
Journal Reference - Archive ouverte UNIGE
139
Journal Reference Clausal and Nominal Complements in Monolingual and Bilingual Grammars SHIM, Ji Young (Guest Ed.), IHSANE, Tabea (Guest Ed.), PARAFITA COUTO, M. Carmen (Guest Ed.) SHIM, Ji Young (Guest Ed.), IHSANE, Tabea (Guest Ed.), PARAFITA COUTO, M. Carmen (Guest Ed.). Clausal and Nominal Complements in Monolingual and Bilingual Grammars. Languages, 2017, vol. 2, Special issue Available at: http://archive-ouverte.unige.ch/unige:150424 Disclaimer: layout of this document may differ from the published version. 1 / 1
-
Upload
khangminh22 -
Category
Documents
-
view
1 -
download
0
Transcript of Journal Reference - Archive ouverte UNIGE

Journal
Reference
Clausal and Nominal Complements in Monolingual and Bilingual
Grammars
SHIM, Ji Young (Guest Ed.), IHSANE, Tabea (Guest Ed.), PARAFITA COUTO, M. Carmen (Guest
Ed.)
SHIM, Ji Young (Guest Ed.), IHSANE, Tabea (Guest Ed.), PARAFITA COUTO, M. Carmen
(Guest Ed.). Clausal and Nominal Complements in Monolingual and Bilingual Grammars.
Languages, 2017, vol. 2, Special issue
Available at:
http://archive-ouverte.unige.ch/unige:150424
Disclaimer: layout of this document may differ from the published version.
1 / 1

languages
Editorial
Introducing the Special Issue: Clausal and NominalComplements in Monolingualand Bilingual Grammars
Ji Young Shim 1, Tabea Ihsane 2,3,* and M. Carmen Parafita Couto 4 ID
1 Department of Linguistics, University of Geneva Room L 306, Rue de Candolle 2, 1205 Geneva, Switzerland;[email protected]
2 Department of English, University of Geneva Room L 306, Rue de Candolle 2, 1205 Geneva, Switzerland3 University Priority Research Program (URPP) Language and Space, University of Zurich, Freiestrasse 16,
8032 Zurich, Switzerland4 Leiden University Center for Linguistics, Van Wijkplaats 3, 2311 BX Leiden, The Netherlands;
[email protected]* Correspondence: [email protected]
Academic Editors: Osmer Balam and Usha LakshmananReceived: 18 December 2017; Accepted: 21 December 2017; Published: 21 December 2017
To introduce this Special Issue entitled Clausal and Nominal Complements in Monolingual andBilingual Grammars, we begin by explaining what originally motivated this Special Issue. The firsttwo co-editors (Ji Young Shim and Tabea Ihsane) worked on the research project entitled Selection atthe Interfaces, in which various linguistic aspects (e.g., syntactic structure, interface with semantics,etc.) of clausal and nominal complements in monolingual grammars were explored.1 To extend aninvestigation of these issues to bilingual contexts, they organized a two-day workshop entitled Clausaland Nominal Complements in Monolingual and Bilingual Grammars in June 2016, where the thirdco-editor (M. Carmen Parafita Couto) of this Special Issue was an invited speaker.2 The workshopaimed to investigate the left periphery of complements, in particular the left periphery of the clauseand the nominal phrase and its edge, such as C(omplementizers) and D(eterminer) and other top-mostfunctional layers, where languages may be parametrized differently, thus leading to linguistic variation.
Within generative grammar, it has long been assumed that language variation is due to variationin the domain of functional categories and their morpho-syntactic properties [1,2]. Followingthis tradition, the left periphery of the clause has been extensively investigated, confirming thehypothesis that the functional category C(omplementizer) and its morpho-syntactic properties may beparameterized differently across languages within research on monolingual grammar [3–6]. In addition,the left periphery of a nominal phrase has also been investigated to a great extent [7–9], based on theproposal that clauses and nominal phrases have parallel structures ([10] and in subsequent work).
In recent years, generative linguists have also started to pay attention to the left periphery ofbilingual grammars, especially in relation to diverse patterns of code-switching, which is the mixeduse of two or more languages in conversation, and which is frequently observed in bilingual speech.Under the assumption that monolingual and bilingual grammars are subject to the same grammaticalprinciples [11–14], several researchers have investigated the grammar of code-switching in variouslanguage pairs and showed that the left periphery of a particular functional category such as C, D,or v may be parameterized differently across languages and derive certain patterns of code-switching,
1 The projected was funded by the Swiss National Science Foundation (#100012_146699/1), and the second Editor was theprincipal investigator of the project.
2 The workshop was funded by the University of Geneva and the Swiss National Science Foundation.
Languages 2017, 2, 28; doi:10.3390/languages2040028 www.mdpi.com/journal/languages

Languages 2017, 2, 28 2 of 5
which confirm the validity of the linguistic proposals that are put forth to account for monolingualgrammars [15–17].
While the workshop Clausal and Nominal Complements in Monolingual and Bilingual Grammarsmotivated us to edit the current Special Issue with the same title, it is important to note that the presentvolume is not a report on the proceedings of the workshop. A separate call for papers for thisvolume was made through Languages. The Special Issue Clausal and Nominal Complements inMonolingual and Bilingual Grammars comprises seven articles in total, which are theory-orientedand/or empirically based in nature. These articles collectively investigate one of the key theoreticalissues that generative linguists have pursued for a long time: how languages are encoded similarly ordifferently. In so doing, three articles concentrate on nominal complements and clausal complementsin monolingual grammars [18–20], and four articles focus on nominal and clausal complements inbilingual grammars [21–24].
For monolingual contexts, Christopher Laenzlinger compares the structure of clauses(Complementizer Phrases; CPs) and noun/determiner phrases (DPs) [18]. Working in the cartographicapproach to the Generative Grammar framework, he reconsiders so-called clause/noun-phrase(non-)parallelism in terms of structure and derivation. Although he assumes that both clausesand nominal phrases have a similar structure, which is divided into three domains—the Nachfeld(‘right periphery’), the Mittelfeld (‘midfield’) and the Vorfeld (‘left periphery’)—he argues that the innerstructures of clauses and noun phrases are not strictly parallel, and in particular the left peripheryof a clause is richer and more developed than that of a noun phrase. As a result, despite the similarpossible types of movement occurring both in the CP and the DP domains (head movement andphrasal movement), there still exists non-parallelism in CPs and DPs in the application of thesetypes of movement. To support the existence of non-parallelism between clauses and nominalphrases, Laenzlinger shows the respective orders of various elements such as adverbs/adjectives,DP/Prepositional Phrase (PP)-arguments and DP/PP-adjuncts in French in comparison with manyother languages.
In addition to Laenzlinger’s analysis [18], two more papers focus on the structure of clausalcomplements in monolingual grammars. Marcel den Dikken [19] revisits Chomsky’s two earlierapproaches to account for the structure of clausal complements of verbs—a preform analysis [25]and a direct clausal embedding analysis [26], the latter of which has replaced the former and hasbecome the generalized view in generative syntax. By comparing factive and non-factive clausalcomplements in Dutch and Hungarian, particularly the relative position of the verb vis-à-vis theclausal complement in Dutch and the co-occurrence of a proleptic noun with the clausal complement inHungarian, den Dikken proposes that there are two structural positions for the object of verbs, the usualcomplement of the verb position and a specifier of VP (or a higher node). While the direct clausalembedding analysis accounts for the complement position of the object, it is the preform analysis(with a small modification) that can explain the specifier position of the object in these two languages.Den Dikken further builds up his proposal into analyzing wh-scope marking and wh-dependencies inHungarian and German.
The distinction between factive and non-factive clausal complements is also discussed in detail byJi Young Shim and Tabea Ihsane [20]. They investigate clausal complements of factive and non-factivepredicates in English, with particular focus on the distribution of overt and null that complementizers.To account for several differences between factive and non-factive clausal complements, including thedistribution of the overt and null complementizers, they propose that overt that clauses and null thatclauses have different underlying structures responsible for their different syntactic behavior. AdoptingRizzi’s split CP structure with two C heads, Force and Finiteness [3], Shim and Ihsane suggest thatnull that clauses are FinPs (Finiteness Phrases) under both factive and non-factive predicates, whereasovert that clauses have an extra functional layer above FinP, lexicalizing either the head Force undernon-factive predicates or the light demonstrative head d under factive predicates. The authors argue

Languages 2017, 2, 28 3 of 5
that this analysis further provides an explanation for the distribution of overt that clauses and null thatclauses outside sentential complements, such as sentential subjects.
The interim conclusion of the papers by Laenzlinger [18], den Dikken [19] and Shim andIhsane [20], which are based on the monolingual grammar of diverse languages, suggest that, despitethe widely assumed structural parallelism between clauses and nominals, the clausal left periphery ismore complex than the nominal left periphery, and the inner structure of the clausal left peripheryalso varies depending on its selection of predicates, such as factivity. Thus, to understand the precisenature of clausal and nominal left peripheries, we must also consider their interface with semanticsand the lexical items that comprise them.
As for bilingual contexts, Robert-Tissot and Morel [21] use a Swiss corpus of code-switching textmessages to test two principles proposed by González Vilbazo [27]: (i) the Principle of FunctionalRestriction (i.e., two functional heads X◦ and Y◦ have to be filled by lexical material of the samelanguage if the functional category of YP is the complement of X◦ and both heads are part of the sameextended projection); and (ii) the Principle of Agreement (i.e., inside a phrase, agreement requirementshave to be satisfied, regardless of the language providing the lexical material). They discuss specificexamples that mostly confirm the validity of the principles, showing the structured nature ofcode-switching as well as contributing to the growing consensus that it is possible to predict thenature of grammatical and ungrammatical code- switched sequences.
In their article, López et al. [22] show how the theoretical construct “phase” can be used to accountfor a number of restrictions on code-switching, in particular those formalized under the Principle ofFunctional Restriction [27] and the Phonetic Form Interface Condition [28]. López et al. postulate theBlock Transfer Hypothesis (BTH), stating that the material that is transferred to the interfaces within aphase is transferred in one block. It follows from the BTH that code-switching may take place at phaseboundaries but not within the phase. They further posit that phases are empirically superior in scope,as they can explain code-switching phenomena not explained by previous accounts (e.g., switchesbetween C and TP, progressive aspect, and switching within the word level). The authors take thisas reinforcement for the fundamental hypothesis that code-switching should be studied using thesame tools that we use for monolingual data, and suggest that phase theory, together with distributedmorphology, may be the way forward.
In both studies (one by Robert-Tissot and Morel [21] and the other by López et al. [22]), the validityof the Principle of Functional Restriction (PFR) is tested. The PFR prohibits code-switching betweentwo functional heads belonging in the same extended projection. Thus, it predicts that code-switchingcannot occur in the left periphery of a nominal phrase (e.g., between a D(eterminer) and a Q(uantifier)and also in the left periphery of a clause (e.g., between a C(omplementizer) and T(ense)). However,both studies found counter-examples that allow code-switching in the left periphery of nominal andclausal domains. For instance, a switch may occur between a D (Italian) and a Q (French) [21] andbetween a C (Spanish) and T (German) if Spec C is not empty [22]. To account for these examples,Robert-Tissot and Morel resort to a non-structural account, whereas López et al. offer a phase-basedsyntactic analysis.
The left periphery of noun phrases in bilingual contexts is explored in two papers in thisvolume. In her contribution [23], Brita Ramsevik Riksem investigates the heritage language AmericanNorwegian and provides a diachronic study of language-mixing within noun phrases, that is,the occurrence of English items in American Norwegian. By comparing data collected in the 1930sand 1940s with recently collected data, she shows that the overall pattern of language-mixing isstable but some systematic diachronic changes are attested, specifically concerning the categories ofnumber and definiteness. These changes consist of the omission of functional exponents and usage ofEnglish functional exponents, such as the plural suffix -s and the determiner the. She proposes twopotential analyses of these patterns based on an exoskeletal approach to grammar, and a theoreticalframework that separates abstract syntactic structure from its phonological exponents. These analysesconsider both the structure and the exponents as the origins of the change. However, on the basis of

Languages 2017, 2, 28 4 of 5
the observed patterns of change, Riksem argues that a structural reanalysis of American Norwegiangrammar is occurring.
Finally, Blokzijl et al. explore the factors that influence the language of determiners in mixed nominalconstructions in two bilingual corpora (Spanish-English speakers in Miami (USA), and Spanish-Englishcreole speakers in Nicaragua) [24]. The results of their comparative analysis indicate that the languageof the determiner matches the matrix language. Crucially, this match between the language of thedeterminer and the matrix language seems to be unaffected by any grammaticized features in thedeterminer, which is unlike that which has been previously argued [29]. Additionally, they found thatthe frequency of switching from the determiner to the noun was asymmetric in the Miami data, beingmore frequent from Spanish to English in the Miami data. In the Nicaragua data, on the other hand, theyonly observed switches from English creole to Spanish. These findings call into question the assumptionthat the same code-switching patterns surface in different bilingual communities, suggesting that weneed to examine the interplay between social and grammatical factors more meticulously.
Overall, this Special Issue provides a timely collection of articles that discuss clausal and nominalcomplements in monolingual and bilingual grammars, especially in the form of code-switching.As evidenced by several papers in this collection, the inner structure of clausal and nominal edgesdiffers from language to language and it further affects patterns of code-switching. We hope thatthe papers in this Special Issue will generate keen interest in this topic and offer a basis for furtherresearch on other related topics. In particular, more work needs to be conducted to examine diachronicstructural changes in bilingual grammars and syntactic variation in bi/multilingual contexts involvinglesser-studied languages such as Creoles (e.g., Nicaragua, Belize, Cape Verde, etc.; see, for instance,the volume edited by Sessarego [30]). This direction of research will have much to tell us aboutlinguistic variation across time and space.
Acknowledgments: We thank all authors who contributed to this Special Issue and the reviewers of themanuscripts. Also we extend our thanks to the Editors of Languages (Osmer Balam and Usha Lakshmanan)and the editorial office for their support and patience to take a long journey with us. Without them, this SpecialIssue could not have been brought out. We hope that the seven papers included in this collection will providereaders with a deeper understanding of the structure of language and further their interest in the topic of clausaland nominal complements in monolingual and bilingual grammars.
Author Contributions: Ji Young Shim, Tabea Ihsane, and M. Carmen Parafita Couto contributed equally tothis Editorial.
Conflicts of Interest: The authors declare no conflict of interest.
References
1. Borer, H. Parametric Syntax, 1st ed.; Foris: Dordrecht, The Netherlands, 1984.2. Chomsky, N. The Minimalist Program, 1st ed.; MIT Press: Cambridge, UK, 1995.3. Rizzi, L. The fine structure of left periphery. In Elements of Grammar; Haegeman, L., Ed.; Kluwer:
Dordrecht, The Netherlands, 1997; pp. 289–330.4. Rizzi, L. (Ed.) The Structure of CP and IP, 1st ed.; Oxford University Press: Oxford, UK, 2004.5. Haegeman, L. Conditional clauses: External and internal syntax. Mind Lang. 2003, 18, 317–339. [CrossRef]6. Saito, M. Semantic and discourse interpretation of the Japanese left periphery. In The Sound Patterns of Syntax,
1st ed.; Erteschik-Shir, N., Rochman, L., Eds.; Oxford University Press: Oxford, UK, 2010; pp. 140–173.7. Laenzlinger, C. French adjective ordering: Perspectives on DP-internal movement types. Lingua 2005,
115, 645–689. [CrossRef]8. Ihsane, T. The Layered DP, 1st ed.; John Benjamins: Amsterdam, The Netherlands, 2008.9. Alexiadou, A. Multiple Determiners and the Structure of DP, 1st ed.; John Benjamins: Amsterdam, The Netherlands, 2014.10. Abney, S. The English Noun Phrase in Its Sentential Aspect. Ph.D. Thesis, Massachusetts Institute of
Technology, Cambridge, MA, USA, 1987.11. Mahootian, S. A Null Theory of Code-Switching. Ph.D. Thesis, Northwestern University, Evanston,
IL, USA, 1993.

Languages 2017, 2, 28 5 of 5
12. Nishimura, S. Lexical categories and code-switching: A study of Japanese/English code-switching in Japan.J. Assoc. Teach. Jpn. 1997, 31, 1–21.
13. MacSwan, J. A Minimalist Approach to Intrasentential Codeswitching, 1st ed.; Routledge: London, UK, 1999.14. Chan, B.H.-S. Aspects of the Syntax, the Pragmatics, and the Production of Code-Switching, 1st ed.; Peter Lang:
New York, NY, USA, 2003.15. Liceras, J.M.; Spradlin, K.T.; Fernández Fuertes, R. Bilingual early functional-lexical mixing and the activation
of formal features. Int. J. Biling. 2005, 9, 227–251. [CrossRef]16. González-Vilbazo, K.; López, L. Little v and parametric variation. Nat. Lang. Linguist. Theory 2012, 30, 33–77.
[CrossRef]17. Shim, J.Y. Mixed verbs in code-switching: The syntax of light verbs. Languages 2016, 1, 8. [CrossRef]18. Laenzlinger, C. A view of the CP/DP-(non)parallelism from the cartographic perspective. Languages 2017,
2, 18. [CrossRef]19. Den Dikken, M. Clausal subordination and the structure of verbal phrase. Languages 2017, 2, 5. [CrossRef]20. Shim, J.Y.; Ihsane, T. A new outlook of complementizers. Languages 2017, 2, 17. [CrossRef]21. Robert-Tissot, A.; Morel, E. The role of functional heads in code-switching evidence from Swiss text messages
(sms4science.ch). Languages 2017, 2, 10. [CrossRef]22. López, L.; Alexiadou, A.; Veenstra, T. Code-switching by phase. Languages 2017, 2, 9. [CrossRef]23. Riksem, B.R. Language mixing and diachronic change: American Norwegian noun phrases then and now.
Languages 2017, 2, 3. [CrossRef]24. Blokzijl, J.; Deuchar, M.; Parafita Couto, M.C. Determiner asymmetry in mixed constructions: The role of
grammatical factors in data from Miami and Nicaragua. Languages 2017, 2, 20. [CrossRef]25. Chomsky, N. Syntactic Structures; Mouton: The Hague, The Netherlands, 1957.26. Chomsky, N. Aspects of the Theory of Syntax; MIT Press: Cambridge, MA, USA, 1965.27. González-Vilbazo, K. Die Syntax des Code-Switching. Esplugisch: Sprachwechsel an der Deutschen Schule
Barcelona. Ph.D. Thesis, University of Cologne, Cologne, Germany, 2005.28. MacSwan, J.; Colina, S. Some consequences of language design: Code switching and the PF interface.
In Grammatical Theory and Bilingual Codeswitching; MacSwan, J., Ed.; MIT Press: Cambridge, MA, USA,2014; pp. 185–200.
29. Liceras, J.; Fernández Fuertes, R.; Perales, S.; Pérez-Tattam, R.; Spradlin, K.T. Gender and gender agreementin bilingual native and non-native grammars: A view from child and adult functional-lexical mixings. Lingua2008, 118, 827–851. [CrossRef]
30. Sessarego, S. Afro-Hispanic linguistics: Current trends in the field. Lingua 2017. [CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
Determiner Asymmetry in Mixed NominalConstructions: The Role of Grammatical Factors inData from Miami and Nicaragua
Jeffrey Blokzijl 1,*, Margaret Deuchar 2 and M. Carmen Parafita Couto 1 ID
1 Leiden University Center for Linguistics, Leiden University,Van Wijkplaats 3, 2311 BX Leiden, The Netherlands; [email protected]
2 Department of Theoretical and Applied Linguistics, University of Cambridge,9 West Road, CB3 9DP Cambridge, UK; [email protected]
* Correspondence: [email protected]; Tel.: +31-615-484-221
Academic Editors: Usha Lakshmanan and Osmer BalamReceived: 28 February 2017; Accepted: 12 September 2017; Published: 6 October 2017
Abstract: This paper focuses on the factors influencing the language of determiners in nominalconstructions in two sets of bilingual data: Spanish/English from Miami and Spanish/English creolefrom Nicaragua. Previous studies (Liceras et al. 2008; Moro Quintanilla 2014) have argued thatSpanish determiners are preferred in mixed nominal constructions because of their grammaticisednature. However, those studies did not take the matrix language into account, even thoughHerring et al. (2010) found that the language of the determiner matched the matrix language.Therefore, we hypothesise that the matrix language is the main influence on the language of thedeterminer in both mixed and unmixed nominal constructions. The results are consistent with ourhypothesis that the matrix language of the clause provides the language of the determiner in mixedand unmixed Determiner Phrases (DPs). Once the matrix language is controlled for, the Miami datashow a greater tendency for Spanish determiners to appear in mixed DPs than English determiners.However, in the Nicaragua data, we found only mixed DPs with an English creole determiner. Thissuggests that bilingual communities do not always follow the same pattern, and that social ratherthan grammatical factors may be at play. We conclude that while the language of the determiner isinfluenced by clause-internal structure, that of its noun complement and the matrix language itselfdepends on extralinguistic considerations.
Keywords: code-switching; matrix language; determiner-phrases; Spanish; English; NicaraguanCreole English
1. Introduction
Since the 1980s, code-switching, “an activity which may be observed in the speech (or writing) ofbilinguals who go back and forth between their two languages in the same conversation” [1], has beenthe focus of intensive study and debate. This linguistic phenomenon is not uncommon and can befound in various bilingual contexts [2]. Previous data have shown that individual utterances cancombine elements from more than one language [3,4]. To date, the Spanish/English language pairis one of the most frequently examined, possibly because of the large number of speakers of bothlanguages and the availability of collected data, such as can be found at the BangorTalk website [5].We shall use the Spanish/English language pair to illustrate the range of possible combinationsinvolving English and Spanish determiners and nouns. Examples (1a) and (1b) show DeterminerPhrases (DPs) where the determiner and noun come from the same language, while examples (2a) and
Languages 2017, 2, 20; doi:10.3390/languages2040020 www.mdpi.com/journal/languages

Languages 2017, 2, 20 2 of 12
(2b) illustrate mixed DPs where the determiner and noun are in different languages. Spanish wordsare shown in italics below, and determiners in both languages are shown in bold font.
1. English unmixed DPa. The house
DET1.DEF N
Spanish unmixed DPb. La casa
DET.DEF.F.S N.F.S
2. Mixed DPa. La house
DET.DEF.F.S N
b. The casaDET.DEF. N.F.S
It has been reported previously that among mixed DPs, type (2a) occurs more frequentlythan type (2b), or in other words, Spanish determiners occur more frequently in mixed DPs thanEnglish determiners. For example, Liceras et al. reported, from their review of research on mixedSpanish–English DPs in spontaneous adult speech and their own study of child speech, that mixed DPswith Spanish determiners are far more frequent than with English determiners [6]. In their own studyof child speech, only about 5% of the mixed DPs had English determiners; in adult speech, Jake et al.found 161 instances of Spanish determiners followed by English nouns, but no examples of Englishdeterminers followed by Spanish nouns [7]. However, Liceras et al. [6] do not provide informationabout the morphosyntactic frame in which the mixed DPs appeared, which Herring et al. [8] foundto be relevant, as will be described below. Liceras et al. also do not consider the proportion of mixedvs. unmixed DPs with a given determiner, in case unmixed Spanish DPs should be more commonthan unmixed English DPs [6]. Instead, they explain the apparently greater frequency of Spanishdeterminers in mixed DPs in terms of the “intrinsic Gender feature of the Spanish Noun and theintrinsic Gender Agreement feature of the Spanish Determiner” [6] (p. 828), both of which features areabsent in English. Moro Quintanilla also reports that Spanish determiners in mixed DPs are far morefrequent in the Gibraltar data collected by Moyer than English determiners (only 2/243), and, likeLiceras et al. [6], explains the distribution in terms of the “presence of an uninterpretable gender featureon the Spanish determiner, as opposed to its absence on the English determiner” [9] (p. 222). However,Moro Quintanilla also does not consider the morphosyntactic frame of the mixed DP or comparethem with unmixed DPs [9]. Myers-Scotton and Jake also appear to concur with Liceras et al. [6],and Moro Quintanilla [9] on the assumption that the gender feature on Spanish determiners requiresthem to be ‘elected’ earlier in the language production process and that early election is related togreater frequency [10]. However, their earlier work had drawn attention to the importance of themorphosyntactic frame of the clause ‘or matrix language’ in influencing the language of the determiner.
The matrix language framework (MLF) was developed by Myers-Scotton [11] in order to accountfor common patterns found in intraclausal code-switching. Its main contribution is to capture acommon asymmetry between the two languages involved, such that one provides the morphosyntacticframe or matrix language, and the other (the ”embedded language”). The matrix language can beidentified by the word order of the clause (the Morpheme Order Principle) and by the languagesource of particular ”system morphemes” (the System Morpheme Principle). System morphemes are
1 DET = Determiner, DEF = Definite, F = Feminine, N = Noun, S = Singular.

Languages 2017, 2, 20 3 of 12
categorized as either ”early” or ”late”. Early system morphemes are “conceptually activated to expressa part of speakers’ meanings that they wish to communicate” [10] (p. 344) and include plural markingon nouns as well as determiners. Early system morphemes in a clause with code-switching can comefrom either the matrix language or the embedded language, but they are more likely to come from thematrix language. Late system morphemes have less semantic content than early system morphemesand a particular subcategory of late system morphemes, “outsider late system morphemes”, can onlycome from the matrix language and are thus important in determining the matrix language of a givenclause. Examples of outsider late system morphemes are case markers or verb inflections which encodesubject–verb agreement.
We can illustrate the identification of the matrix language in examples (3) and (4)2 below:
3. my mom got the manguera,hosepipe
‘My mom got the hosepipe.’ [herring9: CLA]3
4. eso fue en el front desk en el receptionthat was at the at the‘That was at the front desk, at the reception.’ [zeledon1: CAR]
Example (3) has an English matrix language or morphosyntactic frame on the basis of the finiteverb got being English, whereas example (4) has a Spanish matrix language because the finite verbfue ‘was’ is Spanish (word order is not relevant here to distinguish between an English and a Spanishmatrix language).
Returning to the issue of whether or not Spanish determiners occur more frequently in mixedDP constructions, Myers-Scotton and Jake argue for the influence of the matrix language (ML) [10](p. 356) even though they had appeared to support the viewpoints of Liceras et al. [6], and MoroQuintanilla [9]. They state that “If Spanish is the ML in any CS corpus, then it is likely Spanishdeterminers will dominate for this reason alone under an analysis based on the MLF model” [10](p. 356). This prediction had already been captured in the ‘Bilingual NP Hypothesis’ proposed byJake et al. [7] and was motivated by the Uniform Structure Principle according to which the “structuresof the matrix language are always preferred” [11] (p. 8).
Herring et al. attempted a preliminary evaluation of the influence of the matrix language onthe determiner by using Welsh–English and Spanish–English data to assess the extent to which thematrix language matched the source language of the determiner in mixed DP constructions [8]. If welook again at examples (3) and (4) above, we can see that the language of the determiner in (3) isEnglish, and thus matches the English matrix language of (3), while the language of the determiner in(4) is Spanish and thus matches the Spanish matrix language of (4). So, in both these two examples,the language of the determiner and the finite verb match.
In the small amount of the data analysed by Herring et al. [8], there was only one example out of89 of a determiner (Spanish) and matrix language (English) mismatching. The matrix language of theclauses was Spanish in 90% of the cases, and the proportion of mixed DPs with a Spanish determinerfound in those clauses was 91%, supporting the idea of a close relation between the language ofthe determiner and the matrix language of the clause. The distribution of the data also provides apossible explanation for the quantitative results reported by Liceras et al. [6] and Moro Quintanilla [9],i.e., the reason why the majority of mixed DPs appeared in clauses with Spanish as matrix languagewas that Spanish was the matrix language in the majority of cases. In other words, Spanish determiners
2 In examples (3) and (4), English words appear in normal type while Spanish words appear in italics. The mixed DPsare underlined.
3 [filename: speaker’s pseudonym]

