
Karadeniz Teknik Üniversitesi İlahiyat Fakültesi ... - DergiPark
Upload
khangminh22Category
view
1download
0
0
KARADENIZ TECHNICAL UNIVERSITY * INSTITUTE OF SOCIAL SCIENCES
DEPARTMENT OF WESTERN LANGUAGES AND LITERATURE
MASTER’S PROGRAM IN APPLIED LINGUISTICS
A CORPUS-BASED SEMANTIC PROSODIC ANALYSIS OF ENGLISH INTENSIFIERS
IN NATIVE AND NON-NATIVE CORPORA WITH A SPECIAL FOCUS TO THEIR
USAGE PATTERNS AND EVALUATIVE MEANINGS
MASTER'S THESIS
Neslihan KELEŞ
MAY - 2019
TRABZON

0
KARADENIZ TECHNICAL UNIVERSITY * INSTITUTE OF SOCIAL SCIENCES
DEPARTMENT OF WESTERN LANGUAGES AND LITERATURE
MASTER’S PROGRAM IN APPLIED LINGUISTICS
A CORPUS-BASED SEMANTIC PROSODIC ANALYSIS OF ENGLISH INTENSIFIERS
IN NATIVE AND NON-NATIVE CORPORA WITH A SPECIAL FOCUS TO THEIR
USAGE PATTERNS AND EVALUATIVE MEANINGS
MASTER’S THESIS
Neslihan KELEŞ
Thesis Advisor: Asst. Prof. Dr. Ali Şükrü ÖZBAY
MAY - 2019
TRABZON


III
DECLARATION OF ORIGINALITY
I, Neslihan KELEŞ, hereby confirm and certify that;
I am the sole author of this work and I have fully acknowledged and documented in
my thesis all sources of ideas and words, including digital resources, which have
been produced or published by another person or institution,
this work contains no material that has been submitted or accepted for a degree or
diploma in any other university or institution,
all data and findings in the work have not been falsified or embellished,
this is a true copy of the work approved by my advisor and thesis committee at
Karadeniz Technical University, including final revisions required by them.
I understand that my work may be electronically checked for plagiarism by the use of
plagiarism detection software and stored on a third party’s server for eventual future
comparison,
I take full responsibility in case of non-compliance with the above statements in
respect of this work.
21.05.2019

IV
ACKNOWLEDGEMENT
First and foremost, I want to express my sincere gratitude to my thesis supervisor, Asst. Prof.
Dr. Ali Şükrü ÖZBAY for his infectious enthusiasm, wisdom and expert guidance. I am also
thankful to him not only for supplying me with his own corpus, but also for providing immediate
feedback for my research.
I would like to thank the distinguished members of committee, Prof. Dr. Mehmet TAKKAÇ
and Asst. Prof. Dr. Öznur SEMİZ. I am also highly indebted to the academic staff from the
Department of English Language and Literature in Karadeniz Technical University: Assoc. Prof.
Dr. M. Zeki ÇIRAKLI, Assoc. Prof Dr. M. Naci KAYAOĞLU, Asst. Prof. Dr. Fehmi TURGUT
and Prof. Dr. İbrahim YEREBAKAN from whom I have learn a lot with their profound knowledge.
My best friend from university years, Elif AYDIN YAZICI deserves the special thanks for
her sincere motivation. I am sure that whenever I truly need help, she does her best without any
hesitation. We achieved our desired goal together.
I am grateful to Handan İLYAS KARATAŞ, Seyhan ÇAĞLAR ERDOĞAN, Mevlüde
ABDİOĞLU and Binnur OLGUN KAPTAN as my thesisters; an expression coming from the
bottom of my heart referring to ‘thesis sisters’. I have been lucky enough to collaborate with such
fellow researchers. I have also special thanks to my friends Nilgün MÜFTÜOĞLU, Zeynep
ÖZTÜRK DUMAN and Gökçenaz GAYRET for their moral and intellectual support.
My grateful thanks are also extended to Tuncer AYDEMİR for his precious help in using the
corpus tools.
Last but definitely not least, I heartily express my gratitude to my parents Ömer and Nurten
ÖZDEMİR for providing me with their patience and unfailing support throughout my years of
study. I owe my deep sense of appreciation to my husband Mehmet KELEŞ for his continuous
encouragement under all circumstances.
This thesis is dedicated to my precious daughters Mira and Hira from whose time I stole the
most.
May, 2019 Neslihan KELEŞ

V
CONTENTS
ACKNOWLEDGEMENT ............................................................................................................. IV
CONTENTS ...................................................................................................................................... V
ÖZET .............................................................................................................................................. VII
ABSTRACT .................................................................................................................................. VIII
LIST OF TABLES ......................................................................................................................... IX
LIST OF FIGURES ....................................................................................................................... XI
LIST OF ABBREVIATIONS ....................................................................................................... XII
INTRODUCTION ......................................................................................................................... 1-4
CHAPTER ONE
1. FRAMEWORK OF THE STUDY ......................................................................................... 5-11
1.1. Introduction .............................................................................................................................. 5
1.2. Background of the Study .......................................................................................................... 5
1.3. Statement of the Problem ......................................................................................................... 7
1.4. Purpose and Significance of the Study ..................................................................................... 8
1.5. Research Questions ................................................................................................................ 10
1.6. Operational Definitions .......................................................................................................... 10
1.7. Outline of the Study ............................................................................................................... 11
CHAPTER TWO
2. LITERATURE REVIEW ..................................................................................................... 12-45
2.1. Introduction ............................................................................................................................ 12
2.2. The Importance of Corpus Linguistics in Understanding Language ..................................... 12
2.3. Theoretical Background of the Study .................................................................................... 14
2.3.1. Contrastive Interlanguage Analysis (CIA) ................................................................... 15
2.3.1.1. What is Interlanguage? .................................................................................... 16
2.3.1.2. Historical Overview of Contrastive Intelanguage Analysis ............................. 21
2.3.1.3. Studies on Conrastive Interlanguage Analysis ................................................ 23
2.3.2. Computer Learner Corpus (CLC) Research ................................................................ 25
2.3.2.1. The Use of Learner Corpora in SLA and EFL Research ................................. 27

VI
2.3.2.2. Corpus Compilation and Design Criteria ......................................................... 28
2.3.2.3. Reference Corpora ........................................................................................... 29
2.3.3. Semantic Prosody (SP) ................................................................................................ 30
2.3.3.1. Semantic Prosody as an Extended Unit of Meaning (EUM) ........................... 34
2.3.3.2. Semantic Preference vs. Semantic Prosody ..................................................... 35
2.3.3.3. Studies Related to Semantic Prosody ............................................................. 37
2.4. Intensifiers .............................................................................................................................. 39
2.4.1. Amplifiers ..................................................................................................................... 40
2.4.2. Studies on the use of Intensifiers by EFL Learners ...................................................... 41
CHAPTER THREE
3. METHODOLOGY ................................................................................................................ 46-52
3.1. Introduction ............................................................................................................................ 46
3.2. Methodological Framework ................................................................................................... 46
3.2.1. Labelling of Patterns .................................................................................................. 48
3.3. The Selection Criteria of Intensifiers ..................................................................................... 49
3.4. Corpora and Tools for Data Collection .................................................................................. 49
3.4.1. Learner Corpora ........................................................................................................... 49
3.4.2. Reference Corpus ......................................................................................................... 50
3.4.3. Corpus Tools ................................................................................................................ 51
3.5. Data Analysis Procedures ...................................................................................................... 52
CHAPTER FOUR
4. FINDINGS AND DISCUSSION .......................................................................................... 53-83
4.1. Introduction ............................................................................................................................ 53
4.2. Overall Frequency Distribution of Amplifiers ....................................................................... 53
4.2.1. Maximizers .................................................................................................................. 54
4.2.2. Boosters ....................................................................................................................... 59
4.3. Semantic Prosodic Description of Amplifiers ....................................................................... 64
4.3.1. Semantic Profiles of Maximizers ................................................................................. 65
4.3.2. Semantic Profiles of Boosters ...................................................................................... 72
4.4. Pattern Analysis of Amplifiers .............................................................................................. 74
4.4.1. Usage Patterns of Maximizers ..................................................................................... 74
4.4.2. Usage Patterns of Boosters .......................................................................................... 78
4.4.2.1. Very ................................................................................................................. 78
4.4.2.2. So ..................................................................................................................... 80
4.4.2.3. Too ................................................................................................................... 83

VII
CONCLUSION AND SUGGESTIONS ........................................................................................ 85
REFERENCES ................................................................................................................................ 90
APPENDICES ............................................................................................................................... 101
CURRICULUM VITAE ............................................................................................................... 120

VIII
ÖZET
Bu tezin amacı İngilizce’de yer alan pekiştireçlerin ana dili İngilizce ve ana dili Türkçe olan
üniversite seviyesindeki yabancı dil öğrencileri tarafından tartışmacı yazılar içerisindeki kullanım
sıklığını, kullanım şekillerini ve anlamlarını yerli ve yabancı derlem verilerine dayalı olarak
anlamsal bürün (semantik prozodi) açısından incelemektir. Pekiştireçler, yazılı anlatımdaki
ifadeleri güçlendiren ve vurgulayan zarf niteliğinde sözcüklerdir. Son yıllarda dil bilimi alanında
birçok çalışmaya konu olan semantik prozodi kavramı ise dil birimlerinin ve sözcük gruplarının
örtülü biçimde taşıdığı olumlu olumsuz veya nötr anlam yüklerinin belli bir semantik ortamda
kullanılma eğilimi olarak tanımlanmaktadır. Bu çalışma metodolojik açıdan karşılaştırmalı ara dil
analizini benimsemektedir. Bu konuda yapılan araştırmaların ancak bilgisayar destekli derlem
(corpus) verileri ile objektif bir şekilde incelenebilmesi mümkün olabilmektedir. Bu bağlamda,
internet destekli derlem arayüzü olarak Sketch Engine programı kullanılmış olup çalışmaya konu
olan hedef pekiştireçler üç derlemin karşılaştırılması ile anlamsal bürün açısından incelenmiştir.
KTUCLE, TICLE ve LOCNESS derlemleri çalışmamızda temel alınan yerli ve yabancı derlem
kaynakları olarak kullanılmıştır. KTUCLE İngiliz Dili ve Edebiyatı öğrencilerinin yazma (writing)
dersinden elde edilen 709,748 kelimelik bir öğrenici derlemidir. Uluslararası Öğrenici Derlemi
(ICLE)’nin bir alt derlemi olan 199,532 kelime içerikli TICLE çalışmamızdaki ikinci öğrenici
derlemidir. Araştırmamızın referans derlemi olan LOCNESS ise anadili İngilizce olan öğrencilerin
makalelerinden elde edilen 361,054 kelimeden oluşan genel bir derlemdir. Verilerin incelenmesi
neticesinde üniversite düzeyindeki Türk yabancı dil öğrencilerinin kısıtlı pekiştireçleri kullandıkları
ve bu pekiştireçlerin anlamsal bürün ve eşdizim açısından farkındalık düzeylerinin düşük olduğu
ortaya çıkmıştır. Ayrıca ana dili İngilizce olmayan öğrencilerin kullanım ve anlam bakımından
birbirine yakın pekiştireçleri sıkça kullanmayı tercih ettikleri görülmektedir. Bu çalışmanın önemi
yerli derlemlerin yabancı derlemlerle karşılaştırılarak incelenmesi neticesinde anadili İngilizce
olmayan öğrencilerin hedef dilde yazmada pekiştireçleri kullanım şekilleri ve anlam bakımından
farkındalıkları yabancı dilde kelime öğrenimine pedagojik açıdan ışık tutmaktır.
Anahtar Kelimeler: Anlamsal Bürün, Pekiştireçler, Tartışmacı Yazı, Öğrenici Derlemi

IX
ABSTRACT
The primary purpose of the present study is to investigate semantic prosodic nature of
intensifiers used by both native speakers of English and Turkish students of English as a Foreign
Language (EFL) learners in their expository and argumentative essays along with a special focus
on their overall distribution and usage patterns. Intensifiers are degree adverbials modifying
attitudinal or evaluative meaning in written production. Semantic prosody, on the other hand, refers
to a hidden meaning, either positive, negative or neutral, which is revealed when certain node
words frequently collocate with other words from different semantic sets. The study mainly adopts
the methodology of Contrastive Interlanguage Analysis by Granger (1996) in nature. A
comparative corpus research on the semantic prosodic analysis of intensifiers can simply and
objectively be conducted with the help of special corpus tools in a computerized environment. In
this regard, the study investigating the semantic prosodic analysis of ten target intensifiers (the
maximizers absolutely, completely, entirely, fully, perfectly, totally, and utterly as well as the
boosters very, so, and too) utilizes Sketch Engine as the concordancer to compare three distinct
corpora; KTUCLE (Karadeniz Technical University Corpus of Learner English) together with
TICLE for non-native corpora and LOCNESS (Louvain Corpus of Native English Essays) for
native corpus. The local learner corpus of the study, KTUCLE, contains essays written by the
students of a Turkish university called Karadeniz Technical University and consists of 709,749
words. The second learner corpora is TICLE, as Turkish sub-corpus of ICLE (International Corpus
of Learner English), comprises 223,449 tokens in total. It is a collection of argumentative essays
written by Turkish adult learners of English. The reference corpus called LOCNESS contains
essays of native speakers and includes a total of 361,054 words. The results of the data analysis
concludes that tertiary level EFL learners use rather limited range of maximizers such as
completely and totally, and they have little semantic prosodic awareness about their usage. They
predominantly prefer using boosters such as very which are open-ended in use and can be
interchangeably used in all written discourse. This study is significant for revealing semantic
prosodic behavior of non-native EFL learners concerning intensifier use and providing pedagogical
implications for phraseological skills in foreign language learning.
Keywords: Semantic Prosody, Intensifiers, Argumentative Writing, Learner Corpus

X
LIST OF TABLES
Table No. Name of Table Page No.
1. Learner Corpus Design Criteria ..................................................................................... 29
2. Examples of Semantic Prosody ..................................................................................... 34
3. The Components of EUM ............................................................................................... 35
4. Different Categorizations of Intensifiers ........................................................................ 40
5. Partington’s Study on Intensifiers................................................................................... 43
6. The CIA Model of the Study .......................................................................................... 47
7. The Profiles of the Three Corpora Utilized in the Research ........................................... 47
8. Selected Intensifiers ........................................................................................................ 49
9. The Design Criteria of KTUCLE ................................................................................... 50
10. The Design Criteria of TICLE ........................................................................................ 50
11. The Profile of LOCNESS ............................................................................................... 51
12. Overall Distribution of Maximizer + Adjectives ............................................................ 54
13. 1R + Adjective Collocations of completely .................................................................... 55
14. 1R + Adjective Collocations of totally ........................................................................... 56
15. 1R + Adjective Collocations of absolutely ..................................................................... 56
16. 1R + Adjective Collocations of perfectly ....................................................................... 57
17. 1R + Adjective Collocations of entirely ......................................................................... 57
18. 1R + Adjective Collocations of fully .............................................................................. 58
19. 1R + Adjective Collocations of utterly ........................................................................... 58
20. Overall Distribution of Booster + Adjectives ................................................................. 59
21. Log-likelihood Ratio of very in LOCNESS and KTUCLE ............................................ 59
22. Log-likelihood Ratio of very in LOCNESS and TICLE ................................................. 60
23. Log-likelihood Ratio of so in LOCNESS and KTUCLE ................................................ 61
24. Log-likelihood Ratio of so in LOCNESS and TICLE .................................................... 62
25. Log-likelihood Ratio of too in LOCNESS and KTUCLE .............................................. 63
26. Log-likelihood Ratio of too in LOCNESS and TICLE ................................................. 64
27. Semantic Prosodic Profiles of Maximizers + Adjectives ............................................... 65
28. The Semantic Prosodic Profile of absolutely .................................................................. 66
29. The Semantic Prosodic Profile of completely ................................................................. 67
30. The Semantic Prosodic Profile of entirely ...................................................................... 68
31. The Semantic Prosodic Profile of fully ........................................................................... 69

XI
32. The Semantic Prosodic Profile of perfectly .................................................................... 70
33. The Semantic Prosodic Profile of totally ........................................................................ 70
34. The Semantic Prosodic Profile of utterly ........................................................................ 71
35. Semantic Prosodic Profiles of Booster + Adjectives ..................................................... 72
36. Overall Percentages of Maximizer Patterns ................................................................... 74
37. Typical Patterns of ‘INT-adj’ in LOCNESS .................................................................. 76
38. Typical Patterns of ‘INT-adj’ in KTUCLE ..................................................................... 77
39. Typical Patterns of ‘INT-adj’ in TICLE ......................................................................... 77

XII
LIST OF FIGURES
Figure No. Name of Figure Page No.
1. Contrastive Interlanguage Analysis ................................................................................ 15
2. Interlanguage .................................................................................................................. 17
3. The Five Mental Processes of Interlanguage .................................................................. 18
4. Varieties of English ........................................................................................................ 26
5. The Subsets of Intensifiers .............................................................................................. 40

XIII
LIST OF ABBREVIATIONS
BNC : British National Corpus
CIA : Contrastive Interlanguage Analysis
CLC : Contrastive Interlanguage Analysis
EA : Error Analysis
EFL : English as a Foreign Language
IL : Interlanguage
KTUCLE : Karadeniz Technical University Corpus of Learner English
L1 : First Language
LL : Log-likelihood Ratio
LOCNESS : Louvain Corpus of Native English Essays
NL : Native Language
NNS : Non-native Speakers
NS : Native Speakers
SLA : Second Language Acquisition
SP : Semantic Prosody
TICLE : Turkish International Corpus of Learner English
TL : Target Language

1
INTRODUCTION
English is “– the language - on which the sun does not set, whose users never sleep”
(Quirk, 1985: 1)
There has been an increase in the number of non-native speakers of English worldwide; even
they greatly outnumber native ones at present time. The emergence and spread of English as the
world’s first global language, namely as lingua franca, has fundamentally altered the focus of
linguistic studies paving the way for teaching and learning it in an efficient way. Foreign language
acquisition at tertiary level has been a controversial issue for decades in places where English is not
the first language. This fact has been certainly valid in Turkey where English language is the
medium of instruction in many universities today.
University students come across a wide range of challenges and adaptations, many of which
involve even the process of learning a new language (Biber, 2006: 1). Most tertiary level students
as non-native learners of English as a Foreign Language (henceforth, EFL) may not been furnished
with an adequate theoretical knowledge on the target language, so they are likely to encounter some
challenges in putting what they have learned into practice. In other words, even advanced level of
EFL learners may not be well-equipped with vocabulary and grammar rules; hence, they may not
be capable of achieving a proficiency and accuracy in writing skills. According to Pawley and
Syder (1983), the sentences that they generate can be acceptable and correct in terms of grammar,
but they may lack “idiomaticity” and “nativeness” (as cited in Wang, 2017: 3). More specifically,
Lorenz (1998: 53) claimed that advanced learners are typically considered as ‘advanced’ for being
able to command the “basic rules of syntax and morphology”. The students’ diversion from the
native-like usage, particularly in written production, creates an impact of foreign sounding or leads
to “lack of idiomaticity” (Lorenz, 1998: 53).
It is obvious that while acquiring a new language, the EFL learners may inevitably
experience difficulty in putting words together in a meaningful way. This is considerably because a
good command of vocabulary has the central place in language learning process. As Levelt (1989:
181) puts forward, “the lexicon is the driving force behind sentence production.” According to
Meara (1980: 221), English learners unhesitatingly accept the truth that they have serious problems
in learning vocabulary. After overcoming the early stages of foreign language learning process,
almost all of them agree on the point that the vocabulary acquisition still remains a difficult area to
learn. Undoubtedly, writing, as a productive language skill, can be regarded as one of the most

2
problematic ways of language use by learners. Thus, the importance of mastering vocabulary in
writing has entailed more involvement of both EFL learners and researchers in this problematic
area.
The ability to write in foreign language is becoming increasingly fundamental, especially for
academic purposes; thus, productive knowledge of tertiary level EFL learners is considered to be
worth of further investigation through corpus linguistics. In other saying, it is emphasized by Leech
(1998: xviii) that according to most of the EFL learners, writing is an extremely significant
competency, and it is valuable for creating corpora from written learner language. In writing, the
potential problems and errors are inevitable with a limited amount of English that the language
learners have acquired during their interlanguage development. Thus, much attention is required to
be given to interlanguage development level of EFL learners so as to throw light on their awareness
of language use, especially in writing. The term “interlanguage (IL)” can be comprehended easily
when it is considered as a continuing process between first language and foreign language that the
language learners take part in actively and progress in time (Larsen-Freeman and Long, 1991: 60).
To understand the concept better, interlanguage can be defined as a state of language learning
process where target language (L2) is not completely acquired yet, and it still carries the traces of
mother tongue (L1).
One of the many ways eliciting the features of interlanguage is to investigate the awareness of
EFL learners on semantic prosody, which can be described in a way, in which a hidden meaning,
either positive, negative or neutral, is revealed when certain node words frequently collocate with
other words from different semantic sets. Partington (1998) highlights that it is important for non-
native learners to have knowledge of semantic prosody in order to understand “what is
grammatically possible in their language production” as well as which is proper to use and what
really occurs (as cited in Fuqua, 2014: 79). Furthermore, being aware of semantic prosodic aspect
of a language helps language learners and interpreters to make a distinction among synonymous
words (Morley and Partington, 2009: 140). According to Chief et al. (2000), many language users
or learners have to select certain words between lexical options which are provided by context or
their own mental lexicon, either consciously or unconsciously. The choice of the most contextually
appropriate word may not be easy for near-synonymous ones in terms of nuances and collocational
restrictions (as cited in Kara, 2017: 97). Intensifiers are among these near-synonymous words with
which foreign language learners frequently come across in daily life and struggle to choose
correctly between these items having nearly the same meaning. For Biber et al. (1999), the use of
English intensifiers differs in spoken and written production, and the frequency of intensifiers is
found to be more abundant in writing than in speaking (as cited in Dong and Chiu, 2013: 32). In
this sense, this particular corpus-based study concentrates upon semantic prosodic analysis of
intensifiers in Turkish learners’ academic writing and attempts to investigate whether there are any
influences of interlanguage development on their intensifier use.

3
Intensifiers in current English belong to a group of words typically functioning as adverb or
adverbials. Portner (2006: 149) states that there is a wide range of adverbials in world languages,
and it can be difficult to explain what the best way is to comprehend all of them. On the importance
of using intensifiers, Lobov (1984: 43) states that “at the heart of social and emotional expression is
the linguistic feature of intensity.” Partington (1993: 178) describes intensification as “a direct
indication of a speaker’s desire to use and exploit the expression of hyperbole.” In addition, he
underlines the significance of intensification for a successful conversation by adding that
intensifiers are generally used for strengthening the messages by affecting, approving or even
insulting to affect the receivers’ perception.
The EFL learners use different kinds of intensifiers in writing. “Although syntactically
marginal, adjective intensification plays a major role in spoken and written interaction” (Lorenz,
1998: 53). Novice writers might know dictionary meaning of intensifiers in English language;
however, they may ignore all other functions or contextual use of them. Gong and Wu (2012: 4)
points out that conventional dictionaries are inadequate for presenting additional knowledge on
various “usages, collocations, and connotative meanings for lexical words.” Therefore, it remains a
problem for foreign language learners and interpreters to use the vocabulary of the target language
like a native speaker. Another problem concerning the EFL learners’ use of intensifiers in written
discourse is L1 transfer. For example, most of the English intensifiers having some nuances in
meaning have the same equivalence in Turkish language. Therefore, Turkish EFL learners may get
difficulty in making a selection among English intensifiers which sounds more proper in certain
semantic sets. Restraining themselves from using a wide range of intensifiers in writing, they tend
to write with a limited set of intensifiers like very in order to eliminate the potential of making
mistakes. It is quite necessary to gain better insight into underlying problems of non-native learners
of English language while using intensifiers in their written essays, whether they overuse or
underuse them, or they neglect semantic prosodic nature of intensification.
The best and most convenient way to carry out an elaborative semantic prosodic analysis of
intensifiers can only be possible by a computerized corpus analysis. “It should be borne in mind
that semantic prosody is a relatively new concept and as such requires careful elaboration”
(Steward, 2010: 54). “The use of corpus for lexical investigation is not a recent phenomenon but its
full significance and value has, in the last decade, been realized especially after the introduction of
computerized corpus tools by a much larger group of linguists all around globe” (Özbay and
Kayaoğlu, 2016: 343). It is an undeniable truth that human intuition cannot be adequate alone for
disclosing semantic prosodic properties of certain word sets. Native speakers can sometimes make
accurate exemplifications on collocations, but they may not give precise estimations about their
frequency and overall distribution (Stubbs, 1995: 24). Hunston (2007) also claims that it would
hardly be possible to determine the prosodic profile of a word without the technological advances
in the methodology of corpus linguistics. Thanks to corpus linguistics, the study of semantic

4
prosody has become feasible even on larger language data. This corpus-based study aims at
investigating EFL learner’s semantic prosodic behavior while using English intensifiers in written
production in comparison to native speakers.
Apart from this introductory part, the current thesis has four main chapters that are
framework of the study, literature review, methodology, and findings and discussions as well as a
final part presenting conclusion and suggestions along with limitations, pedagogical implications.

5
CHAPTER ONE
1. FRAMEWORK OF THE STUDY
1.1. Introduction
The first chapter which is divided into seven subheadings presents the background of the
study, statement of the problem, significance and purpose of the study, main research questions,
operational definitions and outline of the thesis. The background part highlights the importance of
computerized learner corpora in corpus linguistics as well as Contrastive Interlanguage Analysis as
the research methodology of the thesis. Then, the main problem of the study is discussed in the
light of the research questions. Next part introduces the significance and aim of the research which
tries to investigate semantic prosodic analysis of intensifiers in terms of their usage patterns and
meanings based on native versus non-native corpora. Finally, the first chapter ends with the
operational definitions used in both theoretical and methodological background of the thesis, and it
outlines the research as a whole.
1.2. Background of the Study
Corpus linguistics, to a great extent, has been facilitating the studies on semantic prosody in
recent years. This explanation can be supported with McEnery and Wilson’s argument (2001: 1-2)
which asserts that corpus linguistics works on ‘real life’ evidences, and it is “a methodology rather
than an aspect of language requiring explanation or description.” In an attempt to illuminate corpus
linguistics further, it would be a wise step to touch upon the definition of ‘corpus’ in the first place.
For Atkins and Clear (1992), “a corpus is a body of text assembled according to explicit design
criteria for a specific purpose” (as cited in Granger, 1998: 7). As Francis (1982) defines, corpus is “a
collection of texts assumed to be representative of a given language, dialect, or other subset of a
language, to be used for linguistic analysis (as cited in Tognini-Bonelli, 2001: 53). Corpus linguistics,
which has gained much attention in language teaching area, is valued by Biber and Conrad (2001:
332) in the way that corpus is of high importance because it holds natural evidences in a context, and
it also provides a new insight with its quantitative analysis without which it could be otherwise
impossible for researchers to examine linguistic patterns.
One of the pioneers of corpus linguistics, Granger (1998: 3) asserts that computer has an
important role in corpus linguistics. She confirms that with the widespread use of the computer

6
corpus technology, a new discipline has appeared called ‘corpus linguistics’ which cannot be solely
regarded as a ‘computer-based methodology’, but it is a “new research enterprise, a new way of
thinking about language, which is challenging some of our most deeply-rooted ideas about
language” (Leech, 1992; as cited in Granger, 1998: 3). Granger (2004: 124) puts forward that
“computer learner corpora are electronic collections of spoken or written texts which are produced
by foreign or second language learners.” Aijmer (2002: 56) also claims that different aspects of
interlanguage, which has been a rather difficult area for investigation before, can be analyzed with
the help of computer learner corpora. Similarly, Louw (1993) states that semantic prosody is a
linguistic feature which has been only investigated through computational methods to be able to
reveal its level of progress (as cited in Stewart, 2010: 80).
At the center of many studies utilizing computerized learner corpora lies the methodology of
Contrastive Interlanguage Analysis (CIA). This recent approach, which Granger (1998) calls CIA,
comprises the comparisons of both native speakers versus non-native speakers (NS / NNS) as well
as non-native speakers versus non-native speakers (NNS / NNS). Granger (1998: 13) suggests that
native language and interlanguage (NL / IL) comparisons aim to uncover the features of “non-
nativeness” of learner language whereas the main objective of the comparison of two
interlanguages (IL / IL) is to hold a mirror to the nature of interlanguage. As Barlow (2005) notes,
some concerns occur when a corpus of learner is compared to a corpus of native speakers. The
researcher additionally argues that studies utilizing native corpora as a norm to compare with
learner corpora reflects “the nature of interlanguage” by highlighting the underlying aspects of non-
native speech or writing (Barlow, 2005: 342). Correspondingly, Leech (1998) states that “a
comparison of learner corpora with NS corpora provides data on the properties of interlanguage,
covering features which are typically overused or underused, in addition to those which are
misused by language learners” (as cited in Barlow, 2005: 342).
Among many interlanguage problems that EFL learners have recently encountered in
language learning process is semantic prosody, and it has become an increasingly important and
popular field of linguistic studies in the last two decades. As Zhang (2010: 190) asserts, “the notion
of semantic prosody was primarily introduced by Louw in 1993.” Additionally, Stubbs (1996)
suggests that semantic prosodies are divided into three categories: “some words tend to have a
predominantly negative prosody, a few have a positive prosody and many words are neutral” (as
cited in Wang, 2017: 15). As one of the fundamental fields of inquiry in corpus linguistics, this
study elaborates on semantic prosody roughly following Stubbs’s way of classification into three as
negative, positive or neutral.
The semantic prosody can be investigated through the use of intensification by non-native
learners because it seems a problematic area even for advanced EFL learners having a higher
proficiency in language (Lorenz, 1999). Different forms of intensifiers have been categorized in

7
reference books of English grammar as well as in earlier studies. Quirk et al. (1985: 445) identify two
subcategories of intensifiers: “amplifiers and downtoners.” Lorenz (1999: 24) states that “on the
whole Quirk et al.’s classification has, of course, been highly influential” since many researchers
investigating the intensification employ Quirk et al.’s category in their studies (Partington, 1993;
Lorenz, 1999; Méndez-Naya, 2003; Wang, 2017, etc.). Therefore, the present study adopts the
categorization of Quirk et al. (1985) as the basis of analyzing English intensifiers.
As a significant lexical class in terms of strengthening meaning, intensifiers can also be
examined from different aspects, such as usage pattern and evaluative meaning. For Hunston and
Francis (2000: 3), “a pattern is a phraseology frequently associated with (a sense of) a word,
particularly in terms of the prepositions, groups, and clauses that follow the word.” In a broader
sense, they emphasize the interdependency of meaning and patterns with the explanation that “in
many cases different senses of words are distinguished by their typical occurrence in different
patterns; and secondly because words which share a given pattern tend also to share an aspect of
meaning” (Hunston and Francis, 2000: 3).
To sum, this comparative interlanguage analysis concentrates upon different usage patterns of
adjective intensification and their association with meaning from semantic prosodic point of view
by comparing non-native tertiary level EFL students with native speakers.
1.3. Statement of the Problem
Among four essential language skills, which are listening, speaking, reading, and writing, the
last one is commonly treated as the most challenging by EFL learners. The language learners do
not naturally acquire writing skill, but they learn and practice it over time. For certain, a language
being learnt is enhanced thanks to an adequate amount of exposure. That is to say, written
production in foreign language needs much time and effort in order to gain greater comprehension.
It is an absolute fact that writing in target language is a real concern for most learners.
Although the EFL students endeavor to memorize and learn the meaning of many isolated words,
they still have difficulty in employing them in an appropriate way. Conzett (2000) supports the
view that although learners of a foreign language might have the knowledge of many words or
grammar rules, they may be insufficient in using those words in combination with different
linguistic items; therefore, they may have inadequate competency to create a richer intended
meaning. In other saying, words may have different meanings in different semantic settings. Thus,
EFL learners should know how to use vocabulary and collocations in a context to express
themselves well.

