
A Hybrid Artificial Immune Genetic Algorithm with Fuzzy Rules for Breast Cancer Diagnosis

Mp
ET
a
ARRAA
KMFAD
1
aMfmcatma[as
Iatmot[d
o
1d
Applied Soft Computing 11 (2011) 1965–1974
Contents lists available at ScienceDirect
Applied Soft Computing
journa l homepage: www.e lsev ier .com/ locate /asoc
ining fuzzy rules using an Artificial Immune System with fuzzyartition learning
dward Mezyk, Olgierd Unold ∗
he Institute of Computer Engineering, Control and Robotics, Wroclaw University of Technology, Wyb. Wyspianskiego 27, 50-370 Wroclaw, Poland
r t i c l e i n f o
rticle history:eceived 4 March 2009eceived in revised form 8 April 2010
a b s t r a c t
The paper introduces accuracy boosting extension to a novel induction of fuzzy rules from raw data usingArtificial Immune System methods. Accuracy boosting relies on fuzzy partition learning. The performance,in terms of classification accuracy, of the proposed approach was compared with traditional classifier
ccepted 21 June 2010vailable online 1 July 2010
eywords:achine learning
uzzy logic
schemes: C4.5, Naïve Bayes, K∗, Meta END, JRip, and Hyper Pipes. The result accuracy of these methodsare significantly lower than accuracy of fuzzy rules obtained by method presented in this study (pairedt-test, P < 0.05).
© 2010 Elsevier B.V. All rights reserved.
rtificial Immune Systemata mining
. Introduction
Fuzzy-based data mining is a modern and very promisingpproach to mine data in an efficient and comprehensible way.oreover, fuzzy logic [34] can improve a classification task by using
uzzy sets to define overlapping class definitions. This kind of dataining algorithms discovers a set of rules of the form “IF (fuzzy
onditions) THEN (class)”, whose interpretation is as follows: IFn example’s attribute values satisfy the fuzzy conditions THENhe example belongs to the class predicted by the rule. The auto-
ated construction of fuzzy classification rules from data has beenpproached by different techniques like, e.g., neuro-fuzzy methods27,33,6], genetic-algorithm based rule selection [13,16,18,28,25],nd fuzzy clustering [23,38] in combination with other methodsuch as fuzzy relations and genetic algorithm optimization.
A quite novel approaches, among others, integrate Artificialmmune Systems (AISs) [12] and Fuzzy Systems to find not onlyccurate, but also linguistic interpretable fuzzy rules that predicthe class of an example. The first AIS-based method for fuzzy rules
ining was proposed in [2]. This approach, called IFRAIS (Inductionf Fuzzy Rules with an Artificial Immune System), uses sequen-ial covering and clonal selection to learn IF-THEN fuzzy rules. In30] the speed of IFRAIS was improved significantly by bufferingiscovered fuzzy rules in a clonal selection. One of the AIS-based
∗ Corresponding author.E-mail addresses: [email protected] (E. Mezyk),
[email protected], [email protected] (O. Unold).
568-4946/$ – see front matter © 2010 Elsevier B.V. All rights reserved.oi:10.1016/j.asoc.2010.06.012
algorithms for mining IF-THEN rules is based on extending the neg-ative selection algorithm with a genetic algorithm [15]. Another oneis mainly focused on the clonal selection and so-called a boostingmechanism to adapt the distribution of training instances in itera-tions [1]. A fuzzy AIS was proposed also in [32], however that workaddresses not the task of classification, but the task of clustering.Lei and Ren-hou [24] took a somewhat similar approach to IFRAISfor mining fuzzy rules. In this model each antibody represents afuzzy classification rule, and the algorithm evolves a population ofantibodies using the clonal selection and hypermutation. Despiteapparent similarities, there are distinct differences between [2] and[24] – among others – in the structure of the IF-THEN rule, the fuzzyreasoning, the number of linguistic terms, and the feature selection.Yet another fuzzy AIS uses resource competition, clonal selection,affinity maturation, and memory cell formation to mine IF-THENrules [35].
Note that approaches [2,17,24,35] use a constant, pre-established number of linguistic terms for an attribute. Since thenumber of fuzzy sets can profoundly affect the performance of fuzzymodels, the determination of the right number of intervals for agiven attribute is an important problem in fuzzy data mining [3].The aim of this work is to present a new approach to Inductionof Fuzzy Rules with an Artificial Immune System. The investigatedmethod seeks to boost an accuracy of a standard IFRAIS approach byexploring the use of fuzzy partition learning. To find the optimum
fuzzy partitions directly from data, it employs a clonal selectionalgorithm.This paper is organized as follows. Section 2 describes meth-ods used in the research, reviews related work and exhibits thecontribution of the paper. Section 3 gives details of the proposed
1966 E. Mezyk, O. Unold / Applied Soft Computing 11 (2011) 1965–1974
at
2
2
ce
wurtaovva(tl
acoie
((
�moao(
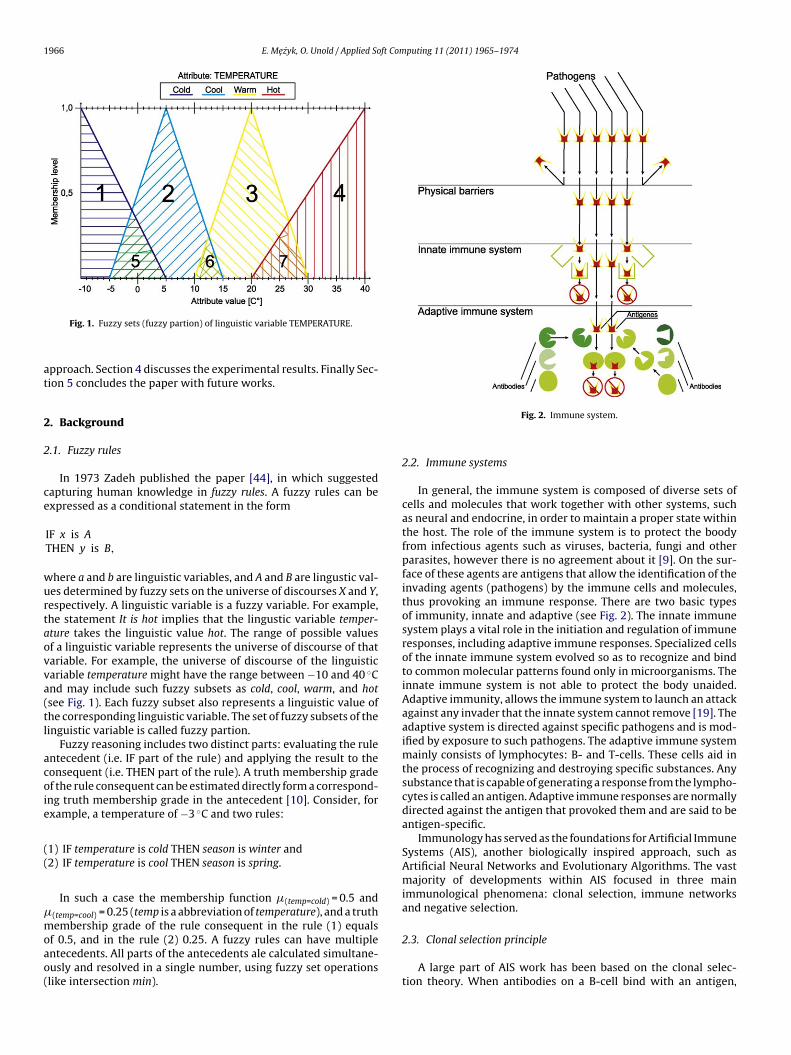
Fig. 1. Fuzzy sets (fuzzy partion) of linguistic variable TEMPERATURE.
