
Lessons in Digital Estimation Theory
161
PRENTICE-HALL SIGNAL PROCESSING SERIES Alan V. Oppenheim, Editor ANDREWS and HUNT Digital Image Restoration BRIGHAM The Fmt Fourier Transform BURDK Underwater Acoustic System Analysis CASTLEMAN Digital Image Processing COWAN and GRANT Adaptive Filters CROCHIERE and RABINER Multirate Digital Signal Processing DUDGEON and MERSEREAU Multidimensional Digital Signal Processing HAMMING Digital Filters, 2nd ed. HAYKIN, ED. Array Signal Processing JAYANT and NOLL Digital Coding of Waveforms KIN0 Acoustic Waves: Devices, Imaging, and Analog Signal Processing LEA, ED. Trends in Speech Recognition LIM, ED. Speech Enhancement MARPLE Digital Spectral Analysis with Applications MCCELLAN and RADER Number Theory in Digital Signal Processing MENDEL Lessons in Digital Estimation Theory OPPENHEIM, ED. Applications of Digital Signal Processing OPPENHEIM, WILLSKY, with YOUNG Signals and Systems OPPENHEIM and SCHAFER Digital Signal Processing RABINER and GOLD Theory and Applications of Digital Signal Processing RABINER and SCHAFER Digital Processing of Speech Signals ROBINSON and TRIETEL Geophysical Signal Analysis STEARNS and DAVID Signal Processing Algorithms TRIBOLET Seismic Applications of Homomorphic Signal Processing WIDROW and STEARNS Adaptive Signal Processing lessons in Digital Estimation Theory Jerry A/l. Mendel Department of Electrical Engineering University of Southern California Los Angeles, California Prentice-Hall, Inc., Englewood Cliffs, New Jersey 07632
-
Upload
khangminh22 -
Category
Documents
-
view
0 -
download
0
Transcript of Lessons in Digital Estimation Theory

PRENTICE-HALL SIGNAL PROCESSING SERIES
Alan V. Oppenheim, Editor
ANDREWS and HUNT Digital Image Restoration BRIGHAM The Fmt Fourier Transform BURDK Underwater Acoustic System Analysis CASTLEMAN Digital Image Processing COWAN and GRANT Adaptive Filters CROCHIERE and RABINER Multirate Digital Signal Processing DUDGEON and MERSEREAU Multidimensional Digital Signal Processing HAMMING Digital Filters, 2nd ed. HAYKIN, ED. Array Signal Processing JAYANT and NOLL Digital Coding of Waveforms KIN0 Acoustic Waves: Devices, Imaging, and Analog Signal Processing LEA, ED. Trends in Speech Recognition LIM, ED. Speech Enhancement MARPLE Digital Spectral Analysis with Applications MCCELLAN and RADER Number Theory in Digital Signal Processing MENDEL Lessons in Digital Estimation Theory OPPENHEIM, ED. Applications of Digital Signal Processing OPPENHEIM, WILLSKY, with YOUNG Signals and Systems OPPENHEIM and SCHAFER Digital Signal Processing RABINER and GOLD Theory and Applications of Digital Signal Processing RABINER and SCHAFER Digital Processing of Speech Signals ROBINSON and TRIETEL Geophysical Signal Analysis STEARNS and DAVID Signal Processing Algorithms TRIBOLET Seismic Applications of Homomorphic Signal Processing WIDROW and STEARNS Adaptive Signal Processing
lessons in Digital
Estimation Theory
Jerry A/l. Mendel Department of Electrical Engineering University of Southern California Los Angeles, California
Prentice-Hall, Inc., Englewood Cliffs, New Jersey 07632

Lessons
in Digita/
Esfimafion Theory

Librar) of Congress Cataloging-in-Publication Data
MENDEL,JERRY M., (date) Lessons in digital estimation theory.
Bibliography: p. Includes index. 1. Estimation theory. I. Title.
QA276.8.M46 1986 511'.4 86-9365 ISBN o-13-530809-7
To my parents, Eleanor and Alfred Mendel and my wife, Letty Mendel
Editorial/production supervision: Gretchen K. Chenenko Cover design: Lundgren Graphics Manufacturing buyer: Gordon Osbourne
.
0 1987 by Prentice-Hall, Inc. A Division of Simon & Schuster Englewood Cliffs, New Jersey 07632
All rights reserved. No part of this book may be reproduced, in any form or by any means, without permission in writing from the publisher.
Printed in the United States of America
10 9 8 7 6 5 4 3 2 1
ISBN 0-13-53U8U~-7 025
PRENTXCE-HALL INTERNATIONAL (UK) LIMITED, London PRENTICE-HALLOFAUSTRALXAPTYLIMITED,~~~~~~ PRENTICE-HALLCANADAINC., Toronto PRENTICE-HALLHISPANOAMERICANASA., Mexico PRENTICE-HALLOFINDIAPRIVATE LIMITED,N~~ Delhi PUMICE-HALL OFJAPAN.INC., Tokyo P~NTIcE-HALLOF~O~THEAST ASIA PIE LTD., Singapore ED~~RAPRENTICE-HALLDOBRASIL, LTDA., Rio deJaneiro
Contents
. . . XIII
LESSON 1 INTRODUCTION, COVERAGE, AND PHILOSOPHY
Introduction 1 Coverage 2 Philosophy 5
LESSON 2 THE LINEAR MODEL
Introduction 7 Examples 7 Notational Preliminaries 14 Problems 15
LESSON 3 LEAST-SQUARES ESTIMATION: BATCH PROCESSING
Introduction 17 Number of Measurements 18 Objective Function and Problem Statement 18 Derivation of Estimator 19 Fixed and Expanding Memory Estimators 23 Scale Changes 23 Problems 25
1

vi
LESSON 4 LEAST-SQUARES ESTIMATION: RECURSIVE PROCESSING
Introduction 26 Recursive Least-Squares: Information Form 27 Matrix Inversion Lemma 30 Recursive Least-Squares: Covariance Form 30 Which Form to Use 31 Problems 32
LESSON 5 LEAST-SQUARES ESTIMATION: RECURSIVE PROCESSING (continued)
Generalization to Vector Measurements 36 Cross-Sectional Processing 37 Multistage Least-Squares Estimators 38 Problems 42
LESSON 6 SMALL SAMPLE PROPERTIES OF ESTIMATORS 43
Introduction 43 Unbiasedness 44 Efficiency 46 Problems 52
LESSON 7 LARGE SAMPLE PROPERTIES OF ESTIMATORS
Introduction 54 Asymptotic Distributions 54 Asymptotic Unbiasedness 57 Consistency 57 Asymptotic Efficiency 60 Problems 61
LESSON 8 PROPERTIES OF LEAST-SQUARES ESTIMATORS
Introduction 63 Small Sample Properties of Least-Squares
Estimators 63 Large Sample Properties of Least-Squares
Estimators 68 Problems 70
Contents
26
35
54
63
Contents
LESSON 9 BEST LINEAR UNBIASED ESTIMATION
Introduction 71 Problem Statement and Objective Function 72 Derivation of Estimator 73 Comparison of iBLU(k) and &u(k) 74 Some Properties of itaL&) 75 Recursive BLUES 78 Problems 79
LESSON 10 LIKELlHOOD
Introduction 81 Likelihood Defined 81 Likelihood Ratio 84 Results Described by Continuous Distributions 85 Multiple I-Iypotheses 85 Problems 87
LESSON tl MAXIMUM-LIKELIHOOD ESTIMATION
Likelihood 88 Maximum-Likelihood Method and Estimates 89 Properties of Maximum-Likelihood Estimates 91 The Linear Model (X’(k) deterministic) 92 A Log-Likelihood Function for an Important
Dynamical System 94 Problems 97
LESSON 12 ELEMENTS OF MULTIVARIATE GAUSSIAN RANDOM VARIABLES
Introduction 100 Univariate Gaussian Density Function 100 Multivariate Gaussian Density Function 101 Jointly Gaussian Random Vectors 101 The Conditional Density Function 102 Properties of Multivariate Gaussian Random
Variables 104 Properties of Conditional Mean 104 Problems 106
81

Contents
LESSON 13 ESTIMATION OF RANDOM PARAMETERS: GENERAL RESULTS
Introduction 108 Mean-Squared Estimation 109 Maximum a Posteriori Estimation 114 Problems 116
LESSON 14 ESTIMATION OF RANDOM PARAMETERS: THE LINEAR AND GAUSSIAN MODEL
Introduction 118 Mean-Squared Estimator 118 Best Linear Unbiased Estimation,
Revisited 121 Maximum a Posteriori Estimator 123 Problems 126
LESSON 15 ELEMENTS OF DISCRETE-TIME GAUSS-MARKOV RANDOM PROCESSES
Introduction 128 Definitions and Properties of Discrete-Time
Gauss-Markov Random Processes 128 A Basic State-Variable Model 131 Properties of the Basic State-Variable
Model 133 Signal-to-Noise Ratio 137 Problems 138
LESSON 16 STATE ESTIMATION: PREDICTION
Introduction 140 Single-Stage Predictor 140 A General State Predictor 142 The Innovations Process 146 Problems 147
118
128
140
Contents
LESSON 17 STATE ESTIMATION: FILTERING (THE KALMAN FILTER)
Introduction 149 A Preliminary Result 150 The Kalman Filter 151 Observations About the Kalman Filter 153 Problems 158
LESSON 18 STATE ESTIMATION: FILTERING EXAMPLES
Introduction 160 Examples 160 Problems 169
LESSON 19 STATE ESTIMATION: STEADY-STATE KALMAN FILTER AND ITS RELATIONSHIP TO A DIGITAL WIENER FILTER
LESSON 20
Introduction 170 Steady-State Kalman Filter 170 Single-Channel Steady-State Kalman Filter 173 Relationships Between the Steady-State
Kalman Filter and a Finite Impulse Response Digital Wiener Filter 176
Comparisons of Kalman and Wiener Filters 181 Problems 182
STATE ESTIMATION: SMOOTHING
Three Types of Smoothers 183 Approaches for Deriving Smoothers 184 A Summary of Important Formulas 184 Single-Stage Smoother 184 Double-Stage Smoother 187 Single- and Double-Stage Smoothers
as General Smoothers 189 Problems 192
149
160
170
183

X
LESSON 21
LESSON 22
LESSON 23
LESSON 24
Contents
STATE-ESTIMATION: SMOOTHING (GENERAL RESULTS)
Introduction 193 Fixed-Interval Smoothers 193 Fixed-Point Smoothing 199 Fixed-Lag Smoothing 201 Problems 202
193
STATE ESTIMATION: SMOOTHING APPLICATIONS
Introduction 204 Minimum-Variance Deconvolution (MVD) 204 Steady-State MVD Filter 207 Relationship Between Steady-State MVD
Fitter and an Infinite Impulse Response Digital Wiener Deconvolution Filter 213
Maximum-Likehhood Deconvolution 215 Recursive Waveshaping 216 Problems 222
204
STATE ESTIMATION FOR THE NOT-SO-BASIC STATE-VARIABLE MODEL
Introduction 223 Biases 224 Correlated Noises 225 Colored Noises 227 Perfect Measurements: Reduced-Order
Estimators 230 Final Remark 233 Problems 233
223
LINEARIZATION AND DISCRETIZATION OF NONLINEAR SYSTEMS
Introduction 236 A Dynamical Model 237 Linear Perturbation Equations 239
236
Contents xi
Discretization of a Linear Time-Varying State-Variable Model 242
Discretized Perturbation State-Variable Model 245
Problems 246
LESSON 25 lTERATED LEAST SQUARES AND EXTENDED KALMAN FILTERING
Introduction 248 Iterated Least Squares 248 Extended Kalman Filter 249 Application to Parameter Estimation 255 Problems 256
LESSON 26 MAXIMUM-LIKELIHOOD STATE AND PARAMETER ESTIMATION
Introduction 258 A Log-Likelihood Function for the Basic
State-Variable Model 259 On Computing i, 261 A Steady-State Approximation 264 Problems 269
LESSON 27 KALMAN-BUCY FILTERING
Introduction 270 System Description 271 Notation and Problem Statement 271 The Kalman-Bucy Filter 272 Derivation of KBF Using a Formal Limiting
Procedure 273 Derivation of KBF When Structure of the
Filter Is Prespecified 275 Steidy-State KBF 278 An Important Application for the KBF 280 Problems 281
270

Contents
LESSON A SUFFICIENT STATISTICS AND STATISTICAL ESTIMATION OF PARAMETERS
Introduction 282 Concept of Sufficient Statistics 282 Exponential Families of Distributions 284 Exponential Families and Maximum-
Likelihood Estimation 287 Sufficient Statistics and Uniformly Minimum-
Variance Unbiased Estimation 290 Problems 294
APPENDIX A GLOSSARY OF MAJOR RESULTS
282
REFERENCES
INDEX
300
Estimation theory is widely used in many branches of science and engineering. No doubt, one could trace its origin back to ancient times, but Karl Friederich Gauss is generally acknowledged to be the progenitor of what we now refer to as estimation theory. R. A. Fisher, Norbert Wiener, Rudolph E. Kalman, and scores of others have expanded upon Gauss’ legacy, and have given us a rich collection of estimation methods and algorithms from which to choose. This book describes many of the important estimation methods and shows how they are interrelated.
Estimation theory is a product of need and technology. Gauss, for ex- ample, needed to predict the motions of planets and comets from telescopic measurements. This “need” led to the method of least squares. Digital com- puter technology has revolutionized our lives. It created the “need” for recur- sive estimation algorithms, one of the most important ones being the Kalman filter. Because of the importance of digital technology, this book presents estimation theory from a digital viewpoint. In fact, it is this author’s viewpont that estimation theory is a natural adjunct to classical digital signal processing. It produces time-varying digital filter designs that operate on random data in an optimal manner.
This book has been written as a collection of lessons. It is meant to be an introduction to the general field of estimation theory, and, as such, is not encyclopedic in content or in references. It can be used for self-study or in a one-semester course. At the University of Southern California, we have cov- ered all of its contents in such a course, at the rate of two lessons a week. We have been doing this since 1978.

xiv Preface
Approximately one half of the book is devoted to parameter estimation and the other half to state estimation. For many years there has been a tendency to treat state estimation as a stand-alone subject and even to treat parameter estimation as a special case of state estimation. Historically, this is incorrect. In the musical “Fiddler on the Roof,” Tevye argues on behalf of tradition . . . “Tradition! . . . ” Estimation theory also has its tradition, and it begins with Gauss and parameter estimation. In Lesson 2 we show that state estimation is a special case of parameter estimation. i.e.. it is the problem of estimating random parameters, when these parameters change from one time to the next. Consequently, the subject of state estimation flows quite naturally from the subject of parameter estimation.
Most of the book’s important results are summarized in theorems and corollaries. In order to guide the reader to these results, they have been summarized for easy reference in Appendix A.
Problems are included for most lessons, because this book is meant to be used as a textbook. The problems fal1 into two groups. The first group con- tains problems that ask the reader to fill in details, which have been “left to the reader as an exercise.” The second group contains problems that are related to the material in the lesson. They range from theoretical to computational problems.
This book is an outgrowth of a one-semester course on estimation theory, taught at the University of Southern California. Since 1978 it has been taught by four different people, who have encouraged me to convert the lecture notes into a book. I wish to thank Mostafa Shiva, Alan Laub, George Papavassilopoulos, and Rama Chellappa for their encouragement. Special thanks goes to Rama Chellappa, who provided supplementary Lesson A on the subject of sufficient statistics and statistical estimation of parameters. This lesson fits in very nicely just after Lesson 14.
While writing this text, the author had the benefit of comments and suggestions from many of his colleagues and students. I especially wish to acknowledge the help of Guan-Zhong Dai, Chong-Yung Chi, Phil Burns, Youngby Kim, Chung-Chin Lu, and Tom I-Iebert. Special thanks goes to Georgios Giannakis. The book would not be in its present form without their contributions.
Additionaliy, the author wishes to thank Marcel Dekker, Inc. for per- mitting him to include material from Mendel, J. M., 1973, Discrere Techniques of Parameter Estimation : the Equation-Error Formulation, in Lessons I-9,11, 18, and 24; and Academic Press, Inc. for permitting him to include material from Mended, J. M., Optimal Seismic Deconvulution: an Estimation-Based Approach, copyright 0 1983 by Academic Press, Inc., in Lessons 11-17, 19-22, and 26.
JERRY M. MENDEL Los Angeles, Califurnia
Lesson 1
Introduction,
Coverage,
and Philosophy
INTRODUCTION
This book is all about estimation theory. It is useful, therefore, for us to understand the role of estimation in relation to the more global problem of modeling. Figure l-l decomposes modeling into four problems: represen- tation, measurement, estimation, and validation. As Mendel (1973, pp. 2-4) states, “The representation problem deals with how something should be mod- eled. We shall be interested only in mathematical models. Within this class of models we need to know whether the model should be static or dynamic, linear or nonlinear, deterministic or random, continuous or discretized, fixed or varying, lumped or distributed. . . , in the time-domain or in the frequency- domain. , . , etc.
“In order to verify a model, physical quantities must be measured. We distinguish between two types of physical quantities, signals, and parameters. Parameters express a relation between signals. . . .
‘*Not all signals and parameters are measurable. The measurementprob- lem deals with which physical quantities should be measured and how they should be measured.
“The estimation problem deals with the determination of those physical quantities that cannot be measured from those that can be measured. We shall distinguish between the estimation of signals (i.e., states) and the estimation of parameters. Because a subjective decision must sometimes be made to classify a physical quantity as a signal or a parameter, there is some overlap between signal estimation and parameter estimation. . . .
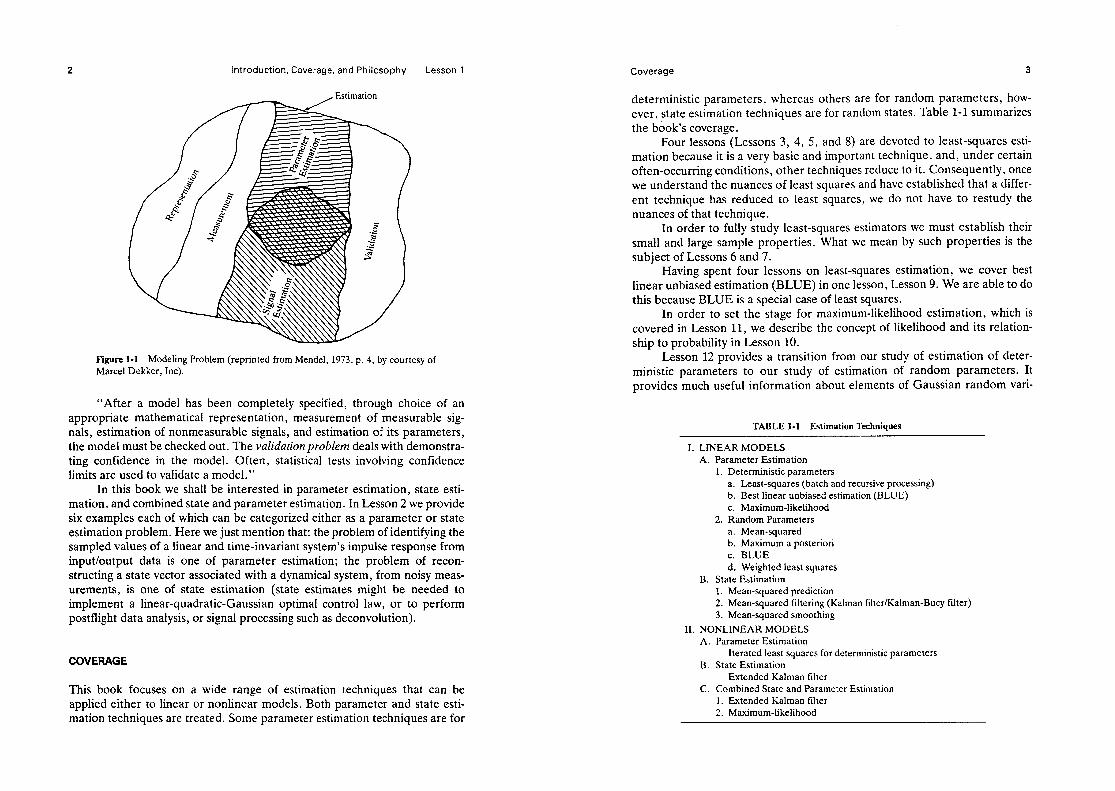
Introduction, Coverage, and Philosophy Lesson 1
Figure l-1 Modeling Problem (reprinted from Mendel, 1973, p. 4, by courtesy of Marcel Dekker, Inc).
“After a model has been completely specified, through choice of an appropriate mathematical representation, measurement of measurable sig- nals, estimation of nonmeasurable signals, and estimation of its parameters, the model must be checked out. The validation problem deals with demonstra- ting confidence in the model. Often, statistical tests involving confidence limits are used to validate a model.”
In this book we shall be interested in parameter estimation, state esti- mation, and combined state and parameter estimation. In Lesson 2 we provide six examples each of which can be categorized either as a parameter or state estimation problem. Here we just mention that: the problem of identifying the sampled values of a linear and time-invariant system’s impulse response from input/output data is one of parameter estimation; the problem of recon- structing a state vector associated with a dynamical system, from noisy meas- urements, is one of state estimation (state estimates might be needed to implement a linear-quadratic-Gaussian optimal control law, or to perform postflight data analysis, or signal processing such as deconvolution).
COVERAGE
This book focuses on a wide range of estimation techniques that can be applied either to linear or nonlinear models. Both parameter and state esti- mation techniques are treated. Some parameter estimation techniques are for
Coverage 3
deterministic parameters, whereas others are for random parameters, how- ever, state estimation techniques are for random states. Table l-l summarizes the book’s coverage.
Four lessons (Lessons 3, 4, 5, and 8) are devoted to least-squares esti- mation because it is a very basic and important technique, and, under certain often-occurring conditions, other techniques reduce to it. Consequently, once we understand the nuances of least squares and have established that a differ- ent technique has reduced to least squares, we do not have to restudy the nuances of that technique.
In order to fully study least-squares estimators we must establish their small and large sample properties. What we mean by such properties is the subject of Lessons 6 and 7.
Having spent four lessons on least-squares estimation, we cover best linear unbiased estimation (BLUE) in one lesson, Lesson 9. We are able to do this because BLUE is a special case of least squares.
In order to set the stage for maximum-likelihood estimation, which is covered in Lesson 11, we describe the concept of likelihood and its relation- ship to probability in Lesson 10.
Lesson 12 provides a transition from our study of estimation of deter- ministic parameters to our study of estimation of random parameters. It provides much useful information about elements of Gaussian random vari-
TABLE l-l Estimation Techniques
I. LINEAR MODELS A. Parameter Estimation
1. Deterministic parameters a. Least-squares (batch and recursive processing) b. Best linear unbiased estimation (BLUE) c. Maximum-likelihood
2. Random Parameters a. Mean-squared b. Maximum a posteriori c. BLUE d. Weighted least squares
B. State Estimation 1. Mean-squared prediction 2. Mean-squared filtering (Kalman filter/Kalman-Bucy filter) 3. Mean-squared smoothing
II. NONLINEAR MODELS A. Parameter Estimation
Iterated least squares for deterministic parameters B. State Estimation
Extended Kalman filter C. Combined State and Parameter Estimation
1. Extended Kalman filter 2. Maximum-likelihood

4 Introduction, Coverage, and Philosophy Lesson 1
abies. To some readers, this lesson may be a review of material already known to them.
General results for both mean-squared and maximum a posteriori esti- mation of random parameters are covered in Lesson 13. These results are specialized to the important case of the linear and Gaussian model in Lesson 14. Best linear unbiased and weighted least-squares estimation are also re- visited in Lesson 14. Lesson 14 is quite important, because it gives conditions under which mean-squared, maximum a posteriori, best-linear unbiased, and weighted least-squares estimates of random parameters are identical. Lesson A, which is a supplemental one, is on the subject of sufficient statistics and statistical estimation of parameters. It fits in very nicely after Lesson 14.
Lesson 15 provides a transition from our study of parameter estimation to our study of state estimation. It provides much useful information about elements of discrete-time Gauss-Markov random processes, and also estab- lishes the basic m&e-variable model, and its statistical properties, for which we derive a wide variety of state estimators. To some readers, this lesson may be a review of material already known to them.
Lessons 16 through 22 cover state estimation for the Lesson 15 basic state-variable model. Prediction is treated in Lesson 16. The important inno- vations process is also covered in that lesson. Filtering is the subject of Lessons 17, 18, and 19. The mean-squared state filter, commonly known as the Kalman filter, is developed in Lesson 17. Five examples which illustrate some interesting numerical and theoretical aspects of Kalman filtering are pre- sented in Lesson 18. Lesson 19 establishes a bridge between mean-squared estimation and mean-squared digital signal processing. It shows how the steady-state Kalman filter is related to a digital Wiener filter. The latter is widely used in digital signal processing. Smoothing is the subject of Lessons 20, 21 and 22. Fixed-interval, fixed-point, and fixed-lag smoothers are devel- oped in Lessons 20 and 21. Lesson 22 presents some applications which illustrate interesting numerical and theoretical aspects of fixed-interval smoothing. These applications are taken from the field of digital signal pro- cessing and include minimum-variance deconvolution, maximum-likelihood deconvolution, and recursive waveshaping.
Lesson 23 shows how to modify results given in Lessons 16, 17, 19, 20 and 21 from the basic state-variable model to a state-variable model that includes the following effects:
1. nonzero mean noise surement equation,
processes and/or known bias function in the mea-
2. correlated noise processes, 3. colored noise processes? and 4, perfect measurements.
Philosophy 5
Lesson 24 provides a transition from our study of esr.Ination for linear models to estimation for nonlinear models. Because many rca(-worId systems are continuous-time in nature and nonlinear, this lesson explains how to linearize and discretize a nonlinear differential equation model.
Lesson 25 is devoted primarily to the extended Kalman filter (EKF), which is a form of the Kalman filter that has been “extended” to nonlinear dynamical systems of the type described in Lesson 24. The EKF is related to the method of iterated least squares (ILS), the major difference between the two being that the EKF is for dynamical systems whereas ILS is not. This lesson also shows how to apply the EKF to parameter estimation, in which case states and parameters can be estimated simultaneously, and in real time.
The problem of obtaining maximum-likelihood estimates of a collection of parameters that appears in the basic state-variable model is treated in Lesson 26. The solution involves state and parameter estimation, but calcu- lations can only be performed off-line, after data from an experiment has been collected.
The Kalman-Bucy fiiter, which is the continuous-time counterpart to the Kalman filter, is derived from two different viewpoints in Lesson 27. We include this lesson because the Kalman-Bucy filter is widely used in linear stochastic optimal control theory.
PHlLOSOPHY
The digital viewpoint is emphasized throughout this book. Our estimation algorithms are digital in nature; many are recursive. The reasons for the digital viewpoint are:
1. much real data is collected in a digitized manner, so it is in a form ready to be processed by digital estimation algorithms, and
2. the mathematics associated with digital estimation theory are simpler than those associated with continuous estimation theory.
Regarding (2), we mention that very little knowledge about random processes is needed to derive digital estimation algorithms, because digital (i.e., discrete-time) random processes can be treated as vectors of random vari- ables. Much more knowledge about random processes is needed to design continuous-time estimation algorithms,
Suppose our underlying model is continuous-time in nature. We are faced with two choices: develop a continuous-time estimation theory and then implement the resulting estimators on a digital computer (i.e., discretize the continuous-time estimation algorithm), or discretize the model and develop a discrete-time (i.e., digital) estimation theory that leads to estimation algo-

introduction, Coverage, and Philosophy Lesson 1
rithms readily implemented on a digital computer. If both approaches lead to algorithms that are implemented digitally, then we advocate the principle of simplicity for their development, and this leads us to adopt the second-choice. For estimation, our modeling philosophy is, therefore, discretize the model at the front end of the problem.
Estimation theory has a long and glorious history (e.g., see Sorenson, 1970); however, it has been greatly influenced by technology, especially the computer. Although much of estimation theory was developed in the mathe- matics, statistical, and control theory literatures, we shall adopt the following viewpoint towards that theory: estimation theory is the extension of classical signalprocessing to the design of digital filters that processs uncertain data in an optimal manner. In fact, estimation algorithms are just filters that transform input streams of numbers into output streams of numbers. b
Most of classical digital filter design (e.g., Oppenheim and Schafer, 1975; Hamming, 1983; Peled and Liu, 1976) is concerned with designs associ- ated with deterministic signals, e.g., low-pass and bandpass filters, and, over the years specific techniques have been developed for such designs. The result- ing filters are usually “fixed” in the sense that their coefficients do not change as a function of time. Estimation theory, on the other hand, leads to filter structures that are time-varying. These filters are designed (i.e., derived) using time-domain performance specifications (e.g., smallest error variance), and, as mentioned above, process random data in an optimal manner. Our philosophy about estimation theory is that it can be viewed as a naturaL adjunct to digital signal processing theory.
Example 1-1 At one time or another we have all used the sample mean to compute an “average.” Suppose we are given a collection of k measured values of quantity X, namely x(l), x(2), . . . , x(k). The sample mean of these measurements, x(k), is
Z(k) = k ’ Ii x(j) (l-1) j-1
A recursive formula for the sample mean is obtained from (l-l), as follows:
i(k + 1) =&$x(j) I”1
=& 2 x(j)+x(k +1) [ j-1 I
x(k + 1) = A’(k) + &(k + 1) (l-2)
This recursive version of the sample mean is used for k = 0, 1, . . . by setting Z(O) = 0. Observe that the sample mean, as expressed in (I -2), is a time-varying recursive
digital filter whose input is measurement x(k). In later lessons we show that the sample mean is also an optimal estimation algorithm; thus, although the reader may not have been aware of it, the sample mean, which he or she has been using since early school- days, is an estimation algorithm. cl
lesson 2
The Linear Model
In order to estimate unknown quantities (i.e., parameters or signals) from measurements and other a priori information, we must begin with model representations and express them in such a way that attention is focused on the explicit relationship between the unknown quantities and the measurements. Many familiar models are linear in the unknown quantities (denoted 6), and can be expressed as
Z(k) = X(k)8 + V(k) (2-l)
In this model, %(k), which is N x 1, is called the measurement vector; 8, which is n x 1, is called the parameter vector; X(k), which is N x n is called the observation matrix; and, V(k), which is N x 1, is called the measurement noise vector. Usually, V(k) is random. By convention, the argument “k” of Z(k), X(k), and V(k) denotes the fact that the last measurement used to construct (2-l) is the kth. All other measurements occur “before” the kth.
Strictly speaking, (2-l) represents an “affine” transformation of param- eter vector 8 rather than a linear transformation. We shall, however, adhere to traditional estimation-theory literature, by calling (2-l) a “linear model.”
Some examples that illustrate the formation of (2-l) are given in this section. What distinguishes these examples from one another are the nature of and interrelationships between 8, X(k) and V(k). The following situations can occur.
7

The Linear Model Lessun 2
A. 8 is deterministic 1. X(k) is deterministic. 2. X(k) is random.
a. X(k) and V(k) are statistically independent. b, X(k) andT(k) are statistically dependent.
B. f# is random I. X(k) is deterministic. 2. X(k) is random.
a. X(k) and V(k) are statisticaIly independent. b. X(k) and V(k) are statistically dependent.
Example 2-l Impulse Response Identification
It is weli known that the output discrete-time system is given by
of a single-input single-output, linear, Iirne-iwariarit, the following convolution-sum relationship
where k = 1,2, . . . , IV, h (Q is the system’s impulse response (IR), u(k) is its input and y (Jc) its output. If u(k) = 0 for k c 0, and the system is causal, so that h(i) = 0 for i 5 0, and, II(~) = 0 for i B n, then
y(k) = i h(lJu(k - i) i==l
Signa y (k) is measured by a sensor which is corrupted by additive measurement noise, p(k), i.e., we only have access to measurement z (Ic), where
z(k) = y(k) + u(k)
and k = 1,2,.**, N* We now collect these AJ measurements as follows:
Examples
Clearly, (2-5) is in the form of (2-l). In this application the n sampled values of the IR, h (i), play the role of unknown
parameters, i.e., 8, = h(l), 62 = h(2), . . .) 0, = h(n), and these parameters are deter- ministic. If input u(k) is deterministic and is known ahead of time (or can be measured) without error, then %‘(N - 1) is deterministic so that we are in case A.l. Often, however, u(k) is random so that X(N - 1) is random; but u(k) is in no way related to measurement noise v(k), so we are in case A.2.a. 0
Example 2-2 Identification of the CoefFcients of a Finite-Difference Equation
Suppose a linear, time-invariant, discrete-time nth-order finite-difference equation
system is described by the following
J(k)+cwly(k-l)+ .** +cr,y(k -n)=u(k -1) P-6) This model is often referred to as an all-pole or autoregressivc (AR) model. It occurs in many branches of engineering and science, including speech modeling, geophysical modeling, etc, Suppose, also, that N perfect measurements of signal y (k) are available. Parameters lyl, cx2, . . . , CX,, are unknown and are to be estimated from the data. To do this, we can rewrite (2-6) as
v(k) = -ctly(k - I) - ‘.w--a,y(k -n) + u(k - 1) (2-7)
and collect y (l), y (2), . , , , y (N) as we did in Example 2-1. Doing this, we obtain f
Y(N) Y(N - 0 y(N-2) y(N-3) -.a YW - 4 Y P.- 1) YW.- 2) W*- 3) YW.- 4) ‘*’ - YW -,n - 1)
. . , .
Y&l = y(n :- 1) y(“:-2) y(ni- 1) -*-- Y@> . .
Yh Yil) YiO) (j .:. 0 , Y(l) Y(O) 0 0 . . f 0
qlN) \ ,
X(N - 1) I u(N - 1)
-aI -ff2 .
x : +
1-1
up- 2) .
.(,I (2-8) -% .
41) 0 40)
\ , V(N - 1)
which, again, is in the form of (2-l). In this example 8 = col(--aal, -cY~,.. . , - cy,, ), and these parameters are deter-
ministic. If input u(k - 1) is deterministic, then the system’s output y(k) will also be deterministic, so that both %e(N - 1) and Sr(N - 1) are deterministic. This is a very special case of case A. 1, because usually “v is random. If, however, u (k - 1) is random then y(k) will also be random; but, the elements of X(N - 1) will now depend on those inV(N - l), because y(k) depends upon u (0). u (l), , . . , u (k - 1). In this situation we are in case A.2.b. q

The Linear Model Lesson 2
Example 2-3 Identification of the initial in an Unforced State Equation Model
Consider the problem of identifying the time-invariant, discrete-time system
n x 1 initial condition vector x(0) of the linear,
Condition
x(k + 1) = @x(k) P-9
from the N measurements z(l), t (2), . . . , z (N), where
z(k) = h’x(k) + v(k) (2-10)
me solution t0 (2-9) is
x(k) = Q&x(O) (2-11)
SO that
z(k) = h’@x(O) + v(k) (2-12)
Collecting the N measurements, as before, we obtain
(2-13)
once again, we have been led to (2-l), and we are in case A.l. 0 Example 2-4 State Estimation state-variable models are widely used in control and communication theory, and in signal processing. Often, we need the entire state vector of a dynamical system in order to implement an optimal control law for it, or, to implement a digital signal processor. Usually, we cannot measure the entire state vector, and our measurements are car- rupted by noise. In state estimation, our objective is to estimate the entire state vector from a limited collection of noisy measurements.
Here we consider the problem of estimating n x 1 state vector x(k), at k = 1, 2 ,..*v N from a scalar measurement z (k), where k = 1,2, . . . , N. The model for this example is
x(k + 1) = #x(k) + yu(k) (2-14)
z(k) = h’x(k) + v(k) (2-15)
we are keeping this example simple by assuming that the system is time-invariant and has only one input and one output; however, the results obtained in this example are easily generalized to time-varying and multichannel systems or multichannel systems
If we try to collect our N measurements as before, we obtain
z(N) = h’x(N) + v(N) z(N - 1) = h’x(N - 1) + v(N - 1)
. . .
! z(l) = h’x(1) + v(l) (2-16)
Examples 11
Observe that a different (unknown) state vector appears in each of the N measurement equations; thus, there does not appear to be a common “0” for the collected mea- surements. Appearances can sometimes be deceiving.
So far, we have not made use of the state equation. Its solution can be expressed as
x(k) = Qk-jx(j) + $ Qk-‘yu(i - 1) i--j+1
(2-17)
where k 2 j + 1. We now focus our attention on the value of x(k) at k = kl, where 1 5 kl 5 N. Using (2-17), we can express x(N), x(/V - l), . . . , x(kl + 1) as an explicit function of x(k,), i.e.,
x(k) = @k-klx(kl) + i Qk-‘yu(i - 1) (2-H) i=kl+l
where k = kl + 1, kl + 2,. . . , N. In order to do the same for x(l), x(2), . . . , x(kl - l), we solve (2-17) for x(j) and set k = kl,
X(,3 = @jmklx(kl) - 5 @j-‘yu(i - 1) (2-19) i-j+ I
where j = kl - 1, kl - 2,. . . , 2, 1. Using (2-18) and (2-19), we can reexpress (2-16) as k
z(k) = hWk - k’ x(kJ + h’ c #k-iyu(i - 1) + v(k) i==kl+l
k =N,N - l,...,k* + 1 z(k,) = h’x(k,) + v(kl)
z(i) = hWfwklx(kl) - h’ 3 cP*-‘yu(i - 1) + v(l) i=I+l
2 = kl - 1, kl - 2,. . . , 1
These N equations can now be collected together, to give
+ M(N, kl)
\
VW) v(N - 1) .
v(1)
(2-20)
1 (2-21)
where the exact structure of matrix M(N, kl) is not important to us at this point. Observe that the state at k = kl plays the role of parameter vector 8 and that both X and ‘V are different for different values of kl.
If x(0) and the system input u(k) are deterministic, then x(k) is deterministic for

12 The Linear Model Lesson 2
all k. 1x-1 this case 6 is deterministic, but V(N, kI) is a superposition of deterministic and random components. On the other hand, if either x(O) or u(k) are random then 0 is a vector of randotn parumeters. This latter situation is the more usual one in state estimation. 1 t corresponds to case B. 1. III
Example 2-5 A Nonlinear Model
Many of the estimation techniques that are described in this book in the cuntext of linear model (Z-I} can also be applied to the estimation of unknown signals or param- eters in nonlinear models, when such models are suitably linearized. Suppose, for example, that
z(k) =f(o,k) + LQ$ (2-22)
where, k = 1, 2,. . . , iv, and the structure of nonlinear function f (0, k) is known explicitly, To see the forest from the trees m this example we assume 0 is a scalar parameter.
Let 0 * denote a nominal value of 19, 86 = 19 - 6 *, and 8~ = z - z *, where
z*(k) = f (t?*, k) (2-23)
Observe that the nominal meusurements, z* (k), can be computed once 0* is specified, because f (. , k) is assumed to be IXIOW~L
Using a frrst-order Taylor series expansion off (0, k) about 19 = 6 * , it is easy to show that
(2-24)
wherek = 1,2,.. . , N. It is easy to see how to collect these N equations, tu give
in which $(8*, k}/H* is short for “$f($, k)/&?evaiuated at 8 = @*.” Observe that X depends on U*. We will discuss different ways for specifying 0* in
Lesson 25. 0
Example 2-6 DeconvoIu?ion (Mended, 19S3b)
In Example 2-I we showed how a convolutional model could be expressed as the linear model S! = X0 + V. In that example we assumed that both input and output mea- surements were available, and, we wanted to estimate the sampled values of the system’s impulse response, Here we begin with the same convolutional model, written as
Examples 13
where k = 1, 2,. . . , N. Noisy measurements z(l), z (2) . . . , z (NJ are available to us, and we assume that we know the system’s impulse response h (13, Vi. What is not known is the input to the system p(l), p(2), . + . , p(N). Deconvolution fi the signal processing procedure for removing the effects of h(j) and v(j) fram the measurements so that one & ieft with an estimate of k(j).
In deconvolution we often assume that input p( 1) is white noise, but is not necessarily Gaussian. This type of deconvolution problem occurs in reflection seis- mology. We assume further that
P w = wq w (2-27)
where t(k) is white Gaussian noise with variance o$ , and q(k) is a random event location sequence of zeros and ones (a Bernoulli sequence). Sequences r(k) and 4 (k) are assumed to be statistically independent.
We now collect the N measurements, but in such a way that p(l), ~(2), . . . , p(N) are treated as the unknown parameters. Doing this we obtain the fohowing linear deconvohrtion model:
h(N -2) . . . h(1) h(O) h(N.-3) . . . h(O) 0
W9 X(N - 1)
We shall often refer to 9 as p. Using (2-27), we can also express 8 = ~1 as
CL = Qqr
r = col (r(l), r(2), . . . , r(N))
and
Q, = diag (4 WY q (21, - a - ) 4 WI)
In this case (2-28) can be expressed as
Z(N) = X(N - l)Q,r + WY)
(2-29)
(2-30)
(2-31)
(2-32)

14 The Linear Model Lesson 2
When event locations q (l), q (2), . . . , q (IV) are known, then we can view (2-32) as a linear model for determining r.
Regardless of which linear deconvolution model we use as our starting point for determining F, we see that deconvolution corresponds to case B.l. Put another way, we have shown that the design of a deconvolution signal processing filter is isomorphic to the problem of estimating random parameters in a linear model. Note, however, that the dimension of 8, which is IV x 1, increases as the number of measurements increase. In all other examples 8 was n x 1 where n is a fixed integer. We return to this point in Lesson 14 where we discuss convergence of estimates of + to their true values.
In Lesson 14, we shall develop minimum-variance and maximum-likelihood &convolution filters. Equation (2-28) is the starting point for derivation of the former filter, whereas Equation (2-32) is the starting point for derivation of the latter filter. Cl
NOTATIONAL PRELIMINARIES
Equation (2-l) can be interpreted as a data generating model; it is a mathe- matical representation that is associated with the data. Parameter vector 0 is assumed to be unknown and is to be estimated using Z(k), X(k) and possibly other a priori information. We use F(k) to denote the estimate of constant parameter vector 8. Argument k in 8(k) denotes the fact that the estimate is based on measurements up to and including the kth. In our preceding exam- ples, we would use the following notation for 6(k):
Example 2-l [see (2-91: i(N) with components &i 1 ZV)
Example 2-2 [see (2-8)]: i(N) Example 2-3 [see (2-13)]: x(0 1 N) Example 2-4 [see (2-21)]: i(kl ] IV) Example 2-5 [see (2-291: s(N) Example 2-6 [see (2-28)]: i(N) with components k(i ] N)
The notation used in Examples 1, 3, 4, and 6 is a bit more complicated than that used in the other examples, because we must indicate the time point at which we are estimating the quantity of interest (e.g., kl or i) as well as the last data point used to obtain this estimate (e.g., N). We often read i(kl I N) as “the estimate of x(k,) conditioned on N” or as “x hat at kl conditioned on N.”
In state estimation (or deconvolution) three situations are possible de- pending upon the relative relationship of N to kl. For example, when N < kl we are estimating a future value of x(k,), and we refer to this as a predicted estimate. When N = kl we are using all past measurements and the most recent measurement to estimate x(k,). The result is referred to as a filtered estimate. Finally, when N > kl we are estimating an earlier value of x(k,) using past, present and future measurements. Such an estimate is referred to as a
Lesson 2 Problems
smoothed or interpolated estimate. Prediction and filtering can be done in real time whereas smoothing can never be done in real time. We will see that the impulse responses of predictors and filters are causal, whereas the impulse response of a smoother is noncausal.
We use 6(k) to denote estimation error, i.e.,
6(k) = 0 - 8(k) (2-33)
In state estimation, %(kl 1 N) denotes state estimation error, and, ji(kl 1 IV’) = x(b) - i(kl 1 N>. In deconvolution @(i 1 N) is defined in a similar manner.
Very often we use the following estimation model for Z(k),
8(k) = X(k)i(k) (2-34)
To obtain (2-34) from (2-l), we assume that V(k) is zero-mean random noise that cannot be measured. In some applications (e.g,, Example 2-2) g(k) represents a predicted value of Z(k). Associated with S(k) is the error S(k), where
2(k) = Z(k) - i(k) (2-35)
satisfies the equation
f%(k) = X(k#(k) + V(k) (2-36)
In those applications where &(k) is a predicted value of Z(k), %(k) is known as a prediction error. Other names for S(k) are equation error and mea- surement residual.
In the rest of this book we develop specific structures for 6(k). These structures are referred to as estimators. Estimates are obtained whenever data is processed by an estimator. Estimator structures are associated with specific estimation techniques, and these techniques can be classified according to the natures of 8 and X(k), and what a priori information is assumed known about noise vector V(k). See Lesson 1 for an overview of all the different estimation techniques that are covered in this book.
PROBLEMS
-1. Suppose r(k) = @I + &k + v(k), where z(1) = 0.2, z(2) = 1.4, z(3) = 3.6, z(4) = 7.5, and z (5) = 10.2. What are the explicit structures of %(5) and X(S)?
2-2. According to thermodynamic principles, pressure P and volume V of a given mass of gas are related by PVy = C, where y and Care constants. Assume that IV measurements of P and V are available. Explain how to obtain a linear model for estimation of parameters y and In C.
2-3. (Mendel, 1973, Exercise 1-16(a), pg. 46). Suppose we know that a relationship exists between y and x1, x2, . . . , X, of the form
Y =exp(alxl+a2x2+ - +a,,u,)

Lesson 2
We desire to estima?e a~, ff2,. . . , fzn from measUremen& of y and x = co1 (x1, x2,..*, xfi). Explain how to do this. (Mendel, 1973, Exercise l-17, pp. 46-47). The efficiency of a jet engine may be viewed as a linear combination of tinctions of inlet pressure p ($ and operating temperature T(i); that is to say,
where the structures of fI? j& and fj are known a priori and v(f) represents modeling error of known mean and variance. From tests on the engine a table of values of E(l), p (t), and T(t) are given at discrete vaiues of L Explain how Cl, C2, CS, and CG are estimated from these data.
lesson 3
feast-Squares
Estimation:
Batch Processing
INTRODUCTION
The method of least squares dates back to Karl Gauss around 1795, and is the cornerstone for most estimation theory, both classical and modern. It was invented by Gauss at a time when he was interested in predicting the motion of planets and comets using telescopic measurements. The motions of these bodies can be completely characterized by six parameters. The estimation
_ problem that Gauss considered was one of inferring the values of these param- eters from the measurement data.
We shall study least-squares estimation from two points of view: the classical batch-processing approach, in which all the measurements are pro- cessed together at one time, and the more modern recursive processing ap- proach, in which measurements are processed only a few (or even one) at a time. The recursive approach has been motivated by today’s high-speed digital computers; however, as we shall see, the recursive algorithms are outgrowths of the batch algorithms. In fact, as we enter the era of very large scale inte- gration (VLSI) technology, it may well be that VLSI implementations of the batch algorithms are faster than digital computer implementations of the recursive algorithms.
The starting point for the method of least squares is the linear model
‘Z(k) = X(k)8 + T(k) (3-l)
where Z(k) = co1 (z(k), z (k - l), . . . , z (k - N + I)), z(k) = h’(k)9 + v(k), and the estimation model for Z(k) is
it(k) = X(k)&k) U-2)
17

Least-Squares Estimation: Batch Processing Lesson 3
We denote the (weighted) least-squares estimator of 8 as [&&k)]&(k). In this lesson and the next two we shall determine explicit structures for this estimator.
NUMBER OF MEASUREMENTS
Suppose that 0 contains n parameters and Z(k) contains N measurements. If N < it we have fewer measurements than unknowns and (3-l) is an under- determined system of equations that does not lead to unique or very meaning- ful values for 8i, &, . . . , 8,. If N = ~1, we have exactly as many measurements as unknowns, and as long as the n measurements are linearly independent, so that %? (k) exists, we can solve (3-l) for 8, as
6 = Ye-’ (kyiqk) - %e-’ (kpqk) (3-3) Because we cannot measure V(k), it is usually neglected in the calculation of (3-3). For small amounts of noise this may not be a bad thing to do but for even moderate amounts of noise this will be quite bad. Finally, if N > it we have more measurements than unknowns, so that (3-l) is an overdetermined sys- tem of equations. The extra measurements can be used to offset the effects of the noise; i.e., they let us “filter” the data. Only this last case is of real interest to us.
OBJECTIVE FUNCTION AND PROBLEM STATEMENT
Our method for obtaining 6(k) is based on minimizing the objective function
J@(k)] = %‘(k)W(k)%(k) P-4)
where
?i(k) = col[Z(k), Z(k - l), . . . , Z(k - N + l)] (3-5)
and weighting matrix W(k) must be symmetric and positive definite, for rea- sons explained below.
No general rules exist for how to choose W(k). The most common choice is a diagonal matrix such as
W(k) = diag[pkBN+l, pkTN+', . . . ,F~]
When 1~~1 c 1 recent measurements are weighted more heavily than past ones. Such a choice for W(k) provides the weighted least-squares estimator with an “aging” or “forgetting” factor. When ‘1~1 > 1. recent measurements are weighted less heavily than past ones. Finally, if p = 1, so that W(k) = I, then all measurements are weighted by the same amount. When W(k) = I, ii(k) = d&k), h w ereas for all other W(k), 6(k) = b-(k),
Our objective is to determine the 6-(k) that minimizes J [d(k)].
Derivation of Estimator 19
DERIVATION OF ESTIMATOR
To begin, we express (3-4) as an explicit function of 8(k), using (3-2):
J@(k)] = !i?(k)W(k)?i(k) = [Z(k) - !i(k)]‘W(k)[%(k) - ii(k)]
= [Z(k) - %e(k)6(k)]‘W(k)[%(k) - X(k)&k)] = %‘(k)W(k)Z(k) - 25ff(k)W(k)X’(k)6(k)
(3-6)
+ 6’(k)X’(k)W(k)X(k)6(k)
Next, we take the vector derivative of J [b(k)] with respect to b(k), but before doing this recall from vector calculus, that:
If m and b are two yt X 1 nonzero vectors, and A is an n x yt symmetric matrix, then
-&b’m) = b P-7)
and
$-(m’Am) = 2Am (3-8) Using these formulas, we find that
mwl p = -2[F(k)W(k)X(k)]’ + 2X’(k)W(k)X(k)&k) d&k) (3 9 -
Setting aY[&k)]/d&k) = 0 we obtain the following formula for b,(k),
&r&k) = [%?(k)W(k)X(k)]-’ X’(k)W(k)%(k) (3-10)
Note, also, that
6,(k) = [X’(k)%e(k)]-‘%e’(k)%(k) (3-11)
Comments
1. For (3-10) to be valid, X’(k)W(k)X(k) must be invertible. This is always true when W(k) is positive definite, as assumed, and X(k) is of max- imum rank.
2. How do we know that &&k) minimizes J [6(k)]? We compute d2J[6(k)]i/d62(k) d an see if it is positive definite [which is the vector calculus analog of the scalar calculus requirement that 8 minimizes J( 6) if dJ(@/dt? = 0 and d2J(6)/d6’ is positive]. Doing this, we see that
- = 2x'(k)W(k)x(k) > 0 db2(k)
(3-12)
because X’(k)W(k)X(k) is invertible.

Least-Squares Estimation: 5atch Processing Lesson 3
3. Estimator 6 I&$ processes the measurements %(Az) Iinearly; thus it is referred to as a Zinear estimator. It processes the data contained in X(k) in a very complicated and nonlinear manner.
4. When (3-9) is set equal to zero we obtain the following system of normal equutions
~~‘(k)W(k)~(k)l~~~(k) = ~‘W+YW(W (13-13) This is a system of n hnear equations in the n components of &&).
In practice, one does not compute &&J$ using (3-N)), because computing the inverse of X’(k)W(k)X(k) is fraught with numerical diffi- culties. Instead, the normal equations are solved using stable algorithms from numerical linear algebra that involve orthogonal transformations (see, e.g., Stewart, 1973; Bierman, 1977; and Dongarra, et al., 1979) Because it is not the purpose of this book to go into detaiIs of numerica linear algebra, we leave it to the reader to pursue this important subject.
Based on this discussion, we must view (3-10) as a useful ‘Me- oretical” formula and not as a useful computational formula. Remember that this is a book on estimation theory, SO for our purposes, theoretical formulas are just fine.
5. Equation [3-13) can also be reexpressed as
6.
f!ff(k)W(k)2C(k) = U’ (3-14)
which can be viewed as an urthogona2it-y condition between $5(k) and W&)X(k). CMhogonality conditions pIay an important role in esti- rnatiun theory. We shall see many more examples of such conditions throughout this book. Estimates obtained from (3-N)) will be random! This is because T(k) is random, and, in some applications even X(k) is random. It is therefore instructive to view (3-10) as a complicated transformation of vectors or matrices of random variables into the vector of random variables &&). In later lessons, when we examine the properties of &,&k), these will be statistical properties, because of the random nature of kvLs(~~.
Example 3-l (Mendel, 1973, pp. 8647) Suppose we wish to calibrate an instrument by making a series of uncorreIated mea- surements on a constant quantity, Denoting the constant quantity as 0, our mea- surement equation becomes
z(k) = 0 + v(k) where /c = 1,X . . . 9 N. Collecting these N measurements, we have
(3-15)
(3-16)
Derivation of Estimator 21
Clearly, X = co1 (1, 1, . . . , I); hence;
which is the sample mean of the mean is a least-squares estimator.
N measurements. We see, therefore, l--l u
(3-17)
sample
Example 3-2 (Mendel, 1973) Figure 3-l depicts simphfied third-order pitch-plane dynamics for a typical, high- performance, aerodynamically controlled aerospace vehicle. Cross-coupling and body- bending effects are neglected. Normal acceleration control is considered with feedback on normal acceleration and angle-of-attack rate. Stefani (1967) shows that if the system gains are chosen as
c-2 KNi = loo (3-18)
and
K& = 100 Ma (3-19)
K C~f1ooM,
No = IOOMJ, (3-20)
(3-21)
Stefani assumes 2, 1845/~ is relatively small, and chooses C1 = 1400 and C, = 14,000. The closed-loop response resembles that of a second-order system with a bandwidth of 2 Hz and a damping ratio of 0.6 that responds to a step command of input acceleration with zero steady-state error.
In general, M,, Mg, and Z, are dynamic parameters and all vary through a large range of values. Also, M, may be positive (unstable vehicle) or negative (stable vehicle). System response must remain the same for al1 values of M,, Mg, and Z,; thus, it is necessary to estimate these parameters so that I&,, &, and KNa can be adapted to keep C, and CZ invariant at their designed values. For present purposes we shah assume that M,, Mb, and Z, are frozen at specific values.
From Fig. 3-1,
8(t) = M,a(t) + M&(t) (3-22)
N4(f) = Zna((f) (3-23)
Our attention is directed at the estimation of M, and Ma in (3-22). We leave it as an exercise for the reader to explore the estimation of 2, in (3-23)
Our approach will be to estimate M, and Ms from the equation
e,(k) = M,a(k) -I- M&k) + vi(k) (3-24)

1 J
I I
I s
K N
a 4
Figu
re 3
-1
Pitc
h-pl
ane
dyna
mic
s an
d no
men
clat
ure:
Ni,
inpu
t no
rmal
acc
eler
atio
n al
ong
the
nega
tive
Z ax
is;
KNi,
gain
on
Ni;
6, c
ontro
l-sur
face
def
lect
ion;
Ms,
con
trol-s
urfa
ce e
ffec-
tiv
enes
s;
6, r
igid
-bod
y ac
cele
ratio
n; a
, an
gle-
of-a
ttack
; M
,, ae
rody
nam
ic m
omen
t ef
fec-
tiv
enes
s; IQ
, con
trol g
ain
on &
; Z,,
norm
al a
ccel
erat
ion
forc
e co
effic
ient
; k,
axi
al v
eloc
ity;
N,,
syst
em-a
chie
ved
norm
al a
ccel
erat
ion
alon
g th
e ne
gativ
e Z
axis
; I&
, co
ntro
l ga
in o
n N
, (re
prin
ted
from
Men
del,
1973
, p. 3
3, b
y co
urte
sy o
f Mar
cel D
ekke
r, In
c.).
Scale Changes 23
where s,(k) denotes the measured value of d(k), that is corrupted by measurement noise v,(k). We shall assume (somewhat unrealistically) that a(k) and 6(k) can both be measured perfectly. The concatenated measurement equation for N measurements is e,(k)
&,(k - 1) .
e,(k -if + 1)
4%) W) a(k - 1) . S(k - 1) . . .
a(k -it’ + 1) S(k - ‘N + 1)
Hence, the least-squares estimates of M, and MS are
Ng’ a*(k - j) -1
Ng’ CY(~ - j)6(k -j) j = 0 J ‘=O
Ng’ a(k - j)6(k -j) Nf’ 6*(k - j) j = 0 j = 0
N$’ a(k - j)&,(k -j) j-0
Ni* S(k - j)&,(k -j)
Cl (3-26)
FIXED AND EXPANDING MEMORY ESTIMATORS
Estimator 6 WLS(k) uses the measurements z (k - N + l), z(k - N + 2), . . . , z(k). When N is fixed ahead of time, 6-(k) uses a fixed window of mea- surements, a window of length N, and, 6-(k) is then referred to as a fixed- memory estimator. A second approach for choosing N is to set it equal to k; then, &&k) uses the measurements t (1), z (2), . . . , z (k). In this case 6-(k) uses an expanding window of measurements, a window of length k, and, b-(k) is then referred to as an expanding-memory estimator.
SCALE CHANGES
Least-squares (LS) estimates may not be invariant under changes of scale. One way to circumvent this difficulty is to use normalized data.
For example, assume that observers A and B are observing a process; but observer A reads the measurements in one set of units and B in another.

Least-Squares Estimation: l3atch Processing Lesson 3
LetMbea symmetric matrix of scale factors relating A to B; ZA (k) and denote the total measurement vectors of A and B, respectively, Then
S&(k) = &i(k)0 + V”(k) = MZA(k) = MX&)@ + M=YA (k) (3-27) which means that
C(k) = M%I (k) (3-28)
Let 6 A,w(Q and i3 B,w(k) denote the WLSE’s associated with observers A and B, respectively; then dB,-(k) = &.&k) if
M&(k) = M-l WA (k)M-1 (3-29)
It seems a bit peculiar though to have different weighting matrices for the two WLSE’s. In fact, if we begin with 6 A,u(k) then it is impossible to obtain i$&k) such that &u(k) = 6,&k). The reason for this is simple. To obtain eA,&k), we set WA(k) = I, in which case (3-29) reduces to WB(k) = (M-1)2 + I.
Next, let NA and NB denote symmetric normalization matrices for %A (k) and !!ZB (k), respectively. We shall assume that our data is always normalized to the same set of numbers, i.e., that
Observe that
N/&&(k) = N,JtA (k)O + NAVA (k) (3-31)
and
N&!&(k) = &M!&(k) = NBM&(~)~ + N&I%(k) (3-32)
From (3-30), (3*31), and (3-32), we see that
WI = NBM (3-33)
We now find that
i&x&k) = (~~M~~W~N~M~~)-‘~~MN~W~N~N~~(k) (3-35) Substituting (3-33) into (3-35), we then find
bB,-(k) = (X;NA WBNAXJ-l X;NA WBNA?&, (k) (3-36)
Comparing (3-36) and (3-34), we conclude that &m(k) = &,ms(k) if WB(k) = WA (k). This is precisely the result we were looking for. It means that, under proper normalization, dB,ms(k) = &m(k), and, as a special case bws(k) = kdb
Lesson 3 Problems 25
PROBLEMS
3-1. Derive the formula for &&k) by completing the square on the right-hand side of the expression for J[B(k))l in (3-6).
3-2. Here we explore the estimation of Z, in (3-23). Assume that N noisy measurements of N,(k) are available, i.e.. h6,(k) = Z,a(k) + v&k). What is the formuIa for the least-squares estimator of Z,?
3-3. Here we explore the simultaneous estimation of M,, Ms, and Z, in (3-22) and (3-23). Assume that Nnoisy measurements of l(k) and N,(k) are available, i.e., &.,,(Jc) = M,a(k) + M&(k) + vg(k) and N,,(k) = Z,a(k) + vK,(k). Determine the least-squares estimator of Ma, Mb, and Z,. Is this estimatpr different from &!=, and fi,, obtained just from 8,(k) measurements, and Z,, obtained just from N,,(k) measurements?
3-4. In a curvefittingproblem we wish to fit a given set of data z(l), z(2), . . . , t (IV’) by the approximating function
i(k) = i Bj&j(k)
j=l
where &((k)(j = 1,2,. . . , n> are a set of prespecified basis functions. (a) Obtain a formula for &IV) that is valid for any set of basis functions. (b) The simplest approximating function to a set of data is the straight line. In
this case i(k) = 8, + t&k, which is known as the least-squares or regression line. Obtain closed-form formulas for 8,&N) and &a(N).
3-5. Suppose z(k) = & + &k, where z(1) = 3 miles per hour and z(2) = 7 miles per hour. Determine &,Ls and &,= based on these two measurements. Next, redo these calcuIations by scaling z(I) and z (2) to the units of feet per second. Are the least-squares estimates obtained from these two calculations the same? Use the results developed in the section entitled “Scale Changes” to explain what has happened here.
3-6. (a) Under what conditions on scaling matrix M is scale invariance preserved for a least-squares estimator?
(b) If our original model is nonlinear in the measurements [e.g., z(k) = ez’(k - 1) + v(k)] can anything be done to obtain invariant WLSE’s under scaling?

Lesson 4
Least-Squares Estimation:
Recursive Processing
INTRODUCTION
In Lesson 3 we assumed that Z(k) contained N elements, where N > dim 8 = n. Suppose we decide to add more measurements, increasing the total number of them from N to N’. Formula (3-10) in Lesson 3 would not make use of the previously calculated value of 6 that is based on N measurements during the calculation of 6 that is based on N’ measurements. This seems quite wasteful. We intuitively feel that it should be possible to compute the estimate based on N’ measurements from the estimate based on N measurements, and a modifi- cation of this earlier estimate to account for the N’-N new measurements. In this lesson we shall justify our intuition.
In Lesson 3 we also assumed that 6 is determined for a fixed value of 12. In many system modeling problems one is interested in a preliminary model in which dimension JZ is a variable. This is becoming increasingly more important as we begin to model large scale societal, energy, economic, etc. systems in which it may not be clear at the onset what effects are most important. One approach is to recompute 6 by means of Formula (3-10) in Lesson 3 for different values of ~1. This may be very costly, especially for large scale sys- tems, since the number of flops to compute 6 is on the order of n3. A second approach is to obtain @ for n = nl, and to use that estimate in a com- putationally effective manner to obtain 6 for n = ~22, where 112 > nl. These estimators are recursive in the dimension of 8. We shall also examine these estimators.
Recursive Least-Squares: Information Form 27
RECURSIVE LEAST-SQUARES: INFORMATION FORM
To begin, we consider the case when one additional measurement z(k + l), made at tk + 1, *becomes available :
z (k + 1) = h’(k + 1)9 + v(k + 1) (4-l)
When this eauation is combined with our earlier linear model we obtain a new linear mode;,
%(k + 1) = X(k + 1)6 + qr(k + 1)
where
(4-2)
(4-3)
(4-4)
(4-5)
%e(k + 1) =
and
V(k + 1) = col(v(k + l)IV(k))
Using (3-10) from Lesson 3 and (4-2), it is clear that
dwLs(k + 1)
= [X’(k + l)W(k + l)X(k + l)]-%‘(k + l)W(k + l)%(k + 1)
TO proceed further we must assume that W is diagonal, i.e.,
W(k + 1) = diag@(k + l)IW(k))
(4-6)
(4-V We shall now show that it is possible to determine &k + 1) from 6(k)
and r(k + 1).
Theorem 4-l. (Information Form of Recursive LSE). A recursive struc- ture for dwLs (k) is
6-(k + 1) = 6-(k) + Kw(k + l)[z(k + 1) - h’(k + 1)6-(k)] (4 8) -
K&k + 1) = P(k + l)h(k + l)w(k + 1) (4-9)
P-‘(k + 1) = P-‘(k) + h(k + l)w(k + l)h’(k + 1) (4-10)
These equations are initialized by 6,,(n) and P-‘(n), where P(k) is defined below in (4-13) and are used for k = n, n + 1, . . . , N - 1.

28 Least-Squares Estimation: Recurske Prmess~ng Lessofl4
PJ-OOJ Substitute (4-3), (4-4) and (4-7) into (4-6) (someGmes dropping the dependence upon k and k + 1, for notational simplicity) to see that
= [W(k + l)W(k + l)X’(k + 1)-J-‘[hwz + X’W%]
Express &&k) as
where
P(k) = [X’(k)W(k)X(k)]-I
From (4-12) and (4-13) it is straightforward to show that
W(k)W(k)fqk) = P-l (k)&*&)
and
P-l (k + 1) = P-l (k) + h(k + l)~+ + l)h’(k + 1)
It now follows that
&,&k + 1) = P(k + l)[hwz + P-I (k)&&k)] = P(k + l){hwz + [P-‘(k + 1) - hwh’]&&c)j
= 6&k) + P(k + l)hhj[z - h’&&k)] = 6&(k) + K& + l)[z - h’&&)]
which is (4-8) when gain matrix I& is defined as in (4-9).
(4-l 1)
(4-12)
(4-13)
(4-14)
(4-S)
(4-X)
l3ased on preceding discussions about dim 6 = n and dim S!+(k) = IV, we know that the first value of IV for which (3-10) in Lesson 3 can be used is AJ = n; thus, (4-8) must be initialized by &&z), which is computed using (3-N)) in Lesson 3. Equation (4-10) is also a recursive equation for P-l (k + l), which is initialized by Pm1 (n) = X’(n)W(n)X(n). q
corYlments
l+ Equation (4-8) can also be expressed as
i&&k + 1) = [I - K&c + l)h’(k + l)]&=(k) + &(k + l)z(k + 1) (4-17)
which demonstrates that the rtxursive [east-squares estimate (LYE) ti a time-varying digital filter that is excited by random inputs (i.e., the mea- surements), one whose plant matrix may itself be random, because Kw and h(k + 1) may be random. The random natures of Kw and (I - Kwh’) make the analysis of this filter exceedingly difficult. If Kw and h are deterministic, then stability of this filter can be studied using Lyapunov stability theory.
Recursive Least-Squares: Information Form 29
7 I.
3.
4.
5.
6.
In (4-Q the term h’(k + 1)6,-~(k) is a prediction of the actual mea- surement z(k + 1). Because 6 ,,(k) is based on Z(k), we express this predicted vaIue as i(k + Ilk), i.e.,
so that
i(k + l/k) = h’(k -i- 1)&&k), (4-18)
&r&k + 1) = &&k) + Kw(k + l)[r(k + 1) - i(k + Ilk)]. (4- 19)
Two recursions are present in our recursive LSE. The first is the vector recursion for 4 ww given by (4-8). Clearly &,&k + 1) cannot be com- puted from this expression until measurement t(k + 1) is available. The second is the matrix recursion for P-l given by (4-10). Observe that values for P-l (and subsequently KH’) can be precomputed before mea- surements are made. A digital computer implementation of (4-8)-(4-10) proceeds as follows:
P-’ (k + 1) --, P(k + l)+Kw(k + l>-+ 8-(k + 1).
Equations (4-8)-(4-10) can also be used for k = the following values for P-’ (0) and &&O):
P-’ (0) = $1” + h(O)w(O)h’(O)
0, l,..., N - 1 using
(4-20)
and
6,,(O) = P(0) [ $ + h(O)w (0)z (O)] (4-21)
In these equations (which ale derived in Mendel, 1973, pp. 101-106; see, aiso, Problem 4-1) Q is a very large number, E is a very small number, E is II ~l,andf=col(~,~,..., e>. When these initial values are used in (4-8)-(4-10) for k = 0, 1, . e . , n - 1, then the resulting values obtained for 6-(n) and P-’ (n) are the very same ones that are obtained from the batch formulas for b,(n) and P-’ (n).
Often z(0) = 0, or there is no measurement made at k = 0, so that we can set z(O) = 0. In this case we can set w (0) = 0 so that P-’ (0) = I, /a’ and 6(O) = a~. By choosing E on the order of l/a’, we see that (4-8)-(4-10) can be initialized by setting e(O) = 0 and P(0) equal to a diagonal matrix of very large numbers. The reason why the results in Theorem 4-1 are referred to as the “infor- mation form” of the recursive LSE is deferred until Lesson 11 where connections are made between least-squares and maximum-likelihood estimators (see the section entitled The Linear Model (X(k) deter- ministic), Lesson 11).

