
Lingüística de corpus en la enseñanza del inglés como lengua extranjera (ILE)
12
RICA PEROMINGO, JUAN PEDRO 1 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE) JUAN PEDRO RICA PEROMINGO Universidad Complutense de Madrid [email protected] English summary Based on corpus linguistics and phraseology, and using Biber et al. 1999 taxonony of lexical bundles, this paper presents a contrastive analysis of the use of phraseological units (PhU) (grammatical collocations and linking and stance lexical bundles) present in English argumentative texts written by non-native writers of the language. Several corpora were used for this purpose: non-native students from the ICLE, specially the Spanish subcorpus (SPICLE), and the CEUNF, the latter being an original corpus of non-native university students of English from different fields studying English as a subject outside their curriculum. These data have been contrasted with two native writers of English corpora: the American university students corpus (LOCNESS) and that of the professional editorialists writing in English (SPE). The analysis of these data will allow us to emphasize the importance of teaching PhU for university students’ written production. The results show that, contrary to common belief, non-native writers resort to PhU significantly more often than native writers of English do and the formers’ production is more characterized by an over-and underuse of certain PhU, probably due to teaching effect and transfer factors. KEY WORDS: corpus linguistics; phraseology; phraseological units; teaching EFL Resumen en español Teniendo como base la lingüística de corpus y la fraseología, y partiendo de la taxonomía utilizada por Biber et al. (1999) sobre grupos léxicos, este artículo presenta un análisis contrastivo sobre el uso de unidades fraseológicas (UF) (colocaciones gramaticales y grupos léxicos de enlace y de postura del escritor) presentes en textos argumentativos en lengua inglesa producidos por estudiantes universitarios no nativos. Para este estudio se han utilizado varios corpus lingüísticos: el constituido por los estudiantes no nativos del ICLE, especialmente el subcorpus de español (SPICLE), y el CEUNF, corpus formado por estudiantes universitarios no nativos que cursan inglés como materia extracurricular en diversas titulaciones. Toda esta producción escrita se ha contrastado con dos corpus nativos: uno de estudiantes universitarios estadounidenses (LOCNESS) y otro de editorialistas profesionales (SPE). El análisis de los datos nos permitirá enfatizar la importancia de la enseñanza de UF en la producción escrita de estudiantes en un contexto universitario. Los resultados muestran que, en primer lugar, y en contra de lo que se ha estipulado en estudios anteriores, los no nativos recurren con mayor frecuencia al uso de UF que los estudiantes y profesionales nativos, y en segundo lugar, que su producción se caracteriza por un uso excesivo y una infrautilización de ciertas UF, posible consecuencia del tipo de enseñanza recibida así como de otros factores de transferencia. PALABRAS CLAVE. Lingüística de corpus; fraseología; unidades fraseológicas; ILE 1. Introducción The acquisition of formulaic speech plays a central role in second language learning (Wong-Fillmore, 1976: 614) El siguiente trabajo presenta un estudio sobre unidades fraseológicas 1 que desarrollaremos dentro de los estudios funcionales o contrastivos de la metodología de la lingüística de corpus. La base teórica en la que se sustenta todo el estudio de este tipo de estructuras es la teoría fraseológica (Cowie, 1998; Howarth, 1996, 1998). Este análisis pretende cubrir el vacío existente en el campo de la fraseología, puesto que no se han llevado a cabo estudios sobre el uso de estas UF por estudiantes universitarios extranjeros que no estén realizando estudios de lengua inglesa y, en general, existen pocos trabajos que se hayan centrado en la adquisición, aprendizaje y uso de este tipo de estructuras por estudiantes adultos. Se han hecho estudios en corpus lingüísticos de estudiantes extranjeros que aprenden inglés, pero en todo momento esos estudiantes realizaron estudios universitarios directamente relacionados con la lengua inglesa (ICLE, 1 Aunque existe una confusión continua con la terminología utilizada para hablar sobre colocaciones (o estructuras prefrabricadas, frases lexicalizadas, etc.), a lo largo de este trabajo utilizaremos únicamente el término colocación para referirnos a aquellas combinaciones frecuentes de unidades léxicas o gramaticales. Del mismo modo, haremos uso del término genérico unidad fraseológica (UF) para todas aquellas unidades que incluyen tanto colocaciones léxicas y gramaticales como grupos léxicos de enlace y de postura del escritor. En Los caminos de la lengua. Estudios en homenaje a Enrique Alcaraz Varó . Alicante: Publicaciones de la Universidad de Alicante. Págs. 1405-1427 (2010)
Transcript of Lingüística de corpus en la enseñanza del inglés como lengua extranjera (ILE)

RICA PEROMINGO, JUAN PEDRO 1
LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUAEXTRANJERA (ILE)
JUAN PEDRO RICA PEROMINGOUniversidad Complutense de Madrid
English summaryBased on corpus linguistics and phraseology, and using Biber et al. 1999 taxonony of lexical bundles, this paperpresents a contrastive analysis of the use of phraseological units (PhU) (grammatical collocations and linking andstance lexical bundles) present in English argumentative texts written by non-native writers of the language. Severalcorpora were used for this purpose: non-native students from the ICLE, specially the Spanish subcorpus (SPICLE),and the CEUNF, the latter being an original corpus of non-native university students of English from different fieldsstudying English as a subject outside their curriculum. These data have been contrasted with two native writers ofEnglish corpora: the American university students corpus (LOCNESS) and that of the professional editorialistswriting in English (SPE). The analysis of these data will allow us to emphasize the importance of teaching PhU foruniversity students’ written production. The results show that, contrary to common belief, non-native writers resort toPhU significantly more often than native writers of English do and the formers’ production is more characterized byan over-and underuse of certain PhU, probably due to teaching effect and transfer factors.
KEY WORDS: corpus linguistics; phraseology; phraseological units; teaching EFL
Resumen en españolTeniendo como base la lingüística de corpus y la fraseología, y partiendo de la taxonomía utilizada por Biber et al.(1999) sobre grupos léxicos, este artículo presenta un análisis contrastivo sobre el uso de unidades fraseológicas (UF)(colocaciones gramaticales y grupos léxicos de enlace y de postura del escritor) presentes en textos argumentativos enlengua inglesa producidos por estudiantes universitarios no nativos. Para este estudio se han utilizado varios corpuslingüísticos: el constituido por los estudiantes no nativos del ICLE, especialmente el subcorpus de español (SPICLE),y el CEUNF, corpus formado por estudiantes universitarios no nativos que cursan inglés como materia extracurricularen diversas titulaciones. Toda esta producción escrita se ha contrastado con dos corpus nativos: uno de estudiantesuniversitarios estadounidenses (LOCNESS) y otro de editorialistas profesionales (SPE). El análisis de los datos nospermitirá enfatizar la importancia de la enseñanza de UF en la producción escrita de estudiantes en un contextouniversitario. Los resultados muestran que, en primer lugar, y en contra de lo que se ha estipulado en estudiosanteriores, los no nativos recurren con mayor frecuencia al uso de UF que los estudiantes y profesionales nativos, y ensegundo lugar, que su producción se caracteriza por un uso excesivo y una infrautilización de ciertas UF, posibleconsecuencia del tipo de enseñanza recibida así como de otros factores de transferencia.
PALABRAS CLAVE. Lingüística de corpus; fraseología; unidades fraseológicas; ILE
1. Introducción
The acquisition of formulaic speech plays a central role in second language learning
(Wong-Fillmore, 1976: 614)
El siguiente trabajo presenta un estudio sobre unidades fraseológicas1 que desarrollaremos dentro de losestudios funcionales o contrastivos de la metodología de la lingüística de corpus. La base teórica en la quese sustenta todo el estudio de este tipo de estructuras es la teoría fraseológica (Cowie, 1998; Howarth,1996, 1998).
