
English Housewifery Exemplified In above Four ... - Livros Grátis
Upload
uni-heidelbergCategory
view
1download
0
Medical Diagnosis Systems exemplified with
Watson by IBM∗
Thomas Haider
Matrikel: 2740256
Universitat Heidelberg
Institut fur Computerlinguistik
Hauptseminar Computerlinguistik und Gesellschaft
Prof. Dr. Michael Strube
March 6, 2014
Abstract
This paper argues for medical diagnosis systems such as the Wat-
son system by IBM, which was originally developed to (successfully)
beat humans in the quiz show Jeopardy! and is now adapted for the
medical domain. The aim is to support physicians in their daily
routine, to eradicate diagnostic errors which hold the majority in
malpractice claims. After expressing reasons for the need of diagno-
sis systems, we review current systems and their limitations to bring
forth the criteria for a successful diagnosis system. Thus, we intro-
duce the technical background of the new IBM system and how it
is adapted to the medical domain, to arrive in a discussion of their
experimental results and conclude with some critisism that raises
technological, ethical and economic implications.
∗A review of: ”David Ferrucci, Anthony Levas, Sugato Bagchi, David Gondek, ErikT. Mueller (2013): ”Watson: Beyond Jeopardy!”, In: Artificial Intelligence, Elsevier”,Henceforth Ferruci et al.
1

1 Introduction
Physicians are swamped. They are overwhelmed with what is to be seen
as their main objective: To make a diagnosis. This might be an exag-
geration, but following several studies regarding diagnostic errors (Graber
2005, Singh & Graber 2010, Schiff 2005, Kirch & Schafii 1996, Shojania
et al. 2003)1 we may determine that diagnostic errors hold the majority
in medical errors. For a set of 100 ”error cases” i.e. malpractice claims,
Graber (2005) reports that 65% of these cases had system related causes
and 75% had cognitive related causes. System errors were “most often re-
lated to policies and procedures, inefficient processes, and difficulty with
teamwork and communication, especially communication of test results.”.
Cognitive errors were primarily due to “faulty synthesis or flawed process-
ing of the available information.” The predominant cause of cognitive error
was premature closure, defined as “the failure to continue considering rea-
sonable alternatives after an initial diagnosis was reached.”. Graber thus
identifies the major contributors to the cognitive errors:
1. Premature closure
2. Faulty context generation
3. Faulty synthesis or flawed processing of the available information
4. Misjudging the salience of a finding
5. Faulty detection or perception
6. Failed use of heuristics
Following Graber, ”cognitive errors [do] overwhelmingly reflect inappropri-
ate cognitive processing and/or poor skills in monitoring one’s own cogni-
tive processes (metacognition)”. He suggests the following:
1. Compiling a complete differential diagnosis to combat the tendency
to premature closure
2. Using the ”crystal ball” experience: If the clinician’s diagnosis is
incorrect, what alternatives should be considered?
3. Augmenting a clincian’s inherent metacognitive skills by using expert
systems
He also notes that clinicians continue to miss diagnostic information. An
aid for this dilemma could be automated systems that support physicians
in their decision-making. Unfortunately though, current systems are not
1References taken from Ferruci et al. 2013 to make a point. Graber (2005) is includedin the references and was read by the author. For the others, please see Ferruci et al.
2

widely used, for several reasons. (1) Those systems are not integrated in
day-to-day operations. (2) Patient data is scattered across many different
computers, if there are any computers anyway. (3) They are difficult to
interact with and (4) the entry of patient data is difficult. Furthermore,
(5) they are not focused enough on actions that are to pursue next and (6)
are unable to ask the practitioner for missing information.
2 Current systems
Question Answering (QA) in its primal form can be understood as Infor-
mation Retrieval, as a form of finding documents for a query that might
be phrased as a question. The system that changed the history of the in-
ternet with this, is, of course, Google. Also mentionable as non-commercial
alternative is DuckDuckGo, which in turn also makes use of a contem-
porary Question Answering System called Wolfram Alpha that is able to
process natural language questions and is especially fit to adress mathe-
matical questions. (Though it is not able to find a scientific publication
about itself). Another one is AnswerBus.