Least-Squares Estimation: Recursive Processing Lesson 4
MATRIX INVERSION LEMMA
Equations (4-10) and (4-9) require the inversion of y1 x TZ matrix P. If n is large than this will be a costly computation. Fortunately, an alternative is available, one that is based on the following matrix inversion lemma.
Lemma 4-1. If the matrices A, B, C, and D satisfy the equation
B-’ = A-’ + C’D-‘C (4-22)
where all matrix inverses are assumed to exist, then
B = A - AC’(CAC’ + D)-‘CA. (4-23)
Proof. Multiply B by B” using (4-23) and (4-22) to show that BB-’ = I. For a constructive proof of this lemma see Mendel(19’73), pp. 96-97. El
Observe that if A and B are n x n matrices, C is m x n, and D is m x m, then to compute B from (4-23) requires the inversion of one m x m matrix. On the other hand, to compute B from (4-22) requires the inversion of one m X m matrix and two YI X n matrices [A-’ and (B-‘)-‘I. When m < n it is definitely advantageous to compute B using (4-23) instead of (4-22). Observe, also, that in the special case when m = 1, matrix inversion in (4-23) is replaced by division.
RECURSIVE LEAST-SQUARES: COVARIANCE FORM
Theorem 4-2. (Covariance Form of Recursive LSE). Another recur- sive structure for &&k) is:
i&r& + 1) = i&&c) + K,(k + l)[z(k + 1) - h’(k + 1)&,&k)] (4-24)
where
K,(k + 1) P(k)h(k + 1) [h’(k + l)P(k)h(k + 1) + ’ 1 -1
= w(k + 1)
(4-25)
and
P(k + 1) = [I - K&k + l)h’(k + l)]P(k) (4-26)
These equations are initialized by b-(n) and P(n) and are used for k = n, n + 1,. . . , N - 1.
Proof. We obtain the results in (4-25) and (4-26) by applying the matrix inversion lemma to (4,lo), after which our new formula for P(k + 1) is substi- tuted into (4-9). In order to accomplish the first part of this, let A = P(k),
Which Form To Use 31
B = P(k + l), C = h’(k + 1) and D = 1 /w(k + 1). Then (4-10) looks like (4-22), so, using (4-23) we see that
P(k + 1) = P(k) - P(k)h(k + l)[h’(k + l)P(k)h(k + 1) + w-l (k + l)]-‘h’(k + l)P(k) (4-27)
Consequently,
Kw(k + 1) = P(k + l)h(k + 1) w(k + 1) = [P - Ph(h’Ph + wl)+ h’P]hw = Ph[I - (h’Ph + w-‘)-‘h’Ph]w = Ph(h’Ph + w-l)-l (h’Ph + w-l - h’Ph)w = Ph(h’Ph + iv-*)-’
which is (4-25). In order to obtain (4-26), express (4-27) as
P(k + 1) = P(k) - Kw(k + l)h’(k + l)P(k) = [I - K&k + l)h’(k + l)]P(k) Cl
Comments
The recursive formula for b-, (4.24), is unchanged from (4-8). Only the matrix recursion for P, leading to gain matrix Kw has changed. A digital computer implementation of (4.24)-(4-26) proceeds as follows: P(k)-, K,(k + l)+ &&k + l)+ P(k + 1). This order of computa- tions differs from the preceding one. When z(k) is a scalar then the covariance form of the recursive LSE requires no matrix inversions, and only one division. Equations (4-24)-(4-26) can also be used for k = 0, 1, . . . , N - 1 using the values for P-’ (0) and &&O) given in (4-20) and (4-21). The reason why the results in Theorem 4-2 are referred to as the “covar- iance form” of the recursive LSE is deferred to Lesson 9 where connec- tions are made between least-squares and best linear unbiased mini- mum-variance estimators (see p. 79).
WHICH FORM TO USE
We have derived two formulations for a recursive least-squares estimator, the information and covariance forms. In on-line applications, where speed of computation is often the most important consideration, the covariance form is preferable to the information form. This is because a smaller matrix needs to be inverted in the covariance form, namely an m x m matrix rather than an m X n matrix (m is often much smaller than n).

Least-Squares Estimation: Recursive Processing Lesson 4
The information form is often more useful than the covariance form in analytical studies. For example, it is used to derive the initial conditions for Pm1 (0) and &&O), which are given in (4-20) and (4-21) (see Mendel, 1973, pp. 101~106) The information form is also to be preferred over the covariance form during the startup of recursive least squares. We demonstrate why this is so next.
We consider the case when
W-4 = a21n (4-28)
where a2 is a very, very large number. Using the information form, we find that, for k = 0, P-l (1) = h(l)w(l)h’(l) + l/a’&, , and, therefore, Kw(l) = [h(l)w (l)h’(l) + 1 /a21$’ h(l)w(l). No difficulties are encountered when we compute Kw(l) using the information form.
Using the covariance form we find, first, that K&) = a2 h(l)[h’(l)a2 h(l)]-’ = h(l)[h’(l)h(l)]-‘, and then that
P(l) = {I - h(l)[h’(l)h(l)]-* h’(l)ju2 (4-29)
however, this matrix is singular. To see this, postmultiply both sides of (4-29) by h(l), to obtain
P(l)h(l) = {h(l) - h(l)[h’(l)h(l)]-’ h’(l)h(l)]a2 = 0 (4-30)
Neither P( 1) nor h(1) equal zero; hence, P(l) must be a singular matrix for P(l)h(l) to equal zero. In fact, once P(l) becomes singular, all other P(j), j ZE 2, will be singular.
In Lesson 9 we shall show that when WY1 (kj = E{V(k)V’(k)} = CR(k), then P(k) is the covariance matrix of the estimation error, 4(k). This matrix must be positive definite, and it will be quite difficult to maintain this property if P(k) is singular; hence, it is advisable to initialize the recursive least-squares estimator using the information form. However, it is also advisable to switch to the covariance formulation as soon after initialization as possible, in order to reduce computing time.
PROBLEMS
4-l. In order to derive the formulas for P-’ (0) and 6 WLs(0), given in (4-20) and (4-21), respectively, one proceeds as follows. Introduce n artificial measurements z= (-l), zti (-2), . . . ,2=(-n), where z”(-j) g E in which E is a very small
number.Then,assumethatthemodelforz’(-lJis-z*(-j) = iQ(j = 1,2,.,,,n) where 0 is a very large number. (a) Show that 6&,(--l) = aq where n X 1 vector E = CO~(E, E, . . . , l ).
Additionally, show that F (-1) = Q' k,. [b) Show that i&&(O) = F (O)[E/CZ + ~(O)W(O)Z(O)] and F (0) = [In /u’ +
h(O)w (O)h’(O)]-‘.
Lesson 4 Problems
(c) Show that when the measurements zU (-n), . . . , za (- 1): z (0), z( 1). . . . : z (I + I) are used, then
I-r 1
1 -1
/+ 1
P=(I + 1) = X,/a’+ c h(j]“(j]h’(j) J=o
(d) Show that when the measurements z(O), z(l), . . . , z(I + 1) are used (i.e., the artificial measurements are not used), then
[ I -1
i+1
w + 1) = c cwW’(~)
J’O
(e) Finally, show that for a >>> and E <<<
PyI i- l)-+P(I + I)
and
4-2. Prove that once P(1) becomes singular, all other P(I], j 2 2, will be singular. 4-3. (Mendel, 1973, Exercise 2-12, pg. 138). The following weighting matrix weights
past measurements less heavily than the most recent measurevents,
W(k + I) = diag(w(k -t I), w(k), . . +, w(l)) A (+pG&j)
where
4-4.
(a) Show that ~(1’) = w(fp +I-‘) forj = l,...,k f 1. (b) How must the equations for the recursive weighted least-squares estimator
be modified for this weighting matrix? The estimator thus obtained is known as a fading memory estimatur (Morrison, 1969).
We showed, in Lesson 3, that it doesn’t matter how one chooses the weights, w(j)? in the method of least squares, because the weights cancel out in the batch formula for 6&k). On the other hand, w(k + 1) appears explicitly in the recursive WLSE, but only in the formula for K,(k + l), i.e.,
Kw(k + 1) = P(k)h(k + l)[h’(k + I)P(k)h(k f I) + w-’ (k -k l>]-’
It would appear that if we set ~(k + 1) = wl, for all k, we would obtain a &(k + 1) value that would be different from that obtained by setting w(k + 1) = w2, for all k. Of course, this cannot be true. Show, using the

34 Least-Squares Estimation: Recursive Processing Lesson 4
formulas for the recursive WLSE, how they can be made independent of w(k + l), when w(k + 1) = w, for allk.
4-5. For the data in the accompanying table, do the following: (a) Obtain the least-squares line y(t) = a + bt by means of the batch processing
least-squares algorithm; (b) Obtain the least-squares line by means of the recursive least-squares
algorithm, using the recursive startup technique (let a = 10” and e = 10-16).
t Y(t)
0 1 1 5 2 9 3 11
LeccOn 5
Least-Squares
Estimation:
Recursive Processing
(continued)
Example 5-l
In order to illustrate some of the Lesson 4 results we shall obtain a recursive algorithm for the least-squares estimator of the scalar 8 in the instrument calibration example (Lesson 3). Gain Kw(k + 1) is computed using (4-9) of Lesson 4, and P(k + 1) is computed using (4-13) of Lesson 4. Generally, we do not compute P(k + 1) using (4-13); but, the simplicity of our example allows us to use this formula to obtain a closed-form expression for P(k + 1) in the most direct way. Recall that %e = co1 (1 1 l), which is a k x 1 vector, and h(k + 1) = 1; thus, setting W(k) = I and & ;’ ;jL 1 (in order to obtain the recursive LSE of 6) in the preceding formulas, we find that
P(k + 1) = [sle’(k + l)%e(k + 1)]-’ = & (5 ‘1) -
and
Kw(k + 1) = P(k + 1) = & (5-2)
Substituting these results into (4-8) of Lesson 4, we then find
&(k + 1) = &&) + &-+(k + 1) - &&)I
or?
i=(k + 1) = (5-3)
35

36 Least-Squares Estimation: Recursive Processing {continued) Lesson 5
Formula (S-3), which can be used for k = 0.1, . . . , iV - 1 by setting &CO) = 0, lets us reinterpret the well-known sample mean estimator as a time-varying digital filter [see, also, (l-2) of Lesson 11. We leave it to the reader to study the stability properties of this first-order filter.
Usually it is in only the simpiest 0: cases Jhat we can obtain closed-form expres- sions for Kw and P and subsequently &=,[or &Q]: however? we can always obtain values for I&(k + 1) and P(k T I) at successive time points using the results in Theorems 4-l or 4-2. q
GENERALIZAION TO VECTOR MEASUREMENTS
A vector of measurements can occur in any application where it is possible to use more than one sensor; however, it is ako possible to obtain a vector of measurements from certain types of individual sensors. In spacecraft applica- tions, it is not unusual to be able to measure attitude, rate, and acceleration. In electrical systems applications, it is not uncommon to be able to measure voltages, currents, and power. Radar measurements often provide informa- tion about range, azimuth, and elevation. Radar is an example of a single sensor that provides a vector of measurements.
In the vector measurement case, (4-l) of Lesson 4 is changed from z(k + I) = h’(k + 110 + v(k + 1) to
z(k + 1) = H(k + l)O + v(k + 1)
where z is now an VI x 1 vector, H is m x PI and v is ?TI x 1. We leave it to the reader to show that all of the results in Lessons 3 and 4
are unchanged in the vector measurement case; but some notation must be altered (see Table 5-l).
TABLE S-1 Transformations from Scalar to Vector Measurement Situations, and Vice-Versa
Scab Measurement Vector of Measurements
z(k + 1) z(k + l), an m X 1 vector v(k + 1) v(k + lJ, an m X 1 vector w(k + 1) w(k + I). an m X m matrix h’(k + 1). a 1 x FI matrix H(k + 1). an ITI x n man-ix T(k). an A’ X 1 vector S(k), an Nm X 1 vecb3r V(k), an N x 1 vector V(k), an Ah X 1 vector W(k). an N x Nmatrix W(k)* an Nm X Nm matrix X(k). an N x n matrix X.(k), an Nm X n matrix
Source: Reprinted from Mendel, 1973. p. 110. Courtesy of Marcel Del&et, Inc., NY.
Cross-Sectional Processing 37
CROSS-SECTIONAL PROCESSING
Suppose that at each sampling time t k + 1 there are q sensors or groups of sensors that provide our vector measurement data. These sensors are cor- rupted by noise that is uncorrelated from one sensor group to another. The m-dimensional vector z(k + 1) can be represented as
z(k + 1) = co1 (z,(k + I), z,(k + I), , , . , z,(k -t 1)) (5-j)
where
Zi(k + I) = H,(k + I)8 + vi(k ’ I) (5-6)
dimz,(k + 1) = mi X 1, 4
z Hli = f?l P-7) i=l
E(v,(k + 1)) = 0, and
E(v, (k + l)v,‘(k + I)) = Ri(k + I)&; P-8) An alternative to processing all m measurements in one batch (i.e.,
simultaneously) is available, and is one in which we freeze time at tl; + 1 and recursively process the 4 batches of measurements one batch at a time. Data zl(k + I) are used to obtain an estimate [fo: notational simplicity, in this section we omit the subscript WLS or LS on 6) 8r(k + 1) with if&(k) k b(k) and z(k + 1) 4 zl(k + 1). When these calculations are completed z?(k + I) is pro- cessed to obtain the estimate &(k + 1). Estimate iI,(k 4 1) is used to initialize &(k + 1). Each set of data is processed in this manner until the final set zq(k + 1) has been included. Then time is advanced to fk + 2 and the cycle is repeated, This type of processing is known as cross-sectional or sequential processing. It is summarized in Figure 5-l and is contrasted with more usual simultaneous recursive processing in Figure 5-2.
AII of this Processing Done at Frozen Time Point t,,,
Figure 5-I Cross-sectional processing of m measurements.

38 Least-Squares Estimation: Recursive Processing (continued) Lesson 5
> Time
m
/
Wk) 8(k + 1) 8(k + 2) B(k + 3)
dim z
W
: Time
/ &k) 6(k + 1) &k + 2) 6(k+3)
Jd’ lrn 2
(W
Figure 5-2 Two ways to reach 6(k + l), $k + 2), . . . . (a) Simultaneous recursive processing performed along the line dim z = m, and (b) cross-sectional recursive processing where, for example, at t Ir+l the processing is performed along the line TIME = fk+l and stops when that line intersects the line dim z = m.
The remarkable property about cross-sectional processing is that
6,(k + 1) = 6(k + 1) (5-9)
where 6(k + 1) is obtained from simultaneous recursive processing. A very large computational advantage exists for cross-sectional pro-
cessing if Rli = 1. In this case the matrix inverse [H(k + l)P(k)H’(k + 1) + w-l (k + l)]-’ needed in (4-25) of Lesson 4 is replaced by the division [h,‘(k + l)Pi(k)hi(k + 1) + l/Wi(k + l)]-‘. See Mendel, 1973, pp. 113-118 for a proof of (5-9)
MULTISTAGE LEAST-SQUARES ESTIMATORS
Suppose we are given a linear model Z(k) = X,(k)& + T(k) with n unknown parameters &, datum {S(k), X,(k)}, and the LSE of Or, 6:,&k), where
@:.I&~ = wxwwr’ %w~w (5-10)
Multistage Least-Squares Estimators
We extend this model to include 2 additional parameters, B2, so that our model is given by
For this model, datum {Z(k), XI(k), &(k)} is available. We wish to compute the least-squares estimates of e1 and e2 for the yt + I parameter model using the previously computed i$&).
Theorem 5-l. Given the linear model in (MI), where & is n x 1 and e2 is l? x 1. The LSEs of e1 and e2 based on datum {Z(k), X,(k), X*(k)} are found from the following equations:
&,Ls(~) = @:.Ls(~) - G(k)C(k)W(k)[fW) - ‘%(k)~?,&)] (5-12) and
bs(k) = W~;(k)[~(k) - &(k)&s(k)] (5-13)
where
G(k) = [X(k)&(k)l-’ W(k)%(k) (5-14)
C(k) = [%(k)%(k) - %(k)%(k)G(k)]-’ (5-15)
The results in this theorem were worked out by Astrom (1968) and emphasize operations which are performed on the vector of residuals for the n parameter model, namely Z(k) - XY,(k)6~&k). Other forms for & &k) and 6*,&k) appear in Mendel(l975).
.
Proof. The derivation of (5-12) and (5-13) is based primarily on the block decompositon method for inverting %e’X, where %e = (XII%e,). See Men- de1 (1975) for the details. 0
Similar results to those in Theorem 5-l can be developed for the removal of 2 parameters from a model, for adding or removing parameters one at a time, and for recursive-in-time versions of all these results (see Mendel, 1975). All of these results are referred to as “multistage LSEs.”
We conclude this section and lesson with some examples which illustrate problems for which multistage algorithms can be quite useful.
Example 5-2 Identification of a Sampled Impulse Response: Zoom-In Algorithm A test signal, u (t) is applied at t = to to a linear, time-invariant, causal, but unknown system whose output, y(t), and input are measured. The unknown impulse response, w (t), is to be identified using sampled values of u (t) and y (t). For such a system
y(tk) = r w(7)u(tk - 7)d7 rO
(5-16)

Least-Squares Estimation: Recursive Processing (conGnuedJ Lesson 5
One qqxoach to identifying NJ(~) is to discretize (5-16) and to only identify w(i) at discrete values of time. If we assume that (1) w(f) * 0 for all f 2 &, (2) [rO, lW] is divided into ?I equal intervals, each of width T, so that n = (I~ - lo)/ T and (3) for Te[fi-l, ii], w(T) = ~*(r~ - I) and ti (l - 7) = u (t - fi - I), then
y(h) = i Wl(b l)U(fk - ia - 1) (5-17) t=l
W](ti - 1) = TW(ll - 1) (518)
It is straightforward to identify the n unknown parameters wI(lO), wI(fI), . . . , ~+(i~ - ,) via least squares (see Example 2-l of Lesson 2); however, for n to be known, I%, must be accurately known and Tmust be chosen most judiciously. In actual practice rW is not known that accurately so that PI may have to be varied. Multistage LSEs can be used to handle this situation, Sometimes T can be too coarse for certain regions of time, in which case significant features of W(I) such as a ripple may be obscured. In this situation, we would like to “zoom-in” on those intervals of time and rediscretize y (1) just over those intervals, thereby adding more terms to (5-17). Multistage LSEs can also be used to handle this situation, as we demonstrate next
For illustrative purposes, we present this procedure for ?he case when the inter- val of interest equals T, i.e., when t E [lx, lx + l ] = Twhich is further divided into q equal intervals, each of width ATX, so that q = (fX + I - &)/AT= = T/AT=. observe that
+ 1 4-3 rx + (i + l)A7x w(+i& - T)dr =
?i w(T)u(tk - r)d7
j=il rx + jAT=
q-1
= x w(tx + jATx)u(tk - tx - jATx)ATx (5-19) j-0
(5-20)
Equation (5-20) contains n + q - 1 parameters. Let
fll = 4331 (w(to), w(t,), . - l , w&x), . - . , w&7 - I)) (5-22)
and assume that available. Let
a least-squares estimate which is based on (547), is
02 = coi[w& + AT& w2(tx + 2ATx), . . , , w& + (q - l)ATx)] (S-23)
To obtain 6= = co! (61+M, 6Z,Ls) proceed as follows: 1) modify ~TJ-~ by scaling &J-s(~~) to k.~(tx )ATX / Tand call the modified result 6* l,Ls: and 2) apply Theorem 5-I to obtain
TABL
E 5-
2 Im
puls
e R
espo
nse E
stim
ates
Num
ber o
f Pa
ram
eter
s in
the
Mod
el
n
Aver
age
Estim
ates
of P
aram
eter
CSh
Aver
age
Perfo
rman
ce
1 0.
34
(1.9
6 2
0.41
0.
75
0.75
3
0.39
0.
78
0.40
0.
63
4 0.
39
0.79
0.
40
-0.1
2 0.
62
5 0.
40
0.79
0.
43
-0.1
7 -0
.41
0.44
6
0.39
0.
79
0.43
-0
.15
-0.4
4 -0
.29
0.40
7
0.39
0.
80
0.44
-0
.16
-0.4
4 -0
.27
0.06
11
.30
8 0.
41
0.81
0.
43
-0.1
5 -0
.47
-0.3
0 0.
12
0.30
(I.
29
9 0.
43
0.83
0.
43
-0.1
4 -0
.47
-0.3
3 0.
10
0.35
0.
23
0.18
10
0.
43
0.81
0.
42
-0.1
5 -0
.46
-0.3
2 0.
10
0.35
0.
22
-- 1
.07
0.13
Sour
ce: R
eprin
ted
from
Men
del,
1975
, pg.
782
, 0 1
975 I
EEE.
“V
alue
s fo
r pa
ram
eter
s sh
own
in p
aren
thes
es ar
e tru
e va
lues
. ‘B
lank
sp
aces
in th
e ta
ble
deno
te “n
o va
lue”
for
par
amet
ers.

42 Least-Squares Estimation: Recursive Processing (continued) Lesson 5
iLs. Note that the scaling of G I,Ls(fX) in Step 1 is due to the appearance of W&&W’ / T instead of IV&) in (j-20).
It is straightforward to extend the approach of this example to regions that include more than one sampling interval, T. q Example 5-3 Impulse Response Identification
An n-stage batch LSE was used to estimate impulse response models having from one to ten parameters [i.e., n in (5-17) ranged from l-101 for a second-order system (natural frequency of 10.47 rad/sec, damping ratio of 0.12, and, unity gain). The system was forced with an input of randomly chosen *l’s each of which was equally likely to occur. The system’s output was corrupted by zero-mean pseudo-random Gaussian white noise of unity variance. Fifty consecutive samples of the noisy output and noise-free input were then processed by the n-stage batch LSE, and this procedure was repeated ten times from which the average values for the parameter estimates given in Table 5-2 (page 41) were obtained.
The ten models were tested using ten input sequences, each containing 50 sam- ples of randomly chosen 51’s. The last column in Table 5-2 gives values for the normalized average performance
r 50 I 50 VQ
Li= 1 I i = 1 J
in which L(ti) denotes an average over the ten runs. Not too surprisingly, we see that average predicted performance improves as n increases.
All the 8i results were obtained in one pass through the n-stage LSE using approximately 3150 flops. The same results could have been obtained using 10 LSEs (Lesson 3); but, that would have required approximately 5220 flops. c3
5-l.
5-2. 5-3. 5-4.
PROBLEMS
Show that, in the vector measurement case, the results given in Lessons 3 and 4 only need to be modified using the transformations listed in Table 5-l. Prove that, using cross-sectional processing, &(k + 1) = 6(k + 1). Prove the multistage least-squares estimation Theorem 5-l. Extend Example 5-2 to regions of interest equal to mT, where m is a positive integer and T is the original data sampling time.
Small Sample
Properties
of Esfimafors
iNTRODUCTlON
How do we know whether or not the results obtained from the LSE, or for that matter any estimator, are good? To answer this question, we make use of the fact that all estimators represent transformations of random data. For exam- ple, our LSE, [X’(k)W(k)X(k)]-‘X’(k)W(k)Z(k), represents a linear trans- formation on Z(k). Other estimators may represent nonlinear transformations of Z(k). The consequence of this is that 6(k) is itself random. Its properties must therefore be studied from a statistical viewpoint.
In the estimation literature, it is common to distinguish between small- sample and large-sample properties of estimators. The term “sample” refers to the number of measurements used to obtain 6, i.e., the dimension of Z. The phrase “small-sample” means any number of measurements (e.g., 1, 2, 100, 104, or even an infinite number), whereas the phrase “large-sample” means an infinite number of measurements. Large-sample properties are also referred to as asymptotic properties. It should be obvious that if an estimator possesses a small-sample property it also possesses the associated large-sample property; but, the converse is not always true.
Why bother studying large-sample properties of estimators if these prop- erties are included in their small-sample properties? Put another way, why not just study small-sample properties of estimators? For many estimators it is relatively easy to study their large-sample properties and virtually impossible to learn about their small-sample properties. An analogous situation occurs in stability theory, where most effort is directed at infinite-time stability behavior rather than at finite-time behavior.

Small Sample Propertks of Estimators Lesson 6
Although “large-sample” means an infinite number of measurements, estimators begin to enjoy their large-sample properties for much fewer than an infinite number of measurements- How few, usually depends on the dimen- sion of 0, n.
A thorpugh study into 6 would mean determining*its probability density function p (9). WsuaUy, it is too difficult to obtain p (0) for most estimators (unless 4 is multivariate Gaussian); thus, it is customary to emphasize the first- and second-order statistics of 6 (or, its associated error 6 = 8 - 6), namely the mean and covariance.
We shall examine the following smaK and large-sample properties of estimators: unbiasedness and efficiency (small-sample)Y and asymptotic un- biasedness, consistency, and asymptotic efficiency (large-sample). Small- sample properties are the subject of this lessonT whereas large-sample proper- ties are studied in Lesson 7+
UNBIASEDNESS
In terms of estimation error, 6(k), unbiasedness means, that
E@(k)] = 0 for ai1 k
Exampk 6- 1
In the instrument calibration example of Lesson 3, we determined the following LSE of 8:
where
z(i) = e + v(i)
Suppose I~{Y (i)} = 0 for L’ = 1,2, , , . , N; then,
which means that &(A$! is an unbiased estimator of 0. R
Unbiasedness
Many estimators are linear transformations of the measurements, i.e.,
i(k) = F(k)%.(k) (6-6)
In least-squares, we obtained this linear structure for i(k) by solving an optimization problem. Sometimes, we begin by assuming that (6-6) is the desired structure for 8(k). We now address the question “when is F(k)Z(k) an unbiased estimator of deterministic 6?”
Theorem 6-f. When 55(k) = X(k)8 + V(k), E(Sr(k)) = 0, and X(k) is deterministic, then b(k) = F(k)%(k) [where F(k) is deterministic] is an unbiased estimator of 0 if and only if
F(k)X(k) = I for ali k (6-7)
Note that this is the first knowledge about noise V(k).
place where we have had to assume any a priori
Pruof a. (Necessity). From the model for S(k) and the assumed structure for
i(k), we see that
6(k) = F(k)%e(k)B + F(k)V(k) (6-S)
If h(k) is an unbiased estimator of 8, F(k) and X(k) are deterministic, and E(V(k)) = 0, then
E{&k)} = 9 = F(k)X(k)B
[I - F(k)X(k)j9 = 0 W-9
Obviously, for 8 # 0, (6-7) is the solution to this equation. b. (Suficiency). From (6-S) and the nonrandomness of F(k) and X(k),
we have
E{&k)} = F(k)X(k)O (6-10)
Assuming the truth of (6-7), it must be that
E{d(k)) = 9
which, of course, means that 6(k) is an unbiased estimator of 9. 0
Example 6-2 Matrix F(k) for the WLSE of 8 is [%“(k)W(k)X(k)]-‘3t?(k)W(k). Observe that this F(k) matrix satisfies (6-7); thus, when X(k) is deterministic the WLSE of9 is unbiased. Unfortunately, in many interesting applications X(k) is random, and we cannot apply Theorem 6-l to study the unbiasedness of the WLSE. We return to this issue in Lesson 8. Cl

Small Sample Properties of Estimators Lesson 6
Suppose that we begin by assuming a Iinear recursive structure for 6, namely
b(k + 1) = A(k + 1)6(k) t b(k + l)z(k + 1) (6-11)
We then have the following counterpart to Theorem 6-l.
Theorem 6-2. When z(k + 1) = h’(k + 1)0 + v(k + l), E{v(k + 1)) = 0, and h(k + 1) is deterministic, then &k + 1) given by (6-11) is an unbiased estimator of 8 if
A(k + 1) = I - b(k + l)h’(k + 1) (6-12)
where A(k + 1) and b(k + 1) are deterministic. 0
We leave the proof of this result to the reader. Unbiasedness means that our recursive estimator does not have two independent design matrices (de- grees of freedom), A(k + 1) and b(k + 1). Unbiasedness constraints A(k + 1) to be a function of b(k + 1). When (6-12) is substituted into (6-H), we obtain the following important structure for an unbiased linear recursive estimator of&
6(k + 1) = i(k) + b(k + l)[z(k + 1) - h’(k + 1)&k)] (6-13)
Our recursive WLSE of 8 has this structure; thus, as long as h(k + 1) is deterministic, it produces unbiased estimates of 8. Many other estimators that we shall study will also have this structure.
Did you hear the story about the conventioning statisticians who all drowned in a lake that was on the average 6 in. deep? The point of this rhetorical question is that unbiasedness by itself is not terribly meaningful. We must also study the dispersion about the mean, namely the variance. If the statisticians had known that the variance about the 6 in. average depth was 120 ft, they might not have drowned!
Ideally, we would like our estimator to be unbiased and to have the smallest possible error variance. We consider the case of a scalar parameter first.
Definition 6-2. An unbiased estimator, i(k) of 0 is said to be more eficient than any other unbiased estimator, 8(k), of 9, if
Var (6(k)) 5 Var (8(k)) for all k 0 (6-14)
Very often, it is of interest to know if 6(k) satisfies (6-14) for all other unbiased estimators, i(k). This can be verified by comparing the variance of
Efficiency 47
8(k) with the smallest error variance that can ever be attained by any unbiased estimator. The following theorem provides a lower bound for E{ h2(k)} when 8 is a scalar deterministic parameter. Theorem 6-4 generalizes these results to the case of a vector of deterministic parameters.
Theorem 6-3 (Cramer-Rao Inequality). Let z denote a set of data
[ i.e., z = co1 (Zi, z2, . . . , zk); z is also short for Z(k)]. If i(k) is an unbiased estimator of deterministic 8, then
E{@(k)} 2 E{[$Q:p(z)r} forazzk
Two other ways for exPressing (6-15) are
E{@(k)} > ‘Ldz PC > Z
(6-15)
for all k (6-16)
E{p(k)} 2 -E i”;“” (‘,)
for all k
de2
(6-17)
where dz is short for dq, dt2, . . . , dzk . cl
Inequalities (6-19, (6-16) and (6-17) are named after Cramer and Rao, who discovered them. They are functions of k because z is.
Before proving this theorem it is instructive to illustrate its use by means of an example.
Example 6-3
We are given M statistically independent observations of a random variable z that is known to have a Cauchy distribution, i.e.,
p(a) = 1 7T[l + (Zi - e)‘]
(6-18)
Parameter 6 is unknown and will be estimated using zl, z2, . . . , ZM. We shall determine the lower bound for the error-variance of any unbiased estimator of 8 using (6-15). Observe that we are able to do this without having to specify an estimator structure for 6. Without further explanation, we calculate:
p(Z) = fi p (Zi) = 1 i(
fl fi [l + (Zi - e)2] i==l i=l
lnP(z) = -Mlnrr - 2 ln[l + (Zi - Q”l ; = 1
(6-19)
(6-20)

48 Smail Sample Properties of Estimators Lesson 6
and
(6-21)
so that
Next, we must evaluate the right-hand side of (6-22). This is tedious to do, but can be accomplished, as follows+ Xote that
Consider TA first, i.e.,
TA = E : 2(zj - @/[l + (zj - O)*] 5 Z(Zj - 8)/[1 + (pi - 0)2] (6-24) i=l j-1
where that
use of statistical independence of the measurements. observe
(6-25)
where y = zi - 8. The integral is zero because the integrand is an odd function of y. Consequently,
TA = 0 (6-26)
Next, consider TEL, i.e.,
TB = E 5 4(Zi - 0)2/[1 + (pi - tQ212
which can also be written as
where
TB = 4 2 TC i-1
TC = E{(Zi - q2/[l + (Zj - ej2J2) Or
Integrating (6-30) by parts twice, we fmd that
(6-27)
(6-23)
(6-29)
(6-30)
(6-31)
because the integral in (6-31) is the area under the Cauchy probability density function, which equals v. Substituting (6-31) into (6-281, we determine that
TB = M/2 (6-32)
Efficiency 49
thus, when (6-23) is substituted into (622), and that result is substituted into (615), we find that
for all M (6-33)
used Observe th at the Cramer-Rao bound depends on the number of measurements
to estimate 8. For large numbers of measurements, this bound equals zero. Cl
Proof uf Theorem 6-3. Because b(k) is an unbiased estimator of t?,
E{@k)} = /= [i(k) - 01 p(z)dz = 0 (4-34) -m
Differentiating (6-34) with respect to 8, we find that
J
r
&k) - $1 --a
%p dz - f p(z) dz = 0
-cc
which can be rewritten as
As an aside, we note that
so that
(6-35)
(6-36)
I (6-37)
Substitute (6-37) into (6-35) to obtain
where equality is achieved when b(z) = ca(z) in which c is an arbitrary con- stant. Next, square both sides of (6-38) and apply (6-39) to the new right-hand side, to see that
1 I [6(k) - Bj’p(z)dz 1-1 [$lnp(z)]:p(z)dz I
or
11 E(b(l;)jE{ [$lnp(z)]?j (6-40)

Small Sample Properties of Estimators Lesson 6
Finally, to obtain (6-Q) solve (6-40) for E{@(k)}. In order to obtain (6-16) from (6-H), observe that
To obtain (6-41) we have also used (6-36). In order to obtain (6-17), we begin with the identitv w
I
x
p(z)dz= 1 -X
and differentiate it twice with respect to 0, using (6-37) after each differ- entiation, to show that
which can also be expressed as
E[ [-$lnp(z)r] = -E[ “n!/} (6-42)
Substitute (6-42) into (6-15) to obtain (6-17). Cl
It is sometimes easier to compute the Cramer-Rao bound using one form 1 i.e., (6-15) or (6-16) or (6-17)] than another. The logarithmic forms are usually used when p (z) is exponential (e.g., Gaussian).
CoroNary 64. If the lower bound is achieved in Theorm 6-3, then
where c is an arbitrary constant.
8(k) 1 d lnp(z) =-- c de (6-43)
Proof. In deriving the Cramer-Rao bound we used the Schwarz in- equality (6-39) for which equality is achieved when b (z) = c ti (z). In our case a(z) = [6(k) - tFJm and b(z) = m (~?/a@ lnp(z)- Setting b(z) = c a(z), we obtain (6-43). Cl
Equation (6-43) links the structure of an estimator tc the property of efficiency, because the left-hand side of (6-43) depends eAxpli,itly on e(k).
We turn next to the general case of a vector of paramzxrrs.
Definition 6-3. An unbiased estimator, i(k), of vecmy 8 is said to be more efficient than any other unbiased estimator, 8(k), of& i- s s
E{[B - i(k)][O - i(k)]‘} 5 E{[6 - $k)][e - & W- z] - - (6-9
Efficiency 51
For a vector of parameters, we see that a more efficient estimator has the smallest error covariance among all unbiased estimators ot8, “smallest” in the sense that E{[8 - b(k)][8 - 6(k)]‘} - E{[6 - e(k)][e - e(k)]‘} is negative semi-definite.
The generalization of the Cramer-Rao inequality to a vector of par;lm- eters is given next.
Theorem 6-4 (Cramer-Rao inequality for a vector of parameters). Let z denote a set of data as in Theorem 6-3, and 8(k) be any unbiased estimator of deterministic 8 based on z. Then
E{ij(k)h’(k)} 2 J-’ for all k (6-45)
where J is the “Fisher information matrix,”
J = E [$np(z)][-$ i
which can also be expressed as
(6-46)
J -E d2 = i I ,zlnp(z) (6-47)
Equality holds in (6-45), if and only if
[$ ln P(Z)]’ = c(e)ii(k) 0 (6-48)
A complete proof of this result is given by Sorenson (1980, pp. 94-96). Although the proof is similar to our proof of Theorem 6-3, it is a bit more intricate because of the vector nature of 8.
Inequality (6-45) demonstrates that any unbiased estimator can have a covariance no smaller than J-‘. Unfortunately, J-l is not a greatest lower bound for the error covariance. Other bounds exist which are tighter than (6-45) [e.g., the Bhattacharyya bound (Van Trees, 1968)], but they are even more difficult to compute than J?
Corollary 6-2. Let z denote a set of data as in Theorem 6-3, and &(kj be any unbiased estimator of deterministic 0i based on z. Then
E{@(k)} 2 (J-‘)ii i = 1,2, . . . ,n and all k (6-49)
where (J-‘)ii is the i-ith element in matrix J-‘.
Proof. Inequality (6-45) means that E{@k)&(k)} - J-l is a positive semi-definite matrix, i.e.,
a’[E{b(k)b’(k)} - J-‘]a 2 0 (6-50)
where a is an arbitrary nonzero vector. Choosing a = ei (the ith unit vector) we obtain (6-49). 0

Small Sample Propedes of Estimators Lesson 6
Results similar tu those in Theorem 6-4 and Corollary 6-2 are also available for a vector of random parameters (e.g., Sorenson, 1980, pp. 99-100). Let p (z, 9) denote the joint probability density function between z and 9. The Cramer-Rao inequality for random parameters is obtained from Theorems 6-3 and 6-4 by replacing p (z) by p (2, 9). Uf course, the expectation is now with respect to z and t3+
PROBLEMS
6-l* Prove Theorem 6-2, which provides an unbiasedness constraint for the two design matrices that appear in a linear recur.sive estimator.
6-2* Prove Theorem 6-4, which provides the Cramer-Rao bound for a vector of parameters,
6-3. Random variabIe X - N(x; P7 4, and we are given {Xl, 12, ’ * * , x,~}. Consider the following estimator for by
a random sample
where a 2 0. For what value(s) of u is b(N) an unbiased estimator of p? 6-4. Suppose zl, z2, . . . , zAt are random samples from a Gaussian distribution with
unknown mean, p, and variance, 0’. Reasonable estimators of p and Q* are the sample mean and sample variance,
and
S2
Is s2 an unbiased estimator of u’? [Hint: Show that I?&‘) = (N - l)c?/Nj 6-S. (Mendel, 1973, first part of Exercise 2-9, pg. 137). Show that if 4 is an unbiased
estimate of 0, a 6 + b is an unbiased estimate of a 8 + b. 6-6.
6-7.
6-S.
suppose that N independent observations variable X that is Gaussian, i.e.,
xN} are made of a random
In this problem only p is unknown. Derive E{F’(N’)} for an unbiased estimator of P*
the Cramer-Rao lower bound of
Repeat Problem 6-6, but in this case assume that only cr’is unknown, i. ,e,, the Cramer-Rao lower bound of E{[&‘(N)]‘] for an unbiased estimator of
derive
Repeat Problem 6-6, but in this case compute J-r when 9 = co1 (p , ~7.
assume both p and U’ are unknown,
Lesson 6 Problems 53
6-9. Suppose 6(k) is a biased estimator of deterministic 8, with bias B( IT?). Show that
E{$(k)} 2 [I +T12
E{ [-$ In p(z)]‘) for a11k

lesson 7
Large Sample
Properties of
Estimators
INTRODUCTION
To begin, we reiterate the fact that “if an estimator possesses a small-sample property it also possesses the associated large-sample property; but, the con- verse is not always true.” In this lesson we shall examine the following large- sample properties of estimators: asymptotic unbiasedness, consistency, and asymptotic efficiency. The first and third properties are natural extensions of the small-sample properties of unbiasedness and efficiency in the limiting situation of an infinite number of measurements. The second property is about convergence of B(k) to 6.
Before embarking on a discussion of these three large-sample proper- ties, we digress a bit to introduce the concept of asymptotic distribution and its associated asymptotic mean and variance (or covariance, in the vector situ- ation). Doing this will help us better understand these large-sample proper- ties.
ASYMPTOTIC DISTRIBUTIONS
According to Kmenta (1971, pg. 163), “. . . if the distribution of an estimator tends to become more and more similar in form to some specific distribution as the sample size increases, then such a specific distribution is called the asymptotic distribution of the estimator in question. . . . What is meant by the asymptotic distribution is not the ultimate form of the distribution, which may
Asymptotic Distributions 55
be degenerate, but the form that the distribution tends to put on in the last part of its journey to the final collapse (if this occurs).” Consider the situation depicted in Figure 7-1, where pi( 6) denotes the probability density function associated with estimator 6 of the scalar parameter 8, based on i mea- surements. As the number of measurements increases, pi (6) changes its shape (although, in this example, each one of the density functions is Gaussian). The density function eventually centers itself about the true parameter value 0, and the variance associated with pi( 6) tends to get smaller as i increases. Ultimately, the variance will become so small that in all probability 8 = 6. The asymptotic distribution refers to pi (6) as it evolves from i = 1,2, . . . , etc., especially for large values of i.
The preceding example illustrates one of the three possible cases that can occur for an asymptotic distribution, namely the case when an estimator has a distribution of the same form regardless of the sample size, and this form is known (e.g., Gaussian). Some estimators have a distribution that, although not necessarily always of the same form, is also known for every sample size. For example, p5( 8) may be uniform, pZO( 8) may be Rayleigh, and pzoo( 6) may be Gaussian. Finally, for some estimators the distribution is not necessarily known for every sample size, but is known only for k + 30.
Asymptotic distributions, like other distributions, are characterized by their moments. We are especially interested in their first two moments, namely, the asymptotic mean and variance.
Definition 7-l. The asymptotic mean is equal to the asymptotic expecta- tion, namely t@m E{i(k)}. IJ
%o~~ n-h.Kl m20 m5
Figure 7-1 Probability density function for estimate of scalar 8, as a function of number of measurements, e.g., pm is the p.d.f. for 20 measurements.

Large Sample Properties of Estimators Lesson 7
As noted in Goldberger (1944, pg. 116), if E{@$ = m for al/ k, then p?m E{t!(k)j = linn m = RL Alternatively, suppose that
E{@k)} = m + k-‘cI + k -‘c2 + l l 9 V-1)
where the c’s are finite constants; then,
p9z E{i(k)] = 1$X {m + k-‘q + ke2c2 + . . l } = m P-9
Thus if E{@c)} is expressible as a power series in k”, k-l, k-‘, . . - , the asymptotic mean of 6(k) is the leading term of this power series; as k + zc the terms of “higher order of smallness” in k vanish.
Definition 7-Z. The usymptutic variurxe, wh@ is short fur “variance of the asymptotic distribution” is not equal to lirnz var [@)]. It is defined as
asymptotic var [8(k)] = L k lee E{k[&k) - limm @(k)}]j II (7-3)
Kmenta (1971, pg. 164) states “The asymptotic variance . . . is not equal to j@= var(@. The reason is that in the case of estimators whose variance decreases with an increase in k, the variance will approach zero as k + m. This will happen when the distribution collapses on a point. But, as we explained, the asymptotic distribution is not the same as the collapsed (degenerate) distribution, and its variance is WC zero.”
Goldberger (1944, pg. 116) notes that if E{[@k) - lim E{&k)}]‘} = u /k for aZI values of k, then asymptotic var [6(k)] = v /k. A&Fnatively, suppose that
E{[&k) - j@= E{i(k)}12j = k--Iv + k-2cI + k-‘cj -+ l 0.
where the the c’s are finite constants; then,
asymptotic var [t?(k)] = i Lirn (V + ke1c2 + ke2c3 + -0 a) *a
Thus if the variance of each 6 (k) is expressible as a power series in k-l, k -2, . l * , the asymptotic variance of 6(k) is the leading term of this power series; as k goes to infinity the terms of “higher order of smallness” in k vanish. Observe that if (7-5) is true then the asymptotic variance of 6(k) decreases as k+m.. . which corresponds to the situation depicted in Figure 7-l.
Extensions of our definitions of asymptotic mean and variance to se- quences of random vectors [e.g.! 6(k), k = lq 2? . . .] are straightforward and can be found in Goldberger (1964, pg. 117).
Consistency 57
ASYMPTOTIC UNBIASEDNESS
Definition 7-3. Estimator 6(k) is an asymptotically unbiased estimator of deterministic 8, if
,!@= E&k)) = 9 (7-6)
or of random 9, if
dinn E&k)) = E(9) 0 P-7)
Figure 7-l depicts an example in which the asymptotic mean of 6 has converged to 8 (note that pzoo is centered about mm = 0).
Note that for the calculation on the left-haqd side of either (7-6) or (7-7) to be performed, the asymptotic distribution of B(k) must exist, because
E{ii(k)) = J= - - .I= l!qk)p(Cqk))&(k) -70 --m U-8)
Example 7-1
RecalI our linear model S.(k) = Z(k)0 + T(k) in which E(Sr(k)} = 0. Let us assume that each component of Y(k) is uncorrelated and has the same variance d. In Lesson 8, we determine an unbiased estimator for CT:. Here, on the other hand, we just assume that
where 2(k) = Z(k) - X(k)&,(k). We leave it to the reader to show that (see Lesson 8)
E{z (k)} = (q) CT?
Observe that I$? (k) is not an unbiased estimator of d; but, it is an asymptotically unbiased estimator, because ,II- [(k - n)/k] & = CJ-?. q
CONSISTENCY
We now direct our attention to the issue of stochastic convergence. The reader should review the different modes of stochastic convergence, especially con- vergence in probability and mean-squared convergence (see, for example, Papoulis, 1965).
Definition 7-4. The probability limit of 6(k) is the point 0* on which the distribution of our estimator collapses. We abbreviate “probability limit of 6(k)” by plim 6(k). Mathematically speaking,
plim 6(k) = 8* -i& Pr [Ii(k) - 8*1 1 e]-,O (7-11)
where E is a small positive number. El

Large Sample Properties of Estimators Lesson 7
Definition 7-5. 6(k) is a consistent estimator of 8 if
plim i(k) = 8 0 (7-12)
Note that “consistency” means the same thing as “convergence in proba- bility.” For an estimator to be consistent, its probability limit 8* must equal its true value 0. Note, also, that a consistent estimator need not be unbiased or asymptotically unbiased.
Why is convergence in probability so popular and widely used in the estimation field? One reason is that plim ( 0) can be treated as an operator. For example, suppose Xk and Yk are two random sequences, for which plim xk = X and plim Yk = Y, then (see Tucker, 1962, for simple proofs of these and other facts),
ph &Yk = (plim xk)(plim Yk) = fl (7-13) and
plim xk x =- =- plim Yk Y (7-14)
Additionally, suppose Ak and Bk are two commensurate matrix sequences, for which plim Ak = A and plim Bk = B [note that plim Ak, for example, means (plim aii(k))ii] ; then
plim AkBk = (plim Ak)(Plirn Bk) = AB (7-15)
plim Ai1 = (plim AJ’ = A-l (7-16)
plim Ai1 Bk = A-‘B (7-17)
The treatment of plim ( .) as an operator often makes the study of consistency quite easy. We shall demonstrate the truth of this in Lesson 8 when we examine the consistency of the least-squares estimator.
A second reason for the importance of consistency is the property that “consistency carries over”; i.e., any continuous function of a consistent esti- mator is itself a consistent estimator [see Tucker, 1967, for a proof of this property, which relies heavily on the preceding treatment of plim ( l ) as an operator].
Example 7-2 Suppose 6 is a consistent estimator of 8. Then 1 / 6 is a consistent estimator of l/ 8, (6)” is a consistent estimator of 8’, and In 6 is a consistent estimator of in 8. These facts are all due to the consistency carry-over property. [7
The reader may be scratching his or her head at this point and wondering about the emphasis placed on these illustrative examples. Isn’t, for example, using 6 to estimate 8? by (6)’ the “natural” thing to do? The answer is “Yes, but only if we know ahead of time that 6 is a consistent estimator of 8 .” If you
Consistency
do not know this to be true, then there is no guarantee that 8 = (6)“. In Lesson 11 we show that maximum-likelihood estimators are consistent; thus
ML = (&L)2. we mention this property about maximum-likelihood esti- mators here, because one must know whether or not an estimator is consistent before applying the consistency carry-over property. Not all estimators are consistent!
Finally, this carry-over property for consistency does not necessarily apply to other properties. For example, if b(k) is an unbiased estimator of 0, then A&) + b will be an unbiased estimator of A8 + b; but, 8(k) will not be an unbiased estimator of 82.
How do you determine whether or not an estimator is consistent? Often, the direct approach, which makes heavy use of plim ( 0) operator algebra, is possible. Sometimes, an indirect approach is used, one which examines whether both the bias in i(k) and variance of t?(k) approach zero as k * 0~). In order to understand the validity of this indirect approach, we digress to discuss mean-squared convergence and its relationship to convergence in probability.
Definition 7-6. Estimator 6 (k) converges to 8 in a mean-squared sense, if
CnlE{[&k) - 6]‘}-+0 q (7-18)
Theorem 7-1. If i(k) converges to 8 in mean-square, then it converges to 8 in probability.
Proof (Papoulis, 1965, pg. 151). Recall the Inequality of Bienayme
WI x- al 2 E] 5 E{lx - a12}/8 (7-19) Let a =Oandx = 6(k) - 6 in (7-19), and take the limit as k + 00 on both sides of (7.19), to see that
hrl Pr[@(k) - 61 2 E] 5 llm E{@(k) - S]*}/E? (7-20)
Using the fact that 6(k) converges to 6 in mean-square, we see that liir Pr[li(k) - 61 => E]-+O (7-21)
thus, 6(k) converges to 6 in probability. cl
Recall, from probability theory, that although mean-squared con- vergence implies convergence in probability, the converse is not true.
Example 7-3 (Kmenta, 1971, pg. 166) Let 6(k) be an estimator of 8, and let the probability density function of 6(k) be
8 1 1-z
k 1 k

Large Sample Propertks of Estimators Lesson 7
In this example t?(k) can only assume two different values, 6 and k. Obviously, 6 (k) is consistent, because as k -+CC the probability that 6(k) equals 8 approaches unity, i.e., plim 6(k) = 0. Observe, also, that E{i(k)] = 1 + G(l - l/k), which means that 6(k) is biased e
Now let us investigate the mean-squared error between i and 0; i.e.,
In this pathological example, the mean-squared error is diverging to infinity; but, 6(k) converges to 0 in probability. 0
Theorem 7-L Let 6(k) denote an estimator uf 0. If bias 6(k) und vari- ance 6(k) both approach zero as k* x, then the mean-squared error between 6(k) and 8 appruuches zero, and, therefore, 6(k) i.s a cunsistent estimatur of 0.
Proc$ From elementary probability theory, we know that
E@(k) - Oj21 = [bias ~(I+z)]~ + variance I!@?) (7-22)
If, as assumed, bias I@) and variance I both approach zero as k + =, then
(7-23)
which means that 6(k) converges to 0 in mean-square. Thus, by Theorem 7-l @c) also converges to 8 in probability. III
test The importance
for consistency. of Theorem 7-2 is that it provides a constructive way to
ASYMPTOTiC EFFICIENCY
Definition 7-7. i(k) is un asymptoticaily efficient estimator of scalar parameter 0, ifi I. 6(k) has an asymptotic distribution with finite mean and variance, 2. 6(k) ti cunsistent, and 3. the variance uf the asymptotic distribu- tion equals
For the case of a vector of parameters conditions 1. and 2. in this definition are unchanged; however, condition 3% is changed to read “if the covariance matrix of the asymptotic distribution equals J-l (see Theorem 6-4). ”
Lesson 7 Problems 61
7-l.
7-2.
7-3.
7-4.
PROBLEMS
Random variable X - N(x ; p, d), and we are given a random sample (x,, x2, * * *, xH). Consider the following estimator for p,
where a 2 0. (a) For what value(s) of a is r;(N) an asymptotically unbiased estimator of p? (b) Prove that F;(N) is a consistent estimator of ~1 for all a 2 0. (c) Compare the results obtained in (a) with those obtained in Problem 6-3. Suppose zl, z2, , . . : zN are random samples from a Gaussian distribution with unknown mean, p, and variance, 2. Reasonable estimators of p and 2 are the sample mean and sample variance
S* = $ .i (Zi - if)’ 1=1
(a) Is sz an asymptotically unbiased estimator of d? [Hint: Show that E(s*} = (N - 1)&N].
(b) Compare the result in (a) with that from Problem 6-4. (c) One can show that the variance of s2 is
ct4 - u” var(s2) =- -
2(p4 - 2$) + p4 - 3u4 N N2 N3
Explain whether or not s* is a consistent estimator of 02. Random variable X - N(x; p ,g). Consider the following estimator of the population mean obtained from a random sample of N observations of X,
/.i(N)=x +;
where a is a finite constant, and f is the sample mean. (a) What are the asymptotic mean and variance of @(IV)? (b) Is r;(N) a consistent estimator of p? (c) Is I;(N) asymptotically efficient? Let Xbe a Gaussian variable with mean p and variance 2. Consider the problem of estimating p from a random sample of observations xl, x2, . . . , xN. Three estimators are proposed:

62 Large Sample Properties of Estimators Lesson 7
You are to study unbiasedness, efficiency, asymptotic unbiasedness, consistency, and asymptotic efficiency for these estimators. Show the analysis that allows you to complete the following table.
Estimator
Properties 61 fi2 c;3
Small sample Unbiasedness Efficiency
Large sample Un biasedness Consistency Efficiency
Entries to this table are yes or no. 7-S. If plim Xk = X and plim Yk = Y where X and Y are constants, then plim
(Xk + Yk) = X + YandplimcXk = cX, where c is a constant. Prove that plim
XkYk = XY{Hint: XkYk = a [(Xk + Yk)2 - (Xk - yk )2])*
Lesson 8 Properties
of L eust-Squares
Estimators
In this lesson we study some small- and large-sample properties of least- squares estimators. Recall that in least-squares we estimate the n X 1 param- eter vector 8 of the linear model Z(k) = X(k)8 + V(k). We will see that most of the results in this lesson require X(k) to be deterministic, or, X(k) and V(k) to be statistically independent. In some applications one or the other of these requirements is met; however, there are many important applications where neither is met.
SMALL SAMPLE PROPERTIES OF LEAST-SQUARES ESTIMATORS
In this section (parts of which are taken from Mendel, 1973, pp. 75-86) we examine the bias and variance of weighted least-squares and least-squares estimators.
To begin, we recall Example 6-2, in which we showed that, when X(k) is deterministic, the WLSE of 0 is unbiased. We also showed [after the statement of Theorem 6-2 and Equation (6-13)] that our recursive WLSE of 8 has the requisite structure of an unbiased estimator; but, that unbiasedness of the recursive WLSE of 8 also requires h(k + 1) to be deterministic.
When X(k) is random, we have the following important result:
Theorem 8-l. The WLSE of 8,
6,(k) = [X’(k)W(k)%e(k)]-’ X’(k)W(k)%(k) (8-1)

is unbiased independent.
web Note that this is the first place where, in connection with least
lave had to assume any a priori knowledge about noise ?F(k),
is m-u mm and if T(k) and X.(k) are stahticuily
Properties of Least-Squares Estimators Lesson 8
squares,
Proof. From (8-l) and %(Ic) = %?(I?)8 + T(k), we find that
i&~(k) = (X’wYey X~W(m3 + V) = 0 + (x’w3e)-WW for all k
where, for notational simplification? we have omitted the functional de- pendences of X, W, and V on k. Taking the expectation on both sides of (8-2), it follows that
E{&&)J = 0 + E{X’WX)-’ ‘X’]WE{=V] for all k w9
In deriving (8-3) we have used the fact that X(k) and T(k) are statistically independent [recall that if two random variables, a and b, are statistically independent p(a, b) = p(ajp(bj; thus, E{ab] = E{@{b] and E&(a)h (b)] = E-&@)}E{!2(b)}]. The second term in (8-3) is zero, because E{V} = 0, and therefore
This theorem only states suficient condi~iom for unbiasedness of i&&k), which means that, if we do not satisfy these conditions, we cannut conclude anything about whether 6 =(k) is unbiased or biased. In order to obtain necessury ccmdifions for unbiasedness, assume that E{&&k)} = 0 and take the expectation on both sides of (8-2). Doing this, we see that
E{(X’WX)-‘X’W’V~ = 0 WI Letting M = (%?W%)-’ X’W and rni’ denote the ith row of matrix M, (8-5) can be expressed as the following collection of orthogonaii~ cmdihms,
E{m/V] = 0 for i =1,2,...,N WI orthogonality [recall that two random variables u and b are orthogonal if E{ab} = O] is a weaker condition than statistical independence, but is often more difficult to verify ahead of time than independence, especially since rn: is a very nonlinear transformation of the random elements of X’. Example 8-l Recall the imp&e response identification Example 2-1, in which 8 = co1 \h (1), h (2), . . . , h(n)], where h (i) is the value of the sampled impulse response at time li. System input u(k) may be deterministic or random.
If{U(k),k =o, 1, .*., *N - l} is deterministic, then ‘X(!V - 1) isee Equation (Z-5)] is deterministic, so that 0 WU(AJ) is an unbiased estimator of 0. Often, one uses a random input sequence for {u(k), k = U: I, . . . , A’ - I}, such as from a random
Smalt Sample Properties of Least-Squares Estimators 65
number generator. This random sequence is in no way related to the measurement noise process, which means that X(N - 1) and V(N) are statistically independent, and again 6wls(AT) will be an unbiased estimate of the impulse response coefficients. We conclude. therefore, that WLSEs of impulse response coefficients are unbiased. 0
Example 8-2 As a further illustration of an application of Theorem 8-1, let us take a look at the weighted least-squares estimates of the n a-coefficients in the Example 2-2 AR model. We shall now demonstrate that X(N - 1) and V(N - l), which are defined in Equa- tion (2-8), are dependent, which means of course that we cannot apply Theorem 8-l to study the unbiasedness of the WLSEs of the a-coefficients.
We represent the explicit dependences of %e and V on their elements in the following manner:
and sr = sr[u(N - l), u(N - 2), . . . ) u(O)] P-8)
Direct iteration of difference equation (7) in Lesson 2 for k = 1, 2, . . . , N - 1, reveals that y (1) depends on u (0), y (2) depends on u (1) and u (0) and finally, that W - 1) depends on u(N - 2) . . . , u (0); thus,
%e[jl(N-l),y(N -2), . . . . Y (011 = Xb W - 21, u 0’ - 3), - . . , u (01, y ((91 (8-9)
Comparing (8-S) and (B-9), we see that X and 9r depend on similar vaiues of random input U; hence, they are statistically dependent. 0
Example 8-3
We are interested in estimating the parameter a in the following first-order system:
y(k +- 1) = -ay(k) + u(k) (8-10)
where u(k) is a zero-mean white noise sequence. One approach to doing this is to collect y (k + l), y(k), . . . , y (1) as follows,
Ye + 1) Y(k)
I-1 Y@ - 1) . . .
Y(l)
‘Z:(k + 1)
-Y (4 -Y(k - 1) : 1
-y(k - 2) n
$0)
u(k) u(k - 1) + u(k -2)
: 1 . . . u (0)
(8-l 1)
W) and, to obtain dts. In order to study the bias of ci LsI we use (8-2) in which W(k) is set equal to I, and X(k) and T(k) are defined in (8-11). We also set 6,(k) = CiLS(k + 1). The argument of ii u is k 4 1 instead of k, because the argument of 5 in (S-11) is k + 1. Doing this, we find that
Ii WvG> &(k+l)=a-“O, (S-12)
c Y’(i) 1-0

66 Properties of Least-Squares Estimators Lesson 8
thus,
E{&(k + 1)) = a - , (8-13)
Note, from @-lo), that y(j) depends at most on u (j - 1); therefore,
E[c} = E{u(k))E[f$] =0 (8-14)
because E(u(k)} = 0. Unfortunately, all of the remaining terms in (8-13), i.e., for i=O,l, . . . . k - 1, will not be equal to zero; consequently,
E&s(k + 1)) = a + 0 + k nonzero terms (8-15)
Unless we are very lucky so that the k nonzero terms sum identically to zero, E{&(k + 1)) $ a, which means, of course, that GLs is biased.
The results in this example generalize to higher-order difference equations, so that we can conclude that least-squares estimates of coeficients in an AR model are biased. Cl
In the method of instrumental variables X(k) is replaced by X*(k) where X*(k) is chosen so that it is statistically independent of V(k). There can be, and in general there will be, many choices of X*(k) that may qualify as instrumental variables. It is often difficult to check that X*(k) is statistically independent of V(k).
Next we proceed to compute the covariance matrix of &&k), where
&&k) = 8 - &q&k) (8-16)
Theorem 8-2. If E(gr(k)} = 0, V(k) and X(k) are statistically independ- ent, and
www)~ = W) (8-17)
then
cov [i&&k)] = EX{(%e’W%e)+ %?W%WX(XWX)-l} (8-18)
Proof. Because E(gr(k)} = 0 and V(k) and X(k) are statistically inde- pendent, E{&&k)} = 0, so that
cov [&r&k)] = E{6,,(k)i&&k)} (8-19)
Using (8-2) in (8016), we see that
ii,(k) = -(X’W%e)-‘X’wsr (8-20) hence
cov [i&&k)] = EX,V{(3’t?W~)-1 %%‘VV’WX(X’WX)-‘) (8-21)
Small Sample Properties of Least-Squares Estimators
where we have made use of the fact that W is a symmetric matrix and the transpose and inverse symbols may be permuted. From probability theory (e.g., Papoulis, 1965), recall that
Ex,v 1 l I = Ex mvpc 1 l I%> (8-22)
Applying (8-22) to (8-21), we obtain (8-18). ci
As it stands, Theorem 8-2 is not too useful because it is virtually impos- sible to compute the expectation in (8-18), due to the highly nonlinear de- pendence of (%e,W~)-l%e,W~~T~(%e’W~)-’ on %e. The following special case of Theorem 8-2 is important in practical applications in which X(k) is deterministic and C&(/C) = d I.
Corollary 8-l. Given the conditions in Theorem 8-2, and that X(k) ti deterministic, and, the components of V(k) are independent and identically distributed with zero-mean and constant variance c& then
. cov [&(k)] = d [X’(k)X(k)]-’ (8-23)
Proof. When X is deterministic, cov [b WLS(k)] is obtained from (8-18) by deleting the expectation on its right-hand side. To obtain cov [b,(k)] when cov [V(k)] = d I, set W = I and a(k) = d I in (8-18). The result is (8-23). q
Usually, when we use a least-squares estimation algorithm we do not know the numerical value of d. If d is known ahead of time, it can be used directly in the estimate of 0. We show how to do this in Lesson 9. Where do we obtain dV in order to compute (8-23)? We can estimate it!
Theorem 8-3. An unbiased estimator of d is
z(k) = !%‘(k)3(k)/(k - n) (8-24)
where
s(k) = Z(k) - X(k)&(k) (8-25)
Proof. We shall proceed by computing E{%‘(k)%(k)} and then approxi- mating it as g’(k)%(k), because the latter quantity can be computed from Z(k) and h&k), as in (8-25).
First, we compute an expression for g(k). Substituting both the linear model for Z(k) and the least-squares formula for i=(k) into (8-25), we find that
(8-26)

Properties of Least-Squares Estim&ors Lesson 8
where Ik is the k X k identity matrix. Let
M = Ik - qx%y X’ Matrix M is idempotent, i.e., M’ = M and Mz = M; therefore,
(s-27)
(8-28)
Recall the following well-known facts about the trace of a matrix:
1. E{tr A} = tr E{A} 2, tr CA = c tr A, where c is a scalar 3. tr (A + B) = tr A + tr B 4. t&l = Iv 5. tr AB = tr BA
Using these facts, we now continue the development of (g-28), as follows:
E{fk%} = tr [ME{VV’l] = tr M% = tr MCT~ = d tr M = 0: tr [Ik - %Y(WX’)-’ %T’] = &k - & tr X(X’X)-’ X’ (8-29) = uz k - CT: tr (X’X)(X’X)-l = dk - &trIn = uz(k -n)
Solving this equation for d, we find that
(8-30)
Although this is an exact result for uz, because we cannot compute E{&$.
it is not one that can be evaluated,
Using the structure of d as a starting point, we estimate & by the simple formula
&; (k) = t!t’(k)~(k)/(k - II) (8-31)
To show that x (k) is an unbiased estimator of c$, we obsewe that
where we have used (8-29) for E{~‘%]. III
LARGE SAMPLE PROPERTIES OF LEAST-SQUARES ESTIMATORS
(8-32)
Many large sample properties of LSE’s are determined by establishing that the LSE is equivalent to another estimator for which it is known that the large sampIe property holds true. In Lesson 11, for example, we will provide condi-
Large Sample Properties of Least-Squares Estimators 69
tions under which the LSE of 8.8:,(k). is the same as the maximum-1ikeIihood estimator of 8, &&k). Because 8,,(k) is consistent, asymptotically efficient, and asymptotically Gaussian, b&k) inherits all these properties.
Theorem 8-4. If
plim [X’(X-)X(k)/k] = CX (8-33)
f-s1 exists, and
plim [W(k)Sr(k)/k] = 0 (8-34)
then
plim Qk) = 6 (8-35)
Note that the probability limit of a matrix equals a matrix each of whose elements is the probability limit of the respective matrix element. Assumption (8-33) postulates the existence of a probability limit for the second-order moments of the variables in X(k), as given by Z&. Assumption (8-34) postu- lates a zero probability limit for the correlation between X(k) and T(k). %e’(k)Sr(k) can be thought of as a “filtered” version of noise vector V(k). For (8-34) to be true “filter X’(k)” must be stable. If, for example, X(k) is deterministic and CT&) < a, then (S-34) will be true.
Proof. Beginning with (8-2), but for i&k) instead of &,&k), we see that
b,,(k) = 8 + (me-‘XT (8-36)
Operating on both sides of this equation with plim, and using properties (7-19, (7-16): and (7-17), we find that
plim i,(k) = 9 + plim [(XX/k)-’ (WV/k)] = 9 + plim (RX/k)-‘plim (WV/k) = 9 + &’ - 0 = 9
which demonstrates that, under the given conditions, &(k) is a consistent estimator of 0. q
In some important applications Eq. (8-34) does not apply, e.g., Example 8-2. Theorem S-4 then does not apply, and, the study of consistency is often quite complicated in these cases.
Theorem 8-5. If (8-33) and (8-34) are me, C,’ exists, and
plim [gr’(k)Sr(k)/k] = IT: (S-37)

Properties of Least-Squares Estimators Lesson 8
plim 3 (k) = d (8-38)
where 8 (k) is given by (8-24).
Proof. From (8-26), we find that
fzi’% = VT - Olc3q~‘~)-‘%e’~ (8-39)
Consequently,
plim 8 (k) = plim %‘t%/(k - n)
= plim VV/(k - n) - plim ~‘X(X’X)-lX’V/(k - n)
= d - plim v’Xl(k - n) . plim [X?tT/(k - n)]-1 . plim %‘V/(k - n)
PROBLEMS
8-1. Suppose that iLs is an unbiased estimator of 0. Is & an unbiased estimator of e’? (Hint: Use the least-squares batch algorithm to study this question.)
8-2. For 6 WLs(Q to be an unbiased estimator of 8 we required ET(k)] = 0. This problem considers the case when ET(k)} f 0. (a) Assume that E(gr(k)} = V o where Sr, is known to us. How is the
concatenated measurement equation Z(k) = %e(k)e + V(k) modified in this case so we can use the results derived in this lesson to obtain bw,,(k) or ii,(k)?
(b) Assume that E(Sr(k)} = m%Tl where m6tp is constant but is unknown. How is the concatenated measurement equation S!(k) = X(k)8 + V(k) modified in this case so that we can obtain least-squares estimates of both 8 and my?
8-3. Consider the stable autoregressive model y(k) = &y(k - 1) + . . l + &y (k - Q + c(k) in which the e(k) are identically distributed random variables with mean zero and finite variance a’. Prove that the least-squares estimates of 8 l,***, & are consistent (see also, Ljung, 1976).
8-4. In this lesson we have assumed that the X(k) variables have been measured without error. Here we examine the situation when 3&(k) = X(k) + N(k) in which X(k) denotes a matrix of true values and N(k) a matrix of measurement errors. The basic linear model is now
Z(k) = X(k)0 + V(k) = X,(k)8 + v(k) - N(k)e].
Prove that iLS(k) is not a consistent estimator of 8.
Lesson 9
Best Linear Unbiased
Estimation
INTRODUCTION
Least-squares estimation, as described in Lessons 3, 4 and 5, is for the linear model
3!(k) = X(k)0 + ‘V(k) (9-l)
where 9 is a deterministic, but unknown vector of parameters, X(k) can be deterministic or random, and we do not know anything about V(k) ahead of time. By minimizing &(k)W(k)?%I(k), where Z%(k) = Z(k) - X(k)&&k), we determined that 6-(k) is a linear transformation of Z(k), i.e., &&k) = F,&k)%(k). After establishing the structure of &&k), we studied its small- and large-sample properties. Unfortunately, 6-(k) is not always unbiased or efficient. These properties were not built into 6-(k) during its design.
In this lesson we develop our second estimator. It will be both unbiased and efficient, by design. In addition, we want the estimator to be a linear function of the measurements %(k). This estimator is called a best linear unbiased estimator (BLUE) or an unbiased minimum-variance estimator (UMVE). To keep notation relatively simple, we will use i&,,(k) to denote the BLUE of 8.
As in least-squares, we begin with the linear model in (9-l) where 8 is deterministic. Now, however, X(k) must be deterministic and V(k) is assumed to be zero mean with positive definite known covariance matrix S(k). An example of such a covariance matrix occurs for white noise. In the case of scalar measurements, z(k), this means that scalar noise v(k) is white, i.e.,
P-2)

Best Linear Unbiased Estimation Lesson 9
where &, is the Kronecker 6 (i.e., &, = 0 for k # j and 6kJ = I for k = j) thus,
3(k) = E{3’-(A-)=V-‘(k)} = diag [d(k)- d(k - l), . . . , &(I? - IV + 1)] P-9
In the case of vector measurements, z(k), this means that vector noise, v(k), is white, i.e.,
E{v( k)v’( j)l = R(k)Skj P-4) thus,
3(k) = diag [R(k), R(k - l), . . . ! R(k - N + 1)]
PROBLEM STATEMENT AND OWECTfVE FUNCTION
We begin by assuming the following linear structure for &&k),
k,(k) = F(QW) WI
where, for notational simplicity, we have omitted subscripting F(k) as FBLU(k). We shall design F(k) such that
a, &&k) is an unbiased estimator of 0, and b. the error variance for each one of the n parameters is minimized- In this
way, &&k) wiZ1 be unbiased afzd eficierzt, by design.
Recall, from Theorem 6-1, that mbiasedness cmzs~raim design mutrix F(k), such Ihut
F(k)X(k) = I for aI k P-7
Our objective now is to choose the elements of F(k), subject to the constraint of (g-7), in such a way that the error variance for each one of the ti parameters is minunized.
In solving for FBLU(k), it will be convenient to partition matrix F(k), as
F(k) =
Equation (9-7) can now be expressed in terms of the vector components of F(k). For our purposes, it iseasier to work with the transpose of (9-7), X’F = 1, which can be expressed as
Derivation of Estimator 73
where ei is the ith unit vector,
e; = co1 (0, 0, * . . ,o, l,O, . . . 70) (9-10)
in which the nonzero element occurs in the ith position. Equating respective elements on both sides of (9-9), we find that
X’(k)f,(k) = ei i = 1,2, . . ..n (9-11)
Our single unbiasedness constraint on matrix F(k) is now a set of n constraints on the rows of F(k).
Next, we express E([& - 6i.BLU(k)]2> in terms of f, (i = 1,2, . . . , IV). We shall make use of (9-ll), (9-l), and the following equivalent representation of (9-6)
&HlJ(~) = f:(k)%(k) i = 1,2,. . , ,n (9-12)
Proceeding, we find that
E{[& - ti r,BLU(k)]2} = E(( ei - fi’%)*} = E{( Oi - SYf,)‘}
= E{aj! - 2&%‘fi + (E’fJ*}
= E{@ - 28,(%33 + T)‘f, + [(%I + T)‘fi]l) = E{$ - 2Oi9’X’fi - ZOiT’fi + [6’X’f; + V’ff]‘)
(9-13)
= E(B;’ - 20i8’ei - 2OiV’fi + [B’ej + V’fj]‘) = E{fi“‘l’Tfi) = fi’9tf;
Observe that the error-variance for the ith parameter depends only on the ith row of design matrix F(k). We, therefore, establish the following objective function:.
Ji(f;, hi) = E{[B; - ii.BLU(k)]Z) + A;‘(X’f, - eJ = fi’$Rf; + A,‘(X’fi - e,) (9-14)
where Ai is the ith vector of the Lagrange multipliers, that is associated with the ith unbiasedness constraint. Our objective now is to minimize Ji with respect to fi and hi (i = 1,2, . . . , iV).
DERIVATION OF ESTIMATOR
A necessary condition for minimizing Ji(fi ,Ai) is 81, (f;,Ai)/ df; = 0 (i = 1,2, ,..) n); hence,
29ifi + XAi = 0 (9-E)
from which we determine fj, as
fl = -;s-‘X& (9-16)