Este análisis pretende cubrir el vacío existente en el campo de la fraseología, puesto que no sehan llevado a cabo estudios sobre el uso de estas UF por estudiantes universitarios extranjeros que noestén realizando estudios de lengua inglesa y, en general, existen pocos trabajos que se hayan centrado enla adquisición, aprendizaje y uso de este tipo de estructuras por estudiantes adultos. Se han hecho estudiosen corpus lingüísticos de estudiantes extranjeros que aprenden inglés, pero en todo momento esosestudiantes realizaron estudios universitarios directamente relacionados con la lengua inglesa (ICLE,
1 Aunque existe una confusión continua con la terminología utilizada para hablar sobre colocaciones (o estructuras prefrabricadas,frases lexicalizadas, etc.), a lo largo de este trabajo utilizaremos únicamente el término colocación para referirnos a aquellascombinaciones frecuentes de unidades léxicas o gramaticales. Del mismo modo, haremos uso del término genérico unidadfraseológica (UF) para todas aquellas unidades que incluyen tanto colocaciones léxicas y gramaticales como grupos léxicos deenlace y de postura del escritor.
En Los caminos de la lengua. Estudios en homenaje a Enrique Alcaraz Varó. Alicante: Publicaciones de laUniversidad de Alicante. Págs. 1405-1427 (2010)

2 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
Internacional Corpus of Learner English y en particular el subcorpus de español, SPICLE). Lacomparación y el análisis que se presentan en este artículo se realizarán con otro corpus de creaciónpropia (CEUNF, Corpus de Estudiantes Universitarios No Filólogos) que contiene la producción escritade estudiantes de 17 estudios universitarios distintos (Comunicación Audiovisual, Historia, Arte,Derecho, etc.) que, en el momento de la recogida de datos (redacciones argumentativas), estudiabaninglés en un centro de estudios de la UCM2, dentro de unos cursos de inglés general con nivel intermedio-alto/avanzado (B1 y B2, según el Marco de Referencia europeo). Este corpus de producción propia secomparará no sólo con el subcorpus de estudiantes españoles SPICLE (compuesto por estudiantesuniversitarios de 3º y 4º de Filología Inglesa de la UCM, también de nivel intermedio-alto/avanzado), ycon el resto de los subcorpus del ICLE (estudiantes universitarios franceses, alemanes, italianos, etc. querealizaban sus estudios universitarios equivalentes a Filología Inglesa en España), sino también con doscorpus de producción nativa: el LOCNESS (Louvain Corpus of Native English Essays), que incluyeestudiantes británicos y estadounidenses que escriben en su L1 (aunque únicamente utilizaremos elbloque de universitarios estadounidenses, ya que la parte de estudiantes británicos corresponde a alumnosde secundaria), y el corpus de editorialistas profesionales (SPE, Signed Professional Editorialists) queescriben en inglés (Marín y Neff, 2001), ambos como corpus de referencia nativos.
Con este trabajo que aquí se presenta se intenta, igualmente, fomentar el uso de la lingüística decorpus en el aula, esto es, el uso de corpus lingüísticos para la enseñanza de una lengua extranjera en uncontexto universitario español. Pero, ¿cómo incluimos estos estudios de corpus en el aula para enfocarnuestra enseñanza más hacia la forma?; ¿cómo podemos implantar un programa léxico3 dentro delcurriculum de enseñanza del ILE? Una de las propuestas más sugerentes (Thurstun y Candlin, 1998;Conrad, 1999; Tribble, 2003; Aston, 2001; Osborne, 2001, Tribble y Jones, 1997; Nesselhauf, 2005) es lautilización del aprendizaje basado en datos –lo que se ha venido a llamar data-driven learning (DDL)–que podríamos definir como “the use in the classroom of computer-generated concordances to getstudents to explore regularities of patterning in the target language, and the development of activities andexercises based on concordance output” (Johns y King, 1991: iii). Este uso de líneas de concordanciaextraídas de corpus lingüísticos nos va a permitir que nuestros estudiantes puedan aprender descubriendoque el estudio de la gramática (o del léxico, del discurso o del estilo) se basa más en la investigación queen el aprendizaje memorístico, o, como indica Paquot (2007), “to introduce new words in context and tofamiliarise learners with the phraseology of these words”. Precisamente con actividades basadas en líneasde concordancia podríamos profundizar en el uso de las UF en inglés. Incluyendo este data-drivenlearning en el aula, podríamos llamar la atención sobre el uso de este tipo de estructuras por parte no sólode los estudiantes nativos, sino también por parte de estudiantes de ILE (que es básicamente el análisisllevado a cabo en el estudio que aquí se presenta). Por lo tanto, la necesidad de incluir estas estructurasfraseológicas en el aula se hace inexcusable, sobre todo en el caso de los estudiantes más avanzados(Hinkel, 2002: 159).
En general, el uso de UF en la producción escrita de estudiantes fue considerado durante muchotiempo periférico fundamentalmente por influencia de la gramática generativa, aunque en la actualidad suimportancia y el papel que desempeñan estas estructuras en el uso y procesamiento lingüístico estánplenamente asumidos. Hasta finales de los 80 y principios de los 90 no empezó la fraseología a tenercomo campo de investigación propio la importancia que no se le había concedido. En los últimos años,sobre todo gracias al gran número de diccionarios y de gramáticas que se han elaborado a partir de corpusgenerales o especializados, publicaciones científicas, proyectos de investigación internacionales, etc., eluso de UF forma ya parte esencial en el currículum de enseñanza de lenguas, tanto del ILE como delespañol.
En definitiva, la finalidad de incluir estudios lingüísticos de corpus en el campo de lainvestigación y en la enseñanza de lenguas, y especialmente de corpus de estudiantes, es poder analizar ycomparar la producción nativa y no nativa, tanto oral como escrita, en lengua inglesa. Esto es lo queGranger (2002: 12-13) ha venido a denominar análisis contrastivo de la interlengua (ContrastiveInterlanguage Analysis, CIA), cuya finalidad es, en primer lugar, identificar el uso excesivo y lainfrautilización de aspectos lingüísticos concretos en el lenguaje de los estudiantes y, en segundo lugar,identificar la transferencia o interferencia de una primera lengua, aspectos que se analizarán con másdetenimiento en este artículo.
2. Objetivos, hipótesis, y metodología de trabajo
2 El centro al que nos referimos es el Centro Superior de Idiomas Modernos (CSIM) de la Universidad Complutense de Madrid.3 Para Sinclair y Renouf (1988: 148), un programa léxico debería centrarse en tres aspectos fundamentales: “(a) the commonestword forms in a language; (b) the central patterns of usage; (c) the combinations which they usually form”.

RICA PEROMINGO, JUAN PEDRO 3
Como queda dicho, el objetivo fundamental de este estudio es demostrar la importancia que tienen elanálisis, el estudio y la enseñanza de UF en la enseñanza y el aprendizaje de lenguas en general, y del ILEen particular, sobre todo porque se considera que los errores fraseológicos cometidos por estudiantes sonla marca más clara que distingue la lengua nativa de la lengua no nativa, y no sólo en un nivelprincipiante, sino también en niveles avanzados. Insistiremos al mismo tiempo en la necesidad de incluiren el currículo de enseñanzas de lenguas un análisis más detallado de lo que son colocaciones y unidadesléxicas. Para ello, se decidió recopilar un corpus de unas 150.000 palabras (CEUNF) que incluyera laproducción escrita de estudiantes universitarios que estuvieran estudiando inglés en un ámbito noespecializado.