Languages 2017, 2, 20 4 of 12
could have been preferred to English determiners in mixed nominal constructions simply becausespeakers selected a Spanish morphosyntactic frame, or matrix language in which they inserted theirmixed DPs.
Recent experimental evidence provides support from two types of acceptability judgments forHerring et al.’s conclusion. To experimentally test these two sets of predictions regarding the languageof the determiner in nominal constructions, Parafita Couto and Stadthagen-González tested twoseparate groups of 40 early Spanish–English bilinguals [12]. Their task was to evaluate the acceptabilityof sentences with code-switches between the determiner and the noun that reflected the predictionsof the Minimalism Program, the MLF, both or none. The first group rated them on a Likert scale,while the second group performed a two-alternative forced-choice acceptability task (2AFC). Bothexperiments yielded converging evidence supporting Herring et al.’s [8] suggested preference for amatch between the language of the determiner and the matrix language.
In the present study, we attempted to build on Herring et al.’s [8] work by investigating thelink between the language of the determiner and the matrix language in a larger dataset than usedpreviously. We focus on both mixed and unmixed nominal constructions in order to try to come closerto an empirically supported account of the regularities involved. Controlling for the matrix language,we measure the proportion of mixed DPs with each determiner as a proportion of the total number ofDPs with the same determiner. Thus, we take into account the possibility that Spanish determinersmight precede nouns more frequently than English determiners for internal linguistic reasons [13–19].4
Our data will come from two language pairs: Spanish–English from Miami, USA, andSpanish–English creole from the south Atlantic coast of Nicaragua. Although the language pairsin the two communities are similar, the differing distribution of matrix languages and determinerswill allow us to consider the relative influence of linguistic and social factors on the code-switchingpatterns found.
2. Data for This Study
For our study, we used two bilingual corpora, one collected from conversations betweenSpanish–English speakers in Miami (FL, USA) [5], and the other from sociolinguistic interviewswith Spanish–English creole speakers in various cities of the South Caribbean Coast AutonomousRegion of Nicaragua. These two corpora have been chosen for comparative analysis because of the factthat English creole, also called Nicaraguan Creole English or Miskito Creole English [20,21], shareswith English the absence of gender or number marking on its determiner, unlike Spanish, whichthe two corpora have in common. This means that if Liceras et al. [6] and Moro Quintanilla [9] arecorrect in assuming the overriding importance of grammatical features in influencing the appearanceof Spanish vs. English determiners in mixed nominal constructions, then we would expect to finda significantly higher proportion of Spanish determiners in both corpora, regardless of the matrixlanguage of the clause.
2.1. Miami Corpus
The Miami corpus [5] was collected in 2008 by Jon Herring and local assistants [22]. From the1960s onwards, Miami has undergone an influx of Spanish speakers, resulting in intensive languagecontact between English and Spanish [23,24]. The first movement of Spanish-speaking immigrantswere Cubans that sought to escape the Cuban revolution. The younger generation of Cuban immigrantsbecame bilingual in English and Spanish. In the 1980s, there was a second influx of young immigrantsfrom Central American countries that were suffering from civil wars. Nowadays, the Spanish speakers
4 Frequency counts also suggest that Spanish determiners are produced more often than English determiners (cf. for example,the rate of Spanish vs. English definite determiners per million words: Spanish 49,820.26 per million words vs. Englishdefinite determiners: 9999.99 per million words) [18,19].
Languages 2017, 2, 20 5 of 12
in Miami are not only from Cuba or Central America but from a wide range of Latin Americancountries, and immigration continues. The corpus has 84 bilingual speakers of Spanish and Englishand provides a total time of 35 h of natural speech conversation. The data have been transcribed,glossed and coded. We analysed the entire dataset, yielding 8586 nominal constructions in 7115 clauses,with some clauses having more than one DP. However, because the Miami data are relatively large,we used an automatic analysis to codify the matrix language of the clauses and identify the nominalconstructions as mixed or unmixed [25]. In order to test the automatic analyses, we took a sample ofthe data (10%) that we checked manually. From this sample, only 7% of clauses had a wrong matrixlanguage assigned. In other words, we can safely conclude that the automatic analysis is reliable.
2.2. Nicaragua Corpus
The Nicaragua data contain sociolinguistic interviews from the South Caribbean CoastAutonomous Region of Nicaragua collected in 2006 by A. Koskinen [26]. This area was first colonisedby the British. In fact, by 1630, the British dominated the total Atlantic area of Central America [21].The British allowed the indigenous populations, the African slaves, and the refugees from Jamaica,to create their own state [20]. The result was creolisation of the English language that was alsoinfluenced by indigenous languages (Miskito, Rama, etc.) of the area. This English creole varietyis now known as Nicaraguan Creole English (NCE). However, in 1860, this area became part ofNicaragua due to intervention from the United States [21,27]. From that moment onwards, the areabecame populated by Nicaraguans from other regions who brought the Spanish language with them.Spanish also became the official language [28]. Nowadays, all citizens of the cities in the SouthCaribbean Coast Autonomous Region (RACCS) are bilingual in both the creole language and Spanish,with both languages being taught at school. The Nicaragua corpus consists of a total of 16 h ofrecordings of 42 bilingual speakers being interviewed in creole at home, work or in school. The dataused for this study consist of 3222 clauses and 3506 determiner phrases that were manually extractedand coded. Data from clauses to which a matrix language could not be assigned were excluded.
The main characteristics of the two corpora are summarised in Table 1 below.
Table 1. Summary of the main characteristics of the two corpora.
Miami Nicaragua
Languages Spanish–English Spanish–Nicaraguan Creole EnglishType of data Natural speech conversation Sociolinguistic interviews
Number of speakers 84 42Time 35 h 12 h
Clauses 7115 3222Determiner Phrases 8586 3506
3. Analysis of Data
All clauses containing a determiner phrase were extracted and coded according to the matrixlanguage of the clause in which they appeared. The automatic analysis of the Miami data includedDPs with both definite and indefinite articles, while the manual analysis of the Nicaragua data alsoincluded demonstratives and possessives to compensate for the difference in corpus size. Because theword order of Spanish, English, and NCE are similar (Subject-Verb-Object), we used the language of thefinite verb to determine the matrix language of the clause in our automatic analysis. Non-finite clauseswere excluded. The nominal constructions were coded according to the language of the determiner,the language of the noun and whether or not the determiner and noun were in the same language(‘unmixed’) or not (‘mixed’). This allowed us to study the proportion of mixed and unmixed DPs inclauses of each matrix language and to determine the extent of match between the language of thedeterminers and the finite verb. Examples (5) and (6) provide examples of an extracted mixed andunmixed DP respectively.
Languages 2017, 2, 20 6 of 12
5. She was trying to be a turistaDET.INDEF N. [maria31: MAR]
In example (5), the underlined mixed DP consists of an English determiner and a Spanish noun,and the matrix language is English. In example (6), below the matrix language is also English but theDP is unmixed since the determiner and noun are both in English.
6. or are you still a turist in your own cityDET.INDEF N. [maria31: MAR]
In example (7), the underlined mixed DP consists of an English creole determiner followed by aSpanish noun, and the matrix language is English creole. After the mixed DP, the speaker producesanother DP that is unmixed.
7. an he uz to fight for ur luna, di moonDET.POSS N. DET.DEF N.
‘and he used to fight for our moon, the moon.’ [F-BLU-9-07]
Table 2 provides an example of our data coding.
Table 2. Example of data coding.
Clause DP Language ofDeterminer Language of Noun Type Finite Verb Language of Verb
she was trying tobe a turista! a turista English Spanish mixed was English
or are you still atourist in your own
city state?a tourist English English unmixed are English
an he uz to fight forur luna, di moon ur luna NCE Spanish mixed uz NCE
an he uz to fight forur luna, di moon di moon NCE NCE unmixed uz NCE
she put it inthe boca the boca English Spanish Mixed put English
no pero talvez consigue un
roommateun roommate Spanish English Mixed consigue Spanish
di king wife wentto waz to diz pila di king wife NCE NCE unmixed went NCE
di king wife wentto waz to diz pila diz pila NCE Spanish Mixed went NCE
DP: Determiner Phrase; NCE: Nicaraguan Creole English.
4. Results
The results of the Miami data analysis can be found in Table 3. The rows show mixed and unmixedDPs and the total number of DPs, while the middle columns indicate the frequency of the determinersmatching vs. not matching the matrix language, with the results for Spanish and English as matrixlanguages given separately. As the Table shows, there is a match of 98.1% between the language of thedeterminer and the matrix language. Thus, the overwhelming majority of both unmixed and mixedDPs have a determiner with the same language as the finite verb of the clause.
Languages 2017, 2, 20 7 of 12
Table 3. Results of Miami data analysis: mixed and unmixed DPs with matching and non-matchingmatrix language (ML).
Language of Determiner Matching ML Not Matching ML Total
Unmixed DPSpanish 3579 94
8310 (96.8%)English 4574 63
Mixed DPSpanish 240 8
276 (3.2%)English 28 0
Total 8421 (98.1%) 165 (1.9%) 8586 (100%)
On the other hand, 1.9% of all DPs have a determiner that does not match the matrix language.Still, of this group, 95.15% (157/165) are embedded language islands. These are all of the unmixedDPs which do not match the ML, as shown in the above table. An example of such an island is givenin example (8). The clause in example (8) has an English matrix language, yet the determiner phraseuna pareja ‘a couple’ has both the determiner and the noun in Spanish.
8. I hope mom doesn’t think they’re una pareja you knowa couple [sastre12: MAD]
In embedded language islands, the grammar of the Embedded Language temporarily prevailsand so we expect its internal constituents to appear unaffected by the matrix language [10] (p. 139).
Of the mixed constructions, only 2.9% (8/276 DPs) did not match the matrix language. This isa very small number but we can note some similarities between those eight cases, of which threeexamples are given below.
9. pero aquí [en el north side]AdvP we don’t ever get direct sun.but here on the north side [María1: MAR]
10. [en los dorms]AdvP they have a laundry roomin the dorms [Herring14: CON]
11. they did a sonogram blah blahblah
tumor en [en el spleen]AdvP.
tumor in in the spleen [Zeledon8: MAR]
Examples (9)–(11) contain mixed DPs that appear in Spanish adverbial phrases introduced bythe Spanish preposition en, ‘on’ in example (9) and ‘in’ in example (10). In the case of (9) and (10),the switch from a Spanish determiner to an English noun may have been anticipating the change ofmatrix language to English which occurs in the following clause (we don’t ever get direct sun in (9) andthey have a laundry room in (10)). All three of these examples could be characterised by what Muyskenhas called “alternational” switching [29], in which the switch occurs at a peripheral place in the clause.Adverbial phrases can be considered peripheral since they are not involved in the argument structureof the verb.
In addition to investigating the link between the language of the determiner and the matrixlanguage, a second aim of our study was to measure the proportion of mixed DPs with each determineras a fraction of the total number of DPs with the same determiner. We conducted this analysis ona subset of the data represented in Table 3, in particular the data shown in the column headed“Matching ML”, where the determiner matched the ML. This was the case for 98.1% of the data asshown above. The results of this second analysis are shown in Table 4. As the Table shows, there is

Languages 2017, 2, 20 8 of 12
indeed a higher proportion5 (6.3%) of Spanish determiners followed by an English noun than Englishdeterminers followed by a Spanish noun (0.6%). Given the tendency of determiners to match thematrix language, this means that bilingual speakers are more likely to switch language after Spanishdeterminers than after English determiners.
Table 4. Results of Miami data analysis: proportion of mixed DPs.
Unmixed DP Mixed DP Proportion of Mixed DPs
English determiner and English matrix language 4574 28 0.6%Spanish determiner and Spanish matrix language 3579 240 6.3%
Total 8153 268 3.1%
Nicaragua Data
The results of the analysis of the Nicaragua data can be found in Table 5. As in Table 3, the rowsshow mixed and unmixed DPs and the total number of DPs, while the middle columns indicate thefrequency of the determiners matching vs. not matching the matrix language. Next to each figure,we provide the percentage out of the total number of DPs. Table 5 shows that there is a match of 99.7%between the language of the determiner and the matrix language.
Table 5. Results of Nicaragua data analysis: mixed and unmixed DPs with matching andnon-matching ML.
Language of Determiner Matching ML Not Matching ML Total
Unmixed DPSpanish 9 9
3364 (96%)NCE 3346 0
Mixed DPSpanish 0 0
142 (4.0%)NCE 142 0
Total 3497 (99.7%) 9 (0.3%) 3506 (100%)
The results of the Nicaragua data support the predictions of the MLF: only 0.3% of the DPs do nothave a match between the language of the determiner and the matrix language of the clause. As in thecase of the Miami data, the mismatched cases involve embedded language islands. An example of suchan island is given in example (12). The clause in example (12) has an English creole matrix language,yet the DP la escuela ‘the school’ is entirely in Spanish. All the islands found were Spanish determinerphrases in a NCE matrix language clause.
12. di refreshment, hav di celebración de la escuelathe have the celebration of the school‘the refreshment, have the celebration in the school.’ [F-BLU-1-06]
All mixed constructions matched the matrix language.Table 6 shows the numbers of unmixed and mixed DPs for each determiner and matrix language.
As is clear, use of a Spanish matrix language is very rare in Nicaragua. However, a Fisher test (p = 0.63)suggests no significant difference between the proportion of mixed DPs with a Spanish determinerand with an NCE determiner.
5 The results of a chi square test showed that the difference is significant: p < 0.01.

Languages 2017, 2, 20 9 of 12
Table 6. Results of Nicaragua data analysis: proportion of mixed DPs.
Unmixed DP Mixed DP Proportion of Mixed DPs
NCE determiner and NCE matrix language 3346 142 4%Spanish determiner and Spanish matrix language 9 0 0%
Total 3355 142 4%
5. Discussion
Our results suggest that speakers do not appear to have much choice regarding the language ofthe determiner: instead, this is influenced by the language of the morpho-syntactic frame or matrixlanguage, and it is in selecting the matrix language that speakers do appear to have some choice. Oncethey have done this and have selected a matching determiner, the next option is whether or not toswitch to a different language when selecting the noun following the determiner. We have notedthat this happens more often where the matrix language (and determiner) is Spanish in the Miamidata. In the Nicaragua data, however, we have only a small number of clauses with Spanish matrixlanguage, and no statistical indication of a difference in the proportion of switched nouns followingSpanish as opposed to NCE determiners. However, in trying to account for the asymmetry that wefind in the Miami data, we may note that previous work by Bhatt on Indian data has suggested thatthe directionality of switches tends to be towards the language of power, or the language with superiorsocial status [30]. Our findings seem consistent with this suggestion in that English has been the officiallanguage of Florida, the state where Miami is located, since 1988 [31]. So the more numerous6 switchesfrom Spanish determiners to English nouns than the reverse are in the direction of the official language.In Nicaragua, we can see that even though there is no significant difference between the proportion ofmixed DPs with a Spanish determiner and with an NCE determiner, all the switches observed are fromcreole to Spanish. If this trend is confirmed in further studies, it would once again indicate switchingin the direction of the language of higher prestige [28,30]. Koskinen reports that although the regionallanguages of the Caribbean coast including English creole were made official in 1993, creole was notused officially in education until 2007 [28]. Koskinen also reports that although the other regionallanguages have gained in status, creole “continues to be considered a form of ‘broken English’ or‘bad English’” [28] (p. 143). Spanish, on the other hand, is described as the “national language” [28](p. 153) and is clearly superior in prestige.
Other explanations for the asymmetrical pattern of switching following determiners in theMiami data would require more exploration, but Fricke and Kootstra’s work on the Miami datahas established the importance of priming by material in the previous discourse, and this could beinvestigated in our data [32]. This account would be supported by the exposure-driven accountposited by Valdés-Kroff [33], whereby bilingual speakers converge upon conventional productionpatterns. Such an emergent approach would offer an alternative as to how to account for asymmetricalstructural distributions such as the ones we observed in our Miami and Nicaragua data. Anotheravenue to pursue would be the idea that code-switching tends to mark high information content asproposed by Myslin and Levy [34]. They consider words with high information content to be lesspredictable than those of lower information content, and to signal to the listener that special attention isneeded. In relation to our data, we would need to examine whether there is evidence of the switches tonouns in the minority language having higher information content than those in the official language.Another variable that could be considered would be the language proficiency or dominance of thespeaker. For example, Liceras et al. argued that it is possible to gain insights from the code-switchingpatterns and preferences which differentiate child and adult native speakers, simultaneous bilingual
6 Although we focused specifically on switches between the determiner and the noun, it is interesting to note that Fricke andKootstra [32] (p. 11), using the same Miami corpus, also found fewer switches of any kind in bilingual clauses with Englishmatrix language than with Spanish matrix language.

Languages 2017, 2, 20 10 of 12
speakers and L2 speakers [35]. This, they say, could account for the conflicting evidence observed inthe spontaneous switches produced in different communities of code-switchers.
One question that remains to be addressed is that of what determines the selection of the matrixlanguage, since we have argued that the language of the determiner follows from this choice. We expectextralinguistic factors such as age of acquisition, language proficiency and the language of socialnetworks to be all relevant, and hope to explore this question in the future.
6. Conclusions
The first objective of this study was to build on previous research that suggested that thelanguage of determiners in mixed nominal constructions depends on the matrix language of theclause. The results confirm our hypothesis that the language of the determiner in mixed and unmixednominal constructions generally does match the matrix language. The match between the language ofthe determiner and the matrix language seems to be unaffected by any grammaticised features in thelanguage of the determiner.
The second objective was to compare the occurrence of mixed and unmixed DPs with Englishand Spanish determiners. We found that the frequency of switching from the determiner to thenoun was asymmetric in the Miami data, being more frequent from Spanish to English in the Miamidata. In the Nicaragua data, we only observed switches from the NCE to Spanish. We consideredsome explanations for our findings, and provisionally suggested that the relative prestige of the twolanguages may help to account for the asymmetry in the Miami data.
To summarise, we found that the matrix language was the most influential factor affecting thelanguage of the determiner in mixed nominal constructions. However, extralinguistic factors seem toinfluence whether or not there is a switch after the determiner.
Acknowledgments: We would like to express our gratitude to the following persons: K. Donnelly, for providingus the automatic analysis of the Miami corpus, A. Koskinen for allowing us to use the Nicaragua corpus,and E. Bierings for her support in analyzing the Nicaragua corpus. We are also thankful to two anonymousreviewers for their comments and suggestions.
Author Contributions: All the authors contributed equally to this work.
Conflicts of Interest: The authors declare no conflict of interest.
References
1. Deuchar, M. Code-switching. In Encyclopedia of Applied Linguistics; Chapelle, C., Ed.; Wiley: New York, NY, USA,2012; pp. 657–664.
2. Inuwa, Y.N.; Althea, C.A.; Haryati, B.H. Factors Motivating Code Switching Within the Social Contact ofHausa Bilinguals. IOSR J. Humanit. Soc. Sci. (IOSR-JHSS) 2014, 19, 43–49. [CrossRef]
3. Poplack, S. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology ofcode-switching. Linguistics 1980, 18, 581–618. [CrossRef]
4. Timm, L.A. Spanish-English code-switching: El porqué y how-not-to. Roman. Philol. 1975, 28, 473–482.5. Canolfan ESRC Centre for Research on Bilingualism. Corpus: MIAMI. Available online: www.bangortalk.
org.uk/speakers.php?c=miami (accessed on 4 October 2017).6. Liceras, J.; Fernández Fuertes, R.; Perales, S.; Pérez-Tattam, R.; Spradlin, K.T. Gender and gender agreement
in bilingual native and non-native grammars: A view from child and adult functional-lexical mixings. Lingua2008, 118, 827–851. [CrossRef]
7. Jake, J.L.; Myers-Scotton, C.; Gross, S. Making a minimalist to code-switching work: Adding the matrixlanguage. Biling. Lang. Cognit. 2002, 5, 69–91. [CrossRef]
8. Herring, J.; Deuchar, M.; Parafita Couto, M.C.; Moro Quintanilla, M. “I saw the madre”: Evaluatingpredictions about codeswitched determiner-noun sequences using Spanish-English and Welsh-English data.Int. J. Biling. Educ. Biling. 2010, 13, 553–573. [CrossRef]

Languages 2017, 2, 20 11 of 12
9. Moro Quintanilla, M. The semantic interpretation and syntactic distribution of determiner phrases inSpanish-English Codeswitching. In Grammatical Theory and Bilingual Codeswitching; Macswan, J., Ed.;MIT Press: Cambridge, MA, USA, 2014; pp. 213–226.
10. Myers-Scotton, C.M.; Jake, J.L. Revisiting the 4-M model: Codeswitching and morpheme election at theabstract level. Int. J. Biling. 2016, 21, 340–366. [CrossRef]
11. Myers-Scotton, C. Contact Linguistics: Bilingual Encounters and Grammatical Outcomes; Oxford UniversityPress: Oxford, UK, 2002.
12. Parafita Couto, M.C.; Stadthagen-González, H. El book or the libro? Insights from acceptability judgmentsinto determiner/noun code-switches. Int. J. Biling. 2017. [CrossRef]
13. Chierchia, G. Reference to kinds across languages. Nat. Lang. Semant. 1998, 6, 339–405. [CrossRef]14. Longobardi, G. Reference and proper names. Linguist. Inq. 1994, 25, 609–665.15. Longobardi, G. How comparative is semantics? A unified parametric theory of bare nouns and proper
names. Nat. Lang. Semant. 2001, 9, 335–369. [CrossRef]16. Pérez-Leroux, A.T.; Schmitt, C.; Munn, A. Syntactic features and discourse factors in children’s interpretation
of definite determiners in inalienable possession. Actes de l’ACL 2002/2002 Can. Linguist. Assoc. Proc. 2003,245–255.
17. Vergnaud, J.-R.; Zubizarreta, M.L. The definite determiner in French and English. Linguist. Inq. 1992, 23,595–652.
18. Brysbaert, M.; New, B. Moving beyond Kucera and Francis: A Critical Evaluation of Current Word FrequencyNorms and the Introduction of a New and Improved Word Frequency Measure for American English.Behav. Res. Methods 2009, 41, 977–990. [CrossRef] [PubMed]
19. Cuetos, F.; Glez-Nosti, M.; Barbon, A.; Brysbaert, M. SUBTLEX-ESP: Spanish word frequencies based on filmsubtitles. Psicologica 2011, 32, 133–143.
20. Bartens, A. Nicaraguan Creole English. In The Survey of Pidgin and Creole Languages; Michaelis, S.M.,Maurer, P., Haspelmath, M., Huber, M., Eds.; Oxford University Press: Oxford, UK, 2013; pp. 115–126.
21. Holm, J.A. The Creole English of Nicaragua’s Miskito Coast: Its Sociolinguistic History and a Comparative Study ofIts Syntax and Lexicon; University of London: London, UK, 1978.
22. Deuchar, M.; Davies, P.; Herring, J.; Parafita Couto, M.C.; Carter, D. Building Bilingual Corpora. In Advancesin the Study of Bilingualism; Thomas, E., Mennen, I., Eds.; Multilingual Matters: Bristol, UK, 2014; pp. 93–110.
23. Carter, D.; Deuchar, M.; Davies, P.; Parafita Couto, M.C. A systematic comparison of factors affecting thechoice of matrix language in three bilingual communities. J. Lang. Contact 2011, 4, 153–183. [CrossRef]
24. Gathercole, V. Miami and North Wales, so far and yet so near: Constructivist account of morpho-syntacticdevelopment in bilingual children. Int. J. Biling. Educ. Biling. 2007, 10, 224–247. [CrossRef]
25. Carter, D.; Broersma, M.; Donnelly, K.; Konopka, A. Presenting the Bangor Autoglosser and the BangorAutomated Clause-Splitter. Digit. Scholarsh. Humanit. 2017. [CrossRef]
26. Koskinen, A. (Universidad de las Regiones Autónomas de la Costa Caribe Nicaraguense). Personalcommunication, 2006.
27. Zapata Webb, Y.H. Módulo 2: Una historia diferente. In Manual de Educación Ciudadana InterculturalY Autonómica, Universidad de las Regiones Autónomas de la Costa Caribe Nicaragüense; Ford FoundationURACCAN: Managua, Nicaragua, 2012.
28. Koskinen, A. Kriol in Caribbean Nicaragua schools. In Creoles in Education: An appraisal of Current Programsand Projects; Bettina Léglise, M.I., Bartens, A., Eds.; John Benjamins: Amsterdam, The Netherlands, 2010;pp. 133–166.
29. Muysken, P. Bilingual Speech: A Typology of Code-Mixing; Cambridge University Press: Cambridge, UK, 2000.30. Bhatt, R. Bilingual Situations in India: Power Relations between Languages Analysed through
Code-Switching. Unpublished work, 2013.31. Tatalovich, R. Nativism Reborn? The Official English Language Movement and the American States; The University
of Kentucky Press: Lexington, KY, USA, 1995.32. Fricke, M.; Kootstra, G.J. Primed codeswitching in spontaneous bilingual dialogue. J. Mem. Lang. 2016, 91,
181–201. [CrossRef]

Languages 2017, 2, 20 12 of 12
33. Valdés-Kroff, J.R. Mixed NPs in Spanish-English bilingual speech: Using a corpus-based approach to informmodels of sentence processing. In Spanish-English Codeswitching in the Caribbean and the US; Guzzardo Tamargo, R.,Mazak, C., Parafita Couto, M.C., Eds.; John Benjamins: Amsterdam, The Netherlands, 2016; pp. 281–300.
34. Myslín, M.; Levy, R. Code-switching and predictability of meaning in discourse. Language 2015, 91, 871–905.[CrossRef]
35. Liceras, J.M.; Fernández Fuertes, R.; Klassen, R. Language dominance and language nativeness: Theview from English-Spanish codeswitching. In Spanish-English Codeswitching in the Caribbean and the US;Guzzardo Tamargo, R., Mazak, C., Parafita Couto, M.C., Eds.; John Benjamins: Amsterdam, The Netherlands,2016; pp. 107–138.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
A View of the CP/DP-(non)parallelism from theCartographic Perspective
Christopher Laenzlinger ID
Département de Linguistique, University of Geneva, 2 rue de Candolle, 1211 Geneva, Switzerland;[email protected]; Tel.: +41-22-379-7306
Academic Editors: Maria del Carmen Parafita Couto and Usha LakshmananReceived: 1 February 2017; Accepted: 21 August 2017; Published: 21 September 2017
Abstract: The aim of this paper is to reconsider some aspects of the so-called clause/noun-phrase(non-)parallelism (Abney 1987 and much subsequent work). The question that arises is to find outwhat is common and what is different between the clause as a Complementizer Phrase (CP)-structureand the noun as a Determiner Phrase (DP)-structure in terms of structure and derivation. An exampleof structural parallelism lies in the division of the clause and the noun phrase into three domains:(i) the Nachfeld (right periphery), which is the thematic domain; (ii) the Mittelfeld (midfield), which isthe inflection, agreement, Case and modification domain and (iii) the Vorfeld (left periphery), which isthe discourse- and operator-related domain. However, we will show following Giusti (2002, 2006),Payne (1993), Bruening (2009), Cinque (2011), Laenzlinger (2011, 2015) among others that the innerstructure of the Vorfeld and of the Mittelfeld of the clause is not strictly parallel to that of the nounphrase. Although derivational parallelism also lies in the possible types of movement occurring inthe CP and DP domains (short head/X-movement, simple XP-movement, remnant XP-movementand pied-piping XP-movement), we will see that there is non-parallelism in the application of thesesorts of movement within the clause and the noun phrase. In addition, we will test the respectiveorders among adverbs/adjectives, DP/Prepositional Phrase (PP)-arguments and DP/PP-adjunctsin the Mittelfeld of the clause/noun phrase and show that Cinque’s (2013) left–right asymmetryholds crosslinguistically for the possible neutral order (without focus effects) in post-verbal/nominalpositions with respect to the prenominal/preverbal base order and its impossible reverse order.
Keywords: Generative Grammar; cartography; noun phrase/clause-(non)parallelism; types ofmovement; left–right asymmetry; head-final vs. head initial languages
1. Introduction
Since the very beginning of Generative Grammar the parallelism between the deverbal nominalconstruction the enemy’s recent destruction of the city and the clause The enemy recently destroyed the cityhas been questioned. Lees proposes that such derived nominals are the result of transformationalrules that apply in syntax [1]. Chomsky argues against this syntactic approach and assumes thatsuch constructions are derived through lexical rules within the framework of what will be called theLexicalist Hypothesis [2].
The structural parallelism between the noun phrase (NP) and the clause has emergedmore strikingly from Abney’s [3] Determiner Phrase (DP)-hypothesis and has been furtherdeveloped and discussed in much subsequent work (Cinque [4], Giusti [5–7], Payne [8],
Languages 2017, 2, 18; doi:10.3390/languages2040018 www.mdpi.com/journal/languages

Languages 2017, 2, 18 2 of 24
Bruening [9], Laenzlinger [10,11], among others; see also Bernstein [12] for an overview).1 The aimof this paper is to revisit some properties related to the so-called clause/noun phrase parallelism.The question that arises is to find out what is common and what is different between the clauseas a Complementizer Phrase (CP)-structure and the noun as a DP-structure in terms of structureand derivation.2
At first sight one case of structural parallelism lies in the division of the clause and the nounphrase into three domains (Grohmann [16], Laenzlinger [10], Wiltschko [17]).
Languages 2017, 2, 18 2 of 24
Laenzlinger [10,11], among others; see also Bernstein [12] for an overview).1 The aim of this paper is
to revisit some properties related to the so-called clause/noun phrase parallelism. The question that
arises is to find out what is common and what is different between the clause as a Complementizer
Phrase (CP)-structure and the noun as a DP-structure in terms of structure and derivation.2
At first sight one case of structural parallelism lies in the division of the clause and the noun
phrase into three domains (Grohmann [16], Laenzlinger [10], Wiltschko [17]).
1. a. [DP … [DP [TP [FPadj1 … [FPadj2 … [nP … [NP .. ] ] ] ] ] ] ]
b. [CP … [CP [NumP [FPadv1 …[FPadv2 ... [vP …[VP .. ] ] ] ] ] ] ]
Vorfeld Mittelfeld Nachfeld
(left periphery) (midfield) (right periphery)
These three domains (DP/CP, NumP/TP and NP/VP) are constituted of multilayered split-
structures. The Nachfeld is the thematic domain where the arguments merge and their θ-role is
assigned/valued (Laenzlinger [10], Larson [18], and Chomsky [19], among others). The Mittelfeld (or
midfield) is the inflection, agreement and Case domain (Pollock [20], Belletti [21], Cinque [4,22]). It is
also the domain where modifiers externally merge (adjectives and adverbs, see Cinque [22,23];
Laenzlinger [10,11,24]). The Vorfeld is the discourse-related, referential and quantificational domain
(Laenzlinger [10], Rizzi [25], Rizzi and Bocci [26], Aboh [27]). However, it will be demonstrated that
the inner structure of the left periphery and of the midfield of the clause is not strictly parallel to that
of the noun phrase (Payne [8], Bruening [9]).
As will be shown in this paper, there is also derivational parallelism in the possible types of
movement occurring in the CP and DP structures: short X-movement, simple XP-movement, remnant
XP-movement and pied-piping XP-movement. Nevertheless, we will see that there is non-parallelism
in the application of these sorts of movement within the clause and the noun phrase. To be more
precise, in this article we will study the order among adverbs/adjectives, DP/Prepositional Phrase
(PP)-arguments and DP/PP-adjuncts in the Mittelfeld and the Vorfeld of the clause/noun phrase and
test if Cinque’s left–right asymmetry [28] (see (2) below) holds for the possible neutral order (without
focus effects) in post-verbal/nominal positions (2c) and (2d) with respect to the base order in (2a) and
the impossible reverse order in (2b).
2. Left–right asymmetry
GermanV-final/Tatar/Japanese
a. (x) y z V/N (base)
b. *z y (x) V/N
GermanV2/English/Romance
c. V/N (x) y z
d. V/N z y (x)
The paper is organized as follows. After the introduction Section 2 deals with the structure of
the left periphery for the clause (Section 2.1) and the noun phrase (Section 2.2). We will present
arguments in favor of a split-CP/DP structure on the basis of multiple complementizer and
determiner occurrences, fronting of arguments and adjuncts for topicalization, focalization and other
1 See also work in the framework of Distributed Morphology (Marantz [13], Alexiadou [14]) where the
parallelism between clauses and derived nominals is also striking (the category of the root is defined
syntactically, i.e., syntax feeds the lexicon, see also Borer’s [15] exo-squeletal lexical approach). 2 In this context it is important to make a distinction between event-denoting nouns (deverbal/derived
nominals) and object-denoting nouns as well as between state-denoting and event-denoting verbs.
These three domains (DP/CP, NumP/TP and NP/VP) are constituted of multilayeredsplit-structures. The Nachfeld is the thematic domain where the arguments merge and their θ-roleis assigned/valued (Laenzlinger [10], Larson [18], and Chomsky [19], among others). The Mittelfeld(or midfield) is the inflection, agreement and Case domain (Pollock [20], Belletti [21], Cinque [4,22]).It is also the domain where modifiers externally merge (adjectives and adverbs, see Cinque [22,23];Laenzlinger [10,11,24]). The Vorfeld is the discourse-related, referential and quantificational domain(Laenzlinger [10], Rizzi [25], Rizzi and Bocci [26], Aboh [27]). However, it will be demonstrated thatthe inner structure of the left periphery and of the midfield of the clause is not strictly parallel to thatof the noun phrase (Payne [8], Bruening [9]).
As will be shown in this paper, there is also derivational parallelism in the possible types ofmovement occurring in the CP and DP structures: short X-movement, simple XP-movement, remnantXP-movement and pied-piping XP-movement. Nevertheless, we will see that there is non-parallelismin the application of these sorts of movement within the clause and the noun phrase. To be moreprecise, in this article we will study the order among adverbs/adjectives, DP/Prepositional Phrase(PP)-arguments and DP/PP-adjuncts in the Mittelfeld and the Vorfeld of the clause/noun phrase andtest if Cinque’s left–right asymmetry [28] (see (2) below) holds for the possible neutral order (withoutfocus effects) in post-verbal/nominal positions (2c) and (2d) with respect to the base order in (2a) andthe impossible reverse order in (2b).
2. Left–right asymmetryGermanV-final/Tatar/Japanese
a. (x) y z V/N (base)
b. *z y (x) V/N
GermanV2/English/Romancec. V/N (x) y z
d. V/N z y (x)
The paper is organized as follows. After the introduction Section 2 deals with the structureof the left periphery for the clause (Section 2.1) and the noun phrase (Section 2.2). We will present
1 See also work in the framework of Distributed Morphology (Marantz [13], Alexiadou [14]) where the parallelism betweenclauses and derived nominals is also striking (the category of the root is defined syntactically, i.e., syntax feeds the lexicon,see also Borer’s [15] exo-squeletal lexical approach).
2 In this context it is important to make a distinction between event-denoting nouns (deverbal/derived nominals) andobject-denoting nouns as well as between state-denoting and event-denoting verbs.

Languages 2017, 2, 18 3 of 24
arguments in favor of a split-CP/DP structure on the basis of multiple complementizer and determineroccurrences, fronting of arguments and adjuncts for topicalization, focalization and other informationalprominence effects. Section 2.1 is concerned with the Nachfeld involving a vP shell structure for theclause and its corresponding nP shell for the noun phrase and their left periphery. The argumentsmerge in the thematic domain according to the Universal Thematic Hierarchy. Immediately abovevP/nP, there are discourse-related positions (e.g., a focus position). In Section 3 the midfield of theclause (Section 3.1) and of the noun phrase (Section 3.2) is described and analyzed comparatively insome languages of different families. The relevant constituents whose respective ordering is studiedare adjectives/adverbs, DP/PP-adjuncts and DP/PP-arguments. We will show that Cinque’s left–rightasymmetry holds for several languages according to their V/N-initial and V/N-final configurations.Section 4 contains the conclusion.
2. The Rich Structure of the Left Periphery
2.1. The Clause (CP)
Since Rizzi [25] the CP layer has been assigned a Force-Finiteness articulation. The cartography ofthe split-CP structure is given in (3) following Rizzi [25,29,30] and Rizzi and Bocci [26].
3. Force > Top* > Int > Top*> Foc > Mod* > Top* > QPembed > Fin > Subj
In French the arguments can move to Topic Phrase (TopP) (recursively in clitic-left dislocation),as illustrated below in (4a, c and d). Movement to Focus Projection (FocP as a single projection) isrestricted to adjuncts in French contrary to Italian, as shown in (4b–c).3
4. a. [TopP De ce livre, [SubjP je sais que tu en parleras]]About this book, I know that you of-it talk-FUT
‘About this book, I know you will talk.’
b. [FocP DEMAIN, [SubjP nous irons à la plage, pas aujourd’hui]]Tomorrow-FOC we go-FUT to the beach, not today‘TOMORROW we will go to the beach, not today.’
c. [FocP DEMAIN, [TopP à la plage, nous y irons, pas aujourd’hui]]Tomorrow-FOC to the beach we there go-FUT, not today‘TOMORROW to the beach we will go, not today.’
d. [TopP A la plage [FocP DEMAIN, nous y irons, pas aujourd’hui]]To the beach tomorrow-FOC we there go-FUT, not today‘To the beach TOMORROW we will go, not today.’
As argued by Rizzi [30], fronted adverbs move to Mod(if)P (modifier projection). Crossing anothermodifier results in a Relativized Minimality effect, as shown in (5) with the adverb probably blockingmovement of lentement.4
5. Lentement, ils se sont (*probablement) tous dirigés vers la sortieSlowly they Pron-REFL are (*probably) all move toward the exit‘Slowly, they (*probably) all move to the exit.’
3 A cleft construction is used for arguments as shown by the contrast between (ia) and (ib).
i. a. *Ce LIVRE-ci j’ai choisi, pas celui-là.
b. C’est ce LIVRE-ci que j’ai choisi, pas celui-là.‘It is this book that I chose, not that one’
4 The celerative adverb lentement ‘slowly’ externally merges in a position lower than the modal projection hosting theadverb probably.