8
In written English, intensification has “a potential to be a challenge for tertiary level EFL
learners since intensifiers may have synonymous meanings” (Özbay and Aydemir, 2017: 40). Biber
(1999) suggests that both in speaking and writing, one should make a selection among a great many
degree adverbials intensifying adjectives which can be used interchangeably like “fully and
‘strongly”, but “in many cases, there is little semantic difference between the degree adverbs. Thus
the adverbs could be exchanged in the following pair of sentences with little or no change of
meaning: That’s completely different. It’s totally different” (as cited in Kennedy, 2003: 470).
Before I was graduated as an English major, I had some concerns about using such adverbials to
put an emphasis or to add evaluative value to my written expressions. I had a great inclination to
use intensifiers in writing; however, I did not pay attention to their collocational nature and had
little semantic awareness about their usage patterns as an EFL learner. The wide range of
intensifiers that I had encountered in native writing samples made me stay focused on this issue as
an individual interest and preference for studying. In order to find out the nuances among near-
synonymous degree adverbials, I decided to conduct a corpus-based study dealing with the
semantic prosodic analysis of intensifiers in English language.
It is obvious that the learners of English language have an inclination to use intensifiers for
capturing readers’ attention on the intended message and to enhance the value of their writing skills.
Having a full command of the dictionary meaning of intensifiers may be insufficient for their
meaningful use. In a similar sense, Ahmadian et al. (2011) claim that learning the meaning of
individual words is not sufficient for acquiring fluency in L2. They argue that “knowing the way
words combine into chunks (collocations) characteristic of the language, as well as being aware of the
conditions of semantic prosody is necessary” (Ahmadian et al., 2011: 294). Concerning this truth, this
study mainly focuses on the semantic prosodic orientation of English intensifiers both in native and
learner language so as to reveal EFL learners’ potential to command their vocabulary knowledge and
skills in certain semantic discourses. Also, the study seeks to examine the role of degree adverbs in
English vocabulary and practicing them in writing skills. As Lorenz (1999: 27) suggests, intensifier
usage of target language learners can be investigated with the purpose of gaining an appreciated
understanding of behavior in target language. This will also contribute to raising EFL learners’
awareness of adverbials and intensification to achieving fluency and accuracy in English.
1.4. Purpose and Significance of the Study
The primary aim of this research work is to investigate semantic prosodic nature of
intensifiers used by both native speakers and Turkish EFL learners in their expository and
argumentative essays. Along with a special focus on usage patterns and meaning of intensifiers, the
study also tries to make a comparison between native and non-native learners regarding their
semantic prosodic awareness on adverbial use. The reason behind choosing the intensifiers as the
subject of study is that intensifiers are the kind of adverbials, which are frequently used by EFL

9
learners in both oral and verbal language with an aim to add an emphasis or force to the meaning,
without paying attention to their positive or negative semantic prosodic features and collocational
usage patterns. In the scope of the study, it is contended that the mastery of these adverbials will
likely to increase the awareness of tertiary level EFL students towards the usage patterns of these
lexical items as well as their semantic prosodic analysis perspectives so that they make more
appropriate lexical decisions as well as consider the prosodic profiles.
From a broader perspective, ‘intensifier’ is used as an umbrella term covering all
intensification types, usage patterns and meanings encountered in the writings of both native and
non-native speakers of English. Although, ‘intensifiers’ are used as a general label on research title,
the focal point of the study is on a specific category of intensifiers, namely ‘amplifiers’. In this
study, the seven frequently used amplifiers selected from the studies of Kennedy (2003) and Wang
(2017) are comparatively analyzed concerning their types and usage patterns. The study tries to
find an answer whether the usage patterns have any effect on the meaning of intensifiers. All these
issues shed light on the semantic prosodic awareness of non-native learners versus native
intensification. In this context, this study aims to draw a detailed picture of the way Turkish EFL
learners use amplifiers having a position adjacently before adjectives in written language.
A comparative corpus research on the semantic prosodic analysis of intensifiers requires an
extensive investigation of large scale of learner corpora; thus, such studies can simply and
objectively be executed with the aid of special corpus tools or concordance programs in a
computerized environment. In an effort to carry out a contrastive corpus analysis, first and
foremost, a corpus needs to be compiled carefully because “the results are only as good as the
corpus” (Sinclair, 1991; as cited in Granger, 1998: 7). Therefore, a good compilation of a corpus is
the key element. Literally, the quality of the data adds great deal to the validity of the investigation
(Granger, 1998). Also, it is not always so easy to have an access to corpus of English learners
which is ready for analysis and freely available. Since I have no experience in teaching as a
profession, I have never had any chance to compile my own corpus. Therefore, with the guidance
of my supervisor, I have decided to heavily concentrate on a learner corpus called KTUCLE
compiled from the essays of tertiary level language students from Department of English Language
and Literature in Karadeniz Technical University.
The study is conducted by utilizing three distinct corpora; KTUCLE (Karadeniz Technical
University Corpus of Learner English) together with TICLE for non-native corpora and LOCNESS
(Louvain Corpus of Native English Essays) for native corpus. The central learner corpus of the
study, KTUCLE, contains essays written by the students of a Turkish university Karadeniz
Technical University and consists of 709,749 words. The second learner corpora is TICLE, as
Turkish sub-corpus of ICLE (International Corpus of Learner English), comprises 223,449 tokens
in total. It is composed of argumentative essays that were written by Turkish adult learners of

10
English. The reference corpus called LOCNESS contains essays of native speakers of English and
includes a total of 361,054 words. The present study analyzes the different usage patterns of
intensifiers and their semantic prosodic nature in the two learner corpora; namely KTUCLE and
TICLE, comparing native speakers of English with reference to LOCNESS by using Sketch Engine
as a concordancer.
More specifically, the study which attempts to investigate the semantic prosodic awareness of
Turkish EFL learners on the use of intensifiers in their argumentative essays in English mainly
adopts the methodological approach of Contrastive Interlanguage Analysis (CIA), which includes
two kinds of comparison in nature as Granger (1998: 12) proposed: comparing native language and
interlanguage (NL vs. IL) and comparison of two distinct interlanguages (IL vs. IL). The purpose
of such a comparative research design is to identify the areas of language use that are resembling
and differentiating between native and non-native speakers of English in order to reveal common
interlanguage aspects of EFL learners. This research is conducted through the use of two learner
corpora: KTUCLE and TICLE as non-native learner corpora as well as LOCNESS for the control
corpus. The use of two different non-native learner corpora is most likely to provide information
about interlanguage features of the EFL learners.
1.5. Research Questions
The major focus of the recent study is on conducting a semantic prosodic analysis of
intensifiers in argumentative writing of Turkish EFL learners with a view to characterizing their
usage patterning and meaning features. The main research question inquires the semantic prosodic
awareness of Turkish EFL learners on the use of intensifiers in their written texts.
Also, this research tries to find answers to the following questions:
1. What is the frequency distribution of intensifiers in argumentative essays of tertiary level
Turkish EFL learners and native speakers of English in selected native and non-native
corpus?
2. Do intensifiers have a specific semantic prosodic profile such as positive, negative or
sometimes neutral as evidenced in the three corpora under investigation?
3. What are the different usage patterns of intensifiers existing in native corpus and non-
native corpora?
1.6. Operational Definitions
Concordancer: Text retrieval programs which are called ‘concordancers’ are among the
extensively used linguistic software devices (Granger, 1998: 14).

11
Corpus: It is an extensive compilation of texts, either spoken or written, which are utilized
for research purposes (Collins Cobuild Dictionary, 2001: 313).
Corpus Linguistics: It is the study of large scale data related to language. Corpus linguistics
takes the advantage of computer in order to analyze huge amounts of transcribed nonverbal texts
(McEnery and Hardie, 2011).
Contrastive Interlanguage Analysis: Introduced by Granger (1998), CIA combines the two
major approaches: an IL vs. IL comparison and an IL vs NL comparison.
Intensifier: Words like very and extremely that are located before an adjective or adverb in
order to enrich its meaning is called ‘intensifier’ (Collins Cobuild Dictonary, 2001: 756)
Learner Corpora: Studies find ‘learner corpora’ helpful in second language acquisition as
they are useful in creating a learner language profile. They focus on error analysis or extensively or
rarely uttered words of the learner compared to native speakers (Baker, et al., 2006: 103).
Reference Corpus: Reference corpus aims to depict the general nature of the language via a
large scale corpus design rather than a sample of and specific written text (Baker, et al., 2006: 138).
Semantic Prosody: It is associated with lexical items collocating with semantic sets of words
that are either positive, negative or sometimes neutral (Stubbs, 1995).
Subcorpus: “A subset of a corpus, either a static component of a complex corpus or a
dynamic selection from a corpus during on-line analysis” (Atkins et al., 1992: 1).
1.7. Outline of the Study
This part presents the overall structure of the thesis which is consisted of five sections: as
follows:
Introduction: As the initial section of the study, it gives overall information and rationale
behind the thesis.
Chapter One: It presents the background information, the aim of the study, the significance
of the study as well as the statement of the problem along with research questions.
Chapter Two: It is the review of the literature which gives detailed information on
definitions of semantic prosody and intensifiers. Besides, it presents previous corpus-based
semantic prosodic studies in other countries related to use of intensifiers.
Chapter Three: It is the methodology part which presents the methods and procedures
employed in this study.
Chapter Four: It is the part of findings and discussion which introduces data obtained
through corpora and its elaborative analysis based on the research questions.
Conclusion and Suggestions: It presents an overview of the study as well as limitations,
pedagogical implications, and suggestions for further research.

12
CHAPTER TWO
2. LITERATURE REVIEW
“I'm glad you like adverbs — I adore them;
they are the only qualifications I really much respect.”
Henry James (1902)
2.1. Introduction
This chapter reviews the relevant literature in the field of applied linguistics. From a general
perspective, this part initially highlights the importance of corpus linguistics in understanding
language and the use of corpora in linguistic investigations. Then, the chapter presents a theoretical
background discussing the major concepts of the study. As the core of the research, this chapter
also evaluates relevant studies on EFL learners’ use of intensifiers in written production with a
special focus to usage pattern and meaning.
2.2. The Importance of Corpus Linguistics in Understanding Language
Language is a system using signs and sounds to convey messages or meanings among the
members of society. A pioneer linguist Chomsky (2006: 88) claims that “when we study human
language, we are approaching what some might call the human essence, the distinctive qualities of
mind that are, so far as we know, unique to man.” Basically, the scientific study of this system
unique to human beings for communication is called linguistics. In addition to the aforementioned
views, “today the field of linguistics studies not just the nuts-and-bolts of forms and their
meanings”, but also the process of language learning, its role of creating interaction, the help of
computers in analyzing language, and the representation of language in human brains (Fasold and
Connor-Linton: 2006: 10).
There are numerous subfields of linguistics each dealing with another aspect of languages.
Corpus linguistic, one of these branches in applied linguistics, has started to develop rapidly in the
last three decades with the availability of computer technology in modern age. Aijmer and
Altenberg (1991: 1) claim that the reason of this development arises from two major cases that
occurred in the 1960s; the first one was launching of the Survey of English Usage (SEU) by
Randolph Quirk and the second event triggered by the development in computational area which

13
paved the way for storing, scanning and grouping materials. The Brown corpus which is well-
known as “the first modern computerized corpus of the English language” was compiled by Nelson
Francis and Henry Kucera at Brown University (Aijmer and Altenberg, 1991: 1). From then on,
especially after 1980s, corpus linguistics gained popularity among scholars and linguistics
(McEnery et al., 2006: 4).
From an etymological point of view, “corpus is derived from the Latin word meaning body”
(Dash and Arulmozi, 2018: 4). Generally speaking, in linguistics, “the term corpus has been
historically stands for ‘body of data’ referring “a sample of utterances or texts – which provides
evidence about the language it comes from” (Cameron and Panovic, 2014: 81). However, they add
that nowadays in corpus linguistics, corpus is mostly used as a body of genuine linguistic input that
is kept in computational form and analyzed applying computational software. McEnery et al.
(2006: 5) summarized the scope of ‘corpus’ echoing the definitions of other scholars such as
Francis (1992) and Atkins et al. (1992); “…there is an increasing consensus that a corpus is a
collection of machine-readable (2) authentic texts (including transcripts of spoken data) which is
(3) sampled to be (4) representative of a particular language or language variety.”
According to Granger (2002: 4), corpus linguistics is a methodology of applied linguistics
which uses electronic linguistic data compiled from texts. She also argues that corpus is not a new
field in linguistics, but it is just the core of the linguistic evidence; thus, it happens to be a strong
methodology. For Kennedy (1998), corpus linguistics differs from other linguistic theories in terms
of the sources of evidence that CL provides (as cited in Şanal, 2007: 21):
Linguists have always needed sources of evidence for theories about the nature, elements,
structure and functions of language, and as a basis for stating what is possible in a language. At
various times, such evidence has come from intuition or introspection, from experimentation or
elicitation, and from descriptions based on observations of occurrence in spoken or written texts.
In the case of corpus-based research, the evidence is derived directly from texts. In this sense
corpus linguistics differs from approaches to language, which depend on introspection for
evidence.
In a similar sense, Altenberg (2011: xiii) holds the view that “although corpus linguistics is
strictly speaking a methodology rather than a theory of language, it has opened up new approaches
to the study of language and new and fruitful ways of matching theory and data.” As a linguist,
Sinclair (2004: 1) notes that working on corpora, a researcher may feel a sense of “creative energy”
which makes the studies applicable, subtle and flexible in nature. Startvik (2007: 23) agrees upon
the idea of Wallace Chafe (1992):
What, then, is a ‘corpus linguist’? I would like to think that it is a linguist who tries to
understand language, and behind language the mind, by carefully observing extensive natural
samples of it and then, with insight and imagination, constructing plausible understandings that

14
encompass and explain those observations. Anyone who is not a corpus linguist in this sense is,
in my opinion, missing much that is relevant to the linguistic enterprise.
Stubbs (1996) claims that “the heuristic power of corpus methods is no longer in doubt” (as
cited in Granger, 2002: 4). Not surprisingly, corpus linguistics enables the exploration of new
aspects of language and provides insights into the areas of language learning and teaching. It has
allowed scholars and linguists to explore many areas which could be difficult to investigate without
the advent of computers. According to Aijmer and Altenberg (1991: 2), the study of corpora
empowers the motivation of English language studies. When compared to old kinds of language
materials, corpus data provides more authentic evidence for the descriptive analysis of “lexis,
syntax, discourse and prosody” in English language. In the second place, corpus provides an
efficient basis for comparison of all aspects of English language in a probabilistic and quantitative
manner.
Apart from its benefits, the use of corpus has some limitations for linguistic studies as
summarized by Hunston (2002: 22-23). First of all, a corpus is thought to give information about
frequency, not possibility. The conclusions that are drawn from a corpus analysis should be
considered as inferences, not truths. In addition, a corpus can provide evidence instead of concrete
information. Lastly, a corpus reflects the aspects of a language “out of its context.”
As this section summarizes, the study of corpora plays an important role in understanding the
nature of language. When conducting a linguistic research, the data should have an objective base
to make an accurate interpretation about the language itself. Thus, corpus linguistics becomes an
inevitable part of language studies with the help of computer-assisted comparative analysis. Instead
of depending solely on the intuitions, the linguists or researchers can reach accurate numerical data
by comparing many aspects of different languages. With this in mind, this study adopts corpus
linguistics as the methodological basis to provide empirical evidences. The theories used in the
current corpus-based study will be explained in the next section.
2.3. Theoretical Background of the Study
The current study of corpus-linguistics investigates the semantic prosodic analysis of English
intensifiers by contrasting two computerized learner corpora with a reference corpus to elicit some
interlanguage problems of Turkish EFL learners. Depending on this main research problem, the
underlying theoretical concepts behind the thesis; respectively contrastive interlanguage analysis
(CIA), computer learner corpus (CLC) research, and semantic prosody (SP), will be discussed in
detail under this title.

15
2.3.1. Contrastive Interlanguage Analysis (CIA)
Linguists have always been dealing with comparing different language systems in pursuit of
eliciting learning difficulties. Contrastive analysis, thus, is considered to have a great contribution
to understanding many dimensions of second or foreign language learning process. On the other
side, the emergence of ‘interlanguage’ theory helps researchers examine learner’s current first
language abilities and their progress towards the target language. Contrastive Interlanguage
Analysis (CIA), which can be considered as an integration of these two approaches, namely
contrastive analysis and interlanguage development research, was proposed by Granger in 1996.
Unlike contrastive analysis ‘in the traditional sense’ embarking on a comparison between the
mother tongue and second language, Contrastive Interlanguage Analysis (CIA) mainly depends on
comparing learner data with native speaker (L2 vs. L1). This new approach, which Selinker (1989)
regarded a “new type of CA” and which Granger called CIA “lies at the heart of CLC-based
studies” (Granger, 1998: 12). According to Granger (1998: 12), “CIA involves two major types of
comparison: (1) NL vs. IL, i.e. comparison of native language and interlanguage, and (2) IL vs. IL,
i.e. comparison of different interlanguages” as shown in the diagram below:
Figure 1: Contrastive Interlanguage Analysis
Source: Granger (1996: 44)
Granger (2015: 8) explains the abbreviations that she used in this diagram with her own
statements as follows:
In this first presentation of CIA, native and learner languages were abbreviated as NL and IL
(interlanguage) respectively and the language used to illustrate the method was English: E1 for
native English and E2 for English as a foreign language. The IL/IL branch of the method was
illustrated with interlanguages representing different mother tongue backgrounds: English of
French learners (E2F), German learners (E2G), Swedish learners (E2S) and Japanese learners
(E2J).

16
Granger (2015: 8) also uses some other abbreviations or ‘labels’ during the presentation of CIA
approach: ‘NS’ represents “native speaker while ‘NNS’ refers to “non-native speaker”. In addition,
‘L1’ is abbreviated for “first/native” and ‘L2’ for “foreign/second language.”
Before in-depth evaluation of Contrastive Interlanguage Analysis, as one of the significant
concepts that the present study adopts by nature, the theory of ‘interlanguage’ needs inevitably a
broad explanation to shed light on the progress that CIA went through until its emergence.
2.3.1.1. What is Interlanguage?
An American linguist Selinker (1972) created the concept ‘interlanguage’ which refers to a
linguistic system. According to Ellis (1997: 33), interlanguage centers on the mother tongue but
again dissimilar with it and the target language. In other words, it is a kind of linguistic state
isolated from both EFL learners’ mother language and the target language. The term interlanguage
was derived from Weinreich’s (1953) “interlingual identifications” (as cited in Selinker 1972: 211).
Today, in addition to interlanguage, the term “language learner language” has been also preferred
by researchers in linguistic studies (Lennon, 2008: 56).
Selinker (1972) describes interlanguage as “a dialect whose rules share characteristics of two
social dialects of languages, whether these languages themselves share rules or not” (Corder, 1981:
17). In other words, the interlanguage is a linguistic organization “in its own right” (Lakshmanan
and Selinker, 2001: 395). It can be supposed to be a stage when the learner is not able to have
fluency and accuracy in language proficiency. Hence, the linguistic proficiency of a learner in
second language or foreign language learning process can precisely be characterized with the
analysis of interlanguage in its specific set of rules. Being discrete in the sense that learner
language is clearly different form mother language and target language, interlanguage is likely to
have the following main features suggested by Trawinski (2005: 54):
erroneous (containing language errors on various language levels)
systematic (rule-governed and common to all learners)
dynamic (constantly changing through the gradual process of accommodation of new rules)
distinct from the L1 and L2 (including grammatical/lexical/phonological elements of both
language)
permeable (open to amendment, not fixed)

17
Figure 2: Interlanguage
Source: adopted from Corder (1981: 17)
The diagram above simply illustrates the theory of interlanguage in which ‘Language A’
stands for first language (L1). In an attempt to explain it further, Larsen-Freeman and Long (1991:
60) point out that interlanguage may be better recognized when it is considered to be a
“continuum” between the mother tongue and the second language. The interlanguage is a system
having its own rules. In its core sense, interlanguage can also be termed as a linguistic system in
progress under the influence of a learner’s both mother tongue and the second language. Likewise,
as Tarone (2006: 747) asserts, the learner language is considered as a detached system in linguistics
which remains diverse from the mother tongue and the target language, but needs both of them to
identify the learners’ interlingual behaviours.
Selinker’s (1972) identification of five principle cognitive processes underlying interlanguage
concept is summarized by Ellis (1994: 351) as follows:
1. Language transfer
2. Transfer of training
3. Strategies of second language learning
4. Strategies of second language communication
5. Overgeneralization of the target language material
These five processes refer to (1) transmitting the knowledge from one language to another (not all
but some elements might be transmitted from mother language to second language), (2)
transmitting the competencies acquired while learning language (a number of interlanguage items
may arise from the aspect of teaching), (3) the techniques used for acquiring foreign language (the
target language learner may define the learning equipment), (4) the techniques for communication
(the target language learner may define the appropriate path for taking part in conversation with
target language user) and (5) employing the general rules for the all elements of foreign language
(the items produced in the process of interlanguage arise from the obvious generalizing of

18
principles and lexical points of target language). This list appears to be valuable in terms of
presenting “mental processes responsible for L2 learning” as well as “key distinctions” such as
overgeneralization and language transfer (Ellis, 1994: 351).
The above-mentioned processes of interlanguage proposed by Selinker are visualized in
following diagram to clarify the mutual relationship among SL, TL and IL:
Figure 3: The Five Mental Processes of Interlanguage
Source: Krezeszowski, 1977 (as cited in Paradowski, 2008)
In his well-known essay “Interlanguage”, Selinker (1972: 214) also introduces three types of IL
produced utterances which are regarded as “psychologically relevant data of L2 learning”: “(1)
utterances in the learner’s native language (L1) produced by the learner; (2) IL utterances produced
by the learner; and (3) TL utterances produced by native speakers of that TL.”
It is crucial to state that interlanguage development plays a vital role in throwing light on the
undiscovered features of second or foreign language learning process. For Hasselgärd and
Johansson (2011: 33),
Learning a foreign language is a slow and, for most people, difficult process which rarely leads
to full mastery. Even advanced language learners make mistakes and normally have a limited
repertoire compared with native speakers of the target language. Problems may be linked to
features of the target language, the learner’s first language or to the learning process itself.
Revealing features of learner language, or interlanguage, has become an important means of
surveying both obvious and more subtle differences between interlanguage and native speaker
performance, and can potentially lead to improved language teaching as well as insights into the
processes of language learning.
In general terms, the concept of interlanguage looks for the answer of two questions (Ellis,
1997: 31) which ask for the nature of linguistic utterances in the target language and how those
utterances evolve as time passes. In order to seek an answer to such inquiries related to
interlanguage development, plenty of linguistic researches can be done through large scale of
computerized corpus analysis using statistical methods. The present contrastive corpus-based study

19
can be shown as an example to interlanguage investigation because it analyzes semantic prosodic
behavior of EFL learners while using English intensifiers in their argumentative essays. The study
is conducted on Turkish EFL learners who are currently going through a developmental process in
language learning. Further insights from previous studies of interlanguage would certainly clarify
the scope of such investigations utilizing learner corpora.
First of all, Hinkel’s (2002) book called Second Language Writers’ Text is actually based on
an interlanguage investigation examining academic written essays of native and non-native
speakers. The purpose of the study is to find out linguistic features of same written tasks given to
both native speakers and advanced non-native learners from different first language backgrounds
such as Chinese, Japanese, Korean, Vietnamese, Indonesian and Arabic nationalities studying in
US universities. The corpus compiled from 1457 essays, 1215 of non-native speakers and 242 of
native speakers, has a size of approximately 434.000 words. The study mainly analyzes the
frequency of 68 different linguistic features and patterns, 26 of which are found to have a
significant difference between L1 and six groups of English Language learners. The statistics show
that ELL texts have higher usage of the forms of ‘to be’ as the main verb, “predicative adjectives,
public and private verbs”, however, writing samples in L1 include “passive voice, perfect aspect,
and reduced adjective clauses”.
Another interlanguage research conducted by Kil (2003) analyzes five immigrant Korean
English learners in U.S. in terms of the common error in their writing samples. The focus was on
common error types such as ‘word order errors, co-occuring articles and determiners’ as well as
‘excessive use of wrong expressions (overgeneralization)’. Kill (2003: 247) concludes that the
errors in learner language progress in time.
In his dissertation, Zhang (2008) investigates the acquisition of ‘to be’ by Chinese learners of
English through a corpus-based approach. By comparing two Chinese learner corpora compiled
from English essays of students from Hong Kong and Mainland China, he aimed at giving a
general overview of the functions of BE in writing. The pedagogical implication drawn from the
research is that it finds solutions to challenges that the learners of second language might face and
presents strategies to overcome the difficulties in obtaining ‘to be’ and its related constructs.
As a recent example to interlanguage research, Asikin (2017) examined the existence and
underlying reasons of interlanguage in EFL students’ narrative writings. Ten narrative texts written
by nine Indonesian students in a high school in city of Kuningan were analyzed concerning the
concept of interlanguage introduced by Selinker in 1972. The results showed that the existence of
interlanguage errors were found in passive sentences, verb selection, using auxiliary verbs, and
translation. According to the researcher, interlanguage occurs due to an effect of first language.

20
From pedagogical point of view, it was implied that students should have an adequate exposure to
appropriate use of English grammar.
The current literature from Turkish L1 background abounds with studies of interlanguage
analysis of written discourse (Atasever, 2014; Bozdağ, 2014; Bozdağ and Badem, 2017; Can, 2009;
Eveyik-Aydın, 2015; Kilimci and Can, 2008; Kilimci, 2001; Özbay and Bozkurt, 2017; Şanal,
2007; Taş, 2008). However, corpus-based interlanguage studies in Turkey through the use of
KTUCLE (Karadeniz Technical University Corpus of Learner English) as the local learner corpus
of the study as well as TICLE (Turkish International Corpus of Learner English) which was
introduced by Kilimci and Can (2008) as a subcorpus of ICLE (International International Corpus
of Learner English) deserve initial mention since the present study utilizes both of them as learner
corpora under investigation.
Şanal (2007) made a lexical investigation in the written language of Turkish EFL learners by
contrasting TICLE and LOCNESS, which are also used as research corpora in my study. Through
the use of a computerized contrastive methodology, the researcher was in pursuit of exploring
learners’ lexical complexity and richness, the differences between reference and learner corpus in
terms of frequently used tokens, and stereotypes of learner corpus. The conclusion that Şanal
(2007: 77) drew from his analysis was that the reference corpus has a more complex lexical
diversity and density in comparison to the learner corpus. There were also some evidences of
overuse and underuse patterns of certain lexical items under the linguistic influence of learners’
mother tongue.
Moreover, Bozdağ (2014) investigated the interlanguage behaviours of Turkish EFL learners
in academic written discourse. In this corpus-based study, the researcher compared TICLE with
LOCNESS to find out the lexical preference of EFL learners by focusing on ten frequently used
“AKL (Academic Keyword List) verbs”. According to the results, the learners were found to
overuse and underuse some certain verbs in academic writing when compared with native speakers.
In their comparative interlanguage analysis, Özbay and Bozkurt (2017) examined tertiary
level Turkish EFL students’ expository argumentative essays in terms of the usage of complex
prepositions by comparing two corpora, respectively LOCNESS and KTUCLE, which is also the
local learner corpus in present research. The focus of paper was on overused and underused or
misused prepositions used by the learners in certain contextual situations. The results indicated that
the overuse and underuse profile in learner corpus have differences in comparison to reference
corpus.
A closer look to the prior relevant literature on the theory of interlanguage suggests that the
methodology of contrastive corpus-based analysis of learner corpora gives researchers and linguists

21
an opportunity to analyze interlanguage development of language learners besides their linguistic
awareness, lexical preference, and potential in making errors, or many other aspects in the process
of language learning.
2.3.1.2. Historical Overview of Contrastive Interlanguage Analysis
Before the emergence of the idea of ‘interlanguage’; linguistic studies employing
comparative procedures had undergone a significant shift from contrastive analysis (CA) to
contrastive interlanguage analysis. According to contrastive analysts, “the second-language
learner’s language was shaped solely by transfer from the native language” (Tarone, 2006: 747).
That is to say, contrastive analysis suggested that potential errors in foreign language learning
process mainly stem from the differences between L1 and L2. It is believed that by a comparison,
many problems and difficulties that learners may encounter in second language learning can be
predicted. As Mackey (2006: 435) stated, “differences between the learner’s L1 and L2 were
thought to be the main source of difficulty for L2 learners, and the phonology and grammatical
structures of languages were compared to predict areas of difficulty. This became formally known
as the contrastive analysis hypothesis (CAH).”
Contrastive Analysis Hypothesis was introduced by Lado (1957) in his book called
Linguistics Across Cultures which is accepted to have launched the contrastive analysis movement
in language teaching (Tajareh, 2015: 1106). Lado (1957) was the first who suggests comprehensive
procedures for contrastive analysis of languages predicting learner difficulties. In his own remarks,
Lado (1957: 2) asserts that “we assume that the student who comes in contact with a foreign
language will find some features of it quite easy and others extremely difficult. Those elements that
are similar to his native language will be simple for him, and those elements that are different will
be difficult.” Lado (1957: 59) also details this issue as follows:
Since even languages as closely related as German and English differ significantly in the form,
meaning, and distribution of their grammatical structures, and since the learner tends to transfer
the habits of his native language structure to the foreign language, we have here the major
source of difficulty or ease in learning the structure of a foreign language. Those structures that
are similar will be easy to learn because they will be transferred and may function satisfactorily
in the foreign language. Those structures that are different will be difficult because when
transferred they will not function satisfactorily in the foreign language and will therefore have to
be changed.
Although there was a consensus on the idea that comparison of languages could facilitate
predicting errors, later researches have shown that challenges in language learning process cannot
be reliably predicted by differences between languages. For example, Whitman and Jackson (1972)
examined four different contrastive analysis conducted in English and Japanese languages and

22
arrived at the conclusion that contrastive analysis may not predict alone the interference problems
of interlanguage (as cited in Larsen-Freeman and Long, 1991: 56).
According to Mackey (2006: 435), “studies have indicated that very few of the errors
produced by L2 learners can be traced to their L1. Instead, many errors are due to developmental
processes common to all learners regardless of L1 background.” Also, CAH was criticized by many
researchers because “many errors predicted by Contrastive Analysis were inexplicably not
observed in learners' language” (Rustipa, 2011: 17). According to Rustipa (2011), Contrastive
Analysis could not estimate difficulties in learning, but it is good at explaining errors.
Moreover, Wardhaugh (1970) distinguishes “the strong and the weak version” of the CAH.
According to the strong version, “contrastive analysis would be able to predict all learning
problems” while weak version implies that “contrastive analysis could explain the cause of many
but far from all, systematic-language learning errors” (as cited in Celce-Murcia et.al, 1996: 20).
Based upon this distinction, Larsen-Freeman and Long (1991: 57) made the following explanation:
“The strong version involved predicting errors in second language learning based upon an a priori
contrastive analysis of the L1 and L2, and as we have seen, the predictions are not always borne
out.” On the contrary, in the weak version researchers focus on learner errors by distinguishing
similarities and differences between two languages.
Error analysis (EA) appeared in the 1960s by Corder and his counterparts to criticize the
opinion that contrastive analysis could predict great majority of errors. Until the late sixties, the
general view held by the behaviorists on the issue of SLA was that the process of learning mostly
depends on acquiring new language habits. Therefore, errors made by learners were supposed to be
predicted by comparing mother tongue and target language. As Corder (1981: 1) emphasized that
“what was overlooked or underestimated were the errors which could not be explained in this
way”. It is an explicit fact that “learners from an error analysis (EA) perspective differs vastly from
the view of learners from the CA perspective.” In contrastive analysis, errors occur as a result of
interference with first language habits which are out of the learners’ control. However, in error
analysis, the learner have an active participation in “processing input, generating hypotheses,
testing them and refining them, all the while determining the ultimate TL level he or she will
attain” (Larsen-Freeman and Long, 1991: 61).
In 1970s, there was a shift from behaviorist methods towards various internal aspects dealing
with language acquisition of learners (Mackey, 2006: 435). Interlanguage theory appeared as a
reaction to the CAH, and it began to lose its importance. “While the status of the IL notion has
been maintained in the field, EA, like CA, fell into disfavor” (Larsen-Freeman and Long, 1991:
61). On the basis of the evidence that CA and EA have “weaknesses and failure”, the benefits of
these two hypotheses should not be underestimated in terms of their influence on SLA research.

