acerca de la definición de consultas SQL de Oracle BI ServerEn este tema se describen los puntos que debe recordar al definir consultas SQL de OracleBI Server.
Tenga en cuenta los siguientes puntos al crear un juego de datos en Oracle BI Server:
• Al crear una consulta SQL de Oracle BI Server utilizando el editor de datos SQL o QueryBuilder, se genera un SQL lógico, y no un SQL físico como otros orígenes de base dedatos.
• Las columnas jerárquicas no están soportadas. Siempre se devuelve el nivel más alto.
• Dentro de un área temática, siempre se crean las condiciones de unión entre tablas; porlo tanto, no tiene que crear uniones en Query Builder. Query Builder no muestra la claveprimaria.
Puede enlazar juegos de datos mediante la función Crear enlace del editor del modelode datos. Consulte Creación de enlaces de nivel de elemento. Para los juegos de datoscreados desde Oracle BI Server, hay un límite de dos enlaces de nivel de elemento paraun único modelo de datos.
• En Query Builder, las funciones Orden de clasificación y Agrupar por mostradas en elseparador Condiciones no están soportadas para las consultas de Oracle BI Server. Siintroduce un Orden de clasificación o selecciona la casilla de control Agrupar por, QueryBuilder construye la sentencia SQL y la escribe en el cuadro de texto Consulta SQL dePublisher, pero si intenta cerrar el cuadro de diálogo Juego de datos, falla la validaciónde la consulta.
Para aplicar la agrupación en los datos recuperados por la consulta SQL, puede utilizarla función Agrupar por del editor del modelo de datos en su lugar. Consulte Creación desubgrupos.
• Si transfiere parámetros a Oracle BI Server y selecciona Valor nulo transferido en Puedeseleccionar todo, asegúrese de gestionar el valor nulo en la consulta.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-11

Definición de consultas SQL de Oracle BI ServerCuando se inicia Query Builder en Oracle BI Server, Query Builder muestra las áreastemáticas del catálogo. Puede arrastrar las áreas temáticas al espacio de trabajo deQuery Builder para mostrar las columnas. Seleccione las columnas que desee incluiren el modelo de datos.
Para definir consultas SQL de Oracle BI Server :
1. En el editor del modelo de datos, haga clic en Nuevo juego de datos y, acontinuación, en Consulta SQL.
2. Introduzca un nombre para el juego de datos.
3. En la lista Origen de datos, seleccione la conexión Oracle BI Server, quenormalmente se muestra como Oracle BI EE.
4. Haga clic en Query Builder para iniciar la página Query Builder.
También puede introducir la sintaxis SQL manualmente en el cuadro de textoConsulta SQL; no obstante, debe utilizar la sintaxis Sentencia SQL lógica utilizadapor Oracle BI Server.
5. En la lista desplegable Catálogo, seleccione un área temática como se muestra acontinuación. En la lista se muestran las áreas temáticas definidas en Oracle BIServer.
6. Seleccione tablas y columnas para la consulta.
7. Haga clic en Guardar.
8. Haga clic en Aceptar para volver al editor del modelo de datos. La sentencia SQLgenerada en una sentencia SQL lógica que sigue un esquema de estrella (esdecir, no es una sentencia SQL física).
9. Guarde los cambios realizados en el modelo de datos.
Capítulo 9Creación de juegos de datos utilizando consultas SQL
9-12

Creación de un juego de datos con una consulta de MDX conrespecto a un origen de datos de OLAP
Publisher soporta consultas de expresiones multidimensionales (MDX) con respecto aorígenes de datos de OLAP.
MDX le permite consultar objetos multidimensionales, como cubos de Essbase y devolverjuegos de celdas multidimensionales que contengan datos del cubo. Para crear consultas deMDX, introduzca manualmente la consulta de MDX o use generador de consultas MDX paracrear la consulta.
• Creación de un juego de datos con una consulta de MDX
• Uso del generador de consultas MDX
Creación de un juego de datos con una consulta de MDXPuede crear consultas MDX introduciendo la consulta MDX manualmente o utilizando elgenerador de consultas MDX para crear la consulta.
En el origen de datos de OLAP, no utilice caracteres Unicode del rango U+F900 a U+FFFEpara definir atributos de metadatos como nombres de columna o nombres de tabla. Esterango de Unicode incluye Japanese Katakana de ancho medio y variantes ASCII de anchocompleto. El uso de estos caracteres provoca errores cuando se generan datos XML para uninforme de visualización perfecta.
Para crear un juego de datos mediante una consulta MDX:
1. En la barra de herramientas, haga clic en Nuevo juego de datos y, a continuación,seleccione Consulta MDX.
A continuación, se muestra el cuadro de diálogo Nuevo juego de datos - Consulta MDX.
2. Introduzca un nombre para el juego de datos.
3. Seleccione el origen de datos para el juego de datos. Solo se muestran en la lista losorígenes de datos definidos como conexiones OLAP.
Capítulo 9Creación de un juego de datos con una consulta de MDX con respecto a un origen de datos de OLAP
9-13

Todas las conexiones de origen de datos OLAP privadas que haya creadotambién estarán disponibles en la lista desplegable Origen de datos.
4. Introduzca la consulta MDX o haga clic en Query Builder.
5. Haga clic en Aceptar para guardar. El editor del modelo de datos valida laconsulta.
Uso del generador de consultas MDXUtilice el generador de consultas MDX para generar consultas MDX básicas sin tenerque codificarlas. El generador de consultas MDX le permite agregar dimensiones aejes de columnas, filas, páginas y punto de vista, así como obtener una vista previade los resultados de la consulta.
MDX Query Builder solo le permite crear juegos de datos de orígenes de datos deEssbase. Para los orígenes de datos de OLAP restantes, debe crear la consultamanualmente.
• Descripción del proceso de generación de consultas MDX
• Uso del cuadro de diálogo Seleccionar cubo
• Selección de dimensiones y medidas
• Realización de acciones de consulta MDX
• Aplicación de filtros de consulta MDX
• Selección de opciones de consulta MDX y guardado de consultas MDX
Descripción del proceso de generación de consultas MDXPuede crear consultas MDX introduciendo la consulta MDX manualmente o utilizandoel generador de consultas MDX para crear la consulta.
Para usar el generador de consultas de MDX para crear una consulta de MDX:
1. En la barra de herramientas, haga clic en Nuevo juego de datos y, acontinuación, seleccione Consulta de MDX para iniciar el cuadro de diálogoNuevo juego de datos - Consulta de MDX.
2. Introduzca un nombre para el juego de datos.
3. Seleccione un origen de datos.
4. Inicie el generador de consultas de MDX.
5. Seleccione un cubo de Essbase para la consulta.
6. Para seleccionar las dimensiones y las medidas, arrástrelas y suéltelas en losejes Columnas, Filas, Divisor/Punto de Vista y Páginas.
7. Opcional: Utilice acciones para modificar la consulta.
8. Opcional: Aplique filtros.
9. Defina las opciones de consulta y guarde la consulta.
Capítulo 9Uso del generador de consultas MDX
9-14

Uso del cuadro de diálogo Seleccionar cuboEn el cuadro de diálogo Seleccionar cubo, seleccione el cubo de Essbase que desea usarpara crear la consulta de MDX.
La conexión al origen de datos de MDX que haya seleccionado previamente determina loscubos de Essbase que se pueden seleccionar.
Selección de dimensiones y medidasPuede crear consultas MDX mediante la selección, de dimensiones para los ejes Columnas,Filas, Divisor/punto de vista y Páginas.
Los miembros de la dimensión Cuenta se muestra individualmente por nombre de miembro.Todos los demás miembros de dimensión se representan por nombre de generación, comose muestra a continuación.
Puede arrastrar generaciones de dimensión y medidas individuales desde la dimensiónCuenta a los ejes Columnas, Filas, Divisor/punto de vista y Páginas.
Cree la consulta mediante el arrastre de miembros de dimensión o medidas desde el panelDimensiones a una de las siguientes áreas de eje:
• Columnas: eje (0) de la consulta
• Filas: eje (1) de la consulta
• Divisor/punto de vista: el eje divisor le permite limitar una consulta a solo una porciónespecífica del cubo de Essbase. Representa la cláusula WHERE opcional de unaconsulta.
Capítulo 9Uso del generador de consultas MDX
9-15

• Páginas: eje (2) de la consulta
Puede anidar miembros de dimensión en los ejes Columnas y Filas, pero solo puedeagregar una única dimensión al eje Divisor/punto de vista.
Adición de miembros de dimensión en el eje Divisor/Punto de vistaAl agregar una dimensión al eje Divisor/Punto de vista, se abre el cuadro de diálogoSelección de miembro.
Solo puede seleccionar un miembro de dimensión para este eje. Solo tiene queseleccionar la dimensión en el cuadro de diálogo Selección de miembro y, acontinuación, hacer clic en Aceptar.
El cuadro de diálogo Selección de miembro no aparece si agrega una medida al ejeDivisor/Punto de vista.
Realización de acciones de consulta MDXLa barra de herramientas Generador de consultas de MDX contiene los siguientesbotones para modificar la consulta de MDX:
• Haga clic en Intercambiar filas y Columnas para cambiar las dimensiones entrelas columnas y las filas.
• Haga clic en Acciones para mostrar las siguientes opciones de menú paraselección:
– Seleccionar cubo: selecciona un cubo de Essbase distinto para la consulta.
– Definir tabla de alias: selecciona la tabla de alias usada para los nombresmostrados de la dimensión. Los nombres de alias se usan para fines devisualización y no se usan en la consulta.
– Refrescamiento automático: muestra los resultados como miembros dedimensión en los ejes Columnas, Filas, Divisor/Punto de vista y Páginas yrefresca automáticamente la sintaxis de la consulta de MDX.
– Borrar resultados: borra los resultados y elimina las selecciones demiembros de todos los ejes y cualquier filtro agregado a la consulta.
– Mostrar columnas vacías: muestra las columnas que no contienen datos.
– Mostrar filas vacías: muestra las filas que no contienen datos.
– Mostrar consulta: muestra la sintaxis de la consulta de MDX resultante decómo se colocan las dimensiones en los ejes Columnas, Filas, Divisor/Puntode vista y Páginas.
Capítulo 9Uso del generador de consultas MDX
9-16

Aplicación de filtros de consulta MDXPuede crear filtros para dimensiones en los ejes Columnas, Filas y Páginas en el generadorde consultas MDX para optimizar aún más la consulta MDX.
Puede crear varios filtros para una consulta, pero solo puede crear un filtro para cada uno delos ejes Columnas, Filas o Páginas.
• Para crear un filtro, haga clic en el botón de flecha abajo de una dimensión en el eje,Columnas, Filas o Página para mostrarlo en el área Filtros. Cree el filtro mediante laselección del miembro de dimensión deseado, como se muestra a continuación.
Selección de opciones de consulta MDX y guardado de consultas MDXUtilice el cuadro de diálogo Opciones para seleccionar las propiedades de dimensión a fin deincluirlas en la consulta para cada una de las dimensiones en los ejes Columnas, Filas yPáginas.
Para seleccionar las opciones de consulta MDX y guardar la consulta:
1. Una vez que ha creado la consulta, haga clic en Guardar para mostrar el cuadro dediálogo Opciones.
2. Seleccione las propiedades de dimensión.
Las propiedades de dimensión son las siguientes:
• Alias de miembro: nombres de alias de miembros de la dimensión según elesquema de Essbase.
• Nombres de ascendientes: nombres de dimensión de ascendientes según elesquema de Essbase.
• Número de nivel: números de nivel de dimensión según el esquema de Essbase.
• Número de generación: número de generación de las dimensiones según elesquema de Essbase.
Capítulo 9Uso del generador de consultas MDX
9-17

Por ejemplo, si selecciona las propiedades Alias de miembro y Número de nivelpara Columnas, los resultados de la consulta MDX son los siguientes:
SELECTNON EMPTY Hierarchize([Market].Generations(2).Members)PROPERTIES MEMBER_ALIAS,LEVEL_NUMBER ON Axis(0),NON EMPTY CROSSJOIN(Hierarchize([Product].Generations(3).Members),{[Accounts].[Margin],[Accounts].[Sales],[Accounts].[Total_Expenses]})ON Axis(1),NON EMPTY [Year].Generations(3).Members ON Axis(2) FROM Demo.Basic
3. Haga clic en Aceptarpara regresar al cuadro de diálogo Nuevo juego de datos -Consulta MDX y revise la salida de la consulta MDX como se muestra acontinuación.
4. Haga clic en Aceptar para regresar al editor del modelo de datos y guardar loscambios.
Si modifica una consulta MDX después de guardarla en Publisher, Oraclerecomienda que guarde manualmente la sintaxis y que no utilice el generador deconsultas MDX para hacerlo.
Creación de un juego de datos mediante un análisisPuede utilizar el catálogo de presentación de Oracle BI para seleccionar un análisiscomo origen de datos.
Un análisis es una consulta realizada en los datos de una organización queproporciona respuestas a peticiones de negocio. Una consulta contiene las sentenciasSQL subyacentes que se emiten a Oracle BI Server.
Las columnas jerárquicas no están soportadas en los modelos de datos de Publisher
Cree un juego de datos utilizando un análisis:
1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas yseleccione Análisis.
2. En el cuadro de diálogo Nuevo juego de datos - Análisis, introduzca un nombrepara este juego de datos.
3. Haga clic en el icono de examinar para conectarse al catálogo de presentación deOracle BI.
4. Cuando se inicie el cuadro de diálogo de conexión al catálogo, desplácese por lascarpetas para seleccionar el análisis que desee utilizar como juego de datos parael informe.
5. Introduzca un valor de Timeout en segundos. Si Publisher no ha recibido losdatos del análisis una vez transcurrido el tiempo especificado en el valor detimeout, Publisher dejará de intentar recuperar los datos del análisis.
6. Haga clic en Aceptar.
Capítulo 9Creación de un juego de datos mediante un análisis
9-18

Notas adicionales sobre juegos de datos de análisisLos parámetros y las listas de valores se heredan de los análisis y se muestran en tiempo deejecución.
El análisis debe tener valores por defecto para las variables de filtro. Si el análisis contienevariables de presentación sin variables por defecto, no puede utilizarlo como origen de datospara los informes en Publisher.
No puede utilizar divisiones de grupo, filtros de grupo, enlaces de datos ni funciones de nivelde grupo al estructurar datos basados en juegos de datos para un análisis. Puede utilizarfunciones de nivel de grupo y definir valores para elementos nulos.
Uso de análisis de autoservicioPuede utilizar análisis de autoservicio para crear juegos de datos para informes.
En Oracle Analytics, puede cargar datos de una gran variedad de orígenes (por ejemplo,hojas de cálculo, archivos CSV y muchas bases de datos) en el sistema, así como explorarlos datos para buscar correlaciones, detectar patrones y ver las tendencias.
Utilice el editor de juegos de datos para capturar los datos analizados en juegos de datosque incluyen tablas y uniones. Puede utilizar estos flujos de datos y juegos de datos deautoservicio para generar informes en línea e informes fuera de línea (informesprogramados).
Nota:
Después de importar un juego de datos de autoservicio en Publisher, si cambia laestructura del juego de datos de autoservicio, debe editar y refrescar manualmentedicho juego de datos de autoservicio. No puede importar las expresiones ni loselementos calculados por el usuario de un juego de datos de autoservicio en unmodelo de datos de Publisher. No puede establecer enlaces entre juegos de datos.
Creación de un juego de datos mediante un juego de datos de autoservicioPuede utilizar juegos de datos de autoservicio que contengan una o más tablas para crearjuegos de datos.
1. En el panel de componentes del editor del modelo de datos, seleccione Juego de datosy seleccione Datos de DV.
El separador Juegos de datos muestra todos los juegos de datos de autoservicio.
2. En el separador Juegos de datos, seleccione el juego de datos que desee utilizar para lageneración de informes de visualización perfecta.
3. Seleccione las columnas de cada tabla que desee utilizar en el juego de datos para lageneración de informes.
4. Haga clic en Siguiente.
5. Introduzca un nombre para el juego de datos.
6. Si desea configurar parámetros, realice los siguientes pasos para cada parámetro.
Capítulo 9Uso de análisis de autoservicio
9-19

a. Haga clic en Agregar parámetro.
b. Seleccione una columna en la lista Nombre de columna.
c. Si desea cambiar el nombre del parámetro, edite el nombre en el campoParámetro.
7. Haga clic en Finalizar.
Creación de un juego de datos mediante un flujo de datos deautoservicio
Puede utilizar flujos de datos de autoservicio para crear juegos de datos.
No puede utilizar los siguientes tipos de flujos de datos para crear juegos de datos:
• Flujos de datos creados con la opción Guardar modelo.
• Flujos de datos con juegos de datos bifurcados.
1. Seleccione Juegos de datos, haga clic en Nuevo juego de datos en elseparador Diagrama y, a continuación, seleccione Datos de DV.
2. En el separador Flujos de datos, seleccione el flujo de datos que desee utilizar yhaga clic en Siguiente.
3. Introduzca un nombre para el juego de datos.
4. Si desea configurar parámetros, realice los siguientes pasos para cada parámetro.
a. Haga clic en Agregar parámetro.
b. Seleccione una columna en la lista Nombre de columna.
c. Si desea cambiar el nombre del parámetro, edite el nombre en el campoParámetro.
5. Haga clic en Finalizar.
Creación de un juego de datos mediante un servicio webPublisher soporta juegos de datos que utilizan orígenes de datos de servicio websimples y complejos para devolver datos XML válidos. Solo están soportados losservicios web de documento/literal.
Se recomiendo que defina primero los parámetros, de modo que los métodos esténdisponibles para su selección al configurar el origen de datos. Los parámetros sedeben configurar en la sección Parámetros de la definición de informe.
El uso de varios parámetros está soportado. Asegúrese de que el nombre del métodosea correcto y de que el orden de los parámetros coincida con el orden en el método.Para llamar a un método en el servicio web que acepte dos parámetros, debe asignardos parámetros definidos en el informe a los dos parámetros en el método. Tenga encuenta que solo están soportados los parámetros del tipo simple; por ejemplo, cadenay entero.
Opciones de origen de datos de servicio webEl administrador puede configurar los datos de un servicio web como origen de datos.
Capítulo 9Creación de un juego de datos mediante un servicio web
9-20

El administrador puede configurar conexiones a orígenes de datos de servicio web y,posteriormente, puede utilizar el origen de datos en varios modelos de datos. Debeconfigurar la conexión para poder crear el modelo de datos.
Publisher soporta juegos de datos que utilizan orígenes de datos de servicio web simples ycomplejos para devolver datos XML válidos.
Creación de un juego de datos mediante un servicio web simpleSi no está familiarizado con los métodos y los parámetros disponibles en el servicio web alque se va a llamar, puede abrir la URL en un explorador para verlos.
Para crear un juego de datos mediante un servicio web simple:
1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas y, acontinuación, seleccione Servicio web.
2. Introduzca el nombre del juego de datos.
3. Seleccione el origen de datos y el método.
4. Haga clic en Aceptar.
5. En el panel Modelo de datos, seleccione Parámetros, haga clic en Crear nuevoparámetro y defina los parámetros para que estén disponibles para el juego de datos delservicio web.
6. Edite el juego de datos del servicio web y agregue los parámetros al juego de datos.
7. Haga clic en Guardar.
Creación de un juego de datos mediante un servicio web complejoPuede utilizar orígenes de datos de un servicio web complejo para devolver datos XMLválidos. Un tipo de servicio web complejo utiliza internamente soapRequest/soapEnvelopepara transferir los valores de parámetro al host de destino.
Para crear un juego de datos mediante un servicio web complejo:
1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas y, acontinuación, seleccione Servicio web.
2. Introduzca el nombre del juego de datos, el origen de datos y el método.
Los métodos disponibles para su selección están basados en el origen de datos delservicio web complejo. Cuando selecciona un método, se muestran los Parámetros.Para ver los parámetros opcionales, seleccione Mostrar parámetros opcionales.
Si no está familiarizado con los métodos y los parámetros disponibles en el servicio web,abra la URL de WSDL URL en un explorador para visualizarlos.
3. Si el inicio de los datos XML para el informe está demasiado embebido en la respuestaXML generada por la solicitud de servicio web, en el campo Datos de respuesta XPath,especifique la ruta de acceso a los datos que se van a utilizar en el informe.
4. Agregue los parámetros necesarios para el servicio web.
5. Pruebe el servicio web.
Capítulo 9Creación de un juego de datos mediante un servicio web
9-21

Información adicional en los juegos de datos de servicio webComo no hay metadatos disponibles de los juegos de datos de servicios web, noestán soportados ni el enlace ni la agrupación.
Creación de un juego de datos mediante un archivo XMLPuede usar un archivo XML para crear un origen de datos.
Puede:
• Coloque el archivo XML en un directorio que su administrador haya configuradocomo origen de datos.
• Cargue el archivo XML en el modelo de datos de un directorio local.
Para usar el editor de diseño y el visor interactivo, guarde datos de ejemplo del origende archivo XML en el modelo de datos.
Acerca de los archivos XML soportadosEl soporte de archivos XML como tipo de juego de datos en Publisher sigue unasdirectrices determinadas.
• Los archivos XML que utiliza como entrada para el motor de datos de Publisherdeben estar codificados en UTF-8.
• No utilice los siguientes caracteres en los nombres de etiqueta XML: ~, !, #, $, %,^, &, *, +, `, |, :, \", \\, <, >, ?, ,, /. Si el archivo de origen de datos contiene algunode estos caracteres, utilice el separador Estructura del editor del modelo de datospara cambiar los nombres de etiqueta a uno que sea aceptable.
• Utilice archivos XML válidos. Oracle proporciona muchas utilidades y métodospara validar archivos XML.
• No hay ningún metadato disponible de los juegos de datos de archivo XML, por loque la agrupación y el enlace no están soportados.
Carga de un archivo XML almacenado localmentePuede crear juegos de datos con archivos XML almacenados localmente.
Para crear un juego de datos con un archivo XML almacenado localmente:
1. En la barra de herramientas, haga clic en Nuevo juego de datos y seleccioneArchivo XML.
2. Introducir un nombre para el juego de datos.
3. Haga clic en Cargar junto al campo Nombre de archivo para buscar y actualizarel archivo XML desde un directorio local. Si se ha cargado el archivo al modelo dedatos, puede seleccionarlo en la lista Nombre de archivo.
4. Haga clic en Cargar.
5. Haga clic en Aceptar.
6. (Necesario) Guarde los datos de ejemplo en el modelo de datos.
Capítulo 9Creación de un juego de datos mediante un archivo XML
9-22

Refrescamiento y supresión de un archivo XML cargadoPuede refrescar y suprimir archivos XML cargados locales.
Después de cargar el archivo, este se muestra en el panel Propiedades del modelo dedatos en la región Anexos, como se muestra a continuación.
Para refrescar el archivo local en el modelo de datos:
1. En el panel de componentes, haga clic en Modelo de datos para ver la páginaPropiedades.
2. En la región Anexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Refrescar.
4. En el cuadro de diálogo Cargar, busque y cargue la versión más reciente del archivo. Elarchivo debe tener el mismo nombre; de lo contrario, no sustituirá la versión anterior.
5. Guarde el modelo de datos.
Para suprimir el archivo local:
1. En el panel de componentes, haga clic en Modelo de datos para ver la páginaPropiedades.
2. En la región Anexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Suprimir.
4. Haga clic en Aceptar para confirmar.
5. Guarde el modelo de datos.
Creación de un juego de datos mediante Content ServerPuede configurar conexiones al origen de datos de Content Server en la páginaAdministración y utilizarlas posteriormente en varios modelos de datos.
Debe configurar la conexión para poder crear un modelo de datos. Cree un modelo de datoscreando primero el juego de datos de consulta SQL (necesario) y cree a continuación eljuego de datos de Content Server.
Capítulo 9Creación de un juego de datos mediante Content Server
9-23

1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas yseleccione Content Server.
En el cuadro de diálogo Nuevo juego de datos - Content Server, realice losiguiente:
2. Introduzca un nombre para el juego de datos en el campo Nombre.
3. Seleccione el origen de datos del servidor de contenidos en el campo Origen dedatos.
4. Seleccione el Grupo principal en la lista de valores.
5. Seleccione el Identificador de documento en la lista de valores.
6. Seleccione el Tipo de contenido en la lista de valores.
7. Haga clic en Aceptar.
Creación de un juego de datos con un archivo MicrosoftExcel
En estos temas se describen los requisitos, las opciones y los procedimientos parausar archivos Microsoft Excel como origen de datos.
• Acerca de los archivos de Excel soportados
• Acceso a varias tablas por hoja
Acerca de los archivos de Excel soportadosEl soporte de archivos Microsoft Excel como tipo de juego de datos en Publisher sigueunas directrices determinadas.
• Guarde los archivos Microsoft Excel con el formato Libro de Excel 97-2003 (*.xls)de Microsoft Excel. No están soportados los archivos creados en una aplicación ouna biblioteca de terceros.
• El archivo Excel de origen puede contener una única hoja o varias hojas.
Capítulo 9Creación de un juego de datos con un archivo Microsoft Excel
9-24

• Cada hoja de trabajo puede contener una o varias tablas. Una tabla es un bloque dedatos ubicado en las filas y las columnas continuas de una hoja.
En cada tabla, Publisher siempre considera que la primera fila es la fila de cabecera dela tabla.
• La primera fila debajo de la fila de cabecera no debe estar vacía y se utiliza paradeterminar el tipo de columna de la tabla. El tipo de dato de los datos de la tabla debeser número, texto o fecha/hora.
• Si hay varias tablas en una única hoja de trabajo, estas deben estar identificadas con unnombre para que Publisher reconozca a cada una. Consulte Acceso a varias tablas porhoja.
• Si no tienen un nombre todas las tablas del archivo Excel, solo se reconocen y serecuperan los datos de la primera tabla.
• Cuando se crea el juego de datos, Publisher trunca todos los ceros finales después delpunto decimal de los números en todos los casos. Para conservar los puntos finales enel informe final, debe aplicar una máscara de formato en la plantilla para mostrar losceros.
• Los parámetros de un solo valor están soportados, pero los parámetros de varios valoresno están soportados.
Acceso a varias tablas por hojaSi la hoja de trabajo de Microsoft Excel contiene varias tablas que desea incluir comoorígenes de datos, debe definir un nombre para cada tabla en Microsoft Excel.
El nombre que defina debe empezar por el prefijo: BIP_; por ejemplo, BIP_SALARIES.
Para acceder a varias tablas por hoja:
1. Inserte la tabla en Microsoft Excel.
2. Seleccione la tabla y defina un nombre con el prefijo BIP_.
Por ejemplo, puede utilizar el comando Define Name de Microsoft Excel 2007 para asignar auna tabla el nombre BIP_Salaries.
Capítulo 9Creación de un juego de datos con un archivo Microsoft Excel
9-25

Uso de un archivo Microsoft Excel almacenado en un origen de datosdel directorio de archivos
Cree juegos de datos mediante archivos Microsoft Excel almacenados en directoriosde archivos.
Tenga en cuenta que para incluir parámetros para el juego de datos, debe definirprimero los parámetros, de modo que estén disponibles para su selección cuandodefina el juego de datos. El tipo de juego de datos de Excel soporta un valor porparámetro. No soporta la selección múltiple para los parámetros.
Para crear un juego de datos mediante un archivo Microsoft Excel de un origen dedatos de directorio de archivos:
1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas yseleccione Archivo Microsoft Excel. Se inicia el cuadro de diálogo Nuevo juegode datos - Archivo Microsoft Excel.
2. Introducir un nombre para el juego de datos.
3. Haga clic en Compartido para activar la lista Origen de datos.
4. Seleccione el origen de datos en el que reside el archivo Microsoft Excel.
5. A la derecha del campo Nombre de archivo, haga clic en el icono para examinarpara buscar el archivo Microsoft Excel en los directorios del origen de datos.Seleccione el archivo.
6. Si el archivo Excel contiene varias hojas o tablas, seleccione el Nombre de lahoja y el Nombre de la tabla adecuados para este juego de datos, como semuestra a continuación.
Capítulo 9Creación de un juego de datos con un archivo Microsoft Excel
9-26

7. Si ha agregado parámetros para este juego de datos, haga clic en Agregar parámetro.Introduzca el Nombre y seleccione el Valor. La lista Valor se rellena según el Nombre deparámetro definido en la sección Parámetros. Solo están soportados parámetros de unúnico valor.
8. Haga clic en Aceptar.
9. Enlace los datos desde esta consulta a los datos de otras consultas o modifique laestructura de salida.
Carga de un archivo Microsoft Excel almacenado localmentePara utilizar un archivo Microsoft Excel local como origen de datos, primero debe cargarlo.
Tenga en cuenta que, para incluir parámetros para el juego de datos, primero debe definir losparámetros de modo que estén disponibles para su selección al definir el juego de datos. Eltipo de juego de datos de Excel soporta un valor por parámetro. No soporta la selecciónmúltiple para los parámetros.
Para crear un juego de datos utilizando un archivo Microsoft Excel almacenado localmente:
1. Haga clic en el botón Nuevo juego de datos de la barra de herramientas y seleccioneArchivo Microsoft Excel. Se inicia el cuadro de diálogo Crear juego de datos - Excel.
2. Introducir un nombre para el juego de datos.
3. Seleccione Local para activar el botón de carga.
4. Haga clic en el icono Cargar para buscar y cargar el archivo Microsoft Excel de undirectorio local. Si se ha cargado el archivo al modelo de datos, puede seleccionarlo enla lista Nombre de archivo.
5. Si el archivo Excel contiene varias hojas o tablas, seleccione el Nombre de la hoja y elNombre de la tabla adecuados para este juego de datos, como se muestra acontinuación.
Capítulo 9Creación de un juego de datos con un archivo Microsoft Excel
9-27

6. Si ha agregado parámetros para este juego de datos, haga clic en Agregarparámetro. Introduzca el Nombre y seleccione el Valor. La lista Valor se propagasegún el Nombre de parámetro definido en la sección Parámetros. Solo estánsoportados parámetros de un único valor.
7. Haga clic en Aceptar.
8. Enlace los datos desde esta consulta a los datos de otras consultas o modifique laestructura de salida.
Refrescamiento y supresión de un archivo de Excel cargadoPuede refrescar y suprimir archivos de Excel local cargados.
Después de cargar el archivo, este se muestra en el panel Propiedades del modelode datos en la región Anexos, como se muestra a continuación.
Capítulo 9Creación de un juego de datos con un archivo Microsoft Excel
9-28

Para refrescar el archivo local en el modelo de datos:
1. Haga clic en Modelo de datos en el panel de componentes para ver la páginaPropiedades.
2. En la regiónAnexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Refrescar.
4. En el cuadro de diálogo Cargar, busque y cargue la última versión del archivo. El archivodebe tener el mismo nombre; de lo contrario, no sustituirá la versión anterior.
5. Guarde el modelo de datos.
Para suprimir el archivo local:
1. Haga clic en Modelo de datos en el panel de componentes para ver la páginaPropiedades.
2. En la región Anexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Suprimir.
4. Haga clic en Aceptar para confirmar.
5. Guarde el modelo de datos.
Creación de un juego de datos mediante un archivo CSVPublisher soporta juegos de datos que usan orígenes de datos de archivos CSV paradevolver datos XML válidos.
En los temas siguientes se describe el uso de requisitos y procedimientos para usar un CSVcomo origen de datos:
• Acerca de los archivos CSV soportados
• Creación de un juego de datos a partir de un archivo CSV almacenado centralmente
• Carga de un archivo CSV almacenado de forma local
Acerca de los archivos CSV soportadosEl soporte de archivos CSV como tipo de juego de datos en Publisher sigue unas directricesdeterminadas.
• Puede utilizar un archivo CSV ubicado en un directorio que el administrador hayaconfigurado como origen de datos.
Puede cargar un archivo de un directorio local.
• Los delimitadores de archivo CSV soportados son Coma, Pleca, Punto y coma yTabulador.
• Si el archivo CSV contiene cabeceras, los nombres de cabecera se utilizan comonombres de etiqueta XML. Los siguientes caracteres no están soportados en losnombres de etiqueta XML: ~, !, #, $, %, ^, &, *, +, `, |, :, \", \\, <, >, ?, ,, /. Si el archivo deorigen de datos contiene uno de estos caracteres en un nombre de cabecera, utilice elseparador Estructura del editor del modelo de datos para editar los nombres de etiqueta.
• Los juegos de datos CSV soportan la edición del tipo de dato asignado en el editor delmodelo de datos. Consulte Edición del tipo de dato. Si actualiza el tipo de dato para un
Capítulo 9Creación de un juego de datos mediante un archivo CSV
9-29

elemento del juego de datos, debe asegurarse de que los datos del archivo soncompatibles con el tipo de dato que ha seleccionado.
• Los archivos CSV que utilice como entrada para el motor de datos de Publisherdeben estar codificados en UTF-8 y no pueden contener cabeceras de columnavacías.
• No están soportadas las divisiones de grupo, los enlaces de datos ni las funcionesde nivel de grupo y expresión.
• Los campos de datos de los archivos CSV deben utilizar el formato de fecha ISOcanónico para los elementos de fecha asignados; por ejemplo,2012-01-01T10:30:00-07:00 y ######.## para los elementos de númeroasignados.
• Los archivos CSV no se validan.
Creación de un juego de datos a partir de un archivo CSValmacenado centralmente
Puede utilizar un archivo CSV de un directorio de archivos para crear un juego dedatos.
1. En la barra de herramientas del editor del modelo de datos, haga clic en Nuevojuego de datos y seleccione Archivo CSV. Se inicia el cuadro de diálogo Nuevojuego de datos - Archivo CSV.
2. Introducir un nombre para el juego de datos.
3. Haga clic en Compartido para activar la lista Origen de datos.
4. Seleccione el Origen de datos donde reside el archivo CSV.
La lista se propaga a partir de las conexiones Origen de datos de archivoconfiguradas.
5. Haga clic en Examinar para conectarse al origen de datos, examinar losdirectorios disponibles y seleccionar el archivo.
6. Seleccione Primera fila como cabecera de columna para especificar si laprimera fila del archivo contiene nombres de columna.
Capítulo 9Creación de un juego de datos mediante un archivo CSV
9-30

Si no selecciona esta opción, se asigna a las columnas un nombre genérico; porejemplo, Column1, Column2. Puede editar los nombres de etiqueta XML y los nombresmostrados en el separador Estructura del editor del modelo de datos.
7. Seleccione el Delimitador de CSV utilizado en el archivo.
La selección por defecto es Coma (,).
8. Haga clic en Aceptar.
Carga de un archivo CSV almacenado de forma localCree juegos de datos utilizando archivos CSV almacenados en directorios de archivoslocales.
Para crear un juego de datos utilizando un archivo CSV almacenado de forma local:
1. En la barra de herramientas, haga clic en Nuevo juego de datos y seleccione ArchivoCSV. Se inicia el cuadro de diálogo Nuevo juego de datos - Archivo CSV, como semuestra a continuación.
2. Introducir un nombre para el juego de datos.
3. Seleccione Local para activar el botón Cargar.
4. Haga clic en Cargar para buscar y cargar el archivo CSV desde un directorio local.
5. Opcional: Seleccione Primera fila como cabecera de columna para especificar si laprimera fila del archivo contiene nombres de columna. Si no selecciona esta opción, seasigna a las columnas un nombre genérico; por ejemplo, Column1, Column2. Losnombres de etiqueta XML y los nombres mostrados asignados se pueden editar en elseparador Estructura del editor del modelo de datos.
6. Seleccione el Delimitador de CSV utilizado en el archivo. La selección por defecto esComa (,).
7. Haga clic en Aceptar.
Capítulo 9Creación de un juego de datos mediante un archivo CSV
9-31

Edición del tipo de datoDespués de cargar un tipo de dato de archivo CSV, puede editarlo según seanecesario.
Para editar el tipo de dato de un elemento de archivo CSV, haga clic en el icono detipo de dato o actualícelo en el cuadro de diálogo Propiedades del elemento.
Los datos de un elemento deben ser compatibles con el tipo de dato que asigne. Lainterfaz de usuario no valida los datos cuando se actualiza el tipo de dato. Si los datosno coinciden (por ejemplo, si hay un valor de cadena para un elemento que hadefinido como Entero), pueden producirse errores en las herramientas de edición dediseño o en tiempo de ejecución.
Solo puede actualizar los tipos de dato para orígenes de datos de archivo CSV.
Refrescamiento y supresión de un archivo CSV cargadoPuede refrescar y suprimir archivos CSV cargados locales.
Después de cargar el archivo, este se muestra en el panel Propiedades del modelo dedatos en la región Anexos, como se muestra a continuación.
Para refrescar el archivo local en el modelo de datos:
1. En el panel de componentes, haga clic en Modelo de datos para ver la páginaPropiedades.
2. En la región Anexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Refrescar.
4. En el cuadro de diálogo Cargar, busque y cargue la versión más reciente delarchivo. El archivo debe tener el mismo nombre; de lo contrario, no sustituirá laversión anterior.
5. Guarde el modelo de datos.
Para suprimir el archivo local:
1. En el panel de componentes, haga clic en Modelo de datos para ver la páginaPropiedades.
Capítulo 9Creación de un juego de datos mediante un archivo CSV
9-32
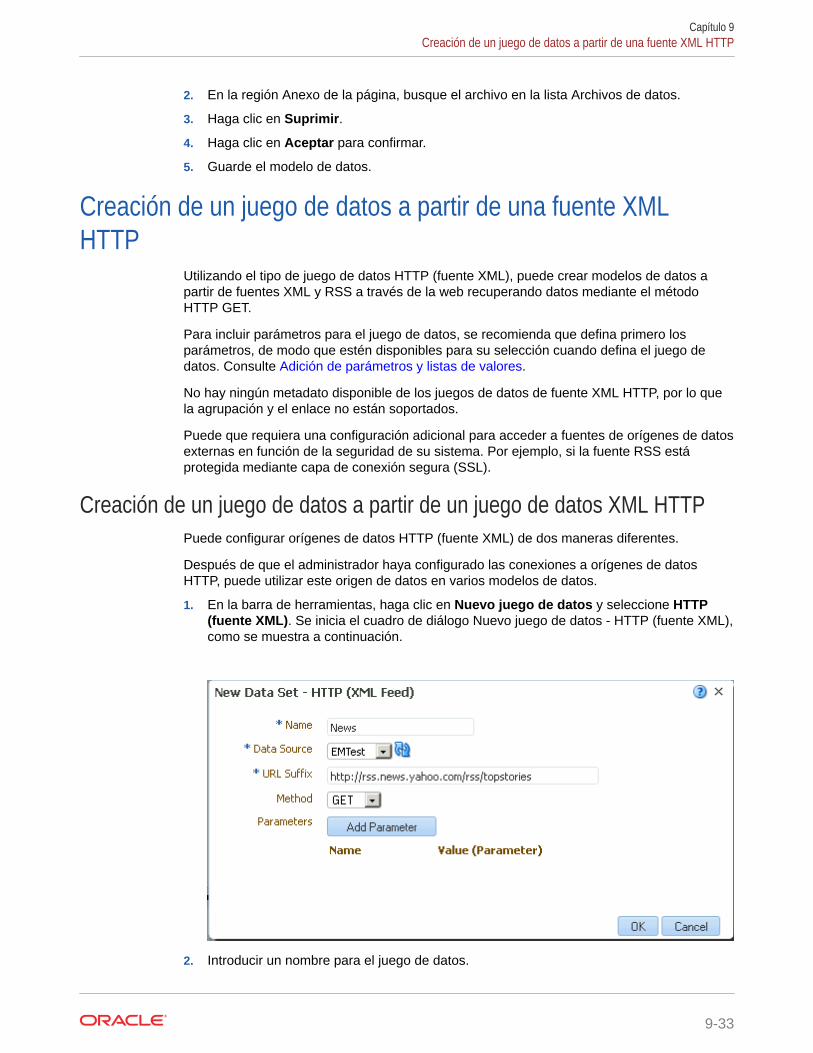
2. En la región Anexo de la página, busque el archivo en la lista Archivos de datos.
3. Haga clic en Suprimir.
4. Haga clic en Aceptar para confirmar.
5. Guarde el modelo de datos.
Creación de un juego de datos a partir de una fuente XMLHTTP
Utilizando el tipo de juego de datos HTTP (fuente XML), puede crear modelos de datos apartir de fuentes XML y RSS a través de la web recuperando datos mediante el métodoHTTP GET.
Para incluir parámetros para el juego de datos, se recomienda que defina primero losparámetros, de modo que estén disponibles para su selección cuando defina el juego dedatos. Consulte Adición de parámetros y listas de valores.
No hay ningún metadato disponible de los juegos de datos de fuente XML HTTP, por lo quela agrupación y el enlace no están soportados.
Puede que requiera una configuración adicional para acceder a fuentes de orígenes de datosexternas en función de la seguridad de su sistema. Por ejemplo, si la fuente RSS estáprotegida mediante capa de conexión segura (SSL).
Creación de un juego de datos a partir de un juego de datos XML HTTPPuede configurar orígenes de datos HTTP (fuente XML) de dos maneras diferentes.
Después de que el administrador haya configurado las conexiones a orígenes de datosHTTP, puede utilizar este origen de datos en varios modelos de datos.
1. En la barra de herramientas, haga clic en Nuevo juego de datos y seleccione HTTP(fuente XML). Se inicia el cuadro de diálogo Nuevo juego de datos - HTTP (fuente XML),como se muestra a continuación.
2. Introducir un nombre para el juego de datos.
Capítulo 9Creación de un juego de datos a partir de una fuente XML HTTP
9-33

3. Seleccione un origen de datos.
4. Introduzca el sufijo de URL para el origen de la fuente RSS o XML.
5. Seleccione el método: GET.
6. Para agregar un parámetro, haga clic en Agregar parámetro. Introduzca elNombre y seleccione el Valor. La lista Valor se propaga según el Nombre deparámetro definido en la sección Parámetros.
7. Haga clic en Aceptar para cerrar el cuadro de diálogo del juego de datos.
Uso de datos almacenados como un objeto grande decaracteres (CLOB) en un modelo de datos
Publisher soporta el uso de datos almacenados como el tipo de dato de objeto grandede caracteres (CLOB) en los modelos de datos Esta función le permite utilizar datosXML generados por un proceso independiente y almacenados en la base de datoscomo entrada para un modelo de datos de Publisher.
Utilice Query Builder para recuperar la columna de la consulta SQL y utilice el editorde modelo de datos para especificar cómo desea estructurar los datos. Cuando seejecuta el modelo de datos, el motor de datos puede estructurar los datos como:
• Un juego de caracteres sin formato en un nombre de etiqueta XML que se puedemostrar en un informe (por ejemplo, una Descripción del elemento)
• Un XML estructurado
Asegúrese de que los datos no incluyen saltos de línea ni retornos de carro. Esposible que los saltos de línea y los retornos de carro en los datos no serepresenten de la forma esperada en los diseños de informe.
Para crear un juego de datos a partir de datos almacenados como un CLOB:
1. En la barra de herramientas, haga clic en Nuevo juego de datos y, acontinuación, seleccione Consulta SQL. Se inicia el cuadro de diálogo Nuevojuego de datos - Consulta SQL.
2. Introduzca un nombre para el juego de datos.
3. Si no está utilizando el origen de datos por defecto para este juego de datos,seleccione Origen de datos en la lista.
4. Introduzca la consulta SQL o utilice Query Builder para construir la consulta pararecuperar la columna de datos CLOB.
Por ejemplo, puede crear una consulta en la que los datos CLOB se almacenenen una columna denominada "DESCRIPTION".
Capítulo 9Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelo de datos
9-34
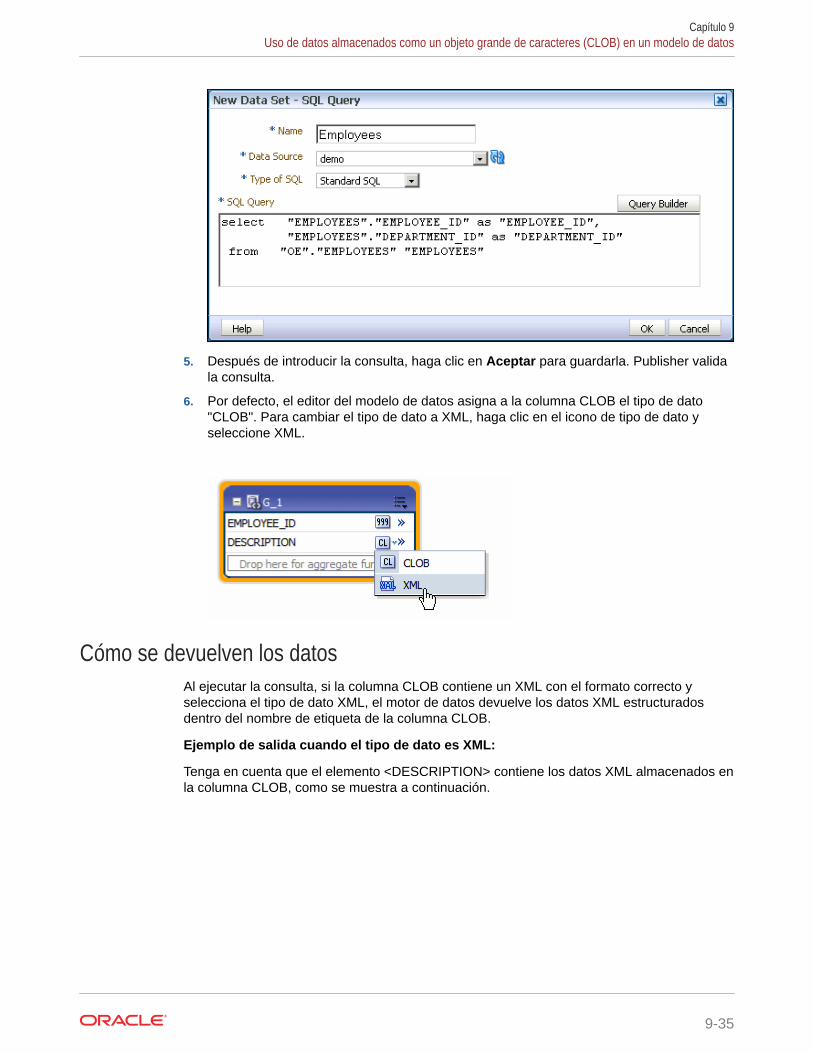
5. Después de introducir la consulta, haga clic en Aceptar para guardarla. Publisher validala consulta.
6. Por defecto, el editor del modelo de datos asigna a la columna CLOB el tipo de dato"CLOB". Para cambiar el tipo de dato a XML, haga clic en el icono de tipo de dato yseleccione XML.
Cómo se devuelven los datosAl ejecutar la consulta, si la columna CLOB contiene un XML con el formato correcto yselecciona el tipo de dato XML, el motor de datos devuelve los datos XML estructuradosdentro del nombre de etiqueta de la columna CLOB.
Ejemplo de salida cuando el tipo de dato es XML:
Tenga en cuenta que el elemento <DESCRIPTION> contiene los datos XML almacenados enla columna CLOB, como se muestra a continuación.
Capítulo 9Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelo de datos
9-35