Languages 2017, 2, 18 4 of 24
The data in (6) indicate that PP-adjuncts target a Top projection rather than a Mod(if)projection provided that there is no Relativized Minimality effect from the intervention of an adverb(Top vs. Mod(if)).
6. a. Dans deux jours, nous irons probablement à la plage.In two days we go-FUT probably to the beach‘In two days we will probably go to the beach’
b. De ses propres mains, il a récemment réparé des Voitures.Of his own hands he has recently repaired DET-INDEF cars‘With his own hands, he recently repaired (some) cars’
The different occurrences of complementizers (que/that si/if, de, à, etc., see Rizzi [25,30]) are furtherarguments in favor of a rich split-CP structure. It is assumed that they occupy distinct positions in theleft periphery (Force, Interrogative (Int), Finite (Fin)). The fact that complementizer doubling exists insome languages (Irish English, Dutch, Picard, Northern Italian dialects, early Romance, spoken Spanish,European Portuguese; see McCloskey [31], Villa-García [32] and Paoli [33] for data and references)gives further support for the split CP. The higher complementizer occurs in Force and the lower onein Fin and a topic or a focus can be sandwiched between them.5 Note that, akin to complementizers,determiner doubling and determiner spreading are attested in languages like Swedish, Romanian,Hebrew and Swiss/German dialects for the former and Greek for the latter. These facts will bediscussed in the next section. As regards complementizer ‘spreading’, Villa-Garcia reports the exampleof spoken Spanish in (7) with multiple topics [32].
7. Me dijeron que si llueve (que) se quedan aquí, y que si nieva (que) también.cl. said that if rains that cl. stay here and that if snows that too‘They told me that they are going to stay here if it rains or snows.’
2.2. The Noun Phrase (DP)
By analogy with Rizzi’s split-CP analysis, some authors (Giusti [5–7], Laenzlinger [10,11,24],Aboh [27], Puskás and Ihsane [35], Ihsane [36] among others) propose a split-DP structure.What corresponds to Force is Ddeixis/specificity and, similarly, Fin is equated to Ddefinitness/determination.Laenzlinger [10,11] puts forth the structure in (8) which also contains dedicated positions for frontedconstituents (topic, focus, etc.).
8. Structure: (QP) > DPdeixis > FocP > TopP/ModifP > DPdet
According to Laenzlinger [10,11] and Cinque [37] the focus projection hosts emphatic frontedadjectives in Romance. This is illustrated in (9a) for French. The ungrammaticality of example (9b)shows that there is a single FocP available in the left periphery.
9. a. C’ est une SUPERBE nouvelle occasion.This is a superb-FOC new occasion‘This is a SUPERB new occasion.’
b. *C’ est une RECENTE SUPERBE voiture rouge italienne.This is a recent-FOC superb-FOC car red Italian‘This is RECENT SUPERB red Italian car.’
French and other Romance languages also have a low FocP (see Samek-Lodovici [38]),situated near NP, as illustrated by the following example (see Sections 2 and 3.2).
5 A similar analysis can be adopted for subjunctive clauses in languages like Greek and Romanian where a subjunctivemarker co-occurs with the higher complementizer. The latter merges in Force, while the former merges in Fin which isa mood-related head (see Soare [34] for Romanian).

Languages 2017, 2, 18 5 of 24
10. (C’est) une voiture rouge italienne SUPERBE.(This is) a car red Italian superb‘(This) is a SUPERB red Italian car.’
The specifier of TopP in (8) is a position for topicalized arguments and adjuncts, while the specifierof ModifP (Modifier Projection) is a position for fronted non-focalized adjectives. The order amongTopP, FocP and ModifP is difficult to establish given that the left periphery of the noun phrase is moreconstrained in terms of constituent fronting than that of the clause. In other words, the informationstructure of the noun phrase is poorer (less developed) than that of the clause. This restriction isarguably due to the fact that DPs are usually embedded within CP (except in elliptic constructions, e.g.,responses to questions or non-verbal expressions, e.g., interjections) and hence have indirect access todiscourse contexts.
The paradigm below exemplifies movement of arguments to TopP or FocP in Serbo-Croatian,Hungarian, Russian and Greek. In (11a/a’) the Dative complement is topicalized in front of theadjective of quality as the result of movement of the DP to the specifier of a left-peripheral TopP.This is also the case of the Genitive DP complement in (11b/b’). The Hungarian example in (11c’)is an instance of movement of the noun’s Dative complement to a topic position in the DP-layer.The Russian example in (11d’) as compared to (11d) shows that the Genitive complement is fronted fortopicalization or focalization effects. In (11e/e’) one can observe that the Genitive Possessor DP canmove to the specifier of a left-peripheral focus projection (see originally Horroks and Stravou [39]).Finally, the Romanian example in (11f’) illustrates movement of the noun’s Genitive complement(see (11f)) to a topic fronted position as a marked option.
11. a. [DP [QualP velikodušana [NP pomoc] [PP u novcu] [DP siromasnima] ]]]generous gift of money the-poor-DAT
a′. [DP [TopP [DP siromasnima] [QualP velikodušana [NP pomoc] [PP u novcu]the-poor-DAT generous gift of money
[DP siromasnima] ]]]to-the-poor
‘a generous gift of money to the poor.’ Serbo-Croatian
b. [DP [QualP lepa [NP cerka] [DP+Gen Slavnoy matematicara]]]nice girl famous mathematician-GEN
‘the famous mathematician’s nice girl.’ Serbo-Croatian
b′. [DP [TopP [DP+Gen slavnoy matematicara] [QualP lepa [NP cerka]]]]famous mathematician-GEN nice girl
c. [DP egy [QualP nagylelkü [NP pénz adomány ] [DP a szegenyeknek] [PP a bank reszerol]]]a generous moneygift the-poor-DAT the bank by
c′. [DP egy [TopP [DP a szegényeknek] [TopP [PP a bank részeéöl] [QualP nagylelküa the-poor-DAT the bank by generous
[NP pénz adomány] [DP a szegenyeknek] [PP a bank reszerol]]]]]money gift the-poor-DAT the bank by
‘a generous gift of money to the poor by the bank.’ Hungarian
d. [DP [[QualP velikolepnaya [NP mašina]] [FPGen [DP moego papi] ]]beautiful car my father-GEN
‘my father’s beautiful car.’ Russian
d′. [DP [TopP/FocP [DP moego papi +Gen] [[QualP velikolepnaya [NP mashina]] [FPpp smy father-GEN beautiful car with
otkryvaiusheisia kryshjei]]]]open roof‘my father’s beautiful car with an open roof.’
e. [DP to [AdjP oreo] [DP to [NP vivlio] [DP+Gen tis Marias]]]the nice the book the Maria-GEN
‘Maria’s nice book.’ Greek [40]

Languages 2017, 2, 18 6 of 24
e′. [DP [FocP [DP tis Marias] [DP to [AdjP oreo] [DP to [NP vivlio ]]]]]the Maria-GEN the nice the book
f. [DP [AdjP frumoasa] [NP masină] [DP+Gen a lui Ion]]beautiful car POSS the Ion-GEN
‘Ion’s beautiful car.’ Romanian
f′. [DP [TopP [DP+Gen a lui Ion] [AdjP frumoasă] [NP masină]]] (marked option)POSS the Ion-GEN beautiful car
‘Ion’s beautiful car.’ Romanian
Note that movement (fronting) of arguments can target a Case position in the left periphery, as inthe Saxon Genitive constructions in (12a,b) and the possessive construction in Hungarian in (12d) inwhich a Dative Case (vs. a Nominative Case in (12c)) is assigned to the possessor.
12. a. [DP [GenP [DP John]’s [DP [NP [[DP John] book] ]]] English
b. [DP [GenP [DP Johanns] [DP [NP [DP Johann] Buch] ]]]6 German
c. [DP (a) [NomP [DP Mari] [QualP szép [NP kalap-ja]]] Hungarian [41]the Mari-NOM nice hat
‘Mari’s nice hat.’
d. [DP [DatP [DP Mari-nak] [DP a [QualP szép [NP kalap-ja ]]]]]Mari-DAT the nice hat
‘Mari’s nice hat.’
As already mentioned, adjective fronting can be triggered by focalization. This is the case notonly in French (example (9a) and (13a)), but also in Greek (example (13b)). English also displaysmovement of adjectives to a left-peripheral focus position (example (13c,d)) and to a quantifier position(example (13e,f)).
13. a. [DP une [FocP SPLENDIDE [AgrP voiture [QualP splendide [NP voiture ]]]]]a splendid-FOC car
‘a SPLENDID car.’ French
b. [DP to [FocP KOKKINO [DP to [NP forema] [QualP kokkino [NP forema ]]]]]the RED the dress
‘the RED dress.’ Greek
c. These are BLACK small dogs, not white ones.
d. [DP [FocP How clever [DP a [QualP how clever [NP boy]]]]] he is !
e. This is [QP too tough [DP a [QualP too tough [question]]]]
f. [QP Such [DP a [question]]] English
6 Note that Saxon Genitive is restricted to [+animate] nouns in German, as compared to English.
ii. meines Vaters Wagen /my father’s cariii. meiner Mutter Wagen/my mother’s cariv. *der Stadt Zerstörung/okthe city’s destruction

Languages 2017, 2, 18 7 of 24
As in Romance, adjectives can be fronted in Serbo-Croatian for prominence effects (see Guisti [5]for data and discussion). The adjective lepa ‘beautiful’ in (14) moves past the possessive elementmoya ‘my’.7
14. [DP [TopP/Modif lepa [PossP moja [QualP lepa [NP devojcica ]]]]]beautiful my girl
‘my beautiful girl.’ Serbo-Croatian
In addition, there are other types of movement to the left periphery. They concern demonstratives,possessives (Genitive DPs, pronouns) and universal quantifiers in Italian, Spanish, Romanian andGreek. In the same vein as Brugè [42,43] we propose that demonstratives occur in two differentpositions. They externally merge in the high portion of the midfield (unlike Brugè for whom it is in thelow portion near NP) and possibly move to DPdeixis, a noun phrase initial position. This is representedin (15).8
Languages 2017, 2, 18 7 of 24
13. a. [DP une [FocP SPLENDIDE [AgrP voiture [QualP splendide [NP voiture ]]]]]
a splendid-FOC car
‘a SPLENDID car.’ French
b. [DP to [FocP KOKKINO [DP to [NP forema] [QualP kokkino [NP forema ]]]]]
the RED the dress
‘the RED dress.’ Greek
c. These are BLACK small dogs, not white ones.
d. [DP [FocP How clever [DP a [QualP how clever [NP boy]]]]] he is !
e. This is [QP too tough [DP a [QualP too tough [question]]]]
f. [QP Such [DP a [question]]] English
As in Romance, adjectives can be fronted in Serbo-Croatian for prominence effects (see Guisti [5]
for data and discussion). The adjective lepa ‘beautiful’ in (14) moves past the possessive element
moya ‘my’.7
14. [DP [TopP/Modif lepa [PossP moja [QualP lepa [NP devojčica ]]]]]
beautiful my girl
‘my beautiful girl.’ Serbo-Croatian
In addition, there are other types of movement to the left periphery. They concern
demonstratives, possessives (Genitive DPs, pronouns) and universal quantifiers in Italian, Spanish,
Romanian and Greek. In the same vein as Brugè [42,43] we propose that demonstratives occur in two
different positions. They externally merge in the high portion of the midfield (unlike Brugè for whom
it is in the low portion near NP) and possibly move to DPdeixis, a noun phrase initial position. This is
represented in (15).8
15. [DPdeixis …[DPdef/indef …[DemP DEM [QuantP-adj [QualP-adj …[NP ]]]]]
7 As regards DP/PP-adjuncts, their fronting to the left periphery is very restricted in the languages studied
in this paper. A case in point is Russian where a few PP-adjuncts can move to the DP-domain as a
contrastive (focus) effect. This is illustrated in (v) and (vi) below.
v. a. Ja vsegda chitala interesnye knigi v tverdom pereplete.
I always read interesting books with hard cover
b. A ja vsegda chitala v mjagkom pereplete interesnye knigi.
And
I always read with soft cover interesting books
vi. a. J kupila krasnoe platje s korotkimi rukavami.
I bought red dress with short sleeves
b. A ja kupila s dlinnymi rukavami krasnoe platje.
And I bought with long sleeves red dress
8 See also Julien [44] for a similar proposition, but also Bernstein [12] who argues against Brugè’s analysis.
The pairs of nominal constructions in (16) show that the demonstrative can occur in two positionsand, when it is initial, it is in complementary distribution with the definite article.
16. a. [DP el [AgrP-NP libro viejo [DemP este [de sintaxis]]]]the book old this of syntax
‘this old book of syntax.’ Spanish
7 As regards DP/PP-adjuncts, their fronting to the left periphery is very restricted in the languages studied in this paper.A case in point is Russian where a few PP-adjuncts can move to the DP-domain as a contrastive (focus) effect. This isillustrated in (v) and (vi) below.
v. a. Ja vsegda chitala interesnye knigi v tverdom pereplete.I always read interesting books with hard cover
b. A ja vsegda chitala v mjagkom pereplete interesnye knigi.And I always read with soft cover interesting books
vi. a. J kupila krasnoe platje s korotkimi rukavami.I bought red dress with short sleeves
b. A ja kupila s dlinnymi rukavami krasnoe platje.And I bought with long sleeves red dress
8 See also Julien [44] for a similar proposition, but also Bernstein [12] who argues against Brugè’s analysis.

Languages 2017, 2, 18 8 of 24
a′. [DPdeixis este [AgrP-NP libro [QualP viejo [de sintaxis]]]]
b. [DP fete [D le] [DemP acestea [QualP frumoase ]]]girls -the these beautiful
‘these beautiful girls.’ Romanian
b′. [DPdeixis aceste [AgrP-NP fete [QualP frumoase ]]]
c. [QP Sve [AgrP-NP lepe zemlje [DemP ove ]]]all beautiful countries these
‘all these beautiful countries.’ Serbo-Croatian
c′. [QP Sve [DPdeixis ove [AgrP-NP lepe zemlje]]]all these beautiful countries
The structures in (17a) and (17b) show that (i) the demonstrative can move from DemP to DPdeixis;(ii) (case 1) the NP alone can move to an agreement position (AgrPNP related to D), which correspondsto example (16b); (iii) (case 2) the QualP including the prenominal adjective and the noun phraseraises to AgrPNP-D (example (16c)) and finally (iv) (case 3) the projection AgrPNP-Adj whose specifieris realized by the raised NP and which includes the adjective-related projection moves to AgrPNP-D
(example 16a).
Languages 2017, 2, 18 8 of 24
(NP) QualP
…NP
DPdeixis Q
…DemP
Dem
AgrPNP-Adj
AgrPNP-D
The pairs of nominal constructions in (16) show that the demonstrative can occur in two
positions and, when it is initial, it is in complementary distribution with the definite article.
16. a. [DP el [AgrP-NP libro viejo [DemP este [de sintaxis]]]]
the book old this of syntax
‘this old book of syntax.’ Spanish
a′. [DPdeixis este [AgrP-NP libro [QualP viejo [de sintaxis]]]]
b. [DP fete [D le] [DemP acestea [QualP frumoase ]]]
girls -the these beautiful
‘these beautiful girls.’ Romanian
b′. [DPdeixis aceste [AgrP-NP fete [QualP frumoase ]]]
c. [QP Sve [AgrP-NP lepe zemlje [DemP ove ]]]
all beautiful countries these
‘all these beautiful countries.’ Serbo-Croatian
c′. [QP Sve [DPdeixis ove [AgrP-NP lepe zemlje]]]
all these beautiful countries
The structures in (17a) and (17b) show that (i) the demonstrative can move from DemP to DPdeixis;
(ii) (case 1) the NP alone can move to an agreement position (AgrPNP related to D), which corresponds
to example (16b); (iii) (case 2) the QualP including the prenominal adjective and the noun phrase
raises to AgrPNP-D (example (16c)) and finally (iv) (case 3) the projection AgrPNP-Adj whose specifier is
realized by the raised NP and which includes the adjective-related projection moves to AgrPNP-D
(example 16a).
17. a. [QP Q [DPdeixis Dem [AgrP-NP ...[DemP Dem [AgrP NP [QualP ADJ [NP N]]]]]]]
b.
Dem
3 2 1 (example 16b)
(example 16a) (example 16c)
QP
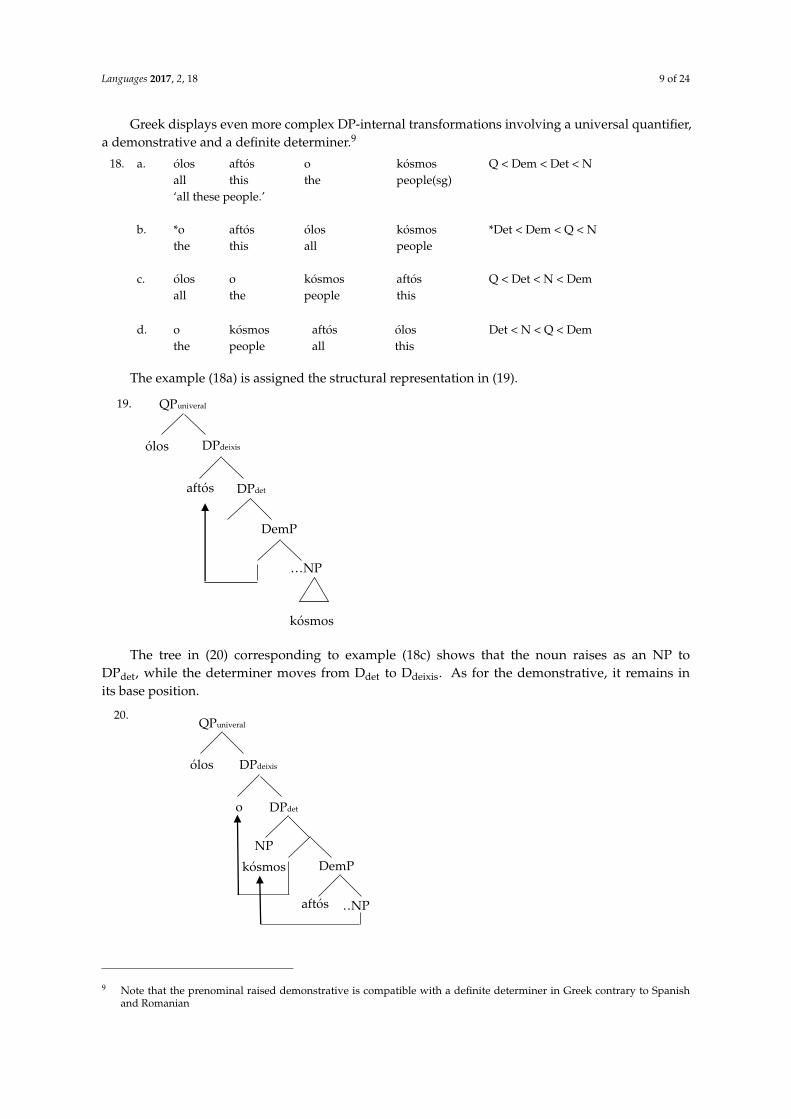
Languages 2017, 2, 18 9 of 24
Greek displays even more complex DP-internal transformations involving a universal quantifier,a demonstrative and a definite determiner.9
18. a. ólos aftós o kósmos Q < Dem < Det < Nall this the people(sg)‘all these people.’
b. *o aftós ólos kósmos *Det < Dem < Q < Nthe this all people
c. ólos o kósmos aftós Q < Det < N < Demall the people this
d. o kósmos aftós ólos Det < N < Q < Demthe people all this
The example (18a) is assigned the structural representation in (19).
Languages 2017, 2, 18 9 of 24
ólos DPdeixis
o DPdet
ólos DPdeixis
aftós DPdet
DemP
…NP
kósmos
Greek displays even more complex DP-internal transformations involving a universal
quantifier, a demonstrative and a definite determiner.9
18. a. ólos aftós o kósmos Q < Dem < Det < N
all this the people(sg)
‘all these people.’
b. *o aftós ólos kósmos *Det < Dem < Q < N
the this all people
c. ólos o kósmos aftós Q < Det < N < Dem
all the people this
d. o kósmos aftós ólos Det < N < Q < Dem
the people all this
The example (18a) is assigned the structural representation in (19).
19.
The tree in (20) corresponding to example (18c) shows that the noun raises as an NP to DPdet, while
the determiner moves from Ddet to Ddeixis. As for the demonstrative, it remains in its base position.
20.
9 Note that the prenominal raised demonstrative is compatible with a definite determiner in Greek contrary
to Spanish and Romanian
QPuniveral
QPuniveral
DemP
…NP
NP
kósmos
aftós
The tree in (20) corresponding to example (18c) shows that the noun raises as an NP toDPdet, while the determiner moves from Ddet to Ddeixis. As for the demonstrative, it remains inits base position.
Languages 2017, 2, 18 9 of 24
ólos DPdeixis
o DPdet
ólos DPdeixis
aftós DPdet
DemP
…NP
kósmos
Greek displays even more complex DP-internal transformations involving a universal
quantifier, a demonstrative and a definite determiner.9
18. a. ólos aftós o kósmos Q < Dem < Det < N
all this the people(sg)
‘all these people.’
b. *o aftós ólos kósmos *Det < Dem < Q < N
the this all people
c. ólos o kósmos aftós Q < Det < N < Dem
all the people this
d. o kósmos aftós ólos Det < N < Q < Dem
the people all this
The example (18a) is assigned the structural representation in (19).
19.
The tree in (20) corresponding to example (18c) shows that the noun raises as an NP to DPdet, while
the determiner moves from Ddet to Ddeixis. As for the demonstrative, it remains in its base position.
20.
9 Note that the prenominal raised demonstrative is compatible with a definite determiner in Greek contrary
to Spanish and Romanian
QPuniveral
QPuniveral
DemP
…NP
NP
kósmos
aftós
9 Note that the prenominal raised demonstrative is compatible with a definite determiner in Greek contrary to Spanishand Romanian

Languages 2017, 2, 18 10 of 24
The structure in (21) holds for the order in (18d). On the basis of the order in (20) there isfurther pied-piping movement of DPdeixis to the specifier of QuantP, hence the final position of theuniversal quantifier.
Languages 2017, 2, 18 10 of 24
ólos DPdeixis
o DPdet
The structure in (21) holds for the order in (18d). On the basis of the order in (20) there is further pied-
piping movement of DPdeixis to the specifier of QuantP, hence the final position of the universal quantifier.
21.
One should notice that the reverse prenominal order cannot be derived from any types of
movement on the basis of the base order in (20). This constraint is reminiscent of Cinque’s left–right
asymmetry (see Section 3).
As in the case of double/multiple complementizers, determiner reduplication provides further
evidence in favor of the split-DP structure. Consider first the case of French superlatives, as in (22).
We can observe that there is definite determiner doubling.
22. [[DP1 la [SuperlP plus belle [DP2 la fille [blonde]]]]]
the most beautiful the girl blond
⇒ [[DP2 la fille [blonde] [DP1 la [SuperlP plus belle [DP t ]]]]
the girl blond the most beautiful
‘the most beautiful blond girl.’
Following recent proposals, the projections labeled SuperlP in (22) contains Corver’s DegP [45]
and can be identified as Alexiadou’s PredP [46], Kayne’s Small Clause [47], or Cinque’s Reduced
Relative Clause [37,48]. Given the derivation in (22) the lower DP2 moves to the specifier of DP1 past
the superlative projection. Each D is realized lexically as a definite determiner.10
Romanian also displays determiner doubling, but with two different determiners, namely –ul
and ce(l) in (23a–c).
23. 23.
a. mărul cel roşu
apple-the (the) red
‘the red apple.’
b. studenţii cei interesaţi (de lingvistică)
students-the
(the) interested (in linguistics)
‘the students interested in linguistics.’
c. casa cea de piatră
house-the (the) of stone
‘the house of stone.’
10 There are alternative analyses in terms of N(P)-ellipsis or postnominal predication (see Alexiadou [46] (pp. 68ff)
and references cited therein).
QuantP
DemP
…NP
NP
kósmos
aftós
One should notice that the reverse prenominal order cannot be derived from any types ofmovement on the basis of the base order in (20). This constraint is reminiscent of Cinque’s left–rightasymmetry (see Section 3).
As in the case of double/multiple complementizers, determiner reduplication provides furtherevidence in favor of the split-DP structure. Consider first the case of French superlatives, as in (22).We can observe that there is definite determiner doubling.
22. [[DP1 la [SuperlP plus belle [DP2 la fille [blonde]]]]]the most beautiful the girl blond
⇒ [[DP2 la fille [blonde] [DP1 la [SuperlP plus belle [DP t]]]]the girl blond the most beautiful
‘the most beautiful blond girl.’
Following recent proposals, the projections labeled SuperlP in (22) contains Corver’s DegP [45]and can be identified as Alexiadou’s PredP [46], Kayne’s Small Clause [47], or Cinque’s ReducedRelative Clause [37,48]. Given the derivation in (22) the lower DP2 moves to the specifier of DP1 pastthe superlative projection. Each D is realized lexically as a definite determiner.10
Romanian also displays determiner doubling, but with two different determiners, namely –ul andce(l) in (23a–c).
23. a. mărul cel rosuapple-the (the) red‘the red apple.’
b. studentii cei interesati (de lingvistică)students-the (the) interested (in linguistics)‘the students interested in linguistics.’
c. casa cea de piatrăhouse-the (the) of stone‘the house of stone.’
10 There are alternative analyses in terms of N(P)-ellipsis or postnominal predication (see Alexiadou [46] (pp. 68ff) andreferences cited therein).

Languages 2017, 2, 18 11 of 24
The determiner-like element ce(l) can be prenominal in front of quantifier-like prenominal elements(as a last resort strategy according to Cornilescu [49]), as in (24).
24. cele două legithe two laws
The postnominal ce(l) is associated with predicative elements, hence it is involved in a predicativestructure (Cornilescu [49] and Cinque [48]; see also Marchis and Alexiadou [50] for an analysisin terms of pseudo-polydefiniteness, Cornilescu and Nicolae [51], Sleeman and Perridon [52],and Sleeman et al. [53] for discussion and references therein).
In Scandinavian (e.g., Norwegian, Swedish) a definite determiner (article) and a definite suffixco-occur only when a prenominal adjective is used.
25. den *(nya) bok-en Swedishthe new book-the‘the new book.’
We assume that den stands in Ddeixis and –en in Ddetermination. The noun plus the adjective(extended NP-movement) moves to the specifier of Ddetermination. The question arises as to whydeterminer doubling is restricted to the context of prenominal adjective occurrence. The presence ofadjectives is a trigger for multiple determiner occurrences in languages like Greek, Romanian andScandinavian. However, Alexiadou shows that the multiple determiner is not a unified phenomenoncrosslinguistically, and this was also the case of the multiple complementizer [46].
Hebrew also displays some sort of determiner reduplication (see Alexiadou [46]), as the examplein (26) shows with the use of the prefix ha-.
26. ha-rabanim ha-fanatim ha-‘elothe-rabbis the-fanatic the-these‘these fanatic rabbis.’
Shlonsky argues that the case in (26) differs from determiner reduplication/spreading in that thereduplicated morpheme ha- is analyzed as an agreement marker rather than a true determiner [54].
Determiner spreading in Greek is a much debated topic in Generative Grammar, especially withinthe framework of the DP-hypothesis (Alexiadou [46], Alexiadou and Wilder [55], Panagiotidis andMarinis [56]). The split-DP analysis sheds new light on this phenomenon. Consider first some facts.Determiner spreading is only possible with the definite determiner, as shown by the contrast between(27) and (28).
27. a. to kókkino (to) vivlióthe red the book‘the red book.’
b. to vivlió (to) kókkinothe Book the red
28. a. ená kókkino (*ená) vivlió (cf. dialects of German)a Red a book‘a red book.’
b. ená vivlió (*ená) kókkinoa book a red
In addition, determiner spreading in (27), which is not obligatory, is possible with prenominaland postnominal predicative adjectives.11 It is also interesting to point out that determiner spreading
11 Determiner Spreading is not possible with non-predicative adjectives such as alleged, Italian and with adjectives selectinga complement like proud of his son N (see Alexiadou and Wilder [54], Cinque [37,48], Laenzlinger [24] and Alexiadou [46]).

Languages 2017, 2, 18 12 of 24
can be total or partial. This is illustrated by the examples in (29) taken from Alexiadou and Wilder [55]and Leu [57].
29. a. to megálo to kókkino to vivlió (total)the big the red the book
b. to megálo to vivlió to kókkino (total)the big the book the red
c. to megálo to kókkino vivlióthe big the red book (partial)‘the big red book.’
d. to megálo kókkino vivlió (partial)the big red book
However, not all partial combinations are permitted given the ungrammaticality of (30).
30. a. *to megálo kókkino to vivlióthe big red the book
b. *to vivlió to megálo kókkinothe book the big red
c. *to vivlió megálo to kókkinothe book big the red
d. *to megálo to vivlió kókkinothe big the book red
On the basis of these facts we propose that determiner spreading is a phenomenon of the leftperiphery involving Ddet-to-Ddeix movement (see (31)) through the head of Modifier Projections whosespecifier is occupied by the prenominal fronted adjective (see (32)). Such movement may leave possiblespelt-out copies of the raised determiner and the chain of copies cannot be broken, as shown by theungrammaticality of (30) (see Larson and Yamakido [58,59] for a similar analysis in terms of spell outof D-copies).12
Languages 2017, 2, 18 12 of 24
In addition, determiner spreading in (27), which is not obligatory, is possible with prenominal
and postnominal predicative adjectives.11 It is also interesting to point out that determiner spreading
can be total or partial. This is illustrated by the examples in (29) taken from Alexiadou and Wilder [55]
and Leu [57].
29. a. to megálo to kókkino to vivlió (total)
the big the red the book
b. to megálo to vivlió to kókkino (total)
the big the book the red
c. to megálo to kókkino vivlió
the big the red book (partial)
‘the big red book.’
d. to megálo kókkino vivlió (partial)
the big red book
However, not all partial combinations are permitted given the ungrammaticality of (30).
30. a. *to megálo kókkino to vivlió
the big red the book
b. *to vivlió to megálo kókkino
the book the big red
c. *to vivlió megálo to kókkino
the book big the red
d. *to megálo to vivlió kókkino
the big the book red
On the basis of these facts we propose that determiner spreading is a phenomenon of the left
periphery involving Ddet-to-Ddeix movement (see (31)) through the head of Modifier Projections whose
specifier is occupied by the prenominal fronted adjective (see (32)). Such movement may leave
possible spelt-out copies of the raised determiner and the chain of copies cannot be broken, as shown
by the ungrammaticality of (30) (see Larson and Yamakido [58,59] for a similar analysis in terms of
spell out of D-copies).12
31. [DP1 [QuantP [ModifP [ModifP [DP2 NP [D to ] ] ] ] ] ]
32. a. [DP1 to [ModifP megálo to [ModifP kókkino to [DP2 vivlió [D to ] ] ] ] ] ]
b. [DP1 to [ModifP megálo (to) [ModifP kókkino (to) [DP2 vivlió [D to ] ] ] ] ] ]
11 Determiner Spreading is not possible with non-predicative adjectives such as alleged, Italian and with
adjectives selecting a complement like proud of his son N (see Alexiadou and Wilder [54], Cinque [37,48],
Laenzlinger [24] and Alexiadou [46]). 12 There are alternative proposals in the literature, especially in terms of Reduced Relative Clause or Small
Clause (Alexiadou and Wilder [55] on the basis of Kayne [47], Cinque [37, 48]; see Alexiadou [46] for a review).
32. a. [DP1 to [ModifP megálo to [ModifP kókkino to [DP2 vivlió [D to ] ] ] ] ] ]
b. [DP1 to [ModifP megálo (to) [ModifP kókkino (to) [DP2 vivlió [D to ] ] ] ] ] ]
The analysis of the example (29b) is quite complex: the adjective of size moves to the left-peripheralModifP, the noun to a topic position within DP and the adjective of color to a focus or Modif position.This is represented in (33).
33. [DP1 to [ModifP megálo to [TopP vivlió to [FocP/ModifP kókkino ] [DP2 [D to ]]]]
A question arises from the impossibility of determiner spreading with indefinites in Greekcontrary to some German/Swiss dialects and Northern Swedish (e.g., ein ganz ein guete Wi ‘a totally
12 There are alternative proposals in the literature, especially in terms of Reduced Relative Clause or Small Clause (Alexiadouand Wilder [55] on the basis of Kayne [47], Cinque [37,48]; see Alexiadou [46] for a review).