74 Best Linear Unbiased Estimation Lesson 9
For (9-16) to be valid, ?R-’ must exist. Any noise V(k) whose covariance matrix % is positive definite qualifies. Of course, if V(k) is white, then $R is diagonal (or block diagonal) and 3-l exists. This may also be true if ‘V(k) is not white. A second necessary condition for minimizing Ji (fi,hi) is dJi (fiyX;)/aXj = 0 (i = 172, l l . 7 n), which gives us the unbiasedness constraints
X’fi=ei i=1,2,...,n (9-17)
To determine Ai, substitute (9-16) into (9-17). Doing this, we find that
Xi = -2(X’%‘Ye)-’ ei (9-18)
whereupon
fi = 9i-’ X(X’%.-’ X)-l ei (9-19)
(i = 1,2, . . . , n). Matrix F(k) is reconstructed from f,(k), as follows:
Hence
FBLU(k) = [X’(k)%-‘(k)%?(k)]-‘X’(k)%-‘(k) (9-21)
which means that
i&&k) = [sle’(k)W’(k)X(k)l-‘%e’(k)W(k)%(k) (9-22)
COMPARISON OF t&(k) AND i,,,Ls(/o
We are struck by the close similarity between i,,,(k) and &&k).
Theorem 94. The BLUE of 0 is the special case of the WLSE of 0 when
W(k) = a-‘(k) (9-23)
If W(k) is diagonal, then (9-23) requires V(k) to be white.
Proof. Compare the formulas for 6 &k) in (9-22) and 6-(k) in (10) of Lesson 3. If W(k) is a diagonal matrix, then 9t(k) is a diagonal matrix only if V(k) is white. Cl
Matrix %-l(k) weights the contributions of precise measurements heav- ily and deemphasizes the contributions of imprecise measurements. The best linear unbiased estimation design technique has led to a weighting matrix that is quite sensible. See Problem 9-2.
Some Properties of &(k) 75
Corollary 9-l. AZ1 results obtained in Lessons 3,4, and 5 for 6,,(k) can be applied to 6 BLu(k) by setting W(k) = K’(k). Cl
We leave it to the reader to explore the full implications of this important corollary, by reexamining the wide range of topics, which were discussed in Lessons 3,4 and 5.
Theorem 9-2 (Gauss-Markov Theorem). If S(k) = d I, then 6&k) = L(k)*
Proof. Using (9-22) and the fact that a(k) = a: I, we find that
Why is this a very important result? We have connected two seemingly different estimators, one of which-&&)-has the properties of unbiased and minimum variance by design; hence, in this case &(k) inherits these properties. Remember though that the derivation of &&) required X(k) to be deterministic; thus, Theorem 9-2 is “conditioned” on X(k) being deterministic.
SOME PROPERTIES OF i&(k)
To begin, we direct our attention at the covariance matrix of parameter esti- mation error 6&k).
Theorem 9-3. If V(k) is zero mean, then
cov [6,,(k)] = [X’(k)%-‘(k)X(k)]-’ (9-24)
Proof. We apply Corollary 9-1 to cov [6,(k)] [given in (18) of Lesson S] for the case when X(k) is deterministic, to see that
‘Ov hdk)l = ‘Ov [s,(k)l/ w(k) = a-‘(k)
= (%e’~-‘%e)-‘%e’~-l~~-‘~(~‘~-‘~)-’
= (x’91-1%e)-1 0
Observe the great simplification of the expression for cov [6%&k)], when W(k) = S-‘(k). Note, also, that the error variance of ij,BLu(k) is given by the ith diagonal element of cov [bBLU(k)].
Corollary 9-2. When W(k) = S-‘(k) then matrix P(k), which appears in the recursive WLSE of 9 equals cov [6BLu(k)], i.e.,
P(k) = cov [6,,,(k)] (9-25)

Best Lrtear Unbiased Estimation Lesson 9
Proof. Recall Equation (13) of Lesson 4, that
P(k) = [%?(k)W(k)X(k)J-’ (9-26)
When W(k) = %‘(A$, then
P(k) = [X’(k)CR-l(k)X(k)]-l (9-27 j
hence, P(k) = cov [6&k)] because of (9-24) . 0
Soon we will examine a recursive BLUE. Matrix P(k) WU have to be calculated, just as it has to be calculated for the recursive WLSE. Every time P(k) is calculated in our recursive BLUE, we obtain a quantitative measure of how well we are estimating 9+ Just look at the diagonal elements of P(k), k = 1,2,. . . . The same statement cannot be made for the meaning of P(k) in the recursive WLSE. In the r?cursive WLSE, P(k) has no special meaning.
Next, we examine cov [9&k)] in more detail.
Theorem 9-4* iBLu(k) k a most efficient estimutm of 0 within the class of at/ unbiased estirnutors that m-e linearly reiated to the mwsurements %(Ic).
proof (Mendel, 1973, pp. 155-156). According to Definition 6-3, we must show that
E = cov [&(k)] - cov [b&k)] (9-28)
is positive semidefinite. In (g-28), 6=(k) is the error associated with an arbi- trary hnear unbiased estimate of 0. For convenience, we write ZZ as
(9-29)
In order to compute X0 we use the facts that
F4(k)X(k) = I (9-31)
thus,
Because 6 BLu(k) = F(k)%(k) and F(k)?@) = 1,
x BLU = FCRF’ (9-33)
Some Properties of k&k! 77
Substituting (9-32) and (9-33) into (9-29), and making repeated use of the unbiasedness constraints X’F’ = %e’Fd = FOX0 = I, we find that
2 = F&RF; - IGRF’ = F,9tF; - F%F’ + 2(X%-‘ste)-’ - (%%-%)-’
- (Ye’%-1x)-* = F,%F; - F9tF’ + 2(%e’9t-%)-1(%e’9t-1%F’) (9-34)
- (XW’%e)-‘(W!R-‘%F;) - (F$Eft-‘X)(X’%-%)-’
Making use of the structure of F(k). given in (9-21), we see that Z can also be written as
C = F,%F; - F%F’ + 2F%F’ - F%F; - F&RF
= (Fa - F)%(F, - F) ’ (9-35)
In order to investigate the definiteness of 2, a’Ga, where a is an arbitrary nonzero vector,
consider the definiteness of
a’za = [(Fn - F)‘a)‘9t[(Fp - F)‘a] (9-36)
Matrix F (i.e., FBLU) is unique; therefore (F, - F)‘a is a nonzero vector, unless F, - F and a are orthogonal, which is a possibility that cannot be excluded. Because matrix CR is positive definite, a’xa 2 0, which means that I: is positive semidefinite, IJ
These results serve as further confirmation that designing F(k) as we have done, by minimizing only the diagonal elements of cov[8&k)], is sound.
Corollary 9-3. If C!&(k) = IZt I, then 6&k) is a most efficient estimator of 8.
The proof of this result is a direct consequence of Theorems 9-2 and 9-4. 0
At the end of Lesson 3 we noted that iwLs(Ic) may not be invariant under changes. We demonstrate next that 4 &k) is invariant to such changes.
Theorem 9-5. 6BLU(k) is invariant under changes of scale.
Prc@(Mendel, 1973, pp. 15157). Assume that observers A and B are observing a process; but, observer A reads the measurements in one set of units and B in another. Let M be a symmetric matrix of scale factors relating A to B (e.g., 5,280 ft/mile, 454 g/lb, etc.), and C&.(k) and Z&(k) denote the total measurement vectors of A and B, respectively. Then
S&(k) = X,(k)B + ‘VB(k) = Mf& (k) = M%e, (k)8 + MT/,(k) (9-37)

Best Linear Unbiased Estimation Lesson 9
which means that
X,(k) = MXA(k)
VB(k> = Msr, (k)
(9-38)
(9-39)
and
SB(k) = M%,(k)M’ = MaA( (9-40)
Let i,,,,(k) and 6 B BLU(k) denote the BLUE’s associated with observers A and B, respectively; then,
RECURSIVE BLUES
Because of Corollary 9-1, we obtain recursive formulas for the BLUE of 8 by setting l/w@ + 1) = r(k + 1) in the recursive formulas for the WLSEs of 8 which are given in Lesson 4. In the case of a vector of measurements, we set (see Table 5-1) w-‘(k + 1) = R(k + 1).
Theorem 9-6 (Information Form of Recursive BLUE). A recursive structure for i&,,(k) is:
&,(k + 1) = 6&k) + KB(k + l)[t(k + 1) - h’(k + 1)6,,,(k)] (9-42)
KB(k + 1) = P(k + l)h(k + l)r-‘(k + 1) (9-43)
P-‘(k + 1) = P-‘(k) + h(k + l)r-‘(k + l)h’(k + 1) (9-44)
These equations are initialized by &u(n) and P-‘(n) [where P(k) is cov [6&k)], given in (9.31)] and, are used for k = n, n + 1, . . . , N - 1. These equations calt also be used for k = 0, 1, . . . , N - 1 as long as i&&O) and P-‘(O) are chosen using Equations (21) and (20) in Lesson 4, respectively, in which w(0) is replaced by r-‘(O). Cl
Theorem 9-7 (Covariance Form of Recursive BLUE). Another recur- sive structure for 6 &k) is (9-42) in which
KB(k + 1) = P(k)h(k + 1) [h’(k + l)P(k)h(k + 1) + r(k + l)]-’ (9-45)
Lesson 9 Problems
and
P(k + 1) = [I - &(k + l)h’(k + l)]P(k) (9-46)
These equations are initialized by and P(n), and are used for k = n, n+l, . . . . N - 1. They can also be used for k = O,l, . . . , N - 1 as long as &3LU(O) and P(O) are chosen using Equations (4-21) and (4-20), respectivezy, in which w(0) is replaced by r-‘(O). Cl
Recall that, in best-linear unbiased estimation, P(k) = COV[&&C)]. Observe, in Theorem 9-7, that we compute P(k) recursively, and not P-l(k). This is why the results in Theorem 9-7 (and, subsequently, Theorem 4-2) are referred to as the covariance form of recursive BLUE.
PROBLEMS
9-l. (Mendel, 1973, Exercise 3-2, pg. 175). Assume X(k) is random, and that km,(k) = F(k)~(k). (a) Show that unbiasedness of the estimate is attained when E{F(k)%e(k)} = I. (b) At what point in the derivation of 6 BLU(k) do the computations break down
because X(k) is random? 9-2. Here we examine the si tuation when ‘V(k) is colored
model to compute wj* Now our linear model is noise and how to use a
z(k + 1) = X(k + lje + v(k + 1)
where v(k) is colored noise modeled as
v(k + 1) = A,v(k) + k(k)
We assume that deterministic matrix A, is known and that E(k) is zero-mean white noise with covariance a,(k). Working with the measurement difference z*(k + 1) = z(k + 1) - A,z(k) write down the formula for i&&k) in batch form. Be sure to define all concatenated quantities.
9-3. (Sorenson, 1980, Exercise 3-15, pg. 130). Suppose and & are unbiased estimators of Blwith var (&j = d and var (&j = u$ Let t!& = (Y& + (1 - a!)&. (a) Prove that 6, is unbiased. (b) Assume that & and & are statistically independent, and find the
mean-squared error of &. (c) What choice of cy minimizes the mean-squared error?
9-4. (Mendel, 1973, Exercise 3-12, pp. 176-177). A series of measurements z(k) are made, where z(k) = H8 + v(k), H is an m x n constant matrix, E{v(k)} = 0, and cov[v(k)] = 3 is a constant matrix. (a) Using the two formulations of the recursive BLUE show that (Ho, 1963, pp.
152-154): (i) P(k + 1jH’ = P(k)H’[HP(k)H’ + RI-‘R, and
(ii) HP(k) = R[HP(k - 1)H’ + RI-‘HP(k - 1).

80 Best Linear Unbiased Estimation Lesson 9
(b) Next, show that (i) P(k)H’ = P[k - 2)Hf[2HP(k - 2)H’ + RI-‘R; (ii) P(k)H’ = P(k - 3)H’[3HP(k - 3)H’ + R]-‘R; and (iii) P(k)H’ = P(O)H’[kHP(O)H’ + R]-‘R.
(c) Finally, show that the asymptotic form (k + m] for the BLUE of 9 is (Ho, 1963, pp. 152-154)
This equation, with its l/(k + 1) weighting multidimensional stochastic approximation.
function, represents a form of
Lesson 10
Likelihood
INTRODUCTION
This lesson provides background material for the method of maximum- likelihood. It explains the relationship of likelihood to probability, and when the terms Zikelihood and likelihood ratio can be used interchangeably. The major reference for this lesson is Edwards (1972), a most delightful book.
LIKELIHOOD DEFINED
To begin, we define what is meant by an hypothesis, H, and results (of an experiment), R. Suppose scaIar parameter 8 can assume only two values, 0 or 1; then, we say that there are two hypotheses associated with 8, namely If0 and H,, where, for I&, 8 = 0, and for HI, 8 = 1. This is the situation of a binary hypothesis. Suppose next that scalar parameter 0 can assume ten values, a, b, c, d, e, f, g, h, i, i; then, we say there are ten hypotheses associated with 8, namely IfI, HZ, H3, . . . , HIo, where, for If,, 0 = a, for Hz, 8 = b, . . . , and for Hlo, 8 = i. Parameter 8 may also assume values from an interval, i.e., a I 8 I b. In this case, we have an infinite, uncountable number of hypo- theses about 0, each one associated with a real number in the interval [a, b]. Finally, we may have a vector of parameters each one of whose elements has a coliection of hypotheses associated with it. For example, suppose that each one of the II elements of 9 is either 0 or 1. Vector 6 is then characterized by 2” hypotheses.
81

82 Likelihood Lesson 10
Results, R, are the outputs of an experiment. In our work on parameter estimation for the linear model Z(k) = X(k)6 + V(X-), the “results” are the data in S(k) and X(k).
We let P(RIH) d enote the probability of obtaining results R given hy- pothesis H according to some probability model, e.g., p[z(k)lO]. In proba- bility, P(R IH) is always viewed as a function of R for fixed values of H. Usually the explicit dependence of P on H is not shown. In order to under- stand the differences between probability and likelihood, it is important to show the explicit dependence of P on H.
Example 10-l Random number generators are often used to generate a sequence of random numbers that can then be used as the input sequence to a dynamical system, or as an additive measurement noise sequence. To run a random number generator, you must choose a probability model. The Gaussian model is often used; however, it is characterized by two parameters, mean p and variance u*. In order to obtain a stream of Gaussian random.numbers from the random number generator, you must fix p and u*. Let m and a$- denote (true) values chosen for p and c*. The Gaussian probability density function for the generator is ~[r (k)lp T, c&l, and the numbers we obtain at its output, z(l), z(2), - l ’ ?
are of course quite dependent on the hypothesis HT = (m, a$). 0
For fixed H we can apply the axioms of probability (e.g., see Papoulis, 1965). If, for example, results RI and R2 are mutually exclusive, then P(R1 or R,IH) = P(RlIH) + P(R,IH).
Definition 10-l (Edwards, 1972, pg. 9). Likelihood, L(HIR), of the hypothesis H given the results R and a specific probability model is proportional to P(RIH), the constant of proportionality being arbitrary, i.e.,
L(HIR) = cP(RIH) q (10-l)
For likelihood R is fixed (i.e., given ahead of time) and H is variable. There are no axioms of likelihood. Likelihood cannot be compared using different data sets (i.e., different results, say, RI and R2) unless the data sets are statistically independent.
Example 10-2
Suppose we are given a sequence of Gaussian random numbers, using the random number generator that was described in Example 10-1, but, we do not know PT and a:. Is it possible to infer (i.e., estimate) what the values of p and u* were that most likely generated the given sequence? The method of maximum-likelihood, which we study in Lesson 11, will show us how to do this. The starting point for the estimation of p and C* will bep [z (Ic&, u*], where now z (k) is fixed and p and u2 are treated as variables. 0
Likelihood Defined
Example 10-3 (Edwards, 1972, pg. 10)
To further illustrate the difference between P(RjH) and L(HIR), following binomial model which we assume describes the occurrence in a family of two children:
P(R[p) = wpm(l -p)’ . .
83
we consider the of boys and girls
(10-2)
wherep denotes the probability of a male child, uz equals the number of male children, f equals the number of female children, and, in this example,
m+f=2 (10-3)
Our objective is to determine p; but, to do this we need some results. Knocking on neighbor’s doors and conducting a simple survey, we establish two data sets:
RI = (1 boy and 1 girl} +rn = 1 and f = 1 (10-4)
R2 = (2 boys) +rn = 2 and f = 0 (10-5)
In order to keep the determination of p simple for this meager collection of data, we shall only consider two values for p, i.e., two hypotheses,
H,:p = l/4 Hz:p = l/2 I
(10-6)
To begin, we create a table of probabilities, in which the entries are P(Ri’lHj fixed), where this is computed using (10-2). For HI (i.e., p = l/4), P(R@/4) = 3/8 and P(R&4) = l/16; for & (i.e., p = l/2), P(R1]1/2) = l/2 and P(R211/2) = l/4. These results are collected together in Table 10-l.
TABLE 10-l P(Ri 1Hj fixed)
Rl R2
H* 318 l/l6 HZ l/2 l/4
Next, we create a table of likelihoods, using (lo-l). In this table (Table 10-2) the entries are L (HilRj fixed). Constants cl and c2 are arbitrary and cl, for example, appears in each one of the table entries in the RI column.
TABLE 10-2 L(H,(R, fixed)
Rl R2
Hl 3/8 cl l/16 C2 H2 l/2 Cl l/4 c2
What can we conclude from the table of likelihoods? First, for data R 1, the likelihood of HI is 3/4 the likelihood of I&. The number 3/4 was obtained by taking the

a4 L\ kelihoocl Lessorl 10
ratio of likehhoods L (Hl!R!) and L (H$?l). S econd, on data R2, the likelihood of IfI is l/4 the likelihood of Hz [note that l/4 = l/l6 c2/ l/4 c2]. Finally, we conclude that, even from our two meager results, the vaIuep = l/Z appears to be more likely than the value p = l/4? which, of course, agrees with our intuition. q
LIKELIHOOD RATIO
In the preceding example we were able to draw conchis~ons about the like- lihood of one hypothesis versus a second hypothesis by comparing ratios of likelihood, defined, of course, on the same set of data. Forming the ratios of Likelihood, we obtain the Zikeiihood ratio.
Definition 10-2 (Edwards, 1972, pg. 10). The Zikelihuud ratiu of two hypotheses un the sum data is the ratio of the likeNmods un the duta. Let L(HI, &\R) denote likelihood ratio; then,
(10-7)
Observe that likelihood ratio statements do not depend on the arbitrary constant c which appears in the definition of Iikehhood, because c cancels out of the ratio c~(R/HJ/cP(R~&).
Theorem 10-l (Edwards, 1972, pg. 11). LikeIihoud ratios of two lzy- potheses on stutisticully independent sets of duta may be multiplied tugether to form the likelihood rutiu uf the combined data.
Proof. Let L (HI, H2iRl & I&) denote the likelihood ratio of HI and I& on the combined data RI & &, i.e.,
Because RI & Rz are fW$W (&iW hence,
statistically independent data, P(Rl & R2iHJ =
Example 10-4 We can now state the conclusions that are given at the end of Example 10-3 more formally. From Table 10-2, we see that L (l/4, l/2iRI) = 3/4 and L (l/4,1/21&) = l/4. Additionally, because RI and R2 are data from independent experiments, L (l/4, 1121
Multiple Hypotheses 85
RI &I R2) = 314 x l/4 = 3/l& This reinforces our intuition that p = 112 is much more likely thanp = l/4. El
RESULTS DESCRIBED BY CONTINUOUS DISTRIBUTIONS
Suppose the results R have a continuous distribution; then, we know from probability theory that the probabilty of obtaining a result that lies in the interval (R, R + dR) is P(R lH)dR, as dR + 0. P(R IH) is then a probability density. In this case, L (HIR) = cP(R lH)dR ; but, cdR can be defined as a new arbitrary constant, cl, so that L (HIR) = clP(R iH)* In likelihood ratio state- ments cl = cdR disappears entirely; thus, likelihood and likelihood ratio are unaffected by the nature of the distribution of R .
Recall, that a transformation of variables greatly affects probability be- cause of the dR which appears in the probability formula. Likelihood and likelihood ratiu, on the other hand, are unaffected by transformations of variables, because of the absorption of dR into cl.
MULTIPLE HYPOTHESES
Thus far, all of our attention has been directed at the case of two hypotheses. In order to apply likelihood and likelihood ratio concepts to parameter esti- mation problems, where parameters take on more than two values, we must extend our preceding results to the case of multiple hypotheses. As stated by Edwards (1972, pg. ll), “Instead of forming all the pairwise likelihood ratios it is simpler to present the same information in terms of the likelihood ratios for the several hypotheses versus one of their number, which may be chosen quite arbitrarily for this purpose.”
Our extensions rely very heavily on the results for the two hypotheses case, because of the convenient introduction of an arbitrary comparison hy- pothesis, H * . Let Hi denote the ith hypothesis; then,
L(H,,HC/R) = L(Hi ]R) L w *lw
Observe, also, that
LwH*IR) uH,IR) L(H, HjR) =I---= L(H,,H*lR) L(HjIR) ” ’
(10-10)
(1041)
which means that we can compute the likelihood-ratio between any two hypotheses H, and Hi if we can compute the likelihood-ratio function L(Hk,H*IR).

Likelihood Lesson 10
I
L(H,/R) W,, H*)R)
I c I H” k H, H” H,
(a> W
Figure 10-l Multiple hypotheses case: (a) likelihood L (Hk (R ) versus Hk , and (b) likelihood ratio L (I& ,H *II?) versus I&. Comparison hypothesis H * has been cho- sen to be the hypothesis associated with the maximum value of L (& (R), L *.
Figure 10-l(a) depicts a likelihood function L (H$?). Any value of Hk can be chosen as the comparison hypothesis. We choose H* as the hypothesis associated with the maximum value of L (Hk IR), so that the maximum value of L(Hk ,H*IR) will be normalized to unity. The likelihood ratio function L (Hk ,H *(R), depicted in Figure lo-l(b), was obtained from Figure lo-l(a) and (10-10). In order to compute L(Hi,HjiR), we determine from Figure lo-l(b), that L(Hi ,H*IR) = a and L(H,,H*IR) = b, so that L(H&IR) = a/b.
Is it really necessary to know H” in order to carry out the normalization of L (Hk ,H*(R) depicted in Figure lo-l(b)? No, because H * can be eliminated by a clever “conceptual” choice of constant c. We can choose c, such that
L(H*IR) = L” f 1
According to (lo-l), this means that
c = l/P(RIH*)
If c is “chosen” in this manner, then
(10-12)
(10-13)
L cHk lR) L(Hk,H*lR) = L(H*IR) = LcHkIR) (10-14)
which means that, in the case of multiple hypotheses, likelihood and likelihood ratio can be used interchangeably. This helps to explain why authors use different names for the function that is the starting point in the method of maximum likelihood, including likelihood function and ZikeZihood-ratio function, .I
Lesson 10 Problems
PROBLEMS
10-l. A test is said to be a likelihood-ratio test if there is a number c such that this test leads to (dj refers to the ith decision)
dl if L(Hl,H,IR) > c & if L(H1,H21R) < c
dl or d2 if L (HI,H2[R) = c
Consider a sequence of IZ tosses of a coin of which m are heads, i.e., P(R[p) = ~“(1 - p)” --. Let HI = pl and H2 = p2 where p1 > p2 and p represents the probability of a head. Show that L(H1,H21R) increases as m increases. Then show that L(HI,H21R) increases whenfi = m In increases, and that the likelihood-ratio test which consists of accepting HI if L (HI ,H2/R) is larger than some constant is equivalent to accepting HI if @ is larger than some related constant.
10-2. Consider it independent observations x1, x2, . . . , X, which are normally distributed with mean p and known standard deviation (T. Our two hypotheses are: HI: p = p1 and H2 : p = p2. Using the sample mean as an estimator of EL, show that the likelihood-ratio test (defined in Problem 10-l) consists of accepting HI if the sample mean exceeds some constant.
10-3. Suppose that the data consists of a single observation z with Cauchy density given by
PW) = 1
rr[l + (2 - e)2]
Test (see Problem 10-I) HI : 8 = 61= 1versusH2:6 = e2= -1whenc = l/2, i.e., show that for c = l/2, we accept Hi when z > -0.35 or when z < -5.65.

lesson 11
Maximum4ikelihood
Estimation
LIKELIHOOD*
Let us consider a vector of unknown parameters 8 that describes a collection of N independent identically distributed observations z (& k = 1,2, . . . , ZV. We collect these measurements into an IV x 1 vector %(A’), (2 for short),
SE = col(z(l),z(2), . . . ,z(N)) (11-l)
The likelihood of 0, given the observations 3, is defined to be proportional to the value of the probability density function of the observations given the parameters
l Fw9 a P cm9 (H-2)
where Z is the likehhood function and J? is the conditional joint probability density function. Because z(i) are independent and identically distributed,
In many applications p (!i@3) is exponential (e.g.: Gaussian). It is easier then to work with the natural logarithm of @~CF,) than with &@iZ). Let
L(@E) = ln 1(01%) (11-4)
Quantity L is sometimes referred to as the log-likelihood function, the support function (Kmenta, 1971), the likelihood function [Mehra (1971), Schweppe
* The material in this section is taken from Mendel (1983b, pp* 94-95).
Maximum-Likelihood Method and Estimates
(1965). and Stepner and Mehra (1973), for example], or the conditional like- lihood function (Nahi, 1969). We shall use these terms interchangeably.
MAXIMUM-LIKELIHOOD METHOD AND ESTIMATES*
The maximum-iikeiihood method is based on the relatively simple idea that different populations generate different samples and that any given sample is more likely to have come from some populations than from others. The maximum-likelihood estimate (MLE) i,, is the value of 6 that maximizes 2 or L for a particular set of measurements 5. The logarithm of I is a monotonic transformation of 1 (i.e., whenever I is decreasing or increasing, in I is also decreasing or increasing); therefore, the point corresponding to the maximum of 1 is also the point corresponding to the maximum of In 1 = L.
Obtaining an MLE involves specifying the likelihood function and find- ing those values of the parameters that give this function its maximum value. It is required that, if L is differentiable, the partial derivative of L (or I) with respect to each of the unknown parameters O,, &, . . . , 0, equal zero:
aww) ae; 8 = 4ML = 0 foralli = 1,2,. . . ,n (11-5)
To be sure that the soIution of (11-5) gives, in fact, a maximum value of L(9\%), certain second-order con$itions must be fulfilled. Consider a Taylor series expansion of L(O/%) about OML, i.e.,
(ei - ii,ML)(“J - bj,ML) + l l * (11-6)
where aL(&alZ)/ &Ii, for example, is short for [aL(t$?E)/ aei]le = &. Be- cause iML is the MLE of 8, the second term on the right-hand side of (11-6) is zero [by virtue of (11-S)]; hence,
Wl~) = L(~M4f-Q
Recognizing that the second term in (11-7) is a quadratic form, we can write it in a more compact notation as l/2(9 - ~~~~)lJO(~hlL~~)(~ - && where J,(&,,&), the observed Fisher irzformation matrix [see Equation (646)], is
J~(L&)=(~)!,=g i,j=LL..,n (H-8) ’ I ML
* The material in this section is taken from Mended (1983b, pp+ 95-98).

Maximum-Likelihood Estimation Lesson 11
Now let us examine sufficient conditions for the likelihood function to be maximum. We assume that, close to 0, L(el%) is approximately quadratic, in which case
(11-10)
From vector calculus, it is well known that a sufficient condition for ij; function of yt variables to be maximum is that the matrix of second partial derivatives of that function, evaluated at the extremum, must be negative definite. For L(el%) in (ll-lo), this means that a sufficient condition for L(elS) to be max- imized is
Jo (i,,le> < 0 (1141)
Example 11-l
This is a continuation of Example 10-2. We observe a random sample {z(l), z (2), . . . , t(N)} at the output of a Gaussian random number generator and wish to find the maximum-likelihood estimators of p and 02.
The Gaussian density function p (z 1~ ,02) is
p (2 1~ ,a’) = (2m2)-‘” exp { -; Kf - PYd] (11-12)
Its natural logarithm is
1 In p (2 1~ ,u2) = -z In (2rc2) - $(z - p)ld2 (11-13)
The likelihood function is
b ,u2) = p (2 (l)lr.~ ,u2)p (2 (91~ ,u2) l l l p(z(N)Ip ,02) (11-14)
and its logarithm is
UPP~) = Si lnp(4p,~2) i=l
(11-15)
Substituting for In p (z (i)lp ,02) gives
L&a’) = 5 i = 1
N = -2ln (271-(r2) -32 tm - PI2 I==1
(11-16)
Properties of Maximum-Likelihood Estimates
There are two unknown parameters in L, p and (T’. Differentiating L with respect to each of them gives
dL - A- 2 [z(i) - ~1 -&I- cr2jz,
dL Nl -=----T+--T 21 $ Lm - PI2 a@*) 2t7 q I-1
(1147a)
(11-17b)
Equating these partial derivatives to zero, we obtain
oMLi=l (11-18a)
(1148b)
For &$rL different from zero (1 l-18a) reduces to
CL 0 zi -: bML] = 0 j z 1
giving
bML=Njcl ’ i r(i)=2 (11-19)
Thus the MLE of the mean of a Gaussian population is equal to the sample mean 2. Once again we see that the sample mean is an optimal estimator.
Observe that (11-18a) and (ll-18b) can be solved for G’,,, the MLE of u*. Multiplying Eq. (11-18b) by 26hL leads to
--Iv& + li[ 0 zi - ,&fd* = 0 i = 1
Substituting z for bML and solving for &‘,, gives
SIL = $5 [z(i) - 21’ i = 1
(H-20)
Thus, the MLE of the variance of a Gaussian population is simply equal to the sample variance. 0
PROPERTIES OF MAXIMUM-LIKELIHOOD ESTIMATES
The importance of maximum-likelihood estimation is that it produces esti- mates that have very desirable properties.
Theorem 1 l-1. Maximum-likelihood estimates are: (1) consistent, (2) 1
asymptotically Gaussian with mean 6 and covariarzce matrix - J-‘, in which J N

92 Maximum-Likelihood Estimation Lesson 11
is the Fisher lnfur-matiun Matrix [Equation (64)]. and, (3) asymptotically efficient.
Pr~uf. For proofs of consistency, asymptotic normality and asymptotic efficiency, see Sorenson (1980, pp. 187-190; 190-192; and 192-193, re- specGvely). Tnese proofs, though somewhat heuristic, convey the ideas needed to prove the three parts of this theorem. More detailed analyses can be found in Cramer (1946) and Zacks (1971). See a!so, Problems U-13, H-14> and 11-15. q
Theorem 11-2 (Invariance- Froperty of MLE’s). Lel g(8) be a vect~~r functiun mapping 0 into an itlterval in r-dimensi~~~al Euclidean space. Let 6ML be a ML E of 0; then g(&) is a A4L E of g(8); i.e.,
(H-21)
B-oaf (See Zacks, 1971). Note that Zacks points out that in many books, this theorem is cited only for the case of one-to-one mappings, g(0). His proof does not require g(9) to be one-to-one. Note, also, that the proof of this theorem is related to the “consistency carry-over” property of a consistent estimator, which was discussed in Lesson 7. El
Example 1 l-2
We wish to obtain a MLE of the variance CT? in our linear model z(k) = h’(k)9 + v(k). One approach is to let $ = D:, establish the log-likelihood function for & and max-
. . imue 11, to determine &,ML. Usual!y, mathematical programming (i.e., search tech- niques) rnust be used to determine @1.ML. Here is where a difficulty can occur, because & (a variance) is known to be positive; thus, 6 IVML must be consfrained to be positive. Unfortunately, constrained mathematical programming techniques are more difficult than unconstrained ones.
A second approach is to let & = CT,,. establish the log-likelihood function for O2 (it will be the same as the one for & , except that 19~ will be replaced by &), and maximize it to determine I&,~~. Because & is a standard deviation, which can be positive or negative, unconstrained mathematica1 programming can be used to determine 62,ML, Finally, we use the Invariance l’roperty of MLE’s to compute &,ML, as
a kML = (LdL)2 El (M-22)
THE LINEAR MODEL (X(k) deterministic)
We return now to the linear model
3(k) = X(k)0 + V(k) (H-23)
in which 9 is an tz x 1 vector of deterministic parameters, X(k) is deferministic, and V(k) is zero mean white noise, with covariance matrix a(k). This is precisely the same model that was used to derive the BLUE of 0, &#). Our
The Linear Model Wk) deterministic1 93
objectives in thisparagraph are twofold: (1) to derive the MLE of 9, iML(k), and (2) to relate &,&I?) to &u(k) and &(k).
In order to derive the MLE of 9, we need to determine a formula for p(S(k)j0). To proceed, we assume that V(k) is Gaussian, with multivariate density function p (T(k)), where
Pwo~ = g l (27i-ypIi(k)i exp
[ -+ V(k)W(k)V(k)] (11-24)
Recall (e.g., Papoulis, 1965) that linear transformations on, and linear combi- nations of, Gaussian random vectors are themselves Gaussian random vec- tors. For this reason, it is clear that when V(k) is Gaussian, s(k) is as well. The multivariate Gaussian density function of s(k), derived from p (V(k)), is
Pcw$J~ = l v(2?;)Npi(k)[ exp
-$ EW)
- X(k)9]‘%-‘(k)[%(k) - X(k)e]j (11-25)
Theorem 11-3. When p(ZlO) is multivariate Gaussian and X&j is deterministic, then the principle of ML leads to the BLUE of 0, i.e.,
kdk) = ~m# (11-26)
Proof We must maximize p (3!]6) with respect to 0. This can be ac- complished by minimizing the argument of the exponential in (11-25); hence, b,,(k) is the solution of
= 0 ML
(11-27)
This equatio-n can also be expressed ,as dJ[&,]ldb = 0 where J[&L] = Y(k)%-‘(k)%(k) and Y,(k) = Z(k) - XeML(k). Comparing this version of (11-27) with Equation (3-4) and the subsequent derivation of the WLSE of 9, we conclude that
but, we also know, from Lesson 9, that
(U-28)
(13-29)
From (11-28) and (ll-29), we conclude that
(U-30)
We now suggest a reason why Theorem 9-6 (and, subsequently, The- orem 4-l) is referred to as the “information form” of recursive BLUE. From

Maximum-Likelihood Estimation Lesson 11
Theorems 11-1 and 11-3 we know that, when X(k) is deterministic, A eBLU - A@; 8, l/N J-l). This means that P(k) = cov [&u(k)] is proportional to J-l. Observe, in Theorem 9-6, that we compute P-’ recursively, and not P. Because P-’ is proportional to the Fisher information matrix J, the results in Theorem 9-6 (and 4-l) are therefore referred to as the “information form” of recursive BLUE.
A second more pragmatic reason is due to the fact that the inverse of any covariance matrix is known as an information matrix (e.g., Anderson and Moore, 1979, pg. 138). Consequently, any algorithm that is in terms of infor- mation matrices is known as an “information form” algorithm.
Corollary 11-l. If p[%(k)le] is multivariate Gaussian, X(k) is deter- ministic, and a(k) = a: I, then
&L(k) = hJ(~) = L(k) (11-31)
These estimators are: unbiased, most estimators), consistent, and Gaussian.
efficient (within the class of linear
Proof. To obtain (H-31), combine the results in Theorems 11-3 and 9-2. The estimators are:
1. 2. 3. 4.
unbiased, because i,,(k) is unbiased; most efficient, because &,(k) is most efficient; consistent, because &IC) is consistent; and Gaussian, because they depend linearly upon Z(k) which is Gaus- sian. 0
Observe that, when Z(k) is Gaussian, this corollary permits us to make statements about small-sample properties of MLE’s. Usually, we cannot make such statements.
A LOG-LIKELIHOOD FUNCTION FOR AN IMPORTANT DYNAMICAL SYSTEM -
In practice there are two major problems in obtaining MLE’s of parameters in models of dynamical systems
1. obtaining an expression for L(elZ}, and 2. maximizing L{6l%} with respect to 8.
In this section we direct our attention to the first problem for a linear, time- invariant dynamical system that is excited by a known forcing function, has deterministic initial conditions, and has measurements that are corrupted by
A Log-Likelihood Function for an Important Dynamical System
additive white Gaussian noise. This system is described by the following state-equation model:
x(k + 1) = @x(k) + ‘Pu(k) (11-32)
z(k + 1) = Hx(k + 1) + v(k + 1) k =O,l,... ,N - 1 (11-33)
In this model, u(k) is known ahead of time, x(0) is deterministic, E{v(k)} = 0, v(k) is Gaussian, and E{v(k)v’( j)} = R6kj.
To begin, we must establish the parameters that constitute 9. In theory 8 could contain all of the elements in @, !P, H and R. In practice, however, these matrices are never completely unknown. State equations are either derived from physical principles (e.g., Newton’s laws) or associated with a canonical model (e.g., controllability canonical form); hence, we usually know that certain elements in @, V and H are identically zero or are known constants.
Even though all of the elements in 0, !P, H and R will not be unknown in an application, there still may be more unknowns present than can possibly be identified. How many parameters can be identified, and which parameters can be identified by maximum-likelihood estimation (or, for that matter, by any type of estimation) is the subject of identifiability of system (Stepner and Mehra, 1973). We shall assume that 8 is identifiable. Identifiability is akin to “existence.” When we assume 8 is identifiable, we assume that it is possible to identify 8 by ML methods. This means that all of our statements are predi- cated by the statement: If 8 is identifiable, then . . . .
We let
0 = co1 (elements of a, TV, H, and R) (11-34)
Example 11-3 The “controllable canonical form” state-variable autoregressive moving average (ARMA) model
representation for the discrete-time
H(z) = (11-35)
which implies the ARMA difference equation (z denotes the unit advance operator)
y (k + n) + aly(k + n - 1) + l l l + any(k) =P*u(k+n -1)+.*.+&u(k) (11-36)
is
xl(k + 1) x2@ + 1) .
x,,(k:+ 1)
Xl(k) x2(k) . .
0
1 0 + O . u(k) (11-37) . i

Maximum-Likelihood Estimation Lesson 11
and
For this model there are no unknown parameters in matrix W, and, @ and H each contain exactly n (unknown) parameters. Matrix @ contains the n a-parameters which are associated with the poles of H(z), whereas matrix H contains the PI p-parameters which are associated with the zero of H(z). In genera/, an &-or&r, single-input single-output system k compkteiy charucterized by 2 n parameters0 0
Our objective now is to determine L(C$E) for the system in (U-32) and (H-33). To begin, we must determine p (910) = p (z(l), z(2), . . . , z(N)/@). This is easy to do, because of the whiteness of noise v(k)? i.e., p (z(l), z(2), . . . , eN = P W~P MW l l l P won thw
Wl~~ = h [IJPMM~] (11-39)
From the Gaussian nature of v(k) and the linear measurement model in (U-33), we know that
[ - ; [z(i) - Hx(i)]‘R-’ [z(i) - Hx(i)]} (11-40)
thus,
L(IqE) = - i i [z(i) - Hx(i)]‘R-’ [z(i) - Hx(i)] i=l
-$hiR/ -$mln27r (11-41)
The log-likelihood function L#!E) is a function of 0. To indicate which quantities on the right-hand side of (U-41) may depend on 6, we subscript all
such quantities with 9. Additionally, because N T~H in 27r does not depend on 8
we negIect it in subsequent discussions. Our final log-Iikelihood function is:
L(@E) = -; 2 [z(i) - &x&)]‘Ri’ [z(i) - Hex&)] - $ In /Rot (11-42) i=l
observe that 8 occurs explicitly and implicitly in L@l%). Matrices I&, and R. contain the explicit dependence of L@lS!) on 8, whereas state vector x@(i) contains the implicit dependence of L@i$!E) on 9. In order to numerically calculate the right-hand side of (1 l-42), we must solve state equation (11-32). This can be done when vaIues of the unknown parameters which appear in @ and V are given specific values; for, then (11-32) becomes
x@(k + 1) = @G@(~) + %Q4 x@(O) known (1 l-43)
Lesson 17 Problems
In essence, then, stute equation (11-43) is a comtraint that is associated with the computatim of the log-likelihood function.
How do we determine bML for L(9[%) given in (11-42) [subject to its constraint in (ll-43)]? No simple closed-form solution is possible, because 8 enters into L($?!I’) in 2 complicated nunlinear manner. The only way presently known for obtaining 9 ML is by means of mathematical programming, which is beyond the scope of this course (e.g., see Mendel, 1983, pp. 141-142).
Comment. This completes our studies of methods for estimating un- known deterministic parameters. Prior to studying methods for estimating unknown random parameters, we pause to review an important body of mate- rial about muhivariate Gaussian random variables.
PROBLEMS
11-I. If i is the MLE of a, what is the MLE of a”O? Explain your answer. 11-2. (Sorenson, 1980, Theorem 5.1, pg. 185). If an estimator exists such that
equality is satisfied in the Cramer-Rao inequality, prove that it can be determined as the solution of the likelihood equation.
11-3. Consider a sequence of independently distributed random variables X1,X2 , . . . ,xN , having the probability density function #xie-‘~, where 8 > 0. (a) Derive &&1v). (b) You want to study whether or not &&N) is an unbiased estimator of 8.
Explain (without working out all the details) how you would do this. 11-4, Consider a random variable z which can take on the values z = 0, 1,2, . . . . This
variable is Poisson distributed, i.e., its probability function P(z) is P(t) = pze “p/z! Let 2 (l), z(2), . . . , z(N) denote N independent observations of t. Find i&&N).
11-5. If p(z) = Be +=, z > 0 and p(z) = 0, otherwise, find I&, given a sample of N independent observations.
11-6. Find the maximum-likelihood estimator of 8 from a sample of N independent observations that are uniformly distributed over the interval (0, 0).
11-7. Derive the maximum-likelihood estimate of the signal power, defined as e, in the signal z(k) = o(k), k = 0, 1,. . . , N, where s(k) is a scalar, stationary, zero-mean Gaussian random sequence with autocorrelation E{s (9s (j)} = 9(j - i>*
11-8. Suppose x is a binary variable that assumes a value of 1 with probability a and a value of 0 with probability (1 - a). The probability distribution of x can be described by
P(x) = (1 - a)” - *‘a”
Suppose we draw a random sample of N values (x1, x2, . . . , x.~‘}. Find the MLE of a.
11-9. (Mendel, 1973, Exercise 3-15, pg. 177). Consider the linear model for which V(k) is Gaussian with zero mean and %(A-) = (~‘1.

98 Maximum-Likelihood Estimation
(a) Show that the maximum-likelihood estimator of u*, denoted &&, is
(f.E - 3tii,J(% - ei,,) &‘,, = . N
1140.
where 6ML is the maximum-likelihood estimator of 8. (b) Show that &* ML is biased, but that it is asymptotically unbiased. We are given N independent samples z(l), z(2), . . . , z(N) of the identically distributed two-dimensional random vector z(i) = co1 [z*(i), z2(i)], with the Gaussian density function
PMi), t*(i)lp> = 1
I z:(i) - 2pz4i)z*(i) + z;(i)
27dc-7 exp -
20 - P’> I
1141.
where p is the correlation coefficient between z1 and z2. (a) Determine i)ML (Hint: You will obtain a cubic equation for jjML and must
show that bL = r, where r equals the sample correlation coefficient). (b) Determine the Cramer-Rao bound for i)ML. It is well known, from linear system theory, that the choice of state variables used to describe a dynamical system is not unique. Consider the n th-order difference equation
y (k + n) + a1y (k + II - 1) + l l l + any(k)
= bim(k + n - 1) + bEeIrn(k + n - 2) + l .* + bym(k).
A state-variable model for this system is
0 0 . . m (4
-‘a*
and
where
y(k) = (1 O...O)x(k)
1142.
Suppose maximum-likelihood estimates have been determined for the ai- and bi-parameters. How does one compute the maximum-likelihood estimates of the by-parameters? Prove that, for a random sample of measurements, a maximum-likelihood estimator is a consistent estimator [Hints: (1) Show that E{d In p (9fl8) / ae(e} = 0; (2) Expand d In p (!%&&% in a Taylor series about 8, and show that d In p(%(6)/de = -(iML - 8)‘a’ ln ~(S@*)/LJO”, where 8* = he + (1 - &)iML and 0 5 h 5 1; (3) Show that d in p(%le)/~% = cfl 1 d In p(z(i))8)/89 and 8 ln
Lesson 11 Lesson 11 Problems
11-13.
11-14.
p (cq0)/ a2 = c;“= ] a’ In p (z (i)!6)/#; (4) Using the strong law of large numbers to assert that, with probability one, sample averages converge to ensemble averages, and assuming that E{B! in p (z(i>le)lde’} is negative definite? show that 6 ML’ 8 with probability one; thus, iML is a consistent estimator of 8. The steps in this proof have been taken from Sorenson, 1980, pp. 187-191.1 Prove that, for a random sample of measurements, a maximum- likelihood estimator is asymptotically Gaussian with mean value 8 and covariance matrix (NJ)-’ where J is the Fisher information matrix for a single measurement 2 (i>. [Hints: (1) Expand d In p (%liML)/ de in a Taylor series about 8 and neglect second- and higher-order terms; (2) Show that
(3) Let s(e) = dlnp ew) la and show that s(e) = xrS 1 si(e), where si(e) =d
ln P (f (i)k9 I% (4) Let S denote the sample mean of Si (e), and show that the distribution of S asymptotically converges to a Gaussian distribution having mean zero and covariance J/N, (5) Using the strong law of large numbers we
know that -+ E{ a’ In p (z (#I) / 80’10); consequently, show
that (i,, - e)‘J is asymptotically Gaussian with zero mean and covariance J/N; (6) Complete the proof of the theorem. The steps in this proof have been taken from Sorenson, 1980, pg. 192.1 Prove that, for a random sample of measurements, a maximum-likelihood estimator is asymptotically efficient [Hints: (1) Let S(e) = -E{a’ in p (%$I)/ a210} and show that S(0) = NJ where J is the Fisher information matrix for a single measurement z (13; (2) Use the result stated in Problem 11-13 to complete the proof. The steps in this proof have been taken from Sorenson, 1980, pg. 193 .]

Lesson 72
Elemenfs of Mulfivar;afe Gcwssiun
Random Variables
INTRODUCTION
Gaussian random variables are important and widely used for at least two reasons. First, they oflen provide a model that is a reasonable approximation to observed random behavior. Second, if the random phenomenon that we observe at the macroscopic level is the superposition of an arbitrarily large number of independent random phenomena, which occur at the microscopic level, the macroscopic description is justifiably Gaussian.
Most (if not all) of the material in this lesson should be a review for a reader who has had a course in probability theory. We collect a wide range of facts about multivariate Gaussian random variables here, in one place, be- cause they are often needed in the remainmg lessons.
UNIVARIATE GAUSSIAN DENSITY FUNCTION
A random variable y is said to be distributed as the wzivariate Gussian distribution with mean q, and variance CI$ [Len, y - IV(y; my, $11 if the density function of y is given as
For notational simplicity throughout this chapter. we do not condition density functions on their parameters; this conditioning is understood. Density JJ (y) is the familiar bell-shaped cume, centered at y = mJ. +
Jointly Gaussian Random Vectors ?Ol
MULTIVARIATE GAUSSIAN DENStTY FUNCTlON
Let yl, ~2,. - -, function
y, be random variables, and y = co1 (yl, y,, . . . , ym). The
Pcyl, L’2, * - .,YnJ =p(s’) = v&qexp +r- WPT,’ (Y - my> 1 (12-2)
is said to be a multivariate (m-variate) Gaussian density function [i.e., y - N(y; m,, P,)]. In (12-2),
my = E(Y) (12-3)
and
p, = WY - my) (Y - my)') (12-4)
Note that, although we refer to p(y) as a density function, it is actually a joint density function between the random variables yl, y2, , . . , y, . If P, is not positive definite, it is more convenient to define the multivariate Gaussian distribution by its characteristic function. We will not need to do this.
JOtNTLY GAUSSfAN RANDOM VECTORS
Let x and y individually be n- and m-dimensional Gaussian random vectors, i.e., x - N(x; m,, Px) and y - N(y; m,, P,). Let P,, and P,, denote the cross- covariance matrices between x and y, i.e.,
P, = Wx - My - my)‘) (12-5)
and
P yx = NY - m,.>(x - m,)‘) (12-6)
We are interested in the joint density between x and y, p (x, y). Vectors x and y are jointly Gaussian if
Ph Yl = 2 - mJ’P,-’ (z - m,) (12-7)
where
2 = co1 (x, y) (12-B)
m, = cd (m,, my) (12-9)
and
(12-10)

102 Elements of Multivariate Gaussian Random Variables Lesson 12
Note that if x and y are jointly Gaussian then they are marginally (i.e., individually) Gaussian. The converse is true if x and y are independent, but it is not necessarily true if they are not independent (Papoulis, 1965, pg. 184).
In order to evaluate p (x, y) in (12-7), we need lPZi and P,‘. It is straight- forward to compute lPZl once the given values for P,, P,, PXy, and PrX are substituted into (12-10). It is often useful to be able to express the components of Pi’ directly in terms of the components of P,. It is a straightforward exercise in algebra (just form P,P,’ = I and equate elements on both sides) to show that
(12-11) where
and
A = (PX - P,P;‘P,)-’ = P,’ + P;‘p,,CP,P;’
B = -AP,P;’ = -P;‘P,C
c = (PY - P,P;‘P,)-’ = Py’ + P,‘P,,AP,,P;’
(12-12)
(12-13)
(12-14)
THE CONDITIONAL DENSITY FUNCTION
One of the most important density functions we will be interested in is the conditional density function p (xly). Recall, from probability theory (e.g., Papoulis, 1965), that
P MY) P(F Y) =-
P(Y) (12-15)
Theorem 12-l. Let x and y be n- and mdimensional vectors that are jointly Gaussian. Then
1 i
1 P(XlY) = q@qqq exp - 2 (x - mW’(x - m) I (12-16)
where
and
m = E{x/y} = mx + P,P;'(y - my) (12-17)
!% = A-’ = P, - Px,P;‘Px (12-18)
This means that p(xly) is also multivariate Gaussian with (conditional) mean m and covariance 9..
Proof. From (12-U), (12-7), and (12-2), we find that
A B B’ C -P;’ (12-19)
The Conditional Density Function
Taking a closer look at the quadratic exponent, which we denote E(x,y), we find that
E(x,y) = (x - m,)‘A(x - m,) + 2(x - mX)‘B(y - m,) + (Y - mJ’(C - PY’>(Y - my) (12-20)
= cx - m,)‘A(x - m,) - 2(x - m,)‘A P,,P;‘(y - m,) + (Y - q)‘qpyxA P,,p;yy - my)
In obtaining (12-20) we have used (12-13) and (12-14). We now recognize that (12-20) looks like a quadratic expression in x - m, and P,,P;‘(y - m,), and . express it in factored form, as
ax, Y) = E(x - mx> - PxyP;‘(Y - m,>l’N(x - mx) - PxyP,‘(Y - m,>l (12-21)
Defining m and ZL as in (12-H) we see that
E(x,y) = (x - m)‘CL-‘(x - m) (12-22)
If we can show that lPZl /IPY[ = (21, th en we will have shown that p (xly) is given by (12-X), which will mean that p (xly) is multivariate Gaussian with mean m and covariance 2.
It is not at all obvious that 121 = IPZI / IP,I. We shall reexpress matrix P, so that l&l can be determined by appealing to the following theorems (Graybill, 1961, pg. 6):
i. If V and G are n x n matrices, then /VGl = IV1 1~1. ii. IfMisa square matrix such that
where Ml1 and Mz2 are square matrices, and if Ml2 = 0 or MS1 = 0, then IMI = IMlll Iw21* We now show that two matrices, L and N, can be found so that
(12-23)
Multiplying the two matrices on the right-hand side of (12-23), and equating the l-l and 2-1 components from both sides of the resulting equationwe find that
px = L + P,,N (12-24)
b = P,.N (12-25)
from which it follows that
N = P,‘P,, (12-26)

Bernems of Multivariate Gaussian Rxdom Varhbks Lesson 12
and
L = Px - PqP;lPfl (12-27)
From (12~23), nye see that
Pzl = IL1 hl
or, ILI = lRlml (12-28)
Comparing the equations for L and 3, we find they are the same; thus, we have proven that
121 = IPzlm (1229)
which completes the proof of this theorem. U
PROPERTIES OF MULTIVARIATE GAUSSIAN RANDOM VARIABLES
From the preceding formulas for p(y), p (x,y) and p (xiy), we see that r4lL variate Gaukan prubabikty density functions are completely characterized by their first two moments, Le., their mean vector and covariance matrix. All other moments can be expressed in terms of their first two moments (see, e.g., Papoulis, 1965)
From probability theory, we also recall the foliowing two important facts about Gaussian random variables:
I. Statistically independent Gaussian random variables are uncorrelated and vice-versa; thus, PW and PYx are both zero matrices.
2, bear (or affine) transformations on and linear (or affine) combinations of Gaussian random variables are themselves Gaussian random vari- ables; thus, if x and y are jointly Gaussian, then z = Ax + By + c is also Gaussian+ We refer to this property as the /inew@ property.
PROPERTIES OF CONDiTIoNAL MEAN
We learned, in Theorem 12-1, that
E{x[y} = rnx + P&‘(y - my)
Because E{xiyl depends on y, which is random, it is also random.
(12-30)
Theorem 12-2. When x and y m-e jointly Gaussian, E{xiyl is multivariate C&&an, and is an uffitx combinatiun of the elements of y.
Properties of Conditional Mean
Proof That E(xjy) is G aussian follows from the linearity property ap- plied to (12-30). An affine transformation of y has the structure Ty + f. E(x\y) has this structure; thus, it is an affine transformation. Note that if m, = 0 and m, = 0, then E{xly} is a linear transformation of y. 5
sian Theorem 12-3. Let x, y, andzben X 1, m X 1 artdr X I
random vectors, If y and z are statistically independent, then jointly Gaus-
Ebty, 2) = E{xly) + E(xlz} - m, (12-31)
Proof. Let 5 = co1 (y.z); then
Ebl5) = m, + PxkP;‘({ - m,) (12-32)
We leave it to the reader to show that
pxt = Px,lPxz) (12-33)
p-p,. 0 (-I-) I- 0 P 2
(12-34)
(the off-diagonal elements in P, are zero if y and z are statistically indepen- dent; this is also true if y and z are uncorrelated, because y and z are jointly Gaussian); thus,
E{xle] = m, I- PxyPF’(y - m,.) + P,P;‘(z - m,) = E(xjyj + E(x/z} - m, q
In our developments of recursive estimators, y and z (which will be associated with a partitioning of measurement vectors 2) are not necessarily independent. The following important generalization of Theorem 12-3 will be needed.
SiUtl
Theorem 12-4. Let x, y, and z ben x 1.m x landr x 1 jointly Gaus- random vectors. Ijy and z are not necessarily statistically independent, then
E(x]y , z} = E(xly , i) (12-35)
where -- z-z - E{z[Y) (12-36)
so that
E(xly,z) = E(x/y} + E{xlZ) - m, (12-37)
Proof (Mendel, 1983b. pg. 53). The proof proceeds in two stages: (a) assume (12-35) is true and demonstrate the truth of (12-37), and (b) demon- strate the truth of (12-35).

Elements of Multivariate Gaussian Random Variables Lesson 12
a. If we can show that y and i are statistically independent, then (12-37) follows from Theorem 12-3. For Gaussian random vectors, however, uncorrelatedness implies independence.
To begin, we assert that y and 21 are jointly Gaussian, because ii = z - E{zly} = z - m, - P,,P;‘(y - my) depends on y and z, which are jointly Gaussian
Xext, we . show that Z is zero mean. This follows from the
calculation
mi = E{z - E{zly}} = E(z) - E{E{zly}} (12-38)
where the outer expectation in the second term on the right-hand side of (12-38) is with respect to y. From probability theory (Papoulis, 1965, pg. 208), E(z) can be expressed as
EM = E(E(zly)Z (12-39)
From (12-38) and (12-39), we see that rni = 0. Finally, we show that y and Z are uncorrelated. This follows from
the calculation
E{(y - my>@ - mi)‘) = E{(y - m&i’} = E{yi’}
= Wyz’l - E(yE(z'jy)~ (12-40) = E{yz’} - E{yz’} = 0
b. A detailed proof is given by Meditch (1969, pp. 101-102). The idea is to (1) compute E{xly,z} in expanded form, (2) compute E{xly,i} in ex- panded form, using Z given in (12-36), and (3) compare the results from (1) and (2) to prove the truth of (12-35). 0
Equation (12-35) is very important. It states that, when z and y are dependent, conditioning on z can always be replaced by conditioning on another Gaussian random vector 5, where Z and y are statistically indepen- dent.
The results in Theorems 12-3 and 12-4 depend on all random vectors being jointly Gaussian. Very similar results, which are distribution free, are described in Problem 13-4; however, these results are restricted in yet another way.
PROBLEMS
12-1. Fill in all of the details required to prove part b of Theorem 12-4. 12-2. Let x, y and z be jointly distributed random vectors: c and h fixed constants; and
g ( 0 ) a scalar-valued function. Assume E(x), E(z). and E(g (y)x} exist. Prove the following useful properties of conditional expectation:
Lesson 12 Problems
(a) E{xjy} = E(x) if x and y are independent (b) WY)XlY~ = g(YPwYl (d E{c lyl = c (d) WY~lY~ = ET(Y) (e) E{cx + hzly} = cE{xly} + hE{z/y} (0 E{x) = E{E{xiyl) h w ere the outer expectation is with respect to y (9) WYbl = WY)EblYH h w ere the outer expectation is with respect to y.
12-3. Prove that the cross-covariance matrix of two uncorrelated random vectors is zero.

Lesson 73
Estimution
of Rcmdom Parameters:
Generd Results
INTRODUCTION
In Lesson 2 we showed that state estimation and deconvolution can be viewed as problems in which we are interested in estimating a vector of random parameters* For us, state estimation and deconvolution serve as the primary motivation for studying methods for estimating random parameters; however, the statistics literature is filled with other apphcations for these methods.
We now view 0 as an PI x 1 vector of random unknown parameters. The information available to us are measurements z(I), z(2), . . . , z(k), which are assumed to depend upon 9. In this lesson, we do not begin by assuming a specific structural dependency between z(i) and 0. This is quite different than what we did in WLSE and BLUE. Those methods were studied for the linear model z(i) = H(i)9 -t v(z’), and, closed-form solutions for 6=(k) and &JJ(~) could not have been obtained had we not begun by assuming the linear model. We shah study the estimatiun of random 0 for the linear model in Lesson 14.
ln this lesson we examine two methods for estimating a vector of random parameters. The first method is based upon minimizing the mean-squared error between 0 and 6(k). The resulting estimator is called a mean-squared estimator, and is denoted ~&Jc). The second method is based upon max- imizing an unconditional likelihood function, one that not only requires knowledge of ~(9!~8) but also of p(9). The resulting estimator is called a maximum a posteriori estimakw, and is denoted iMAp(
Mean-Squared Estimation
MEAN-SQUARED ESTIMATION
Many different measures of parameter estimation error can be minimized in order to obtain an estimate of 6 [see Jazwinski (1970), Meditch (1969), van Trees (1968), and Sorenson (1980), for example]; but, by far the most widely studied measure is the mean-squared error.
Objective Function and Problem Statement
Given measurements z(l), . . . , z(k), we shall determine an estimator of 6, namely
&s(k) = +[z(i), i = 1,2, . a . , rl-] (13-1) such that the mean-squared error
Jh,&)l = E~~~s(k)e,s(~)~ (13-2)
is minimized. In (13-2), &s(k) = 8 - i&k). The right-hand side of (13-1) means that we have some arbitrary and as
yet unknown function of all the measurements. The n components of 0,,(k) may each depend differently on the measurements. The function +[z(i), i = 1, 2 ,-‘., k] may-be nonlinear or lineat. Its exact structure will be determined by minimizing J[9&k)]. If perchance 0&/c) is a linear estimator, then
We now calculation of
The underlying random quantities in our estimation problem are 9 and Z(k). We assume that their joint density function p[e,!E(k)] exists, so th .at
6&k) = c A(i)+) i= 1
conditional show that the notion of &&c). As usual, we let
is expectation
(13-3)
to the
95(k) = co1 [z(k), z(k - l), . . . , z(l)] (13-4)
where d9 = d&d& . . . de,, d%(k) = dzr(1) . . . dri(k)dzz(l) . . . dz,(k) . . . dz,(l) . . . dz,(k), and there are H + km integrals. Using the fact that
p WW)l = p C@V)$ [Wdl (13-6) we rewrite (13-5) as
(13-7)

Estimation of Random Parameters: General Results Lesson 13
From this equation we see that minimizing the conditional expectation E{@&)&&)~%(k)} with respect to &.&j is equivalent to our original objec- tive of minimizing the total expectation E{6~s(k)8Ms(k)}. Note that the inte- grals on the right-hand side of (13-7) remove the dependency of the integrand on the data S(k).
In summary, we have the following mean-squared estimation problem: Given the measurements z(l), z(2), . . . , z(k), determine an estimator of 8, namely,
6&k) = @[z(i), i = 1,2,. . . , k] such that the conditional mean-squared error
mLs(k)l = E(&&)L(k)l4~), - ’ l 7 z(k)) (13-8)
is minimized.
Derivation of Estimator
The solution to the mean-squared estimation problem is given in The- orem 13-1, which is known as the Fundamental Theorem of Estimation Theory.
Theorem 13-l. The estimator that minimizes the mean-squared error is
hMS(JC) = WI~(kj~ (13-9)
Proof (Mendel, 1983b). In this proof we omit all functional depen- dences on k, for notational simplicity. Our approach is to substitute i&&k) = 8 - 6,,(k) into (13-8) and to complete the square, as follows:
J1[~MS(k)I = we - hMSjv - ~MsjIffJ = E{e’e - efhMS - i&e + iifrlSiiMSpQ = E{e’ep) - E{ep$iMs - i&E{ela) + &,JiMs
(13-10)
= E{efel%} + [bMS - E{elk3f>]@Ms - E{ele>] - E{8’pI}E{8]~}
To obtain the third line we used the fact that 6 MS, by definition, is a fUnCtiOn of %; hence, E{&SI%} = 6MS. The first and last terms in (1340) do not depend on && hence, the smallest value of J1[6Ms(k)] is obviously attained by setting the bracketed terms equal to zero. This means that 6,s must be chosen as in (13-9). cl
Let J,*[e,,(k)] denote the minimum Vahe of &[&s(k)]. we see, from (1340) and (13-g), that
&@&k)] = E{e’el%} - &s(k)&s(k) (1341)
As it stands, (13-9) is not terribly useful for computing g,s(k). In gen- eral, we must first compute p [cl%(k)] and then perform the requisite number of integrations of ep[el%(k)] to obtain bMS(k). In the special but important case
Mean-Squared Estimation 111
when 8 and Z(k) are jointly Gaussian we have a very important and practical corollary to Theorem 13-l.
Corollary 13-l. When 8 and Z(k) are jointly Gaussian, the estimator that minimizes the mean-squared error is
k&) = m6 + P,(Wi’OPW - m&41 (13-12)
Proof. When 8 and Z(k) are jointly Gaussian then E{OI%(k)} can be evaluated using (12-17) of Lesson 12. Doing this we obtain (13-12). 0
Corollary 13-1 gives us an explicit structure for 6&k). We see that 6&k) is an affine transformation of Z(k). If me = 0 and m&c) = 0, then 6&k) is a linear transformation of Z(k).
In order to compute 6&k) using (13-12), we must know me and m& and we must first compute P&k) and P&k). We perform these computations in Lesson 14 for the linear model, Z(k) = X(k)0 + V(k).
Corollary 13-2. Suppose 8 and %(k) are not necessarily jointly Gaussian, and that we know me, m%(k), Pz(k) and P&k). In this case, the estimator that is constrained to be an affine transformation of Z(k), and that minimizes the mean-squared error is also given by (13-12).
Proof. This corollary can be proved in a number of ways. A direct proof begins by assuming that 6&k) = A(k)%(k) + b(k) and choosing A(k) and b(k) so that 6&k) is an unbiased estimator of 8 and E{6Eyis(k)&s(k)} = trace E(&&)%&)1 is minimized. We leave the details of this direct proof to the reader.
A less direct proof is based upon the following Gedanken experiment. Using known first and second moments of 8 and Z(k), we can conceptualize unique Gaussian random vectors that have these same first and second mo- ments. For these statistically-equivalent (through second-order moments) Gaussian vectors, we know, from Corollary 13-1, that the mean-squared esti- mator is given by the affine transformation of S(k) in (13-12). 0
Corollaries 13-1 and 13-2, as well as Theorem 13-1, provide us with the answer to the following important question: When is the linear (affine) mean- squared estimator the same as the mean-squared estimator? The answer is, when 8 and Z(k) are jointly Gaussian. If 8 and ttI(k) are not jointly Gaussian, then 6&k) = E{OIZ(k)}, which, in general, is a nonlinear function of mea- surements s(k), i.e., it is a nonlinear estimator.
Corollary 13-3 (Orthogonality Principle). Suppose f [Z(k)] is any func- tion of the data Z(k). Then the error in the mean-squared estimator is orthogo- nal to f [S(k)] in the sense that
E(Ee - kls(wlf’Ew)lI = 0 (13-13)

112 Estimation of Random Parameters: General Results Lesson 13
Proof (Mendel, 1983b, pp. 46-47). We use the following result from probability theory (Papoulis, 1945; see, also: Problem 12-2(g)). Let CK and @ be jointly distributed random vectors and g (fi) be a scalar-valued function; then
where the outer expectation on the right-hand side proceed as follows (again, omitti ng the argument k):
is with respect to f!. We
where we have used the facts that bMS is no longer random when !I!, is specified and E{@%~ = iMS. q
A frequently encountered special case of (13-13) occurs when f [2(k)] = d&k); then Corollary 13-13 can be written as
~oLs~~~k@~l = 0 (13-S)
PropertIes of Mean-Squared Estimates When 9 and 3%) are Gaussian
In this section we present a collection of important and useful properties associated with 9&k) for the case when 0 and g(k) are jointly Gaussian. In this case 6&k) is given by (1342).
Property 1 (Unbiasedness). The mean-squared estimator, &s(k) in (13-12), is unbiased.
?vof. Taking the expected value of (13-12), we see that E&&k)} = Q; thus, O&k) is an unbiased estimator of 0. Cl
Property 2 (Minimum Variance). Dispersion about the mean value of t&&k) is measured by the error variance c$ Ms(k), where i = 1, 2, . . . , n. An estimator that has the smallest error variance’is a minimum-variance estimator (an MVE). Th e mean-squared estimator in (13-12) is an MVE.
Proof. From Property 1 and the definition of error variance, we see that
c-r;8 Ms(k) = E{@&(k)} i = 1,2,. . . , II (13-X) . Our mean-squared estimator was obtained by minimizing .J[&&k)] in (13-2), which can now be expressed as
(13-17)
Mean-Squared Estimation 113
Because variances are aIways positive the minimum value of J{&,(k)] must be achieved when each of the n variances is minimized; hence, our mean-squared estimator is equivalent to an MVE. [7
Property 3 (Linearit)‘). 6&k) in (13-12) is a “linear” (i.e., affine) estimator.
Proof. This is obvious from the form of (13-12). 0
Linearity of i&k) permits us to infer the foIlowing very important property about both i,,(k) and &s(k).
Property 4 (Gaussian). Both 6&k) and 6&k> are multivariate Gaus- Sian.
Proof. We use the linearity property of jointly Gaussian random vectors stated in Lesson 12. Estimator 6&k) in (13-12) is an affine transformation of Gaussian random vector Z(k); hence, &,&k) is multivariate Gaussian. Esti- mation error 8&k) = 9 - 6&k) is an affine transformation of jointly Gaus- sian vectors 8 and 5!‘.(k); hence, 6&k) is also Gaussian. 0
Estimate 6&k) in (13-12) is itself random, because measurements Z(k) are random. To characterize it completely in a statistical sense, we must specify its probability density function, Generally, this is very difficult to do, and often requires that the probability density function of 6&) be approxi- mated using many moments (in theory an infinite number are required). In the Gaussian case, we have just le_arned that the structure of the probability density function for &.&k) [and 6,,(k)] is k nown. Additionally, we know that a Gaussian density function is completely specified by exactly two moments, its mean and covariance; thus, tremendous simplifications occur when 6 and Z(k) are jointly Gaussian.
Property 5 (Uniqueness). Mean-squared estimator 6&k), in (13-12), is unique.
The omitted.
proof of this property is not central to our developments; hence, it is
Generahations
Many of the results presented in this section are applicable to objective functions other than the mean-squared objective function in (13-2). See Me- ditch (1969) for discussions on a wide number of objective functions that lead to E{elS(k)> as the optimal estimator of 8.