Ejemplo de salida cuando el tipo de dato es CLOB:
Si selecciona devolver los datos como el tipo de dato CLOB, los datos devueltos seestructuran como se muestra a continuación.
Capítulo 9Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelo de datos
9-36

Notas adicionales sobre los juegos de datos con datos de la columna CLOBDispone de más información en los datos de la columna CLOB.
Para consultar notas específicas sobre el uso de los datos de la columna CLOB en unaconsulta de repartición, consulte Uso de una consulta SQL para agregar una definición derepartición al modelo de datos.
Gestión de datos XHTML almacenados en una columna CLOBLos datos de documentos XHTML almacenados en una columna CLOB de base de datospueden representar el marcador en el informe generado.
Para que el motor de representación de informes pueda gestionar las etiquetas de marcador,debe encapsular los datos XHTML en una sección CDATA dentro de los datos del informeXML que transfiere el motor de datos.
Se recomienda que almacene los datos en la base de datos encapsulados en la secciónCDATA. A continuación, puede utilizar una sentencia select simple para extraer los datos. Silos datos no están encapsulados en la sección CDATA, debe incluir instrucciones en lasentencia SQL para encapsularlos.
En las secciones siguientes se describe cómo extraer datos XHTML en cada caso:
• Recuperación de datos XHTML encapsulados en CDATA
• Encapsulamiento de datos XHTML en CDATA en la consulta
Solo las plantillas RTF soportan la representación del marcador HTML en un informe.
Recuperación de datos XHTML encapsulados en CDATAEn este ejercicio se asume que tiene los siguientes datos almacenados en columna de basede datos denominada "CLOB_DATA".
<![CDATA[<p><font style="font-style: italic; font-weight: bold;" size="3"><a href="http://www.oracle.com">oracle</a></font> </p><p><font size="6"><a href="http://docs.oracle.com/">Oracle Documentation</a></font></p>]]>
Recupere los datos de la columna con una sentencia SQL sencilla, por ejemplo:
select CLOB_DATA as "RTECODE" from MYTABLEEn el editor de modelo de datos, defina el tipo de dato de la columna RTECODE en XML,como se muestra a continuación.
Capítulo 9Uso de datos almacenados como un objeto grande de caracteres (CLOB) en un modelo de datos
9-37

Encapsulamiento de datos XHTML en CDATA en la consultaEn este ejercicio se asume que tiene los siguientes datos almacenados en la columnade base de datos denominada "CLOB_DATA".
<p><font style="font-style: italic; font-weight: bold;" size="3"><a href="http://www.oracle.com">oracle</a></font> </p><p><font size="6"><a href="http://docs.oracle.com/">Oracle Documentation</a></font></p>
Utilice la siguiente sintaxis de la consulta SQL para recuperarla e incluirla en lasección CDATA:
select '<![CDATA' || '['|| CLOB_DATA || ']' || ']>' as "RTECODE"from MYTABLE
En el editor de modelo de datos, defina el tipo de dato de la columna RTECODE enXML.
Prueba de modelos de datos y generación de datos deejemplo
El editor de modelo de datos le permite probar el modelo de datos y ver el resultadopara asegurarse de que la salida en la esperada.
Después de ejecutar una prueba correcta, puede seleccionar guardar la salida de laprueba como datos de ejemplo para el modelo de datos. También puede utilizar lafunción Exportar para exportar datos de ejemplo a un archivo. Si falla la ejecución delmodelo de datos, puede ver el log del motor de datos.
Para probar el modelo de datos:
1. En el editor del modelo de datos, seleccione el separador Datos, como semuestra a continuación.
Capítulo 9Prueba de modelos de datos y generación de datos de ejemplo
9-38

2. Para los juegos de datos de objeto de vista, análisis y consulta SQL: en el separadorDatos, seleccione el número de filas que se va a devolver. Si ha incluido parámetros,introduzca los valores deseados para la prueba.
3. Haga clic en Ver para mostrar el XML que devuelve el modelo de datos.
4. Seleccione una de las siguientes opciones para mostrar los datos de ejemplo:
• Utilice la Vista de árbol para ver los datos de ejemplo en una jerarquía de datos.Esta es la opción de visualización por defecto.
• Utilice Vista de tabla para ver los datos de ejemplo en una tabla con formato comola que se muestra en los informes de Publisher.
Puede crear un informe basado en este modelo de datos.
Para guardar el juego de datos de prueba como datos de ejemplo del modelo de datos:
1. Una vez que se ha ejecutado correctamente el modelo de datos, haga clic en Guardarcomo datos de ejemplo. Los datos de ejemplo se guardan en el modelo de datos.
Para exportar los datos de prueba:
1. Para los juegos de datos de objeto de vista, análisis y consulta SQL: en el separadorDatos, seleccione el número de filas que se va a devolver.
2. Una vez que se ha ejecutado correctamente el modelo de datos, haga clic en Exportar.Se le solicitará que abra o guarde el archivo en un directorio local.
Para ver el log del motor de datos:
1. Haga clic en Ver log de motor de datos. Se le solicitará que abra o guarde el archivo enun directorio local. El archivo log del motor de datos es un archivo XML.
Para probar el juego de datos de UCM:
Para Content Server, en función del identificador de documento y el tipo de contenido, elcontenido del documento se recupera del servidor (UCM) de contenidos. Sin embargo, si elidentificador de documento es nulo o está vacío, el contenido del documento estará vacío.
Editar un juego de datos existentePuede modificar modelos de datos mediante la edición de los juegos de datos de un modelode datos.
Para editar un juego de datos existente:
1. En el panel de componentes del editor del modelo de datos, haga clic en Juegos dedatos. Se muestran todos los juegos de datos de este modelo de datos.
2. Haga clic en el juego de datos que desea editar.
3. Haga clic en Editar juego de datos seleccionado. Se abre el cuadro de diálogo para eljuego de datos.
Capítulo 9Editar un juego de datos existente
9-39
4. Realice los cambios en el juego de datos y haga clic en Aceptar.
5. Guarde el modelo de datos.
6. Pruebe el modelo de datos editado y agregue nuevos datos de ejemplo.
Inclusión de información de usuario almacenada envariables del sistema en los datos del informe
Publisher almacena información sobre el usuario actual a la que puede acceder elmodelo de datos del informe.
La información de usuario se almacena en las variables del sistema como se describea continuación.
Variable del sistema Descripción
xdo_user_name Identificador de usuario del usuario que envía el informe.Por ejemplo: Administrador
xdo_user_roles Roles asignados al usuario que envía el informe. Porejemplo: XMLP_ADMIN, XMLP_SCHEDULER
xdo_user_report_oracle_lang
Idioma del informe de las preferencias de cuenta delusuario. Por ejemplo: ZHS
xdo_user_report_locale Configuración regional del informe de las preferencias decuenta del usuario. Por ejemplo: en-US
xdo_user_ui_oracle_lang Idioma de la interfaz de usuario de las preferencias decuenta del usuario. Por ejemplo: US
xdo_user_ui_locale Configuración regional de la interfaz de usuario de laspreferencias de cuenta del usuario. Por ejemplo: en-US
Publisher rellena las variables del sistema en un informe en línea. En un trabajoprogramado, Publisher no rellena las variables del sistemaXDO_USER_REPORT_LOCALE, XDO_USER_UI_LOCALE niXDO_USER_UI_ORACLE_LANG.
Capítulo 9Inclusión de información de usuario almacenada en variables del sistema en los datos del informe
9-40

Adición de las variables del sistema de usuario como elementosPara agregar la información de usuario al modelo de datos, puede definir las variables comoparámetros y definir el valor del parámetro como elemento en su modelo de datos.
También puede simplemente agregar las variables como parámetros para, a continuación,hacer referencia a los valores de parámetros en su informe.
La siguiente consulta:
select:xdo_user_name as USER_ID,:xdo_user_roles as USER_ROLES,:xdo_user_report_oracle_lang as REPORT_LANGUAGE,:xdo_user_report_locale as REPORT_LOCALE,:xdo_user_ui_oracle_lang as UI_LANGUAGE,:xdo_user_ui_locale as UI_LOCALEfrom dual
devolverá el siguiente resultado:
<?xml version="1.0" encoding="UTF-8"?><! - Generated by Publisher - ><DATA_DS><G_1><USER_ROLES>XMLP_TEMPLATE_DESIGNER, XMLP_DEVELOPER, XMLP_ANALYZER_EXCEL, XMLP_ADMIN, XMLP_ANALYZER_ONLINE, XMLP_SCHEDULER </USER_ROLES><REPORT_LANGUAGE>US</REPORT_LANGUAGE><REPORT_LOCALE>en_US</REPORT_LOCALE><UI_LANGUAGE>US</UI_LANGUAGE><UI_LOCALE>en_US</UI_LOCALE><USER_ID>administrator</USER_ID></G_1></DATA_DS>
Caso de uso de ejemplo: Límite del juego de datos devuelto por el ID deusuario
En el siguiente ejemplo se limitan los datos que devuelve el ID de usuario.
select EMPLOYEES.LAST_NAME as LAST_NAME, EMPLOYEES.PHONE_NUMBER as PHONE_NUMBER, EMPLOYEES.HIRE_DATE as HIRE_DATE, :xdo_user_name as USERID from HR.EMPLOYEES EMPLOYEESwhere lower(EMPLOYEES.LAST_NAME) = :xdo_user_name
Observe el uso de la función lower(). El elemento xdo_user_name siempre tiene el formatode minúsculas. Publisher no tiene un elemento USERID, por lo que debe usar el nombre deusuario y usarlo directamente en la consulta, o bien podría realizar una consulta en una tablade búsqueda para encontrar un ID de usuario.
Capítulo 9Inclusión de información de usuario almacenada en variables del sistema en los datos del informe
9-41

Creación de variables de enlace desde los valores de atributo de usuario deLDAP
Para enlazar los valores de atributo de usuario almacenados en su directorio de LDAPa una consulta de datos, puede definir los nombres de atributos en Publisher paracrear las variables de enlace necesarias.
RequisitoLos atributos que se pueden usar para crear las variables de enlace las debe definiren la página Configuración de seguridad un administrador.
Los atributos se definen en el campo Nombres de atributo para variables de enlace deconsultas de datos de la definición del modelo de seguridad LDAP. Se puede usarcualquier atributo definido para los usuarios (por ejemplo: memberOf,sAMAccountName, primaryGroupID, mail).
Cómo construye Publisher la variable de enlacePuede hacer referencia a los nombres de atributo que introduce en el campoNombres de atributo para variables de enlace de consultas de datos de ladefinición Modelo de seguridad de LDAP en la consulta.
A continuación, se muestra cómo se construyen las variables de enlace:
xdo_<attribute name>
Suponga que ha introducido los atributos de ejemplo: memberOf, sAMAccountName,primaryGroupID, mail. Estos se pueden utilizar a continuación en una consulta comolas siguientes variables de enlace:
xdo_memberofxdo_SAMACCOUNTNAMExdo_primaryGroupIDxdo_mail
Tenga en cuenta que se omiten las mayúsculas y minúsculas del atributo; sinembargo, el prefijo "xdo_" debe estar en minúsculas.
Utilícelos en un modelo de datos como se muestra a continuación:
SELECT:xdo_user_name AS USER_NAME,:xdo_user_roles AS USER_ROLES,:xdo_user_ui_oracle_lang AS USER_UI_LANG,:xdo_user_report_oracle_lang AS USER_REPORT_LANG,:xdo_user_ui_locale AS USER_UI_LOCALE,:xdo_user_report_locale AS USER_REPORT_LOCALE,:xdo_SAMACCOUNTNAME AS SAMACCOUNTNAME,:xdo_memberof as MEMBER_OF,:xdo_primaryGroupID as PRIMARY_GROUP_ID,
Capítulo 9Inclusión de información de usuario almacenada en variables del sistema en los datos del informe
9-42

:xdo_mail as MAILFROM DUAL
Las variables de enlace de LDAP devuelven los valores almacenados en el directorio deLDAP para el usuario que está conectado.
Capítulo 9Inclusión de información de usuario almacenada en variables del sistema en los datos del informe
9-43

10Estructuración de datos
En este tema se describen las técnicas para estructurar los datos que devuelve el motor dedatos de Publisher, incluida la agrupación, el enlace, los filtros de grupo, así como lasfunciones de nivel global y de grupo.
Temas:
• Trabajar con modelos de datos
• Funciones del editor del modelo de datos
• Acerca de la interfaz
• Crear enlaces entre juegos de datos.
• Creación de enlaces de nivel de elemento
• Creación de subgrupos
• Movimiento de un elemento entre un grupo principal y un grupo secundario
• Creación de elementos de agregado de nivel de grupo
• Creación de filtros de grupo
• Realización de funciones a nivel de elemento
• Definición de propiedades de elementos
• Ordenar datos
• Realización de funciones de nivel de grupo
• Realización de funciones de nivel global
• Uso de la vista Estructura para editar la estructura de datos
• Referencia de función
Trabajar con modelos de datosEl diagrama Modelo de datos le ayuda a definir de forma rápida y sencilla juegos de datos,grupos de división y totales para un informe en función de varios juegos de datos.
• Acerca de los juegos de datos no relacionados de varias partes
• Acerca de los juegos de datos relacionados de varias partes
• Directrices para trabajar con juegos de datos
Acerca de los juegos de datos no relacionados de varias partesSi no enlaza los juegos de datos (o consultas), el motor de datos produce un juego de datosde consulta no relacionados de varias partes.
Por ejemplo, en el modelo de datos, cuya imagen aparece abajo, una consulta seleccionaproducts y otra selecciona customers. No existe relación entre los productos y los clientes.
10-1

El resultado se muestra en la estructura de datos tal y como aparece en la siguienteimagen.
Capítulo 10Trabajar con modelos de datos
10-2
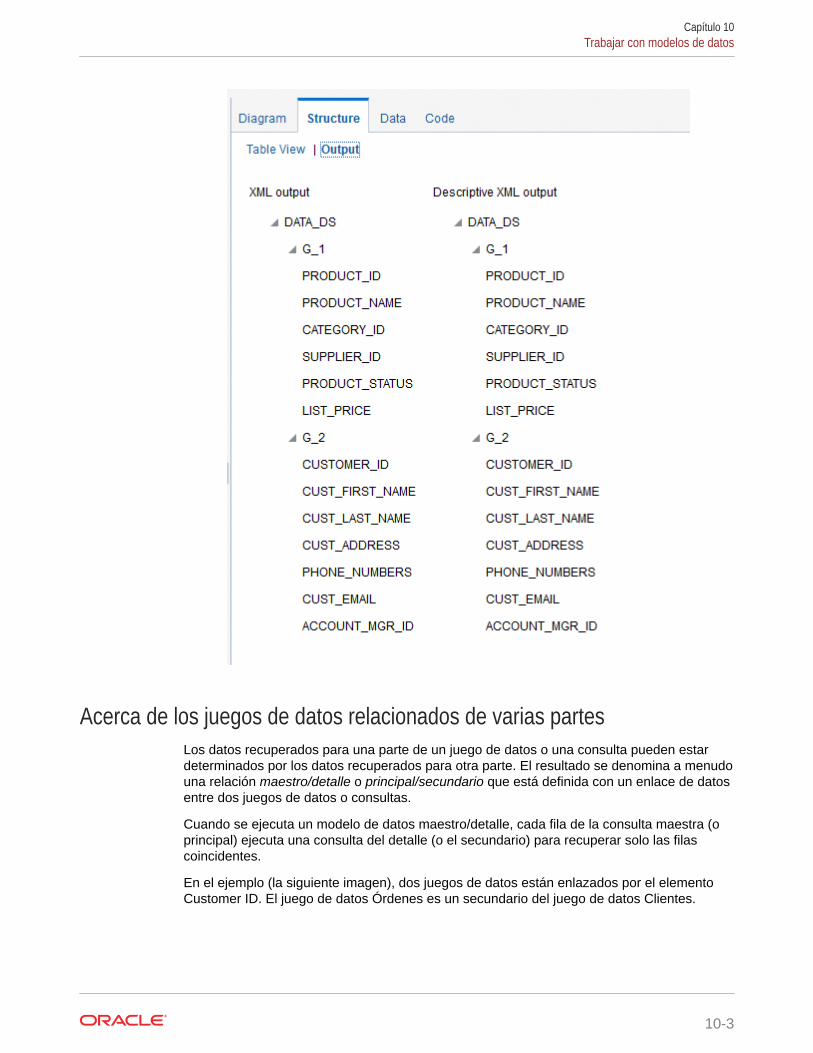
Acerca de los juegos de datos relacionados de varias partesLos datos recuperados para una parte de un juego de datos o una consulta pueden estardeterminados por los datos recuperados para otra parte. El resultado se denomina a menudouna relación maestro/detalle o principal/secundario que está definida con un enlace de datosentre dos juegos de datos o consultas.
Cuando se ejecuta un modelo de datos maestro/detalle, cada fila de la consulta maestra (oprincipal) ejecuta una consulta del detalle (o el secundario) para recuperar solo las filascoincidentes.
En el ejemplo (la siguiente imagen), dos juegos de datos están enlazados por el elementoCustomer ID. El juego de datos Órdenes es un secundario del juego de datos Clientes.
Capítulo 10Trabajar con modelos de datos
10-3

Este ejemplo genera la estructura de datos que se muestra en la siguiente imagen.
Capítulo 10Trabajar con modelos de datos
10-4

Directrices para trabajar con juegos de datosSe recomiendan unas directrices determinadas para crear modelos de datos.
• Reduzca el número de juegos de datos o consultas en el modelo de datos tanto comosea posible. En general, cuantos menos juegos de datos y consultas tenga, más rápidose ejecutará el modelo de datos. Si bien los modelos de datos de varias consultas amenudo son más sencillos de entender, los modelos de datos de una sola consultasuelen ejecutarse con más rapidez. Es importante entender que en las consultasprincipal-secundaria, para cada principal, se ejecuta la consulta secundaria.
• Solo debe utilizar modelos de datos de varias consultas en los siguientes casos:
– Para realizar funciones que no están soportadas directamente por el tipo deconsulta, como una consulta SQL.
Capítulo 10Trabajar con modelos de datos
10-5
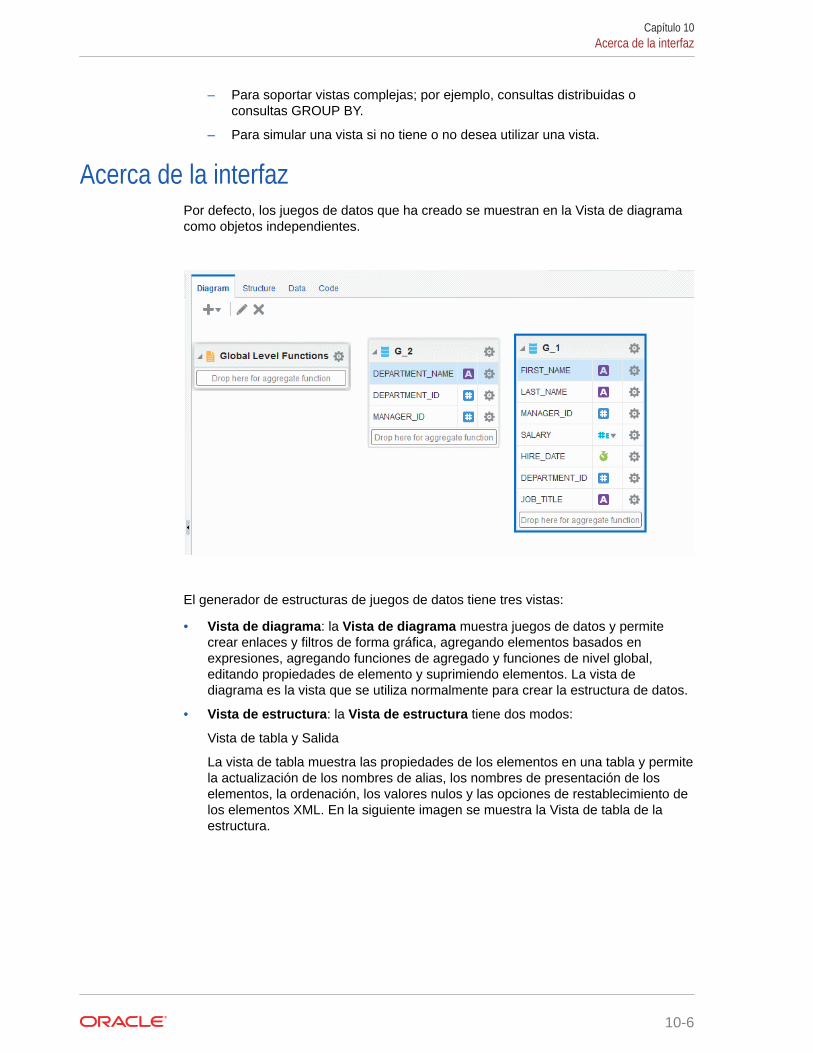
– Para soportar vistas complejas; por ejemplo, consultas distribuidas oconsultas GROUP BY.
– Para simular una vista si no tiene o no desea utilizar una vista.
Acerca de la interfazPor defecto, los juegos de datos que ha creado se muestran en la Vista de diagramacomo objetos independientes.
El generador de estructuras de juegos de datos tiene tres vistas:
• Vista de diagrama: la Vista de diagrama muestra juegos de datos y permitecrear enlaces y filtros de forma gráfica, agregando elementos basados enexpresiones, agregando funciones de agregado y funciones de nivel global,editando propiedades de elemento y suprimiendo elementos. La vista dediagrama es la vista que se utiliza normalmente para crear la estructura de datos.
• Vista de estructura: la Vista de estructura tiene dos modos:
Vista de tabla y Salida
La vista de tabla muestra las propiedades de los elementos en una tabla y permitela actualización de los nombres de alias, los nombres de presentación de loselementos, la ordenación, los valores nulos y las opciones de restablecimiento delos elementos XML. En la siguiente imagen se muestra la Vista de tabla de laestructura.
Capítulo 10Acerca de la interfaz
10-6

La vista Salida proporciona una vista clara de la estructura XML que se genera. La vistaSalida no se puede actualizar. En la figura se muestra la vista Salida.
Capítulo 10Acerca de la interfaz
10-7

• Vista de código: la Vista de código muestra el código de estructura de datoscreado por el generador de estructuras de datos que lee el motor de datos. Puedeactualizar el contenido en la vista de código. En la figura se muestra la vista decódigo.
Capítulo 10Acerca de la interfaz
10-8

Crear enlaces entre juegos de datos.Puede utilizar el motor de datos de Publisher para combinar y estructurar datos después deextraerlos del origen de datos.
A veces, no es posible la unión y la estructuración de datos en el origen en un juego dedatos combinado. Por ejemplo, no puede unir datos en el origen si los datos residen enorígenes diferentes, como Microsoft SQL Server y una base de datos Oracle Database.Incluso si los datos proceden del mismo origen, si va a crear informes o documentos grandesque puedan contener cientos de miles de filas o páginas, la estructuración de los datos paraque coincidan con el diseño deseado optimiza la generación de documentos.
Cree un enlace para definir una relación maestro-detalle o principal-secundaria entre dosjuegos de datos. Puede crear enlaces como enlaces de nivel de elemento. Los enlacesgrupo-nivel se proporcionan para la compatibilidad con plantillas de datos de versionesanteriores de Publisher. Para los juegos de datos migrados, suprima los enlaces de grupo ycree enlaces de elemento. Si se crean enlaces de nivel de grupo entre juegos de datos, sepueden corromper los datos.
Un enlace de datos o una relación principal-secundario relaciona los resultados de variasconsultas. Un enlace de datos puede establecer las siguientes relaciones:
• Entre una columna de una consulta y una columna de otra consulta.
• Entre un grupo de una consulta y un grupo de otra consulta; es útil cuando se desea quela consulta secundaria conozca los datos de su principal.
Acerca de los enlaces de nivel de elementoLos elementos de nivel de elemento crean un enlace (unión) entre dos juegos de datos ydefinen una relación maestro-detalle (principal-secundario) entre ellos.
Capítulo 10Crear enlaces entre juegos de datos.
10-9

Cree enlaces de nivel de elemento, el método preferido, para definir relacionesmaestro-detalle entre los juegos de datos. Al usar enlaces de nivel de elemento paraenlazar juegos de datos, no necesita codificar una unión entre los dos juegos de datosmediante una variable de enlace.
Creación de enlaces de nivel de elementoEnlace los juegos de datos para definir una relación maestro-detalle o principal-secundario entre dos juegos de datos.
Al definir un enlace de nivel de elemento le permite establecer el enlace entre loselementos de los juegos de datos maestros y de detalle.
1. Abra el menú de acción de elemento y haga clic en Crear enlace
2. En el cuadro de diálogo Crear enlace, seleccione el elemento y haga clic enAceptar para crear el enlace.
A continuación se muestra el cuadro de diálogo Crear enlace.
Eliminación de enlaces de nivel de elementoPuede suprimir tanto los enlaces a nivel de grupo como los enlaces a nivel deelemento entre juegos de datos.
• Puede:.
– Abra el menú de acción de elemento para el elemento y haga clic en Suprimirenlace
– Seleccione el conector de elementos para mostrar los nombres de elementosenlazados y haga clic en el botón Suprimir.
Capítulo 10Creación de enlaces de nivel de elemento
10-10
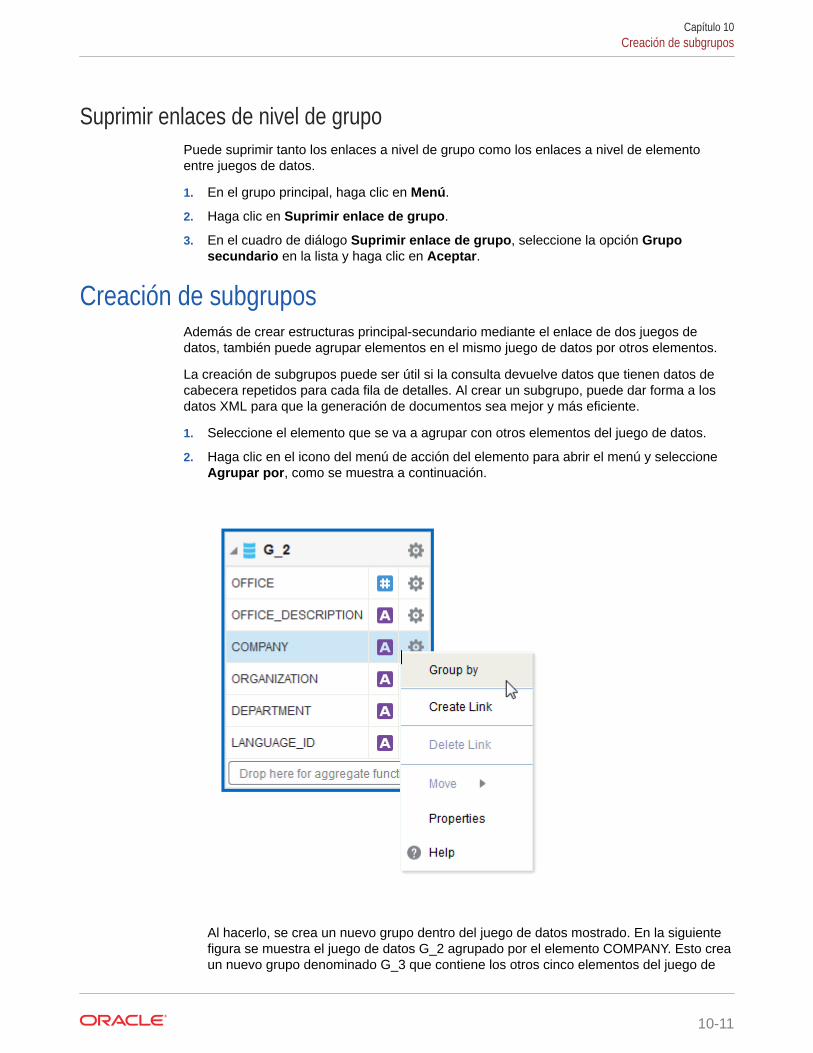
Suprimir enlaces de nivel de grupoPuede suprimir tanto los enlaces a nivel de grupo como los enlaces a nivel de elementoentre juegos de datos.
1. En el grupo principal, haga clic en Menú.
2. Haga clic en Suprimir enlace de grupo.
3. En el cuadro de diálogo Suprimir enlace de grupo, seleccione la opción Gruposecundario en la lista y haga clic en Aceptar.
Creación de subgruposAdemás de crear estructuras principal-secundario mediante el enlace de dos juegos dedatos, también puede agrupar elementos en el mismo juego de datos por otros elementos.
La creación de subgrupos puede ser útil si la consulta devuelve datos que tienen datos decabecera repetidos para cada fila de detalles. Al crear un subgrupo, puede dar forma a losdatos XML para que la generación de documentos sea mejor y más eficiente.
1. Seleccione el elemento que se va a agrupar con otros elementos del juego de datos.
2. Haga clic en el icono del menú de acción del elemento para abrir el menú y seleccioneAgrupar por, como se muestra a continuación.
Al hacerlo, se crea un nuevo grupo dentro del juego de datos mostrado. En la siguientefigura se muestra el juego de datos G_2 agrupado por el elemento COMPANY. Esto creaun nuevo grupo denominado G_3 que contiene los otros cinco elementos del juego de
Capítulo 10Creación de subgrupos
10-11
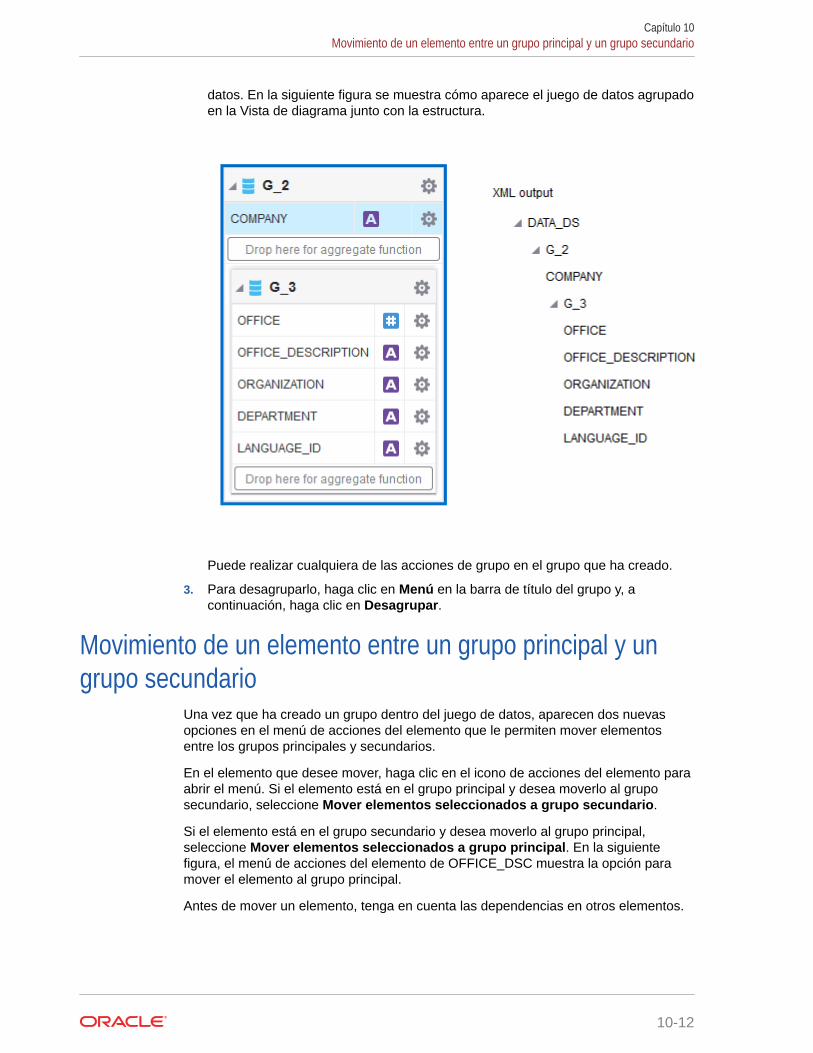
datos. En la siguiente figura se muestra cómo aparece el juego de datos agrupadoen la Vista de diagrama junto con la estructura.
Puede realizar cualquiera de las acciones de grupo en el grupo que ha creado.
3. Para desagruparlo, haga clic en Menú en la barra de título del grupo y, acontinuación, haga clic en Desagrupar.
Movimiento de un elemento entre un grupo principal y ungrupo secundario
Una vez que ha creado un grupo dentro del juego de datos, aparecen dos nuevasopciones en el menú de acciones del elemento que le permiten mover elementosentre los grupos principales y secundarios.
En el elemento que desee mover, haga clic en el icono de acciones del elemento paraabrir el menú. Si el elemento está en el grupo principal y desea moverlo al gruposecundario, seleccione Mover elementos seleccionados a grupo secundario.
Si el elemento está en el grupo secundario y desea moverlo al grupo principal,seleccione Mover elementos seleccionados a grupo principal. En la siguientefigura, el menú de acciones del elemento de OFFICE_DSC muestra la opción paramover el elemento al grupo principal.
Antes de mover un elemento, tenga en cuenta las dependencias en otros elementos.
Capítulo 10Movimiento de un elemento entre un grupo principal y un grupo secundario
10-12

Creación de elementos de agregado de nivel de grupoPuede utilizar el editor de modelo de datos para agregar datos en el nivel de grupo o deinforme.
Por ejemplo, si agrupa los datos de ventas por Nombre del cliente, puede agregar ventaspara obtener un subtotal de las ventas de cada cliente. Solo se pueden agregar datos en elnivel principal para un elemento secundario.
Las funciones de agregado son las siguientes:
• Media: calcula la media de todas las incidencias de un elemento.
• Recuento: cuenta el número de incidencias de un elemento.
• Primero: muestra el valor de la primera incidencia de un elemento en el grupo.
• Último: muestra el valor de la última incidencia de un elemento en el grupo.
• Máximo: muestra el valor más alto de todas las incidencias de un elemento en el grupo.
• Mínimo: muestra el valor más bajo de todas las incidencias de un elemento en el grupo.
• Resumen: muestra el valor de todas las incidencias de un elemento en el grupo.
1. Arrastre el elemento hasta el campo Suelte aquí la función de agregado en el grupoprincipal.
En la siguiente figura se muestra la creación de una función de agregado de nivel degrupo en G_DEPT basada en el elemento SALARY.
Capítulo 10Creación de elementos de agregado de nivel de grupo
10-13

Cuando se suelta el elemento, se crea un nuevo elemento en el grupo principal.Por defecto, se aplica la función Recuento. El icono situado junto al nombre delnuevo elemento de agregado indica la función. Detenga el cursor sobre el iconopara mostrar la función.
En la siguiente figura se muestra el nuevo elemento de agregado, CS_1, con lafunción por defecto Recuento definida.
Capítulo 10Creación de elementos de agregado de nivel de grupo
10-14
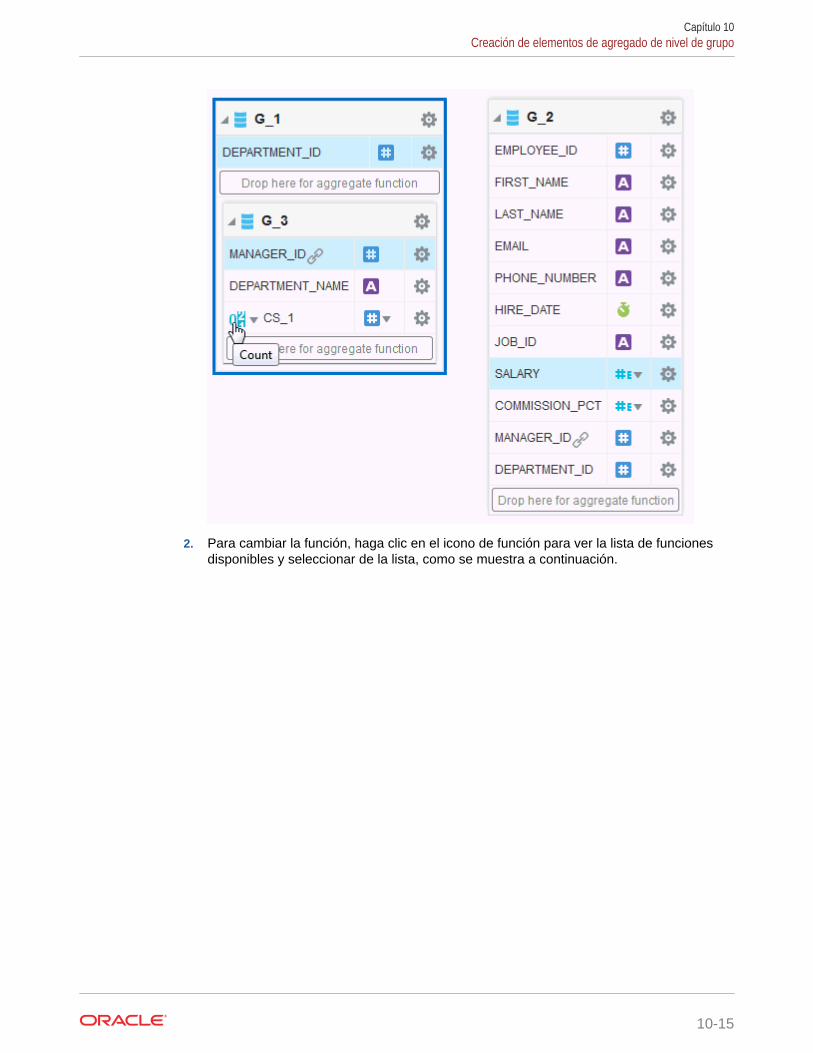
2. Para cambiar la función, haga clic en el icono de función para ver la lista de funcionesdisponibles y seleccionar de la lista, como se muestra a continuación.
Capítulo 10Creación de elementos de agregado de nivel de grupo
10-15

3. Para renombrar el elemento o actualizar otras propiedades, haga clic en el iconode menú Acción del elemento. Compruebe si el elemento tiene una dependenciade otros elementos antes de renombrarlo.
Capítulo 10Creación de elementos de agregado de nivel de grupo
10-16

En el menú, haga clic en Propiedades. A continuación, se muestra el cuadro de diálogoPropiedades.
4. En el cuadro de diálogo Editar propiedades, configure las propiedades según seanecesario.
Capítulo 10Creación de elementos de agregado de nivel de grupo
10-17

• Nombre de columna: nombre interno que asigna al elemento el editor demodelo de datos de Publisher. Este nombre no se puede actualizar.
• Alias (nombre de etiqueta XML): Publisher asigna un nombre de etiquetapor defecto para el elemento en el archivo de datos XML. Puede actualizareste nombre de etiqueta para asignar un nombre más fácil de recordar en elarchivo de datos.
• Nombre mostrado: el nombre mostrado aparece en las herramientas dediseño de informe. Actualice este nombre para que sea significativo para losusuarios de negocio.
• Función: si aún no ha seleccionado la función deseada, puede seleccionarlaen esta lista.
• Tipo de dato: Publisher asigna un tipo de dato Entero o Doble por defectosegún la función. Algunas funciones también proporcionan la opción Flotante.
• Valor si es Nulo: si el valor que devuelve la función es nulo, puedeproporcionar aquí un valor por defecto para evitar que haya un valor nulo enlos datos.
• Redondear: por defecto, el valor se redondea al tercer decimal más cercano.Puede cambiar el valor de redondeo, si es necesario.
• Do restablecer: por defecto, la función se restablece en el nivel de grupo. Porejemplo, si el juego de datos se agrupa por DEPARTMENT_ID y ha definidouna función de suma para SALARY, la suma se restablece para cada grupode datos de DEPARTMENT_ID, lo cual le proporciona la suma SALARY solopara dicho departamento. Si, por el contrario, desea que la función serestablezca solo en el nivel global, y no en el nivel de grupo, seleccione Norestablecer. De este modo, se crea un total actualizado SALARY para todoslos departamentos. Esta propiedad es solo para las funciones de nivel degrupo.
Creación de filtros de grupoLos filtros le permiten eliminar condicionalmente registros seleccionados por susconsultas.
Los filtros de grupo funcionan para las columnas dentro de los elementos del grupo dejuego de datos. Es posible que los filtros de grupo no funcionen para los elementos deexpresión y los elementos de grupos de otro juego de datos.
Los grupos pueden tener dos tipos de filtro:
• Expresión: cree una expresión utilizando funciones y operadores predefinidos
• Función PL/SQL: cree un filtro personalizado
Una vez que ha agregado un filtro de grupo, el objeto de juego de datos muestra elindicador de filtro.
Para crear filtros de grupo:
1. Haga clic en Menú y, a continuación, seleccione Crear filtro de grupo.
2. Seleccione el Tipo de filtro de grupo: Expresión o PL/SQL. Para los filtros PL/SQL, asegúrese de especificar el Paquete PL/SQL como Paquete por defectoOracle DB en las propiedades del modelo de datos.
Capítulo 10Creación de filtros de grupo
10-18