Como ya se había analizado en bastante profundidad el subcorpus de españoles universitarios deFilología Inglesa, el SPICLE, nos llamó la atención el número tan elevado de UF que los SPICLEutilizaban en sus redacciones. Nuestra motivación principal era el saber si lo que estaban haciendo estosestudiantes a la hora de escribir en inglés era algo similar o diferente a lo que harían otros estudiantesuniversitarios con un nivel equivalente, pero cuyos estudios principales no fueran Filología Inglesa. Deahí la decisión de recopilar el CEUNF con estudiantes universitarios no filólogos. En concreto, lashipótesis de trabajo que sugerimos son las siguientes:
a) Los estudiantes universitarios con otros estudios universitarios que no son Filología Inglesa(CEUNF) utilizarán un número de UF cuantitativa y cualitativamente distinto al utilizado por losestudiantes de Filología Inglesa (SPICLE).
b) El uso de colocaciones gramaticales y grupos léxicos de enlace realizado por estudiantesuniversitarios españoles que están aprendiendo inglés (CEUNF y SPICLE) será más reducidoque el de los estudiantes nativos de inglés (LOCNESS) y editorialistas profesionales (SPE) entérminos totales, aunque se demostrará que existe un uso excesivo de ciertas unidades léxicas porparte de los CEUNF y de los SPICLE, especialmente por los primeros.
Como metodología de trabajo, se ha utilizado software informático (Wordsmith 3.0) para la obtención dedatos, búsquedas en los corpus y análisis cuantitativo de los resultados. Este software permite laobtención de datos de una manera rápida y fiable, así como aplicar cálculos estadísticos sobre los tipos deUF basados en las categorías propuestas por la teoría fraseológica (Hausmann, 1989 y especialmenteBenson et al., 1986a, 1986b). Esto se ha hecho principalmente en colocaciones gramaticales (los verbosde comunicación y de procesos mentales (VCPM) y las estructuras lexicalizadas que los acompañan) y enla taxonomía de grupos léxicos propuesta por Biber et al. (1999), especialmente los que se refieren agrupos léxicos adverbiales de enlace (GLAE). Igualmente, hemos utilizado Excel para llevar a cabo laPrueba.T para los análisis estadísticos de algunos de los resultados obtenidos. Es precisamente esteprograma, entre todos los disponibles en el mercado, el que mayor aceptación tiene entre los lingüistaspara un estudio sobre UF4, en especial por ser fácil de utilizar (user-friendly) por su distribución visual yno sólo porque incluye las principales funciones de extracción de datos de corpus (concordancia, listas depalabras, palabras claves, extracción de grupos léxicos, colocaciones, etc.), sino también porque permiterealizar automáticamente el cálculo estadístico de probabilidades y frecuencias, aspecto éste que resultafundamental para el cálculo cuantitativo de los datos obtenidos.
Dentro de toda la producción posible sobre colocaciones y grupos léxicos, hemos tenido quedelimitar la investigación a dos estructuras concretas: por un lado, el uso de verbos de comunicación y deprocesos mentales y las estructuras lexicalizadas que acompañan y, por otro, los grupos léxicosadverbiales de enlace. Esta es la primera razón por la que hemos elegido esas dos estructurasfraseológicas, pero en segundo lugar, también queremos dejar constancia de la necesidad de acotar elestudio, ya que es imposible analizar todo el ámbito de colocaciones y de grupos léxicos; o como afirmaBiber (1993: 531): “Simply determining the number of different senses in a database of this size is adounting task”. Se refería aquí a su estudio de colocaciones del término certain en el Longman/LancasterCorpus, que contiene 11,6 millones de palabras5.
Evidentemente, intentar analizar todas las colocaciones gramaticales y grupos léxicos posibles enel cómputo total de palabras que integra el análisis de este trabajo de investigación (cerca de 3 millonesde palabras)6 es una tarea de proporciones inabarcables; de ahí la delimitación a los dos tipos de UF quehemos comentado anteriormente.
4 Tanto la versión 4.0. como la 5.0. ya están disponibles (http://www.lexically.net/wordsmith/index.html). Entre las novedades deestas nuevas versiones se encuentra una nueva función (la WebGetter) que permite a los usuarios construir su propio corpusutilizando páginas web que contienen la estructura gramatical o léxica que el usuario quiere analizar. En nuestro caso, ya que loscorpus utilizados ya están recopilados, no ha sido necesario utilizar esa nueva función.5 En este estudio se generaron 3.424 entradas del término analizado, y otro tanto ocurrió con la búsqueda de colocaciones con eltérmino right, que generó 7.619 entradas.6 El número total de palabras de los corpus utilizados para este estudio es exactamente de 2.871.446 palabras (véase Tabla 1).

4 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
3. El CEUNF (Corpus de Estudiantes Universitarios No Filólogos) y los corpus utilizados en elestudio
El CEUNF contiene más de 150.000 palabras. Los textos que se incluyen son redaccionesargumentativas sobre distintos temas de actualidad con los que los estudiantes están familiarizados, yaque en el momento de la escritura eran asuntos de continua cobertura en los medios de comunicación 7.Los sujetos que conforman el corpus son estudiantes adultos universitarios que, en el momento de larecogida de datos, se encontraban estudiando inglés como estudios complementarios a sus propiascarreras universitarias. La administración, recogida e informatización de los datos del CEUNF, así comola entrega y recogida de los Perfiles del estudiante, las ha llevado a cabo el autor de este artículopersonalmente en los últimos años, y ésta es una de las razones por las que el número de palabras delCEUNF es inferior al del resto de los corpus de estudiantes utilizados para este estudio (excepto elLOCNESS).
Quizás el proceso más largo y laborioso haya sido el de la informatización de las redacciones, nosólo por el hecho de haberla realizado una a una, sino también porque, de entre las 400 redacciones quecomponen el CEUNF, sólo alrededor de 100 fueron entregadas en formato electrónico. El resto de lasredacciones tuvieron que ser informatizadas manualmente, agrupadas y convertidas al formato requerido(formato .txt) para ser analizadas por el Wordsmith 3.0. Al mismo tiempo, ha sido necesario comprobarque los errores que se han ido encontrando y que aparecen en la versión electrónica escaneada eranerrores cometidos por los estudiantes en sus redacciones, y no errores añadidos durante el proceso deinformatización de las redacciones.
El tamaño de los corpus que se han utilizado en este estudio se especifica en la siguiente tabla(Tabla 1), que recoge tanto el corpus propio y los corpus nativos de referencia como los subcorpus delICLE.
Corpus Nº de palabrasCEUNF (Corpus de Estudiantes Universitarios No Filólogos) 153.721ICLE8
(Internacional Corpus of Learner English)FRICLE (French ICLE) 287.631
GERICLE (German ICLE) 203.647DICLE (Dutch ICLE) 237.631
SWICLE (Swedish ICLE) 206.940FINICLE (Finnish ICLE) 249.980
PICLE (Polish ICLE) 235.047CZICLE (Czech ICLE) 207.146
BICLE (Bulgarian ICLE) 200.704RICLE (Russian ICLE) 214.009ITICLE (Italian ICLE) 226.988
SPICLE (Spanish ICLE) 194.845LOCNESS (Louvain Corpus of Native English Essays) Amer.: 149.790
SPE (Signed Professional Editorialists) 103.367
Nº TOTAL DE PALABRAS DE TODOS LOS CORPUS 2.871.446
Tabla 1. Corpus utilizados en el estudio y número de palabras
Se puede observar que el número de palabras que integra cada uno de los corpus no eshomogéneo, y que existen diferencias bastante notables entre los corpus utilizados. Para evitar resultadospoco fiables que pudiéramos conseguir cuantitativamente en el análisis posterior de datos, hemosdecidido normalizar todos los resultados obtenidos por 10.000 palabras (Biber, Conrad y Reppen, 1998),para que las comparaciones de esos resultados sean equilibradas y puedan ser justificadasestadísticamente en todos los corpus.
4. El estudio: unidades fraseológicas (colocaciones gramaticales y grupos léxicos) en la producciónescrita de estudiantes españoles
Como hemos comentado anteriormente, este análisis parte del planteamiento de categorías sobrecolocaciones gramaticales sugerido por varios autores pertenecientes a la corriente fraseológica, así como
7 He aquí una muestra de estos temas: Smoking should be banned in public places; Exams are not useful; Wars are always wrong; Inorder to study English, people need to travel, live and work in an English-speaking country; Mass media is of great importance in the Spanish society.8 Los datos sobre número de palabras del ICLE están actualizados a 2002 y obtenidos de Granger, Dagreaux y Meunier, página 27.