Estimation of Random Parameters: General Results Lesson 13
MAXIMUM A POSTERIOR1 ESTIMATION
Recall Bat.es’s rule (Papoulis, 1965, pg. 39): .
in which density functionp@j%(k)) l k 1s nown as the a posteriori (or posterior) conditional density function, and p (0) is the prior probability density function for 8. Observe that p(f$!E(k)) is related to likelihood function Z(ele(k)}, be- cause Z{C$!Z@)} ap (%(k)le). Additionally, because p (%(k)) does not depend on 8,
(13-19)
In maximum a posteriori (MAP) estimation, values of 8 are found that maximize p (e/%(k)) in (13-19); such estimates are known as MAP estimates, and will be denoted as &&j.
If 01, 62, . . . ) & are uniformly distributed, then p (f$E(k)) ap (Zf(k)lO), and the MAP estimator of 8 equals the ML estimator of 8. Generally, MAP estimates are quite different from ML estimates. For example, the invariance property of MLE’s usually does not carry over to MAP estimates. One reason for this can be seen from (13-19). Suppose, for example, that + = g(8) and we want to determine C$ MAP by first computing 6 MAP. Because p (0) depends on the Jacobian matrix of g-l(+), 4 MAP # @MAP). Kashyap and Rao (1976, pg. 137) note, “the two estimates are usually asymptotically identical to one another since in the large sample case the knowledge of the observations swamps that of the prior distribution.” For additional discussions on the asymptotic proper- ties of MAP estimators, see Zacks (1971).
Quantity p (elZ(k)) in (13-19) is sometimes called an unconditional Zike- Zihood function, because the random nature of 8 has been accounted for by p (0). Density p (%(k)le> is then called a conditional likelihood function (Nahi, 1969).
Obtaining a MAP estimate involves specifying both p (%(#3) and p (0) and finding those values of 8 that maximize p (Ol%(k)), or In p @l%(k)). Gener- ally speaking, mathematical programming must be used to compute &&&k). When s(k) is related to 8 by our linear model, %(k) = X(li)B + V(k), then it may be possible to obtain &A#) in closed form. We examine this situation in some detail in Lesson 14.
Example 13-l
This is a continuation of Example 11-l. We observe a random sample {I (l), t (2), . . . , z(N)} at the output of a Gaussian random number generator, i.e., z(i) - N(z (i>; p, CT). Now, however, p is a random variable with prior distribution N(p; 0, 0:). Both a: and oc are assumed known, and we wish to determine the MAP estimator of p.
We can view this random number generator as a cascade of two random number generators. The first is characterized by N(p; 0, o:> and provides at its output a single realization for p, say pR. The second is characterized by N@(i); pR, 0:). Observe that
Maximum a Posteriori Estimation
j.&, which is unknown to us in this example, is transferred from the first random number generator to the second one before we can obtain the given random sample
Using the facts that
p (z (i)lp) = (2m+‘” exp { -$ [z(i) - @j’/d}
p(j~) = (2m~)+* exp {+w}
(13-20)
(13-21)
(13-22)
(13-23)
Taking the we obtain
logarithm of (13-23) and neglecting the terms which do not depend upon p,
LMAP(#E(RJ)) = -i j? {[z(i) - pl*1(+3 - i CL214 1=1
Setting ~LMAP/@ = 0, and solving for bMA&V), we find that
bMAP(R?
(13-24)
(13-25)
Next, we compare bMAP(lV) and b&v), where [see (19) from Lesson 111
l bdRJ) = jQ, f z(i) (13-24) I= 1
In general GMAp (N) # &,&V). If, however, no a priori information about p is avail- able, then we let &+a, in which case fiMAp(IV) = fi&V). Observe, also that, as N+ 00 cMAP(lV) = bML(1V), which implies (Sorenson, 1980) that the influence of the prior knowledge about p [i.e., p - A@; 0, cri)] diminishes as the number of mea- surements increase. D
Theorem 13-2. If Z(k) and 8 are jointly Gaussian, then i&&k) = kdk)~
Proof. If SC(k) and 0 are jointly Gaussian, then (see Theorem 12-1)
P @lw)) 1 1 i
= ~(271.)“l’Z(k)l exp -2 [e - m(k)]‘S!?(k)[8 - mwl] (13-27)

Estimation of Random Parameters: General Results Lesson 13
where
III(~) = E@/%(k)] (13-28)
&&k) is found by maximizing JJ (@I!@)]~ or equivalentiy by minimizing the argument of the exponential in (13-27). The minimum value of [O - m(k)]‘LT!F(k)[6 - III(~)] is zero, and this occurs when
The result in Theorems 13-2 is true regardless of the nature of the model relating 0 to Z(k). Of course, in order to use it, we must first establish that %(A$ and 0 are jointly Gaussian. Except for the linear model, which we examine in Lesson 14, this is very diffkuh to do.
PROBLEMS
13-l. Prove that 6&k), given in (13-12). is unique. 13-2. Prove Corollary 13-Z by means of a direct proof. 13-3. Let 0 and %(N) be zero mean n x 1 and IV X 1 random vectors, respectively,
with known second-order statistics, P8, P5, Pm, and Pz@+ View Z(N) as a vector of measurements. It is desired to determine a linear estimator of 6,
where KL(v is an n x N matrix that is chosen to minimize the mean-squared error Ei b - & Q+fE(NLl’[fl - &. (NEW)]}. [a) Show that the gain matrix, which minimizes the mean-squared error, is
KL(w = E~e~‘(~~~E~~(~~‘(~}]-’ = Pa PG’. (b) Shoy that the covariance matrix, P(N), of the estimation error, 6(N) =
9 - e(N), is
(c) Relate the results obtained in this problem to those in Corollary 13-2. 13-4, For random vectors 0 and Z(k), the hear projection, 9*(k), of 0 on a Hilbert
space spanned by s(k) is defmed as 9*(k) = a + B%(k), where E{0*(k)} = E{O] end E{[O - O*(k)B’(k)} = U. We denote the linear projection, 0*(k), as Jo MW (a} rrove that the linear (i*e., affine), unbiased mean-squared estimator of 9,
6(k), is the linear projection of 0 on 9(k). tb} Prove that the linear projection, O*(k), of 9 on the Hilbert space spanned by
Lesson 13 Problems If7
S’(k) is uniquely equal to the linear (i.e., affine), unbiased mean-squared estimator of 0,4(k).
(c) For random vectors x, y, z, where y and z are uncorrelated. prove that
k(x/y.z} = E{xly) + IQXIZ) - m.
(d) For random vectors x, y, z, where y and z are correlated, prove that
ii{xly3z} = i{x/y.Z}
where
so that
z = z - i{zly}
&ly,z} = k{xly} + i&Ii} - m,
Parts (c) and (d) show that the results given in Theorems 12-3 and 12-4 are “distribution free” within the class of linear (i.e., affine), unbiased, mean- squared estimators. Consider the linear model z(k) = 28 + n(k), where
to, otherwise A random sample of N measurements is available. Explain how to find the ML and MAP estimators of 8, and be sure to list all of the assumptions needed to obtain a solution (they are not all given).

Lesson 14
Estimation of
Random Parameters:
The Linear ,
and Gaussian Model
INTRODUCTION
In this lesson we begin with the linear model
9!(k) = X(k)6 + “V(k) (14-1)
where 6 is an y2 x 1 vector of random unknown parameters, X(k) is deter- ministic, and V(k) is white Gaussian noise with known covariance matrix CR(k). We also assume that 8 is multivariate Gaussian with known mean, me, and covariance, PO, i.e.,
0 - WC me, Pe) (14-2)
and, that 8 and V(k) are Gaussian and mutually uncorrelated. Our main objectives are to compute 6,,(k) and 6 MAP(k) for this linear Gaussian model, and to see how these estimators are related. We shall also illustrate many of our results for the deconvolution and state estimation examples which were described in Lesson 2.
MEAN-SQUARED ESTIMATOR
Because 8 and V(k) are Gaussian and mutually uncorrelated, they are jointly Gaussian. Consequently, Z(k) and 0 are also jointly Gaussian; thus (Corollarv w d 13-l),
&s(k) = me + ~e@)P,‘(k)~~(k) - m&l (14-3)
118
Mean-Squared Estimator 119
It is straightforward, using (14-1) and (14-2) to show that
m%(k) = W)m* P%(k) = X(k)P,X’(k) + a(k)
and Pa(k) = P&?‘(k)
consequently,
(14-4)
(14-5)
(14-6)
h(k) = me + P&W(k)[%e(k)PJt’(k) + S(k)]-‘[Z(k) - X(k)m,l (14-7)
Observe that &&k) depends on all the given information, namely, %(k), X(k), me and Pg.
Next, we compute the error-covariance matrix, P&k), that is associated with i&&k) in (14-7). Because 6&k) is unbiased, we know that E{&,(k)} = 0 for all k; thus,
P&k) = E{&,&)&(k)) (14-8)
From (14.7), and the fact that 8,,(k) = 8 - 6&k), we see that
bMs(k) = (0 - m,) - P,X’(XP,X’ + a)-‘(% - Xrn& (14-9)
From (14-9), (14-8) and (14-l) it is a straightforward exercise to show that
P&k) = Ps - PJt’(k)[X(k)PJt’(k) + St(k)]-‘X(k)P, (14-10)
Applying Matrix Inversion Lemma 4-l to (14-lo), we obtain the following alternate formula for P&k),
P&k) = [Pi’ + X’(k)%-‘(k)X(k)]-’ (14-11)
Next, we express h&k) as an explicit function of P&k). To do this, we note that
PJe’(XPJe’ + %)-’ = P$e’(SePJe’ + %)-’ (ZePJe + 9k - XPJe’)W
= P,X’[I - (XPJe’ + %)-%P&W]W = [Pe - PJe’(XP,X’ + %)-%P,]WW = P&!e’W
(14-12)
hence, I I
b&k) = me + PMs(k)X’(k)W1(k)[%(k) - X’(k)m] (14-13)

Estimation of Random Parameters: The Linear and Gaussian Model lesson 14
Theorem lb 1.
Proof. Set Pi’ = 0 in (14-ll), to see that
P&k) = [x’(k)W(k)x(k)J-l
and, therefore,
(14-H)
(14-16)
Compare (14-16) and (9-ZZ), to conclude that &IS(~) = &(Q q
One of the most startIing aspects of Theorem 14-I is that it shows us that I3LL-J estirnathn upplies to random parameters as we!! us tu deterministic parameters. We return to a reexamination of BLUE below.
What does the condition Pi1 = 0, given in Theorem 14-1, mean? Sup- pose, for example, that the elements of 0 are uncorrelated; then, PO is a diagonal matrix! with diagonal elements & When all of these variances are very large, then Pi* = 0. A large variance for 8, means we have no idea where 19~ is located about its mean value.
Example 14-l [Minimum-Vkance Deconvolution) In Example 2-6 we showed that, for the application of deconvolution, our linear modei is
qlv) = X(N - l)p + qly) (14-17)
We shall assume that p and V(N) are jointly Gaussian, and, that rn@ = 0 and rn=+- = 0; hence, rn% = 0, Additionally, we assume that cove] = pI. From (l4-7), we deter- mine the following formula for bMS(N),
~&v) = FJe’(N - l)[X(N - l)PJe’(N - 1) + p1]-?qN) (14-18)
Recall, from Example 2-6, that when g(k) is described by the product model A4 = q W W, then
P = QG (14-19)
where
and (14-20)
r = col(r(l), r(2), . . . , r(N)) (14-21)
In the product model, r(k) is white Gaussian noise with variance OF, and q (k) Bernoulli sequence. 0bviously, if we know Qq then p is Gaussian, in which case
is a
where we have used (14-18) becomes
the fact that Qi = Qq, because q(k) = 0 or 1, When known,
Best Linear Unbiased Estimation, Revisited
Although bMS is a mean-squared estimator, so that it enjoys all of the properties of such an estimator (e.g., unbiased? minimum-variance. etc.), bMS is not a consistent estimator of )I. Consistency is a large sample property of an estimator: however. as N increases, the dimension of p increases. because p is Iv X 1. Consequently, we cannot prove consistency of kMS (recall that, in all other problems, 9 is n x 1, where n is data independent; in these problems we can study consistency of 6).
Equations (14-18) and (14-23) are not very practical for actually computing kMSr because both require the inversion of an N x N matrix, and N can become quite large (it equals the number of measurements). We return to a more practical way for computing gMS in Lesson 22. 0
BEST LINEAR UNBIASED ESTIMATION, REVfSITED
In Lesson 9 we derived the BLUE of 9 for the linear model (14-l), under the following assumptions about this model:
1. 8 is a deterministic but unknown vector of parameters, 2. X(k) is deterministic, and 3. V(k) is zero-mean noise with covariance matrix a(k).
We assumed that 6 &k) = F(k)Z(k) and chose FBLU(k) so that iBLv(k) is an unbiased estimator of 9, and the error variance for each one of the n elements of 9 is minimized. The reader should return to the derivation of 6&k) to see that the assumption “0 is deterministic” is never needed, either m the deri- vation of the unbiasedness constraint [see the proof of Theorem 6-1, in which Equation (6-9) becomes [I - F(k)X(k)]E(9) = 0, if 8 is random], or in the derivation of Ji[fj, hi) in Equation (9-14) (due to some remarkable cancel- lations); thus, 9,Lu(k), given in (g-22), is applicable to random us well us deterministic parameters in our linear model (14-I); an<, because the BLUE of 9 is the special case of the WISE when W(k) = 91-‘(k), B-(k), given in (3-lo), is also applicable to random as well as deterministic parameters in our linear model.
Theorem 14-I relates bMS(k) and i,,,(k) under some very stringent con- ditions that are needed in order to remove the dependence of iMs on the a priori statistical information about 9 (i.e.. m, and PO), because this information was never used in the derivation of &&k).
Next, we derive a different BLUE of 9, one that incorporates the a priori statistical information about 0. To do this (Sorenson, 1980, pg. 210), we treat m as an additional measurement which will be augmented to Z(k). Our additional measurement equation is obtained by adding and subtracting 8 in the identity me = Q, i.e.,
m, = 9 + (me - 6) (14-24)

122 Estimation of Random Parameters: The Linear and Gaussian Model Lesson 14
Quantity me - 6 is now treated as zero-mean noise with covariance matrix PO. Our augmented linear model is
fw) = (Ep)() + (lw) (14-25) \ / L”, L J
%a xc7 Yl which can be written, as
f&(k) = K(k)6 + X(k) (14-26)
where 3, (k), %e, (k), and V0 (k) are defined in (14-25). Additionally,
E&z(k)=‘C(k)} 2 R(k) = (,%) (14-27)
We now treat (14-26) as the starting point for derivation of a BLUE of 8, which we denote 6:&k). Obviously,
6&,(k) = [%e,‘(k)~,‘(k)~,(k)]-‘~,,(k)~,‘(k)~,(k) (14-28)
Theorem 14-2. For the linear Gaussian model, when X(k) is deter- ministic it is always true that
&4S(k) = &w(k) (14-29)
Proof. To begin, substitute the definitions of %e, ,a,, and %, into (14-28), and multiply out all the partitioned matrices, to show that
i”,,,(k) = (Pi1 + X’%‘%e)-‘(P~‘me + %e’%?E) (14-30)
From (14.11), we recognize (Pi1 + X’%?X)-l as PMs; hence,
6&(k) = PMs(k)[P;‘me + X’(k)9P(k)ZE(k)]
Next, we rewrite 6&k) in (14-13), as
6&k) = [I - PMs%e’W%]me + PMS%er%-lZ
however,
(14-31)
(14-32)
(14-33)
where we have again used (14-11). Substitute (14-33) into (14-32) to see that
&k) = PMs(k)[P,‘m, + X’(k)%-‘(k)%(k)] (14-34)
hence, (14-29) follows when we compare (14-31) and (14-34). q
Maximum a Posteriori Estimator 123
tive To conclude this section, we note that the
function that is associated with 6”,,(k) is weighted-least squares objec-
J,[&(k)] = %;(k)%;l(k)%,(k)
= (me - O)‘P;‘(me - 6) + %‘(k)%-‘(k)%(k) (14-35)
The first term in (14-35) contains all the a priori information about 8. Quantity me - 8 is treated as the difference between “measurement” me and its noise- free model, 6.
MAXIMUM A POSTERIOR1 ESTIMATOR
In order to determine 6 MAP(k) for the linear model in (14-1) we first need to determinep @l%(k)). Using the facts that 8 - N(0; me, PO) andV(k) - N(V(k); 0, a(k)), it follows that
1 {
1 P 60 = vm exp - 2 (0 - m&W(e - me) I (14-36)
exp { - $ [S(k) - %e(k)e]‘%-‘(k)[Z(k) - X(k)B]} (14-37)
hence,
mJ’Pi’(B - me) - i (z - %ee)w~(a - xe) (14-38)
To find &&k) we must maximize In p (e[%) in (14-38). Note that to find 6&(k) we had to maximize &[$(k)] in (14-35); but,
In P WV a -J@“(k)] (14-39)
This means that maximizing in p(O/fE) leads to the same value of 6 as does minimizing J,[&(k)]. We have, therefore, shown that &,,(k) = &&k).
Theorem 14-3. For the linear Gaussian model, when X(k) is deter- ministic it is always true that
L&) = &w(k) El (14-40)
Combining the results in Theorems 14-2 and 14-3, we have the very important result, that for the linear Gaussian model
k&) = &b,(k) = bw(k) (14-41)

Estimation of Random Parameters: The Linear and Gaussian Model Lesson 14
Put another way, for the linear Gaussian model. all roads lead to the same estimator.
Of course, the fact that &&k) = &&c) should not come as any sur- prise, because we already established it (in a model-free environment) in Theorem 13-2.
Example 14-2 (Maxirrtum-Likelihood Deconvolution] As in Example 14-1, we begin with the deconvolution linear model
Z(N) = ?e(lv - l)p + V(N) (14-42)
Nuw, however, we use the product model for F, given in (l&19), to express 5(N) as
fw) = 3e(N - 1)&r + %yN) (14-43)
For notational convenience, let
q=col(q(l),q(2),...,q(~) (14-44)
Our objectives in this example are to obtain MAP estimators for both q and r. In the literature on maximum-likelihood deconvolution (e.g., Mend& 1983) these estimators are referred to as unconditional ML estimators, and are denoted i and G* We denote these estimators as eMAp and 4 MAP, in order to be consistent with this book’s notation.
The starting point for determining GMAp and &p is the joint density function P k @W% th-e
(14-45)
but
P @dll = P (Mwl) ( 14-46)
Equation (14-46) uses a probability function for q rather than a probability density function, because q (Ic) takes on only two discrete values, 0 and 1. Substituting (14-46) into (14-45), we find that
(14-47)
Note, also, that
(14-48)
where we have used the fact that r and q are statistically independent* Substituting (14-48) for p (Z(N)~r,qJ into (14-47), we see that
P wGw9~ =P wwwwl~ (14-49)
Observe that the r dependence of the MAP-likelihood function is completely con- tained in p(r,%(N)iq). Additionally, when q is given, the only remaining random quantities are the zero-mean Gaussian quantities r and Z(w; hence, p(r,C!Z(~iq) is muitivariate Gaussian. Letting
x = co1 (r,%(N)) (14-50)
Maximum a Posteriori Estimator 125
and
P, = E{xx’/q} (14-51)
then
p(r.CIC(N)jq) = (23--KjP,)-*/2 exp (- i x’P;‘x) (13-52)
We leave, as an exercise for the reader, the maximization of p (r,qlCX(N)), from which it follows (Mended, 1983b, pp. 112-114) that
r*(Nlq) = u?Q,%e’(N - l)[c&‘(N - l)Q,X’(N - 1) + pII-‘%(N) (14-53)
&,P can be found by maximizing
(14-54)
where
Pr(q) = fi Pr[q (k)] = Amq(l - A)N - mq k-1
(14-55)
(14%)
and finally,
i,,, = r*(NIhM*P) (14-57)
Equations (14-54) and (14-57) are quite interesting results. Observe that we are permitted first to direct our attention to finding iWAP and then to finding iMAP. Ob- n serve, also, that rM,+p = j&&V]QJ [compare (14-53) and (14-23)].
There is no simple solution for determining GMAP. Because the elements of q in p(r*,q[%(N)) have nonlinear interactions, and because the elements of q are con- strained to take on binary values, it is necessary to evaluate p(r*,qlS(N)) for every possible q sequence to find the q for which p (r * ,ql%(N)) is a global maximum. Because q(k) can take on one of two possible values, there are 2N possible sequences where N is the number of elements in q. For reasonable values of N (such as N = 400), finding the global maximum of p (r * ,qj%‘(N)) would require several centuries of computer time.
We can always design a method for detecting significant values of p(k) so that the resulting 4 will be nearly as likely as the unconditional maximum-likelihood esti- mate, &,P. Two MAP detectors for accomplishing this are described in MendeI (1983b, pp. 127-137). [Note: The reader who is interested in more details about these MAP detectors should first review Chapter 5 in Mendel, 1983b, because they are designed using a slightly different likelihood function than the one in (14-54).] III

Estimation of Random Parameters: The Linear and Gaussian Model Lesson 14
Example 14-3 (State-Estimation)
In Example model is
2-4 we that, for the application of state estimation, our linear
ffV9 = X(N, kl)x(kl) + V(N, k,) (14-58)
From (2-17), we see that
x(k,) = Cpklx(0) + $ @’ - i yu(i - 1) = @“lx(O) + Lu (14-59) I= 1
u = co1 (u(O), u(l), . . . ,u (Iv)) (14-60)
and L is an n x (N + 1) matrix, the exact structure of which is not example. Additionally, from (2-21), we see that
important for this
Sr(N, kl) = M(N, kl)u + v (14-61)
v = col(v(l), v(2), . . . ) v(N)) (14-62)
Observe that both x(k,) andSr(N, kl) can be viewed as linear functions of x(O), u and v. We now assume that x(O), u and v are jointly Gaussian. Reasons for doing this
are discussed in Lesson 15. Then, because x(kl) and ‘V(N, kl) are linear functions of x(O), u and v, x(k,) and V(N, kl) are jointly Gaussian (Papoulis, 1965, pg. 253); hence,
(14-63)
and
In order to evaluate &(klIw we must first compute mxck I1 and Pxck I)’ We show how to do this in Lesson 15.
Formula (14-63) is very cumbersome. It appears that its right-hand side changes as a function of kl (and N). We conjecture, however, that it ought to be possible to express &(k$V) as an affine transformation of &(kl - l(N), because x(kl) is an affine transformation of x(kl - l), i.e., x(kl) = cPx(kl - 1) + yu(kl - 1).
Because of the importance of state estimation in many different fields (e.g., control theory, communication theory, signal processing, etc.) we shall examine it in great detail in many of our succeeding lessons. 0
PROBLEMS
14-l. Derive Eq. (14-10) for P&k). 14-2. Show that r*(Nlq) is given by Eq. (14-53) and that GMAP can be found by
maximizing (14-54).
Lesson 14 Problems 127
14-3. x and v are independent Gaussian random variables with zero means and variances O$ and d, respectively. We observe the single measurement 2 =x+v=l. (a) Find &. (b) Find iMAP.
14-4. For the linear Gaussian model in which X(k) is deterministic, prove that iMAP is a most efficient estimator of 8. Do this in two different ways. Is &,&) a most efficient estimator of 6?

Lesson 15
Elements
of DiscreteJiime GaussmMarkov Random Processes
Lessons 13 and 14 have demonstrated the importance of Gaussian random variables in estimation theory. In this lesson we extend some of the basic concepts that were introduced in Lesson 12, for Gaussian random variables, to indexed random variables? namely random processes. These extensions are needed in order to develop state estimators.
DEFlNlTH3NS AND PROPERTIES UF DISCRETE-TIME GAUSS-MARKOV RANDOM PROCESSES
Recall that a random process is a coIIection of random variables in which the notion of time plays a role.
Definition 15-l (Meditch, 1969, pg. 106). A vector random prucess is a family of randurn vecturs (s(t), ~4) indexed by a parameter t aU uf whuse values lie in some appropriate index set 9. When 9 = {k: k = 0, I, . . . ] we have a discrete4me randurn process. El
Definition U-2 (Meditch, 1969, pg. 117). A vector randurn prucess {s(t), k%} Ls defined tu be multivariate Gaasian if, fur any t time points t1, t2, . . l , t[ in $ where t zk an integer, [he set uf e randum n vecturs s@J, w7 * ’ * , s(Q is juintly Gaussian distributed. I3
128
Definitions and Properties of Discrete-Time Gauss-Markov Random Processes
Let Y(I) be defined as
then, Definition 15-2 means that
in which
my(l) = EiW)} (15-3)
and PY(l) is the n/ x nl matrix E([Y(I) - m,(l)][Y(I) - my(/)]‘} with elements Py(i, f, where
Pdi 3 11 = EMi) - mdh)JLs(~j) - m&>l’~ (15-4)
ki = 1,2, . . . , 1.
Defmition 15-3 (Meditch, 1969, pg. 118). A vector random Process (s(t), k.9) is a Murkuv process, if, for any m time points tl < f2 < . . . < t, in 9, where m is any integer, it is true that
For continuous random variables, this means Ihat
Note that, in (U-5), s(tm) 5 S(t,,,) means si(tm) I Si(tm) for i = 1, 2,. . . , n. If we view time point t,,, as the present time and time points t . . . . tl as the past, then a Markov process is one whose probability law Git’, probability density function) depends only on the immediate past value, t,,, - 1. This is often referred to as the Markuv property for a vector random process. Because the probability law depends only on the immediate past value we often refer to such a process as a first-order Markov process (if it depended on the immediate two past values it would be a second-order Mar- kov process).
Theorem 15-l. Let (s(t), tE.%} be a first-order Markav process, and tl < t* < , . . < t, be any time points in 9, where m is an integer. Then

130 Elements of Discrete-Time Gauss-Markov Random Processes Lesson 15
PRX$ From probability theory (e.g., Papoulis, 1965) and the Markov property of s(t), we know that
pb(G?l>, a?i - I), l l l 7 s(4)l = PEGz>lS(fm - I>7 l l l 7 s(4)lp [s(L - I), l l * 9 s(4)] = p bh?l>lS(f* - I)lP[s(L - I>, l * l 7 s(h)1
In a similar manner, we find that
Pb(Ll), l l l ? $I)1 = p Cs(tm - I)IG?l - *)I p [s(tm - 2), l l l 7 s(t1)l pb(t,-*), l l l 9 s(h)1 = p [s(G?l - ?)Is(fm - $1 p b(Ll - 31, l ’ l 7 s(h)]
. . .
(15-8)
I (15-9)
Equation (15-7) is obtained by successively substituting each one of the equa- tions in (15-9) into (15-8). 0
Theorem 15-l demonstrates that a first-order Markov process is com- pletely characterized by two probability density functions, namely, the transi- tion probability density function, p [s(ti)ls(ti _ JJ, and the initial (prior) proba- bility density function p[s(t,)]. Note that generally the transition probability density functions can all be different, in which case they should be subscripted [e.g., pmb(tm)ls(L - 111 and pm - I[& - I>I& - JII
Theorem 15-2. For a first-order Markov process,
Ew?l >Is(tm - I), l l l 9 s(4>) = ~~s(t,)Is(L - I>> 0 (15-10)
We leave the proof of this useful result as an exercise. A vector random process that is both Gaussian and a first-order Markov
process will be referred to in the sequel as a Gauss-Markov process.
Definition 15-4. A vector random process {s(t), te.9) is said to be a Gaussian white process if, for any m time points tl, t2, . . . , t, in 9, where m is any integer, the m random vectors s(tr), s(t& . . . , s(t,,,) are uncorrelated Gaus- sian random vectors. 0
White noise is zero mean, or else it cannot have a flat spectrum. For white noise
E{s(ti)s’(t,)) = 0 for all i # j (15-11)
Additionally, for Gaussian white noise
P tw1 = P [WI P [S(h)1 l l l P [s(tJl (15-12)
[because uncorrelatedness implies statistical independence (see Lesson 12)] where p [s(ti)] is a multivariate Gaussian probability density function.
A Basic State-Variable Model 131
Theorem 15-3. A vector Gaussian white process s(t) can be veiwed as a first-order Gauss-Markov process for which
P csw~>l = P w (15-13)
for all t, ~e.9 and t =f T.
Proof. For a Gaussian white process, we know, from (H-12), that
P b(t)7 WI = p [s(t)lp [s( +I (15-14)
but, we also know that
P b(t), SW1 = P b(olw P M7)l Equating (15-14) and (15-15), we obtain (15-13). 0
(15-15)
Theorem 15-3 means that past and future values of s(t) in no way help determine present values of s(t). For Gaussian white processes, the transition probability density function equals the marginal density function, p [s(t)], which is multivariate Gaussian. Additionally,
E{s(t,)&l - I), l l l ? s(h)> = WL 1) (15-16)
A BASIC STATE-VARIABLE MODEL
In succeeding lessons we shall develop a variety of state estimators for the following basic linear, (possibly) time-varying, discrete-time dynamical sys- tem (our basic state-variable modeo, which is characterized by YI x 1 state vector x(k) and m x 1 measurement vector z(k):
x(k + 1) = @(k + l,k)x(k) + I-(k + l?k)w(k) + ‘If(k + l,k)u(k) (15-17)
and
z(k + 1) = H(k + l)x(k + 1) + v(k + 1) (15-M)
where k = 0, 1, . . . . In this model w(k) and v(k) are p x 1 and m x 1 mutu- . ally uncorrelated (possibly nonstationary) jointly Gaussian white noise se-
quences; i.e.,
/Elrou.(j))=a(ns,
E{v(i)v’( i)} = R(i)&

132 Elements of Discrete-Tmx Gauss-Markov Random Process~ tzsson 75
and I I 1 E{w(+‘(j)j = S = 0 for all i and j’
I (15-21)
Covariance matrix Q(i) is positive semidefinite and R(i) is positive definite [so that R-*(i) exists]. Additionally, u(k) is an 2 x 1 vector of known system inputs, and initial state vector x(O) is multivariate Gaussian, with mean m&l) and covariance PK(0), i.e.,
(15-22)
and9 x(O) is not correlated with w(k) and v(k). The dimensions of matrices @, I’, 9, H, Q and R are n X n, n x p, fl x 2, m X n, p x p, and m x m, respectively.
Disturbance w(k) is often used to model the following types of uncer- tainty:
1. disturbance forces acting on the system (e,g., wind that buffets an air- plane) ;
2. errors in modeling the system (e.g., neglected effects); and 3. errors, due to actuators, in the translation of the known input, u(k), into
physical signals.
Vector v(k) is often used to model the following types of uncertainty:
1. errors in measurements made by sensing instruments; 2. unavoidable disturbances that act directly on the sensors; and 3. errors in the realization of feedback compensators using physical com-
ponents [this is valid only when the measurement equation contains a direct throughput of the input u(k), i.e., when z(k + 1) = I-I(k + 1) x(k + 1) + G(k + l)u(k + 1) + v(k + 1); we shall examine this situ- ation in Lesson 231.
0f course, not all dynamical systems are described by this basic model. In general, w(k) and v(k) may be correlated, some measurements may be made so accurate that, for all practical purposes, they are “perfect” (Le., there is no measurement noise associated with them), and either u(k) or v(k), or both, may be colored noise processes. We shall consider the modification of our basic state-variable model for each of these important situations in Lesson 23.
Properties of the Basic State-Variable Model
PROPERTIES OF THE BASIC STATE-VARIABLE MODEL
In this section we state and prove for our basic state-variable model
a number of important statistical properties
k= Theorem 15-4. When x(O) and w(k)
0, l,...) is a Gauss-Markov sequence. are jointly Gaussian then (x(k),
Note that if x(O) and w(k) are individually Gaussian and statistically independent (or uncorrelated), then they will be jointly Gaussian (Papoulis, 1965).
Proof a. Gaussian Property [assuming u(k) nonrandom]. Because u(k) is non-
random, it has no effect on determining whether x(k) is Gaussian; hence, for this part of the proof we assume u(k) = 0. The solution to (15-17) is
x(k) = @(k,O)x(O) + i @(k,i)r(i,i - l)w(i - 1) (15-23) i=l
where
Q&i) = @(k,k - l)@(k - 1,k - 2). . . @,(i + 1,i) (15-24)
Observe that x(k) is a Iinear transformation of jointly Gaussian random vectors x(O), w(O), w(l), . . . , w(k - 1); hence, x(k) is Gaussian,
b. Markov Property. This property does not require x(k) or w(k) to be Gaussian. Because x satisfies state equation (1517), we see that x(k) depends only on its immediate past value; hence, x(k) is Markov. 0
We have been able to show that our dynamical system is Markov because we specified a model for it. Without such a specification, it would be quite difficult (or impossible) to test for the Markov nature of a random process.
By stacking up x(l), x(2), , . . into a supervector it is easily seen that this supervector is just a linear transformation of jointly Gaussian quantities x(O), w(O), w(l), - - - ; hence, x(l), x(2), . . . are themselves jointly Gaussian.
A Gauss-Markov sequence can be completeIy characterized in two ways:
1. specify the marginal density of the initial transition density P[x(k + 1)1x(k)], or
state vector, P Ex(O)l and the
2. specify the mean and covariance of the state vector sequence. The sec- ond characterization is a complete one because Gaussian random vec- tors are completely characterized by their means and covariances (Les- son 12). We shall find the second characterization more useful than the first.

Elements of Discrete-Time Gauss-Markov Random Processes Lesson 15
The Gaussian density function for state vector x(k) is
p[x(k)] = [(2n)“lP,(k)j]-“* exp
- m,(k>l’K’(k)[x(k) - x m WI} (15-25)
where
m,(k) = EW)l (15-26)
P,(k) = Eew - mxwmw - mxvw (15-27)
We now demonstrate that m,(k) and P,(k) can be computed by means of recursive equations.
Theorem 15-5. For our basic state-variable model,
a. m,(k) can be computed from the vector recursive equation
m,(k + 1) = @(k + l,k)m,(k) + 3!(k + l,k)u(k) (15-28)
where k = 0, 1, . . . , and mx(0) initializes (O-28), b. P,(k) can be computed from the matrix recursive equation
P,(k + 1) = iP(k + l,k)P,(k)@‘(k + 1,k) + r(k + l,k)Q(k)r’(k + 1,k) (15-29)
wherek=O,l,..., and P,(O) initializes (U-29), and c. E{ [x(i) - mJi)][x(j> - m,(j)]‘} 4 P,(i, j) can be computed from
W, j)Px(j) pX(iy i> = Px(i)Qr(j, i)
wheni > j wheni <j
(B-30)
Proof a. Take the expected value of both sides of (15.17), using the facts that
expectation is a linear operation (Papoulis, 1965) and w(k) is zero mean, to obtain (S-28).
b. For notational simplicity, we omit the temporal arguments of @ and r in this part of the proof. Using (15-17) and (15-28), we obtain
P,(k + 1) = E{ [x(k + 1) - mx(k + l)][x(k + 1) - m,(k + l)]‘}
= E{ ww) - mx(k>l + w41 PCW - mx(k)l + rww’1 (15-31)
= @P,(k)@’ + I’Q(k)I” + QE{ [x(k) - mx(k)]wf(k)}rr + FE{w(k)[x(k) - mX(k)]‘}@’
Because m,(k) is not random and w(k) is zero mean, E{m,(k)w’(k)) = \ -
Properties of the Basic State-Variable Model
c.
mx(k)E(w’(k)l = 0, and E{w(k)m#)} = 0. State vector x(k) depends at most on random input w(k - 1) [see (B-17)]; hence,
E{x(k)w’(k)} = E{x(k)}E{w’(k)} = 0 (15-32)
and E{w(k)x’(k)} = 0 as well. The last two terms in (15-31) are therefore equal to zero, and the equation reduces to (15-29). We leave the proof of (H-30) as an exercise. Observe that once we know covariance matrix P,(k) it is an easy matter to determine any cross- covariance matrix between state x(k) and x(i)@ # k). The Markov nature of our basic state-variable model is responsible for this. Cl
Observe that mean vector m,(k) satisfies a deterministic vector state equation, (U-28), covariance matrix P,(k) satisfies a deterministic matrix state equation, (15-29), and (15-28) and (15-29) are easily programmed for digital computation.
Next we direct our attention to the statistics of measurement vector z(k).
Theorem 15-6. For our basic state-variable model, when x(O), w(k) and v(k) are jointly Gaussian, then {z(k), k = 1, 2, . . . } is Gaussian, and
m,(k + 1) = H(k + l)m,(k + 1) (15-33)
P,(k + 1) = H(k + l)P,(k + l)H’(k + 1) + R(k + 1) (15-34)
where m,(k + 1) and P,(k + 1) are computed from (15-28) and (1529), respectively. Cl
We leave the proof as an exercise for the reader. Note that if x(O), w(k) and v(k) are statistically independent and Gaussian they will be jointly Gaus- sian.
Example 15-l Consider the simple single-input single-output first-order system
x(k + 1) = $x(k) + w(k) (15-35)
z(k + 1) =x(k + 1) + v(k + 1) (15-36)
where w(k) and v (k) are wide-sense stationary white noise processes, for which q = 20 and r = 5. Additionally, m, (0) = 4 and p,(O) = 10.
The mean of x(k) is computed from the following homogeneous equation
1 m,(k + 1) = ?mx(k) ??z,(O) = 4 (15-37) A

136 Elements of Discrete-Tme Gauss-Markov Random Processes Lesson 15
and, the variance of X(/C) is computed from Equation (15-29), which in this case simplifies to
pJk -I 1) = ipx(k) + 20 px(O) = 10 (15-33)
Additionally, the mean and variance of z(k) are computed from
and
?&(k + 1) = mx(k + 1) (1539)
pr(k + 1) = px[k + 1) + 5 (15-40)
Figure 15-l depicts TTL(~) and pr2(k). Observe that tnX (k) decays tu zero very rapidly and that pln(JQ approaches a steady-state value. piQ = 5.163. This steady-state value can be computed from equation (15-38) by setting JJ~(Jc) = pX(k + 1) = j%. The existence of j& is guaranteed by our first-order system being stable.
Although ~T=z~ (Jz) -+ 0 there is a lot of uncertainty about x(k), as evidenced by the large value of j&.There will be an even larger uncertainty about .7(k), because FZ -+ 31.66. These large values for j& and j& are due to the large values of q and r. In many practical applications, both q and r will be much less than unity in which case & and pX wil1 be quite small. D
8-
7-
6-
Figure E-1 Mean (15-35) and (B-36).
(dashed) and standard deviation (bars) for first-order system
Signal-To-Noise Ratio 137
If our basic state-variable model is time-invariant and stationary, and, if @ is associated with an asymptotically stable system (i.e., one whose poles all lie within the unit circle), then (Anderson and Moore. 1979) matrix P,(k) reaches a limiting (steady-state) solution P,, i.e.,
Fz P,(k) = p, (15-41)
Matrix f, is the solution of the following steady-state version of (1529),
px = @,W + rQl? (15-42)
This equation is called a discrete-time Lyupunov equation. See Laub (1979) for an excellent numerical method that can be used to solve (15-42) for FX.
SIGNAL-TO-NOISE RATIO
In this section we simplify our basic state-variable model (15-17) and (15-B) to a time-invariant, stationary, singIe-input single-output model:
x(k + 1) = @x(k) + yw(k) + +u (k) (15-43)
z (k + 1) = h’x(k + I) + v(k + 1) (15-44)
Measurement z (k) is of the classical form of signal plus noise, where “signal” s(k) = h’x(k).
The signal-to-noise ratio is an often-used measure of quality of mea- surement z(k). Here we define that ratio, denoted by SNR(k), as
d(k) SNR(k) = - t (15-45)
From preceding analyses, we see that
SNR(k) = F
Because P,(k) is in general a function of time, SNR(k) is also a function of time. If, however, @ is associated with an asymptotically stable system then (15-41) is true. In this case we can use FX in (15-46) to provide us with a single number, SNR, for the signal-to-noise ratio, i.e.,
h’F,h SNR=- r (15-47)
Finally, we demonstrate that SNR(k) (or SNR) can be computed without knowing q and r explicitly; all that is needed is the ratio q /r . Multiplying and dividing the right-hand side of (15-46) by q, we find that
SNR(k) = [h’ y h] (q /r) (15-48)

Elements of Discrete-Time Gauss-Markov Random Processes Lesson 15
Scaled covariance matrix P,(k)/q is computed from the following version of (15-29)
(15-49)
One of the most useful ways for using (15-48) is to compute q /I- for a given signal-to-noise ratio SNR, i.e.,
4 SNR - =- r h’ E
Th
(15-50)
In Lesson 18 we show that q /r can be viewed as an estimator tuning param- eter; hence, signal-to-noise ratio, SNR, can also be treated as such a param- eter.
Example 15-2 (Mendel, 1981) Consider the first-order system
x(k + 1) = &(k) + v(k) (15-51)
z(k + 1) = hx(k + 1) + v(k) (15-52)
In this case, it is easy to solve (15-49), to show that
R/q = yzl(1 - 4’) (15-53)
hence,
SNR= (g$)(;) (15-54)
Observe that, if h2y = 1 - &2, then SNR = q /r. The condition h2y = 1 - 42 is satis- fiedif,forexample,y= l,+= l/fiandh = l/G. 0
PROBLEMS
15-l. Prove Theorem 15-2, and then show that for Gaussian white noise Eb(t,)[s(t, - I), l . l , s(h)} = E{s(t,)}.
15-2. Derive the formula for the cross-covariance of x(k), P,(i, j), given in (15-30). 15-3. Derive the first- and second-order statistics of measurement vector z(k), that are
summarized in Theorem 15-6. 15-4. Reconsider the basic state-variable model when x(0) is correlated with w(O), and
w(k) and v(k) are correlated [E{w(k)v’(k)} = S(k)]. (a) Show that the covariance equation for z(k) remains unchanged. (b) Show that the covariance equation for x(k) is changed, but only at k = 1. (c) Compute E{z(k + l)z’(k)}.
Lesson 15
15-5.
Problems 139
I v(k)
In this problem, assume that u(k) and v(k) are individually Gaussian and uncorrelated. Impulse response h depends on parameter a, where a is a Gaussian random variable that is statistically independent of u (k) and v(k). (a) Evaluate E{z (k)}. (b) Explain whether or not ,7(k) is Gaussian.

Lesson 16
State Esf,imatlon:
Predktion
INTRODUCTION
We have mentioned, a number of times in this book, that in state estimation three situations are possible depending upon the relative relationship of total number of available measurements, IV, and the time point, k, at which we estimate state vector x(k), namely: prediction (N -C k), filtering (IV = k), and smoothing (ZV > k). In this lesson we develop algorithms for mean-squared predicted estimates, &(kij), of state x(k). In order to simplify our notation, we shall abbreviate &(k 1~) as i(k ij). (Just in case you have forgotten what the notation S(k 1~) stands for, see Lesson 2.) Note that, in prediction, k > j.
SINGLE-STAGE PREDICTOR
The most important predictor of x(k) for our future work on filtering and smoothing is the sin&e-stage predictor g(k/k - 1). From the Fundamental Theorem of Estimation Theory (Theorem 13-l), we know that
i(kik - 1) = E{x(k)f%(k - 1)) (16-l) where
%(k - 1) = co1 (z(I), z(2), . . . , z(k - 1)) (16-2)
It is very easy to derive the state equation
a formula for i(k ik - I) by operating on both sides of
x(k) = @(k,k - l)x(k - 1) + r(k,k - l)w(k - 1) + ‘I’(k?k - l)u(k - 1) (16-3)
Single-Stage Predictor 141
with the linear expectation operator E{ =I?X(k - 1)). Doing this, we find that
i(klk - 1) = @(k,k - l)ii(k - Ilk - 1) + V(k,k - l)u(k - 1) (16-4)
where k =l, 2,.... To obtain (16-4) we have used the facts that E{w(k - 1)) = 0 and u(k - 1) is deterministic.
Observe, from (l&4), that the single-stage predicted estimate, i(klk - l), depends on the filtered estimate, i(k - Ilk - l), of the preceding state vector x(k - 1). At this point, (16-4) is an interesting theoretical result; but, there is nothing much we can do with it, because we do not as yet know how to compute filtered state estimates. In Lesson 17 we shall begin our study into filtered state estimates, and shall learn that such estimates of x(k) depend on predicted estimates of x(k), just as predicted estimates of x(k) depend on filtered estimates of x(k - 1); thus, filtered and predicted state estimates are very tightly coupled together.
Let P(k jk - 1) denote the error-covariance matrix that is associated with i(k(k - l), i.e.,
P(klk - I) = E{ [%(klk - 1) - m;(kjk - l)][S(klk - 1) - m,(k [k - I)]‘) (16-5)
where
x(k Ik - 1) = x(k) - ri(kik - 1) (16-6)
Additionally, let P(k - Ilk - 1) denote the error-covariance matrix that is associated with i(k - Ilk - I), i.e.,
P(k - Ilk - 1) = E{[ji(k - ilk - 1) - m,(k - 11k - l)][g(k - Ilk - 1) - m,(k - Ilk - l)]‘} (16-7)
For our basic state-variable model (see Property 1 of Lesson 13), m(k Ik - 1) = 0 and mi(k - Ilk - 1) = 0, so that
P(klk - 1) = E{%(klk - l)i’(klk - 1)) (16-8)
and
P(k - Ilk - 1) = E(%(k - Ilk - l)Ji’(k - lbk - 1)) (16-9)
Combining (16-3) and (16-4), we see that
G(klk - 1) = @(k,k - l)x(k - Ilk - 1) + T(k,k - l)w(k - 1) (16-10)

142 State Estimation: Prediction Lesson 16
A straightforward calculation leads to the following formula for P(klk - l),
P(kJk - .l) = a?(k,k - I)P(k - ilk - l)W(k,k - 1) + r(k,k - l)Q(k - l)T’(k,k - 1) (16-H)
where k = 1,2, . . . . Observe, from (16-4) and (16-ll), that x(010) and P(O(0) initialize the
single-stage predictor and its error-covariance. Additionally,
ri(O[O) = E{x(O)( no measurements} = m,(O) (16-12)
and
P(O10) = E(x(O~O)~‘(O~O)} = W&(O) - mx(~)l[x(~> - m,(W> = P,(O) (16-13)
Finally, recall (Property 4 of Lesson 13) that both x(k jk - 1) and X(kjk - 1) are Gaussian.
A GENERAL STATE PREDICTOR
In this section we generalize the results of the preceding section so as to obtain predicted values of x(k) that look further into the future than just one step. We shall determine r2(klj) where k > j under the assumption that filtered state estimate x(jlj) and its error-covariance matrix E{ii( jlj)i’( jl j)} = P( jl j) are known for some j = 0, 1, . . . .
Theorem 164 a. If input u(k) is deterministic, or does not depend on any measurements,
then the mean-squared predicted estimator of x(k), i(k( j), is given by the expression
Wi) = @OWi(jli), + 2 @(k,i)*(i,i - l)u(i - 1) k>j (16-14)
i=j+1
b. The vector random process {x(kl j), k = j + 1, j + 2, . . . } is: i. zero mean, ii. Gaussian, and
iii. first-order Markov, and iv. its covariance matrix is governed by
P(klj) = @(k,k - l)P(k - llj)@‘(k,k - 1) + r(k,k - l)Q(k - l)l?(k,k - 1) (16-15)
A General State Predictor 143
Before proving this theorem, let us observe that the prediction formula (16-14) is intuitively what one would expect. Why is this so? Suppose we have processed all of the measurements z(l), z(2), . . . , z(j) to obtain i(jlj) and are asked to predict the value of x(k), where k > j. No additional measurements can be used during prediction. All that we can therefore use is our dynamical state equation. When that equation is used for purposes of prediction we neglect the random disturbance term, because the disturbances are not mea- surabie. We can only use measured quantities to assist our prediction efforts. The simpiified state equation is
x(k + 1) = @(k + l&)x(k) + !I!& + l&u(k)
a solution of which is
(16-16)
x(k) = @(k,j)x( j) + c @(k,i)!I!(i,i - l)u(i - 1) (16-17) i=j+ 1
Substituting i(jl j) for x(j), we obtain the predictor in (16-14). In our proof of Theorem 16-1 we establish (16-14) in a more rigorous manner.
Proof a. The solution to state equation (16-3), for x(k), can be expressed in terms
of x(j), where j < k, as
x(k) = @(k,j)x(j) + $ @(k,i)[I”(i,i - l)w(i - 1) i=j+ 1
+ V(i,i - l)u(i - l)] (16-M)
We apply the Fundamental Theorem of Estimation Theory to (16-18) by taking the conditional expectation with respect to Z(j) on both sides of it. Doing this, we find that
i(kl j) = @(k,j)i(jlj) + i Q(k,i)[I’(i,i - l)E{w(i - 1)1%(j)} i=j+ 1
+ *(i,i - l)E{u(i - l)lZ( j)}] (16-19)
Note that on w(j -
j) depends at most Consequently,
on x(j) which, in turn, depen ds at
E{w(i - lW(i)l = E{w(i - l)lw(O), w(l), . . l $ w(j - 01 (16-20)
where i = j + 1, j + 2,. . . , k. Because of this range of values on argu- ment i, w(i - 1) is never included in the conditioning set of values w(O), w(l), . . . , w(j - 1); hence,
E{w(i - 1)1%(j)} = E{w(i - 1)) = 0 (16-21) for all i = j+l,j+2 ,..., k.
Note, also, that E{u(i - 1)13(j)} = E{u(i - 1)) = u(i - 1) (16-22)
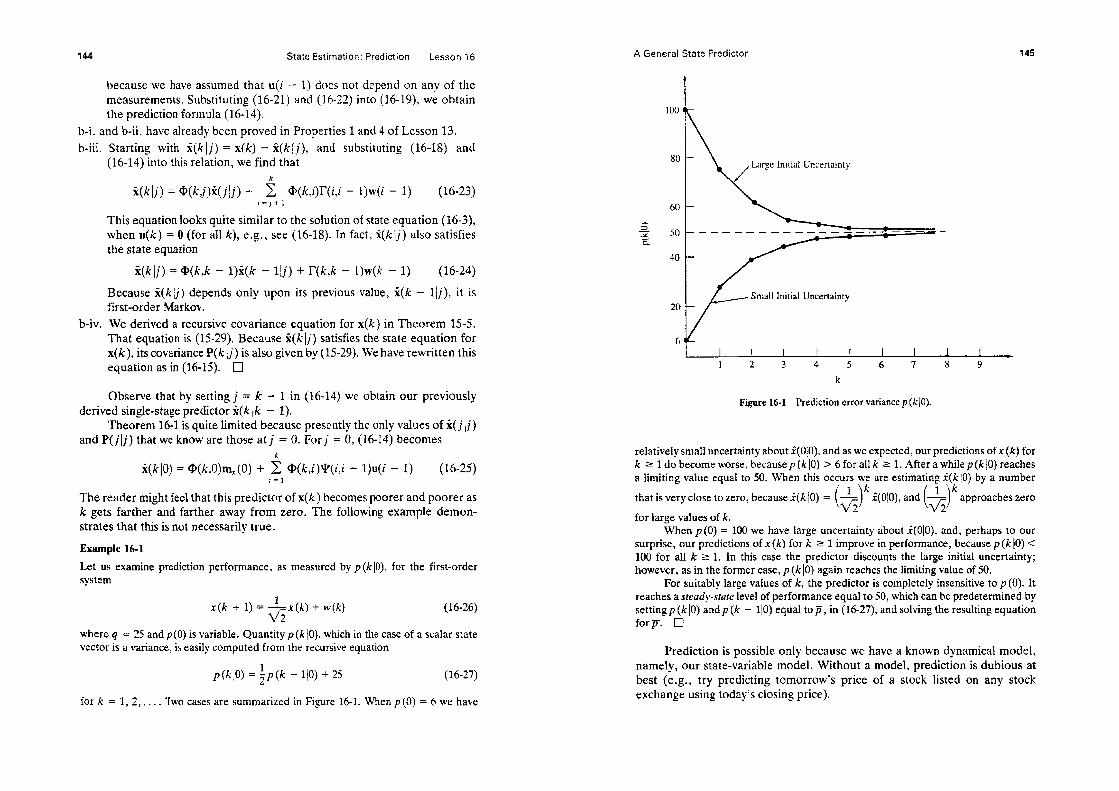
State Estimation: Prediction Lesson 16
because we have assumed that U@ - 1) does not depend on any of the measurements. Substituting (16-21) and (16-22) mto (l&19), we obtain the prediction formula (16-14).
b-i. and b-ii. have already been proved in Properties 1 and 4 of Lesson 13. b-iii. Starting with i(k 1 j) = x(k) - ?(k/j), and substituting (16-18) and
(M-14) into this relation, we find that
ii(kij) = @(k,j)k(j/j) + $ @(k$)F(iJ - l)w(i - 1) (X-23) i=j+l
This equation looks quite similar to the solution of state equation (16-3), when u(k) = 0 (for all k), e.g., see (16-H). In fact, i(k jj) also satisfies the state equation
5[kij) = @(k,k - l)k(k - lij) + r(k,k - I)w(k - 1) (16-24)
E3ecause 5(k ij) depends only upon its previous value, g(k - lij), it is first-order Markov.
b-iv. We derived a recursive covariance equation for x(k) in Theorem H-5. That equation is (15-29) Because ii(k ij) satisfies the state equation for x(k), its covariance P(k ij) is also given by (1529). We have rewritten this equation as in (16-H). q
Observe that by setting j = k - 1 in (16-14) we obtain our previously derived single-stage predictor k(k ik - 1).
Theorem 16-l is quite limited because presently the only values of i( j ij) and P( jij) that we know are those at j = 0. For j = 0, (16-14) becomes
i(kiU) = @(k,O)mX(0) + i @(k,i)‘P(z’,z’ - l)U@ - 1) (16-25) i=l
The reader might feel that this predictor of x(k) becomes poorer and poorer as k gets farther and farther away from zero. The following example demon- strates that this is not necessarily true.
Example 16-l
Let us system
examine prediction performance, as measured by p (k/0), for the first-order
x(k + 1) = Lx(k) + w(k) VT
(14-26)
where q = 25 and p (0) is variable. Quantity p (k IO), which in the case of a scalar state vector is a variance, k easily computed from the recursive equation
p(kiO) = $7 (k - l/O) + 25 (16-27)
for k = 1,2.*... Two cases are summarized in Figure 16-l- JA%en p (0) = 6 we have
A General State Predictor 145
Figure 16-1 Prediction error variance p (k/O).
relatively small uncertainty about ;(O/O), and as we expected, our predictions of x (k) for k 2 1 do become worse, because p (k10) > 6 for all k 2 1. After a whilep(kj0) reaches a limiting value equal to 50. When this occurs we are estimating i(k/O) by a number
1 k that is very close to zero, because i(k IO) = - ( 1
1 k
y’z ;(OjO), and - i i lh
approaches zero
for large values of k. When p(O) = 100 we have large uncertainty about ;(OlO), and, perhaps to our
surprise, our predictions of x(k) for k L 1 improve in performance, because p(k[O) < 100 for all k 2 1. In this case the predictor discounts the large initial uncertainty; however, as in the former case, p (k IO) again reaches the limiting value of 50.
For suitably large values of k, the predictor is completely insensitive to p (0). It reaches a steady-state level of performance equal to 50, which can be predetermined by setting p (k IO) and p (k - 110) equal top, in (N-27), and solving the resulting equation forjT. El
Prediction is possible only because we have a known dynamical model, namely, our state-variable model. Without a model, prediction is dubious at best (e.g., try predicting tomorrow’s price of a stick listed on any stock exchange using today’s closing price).

State Estimation: Prediction Lesson 16
THE INNOVATIONS PROCESS
Suppose we have just computed the single-stage, predicted estimate of x(k + l), j;(k + l(k). Then the single-stage predicted estimate of z(k + l), i(k + Ilk), is
?(k + Ilk) = E{z(k + l)/%(k)} = E{[H(k + l)x(k + 1) + v(k + 1)-$X(k)}
i(k + Ilk) = H(k + l)zi(k + Ilk) (16-28) The error between z(k + 1) and i(k + lik) is i(k + l/k), i.e.,
Z(k + l/k) = z(k + 1) - i(k + l/k) (16-29)
Signal Z(k + Ilk) is often referred to either as the inrtovations process, predic- tion error process, or measurement residual process. We shall refer to it as the innovations process, because this is most commonly done in the estimation theory literature (e.g., Kailath, 1968). The innovations process plays a very important role in mean-squared filtering and smoothing. We summarize im- portant facts about it in the following:
Theorem 16-2 (Innovations) a. The following representations of the innovations process Z(k + l/k) are
equivalent:
Z(k + Ilk) = z(k + 1) - i(k + Ilk) (16-30)
E(k + Ilk) = z(k + 1) - H(k + l)i(k + Ilk) (16-31)
%(k + lik) = H(k + l)ji(k + Ilk) + v(k + 1) (16-32)
b. The innovations is a zero-mean Gaussian white noise sequence, with
E{%(k + llk)Z’(k + Ilk)} = PC(k + ljk) = H(k + l)P(k + llk)H’(k + 1) + R(k + 1) (16-33)
Proof (Mendel, 1983b) a. Substitute (16-28) into (16-29) in order to obtain (16-31). Next, substi-
tute the measurement equation z(k + 1) = H(k + l)x(k + 1) + v(k + 1) into (16.31), and use the fact that ji(k + Ilk) = x(k + 1) - i(k + l(k), to obtain (16-32).
b. Because g(k + Ilk) and v(k + 1) are both zero mean, E{Z(k + Ilk)} = 0. The innovations is Gaussian because z(k + 1) and S(k + l/k) are Gaus- sian, and, therefore, 2(k + l(k) is a linear transformation of Gaussian
Lesson 16 Problems
random that
vectors. To prove that t(k + Ilk) is white noise we must show
E{z(i + lli)Z’(j + llj)} = P&i + l[i)S, (16-34)
We shall consider the cases i > j and i = j, leaving the case i < j as an exercise for the reader. When i > j,
E{Z(i + lJi)Z’( j + l]j)} = E{ [H(i + l)X(i + lli) + v(i + l)] [H(j + VW + 1113 + v(i + N’I
= E{H(i + l)X(i + l[i)
D-W + Mi + lI/? + v(i + WI because E{v(i + l)v’( j + 1)) = 0 and E{v(i + l)X’( j + llj)} = 0. The latter is true because, for i > j, X( j + llj) does not depend on mea- surement z(i + 1); hence, for i > j, v(i + 1) and X( j + 11~) are indepen- dent, so that E{v(i + l)?‘( j + llj)} = E{v(i + l)}E{S( j + llj)} = 0. We continue, as follows:
E(z(i + lli)Z’(j + llj)} = H(i + l)E{x(i + lji)[z( j + 1) - H( j + l)ri( j + 11 j)]‘} = 0
by repeated application of the orthogonality principle (Corollary 13-3). When i = j,
P%(i + lli) = E{ [H(i + l),(i + lli) + v(i + l)][H(i + l),(i + lli) + v(i + 1)]‘} = H(i + l)P(i + lli)H’(i + 1) + R(i + 1)
because, once again E{v(i + l)X’(i + Iii)} = 0, and P(i + 1) = E{x(i + l\i) X’(i + Iii)}. Cl
rse of Pi;(k + l]k) is needed; hence, we shall llk)H’(k + 1) + R(k + 1) is nonsingular. This is
usually true and will always be true if, as in our basic state-variable model, R(k + 1) is positive definite.
PROBLEMS
16-l. Develop the counterpart to Theorem 16-1 for the case when input u(k) is random and independent of Z( 1). What happens if u(k) is random and dependent upon w=P
16-2. For the innovations process i(k + Ilk), prove that E{Z(i + lli)Z’(j + 11~)) = 0 when i < j.
16-3. In the proof of part (b) of Theorem 16-2 we make repeated use of the orthogonality principle, stated in Corollary 13-3. In the latter corollary f’[S(k)]

148 State Estimation: Prediction Lesson 16
appears to be a function of 011 of the measurements used in i&k). h-r the expression E{%(i + lii)z’(j + l)}, i > j, z’(j + I.) certainly is not a function of all the measurements used n-r x(i + lji). What is f [ -1, when we apply the orthogonality principle to E{i(i + lii)z’(j + l)j, i > j, to conclude that this expectation is zero?
16-4. Refer to Problem H-5. Assume that [l(k) can be measured [e.g., u (k) might be the output of a random number generator], and that LI = Q[Z (1), 2 (2), . . . , 4k - l)]. What is ?(kjk - l)?
16-5, Consider the following autoregressive model, z(k + FZ) = LI~Z (k + II - 1) - ag(k +n - 2) - a.9 - anz(k) + w(k + ~2) in which w(k) is white noise. Measurements z(k), z (k + l), . . . , z (k + n - I) are available. (a) Compute i(k + n ik + n - 1). (b) Explain why the result in (a) is the overall mean-squared prediction of
z (k + rt) even if IV (k + n) is non-Gaussian.
Lesson 17
State Estimation:
Filtering (the Kalmun
Filter)
INTRODUCTION
In this lesson we shall develop the Kalman filter, which is a recursive mean- squared error filter for computing fi(k + Ilk + l), k = 0, 1, 2,. . . . As its name implies, this filter was deveioped by KaIman [circa 1959 (Kalman, 1960)].
From the Fundamental Theorem of Estimation Theory, Theorem 13-1, we know that
r2(k + Ilk + 1) = E{x(k + l)lZ(k + 1)) (174)
Our approach to developing the Kalman filter is to partition E(k + sets of measurements, 3!(k) and z(k + 11, and to then expand the expectation in terms of data sets S(k) and z(k + l), i.e.,
3) into two conditional
%(k + l(k + 1) = E(x(k + 1)1%(k), z(k + 1)) (17-2)
What complicates this expansion is the fact that Z(k) and z(k + 1) are statistically dependent. Measurement vector SE(k) depends on state vectors x(l), x(2), - * - 9 x(k), because z(j) = H(j)x(j) + v(j)(j = 1, 2, . . . , k). Mea- surement vector z(k + 1) also depends on state vector x(k), because z(k + 1) = H(k + l)x(k + 1) + v(k + 1) and x(k + 1) = @(k + l,k)x(k) + r(k t l,k)w(k) + YT(k + l,k)u(k), Hence S(k) and z(k + 1) both depend on x(k) and are, therefore, dependent.

150 State Estimation: Filtering (the Kaiman Filter) Lesson 17
Recall that x(k + l), Z(k) and z(k + 1) are jointly Gaussian random vectors; hence, we can use Theorem 12-4 to express (17-2) as
i(k + Ilk + 1) = E{x(k + l)la(k),i) (17-3)
where
i = z(k + 1) - E-w + mw)l (17-4)
We immediately recognize Z as the innovations process Z(k + Ilk) [see (X-29)]; thus, we rewrite (17-3) as
i(k + Ilk + 1) = E{x(k + l)lfE(k),i(k + Ilk)} (17-5)
Applying (12-37) to (17-5), we find that
i(k + ilk + 1) = E{x(k + 1)1%(k)} + E{x(k + l)IZ(k + Ilk)} - m,(k + 1) (17-6)
We recognize the first term on the right-hand side of (17-6) as the single-stage predicted estimator of x(k + l), r2(k + Ilk); hence,
%(k + l]k + 1) = ?(k + l/k) + E{x(k + l)(Z(k + l(k)} - m,(k + 1) (17-7)
This equation is the starting point for our derivation of the Kalman filter. Before proceeding further, we observe, upon comparison of (17-2) and
(17-5), that our original conditioning on z(k + 1) has been replaced by condi- tioning on the innovations process i(k + Ilk). One can show that Z(k + Ilk) is computable from z(k + l), and that z(k + 1) is computable from ?(k + Ilk); hence, it issaid that z(k + 1) and Z(k + Ilk) are causally invertible (Anderson and Moore, 1979). We explain this statement more carefully at the end of this lesson.
A PRELIMINARY RESULT
In our derivation of the Kalman filter, we shall determine that
?(k + Ilk + 1) = i(k + Ilk) + K(k + l)i(k + Ilk) (17-8)
where K(k + 1) is an n x m (Kalman) gain matrix. We will calculate the optimal gain matrix in the next section.
Here let us view (17-8) as the structure of an abitrary recursive linear filter, which is written in so-called predictor-corrector format; i.e., the filtered estimate of x(k + 1) is obtained by a predictor step, x(k + Ilk), and a cor- rector step, K(k + l)i(k + Ilk). The predictor step uses information from the state equation, because r2(k + ilk) = @(k + l,k)i(klk) + q(k + l,k)u(k). The corrector step uses the new measurement available at tk + 1. The correction is proportional to the difference between that measurement and its best pre-
The Kaiman Filter
dieted value, i(k + Ilk). The following result provides us with the means for evaluating %(k + l[k + 1) in terms of its error-covariance matrix P(k + Ilk + 1).
Preliminary Result. Filtering error-covariance matrix P(k + Ilk + 1) for the arbitrary linear recursive filter (17-8) is computed from the following equation:
P(k + Ilk + 1) = [I - K(k + l)H(k + l)]P(k + llk)[I - K(k + l)H(k + l)]’ + K(k + l)R(k + l)K’(k + 1) (17-9)
Proof. Substitute (16-32) into (17-8) .ation from x(k + 1) in order to obtain
and then subtract the resulting
Z(k + lik + 1) = [I - K(k + l)H(k + l)]%(k + l(k) - K(k + l)v(k + 1) (1740)
Substitute this equation into P(k + lfk + 1) = E{fs(k + Ilk + l)X’(k + 11 k + 1)) to obtain equation (17-9). As in the proof of Theorem 16-2, we have used the fact that %(k + Ilk) and v(k + 1) are independent to show that E{g(k + llk)v’(k + 1)) = 0. Cl
The state prediction-error covariance matrix P(k + Ilk) is given by equation (1641). Observe that (17-9) and (16-11) can be computed recur- sively, once gain matrix K(k + 1) is specified, as follows: P(OI0) + P(l)O)+P(ljl)+ P(2ll)+P(212)-, l l . etc.
It is important to reiterate the fact that (17-9) is true for any gain matrix, including the optimal gain matrix given next in Theorem 17-l.
I+
THE KALMAN FILTER
Theorem 17-l a. The mean-squared filtered estimator of x(k + l), ii(k + Ilk + I), written
in predictor-corrector format, is
i(k + l(k + 1) = i(k + Ilk) + K(k + l)z(k + Ilk) (17-11)
fork = 0, 1,. . . , where %(0/O) = m,(O), and z(k + l/k) is the innovations process [E(k + Ilk) = z(k + 1) - H(k + l)j2(k + l(k)].
b. K(k + 1) is an n x m matrix (commonly referred to as the Kalman matrix or weighting matrix) which is specified by the set of relations
gain
K(k + 1) = P(k + llk)H’(k + l)[H(k + l)P(k + llk)H’(k + 1) + R(k + l)]-’ (1742)
P(k + ilk) = @(k + l,k)P(kIk)W(k + l,k) + I-(k + l,k)Q(k)I-“(k + 1,k) (17-13)

State Estimation: Filtering (the Katman Filter) Lesson 17
P(k + lik + 1) = [I - K(k + l)H(k + l)]P(k + Ilk) (17-14)
jbrk=O,l,...: where I is the n X n iderzfity mufrix. fzmi P(Oj0) = Px(0). c. The stochastic process {2( k + 1 ik + l), k = 0, 1, . . . }5 which is defined by
the filteriq error relation
C(k + l/k + 1) = x(k -!- 1) - ?(k + l/k + 1) (17-H)
lc=O,l,*-., is u zero-mean Gauss-Murkov sequence whose covariance matrix is given by (U-H).
Pruof (Mendel, 1983b, pp. 5657) a, We begin with the formula for S(k + l/k + 1) in (17-7). Recall that
x(/c + 1) and z(k + 1) are jointly Gaussian. Because z(k + 1) and i(k + l[k) are causally invertible, x(k + 1) and @k + lik) are also jointly Gaussian. Additionally, E{i(k + Ilk)) = 0; hence,
E{x(k + l)ii(k + l\k)} = mX(k + 1) + Pti(k + 1,k + l/k)P;‘(k + l/k)i(k + l]k) (1746)
We define gain matrix K(k + 1) as
K(k + 1) = Pti(k + 1,k + l]k)Pg’(k t ilk) (1747)
Substituting (17-16) and (17-17) into (17-7) we obtain the Kalman filter equation (17-l 1). Because i(k + l]k) = @(k + l,k)%(kik) + !Qk + 1 ,k)u(k), equation (17-l 1) must be initialized by i(O/O), which we have shown must equal mx(0) [see Equation (16-K?)].
b. In order to evaluate K(k + 1) we must evaluate PG and Pi’. Matrix PG has been computed in (X-33). By definition of cross-covariance,
Pti = E{[x[k + 1) - mx(k + l)-&‘(k + l/k)} = E{x(k + 1)2(k + ljk)} (1748)
because i(k + l]k) is zero-mean. Substituting (16-32) into this expression, we find that
Pti = E{x(k + l)%‘(k + lik)}H’(k + 1) (1749)
because E{x(k + l)v’(k + 1)) = 0. Finally, expressing x(k + 1) as %(k + l]k) + $(k + l]k) and applying the orthogonahty principle (I3-15), we find that
Pti = P(k + #)H’(k + 1) (17-20)
Combining equations (17-20) and (16-33) into (17-l’?), we obtain equation (1742) for the Kalman gain matrix.
State prediction-error covariance matrix P(k + l/k) was derived in Lesson 16.
Observations About the Kalman Filter
State filtering-error covariance matrix P(k + ljk + 1) is obtained by substituting (17-12) for K(k + 1) into (17-4) as follows:
P(k + Ilk + 1) = (I - KH)P(I - KH)’ + KRK’ = (I - KH)P - PH’K’ + KHPH’K’ + KRK’ = (I - KH)P - PH’K’ + K(HPH’ + R)K’ (17-21)
. = (I - KH)P - PH’K’ + PH’K’ = (I - KH)P
c. The proof that ii(k + l\k + 1) is zero-mean, Gaussian and Markov is so similar to the proof of part b of Theorem 16-l that we omit its details [see Meditch (1969, pp. lSl-182)]. Cl
OBSERVATIONS ABOUT THE KALMAN FILTER
1. Figure 17-l depicts the interconnection of our basic dynamical system [equations (15-17) and (U-18)] and Kalman filter system. The feedback nature of the Kalman filter is quite evident. Observe, also, that the Kalman filter contains within its structure a model of the plant.
The feedback nature of the Kalman filter manifests itself in fw~ different ways, namely in the calculation of i(k + Ilk + 1) and also in the calculation of the matrix of gains, K(k + 1), both of which we shall explore below.
2. The predictor-corrector form of the Kalman filter is illuminating from an information-usage viewpoint. Observe that the predictor equations, which compute Ei(k + ljk) and P(k + ilk), use information only from the state equation, whereas the corrector equations, which compute K(k + l), ji(k -+ l(k + I) and P(k + Ilk + l), use information only from the measurement equation.
3. Once the gain matrix is computed, then (17-11) represents a time-varying recursive digital filler. This is seen more clearly when equations (16-4) and (16-31) are substituted into (17-11). The resulting equation can be rewritten as
i(k + Ilk + 1) = [I - K(k + l)H(k + l)J@(k + l,k)li(k)k) + K(k + l)z(k + 1) +[I - K(k + l)H(k + l)]‘P(k + l,k)u(k)
(17-22)
for k =0, l,.... This is a state equation for state vector ri, whose time-varying plant matrix is [I - K(k + l)H(k + l)]Ql(k + 1,k). Equation (17-22) is time-varying even if our dynamical system in equations (1517) and (15-B) is time-invariant and stationary, because gain matrix K(k + 1) is still time-varying in that case. It is possible,

c
154
Observations About the Kalman Filter 155
however, for K(k + 1) to reach a limiting value (i.e., a steady-state value, K), in which case (17-22) reduces to a recursive constant coefficient filter. We will have more to say about this important steady-state case in Lesson 19.
Equation (17-22) is in a recursive filter form, in that it relates the filtered estimate of x(k + l), x(k + lik + l), to the filtered estimate of x(k), x(k[k). Using substitutions similar to those used in the derivation of (17-22), one can also obtain the following recursive predictor form of the Kalman filter (details left as an exercise),
i(k + Ilk) = @(k + l,k)[I - K(k)H(k)]x(kIk - 1)
+Q(k + l,k)K(k)z(Fi) + V(k + l&u(k) (17-23)
Observe that in (17-23) the predicted estimate of x(k + 1), x(k + ilk), is related to the predicted estimate of x(k), i(k[k - 1). Interestingly enough, the recursive predictor (17-23), and not the recursive filter (17-22), plays an important role in mean-squared smoothing, as we shall see in Lesson 21.
The structures of (17-22) and (17-23) are summarized in Figure 17-2. This figure supports the claim made in Lesson 1 that our recursive estimators are nothing more than time-varying digital filters that operate on random (and also deterministic) inputs.
4. Embedded within the recursive Kalman filter equations is another set of recursive equations-( 17-12), (17-13) and (17-14). Because P(Ol0) initializes these calculations, these equations must be ordered as follows: P(klk)-,P(k + llk)-*K(k + l)+P(k + l]k + l)--,etc.
By combining these three equations it is possible to get a matrix recursive equation for P(k + Ilk) as a function of P(k (k - l), or a similar equation for P(k + ilk + 1) as a function of P(kJk). These equations are nonlinear and a known as matrix Riccati equations. For
50 example, the matrix Riccati equa l q for P(k + Ilk) is
P(k + Ilk) = <PP(kIk - l){I - H’[HP(-# - l)H’ + R] - ’ HP(klk - l)}@’ + I’QF’ (17-24)
Figure 17-2 Input-output interpretation of the Kalman filter.