pproach. Section 4 discusses the experimental results. Finally Sec-ion 5 concludes the paper with future works.
. Background
.1. Fuzzy rules
In 1973 Zadeh published the paper [44], in which suggestedapturing human knowledge in fuzzy rules. A fuzzy rules can bexpressed as a conditional statement in the form
IF x is ATHEN y is B,
here a and b are linguistic variables, and A and B are lingustic val-es determined by fuzzy sets on the universe of discourses X and Y,espectively. A linguistic variable is a fuzzy variable. For example,he statement It is hot implies that the lingustic variable temper-ture takes the linguistic value hot. The range of possible valuesf a linguistic variable represents the universe of discourse of thatariable. For example, the universe of discourse of the linguisticariable temperature might have the range between −10 and 40 ◦Cnd may include such fuzzy subsets as cold, cool, warm, and hotsee Fig. 1). Each fuzzy subset also represents a linguistic value ofhe corresponding linguistic variable. The set of fuzzy subsets of theinguistic variable is called fuzzy partion.
Fuzzy reasoning includes two distinct parts: evaluating the rulentecedent (i.e. IF part of the rule) and applying the result to theonsequent (i.e. THEN part of the rule). A truth membership gradef the rule consequent can be estimated directly form a correspond-ng truth membership grade in the antecedent [10]. Consider, forxample, a temperature of −3 ◦C and two rules:
1) IF temperature is cold THEN season is winter and2) IF temperature is cool THEN season is spring.
In such a case the membership function �(temp=cold) = 0.5 and(temp=cool) = 0.25 (temp is a abbreviation of temperature), and a truthembership grade of the rule consequent in the rule (1) equals
f 0.5, and in the rule (2) 0.25. A fuzzy rules can have multiplentecedents. All parts of the antecedents ale calculated simultane-usly and resolved in a single number, using fuzzy set operationslike intersection min).
Fig. 2. Immune system.
2.2. Immune systems
In general, the immune system is composed of diverse sets ofcells and molecules that work together with other systems, suchas neural and endocrine, in order to maintain a proper state withinthe host. The role of the immune system is to protect the boodyfrom infectious agents such as viruses, bacteria, fungi and otherparasites, however there is no agreement about it [9]. On the sur-face of these agents are antigens that allow the identification of theinvading agents (pathogens) by the immune cells and molecules,thus provoking an immune response. There are two basic typesof immunity, innate and adaptive (see Fig. 2). The innate immunesystem plays a vital role in the initiation and regulation of immuneresponses, including adaptive immune responses. Specialized cellsof the innate immune system evolved so as to recognize and bindto common molecular patterns found only in microorganisms. Theinnate immune system is not able to protect the body unaided.Adaptive immunity, allows the immune system to launch an attackagainst any invader that the innate system cannot remove [19]. Theadaptive system is directed against specific pathogens and is mod-ified by exposure to such pathogens. The adaptive immune systemmainly consists of lymphocytes: B- and T-cells. These cells aid inthe process of recognizing and destroying specific substances. Anysubstance that is capable of generating a response from the lympho-cytes is called an antigen. Adaptive immune responses are normallydirected against the antigen that provoked them and are said to beantigen-specific.
Immunology has served as the foundations for Artificial ImmuneSystems (AIS), another biologically inspired approach, such asArtificial Neural Networks and Evolutionary Algorithms. The vastmajority of developments within AIS focused in three mainimmunological phenomena: clonal selection, immune networksand negative selection.
2.3. Clonal selection principle
A large part of AIS work has been based on the clonal selec-tion theory. When antibodies on a B-cell bind with an antigen,

E. Mezyk, O. Unold / Applied Soft Com
tAtbtstaematoaofcee
tiEtbpaasg
bbaAWee
consists of fuzzy conditions and class value, antibody comprises
Fig. 3. Clonal selection.
he B-cell becomes activated and begins to proliferate (see Fig. 3).ccording to the clonal selection principle [4], it is important
o note that only those B-cells will proliferate, which are capa-le of recognizing an antigenic stimulus. Next, exact copy ofhe parent B-cell are produced (B-cell clones), that then undergoomatic hypermutation and produce antibodies that are specifico the invading antigen. Clonal selection operates on both T-cellsnd B-cells. The B-cells, in addition to proliferating or differ-ntiating into plasma cells, can differentiate into long-lived Bemory cells. Memory cells circulate through the blood, lymph
nd tissues. After recovering from an infection, the concentra-ion of antibodies against the infectious agent gradually declinesver a time. The initial exposure to an antigen that stimulatesn adaptive immune response is handled by a small numberf B-cells. Storing some high affinity antibody producing cellsrom the first infection, so as to form a large initial specific B-ell clones for subsequent encounters, considerably enhances theffectiveness and speed of the immune response to secondaryncounters.
