
Los índices de relatividad, densidad y eficiencia informativa ...
44
ELUA ISSN 2171-6692 Núm. 37, 2022, págs. 23-66 https://doi.org/10.14198/ELUA.18583 Los índices de relatividad, densidad y eficiencia informativa en las lenguas: estudio de las correlaciones matemáticas entre palabras y fonemas Indices of relativity, density and informative efficiency of languages: a study of mathematical correlations between words and phonemes ENRIQUE J. VERCHER GARCÍA Universidad Complutense de Madrid, España [email protected] https://orcid.org/0000-0002-3263-6199 MANUEL BULLEJOS LORENZO Universidad de Granada, España [email protected] https://orcid.org/0000-0001-6914-8052 Resumen El presente artículo recoge y analiza en 459 len- guas del mundo el número de palabras (tokens) y el número de sonidos y fonemas (unidades fónicas convencionales de token o UFCT) que emplean dichas lenguas para expresar una misma información (en el análisis central de nuestro estudio el texto fuente empleado, en concreto, son los 10 primeros artículos de la Declaración Universal de los Derechos Hu- manos). Asimismo, estudia las correlaciones Para citar este artículo: Vercher García, E. J.; Bullejos Lorenzo, M. (2022). Los índices de relativi- dad, densidad y eficiencia informativa en las lenguas: estudio de las correlaciones matemáticas entre palabras y fonemas. ELUA, (37), 23-66. https://doi.org/10.14198/ELUA.18583 Recibido: 05/01/2021, Aceptado: 06/05/2021 © 2022 Enrique J. Vercher García, Manuel Bullejos Lorenzo Este trabajo está sujeto a una licencia de Reconocimiento 4.0 Internacional de Creative Commons (CC BY 4.0) Abstract This article compiles and analyses, in 459 world languages, the number of words (to- kens) and the number of sounds and pho- nemes (token conventional phonemic units or TCPU) that these languages use to express the same information (the source text used in the main analysis of our study is, specifically, the first 10 articles of the Universal Declaration of Human Rights). Additionally, it studies the mathematical correlations existing between
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Los índices de relatividad, densidad y eficiencia informativa ...

ELUAISSN 2171-6692Núm. 37, 2022, págs. 23-66https://doi.org/10.14198/ELUA.18583
Los índices de relatividad, densidad y eficiencia informativa en las lenguas: estudio de las correlaciones matemáticas entre
palabras y fonemas
Indices of relativity, density and informative efficiency of languages: a study of mathematical correlations between words and phonemes
EnriquE J. VErchEr García
Universidad Complutense de Madrid, Españ[email protected]
https://orcid.org/0000-0002-3263-6199
ManuEl BullEJos lorEnzo
Universidad de Granada, Españ[email protected]
https://orcid.org/0000-0001-6914-8052
ResumenEl presente artículo recoge y analiza en 459 len-guas del mundo el número de palabras (tokens) y el número de sonidos y fonemas (unidades fónicas convencionales de token o UFCT) que emplean dichas lenguas para expresar una misma información (en el análisis central de nuestro estudio el texto fuente empleado, en concreto, son los 10 primeros artículos de la Declaración Universal de los Derechos Hu-manos). Asimismo, estudia las correlaciones
Para citar este artículo: Vercher García, E. J.; Bullejos Lorenzo, M. (2022). Los índices de relativi-dad, densidad y eficiencia informativa en las lenguas: estudio de las correlaciones matemáticas entre palabras y fonemas. ELUA, (37), 23-66. https://doi.org/10.14198/ELUA.18583
Recibido: 05/01/2021, Aceptado: 06/05/2021
© 2022 Enrique J. Vercher García, Manuel Bullejos Lorenzo
Este trabajo está sujeto a una licencia de Reconocimiento 4.0 Internacional de Creative Commons (CC BY 4.0)
AbstractThis article compiles and analyses, in 459 world languages, the number of words (to-kens) and the number of sounds and pho-nemes (token conventional phonemic units or TCPU) that these languages use to express the same information (the source text used in the main analysis of our study is, specifically, the first 10 articles of the Universal Declaration of Human Rights). Additionally, it studies the mathematical correlations existing between

24 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
matemáticas existentes entre tokens, unidades fónicas convencionales de token y contenido informativo; correlaciones que dan lugar a los denominados índice de relatividad informativa (coeficiente resultante de dividir el número de tokens entre el número de UFCT), índice de densidad informativa (coeficiente resultante de dividir el número de UFCT entre el núme-ro de tokens), índice de eficiencia informativa léxica (coeficiente resultante de dividir 100 en-tre el número de tokens) e índice de eficiencia informativa fónica (coeficiente resultante de dividir 100 entre el número de UFCT). El ob-jetivo del análisis es aportar algo más de luz a los principios matemáticos del lenguaje, a la denominada economía del lenguaje y al conoci-miento sobre las características de las distintas lenguas según su tipología morfológica.
La investigación se centra en analizar la re-lación existente entre estos índices y la tipología morfológica predominante de cada lengua.
El resultado es una gran cantidad de datos y estadísticas de las que extraemos una serie de conclusiones referidas al uso de recursos léxicos y fónicos en las lenguas: 1) los índi-ces de relatividad informativa y de densidad informativa tienen una relación directa con el tipo morfológico; 2) el número total de UFCT empleadas para expresar un mismo contenido de información no depende del tipo morfoló-gico; 3) la diferencia entre el número total de UFCT empleadas por distintas lenguas puede ser muy elevada; 4) la correlación entre número de tokens y valor medio de UFCT por token muestra una relación lineal negativa (es decir, a mayor número de palabras, las longitudes de las palabras disminuyen); 5) a mayor número de tokens totales empleado para expresar una mis-ma información corresponde por regla general un mayor número de UFCT totales (a mayor número de palabras totales, mayor número de fonemas totales); 6) la denominada economía del lenguaje no parece funcionar de igual ma-nera en todas las lenguas, al menos en lo que a uso de recursos (fonemas) se refiere.
El presente trabajo introduce como nuevos factores de estudio y descripción de las lenguas los citados índices, así como una serie de he-rramientas de estudio que podrían ser aplicadas en el futuro a otras investigaciones lingüísticas.
tokens, token conventional phonemic units and informative content; correlations which result in the so-called index of informative relativity (coefficient resulting from divid-ing the number of tokens by the number of TCPU’s), index of informative density (co-efficient resulting from dividing the number of TCPU’s by the number of tokens), lexi-cal informative efficiency index (coefficient resulting from dividing 100 by the number of tokens) and phonetic informative efficiency index (coefficient resulting from dividing 100 by the number of TCPU’s). The objective of the analysis is to shed more light on the math-ematical principles of language, the so-called economy of language and knowledge of the characteristics of different languages based on their morphological typology.
The research is focused on analysing the relationship existing between these indices and the predominant morphological typology of each language.
The result is a large quantity of data and statistics from which we draw a series of con-clusions regarding the use of lexical and pho-netic resources in languages: 1) the index of informative relativity and the index of informa-tive density depend on the morphological type; 2) the total number of TCPUs used to express the same information does not depend on the morphological type; 3) the difference between the total number of TCPUs used by different languages may be very large; 4) the correla-tion between the number of tokens and average TCPU value per token has a negative linear relationship (that is, the larger the number of words, the shorter the lengths of words); 5) a larger number of total tokens used to express the same information corresponds to a larger number of total TCPUs (the greater the total number of words, the greater the total number of phonemes); 6) the so-called economy of lan-guage does not seem to work in the same way in all languages, at least with regard to use of resources (phonemes).
The present article introduces the afore-mentioned indices as new factors of study and description of languages, as well as a series of study tools that could be applied in the future to other linguistic research.

25EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
KEYWORDS: index of informative rela-tivity; index of informative density; lexical in-formative efficiency index; phonetic informative efficiency index; tokens.
PALABRAS CLAVE: índice de relatividad informativa; índice de densidad informativa; ín-dice de eficiencia informativa léxica; índice de eficiencia informativa fónica; tokens.
1. INTRODUCCIÓN
La idea para la elaboración del presente estudio surgió de nuestra experiencia en el mundo de la traducción, en el que se constataba la gran diferencia en el número de palabras que em-pleaban dos lenguas distintas para expresar una misma información (texto). Comenzó, así, un arduo trabajo de búsqueda y descripción de varios cientos de idiomas con el fin de registrar el número de palabras y el número de fonemas que empleaba cada uno para expresar un mismo contenido semántico. El presente artículo es el fruto del análisis de la correlación entre el nú-mero de palabras y el número de fonemas empleados en cada una de las lenguas estudiadas, así como de la relevancia que pudiera tener en estas correlaciones el tipo morfológico.
El objetivo del análisis es aportar algo más de luz a los principios matemáticos del len-guaje, a la denominada economía del lenguaje y al conocimiento sobre las características de las distintas lenguas según su tipología morfológica. Estos datos aportarán un mayor conocimiento sobre la estructuración y funcionamiento de las lenguas.
Así pues, lo que realizamos en el presente estudio es un análisis de textos en el que cuantificamos la proporción entre el número de palabras y el número de fonemas empleados, pero también analizamos la correlación entre el número de fonemas que posee una lengua y el número de fonemas que necesita usar para transmitir una misma información.
El concepto mismo de palabra es polémico y carece de una definición unánime. Ha sido ampliamente debatido en la lingüística por autores como Jespersen, Admoni, Brøndal, Šahmatov, Vinogradov, González Calvo, Ušakova, Mauro, Krivonosov, Ščerba, Steblin-Kamenskij, Serebrennikov, Suprun, Sunik, Migirin, Reichenbach, Potebnja, Hockett y un largo etcétera y ya lo tratamos también nosotros en otros trabajos (Vercher García, 2011: 54 y ss.; Vercher García, 2019)1. Sea como fuere, la división de palabras también forma parte de la “lengua natural”, en tanto en cuanto los hablantes de una lengua son conscientes y coinci-den en la identificación de las palabras (y aun así, existirían algunas vacilaciones). Para este estudio nos atenemos, pues, a las convenciones y normas de cada lengua en la identificación y división de sus palabras. Creemos, además, que esta decisión queda justificada por ser este un trabajo cuantitativo-estadístico, no un trabajo de análisis morfo-sintáctico o semántico, en cuyo caso sería más apropiado el uso de conceptos como los de sintema y silema, intro-ducidos por A. Martinet (1985; 1989).
Nosotros para el presente trabajo nos vamos a valer del concepto de token, empleado en estudios relacionados con la carga de la información, y que en nuestro caso cuantitativa-mente va a equivaler a la palabra según la división convencional que cada lengua hace de sus propias unidades léxicas.
1 Aprovechamos para comentar que, dado que para un trabajo de esta naturaleza se ha tenido que manejar un elevado número de obras bibliográficas, no vamos a saturar el texto con referencias, remitimos desde un primer momento a las descripciones de las distintas lenguas que se realizan en las obras que se recogen en la bibliografía.

26 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Por otro lado, como unidades fónicas que constituyen cada uno de los token emplea-remos el concepto de unidad fónica convencional de token (UFCT). Las UFCT en ciertas lenguas de nuestro estudio (aquellas con un mayor alejamiento entre escritura y fonética o de las que disponemos como lingüistas de un mayor conocimiento y herramientas de estudio) están tomadas de transcripciones fonéticas y, por tanto, corresponden exactamente a sonidos; es el caso del alemán, catalán, danés, español, francés, hebreo, inglés, inuktitut, irlandés, italiano, japonés, latín, luxemburgués, portugués, tamil, telugu y turco. En el resto de casos, cuando por cuestiones técnicas no ha sido posible contar con transcripciones foné-ticas fiables, y tratándose, además, de lenguas con sistemas de escritura más recientes y más fonéticas, las UFCT se corresponden con las grafías del texto escrito. Para el presente tipo de estudio (datos macroestadísticos y matemáticos) son equivalentes cuantitativamente los sonidos y los fonemas; así, por ejemplo, /ˈdweNde/ (transcripción fonológica) y [ˈdwẽ̞n̪de̞] (transcripción fonética) tienen el mismo número de UFCT: seis2.
Las diferentes proporciones entre tokens y UFCT nos dan una serie de índices sobre el número de palabras necesario para expresar un contenido semántico y la cantidad de recur-sos fónicos (cantidad de fonemas o sonidos) necesarios para expresar ese mismo contenido semántico.
Así, por índice de relatividad informativa entenderemos el coeficiente resultante de divi-dir el número de tokens entre el número de UFCT, ya que estamos hablando de la proporción entre el número de tokens y el número de UFCT empleados en un mismo texto. El índice de relatividad informativa tiene como potencial valor máximo 1 (si un idioma tuviera tantas palabras como número de UFCT).
Por su parte, denominamos índice de densidad informativa al coeficiente resultante de dividir el número de UFCT entre el número de tokens, ya que indica proporcionalmente la cantidad de información contenida en cada UFCT (evidentemente, hablamos de una propor-ción matemática, de uso de recursos, no de que la información –la carga semántica– pueda ser fragmentada en fonemas). Este índice viene a indicar de facto la longitud media de las palabras en una lengua.
Estos dos índices reflejan valores resultantes del análisis dentro de una misma lengua dada (proporción entre tokens y UFCT empleados por esa lengua).
Sin embargo, también sería útil comparar los recursos lingüísticos en forma de unidades léxicas y unidades fónicas que necesitan distintas lenguas para expresar una misma infor-mación. Así pues, si aplicamos el valor numérico de 100 a la información contenida en un texto dado, el coeficiente resultante de dividir 100 entre el número de tokens o entre el número de UFCT empleados para expresar esa misma información en distintas lenguas nos dará como resultado lo que denominaremos índice de eficiencia informativa léxica e índice de eficiencia informativa fónica respectivamente3.
2 Para el conteo de UFCT hay que precisar también que las africadas se contabilizan como una única unidad y que rasgos como el tono, la aspiración o la longitud no contabilizan como una unidad más, sino que se consideran rasgos propios de un mismo fonema y sonido y por tanto de la misma UFCT.3 Para ser estrictos, al analizar los índices informativos a partir de un texto dado lo que obtenemos son los datos con respecto a ese texto concreto. Los índices informativos podrían variar en función del tipo de texto (literario o coloquial, técnico o poético, etc.) dentro de una misma lengua. No obstante, el presente estudio nos va a dar una idea general de los índices de relatividad, densidad y eficiencia en los que se mueven las distintas lenguas anali-zadas.

27EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Los índices de eficiencia informativa léxica y fónica son valores relativos resultantes de comparar los coeficientes obtenidos en distintas lenguas sobre la base de un mismo con-tenido informativo (un mismo texto traducido a distintas lenguas). Evidentemente, somos conscientes de que no existe una única traducción posible exacta, pero, no obstante, creemos que el uso de ciertos textos minoriza este problema. Es por ello que en nuestro estudio nos valemos principalmente de la Declaración Universal de los Derechos Humanos, ya que se trata de un texto con un contenido preciso que no da lugar a muchas interpretaciones ni va-riaciones, además de ser un texto accesible en gran cantidad de lenguas y de ser un texto de redacción reciente y con traducciones a las distintas lenguas en un periodo bastante reducido en términos históricos y de evolución de las lenguas.
Para el presente estudio hemos analizado un total de 459 lenguas pertenecientes a fa-milias, macrofamilias y filos (o phyla) lingüísticos diferentes (incluyendo lenguas aisladas) y de características lingüísticas y tipología morfológica variada. Como curiosidad, entre las lenguas analizadas se incluyen algunas lenguas artificiales, lo que nos permitirá ver los valores y correlación que tienen estas lenguas con respecto a lenguas naturales.
2. EXPOSICIÓN Y ANÁLISIS ESTADÍSTICO DE LOS ÍNDICES DE RELATIVI-DAD, DENSIDAD Y EFICIENCIA INFORMATIVA DE LAS LENGUAS
En el presente trabajo nos valemos de un doble método: estadística descriptiva para mostrar los datos cuantitativos obtenidos durante la recogida de muestras de las distintas lenguas (se muestra en las distintas tablas y figuras insertadas) y estadística inferencial para extraer conclusiones basándonos en los datos obtenidos (es lo que se desarrolla en el cuerpo del texto de los apartados 3 –Análisis de datos– y 4 –Conclusiones–).
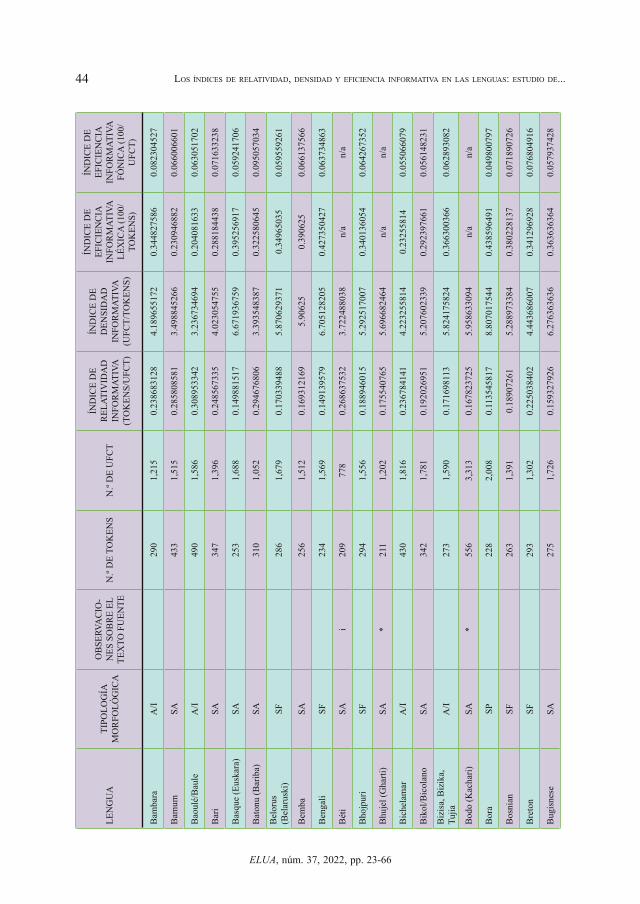
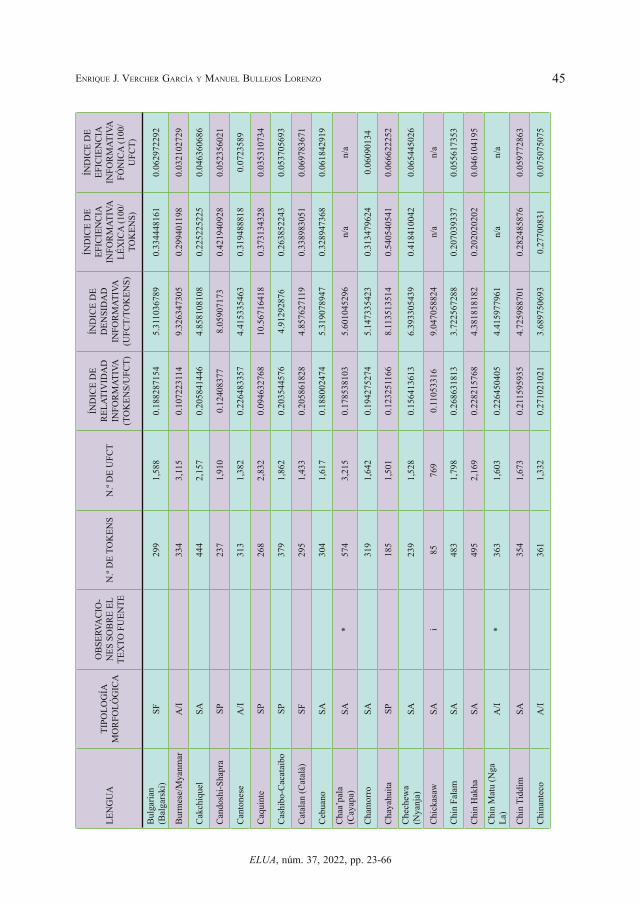
En la tabla 2 insertada como Apéndice al final del artículo exponemos los datos obteni-dos en las lenguas analizadas indicando tipología morfológica, n.º de tokens, n.º de UFCT, índice de relatividad informativa, índice de densidad informativa, índice de eficiencia in-formativa léxica e índice de eficiencia informativa fónica. Pasamos, previamente, a aclarar algunas cuestiones sobre la misma (vid. Tabla 2 en el Apéndice).
En la columna de tipología morfológica indicamos el tipo morfológico predominante de cada lengua: A/I (analítica-aislante), SA (sintética aglutinante), SF (sintética fusionante) y SP (sintética polisintética). Entendemos que la moderna tipología lingüística a partir de J. Greenberg no habla de “tipos morfológicos puros”, sino de índices graduales como el índice de síntesis (que varía de lenguas más analíticas a lenguas más sintéticas) o el índice de aglutinación (entre lenguas más aglutinantes –mayor segmentación de las marcas morfológi-cas– y lenguas más fusionantes), además de los índices de flexión, composición, prefijación, sufijación, aislamiento, flexión pura y concordancia (vid. Greenberg, 1954). No obstante esta puntualización, lo cierto es que en las descripciones de las lenguas se suele hablar de predominio de un tipo morfológico y, dado el carácter de estudio macroestadístico que aquí presentamos, nos valdremos de esta clasificación en tipos morfológicos predominantes, pues nos vale para los objetivos del presente estudio. Asimismo, vamos a considerar en nuestro estudio como un mismo grupo las lenguas aislantes y analíticas, ya que la diferencia entre estas dos nociones no afecta a los resultados cuantitativos con los que trabajamos.
También incluimos una columna con observaciones sobre el texto fuente utilizado. En la mayor parte de los casos se trata de la traducción completa y correcta de los 10 primeros ar-

28 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
tículos de la Declaración Universal de los Derechos Humanos (DUDH), como se ha señala-do. En estos casos se han usado las lenguas para el análisis de los cuatro índices estudiados.
En algunos casos la traducción de esos 10 primeros artículos es incompleta, hecho que hemos indicado con la letra “i”. En otros casos no nos hemos podido valer de la traducción de los 10 primeros artículos de la DUDH y hemos usado otros textos fuentes. En estos dos últimos casos hemos usado las lenguas para el análisis del índice de relatividad informativa y del índice de densidad informativa por ser valores intralingüísticos, pero no los hemos usado para el análisis del índice de eficiencia informativa léxica ni del índice de eficiencia fónica por ser valores relativos que se basan, precisamente, en la comparación con otras lenguas.
Puntualizamos igualmente que nos valemos del sistema lingüístico tal y como aparece en los textos fuentes, y que normalmente será la lengua estandarizada literaria, cuando exista, o una variante lingüística concreta en el caso de lenguas con un continuum de hablas (por ejemplo, el aymara). El sistema de análisis que proponemos permitiría, no obstante, hacer un estudio de una variedad lingüística dada, si así se quisiera. Por ejemplo, en ciertas zonas de Andalucía la sílaba terminada en vocal + /s/ pierde el fonema /s/ abriendo la vocal, con lo que numéricamente sería un fonema en lugar de dos en esas variedades lingüísticas.
Una vez expuestos los datos obtenidos, pasaremos a analizarlos y extraer las posibles conclusiones (estadística inferencial). Puntualizamos previamente que trabajamos con tres conjuntos de lenguas. El primer conjunto sería el conformado por todas las lenguas consul-tadas (459), conjunto que puede servir para el estudio de ciertas cuestiones como los índices de relatividad informativa y densidad informativa, ya que, como apuntábamos anterior-mente, son coeficientes intralingüísticos independientes para cada lengua (en la Tabla 1 se muestran todas estas lenguas). Sin embargo, ciertos datos de lenguas para los que no hemos usado un mismo texto fuente (los 10 primeros artículos de la DUDH) podrían distorsionar los resultados, con lo que en nuestra investigación y análisis de datos hemos descartado aquellas lenguas que no usaban dicho texto como texto fuente y hemos trabajado también, por tanto, con un segundo conjunto de lenguas formado solo por aquellas cuyo texto fuente han sido los diez primeros artículos completos y fiables de la DUDH (376 lenguas). Final-mente, como ocurre en cualquier análisis estadístico, los valores extremos pueden distor-sionar resultados, por lo que paralelamente también realizaremos un análisis valiéndonos de un tercer conjunto constituido solo por las lenguas resultantes tras depurar las que presentan valores extremos; en este caso el número de lenguas con las que hemos trabajado es de 296.
De este modo, el número de lenguas de cada tipo morfológico predominante y su por-centaje con respecto al total son los que exponemos en los cuadros 1 y 2:
Cuadro 1. Número de lenguas por tipo morfológico predominante (análisis bruto de 376 lenguas)
Tipos morfológicos Frecuencia Porcentaje
A/I 65 17.29 %SA 172 45.74 %SF 94 25 %SP 45 11.97 %
Todos 376 100 %

29EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Cuadro 2. Número de lenguas por tipo morfológico predominante (análisis depurado de 296 lenguas)
Tipos morfológicos Frecuencia PorcentajeA/I 55 18.58 %SA 150 50.67 %SF 67 22.63 %SP 24 8.10 %
Todos 296 100 %
3. ANÁLISIS DE DATOS
De los datos obtenidos en el conjunto de todas las lenguas podemos concluir, en primer lugar, que los índices de relatividad informativa y de densidad informativa tienen una relación directa con el tipo morfológico. Así pues, las lenguas analíticas-aislantes van a emplear mayor número de palabras para expresar un mismo contenido y las lenguas polisintéticas un menor número de palabras. Por otro lado, las lenguas analíticas-aislantes presentan las palabras más breves, mientras que las lenguas polisintéticas presentan las palabras más largas. Y estos datos se consi-guen tanto analizando todas las 376 lenguas que tienen los diez primeros artículos de la DUDH como texto fuente, como depurando el análisis a 296 lenguas eliminando los valores extremos. Estas conclusiones, que podrían ya a priori parecer lógicas, se ven confirmadas y expuestas con exactitud cuantitativamente en nuestro estudio. Es lo que mostramos en los cuadros 3 y 4, en los que incluimos las medias (el promedio del conjunto de valores), las medianas (el valor que ocupa el lugar central de todos los datos cuando estos están ordenados de menor a mayor) y las desviaciones típicas (medida de la dispersión de los datos respecto a la media) para tokens.
Cuadro 3. Medias, Medianas y Desviaciones típicas para tokens (análisis bruto de 376 lenguas)
Tipos morfológicos Medias para tokens
Medianas para tokens
Desviaciones típicas para tokens
A/I 373.5538 361.0 81.92261SA 281.5116 266.0 75.50543SF 291.5000 288.5 46.77026SP 276.4889 247.0 81.81287
Cuadro 4. Medias, Medianas y Desviaciones típicas para tokens (análisis depurado de 296 lenguas)
Tipos morfológicos Medias para tokens
Medianas para tokens
Desviaciones típicas para tokens
A/I 382.1091 373.0 77.33230SA 271.0333 264.0 57.81217SF 298.8209 294.0 31.84381SP 239.7917 231.5 43.34491

30 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
El dato de las desviaciones típicas para tokens nos indica que las lenguas sintéticas fu-sionantes tienden a estar más agrupadas en el valor medio del número de tokens empleado para expresar una misma información, tienen menos dispersión en términos estadísticos. Es decir, para expresar el contenido de los diez primeros artículos de la Declaración Universal de los Derechos Humanos las lenguas fusionantes han usado una media de 291 tokens y en general todas las lenguas fusionantes se mueven en torno a esa cifra (298 tokens en el análisis depurado). Sin embargo, vemos que las lenguas analíticas-aislantes han usado una media de 373 tokens (382 en el análisis depurado) y las polisintéticas, de 276 (239 en el análisis depurado), pero que hay muchas lenguas de estos dos tipos morfológicos que se alejan de esa media, cosa que ocurre tanto en el análisis del conjunto de 376 lenguas como en el depurado de solo 296 lenguas. En nuestra opinión, esta mayor coherencia de las len-guas fusionantes podría estar relacionada con el hecho de pertenecer la mayoría de ellas a un mismo filo lingüístico (el indoeuropeo), frente a la mayor dispersión genética de las lenguas analíticas-aislantes y las polisintéticas. Las lenguas aglutinantes, por su parte, emplean una media de 281 tokens (271 en el análisis depurado).
El índice de relatividad informativa, como dato que muestra la potencial capacidad semántica de cada unidad fónica con respecto al número total de tokens utilizado por esa lengua, oscila entre los 0.3840 del toba y los 0.06993 del inuktitut de Canadá. O dicho de manera sencilla, el toba va a necesitar de media apenas algo más de 2.5 fonemas para for-mar una palabra, mientras que el inuktitut va a necesitar más de 14 fonemas de media para formar una palabra.
Por otro lado, los datos registrados también muestran que las lenguas analíticas-aislantes presentan unos valores de índice de densidad informativa claramente menores que el resto de tipos morfológicos, con una media de 4.3035 (o dicho de manera sencilla, las palabras de las lenguas analíticas-aislantes tienen una media de 4.3 fonemas) y una dispersión muy pequeña (prácticamente todas las lenguas analíticas-aislantes se van a mover en torno a un valor muy similar a ese). En el otro extremo estarían las lenguas polisintéticas con un ín-dice de densidad informativa de 6.8032 (es decir, las palabras de las lenguas polisintéticas tienen una media de 6.8 fonemas). Por su parte, las lenguas aglutinantes tendrían un índice de densidad informativa de 5.7769 y las fusionantes, de 5.36444 (vid. Figura 1):
4 El análisis depurado con solo 296 lenguas viene a aumentar todavía más la diferencia entre grupos morfoló-gicos (en torno al 4 de las A/I, frente a las SP que superarían el 7 de media).

31EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Figura 1. Dispersión respecto a la media para índice de densidad informativa (WLen)
En segundo lugar, podemos concluir que el número total de UFCT empleadas para expre-sar un mismo contenido de información no depende del tipo morfológico. Todos los tipos mor-fológicos han empleado un número medio de UFCT estadísticamente similar que se mueve entre los 1,533 de media de las lenguas SF, los 1,546 de las SA, los 1,570 de las A/I y los 1,809 de las SP (y teniendo en cuenta las medianas, incluso valores más próximos: 1,558.0 las A/I, 1,543.5 las SA, 1,540.5 las SF y 1,664.0 las SP)5. La caja de dispersión de la media de UFCT empleadas, además, es muy pequeña, lo que quiere decir que, en general, todas las lenguas de todos los tipos morfológicos se van a mover en valores muy cercanos a la media (quizá con la excepción de las lenguas SP, que vemos que presentan una mayor dispersión en valores por encima de la media). Es lo que mostramos gráficamente en el Cuadro 5 y la Figura 2:
Cuadro 5. Medias, Medianas y Desviaciones típicas para UFCT (análisis bruto de 376 lenguas)
Tipos morfológicos Medias para UFCT Medianas para UFCT Desviaciones típicas para UFCT
A/I 1,570.431 1,558.0 337.0922SA 1,546.506 1,543.5 289.2658SF 1,533.691 1,540.5 166.6511SP 1,809.533 1,664.0 495.1565
5 El análisis depurado con solo 296 lenguas arroja valores muy similares.