156 State Estimation: Filtering (the Kalman Filter) Lesson 17
where we have omitted the temporal arguments on 0, I?. H, Q and R for notational simplicity [their correct arguments are @(k + I&), W + Lk): H(k), QM and R(k)]+ The matrix Riccati equation for P(k + l]k + 1) is obtained by substituting (17-E) into (17-14), and then (17-13) into the resulting equation. We leave its derivation as an exercise.
5. A measure of recursive predictor performance is provided by matrix P(k + l\k). This covariance matrix can be calculated prior to any processing of real data, using its matrix Riccati Equation (17-24) or Equations (17-13) (17~14), and (17-12) A measure of recursive fiIter performance is provided by matrix P(k + lik + l), and this covariance matrix can also be calculated prior to any processing of real data. Note that P(k + l/k + I) + P(k + l/k). These calculations are often referred to as performance urr+es. It is indeed interesting tlrat the Kalman filter utilizes a measure of its mean-squared error during its real-time operation.
6. Two formulas are available for computing P(k + lik + l), namely (17-14) which is known as the standard form, and (17-g), which is known as the stabilized form. Although the stabilized form requires more com- putations than the standard form, it is much less sensitive to numerical errors from the prior calculation of gain matrix K(k + 1) than is the standard form. In fact, one can show that first-order errors in the calcu- lation of K(k + 1) propagate as first-order errors in the calculation of P(k + l/k + l), when the standard form is used, but only as second- order errors in the calculation of P(k + Ilk + 1) when the stabilized form is used. This is why (17-g) is called the stabilized form [for detailed derivations, see Aoki (1967), Jazwinski (1970), or Mendel(l973)].
7. On the subject of computation, the calculation of P(k + lik) is the most costly one for the Kalman filter, because of the term @(k + l,k)P(k/k) Q’(k + l,k), which entails two multiplications of two n x n matrices l i.e., P(k ik)@‘(k + l,k) and @(k + l,k)(P(kik)@‘(k + l,k))]. Total computation for the two matrix multiplications is on the order of 2n3 multiplications and 2n3 additiuns [for more detailed computation counts, including storage requirements, for all of the Kalman filter equations, see Mendel (1971), Gura and Bierman (1971), and Bierman (1973a)].
One must be very careful to code the standard or stabilized forms for P(k + l/k + 1) so that ?z x H matrices are never multiplied. We leave it to the reader to show that the standard algorithm can be coded in such a manner that it only requires on the order of $ mn2 multiplications, whereas the stabilized algorithm can be coded in such a manner that it only requires on the order of $ mn2 multiplications. In many applications, system order n is larger than number of measurements rn? so that rnn’ C= n3. Usually, computation is most sensitive to system order; so, whenever pssibk, use low-order (but adequate) models.
Observations About the Kalman Filter 157
8. Because of the equivalence between mean-squared, best-linear un- biased, and weighted-least squares filtered estimates of our state vector x(k) (see Lesson 14) we must realize that our Kalman filter equations are just a recursive solution to a system of normal equations (see Lesson 3). Other implementations of the Kalman filter that solve the normal equations using stable algorithms from numerical linear algebra (see, e.g., Bierman, 1977) and involve orthogonal transformations, have bet- ter numerical properties than (17-l l)-( 17-14). We reiterate, however, that because this is a book on estimation theory, theoretical formulas such as those in (17-l I)-( 17-14) are appropriate.
9. In Lesson 4 we developed two forms for a recursive least-squares esti- mator, namely, the covariance and information forms. Compare K(k + 1) in (17-12) with K,(k + 1) in (4-25) to see they have the same structure; hence, our formulation of the Kalman filter is often known as the covariance formuiatiun. We leave it to the reader to show that K(k + 1) can also be computed as
K(k + I) = P(k + Ijk + l)H’(k + l)R-‘(k + 1) (17-25)
where P(k + Ilk + 1) is computed as
P-‘(k + Ilk + 1) = P-‘(k + Ilk)
10.
11 .
+ H’(k + l)R-‘(k + l)H(k + 1) (17-26)
When these equations are used along with (17-11) and (17-13) we have the information formulation of the Kalman filter. Of course, the order- ing of the computations in these two formulations of the Kalman filter are different. See Lessons 4 and 9 for related discussions. In Lesson 14 we showed that &&kl/ZV) = EiMS(kljlV); hence,
hw(k lk) = hdk (k) (17-27)
This means that the Kalman filter also gives MAP estimates of the state vector x(k) for our basic state-variable model. At the end of the introduction section in this lesson we mentioned that z(k + 1) and Z(k + Ilk) are causally invertible. This means that we can compute one from the other using a causal (i.e., realizable) system. For example, when the measurements are available, then Z(k + Ilk) can be obtained from Equations (17-23) and (16-31) which we repeat here for the convenience of the reader:
li(k + Ilk) = @(k + l.k)[I - K(k)H(k)]i(klk - 1)
+ ‘Z’(k + l,k)u(k) + @,(k + l,k)K(k)z(k)
and
ijk + ljk) = -H(k + l)ri(k + Ilk) t z(k i- I) k = 0, 1,. . .
(17-28)
(17-29)

17-l. 17-2. 17-3. 17-4. 17-5.
17-6.
17-7.
State Estimation: Filtering (the Kalman Filter) Lesson 17
We refer to (17-28) and (17-29) in the rest of this book as the Kalman innovations system. It is initialized by i(Ol- 1) = 0.
On the other hand, if the innovations are given a priori, then z(k + 1) can be obtained from
?(k + lik) = Q(k + l,k)r2(klk - 1) + ‘P(k + l,k)u(k) + @(k + l,k)K(k)Z(klk - 1) (17-30)
z(k + 1) = H(k + l)f(k + Ilk) + Z(k + Ilk) k =O,l,... (17-31)
Equation (17-30) was obtained by rearranging the terms in (17-28), and (17-31) was obtained by solving (17-29) for z(k + 1). Equation (17-30) is again initialized by i(Ol- 1) = 0.
Note that (17-30) and (17-31) are equivalent to our basic state- variable model in (1517) and (1518), from an input-output point of view. Consequently, model (17-30) and (17-31) is often the starting point for important problems such as the stochastic realization problem (e.g., Faurre, 1976).
PROBLEMS
Prove that %(k + ilk + 1) is zero mean, Gaussian and first-order Markov. Derive the recursive predictor form of the Kalman filter, given in (17-23). Derive the matrix Riccati equation for P(k + Ilk + 1). Show that gain matrix K(k + 1) can also be computed using (17-25). Suppose a small error SK is made in the computation of the Kalman filter gain K(k + 1). (a) Show that when P(k + Ilk + 1) is computed from the “standard form”
equation, then to first-order terms,
6P(k + l[k + 1) = -SK(k + l)H(k + l)P(k + Ilk)
(b) Show that when P(k + Ilk + 1) is computed from the “stabilized form” equation, then to first-order terms
6P(k + Ilk + 1) ‘c 0
Consider the basic scalar system x (k + 1) = +x(k) + w(k) and z (k + 1) = x(k + 1) + v(k + 1). (a) Show that p(k + ilk) 2 4, which means that the variance of the system
disturbance sets the performance limit on prediction accuracy. (b) Show that 0 5 K(k + 1) 5 1. (c) Show that 0 5 p(k + Ilk + 1) : r. An RC filter with time constant 7 is excited by Gaussian white noise, and the output is measured every T seconds. The output at the sample times obeys the
Lesson 17 Problems 159
equation x(k) = e --‘ISTX(k - 1) + w(k - l), where E{x (0)) = 1, E{x2(0)} = 2, 4 = 2, and T = 7 = 0.1 sec. The measurements are described by z(k) = x(k) + v(k), where v(k) is a white but non-Gaussian noise sequence for which E{v(k)} = 0 and E{v2(k)} = 4. Additionally, w(k) and v(k) are uncorrelated. Measurements z(1) = 1.5 and z(2) = 3.0. (a) Find the best linear estimate of x(1) based on t(l). (b) Find the best linear estimate of x (2) based on z (1) and z (2).
17-8. Table 17-l lists multiplications and additions for all the basic matrix operations used in a Kalman filter. Using the formulas for the Kalman filter given in Theorem 17-1, establish the number of multiplications and additions required to compute i(k + l/k), P(k + lik), K(k + l), i(k + ilk + l), and P(k + Ilk + 1).
TABLE 17-1 Operation Characteristics
Name Function Multiplications Additions
Matrix addition Matrix subtraction Matrix multiply Matrix transpose
multiply Matrix inversion Scalar-vector
product
C MN = AMN + BMN MN c MN = &MN - BYN - MN C ML = AMNBNL MNL ML(N - 1)
C MN = AML(&L) MNL ML(N- 1) A NN+ Ai,: u!N3 PN3
C Nl = PANI N -
17-9. Show that the standard algorithm for computing P(k + l(k + 1) only requires on the order of $ mn2 multiplications, whereas the stabilized algorithm requires on the order of $ mrz2 multiplications (use Table 17-l). Note that this last result requires a very clever coding of the stabilized algorithm.

Lesson 78
St&e Estimation:
Fi/tering Exampies
INTRODUCTICN’J
In this lesson (which is an excellent one for self-study) we present five exam- ples, which illustrate some interesting numerical and theoretical aspects of Kalman filtering.
EXAMPLES
Example 1% 1
In Lesson 17 we learned that the Kalman filter is a dynamical feedback system. Its gain matrix and predicted- and filtering-error cuvariance matrices comprise a matrix feedback system operating within the Kalman filter. Of course, these matrices can be calculated prior to processing of data, and such calculations constitute a performance mdysis of the Kalman filter, Here we examine the results of these calculations for two second-order systems, III(z) = 1 /(z’ - 1.322 + 0.875) and Hz(z) = 1 /(z’ - 1.362 + 0.923). The second system is less damped than the first. Impulse responses of both systems are depicted in Figure 18-l.
In Figure 18-l we also depict pII(k ik), p&kik), Kl(k) and h(k) versus k for both systems. In both cases P(OiO) was set equal to the zero matrix. For system 1, CJ = 1 and r = 5, whereas for system 2 q = 1 and r = 20. Observe that the error variances and Kalman gains exhibit a transient response as well as a steady-state response; i*e., after a certain value of k (k s 10 for system-l and k = 15 for system-2) p,(kik), p&k!k), ICI(&), and &(k) reaching limiting values, These limiting values do not depend on P(OiO), as can be seen from Figure 18-2. The Kalman filter is initially influenced by its initial conditions, but eventually ignores them. paying much greater attention to model
2 I I
2 \ Y’ I
I
I
I I
7 I

d +
-N c-4 m . 4
I
“N
162
Examples
parameters and the measurements. The relatively large pz2 are due to the large values of r. 0
steady-state values for pll and
Example 18-2 A state estimate is implicitly conditioned on knowing the true values for all system parameters (i.e., @, r, v’, H, Q, and R). Sometimes we do not know these values exactly; hence, it is important to learn how sensitive (i.e., robust) the Kalman filter is to parameter errors. Many references which treat Kalman filter sensitivity issues can be found in Mendel and Gieseking (1971) under category 2f, “State Estimation: Sensitivity Considerations.”
Let 8 denote any parameter that may appear in @, r, q, H, Q, or R. In order to determine the sensitivity of the Kalman filter to small variations in 6 one computes &(k + Ilk + 1) /a& whereas, for large variations in 0one computes ti(k + l/k + 1) / Ahe. An analysis of A%(k + Ilk + 1)/A& for example, reveals the interesting chain of events, that: A?(k + l/k + l)/Ae depends on AK(k + 1)/A& which in turn depends on AP(k + ilk) / A6, which in turn depends on AP(k Ik) / A0. Hence, for each variable parameter, 8, we have a Kalman filter sensitivity system comprised of equations from which we compute Ari(k + l]k + l)/A8 (see also, Lesson 26). An alternative to using these equations is to perform a computer perturbation study. For example,
AK(k + 1) Wk + 1)( 8 = eN + A0 (j N A8 = A8
(18-l)
where & denotes a nominal value of 8. We define sensitivity as the ratio of the percentage change in a function [e.g.,
K(k + l)] to the percentage change in a parameter, 8. For example,
A&(k + 1)
g+(k + 1) = &tk + l> A6 8
(18-2)
denotes the sensitivity of the ijth eleme atrix K(k + 1) with respect to parameter \d similarly. 0. All other sensitivities, such as Sp@lk), are de
Here we present some numerical sensitivity results for the simple first-order system
x(k + 1) = ax(k) + b w(k) (18-3)
z(k) = hx(k) + n(k) (18-4)
where ON = 0.7, bN = 1.0, hN = 0.5, qN = 0.2, and rN = 0.1. Figure 18-3 depicts p + 1) s,“C” + 1) , sfck + ‘I, St(’ + *) , and S,“(” + *) for parameter variations of 55%) flO%, ‘220%) and 50% about nominal values, &V, bN, hN, qNY and rN l
Observe that the sensitivity functions vary with time and that they all reach steady-state values. Table 18-l summarizes the steady-state sensitivity coefficients SK(k + 1)
8 , sr(kIk) and Sr’k + l(k) .
Some conclusions that can be drawn from these numerical results are: (1) K(k + l), P(klk) and P(k + l(k) are most sensitive to changes in parameter b, and

164 State Estimation: Filtering Examples Lesson 18
(2) p + 1) = pw for 8 = a, b , and q . This last observation could have been fore- seen, because of our alternate equation for K(k + I) [Equation (17-Z)].
K(k + 1) = P(k + Ilk + l)H(k + I)R-‘(k + 1) (N-5)
This expression shows that if !I and r are fixed then K(k + 1) varies exactly the same way as P(k + Ilk + 1).
2 + 2 vf
0.5
O-4
0.3
02 J I I I I I 1 t I I 0 12 3 4 5 6 7 8 9 IO
k
1.3
1.1
O-9
0.7
02
0.3
I I t I I I t I 1 0 1 2 3 4 5 6 7 8 9 IO
k
5% 5% 10%
50% 20% 10% 5% 5% fO%
Figure 18-3 Sensitivhy plots.
Examples 165
0.2
-
-0.2
0.4 I 1 1 I I I I J - 0 1 2 3 4 5 6 7 8 9 10
k
0.8
t
0.6
0.4
0.2
0.0 I I t I I I 1 I I I 0 I 1 3 4 5 6 7 8 9 IO
k (d)
- -
- 20% - 10% -5% + WC + 10% + 20% + 50%
- 0.7
-0.8 1 I I I I I I t I 0 1 2 3 4 5 6 7 8 9 10
10% 5% 5% 10% 20%
(e)
Figure 18-3 Cont.

166 State Estimation: Filtering Examples Lesson 18
TABLE 18-l Steady State Sensitivity Coefficients
ia) 37” + l) 6 +50 +20
Percentage Change in 8 +lO +5 -5 -10 -20 -50 ~~~
: .838 .506 ,451 ,937 .430 .972 .419 .989 1.025 .396 1.042 .384 1.077 .361 1.158 .294
h -.108 - ,053 - .026 - ,010 ,026 .O47 .096 .317 9 .417 ,465 .483 .493 ,515 .526 .551 ,648 r - .393 - .452 - .476 - ,490 -.518 - ,534 - .570 - .717
(b) s;k’kf 9 +50 +20
Percentage Change in 6 +lO +5 -5 -10 -20 -50
; .506 .838 ,451 .937 .430 -972 .419 ,989 1.025 .396 1.042 .384 1.077 .361 1.158 .294
h - ,739 - .877 - .932 - ,962 -1.025 -1.059 -1.130 -1.367 9 .417 .465 .483 ,493 .515 .526 .551 .648
- f .410 .457 .476 .486 .507 ,519 ,544 .642
+50 +20 Percentage Change in 8
+lO +5 -5 -10 -20 -50
a 1.047 .820 .754 .723 .664 .637 .585 .453 b 2.022 1.836 1.775 1.745 1.684 1.653 1.591 1.402 h - .213 - ,253 - .268 - .277 - .295 - .305 - ,325 -.393 9 .832 .846 .851 .854 .860 ,864 .871 .899 r ,118 .131 .137 .140 .146 ,149 .157 .185
Here is how to use the results in Table 18-1. From Equation (18-2), for example, we see that
(18-6)
or
% Change in Kij(k + 1) = (% Change in 6) x SF@ + ‘) (18-7)
From Table 18-1 and this formula we see, for example, that a 20% change in a produces a (20)(.451) = 9.02% change in K, whereas a 20% change in h only produces a (20)( - .053) = -1.06% change in K, etc. 0
Example 18-3 In the single-channel case, when w(k), z(k) and v(k) are scalars, then K(k + 1), P(k + Ilk) and P(k + Ilk + 1) do not depend on 4 and r separately. Instead, as we demonstrate next, they depend only on the ratio 4 /r . In this case, H = h’, r = y, Q = 4 and R = I, and Equations (17-12), (17-13) and (17-14) can be expressed as
K(k + 1) = ‘ck + ‘ik) h h, ‘tk + Ilk) h + 1 -’ r E r 1 (18-8)
P(k + ilk) = @ w lk) r
-@’ + 4yyt r r (18-9)
Examples
and P(k + 1Jk + 1)
r = [I - K(k + l)h’] ‘@ ; @) (18-10)
Observe that, given ratio q/r, we can compute P(k + llk)/r, K(k + l), and P(k + Ilk + 1)/r. We refer to Equations (l&8), (l&9), and (18-10) as the scaled Kalman filter equations.
Ratio q /r can be viewed as a filter tuning parameter. Recall that, in Lesson 15, we showed q /r is related to signal-to-noise ratio; thus, using (15-50) for example, we can also view signal-to-noise ratio as a (single-channel) Kalman filter tuning parameter. Suppose, for example, that data quality is quite poor, so that signal-to-noise ratio, as measured by SNR, is very small. Then q/r will also be very small, because 4/r = SNR/h’(P,/q)h. In this case the Kalman filter rejects the low-quality data, i.e., the Kalman gain matrix approaches the zero matrix, because
P(k + 1Jk) ~plk)(p+) r r
(18-11)
The Kalman filter is therefore quite sensitive to signal-to-noise ratio, as indeed are most digital filters. Its dependence on signal-to-noise ratio is complicated and non- linear. Although signal-to-noise ratio (or q /r) enters quite simply into the equation for P(k + llk)/r, it is transformed in a nonlinear manner via (18-8) and (M-10). 0
Example 18-4 A recursive unbiased minimum-variance estimator (BLUE) of a random parameter vector 6 can be obtained from the Kalman filter equations in Theorem 17-l by setting x(k) = 9, @(k + 1,k) = I, IY(k + 1,k) = 0, Vl(k + 1,k) = 0, and Q(k) = 0. Under these conditions we see that w(k) = 0 for all k, and
x(k + 1) = x(k)
which means, of course, equations reduce to
that x(k) is a vector of constants, namely 8. The Kalman
i(k + Ilk + 1) = i(klk) + K(k + l)[z(k + 1) - H(k + l)ii(klk)],
P(k + l(k) = P(klk)
(18-12)
K(k + 1) = P(kjk)H’(k + l)[H(k + l)P(klk)H’(k + 1) + R(k + l)]-’ (18-13)
P(k + Ilk + 1) = [I - K(k + l)H(k + l)]P(klk) (18-14)
Note that it is no longer nF*wry-t&Minguish between filtered and predicted quantities, because 6(k + 1lkJ = 6(k(k) and P(k + Ilk) = P(kjk); hence, the nota- tion h(k Ik) can be simplified to 6(k), for example. Equations (18-12), (M-13), and (18-14) were obtained earlier in Lesson 9 (see Theorem 9-7) for the case of scalar measurements. Cl
Example 18-5
This example illustrates the divergence phenomenon, which often occurs when either process noise or measurement noise or both are small. We shall see that the Kalman filter locks onto wrong values for the state, but believes them to be the true values, i.e., it “learns” the wrong state too well.

State Estimation: Filtering Exampks Lesson 18
0ur example is adapted from Jazwinski (1970, pp. 302-303). We begin with the following simple first-order system
where b is a very small bias, so smail that , when we design our Kalman filter, we to neglect it. Our Kalman filter is based on the following model
x(k + 1) =x(k) + b
z(k + 1) = x(k + 1) + V(k + 1)
(1845)
(18-16)
choose
z(k 3- 1) = xm(k + 1) + u(k + 1) (18-18)
Using this model we estimate x(k) and c&,, (k /k), where it is straightfoward to show that
Iqk + 1)
observe that, as k -+m, K(k + 1) -0 SO that im(k + lik + l)+&(kik). The Ka- lman filter is rejecting the new measurements because it believes (1%17) to be the true model for x(k); but* of course, it is not the true model.
The Kalman filter computes the error variance, pm (k ik), between im (k ik) and x,.,, (k). The true error variance is associated with Z(k ik), where
i(k ik) = x(k) - im (k lk) (18-20)
We leave it to the reader to show that
As k-+ m, i(kjk) + m because the third term on the right-hand side of (18-21) diverges to infinity. This term contains the bias II that was neglected in the model used by the Kalman filter- Note also that L, (k lk) = xm(k) - &(kik)+ 0 as k + m; thus, the Kalman filter has locked onto the wrong state and is unaware that the true error variance is diverging.
A number of different remedies have been proposed for controlling divergence effects, including:
1. adding fictitious process noise, 2. finite-memory filtering, and 3. fading memory filtering.
Fictitious process noise, which appears in the state equation, can be used to account for neglected modeling effects that enter into the state equation (e.g., trun- cation of second- and higher-order effects when a nonlinear state equation is hnear- iced, as described in Lesson 24). This process noise introduces Q into the Kalman filter equations, observe, in our first-order example, that Q does not appear in the equa-
Lesson 18 Problems
tions for i,(k + Ilk + 1) or x(k Ik), because state equation (18-17) contains no process noise.
Divergence is a large-sample property of the Kalman filter. Finite-memory and fading memory filtering control divergence by not letting the Kalman filter get into its “large sample” regime. Finite-memory filtering (Jazwinski, 1970) uses a finite window of measurements (of fixed length W) to estimate x(k). As we move from c = kl to I = kl + 1, we must account for two effects, namely, the new measurement at r = kl + 1 and a discarded measurement at f = kl - W. Fading-memory filtering, due to Sorenson and Sacks (1971) exponentially ages the measurements, weighting the recent measurement most heavily and past measurements much less heavily. It is analogous to weighted least squares, as described in Lesson 3.
Fading-memory filtering seems to be the most successful and popular way to control divergence effects. q
PROBLEMS
18-l. Derive the equations for &,,(k + Ilk + 1) and i(kjk), in (16-19) and (l&21), respectively.
18-2. In Lesson 5 we described cross-sectional processing for weighted least-squares estimates. Cross-sectional (also known as sequential) processing can be performed in Kalman filtering. Suppose z(k + 1) = co! (z,(k + l), z,(k + I), . . . , z,(k + l)), where zi(ll- + 1) = H,x(k + 1) + vj(k + l), vi(k + 1) are mutually uncorrelated for i = 1, 2,. , , , zi(k + 1) is m, x 1, and ml + rnt + .*- -I- mq = me Let k,(k + ilk + 1) be a “corrected” estimate of x(k + 1) that is associated with processing z,(k + I). (a) Using the Fundamental Theorem of Estimation Theory, prove that a cross-
sectional structure for the corrector equation of the Kalman filter is:
i,(k -t Ilk + 1) = ri(k + ljk) + E{x(k + l)!&(k + ilk)}
i,(k + Ilk + 1) = %(k + Ilk + 1) + E(x(k + l)Ii,(k + Ilk))
f&(k + Ilk + 1) = k- j(k + ljk + 1) + E{x(k + l)&(k + l/k)) = fi(k + l/k + 1)
(b) Provide equations for computing E{x(k + l)lZ, (k t l/k)}. 18-3. (Project) Choose a second-order system and perform a thorough sensitivity
study of its associated Kalman filter. Do this for various nominal values and for both small and large variations of the system’s parameters. You will need a computer for this project. Present the results both graphically and tabularly, as in Example 18-2. Draw as many conclusions as possible.

Lesson 79
State Estimation:
SteadyGtate Ku/man
Relationship to a
Digital Wiener Filter INTRODUCTION
In this lesson we study the steady-state Kalman filter from different points of view, and we then show how it is related to a digital Wiener filter.
STEADY-STATE KALMAN FILTER
For time-invariant and stationary systems, if lim P(k + l/k) = P exists, then lim K(k)+?r; and the Kalman filter (17-11) b<comes a constant coefficient !%er. Because P(k + l(k) and P(klk) are intimately related, then, if p exists, pz Wlk) k P, also exists. We have already observed limiting behaviors for K(k + 1) and P(klk) in Example 18-1. The following theorem, which is adop- ted from Anderson and Moore (1979, pg. 77), tells us when F exists, and assures us that the steady-state Kalman filter will be asymptotically stable.
Theorem 19-l (Steady-State Kalman Filter). Ifour dynamical model in Equations (15-l 7) and (15-18) is time-invariant, stationary, and asymptotically stable (i.e., all the eigenvalues of Q, lie inside the unit circle), then:
a. For any nonnegative-definite symmetric initial condition P(OI- 1), one has li+i P(k + 1Jk) = p with p independent of P(OI-1) and satisfying the following steady-state version of Equation (17-24):
i? = @[I - H’(HFH’ + R)-lHP]@r + I’QF’ (19-l)
170
Steady-State Kalman Filter 171
Equation (19-l) is often referred to either as a steady-state or algebraic Riccati equation.
b. The eigenvalues of the steady-state KaZman filter, @I? - KIWJ, all lie within the unit circle, so that the filter is asymptotically stable; i.e.,
Ih[@ - KH@] / 4 (19-2)
If our dynamical modet in Equations (1.54 7) and (15-18) is time- invariant and stationary, but is not necessarily asymptotically stable, then points (a) and (b) still hold as long as the system is completely stabilizable and detectable. Cl
A proof of this theorem is beyond the scope of this textbook. It can be found in Anderson and Moore, pp. 78-82 (1979). For definitions of the system-theoretic terms stabilizable and detectable, the reader should consult a textbook on linear systems, such as Kailath (1980) or Chen (1970). By com- pletely detectable and completely stabihzable, we mean that (@,H) is com- pletely detectable and (@,I’QI) is completely stabilizable, where Q = QIQ;. Additionally, any asymptotically stable model is always completely sta- bilizable and detectable.
Probably the most interesting case of a system that is not asymptotically stable, for which we want to design a steady-state Kalman filter, is one that has a pole on the unit circle.
Example 19-1
In this example (which is similar to Example 5.4 in Meditch, 1969, pp. 189-190) we consider the scalar system
x(k + 1) =x(k) + w(k) (19-3)
z(k + 1) =x(k + 1) + v(k + 1) (19-4)
It has a pole on the (17-14) reduce to:
unit circle. When 4 = 20 and r = 5, Equations (17-13), (17-12) and
p(k + lik) =&k[k) + 20 (19-5)
K(k + 1) = P(W + 20 P(W + 25
p(k + l[k + 1) =
(19-6)
(19-7)
Starting with p (010) = p,(O) = 50, it is a relatively simple matter to compute p(k + ilk), K(k + 1) and p(k + ‘Ilk + 1) for k = 0, 1,. . . . The results for the first few iterations are given in Table 19-1.

172 State Estimation: Kalman Filter and Wiener Filter Lesson 19
T-4BLE 19-l Kahnan Filter QuanMes
0 . . * . . . 50 1 70 0.933 4.67 7 24.67 o.s31 4.16 3 24.14 0.829 4.14 4 24.14 0*828 4.14
The steady-state value of I? is obtained by setting p(k + l[k + 1) = p (k ik) = pI in the last of the above three relations to obtain
Because pI is a variance it must be nonnegatke: hence, only the solution j& = 4.14 is valid. Comparing this result with p (313) we see that the filter is in the steady state to within the indicated computationa accuracy aher processing just three measurements. In steady-state, the Kalman filter equation is
i(k + lik + 1) = i(+) + O.S28[z(k + 1) - i(k\k)] = O.l72i(kik) + 0.828 z(k + 1)
(19-9)
Observe that the filter’s pole at 0.1’72 lies inside the unit circle. 0
Many ways have been reported for solving the algebraic Riccati equation (19-l) [see Laub (1979), for example], ranging from direct iteration of the matrix Riccati Equation (17-24) until P(k + l!k) does not change appreciably from P(k jk - I), to solving the nonlinear algebraic Riccati equation via an iterative Newton-Raphson procedure, to solving that equation in one shot by the Schur method. Iterative methods are quite sensitive to error accumu- lation. The one-shot Schur method possesses a high degree of numerical integrity, and appears to be one of the most successful ways for obtaining F. For details about this method, see Laub (1979).
In summary, then, to design a steady-state Kalman filter:
1. given (@,r,V,H,Q,R), compute F, the positive definite solution of (19-l);
2. computez, as
ii=Fw(~F~r + R)-l (19-10)
3. use (19-10) in
k(k + lik + 1) = Wi(kik) + ‘h(k) + %(k + Ilk) = (I - EH)@k(k !k) + itz(k + 1) (19-11)
+ (I - KH)‘h(k]
Single-Channel Steady-State Kaiman Filter
SINGLE-CHANNEL STEADY-STATE KALMAN FILTER
The steady-state Kalman filter can be viewed outside of the context of esti- mation theory as a recursive digital filter. As such, it is sometimes useful to be able to compute its impulse response, transfer function, and frequency re- sponse. In this section we restrict our attention to the single-channel steady- state Kalman filter. From (19-11) we observe that this filter is excited by two inputs, z(k + 1) and u(k) [in the single-channel case, z(k + 1) and u(k)]. In this section we shall only be interested in transfer functions which are associ- ated with the effect of z(k + 1) on the filter; hence, we set u(k) = 0. Addi- tionally, we shall view the signal component of measurement z(k) as our desired output. The signai component of z(k) is h’x(k).
Let Hi(z) denote the z-transform of the impulse response of the steady- state filter; i.e.,
H,(z) = !E{i(kjk) when z(k) = s(k)} (N-12)
This transfer function is found from the following steady-state fiZter system:
i(klk) = [I - iih’]@i(k - Ilk - I) + h(k)
i(klk) = h’i(klk)
(19-13)
(19-14)
Taking the r-transform of (19-13) and (19-14), it follows that
Hf (z) = h’(1 - $z-I)-’ K (19-X)
where
(19-16)
Equation (19-15) can also be written as
Hf(Z) = h,(O) + h,(l)z-’ + hf(2)2-? + *.* (19-17)
where the filter’s coefficients (i.e., Markov parameters), h, (j), are .-
h,(j) = h’@! K (19-18)
forj =O,l,.... In our study of mean-squared smoothing, in Lessons 20,21, and 22, we
will see that the steady-state predictor system plays an important role. The steady-state predictor, obtained from (17-23), is given by
ii(k + Ilk) = @&kIk - 1) + y,z(k) (19-19)
(I$, = @(I - Kh’) (19-20)
and
y,=@E (19-21)

State Estimation: Kalman Filter and Wiener Filter Lesson 19
Let HP (z) denote the z-transform of the impulse response of the steady- state predictor, i.e.,
H,(z) = Cif{f(klk - 1) when z(k) = 6(k)} (19-22)
This transfer function is found from the following steady-state predictor system:
%(k + Ilk) = @$(klk - 1) + y/J(k) (19-23)
i(klk - 1) = h’k(klk - 1) (19-24)
Taking the z-transform of these equations, we find that
H,(z) = h’(I - $,z-‘)-‘z-‘yP (19-25)
which can also be written as
HP(z) = h,(l)z-’ + hP(2)z-2 + l . . (19-26)
where the predictor’s coefficients, hJj), are
hP(j) = h’W;-’ yP (19-27)
for j = 1,2,.... Although Hf(z) and H,(z) contain an infinite number of terms, they can
usually be truncated, because both are associated with asymptotically stable filters.
Example 19-2 In this example we first-order system
examine the response of the steady-state predictor
x(k + 1) =&x(k) v5
+ w(k) (19-28)
z(k + 1) =&(k + 1) + v(k + 1) ti
(19-29)
In Example 15-2 of Lesson 15, we showed that ratio 4 /r is proportional to signal-to- noise ratio, SNR. For this example, SNR = 4 /r . Our numerical results, given below, are for SNR = 20, 5, 1 and use the scaled steady-state prediction-error variance B /t , which can be solved for from (19-1) when it is written as:
(19-30)
Note that we could just as well have solved (19-l) for p /q but the structure of its equation is more complicated than (19-30). The positive solution of (19-30) is
FJ - r Z(SNR-1)++v(SNR-1)‘+8SNR (19-31)
Additionally,
(19-32)
Single-Channel Steady-State Kalman Filter 175
Table 19-2 summarizes 7 /r , r, C& and yP , quantities which are needed to compute the impulse response I+(k) for k 2 0, which is depicted in Figure 19-l. Observe that all three responses peak at j = 1; however, the decay time for SNR = 20 is quicker than
TABLE 19-2 Steady-State Predictor Quantities
SNR p/r K 4 ‘YP
20 20.913 1.287 0.064 0.910 5 5.742 1.049 0.183 0.742 1 1.414 0.586 0.414 0.414
700
SNR=20 (0) H,(z)=OA43z-‘+O.O41z-* + o.003z-3
SNR = 5 (a) H,(z) = 0.524~ - 1 + 0.096~ -2 + 0.008z-3+0.001z-4
SNR= 1 (A) HP(z)=0.293z-‘+O.l2lz-2 + 0.050~-~+0.021~-~ + o.oo9z-5+o.oo4z-6 + 0.0012-‘+0.0012-*
0 1 2 3 4 5 6 7 8
j Figure 19-1 Impulse response of steady-state predictor for SW? = 20, 5 and 1. H,(z) is shown to three significant figures (Mendel, 1981, 0 1981, IEEE).
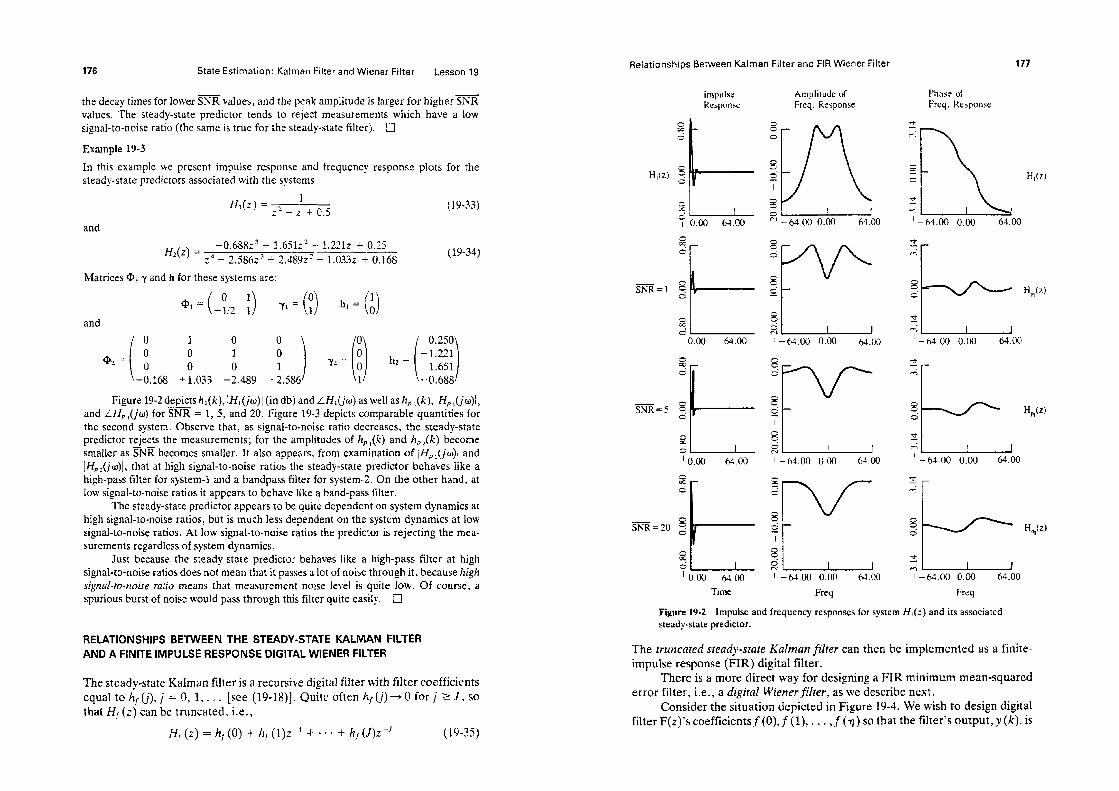
176 State Estimation: Kalman Filter and Wiener Filter Lesson 19
the decay times for lower SNR values, and the peak amplitude is larger for higher SNR values. The steady-state predictor tends to reject measurements which have a low signal-to-noise ratio (the same is true for the steady-state filter). Cl
Example 19-3
In this example we present impulse response and frequency response plots for the steady-state predictors associated with the systems
(19-33)
and
f&(z) = -0.688~~ + 1.651~~ - 1.2212 + 0.25
z4 - 2.58@ + 24t89z2 - 1.033.? -io 0.168 (N-34)
Matrices a, y and h for these systems are:
and 1 u 0
+ I.033 -2.489 +2.586
Figure 19-2depicts II~(Ic), /HI@)1 (in db) and LMI(jw) as well as IzP ,(k), iHP ,(j~)[, and LHP,(iu) for WR = 1, 5, and 20. Figure 19-3 depicts comparable quantities for the second system. observe that, as signal-to-noise ratio decreases, the steady-state predictor rejects the measurements; for the amplitudes of hP I(k) and hpz(k) become smaller as SNR becomes smaller. It also appears, from examination of /HPI(ju)/ and ]H,,2(jw)i, that at high signal-to-noise ratios the steady-stale predictor behaves like a high-pass filter for system-1 and a bandpass filter for system-2. 0n the other hand, at low signal-to-noise ratios it appears to behave like a band-pass filter.
The steady-state predictor appears to be quite dependent on system dynamics at high signal-to-noise ratios, but is much less dependent on the system dynamics at low signal-to-noise ratios. At iow signal-to-noise ratios the predictor is rejecting the mea- surements regardless of system dynamics.
Just because the steady-state predictor behaves like a high-pass fiiter at high signal-to-noise ratios does not mean that it passes a lot of noise through it, because high signal-to-noise rasjo means that measurement noise level is quite low* Of course, a spurious burst of noise would pass through this filter quite easily. Cl
RELATIONSHIPS BETWEEN THE STEADY-STATE KALMAN FILTER AND A FINITE IMPULSE RESPONSE DiGiTAL WIENER FILTER
The steady-state Kahnan filter is a rewrsive digital filter with filter coefficients equal to !zf(j),j = 0, I,. , a [see (19-H)]. Quite often h! (j)+ 0 for j’ 2 J! so . . that Hf (z) can be truncated, i.e.,
k&j = hj(O) + hj(l)P + *-* + h&qz-J (19-35)
Relationships Between Kalman Filter and FIR Wiener Filter
impulse Response
SNR=I
SNR=5
Amplitude of Freq. Response
Time Freq
Phase of Freq. Response
H,(z)
H,(z)
Freq
Figure 19-2 Impulse and frequency responses for system HI(z) and its associated steady-state predictor.
The truncated steady-stare Kalman filter can then be implemented as a finite- impulse response (FIR) digital filter.
There is a more direct way for designing a FIR minimum mean-squared error filter, i.e., a digital Wiener.fiZter. as we describe next.
Consider the situation depicted in Figure 19-4. We wish to design digital filter F(z)% coefficientsf (O),f (l), . . . ,f(~) so that the filter’s output, y (k), is
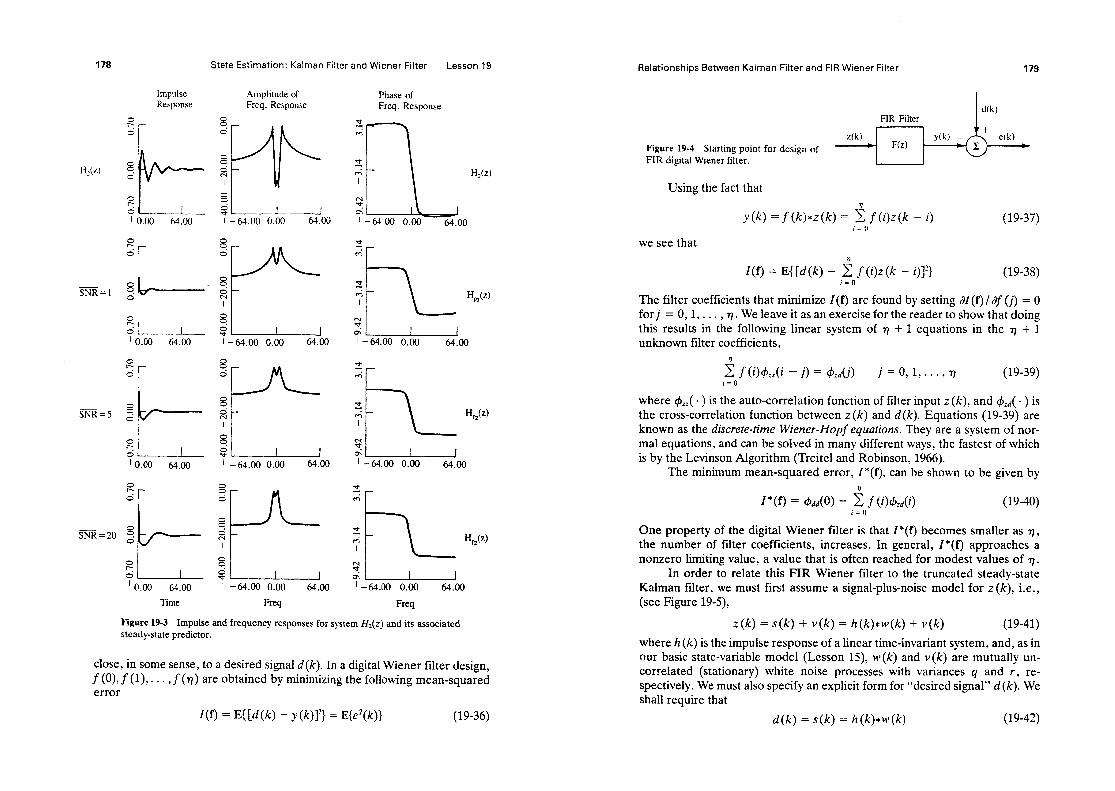
178 State Estimation: Kalman Filter and Wiener Filter Lesson 19
Impulse Response
Amplitude of Freq. Response
Phase of Freq. Response 8 6 r 8 . 8 I + 1
-e vi
* t-4
~1L
I
G 0; ’ -64.00 0.00 64.00
Hz(z) HJz)
$1 1 J I -tj4.00 0.00 64.00 ’ 0.00 64.00
c-- 6 i 8 d
8 . 8 I
0 a .
s M
I-64.00 0.00 64.00
s cc; r zs r; I
?L
&--- SNR=l H,(z)
?lI I-64.00 0.00 64.00
?, di I
’ 0.00 64.00
:p- s I 8 . s r ’ -64.00 0.00 64.00 SNR=5
%i ’ 0.00 64.00 ’ -64.00 0.00 64.00
8 6 If- SNR = 20
51 I ’ 0.00 64.00 I -64.00 0.00 64.00
Freq Time Freq
Figure 19-3 Impulse and frequency responses for system l&(z) and its associated steady-state predictor.
close, in some sense, to a desired signal d(k). In a digital Wiener filter design, fmf(%-J(rl) are obtained by minimizing the following mean-squared error
W) = E{ [d(k) - y (k)fz) = w*(k)) (19-36)
Relationships Between Kalman Filter and FIR Wiener Filter
FIR Filter
Figure 19-4 Starting point for design of FIR digital Wiener filter.
c
z(k)
t F(z)
*
Using the fact that
y(k) = f (k)*z(k) = 5 f (i)z(k - i) i = 0
(19-37)
we see that
I(f) = E{ [d(k) - 2 f (i)z(k - i)]‘} i=o
(19-38)
The filter coefficients that minimize I(f) are found by setting ar(f)/@ (j) = 0 forj =O,l,..., r). We leave it as an exercise for the reader to show that doing this results in the following linear system of or) + 1 equations in the r) + 1 unknown filter coefficients,
if(W& -j)= &d(j) j =O,l,...,q (19-39) i = 0
where &( . ) is the auto-correlation function of filter input z(k), and &( . ) is the cross-correlation function between z (k) and d(k). Equations (19-39) are known as the discrete-time Wiener-Hopf equations. They are a system of nor- mal equations, and can be solved in many different ways, the fastest of which is by the Levinson Algorithm (Treitel and Robinson, 1966).
The minimum mean-squared error, I*(f), can be shown to be given by
I*(f) = hid(O) - i f (+l%d(i) (19-40) i = 0
One property of the digital Wiener filter is that I*(f) becomes smaller as ‘I, the number of filter coefficients, increases. In general, I*(f) approaches a nonzero limiting value, a value that is often reached for modest values of q.
In order to relate this FIR Wiener filter to the truncated steady-state Kalman filter, we must first assume a signal-plus-noise model for z(k), i.e., (see Figure 19.5),
z(k) = s(k) + v(k) = h(k)*w(k) + v(k) (19-41)
where h (k) is the impulse response of a linear time-invariant system, and, as in our basic state-variable model (Lesson 15), w(k) and v(k) are mutually un- correlated (stationary) white noise processes with variances q and r, re- spectively. We must also specify an explicit form for “desired signal” d(k). We shall require that
d(k) = s(k) = h(k)*w(k) (19-42)

State Estimation: Kalman Filter ard Wiener Filler Lessor7 19
Figure 19-5 Signal-plus-noise model incorporated into the design of a FIR digital Wiener filter. The dashed lines denote paths that exist only during the design stage; these paths do not exist in the implementation of the filter.
which means, of course, that we want the output of the FIR digital Wiener filter to be as close as possible to signal 8(k).
Using (19-41) and (N-42), it is another straightforward exercise to com- pute +& - j) and &&). The resulting discrete-time Wiener-Hopf equations are
where
(19-44)
Observe, that, as in the case of a single-channel Kahnan filter? our single channel Wiener filter only depends on the ratio q/r (and subsequently on SNR).
Theorem U-2. T/w steady-state Kuimun filter is an infinite-kngth digi- tal Wiener filter. The truncated steady-state K&nan filter ti a FIR digital Wiener fiZter.
Pruuf (heuristic). The digital Wiener filter has constant coefficients as does the steady-state Kalman filter. Both filters minimize error variances. The infinite-length Wiener filter has the smallest error variance of all Wiener filters, as does the steady-state Kalman filter; hence, the steady-state Kalman filter is an infinite length digital Wiener filter.
The second part of the theorem is proved in a similar manner. El
Using Theorem 19-2. we suggest the following proceduwfor designirzg a recursive Wiener filter (i. e . 7 a steady-state Kalman fiber):
Comparisons of Kalman and Wiener Filters 181
1. obtain a state-variable representation of h(k); 2. determine the steady-state Kalman gain matrix, ii, as described above ; 3. implement the steady-state Kalman filter (19-11); 4. compute the estimate of desired signal s(k), as
s^(k !k) = h ‘i(klk) (D-45)
COMPARISONS OF KALMAN AND WIENER FILTERS
We conclude this lesson with a brief comparison of Kalman and Wiener filters. First of all, the filter designs use different types of modeling information, Auto-correlation information is used for FIR digital Wiener filtering, whereas a combination of auto-correlation and difference equation information is used in Kalman filtering. In order to compute I&(Z), h(k) must be known; it is always possible to go directly from h (k) to the parameters in a state-variable model [Le., (a, y, h)], using an approximate realization procedure (e.g., Kung, 1978).
Because the Kalman filter is recursive, it is an infinite-length filter; hence, unlike the FIR Wiener filter, where filter length is a design variable, the filter’s length is not a design variable in the Kalman filter.
Our derivation of the digital Wiener filter was for a single-channel model, whereas the derivation of the Kalman filter was for a more general multichannel model (i.e., the case of vector inputs and outputs). For a deri- vation of a multichannel digital Wiener filter, see Treitel (1970).
There is a conceptual difference between Kalman and FIR Wiener fil- tering. A Wiener filter acts directly on the measurements to provide a signal s^(k jk) that is “close” to s(k). The Kalman filter does not do this directly. It provides us with such a signal in two steps. In the first step, a signal is obtained that is “close” to x(k), and in the second step, a signal is obtained that is “close” to s(k). The first step provides the optimal filtered value of x(k), i(kjk); the second step provides the optimal filtered value of s(k), because s^(klk) = h’ii(klk).
Finally, we can picture a diagram similar to the one in Figure 19-5 for the Kalman filter, except that the dashed lines are solid ones. In the Kalman filter the filter coefficients are usually time-varying and are affected in real time by a measure of error e(k) (i.e., by error-covariance matrices), whereas Wiener filter coefficients are constant and have only been affected by a measure of e (k) during their design,
In short, a Kalman filter is a generalization of the FIR digital Wiener filter to include time-varying filter coefficients which incorporate the effects of error in an active manner. Additionally, a Kalman filter is applicable to either time-varying or nonstationary systems or both, whereas the digital Wiener filter is not.

182 State Estimation: Kalman Filter and Wiener Filter Lesson 19
PROBLEMS
19-l. Derive the discrete-time Wiener-Hopf equations given in (19-39). 19-2. Prove that the minimum mean-squared error, I*(f), given in (19-40), becomes
smaller as 7, the number of filter coefficients, increases.
19-3
19-4.
2 Consider the basic state-variable model, x(k + 1) = - x(k) + w(k) and ti
z(k +l)=x(k+l)+v(k+l), where 4=2, r=l, m,(O)=0 and E(x 2(0)}=2. (a) Specify i(OlO) and p (010). (b) Give the recursive predictor for this system. (c) Obtain the steady-state predictor. (d) Suppose z(5) is not provided (i.e., there is a gap in the measurements at
k = 5). How does this affect p (615) and p (100/99)? Consider the basic scalar system x(k + 1) = 4x(k) + w(k) and z (k + 1) = x(k + 1) + v(k + 1). Assume that 4 = 0 and let l@p(kIk) = PI. (a) Show that p1 = 0 and p1 = (42 - 1)r /42.
Which of the two solutions in (a) is the correct one when < l?
lesson 20
State Estimation:
Smoothing
THREE TYPES OF SMOOTHERS
Recall that in smoothing we obtain mean-squared estimates of state vector x(k), i(klj) for which k c j. From the Fundamental Theorem of Estimation Theory, Theorem 13-1, we know that the structure of the mean-squared smoother is
v Ii) = Gwfw~ where k <j (20-l)
In this lesson we shall develop recursive smoothing algorithms that are com- parable to our recursive Kalman filter algorithm.
Smoothing is much more complicated than filtering, primarily because we are using future measurements to obtain estimates at earlier time points. Because there is some flexibility associated with how we choose to process future measurements, it is convenient to distinguish between three types of smoothing (Meditch, 1969, pp. 204-208): fixed-interval, fixed-point, and fixed-lag.
The fixed-interval smoother is i(k IN), k = 0, 1, . . . , N - 1, where N is a fixed positive integer. The situation here is as follows: with an experiment completed, we have measurements available over the fixed interval 1 5 k 5 N. For each time point within this interval we wish to obtain the optimal estimate of state vector x(k), which is based on all the available measurement data {z(j), j = 1, 2, * s j ) N). Fixed-interval smoothing is very useful in signal processing, where the processing is done after all the data is

State Estimation: Smoothing Lesson 20
collected. It cannot be carried out on-line during an experiment, as filtering can be. Because alI the available data is used, one cannot hope to do better (by other forms of smoothing) than by fixed-interval smoothing.
The +&@n? smoothed estimate is i(k 1 j), j = k + 1, k + 2, . . . where k is a fixed positive integer. Suppose we want to improve our estimate of a state at a specific time by making use of future measurements. Let this time be z. Then fixed-point smoothed estimates of x(z) will be $$ + l), k(iqZ + 2),..., etc. The last possible fixed-point estimate is I@$V), which is the same as the fixed-interval estimate of x(x). Fixed-point smoothing can be carried out on-line, if desired, but the calculation of k(%iz + dj is subject to a delay of Osec.
TheftieGzg smoothed estimate is i(# + I,), k = 0, 1, , . . , where L is a fixed positive integer. In this case, the point at which we seek the estimate of the system’s state lags the time point of the most recent measurement by a fried interval of time, ~5; i.e., lk + L - I& = L which is a positive constant for al1 k =O,l,e.. . This type of estimator can be used where a constant lag between measurements and state estimates is permissible- Fixed-lag smoothing can be carried out on-line, if desired, but the calculation of %(kik + L) is subject to an LT set delay.
APPROACHES FOR DERWING SMOOTHERS
The literature on smoothing is f3led with many different approaches for deriving recursive smoothers. By augmenting suitably defined states to (1517) and (15-l@, one can reduce the derivation of smoothing formulas to a Kalman filter for the augmented state-variable model (Anderson and Moore, 1979). The “filtered” estimates of the newly-introduced states turn out to be equiv- alent to smoothed values of x(k). We shall examine this augmentation ap- proach in Lesson 21. A second approach is to use the orthogonality principle to derive a discrete-time Wiener-Hopf equation, which can then be used to establish the smoothing formulas. We do not treat this approach in this book.
A third approach, the one we shall follow in this lesson, is based on the causal invertibility between the innovations process i(k -t ~IJc + j - 1) and measurement z(k + j), and repeated applications of Theorem 12-4.
A SUMMARY OF IMPORTANT FORMULAS
The following formulas, which have been derived in earlier lessons, are used so frequently in this lesson, as well as in Lesson 21, that we collect them here for the convenience of the reader:
Single-Stage Smoother
i(k + Ilk) = z(k + 1) - H(k + l)ii(k + Ilk) (20-2)
i(k + Ilk) = H(k + l)X(k -t- Ilk) + v(k + 1) (20-3)
P;;(k + ljk) = H(k + l)P(k + llk)H’(k + 1) + R(k + 1) (20-4)
$k + l/k) = QP(k + l,k)%(klk) + r(k + l,k)w(k) (20-5)
and
,(k + ljk -t 1) = [I - K(k + l)H(k + l))ji(k + Ilk) - K(k + l)v(k + 1) (20-6)
SINGLE-STAGE SMOOTHER
As in our study of prediction, it is useful first to smoother and then to obtain more general smoothers.
X(k)? Theorem 20-l. The single-stage mean-squared i(k[k + 1 ), is given by the expression
develop a single-stage
smoothed estimator of
i(kjk + 1) = i(klk) + M(klk + l)Z(k + Ilk) (20-7)
where single-stage smoother gain matrix, M(klk + I), is
M(kIk + 1) = P(kIk)W(k + l,k)H’(k + 1) [H(k -+ l)P(k + llk)H’(k + 1) + R(k + l)]-’ (20-S)
Proof. From the Fundamental Theorem of Estimation Theory and The- orem 12-4, we know that
G(klk + 1) = E{x(k)/%(k + 1)) = %WkWMk + 1)) = E(x(k)l%(k),Z(k + l(k)}
= E(x(k)lZ(k)} + E{x(k)li(k + Ilk)) - m,(k)
(20-9)
which can also be expressed as (see Corollary 13-l)
i(klk + 1) = fr(klk) + P;(k ,k + l]k)P;‘(k + llk)Z(k + Ilk)
Defining single-stage smoother gain matrix M(k Jk + 1) as
M(kIk + 1) = P,(k .k + llk)P;;‘(k + ljk)
(20-10)
(20-l 1)
(20-10) reduces to (20-7). Next, we must show that M(k\k + 1) can also be expressed as in (20-g).
We already have an expression for Pii(k + l(k), namely (20-4); hence, we

State Estimation: Smoothing Lesson 20
must compute P&k ,k + Ilk). To do this, we make use of (20-3), (20-5) and the orthogonahty principle, as foliows:
P,(k,k + Ilk) = E{x(k)Z’(k + Illi)} = E{x(k)[H(k + l)%(k + l[k) + v(k + l)]‘} = E{x(k)i’(k + llk)}H’(k + 1)
= E{x(k)[@(k + l,k)x(k[k) + r(k + l,k)w(k)]‘}H’(k + 1)
(20-12)
= E{x(k)?‘(klk)}@‘(k + Z,k)H’(k + 1) = E{[f(klk) + ?(klk)]ji’(k Ik)}@‘(k + l,k)H’(k + 1) = P(kIk)Q,‘(k + J,k)H’(k + 1)
Substituting (20-12) and (20-4) into (20-19, we obtain (20-8). q
For future reference, we record the following fact,
E{x(k)%‘(k + Ilk)} = P(k)k)@‘(k + 1,k) (20-13)
This is obtained by comparing the third and last lines of (20-12). Observe that the structure of the single-stage smoother is quite similar to
that of the Kalman filter. The Kalman filter obtains r2(k + Ilk + 1) by adding a correction that depends on the most recent innovations, i(k + Ilk), to the predicted value of x(k + 1). The single-stage smoother, on the other hand, obtains i(klk + 1) by adding a correction that also depends on i(k + ljk), to the filtered value of x(k). We see that filtered estimates are required to obtain smoothed estimates.
Coroliary 20-l. Kalman gain matrix K(k + 1) is a factor in M(klk + 1), i.e.,
M(kIk + 1) = A(k)K(k + 1) (20-14) where
A(k) A P(kIk)W(k + l,k)P-‘(k + Ilk) (20-15)
Proof. Using the fact that [Equation (17-12)j
K(k + 1) = P(k + llk)H’(k + 1) [H(k + l)P(k + llk)H’(k + 1) + R(k + l)]-’
we see that (20-16)
H’(k + l)[H(k + l)P(k + llk)H’(k + 1) + R(k + l)]-’ = P-‘(k + llk)K(k + 1) (20-17)
When (20-17) is substituted into (20.8), we obtain (20-14). 0
Corollary 20-2. Another way to express ri(klk + 1) is
Double-Stage Smoother
k(klk + 1) = %(kjk) + A(k)[%(k + Ilk + 1) - i(k + Ilk)] (20-18)
Proof. Substitute (20-14) into (20-7) to see that
k(k lk + 1) = i(klk) + A(k)K(k + l)Z(k + Ilk)
but [see (l7-ll)]
(20-19)
K(k + l)Z(k + ilk) = S(k + Ilk + 1) - ri(k + Ilk) (20-20)
Substitute (20-20) into (20-19) to obtain the desired result in (20-18). 0 Formula (20-7) is useful for computational purposes, whereas (20-18) is
most useful for theoretical purposes. These facts will become more clear when we examine double-stage smoothing in our next section.
Whereas the structure of the single-stage smoother is similar to that of the Kalman filter, we see that M(kIk + 1) does not depend on single-stage smoothing error-covariance matrix P(klk + 1). Kalman gain K(k + 1), of course, does depend on P(k + Ilk) [or P(kIk)]. In fact, P(klk + 1) does not appear at all in the smoothing equations and must be computed (if one desires to do so) separately. We address this calculation in Lesson 21.
DOUBLE-STAGE SMOOTHER
Instead of immediately generalizing the single-stage smoother to an hT stage smoother, we first present results for the double-stage smoother. We will then be able to write down the general results (almost) by inspection of the single- and double-stage results.
Theorem 20-2. The double-stage mean-squared smoothed estimator of x(k), %(k)k + 2), is given by the expression
ri(k(k + 2) = f(k)k + 1) + M(kIk + 2)2(k + 21k + 1) (20-21)
where double-stage smoother gain matrix, M(klk + 2), is
M(kIk + 2) = P(kIk)W(k + l,k)[I - K(k + 1) H(k + l)]‘@‘(k + 2,k + 1) H’(k + 2)[H(k + 2)P(k + 21k + 1) H’(k + 2) + R(k + 2)]-’
(20-22)
Proof. From the Fundamental Theorem of Estimation Theory, The- orem 12-4, and Corollary 13-1, we know that
i(klk + 2) = E{x(k)lS(k + 2)) = E{x(k)l%(k + l), z(k + 2)) = E{x(k)lZ(k + l), i(k + 21k + 1))
(20-23) \ ,
= E{x(k)lZ(k + 1)) + E{x(k)li(k + 2Ik + 1)) - m,(k)

188
which can also be expressed as
?(kjk -+ 2) = k(kik + 1)
State Estimation: Smoothing Lesson Xl
+ PG(k,k + 2ik + l)P&‘(k + 2ik + l)i(k + 2ik + I)
Defining double-stage smoother gain matrix M(k\k + 2) as
(20-24)
M(kik + 2) = Pti(k ,k + 2/k + l)Pg’(k + 2ik + 1)
(20-24) reduces to (20-21).
(20-25)
In order to show that M(k/k + 2) in (20-25) can be expressed as in (2O-22), one proceeds as in our derivation of M(k !k + 1) in (20-12); however, the details are lengthier because ii(k + 2ik + 1) involves quantities that are two time units away from x(k), whereas i(k + lik) involves quantities that are only one time unit away from x(k). Equation (20-13) is used during the deri- vation. We leave the detailed derivation of (20-22) as an exercise for the reader. q
Whereas (20-22) is a computationally useful formula, it is not useful from a theoretical viewpoint; i.e., when we examine M(k jk + 1) in (20-8) and M(k!k + 2) in (20-22), it is not at al1 obvious how to generalize these formulas to hS(k[k + N), or even to M(kik + 3) The following result for M(kik + 2) is easily generalized.
Corollary 20-3, Kalman pin mcztrix K(k + 2) isa factor in M(kik + 2), i.e.,
M(kik + 2) = A(k)A(k + l)K(k -+ 2)
where A(k) is defined in (20-15).
Pruuf. Increment k to k + 1 in (2047) to see that
H’(k + 2)[H(k + 2)P(k + 2ik + l)H’(k + 2) + R(k + 2)]-’ = P-l (k + 2lk + I)K(k + 2)
Next, note from (17-14), that
I - K(k + l)H(k + 1) = P(k + l/k + l)P-’ (k + lik)
hence,
(20-26)
(2U-27)
(20-28)
[I - K(k + l)H(k + l)]’ = I’-‘(k + llk)P(k + l[k + 1) (20-29)
Substitute (2U-27) and (20-29) into (20-22) to see that
M(kik + 2) = P(klk)@‘(k + 1 ,k)P-’ (k + lik) P(k + ilk + l)W(k + 2,k -+ 1) P-* (k + 2lk + l)K(k + 2) (20-30)
Single- and Double-Stage Smoothers as General Smoothers 189
Using the definition of matrix .4(k) in (20-151, we see that (20-30) can be expressed as in (20-26). [7
Corollary 20-4. Trvo other ways to express %(klk + 2) are:
i(klk + 2) = i(klk + 1) + A(k)A(k + l)[i(k + 21k + 2) - i(k + 21k + I)] (20-31)
and
i(klk + 2) = i(klk) + A(k)[%(k + l/k + 2) - i(k + Ilk)] (20-32)
Procf’. The derivation of (20-31) follows exactly the same path as the derivation of (20-H), and is therefore left as an exercise for the reader. Equation (20-31) is the starting place for the derivation of (20-32). Observe, from (20-18), that
A(k + l)[i(k + 21k + 2) - ji(k + 2/k + I)] = G(k + Ilk + 2) - i(k + Ilk + 1)
thus, (20-31) can be written as
ji(klk + 2) = i(k jk + 1)
(20-33)
+ A(k)[ri(k + Ilk + 2) - i(k + Ilk + l)] (20-34)
Substituting (20-18) into @O-34), we obtain the desired result in (20-32). III
The alternate forms we have obtained for both i(klk + 1) and f(klk + 2) will suggest how we can generalize our single- and double-stage smoothers to N-stage smoothers.
SINGLE- AND DOUBLE-STAGE SMOOTHERS AS GENERAL SMOOTHERS
At the beginning of this lesson we described three types of smoothers, namely: fixed-interval, fixed-point, and fixed-lag smoothers. Table 20-l shows how our single- and double-stage smoothers fit into these three categories.
In order to obtain the fixed-interval smoother formulas, given for both the single- and double-stage smoothers, set k + 1 = N in (20-18) and k + 2 = N in (20-32), respectively. Doing this forces the left-hand side of both equa- tions to be conditioned on data length N. Observe that, before we can com- pute %(N - IIN) or i(N - 2jN), we must run a Kalman filter on all of the data in order to obtain li(NIN), This last filtered state estimate initializes the back- ward running fixed-interval smoother. Observe, also, that we must compute i(N - l/N) before we can compute Ei(N - 21N). Clearly, the limitation of our results so far is that we can only perform fixed-interval smoothing for

s 0 TA
BLE
20-l
Smoo
thin
g In
terre
latio
nshi
ps
Sing
le-S
tage
D
oubl
e-St
age
Fixe
d-In
terv
al
f (N
-
IIN)
= &
(N -
l(N
-
1) +
A(N
-
1)
I WIN
, -
&(N
lN -
l)]
f(N
- W
I W
IN)
Smoo
ther
I
’ +Y
Tim
e N
-l%-
/N
Scal
e
Solu
tion
proc
eeds
in re
vers
e tim
e,
from
N to
N -
1,
whe
re N
is fi
xed.
Fixe
d-Po
int
a(@
+ 1
) =
a(@
) +
A(k)
[2
(X +
1l
Z +
1) -
s(k
+ Ilk
)]
k fix
ed a
t k
i(Zli)
a(
i +
l(i
+ 1)
Fi
lter
k k+
1
F
3 Ti
me
Scal
e
n(kl
k +
1) S
moo
ther
y
Tim
e i
Scal
e
So!u
tion
proc
eeds
in fo
rwar
d tim
e fro
m k
to
k +
1 on
the
filte
ring
time
scal
e and
then
ba
ck to
$ o
n th
e sm
ooth
ing t
ime
scal
e. A
on
e-un
it tim
e de
lay
is p
rese
nt.
fi (N
-
21N
) =
2 (N
-
21N
- 2)
+
A(N
-
2)
[B(N
-
IIN)
- B(
N -
11N
- 2)
]
S(N
-
21N
) B(
N -
1I
N)
WIN
)
1 :J
? N
-2
N-l
N
Solu
tion
proc
eeds
in re
vers
e tim
e, fr
om
Nto
N
- 1,
toN
-
2, w
here
Nis
fixed
.
a(@
+
2)
= 2(
@
+ 1)
+ A
(k)A
(%
+ 1)
[ii
(k
+ 21
k +
2)
- ri(
k +
2(z
+ l)]
k fix
ed a
t i ir(
iiIii)
ng
+ lp
i+ 1
) j;(
i; +
2pi +
2)
1 I
i;l
-23
-G+
‘ii+2
Solu
tion
proc
eeds
in fo
rwar
d tim
e. R
esul
ts
from
sin
gle-
stag
e sm
ooth
_er as
wel
l as o
ptim
al
filte
r_ar
e req
uire
d at Y
=k
+ 1,
whe
reas
at
Y’=
k on
ly r
esul
ts fr
om o
ptim
al fi
lter
are
requ
ired.
A t
wo-
unit
time
dela
y is
pres
ent.
Tabl
e 20
-l C
ont.
Sing
le-S
tage
D
oubl
e-St
age
Fixe
d-La
g %
(klk
+
I) =
ir(kl
k) +
A(k
) [fi
(k +
Ilk
+
1) -ii
(k
+ Ilk
)]
k va
riabl
e k
varia
ble
Pict
ure a
nd d
iscu
ssio
n sam
e-as
in
Fixe
d-Po
int c
ase,
repl
acin
g k b
y k.
H
ere
we
have
a on
e-un
it win
dow
from
kt
ok
+ 1.
1 2
3 I
I I
I *
I IJ
I W
indo
w
Win
dow
fo
r n(
112)
fo
r %
(2]3
)
R(k
lk +
2)
= Q
klk
+ 1)
+ A(
k)A(
k +
1)
[jZ(k
+
21k
+ 2)
-f(k
+
21k
+ l)]
Pict
ure
and
disc
ussi
on sa
me-
as in
Fi
xed-
Poin
t cas
e, re
plac
ing k
by
k.
Her
e w
e ha
ve a
two-
unit
win
dow
from
kt
ok
+ 2.
Win
dow
for
jz;( 1
13)
I W
indo
w fo
r si
(214
)