As Ferruci et al. (2013) put it, there are three types of medical QA sys-
tems, categorized by the way they organize their information: First, struc-
tured knowledge systems, which usually operate on a manually constructed
knowledge base, using production rules in the early days and probabilis-
tic reasoning later on. Second, unstructured knowledge systems, that are
most similar to Information Retrieval, where disorders/diseases are tagged
in documents that will be retrieved. The third kind operates on clinical
rules where disorders/diseases are adressed directly by some kind of ques-
tionnaire.
Examples for recent medical diagnosis systems are askHermes (Cao et
al., 2011) and medQA (Lee et al., 2006). askHermes and medQA both
originate from Columbia University and seem to share a great deal of sim-
ilarities. They are both passage retrieval systems with additional summa-
rization of those passages. Unfortunately, medQA is only fit for definitional
questions and the evaluation reveals that it performs poorly, especially in
terms of relevance and usefulness. askHermes is a bit more elaborated.
Their main focus is on the analysis of complex clinical input-questions, a
dynamic model to rank answers and a question-oriented display of answers.
Cao et al. (2011) also contains a comprehensive list of QA systems and
they make heavy use of the ontology UMLS for query term expansion. The
3

evaluation is carried out with a manual judgement of 60 question by three
physicians on the following dimensions:
1. Ease of Use (scale of 1 to 5).
2. Quality of Answer (scale of 1 to 5).
3. Time Spent (in s).
4. The Overall Performance (scale of 1 to 5).
The overall evaluation with all four dimensions combined does not yield any
statistically significant superiority over Google or the engine UpToDate.
The numbers for the dimensions 1, 3 and 4 are slightly better than the
other two, but askHermes definetely lacks in quality of its answers. It has
an online interface at http://www.askhermes.org/
With this bad (and recent) example we may say that passage retrieval
alone does not seem to be the way to go. However, the TREC-8 Question
Answering Track Report (Vorhees, 1999) puts it this way:
The goal in the QA task is to retrieve small snippets of text that
contain the actual answer to a question rather than the docu-
ment lists traditionally returned by text retrieval systems. The
assumption is that users would usually prefer to be given the
answer rather than find the answer themselves in the document.
So basically, a QA system should return a natural language answer to a nat-
ural language question, ideally interact as humanly as possible. Ferruci et
al. (2013) conclude that ”system input must be minimal and efficient, and
information provided must be unobtrusive and relevant.”. Furthermore, it
should be able to track the history of users and operate on natural language
questions, primarily to tackle the problem of (1) premature closure and (2)
faulty context generation.
3 DeepQA and the Jeopardy! challenge
3.1 Jeopardy!
Jeopardy! (note the exclamation mark as part of the name) is an american
television quiz show that first aired mid-1964 and is still actively produced.
The task for players is to find questions for given answers from a broad
domain, using rich and varied natural language expressions. (Ambiguities,
puns, or other opaque references). Note that here we use the usual (re-
versed) terminology, which is to get questions and deliver an answer. To
4

stand a chance, players have to buzz in for at least 70% of questions and
be able to answer more than 85% of those buzzed questions. (cf. Ferruci et
al.) Moreover, answering must be very fast. Buzzing must be done quickly
to preempt opponents consitently. Hence, determining the answer must be
fast as well then, too. An example for a question might be:
Q: These toys represent one’s common sense; don’t ”lose” them
A: What is ”marbles”?2
Finally, in 2011, after four years of development, Watson was capable to
beat the greatest human players.
3.2 DeepQA Architecture
Figure 1: DeepQA architecture, Figure 1 in Ferruci et al.
For Ferruci et al. (2013) it is important to emphasize that DeepQA is
not a simple question-answer mapping, but that it is a ”Massive Parallel
Component based Pipeline”. The core algorithm employs abductive rea-
soning, supported by plenty of NLP algorithms and models. As can be
seen in Figure 1, the first step following an input-question is to analyze
the question and conduct a topic analysis. Following this, the question is
decomposed and several hypotheses are generated, based on forward chain-
ing. Forward chaining uses Modus Ponens rules for inference, i.e. those
rules are executed until a goal is reached, presumably until the inference
rules are exhausted or a certain treshold in number of hypothesis is met.