RICA PEROMINGO, JUAN PEDRO 5
del propuesto por Biber et al. (1999). Ante tal volumen de corrientes, posibilidades y combinaciones, seha tenido que restringir el estudio a la taxonomía de grupos léxicos adverbiales de enlace propuestos porBiber et al. y a las colocaciones gramaticales que se forman con los verbos de comunicación y deprocesos mentales (taxonomía de Benson et al). Un análisis futuro y más detallado deberá incluir lascategorías propuestas por la teoría fraseológica (expresiones fijas, colocaciones y modismos oexpresiones idiomáticas) (Moon, 1998: 3), más tipos de colocaciones gramaticales (propuestas porBenson et al.), y las demás categorías propuestas por Biber et al. (modismos, colocaciones y asociacionesléxico-gramaticales) (Biber et al., 1999: 988-990).
4.1. Verbos de comunicación y de procesos mentales (VCPM)
Si como punto de partida para justificar la selección de este tipo de verbos definimos colocaciones comoestructuras compuestas por más de una palabra que, de alguna manera, son fijas léxica o semánticamente,estamos seguros de que algunas estructuras que se formarán con estos verbos van a componercolocaciones gramaticales en la producción escrita de los estudiantes. Es cierto que muchos de los gruposfraseológicos que nos van a aparecer en los datos obtenidos han sido denominados por autores comoSinclair (1991) como “coligaciones” (un término de contenido más un término funcional, por ejemplo, unthat completivo) sin que se les pueda considerar realmente colocaciones, pero también es cierto quedentro de la teoría fraseológica a ese tipo de estructuras se les denomina (Benson et al., 1986a, 1986b)colocaciones gramaticales. De lo que no nos cabe duda es de que el uso de UF del tipo I think that nopueden considerarse simplemente la coligación de un término de contenido, think, más dos términosfuncionales, I y that, y que cuando utilizamos este tipo de verbos el resultado debe ser algo más que lasimple unión de una estructura “esperable”. Ya mencionamos en algún otro sitio (Neff et al., 2003b) eluso de ciertas estructuras lexicalizadas (we can think, we can say, we can see) en la producción escrita delos estudiantes del SPICLE y la predilección por el uso de esta estructura con verbos, precisamente, deprocesos mentales y de comunicación. Creemos, por tanto, que algunas de las estructuras que hemosencontrado al analizar los datos que incluyen este tipo de verbos constituyen lo que conocemos comocolocaciones, en este caso gramaticales.
Por un lado, los verbos de comunicación corresponden a una subcategoría de lo que son verbosde actividad, pero en este caso la actividad que conllevan es de índole comunicativa, como hablar oescribir, y la transmisión de ideas por parte del hablante o del escritor. Las formas verbales quepertenecen a esta categoría son del tipo: announce, call, discuss, explain, say, shout, speak, state, suggest,talk, tell, write.
Por otro lado, los verbos de procesos mentales expresan un abanico de actividades y estados queexperimentamos los seres humanos. Son típicamente estáticos y, consecuentemente, no pueden apareceren forma progresiva. Estas formas verbales no indican actividad física y no suponen voluntad, e incluyenverbos con significado cognitivo y emocional que representan significados emotivos que expresan variasactitudes y deseos, percepción y receptor de la comunicación. Dentro del grupo de verbos de procesosmentales podemos diferenciar un subgrupo más dinámico que describe actividades cognitivas (calculate,consider, decide, discover, examine, learn, read, solve y study) y un segundo grupo que contiene verbosmás estáticos en lo que respecta al significado, como son aquellos que describen estados cognitivos(believe, doubt, guess, know, recognise, remember, think, forget, mean y understand) u otros quedescriben estados emocionales y de actitud (enjoy, feel, fear, hate, like, love, prefer, suspect, want). Paranuestros propósitos, hemos agrupado tanto los verbos de comunicación como los de procesos mentalescon los propuestos por Downing y Locke (1992), Biber et al. (1999) y Halliday (1985).
Con estos dos grupos de verbos, se han analizado las colocaciones gramaticales posibles quepueden acompañar a verbos de este tipo, sobre todo porque, en la mayoría de los casos, son verbosnecesarios a la hora de escribir redacciones argumentativas en inglés, pues reflejan claramente la posturadel escritor (writer stance) ante el tema que se discute.
4.2. Grupos léxicos adverbiales de enlace (GLAE)
Si el primer grupo de UF que analizaremos se corresponde con el grupo de colocaciones gramaticales quepropugna la teoría fraseológica, el segundo aspecto que se va a analizar en este trabajo es el de los gruposléxicos adverbiales de enlace (linking adverbials), el segundo tipo de UF, en este caso, según la tipologíapropuesta por Biber et al. (y estudiada por Conrad, 1999). La función primordial de los grupos léxicosadverbiales de enlace (GLAE) es, según Biber et al.: “to state the speaker/writer’s perception of therelationship between two units of discourse” (Biber et al., 1999: 875). ¿Por qué hemos elegido los gruposléxicos adverbiales de enlace (GLAE)? Podemos utilizar las palabras de Biber et al. para justitficarlo:

6 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
“Because they explicitly signal the connections between passages of text, linking adverbials are importantdevices for creating textual cohesion, alongside coordinators and subordinators” (ibid.: 875).
Igualmente, la conexión existente entre este tipo de adverbios (GLAE) y el tipo de verbosanalizados (VCPM) en el punto anterior es directa en el discurso escrito: los verbos de comunicación yprocesos mentales (VCPM) introducen la postura del escritor (writer stance) frente al tema del que tratala redacción, y los grupos léxicos adverbiales de enlace (GLAE) permiten la enumeración, adición,recapitulación, aposición, resultado, etc. de la postura adoptada por aquel.
Los adverbiales de enlace pueden aparecer en el discurso escrito expresados con unidades quecontengan un solo término o a través de grupos léxicos. Analizaremos ambos tipos, aunque el interésprimordial aquí sea el de los grupos léxicos. No obstante, en el caso de que no utilicen dichos GLAEpodremos constatar que utilizan otro tipo de adverbiales. Es decir, encontraremos que, a través de variasestructuras sintácticas, podemos representar las ideas que comunican los adverbiales de enlace. Comocaracterística fundamental comentaremos que este tipo de estructuras adverbiales tienen una relación másperiférica con el resto de la oración que cualquier otro tipo de formas adverbiales (circunstanciales o quemarcan la posición del escrito: stance adverbials). Estas estructuras, en palabras de Biber et al. (1999:765), “rather than adding information to a clause, they serve a connective function. They make explicitthe relationship between two units of discourse”.
Se hace necesario, pues, analizar todas las estructuras sintácticas (tanto las estructurasfraseológicas como los adverbios solos) y ver cómo se producen en los corpus analizados. De esa manera,podremos observar si los estudiantes (tanto de los dos grupos españoles, como los estudiantes nativos o elresto de los estudiantes extranjeros del ICLE) tienden a utilizar en mayor o menor medida grupos léxicosadverbiales o, por el contrario, confían más en adverbios únicamente para indicar la categoría de enlaceen sus redacciones. Igualmente, podremos contrastar qué grupos de estudiantes no nativos confían más enaquellas UF más utilizadas y comparar su uso con el de los estudiantes nativos y editorialistasprofesionales que escriben en inglés como su L1. De todos modos, como ya hemos comentadoanteriormente, el análisis principal de dichas UF se llevará a cabo fundamentalmente en los dos grupos deestudiantes universitarios españoles (el subcorpus del ICLE, SPICLE, y el de producción propia CEUNF)y en su comparación con los dos corpus nativos (el de estudiantes universitarios estadounidenses,LOCNESS, y el de editorialistas profesionales, SPE).
La tipología de los grupos léxicos adverbiales de enlace sugerido por Biber et al. (1999), y queservirá como taxonomía para este trabajo, aparece a continuación (Tabla 2).