Languages 2017, 2, 18 13 of 24
a good wine’, en store n kar ‘a big a man’, examples drawn from Alexiadou [46] (pp. 96–97). Again,this contrast shows that “multiple determiner” is not a uniform phenomenon crosslinguistically.13
So far, we have observed some structural and derivational parallelism in terms of split-C/split-D,Fin-to-Force/Ddet-to-Ddeix-movement and complementizer/determiner doubling and spreading.However, there are differences in the occurrence and inner configuration of discourse-relatedprojections between the CP and DP layer, and the CP-domain is richer than the DP-domain in terms ofinformation structure.
2.3. vP/ nP and Their Left Periphery
vP and nP are the thematic domain of the clause and of the noun phrase, respectively. Argumentsexternally merge in this domain according to the following Universal Thematic Hierarchy14 (Grimshawfor the clause [61], Jackendoff [62], Baker [63]) and Universal Thematic Assignment hypothesis(Baker [64]).
34. (POSS >) AGENT > (EXPER) > BENEF > THEME/PATIENT > LOCATION
Right above the thematic domain, there are focus and topic projections at the left-border of vP(Belletti [65,66], Lahousse et al. [67]) and possibly nP (Laenzlinger [24], Samek-Lodovici [38]). As far asthe clause is concerned, the right periphery (Nachfeld) looks like (35).
35. . . . [TopP Top15 [FocP Foc [vP Agent [VP Beneficiary V Theme/Patient]]]]
As for the noun, deverbal and agent-related nouns (destruction, gift, picture, painting, etc.) areparticularly relevant to the hierarchy in (34) (e.g., the bankAgent’s gift of moneyTheme to the poorBeneficiary).As proposed by Laenzlinger [10,11], the left periphery of NP is also the locus of a focus position anda predicative projection. In (36a) the right-hand focalized adjective occurs in the low focus position,and the predicative participial adjective in (36b) occupies the specifier of a low predicative projection(or reduced RC). The noun and the other adjectives/adjuncts are situated at Spell-Out in positionshigher than FocP/PredP and the NP-domain (see Section 3.2 for details).
36. a. une voiture italienne rouge [FocP (vraiment resplendissante) /SPLENDIDE [NP ]]a car Italian red (really resplendent) /SPENDID‘a SPLENDID red Italian car (really resplendent).’
b. une voiture rouge De sport [PredP toute équipée [NP ]]a car red of sport all equipped‘a red sport car all equipped.’
As for arguments, they leave the domain where they externally merge to reach dedicated positionswhere their case- and ϕ-features as well as their information structural features can be valued. This isexpressed in the full nP/vP evacuation principle in (37).16
13 As suggested by an anonymous reviewer, this difference may be due to the fact that indefinites are quantifiers, not articles,in Greek (see Laenzlinger [24] (p. 178) for a similar proposal).
14 See the references cited in Alexiadou et al. [60] (pp. 503ff) for the thematic hierarchy within the noun phrase. This analysisin terms of NP-internal thematic hierarchy has been challenged by Grimshaw [61] among others.
15 TopP is higher than FocP, as shown by the following contrast:
vii. Chi ha letto questo libro? Ha [TopP letto questo libro [FocPGianni [vP letto ]questo libro]]]Who (has) read this book (Has) read this book Giannivs. *Ha letto [FocP Gianni [TopP questo libro [vP letto questo libro]]] [64]
16 This principle is based on the fact that nP and vP are phases (see Svenonius [68], Cornilescu and Nicolae [51]) and theirarguments must move to an edge position to be accessible for Agree (to be probed). This position is externally to nP and vPgiven Kayne’s Linear Corresponding Axiom [47] (nP and vP cannot have more than one specifier).

Languages 2017, 2, 18 14 of 24
37. Full nP/vP evacutation principle: “All arguments must leave the vP (and nP) domain in order to havetheir A-features (i.e., Case and ϕ) and I-features (i.e., informational features such as top, foc)checked/matched/assigned/valued in the overt syntax.” [69] (p. 19); [10]
Laenzlinger [24] proposes that the information structural features are parasitic onCase/Agreement features in the Mittelfeld and are realized on dedicated heads/projections in theleft and right periphery (Rizzi [25,29], Belletti [65,66]). Within the same framework it is argued thatverb raising is realized as (possibly extended) vP-movement and noun raising as (possibly extended)nP-movement. Since the arguments have evacuated the vP/nP domain, such movement is an instanceof remnant movement. Recall that head movement is very local and limited to V to v, N to n, Fin toForce, and Ddet to Ddeix.
3. The Midfield: The Order Among Complements and Adjuncts
In Section 1 we have introduced Cinque’s [28] left–right asymmetry schematized as (38).
38. a. okAB(C) H◦
b. *(C)BA H◦
c. okH◦ AB(C)
d. ok H◦ (C)BA
We will test the validity of this asymmetry for portions of the Midfield of the clause, where thehead H◦ in (38) corresponds to the verb (V), and, similarly, for portions of the noun phrase, where H◦
corresponds to the noun (N).On the basis of (38), Cinque accounts for Greenberg’s Universal 20 involving the respective
orderbof demonstratives, numerals and adjectives in pre- and postnominal position [70]. Given thebase order in (39) realized in English (no NP-movement), it is possible to have the same linearpostnominal order in (40) realized in Kîîtharaka, a Bantu language. This order results from successiveNP-movement past the demonstrative, the numeral and the adjective. In Gungbe (example (41) fromAboh [27]) the postnominal order of Dem, Num and Adj is the mirror-image one of the prenominalorder in English (39). This order is obtained after successive pied-piping roll-up movement (Cinque [70](p. 324)). Leaving aside some other postnominal possible orders, the prenominal sequence in (42) is notattested crosslinguistically. In fact, without NP-movement, there is no way to derive such a prenominalreverse order from the base order in (39).
39. Dem > Num > Adj > Nthese five nice cars
40. N > Dem > Num > Adj (NP-movement)i-kombe bi-bi bi-tano bi-tune8-cup 8-this 8-five 8-red‘these five red cups.’ Kîîtharaka, Bantu
41. N > Adj > Num > Dem
àgásá
Languages 2017, 2, 18 15 of 24
41. N > Adj > Num > Dem
àgásá ɖàxó àtɔ n éhè lɔ lέ
crabs big three DEM DET NB
‘these three big crabs.’ Gungbe
42. *Adj > Num > Dem > N
Another illustration of Cinque’s left–right asymmetry within the noun phrase is adjective
ordering in pre- and postnominal contexts. The sequence of adjectives in Germanic illustrated in (43)
for English is considered the basic one. The postnominal order of adjectives in (44) is linearly the
same as in the prenominal order in (43). This order is attested in Romance and Gaelic and results
from NP-movement past the adjectives. The examples of French (Romance) and Hebrew in (45),
which contain adjectives of different types, display the reverse order of postnominal adjectives as
compared to the basic prenominal order in (43). Such an order results from pied-piping roll-up
movement (extended NP-movement, see Laenzlinger [11], Shlonsky [54] for details). As in the case
of (42), the reverse order of prenominal adjectives with respect to the basic order in (43) is not possible
unless the first adjective is focalized (‘These are black small dogs, but not white ones’). In the absence
of NP-movement, this order cannot be derived. The case of adjective focalization results from
movement of the adjective to a left-peripheral focus position (see Section 2.2).
43. Adj1 > Adj2 > N Germanic
red American car
44. N > Adj1 > Adj2
a. un vase ovale chinois
a vase oval Chinese
‘an oval Chinese vase.’ Romance (French)
b. cupán mór cruinn
cup large green
‘a large green cup.’ Irish (see also Welsh)
45. N > Adj2 > Adj1
a. une voiture américaine rouge/splendide
a car American red/splendid French
‘a splendid red American car.’
b. para švecarit xuma
cow Swiss brown
‘a Swiss brown cow.’ Hebrew
46. *Adj2 > Adj1 > N unless Adj2 is focalized
(These are BLACK small dogs, not white ones.)17
Let us now consider whether the left–right asymmetry in (38) holds for the distribution of
complements and adjuncts around the verb within the clause (Section 3.1) and the noun within the
noun phrase (Section 3.2).
17 However, there are limits to such mirror-ordering of adjectives under focalization, as shown by the contrast
between (i) and (ii).
viii. beautiful small black dogs
ix. *BLACK beautiful small dogs/*BLACK small beautiful dogs.
àtón éhè
Languages 2017, 2, 18 15 of 24
41. N > Adj > Num > Dem
àgásá ɖàxó àtɔ n éhè lɔ lέ
crabs big three DEM DET NB
‘these three big crabs.’ Gungbe
42. *Adj > Num > Dem > N
Another illustration of Cinque’s left–right asymmetry within the noun phrase is adjective
ordering in pre- and postnominal contexts. The sequence of adjectives in Germanic illustrated in (43)
for English is considered the basic one. The postnominal order of adjectives in (44) is linearly the
same as in the prenominal order in (43). This order is attested in Romance and Gaelic and results
from NP-movement past the adjectives. The examples of French (Romance) and Hebrew in (45),
which contain adjectives of different types, display the reverse order of postnominal adjectives as
compared to the basic prenominal order in (43). Such an order results from pied-piping roll-up
movement (extended NP-movement, see Laenzlinger [11], Shlonsky [54] for details). As in the case
of (42), the reverse order of prenominal adjectives with respect to the basic order in (43) is not possible
unless the first adjective is focalized (‘These are black small dogs, but not white ones’). In the absence
of NP-movement, this order cannot be derived. The case of adjective focalization results from
movement of the adjective to a left-peripheral focus position (see Section 2.2).
43. Adj1 > Adj2 > N Germanic
red American car
44. N > Adj1 > Adj2
a. un vase ovale chinois
a vase oval Chinese
‘an oval Chinese vase.’ Romance (French)
b. cupán mór cruinn
cup large green
‘a large green cup.’ Irish (see also Welsh)
45. N > Adj2 > Adj1
a. une voiture américaine rouge/splendide
a car American red/splendid French
‘a splendid red American car.’
b. para švecarit xuma
cow Swiss brown
‘a Swiss brown cow.’ Hebrew
46. *Adj2 > Adj1 > N unless Adj2 is focalized
(These are BLACK small dogs, not white ones.)17
Let us now consider whether the left–right asymmetry in (38) holds for the distribution of
complements and adjuncts around the verb within the clause (Section 3.1) and the noun within the
noun phrase (Section 3.2).
17 However, there are limits to such mirror-ordering of adjectives under focalization, as shown by the contrast
between (i) and (ii).
viii. beautiful small black dogs
ix. *BLACK beautiful small dogs/*BLACK small beautiful dogs.
Languages 2017, 2, 18 15 of 24
41. N > Adj > Num > Dem
àgásá ɖàxó àtɔ n éhè lɔ lέ
crabs big three DEM DET NB
‘these three big crabs.’ Gungbe
42. *Adj > Num > Dem > N
Another illustration of Cinque’s left–right asymmetry within the noun phrase is adjective
ordering in pre- and postnominal contexts. The sequence of adjectives in Germanic illustrated in (43)
for English is considered the basic one. The postnominal order of adjectives in (44) is linearly the
same as in the prenominal order in (43). This order is attested in Romance and Gaelic and results
from NP-movement past the adjectives. The examples of French (Romance) and Hebrew in (45),
which contain adjectives of different types, display the reverse order of postnominal adjectives as
compared to the basic prenominal order in (43). Such an order results from pied-piping roll-up
movement (extended NP-movement, see Laenzlinger [11], Shlonsky [54] for details). As in the case
of (42), the reverse order of prenominal adjectives with respect to the basic order in (43) is not possible
unless the first adjective is focalized (‘These are black small dogs, but not white ones’). In the absence
of NP-movement, this order cannot be derived. The case of adjective focalization results from
movement of the adjective to a left-peripheral focus position (see Section 2.2).
43. Adj1 > Adj2 > N Germanic
red American car
44. N > Adj1 > Adj2
a. un vase ovale chinois
a vase oval Chinese
‘an oval Chinese vase.’ Romance (French)
b. cupán mór cruinn
cup large green
‘a large green cup.’ Irish (see also Welsh)
45. N > Adj2 > Adj1
a. une voiture américaine rouge/splendide
a car American red/splendid French
‘a splendid red American car.’
b. para švecarit xuma
cow Swiss brown
‘a Swiss brown cow.’ Hebrew
46. *Adj2 > Adj1 > N unless Adj2 is focalized
(These are BLACK small dogs, not white ones.)17
Let us now consider whether the left–right asymmetry in (38) holds for the distribution of
complements and adjuncts around the verb within the clause (Section 3.1) and the noun within the
noun phrase (Section 3.2).
17 However, there are limits to such mirror-ordering of adjectives under focalization, as shown by the contrast
between (i) and (ii).
viii. beautiful small black dogs
ix. *BLACK beautiful small dogs/*BLACK small beautiful dogs.
crabs big three DEM DET NB
‘these three big crabs.’ Gungbe
42. *Adj > Num > Dem > N
Another illustration of Cinque’s left–right asymmetry within the noun phrase is adjective orderingin pre- and postnominal contexts. The sequence of adjectives in Germanic illustrated in (43) for Englishis considered the basic one. The postnominal order of adjectives in (44) is linearly the same as in the

Languages 2017, 2, 18 15 of 24
prenominal order in (43). This order is attested in Romance and Gaelic and results from NP-movementpast the adjectives. The examples of French (Romance) and Hebrew in (45), which contain adjectives ofdifferent types, display the reverse order of postnominal adjectives as compared to the basic prenominalorder in (43). Such an order results from pied-piping roll-up movement (extended NP-movement,see Laenzlinger [11], Shlonsky [54] for details). As in the case of (42), the reverse order of prenominaladjectives with respect to the basic order in (43) is not possible unless the first adjective is focalized(‘These are black small dogs, but not white ones’). In the absence of NP-movement, this order cannot bederived. The case of adjective focalization results from movement of the adjective to a left-peripheralfocus position (see Section 2.2).
43. Adj1 > Adj2 > N Germanicred American car
44. N > Adj1 > Adj2a. un vase ovale chinois
a vase oval Chinese‘an oval Chinese vase.’ Romance (French)
b. cupán mór cruinncup large green‘a large green cup.’ Irish (see also Welsh)
45. N > Adj2 > Adj1a. une voiture américaine rouge/splendide
a car American red/splendid French‘a splendid red American car.’
b. para švecarit xumacow Swiss brown‘a Swiss brown cow.’ Hebrew
46. *Adj2 > Adj1 > N unless Adj2 is focalized(These are BLACK small dogs, not white ones.)17
Let us now consider whether the left–right asymmetry in (38) holds for the distribution ofcomplements and adjuncts around the verb within the clause (Section 3.1) and the noun within thenoun phrase (Section 3.2).
3.1. The Clause
Cinque proposes the universal hierarchy of adverbs in (47) [22].
17 However, there are limits to such mirror-ordering of adjectives under focalization, as shown by the contrast between (i) and (ii).
viii. beautiful small black dogsix. *BLACK beautiful small dogs/*BLACK small beautiful dogs.

Languages 2017, 2, 18 16 of 24
47. [Frankly/Franchement Moodspeech act > [unfortunately/malheureusement Moodevaluative >[apparently/apparemment Moodevidential > [probably/probablement Modepistemic > [once/autrefois Tpast >[then/ensuite Tfuture> [maybe/peut-être Mod(ir)realisis > [necessarily/nécessairement Modnecessity > [possiblyModpossibility > [deliberately/intentionnellement Modvolitional > [inevitably/inévitablement Modobligation >[cleverly/intelligemment Modability/permission > [usually/habituellement Asphabitual > [again/de nouveauAsprepetitive > [often/souvent Aspfrequentative > [quickly/rapidement Aspcelerative> [already/déjà Tanterior >[no longer/plus Aspperfect > [still/encore Aspcontinuative > [always/toujours Aspperfect > [just/justeAspretrospective > [soon/bientôt Aspproximative > [briefly/brièvement Aspdurative > [typically/typiquementAspgeneric/progressive > [almost/presque Aspprospective > [completely/complètement AspSgCompletive(I) >[all/tout AspPlCompl > [well/bien Voice > [fast/vite Aspcelerative(II) > [completely/complètementAspSgCompletive(II) > [again/de nouveau Asprepetitive(II) > [often/souvent Aspfrequentative ]]]]]]]]]]]]]]]]]]]]]]]]]
Cinque explicitly points out that there should be DP/PP-related positions among (some classes)of adverbs for verb’s complements [22]. Along the same lines, Laenzlinger [24,71,72] argues ina crosslinguistic study that the verb and its arguments can float among adverbs depending on Case andInformation Structure conditions. For instance, in French the participial verb and its direct complementcan occur before or after a temporal adverb and a manner adverb. This is illustrated in (48).18
48. Jean a probablement fini dernièrement (fini) son travail soigneusement (fini) (son travail)Jean has probably achieved recently his work carefully
In addition, there is a hierarchy of Case- and P-related positions in the Mittelfeld forDP/PP-complements and DP/PP-adjuncts (Cinque [28], Kayne [73], and Krapova and Cinque [74]).Recall that all arguments left their thematic domain to reach dedicated position in the Mittelfeld. As foradjuncts, they externally merge in the midfield according to the hierarchy proposed by Krapova andCinque [74,75] and expressed in Cinque [23] as (49).
49. DP time > DP location > . . . > DP instrument > . . . > DP manner > . . .> DP agent > DP goal > DP theme > V (Cinque [23] (p. 10))
In order to know whether there is a hierarchy of Case and P-related positions in the midfield,we have to take into consideration Case-marking languages with V-final configurations like Germanor Japanese (Soare [34], Laenzlinger [24,71]). The German sentences in (50a–c), which display theneutral order of constituents, show that the manner PP-adjunct most naturally precedes the verb’scomplements and the Dative complement precedes the Accusative complement which gives rise to themidfield neutral preverbal order in (51) (see Laenzlinger [71], and Pittner [76]).
50. a. Hans hat aus Großzügigkeit seinem Bruder Geld geschickt.Hans has by generosity his-DAT brother money sent‘Hans sent money to his brother with much generosity’
b. Die Bank hat kürzlich aus Großzügigkeit den Armen Geld gegeben.The Bank has recently by generosity the-DAT poor money given‘The bank recently gave money to the poor with much generosity’
c. Hans hat mit viel Spaß seinem Bruder ein/dieses Geschenkgesendet.Hans has with much pleasure his-DAT brother a/this gift sent‘Hans sent a/this gift to his brother with much pleasure’ Laenzlinger [71]
51. [DP/PPadjunct < DPDat < DPAcc < V]
In V-initial contexts (SVO), where adjuncts and complements follow the verb, as in French andEnglish, the neutral order of constituents is the mirror-image of the order in (50/51) (see Cinque [77],
18 This also holds in other Romance languages (e.g., Italian) and more restrictively in English (as pointed out by an anonymousreviewer). See Laenzlinger [24] for a large comparative study of adverb intervention.

Languages 2017, 2, 18 17 of 24
Schweikert [78], Tescari Neto [79] for relevant discussion).19 This is illustrated in (52) and representedin (53).
52. a. La banque a récemment donné de l’argent aux pauvres avec une grande générosité.
b. The bank recently gave some money to the poor with great generosity.
53. [V < DPAcc < DPDat < PPadjunct]20
The reverse order in (52) is obtained after successive roll-up derivation giving rise to “snowballing”effects. This is represented in (54) in a simplified way. After the Acc- and Dat-arguments haveevacuated vP and reached their Case-related position, the verb raises cyclically, first as vP pastthe Acc-argument, then as the extended projection containing the verb and its Acc-object past theDat-object and finally as the extended projection containing the verb and two object arguments past thePP-adjunct position which merges in a position higher than the objects, hence the “snowballing” effect.
Languages 2017, 2, 18 17 of 24
DP/PPadjunct > DParg-dat > DParg-acc > VP V
In V-initial contexts (SVO), where adjuncts and complements follow the verb, as in French and English,
the neutral order of constituents is the mirror-image of the order in (50/51) (see Cinque [77], Schweikert [78],
Tescari Neto [79] for relevant discussion).19 This is illustrated in (52) and represented in (53).
52. a. La banque a récemment donné de l’argent aux pauvres avec une grande générosité.
b. The bank recently gave some money to the poor with great generosity.
53. [V < DPAcc < DPDat < PPadjunct]20
The reverse order in (52) is obtained after successive roll-up derivation giving rise to
“snowballing” effects. This is represented in (54) in a simplified way. After the Acc- and Dat-
arguments have evacuated vP and reached their Case-related position, the verb raises cyclically, first
as vP past the Acc-argument, then as the extended projection containing the verb and its Acc-object
past the Dat-object and finally as the extended projection containing the verb and two object
arguments past the PP-adjunct position which merges in a position higher than the objects, hence the
“snowballing” effect.
54.
As such, this is a (partial) illustration of Cinque’s [23, 28] left–right asymmetry in natural
language applied to the Mittelfeld’s neutral order (Adjunct OV vs. VO Adjunct).
To summarize, the possible types of movement that apply to the clausal internal structure are
given in (55).
55. Once the arguments evacuated from vP, the verb alone can undergo remnant (possibly extended)
vP-movement. As further steps, the verb and its extended projection can undergo pied-piping
19 This is similar for the noun phrase (Laenzlinger [24] and see also Section 3.2).
x. a. le récent don d’argent aux pauvres (par la banque) avec/d’une grande générosité
b. the recent gift of money to the poor (by the bank) with great generosity 20 In German V2 contexts, as in the SVO configuration in (ia-b), the reverse postverbal order is also possible,
although this word order is rather marked (Accusative preceding Dative and the PP-adjunct occurring in
sentence-final position).
xi. a. Hans schickte das Geld seinem Bruder aus Großzügigkeit.
Hans sent the money his-DAT brother by generosity
‘Hans sent the money to his brother with much generosity.’
b. Die Bank gab das Geld den Armen aus Großzügigkeit.
The bank gave the money the-DAT poor by generosity (more marked)
‘The bank gave money to the poor with much generosity.’
In addition, the order in (iia) is also marked. The less marked order is the one given in (iib), as in V-final clauses.
xii. a. Die Bank gab den Armen das Geld aus Großzügigkeit. (marked)
b. Die Bank gab aus Großzügigkeit den Armen das Geld. (less marked)
As such, this is a (partial) illustration of Cinque’s [23,28] left–right asymmetry in natural languageapplied to the Mittelfeld’s neutral order (Adjunct OV vs. VO Adjunct).
To summarize, the possible types of movement that apply to the clausal internal structure aregiven in (55).
55. Once the arguments evacuated from vP, the verb alone can undergo remnant (possibly extended)vP-movement. As further steps, the verb and its extended projection can undergo pied-piping movementof two types: whose-picture (Spec-head, i.e., [V + Adv]) or picture of whom (Head-Compl, i.e., [ Adv + V]).If pied-piping movement is successive, roll-up effects are obtained (snowballing).
19 This is similar for the noun phrase (Laenzlinger [24] and see also Section 3.2).
x. a. le récent don d’argent aux pauvres (par la banque) avec/d’une grande générosité
b. the recent gift of money to the poor (by the bank) with great generosity
20 In German V2 contexts, as in the SVO configuration in (ia-b), the reverse postverbal order is also possible, although thisword order is rather marked (Accusative preceding Dative and the PP-adjunct occurring in sentence-final position).
xi. a. Hans schickte das Geld seinem Bruder aus Großzügigkeit.Hans sent the money his-DAT brother by generosity‘Hans sent the money to his brother with much generosity.’
b. Die Bank gab das Geld den Armen aus Großzügigkeit.The bank gave the money the-DAT poor by generosity (more marked)‘The bank gave money to the poor with much generosity.’
In addition, the order in (iia) is also marked. The less marked order is the one given in (iib), as in V-final clauses.
xii. a. Die Bank gab den Armen das Geld aus Großzügigkeit. (marked)
b. Die Bank gab aus Großzügigkeit den Armen das Geld. (less marked)

Languages 2017, 2, 18 18 of 24
3.2. The Noun Phrase
As in the case of adverbs within the clause, there is a hierarchy of adjectives within the nounphrase. Following Cinque [4], Laenzlinger [10,11,24], and Scott [80], the simplified hierarchy canbe established in (56) for event-denoting nouns and (57) for object-denoting nouns Laenzlinger [11](p. 650).
56. Adjspeaker-oriented > Adjsubject-oriented > Adjmanner > Adjthematic‘the probable clumsy immediate American reaction to the offense’
57. Adjquantification > Adjquality > Adjsize > Adjshape >Adjcolor > Adjnationality‘numerous wonderful big American cars’‘various round black Egyptian masks’
Cinque provides a more fine-grained hierarchy with dual positions for direct/indirect adjectivalmodifiers [37] (see also Sproat and Shih [81,82], Larson [83]) and the possible position for the noun inGermanic and Romance. See (58) and Table 1.
58. a. English: AP in a reduced RC > direct modification AP > N > AP in a reduced RC
b. Italian: direct modification AP > N > direct modification AP > AP in a reduced RC
Table 1. APs in reduced RCs vs. APs in direct modification.
APs in Reduced RCs (Only Predicative) APs in Direct Modification (Only Non-Predicative)
intersective (bald, blonde, ...) adverbial (former, total, mere, ...)‘for a N’ subsective (tall, big, ...) modal (possible, alleged, ...) ‘as a N’ subsective
(skillful, beautiful, ...) privative (false, fake, ...)
This paper is not only concerned with adjective ordering and positioning, but also with therespective order of complements and adjuncts before and after the noun.21
The order of DP/PP-complements/arguments and adjuncts is tested with deverbal nouns sincethey overtly express a thematic and Case-hierarchy. We first consider N-final languages like Japaneseand Tatar which display neutral order of prenominal elements, as illustrated in (59) and representedin (60).
59. Japanese (=Tatar, a head-final Turkic language)a. kooseinoo bakudan-de-no Amerikajin niyoru machi-no yôshanai hakai
high-tech weapon-with-GEN American by city-GEN brutal destruction‘the destruction of the city by the Americans with high-tech weapons’
b. ginkô niyoru mazushii hito e no okane-no kandaina kifubank by poor people to-DAT money-GEN generous gift‘a generous gift of money to the poor by the bank’
60. PPadjunct > PPargument > DPDative > DPGenitive > Adjectives > N Japanese and Tatar (unmarked/neutral order)
The nominal constructions in French and English given in (61a–d) show that the neutral linearorder of postnominal elements is the mirror-image of the prenominal order in (60), as representedin (62).
21 Note, however, that the hierarchy of adjectives shows differences with respect to the hierarchy of adverbs, especially inthe case object-denoting nouns. Despite the fact that adjectives and adverbs share this common property of merging asunique ordered specifiers, adjectives can have dual merged positions contrary to adverbs (except for few of them, i.e.,often and completely).

Languages 2017, 2, 18 19 of 24
61. a. the brutal destruction of the city by the enemy with heavy artillery
b. la destruction brutale de la ville par l’ennemi avec de la grosse artillerie
c. a recent gift of money to the poor by the bank with great generosity
d. le don récent d’argent aux pauvres par la banque avec/d’une grande générosité
62. of/de (GEN) < to/à (DAT) < by/par (OBL) < PPAdjunct
Given the base order in (60), the nominal structure in (62) contains a hierarchy of PP-relatedprojections22 in the Mittelfeld between the DP-border and the adjective-related projections.The unmarked sequences of PPs in (61a–d) are derived from successive roll-up movement,as schematized in (63). More precisely, as a first step the arguments leave the nP-domain and move totheir dedicated argumental PP-related position (FPby > FPto > FPof). The adjective-related projectionwhich contains the adjective and the noun undergoes successive roll-up movement through PP-relatedprojections and reaches a position higher than that of the PP-adjunct.
1
DP
FPPP-adjunct
FPby/par = Agent
FPto/à = Beneficiary
FPof/de = Theme
FPadj
nP
NP
Theme N
Beneficiary
Agent
63.
D
So far, the higher part of the French Mittelfeld has been made of the following sequence of PPs:(recursive) de-phrase < à-phrase < par-phrase. Such an order can be refined if we take the co-occurrenceof de-PPs into consideration, as exemplified in (64) (see Laenzlinger [10] for a thematic hierarchy ofPP-positions in the French noun phrase).23
22 The categories K and P (Kayne [73]) are simplified here as FPpp for ease of representation. This more simplified notationwill be used in the remaining part of the present paper.
23 Some of these examples are borrowed from Milner [84], Ruwet [85] and Cinque [86] (see also Alexiadou et al. [60] (p. 583)),and are slightly modified.

Languages 2017, 2, 18 20 of 24
64. a. le tableau d’Aristote de ce collectionneur par Rembrandt (d’une grande beauté)the painting of Aristote of this collector by Rembrandt (of great beauty)‘This collector’s painting of Aristote by Rembrandt (of great beauty).’
b. le tableau de Rembrandt du Louvre (d’une grande beauté)the painting of Rembrandt from the Louvre (of great beauty)‘Rembrandt’s painting from the Louvre (of great beauty).’
c. l’ordre de départ du général à ses troupes (par le général) avec fermetéthe order of departure of the general to his troops (by the general) with strictness’
d. la promesse de bonté de Jean à l’Eglise (avec sincérité)the promise of kindness of Jean to the Church (with sincerity)‘Jean’s promise of kindness to the Church (with sincerity).’
e. l’envoi d’une lettre à Marie de Paris par Jean (avec amour)the sending of a letter to Marie from Paris by Jean (with love)
The unmarked orders of postnominal complements realized in these examples show thatco-occurring de-PPs are (preferably) used according to the linear series of PPs in (65).
65. D < N < de-Theme < de-Agent < à-Goal < de-Source < par-Agent < Adjunct
This order is derived from successive roll-up movement steps that apply to the midfield structurein (66), which gives rise to the mirror-image order (see also 63 above for some details in terms ofderivation).
66. DP > FPpp [ADJUNCT] > FPpar [AGENT] > FPde [SOURCE] > FPà [GOAL] > FPde [AGENT] > FPde[THEME] > . . . n/NP (see Laenzlinger [24,71])
Scrambling/reordering of postnominal elements is always possible as a marked option.These alternative orders involve subtle information structural effects, as for instance in French:
67. a. l’envoi par Jean d’une lettre à Marie de Paris avec amourthe sending by John of a letter to Mary from Paris with love
b. l’envoi à Marie d’une lettre par Jean avec amourthe sending to Mary of a letter by John with love
This is a case of DP-internal scrambling, probably an instance of single XP-movement and issimilar to CP/TP-internal scrambling of arguments/complements (German, Japanese, French).
So far, the possible types of movement within the noun phrase are summarized as (68).
68. The noun alone can undergo remnant (possibly extended) nP/NP-movement. Then, the noun and itsextended projection can undergo pied-piping movement of two types: whose-picture (Spec-head, i.e.,N + Adj) or picture of whom (Head-Compl, i.e., Adj + N). If pied-piping movement is successive,roll-up effects are obtained (snowballing).
Thus, we can observe that both the clause and the noun phrase display the same types ofmovement (compare (68) with (55)), although their application is not strictly parallel due to structuraldifferences, especially in the midfield and the left periphery.
4. Conclusions
In this paper, we have offered a cartographic study of the left periphery, the midfield and,to a lesser extent, the Nachfeld (thematic domain and its left periphery) of both the clause and thenoun phrase in several languages of different families (Romance, Germanic, Slavic, Greek, etc.).We have seen that Cinque’s left–right asymmetry holds for different parts of the clausal and nominal

Languages 2017, 2, 18 21 of 24
structure, especially concerning the order of adjuncts and arguments in the midfield, on the basis ofa comparison between head-final and head-initial configurations. The so-called parallelism betweenthe clause and the noun concerns (i) the division of both the clausal and nominal structures into threeparallel domains and (ii) the possible types of movement (short head-movement, single XP-movement,remnant movement and pied-piping movement). However, there are differences in the conditions ofapplication on some of these movement types between the clause and the noun phrase. More precisely,the derivational steps of vP and nP movement proceed differently due to Case and agreementproperties. This is also the case for possible derivations involving complements/arguments within theclause and the noun phrase.
In addition, we have observed that the left periphery as well as the midfield of the clause andthe noun phrase show significant differences (i.e., non-parallelism) in their internal organizationinvolving the respective distribution of adverbs/adjectives,24 DP/PP-arguments and DP/PP-adjuncts.More precisely, we have seen that the left periphery is richer, or more developed, in terms of structuresand discourse properties in the clause than in the noun phrase. This is attributed to the fact that thenoun phrase has a less direct access to the discourse context being usually embedded within the clause.
Acknowledgments: I would like to thank the editors of the present issue of Languages and the four anonymousreviewers for their relevant comments and suggestions concerning the form and content of the paper. Many thanksgo to my colleagues for their empirical and theoretical support: Goljian Kacheava, Eric Haeberli, Genoveva Puskas,Gabriela Soare, Luigi Rizzi, Ur Shlonsky, Giuliano Bocci, and Richard Zimmerman.
Conflicts of Interest: The author declares no conflict of interest.
References
1. Lees, R.B. The Grammar of English Nominalizations; Indiana University Press: Bloomington, IN, USA, 1960.2. Chomsky, N. Remarks on Nominalization. In Readings in English Transformational Grammar; Jacobs, R.A.,
Rosenbaum, P.S., Eds.; Ginn: Waltham, MA, USA, 1970; pp. 184–221.3. Abney, S. The English Noun Phrase in Its Sentential Aspect. Ph.D. Thesis, Massachusetts Institute of
Technology, Cambridge, MA, USA, 1987.4. Cinque, G. On the evidence for partial N movement in the Romance DP. In Paths Towards Universal Grammar;
Cinque, G., Koster, Pollock, J.-Y., Rizzi, L., Zanuttini, R., Eds.; Georgetown University Press: Georgetown,WA, USA, 1994; pp. 85–110.
5. Giusti, G. Is there a FocusP and TopicP in the Noun Phrase Structure? Univ. Venice Work. Pap. Linguist. 1996,6, 105–128.
6. Giusti, G. The Functional Structure of Noun Phrases: A Bare Phrase Structure Approach. In FunctionalStructure in DP and IP. The Cartography of Syntactic Structures; Cinque, G., Ed.; Oxford University Press:Oxford, UK; New York, NY, USA, 2002; Volume 1, pp. 54–90.
7. Giusti, G. Parallels in clausal and nominal periphery. In Phases of Interpretation; Frascarelli, M., Ed.;Mouton de Gruyter: Berlin, Germany, 2006; pp. 163–184.
8. Payne, J. The Headedness of Noun Phrases: Slaying the Nominal Hydra. In Heads in Grammatical Theory;Corbett, G.G., Fraser, N.M., McGlashan, S., Eds.; Cambridge University Press: Cambridge, UK, 1993;pp. 114–139.
9. Bruening, B. Selectional Asymmetries between CP and DP Suggest That the DP Hypothesis Is Wrong.Univ. Pa. Work. Pap. Linguist. 2009, 15, 5.
10. Laenzlinger, C. Some Notes on DP-internal Movement. GG@G 2005, 4, 227–260.11. Laenzlinger, C. French Adjective Ordering: Perspectives on DP-internal Movement Types. Lingua 2005, 115,
645–689. [CrossRef]
24 Adverbs and adjectives as modifiers merge as unique specifiers, but they are not organized in the same way hierarchically(Cinque [22], Cinque [37]) except in the case of derived/deverbal nominals.