Clonal selection algorithms evolve candidate solutions inerms of optimization, or pattern detectors in terms of learn-ng. Evolving consists of a cloning, mutation and selection phase.ach of these algorithms have populations of B-cells (solu-ion to be searched) that match against antigens (function toe optimized). These B-cells then undergo cloning (usually inroportion to the strength of the match) and mutation (usu-lly, inversely proportional to the strength of the match). Highffinity B-cells are then selected to remain in the population,ome low affinity cells are removed and new random cells areenerated.
Great efforts are made to handle with optimization problemsy clonal selection applications, such as the work on CLONALGy de Castro and Von Zuben [5], the work by Cutello et al. [11]nd the work by Garrett [14] on parameter free clonal selection.
s to applications dedicated to solve learning problems, AIRS byatkins [39,41], a distributed version of CLONALG by Watkinst al. [40], DynamicCS by Kim and Bentley [22], IFRAIS by Alvest al. [2], and improved versions of IFRAIS by Mezyk and Unold
puting 11 (2011) 1965–1974 1967
[30,31,21] are to be noted. In [30,31] learning time of IFRAISwas improved significantly by rules buffering in clonal selectionalgorithm, and removing the randomness in generating the ini-tial population step in clonal selection appropriately. In [21] thepreliminary and sketch results of fuzzy partition learning wereprovided.
There are three main contributions of this paper. The principalcontribution is the detailed description of the partition learningmethod based on a clonal selection. The second contribution is thor-oughly performed the set of experiments with a statistical analysis.The third major contribution of this paper is a complexity analysisof the proposed algorithm, including exhausted experiments prov-ing linear dependency between the number of linguistic terms anda performance time.
3. Methods
3.1. IFRAIS
Data preparation for learning in IFRAIS consists of the followingsteps: (1) create a fuzzy variable for each attribute in data set; (2)create class list for actual data set; (3) and compute informationgain for each attribute in data set.
IFRAIS uses a sequential covering as a main learning algorithm(see Listing 1). In the first step a set of rules is initialized as anempty set. Next, for each class to be predicted the algorithm ini-tializes the training set with all training examples and iterativelycalls clonal selection procedure with the parameters: the currenttraining set and the class to be predicted. The clonal selection pro-cedure returns a discovered rule and next the learning algorithmadds the rule to the rule set and removes from the current trainingset the examples that have been correctly covered by the evolvedrule.
Clonal selection algorithm is used to induct rule with the bestfitness from training set (see Listing 2). Basic elements of thismethod are antigens and antibodies which refers directly to bio-logical immune systems. Antigen is an example from data set andantibody is a fuzzy rule. Similarly to fuzzy rule structure, which
genes and informational gene. Number of genes in antibody is equalto number of attributes in data set. Each gene consists of a fuzzyrule and an activation flag that indicates whether fuzzy conditionis active or inactive.

1 ft Com
pilt(a
F
w
Faf
A
wactcc(Iatrohti
968 E. Mezyk, O. Unold / Applied So
In the first step the algorithm generates randomly antibodiesopulation with informational gene equals to class value c passed
n algorithm parameter. Next each antibody from generated popu-ation is pruned. Rule pruning has a twofold motivation: reducinghe overfitting of the rules to the data and improving the simplicitycomprehensibility) of the rules [42]. Fitness of the rule is computedccording to the formula
ITNESS(rule) = TP
TP + FN· TN
TN + FP(1)
here
TP – is number of examples satisfying the rule and having the sameclass as predicted by the rule;FN – is the number of examples that do not satisfy the rule buthave the class predicted by the rule;TN – is the number of examples that do not satisfy the rule and donot have the class predicted by the rule;FP – is the number of examples that satisfy the rule but do not havethe class predicted by the rule.
Since the rules are fuzzy, the computation of the TP, FN, TN andP involves measuring the degree of affinity between the examplend the rule. This is computed by applying the standard aggregationuzzy operator min
FFINITY(rule, example) = mincondCounti=1 (�i(atti)) (2)
here �i(atti) denotes the degree to which the correspondingttribute value atti of the example belongs to the fuzzy set asso-iated with the ith rule condition, and condCount is the number ofhe rule antecedent conditions. The degree of membership is notalculated for an inactive rule condition, and if the ith conditionontains a negation operator, the membership function equals to1 − �i(atti)) (complement). An example satisfies a rule if AFFIN-TY(rule, example) > L, where L is an activation threshold. Next,ntibody to be cloned is selected by tournament selection fromhe antibodies population. For each antibody to be cloned the algo-
ithm produces x clones. The value of x is proportional to the fitnessf the antibody. Next, each of the clones undergoes a process ofypermutation, where the mutation rate is inversely proportionalo the clone’s fitness. Once a clone has undergone hypermutation,ts corresponding rule antecedent is pruned by using the previouslyputing 11 (2011) 1965–1974
explained rule pruning procedure. Finally, the fitness of the cloneis recomputed, using the current training set. In the last step theT-worst fitness antibodies in the current population are replacedby the T best-fitness clones out of all clones produced by the clonalselection procedure. Finally, the clonal selection procedure returnsthe best evolved rule, which will then be added to the set of discov-ered rules by the sequential covering. More details of the IFRAIS isto be found in [2].
3.2. IFRAIS with fuzzy partition learning
IFRAIS, as an Artificial Immune System evolves a population ofantibodies representing the IF part of a fuzzy rule, whereas eachantigen represents an example. As was stated, each rule antecedentconsists of a conjunction of rule condition. In IFRAIS approach threeand only three linguistic terms (low, medium, high) are associatedwith each continuous attribute. Each linguistic term is representedby the triangular membership functions. It seems to be purposefulto infer a fuzzy partition for each continuous attribute over the dataset instead of stiff, and the same for different attributes partition-ing. There exist various methods to learn a fuzzy partions over aset of data [29]. We consider using a clonal selection algorithm toautomatic infer partition for each attribute, both crisp and contin-uous one. In such an approach a population of antibodies representa set of partitions, and an antigen is a whole set of data.