32 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Figura 2. Dispersión respecto a la media para UFCT
Estas dos primeras conclusiones no son incompatibles entre sí: el tipo morfológico de una lengua determina que esta emplee mayor o menor número de palabras para expresar una misma información y que sus palabras de media sean más largas o más cortas, pero también significa que el número total de fonemas o sonidos que necesita para expresar esa información no depende de su tipo morfológico. Sin embargo, nuestro estudio también revela que, aunque el tipo morfológico no determine el número total de UFCT empleadas, la diferencia entre el número total de UFCT empleadas por distintas lenguas puede ser muy elevada. Así, entre el arabela (con 2,299 UFCT empleadas y un índice de eficiencia informativa fónica de 0.0435) y el diola (914 UFCT, índice de eficiencia informativa fónica 0.1094) hay una diferencia de 2.5 veces. Y eso tomando en consideración solo las lenguas del análisis depurado, en el no depurado las diferencias son mucho mayores. Es decir, lenguas como el arabela, el amahuaca o el aguaruna emplean más del doble de fonemas que el diola, el kabyé, el kaonde o el twi para transmitir un mismo contenido informativo. Esto se ve corroborado si los comparamos con otros textos fuentes: mientras que el arabela necesita 520 UFCT para expresar el Padrenuestro, lenguas como el diola (163), el twi (170) o el wolof (183) emplean muchas menos.
Dicho esto, comprobamos, asimismo, que la correlación entre número de tokens y valor medio de UFCT por token muestra una relación lineal negativa (es decir, a mayor número de palabras, las longitudes de las palabras disminuyen). La ratio de esa relación lineal no es la misma, no obstante, en todos los grupos morfológicos. El coeficiente medio teniendo en cuenta todas las lenguas es de -.6781; y teniendo en cuenta los tipos morfo-lógicos oscilaría entre el -.7253 de coeficiente medio que tienen las lenguas aglutinantes
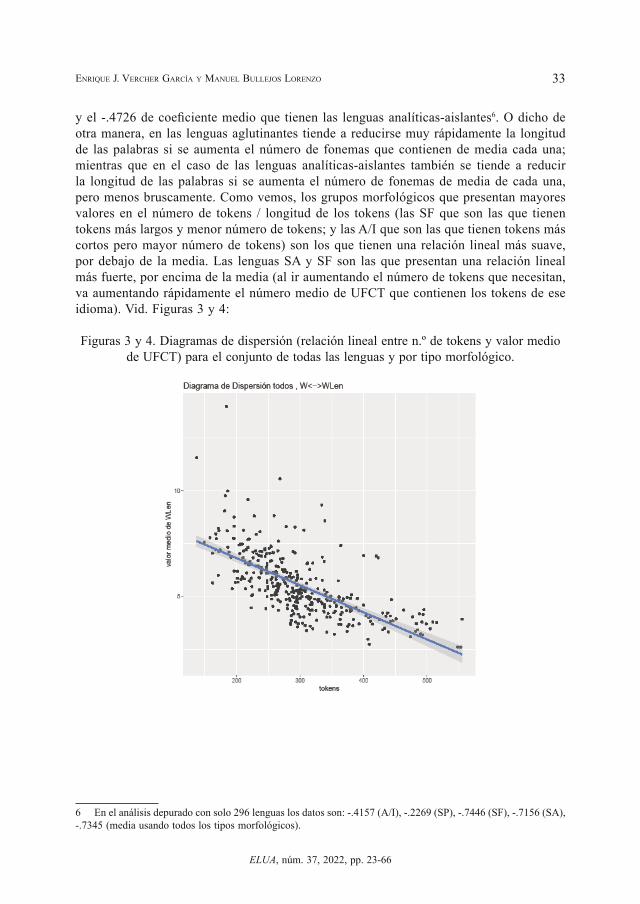
33EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
y el -.4726 de coeficiente medio que tienen las lenguas analíticas-aislantes6. O dicho de otra manera, en las lenguas aglutinantes tiende a reducirse muy rápidamente la longitud de las palabras si se aumenta el número de fonemas que contienen de media cada una; mientras que en el caso de las lenguas analíticas-aislantes también se tiende a reducir la longitud de las palabras si se aumenta el número de fonemas de media de cada una, pero menos bruscamente. Como vemos, los grupos morfológicos que presentan mayores valores en el número de tokens / longitud de los tokens (las SF que son las que tienen tokens más largos y menor número de tokens; y las A/I que son las que tienen tokens más cortos pero mayor número de tokens) son los que tienen una relación lineal más suave, por debajo de la media. Las lenguas SA y SF son las que presentan una relación lineal más fuerte, por encima de la media (al ir aumentando el número de tokens que necesitan, va aumentando rápidamente el número medio de UFCT que contienen los tokens de ese idioma). Vid. Figuras 3 y 4:
Figuras 3 y 4. Diagramas de dispersión (relación lineal entre n.º de tokens y valor medio de UFCT) para el conjunto de todas las lenguas y por tipo morfológico.
6 En el análisis depurado con solo 296 lenguas los datos son: -.4157 (A/I), -.2269 (SP), -.7446 (SF), -.7156 (SA), -.7345 (media usando todos los tipos morfológicos).

34 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Esta conclusión que acabamos de analizar no es incompatible con otra tendencia estadística presente en el estudio realizado: la de que a mayor número de tokens totales empleado para expresar una misma información corresponde por regla general un mayor número de UFCT totales (a mayor número de palabras totales, mayor número de fone-mas totales), independientemente de su tipo morfológico. O ejemplificándolo con dos casos concretos: tanto el wayuu como el shipibo-conibo son lenguas polisintéticas y de media sus palabras son más largas que las de lenguas analíticas-aislantes, pero, mientras que el wayuu ha empleado 167 tokens y 1,206 UFCT para expresar los diez primeros artículos de la DUDH, el shipibo-conibo ha empleado 423 tokens y 2,892 UFCT, es decir, muchas más palabras, pero también muchos más fonemas. Un estudio como el que hemos realizado permite nuevamente, no obstante, afinar esta tendencia general: el coeficiente de correlación entre número de palabras y número de letras presenta una relación lineal positiva en torno al 0.33 (si tenemos en cuenta todas las lenguas) y es independiente del tipo morfológico. Es decir, las lenguas van a aumentar su número de fonemas si aumenta su número de palabras en una proporción similar, en torno al 0.33, siendo las lenguas A/I las que presentan una relación lineal más brusca (0.5112). En el análisis depurado con solo 296 lenguas los resultados son los siguientes: 0.8691 (A/I), 0.8293 (SP), 0.5294 (SF), 0.3866 (SA), 0.4115 (media usando todos los tipos morfológicos).
No podemos dejar de mencionar el caso de las lenguas artificiales analizadas en el pre-sente estudio (ido, esperanto e interlingua). Los datos concretos para estas lenguas son los siguientes:

35EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Tabla 1. Lenguas artificiales, tipología morfológica, n.º de tokens, n.º de UFCT, índice de relatividad informativa, índice de densidad informativa, índice de eficiencia informativa
léxica, índice de eficiencia informativa fónica.
LENGUA
TIPO-LOGÍA MORFO-LÓGICA
OBSERVA-CIONES SOBRE EL TEXTO FUENTE
N.º DE TOKENS
N.º DE UFCT
ÍNDICE DE RELATIVIDAD INFORMATIVA (TOKENS/UFCT)
ÍNDICE DE DENSIDAD INFORMATIVA (UFCT/TOKENS)
ÍNDICE DE EFICIENCIA INFORMATIVA LÉXICA (100/TOKENS)
ÍNDICE DE EFICIENCIA INFORMATIVA FÓNICA (100/UFCT)
Ido SA A 248 1,240 0.2 5 0.403225806 0.080645161Esperanto SA A 314 1,538 0.204161248 4.898089172 0.318471338 0.065019506Interlingua SF A 313 1,567 0.199744735 5.006389776 0.319488818 0.063816209
De estos datos extraemos la conclusión de que las lenguas artificiales no presentan va-lores extremos, sino que están acordes con la media general de las lenguas naturales. Sus números de tokens y de UFCT totales empleados están dentro de la media general. Sus valores para los índices estudiados y las conclusiones que podríamos extraer también son coherentes con los de las lenguas naturales. De hecho, no se ha eliminado ninguna de ellas en el análisis matemáticamente depurado. Entendemos que esto es así porque las lenguas artificiales analizadas (ido, esperanto e interlingua), a pesar de ser lenguas construidas, se basan en gran medida (por ejemplo, su vocabulario) en lenguas naturales.
A este respecto también sería interesante comprobar los datos que arrojan lenguas artifi-ciales no basadas en lenguas naturales (por ejemplo, quenya, sindarin o klingon). Si toma-mos como texto fuente el Padrenuestro vemos que los valores de los índices de relatividad informativa (quenya: 0.1990; sindarin: 0.2378; klingon: 0.1189) y de densidad informativa (quenya: 5.0244; sindarin: 4.2045; klingon: 8.4074) no sobrepasan los valores extremos ni por arriba ni por debajo de algunas lenguas naturales que hemos analizado.
4. CONCLUSIONES
Los datos arrojados por el estudio nos llevan a una conclusión sorprendente: la denominada economía del lenguaje no parece funcionar de igual manera en todas las lenguas, al menos en lo que a uso de recursos (fonemas) se refiere. Si bien es verdad, como hemos visto ante-riormente, que todos los tipos morfológicos se mueven en unos valores medios similares (es decir, el número total de fonemas empleados no está en correlación con el tipo morfológico), lo cierto es que hay una gran diferencia entre el número de UFCT empleados por las lenguas que presentan los valores más bajos de número de UFCT y las lenguas con valores más altos.
Pero nuestro estudio también aporta otros datos interesantes para el conocimiento de ciertas características de las lenguas que sí van a depender de aspectos como la tipología morfológica. Datos que, en nuestra opinión, abren la puerta a nuevas categorizaciones lingüísticas más allá de la tipología morfológica tradicional o de los índices de sínte-sis, aglutinación, flexión, composición, prefijación, sufijación, aislamiento, flexión pura y concordancia. De este modo, entrarían como factor de estudio y descripción de las lenguas los índices de relatividad informativa, densidad informativa, eficiencia informativa léxica y eficiencia informativa fónica. En nuestro estudio nos hemos centrado en el aspecto de la tipología morfológica, pero sería aplicable a otros campos como la tipología genética, los sistemas fonético-fonológicos de las lenguas, etc.

36 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Los índices de relatividad y densidad informativa suponen nuevos indicadores para el estudio de la tipología morfológica. Además, existe una cierta correlación entre estos índices y el índice de síntesis, ya que, por regla general, cuanto más analítica sea una lengua mayor será su relatividad informativa (y menor será su densidad informativa).
El índice de eficiencia informativa léxica puede tener aplicaciones en el campo de la traductología, ya que establece de manera precisa la variación en número de palabras que tendrá un texto en la lengua de partida y en la lengua meta (hablamos de valores generales extraídos a partir del estudio realizado, evidentemente en cada caso concreto de una traduc-ción el número de palabras puede variar, además de que por regla general en la lengua meta de una traducción se suele aumentar el número de palabras). Esto puede ser importante en el mercado de la traducción profesional, puesto que hoy en día se suele tarifar por palabra.
Estos índices también pueden ayudar a identificar o descifrar lenguas. A modo de ejemplo curioso, el voynichés, la lengua del manuscrito Voynich (con 37,919 tokens y unas 170,000 UFCT) tiene un índice de densidad informativa inferior a 4.5, lo que descartaría, en cualquier caso, que se trate de una lengua polisintética o de un idioma con un alto índice de síntesis.
El presente trabajo supone en realidad la elaboración de una serie de herramientas de estudio que podrían ser aplicadas en el futuro a otras investigaciones (análisis de un corpus mayor, comparación entre textos fuente de diversa naturaleza dentro de una misma lengua, comparación bilateral más profunda entre dos lenguas o dos familias, incorporación de los índices presentados en este trabajo a estudios de tipología lingüística, aplicación de estos índices en el caso de lengua hablada y de otros registros lingüísticos, etc.). Queda abierto todo un campo de investigación en materia de tipología y de lingüística matemática.
REFERENCIAS BIBLIOGRÁFICAS
Adone, D., Brück, M. A. y Gabel, A. (2018). Kot nou vire tourne nou tand li. Serial Verb Constructions at the Interface between Grammar and Culture: Case-Study Kreol Seselwa (Seychelles Creole). Quaderni di Linguistica e Studi Orientali, 4, 15-46. http://dx.doi.org/10.13128/QULSO-2421-7220-23838
Aikhenvald, A. Y. (2000). Classifiers: A typology of noun categorization devices. Oxford University Press.
Ainsworth, Z. (2018). The Veps Illative: The Applicability of an Abstractive Approach to an Agglutinative Language. Transactions of the Philological Society. https://doi.org/10.1111/1467-968X.12142
Anderson, J. D. (1895). A Collection of Kachári Folk-Tales and Rhymes. Assam Secretariat Printing Office (online en The Project Gutenberg https://www.gutenberg.org/files/53506/53506-h/53506-h.htm).
Anderson, S. C. (2015). A Phonological Sketch of Lamnso’. SIL. https://www.sil.org/sys tem/f i les / reapdata /16/87/00/16870014076648162723540523929249624288/LamnsoPhonologySketch2015A4.pdf.
Aronoff, M. y Fudeman, K. (2005). What is morphology? Blackwell.Berg, A., Pretorius, R. y Pretorius, L. (2012). Exploring the Treatment of Selected Typological
characteristics of Tswana in LFG. En M. Butt y T. Holloway King (eds.). Proceedings of the LFG12 Conference. http://web.stanford.edu/group/cslipublications/cslipublications/LFG/17/papers/lfg12bergetal.pdf.
Beshears, A. (2017). The Demonstrative Nature of the Hindi/Marwari Correlative [tesis doctoral, Queen Mary University of London]. https://www.sil.org/system/files/reapdata/13/53/97/135397489734230802427407731441106180531/Beshears_A_PhD_131017.pdf.
https://www.sil.org/system/files/reapdata/16/87/00/16870014076648162723540523929249624288/LamnsoPhon
https://www.sil.org/system/files/reapdata/16/87/00/16870014076648162723540523929249624288/LamnsoPhon

37EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Bhosale, G., Kembhavi, S., Amberkar, A., Mhatre, S. y Popale, L. (2011). Processing of Kridanta (Participle) in Marathi. En Proceedings of ICON-2011: 9th International Conference on Natural Language Processing. Macmillan Publishers. https://www.cse.iitb.ac.in/~pb/papers/icon11-marathi-kridant.pdf.
Biggs, B. (1960). Morphology-Syntax in a Polynesian Language. The Journal of the Polynesian Society, 69 (4), 376-379. https://www.jstor.org/stable/20703854?seq=1#page_scan_tab_contents
Borchers, D. (2008). A Grammar of Sunwar: Descriptive Grammar, Paradigms, Texts and Glossary. BRILL.
Brassett, C., Brassett, P. y Lu, M. (2006). The Tujia language. Lincom Europa. Cope, A. T. (1966). Zulu Phonology, Tonology and Tonal Grammar [tesis doctoral, University of
Natal] https://researchspace.ukzn.ac.za/handle/10413/3320 Coupe, A. R. (2007). A Grammar of Mongsen Ao. De Gruyter Mouton. https://doi.
org/10.1515/9783110198522 Creissels, D. (2019). Morphology in Niger-Congo Languages. En The Oxford Encyclopedia of
Morphology. http://www.deniscreissels.fr/public/Creissels-morphNC.pdf. https://doi.org/10.1093/acrefore/9780199384655.013.535
Damonte, F. (2005). The Mirror Principle and the Order of Verbal Extensions: Evidence from Pular. En G. Booij et al. (eds.). On-line Proceedings of the Fifth Mediterranean Morphology Meeting (pp. 337-358). University of Bologna.
DeLancey, S. (2011). On the Origins of Sinitic. En Z. Jing-Schmidt (ed.). Proceedings of the 23rd North American Conference on Chinese Linguistics, (vol.1., pp. 51-64). University of Oregon.
Driem, G. van (1987). A Grammar of Limbu. Mouton De Gruyter. https://doi.org/10.1515/9783110846812 Ferguson, C. A. (1982). Simplified registers and linguistic theory. En L. K. Obler y L. Menn (ed.).
Exceptional Language and Linguistics (pp. 49-66). Academic Press.Gelderen, E. van (2016). Cyclical Change Continued. John Benjamins. https://doi.org/10.1075/la.227 Genetti, C. (2004). Tibeto-Burman languages of Nepal: Manange and Sherpa. Pacific Linguistics-The
Australian National University.Gerner, M. (2013). A Grammar of Nuosu. Mouton De Gruyter. https://doi.org/10.1515/9783110308679 Gilley, L. (2004). Morphophonemic Orthographies in Fusional Languages: The Cases of Dinka and
Shilluk. University of Khartoum- SIL International.Good, J. (2012). How to become a “Kwa” noun. Morphology, 22(2), 1-37. https://doi.org/10.1007/
s11525-011-9197-2Greenberg, J. H. (1954). A Quantitative Approach to the Morphological Typology of Languages. En
R. F. Spencer (ed.). Method and Perspective in Anthopology: Paper in Honor of Wilson D. Wallis (pp. 192-220). University of Minnesota Press.
Greksáková, Z. (2018). Tetun in Timor-Leste: The Role of Language Contact in its Development. [Tesis doctoral, Universidade de Coimbra]. https://estudogeral.uc.pt/handle/10316/80665
Hale, A. y Sresthacharya, I. (1972). Toward a revision of Hale’s roman Newari orthography. Kathmandu: Summer Institute of Linguistics (disponible online https://www.sil.org/resources/archives/36851).
Hardman, M. J., Vásquez, J., Yapita, J. de D., et al. (2001). Aymara: Compendio de estructura fonológica y gramatical. Instituto de Lengua y Cultura Aymara. https://fhcevirtual.umsa.bo/btecavirtual/?q=node/166
Hari, A. M. (2010). Yohlmo Grammar Sketch. Tribhuvan University.Haspelmath, M., Dryer, M., Gil, D. y Comrie, B. (2005). The World Atlas of Language Structures.
Oxford University Press.Haspelmath, M. y Michaelis, S. M. (2017). Analytic and synthetic: Typological change in varieties
of European languages. En I. Buchstaller y B. Siebenhaar (eds.). Language Variation - European Perspectives VI: Selected papers from the 8th International Conference on Language Variation in Europe (ICLaVE 8), Leipzig 2015. John Benjamins. https://doi.org/10.1075/silv.19.01has
Heine, B. y Nurse, D. (2008). A linguistic geography of Africa. Cambridge University Press. https://doi.org/10.1017/CBO9780511486272