3. Introduzca el filtro:
• Para introducir una expresión, seleccione los elementos y muévalos al cuadro dedefinición Filtro de grupo. Haga clic en las funciones y los operadores predefinidospara insertarlos en el cuadro Filtro de grupo.Haga clic en Validar expresión para asegurarse de que la entrada es válida.
• Para introducir una función PL/SQL, seleccione el paquete PL/SQL en el cuadroDisponible y mueva la función al cuadro Filtro de grupo.La función PL/SQL del paquete por defecto debe devolver un tipo booleano.
Realización de funciones a nivel de elementoPuede realizar varias funciones a nivel de elemento.
• Agrupo por un elemento para crear un subgrupo, como se describe en Creación desubgrupos
• Cree enlaces de nivel de elemento entre juegos de datos, como se describe en Creaciónde enlaces de nivel de elemento
• Defina las propiedades de elementos, como se describe en Definición de propiedades deelementos
Definición de propiedades de elementosPuede definir propiedades para elementos individuales.
Tenga en cuenta que estas propiedades también se pueden editar en la vista de estructura.Si necesita actualizar varias propiedades de elemento, puede ser más eficiente utilizar lavista de estructura.
Para definir las propiedades de nivel de elemento mediante el cuadro de diálogo delelemento:
1. Haga clic en el icono del menú de acciones del elemento. En el menú, seleccionePropiedades.
2. Defina las propiedades según sea necesario.
• Alias: Publisher asigna un nombre de etiqueta por defecto al elemento en el archivode datos XML. Puede actualizar este nombre de etiqueta para asignar un nombremás fácil de recordar en el archivo de datos.
• Nombre mostrado: el Nombre mostrado aparece en las herramientas de diseño deinforme y el nombre de columna en los informes. Actualice este nombre para quesea significativo para los usuarios de negocio.
• Tipo de dato: Publisher asigna un tipo de dato por defecto. Los valores válidos sonCadena, Fecha, Entero, Doble, Flotante.
• Ordenación: puede ordenar los datos XML de un grupo por uno o más elementos.Por ejemplo, si en un juego de datos los empleados se agrupan por departamento ygestor, puede ordenar los datos XML por departamento. Dentro de cadadepartamento, puede agrupar y ordenar los datos por gestor, y dentro de cadasubgrupo de gestor, los empleados se pueden ordenar por salario. Si el elemento noestá en un grupo principal, la propiedad Orden de clasificación no está disponible.
• Valor si es nulo: i el valor de una incidencia del elemento es nulo, puede suministrarun valor por defecto aquí para evitar un valor nulo en los datos.
Capítulo 10Realización de funciones a nivel de elemento
10-19
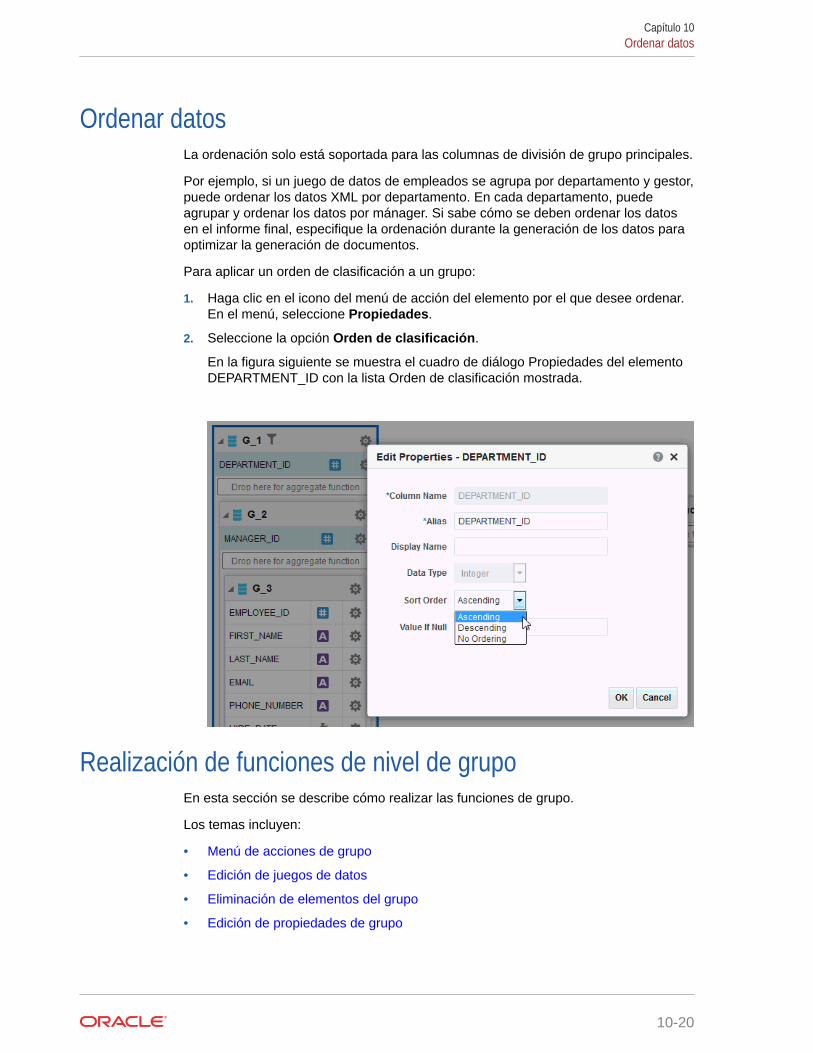
Ordenar datosLa ordenación solo está soportada para las columnas de división de grupo principales.
Por ejemplo, si un juego de datos de empleados se agrupa por departamento y gestor,puede ordenar los datos XML por departamento. En cada departamento, puedeagrupar y ordenar los datos por mánager. Si sabe cómo se deben ordenar los datosen el informe final, especifique la ordenación durante la generación de los datos paraoptimizar la generación de documentos.
Para aplicar un orden de clasificación a un grupo:
1. Haga clic en el icono del menú de acción del elemento por el que desee ordenar.En el menú, seleccione Propiedades.
2. Seleccione la opción Orden de clasificación.
En la figura siguiente se muestra el cuadro de diálogo Propiedades del elementoDEPARTMENT_ID con la lista Orden de clasificación mostrada.
Realización de funciones de nivel de grupoEn esta sección se describe cómo realizar las funciones de grupo.
Los temas incluyen:
• Menú de acciones de grupo
• Edición de juegos de datos
• Eliminación de elementos del grupo
• Edición de propiedades de grupo
Capítulo 10Ordenar datos
10-20

Menú de acciones de grupoEl botón Menú está disponible en el nivel de grupo y permite realizar varias funciones.
• Cree, edite y suprima filtros de grupo, como se describe en Creación de filtros de grupo.
• Agregue un elemento al grupo basado en una expresión, como se describe en Adiciónde un elemento de nivel de grupo o de nivel global por expresión.
• Edite el juego de datos, como se describe en Edición de juegos de datos.
• Elimine elementos del grupo, como se describe en Eliminación de elementos del grupo.
• Edite las propiedades del grupo, como se describe en Edición de propiedades de grupo.
Edición de juegos de datosInicie el editor de juegos de datos para modificar las propiedades de los juegos de datosseleccionados.
Para editar el juego de datos a nivel de grupo:
1. Haga clic en el menú a nivel de grupo.
2. Seleccione Editar juego de datos para iniciar el editor de juegos de datos.
Eliminación de elementos del grupoPuede eliminar los elementos de grupos necesarios.
Para eliminar un elemento del grupo:
• En la fila de elementos, haga clic en el menú y, a continuación, haga clic en Eliminarelemento. A continuación aparece un ejemplo. Solo puede eliminar elementosagregados como función de grupo (sum, count, etc.) o agregados como expresión.
Capítulo 10Realización de funciones de nivel de grupo
10-21

Edición de propiedades de grupoEdite las propiedades necesarias de un grupo.
1. Haga clic en Menú y seleccione Propiedades.
2. Edite la opción Nombre del grupo o Nombre mostrado y haga clic en Aceptar,como se muestra a continuación.
Realización de funciones de nivel globalLas funciones de nivel global le permiten agregar elementos al juego de datos delinforme en el nivel de informe superior.
Puede agregar los siguientes tipos de elementos como datos de nivel superior:
• Elementos basados en funciones de agregado
• Elementos basados en expresiones
• Elementos basados en sentencias PL/SQL (para orígenes de datos de OracleDatabase)
Asegúrese de ordenar correctamente las funciones de nivel global. Las funciones denivel global se ejecutan secuencialmente.
Si selecciona el tipo de dato Entero para cualquier elemento calculado y la expresióndevuelve una fracción, no se truncan los datos. A continuación, se muestra el objetoFunciones de nivel global. Para agregar elementos según las funciones deagregado, arrastre el elemento hasta el espacio "Suelte aquí para la función deagregado" del objeto. Para agregar un elemento según una expresión o PL/SQL, hagaclic en Menú y seleccione la acción adecuada.
Capítulo 10Realización de funciones de nivel global
10-22
Adición de una función de agregado de nivel globalPuede agregar funciones de agregado de nivel global según los elementos seleccionados.
Las funciones disponibles son las siguientes:
• Recuento
• Media
• Primero
• Último
• Máximo
• Mínimo
• Resumen
1. Arrastre el elemento de datos del juego de datos y suéltelo en el área Suelte aquí parala función de agregado del objeto Funciones de nivel global.
Por ejemplo, en la imagen siguiente se muestra la creación de una función de agregadode nivel global según el elemento Salary.
Capítulo 10Realización de funciones de nivel global
10-23
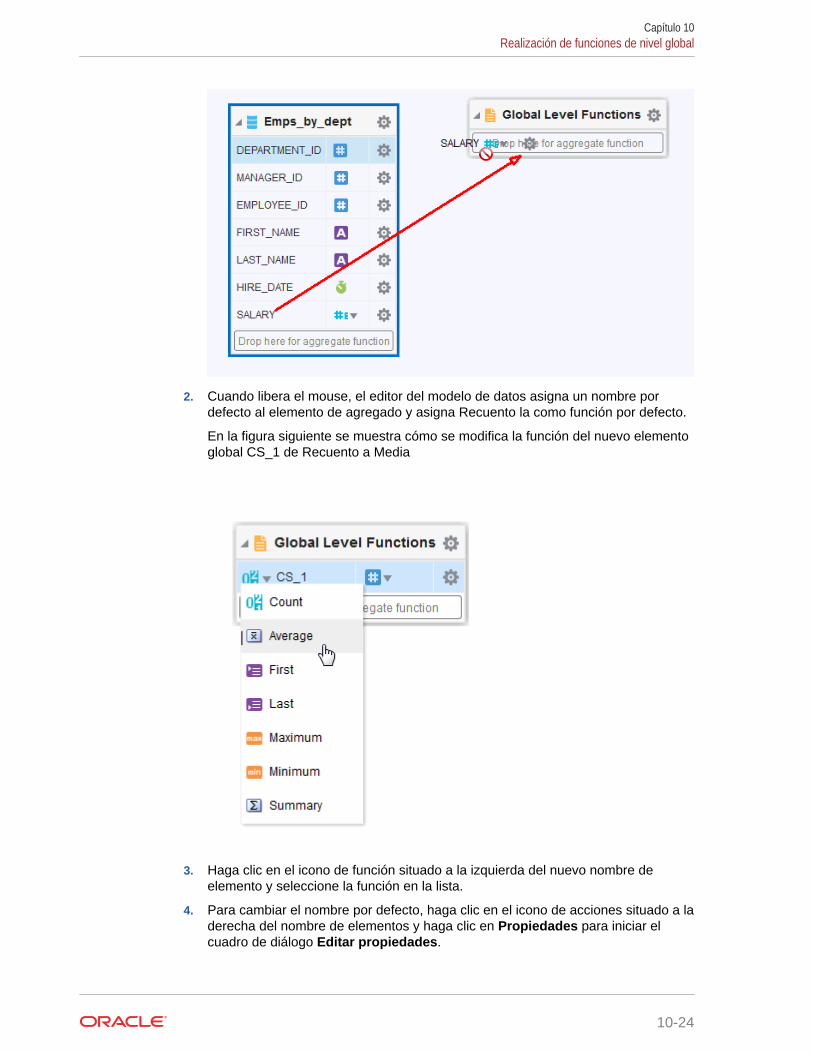
2. Cuando libera el mouse, el editor del modelo de datos asigna un nombre pordefecto al elemento de agregado y asigna Recuento la como función por defecto.
En la figura siguiente se muestra cómo se modifica la función del nuevo elementoglobal CS_1 de Recuento a Media
3. Haga clic en el icono de función situado a la izquierda del nuevo nombre deelemento y seleccione la función en la lista.
4. Para cambiar el nombre por defecto, haga clic en el icono de acciones situado a laderecha del nombre de elementos y haga clic en Propiedades para iniciar elcuadro de diálogo Editar propiedades.
Capítulo 10Realización de funciones de nivel global
10-24
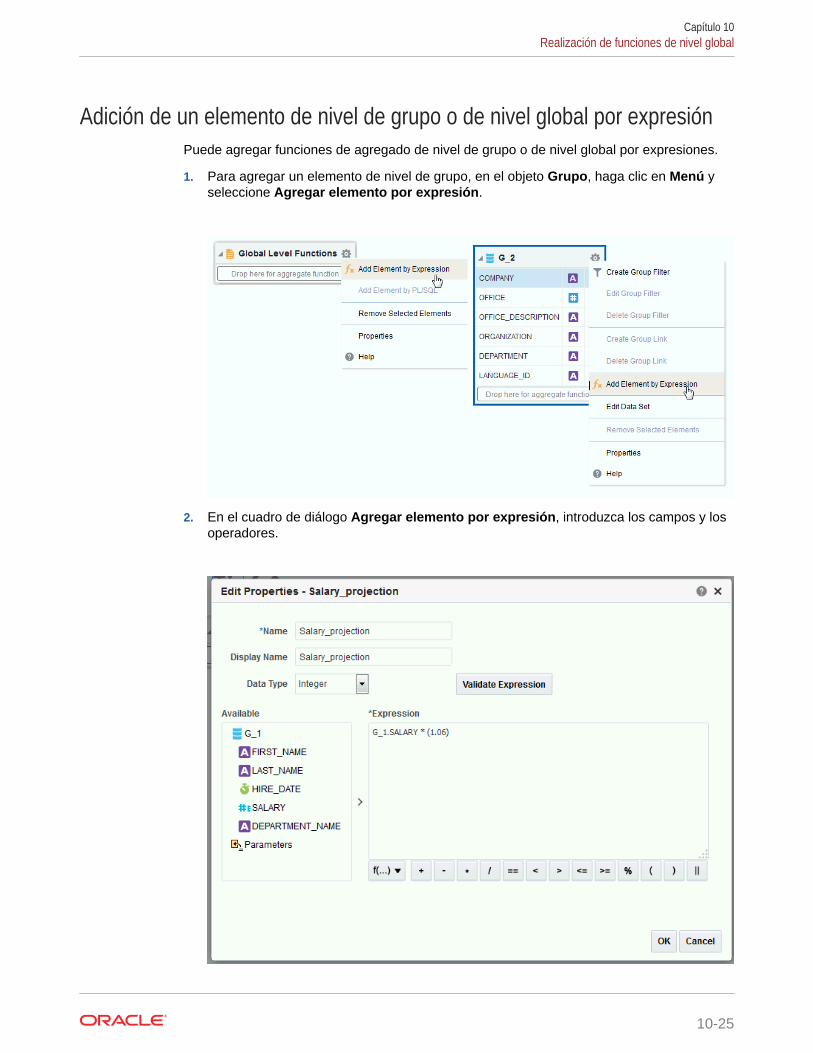
Adición de un elemento de nivel de grupo o de nivel global por expresiónPuede agregar funciones de agregado de nivel de grupo o de nivel global por expresiones.
1. Para agregar un elemento de nivel de grupo, en el objeto Grupo, haga clic en Menú yseleccione Agregar elemento por expresión.
2. En el cuadro de diálogo Agregar elemento por expresión, introduzca los campos y losoperadores.
Capítulo 10Realización de funciones de nivel global
10-25

3. En el campo Nombre mostrado, introduzca un nombre que sea significativo paralos usuarios profesionales.
4. Opcional: Seleccione un tipo de dato.
5. Utilice la flecha selectora para mover los elementos de datos necesarios para laexpresión del cuadro Disponible al cuadro Expresión.
6. Haga clic en un operador para insertarlo en el cuadro Expresión o seleccióneloen la lista de funciones.
7. Haga clic en Validar expresión para validar la expresión.
Adición de un elemento de nivel global por PL/SQLLa función PL/SQL debe devolver un tipo de dato VARCHAR.
1. En la página Propiedades, especifique el Paquete PL/SQL como el Paquete pordefecto Oracle DB en las propiedades del modelo de datos.
2. En el objeto Funciones de nivel global, haga clic en Menú y, a continuación, enAgregar elemento por PL/SQL.
3. En el cuadro de diálogo Agregar elemento por PL/SQL, introduzca los siguientescampos:
• Nombre: introduzca un nombre significativo para el elemento.
• Nombre mostrado: introduzca un nombre mostrado. Este aparece en lasherramientas de diseño del informe. Introduzca un nombre que seasignificativo para los usuarios profesionales.
• Tipo de dato: seleccione Cadena.
4. Seleccione el paquete PL/SQL en el recuadro Disponible y haga clic en el botónselector para mover la función al recuadro Filtro de grupo.
Capítulo 10Realización de funciones de nivel global
10-26

Uso de la vista Estructura para editar la estructura de datosLa vista Estructura le permite obtener una vista previa de la estructura del modelo de datos.
En la columna Origen de datos se muestran los elementos de fecha en un árbol jerárquicoque puede reducir y ampliar. Utilice esta vista para verificar la precisión de la estructura delmodelo de datos para realizar las siguientes ediciones:
• Cambio de nombre de elementos
• Adición de un valor para elementos nulos
La vista Estructura se muestra a continuación.
Cambio de nombre de elementosUse la página Estructura para definir nombres fáciles de recordar para elementos del modelode datos.
Puede cambiar el nombre tanto de la etiqueta del elemento XML (Vista XML) como el queaparece en las herramientas de diseño del informe (Vista de negocio). En la figura siguientese muestra el cambio de nombre de los elementos del origen de datos por nombres de vistade negocio más fáciles de recordar.
Capítulo 10Uso de la vista Estructura para editar la estructura de datos
10-27

Adición de un valor para elementos nulosLa opción Estructura también le permite introducir un valor que usar para un elementosi el modelo de datos devuelve un valor nulo para el elemento.
1. Haga clic en el separador Estructura.
2. Introduzca el valor que usar en el campo Valor si es nulo para el elemento.
Referencia de funciónEn la siguiente tabla, se describe el uso de las funciones soportadas disponibles en elcuadro de diálogo Agregar elemento por expresión y el cuadro de diálogo Editar filtrode grupo.
Función Descripción Sintaxis Ejemplo
IF Operador IF lógicoEvalúa boolean_expr ydevuelve true_return siboolean_expr esverdadera, yfalse_return siboolean_expr es falsa.
IF (boolean_expr,true_return,false_return)
IF(G_1.DEPARTMENT_ID== 10, 'PASSED','FAIL')returns 'PASSED'if DEPARTMENT_ID =10, otherwise returns'FAIL'
NOT Operador NOT lógicoEvalúa boolean_expr ydevuelve true siboolean_expr es falsa.
STRING(NOT(boolean_expr))
STRING(NOT(G_1.JOB_ID == 'MANAGER'))devuelve 'TRUE' siJOB_ID = MANAGER; delo contrario, devuelve'FALSE'
Capítulo 10Referencia de función
10-28

Función Descripción Sintaxis Ejemplo
AND Operador AND lógicoEvalúa boolean_expr1 yboolean_expr2 ydevuelve true si ambasexpresiones booleanasson verdaderas; en casocontrario, devuelvefalse.
STRING(AND(boolean_expr1,boolean_expr2, ...))
STRING(AND(G_1.JOB_ID =='MANAGER',G_1.DEPARTMENT_ID== 10)) devuelve 'TRUE'si JOB_ID = MANAGER yDEPARTMENT_ID = 10;de lo contario, devuelve'FALSE'
&& Operador AND lógicoEvalúa boolean_expr1 yboolean_expr2 ydevuelve true si ambasexpresiones booleanasson verdaderas; en casocontrario, devuelvefalse.
STRING(boolean_expr1 && boolean_expr2)
STRING(G_1.JOB_ID =='MANAGER' &&G_1.DEPARTMENT_ID== 10)devuelve 'TRUE' siJOB_ID = MANAGER yDEPARTMENT_ID = 10;de lo contrario,devuelve 'FALSE'
|| Operadores OR lógicosEvalúa boolean_expr1 yboolean_expr2 ydevuelve true si una oambas expresionesbooleanas sonverdaderas; en casocontrario, devuelvefalse.
STRING(OR(boolean_expr1, boolean_expr2)
STRING(OR (G_1.JOB_ID== 'MANAGER',G_1.DEPARTMENT_ID== 10))devuelve 'TRUE' siJOB_ID = MANAGER oDEPARTMENT_ID = 10;de lo contrario,devuelve 'FALSE'
MAX Devuelve el valormáximo del elemento enel juego.
MAX(expr1, expr2,expr3, ...)
MAX(G1_Salary, 10000)devuelve el máximo delsalario o 10000
MIN Devuelve el valormínimo del elemento enel juego.
MIN(expr1, expr2,expr3, ...)
MIN(G1_Salary,5000)devuelve el mínimo delsalario o 5000
ROUND Devuelve un númeroredondeado a lasposiciones de enteros ala derecha de la comadecimal.
ROUND(number[,integer])Si se omite el entero,el número seredondea a 0posiciones.El entero puede sernegativo pararedondear dígitos a laizquierda de la comadecimal.Integer debe ser unentero.
ROUND(2.777)devuelve 3ROUND(2.777, 2)devuelve 2.78
FLOOR Devuelve el entero máspequeño que sea igual omenor que n.
FLOOR(n) FLOOR(2.777)devuelve 2
CEILING Devuelve el entero másgrande que sea mayor oigual que n.
CEILING(n) CEILING(2.777)devuelve 3
Capítulo 10Referencia de función
10-29

Función Descripción Sintaxis Ejemplo
ABS Devuelve el valorabsoluto de n.
ABS(n) ABS(-3)devuelve 3
AVG Devuelve el valor mediode la expresión.
AVG(expr1, expr2,expr3, ...)
AVG(G_1.SALARY,G_1.COMMISSION_PCT*G_1.SALARY)devuelve la media deSALARY y COMMISSIONPor ejemplo, si SALARY= 14000 yCOMMISSION_PCT = .4,la expresión se evalúacomo 9800.0
LENGTH Devuelve la longitud deuna matriz.La función LENGTHcalcula la longitudutilizando los caracteresque se definen en eljuego de caracteres deentrada.Si char es nulo, lafunción devuelve null.Si char es una matriz,devuelve la longitud dela matriz.
LENGTH(expr) Ejemplo de devoluciónde la longitud de unamatriz: LENGTH{1, 2, 4,4}) devuelve 4Ejemplo de devoluciónde la longitud de unacadena:LENGTH('countries')devuelve 9
SUM Devuelve la suma delvalor de la expresión.
SUM(expr1, expr2, ...) SUM (G_1.SALARY,G_1.COMMISSION_PCT*G_1.SALARY)devuelve la suma delsalario y la comisiónPor ejemplo, si SALARY= 14000 yCOMMISSION_PCT =.4,la expresión se evalúacomo 19,600.0
NVL Sustituye null (sedevuelve como unespacio en blanco) poruna cadena en elresultado de unaconsulta.
NVL(expr1, expr2)Si expr1 es nula, NVLdevuelve expr2.Si expr1 no es nula,NVL devuelve expr1.
NVL(G_1.COMMISSION_PCT, .3) devuelve .3 siG_1.COMMISSION_PCTes nulo
CONCAT Devuelve char1concatenado con char2.
CONCAT(char1, char2) CONCAT(CONCAT(First_Name, ' '), Last_Name)donde First_Name = Joey Last_Name = Smithdevuelve Joe Smith
STRING Devuelve char como tipode dato de cadena.
STRING(expr) STRING(G1_SALARY)donde salary = 4400devuelve 4400 comocadena
Capítulo 10Referencia de función
10-30

Función Descripción Sintaxis Ejemplo
SUBSTRING Extrae una subcadenade una cadena.
SUBSTRING(string,start_pos, end_pos)string es la cadena deorigen.start_pos es laposición para iniciarla extracción.end_pos es la posiciónfinal de la cadena quese va a extraer(opcional).
SUBSTRING('this is atest', 5, 7) devuelve "is"(es decir, los caracteresdel 6 al 7)SUBSTRING('this is atest', 5) devuelve "is atest"
INSTR Devuelve la posición/ubicación del primercarácter de unasubcadena en unacadena
INSTR(string1,string2)string1 es la cadenaque se va a buscar.string2 es lasubcadena que se va abuscar en string1.
INSTR('this is a test', 'isa')devuelve 5
DATE Convierte una cadena defecha Java válida en untipo de dato de fechacon formato canónico.
DATE(char,format_string)donde (1) char escualquier cadena defecha Java válida (porejemplo, 13-JAN-2013)(2) format_string es elformato de fecha Javade la cadena deentrada (por ejemplo,dd-MMM-yyyy) Lascadenas de entrada yformato deben seruna cadena conformato de fecha Javaválida.
DATE(01-Jan-2013,'dd-MMM-yyyy')devuelve2013-01-01T08:00:00.000+00:00
FORMAT_DATE
Convierte un argumentode fecha con formato defecha Java en unacadena con formato.
FORMAT_DATE(date,format_string)
FORMAT_DATE(SYSDATE,'dd-MMM-yyyy')donde el valor SYSDATE=2013-01-24T16:32:45.000-08:00 devuelve 24-Jan-2013
FORMAT_NUMBER
Convierte un número ouna cadena numérica enuna cadena con elformato numéricoespecificado.
FORMAT_NUMBER(number,format_string)
FORMAT_NUMBER(SOME_NUMBER, '$9,999.00')donde el valor deSOME_NUMBER =12345.678devuelve $12,345.68
Capítulo 10Referencia de función
10-31

Función Descripción Sintaxis Ejemplo
DECODE Sustituye el valor de unaexpresión por otro valorsegún la búsquedaespecificada y loscriterios de sustitución.
DECODE(expr, search,result [, search,result]...[, default])
DECODE(PROD_FAMILY_CODE,100,'Colas',200,'Root Beer',300,'CreamSodas',400,'FruitSodas','Other') devuelve(1) 'Colas' siPROD_FAMILY_CODE =100 (2) 'Root Beer' siPROD_FAMILY_CODE =200 (3) 'Cream Sodas' siPROD_FAMILY_CODE =300 (4) 'Fruit Sodas' siPROD_FAMILY_CODE =400 (5) 'Other' siPROD_FAMILY_CODE escualquier otro valor
REPLACE Sustituye una secuenciade caracteres en unacadena por otro juego decaracteres.
REPLACE(expr,string1,string2)donde string1 es lacadena que se va abuscar y string2 es lacadena por la que seva a sustituir.
REPLACE(G_1.FIRST_NAME,'B','L')donde G_1.FIRST_NAME= Barrydevuelve Larry
Capítulo 10Referencia de función
10-32

11Adición de parámetros y listas de valores
En este tema se describe cómo agregar parámetros y listas de valores a un modelo dedatos.
Temas:
• Acerca de los parámetros
• Adición de un nuevo parámetro
• Acerca de las listas de valores
• Adición de listas de valores
• Adición de parámetros de campos flexibles
Acerca de los parámetrosLos parámetros de un modelo de datos le permiten interactuar con los datos cuando sevisualizan informes.
Tipos de parámetro soportados:
• Texto: permite introducir una cadena de texto para transferirla como parámetro.
• Menú: permite realizar seleccione en una lista de valores. Una lista de valores puedecontener datos fijos que ha especificado o una lista creada mediante una consulta SQLque se ejecuta en cualquier de los orígenes de datos definidos. Esta opción soporta laselección múltiple, una opción Seleccionar todo y el refrescamiento de página parcialpara parámetros en cascada.
Para crear un parámetro de tipo menú, defina la lista de valores y, a continuación, definael parámetro y asócielo a la lista de valores.
• Fecha: le permite seleccionar una fecha como parámetro. Debe utilizar el tipo de datoDate y el formato de fecha de Java.
• PDV: le permite utilizar un punto de vista jerárquico como parámetro para seleccionardatos de Essbase. Puede visualizar una dimensión de cubo, ampliar un nodo deestructura de datos y aumentar el detalle para seleccionar datos de un PDV. Debe utilizaruna consulta MDX para crear una lista de valores para un parámetro de PDV.
• Búsqueda: le permite especificar un texto de búsqueda y seleccionar un valor en unalarga lista de valores.
Puede definir parámetros obligatorios para el informe. Un símbolo de asterisco junto a unaetiqueta de parámetro indica que el parámetro está marcado como obligatorio en el modelode datos. Debe proporcionar valores para los parámetros obligatorios de un informe, sidesea ejecutar el informe en línea o programar el informe.
Una vez que ha definido los parámetros del modelo de datos, puede configurar cómo semuestran los parámetros en el informe.
11-1

Puede utilizar parámetros de varias maneras en función del tipo de juego de datos.Por ejemplo, puede utilizar todas las funciones de parámetro con juegos de datos deconsultas SQL. Con otros tipos de juegos de datos, puede utilizar todas las funcionesde parámetro, ninguna o un subjuego, como se describe en esta tabla.
Tipo de juego dedatos
Parámetrosoportado
Selecciónmúltiple
Puedeseleccionartodo
Refrescar otrosparámetros alcambiar
Consulta SQL SíSoporta todoslos tipos deparámetro
Sí Sí Sí
Consulta de LDAP SíSoporta solo elparámetro detipo Texto
No No No
Consulta de MDX SíSoporta lostipos deparámetroTexto y PDV,que devuelvenun valor detexto
No No No
Análisis Heredado delanálisis
Sí (utilizandopaneles deOracle BI)
Sí (utilizandopaneles deOracle BI)
Sí (utilizandopaneles de OracleBI)
Juego de datos deDV
SíSoporta todoslos tipos deparámetro
Sí Sí No
HTTP (fuente XML) SíSoporta sololos tipos deparámetroTexto y Fecha
No No No
Servicio web SíSoporta sololos tipos deparámetroTexto y Fecha
No No No
Archivo CSV No No No No
Archivo MicrosoftExcel
SíSoporta sololos tipos deparámetroTexto y Fecha
No No No
Archivo XML No No No No
Servidor decontenidos
No No No No
Capítulo 11Acerca de los parámetros
11-2

Adición de un nuevo parámetroCree un parámetro asignándole un nombre y otras propiedades.
El nombre del parámetro que elija no debe exceder la longitud máxima que permita su basede datos para un identificador. Consulte la documentación de la base de datos para conocerlas limitaciones de longitud del identificador.
Cuando diseña diseños de informe con el Editor de diseño, la vista previa de la salida delinforme utiliza los valores por defecto de los parámetros.
Puede configurar la colocación de filas en el nivel de informe. La definición de informesoporta opciones de visualización adicionales para los parámetros.
Para agregar un nuevo parámetro:
1. En el panel de componentes Modelo de datos, haga clic en Parámetros y, acontinuación, en Crear nuevo parámetro.
2. Introduzca un Nombre para el parámetro.
El nombre debe coincidir con todas las referencias a este parámetro en el juego dedatos.
3. Seleccione el Tipo de dato en la lista. Un tipo de dato Fecha solo soporta un Tipo deparámetro de fecha.
4. Introduzca un Valor por defecto para el parámetro. Se recomienda para evitar consultasde larga duración.
5. Seleccione el Tipo de parámetro.
6. Para marcar el parámetro como obligatorio, seleccione Obligatorio.
Si no se proporcionan valores para los parámetros obligatorios, no podrá probar uninforme con la opción Ver datos, ejecutar el informe en línea ni programar el informe.
7. En el valor Colocación de filas, configure el número de filas para mostrar losparámetros y en qué fila desea colocar cada parámetro.
Por ejemplo, si el informe tiene seis parámetros, puede asignar cada parámetro a unafila diferente de la 1 a la 6, donde 1 es la fila superior; o bien asignar dos parámetros acada una de las filas 1, 2, 3. Por defecto, todos los parámetros se asignan a la fila 1.
Creación de un parámetro de textoEl parámetro del tipo Texto proporciona un cuadro de texto para solicitar al usuario queintroduzca una entrada de texto como parámetro en el origen de datos.
Para crear un parámetro de texto:
1. Seleccione Texto en la lista Tipo de parámetro.
2. Introduzca la Etiqueta mostrada. Por ejemplo, Department.
3. Introduzca el Tamaño campo de texto como un entero. Este campo determina eltamaño (ancho) del campo, pero no limita el número de caracteres que puede introducirel usuario en el cuadro de texto.
4. Active las siguientes Opciones, si es necesario:
Capítulo 11Adición de un nuevo parámetro
11-3

• El campo de texto contiene valores separados por comas: permite alusuario introducir varios valores delimitados por comas para este parámetro.Se debe definir el parámetro del origen de datos para que soporte variosvalores.
• Refrescar otros parámetros al cambiar: realiza un refrescamiento parcialpara refrescar cualquier otro parámetro cuyo valor dependa del valor de este.
Creación de un parámetro de menúUn parámetro de tipo Menú presenta una lista de valores al usuario.
Primero, debe definir la lista de valores. El parámetro de tipo Menú solo soporta lostipos de dato Cadena y Entero.
Para crear un parámetro de menú:
1. Seleccione Menú en la lista Tipo de parámetro. El panel inferior muestra loscampos adecuados.
2. En Tipo de datos, seleccione Cadena o Entero.
3. Introduzca la Etiqueta mostrada. La etiqueta mostrada es la etiqueta que semuestra a los usuarios cuando visualizan el informe. Por ejemplo: Department.
4. Seleccione la Lista de valores que ha definido para este parámetro.
5. Introduzca el Número de valores para mostrar en la lista. Si el número devalores de la lista excede la entrada de este campo, el usuario debe hacer clic enBuscar para buscar un valor no mostrado, como se muestra en la siguientefigura. El valor por defecto de este campo se establece en 100.
6. Active las siguientes Opciones, si es necesario:
• Selección múltiple: permite al usuario seleccionar varias entradas en la lista.El origen de datos debe admitir varios valores para el parámetro. Lavisualización de un parámetro de menú que soporta la selección múltiple esdiferente. Consulte las dos figuras siguientes.
• Puede seleccionar todo: inserta una opción Todo en la lista.Cuando el usuario selecciona Todo en la lista de valores, puede transferir unvalor nulo para el parámetro.
El uso de * transfiere un valor nulo, por lo que debe gestionar este valor nuloen el origen de datos. Un método para gestionar el valor nulo sería elcomando NVL estándar de Oracle; por ejemplo: where customer_id =nvl(:cstid, customer_id) donde cstid es un valor transferido de la lista devalores, y cuando el usuario selecciona Todo, transfiere un valor nulo.
Capítulo 11Adición de un nuevo parámetro
11-4
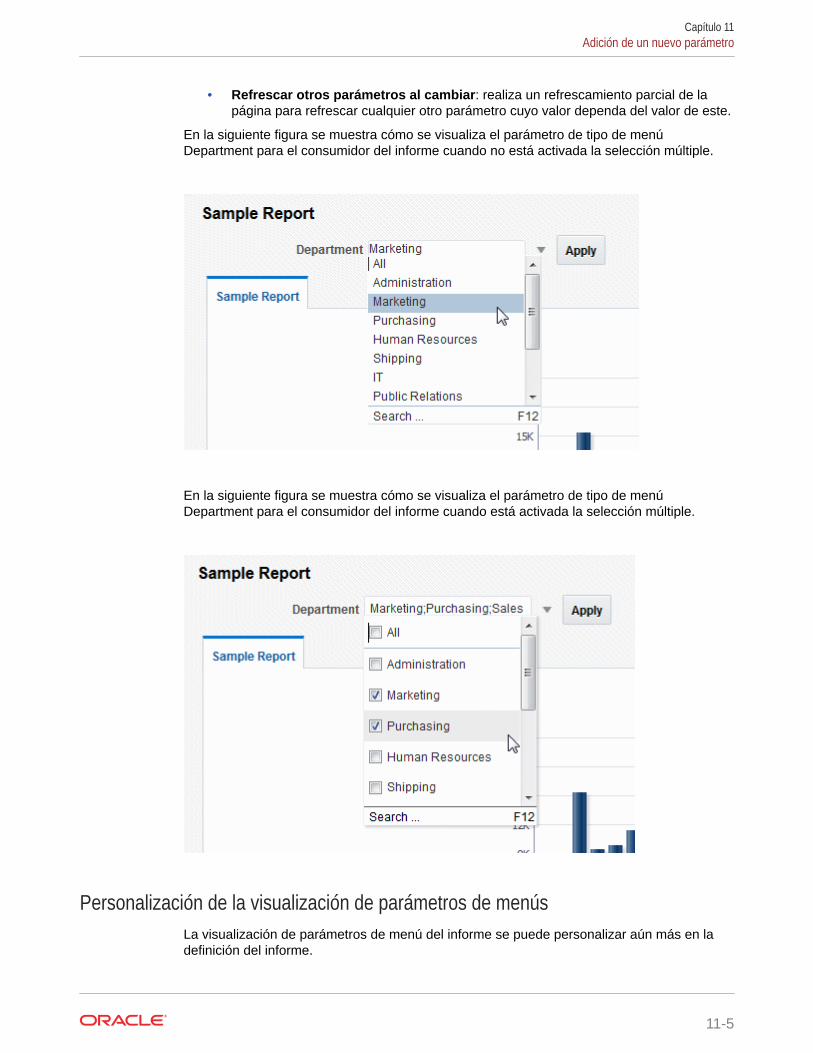
• Refrescar otros parámetros al cambiar: realiza un refrescamiento parcial de lapágina para refrescar cualquier otro parámetro cuyo valor dependa del valor de este.
En la siguiente figura se muestra cómo se visualiza el parámetro de tipo de menúDepartment para el consumidor del informe cuando no está activada la selección múltiple.
En la siguiente figura se muestra cómo se visualiza el parámetro de tipo de menúDepartment para el consumidor del informe cuando está activada la selección múltiple.
Personalización de la visualización de parámetros de menúsLa visualización de parámetros de menú del informe se puede personalizar aún más en ladefinición del informe.
Capítulo 11Adición de un nuevo parámetro
11-5

Los parámetros de tipo de menú soportan la opción de visualización adicional comolista estática de casillas de control o botones de radio.
Definición de un parámetro de fechaEl parámetro de tipo Fecha proporciona un selector de fecha que solicita al usuarioque introduzca una fecha para transferirla como parámetro al origen de datos.
1. Seleccione Fecha en la lista Tipo de parámetro El panel inferior muestra loscampos adecuados para que realice su selección.
2. Introduzca la Etiqueta mostrada. La etiqueta mostrada es la etiqueta que semuestra a los usuarios cuando visualizan el informe. Por ejemplo: Hire Date.
3. Introduzca el Tamaño campo de texto como un entero. Este campo determina elnúmero de caracteres que puede introducir el usuario en el cuadro de texto parala entrada de fecha. Por ejemplo: 10.
4. Opcional: Seleccione Ignorar zona horaria de usuario si desea mostrar el valorde parámetro de fecha en UTC.
5. Introduzca la Cadena de formato de fecha. El formato debe ser un formato defecha Java; por ejemplo, MM-dd-yyyy.
6. Opcional: Introduzca una Fecha de inicio y una Fecha de finalización. Lasfechas que se introducen aquí definen el rango de fechas que se presenta alusuario en el selector de fecha. Por ejemplo, si introduce la Fecha de inicio01-01-1990, el selector de fecha no permite al usuario seleccionar una fechaanterior a 01-01-1990. Deje la Fecha de finalización en blanco para permitirtodas las fechas futuras.
En la figura se puede ver cómo se muestra el parámetro Hire Date al consumidor delinforme.
Capítulo 11Adición de un nuevo parámetro
11-6

Creación de un parámetro de punto de vista (POV)El parámetro de tipo PDV (punto de vista) le proporciona una vista multidimensional.
Puede especificar directamente un parámetro de PDV en una consulta MDX y crear elparámetro de PDV, o bien crear primero un parámetro de PDV y, a continuación, actualizaruna consulta MDX para incluir el parámetro de PDV en la cláusula WHERE. Antes de crearun parámetro de tipo PDV en un modelo de datos, defina la lista de valores para elparámetro de PDV.
Para crear un parámetro de PDV:
1. En el panel de componentes Modelo de datos, haga clic en Parámetros.
2. Haga clic en Crear nuevo parámetro.
3. Introduzca un nombre para el parámetro en el campo Nombre.
4. Seleccione PDV en la lista Tipo de parámetro.
5. En la lista Tipo de datos, seleccione Texto.
6. Introduzca un valor por defecto para el parámetro en el campo Valor por defecto.
7. En el valor Colocación de filas, configure el número de filas para mostrar losparámetros.
8. Utilice la columna Volver a ordenar para especificar el orden para el parámetro.
9. Introduzca una etiqueta en el campo Etiqueta mostrada.
10. Seleccione una lista de valores para el parámetro de PDV en la lista Lista de valores.
Inclusión de un valor de parámetro de PDV en una consulta MDXPuede buscar una dimensión en un cubo e incluir un valor de parámetro de PDV en unaconsulta MDX.
Si incluye un parámetro de PDV en una consulta MDX de un modelo de datos y si eseparámetro de PDV no existe en el modelo de datos, Publisher crea ese parámetro de PDVen el modelo de datos cuando guarda la consulta.
Para incluir un valor de parámetro de PDV en una consulta MDX:
1. En el panel de componentes del editor del modelo de datos, haga clic en Juegos dedatos.
2. Haga clic en el juego de datos de la consulta MDX que desea editar.
3. Haga clic en Editar juego de datos seleccionado.
4. En la cláusula WHERE de la consulta MDX, introduzca el nombre del parámetro de PDVdelimitado por ${ }.
Por ejemplo, si desea crear un parámetro de PDV con el nombre P_Year o si elparámetro de PDV P_Year existe en el modelo de datos, especifique la condición comoWHERE ([Year].[${P_Year}]
5. En el cuadro de diálogo de enlace del valor de parámetro, haga clic en el icono debúsqueda situado junto al parámetro.
6. En el cuadro de diálogo de selección de dimensión, seleccione el cubo, la dimensión y elvalor para el parámetro.
Capítulo 11Adición de un nuevo parámetro
11-7

7. Haga clic en Seleccionar.
8. Haga clic en Aceptar.
9. Guarde el modelo de datos.
Creación de un parámetro de búsquedaPuede utilizar el parámetro del tipo Buscar para proporcionar un cuadro que permitaintroducir un texto de búsqueda y un icono de búsqueda para buscar y mostrar losvalores que coincidan con las búsqueda a fin de que los usuarios puedan realizar suselección.
Utilice el parámetro del tipo Buscar para buscar un valor dentro de una larga lista devalores. Debe crear una lista de valores para el parámetro para poder definir elparámetro del tipo Buscar.
Para crear un parámetro del tipo Buscar:
1. En el panel de componentes del modelo de datos, haga clic en Parámetros y, acontinuación, en Crear nuevo parámetro.
2. Introduzca un nombre para el parámetro, seleccione Cadena en la lista Tipo dedato e introduzca un valor por defecto para el parámetro.
3. Seleccione Buscar en la lista Tipo de parámetro.
4. Introduzca una etiqueta para el parámetro en el campo Etiqueta mostrada.
5. Seleccione la lista de valores para el parámetro en la lista Lista de valores.
6. Opcional: Seleccione Refrescar otros parámetros al cambiar.
Acerca de las listas de valoresUna lista de valores es un juego de valores definido en el que el consumidor de uninforme puede realizar su selección para transferir un valor de parámetro al origen dedatos.
Si define un parámetro del tipo menú, la lista de valores proporciona el menú deopciones. Debe definir la lista de valores antes de definir el parámetro de menú.
Rellene la lista mediante uno de los siguientes métodos:
• Consulta SQL: recupera los valores de una base de datos mediante una consultaSQL.
• Datos fijos: recupera los valores que un usuario introduce de forma manual.
• Consulta MDX: recupera los valores de un PDV o un divisor.
Adición de listas de valoresPuede crear listas de valores de Consulta SQL o Datos fijos.
1. En el panel de componentes de Modelo de datos, haga clic en Lista de valores y,a continuación, haga clic en Crear nueva lista de valores.
Capítulo 11Acerca de las listas de valores
11-8