3.2.1. RepresentationEach partition is represented by two crisp tables: a size table
S and a range table R. S is one-dimensional table S = {s1, s2, . . .,ssetsCount}, where setsCount is the number of fuzzy sets the parti-tion is consisted of (the number of linguistics terms). setCount isdrawn from the range [3, 12] during inference. si is a size of a fuzzyset and is expressed in so-called “division points” pv. For a crispattribute pv corresponds to one attribute value. For an attribute tobe fuzzified pv is computed as follows
pv = maxValue − minValue, (3)
apc
where maxValue is a maximal attribute value, minValue is a minimalattribute value, and apc = setsCount · pc defines the number of pv-points allocated to the attribute. pc is an algorithm parameter setto 10, and pc is interpreted as a number of pv-points assigned to one
E. Mezyk, O. Unold / Applied Soft Computing 11 (2011) 1965–1974 1969
y part
ftbfaa
{rtrl
cwprscactt[bri
including one point
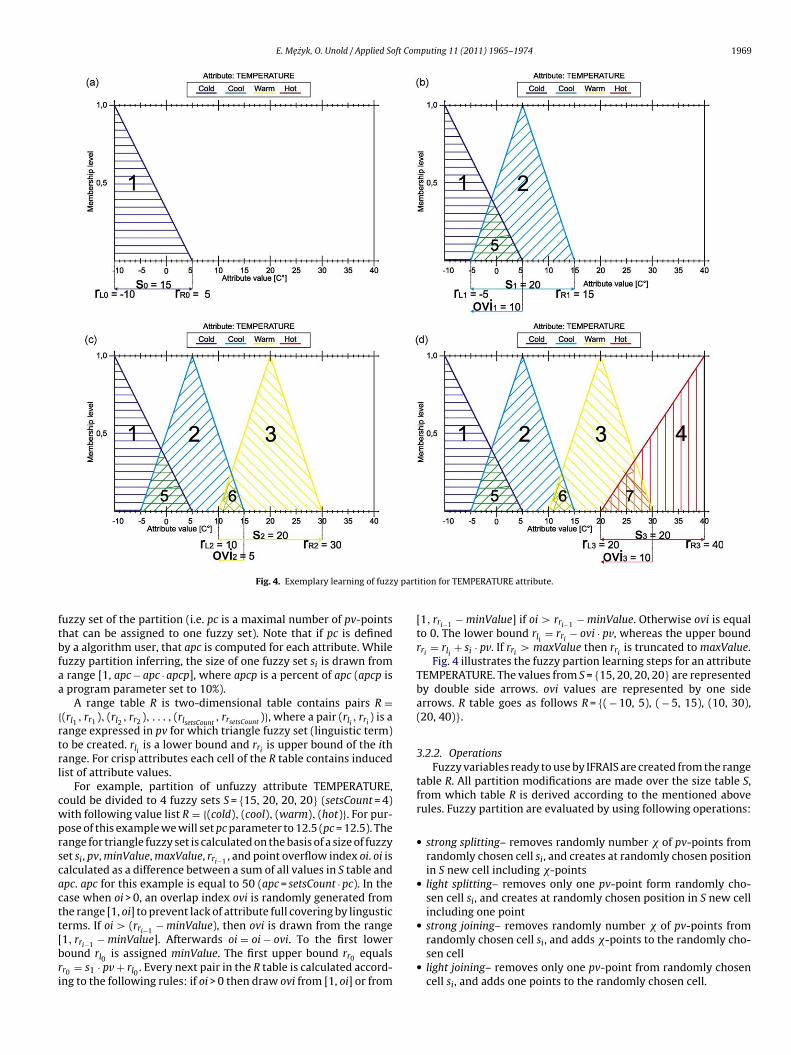
Fig. 4. Exemplary learning of fuzz
uzzy set of the partition (i.e. pc is a maximal number of pv-pointshat can be assigned to one fuzzy set). Note that if pc is definedy a algorithm user, that apc is computed for each attribute. Whileuzzy partition inferring, the size of one fuzzy set si is drawn fromrange [1, apc − apc · apcp], where apcp is a percent of apc (apcp isprogram parameter set to 10%).
A range table R is two-dimensional table contains pairs R =(rl1 , rr1 ), (rl2 , rr2 ), . . . , (rlsetsCount
, rrsetsCount )}, where a pair (rli, rri
) is aange expressed in pv for which triangle fuzzy set (linguistic term)o be created. rli
is a lower bound and rriis upper bound of the ith
ange. For crisp attributes each cell of the R table contains inducedist of attribute values.
For example, partition of unfuzzy attribute TEMPERATURE,ould be divided to 4 fuzzy sets S = {15, 20, 20, 20} (setsCount = 4)ith following value list R = {(cold), (cool), (warm), (hot)}. For pur-ose of this example we will set pc parameter to 12.5 (pc = 12.5). Theange for triangle fuzzy set is calculated on the basis of a size of fuzzyet si, pv, minValue, maxValue, rri−1 , and point overflow index oi. oi isalculated as a difference between a sum of all values in S table andpc. apc for this example is equal to 50 (apc = setsCount · pc). In thease when oi > 0, an overlap index ovi is randomly generated fromhe range [1, oi] to prevent lack of attribute full covering by lingustic
erms. If oi > (rri−1 − minValue), then ovi is drawn from the range1, rri−1 − minValue]. Afterwards oi = oi − ovi. To the first loweround rl0 is assigned minValue. The first upper bound rr0 equalsr0 = s1 · pv + rl0 . Every next pair in the R table is calculated accord-ng to the following rules: if oi > 0 then draw ovi from [1, oi] or fromition for TEMPERATURE attribute.
[1, rri−1 − minValue] if oi > rri−1 − minValue. Otherwise ovi is equalto 0. The lower bound rli
= rri− ovi · pv, whereas the upper bound
rri= rli
+ si · pv. If rri> maxValue then rri
is truncated to maxValue.Fig. 4 illustrates the fuzzy partion learning steps for an attribute
TEMPERATURE. The values from S = {15, 20, 20, 20} are representedby double side arrows. ovi values are represented by one sidearrows. R table goes as follows R = {( − 10, 5), ( − 5, 15), (10, 30),(20, 40)}.
3.2.2. OperationsFuzzy variables ready to use by IFRAIS are created from the range
table R. All partition modifications are made over the size table S,from which table R is derived according to the mentioned aboverules. Fuzzy partition are evaluated by using following operations:
• strong splitting– removes randomly number � of pv-points fromrandomly chosen cell si, and creates at randomly chosen positionin S new cell including �-points
• light splitting– removes only one pv-point form randomly cho-sen cell si, and creates at randomly chosen position in S new cell
• strong joining– removes randomly number � of pv-points fromrandomly chosen cell si, and adds �-points to the randomly cho-sen cell
• light joining– removes only one pv-point from randomly chosencell si, and adds one points to the randomly chosen cell.