Enumeración y adición Enumeración: First, Second, Firstly, Secondly, Thirdly, In the first place, In the second place, First of all, For
one thing, For another thing, To begin with, Next, Finally, Lastly. Adición: In addition, Further, Furthermore, Similarly, Also, By the same token, Likewise, Moreover.Suma: All in all, In conclusion, Overall, To conclude, To summarize, To sum up, In sum, To conclude.Aposición: Which is to say, In other words, i.e., that is, e.g., for example, for instance, Namely, specificallyResultado/inferencia: Therefore, Consequently, Thus, As a result, Hence, In consequence, So, ThenContraste/concesión Contraste: On the one hand, On the other hand, In contrast, Alternatively, Conversely, Instead,
On the contrary, By comparison Concesión: Though, And anyway, However, Yet, Anyhow, Besides, Nevertheless, Still, In any
case, At any rate, In spite of that, Alter allTransición: By and by, Incidentally, By the way, Now, Meanwhile
Tabla 2. Taxonomía de grupos léxicos adverbiales de enlace
5. Resultados y discusión
Después de haber analizado todas las UF en los corpus de escritores no nativos españoles y comparadoséstos con los dos corpus de producción nativa, los resultados son los siguientes:1. Con respecto a las colocaciones gramaticales encontradas con los verbos de comunicación, no
existen diferencias significativas entre los escritores nativos y no nativos (p<0,2), aunque se apreciaun mayor uso de este tipo de UF por parte de los nativos. Tampoco existen diferencias significativasentre los dos grupos de corpus españoles, o entre los dos grupos de corpus nativos.
2. Con respecto a las colocaciones gramaticales encontradas con los verbos de procesos mentales, noexisten diferencias significativas entre los escritores nativos y no nativos (p<0,2), aunque de nuevose aprecia un mayor uso de este tipo de unidades por parte de los primeros. Donde sí existendiferencias significativas es al comparar tanto a los dos grupos de escritores españoles entre sí(p<0,05, con un mayor uso de colocaciones gramaticales por parte de los CEUNF) como a los dos
RICA PEROMINGO, JUAN PEDRO 7
grupos de escritores nativos (p<0,01, con un mayor uso de colocaciones gramaticales por parte delos LOCNESS).
3. Finalmente, en lo que respecta a los grupos léxicos adverbiales de enlace, existen diferenciassignificativas (p<0,03) entre los escritores nativos y no nativos, con un mayor uso de este tipo deestructuras por parte de los segundos. Las diferencias entre CEUNF y SPICLE no son significativas(p<0,9), aunque se aprecia un uso ligeramente mayor por parte de los CEUNF. Por otro lado, síexisten diferencias significativas entre los dos grupos nativos (p<0,02), con un uso mayor de UF porparte de los estudiantes del LOCNESS.
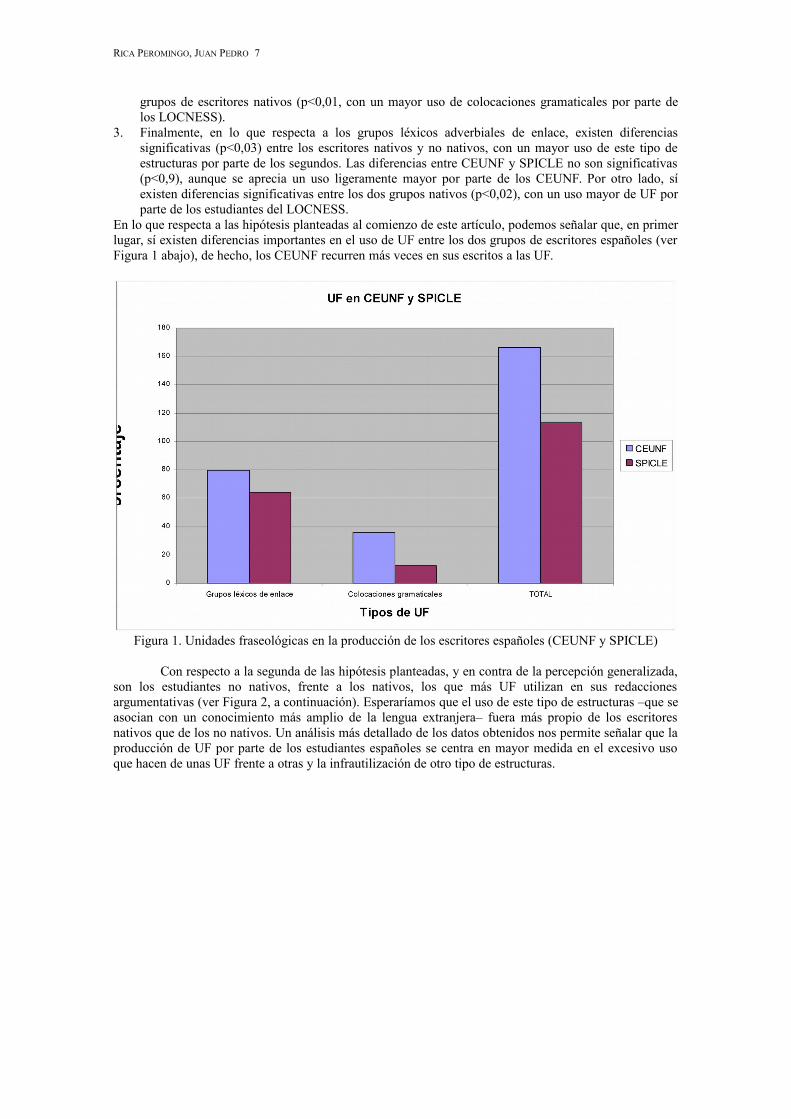
En lo que respecta a las hipótesis planteadas al comienzo de este artículo, podemos señalar que, en primerlugar, sí existen diferencias importantes en el uso de UF entre los dos grupos de escritores españoles (verFigura 1 abajo), de hecho, los CEUNF recurren más veces en sus escritos a las UF.
Figura 1. Unidades fraseológicas en la producción de los escritores españoles (CEUNF y SPICLE)
Con respecto a la segunda de las hipótesis planteadas, y en contra de la percepción generalizada,son los estudiantes no nativos, frente a los nativos, los que más UF utilizan en sus redaccionesargumentativas (ver Figura 2, a continuación). Esperaríamos que el uso de este tipo de estructuras –que seasocian con un conocimiento más amplio de la lengua extranjera– fuera más propio de los escritoresnativos que de los no nativos. Un análisis más detallado de los datos obtenidos nos permite señalar que laproducción de UF por parte de los estudiantes españoles se centra en mayor medida en el excesivo usoque hacen de unas UF frente a otras y la infrautilización de otro tipo de estructuras.

8 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
Figura 2. Unidades fraseológicas en los escritores no nativos (CEUNF y SPICLE) frente a los escritoresnativos (LOCNESS y SPE)
Una de las razones por las que creemos que se han producido estas diferencias entre los cuatrogrupos de escritos podría ser una diferencia de instrucción (teaching effect), fundamentalmente por laenseñanza poco sistemática de este tipo de estructuras léxicas. Analizando varios libros de texto existentesen el mercado para la enseñanza de ILE, nos encontramos con una falta prácticamente generalizada deactividades o ejercicios sobre UF.
La segunda de las razones que esgrimimos para las diferencias significativas encontradas puedehallarse en la influencia de una primera lengua (L1) sobre la segunda lengua (L2) o lengua extranjera(positive transfer), especialmente por la similitud y existencia de ciertas UF en las L1 de los escritoresespañoles (For example, In conclusion, In my opinion, I think that), lo que puede provocar que losestudiantes no nativos, primero, confíen más en aquellas unidades léxicas que existan en su lenguamaterna, segundo, en aquellas que se utilizan en la producción escrita de su L1 y, finalmente, en las UFcon cierta similitud estructural. Este aspecto justificaría por qué existe un uso excesivo (For example, Inconclusion, In my opinion, I think that) o una infrautilización (Overall, For instance, I believe that) deciertas UF en la producción escrita de los estudiantes españoles.