23
For Zhang (2008: 10), a contrastive analysis between mother language and target language enable
researchers to understand the basis of learner language. On the other side, the researcher considers
error analysis as a simple method for analyzing difficulties in language learning process and fruitful
tool for teachers to identify EFL learners’ common problems. Nevertheless, many scholars turned
their attention towards interlanguage development to search for second language acquisition. It was
widely agreed upon that learners` linguistic systems were somehow different from both their L1
and L2. “Interlanguage is a theoretical construct which underlies the attempts of SLA researchers
to identify the stages of development through which L2 learners pass on their way to L2 (or near
L2) proficiency” (Ellis, 1989: 42).
In order or to better understand the scope of Contrastive Interlanguage Analysis, the
researchers should internalize all the aforementioned historical phases it has passed through so far.
An interlanguage analysis gives information about the nature of acquiring a foreign or second
language and focuses on the progress in learner language instead of predicting errors depending on
their first language. In that sense, this study carries out a contrastive analysis to elicit the
interlanguage problems and tendencies of tertiary level EFL learners in using intensifiers
2.3.1.3. Studies on Contrastive Interlanguage Analysis
As noted earlier, Contrastive Interlanguage Analysis compares native corpora with non-
native corpora to reveal linguistic features of learners based on their authentic speech or writing
samples. “NS/NNS comparisons can highlight a range of features of non-nativeness in learner
writing and speech, i.e. not only errors, but also instances of under and over representation of
words, phrases and structures” (Granger, 2002: 12). Some examples of studies applying the
methodology of CIA are reviewed here so as to outline the importance of learner corpora in SLA
and EFL research settings.
It is worth to begin with a study of Granger, who is well-known as the pioneer researcher of
Contrastive Interlanguage Analysis. Granger and her colleague Altenberg (2001) investigated EFL
learner use of high frequency verbs with a special focus on the usage of the verb ‘make.’ In
particular, the study aimed at finding out the overuse and underuse of these verbs by comparing
authentic learner data with computerized native speaker corpora. There were two groups of EFL
learners from Swedish and French backgrounds. The learner corpus was consisted of samples from
ICLE (International Corpus of Learner English) database including the essays of French and
Swedish learners. On the other hand, LOCNES was used as the control native corpus of the study.
According to results, it is obvious that “EFL learners, even at an advanced proficiency level have
great difficulty with a high frequency verb such as make” (Altenberg and Granger, 2001: 173).

24
Granger (2004.132) draws the attention to many researchers adopting CIA such as Ringbom
(1998), Aijmer (2002), and Nesselhauf (2003). For instance, Ringbom (1998) identified the use of
high frequency of lexis having generality such as nouns like ‘people’ and ‘thing’ in EFL learners’
written production by making a comparison of learner corpora with a similar native speaker corpus.
In other CIA based research, Aijmer (2002) detected the use of modals by Swedish, German and
French EFL learners by comparing student essays with essays of native speakers. She found out the
overuse of modals by these three learner groups. It is clearly understood from the research that
learners from different language backgrounds prefer different modals which are correspondingly
similar to their native language usage. Likewise, Nesselhauf (2003) explored the use of
collocations by advanced German EFL students based on the data from German subcorpus of ICLE
in comparison with dictionaries and British National Corpus. The study is resulted in that the
influence of first language on the production of English collocations by German EFL learners was
significantly high.
The methodology of comparing learner and native corpus is also adopted by Leńko-
Szymańska (2004) who investigated the overuse and underuse of demonstratives in detailed. In this
two-way comparison analysis, the researcher used the PELCRA corpus of learner English compiled
from written essays of Polish university students and the British National Corpus (BNC) to identify
native-like use of demonstratives. The results showed that Polish EFL learners need specific
assistance in learning this particular feature of language. As Leńko-Szymańska concluded that even
the tiniest details of interlanguage problems which have not been explored yet can be enlightened
by learner corpus data (as cited in Aston et al., 2004: 4).
A recent research from Turkey conducted by Babanoğlu and Can (2018) employs the
methodology of CIA to analyze the use of adverbial connectors in Turkish EFL learners’
argumentative essays. With this in mind, four corpora were compared in this study: three learner
corpora which were respectively TICLE, SPICLE (Spanish Corpus of Learner English), and
JPICLE (Japanese Corpus of Learner English) besides one native speaker corpus, LOCNESS. The
findings obtained from the contrastive analysis of connector usage indicate that the overuse
connectors are commonly used by many Turkish EFL learners. Babanoğlu and Can (2018: 27)
found in the study that the overuse of adverbial connectors in three EFL learner corpora can be
considered as a general inclination for sharing common interlanguage properties.
Another study carried out by Turkish researchers Akbana and Koşar (2015) examines the
highest-frequency vocabulary in advanced learners and native speakers through contrastive
interlanguage analysis. The data retrieved from two corpora, LOCNESS and TICLE, have been
analyzed on the basis of CIA to investigate the use of the top ten words. The study came to the
conclusion that the overuse and underuse of the words seem to have a common interlanguage use.

25
Apart from these, in a research carried out by Özbay and Kabakçı (2016), the support verb
construction use of tertiary level EFL learners was examined through native and non-native
academic and argumentative corpora. The study uses two native and two non-native corpora for the
investigation of SVC use: BAWE (British Academic Written English), KTUCALE (Karadeniz
Technical University Corpus of Academic Learner English), TICLE (Turkish International Corpus
of Learner English) and LOCNESS (The Louvain Corpus of English Essays). Özbay and Kabakçı
(2016: 1462) put forward that tertiary level Turkish EFL learners had a tendency to use fewer and
specific SVCs.
2.3.2. Computer Learner Corpus (CLC) Research
Computer learner corpus research (CLC, hereafter) has been a relatively new method which
“is still in its infancy”; and it uses the methods and tools of corpus linguistics to throw light into
authentic learner language (Granger, 1998: xvi). For Leech (1998, as cited in Granger, 1998: 123),
CLC is “a new research enterprise, a new way of thinking about learner language, which is
challenging some of our most deeply-rooted ideas about learner language.” Granger (2004: 124)
simply defines computer learner corpora as “electronic collections of spoken or written texts
produced by foreign or second language learners.” In order to expand upon the explanation of
CLC, Granger (2002: 7) adopted Sinclair’s (1996) definition below:
Computer learner corpora are electronic collections of authentic FL/SL textual data assembled
according to explicit design criteria for a particular SLA/FLT purpose. They are encoded in a
standardised and homogeneous way and documented as to their origin and provenance.
It is an undeniable fact that computers and software corpus tools play an important role in
fast-changing nature of language learning and teaching. Since 1990s, “the rapid development of
automatic data processing and information technology has opened up new prospects for contrastive
approaches through the potential of large corpora” (Tajareh, 2015: 1107). Until quite recently, the
researchers dealing with SLA or EFL studies needed great time and effort to collect and analyze
even small amounts of learner data. Granger (1998: 3) cited Rundell and Stock’s (1992) statement
to emphasize that computers liberate linguists “from drudgery and empowers [them] to focus their
creative energies on doing what machines cannot do.” Accordingly, Hunston (2002: 3) argues:
Strictly speaking, a corpus by itself can do nothing at all, being nothing other than a store of
used language. Corpus access software, however, can re-arrange that store so that observations
of various kinds can be made. If a corpus represents, very roughly and partially, a speaker’s
experience of language, the access software re-orders that experience so that it can be examined
in ways that are usually impossible. A corpus does not contain new information about language,
but the software offers us a new perspective on the familiar.
On the benefit of electronically encoding of corpus data, Baker (2006: 2) asserts that
“complex calculations can be carried out on large amounts of text, revealing linguistic patterns and

26
frequency information that would otherwise take days or months to uncover by hand, and may run
counter to intuition.” For Kennedy (1998: 5), “the analysis of huge bodies of text ‘by hand’ can be
prone to error and is not always exhaustive or easily replicable.” However, today, the progress in
technology enables us to compile larger sizes of learner data on computer and analyze them on
linguistic software programs (Granger: 2002: 7).
Before dwelling on the importance of computer-aided analysis of learner corpora in language
teaching and learning settings, the varieties of English language should be clarified in detail.
Granger (2002) states that learner corpora are centered on the non-native varieties of English and
can be categorized as follows:
Figure 4: Varieties of English
Source: Granger (2002: 9)
ENL refers to English as a native language spoken by people who acquired it as their first
language or mother tongue. The non-native varieties of English, on the other hand, include “EOL
(English as an Official Language), ESL (English as a Foreign Language), and EFL (English as a
Foreign Language)”, and in her own explanation, she defined these varieties as (Granger, 2002: 9):
EOL is a cover term for indigenised or nativised varieties of English, such as Nigerian English
or Indian English. ESL is sometimes referred to as Immigrant ESL: it refers to English acquired
in an English-speaking environment (such as Britain or the US). EFL covers English learned
primarily in a classroom setting in a non-English-speaking country (Belgium, Germany, etc.).
Learner corpora cover the last two non-native varieties: EFL and ESL.
The present study focuses on tertiary level EFL students to find out the semantic prosodic
behavior of their intensifier usage based on two learner corpora and a reference corpus. With this in
mind, the use of learner and reference corpora in second or foreign language learning environment
will henceforth be explained in detail.

27
2.3.2.1. The Use of Learner Corpora in EFL and SLA Research
In general terms, Hunston (2000: 15) describes learner corpora as the compilation of texts
like essays which are produced by language learners in order to identify to what extent and in what
respects learners differ from each other and from native speakers. In analyzing language learning
use, Hunston (2002: 212) puts emphasis on two major advantages of learner corpora over other
methods in corpus-based studies:
Firstly, it makes the basis of the assessment entirely explicit: learner language is compared with,
and if necessary measured against, a standard that is clearly identified by the corpus chosen. If
that standard is considered to be inappropriate (if, for example, the appropriate target for
Norwegian school children is considered to be expert Norwegian speakers of English rather than
British speakers of English), then the relevant corpus can be replaced. Secondly, the basis of
assessment is realistic, in that what the learners do is compared with native/expert speakers
actually do rather than what reference books say they do. Many of the parameters of difference
noted, such as vocabulary range, or word-class preference, do not appear in most grammar
books.
Similarly, Reppen (2006) claims that second language learner corpora are used by researchers
to investigate language patterns of EFL learners “rather than relying on information from case
studies and single examples” (as cited in Babanoğlu and Can, 2018: 17). Comparative studies based
on learner corpora make it perfectly possible for teachers and researchers to find out various types
of learner errors and weaknesses in addition to the differences between native and non-native
performance eliciting interlanguage development properties “which were not or hardly accessible
via the previous methods” (Şanal, 2007: 26).
To Leech (1998), learner corpora is “a useful resource for anyone wanting to find out how
people learn languages and how they can be helped to learn them better” (as cited in Kilimci, 2014:
401). In the preface of book called Learner English on Computer, Leech (1998: xvii) also puts
forward:
…[L]earner corpus is a new phenomenon: it enables us to investigate the nonnative speaking
learners’ language (in relation to the native speaker’s) not only from a negative point of view
(what did the learner get wrong) but from a positive one (what did the learner get right?). For the
first time it also allows a systematic and detailed study of the learner’s linguistic behaviour from
the point of view of ‘overuse’ (what linguistic features does the learner use more than a native
speaker?) and ‘underuse’ (what features does the learner use less than a native speaker?)
Finally, authenticity is an important criterion for learner corpora. James (1992) noted “the
really authentic texts for foreign language learning are not those produced by native speakers for
native speakers, but those produced by learners themselves” (as cited in Baker et al., 2006: 103). In
other words, a learner corpus contains L2 output produced by language learners of any proficiency
level. However, the aspect of authenticity is considered somehow problematic with regard to
learner language. For Granger (2002: 8),

28
Even the most authentic data from non-native speakers is rarely authentic as native speaker
data, especially in the case of EFL learners, who learn English in the classroom. We all know
that the foreign language teaching context usually involves some degree of ‘artificiality’ and
that learner data is therefore rarely fully natural. A number of learner corpora involve some
degree of control.
Upon authenticity, Widdowson (1998, 2000; as cited in Tono, 2016: 35) argues that corpus
data is not authentic language since the text is separated from its original context, and he also
claims that “in language learning contexts, learners are often authenticate genuine text as they do
not belong to the community for which the texts are created.”
2.3.2.2. Corpus Compilation and Design Criteria
According to Sinclair (1996), “a corpus is a collection of pieces of language that are selected
and ordered according to explicit linguistic criteria in order to be used a sample of the language”
(McEnery et al., 2006: 4). The corpora are built for various purposes “which in turn influence the
design, size and nature of the individual corpus” (Kennedy, 1998: 3). The most frequent corpus
types can be listed as “specialised corpus, general corpus, comparable corpora, parallel corpora,
learner corpus, pedagogic corpus, historical or diachronic corpus, and monitor corpus” (Hunston,
2002: 15-16). This study deals with written learner corpus to compare with native speakers.
Granger (2002: 10) also lists different kinds of learner corpus typology designed or compiled for
many different purposes such as synchronic or diachronic, monolingual or bilingual, general or
technical, spoken or written.
Briefly to say, there are some essential aspects in corpus compilation such as size, content,
and representativeness (Hunston: 2002: 25). The size of a corpus is a fundamental issue in corpus
design. As it is previously noted, the advances in computer technology make it easy and reliable to
store and analyze even larger size of corpora. As Hunston (2002: 25) claims, “the feasible size of a
corpus is not limited so much by the capacity of a computer to store it, as by the speed and
efficiency of the access software.” Researchers may also prefer using smaller size of corpus to
work on to have an access to reliable data. The content of a corpus depends on the scope and
purpose of the research. Representativeness of a corpus is closely associated with the sampling.
Biber (1993: 243) states that “representativeness refers to the extent to which a sample includes the
full range of variability in a population.” According to Leech (1991: 27), “in practical terms a
corpus is ‘representative’ to the extent that findings based on its contents can be generalized to a
larger hypothetical corpus.” However, the representativeness of a corpus may change over time and
it becomes ‘unrepresentative’ if not updated regularly (Hunston: 2002: 30).
It is quite obvious that a learner corpus should be carefully compiled on the basis of some
certain features. The texts that learner corpus include may not be supposed to be called as

29
“naturally occurring texts” like texts in native corpora (Nesselhauf, 2005: 40). A clear design
criteria is a must for the compilation of a learner language corpus since it is ‘heterogeneous’ for
holding various kinds of learners from different learning backgrounds (Granger: 1998: 7). Granger
(1998) lists some of the main features which are relevant to learner corpus compilation:
Table 1: Learner corpus design criteria
Language Learner
Medium Age
Genre Sex
Topic Mother Tongue
Technicality Region
Task Setting Other Foreign Languages
Level
Learning Context
Practical Experience
Source: Granger (1998: 8)
Granger (1998: 8) explains that the attributes in the category of language shown in the table
are quite similar to criteria used in native corpus design. Medium represents written or spoken
corpora in which different genres can be used such as “argumentative vs. narrative writing or
spontaneous conversation vs. informal interview.” The topic is of high importance since it has an
effect on ‘lexical choice’ while technicality determines both the “lexis and grammar.” Task setting
is related to features such as preparedness (time limit) or being part of an exam. Except for “age
and sex”, all the attributes belonging to the learner are unique to learner corpora. Learner’s mother
tongue, other foreign languages s/he knows, language varieties spoken in his or her region,
language level, learning context, and practical experience all have a potential to influence ‘L2
output’.
2.3.2.3. Reference corpora
Reference corpus represents the standards and norms of native speakers. It is supposed to be
large enough to comprise all varieties and characteristics of a language in order to be used as a
reliable reference. Leech (1998: xv) defines the reference corpus as “a standard of comparison, a
norm against which to measure the characteristics of the learner corpora.” Granger (2002: 12)
highlights that there are quite many native corpora available today for contrastive analysis to take
as a norm. Baker (2006: 43) concantrates upon the benefits of reference corpora in linguistic
researches. Iniatially, he states that reference corpora can represent a specific genre to provide
evidence of its discourse. He adds that “a reference corpus acts as a good benchmark of what is

30
‘normal’ in language, by which your own data can be compared to”. In addition to these, reference
corpora can be used to test linguistic theories (Baker, 2006: 43).
It seems an obvious truth that writing texts produced by native speakers can serve as
professional criteria to be compared for eliciting learners’ interlanguage development. As Adel
(2006; as cited in Paquot, 2010: 72) puts forward,
On the one hand, it can be argued that in order to evaluate foreign learner writing by students
justly, we need to use native-speaker writing that is also produced by students for comparison.
On the other hand, it can also be argued that professional writing represents the norm that
advanced foreign learner writers try to reach and their teachers try to promote. In this respect, a
useful corpus for comparison is one which offers a collection of what Bazerman (1994: 131)
calls ‘expert performances.’
What is more, Hunston (2002: 20) highlights the importance of using native corpora in
language studies as follows:
A corpus essentially tells us what language is like, and the main argument in favor of using a
corpus is that it is a more reliable guide to language use than native speaker intuition is.
Although a native speaker has experience of very much more language than is contained in
even the largest corpus, much of that experience remains hidden from introspection… Intuition
is a poor guide to at least four aspects of language: collocation, frequency, prosody and
phraseology.
Thus, the current study which is mainly based on semantic prosodic analysis of English
intensifiers employs the utilization of native corpus in comparison with learner corpora to
investigate interlanguage development of EFL learners. Through the use of corpora, one can
analyze the prosodic nature of lexical items, namely semantic prosody, which refers to “the
spreading of connotational coloring beyond single word boundaries” (Louw, 1993: 157). When the
learner corpora, KTUCLE and TICLE are compared with a reference corpus such as LOCNESS, it
means that L1 corpus is taken as a standard reference with which the learner data from a L2 corpus
will be compared.
2.3.3. Semantic Prosody (SP)
Semantic prosody has aroused intense interest among corpus linguists for almost twenty years
(Stewart, 2010: 6). “Louw was the linguist who introduced the term semantic prosody to the
linguistic field” (Al-Sofi et al., 2014: 121). He explained the concept as “a consistent aura of
meaning with which a form is imbued by its collocates” (Louw, 1993: 157). This is obviously a
short definition, but the use of metaphors is worth to be explained in detail to understand the SP
concept in a broader sense. Semantic prosody is a meaning transferred from one word to another,
and here this transfer is expressed metaphorically with the verb ‘to imbue’ which can be simply
explained by Whitsitt (2015: 288) as follows:

31
…in order to better understand these terms and how they are linked, we need to understand
what the word imbue means and how it is used. In the Oxford English Dictionary we find
“imbue” as a transitive verb with a literal and figurative meaning. The literal sense is linked
with fluids: when one imbues something, it means: “to saturate, wet thoroughly (with moisture);
to dye, to tinge, impregnate (with colour.).” The figurative meaning refers to immaterial
principles, such as spirit, moral vigor, beliefs, as in “to impregnate, permeate, pervade, or
inspire (with opinions, feelings, habits, etc.).” What seems to be happening here is that
immaterial things such as spirit, meanings, and beliefs can be transferred by imbuing because
they are thought of as liquids.
There is another metaphor used in Louw’s well-known definition that meaning is thought of
as an ‘aura’ which is described in Oxford English Dictionary as “the distinctive atmosphere or
quality that seems to surround and be generated by a person, thing, or place.” Similar to Louw’s
above-mentioned metaphorical description of SP as “aura of meaning”, Bublitz (1996) suggests
that “words can have a specific halo or profile, which may be positive, pleasant and good, or else
negative, unpleasant and bad” (as cited in Cheng, 2013: 1).
To define the concept better, Louw (2000: 60) expands the scope of SP in his working
definition:
A semantic prosody refers to a form of meaning which is established through the proximity of a
consistent series of collocates, often characterisable as positive or negative, and whose primary
function is the expression of the attitude of its speaker or writer towards some pragmatic
situation.
It can be clearly derived from above-quoted description that Louw’s understanding of
semantic prosody depends on the consistency of two fundamental issues that are ‘collocation’ and
‘attitudes’. Semantic prosody is often found in the company of the term ‘collocation’. This fact can
be explained briefly as follows “if several different words all sharing the same semantic trait are
frequently used with another word, meaning will be passed, over time, from that group of words to
the other word” (Whitsitt, 2000: 284). In other words, in semantic prosody certain individual words
have a tendency to collocate with positive, negative, or neutral items by nature. According to
Stubbs (1995: 25), “it is becoming increasingly well documented that words may habitually
collocate with other words from a definable semantic set.” Hunston (1999) also agrees that “briefly,
a word may be said to have a particular semantic prosody if it can be shown to co-occur typically
with other words that belong to a particular semantic set” (as cited in Hunston and Francis, 2000:
104).
Another definition is provided by Sinclair (1996), who had originally suggested the idea of
SP to Louw during a “personal communication in 1988” as Louw himself stated in his well-known
article “Irony in the Text or Insincerity in the Writer?” (Louw, 1993: 158). Even though Louw
(1993) is known as the first researcher who introduced the concept of semantic prosody, Sinclair

32
initially mentioned and caught the attention to it. As it is deduced from the following definition,
Sinclair (1996: 87) actually adopts a pragmatic approach to SP:
Semantic prosody…is attitudinal, and on the pragmatic side of the semantics / pragmatics
continuum. It is thus capable of a wide range of realisation, because in pragmatic expressions the
normal semantic values of the words are not necessarily relevant. But once noticed among the
variety of expression, it is immediately clear that the semantic prosody has a leading role to play
in the integration of an item with its surroundings.
Partington (2004: 131) states that Sinclair (1987, 1996, 1998), Louw (1993) and Stubbs
(2001) are among the most notable linguistics elaborating on the concept of semantic prosody.
Hunston (2007) puts forward that Sinclair’s study of set in (1991), Stubbs’ study on cause (1995)
and Louw’s analysis of utterly (1993) are the common examples on semantic prosody which have
caught the most attention among many other linguists. In the first place, Louw’s example of adverb
‘utterly’ which carries a negative semantic prosodic effect, is mostly combined with undesirable
collocations such as depression, terrified, against, destroying, demolished, etc. Retrieved from
Cobuild corpus, above-mentioned concordances of ‘utterly’ indicates that it has mostly ‘bad’
prosody and just a few ‘good’ collocations (Louw, 1993: 161). Based on Cobuild corpus, Louw
also finds out that bent on usually collocates with pretty unpleasant items; for instance, bent on
destroying / harrying / mayhem (Partington, 2004: 133).
In addition, Stubbs (1995) explains in the abstract of his article that “using data from corpora
of up to 12 million words, it is shown that the lemma CAUSE occurs in predominantly ‘unpleasant’
collocations, such as cause of the trouble and cause of the death.” Since cause tends to collocate
frequently with negative items, researchers are more likely to label it as bearing negative prosody
(Wachter, 2008: 13). However, this negative prosodic identification of the lemma cause is
criticized by Huntson (2007) by emphasizing the significance of context. According to Huntson
(2007: 263):
With respect to CAUSE, for example, it would be possible to suggest that this verb loses its
association with negative evaluation when it occurs in ‘scientific’ registers. A more sustainable
argument, however, might be that…the attitudinal meaning associated with CAUSE applies only
when the ‘caused entity’ concerns animate beings, their activities and goals. Where the ‘caused
entity’ is an inanimate object unrelated to human goals no attitudinal meaning is implied. If a
register makes more use of the second phenomenon than the first, it will appear that in that
register CAUSE has no attitudinal meaning.
It is clearly understood from this explanation that Hunston agrees with Stubbs who thought cause
generally tends to have an undesirable meaning when the context is related to something animate or
human properties. In the example of Wachter (2012: 13), “these proteins cause a smell to be less
strong”, cause refers to inanimate thing, and it cannot be regarded as having negative prosody. That
is to say, semantic prosody depends on the collocations of a word.