38 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Jitwiriyanon, S. (2019). Ban Pa La-U Sgaw Karen Tones: an Analysis of Semitones, Quadratic Trendlines and Coefficients. En RGJ Seminar Series LXXXII on Southeast Asian Linguistics (pp. 60-77). Research Institute for Languages and Cultures of Asia at Mahidol University.
Kilarski, M. (2013). Nominal Classification: A History of its Study from the Classical Period to the Present. John Benjamins Publishing Company. https://doi.org/10.1075/sihols.121
King, D. (2010). Voice and Valence-Altering Operations in Falam Chin: A Role and Reference Grammar Approach [Tesis doctoral, The University of Texas at Arlington] http://www.tibeto-burman.net/files/King_2010_Voice_and_valence-altering_operations_in_Falam_Chin.pdf.
King, J. T. (2008). A grammar of Dhimal [Tesis doctoral, Leiden University]. https://openaccess.leidenuniv.nl/bitstream/handle/1887/13072/Kopie%20van%20Dhimal%20Grammar.pdf?sequence=1
Konnerth, L., Morey, S., Sarmah, P. y Amos, T. (2015). North East Indian Linguistics 7. The Australian National University. https://core.ac.uk/download/pdf/156698443.pdf.
Kornai, A. (2001). Mathematical Linguistics. Springer-Verlag https://eprints.sztaki.hu/7913/1/Kornai_1762289_ny.pdf
Krishan, S. (2001). A Sketch of Raji Grammar. 国立民族学博物館調査報告, 19, 449-497. http://doi.org/10.15021/00002153
Laboratorio de Lengua y Cultura Víctor Franco (2019). Jñatjo (mazahua). Centro de Investigaciones y Estudios Superiores en Antropología Social.
Launey, M. (1992). Introducción a la lengua y a la literatura Náhuatl. Universidad nacional autónoma de México.
Lee, S.-W. (2011). Eastern Tamang Grammar Sketch [Trabajo de fin de máster, Graduate Institute of Applied Linguistics]. https://www.sil.org/resources/archives/42567.
Leufkens, S. (2011). Kharia: A transparent language. Linguistics in Amsterdam, 4, 75-95. https://www.researchgate.net/publication/241888149_Kharia_a_transparent_language.
Mandelbrot, B. (1961). On the theory of word frequencies and on relatedmarkovian models of discourse. En R. Jakobson (ed.). Structure of language and its mathematical aspects (pp. 190-219). American Mathematical Society. https://doi.org/10.1090/psapm/012/9970
Manson, K. (2003). Karenic Language Relationships: A Lexical and Phonological Analysis. Payap University. https://www.sil.org/system/files/reapdata/76/92/97/76929773418782758038670312229278361244/Manson_2003___Karen_lg_relationships.pdf. https://doi.org/10.1024/0369-8394.92.3.97
Martinet, A. (1955). Économie des changements phonétiques. Traité de phonologie diachronique. Éditions A. Francke.
Martinet, A. (1987). Sintaxis general. Gredos. Martinet, A. (1993). Función y dinámica de las lenguas. Gredos.Mchombo, S. (2004). The Syntax of Chichewa. Cambridge University Press. https://doi.org/10.1017/
CBO9780511486302 Mensah, E. O. (2010). On Efik Prefixing Morphology. The Buckingham Journal of Language and
Linguistics, 3, 187-203. https://doi.org/10.5750/bjll.v3i0.31 Michaud, A. (2012). The Complex Tones of East/Southeast Asian Languages: Current Challenges
forTypology and Modelling. Third International Symposium on Tonal Aspects of Languages (TAL2012), Nanjing, China, 2012, pp. 1-7. HAL Id: halshs-00676251. https://halshs.archives-ouvertes.fr/halshs-00676251.
Micheli, I. (2018). Grammatical Sketch and Short Vocabulary of the Ogiek Language of Mariashoni. Università di Trieste.
Mihas, E. (2010). Essentials of Ashéninka Perené Grammar [Tesis doctoral, University of Wisconsin-Milwaukee]. https://www.researchgate.net/publication/50198629_ESSENTIALS_OF_ASHENINKA_PERENE_GRAMMAR.
Mnguhenen Sokpo, R. (2016). An Autosegmental Analysis of Tiv Phonology [Tesis doctoral, Benue State University] https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.424.286&rep=rep1&type=pdf
国立民族学博物館調査報告
http://www.tibeto-burman.net/files/King_2010_Voice_and_valence-altering_operations_in_Falam_Chin.pdf

39EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Moran, S. y McCloy, D. (2019). PHOIBLE 2.0. Max Planck Institute for the Science of Human History. http://phoible.org (21-10-2019).
Moreno Cabrera, J. C. (2003). Síntesis y análisis en las lenguas. Crítica de la morfología clásica y de algunas de sus aplicaciones sincrónicas y diacrónicas. Estudios de Lingüística de la Universidad de Alicante, 17, 465-504. https://core.ac.uk/download/pdf/16359747.pdf
Moreno Cabrera, J. C. (1997). Introducción a la Lingüística. Enfoque tipológico y universalista. Síntesis.
Musumali, G. (2014). Zambezi Lunda and Zambezi Luvale. Phonological and Lexical Similarities. Series 1. Phonemic contrasts. Autoedición. https://www.academia.edu/39625196/series_1_phonemic_contrasts_of_lunda_and_luvale.
Mutaka, N. M. (2007). Kinande: A Grammar Sketch (Version 1.0). Rutgers, The State University of New Jersey-Afranaph Project.
Naula Guacho, J. y Burns, D. D. (1975). Bosquejo gramatical del quichua de Chimborazo. Universidad Central del Ecuador.
Nchare, A. L. (2012). The Grammar of Shupamem. New York University. ling.auf.net/lingbuzz/001441/current.pdf.
Ndze, W. F. (2015). A Comparative Morphological Analysis of Lamnsó and the English Compound Words. Ahmadu Bello University.
Nurse, D. (2007). Did the Proto-Bantu verb have a Synthetic or an Analytic Structure? SOAS Working Papers in Linguistics, 15, 239-256. https://www.soas.ac.uk/linguistics/research/workingpapers/volume-15/file37812.pdf.
Osada, T. (2008). Mundari. En D.S. Anderson (ed.). The Munda Languages (pp. 99-164). Routledge.Overall, S. E. (2007). A Grammar of Aguaruna. Research Centre for Linguistic Typology-La Trobe
University.Owen-Smith, T. (2014). Grammatical Relations in Tamang, a Tibeto-Burman Language of Nepal
[Tesis doctoral, University of London] https://eprints.soas.ac.uk/23664/1/Owen-Smith_4167.pdf.Paster, M. (2010). The Verbal Morphology and Phonology of Asante Twi. Studies in African Linguistics,
39(1), 77-120. https://doi.org/10.32473/sal.v39i1.107285 Paudyal, K. P. (2013). A Grammar of Chitoniya Tharu [Tesis doctoral, Tribhuvan University].
http://202.45.147.21:8080/jspui/bitstream/123456789/297/1/75.%20Krishna%20Prasad%20Paudyal.pdf.
Passy, P. (1890). Etude sur les changements phonétiques et leurs caractères généraux. Firmin-Didot.Payne, D. L. (1974). Nasality in Aguaruna. The University of Texas at Arlington.Peirce, C. S. S. (1906). Prolegomena to an Apology for Pragmaticism. The Monist, 16, 492-546.
https://archive.org/details/jstor-27899680. https://doi.org/10.5840/monist190616436Peterson, J. (2010). Kharia Texts. Glossed, translated and annotated by John Peterson. Autoedición.
https://pure.mpg.de/rest/items/item_402190_2/component/file_679587/content.Phillips, A. (1999). Western Thailand Pwo Karen Text Collection. Thammasat University-Summer
Institut of Linguistics.Plaisier, H. (1968). A Grammar of Lepcha [Tesis doctoral, Universidad de Leiden]. https://
scholarlypublications.universiteitleiden.nl/handle/1887/4379Poeta, T. (2016). Reference to objects in Makhuwa and Swahili discourse. University of London.
https://eprints.soas.ac.uk/26161/1/4437_Poeta.pdf.Pokharel, M., Donohue, M. y Gautam, B. (AÑO). Kusunda linguistics. The Australian National
University. http://kusunda.linguistics.anu.edu.au/index.php Poletto, R. (1998). Topics in Runyankore Phonology [Tesis doctoral, The Ohio State University].Provencher, C. (2012). A Morpho-Syntactic Analysis of Marshallese Determiner Phrases [Tesis
doctoral, Université du Québec à Montréal]. https://archipel.uqam.ca/4685/1/M12379.pdf.Rai, T. M. (2017). A Sociolinguistic Survey of Chamling: A Tibeto-Burman Language. Tribhuvan
University. http://cdltu.edu.np/site/images/linsun/chamling.pdf.

40 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
Ramos, P. A. (2015). La fonología y morfología del zapoteco de San Pedro Mixtepec [Tesis doctoral, Centro de Investigaciones y Estudios Superiores en Antropología Social]. http://repositorio.ciesas.edu.mx/bitstream/handle/123456789/399/D278.pdf?sequence=1&isAllowed=y
Regmi, D. R. y Regmi, A. (2011). A Sociolinguistic Survey of Bhujel: A Tibeto-Burman Language. Tribhuvan University. http://cdltu.edu.np/site/images/linsun/bhujel.pdf.
Rich, F. (1963). Arabela phonemes and high-level phonology. En Benjamin F. Elson (ed.). Studies in Peruvian Indian Languages: I (pp. 193-206). Summer Institute of Linguistics of the University of Oklahoma.
Ringmacher, M. (1989). Los modelos tipológicos y la descripción del Guaraní. Amerindia, 14. https://www.researchgate.net/publication/268000650_Los_modelos_tipologicos_y_la_descripcion_del_Guarani.
Romano, A. (2018). Preliminary Analysis of Ditammari Tonal Patterns. Studi e Ricerche, 3, 251-261.Sapir, J. D. (1969). A Grammar of Diola-Fogny. Cambridge University Press.Sayce, A. H. (1880 [2015]). Introduction to the Science of Language. Volume 2. Cambridge University
Press.Schackow, D. (2015). A grammar of Yakkha (Studies in Diversity Linguistics 7). Language Science
Press-Freie Universität. https://doi.org/10.26530/OAPEN_603340 Schadeberg, T. C. (1982). Nasalization in Umbundu. Journal of African Languages and Linguistics,
4, 109-132. https://openaccess.leidenuniv.nl/bitstream/handle/1887/8809/5_1234891_024.pdf. https://doi.org/10.1515/jall.1982.4.2.109
Sibanda, G. (2004). Verbal Phonology and Morphology of Ndebele [Tesis doctoral, University of California]. https://escholarship.org/uc/item/6cf9w3j2.
Štekauer, P., Valera, S. y Kőrtvélyessy, L. (2012). Word-Formation in the World’s Languages: A Typological Survey. Cambridge University Press. https://doi.org/10.1515/lity-2013-0022
Sweet, H. (1888). A history of English sounds from the earliest period. Clarendon Press.Thurgood, G. y LaPolla, R. J. (2003). The Sino-Tibetan Languages. Routledge.Turin, M. (2012). A grammar of the Thangmi language: with an ethnolinguistic introduction to the
speakers and their culture. BRILL.UNITED NATIONS, Universal Declaration of Human Rights. https://readtiger.com/www.unicode.org/
udhr/assemblies/full_all.html and https://www.ohchr.org/SP/UDHR/Pages/SearchByLang.aspx. Vendryes, J. (1939). Parler par Èconomie. En Mélanges de linguistique offerts à Charles Bally (pp.
49-62). Université de Genève-Georg & Cie.Vercher García, E. J. (2011). Estudio comparado de partículas modales en ruso y español. EAE
Publishing.Vercher García, E. J. (2019). El modelo estructural-funcional del sistema de clases de palabras. El
caso de las partículas modales en la lengua española. Analecta Malacitana (AnMal Electrónica), 46, 111-130.
Vesalainen, O. (2016). A Grammar Sketch of Lhomi. SIL International. https://www.sil.org/system/files/reapdata/27/32/78/27327800011828341569489257185488473676/sillcdd_34.pdf.
Vuillermet, M. (2013). The grammar of fear in Ese’eja. Syntax Circle. University of California.Vydrin, V. (2016). Tonal inflection in Mande languages: The cases of Bamana and Dan-Gwtaa. En E.
Palancar y L. Jean Léo (eds.). Tone and Inflection: New facts and new perspectives (pp. 83-105). De Gruyter. https://doi.org/10.1515/9783110452754-005
Walls, T. (2015). Tsafiki: A Linguistic Analysis of the Ecuadorian Language. [Trabajo de fin de grado, University of Central Arkansas] https://www.academia.edu/12048805/Tsafiki_A_Linguistic_Analysis_of_the_Ecuadorian_Language.
Welmers, W. E. (1952). Notes on the Structure of Bariba. Language, 28 (1), 82-103. https://doi.org/10.2307/409991
Wetzel, L. (2018). Types and Tokens. En E. N. Zalta (ed.). The Stanford Encyclopedia of Philosophy (Fall 2018 Edition). The Metaphysics Research Lab.
https://www.researchgate.net/publication/268000650_Los_modelos_tipologicos_y_la_descripcion_del_Guar
https://www.researchgate.net/publication/268000650_Los_modelos_tipologicos_y_la_descripcion_del_Guar

41EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
Wilde, C. P. (2008). A Sketch of the Phonology and Grammar of Rājbanshi. University of Helsinki https://helda.helsinki.fi/bitstream/handle/10138/19290/asketcho.pdf?sequence=1&isAllowed=y.
Wojtylak, K. (2017). Verbal classifiers in Murui (Witotoan) - What are they? En International Workshop “Genders and classifiers in Amazonia and beyond”, 10 de agosto de 2017. https://www.academia.edu/34231601/Verbal_Classifiers.
Wozny, D. y Cassin, B. (dirs.) (2014). Les intraduisibles du patrimoine en Afrique subsaharienne. Demopolis. https://doi.org/10.4000/books.demopolis.515
Zariquiey Biondi, R. (2011). A grammar of Kashibo-Kakataibo [Tesis doctoral, La Trobe University]. http://etnolinguistica.wdfiles.com/local--files/tese%3Azariquiey-2011/zariquiey_biondi_2011.pdf.
Zerbian, S. (2007). A First Approach to Information Structuring in Xitsonga/Xichangana. SOAS Working Papers in Linguistics, 15, 65-78. https://www.soas.ac.uk/linguistics/research/workingpapers/volume-15/file37800.pdf.
Zipf, G. K. (1949). Human Behavior and the Principle of Least Effort. Addison-Wesley Press.
Expresamos nuestro agradecimiento a Tania García Arévalo, Taidor Lam, Vicente García Rojas, Elena Erickson de Hollenbach, Klaus Zimmermann, Nicholas R. Rolle, Faust Noam, Justin B. Hopkins, John Smith, Ronald Asher, Maria Keet, Joan Byamugisha, Victor Tapuyo Pianchiche, Huia Jahnke, Charles Marfo, Regina Caesar y Hona Black.