Finalmente, y puesto que no se han encontrado diferencias significativas entre los dos grupos deestudiantes españoles, no podemos constatar que la competencia lingüística (linguistic competente) sea unfactor que influya en el uso de UF en la producción escrita de los no nativos.
6. Conclusiones
Comenzábamos este artículo con una cita de Wong-Filmore sobre la importancia de la adquisición deestructuras léxicas en el aprendizaje de lenguas extranjeras, y es precisamente con el papel esencial quedesempeñan la fraseología y el aprendizaje de UF con el que queremos concluir este artículo. Comoseñala Hill (2000: 53-54): “The most obvious reason why collocation is important is because the waywords combine in collocations is fundamental to all language use […] and allow us to think more quicklyand communicate more efficiently”. Afortunadamente, en la literatura sobre estudios fraseológicosanteriores al que aquí presentamos ya se ha señalado la importancia de incluir este tipo de estudios léxicosen el currículum de la enseñanza del ILE (Allerton, Nesselhauf y Skandera, 2004; Alonso, Neff y Rica,2000; Nesselhauf, 2003, 2005; Neff et al., 2003a; Wray, 2000, 2002), o en el de otras lenguas, como porejemplo, español como lengua extranjera (Corpas Pastor, 1997; Forment, 1998). Sin embargo, tambiénhemos recordado anteriormente que estos estudios se han centrado fundamentalmente en el uso,aprendizaje y enseñanza de colocaciones léxicas, no tanto de grupos léxicos o colocaciones gramaticales.
El estudio aquí presentado pretende analizar el que consideramos, y es considerado por variosautores, como uno de los aspectos más importantes en el campo del aprendizaje del léxico inglés: las UF,y dentro de ellas, en concreto, el estudio de grupos léxicos de enlace y colocaciones gramaticales en

RICA PEROMINGO, JUAN PEDRO 9
textos argumentativos producidos por estudiantes no nativos. Nuestro objetivo al analizar este tipo deestructuras es que nuestros estudiantes sean capaces de identificar cómo las palabras coexisten con otras,es decir, tal como indica Brown (1994: 25): “teaching them to look not simply for new words, but at thewords they know already; not simply at the words they know already, but at these in relation to otherwords”. Para ello, hemos presentado los subcorpus del ICLE y el corpus de producción propia CEUNF deestudiantes universitarios españoles no filólogos en la UCM, y, así, comparar la producción de UF entrecorpus de estudiantes con la de escritores universitarios estadounidenses (LOCNESS) y editorialistasprofesionales (SPE).
Hemos podido constatar en primer lugar la importancia del uso de corpus de estudiantes para laenseñanza de aspectos léxicos de ILE, y que ha sido señalada por varios autores (como, por ejemplo,Flowerdew, 2001) como la base metodológica más fiable en este tipo de enseñanza. El uso de programasinformáticos (Wordsmith 3.0), de análisis estadístico (Prueba.T) y el análisis de corpus lingüísticos deestudiantes nos ha permitido analizar de una manera fiable, directa y objetiva cuál es la producción decolocaciones gramaticales y de grupos léxicos de enlace en todos los grupos de estudiantes no nativos quecomponen el CEUNF y el ICLE, y al mismo tiempo, comparar dicha producción con la de estudiantes yprofesionales nativos.
En segundo lugar, hemos comentado la importancia del uso de los grupos léxicos adverbiales deenlace y de colocaciones gramaticales en un discurso argumentativo, fundamentalmente debido al ampliouso de UF que todos los estudiantes no nativos –y en concreto, los CEUNF– hacen en sus escritos, y quearroja diferencias significativas no sólo por parte de los estudiantes universitarios españoles con respectoa los estudiantes y editorialistas profesionales nativos, sino incluso dentro de cada uno de los gruposespañoles: por un lado, los CEUNF utilizan más UF que los SPICLE, y, por otro lado, los LOCNESSconfían más en UF para su producción escrita que los SPE. Esta es, quizás, una de las conclusiones másllamativas a las que hemos llegado tras el análisis de los datos.
La primera de las hipótesis que planteábamos era que, dentro de los grupos de estudiantes nonativos, la producción de estructuras lexicalizadas por parte de los estudiantes universitarios no filólogos(CEUNF) iba a ser distinta cuantitativa y cualitativamente del otro grupo de universitarios españolesfilólogos que forman parte del ICLE (el subcorpus SPICLE). En el análisis de los datos hemos podidocomprobar que el uso de UF por parte de los CEUNF es significativamente mayor que el de los SPICLE,y que su producción se concentra en un determinado grupo de UF que utilizan continuamente en susescritos. En lo que ambos grupos coinciden (lo cual es extensible a todos los demás grupos de estudiantesno nativos del ICLE y no incluidos en este artículo) es en el empleo excesivo de ciertas estructuras y lainfrautilización de otras, uso que, comparado con los dos corpus nativos, constituye una de las diferenciasmás significativas entre nativos y no nativos.
La segunda de nuestras hipótesis era que los nativos harían uso de un mayor número de UF quelos no nativos, ya que el uso de UF complejas se asocia normalmente más con la producción nativa quecon la no nativa. Nuestros resultados han refutado esta afirmación: precisamente son los no nativos losque más estructuras lexicalizadas utilizan. Sí que es cierto que existe un número de UF que losestudiantes no nativos del ICLE (y en especial los SPICLE) y del CEUNF utilizan de forma excesiva yotras que infrautilizan en su producción escrita, y que los nativos, aunque con un menor número de UF,muestran más variedad de construcciones léxicas. Pero efectivamente podemos concluir que los nonativos confían más en el uso de estructuras fraseológicas que los estudiantes y profesionales nativos.
Las razones que hemos esgrimido para justificar esta diferencia significativa en el uso de UF porparte de los no nativos fueron dos: el tipo de instrucción recibida en las clases (teaching effect), sobretodo en el caso de los estudiantes españoles, y la influencia de la L1. En lo que respecta al tipo deinstrucción que reciben los estudiantes universitarios españoles, la impresión general es que se presentanlas estructuras fraseológicas a los estudiantes de una forma poco sistemática, es decir, no se saberealmente cómo incluir este aspecto léxico-gramatical en el programa general de enseñanza de ILE en unámbito universitario.
En cuanto a la segunda razón, como ya dijimos, la existencia o similitud de ciertas estructurascomo las que se utilizan en las distintas L1 de los estudiantes no nativos que componen el ICLE y elCEUNF puede provocar que los estudiantes confíen en mayor medida en aquellas UF que existen en sulengua materna, que se utilizan en la producción escrita en ésta y que tienen cierta similitud estructural.Esta transferencia positiva es crucial en el aprendizaje de segundas lenguas y lenguas extranjeras, y esinevitable que los estudiantes utilicen su conocimiento sintáctico-gramatical y léxico a la hora de expresarsus opiniones en un texto argumentativo en inglés: si, por ejemplo, la estructura I think that comocolocación gramatical es aprendida en inglés y utilizada para expresar la opinión personal y la manera deintroducir la postura de cualquier escritor, y en español, en alemán o en francés existe la misma estructura(creo que, Ich glaube, daβ, je crois que), utilizada en el mismo contexto, lo lógico es que los estudiantesespañoles, alemanes y franceses utilicen mayoritariamente en sus textos escritos en inglés esta colocación

10 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
gramatical y no otras (I believe that) que también se podrían utilizar en el mismo contexto y con la mismafunción. El riesgo que corremos, en nuestra opinión, es que esa transferencia de aspectos léxico-gramaticales de su L1 provoque el uso excesivo de un grupo concreto de UF (aquellas que son similares asu L1) e impida el uso y aprendizaje de otras formas más elaboradas e igualmente comunes en laproducción nativa.