33
Moreover, Sinclair gives an example to semantic prosody by putting an emphasis on the
negative effect of phrasal verb ‘set in’. The collocations of this phrasal verb always has a bad
semantic profile in the data he examined. On set in, Sinclair (1987, as cited in Partington, 2004:
132) notes:
The most striking feature of this phrasal verb is the nature of the subjects. In general they refer
to unpleasant states of affairs. Only three refer to the weather; a few are neutral, such as reaction
and trend. The main vocabulary is rot (3), decay, ill-will, decadence, impoverishment, infection,
prejudice, vicious (circle), rigor mortis, numbness, bitterness, mannerism, anticlimax, anarchy,
disillusion, disillusionment, slump. Not one of these is desirable or attractive.
Partington (1998: 68) explains semantic prosody as “the spreading of connotational coloring
beyond single word boundaries.” Partington (1998: 67) adds that “often a favaourable or
unfavourable connotations is not contained in a single item, but is expressed by that item in
association with others, with its collocates.” Partington (1998: 67) provides an example to
unfavorable prosody with the term rife since it has a tendency to co-occur with words like
“corruption, violence, speculation, crime, misery and disease.”
Concerning all the examples above, Partington (2004) points out that in such cases, the word
seems to collocate frequently with many items sharing distinct semantic set, but having evaluative
meaning in common. Similarly, Hunston and Thompson (2000: 5) emphasize the attitudinal
function of SP which they describe as “the speaker or writer’s attitude or stance towards, viewpoint
or feelings about the entities and propositions that he or she is talking about.” It is also defined as
an indicator of good or bad (Partington, 2004, 131).
It is well-known that computer-held studies have greatly contributed to the semantic prosodic
analysis in recent years. “Semantic prosodies have, in large measure and for thousands of years,
remained hidden from our perception and inaccessible to our intuition” (Louw, 1993: 173). In other
words, human introspection is not a reliable source for retrieving semantic prosodies. In this vein,
Zethsen (2006: 279) highlights the significance of corpus studies:
The important discovery of the existence of semantic prosodies means that we cannot reveal
connotative meaning in a text by simply looking at individual words. We must take into account
the wider semantic/collocational patterns which these words form part of in order to reach the
evaluations which are likely to be triggered in a reader’s mind and for this we need computers
and corpus studies.
Xiao and McEnery (2006: 106) also assert that “yet as the size of corpora has grown, and
tools for extracting semantic prosodies have been developed, semantic prosodies have been
addressed much more frequently by linguists as exemplified” and summarized below by them:

34
Table 2: Examples of Semantic Prosody
Author Negative Prosody Positive Prosody
Sinclair (1991)
BREAK OUT
HAPPEN
SET in
Louw (1993, 2000)
bent on
build up of BUILD up a
END up verbing
GET oneself verbed
a receipe for
Stubbs (1995, 1996, 2001a, 2001b)
ACCOST PROVIDE
CAUSE career
FAN the flame
signs of underage
teenager(s)
Partington (1998)
COMMIT
PEDDLE/peddler
Dealings
Hunston (2002) SIT thorough
Schmitt and Carter (2004) bordering on
Source: Xiao and McEnery (2006: 106)
2.3.3.1. Semantic Prosody as an Extended Unit of Meaning (EUM)
“The starting point of the description of meaning in language is the word” writes John
Sinclair (2004: 24) in his book Trust the Text to put an emphasis on the importance of words as the
smallest basic units conveying the meaning. However, Stubbs (2009: 124) puts forward that an
individual word is not enough for conveying meaning. The meaning of an individual lexical item
may differ in a context through its connections with different words. In other words, the unit of
meaning lies at the heart of the phrases that a word collocates with.
One of the forerunners of corpus linguistics, Sinclair’s model of ‘the unit of meaning’ is
consisted of four types of co-selection categories: “collocation, colligation, semantic preference
and semantic prosody.” The following descriptions of these four units of meaning are ordered from
concrete to abstract (Stubbs, 2009: 124-125):
(1) COLLOCATION is the relation of co-occurrence between an obligatory core word or phrase
(the node) and individual COLLOCATES: word/tokens which are directly observable and
countable in texts.
(2) COLLIGATION is the relation of co-occurrence between the node and abstract grammatical
categories (e.g. past participles or quantifiers). A traditional category such as ‘‘negative’’ may

35
be realized grammatically (would not budge) or semantically (would hardly budge, refused to
budge).
(3) SEMANTIC PREFERENCE is the relation of co-occurrence between the phrasal unit and
words from characteristic lexical fields. Recurrent collocates provide observable evidence of the
characteristic topic of the surrounding text (e.g. typical subjects or objects of a verb).
(4) SEMANTIC PROSODY is the function of the whole extended unit. It is a generalization
about the communicative purpose of the unit: the reason for choosing it (and is therefore related
to the concept of illocutionary force).
To sum up, the model of ‘Extended Units of Meaning’ has the following main components:
Table 3: The components of EUM
COLLOCATION tokens co-occurring word-forms
COLLIGATION classes co-occurring grammatical classes
SEMANTIC PREFERENCE topics textual coherence
SEMANTIC PROSODY motivation communicative purpose
Source: (Stubbs, 2009: 125)
As Tognini-Bonelli (2001: 19) adds, “the units thus described are ‘extended units of
meaning’ because, having started with a node as a core, they have incorporated other words in the
co-text that appeared to be co-selected with it and form a regular pattern.” Last but not least,
Sinclair (1996, as cited in Zethsen, 2006: 279) concludes that “so strong are the co-occurrence
tendencies of words [collocation], word classes [colligation], meanings [semantic preference] and
attitudes [semantic prosody] that we must widen our horizons and expect the units of meaning to be
much more extensive and varied than is seen in a single word.”
2.3.3.2. Semantic Preference vs. Semantic Prosody
Semantic preference is “the relation, not between individual words, but between a lemma or
word-form and a set of semantically related words” (Stubbs, 2001: 65). In other words, semantic
preference is closely related to the issue of collocation in which a particular lexical item collocates
not with another individual item, but with a series of items in a semantic field (Partington, 2004:
150). For instance, Stubbs examines the word large in a corpus having 200 million tokens and
reveals that the 25% of 56,000 examples frequently collocates with lexical items such as “number,
scale, part, amounts, quantities etc.” belonging to the same semantic category; and the semantic
preference of large is typically “quantities and sizes” (Begagić, 2013: 404). Semantic prosody, on
the other side, is regarded by Sinclair as “an obligatory property of a unit of meaning, although it
may be more or less explicit in any one example” (Hunston, 2007: 250) essentially being either
positive or negative in its context. There are various “two-term” evaluations of SP in the literature:
“positive and negative, favourable and unfavourable, desirable and undesirable” (Morley and

36
Partington and, 2009: 141). When a word is not associated with positive or negative items in a
context, it can be considered as having neutral prosody in nature (Ünaldı, 2013: 42).
For Stubbs (2009: 126), “the concepts of semantic preference and semantic prosody has
received substantial commentary” among many linguists such as Partington (2004) and Hunston
(2007). However, these two units of meaning in Sinclair’s EUM model seem to lead to confusion
on many readers. In a similar sense, Bednarek (2008: 119) states that these two terms are likely to
be often confusing due to being two distinct but related phenomena at the same time. According to
Stubbs (2001), “the distinction […] is not entirely clear-cut. It is partly a question of how open-
ended the list of collocates is: it might be possible to list all words in English for quantities and
sizes, but not for unpleasant things” (as cited in Partington, 2004: 149). Hence, Stubbs (2009: 126)
offeres that the complication between semantic preference and semantic prosody might be
prevented by using different terms “in order to distinguish between semantic relations (to the topic
of the surrounding text) and the pragmatic function (of the whole phrasal unit).”
To McEnery and Hardie (2012: 138), “semantic preference links the node to some word in its
context drawn from a particular semantic field, whereas semantic prosody links the node to some
expression of attitude or evaluation which may not be a single word, but may be given in the wider
context.” Sinclair’s analysis of the naked eye can be given as an example to clarify the distinction
between these two concepts. According to the concordances below, Sinclair (as cited in McEnery
and Hardie, 2012, 138) discusses that expression of “the naked eye has a semantic preference of
visibility” which is clearly derived from the words such as “seen, visible and perceived.”
…too faint to be seen with the naked eye
…it is not really visible to the naked eye
…cannot always be perceived by the naked eye
In other respects, the expression of “the naked eye has a semantic prosody of difficulty.” However,
this semantic meaning cannot be deduced from the isolated words in the context, but by pragmatic
interpretation of readers of analysts (McEnery and Hardie, 2012: 138). “Semantic prosodies are
evaluative or attitudinal and are used to express the speaker’s approval (good prosody) or
disapproval (bad prosody) of whatever topic is momentarily the object of discourse” (Sinclair,
(1996, as cited in Partington, 2004: 150).
The core of the current study is on intensifiers which are the attitudinal way of expressing
one’s perspective, opinion, or point of view. Therefore, the main focus of the analysis and
discussion will be on semantic prosody within Sinclair’s EUM model, which is evaluative and
attitudinal in nature.

37
2.3.3.3. Studies Related to Semantic Prosody
Recently in the field of corpus linguistics, a great many investigations have been carried out
on semantic prosody by well-known linguists mentioned before (Louw, 1993; Sinclair, 1996;
Partington, 1998, 2004; Stubbs, 2001). In addition to western studies, the SP concept has begun to
arouse attention in the past few years among many scholars from other countries, especially from
China.
To begin with the Chinese researchers, Wei (2002) investigated semantic prosody of the verb
CAUSE in English language, and he found out that it has a negative semantic prosody similar to
other researchers’ findings. His analysis also indicated that there are different semantic prosodic
features in specialized genres and texts. For instance, the word cause has predominantly negative
prosodic nature in academic texts than general writing texts (Zhang, 2009). Wang and Wang (2005)
also conducted a comparative study on the semantic prosodic analysis of the lemma CAUSE. The
study focused on the English written texts produced by native speakers and Chinese learners, and
utilized two corpus: Chinese Learner English Corpus (CLEC) and part of the British National
Corpus (SBNC). With this in mind, the collocates of CAUSE were retrieved from the two corpora
and then two of most frequent collocates were determined for comparison: change(s) and great(er,
est). The analysis indicated that a significant difference occurred between native speakers and non-
native Chinese learners concerning semantic prosodic usage of CAUSE. Chinese EFL learners
were found to underuse the typical negative semantic prosody of the lemma CAUSE while they
tend to overuse its positive SP.
McEnery and Xiao’s (2006) study compared the collocational semantic prosodic behavior of
three groups of near-synonyms in English with those in Chinese language from a cross-linguistic
perspective. They used English and Chinese corpora to conduct their research. Based on the
statistical analysis, they drew the conclusion that semantic prosodic nature of both languages are
observable and similar in manner. Similarly, another investigation carried out by Gong and Wu
(2012) examined the issue of collocation, semantic prosody and near-synonymy like McEnery and
Xiao (2006). Their focus was on the collocational and semantic prosodic nature of two verbs used
for ‘help’ in Mandarin Chinese, and they utilized a Chinese corpus called Chinese Word Sketch to
make their analysis. According to the results of their research, it was found out that the near-
synonymous words have different collocations in terms of semantic prosody.
Zhang (2010) conducted a comparative study on Chinese EFL learners’ semantic prosodic
use of the verb COMMIT by contrasting learner corpus CLEC and reference corpus BROWN. The
analysis indicated that Chinese EFL learners had somehow similar prosodic behaviour when
compared to native speakers. Nonetheless, some collocations and patterns of semantic prosody far

38
from nativeness and harmony were observed in EFL learners who were in their interlanguage
development period.
Sardinha (2000) carried out a contrastive corpus-based investigation identifying semantic
prosody of equivalent items in English and Portuguese languages. According to the findings, the
striking features of semantic prosody were observed through a 140-million word corpus of
Portuguese. BNC is also used as reference corpus. In their corpus-based analysis, Oster and Lawick
(2008) investigated translation aspects of co-occurrence patterns for selected idioms in German,
Spanish and/or Catalan in order to find out similarities and differences regarding semantic
preference and semantic prosody.
McGee (2012) examined the semantic prosodic awareness of three groups of participants
consisted of non-native university undergraduate students, Arab English teachers, and native
speaker English teachers in terms of seven lexical items, respectively bring about, cause,
completely, face, potentially, provide, regime. The goal of the research was to investigate to what
extent two non-native speaker groups of different English language level are aware of the semantic
prosodic usage of these words in comparison to native speakers. The results showed that semantic
prosodic awareness did not actually develop in non-native learners’ use of lexical items under
investigation, whereas the group of native speakers was observed to have semantic prosodic
tendencies for all seven items.
Begagić (2013) researched one of the most frequently used V-N collocations make sense in
terms of semantic preference and semantic prosody, which are two notions that have been recently
studied in corpus linguistics. First 100 occurrences of make sense were selected randomly from the
Corpus of Contemporary American English (COCA) and analyzed manually in detail.
As a Turkish researcher, Ünaldı (2013) examined the semantic prosodic properties of the
word pose in English in COCA, a 464-million-word corpus. The collocational occurrences of the
target word pose in academic contexts were compared with other genres. The findings indicated
that pose seems to combine with negative lexical items in academic contexts, whereas in others it
has a tendency to have neutral semantic prosody.
There are also studies examining the semantic prosodic aspects of Turkish language. For
instance, a corpus-based research implemented by Aksan et al. (2008) aimed at analyzing two
groups of synonymous Turkish words: (1) aşk, sevda, sevgi; standing for ‘love’; and (2) Tanrı,
Allah; for ‘God’. The study utilized the METU Turkish Language Corpus to examine these word
groups in terms of semantic prosody. Çalışkan (2014) also had a study based on different semantic
prosodic aspects of Turkish language. The target node words of the study, namely “aksettirmek,
...dan ibaret, ...nin teki, karşı karşıya, varsa yoksa”, were analyzed through the demo version of the

39
Turkish National Corpus. In addition, Kara (2017) carried out another research concerning the
issue of semantic prosody in Turkish language based on Turkish National Corpus. His study
investigated Turkish near-synonymous words “örgüt, kurum, kuruluş, teşkilat, şebeke” all denoting
a meaning of ‘institution’. Pilten (2017) also elaborated on the concept of SP by giving examples
from Turkish language and previous relevant studies from abroad.
2.4. Intensifiers
Many researchers (Quirk, et al., 1985; Partington, 1993; Lorenz, 1999) have extensively
studied intensifiers. Bolinger (1972: 17) defines the term intensifier as “any device that scales a
quality, whether up or down or somewhere between the two.” Intensifiers are also labelled as
‘degree adverbs’ or ‘degree modifiers’. With regard to this issue, Quirk et al. (1985: 445) came up
with an explanation that “most commonly, the modifying adverb is a scaling device called an
intensifier, which cooccurs with a gradable adjective.”
Different forms of intensifiers have been categorized in reference books of English grammar
as well as in earlier studies. Stoffel (1901) is the first linguist who made a distinction between
“intensives and down-toners, which respectively express a high or a low degree of the adjective
that is being premodified, e.g. extremely good and rather good” (Wittouck, 2011: 11). This
categorization was later adopted and developed by Quirk and his counterparts. Referring to
intensifiers as degree adverbs, Quirk et al. (1985: 445) identify two subcategories of intensifiers
which are “amplifiers and downtoners”. Amplifiers indicate “scale upwards from an assumed
norm” (e.g ‘a very funny film’) while downtoners “have a generally lowering effect, usually
scaling downwards from an assumed norm” (e.g ‘It was almost dark’). Bolinger’s (1972) definition
of intensifiers is similar to that of Quirk et al.’s; however, he divided intensifiers “differently into
Boosters (Quirk et al.’s Amplifiers), Compromisers (Quirk et al.’s Approximators and
Comprimisers), Diminishers, and Maximizers” (as cited in King, 2016: 2). Lorenz (2002) also
categorizes intensifiers into “five semantic categories according to their sources: (a) scalar, which
just scale a quality, with no additional propositional content, e.g. very; (b) feature copying, which
achieve ‘their intensifying effect by copying a substantial part of the adjective’s denotation’ as in
blatantly clear; (c) evaluative, which express an evaluation on the part of the speaker, e.g.
ridiculously low; (d) comparative, like eminently or especially; and (e) modal, which state the
degree to which the quality holds true” (as cited in Méndez-Naya, 2003: 378). The table below
demonstrates different categorizations of intensifiers suggested by eminent scholars:

40
Table 4: Different Categorizations of Intensifiers
Scholar Categories for Scale of Degree
Stoffel (1901) Intensives, Down-toners
Bolinger (1972) Boosters, Compromizers Diminishers, Minimizers
Quirk et al. (1973) Amplifiers (Maximizers, Boosters)
Downtoners (Approximators, Compromizers, Diminishers, Minimizers)
Biber et al. (1999) Amplifiers / Intensifiers, Diminishers / Downtoners
Lorenz (2002) Scalar, copying, evaluative, comparative, modal
Quirk et al.’s (1985) classification of intensifiers actually deserves special mention since it is
widely recognized and cited in many recent studies related to the use of intensifiers (Tagliamonte,
2008; Wittouck, 2011; Yaoyu and Lei, 2011; 2014; Özbay and Aydemir, 2017; Wang, 2017).
Quirk et al. (1985: 590) classify amplifiers into “two subgroups a) maximizers which can denote
the upper extreme of the scale b) boosters which denote a high degree, a high point on the scale.”
Downtoners, on the other hand, are divided into four subcategories: (a) approximators which refer
“to express an approximation to the force of the verb”, (b) compromisers that “have only a slight
lowering effect”, (c) diminishers that “scale downwards and roughly mean ‘to a small extent”, (d)
minimizers which are “negative maximizers (not) to any extent” (Quirk et al., 1985: 597). The
following table illustrates all subcategories of intensifiers proposed by Quirk and his colleagues:
Figure 5. The Subsets of Intensifiers
Maximizers (e.g. completely)
(I) AMPLIFIERS
Boosters (e.g. very much)
Approximators (e.g. almost)
(II) DOWNTONERS Compromisers (e.g. more or less)
Diminishers (e.g. partly)
Minimizers (e.g. hardly)
Source: Quirk et al., (1985: 589-590)
The subcategory of intensifiers proposed by Quirk et al. (1985) will be henceforth the focus
of the present study, and the research will mostly revolve around amplifiers.
2.4.1. Amplifiers
The current study focuses on amplifiers because they are the most frequent category of
intensifiers in British National Corpus (Kennedy, 2003: 472). According to Altenberg (1991: 128),

41
“what makes amplifiers an interesting category to study from a collocational point of view is that
they are subject to a number of syntactic, semantic, lexical and stylistic restrictions affecting their
use in various ways and fostering a great deal of competition between them.” In a similar vein, on
amplifiers, Granger (as cited in Lorenz, 1999: 27) remarks:
They constitute a particularly rich category of lexical collocation involving as they do a
complex interplay of semantic, lexical and stylistic restrictions and covering the whole
collocational spectrum, ranging from restricted collocability – as in bitterly cold – to wide
collocability – as in completely different/new/free etc.
Briefly, the amplifying intensifiers “scale upwards from an assumed norm” (Quirk et al.,
1985: 590). For Biber et al. (1999: 554), “traditionally, degree adverbs that increase intensity are
called amplifiers.” The amplifiers are divided into two categories: “(a) ‘maximizers’ (absolutely,
completely, entirely, totally, utterly, etc.), which denote an absolute degree of intensity and
therefore occupy the extreme upper end of the scale, and (b) ‘boosters’ (very, awfully, terribly,
bloody, tremendously, etc.), which denote a high degree but without reaching the extreme end of
the scale” (Altenberg, 1991: 128). According to Altenberg (1991: 129), maximizers and boosters
differ in terms of “their different demands on the gradability of the intensified element.”
Maximizers signify ‘nonscalar’ items which “do not normally permit grading (e.g. empty,
impossible, wrong)”, whereas boosters basically modify ‘scalar’ items which are “fully gradable
(e.g. very beautiful)”.
Many EFL learners consciously overuse adjective intensification in their written performance
on the purpose of keeping readers’ attention and focus. Another reason for non-native learners’
tendency to overuse of amplifiers is that they would like to conceal their insufficient knowledge of
vocabulary. “The learners not only use more intensification, they also use it in places where it is
semantically incompatible, communicatively unnecessary or syntactically undesirable” (Lorenz,
1998: 64). EFL learners believe that an amplifier may be easily replaced by its synonyms in a
context. Although amplifiers can be regarded as near-synonymous pairs and can be used
interchangeably in the same pattern, there are slight differences related to their meaning. Near-
synonymous lexical items that have similar meanings pose a challenge for EFL learners.
2.4.2. Studies on the use of Intensifiers by EFL Learners
There are a great number of studies investigating EFL learners’ use of intensifiers in spoken
and written language. As being relevant to the scope of present study, the researches elaborating on
intensifier use especially in writing are widely mentioned in this section. A couple of investigations
belonging to prominent scholars or linguists (Lorenz, 1998; Granger, 1998; Kennedy, 2003;
Partington, 2004) are initially presented. Then, various studies conducted by other researchers, who

42
are studying or interested in applied linguistics, are discussed to throw light at the issue of EFL
learners’ intensification in their writing.
First of all, Lorenz (1998) examined adjective intensification in German EFL students’
writing by comparing them with British native speaker students. Totally four corpora were used in
the study: two learner corpora compiled from German teenagers and German university students of
English, and two native speaker corpora, namely ICLE and LOCNESS. The findings show that
advanced German EFL learners were observed to overuse adjective intensification.
Furthermore, Granger (1998) compared French EFL learners with native speakers of English
concerning their use of –ly ending amplifiers in writing. Only three amplifiers (completely, totally
and highly) were found to have statistically significant differences. French students overused
completely and totally while they underused highly. On the other hand, the frequency of boosters
was less than the ones native speakers used. It is found out that French EFL learners had a tendency
to use fewer amplifier collocations than native speakers. Besides, French learners had a tendency to
use proper collocations that might be resulted from the L1 transfer (Granger, 1998: 6).
Kennedy (2003) thoroughly analyzed the use of twenty four most frequently used amplifiers
in British National Corpus. The researcher examined frequencies and collocations of selected
amplifiers. The maximizers under investigation were “fully, completely, entirely, absolutely, totally,
perfectly, utterly, and dead”. The selected boosters were “very, particularly, clearly, highly, very
much, extremely, badly, heavily, deeply, greatly, considerably, severely, terribly, enormously, and
incredibly”. Fundamentally, this particular research is crucial because the seven of the selected
maximizers, excluding dead, are also analyzed in this thesis.
As the title of his paper “Utterly Content in Each Other’s Company” suggests, Partington
(2004) examined a group of maximizers used in British English by utilizing 10 million-word
Cobuild corpus. The amplifiers “absolutely, perfectly, entirely, completely, thoroughly, totally and
utterly” were analyzed in terms of semantic preference as well as semantic prosody so as to find
out whether they collocate with favorable or unfavorable items. The table below summarizes the
observations that Partington (2014) made throughout his study on intensifier usage:

43
Table 5: Partington’s Study on Intensifiers
Maximizer Preference for Prosody
absolutely hyperbole, superlatives
perfectly favourable
utterly absence / change of state unfavourable
totally absence / change of state
completely absence / change of state
entirely absence / change of state, (in) dependency
thoroughly emotions / liquid penetration
Source: Partington (2014: 218)
Liang (2004) compared Chinese EFL learners’ way of maximizer use with native English
speakers in their spoken language. The frequency of maximizers in Chinese corpus was found to be
less than those used by native English speakers. The researcher made the inference based on the
finding that non-native English speakers are supposed to have an insufficient knowledge of
maximizers; thus they are likely to use the same maximizers with different collocates in various
contexts.
Yaoyu and Lei (2011) investigated amplifiers in the doctoral dissertations of Chinese EFL
learners to evaluate their use in academic writings in a strict sense. There were two corpora in the
study compiled by the researchers. CND is the corpus consisted of 20 dissertations written by
native Chinese EFL learners, while USD is the control corpus consisting of the dissertations by
native English speakers in the United States of America. The results indicated that Chinese EFL
learners seem to use more amplifier collocations when compared to native speakers.
Many investigations on intensifier collocation or adjective intensification in second or foreign
language learning concern corpus studies of semantic prosody. For example, Eriksson (2013)
investigated American and Swedish journalists’ use of maximizers in writing. With this purpose,
maximizers are analyzed in two corpora which are SWENC (The Swedish-English Corpus) and
TIME (Time Corpus of American English). Based on the investigation, the researcher concluded
that there are some differences between Swedes and Americans in terms of maximizer usage. The
frequency of each maximizer between the two corpora does not show a significant difference.
However, larger variations were found in the use of intensifier collocations and semantic prosody.
Turkish researchers Özbay and Aydemir (2017) examined tertiary level Turkish EFL
learners’ use of intensifiers based on two learner corpora named as Karadeniz Technical University
Corpus of Academic Learner English (KTUCALE) and British Academic Written English
(BAWE). The study attempted to investigate EFL learners’ semantic prosodic awareness while
using maximizers such as “absolutely, completely, entirely, totally, utterly, fully and perfectly” in

44
their academic writing. The results indicated that Turkish EFL learners are observed to have a
restricted knowledge of intensifiers. According to the findings, absolutely, entirely, fully and
perfectly are found principally positive, while completely is observed as a neutral maximizer. On
the other hand, totally and utterly have negative semantic prosody with their high proportion of
negative collocates.
The subject of intensifiers and their semantic prosodic nature have recently attracted
much interest from Chinese researchers, as well. Zhang (2013) conducted a study on semantic
prosodic change of intensifiers based on historical and modern corpus data. The Bank of English
Corpus (BOE) and the Corpus of Late Modern English Texts (CLMETEV) were utilized in the
study. Four adverbial intensifiers were examined in the study, namely “terribly, awfully, horribly
and dreadfully”. The results showed that intensifiers having negative semantic prosody may co-
occur with items in neutral or positive meaning.
Huang (2007) conducted a research on Chinese EFL learners in terms of their semantic
prosodic behavior in adjective intensification based on two corpora: CLEC and BNC. According to
results, the semantic prosodic use of amplifiers was generally in parallel with that of native
speakers, but the frequency, types, and idiomaticity of amplifier collocations varied when language
proficiency of the learners have a progress in level. In addition, Chinese learners were observed to
misuse totally and very much in terms of semantic prosody and they have a tendency to underuse
the positive semantic prosody of terribly.
Kim and Lee (2009) analyzed synonymous lexical items such as totally, absolutely, utterly,
completely, and entirely by comparing contemporary authentic American language and Korean
English textbook use. The American National Corpus consisting of 3.9 million spoken and 18.5
million written words was exploited for reference to make the analysis of authentic data. The
Korean High School textbooks were composed of 291,501 words. A closer look at results revealed
that intensifiers absolutely and entirely have semantic prosody, with a frequency percentage that is
more than half the total frequency rate. On the other hand, the words totally, utterly and completely
have an orientation towards negative semantic prosody.
Furthermore, Dao (2014) examined English amplifiers absolutely, completely, and totally
from grammatical and functional aspects by using the Corpus of Contemporary American English
(COCA) and various mini-corpora (MC) of everyday language use. These mini-corpora contain
677,930 words compiled from authentic texts such as letters of complaint, letters of application,
chart descriptions, fairy tales, event announcements, bad news deliveries, and everyday
conversations. The conclusion drawn from the statistical analysis showed that absolutely can
probably co-occur more with positive adjectives, verbs, and adverbs; whereas the amplifiers
completely and totally tend to modify items that have a negative semantic meaning.

45
Yang (2014) investigated Chinese English Learners’ usage of one of the downtoners
somewhat by comparing them with native speakers in terms of features such as semantic prosody,
semantic preference, frequency, collocation, and colligation. The native English corpus used in the
present study is the BYU-BNC developed in accompany with the BNC. The learner corpus of the
study is the Chinese Learners’ English Corpus (CLEC). The Chinese EFL learners tend to use less
somewhat when compared with the native English speakers. As Yang (2014: 2336) stated that the
downtoner usage of Chine EFL learners is significantly different in terms of collocations,
colligation, semantic preference and semantic prosody.
Su (2016) conducted a study on intensifiers used by second or foreign language learners of
English in China. Four general intensifiers were selected for the focus of the research: quite, pretty,
rather, and fairly. There were three corpora in the study: the British National Corpus (BNC), the
Written English Corpus of Chinese Learner (WECCL), and the Chinese Learner English Corpus
(CLEC), which are compared in terms of practical usage and semantic prosodic features. It was
observed that native speakers and EFL learners had different preferences and understanding on the
use of four intensifiers in their writing.
Last but not least, the book of Wang (2017) under the title of Patterns and Meanings of
Intensifiers in Chinese Learner Corpora is vital in respect of its scope as the present thesis focuses
on similar issues to investigate on Turkish EFL learners’ intensifier use. The book includes an
extensive corpus investigation of Chinese EFL learners’ amplifier usage distribution and patterns as
well as features related to semantic prosody and preference. The frequency of intensifiers in learner
corpora was in comparison with that in LOCNESS as reference corpus. As major findings, Wang
(2017: 124) found that data distribution of intensifiers in the learner corpus had remarkably
different features from those in the native corpus. A general tendency prevailing in the research
was that Chinese learners of English tend to overuse intensifiers in terms of tokens but underuse
intensifiers in terms of types. Moreover, learners demonstrate specific semantic prosodic behaviors
and semantic preferences in using intensifiers (Wang, 2017: 125).

46
CHAPTER THREE
3. METHODOLOGY
3.1. Introduction
This chapter outlines the methodological framework of the study including procedures for
data selection, collection and analysis. The methodology section also presents design criteria of two
learner corpora and features of one reference corpus utilized in the study.
The aim of the current corpus-based study is to investigate the frequency level as well as
semantic prosodic awareness of tertiary level Turkish EFL students in terms of using English
intensifiers in their expository argumentative essays. By comparing two computerized learner
corpora with a native speaker corpus, this research is conducted to reveal different patterns of
intensifiers and the existing problems of intensifier use in learner English within interlanguage
development period. From a pedagogical point of view, it can be assumed that the evaluation of
intensifier usage by EFL learners focusing on their semantic prosodic awareness offers insights into
the present levels of language learning and teaching settings in Turkey as well as the tertiary level
Turkish EFL learners’ existing practices and preferences in terms of using lexical and grammatical
properties of English with a focus to their usage patterns of intensifiers. In other words, the most
frequently used intensifiers by Turkish EFL learners will be described and presented in tables and
graphics in terms of their patterning and the existing semantic prosodic features.
3.2. Methodological Framework
Methodologically, the study follows quantitative research techniques depending on the
computer-aided analysis of three written corpora under investigation. As explained in the
introductory chapter before, the present study mainly adopts the methodology of Granger’s
Contrastive Interlanguage Analysis (CIA) by nature with the help of two computerized non-native
corpora and one native corpus as illustrated in Table 6:

47
Table 6: The CIA Model of the Study
L2 vs. L1 L2 vs. L2
KTUCLE vs. LOCNESS KTUCLE vs. TICLE
TICLE vs. LOCNESS
One of the above-mentioned non-native corpora, KTUCLE is the local learner corpus of the
study and stands for Karadeniz Technical University Corpus of Learner English. Being an in-
house learner corpus compiled by MA thesis supervisor of the researcher in Karadeniz Technical
University in Turkey, KTUCLE is particularly preferred as the central L2 corpus to examine the
written productions of EFL students in an attempt to study intensifier usage patterns. The second
non-native corpus under research is TICLE (Turkish International Corpus of Learner English) as
Turkish sub-corpus of ICLE (International Corpus of Learner English). The utilization of TICLE
for complementary means helps to reveal alternative data for usage frequency and patterns in
different Turkish speaking EFL settings. All the findings derived from these two leaner corpora
were compared with a native corpus called LOCNESS in order to make a comparison between the
usage patterns and overuse/underuse levels in all corpora. LOCNESS (The Louvain Corpus of
Native English Essays) as the reference corpus employed in this investigation is supposed to shed
light on the standard use of English intensifiers by native speakers.
The learner corpus KTUCLE contains essays written by tertiary level preparatory students of
a Turkish university in the city of Trabzon and all the essays are expository in character. The
second learner corpus TICLE is consisted of essays collected from students in three universities in
Turkey: Çukurova University, Mersin University and Mustafa Kemal University (Kilimci and Can,
2008). The reference corpus LOCNESS contains expository argumentative essays written by
American and British university students (Granger, 1998). It is a corpus of native English made up
of total 361,054 words. The profile and distribution of these corpora are shown in the following
table:
Table 7: The Profiles of the Three Corpora Utilized in the Research
KTUCLE TICLE LOCNESS
Tokens 709,748 223,449 361,054
Texts 1600 280 282+
L1 Turkish Turkish American English, British English
Genre Expository Expository Argumentative Expository Argumentative
As emphasized in the previous sections, this research initially attempts to find out the overall
usage frequency of intensifiers in learner English. Intensifiers are modifying phrases which carry
the traces of speakers’ attitudes. The data distribution of intensifiers in learner corpora in
comparison with those in native corpus will also uncover different usage patterns and features of

48
semantic meaning. While analyzing form or patterns, one can also obtain information about
meaning. Obviously, such descriptions of meaning can be made possible through the analysis of
large-scale corpora.
In the light of corpus data, “the co-occurrence of particular words with particular grammatical
patterns” can be identified (Carter, 2004: 72). According to Hunston et al. (1997) “there are two
main points about patterns to be made: Firstly, that all words can be described in terms of patterns;
secondly, that words which share patterns, share meanings” (as cited in Carter, 2004: 73). In order
to investigate the function of meaning, semantic prosodic attitude of both non-native learners and
native speakers of English in terms of using intensifiers in written production will be evaluated in
this study in a descriptive manner based on Stubbs’ (1996) classification of semantic prosody as
positive, negative, and neutral.
3.2.1. Labelling of Patterns
For pattern analysis of intensifiers, the study employs the approach of ‘pattern grammar’ held
by Hunston and Francis (2000) in their book with the same name. To define it simply, the notion of
pattern can be supposed as a grammatical form of a lexical item. In this study, ‘pattern’ is used as
an indicator showing both the grammar and meaning function of a specific word. The patterns of
major word-classes are simply labeled by Francis et al. (1996, 1998) as follows (Hunston and
Francis, 2000: 51):
v: verb group
n: noun group
adj: adjective group
adv: adverb group
that: clause introduced by that (realised or not)
-ing: clause introduced by an ‘-ing’ form
to-inf: clause introduced by a to-infinitive form
wh: clause introduced by a wh-word (including how)
with quote: used with direct speech
The labeling of intensifier patterns as Wang (2017) employed in his research based on the
method of Hunston’s pattern grammar are adopted in this study. Intensifier plus adjective
combination is labelled by Wang (2017) as ‘INT-adj’ in which intensifer is “the node word that is
capitalized and abbreviated for pattern expression” (Wang, 2017: 52). INT-adj (intensifier +
adjective) is the focused type of investigated intensifier collocations; therefore, other intensifier
patterns such as modifying nouns, adverbs or verbs are not included within the scope of the current
investigation.