42 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
APÉ
ND
ICE
Tabl
a 2.
Len
guas
, tip
olog
ía m
orfo
lógi
ca, n
.º de
toke
ns, n
.º de
UFC
T, ín
dice
de
rela
tivid
ad in
form
ativ
a, ín
dice
de
dens
idad
info
rmat
i-va
, índ
ice
de e
ficie
ncia
info
rmat
iva
léxi
ca, í
ndic
e de
efic
ienc
ia in
form
ativ
a fó
nica
.
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Abk
haz
SA21
11,
508
0.13
9920
424
7.14
6919
431
0.47
3933
649
0.06
6312
997
Ach
ehne
se
SA32
51,
901
0.17
0962
651
5.84
9230
769
0.30
7692
308
0.05
2603
893
Ach
uar-S
hiw
iar
SA28
92,
060
0.14
0291
262
7.12
8027
682
0.34
6020
761
0.04
8543
689
Adj
a A
/I41
11,
575
0.26
0952
381
3.83
2116
788
0.24
3309
002
0.06
3492
063
Ady
ghe
SA25
11,
826
0.13
7458
927
7.27
4900
398
0.39
8406
375
0.05
4764
513
Afa
an O
rom
o (O
rom
iffa)
SA
239
1,50
20.
1591
2117
26.
2845
1882
80.
4184
1004
20.
0665
7789
6
Afr
ikaa
nsA
/I29
51,
473
0.20
0271
555
4.99
3220
339
0.33
8983
051
0.06
7888
663
Agu
arun
aSA
338
2,25
00.
1502
2222
26.
6568
0473
40.
2958
5798
80.
0444
4444
4
A’in
gae
SP20
61,
542
0.13
3592
737
7.48
5436
893
0.48
5436
893
0.06
4850
843
Alb
ania
nSF
317
1,56
90.
2020
3951
64.
9495
2681
40.
3154
5741
30.
0637
3486
3
Alta
ySA
296
1,73
50.
1706
0518
75.
8614
8648
60.
3378
3783
80.
0576
3688
8
Am
ahua
caSP
259
2,28
40.
1133
9754
88.
8185
3281
90.
3861
0038
60.
0437
8283
7
Am
arak
aeri
SP29
22,
062
0.14
1610
087
7.06
1643
836
0.34
2465
753
0.04
8496
605
Am
azig
h /
Tam
azig
ht,
Cen
tral A
tlas
SA31
91,
490
0.21
4093
964.
6708
4639
50.
3134
7962
40.
0671
1409
4
Am
is
SA26
51,
283
0.20
6547
155
4.84
1509
434
0.37
7358
491
0.07
7942
323
Am
uesh
a-Ya
nesh
aSP
420
2,90
30.
1446
7791
96.
9119
0476
20.
2380
9523
80.
0344
4712
4

43EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Ao
SA21
41,
148
0.18
6411
155.
3644
8598
10.
4672
8972
0.08
7108
014
Ara
bela
SP
335
2,29
90.
1457
1552
86.
8626
8656
70.
2985
0746
30.
0434
9717
3
Ara
bic
SF27
81,
645
0.16
8996
965.
9172
6618
70.
3597
1223
0.06
0790
274
Arm
enia
n SA
261
1,60
90.
1622
1255
46.
1647
5095
80.
3831
4176
20.
0621
5040
4
Asa
nte
A/I
316
1,13
80.
2776
8014
13.
6012
6582
30.
3164
5569
60.
0878
7346
2
Ash
ánin
ca
SP21
82,
088
0.10
4406
139.
5779
8165
10.
4587
1559
60.
0478
9272
Ass
ames
eSF
*23
138
0.16
6666
667
6n/
an/
a
Ass
yria
n (A
tora
ya)
SF*
185
920
0.20
1086
957
4.97
2972
973
n/a
n/a
Ast
uria
n (B
able
)SF
340
1,74
00.
1954
0229
95.
1176
4705
90.
2941
1764
70.
0574
7126
4
Awad
hi
SF*
6628
00.
2357
1428
64.
2424
2424
2n/
an/
a
Awap
it SA
195
1,51
20.
1289
6825
47.
7538
4615
40.
5128
2051
30.
0661
3756
6
Aym
ara
SA15
81,
228
0.12
8664
495
7.77
2151
899
0.63
2911
392
0.08
1433
225
Ayor
eo
SFi
185
796
0.23
2412
064.
3027
0270
3n/
an/
a
Aze
ri/A
zerb
aija
niSA
272
1,70
70.
1593
4387
86.
2757
3529
40.
3676
4705
90.
0585
8230
8
Bah
asa
Indo
nesi
aSA
296
1,78
50.
1658
2633
16.
0304
0540
50.
3378
3783
80.
0560
2240
9
Bah
asa
Mel
ayu
(Mal
ay)
SA27
11,
793
0.15
1143
335
6.61
6236
162
0.36
9003
690.
0557
7244
8
Bai
A/I
283
1,68
40.
1680
5225
75.
9505
3003
50.
3533
5689
0.05
9382
423
Bel
anda
Viri
SA34
21,
133
0.30
1853
486
3.31
2865
497
0.29
2397
661
0.08
8261
253
Bal
ines
e SA
294
1,81
90.
1616
2726
86.
1870
7483
0.34
0136
054
0.05
4975
261
Bal
ochi
SF
*29
11,
307
0.22
2647
284
4.49
1408
935
n/a
n/a
44 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Bam
bara
A
/I29
01,
215
0.23
8683
128
4.18
9655
172
0.34
4827
586
0.08
2304
527
Bam
um
SA43
31,
515
0.28
5808
581
3.49
8845
266
0.23
0946
882
0.06
6006
601
Bao
ulé/
Bau
leA
/I49
01,
586
0.30
8953
342
3.23
6734
694
0.20
4081
633
0.06
3051
702
Bar
i SA
347
1,39
60.
2485
6733
54.
0230
5475
50.
2881
8443
80.
0716
3323
8
Bas
que
(Eus
kara
)SA
253
1,68
80.
1498
8151
76.
6719
3675
90.
3952
5691
70.
0592
4170
6
Bat
onu
(Bar
iba)
SA31
01,
052
0.29
4676
806
3.39
3548
387
0.32
2580
645
0.09
5057
034
Bel
orus
(B
elar
uski
)SF
286
1,67
90.
1703
3948
85.
8706
2937
10.
3496
5035
0.05
9559
261
Bem
ba
SA25
61,
512
0.16
9312
169
5.90
625
0.39
0625
0.06
6137
566
Ben
gali
SF23
41,
569
0.14
9139
579
6.70
5128
205
0.42
7350
427
0.06
3734
863
Bét
i SA
i20
977
80.
2686
3753
23.
7224
8803
8n/
an/
a
Bho
jpur
i SF
294
1,55
60.
1889
4601
55.
2925
1700
70.
3401
3605
40.
0642
6735
2
Bhu
jel (
Gha
rti)
SA*
211
1,20
20.
1755
4076
55.
6966
8246
4n/
an/
a
Bic
hela
mar
A
/I43
01,
816
0.23
6784
141
4.22
3255
814
0.23
2558
140.
0550
6607
9
Bik
ol/B
icol
ano
SA34
21,
781
0.19
2026
951
5.20
7602
339
0.29
2397
661
0.05
6148
231
Biz
isa,
Biz
ika,
Tu
jiaA
/I27
31,
590
0.17
1698
113
5.82
4175
824
0.36
6300
366
0.06
2893
082
Bod
o (K
acha
ri)SA
*55
63,
313
0.16
7823
725
5.95
8633
094
n/a
n/a
Bor
a SP
228
2,00
80.
1135
4581
78.
8070
1754
40.
4385
9649
10.
0498
0079
7
Bos
nian
SF26
31,
391
0.18
9072
615.
2889
7338
40.
3802
2813
70.
0718
9072
6
Bre
ton
SF29
31,
302
0.22
5038
402
4.44
3686
007
0.34
1296
928
0.07
6804
916
Bug
isne
se
SA27
51,
726
0.15
9327
926
6.27
6363
636
0.36
3636
364
0.05
7937
428
45EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Bul
garia
n (B
alga
rski
)SF
299
1,58
80.
1882
8715
45.
3110
3678
90.
3344
4816
10.
0629
7229
2
Bur
mes
e/M
yanm
arA
/I33
43,
115
0.10
7223
114
9.32
6347
305
0.29
9401
198
0.03
2102
729
Cak
chiq
uel
SA44
42,
157
0.20
5841
446
4.85
8108
108
0.22
5225
225
0.04
6360
686
Can
dosh
i-Sha
pra
SP23
71,
910
0.12
4083
778.
0590
7173
0.42
1940
928
0.05
2356
021
Can
tone
se
A/I
313
1,38
20.
2264
8335
74.
4153
3546
30.
3194
8881
80.
0723
589
Caq
uint
e SP
268
2,83
20.
0946
3276
810
.567
1641
80.
3731
3432
80.
0353
1073
4
Cas
hibo
-Cac
atai
boSP
379
1,86
20.
2035
4457
64.
9129
2876
0.26
3852
243
0.05
3705
693
Cat
alan
(Cat
alà)
SF29
51,
433
0.20
5861
828
4.85
7627
119
0.33
8983
051
0.06
9783
671
Ceb
uano
SA
304
1,61
70.
1880
0247
45.
3190
7894
70.
3289
4736
80.
0618
4291
9
Cha
a’pa
la
(Cay
apa)
SA*
574
3,21
50.
1785
3810
35.
6010
4529
6n/
an/
a
Cha
mor
ro
SA31
91,
642
0.19
4275
274
5.14
7335
423
0.31
3479
624
0.06
0901
34
Cha
yahu
ita
SP18
51,
501
0.12
3251
166
8.11
3513
514
0.54
0540
541
0.06
6622
252
Che
chew
a (N
yanj
a)SA
239
1,52
80.
1564
1361
36.
3933
0543
90.
4184
1004
20.
0654
4502
6
Chi
ckas
aw
SAi
8576
90.
1105
3316
9.04
7058
824
n/a
n/a
Chi
n Fa
lam
SA48
31,
798
0.26
8631
813
3.72
2567
288
0.20
7039
337
0.05
5617
353
Chi
n H
akha
SA49
52,
169
0.22
8215
768
4.38
1818
182
0.20
2020
202
0.04
6104
195
Chi
n M
atu
(Nga
La
)A
/I*
363
1,60
30.
2264
5040
54.
4159
7796
1n/
an/
a
Chi
n Ti
ddim
SA35
41,
673
0.21
1595
935
4.72
5988
701
0.28
2485
876
0.05
9772
863
Chi
nant
eco
A/I
361
1,33
20.
2710
2102
13.
6897
5069
30.
2770
0831
0.07
5075
075

46 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Chi
nant
eco,
A
jitlá
nA
/Ii
269
798
0.33
7092
732
2.96
6542
751
n/a
n/a
Chi
nese
(M
anda
rin)
A/I
294
1,31
90.
2228
9613
34.
4863
9455
80.
3401
3605
40.
0758
1501
1
Chi
quita
no
SP*
227
1,50
20.
1511
3182
46.
6167
4008
8n/
an/
a
Chu
uk (T
ruke
se)
SA38
81,
735
0.22
3631
124
4.47
1649
485
0.25
7731
959
0.05
7636
888
Chu
vash
SA
316
1,83
40.
1723
0098
15.
8037
9746
80.
3164
5569
60.
0545
2562
7
Cok
we
SA22
41,
225
0.18
2857
143
5.46
875
0.44
6428
571
0.08
1632
653
Cor
sica
n SF
318
1,50
10.
2118
5876
14.
7201
2578
60.
3144
6540
90.
0666
2225
2
Crio
ulo
(Cab
o Ve
rde)
A/I
437
1,84
30.
2371
1340
24.
2173
9130
40.
2288
3295
20.
0542
5936
Crio
ulo
da G
uiné
-B
issa
u (G
uine
a B
issa
u C
reol
e)
SF31
61,
458
0.21
6735
254
4.61
3924
051
0.31
6455
696
0.06
8587
106
Cro
atia
n SF
258
1,41
30.
1825
9023
45.
4767
4418
60.
3875
9689
90.
0707
7140
8
Cym
raeg
(Wel
sh)
SF29
01,
436
0.20
1949
861
4.95
1724
138
0.34
4827
586
0.06
9637
883
Cze
ch (C
esky
)SF
248
1,40
60.
1763
8691
35.
6693
5483
90.
4032
2580
60.
0711
2375
5
Dag
aare
SA
430
1,47
40.
2917
2320
23.
4279
0697
70.
2325
5814
0.06
7842
605
Dag
bani
SA
393
1,45
60.
2699
1758
23.
7048
3460
60.
2544
5292
60.
0686
8131
9
Dan
gme
A/I
548
1,43
10.
3829
4898
72.
6113
1386
90.
1824
8175
20.
0698
8120
2
Dan
ish
(Dan
sk)
SF28
31,
384
0.20
4479
769
4.89
0459
364
0.35
3356
890.
0722
5433
5
Den
di
SAi
241
868
0.27
7649
773.
6016
5975
1n/
an/
a
Dha
nuk
(Mag
ahi)
SF25
51,
245
0.20
4819
277
4.88
2352
941
0.39
2156
863
0.08
0321
285
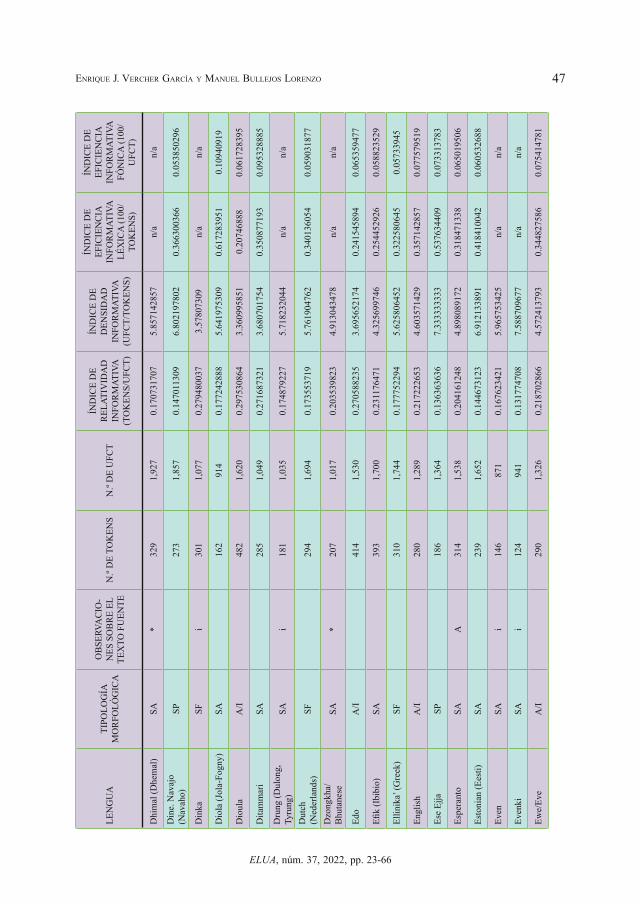
47EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Dhi
mal
(Dhe
mal
)SA
*32
91,
927
0.17
0731
707
5.85
7142
857
n/a
n/a
Din
e. N
avaj
o (N
avah
o)SP
273
1,85
70.
1470
1130
96.
8021
9780
20.
3663
0036
60.
0538
5029
6
Din
ka
SFi
301
1,07
70.
2794
8003
73.
5780
7309
n/a
n/a
Dio
la (J
ola-
Fogn
y)SA
162
914
0.17
7242
888
5.64
1975
309
0.61
7283
951
0.10
9409
19
Dio
ula
A/I
482
1,62
00.
2975
3086
43.
3609
9585
10.
2074
6888
0.06
1728
395
Dita
mm
ari
SA28
51,
049
0.27
1687
321
3.68
0701
754
0.35
0877
193
0.09
5328
885
Dru
ng (D
ulon
g,
Tyru
ng)
SAi
181
1,03
50.
1748
7922
75.
7182
3204
4n/
an/
a
Dut
ch
(Ned
erla
nds)
SF29
41,
694
0.17
3553
719
5.76
1904
762
0.34
0136
054
0.05
9031
877
Dzo
ngkh
a/B
huta
nese
SA*
207
1,01
70.
2035
3982
34.
9130
4347
8n/
an/
a
Edo
A/I
414
1,53
00.
2705
8823
53.
6956
5217
40.
2415
4589
40.
0653
5947
7
Efik
(Ibi
bio)
SA39
31,
700
0.23
1176
471
4.32
5699
746
0.25
4452
926
0.05
8823
529
Ellin
ika’
(Gre
ek)
SF31
01,
744
0.17
7752
294
5.62
5806
452
0.32
2580
645
0.05
7339
45
Engl
ish
A/I
280
1,28
90.
2172
2265
34.
6035
7142
90.
3571
4285
70.
0775
7951
9
Ese
Ejja
SP18
61,
364
0.13
6363
636
7.33
3333
333
0.53
7634
409
0.07
3313
783
Espe
rant
o SA
A31
41,
538
0.20
4161
248
4.89
8089
172
0.31
8471
338
0.06
5019
506
Esto
nian
(Ees
ti)SA
239
1,65
20.
1446
7312
36.
9121
3389
10.
4184
1004
20.
0605
3268
8
Even
SAi
146
871
0.16
7623
421
5.96
5753
425
n/a
n/a
Even
ki
SAi
124
941
0.13
1774
708
7.58
8709
677
n/a
n/a
Ewe/
Eve
A/I
290
1,32
60.
2187
0286
64.
5724
1379
30.
3448
2758
60.
0754
1478
1