ModusPonens : Q,P → Q ` P (1)
2Show #2905 - Friday, March 28, 1997;http://www.j-archive.com/showgame.php?game_id=1367
5

Subsequently, the system attempts to (iteratively) prove those hypothesis
with evidence, particularly with dimensions of evidence. For Jeopardy!,
those dimensions are type classification, time, geography, popularity, pas-
sage support, source reliability and semantic relatedness. Ferruci et al.
(2013): ”This analysis produces hundreds of features. These features are
then combined based on their learned potential for predicting the right an-
swer. The final result of this process is a ranked list of candidate answers,
each with a confidence score indicating the degree to which the answer is
believed correct, along with links back to the evidence.”.
Figure 2 shows the dimensions of evidence for the Jeopardy! clue ”Chile
shares its longest land border with this country.”.
For the medical domain, dimensions of evidence are based on the patient’s
Figure 2: Dimensions of evidence for Jeopardy!, Figure 2 in Ferruci et al.
electronic medical record (EMR), including symptoms, findings, patient
history, familiy history, demographics, current medication and many others.
Dimensions such as source reliabilty and popularity are still included. See
the Appendix for an illustration what the display of a differential diagnosis
should look like and how physicians are able to see comprehensive lists of
present and absent symptoms and how it is possible to give feedback to the
system, e.g. by rating the sources.
3.3 Medical Domain Adaptation
For a first experiment to adapt Watson for the medical domain, Ferruci
et al. obtained 5000 medical questions with their respective answers from
ACP Doctor’s Dilemma. An example of a question-answer pair looks like
this:
6

Figure 3: Dimensions of evidence for differential diagnosis, Figure 3 inFerruci et al.
Q: The syndrome characterized as joint pain, palpable purpura, and a
nephritic sediment.
A: Henoch-Schonlein purpura
With this data they attempt to extend the original domain, which is rather
broad but nonetheless intended for Jeopardy!. There are three areas in
which it should be adapted. Enumeration from Ferruci et al. (2013).
1. Content adaptation involves organizing the domain content for hy-
pothesis and evidence generation, modeling the context in which
questions will be generated.
2. Training adaptation involves adding data in the form of sample train-
ing questions and correct answers from the target domain so that the
system can learn appropriate weights for its components when esti-
mating answer confidence.
3. Functional adaptation involves adding new domain-specific question
analysis, candidate generation, hypothesis scoring and other compo-
nents.
3.4 Content adaptation
Content is to be understood as textbooks, dictionaries, clinical guidelines,
research articles and public information on the web. For Watson, the devel-
opers focused on content from internal medicine and decided to incorporate
7

ACP Medicine, the Merck Manual for Diagnosis and Therapy, PIER (a col-
lection of guidelines and evidence summaries) and MKSAP (a study guide
from ACP). They scanned the header hierachy for disease names and key-
word variants for their causes, symptoms, diagnostic tests and treatments,
ultimately as input for an Information Retrieval System. The Information
Retrieval is based on ’pseudo-documents’ into which found passages about
diseases are extracted. The Retrieval itself is split into four stages:
1. Search for documents and propose as candidate answer.
2. Search entire source content for relevant passages.
3. Find textual support for evidencing.
4. Extract associations between symptoms, findings and tests as knowl-
edge base for hypothesis generation.
3.5 Training adaptation
Training adaptation utilizes machine learning techniques to determine how
to weigh the contribution of the various search and scoring components in
the question answering pipeline. Basically, they trained an unmentioned
algorithm on 1322 Doctor’s Dilemma questions, a subset of the 5000 ques-
tions mentioned earlier. Note that they did not only use diagnosis ques-
tions, but also non-diagnosis questions, since performance then seemed to
improve.