49
3.3. The Selection Criteria of Intensifiers
Intensifier is used as an umbrella term to analyze adjective intensification. Quirk et al.’s
(1985) taxonomy of intensifiers is taken as a reference in this study as it is widely-used in related
corpus-based investigations. In this aforementioned categorization, there are two main sub-
categories: amplifiers and downtoners. As their name suggests, amplifiers are the intensifiers that
scale upwards while downtoners are the ones that scale downwards. Prior studies (Lorenz, 1999,
Wang, 2017) have shown that amplifiers outnumber downtoners in learner English. Therefore,
amplifiers were the main focus of the study to see to what degree native or learner speakers use
them in their written production. There are two sub-sets of amplifiers which are maximizers and
boosters. The most frequently used amplifiers are determined and investigated in terms of their
usage patterns and semantic prosodic function. The selected intensifiers under investigation are
shown below:
Table 8: Selected Intensifiers
Amplifiers
Maximizers Boosters
absolutely very
completely so
entirely too
fully
perfectly
totally
utterly
3.4. Corpora and Tools for Data Collection
This corpus-based investigation, as mentioned above, is conducted through the utilization of
three corpora. The first two are Turkish learner corpora and the third one is a reference native
corpus. This section summarizes the design criteria of the learner corpora as well as the features of
native speaker corpus. Besides, corpus tools to be used in the study are presented below.
3.4.1. Learner Corpora
“A type of corpus that is immediately related to the language classroom is a learner corpus”
(McEnery et. al, 2006: 65). It is inevitable that a learner corpus should be carefully compiled and
have a strict design criteria. The design criteria of learner corpora is composed of language and
learner variables. Language variables are categorized into five main subtitles: “medium of
language, genre, topic, technicality and task setting.” Learner variables, on the other hand, identify
features such as “age, sex, mother tongue, region, other foreign languages, level, learning context

50
and practical experience” (Granger, 1985). The following table illustrates the language and learner
variables of KTUCLE as the local learner corpus:
Table 9: The Design Criteria of KTUCLE
Language Variables Learner Variables
Medium written Mother Tongue Turkish
Genre argumentative Age 18-22
Topic education, literature,
society Gender
Female 79%
Male 21%
Technicality academic essay Language Proficiency B2
Task Setting untimed essay 90%
exam 10% Learning Context EFL classroom setting
The table below presents the design criteria of second learner corpus TICLE which is the
Turkish sub-corpus of ICLE (International Corpus of Learner English):
Table 10: The Design Criteria of TICLE
Language Variables Learner Variables
Medium written Mother Tongue Turkish
Genre argumentative Age 21-23
Topic education, society Gender Female 81%
Male 19%
Technicality academic essay Language Proficiency B2-C2
Task Setting untimed essay Learning Context EFL classroom setting
Source: Can, 2011 (as cited in Akbana and Koşar, 2015)
3.4.2. Reference Corpus
In a comparative corpus-based research, the use reference corpus provides the standards and
norms of native speakers. A native control corpus is required to make a comparison between
learner language use and native use (Altenberg and Granger, 2001: 175). The present study utilizes
Louvain Corpus of Native English Essays (LOCNESS) as the control corpus of this research. Table
11, which is constituted based on the information on University of Louvain webpage, illustrates the
features and data distribution of LOCNESS in detail:

51
Table 11: The Profile of LOCNESS
LOCNESS Setting Task Genre Text Number
British Essays
unknown exam literary 15
unknown exam expository – historical 18
unknown exam literary 24
unknown not rigidly timed argumentative 33
British Essays (A Level) unknown untimed essays argumentative Unknown
American Argumentative Essays
Marquette University untimed essays argumentative 46
Indiana University timed essays argumentative 28
Presbyterian College untimed essays argumentative 6
University of South
Carolina
untimed essays argumentative 6
timed essays argumentative 17
untimed essays argumentative 13
untimed essays argumentative 17
University of Michigan timed essays argumentative 43
American Literary Mixed-Essays Presbyterian College exam literary-mixed 16
Total Text Number 282+
Source: https://uclouvain.be/en/research-institutes/ilc/cecl/locness.html
The selection of a reference corpus seems to be a significant methodological decision since it
may affect the outcome of the analysis. It should be better to choose a control corpus having
representativeness and similarities in size, participants, topic, and text types. For this purpose,
LOCNESS is selected as the reference corpus and it is highly comparable to learner corpora for
containing texts written in argumentation by students and having similar age of participants.
3.4.3. Corpus Tools
In corpus linguistics, it may be easy to make an introspection through smaller size of corpora.
However, larger corpora could not be easily analyzed without the help of concordance programs or
computer-aided methods comparing data and estimating their frequency. “A concordance brings
together utterances which have been produced at different times by different speakers, makes
visible recurrent patterns, and allows us to count them” (Stubbs, 2009: 117). Sketch Engine, which
was utilized for the quantitative analysis of the current corpus research, is one of the most preferred
kind of such software tools in corpus linguistics field. Granger (2008: 93) states that by utilizing
such tools, researchers immediately retrieve frequency information of words from their corpus.
This online concordancer contains ready to use corpora; besides, it also enables researchers to
build or upload their own corpora. The three corpora under investigation were uploaded to the
system and the requested data were retrieved automatically for the analysis. All the concordance

52
lines related to intensifier collocations were extracted. Then, the raw frequencies of the data were
normalized per one million automatically by using Sketch Engine program since raw frequencies
do not show the proportional data in comparison process.
3.5. Data Analysis Procedures
The study is mainly based on quantitative research method because it tries to obtain
frequency-based statistical data. In the matter of quantitative analysis of corpus, Stubbs (2009: 117)
stated that “corpora are just data and quantitative methods are just methods, but their combination
has led to a major shift in theory, and it is this theory which has to be evaluated.”
In this study, the frequency of intensifier collocations gathered from two learner corpora and
one native speaker corpus are compared with each other via log-likelihood measurement. LL (log-
likelihood) ratio is regarded as “the most useful statistical device to measure the comparison
between two corpora as it calculates the frequency regarding the corpus word size” (Babanoğlu and
Can, 2018: 21) An online log-likelihood calculator of Lancaster University was used to find LL
scores of selected intensifiers to see whether the frequency differences of three corpora in
comparison have reached any statistical significance. In addition, the rate of overuse and underuse
of intensifiers can be found out with the help of log likelihood measurement. To explain it better, if
the log likelihood score is greater than 6.63, the difference between the two corpora is less than 1%.
The result is usually expressed as p < 0.01 and it means that we are 99% certain of the result. If the
log likelihood score is 3.84 or more, the probability of its happening by chance is less than 5% and
it is expressed as p < 0.05. This means that we are 95% certain of the result. In short, the higher the
critical value, the more significant the difference happens to be between two corpora.

53
CHAPTER FOUR
4. FINDINGS AND DISCUSSION
4.1. Introduction
The present descriptive corpus-based research investigates the use of intensifiers by tertiary
level Turkish EFL learners and native speakers of English with a special focus to their usage
patterns and evaluative meaning. Initially, this chapter reveals the overall data distribution of
intensifiers in native speaker corpus LOCNESS and two Turkish learner corpora, namely KTUCLE
and TICLE. The target intensifiers under investigation are amplifiers which are divided into
subcategories as maximizers and boosters. The selected amplifiers with their adjective collocates
(INT-adj) in three corpora are retrieved and described in terms of their raw and normalized
frequencies with the help of a corpus tool called Sketch Engine. Then, the tendency of tertiary level
EFL learners to overuse and underuse amplifiers in writing are also identified based upon the Log-
likelihood measurements. Finally, the most frequent amplifier collocations of adjectives in learner
corpora and their semantic prosodic profiles as positive, negative or neutral are presented to shed
light on the awareness of EFL learners’ adjective intensification by comparing them with native
speakers of English. The amplifiers in each corpora are also analyzed in terms of their common
usage patterns.
4.2. Overall Frequency Distribution of Amplifiers
In this quantitative research, the overall frequency of intensifiers in each corpus was initially
calculated to make inferences about their usages by native speakers of English and non-native EFL
learners. The raw frequency of each intensifier was normalized into a value per million
automatically by Sketch Engine in order to compare frequencies between corpora of different sizes.
Then, Log-Likelihood (LL) scores were measured in an attempt to illustrate the differences or
similarities between native speakers and EFL learners in overusing or underusing amplifiers in
their written production. Aforementioned in the section of methodology, the LL score greater than
6.63 signifies that the difference between the two corpora is less than 1%. When the LL score is
3.84 or more, the difference between the two corpora is less than 5%. Based upon these
calculations, maximizers and boosters in all corpora are separately analyzed concerning their
overall distribution.

54
4.2.1. Maximizers
As a subcategory of amplifiers, there are seven target maximizers in the study: absolutely,
completely, entirely, fully, perfectly, totally and utterly. The findings on concordance program
reveal that there are 495 additional occurrences of intensifiers modifying adverbs, verbs or nouns in
three corpora under investigation. As the focus of the study, the number of maximizer plus
adjective combinations is 164 in total and they compose 33% of the whole types of occurrences.
Although there are many other occurrences of maximizers in all corpora, the total number of
maximizer plus adjective combinations is limited. Table 12 illustrates the raw frequencies and
percentages of maximizers in an alphabetical order in the three corpora.
Table 12: Overall Distribution of Maximizer + Adjectives
Maximizers
(INT-adj)
LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
Frequency Percentage Frequency Percentage Frequency Percentage
absolutely 5 8,06 221 29,33 3 11,11
completely 15 24,19 282 37,33 11 40,74
entirely 8 12,90 5 6,66 1 3,70
fully 7 11,29 2 2,66 6 22,22
perfectly 14 22,58 2 2,66 0 0
totally 12 19,35 15 20 6 22,22
utterly 1 1,61 1 1.33 0 0
TOTAL 62 100 75 100 27 100
Table 12 shows that in native corpus LOCNESS, completely (f = 15) and perfectly (f = 14)
are the most frequent maximizers while utterly (f = 1) is the least frequent one. On the other hand,
according to the distribution in the local learner corpus KTUCLE, completely (f = 28) and
absolutely (f = 22) have the highest percentages while utterly (f = 1), fully (f = 2) and perfectly (f =
2) have the lowest percentages. Finally, in TICLE, as the second learner corpus of the study,
completely (f = 11) has the highest percentage, whereas perfectly and utterly have no hits, and
entirely (f = 1) is low in percentage.
Considering the overall distribution of maximizers, completely is the most frequently used
maximizer both in native corpus and learner corpora. On the contrary, utterly is the least frequent
maximizer used in the three corpora. Another commonly employed maximizer in KTUCLE and
TICLE is totally which has a function scaling upwards like the maximizer completely. For Kennedy
1 In KTUCLE, there are actually 24 concordance lines of absolutely retrieved from Sketch Engine, but two occurrences
are excluded from the scope of the analysis since they do not collocate with adjectives (see Appendix 2, lines 11-12). 2 Two concordance lines of completely + adjective combinations in KTUCLE are repeated in Sketch Engine, hence the
total number of occurrences is taken as 28. (See Appendix 2, lines 5-10 and 12-13).

55
(2007: 154-155) some amplifiers such as completely and totally are supposed to be synonymous,
but according to British National Corpus (BNC) “even apparently synonymous amplifiers seem to
prefer to keep different company.”
The following tables present the 1R adjective collocations of completely and totally occurred
in both native and non-native corpora. As shown in Table 13 and Table 14, these two distinct
maximizers have a different distribution of collocations. The only common adjective combination
of completely placed in all corpus is ‘completely different’ and obviously it is not the most frequent
collocation in any corpus (KTUCLE f = 5, LOCNESS f = 2, and TICLE f =1). When the number of
tokens in three groups of corpora is taken into consideration, no judgments can be made about the
presence of any overuse or underuse regarding the use of ‘completely different’ as an intensified
adjective collocation.
Table 13: 1R + Adjective Collocations of completely
COMPLETELY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
completely
+
1R adj
indifferent
innocent
different
recyclable
erroneous
unjustified
abhorrent
false
ethical
equal
new
impossible
2
2
2
1
1
1
1
1
1
1
1
1
wrong
different
good
useful
clear
misguided
coherent
independent
innocent
valid
helpful
true
dependent
possible
6
5
4
3
1
1
1
1
1
1
1
1
1
1
unpleasant
opposite
special
safe
adequate
right
theoretical
human
true
equal
different
1
1
1
1
1
1
1
1
1
1
1
TOTAL 15 28 11
As regards totally, there is no common occurrence of intensified adjective collocation in three
corpora. ‘Wrong’ is the most frequent INT-adj collocation in KTUCLE, but TICLE holds only one
occurrence. ‘Different’ and ‘true’ are among the adjectives that collocate no more than once or
twice with the maximizer totally. Surprisingly, there is no occurrence of ‘totally different’ in
KTUCLE unlike to ‘completely different’.

56
Table 14: 1R + Adjective Collocations of totally
TOTALLY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
totally
+
1R adj
unacceptable
dependent
alien
absurd
powerless
abhorrent
blameless
futile
unrealistic
different
2
2
1
1
1
1
1
1
1
1
wrong
bad
useful
distribute
dependable
poisonous
opposite
right
harmful
true
4
2
2
1
1
1
1
1
1
1
different
invaluable
wrong
true
little
2
1
1
1
1
TOTAL 12 15 6
The second highest collocation found in KTUCLE is absolutely. However, the other two
corpora do not display its usage as much as KTUCLE (TICLE f = 3, LOCNESS f = 5). Table 15
represents that there are various adjectives modified by the maximizer absolutely, but no common
collocation has been identified in each group. Similarly as in totally and completely, ‘wrong’ is the
most frequent adjective collocation of absolutely in KTUCLE. The native speakers, on the other
side, prefer using ‘wrong’ just one time in combination with absolutely. It is because the EFL
learners may tend to use the same adjective with near-synonymous maximizers regardless of their
semantic nuances.
Table 15: 1R + Adjective Collocations of absolutely
ABSOLUTELY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
absolutely
+
1R adj
unacceptable
huge
ridiculous
necessary
wrong
1
1
1
1
1
wrong
necessary
right
efficacious
barbaric
express
false
unnecessary
essential
aware
important
9
3
2
1
1
1
1
1
1
1
1
meaningless 1
compulsory 1
impossible 1
1
1
1
TOTAL 5 22 3
As presented in Table 16, perfectly is the second most frequent maximizer in reference
corpus, but it is found to be less favored by EFL learners (LOCNESS f = 14, KTUCLE f = 2,
TICLE f = 0). Even, no occurrence of perfectly plus adjective has been found out in TICLE. The

57
sole common collocation in LOCNESS and KTUCLE is ‘perfectly healthy’. The low usage
frequency of perfectly in learner corpora confirms that Turkish EFL learners often make use of a
small repertoire of maximizers such as completely and totally in writing to enhance the evaluative
value of their focus.
Table 16: 1R + Adjective Collocations of perfectly
PERFECTLY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
perfectly
+
1R adj
legal
natural
safe
good
comparable
understandable
visible
healthy
logical
acceptable
2
2
2
2
1
1
1
1
1
1
healthy
safe
1
1
TOTAL 14 2 0
As shown in Table 17 and Table 18, the maximizers entirely and fully apparently have quite
similar frequencies in LOCNESS. In KTUCLE, both maximizers in adjective head are not much
preferred. LOCNESS and KTUCLE share ‘entirely dependent’ as the only common collocation. In
TICLE, there is only one occurrence of entirely.
Table 17: 1R + Adjective Collocations of entirely
ENTIRELY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
Entirely
+
1R adj
true
separate
unfounded
voluntary
contradictory
dependent
ethical
2
1
1
1
1
1
1
obsolete
man-made
clear
wrong
dependent
1
1
1
1
1
unnecessary
1
TOTAL 8 5 1
Whereas the two maximizers entirely and fully may both appear to be roughly synonymous,
they each collocate strongly with different adjectives as illustrated in Table 17 and Table 18.

58
Table 18: 1R + Adjective Collocations of fully
FULLY LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
fully
+
1R adj
integrated
presidential
reassured
intergrated3
redundant
human
aware
1
1
1
1
1
1
1
useless
individual
1
1
conscious
human
functioning
3
2
1
TOTAL 7 2 6
The expression of ‘fully human’ is the only common collocation that appear in LOCNESS
and TICLE. At first sight, one can suppose that ‘human’ is a noun, so it should be beyond the scope
of the study. On the contrary, the concordances extracted from both corpora confirm that they have
an adjective function (e.g. the unborn is not fully human). According to online Oxford Learner’s
Dictionary, ‘human’ in adjective form means “having the same feelings and emotions as most
ordinary people (e.g. He's really very human when you get to know him.)”. When the proficiency
level of EFL learners get higher, they can be able to distinguish between the correct word classes in
English.
According to Table 19, the last and the least frequent maximizer is utterly which has no
common adjective collocations in each corpora. It is a rarely used maximizer either in combination
with adjectives or other items.
Table 19: 1R + Adjective Collocations of utterly
UTTERLY
LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
utterly
+ 1R adj
devoid 1
different 1
TOTAL 1 1 0
It can be concluded that Turkish EFL learners significantly overuse a limited range of
intensifiers such as completely, totally and absolutely. However, some certain maximizers such as
perfectly are rarely used or not preferred by EFL learners when compared to native speakers of
English. This issue may be a characteristic feature of interlanguage during which EFL learners’
linguistic ability does not match with that of native speakers in language production. The learners
of English may not be competent enough to master vocabulary in an efficient way.
3 The mispelling of the adjective ‘integrated’ is corrected and accounted as having two occurences in LOCNESS.
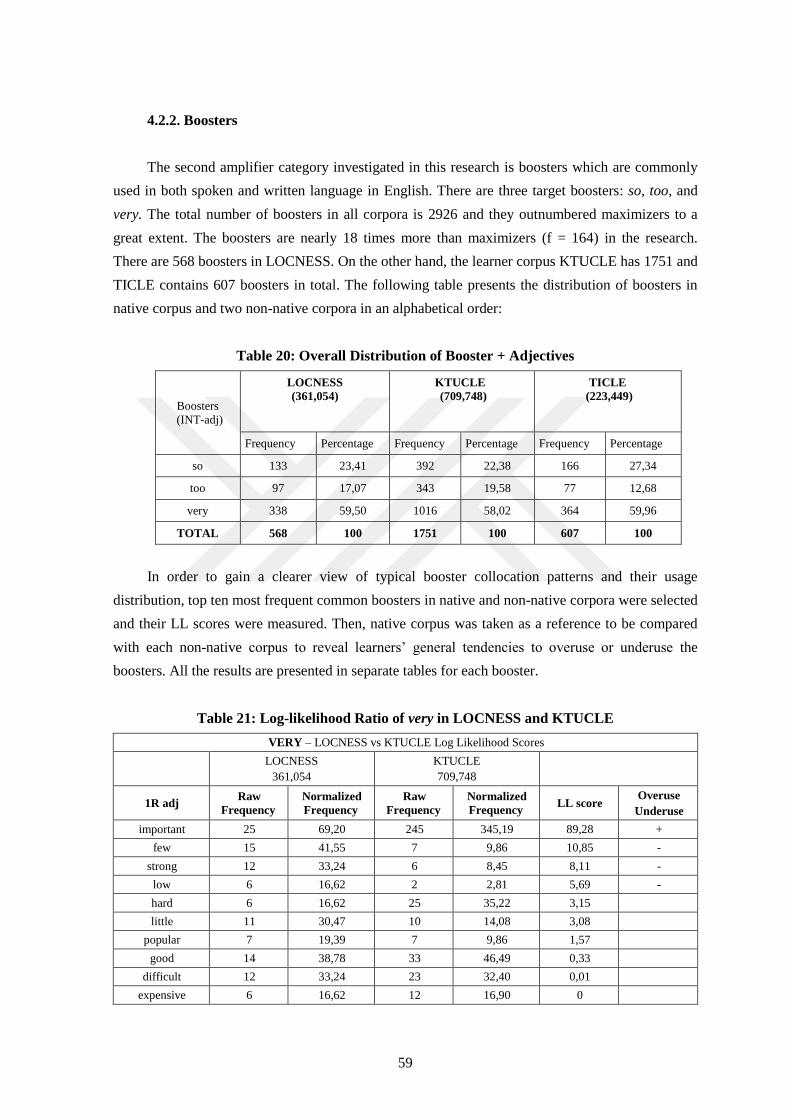
59
4.2.2. Boosters
The second amplifier category investigated in this research is boosters which are commonly
used in both spoken and written language in English. There are three target boosters: so, too, and
very. The total number of boosters in all corpora is 2926 and they outnumbered maximizers to a
great extent. The boosters are nearly 18 times more than maximizers (f = 164) in the research.
There are 568 boosters in LOCNESS. On the other hand, the learner corpus KTUCLE has 1751 and
TICLE contains 607 boosters in total. The following table presents the distribution of boosters in
native corpus and two non-native corpora in an alphabetical order:
Table 20: Overall Distribution of Booster + Adjectives
Boosters
(INT-adj)
LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
Frequency Percentage Frequency Percentage Frequency Percentage
so 133 23,41 392 22,38 166 27,34
too 97 17,07 343 19,58 77 12,68
very 338 59,50 1016 58,02 364 59,96
TOTAL 568 100 1751 100 607 100
In order to gain a clearer view of typical booster collocation patterns and their usage
distribution, top ten most frequent common boosters in native and non-native corpora were selected
and their LL scores were measured. Then, native corpus was taken as a reference to be compared
with each non-native corpus to reveal learners’ general tendencies to overuse or underuse the
boosters. All the results are presented in separate tables for each booster.
Table 21: Log-likelihood Ratio of very in LOCNESS and KTUCLE
VERY – LOCNESS vs KTUCLE Log Likelihood Scores
LOCNESS
361,054
KTUCLE
709,748
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
important 25 69,20 245 345,19 89,28 +
few 15 41,55 7 9,86 10,85 -
strong 12 33,24 6 8,45 8,11 -
low 6 16,62 2 2,81 5,69 -
hard 6 16,62 25 35,22 3,15
little 11 30,47 10 14,08 3,08
popular 7 19,39 7 9,86 1,57
good 14 38,78 33 46,49 0,33
difficult 12 33,24 23 32,40 0,01
expensive 6 16,62 12 16,90 0

60
To start with very, which has the highest frequency among three boosters with the raw
frequency of 1718 in total, it can be argued that it is highly exploited by the participants in three
corpora with similar usage proportions. When the reference corpus LOCNESS and the local learner
corpus KTUCLE are compared in terms of their overuse and underuse patterns, it can be possibly
inferred that non-native corpus participants overused the intensification ‘very important’ with the
LL score of +89,28, and it is the most frequently used adjective in KTUCLE. On the other hand,
LOCNESS participants used the aforementioned intensification in their written materials with
69,20 normalized frequency while KTUCLE participants involved it with 89,28 normalized
frequency. Concerning their normalized frequencies and corpus sizes, the difference between
native and non-native corpus seems significantly high as it leads to the overuse by KTUCLE
students with the LL score of +89,28.
Having mentioned one occurrence of overuse in KTUCLE, there remain three underuse
examples of adjective intensifications: ‘very few’, ‘very strong’ and ‘very low’. As illustrated in
Table 21, LOCNESS holds 15 evidences with the normalized frequency of 41,55, whereas the non-
native corpus participants use ‘few’ 7 times with the normalized frequency of 9,86. Despite being
featured as the largest corpus in the study, KTUCLE has a relatively low frequency of ‘few’; and it
seems that this booster intensification is underused with the LL measure of -10,85. Other recurrent
adjective collocations ‘very strong’ and ‘very low’ are also underused by the EFL learners with
their LL measures of -8,11 and -5,69 respectively. ‘Strong’ holds the normalized frequency of
33,24 in LOCNESS whereas it is included in KTUCLE with the normalized frequency of 8,45.
Table 22: Log-likelihood Ratio of very in LOCNESS and TICLE
VERY – LOCNESS vs TICLE Log Likelihood Scores
LOCNESS
361,054
TICLE
223,449
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
important 25 69,20 44 196,91 18,35 +
few 15 41,55 1 4,47 8,89 -
strong 12 33,24 1 4,47 6,43 -
difficult 12 33,24 17 76,08 4,92 +
hard 6 16,62 11 49,22 4,86 +
little 11 30,47 15 67,12 4,02 +
good 14 38,78 16 71,60 2,80
expensive 6 16,62 2 8,95 0,63
popular 7 19,39 3 13,42 0,30
low 6 16,62 4 17,90 0,01

61
Very + adjective comprises four overuse and two underuse examples in TICLE when
compared to LOCNESS. TICLE participants overuse the adjective intensifications ‘very
important’, ‘very difficult’, ‘very hard’ and ‘very little’ with the LL measures of +18,35, +4,92,
+4,86 and +4,02 correspondingly. The booster + adjective collocation ‘very important’ is the
highest occurrence of overuse since LOCNESS has a normalized value of 69,20, while TICLE has
196,91. Thus, the LL score of +18, 35 makes this collocation the most overused one as occurred in
KTUCLE. Besides, ‘very difficult’ (LL = +4,86), ‘very hard’ (LL = +4,92) and ‘very little’ (LL =
+4,02) are three other overused collocations with approximately similar LL scores.
In addition to the overuses in TICLE, there are two underuse examples of very + adjective
collocations: ‘very few’ and ‘very strong’. Correspondingly, the two non-native learner groups are
found to show a tendency to underuse ‘very few’ and ‘very strong’ in writing. However, ‘very low’
which is the third underused intensifier collocation in KTUCLE is not an evidence of underuse in
TICLE because its LL score is not found significantly different from the native corpus.
So is the second highest booster intensification having totally 690 occurrences in all corpora
as shown above in Table 20 (LOCNESS f =132, KTUCLE f =392 and TICLE f =166). The
following two tables give the information about the common adjective use with the head of booster
so in all groups of corpora.
Table 23: Log-likelihood Ratio of so in LOCNESS and KTUCLE
SO – LOCNESS vs KTUCLE Log Likelihood Scores
LOCNESS
361,054
KTUCLE
709,748
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
important 2 5,53 44 61,99 24,09 +
little 5 13,84 1 1,40 6,29 -
bad 1 2,76 8 11,27 2,48
many 40 110,78 57 80,31 2,38
useful 1 2,76 7 9,86 1,90
easy 2 5,53 8 11,27 0,92
different 1 2,76 5 7,04 0,88
hard 7 19,38 9 12,68 0,69
much 19 52,62 46 64,81 0,60
difficult 2 5,53 7 9,86 0,57
KTUCLE includes one example of overuse and underuse in so + adjective collocations. ‘So
important’ is applied 2 times in the native corpus while KTUCLE consists 44 raw frequencies of it.
Therefore, this booster + adjective collocation is regarded as being overused in KTUCLE with the

62
LL score of +24,09. ‘So little’ has only 1 raw frequency with a normalized frequency of 1,40 in
KTUCLE while LOCNESS involves 5 raw frequencies with a normalized frequency of 13,84.
Thus, this refers to an evidence of underuse with the LL measure of -6,29. ‘So many’ and ‘so
much’ are among the most favored collocations, but the difference between two corpora is not
statistically significant to mention about any instance of overuse or underuse.
While KTUCLE includes one example of overuse of so + adjective collocations, TICLE, by
contrast, involves 3 evidences: ‘so important’, ‘so many’ and ‘so easy’. The adjective
intensification of ‘so important’ holds a normalized frequency of 5,53 in the native corpus while it
exists in TICLE with a normalized frequency of 67,12. Therefore, the LL score calculated as
+18,46 refers to the overuse of ‘so important’ in TICLE as shown in Table 24. ‘So many’ is the
second example of overuse with the LL score of +9,58 in TICLE. The last overused so + adjective
collocation is ‘so easy’ with the normalized frequency of 110,78 in LOCNESS while it holds the
normalized frequency of 214,81 in TICLE. Apart from these, KTUCLE and TICLE hold one so +
adjective collocation in common as an evidence of overuse which is ‘so important’.
Table 24: Log-likelihood Ratio of so in LOCNESS and TICLE
SO – LOCNESS vs TICLE Log Likelihood Scores
LOCNESS
361,054
TICLE
223,449
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
important 2 5,53 15 67,12 18,46 +
many 40 110,78 48 214,81 9,58 +
easy 2 5,53 9 40,27 8,80 +
different 1 2,76 4 17,90 3,65
much 19 52,62 21 93,98 3,34
little 5 13,84 1 4,47 1,33
bad 1 2,76 2 8,95 0,99
hard 7 19,38 6 26,85 0,34
useful 1 2,76 1 4,47 0,11
difficult 2 5,53 1 4,47 0,03
Following the analysis of the adjectives with the booster so, Table 25 and Table 26 introduce
the most common ten booster + adjective collocations with too in KTUCLE and TICLE and their
frequencies in comparison with the native control corpus LOCNESS. Too is the least frequent
booster among three corpora with the total raw frequency of 517 (LOCNESS f= 97, KTUCLE f=
343 and TICLE f= 77) as illustrated before in Table 20 presenting the overall distribution of
boosters.