792 State Estimation: Smoothing LE?sson 20
k=N-land?+- 2. More general results, that will permit us to perform fixed-interval smoothing for any k c N, are described in Lesson 21.
In order tu obtain the fixed-point smoother formulas, given for both the single- and double-stage smoothers, set k = z in (20-18) and (20-31J7 re- spectively. Time puint x represents the fixed point in our smoother formulas. As nuted at the beginning of this lesson, fixed-point smoothing can be carried out on-line, but it is subject to a delay. From an information availability point of view, a one-unit time delay is present in the single-stage fried-point smoother, because our smoothed estimate at k = x uses the filtered estimate computed at k = z + 1. A two-unit time delay is present in the double-stage fixed-point smoother, because our smoothed estimate at 3’ = % + 1 uses the filtered estimate computed at k = x +- 1 and z + 2.
The fixed-lag smoother formulas look just like the fixed-point formulas, except that IC is a variable in the former and is fixed in the latter* Observe that the windows of measurements used in the single-stage fixed-lag smoother are nonoverlapping, whereas they are overlapping in the case of the double-stage fixed-lag smoother. As in the case of fixed-point smoothing, fixed-interval smoothing can be carried out on line, subject, of course, to a fixed deiay equal to the “lag” of the smoother*
PROBLEMS
20-l. Derive the formula for the double-stage smoother gain matrix M(k ik + 2), given in (20-22).
20-2, Derive the alternative expression for k(kik + 2) given in (20-31). 20-3. Using the FundamentaI Theorem of Estimation Theory, derive expressions for
G(k jk + I) and G(k ik + 2). These represent single- and double-stage estimators of disturbance w(k).
Lesson 21
State=Estimation:
Smoothing
(General Results)
INTRODUCTION
In Lesson 20 we introduced three general types of smoothers, namely, fixed- interval, fixed-point, and fixed-lag smoothers, We also developed formulas for single-stage and double-stage smoothers and showed how these specialized smoothers fit into the three general categories. In this lesson we shall develop general formulas for fixed-interval, fixed-point, and fixed-lag smoothers.
FIXED-INTERVAL SMOOTHERS
In this section we develop a number of algorithms for the fixed-interval smoothed estimator of x(k), i(k]N). Not all of them will be useful, because we will not be able to compute with some. Only those with which we can compute will be considered useful.
Recall that
It is straightforward to proceed as we did in Lesson 20, by showing first that
i(kIN) = E{x(k)l%(N - I).Z(N/N - I)) = E(x(k)l%(N - I)} + E{x(k)Ii(NIN - I)} - m,(k) (21-2) = i(klN - 1) + M(kIN)i(NIZV - 1)

State Estimation: Smoothing (General Results) Lesson 21
where
M(klN) = P,(k,NIN - l)P,‘(NlN - 1) (21-3)
and then that
M(kjN) = A(k)A(k + 1). . .A(N - l)K(N) (21-4)
and, finally, that other algorithms for ri(klN) are
ri(klN) = i(k(N - 1) + “ij’A(i) [i(N(N) - rZ(NIN - l)] [ 1 (21-5) i=k
i(klN) = i(k]k) + A(k)[ri(k + l[N) - i(k + Ilk)] (21-6)
A detailed derivation of these results that uses a mathematical induction proof, can be found in Meditch (1969, pp. 2X-220). The proof relies, in part, on our previously derived results in Lesson 20, for the single- and double-stage smoothers. The reader, however, ought to be able to obtain (21.4), (21-Q and (21-6) directly from the rules of formation that can be inferred from the Lesson 20 formulas for M(klk + 1) and M(kIk + 2), and G(klk + 1) and i(kjk + 2).
In order to compute r2(k IN) for specific values of k, all of the terms that appear on the right-hand side of an algorithm must be available. We have three possible algorithms for r2(k IN); however, as we explain next, only one is “useful. ”
The first value of k for which the right-hand side of (21-2) is fully available is k = N - 1. By running a Kalman filter over all of the mea- surements, we are able to compute ?(N - 1lN - 1) and Z(NIN - l), so that we can compute i(N - 1IN). We can now try to iterate (21-2) in the backward direction, to see if we can compute i(N - 2/N), jz(N - 31N), etc. Setting k = N - 2 in (21.2), we obtain
i(N - 21N) = i(N - 21N - 1) + M(N - 21N)i(NIN - 1) (21-7)
Unfortunately, f(N - 21N - l), which is a single-stage smoothed estimate of x(N - 2), has not been computed; hence, (21-7) is not useful for computing i(N - 21IV). We, therefore, reject (21-2) as a useful fixed-interval smoother.
A similar argument can be made against (21-5); thus, we also reject (21-5) as a useful fixed-interval smoother.
Equation (214 is a useful fixed-inerval smoother, because all of its terms on its right-hand side are available when we iterate it in the backward direc- tion. For example,
i(N - 1IN) = ri(N - 1IN - 1) + A(N - l)[ri(NIN) - k(N]N - l)] (21-8)
Fixed-interval Smoothers 195
and
jz(N - 2/N) = i(N - 21N - 2) + A(N - 2)[i(N - l[N) - f(N - 1iN - 2)] (21-9)
Observe how i(N - 11N) is used in the calculation of i(N - 21N). Equation (21-6) was developed by Rauch, et al. (1965).
Theorem 21-l. A useful mean-squared fixed-interval mator of x(k), i(klN), is given by the expression
smoothed esti-
?(klN) = i(k)k) + A(k)[k(k + 1IIV) - i(k + Ilk)] (21-10)
where matrix A(k) is defined in (20~I5), and k = N - 1, N - 2, . . . , 0. Additionally, the error-covariance matrix associated with i(klN), P(klN), is given by . P(klN) = P(klk) + A(k)[P(k + 1IN’) - P(k + lIk)]A’(k) (21-11)
where k = N - 1, N - 2,. . . , 0.
Proof. We have already derived (21-10); hence, we direct our attention at the derivation of the algorithm for P(k IN). Our derivation of (21-11) follows the one given in Meditch, 1969, pp. 222-224. To begin, we know that
%(klN) = x(k) - ir(klN) (21-12)
Substitute (21-10) into (21-12) to see that
X(klN) = 2(kjk) - A(k)[i(k + 1IN) - f(k + l(k)] (21-13)
Collecting terms conditioned on N on the left-hand side, and terms condi- tioned on k on the right-hand side, (21-13) becomes
i(klN) + A(k)i(k + 1IN) = i(k)k) + A(k)rZ(k + Ilk) (21-14)
Treating (21-14) as an identity, we see that the covariance of its left-hand side must equal the covariance of its right-hand side; hence, [in order to obtain (21-15) we use the orthogonality principle to eliminate all the cross-product terms]
P(klN) + A(k)P;;(k + lIN)A’(k) 7 P(klk) + A(k)P&k + llk)A’(k) (21-15)
P(klN) = P(klk) + A(k)[PG(k + ilk) - P;,(k + lIN)]A’(k) (21-16)
We must now evaluate the two covariances PG(k + Ilk) and PG(k + 1JN). Recall that x(k + 1) = r2(k + Ilk) + ii(k + ilk); thus,
P,(k + 1) = P;;(k + Ilk) + P(k + Ilk) (21-17)

196 State Estimation: Smoothing (General Results) Lc?ssan 21
Additionally, x(k + 1) = i(k + IIN) + G(k + l[ZV). so that
Px(k + 1) = IQk + 1iN) + P(k + l/N) (21-B)
Equating (2147) and (2148) we find that
Pti(k + Ilk) - Pti(k + liw = P(k + 1iA’) - P(k + l/k) (2149)
Finally, substituting (2149) into (21~16), we obtain the desired expression for P(qQ (21-11). EI
We leave proof of the fact that {%(k~N), k = N, N - 1, . . . , O} is a zero-mean secund-order Gauss-Markov process as an exercise for the reader.
Example 21-l In order to illustrate fixed-interval smoothing and obtain at the same time a corn- parison of the relative accuracies of smoothing and filtering, we return to Example 19-l. To review briefly, we have the scaIar system x(k + 1) = x(k) +- IV(~) with the scalar measurement z(k + I) = x(k + 1) + v(k + 1) and P(0) = Xl, q = 20. and r = 5. In this example (which is similar to Example 6.1 in Meditch 1969, pg. 225) we choose N = 4 and compute quantities that are associated with i(ki4), where from (21-10)
Z(k[4) = i(kik) -+ A (k)[i (k + 114) - i(k + l/k)]
k = ?, 2, 1,O. Because @ = 1 andp{k + ltk) = P(kik) + 20
(21-20)
A(k) = P(kfk)@‘p -‘(k + ljk) = P (k IkI p(kik) t 20
(21-21)
and, therefore,
Utilizing these last two expressions, we compute A (k) and P (k 14) for k = 3,&l, 0 and present them, along with the results summarized in Table 19-1, in Table 21-l. The three estimation error variances are given in adjacent cohunns for ease in comparison.
TAl3LE 21-l Kalman Filter and Fixed-interval Smoother Quantities
0 50 16.31 0.714 1 iI- 4.67 3.92 i9.3-3 0.189 2 24.67 4.16 3.56 0.831 0.172 3 24.14 4.14 3.74 0.329 0.171 4 24.14 4.14 4.14 0.828 0.171
Observe the large improvement (percentage wise) of JJ (ki4) over p (k !k). Im- provement seems to get larger the farther away we get from the end of our data; thus, P (014) is more than three times as small as p(O/Oj. Of course. it should be, because
Fixed-Interval Smoothers
~(010) is an initial condirion that is data independent, whereas ~(014) is a result of processing r(l), z(2), f (3), and z (4). In essence, fixed-interval smoothing has let us look into the future and reflect the future back to time zero.
Finally, note that, for large values of k , A(k) reaches a steady-state value, x, where in this example
x = g@h + 20) = 0.171 (21-23)
This steady-state value is achieved for k = 3. 0
Equation (21-10) requires the multiplication of 3 n X n matrices as well as a matrix inversion at each iteration; hence, it is somewhat limited for practical computing purposes. The following results, which are due to Bryson and Frazier (1963) and Bierman (1973b), represent the most practical way for computing x(kIN) and also P(klN).
Theorem 21-2. (a) A estimator @x(k), %(k]N), is
useful mean-squared fixed-interval smoothed
i(kpv) = i(k lk - 1) + P(k ik - l)r(k jN) (21-24)
where k = N - 1, recursive equation
N-2,..., 1, and n x 1 vector r satisfies the backward-
r(jlN) = @Ji + L.i)r(j + 1IN) + H’(j)[H(j)P(jIj - l)H’(i) + R(j)]-‘Z(jb - 1) (21-25)
where j = N, N - 1,. . . ,1 and r(N + lb9 (b) The smoothing error-covariance matrix, $iN), is
P(k IN) = P(k/k - 1) - P(klk - l)S(k [N)P(k Ik - 1) (21-26)
where k = N - 1, N - 2, . . . , 1, and n X n matrix S( jjN), which is the covar- iunce matrix of r( j IN), satisfies the backward-recursive equation
S(jIN) = Qp’(j + l,j)S(j + lIN)$ (j + 1,j)
+ wmwP(~Ij - W(i) + wH-‘a(i) (21-27)
where j = N, N - 1, . . . , (21-33).
1 and S(N + l/N) = 0. Matrix Qp is defined in
Proof. (Mendel, 1983b, pp. 64-65). (a) Substitute the Kalman filter equation (1741) for i(klk) into Equation (21~lo), to show that
i2(kIN) = i(klk - 1) + K(k)Z(klk - I>
+ A(k)[i(k + 1IN) - i(k + Ilk)] (21-28)
Residual state vector r(k IN) is defined as
r(k IN) = P-‘(klk - l)[i(k IN) - i(klk - I)] (21-29)

State Estimation: Smoothing (General Results) Lesson 21
Next, substitute r(kIN) and r(k + l[N), using (21-29) into (21-28) to show that
r(kIN) = P-‘(k/k - l)[K(k)i(k[k - 1) + P(k Ik)W(k + l,k)r(k + l/N)] (21-30)
From (17-12) and (17-13) and the symmetry of covariance matrices, we find that
I’-‘(klk - l)K(k) = H’(k)[H(k)P(klk - l)H’(k) + R(k)]-’ (21-31)
and
P-‘(klk - l)P(k)k) = [I - K(k)H(k)]’ (21-32)
Substituting (21-31) and (21-32) into Equation (21-30), and defining
Op(k + 1,k) = <P(k + l,k)[I - K(k)H(k)] (21-33)
we obtain Equation (21-25). Setting k = N + 1 in (21.29), we establish r(N + 1IN) = 0. Finally, solving (21-29) for i(kIN) we obtain Equation (21-24). (b) The orthogonality principle in Corollary 13-3 leads us to conclude that
E{%(k IN)r’(k IN)} = 0 (21-34)
because r(kIN) is simply a linear combination of all the observations z(l), z(2), ’ l . 9
z(N). From (21-24) we find that
ii(klk - 1) = ii(kliV) - P(klk - l)r(kIN) (21-35)
and, therefore, using (21-34), we find that
P(klk - 1) = P(kIN) - P(kfk - l)S(klN)P(klk - 1) (21-36)
S(klN) = E{r(klN)r’(klN)} (21-37)
is the covariance-matrix of r(klN) [note that r(kIN) is zero mean]. Equation (21-36) is solved for P(klN) to give the desired result in Equation (21-26).
Because the innovations process is uncorrelated, (21-27) follows from substitution of (21-25) into (21-37). Finally, S(N + 1IN) = 0 because r(N + 11N) = 0. 0
Equations (21-24) and (21-25) are very efficient; they require no matrix inversions or multiplications of 12 x y1 matrices. The calculation of P(k IN> does require multiplications of n x n. matrices.
Matrix (I+-, (k + 1 ,k) in (21-33) is the plant matrix of the recursive predic- tor (Lesson 16). It is interesting that the recursive predictor and not the recursive filter plays the predominant role in fixed-interval smoothing. This is further borne out by the appearance of predictor quantities on the right-hand side of (21-24). Observe that (21-25) looks quite similar to a recursive predic-
Fixed-Point Smoothing 199
tor which is excited by the innovations-one which is running in a backward direction.
Finally, note that (21-24) can also be used for k = N, in which case its right-hand side reduces to %(NlN - 1) + K(N)Z(NIN - l), which, of course, is i((NIN).
FlXED-POINT SMOOTHING
A fixed-point smoother, i(kl j) where j = k + 1, k + 2, . . . , can be obtained in exactly the same manner as we obtained fixed-interval smoother (21-5). It is obtained from this equation by setting N equal to j and then letting j = k + 1, k + 2,. . . ; thus,
i(klj) = r2(klj - 1) + WMjlj) - %jlj - l>l (21-38)
where j-l
B(j) = II A(i) j = k
(21-39)
and j = k + 1, k + 2,. . . . Additionally, one can show that the fixed-point smoothing error-covariance matrix, P(kl j), is computed from
Wlj) = Wlj - 1) + BbW(A.0 - Wlj - WW) (21-40)
where j = k + 1, k + 2,. . . . Equation (21-38) is impractical from a computational viewpoint, be-
cause of the many multiplications of n x n matrices required first to form the A(i) matrices and then to form the B(j) matrices. Additionally, the inverse of matrix P(i + lli) is needed in order to compute matrix A(i). The following results present a “fast” algorithm for computing r2(kl j). It is fast in the sense that no multiplications of yt x y1 matrices are needed to implement it.
Theorem 21-3. A most useful mean-squared fixed-point smoothed mator of x(k), %(klk + 4 where 1 = 1 ,L**, is given by the expression
es ti-
i(klk + I) = i(klk + Z - 1) + N,(klk + Z)[z(k + I) - H(k + Z)r2(k + Ilk + Z - l)] (21-41)
where
N,(klk + I) = S,(k,Z)H’(k + I)
[H(k + I)P(k + Ilk + Z - l)H’(k + 2) + R(k + Z)]-’ (21-42)
and
9,(k,Z) = 9,(k,Z - 1) [I - K(k + Z - ljH(k + I - l)]W(k + Z,k + 2 - 1) (21-43)

State Estimation: Smoothing (Generd Fksults) Lesson 21
Equutions (21-#I) and (21-43) are initialized by %(kik) and !Z&(k,l) = P(kik)@‘(k + 1 ,k), respe&ely. Additio&ly,
P(klk + 2) = P(kjk + 1 - 1) - N#/k + I)[H(k + Z)P(k + Zik + 2 - 1) H’(k + Z) + R(k + Z)]N;(kik + Z) (21-44)
which is initialized by P(kik). III
We leave’ the proof of this useful theorem, which is similar to a result given by Fraser (1967), as an exercise for the reader. Example 21-2
Here we consider the problem of fixed-point smoothing to obtain a refined estimate of the initial condition for the system described in Example 21-l. Recall that JJ (010) = 50 and that by fixed-interval smoothing we had obtained the result p (014) = 16.31, which is a significant reduction in the uncertainty associated with the initial condition.
Using Equation (21-40) or (21-44) we compute ~1(0/1), ~1(0/2), and ~(013) to be 16.69, l&32? and 16.31, respectively. Observe that a major reduction in the smoothing error variance occurs as soon as the first measurement is incorporated, and that the improvement in accuracy thereafter is relatively modest. This seems to be a general trait of fixed-point smoothing. IJ
Another way to derive fixed-point smoothing formulas is by the follow- ing state augmentatiun procedure (Anderson and Moore, 1979). We assume that for IL 2 j
W) A x(j) (21-45)
The state equation for state vector x0(k) is
x,,(k + 1) = xG(k) k + (21-46)
It is initialized at k = j by (21-45). Augmenting (21-46) to our basic state- variable model in (15-17) and (S-18), we obtain the following augmented basic state-variable mod&
z(k + 1) = (H(k + 1) 0) [;:$I + v(k + 1) Q
(21-48)
The foIlowing two-step procedure can be used to obtain an algorithm for S( jik):
1. Write down the KaIman filter equations for the augmented basic state-
Fixed-Lag Smoothing
variable model. Anderson and Moore (1979) give these equations for the recursive predictor; i.e., they find
where k ~j. The last equality in (21-49) makes use of (21-46) and (21-45). Observe that i(jlk), the fixed-point smoother of x(j), has been found as the second component of the recursive predictor for the aug- mented model.
2. The Kalman filter (or recursive predictor) equations are partitioned in order to obtain the explicit structure of the algorithm for ri(jlk). We leave the details of this two-step procedure as an exercise for the reader.
FIXED-l&G SMOOTHING
The earliest attempts to obtain a fixed-lag smoother i(kjk + L) led to an algorithm (e.g., Meditch, 1969), which was later shown to be unstable (Kelly and Anderson, 1971). The following state augmentation procedure leads to a stable fixed-interval smoother for li(k - L Ik).
We introduce t + 1 state vectors, as follows: xl(k + 1) = x(k), xz(k + 1) = x(k - l), xj(k + 1) = x(k - 2), . . . , xL + I(k + 1) = x(k - L) [i.e., xi(k + 1) = x(k + 1 - i), i = 1, 2,. . . , L + 13. The state equations for these L + 1 state vectors are
xl(k + 1) = x(k) xz(k + 1) = x,(k) xj(k + 1) = x,(k) (X-50)
xL+l(k + ;; = XL(k) I
Augmenting (21-50) to our basic state-variable model in (15-17) and (15-18), we obtain yet another augmented basic state-variable model:
+ u(k) + w(k) (21-51)

202 State Estimation: Smoothing (General Results) Lesson 21
The following two-step procedure can be used to obtain an algorithm for k(k - 1 IL\*
1.
2.
1.
2.
3.
21-1.
21-2.
21-3.
21-4.
21-5.
21-6.
Write down the Kalman filter equations for the augmented basic state- variable model. Anderson and Moore (1979) give these equations for the recursive predictor; i.e., they find
E{col (x(k + 1),x1@ + l), . . . ,xL + I@ + l)f%(k)} = co1 (r2(k + l(k),i@ + l[k), . . . ) IiL + I(k + 1Jk)) (21-52) = co1 (f(k + llk),i(klk),i(k - l/k), . . . f i(k - Llk))
The last equality in (21-52) makes use of the fact that xi(k + 1) = x(k + 1 - i), i = 1,2,. . . , L + 1. The Kaiman filter (or recursive predictor) equations are partitioned in order to obtain the explicit structure of the algorithm for ji(k - Llk). The detailed derivation of the algorithm for i(k - LIk) is left as an exercise for the reader (it can be found in Anderson and Moore, 1979, pp. 177-181).
Some aspects of this fixed-lag smoother are:
It is numerically stable, because its stability is determined by the stability of the recursive predictor (i.e., no new feedback loops are introduced into the predictor as a result of the augmentation procedure); In order to compute i(k - L (k), we must also compute the L - 1 fixed- lag estimates, i(k - Ilk), i(k - 21k), . . . , g(k - L + Ilk); this may be costly to do from a computational point of view; and Computation can be reduced by careful coding of the partitioned recur- sive predictor equations.
PROBLEMS
Derive the formula for x(kIN) in (21-5) using mathematical induction. Then derive i(klN) in (21-6). Prove that {%(kIN), k = N, IV - 1, . . . , 0) is a zero-mean, second-order Gauss- Markov process. Derive the formula for the fixed-point smoothing error-covariance matrix, P(kl j), given in (21-40). Prove Theorem 21-3, which gives formulas for a most useful mean-squared fixed-point smoother of x(k), i(klk + l), I = 1,2,. . . . Using the two-step procedure described at the end of the section entitled Fixed-Point Smoothing, derive the resulting fixed-point smoother equations. Using the two-step procedure described at the end of the section entitled
Lesson 21 Problems 203
Fixed-Lag Smoothing, derive the resulting fixed-lag smoother equations. Show, by means of a block diagram, that this smoother is stable.
21-7. (Meditch, 1969, Exercise 6-13, pg. 245). Consider the scalar system x(k + 1) = 2-kx(k)+w(k),z(k+1)=x(k+1),k=O,l,...,wherex(0)hasmeanzero and variance U& and w(k), k = 0, 1, . . . is a zero mean Gaussian white sequence which is independent of x(0) and has a variance equal to 4. (a) Assuming that optimal fixed-point smoothing is to be employed to determine
x(Olj), j = 1, 2, . . . , what is the equation for the appropriate smoothing filter?
(b) What is the limiting value of p (01 j) as j + w? (c) How does this value compare with p (OIO)?

lesson 22
State Estimation:
Smoothing
Appkations
INTRODUCTION
In this lesson we present some applications that illustrate interesting numer- ical and theoretica aspects of fixed-interval smoothing. These applications are taken from the field of digital signa processing.
MINIMUM-VARIANCE DECCH’WOLUTION [MVD)
Here, as in ExampIes Z-6 and 14-1, we begin with the convolutional model
z(k) = 2 p(i)h (k - i) + v(k), k =1,2,...,N (22-l) i=l
Recall that deconvolution is the signal processing procedure for removing the effects of !z (j) and v(j) from the measurements so that one is left with an estimate of p(j), Here we shah obtain a useful algorithm for a mean-squared fixed-interval estimator of p ( j).
To begin, we must convert (22-l) into an equivalent state-variable model.
Theorem 22-l (Mendel, 1983a, pp. 13-14). The single-channel Jtatea varia b/e mudei
x(k + I) = @x(k) + Tp(k) (22-Z)
z(k) = h’x(k) + r’(k) (22-3)
204
Minimum-Variance Deconvolution (MVD) 205
is equivalent to the convolutiorzaIsum model in (22-I) when x(0) = 0, ~(0) = 0, h(0) = 0. and
h(I) = h’@ - ‘y, 1 = 1,2,... (22-4)
Proof. Iterate (22-2) and substitute the results into (22-3). Compare the resulting equation with (22-l) to see that, under the conditions x(O) = 0, p(O) = 0 and h (0) = 0, they are the same. •l
The condition x(0) = 0 merely initializes our state-variable model. The condition ~(0) = 0 means there is no input at time zero. The coefficients in (22-4) represent sampled values of the impulse response. If we are given impulse response data {h (1) h (2): . . . , h (L)) then we can determine matrices @, y and h as well as system order n by applying an approximate realization procedure, such as Kung’s (1978), to {h (l), h (2), . . . , h (L)). Additionally, if h (0) + 0 it is simple to modify Theorem 22-l.
In Example 14-l we obtained a rather unwieldy formula for l&(N). Note that, in terms of our conditioning notation, the elements of b&N) are jh.&lN, k = 1, 27-v N. We now obtain a very useful algorithm for j&&k IN. For notational convenience, we shorten bMS to b.
Theorem 22-2 (Mendel, 1983a, pp. 68-70)
a. A two-puss fixed-interval smoother for I is
b. wherek=N-l,N - 2,. . . ,l. The smoothing error variance, Gp (klN), is
~6 (klhr) = q (4 - q Wy’S(k + 1IN)yq (k) (22-6)
where k = N-l,N-2,..., 1. In these formulas r(klN) and S(klN) are computed using (21-25) and (21-27), respectiveZy, and E{p’(k)) = q(k) [here q(k) d enotes the variance of p(k), and should not be confused with the event sequence; which appears in the product model for p(k)].
Proof a. To begin, we apply the fundamental theorem of estimation theory, Theorem 13-1, to (22-2). We operate on both sides of that equa- tion with E{ . I%‘(N)}, to show that
yb(klN) = li(k + 1IN) - @ri(kIN) (22-7)
By performing appropriate manipulations on this equation we can derive (22-5) as follows. Substitute ir(klN) and li(k + 1jN) from Equation (21-24) into Equation (22-7), to see that

State Estimation: Smoothing Applications Lesson 22
yji(kllV) = i(k + Ilk) + P(k + llk)r(k + liIV> - @[i(klk - 1) + P(k jk - l)r(klN)] = %(k + l]k) - <P#k - 1)
(2243)
+ P(k + llk)r(k + l[N) - @P(k(k - l)r(k IN)
Applying (17-11) and (16-4) to the state-variable model in (22-2) and (22-3), it is straightforward to show that
%(k + l/k) = @x(kIk - 1) + @K(k)Z(klk - 1) (22-9)
hence, (22-8) reduces to
y$(klN) = QK(k)i(kIk - 1) + P(k + llk)r(k + 1IN) - @P(kIk - l)r(k
Next, substitute (21-25) into (22-lo), to show that
yb(k]N) = @K(k)t(kIk - 1) + P(k + #)r(k + l\NJ - @P(k[k - l)@Jk + l,k)r(k + l!IV)
N) (22-10)
(22-11) - (PP(kIk - l)h’[h’P(klk - 1)h + r]-‘z(k[k - 1)
Making use of Equation (17-12) for K(k), we find that the first and last terms in Equation (22-11) are identical; hence,
yji(kIN) = P(k + llk)r(k + l!N) - @P(k(k - 1) @i(k + l,k)r(k + l!IV) (22-12)
Combine Equations (17-13) and (17-14) to see that
P(k + Ilk) = <PP(k[k - l)a$(k + 1,k) + yq(k)y’ (22-13)
Finally, substitute (22-13) into Equation (22-12) to observe that
YWIN) = Y4oY’r(k + 1IN) which has the unique solution given by
WIN) = 4ww(k + WI which is Equation (22-5).
(22-14)
b. To derive Equation (22-6) we use (22-S) and the definition of estimation error b(k IN),
iwYJ = P(k) - fiwv (22-15)
to form
P(k) = WIN) + 4 Wr(k + l!N) (22-16)
Taking the variance of both sides of (22-16), and using the orthogonality condition
wwN)r(k + WH = 0 (22-17)
Steady-State MVD Filter 207
we see that
(2248)
which is equivalent to (22-6). c]
Observe, from (22-5) and (224, that iIi(kllV) and c$ (klN) are easily computed once r(k IN) and S(k [A/‘) have been computed.
The extension of Theorem 22-2 to a time-varying state-variable model is straightforward and can be found in Mendel(1983).
Example 22-1 In this example we compute b(kIN), first for a broadband channel IR, h#), and then for a narrower-band channel IR, h*(k). The transfer functions of these channel models are
HI(Z) = -0.76286~~ + 1.58842’ - 0.823562 + 0.000222419 z4 - 2.2633~~ + 1.777342’ - 0.498032 + 0.045546
(22-19)
Hz(z) = 0.0378417~~ - 0.0306517~ Z4 - 3.4016497~~ + 4.5113732~~ - 2.7553363~ + 0.6561
(22-20)
respectively. Plots of these IR’s and their squared amplitude spectra are depicted in Figures 22-l and 22-2.
Measurements, z(k) (k = 1,2,. . . ,250, where T = 3 msec), were generated by convolving each of these IR’s with a sparse spike train (i.e., a Bernoulli-Gaussian sequence) and then adding measurement noise to the results. These measurements, which, of course, represent the starting point for deconvolution, are depicted in Figure 22-3.
Figure 22-4 depicts fi(k IN). Observe that much better results are obtained for the broadband channel than for the narrower-band channel, even though data quality, as measured by SNR, is much lower in the former case. The MVD results for the narrower-band channel appear “smeared out,” whereas the MVD results for the broadband channel are quite sharp. We provide a theoretical explanation for this effect below.
Observe, also, that fi(k IN) tends to undershoot p(k). See Chi and Mendel(l984) for a theoretical explanation about why this occurs. 0
STEADY-STATE MVD FILTER
For a time-invariant IR and stationary noises, the Kalman gain matrix, as well as the error-covariance matrices, will reach steady-state values. When this occurs, both the Kalman innovations filter and anticausal p-filter [(22-5) and (21.25)] become time invariant, and we then refer to the MVD filter as a steady-state MVD filter. In this section we examine an important property of this steady-state filter.

208 State Estimation: Smoothing Applications Lesson 22
0.60
0.30
0.00
-0.30
- 0.60
- 0.90 0.00 60.0 120.0 ISO* 240.0 3ou.o
0.00 0.80 I.60 2.40 3.20 4.00
Figure 22-l (a) Fourth-order broad-band channel IR, and (b) its squared ampli- tude spectrum (Chi, 1983).
Steady-State MVD filter
(msecs)
(4
20.0 [
16.0
12.0
8.0
4.0
0.0 I 1 I 0.00 0.80 1.60 2.40 3.20 4.00
(radians) (b)
Figure 22-2 (a) Fourth-order narrower-band channel, IR, and (b) its squared amplitude spectrum (Chi and Mendel, 1984, 0 1984, IEEE).

210 State Estimation: Smoothing Applications Lesson 22
0.06
- 0.06
-0.12
(msecs) (a)
450 600 750
0.10
0.05
0.00
-0.05
-0.10
0.00 150 300
(msecs) (b)
450 750
Figure 22-3 Measurements associated with (a) broad-band channel (SAN = 10) and (b) narrower-band channel (SNR = NO), (Chi and Mendel, 1984, 0 1984, IEEE).
Steady-State MVD Filter 211
0.20 - 0
0.10 - 0 0
0
0
0.00 150 300 450 750
(msecs)
(a)
.
0.20 0
0
0 0.10 0
,.,,,,,
0 0
0 0 0
0.00
0 0
-0.10 - 0
-0.20 - 0 0
1 I I I 0.00 150 300 450 750
(msecs) (b)
Figure 22-4 b&IN) for (a) broadband channel (SNR = 10) and (b) narrower- band channel (SNR = 100). Circles depict true p(k) and bars depict estimate of p(k), (Chi and Mendel, 1984,O 1984, IEEE).

212 St&e Estimation: Smoothing Applications Lesson 22
Let /z#) and h&(k) denote the IR’s of the steady-state Kalman inno- vations and anticausa1 p-filters, respectively. Then,
b(kpl) = hJk)*j(kik - 1) = hp(k)*hi(k)*z (k) = hJk)*hi(k)*h (k)*p(k)
+ hK(k)*hi(k)*v(k)
(22-21)
which can also be expressed as
Lwv = lwlxl + N+Yl (22-22)
where the sigml component of ,il(k IA/), fis (k IN’), is
fis(kIW z= h~(k)*hi(k)~h(k)~~~k) (22-23)
and the noise component of b(kiq, n (k/N), is
n(kiN) = hp(k)*hi(k)*v(k) (22-24)
We shall refer to hp(k)*hi (k) as the IR of the MVD filter, h&k), i.e.,
h@-J = h,.G) *hi W (22-25)
The following result has been proven by Chi and Mendel (1984) for the slightly modified model x(k + l,l = @x(k) + yp(k + 1) and z(k) = h’x(k) + v (k) [because of the p(k + 1) input instead of the p(k) input, h (0) + 01.
Theorem 22-3,
a. The Fourier transform of hMv(k) is
(22-26)
where H*(U) denotes the compiex conjugate uf H(u); and b. the signd component of &(kiN), bS(kiN), ti given by
fis (k INI = I3 w *w where R(k) ti the auto-correlatbz function
(22-27)
WI = t[h(k)*hi(k)]*[h(-k)*hi(*k)] (22-28)
in which
additionally, v = h’Fh + r (22-29)
(22-30)
Reiationship Between MVD Filter and IIR Wiener Deconvolution Filter 213
We leave the proof of this theorem as an exercise for the reader. Observe that part (b) of the theorem means that bs(kjiV) is a zero-phase wave-shaped version of p(k). Observe, also, that R(w) can be written as
R(w) = lw4124 /r 1 + p(w)t2q /r
(22-31)
which demonstrates that q /r , and subsequently SNR, is an MVD filter tuning parameter. As 4 / t + DC, R(o)* 1 so that R(k) + s(k); thus, for high signal- to-noise ratios fis(klN)+ p.(k). Additionally, when /H(w)12q /r >> 1, R(w)+ 1, and once again R(kj -+ 6(k). Broadband IRS often satisfy this condition. In general, however, &(klN) is a smeared-out version of I; however, the nature of the smearing is quite dependent on the bandwidth of h(k) and SNR.
Example 22-2 This example is a continuation of Example 22-1. Figure 22-5 depicts R (k) for both the broadband and narrower-band IRS. hi(k) and hz(k), respectively. As predicted by (22-31), RI(~) is much spikier than R,(k), which explains why the MVD results for the broadband IR are quite sharp, whereas the MVD results for the narrower-band IR are smeared out. Note, also, the difference in peak amplitudes for R,(k) and R,(k). This explains why b(kfN) un erestimates the true values of p(k) by such large amounts in d the narrower-band case (see Figs. 22-4a and b). E3
RELATlONSHlP BETWEEN STEADY-STATE MVD FILTER AND AN INFlNtTE IMPULSE RESPONSE DIGITAL WIENER DECONVOLUTION FILTER
We have seen that an MVD filter is a cascade of a causal Kalman innovations filter and an anticausal p-filter; hence, it is a noncausal filter. Its impulse response extends from k = --3c to k = +=, and the IR of the steady-state MVD filter is given in the time-domain by hMv(k) in (22-23, or in the fre- quency domain by HMv(w) in (22-26).
There is a more direct way for designing an IIR minimum mean-squared error deconvolution filter, i.e., an IIR digital Wiener deconvolution filter, as we describe next.
We return to the situation depicted in Figure 19-4, but now we assume that: Filter F(z) is an IIR filter, with coefficients (f(j), j = 0, 21, 52, . . . );
d(k) = CL(k) (22-32)
where p(k) is a white noise sequence; p(k), v(k), and n (k) are stationary; and, p(k) and v(k) are uncorrelated. In this case, (19-39) becomes
C f (i)&(i - 1) = 4+(j), j = 0, -tL 56 . . . (22-33) iz -3
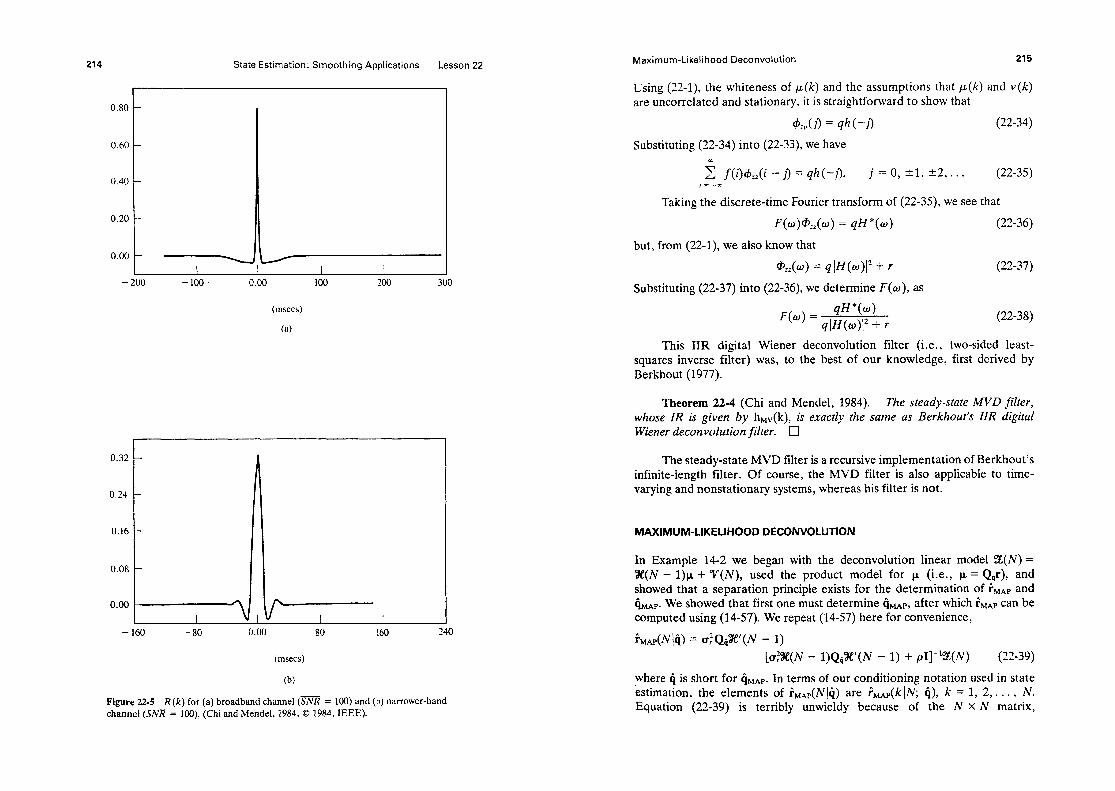
214 State Estimation: Smoothing Applications Lesson 22
r 0.80
0.60
0.40
0.20
-200 - loo - 200 300
(a)
0.32
0.24
0.16
0.08
0.00
-160 -80 0.00 80 160 240
(b)
Figure 22-5 R(k) for (a) broadband channel (SNR = 100) and (b) narrower-band channel (SlVR = lOO), (Chi and Mendel, 1984, 0 1984, IEEE).
Maximum-Likelihood Deconvoiution 215
Using (22-l), the whiteness of p(k) and the assumptions that p(k) and v(k) are uncorrelated and stationary, it is straightforward to show that
42,(i) = qh (71 (22-34)
Substituting (22-34) into (22.33), we have
i f(i)&(i -j) = qh(-j), j = 0, 21, +2,. . . (22-35) i= -es
Taking the discrete-time Fourier transform of (22-35), we see that
(22-36)
but, from (22-l), we also know that
(22-37)
Substituting (22-37) into (22-36), we determine F(o), as
F(o) = qH*(w) 41HW12 + r
(22-38)
This IIR digital Wiener deconvolution filter (i.e., two-sided least- squares inverse filter) was, to the best of our knowledge, first derived by Berkhout (1977).
Theorem 22-4 (Chi and Mendel, 1984). The steady-state MVD filter, whose IR is given by hMv(k), is exactly the same as Berkhout’s IIR digital Wiener deconvolution filter. Cl
The steady-state MVD filter is a recursive implementation of Berkhout’s infinite-length filter. Of course, the MVD filter is also applicable to time- varying and nonstationary systems, whereas his filter is not.
MAXIMUM-IJKELIHOOD DECONVOLUTION
In Example 14-2 we began with the deconvolution linear model Z(N) = X(N - 1)~ + v(N), used the product model for p (i.e., p = Q,r), and showed that a separation principle exists for the determination of iMAP and GmP. We showed that first one must determine GMAP, after which iMAP can be computed using (14-57). We repeat (14-57) here for convenience,
h&N(4) = +Qix'(N - 1) [&E(N - l)Q$‘(N - 1) + PI]-‘e(N) (22-39)
where 4 is short for hMAP. In terms of our conditioning notation used in state estimation, the elements of &(N)$ are ihlA#C IN; ii), k = l? 2? . . . , N. Equation (22-39) is terribly unwieldy because of the N X N matrix,

State Estknation: Smoothing Applications lesson 22
CTptyN - I)Q$‘(N - 1) + ~1, that must be inverted. The following theorem provides a more practical way to compute &&!IC; 4).
Theorem 22-5 (Mend& 1983b). unconditionul maximum-likelihuod (i.e., MAP) estimates uf r can be ubtained by applying hWD formuh tu the state-vuriable mudel
x(k + 1) = @x(k) + y&&k)+) (22-40)
z(k) = Wx(k) + v(k)
where qM&k) is a MAP estimate of q (k).
(22-4 1)
&~f. Example 14-2 showed that a MAP estimate of q can be obtained prior tu finding a MAP estimate of r. By using the product model for p(k), and hMAp, our state-variable model in (22-2) and (22-3) can be expressed as in (22-40) and (22-41). Applving (14-41) to this system, we see that d
ki&j~ = ;MS@ IN) (22-42)
but, by comparing (22-40) and (22-2), and (22-41) and (22s3), we see that &&#V) can be found from the MVD algorithm in Theorem 22-2 in which we replace p(k) by r(k) and set q (k) = u&&k). Cl
RECURSIVE WAVESHAPING
In Lesson 19 we described the design of a FIR waveshaping filter (e.g., see Figure 19-4). In this section we shall develop a recursive waveshaping filter in the framework of state-variable modeis and mean-squared estimation theory. other approaches to the design of recursive waveshaping filters have been given by Shanks (1967) and Aguilara? et al. (1970).
We direct our attention at the situation depicted in Figure 22-6. To
Figure 224 W?veshaping probiern swdied in this section. Information about 2 (k), not necessaAy I! itself- is used to drive the (time-varying) recursive waveshaping fiIter, (Mendel. 1983a, G 1983, IEEE).
Recursive Waveshaping
begin, we must obtain the following state-variable models for h(k) and d(k) [i.e., we must use an approximate realization procedure (Kung, 1978) or any other viable technique to map (h(i), i = 0, 1,. . . , 1,) into {a,, yI, h,}, and {d(i), i = 0, 1,. . . ) &I into {@2, 72, h)]:
x@ + 1) = @,lxO) + y&W (22-43) h(k) = hfx,(k) (22-44)
and
xz(k + 1) = @x2(k) + y?S(k) (22-45) d(k) = h;x:(k) (22-46)
State vectors x1 and x2 are nl x 1 and n2 x 1, respectively. Signal 6(k) is the unit spike.
In the stochastic situation depicted in Figure 22-6, where h(k) is excited by the white sequence w(k) and noise, v(k), corrupts s(k), the best we can possibly hope to achieve by waveshaping is to make z(k) = w (k)*h (k) + v(k) look like w(k)*d(k) (Figure 22-7). This is because both h(k) and d(k) must be excited by the same random input, w fk), for the waveshaping problem in this situation to be well posed. The state-variable model for this situation is
Y,: xr(k + 1) = @xl(k) + y+(k) (22-47)
z(k) = hjx,(k) + v(k) (22-48)
Figure 22-7 State-variable formulation of recursive waveshaping problem (Men- del, 1983a, Q 1983, IEEE).

State Estimation: Smoothing Applications Lesson 22
92: xt(k + 1) = azxz(k) + y2w(k) (22-49)
d,(k) = %x2(k) (22-50)
Observe that both Y, and sP2 are excited by the same input, w(k). Addi- tionally, w(k) and v(k) are zero-mean mutually uncorrelated white noise sequences, for which
E-b2W = 4 (22-51)
E{v2(k)} = r (22-52)
We now proceed to formulate the recursive waveshaping filter design problem in the context of mean-squared estimation theory. Our filter design problem is: Given the measurements z (l), z (2), . . . , z (j) determine an esti- mator &(klj) such that the mean-squared error
J[&(k 1j)l = E{ C&(k 1 j)12) (22-53)
is minimized. The solution to this problem is given next.
Theorem 22-6 (Structure of Minimum-Variance Waveshaper, Dai and Mendel, 1986). The Minimum-Variance Waveshaping filter consists of two components 1. stochastic inversion, and 2. waveshaping.
Proof. According to the Fundamental Theorem of Estimation Theory, Theorem 13-1, the unbiased, minimum-variance estimator of d,(k) based on the measurements (2 (1) 2 (2), . . . , 2 (j)} is
h(k ii) = E(d~(k)IfKi~l (22-54)
where ?I!( j) = co1 (2 (l), 2 (2), . . . ) t(j)). Observe, from Figure 22-7, that
d,(k) = w (k)*d(k) (22-55)
hence,
= E{w (k)IflE( j)}*d (k) = @(k jj)*d (k) (22-56)
Equation (22-56) tells us that there are two steps to obtain &(k /j):
1. first obtain G(k ii>, and 2. then convolve the desired signal with G(klJ.
Step 1 removes the effects of the original wavelet and noise from the mea-
Recursive Waveshaping
surements. It is the problem of stochastic inversion and can be performed by means of minimum-variance deconvolution. 0
In this book we have only discussed fixed-interval MVD, from which we obtain G(k[N). Fixed point algorithms are also available (e.g., Mendel, 1983).
Theorem 22-7 (Recursive waveshaping, Mendel, 1983a, pg. 600). Let w(kjN) denote the fixed-interval estimate of w(k), which can be obtainet from S1 via minimum-variance deconvolution (MVD), (Theorem 22-2). Then dl(klN) is obtained from the waveshaping filter
ci,(klN) = hjji,(kIN) (22-57)
&(k + 1IN) = @&(kIN) + ygC(klN) (22-58)
where k = 0, 1, . . . , N - 1, and &(O[N) = 0. q
We leave the proof of this theorem as an exercise for the reader. Some observations about Theorems 22-6 and 22-7 are in order. First,
MVD is analogous to solving a stochastic inverse problem; hence, an MVD filter can be thought of as an optimal inverse filter. Second, if w(k) was deterministic and v(k) = 0, then our intuition tells us that the recursive wave- shaping filter should consist of the following two distinct components: an inverse filter, to remove the effects of H(z), followed by a waveshaping filter, whose transfer function is D (2). The transfer function of the recursive wave-
1 shaping filter would then be - H(z)
D(z), so that D(z) I = DW
Finally, the results in these theorems support our intuition even in the sto- chastic case; for, &(klN), for example, is also obtained in two steps. As shown in Figure 22-8, first G(klN) to give &(klN).
is obtained via MVD. Then this signal is reshaped
Note, also, that in order to compute &(klN) it is not really necessary to use the state-variable model for &(klN). Observe, from (22~56), that
ci,(kIN) = d(k)*&(k(N) (22-59)
Example 22-3
In this example we describe a simulation study for the Bernoulli-Gaussian input se- quence [i.e., w(k)] depicted in Figure 22-9. When this sequence is convolved with the fourth-order IR depicted in Figure 22.la and noise is added to the result we obtain measurements z(k), X- = 1,2,. . . , 1000, depicted in Figure 2240.
In Figure 22-11 we see $(k IN). Observe that the large spikes in w(k) have been estimated quite well. When C&IN) is convolved with a first-order decaying ex- ponential [&(f) = em3001, we obtain the shaped signal depicted in Figure 22-12. Some “smoothing” of the data occurs when 6(k IN’) is convolved with the exponential d*(k).