48 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Fant
e A
/I34
21,
376
0.24
8546
512
4.02
3391
813
0.29
2397
661
0.07
2674
419
Faro
ese
SF26
11,
355
0.19
2619
926
5.19
1570
881
0.38
3141
762
0.07
3800
738
Fars
i/Per
sian
SA31
61,
373
0.23
0152
954.
3449
3670
90.
3164
5569
60.
0728
3321
2
Fijia
n A
/I31
91,
390
0.22
9496
403
4.35
7366
771
0.31
3479
624
0.07
1942
446
Filip
ino
(Tag
alog
)SA
302
1,65
20.
1828
0871
75.
4701
9867
50.
3311
2582
80.
0605
3268
8
Finn
ish
SA21
81,
678
0.12
9916
567
7.69
7247
706
0.45
8715
596
0.05
9594
756
Fiot
e/K
ongo
/K
ikon
go (A
ngol
a)SA
298
1,53
10.
1946
4402
45.
1375
8389
30.
3355
7047
0.06
5316
786
Fon
A/I
409
1,12
00.
3651
7857
12.
7383
8630
80.
2444
9877
80.
0892
8571
4
Fran
copr
oven
çal /
O
ccita
n (F
ribou
rg)
SF33
71,
452
0.23
2093
664
4.30
8605
341
0.29
6735
905
0.06
8870
523
Fran
copr
oven
çal /
O
ccita
n (S
avoi
e)SF
344
1,44
50.
2380
6228
44.
2005
8139
50.
2906
9767
40.
0692
0415
2
Fran
copr
oven
çal /
O
ccita
n (V
alai
s)SF
329
1,57
30.
2091
5448
24.
7811
5501
50.
3039
5136
80.
0635
7279
1
Fran
copr
oven
çal /
O
ccita
n (V
aud)
SF38
11,
657
0.22
9933
615
4.34
9081
365
0.26
2467
192
0.06
0350
03
Fren
ch (F
ranç
ais)
SF32
51,
408
0.23
0823
864
4.33
2307
692
0.30
7692
308
0.07
1022
727
Fris
ian
SF28
91,
529
0.18
9012
426
5.29
0657
439
0.34
6020
761
0.06
5402
224
Friu
lian
(Friu
lano
)SF
335
1,55
70.
2151
5735
44.
6477
6119
40.
2985
0746
30.
0642
2607
6
Fulfu
de, F
ula
(Nig
eria
n)SA
245
1,29
10.
1897
7536
85.
2693
8775
50.
4081
6326
50.
0774
5933
4
Ga
A/I
377
1,38
60.
2720
0577
23.
6763
9257
30.
2652
5198
90.
0721
5007
2
Gae
ilge
(Iris
h G
aelic
)SF
326
1,26
40.
2579
1139
23.
8773
0061
30.
3067
4846
60.
0791
1392
4
Gag
auz
SA22
91,
478
0.15
4939
107
6.45
4148
472
0.43
6681
223
0.06
7658
999

49EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Gài
dhlig
Alb
anac
h (S
cotti
sh G
aelic
)SF
323
1,57
70.
2048
1927
74.
8823
5294
10.
3095
9752
30.
0634
1154
1
Gal
icia
n (G
aleg
o)SF
288
1,55
30.
1854
4752
15.
3923
6111
10.
3472
2222
20.
0643
915
Gan
A
/I*
281
1,33
80.
2100
1494
84.
7615
6583
6n/
an/
a
Gan
daSA
214
1,41
10.
1516
6548
56.
5934
5794
40.
4672
8972
0.07
0871
722
Gar
hwal
i SF
*61
322
0.18
9440
994
5.27
8688
525
n/a
n/a
Gar
ifuna
SP
220
1,26
40.
1740
5063
35.
7454
5454
50.
4545
4545
50.
0791
1392
4
Geo
rgia
n SA
244
1,76
80.
1380
0905
7.24
5901
639
0.40
9836
066
0.05
6561
086
Ger
man
(Deu
tsch
)SF
268
1,49
70.
1790
2471
65.
5858
2089
60.
3731
3432
80.
0668
0026
7
Gon
di, N
orth
ern
SA*
271
1,11
30.
2434
8607
44.
1070
1107
n/a
n/a
Gon
ja
A/I
320
1,11
30.
2875
1123
13.
4781
250.
3125
0.08
9847
26
Gre
enla
ndic
SP18
42,
573
0.07
1511
854
13.9
8369
565
0.54
3478
261
0.03
8865
138
Gua
rani
SP
235
1,63
20.
1439
9509
86.
9446
8085
10.
4255
3191
50.
0612
7451
Gua
rayo
SA
239
1,46
20.
1634
7469
26.
1171
5481
20.
4184
1004
20.
0683
9945
3
Gue
n (G
en, M
ina)
A/I
425
1,66
40.
2554
0865
43.
9152
9411
80.
2352
9411
80.
0600
9615
4
Guj
arat
iSF
269
1,82
30.
1475
5896
96.
7769
5167
30.
3717
4721
20.
0548
5463
5
Hai
tian
Cre
ole
(Kre
yol)
A
/I38
41,
506
0.25
4980
083.
9218
750.
2604
1666
70.
0664
0106
2
Hai
tian
Cre
ole
(pop
ular
)A
/I50
91,
932
0.26
3457
557
3.79
5677
80.
1964
6365
40.
0517
5983
4
Han
i A
/I35
71,
639
0.21
7815
741
4.59
1036
415
0.28
0112
045
0.06
1012
813
Han
kuko
(Kor
ean)
SA29
71,
237
0.24
0097
009
4.16
4983
165
0.33
6700
337
0.08
0840
744
Hau
sa
A/I
442
1,80
30.
2451
4697
74.
0791
8552
0.22
6244
344
0.05
5463
117

50 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Hau
sa/H
aous
sa
SF44
21,
803
0.24
5146
977
4.07
9185
520.
2262
4434
40.
0554
6311
7
Haw
aiia
n A
/I37
51,
348
0.27
8189
911
3.59
4666
667
0.26
6666
667
0.07
4183
976
Hay
u (W
ayu)
SF*
178
1,23
70.
1438
9652
46.
9494
3820
2n/
an/
a
Heb
rew
SF
236
1,25
40.
1881
9776
75.
3135
5932
20.
4237
2881
40.
0797
4481
7
Hili
gayn
on
SA33
81,
792
0.18
8616
071
5.30
1775
148
0.29
5857
988
0.05
5803
571
Hin
di
SF32
81,
759
0.18
6469
585
5.36
2804
878
0.30
4878
049
0.05
6850
483
Hm
ong
(Mia
o)
Nju
aA
/I51
51,
940
0.26
5463
918
3.76
6990
291
0.19
4174
757
0.05
1546
392
Hm
ong
(Mia
o)
Nor
ther
n Q
iand
ong
A/I
499
1,85
10.
2695
8400
93.
7094
1883
80.
2004
0080
20.
0540
2485
1
Hm
ong
(Mia
o)
Sout
hern
Q
iand
ong
A/I
442
1,69
10.
2613
8379
73.
8257
9185
50.
2262
4434
40.
0591
3660
6
Ho
SA*
346
1,56
00.
2217
9487
24.
5086
7052
n/a
n/a
Hok
kien
A
/I*
5322
70.
2334
8017
64.
2830
1886
8n/
an/
a
Hua
stec
(San
Lui
s Po
tosí
)SA
294
1,33
60.
2200
5988
4.54
4217
687
0.34
0136
054
0.07
4850
299
Hua
stec
(Sie
rra
de
Oto
ntep
ec)
SA37
91,
662
0.22
8038
508
4.38
5224
274
0.26
3852
243
0.06
0168
472
Hua
stec
(Ver
acru
z)SA
224
1,12
90.
1984
0566
95.
0401
7857
10.
4464
2857
10.
0885
7395
9
Hui
toto
Mur
uiSP
201
1,24
40.
1615
7556
36.
1890
5472
60.
4975
1243
80.
0803
8585
2
Hun
garia
n SA
245
1,68
90.
1450
5624
66.
8938
7755
10.
4081
6326
50.
0592
0663
1
Hyo
lmo
SA*
227
1,13
10.
2007
0733
94.
9823
7885
5n/
an/
a
Icel
andi
c (ís
lens
ka)
SF29
01,
505
0.19
2691
035.
1896
5517
20.
3448
2758
60.
0664
4518
3

51EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Ido
SAA
248
1,24
00.
25
0.40
3225
806
0.08
0645
161
Idom
a SA
363
1,42
40.
2549
1573
3.92
2865
014
0.27
5482
094
0.07
0224
719
Igbo
A
/I37
31,
614
0.23
1102
854.
3270
7774
80.
2680
9651
50.
0619
5786
9
Ijaw
SA
i19
679
30.
2471
6267
34.
0459
1836
7n/
an/
a
Iloko
/Iloc
ano
SA33
51,
931
0.17
3485
241
5.76
4179
104
0.29
8507
463
0.05
1786
639
Indo
nesi
an /
Bah
asa
Indo
nesi
aSA
276
1,72
40.
1600
9280
76.
2463
7681
20.
3623
1884
10.
0580
0464
Inte
rling
ua
SFA
313
1,56
70.
1997
4473
55.
0063
8977
60.
3194
8881
80.
0638
1620
9
Inuk
titut
(Can
ada)
SP*
201
2,87
40.
0699
3737
14.2
9850
746
n/a
n/a
Italia
n SF
311
2,03
40.
1529
0068
86.
5401
9292
60.
3215
4340
80.
0491
6420
8
Japa
nese
SA35
71,
619
0.22
0506
485
4.53
5014
006
0.28
0112
045
0.06
1766
523
Java
nese
SA
315
1,97
90.
1591
7129
96.
2825
3968
30.
3174
6031
70.
0505
3057
1
Jñat
jo (M
azah
ua)
A/I
i20
689
00.
2314
6067
44.
3203
8835
n/a
n/a
Kab
ardi
an
SA24
71,
736
0.14
2281
106
7.02
8340
081
0.40
4858
30.
0576
0368
7
Kab
uver
dian
uA
/I43
81,
850
0.23
6756
757
4.22
3744
292
0.22
8310
502
0.05
4054
054
Kab
yè
SA22
399
60.
2238
9558
24.
4663
6771
30.
4484
3049
30.
1004
0160
6
Kan
auji
SF*
360
1,64
30.
2191
1138
24.
5638
8888
9n/
an/
a
Kan
nada
SA
182
1,77
70.
1024
1980
99.
7637
3626
40.
5494
5054
90.
0562
7462
Kan
uri Y
erw
aSA
216
1,32
10.
1635
1249
16.
1157
4074
10.
4629
6296
30.
0757
0022
7
Kao
nde
SA17
11,
027
0.16
6504
382
6.00
5847
953
0.58
4795
322
0.09
7370
983
Kap
ampa
ngan
(P
ampa
ngan
)SA
303
1,66
70.
1817
6364
75.
5016
5016
50.
3300
3300
30.
0599
8800
2

52 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Kar
akal
pak
SA26
21,
619
0.16
1828
289
6.17
9389
313
0.38
1679
389
0.06
1766
523
Kar
elia
n SA
245
1,76
50.
1388
1019
87.
2040
8163
30.
4081
6326
50.
0566
5722
4
Kar
en (S
’gaw
)A
/I*
145
1,63
00.
0889
5705
511
.241
3793
1n/
an/
a
Kas
em
SA37
41,
255
0.29
8007
968
3.35
5614
973
0.26
7379
679
0.07
9681
275
Kas
hmiri
SF
*15
863
10.
2503
9619
73.
9936
7088
6n/
an/
a
Kaz
akh
SA24
81,
630
0.15
2147
239
6.57
2580
645
0.40
3225
806
0.06
1349
693
Kha
kas
SA26
21,
687
0.15
5305
276
6.43
8931
298
0.38
1679
389
0.05
9276
823
Kha
ria
SA*
313
1,69
20.
1849
8818
5.40
5750
799
n/a
n/a
Kha
siA
/I45
11,
778
0.25
3655
793
3.94
2350
333
0.22
1729
490.
0562
4297
Khm
er
A/I
360
2,06
70.
1741
6545
75.
7416
6666
70.
2777
7777
80.
0483
7929
4
Kib
ushi
(Shi
bush
i, K
ibus
hi)
SA28
91,
712
0.16
8808
411
5.92
3875
433
0.34
6020
761
0.05
8411
215
K’ic
he’ (
Qui
ché)
SP34
11,
664
0.20
4927
885
4.87
9765
396
0.29
3255
132
0.06
0096
154
Kim
bund
u SA
*31
61,
395
0.22
6523
297
4.41
4556
962
n/a
n/a
Kin
yam
wez
i (N
yam
wez
i)SA
193
1,03
70.
1861
1379
5.37
3056
995
0.51
8134
715
0.09
6432
015
Kin
yarw
anda
SA
196
1,21
50.
1613
1687
26.
1989
7959
20.
5102
0408
20.
0823
0452
7
Kiru
ndi
SA23
41,
566
0.14
9425
287
6.69
2307
692
0.42
7350
427
0.06
3856
96
Kla
u SA
278
1,45
20.
1914
6005
55.
2230
2158
30.
3597
1223
0.06
8870
523
Koi
ts-S
unuw
arSF
*11
356
30.
2007
1048
4.98
2300
885
n/a
n/a
Kom
i-Per
mia
nSF
207
1,20
40.
1719
2691
5.81
6425
121
0.48
3091
787
0.08
3056
478
Kou
lang
o A
/Ii
208
727
0.28
6107
293.
4951
9230
8n/
an/
a

53EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Kpe
lew
o (K
pelle
)A
/Ii
263
940
0.27
9787
234
3.57
4144
487
n/a
n/a
Krio
A
/Ii
308
1,03
40.
2978
7234
3.35
7142
857
n/a
n/a
Kur
dish
, Cen
tral
SF28
81,
245
0.23
1325
301
4.32
2916
667
0.34
7222
222
0.08
0321
285
Kur
ug, K
uruk
hSA
*32
41,
481
0.21
8771
101
4.57
0987
654
n/a
n/a
Kus
unda
(K
usan
da)
SA*
231
937
0.24
6531
483
4.05
6277
056
n/a
n/a
Kve
n SA
255
1,70
80.
1492
9742
46.
6980
3921
60.
3921
5686
30.
0585
4800
9
Kyr
gyz
SA26
61,
703
0.15
6194
956.
4022
5563
90.
3759
3985
0.05
8719
906
Ladi
n SF
339
1,56
70.
2163
3695
4.62
2418
879
0.29
4985
251
0.06
3816
209
Ladi
no
SF29
31,
543
0.18
9889
825
5.26
6211
604
0.34
1296
928
0.06
4808
814
Lam
nso’
(Lám
ns
o’)
SA35
41,
139
0.31
0798
946
3.21
7514
124
0.28
2485
876
0.08
7796
313
Lao
A/I
285
1,73
70.
1640
7599
36.
0947
3684
20.
3508
7719
30.
0575
7052
4
Latin
(Lat
ina)
SF23
21,
628
0.14
2506
143
7.01
7241
379
0.43
1034
483
0.06
1425
061
Latv
ian
SF24
81,
611
0.15
3941
651
6.49
5967
742
0.40
3225
806
0.06
2073
246
Lepc
ha (N
ünpa
, R
ong,
Ron
gpa)
SA*
368
2,08
50.
1764
9880
15.
6657
6087
n/a
n/a
Lhom
i SA
*33
31,
581
0.21
0626
186
4.74
7747
748
n/a
n/a
Ligu
rian
SF30
21,
561
0.19
3465
727
5.16
8874
172
0.33
1125
828
0.06
4061
499
Lim
ba
SAi
234
888
0.26
3513
514
3.79
4871
795
n/a
n/a
Lim
bu
SF*
6144
20.
1380
0905
7.24
5901
639
n/a
n/a
Ling
ala
SA31
91,
480
0.21
5540
541
4.63
9498
433
0.31
3479
624
0.06
7567
568
Lith
uani
an
(Lie
tuvi
skai
)SF
247
1,50
60.
1640
1062
46.
0971
6599
20.
4048
583
0.06
6401
062