63
Table 25: Log-likelihood Ratio of too in LOCNESS and KTUCLE
TOO – LOCNESS vs KTUCLE Log Likelihood Scores
LOCNESS
361,054
KTUCLE
709,748
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
much 23 63,70 182 256,42 55,76 +
high 4 11,07 1 1,40 4,52 -
late 5 13,84 23 32,40 3,51
difficult 1 2,76 7 9,86 1,90
important 3 8,30 10 14,08 0,70
long 2 5,53 3 4,22 0,09
many 14 38,77 29 40,85 0,03
big 1 2,76 2 2,81 0
young 1 2,76 2 2,81 0
strong 1 2,76 2 2,81 0
KTUCLE includes the adjective intensification ‘too much’ with a normalized value of 256,42
whereas the native corpus holds a normalized frequency of 63,70. Therefore, the LL score of
+55,76 indicates that it is the sole instance of overused example in KTUCLE. Surprisingly,
KTUCLE, a corpus of 709,748 tokens, has one evidence of underuse concerning too + adjective
collocation, which is ‘too high’ with 1 raw frequency. However, this particular collocation appears
4 times in LOCNESS, and the Log-likelihood score is found -4,52. The remaining adjectives do not
have any statistically significant difference in terms of overuse or underuse of booster too.
One outstanding finding is the use of ‘too many’ that is the second most preferred booster +
adjectives in KTUCLE and LOCNESS. Its normalized frequencies in native and non-native
corpora indicate that there is not a meaningful difference concerning its usage Although ‘too much’
is overly used by non-native English major students when compared to native speakers, the
occurrence of ‘too many’ in KTUCLE is found to be consistent with the native usage frequency.
There is no evidence of underuse or overuse regarding ‘too many’. Another striking result is that
‘much’ is one of the high frequently used adjectives in combination with too, but it does not appear
among the top ten common booster + 1R adjective collocations of very. That is to say, ‘very much’
(LOCNESS f = 2, KTUCLE, f = 11, TICLE f = 4, see Apendix 4,5 and 6) is not preferred as widely
as ‘too much’ in writing. Their semantic difference will be further analyzed in depth in the section
of semantic prosodic description.
The following table displays the normalized frequencies and LL scores of too with the use of
adjectives both in TICLE and LOCNESS:

64
Table 26: Log-likelihood Ratio of too in LOCNESS and TICLE
TOO – LOCNESS vs TICLE Log Likelihood Scores
LOCNESS
361,054
TICLE
223,449
1R adj Raw
Frequency
Normalized
Frequency
Raw
Frequency
Normalized
Frequency LL score
Overuse
Underuse
difficult 1 2,76 6 26,85 6,76 +
much 23 63,70 29 129,78 6,54 +
young 1 2,76 4 17,90 3,65
high 4 11,07 1 4,47 0,77
late 5 13,84 5 22,37 0,57
important 3 8,30 1 4,47 0,31
long 2 5,53 2 8,95 0,23
many 14 38,77 7 31,32 0,22
big 1 2,76 1 4,47 0,11
strong 1 2,76 1 4,47 0,11
While KTUCLE includes one example of overuse and one evidence of underuse when
compared to LOCNESS, TICLE holds no evidences of underuse in terms of too + adjective
collocations. Instead, there exist two overuses of booster + adjectives that are ‘too difficult’ and
‘too much’. ‘Too much’ is the only collocation that is overused in KTUCLE; in other words, it is
correspondingly overused in both non-native corpora.
Moreover, TICLE participants use ‘too difficult’ with a normalized frequency of 26,85 while
the native corpus includes 1 occurrence of it with a normalized frequency of 2,76. Therefore, this
booster + adjective collocation has the LL score of +6,76 which stands for its overuse in TICLE.
Additionally, ‘too much’ is used with the normalized frequency of 63,70 in LOCNESS while it is
employed with the normalized frequency of 129,78 in TICLE. The LL measure of the
aforementioned adjective collocation is +6,54 in TICLE and therefore it is the second example of
overuse in written production .
To sum up, although these three distinct boosters, so, too and very are near-synonymous,
native speakers or EFL learners may intentionally prefer using certain adjectives in the company of
these boosters. Their semantic prosodic profiles described in the following section may hold a
mirror to the EFL learners’ specific preferences for adjective intensification in writing.
4.3. Semantic Prosodic Description of Amplifiers
The language learners should have an awareness of semantic prosodic properties associated
with the usage of intensifiers in a similar manner that native speakers do. This section is concerned

65
specifically with the semantic prosodic analysis of amplifiers in English to reveal similarities and
differences between tertiary level Turkish EFL learners and native speakers in the use of adjective
intensification. Retrieved from both native corpus LOCNESS and non-native corpora KTUCLE
and TICLE, two amplifier clusters, which are maximizers (absolutely, completely, entirely, fully,
perfectly, totally, utterly) and boosters (so, too, very), are analyzed in terms of semantic prosody.
Considering this, all the maximizers and boosters in combination with adjectives are categorized
based on Stubbs’ (1996) classification of SP such as positive, negative, or neutral.
4.3.1. Semantic Profiles of Maximizers
The maximizers under scrutiny are all separately analyzed with a focus on their common
adjective collocates. Initially, the raw frequencies of each maximizer + adjective collocations that
are categorized according to their semantic profiles are shown in Table 27. The typical usage of
maximizers in native corpus is taken as a reference to distinguish improper usages of EFL leaners
and their semantic prosodic behavior.
Table 27: Semantic Prosodic Profiles of maximizers + adjectives
absolutely completely entirely fully perfectly totally utterly
LOCNESS
Positive 2 6 3 3 13 1 0
Negative 3 5 3 1 0 10 1
Neutral 0 4 2 2 1 1 0
KTUCLE
Positive 10 15 1 0 2 4 0
Negative 12 5 3 1 0 11 1
Neutral 0 8 1 1 0 0 0
TICLE
Positive 0 7 0 6 0 2 0
Negative 3 2 1 0 0 2 0
Neutral 0 2 0 0 0 2 0
Depending on the maximizer + 1R adjective collocations in the reference corpus, it can be
inferred that perfectly, completely and fully seem to have positive semantic profile and totally,
absolutely and utterly have a negative profile, while entirely tends to occur between negative and
positive polarity. It must be noted that a certain maximizer may collocate with adjectives bearing a
positive meaning, but in its context it may have an underlying negative evaluation. Thus,
concordance lines in reference corpus should be examined in depth to uncover semantic prosodic
features of each maximizer because the raw frequencies of their adjective collocations may not
reflect their exact semantic orientation in native usage.
Acting mainly as an adjective modifier, absolutely denotes the meaning of “to the fullest
extent; in the highest or utmost degree” (Lorenz, 1999: 83). It is clearly seen in Table 28 that

66
absolutely can be used either with positive or negative adjectives for not being employed in a
regular prosody. Partington (2004: 146) found out that there is “a balance between favourable and
unfavourable items” that collocate with absolutely. The randomly selected examples from online
Oxford Dictionary also indicate positive, negative and neutral prosodic usage of absolutely are
“absolutely incapable, absolutely correct, and absolutely personal.”
Table 28: The Semantic Prosodic Profile of absolutely
ABSOLUTELY
LOCNESS
Positive (2) huge, necessary
Neutral
Negative (3) unacceptable, ridiculous, wrong
KTUCLE
Positive (10) necessary (3), right (2), efficacious, express, essential, aware, important
Neutral
Negative (12) wrong (9), barbaric, false, unnecessary
TICLE
Positive
Neutral
Negative (3) meaningless, compulsory, impossible
The findings related to absolutely in the reference corpus LOCNESS confirms that the use of
this maximizer is distributed in a roughly balanced manner (negative f= 3, positive f=2). The same
situation is valid for the frequency of maximizers in KTUCLE (positive f = 10, negative f= 12).
Such a distribution of adjective collocation in native and non-native corpora may not be enough to
label absolutely as having a positive or a negative prosody, but having a mixed semantic profile to
put it in a simple terms.
Completely is a maximizer which tends to co-occur predominantly with negative adjectives
(Louw, 1993; Paradis, 1997; Kennedy, 2003; Wang, 2017). For Greenbaum (1970, as cited in
Johansson and Stenström, 1991: 137), completely is commonly used with “verbs denoting a failure
to attain a desirable goal or state” (e.g. ‘forget’ and ‘ignore’). In his study based on Cobuild
Corpus, Partington (2004: 148) found out that completely collocates with a number of items
expressing a state of ‘change’ (e.g. “hopeless, ignored, lost, and unexpected”) or ‘absence’ (e.g.
“altered, changed, destroyed, and different”). Oxford Dictionary gives examples in parallel with
Parrington’s findings such as “completely unsatisfactory, completely ridiculous, completely untrue,
completely different, and completely transformed.”

67
Table 29: The Semantic Prosodic Profile of completely
COMPLETELY
LOCNESS
Positive (6) innocent (2), recyclable, ethical, equal, new
Neutral (4) indifferent (2), different (2)
Negative (5) erroneous, unjustified, abhorrent, false, impossible
KTUCLE
Positive (15) good (4), useful (3), clear (1), coherent, independent, innocent, valid, helpful, true, possible
Neutral (5) different (5)
Negative (8) wrong(6), misguided, dependent
TICLE
Positive (7) special, safe, adequate, right, human, true, equal
Neutral (2) theoretical, different
Negative (2) unpleasant, opposite
In contrary to the findings of above-mentioned researchers, completely is observed to have
seemingly a good prosody according to Table 29. Surprisingly, the native corpus in the study also
seems to collocate with adjectives being positive in meaning, but actually many of them have a
negative association in the context as shown in the concordance lines retrieved from LOCNESS:
…a lot for the better, not everything is completely equal. Men are just lime woman, some of them
may (LOCNESS)
… of universal guilt because no one can be completely innocent. Camus raises the idea that even
Jesus (LOCNESS)
KTUCLE which is composed of participants of Turkish EFL learners include a great many
positive adjective collocations with the maximizer completely (positive f = 16). In TICLE, there
appears positive adjectives more than other two prosodic profiles (positive f = 7). It can be inferred
that EFL learners are not fully aware of the negative attitudinal meaning of completely. The results
also point out that the adjectives are mostly compounded with negative prefixes similar to Wang’s
(2007: 90) findings that “the intensifier completely has a strong tendency to collocate with
adjectives with negative prefixes” (e.g. indifferent, unjustified, impossible, abhorrent, misguided,
unpleasant). The only common adjective employed in three corpora is ‘different’ which has no
evidence of prosody for being neutral in meaning.
As shown in Table 30, there is a balanced distribution of negative and positive adjectives
intensified by the maximizer entirely, and the number of neutral items are found to be roughly
similar in LOCNESS. That is to say, there appears no noticeable semantic prosodic distribution of
adjectives in control corpus. In the corpus-based research of amplifiers conducted by Kennedy

68
(2003: 476), entirely is found with items having either positive or negative associations. For
Partington (2004: 148), “the collocations of entirely, however, also seem to encompass a slightly
wider range of senses than those of the others. They include a number of words which express an
opposition between dependence-independence or relatedness-unrelatedness.” It can be claimed that
there is “no clear-cut distinction” for entirely in terms of semantic prosodic categories (Özbay and
Aydemir, 2017: 47).
Table 30: The Semantic Prosodic Profile of entirely
ENTIRELY
LOCNESS
Positive (3) true (2), voluntary
Neutral (2) separate, ethical
Negative (3) unfounded, contradictory, dependent
KTUCLE
Positive (1) clear
Neutral (1) man-made
Negative (3) obsolete, wrong, dependent
TICLE
Positive
Neutral
Negative (1) unnecessary
In present study, the native speakers are likely to use entirely with negative adjectives such as
‘unfounded’, ‘dependent’ or in negative pattern. The two positive intensification examples in
LOCNESS employed with the adjective ‘true’ are used in negation (e.g. ‘not entirely true’). The
result that can be derived from the findings is that entirely collocates mainly with neutral or
negative items. On the other hand, Turkish EFL learners do not highly prefer making use of this
maximizer in their written discourse.
The maximizer fully can be supposed to have a positive orientation. According to Altenberg
1991: 137) synonymous maximizers such as entirely, completely, totally and fully are considered to
“share the sense in every respect.” The definition of fully in Oxford Dictionary is “completely or
entirely; to the fullest extent” and the examples of fully in combination with adjectives include
“fully determined, fully aware, fully candid, fully interactive” all having positive meaning.
Additionally, Kennedy (2003) reported that the maximizer fully has exclusively bond with positive
adjectives having –able or –ible suffix.

69
Table 31: The Semantic Prosodic Profile of fully
FULLY
LOCNESS
Positive (3) reassured, human, aware
Neutral (3) integrated (2), presidential
Negative (1) redundant
KTUCLE
Positive
Neutral (1) individual
Negative (1) useless
TICLE
Positive (6) conscious (3), human (2), functioning
Neutral
Negative
In this study, the only negative prosody in LOCNESS is ‘redundant’ and the sentence is
structured in negation as given below:
…the case, then the human brain will never become fully redundant. There has (LOCNESS)
There are solely evidences of positive associations in TICLE (positive f = 6), whereas no
positive semantic usage is found in KTUCLE. Fully is not a highly preferred amplifier among EFL
learners, though. Instead of it, EFL learners may have a tendency to use completely that can be
more familiar to them in reading materials or books in English language.
Perfectly, as its name suggests, strongly has a positive semantic prosody. According to
Bäcklund (1970) “Perfectly tends to collocate with words referring to positive or commendable
qualities” (as cited in Altenberg, 1991: 137). Partington (2004: 146) stated that perfectly
demonstrates a “distinct tendency” to bond with good things. It can be noted that the adjectives
intensified by this maximizer should not be combined with negative prefixes since perfectly sounds
‘strange’ when collocate with words having negative morphemes such as ‘perfectly unhealthy’
(Paradis, 1997: 81). Likewise, there are13 positive occurrences in LOCNESS as Table 32 displays:

70
Table 32: The Semantic Prosodic Profile of perfectly
PERFECTLY
LOCNESS
Positive (13) legal (2), natural (2), safe (2), good (2), understandable, visible, healthy, logical, acceptable
Neutral (1) comparable
Negative
KTUCLE
Positive (2) healthy, safe
Neutral
Negative
TICLE
Positive
Neutral
Negative
An interesting finding is that despite of being a large corpus KTUCLE has only 2 occurrences
of positive prosody while TICLE has no evidence of any semantic category. In KTUCLE and
LOCNESS, ‘safe’ and ‘healthy’ are common adjective collocations with perfectly. Although
perfectly has a predominant positive reflection in use and creates no prosodic complexity, the EFL
learners do not prefer using it in their writing.
Paradis (1997: 82) stated that “completely and totally are the modifiers par preference with
adjectives with negative morphemes”. Kennedy (2003) also ascertained in his research that totally
co-occurs mainly with negative associations.
Table 33: The Semantic Prosodic Profile of totally
TOTALLY
LOCNESS
Positive (1) blameless
Neutral (1) different
Negative (10) unacceptable (2), dependent (2), alien, absurd, powerless, abhorrent, futile, unrealistic
KTUCLE
Positive (4) useful (2), right, true
Neutral
Negative (11) wrong (4), bad (2), distribute, dependable, poisonous, opposite, harmful
TICLE
Positive (2) invaluable, true
Neutral (2) different (2)
Negative (2) wrong, little

71
It is obviously seen in Table 33 that the negative associations of totally in LOCNESS and
KTUCLE outnumber positive and neutral prosodies. However, TICLE has an equal distribution of
semantic categories. The sole example concerning the positive prosody of totally + adjective
collocation retrieved from LOCNESS is used in negation.
…the scientists involved, by they by no means totally blameless. I suggest the alternative opinion
(LOCNESS)
The particular example below indicates that the EFL learner participants in TICLE may have
no semantic awareness in the use of totally with adjectives.
…from the problems of the life maybe this is not totally true, but not totally wrong. And again
what (TICLE)
Additionally, totally is often used by EFL learners in a positive manner regardless of its
underlying negative prosodic effect.
…and healthy way to use animals on testing. It is totally true that animal testing is beneficial for
(KTUCLE)
…on the other hand, the others say it is totally useful for us. In my opinion cell phone is really
(KTUCLE)
Lastly, the maximizer utterly seems to be associated with unpleasant events. According to the
observations of Greenbaum (1970) and Louw (1993), utterly falls into the category of unfavorable
semantic prosody (as cited in Partington, 2004: 147).
Table 34: The Semantic Prosodic Profile of utterly
UTTERLY
LOCNESS
Positive
Neutral
Negative (1) devoid
KTUCLE
Positive
Neutral (1) different
Negative
TICLE
Positive
Neutral
Negative

72
According to this analysis, utterly is the least frequent type of maximizer + adjective
collocation of all. It has only two evidences, one of which is negative prosody in LOCNESS and
the second one is neutral prosody in TICLE. Thus, the findings cannot be adequate to make any
inference on its semantic prosodic use in learner corpora. It may be concluded that utterly is not
preferred by tertiary level EFL learners in academic writing.
Overall, it can be noted that the target maximizers in the study all have a distinct semantic
prosodic profile. The findings of Bublitz (1998: 26) go in parallel with the results of the current
study: Completely and entirely exhibit a shared “up-scaling” meaning, but concerning the
distribution of negative and positive semantic prosody, these two near-synonymous amplifiers are
not regarded as ‘complementary’. That is to say, they differ in a way that “completely has a clear
negative semantic prosody” while “entirely has no definite semantic prosody at all” which has a
potential to collocate with negative, positive, and neutral items. On the other hand, he added that
the remaining scalar maximizers utterly (negative), totally (negative) and perfectly (positive) have
an obvious semantic prosody.
4.3.2. Semantic Profiles of Boosters
The three selected boosters so, too and very are classified according to their semantic profiles
as shown in Table 35. The boosters can be interchangeably used in combination with adjectives for
expressing negative, positive and neutral evaluations. It is much difficult to identify precise
prosodic nature of boosters due to having a wide range of semantic relationship when compared to
maximizers. All the adjective collocations used with target boosters are given in the Appendices
between 4 and 12.
Table 35: Semantic Prosodic Profiles of Booster + Adjectives
Booster +
1R adj Semantic
Prosody
so too very
Frequency Percentage Frequency Percentage Frequency Percentage
LOCNESS
(361,054)
Positive 89 66,91 62 63,91 151 44,67
Neutral 11 8,27 9 9,27 78 23,07
Negative 33 24,81 26 26,80 109 32,24
KTUCLE
(709,748)
Positive 269 68,62 237 69,09 623 61,31
Neutral 26 6,63 39 11,37 149 14,66
Negative 97 24,74 67 19,53 244 24,01
TICLE
(223,449)
Positive 118 71,08 49 63,63 178 48,90
Neutral 13 7,83 9 11,68 86 23,62
Negative 35 21,08 19 24,67 100 27,47

73
The reference corpus LOCNESS reveals that the three boosters similarly have a high
frequency of positive semantic prosodic profile and ‘ very important’ is the first most common
positive adjective collocation in three corpora. It is explicitly seen in the findings that the semantic
profiles of very in LOCNESS have a mixed nature in use since there is not a substantial difference
among percentages. The positive semantic profile of very constitutes 44% of whole while negative
prosodic percentage is 32% and neutral is 23%. The frequencies of very in TICLE is relatively
close to results in LOCNESS. However, in KTUCLE, the EFL learners tend to use very in positive
semantic orientation with a percentage over 60%. The adjectives having negative and neutral
prosodies are used less when compared to positive ones. The tertiary level EFL learners prefer very
as it can be simply combined with adjectives with various meanings. For having a broader
collocational range, very is highly exploited by language learners when compared to other boosters
or maximizers.
The booster so is the second most common booster preferred by the participants in three
corpora as illustrated in Table 35. The positive, negative and neutral semantic usage percentages of
so in native corpus and non-native corpora are very close to each other. The positive prosodic
usage of so is similarly high in each corpus with the percentage ranging between 67 and 71%.
However, this booster cannot be labeled as having a positive prosody because different ranges of
adjectives are likely to be used properly in combination with so. Some common examples to
adjective collocations of so having positive meaning are ‘important’, ‘useful’, and ‘easy’; those
having negative meanings are ‘hard’, ‘bad’, and ‘difficult’; and those having neutral meanings are
‘different’, ‘general’ and ‘little’.
Both in native corpus and non-native corpora, too is the less frequent one among other
boosters under investigation. The results seemingly imply that this booster mostly tends to intensify
adjectives carrying positive meanings. The percentages of too in LOCNESS go parallel with the
frequency in TICLE. Table 35 indicates that these two corpora have a positive semantic profile
with the percentage of 63% while KTUCLE has the percentage of 69%. However, these findings
tell us little about its underlying semantic profile. ‘Too many’ and ‘too much’ are the two most
common adjective collocations of too in all corpora. The total frequency of ‘much’ and ‘many’
constitutes 90% (f = 211) of whole positive adjectives in KTUCLE (f = 232). In LOCNESS,
‘much’ and ‘many’ compose 66% (f = 41) of whole positive adjectives in combination with too (f =
62), while they are exposed of 73% (f = 36) of positive ones in TICLE (f = 49). However, when the
concordance lines are analyzed in depth, it is clearly seen that ‘too much’ or ‘too many’ are highly
used for expressing exaggeration or negation. Although ‘many’ and ‘much’ seem to be adjectives
with positive attitudes, a negative association can be revealed when they collocate with too in
certain usage patterns such as ‘too much / many that’. Such occurrences will be analyzed in the next
pattern analysis section.

74
4.4. Pattern Analysis of Amplifiers
In this part, the most frequent usage patterns of amplifiers in non-native corpora KTUCLE
and TICLE are analyzed in comparison with those in LOCNESS based on the patterning labels of
Hunston and Francis (2000) in their book titled Pattern Grammar. In this particular research, a
pattern is regarded as “the combination of both grammar and lexis of a given node word, which
carries a specific meaning, and to realize certain function” (Wang 2017: 51). Adopted from Wang
(2017), the labelling of adjective intensification is abbreviated and expressed as ‘INT-adj’ which
refers to ‘intensifier + 1R adjective’ collocation. Intensifier (INT) is used as a representation for all
target amplifiers. As the focus of the study, the coding of intensifier is shown in capital letters
while other elements or word classes are in lower case letters. The elements representing an actual
word such as prepositions are coded in italics (Hunston and Francis, 2000: 33).
4.4.1. Usage Patterns of Maximizers
Seven maximizers totally, completely, absolutely, entirely, fully, utterly and perfectly in
native and non-native corpora were analyzed in terms of their patterning features. Different types
of maximizer plus adjective collocations were found in three corpora. However, it was observed
that most of the maximizer patterns were not abundantly used by both native speakers and non-
native learners. There are three common types of maximizer plus adjective collocation patterns
among seven types in three corpora. In its simplest form, the first pattern is intensifier + adjective
following a link verb which is abbreviated as ‘v-link INT adj’. Another major usage of maximizers
is negative form of the first pattern that is ‘v-link not INT adj’. The other frequent usage pattern is
intensifier + adjective clause modifying a noun labelled as ‘INT adj n’. Additionally, there are
other patterns such as ‘V int adj’, ‘modal v-link INT adj’, ‘v n/pron INT adj’ and independent use
of ‘INT adj’ which were not frequently used in native and non-native corpora. Therefore, these four
pattern types having a low percentage are categorized as ‘other patterns’ in Table 36.
Table 36: Overall Percentages of Maximizer Patterns
Maximizers
(INT-adj patterns)
LOCNESS
(361,054)
KTUCLE
(709,748)
TICLE
(223,449)
Frequency Percentage Frequency Percentage Frequency Percentage
v-link INT adj 41 66,12 53 70,66 12 44,40
INT adj n 14 22,58 12 16,00 6 22,22
v-link not INT adj 2 3,22 5 6,66 7 25,92
Other Patterns 5 8,06 5 6,66 2 7,40
TOTAL 62 100 75 100 27 100

75
According to the findings, most frequently used maximizer patterns in two learner corpora
are similar to ones in native corpus. In all three corpora, the first three patterns have the highest
percentages despite of the differences regarding the proportions. The ‘v-link INT adj’ is the
dominant pattern in LOCNESS, KTUCLE and TICLE. This pattern composes 70% of overall
usage in KTUCLE and 66% in LOCNESS. It is clearly seen that maximizers as modifying
adverbials preceding adjectives were mainly used for a predicative function. A predicate in a
sentence is thought to contain a verb explaining the action along with modifiers and other
complements. The concordance lines retrieved from three corpora under scrutiny are given below
to exemplify this pattern:
Pattern 1: v-link INT adj
…as you get older. They are skills that are absolutely essential in community organizations, in
(KTUCLE)
On the other hand, they can’t be equal as they’re totally different. First of all, their roles are (TICLE)
Additionally, the statistics show that the second pattern ‘INT adj n’ is also preferred by native
speakers and non-native learners with almost the same percentages. In this pattern, maximizers
were used as attributives accompanying with adjective to intensify noun as shown in the examples
below:
Pattern 2: INT adj n
…and you can communicate with people in a completely different environment and you
cannot (KTUCLE)
…everyday of the year, hundreds of fully conscious animals are scalded, beaten or (TICLE)
The negative form of the first pattern ‘v-link not INT adj’ is also seen in three corpora.
However, the learners have a tendency to use this type of negative pattern more than native
speakers. One reason is that native speakers use various negation forms (e.g. no, nobody, no one,
no longer, nothing, never, neither, nor) instead of negative maximizer patterns including not.
Another reason is that learners may be lack of awareness concerning semantic prosody, thus they
may refrain from using various negative maximizer patterns to express judgments.
… for rail transport, and as their problems are completely different in most respects, it must be clear
(LOCNESS)
…only should we study it should be given as an entirely separate discipline. Joseph Zaitchik,
editor (LOCNESS)

76
Pattern 3: v-link not INT adj
Yes, we use very a lot yet we are not totally dependable. In my opinion, if we have not the
(KTUCLE)
…from the problems of the life maybe this is not totally true, but not totally wrong. And
again (TICLE)
The total number of maximizers used in three corpora is not high in numbers; therefore, their
raw frequencies (or exact number of occurrences) can be shown in distinct tables in order to see
different usage patterns of each node words. It can be concluded there are some slight differences
in terms of usage. Table 37, Table 38 and Table 39 illustrate the overall occurrences of maximizer
+ adjective patterns in LOCNESS as reference corpus and KTUCLE and TICLE as learner corpora
under investigation:
Table 37: Typical patterns of ‘INT-adj’ in LOCNESS
LOCNESS (361,054) completely absolutely totally entirely fully perfectly utterly
1 v-link INT adj 10 4 10 5 3 9 -
2 v-link not INT adj - - 1 1 - - -
3 INT adj n 3 1 1 2 2 5 -
4 v INT adj - - - - 2 - 1
5 modal v-link INT adj 2 - - - - - -
6 v n/pron INT adj - - - - - - -
7 INT adj - - - - - - -
TOTAL 15 5 12 8 7 14 1
In LOCNESS, the first pattern has the highest percentage similar to learner corpora. Even
perfectly, which is scarce in learner English, is abundantly used in the pattern of ‘v-link INT adj’.
Completely and totally are similarly the most frequent maximizers in LOCNESS. Negative
predicative forms are not widely preferred by native speakers. That is to say, they often express
their judgments by adding negative prefixes to adjectives or using other items having negative
meaning such as never, no, nobody etc.
…the scientists involved, they are by no means totally blameless. I suggest the alternative
opinion (LOCNESS)
…of universal guilt because no one can be completely innocent. Camus raises the idea that
even Jesus (LOCNESS)
… the case, then the human brain will never become fully redundant… There has
(LOCNESS)
… ‘of making the best of it’. Caligula is not a totally abhorrent character in this play. Camus
gives (LOCNESS)

77
Table 38: Typical patterns of ‘INT-adj’ in KTUCLE
KTUCLE (709,748) completely absolutely totally entirely fully perfectly utterly
1 v-link INT adj 16 19 12 3 1 1 1
2 v-link not INT adj 3 - 1 1 - - -
3 INT adj n 7 1 1 1 1 1 -
4 v INT adj 1 1 1 - - - -
5 modal v-link INT adj 1 1 - - - - -
6 v n/pron INT adj - - - - - - -
7 INT adj - - - - - - -
TOTAL 28 22 15 5 2 2 1
KTUCLE, as the local learner corpus, is larger than other corpora concerning token number,
but many of the maximizer patterns are not much in this learner corpus. Completely, absolutely and
totally are the most common maximizers. Although completely most often appears having a
positive meaning in native corpus, the non-native students are more likely to use this maximizer in
negative sentences. Completely is also highly used in the third pattern.
Table 39: Typical patterns of ‘INT-adj’ in TICLE
In TICLE, the second learner corpus of the research, completely is the most frequent
maximizer and it is also used in negative predicative form similar to the findings in KTUCLE. Not
surprisingly, there is no occurrence of perfectly and utterly. Strikingly, the last two patterns in the
table ‘v n/pron INT adj’ and independent use of INT + adjective are only found in TICLE despite
of being a learner corpus. These two rare maximizer patterns occur with the use of absolutely as
shown in following concordance lines:
Pattern 6: v n/pron INT adj’
The conception of ‘ABORTION’. They may feel it absolutely compulsory to let the infant
off to get rid of (TICLE)
TICLE (223,449) completely absolutely totally entirely fully perfectly utterly
1 v-link INT adj 7 1 2 1 1 - -
2 v-link not INT adj 3 - 3 - 1 - -
3 INT adj n 1 - 1 - 4 - -
4 v INT adj - - - - - - -
5 modal v-link INT adj - - - - - - -
6 v n/pron INT adj - 1 - - - - -
7 INT adj - 1 - - - - -
TOTAL 11 3 6 1 6 0 0

78
Pattern 7: INT adj’
… a life is gone away and you want to go back. Absolutely impossible! So, how are you
going to keep this (TICLE)
4.4.2. Usage Patterns of Boosters
The three most frequently used boosters in English language, respectively so, too and very,
are examined in terms of their usage patterns in non-native corpus and learner corpora. It is
obviously seen that there is a strong predominance of boosters in the category of amplifiers. The
findings show that they are quite more than maximizers in three corpora (see Table 20). For this
reason, the frequency of each booster + adjective pattern is not counted one by one as it is done in
the pattern analysis of maximizers. Instead, the raw frequencies of each target booster are given
along with their percentages by focusing on differences and similarities in terms of typical patterns
and functions between native speakers and learners of English.
KTUCLE is the larger corpus in size; thus, three selected boosters are normally higher than
those in other two corpora. In all corpora, the order of most frequently boosters are the same,
respectively very, so and too. The analysis of three corpora revealed that there are not many
outstanding differences concerning the types of booster + adjective patterns. However, native
speakers and EFL learners significantly differ not in using various types of booster patterns but in
frequency of their occurrence. Randomly selected concordance lines exemplifying common pattern
varieties of each target booster + adjective combinations are retrieved from three corpora and will
be treated separately in depth under following subsections.
4.4.2.1. Very
Very is one of the most frequently encountered English amplifiers either in spoken or written
language. According to Lorenz (1999: 64), “very is the booster par excellence. It is highly versatile
in its collocability and combines almost freely with adjectives.” According to Table 20, nearly 60%
of total boosters in native corpus is composed of the booster very. The percentage of very in
LOCNESS is almost similar to that of TICLE with 60.36. KTUCLE has the highest frequency of
very, but its percentage of the whole is under 50. The concordance lines given below present
typical pattern types of booster combinations with the use of very:
Pattern 1: v-link INT adj
…good more than harm. Primarily, internet is very important in our daily lives as well as in
(KTUCLE)
…or not, but I do know that life for some people is very difficult and unless someone can really
feel (LOCNESS)