2. Introduzca un nombre para la lista y seleccione un valor en Tipo.
Creación de una lista a partir de una consulta SQLEl motor de datos espera un par nombre-valor (mostrado) de la consulta de lista de valores.En la lista de valores Sentencia Select, la columna que aparece primero se utiliza comonombre mostrado, y la segunda se utiliza para el valor que se transfiere al parámetro en laconsulta de juego de datos mediante el motor de datos.
Si la consulta solo devuelve una columna, se utiliza el mismo valor de columna tanto comonombre mostrado de la lista de valores que se muestra al usuario como el valor que setransfiere el parámetro.
1. Seleccione un Origen de datos en la lista.
2. En el panel inferior, seleccione Almacenar resultado en caché (recomendado) si deseaque los resultados de la consulta se almacenen en la caché para la sesión de informe.
3. Introduzca la consulta SQL o utilice Query Builder. En la siguiente figura se muestra unalista de valores de tipo de consulta SQL.
Capítulo 11Adición de listas de valores
11-9
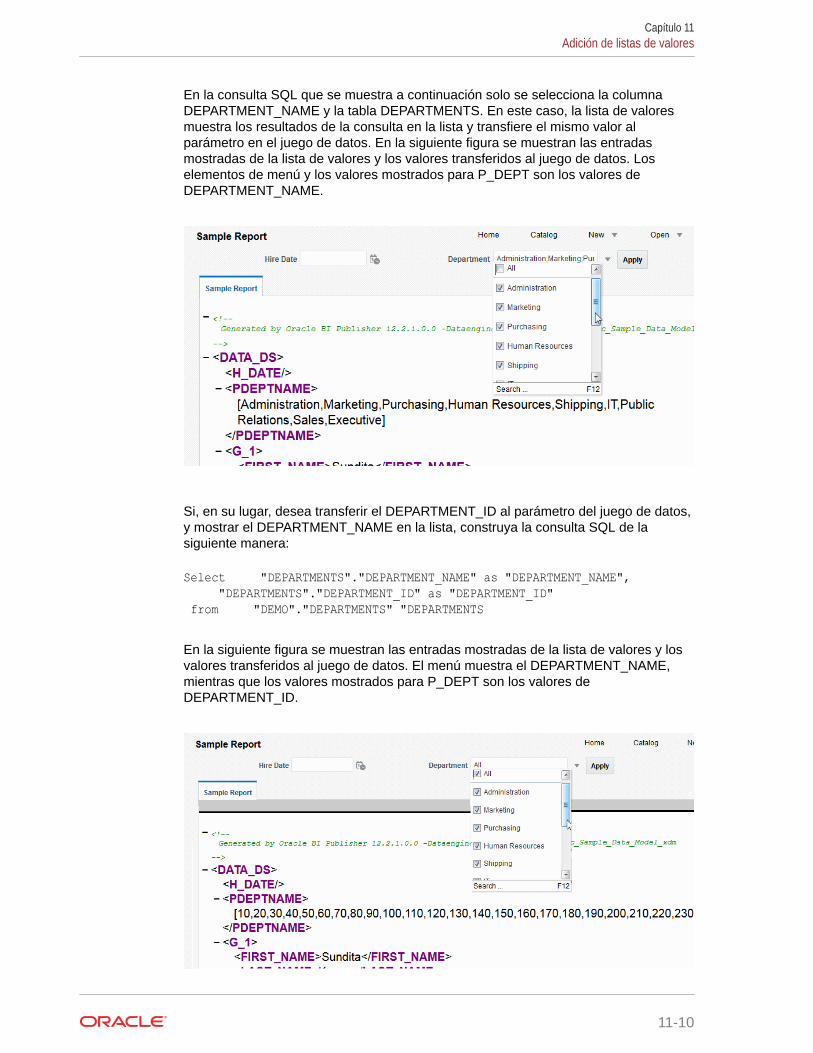
En la consulta SQL que se muestra a continuación solo se selecciona la columnaDEPARTMENT_NAME y la tabla DEPARTMENTS. En este caso, la lista de valoresmuestra los resultados de la consulta en la lista y transfiere el mismo valor alparámetro en el juego de datos. En la siguiente figura se muestran las entradasmostradas de la lista de valores y los valores transferidos al juego de datos. Loselementos de menú y los valores mostrados para P_DEPT son los valores deDEPARTMENT_NAME.
Si, en su lugar, desea transferir el DEPARTMENT_ID al parámetro del juego de datos,y mostrar el DEPARTMENT_NAME en la lista, construya la consulta SQL de lasiguiente manera:
Select "DEPARTMENTS"."DEPARTMENT_NAME" as "DEPARTMENT_NAME", "DEPARTMENTS"."DEPARTMENT_ID" as "DEPARTMENT_ID" from "DEMO"."DEPARTMENTS" "DEPARTMENTS
En la siguiente figura se muestran las entradas mostradas de la lista de valores y losvalores transferidos al juego de datos. El menú muestra el DEPARTMENT_NAME,mientras que los valores mostrados para P_DEPT son los valores deDEPARTMENT_ID.
Capítulo 11Adición de listas de valores
11-10

Creación de una lista desde un juego de datos fijoCree una lista a partir de un juego de datos fijo para cada par de etiqueta/valor necesario.
Al crear un par de etiqueta/valor, la etiqueta se muestra al usuario en la lista. El valor setransfiere al motor de datos.
1. En el panel inferior, haga clic en el icono Crear una lista de valores nueva para agregarun par de etiqueta y valor.
2. Repita para cada par de etiqueta/valor necesario.
En la figura siguiente se muestra una lista de valores de tipo de dato fijo.
Creación de una lista a partir de una consulta MDXPuede utilizar una consulta MDX para crear una lista de valores multidimensionalesespecificando la porción de un cubo de Essbase.
Para crear una lista a partir de una consulta MDX:
1. En el panel de componentes del modelo de datos, haga clic en Lista de valores.
2. Haga clic en Crear nueva lista de valores.
3. Introduzca un nombre para la lista en el campo Nombre.
4. Seleccione Consulta MDX en la lista Tipo.
5. Seleccione un origen de datos de OLAP en la lista Origen de datos.
6. En el panel inferior, seleccione Almacenar resultado en caché (recomendado) si deseaque se almacenen los resultados en la caché para la sesión de informe.
Capítulo 11Adición de listas de valores
11-11

7. Seleccione el PDV/divisor para la consulta MDX.
a. Haga clic en el icono de búsqueda POV/divisor.
b. Seleccione un cubo.
c. Seleccione una dimensión.
El campo PDV/divisor muestra el cubo y la dimensión seleccionados con elformato cubo.dimensión.
Adición de parámetros de campos flexiblesLos clientes de Oracle E-Business Suite que hayan configurado Publisher para utilizarla seguridad de E-Business Suite pueden crear informes que utilicen campos flexiblesclave como parámetros.
Cuando define un modelo de datos para transferir un campo flexible clave como unparámetro, Publisher presenta un cuadro de diálogo al consumidor del informe pararealizar selecciones a fin de transferir los segmentos de campo flexible comoparámetros al informe, de manera similar a la forma en la que se presentan loscampos flexibles cuando se ejecutan informes a través del gestor simultáneo en E-Business Suite.
La lista de valores de campo flexible aparece en el visor de informes como se muestraa continuación.
La lista de valores de campo flexible aparece como un cuadro de diálogo en el quepuede seleccionar los valores de segmento, como se muestra a continuación.
Requisitos para la utilización de campos flexiblesAl definir una lista de valores, los clientes de E-Business Suite ven una lista Tipodenominada "Campo flexible".
Capítulo 11Adición de parámetros de campos flexibles
11-12

Para activar la lista de valores de tipo Campo flexible, configure el uso de E-Business SuiteSecurity. El campo flexible ya debe estar definido en E-Business Suite.
Adición de un parámetro de campo flexible y de una lista de valoresAgregue parámetros de campo flexible mediante la adición de la lista de valores.
La lista de valores de tipo de campo flexible recupera la definición de metadato de campoflexible para presentar los valores adecuados para cada segmento en el cuadro de diálogode selección de lista de valores de campo flexible. Utilice el parámetro de campo flexiblepara transferir valores al campo flexible definido en el modelo de datos.
En tiempo de ejecución, la referencia &flexfield_name se sustituye por el código léxicoconstruido según los valores en la definición de componente de campo flexible.
1. Agregue la lista de valores de campo flexible.
2. Agregue un parámetro y asócielo a la lista de valores de campo flexible mediante laselección de la lista de valores de campo flexible como menú de origen del parámetro.
3. Agregue el componente de campo flexible al modelo de datos.
4. Haga referencia al campo flexible en la consulta SQL utilizando la sintaxis&flexfield_name.
Adición de lista de valores de campo flexibleAgregue una lista de valores recuperada de una definición de campo flexible.
Si selecciona Campos flexibles como Tipo, la opción Origen de datos ya no se podrá editar.Todas las listas de valores del tipo Campos flexibles utilizan Oracle E-Business Suite comoorigen de datos.
1. En el panel de componentes del modelo de datos, haga clic en Lista de valores y, acontinuación, en Crear nueva lista de valores.
2. Introduzca un Nombre para la lista y seleccione Campos flexibles como Tipo.
3. En el panel Flex_Acct_List:Tipo: Flexfields, introduzca lo siguiente:
• Abreviatura de la aplicación: abreviatura de la aplicación de E-Business Suite, porejemplo: SQLGL.
• Código flexible de ID: código de campo flexible definido para este campo flexible enla pantalla Registrar campos flexibles clave, por ejemplo: GL#.
• Número flexible de ID: nombre de la columna o el parámetro de origen quecontiene la información de estructura de campo flexible, por ejemplo: 101o :STRUCT_NUM. Si utiliza un parámetro, asegúrese de definirlo en el modelo dedatos.
En la imagen se muestra un ejemplo del tipo campo flexible, LOV.
Capítulo 11Adición de parámetros de campos flexibles
11-13

Adición del parámetro de menú para la lista de valores de campo flexibleDefina el parámetro para mostrar la lista de valores de campo flexible y capturar losvalores seleccionados por el usuario.
La definición del parámetro de tipo Campo flexible incluye un campo adicionaldenominado Rango para soportar campos flexibles de rango. Un campo flexible derango soporta valores altos y bajos para cada segmento clave en lugar de valoresúnicos. Puede personalizar el valor por defecto del campo flexible y la colocación defilas en la definición de informe. La colocación de filas determina si este parámetroaparece en el visor de informes.
Las siguientes opciones están desactivadas para los parámetros de campo flexible:Número de valores para mostrar en la lista, Selección múltiple, Puedeseleccionar todo y Refrescar otros parámetros al cambiar.
1. En el panel de componentes Modelo de datos, haga clic en Parámetros y, acontinuación, en Crear nuevo parámetro.
2. Seleccione Menú en la lista Tipo de parámetro.
3. Seleccione Cadena o Entero como Tipo de dato.
4. Introduzca un Valor por defecto para el parámetro de campo flexible.
5. Introduzca la Colocación de filas.
6. Introduzca la Etiqueta mostrada. La etiqueta mostrada es la etiqueta que semuestra a los usuarios cuando visualizan el informe. Por ejemplo: Cuenta de.
7. Seleccione la Lista de valores que ha definido para este parámetro.
Cuando se selecciona una lista de valores que es del tipo Campo flexible, semuestra un campo adicional denominado Rango.
En la imagen se muestra una definición de parámetro para la lista de valores decampo flexible.
Capítulo 11Adición de parámetros de campos flexibles
11-14

Uso del parámetro de campo flexible para transferir valores a un campo flexibledefinido en el modelo de datos
Después de agregar el parámetro de menú a la lista de valores del campo flexible, puedetransferir los valores de parámetro a un componente de campo flexible del modelo de datos.
Para definir el campo flexible en el modelo de datos:
1. En el panel de componentes del modelo de datos, haga clic en Campos flexibles y, acontinuación, en Crear nuevo campo flexible.
2. Introduzca lo siguiente:
• Nombre: introduzca un nombre para el componente de campo flexible.
• Tipo: seleccione el tipo de campo flexible en la lista. El tipo que seleccione aquídetermina los campos adicionales necesarios.
• Abreviatura de la aplicación: introduzca la abreviatura de la aplicación Oracle quees propietaria de este campo flexible (por ejemplo, GL).
• Código flexible de ID: introduzca el código de campo flexible definido para estecampo flexible en la pantalla Registrar campo flexible clave (por ejemplo, GL#).
• Número flexible de ID: introduzca el nombre de la columna de origen o delparámetro que contiene la información de la estructura de campo flexible. Porejemplo: 101. Para utilizar un parámetro, añada dos puntos como prefijo al nombredel parámetro; por ejemplo, :PARAM_STRUCT_NUM.
3. En la región inferior de la página, introduzca los detalles del tipo de campo flexible queha seleccionado. En el campo que va a tomar el valor de parámetro, introduzca elnombre del parámetro precedido de dos puntos; por ejemplo, :P_Acct_List.
En la figura que se muestra a continuación, el componente de campo flexible se definecomo un Tipo "Where". El parámetro :P_Acct_List se introduce en el campo Operando1.En tiempo de ejecución, los valores seleccionados por el usuario para el parámetroP_Acct_List se utilizarán para crear la cláusula where.
Capítulo 11Adición de parámetros de campos flexibles
11-15

Referencia al campo flexible en la consulta SQLPor último, cree la consulta SQL en la base de datos de E-Business Suite.
Use la sintaxis léxica en la consulta SQL. En la figura siguiente, &Acct_Flex es elléxico del campo flexible que se llama en la condición where de la consulta SQL.
Transferencia de un rango de valoresPara definir los parámetros para las listas de valores de campo flexible cuando deseetransferir un rango de valores, debe crear dos parámetros de menú que haganreferencia a la misma lista de valores de campo flexible.
En tiempo de ejecución, los usuarios seleccionan un valor alto en la lista de valores yun valor bajo en la misma lista de valores. Estos dos valores se transfieren acontinuación como operandos al componente de campo flexible del modelo de datos.
Capítulo 11Adición de parámetros de campos flexibles
11-16
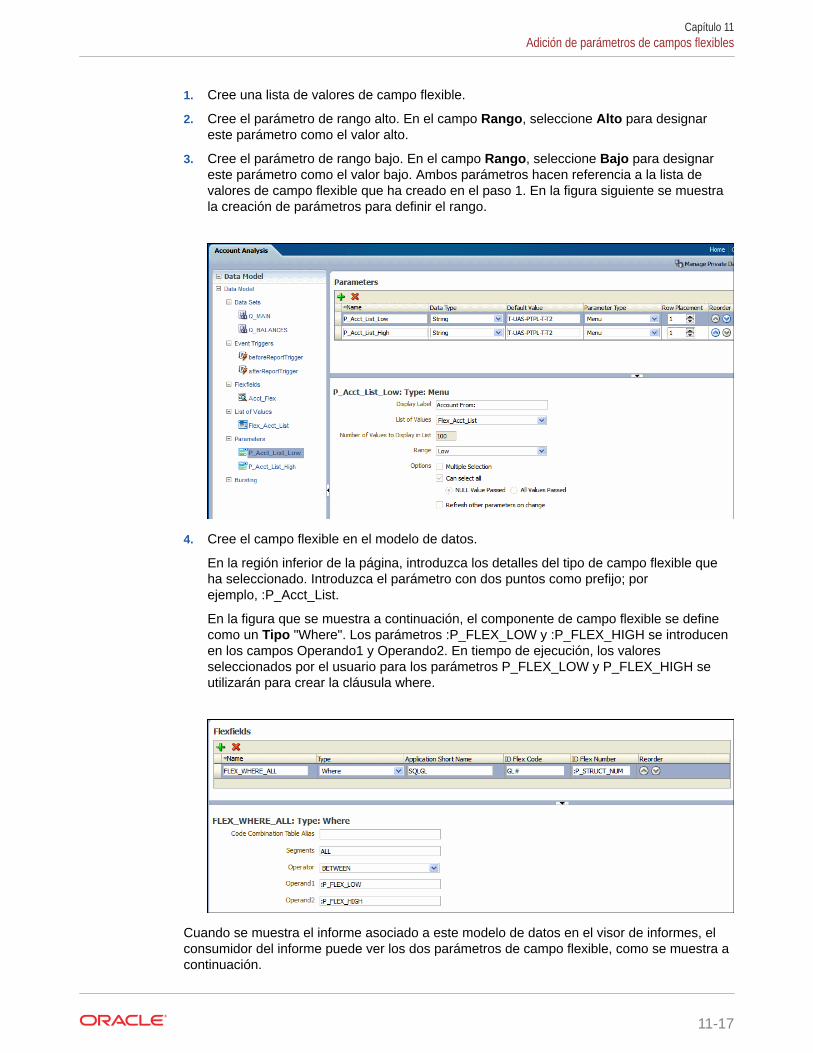
1. Cree una lista de valores de campo flexible.
2. Cree el parámetro de rango alto. En el campo Rango, seleccione Alto para designareste parámetro como el valor alto.
3. Cree el parámetro de rango bajo. En el campo Rango, seleccione Bajo para designareste parámetro como el valor bajo. Ambos parámetros hacen referencia a la lista devalores de campo flexible que ha creado en el paso 1. En la figura siguiente se muestrala creación de parámetros para definir el rango.
4. Cree el campo flexible en el modelo de datos.
En la región inferior de la página, introduzca los detalles del tipo de campo flexible queha seleccionado. Introduzca el parámetro con dos puntos como prefijo; porejemplo, :P_Acct_List.
En la figura que se muestra a continuación, el componente de campo flexible se definecomo un Tipo "Where". Los parámetros :P_FLEX_LOW y :P_FLEX_HIGH se introducenen los campos Operando1 y Operando2. En tiempo de ejecución, los valoresseleccionados por el usuario para los parámetros P_FLEX_LOW y P_FLEX_HIGH seutilizarán para crear la cláusula where.
Cuando se muestra el informe asociado a este modelo de datos en el visor de informes, elconsumidor del informe puede ver los dos parámetros de campo flexible, como se muestra acontinuación.
Capítulo 11Adición de parámetros de campos flexibles
11-17
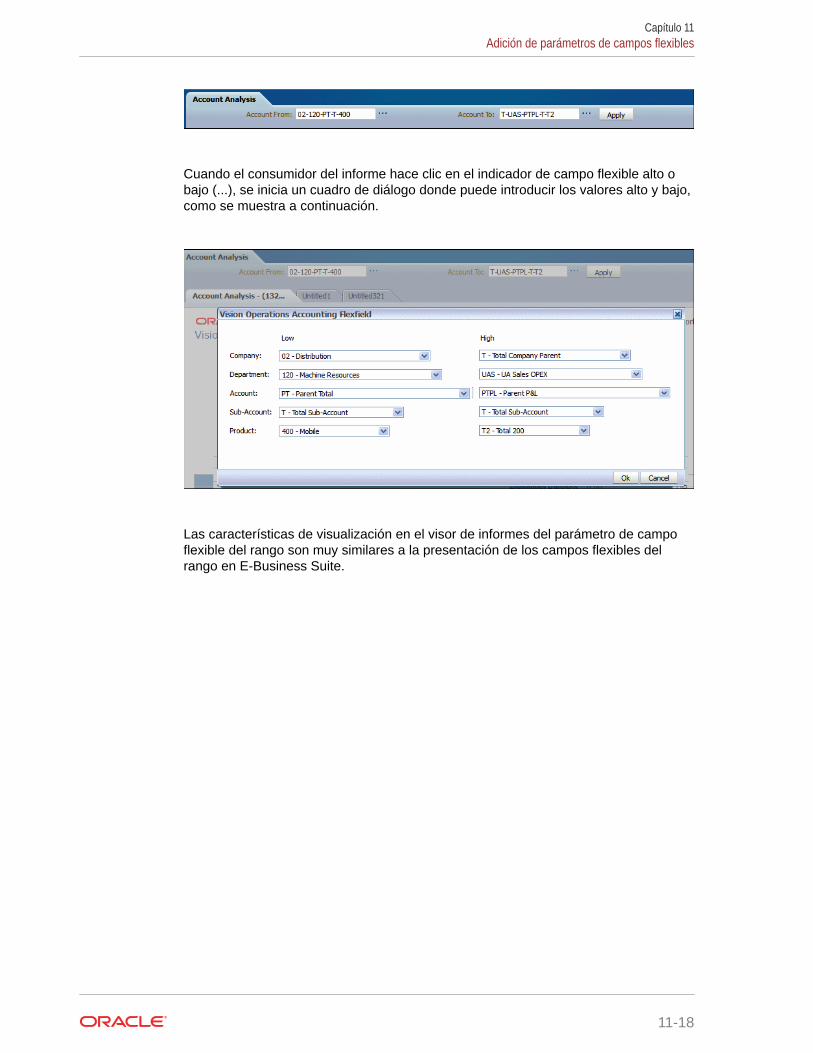
Cuando el consumidor del informe hace clic en el indicador de campo flexible alto obajo (...), se inicia un cuadro de diálogo donde puede introducir los valores alto y bajo,como se muestra a continuación.
Las características de visualización en el visor de informes del parámetro de campoflexible del rango son muy similares a la presentación de los campos flexibles delrango en E-Business Suite.
Capítulo 11Adición de parámetros de campos flexibles
11-18

12Adición de disparadores de eventos
En este tema se describe cómo definir los disparadores en su modelo de datos. Los modelosde datos soportan disparadores de eventos Antes de datos y Después de datos ydisparadores de programación.
Temas:
• Acerca de los disparadores
• Adición de disparadores de datos Antes de datos y Después de datos
• Creación de disparadores de programación
Acerca de los disparadoresUn disparador de eventos comprueba si se produce un evento y, cuando este se produce,ejecuta el código asociado al disparador.
Publisher soporta tres tipos:
• Antes de datos: se activa justo antes de que se ejecute el juego de datos.
• Después de datos: se activa justo después de que el motor de datos ejecute todos losjuegos de datos y genere el XML.
• Disparador de programación: se activa cuando se dispara un trabajo programado yante de que este se ejecute.
Los disparadores antes y después de datos ejecutan una función PL/SQL almacenada en unpaquete PL/SQL en Oracle Database. El tipo de dato de retorno de una función PL/SQLdentro del paquete debe ser un tipo booleano y la función debe devolver de forma explícitaTRUE o FALSE.
Un disparador de programación se asocia a un trabajo programado. En el momento en queun trabajo de informe está programado para ejecutarse, lo que se ejecuta es una consultaSQL. Si la sentencia SQL devuelve algún dato, se ejecuta el trabajo de informe. Si laconsulta SQL no devuelve ningún dato, se omite la instancia del trabajo.
Los disparadores de eventos solo aceptan un valor en un parámetro. Si transfiere variosvalores a un parámetro de disparador de evento programado, el estado del trabajoprogramado se define en Omitido.
Los disparadores de eventos no se utilizan para rellenar los datos utilizados en unadefinición de repartición. Consulte Adición de definiciones de repartición.
12-1

Adición de disparadores de datos Antes de datos y Despuésde datos
Puede agregar disparadores de eventos que se inicien antes y después de los datos.
Si define un paquete por defecto, debe definir todos los parámetros como una variablePL/SQL global en el paquete PL/SQL. A continuación, puede transferir los parámetrosde forma explícita al disparador de la función PL/SQL, o bien todos los parámetrosestarán disponibles como variable PL/SQL global. Consulte Propiedades de modelode datos
1. En el panel Propiedades del modelo de datos, introduzca el Paquete pordefecto Oracle DB que contiene la firma de la función PL/SQL que se va aejecutar cuando se inicie el disparador.
2. En el panel de tareas, haga clic en Disparadores de eventos.
3. En el panel Disparadores de eventos, haga clic en Crear nuevo disparador deevento.
4. Introduzca lo siguiente para el disparador:
• Nombre: asigne al disparador un nombre significativo.
• Tipo: seleccione Antes de datos o Después de datos.
• Lenguaje: seleccione PL/SQL.
En la figura siguiente se muestra un disparador de evento.
5. Seleccione el paquete en el cuadro Funciones disponibles y haga clic en laflecha para mover una función al cuadro Disparador del evento.
Capítulo 12Adición de disparadores de datos Antes de datos y Después de datos
12-2

El nombre aparece como <nombre de paquete>.<nombre de función> PL/SQL.
Orden de ejecuciónSi define varios disparadores del mismo tipo, se activan en el orden en que aparezcan en latabla (de la parte superior a la inferior).
Para cambiar el orden de la ejecución:
• Utilice las flechas de Volver a ordenar para colocar los disparadores en el ordencorrecto.
Creación de disparadores de programaciónUn disparador de programación se dispara cuando un trabajo de informe está programadopara que se ejecute. Los disparadores de programación son de tipo Consulta SQL.
Cuando se programa un trabajo de informe para su ejecución, el disparador de programaciónejecuta la sentencia SQL definida para el disparador. Si se devuelven datos, se envía eltrabajo de informe. Si no se devuelven datos de la consulta SQL del disparador, el trabajo deinforme se omite.
El disparador de programación que asocie con un trabajo de informe puede residir encualquier modelo de datos del catálogo. No es necesario crear el disparador deprogramación en el modelo de datos del informe para el que desee ejecutar el disparador.Puede reutilizar los disparadores de programación en varios trabajos de informe.
1. En el panel de tareas del editor del modelo de datos, haga clic en Disparadores delevento.
2. En el panel Disparadores del evento, haga clic en el icono Crea nuevo.
3. Introduzca lo siguiente para el disparador:
• Nombre: introduzca un nombre para el disparador.
• Tipo: seleccione Programación.
• Idioma: acepte el valor por defecto, Consulta SQL.
4. En el panel inferior, introduzca lo siguiente:
• Opciones: seleccione esta casilla de control para almacenar en la caché losresultados de la consulta de disparador.
• Origen de datos: seleccione el origen de datos para la consulta de disparador.
• Consulta SQL: introduzca la consulta en el área de texto o haga clic en QueryBuilder para utilizar esta utilidad para construir la consulta SQL; consulte Uso deSQL Query Builder.
Puede incluir parámetros en la consulta de disparador. Defina el parámetro en elmismo modelo de datos que el disparador. Introduzca los valores de parámetrocuando programe el trabajo de informe.
Las consultas del disparador de programación no soportan parámetros de selecciónmúltiple. Si la consulta espera un juego de valores, modifique la consulta.
Si la consulta SQL devuelve algún resultado, se ejecuta el trabajo de informeprogramado. En la siguiente figura se muestra un disparador de programación para
Capítulo 12Creación de disparadores de programación
12-3

probar niveles de inventario según un valor de parámetro que se puede introduciren tiempo de ejecución.
Capítulo 12Creación de disparadores de programación
12-4

13Agregar campos flexibles
En este tema se describe el soporte de campos flexibles en los modelos de datos
Temas:
• Acerca de los campos flexibles
• Adición de campos flexibles clave
Acerca de los campos flexiblesUn campo flexible es un campo de datos que puede personalizar la organización según susnecesidades de negocio sin programación
Las aplicaciones Oracle utilizan dos tipos de campos flexibles:
• Campos flexibles clave
Un campo flexible clave es un campo que puede personalizar para introducir valoresmultisegmento como números de artículo, números de cuenta, etc.
• Campos flexibles descriptivos
Un campo flexible descriptivo es un campo que puede personalizar para introducirinformación adicional para la que el producto de las aplicaciones Oracle no haproporcionado un campo.
Si va a generar informes sobre datos de aplicaciones Oracle, utilice el componente decampo flexible del modelo de datos para recuperar datos de campo flexible.
Antes de incluir campos flexibles en los informes, debe entender los campos flexibles de lasaplicaciones.
Uso de campos flexibles en su modelo de datosUse de campos flexibles basados en sentencias SQL SELECT de su modelo de datos.
Para usar campos flexibles en su modelo de datos basado en SQL:
13-1

• Agregue el componente Campo flexible al modelo de datos como se describe eneste capítulo.
• Defina la sentencia SQL SELECT con respecto a las tablas de datos de lasaplicaciones.
• En la sentencia SELECT, defina cada campo flexible como léxico. Utilice elelemento &LEXICAL_TAG para incrustar léxicos relacionados con los camposflexibles en la sentencia SELECT.
Adición de campos flexibles clavePuede utilizar referencias de campo flexible clave para reemplazar las cláusulas queaparecen después de SELECT, FROM, WHERE, ORDER BY o HAVING.
Utilice una referencia de campo flexible cuando desee que el parámetro reemplacevarios valores en tiempo de ejecución. El editor del modelo de datos soporta lossiguientes tipos de campo flexible:
• Donde: este tipo de léxico se utiliza en la sección WHERE de la sentencia.Utilícelo para modificar la cláusula WHERE para que la sentencia SELECT puedafiltrar en función de los datos del segmento de campo flexible clave.
• Ordenar por: este tipo de léxico se utiliza en la sección ORDER BY de lasentencia. Utilícelo para obtener una lista de expresiones de columna de modoque la salida resultante se pueda ordenar por los valores del segmento flexible.
• Seleccionar: este tipo de léxico se utiliza en la sección SELECT de la sentencia.Utilícelo para recuperar y procesar datos relacionados con la combinación decódigo de campo flexible clave (KFF) según la definición de léxico.
• Filtrar: este tipo de léxico se utiliza en la sección WHERE de la sentencia.Utilícelo para modificar la cláusula WHERE para que la sentencia SELECT puedafiltrar en función del identificador de filtro transferido desde el servicio deprogramación de Oracle Enterprise.
• Metadatos de segmento: utilícelo para recuperar metadatos relacionados concampos flexibles. No es necesario escribir código PL/SQL para recuperar estosmetadatos. En su lugar, defina una sentencia SELECT ficticia y, a continuación,utilice este léxico para obtener los metadatos. Este léxico debe devolver unacadena constante.
Después de configurar los componentes de campo flexible del modelo de datos, creeuna referencia léxica de campo flexible en la consulta SQL mediante la siguientesintaxis:
&LEXICAL_TAG ALIAS_NAME
Por ejemplo:
&FLEX_GL_BALANCING alias_gl_balancing
Después de introducir la consulta SQL, al hacer clic en Aceptar
• Introduzca lo siguiente:
– Nombre de léxico: introduzca un nombre para el componente de campoflexible.
– Tipo de campo flexible: seleccione Campo flexible clave.
Capítulo 13Adición de campos flexibles clave
13-2

– Tipo de léxico: seleccione el tipo en la lista. La selección que realice aquí determinalos campos adicionales necesarios. Consulte Introducción de detalles de campoflexible.
– Abreviatura de la aplicación: introduzca la abreviatura de la aplicación Oracle quees propietaria de este campo flexible; por ejemplo, GL.
– Código de campo flexible: introduzca el código de campo flexible definido paraeste campo flexible. En Oracle E-Business Suite, este código se define en la pantallaRegistrar campo flexible clave: por ejemplo, GL#.
– Número flexible de ID: introduzca el nombre de la columna de origen o delparámetro que contiene la información de la estructura de campo flexible. Porejemplo: 101. Para utilizar un parámetro, añada dos puntos como prefijo al nombredel parámetro; por ejemplo, :PARAM_STRUCT_NUM.
Introducción de detalles de campo flexibleLa región Detalles muestra los campos adecuados según el Tipo de léxico que seleccione.
Campos para el tipo de campo flexible clave: Metadatos de segmento
En esta tabla se describen los campos de detalles para los metadatos segmentados.
Campo Descripción
Número de instancia deestructura
Introduzca el nombre de la columna de origen o del parámetroque contiene la información de la estructura de campo flexible.Por ejemplo: 101. Para utilizar un parámetro, añada dos puntoscomo prefijo al nombre del parámetro; porejemplo, :PARAM_STRUCT_NUM.
Segmentos (Opcional) Identifica para qué segmentos se solicitan estos datos.El valor por defecto es "ALL". Consulte Oracle E-Business SuiteDeveloper's Guide para conocer la sintaxis.
Mostrar segmentosprincipales
Seleccione esta casilla para que se muestren automáticamente lossegmentos principales de los segmentos dependientes incluso sino se muestran en el atributo de los segmentos.
Tipo de metadatos Seleccione el tipo de metadatos que se van a devolver:Petición datos de segmentos anterior — Petición datos desegmento(s) anterior.Petición datos segmentos izquierda — Petición datos segmento(s)izquierda
Capítulo 13Adición de campos flexibles clave
13-3
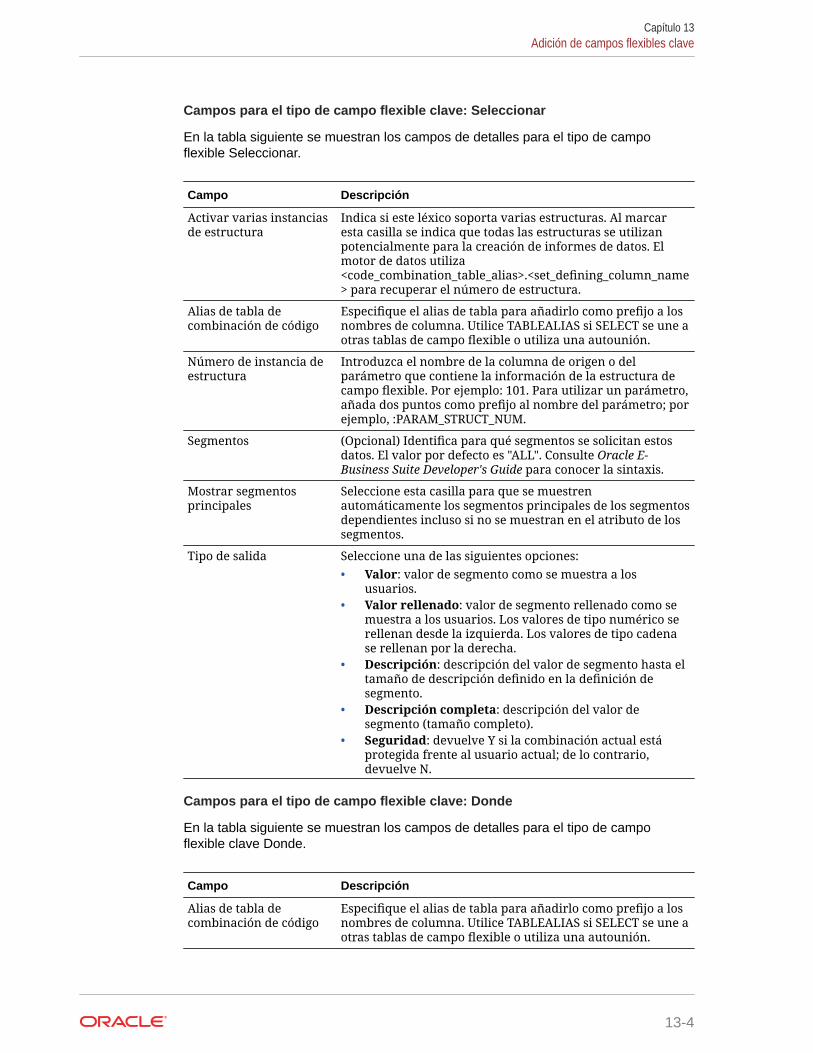
Campos para el tipo de campo flexible clave: Seleccionar
En la tabla siguiente se muestran los campos de detalles para el tipo de campoflexible Seleccionar.
Campo Descripción
Activar varias instanciasde estructura
Indica si este léxico soporta varias estructuras. Al marcaresta casilla se indica que todas las estructuras se utilizanpotencialmente para la creación de informes de datos. Elmotor de datos utiliza<code_combination_table_alias>.<set_defining_column_name> para recuperar el número de estructura.
Alias de tabla decombinación de código
Especifique el alias de tabla para añadirlo como prefijo a losnombres de columna. Utilice TABLEALIAS si SELECT se une aotras tablas de campo flexible o utiliza una autounión.
Número de instancia deestructura
Introduzca el nombre de la columna de origen o delparámetro que contiene la información de la estructura decampo flexible. Por ejemplo: 101. Para utilizar un parámetro,añada dos puntos como prefijo al nombre del parámetro; porejemplo, :PARAM_STRUCT_NUM.
Segmentos (Opcional) Identifica para qué segmentos se solicitan estosdatos. El valor por defecto es "ALL". Consulte Oracle E-Business Suite Developer's Guide para conocer la sintaxis.
Mostrar segmentosprincipales
Seleccione esta casilla para que se muestrenautomáticamente los segmentos principales de los segmentosdependientes incluso si no se muestran en el atributo de lossegmentos.
Tipo de salida Seleccione una de las siguientes opciones:• Valor: valor de segmento como se muestra a los
usuarios.• Valor rellenado: valor de segmento rellenado como se
muestra a los usuarios. Los valores de tipo numérico serellenan desde la izquierda. Los valores de tipo cadenase rellenan por la derecha.
• Descripción: descripción del valor de segmento hasta eltamaño de descripción definido en la definición desegmento.
• Descripción completa: descripción del valor desegmento (tamaño completo).
• Seguridad: devuelve Y si la combinación actual estáprotegida frente al usuario actual; de lo contrario,devuelve N.
Campos para el tipo de campo flexible clave: Donde
En la tabla siguiente se muestran los campos de detalles para el tipo de campoflexible clave Donde.
Campo Descripción
Alias de tabla decombinación de código
Especifique el alias de tabla para añadirlo como prefijo a losnombres de columna. Utilice TABLEALIAS si SELECT se une aotras tablas de campo flexible o utiliza una autounión.
Capítulo 13Adición de campos flexibles clave
13-4

Campo Descripción
Número de instancia deestructura
Introduzca el nombre de la columna de origen o delparámetro que contiene la información de la estructura decampo flexible. Por ejemplo: 101. Para utilizar un parámetro,añada dos puntos como prefijo al nombre del parámetro; porejemplo, :PARAM_STRUCT_NUM.
Segmentos (Opcional) Identifica para qué segmentos se solicitan estosdatos. El valor por defecto es "ALL". Consulte Oracle E-Business Suite Developer's Guide para conocer la sintaxis.
Operador Seleccione el operador adecuado.
Operando1 Introduzca el valor que se va a utilizar en el lado derecho deloperador condicional.
Operando2 (Opcional) Valor superior para el operador BETWEEN.
Campos para el tipo de campo flexible clave: Ordenar por
En la tabla siguiente se muestran los campos de detalles para el tipo de campo flexibleOrdenar por.
Campo Descripción
Activar varias instancias deestructura
Indica si este léxico soporta varias estructuras. La selección deesta casilla indica que todas las estructuras se utilizanpotencialmente para la creación de informes de datos. El motor dedatos utiliza<code_combination_table_alias>.<set_defining_column_name>para recuperar el número de estructura.
Número de instancia deestructura
Introduzca el nombre de la columna de origen o del parámetroque contiene la información de la estructura de campo flexible.Por ejemplo: 101. Para utilizar un parámetro, añada dos puntoscomo prefijo al nombre del parámetro; porejemplo, :PARAM_STRUCT_NUM.
Alias de tabla decombinación de código
Especifique el alias de tabla para añadirlo como prefijo a losnombres de columna. Utilice TABLEALIAS si SELECT se une aotras tablas de campo flexible o utiliza una autounión.
Segmentos (Opcional) Identifica para qué segmentos se solicitan estos datos.El valor por defecto es "ALL". Consulte Oracle E-Business SuiteDeveloper's Guide para conocer la sintaxis.
Mostrar segmentosprincipales
Seleccione esta casilla para que se muestren automáticamente lossegmentos principales de los segmentos dependientes incluso sino se muestran en el atributo de los segmentos.
Campos para el tipo de campo flexible clave: Filtrar
En la tabla siguiente se muestran los campos de detalles para el tipo de campo flexibleFiltrar.
Campo Descripción
Alias de tabla decombinación de código
Especifique el alias de tabla para añadirlo como prefijo a losnombres de columna. Utilice TABLEALIAS si SELECT se une aotras tablas de campo flexible o utiliza una autounión.
Capítulo 13Adición de campos flexibles clave
13-5

Campo Descripción
Número de instancia deestructura
Introduzca el nombre de la columna de origen o del parámetroque contiene la información de la estructura de campo flexible.Por ejemplo: 101. Para utilizar un parámetro, añada dos puntoscomo prefijo al nombre del parámetro; porejemplo, :PARAM_STRUCT_NUM.
Capítulo 13Adición de campos flexibles clave
13-6

14Adición de definiciones de repartición
En este tema se describe el soporte para los informes de repartición, y cómo configurar unadefinición de repartición en el modelo de datos con el fin de dividir y entregar el informe avarios destinatarios.
Temas:
• Acerca de la repartición
• ¿Qué es una definición de depuración?
• Requisitos para agregar definiciones de repartición
• Uso de una consulta SQL para agregar una definición de repartición al modelo de datos
• Uso de un juego de datos visualizado para agregar una definición de repartición almodelo de datos
• Definición de la consulta para la entrega de un archivo XML
• Transferencia de un parámetro a la consulta de repartición
• Definición de los elementos Dividir por y Entregar por para un juego de datos CLOB/XML
• Configuración de un informe para usar una definición de repartición
• Consulta de repartición de ejemplo
• Creación de una tabla para utilizarla como origen de datos de una entrega
Acerca de la reparticiónLa repartición es un proceso de división de datos en bloques que genera documentos paracada bloque y entrega los documentos a uno o varios destinos.
Los datos para el informe se generan mediante la ejecución de una consulta una vez y ladivisión a continuación de los datos según un valor Key. Para cada bloque de datos, segenera y se entrega un documento independiente.
El uso de Publisher durante la repartición permite dividir un único informe en función de unelemento del modelo de datos y entregar el informe en función de un segundo elemento delmodelo de datos. Según el elemento de entrega, puede aplicar una plantilla, un formato desalida, un método de entrega y una configuración regional diferentes a cada segmentodividido del informe. Las implantaciones de ejemplo son:
• Generación y entrega de facturas según los diseños específicos del cliente y lapreferencia de entrega.
• Generación de informes financieros para generar un informe maestro de todos loscentros de costo, dividiendo en informes de centros de costo individuales para el gestoradecuado.
• Generación de nóminas para todos los empleados basada en una extracción y entregapor correo electrónico.
14-1

¿Qué es una definición de depuración?Una definición de depuración es un componente del modelo de datos. Después dedefinir los juegos de datos para el modelo de datos, puede configurar una o másdefiniciones de depuración.
Al configurar una definición de depuración, debe definir lo siguiente:
• El elemento Dividir por gobierna cómo se dividen los datos. Por ejemplo, paradividir un lote de facturas por cada factura, puede utilizar un elementodenominado CUSTOMER_ID. Se debe ordenar o agrupar el juego de datos poreste elemento.
• Entregar por gobierna cómo se aplican las opciones de formato y entrega. En elejemplo de la factura, es probable que cada factura tenga criterios de entregadeterminados por el cliente; por lo tanto, el elemento Entregar por también seríaCUSTOMER_ID.
• La Consulta de entrega es una consulta SQL que define para construir el archivode datos XML de entrega. La consulta debe devolver los detalles de formato yentrega.
Requisitos para agregar definiciones de reparticiónEn este tema se muestran los requisitos para agregar una definición de repartición almodelo de datos.
Antes de definir la repartición y de activarla en el informe, asegúrese de lo siguiente:
• Ha definido un juego de datos de consulta SQL o un juego de datos de DataModeler para este modelo de datos.
• El juego de datos se ordena o agrupa por el elemento por el que desee dividir losdatos en la definición de repartición.
• La información de entrega y formato está disponible para Publisher. Puedeproporcionar la información en tiempo de ejecución para Publisher de una de lassiguientes formas:
– La información se almacena en una tabla de base de datos disponible paraPublisher para una definición de entrega dinámica.
– La información se codifica en el SQL de entrega para una definición deentrega estática.
• La definición de informe para este modelo de datos se ha creado e incluye losdiseños que se van a aplicar a los datos del informe.
Uso de una consulta SQL para agregar una definición derepartición al modelo de datos
En la tabla Definiciones de repartición, agregue una definición de reparticiónespecificando el nombre, el tipo, el origen de datos y otras propiedades.
Utilice una consulta SQL para agregar una definición de repartición al modelo dedatos y activar la repartición en el informe. Las validaciones de consulta SQL
Capítulo 14¿Qué es una definición de depuración?
14-2

garantizan que la consulta SQL para la repartición devuelva filas distintas. La consulta SQLfalla con un error si el tamaño de los resultados de una consulta de repartición supera las200 000 filas.
1. En el panel de componentes del editor del modelo de datos, haga clic en Reparticiónpara crear una consulta de repartición.
2. En la tabla Definición de reparticiones, haga clic en el botón Crear repartición.
3. Introduzca lo siguiente para esta definición de repartición:
• Nombre: introduzca un nombre para la consulta. Por ejemplo, Repartir en archivo.
• Tipo: seleccione Consulta SQL.
• Origen de datos: seleccione el origen de datos que contiene la información deentrega.
4. En la región inferior, introduzca lo siguiente para esta definición de repartición:
• Dividir por: seleccione el elemento del juego de datos por el que desea dividir losdatos.
• Entregar por: seleccione el elemento del juego de datos por el que desea darformato a los datos y entregarlos.
• Activar salida consolidada: seleccione esta opción para generar un único informeconsolidado.
• Agrupar datos por valores clave de división: seleccione esta opción para agruparlos datos según los valores de clave de división.
• Consulta SQL: introduzca la consulta o haga clic en QueryBuilder para crear laconsulta de repartición.
• Anexo: asocie archivos PDF externos al PDF del resultado de repartición si esnecesario.
5. En el cuadro de diálogo Propiedades del informe, seleccione Activar repartición paraactivar la repartición para un informe.
Si los elementos split-by y deliver-by residen en un documento XML almacenado comoun CLOB en la base de datos, debe introducir la XPATH completa en los campos Dividir pory Entregar por.
Asociación de PDF a informes mediante el motor de reparticiónPuede que deba asociar archivos PDF junto con las facturas para los clientes. Ahora puedeagregar estos documentos a la factura durante la repartición.
Una vez definida una consulta de repartición, puede introducir la consulta de anexo en elseparador Anexo. El anexo espera que el origen del repositorio sea un contenido deWebCenter, el cual puede definir el administrador como origen de datos.
1. Haga clic en el separador Anexo.
2. Seleccione el nombre del servidor de contenido en la lista de valores Repositorios deanexos.
3. Defina la consulta SQL para el anexo en el servidor de contenidos.
4. Haga clic en el icono Guardar después de realizar los cambios en el modelo de datos.
5. Haga clic en el botón Ver datos.
Capítulo 14Uso de una consulta SQL para agregar una definición de repartición al modelo de datos
14-3