Languages 2017, 2, 18 22 of 24
12. Bernstein, J.B. The DP Hypothesis: Identifying Clausal Properties in the Nominal Domain. In The Handbookof Contemporary Syntactic Theory; Baltin, M., Collins, C., Eds.; Blackwell Publishers: Malden, MA, USA, 2001;pp. 536–561.
13. Marantz, A. No escape from syntax: Don’t try morphological analysis in the privacy of your own Lexicon.Univ. Pa. Work. Pap. Linguist. 1997, 4, 201–225.
14. Alexiadou, A. Adjective syntax and noun raising: Word order asymmetries in the DP as the result of adjectivedistribution. Stud. Linguist. 2001, 55, 217–248. [CrossRef]
15. Borer, H. Structuring Sense. In Name Only; Oxford University Press: Oxford, UK, 2005; Volume 1.16. Grohmann, K. Prolific Domains; John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2003.17. Wiltschko, M. The Universal Structure of Categories: Towards a Formal Typology; Cambridge Studies in Linguistics
Series 142; Cambridge University Press: Cambridge, UK, 2014.18. Larson, R.K. On the Double Object Construction. Linguist. Inq. 1998, 19, 335–391.19. Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 1995.20. Pollock, J.-Y. Verb movement, UG and the structure of IP. Linguist. Inq. 1989, 20, 365–425.21. Belletti, A. Generalized Verb Movement: Aspects of Verb Syntax; Rosenberg & Sellier: Turin, Italy, 1989.22. Cinque, G. Adverbs and Functional Heads: A Cross-linguistic Perspective; Oxford University Press: Oxford, UK;
New York, NY, USA, 1999.23. Cinque, G. Word Order Typology. A Change of Perspective. In Proceedings of the TADWO Conference;
Sheehan, M., Newton, G., Eds.; Oxford University Press: Oxford, UK; New York, NY, USA, 2010.24. Laenzlinger, C. Elements of Comparative Generative Grammar: A Cartographic Approach; Unipress: Padova,
Italy, 2011.25. Rizzi, L. The Fine Structure of the Left Periphery. In Elements of Grammar; Haegeman, L., Ed.; Kluwer
Academic Publishers: Dordrecht, The Netherlands, 1997; pp. 281–337.26. Rizzi, L.; Bocci, G. The left periphery of the clause—Primarily illustrated for Italian. In The Wiley Blackwell
Companion to Syntax, 2nd ed.; Everaert, M., Van Riemsdijk, H.C., Eds.; Wiley-Blackwell: Hoboken, NJ, USA,2017; pp. 1–30.
27. Aboh, E. Topic and Focus within D. Linguistics in The Netherlands 2004, 21, 1–12.28. Cinque, G. Cognition, universal grammar, and typological generalizations. Lingua 2013, 130, 50–65.
[CrossRef]29. Rizzi, L. On the position “Int(errogative)” in the left periphery of the clause. In Current studies in Italian
syntax. Essays offered to Lorenzo Renzi; North-Holland Linguistic Series 59; Cinque, G., Salvi, G., Eds.; Elsevier:Amsterdam, The Netherlands, 2001; pp. 287–296.
30. Rizzi, L. Locality and the left periphery. In Structures and Beyond. The Cartography of Syntactic Structures;Belletti, A., Ed.; Oxford University Press: Oxford, UK; New York, NY, USA, 2004; Volume 3, pp. 104–131.
31. McCloskey, J. Questions and questioning in a local English. In Crosslinguistic Research in Syntax and Semantics;Zanuttini, R., Ed.; Georgetown University Press: Washington, DC, USA, 2006; pp. 87–123.
32. Villa-García, J. Recomplementation and locality of movement in Spanish. Probus 2012, 24, 257–314.33. Paoli, S. The Fine structure of the left periphery: COMPs and subjects; evidence from Romance. Lingua 2007,
117, 1057–1079. [CrossRef]34. Soare, G. The Syntax-Information Structure Interface and Its Effects on A-Movement and A’-Movement in
Romanian. Ph.D. Thesis, University of Geneva, Geneva, Switzerland, 2009.35. Puskás, G.; Ihsane, T. Specific is not Definite. GG@G 2001, 2, 39–54.36. Ihsane, T. The Layered DP: Form and Meaning of French Indefinites. John Benjamins: Amsterdam,
The Netherlands; Philadelphia, PA, USA, 2008.37. Cinque, G. The Syntax of Adjectives; MIT Press: Cambridge, MA, USA, 2011.38. Samek-Lodovici, V. Final and non-final focus in Italian DPs. Lingua 2010, 120, 802–808. [CrossRef]39. Horroks, G.; Stravou, M. Bounding Theory and Greek syntax: Evidence from wh-movement in NP. J. Linguist.
1987, 23, 79–176. [CrossRef]40. Ntelitheos, D. Possessor Extraction and the Left Periphery of the DP; Unpublished manuscript; Department of
Linguistics, UCLA: Los Angeles, CA, USA, 2002.41. Szabolcsi, A. The Noun Phrase. In The Syntactic Structure of Hungarian; Syntax and Semantics Series 27;
Kiefer, F., Kiss, K.É., Eds.; Academic Press: San Diego, CA, USA, 1994; pp. 179–274.

Languages 2017, 2, 18 23 of 24
42. Brugè, L. Demonstrative Movement in Spanish: A Comparative Approach. Univ. Venice Work. Pap. Linguist.1996, 6, 1–53.
43. Brugè, L. The Positions of Demonstratives in the Extended Nominal Projection. In Functional Structure inDP and IP: The Cartography of Syntactic Structures; Cinque, G., Ed.; Oxford University Press: Oxford, UK;New York, NY, USA, 2002; Volume 1, pp. 15–53.
44. Julien, M. Nominal Phrases from a Scandinavian Perspective; Linguistik Aktuell Series 87; John Benjamins:Amsterdam, The Netherlands; Philadelphia, PA, USA, 2005.
45. Corver, N. Much-support as last resort. Linguist. Inq. 1997, 28, 119–124.46. Alexiadou, A. Multiple Determiners and the Structure of DPs; John Benjamins: Amsterdam, The Netherlands;
Philadelphia, PA, USA, 2013.47. Kayne, R. The Antisymmetry of Syntax; MIT Press: Cambridge, MA, USA, 1994.48. Cinque, G. Two types of non-restrictive relatives. Presented at Colloque de Syntaxe et Sémantique à Paris,
Paris, France, 4–6 October 2007; Empirical Issues in Syntax and Semantics 7. Bonami, O., Cabredo Hofherr, P.,Eds. Available online: http://www.cssp.cnrs.fr/eiss7/cinque-eiss7.pdfsp.cnrs.fr/eiss7/cinque-eiss7.pdf(accessed on 4 April 2016).
49. Cornilescu, A. Modes of Semantic Combinations: NP/DP. Adjectives and the Structure of the Romanian DP.In Romance Languages and Linguistic Theory 2004; Doetjes, J., Gonzàlez, P., Eds.; John Benjamins: Amsterdam,The Netherlands; Philadelphia, PA, USA, 2006; pp. 43–69.
50. Marchis, M.; Alexiadou, A. On the distribution of adjectives in Romanian: The cel construction. In RomanceLanguages and Linguistic Theory: Selected Papers from ‘Going Romance’, Amsterdam, The Netherlands, 6–8 December2007; Aboh, E., van der Linden, E., Quer, J., Sleeman, P., Eds.; John Benjamins: Amsterdam, The Netherlands;Philadelphia, PA, USA, 2008; pp. 161–178.
51. Cornilescu, A.; Nicolae, A. On the Syntax of Romanian Definite Phrases: Changes in the Patterns ofDefiniteness Checking. In The Noun Phrase in Romance and Germanic. Structure, Variation, and Change;Sleeman, P., Perridon, H., Eds.; John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2011;pp. 193–221.
52. Sleeman, P.; Perridon, H. The Noun Phrase in Romance and Germanic: Structure, Variation and Change;John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2011.
53. Sleeman, P.; Van de Velde, F.; Perridon, H. Adjectives in Germanic and Romance; John Benjamins: Amsterdam,The Netherlands; Philadephia, PA, USA, 2014.
54. Shlonsky, U. The form of Semitic noun phrases. Lingua 2004, 114, 1465–1526. [CrossRef]55. Alexiadou, A.; Wilder, C. Adjectival Modification and Multiple Determiners. In Predicates and Movement in
the DP; Alexiadou, A., Wilder, C., Eds.; John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA,USA, 1998; pp. 303–332.
56. Panagiotidis, P.; Marinis, T. Determiner spreading as DP-predication. Stud. Linguist. 2011, 65, 268–298.[CrossRef]
57. Leu, T. A Sketchy Note on the Article-Modifier Relation: Evidence from Swiss-German which Sheds Lighton Greek Determiner Spreading. GG@G 2001, 2, 55–70.
58. Larson, R.K.; Yamakido, H. Zazaki ‘double Ezafe’ as Double Case-Marking. Presented at the LinguisticsSociety of America Annual Meeting, Albuquerque, NM, USA, 8 January 2006; Available online: https://semlab5.sbs.sunysb.edu/~rlarson/lsa06ly.pdf (accessed on 6 June 2016).
59. Larson, R.K.; Yamakido, H. Ezafe and the Deep Position of Nominal Modifiers. In Adjectives and Adverbs.Syntax, Semantics, and Discourse; McNally, L., Kennedy, C., Eds.; Oxford University Press: Oxford, UK;New York, NY, USA, 2008; pp. 43–70.
60. Alexiadou, A.; Haegeman, L.; Stravou, M. Noun Phrase in the Generative Perspective; Mouton de Gruyter:Berlin, Germany, 2007.
61. Grimshaw, J. Argument Structure; MIT Press: Cambridge, MA, USA, 1990.62. Jackendoff, R.S. Semantic Structures; MIT Press: Cambridge, MA, USA, 1990.63. Baker, M.C. Thematic Roles and Syntactic Structure. In Elements of Grammar: Handbook of Generative Syntax;
Haegeman, L., Ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1997; pp. 73–137.64. Baker, M.C. Incorporation. A Theory of Grammatical Function Changing; The University of Chicago Press:
Chicago, IL, USA; London, UK, 1988.

Languages 2017, 2, 18 24 of 24
65. Belletti, A. Inversion as focalization. In Subject Inversion in Romance and the Theory of Universal Grammar;Hulk, A., Pollock, J.-Y., Eds.; Oxford University Press: Oxford, UK; New York, NY, USA, 2001; pp. 60–90.
66. Belletti, A. Aspects of the low IP area. In The Structure of IP and CP. The Cartography of Syntactic Structures;Rizzi, L., Ed.; Oxford University Press: Oxford, UK; New York, NY, USA, 2004; Volume 2, pp. 16–51.
67. Lahousse, K.; Laenzlinger, C.; Soare, G. Intervention at the Periphery. Lingua 2014, 143, 56–85. [CrossRef]68. Svenonius, P. On the Edge. In Peripheries. Syntactic Edges and Their Effects; Adger, D., de Cat, C., Tsoulas, G.,
Eds.; Kluwer: Dordrecht, The Netherlands, 2004; pp. 259–288.69. Laenzlinger, C.; Soare, G. On merging positions for arguments and adverbs in the Romance Mittelfeld.
In Contributions to the Thirtieth Incontro di Grammatica Generativa; Schweikert, W., Munaro, N., Eds.;Libreria Editrice Cafoscarina: Venice, Italy, 2005; pp. 105–128.
70. Cinque, G. Deriving Greenberg’s Universal 20 and Its Exceptions. Linguist. Inq. 2005, 36, 315–332. [CrossRef]71. Laenzlinger, C. Comparative Adverb Syntax: A Cartographic Approach. In Adverbs: Diachronic and Functional
Aspects; Pittner, K., Ed.; John Benjamins: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2015;pp. 207–238.
72. Laenzlinger, C. The CP/DP (non-)parallelism Revisited. In Syntactic Cartography: Where Do We Go from Here?Shlonsky, U., Ed.; Oxford University Press: Oxford, UK; New York, NY, USA, 2015; pp. 128–150.
73. Kayne, R. On Some Prepositions that Look DP-internal: English of and French de. Catalan J. Linguist. 2002, 1,71–116.
74. Krapova, I.; Cinque, G. On the Order of Wh-phrases in Bulgarian Multiple Wh-fronting. Univ. Venice Work.Pap. Linguist. 2005, 15, 171–197.
75. Krapova, I.; Cinque, G. On the Order of wh-Phrases in Bulgarian Multiple wh-Fronting. In Formal Descriptionof Slavic Languages: The Fifth Conference, Leipzig 2003; Zybatow, G., Szucsich, L., Junghanns, U., Meyer, R.,Eds.; Peter Lang: Frankfurt am Main, Germany, 2008; pp. 318–336.
76. Pittner, K. Adverbial positions in the German middle field. In Adverbials. The Interplay between Meaning,Context and Syntactic Structure; Austin, J.R., Engelberg, S., Rauh, G., Eds.; John Benjamins: Amsterdam,The Netherlands; Philadelphia, PA, USA, 2004; pp. 253–287.
77. Cinque, G. Complement and Adverbial PPs: Implications for Clause Structure. In Proceedings of the GLOW25, Amsterdam, The Netherlands, 9–11 April 2002.
78. Schweikert, W. The Order of Prepositional Phrases in the Structure of the Clause; John Benjamins: Amsterdam,The Netherlands; Philadelphia, PA, USA, 2005.
79. Tescari Neto, A. On Verb Movement in Brazilian Portuguese: A Cartography Study. Ph.D. Thesis, Ca’FoscariUniversity, Venice, Italy, 2013.
80. Scott, G.-J. Stacked Adjectival Modification and the Structure of Nominal Phrases. In Functional Structurein DP and IP: The Cartography of Syntactic Structures; Cinque, G., Ed.; Oxford University Press: Oxford, UK,2002; Volume 1, pp. 91–120.
81. Sproat, R.; Shih, C. Prenominal adjective ordering in English and Mandarin. NELS 1988, 18, 465–489.82. Sproat, R.; Shih, C. The cross-linguistic distribution of adjective ordering restrictions. In Interdisciplanary
Approaches to Language. Essays in Honor of S. Y. Kuroda; Georgopoulos, C., Ishihara, R., Eds.; Kluwer AcademicPublishers: Dordrecht, The Netherlands, 1991; pp. 565–593.
83. Larson, R.K. Events and modification in nominals. In Proceedings from Semantics and Linguistic Theory (SALT)VIII; Strolovitch, D., Lawson, A., Eds.; Cornell University Press: Ithaca, NY, USA, 1998; pp. 145–168.
84. Milner, J.-C. Ordres et Raisons de la Langue; Le Seuil: Paris, France, 1982.85. Ruwet, N. Théorie Syntaxique et Syntaxe du Français; Le Seuil: Paris, France, 1972.86. Cinque, G. On Extraction from NP. J. Ital. Linguist. 1980, 5, 47–99.
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
A New Outlook of Complementizers
Ji Young Shim 1,* and Tabea Ihsane 2,3
1 Department of Linguistics, University of Geneva, 24 rue du Général-Dufour, 1211 Geneva, Switzerland2 Department of English, University of Geneva, 24 rue du Général-Dufour, 1211 Geneva, Switzerland;
[email protected] University Priority Research Program (URPP) Language and Space, University of Zurich, Freiestrasse 16,
8032 Zurich, Switzerland* Correspondence: [email protected]; Tel.: +41-22-379-7236
Academic Editor: Usha LakshmananReceived: 28 February 2017; Accepted: 16 August 2017; Published: 4 September 2017
Abstract: This paper investigates clausal complements of factive and non-factive predicates in English,with particular focus on the distribution of overt and null that complementizers. Most studies on thistopic assume that both overt and null that clauses have the same underlying structure and predict thatthese clauses show (nearly) the same syntactic distribution, contrary to fact: while the complementizerthat is freely dropped in non-factive clausal complements, it is required in factive clausal complementsby many native speakers of English. To account for several differences between factive and non-factiveclausal complements, including the distribution of the overt and null complementizers, we proposethat overt that clauses and null that clauses have different underlying structures responsible for theirdifferent syntactic behavior. Adopting Rizzi’s (1997) split CP (Complementizer Phrase) structurewith two C heads, Force and Finiteness, we suggest that null that clauses are FinPs (FinitenessPhrases) under both factive and non-factive predicates, whereas overt that clauses have an extrafunctional layer above FinP, lexicalizing either the head Force under non-factive predicates or thelight demonstrative head d under factive predicates. These three different underlying structuressuccessfully account for different syntactic patterns found between overt and null that clauses invarious contexts.
Keywords: (null) complementizer; (non-)factive; clausal complements; selection
1. Introduction
When a verb takes a clausal complement, it may be headed by an overt lexical complementizer(COMP), which is obligatory in many languages in the world. Yet, languages vary with respectto whether verbs taking a finite clausal complement allow the deletion of the COMP. For instance,the finite declarative COMP that can be freely omitted in clausal complements of non-factive verbs inEnglish, as shown in (1a). In contrast, the deletion of the COMP under factive verbs (e.g., know, realize,regret) seems to be of a more contentious issue: since the seminal work by Kiparsky and Kiparsky [1],it has long been assumed that that cannot be deleted in clausal complements of factive verbs, as in (1b).
1. a. Dean believes/says/thinks that Lily doesn’t eat vegetables non-factive
b. Dean knows/realizes/regrets *(that) Lily doesn’t eat vegetables factive
Much previous work on the English COMP that seems to divide into two major schools. The firstapproach focuses on clausal complements of non-factive predicates of the type in (1a), where overtand null COMPs freely alternate. The main goal of this research is to investigate the structures of overt
Languages 2017, 2, 17; doi:10.3390/languages2030017 www.mdpi.com/journal/languages

Languages 2017, 2, 17 2 of 18
and null COMPs, and explain how the null COMP is allowed in addition to the overt COMP in thisenvironment [2–4]. The second approach explores clausal complements of factive predicates of thetype in (1b), assuming that the COMP is obligatory [5–8].
However, this long-held assumption between factive and non-factive verbs with regard to thedeletion of COMP seems to blur in contemporary English. We conducted an informal survey ofacceptability judgment task involving various sentence pairs, each sentence constructed with theCOMP that in its clausal complement and without the COMP that in the same condition. The resultsfrom 10 native speakers of various varieties of English (five American English, two Canadian English,two British English, and one New Zealand English), show that the COMP that can be optional underboth factive and non-factive predicates alike except with the verb regret, after which that is obligatory.The examples below show this new pattern of COMP deletion under factive predicates.
2. a. Dean knows/realizes that Lily doesn’t eat vegetables
b. Dean regrets *(that) Lily doesn’t eat vegetables
To our knowledge, there is no study available that looks into the distribution of null COMPs infactive complements of the type in (2a), whose patterns differ from the traditional judgments reportedin the literature. Interestingly, the contrast between (2a) and (2b) corroborates Karttunen’s observationthat there are two types of factive verbs, semi-factives (e.g., know, realize) and strong/true factives(e.g., regret) [9]. Semi-factives are distinguished from strong factive predicates, for they lose theirfactivity in questions and conditionals.1
The goal of the present study is to develop an analysis of the distribution of overt and null COMPsin clausal complements of non-factive and factive predicates provided in (1) and (2). One may questionthe validity of the data presented in (2), as they were collected from a small number of people via arather informal data collection method. While we acknowledge that we need to conduct a large-scaleexperiment with more test materials and participants to confirm the results, we are confident to presentour data in this paper due to the following two reasons.
First, despite its rather informal nature, a small-scale acceptability judgment task that we usedin our study has been predominantly exercised as a major data collection method in the field ofgenerative linguistics, based on which diverse syntactic theories have been proposed. In this regard,our method is no different from most studies available and the number of informants we had, 10, isconsidered relatively high in practice; many linguists often rely on their own judgments alone. Inaddition, a recent study [11] that compares the results of the so-called traditional informal judgmentcollection methods with the results of large-scale formal judgment collection methods reveals that thedifferences between these two methods are relatively small, a convergence rate of 95%, with a marginof error of ±5.3–5.8% ([11], p. 229).2
Thus, we include this new set of data in (2) in addition to those that are more traditionallyassumed in the literature in developing our analysis. The central hypothesis is that overt that clausesand null that clauses have different underlying structures that result in different syntactic behavior.We will argue that overt that complements of non-factive predicates and overt that complements offactive predicates also have different underlying structures, despite their resemblance on the surface.
The remainder of the paper is organized as follows. In Section 2, we briefly discuss previousaccounts of the distribution of null COMPs and show that none of the existing accounts can fullyexplain various distributional patterns of null COMPs. Thus, we propose a new outlook of syntacticstructures for overt and null COMPs in factive and non-factive complements. Section 3 extends theanalyses proposed in Section 2 to sentential subjects and concludes the paper.
1 The properties of these different factive predicates are further discussed in Hooper and Thompson [10].2 We thank the anonymous reviewer who brought this study to our attention.

Languages 2017, 2, 17 3 of 18
2. Different Structures for Overt and Null Complementizers
Most studies on the distribution of the null COMP have an overarching proposal that overt thatclauses and null that clauses have an identical syntactic structure, in which the COMP, either overt ornull, represents a C head. Under this view, both overt and null that clauses are predicted to show thesame or at least very similar syntactic distributions. However, this prediction is not borne out. It iswell known that while the so-called “root transformations” (RTs) or “main clause phenomena” (MCP)or “embedded root phenomena” (ERP) such as argument topicalization are permitted when the COMPis overt, they are not allowed when the COMP is null as shown in (3) [12].
3. Dean believes/thinks/says *(that) vegetables Lily doesn’t eat vegetables
Doherty argues that the unified CP (Complementizer Phrase) analysis for overt and null COMPsfails to account for different syntactic patterns between overt and null that clauses [13]. He insteadproposes that overt that clauses and null that clauses are structurally distinguished, the former being aCP and the latter being an IP (Inflectional Phrase). In addition, he adopts The Adjunction Prohibition [14],which forbids adjunction to a phrase that is s(ementically)-selected by a lexical head. Thus, in anovert that clause where the IP is selected by a C head, which is not a lexical head, IP adjunction(e.g., topicalization) is possible. On the other hand, IP adjunction is banned in a null that clause wherethe IP is selected by a lexical verb, not by a C head. This explains why the COMP must be presentin (3).
While Doherty’s proposal accounts for the contrast between overt and null that clauses undernon-factive predicates, it cannot be extended to clausal complements of factive predicates. Despite thepresence of the COMP that, RTs are banned in the clausal complement of a factive predicate [8,14–17]as exemplified in (4).3
4. a. *Mary realizes that this book John read [19] (p. 52)
b. ?*I regret that Mary my antics upset as much as they did [20] (p. 179)
There are, however, speakers who allow RTs in clausal complements of some factive predicates, asa reviewer points out. And this is precisely limited to the so-called semi-fative predicates, which alsoallow the null COMP in their complements as in (2a). Thus, it seems that while true factives behavedifferently from non-factives with regard to COMP deletion and RTs, semi-factives may pattern alongwith non-factives.
5. a. The public doesn’t realize that even more corrupt is the Republic Party [15] (p. 480)
b. I discovered that this book, it has the recipes in it [15] (p. 481)
To explain several differences found in clausal complements of factive and non-factive predicates,researchers have proposed two contrasting analyses. A more traditional view is that clausalcomplements of factive predicates are nominal in nature, and they are in fact a nominal complementin which a nominal head selects the clausal complement [1,8,19,21]. In other words, the structureof factive clausal complements is more complex than that of non-factive complements. On thecontrary, more recent studies propose that the structure of factive complements is simpler than that ofnon-factive complements, and the limited syntactic behavior of factive complements is related to itssimpler/reduced CP structure [22,23].
3 Factive and non-factive complements are further distinguished from each other in several ways, including the presence vs.absence of presupposition and the presence vs. absence of (weak-) islandhood, which will not be further discussed due tothe limited space and scope of this paper. We refer interested readers to Shim and Ihsane and the references therein [18].

Languages 2017, 2, 17 4 of 18
Building on the above-mentioned views that (a) the structure of overt that clauses is more complexthan the structure of null that clauses, (b) factive complements are nominal in nature, and (c) thestructure of non-factive that complements is richer than the structure of factive that complements,we propose the following underlying structures of clausal complements of non-factive and factivepredicates with an overt COMP and a null COMP.
Non-factive complements
6. a. [ForceP Force = that (Topic) (Focus) [FinP Fin = Ø]] overt COMP
b. b[FinP Fin = Ø] null COMP
Factive complements
7. [dP d = that [FinP Fin = Ø]]
The examples in (6) show that the underlying structure of non-factive complements have twovariants; when the COMP is overt, it is a ForceP, whose head is lexicalized by that. When the COMPis null, Force is not projected, a possibility hinted at but not discussed in Rizzi and Shlonsky [24].On the other hand, true factive predicates such as regret, which do not allow a null COMP and RTs inits clausal complement, take a nominal complement, whose head is lexicalized by that, as shown in(7).4 Finally, semi-factive predicates such as know and realize, may take the clausal complements in (6)or the nominal complement in (7). For speakers who permit neither the null COMP nor RTs in thisenvironment, they have access to the structure in (7) for both strong and semi-factives. In contrast,for those who allow COMP deletion and RTs, as in (2a) and (5), the structures in (6) represent theclausal complements of both non-factive and semi-factive predicates.
In what follows, we will provide evidence supporting the structures proposed in (6) and (7),which further explain different syntactic behavior observed between overt that clauses and null thatclauses and between non-factive and factive complements.
2.1. Non-Factive Clausal Complements
Rizzi [25] proposes an articulated structure of COMPs, splitting C into two functional categories,Force and Fin(iteness), between which Topic and Focus may be optionally projected, as illustratedin (8). While the head Force encodes a sentence type, such as a declarative or an interrogative, the headFin specifies whether a sentence is finite or non-finite. Rizzi further argues that the finite declarativeCOMP che in Italian represents a Force head, higher than topicalized and focalized elements.
8. Force (Topic) (Focus) Fin IP
Rizzi suggests that the COMP that also represents Force in English, similar to the Italian COMPche, which corresponds to the structure of the overt COMP proposed in (6a). On the other hand,the null COMP originates under Fin, as shown in (6b). When Topic or Focus is optionally projectedbetween Force and Fin, the Force–Finiteness system must remain split, Force being lexicalized by thatand Fin being realized by the null COMP. When there is no intervening head such as Topic or Focus,the Force–Finiteness system can be expressed on a single head in English, as a result of which the overtCOMP and the null COMP alternate.
What is not clear, though, is the process of expressing the Force-Finiteness system on a singlehead, when neither Topic nor Focus are projected. Rizzi explains that the split CP structure is forcedby the activation of Topic and Focus [25] (p. 314). Otherwise, only a single C head is projected foreconomy reasons, which can remain null or be spelled out as that. In other words, the structure of
4 The head d in (7) is light in the sense that it lacks ϕ-features. We will further explain the nature of the light d head inSection 2.2.

Languages 2017, 2, 17 5 of 18
the COMP that can be either the one in (6a), where two C heads, Force and Fin, remain separate or itcan be a single CP structure where the C head is an amalgam of Force and Fin. On the other hand,the structure of the null COMP represents a single CP structure.
We adopt Rizzi’s insight that the COMP that lexicalizes a higher C head, Force, and the nullCOMP originates under Fin, a lower C head in the split/multiple CP structures. But we depart fromhim in that Force and Fin make a single head when there is no intervening head such as Topic or Focus.Rizzi argues that there is cross-linguistic variation in the mechanism of expressing Force and Finitenesson a single head; for instance, while such an option is available in English, it is not available in Italian.This explains why the null COMP is possible in English, but not in Italian. However, Rizzi does notexplain why forming the complex Force + Fin head is only allowed in English, but not in Italian.
Instead, we take a unified view that Force and Fin remain separate in the syntactic derivationboth in English and Italian. Thus, when the lower C head, Fin, is projected, this C head is phoneticallyempty, resulting in a null COMP in English, as in (6b). When an additional C layer is projected in thestructure, this higher C head is spelled out as that, resulting in an overt COMP as in (6a). As for Italian,we follow Rizzi and assume that Force and Fin also remain separate and the head Force is lexicalizedby che and Fin is null. But we take a difference stance from him to account for the cross-linguisticvariation between these two languages. The existence of the null COMP in English, but its absence inItalian is due to different selectional requirements of a predicate in these languages. When a predicateselects a clausal complement, it can be either a ForceP (overt COMP) or a FinP (null COMP) in English.In Italian, on the other hand, a predicate may select only a ForceP (overt COMP).5 We leave this topic,which is beyond the scope of this paper, for future research.
The structures in (6) can explain why RTs are possible when the COMP is overt in (3). In an overtthat clause (6a), Topic and Focus may be optionally projected between ForceP and FinP, allowing RTs.On the other hand, it is not self-evident why Topic and/or Focus cannot be projected in (6b), assumingthat the projection of Topic and/or Focus is optional above Fin: Top(ic)P and Foc(us)P should beallowed above FinP in (6b), if these projections are optional. If this were the case, RTs would be possiblein (3) when the COMP is null, contrary to fact. How can we then rule out the projection of TopP andFocP in (6b)?
Rizzi argues that the split CP structure is forced by the activation of Topic and Focus [25] (p. 314),explaining that in a single CP structure such as the one in (6b), Topic and Focus are missing. Once again,however, this seems to be limited to English, not in Italian. For unknown reasons, it seems that whileTopic and Focus may or may not be activated in English, allowing a split CP structure of a singleCP structure, they must be always activated in Italian, for a single CP structure is not allowed inthis language.
Under our unified analysis that Force and Fin remain separate both in English and Italian, this canbe answered differently in terms of selectional requirements of the matrix predicate. When a predicateselects a clausal complement/CP in English, the clausal complement must be either a ForceP or a FinP,whose head corresponds to C. The projection of Topic and Focus is optional, expressing the informationstructure of a clause. That is, neither TopP nor FocP are qualified to be a complement of a predicate,which cannot be optional. In other words, when TopP or FocP is projected above FinP in (6b), it cannotbe directly selected by the matrix predicate. This explains why RTs are banned in a null that clausein English.
We have proposed that overt that clauses are ForcePs and null that clauses are FinPs undernon-factive predicates. In support of our proposal that ForceP is not projected when the COMP isnull as in (6b), the following line of thought is considered. First, adopting Rizzi’s original proposal,the Fin head contains a feature [+finite] or [-finite], perhaps along with ϕ-features. Second, a functional
5 Rizzi expresses that a matrix predicate selects ForceP only (both in English and Italian) [25].