3.6 Functional adaptation
Functional adaptation is by far the most extensively discussed adaptation
method in Ferucci et al.. Apparently, this is their main research task, since
(as we will see later on) the earlier two adaptation methods (though effec-
tive) do not yield much more room for improvement. Watson for Jeopardy!
is mostly reusable, since it is rather domain independent already. Nonethe-
less are the dimensions of evidence different which affects hypothesis evi-
dencing. Additionally, it has to be revisited how questions are analyzed and
interpreted, how searching, generating the candidate hypothesis, retrieving
supporting evidence and scoring and ranking answers is carried out. Plus,
there should be new analytic components from domain-specific resources
such as taxonomies, corpora and also reasoning axioms.
8

3.6.1 Domain-specific taxonomies and reasoning
UMLS is a medical ontology which contains the taxonomies MeSH and
SNOMED. Those encode information regarding (1) paraphrasing, e.g. that
age-related hearing loss is refered to as presbycusis and (2) hyponymy like
the fact that pyoderma gangrenosum is a of skin disease.
3.6.2 Concept detection
Concept detection aims at named entity disambiguation, measurement
recognition and interpretation as well as unary relations. First, the system
should recognize that hypertension can be interpreted as either hypertensive
disease or hypertensive adverse effect. The measurement issue regards that
a 22 year old person is a young adult and that a value of 320 mg/dL in blood
glucose is a case of hyperglycemia. Unary relations describe the problem
that values can be expressed lexically (e.g. elevated T4) and that concepts
may be negated. For the first, Watson uses statistical classifiers and rule
based detectors. The negated concepts can be detected with NegEx, which
locates trigger terms and their scope, specifically for the medical domain
though.
3.6.3 Reasoning over concepts using taxonomic resources
This is used for hypothesis evidencing using unstructured knowledge. The
algorithms attempt to compute the similarity between hypothesis and sup-
porting passages in documents. Concept term matching is used by DeepQA
passage scorers by matching (sub)sequences or align predicate argument
structures between the hypothesis and the passage.
Type coercion is an entity disambiguation that maps candidate answers
from text to medical taxonomies. Coercion denotes ”how easily a candi-
date answer may be ”coerced” to the desired lexical answer type of the
question.”. (Ferruci et al. 2013)
Answer specificity is important to decide how general or specific certain
diseases are, since specific diseases are rare.
Finally, answer merging finds variant realisations of answers and merges
them to eliminate redundancy. Again, this is done by utilizing taxonomies.
3.6.4 Resources mined over medical text
A mined resource here means a matrix created through Latent Semantic
Analysis (LSA). This loosely captures topics and then computes similarities
9

between the terms in the clue and the terms associated with the candidate
answer in the LSA index. Next, Structured Symptom Matching attempts to
measure the informativeness of a symptom for a given condition. Ferruci et
al. (2013) create an unsupervised resource from their unstructured medical
content. As similarity measure they use Mutual Information.
3.6.5 Refinements to handle medical text
As last functional adaptations, Ferruci et al. (2013) employ some refine-
ments. The first is called Multidimensional Passage Scoring which segments
a question into multiple factors describing correct hypothesis to find those
factors in other passages. The second refinement is Supporting Passage
Discourse Chunking. Usually it is assumed that a retrieved passage text
is associated with the candidate answer. This appears to be violated quite
frequently in the medical domain. This might be one major issue why the
askHermes system discussed earlier performs so poorly in quality of the
answer. However, consider the following example:
Collagenous colitis and lymphocytic colitis are distin-
guished by the presence or absence of a thinkened subepithelial
collagen layer. The cause of microscopic colitis syndrome is
uncertain.
A Bag-of-words model would associate each colitis with each. So it needs
to be parsed syntactically to map presence to collagenous and absence to
lymphocytic. Further, they implement what they call ’Simple Discourse
Chunking’. According to the information provided by the paper this does
sound like sentence splitting, since it only separates the second sentence.