6. Haga clic en Ver para ver los datos.
7. Guarde los datos haciendo clic en Guardar como datos de ejemplo.
8. Para crear un informe basado en el modelo de datos que ha creado, haga clic enCrear informe.
Tenga en cuenta que los anexos PDF se entregan a los destinatarios junto con elinforme principal como un único archivo PDF. El documento anexo no se embebe porseparado, sino que se agrega al informe.Si desea guardar el informe PDF completo junto con los anexos como un únicoarchivo consolidado, marque la opción Activar salida consolidada debajo de laconsulta de repartición. La salida consolidada contiene la fusión secuencial de informey anexo de cada repartición. El usuario (con el rol de consumidor) que programa eltrabajo de informe de repartición y el administrador podrán ver la salida consolidadaen la página Detalles de historial de trabajos.
Uso de un juego de datos visualizado para agregar unadefinición de repartición al modelo de datos
Puede utilizar un juego de datos visualizado de Data Modeler para agregar unadefinición de repartición al modelo de datos y, a continuación, activar la repartición enel informe.
Si desea agregar los juegos de datos que se crean en Data Modeler a la definición derepartición, asegúrese de crear la consulta correcta en Data Modeler, ya que no esposible cambiar la clave y los canales de entrega después de agregar el juego dedatos a la definición de repartición en Publisher. En Data Modeler, puede crearmodelos de datos desde el principio o utilizar datos empresariales modeladospreviamente con Oracle BI Enterprise Edition.
Para utilizar un juego de datos de Data Modeler para definir la repartición en elmodelo de datos y, a continuación, activar la repartición en el informe:
1. En el panel de componentes del editor del modelo de datos, haga clic enRepartición para crear una consulta de repartición.
2. En la tabla de definiciones Repartición, haga clic en el botón Crear nuevarepartición.
3. Introduzca lo siguiente para esta definición de repartición:
Nombre: introduzca un nombre para la consulta. Por ejemplo, Repartir en correoelectrónico.
Tipo: seleccione los Juegos de datos de DV para utilizar un juego de datosdefinido en Data Modeler.
4. En la región inferior, introduzca lo siguiente para esta definición de repartición:
Dividir por: seleccione el elemento del juego de datos por el que desea dividir losdatos.
Entregar por: seleccione el elemento del juego de datos por el que desea darformato a los datos y entregarlos.
Activar salida consolidada: seleccione esta opción para generar un únicoinforme consolidado.
Capítulo 14Uso de un juego de datos visualizado para agregar una definición de repartición al modelo de datos
14-4

Agrupar datos por valores clave de división: seleccione esta opción para agrupar losdatos según los valores de clave de división.
Nombre del juego de datos: seleccione el juego de datos definido en Data Modeler.
5. En el cuadro de diálogo Propiedades del informe, seleccione Activar repartición paraactivar la repartición para un informe.
Si los elementos split-by y deliver-by residen en un documento XML almacenado comoun CLOB en la base de datos, debe introducir la XPATH completa en los campos Dividir pory Entregar por.
Definición de la consulta para la entrega de un archivo XMLLa consulta de repartición es una consulta SQL que define para proporcionar la informaciónnecesaria para formatear y entregar el informe.
Publisher utiliza los resultados de la consulta de repartición para crear el XML de entrega.
El motor de repartición de utiliza el XML de entrega como tabla de asignación para cadaelemento Entregar por. La estructura del XML de entrega que requiere Publisher es lasiguiente:
<ROWSET> <ROW> <KEY></KEY> <TEMPLATE></TEMPLATE> <LOCALE></LOCALE> <OUTPUT_FORMAT></OUTPUT_FORMAT> <DEL_CHANNEL></DEL_CHANNEL> <TIMEZONE></TIMEZONE> <CALENDAR></CALENDAR> <OUTPUT_NAME></OUTPUT_NAME> <SAVE_OUTPUT></SAVE_OUTPUT> <PARAMETER1></PARAMETER1> <PARAMETER2></PARAMETER2> <PARAMETER3></PARAMETER3> <PARAMETER4></PARAMETER4> <PARAMETER5></PARAMETER5> <PARAMETER6></PARAMETER6> <PARAMETER7></PARAMETER7> <PARAMETER8></PARAMETER8> <PARAMETER9></PARAMETER9> <PARAMETER10></PARAMETER10> </ROW></ROWSET>
• KEY: clave de entrega, que debe coincidir con el elemento Entregar por. El motor derepartición utiliza la clave para enlazar los criterios de entrega a una sección específicade los datos repartidos. Asegúrese de introducir "KEY" entre comillas dobles en lasentencia select; por ejemplo:
select d.department_name as "KEY",• TEMPLATE: nombre del diseño que se va a aplicar. Tenga en cuenta que el valor es el
nombre del diseño (por ejemplo, 'Customer Invoice'), y no el nombre del archivo deplantilla (por ejemplo, invoice.rtf).
Capítulo 14Definición de la consulta para la entrega de un archivo XML
14-5

• LOCALE: configuración regional de la plantilla; por ejemplo, 'en-US'.
• OUTPUT_FORMAT: formato de salida. En la tabla siguiente se muestran losvalores válidos que se deben introducir para la consulta de repartición.
Formato de salida Valor paraintroducir en laconsulta derepartición
Tipos de plantilla que pueden generar esteformato de salida
Interactivo N/A No está soportado para la repartición
HTML html – Publisher– RTF– Hoja de estilo XSL (FO)
PDF pdf – Publisher– RTF– PDF– Hoja de estilo XSL (FO)
RTF rtf – Publisher– RTF– Hoja de estilo XSL (FO)
Excel (*.xlsx) xlsx – Publisher– RTF– Hoja de estilo XSL (FO)
PowerPoint (*.pptx) pptx – Publisher– RTF– Hoja de estilo XSL (FO)
MHTML MHTML – Publisher– RTF– Hoja de estilo XSL (FO)
PDF/A PDFA – Publisher– RTF– Hoja de estilo XSL (FO)
PDF/X PDFX – Publisher– RTF– Hoja de estilo XSL (FO)
PDF comprimidos PDFZ – Publisher– RTF– PDF– Hoja de estilo XSL (FO)
XML con formatoFO
xslfo – Publisher– RTF– Hoja de estilo XSL (FO)
Datos (XML) xml – Publisher– RTF– PDF– Excel– Hoja de estilo XSL (FO)– Hoja de estilo XSL (XML HTML/Texto)– Etext
Capítulo 14Definición de la consulta para la entrega de un archivo XML
14-6

Formato de salida Valor paraintroducir en laconsulta derepartición
Tipos de plantilla que pueden generar esteformato de salida
Datos (CSV) csv – Publisher– RTF– PDF– Excel– Hoja de estilo XSL (FO)– Hoja de estilo XSL (XML HTML/Texto)– Etext
XML txml Hoja de estilo XSL (XML HTML/Texto)
Texto texto – Hoja de estilo XSL (XML HTML/Texto)– Etext
• SAVE_OUTPUT: indica si se deben guardar los documentos de salida en las tablas delhistorial de Publisher para que se pueda ver y descargar el historial en la página Historialde trabajos de informe.
Los valores válidos son 'true' (por defecto) y 'false'. Si no está definida esta propiedad, seguarda la salida.
• DEL_CHANNEL: método de entrega. Los valores válidos son:
– CECS
– FAX
– FILE
– FTP
– OBJECTSTORAGE
– WCC
• TIMEZONE: zona horaria que se va a utilizar para el informe. Los valores deben tener elformato Java; por ejemplo: 'America/Los_Angeles'. Si no se proporciona la zona horaria,se utiliza la zona horaria por defecto del sistema para generar el informe.
• CALENDAR: calendario que se va a utilizar para el informe. Los valores válidos son:
– GREGORIAN
– ARABIC_HIJRAH
– ENGLISH_HIJRAH
– JAPANESE_IMPERIAL
– THAI_BUDDHA
– ROC_OFFICIAL (Taiwán)
Si no se proporciona, se utiliza el valor 'GREGORIAN'.
• OUTPUT_NAME: nombre que se va a asignar al archivo de salida en el historial detrabajos de informe.
Capítulo 14Definición de la consulta para la entrega de un archivo XML
14-7
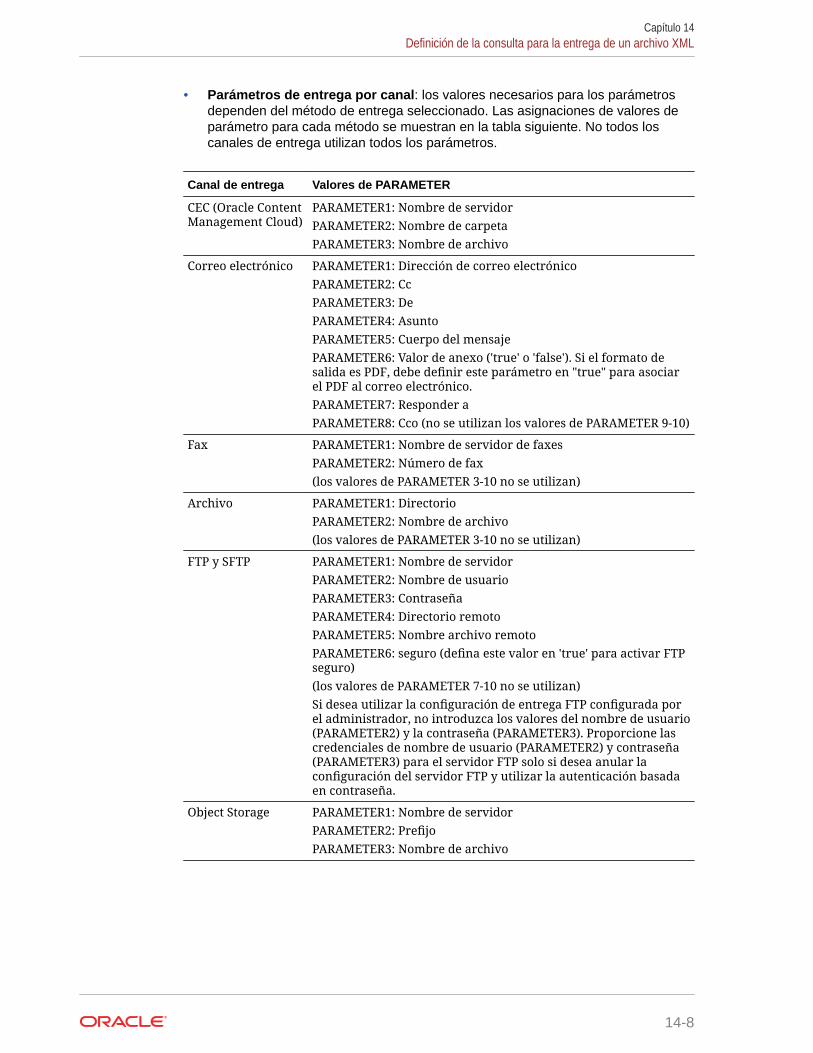
• Parámetros de entrega por canal: los valores necesarios para los parámetrosdependen del método de entrega seleccionado. Las asignaciones de valores deparámetro para cada método se muestran en la tabla siguiente. No todos loscanales de entrega utilizan todos los parámetros.
Canal de entrega Valores de PARAMETER
CEC (Oracle ContentManagement Cloud)
PARAMETER1: Nombre de servidorPARAMETER2: Nombre de carpetaPARAMETER3: Nombre de archivo
Correo electrónico PARAMETER1: Dirección de correo electrónicoPARAMETER2: CcPARAMETER3: DePARAMETER4: AsuntoPARAMETER5: Cuerpo del mensajePARAMETER6: Valor de anexo ('true' o 'false'). Si el formato desalida es PDF, debe definir este parámetro en "true" para asociarel PDF al correo electrónico.PARAMETER7: Responder aPARAMETER8: Cco (no se utilizan los valores de PARAMETER 9-10)
Fax PARAMETER1: Nombre de servidor de faxesPARAMETER2: Número de fax(los valores de PARAMETER 3-10 no se utilizan)
Archivo PARAMETER1: DirectorioPARAMETER2: Nombre de archivo(los valores de PARAMETER 3-10 no se utilizan)
FTP y SFTP PARAMETER1: Nombre de servidorPARAMETER2: Nombre de usuarioPARAMETER3: ContraseñaPARAMETER4: Directorio remotoPARAMETER5: Nombre archivo remotoPARAMETER6: seguro (defina este valor en 'true' para activar FTPseguro)(los valores de PARAMETER 7-10 no se utilizan)Si desea utilizar la configuración de entrega FTP configurada porel administrador, no introduzca los valores del nombre de usuario(PARAMETER2) y la contraseña (PARAMETER3). Proporcione lascredenciales de nombre de usuario (PARAMETER2) y contraseña(PARAMETER3) para el servidor FTP solo si desea anular laconfiguración del servidor FTP y utilizar la autenticación basadaen contraseña.
Object Storage PARAMETER1: Nombre de servidorPARAMETER2: PrefijoPARAMETER3: Nombre de archivo
Capítulo 14Definición de la consulta para la entrega de un archivo XML
14-8

Canal de entrega Valores de PARAMETER
Impresora PARAMETER1: Grupo de impresorasPARAMETER2: Nombre de impresora o de una impresora en CUPS,el URI de la impresora; por ejemplo: ipp://myserver.com:631/printers/printer1PARAMETER3: Número de copiasPARAMETER4: Caras. Los valores válidos son:• "d_single_sided" para una cara• "d_double_sided_l" para dúplex/borde largo• "d_double_sided_s" para cambio de cara/borde cortoSi no se especifica el parámetro, se utiliza el valor de una cara.PARAMETER5: Bandeja. Los valores válidos son:• "t1" para "Bandeja 1"• "t2" para "Bandeja 2"• "t3" para "Bandeja 3"Si no se especifica, se utiliza el valor por defecto de impresora.PARAMETER6: Rango de impresión. Por ejemplo, "3" imprime solola página 3, "2-5" imprime las páginas 2-5, "1,3-5" imprime laspáginas 1 y 3-5(los valores de PARAMETER 7-10 no se utilizan)
WCC PARAMETER1: Nombre de servidorPARAMETER2: Grupo de seguridadPARAMETER3: AutorPARAMETER4: Cuenta (opcional)PARAMETER5: TítuloPARAMETER6: Archivo primario (o Nombre de archivo)PARAMETER7: Comentarios (opcional)PARAMETER8: ID de contenido (opcional, el ID de contenido debeser único).PARAMETER9: Personalizar metadatos
Transferencia de un parámetro a la consulta de reparticiónPuede transferir el valor de un elemento del XML de repartición mediante un parámetrodefinido en el modelo de datos.
Por ejemplo, si desea poder seleccionar la plantilla en el momento del envío, puede definirun parámetro en el modelo de datos y utilizar la sintaxis :parameter_name en la consulta. Enel siguiente ejemplo, se muestra este caso de uso de un parámetro en una consulta derepartición.
Supongamos que la definición de informe incluye tres diseños: layout1, layout2 y layout3. Enel momento del envío, desea seleccionar el diseño (o la TEMPLATE, definida en la consultade repartición) que se va a utilizar.
Para transferir un parámetro a la consulta de repartición:
1. En el modelo de datos, defina una lista de valores con los nombres de diseño
Capítulo 14Transferencia de un parámetro a la consulta de repartición
14-9

2. Cree un parámetro del tipo menú. Introduzca P1 como nombre y seleccione Listade diseños en Lista de valores.
3. En la consulta de repartición, transfiera el valor del parámetro al campoTEMPLATE mediante :P1como se muestra en la siguiente figura:
Definición de los elementos Dividir por y Entregar por paraun juego de datos CLOB/XML
Si los elementos split-by y deliver-by necesarios para la definición de reparticiónresiden en un juego de datos recuperado de una columna CLOB de una base de
Capítulo 14Definición de los elementos Dividir por y Entregar por para un juego de datos CLOB/XML
14-10
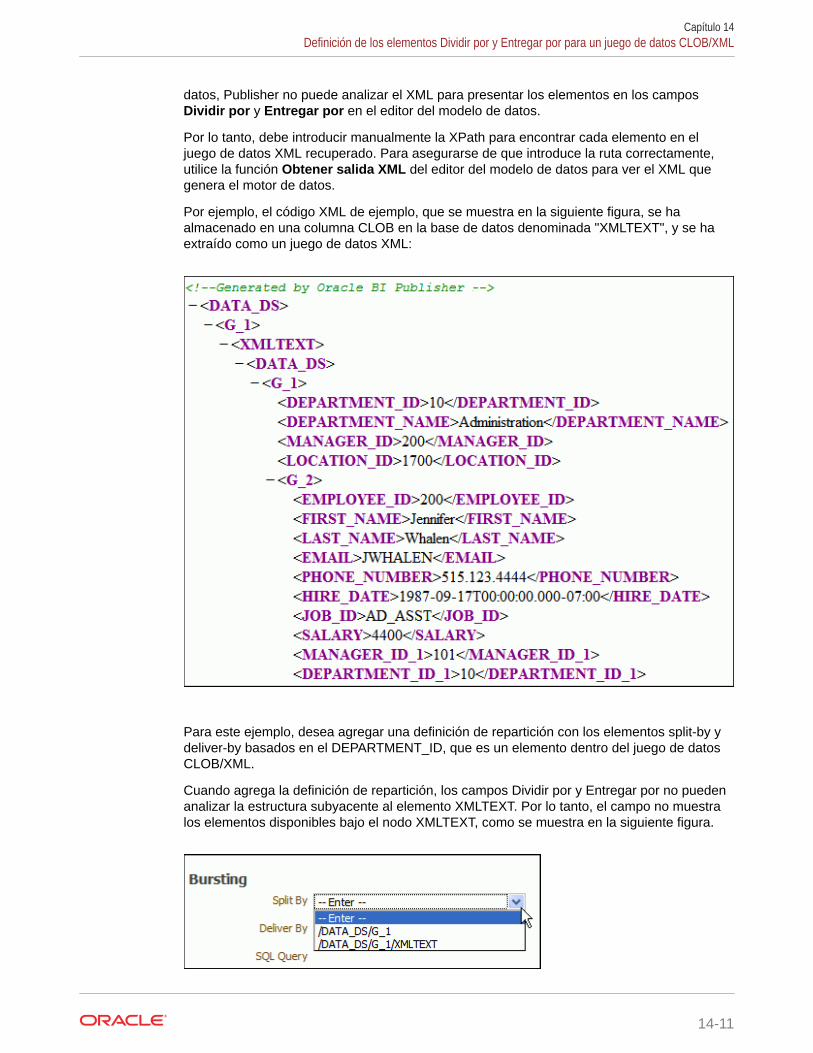
datos, Publisher no puede analizar el XML para presentar los elementos en los camposDividir por y Entregar por en el editor del modelo de datos.
Por lo tanto, debe introducir manualmente la XPath para encontrar cada elemento en eljuego de datos XML recuperado. Para asegurarse de que introduce la ruta correctamente,utilice la función Obtener salida XML del editor del modelo de datos para ver el XML quegenera el motor de datos.
Por ejemplo, el código XML de ejemplo, que se muestra en la siguiente figura, se haalmacenado en una columna CLOB en la base de datos denominada "XMLTEXT", y se haextraído como un juego de datos XML:
Para este ejemplo, desea agregar una definición de repartición con los elementos split-by ydeliver-by basados en el DEPARTMENT_ID, que es un elemento dentro del juego de datosCLOB/XML.
Cuando agrega la definición de repartición, los campos Dividir por y Entregar por no puedenanalizar la estructura subyacente al elemento XMLTEXT. Por lo tanto, el campo no muestralos elementos disponibles bajo el nodo XMLTEXT, como se muestra en la siguiente figura.
Capítulo 14Definición de los elementos Dividir por y Entregar por para un juego de datos CLOB/XML
14-11

Para utilizar el elemento DEPARTMENT_ID como elemento Dividir por, escribamanualmente la XPath al campo, como se muestra en la siguiente figura.
Configuración de un informe para usar una definición derepartición
Aunque se pueden definir varias definiciones de repartición para un solo modelo dedatos, solo se puede activar una para un informe.
Para configurar un informe para utilizar una definición de repartición:
1. Permita que un informe utilice una definición de repartición en el cuadro dediálogo Propiedades del informe del editor de informes.
2. Programe un trabajo para este informe.
3. Seleccione que se utilice la definición de repartición para formatear y entregar elinforme.
Puede seleccionar que no se utilice la definición de repartición y seleccionar supropia salida y destino como un informe programado normal.
Consulta de repartición de ejemploEl siguiente ejemplo de consulta de repartición está basado en un informe de factura.Este informe lo entregará CUSTOMER_ID a la dirección de correo electrónicoindividual de cada cliente.
En este ejemplo se asume que las preferencias de entrega y formato para cadacliente se incluyen en una tabla de base de datos denominada "CUSTOMERS". Latabla CUSTOMERS incluye las siguientes columnas que se recuperarán para creardinámicamente el XML de entrega en tiempo de ejecución:
• CST_TEMPLATE
• CST_LOCALE
• CST_FORMAT
• CST_EMAIL_ADDRESS
El CUSTOMER_ID se utilizará como KEY y también para definir el nombre del archivode salida.
Capítulo 14Configuración de un informe para usar una definición de repartición
14-12

El código SQL para generar el juego de datos de entrega para este ejemplo es el siguiente:
select distinctCUSTOMER_ID as "KEY",CST_TEMPLATE TEMPLATE,CST_LOCALE LOCALE,CST_FORMAT OUTPUT_FORMAT,CUSTOMER_ID OUTPUT_NAME,'EMAIL' DEL_CHANNEL,CST_EMAIL_ADDRESS PARAMETER1,'[email protected]' PARAMETER2,'[email protected]' PARAMETER3,'Your Invoices' PARAMETER4,'Hi'||CUST_FIRST_NAME||':'|| 'Please find attached yourinvoices.' PARAMETER5,'true' PARAMETER6,'[email protected]' PARAMETER7from CUSTOMERS
Creación de una tabla para utilizarla como origen de datos deuna entrega
Si la información de entrega no está disponible fácilmente en los orígenes de datosexistentes, puede considerar crear una tabla y utilizarla para que la consulta pueda crear elXML de entrega.
A continuación, se muestra un ejemplo:
CREATE TABLE "XXX"."DELIVERY_CONTROL" ( "KEY" NUMBER, "TEMPLATE" VARCHAR2(20 BYTE), "LOCALE" VARCHAR2(20 BYTE), "OUTPUT_FORMAT" VARCHAR2(20 BYTE), "DEL_CHANNEL" VARCHAR2(20 BYTE), "PARAMETER1" VARCHAR2(100 BYTE), "PARAMETER2" VARCHAR2(100 BYTE), "PARAMETER3" VARCHAR2(100 BYTE), "PARAMETER4" VARCHAR2(100 BYTE), "PARAMETER5" VARCHAR2(100 BYTE), "PARAMETER6" VARCHAR2(100 BYTE), "PARAMETER7" VARCHAR2(100 BYTE), "PARAMETER8" VARCHAR2(100 BYTE), "PARAMETER9" VARCHAR2(100 BYTE), "PARAMETER10" VARCHAR2(100 BYTE), "OUTPUT_NAME" VARCHAR2(100 BYTE), "SAVE_OUTPUT" VARCHAR2(4 BYTE), "TIMEZONE" VARCHAR2(300 BYTE), "CALENDAR" VARCHAR2(300 BYTE) ) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "EXAMPLES";
Capítulo 14Creación de una tabla para utilizarla como origen de datos de una entrega
14-13

Si el controlador JDBC que utiliza no soporta alias de columna, cuando defina la tablade control de repartición, las columnas deben coincidir exactamente con el nombre dela etiqueta XML de control. Por ejemplo, la columna KEY debe denominarse KEY, ydebe estar en mayúsculas. PARAMETER1 debe denominarse PARAMETER1, noparameter1 ni param1, ni ningún otro nombre que no coincida.
Consejos para crear una tabla de creación de entrega de repartición:
• Si el juego de datos dividido no contiene un valor DELIVERY_KEY, el documentono se entrega ni se genera. Por ejemplo, utilizando el ejemplo anterior, si el clientecon el identificador 123 no está definido en la tabla de entrega de repartición, nose genera el documento de este cliente.
• Para permitir que un juego de datos dividido genere más de un documento oentregue a más de un destino, duplique el valor DELIVERY_KEY y proporcionejuegos diferentes de OUTPUT_FORMAT, DEL_CHANNEL u otros parámetros. Porejemplo, el cliente con el identificador 456 desea que su documento se entregueen dos direcciones de correo electrónico. Para ello, inserte dos filas en la tabla,ambas con 456 como DELIVERY_KEY y cada una con su propia dirección decorreo electrónico.
Capítulo 14Creación de una tabla para utilizarla como origen de datos de una entrega
14-14

15Adición de metadatos personalizados paraOracle WebCenter Content Server
En este tema se describe cómo utilizar el editor del modelo de datos para asignar camposdel origen de datos a campos de metadatos personalizados. Al entregar informes a OracleWebCenter Content, Publisher puede rellenar los campos de metadatos personalizadosdefinidos en los perfiles de documento.
Temas:
• Acerca de la asignación de metadatos personalizados
• Asignación de campos de datos a campos de metadatos personalizados
• Supresión de campos de metadatos no usados
Acerca de la asignación de metadatos personalizadosEl componente Personalizar metadatos permite la asignación de campos de datos, porejemplo, el número de factura o de cliente, del modelo de datos a los campos de metadatosdefinidos en las reglas de perfil de documento configuradas en el servidor de OracleWebCenter Content.
Al ejecutar el informe y seleccionar el servidor de Oracle WebCenter Content como destinode entrega, Publisher genera y almacena el documento en el servidor de contenido con losmetadatos.
RequisitosSe deben cumplir determinados requisitos para usar esta función del editor de modelos dedatos.
Requisitos:
• Se debe configurar el servidor de contenido como destino de entrega con metadatospersonalizados activados.
• Para asignar los campos de metadatos personalizados a campos de datos de su juegode datos del modelo de datos, el juego de datos debe ser de un tipo cuya estructura dedatos pueda recuperar el editor de modelo de datos, por ejemplo, están soportados losjuegos de datos SQL y de Excel; sin embargo, no están soportados los juegos de datosdel servicio web.
Asignación de campos de datos a campos de metadatospersonalizados
Puede iniciar metadatos en un perfil de documento.
Para asignar metadatos personalizados:
15-1

1. En el panel de tareas del editor del modelo de datos, haga clic en Metadatospersonalizados.
2. Oracle WebCenter Content Server almacena los metadatos en un perfil dedocumento. Un perfil de documento se anida posteriormente en reglas. Pararecuperar los campos de metadatos para la asignación, primero debe seleccionarel servidor de WebCenter, a continuación, el Perfil de contenido y, por último, eljuego de Reglas.
En la región de cabecera Metadatos personalizados, seleccione las Reglas de lasiguiente manera:
• Servidor: seleccione el servidor de contenidos web donde está definido elperfil de contenido.
• Perfil de contenido: seleccione el perfil de contenido que incluye las reglasque definen los campos de metadatos personalizados.
• Reglas: seleccione el juego de reglas que especifica los campos demetadatos.
Si no selecciona un juego de reglas, Publisher carga los metadatos para todaslas reglas en Perfil de contenido.
3. Haga clic en Cargar metadatos. El panel inferior muestra los campos demetadatos definidos en las Reglas que ha seleccionado.
Capítulo 15Asignación de campos de datos a campos de metadatos personalizados
15-2
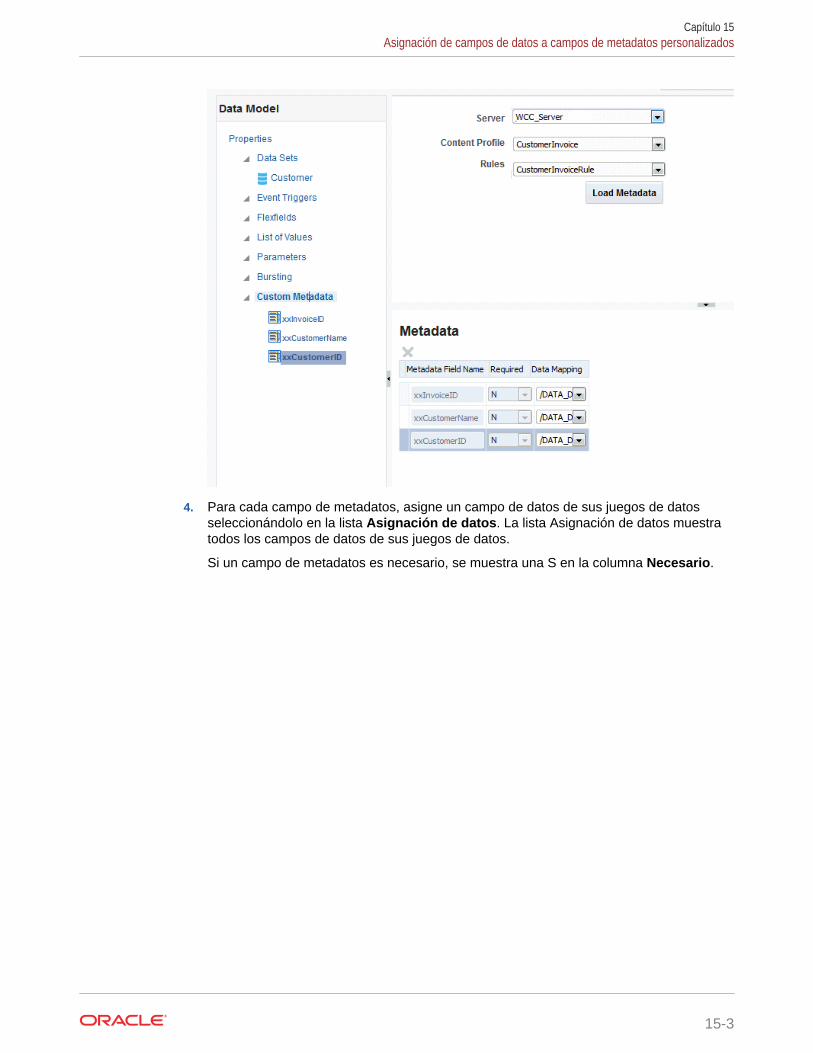
4. Para cada campo de metadatos, asigne un campo de datos de sus juegos de datosseleccionándolo en la lista Asignación de datos. La lista Asignación de datos muestratodos los campos de datos de sus juegos de datos.
Si un campo de metadatos es necesario, se muestra una S en la columna Necesario.
Capítulo 15Asignación de campos de datos a campos de metadatos personalizados
15-3

5. Cuando haya terminado con la asignación de campos de metadatos, haga clic enGuardar.
Supresión de campos de metadatos no usadosPublisher carga todos los campos de metadatos definidos para el juego de reglas queseleccione. Puede suprimir los campos de metadatos personalizados no necesarios.
1. Seleccione el campo de metadatos, ya sea haciendo clic en el nombre de campodel panel de la izquierda o haciendo clic en la columna de selección de la tabla.
2. Haga clic en el botón Suprimir.
Capítulo 15Supresión de campos de metadatos no usados
15-4

16Mejores prácticas de rendimiento
En este tema se proporcionan consejos para crear modelos de datos eficientes para unmejor rendimiento.
Temas:
• Información sobre la opción Timeout por defecto de Oracle WebLogic Server
• Mejores prácticas para juegos de datos de SQL
• Límite de las listas de valores
• Trabajar con parámetros de fecha
• Ejecución del informe en línea/fuera de línea (programación)
• Definición de propiedades de modelo de datos para evitar errores de memoria
• Ajuste de consultas SQL
• Validación de modelos de datos
Información sobre la opción Timeout por defecto de OracleWebLogic Server
WebLogic Server tiene un timeout por defecto de 600 segundos para cada thread desolicitud.
Cuando el tiempo sea más de 600 segundos, Oracle WebLogic Server marca el thread comoParado. Cuando el número de threads parados llegue a los 25, el servidor se cierra.
Para evitar este problema, verifique que el tiempo de ejecución de SQL no exceda laconfiguración de WebLogic Server.
Mejores prácticas para juegos de datos de SQLTenga en cuenta los siguientes consejos que le facilitarán la creación de juegos de datosSQL más eficientes:
• Solo devuelva los datos que necesite
• Uso de alias de columnas para acortar la longitud del archivo XML
• Evite usar filtros de grupo mediante la mejora de la consulta
• Cómo evitar llamadas PL/SQL en cláusulas WHERE
• Evite usar la tabla dual del sistema
• Cómo evitar llamadas PL/SQL en el nivel de elemento
• Cómo evitar incluir varios juegos de datos
• Evitar juegos de datos anidados
16-1

• Evite las consultas en línea como columnas de resumen
• Cómo evitar valores de enlace de parámetros excesivos
• Consejos sobre los parámetros de varios valores
• Agrupación de divisiones y ordenación de datos
Solo devuelva los datos que necesiteAsegúrese de que la consulta devuelve solo los datos que necesita para los informes.La devolución de un exceso de datos es un riesgo de que se produzcan excepcionesOutOfMemory.
Por ejemplo, no debe devolver simplemente todas las columnas como en:
SELECT * FROM EMPLOYEES;
Evite siempre el uso de *.
Las dos mejores prácticas para restringir los datos devueltos son las siguientes:
• Seleccione siempre solo las columnas que necesite
Por ejemplo:
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES;• Utilice una cláusula WHERE y parámetros de enlace siempre que sea posible
para restringir los datos devueltos con más precisión.
En este ejemplo solo se seleccionan las columnas necesarias y solo aquellas quecoinciden con el valor del parámetro:
SELECT DEPARTMENT_ID, DEPARTMENT_NAME FROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
Uso de alias de columnas para acortar la longitud del archivo XMLCuanto más corto sea el nombre de la columna, más pequeño será el archivo XMLresultante; cuanto menor sea el archivo XML, de forma más rápida lo analiza elsistema.
Acorte los nombres de columna con alias para acortar el tiempo de procesamiento dela E/S y mejorar la eficacia de los informes.
En este ejemplo, DEPARTMENT_ID se acorta a "id" y DEPARTMENT_NAME se acorta a"name":
SELECT DEPARTMENT_ID id, DEPARTMENT_NAME nameFROM EMPLOYEES WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-2

Evite usar filtros de grupo mediante la mejora de la consultaSi bien la función Filtro de grupo de Data Modelo le permite eliminar los registros que hayarecuperado su consulta. Este proceso tiene lugar en el nivel medio, que es mucho menoseficaz que el nivel de la base de datos.
Es mejor eliminar los registros innecesarios mediante su consulta usando en su lugar lascondiciones de la cláusula WHERE.
Cómo evitar llamadas PL/SQL en cláusulas WHERELas llamadas a la función PL/SQL en la cláusula WHERE de la consulta pueden provocarvarias ejecuciones.
Estas llamadas a funciones se ejecutan para cada fila encontrada en la base de datoscoincidente. Es más, en esta construcción es necesario que PL/SQL cambie de contexto conSQL, lo que no es eficiente.
Como mejor práctica, evite las llamadas PL/SQL en la cláusula WHERE; en su lugar, una lastablas base y agregue filtros.
Evite usar la tabla dual del sistemaUsar la tabla DUAL del sistema para devolver las constantes sysdate o de otro tipo no es unmétodo eficaz. Debe evitar el uso de la tabla DUAL del sistema cuando no sea necesario.
Por ejemplo, en lugar de:
SELECT DEPARTMENT_ID ID, (SELECT SYSDATE FROM DUAL) TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
Debe:
SELECT DEPARTMENT_ID ID, SYSDATE TODAYS_DATE FROM DEPARTMENTS WHERE DEPARTMENT_ID IN (:P_DEPT_ID)
En el primer ejemplo, no se necesita DUAL. Puede acceder a SYSDATE directamente.
Cómo evitar llamadas PL/SQL en el nivel de elementoLas llamadas a las funciones del paquete a nivel de elemento, grupo o fila no estánpermitidas. Puede incluir llamadas a funciones de paquete a nivel de elemento global porqueestas funciones solo se ejecutan una vez por solicitud de ejecución modelo de datos.
Ejemplo:
<dataStructure> <group name="G_order_short_text" dataType="xsd:string" source="Q_ORDER_ATTACH"> <element name="order_attach_desc" dataType="xsd:string" value="ORDER_ATTACH_DESC"/>
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-3

<element name="order_attach_pk" dataType="xsd:string" value="ORDER_ATTACH_PK"/>
El siguiente elemento es incorrecto:
<element name="ORDER_TOTAL _FORMAT" dataType="xsd:string" value=" WSH_WSHRDPIK_XMLP_PKG.ORDER_TOTAL _FORMAT "/><!-- This is wrong should not be called within group.--></group>
<element name="S_BATCH_COUNT" function="sum" dataType="xsd:double" value="G_mo_number.pick_slip_number"/></dataStructure>
Cómo evitar incluir varios juegos de datosPuede resultar deseable crear un modelo de datos con varios juegos de datos paraofrecer varios informes, pero esta práctica hace que se reduzca mucho el rendimiento.
Cuando se ejecuta un informe, el procesador de datos ejecuta todos los juegos dedatos con independencia de si los datos se usan en la salida final.
Para obtener un mejor rendimiento del informe y mayor eficiencia de la memoria,piénselo bien antes de usar un solo modelo de datos para utilizar varios informes.
Evitar juegos de datos anidadosEl modelo de datos proporciona un mecanismo para crear una jerarquía principal-secundario mediante el enlace de elementos de un juego de datos a otro.
En tiempo de ejecución, el procesador de datos ejecuta la consulta principal y paracada fila del principal ejecuta la consulta secundaria. Cuando un modelo de datostiene muchas relaciones principal-secundario anidadas, puede dar lugar a unprocesamiento lento.
Un mejor enfoque para evitar juegos de datos anidados es combinar varias consultasde juego de datos en una única consulta mediante una cláusula WITH.
A continuación, se ofrecen algunos consejos generales sobre cuándo combinar variosjuegos de datos en un juego de datos:
• Cuando el principal y el secundario tienen una relación de 1 a 1 (es decir, cada filaprincipal tiene exactamente una fila secundaria), fusione los juegos de datosprincipal y secundario en una única consulta.
• Cuando la consulta principal tiene muchas más filas en comparación con laconsulta secundaria. Por ejemplo, una tabla de distribución de facturas enlazada auna tabla de facturas en la que la tabla de distribución tiene millones de filas encomparación con la tabla de facturas. Aunque la ejecución de cada consultasecundaria tarda menos de un segundo, la ejecución de la consulta secundaria decada distribución puede causar threads STUCK.
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-4

Ejemplo de cuándo se debe utilizar una cláusula WITH:
Query Q1: SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMMFROM EMPLOYEES
Query Q2: SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOCFROM DEPARTMENTS
Combine las tres consultas en una utilizando la cláusula WITH de la siguiente manera:
WITH Q1 as (SELECT DEPARTMENT_ID DID,DEPARTMENT_NAME DNAME,LOCATION_ID LOCFROM DEPARTMENTS),Q2 as (SELECT DEPARTMENT_ID EDID,EMPLOYEE_ID EID,FIRST_NAME FNAME,LAST_NAME LNAME,SALARY SAL,COMMISSION_PCT COMMFROM EMPLOYEES)SELECT Q1.*, Q2.*FROM Q1 LEFT JOIN Q2ON Q1.DID=Q2.EDID
Evite las consultas en línea como columnas de resumenLas consultas en línea se ejecutan para cada columna y fila. Por ejemplo, si una consultaprincipal tiene 100 columnas y ofrece 1000 filas, cada consulta de columna se ejecuta 1000veces.
Evite el siguiente uso de consultas en línea. Si esta consulta solo devuelve unas pocas filas,este proceso puede funcionar bien. Sin embargo, si la consulta devuelve 10000 filas, cadasubconsulta o consulta en línea se ejecuta 10000 veces, lo que puede provocar que losthreads se paren.
SELECTNATIONAL_IDENTIFIERS,NATIONAL_IDENTIFIER,PERSON_NUMBER,PERSON_ID,STATE_CODEFROM(select pprd.person_id,(select REPLACE(national_identifier_number,'-') from per_national_identifiers pni where pni.person_id = pprd.person_id and rownum<2) national_identifiers,(select national_identifier_number from per_nationalidentifiers pni where pni.person_id = pprd.person_id and rownum<2) national_identifier,(select person_number from per_all_people_f ppfwhere ppf.person_id = pprd.person_idand :p_effective_start_date between ppf.effective_start_date and ppf.effective_end_date) PERSON_NUMBER(Select hg.geography_code from hz_geographies hgwhere hg.GEOGRAPHY_NAME = paddr.region_2and hg.geography_type = 'STATE') state_code
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-5

Cómo evitar valores de enlace de parámetros excesivosOracle Database le permite enlazar un máximo de 1000 valores por parámetro.
Enlazar un gran número de valores de parámetros no es eficiente. Evite enlazar másde 100 valores a un parámetro.
Cuando cree un parámetro de tipo Menú y su lista de valores contenga varios valores,asegúrese de que activa tanto la opción Selección múltiple como Puede seleccionartodo y, a continuación, también seleccione el valor NULO transferido para garantizarque no se transfieran varios valores.
Consejos sobre los parámetros de varios valoresLos consumidores de informes a menudo deben ejecutar informes que soportandeterminadas condiciones.
• Si no se selecciona ningún parámetro (nulo), se devuelve todo.
• Permitir la selección de varios valores de parámetro
En estos casos, el uso de NVL() no funciona; por lo tanto, debe utilizar
• COALESCE() para consultas de Oracle Database
• CASE / WHEN para consultas (lógicas) de Oracle BI EE
Ejemplo:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEESWHERE DEPARTMENT_ID = NVL(:P_DEPT_ID, DEPARTMENT_ID
La sintaxis de consulta anterior solo es correcta si el valor de P_DEPT_ID es un solovalor o es nulo. La sintaxis no funciona si se transfiere más de un solo valor.
Para soportar varios valores, utilice la siguiente sintaxis:
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-6