Languages 2017, 2, 17 6 of 18
category may remain phonetically null if there is no lexical item to spell it out. We suggest that Englishhas no lexical item to spell out Fin with [+finite], whereas Fin with [-finite] may be spelled out as for.6
One may wonder how a null that clause is interpreted as a declarative sentence if Force is notprojected, assuming that Force is the locus of deciding a sentence type (e.g., declarative, interrogative).Roberts argues that ForceP is either absent or inert in root declaratives, suggesting that root declarativesare the unmarked clause type [26]. On the other hand, Roberts assumes that ForceP is present inembedded clauses, in which the COMP that raises from Fin to Force. While we agree with Robert’sidea that root declaratives are the unmarked clause type, the question arises why only in root clauses,not in embedded clauses, declaratives are unmarked. Roberts does not provide an answer to thisquestion, and we adopt his suggestion for root clauses and hypothesize that in embedded clauses too,declaratives are the unmarked clause type (in English). In other words, declarative force may not beencoded on Force per se, but it is granted as the unmarked sentence type at the level of FinP both inmatrix and embedded clauses.7 On the other hand, the information delivering other sentence typesthan declaratives (e.g., interrogatives) is encoded on Force by their relative features, for instance [+wh].On this assumption, the label of Force in (6a) seems to be misleading, and needs to be reconsidered.Nonetheless, we will continue to use the label Force in this paper for expository purposes.8
Researchers argue that the COMP delivers the information of the clausal type [27] or thespecification of force [28]. Yet, our proposal challenges this view: the COMP that originates under thehead Force, but declarative force itself is not encoded on Force per se but it is granted as the unmarkedsentence type at the level of FinP. To support our new outlook of COMPs, we provide cross-linguisticevidence from Korean, a language that is head-final (Subject-Object-Verb order) and agglutinativein its morphology. In (9), the COMP ko does not convey the force of the embedded clause, and the
6 Alternatively, one may assume that Fin with [+finite] is spelled out as that, which raises on to Force [26]. On this assumption,however, it is not clear how to account for a null COMP. It seems that Fin with [+finite] is then spelled out as that orphonetically null.
7 This may not be universal across languages. While it is reasonable to assume that ForceP may be absent in English rootdeclaratives, it is always projected in Korean. As shown in (i) both the matrix sentence and the embedded clause must bemarked with the declarative morpheme -ta in a formal speech.
i. Joon-un Mari-ka yeppu-*(ta)-ko sayngkakha-n-*(ta)Joon-TOP Mari-NOM pretty-DECL-COMP think-PRES-DECL‘Joon thinks that Mari is pretty.’
An anonymous reviewer points out that the declarative morpheme -ta is missing in the so-called “panmal” or -a/e style ofspeech, which may indicate that ForceP may be absent in Korean root declaratives. The “panmal” or -a/e style of speech isan informal, non-polite colloquial speech act and data in question are provided in (ii) below.
ii. Mari-ka yepp-eMari-NOM pretty-e‘(I think that) Mari is pretty.’
The example in (ii) is marked by the informal sentence ending particle -e instead of the formal declarative marker -ta.The reason that the declarative morpheme -ta is missing in the matrix clause in (ii) is related to the speech act of thesentence; the formal declarative marker -ta cannot appear in the informal colloquial “panmal” or -a/e style of speech. Instead,the sentence type information (in this case, declarative) may be encoded on the morpheme -e in (ii).
8 Alternatively, we may wonder whether the head Force could be re-labelled into Assert, following the insight suggestedby Hooper & Thompson [10]. Assertion is defined as the core meaning of the proposition, the part that can be questionedor negated, and Hooper & Thompson argue that assertion is the crucial property that licenses RTs in embedded clauses;for an embedded clause to be compatible with RTs, it must be asserted. Factive complements are presupposed, not asserted,thus, they are not compatible with RTs.While assertion is generally considered to be a property of main clauses, Hooper &Thompson show that it can also be a property of embedded clauses and demonstrate that some clausal complements maybe asserted, as in the case of semi-factives. Accordingly, factive complements that are asserted allow RTs, whereas factivecomplements that are presupposed do not permit RTs. Adopting the semantic label Assert for Force will, however, lead toother problems, as a reviewer suggests. One potential problem is that the labeling Force as Assert cannot be extended toembedded interrogative sentences.

Languages 2017, 2, 17 7 of 18
specification of force is marked by a separate morpheme, the declarative marker -ta in (9a) and theinterrogative marker -nya in (9b).
9. a. Joon-un [Mari-ka yachae-lul mek-ess-ta-(ko)] mit-ess-taJoon-TOP Mari-NOM vegetables-ACC eat. PAST-DECL-COMP believe-PAST-DECL
‘Joon believed that Mari ate vegetables.’b. Joon-un [Mari-ka yachae-lul mek-ess-nya-(ko)] mwul-ess-ta
Joon-TOP Mari-NOM vegetables-ACC eat. PRES-INT-COMP ask-PAST-DECL
‘Joon asked if Mari ate vegetables.’
It is generally assumed in the literature that ko is a COMP and merges as a C head [29–32], but Shimand Ihsane [33] analyze the COMP ko as a functional category higher than Force, correspondingto Report, a functional category which was proposed to represent the Japanese COMP to [34].Thus, the function and property of COMPs seem to differ from language to language and the leftperiphery of CP needs to be further investigated.9
2.2. Factive Clausal Complements
The structures in (6) represent clausal complements of non-factive predicates, where the overtCOMP that and the null COMP alternate. However, they cannot be the underlying structures of clausalcomplements of strong factive predicates such as regret, which do not permit COMP deletion. In otherwords, the FinP clausal complement in (6b) cannot be selected by true factive predicates such as regretor semi-factive predicates if the speaker does not allow a null COMP. The structure in (6a) is alsoproblematic to represent the structure of factive complements when the COMP is overt. As mentionedearlier, RTs are impossible in the complement of regret and many speakers do not accept RTs in othersemi-factive predicates even if the COMP is overt. If (6a) represented the underlying structure ofclausal complements of both non-factive and factive predicates, it is mysterious why Topic and Focuscan be projected under non-factive predicates, but cannot under factive predicates.
Haegeman suggests a way to solve this mismatch between factive and non-factive complements,and argues that the head Force is the locus of “speaker deixis”, which encodes the anchoring of theproposition to the speaker [22]. In complements of factive predicates, speaker deixis is arguably lackingand the factive reading arises from the lack of speaker deixis. Based on this, she proposes a reduced CPstructure for clausal complements of factive predicates, where ForceP is not projected. Assuming thatTopic and Focus are licensed by speaker deixis (of the Force head), neither TopP nor FocP are projectedwhen Force is missing in the structure.
Haegeman’s reduced/truncated CP structure explains why Topic and Focus seem to be missing inthe clausal complement of a factive predicate, but she does not clarify where the COMP that is locatedin the structure when the head Force is missing, as shown in (10) (with Mod standing for Modifier).10
In other words, (10) suggests that the COMP that is above FinP but it is not located under Force.11
10. That Mod* Fin [23] (p. 1665)
9 Haegeman [22], for instance, proposes the head Sub(ordinator), distinguished from Force, where the subordinatingconjunction elements originate.
10 De Cuba [23] makes a similar proposal on the distinction between factive and non-factive complements: while non-factivecomplements have a full-fledged CP structure, cP and CP, which roughly correspond to ForceP and FinP, factive complementshave a smaller structure, where the higher cP is not projected. He argues that the COMP that can merge either as the c heador the C head. However, it is not clear on what conditions that spells out c or C, and when it is not spelled out at all, leadingto a null COMP.On the other hand, Basse [7] maintains the view that ForceP is projected both in factive and non-factivecomplements, with its head being spelled out as that. The difference between factives and non-factives lies in the absenceand the presence of an assertion feature on Force, respectively.
11 In more recent work with Ürögdi [35], Haegeman abandons her earlier proposal that factive clausal complements have areduced structure. Instead, they propose an operator movement analysis, which prevents RTs in factive clausal complements.RTs are not possible due to the interference of a null operator that moves from a position above TP to Spec, CP with themovement of other elements to this position, typically fronted arguments as observed in RTs.

Languages 2017, 2, 17 8 of 18
Adopting and adapting Haegeman’s idea that the structure of factive clausal complements doesnot have a full-fledged CP and the COMP that is above Fin, we propose an alternate structure torepresent the clausal complement of a factive predicate in (7), repeated below.
7. [dP d = that [FinP Fin = Ø]]
We propose that that in non-factive clausal complements and that in factive clausal complementsdiffer in nature: the former is a finite (declarative) COMP and the latter is a weak demonstrative.Thus, a non-factive clausal complement headed by that is a ForceP, with the head Force lexicalized bythat, as in (6a), whereas a factive clausal complement headed by that is a dP, and the d head is spelledout as that, as shown in (7). To put it differently, non-factive (that-) complements are clausal and factive(that-) complements are nominal, a view prevailing in generative linguistics [1,8,19,21].12 To supportthe structure in (7) where a D element, such as a demonstrative or a determiner, is projected abovethe clausal/FinP complement, we provide cross-linguistic evidence showing that a determiner or ademonstrative appears before the COMP, as exemplified in (11).
11. a. man mi-dun-am (in) ke Giti mi-a-d PersianI DUR-know-1SG DEM COMP DUR-come-3SG
‘I know that Giti is coming.’ Modified from [38] (p. 6)
b. (to) oti perase to ksero Modern GreekDET.ACC
COMP
DET.ACC
COMPpassed-3SG it.ACC know-1SG
‘I know that he passed the exam.’ [40] (p. 92)
The examples in (11) provide morphological evidence of a D element combining with a COMP ina clausal complement. Although researchers do not converge in their views on how to analyze theinternal structure of a sentential complement with an optional D element preceding the COMP, severalscholars have proposed that the sentential complement with a D element should be analyzed as a DP(or a nominal structure) rather than a CP [38–40], the view that we adopt and adapt in order to analyzefactive clausal complements headed by that in English.
The idea that a clausal complement may be optionally realized as a DP rather than a CP in Englishwas taken by Takahashi [41], who proposes a covert determiner structure for clausal complementsheaded by that. Although English does not show an overt spell-out of a determiner or a demonstrativebefore the COMP that in a clausal complement, Takahashi claims that an English sentential complementis in fact a DP, in which the D head is realized by a covert determiner THE, as in (12).
12. [DP THE [CP that . . . ]]
Takahashi proposes the structure in (12) to explain why a moved clausal/CP complement exhibitsproperties of DPs in its base-generated position; a moved clausal complement must involve a DPstructure headed by a covert determiner. In (12), a clausal complement is analyzed as a DP structure
12 A reviewer asks what the featural differences are between “clausal” and “nominal” complements. Although it is aninteresting question worth pursuing, we do not propose any featural analysis to distinguish between clausal and nominalcomplements. We simply use these terms to describe syntactic differences found between non-factive complements andfactive complements in accordance with what others say. More specifically, factive clausal complements may show syntacticbehavior similarly to nominal complements. One way to distinguish between “clausal” and “nominal” complements couldbe to adopt a relativization structure for factive complements. The idea that factives are relative clauses has been proposedfor Kwa languages [36,37] on the basis of examples where an argument DP or an entire VP is fronted to Spec, CP in factiveclauses. Aboh extends this analysis to German and French factive clauses, where, he assumes, a null operator, rather than anovert constituent, moves to Spec, CP [36]. The relativization approach was further adopted by Haegeman and Ürögdi [35],who account for differences found between clausal complements of factive and non-factive verbs, including various RTphenomena or absence thereof. If we adopt this view, factive complements are relativized clauses with the null nominalhead (the original idea goes back to [1]), whereas non-factive complements are not relativized. The details need to be workedout (e.g., presence/absence of a null operator), which we leave for future research.

Languages 2017, 2, 17 9 of 18
where a null D head takes a CP complement. This is in line with our view of analyzing clausalcomplements headed by that as a nominal structure in (7). Yet, we limit this analysis to clausalcomplements of factive predicates only, not those of non-factive predicates; there is no nominal layerin non-factive clausal complements. Also, the structure we propose in (7) significantly differs from(12) in that that lexicalizes the d head, not C. In what follows, we will show that the dP structure in(7) explains several peculiar facts found in factive clausal complements, such as speaker variation inobligatory vs. optional presence of that and the lack of RTs.
As has long been advocated in the literature, many speakers do not accept the omission of thatin factive clausal complements, whereas they allow that deletion in non-factive clausal complements.The dP structure in (7) can explain why that is obligatory under factive predicates, unlike non-factivepredicates: a factive predicate selects a nominal complement, a dP, whose head is lexicalized by that.On the other hand, a non-factive predicate selects a clausal complement, either a ForceP or a FinP.When it selects a ForceP, the complement is headed by that. When it selects a FinP, the complement isnull-headed, leading to a that-less clause.
Then how do we exclude the projection of Topic or Focus in the dP structure in (7)? In order toexplain this, we further elaborate our claim that that in (7) is a weak demonstrative, distinguished froma strong demonstrative that: that is a weak, light demonstrative in the sense that it lacks ϕ-featuresin (7) in contrast with a strong demonstrative that with ϕ-features. A strong demonstrative thathas a plural form those, showing ϕ-feature/number agreement with the following nominal element(e.g., that woman vs. those women). But that in sentential complements has no plural counterpart.13
13. we think that/*those you’re wrong [44] (p. 112)
Also, the claim that the d head lexicalized as that in (7) is a light, ϕ-feature lacking head,distinguished from a (strong) D head, has a consequence in syntactic derivations, disallowing theprojection of Topic or Focus above FinP in (7). Based on word order in French and Hungarian nominals,Ihsane and Puskás [45] propose a split DP structure, where two DPs, a Det(erminer) Phrase and aDef(inite) Phrase, correspond to ForceP and FinP in Rizzi’s split CP structure respectively. Parallel tothe clausal domain, Topic and Focus may optionally appear between DetP and DefP, as shown in (14).
14. DetP (Topic) (Focus) DefP
They further argue that specificity and definiteness are separate notions and encoded on differentfunctional heads, Topic and Def, respectively. They further assume that demonstratives have [+specific,+definite] features which merge under Def and move up to Topic. Since ϕ-features are not employedin their nominal system, the role of ϕ-features with respect to movement of demonstratives isnot discussed in [45]. Yet, we pursue the distinction between strong and weak demonstrativesin English and argue that the weak demonstrative that in (7) does not move in the course of derivationbut remains in situ, due to the lack of certain features, such as ϕ-features. In contrast, strongdemonstratives move further up to Topic (or even higher). This means that the dP in (7) headedby that, a weak/light/ϕ-feature lacking demonstrative, is structurally lower than Topic and Focusin (14). In other words, Topic and Focus may optionally appear above dP, not between dP andFinP in (7). Nonetheless, the projection of Topic is not allowed above dP, as demonstrated in (15).The ungrammaticality of topicalization above dP/that complements in (15) is due to the fact that TopP
13 Similarly, this cannot be used as a complementizer, as pointed out to us by an anonymous reviewer. According to Kayne [42],the complementizer that, the relative that, and the demonstrative that are all instances of the demonstrative that synchronically.More precisely, relative that is an instance of demonstrative that and sentential that is a subcase of relative that. This cannot beused as a complementizer due to the fact that there is no relative pronoun this. Although this unitary analysis is attractive,there seems to be counter-evidence from different languages [43]. As mentioned in footnote 12, a relativization analysis offactive complements (in contrast to non-factive complements) may be an interesting way to distinguish between nominaland clausal complements.

Languages 2017, 2, 17 10 of 18
cannot be selected by the matrix predicate, as explained earlier to account for unavailability of RTs in anull that clausal complement.
15. *Dean knows/realizes/regrets vegetables that Lily doesn’t eat
A reviewer mentions that in contexts known as “emphatic topicalization” (ET) non-wh XPs canmove to the left of the complementizer in languages/dialects such as Southern German and Bangla [46],a sequence that should be ruled out by (7). It is further noted, however, that when ET occurs in theselanguages, it further triggers movement of the topicalized CP to the front of the clause that immediatelydominates it for convergence; in other words, the examples such as (15) are allowed neither in Englishnor Southern German and Bangla. The reason that (15) is not possible in all of these languages can beexplained by our earlier statement; TopP cannot be a complement.
While such a derivation crashes in English, in languages such as Southern German and Bangla,there is a way to salvage it; the entire TopP must move to the left periphery to the clause. Bayer callsthis “emphasis” [47], which is triggered by some type of Topic feature on C. If we adopt this analysis,languages vary concerning the process of emphasis.
Our proposal that that in factive clausal complements is a light or weak demonstrative lackingϕ-features can be further supported by cross-linguistic facts from Korean, which shows similardistributional patterns of the COMP. In Korean, both factive and non-factive complements are headedby the COMP ko. Similar to that, ko may be optional under non-factive predicates, but it is stronglypreferred under factive predicates.14
16. Joon- un [Mari-ka yachae-lul an mek-nun-ta-(ko)] mit-nun-taJoon-TOP Mari-NOM vegetables-ACC NEG eat.PRES-DECL-COMP believe-PRES-DECL
sayngkakha-n-ta (??*)yookamsuleweha- n-tathink-PRES-DECL regret-PRES-DECL
‘Joon believes/thinks/regrets that Mari doesn’t eat vegetables.’
In addition, similar to that in English, the COMP ko may also be used as a demonstrative inmodern Korean. When it is used as a demonstrative, however, it seems to lack ϕ-features in starkcontrast to other types of demonstratives. As shown in (17), Korean has three types of definitedescriptions/demonstratives: i ‘this’ (a proximal form), ku ‘the’ or ‘that’ (a neutral form: close to thehearer or known to both the speaker and the hearer), and ce ‘that’ (a distal form). In (17b), ko may beused instead of the demonstrative/definite marker ku.15
14 Similar to that, there is speaker variation with ko deletion under factive predicates. While several informants of ours allowomission of ko in all of three predicates, a reviewer judges that ko deletion is only possible with strong non-factive predicates,such as ‘think’, not with predicates such as ‘believe’ (marginal) or ‘regret’ (unacceptable).
15 A reviewer asks whether there is any independent evidence that ko is used as a demonstrative in Korean and ko in (17) is notan accidental homonym. If one takes this stance, the same question should be applied to that in English, which can be useda COMP and as a demonstrative. It is well documented that demonstratives have grammaticalized as complementizers inmany languages, especially in the Germanic language family. Although Korean is not a member of this language family andthere is little diachronic evidence showing that the COMP ko originates from a demonstrative, ko is synchronically used as aCOMP as a demonstrative in modern Korean, showing a similar distributional pattern with many other languages aroundthe world.

Languages 2017, 2, 17 11 of 18
17. a. i ai-nun cham yeppu-tathis child-TOP really pretty-DECL
‘This child is really cute.’b. ku/ko ai-nun cham yeppu-ta
the/that child-TOP really pretty-DECL
‘The/that child is really cute.’
c. ce ai-nun cham yeppu-tathat child-TOP really pretty-DECL
‘That child (over there) is really cute.’
Similar to English demonstratives such as this and that, the demonstratives in Korean may beused as pronouns and be inflected by the plural morpheme tul. What is striking is that unlike otherdemonstratives, ko cannot be inflected by the plural morpheme tul in (18b), which strongly suggeststhat ko is lacking ϕ-features.16
18. a. i-tulthis-PL
‘these people.’
b. ku/*ko-tulthe/that-PL
‘the/those people.’
c. ce-tulthat-PL
‘those people.’
Thus, the existence of the ϕ-feature lacking demonstrative ko in Korean, which is also used as aCOMP in a clausal complement, supports our hypothesis that that is a ϕ-feature lacking demonstrativein (7).
The proposal that factive complements are light dPs in contrast with strong DPs can also explainwhy factive complements and DPs share some properties, but not all. For instance, factive complementsare weak islands [5,7,21] whereas DPs are strong islands for object extraction, as in (19). Also, factivecomplements can be complements of adjectives but not of prepositions in contrast with DPs [35],as exemplified in (20). Thus, it seems that there is a difference between light dPs and DPs regardingtheir distributions and syntactic behavior, which needs to be investigated further.
19. a. ?What did you regret [dP that John stole]? [7] (p. 54)
b. *What did you believe [DP the claim that John stole]?
20. a. I was surprised [dP that he left] [35] (p.136)
b. *John forgot about [dP that Jane left too early]
In this section, we have proposed that factive complements have an underlying structuredistinguished from non-factive complements. Factive complements are dPs, where the light d headis lexicalized by a weak demonstrative that. On the other hand, non-factive complements are eitherForcePs when the COMP is overt and FinPs when the COMP is null. The underlying structure forfactive complements in (7) was proposed based on different syntactic behavior exhibited by factivecomplements, in particular the obligatory presence of the COMP and the lack of RTs, as reported
16 Unlike plurality, neither person nor gender features are morphologically marked in Korean.

Languages 2017, 2, 17 12 of 18
in the literature. However, as noted earlier, some speakers allow COMP deletion and RTs in factivecomplements, and interestingly, they are limited to so-called semi-factive predicates, which lose theirfactivity in certain contexts (i.e., they lose their presupposed reading).
Thus, it seems that there is speaker variation regarding their judgment of factive complements.For those who have a clear cut between factive and non-factive predicates but do not differentiatebetween factive and semi-factive predicates with respect to COMP deletion and the allowance of RTs,(6) represents non-factive complements and (7) represents factive complements. On the other hand,for those who distinguish between true/strong factives and semi-factives, with the latter mimickingnon-factives, the structure in (6) may represent non-factive and semi-factive predicates. Alternatively,we can think that both true factive complements and semi-factive complements have the dP structurein (7), distinguished from non-factive complements. Yet, the structure of semi-factives may be lessimpoverished/truncated than that of true factives, and contain a type of TopP allowing RTs.17 If thisanalysis holds true, we predict that there will be further differences found between true factives andsemi-factives for their syntactic behavior, which we plan to investigate in the future.
2.3. Interplay between Matrix Predicates and Complements
To account for the distribution of overt and null COMPs in clausal complements of non-factive andfactive predicates, we have proposed three different underlying structures of (a) overt that non-factivecomplements, (b) overt that factive complements, and (c) null that non-factive and factive complements,repeated in (19a–c), respectively.
21. a. [ForceP Force = that (Topic) (Focus) [FinP Fin = Ø]]
b. [dP d = that [FinP Fin = Ø]]
c. [FinP Fin = Ø]
The head Force in an embedded clause may be spelled out by different lexical items, such as thatin declaratives and if or whether in questions in English. We have proposed that declarative force is theunmarked clause type at the level of FinP. Declarative sentences can be either asserted or presupposed,and it is widely assumed that non-factive complements are asserted regardless of the presence orabsence of the COMP and factive complements are presupposed. Under our proposal that postulatesdifferent structures for overt that and null that complements, as in (21), one may wonder how theclausal complement without an overt COMP (21c) can be interpreted as assertion in the absence of aForceP in its structure.
22. a. Dean believes/says/thinks [ForceP that Lily went to Paris last year]
b. Dean believes/says/thinks [FinP Lily went to Paris last year]
Under our proposal that declaratives are the unmarked type at the level of FinP, it is notproblematic. The clausal complements in (22), with or without the COMP, are semantically assertedunder non-factive predicates. However, it becomes more complex if factive complements with anull COMP are taken into account. When the COMP is null, both non-factive and semi-factive
17 It could be one of the projections in the hierarchy of topics advocated in Frascarelli and Hinterhölzl [48]. This projectioncould also be projected in the structure of examples considered as true factives by the authors, like (iii), although this notuncontroversial [35].
iii. I am glad that this unrewarding job, she has finally decided to give up [49] (p. 69)
As our focus here is on the null/overt COMP (non-)alternation, we leave the question open. What is important to us is thatthe structure of factive clausal complements is nominal.

Languages 2017, 2, 17 13 of 18
complements have the same structure of (21c). Yet, a non-factive complement is asserted whereas afactive complement is presupposed, as shown in (23).
23. a. Dean believes/says/thinks [FinP Lily went to Paris last year] assertion
b. Dean knows/realizes [FinP Lily went to Paris last year] presupposition
To account for this, we take the stance that by default a declarative clausal complement is assertedwhen it is selected by a non-factive predicate, whereas it is presupposed when it is selected by afactive predicate. The semantic/pragmatic information of the complement, whether it is assertedor presupposed, is not affected by the presence or the absence of the COMP. In this paper, we havepostulated different syntactic structures for clausal complements with an overt COMP and a nullCOMP, a ForceP or a dP for the former and a FinP for the latter. Since both overt that and null thatcomplements are asserted under non-factive predicates, as in (22), the presence of a ForceP in adeclarative complement per se does not determine that the complement is asserted; both the ForcePin (22a) and the FinP in (22b) are asserted; the assertive reading of the complement comes fromthe non-factive matrix predicate. In the same vein, whether the complements in (23) are assertedor presupposed depends on the predicate selecting them: when the matrix predicate is non-factive,the complement is asserted, as in (23a). On the other hand, the complement is presupposed if it isselected by a factive predicate, as in (23b).
We close this section by mentioning some interesting cross-linguistic facts regarding an interactionbetween the matrix predicate and its complement. Shim and Ihsane argue that the presupposition ofclausal complements is not solely determined by the type of the matrix predicate but rather influencedby an interplay between the type of a matrix predicate and the type of a clausal complement, based onvarious syntactic and semantic patterns of clausal complements in Korean [18]. Korean has threetypes of clausal complements, (a) the ko clause, (b) the kes clause with an overt tense morpheme and a(declarative) force marker, and (c) the kes clause without an overt tense morpheme and a force marker,as exemplified in (24a–c), respectively.
24. a. Kibo-nun [Dana-ka i chayk-ul ilk-ess-ta-ko] [18] (p. 131)Kibo-TOP Dana-NOM this book-ACC read-PAST-DECL-COMP
b. Kibo-nun [Dana-ka i chayk-ul ilk-ess-ta-nun kes-ul]Kibo-TOP Dana-NOM this book-ACC read-PAST-DECL-LNK thing-ACC
c. Kibo-nun [Dana-ka i chayk-ul ilk-un kes-ul]Kibo-TOP Dana-NOM this book-ACC read-LNK thing-ACC
yukamsulewehay-ss-ta / mit-ess-taregret-PAST-DECL / believe-PAST-DECL
‘Kibo regretted/believed that Dana read this book.’
What is interesting in the examples in (22) is that all three types of complements of the factive verbyukamsuleweha ‘regret’ are presupposed, but not all of the complements of the non-factive predicatemit ‘believe’ are asserted; more specifically, the ko complement in (23a) and the kes complement withan overt tense morpheme and a (declarative) force marker in (23b) are asserted, whereas the kescomplement without an overt tense morpheme and a force marker in (23c) are presupposed underthe non-factive verb mit. This suggests that factivity and presupposition may not be as closely tiedto each other as widely believed, and Shim and Ihsane argue that the presuppositional reading ofclausal complements is not solely determined by the nature of the matrix predicate, but is derivedfrom two related factors, namely the type of a matrix predicate (factives or non-factives) and the typeof its complement in Korean [18].
At first glance, the distinction between factive complements and non-factive complements seemsto be rather clear in English, unlike Korean; the former is presupposed and the latter is not. But English

Languages 2017, 2, 17 14 of 18
too suggests that factivity and presupposition may be loosely related, as opposed to what is widelyassumed in the literature. The example in (23) embeds a nominal complement, whose head fact furtherembeds an overt that clause, indicating that it is a factive complement.
25. (*)Dean denies/doubts the fact that Lily doesn’t eat vegetables
Yet, the judgment of the sentence in (23) differ among our informants. While a few speakersjudged it unacceptable, stating that the factive complement cannot be negated, most speakers fullyaccepted it, which suggests that a factive complement may not be always presupposed. Taking thesefacts all together, we conclude that the presupposition/assertion reading of clausal complementsshould not be taken in isolation, but their selectional environment, including the matrix predicate,should be considered.
3. Conclusions
In this paper, we have proposed that factive clausal complements and non-factive clausalcomplements have different underlying structures; while factive complements are dPs whose headis lexicalized by a weak demonstrative that, non-factive complements are either ForcePs (when theCOMP that is present) or FinPs (when the COMP is null). This novel approach is in line with the extantproposals that the structure of overt that complements is more complex than the structure of null thatcomplements and that the structure of non-factive that complements is richer than the structure offactive that complements. Our analysis further provides an explanation for the distribution of overtthat clauses and null that clauses outside sentential complementation. As shown in (26), for instance,a sentential subject must be headed by that.
26. a. *(That) Lily doesn’t eat vegetables is well-known factive
b. *(That) Lily doesn’t eat vegetables is well-known non-factive
To account for the obligatory presence of that in (26), we adopt the following two proposalsavailable in the literature. First, a sentential subject headed by overt that is not at Spec, T(ense)P butoccupies the Topic position linked to a null DP at Spec, TP [20,50], as illustrated in (27).18
27. a. [TopP [dP That Lily doesn’t eat vegetables]i [TP DP∅i is well-known]]
b. [TopP [ForceP That Lily doesn’t eat vegetables]i [TP DP∅i turns out to be false]]
We also take a syntactic derivational approach to information structure proposed by López [53].López (re)defines the notions of Topic and Focus as Anaphor and Contrast and argues that syntacticallydislocated constituents, such as left or right dislocates or hanging topics, are strong anaphors, havingan antecedent in the previous discourse or the immediate context. Based on this view, we suggestthat the element occurring in the Topic position should be a strong anaphor in order to be linkedto an antecedent. López further proposes that a discourse anaphoric constituent bears the feature[+a(naphoric)], which is assigned at the syntax–pragmatic interface.
Kim also makes a similar proposal to ours and argues that clausal subjects are in fact Topics,which are referential and bear [+nominal] feature [54]. If we adopt this analysis, the sentential subjectin (27a) is a dP, thus nominal, and it can be a Topic. But the sentential subject in (27b) is not nominal,yet it still serves as Topic. Thus, we depart from him and suggest an alternate way.
Building on the view that the COMP that originates as a demonstrative [42], we argue that theForce head lexicalized as that can be referential. To put it differently, both the d head and the Forcehead lexicalized by that in (27a) and (27b) can serve as Topic.
18 This contrasts with other studies that treat clausal subjects as occurring in the canonical subject position, i.e., Spec, IP/TP(cf. Rosenbaum [51], Emonds [52] among others). We thank a reviewer for highlighting Rosenbaum’s work.

Languages 2017, 2, 17 15 of 18
The idea that for a sentential subject to serve as Topic it should be anaphoric can be furthersupported by the structures proposed in (21) and our earlier proposals that a functional categorylexicalized by that has a d-feature. Overt that clauses are either ForcePs or dPs, whose head bears ad-feature, whereas null that clauses are FinPs, lacking a d-feature. Hence, null that clauses cannot serveas Topic, which explains its absence at the sentence subject position.
It has been documented in the literature that RTs are not allowed in clausal subjects regardless ofthe presence of the COMP, as in (28).
28. a. *That this book Mary read thoroughly is true [55] (p. 332)
b. *That Mary your antics will upset is obvious [20] (p. 179)
The example in (28a) is a factive sentence, and the ban on argument fronting in the that clausecan be explained by the proposal that the sentential subject in (28a) is a dP, inside which Topic andFocus cannot be projected.19 On the other hand, it is not clear whether the example in (28b) is factiveor not. If it is not factive, the sentential subject has the ForceP structure of (21a), in which RTs shouldbe allowed, contrary to fact.
Based on the examples in (28), De Cuba argues that only factive complements, but not non-factivecomplements, can appear at the subject position [23].
29. a. [That there are porcupines in our basement] makes sense to me
b. *[That there are porcupines in our basement] seems to me
However, we suspect that the contrast found in (29a) and (29b) has nothing to do with factivitybut is due to the different syntactic behavior of the matrix predicates, make sense and seem, the latterof which does not allow raising of the that clause from its underlying position. Yet, if it is true thatonly factive complements can serve as subject, as De Cuba argues, the ban on RTs in sentential subjectscan be explained by the dP structure of factive that complements. Further research should be done toinvestigate this.
We conclude this paper by mentioning some puzzling data that seem to challenge our analysisof overt vs. null COMPs. In general, the COMP that is optional if the clausal complement is adjacentto the non-factive predicate, as in (30a). Yet, it is obligatory when the clausal complement is separatefrom its selecting predicate, as illustrated in (30b).
30. a. I believe (that) John liked linguistics [56] (p. 39)
b. I believe very strongly *(that) John liked linguistics
Under our proposal that non-factive predicates select either a ForceP (overt that clauses) or a FinP(null that clause), it is indeed unexpected that the COMP is required when there is an interveningmaterial between the matrix predicate and its complement. An [56] suggests that syntax alone cannotaccount for this behavior and offers a syntax-phonology account. He assumes that the null COMP isa result of PF (Phonetic Form) deletion of C and proposes that if a clause is obligatorily parsed as aseparate intonational phrase (I-phrase), it cannot be headed by a null C (null C generalization, [56](p. 58)).20 While a clausal complement in its canonical position, as in (30a), is optionally parsed asseparate I-phrase, it is obligatorily parsed as a separate I-phrase at a non-canonical position in (30b);the clausal complement is extraposed to the right. Thus, the C head cannot be null and it is spelled outas that.
In fact, our proposal is not in conflict with An’s [56]. If his null C generalization holds true, it ispredicted that overt that clauses can appear in non-canonical positions, for its head Force is lexicalized
19 (Be) true is non-factive according to Hooper and Thompson (Class A) [10], whereas be odd/strange is factive.20 We thank a reviewer for referring to An’s work [56].