220 State Estimation: Smoothing Applications
Recursive Waveshaping Filter
Lesson 22
Figure 22-8 Details of recursive linear waveshaping filter. (Mendel, 1983a, @ 1983 IEEE.)
Figure 22-9 I3ernoullLGaussian input sequence (Mendel, 1983a, C 1933, IEEE).
Recursive Waveshaping
I t
221
0.24 -
0.12
~~~~
0.00 0.20 0.40 0.60 0.80 1.0
Time (set)
Figure 22-N Noise-corrupted signal t(k). Signal-to-noise ratio chosen equal to ten (Mendel, 1983a. 0 1983. IEEE).
I I I 0.00 0.20 0.40 0.60 0.80 1 .o
Time (set)
Figure 22-11 k(k(N), (Mendet, 1983a. 0 1983, IEEE).

222 State Estimation: Smoothing Applications Lesson 22
0.00 0.20 0.40 0.60 0.80 1.0
Time (set)
Figure 22-12 &(kIN) when d,(t) = ea300r (Mendel 1983a, 0 1983, IEEE).
More smoothing is achieved when C(k IN’) is convolved with a zero-phase wave- form. 0
Finally, note that, because of Theorem 22-3, we know that perfect wave- shaping is not possible. For example, the signal component of &(k/I?), &(I@), is given by the expression
&(k Ih’) = d (k)*R (k)*w (k) (22-60)
How much the auto-correlation function R(k) will distort &(kIN) from d (k)*w (k), depends, of course, on bandwidth and signal-to-noise ratio consid- erations.
PROBLEMS
22-l. Rederive the MVD algorithm for fi(kIIV), which is given in (22-5), from the Fundamental Theorem of Estimation Theory, i.e., fi(klN) = E{&k)l%(IV)}.
22-2. Prove Theorem 22-3. Explain why part (b) of the theorem means that fiS (k IN) is a zero-phase waveshaped version of p(k).
22-3. This problem is a memory refresher. You probably have either seen or carried out the calculations asked for in a course on random processes. (a) Derive Equation (22-34); (b) Derive Equation (22-37).
22-4. Prove the recursive waveshaping Theorem 22-7.
Lesson 23
State Estimation
for the /t/o+So-Basic
State-Variable Model
INTRODUCTION
In deriving all of our state estimators we assumed that our dynamical system could be modeled as in Lesson 15, i.e., as our basic state-variable model. The results so obtained are applicable only for systems that satisfy all the condi- tions of that model: the noise processes w(k) and v(k) are both zero mean, white, and mutually uncorrelated, no known bias functions appear in the state or measurement equations, and no measurements are noise-free (i.e., perfect). The following cases frequently occur in practice:
1. either nonzero-mean noise processes or known bias functions or both in the state or measurement equations
2. correlated noise processes, 3. colored noise processes, and 4. some perfect measurements.
In this lesson we show how to modify some of our earlier results in order to treat these important special cases. In order to see the forest from the trees, we consider each of these four cases separately. In practice, some or all of them may occur together.
223

224 State Estimation for the Not-So-Bask State-Variable Model Lesson 23
BIASES
Here we asswrx that our basic state-variable model, given in (15-17) and (H-18), has been modified IO
x(k + 1) = @(k + l.k)x(k) + r(k + Lk)w](k) + ‘P(k + l,k)u(k)
z(k + 1) = H(k + l)x(k +- 1) + G(k + l)u(k + I) + vI(k + I)
(23-l)
(23-2)
where WI(k) and y(k) are nonzero mean, correlated Gaussian noise sequences, i.e.,
individually and mutually un-
J3w(k)l = ml(k) + 0 m,Jk) known (23-3)
%(k)) = ml(k) + 0 rq(k) known (23-4)
WW - ~&~lbd19 - ~wI~~~l’I = QWO, W b&J - mI~NW~ - ml(j)l’l = R(i)&,, and E-h(i) - ~wl(t’)l[~~(~~ - mJ~91’1 = 0.
This case is handled by reducing (23-l) and (23-2) to our previous basic state-variable model, using the following simple transformations. Let
w(k) A w#c) - mwI(k) (23-5) and
v(k) A vdk) - ml(k) (23-6)
Observe that both w(k) and v(k) are zero-mean white noise processes, with covariances Q(k) and R(k), respectively. Adding and subtracting W + 1 &)a1 (k) in state equation (23-l) and mvI(k + 1) in measurement equation (23-2), these equations can be expressed as
x(k + 1) = Q(k + l,k)x(k) + r(k + 1 ,k)w(kJ + uI(k) (23-7)
q(k + 1) = H(k + I)x(k + I) + v(k + 1) (23-8)
uI(k) = q(k + l,k)u(k) + lY(k + l,k)m,,Jk) (23-9)
xdk + 1) = z(k + 1) - G(k + l)u(k + I) - m,Jk + 1) (23- 10)
Clearly, (23-7) and (23-8) is once again a basic state-variable model, one in which uI(k) plays the role of g(k + l,k)u(k) and zI(k + 1) plays the role of z(k + 1).
Theorem 23-I. When biases are present in a state-variable model, then that mude! can always be reduced tu u basic state-variable mode/ [e.g., (23-7) to (23-N)]. All uf our previuus slate estimators can be applied to this basic state- variable mode2 by replacing z(k) by q(k) and V(k + l,k)u(k) by u*(k). Cl
Correlated Noises
CORRELATED NOISES
Here we assume that our basic state-variable model is given by (15-17) and (15-M), except that now w(k) and v(k) are correlated, i.e.,
E{w(k)v’(k)} = S(k) # 0 (23-12)
There are many approaches for treating correlated process and measurement noises, some leading to a recursive predictor, some to a recursive filter, and others to a filter in predictor-corrector form, as in the following:
Theorem 23-2. When w(k) and v(k) are correlated, then u predictor- correctur form uf the Kalman filter is
i(k + Ilk) = @(k + l,k)i(klk) + ‘F(k + l,k)u(k)
+ r(k + l,k)S(k)[H(k)P(klk - l)H’(k) + R(k)]-‘i(k jk - 1) (2342)
and ji(k + l(k + I> = g(k + Ilk) + K(k + l)i(k + Ilk) (2343)
where Kalman gain matrix, K(k + I), is given by (17-12). filtering-error covar- iance matrix, P(k + Ilk + I>, is given by (17-l@, and, prediction-error covar- iance matrix, P(k + l(k), is given by
P(k + Ilk) = @(k + l,k)P(klk)@;(k + I,k) + Q,(k) (23-14) in which
@,(k + l,k) = @(k + 1,k) - r(k + l,k)S(k)R-‘(k)H(k) (23-15)
and
Ql(k) = r(k + l,k)Q(k)I”(k + l,k) - T(k + l,k)S(k)R-‘(k)S’(k)l-“(k + l,k) (23-16)
Observe that, if S(k) = 0, then (23-12) reduces to the more familiar predictor equation (16-4), and (23-14) reduces to the more familiar (17-13).
P~oc$, The derivation of correction equation (23-13) is exactly the same, when w(k) and v(k) are correlated, as it was when w(k) and v(k) were assumed uncorrelated. See the proof of part (a) of Theorem 17-1 for the details.
In order to derive predictor equation (23-12), we begin with the Funda- - mental Theorem of Estimation Theory, i.e ,
r2(k + ilk) = E(x(k + 1)/55(k)) (23-17)
Substitute state equation (15-17) into (23-171, to show that
ii(k + l(k) = @(k + l,k)i(k!k) + Y(k + I .k)u(k)
+ T(k + l.k)E{w(k)l%(k)) (23-N)

226 State Estimation for the Not-So-Basic State-Variable Model Lesson 23
Next, we develop an expression for E{w(k)lZ(k)}. Let Z(k) = co1 (%(k - l), z(k)); then,
E{w(k)l~(k)} = E(w(k)l~(k - l),z(k)) = E{w(k)l%(k - l),i(kJk - 1)) = E{w(k)l%(k - 1)) + E{w(k)fi(kIk - 1))
- E(w(k)l (23-19)
= E{w(k)[i(kIk - 1))
In deriving (23-19) we used the facts that w(k) is zero mean, and w(k) and %(k - 1) are statistically independent. Because w(k) and i(klk - 1) are jointly Gaussian,
E{w(k)li(klk - 1)) = P,;(k,klk - l)P;i’(klk - l)g(klk - 1) (23-20)
where Pi; is given by (16-33), and
P,(k,kIk - 1) = E{w(k)Z’(klk - 1)) = E{w(k)[H(k)%(klk - 1) + v(k)]‘} = S(k)
(23-21)
In deriving (23-21) we used the facts that i(klk - 1) and w(k) are statistically independent, and w(k) is zero mean. Substituting (23-21) and (16-33) into (23-20), we find that
E{w(k)lZ(kIk - 1)) = S(k)[H(k)P(klk - l)H’(k) + R(k)]-’ (23-22)
Substituting (23-22) into (23-19), and the resulting equation into (23-18) com- pletes our derivation of the recursive predictor equation (23-12).
We leave the derivation of (23-14) as an exercise. It is straightforward but algebraically tedious. 0
Recall that the recursive predictor plays the predominant role in smooth- ing; hence, we present
Corollary 23-l. When w(k) and v(k) are correlated, then a recursive predictor for x(k + l), is
i(k + ilk) = 4P(k + l,k)i(klk - 1) + V(k + l,k)u(k) + L(k)s(k[k - 1
where
L(k) = [@(k + l,k)P(klk - l)H’(k) + r(k + l,k)S(k)l[H(k)P(kjk - l)H’(k) + R(k)]-
) (23-23)
-1 (23-24)
Colored Noises 227
and
P(k + lik) = [@(k + 1,k) - L(k)H(k)]P(klk - 1) [QP(k + 1,k) - L(k)H(k)]’
+ r(k + l,k)Q(k)I-‘(k + l,k) - r(k + l,k)S(k)L’(k) - L(k)S(k)Y(k + 1,k) + L(k)R(k)L’(k)
(23-25)
Proof. These results follow directly from Theorem 23-2; or, they can be derived in an independent manner, as explained in Problem 23-2. Cl
Corollary 23-2. When w(k) and v(k) are correlated, then a recursive filter for x(k + 1) is
i(k + Ilk + 1) = (I?l(k + l,k)i(k\k) + *(k + l,k)u(k) + D(k)z(k) + K(k + l)Z(k + Ilk) (23-26)
where
D(k) = I’(k + l,k)S(k)R-‘(k) (23-27)
and all other quantities have been defined above.
Proof. Again, these results follow directly from Theorem 23-2; how- ever, they can also be derived, in a much more elegant and independent manner, as described in Problem 23-3. q
COLORED NOISES
Quite often, some or all of the elements of either v(k) or w(k) or both are colored (i.e., have finite bandwidth). The following three-step procedure is used in these cases:
1. model each colored noise by a low-order difference equation that is excited by white Gaussian noise;
2. augment the states associated with the step 1 colored noise models to the original state-variable model;
3. apply the recursive filter or predictor to the augmented system.
i,e,) We try to model colored noise processes by low-order Markov processes, low-order difference equation s. Usually, first- or second-order models

228 State Estimation for the Not-So-Basic State-Variable Model Lesson 23
are quite adequate. Consider the following first-order model for colored noise process w(k),
u(k + 1) = cm(k) + n(k) (23-28)
In this model n(k) is white noise with variance & ; thus, this model contains two parameters: ct and d, which must be determined from a priori knowledge abut u(k). We may know the amplitude spectrum of m(k), correlation infor- mation about w(k), steady-state varknce of u(k), etc. Two independent pieces of information are needed in order to uniquely identify a and dn.
Example 23-l We are given the facts that scalar noise w(k) is stationary with the properties E{w(k)} = 0 and E{w(i)w(~]] = e -‘b- 4. A first-order Markov model for w(k) can easily be obtained as
t(k + I) = e -2((k) +- Vl - cd n(k) (23-29)
4kJ = w (23-30)
where E{t(O)] = 0, E{[‘(O)] = I, E{n (k)] = tl and E{n (~]n (I]} = &. 0
Example 23-2 Here we illustrate the state augmentation procedure for the first-order system
Xck + 1) = a,X(k) + w(k) (23-31)
z (k + 1) = hX(k + 1) + v(k + 1) (23-32)
where w(k) is a first-order Markov process, i.e.,
u(k + 1) = ulw(k) + n(k) (23-33)
and v(k) and n(k) are white noise processes. We “augment” (23-33) to (23-31), as follows. Let
x(k) = co1 (X(k), u(k)) (23-34)
then (23-31) and (23-33) can be combined, to give
(23-35) \ ’ -u - x(k + 1) (D w Y
Equation (23-25) is our augmented stute equutioa Observe that it is once again excited by a white noise process, just as our basic state equation (15-17) is.
In order to complete the description of the augmented state-variable model, we must express measurement z (Ic + 1) in terms of the augmented state vector, x(k + l), i.e.,
z(k + 1) = (h 0) ($ ; ;;) + v(k + 1)
-w H x(k + 1)
(23-36)
Colored Noises 229
Equations (23-35) and (23-36) constitute the augmented state-variable model. We observe that. when the original process noise is colored and the measurement noise is white, the state augmentation procedure leads us once again to a basic (augmented) state-variable model. one that is of higher dimension than the original model because of the modeled colored process noise. Hence, in this case we can apply all of our state estimation algorithms to the augmented state-variable model. E
Example 23-3 Here we consider the situation where the process noise is white but the measurement noise is colored, again for a first-order system,
X(k + 1) = a,X(k) t w(k) (23-37)
z(k + 1) = hx(k + 1) + ~(k + 1) (23-38)
As in the preceding example, we model v(k) by the following first-order Markov process
v(k + 1) = ap(k) + n(k) (23-39)
where n(k) is white noise. Augmenting (23-39) to (23-37) and reexpressing (23-38) in terms of the augmented state vector x(k), where
x(k) = co1 (X(k), v(k)) (23-40)
we obtain the following augmented state-variable model,
and
(23-4 1)
(23-42)
H x(k + 1)
Observe that a vector process noise now excites the augmented state equation and that there is no measurement noise in the measurement equation. This second observation can lead to serious numerical problems in our state estimators, because it means that we must set R = 0 in those estimators, and, when we do this, covariance matrices become and remain singular. 0
Let us examine what happens to P(k + Ilk + 1) when covariance matrix R is set equal to zero. From (17-14) and (17-12) (in which we set R = O>, we find that
P(k + Ilk + 1) = P(k + Ilk) - P(k + llk)H’(k + 1) [H(k + l)P(k + llk)H’(k + l)]-‘H(k + l)P(k + Ilk) (23-43)
Multiplying both sides of (23-43) on the right by H’(k + l), we find that
P(k + l[k + l)H’(k + 1) = 0 (23-44)

230 State Estimation for the Not-So-Basic State-Variable Model Lesson 23
Because H’(k + 1) is a nonzero matrix, (23-44) implies that P(k + Ifk + 1) must be a singular matrix. We leave it to the reader to show that once P(k + Ilk + 1) becomes singular it remains singular for all other values of k.
PERFECT MEASUREMENTS: REDUCED-ORDER ESTIMATORS
We have just seen that when R = 0 (or, in fact, even if some, but not all, measurements are perfect) numerical problems can occur in the Kalman filter. One way to circumvent these problems is ad hoc, and that is to use small values for the elements of covariance matrix R, even through measurements are thought to be perfect. Doing this has a stabilizing effect on the numerics of the Kalman filter.
A second way to circumvent these problems is to recognize that a set of “perfect” measurements reduces the number of states that have to be esti- mated. Suppose, for example, that there are 2 perfect measurements and that state vector x(k) is n X 1. Then, we conjecture that we ought to be able to estimate x(k) by a Kalman filter whose dimension is no greater than n - e. Such an estimator will be referred to as a reduced-order estimator. The payoff for using a reduced-order estimator is fewer computations and less storage.
In order to illustrate an approach to designing a reduced-order esti- mator, we limit our discussions in this section to the following time-invariant and stationary basic state-variable model in which u(k) A 0 and all mea- surements are perfect,
x(k + 1) = @x(k) + Tw(k) (23-45)
y(k + 1) = Hx(k + 1) (23-46)
In this model y is I x 1. What makes the design of a reduced-order estimator challenging is the fact that the I perfect measurements are linearly related to the n states, i.e., H is rectangular.
To begin we introduce a reduced-order state vector, p(k), whose dimen- sion is (n - 2) x 1; p(k) is assumed to be a linear transformation of x(k), i.e.,
p(k) 4 Cx(k) (23-47)
Augmenting (23-47) to (23-46), we obtain
(23-48)
H Design matrix C is chosen so that c ( > is invertible. Of course, many differ-
ent choices of C are possible; thus, this first step of our reduced-order esti- mator design procedure is nonunique. Let
= &IL,) (23-49)
Perfect Measurements: Reduced-Order Estimators 231
where L1 is n x I and L2 is n x (n - 1); thus,
x(k) = LlYW) + LP(k) (23-50)
In order to obtain a filtered estimate of x(k), we operate on both sides of (23-50) with E{ l I%(k)}, where
9(k) = co1 (Y(l), Y(2), l l l 9 Y(k)) (23-51)
Doing this, we find that
wqk) = L,Y(k) + L2i-q lk) (23-52)
which is a reduced-order estimator for x(k). Of course, in order to evaluate ii(k lk) we must develop a reduced-order Kalman filter to estimate p(k). Know- ing fi(k ]k) and y(k), it is then a simple matter to compute jZ(k ]k), using (23-52).
In order to obtain fi(klk), using our previously-derived Kalman filter algorithm, we first must establish a state-variable model for p(k). A state equation for p is easily obtained, as follows:
p(k + 1) = Cx(k + 1) = C[@x(k) + rw(k)] = C@[L,y(k) + Lzp(k)] + CTw(k) = CQLzp(k) + C@Lly(k) + Ww(k)
(23-53)
Observe that this state equation is driven by white noise w(k) and the known forcing function, y(k).
A measurement equation is obtained from (23-46), as
y(k + 1) = Hx(k + 1) = H[@x(k) + Tw(k)]
= H@[Lly(k) + L*p(k)] + HTw(k) = H@Lzp(k) + H@Lly(k) + HTw(k)
(23-54)
At time k + 1 we know y(k); hence, we can reexpress (23-54) as
yl(k + 1) = H@L*p(k) + HI’w(k) (23-55)
yl(k + 1) 4 y(k + 1) - HQLy(k) (23-56)
Before proceeding any farther, we make some important observations about our state-variable model in (23-53) and (23-55). First, the new mea- surement yl(k + 1) represents a weighted difference between measurements y(k + 1) and y(k). The technique for obtaining our reduced-order state- variable model is, therefore, sometimes referred to as a measurement- diflerencing technique (e.g., Bryson and Johansen, 1965). Because we have already used y(k) to reduce the dimension of x(k) from n to n - 1, we cannot again use y(k) alone as the measurements in our reduced-order state-variable model. As we have just seen, we must use both y(k) and y(k + 1).

232 State Estimation for the Not-So-Basic State-Vkable Model Lesson 23
second, measurement equation (23-55) appears to be a combination of signal and noise. Unless HI? = U, the term Hrw(k) will act as the measurement noise in our reduced-order state-variable model. Its covariance matrix is HrQr’E#‘. Unfortunately, it is possible for Hr to equal the zero matrix. From linear system theory, we know that IV is the matrix of first IvIarkov param- eters for our originai system in (23-45) and (23-46), and Hr may equal zero. If this occurs, then we must repeat all of the above until we obtain a reduced- order state vector whose measurement equation is excited by white noise. We see, therefore, that depending upon system dynamics, it is possible to obtain a reduced-order estimator of x(k) that uses a reduced-order Kalman filter of dimension less than n - 1,
Third, the noises, which appear in state equation (23-53) and mea- surement equation (23-S) are the same, namely w(k); hence, the reduced- order state-variable model involves the correlated noise case that we described before in this chapter in the section entitled Correlated Noises.
Finally, and most important, measurement equation (23-55) is non- standard, in that it expresses yl at k + I in terms of p at k rather than p at k + 1. Recall that the measurement equation in our basic state-variable model is z(k + 1) = Hx(k + 1) -t v(k + 1). We cannot immediately apply our Kal- man filter equations to (23-53) and (23-S) until we express (23-55) in the standard way.
To proceed, we let
so that
c(k) = H@L?p(k) + Hrw(k) (23-58)
Measurement equation (23-58) is now in the standard form; however, because g(k) equals a future value of yI, namely yl(k + l), we must be very careful in applying our estimator formulas to our reduced-order model (23-53) and (23-58).
In order to see this more clearly, we define the foIlowing two data sets,
By@ + 1) = -h(l), y,(2), . . . , ydk + I), . . .I (23-59)
and
Obviously,
Letting
(2340)
(23-61)
and
(23-62)
(23-63)
Lesson 23 Problems
we see that
&,(k + Ilk + 1) = &(k + ilk) (23-64)
Equation (23-64) tells us to obtain a recursive filter for our reduced-order model, that is in terms of data set 9,:(k + l), we must first obtain a recursive predictor for that model, which is in terms of data set B{(k). Then, wherever t(k) appears in the recursive predictor, it can be replaced by yl(k + 1).
Using Corollary 23-1, applied to the reduced-order model in (23-53) and (23-58): we find that
@,(k + l/k) = C@L&(@ - 1) + C@L,y(k)
thus,
fi,,(k + l(k + 1) = C~L&,(k~k) + CQLly(k)
+ L(~)[YI(~ + 1) - H@bfi,,(kh)l (23-66)
Equation (23-66) is our reduced-order Kalman filter. It provides filtered esti- mates of p(k + 1) and is only of dimension (n - I) x 1. Of course, when L(k) and P,,(k + Ilk + 1) are computed using (23-13) and (23-14), respectively, we must make the folIowing substitutions: @(k + l,k)* C@L?, H(k)-+ H@Lz, f(k + 1 ,k)-* CT, Q(k) --f Q, S(k) + QT’H’, and R(k)-+ HT’QT’H’.
FINAL REMARK
In order to see the forest from the trees, we have considered each of our special cases separately. In actual practice, some or all of them may occur simultaneously. The exercises at the end of this lesson will permit the reader to gain experience with such cases.
PROBLEMS
23-l. Derive the prediction-error covariance equation (23-14). 23-2. Derive the recursive predictor, given in (23-23), by expressing ri(k f l(k) as
E(x(k t- l)~~(k)) = E(x(k + l)jZE(k - l),i(kjk - 1)). 23-3. Here we derive the recursive filter, given in (23-26), by first adding a convenient
form of zero to state equation (1517): in order to decorrelate the process noise in this modified basic state-variable model from the measurement noise v(k). Add D(k)[z(k) - H(k)x(k) - v(k)] to-(15-17). The process noise, w,(k), in the modified basic state-variable model, is equal to r(k f l,k)w(k) - D(k)v(k). Choose “decorrelation” matrix D(k) so that E{w,(k)v’(k)] = 0. Then complete the derivation of (23-26). Observe that (23-14) can be obtained by inspection, via this derivation.

State Estimation for the Not-So-Basic State-Variable Model Lesson 23
23-4. In solving Problem 23-3, one arrives at the following predictor equation,
i(k + l(k) = QI(k + l,k)i(k(k) + ‘P(k + l,k)u(k) + D(k)@)
Beginning with this predictor equation, and corrector equation (Z-13) derive the recursive predictor given in (23-23).
23-5. Show that once P(k + l/k + 1) becomes singular it remains singular for all other values of k.
23-6. Assume that R = 0, HF = 0, and HOPI’ f 0. Obtain the reduced-order estimator and its associated reduced-order Kalman filter for this situation. Contrast this situation with the case given in the text, for which NT f 0.
23-7. Develop a reduced-order estimator and its associated reduced-order Kalman filter for the case when 2 measurements are perfect and m - I measurements are noisy.
23-8. Consider the first-order system x(k + 1) = ix(k) + w*(k) and z (k + 1) = x(k + 1) + v(k + 1), where E{wi(k)} = 3, E{v(k)} = 0, w,(k) and v(k) are both white and Gaussian, E{w:(k)} = 10, E{v2(k)} = 2, and, w,(k) and v(k) are correlated, i.e., E{wl(k)v (k)} = 1. (a) Obtain the steady-state recursive Kalman filter for this system. (b) What is the steady-state filter error variance, and how does it compare with
the steady-state predictor error variance? 23-9. Consider the first-order system x(k + 1) = $x(k) + w(k) and z(k + 1) =
x (k + 1) + v(k + l), where w(k) is a first-order Markov process and v(k) is Gaussian white noise with E{v (k)} = 4 and r = 1. (a) Let the model for w(k) be w(k + 1) = w(k) + u(k), where u(k) is a
zero-mean white Gaussian noise sequence for which E{u ‘(k)} = d. Additionally, E{w(k)} = 0. What value must cy have if E(w’(k)} = W for all k?
(b) Suppose W2 = 2 and 02, = 1. What are the Kalman filter equations for estimation of x (k) and w(k)?
2340. Consider the first-order system x(k + 1) = - $x(k) + w(k) and t (k + 1) = x(k + 1) + v(k + l), where w(k) is white and Gaussian [w(k) - N(w(k); 0, 1)] and v (k) is also a noise process. The model for v(k) is summarized in Figure P23-10. (a) Verify that a correct state-variable model for v(k) is,
xl@ + 1) = -&xl(k) + $n(k)
v(k) = xl(k) + n(k)
(b) Show that v(k) is also a white process. (c) Noise n(k) is white and Gaussian [n(k) - N(n (k); 0, l/4)].
What are the Kalman fiIter equations for finding i(k + l(k + l)?
Figure P23-10
Lesson 23 Problems 235
23-11, Obtain the equations from which we can find &(k + Ilk + 1) i,(k + ilk + 1) and c(k + l]k + 1) for the following system:
Xl(k + 1) = --xl(k) + x*(k) X2(k + 1) = x2(k) + w(k)
z(k + 1) = xI(k + 1) + v(k + 1)
where v(k) is a colored noise process, i.e.,
v(k + 1) = - $ v(k) + n(k)
Assume that w(k) and n (k) are white processes and are mutually uncorrelated, and, c&(k) = 4 and $,(k) = 2. Include a block diagram of the interconnected system and reduced-order KF.
23-12. Consider the system x(k + 1) = @x(k) + yp(k) and z(k + 1) = h’x(k + 1) + v (k + 1), where p(k) is a colored noise sequence and v(k) is zero-mean white noise. What are the formulas for computing fi(kIk + l)? Filter &i(k Ik + 1) is a deconvolution filter.
23-13. Consider the scalar moving average (MA) time-series model
z(k) = r(k) + r(k - 1)
where r(k) is a unit variance, white Gaussian sequence. Show that the optimal one-step predictor for this model is [assume P(OI0) = I]
i(k + l/k) = & [z(k) - i(klk - I)]
(Hint: Express the MA model in state-space form.) 23-14. Consider the basic state variable model for the stationary time-invariant case.
assume also that w(k) and v(k) are correlated, i.e., E{w(k)v’(k)} = S. (a) Show, from first principles, that the single-stage smoother of x(k), i.e.,
%( k jk + 1) is given by
i(klk + 1) = i(klk) + M(klk + l)i(k + Ilk)
where M(kIk + 1) is an appropriate smoother gain matrix. (b) Derive a closed form solution for M(kIk + 1) as a function of the
correlation matrix S and other quantities of the basic state-variable model.

fesson 24
f inecwizafion
und Discretization of Nonlinear Systems
INTRODUCTION
Many real-world systems are continuous-time in nature and quite a few are also nonlinear. For example, the state equations associated with the motion of a satellite of mass nz about a spherical planet of mass A!, in a planet-centered coordinate system, are nonlinear, because the planet’s force field obeys an inverse square law. Figure 24-l depicts a situation where the measurement equation is nonlinear. The measurement is angle 4, and is expressed in a rectangular coordinate system, i.e., +i = tan-’ [y /(x - ii)], Sometimes the state equation may be nonlinear and the measurement equation linear, or vice-versa, or they may both be nonlinear. Occasionally, the coordinate sys- tern in which one chooses to work causes the two former situations. For example, equations of motion in a polar coordinate system are nonlinear, whereas the measurement equations are linear. In a polar coordinate system, where # is a state-variable, the measurement equation for the situation de- picted in Figure 24-1 is zj = &, which is linear. In a rectangular coordinate system, on the other hand, equations of motion are linear, but the mea- surement equations are nonlinear.
Finally, we may begin with a linear system that contains some unknown parameters. When these parameters are modeled as first-order Markov processes? and these models are augmented to the original system, the aug- mented model is nonlinear, because the parameters that appeared in the original “linear” model are treated as states. We shall describe this situation in much more detail in Lesson 25.
236
A Dynamical Model 237
Figure 24-l A and 3.
Coordinate system for an angular measurement between two objects
The purpose of this lesson is to explain how to linearize and discretize a nonlinear differential equation model. We do this so that we will be able to apply our digital estimators to the resulting discrete-time system.
A DYNAMICAL MODEL
The starting point for this lesson is the nonlinear state-variable model
g(f) = f[x(&u(t),t] + G(t)w(l)
z(f) = hb(+.+),d + ~0)
(24-l)
(24-Z)
We shall assume that measurements are only available at specific values of time, namely at t = ti, i = 1, 2, . . . ; thus, our measurement equation will be treated as a discrete-time equation, whereas our state equation will be treated as a continuous-time equation. State vector x(i) is n X 1; u(t) is an 1 X I vector of known inputs; measurement vector z(t) is m x 1; ii(f) is short for dx(t)/dt; nonlinear functions f and h may depend both implicitly and explicitly on l, and we assume that both f and h are continuous and continuously differentiable with respect to all the elements of x and u; w(t) is a continuous-time white noise process, i.e., E{w(t)) =. 0 and
E(w(~)w’(T)) = Q(r)?+ - 7); (24-3)
v(ti) is a discrete-time and
white noise process, i.e., E(v(t,)) = 0 for t = E, , i = 1,
E(v(~~)v’(~j)) = R(ti)6, ; (24-4)
and, w(f) and V(Q) are mutually uncorrelated at all E = t,, i.e.:
E(w(r)v’(~J} = 0 fort = t, i = 1,2,. . . (24-5)

238 Linearization and Discretization of Nonlinear Systems Lesson 24
Example 24 1
Here we expand upon the previously mentioned satellite-planet example. Our example is taken from Meditch (1969, pp. 60-61), who states. . . “Assuming that the planet’s force field obeys an inverse square law, and that the only other forces present are the satellite’s two thrust forces u,(t) and u@(t) (see Figure 24-2), and that the satellite’s initial position and velocity vectors lie in the plane, we know from elementary particle mechanics that the satellite’s motion is confined to the plane and is governed by the two equations
. . r = r(j2 - - y+
1
r2 ; u40 (24-6)
and
_ li = 2G + 1 r ; ue (0 (24-7)
where y = GM and G is the universal gravitational constant. “Definingxl=r,xz= i,x~=9,xq=8,ul=ur,anduz=u,,wehave
(24-8)
which is of the form in (24-l). . . . Assuming . . . that the measurement made on the satellite during its motion is simply its distance from the surface of the planet, we have the scalar measurement equation
z(t) = r(t) - r() + v(t) = x1(t) - ro + v(t) (24-9)
where r. is the planet’s radius.”
_ Reference Axis
Planet, M
Figure 24-2 Schematic for satellite-planet system (Copyright 1969, McGraw-Hill).
Linear Perturbation Equations
Comparing (24-8) and (24-l), and (24-9) and (24-2), we conclude that
fb(t),u(t>Jl = co1 x2, x1x: - $+ 1 2.w4 +l Xl mU1=X4’ -- Xl
mu2 1 (24-10)
and
h[x(t),u(t),t] = x1 - ro (24-11)
Observe that, in this example, only the state equation is nonlinear. 0
LINEAR PERTURBATION EQUATIONS
In this section we shall linearize our nonlinear dynamical model in (24-l) and (24-2) about nominal values of x(t) and u(t), x*(t) and u*(t), respectively. If we are given a nominal input, u*(t), then x*(t) satisfies the following nonlinear differential equation,
g*(t) = f [x*(t),u*(t),t] (24-12)
and associated with x*(t) and u*(t) is the following nominal measurement, z*(t), where
Z*(t) = h [x*(t),u*(t)] t = ti i = 1, 2, . . . (24-13)
Throughout this lesson, we shall assume that x*(t) exists. We discuss two methods for choosing x*(t) in Lesson 25. Obviously, one is just to solve (24-12) for x*(t).
Note that x*(t) must provide a good approximation to the actual behav- ior of the system. The approximation is considered good if the difference between the nominal and actual solutions can be described by a system of linear differential equations, called linear perturbation equations. We derive these equations next.
Let
6x(t) = x(t) - x*(t) (24-14)
h(t) = u(t) - u*(t) (24-15)
then,
-$8x(t) = M(t) = k(t) - g*(t) = f[x(t)g(t),t]
+ wb@) - f Lx* (t),u* (WI (24-16)

240 Linearization and Discretization of Nonlinear Systems Lesson 24
Fact 1. When f [x(&u(j),f] is expanded in a Taylor series about x*(t) and u*(t), we obtain
f[x(t)u(t),t] = f[x*(t),u*($f] + ~[x*(~),u*(~),~]~x(t) + FU[x*(t),u*(&@u(t) + higher-order terms
where FX aud FU are n x n and n x f Jacobian matrices, i.e.,
(24-17)
(24-18)
(24-19)
(24-20)
(24-21)
Proof. The Taylor series expansion of the ith component of f [x(t),u(t),t] iS
+ $ [x&) - x;(t)] + 3 [u#) - u?(t)] + - * . (24-22) tl 1
+ $L 0 i u,t - I*
ul*(r)] + higher-order terms
wherei = 1,2,..., n. Collecting these II equations together in vector-matrix format, we obtain (24-17), in which FX and FU are defined in (24-18) and (24-19), respectively. El
Substituting (24-17) into (24-X) and neglecting the “higher-order terms,” we obtain the following perturbation sttiie equatim
G(t) = FX [x*(f),u*(t),#x(t) + FU [x*(r},u*(t)~]&~(t) + G(+v(f) (24-23)
1’ ’
Linear Perturbation Equations 241
Observe that, even if our original nonlinear differential equation is not an explicit function of time (i.e., f [x(r>.u(t),f] = f [x(f),u(t)]), our perturbation state equation is always time-varying because Jacobian matrices F, and F, vary with time, because x” and u* vary with time.
Next, let
Sz(r) = z(t) - z*(t) (24-24)
Fact 2. When h[x(t).u(t).t] is expanded in a Tuylor series about x*(t)
and u*(t), we obtain
h[x(t),u($f] = h[x*(t),u*(r),t3 + H, [x*(t>,u*(t)~]~x(~) + H, [x*(t),u*(t),fjSu(~) + higher-order terms (24-25)
c where H, and H, are m x n and m x P Jacobian matrices, i.e.,
(
ah, f ax,* 4 - - dh,/dx,* H,[x*(t),u*(r).t] = ; *-. ;
ah,/&,* .*a ah&x,* 1
and
H,[x*(f),u*(t),f] = ; -nI ; (
8h,l&i;r . . - dhIf&
dh, /au,* . , - dh, / du/* 1
In these expressions dhi/axT and ahi/au; are short for
dhi &j* -
dhi Cx(~)*u(t),tI 1 % (0 ix(t) = x*(f),u(t) = u*(t)
and
dhi dhi[x(l).u(t)J] aLdj* - aui (0 x(f) = x*(t),u(t) = u*(t) 0
(24-26)
(24-27)
(24-28)
(24-29)
We leave the derivation of this fact to the reader, because it is analogous to the derivation of the Taylor series expansion off [x(f),u(t),/].
Substituting (24-25) into (24-24) and neglecting the “higher-order terms ,” we obtain the following perturbation measurement equation
6z(r) = H, [x*(t>,u*(r),r]Sx(r) + H~[X*(t),U*(t)yt]SU(t) + V(f) t = Ii, i = 2,2,... (24-30)
tions, Equations (24-23) and (24-30) constitute our linear perturbation equa- or our linear perturbation stare-variable model.

242 Linearization and Discretization of Nonlinear Systems Lesson 24
Example 24-2 Returning to our satellite-planet Example 24-1, we find that
/ 0 1 0 0 \
FX [x*(t>,u*(t),t] = FX [x*(t)] =
F,[x*(t),u*(t),t] = FU =
0 0
; 0
0 0
0 - l m
Hx [x*(t),u*(t),t] = H, = (1 0 0 0)
and
H, [x*(t),u*(t),t] = 0
In the equation for FX [x*(t)], the notation ( )* means that all xi(t) within the matrix are nominal values, i.e., xi(t) = xi*(t).
Observe that the linearized satellite-planet system is time-varying, because its linearized plant matrix, F,[x*(t)], depends upon the nominal trajectory x*(t). 0
DISCRETlZATlON OF A LINEAR TIME-VARYING STATE-VARIABLE MODEL
In this section we describe how one discretizes the general linear, time-varying state-variable model
k(t) = F(t)x(t) + C(r)u(t) + G(t)w(t) (24-31)
Z(t) = H(t)x(t) + v(t) t = ti, i = 1729 l . . (24-32)
The application of this section’s results to the perturbation state-variable model is given in the following section.
In (24-31) and (24-32), x(t) is n X 1, control input u(t) is I X 1, process noise w(t) is p x 1, and z(t) and v(t) are each wt x 1. Additionally, w(t) is a continuous-time white noise process, V(ti> is a discrete-time white noise pro- cess, and, w(t) and v(ti) are mutually uncorrelated at all t = ti, i = 1, 2, . . . , i.e., E{w(?)} = 0 for all t, E{v(ti)} = 0 for all ti, and
E{w(t)w’(T)} = Q(t)s(t - T) (24-33)
E{v(ti)v’(tj)} = R(ti)ajj (24-34)
Discretization of a Linear Time-Varying State-Variable Model
and E{W(t)V’(ti)} = 0 fort=& i=l,2,... (24-35)
Our approach to discretizing state equation (24-30) begins with the solution of that equation.
Theorem 24-l. The solution to state equation (24-31) can be expressed
x(t) = @(t,to)x(to) + ~‘@(w)[W)u(r) + G(++)ld~ (24-36) t0
where state transition matrix @(t,T) is the homogeneous differential equation,
solution to the following matrix
&(t,r) = F(t)<P(t,T) @(t,t) = I (24-37)
This result should be a familiar one to the readers of this book; hence, . we omit its proof.
Next, we assume that u(t) is a piecewise constant function of time for t E [tk ,tk + J, and set to = t& and t = t& + 1 in (24-36), to obtain
x(tk + 1) = @(tk + l,fk)X(tk) +
+ 1
@(tk + l,$(+r u(fk)
I
can also be written as
x(k + 1) = @(k + 1, k)x(k) + ‘P(k + l,k)u(k) + Wd ck)
and wd(k) is a alent to
@(k + 1,k) = @(tk + dk)
‘P(k + 1,k) I tk + 1 =
@(tk + tk
discrete-time white Gaussian sequence that is statistically
I rk + 1 + @(tk + It7
‘k
I tk + 1
@(tk + 1J )G(T)w(7)dT tk
(24-38)
(24-39)
(24-40)
(24-41)
The mean and covariance matrices of wd(k) are
@(t, + l,T)G(+V(T)dT = 0 (24-42)

Linearization and Discretization of Nonlinear Systems Lesson 24
respectively. Ubserve, from the right-hand side of Equations (24-40), (24-41), and
(24-43), that these quantities can be computed from knowIedge about F(l), C(f), G(t), and Q(l). In general, we must compute @@ + l,kj, q(k + l,k), and Qd(k) using numerical integration, and, these matrices change from one time interval to the next because F(l), C(t), G(l), and Q(r) usually change from one time interval to the next.
Because our measurements have been assumed to be available only at sampled values of t, namely at t = fi, i = 1, 2, . . . , we can express (24-32) as
z(k -+ I) = H(k + l)x(k + 1) + v(k + 1) (24-44)
Equations (24-39) and (24-44) constitute our discretized state-variable model.
Example 24-3
Great simplifications of the calculations in (24-40), (24-41) and (24-43) occur if F(I), C(l), G(r)? and Q(t) are approximateIy constant during the time interval [rk, tk + I], i.e., if
(24-45)
To begin, (24-37) is easily integrated to yield
hence,
@(k + l,k) = eFAT (24-47)
where we have assumed that lk + l - fk = T. The matrix exponentia1 is given by the infinite series
(24-43)
and, for sufficiently small values of T
e FkT = I -I- FkT (24-49)
We use this approximation for eFkT in deriving simpler expressions for q(k Qd (k). Comparable results can be obtained for higher-order truncations of
+ 1,k) and FkT e .
Discretized Perturbation State-Variable Model
Substituting (24-46) into (24-41), we find that
Vr(k + 1,k) = I’* -’ @(tk + t,7)Ckd7 = 1” + ’ eFncrk + l -r’ Ckd7 lk tk
I
lk + 1
z [I + F&k+ t - ‘;>Jc,d~ fk
I
tk + 1
= CkT + FkCktk+ IT - FkCk 7dr Ik
where we have truncated *(k + 1 ,k) to its first-order manner for Qd(k), it is straightforward to show that
term in T, Proceeding in a similar
(24-50)
Q&j = GkQ&iET (24-51)
Note that (24-47), (24~49), (24-50), and (24-51), while much simpIer than their original expressions, can change in values from one time-interval to another, because of their dependence upon k. Cl
DISCRET12ED PERTURBATION STATE-VARIABLE MODEL
Applying the results of the preceding section to the perturbation state-variable model in (24-23) and (24-30), we obtain the following d&refired perturbation state-variable model
Sx(k + I) = @(k + l,k;*)ax(k) + ‘P(k -t l.k;*)h(k) + m(k) (24-52)
Sz(k + 1) = H,(k + l;*)Sx(k + 1) + H,(k + l;*)Su(k + 1) + v(k + 1) (2443)
The notation @(k + l,k;*), for example, denotes depends on x* (t) and u*(t). More specifically,
the fact that this matrix
@(k + l,k;*) = @(t, + I&;*) (24-54)
where
&(r,r;*) = Fx[x*(r~~u*(t),r]~(t,T;*) (24-55)
@(t,t;*) = I
Additionally,
‘I’(k + l,k;*) = 1” +I @(tk + I,f;*)FU[x*(r),u*(r),~]dT II,
(24-56)
Qd(k;*) = i” + ’ @(t, + I,T;*)G(~)Q(~)G’(r)W(t~ + l,q*)dr (24-57) ‘A

Linearization and Discretization of Nonlinear Systems Lesson 24
PROBLEMS
24-l. Derive the Taylor series expansion of h[x(t), u(t), t] given in (24-25). 24-2. Derive the formula for Q&C) given in (24-51). 24-3. Derive formulas for !P(k + 1,k) and Q&k) that include first- and second-order
effects of T, using the first three terms in the expansion of eFkT. 24-4. Let a zero-mean stationary Gaussian random process v(f) have the auto-
correlation function +“(7) given by 4” (7) = e-l” + ee2! (a) Show that this colored-noise process can be generated by passing white noise
p(f) through the linear system whose transfer function is
6 s+ lf5
(s + l)(s + 2)
(b) Obtain a discrete-time state-variable model for this colored noise process (assume T = 1 msec).
24-5. This problem presents a model for estimation of the altitude, velocity, and constant ballistic coefficient of a vertically falling body (Athans, et al., 1968). The measurements are made at discrete instants of time by a radar that measures range in the presence of discrete-time white Gaussian noise. The state equations for the falling body are
il = -x2 i2 = -e -yxlxG&3
A!3 = 0
where y = 5 x lo-‘, x1@) is altitude, x2(f) is downward constant ballistic parameter. Measured range is given by
velocity, and x3 is a
z(k) = <M’ + [x,(k) - H]* + v(k) k = 1,2,. . . ,
where M is horizontal distance and H is radar altitude. Obtain the discretized perturbation state-variable model for this system.
24-6. Normalized equations of a stirred reactor are
= -(cl + c4)x1 + c3(1 + x4)2 exp [&xl/(1 + x1)] + cd2 + cl& i2 = -(cg + c(j)& + c5x) + &x3
-f3 = -(c7 + 4x3 + CgX2 + c7u2
i4 = - ClX4 - ~~(1 + x4)* exp [K&(1 + x1)] + clu3
inwhich ul, u2, and u3 are control inputs. Measurements are
zi(k) = xi(k) + vi(k) i = 1,2, 3,
where vi(k) are zero-mean white Gaussian noises with variances ri. Obtain the discretized perturbation state-variable model for this system.
24-7. Obtain the discretized perturbation-state equation for each of the following nonlinear systems: (a) Equation for the unsteady operation of a svnchronous motor: M
X(t) + Ci(t) + p sin x(t) = L (1)
Lesson 24 Problems
(b) Duffing’s equation:
if(t) + Ci(f) + ax(f) + )&x3(r) = F cos wt
(c) Van der PoI’s equation:
X(f) - ci(i)[l - $2(f)] +x(t) = m(f)
(d) Hill’s equation:
X(t) - ux (r) + bp (t)x(t) = m(t)
where p (t> is a known periodic function.

Lesson 25
fterated Least Squcwes
and Extended Ku/man
Filtering
This Iesson is primarily devoted to the extended Kalman fiber (EKF), which is a form of the Kalman filter “extended” to nonlinear dynamical systems of the type described in Lesson 24. We shall show that the EKF is related to the method of iterated least squares (ILS), the major difference being that the EKF is for dynamical systems whereas ILS is not.
ITERATED LEAST SQUARES
We shall illustrate the method of ILS for the nonlinear model described in Example 2-5 of Lesson 2, i.e., for the model
z(k) =f (W + +) (25-l) wherek = 1,2 ,..., N.
Iterated Ieast squares is basically a four step procedure.
1. Linearizef(&k) about a nominal value of O,O*. Doing this, we obtain the perturbutim meusuremerzl tyuutkm
where Sz(k) = Fo(k;O*)cW + v(k) k = 1,2,. . . , N (25-2)
Sz(k) = z(k) - z*(k) = z(k) -j@*.k) (25-3)
M= e - e* (25-4)
24a
Extended Kalman Filter
and
(25-5)
2.
3.
Concatenate (252) 3 formulas. Solve the equation
and compute [or ~fLP)l using our Lesson
&l~Ls(Aq = i&&N) - 8” (25-6)
for km(N), i.e.,
i&&v) = tl* + &T&v) (25-7)
4. Replace 8* with L(N) and return to Step 1. Iterate through these steps until convergence occurs. Let h(N) and m(N) denote esti- mates of 8 obtained at the ith and (i + l)st iterations, respectively. Con- vergence of the ILS method occurs when
[@d(N) - i&&v)I < E (25-8)
where E is a prespecified small positive number.
We observe, from this four-step procedure, that ILS uses the estimate obtained from the linearized model to generate the nominal value of 6 about which the nonlinear model is relinearized. Additionally, in each complete cycle of this procedure, we use both the nonlinear and linearized models. The nonlinear model is used to compute z *(AC), and subsequently 6~ (k), using (25-3).
The notions of relinearizing about a filter output and using both the nonlinear and linearized models are also at the very heart of the EKF.
EXTENDED KALMAN FILTER
The nonlinear dynamical system of interest to us is the one described in Lesson 24. For convenience to the reader, we summarize aspects of that system next. The nonlinear state-variable model is
i(t) = f [x(t),u(t),t] + G(t)w(t) (25-9)
~(0 = h ~xO),u(O,d + v(t) t = tj i = 1,2 ,--a (25-10)
Given a nominal input, u*(l), and assuming that a nominal trajectory, x*(t), exists, x*(f) and its associated nominal measurement satisfy the following nominal system model,
i*(t} = f [x*(r),u*(t).t] (25-l 1)
z*(t) = h [x*(r).u*(t).t] t = t, i = I,2 ) . . * (25-12)

Iterated Least Squares and Extended Kalman Filtering Lesson 25
Letting &x(t) = x(l) - x*(t), h(t) = u(t) - u*(t), and 6z(t) = z(t) - z*(t), we also have the following discretized perturbation state-variable model that is associated with a linearized version of the original nonlinear state-variable model,
Sx(k + 1) = @(k + l,k;*)Sx(k) + V(k + l,k;*)Gu(k) + W&) (25-13) Sz(k + 1) = H,(k + 1;*)6x(k + 1)
+ H,(k + l;*)Su(k + 1) + v(k + 1) (25-14)
In deriving (25-13) and (2514), we made the important assumption that higher-order terms in the Taylor series expansions of f[x(t),u(t)?t] and h [x(t),u(t),t] could be neglected. Of course, this is only correct as long as x(t) is “close” to x*(t) and u(t) is “close” to u*(t).
If u(t) is an input derived from a feedback control law, so that u(t) = u[x(t),t], then u(t) can differ from u*(t), because x(t) will differ from x*(t). On the other hand, if u(t) does not depend on x(t) then usually u(t) is the same as u*(t), in which case Su(t) = 0. We see, therefore, that x*(t) is the critical quantity in the calculation of our discretized perturbation state- variable model.
Suppose x*(t) is given a priori; then we can compute predicted, filtered, or smoothed estimates of 6x(k) by applying all of our previously derived estimators to the discretized perturbation state-variable model in (25-13) and (25-14). We can precompute x*(t) by solving the nominal differential equation (25-11). The Kalman filter associated with using a precomputed x*(t) is known as a relinearited KF.
A relinearized KF usually gives poor results, because it relies on an open-loop strategy for choosing x*(t). When x*(t) is precomputed there is no way of forcing x*(t) to remain close to x(t), and this must be done or else the perturbation state-variable model is invalid. Divergence of the relinearized KF often occurs; hence, we do not recommend the relinearized KF.
The relinearized KF is based only on the discretized perturbation state- variable model. It does not use the nonlinear nature of the original system in an active manner. The extended Kalman filter relinearizes the nonlinear sys- tem about each new estimate as it becomes available; i.e., at k = 0, the system is linearized about x(010). Once z(1) is processed by the EKF, so that %( 111) is obtained, the system is linearized about x( 111). By “linearize about x( ill),” we mean x(111) is used to calculate all the quantities needed to make the transi- tion from x( 111) to i(2/1), and subsequently x(212). This phrase will become clear below. The purpose of relinearizing about the filter’s output is to use a better reference trajectory for x*(t). Doing this, 6x = x - i will be held as small as possible, so that our linearization assumptions are less likely to be violated than in the case of the relinearized KF.
The EKF is developed below in predictor-corrector format (Jazwinski, 1970). Its prediction equation is obtained bv integrating the nominal differ- - c ential equation for x*(t), from tk to t k + 1. In order to do this, we need to know
Extended Kalman Filter 251
how to choose x*(l) for the entire interval of time t E [fk ,tk + J. Thus far, we have only mentioned how x*(t) is chosen at tk, i.e., as r2(kIk).
Theorem 251. As a consequence of relinearizing about i(klk) (k = 0, 1 >Y ? l ’ l
si(tlt,) = 0 for all t E [tk ,tk + J (25-15)
This means that
x*(t) = %(tlfk) for ai/ t E [tk ?fk + 11 (2516)
Before proving this important result, we observe that it provides us with a choice of x*(t) over the entire interval of time t E [tk ,tk + J, and, it states that at the left-hand side of this time interval x*(&) = i(kIk), whereas at the right-hand side of this time interval x*(tk + 1) = f(k + Ilk). The transition from jZ(k + Ilk) to i(k + ilk + 1) will be made using the EKF’s correction equa- tion.
Proof. Let tl be an arbitrary value oft lying in the interval between fk and tk + 1 (see Figure 25-l). For the purposes of this derivation, we can assume that h(k) = 0 [i.e., perturbation input &u(k) takes on no new values in the interval from tk to tk + 1; recall the piecewise-constant assumption made about u(t) in the derivation of (24-37)], i.e.,
6x(k + 1) = <P(k + l,k;*)ax(k) + wd(k) (25-17)
Using our general state-predictor results given in (16-14), we see that (remem- ber that k is short for tk , and that tk + 1 - fk does not have to be a constant; this is true in all of our predictor, filter, and smoother formulas)
s;i(t, Itk) = @(t, ,tk ;*)sg(t, I&) = @(t,,tk;*)[k(kIk) - x*(k)] (2518)
tk t k+l
Figure 25-l Nominal state trajectory x* (t).

252 Iterated Least Squares and Extended Kalman Filtering lesson 25
In the EKF we set x*(k) = G(#); thus, when this is done,
sk(t&) = 0 for & $1 E [lk ,t& & 1-j (X-20)
which is (25-U). Equation (25-16) follows from (25-20) and the fact that iG(t//t&) = %(f$&) - x*(t,). cl
We are now able to derive the EKF. As mentioned above, the EKF must be obtained in predictor-corrector format. We begin the derivation by obtain- ing the predictur equation for g(k + l/k).
Recall that X*(I) is the solution of the nominal state equation (2541). Using (25-X) in (Z-H), we find that
Integrating this equaticm from l = ik to l = fk + I, we obtain
I 1
which is the EKFpredicbz equa&im. Observe that the nonlinear nature of the system’s state equation is used to determine S(k -+ Ilk). The integral in (25.22) is evaluated by means of numerical integration formulas that are initialized by f[~(t~l~~~,u~(~~),~~l.
The corrector equation for g(k + ljk + 1) is obtained from the Kalman filter associated with the discretized perturbation state-variable model in (25-13) and (25-14), and is
8%(k + lik + 1) = G(k + l\k) + K(k + l;*)[az(k + 1) - &(k + l;*)Z(k + l/k) - &(k + l;*)&(k + I)]
As a consequence of relinearizing about #k), we know that
G(k + l/k) = 0
G(k + l[k + 1) = g(k + Ilk + 1) - x*(k + 1) = G(k + l\k + 1) - %(k + l/k)
(25-23)
(25-24)
(2525)
and
ih(k -+ 1) = z(k + 1) - z*(k + 1) = z(k + 1) - h[x*(k + l), u*(k + I), k + 1-j
= z(k + 1) - h [i(k -t Ilk). u*(k + l), k + I] (X-26)
Extended Kalman Filter
Substituting these three equations into (25-23) we obtain
i(k -I- Ilk + 1) = i(k + Ilk) + K(k + l:*){z(k + 1) - h[i(k + l)k),u”(k + l),k + I] - H,(k + 1;*)6u(k + 1))
(25-27)
which is the EKFcorrection equation. Observe that the nonlinear nature of the system’s measurement equation is used to determine i(k + l/k + 1). One usually sees this equation for the case when 6u = 0, in which case the last term on the right-hand side of (25-27) is not present.
In order to compute G(k + lik + l), we must compute the EKF gain matrix K(k + I;*). This matrix, as well as its associated P(k + Ilk;*) and P(k + Ilk + l;*) matrices, depends upon the nominal x*(r) that results from prediction, namely k(k + l(k). Observe, from (25-16), that x*(k + 1) = i(k + Ilk), and that the argument of K in the correction equation is k + 1; hence, we are indeed justified to use ri(k + Ilk) as the nominal value of x* during the calculations of K(k + l;*), P(k + l]k;*), and P(k + Ilk + I;*). These three quantities are computed from
K(k + l;*> = P(k + llk;*)H:(k + l;*)[H,(k + l;*) P(k + ljk;*)H;(k + l;*) + R(k + l)]-’ (25-28)
P(k + Ilk;*) = G’(k + l,k;*)P(klk;*)@‘(k + l,k;*) + Q&;*) (25-29)
P(k + Ilk + I;*) = [I - K(k + l;*)H,(k + l;*)]P(k + ilk;*) (25-30)
Remember that in these three equations * denotes the use of i(k + l(k). The EKF is very widely used, especially in the aerospace industry;
however, it does not provide an optima1 estimate of x(k). The optimal estimate of x(k) is still E{x(k)f%(k)}, regardless of the linear or nonlinear nature of the system’s model. The EKF is a first-order approximation of E{x(k)l%(k)) that sometimes works quite well, but cannot be guaranteed always to work well. No convergence results are known for the EKF; hence, the EKF must be viewed as an ad hoc filter. Alternatives to the EKF, which are based on nonlinear filtering, are quite complicated and are rarely used.
The EKF is designed to work well as long as 6x(k) is “small.” The iterated EKF (Jazwinski, 1970), depicted in Figure 25-2, is designed to keep 6x(k) as small as possible. The iterated EKF differs from the EKF in that it iterates the correction equation L times until llkL(k + Ilk + 1) - jiLsl(k + Ilk + 1)11 5 E. Corrector Rl computes K(k + l;*), P(k -I- Ilk;“), and P(k + l/k + l;*) using x* = li(k + Ilk); corrector #2 computes these quantities using x* = gl(k + Ilk + 1); corrector #3 computes these quantities using x* = iz(k + l!k + 1): etc.
Often, just adding one additiona corrector (i.e., L = 2) leads to sub- stantially better results for i(k + Ilk + 1) than are obtained using the EKF.

Wlk
) W
+
Ilk)
Cor
rect
or
g,(k
+
Ilk
+ 1)
4.
- I(k
+
Ilk
+ 1)
co
rrect
or
S,jk
-t Ilk
+ I)?
i(k+I
Ik+I
) W
Pr
edic
tor
= +
#I
+ooo
b-
#L
*
W+)
fi(
k+
Ilk+
I)
4 a
‘k
t ktl
Figu
re 2
52
Itera
ted
EKF.
Al
l of
the
cal
cula
tions
pro
vide
us
with
a r
efin
ed e
stim
ate
of
x(k
+ l),
ii(k
+ I
lk
+ l),
sta
rting
with
r2(
kIk)
.
Application to Parameter Estimation
APPLICATION TO PARAMETER ESTIMATION
One of the earliest applications of the extended Kalman filter was to param- eter estimation (Kopp and Orford, 1963). Consider the continuous-time linear system
2(t) = Ax(t) + w(t) (2531a)
Z(t) = Hx(t) + V(t) t = ti i = 1, 2,. . . (25-m)
Matrices A and H contain some unknown parameters, and our objective is to estimate these parameters from the measurements Z(ti> as they become avail- able.
To begin, we assume differential equation models for the unknown parameters, i.e., either
t&(t) = 0 I = 1,2,. . . $ z* (2532a)
t;j(t)=O i=l,2,...,j* (2532b)
4(t) = w(t) + n&) I = 1,2,. . .) I” (25-33a)
hj(t) = djhj(t) + qi(t) j = 1, 2, l . l ,i* (25-33b)
In the latter models n/(t) and qj(t) are white noise processes, and one often chooses cl = 0 and dj = 0. The noises n,(t) and qj(t) introduce uncertainty about the “constancy” of the al and hj parameters.
Next, we augment the parameter differential equations to (25-31a) and (25031b). The resulting system is nonlinear, because it contains products of states [e.g., al(t)xi(t)]. The augmented system can be expressed as in (25-9) and (25-lo), which means we have reduced the problem of parameter esti- mation in a linear system to state estimation in a nonlinear system.
Finally, we apply the EKF to the augmented state-variable model to ob- tain cil(klk) and hj(klk).
Ljung (1979) has studied the convergence properties of the EKF applied to parameter estimation, and has shown that parameter estimates do not converge to their true values. He shows that another term must be added to the EKF corrector equation in order to guarantee convergence. For details, see his paper.
Example 25-l
Consider the satellite and planet governed by the two equati .ons
Example 24-1, in which the satellite’s motion is
. . r=$-- y+ 1 *’ m uro (25-34)

Iterated Least Squares and Extended Kalman Filtering Lesson 25
and
(2535)
We shall assume that m and y are unknown constants, and shall model them as
h+(r) = 0 (25-36)
j(r) = 0 (2537)
(2533)
NOW,
We note, finally, that the modeling and augmentation approach to parameter estimation? described above, is not restricted to continuous-time linear systems. Additiona situations are described in the exercises.
PROBLEMS
25-L In the first-order system, x(k + 1) = ax(k) + w(k), and z (k + 1) = x(k + 1) + v(k + 11, k = 1, 2, . . . , N, a is an unknown parameter that is to be estimated. Sequences w(k) and v(k) are, as usual, mutually uncorrelated and white, and, w(k) - jV(w(k);O,l) and v(k) - N(v(k);O,h). Explain, using equations and a flowchart, how parameter a can be estimated using an EKF.
25-2. Repeat the preceding problem where all conditions are the same except that now w(k) and v(k) are correlated, and E{w (k)v (k)] = ~4.
25-3. The system of differential equations describing the motion of an vehicle about its pitch axis can be written as (Kopp and Orford ‘9 1963)
aerospace
ii 1(t) = x2(t) i2(@ = Q)k(q -I- h(t)%(r) + 03O)W)
where xl = i(f), which is the actual pitch rate. Sampled measurements are made of the pitch rate, i.e.,
z(r) = x,(r) + v(r) 1 = f, i = 1,2,...,N
Lesson 25 Pfoblems
Noise u (t, > is white and Gaussian, and &(f,) is given. The control the sum of a desired control signal u”(r) and additive noise, i.e.,
The additive noise SU (f) is a normally distributed a function of the desired control signal. i.e.,
random variable modulated bY
su (f) = S[u *(r)Jwo(r) where we(t) is zero-mean white noise with intensity and as(t) may be unknown and are modeled as
h(r) = ar(r)[a,(t) - i%(t)] + w,(t)
&.
signal u(t) is
Parameters
i = 1, 2,3
In this model the parameters Q, (t) are assumed given, as are the a priori values of a,(t) and e,(l), and, r+pi(t) are zero-mean white noises with intensities cr$,. (a) What are the EKF formulas for estimation of x1, x2, al, and ~2, assuming that
us is known? (b) Repeat (a) but now assume that u3 is unknown.
25-4. Suppose we begin with the nonlinear discrete-time system,
x(k + 1) = f[x(k),k] + w(k)
z(k) = h[x(k),k] + v(k) k = 1,2,...
25-S.
Develop the EKF for this system [Hint: expand f [x(k),k] and h [x(k),k] in Taylor series about ri(k jk) and i(klk - l), respectively]. Refer to Problem 24-7. Obtain the EKF for (a) Equation for the unsteady operation of a synchronous motor, in which C and
p are unknown; (b) Duffing’s equation, in which C, cy , and p are unknown; (c) Van der Pal’s equation, in which E is unknown; and (d) Hill’s equation, in which a and b are unknown.

Lesson 26
Maximum-Likelihood
State and Parameter
Estimation
INTRODUCTION
In Lesson 11 we studied the problem of obtaining maximum-likelihood esti- mates of a collection of parameters, 0 = co1 (elements of Qp, T, H, and R), that appear in the state-variable model
x(k + 1) = @x(k) + Vu(k) (26-l)
z(k + 1) = Hx(k + 1) + v(k + 1) k =O,l,...,N- 1 (26-2)
We determined the log-likelihood function to be
L(8pfJ = - i 5 [z(i) - HB xg (i)]‘Ril [z(i) - He x0 (i)] - $ In lRel (26-3) i = 1
where quantities that are subscripted 8 denote a dependence pointed out that the state equation (26-l), written as
on 8. Finally, we
xe (k + 1) = Qexe (k) + ‘I!,u(k) xe (0) known (26-4)
acts as a constraint that is associated with the computation of the log- likelihood function. Parameter vector 0 must be determined by maximizing L(f@!l) subject to the constraint (26-4). This can only be done using mathe- matical programming techniques (i.e., an optimization algorithm such as steepest descent or Marquardt-Levenberg).
In this lesson we study the problem of obtaining maximum-likelihood
A Log-Likelihood Function for the Basic State-Variable Model 259
estimates of a collection of para basic state-variable model,
meters, also denoted 8, that appear in our
x(k + 1) = @x(k) + rw(k) + *u(k) (26-5)
z(k -t 1) = Hx(k + 1) + v(k + 1) k=O,l,...,N-1 (26-6)
Now, however, 8 = co1 (elements of @, r, q? H, Q, and R) (26-7)
and, we assume that 6 is d x 1. As in Lesson 11, we shall assume that 6 is identifiable.
Before we can determine 4 ML we must establish the log-likelihood func- tion for our basic state-variable model.
A LOG-LIKELIHOOD FUNCTION FOR THE BASIC STATE-VARIABLE MODEL
As always, we must compute p (3!@) = p (z(l), z(2), . . . , z(N#). This is diffi- cult to do for the basic state-variable model, because
The measurements are all correlated due to the presence of either the process noise, w(k), or random initial conditions or both. This represents the major difference between our basic state-variable model, (26-5) and (26-6), and the state-variable model studied earlier, in (26-l) and (26-2). Fortunately, the measurements and innovations are causally invertible, and the innovations are all uncorrelated, so that it is still relatively easy to determine the log-likelihood function for the basic state-variable model.
Theorem 264. The log-likelihood function for our basic state-variable model in (26-5) and (26-6) is
L(813) = - i 5 [Zi (jlj - l)JV,l (jlj - l)&(j(j - 1) j=l
+ WWli - 1)ll (26-9)
where &,( j(j - 1) is the innovations process, and & ( jl j - 1) is the covariance of that process [in Lesson 16 we used the symbol Pti (jlj - 1) for this covar- iance],
&(jlj - 1) = HftPe( jlj - l)Hi + RB (26-10)
This theorem is also applicable to either time-varying or nonstationary systems or both. Within the structure of these more complicated systems there must still be a collection of unknown but constant parameters. It is these parameters that are estimated by maximizing L (61%).

Maximum-Likelihood State and Parameter Estimation Lesson 26
Pro@ (Mended, 1983b, pp. lOl-1031. We must first obtain the joint density function p (S!@) = p (z(l), . . . , z(N)~9). In Lesson 17 we saw that the innovations process i(+ - 1) and measurement z(i) are causaIiy invertible; thus, the density function
jqi(liO), qq), . . . , qqN - l#)
contains the same data informatiop as- p (z(l), . . . , z(N@) does. Conse- quently, L (91% j can be replaced by I,@/?E), where
and 2 = co1 (i( liO), . * . , i(Npv - 1)) (26-l 1)
L@@) = inJqql~o), . l l , i(AqN - 1)/e) (2642)
Now, however, we use the fact that the innovations process is Gaussian white noise to express A$!$$) as
For our basic state-variable model, the innovations are Gaussian distributed, which means that pj (i(jlj - 1)19) = ~?(i(jij - 1)10) forj = 1, . . . , W, hence,
L(@Q = ln fi p(i(jij - 1)/e) (26-14) j=l
From part (b) of Theorem 16-2 in Lesson 16 we know that
Substitute (26-H) into (26-14) to show that
L(0pt) = -; $ [Z’(jij - 1)N-1 (j[j - l)Z(jlj - 1) j-1
+ wwl~ - w (2646)
where by convention we have neglected the constant term -ln(2r)& because it does not depend on 0.
Because jj( # 19) and JJ( # 10) contain the same information about the data, L(@‘) and L(@Z) must also contain the same information about the data; hence, we can use ~(f$E) to denote the right-hand side of (26~16), as in (26-9). To indicate which quantities on the right-hand side of (26-9) may depend on 8, we have subscripted all such quantities with 9. IJ
The innovations process &,( j /j - 1) can be generated by a Kalman filter; hence, the Kalman filter acts as a cunstraint that is asuciated with the corn- put&on uf the log-likelihuud function fur the basic stute-variable mudel.
On Computing &, 261
In the present situation, where the true values of 9, 8~~ are not known but are being estimated, the estimate of x(i) obtained from a Kalman filter will be suboptimal due to wrong values of 8 being used by that filter. In fact, we must use iML in the implementation of the Kalman filter, because hML will be the best information available about OT at tj. If bML-+ OT as Iv-+ x, then &,,Mi - I>+ G,(jIj - 1) as iV--+ x, and the suboptimal KaIman filter will approach the optimal Ratman filter. This result is about the best that one can hope for in maximum-likelihood estimation of parameters in our basic state- variable model.
Note also, that although we began with a parameter estimation problem, we wound up with a simultaneous state and parameter estimation problem. This is due to the uncertainties present in our state equation, which necessi- tated state estimation using a Kalman filter.
ON COMPUTING ii,,
How do we determine 6 ML for L (@X> given in (26-9) (subject to the constraint of the Kalman filter)? No simple closed-form solution is possible, because 8 enters into L (elfq in a comphcated nonlinear manner. The only way presently known to obtain 8 ML is by means of mathematical programming.
The most effective optimization methods to determine &$L require the computation of the gradient of L(C@E) as well as the Hessian matrix, or a pseudo-Hessian matrix of ,5(01%). The Marquardt-Levenberg algorithm (also known as the Levenberg-Marquardt algorithm [Bard, 1970; Marquardt, 1963]), for example, has the form
8 *‘i+ 1 = A.
ML &vi, - (6 + Q)-lg, i = 0, 1, , . . (26-17)
where &- denotes the gradient
H, denotes a pseudo-Hessian
H i -- *1 8 = eML
(2648)
(2649)
and Di is a diagonal matrix chosen to force Hi + D, to be positive definite, so that (H, + D‘)-’ will always be computable.
We do not propose to discuss details of the Marquardt-Levenberg algo- rithm. The interested reader should consult the preceding references for gen- eral discussions, and Mendel (1983) or Gupta and Mehra (1974) for dis- cussions directly related to the application of this algorithm to the present problem, maximization of L (9[%).

Maximum-Likelihood State and Parameter Estimation Lesson 26
We direct our attention to the calculations of gi and Hi. The gradient of L(O~%) will require the calculations of
The innovations depend upon i, (jlj - 1); hence, in order to compute Wjlj - l)/a9, we must compute a&( jlj - 1)/J& A Kalmanfilter must be used to compute f, (jlj - 1); but this filter requires the following sequence of calculations: Pg(klk)+PB(k + llk)+K,(k + l)+&(k + llk)+&(k + 11 k + 1). Taking the partial derivative of the prediction equation with respect to 6i we find that
mi +xu(k) i = 1,2,...,d (26-20) i
We see that to compute &(k + Ilk) / a6i, we must also compute &(k Ik) / aei. Taking the partial derivative of the correction equation with respect to 6i, we find that
d&(k + Ilk + 1) = 89i
&,(k + ilk) + dK*(k + 1) 86i 30i [z(k + 1) - H&k + Ilk)]
-&(k + 1) [$+(k + Ilk) i
+H h(k + ilk) 8 tMi 1 i = 1,2, . . . , d (26-21)
Observe that to compute &(k + Ilk + l)/dei, we must also compute &(k + l)/ aei. We leave it to the reader to show that the calculation of &(k + l)/ a0i requires the calculation of dP@(k + Ilk)/ 80i, which in turn requires the calculation of dPO(k + 1 jk + l)/ Joi.
The system of equations
a&(k + Ilk)/aOi &(k + 1Jk + l)/Hi a&(k + l)/aOi dPe(k + l)k)/dOi dPo(k + Ilk + 1)/J&
is called a Kalman filter sensitivity system. It is a linear system of equations, just as the Kalman filter, which is not only driven by measurements z(k + 1) [e.g., see (2621)] but is also driven by the Kalman filter [e.g., see (26-20) and (2621)]. We need a total of d such sensitivity systems, one for each of the d unknown parameters in 0.
Each system of sensitivity equations requires about as much com- putation as a Kalman filter, Observe, however, that Kalman filter quantities
On Computing 6,, 263
are used by the sensitivity equations; hence, the Kalman filter must be run together with the d sets of sensitivity equations. This procedure for recursively calculating the gradient dL (Ofa)l d0 therefore requires about as much com- putation as d + 1 Kalman filters. The sensitivity systems are totally uncoupled and lend themselves quite naturally to parallel processing (see Figure 26-l).
The Hessian matrix of L (01%) is quite complicated, involving not only first derivatives of Ze( j 1 j - 1) and N,( j 1 j - l), but also their second deriva- tives. The pseudo-Hessian matrix of L (Ol%) g i nores all the second derivative terms; hence, it is relatively easy to compute because all the first derivative terms have already been computed in order to calculate the gradient of L(Ol%). Justification for neglecting the second derivative terms is given by Gupta and Mehra (1974), who show that as iML approaches &-, the expected value of the dropped terms goes to zero.
The estimation literature is filled with many applications of maximum- likelihood state and parameter estimation. For example, Mendel (1983b) ap- plies it to seismic data processing, Mehra and Tyler (1973) apply it to aircraft parameter identification and McLaughlin (1980) applies it to groundwater flow.
113111v rry
her a 1-q dLld6,
i G L Sensitwty ,
Filter 0, =- aLldeZ - R A
z(k) ( Filter D I
0 E 0 N 0 T
1 :nsitiviry llter 0,
gi
Figure 26-l Calculations needed to compute gradient vector gi. Note that 0j de- notes the jth component of 8 (Mendel, 1983b, 0 1983, Academic Press, Inc.).

Maximum-Likelihood State and Parameter Estimation Lesson 26
A STEADY-STATE APPROX!MATlON
Suppose our basic state variabIe mode1 is time-invariant and stationary so that F = ht$ P(j\j- - 1) exists. Let
x=E@H’+R (26-22)
and
Log-likelihood function ~(9~5!!) is a steady-state approximation of I. (C$iC). The steady-state Kalman filter used to compute i(j[j - 1) and x is
i(k + l/k) = cD%(k\k) -I- ml(k)
i(k + Ilk + I) = i(k + lik) + K[z(k + 1) - Hi(k + l\k)]
(X-24)
(26-25)
in which E is the steady-state Kalman gain matrix. Recall that
0 = co1 (elements of Q, IY, q, H, Q, and R) (26-26)
We now make the following transformations of variables:
We ignore r (initially) for reasons that are explained below Equation (26-32). Let
+ = co1 (elements of @, V, H, p, and z) (26-28)
where + isp x I, and view E as a function of 4, i-e,,
m@l = - ; g i;( j/j - 1)x&( j[j - I) - ; IV In ix+1 (26-29) j-l
Instead of finding 6 ML that maximizes ~(O~~], subject to the constraints of a fulI-blown Kalman filter, we now propose to find &L that maximizes ~(c#X), subject ?o the cunstraints of the foIlowing filter:
&,(k + lik) = @&,(k/k) + ‘P&k)
&(k + lik + 1) = &(k + Ilk) + ii&&k + lik)
(26-30)
(26-31)
A Steady-State Approximation 265
and
i+(k f l/k) = z(k + 1) - H,&,(k + ilk) (26-32)
Once we have computed +ML we can compute &IL by inverting the trans- formations in (26-27). Of course, when we do this, we are also using the invariance property of maximum-likelihood estimates.
Observe that z(+j%) in (26-29) and the filter in (2630)-(26-32) do not depend on r; hence, we haye not included r in any definition of $. We explain how to reconstruct r from $ ML following Equation (26-44).
Because maximum-likelihood estimates are asymptoticahy efficient (Lesson ll), once we have determined ?*i ML, the filter in (26-30) and (26-31) will be the steady-state Kalman filter.
The major advantage of this steady-state approximation is that the filter sensitivity equations are greatly simplified. When K and x are treated as matrices of unknown parameters we do not need the predicted and corrected error-covariance matrices to “compute” K and x. The sensitivity equations for (26-32), (26-30), and (26-31) are
Wk + w = _ dG(k + Ilk) d#i IG w (26-33)
d%(k + Ilk) = Qr &&Ik) ’
- % %+(k + ilk) 1
a@, * J% d#i +- Wi + 3 Gw + x 44 (26-34)
I 1
d%+(k + Ilk + 1) = d%+(k + Ilk) - Wi Wi
+ $‘[z(k + 1) - H&k tk + l)]
-G&J a&(k + l/i)
dd+
-&,2 &(k + Ilk) (26-35) 1
where i = 1, 2, . . . , p. Note that d&,/d#i is zero for all & not in q and is a matrix filled with zeros and a single unity value for & in 5.
There are more elements in + than in 9, because .K and K have more unknown elements in them than do Q and R, i.e., p > d. Additionally, x does not appear in the filter equations; it only appears in ‘t(t$l~). It is, therefore, 1 possible to obtain a closed-form solution for xML,
Theorem 26-Z. A closed-form solution for matrix gML is
(26-36)

266 Maximum-Likelihood State and Parameter Estimation Lesson 26
Proof. To determine % hlL we must set dz:(+[%)/%& = 0 and solve the resulting equation for I&,. This is most easily accomplished by applying gradient matrix formulas to (26-29) that are given in Schweppe (1974). Doing this, we obtain
(26-37)
whose solution is gM, in (26-36). 0
Observe that & is the sample steady-state-covariance matrix of &; i.e.,
A
cb ML'& ZML+ lim cov [Z( j lj - l)] j-32 A A
Suppose we are also interested in determining QML and RML. How do we a obtain these quantities from $ML?
As in Lesson 19, we let K, i’, and PI denote the steady-state values of K(k + l), P(k + Ilk), and P(k lk), respectively, where
K = PH’(H~@ + R)-1 = jQfp-1 (26-38)
p = @i!@ + I’QI” (26-39) and
i!, = (I - KH)i! (26-40)
Additionally, we know that
x = HFH’ + R ((26-41)
By the invariance property of maximum-likelihood estimates, we know that
2ML (26-43)
Solving (26-43) for -irk’ ML and substitu$ng the resulting expression into (26-42), we obtain the following solution for RML,
A
RML = (1 - fiM,KML)~ML (26-44)
No closed-form solution exists for QML. Substituting (aML, &, &, and &r+ into (26.38)-(26-40) and combining (26-39) and (26-40), we obtain the followi ng two equations
and
(26-46)
A Steady-State Approximation
These equations must be solved simultaneously for p and @Q&L using iterative numerical techniques. For details, see Mehra (1970a).
Note finally, that the best for which we can hope by this approach is not I?& and QML, but only= ML. This is due to the fact that, when I’ and Q are both unknown, there will be an ambieuitv in their determination, i.e., the term rw(k) which appears in our basic- state-variable model [for which EbWw’(~)~ = Ql cannot be distinguished from the term w@), for which
E{w,(k)w;(k)} = Q1 = I’QI” (26-47)
This observation is also applicable to the original problem formulation wherein we obtained & directly; i.e.? when both I’ and Q are unknown, we should really choose
8 = co1 (elements of @, V, H, rQr’, and R) (26-48)
In summary, when our basic state-variable model is time-invariant and stationary, we can first obtain 4 ML by maximizing Z($la) given in (26-29), subject to the constraints of the simple filter in (26-30), (26-31), and (26-32). A mathematical programming method must be used to obtain those elements of +ML associated with &ML, $i&, tiMLY and &. The closed-form solution, given in (26-36), is used for x ML. Finally, if we want to reconstruct RML and (I’QI?)ML, we use (26-44) for the former and must solve (26-45) and (26-46) for the Iatter.
Example 26-1 (Mehra, 1971)
The following fourth-order system, which represents the first bending mode of a missile, was simulated:
short period dynamics and the
0 0 0 0 0 1 0 0 0 0 1 0
-a!1 -a2 -cY3 -a4
z(k + 1) = xl(k + I) + v(k + 1) (26-50)