Para Oracle Database:
SELECT EMPLOYEE_ID ID, FIRST_NAME FNAME, LAST_NAME LNAME FROM EMPLOYEESWHERE (DEPARTMENT_ID IN (:P_DEPT_ID) OR COALESCE (:P_DEPT_ID, null) is NULL)
Para el origen de datos de Oracle BI EE:
(CASE WHEN ('null') in (:P_YEAR) THEN 1 END =1 OR "Time"."Per Name Year" in (:P_YEAR))
Para Oracle BI EE, el tipo de dato del parámetro debe ser una cadena. Los tipos de dato denúmero y fecha no están soportados.
Agrupación de divisiones y ordenación de datosEl modelo de datos proporciona una función para crear divisiones de grupo y ordenar datos.
La ordenación solo está soportada para las columnas de división de grupo principales. Porejemplo, si un juego de datos de empleados se agrupa por departamento y gestor, puedeordenar los datos XML por departamento. Si sabe cómo deben ordenarse los datos en elinforme o la plantilla final, especifique la ordenación en tiempo de generación de datos paraoptimizar la generación de documentos. El orden de columna especificado en la cláusulaSELECT debe coincidir exactamente con los órdenes de elemento de la estructura de datos.De lo contrario, puede que la división de grupo y la ordenación no funcionen. Debido a sucomplejidad, no está permitido realizar varias agrupaciones con varias ordenaciones endiferentes niveles de grupo.
Ejemplo: en el ejemplo que se muestra a continuación, la ordenación y la división de gruposolo se aplican al grupo principal; es decir, G_1. Observe el orden de columna en la consulta,el cuadro de diálogo del juego de datos y la estructura de datos. El orden de columna SQLdebe coincidir exactamente con el orden de campo del elemento de estructura de datos; delo contrario, se puede producir la corrupción de los datos.
Ejemplo:
SELECT d.DEPARTMENT_ID DEPT_ID, d.DEPARTMENT_NAME DNAME, E.FIRST_NAME FNAME,E.LAST_NAME LNAME,E.JOB_ID JOB,E.MANAGER_IDFROM EMPLOYEES E,DEPARTMENTS D WHERE D.DEPARTMENT_ID = E.DEPARTMENT_ID ORDER BY d.DEPARTMENT_ID, d.DEPARTMENT_NAME
Una vez que ha definido la consulta, puede utilizar el diseñador del modelo de datos paraseleccionar elementos de datos y crear divisiones de grupo como se muestra a continuación.
Capítulo 16Mejores prácticas para juegos de datos de SQL
16-7
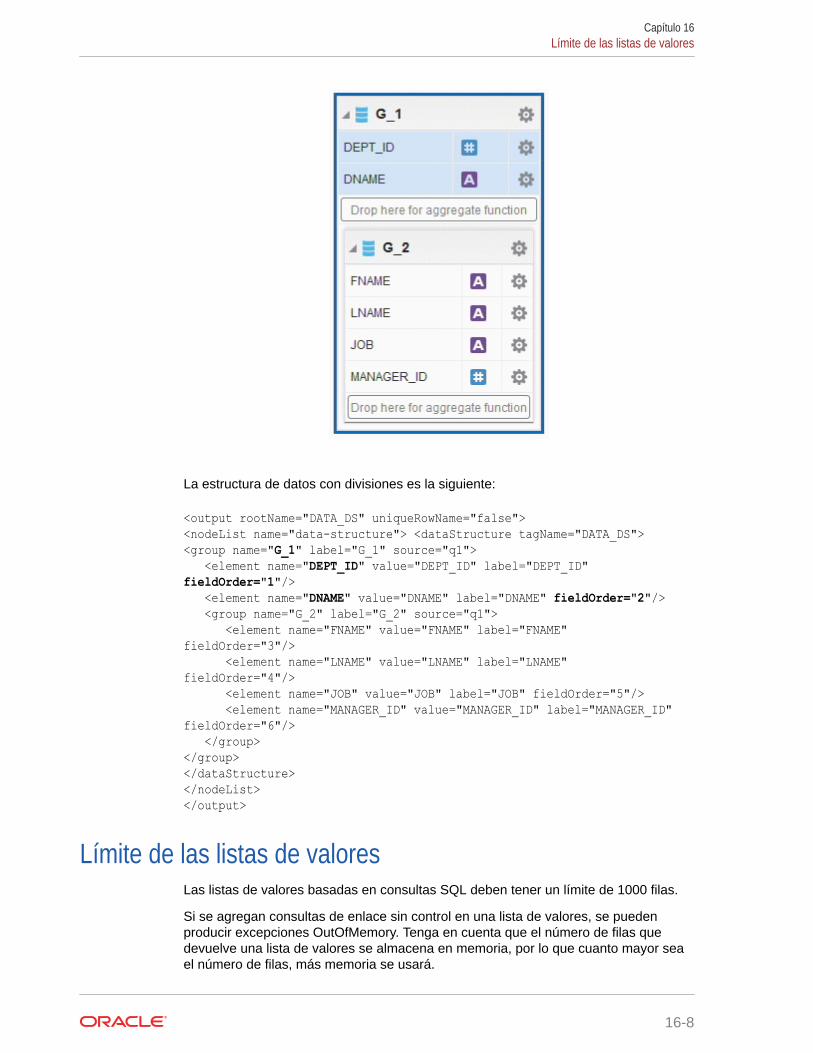
La estructura de datos con divisiones es la siguiente:
<output rootName="DATA_DS" uniqueRowName="false"><nodeList name="data-structure"> <dataStructure tagName="DATA_DS"><group name="G_1" label="G_1" source="q1"> <element name="DEPT_ID" value="DEPT_ID" label="DEPT_ID" fieldOrder="1"/> <element name="DNAME" value="DNAME" label="DNAME" fieldOrder="2"/> <group name="G_2" label="G_2" source="q1"> <element name="FNAME" value="FNAME" label="FNAME" fieldOrder="3"/> <element name="LNAME" value="LNAME" label="LNAME" fieldOrder="4"/> <element name="JOB" value="JOB" label="JOB" fieldOrder="5"/> <element name="MANAGER_ID" value="MANAGER_ID" label="MANAGER_ID" fieldOrder="6"/> </group></group></dataStructure></nodeList></output>
Límite de las listas de valoresLas listas de valores basadas en consultas SQL deben tener un límite de 1000 filas.
Si se agregan consultas de enlace sin control en una lista de valores, se puedenproducir excepciones OutOfMemory. Tenga en cuenta que el número de filas quedevuelve una lista de valores se almacena en memoria, por lo que cuanto mayor seael número de filas, más memoria se usará.
Capítulo 16Límite de las listas de valores
16-8

Trabajar con parámetros de fechaPublisher siempre enlaza el parámetro de fecha o columna de fecha como objeto de registrode hora.
Para evitar la conversión de registro de hora, defina el parámetro como cadena y transfierael valor con el formato 'DD-MM-AAAA' para que coincida con el formato de fecha delRDBMS.
Ejecución del informe en línea/fuera de línea (programación)La ejecución de informes en modo interactivo/en línea utiliza el procesamiento en memoria.
Utilice las siguientes directrices para decidir cuándo es adecuado un informe para laejecución en línea.
Para el modo en línea/interactivo:
• Cuando el tamaño de salida del informe es inferior a 50 MB
Los exploradores no ajustan la escala cuando cargan grandes volúmenes de datos. Lacarga de más de 50 MB en el explorador ralentizará o posiblemente bloqueará la sesión.
• El timeout de consulta SQL del modelo de datos es inferior a 500 segundos
Todas las ejecuciones de consultas SQL que tardan más de 500 segundos producenthreads de parada de WebLogic Server. Para evitar esta condición, programe consultasde larga duración. El proceso del programador utiliza sus propios threads de JVM enlugar de los threads de servidor de Weblogic. Es más eficiente programar informes queejecutar informes en línea.
• El número total de elementos de la estructura de datos es inferior a 500
Cuando la estructura de datos del modelo de datos contiene muchos elementos dedatos, el procesador de datos debe conservar los valores de elemento en la memoria, locual puede causar excepciones OutOfMemory. Para evitar esta condición, programeestos informes. Para los informes programados, el procesador de datos utiliza el sistemade archivos temporales para almacenar y procesar datos.
• Ninguna columna CLOB o BLOB
El procesamiento en línea guarda las columnas CLOB o BLOB completas en la memoria.Debe programar informes que incluyan columnas CLOB o BLOB.
Definición de propiedades de modelo de datos para evitarerrores de memoria
Puede usar las propiedades del modelo de datos para ayudar a evitar los errores dememoria en el sistema.
Puede definir las propiedades Timeout de consulta, Activar eliminación de SQL y Omitirconsulta de juegos de datos no utilizados en el nivel del modelo de datos.
Solo un administrador puede definir las propiedades de tiempo de ejecución Activar modoescalable de modelo de datos y Tamaño de recuperación de base de datos para todoslos modelos de datos.
Capítulo 16Trabajar con parámetros de fecha
16-9

Timeout de consultaLa propiedad Timeout de consulta especifica el límite de tiempo en segundos dentrodel cual la base de datos debe ejecutar sentencias SQL para informes programados.
El valor por defecto del timeout de consulta SQL para informes programados es de600 segundos. Especifique el límite de tiempo en el modelo de datos. Mediante elaumento del número de segundos, se arriesga a obtener threads de parada en OracleWebLogic Server. No aumente el valor a menos que ya se hayan utilizado otrasoptimizaciones y alternativas.
Las consultas que no pueden ejecutarse en menos de 600 no están bien optimizadas.Pida al DBA o al experto en rendimiento que analice y ajuste la consulta. Aumente elnúmero de segundos solo después de intentar las optimizaciones de la consulta.
Activar eliminación de SQLLa propiedad de depuración de SQL especifica si se deben recuperar solo lascolumnas que se utilizan en el diseño/la plantilla del informe.
Defina la propiedad Activar depuración de SQL en Activado en la páginaPropiedades del modelo de datos para mejorar el rendimiento permitiendo al sistemarecuperar solo las columnas utilizadas en el diseño o la plantilla del informe. Elsistema no recuperará las columnas que están definidas en la consulta pero que nose han utilizado en el informe. Esta propiedad no modifica la cláusula WHERE; enlugar de ello, encapsula la consulta SQL completa con las columnas especificadas enel diseño.
Si ha activado la depuración SQL, puede utilizar la propiedad Omitir consulta dejuegos de datos no utilizados para omitir la ejecución de juegos de datos noutilizados en un diseño.
Tamaño de recuperación de base de datosLa propiedad de tiempo de ejecución Tamaño de recuperación de base de datosespecifica el número de filas de datos que se recuperan de la base de datos a la vez.
Un administrador puede configurar la propiedad de tiempo de ejecución Tamaño derecuperación de base de datos para todos los modelos de datos. Un númeroelevado reduce el número de llamadas a la base de datos, pero consume másmemoria para el almacenamiento de más filas de datos. Defina la propiedad Activarmodo automático de tamaño de recuperación de base de datos en true parapermitir al sistema calcular el tamaño de recuperación óptimo en tiempo de ejecución.
Modo escalableEn la propiedad de modo escalable del modelo de datos se especifica si se va a usarel sistema de archivos temporales para generar datos.
El administrador puede definir la propiedad de tiempo de ejecución Activar modoescalable de modelo de datos para todos los modelos de datos.
Si selecciona Activar modo escalable de modelo de datos, Publisher utiliza elsistema de archivos temporal para generar datos, mientras que el procesador dedatos utiliza la mínima memoria disponible.
Capítulo 16Definición de propiedades de modelo de datos para evitar errores de memoria
16-10

Ajuste de consultas SQLEl ajuste de las consultas es el paso más importante para mejorar el rendimiento decualquier informe.
La explicación del plan, la supervisión SQL y la instalación de rastreo SQL con TKPROF sonlas herramientas de diagnóstico de rendimiento más básicas que pueden ayudar a ajustarlas sentencias SQL en aplicaciones que se ejecuten en Oracle Database.
Publisher proporciona un mecanismo para generar los informes de explicación del plan ysupervisión SQL, y para activar el rastreo de sesión SQL. Esta funcionalidad solo esaplicable en sentencias SQL que se ejecutan en Oracle Database. Las consultas lógicas decualquier otro tipo de base de datos no están soportadas.
Generación de la explicación del planPuede generar una explicación del plan en el nivel del juego de datos para una sola consultao a nivel de informe para todas las consultas de un informe.
Para obtener más información sobre cómo interpretar la explicación del plan, consulte OracleDatabase SQL Tuning Guide.
Explicación del plan para una sola consultaEn el cuadro de diálogo Editar del juego de datos SQL puede generar una explicación delplan antes de ejecutar realmente la consulta. De esta forma se consigue la mejor estimaciónposible de un plan. La consulta se ejecutará al enlazarse con valores nulos.
Haga clic en Generar explicación del plan en el cuadro de diálogo Editar consulta SQL.Abra el documento generado en un editor de texto como, por ejemplo, Bloc de notas oWordpad.
Explicación del plan para informesPara generar una explicación del plan para un informe, ejecute un informe a través deScheduler.
1. En el menú Nuevo, seleccione Trabajo de informe.
2. Seleccione el informe que se va a programar y, a continuación, haga clic en el separadorDiagnóstico.
Debe tener privilegios de administrador de BI o de desarrollador de modelos de datos deBI para acceder al separador Diagnóstico.
3. Seleccione Activar plan de explicación SQL y Activar diagnóstico de motor de datos.
• Activar plan de explicación SQL: genera un log de diagnóstico con información delinforme de supervisión de plan de explicación/SQL.
• Activar diagnóstico de motor de datos: genera un log de procesador de datos.
• Activar diagnóstico de procesador de informes: genera FO (opciones de formato) einformación de log relacionada con el servidor.
Capítulo 16Ajuste de consultas SQL
16-11

• Activar diagnóstico de trabajo consolidado: genera el log completo, queincluye detalles del log del programador, del log del procesador de datos y dellog de FO y del servidor.
4. Ejecute el informe.
5. En la página inicial, en Examinar/gestionar, seleccione Historial de trabajos deinforme.
6. Seleccione el informe para ver los detalles. En Salida y entrega, haga clic en Logde diagnóstico para descargar la salida de la explicación del plan.
Ejemplo de explicación del plan:
Directrices para ajustar las consultasAjuste las consultas siguiendo un juego de directrices.
• Analice la explicación del plan e identifique sentencias SQL de alto impacto.
• Agregue las condiciones de filtro necesarias y elimine las uniones no deseadas.
• Evite y elimine las exploraciones de tabla completa (FTS) en tablas grandes.Tenga en cuenta que, en algunos casos, las exploraciones de tabla completa entablas pequeñas son más rápidas y mejoran la recuperación de consultas.Asegúrese de utilizar la recuperación para las tablas pequeñas.
• Utilice las indicaciones SQL para forzar el uso de los índices adecuados.
• Evite las subconsultas complejas y utilice tablas temporales globales cuando seanecesario.
• Utilice las funciones de análisis de Oracle SQL para varias agregaciones.
• Evite usar demasiadas subconsultas en las cláusulas where, si es posible. En sulugar, reescriba las consultas con uniones externas.
Capítulo 16Ajuste de consultas SQL
16-12

• Evite las funciones de grupo, como las condiciones HAVING e IN / NOT IN de cláusulawhere.
• Utilice sentencias CASE y funciones DECODE para funciones de agregado complejas.
Consejos para ajustar la base de datosSiga las mejores prácticas al realizar el ajuste de una base de datos.
• Trabaje con el administrador de la base de datos para recopilar estadísticas en lastablas.
• Si el servidor es muy lento, analice las incidencias de red, E/S o disco y optimice losparámetros del servidor.
• En algunos escenarios, cuando no se puede evitar una recuperación de datos de grantamaño, es posible que se produzcan errores de tamaño de montón de PGA en la basede datos. Para resolver estas incidencias, aumente el tamaño de montón de PGA comoúltimo recurso. Utilice la siguiente sentencia para aumentar el tamaño de montón:
alter session set events '10261 trace name context forever, level 2097152'
Validación de modelos de datosSi valida modelos de datos, los mensajes de validación le ayudan a corregir modelos dedatos, optimizar consultas, reducir threads de parada y mejorar el rendimiento de la creaciónde informes.
Una vez creado o editado un modelo de datos que se ha creado en la versión actual o enuna versión anterior, si hace clic en Validar, Publisher:
1. Comprueba las consultas utilizadas para los juegos de datos, las listas de valores y lasdefiniciones de repartición.
2. Genera el plan de ejecución para las consultas SQL.
3. Muestra una lista de mensajes de error y advertencia.
Realice la acción necesaria según el mensaje de validación. Consulte Resultados devalidación del modelo de datos.
Tenga en cuenta que si ha cambiado de versión de Publisher desde una versión anterior, losmodelos de datos existentes se marcan como no validados.
Resultados de validación del modelo de datosEn este tema se muestran los mensajes de validación del modelo de datos para referencia.
Tipos de mensaje
• Error: debe resolver los errores del modelo de datos si desea utilizarlo para ejecutar uninforme.
• Advertencia: realice la corrección sugerida en el mensaje de advertencia. El rendimientodel informe puede verse afectado si selecciona que se ejecute el informe ignorando laadvertencia.
Capítulo 16Validación de modelos de datos
16-13

Referencia de mensaje
Tipo devalidación
Tipo de mensaje Mensaje Límite
Consulta Advertencia La consulta SQL contiene SELECT *. El usode '*' está restringido. Seleccione lascolumnas específicas.
Consulta Advertencia El modelo de datos contiene consultas JDBCde BI anidadas. El enlace de consultaslógicas está restringido. Utilice OTBI enlugar de los informes de Publisher oelimine el enlace entre los juegos de datosde OBIEE.
Consulta Advertencia El plan de ejecución de consulta SQLcontiene uniones cartesianas fusionadas.Genere el plan de explicación para laconsulta SQL e identifique las unionescartesianas fusionadas. Agregue los filtrosque sean necesarios a la consulta SQL.
Tiempo deejecución
Advertencia Un número de valores de enlace porparámetro superior al límite de {0}produce un bajo rendimiento. Reduzca elnúmero de valores de enlace.
100
Consulta Advertencia El número de columnas en SELECT excedeel límite de {0}. Seleccione solo lascolumnas necesarias y active ladepuración.Consulte Publisher Best Practices for SaaSEnvironments (identificador de documento2145444.1).
30
Consulta Advertencia El número de columnas en SELECT excedeel límite de {0}. Seleccione solo lascolumnas necesarias.
100
Consulta Advertencia La consulta SQL contiene uniones nouniformes. La generación de filasintermedias puede causar problemas derendimiento. Reemplace las uniones nouniformes por una unión uniforme o unaunión externa.
Consulta Advertencia La longitud del nombre de columnaseleccionado excede el límite de {0}. Lalongitud del nombre de columna no debeser superior a 15 caracteres. Utilice un aliascorto para los nombres de columna.
15
Consulta Advertencia El número de consultas o subconsultas enlínea excede el límite de {0}. Elimine lasconsultas en línea adicionales elegidas.
10
Consulta Advertencia La consulta SQL contiene la cláusula FROMDUAL. La consulta SQL contienedemasiadas tablas DUAL. Evite el uso de lacláusula FROM DUAL.
Capítulo 16Validación de modelos de datos
16-14

Tipo devalidación
Tipo de mensaje Mensaje Límite
Consulta Advertencia El número de columnas LOB en SELECTexcede el límite de {0}. Seleccione solo lascolumnas necesarias.
2
Consulta Error La consulta contiene palabras clave DDL oDML. Elimine las palabras clave DDL oDML de la consulta SQL.
Estructura Advertencia El número de divisiones de grupo en unúnico juego de datos excede el límite de {0}.Elimine varios grupos del juego de datos.
2
Estructura Advertencia El modelo de datos contiene filtros degrupo. Reemplace los filtros de grupo por lacláusula WHERE en la consulta SQL.
Tiempo deejecución
Error La propiedad del modelo de datos no esválida o contiene valores no válidos.Especifique la propiedad de modelo dedatos correcta y compruebe el valor de lapropiedad.
Consulta Advertencia El plan de ejecución de consulta SQLcontiene exploraciones de tabla completa.Proporcione los filtros necesarios en lascolumnas indexadas de la consulta SQL.
Consulta Advertencia El plan de ejecución de consulta SQLcontiene un alto número de lecturas debuffer. Las lecturas de buffer exceden ellímite de 1 GB. Agregue filtros en laconsulta SQL para reducir el volumen derecuperación de datos.
Consulta Advertencia El plan de ejecución de consulta SQLcontiene un alto número de ciclos de CPU.Agregue filtros necesarios en la consultaSQL para reducir el volumen derecuperación de datos.
Consulta Advertencia El plan de ejecución de consulta SQLcontiene llamadas de función en lascolumnas de filtro. Utilice las llamadas defunción SQL en los resultados de lascolumnas de índice con bajo rendimiento.Elimine las llamadas de función en lascolumnas de filtro.
Consulta Advertencia Llamadas de función detectadas enpredicados de la cláusula WHERE.
Consulta Advertencia Llamadas detectadas a funciones PL/SQLen la lista SELECT; estas llamadas puedenafectar significativamente al rendimiento.
Consulta Advertencia Las subconsultas escalares sonsubconsultas de la lista SELECT. Debendevolver exactamente un valor. El uso deROWNUM o de DISTINCT para restringir lasalida indica un problema de rendimientopotencial.
Capítulo 16Validación de modelos de datos
16-15

Tipo devalidación
Tipo de mensaje Mensaje Límite
Consulta Advertencia Demasiados valores en el filtro IN-LISTpodrían impedir que el optimizadorencuentre un plan más eficiente.
Tiempo deejecución
Advertencia Un predicado de seguridad estáencapsulado en una subconsulta, causandouna anidación innecesaria. BI Server hagenerado demasiadas uniones entre lassubconsultas WITH usando la funciónSYS_OP_MAP_NONNULL no soportada.
Consulta Advertencia BI Server ha generado demasiadas unionesentre las subconsultas WITH usando lafunción SYS_OP_MAP_NONNULL nosoportada.
Consulta Advertencia Una tabla o una vista en línea detectadaestaba unida externamente medianteOUTER en el lado opcional de la unión y notiene ningún dato seleccionado en ella.
Consulta Advertencia Las subconsultas escalares sonsubconsultas de la lista SELECT. Lainclusión de una cláusula WITH en unasubconsulta escalar puede crear gravesproblemas de rendimiento.
Consulta Advertencia Las tablas que se muestran en una consultay están unidas a otras tablas pero quenunca se han utilizado en una cláusulaSELECT FROM pueden ser redundantes.Compruebe si esta tabla está unida en lacolumna de clave primaria a las columnasde clave ajena de otras tablas.
Consulta Advertencia La columna se define como unasubconsulta escalar correlacionada y seutiliza posteriormente en una expresión defiltro o de unión. Esto puede provocar unadegradación grave del rendimiento.
Consulta Advertencia Predicados que utilizan variables de enlacede no trivial. Por ejemplo, (:JCODE IS NULLOR mcd.JCODE LIKE :JCODE).
Consulta Advertencia La expresión CASE contiene más de 10expresiones WHEN ... THEN complejas.
Consulta Advertencia Se ha hecho referencia a columnasdefinidas como constantes (literales) de unobjeto de vista en los predicados de uniónde una consulta.
Consulta Advertencia La sentencia SQL tiene más de 10bifurcaciones de UNION en unasubconsulta.
Consulta Advertencia Elimine la referencia innecesaria a la tabla,ya que se utiliza la misma columna enSELECT, JOIN y FILTER.
Estructura Advertencia No almacene datos en CLOB y lo conviertaa XML. Almacénelos en XML paraoptimizar el rendimiento.
Capítulo 16Validación de modelos de datos
16-16

Parte IVUso de modelos semánticos de Oracle BIEnterprise Edition
En esta parte se describe cómo puede volver a utilizar modelos semánticos que haya creadocon Oracle BI Enterprise Edition en Oracle Analytics Cloud.
Capítulos:
• Carga de modelos semánticos desde Oracle BI Enterprise Edition

17Carga de modelos semánticos desde OracleBI Enterprise Edition
Los administradores pueden cargar modelos semánticos creados con Oracle BI EnterpriseEdition en Oracle Analytics Cloud. Después de cargar un archivo .rpd de modelo semánticoen la nube, los autores de contenido pueden generar visualizaciones de datos, paneles decontrol y análisis con normalidad.
Temas
• Acerca de la carga de modelos semánticos de Oracle BI Enterprise Edition en la nube
• Preparación del archivo de modelo semántico
• Carga de modelos semánticos desde un archivo .rpd mediante la consola
• Acerca de la edición de modelos semánticos cargados desde Oracle BI EnterpriseEdition
• Descarga e instalación de Oracle Analytics Client Tools
• Conexión a un modelo semántico en la nube
• Edición de un modelo semántico en la nube
• Carga de un modelo semántico en la nube
• Conexión a un origen de datos utilizando una conexión definida mediante consola
• Solución de problemas con la herramienta de administración de modelos (OracleAnalytics Client Tools)
• Creación de un modelo semántico a partir de vistas analíticas en Oracle AutonomousData Warehouse
Nota:
Los administradores pueden utilizar instantáneas para migrar contenido, ademásde modelos semánticos de Oracle BI Enterprise Edition. Consulte Migración deOracle Analytics Cloud utilizando instantáneas.
Acerca de la carga de modelos semánticos de Oracle BIEnterprise Edition en la nube
Si ya ha modelado los datos de negocio con Oracle BI Enterprise Edition, no tiene queempezar desde cero en Oracle Analytics Cloud. Pida a un administrador que cargue elarchivo de modelo semántico en Oracle Analytics Cloud, y empiece a explorar los datos através de visualizaciones, análisis y paneles de control.
Oracle Analytics Cloud permite cargar un archivo .rpd de modelo semántico con:
17-1

• Uno o más modelos semánticos
• Conexiones a una o más bases de datos
Deberá validar el archivo .rpd de modelo semántico y configurar los detalles deconexión a la base de datos en Oracle BI Enterprise Edition.
Cuando el administrador carga un archivo .rpd de modelo semántico desde Oracle BIEnterprise Edition, los modelos semánticos existentes (si los hubiera) se suprimen yse sustituyen por contenido del archivo cargado, y se desactiva Data Modeler. Losmodelos semánticos cargados del archivo están disponibles para los autores decontenido a través del panel Área temáticas.
Si son necesarios cambios en el modelo, los administradores pueden usar laherramienta de administración de modelos para editar y desplegar sus actualizacionesen Oracle Analytics Cloud. Esta herramienta está disponible con Oracle AnalyticsClient Tools. Consulte Descarga e instalación de Oracle Analytics Client Tools.
Nota:
Oracle publica una nueva versión de Oracle Analytics Client Tools con cadaactualización de Oracle Analytics Cloud. Después de que Oracle actualicesu entorno de Oracle Analytics Cloud, siempre debe descargar y comenzar ausar la última versión de Oracle Analytics Client Tools.
Si desea copiar los informes y los paneles de control integrados en Oracle BIEnterprise Edition en Oracle Analytics Cloud, también puede hacerlo. Consulte Cargade contenido de un archivo de catálogo en Visualización de datos y creación deinformes en Oracle Analytics Cloud.
Preparación del archivo de modelo semánticoTómese su tiempo para preparar el archivo .rpd de modelo semántico para la nube.
1. Verifique que está utilizando Oracle BI Enterprise Edition 11.1.1.7 o posterior.
2. Abra el archivo .rpd de modelo semántico y utilice el Gestor de comprobación deconsistencia para ejecutar comprobaciones de consistencia.
3. Elimine todos los bloques de inicialización que definen las variables de sesiónUSER, ROLES o GROUP.
Oracle Analytics no soporta las variables :user y :password en las credenciales deconexión de origen de datos.
4. Verifique que la información de conexión a la base de datos del modelo semánticoestá actualizada.
Revise la configuración de pool de conexiones desde la herramienta deadministración de Oracle BI:
• El Nombre del origen de datos debe contener la cadena de conexióncompleta de la base de datos en la que se almacenan los datos.
No puede especificar un nombre de servicio de red aquí.
• La interfaz de llamada debe ser Oracle Call Interface (OCI).
Capítulo 17Preparación del archivo de modelo semántico
17-2

Si el modelo semántico se conecta a varias bases de datos, asegúrese de que laconfiguración de cada pool de conexiones es correcta.
5. Desactive las áreas temáticas que no desee exponer o que no tengan una conexiónactiva.
Si falta la información de conexión, los usuarios verán el mensaje Error derecuperación de las áreas temáticas si intentan consultar las áreas temáticas enOracle Analytics Cloud.
6. Realice una copia de seguridad de Oracle Analytics Cloud en una instantánea queincluya el modelo semántico actual, por si necesita restaurar esta versión.
Cuando el modelo semántico esté listo, puede cargarlo en Oracle Analytics Cloud.
Carga de modelos semánticos desde un archivo .rpd mediantela consola
Los administradores pueden cargar modelos semánticos creados con Oracle BI EnterpriseEdition en Oracle Analytics Cloud. Tras migrar los modelos semánticos a la nube, los autoresde contenido pueden visualizar los datos con normalidad.
Cuando se cargan modelos semánticos desde Oracle BI Enterprise Edition, se suprimeinformación del modelo semántico existente en Oracle Analytics Cloud y se sustituye porcontenido del archivo .rpd de modelo semántico. Los modelos semánticos que cargue estándisponibles para los autores de contenido como áreas temáticas.
Nota:
También puede cargar archivos .rpd de modelo semántico en Oracle AnalyticsCloud utilizando la herramienta de administración de modelos (Oracle AnalyticsClient Tool).
1. Verifique el archivo .rpd de modelo semántico y las conexiones de base de datosasociadas.
2. En Oracle Analytics Cloud, haga clic en Consola.
3. Seleccione Instantáneas.
4. Realice una instantánea del modelo semántico actual en caso de que necesite restauraresta versión.
5. En el menú de página, haga clic en Reemplazar modelo de datos.
6. Haga clic en Examinar y seleccione el archivo .rpd de modelo semántico que deseacargar.
7. Introduzca la contraseña para el archivo.
8. Haga clic en Aceptar.
9. Vaya a la página inicial, haga clic en Datos y, a continuación, en Juegos de datos paraver los modelos semánticos que ha cargado, disponibles como áreas temáticas.
Capítulo 17Carga de modelos semánticos desde un archivo .rpd mediante la consola
17-3

10. Opcional: Si el archivo .rpd de modelo semántico incluye permisos y filtros dedatos, puede crear roles de aplicación coincidentes en Oracle Analytics Cloudpara garantizar la seguridad de los datos en la nube.
a. Cree roles de aplicaciones con exactamente los mismos nombres que losdefinidos en la herramienta de administración de Oracle BI.
b. Asigne usuarios (y roles de usuario) a los roles de aplicación según seanecesario.
Acerca de la edición de modelos semánticos cargadosdesde Oracle BI Enterprise Edition
Los administradores pueden utilizar la consola para cargar modelos semánticos deOracle BI Enterprise Edition en Oracle Analytics Cloud. Una vez que se carga elmodelo semántico, los desarrolladores de modelos semánticos pueden usar laherramienta de administración de modelos para editar y desplegar sus actualizacionesen Oracle Analytics Cloud. Los usuarios pueden empezar a explorar los datos conayuda de visualizaciones, análisis y paneles de control.
Requisitos
• Oracle BI Enterprise Edition 11.1.1.7 o posterior.
• Una máquina Windows de 64 bits en la que descargar Oracle Analytics ClientTools y ejecutar la herramienta de administración de modelos. Consulte Descargae instalación de Oracle Analytics Client Tools.
Nota:
Oracle publica una nueva versión de Oracle Analytics Client Tools concada actualización de Oracle Analytics Cloud. Después de que Oracleactualice su entorno de Oracle Analytics Cloud, siempre debe descargary comenzar a usar la última versión de Oracle Analytics Client Tools.
• Un archivo .rpd de modelo semántico validado.
• Credenciales de usuario válidas. Un usuario en el sistema de gestión de identidadde Oracle Cloud asociado con Oracle Analytics Cloud que tenga permisos deadministrador en Oracle Analytics Cloud (es decir, un usuario con el rol deaplicación BIServiceAdministrator).
Oracle Analytics Cloud utiliza uno de estos sistemas de gestión de identidad deOracle Cloud:
– Oracle Identity Cloud Service (IDCS): si Oracle Analytics Cloud se federacon Oracle Identity Cloud Service, debe conectarse con las credenciales deusuario de Oracle Identity Cloud Service.
– Dominios de identidad de Oracle Cloud Infrastructure Identity andAccess Management (IAM): si Oracle Analytics Cloud utiliza un dominio deidentidad de IAM para la gestión de identidad, debe conectarse con lascredenciales de usuario del dominio de identidad.
Si no está seguro, pregunte al administrador de servicio de nube. Consulte Acercade la configuración de usuarios y grupos.
Capítulo 17Acerca de la edición de modelos semánticos cargados desde Oracle BI Enterprise Edition
17-4

Si Oracle Analytics Cloud usa un proveedor de identidad externo como Active Directorypara la conexión única e intenta conectarse con sus credenciales de usuario de conexiónúnica, verá el mensaje "Connection failed 401: Unauthorized" cuando intenteconectarse.
• Compruebe con el administrador de servicio de nube que el número de puerto requeridoestá abierto (es decir, el puerto 443 para el acceso HTTPS a Oracle Analytics Cloud; sino, el puerto 80 para el acceso HTTP).
Flujo de trabajo habitual para utilizar la herramienta de administración de modelospara editar el modelo semántico
• Cargar el modelo semántico. Consulte Carga de modelos semánticos desde unarchivo .rpd mediante la consola.
• Editar el modelo semántico. Consulte Edición de un modelo semántico en la nube.
• Copie los análisis y los paneles de control integrados en Oracle BI Enterprise Edition enOracle Analytics Cloud. Consulte Carga de contenido de un archivo de catálogo enVisualización de datos y creación de informes en Oracle Analytics Cloud.
Descarga e instalación de Oracle Analytics Client ToolsDescargue e instale Oracle Analytics Client Tools si desea editar el modelo semántico(archivo .rpd) o activar las conexiones remotas desde los análisis y los paneles de control deinformes. Instale Oracle Analytics Client Tools en una máquina de Windows. El paquete desoftware instala la herramienta de administración de modelos, el gestor de catálogos y elgestor de trabajos.
Nota:
Oracle publica una nueva versión de Oracle Analytics Client Tools con cadaactualización de Oracle Analytics Cloud. Después de que Oracle actualice suentorno de Oracle Analytics Cloud, siempre debe descargar y comenzar a usar laúltima versión de Oracle Analytics Client Tools.
1. Descargue la versión más reciente de Oracle Analytics Client Tools.
a. Navegue a:
Página de descarga de Oracle Analytics Client Tools.
b. Para iniciar la descarga, haga clic en el enlace de Oracle Analytics Client Toolsque coincida con su entorno de Oracle Analytics.
En la mayoría de los casos, será la versión más reciente disponible.
c. Acepte el acuerdo de licencia de Oracle si se le solicita y haga clic en el enlace paradescargar el software en la máquina local.
2. Instale Oracle Analytics Client Tools en su máquina local.
a. Descomprima el archivo ZIP descargado para extraer el archivo de instaladorsetup_bi_client-<update ID>-win64.exe.
b. Haga doble clic en el archivo setup_bi_client-<update ID>-win64.exe para iniciarel instalador.
Capítulo 17Descarga e instalación de Oracle Analytics Client Tools
17-5

c. Siga las instrucciones que aparecen en la pantalla.
Para iniciar las herramientas, vaya al menú Inicio de Windows, haga clic en OracleAnalytics Client Tools y, a continuación, seleccione el nombre de la herramienta quedesee usar. Por ejemplo, si desea editar su modelo semántico, haga clic enHerramienta de administración de modelos.
Conexión a un modelo semántico en la nubeDebe introducir los detalles de conexión para Oracle Analytics Cloud antes de abrir,publicar o cargar un modelo semántico en Oracle Analytics Cloud mediante laherramienta de administración de modelos.
1. Abra la herramienta de administración de modelos.
Vaya al menú Inicio de Windows, haga clic en Oracle Analytics Client Tools yseleccione la herramienta de administración de modelos.
2. En la herramienta de administración de modelos, seleccione cómo deseaconectarse a Oracle Analytics Cloud.
Por ejemplo, haga clic en Archivo, luego en Cloud y, a continuación, en Abrir,Publicar, o Cargar.
3. Introduzca la información de conexión de Oracle Analytics Cloud.
a. En Usuario, especifique un usuario en el sistema de gestión de identidad deOracle Cloud asociado con Oracle Analytics Cloud que tenga permisos deadministrador en Oracle Analytics Cloud (es decir, un usuario con el rol deaplicación BIServiceAdministrator).
Si su Oracle Analytics Cloud se federa con un sistema de gestión de identidadexterno, probablemente se conecta a Oracle Analytics Cloud con suscredenciales de conexión única. No puede usar sus credenciales de conexiónúnica para conectarse a Oracle Analytics Cloud desde la herramienta deadministración de modelos; debe usar las credenciales de usuario de gestiónde identidad de Oracle Cloud. Consulte Requisitos.
b. En Contraseña, introduzca la contraseña para el Usuario especificado.
c. En Nube, introduzca bootstrap.
d. En Nombre del host, introduzca la URL de Oracle Analytics Cloud,excluyendo https:// y /ui/dv.
Por ejemplo, si la URL de Oracle Analytics Cloud es https://oac123456-oacppacm12345.uscom-central-1.oraclecloud.com/ui/dv, introduzcaoac123456-oacppacm12345.uscom-central-1.oraclecloud.com.
Puede obtener la URL de Oracle Analytics Cloud desde la consola de OracleCloud Infrastructure. Desplácese hasta la instancia de Oracle Analytics Cloudy, a continuación, copie el valor en el campo URL. En productos anteriores deOracle Analytics Cloud, haga clic en Gestionar esta instancia y copie ladirección del enlace para URL de Oracle Analytics Cloud.
e. En Número de puerto, introduzca 443.
f. Seleccione SSL.
En Almacén de confianza, haga clic en Examinar y seleccione el almacénde claves de JDK por defecto enlazado con JRE:
Capítulo 17Conexión a un modelo semántico en la nube
17-6

<OAC client home>\oracle_common\jdk\jre\lib\security\cacertsEn Contraseña, especifique la contraseña para el almacén de confianza (JSK) quecontiene el certificado de CA de confianza que ha utilizado para firmar el certificadode Oracle Analytics Cloud. El certificado de Oracle Analytics Cloud lo firma una CAconocida, por lo que puede utilizar el cacerts (el almacén de confianza de JKS pordefecto que confía en CA conocidas) de Java regular.
g. Si ha desplegado la herramienta de administración de modelos en una máquinaconectada a una red con proxy activado, seleccione Proxy.
Pregunte al administrador de red por la URL del servidor proxy y el número depuerto.
Se estima que la conexión inicial tarda entre 3 y 15 minutos, dependiendo del tamaño delmodelo semántico.
Edición de un modelo semántico en la nubeUse la herramienta de administración de modelos para editar un modelo semántico que hayacargado previamente en Oracle Analytics Cloud.
1. Abra la herramienta de administración de modelos.
Vaya al menú Inicio de Windows, haga clic en Oracle Analytics Client Tools yseleccione la herramienta de administración de modelos.
2. En la herramienta de administración de modelos, haga clic en el menú Archivo,seleccione Abrir y En la nube.
3. Introduzca la información de conexión de Oracle Analytics Cloud.
4. Actualice su modelo.
a. Realice cambios en el modelo, según sea necesario.
b. Para validar los cambios, haga clic en Herramientas, en Mostrar comprobador deconsistencia y, a continuación, en Comprobar todos los objetos.
c. Para guardar los cambios localmente, haga clic en Archivo y, a continuación, enGuardar.
5. Para cargar los cambios en Oracle Analytics Cloud, haga clic en Archivo, en Nube y, acontinuación, en Publicar.
Utilice el menú secundario Archivo para refrescar o desechar los cambios:
• Refrescar: utilice esta opción para refrescar su modelo semántico con las últimasactualizaciones. Si otro desarrollador ha modificado el modelo semántico, se le solicitaráque inicie una fusión.
• Desechar: utilice esta opción para cancelar los cambios implantados en el modelosemántico en la sesión actual.
Capítulo 17Edición de un modelo semántico en la nube
17-7

Carga de un modelo semántico en la nubePuede utilizar la herramienta de administración de modelos para cargar el archivo .rpdde modelo semántico en Oracle Analytics Cloud.
Nota:
Los administradores también pueden usar la consola para archivos .rpd demodelo semántico. Consulte Carga de modelos semánticos desde unarchivo .rpd mediante la consola.
1. En la herramienta de administración de modelos, abra su archivo .rpd de modelosemántico.
2. En el menú Archivo, haga clic en Nube y, a continuación, en Cargar.
3. Introduzca la información de conexión de Oracle Analytics Cloud.
Utilice el menú secundario Archivo para refrescar o desechar los cambios:
• Refrescar: utilice esta opción para refrescar su modelo semántico con las últimasactualizaciones. Si otro desarrollador ha modificado el modelo semántico, se lesolicitará que inicie una fusión.
• Desechar: utilice esta opción para cancelar los cambios implantados en el modelosemántico en la sesión actual.
Conexión a un origen de datos utilizando una conexióndefinida mediante consola
Los administradores pueden definir conexiones de base de datos para modelossemánticos mediante la consola de Oracle Analytics Cloud. Esto incluye bases dedatos como Oracle Database Cloud Service, Oracle Autonomous Data Warehouse yOracle Autonomous Transaction Processing.
Si desea volver a utilizar las mismas conexiones de base de datos en la herramientade administración de modelos, no tiene que volver a introducir los detalles de laconexión. Puede hacer referencia a las conexiones de la base de datos "por nombre"en el cuadro diálogo Pool de conexiones.
Si aún no lo ha hecho, cree la conexión de base de datos en la consola y escriba sunombre. Por ejemplo, MyCloudSalesDB.
1. En la herramienta de administración de modelos, vaya al panel Capa física y abrael cuadro de diálogo Pool de conexiones.
2. En Nombre, introduzca un nombre para el origen de datos.
3. Seleccione la casilla de control Usar conexión de consola.
4. En Nombre de conexión, introduzca el nombre de la conexión de la base dedatos tal como se define en la consola (distinción entre mayúsculas y minúsculas).Por ejemplo, MyCloudSalesDB.
Capítulo 17Carga de un modelo semántico en la nube
17-8

Ignore el resto de opciones en este cuadro de diálogo, por ejemplo Nombre de origende datos, Nombre de usuario de conexión compartido and Contraseña.
Conexión de un modelo semántico a un origen de datos deSpark
Si desea conectar el modelo semántico a un origen de datos de Spark, debe especificar losdetalles de las conexiones de Spark en el archivo .rpd.
1. En la herramienta de administración de modelos, abra el archivo .rpd, vaya al panelFísico, haga clic con el botón derecho y seleccione Nueva base de datos.
2. Introduzca un nombre para la conexión de la base de datos y establezca Tipo de basede datos en ODBC avanzado.
3. Haga clic en Pool de conexiones y agregue un pool de conexiones.
4. Introduzca un nombre para el pool de conexiones y establezca Interfaz de llamadas enODBC 3.5.
5. En el campo Nombre de origen de datos (DSN), haga lo siguiente:
Sustituya los valores HOST y PORT por la dirección IP del valor del host y puerto de HiveThrift:
DRIVER=Oracle 8.0 Apache Hive WireProtocol;HOST=<hive_host_ip_address>;PORT=<binaryprotocol port for hive>
6. Agregue los detalles de autenticación y guarde el pool de conexiones.
7. Importe el objeto de capa física y complete el modelo semántico antes de cargar elarchivo .rpd en Oracle Analytics.
Trabajo con la herramienta de administración de modelosUtilice estas opciones para gestionar y publicar un modelo semántico utilizando laherramienta de administración de modelos.
Cuando se conecte a Oracle Analytics Cloud en la herramienta de administración demodelos, debe introducir las credenciales de un usuario del sistema Oracle Cloud IdentityManagement asociado con Oracle Analytics Cloud. No podrá conectarse como usuario deconexión única desde un sistema externo de gestión de identidad federado. Consulte Requisitos.
Opción de menú Úsela para:
Archivo, después Nube, despuésAbrir
Abra un modelo semántico que haya cargado en OracleAnalytics Cloud para poder editarlo.
Archivo, después Nube, despuésPublicar
Publique los cambios que haya realizado en el modelo dedatos. Los usuarios verán los cambios la próxima vez queinicie sesión en Oracle Analytics Cloud.
Capítulo 17Conexión de un modelo semántico a un origen de datos de Spark
17-9

Creación de un modelo semántico a partir de vistasanalíticas en Oracle Autonomous Data Warehouse
En Oracle Analytics, puede modelar las vistas analíticas de Autonomous DataWarehouse en Oracle Analytics y visualizar los datos.
Temas:
• Visión general de la conexión a las vistas analíticas
• Creación y carga de un modelo semántico basado en una vista analítica
• Conexión a vistas analíticas en Oracle Autonomous Data Warehouse
Visión general de la conexión a las vistas analíticasEn Oracle Analytics, puede modelar las vistas analíticas de Autonomous DataWarehouse y visualizar los datos. Las vistas analíticas aceleran las consultasanalíticas de datos almacenados en las tablas y vistas de Oracle. Las vistas analíticasle permiten agregar fácilmente agregaciones y cálculos a los datos que se puedenconsultar con SQL relativamente sencillo.
Debe incluir las vistas analíticas en un modelo semántico y, a continuación, cargar elmodelo semántico en Oracle Analytics. Después de cargar el modelo semántico,puede ver las dimensiones, las medidas y las medidas calculadas personalizadas enlos libros de trabajo de visualización de Oracle Analytics.
Elementos necesarios
• Oracle Autonomous Data Warehouse, 18c o posterior
• Oracle SQL Developer, 19.x o posterior
• Oracle Analytics Cloud, última versión.
• Oracle Analytics Client Tools (herramienta de administración de modelos), últimaversión (versión mínima 6.0)
Creación y carga de un modelo semántico basado en una vistaanalítica
Cree y cargue un modelo semántico basado en una vista analítica en una instancia deOracle Autonomous Data Warehouse para poder visualizar los datos.
Antes de empezar, asegúrese de que tiene los componentes necesarios; consulte Visión general de la conexión a las vistas analíticas.
1. Opcional: Utilice SQL Developer para identificar y validar las vistas analíticas en elorigen de datos de Oracle Autonomous Data Warehouse que desee visualizar enOracle Analytics.
Capítulo 17Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous Data Warehouse
17-10