En definitiva, creemos que uno de los aspectos más importantes de lo presentado en este estudioes que los estudiantes de ILE, en primer lugar, sean conscientes del fenómeno de las UF, gracias a lacreación por parte del profesor de ciertas actividades destinadas a la práctica de grupos léxicos y decolocaciones gramaticales, modificando y adaptando, si fuera necesario, los libros de texto que utilizamosen nuestras clases de ILE; en segundo lugar, creemos necesario que a los estudiantes se les proporcionenestrategias de aprendizaje de este tipo de estructuras; y en tercer lugar, proponemos que se les enseñecómo utilizarlas en sus escritos con la presentación de ejemplos reales extraídos de corpus de estudiantes(nativos y no nativos) y con la ayuda de diccionarios bilingües y monolingües sobre UF. Se debería, portanto, incentivar una enseñanza explícita de estructuras lexicalizadas que combine creatividad, fluidez yprecisión (Lewis, 2000), al mismo tiempo que también promueva lo que se ha denominado rote learning(memorización) de ciertas estructuras (Willis, 1990). El problema con todos estos estudios anteriores esque se centran, como ya comentamos, en el análisis de colocaciones léxicas nominales y verbales, pero noexisten estudios hasta el momento que incidan en la necesidad de enseñar otros tipos de UF (gruposléxicos adverbiales de enlace o colocaciones gramaticales, como el estudio que aquí se presenta), que sonigual de necesarios para una correcta producción escrita de los estudiantes de una L2. Sí que va en la líneade nuestro trabajo el estudio de Nesselhauf (2005: 254), que aboga porque sus sugerencias para laenseñanza de colocaciones se puedan extender a otro tipo de colocaciones, distintos tipos de estudiantes,niveles y tipos de cursos.
En general, para la enseñanza de UF, varios autores han propuesto que la enseñanza deestructuras léxicas se base en varios criterios, entre los que se encuentran la frecuencia de uso, lasnecesidades del estudiante, la disponibilidad y familiaridad, la dificultad de las estructuras y laregularidad. En todos los casos, y gracias a la lingüística de corpus (Halliday et al., 2004), podemosaplicar estos criterios en nuestro análisis de corpus de estudiantes y podemos observar su uso en contextosreales de producción. Por ejemplo, cuando analizamos los grupos léxicos adverbiales de enlace en elapartado anterior, encontramos que había una serie de UF más frecuentes en la producción nativa (afterall) y menos frecuentes en la producción no nativa, y que, por lo tanto, pueden provocar mayor dificultadpara su aprendizaje. Lo mismo sucedió con colocaciones gramaticales del tipo he states that, tan comúnen los nativos (especialmente en los universitarios estadounidenses) y prácticamente inexistente en los nonativos. Deberíamos, por lo tanto, incluir en nuestros programas de enseñanza actividades queprofundicen en este tipo de UF, tomando los corpus nativos y no nativos como referencia paraejemplificar y observar la frecuencia de uso en unos y otros, extraer ejemplos de los corpus nativos eintentar ver por qué resultan tan difíciles para los CEUNF y SPICLE, por ejemplo. Por último, resultaprimordial intentar ver con los estudiantes si la falta de uso de ciertas UF puede provocar pérdida delmensaje que se quiera transmitir, tanto porque los estudiantes estén evitando utilizar esa estructura yutilicen otra incorrecta, como si no la están utilizando o utilizan de una manera excesiva otras UFsimilares (for example frente a for instance, o I think that frente a I believe that). En definitiva, si enestudios anteriores (Lewis, 2000: 17; Nesselhauf, 2005: 259) se ha encontrado que las UF másproblemáticas son las expresiones más comunes, y que las que menos problemas causan a los estudiantesson las más especializadas, entonces deberemos centrarnos en aquellas estructuras tan comunes como forinstance e intentar enseñar su uso de una forma correcta o, al menos, que no se produzca unainfrautilización de estructuras como ésta, tan común en la producción nativa.
Estamos convencidos, pues, de que debemos aprovechar la metodología de la lingüística decorpus para identificar el uso excesivo y la infrautilización de aspectos lingüísticos concretos en ellenguaje que utiliza el estudiante (Granger, Dagreaux y Meunier, 2002: 12-13), y, en segundo lugar,identificar la transferencia (Kellerman, 1995) o interferencia de una L1 en su producción en la L2.Podemos, como ejemplo, utilizar una de las estructuras léxicas más comunes en la producción escrita delos no nativos —la UF for example— y analizar otras UF o combinaciones léxicas que pueden utilizarseen el mismo contexto. Si queremos que nuestros estudiantes practiquen la lengua inglesa y, sobre todo,que sean conscientes del uso de UF en sus escritos, debemos utilizar ejemplos reales de la producciónescrita de otros estudiantes y comparar las estructuras léxicas en cuestión con la producción escrita deestudiantes o profesionales nativos. Para ello, con el software necesario extraemos líneas de concordanciacon ejemplos tanto de corpus no nativos (el CEUNF, por ejemplo) como de nativos (el LOCNESS) ycomprobamos qué otras combinaciones son posibles con el término example. De esta manera, losestudiantes podrán ver que existen otras UF (sobre todo léxicas) que también se pueden utilizar en el

RICA PEROMINGO, JUAN PEDRO 11
mismo contexto y pueden expresar la misma idea, sobre todo si estos ejemplos provienen de textos realesde una producción nativa que, al fin y al cabo, sirva como modelo para dichos estudiantes.
Este estudio puede servir como punto de partida para otros posteriores sobre el uso de UF yextender el análisis a otro tipo de estructuras: verbos modales, otro tipo de UF, como por ejemplo, otrosgrupos léxicos o frases idiomáticas propuestas por Biber et al., y el resto de las colocaciones gramaticalespropuestas por Benson et al. en su taxonomía, o lo que Hyland (1998) denomina boosters9. Igualmente,podremos comparar la producción de los estudiantes españoles con los otros estudiantes no nativos delICLE. Este análisis se puede extender igualmente a otros registros más especializados, ya que existe unaserie de UF más típicas de un discurso que de otro, incluso a subgrupos dentro de lo que se hadenominado “discurso académico”. Y, finalmente, el análisis también se podrá ampliar al estudio de estasestructuras léxicas en los escritos de otro tipo de estudiantes (la aplicación de los resultados de nuestroestudio en estudiantes con un nivel competencial menor o de nivel no universitario), especialmente condistintas L1. Igualmente, este estudio cuantitativo constituye la antesala y la herramienta fundamentalpara la interpretación posterior –en un estudio más amplio– de los datos obtenidos (análisis cualitativo),ya que, como dice Conrad (2002: 78), “numbers alone give little inside about language. Even the mostsophisticated quantitative analysis must be tied to functional interpretations of the language patterns”.
No podemos estar más de acuerdo con la afirmación de Nesselhauf (2003: 238): “collocations dodeserve a place in language teaching”. Sirva esta frase como acicate para estudios ulteriores sobre estecampo.
Referencias bibliográficas
Allerton, D.J., Nesselhauf, N. y Skandera, P. (2004): Phraseological Units: basic concepts and their application.Basilea, Schwabe.
Alonso, C., Neff, J. y Rica, J.P. (2000): “Cross-linguistic influence in language learning”, Estudios de FilologíaModerna, 1, págs. 65-84.
Aston, G. (2001): Learning with Corpora. Houston, TX, Athelstan.Benson, M., Benson, E. e Ilson, R. (1986a): Lexicographic Description of English (Studies in Language Companion
Series, No 14). Ámsterdam, John Benjamins.Benson, M., Benson, E. e Ilson, R. (1986b): The BBI Combinatory Dictionary of English: A Guide to Word
Combinations. Ámsterdam, John Benjamins.Biber, D. (1993): “Co-occurrence Patterns among Collocations: A Tool for Corpus-Based Lexical Knowledge
Acquisition”, Computational Linguistics, 19(3), págs. 531-538.Biber, D., Conrad, S. y Reppen, R. (1998): Corpus Linguistics. Investigating Language Structure and Use.