For this model, it was assumed that x(O) = 0, 4 = 1.0, r = 0.25, cyl = -0.656, cy2 = 0.784, a3 = -0.18, and cy4 = 1.0.
Using measurements generated from the simulation, maximum-likelihood esti- mates were obtained for $, where
+ = co1 (al, cY2, a!3, cY4, x, L L k.77 7;4> (26-51) -
In (2651), SIT is a scalar because, in this example, t (k) is a scalar. Additionally, it was assumed that x(0) was known exactly. According to Mehra (1971, pg. 30) “The starting values for the maximum likelihood scheme were obtained using a correlation technique given in Mehra (1970b). The results of successive iterations are shown in Table 26-l. The variances of the estimates obtained from the matrix of second partial derivatives (i.e., the Hessi .an matrix of E) are also given. For comparison purposes, tained by using 1000 data points and 100 data points are given. ” Cl
results ob-

TABLE 26-I Parameter Estimates for Missile Example
0 Results from correlation technique, Mehra (197Ob).
1 - I.0706 2.3800 -0.5965 (I.8029 -0.1360 0.8696 0.6830 0.2837 0.4191 0.8207 M.L. estimates using 1000 points
2 -1.06fkl 2.3811 -O-S938 3 - 1.0085 2.4026 -0.6054 4 -0.9798 2.4409 -0*6u36 5 -0.9785 2.4412 -0.5999 6 -0.9771 2.4637 -0.6014 7 -0.9769 2.4603 -Oh023 8 - 0.9744 2.5240 -0.6313 9 -0.9743 2.5241 -0.6306
10 -0.9734 2 S270 -0.6374 11 -0.9728 2.5313 -0.6482 12 -0.9720 2.5444 -0.66U2 13 -0.9714 2.5600 -0.6634 14 -0.9711 2.5657 -0.6624
M.L, estimates using 100 points 30 -0.9659 2.620 -0Ao94
Actual values -0.94 2.557 -o.twlo
Estimates of standard deviation using 1WO points 0.0317 0.0277
Estimates of standard deviation using 100 points 0.149 0.104
0.8029 -0.1338 0.8759 0.6803 0.2840 0.7452 -0.1494 0.9380 0.6304 0.2888 0.8161 -0,140s 0.8540 0.6801 0.3210 0.8196 -OS 1370 0.8%0 0.6803 0.3214 0.8086 -0.1503 0.884 1 0.7068 0.3479 0.8 130 -0.1470 0.8773 0.7045 0.3429 0.8105 -0.1631 0.9279 0.7990 0.37% 0.8 108 -Om1622 O-9296 0.7989 0.3749 0.7961 -0.1630 0.9so5 0*7974 0.3568 0.7987 -Owl620 0.9577 0.8103 0.3443 0.7995 -0.1783 0.9866 0.8487 0.3303 0.7919 -0.2036 1.0280 0.8924 0.3143 0.7808 -0.2148 1.0491 0.9073 0.325 i
0.42oU 0.8312 0+4392 I.U3lk OA 108 1.1831 U.6107 1.1835 0.6059 1.2200 0.6lCI6 1.2104 0.6484 1.2589 0.6480 1.2588 0.6378 1.2577 0.6403 1,235i O.m33 1.2053 II.6014 1.2OS4 0.6122 I .2200
O-7663 -0.1987 1,0156 1.24 0.136 0.454 1.103
0.7840 -0,180O 1.00 0.8937 0.2957 0.6239 1.2510
OS0247 0.0275 0.0261 0.0302 0.0323 o.K+02 0.029
0.131 0.084 0.184 0,303 0.092 0.082 0.09
Source: Mehra (1971, pg. 301, Q 1971, AlAA.
Lesson 26 Problems
PROBLEMS
26-l. Obtain the sensitivity equations for dKe(k f l)/ Jfl,, aP,(k + llk)/&$ and JPe(k + Ilk i- l)/ &I,. Explain why the sensitivity system for &(k + l/k)/ at?, and d&+(k + I/k + Q/&3, is linear.
26-2. Compute formulas for g, and H,. Then simplify H, to a pseudo-Hessian. 26-3, In the first-order system x (k + 1) = ax(k) + w(k). and z (k + 1) = x(k + 1) +
v(k + l), k = 1, 2, . . a ) N, a is an unknown parameter that is to be estimated. Sequences w(k) and v(k) are, as usual, mutually uncorreiated and white, and, w(k) - N(rr*(k); 0,l) and v(k) - N(v(k); 0, l/z). Explain, using equations and a flowchart, how parameter a can be estimated using a MLE.
26-S.
Repeat the preceding problem where all conditions are w(k) and v (k) are correlated, and E{w(k)v(k)} = V4.
We are interested in system:
estimating the parameters a and r in the following first-order
except that now
x(k + 1) + ax(k) = w(k)
z(k) = x(k) -t v(k) k = 1,2,. . . , N
Signals w(k) and v (k) are mutualIy uncorrelated, white, and Gaussian, and, E{w’(k)) = 1 and E{n’(k)) = r. (a) Let 9 = co1 (a,$. What is the equation for the log-likelihood function? (b) Prepare a macro flow chart that depicts the sequence of calculations required
to maximize ,5(9/%), Assume an optimization algorithm is used which re- quires gradient information about L (9/Z.).
(c) Write out the Kalman filter sensitivity equations for parameters a and r. 26-6. Develop the sensitivity equations for the case considered in Lesson 11, i.e., for
the case where the only uncertainty present in the state-variable model is mea- surement noise. Begin with t(1319) in (11-42).
26-7. Refer to Problem 24-7. Explain. using equations and a flowchart, how to obtain MLE’s of the unknown parameters for: (a) equation for the unsteady operation of a synchronous motor, in which C and
p are unknown; (c) Duffing’s equation, in which C, ct , and /3 are unknown; (c) Van der Pal’s equation, in which e is unknown; and (d) Hill’s equation, in which a and b are unknown.

Lesson 27
Kalmam-Bucy Filtering
INTRODUCTION
The Kalman-Bucy filter is the continuous-time counterpart to the Kalman filter. It is a continuous-time minimum-variance filter that provides state estimates for continuous-time dynamical systems that are described by linear, (possibly) time-varying, and (possibly) nonstationary ordinary differential equations.
The Kalman-Bucy filter (KBF) can be derived in a number of different ways, including the following three:
1. Use a formal limiting procedure to obtain the KBF from the KF (e.g., Meditch, 1969).
2. Begin by assuming the optimal estimator is a linear transformation of all measurements. Use a calculus of variations argument or the ortho- gonality principle to obtain the Wiener-Hopf integral equation. Em- bedded within this equation is the filter kernal. Take the derivative of the Wiener-Hopf equation to obtain a differential equation which is the KBF (Meditch, 1969).
3. Begin by assuming a linear differential equation structure for the KBF, one that contains an unknown time-varying gain matrix that weights the difference between the measurement made at time t and the estimate of that measurement. Choose the gain matrix that minimizes the. mean- squared error (Athans and Tse, 1967).
We shall briefly describe the first and third approaches, but first we must define our continuous-time model and formally state the problem we wish to solve.
270
Notation and Problem Statement 271
SYSTEM DESCRIPTION
Our continuous-time system is described by the following state-variable model,
2(t) = F(t)x(t) + G(t)w(t) (27-l)
z(t) = H(t)x(t) + v(t) (27-2)
where x(t) is y1 X 1, w(t) is p X 1, z(t) is m X 1, and v(t) is m X 1. For sim- plicity, we have omitted a known forcing function term in state equation (27-l). Matrices F(t), G(t), and H(t) have dimensions which conform to the dimensions of the vector quantities in this state-variable model. Disturbance w(t) and measurement noise v(t) are zero-mean white noise processes, which are assumed to be uncorrelated, i.e., E{w(t)} = 0, E{v(t)} = 0,
E{w(t)w’(r)} = Q(t)s(t - T) (27-3)
E{v(t)v’(T)} = R(t)S(t - 7) (27-4)
E{w(t)v’(r)} = 0 (27-5)
Equations (27.3), (27,4), and (27-5) apply for t 2 to. Additionally, R(t) is continuous and positive definite, whereas Q(t) is continuous and positive semidefinite. Finally, we asume that the initial state vector x(to) may be ran- dom, and if it is, it is uncorrelated with both w(t) and v(t). The statistics of a random x(to) are
Wt,)~ = m&o) (27-6)
and
cov b(to)l = R&o) (27-7)
Measurements z(t) are assumed to be made for to s t s 7. If x(to), w(t), and v(t) are jointly Gaussian for all t t [to,?], then the KBF
will be the optimal estimator of state vector x(t). We will not make any distributional assumptions about x(to), w(t), and v(t) in this lesson, being content to establish the linear optimal estimator of x(t).
NOTATION AND PROBLEM STATEMENT
Our notation for a continuous-time estimate of x(t) and its associated esti- mation error parallels our notation for the comparable discrete-time quan- tities, i.e., ?(t It) denotes the optimal estimate of x(t) which uses all the mea- surements z(t), where t 2 to, and
qt It) = x(t) - k(tlt) (27-8)

272 KalmwI-Bucy Filtering Lesson 27
The mean-squared state estimation error is
J [i(t ll)] = E{%‘(t it)i(t It)] (27-9)
We shall determine Qit) that minimizes J [%(tit)], subject to the constraints of our state-variable model and data set.
THE KALMAWWCY FILTER
The solution to the problem stated in the preceding section is the Bucy Filter, the structure of which is summarized in the following:
Kalman-
Theorem 27-l. The KBF is described by the vector di#erentia/ equation
i(tit) = F(t)g(t[t) + K(t)[z(t) - H(t)i(t It)] (27-N)
where t 2 to, k(t&) = rn&),
K(t) = P(t ir)H’(t)R-l(t) (27-U)
and
I$]t) = F(t)P(t/t) + P(tlt)F’(t) - P(tlt)H’(t)R-‘(t)H(t)P(tlt) + wNw’~~~ (27-12)
Epatiun (27-L& which is a matrix Riccati differential equatiun, is initialized by qt&J = R(k?). El
Matrix K(t) is the Kaiman-Bucy gain estimation-error covariance matrix, i.e+,
matrix, and P(t/t) is the state-
P(tlt) = E{%(tlt)S(tlt)} (27-13)
Equation (27-10) can be rewritten as
i(tlt) = [F(t) - K(t)H(t)]i(t[t) + K(t)z(t) (27-14)
which makes it very clear that the KBF is a time-varying filter that processes the measurements linearly to produce k(tlt).
The solution to (27-14) is
where the state transition matrix @(t,r) is the solution to the matrix differ- ential equation
&‘(t,r) = [F(t) - K(t)H(t)]@(t,T) @(t,t) = I (27-16)
Derivation of KBF Using a Formal Limiting Procedure 273
If Ei(@,) = 0, then
g(tlf) = j-’ @(t,~)K(~)z(~)d7 = jr A(~J)z(T)& (27-17) ID IO
where the filter kernel A(t,r) is
A(~,T) = @(!,r)K(r) (27-18)
The second approach to deriving the KBF, mentioned in the intro- duction to this chapter. begins by assuming that i(rir) can be expressed as in (27-17) where A(f,7) is unknown. The mean-squared estimation error is min- imized to obtain the following Wiener-ISopf integral equation:
E{x(t)z’(~)} - 1’ A(t,~)E{z(r)z’(a)}d7 = 0 *o
(27-19)
where lo I (7 5 t. When this equation is converted into a differential equation, one obtains the KBF described in Theorem 27-l. For the details of this derivation of Theorem 27-1 see Meditch, 1969, Chapter 8.
DERIVATION OF KBF USING A FORMAL LIMITING PROCEDURE
Kalman filter Equation (17-ll), expressed as
i(k + l]k + 1) = @(k + l,k)ir(kjk)
+ K(k + l)[z(k + 1) - H(k + l)@(k + l,k)ri(klk)]
can also be written as
(27-20)
G(t + Atlt + At) = @(t + At,t)i(tIr> + K(r + At)[z(t + At) - H(f + At)@(t + At,r)k(rir>] (27-21)
where we have let fk = t and tk + r = t + AL In Example 24-3 we showed that
@(t + At,t) = I + F(f)At + O(Ar’) (27-22)
and
Q&) = G(r)Q(t)G’(t)At + O(Ar’) (27-23)
Observe that Qd(f) can also be written as
Q&) = [G(t)Af] [y ] [G(t)Aij’ + O(Ar’) (27-24)
and, if we express wd(k) as r(k + l,k)w(k), so that Qd(k) = T(k + l?k)Q(k) r’(k + Z,k), then
r(f + At,?) = G(f)Ar + O(At’) (27-25)

274 Kalman-Bucy Filtering Lesson 27
Q( > t Q(k =t>+ At (27-26)
Equation (27-26) means that we replace Q(k = t) in the KF by Q(t)/At. Note that we have encountered a bit of a notational problem here? because we have used w(k) [and its associated covariance, Q(k)] to denote the disturbance in our discrete-time model, and w(t) [and its associated intensity, Q(t)] to denote the disturbance in our continuous-time model.
Without going into technical details, we shall also replace R(t + At) in the KF by R(t + At)/At, i.e.,
R(k + 1 = t + At)+R(t + At)lAt (27-27)
See Meditch (1969, pp. 139-142) for an explanation. Substituting (27-22) into (27-21), and omitting all higher-order terms in
At, we find that
ii(t + At It + At) = [I + F(t)At]%(t(t) + K(t + At){z(t + At) - H(t + At)[I + F(t)At]i(t It)} (27-28)
from which it follows that
lim i;(t + At It + At) - i(tIt) Ar-*O At = F(t)ri(t It)
+ lim K(t + At){z(t + At) - H(t + At)[I + F(t)At]i(tlt)}/At At-*0
or
i(tlt) = F(t)i(tIt) + lim K(t + At){z(t + At) Al-r0
- H(t + At)[I + F(t)At]Ei(tlt)}/At (27-29)
Under suitable regularity conditions, which we shall assume are satisfied here, we can replace the limit of a product of functions by the product of limits, i.e.,
lim K(t + At){z(t + At) - H(t + At)[I + F(t)At]rZ(t]t)}/At At-0
K(t + At) = lim At
Ar-0 lim {z(t + At) - H(t + At)[I + F(t)At]ii(t[t)} Al-+0
(27-30)
The second limit on the right-hand side of (27-30) is easy to evaluate, i.e.,
lim {z(t + At) At+0
- H(t + At)[I + F(t)At]zZ(tIt)} = z(t) - H(t)jZ(tIt) (27-31)
In order to evaluate the first limit on the right-hand side of (27-30), we first substitute R(t + At)/At for R(k + 1 = t + A ) in (17~12), to obtain
K(t + At) = P(t + Atlt)H’(t + At) [H(t + At)P(t + Atlt)H’(t + At)At + R(t + At)]-‘At (27-32)
Derivation of KBF When Structure of the Filter is Prespecified 275
Then, we substitute Q(t)/dt for Q(k = t> in (17-13), to obtain
P(t + At It) = @(t + dt,t)P(t It)@‘@ + At,t)
+ r(t + At,t) Q(t) --&- ryt + dt,?) (27-33)
We leave it to the reader to show that
hence,
lim P(t + AtIt) = P(@) At+ 0
(27-34)
lim K(t + dt) At-0 At = P(tlt)H’(t)R-‘(t) g K(t) (27-35)
Combining (27-29), (27.30), (27-31), and (27-35), we obtain the KBF in (27-10) and the KB gain matrix in (27-11).
In order to derive the matrix differential equation for P(t It), we begin with (17-14), substitute (27-33) along with the expansions of @(t + dt,t) and r(t + dt,t) into that equation, and use the fact that K(t + 4t) has no zero- order terms in dt, to show that
P(t + At It + At) = P(t + 4tlt) - K(t + At)H(t + 4?)P(t + AtIt) = P(tlt) + [F(t)P(tIt) + P(tlt)F’(t)
+ W~Q(OG’ (t)lAt
Consequently, - K(t + dt)H(t + At)P(t + 4tlt) (27-36)
lim P(t + At It + 49 - P@(r) Jr+0 At = ti(tlt) = F(t)P(tIt) + P(tjt)F’(t)
+ G(t)Q(t)G’(t) - lim K(t + At)H(t + dt)P(t + 4tlt)
At At-0 (27-37)
or finally, using (27-35)
*(tit) = F(t)P(tIt) + P(t]t)F’(t) + G(t)Q(t)G’(t) - P(t It)H’(t)R-‘(t)H(t)P(t It) (27-38)
This completes the derivation of the KBF using a formal limiting pro- cedure. It is also possible to obtain continuous-time smoothers by means of this procedure (e.g., see Meditch, 1969, Chapter 7).
DERIVATION OF KBF WHEN STRUCTURE OF THE FILTER IS PRESPECIFIED
in this derivation of the KBF we begin by assuming following structure,
i(t It) = F(t)i(t It) + K(t)[z(t) - Hk( t
that the filter has the
I )I t (27-39)

Kaiman-Bucy Filtering Lesson 27
Our objective is to find the m&x following mean-squared error,
function K(T), to 5 f 5 7: that minimizes the
J[K(r)] = E{e’(r)e(r)} (27-40)
e(7) = x(7) - ?(T~T) (27-41)
This optimization problem is a fixed-time, free-end-point (i.e., 7 is fixed but e(T) is not fixed) problem in the calculus of variations (e.g., Kwakernaak and Sivan, 1972; Athans and Falb, 1965; and Bryson and Ho, 1969).
It is straightforward to show that @e(r)] = 0, so that E{ [e(T) - E{e(r)}] [e(r) - E{e(T)l]‘] = E{e(T)e’(r)J. Letting
P(f It) = E{e(l)e’(f)} (27-42)
we know that J[K@)] can be reexpressed as
(27-43)
and i We leave it to the reader to derive ts associat .ed covariance equation,
the following state equation for e(f),
4(f) = [F(t) - K(l)H(t)]e(f) + G(l)w(t) - K(f)v(t) (27-44)
I$!r) = [F(f) - K(t)H(r)]P(rit) + P(+)[F(t) - K(l)H(r)]’ + G(t)Q(f)G’(l) + K@)R(l)K’(f) (27-45)
where e(lO) = 0 and P(loitO) = PX(tO). Our optimization problem for determining K(f) is: given & matrix dv-
ferential equation (27-45), sutisfied by the error-cuvariunce matrix P(tit), u terminal lime T, and the cost functiunal ~[K(T)] in (27-43), determine the rnutrix K(t), to 5 t 5 T that minimizes J[K(t)].
The elements J+(#) of P(rit) may be viewed as the state variables of a dynamical system, and the elements k;j(t) of K(l) may be viewed as the control variables in an optimal control problem. The cost functional is then a terminal time penalty function on the state variables plj(tlt)+ Euler-Lagrange equations associated with a free end-point problem can be used to determine the optimal gain matrix K(t).
To do this we define a set of costate variables u&f) that correspond to the p&it), i,j = 1, 2, . . . , n. Let X(f) be an PI x n costate matrix that is associated with P(tlf), i.e., Z(t) = (uo(Q)q. Next, we introduce the Hamiltonian function X(K,P?Z) where for notational convenience we have omitted the dependence of K? P, and Z on 1, and,
(27-46)
Derivation of KBF When Structure of the Filter is Prespecified 277
Substituting (27-45) into (27-46), we see that
‘X(K.P.C) = tr [F(t)P(t!@‘(t)] - tr [K(t)H(t)P(t I@‘(r)] + tr [P(tjt)F’(t)C’(r)] - tr [P(tlt)H’(QK’(t)X’(t)l + tr ~W)QW’(O~‘(Ol + tr [~(l)~(t)~‘(t)X’(t)]
(27-47)
The Euler-Lagrange equations for our optimization problem are:
(27-48)
m(K 3,X:) Z”;(f) = .- ap * (27-49)
and
x*(7) = -& tr P(+)
(27-50)
(27-51)
In these equations starred quantities denote optimal quantities, and I* denotes the replacement of K, P, and X by K*, P*, and Z* afier the appropriate derivative has been calculated. Note, also, that the derivatives of X(K,P,Z) are derivatives of a scalar quantity with respect to a matrix (e.g., K, P, or X). The calculus of gradient matrices (e.g., Schweppe, 1974; or Athans and Schweppe, 1965) can be used to evaluate these derivatives. The results are:
-x*p*qjf - s*‘p*H’ + BIKER + ~*‘K*R = 0 (27-52)
%* = -S*(F - K*H) - (F - K*H)‘s* (27-53)
Ij* = (F - K*H)P* + P*(F - K*H)’ + GQG’ + K*RK*’ (27-54)
and
P(r) = I
Our immediate objective is to obtain an expression for K*(t).
(27-55)
Fact. Matrix X*(t) is symmetric and positive definite. a
We leave the proof of this fact as an exercise for the reader, Using this fact, and the fact that covariance matrix P*(t) is symmetric, we are able to express (27-52) as
2X*(K*R - P’H’) = 0 (27-56)

Kalman-Bucy Filtering Lesson 27
Because C* > 0, (C*)-’ exists so that (27-56) has for its only solution
K*(t) = P*(tlt)H’(t)R-‘(t) (27-57)
which is the Kalman-Bucy gain matrix stated in Theorem 27-l. In order to obtain the covariance equation associated with K*(t), substitute (27-57) into (27-54). The result is (27-12).
This completes the derivation of the KBF when the structure of the filter is prespecified.
STEADY-STATE KBF
If our continuous-time system is time-invariant and stationary, then, when certain system-theoretic conditions are satisfied (see, e.g., Kwakernaak and Sivan, 1972), P(tlt)+ 0 in which case P(tlt) has a steady-state value, denotedi? In this case, K(t) + K, where
jf = jQl~--* (27-58)
i? is the solution of the algebraic Riccati equation
F-i? + i?F’ - FH’R-‘HF + GQG’ = 0 (27-59)
and the steady-state KBF is asymptotically stable, i.e., the eigenvalues of F - %3 all lie in the left-half of the complex s-plane.
Example 27- 1 Here we examine the steady-state KBF for the simplest second-order system, the double integrator,
X(t) = w(t) (27-60) and
z(t) = x(t) + v(t) (27-61)
in which w(t) and v (t) are mutually uncorrelated white noise processes, with intensities 4 and r, respectively. With xl(t) = x (t) and x2(t) = i(t), this system is expressed in state-variable format as
Z = (1 0) (;:) + v
(27-62)
(27-63)
The algebraic Riccati equation for this system is
(27-64)
Steady-State KBF 279
which leads to the following three algebraic equations:
(27-65a)
F22 1 --
- ;p11p12 = 0 (27-65b)
l-2 -712 + q = 0 (27-65~)
It is straightforward to show that the unique solution of these nonlinear algebraic equations, for which P > 0, is
7l2= r (4 ) l/2 (27-66a)
711 = fi q l/4r3/4 (27-66b)
F22 = fi q 3/4r 114 (27-66~)
The steady-state KB gain matrix is computed from (27~58), as
(27-67)
Observe that, just as in the discrete-time case, the single-channel KBF depends only on the ratio q /r.
Although we only needed F1, and F12 to compute K, F22 is an important quantity, because
Additionally,
722 = lim E{ [i(t) - i(tlt)32) I--+= (27-68)
Fll = lim E{ [X (t) - Z(tIt)]‘} (27-69) t+=J
Using (27-66b) and (27-66c), we find that
p-22 = (q wjh (27-70)
If q /r > 1 (i.e., SNR possibly greater than unity), we will always have larger errors in estimation of i(t) than in estimation of x(t). This is not too surprising because our measurement depends only on x(t), and both w(t) and v(t) affect the calculation of i(t It).
The steady-state KBF is characterized by the eigenvalues matrix F-ii%, where
These eigenvalues are solutions of the equation
(27-71)
s2 + V5 (q /r)"4 s + (q /r)1'2 = 0 (27-72)

280 l Kalman-Bucy Filtering Lesson 27
When this equation is expressed in the normaiized form
we find that
(43 = (q /r)1’4 (27-73)
6 = 0.707 (27-74)
thus, the steady-state KBF for the simpk duuble integrator system is damped at 0.707. The filter’s pules lie on the 45’ line depicted in Figure 27-I. They can be moved along this line by adjusting the ratio q /r; hence, once again. we may view q /r as a filter tuning parameter. •l
Figure 27-l Eigenvalues of steady-state Kl3F Lie along 245 degree lines+ In- creasing q /r moves them farther away from the origin. whereas decreasing q /r moves them doser to the origin.
AN MPORTANT APPLtCATtON FOR THE K8F
Consider the system
k(r) = F(t)x(r) + B(I)u(~) + G(f)w(~) QJ = x0
(27-75)
for l 2 ffl where x0 is a random initial condition vector with mean m&J and covariance matrix P&J. Measurements are given by
z(f) = H(f)x(f) + v(r) (27-76)
for t 2 lo. The joint random process co1 [w(~),v(I)] is a white noise process with intensity
Lesson 27 Problems
The controlled variabk can be expressed as
The stochastic linear optimal of finding the functional
output feedback regula tar problem problem
u(t) = f[Z(T) to 5 I 5 t] (27-78)
for to I t 5 f1 such that the objective function
q-u] = E (; x’(tl)Wlx(tl) + ; 1; HW&(4 + ~‘Wbu(~)ld~ ) (27-79)
is minimized. Here W1, WZ, and W3 are symmetric weighting matrices, and, W1 I 0, W, > 0, and W3 > 0 for to I t I tl.
In the control theory literature, this problem is also known as the linear- quadratic-Gaussian regulator problem (i.e., the LQG problem; see, Athans, 1971, for example), We state the structure of the solution to this problem, without proof, next.
The optimal control, u*(t), which minimizes J[u] in (27-79) is
u*(t) = -F’(t)i(tlt) (27-80)
where p(t> is an optimal gain matrix, computed as
P(t) = W,‘B(r)P,(t) (27-81)
where PC(t) is the solution of the control Riccati equation
--Ii=(t) = F’(r)P,(t) + P,(t)F(f) - P,(t)B(t)W;‘B’(r)P,(t) + D’(t)W,D(t)
I (2742)
PC( t ,) given
and i(t/t) is the output of a KBF, properly modified to account for the control term in the state equation, i.e.,
i(t It) = F(t)?(+) + B(t)u*(r) + K(f)[z(t) - H(t)?(+)] (27-83)
We see that the KBF plays an essential role in the solution of the LQG problem.
PROBLEMS
27-l. Explain the replacement of covariance matrix R(k + 1 = t + df) by R(t + At)/Ar in (27-27).
27-2. Show that GIO P(t + AtIt) = P(tIt). 27-3. Derive the state equation for error e(r). given in (27-44), and its associated
covariance equation (27-45). 27-4. Prove that matrix Z*(t) is symmetric and positive definite.

Lesson A
Sufficient Statistics
and Statistical
Estimation
of Parameters
INTRODUCTION
In this lesson,* we discuss the usefulness of the notion of sufficient statistics in statistical estimation of parameters. Specifically, we discuss the role played by sufficient statistics and exponential families in maximum-likelihood and uni- formly minimum-variance unbiased (UMVU) parameter estimation.
CONCEPT OF SUFFICIENT STATISTICS
The notion of a sufficient statistic can be explained intuitively (Ferguson, 1967), as follows. We observe 3(N) (3 for short), where 55 = co1 [z(l), z(2),
z(N)], in which z(l), . . . , z(N) are independent and identically distrib- ute; random vectors, each having a density function p(z(i)l8), where 8 is unknown. Often the information in % can be represented equivalently in a statistic, T(Z), whose dimension is independent of N, such that T(%) contains all of the information about 0 that is originally in %. Such a statistic is known as a sufficient statistic.
Example A-l Consider a sampled sequence of N manufactured cars. For each car we record whether it is defective or not. The observed sample can be represented as % = co1 [z(l), . . . ,
* This lesson was written by Dr. Rama Chellappa, Department of Electrical Engineering- Systems, Unversity of Southern California. Los Angeles: CA 9089.
282
Concept of Sufficient Statistics 283
z (IV)], where z(i) = 0 if the ith car is not defective and z(i) = 1 if the ith car is defective. The total number of observed defective cars is
T(Z) = 5 z(i) i=l
This is a statistic that maps many different values of z (l), . . . , z (IV) into the same value of T(%). It is intuitively clear that, if one is interested in estimating the proportion 0 of defective cars, nothing is lost by simply recording and using T(3) in place of z (l), . . . , z (IV). The particular sequence of ones and zeros is irrelevant. Thus, as far as estimating the proportion of defective cars, T(Z) contains all the information contained in %. 0
An advantage associated with the concept of a sufficient statistic is dimensionality reduction. In Example A-l, the dimensionality reduction is fromNt0 1.
Definition A-l. A statistic T(Z) is sufficient for vector parameter 8, if and only if the distribution of %, conditioned on T(S) = t, does not involve 8. cl
Example A-2 This example illustrates the application of Definition A-l to identify a sufficient statis- tic for the model in Example A-l. Let 8 be the probability that a car is defective. Then z(l), 42),.*., z(N) is a record of IV Bernoulli trials with probability 8; thus, Wt) = ey1 - e)“- f, 0 < 8 c 1, where t = xr’ 1 z(z), and t(i) = 1 or 0. The condi- tional distribution of z (l), . . . , z (N), given xy= 1 z (i) = t, is
P[%/T = t] = P[S,T = t] eyi - e)N-r 1 =-
which is independent of 8; hence, T(S) = Cy= 1 z(i) is sufficient. Any one-to-one function of T (3) is also sufficient. 0
This example illustrates that deriving a sufficient statistic using Defini- tion A-l can be quite difficult. An equivalent definition of sufficiency, which is easy to apply, is given in the following:
Theorem A-l (Factorization Theorem). A necessary and sufficient condition for T(Z) to be sufficient for 8 is that there exists a factorization
where the first factor in (A-l) may depend on 8, but depends on 9 only through T(Z), whereas the second factor is independent of 8. Cl
The proof of this theorem is given in Ferguson (1967) for the continuous case and Duda and Hart (1973) for the discrete case.

Sutiicient Statistics and Statistical Estimation of Parameters Lesson A
Example A-3 (Continuation of Example A-2)
In Example A-2, the probability distribution of samples z [ l), . . . , z (NJ is
where the total number of defective cars is t = Ecluation (A-2) can be written quivalently as
either 0 or 1.
Comparing (A-3) with (A-I), we conclude that
h(S) = 1
+e + N ln (1 - 0) 1
Using the Factorization Theorem, it was easy to determine T(9). 0
Exztmple A-4 LetS=col[z(l), . . ..z(N)]be distribution, with unknown mean
a random sample drawn from a univariate G p, and, known variance 42 > 0. Then
.aussian
Based on the statistic for p.
h (3) = exp
Theorem Factorization 0
we identify z(i) as a sufficient
Because the concept of sufficient statistics involves reduction of data, it is \vorthwhile to know how far such a reduction can be done for a given problem The dimension of the smallest set of statistics that is still sufficient for the parameters is caIled a minimu/ sufficienf aaktic. See Barankin (1959) and Datz (1959) for techniques useful in identifying a minimal sufficient statistic.
EXP0NENTiAL FAMILIES OF DISTRIBUTIONS
It is of interest to study families of distributions, ~(z(#) for which, irre- spective of the sample size N, there exists a sufficient statistic of fixed dimen- sion. The exponential families of distributions have this property. For exam-
Exponental Families of Distributions
pie, the family of normal distributions N(~,c?), with 2 known and p unknown, is an exponential family which, as we have seen in Example A-4, has a one-dimensional sufficient statistic for CL, that is equal to xr’ 1 z(i). As Bickel and Doksum (1977) state,
Definition A-2 (Bickel and Doksum, 1977). If there exist real-valued functions a@), and b(9) on parameter space 0, and real-valued functions T(z) [z is short for z(i)] and h(z) on R’, such that the density function ~(~10) can be written as
p(zl0) = exp [a’@)T(z) + b(0) + h(z)] (A-4)
then p(zjO), 8 E 9, is said to be a one-parameter exponential family of dktributions. 0
The Gaussian, Binomial, Beta, Rayleigh, and Gamma distributions are examples of such one-parameter exponential families.
In a one parameter exponential family, T(z) is sufficient for 8. The family of distributions obtained by sampling from one-parameter exponential families is also a one-parameter exponential family. For example, suppose that z(l), . . . , z(N) are independent and identically distributed with common density p (~10); then,
.
p(fEj6) = exp a’(9) 5 T(z(i)) + Nb(9) + E h(z(i)) 1 (A-5) r=l i=l
The sufficient statistic T(Z) for this situation is
T(S) = 5 T(z(i)) i-l
Example A-5 Let z(l), . , . , z(N) be a random sample from a multivariate Gaussian distribution with unknown d X 1 mean vector p and known covariance matrix P&. Then [z is short for z(i)3
~(414 = =P WbJW + bbL) + h WI where
a’(p) = p’P,’
b(p) = -$.dP;’ )L
T(z) = z
- i ln det P& I

286 Sufficient Statistics and Statistical Estimation of Parameters Lesson A
Additionally,
where
T(g) = 5 z(i)
and
h(S) = exp - + j z’(i) Pi’ z(i) I-1
Nd -2ln 277
The notion of a one-parameter exponential family of distributions as stated in Bickel and Doksum (1977) can easily be extended to m parameters and vector observations in a straightforward manner.
Definition A-3. If there exist real matrices Al, . . . , A,, a real function b of 8, where 8 E 8, real matrices I@) and a real function h(z), such that the density function ~(~19) can be written as
II exp UJ (0) + h (z)) (A-6)
then p(z]O), 0 E 8 is said to be an m-parameter exponential family of distributions. Cl
Example A-6 The family of d-variate normal distributions N(p,P,), where both p and Pp are un- known, is an example of a 2-parameter exponential family in which 8 contains k and the elements of Pk. In this case
Al(e) = al(e) = Pi1 p T*(z) = z’
A*(e) = -;P;l
T2(z) = zz’
and h(z) = 0 113
As is true for a one-parameter exponential family of distributions, if z(l), l l l ?
z(N) are drawn randomly from an m-parameter exponential family, then p[z(l), . . . , z(N)le] form an m-parameter exponential family with suf- ficient statistics T@Ej, . . . 9 T&E), where Il,(!Z) = cr= 1 T [z(j)].
Exponental Families and Maximum-Likelihood Estimation 287
EXPONENTIAL FAMILIES AND MAXIMUM-LIKELIHOOD ESTIMATION
Let us consider a vector of unknown parameters 6 that describe a collection of l
N independent and identically distributed observations 2% = co1 [z(l), . . . , z(N)]. The maximum-likelihood estimate (MLE) of 0 is obtained by max- imizing the likelihood of 8 given the observations %. Likelihood is defined in Lesson 11 to be proportional to the value of the probability density of the observations, given the parameters, i.e.,
As discussed in Lesson 11, a sufficient condition for I (01%) to be maximized is
where
and L(@Z) = In 2(0/Z). M aximum-likelihood estimates of 8 are obtained by solving the system of n equations
ww3 = 0 ae,
i = 1,2,. . . , n (A-8)
for eML and checking whether the solution to (A-8) satisfies (A-7). When this technique is applied to members of exponential families, iML
can be obtained by solving a set of algebraic equations. The following theorem paraphrased from Bickel, and Doksum (1977) formalizes this technique for vector observations.
Theorem A-2 (Bickel and Doksum, 1977). Let p(zle) =exp[a’(O)T(z) + b(8) + h(z)] and let ~4 denote the interior of the range of a(e). If the equation
WT(z)l = T(z) (A-9) has a solution e(z) for which a[b(z)] t d, then e(z) is the unique MLE of 8. q
The proof of this theorem can be found in Bickel and Doksum (1977).
Example A-7 (Continuation of Example A-5) In this case
T(Z) = 5 z(i) I’ 1
and

zaa Sufficient Statistics and Statistical Eskmtion of Parameters Lesson A
hence (A-9) becomes
whose solution, &, is
which is the well-known MLE of p. 0
Theorem A-2 can be extended to the m-parameter exponential family case by using Definition A-3. We illustrate the applicability of this extension using the example given below. Exam@ A-8 (see, also, Example A-6) Let z = co1 [z(l), . + . , z(N)] be randomly drawn from p (~10) = IV (P,P~), where both p and PF are unknown, so that 9 contains p and the elements of Pp. Vector p is cI x 1 and matrix P@ is d x cI, symmetric and positive d&mite. We express p (2/O) as
p (3@) = (Z+‘fd’* (det Ph)-N’2
Using Theorem A-1 or Definition A-3 it can be seen that zy= Iz(Q and X7= I z(qz’(i) are sufficient for (p, Pw). Letting
we find that
Exponental Families and Maximum-Likelihood Estimation
and
E&b (%)I = A’ (P, + 14)
Applying (A-9) to both TI (3e) and T2 (9): we obtain
Np = 2 z(i) i=l
whose solutions, I; and P&, are
which are the MLE’s of J.L and P,- Cl
Exampie
Consider
A-9 the
(Linear Model) linear model
zqk) = %e(k)fl + T(k)
in which 13 is an n X 1 vector of deterministic parameters, X(k) is deterministic, and V(k) is a zero-mean white noise sequence, with known covariance matrix C&(k). From (1X-25) in Lesson 11, we can express p (S(k)l9), as
and
a’(O) = 0’ T(zE(k)) = W(k)W(k)zE(k)
N b(e) = --ln27r 2 - i In det a(k) - i ew(k)W(k)3e(kp
Observe that
Ee (X(k)W’(k)5T(k)} = W(k)9V’(k)%e(k)B
hence, applying (A-9), we obtain
X(k)W(k)X(k)il = ‘x’(k)w’(k)zE(k)

Sufficient Statistics and Statistical Estimation of Parameters Lesson A
whose solution, 6(k), is
ii(k) = [X’(k)9i-1(k)%e(k)]-1W(k)9i-‘(k)%(k)
which is the well-known expression for the MLE of 8 (see Theorem 11-3). The case when R(k) = $1, where 2 is unknown can be handled in a manner very similar to that in Example A-8. ci
SUFFICIENT STATlSTICS AND UNIFORMLY MINIMUM-VARIANCE UNBIASED ESTIMATION
In this section we discuss how sufficient statistics can be used to obtain uni- formly minimum-variance unbiased (UMVU) estimates. Recall, from Lesson 6, that an estimate 6 of parameter 8 is said to be unbiased if
E(8) = 9 (A-10)
Among such unbiased estimates, we can often find one estimate? denoted 8”) which improves all other estimates in the sense that
var (0*) 5 var (i) (A-11)
When (A-l 1) is true for all (admissible) values of 6, 0” is known as the UMVU estimate of 8. The UMVU estimator is obtained by choosing the estimator which has the minimum variance among the class of unbiased esti- mators. If the estimator is constrained further to be a linear function of the observations, then it becomes the BLUE which was discussed in Lesson 9.
Suppose we have an estimate, i(Z), of parameter 6 that is based on observations Z = co1 [z(l), . . . , z(N)]. Assume further that p (910) has a finite-dimensional sufficient statistic, T(Z), for 8. Using T(s), we can con- struct an estimate e*(Z) which is at least as good as, or even better, than i by the celebrated Rao-Blackwell Theorem (Bickel and Doksum, 1977). We do this by computing the conditional expectation of @Z), i.e.,
e*(z) = E{@l!I)~T(%)} (A-12)
Estimate 0*(Z) is “better than 6” in the sense that E{ [O*(Z) - 01’) < E{ [t!(%) - el’}. B ecause T(Z) is sufficient, the conditional expectation E{@%)[T(E)} ‘11 wi not depend on 8; hence, e*(Z) is a function of % only. Application of this conditioning technique can only improve an estimate such as e(Z); it does not guarantee that 0*(%) will be the UMVU estimate. To obtain the UMVU estimate using this conditioning technique, we need the additional concept of completeness.
Definition A-4 [Lehmann (1959; 1980); Bickel and Doksum (1977)]. A sufficient statistic T(S) is said to be complete, if the only real-valued function, g, defined on the range of T(3), which satisfies Ee(g(T)} = 0 for all 0, is the function g(T) = 0. 0
Sufficient Statistics and Uniformly Minimum-Variance Unbiased Estimation 291
Completeness is a property of the family of distributions of T(Z) gener- ated as ovaries over its range. The concept of a complete sufficient statistic, as stated by Lehmann (1983), can be viewed as an extension of the notion of sufficient statistics in reducing the amount of useful information required for the estimation of 6. Although a sufficient statistic achieves data reduction, it may contain some additional information not required for the estimation of 8. For instance, it may be that E&( T(%))] is a constant independent of 6 for some nonconstant function g. If so, we would like to have E&( T(S))] = c, (constant independent of 6) imply that g( T(Z)) = c. By subtracting c from EB Gmwl~ one arrives at Definition A-4. Proving completeness using Defi- nition A-4 can be cumbersome. In the special case when p (z(k)16) is a one- parameter exponential family, i.e., when
(A-13)
the completeness of T(z(k)) can be verified by checking if the range of a (0) has an open interval (Lehmann, 1959).
Example A-10
Let 3 = co1 [r(l), . . . , z(N)] be a random sample drawn from a univariate Gaussian distribution whose mean p is unknown, and whose variance 2 > 0 is known. From Example A-5, we know that the distribution of % forms a one-parameter exponential family, with T(Z) = xy= 1 z(i) and a(p) = p lo? Because a(p) ranges over an open interval as p varies from -- to +m, T(%) = CrX 1 r(i) is complete and sufficient.
The same conclusion can be obtained using Definition A-4 as follows. We must show that the Gaussian family of probability distributions (with p unknown and 2 fixed) is complete. Note that the sufficient statistic T(2) = cy= l z (i) (see Example A-5) is Gaussian with mean Np and variance N’c?. Suppose g is a function such that E,(g( T)} = 0 for all -- < p < 0~; then,
= \:- &g(vaN + Np) exp (-g) dv = 0 (A-14)
implies g ( l ) = 0 for all values of the argument of g. 0
Other interesting examples that prove completeness for families of dis- tributions are found in Lehmann (1959).
Once a complete and sufficient statistic T(Z) is known for a given pa- rameter estimation problem, the Lehmann-Scheffe Theorem, given next, can be used to obtain a unique UMVU estimate. This theorem is paraphrased from Bickel and Doksum (1977).
Theorem A-3 [Lehmann-Scheffe Theorem (e.g., Bickel and Doksum, 1977)]. If a complete and sufficient statistic, T(Z), exists for 8, and 6 is an unbiased estimator of 8, then O*(S) = E{ iIT( is an UMVU estimator of 8. If

292 Sufficient Stdstks and Statistical Estima?ion of Parameters Lesson A
A proof of this theorem can be found in Bickel and Doksum (1977). This theorem can be applied in two ways to determine an UMVU esti-
mator [Kckel and Doksum (1977), and Lehmann (1959)].
Method I. Find a staGstic of the form h (T(T)) such that
where T(S) is a complete and sufficient statistic for 8. Then, h (T(g)) is an UMVU estimator of 0. This follows from the fact that
Method 2. Find an unbiased estimator, i, of 0; then, E{@(Z)j is an UMVU estimator of 8 for a complete and sufficient statistic T(S).
Example A-11 (Continuation of Example A-10)
We know that T(S) = xy= I z (i) is a complete and sufficient statistic for g, Further- rnore, l/N I!/= I z i is an unbiased estimator of p; hence, we obtain the well-known ( ) result from Method 1, that the sample mean, l/N zyS I z(i), is an UMVU estimate of p. Because this estimator is linear, it is also the BLUE of p+ 0
ExampIe A-12 (Linear Model ) the linear As in Example A-9, consider
?x(k) = x(k)e + T(k) (A-16)
where 8 is a deterministic but unknown n x 1 vector of parameters, X(k) is deter- ministic, and Ew(k)} = 0. Additionally, assume that V(k) is Gaussian with known covariance matrix 3(&z). Then, the statistic T@(k)) = X’(k)%-%(k) is sufficient (see Example A-9). That it is also complete can be seen by using Theorem A-4. To obtain UMVU estimate 6, we need to identify a function Iz[T(Z(k))] such that F$z [T@!(k))]) = 9. The structure of /I [T@(k))] is obtained by observing that
E{T(%(k))} = E{X’(k)%-l(k)%(k)} = X’(k)%-‘(k)?@-)9
hence,
Consequently? the UMW estimator of 9 is
which agrees with Equation (9-26). 0
We now generalize the discussions given above to the case of an m-parameter exponential family, and scalar observations. This theorem is paraphrased from Bickel and Doksum (1977)
Sufficient Statistics and Uniformty Minimum-Variance Unbiased Estimation 293
Theorem A-4 [Bickel and Doksum (1977) and Lehmann (1959)]. Let p(zle) be an m-parameter exponentialfamily given by
p(zlf3) = exp 5 Qj (e)1;:(2) + b(e) + h(z) [ i= 1 1
where a,, . . . , a, and b are real-valued functions of 0, and T,, . . . , T, and h are real-valued functims of z. Suppose that the range of a = co1 [al(O), . . . , a,(9)] has an open m-rectangle [if (x,, yJ, . . . , (xm,ym> are m open intervals, the set -@I,..., S,): Xi < Si < yj, 1 I i zs m) is called the open m-rectangle], rhen T(z) = col [TI(z), . . . , Tm(z)] is complete as well as sufficient. •1
Example A-13 (This example is taken from Bickel and Doksum, 1977, pp. 123-124)
As in Example A-4, let 9 = co1 [z(l), . . . , z (Iv)] be a sample from a IV@ ,2) popu- lation where both p and d are unknown. As a special case of Example A-6, we observe that the distribution of 2 forms a two-parameter exponential family where 9 = co1 (CL ,d). Because co1 [al(9), a2(e)] = co1 (p /c?,-I/X?) ran g es over the lower halfplane, as 9 ranges over co1 [(- m,m), (O,m)], the conditions of Theorem A-4 are satisfied. As a result, T(S) = co1 [Cf”= 1 z (i), ‘$= 1 z ‘(i)] is complete and sufficient. Cl
Theorem A-3 also generalizes in a straightforward manner to:
Theorem A-5. If a complete- and sufficient statistic T(Z) = co1 (-W-Q, + . . 7 Tm(W e*(Z) = E(@T(Z))
exists for 8, and 8 is an unbiased estimator of 0, then is an UMVU estimator of 8. If the elements ofthe covariance
matrix of 8* (2.) are < m for all 8, then B*(Z) is the unique UMVU estimate of 8. 0
The proof of this theorem is a straightforward extension of the proof of Theorem A-3, which can be found in Bickel and Doksum (1977).
Example A-14 (Continuation of Example A-13)
In Example A-13 we saw that co1 [T,(Z), G(Z)] = co1 [zyz 1 z(i), xi”,. , z’(i)] is suf- ficient and complete for both p and 2. Furthermore, since
and
are unbiased estimators of ~1 and d, respectively, we use the extension of Method 1 to the vector parameter case to conclude that 5 and @’ are UMW estimators of p and d. El
It is not always possible to identify a function h (T(2)) that is an’un- biased estimator of 8. Examples that use the conditioning Method 2 to obtain

Sufficient Statistics and Statistical Estimation of Parameters Lesson A
UMVU estimators are found, for example, in Bickel and Doksum (1977) and Lehman (1980).
A-l.
A-2.
A-3.
A-4.
A-S.
A-6.
A-7.
A-8.
A-9.
A-10.
A-11.
PROBLEMS
Suppose z(l), . . . , z(N) are independent random variables, each uniform on [0,6], where 8 > 0 is unknown. Find a sufficient statistic for 8. Suppose we have two independent observations from the Cauchy distribution,
1 P(Z) = -
1 -7r 1 + (2 - 0)”
-xc<zx
Show that no sufficient statistic exists for 8. Let z(l), z(2), . . . , z(N) be generated by the first-order auto-regressive process,
z(i) = &(i - 1) + fPw(9
where {w(i), i = l,..., N} is an independent and identically distributed Gaussian noise sequence with zero mean and unit variance. Find a sufficient statistic for 8 and p. Suppose that T(%) is sufficent Afor 8, and that 6(s) is a maximum- likelihood estimate of 8. Show that e(Z) depends on (r: only through T(3). Using Theorem A-2, derive the maximum-likelihood estimator of 8 when observations z (l), . . . , z(N) denote a sample from
p (2 (i)le) = 8e -e4i) z(i) rO,e >O
Show that the family of Bernoulli distributions, with unknown probability of success p (0 2s p ~5 l), is complete. Show that the family of uniform distributions on (0,Q where 8 > 0 is unknown, is complete. Let z(l), . . . , z(N) be independent and identically distributed samples, where p (z (i)iS) is a Bernoulli distribution with unknown probability of success p (0 5 p 5 1). Find a complete sufficient statistic, T; the UMVU estimate 4(T) of p; and, the variance of 4(T). [Taken from Bickel and Doksum (1977)]. Let z(l), z(2), . . . , z(N) be an independent and identically distributed sample from N&,1). Find the UMVU estimator of pg [z (1) 101. [Taken from Bickel and Doksum (1977)]. Suppose that & and z are two UMVU estimates of 8 with finite variances. Show that z = T2. In Example A-12 prove that T@!(k)) is complete.
Appendix A
Glossary of Maior Results
Equations (3-10) and (3-11)
Theorem 4-1 Lemma 4-l Theorem 4-2 Theorem 5-l Theorem 6-l
Theorem 6-2
Theorem 6-3 Corollary 6-l Theorem 6-4
Corollary 6-2 Theorem 7-l
Theorem 7-2
Theorem 8-l
Theorem 8-2
Batch formulas for &+&k) and &#).
Information form of recursive LSE. Matrix inversion lemma. Covariance form of recursive LSE. Multistage LSE. Necessary and sufficient conditions for a linear
batch estimator to be unbiased. Sufficient condition for a linear recursive esti-
mator to be unbiased. Cramer-Rao inequality for a scalar parameter. Achieving the Cramer-Rao lower bound. Cramer-Rao inequality for a vector of param-
eters. Inequality for error-variance of ith parameter. Mean-squared convergence implies convergence
in probability. Conditions under which i(k) is a consistent esti-
mator of 8. Sufficient conditions for &&) to be an unbiased
estimator of 8. A formula for cov [&&)].

Glossary of Major Results
Corollary 8-l
Theorem 8-3 Theorem 8-4
Theorem 8-5
Equation (9-22) Theorem 9-l Corollary 9- 1
Theorem 9-2
peorem 9-3 Corollary 9-2 Theorem 9-4 Corollary 9-3 Theorem 9-5 Theorem 9-6 Theorem 9-7 Definition 10-l Theorem lo- 1
Theorem 11-l
Theorem 1 l-2 Theorem I l-3 Corollary 11-l
Theorem 12-l
Theorem 12-2
Theorem 12-3
Theorem 12-4
A formula for cov [&(k)~ under special condi- tions on the measurement noise.
An unbiased estimator of 2. Sufficient conditions for &(k) to be a consistent
estimator of 0. Sufficienl conditions for & (k) to be a consistent
estimator of 2”. Batch formula for &&IQ The relationship between &(ti) and &&). When all the results obtained iyLessons 3,4 and 5
for b-(k) can be applied to Or&k). When 6&k) equals 6&) (Gauss-Markov ,The-
orem). A formula for cov [6&Q]. The equivalence between P(k) and cov [&&)]. Most efficient estimator property of 6&k). When 6&) is a most efficient estimator of 6. Invariance of hBLu(k) to scale changes. Information form of recursive BLUE. Covariance form of recursive J3LUE. Likelihood defined. Likelihood ratio of combined data from statisti-
cally independent sets of data. Large-sample properties of maximum-likelihood
estimates. Invariance property of MLE’s. Condition under which 6&) = 6&k). Conditions under which &(k) = &&c) =
iLS( k), and, resulting estimator properties. A formula for ~(xiy) when x and y are jointly
Gaussian. Properties of E{xiyl when x and y are jointly Gaus-
sian. Expansion formula for E{x\y ,zl when x, y, and z
are jointly Gaussian, and y and z are statistically independent.
Expansion formula for lZ{x~y,z~ when x, y and z are jointly Gaussian and y and z are not neces- sarily statistically independent.
Appendix A
Theorem 13-l
Corollary 13-1
Corollary 13-2
Corollary 13-3 Theorem 13-2 Theorem 14-1 Theorem 14-2 Theorem 14-3 Theorem 15-l
Theorem 15-2
Theorem 15-3
Equations (U-17) & (15-18)
Theorem 15-4
Theorem 15-5
Theorem 15-6 Equations (16-4) &
(16-11) Theorem 16-l
Theorem 16-2
Theorem 17-l
Theorem 19-l Theorem 19-2
Theorem 20- 1 Corollary 20-l
A formula for 8,,(k) (The Fundamental Theorem of Estimation Theory).
A formula for i&k) when 8 and Z(k) are jointly Gaussian.
A linear mean-squared estimator of 8 in the non- Gaussian case.
Orthogonality principle. When 6 MAP(k) = k&). Conditions under which i,,(k) = &&k)- Condition under which 8&k) = &Ltj(k). Condition under which &*~(k) = &LU(~). Expansion of a joint probabihty density function
for a first-order Markov process. Calculation of conditional expectation for a first-
order Markov process. noise as a special Interpretation of Gaussian white
first-order Markov process. The basic state-variable model.
Conditions under which x(k) is a Gauss-Markov sequence.
Recursive equations for computing mX(k) and R(k).
Formulas for computing m, (k) and P, (k). Single-stage predictor formulas for i(k jk - 1)
and P(k jk - 1). Formula for and properties of general state pre-
dictor, i(klj), k > j. Representations and properties of the innovations
process. KaIman filter formulas and properties of resulting
estimates and estimation error. Steady-state Kalman filter. Equivalence of steady-state Kalman filter and in-
finite length digita Wiener filter. Single-state smoother formula for i(kjk + 1).
smoothing gain ReIationship matrix and
between Kalman
single-stage gain matrix,
Corollary 20-2 Another way to express d(klk + 1).

298
Theorem 20-2 Corollary 20-3
Corollary 20-4 Theorem 21-1
Theorem 21-2
Theorem 21-3
Theorem 22-l
Theorem 22-2
Theorem 22-3
Theorem 22-4
Theorem 22-5 Theorem 22-6 Theorem 22-7 Theorem 23-1
Theorem 23-2
Corollary 23-1
Corollary 23-2
Equations (24-l) & (24-2)
Equations (24-23) & (24-30)
Theorem 24-1
Glossary of Major Results
Double-stage smoother formula for ri(klk + 2). Relationship between double-stage smoothing gain
matrix and Kalman gain matrix. Two other ways to express i(k jk + 2). Formulas for a useful fixed-interval smoother of
x(k), %k IN), and its error-covariance matrix, P(k IN):
Formulas for a most useful two-pass fixed-interval smoother of x(k) and its associated error- covariance matrix.
Formulas for a most useful fixed-point smoothed estimator of x(k), jZ(k Ik + Z) where Z = 1, 2 and its associated error-covariance ma- t&i ;?‘(klk + I).
Conditions under which a single-channel state- variable model is equivalent to a convolutional sum model.
Recursive minimum-variance deconvolution for- mulas.
Steady-state MVD filter, and zero phase nature of 6s wo
Equivalence between steady-state MVD filter and Berkhout’s infinite impulse response digital Wiener deconvolution filter.
Maximum-likelihood deconvolution results. Structure of minimum-variance waveshaper. Recursive fixed-interval waveshaping results. How to handle biases that may be present in a
state-variable model. Predictor-corrector Kalman filter for the cor-
related noise case. Recursive predictor formulas for the correlated
noise case. Recursive filter formulas for the correlated noise
case. Nonlinear state-variable model.
Perturbation state-variable model.
Solution to a time-varying continuous-time state equation.
Appendix A 299
Equations (24-39) & (24-44)
Theorem 25-1 Equations (25-22) &
(25-27) Theorem 26-l
Theorem 26-2
Theorem 27-l Definition A-l Theorem A-l Theorem A-2
Theorem A-3
Theorem A-4
Theorem A-5
Discretized state-variable model.
A consequence of relinearizing about i(kIk). Extended Kalman filter prediction and correction
equations. Formula for the log-likelihood function of the
basic state-variable model. Closed-form formula for the maximum-likelihood
estimate of the steady-state value of the inno- vation’s covariance matrix.
Kalman-Bucy filter equations. Sufficient statistic defined. Factorization theorem. A method for computing the unique maximum-
likelihood estimator of 0 that is associated with exponential families of distributions.
Lehmann-Scheffe Theorem. Provides a uniformly minimum-variance unbiased estimator of 8.
Method for determining whether or not T(z) is complete as well as sufficient when p (~10) is an m-parameter exponential family.
Provides a uniformly minimum-variance unbiased estimator of vector 0.

References
AGLXLERA, IL J. A. DEBREMAECKER, and S. HERNANDEZ. 1970. “Design of recursive filters.” Geophysics, Vol. 35, pp. 247-253.
ANIIERSON, B. D. 0.. and J. B. MOORE. 1979, QptimaZ Fikering. Eqlewood Cliffs, NJ: Prentice-Hall.
ACM, M. 1967. Optimization of Stochastic Systems- Tupics in Discrete- Time Systems. NY: Academic Press.
ASTR~M, K. J. 196K “Lectures on the identification probiem-the least squares method.” Rept. No, 6806% Lund Institute of Technology, Division of Automatic CcmtroL
ATHA?& M. 1971. “The role and use of the stochastic linear-quadratic-Gaussian prob- lem in control system design.” IEEE Trans. on Automatic ContruI, Vol. AC-16 pp. 529-552.
ATHANS. M., and P. L. FALB. 1965. Optimal Contr~k Ati l~troductbn to the Theory and Its Applications. NY: McGraw-Hill.
AI-HANS, M., and F. SCFIWEPPE. 1965. “Gradient matrices and matrix calculations.” MIT Lincoln Labs., Lexington, MA, Tech, Note 196553.
ATHANS, M., and E. TSE. 1967. “A direct derivation of the optimai linear filter using the maximum principle,” IEEE Trans. OJI Automatic Contrd, Vol. AC-12, pp. 690-698.
ATHANS. M., R. P. WISHNER, and A. BERTOLIM 1968. ‘Suboptimal state estimation for continuous-time noniinear systems from discrete noisy measurements.*’ IIZI!X Trans. WI Automatic Control, Vol. AC-13, pp. 504-514.
BARAMUN, E. W., and M, KATZ, JR. 1959. “Sufficient Statistics of Minimal Dimen- sion,” Sunkhya, Vol. 21, pp. 217-246.
BARANKIN, E. W. 1961. “Application to Exponential Families of the Sohnion to the Mn-nmal Dimensionality Problem for Sufficient Statistics.” Buk hs~. hterrmt. Stat., Vol. 38, pp. 141-150.
References
BARD, Y. 1970. “Comparison of gradient methods for the solution of nonlinear param- eter estimation problems.” SIAM J. Numerical Analysis, Vol. 7, pp. 157-186.
% BERKHOUT. A. G. 1977. “Least-squares inverse filtering and wavelet deconvolution.” Geophysics, Vol. 42, pp. 1369-1383.
BICKEL, P. J.. and K. A. DOKSUM. 1977. Marhematical Starisfics: Basic Ideas and Selected Topics. San Francisco: HoIden-Day, Inc.
BERMAN, G. J. 1973a. “A comparison of discrete hnear filtering algorithms.” KEE Trans. on Aerospace and Electronic Sysrems, Vol. AES-9, pp. 28-37,
BIERMAN, G. J. 1973b. “Fixed-interval smoothing with discrete measurements.” Inr. J. Conrrui, Vol. 18, pp. 65-75.
BIERMAN, G. J. 1977. Factorization Methods for Discrete Sequential Esrimation. NY: Academic Press.
BRYSOK, A. E., JR., and M. FRAZIER. 1963. “Smoothing for linear and nonlinear dy- namic systems.” TDR 63-119, pp. 353-364, Aero. Sys. Div., Wright-Patterson Air Force Base, Ohio.
BRYSON, A. E., JR., and D. E. JOHANSEN. 1965. “Linear filtering for time-varying systems using measurements containing colored noise.” IEEE Trans. on Automatic Control, Vol. AC-10, pp. 4-10.
BRYSON, A. E., JR., and Y. C. Ho. 1969. Applied Optimal Control. Waltham, MA: Blaisdell.
CHEN, C, T. X970. Introduction to Linear Sysrem T/zeory. NY: I-Iolt. CHI, C. Y. 1983. “Single-channel and multichannel deconvolution.” Ph.D. dis-
sertation, Univ. of Southern Cahfiornia, Los Angeles, CA. CHI, C. Y., and J. M. MENDEL. 1984. “Performance of minimum-variance decon-
volution fiiter.” IEEE Trans. on Acoustics, Speech and Signal Processing, Vol. ASSP-32, pp. 1145-1153.
CRAMER, H. 1946. Mathematical Methods of Statisrics, Princeton, NJ: Princeton Univ. Press.
DAI, G-Z.. and 3. M. MENDEL. 1986. “General Problems of Minimum-Variance Recur- sive Waveshaping.” IEEE Trans. on Acoustics, Speech and Signal Processing, Vol. ASSP-34.
DONGARRA, J.J.,J.R. BUNCH.~. B. MOLER, and G.W. STEWART. 1979. LINPACK User’s Guide, Philadelphia: SIAM.
DUDA, R. D., and P. E. HART. 1973. Pattern Clussification and Scene Analysis. NY: Wiley Interscience.
EDWARDS, A. W. F. 1972. Likelihood. London: Cambridge Univ. Press. FAURRE. P. L. 1976. “Stochastic Realization Algorithms.” in System Identificarion:
Advances and Case Studies (eds., R. K. Mehra and D. G. Lainiotis), pp. l-25. NY: Academic Press.
FERGWSON, T. S. 1967. MarhematicaZ Starisrics: A Decision Theoretic Approach. NY: Academic Press.
FRASER, D. 1967. “Discussion of optimal fixed-point continuous linear smoothing (by J. S. Meditch).” Proc. 1967 Joint Automatic Conrrol Conf., p. 249, Univ. of PA, Philadelphia.

References
GOLDBERGER, A. S. 1964. Econometric Theory. NY: John Wiley. GRAYBILL, F. A. 1961. An Introduction to Linear Statistical Models. Vol. 1, NY:
McGraw-Hill. GUPTA, N. K., and R. K. MEHRA. 1974. “Computational aspects of maximum like-
lihood estimation and reduction of sensitivity function calculations.” IEEE Trans. on Automatic Control, Vol. AC-19, pp. 774-783.
GURA, I. A., and A. B. BIERMAN. 1971. “On computational efficiency of linear filtering algorithms. ” Automatica, Vol. 7, pp. 299-314.
HAMMING, R. W. 1983. Digital Filters, 2nd Edition. Englewood Cliffs, NJ: Prentice- Hall.
HO, Y. C. 1963. “On the stochastic approximation Math. Ana!. and Appl., Vol. 6, pp. 152-154.
and optimal filtering.” J. of
JAZWINSKI, A. H. 1970. Stochastic Processes and Filtering Theory. NY: Academic Press.
KAILATH, T. 1968. “An innovations approach to least-squares estimation-Part 1: Linear filtering in additive white noise.” IEEE Trans. on Automatic Control, Vol. AC-13, pp. 646-655.
KAILATH, T. K. 1980. Linear Systems. Englewood Cliffs, NJ: Prentice-Hall. ULMAN. R. E. 1960. “A new approach to linear filtering and prediction problems.”
Trans. ASME J. Basic Eng. Series D, Vol. 82, pp. 35-46. KALMAN, R. E., and R. BUCY. 1961. “New results in linear filtering and prediction
theory.” Trans. ASME, J. Basic Eng., Series D, Vol. 83, pp. 95-108. KASHYAP, R. L., and A. R. RAO. 1976. Dynamic Stochastic Models from Empirical
Data. NY: Academic Press. KELLY, C. N., and B. D. 0. ANDERSON. 1971. “On the stability of fixed-lag smoothing
algorithms.” J. Franklin Inst., Vol. 291, pp. 271-281. KMENTA, J. 1971. Elements of Econometrics. NY: MacMillan. KOPP, R. E., and R. J. ORFORD. 1963. “Linear regression applied to system identi-
fication for adaptive control systems.” AZAA J., Vol. 1, pp. 2300. KUNG, S. Y. 1978. “A new identification and model reduction algorithm via singular
value decomposition.” Paper presented at the 12th Annual Asilomar Conference on Circuits, Systems, and Computers, Pacific Grove, CA.
KWAKEFWAAK, H., and R. SIVAN. 1972. Linear Optimal Control Systems. NY: Wiley- Interscience.
LAUB, A. J. 1979. “A Schur method for solving algebraic Riccati equations.” IEEE Trans. on Automatic Control, Vol. AC-24, pp. 913-921.
LEHMANN, E. L. 1959. Testing Statistical Hypotheses. NY: John Wiley. LEHMANN, E. L. 1980. Theory of Point Estimation. NY.: John Wiley. LJUNG, L. 1976. “Consistency of the Least-Squares Identification Method.” IEEE
Trans. on Automatic Control. Vol. AC-21, pp. 779-781. LJUNG, L. 1979. “Asymptotic behavior of the extended Kalman filter as a parameter
estimator for linear systems.” IEEE Trans. on Automatic Control, Vol. AC-24, pp. 36-50.
References
MARQUARDT, D. W. 1963. “An algorithm for least-squares estimation of nonlinear parameters. ” J. Sot. Indust. Appl. Math., Vol. 11, pp. 431-441.
MCLOUGHLIN, D. B. 1980. “Distributed systems-notes.” Proc. 1980 Pre-JACC Tu- torial Workshop on Maximum-Likelihood Identification, San Francisco, CA.
MEDITCH, J. S. 1969. Stochastic Optimal Linear Estimation and Control. NY: McGraw- Hill.
MEHRA, R. K. 1970a. “An algorithm to solve matrix equations PHT = G and P = @P<p’ + ITT.” IEEE Trans. on Automatic ControZ, Vol. AC-15
MEHRA, R. IS. 1970b. “On-line identification of linear dynamic systems with applica- tions to Kalman filtering.” Proc. Joint Automatic Control Conference, Atlanta, GA, pp. 373-382.
MEHRA, R. K. 1971. “Identification of stochastic linear dynamic systems using Kalman filter representation.” AIAA J., Vol. 9, pp. 28-31.
MEHRA, R. K., and J. S. TYLER. 1973. “Case studies in aircraft parameter identi- fication. ” Proc. 3rd IFAC Symposium on Identification and System Parameter Estimation, North Holland, Amsterdam.
MENDEL, J. M. 1971. “Computational requirements for a discrete Kalman filter.” IEEE Trans. on Automatic Control, Vol. AC-16, pp. 748-758.
MENDEL, J. M. 1973. Discrete Techniques of Parameter Estimation: the Equation Error Formulation. NY: Marcel Dekker.
MENDEL, J. M. 1975. “Multi-stage least squares parameter estimators.” IEEE Trans. on Automatic Control, Vol. AC-20, pp. 775-782.
MENDEL, J. M. 1981. “Minimum-variance deconvolution.” ZEEE Trans. on Geoscience and Remote Sensing, Vol. GE-19, pp. 161-171.
MENDEL, J. M. 1983a. “Minimum-variance and maximum-likelihood recursive wave- shaping.” IEEE Trans. on Acoustics, Speech, and Signal Processing, Vol. ASSP-31, pp. 599-604.
MENDEL, J. M. 1983b. Optimal Seismic Deconvolution: an Estimation Based Approach. NY: Academic Press.
MENDEL, J. M., and D. L. GIESEKING. 1971. “Bibliography on the linear-quadratic- gaussian problem. ” IEEE Trans. on Automatic Control, Vol. AC-16, pp. 847-869.
MORRISON, N. 1969. Introduction to Sequential Smoothing and Prediction. NY: McGraw-Hill.
NAHI, N. E. 1969. Estimation Theory and Applications. NY: John Wiley. OPPENHEIM, A. V., and R. W. SCHAFER. 1975. Digital Signal Processing. Englewood
Cliffs t NJ: Prentice-Hall. PAPOULIS, A. 1965. Probability, Random Variables, and Stochastic Processes. NY:
McGraw-Hill. &LED, A., and B. LIU. 1976. Digital SignaZ Processing: Theory, Design, and
Implementation. NY: John Wiley. RAUCH, H. E., F. TUNG, and C. T. STRIEBEL. 1965. “Maximum-likelihood estimates of
linear dynamical systems. ” AIAA J., Vol. 3, pp. 1445-1450. SCHWEPPE, F. C. 1965. “Evaluation of likelihood functions for gaussian signals.” IEEE
Trans. on Information Theory, Vol. IT-11, pp. 61-70.

References
SCHWEWE, F. C. 1973. Uncertain Dynumzc ~ystemx. Englewood Cliffs, NJ: Prentice- Hall.
SH+4mS. J. L. 1967. “Recursion filters for digital processing.” CUX$Z~~~C~~ Vol. 32. pp. 32-X
SORENSON, H. W. 1970. “Least-squares estimation: from Gauss to Kahnan.” I,&!% spectrum, Vol. 7? pp. 63-68.
SORENSON, H. LV. 1980. Parameter Estimation: Principies and Prublems. NY: Marcel Dekker.
SORENSON, IX W., and J. E. SACKS. 1971. mahm Science, Vol* 3, pp. 101-119.
“Recursive fading memory filtering.” I@r-
STEFANI, R. T. 1967. “Design and simulation of a high performance, digital, adaptive, normal acceleration control system using modern parameter estimation tech- niques.” Rept. No. DAC-6U637, Douglas Air&t Co,, Santa Monica, CA.
STEPNER, ID. E., and R. K. MEIIRA. 1973. “Maximum likelihood identification and optimal input design for identifying aircraft stability and coritroi derivatives.” Ch. IV, NASA-CR-2200.
STEWART, G. W. 1973. Introduction to Matrix Compututions. NY: Academic Press. TREEL, S. 1970- “Principles of digital multichannel tiitering.” Geophysics? VoI.
XXXV, pp. 785-81 I. TREEEL, S., and E. A. ROBINSON. 1966. “The design of high-resolution digital filters.”
IEEE Trans. on Geoscience and Electronics, Vol. GE-4, pp. 25-38. TUCKER, H. G. 1962. An Introduction to Probabiiity und Mathematics! Stdstics. NY:
Academic Press. TUCKER, FL G. 1967. A Gruduute Course in Probabi&y. NY: Academic Press. VAE TREES, H L. 1968. Detection, Estimution und Modulufion Theory, Vol. I. NY:
John Wiley. ZACKS, S. 1971. The Theory of statisticul Inference. NY: John Wiley.
lndex
Aerospace vehicle example, 21-23 Algebraic Riccati equation, 17&
171,278 Asymptotic distributions, U-56 Asymptotic efficiency (see Large
sam le properties of estima- tors P
asymptotic mean. 55-56 Asymptoticunbiasedness (see Large
sam le properties of esrima- tors P
Asymptotic variance, 56
Basic state-variable modeI: defined, 131-132 properties of, 133--137
Batch processing (set Least-squares estimation)
Best linear unbiased estimation, 73-79
Best linear unbiased estimator: comparison with maximum a pos-
teriori estimator, 123-124 comparison with mean-squared
estimator, 122-123 comparison with weighted least-
squares estimator, 74-7; derivation of batch form. 7374 properties, 75-78 for random parameters, l2l-123 recursive forms, 78-79, 167
Biases (see Not-so-basic state- variable model)
BLUE (see Best linear unbiased es- timator)
Causal invertibility, 157-158 Colored noises (see Not-so-basic
state-variable model) Condttionai mean:
defined. 102 properties of, 104-306
Consistency (see Large sample properties of estimators)
Convergence in mean-s uare, 59 Convergence in probabi lty, 58 1. Correlated noises (see Not-so-basic
state-variable model) Covariance form of recursive least-
squares estimator, 31,79 Cramer-Rao inequality:
scalar parameter, 47 vector of parameters, 51
Cross-sectiona processing (see Least-squares estimation)
Deconvolution: maximum-likelihood
124-125.215-216 (MLD).
minimum-variance (MVD). 121% 121.X%21s
model formulation. 12-14 Discretization of linear time-
varying state-variable model. 242-245
Divergence phenomenon. 167-169
Efficiency (see SmalI sample prop- erties of estimators)
Estimate types, 14-15 (see also Pre- diction: Filtering; Smoothing)
Estimation of deterministic param- eters (see Least-squares esti- mation: Best linear unbiased
estimation; Maximum-likeli- hood estimation)
Estimator properties (see Small sample properties of estima- tors: Large sample properties of estimators)
Estimation of random parameters (see Mean-squared estimation; Maximum a posteriori estima- tion; Best linear unbiased esti- mator; Least-squares estima- tor)
Estimation techni ues, Best linear un tased Ii
3 (see estima-
tor: Least-squares estimator; Maximum-likelihood estima- tors; Mean-squared estima- tors; Maximum a posteriori estimation; State estimation)
Expanding memory estimator, 23 Exponential family of distributions,
284-286 Extended Kaiman filter:
application to parameter estima- tion, 255-256
correction equation, 253 derived, 249-253 iterated, 253-254 prediction equation, 252
Factorization theorem, 283 Fibering:
computations, 156 covariance formulation, 157 diy;-ce phenomenon, 167-
examples, 160-169 Kalman filter derivation, 151-153 properties. 153--158 recursive filter. 153 relationship to Wiener filtering,
176-181 steady-state Kalman filter, 17C-
176 Finite-difference equation coeffi-
cient identification (see Identi- fication of)
Fisher informatin matrix, 51 Fixed-interval smoother, 183-184,
190.193-199 Fixed-lag smoother, 184, 191,
24X-202 Fixed memory estimator. 23 Fiiebpgi;ml smoother, 184, 190,
Gauss-Markov random processes defined. 128-129
Gaussian random processes (see Gauss-Markov random pro- cesses)
Gaussian random variables (see also Conditional mean)
conditional density function, 102-
joi?densitv function 101-102 multivariate density finction, 101 properties of, 104 univariate density function, 100
Glossary of major results. 295-299
Hypotheses: binarv, 81 multiple, 85-86
Identifiability. 95-96 Identification of:
coefficients of a finite-difference equation. 9.65
impulse response. 8-9. 3p-42. 64-65
initial condition vector in an un-
forced state equatron model, 10
ImpuIse response identification (see Identification of)
Information form of recursive least- squares estimator. 29. 91
fnitial condition identification (see Identification of)
Innovations process: defined. 146 properties of. 146-147
Instrument calibration example, 20-21.35-36
Invariance property of maximum- likehhood estimators Maximum-likelihood
(see
estimates) Iterated least squares, 248-249
Kalman-Bucy filtering: derivation using a formal limiting
procedure. 27X275 derivation when structure of filter
is prespecified, 275-278 notation and problem statement
for derivation, 27l-272 optima1 control application, 28& 101
,201
statement of, 272 steady-state, 278-280 system description for derivation, me*
LII Kalman-Bucy ain matrix, 272 Kahnan filter see Filtering; Steady- cg
state Kalman filtering) Kalman filter sensitivity system,
163,262-263 Kalman filter tuning parameter, 167 Kalman gain matrix, 151
Large sample properties of estiina- tars (see also Least-squares es- timator):
asymptotic efficient , 60 asymptotic unbiase cy ness, 57 consistency. 57-60
Least-squares estimation process- ing:
batch, 17-24 cross-sectional. 37-38 recursive, 2632.3-M2
Least-squares estimator: derivation of batch form, 19-20 derivation of recursive covar-
iance form, 30-31 derivation of recursive informa-
tion form. 27-28 exam initia lzation of recursive forms, P
les. 20-23, 3-5-36
arz sample properties. 68-70 multistage. 38-4, properties. 63-70 for random parameters. 121 small sample properties. 63-68 for vector measurements, 36
Lehmann-Scheffetheorem.297-293 Likelihood:
compared with probability, 81-82 conditional, 1 l4 continuous distributions. 85.88 defined. 82-84 unconditional, 114
Likelihood rato: defined for multipIe hypotheses,
S-86 defined for two hypotheses. 84-86
Linear model: defined. 7 examples of. &I4 (see also Iden-
tification of; State estimation example: Dcconvolution; Non- ]incar mcasurcmfn~ rnrlrirll

hlarkov process. 129- 130 hMrix inversion lemma, 30 Matrix Riccaci differential equa-
tion* 272 >Iatrix Ricca!i equation+ 15s Maximum a posteriori estimation:
comparison with best linear un- biased estimator, 12-%I24
comparison with mean-squared cstimatnr. i l-%116
Gaussian linear model, 123-124 general case. 114-l 16
~~aximurn-~~keli~~~~~d deconvolu- tion (set DeconvoIution)
Maximum-likelihood estimation, w97
Maximum-likelihood estimators: compatison with best linear un-
biased estimator, 93-94 comparison with least-squares es-
timator. 94 for exponential families, 287-290 the linear model, 92-94 obtaining ?hem+ 89-91 properties. 91-92
Maximum-likelihood method, $9 h$aximum-IikeIihood state and pa-
rameier estimation: computing &. 261 log-likelihood function for the
basic state-variable model, 259-261
steady-state approximation, 264- 268
Mean-squared convergence (see Convergence in mean-square)
blean-squared estimation, 109-113 Mean-squared e5timators:
comparison with best linear un- biased estimator, 122-123
comparison with maximum a pos- tcriori estimator. ll-$116
derivation. 110 Gaussian case. 11 l-1 13 for linear and Gaussian model,
1 l&l20 properties of, 112-l 13
Measurement differencing tech- nique, 231
Minimum-variance deconvoiution (see Deconvolution)
MLD (PC Deconvolution) Mod& ng:
estimation problem, 1 measurement problem. 1 re resent&on
Y roblem, 1
va idation prob cm, 2 r Multistage least-squares (XC Least-
Squares estimator) Multivariate Gaussian random sari-
ables (-Tee Gaussian random variables)
MVD (see Deconvolution)
Nonlinear dvnarnical systems: discrctized petturbalion state-
variable model, 24s linear perturbation equaCor)s,
23?-242 model, 237-239
Nonlinear measurement model. 12 Not-so-basic state-variable model:
biases, 224 colored noises, 227-230 correlated noises, 22-5227 perfect measurements, 23&233
Notation, 14-15
Orthogonality principle, 11 l-l 12
Parameter estimation (Jee Ex- tended Kaiman filter)
Perfect measuremen& (see Not-so- basic state-variable model)
Perturbation equations (JC~ Han- linear dynamical systems)
Philosoph!: estimation theory, 6 modeling, 5-6
Prediction: general, 142-145 recursive predictor, 155 single-stage, 140-142 steady-state predictor. 173
Predictor-corrector form of Kalman filter, 151-W
Properties of best linear unbiased estimators [see Best linear un- biased estimator]
Propertie of estimators (see Small sample properties of estima- tors: Large sample properties of estimators)
Properties of least-squares estima- tar (see Least-squares estima- tar)
Propetiies of maximum-likciihood estimators (see Maximum- likelihood estimators]
Properties of mean-squared estima- tars (see Mean-squared estima- tors)
Random processes (,qce Gauss- Matkov random processes)
Random variables (XC Gaussian random variabIes)
Recursive calculation of state co- variance matrix, 134
Recursive calculation of state mean vector, 134
Recursive processing (see Least- squares estimation Best linear unbiase cr
recessing; estimator)
Recursive wavesha r
ing, 21&222 Reduced-order Ka man filter, 231 Reduced-order state estimator. 231 Riccati equation (see Matrix Riccati
equation: Algebraic Riccati equation)
Sarn;te;yn as a recursive digital
Scaie cha&es: best linear unbiased estimator,
77-78
icasl squares. 2-&24 Sensitivity of Kalman filter, 16-L
166 Signal-to-noise ralio, 137-138. 167 Smglc-channel steady-state Kalrnan
tiller* 17-s 176 Small sample Dropertics of estima-
tars (5ee &o-Least-squares es- timator\:
efficiency:&-S2 unbiasedness, 44-46
Smnothine: applications. X%222 double-stage. 187-189 fixed-internal, 190, 19-3-199 fixed-lag, 191.201-202 fixed-point. 190, 199-201 single-stage, 18-Gl87 three types. 183-184
Stabilized fotrn for computing I’(k + l/A + I], IS6
Standard form for computing P(k + lik +- l),l%
State estimation (see Prediction; Filte+ng:.Smoothing)
Statel;;tlmatlon example, 10-12,
State-variable model (see Basic state-variable model; Not-so- basic state-variable model)
Steady-state a Maximum- i r!
roximation (5ee elihood state and
parameter estimation) Steady-state filter system, 173 Steadv-state Kalman filter, I?&172 Steadi-state MVD filter:
defined, 207 properties of, 212-213 relationship m HR Wiener de-
convolution filter, 213-215 Steady-state predictor system, 173 Stochastic linear optimal output
feedback regulator problem, 281
Sufficient statistics: defined, 282-284 for exponential families of distri-
buttons. 285286,287-290 and uniformlv minimum-variance
unbiased e&nation, 290-294
Wnbiasedness (set Small sample properties of estimators)
Uniformly minimum-variance un- biased estimation (see Suffi- cient statistics)
Variance estimator, 6748
Waveshapin (see Recursive wave- shaping f
Weighted least-squares estimator (see Least-square5 estimator; Best linear unbiased estimator)
White noise discrete, 130-131 Wiener fiIter:
derivation. 178-179 relation to Kalman filter, 18&181
Wiener-Hopf equations, 179
&m-in algorithm. 3!H2




