Por ejemplo, si está usando SQL Developer, haga clic con el botón derecho en la vistaanalítica y seleccione Validar vista analítica. Asegúrese de que la vista analítica esválida antes de continuar.
2. Para incluir sus vistas analíticas en un nuevo modelo semántico y poder cargarlo enOracle Analytics:
a. En la herramienta de administración de modelos, haga clic en Archivo y en Nuevorepositorio.
b. En la página Información del repositorio, especifique un Nombre y una Contraseña.
c. En la página Seleccionar origen de datos:
Para Tipo de conexión, seleccione Vistas analíticas de Oracle.
Para Nombre de origen de datos, copie la URL de conexión de Oracle AutonomousData Warehouse del archivo tnsnames.ora. En la instancia de Oracle AutonomousData Warehouse, extraiga el archivo tnsnames.ora del archivo wallet.zip. Copie lacadena de descripción de texto, incluidos los paréntesis, tal y como se muestra.
Capítulo 17Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous Data Warehouse
17-11
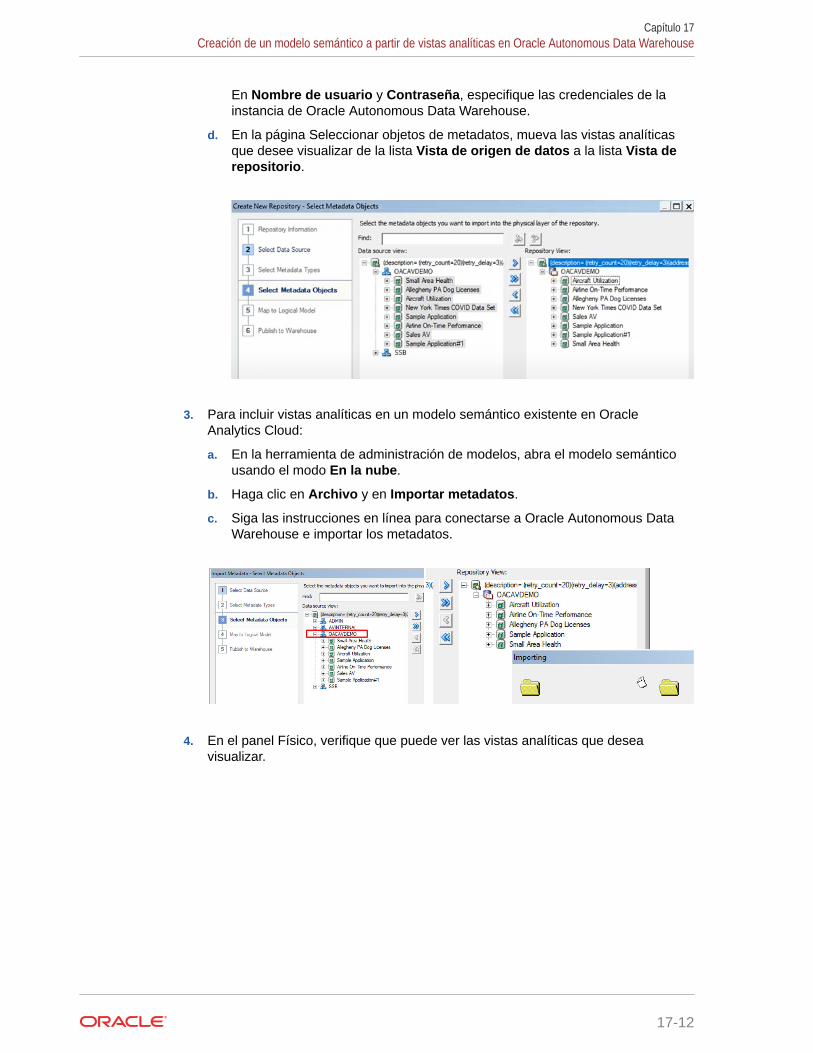
En Nombre de usuario y Contraseña, especifique las credenciales de lainstancia de Oracle Autonomous Data Warehouse.
d. En la página Seleccionar objetos de metadatos, mueva las vistas analíticasque desee visualizar de la lista Vista de origen de datos a la lista Vista derepositorio.
3. Para incluir vistas analíticas en un modelo semántico existente en OracleAnalytics Cloud:
a. En la herramienta de administración de modelos, abra el modelo semánticousando el modo En la nube.
b. Haga clic en Archivo y en Importar metadatos.
c. Siga las instrucciones en línea para conectarse a Oracle Autonomous DataWarehouse e importar los metadatos.
4. En el panel Físico, verifique que puede ver las vistas analíticas que deseavisualizar.
Capítulo 17Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous Data Warehouse
17-12
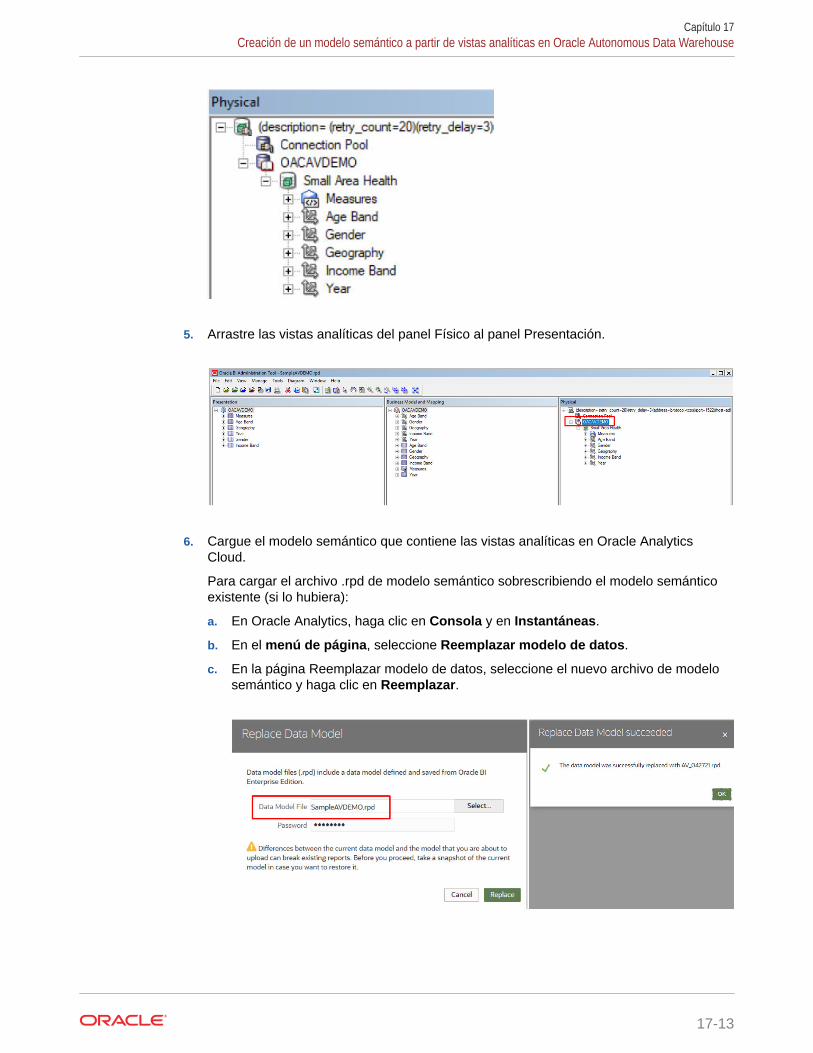
5. Arrastre las vistas analíticas del panel Físico al panel Presentación.
6. Cargue el modelo semántico que contiene las vistas analíticas en Oracle AnalyticsCloud.
Para cargar el archivo .rpd de modelo semántico sobrescribiendo el modelo semánticoexistente (si lo hubiera):
a. En Oracle Analytics, haga clic en Consola y en Instantáneas.
b. En el menú de página, seleccione Reemplazar modelo de datos.
c. En la página Reemplazar modelo de datos, seleccione el nuevo archivo de modelosemántico y haga clic en Reemplazar.
Capítulo 17Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous Data Warehouse
17-13

Para cargar cambios en un modelo semántico existente que ha abierto usando elmodo En la nube, publique el modelo semántico en Oracle Analytics Cloud. En laherramienta de administración de modelos, haga clic en Archivo, en Nube y enPublicar.
Ya puede visualizar los datos de las vistas analíticas.
Conexión a vistas analíticas en Oracle Autonomous Data WarehouseConéctese a vistas analíticas para visualizar datos en Oracle Autonomous DataWarehouse.
Antes de comenzar, pídale a su administrador de Oracle Analytics que ponga a sudisposición las vistas analíticas en un área temática local (modelo semántico).
1. En Oracle Analytics, en la página inicial, haga clic en Crear y después en Juegode datos.
2. Haga clic en Área temática local.
3. Seleccione un área temática basada en una vista de análisis.
4. Seleccione los hechos y las medidas que quiere analizar y agréguelos a un nuevojuego de datos.
Ya puede visualizar los datos en el juego de datos.
Capítulo 17Creación de un modelo semántico a partir de vistas analíticas en Oracle Autonomous Data Warehouse
17-14

Parte VReferencia
Este apartado ofrece información de referencia.
• Preguntas frecuentes
• Solución de problemas
• Referencia del editor de expresiones

APreguntas frecuentes
Esta referencia responde a algunas preguntas habituales que suelen tener losadministradores y analistas de inteligencia empresarial responsables de modelar datosempresariales en Oracle Analytics Cloud.
Temas:
• Preguntas más frecuentes sobre Data Modeler (modelos semánticos)
– ¿Puedo utilizar los mismos datos para diferentes análisis?
– Después de agregar nuevas columnas a mi tabla de origen, ¿puedo incluir lasnuevas columnas en mi modelo semántico?
– ¿En qué situaciones debo crear objetos de modelo basados en vistas de origen?
– ¿Puedo incluir columnas de una tabla o vista de origen diferente en mi tabla dedimensiones existente si se basa directamente en una tabla de origen?
– ¿Puedo incluir columnas de una tabla o vista de origen diferente en mi tabla dedimensiones existente si se basa en una tabla de origen?
– ¿Puedo crear una vista de origen que se base en otra vista de origen?
– ¿Puedo migrar mi modelo semántico de un entorno a otro?
• Principales preguntas frecuentes para el editor de modelo de datos (informes deimpresión perfecta)
– ¿Cómo compruebo si el modelo de datos genera datos correctamente?
– ¿Cómo fragmento los datos XML para procesar juegos de datos grandes?
– ¿Cuál es el límite de tamaño de una consulta SQL para la repartición?
– ¿Cómo optimizo las consultas SQL?
Preguntas más frecuentes sobre Data Modeler (modelossemánticos)
En este tema, se identifican las preguntas más frecuentes sobre el modelado de datos.
¿Puedo utilizar los mismos datos para diferentes análisis?
Sí. Puede crear vistas de origen que muestren las mismas columnas de origen en diferentescontextos. Puede utilizar las vistas para incluir los mismos objetos de origen en variasdimensiones. Por ejemplo, para utilizar datos de tiempo para las dimensiones Order Date yShip Date, cree dos vistas basadas en la tabla de origen de tiempo, time_order_date_v ytime_ship_date_v. Las vistas se podrán utilizar a continuación como orígenes de lasdimensiones Order Date y Ship Date.
A-1

Después de agregar nuevas columnas a mi tabla de origen, ¿puedo incluir lasnuevas columnas en mi modelo semántico?
Sí. Puede incluir las columnas de origen recién creadas. Para incluir las nuevascolumnas, seleccione Sincronizar con base de datos en el menú Acciones de latabla de hechos o de dimensiones correspondiente del modelo semántico. Acontinuación, en la lista de mensajes, seleccione el elemento de mensaje quedescribe las nuevas columnas y seleccione Sincronización seleccionada en el menúAcciones de mensajes.
¿En qué situaciones debo crear objetos de modelo basados en vistas deorigen?
Cree una vista de origen siempre que crea que va a realizar cambios posteriores,como la ampliación de los objetos de modelo, la creación de filtros y la adición decálculos. La creación de modelos basados en vistas de origen proporciona una mayorflexibilidad que el uso directamente de tablas de origen.
¿Puedo incluir columnas de una tabla o vista de origen diferente en mi tabla dedimensiones existente si se basa directamente en una tabla de origen?
Sí. Es fácil agregar columnas de otra tabla o vista de origen en una tabla dedimensiones existente. Para ello, arrastre y suelte la tabla o vista en su tabla dedimensiones existente Consulte Adición de columnas de otro origen a una tabla dedimensiones.
¿Puedo incluir columnas de una tabla o vista de origen diferente en mi tabla dedimensiones existente si se basa en una tabla de origen?
Sí. Para ello, existen dos métodos. Puede arrastrar y soltar la tabla en la tabla dedimensiones para incluir las columnas. También puede editar la vista para incluir lasnuevas columnas de origen y sincronizar la tabla de dimensiones con los cambiosrealizados en la base de datos. La sincronización identifica las nuevas columnas de lavista y las agrega a su tabla de dimensiones.
¿Puedo crear una vista de origen que se base en otra vista de origen?
Sí. Para ello, arrastre y suelte la vista de origen en el área Columnas del separadorVisión general al crear la vista, o seleccione una vista de origen en el cuadro dediálogo Agregar columnas como origen.
Por ejemplo, suponga que tiene las tablas de origen time y time_fiscal. Ha creado unavista denominada time_v que combina time y time_fiscal. Desea crear variasdimensiones basadas en los datos de tiempo, como Order Day y Ship Day. En primerlugar debe crear la dimensión Order Day basada en time_v y, a continuación, crearotra vista al principio de time_v para crear Ship Day. (Tenga en cuenta que tambiénpuede crear una vista paralela denomina ship_day_v que combine también time ytime_fiscal.)
¿Puedo migrar mi modelo semántico de un entorno a otro?
Sí. Realice una instantánea de su entorno y mígrela al nuevo entorno. Consulte Realización de instantáneas y restauración.
¿Puedo localizar análisis y paneles de control almacenados en el catálogo?
Sí. Siga el procedimiento Localización de leyendas de catálogo.
Apéndice APreguntas más frecuentes sobre Data Modeler (modelos semánticos)
A-2

¿Puedo usar un archivo .rpd de modelo semántico de Oracle BI Enterprise Edition?
Sí. Si ha modelado los datos de negocio con Oracle BI Enterprise Edition, no tiene queempezar desde cero en Oracle Analytics Cloud. En lugar de utilizar Data Modeler, puedeusar la consola o la herramienta de administración de modelos para cargar el archivo .rpd demodelo semántico en Oracle Analytics Cloud. La herramienta de administración de modelosestá disponible al descargar Oracle Analytics Client Tools. Consulte Carga de modelossemánticos desde Oracle BI Enterprise Edition.
¿Puedo editar mi archivo .rpd de modelo semántico después de haberlo cargado enOracle Analytics Cloud?
Sí. Consulte Edición de un modelo semántico en la nube.
Principales preguntas frecuentes para el editor de modelo dedatos (informes de impresión perfecta)
En este tema se identifican las principales preguntas frecuentes para crear y gestionar losmodelos de datos para informes de pixelado perfecto.
¿Cómo compruebo si el modelo de datos genera datos correctamente?
Abra el modelo de datos, haga clic en Datos y seleccione Ver para ver un máximo de 200filas de datos. Si desea ver los datos completos, cree un informe y consúltelo en línea oprográmelo.
¿Cómo fragmento los datos XML para procesar juegos de datos grandes?
Active la fragmentación de datos XML a nivel de instancia o a nivel de modelo de datos.
¿Cuál es el límite de tamaño de una consulta SQL para la repartición?
El límite de tamaño de los resultados de una consulta SQL es 200 000 filas.
¿Cómo optimizo las consultas SQL?
Use las propiedades de modelos de datos Omitir consulta de juegos de datos noutilizados, Optimizar ejecución de consultas y Emplear varios threads para laejecución de consultas para optimizar las consultas SQL.
Apéndice APrincipales preguntas frecuentes para el editor de modelo de datos (informes de impresión perfecta)
A-3

BSolución de problemas
En este tema se describen problemas comunes que puede encontrar al modelar los datosempresariales en Oracle Analytics Cloud y se explica cómo solucionarlos.
Temas:
• Solución de problemas con Data Modeler
– No veo ninguna tabla o vista en Data Modeler
– No veo el panel izquierdo en Data Modeler
– No puedo editar objetos en Data Modeler
– No puedo bloquear el modelo de datos
– No puedo publicar el modelo de datos
– Conveniencia de utilizar el separador Consulta SQL para editar una unión o filtropara una vista
– Aparece un mensaje indicando un error de cluster y que no se encuentra el nodo delservidor activo
Solución de problemas con Data ModelerEn este tema se describen los problemas más comunes que puede encontrar al utilizar DataModeler y explica cómo solucionarlos.
No veo ninguna tabla o vista en Data Modeler
Si inicia Data Modeler y no ve ninguna tabla o vista, puede que se haya dado alguna de lassiguientes situaciones:
• No hay ninguna tabla en la base de datos conectada a su servicio. Utilice una de lasherramientas de carga de datos soportadas para cargar algunos datos.
• Data Modeler no muestra los últimos objetos de base de datos. Para ver los últimosobjetos, refresque el panel Base de datos en Data Modeler.
No veo el panel izquierdo en Data Modeler
El panel izquierdo en Data Modeler está reducido. Para mostrar el panel izquierdo, haga clicen el icono Restaurar panel que se muestra a la izquierda de la página.
No puedo editar objetos en Data Modeler
Siempre debe bloquear el modelo semántico antes de realizar ningún cambio. Haga clic enBloquear para editar para bloquear el modelo semántico.
B-1

No puedo bloquear el modelo semántico
Compruebe si alguien ha bloqueado el modelo semántico. Si usted es eladministrador, puede sustituir el bloqueo. De lo contrario, espere a que se libere elbloqueo. Para obtener más información, consulte Sustitución de bloqueos en Bloqueodel modelo de datos.
No puedo publicar el modelo semántico
Compruebe si Data Modeler está abierto en varios separadores o ventanas delexplorador. En caso afirmativo, cierre los separadores o ventanas adicionales delexplorador que ejecutan Data Modeler e intente publicar de nuevo el modelo. Si sesigue produciendo un error de publicación, reinicie el explorador.
Conveniencia de utilizar el separador Consulta SQL para editar una unión o filtropara una vista
El mensaje que indica que se utilice el separador Consulta SQL para editar uniones/filtros se muestra al hacer clic en el separador Uniones o en el separador Filtros en eleditor de vistas por uno de los siguientes motivos:
• Oracle Analytics Cloud no puede analizar la consulta SQL para la vista de labase de datos
Si utiliza únicamente los separadores Visión general, Uniones y Filtros para editaruna vista de base de datos, Oracle Analytics Cloud crea una consulta SQL simplepara usted. Si decide editar el SQL manualmente a través del separador ConsultaSQL, las consultas simples se vuelven a reflejar en los separadores Visióngeneral, Unión y Filtros, de modo que pueda utilizar estos separadores paraseguir editando la vista posteriormente. Sin embargo, si ha utilizado el separadorConsulta SQL para realizar cambios de código más avanzados, no puede utilizarlos separadores Visión general, Uniones o Filtros para seguir editando la vistaporque Oracle Analytics Cloud no puede verificar las actualizaciones. Por ejemplo,si incluye:
– Funciones de agregación SQL, cláusula GROUP BY, cláusula HAVING– Cláusula ORDER BY– Palabra clave OR en la cláusula WHERE– Cláusula UNION
• Oracle Analytics Cloud no puede acceder a la vista de la base de datos
Si el problema persiste, informe del problema a su administrador. El administradorpuede investigar los problemas de conexión relacionados con el servicio de basede datos.
Aparece un mensaje indicando un error de cluster y que no se encuentra elnodo del servidor activo
La instancia puede estar inactiva o la base de datos puede estar bloqueada. Si elproblema persiste, informe del problema al administrador.
Apéndice BSolución de problemas con Data Modeler
B-2

Solución de problemas con la herramienta de administración demodelos (Oracle Analytics Client Tools)
Estos son algunos consejos sobre cómo solucionar problemas cuando intenta conectarse aOracle Analytics Cloud desde la herramienta de administración de modelos. La herramientade administración de modelos está disponible al descargar Oracle Analytics Client Tools.
Acceda a estos archivos log en la máquina cliente:
• BI_client_domainhome\domains\bi\servers\obis1\logs\user_name_NQSAdminTool.log
• BI_client_domain_home\domains\bi\clients\datamodel\logs\datamodel.logEn esta tabla se describen algunos problemas de conexión comunes y cómo se puedenresolver.
Problemas de conexión comunes Causa y resolución
401: No autorizado O Fallo deautenticación
Las credenciales de conexión no son válidas.• Asegúrese de que existe la cuenta de usuario.• Asegúrese de que ha escrito correctamente el nombre
de usuario y la contraseña.• Asegúrese de que la contraseña no contiene signos de
exclamación (!).• Asegúrese de que el usuario tiene el rol de aplicación
de administrador de servicio de BI.
Error al inicializar laconexión TLS segura oexcepción de proxy:java.security.NoSuchAlgorithmException: Error al crear laimplantación (algoritmo: pordefecto, proveedor: SunJSSE,clase:sun.security.ssl.SSLContextImpl$DefaultSSLContext)OError al inicializar laconexión TLS segura oexcepción de proxy: el hostremoto ha cerrado la conexióndurante el establecimiento dela comunicación
El problema tiene varias causas:• La conexión apunta a un archivo no ubicado en un
almacén clave o de confianza.• La conexión apunta a un almacén clave o de
confianza que no contiene un certificado paraverificar el certificado del servidor.
• La contraseña del almacén de confianza no escorrecta.
Utilice el almacén de claves de JDK por defecto ubicadoen:BI_client_domain_home\oracle_common\jdk\jre\lib\security\cacerts.
Apéndice BSolución de problemas con la herramienta de administración de modelos (Oracle Analytics Client Tools)
B-3

Problemas de conexión comunes Causa y resolución
Fallo de conexión. Puede quelos procesos del servidorestén caídos o que el nombrede host, el número de puerto,la instancia de servicio o elprotocolo (http/https) nosean correctos
El problema tiene varias causas:• Asegúrese de que ha especificado el nombre de host y
el número de puerto correctos. Consulte Conexión a unmodelo semántico en la nube.
• Si el archivo datamodel.log registra Connectiontimed out, compruebe si la máquina en la que hainstalado Oracle Analytics Client Tools se encuentraen una red con proxy activado. Si es así, póngase encontacto con el administrador de red para obtenerinformación sobre el servidor y el puerto de proxy, yespecifíquelos cuando se conecte al modelosemántico.
• Si no puede diagnosticar un problema de conexiónutilizando los archivos log del cliente y OracleAnalytics Cloud está desplegado en un entornogestionado por el cliente, compruebe los archivos logdel servidor bi-lcm-rest.log.0 y bi_server1.out.
Por ejemplo, si el usuario de la base de datos nodispone del rol de aplicación BIServiceAdministrator,el archivo bi_server1.out informa de un errorparecido a:oracle.bi.restkit.security.auth.RequiredGroupAuthoriser> <BEA-000000> <Failedauthorisation for user: weblogic>
No puedo usar la herramienta deadministración de modelos enmodo SSL
Si los certificadores de seguridad por defecto nofuncionan, importe los certificados de seguridad delservidor. Por ejemplo, en la máquina en la que hayadescargado e instalado Oracle Analytics Client Tools, talvez desee usar la herramienta de gestión de certificados yclaves (herramienta de claves) para ejecutar estoscomandos:
C:\Oracle\Middleware\oracle_common\jdk\jre\bin\keytool.exe -importcert -alias oacserver -fileC:\Oracle\Middleware\oracle_common\jdk\jre\lib\security\server.crt -keystoreC:\Oracle\Middleware\oracle_common\jdk\jre\lib\security\cacerts -storepasspassword
Apéndice BSolución de problemas con la herramienta de administración de modelos (Oracle Analytics Client Tools)
B-4

CReferencia del editor de expresiones
En esta sección se describen los elementos de expresión que puede utilizar en el editor deexpresiones.
Temas:
• Objetos de modelo semántico
• Operadores SQL
• Expresiones condicionales
• Funciones
• Constantes
• Tipos
• Variables
Objetos de modelo semánticoPuede utilizar objetos de modelo semántico en expresiones, como niveles de tiempo,columnas de dimensiones y columnas de hechos.
Para hacer referencia a un objeto de modelo semántico, utilice la sintaxis:
" Nombre de la tabla de hechos/dimensiones "." Nombre de columna "
Por ejemplo: "Order Metrics"."Booked Amount"-"Order Metrics"."Fulfilled Amount"La sección Elementos de expresión solo incluye elementos relevantes para la tarea, por loque puede que no se muestren todas las tablas de hechos y de dimensiones. De igualmanera, las jerarquías de tiempo solo se incluyen si la tabla de hechos Time está unida a latabla actual.
Operadores SQLLos operadores SQL se utilizan para especificar comparaciones entre expresiones.
Puede utilizar varios tipos de operadores SQL.
Operador Ejemplo Descripción Sintaxis
BETWEEN "COSTS"."UNIT_COST" BETWEEN100.0 AND5000.0
Determina si un valor está entre doslímites no inclusivos.BETWEEN puede precedido por NOTpara negar la condición.
BETWEEN[LowerBound] AND[UpperBound]
IN "COSTS"."UNIT_COST" IN(200,600, 'A')
Determina si un valor está presenteen un juego de valores.
IN ([CommaSeparated List])
C-1

Operador Ejemplo Descripción Sintaxis
IS NULL "PRODUCTS"."PROD_NAME" IS NULL
Determina si un valor es nulo. IS NULL
LIKE "PRODUCTS"."PROD_NAME" LIKE'prod%'
Determina si un valor coincide contoda una cadena o con parte de ésta.Se suele utilizar con caracterescomodín para indicar cualquiercoincidencia de cadenas decaracteres de cero o varioscaracteres (%) o cualquiercoincidencia de carácter único (_).
LIKE
+ (FEDERAL_REVENUE +LOCAL_REVENUE)-TOTAL_EXPENDITURE
Signo más para sumar. +
- (FEDERAL_REVENUE +LOCAL_REVENUE)-TOTAL_EXPENDITURE
Signo menos para restar. -
* o X SUPPORT_SERVICES_EXPENDITURE *1.5
Signo de multiplicación paramultiplicar.
*X
/ CAPITAL_OUTLAY_EXPENDITURE/1.05
Signo de división para dividir. /
% Porcentaje %|| STATE||
CAST(YEAR ASCHAR(4))
Concatenación de cadenas decaracteres.
||
( (FEDERAL_REVENUE +LOCAL_REVENUE)-TOTAL_EXPENDITURE
Paréntesis de apertura. (
) (FEDERAL_REVENUE +LOCAL_REVENUE)-TOTAL_EXPENDITURE
Paréntesis de cierre. )
Apéndice COperadores SQL
C-2
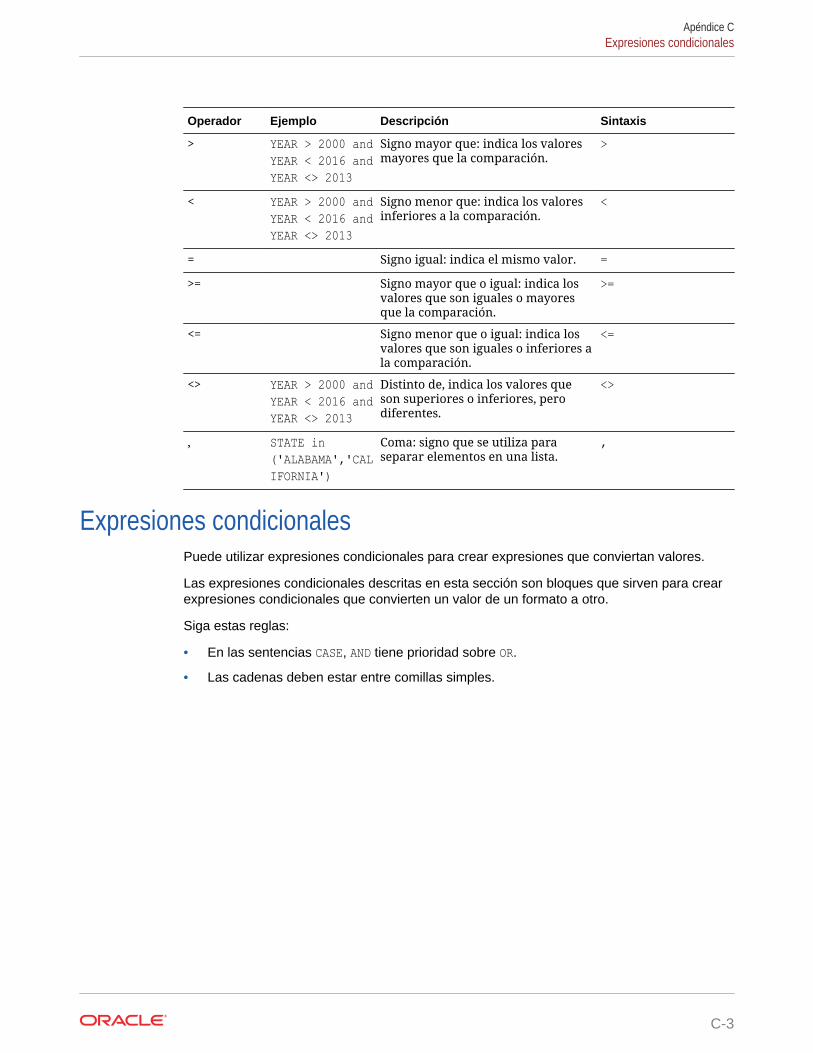
Operador Ejemplo Descripción Sintaxis
> YEAR > 2000 andYEAR < 2016 andYEAR <> 2013
Signo mayor que: indica los valoresmayores que la comparación.
>
< YEAR > 2000 andYEAR < 2016 andYEAR <> 2013
Signo menor que: indica los valoresinferiores a la comparación.
<
= Signo igual: indica el mismo valor. =>= Signo mayor que o igual: indica los
valores que son iguales o mayoresque la comparación.
>=
<= Signo menor que o igual: indica losvalores que son iguales o inferiores ala comparación.
<=
<> YEAR > 2000 andYEAR < 2016 andYEAR <> 2013
Distinto de, indica los valores queson superiores o inferiores, perodiferentes.
<>
, STATE in('ALABAMA','CALIFORNIA')
Coma: signo que se utiliza paraseparar elementos en una lista.
,
Expresiones condicionalesPuede utilizar expresiones condicionales para crear expresiones que conviertan valores.
Las expresiones condicionales descritas en esta sección son bloques que sirven para crearexpresiones condicionales que convierten un valor de un formato a otro.
Siga estas reglas:
• En las sentencias CASE, AND tiene prioridad sobre OR.
• Las cadenas deben estar entre comillas simples.
Apéndice CExpresiones condicionales
C-3

Expresión Ejemplo Descripción Sintaxis
CASE (If) CASEWHEN score-par < 0THEN 'Bajo par'WHEN score-par = 0THEN 'Par'WHEN score-par = 1THEN 'Bogey'WHEN score-par = 2THEN 'Doble Bogey'ELSE 'Triple bogey opeor'END
Evalúa cada condiciónWHEN y, si se cumple,asigna el valor a laexpresión THENcorrespondiente.Si no se cumple ningunacondición WHEN, se asignael valor por defectoespecificado en laexpresión ELSE. Si no seespecifica ningunaexpresión ELSE, elsistema agregaráautomáticamente ELSENULL.
Nota: Consulte Mejoresprácticas para el uso desentencias CASE enanálisis y visualizaciones.
CASE WHENrequest_condition1 THEN expr1 ELSEexpr2 END
CASE(Switch)
CASE Score-parWHEN -5 THEN 'Birdieen el par 6'WHEN -4 THEN 'Debeser Tiger'WHEN -3 THEN 'Tresbajo par'WHEN -2 THEN 'Dosbajo par'WHEN -1 THEN 'Birdie'WHEN 0 THEN 'Par'WHEN 1 THEN 'Bogey'WHEN 2 THEN 'DobleBogey'ELSE 'Triple bogey opeor'END
También se conoce comoCASE (Lookup). Seexamina el valor de laprimera expresión y, acontinuación, de lasexpresiones WHEN. Si laprimera expresióncoincide con cualquierexpresión WHEN, asigna elvalor de la expresiónTHEN correspondiente.
Si no coincide ningunade las expresiones WHEN,se le asigna el valor pordefecto especificado en laexpresión ELSE. Si no seespecifica ningunaexpresión ELSE, elsistema agregaráautomáticamente ELSENULL.
Si la primera expresióncoincide con unaexpresión en variascláusulas WHEN, solo seasignará la expresiónposterior a la primeracoincidencia.Nota Consulte Mejoresprácticas para el uso desentencias CASE enanálisis y visualizaciones.
CASE expr1 WHENexpr2 THEN expr3ELSE expr4 END
Apéndice CExpresiones condicionales
C-4

Expresión Ejemplo Descripción Sintaxis
IfCase >ELSE
- - ELSE [expr]
IfCase >IFNULL
- - IFNULL([expr],[value])
IfCase >NULLIF
- - NULLIF([expr],[expr])
IfCase >WHEN
- - WHEN [Condition]THEN [expr]
IfCase >CASE
- - CASE WHEN[Condition] THEN[expr] END
SwitchCase> ELSE
- - ELSE [expr]
SwitchCase>IFNULL
- - IFNULL([expr],[value])
SwitchCase> NULLIF
- - NULLIF([expr],[expr])
SwitchCase> WHEN
- - WHEN [Condition]THEN [expr]
FuncionesHay varios tipos de funciones que puede utilizar en expresiones.
Temas:
• Funciones de agregación
• Funciones analíticas
• Funciones de fecha y hora
• Funciones de conversión
• Funciones de visualización
• Funciones de evaluación
• Funciones matemáticas
• Funciones de agregado de ejecución
• Funciones espaciales
• Funciones de cadena
• Funciones del sistema
• Funciones de serie temporal
Apéndice CFunciones
C-5

Funciones de agregaciónLas funciones agregadas realizan operaciones en varios valores para crear resultadosde resumen.
En la lista siguiente se describen las reglas de agregación que están disponibles paralas columnas y las columnas de medida. La lista también incluye funciones que puedeutilizar al crear un elemento calculado para realizar análisis.
• Predeterminado: aplica la regla de agregación predeterminada como en elmodelo semántico o por el autor original del análisis. No disponible paraelementos calculados en los análisis.
• Determinado por el servidor: aplica la regla de agregación determinada porOracle Analytics (como, por ejemplo, la regla que se define en el modelosemántico). La agregación se realiza en Oracle Analytics para reglas simplescomo suma, mínimo y máximo. No está disponible para columnas de medida delpanel Diseño ni para elementos calculados en análisis.
• Suma: calcula la suma obtenida al agregar todos los valores en el juego deresultados. Utilícela para elementos que tengan valores numéricos.
• Mínimo: calcula el valor mínimo (valor numérico inferior) de las filas en el juegode resultados. Utilícela para elementos que tengan valores numéricos.
• Máximo: calcula el valor máximo (valor numérico superior) de las filas en el juegode resultados. Utilícela para elementos que tengan valores numéricos.
• Media: calcula la media de un elemento en el juego de resultados. Utilícela paraelementos que tengan valores numéricos. Las medias de tablas y tablasdinámicas se redondean al número entero más próximo.
• Primero: en el juego de resultados, selecciona la primera incidencia del elementopara medidas. Para los elementos calculados, selecciona el primer miembrosegún la pantalla de la lista Seleccionados. No está disponible en el cuadro dediálogo Editar fórmula de columna.
• Último: en el juego de resultados, seleccione la última incidencia del elemento.Para los elementos calculados, selecciona el último miembro según la pantalla enla lista Seleccionados. No está disponible en el cuadro de diálogo Editar fórmulade columna.
• Recuento: calcula el número de filas en el juego de resultados que tienen unvalor no nulo para el elemento. El elemento es normalmente un nombre decolumna, en cuyo caso se devuelve el número de filas con valores no nulos paradicha columna.
• Recuento de los Valores Distintos: agrega procesamientos distintos a la funciónRecuento, lo que significa que cada incidencia distinta del elemento se cuentasólo una vez.
• Ninguno: no aplica agregación. No disponible para elementos calculados en losanálisis.
• Total basado en informe (si procede): si no se selecciona, especifica queOracle Analytics debe calcular el total en base a todo el juego de resultados antesde aplicar ningún filtro a las medidas. No está disponible en el cuadro de diálogoEditar fórmula de columna ni para elementos calculados en los análisis. Sólodisponible para columnas de atributo.
Apéndice CFunciones
C-6

Función Ejemplo Descripción Sintaxis
AGGREGATEAT
AGGREGATE(salesAT month,region)
Agrega columnas según el nivel o losniveles que especifique.measure es el nombre de una columna demedida. level es el nivel en el que desearealizar la agregación. También puedeespecificar más de un nivel. No se puedeespecificar un nivel a partir de unadimensión que contenga los niveles quese están utilizando como nivel de medidapara la medida especificada en el primerargumento. Por ejemplo, no puedeescribir la función comoAGGREGATE(yearly_sales AT month), yaque month procede de la mismadimensión de tiempo que se estáutilizando como nivel de medida parayearly_sales.
AGGREGATE(measure ATlevel [, level1,levelN])
AVG Avg(Sales) Calcula la media (promedio) de un juegonumérico de valores.
AVG(expr)
AVGDISTINCT Calcula la media de todos los valoresdistintos de una expresión.
AVG(DISTINCT expr)
BIN BIN(revenue BYproductid, yearWHERE productid> 2 INTO 4 BINSRETURNINGRANGE_LOW)
Clasifica una determinada expresiónnumérica en un número especificado decubos del mismo ancho. La funciónpuede devolver el número de bin o unode los dos puntos finales del intervalo debins. numeric_expr es la medida o elatributo numérico en el bin. BYgrain_expr1,…, grain_exprN es una listade expresiones que define el detalle conel que se calcula el valor denumeric_expr. BY es necesario para lasexpresiones de medida, y es opcionalpara las expresiones de atributo. WHEREes un filtro que se aplica a numeric_exprantes de que se asignen los valoresnuméricos a los bins INTOnumber_of_bins BINS es el número debins que devolver. BETWEEN min_valueAND max_value son los valores mínimo ymáximo que se utilizan como puntosfinales de los bins más externos.RETURNING NUMBER indica que el valorde retorno debe ser el número de bins (1,2, 3, 4, etc.). Éste es el estado por defecto.RETURNING RANGE_LOW indica el valormás bajo del intervalo de bins.RETURNING RANGE_HIGH indica el valormás alto del intervalo de bins
BIN(numeric_expr [BYgrain_expr1, ...,grain_exprN] [WHEREcondition] INTOnumber_of_bins BINS[BETWEEN min_valueAND max_value][RETURNING {NUMBER |RANGE_LOW |RANGE_HIGH}])
Apéndice CFunciones
C-7

Función Ejemplo Descripción Sintaxis
BottomN Clasifica los n valores más bajos delargumento de la expresión de 1 a n,donde 1 corresponde al valor numéricomás bajo.expr es una expresión que se evalúacomo un valor numérico. integer escualquier entero positivo. Representa elnúmero más bajo de las clasificacionesque aparecen en el conjunto deresultados (1 es la clasificación más baja).
BottomN(expr,integer)
COUNT COUNT(Products) Determina el número de elementos conun valor no nulo.
COUNT(expr)
COUNTDISTINCT
Agrega un procesamiento distinto a lafunción COUNT.expr es cualquier expresión.
COUNT(DISTINCT expr)
COUNT* SELECT COUNT(*)FROM Facts
Cuenta el número de filas. COUNT(*)
Primero First(Sales) Selecciona el primer valor devuelto nonulo del argumento de la expresión. Lafunción First funciona en el nivel másdetallado especificado en la dimensiónque haya definido de forma explícita.
First([NumericExpression)]
Último Last(Sales) Selecciona el último valor devuelto nonulo de la expresión.
Last([NumericExpression)]
MAVG Calcula el promedio (media) móvil de lasúltimas n filas de datos en el juego deresultados, incluida la fila actual.expr es una expresión que se evalúacomo un valor numérico. integer escualquier entero positivo. Representa elvalor medio de las últimas n filas dedatos.
MAVG(expr, integer)
MAX MAX(Revenue) Calcula el valor máximo (valor numéricomás elevado) de las filas que cumplen elargumento de expresión numérica.
MAX(expr)
MEDIAN MEDIAN(Sales) Calcula el valor medio de las filas quecumplen el argumento de expresiónnumérica. Cuando hay un número par defilas, la mediana es la media de las dosfilas centrales. Esta función siempredevuelve un doble.
MEDIAN(expr)
MIN MIN(Revenue) Calcula el valor mínimo (valor numéricomínimo) de las filas que cumplen elargumento de la expresión numérica.
MIN(expr)
Apéndice CFunciones
C-8
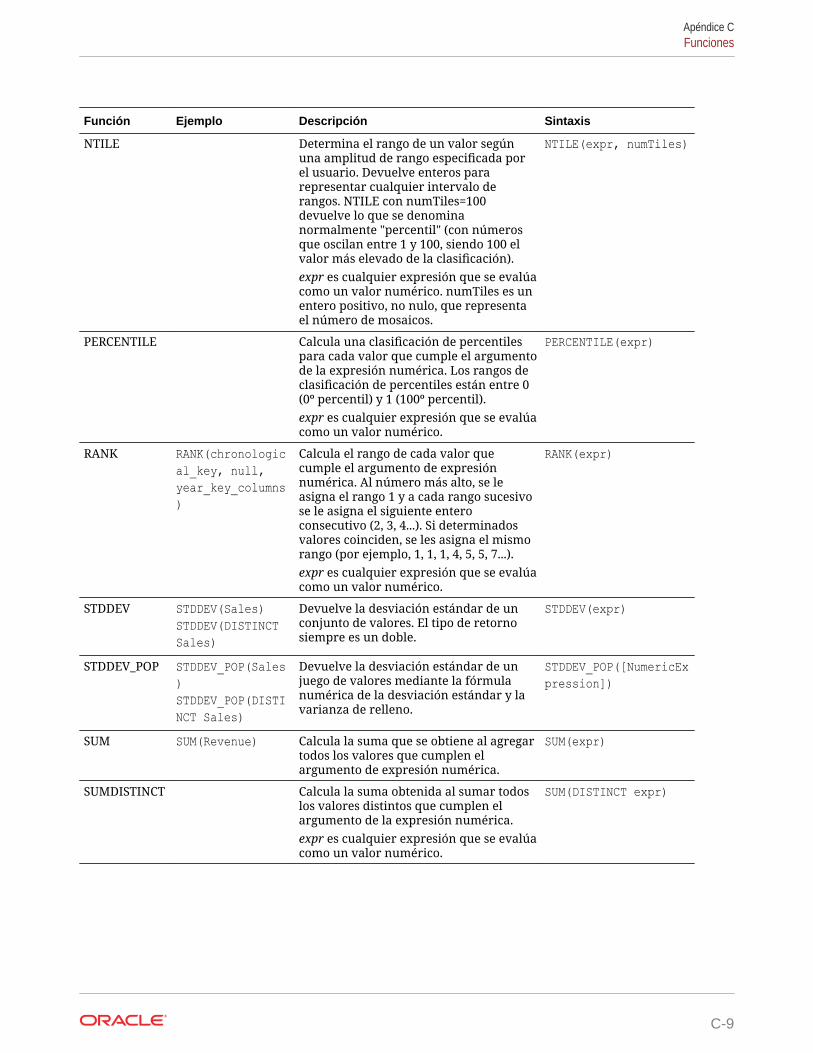
Función Ejemplo Descripción Sintaxis
NTILE Determina el rango de un valor segúnuna amplitud de rango especificada porel usuario. Devuelve enteros pararepresentar cualquier intervalo derangos. NTILE con numTiles=100devuelve lo que se denominanormalmente "percentil" (con númerosque oscilan entre 1 y 100, siendo 100 elvalor más elevado de la clasificación).expr es cualquier expresión que se evalúacomo un valor numérico. numTiles es unentero positivo, no nulo, que representael número de mosaicos.
NTILE(expr, numTiles)
PERCENTILE Calcula una clasificación de percentilespara cada valor que cumple el argumentode la expresión numérica. Los rangos declasificación de percentiles están entre 0(0º percentil) y 1 (100º percentil).expr es cualquier expresión que se evalúacomo un valor numérico.
PERCENTILE(expr)
RANK RANK(chronological_key, null,year_key_columns)
Calcula el rango de cada valor quecumple el argumento de expresiónnumérica. Al número más alto, se leasigna el rango 1 y a cada rango sucesivose le asigna el siguiente enteroconsecutivo (2, 3, 4...). Si determinadosvalores coinciden, se les asigna el mismorango (por ejemplo, 1, 1, 1, 4, 5, 5, 7...).expr es cualquier expresión que se evalúacomo un valor numérico.
RANK(expr)
STDDEV STDDEV(Sales)STDDEV(DISTINCTSales)
Devuelve la desviación estándar de unconjunto de valores. El tipo de retornosiempre es un doble.
STDDEV(expr)
STDDEV_POP STDDEV_POP(Sales)STDDEV_POP(DISTINCT Sales)
Devuelve la desviación estándar de unjuego de valores mediante la fórmulanumérica de la desviación estándar y lavarianza de relleno.
STDDEV_POP([NumericExpression])
SUM SUM(Revenue) Calcula la suma que se obtiene al agregartodos los valores que cumplen elargumento de expresión numérica.
SUM(expr)
SUMDISTINCT Calcula la suma obtenida al sumar todoslos valores distintos que cumplen elargumento de la expresión numérica.expr es cualquier expresión que se evalúacomo un valor numérico.
SUM(DISTINCT expr)
Apéndice CFunciones
C-9