79
…immediately. The system in education is very strict, it uses the student only as a model.
(TICLE)
Pattern 2: INT adj n
…of the instant noticing. You can also see very beautiful places especially overseas, which
(KTUCLE)
…so many inventions in the 20th century and had very large impacts on our lives. They
changed our (TICLE)
Pattern 3: v-link INT adj for n/pron
…get used to live alone, living with a child is very hard for them. Secondly, they don’t
supply life (KTUCLE)
…best decision for the parents to divorce. It is very hard for the children to be witness to
their (TICLE)
Pattern 4: v-link INT adj to inf
…of treatment methods and medicines are very important to destroy these diseases. In this
(KTUCLE)
on the screen of your computer. Nowadays, it is very popular to find friends by the help of
computers (TICLE)
Pattern 5: modal v-link INT adj
…want assurance from someone eye contact can be very important in getting your thoughts
across. When (KTUCLE)
…there is an immediate event or warning it can be very good. They can reach you wherever you
are, but (TICLE)
Pattern 6: v INT adj
…is attack to animal rights. Scientists have very good reason for do it. To save the human life is
(KTUCLE)
…may be illogical, rubbish way which may seem very reasonable at first. A person is born alone,
(TICLE)
…bring up the point that coal mining is a very dangerous job. Coal miners can contract lung
(LOCNESS)
… nuclear power being so new and different, it is very scary for people. In order for these
people to be (LOCNESS)
…where relativism reign supreme. It would be very difficult to impose such an ethic on members of
(LOCNESS)
…to Hamlet’s uncle, Claudius. Hamlet can be very clever when it is necessary. When he suspects
(LOCNESS)
Again at peak times, trains can become very cramped with very few facilities and often (LOCNESS)

80
Pattern 7: v-link not INT adj
…or friends help us but a teacher safe us. It is not very complex. Sometimes we need to talk just a
(KTUCLE)
…like everything in our life television is not a very bad thing or not a very good thing in people’s
(TICLE)
The present investigation conducted on a native corpus and two learner corpora indicate that
there are seven above-mentioned common patterns of booster + adjective collocations. In addition
to these typical patterns appearing in all corpora with different proportions, there are some other
patterns which are not abundant but have some relatively significant nuances. It is apparent that
there are much different types of pattern in native corpus. For instance, in native corpus, some
examples to ‘v something INT adj’ pattern are found (e.g. find something very difficult to take).
Besides, ‘v-link prep INT adj n’ combinations are also encountered (e.g. under very fierce
competition). In LOCNESS, ‘INT adj n’ pattern is also found in the form of subject at the initial
position of sentence (e.g. Very little freight is transposed by rail these days.). The verb collocations
on the left are more likely to be varied in LOCNESS such as find, seem, offer, become make, feel,
have while in learner corpora verbs such as make, become, and have are observed. Different
negative forms are not preferred much with this adjective modifier. Patterns like ‘there v-link INT
adj’ and ‘this/that v-link INT adj’ are widely used in each corpus.
4.4.2.2. So
So is the second booster having the high-frequency adjective combinations in the present
study. So has the percentage of 34 of total booster use in KTUCLE while in TICLE so is employed
with the proportion of 27 percent (see Table 20). On the other hand, so composes nearly half of the
boosters in reference corpus. There are five typical patterns of so + adjective combinations in
LOCNESS, KTUCLE and TICLE. As in other amplifiers, the first two patterns, that are ‘v-link
INT adj’ and ‘INT adj n’, are dominantly observed with the use of so. The form of ‘v-link INT adj
that’ is another common pattern peculiar to the use of so + adjective, and the EFL learners’ usage
frequency of this pattern is found to be no fewer than the native speakers. The fourth booster
pattern accompanying to-infinitive is also preferred in both native corpus and two learner corpora.
Here are the concordance lines randomly extracted from three corpora:
Pattern 1: v-link INT adj
…a lot of disaster. Every people know that it is so harmful but they don’t want to believe
it’s (KTUCLE)
…role has evolved. In the constitution it is not very clear who exactly in charge. Some articles
(LOCNESS)
…in many different places because travel is so easy. The last area I’m going to touch on is
(LOCNESS)

81
…right to decide his own death. His children are so emotional and selfish. Because they
think (TICLE)
Pattern 2: INT adj n
…our mental process will work. Some may say ‘I am so sociable person and I learned a lot
of things to (KTUCLE)
…people. Although giving these two causes is so selfish attitude, the human being is only
think (TICLE)
Pattern 3: v-link INT adj that
…that situation was proved in the past. It is not so bad that death of animals, in the
environment (KTUCLE)
…a great effect on the child’s character. It is so obvious that violence has so many bad
effects (TICLE)
Pattern 4: v-link INT adj to inf
…have an enjoyable time. However, recently it is so rare to see anybody visiting his/her
friend or (KTUCLE)
…arrived at this point in his ongoing life, it is so hard to turn back. Maybe you don’t really
want to (TICLE)
Pattern 5: v INT adj
…, he went on. As she was telling to me felt so bad. She said he suffered much while he
was dying (KTUCLE)
…think that computers are not beneficial. It has so many advantages that I cannot mention
all of (TICLE)
Surprisingly, a widespread pattern in learner corpora is ‘v-link INT adj for n/pron’ where the
adjective is followed by for to signify someone or something ‘relating to’ or ‘connected with’ the
intensified thing. However, in LOCNESS, such usage type is not found.
Pattern 6: v-link INT adj for n/pron
…every time. First of all, family life is so important for a student. If a student’s family
(KTUCLE)
…each stage we take in life, we need money. It is so vital for people that one feels that
she/he can (TICLE)
The EFL learners tend to be lack of variety in forming negative sentences with boosters, as
well. They only prefer using not with link verbs to express negation in intensification, while native
speakers use other negative words.
…and authority. By showing how the networks have so little regard for that status that the
(LOCNESS)
...state of mind, health, and body. Disorder so severe that there is such a strong (LOCNESS)
...Hoederer in a bad light and the fact that he takes so long to carry out the act is because he’s
not (LOCNESS)
…jobs with good salaries, they may then become so preoccupied with their job and success,
that (LOCNESS)

82
Pattern 7: v-link NEG INT adj
Some frequent verbs collocating with boosters in learner corpora are become, feel, have,
know, and there are a few occurrences of love, need and provide in KTUCLE. Despite of being not
many in numbers, the verbs preceding so + adjective combination in TICLE contain give, have,
make, take and become. In LOCNESS, there are a variety of verbs collocating with boosters:
become, have, seem, spend, try, take, endure, and make. The modals such as must, can, could, will,
and should are also used in the pattern of ‘modal v-link INT adj’.
Lorenz (1999: 70) stated that “where there is no basis of comparison, the boosting function of
so is even more apparent, mostly in connection with emotive predications” (e.g. It looked so brutal
and disgusting). In fact, very is a more commonly used booster in English, but so is intentionally
preferred in some certain cases bearing correlative function. It is noticeable that ‘so much’ and ‘so
many’ are the high frequency combinations which can be proceeded immediately by ‘that clause’.
‘Much’ and ‘many’ can be regarded as adjectives in the scope of this study since they are denoting
quantity. All three groups are found to employ the patterns of ‘v-link INT adj that’ or sometimes
‘v-link INT adj to inf’ by using ‘so much’ or ‘so many’. Furthermore, the use of so plus adjective
in the function of a subject at initial position in a sentence structure is also encountered a few times
in learner corpora (e.g. So many people use the Internet for work.). The findings show that ‘so
many’ (LOCNESS f = 40, KTUCLE f = 57, TICLE f = 48) is more frequently preferred over ‘so
much’ (LOCNESS f = 19, KTUCLE f = 46, TICLE f = 21) in all corpora. However, it can be noted
that EFL learners have difficulty in writing grammatically correct form of countable and
uncountable nouns. They have an inclination to use ‘so much’ with countable things and ‘so many’
with vice versa. Even, in learner corpora, there are some misuses of plural and singular forms of
nouns. Turkish EFL learners often tend to forget adding –s to regular nouns to make them plural.
Most probably, this can be derived from the transfer of Turkish language, in which plural suffixes
(-ler or -lar) are not added to nouns when used with certain indefinite adjectives (e.g. birkaç, az,
biraz, çok, birçok, her, herhangi bir, hiçbir). The concordance lines below give examples to
improper use of many and much:
…the house, independently, as there are not so much children to look after. And if there are
(TICLE)
…it becomes like this every summer and we lost so much forests like this way every year.
Finally (KTUCLE)
…in most of the research. As important, there are so many study on genetics. Moreover, it
also (KTUCLE)
…society. A university in each city can provide so much things which are seem irrelevant
about (KTUCLE)
…compensation for services rendered is never so simple as remitting a predetermined salary
(LOCNESS)
…family unit. Family members are no longer so dependent on one another. They can go
elsewhere (LOCNESS)

83
…convenience to our life. Scientifically so many thing has changed that 50 years ago some
(KTUCLE)
…women but also men are use cosmetic products. So much product should be test again
before be our (KTUCLE)
4.4.2.3. Too
Too is the third most-frequent amplifier in current study. According to Table 18, LOCNESS
and KTUCLE have the similar percentages in using too as a booster although KTUCLE is almost
two times larger than LOCNESS in size. With the proportion of 12%, too is less frequent in TICLE
when compared to other two corpora. There are some common pattern clusters of too shared by
both native speakers and learners of English, which are ‘v-link INT adj’, v-link INT adj n’ and ‘v-
link INT adj for n/pron’. In addition, there is a major type of pattern with too often encountered in
all corpora: ‘v-link INT adj to inf’. The remaining patterns include booster intensification with
modals and verbs on the left position.
Pattern 1: v-link INT adj
…even though the distance between two houses was too distant, their neighbour, in village
they (KTUCLE)
…want to study for the exam, if the questions are too difficult, it they can only be answered
by (TICLE)
Pattern 2: INT adj n
For instance, in middle school, I have too much homework and school projects. I couldn’t
(KTUCLE)
… will help me; Professors deserve it because of too many assignments, poor teaching, and
unfair (TICLE)
Pattern 3: v-link INT adj for n/pron
…to move finger. Moreover, especially it is too important for women because internet
provides (KTUCLE)
…in order to have much money it means that you are too ambitious for money. Money
ambitious is not a (TICLE)
Pattern 4: v-link INT adj to inf
... can work outside at the same time. Of course, it is too hard to overcome this situation
(KTUCLE)
As well as the pointlessness of fox hunting it is too brutal on the now endangered wild fox
(LOCNESS)
…flaws, but his lack of respect for others and too much pride in himself lead Hamlet to his
(LOCNESS)
…initiative. Taking Richard away now would be too traumatic for him, or for that matter any
four (LOCNESS)
…in the ring as is sometimes the tragic case. It is too easy to allow emotion to control the
argument (LOCNESS)

84
…and he learns that this illness is very bad and too difficult to cure. Should the doctor
decide to (TICLE)
The pattern 2 ‘INT adj n’ is widely used booster pattern in both native and learner corpora.
Actually, boosters intensifying scalar words frequently collocate with ‘much’ and ‘many’. The
findings confirm that in three corpora, ‘much’ is found the first frequent collocation of too
(LOCNESS f = 23, KTUCLE f = 182, TICLE f = 29). As encountered in the collocations of ‘so
many’ and ‘so much’, non-native learners are observed to have problems in countable/uncountable
nouns placed in the collocation of ‘too much’ and ‘too many’.
…were used to save the world. But there are too much animals killed by experiments and I
could (KTUCLE)
As it is known, it youth period people have got too much problems and they seek away to
solve their (TICLE)
Additionally, the pattern ‘v-link INT adj to inf’ is found among the most common types of
adjective intensification with the head of booster too in all groups of corpora. Another version of
this pattern is ‘v-link INT adj to be v-ed’ which is less frequently observed in learner corpora. In
TICLE, there is just one concordance line containing this type of usage pattern; however in
KTUCLE, no such occurrence has been discovered. In LOCNESS, there are five occurrences in
this passive form. This result may be stem from the learners’ inadequate grammatical and lexical
knowledge of L2 which leads them to rely much on some certain intensifier patterns in written
production.
Pattern 5: v-link INT adj to be v-ed’
I put myself into a patient’s shoes who is too ill to be cured and the parents decide on
euthanasia (TICLE)
There are some common verbs collocates with INT + adj on the left position in the pattern of
‘v INT adj’. Most frequent common verbs used with adjective intensification are become, get, have,
take, give, seem, etc. in all three corpora. Even, EFL learners have been found to use different verbs
such as waste, use, spend, need, earn, want, cost, pay in a context where the subject is about
‘money’. However, this cannot be regarded as an indicator of a profound knowledge in L2. The
native speakers, on the other side, have an inclination to use a variety of different adverbs with
booster too such as all, far, almost, already, much, which is not seen in learner corpora (e.g. far too
many, all too much etc.) This is certainly a skill peculiar to the native speakers who are good at
collocating different words to intensify their message.
…believes that the responsibility of freedom is too great to be faced alone, advocates the
(LOCNESS)
… up to £9 million on any normal lottery draw) was too much to be given to just one party.
The recent (LOCNESS)

85
CONCLUSION AND SUGGESTIONS
As previously mentioned, the present corpus-based research carried out an investigation to
reveal semantic prosodic awareness of Turkish EFL learners at tertiary level on the use of English
intensifiers in expository argumentation. For this purpose, the methodology of the research mainly
adopted the approach of Granger’s (1998) Contrastive Interlanguge Analysis by nature and
compared one native corpus with two native corpora in order to reveal typical patterns of native
speakers and EFL learners concerning the usage of intensifiers in written production. Although
intensifier was used as an umbrella term, the aim of the study was to investigate the overall
frequency distribution of amplifiers in combination with adjectives as well as their patterning and
semantic prosodic features. Based on the intensifier classification of Quirk et al. (1985), the
analysis was conducted in two subcategories as maximizers and boosters. The high frequent
maximizers and boosters with their adjective collocations were analyzed in depth. Adjective
intensification was intentionally entailed for the analysis because in practice such degree adverbs
strongly collocate with adjectives (Kennedy, 2010: 240). The target maximizers were absolutely,
completely, entirely, fully, perfectly, totally, and utterly while the boosters were so, too, and very.
The reference corpus of the study is LOCNESS (Louvain Corpus of Native English Essays)
that is consisted of 361,054 words compiled from the essays of native speakers. The local learner
corpus is KTUCLE with 709,749 tokens composed of the essays written by tertiary level EFL
students at Karadeniz Technical University. As the second learner corpus, TICLE (Turkish
International Corpus of Learner English) contains 223,449 words extracted from argumentative
essays by Turkish adult EFL learners. These three corpora were compared with the use of a
concordance tool called Sketch Engine. On this online concordancer, the raw frequencies of each
target amplifier and their normalized values were measured automatically. Since three corpora
under investigation differ in size, normalized frequency and Log-likelihood scores are of high
importance to make a comparison between the usage frequencies and overuse and underuse levels.
The starting point of the current study was to investigate the semantic prosodic awareness of
Turkish EFL learners on the use of intensifiers in their written essays. With this in mind, the
analysis of the study was divided into three main sections in search for overall frequency
distribution of amplifiers in native and non-native corpora, their overuse and underuse levels, and
semantic prosodic nature of amplifiers and their usage patterns as well. Initially, the overall
distribution of amplifiers plus adjectives both in native corpus and non-native corpora were
retrieved to make inference on their usage. It is clearly seen that boosters outnumbered maximizers

86
to a great extent. In this regard, Quirk et al. (1985) stated that “while maximizers are a restricted
set, the class of boosters is more open-ended” (as cited in Baker, 2010: 113). The total number of
boosters is 2926, and maximizers are 164. The raw frequency of maximizers in the reference
corpus is 62, while in KTUCLE, at least two times larger than LOCNESS and even the largest of
all, the frequency of maximizers is 75. TICLE, as the smallest learner corpus in the study, has only
27 maximizers in total. When normalized per million with the following formula (Standardized
Frequency = Raw Frequency x 1.000.000 / Corpora Content), LOCNESS is found to have a
standard frequency of 17,17 while KTUCLE has 10,56. It can be inferred that the usage of
maximizer collocations by non-native participants in KTUCLE is slightly less than native speakers.
However, it was observed that only three of the maximizers such as absolutely, completely and
totally are commonly used by EFL learners, while they underuse perfectly, and never have a
tendency to use utterly. The results of the frequency analysis demonstrate that Turkish non-native
learners of English at tertiary level use rather limited range of maximizers some of which such as
completely and totally are most often used by native speakers. The excessive reliance of EFL
learners on certain types of maximizers may be resulted from their restricted command of
vocabulary and language proficiency level. Another possible explanation can be that the students
are quite familiar with the frequent maximizers and pre-fabricated or prefixed collocations such as
‘totally wrong’, ‘absolutely necessary’, and ‘completely different’ that may possibly appear much
in English learning materials, books and academic writing. The remaining maximizers such as
entirely, fully, perfectly, and utterly are not preferred by non-native learners, and surprisingly most
of them are not also widely used by native speakers instead of perfectly.
Boosters, on the contrary, are highly exploited by tertiary level Turkish EFL learners. The
findings revealed that KTUCLE has the highest frequency of the boosters very, so and too, while
TICLE and LOCNESS are quite similar in terms of their percentages. Very is the most frequent
booster in three corpora. Very is heavily overused by non-native speakers “in overall occurrences
as well as adj-int function” (Lorenz, 1999: 30). It gets confirmed through the higher use of very that
“learners prefer using ‘all-round amplifiers’ or ‘safe-bets’ strategies, especially very, to minimize
errors” (Xiaohua and Haihua, 2007: 759). That is to say, on account of having limited
phraseological skills, foreign language learners refrain from using complex or unfamiliar phrases
so as to avoid making mistakes in language production. Very is an intensifier than can be easily
employed by EFL learners in various usage patterns without any semantic prosodic concern.
In order to distinguish typical collocation patterns of booster intensification, which are
apparently high in number, the top ten most frequent common boosters in all groups of corpora
were analyzed. For each booster, the reference corpus was compared separately with KTUCLE and
TICLE based on Log-likelihood scores to identify overuse and underuse levels of EFL learners.
‘Very important’ is found to be the highest overused collocation both in KTUCLE and TICLE

87
when compared to the LOCNESS. The common underused booster + adjective intensification
patterns in KTUCLE and TICLE are ‘very few’ and ‘very strong’.
So is the second highest booster in three corpora. Lorenz (1999: 70) stated that when there is
no basis of comparison, the boosting function of so becomes more apparent. As occurs with very,
‘so important’ is also overused by the participants in two learner corpora. Not surprisingly, ‘so
many’ and ‘so much’ are the widely-preferred booster collocation in two learner corpora; however,
they are also widely used by native speakers. Lastly, too is the least frequent booster among three
corpora. According to Lorenz (1999: 70), while modifying an adjective, too certainly has a function
to scale upwards unless used in negation, and he added that “in this boosting function, and in its
virtually unrestricted collocability, it resembles very, the booster par excellence.” ‘Too much’ is the
common overuse pattern in KTUCLE and TICLE. ‘Too many’ is also highly preferred by the
participants in two corpora, but no considerable difference was found between non-native corpora
and native corpus.
Semantic prosody, as the core of the study, was analyzed based on Stubbs’ (1996)
classification as positive, negative, and neutral. The target amplifiers in combination with
adjectives in native and non-native corpora were all examined in terms of their semantic prosodic
profiles. The results showed that completely and totally are the most common maximizers preferred
by EFL learners. Since these two near-synonymous maximizers have an underlying negative
association in meaning, they can be used in a similar manner. However, EFL learners are not fully
conscious of the bad semantic prosodic nature of completely. Besides, they have a tendency to use
totally with adjectives bearing positive meaning. This can be attributed to their inadequate
competence in pragmatics. Another striking result is that EFL learners are more likely to use
familiar types of maximizers for adjective intensification such as completely, absolutely, and
totally, and they underuse other intensifiers such as perfectly and utterly. According to Wang
(2017: 125), “L1 transfer plays an obvious role in causing the overuse, underuse and misuse of
certain intensifiers.” Additionally, boosters very, so and too can be freely and interchangeably used
for negative, positive and neutral attitudes. That is why, Turkish EFL learners tend to use boosters
much predominantly in writing than maximizers.
As a special focus of the research, the usage patterning of amplifiers were examined based
on the patterning labels of Hunston and Francis (2000). Adopted from Wang (2017), the labelling
of adjective intensification was abbreviated as ‘INT-adj’. The most common usage patterns of
amplifiers in three corpora are ‘v-link INT adj’, ‘INT adj n’, and ‘v-link not INT adj’ which are
basic patterns constructed in writing. The non-native speakers use negative maximizer patterns
including not more than natives, because the learners may lack of semantic prosodic awareness to
use intensifiers in negative pattern for expressing attitudes. However, native speakers use various
negation forms (e.g. no, nobody, no one, no longer, nothing, never, neither, nor). The EFL learners

88
also underuse some usage patterns such as ‘v-link TOO adj to be v-ed’ which is peculiar to native
use. In addition, EFL learners were found to be lack of variety in using different items such as far,
all, almost with intensifiers as native speakers do. There are also a great many link verbs preceding
adjective intensification in the control corpus. It was also observed that ‘many’ and ‘much’ are
predominantly used with so and too, but Turkish EFL learners have a difficulty in distinguishing
countable and uncountable nouns while using with intensification. This can be resulted from the
transfer of Turkish language, in which plural suffixes are not added to nouns when used with
certain indefinite adjectives. It can be concluded that all these features may stem from the learners’
inadequate grammatical and lexical knowledge of L2.
From a pedagogical point of view, the study draws the implication that grammatical
competence is not enough to be competent in a foreign language. Instead, foreign language students
should be competent in pragmatic skills to master the vocabulary in target language. Near-
synonymous words like intensifiers have potential to be a challenge for foreign language learners
due to the nuances they bear in meaning. Thus, they should pay much attention to their semantic
prosodic nature to have a proficiency in using such adverbials. The curriculum may not include
explicit teaching of intensifiers, but some pragmatic classroom activities can be designed for
foreign language learners to raise their level of awareness of semantic prosody.
Concerning the limitations, it can be stated the present study solely focuses on adjective
intensification (INT-adj) which is supposed to be more abundant in language use. The degree
adverbials intensifying verbs, adverbs, nouns, or prepositional phrases are beyond the scope of this
research. Besides, a narrow-downed category of intensifiers with a limited number is
predetermined for the analysis. The scope of the research, otherwise, would be more complex and
wider to be analyzed. However, according to Lorenz (1998: 53-54), to scale the quality of
intensification “it would not have been sufficient to search and retrieve a set of previously
identified intensifiers.” It is necessary to make an analysis of intensification as comprehensive as
possible “rather than checking the corpora for a pre-defined finite set.” Furthermore, the research
embarks on the interlanguage problems of non-native learners, analyzing how frequently they
overuse or/and underuse intensifiers in written English. The misuse of intensifiers by Turkish EFL
learners is not examined in depth because “the strength of learner corpus analysis lies in the
detection of patterns, not errors” (Lorenz, 1998: 9).
For further studies, a similar research may be conducted through two or more learner corpora
including participants from different language proficiency levels. In this way, the interlanguage
development features of EFL learners in using intensifiers can be compared and identified to what
extent they progress in terms of semantic prosodic behavior. Secondly, a corpus-based comparative
study can be carried out on female or male EFL learners focusing on gender preference in
employing intensification in academic writing. The usage of intensifiers by native speakers and

89
non-native learners in conversational settings can also be investigated to uncover which types of
intensifiers are more preferred in spoken discourse.

90
REFERENCES
Ahmadian, Moussa et al. (2011), “Assessing English Learners’ Knowledge of Semantic Prosody
through a Corpus-Driven Design of Semantic Prosody Test”, Canadian Center of Science
and Education, English Language Teaching, 4(4), 288-298.
Aijmer, Karin (2002), “Modality in Advanced Swedish Learners’ Written Interlanguage”, Sylvia
Granger et al. (Eds.), Computer Learner Corpora, Second Language Acquisition and
Foreign Language Teaching, in (55-76), John Benjamins, Amsterdam.
Aijmer, Karin and Altenberg, Bengt (Eds.) (1991), English Corpus Linguistics, New York:
Longman.
Akbana, Yunus Emre and Koşar, Gülten (2015), “Contrastive Interlanguage Analysis of the
Highest-Frequency Vocabulary in Advanced and Native English”, The International
Academic Forum.
Aksan, Yeşim et al. (2012), “Construction of the Turkish National Corpus (TNC)”, Nicoletta
Calzolari (Ed.), Proceedings of the Eight International Conference on Language
Resources and Evaluation, 3223-3227.
Al-Sofi, Kholood et al. (2014), “Semantic Prosody in the Qur’an”, International Journal of
Linguistics, 6(2), 120-131
Altenber, Bengt and Granger, Sylviane (2001), “The Grammatical and Lexical Patterning of
MAKE in Native and Non-native Student Writing”, Applied Linguistics, Oxford University
Press, 22(2), 173-195,
Altenberg, Bengt (1991), “Amplifier Collocations in Spoken English”, Stig Johansson and Anna-
Brita Stenström (Eds.), English Computer Corpora, in (127–147), Mouton, Berlin.
______________ (2011), “Preface”, Fanny Meunier et al. (Eds.), A Taste for Corpora: In
Honour of Sylviane Granger, in (xiii-1), John Benjamin Publishing Company, Amsterdam.
Asikin, Nida A. (2017), “The Analysis of Interlanguage Produced by 3rd Grade High School
Students in Narrative Writing Text, Indonesian EFL Journal, 3(1), 45-50.
Aston, Guy et al. (2004), Corpora and Language Learner, John Benjamin Publishing,
Amsterdam.

91
Atasever, Serap (2014), A Comparative Analysis in Written Discourse: A Corpus-Based Study
on Frame Marker Use in Native and Non-native Students” Argumentative Essays,
Unpublished Master Thesis, Anadolu University.
Atkins, Sue et al. (1992), “Corpus Design Criteria”, Literary and Linguistic Computing, 7(1), 1-
16.
Babanoğlu, Pınar and Can, Cem (2018), “Adverbial Connectors in Turkish EFL Learners’
Argumentative Essays”, Academic Studies in Educational Sciences, Gece Publishing, 17-
29.
Baker, Paul (2006), Using Corpora in Discourse Analysis, Continuum, London.
_________ (2010), Sociolinguistics and Corpus Linguistics, Edinburg University Press, UK
Baker, Paul et al., (Eds.) (2006), A Glossary of Corpus Linguistics, Edinburgh University Press.
Barlow, Michael (2005), “Computer-based analysis of learner language”, Rod Ellis and Gary
Barkhuizen (Eds.), Analyzing Learner Language, in (335-357), Oxford University Press,
Oxford.
Bednarek, Monika (2008), “Semantic Preference and Semantic Prosody Re-examined”, Corpus
Linguistics and Linguistic Theory, Walter de Gruyter, 4(2), 119–139.
Begagić, Mirna (2013), “Semantic Preference and Semantic Prosody of the Collocation make
sense”, Jezikoslovlje, 14(2-3), 403-416.
Biber, Douglas (1993), “Representativeness in Corpus Design”, Literary and Linguistic
Computing, 8(4): 243-57.
Biber, Douglas (2006), University Language: A Corpus-based Study of Spoken and Written
Registers, John Benjamins, Amsterdam.
Biber et al. (1999), Longman Grammar of Spoken and Written English. Longman, London.
Biber, Douglas and Conrad, Susan (2001), “Corpus-based research in TESOL, Quantitative
Corpus-based Research: Much more than bean counting”, Patricia A. Duff (Ed.), in (331-
336), TESOL Quarterly, 35(2).
Bolinger, Dwight (1972), Degree Words, The Hague, Mouton, Paris.
Bozdağ, Fatih, Ü. (2014), Lexical Verbs in Academic Writings of Turkish Leaners of English
as a Second Language: A Corpus Based Study, Unpublished Master Thesis, Çukurova
University, Institute of Social Sciences.
Bozdağ, Fatih and Badem, Nebahat (2017), A Comparison of Communication Verbs Used by
Turkish EFL Learners and English Native Speakers: A Corpus Based Study, Gaziantep
University Journal of Social Sciences, 16 (3), 879-891. DOI: 10.21547/jss.31506.

92
Bublitz, Wolfram (1998), “I entirely dot dot dot: Copying Semantic Features in Collocations with
Up-scailing Intensifiers”, Rainer Schulze (Ed.), Making Meaninful Choices in English: On
Dimensions, Perspectives, Metholdogy and Evidence, in (7-11), Gunter Narr Verlag
Tübingen, Germany.
Can, Cem (2009), “İkinci Dil Edinimi Çalışmalarında Bilgisayar Destekli Bir Türk Öğrenici
İngilizcesi Derlemi: ICLE’nin Bir Altderlemi Olarak Ticle”, Dil Dergisi, 144, Nisan-Mayıs-
Haziran.
Cameron, Deborah and Panovic, Ivan (2014), Working with Written Discourse, SAGE, London.
Carter, Ronald (2004), Vocabulary: Applied Linguistic Perspectives, Routledge, London.
Celce-Murcia et al. (1996), Teaching Pronunciation: A Reference for Teachers of English to
Speakers of Other languages, Cambridge University Press, Cambridge.
Cheng, Winnie (2013), “Semantic Prosody”, In Carol, A. Chapelle (Ed.), The Encyclopedia of
Applied Linguistics, (1-7), Wiley-Blackwell Publishing Ltd, Oxford, England.
Chief, Lian-Cheng et al. (2000), “What Can Near Synonyms Tell Us?”, Computational
Linguistics and Chinese Language Processing, 5, 47-59.
Chomsky, Noam (2006), Language and Mind, Cambridge University Press, Cambridge.
Collins Cobuild Advanced Learner’s English Dictionary (2001), John Sinclair (Ed.), Harper
Collins, London.
Conzett, Jane (2000), “Integrating Collocation into Reading and Writing Course”, Michael Lewis
(Ed.), Teaching Collocation: Further Developments in the Lexical Approach, in (70-86),
Language Teaching Publications, Hove.
Corder, Stephen Pit (1967), “The Significance of Learners’ Errors”, International Review of
Applied Linguistics, 5, 161-170.
________________ (1971), “Idiosyncratic Dialects and Error Analysis”, International Review of
Applied Linguistics, 9(2), 147-159.
________________ (1981), Error Analysis and Interlanguage, Oxford University Press, Great
Britain.
Çalışkan, Nihal (2014), “The Concept of Semantic Prosody and Examples from Turkish:
“aksettirmek, ...dan ibaret, ...nin teki, karşı karşıya, varsa yoksa”, Journal of World of
Turks, 6(1), 139-166.
Dao, Trung, N. (2014), “Using Corpora to Teach English Amplifiers in ESL/EFL classrooms”,
Hawaii Pacific University TESOL Working Paper Series, 12, 32-57.