1970 E. Mezyk, O. Unold / Applied Soft Computing 11 (2011) 1965–1974
zy partitions for BUPA.
3
(mmacatm
m
wtf
Table 1Data sets and number of rows, attributes, continuous attributes, and classes.
Data set #Rows #Attrib. #Cont. #Class.
Bupa 345 6 6 2Crx 653 15 6 2
In order to assess the improvement in prediction accuracy thatcan be achieved using our approach, both IFRAIS and an improvedIFRAIS were applied to 6 public domain data sets available from
Fig. 5. Initial fuz
.2.3. InferringFuzzy partition inferring is based on clonal selection algorithm
see Listing 3). In this algorithm it is worth underlining a cloneutation which undergoes for all clones in a population. Whileutating, only the sizes of fuzzy sets (table S) for chosen attribute
re generated according to the mentioned above rules, but withouthanging the number of linguistic terms (the size of table S). Afternew partition generation, the operations (strong and light split-
ing, strong and light joining) are fired, each with the probabilityuteRatio
uteRatio = min + (max − min) · (1 − f + No)2
(4)
here min and max are minimal and maximal probability respec-ively (algorithm parameters), No is a number taken at randomrom [0, 1], and f is a normalized clone fitness before mutation.
Hepatitis 80 19 6 2Ljubljana 277 9 9 2Wisconsin 683 9 9 2Votes 232 16 0 2
4. Experimental results
4.1. Datasets
E. Mezyk, O. Unold / Applied Soft Computing 11 (2011) 1965–1974 1971
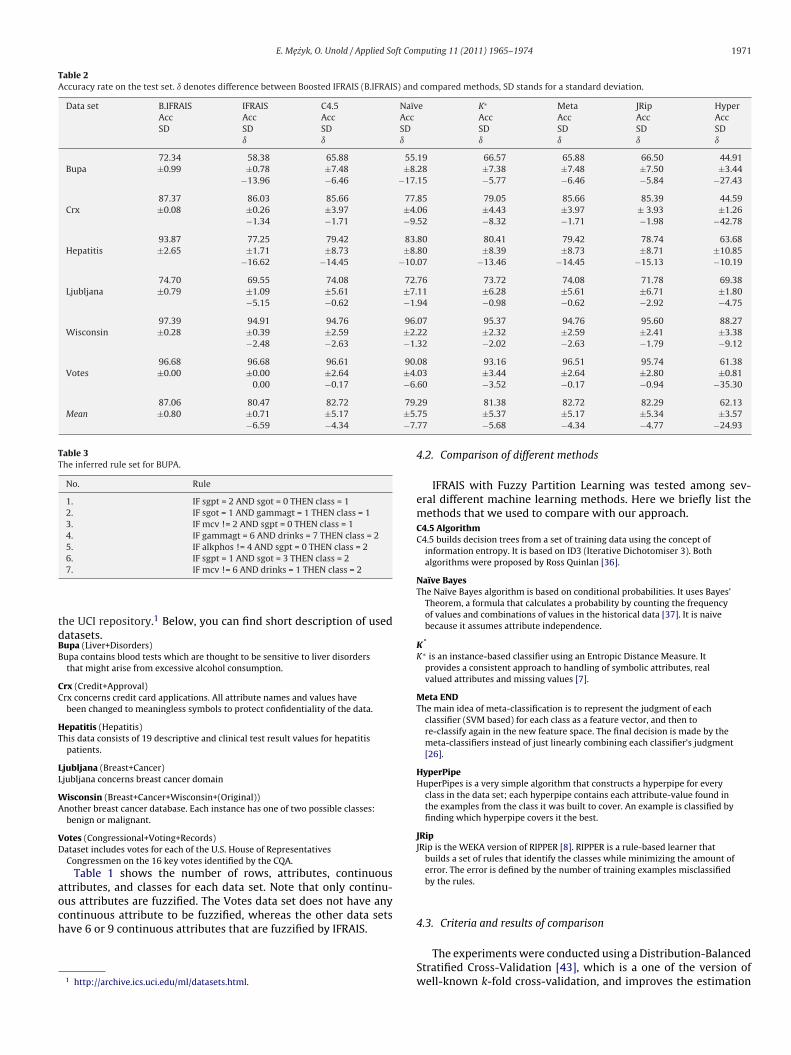
Table 2Accuracy rate on the test set. ı denotes difference between Boosted IFRAIS (B.IFRAIS) and compared methods, SD stands for a standard deviation.
Data set B.IFRAIS IFRAIS C4.5 Naïve K∗ Meta JRip HyperAcc Acc Acc Acc Acc Acc Acc AccSD SD SD SD SD SD SD SD
ı ı ı ı ı ı ı
72.34 58.38 65.88 55.19 66.57 65.88 66.50 44.91Bupa ±0.99 ±0.78 ±7.48 ±8.28 ±7.38 ±7.48 ±7.50 ±3.44
−13.96 −6.46 −17.15 −5.77 −6.46 −5.84 −27.43
87.37 86.03 85.66 77.85 79.05 85.66 85.39 44.59Crx ±0.08 ±0.26 ±3.97 ±4.06 ±4.43 ±3.97 ± 3.93 ±1.26
−1.34 −1.71 −9.52 −8.32 −1.71 −1.98 −42.78
93.87 77.25 79.42 83.80 80.41 79.42 78.74 63.68Hepatitis ±2.65 ±1.71 ±8.73 ±8.80 ±8.39 ±8.73 ±8.71 ±10.85
−16.62 −14.45 −10.07 −13.46 −14.45 −15.13 −10.19
74.70 69.55 74.08 72.76 73.72 74.08 71.78 69.38Ljubljana ±0.79 ±1.09 ±5.61 ±7.11 ±6.28 ±5.61 ±6.71 ±1.80
−5.15 −0.62 −1.94 −0.98 −0.62 −2.92 −4.75
97.39 94.91 94.76 96.07 95.37 94.76 95.60 88.27Wisconsin ±0.28 ±0.39 ±2.59 ±2.22 ±2.32 ±2.59 ±2.41 ±3.38
−2.48 −2.63 −1.32 −2.02 −2.63 −1.79 −9.12
96.68 96.68 96.61 90.08 93.16 96.51 95.74 61.38Votes ±0.00 ±0.00 ±2.64 ±4.03 ±3.44 ±2.64 ±2.80 ±0.81
0.00 −0.17 −6.