Languages 2017, 2, 17 16 of 18
by the COMP that. On the other hand, null that clauses are not allowed in this position, due to the factthat its Fin head is phonetically empty.
Acknowledgments: We would like to thank Languages and the two anonymous reviewers for their helpfulcomments. This research is supported by a Swiss National Science Foundation grant (#100012_146699/1), which isgratefully acknowledged.
Author Contributions: The first author wrote the first draft of the paper, which underwent several revisionstogether with the second author.
Conflicts of Interest: The authors declare no conflict of interest.
References
1. Kiparsky, P.; Kiparsky, C. Fact. In Progress in Linguistics, 1st ed.; Bierwisch, M., Heidolph, K.E., Eds.; Mouton:The Hague, The Netherlands, 1970; pp. 143–173.
2. Stowell, T.A. Origins of Phrase Structure. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge,MA, USA, 1981.
3. Pesetsky, D. Zero Syntax Vol. 2: Infinitives. Available online: http://lear.unive.it/jspui/handle/11707/80(accessed on 28 August 2017).
4. Boškovic, Z.; Lasnik, H. On the Distribution of Null Complementizers. Linguist. Inq. 2003, 34, 527–546.[CrossRef]
5. Hegarty, M.V. Adjunct Extraction and Chain Configurations. Ph.D. Thesis, Massachusetts Institute ofTechnology, Cambridge, MA, USA, 1992.
6. Varlokosta, S. Factivity, factive complements and wh-extraction. MIT Work. Pap. Linguist. 1994, 23, 317–336.7. Basse, G. Factive Complements as Defective Phases. In Proceedings of the 27th West Coast Conference on
Formal Linguistics, Los Angeles, CA, USA, May 2008; pp. 52–62.8. Haegeman, L. Locality and the distribution of main clause phenomena. In Locality, 1st ed.; Aboh, E.O.,
Guasti, M.T., Roberts, I., Eds.; Oxford Scholarship Online; Oxford University Press: Oxford, UK, 2014.9. Karttunen, L. Some Observations on Factivity. Pap. Linguist. 1971, 4, 55–69. [CrossRef]10. Hooper, J.; Thompson, S. On the applicability of root transformations. Linguist. Inq. 1973, 4, 465–497.11. Sprouse, J.; Schütze, C.T.; Almeida, D. A comparison of informal and formal acceptability judgments using a
random sample in Linguistic Inquiry 2001–2010. Linguist. Inq. 2013, 134, 219–248. [CrossRef]12. Green, G. Main clause phenomena in subordinate clauses. Language 1976, 52, 382–397. [CrossRef]13. Doherty, C. Clauses without That: The Case for Bare Sentential Complementation in English, 1st ed.; Routledge:
Oxford, UK, 2000.14. McClokey, J.; University of California, Santa Cruz, CA, USA. Adjunction, Selection and Embedded Verb
Second. Unpublished work. 1992.15. Emonds, J.E. A Transformational Approach to English Syntax, 1st ed.; Academic Press: New York, NY, USA,
1976.16. Anderson, L.-G. Form and Function of Subordinate Clauses. Ph.D. Thesis, University of Gotenburg,
Gotenburg, Sweden, 1975.17. Heycock, C. Embedded root phenomena. In Blackwell Companion to Syntax, 1st ed.; Everaert, M.,
van Riemsdink, H., Eds.; Blackwell: Malden, MA, USA, 2006; Volume 2, pp. 174–209.18. Shim, J.Y.; Ihsane, T. Facts: The interplay between the matrix predicate and its clausal complement.
Newctle. Northumbr. Work. Pap. Linguist. 2005, 21, 130–144.19. Hegarty, M.; University of Pennsylvania, Philadelphia, PA, USA. Familiar Complements and Their
Complementizers: On Some Determinants of A’-locality. Unpublished work. 1992.20. Alrenga, P. A sentential subject asymmetry in English and its implications for complement selection. Syntax
2005, 8, 175–207. [CrossRef]21. Melvold, J. Factivity and definiteness. MIT Work. Pap. Linguist. 1991, 15, 97–117.22. Haegeman, L. Conditionals, factives and the left periphery. Lingua 2006, 116, 1651–1669. [CrossRef]23. De Cuba, C.F. On (Non)Factivity, Clausal Complementation and the CP-field. Ph.D. Thesis, Stony Brook
University, Stony Brook, NY, USA, 2007.

Languages 2017, 2, 17 17 of 18
24. Rizzi, L.; Shlonsky, U. Strategies of Subject Extraction. In Interfaces + Recursion = Language? Chomsky’sMinimalism and the View from Syntax-Semantics; Gärtner, H-M., Sauerland, U., Eds.; Mouton de Gruyter:Berlin, Germany, 2007; pp. 115–160.
25. Rizzi, L. The Fine Structure of Left Periphery. In Elements of Grammar; Haegeman, L., Ed.; Kluwer: Dordrecht,The Netherlands, 1997; pp. 289–330.
26. Roberts, I. Head movement. In The Handbook of Contemporary Syntactic Theory, 1st ed.; Steinberg, D.D.,Jakobovits, L.A., Eds.; Wiley-Blackwell: Oxford, UK, 2008; pp. 112–147.
27. Cheng, L. On the Typology of Wh-Questions. Ph.D. Thesis, Massachusetts Institute of Technology,Cambridge, MA, USA, 1991.
28. Chomsky, N. The Minimalist Program, 1st ed.; MIT Press: Cambridge, MA, USA, 1995.29. Choe, H.-S. Restructuring Parameters and Complex Predicates: A Transformational Approach. Ph.D. Thesis,
Massachusetts Institute of Technology, Cambridge, MA, USA, 1988.30. Ahn, H.-D.; Yoon, H.-J. Functional categories in Korean. In Harvard Studies in Korean Linguistics 3; Whitman, J.,
Kang, Y.-S., Lee, I.-H., Bak, S.-Y., Kim, Y., Kuno, S., Eds.; Harvard University Press: Cambridge, MA, USA,1989; pp. 79–88.
31. Whitman, J. Topic, modality, and IP structure. In Harvard Studies in Korean Linguistics 3; Whitman, J.,Kang, Y-S., Lee, I-H., Bak, S.-Y., Kim, Y., Kuno, S., Eds.; Harvard University Press: Cambridge, MA, USA,1989; pp. 341–356.
32. Sells, P. Korean and Japanese morphology from a lexical perspective. Linguist. Inq. 1995, 26, 277–325.33. Shim, J.Y.; Ihsane, T. English overt and null complementizers. Stud. Gener. Gramm. 2017. accepted.34. Saito, M. Sentence Types and the Japanese Right Periphery. In Discourse and Grammar: From Sentence Types to
Lexical Categories; Grewendorf, G., Zimmermann, T. E., Eds.; De Gruyter: Berlin, Germany, 2012; pp. 147–176.35. Haegeman, L.; Ürögdi, B. Referential CPs and DPs: An Operator movement account. Theo. Linguist. 2010, 36,
111–152. [CrossRef]36. Collins, C. The factive construction in Kwa. In Travaux de Recherche sur le Créole Haïtien; Lefebvre, C., Ed.;
Départment de Linguistique, Université du Québec à Montréal: Montréal, Canada, 1994; pp. 31–65.37. Aboh, E. Deriving relative and factive constructions in Kwa. In Contributions to the Thirtieth Incontro di
Grammatica Generativa; Brugè, L., Giusti, G., Munaro, N., Schweikert, W., Turano, G., Eds.; Libreria EditriceCafoscarina: Venice, Italy, 2005; pp. 265–285.
38. Farudi, A. An Antisymmertic Approach to Persian Clausal Complements. Available online: http://lear.unive.it/jspui/handle/11707/215 (accessed on 28 August 2017).
39. Roussou, A. Nominalized clauses in the syntax of Modern Greek. UCL Work. Pap. Linguist. 1991, 3, 77–100.40. Aghaei, B. Clausal Complementation in Modern Persian. Ph.D. Thesis, University of Texas at Austin, Austin,
TX, USA, 2006.41. Takahashi, S. The hidden side of clausal complements. NLLT 2010, 38, 343–380. [CrossRef]42. Kayne, R. Why isn’t This a Complementizer? In Comparison and Contrasts; Kayne, R., Ed.; Oxford University
Press: Oxford, UK, 2010; pp. 190–227.43. Franco, L. Complementizers are not (Demonstrative) Pronouns and Vice Versa. Available online:
http://ling.auf.net/lingbuzz/001539 (accessed on 24 July 2017).44. Roberts, I.; Roussou, A. Syntactic Change: A Minimalist Approach to Grammaticalization, 1st ed.; Cambridge
University Press: Cambridge, UK, 2003.45. Ihsane, T.; Puskás, G. Specific is not definite. Gener. Gramm. Geneva 2001, 2, 39–54.46. Bayer, J.; Dasgupta, P. Emphatic Topicalization and the Structure of the Left Periphery: Evidence from
German and Bangla. Syntax 2016, 19, 309–353. [CrossRef]47. Bayer, J. Asymmetry in emphatic topicalization. In Audiatur Vox Sapientiae; Féry, C., Sternefeld, W., Eds.;
Akademie-Verlag: Berlin, Germany, 2001; pp. 15–47.48. Frascarelli, M.; Hinterhölzl, R. Types of topics in German and Italian. In Information Structure, Meaning and
Form; Schwabe, K., Winkle, S., Eds.; John Benjamins: Amsterdam, The Netherlands, 2007; pp. 87–116.49. Bianchi, V.; Frascarelli, M. Is Topic a Root Phenomenon? Iberia 2010, 2, 43–88.50. Koster, J. Why subject sentences don’t exist. In Recent Transformational Studies in European Languages, 1st ed.;
Keyser, S.J., Ed.; MIT Press: Cambridge, MA, USA, 1978; pp. 53–64.51. Rosenbaum, P.S. The Grammar of English Predicate Complement Constructions; MIT Press: Cambridge, MA,
USA, 1967.

Languages 2017, 2, 17 18 of 18
52. Emonds, J. A reformulation of certain syntactic transformations. In Goals of Linguistic Theory; Peters, S., Ed.;Prentice-Hall: Englewood Cliffs, NJ, USA, 1972; pp. 21–62.
53. López, L. A Derivational Syntax for Information Structure, 1st ed.; Oxford University Press: Oxford, UK, 2009.54. Kim, K.-S. Movement paradoxes are not paradoxes: A raising approach. Lingua 2011, 121, 1009–1041.
[CrossRef]55. Authier, J.-M. Iterated CPs and embedded topicalisation. Linguist. Inq. 1992, 23, 329–336.56. An, D.-H. Clauses in noncanonical positions at the syntax-phonology interface. Syntax 2007, 10, 38–79.
[CrossRef]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
The Role of Functional Heads in Code-SwitchingEvidence from Swiss Text Messages (sms4science.ch)
Aurélia Robert-Tissot 1,* and Etienne Morel 1,2
1 Romanisches Seminar, University of Zurich, Zürichbergstrasse 8, CH-8032 Zürich, Switzerland2 Institut des sciences du langage et de la communication, University of Neuchâtel, Avenue DuPeyrou 6,
CH-2000 Neuchâtel, Switzerland; [email protected]* Correspondence: [email protected]
Academic Editors: Ji Young Shim and Maria del Carmen Parafita CoutoReceived: 28 November 2016; Accepted: 5 July 2017; Published: 13 July 2017
Abstract: This study aims to test two principles of code-switching (CS) formulated by GonzálezVilbazo (2005): The Principle of the Functional Restriction (PFR) and the Principle of Agreement (PA).The first states that a code-switch between the morphological exponents of functional heads belongingto the same extended projection of a lexical category (N◦ or V◦) is not possible. The second claims thatinside a phrase, agreement requirements have to be satisfied, regardless of the language providingthe lexical material. The corpus on which we tested these hypotheses consists of 25,947 authentic textmessages collected in Switzerland in 2009 and 2010. In our corpus, the PA is maintained. The PFRalso seems to hold, even if data is limited. Interestingly, contradicting examples can be explained byphonological principles or the sociolinguistic background of the authors, who are not native speakers.Overall, the evidence found in spontaneously written non-standard data like text messages seems toconfirm the validity of the two principles.
Keywords: code-switching; SMS; syntactic principle; functional restriction; agreement
1. Introduction
In this contribution, we present the results of a pilot study on the syntactic restrictions ofcode-switching (CS). More precisely, we will test two principles proposed by González Vilbazo [1] ona corpus of genuine text messages collected in Switzerland. González Vilbazo’s principles build onprevious generative analyses of CS, to which he integrates the results of his analysis carried out ona corpus of spoken interaction between young Spanish-German bilinguals [1]. We will see that hisprinciples are not only valid for spoken, but also for written informal interaction, at least for switchesbetween and within Germanic (English, German) and Romance (French, Spanish, Italian) languages.This is a relevant observation, as it indicates that the principles may in fact guide the syntactic structureof CS for a larger variety of languages and independently from the extralinguistic context in whichCS occurs.
In what follows, we first present some of the challenges faced when approaching CS and makeexplicit our approach to CS in this paper (Section 1.1). Section 1.2 gives a short outline of existingapproaches to CS and grammar, followed by a detailed presentation of the principles tested inSection 1.3, focusing on the differences between González Vilbazo’s approach [1] and the alternativeproposals. In Section 1.4 we briefly review existing studies on CS in texting. The data and methodsused in this study are presented in Section 2. Section 3 deals with the results of the analysis anddiscusses them. The conclusion in Section 4 addresses some limitations of this study and provides anoutlook for further research.
Languages 2017, 2, 10; doi:10.3390/languages2030010 www.mdpi.com/journal/languages

Languages 2017, 2, 10 2 of 21
1.1. Approaching Code-Switching
Since its first use by Vogt in 1954 [2], the term CS was adopted by different fields in linguistics.Following Gumperz’ much cited definition, CS can be described as the “juxtaposition within thesame speech exchange of passages of speech belonging to two different grammatical systems orsubsystems” [3] (p. 59). However, depending on the theoretical approach (formal, sociolinguistic,interactional etc.), the unity of analysis in question (sentence, turns in talk, sequences of interaction),and sometimes on the specific extralinguistic context, what can all be referred to as CS, can prove tobe very differing phenomena (see [4,5] for a discussion). In fact, both facets of the term CS (code andswitching) raise important questions as to their precise definition.
Firstly, it is not straightforward to define without ambiguities what a ”code” exactly is. It is asubject to debate whether a given linguistic material can always be attributed to a labeled language orwhether it can be legitimately assumed to belong to different languages or varieties of languages [6–8];the type of data studied here (written, mainly informal interaction) and the social activities thatare often conducted in this context (playful language use, see Section 1.4) may even amplify thesechallenges [7,8].
Secondly, it is not evident what represents an actual instance of switching, even if the codes areunambiguously labelled: Which criteria (sociopragmatic, morphological, etymological/lexicographic)and which perspective (the researcher’s or the participants’) is more appropriate to identify a switch?
Thirdly, the mere impossibility of finding a widely accepted definition of CS goes hand in handwith the difficulty in distinguishing CS from other linguistic contact phenomena, especially fromborrowing [4,9]. The lack of a clear-cut distinction leaves us with a continuum ranging from clearinstances of CS to clear instances of borrowings shared by a larger linguistic community. In thecorpus of text messages under analysis (see Section 2), many allogenic items appear to be neither usedcompletely spontaneously, nor to be really integrated into the repertoire shared by a larger community,hence belonging to the grey zone of the continuum between the two categories [4,8,10].
These caveats being formulated, we underline the fact that the present paper focuses on the formalanalysis of CS based on two syntactic principles formulated by González Vilbazo [1], which we testwithout any theoretical presupposition on what grammatical CS entails. It is based on the empiricalidentification of two or more constituents that expose the morphological material of what appears-toresearchers-as different languages or varieties inside the relevant syntactic boundaries. This may alsoimply simple word insertions, which are not considered to be CS by any of the theoretical approaches(see [4] for a discussion).
1.2. Code-Switching and Grammar
Since the seminal work of Poplack [11], research on syntactic restrictions in CS has grown to alarge body of works, which we will not be able to address in detail here; for the sake of brevity, wefocus on the research that is particularly relevant to the principles tested, see Section 1.3.
In the generative framework, CS has become popular with Poplack’s proposal of an EquivalenceConstraint on CS [11]. However, this constraint stating that parallel structures in two languages areneeded in order to switch from one language to the other1 has repeatedly been shown not to holdup to scrutiny (cf. [1] (p. 30) and [8] (pp. 40–54)). Other constraints have been proposed to overcomethe shortcomings of the Equivalence Constraint, such as Belazi et al.’s Functional Head Constraint(FHC) [12]. Instead of focusing on the surface structure, the FHC takes into account the syntacticstructure of phrases; it supposes that it is impossible to switch language between a functional headand its complement because of the strong relation between the two constituents. Yet, this would
1 Code-switches tend to occur at points in discourse where the juxtaposition of L1 and L2 elements does not violate a syntacticrule of either language, i.e., at points around which the surface structure of the two languages map onto each other [11](p. 586).
Languages 2017, 2, 10 3 of 21
imply that CS is not possible between a determiner and its complement, as González Vilbazo pointsout [1] (p. 41), a fact that is not confirmed in his corpus, neither by our examples, as we will see inSection 3.2. Then, MacSwan’s minimalist approach is based on the selectional properties of lexicalitems [13], since according to early minimalism, the relevant linguistic properties are all encoded inthe lexicon. As a consequence, CS would only be constrained by feature mismatches of lexical itemsduring computation. On this account, CS should be possible regardless of the heads involved, anassumption that does not seem to hold either. For instance, a relative pronoun must be followed byfunctional material of the same language, as shown by the following example taken from [1] (p. 79);the Spanish relative que ‘who’ has to be followed by the Spanish inflected verb da ‘gives’ (1a), while itis not possible to combine the German relative der ‘who’ with Spanish verbal morphology, be it in theSpanish (2b) or the German (2c) word order.
1. a. El Lehrer, que da schlechte mündliche Noten...2
the teacher who gives bad oral marks
b. *El Lehrer, der da schlechte mündliche Notenthe teacher who gives bad oral marks
c. *El Lehrer, der schlechte mündliche Noten dathe teacher who bad oral marks gives‘The teacher who gives bad oral marks . . . ” [1] (p. 79)
In this approach, it is not clear how different word order properties (cf. example 10 below) aredealt with.
The last model we want to mention is the Matrix Language Frame (MLF) model [14], of which the4-M model, named after four distinctive morpheme classes, i.e. content morphemes and three types ofsystem morphemes, whose characteristics play a crucial role when it comes to CS, (e.g., [15,16]) is arefined version. This model takes its origin in the assumption that there is a matrix language definedfor a whole CP. Inside a CP, only the so-called “outsider late system morphemes” have to be in thematrix language (ML). This includes all functional morphemes showing a grammatical relation withconstituents that are outside the immediate maximal projection, e.g., subject-agreeing morphemes onverbs. The MLF also allows for embedded language (EL) islands in which a whole chunk appearsin the EL without being affected by the ML. This last component of the model is at the same time itsweak point, since EL occurrences that do not confirm the expectations can be regarded as such islands.A more promising approach would be to propose alternative explanations for examples which, at firstsight, do not seem to fit into the model.
Given the fact that the models discussed in this section seem to all have their downsides, we willtest two principles more recently proposed by González Vilbazo [1], for which little research has beendone so far. These principles are presented in more detail in the next section.
1.3. Presentation of the Principle of Agreement and the Principle of Functional Restriction
The principles we are going to test on our corpus are the Principle of Agreement (PA), and thePrinciple of Functional Restriction (PFR):
The PA states that:
All the morphosyntactic requirements of all the lexical and functional entities have to besatisfied in the sentence. Among these there is selection, agreement in the narrow sense,
2 When there are different source languages in the examples, these are made evident by different fonts (e.g., recte vs. italicsvs. bolt).

Languages 2017, 2, 10 4 of 21
and the attribution of case and theta roles. The language of the lexical entities does notmatter, as long as they satisfy the requirements.3 [1] (p. 157, our translation)
The second principle, the PFR, is about where CS can occur, stating that:
Two functional heads X◦ and Y◦ have to be filled by lexical material of the same language ifthe functional category of YP is the complement of X◦ and both heads are part of the sameextended projection.4 [1] (p. 94, our translation)
Because the PFR applies to extended projections, we focus our analysis on two extended projections,namely the extended projection of the noun (the DP) and the extended projection of the verb (CP).Extended projections form the functional overhead of the lexical categories. Hence, besides the lexicalnoun head N◦, the DP contains at least a quantifier head Q◦ as well as a determiner head D◦.5 FollowingGonzález Vilbazo [1] (p. 108) and Bhatt [17], the DP can be represented as in Figure 1:
Languages 2017, 2, 10 4 of 21
The second principle, the PFR, is about where CS can occur, stating that:
Two functional heads X° and Y° have to be filled by lexical material of the same
language if the functional category of YP is the complement of X° and both heads
are part of the same extended projection [1] (p. 94, our translation).4
Because the PFR applies to extended projections, we focus our analysis on two extended
projections, namely the extended projection of the noun (the DP) and the extended projection of the
verb (CP). Extended projections form the functional overhead of the lexical categories. Hence,
besides the lexical noun head N°, the DP contains at least a quantifier head Q° as well as a
determiner head D°.5 Following González Vilbazo [1] (p. 108) and Bhatt [17], the DP can be
represented as in Figure 1:
Figure 1. Simplified structure of the DP.
The determiner occupies the D°‐head, the numeral the Q°‐head, and the nominal expression the
N°‐head. It is not uncontroversial whether quantifiers have to be analyzed as heads or as phrases (or
even as “semi‐functional or semi‐lexical categories” [18] (p. 408; for a general discussion, see Part III,
Chap. 2)); for reasons that will become clear later, we follow [1], which considers them as heads. The
DP can be modified by adjectives, which according to Cinque are phrases (occupying the specifier
position of the adjective phrase) [19]. The adjective phrase is left‐adjoined to the noun phrase as
in Figure 2:
Thetarollen. Aus welcher Sprache die lexikalischen Einheiten stammen ist hierbei irrelevant, solange sie die
Anforderungen erfüllen. 4 German original: Zwei funktionale Köpfe X° und Y° müssen lexikalisch mit Material aus derselben Sprache gefüllt
sein, wenn die funktionale Kategorie YP Komplement von X° ist und beide Köpfe Teil des selben [sic] funktionalen
Überbaus sind. 5 Here we are simplifying the structure for the sake of clarity. Romance DPs for example also contain at least a
Gender and a Case head cf. [19] (Part II, Chap. 3).
Figure 1. Simplified structure of the DP.
The determiner occupies the D◦-head, the numeral the Q◦-head, and the nominal expression theN◦-head. It is not uncontroversial whether quantifiers have to be analyzed as heads or as phrases(or even as “semi-functional or semi-lexical categories” [18] (p. 408; for a general discussion, seePart III, Chap. 2)); for reasons that will become clear later, we follow [1], which considers them asheads. The DP can be modified by adjectives, which according to Cinque are phrases (occupying thespecifier position of the adjective phrase) [19]. The adjective phrase is left-adjoined to the noun phraseas in Figure 2:Languages 2017, 2, 10 5 of 21
Figure 2. Simplified structure of the DP.
Coming back to the PA, the prediction is that inside, the DP agreement must be preserved
regardless of the lexical item’s origin language. So, in Figure 2 we can see the feminine plural
agreement on both the German and the French determiner as well as on the adjectives, triggered by
the feminine plural cherries (Kirschen and cerises, respectively). It would be ungrammatical not to
have agreement on lexical items that usually display it:
2. die drei gross*(e)*(n) Kirschen
the.PL three big(F)(PL) cherries
3. les/*la trois grand*(e)*(s) cerises
the.PL/the.F three big(F)(PL) cherries
Taking the determiner and the quantifier to be functional heads, a CS from the determiner to
the quantifier is banned according to the PFR, since they are two functional heads of the same
extended projection. The adjectival lexical item on the other hand, can originate from a different
language, since it constitutes a lexical phrase:
4. die drei/trois grossen/grandes Kirschen/cerises
the.PL three big.F.PL cherries
The second extended projection we look at is the complementizer phrase CP, the functional
overhead of the verb. The CP consists of the lexical verb V°, the “functional” verb little v°, the
temporal head T° and the complementizer C°. In German, the CP does not show exactly the same
configuration as in the Romance languages and English. This is mainly due to the fact that German is
a verb‐second language displaying a V2 word order in the main clause and a V‐final word order in
the embedded clause, whereas the Romance languages and English show a rather consistent SVO
word order. This has two main consequences: in the main clause, the German inflected verb raises to
C°, hence triggering the V2 word order. In the embedded clause on the other hand, it remains in T°
because C° is occupied by the complementizer. Since German shows a head‐final configuration, the
inflected verb will appear at the end of the embedded clause. Moreover, it has been shown that the
German participle does not move out of V°. This means that it remains in the lexical domain, not
entering the functional (extended) projection of the verb [1] (p. 86).
5. Ich habe das Buch der Marie geschenkt.
I have the book the.DAT Mary given
‘I have given the book to Mary.’
6. …dass ich das Buch der Marie geschenkt habe.
that I the book the.DAT Mary given have
‘… that I have given the book to Mary.’
Figure 2. Simplified structure of the DP.
3 German original: Alle morphosyntaktischen Anforderungen aller lexikalischen und funktionalen Einheiten müssen im Satz erfülltsein. Dazu gehört Selektion, Kongruenz im engeren Sinne und das Zuweisen von Kasus und Thetarollen. Aus welcher Sprache dielexikalischen Einheiten stammen ist hierbei irrelevant, solange sie die Anforderungen erfüllen.
4 German original: Zwei funktionale Köpfe X◦ und Y◦ müssen lexikalisch mit Material aus derselben Sprache gefüllt sein, wenn diefunktionale Kategorie YP Komplement von X◦ ist und beide Köpfe Teil des selben [sic] funktionalen Überbaus sind.
5 Here we are simplifying the structure for the sake of clarity. Romance DPs for example also contain at least a Gender and aCase head cf. [19] (Part II, Chap. 3).

Languages 2017, 2, 10 5 of 21
Coming back to the PA, the prediction is that inside, the DP agreement must be preservedregardless of the lexical item’s origin language. So, in Figure 2 we can see the feminine pluralagreement on both the German and the French determiner as well as on the adjectives, triggered bythe feminine plural cherries (Kirschen and cerises, respectively). It would be ungrammatical not to haveagreement on lexical items that usually display it:
2. die drei gross*(e)*(n) Kirschenthe.PL three big(F)(PL) cherries
3. les/*la trois grand*(e)*(s) cerisesthe.PL/the.F three big(F)(PL) cherries
Taking the determiner and the quantifier to be functional heads, a CS from the determiner to thequantifier is banned according to the PFR, since they are two functional heads of the same extendedprojection. The adjectival lexical item on the other hand, can originate from a different language, sinceit constitutes a lexical phrase:
4. die drei/trois grossen/grandes Kirschen/cerisesthe.PL three big.F.PL cherries
The second extended projection we look at is the complementizer phrase CP, the functionaloverhead of the verb. The CP consists of the lexical verb V◦, the “functional” verb little v◦, thetemporal head T◦ and the complementizer C◦. In German, the CP does not show exactly the sameconfiguration as in the Romance languages and English. This is mainly due to the fact that Germanis a verb-second language displaying a V2 word order in the main clause and a V-final word orderin the embedded clause, whereas the Romance languages and English show a rather consistent SVOword order. This has two main consequences: in the main clause, the German inflected verb raisesto C◦, hence triggering the V2 word order. In the embedded clause on the other hand, it remains inT◦ because C◦ is occupied by the complementizer. Since German shows a head-final configuration,the inflected verb will appear at the end of the embedded clause. Moreover, it has been shown thatthe German participle does not move out of V◦. This means that it remains in the lexical domain, notentering the functional (extended) projection of the verb [1] (p. 86).
5. Ich habe das Buch der Marie geschenkt.I have the book the.DAT Mary given‘I have given the book to Mary.’
6. . . . dass ich das Buch der Marie geschenkt habe.that I the book the.DAT Mary given have‘ . . . that I have given the book to Mary.’
The examples in (5) and (6) are schematized in the tree-structures in Figures 3 and 4. The treesare not meant to represent antisymmetric trees; we adopt the representation proposed by [1].The discontinuing arch delimits the functional from the lexical domain of the verb.
Languages 2017, 2, 10 6 of 21
The examples in (5) and (6) are schematized in the tree‐structures in Figures 3 and 4. The trees
are not meant to represent antisymmetric trees; we adopt the representation proposed by [1]. The
discontinuing arch delimits the functional from the lexical domain of the verb.
Figure 3. Structure of the German main clause.
Figure 4. Structure of the German subordinate clause.
The French and English main and embedded clauses do not differ from each other apart from
the complementizer that usually introduces the embedded clause: Both are head‐initial with the
inflected verb staying in T°. The participle moves to v°, hence entering the functional domain of the
verb [1] (p. 95) (see also [20]). Again, examples (7) and (8) are represented by the tree‐structures in
Figures 5 and 6 below.
7. J’ ai donné le livre à Marie.
I have given the book to Mary
8. …que j’ ai donné le livre à Marie.
…that I have given the book to Mary
Figure 3. Structure of the German main clause.

Languages 2017, 2, 10 6 of 21
Languages 2017, 2, 10 6 of 21
The examples in (5) and (6) are schematized in the tree‐structures in Figures 3 and 4. The trees
are not meant to represent antisymmetric trees; we adopt the representation proposed by [1]. The
discontinuing arch delimits the functional from the lexical domain of the verb.
Figure 3. Structure of the German main clause.
Figure 4. Structure of the German subordinate clause.
The French and English main and embedded clauses do not differ from each other apart from
the complementizer that usually introduces the embedded clause: Both are head‐initial with the
inflected verb staying in T°. The participle moves to v°, hence entering the functional domain of the
verb [1] (p. 95) (see also [20]). Again, examples (7) and (8) are represented by the tree‐structures in
Figures 5 and 6 below.
7. J’ ai donné le livre à Marie.
I have given the book to Mary
8. …que j’ ai donné le livre à Marie.
…that I have given the book to Mary
Figure 4. Structure of the German subordinate clause.
The French and English main and embedded clauses do not differ from each other apart from thecomplementizer that usually introduces the embedded clause: Both are head-initial with the inflectedverb staying in T◦. The participle moves to v◦, hence entering the functional domain of the verb [1](p. 95) (see also [20]). Again, examples (7) and (8) are represented by the tree-structures in Figures 5and 6 below.
7. J’ ai donné le livre à Marie.I have given the book to Mary
8. . . . que j’ ai donné le livre à Marie.. . . that I have given the book to MaryLanguages 2017, 2, 10 7 of 21
Figure 5. Structure of the French main clause.
Figure 6. Structure of the French subordinate clause.
According to the PA, the theta filter (thematic roles, cf. [21]) must be satisfied and there is
agreement (person, number) inside the CP (e.g., between the subject and the verb). The PFR further
states that there should not be any CS in the functional domain, namely between the morphological
exponents of the complementizer (C°) and the verbal morphology (the exponents of T° and v°). The
differences between the syntactic architecture of German and that of French and English lead to
interesting asymmetries in the possibility for CS, as [1] has been observed for German‐Spanish
bilinguals. Since the participle enters the functional domain in Spanish, but not in German, it is
possible to switch the code for the German participle (9b), but not for the Spanish one (9a):
9. a. Er hat *contado.
b. Ha erzählt.
‘(He) has told.’
Figure 5. Structure of the French main clause.