4 Experimental Results and Discussion
4.1 Precision on ACP Doctor’s Dilemma questions
The evaluation of Ferruci et al. needs to be prefaced with the measurements
they use. Figure 4 uses Precision and Percent answered. Precision measures
the percentage of questions the system gets right with its top answer, so
for the differential diagnosis only the best match is considered which makes
a lot of sense in the context of Jeopardy!, since only one answer is correct.
Percent answered shows the percentage of questions the system is required
to answer, which it selects according to its highest estimated confidence
10

score on the top answer, i.e. the system selects those questions which it is
most confident to answer first. This is a somewhat unrealistic setting, but
makes the graph look nice. Figure 5 uses Recall@10, meaning that the right
answer is in the top 10 of retrieved answers. This is generally a good idea
in the setting of differential diagnosis, but the treshold of 10 seems rather
high since it may obfuscate poor performance. Granted, the precision in
Figure 4 gives a point of comparison on the rightmost side of the graph
where all questions were answered, but neither does the Recall@10 reveal
the position of the correct diagnosis, nor does it show how pracitioners
would interact with the system and select the actual (correct) diagnosis.
It might be a long way from this evaluation until a state is reached where
this system is reliable to trust it with people’s lives. Just imagine a setting
where doctors solely trust the system, or even worse, a cell phone app to
diagnose yourself. But more on the ethical implications later.
First, a discussion about the actual evaluation figures. Figure 4 shows
the performance of the adaptation methods stacked successively on the
baseline (core). It it obvious to see, the more sophisticated the models, the
better the performance. The models answer those questions which they are
most confident about first. We see a steep drop in performance in the first
20% of answered questions for Core and Core+Content. This could mean
that the training adaptation improves the model to a steady confidence
that gradually decreases. The leftmost i.e. most confident answers are
probably simple question-answer mappings with few (if any) alternative
hypotheses. The intersecting lines between Train and Train+FuncAdap in