87.06 80.47 82.72 79.Mean ±0.80 ±0.71 ±5.17 ±5.
−6.59 −4.34 −7.
Table 3The inferred rule set for BUPA.
No. Rule
1. IF sgpt = 2 AND sgot = 0 THEN class = 12. IF sgot = 1 AND gammagt = 1 THEN class = 13. IF mcv != 2 AND sgpt = 0 THEN class = 14. IF gammagt = 6 AND drinks = 7 THEN class = 25. IF alkphos != 4 AND sgpt = 0 THEN class = 2
tdBB
CC
HT
LL
WA
VD
aoch
6. IF sgpt = 1 AND sgot = 3 THEN class = 27. IF mcv != 6 AND drinks = 1 THEN class = 2
he UCI repository.1 Below, you can find short description of usedatasets.upa (Liver+Disorders)upa contains blood tests which are thought to be sensitive to liver disordersthat might arise from excessive alcohol consumption.
rx (Credit+Approval)rx concerns credit card applications. All attribute names and values havebeen changed to meaningless symbols to protect confidentiality of the data.
epatitis (Hepatitis)his data consists of 19 descriptive and clinical test result values for hepatitispatients.
jubljana (Breast+Cancer)jubljana concerns breast cancer domain
isconsin (Breast+Cancer+Wisconsin+(Original))nother breast cancer database. Each instance has one of two possible classes:benign or malignant.
otes (Congressional+Voting+Records)ataset includes votes for each of the U.S. House of RepresentativesCongressmen on the 16 key votes identified by the CQA.
Table 1 shows the number of rows, attributes, continuousttributes, and classes for each data set. Note that only continu-
us attributes are fuzzified. The Votes data set does not have anyontinuous attribute to be fuzzified, whereas the other data setsave 6 or 9 continuous attributes that are fuzzified by IFRAIS.1 http://archive.ics.uci.edu/ml/datasets.html.
60 −3.52 −0.17 −0.94 −35.30
29 81.38 82.72 82.29 62.1375 ±5.37 ±5.17 ±5.34 ±3.5777 −5.68 −4.34 −4.77 −24.93
4.2. Comparison of different methods
IFRAIS with Fuzzy Partition Learning was tested among sev-eral different machine learning methods. Here we briefly list themethods that we used to compare with our approach.C4.5 AlgorithmC4.5 builds decision trees from a set of training data using the concept of
information entropy. It is based on ID3 (Iterative Dichotomiser 3). Bothalgorithms were proposed by Ross Quinlan [36].
Naïve BayesThe Naïve Bayes algorithm is based on conditional probabilities. It uses Bayes’
Theorem, a formula that calculates a probability by counting the frequencyof values and combinations of values in the historical data [37]. It is naivebecause it assumes attribute independence.
K *
K∗ is an instance-based classifier using an Entropic Distance Measure. Itprovides a consistent approach to handling of symbolic attributes, realvalued attributes and missing values [7].
Meta ENDThe main idea of meta-classification is to represent the judgment of each
classifier (SVM based) for each class as a feature vector, and then tore-classify again in the new feature space. The final decision is made by themeta-classifiers instead of just linearly combining each classifier’s judgment[26].
HyperPipeHuperPipes is a very simple algorithm that constructs a hyperpipe for every
class in the data set; each hyperpipe contains each attribute-value found inthe examples from the class it was built to cover. An example is classified byfinding which hyperpipe covers it the best.
JRipJRip is the WEKA version of RIPPER [8]. RIPPER is a rule-based learner that
builds a set of rules that identify the classes while minimizing the amount oferror. The error is defined by the number of training examples misclassifiedby the rules.
4.3. Criteria and results of comparison
The experiments were conducted using a Distribution-BalancedStratified Cross-Validation [43], which is a one of the version ofwell-known k-fold cross-validation, and improves the estimation

1972 E. Mezyk, O. Unold / Applied Soft Computing 11 (2011) 1965–1974
zzy pa
qt
fp
s
wIIrwb(oadbod
m
Fig. 6. Inferred fu
uality by providing balanced intraclass distributions when parti-ioning a data set into multiple folds.
All experiments with IFRAIS were repeated 50-times using 5-old cross-validation. The statistical analysis was performed byaired t-test.
An example of initial fuzzy partions for the BUPA database ishown in the Fig. 5.
Table 2 shows for each data set the average accuracy rateith standard deviation (Acc) and difference between Boosted
FRAIS and each compared algorithm (ı). As shown in Table 2 theFRAIS improved by Partition Learning Algorithm obtained betteresults than any other algorithm presented in the table. Best resultsere achieved for two sets, Bupa and Hepatitis, where difference
etween Boosted IFRAIS and other algorithms is oscillating in range5–30%(!)). For example, the accuracy obtained by C4.5 algorithmn Hepatitis data set is 77.25% and the accuracy for the same datasetchieved by Boosted IFRAIS is 93.87% (16% better). For the otherata sets the accuracy of presented in this paper approach is also
etter, only for seven cases the accuracy is not so significant as forthers, below 1% of difference. All this cases appear only in twoatasets, Ljubljana and Votes.The statistical paired t-tests were performed on the comparedethods. IFRAIS with Fuzzy Partition Learning significantly outper-
Fig. 7. Influence of the number of linguistic terms in a partition on the computat
rtitions for BUPA.
forms all of tested machine learning methods as well as a standardIFRAIS (P < 0.05).
Table 3 contains an exemplary set of the inferred rules by IFRAISwith Partition Learning algorithm for BUPA data set (72.34 ± 0.99 ofan accuracy). Fig. 6 shows the inferred and optimized partions forthe attributes of BUPA data set. The unused terms were removed.Below, you can find a definition of the attributes:mcv – mean corpuscular volume,alkphos – alkaline phosphotase,sgpt – alamine aminotransferase,sgot – aspartate aminotransferase,gammagt – gamma-glutamyl transpeptidase,drinks – number of half-pint equivalents of alcoholic beverages drunk per day,class – field used to split data into two sets.
It is not hard to observe that the inferred rules use all theattributes of BUPA data set. To the most influential attributes inthis data set belong sgpt and sgot: sgpt is used 4 times, sgot 3 times.
4.4. Analysis of the algorithm
Complexity of an algorithm refers to the worst-case amount oftime and memory space required during execution [20]. Deter-mining the performance parameters of a computer program –especially memory space – is not a trivial task and depends on a
ion time and the performance: BUPA, HEPATITIS, and LJUBLJANA data sets.