54 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Lobi
ri SA
485
1,66
20.
2918
1708
83.
4268
0412
40.
2061
8556
70.
0601
6847
2
Lozi
SA
300
1,21
10.
2477
2914
94.
0366
6666
70.
3333
3333
30.
0825
7638
3
Luba
-Kas
ai
(Tsh
iluba
)SA
308
1,61
30.
1909
4854
35.
2370
1298
70.
3246
7532
50.
0619
9628
Luga
nda/
Gan
daSA
214
1,41
10.
1516
6548
56.
5934
5794
40.
4672
8972
0.07
0871
722
Lund
a/C
hokw
e-lu
nda
SA17
21,
227
0.14
0179
299
7.13
3720
930.
5813
9534
90.
0814
9959
3
Luva
le
SA19
61,
519
0.12
9032
258
7.75
0.51
0204
082
0.06
5832
785
Luxe
mbo
urgi
sh
(Lët
zebu
erge
usch
)SF
310
1,54
30.
2009
0732
34.
9774
1935
50.
3225
8064
50.
0648
0881
4
Mac
edon
ian
SF28
81,
441
0.19
9861
207
5.00
3472
222
0.34
7222
222
0.06
9396
253
Mad
ures
e SA
250
1,53
10.
1632
9196
66.
124
0.4
0.06
5316
786
Mag
ahi
SF25
51,
290
0.19
7674
419
5.05
8823
529
0.39
2156
863
0.07
7519
38
Mag
ar (D
hut)
SA*
3715
20.
2434
2105
34.
1081
0810
8n/
an/
a
Mai
thili
SF
234
1,50
90.
1550
6958
36.
4487
1794
90.
4273
5042
70.
0662
6905
2
Mai
unan
, Mao
nan
A/I
223
1,30
80.
1704
8929
75.
8654
7085
20.
4484
3049
30.
0764
5259
9
Mak
onde
SA
i13
690
40.
1504
4247
86.
6470
5882
4n/
an/
a
Mak
ua, M
akhu
wa
(Moz
ambi
que)
SA19
11,
308
0.14
6024
465
6.84
8167
539
0.52
3560
209
0.07
6452
599
Mal
agas
y SA
262
1,52
10.
1722
5509
55.
8053
4351
10.
3816
7938
90.
0657
4622
Mal
ayal
am
SA13
71,
584
0.08
6489
899
11.5
6204
380.
7299
2700
70.
0631
3131
3
Mal
divi
an
(Dhi
vehi
)SF
*28
229
0.12
2270
742
8.17
8571
429
n/a
n/a
Mal
tese
SF
263
1,60
70.
1636
5899
26.
1102
6616
0.38
0228
137
0.06
2227
754

55EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Mam
SA
301
1,61
80.
1860
3213
85.
3754
1528
20.
3322
2591
40.
0618
0469
7
Man
inka
A
/I28
51,
064
0.26
7857
143
3.73
3333
333
0.35
0877
193
0.09
3984
962
Man
ipur
iSA
*26
200
0.13
7.69
2307
692
n/a
n/a
Mao
ri A
/I55
52,
181
0.25
4470
426
3.92
9729
730.
1801
8018
0.04
5850
527
Mao
ri (C
ook
Isla
nds)
(R
arot
onga
n)A
/I47
71,
929
0.24
7278
383
4.04
4025
157
0.20
9643
606
0.05
1840
332
Map
udun
gun
(Map
uzgu
n)SP
225
1,14
20.
1970
2276
75.
0755
5555
60.
4444
4444
40.
0875
6567
4
Mar
athi
SA
265
1,89
80.
1396
2065
37.
1622
6415
10.
3773
5849
10.
0526
8703
9
Mar
shal
lese
SF
446
1,71
70.
2597
5538
73.
8497
7578
50.
2242
1524
70.
0582
4111
8
Mar
war
i SF
*22
380
00.
2787
53.
5874
4394
6n/
an/
a
Mat
sés
SA36
42,
698
0.13
4914
752
7.41
2087
912
0.27
4725
275
0.03
7064
492
May
an (Y
ucat
eco)
SP38
11,
938
0.19
6594
427
5.08
6614
173
0.26
2467
192
0.05
1599
587
Maz
atec
o SP
239
1,47
70.
1618
1448
96.
1799
1631
80.
4184
1004
20.
0677
0480
7
Men
de
A/I
308
1,11
80.
2754
9195
3.62
9870
130.
3246
7532
50.
0894
4543
8
Miji
sa
SA30
61,
235
0.24
7773
279
4.03
5947
712
0.32
6797
386
0.08
0971
66
Mik
maq
/Mic
mac
SP21
81,
596
0.13
6591
479
7.32
1100
917
0.45
8715
596
0.06
2656
642
Min
angk
abau
SA
279
1,64
00.
1701
2195
15.
8781
3620
10.
3584
2293
90.
0609
7561
Min
jiang
(spo
ken)
A/I
295
1,30
20.
2265
7450
14.
4135
5932
20.
3389
8305
10.
0768
0491
6
Min
jiang
(writ
ten)
A/I
280
1,24
10.
2256
2449
64.
4321
4285
70.
3571
4285
70.
0805
8017
7
Mis
kito
SA
347
1,57
70.
2200
3804
74.
5446
6858
80.
2881
8443
80.
0634
1154
1

56 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Mix
e SP
221
1,26
30.
1749
8020
65.
7149
3212
70.
4524
8868
80.
0791
7656
4
Mix
teco
A
/Ii
235
1,01
20.
2322
1343
94.
3063
8297
9n/
an/
a
Miz
o SA
355
1,52
80.
2323
2984
34.
3042
2535
20.
2816
9014
10.
0654
4502
6
Mob
aSA
407
1,21
30.
3355
3173
92.
9803
4398
0.24
5700
246
0.08
2440
231
Mon
A/I
*26
860.
3023
2558
13.
3076
9230
8n/
an/
a
Mon
golia
n (H
alh,
K
halk
ha)
SA27
71,
556
0.17
8020
566
5.61
7328
520.
3610
1083
0.06
4267
352
Mon
tene
grin
SF
265
1,48
70.
1782
1116
35.
6113
2075
50.
3773
5849
10.
0672
4949
6
Moo
ré/M
ore
SA43
91,
460
0.30
0684
932
3.32
5740
319
0.22
7790
433
0.06
8493
151
Mox
eño
Trin
itario
SP22
61,
605
0.14
0809
969
7.10
1769
912
0.44
2477
876
0.06
2305
296
Moz
arab
ic (A
jam
i)SF
302
1,76
10.
1714
9347
5.83
1125
828
0.33
1125
828
0.05
6785
917
Mun
dari
SP*
220
1,58
30.
1389
7662
77.
1954
5454
5n/
an/
a
Muz
zi
A/I
315
1,53
60.
2050
7812
54.
8761
9047
60.
3174
6031
70.
0651
0416
7
Nah
uatl
SP32
02,
105
0.15
2019
002
6.57
8125
0.31
250.
0475
0593
8
Nan
ai
SA21
51,
549
0.13
8799
225
7.20
4651
163
0.46
5116
279
0.06
4557
779
Nde
bele
(N
orth
ern)
SA16
71,
329
0.12
5658
397.
9580
8383
20.
5988
0239
50.
0752
4454
5
Nen
ets
SF24
81,
426
0.17
3913
043
5.75
0.40
3225
806
0.07
0126
227
Nep
ali
SF22
61,
544
0.14
6373
057
6.83
1858
407
0.44
2477
876
0.06
4766
839
New
ar (N
epal
B
hasa
)SF
*72
325
0.22
1538
462
4.51
3888
889
n/a
n/a
Nga
nasa
n SA
230
1,64
80.
1395
6310
77.
1652
1739
10.
4347
8260
90.
0606
7961
2
Nga
ngel
a, N
yem
baSA
*35
51,
754
0.20
2394
527
4.94
0845
07n/
an/
a

57EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Nig
eria
n Pi
dgin
En
glis
hA
/I50
51,
756
0.28
7585
421
3.47
7227
723
0.19
8019
802
0.05
6947
608
Niu
e A
/I43
51,
771
0.24
5623
941
4.07
1264
368
0.22
9885
057
0.05
6465
274
Niv
kh
SA23
91,
471
0.16
2474
507
6.15
4811
715
0.41
8410
042
0.06
7980
965
Nom
atsi
guen
ga
SP21
11,
715
0.12
3032
078.
1279
6208
50.
4739
3364
90.
0583
0903
8
Nor
weg
ian
(Bok
mål
)SF
265
1,42
40.
1860
9550
65.
3735
8490
60.
3773
5849
10.
0702
2471
9
Nor
weg
ian
(Nyn
orsk
)SF
293
1,39
30.
2103
3740
14.
7542
6621
20.
3412
9692
80.
0717
8750
9
Nue
r SF
*26
292
10.
2844
7339
83.
5152
6717
6n/
an/
a
Nuo
su/Y
iA
/I*
271
783
0.34
6104
725
2.88
9298
893
n/a
n/a
Nya
nja/
Chi
nyan
ja
(Che
chew
a,
Chi
chew
a)SA
239
1,52
80.
1564
1361
36.
3933
0543
90.
4184
1004
20.
0654
4502
6
Nze
ma
A/I
366
1,55
80.
2349
1656
4.25
6830
601
0.27
3224
044
0.06
4184
852
Ñah
ñú (O
tom
í)SF
i27
791
60.
3024
0174
73.
3068
5920
6n/
an/
a
Occ
itan
SF28
21,
443
0.19
5426
195
5.11
7021
277
0.35
4609
929
0.06
9300
069
Occ
itan
Auv
ergn
atSF
287
1,49
50.
1919
7324
45.
2090
5923
30.
3484
3205
60.
0668
8963
2
Occ
itan
Lang
uedo
cien
SF32
81,
597
0.20
5385
097
4.86
8902
439
0.30
4878
049
0.06
2617
408
Ogi
ek
SA16
21,
142
0.14
1856
392
7.04
9382
716
0.61
7283
951
0.08
7565
674
Ojib
wa
/ Ojib
way
/ O
jibw
eSP
*18
182
0.09
8901
099
10.1
1111
111
n/a
n/a
Oriy
a SF
*59
374
0.15
7754
011
6.33
8983
051
n/a
n/a
Oro
kSA
220
1,69
80.
1295
6419
37.
7181
8181
80.
4545
4545
50.
0588
9281
5

58 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Oro
mo,
Bor
ana-
Ars
i-Guj
iSA
219
1,42
50.
1536
8421
16.
5068
4931
50.
4566
2100
50.
0701
7543
9
Oro
qen
SA18
81,
335
0.14
0823
977.
1010
6383
0.53
1914
894
0.07
4906
367
Ose
tin (O
sset
ian)
SA20
21,
147
0.17
6111
595
5.67
8217
822
0.49
5049
505
0.08
7183
958
Osh
iwam
bo
(Ndo
nga)
SA23
61,
389
0.16
9906
407
5.88
5593
220.
4237
2881
40.
0719
9424
Otu
ho
SA26
01,
321
0.19
6820
595.
0807
6923
10.
3846
1538
50.
0757
0022
7
Paez
SP
204
1,51
70.
1344
7593
97.
4362
7451
0.49
0196
078
0.06
5919
578
Pala
uan
A/I
338
1,44
10.
2345
5933
44.
2633
1360
90.
2958
5798
80.
0693
9625
3
Panj
abi (
Punj
abi)
SF39
01,
913
0.20
3868
274.
9051
2820
50.
2564
1025
60.
0522
7391
5
Papi
amen
tu
A/I
330
1,61
10.
2048
4171
34.
8818
1818
20.
3030
3030
30.
0620
7324
6
Pash
to/P
akht
oSF
*38
148
0.25
6756
757
3.89
4736
842
n/a
n/a
Pica
rd
SF33
81,
523
0.22
1930
401
4.50
5917
160.
2958
5798
80.
0656
5988
2
Pint
upi-L
uritj
aSP
339
2,90
60.
1166
5519
68.
5722
7138
60.
2949
8525
10.
0344
1156
2
Pipi
l SA
266
1,15
60.
2301
0380
64.
3458
6466
20.
3759
3985
0.08
6505
19
Polis
h (P
olsk
i)SF
274
1,69
00.
1621
3017
86.
1678
8321
20.
3649
6350
40.
0591
7159
8
Pona
pean
, Po
hnpe
ian
A/I
284
1,36
60.
2079
0629
64.
8098
5915
50.
3521
1267
60.
0732
0644
2
Portu
gues
e SF
297
1,55
00.
1916
1290
35.
2188
5521
90.
3367
0033
70.
0645
1612
9
Prou
venç
au
SF28
21,
443
0.19
5426
195
5.11
7021
277
0.35
4609
929
0.06
9300
069
Pula
ar
SA26
31,
340
0.19
6268
657
5.09
5057
034
0.38
0228
137
0.07
4626
866
Pula
rSA
i18
390
40.
2024
3362
84.
9398
9071
n/a
n/a
Purh
épec
ha
SA24
01,
708
0.14
0515
222
7.11
6666
667
0.41
6666
667
0.05
8548
009

59EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Q’e
chi/K
ekch
iSP
249
1,36
20.
1828
1938
35.
4698
7951
80.
4016
0642
60.
0734
2143
9
Que
chua
SA30
62,
491
0.12
2842
232
8.14
0522
876
0.32
6797
386
0.04
0144
52
Qui
chua
SA
174
1,25
30.
1388
6672
7.20
1149
425
0.57
4712
644
0.07
9808
46
Raj
asth
ani
SF*
3114
00.
2214
2857
14.
5161
2903
2n/
an/
a
Raj
bans
hi /
Ran
gpur
i /
Kam
tapu
ri SF
*30
01,
293
0.23
2018
561
4.31
n/a
n/a
Raj
i A
/I*
101
348
0.29
0229
885
3.44
5544
554
n/a
n/a
Rha
eto-
Rom
ance
(R
uman
tsch
)SF
292
1,53
80.
1898
5695
75.
2671
2328
80.
3424
6575
30.
0650
1950
6
Rom
agno
lo
(Sam
mar
ines
e)SF
348
1,66
80.
2086
3309
44.
7931
0344
80.
2873
5632
20.
0599
5203
8
Rom
ani
SF26
41,
386
0.19
0476
195.
250.
3787
8787
90.
0721
5007
2
Rom
ania
n (R
omân
a)SF
309
1,64
80.
1875
5.33
3333
333
0.32
3624
595
0.06
0679
612
Ruk
onzo
(Kon
jo)
SA27
82,
308
0.12
0450
607
8.30
2158
273
0.35
9712
230.
0433
2755
6
Run
diSA
221
1,47
20.
1501
3587
6.66
0633
484
0.45
2488
688
0.06
7934
783
Run
yank
ore-
ruki
ga/N
kore
-kig
aSA
149
1,12
60.
1323
2682
17.
5570
4698
0.67
1140
940.
0888
0994
7
Rus
sian
(Rus
sky)
SF27
91,
713
0.16
2872
154
6.13
9784
946
0.35
8422
939
0.05
8377
116
Saam
i/Lap
pish
SA25
41,
875
0.13
5466
667
7.38
1889
764
0.39
3700
787
0.05
3333
333
Sala
r SA
201
1,17
80.
1706
2818
35.
8606
9651
70.
4975
1243
80.
0848
8964
3
Sam
oan
A/I
492
1,86
50.
2638
0697
13.
7906
5040
70.
2032
5203
30.
0536
1930
3
Sang
o (S
angh
o)A
/I38
31,
385
0.27
6534
296
3.61
6187
990.
2610
9660
60.
0722
0216
6
Sans
krit
SF18
11,
637
0.11
0568
112
9.04
4198
895
0.55
2486
188
0.06
1087
355