Cambridge, Cambridge University Press.Biber, D., Johansson, S., Leech, G., Conrad, S. y Finegan, E. (1999): The Longman Grammar of Spoken and Written
English. Londres, Longman.Brown, P. (1994): “Lexical Collocation: A Strategy for Advanced Learners”, MET, 3(2), págs. 24-27.Conrad, S. (1999): “The importance of corpus-based research for language teachers”, System, 27, págs. 1-18.Conrad, S. (2002): “Corpus linguistic approaches for discourse analysis”, Annual Review of Applied Linguistics, 22,
págs. 75-95.Corpas Pastor, G. (1997): Manual de Fraseología Española. Madrid, Gredos. Cowie, A.P. (ed.) (1998): Phraseology. Theory, Analysis, and Applications. Oxford, Clevendon Press.Downing, A. y Locke, P. (1992): A University Course in English Grammar. Hemel Hempstead, Prentice Hall.Flowerdew, L. (2001): “The Exploitation of Small Learner Corpora in EAP Materials Design”. En Ghadessy, M.,
Henry, A. y R.L. Roseberry (eds.): Small Corpus Studies and ELT. Theory and practice. Ámsterdam, PA,John Benjamins, págs. 363-379.
Forment, Mª del M. (1998): “La didáctica de la fraseología ayer y hoy: del aprendizaje memorístico al agrupamientoen los repertorios de funciones comunicativas". En Moreno, F.G. y K.M.-Alonso: La enseñanza del españolcomo lengua extranjera: del pasado al futuro. Actas del VIII Congreso Internacional de ASELE. Alcalá deHenares, Publicaciones de la Universidad de Alcalá de Henares, págs. 339-347.
Granger, S. (2002): “A bird’s-eye view of learner corpus research”. En Granger, S., Hung, J. y S. Petch-Tyson (eds.):Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching. Lund, LundUniversity, págs. 38-51.
Granger, S., Dagreaux, E. y Meunier, F. (eds.) (2002): International Corpus of Learner English. Handbook and CD-ROM. Lovaina, Université Catholique de Louvain Press.
Halliday, M.A.K. (1985): An Introduction to Functional Grammar. Londres, Edward Arnold.Halliday, M.A.K., Teubert, W., Yallop, C. y Čermáková, A. (2004): Lexicology and Corpus Linguistics. An
Introduction. Londres, Continuum.
9 Hyland (1998: 350) define boosters como: “those expressions which allow writers to express conviction and assert a propositionwith confidence, representing a strong claim about a state of affair. Affectively they also mark involvement and solidarity with anaudience, stressing shared information, group membership, and direct engagement, with readers”.

12 LINGÜÍSTICA DE CORPUS EN LA ENSEÑANZA DEL INGLÉS COMO LENGUA EXTRANJERA (ILE)
Hausmann, F.J. (1989): “Le dictionnaire de collocations”. En Hausmann, F.J., Reichmann, O., Wiegand, H.E. y L.Zgusta (eds): Wörterbücher. Dictionaries. Dictionnaires. Ein internationales Handbuch zur Lexikographie.An International Encyclopedia of Lexicography. Encyclopédie internationale de lexicographie. Vol. 1.Berlín, Nueva York, Walter de Gruyter.
Hill, J. (2000): “Revising priorities: From grammatical failure to collocational success”. En M. Lewis (ed.): TeachingCollocation. Further Developments in the Lexical Approach. Hove, LTP, págs. 47-69.
Hinkel, E. (2002): Second Language Writers’ Text. Linguistic and Rhetorical Features. Mahwah, NJ, LawrenceErlbaum.
Howarth, P. (1996): Phraseology in English Academic Writing. Some Implications for Language Learning andDictionary Making. Tübingen, Niemeyer.
Howarth, P. (1998): “Phraseology and Second Language Proficiency”, Applied Linguistics, 19, págs. 24-44.Hyland, K. (1998): “Boosting, Hedging and the Negotiation of Academic Knowledge”, Text, 18(3), págs. 349-382.Johns, T. y King, P. (1991). (eds.): “Classroom concordances”, ELR Journal (New Series) 4.Kellerman, E. (1995): “Crosslinguistic influence: transfer to nowhere?”, Annual Review of Applied Linguistics, 15,
págs. 125-150.Lewis, M. (2000): Teaching collocation. Further Developments in the Lexical Approach. Hove, LTP.Marín, J. y Neff, J. (2001): "Contrastive analysis of evidentiality in English and Spanish: corpus studies of
argumentative texts written by native and non-native writers", Conferencia en el II InternationalContrastive Linguistics Conference. Santiago de Compostela: Universidad de Santiago de Compostela.
Moon, R. (1998): Fixed expressions and idioms in English: a corpus-based approach. Oxford, Clarendon Press,Oxford Studies in Lexicography and Lexicology.
Neff, J., Martínez, F., y Rica, J.P. (2003a): “A Contrastive Study of Qualification Devices in Native and Non-nativeArgumentative Texts in English”, ERIC (Educational Resources Information Center) DataBase.Washington, EE.UU.
Neff, J., Dafouz, E., Díez, M., Martínez, F., Prieto, R. y Rica, J.P. (2003b): “Evidentiality and the construction of writerstance in native and non-native texts”. En J. Hladký (ed.): Language and Function. To the memory of JanFirbas. Ámsterdam, John Benjamins, págs. 223-235.
Nesselhauf, N. (2003): “The use of collocations by advanced learners of English and some implications for teaching”,Applied Linguistics, 24, págs. 223-242.
Nesselhauf, N. (2005): Collocations in a Learner Corpus. Ámsterdam, John Benjamins.Oakey, D. (2002): “Lexical Phrases for Teaching Academic Writing in English: Corpus Evidence”. En S. Nuccorini
(ed.): Phrases and Phraseology - Data and Descriptions. Frankfurt am Main, Peter Lang, págs. 81-105.Sinclair, J. (1991): Corpus, Concordance, Collocation. Oxford, Oxford University Press.Sinclair, J. y Renouf, A. (1988): “A lexical syllabus for language learning”. En Carter, R. y M. McCarthy (eds.):
Vocabulary and Language Teaching. Londres, Longman.Osborne, O. (2001): “Integrating corpora into a language-learning syllabus”. En B. Lewandowska-Tomaszczyk (ed.):
PALC 2001: Practical Applications in Language Corpora. Francfort, Peter Lang, págs. 479-492.Paquot, M. (2007): “Towards a productively-oriented academic word list”. En Walinski, J., Bredens, K. y S. Gozdz-
Roszkowski (eds.): Practical Applications in Language and Computers 2005. Frankfurt am Main, PeterLang.
Thurstun, J. y Candlin, C. (1998): “Concordancing and the teaching of the vocabulary of academic English”, Englishfor Specific Purposes, 17, págs. 267-280.
Tribble, C. (2001): “Small corpora and teaching writing. Towards a corpus-informed pedagogy of writing”. EnGhadessy, M., Henry, A. y R.L. Roseberry: Small Corpus Studies and ELT. Theory and practice.Ámsterdam, PA, John Benjamins, págs. 381-406.
Tribble, C. (2003): “The text, the whole text… or why large published corpora aren’t much use to language learnersand teachers”. En B. Lewandowska-Tomaszczyk (ed.): Practical Applications in Language and Computers.Francfort, Peter Lang, págs. 303-318.
Tribble, C. y Jones, G. (1997): Concordances in the Classroom: Using Corpora in Language Education. Houston,TX, Athelstan.
Willis, D. (1990): The Lexical Syllabus. A New Approach to Language Teaching. Londres, Collins.Wong-Fillmore, L. (1976): The Second Time Around: Cognitive and Social Strategies in Second Language
Acquisition. Tesis doctoral no publicada. Stanford University.Wray, A. (2000): Formulaic Sequences in Second Language Teaching: Principle and Practice, Applied Linguistics,
21/4, págs. 463-489.Wray, A. (2002): Formulaic Language and the Lexicon. Nueva York, Cambridge University Press.




