ft Com
namsitm(Tpl
ofatoLelcctrll
Nadta
5
auprop
RtifiafuWapp
C
A
a
[
[
[
[
[
[
[
[
[
[
[[
[
[
[
[
[
[
[
E. Mezyk, O. Unold / Applied So
umber of factors, such as data representation and/or the computerrchitecture being used. Instead of dealing with hard to estimateemory requirements, we use parameters that characterize input
ize of the algorithm, the number of clones, and the number ofterations. Analysing the algorithm of IFRAIS improved by Parti-ion Learning Algorithm (Listening 3), one can easily notice, that
uch nested instruction is COMPUTE-FITNESS(K, training data set)step 14), which is in fact invoking a standard IFRAIS method.his instruction is repeated number of generations· size of clonesopulation– times. This is an overhead time involved in a partitionearning.
An interesting question arises when we ask what is the effectf using more than three linguistic terms on the time and the per-ormance. Note that a standard IFRAIS uses only 3 linguistic terms,nd no one more. In the proposed approach the number of linguisticerms for each attribute can vary between 3-12. The computationf a fitness of each clone from a population of clones (see step 16 inistening 2) involves measuring the degree of affinity between thexample and the rule. In order to calculate affinity, the algorithmooks through all fuzzy sets of all attributes in the rule antecedentondition. The conclusion is the more linguistic terms, the moreomputation time is required. The experimental analysis confirmshis corollary. The results of the experiments show that, the algo-ithm has running times that vary linearly with the number ofinguistic terms (see Fig. 7). What is interesting, the number ofinguistic terms does not influence the performance.
As to input size, each data set consists of M-rows containing-attributes. Note that due to rule pruning in a clonal selectionlgorithm (see Listing 2), the number of attributes is reduced andoes not exceed 4. The computation time required to process allhe elements of a data set is O(k · M), where k is a constant. That isfeature both of IFRAIS and B.IFRAIS.
. Conclusion
The accuracy boosting extension was introduced to the IFRAISlgorithm – an AIS-based method for fuzzy rules mining. Boostingses the fuzzy partion learning based on the clonal selection. Theartition inferring improves significantly effectiveness of an algo-ithm. Although the proposed improvements increase the accuracyf the whole algorithm, it is to be noted that the learning of fuzzyartition is additional time-consuming procedure.
It seems to be still possible to improve the Induction of Fuzzyules with Artificial Immune Systems, and not only consideringhe effectiveness of the induced fuzzy rules but also time of work-ng. These two goals could be achieved mostly by modifying thetness function to reinforce the fitness of high-accuracy rules,s in [1]. We also consider changing the triangular membershipunctions to various more sophisticated functions and manip-lating all system parameters to obtain higher quality results.e have performed preliminary experiments, in which speed
nd accuracy boosting IFRAIS with modified fitness function andarameters is trained on well known data sets. The results are veryromising.
onflict of interest
No conflict of interest.
cknowledgment
The authors would like to thank Dr. Robert Alves for makingvailable to them his source code of IFRAIS.
[
[
[
puting 11 (2011) 1965–1974 1973
References
[1] B. Alatas, E. Akin, Mining fuzzy classification rules using an artificial immunesystem with boosting, in: J. Eder (Ed.), ADBIS 2005, LNCS, vol. 3631, Springer-Verlag, Berlin Heidelberg, 2005, pp. 283–293.
[2] R.T. Alves, M.R. Delgado, H.S. Lopes, A.A. Freitas, An artificial immune systemfor fuzzy-rule induction in data mining, in: X. Yao (Ed.), Parallel Problem Solv-ing from Nature—PPSN VIII, LNCS, vol. 3242, Springer, Heidelberg, 2004, pp.1011–1020.
[3] W.-H. Au, K.C.C. Chan, A.K.C. Wong, A fuzzy approach to partioning contin-uous attributes for classification, IEEE Transactions on Knowledge and DataEngineering 18 (5) (2006) 715–719.
[4] F. Burnet, The Clonal Selection Theory of Acquired Immunity, Cambridge Uni-versity Press, Cambridge, 1959.
[5] L.N. de Castro, F.J. Von Zuben, Learning and optimization using the clonal selec-tion principle, IEEE Transactions on Evolutionary Computation 6 (3) (2002)239–251.
[6] D. Chakraborty, N.R. Pal, A neuro-fuzzy scheme for simultaneous feature selec-tion and fuzzy rule-based classification, IEEE Transactions on Neural Networks15 (1) (2004) 110–123.
[7] J.G. Cleary, L.E. Trigg, K*: an instance-based learner using an entropic distancemeasure, in: Proceedings of the 12th International Conference on MachineLearning, 1995, pp. 108–114.
[8] W.W. Cohen, Fast effective rule induction, in: Machine Learning: Proceedingsof the Twelfth International Conference’ (ML95), 1995.
[9] I.R. Cohen, Tending Adam’s Garden: Evolving the Cognitive Immune Self, Else-vier Academic Press, 2000.
10] E. Cox, The Fuzzy Systems Handbook: A Practitioner’s Guide to Building, Using,and Maintaining Fuzzy Systems, Academic Press, Cambridge, 1994.
11] V. Cutello, G. Nicosia, M. Parvone, Exploring the capability of immune algo-rithms: a characterization of hypermutation operators, in: LNCS, vol. 3239,Springer, 2004, pp. 263–276.
12] D. Dasgupta (Ed.), Artificial Immune Systems and their Applications, Springer-Verlag, Berlin, Heidelberg, Germany, 1999.
13] A. Fernández, M.J. del Jesus, F. Herrera, Hierarchical fuzzy rule based classifica-tion systemswith genetic rule selection for imbalanced data-sets, InternationalJournal of Approximate Reasoning 50 (3) (2008) 561–577.
14] S. Garrett, Parameter-free, adaptive clonal selection, in: Congress on Evolu-tionary Computation CEC 2004, vol. 1, Dept. of Comput. Sci., Wales Univ.,Aberystwyth, UK, 2004, pp. 1052–1058.
15] F.A. Gonzales, D. Dasgupta, An immunogenetic technique to detect anomaliesin network traffic, in: Proceedings of Genetic and Evolutionary Computation,Morgan Kaufmann, San Mateo, 2002, pp. 1081–1088.