60 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Sant
hali
SA*
327
1,53
30.
2133
0724
14.
6880
7339
4n/
an/
a
Sãot
omen
seSF
286
1,10
70.
2583
5591
73.
8706
2937
10.
3496
5035
0.09
0334
237
Sard
inia
n,
Logu
dore
seSF
348
1,73
80.
2002
3015
4.99
4252
874
0.28
7356
322
0.05
7537
399
Sarn
ámi
Hin
dust
ani
SF37
91,
628
0.23
2800
983
4.29
5514
512
0.26
3852
243
0.06
1425
061
Saxo
n, L
owSF
333
1,57
90.
2108
9297
4.74
1741
742
0.30
0300
30.
0633
3122
2
Scot
s SF
278
1,35
40.
2053
1757
84.
8705
0359
70.
3597
1223
0.07
3855
244
Seco
yaSP
227
1,39
10.
1631
9194
86.
1277
5330
40.
4405
2863
40.
0718
9072
6
Seer
eer
SA29
31,
112
0.26
3489
209
3.79
5221
843
0.34
1296
928
0.08
9928
058
Serb
ian
(Srp
ski)
SF24
91,
337
0.18
6237
846
5.36
9477
912
0.40
1606
426
0.07
4794
316
Sese
lwa
Cre
ole
Fren
chSA
328
1,57
80.
2078
5804
84.
8109
7561
0.30
4878
049
0.06
3371
356
Shan
gani
SA
361
1,80
00.
2005
5555
64.
9861
4958
40.
2770
0831
0.05
5555
556
Shar
anah
uaSP
i13
81,
106
0.12
4773
968.
0144
9275
4n/
an/
a
Sher
pa
A/I
*14
356
60.
2526
5017
73.
9580
4195
8n/
an/
a
Shill
ukSF
i22
483
00.
2698
7951
83.
7053
5714
3n/
an/
a
Shim
aore
SA
367
1,76
50.
2079
3201
14.
8092
6430
50.
2724
7956
40.
0566
5722
4
Shin
gazi
dja
SA29
51,
631
0.18
0870
632
5.52
8813
559
0.33
8983
051
0.06
1312
078
Ship
ibo-
Con
ibo
SP42
32,
892
0.14
6265
566.
8368
7943
30.
2364
0661
90.
0345
7814
7
Shon
aSA
245
1,77
90.
1377
1781
97.
2612
2449
0.40
8163
265
0.05
6211
355
Shor
SAi
150
865
0.17
3410
405
5.76
6666
667
n/a
n/a
Sia
Pede
eSP
247
1,55
10.
1592
5209
56.
2793
5222
70.
4048
583
0.06
4474
533

61EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Sind
hiSF
*32
157
0.20
3821
656
4.90
625
n/a
n/a
Sinh
ala
SF25
21,
775
0.14
1971
831
7.04
3650
794
0.39
6825
397
0.05
6338
028
Sion
aSP
223
1,45
80.
1529
4924
66.
5381
1659
20.
4484
3049
30.
0685
8710
6
Sirio
nó
SA24
61,
089
0.22
5895
317
4.42
6829
268
0.40
6504
065
0.09
1827
365
siSw
ati (
Swaz
i)SA
292
2,41
90.
1207
1103
88.
2842
4657
50.
3424
6575
30.
0413
3939
6
Slov
akSF
248
1,42
30.
1742
7969
15.
7379
0322
60.
4032
2580
60.
0702
7406
9
Slov
enia
n (S
love
nsci
na)
SF25
61,
446
0.17
7040
111
5.64
8437
50.
3906
250.
0691
5629
3
Som
ali
SA30
01,
472
0.20
3804
348
4.90
6666
667
0.33
3333
333
0.06
7934
783
Soni
nké
(Son
inka
nxaa
ne)
A/I
297
1,10
60.
2685
3526
23.
7239
0572
40.
3367
0033
70.
0904
1591
3
Sorb
ian
SF26
21,
552
0.16
8814
433
5.92
3664
122
0.38
1679
389
0.06
4432
99
Soth
o, N
orth
ern/
Pedi
/Sep
edi
SA40
41,
657
0.24
3814
122
4.10
1485
149
0.24
7524
752
0.06
0350
03
Soth
o, S
outh
ern
/ So
tho
/ Ses
otho
/ Su
tu /
Sesu
tuSA
315
1,31
20.
2400
9146
34.
1650
7936
50.
3174
6031
70.
0762
1951
2
Soth
o, W
este
rn/
Tsw
ana/
Sets
wan
aSA
373
1,69
90.
2195
4090
64.
5549
5978
60.
2680
9651
50.
0588
5815
2
Span
ish
SF29
91,
580
0.18
9240
506
5.28
4280
936
0.33
4448
161
0.06
3291
139
Suku
ma
SA21
21,
237
0.17
1382
377
5.83
4905
660.
4716
9811
30.
0808
4074
4
Sund
anes
e A
/I29
61,
748
0.16
9336
384
5.90
5405
405
0.33
7837
838
0.05
7208
238
Sure
l (Su
nwar
)SA
*61
333
0.18
3183
183
5.45
9016
393
n/a
n/a
Suss
u / S
ouss
ou
/ Sos
so /
Soso
/ Su
suA
/Ii
199
927
0.21
4670
982
4.65
8291
457
n/a
n/a

62 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Swah
ili/K
isw
ahili
SA26
91,
280
0.21
0156
254.
7583
6431
20.
3717
4721
20.
0781
25
Swam
py C
ree
SA*
2321
80.
1055
0458
79.
4782
6087
n/a
n/a
Swed
ish
(Sve
nska
)SF
264
1,47
30.
1792
2606
95.
5795
4545
50.
3787
8787
90.
0678
8866
3
T’Si
man
eSA
i18
81,
091
0.17
2318
973
5.80
3191
489
n/a
n/a
Taca
na
SPi
188
968
0.19
4214
876
5.14
8936
17n/
an/
a
Taga
log
SA30
21,
652
0.18
2808
717
5.47
0198
675
0.33
1125
828
0.06
0532
688
Tahi
tian
A/I
488
2,04
30.
2388
6441
54.
1864
7541
0.20
4918
033
0.04
8947
626
Tajik
SF
303
1,51
60.
1998
6807
45.
0033
0033
0.33
0033
003
0.06
5963
061
Taly
sh
SF26
31,
447
0.18
1755
356
5.50
1901
141
0.38
0228
137
0.06
9108
5
Tam
ang
/ Tam
(E
aste
rn)
SA*
208
938
0.22
1748
401
4.50
9615
385
n/a
n/a
Tam
ashe
q SA
286
1,16
90.
2446
5355
4.08
7412
587
0.34
9650
350.
0855
4319
9
Tam
azig
htSA
296
1,39
40.
2123
3859
44.
7094
5945
90.
3378
3783
80.
0717
3601
1
Tam
ilSA
*21
224
0.09
375
10.6
6666
667
n/a
n/a
Tata
r SA
258
1,58
60.
1626
7339
26.
1472
8682
20.
3875
9689
90.
0630
5170
2
Telu
gu
SA18
61,
858
0.10
0107
643
9.98
9247
312
0.53
7634
409
0.05
3821
313
Tem
SA
266
1,45
30.
1830
6951
15.
4624
0601
50.
3759
3985
0.06
8823
125
Tetu
nSA
257
1,16
80.
2200
3424
74.
5447
4708
20.
3891
0505
80.
0856
1643
8
Tetu
n D
iliA
/Ii
229
944
0.24
2584
746
4.12
2270
742
n/a
n/a
Thai
A
/I36
81,
798
0.20
4671
858
4.88
5869
565
0.27
1739
130.
0556
1735
3
Than
gmi
SA*
142
739
0.19
2151
556
5.20
4225
352
n/a
n/a

63EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Thar
u-D
anga
ura
SF*
205
1,10
20.
1860
2540
85.
3756
0975
6n/
an/
a
Them
neSA
364
1,33
90.
2718
4466
3.67
8571
429
0.27
4725
275
0.07
4682
599
Tibe
tan
SA49
42,
053
0.24
0623
478
4.15
5870
445
0.20
2429
150.
0487
0920
6
Ticu
naSP
348
1,74
70.
1991
9862
65.
0201
1494
30.
2873
5632
20.
0572
4098
5
Tigr
inya
(Tig
rigna
)SF
231
1,83
40.
1259
5419
87.
9393
9393
90.
4329
0043
30.
0545
2562
7
Tiv
SA49
31,
571
0.31
3812
858
3.18
6612
576
0.20
2839
757
0.06
3653
724
Toba
SP55
31,
440
0.38
4027
778
2.60
3978
30.
1808
3182
60.
0694
4444
4
Tojo
l-a’b
’al
SP40
01,
837
0.21
7746
326
4.59
250.
250.
0544
3658
1
Tok
Pisi
nA
/I35
31,
493
0.23
6436
705
4.22
9461
756
0.28
3286
119
0.06
6979
236
Tong
a (Z
ambi
a)SA
209
1,56
20.
1338
0281
77.
4736
8421
10.
4784
689
0.06
4020
487
Tong
an (T
onga
)A
/I46
32,
020
0.22
9207
921
4.36
2850
972
0.21
5982
721
0.04
9504
95
Toto
naco
SP
266
2,02
60.
1312
9318
97.
6165
4135
30.
3759
3985
0.04
9358
342
Tsafi
ki
SF19
81,
122
0.17
6470
588
5.66
6666
667
0.50
5050
505
0.08
9126
56
Tson
ga
(Moz
ambi
que)
SA37
71,
707
0.22
0855
302
4.52
7851
459
0.26
5251
989
0.05
8582
308
Tson
ga
(Zim
babw
e)SA
362
1,80
00.
2011
1111
14.
9723
7569
10.
2762
4309
40.
0555
5555
6
Tsw
ana
SA37
31,
699
0.21
9540
906
4.55
4959
786
0.26
8096
515
0.05
8858
152
Turk
ish
(Tür
kçe)
SA23
61,
505
0.15
6810
631
6.37
7118
644
0.42
3728
814
0.06
6445
183
Turk
men
SA
212
1,41
80.
1495
0634
76.
6886
7924
50.
4716
9811
30.
0705
2186
2
Tuva
nSA
237
1,69
10.
1401
5375
57.
1350
2109
70.
4219
4092
80.
0591
3660
6
Twi (
Aka
n K
asa)
[A
kuap
em]
A/I
304
1,13
50.
2678
4141
3.73
3552
632
0.32
8947
368
0.08
8105
727

64 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Twi (
Aka
n K
asa)
[A
sant
e, a
shan
ti]A
/I29
61,
057
0.28
0037
843
3.57
0945
946
0.33
7837
838
0.09
4607
379
Tzel
tal,
Oxc
huc
SP33
51,
568
0.21
3647
959
4.68
0597
015
0.29
8507
463
0.06
3775
51
Tzot
zil (
Cha
mul
a)SA
361
1,74
40.
2069
9541
34.
8310
2493
10.
2770
0831
0.05
7339
45
Uig
hur
SA25
71,
820
0.14
1208
791
7.08
1712
062
0.38
9105
058
0.05
4945
055
Ukr
aini
anSF
275
1,56
80.
1753
8265
35.
7018
1818
20.
3636
3636
40.
0637
7551
Um
bund
u SA
220
1,43
30.
1535
2407
56.
5136
3636
40.
4545
4545
50.
0697
8367
1
Ura
rina
SP25
81,
824
0.14
1447
368
7.06
9767
442
0.38
7596
899
0.05
4824
561
Urd
uSF
364
1,51
10.
2409
0006
64.
1510
9890
10.
2747
2527
50.
0661
8133
7
Uzb
ek
SA26
51,
701
0.15
5790
711
6.41
8867
925
0.37
7358
491
0.05
8788
948
Vai
SA47
41,
472
0.32
2010
873.
1054
8523
20.
2109
7046
40.
0679
3478
3
Vend
aSA
365
1,63
70.
2229
6884
54.
4849
3150
70.
2739
7260
30.
0610
8735
5
Vene
tian
SF29
51,
457
0.20
2470
834.
9389
8305
10.
3389
8305
10.
0686
3418
Veps
SA24
71,
581
0.15
6230
234
6.40
0809
717
0.40
4858
30.
0632
5110
7
Vie
tnam
ese
A/I
411
1,66
80.
2464
0287
84.
0583
9416
10.
2433
0900
20.
0599
5203
8
Vla
ch
SF19
61,
715
0.11
4285
714
8.75
0.51
0204
082
0.05
8309
038
Waa
ma
SAi
157
545
0.28
8073
394
3.47
1337
58n/
an/
a
Wal
loon
/Wal
lon
SF37
41,
852
0.20
1943
844
4.95
1871
658
0.26
7379
679
0.05
3995
68
Wao
rani
/Wao
Te
dedo
/Hua
oran
iSP
235
1,38
70.
1694
3042
55.
9021
2766
0.42
5531
915
0.07
2098
053
War
ay/W
aray
-W
aray
SA34
31,
652
0.20
7627
119
4.81
6326
531
0.29
1545
190.
0605
3268
8

65EnriquE J. VErchEr García y ManuEl BullEJos lorEnzo
ELUA, núm. 37, 2022, pp. 23-66
LEN
GU
ATI
POLO
GÍA
M
OR
FOLÓ
GIC
A
OB
SERV
AC
IO-
NES
SO
BR
E EL
TE
XTO
FU
ENTE
N.º
DE
TOK
ENS
N.º
DE
UFC
T
ÍND
ICE
DE
REL
ATIV
IDA
D
INFO
RM
ATIV
A
(TO
KEN
S/U
FCT)
ÍND
ICE
DE
DEN
SID
AD
IN
FOR
MAT
IVA
(U
FCT/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
LÉ
XIC
A (1
00/
TOK
ENS)
ÍND
ICE
DE
EFIC
IEN
CIA
IN
FOR
MAT
IVA
FÓ
NIC
A (1
00/
UFC
T)
Way
uu
SP16
71,
206
0.13
8474
295
7.22
1556
886
0.59
8802
395
0.08
2918
74
Wee
nhay
ek
SP31
22,
054
0.15
1898
734
6.58
3333
333
0.32
0512
821
0.04
8685
492
Wol
of
SA29
31,
110
0.26
3963
964
3.78
8395
904
0.34
1296
928
0.09
0090
09
Xho
sa
SA19
61,
631
0.12
0171
674
8.32
1428
571
0.51
0204
082
0.06
1312
078
Yagu
a SA
172
1,39
70.
1231
2097
48.
1220
9302
30.
5813
9534
90.
0715
8196
1
Yakk
haSF
*15
791
20.
1721
4912
35.
8089
1719
7n/
an/
a
Yaku
tSA
254
1,86
60.
1361
2004
37.
3464
5669
30.
3937
0078
70.
0535
9056
8
Yano
mam
öSP
339
1,51
80.
2233
2015
84.
4778
7610
60.
2949
8525
10.
0658
7615
3
Yao
SA21
01,
436
0.14
6239
554
6.83
8095
238
0.47
6190
476
0.06
9637
883
Yape
se
A/I
309
1,40
60.
2197
7240
44.
5501
6181
20.
3236
2459
50.
0711
2375
5
Yid
dish
SF
280
1,53
70.
1821
7306
45.
4892
8571
40.
3571
4285
70.
0650
6180
9
Yoru
ba (Y
orùb
á)A
/I40
81,
628
0.25
0614
251
3.99
0196
078
0.24
5098
039
0.06
1425
061
Yuka
gir
SA16
81,
299
0.12
9330
254
7.73
2142
857
0.59
5238
095
0.07
6982
294
Yura
caré
SA20
51,
442
0.14
2163
662
7.03
4146
341
0.48
7804
878
0.06
9348
128
Zápa
roSP
209
1,24
10.
1684
1257
15.
9377
9904
30.
4784
689
0.08
0580
177
Zapo
teco
A
/Ii
248
876
0.28
3105
023
3.53
2258
065
n/a
n/a
Zhua
ngA
/I25
41,
475
0.17
2203
395.
8070
8661
40.
3937
0078
70.
0677
9661
Zulu
SA
171
1,40
60.
1216
2162
28.
2222
2222
20.
5847
9532
20.
0711
2375
5

66 Los índices de reLatividad, densidad y eficiencia informativa en Las Lenguas: estudio de...
ELUA, núm. 37, 2022, pp. 23-66
OBSERVACIONES SOBRE EL TEXTO FUENTE:(sin marca): 10 primeros artículos de la Declaración Universal de los Derechos Humanos.i: 10 primeros artículos de la Declaración Universal de los Derechos Humanos incompletos.*: otros textos.A: lengua artificial.
CLAVES DE LA TIPOLOGÍA MORFOLÓGICA:A/I: lengua predominantemente analítica-aislante.SA: lengua predominantemente sintética aglutinante.SF: lengua predominantemente sintética fusionante.SP: lengua predominantemente sintética polisintética.




