the first 20% probably occur because the Train+FuncAdap model is more
general. On the rightmost side of the graph, where all test-questions are
answered we see that the two bottom lines and the two top lines are closer
to each other. This reveals that Content and FuncAdap bring relatively
small improvements compared to the Train model which has quite some
impact. We also see this effect in Figure 5 which is basically a histogram
of the rightmost side of Figure 4, just that it is counted as success if the
correct answer is in the top 10 of the ranked list and not only the top
match.
4.2 Conclusion and Criticism
The largest improvement over the baseline is achieved through the training
adaptation. Apparently though, the model seems to saturate. Therefore
do Ferrucci et al. conclude that future improvements have to be made in
11
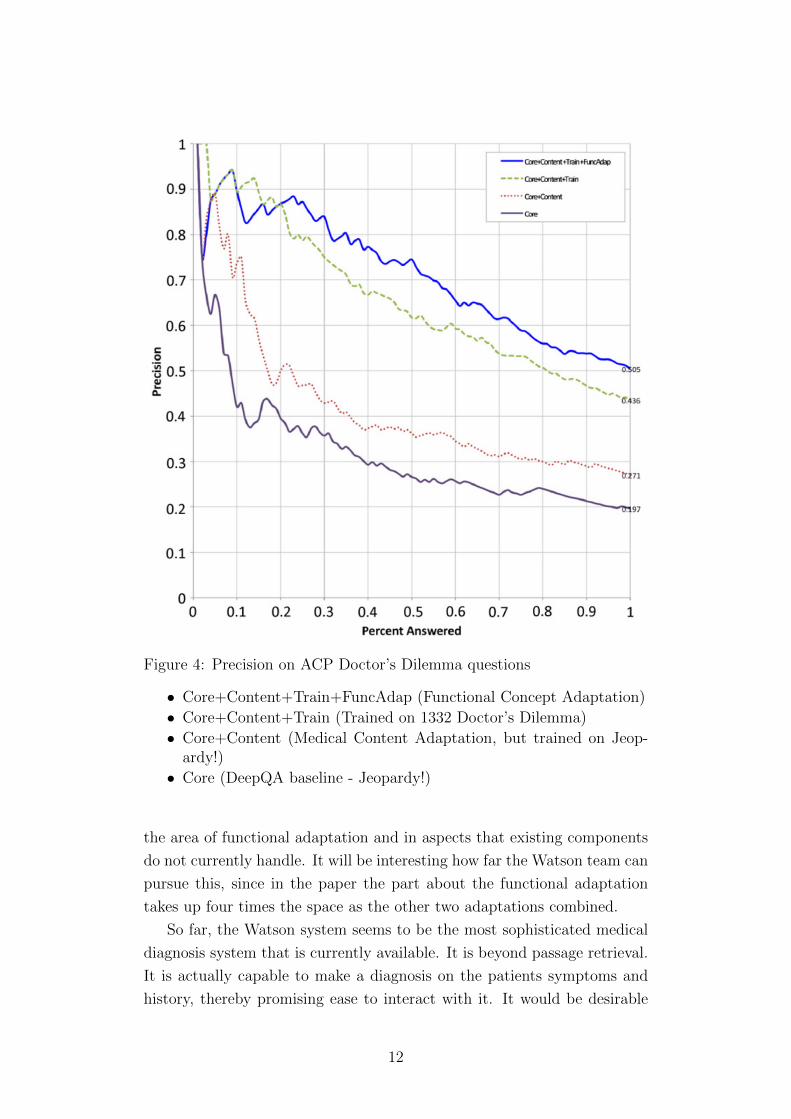
Figure 4: Precision on ACP Doctor’s Dilemma questions
• Core+Content+Train+FuncAdap (Functional Concept Adaptation)
• Core+Content+Train (Trained on 1332 Doctor’s Dilemma)
• Core+Content (Medical Content Adaptation, but trained on Jeop-ardy!)
• Core (DeepQA baseline - Jeopardy!)
the area of functional adaptation and in aspects that existing components
do not currently handle. It will be interesting how far the Watson team can
pursue this, since in the paper the part about the functional adaptation
takes up four times the space as the other two adaptations combined.
So far, the Watson system seems to be the most sophisticated medical
diagnosis system that is currently available. It is beyond passage retrieval.
It is actually capable to make a diagnosis on the patients symptoms and
history, thereby promising ease to interact with it. It would be desirable
12
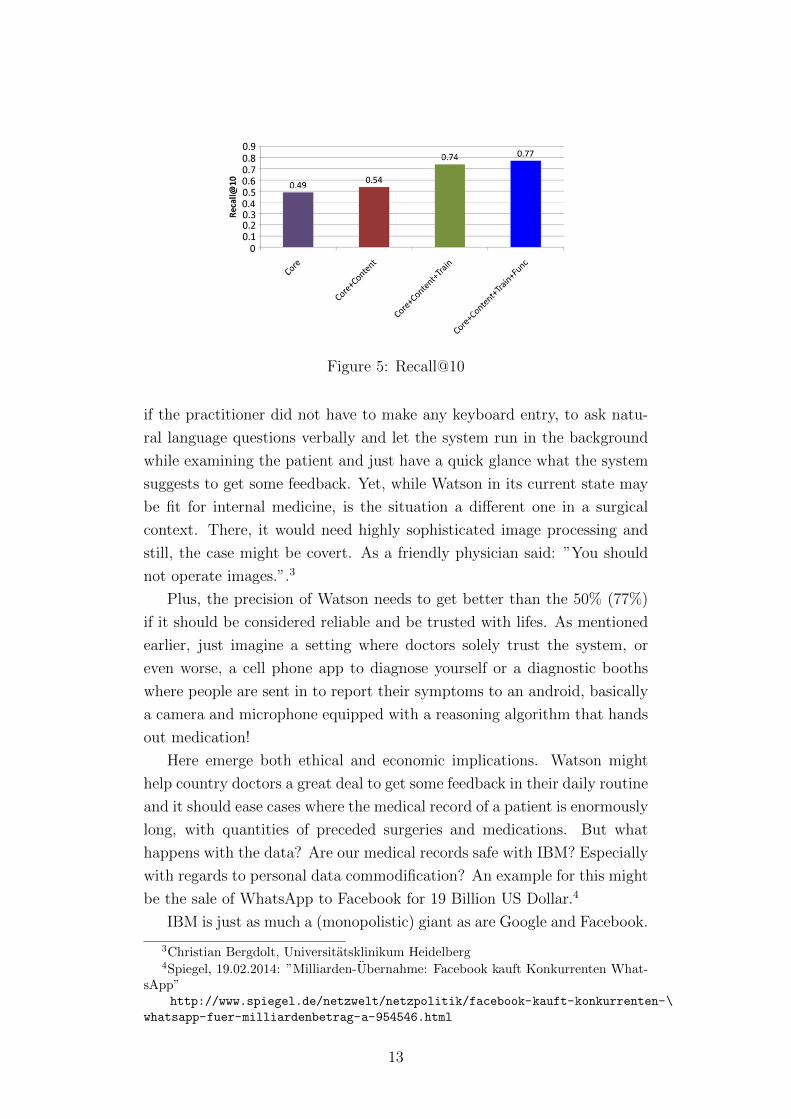
Figure 5: Recall@10
if the practitioner did not have to make any keyboard entry, to ask natu-
ral language questions verbally and let the system run in the background
while examining the patient and just have a quick glance what the system
suggests to get some feedback. Yet, while Watson in its current state may
be fit for internal medicine, is the situation a different one in a surgical
context. There, it would need highly sophisticated image processing and
still, the case might be covert. As a friendly physician said: ”You should
not operate images.”.3
Plus, the precision of Watson needs to get better than the 50% (77%)