Función Ejemplo Descripción Sintaxis
TOPN Clasifica los n valores más altos delargumento de expresión de 1 a n, deforma que 1 corresponde al valornumérico más alto.expr es una expresión que se evalúacomo un valor numérico. integer escualquier entero positivo. Representa elnúmero más alto de clasificaciones que semuestran en el juego de resultados,donde 1 es el rango más alto.
TOPN(expr, integer)
Funciones analíticasLas funciones de análisis permiten explorar los datos utilizando modelos comoTendencia Lineal y Cluster.
Función Ejemplo Descripción Sintaxis
TRENDLINE TRENDLINE(revenue,(calendar_year,calendar_quarter,calendar_month) BY(product), 'LINEAR','VALUE')
Oracle recomienda queaplique una línea detendencia utilizando lapropiedad Agregarestadísticas al mostraruna visualización.Consulte Ajuste depropiedades devisualización.Ajusta un modelo lineal,polinómico oexponencial y devuelvelos valores o el modeloajustados. numeric_exprrepresenta el valor Y dela tendencia, y series(columnas de tiempo)representan el valor X.
TRENDLINE(numeric_expr,([series]) BY([partitionBy]),model_type, result_type)
CLUSTER CLUSTER((product,company),(billed_quantity,revenue), 'clusterName','algorithm=k-means;numClusters=%1;maxIter=%2;useRandomSeed=FALSE;enablePartitioning=TRUE', 5, 10)
Recopila un juego deregistros en gruposbasándose en una o másexpresiones de entradamediante K-Means o laagrupación en clustersjerárquica.
CLUSTER((dimension_expr1, ... dimension_exprN),(expr1, ... exprN),output_column_name,options,[runtime_binded_options])
Apéndice CFunciones
C-10

Función Ejemplo Descripción Sintaxis
OUTLIER OUTLIER((product,company),(billed_quantity,revenue), 'isOutlier','algorithm=kmeans')
Clasifica un registrocomo valor atípico enfunción de una o másexpresiones de entradamediante K-Means,agrupación en clustersjerárquica o algoritmosde detección de valoresatípicos de variasvariables.
OUTLIER((dimension_expr1, ... dimension_exprN),(expr1, ... exprN),output_column_name,options,[runtime_binded_options])
REGR REGR(revenue,(discount_amount),(product_type, brand),'fitted', '')
Ajusta un modelo lineal ydevuelve los valores o elmodelo ajustados. Estafunción puede utilizarsepara ajustar una curvalineal en dos medidas.
REGR(y_axis_measure_expr,(x_axis_expr),(category_expr1, ...,category_exprN),output_column_name,options,[runtime_binded_options])
Funciones de fecha y horaLas funciones de fecha y hora manipulan los datos según DATE y DATETIME.
Función Ejemplo Descripción Sintaxis
CURRENT_Date
CURRENT_DATE Devuelve la fecha actual.La fecha se determina en el sistemadonde se ejecuta Oracle BI.
CURRENT_DATE
CURRENT_TIME
CURRENT_TIME(3) Devuelve la hora actual al númeroespecificado de dígitos de precisión, porejemplo: HH:MM:SS.SSSSi no se especifica ningún argumento, lafunción devuelve la precisión pordefecto.
CURRENT_TIME(expr)
CURRENT_TIMESTAMP
CURRENT_TIMESTAMP(3)
Devuelve la fecha/registro de hora actualal número especificado de dígitos deprecisión.
CURRENT_TIMESTAMP(expr)
DAYNAME DAYNAME(Order_Date)
Devuelve el nombre del día de la semanade una expresión de fecha especificada.
DAYNAME(expr)
DAYOFMONTH DAYOFMONTH(Order_Date)
Devuelve el número correspondiente aldía del mes de una expresión de fechaespecificada.
DAYOFMONTH(expr)
DAYOFWEEK DAYOFWEEK(Order_Date)
Devuelve un número entre 1 y 7correspondiente al día de la semana deuna expresión de fecha especificada. Porejemplo, 1 siempre corresponde aldomingo, 2 al lunes, y así sucesivamentehasta el sábado, que corresponde alnúmero 7.
DAYOFWEEK(expr)
Apéndice CFunciones
C-11

Función Ejemplo Descripción Sintaxis
DAYOFYEAR DAYOFYEAR(Order_Date)
Devuelve el número (entre 1 y 366)correspondiente al día del año de unaexpresión de fecha especificada.
DAYOFYEAR(expr)
DAY_OF_QUARTER
DAY_OF_QUARTER(Order_Date)
Devuelve un número (entre 1 y 92) quecorresponde al día del trimestre de laexpresión de fecha especificada.
DAY_OF_QUARTER(expr)
HOUR HOUR(Order_Time) Devuelve un número (entre 0 y 23)correspondiente a la hora de unaexpresión de hora especificada. Porejemplo, 0 corresponde a las 00:00 y 23corresponde a las 23.00.
HOUR(expr)
MINUTE MINUTE(Order_Time)
Devuelve un número (entre 0 y 59)correspondiente al minuto de unaexpresión de tiempo especificada.
MINUTE(expr)
MONTH MONTH(Order_Time)
Devuelve el número (entre 1 y 12)correspondiente al mes de una expresiónde fecha especificada.
MONTH(expr)
MONTHNAME MONTHNAME(Order_Time)
Devuelve el nombre del mes de unaexpresión de fecha especificada.
MONTHNAME(expr)
MONTH_OF_QUARTER
MONTH_OF_QUARTER(Order_Date)
Devuelve el número (entre 1 y 3)correspondiente al mes del trimestre deuna expresión de fecha especificada.
MONTH_OF_QUARTER(expr)
NOW NOW() Devuelve la fecha/hora actual. La funciónNOW es equivalente a la funciónCURRENT_TIMESTAMP.
NOW()
QUARTER_OF_YEAR
QUARTER_OF_YEAR(Order_Date)
Devuelve el número (entre 1 y 4)correspondiente al trimestre del año deuna expresión de fecha especificada.
QUARTER_OF_YEAR(expr)
SECOND SECOND(Order_Time)
Devuelve el número (entre 0 y 59)correspondiente a los segundos de unaexpresión de tiempo especificada.
SECOND(expr)
TIMESTAMPADD
TIMESTAMPADD(SQL_TSI_MONTH,12,Time."OrderDate")
Agrega el número especificado deintervalos a un registro de hora ydevuelve un solo registro de hora.Las opciones de intervalo son:SQL_TSI_SECOND, SQL_TSI_MINUTE,SQL_TSI_HOUR, SQL_TSI_DAY,SQL_TSI_WEEK, SQL_TSI_MONTH,SQL_TSI_QUARTER, SQL_TSI_YEAR
TIMESTAMPADD(interval, expr, timestamp)
TIMESTAMPDIFF
TIMESTAMPDIFF(SQL_TSI_MONTH,Time."OrderDate",CURRENT_DATE)
Devuelve el número total de intervalosespecificados entre dos indicaciones defecha/hora.Utilice los mismos intervalos queTIMESTAMPADD.
TIMESTAMPDIFF(interval, expr, timestamp2)
WEEK_OF_QUARTER
WEEK_OF_QUARTER(Order_Date)
Devuelve un número (entre 1 y 13) quecorresponde a la semana del trimestre dela expresión de fecha especificada.
WEEK_OF_QUARTER(expr)
Apéndice CFunciones
C-12

Función Ejemplo Descripción Sintaxis
WEEK_OF_YEAR
WEEK_OF_YEAR(Order_Date)
Devuelve un número (entre 1 y 53) quecorresponde a la semana del año de laexpresión de fecha especificada.
WEEK_OF_YEAR(expr)
YEAR YEAR(Order_Date) Devuelve el año de la expresión de fechaespecificada.
YEAR(expr)
Funciones de conversiónLas funciones de conversión convierten un valor de un formato a otro.
Función Ejemplo Descripción Sintaxis
CAST CAST(hiredate ASCHAR(40)) FROMemployee
Cambia el tipo de dato de unaexpresión o un literal nulo a otrotipo de dato. Por ejemplo, se puedeconvertir customer_name (un tipode datos CHAR o VARCHAR) o birthdate(un literal de fecha y hora).Utilice CAST para cambiar a un tipode dato Date.No utilice TODATE.
CAST(expr AS type)
IFNULL IFNULL(Sales, 0) Prueba si una expresión se evalúaen un valor nulo y, en casoafirmativo, asigna el valorespecificado a la expresión.
IFNULL(expr, value)
INDEXCOL SELECTINDEXCOL(VALUEOF(NQ_SESSION.GEOGRAPHY_LEVEL), Country,State, City), RevenueFROM Sales
Utiliza información externa paradevolver la columna adecuada paraque la pueda ver el usuarioconectado.
INDEXCOL([integerliteral], [expr1] [,[expr2], ?-])
NULLIF SELECT e.last_name,NULLIF(e.job_id,j.job_id) "Old JobID" FROM employees e,job_history j WHEREe.employee_id =j.employee_id ORDERBY last_name, "OldJob ID";
Compara dos expresiones. Si soniguales, la función devuelve NULL.Si no son iguales, la funcióndevuelve la primera expresión. Nopuede especificar el literal NULLpara la primera expresión.
NULLIF([expression],[expression])
To_DateTime SELECT To_DateTime('2009-03-0301:01:00', 'yyyy-mm-ddhh:mi:ss') FROM sales
Convierte los literales de cadena deformato DateTime a un tipo de datoDateTime.
To_DateTime([expression], [literal])
Apéndice CFunciones
C-13

Función Ejemplo Descripción Sintaxis
VALUEOF SalesSubjectArea.Customer.Region =VALUEOF("RegionSecurity"."REGION")
Hace referencia al valor de unavariable de modelo semántico en unfiltro.Utilice variables expr comoargumentos de la función VALUEOF.Utilice el nombre para hacerreferencia a las variables de modelosemántico.
VALUEOF(expr)
Funciones de visualizaciónLas funciones de visualización se utilizan en el juego de resultados de una consulta.
Función Ejemplo Descripción Sintaxis
BottomN BottomN(Sales,10)
Devuelve los n valores inferiores de laexpresión, clasificados de menor amayor.
BottomN([NumericExpression], [integer])
FILTER FILTER(SalesUSING Product ='widget')
Calcula la expresión con el filtro deagregación previa especificado.
FILTER(measure USINGfilter_expr)
MAVG MAVG(Sales, 10) Calcula el promedio (media) móvil de lasúltimas n filas de datos en el juego deresultados, incluida la fila actual.
MAVG([NumericExpression], [integer])
MSUM SELECT Month,Revenue,MSUM(Revenue, 3)as 3_MO_SUM FROMSales
Calcula una suma móvil de las últimas nfilas de datos, incluida la fila actual.La suma de la primera fila es igual a laexpresión numérica de la primera fila. Lasuma de la segunda fila se calculatomando la suma de las dos primerasfilas de datos, etc. Cuando se llega a la filan , la suma se calcula en función de lasúltimas n filas de datos.
MSUM([NumericExpression], [integer])
NTILE NTILE(Sales,100)
Determina el rango de un valor segúnuna amplitud de rango especificada porel usuario. Devuelve enteros pararepresentar cualquier intervalo derangos. El ejemplo muestra un rangodesde 1 hasta 100, donde la menor venta= 1 y la mayor venta = 100.
NTILE([NumericExpresssion], [integer])
PERCENTILE PERCENTILE(Sales)
Calcula el rango de porcentaje de cadavalor que cumple el argumento deexpresión numérica. Oscila entre 0(primer percentil) y 1 (100º percentil),incluidos.
PERCENTILE([NumericExpression])
Apéndice CFunciones
C-14

Función Ejemplo Descripción Sintaxis
RANK RANK(Sales) Calcula el rango de cada valor quecumple el argumento de expresiónnumérica. Al número más alto, se leasigna el rango 1 y a cada rango sucesivose le asigna el siguiente enteroconsecutivo (2, 3, 4...). Si determinadosvalores coinciden, se les asigna el mismorango (por ejemplo, 1, 1, 1, 4, 5, 5, 7...).
RANK([NumericExpression])
RCOUNT SELECT month,profit,RCOUNT(profit)FROM sales WHEREprofit > 200
Toma un juego de registros como entraday cuenta el número de registrosencontrados hasta ese momento.
RCOUNT([NumericExpression])
RMAX SELECT month,profit,RMAX(profit)FROM sales
Toma un juego de registros como entraday muestra el valor máximo a partir de losregistros encontrados hasta esemomento. El tipo de grupos especificadodebe ser uno que se pueda ordenar.
RMAX([NumericExpression])
RMIN SELECT month,profit,RMIN(profit)FROM sales
Toma un juego de registros como entraday muestra el valor mínimo a partir de losregistros encontrados hasta esemomento. El tipo de grupos especificadodebe ser uno que se pueda ordenar.
RMIN([NumericExpression])
RSUM SELECT month,revenue,RSUM(revenue) asRUNNING_SUM FROMsales
Calcula una suma de valores a partir delos registros encontrados hasta esemomento.La suma de la primera fila es igual a laexpresión numérica de la primera fila. Lasuma de la segunda fila se calculatomando la suma de las dos primerasfilas de datos, etc.
RSUM([NumericExpression])
TOPN TOPN(Sales, 10) Devuelve los n valores superiores de laexpresión, clasificados de mayor amenor.
TOPN([NumericExpression], [integer])
Funciones de evaluaciónLas funciones de evaluación son funciones de base de datos que se pueden utilizar paratransferir expresiones para obtener cálculos avanzados.
Las funciones de base de datos embebidas pueden necesitar una o más columnas. Se hacereferencia a ellas mediante %1 ... %N en la función. Las columnas reales deben enumerarsedespués de la función.
Apéndice CFunciones
C-15

Función Ejemplo Descripción Sintaxis
EVALUATE SELECTEVALUATE('instr(%1, %2)',address, 'FosterCity') FROMemployees
Transfiere la función de la base de datosespecificada con columnas opcionales alas que se hace referencia comoparámetros a la base de datos paraevaluación.
EVALUATE([stringexpression], [commaseparatedexpressions])
EVALUATE_AGGR
EVALUATE_AGGR('REGR_SLOPE(%1,%2)',sales.quantity,market.marketkey)
Transfiere la función de la base de datosespecificada con columnas opcionales alas que se hace referencia comoparámetros a la base de datos paraevaluación. Esta función se utiliza paraagregar funciones con una cláusulaGROUP BY.
EVALUATE_AGGR('db_agg_function(%1...%N)'[AS datatype] [,column1, columnN])
Funciones matemáticasLas funciones matemáticas descritas en esta sección realizan operacionesmatemáticas.
Función Ejemplo Descripción Sintaxis
ABS ABS(Profit) Calcula el valor absoluto de unaexpresión numérica.expr es cualquier expresión que se evalúacomo un valor numérico.
ABS(expr)
ACOS ACOS(1) Calcula el arcocoseno de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
ACOS(expr)
ASIN ASIN(1) Calcula el arcoseno de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
ASIN(expr)
ATAN ATAN(1) Calcula el arcotangente de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
ATAN(expr)
ATAN2 ATAN2(1, 2) Calcula la arcotangente de y /x, donde y esla primera expresión numérica, y x lasegunda.
ATAN2(expr1, expr2)
CEILING CEILING(Profit) Redondea una expresión numérica noentera al siguiente entero superior. Si laexpresión numérica se evalúa como unentero, la función CEILING devuelve eseentero.
CEILING(expr)
COS COS(1) Calcula el coseno de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
COS(expr)
Apéndice CFunciones
C-16

Función Ejemplo Descripción Sintaxis
COT COT(1) Calcula la cotangente de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
COT(expr)
DEGREES DEGREES(1) Convierte una expresión de radianes agrados.expr es cualquier expresión que se evalúacomo un valor numérico.
DEGREES(expr)
EXP EXP(4) Eleva el valor a la potencia especificada.Calcula e elevado a la potencia n, donde ees la base del logaritmo natural.
EXP(expr)
ExtractBit IntExtractBit(1, 5)
Recupera un bit en una posicióndeterminada en un entero. Devuelve unentero de 0 o 1 que corresponde a laposición del bit.
ExtractBit([SourceNumber], [Digits])
FLOOR FLOOR(Profit) Redondea una expresión numérica noentera al siguiente entero inferior. Si laexpresión numérica se evalúa como unentero, la función FLOOR devuelve eseentero.
FLOOR(expr)
LOG LOG(1) Calcula el logaritmo neperiano de unaexpresión.expr es cualquier expresión que se evalúacomo un valor numérico.
LOG(expr)
LOG10 LOG10(1) Calcula el logaritmo decimal de unaexpresión.expr es cualquier expresión que se evalúacomo un valor numérico.
LOG10(expr)
MOD MOD(10, 3) Divide la primera expresión numéricaentre la segunda expresión numérica ydevuelve la parte restante del cociente.
MOD(expr1, expr2)
PI PI() Devuelve el valor constante de pi. PI()POWER POWER(Profit, 2) Toma la primera expresión numérica y la
eleva a la potencia especificada en lasegunda expresión numérica.
POWER(expr1, expr2)
RADIANS RADIANS(30) Convierte una expresión de grados aradianes.expr es cualquier expresión que se evalúacomo un valor numérico.
RADIANS(expr)
RAND RAND() Devuelve un número pseudoaleatorioentre 0 y 1.
RAND()
RANDFromSeed
RAND(2) Devuelve un número pseudoaleatoriobasado en un valor original. Para unvalor semilla concreto, se genera elmismo conjunto de números aleatorios.
RAND(expr)
Apéndice CFunciones
C-17

Función Ejemplo Descripción Sintaxis
ROUND ROUND(2.166000,2)
Redondea una expresión numérica a ndígitos de precisión.expr es cualquier expresión que se evalúacomo un valor numérico.Un entero es cualquier entero positivoentero que representa el número dedígitos de precisión.
ROUND(expr, integer)
SIGN SIGN(Profit) Devuelve lo siguiente:• 1 si la expresión numérica se evalúa
como un número positivo• -1 si la expresión numérica se evalúa
como un número negativo• 0 si la expresión numérica se evalúa
como cero
SIGN(expr)
SIN SIN(1) Calcula el seno de una expresiónnumérica.
SIN(expr)
SQRT SQRT(7) Calcula la raíz cuadrada del argumentode expresión numérica. La expresiónnumérica debe evaluar un número nonegativo.
SQRT(expr)
TAN TAN(1) Calcula la tangente de una expresiónnumérica.expr es cualquier expresión que se evalúacomo un valor numérico.
TAN(expr)
TRUNCATE TRUNCATE(45.12345, 2)
Trunca un número decimal para devolverel número especificado de decimalesdesde el separador de decimales.expr es cualquier expresión que se evalúacomo un valor numérico.Un entero es cualquier entero positivoque representa el número de caracteres ala derecha del lugar decimal que sedevuelve.
TRUNCATE(expr,integer)
Funciones de agregado de ejecuciónLas funciones de agregado de ejecución realizan operaciones en varios valores paracrear resultados de resumen.
Función Ejemplo Descripción Sintaxis
MAVG Calcula el promedio (media) móvil de lasúltimas n filas de datos en el juego deresultados, incluida la fila actual.expr es cualquier expresión que se evalúacomo un valor numérico. integer escualquier entero positivo. Representa elvalor medio de las últimas n filas dedatos.
MAVG(expr, integer)
Apéndice CFunciones
C-18

Función Ejemplo Descripción Sintaxis
MSUM select month,revenue,MSUM(revenue, 3)as 3_MO_SUM fromsales_subject_area
Calcula una suma móvil de las últimas nfilas de datos, incluida la fila actual.expr es cualquier expresión que se evalúacomo un valor numérico. integer escualquier entero positivo. Representa lasuma de las últimas n filas de datos.
MSUM(expr, integer)
RSUM SELECT month,revenue,RSUM(revenue) asRUNNING_SUM fromsales_subject_area
Calcula una suma de valores a partir delos registros encontrados hasta esemomento.expr es cualquier expresión que se evalúacomo un valor numérico.
RSUM(expr)
RCOUNT select month,profit,RCOUNT(profit)fromsales_subject_area where profit> 200
Toma un juego de registros como entraday cuenta el número de registrosencontrados hasta ese momento.expr es una expresión de cualquier tipode dato.
RCOUNT(expr)
RMAX SELECT month,profit,RMAX(profit) fromsales_subject_area
Toma un juego de registros como entraday muestra el valor máximo a partir de losregistros encontrados hasta esemomento.expr es una expresión de cualquier tipode dato.
RMAX(expr)
RMIN select month,profit,RMIN(profit) fromsales_subject_area
Toma un juego de registros como entraday muestra el valor mínimo a partir de losregistros encontrados hasta esemomento.expr es una expresión de cualquier tipode dato.
RMIN(expr)
Funciones espacialesLas funciones espaciales le permiten realizar análisis geográficos al modelar los datos. Porejemplo, podría calcular la distancia entre dos áreas geográficas (conocidas como formas opolígonos).
Nota:
No puede usar estas funciones espaciales en cálculos personalizados para librosde trabajo de visualización.
Función Ejemplo Descripción Sintaxis
GeometryArea GeometryArea(Shape) Calcula el área que ocupauna forma.
GeometryArea(Shape)
Apéndice CFunciones
C-19
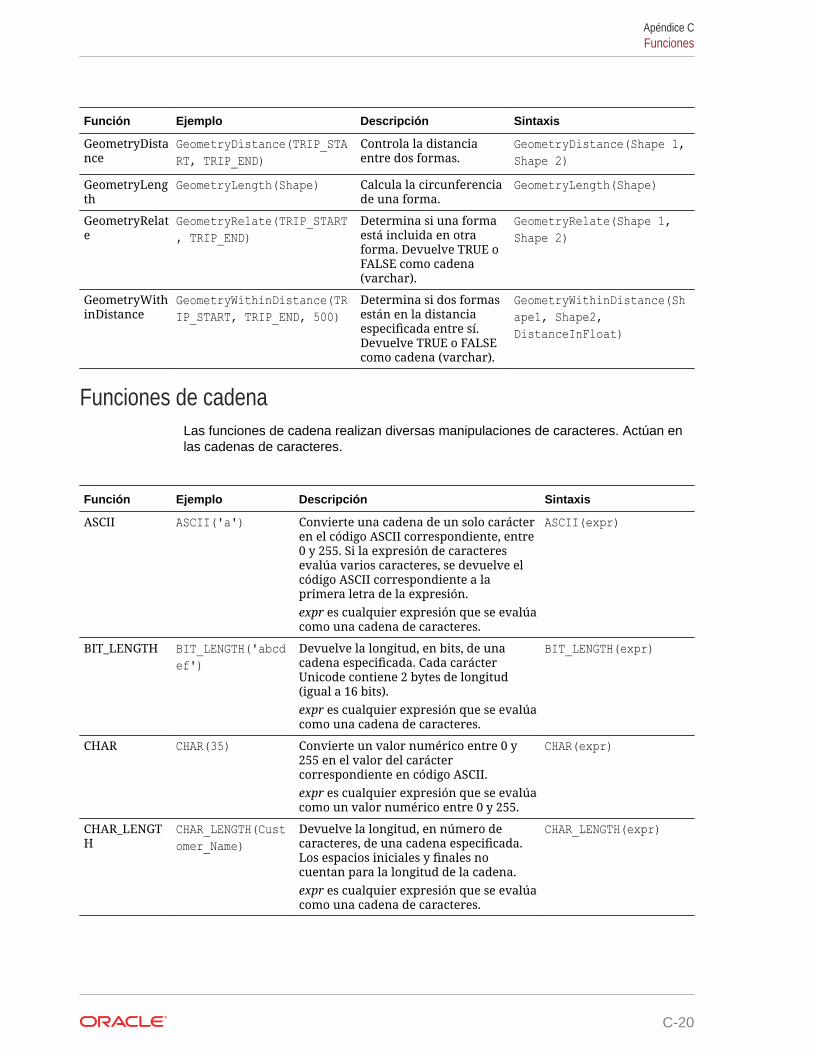
Función Ejemplo Descripción Sintaxis
GeometryDistance
GeometryDistance(TRIP_START, TRIP_END)
Controla la distanciaentre dos formas.
GeometryDistance(Shape 1,Shape 2)
GeometryLength
GeometryLength(Shape) Calcula la circunferenciade una forma.
GeometryLength(Shape)
GeometryRelate
GeometryRelate(TRIP_START, TRIP_END)
Determina si una formaestá incluida en otraforma. Devuelve TRUE oFALSE como cadena(varchar).
GeometryRelate(Shape 1,Shape 2)
GeometryWithinDistance
GeometryWithinDistance(TRIP_START, TRIP_END, 500)
Determina si dos formasestán en la distanciaespecificada entre sí.Devuelve TRUE o FALSEcomo cadena (varchar).
GeometryWithinDistance(Shape1, Shape2,DistanceInFloat)
Funciones de cadenaLas funciones de cadena realizan diversas manipulaciones de caracteres. Actúan enlas cadenas de caracteres.
Función Ejemplo Descripción Sintaxis
ASCII ASCII('a') Convierte una cadena de un solo carácteren el código ASCII correspondiente, entre0 y 255. Si la expresión de caracteresevalúa varios caracteres, se devuelve elcódigo ASCII correspondiente a laprimera letra de la expresión.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
ASCII(expr)
BIT_LENGTH BIT_LENGTH('abcdef')
Devuelve la longitud, en bits, de unacadena especificada. Cada carácterUnicode contiene 2 bytes de longitud(igual a 16 bits).expr es cualquier expresión que se evalúacomo una cadena de caracteres.
BIT_LENGTH(expr)
CHAR CHAR(35) Convierte un valor numérico entre 0 y255 en el valor del caráctercorrespondiente en código ASCII.expr es cualquier expresión que se evalúacomo un valor numérico entre 0 y 255.
CHAR(expr)
CHAR_LENGTH
CHAR_LENGTH(Customer_Name)
Devuelve la longitud, en número decaracteres, de una cadena especificada.Los espacios iniciales y finales nocuentan para la longitud de la cadena.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
CHAR_LENGTH(expr)
Apéndice CFunciones
C-20

Función Ejemplo Descripción Sintaxis
CONCAT SELECT DISTINCTCONCAT ('abc','def') FROMemployee
Concatena dos cadenas de caracteres.exprs son expresiones que se evalúancomo cadenas de caracteres separadaspor comas.Debe utilizar datos no procesados, datossin formato, con CONCAT.
CONCAT(expr1, expr2)
INSERT SELECTINSERT('123456',2, 3, 'abcd')FROM table
Inserta una cadena de caracteresdeterminada en una ubicaciónespecificada de otra cadena de caracteres.expr1 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena de caracteres dedestino.integer1 es cualquier entero positivo querepresenta el número de caracteres desdeel principio de la cadena de destino en laque se insertará la segunda cadena.integer2 es cualquier entero positivo querepresenta el número de caracteres de lacadena de destino que se sustituirá por lasegunda cadena.expr2 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena de caracteres que seinsertará en la cadena de destino.
INSERT(expr1,integer1, integer2,expr2)
LEFT SELECTLEFT('123456',3) FROM table
Devuelve un número de caracteresespecificado a la izquierda de la cadena.expr es cualquier expresión que se evalúacomo una cadena de caracteres.integer es cualquier entero positivo querepresenta el número de caracteres de laparte izquierda de la cadena que se va adevolver
LEFT(expr, integer)
LENGTH LENGTH(Customer_Name)
Devuelve la longitud, en número decaracteres, de una cadena especificada.Se devuelve el tamaño excluyendo loscaracteres finales en blanco.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
LENGTH(expr)
LOCATE LOCATE('d''abcdef')
Devuelve la posición numérica de unacadena de caracteres en otra cadena decaracteres. Si la cadena de caracteres nose encuentra en la cadena en que se estábuscando, la función devuelve un valorde 0.expr1 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena que se va a buscar.expr2 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena que se va a buscar.
LOCATE(expr1, expr2)
Apéndice CFunciones
C-21

Función Ejemplo Descripción Sintaxis
LOCATEN LOCATEN('d''abcdef', 3)
Al igual que LOCATE, devuelve laposición numérica de una cadena decaracteres en otra cadena de caracteres.LOCATEN incluye un argumento deentero que permite especificar unaposición inicial para empezar labúsqueda.expr1 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena que se va a buscar.expr2 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena que se va a buscar.integer es cualquier entero positivo (queno sea cero) que representa la posicióninicial para empezar a buscar la cadenade caracteres.
LOCATEN(expr1, expr2,integer)
LOWER LOWER(Customer_Name)
Pasa a minúsculas una cadena decaracteres.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
LOWER(expr)
OCTET_LENGTH
OCTET_LENGTH('abcdef')
Devuelve el número de bytes de unacadena especificada.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
OCTET_LENGTH(expr)
POSITION POSITION('d','abcdef')
Devuelve la posición numérica destrExpr1 en una expresión de caracteres.Si no se encuentra strExpr1, la funcióndevuelve 0.expr1 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena que se buscará en lacadena de destino.expr2 es cualquier expresión que seevalúa como una cadena de caracteres.Identifica la cadena de destino que se vaa buscar.
POSITION(expr1 INexpr2)
REPEAT REPEAT('abc', 4) Repite una expresión especificada nveces.expr es cualquier expresión que se evalúacomo una cadena de caracteres.integer es cualquier entero positivo querepresenta el número de veces que serepetirá la cadena de caracteres.
REPEAT(expr, integer)
Apéndice CFunciones
C-22

Función Ejemplo Descripción Sintaxis
REPLACE REPLACE('abcd1234', '123', 'zz')
Reemplaza uno o más caracteres de unaexpresión de caracteres especificada poruno o más caracteres.expr1 es cualquier expresión que seevalúa como una cadena de caracteres.Esta es la cadena en la que se sustituiránlos caracteres.expr2 es cualquier expresión que seevalúa como una cadena de caracteres.Esta segunda cadena identifica loscaracteres de la primera cadena que sesustituirán.expr3 es cualquier expresión que seevalúa como una cadena de caracteres.Esta tercera cadena especifica loscaracteres que se sustituirán en laprimera cadena.
REPLACE(expr1, expr2,expr3)
RIGHT SELECTRIGHT('123456',3) FROM table
Devuelve un número especificado decaracteres a la derecha de la cadena.expr es cualquier expresión que se evalúacomo una cadena de caracteres.integer es cualquier entero positivo querepresenta el número de caracteres de laparte derecha de la cadena que se va adevolver.
RIGHT(expr, integer)
SPACE SPACE(2) Inserta espacios en blanco.integer es cualquier entero positivo queindica el número de espacios que se van ainsertar.
SPACE(expr)
SUBSTRING SUBSTRING('abcdef' FROM 2)
Crea una nueva cadena que empieza enun número fijo de caracteres en la cadenaoriginal.expr es cualquier expresión que se evalúacomo una cadena de caracteres.startPos es cualquier entero positivo querepresenta el número de caracteres desdeel inicio de la parte izquierda de lacadena por donde debe empezar elresultado.
SUBSTRING([SourceString] FROM[StartPostition])
Apéndice CFunciones
C-23

Función Ejemplo Descripción Sintaxis
SUBSTRINGN SUBSTRING('abcdef' FROM 2 FOR 3)
Al igual que SUBSTRING, crea una nuevacadena que empieza en un número fijode caracteres en la cadena original.SUBSTRINGN incluye un argumento deentero que permite especificar la longitudde la nueva cadena en número decaracteres.expr es cualquier expresión que se evalúacomo una cadena de caracteres.startPos es cualquier entero positivo querepresenta el número de caracteres desdeel inicio de la parte izquierda de lacadena por donde debe empezar elresultado.
SUBSTRING(expr FROMstartPos FOR length)
TrimBoth Trim(BOTH '_'FROM '_abcdef_')
Elimina los caracteres iniciales y finalesespecificados de una cadena decaracteres.char es un carácter cualquiera. Si omiteesta especificación (y las comillas simplesnecesarias), se utiliza un carácter enblanco como valor por defecto.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
TRIM(BOTH char FROMexpr)
TRIMLEADING TRIM(LEADING '_'FROM '_abcdef')
Elimina los caracteres inicialesespecificados de una cadena decaracteres.char es un carácter cualquiera. Si omiteesta especificación (y las comillas simplesnecesarias), se utiliza un carácter enblanco como valor por defecto.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
TRIM(LEADING charFROM expr)
TRIMTRAILING
TRIM(TRAILING'_' FROM'abcdef_')
Elimina los caracteres finalesespecificados de una cadena decaracteres.char es un carácter cualquiera. Si omiteesta especificación (y las comillas simplesnecesarias), se utiliza un carácter enblanco como valor por defecto.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
TRIM(TRAILING charFROM expr)
UPPER UPPER(Customer_Name)
Pasa a mayúsculas una cadena decaracteres.expr es cualquier expresión que se evalúacomo una cadena de caracteres.
UPPER(expr)
Apéndice CFunciones
C-24

Funciones del sistemaLa función del sistema USER devuelve valores relacionados con la sesión. Por ejemplo, elnombre de usuario con el que se ha conectado.
Función Ejemplo Descripción Sintaxis
DATABASE Devuelve el nombre del área temática ala que se ha conectado.
DATABASE()
USER Devuelve el nombre de usuario para elmodelo semántico al que está conectado.
USER()
Funciones de serie temporalLas funciones de serie temporal son funciones de agregación que se utilizan en lasdimensiones de tiempo.
Los miembros de la dimensión de tiempo deben estar en el nivel de la función o por debajode éste. Por este motivo, deben proyectarse una o varias columnas que permiten identificarde forma exclusiva miembros en un nivel determinado o por debajo de éste en la consulta.
Función Ejemplo Descripción Sintaxis
AGO SELECT Year_ID,AGO(sales, year,1)
Calcula el valor agregado de una medidadesde la hora actual hasta un período detiempo especificado en el pasado. Porejemplo, AGO puede producir ventas paracada mes del trimestre actual y las ventascorrespondientes al trimestre anterior.
AGO(expr, time_level,offset)
PERIODROLLING
SELECT Month_ID,PERIODROLLING(monthly_sales,-1, 1)
Calcula el agregado de una medida a lolargo del período que comienza por xunidades de tiempo y finaliza por yunidades de tiempo a partir de la horaactual. Por ejemplo, PERIODROLLINGpuede calcular las ventas de un períodoque empieza en un trimestre anterior alactual y termina en un trimestreposterior al actual.measure es el nombre de una columna demedidas.x es un entero que especifica eldesplazamiento con respecto al momentoactual.y especifica el número de unidades detiempo sobre las que se calcula lafunción.hierarchy es un argumento opcional queespecifica el nombre de una jerarquía enuna dimensión de tiempo, como yr, mon,day, que desea utilizar para calcular elintervalo de tiempo.
PERIODROLLING(measure, x [,y])
Apéndice CFunciones
C-25

Función Ejemplo Descripción Sintaxis
TODATE SELECT Year_ID,Month_ID, TODATE(sales, year)
Agrega una medida desde el principio deun período de tiempo especificado hastala hora mostrada actualmente. Porejemplo, esta función puede calcular lasventas de Acumulado Anual.expr es una expresión que hacereferencia a una columna de medidacomo mínimo.time_level es el tipo de período de tiempo,como trimestre, mes o año.
TODATE(expr,time_level)
Función FORECAST
Crea un modelo de series temporal de la medida especificada sobre las seriesmediante el suavizado exponencial (ETS), estacional ARIMA o ARIMA. Esta funciónda como resultado una previsión para el conjunto de periodos según se haespecificado en el argumento numPeriods.
Syntax FORECAST(numeric_expr, ([series]), output_column_name, options,[runtime_binded_options])])Donde:
• numeric_expr indica la media de la que realiza la previsión, por ejemplo, los datosde ingresos de los que realizar la previsión.
• series indica el detalle de tiempo empleado para crear un modelo de previsión. Laserie es una lista de una o más columnas de dimensión de tiempo. Si omiteseries, el detalle de tiempo viene determinado por la consulta.
• output_column_name indica los nombres de columna válidos de forecast, low,high y predictionInterval.
• options indica una cadena con una lista de pares de nombre y valor separadospor puntos y comas (;). El valor puede incluir %1 ... %N especificado enruntime_binded_options.
• runtime_binded_options indica una lista separada por comas de columnas yopciones. Los valores de estas columnas y opciones se evalúan y se resuelvendurante el tiempo de ejecución de consultas individuales.
Opciones de la función FORECAST En la siguiente tabla se muestran las opcionesdisponibles que se pueden usar con la función FORECAST.
Nombre de la opción Valores Descripción
numPeriods Entero Número de períodos del querealizar la previsión
predictionInterval De 0 a 100, donde los valoressuperiores especifican una mayorconfianza
Nivel de confianza para lapredicción.
modelType ETSSeasonalArimaARIMA
Modelo que utilizar para laprevisión.
Apéndice CFunciones
C-26
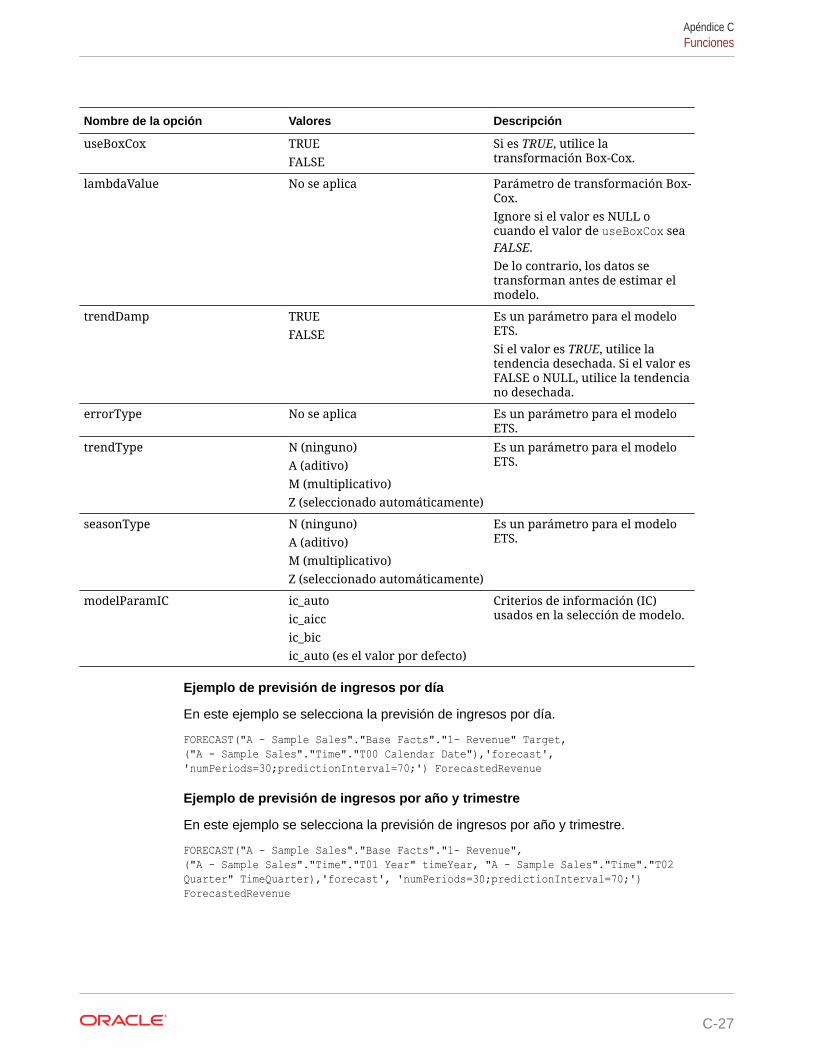
Nombre de la opción Valores Descripción
useBoxCox TRUEFALSE
Si es TRUE, utilice latransformación Box-Cox.
lambdaValue No se aplica Parámetro de transformación Box-Cox.Ignore si el valor es NULL ocuando el valor de useBoxCox seaFALSE.De lo contrario, los datos setransforman antes de estimar elmodelo.
trendDamp TRUEFALSE
Es un parámetro para el modeloETS.Si el valor es TRUE, utilice latendencia desechada. Si el valor esFALSE o NULL, utilice la tendenciano desechada.
errorType No se aplica Es un parámetro para el modeloETS.
trendType N (ninguno)A (aditivo)M (multiplicativo)Z (seleccionado automáticamente)
Es un parámetro para el modeloETS.
seasonType N (ninguno)A (aditivo)M (multiplicativo)Z (seleccionado automáticamente)
Es un parámetro para el modeloETS.
modelParamIC ic_autoic_aiccic_bicic_auto (es el valor por defecto)
Criterios de información (IC)usados en la selección de modelo.
Ejemplo de previsión de ingresos por día
En este ejemplo se selecciona la previsión de ingresos por día.
FORECAST("A - Sample Sales"."Base Facts"."1- Revenue" Target,("A - Sample Sales"."Time"."T00 Calendar Date"),'forecast', 'numPeriods=30;predictionInterval=70;') ForecastedRevenue
Ejemplo de previsión de ingresos por año y trimestre
En este ejemplo se selecciona la previsión de ingresos por año y trimestre.
FORECAST("A - Sample Sales"."Base Facts"."1- Revenue",("A - Sample Sales"."Time"."T01 Year" timeYear, "A - Sample Sales"."Time"."T02 Quarter" TimeQuarter),'forecast', 'numPeriods=30;predictionInterval=70;') ForecastedRevenue
Apéndice CFunciones
C-27

ConstantesPuede usar constantes para incluir fechas y horas específicas en las expresiones.
Entre las constantes disponibles se incluyen Date, Time y Timestamp.
Constante Ejemplo Descripción Sintaxis
DATE DATE[2014-04-09]
Inserta una fecha específica. DATE [yyyy-mm-dd]
TIME TIME [12:00:00] Inserta una hora específica. TIME [hh:mi:ss]TIMESTAMP TIMESTAMP
[2014-04-0912:00:00]
Inserta un registro de hora específico. TIMESTAMP [yyyy-mm-dd hh:mi:ss]
TiposPuede utilizar tipos de dato, como CHAR, INT y NUMERIC en las expresiones.
Por ejemplo, puede utilizar tipos al crear expresiones CAST que cambien el tipo dedato de una expresión o un literal nulo a otro tipo de dato.
VariablesLas variables se utilizan en expresiones.
Puede utilizar una variable en una expresión.
Apéndice CConstantes
C-28




