93
Dash, Niladri Sekhar and Arulmozi, S. (2018), History, Features, and Typology of Language
Corpora, Springer, Singapore.
Dong, Dahui and Chiu, Andrew (2013), “The Importance of Downtoners in English Writing and
Translation - with Reference to Chinese Movie Subtitle Translations”, Global Journal of
Human Social Science, Global Journals Inc.,USA, 13(5), 31-43.
Ellis, Rod (1989), Understanding Second Language Acquisition, Oxford University Press,
United Kingdom.
________ (1994), The Study of Second Language Acquisition, Oxford University Press, United
Kingdom.
_________ (1997), Second Language Acquisition, Oxford University Press, United Kingdom.
Eriksson, Sanna (2013) “Maximizers - Completey complex adverbs - A Corpus Study of the
Maximizer Usage in American and Swedish Journalists’Wwriting in English”, Independent
Theis.
Eveyik-Aydın, Evrim (2015), Moves in Discussions: A Corpus-Based Genre Analysis of the
Discussion Sections in Applied Linguistics Research Articles Written in English,
Unpublished Master Thesis, Yeditepe University, Institute of Educational Sciences.
Fasold, Ralph, W. and Connor-Linton, Jeff (Eds.) (2006), An Introduction to Language and
Linguistics, in (445-477), Cambridge University Press, UK.
Fuqua, Jason (2014), “Semantic Prosody: The Phenomenon of ‘Prosody’ in Lexical Patterning”,
The Journal of Language Teaching and Learning, 2, (76-83).
Gong, Shu-Ping and Wu, Pei-Yan (2012), “Collocation, Semantic Prosody, and Near-synonymy:
The HELP Verbs in Mandarin Chinese”, International Journal of Computer Processing
Of Languages, World Scientific Publishing Company, 24(1), 3-15.
Granger, Sylviane (1996), “From CA to CIA and back: An integrated approach to computerized
bilingual and learner corpora”. Karin Aijmer (Ed.), Languages in Contrast, in (37-51), Text-
based cross-linguistic studies, Lund University Press, Lund 1996.
_______________ (1998), “The Computer Learner Corpus: A Versatile New Source of Data for
SLA Research”, Sylviane Granger (Ed.), Learner English on Computer, in (3-18), Addison
Wesley Longman, London & New York.
_______________ (2002), “A Bird’s-eye view of learner corpus research”, Sylvine Granger et al.
(Eds.), Computer Learner Corpora, Second Language Acquisiton and Foreign
Language Teaching, John Benjamins Publishing Company, Amsterdam, Philadelphia

94
_______________ (2004), “Computer Learner Corpus Research: Current Status and Future
Prospects”, Ulla Connor and Thomas, A. Upton (Eds.), Applied Corpus Linguistics: A
Multidimensional Perspective, (123-147), Radopi, Amsterdam, New York
_______________ (2015), “Contrastive Interlanguage Analysis: A Reappraisal”, International
Journal of Learner Corpus Research, 1. 7-24
Hasselgärd, Hilde and Johansson, Stig (2011), “Learner Corpora and Contrastive Interlanguage
Analysis”, Fanny Meunier et al. (Eds.), A Taste for Corpora: In Honour of Sylviane
Granger, in (33-61), John Benjamins Publishing Company, Amsterdam.
Hinkel, Eli (2002), Second Language Writers’ Text: Linguistic and Rhoterical Features,
Lawrence Erlbaum Associates, New Jersey.
Huang, R.H., (2007), “A corpus-based study of semantic prosody of adjectives amplifiers of
Chinese English learners”, Foreign Language Education, 28 (5), 57-60.
Hunston, Susan and Francis, Gill (2000), Pattern grammar: A Corpus-driven Approach to the
Lexical Grammar of English, John Benjamins, Amsterdam and Philadelphia.
Hunston, Susan and Thompson, Geoffrey (2000), Evaluation in Text: Authorial Stance and the
Construction of Discourse, Oxford University Press, UK.
Hunston, Susan (2002), Corpora in Applied Linguistics, Cambridge University Press, United
Kingdom.
____________ (2007), “Semantic prosody revisited”, International Journal of Corpus
Linguistics, John Benjamins Publishing Company, 12(2), 249–268.
James, Henry (1920), The Letters of Henry James, (1st American ed.), Percy Lubbock (Ed.),
New York: Charles Scribner's Sons.
Kara, Abdurrahman (2017), “A Corpus-based Approach to Dictionary Definitions in the Interface
of Semantic Prosody and Near-synonymy”, The Journal of International Social Research,
10(50), 97-103.
Kennedy, Graeme (1998), An Introduction to Corpus Linguistics, Routledge, London and New
York.
Kennedy, Graeme (2003), “Amplifier Collocations in the British National Corpus: Implications for
English Language Teaching”, TESOL Quarterly, 37(3), 467-487.
_______________ (2007), “An Under Exploited Research: Using the BNC for Exploring the
Nature of Language Learning”, Marianne Hundt et al. (Eds), Corpus Linguistics and the
Web, in (151,160), Radopi, New York.
Kil, Insook (2003), “The Interlanguage Development of Five Korean English Learners”, The
Linguistic Association of Korea Journal, 11(4), 247-264.

95
Kilimci, Abdurrahman (2001), “Automatic Extraction of The Lexical Profile of EFL Learners
Through Corpus Query Techniques”, Journal of Faculty of Education, Çukurova
University, 2(21), 37-46.
___________________ (2014), “LINDSEI-TR: A New Spoken Corpus of Advanced Learners of
English”, International J. Social Sciences & Education, 4(2), 401-410.
Kilimci, Abdurrahman and Can, Cem (2008), “TICLE: Uluslararası Turk Oğrenici İngilizcesi
Derlemi”, M. Sarıca, N. Sarıca ve A. Karaca (Eds.), Paper presented at the XXIInd
Ulusal
Dilbilim Kurultayı, 8-9 May, Van, Yüzüncü Yıl Üniversitesi Yayınları, 1(11), Ankara.
Kim, Hijean and Lee, Jae-Eun (2009), “The Authenticity of English maximzers in High School
English Textbooks: The Cases of Absolutely, Totally, Utterly, Completely, Entirely”, The
Discourse Cognitive Linguistics Society of Korea Summer Conference, Hankuk
University of Foreign Studies, Seoul, 106-118.
King, Kevin (2016), “Intensifiers and Image Schemas: Schema Type Determines Intensifier Type”,
Linguistic Society of America, Conference Paper, 1(5), 1-9, 2016 Annual Meeting, At
Washington, D.C.
Labov, William (1984), “Intensity”, In Deborah Schiffrin (Ed.), Meaning, Form and Use in
Context: Linguistic Applications, in (43–70), Georgetown University Press, Washington,
DC.
Lado, Robert (1957), Linguistics Across Cultures: Applied Linguistics for Language Teachers,
University of Michigan Press.
Lakshmanan, Usha and Selinker, Larry (2001), “Analysing Interlanguage: How do we know what
learners know?”, Second Language Research, 17, 393-420.
Larsen-Freeman, Diane and Long, Michael H. (1991), An Introduction to Second Language
Acquisition Research, Routledge, London and New York.
Leech, Geoffrey (1991), “The State of the Art in Corpus Linguistics”, Aijmer Karin and Bengt
Altenberg (Eds.), English Corpus Linguistics in (8-30), New York: Longman.
______________ (1998), “Preface”, Sylviane Granger (Ed.), Learner English on Computer,
(xiv-xx), Longman, London and New York.
Lennon, Paul (2008), “Contrastive Analysis, Error Analysis, Interlanguage”, Stephan Gramley and
Vivian Gramley (Eds), Bielefeld Introduction to Applied Linguistics, in (51-60),
Aisthesis, Bielefeld.
Levelt, William. J. M. (1989), Speaking: From Intention to Articulation, MIT Press, Cambridge,
MA.

96
Liang, Maocheng (2004), “A Corpus-based Study of Intensifiers in Chinese EFL Learners’ Oral
Production”, Asian Journal of English Language Teaching, 14, 105–118.
Lorenz, Gunter, R. (1998), “Overstatement in Advanced Learners’ Writing: Stylistic Aspects of
Adjective Intensification”, In Sylviane Granger (Ed.), Learner English on Computer, (53-
79), Longman, London and New York.
______________ (1999), Adjective Intensification – Learners versus Native Speakers: A
Corpus Study of Argumentative Writing, Rodopi, Amsterdam.
Louw, Bill (1993), “Irony in the Text or Insincerity in the Writer? The Diagnostic Potential of
Semantic Prosodies”, Mona Baker et al. (Eds.), Text and Technology: In hounour of John
Sinclair, in (157-176), John Benjamins, Amsterdam.
_________ (2000), “Contextual Prosodic Theory: Bringing Semantic Prosodies to Life”, Chris
Heffer et al. (Eds.), Words in context: A tribute to John Sinclair on His Retirement, in
(48-94) University of Birmingham, Birmingham, UK.
Mackey, Allison (2006), “Second Language Acquition”, Ralph W. Fasold et al. (Eds.), An
Introduction to Language and Linguistics, in (445-477), Cambridge University Press, UK.
McGee, Iain (2012), “Should We Teach Semantic Prosody Awareness?”, RELC Journal, 43(2),
169–186.
McEnery, Tony et al. (2006), Corpus-based Language Studies: An Advanced Resource Book,
Routledge Applied Linguistics, London.
McEnery, Tony and Xiao, Richard (2006), “Collocation, Semantic Prosody, and Near Synonymy:
A Cross-Linguistic Perspective”, Applied Linguistics, Oxford University Press, 27(1), 103–
129.
McEnery, Tony and Hardie, Andrew (2012), Corpus Linguistics: Method, Theory and Practice,
Cambridge Textbooks in Linguistics. Cambridge University Press.
McEnery, Tony and Wilson, Andrew (2001), Corpus Linguistics, 2nd
Edition, Edinburgh
University Press, Edinburgh.
Meara, Paul (1980), “Vocabulary Acquisition: A neglected Aspect of Language Learning”,
Language Teaching and Linguistics, Abstracts 13(4), 221-246.
Méndez-Naya, Belén (2003), On Intensifiers and Grammaticalization: The Case of SWIþE,
English Studies, 84(4), 372-391.
Morley, John and Partington, Alan (2009), “A few Frequently Asked Questions about Semantic -
or Evaluative - Prosody”, International Journal of Corpus Linguistics, 14, 139-158.
Nesselhauf, Najda (2003), “The Use of Collocations by Advanced Learners of English and Some
Implications for Teaching, Applied Linguistics, 24, 223-242

97
_______________ (2005), Collocations in a Learner Corpus, John Publishing Company,
Amsterdam.
Oster, Ulrike and Lawick, Heike van (2008), “Semantic Preference and Semantic Prosody: A
Corpus-based Analysis of Translation-Relevant Aspects of the Meaning of Phraseological
Units”, Translation and Meaning, Part 8, 333-344.
Özbay, Ali Şükrü and Kayaoğlu, M., Naci (2016), “Computerized Corpus Based Investigation of
the Use of Multi Word Combinations and the Developmental Stages by Tertiary Level EFL
Learners”, EPiC Series in Language and Linguistics, 1, 341-350.
Özbay, Ali Şükrü and Kabakçı, Büşra (2016), “Corpus Analysis of Support Verb Construction Use
through Native and Non-Native Academic and Argumentative Corpora”, TOJET: The
Turkish Online Journal of Educational Technology, 1462-1467.
Özbay, Ali Şükrü and Aydemir, Tuncer (2017), “The Use of Maximizers and Semantic Prosodic
Awareness of Tertiary Level Turkish EFL Learners”, Journal of Education and Practice, 8,
40-50.
Özbay Ali Şükrü and Bozkurt, Sümeyye (2017), “Tertiary Level EFL Learners’ Use of Complex
Prepositions in KTUCLE, TICLE versus LOCNESS”, The International Journal of
Educational Researchers, 8, 32-41.
Paradis, Carita (1997), “Degree modifiers of adjectives in spoken British English, Lundt Studies
in English, 92. Lundt University Press.
Paradowski Michal B. (2008), “Interlanguage” [Internet Source]. Version 1, Sciencebin.
Partington, Alan (1993), “Corpus Evidence of Language Change: The Case of the Intensifier”,
Mona Baker et al. (Eds.), Text and Technology: In Honour of John Sinclair, in (177-92),
John Benjamins, Amsterdam.
______________(1998), Patterns and Meanings: Using Corpora for English Language
Research and Teaching, John Benjamins Publishing, Amsterdam.
______________ (2004), “Utterly Content in Each Other’s Company”: Semantic Prosody and
Semantic Preference”, International Journal of Corpus Linguistics, John Benjamins
Publishing Company, 9 (1), 131-156.
Paquot, Magali (2010), Academic Vocabulary in Learning Writing, Continuum International
Publishing, London.
Pilten, Şahru, U. (2017), “Evaluations on the Concept of Semantic Prosody”, Eurasscience
Journals, 5(1), 1-10.
Portner, Paul (2006), “Chapter 4: Meaning”, Fasold, Ralph, et al. (Eds.), An Introduction to
Language and Linguistics, in (137-168), Cambridge University Press.

98
Quirk, Randolph (1985), “The English Language in a Global Context”, In Quirk, Randolph and
Widdowson, H. G. (Eds.), English in the World: Teaching and Learning the Language
and Literatures, (1-6), Cambridge University Press. London and New York.
Quirk et al. (1985), A Comprehensive Grammar of the English Language, Longman, London
and New York.
Ringbom, Håkan (1998), “Vocabulary frequencies in advanced learner English: A cross-linguistic
approach”, Sylviane Granger (Ed.), Learner English on Computer, in (41-52), Addison
Wesley Longman, London..
Rustipa, Katharina, (2011), Contrastive Analysis, Error Analysis, Interlanguage and the Implication
to Language Teaching, Ragam Jurnal Pengembangan Humaniora, 11(1).
Sardinha, Tony, B. (2000), “Semantic Prosodies in English and Portugese: A Contrustive Study”,
Cuadernos de Filologia Inglesa, 9(1), 93-109.
Selinker, Larry (1972), “Interlanguage”, International Review of Applied Linguistics in
Language Teaching, 10(3).
______________ (1989), “CA/EA/IL: The Earliest Experimental Record”, International Review
of Applied Linguistics in Language Teaching, 27(4), 267-291.
Sinclair, John (1996), “The Search for Units of Meaning”, Textus, 9(1), 75-106.
___________ (2004) Trust the Text: Language Corpus and Discourse. Routledge, London.
Startvik, Jan (2007), “Corpus linguistics 25+ years on”, Roberta Facchinetti (Ed.), Corpus
Linguistics 25 Years On, in (11-27), Radopi, Amsterdam, New York.
Steward, Dominic et al. (2004), “Introduction: Ten Years of TaLC” (2004), Guy Aston et al. (Eds.),
Corpora and Language Learners, in (1-21), John Benjamins Publishing, Amsterdam.
Steward, Dominic (2010), Semantic Prosody: A Critical Evaluation, Routledge, New York.
Stubbs, Michael (1995), “Collocations and Semantic Profiles: On the cause of trouble with
quantitative studies”, Functions of Language, 2(1), 23-55, John Benjamins Publishing
Company.
_______________ (1996). Text and Corpus Analysis: Computer-assisted Studies of Language
and Culture, Blackwell, Oxford.
_______________ (2001), Words and Phrases: Corpus Studies of Lexical Semantics,
Blackwell, Oxford.
_______________ (2009), “The Search for Units of Meaning: Sinclair on Empirical Semantics”,
Applied Linguistics, Oxford University Press, 30 (1), 115-137.

99
Su, Yujie (2016), “Corpus-based comparative study of intensifiers: quite, pretty, rather and fairly”,
Journal of World Languages, 3(3).
Şanal, Fahrettin (2007), A Learner Corpus Based Study on Second Language Lexicology of
Turkish Students of English, Unpublished Doctoral Dissertation, Çukurova University, The
Institute of Social Sciences.
Tagliamonte, Sali, A. (2008), “So Different and Pretty Cool! Recycling Intensifiers in Toronto,
Canada”, English Language and Linguistics, Cambridge University Press, 12(2), 361-393.
Tajareh, Mahboobeh J. (2015) “An Overview of Contrastive Analysis Hypothesis”, Cumhuriyet
University Journal of Faculty of Science, 36(3).
Tarone, Elaine (2006), “Interlanguage”, Keith Brown (Ed.), Encyclopedia of Language and
Linguistics, 4, in (1715–1719), Elsevier Science, Amsterdam.
Taş, Işık, Elvan, E. (2008), Corpus-Based Analysis of Genre-Specific Discourse of Research:
The PHD Thesis and the Research Article in ELT, Unpublished Doctoral Thesis, Middle
East Technical University, The Institute of Social Sciences.
Tognini-Bonelli, Elena (2001), Corpus Linguistics at Work, John Benjamin Publishing,
Amsterdam.
Tono, Yukio (2006), “Chapter: 2: What is Missing in Learner Corpus Design?”, ?”, Margarita
Alonso Ramos (Ed.), Spanish Learner Corpus Research: Current Trends and Future
Perspectives, in (33-52), John Benjamin Publishin, Amsterdam.
Trawinski, Mariusz (2005), An Outline of Second Language Acquisition Theories,
Wydawnictwo Naukowe Akademii Pedagogicznej, Krakow.
Ünaldı, İhsan (2013), “Genre Specific Semantic Prosody: The Case of Pose”, Mustafa Kemal
University Journal of Social Sciences Institute, 10(21), 37-54.
Wachter, A., Rebecca, (2012), “Semantic Prosody and Intensifier Variation in Academic
Speech”, Unpublished Master Thesis, University of Georgia, Athens.
Wang, Chunyan (2017), Patterns and Meanings of Intensifiers in Chinese Learner Corpora,
Routledge, London.
Wang, H., and Wang, T. (2005), “A contrastive Study on the Semantic Prosody of CAUSE”,
Modern Foreign Language, 28(3), 297-307.
Wei, Naixing (2002), “Research methods in the studies of semantic prosody”, Foreign Language
Teaching and Research, (34)4, 300-307.
Whitsitt, Sam (2005), “A Critique of the Concept of Semantic Prosody”, International Journal of
Corpus Linguistics, 10(3), 283-305, John Benjamins Publishing Company.

100
Wittouck, Hermien (2011), “A Corpus-Based Study on the Rise and Grammaticalisation of
Intensifiers in British and American English”, Unpublished Master Thesis, University of
Gent, Belgium.
Xiao, Richard and McEnery, Tony (2006), “Collocation, Semantic Prosody, and Near Synonymy:
A Cross-Linguistic Perspective”, Applied Linguistics, Oxford University Press, 27(1), 103-
129.
Xiaohua, Shang and Haihua, Wang (2007), “A Corpus-based Study on the Developmental Features
of Chinese EFL Learners’ Use of Amplifier Collocations”, Barbara Lewandowska-
Tomaszczyk (Ed.), Corpus Linguistics, Computer Tools, and Applications - State of the
Art, in (757), Peter Lang, Germany.
Yaoyu, Wei and Lei, Lei (2011), “The Use of Amplifiers in the Doctoral Dissertations of Chinese
EFL Learners”, Chinese Journal of Applied Linguistics (Quarterly), 34(11), 47-61.
Yang, Qiang (2014), “A Corpus-based Study of Chinese English Learners’ Use of Somewhat”,
Theory and Practice in Language Studies, 4 (11), 2331-2336.
Zethsen, Karen, K. (2006), Semantic Prosody: Creating Awareness about a Versatile Tool,
Tidsskrift for Sprogforskning, 4(1-2), 275-294.
Zhang, Yanyan (2008), “A Corpus-based Study of the Forms and Functions of BE in the
Interlanguage Grammars of Chinese Learners of English”, Theses and Dissertations, 869,
Zhang, Weiming (2009), “Semantic Prosody and ESL/EFL Vocabulary Pedagogy”, TESL Canada
Journal, 26 (2), 1-12.
Zhang, Changhu (2010), “An Overview of Corpus-based Studies of Semantic Prosody”, Asian
Social Science, 6(6), 190-194.
Zhang, Ruihua (2013), A Corpus-based Study of Semantic Prosody Change: The Case of The
Adverbial Intensfier, Concentric: Studies in Linguistics, 39(2), 61-82.

101
APPENDICES

102
Appendix 1: Concordances from Sketch Engine showing maximizers in LOCNESS

103

104
Appendix 2: Concordances from Sketch Engine showing maximizers in KTUCLE

105

106

107
Appendix 3: Concordance from Sketch Engine showing maximizers in TICLE

108
Appendix 4: The Semantic Profiles of VERY + 1R adjectives in LOCNESS
POSITIVE NEGATIVE NEUTRAL
important
good
strong
popular
competitive
powerful
real
significant
successful
interesting
positive
young
happy
large
easy
impressionable
sensitive
clever
favourable
proud
influential
simple
effective
true
interested
much
magnanimous
credible
affective
idealistic
useful
self-concerned
unique
patient
resilient
helpful
careful
viable
profitable
beneficial
possible
ready
clear
safe
fair
great
respectable
amusing
rich
logical
new
aware
realistic
substantial
special
25
14
12
7
5
5
5
5
3
3
3
3
3
3
3
2
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
few
difficult
expensive
low
hard
dangerous
controversial
rare
subtle
boring
unpopular
weak
disturbing
thin
capricious
upset
scary
ignorant
depressed
misguided
confused
unsure
painful
doubtful
sceptical
harsh
violent
negative
complex
complicated
ugly
unfair
uncomfortable
unrealistic
angry
sick
fierce
cramped
unreliable
severe
damaging
contagious
wary
least
dependent
busy
stressful
overpopulated
devastating
alarming
melancholy
cruel
heated
timid
apprehensive
15
12
6
6
6
5
3
3
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
little
small
high
similar
likely
long
big
large
specific
basic
own
recent
first
same
common
different
masculine
soft
ethnocentric
functional
impersonal
authoritative
technical
raw
direct
stereo-typical
typical
grey
individual
personal
natural
wide
obvious
ironic
sound
11
5
5
5
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1

109
exciting
exclusive
intense
patriotic
1
1
1
1
serious
debatable
1
1
TOTAL 151 TOTAL 109 TOTAL 78

110
Appendix 5: The Semantic Profiles of VERY + 1R adjectives in KTUCLE
POSITIVE NEGATIVE NEUTRAL
important
useful
good
easy
high
much
beneficial
necessary
happy
helpful
simple
popular
sensitive
significant
beautiful
attractive
interesting
effective
strong
successful
essential
careful
young
valuable
interested
enjoyable
clear
healthy
unique
reliable
powerful
excited
modern
substantial
awesome
proud
portable
noble
exciting
crucial
comfortable
pleasant
lucky
cheap
suitable
true
prestigious
admirable
imperceptible
grateful
hard-working
virtuous
fascinating
ambitious
superficial
245
66
33
21
17
11
11
10
9
9
8
7
7
7
7
6
6
6
6
6
5
5
5
4
4
4
4
4
3
3
3
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
dangerous
hard
harmful
difficult
bad
expensive
sad
few
heavy
tired
wrong
strange
thoughtless
old
remote
rare
useless
sorry
strict
angry
stressful
complex
painful
nervous
cruel
unhealthy
ill
low
poor
busy
dramatic
loud
vulnerable
inefficient
noisy
uncomfortable
notorious
unusual
unstable
exhausting
bitter
asocial
lazy
unnecessary
awful
negative
selfish
nonsense
weak
aggressive
risky
anti-social
deceptive
thin
critical
35
25
24
23
19
12
11
7
5
4
4
3
3
3
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
different
big
short
small
little
serious
common
large
huge
long
similar
normal
early
widespread
first
hot
general
broad
personal
natural
basic
present
conservative
direct
liberal
classic
technological
ordinary
near
close
deliberate
22
20
14
11
10
9
9
5
5
5
4
4
3
3
3
3
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1

111
fashionable
knowledgeable
stout
extensive
harmless
decisive
reprehensible
sensible
joyful
handy
civilized
fond
meaningful
fantastic
profitable
alert
accurate
reasonable
brave
vital
cheerful
optimistic
fundamental
super
quick
necessary
precious
clever
emotional
great
nice
active
funny
available
positive
fast
silent
appropriate
real
social
possible
special
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
irresponsible
tragic
shy
minor
sorrowful
boring
merciless
dissuasive
1
1
1
1
1
1
1
1
TOTAL 623 TOTAL 244 TOTAL 149

112
Appendix 6: The Semantic Profiles of VERY + 1R adjectives in TICLE
POSITIVE NEGATIVE NEUTRAL
important
good
successful
useful
easy
simple
high
great
rich
much
interesting
careful
popular
beautiful
effective
young
handsome
helpful
surprising
clever
practical
clear
beneficial
invaluable
surprised
rightful
attractive
alluring
independent
intense
prestigious
nice
delicious
affective
colourful
ideal
comfortable
elegant
exciting
reasonable
skilful
experienced
essential
sweet
fast
cheap
powerful
emotional
happy
strong
necessary
many
sensitive
emotive
44
16
10
9
9
8
7
4
4
4
3
3
3
3
3
3
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
difficult
bad
hard
ill
serious
dangerous
low
harmful
old
lonely
strict
useless
expensive
cruel
wrong
embarrassing
distressing
faulty
sad
negative
fat
nervous
hopeless
complex
miserable
dirty
curious
thin
disturbing
merciless
poor
few
sick
tired
afraid
17
14
11
6
5
5
4
3
3
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
big
little
short
different
small
common
long
detailed
close
widespread
first
deep
general
obvious
ordinary
large
early
cold
15
15
14
12
6
5
4
2
2
2
2
1
1
1
1
1
1
1
TOTAL 178 TOTAL 100 TOTAL 86

113
Appendix 7: The Semantic Profiles of TOO + 1R adjectives in LOCNESS
POSITIVE NEGATIVE NEUTRAL
much
many
easy
high
great
important
adventurous
precise
self-interested
new
young
strong
23
14
5
4
3
3
1
1
1
1
1
1
late
costly
loud
busy
lazy
vague
long
old
bad
lethargic
traumatic
violent
low
difficult
big
large
5
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
wet
utopic
premature
minute
traditional
brutal
abstract
radical
apparent
cold
little
1
1
1
1
1
1
1
1
1
1
1
TOTAL 58 TOTAL 28 TOTAL 11

114
Appendix 8: The Semantic Profiles of TOO + 1R adjectives in KTUCLE
POSITIVE NEGATIVE NEUTRAL
much
many
important
sensitive
young
strong
easy
sensible
intense
ready
fast
careful
simple
high
useful
182
29
10
2
2
2
2
1
1
1
1
1
1
1
1
dependent
difficult
hard
less
expensive
dangerous
bad
complex
lazy
tired
few
scary
distant
extreme
regretful
critical
blind
remote
serious
weak
sad
26
7
4
3
3
3
3
2
2
2
2
1
1
1
1
1
1
1
1
1
1
late
long
early
big
hot
little
close
cold
short
small
23
3
3
2
2
2
1
1
1
1
TOTAL 237 TOTAL 67 TOTAL 39

115
Appendix 9: The Semantic Profiles of TOO + 1R adjectives in TICLE
POSITIVE NEGATIVE NEUTRAL
much
many
young
ambitious
smart
helpful
strong
simple
high
interested
useful
important
29
7
4
1
1
1
1
1
1
1
1
1
difficult
expensive
hard
long
few
strict
busy
insufficient
low
ill
complicated
6
2
2
2
1
1
1
1
1
1
1
late
systematic
materialistic
theoretical
big
5
1
1
1
1
TOTAL 49 TOTAL 19 TOTAL 9

116
Appendix 10: The Semantic Profiles of SO + 1R adjectives in LOCNESS
POSITIVE NEGATIVE NEUTRAL
many
much
great
simple
easy
important
eager
intent
funny
inexpensive
intense
full
quick
advanced
proud
emotional
positive
new
useful
powerful
righteous
popular
strong
reliant
immense
40
19
5
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
hard
rare
low
difficult
preoccupied
embarrassing
undisciplined
sudden
addictive
uncommon
heated
tragic
unable
unreliable
severe
dependent
negative
old
expensive
bad
wrong
jaded
rampant
ambiguous
7
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
little
long
prevalent
general
different
5
3
1
1
1
TOTAL 89 TOTAL 33 TOTAL 11

117
Appendix 11: The Semantic Profiles of SO + 1R adjectives in KTUCLE
POSITIVE NEGATIVE NEUTRAL
many
much
important
happy
easy
useful
beneficial
lucky
strong
necessary
popular
most
simple
young
good
logical
cute
famous
innocent
remarkable
great
smart
enjoyable
reliable
beautiful
cheap
social
healthy
successful
effective
true
advantageous
swift
soft
skilful
non-violent
sociable
quality
wonderful
progressed
regular
glad
rich
excited
rational
sophisticated
quick
magnificent
clever
significant
clear
sympatric
powerful
certain
modern
full
57
46
44
9
8
7
6
5
4
4
3
3
3
3
3
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
hard
harmful
bad
difficult
heavy
stressful
awful
sad
wrong
upset
depressed
disturbing
poor
busy
dangerous
dependent
lost
intolerant
provocative
intolerable
wicked
insensitive
sharp
unlucky
monotone
alarming
problematic
pathetic
hazardous
rough
slow
absurd
heartless
unacceptable
rare
deceptive
ridiculous
distant
exhausting
addicted
risky
wild
selfish
violent
sorry
less
cruel
nonsense
limited
boring
ill
expensive
9
9
8
7
4
3
3
3
3
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
normal
different
close
widespread
big
interbedded
routine
ironic
common
dry
little
small
wide
quiet
6
5
2
2
2
1
1
1
1
1
1
1
1
1

118
convenient
funny
preferable
real
1
1
1
1
TOTAL 267 TOTAL 99 TOTAL 26

119
Appendix 12: The Semantic Profiles of SO + 1R adjectives in TICLE
POSITIVE NEGATIVE NEUTRAL
many
much
important
easy
clear
good
effective
necessary
fresh
brave
sweet
ambitious
vital
fast
essential
free
emotional
new
strong
high
striking
useful
48
21
15
9
4
3
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
hard
weak
tired
cruel
bad
hurtful
odd
irresponsible
selfish
horrible
immoral
disabled
unhappy
disturbing
merciless
helpless
unnecessary
busy
insufficient
expensive
harmful
wrong
dangerous
low
ill
difficult
6
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
different
routine
colourful
natural
obvious
ordinary
tight
little
big
long
4
1
1
1
1
1
1
1
1
1
TOTAL 118 TOTAL 35 TOTAL 13

120
CURRICULUM VITAE
Neslihan KELEŞ was born in Trabzon in 1986. She is originally from Artvin. Her high
school education was between the years of 1997 and 2004 in Akçaabat Anatolian High School. She
was graduated from the Department of English Language and Literature and got an English
Language Teaching Certificate from the Faculty of Education at Karadeniz Technical University.
After graduation, she was granted as Comenius Language Assistant by Turkish National Agency to
work in a primary school in Italy for six months in 2009-2010 academic year. She has been
studying for a master degree in applied linguistics at Karadeniz Technical University. She also has
an undergraduate degree in International Relations from the Faculty of Open Education in Anadolu
University. She has been currently working as chief human resources officer in Eastern Blacksea
Development Agency in Trabzon since 2011.
She is married and mother of two daughters.
Copyright © 2022 FDOKUMEN




