if it should be considered reliable and be trusted with lifes. As mentioned
earlier, just imagine a setting where doctors solely trust the system, or
even worse, a cell phone app to diagnose yourself or a diagnostic booths
where people are sent in to report their symptoms to an android, basically
a camera and microphone equipped with a reasoning algorithm that hands
out medication!
Here emerge both ethical and economic implications. Watson might
help country doctors a great deal to get some feedback in their daily routine
and it should ease cases where the medical record of a patient is enormously
long, with quantities of preceded surgeries and medications. But what
happens with the data? Are our medical records safe with IBM? Especially
with regards to personal data commodification? An example for this might
be the sale of WhatsApp to Facebook for 19 Billion US Dollar.4
IBM is just as much a (monopolistic) giant as are Google and Facebook.
3Christian Bergdolt, Universitatsklinikum Heidelberg4Spiegel, 19.02.2014: ”Milliarden-Ubernahme: Facebook kauft Konkurrenten What-
sApp”http://www.spiegel.de/netzwelt/netzpolitik/facebook-kauft-konkurrenten-\
whatsapp-fuer-milliardenbetrag-a-954546.html
13

And it appears that what they are doing with Watson will have some im-
pact on the medical world. The Google query ”watson medical diagnosis”
returns 4.900.000 pages. So at least the medial attention is ensured. And
it is obvious that IBM is in this for the money, since they are driven by the
economy. The kick-off funding for the project was one billion dollar. From
this, they expect to pay up to 2000 employees, at least that is what they
want to have until the end of the year.5 As if that was not enough: IBM
found a new domain to adapt Watson to: Finance!
5 References
YongGang Cao, 1, Feifan Liu, Pippa Simpson, Lamont Antieau,
Andrew Bennett, d, James J. Cimino, John Ely, Hong Yu (2011):
AskHERMES: An online question answering system for complex clin-
ical questions, In: Journal of Biomedical Informatics Volume 44, Issue
2, April 2011, Pages 277–288, Elsevier
David Ferrucci, Anthony Levas, Sugato Bagchi, David Gondek, Erik
T. Mueller (2013): ”Watson: Beyond Jeopardy!”, In: Artificial Intel-
ligence, Elsevier
M. Graber, N. Franklin, R. Gordon (2005): ”Diagnostic error in in-
ternal medicine”, In: Arch. Intern. Med. 165, 1493–1499.