16] F. Hoffmann, B. Baesensb, C. Muesb, T. Van Gesteld, J. Vanthienen, Inferringdescriptive and approximate fuzzy rules for credit scoring using evolutionaryalgorithms, European Journal of Operational Research 177 (1) (2007) 540–555.
17] Y.-C. Hua, R.-S. Chena, G-H. Tzengb, Discovering fuzzy association rules usingfuzzy partition methods, Knowledge-Based Systems 16 (2003) 137–147.
18] H. Ishibuchi, Y. Nojima, Analysis of interpretability-accuracy tradeoff of fuzzysystems by multiobjective fuzzy genetics-based machine learning, Interna-tional Journal of Approximate Reasoning 44 (1) (2007) 4–31.
19] C.A. Janeway, P. Travers Jr., Immunobiology: The Immune System in Health andDisease, 3rd ed., Garland Publishing, New York, 1997.
20] R. Johnsonbaugh, Discrete Mathematics, 4th ed., Prentice Hall, 1997.21] A. Kalina, E. Mezyk, O. Unold, Accuracy boosting induction of fuzzy rules with
artificial immune systems, in: Proceedings of the International Multiconferenceon Computer Science and Information Technology, Wisla, Poland, 2008, pp.155–159.
22] J. Kim, P.J. Bentley, A model of gene library evolution in the dynamic clonalselection algorithm, in: Timmis, J., Bentley, P. (Eds.). Proceedings of the 1stInternational Conference on Artificial Immune Systems ICARIS, University ofKent at Canterbury, University of Kent at Canterbury Printing Unit, 2002, pp.182–189.
23] C.Y. Lee, C.J. Lin, H.J. Chen, A self-constructing fuzzy CMAC model and its appli-cations, Information Sciences 177 (1) (2007) 264–280.
24] Z. Lei, L. Ren-hou, Designing of classifiers based on immune principles and fuzzyrules, Information Sciences 178 (7) (2008) 1836–1847.
25] M. Li, Z. Wang, A hybrid coevolutionary algorithm for designing fuzzy classifiers,Information Sciences 179 (2009) 1970–1983.
26] W. Lin, R. Jin, A. Hauptmann, Meta-classification of multimedia classifiers, in:International Workshop on Knowledge Discover in Multimedia and ComplexData, Taipei, Taiwan, 2002.
27] C.T. Lin, C.S.G. Lee, Neural network-based fuzzy logic control and decision sys-tem, IEEE Transactions on Computers 40 (12) (1991) 1320–1336.
28] E.G. Mansoori, M.J. Zolghadri, S.D. Katebi, SGERD: a steady-state genetic algo-rithm for extracting fuzzy classification rules from data, IEEE Transactions onFuzzy Systems 16 (4) (2008) 1061–1071.
29] C. Marsala, Fuzzy Partitioning Methods, Granular Computing: An EmergingParadigm, Physica-Verlag GmbH, Heidelberg, Germany, 2001, pp. 163–186.
30] E. Mezyk, O. Unold, Speed boosting induction of fuzzy rules with artificial
immune systems, in: E.M. Mastorakis (Ed.), Proceedings of the 12th WSEASInternational Conference on Systems, Heraklion, Greece, July 22–24, 2008, pp.704–706.31] E. Mezyk, O. Unold, Improving mining fuzzy rules with artificial immunesystems by uniform population, in: J. Mehnen (Ed.), Applications of Soft Com-puting, AISC 58, Springer-Verlag, Berlin/Heidelberg, 2009, pp. 295–303.

1 ft Com
[
[
[
[
[
[
[
[
[
[
[
974 E. Mezyk, O. Unold / Applied So
32] O. Nasaroui, F. Gonzales, D. Dasgupta, The fuzzy artificial immune system:motivations, basic concepts, and application to clustering and web profiling,in: Proceedings of IEEE International Conference on Fuzzy Systems, 2002, pp.711–716.
33] D. Nauck, R. Kruse, A neuro-fuzzy method to learn fuzzy classification rulesfrom data, Fuzzy Sets and Systems 89 (3) (1997) 277–288.
34] W. Pedrycz, F. Gomide, An Introduction to Fuzzy Sets. Analysis and Design, MITPress Cambridge, 1998.
35] K. Polat, S. Sahan, S. Günes, A new method to medical diagnosis: artificialimmune recognition system (AIRS) with fuzzy weighted preprocessing andapplication to ECG arrhythmia, Expert Systems with Applications 31 (2) (2006)264–269.
36] J.R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann, SanMateo, 1993.
37] I. Rish, An empirical study of the naive Bayes classifier, in: IJCAI 2001 Workshopon Empirical Methods in Artificial Intelligence, 2001.
38] J.A. Roubos, M. Setnes, J. Abonyi, Learning fuzzy classification rules from labeleddata, Information Science 150 (2003) 77–93.
[
[
puting 11 (2011) 1965–1974
39] A. Watkins, An artificial immune recognition system, MSc Thesis, MississippiState University, 2001.
40] A. Watkins, B. Xintong, A. Phadke, Parallelizing an immune-inspired algorithmfor efficient pattern recognition, in: Intelligent Engineering Systems ThroughANN: Smart Engineering System Design: Neural Networks, Fuzzy Logic, Evolu-tionary Programming, Complex Systems and Artificial Life, ASME Press, 2003,pp. 224–230.
41] A. Watkins, J. Timmis, et al., Exploiting parallelism inherent in AIRS, an artifi-cial immune classifier, in: G. Nicosia (Ed.), Third International Conference onArtificial Immune Systems, vol. 3239 in LNCS, Springer, 2004, pp. 427–438.
42] I.H. Witten, E. Frank, Data Mining: Practical Machine Learning Tools and Tech-niques, 2nd ed., Morgan Kaufmann, San Mateo, 2005.
43] X. Zeng, T.R. Martinez, Distribution-balanced Stratified Cross-validation forAccuracy Estimations, Journal of Experimental and Theoretical Artificial Intel-ligence 12 (2000) (1) 1–12 (Taylor and Francis Ltd).
44] L. Zadeh, Outline of a new approach to the analysis of complex systems anddecision process, IEEE Transactions on Systems, Man, and Cybernetics, SMC 3(1) (1973) 28–44.
Copyright © 2022 FDOKUMEN




