Minsuk Lee, MS,1 James Cimino, MD,2 Hai Ran Zhu, MS,3 Carl
Sable, PhD,4 Vijay Shanker, PhD,5 John Ely, MD,6 and Hong Yu,
PhD1 (2006): ”Beyond Information Retrieval—Medical Question An-
swering”, In: AMIA Annu Symp Proc. 2006; 2006: 469–473. PM-
CID: PMC1839371
E. Voorhees (1999): The TREC-8 Question Answering Track Report.
In Proceedings of the 8th Text Retrieval Conference (TREC8), pp.
77-82, NIST, Gaithersburg, MD, 1999.
5Frankfurter Allgemeine Zeitung, 09.01.2014: ”Derschlauste Computer der Welt soll jetzt auch Geld verdi-enen” http://www.faz.net/aktuell/wirtschaft/netzwirtschaft/
watson-der-schlauste-computer-der-welt-soll-jetzt-auch-geld-verdienen-12743829.
html
14
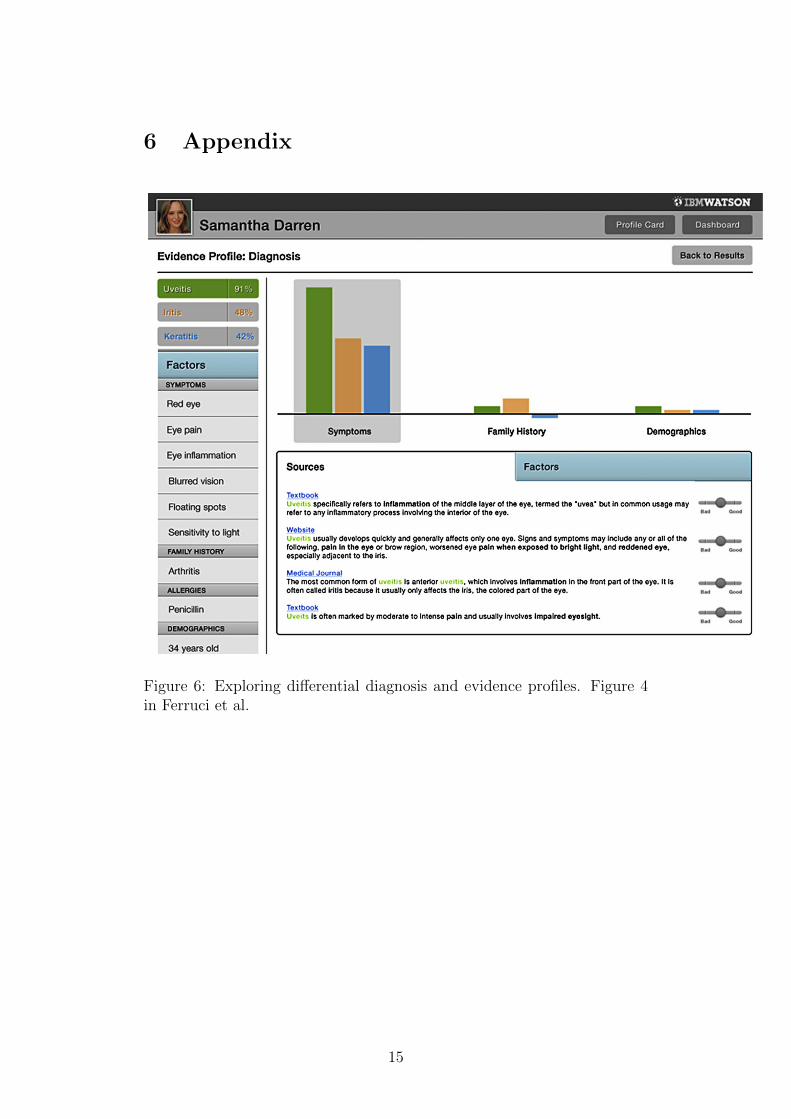
6 Appendix
Figure 6: Exploring differential diagnosis and evidence profiles. Figure 4in Ferruci et al.
15

Figure 7: Factors related to Uveitis diagnosis. Figure 5 in Ferruci et al.
16
Copyright © 2022 FDOKUMEN




