Languages 2017, 2, 10 7 of 21
Languages 2017, 2, 10 7 of 21
Figure 5. Structure of the French main clause.
Figure 6. Structure of the French subordinate clause.
According to the PA, the theta filter (thematic roles, cf. [21]) must be satisfied and there is
agreement (person, number) inside the CP (e.g., between the subject and the verb). The PFR further
states that there should not be any CS in the functional domain, namely between the morphological
exponents of the complementizer (C°) and the verbal morphology (the exponents of T° and v°). The
differences between the syntactic architecture of German and that of French and English lead to
interesting asymmetries in the possibility for CS, as [1] has been observed for German‐Spanish
bilinguals. Since the participle enters the functional domain in Spanish, but not in German, it is
possible to switch the code for the German participle (9b), but not for the Spanish one (9a):
9. a. Er hat *contado.
b. Ha erzählt.
‘(He) has told.’
Figure 6. Structure of the French subordinate clause.
According to the PA, the theta filter (thematic roles, cf. [21]) must be satisfied and there isagreement (person, number) inside the CP (e.g., between the subject and the verb). The PFR furtherstates that there should not be any CS in the functional domain, namely between the morphologicalexponents of the complementizer (C◦) and the verbal morphology (the exponents of T◦ and v◦).The differences between the syntactic architecture of German and that of French and English leadto interesting asymmetries in the possibility for CS, as [1] has been observed for German-Spanishbilinguals. Since the participle enters the functional domain in Spanish, but not in German, it ispossible to switch the code for the German participle (9b), but not for the Spanish one (9a):
9. a. Er hat *contado.
b. Ha erzählt.‘(He) has told.’
Our grammaticality judgments as native German-French bilinguals reflect the same asymmetry.If we try to switch the code inside the periphrastic verbal construction of examples (6) and (8) above,we obtain the possible combinations in (10) of which only the alternative (10a) with the German lexicalitem schenk- endowed with the French past participle morphology -é is perfectly fine. Alternative (10b)does not seem completely impossible but is very marked; acceptability improves without a followingindirect object (like in example (9b) above). This contrast is probably induced by the fact that theGerman participle, which remains in V◦, follows all objects in the syntax of German (recall that itdisplays a V-final word order in embedded clauses). The two last alternatives with a French participleintegrated in a German clause, both with French or German morphology are excluded.
10. a. . . . que j’ai schenké le livre à Marie.
b. . . . que j’ai ??/*geschenkt le livre à Marie.
c. . . . dass ich das Buch der Marie *donné habe.
d. . . . dass ich das Buch der Marie *gedonnt habe.
This pattern is expected under the PFR: we assume that lexical material merged in a low positioncan take part in syntactic operations (namely the German participle that can be endowed with French

Languages 2017, 2, 10 8 of 21
morphology by moving to v◦), while it is not possible to have a functional exponent (namely theFrench participle in v◦) of a different language than the complementizer.
What sets González Vilbazo’s analysis [1] apart from the MLF, the MLF being arguably the mostpromising model for the last decade, is the claim that a ML is set on the level of extended projectionsinstead of the whole CP. As a consequence, no language has to dominate since the phrase structureof every extended projection can be built according to a different grammar. González Vilbazo’s PFRdiffers also form the 4-M model (a refinement of the MLF, see Section 1.2) in the theoretical assumptionabout the “outsider late system morphemes” of the 4-M model [15,16]. Theoretically, the 4-M modelpredicts that structural case markers (i.e., for the nominative and accusative cases) should in factoriginate from the same language as the verb’s functional morphemes, since these cases depend onthe functional properties of the verb. According to the PFR on the other hand, it suffices that thefeatures match. González Vilbazo himself does not discuss this point, but gives example (1), repeatedas example (11), in which there is a German direct complement (schlechte mündliche Noten ‘bad oralmarks’) paired with a Spanish inflected verb (da ‘gives’) [1]. Unfortunately, with plural nouns, thenominative and accusative cases are syncretic in German. However, if we replace the complement bya masculine singular noun in (12), the accusative morphology is apparent (einen guten Kurs ‘a goodcourse’ vs. nom: ein guter Kurs).
11. El Lehrer, que da schlechte mündliche Noten . . .the teacher which gives bad.F.PL.NOM/ACC oral.F.PL.NOM/ACC grade.F.PL.NOM/ACC
‘The teacher, which gives bad oral grades . . . ’ [1] (p. 79)
12. El Lehrer, que da einen guten Kurs . . .the teacher which gives a.M.SG.NOM good.M.SG.NOM course.M.SG.NOM
‘The teacher, which gives a good course . . . ’ (our adaption)
Moreover, in more recent publications, Myers-Scotton and Jake argue that complementizersare not all of the same kind, since their classification is based on a conceptually relevant versussystem-relevant distinction [16] (pp. 351–354). Some complementizers are claimed to be late systemmorphemes (the “outsiders”) while others are content morphemes or both. The former usually appearin the ML (even if different from the CP they introduce) while the latter are more likely to occurin the language of the CP they introduce. As a consequence, and in contrast to González Vilbazo’sapproach [1], the C◦ head could appear in a different language than the functional elements of the CP itintroduces. But again, since it is not clearly defined which complementizers are outsiders and becausethere seems to be variation according to the languages involved in CS, this prediction is difficult toprove or falsify. However, if there is indeed a case of mismatch between a complementizer and thefollowing functional material, this could falsify the PFR, but only if the connector is really a head.This last restriction is fundamental, as González Vilbazo points out [1] (pp. 81–84). For example,connectors conveying the same meaning in two languages are not automatically C-heads in both ofthem. There exist also different kinds of connectors bearing the same meaning in one and the samelanguage, as is shown by the complementizer weil contrasting with the coordinating connector denn,both meaning ‘because, since’ in German, but only the first being a subordinating device, as can easilybe seen by the German word order.
Having said that, Myers-Scotton and Jake also give some examples which are challenging forGonzález Vilbazo’s claims [1], since they show that bridge connectors like English that vary accordingto whether they are morphological exponents of the language of the matrix CP, such as in (13) from aPalestinian Arabic–English CS, or of the embedded CP [16] (pp. 352–353).
13. [ . . . ] kaan el-doctor yišuk it is not reliable[ . . . ] PERF.3MASC.be the-doctor IMPERF.3MASC.doubt it is not reliable‘[he] was, the doctor, doubting that it was not reliable.’ [22] (p. 71), in [16] (p. 353)
In the former case, Myers-Scotton and Jake propose to analyze the “entire multi-clausal constituentin one language” [16] (p. 353), i.e., the language of the matrix CP, and the following TP-clause is an

Languages 2017, 2, 10 9 of 21
embedded island, and not the ML of the embedded CP. A CS from a complementizer to its followingTP is unexpected under the PFR and has been argued several times (cf. [12], (pp. 224–225) amongothers) to be ungrammatical. Interestingly, the examples given in [16] are all with saying verbs likesay, confirm or doubt. Now, it is well known that the bridge following this type of verb is a ratherloose connector, introducing sentences that are less integrated in the matrix sentence. Accordingto Haegeman [23], the relation between the matrix sentence and these loosely embedded sentencesis more one of coordination than of subordination, which could explain the unexpected CS here:coordinating linking words are not subject to the PFR.
It is also worth considering that in the reported examples of CS between English and Arabicin [16], the Arabic complementizers equivalent of that show morphological agreement. We cannotdiscuss this issue in detail here, but it could point towards a difference in CS depending on whetherthe subordinating head expresses the Force-head or the Fin-head in Rizzi’s split-CP hypothesis [24].Rizzi [24] (p. 312) and Rizzi and Shlonsky [25] argue that only the Fin-head, but not the Force-head,can be associated with agreement. If the complementizers which do not match the language of thefollowing TP are instances of Fin◦, we could speculate that it is Force◦ which sets the ML of the CPand Fin◦ might not be bound to the PFR since it carries more lexical features (besides functional ones).If there can be shown such a correlation across languages, this would be welcome, otherwise, noprinciple can be stated for the complementizer’s language in CS. However, these considerations haveto remain speculative for the time being.
1.4. Code-Switching in Texting
The formal analysis discussed in this paper aims to complement and build on previous workpertaining to CS in text messaging, which now comprises a rather large number of studies on differentcontexts (for a more complete literature review see [8,26,27]; for research on texting in general see [28]).
A first body of research focuses on CS of individuals who regularly use different languages in alltheir everyday activities, including text messages, in language combinations like Tagalog–English in thePhilippines [29], Spanish–English in the U.S. [30], English–isiXhosa in South Africa [31], English–Arabicin Kuwait [32], Nigerian English-standard English-vernaculars in Niger [33] and French–Wolof (andother languages) in Senegal [34]. Particular attention has been given to the influence of CS on thelength of messages [29], assuming that CS leads to shorter messages, although this hypothesis hassince been falsified [30,31]. These studies illustrate diversified and culturally specific CS practices andinterpret them on a sociolinguistic background, assuming ‘sociosymbolic values’ of certain languages.However, they generally disregard formal aspects of CS and do not explicitly refer to any theoreticalCS framework.6
A second body of research relates to work carried out within the project “sms4science”, especiallyin Belgium [36], La Réunion [37] and Switzerland; in the Swiss context, CS was analyzed in textmessages with Swiss German [26], French [8,27], Italian [38] and Romansh [39] as main text language(see also [7,40] for transversal and comparative elements).
These contributions use linguistic categories to describe the data mainly in a variational [8,26,40]and/or interactional [8,27] approach to language contact phenomena, but pay less attention tosyntactic constrains on CS. Based on Poplack [11], the authors distinguish between intersententialand intrasentential CS. For the latter they further use Muysken’s CS typology [41] to discriminatethe insertion of elements originating from a language x into the utterance (or proposition) whosebase language is y (called “transfer” by Auer [42] and “embedding” by Myers-Scotton [43]) and thealternation between two distinct base languages.
6 See however [35] who worked on Arabic-English CS in Jordanian texting and show that certain linguistic units are moreused than others: they attest a high proportion of single nouns (34%), but also clauses (12%), phrases (21%) and functionalcategories such as conjunctions (8%), articles (7%), and pronouns (5%).

Languages 2017, 2, 10 10 of 21
The results from analyses of language-specific subcorpora in the context of the Swiss sms4scienceproject show that even though CS is quite frequent (57% of the Romansh messages, 23% of the Italianmessages, 22% of the Swiss German messages and 18% of the French messages contain at least oneswitch), the patterns are minimal in nature, as most of the elements are very short, potentially formulaicintersentential alternations (e.g., hola ‘hi’, ti amo ‘I love you’, besos ‘kisses’, what else?).
Overall, more complex intrasentential alternations, intersentential CS and language changefrom one message to another are mainly found with older participants who consider themselvesto be plurilingual.7 Due to the high proportion of short and recurrent intersentential alternations,often combined with recurrent language play, the usefulness of syntactic analyses of CS has beenquestioned for the corpus at hand (e.g., [8]) and syntactic constraints were not tested on any subpartof the corpus so far. However, in spite of the fact that the sequences of CS with which it is dealt arerather short and relevant cases perhaps limited in number, this does not imply that they could notbe used to test hypotheses, especially if these focus on the transition point from one variety to theother in CS, since syntactic principles should apply to every kind of CS, regardless of their length orcommunicative intention.
Apart from that, a corpus of Swiss text messages seems to be an ideal ground for testinghypotheses on CS for two reasons. Firstly, the informal context, in which most of the text messages arewritten, facilitates CS with respect to other more formal contexts where CS is stigmatized. Secondly, inSwitzerland, people not only switch from their mother tongue to English (which is taught as a foreignlanguage at school)8, but also to other languages spoken (and regionally taught as L2) in the country,namely (Swiss) German, French, Italian and Romansh (see Section 2 for further details). This particularsociolinguistic situation allows us to test if the syntactic restrictions under study (the PA and thePFR, see Section 1.3) hold across different types of (informal) communication and different languagepairs. If this is the case, it may be a strong hint towards the interlinguistic, if not universal validity ofthe principles.
As mentioned above, we are going to test the two proposed principles on a corpus of multilingualSwiss text messages. In the next section, we introduce the corpus and the methodology we used; theresults are presented and discussed in Section 3.
2. Materials and Methods
Our corpus consists of 25,947 text messages, collected in Switzerland between 2010 and 2011.The corpus was compiled in the context of the project sms4science.ch [44]. In order to get genuine textmessages, a publicity campaign was launched in order to invite people to send a copy of their originalmessages to a free phone number. In addition, the participants were sent a link to fill in an onlineform to provide sociodemographic information. The data were then anonymized and linked to thequestionnaires by a code number.
More than 10,700 of the collected messages are written in a German dialect, about 7300 in nearstandard German, circa 4600 are in French, about 1500 show an Italian variety, and 1100 a Romansh one.The corpus also contains nearly 500 English messages as well as about 200 messages in other languagesand varieties. These indications rely on the main language of the message, since, as mentioned before,about a quarter of them contain at least one CS element.9 The text messages were sent by 2627 differentmobile devices. Note that in 2010/2011 when the corpus was built, smartphones were not widespread
7 For the Swiss German corpus, Bucher [26] also shows an effect of age, standard German alternations being used moreoften by older participants, English insertions being preferred by the younger ones (age is used as a continuous variable byBucher). No analysis linked to L1 and L2 was carried out.
8 Following Cathomas et al. [40], English is used in the following proportions for the respective subcorpora: 44.1% for SwissGerman, 59.1% for French, 28.7% for Italian, and 22.6% for Romansh.
9 For each text message, a main language was defined as the dominant language, i.e. the most used language in the messagein terms of words (tokens).

Languages 2017, 2, 10 11 of 21
in Switzerland, hence almost all messages were texted with a traditional mobile phone keyboard and,according to the questionnaires, without a spell checker.
The data were complemented by a manually standardized layer, which means that sequenceswere transcribed into standard orthography or, in the case of German dialects, translated into StandardGerman. Each token from a different variety than the main language of the message was manuallyattributed a corresponding tag.10
Subsequently, the subcorpora were parsed by an automatic Part-of-Speech (PoS) tagger, giventhe large amount of data. For this task, different taggers were used, since the available taggers areall trained for different languages. This fact leads to the inconvenient result that the subcorpora aretagged with different labels in different subcorpora. In addition, the accuracy of the PoS-tagging isslightly degraded because text message data display non-standard language, whereas the taggers aretrained on near standard corpora. Specifically, repetitive code-switches induced the automatic taggersin error. These drawbacks have to be kept in mind for the interpretation of the results. However, inanalyzing specific examples, the original messages were looked at and reported here in order to makesure that the analysis is not biased by standardizing issues.
For the present study, the data was searched semi-automatically using the search engine ANNIS(http://corpus-tools.org/annis/)11, combining language labeling and PoS-tagging. Unfortunately, thedescribed methodology did not allow for a quantification of the results because there are too manyfalse positives and false negatives in the search results. Hence, we will offer a qualitative analysisshowing the tendencies, but we make no claim to completeness. This is also the reason why we aregoing to discuss specific examples rather than provide statistical data; the quantitative analysis of thedata is left to future research.
3. Results
In this section we report first general observations on CS in the corpus (Section 3.1). Then, we givesome examples on which the PA (Section 3.2) and the PFR (Section 3.3) can be confirmed. Section 3.4shows instances of CS that contradict Poplack’s Equivalence Constraint [11] and Belazi et al.’sFunctional Head Constraint [12]. In Section 3.5 we analyze apparent counterexamples to the PFR; wepropose an alternative explanation for the unexpected data and discuss them with regards to otherCS models.
3.1. General Observations
From earlier studies on the same corpus, we know that most of the code-switches are in factisolated items (e.g., greetings, excuses, wishes etc.), insertions of a single item (cf. (14)), or abbreviations(e.g., lol ‘laughing out loud’, cya ‘see you’, tvttb (ti voglio tanto bene) ‘I wish you all the best’) [40].
14. je viens pas à Neuch today!I come not to Neuchâtel today‘I will not come to Neuchâtel today!’
More complex code-switches (of more than three tokens) are less frequent and the switch is oftenintersentential (even indicated by a full stop in (15)):12
10 A token is technically defined here as a single character or a series of characters delimited by a space on both its extremities.11 The sms4science.ch corpus is publicly accessible online via the corpus website (www.sms4science.ch). The data can be
consulted using two different browsers, the Korpusnavigator and ANNIS2. As the latter allows for more specific searches(exploiting PoS-tagging, language tagging and the normalized language level), it was preferred to the first.
12 E.g., in the French subcorpus, only 0.8% of the CS are intrasentential [8].

Languages 2017, 2, 10 12 of 21
15. Grr anche noi ti amiamo tanto tanto mio geologo papa.grr also us.NOM you.ACC love.1PL so.much so.much my geologist daddy
Pourrais tu ramener tous les pijama rangé ds l armoire à Maria?Could.2SG you bring all the pijamas stored in the wardrobe of Maria?‘Grr, we too like you so much my daddy geologist. Could you bring all the pijamas stored inMaria’s wardrobe?’
From a sociolinguistic point of view, the French subcorpus shows that the code-switch consistingof only one token are mostly English items and that they are more frequently used by people who are25 years old or younger. Not surprisingly, the more complex code-switches are performed by peoplewho declared to be plurilingual. With these people, the switched items are more often of a varietyspoken in Switzerland (e.g., French, Swiss German or Italian) than English [8].
On the whole, from our research questions we can make three main observations which will bediscussed in further detail in the following sections:
• We did not find any counterexample to the PA: where the agreement features are spelt out, theyagree inside the DP and the CP.
• Overall, there are very few examples on which the PFR can be verified (or falsified). This is mainlydue to the aforementioned fact that the vast majority of CS is intersentential.
• If there are switches inside an extended projection, they almost always occur on lexical heads.This is expected by the PFR. The few cases that do not conform to the PFR will be discussed inSection 3.5.
In what follows we will illustrate these observations with a detailed examination ofsome examples.
3.2. On Confirming the Principle of Agreement
In (16) below,13 there are two instances of CS, one for the greeting and one for the farewell:
16. Ciaobella, ischgestabigguetgange?hi.beauty, is.yesterday.evening.well.gone?händallwidrdierichtigijagemitheigno?have.all.again.the.right.jacket.with-them.home.taken?Heiichwùnscheeuerholsamiundsunnerichitägufkreta . . . dickebacino.hey.I.wish.youPL.relaxing.and.sunflooded.days.on.Crete . . . bigM.kissM.DIM
‘Hi [my] beauty, has it gone well yesterday evening? Has everybody taken home the right jacket?Hey, I wish you relaxing and sunny days in Crete . . . Big kiss.’
The farewell is interesting, since it shows masculine agreement on the Swiss German adjectivedicke ‘big’ according to the gender of the Italian diminutive bacino ‘little kiss’. The diminutives in SwissGerman on the other hand are all neuter (Küssli, ‘little kiss’) and would trigger the neuter agreementmorpheme -s on the adjective (dicks, ‘big’). This shows that the Principle of Agreement indeed applies:irrespective of the variety from which the morphemes originate, the noun has an intrinsic gender thattriggers agreement on the adjective.
In (17) we have a similar case: the Italian proper noun Ticino triggers masculine agreement notonly on the Italian adjective bello ‘lovely, beautiful’, but also on the Swiss German determiner dä ‘the’.The German corresponding Tessin ‘Ticino’ however is neuter, which would trigger neuter agreementon the determiner (d)s ‘the’:
13 We kept the original orthography of the messages. In this case, the writer chose not to separate the words by blank spaces).

Languages 2017, 2, 10 13 of 21
17. Schön, dass äs dir guät goth & du dä bellonice that it you.DAT well goes & you the.M.SG lovely. M.SG
Ticino so chasch gnüssäTicino. M.SG so can.2SG delight‘Nice, that you are doing well and that you can so appreciate the lovely Ticino.’
Example (18) shows that even the English nouns like shower trigger, in this case, feminineagreement on the adjective, since it is most probably interpreted as inherently feminine as is theFrench douche:
18. ouf, ben quel timing! moi j ai pas arrêté de courir entreouf well what.a timing me I have not ceased of run. INF between
lessives, courses, ménage et théâtre. bises et bonne baby shower!!!laundries shopping housework and theatre kisses and good.F baby shower
Since Poplack et al. [9], it is consented that case assignment to borrowed or switched nounsdepends on different factors. However, in the present case, there is no biological gender involved, nordoes the noun’s morphological pattern correlate with a specific grammatical gender (as it rarely doesin French in general). Having excluded these clues, we are left with a high probability that genderassignment here is in fact due to analogy with the French equivalent, a factor that has turned out to bea strong indicator especially in languages which show little correlation between noun morphologyand gender.
Of course, these are only a few examples in which the agreement pattern can be shown to holdacross different varieties. The challenge here is to track morphologically visible agreement that istriggered by a noun (or a pronoun) which does not bear the same inherent case or number in boththe varieties in order to verify the PA. In our corpus, this configuration appears either with Romancenouns whose German counterpart would bear neuter gender and an agreeing German adjective orarticle (cf. (16) and (17)), or with English nouns, which do not show overt gender at all with anagreeing German or Romance adjective or article (cf. (18)). But still, we did not come across anycounterexamples to the PA in the corpus.
3.3. On Confirming the Principle of Functional Restriction
Turning to the PFR, consider (19):
19. J’ ai pas looké mon foneI have not looked my phone‘I did not look at my phone’
Here, a French auxiliary (ai) is accompanied by an English lexical verb (look), that is endowedwith French participial morphology (-é). In Section 1.3 we have seen that this pattern is expectedto occur: once the functional T◦-head is filled by the French auxiliary, the participle must also bearFrench morphology because it moves to the functional domain (i.e., to v◦). In contrast, the lexical item,introduced very low in the derivation (i.e., in V◦), can freely be of another variety than the functionalheads. Tellingly, the verbal complement is linked to the verb according to the French subcategorizationframe, namely as a DP, whereas the English frame would require the preposition at. This seemsto confirm the principle, according to which the functional requirements must follow one and thesame grammar.
In a similar vein, example (20) shows that even if German lexical material is introduced betweenthe English auxiliary do and the participle, the latter preferably displays the English morphology:
20. how did das neue jahr begin?how did the new year begin‘How did the new year begin?’

Languages 2017, 2, 10 14 of 21
In principle, according to the PFR it would be possible to combine the do-auxiliary with a Germaninfinitive (beginnen ‘to start’), as it remains in V◦, even if standard German does not form the past tensewith the auxiliary do.
21. ?how did das neue Jahr beginnen?how did the new year begin.INF
‘How did the new year begin?’
However, it is completely banned to form a mixed structure that combines the German pastperfect consisting of a have-auxiliary plus participle (22a) with the English do-auxiliary (22b). Thisis again predicted by the PFR since the functional T◦ head determines the shape of the followingfunctional elements; the participle relating to an English T◦ head must rise to the functional domainand adopt English morphology.
22. a. wie hat das neue Jahr begonnen?how has the new year begin.PTCP
b. *how did the new year begonnen?how did the new year begin.PTCP
The PFR seems to hold even for further functional relations. For instance, in (23), the prepositionpour ‘for’ governing the lexically English infinitive ride triggers French infinitival morphology (-er) onthe verb. This is again in sharp contrast to the English counterpart, which takes a verbal -ing form afterthe preposition for, corresponding to the French pour.
23. je dois aller m acheter une new veste pour rider ok?I must go.INF REFL buy.INF a new jacket for ride.INF ok?‘I have to buy myself a new jacket for riding, ok?’
But, as we shall see in the next section, the fact that a specific structure does not exist in one of thetwo CS-languages is not per se a prohibiting factor for switching.
3.4. Against an Equivalence Constraint and the Functional Head Constraint
As already mentioned in Section 1.2, the Equivalence Constraint proposed by Poplack [11] cannotexplain the restrictions to which the syntax of CS obeys. In particular, we find switched lexical materialin structures that only exist in one of the involved languages. For example in (24), the English tensedverb have takes a Swiss German complement that cannot be translated word by word into Englishbecause there is no corresponding phrasal verb to the standard or Swiss German gern haben, viz. gärnha ‘to like’ (cf. (24b)).14
24. a. I haveyou eifach molto gärnI haveyou simply very -
b. Ich han dich eifach sehr gärn!‘I like you simply very much!’
Nevertheless, as we can see, the complement of the English verb consists of German lexicalmaterial. This is possible because the heads of the functional extended projection of the verb are allfilled with English material. Moreover, the Swiss German complement eifach . . . gärn (‘simply . . . -’)meets the subcategorization requirements of the (English) verb. Hence, there is no restriction thatwould prohibit CS here.
14 This echoes the use of linguistic creativity in CS as addressed by Lakshmanan et al. especially for contexts where CS“is inclusive of hybrid structure and/or patterns that evince innovation and language change” [45] (p. 1). For recentsociolinguistic work arguing in favor of a shift away from additive models of bilingualism towards more holistic perspectiveson different linguistic resources see, for instance [46]. In the specific context of texting see also [8].

Languages 2017, 2, 10 15 of 21
Strictly speaking, according to the Equivalence Constraint [11], each occurrence of a composedverb form of a Romance language or English should not be compatible with a German complement; aswe have seen in Section 1.3, German participles remain in a lower syntactic position than e.g., Frenchor English participles and hence are placed at the end of a proposition, while in the other languages itprecedes the complement. There is a (surface) ordering mismatch between the two types of languagesinvolved and switching should be banned. But this prediction is not fulfilled, as we can see in (25).In (25a) we give the original message and in (25b) and (25c) we provide a French and a Swiss Germantranslation, respectively. Not only does the Swiss German prefer the construction with the prepositionmit ‘with’ like in English, but more crucially the complement precedes the participle, and this wouldalso be the case if the complement was direct (i.e., without a preposition) in German.
25. a. Je t’ appelle quand j’ ai fini le schwitzertütsch.I you.ACC call when I have finished the Swiss.German
b. Je t’ appelle quand j’ ai fini le suisse allemandI you.ACC call when I have finished the Swiss German
c. Ich lüte dir a wänn ich mit em Schwitzertütsch fertig binI call you VP15 when I with the.M.SG.DAT Swiss.German finished am‘I call you when I’m done with the Swiss German [course].’
We have already mentioned that Belazi et al.’s [12] Functional Head Constraint (see Section 1.2)is not respected in our data. First, assuming that the determiner is a D◦-head, it should only be ableto select nouns of the same language, which is clearly not true as we have just seen in example (25).Further, example (20) above shows that the complement of the verb has not necessarily to be in thesame language as the verb itself. Of course, the lexical verb V◦ is not a functional head. However,if we assume that the French infinitival and participial morphology stems from v◦, then cases in whicha foreign lexical verb is taking a French morphology should be banned, since the lexical verb V◦ isthe complement of the functional verb v◦. Nevertheless, example (19) above shows the contrary: theEnglish lexical verb look is the complement of the functional verbal head v◦. And this v◦ clearly showsFrench properties providing the verb with the French participial morpheme -é.
As for the 4-M model, its predictions are quite similar to the PA and the PFR. An empirical factthat could discriminate between the two models is the case marking on nominative or accusativeconstituents that would not correspond to the functional morphemes of the verb, as already discussedin Section 1.3. Our corpus provides rather limited exploitable data. This is mainly due to the fact thatvery often, the verbal morphology in the two languages involved in the switch is either homophonousas in example (26), or the chosen orthography can be interpreted as reflecting either the pronunciations,such as in example (27). In (26), the ending -e corresponds to both the English and the French inflectionfor the first person. In (27), the orthography <phone> can either be read as the English
Languages 2017, 2, 10 16 of 21
the pronunciations, such as in example (27). In (26), the ending -e corresponds to both the English and the French inflection for the first person. In (27), the orthography <phone> can either be read as the English [fəʊn] or as a morphologized Swiss German [fəʊnə] with a schwa for the infinitive.
26. Je te phone demain pour t’ engueuler! :) I you phone tomorrow for you give a roasting ‘I phone you tomorrow to give you a roasting.’ 27. Wa söl i am Timo ez Säqe? CHasH mia pHone? what shall I to.the. DAT Timo now say Can.you me. DAT phone ‘What shall I say to Timo now? Can you phone me?
Now, the 4-M model would only be contradicted if in these examples the English variant was intended: the agreeing morpheme on the verb would not correspond to the language of the case marked pronouns. But the fact that in (27) the complement pronoun mia is marked for dative hints towards a German like phone: while phone takes a direct complement in English, the Swiss German translation alüte takes an indirect complement.
3.5. How to Explain Apparent Counter-Examples to the Principle of the Functional Restriction
So far we have presented data that entirely support the two principles we are testing. However, we also found some data that appear problematic at first sight. Consider (28):
28. A proposito, sempre di quel capitolo, le trois grandes routes By the way, always of this chapter the.f.pl. three big.f.pl. roads de la persuasion sono le 3 implicazioni (forte, moyenne, nulle)? of the persuasion are the 3 implications strong medium null ‘By the way, concerning the same chapter, the trois grandes routes de la persuasion are the 3
implications (strong, medium, zero)?’
Unexpectedly, this example shows an Italian determiner followed by a French quantifier. Relying on the extended projection of the noun as presented in González Vilbazo [1], the determiner and the quantifier are both functional heads staying in D° and Q°, respectively. These two heads belong to the same extended projection, so they should be filled by lexical exponents of the same variety.
In the present case, however, we know that the texter is a native Italian speaker. Our explanation for the theoretically impossible CS inside the nominal functional extended projection is based on the assumption that the author does not analyse the components of the nominal expression one by one; she rather reanalyses the sequence trois grandes routes de la persuasion ‘three big roads of the persuasion’ as one and the same proper noun relating to a specific philosophic or psychologic concept. This assumption is plausible, firstly because the writer is not French speaking and secondly because it seems to be a quotation of a concept that both the writer and the addressee have been taught in a lecture they have attended together. If our assumption is correct, the PFR is not any longer violated: the Italian determiner simply combines with a French noun. According to the MFL, the sequence would be analysed as an EL island. A further option to analyse this example is to regard numerals as lexical heads instead of quantifiers. Then they do not constitute a problem for the proposed principle at all, since lexical heads are not affected by the predictions. But assuming that numerals are lexical heads weakens the predictive force of the PFR, since there remain very few cases in which it actually can be violated.
Another explanation for (28) could rely on the phonetic similarity between the Italian and the French determiner (le [lɛ] and les [le] respectively): even if the determiner is spelt the Italian way, it could also be interpreted as the French [le], in the sense of phonetic spelling (cf. [47]). Perhaps this second hypothesis is farfetched for (28), since this would be the only string that is not spelt according to the standard orthography in this example.
However, in (29) below, the ”phonetic spelling” explanation is much more verisimilar. The message is obviously a conscious wordplay, mixing English and Swiss German:
or as amorphologized Swiss German
Languages 2017, 2, 10 16 of 21
the pronunciations, such as in example (27). In (26), the ending -e corresponds to both the English and the French inflection for the first person. In (27), the orthography <phone> can either be read as the English [fəʊn] or as a morphologized Swiss German [fəʊnə] with a schwa for the infinitive.
26. Je te phone demain pour t’ engueuler! :) I you phone tomorrow for you give a roasting ‘I phone you tomorrow to give you a roasting.’ 27. Wa söl i am Timo ez Säqe? CHasH mia pHone? what shall I to.the. DAT Timo now say Can.you me. DAT phone ‘What shall I say to Timo now? Can you phone me?
Now, the 4-M model would only be contradicted if in these examples the English variant was intended: the agreeing morpheme on the verb would not correspond to the language of the case marked pronouns. But the fact that in (27) the complement pronoun mia is marked for dative hints towards a German like phone: while phone takes a direct complement in English, the Swiss German translation alüte takes an indirect complement.
3.5. How to Explain Apparent Counter-Examples to the Principle of the Functional Restriction
So far we have presented data that entirely support the two principles we are testing. However, we also found some data that appear problematic at first sight. Consider (28):
28. A proposito, sempre di quel capitolo, le trois grandes routes By the way, always of this chapter the.f.pl. three big.f.pl. roads de la persuasion sono le 3 implicazioni (forte, moyenne, nulle)? of the persuasion are the 3 implications strong medium null ‘By the way, concerning the same chapter, the trois grandes routes de la persuasion are the 3
implications (strong, medium, zero)?’
Unexpectedly, this example shows an Italian determiner followed by a French quantifier. Relying on the extended projection of the noun as presented in González Vilbazo [1], the determiner and the quantifier are both functional heads staying in D° and Q°, respectively. These two heads belong to the same extended projection, so they should be filled by lexical exponents of the same variety.
In the present case, however, we know that the texter is a native Italian speaker. Our explanation for the theoretically impossible CS inside the nominal functional extended projection is based on the assumption that the author does not analyse the components of the nominal expression one by one; she rather reanalyses the sequence trois grandes routes de la persuasion ‘three big roads of the persuasion’ as one and the same proper noun relating to a specific philosophic or psychologic concept. This assumption is plausible, firstly because the writer is not French speaking and secondly because it seems to be a quotation of a concept that both the writer and the addressee have been taught in a lecture they have attended together. If our assumption is correct, the PFR is not any longer violated: the Italian determiner simply combines with a French noun. According to the MFL, the sequence would be analysed as an EL island. A further option to analyse this example is to regard numerals as lexical heads instead of quantifiers. Then they do not constitute a problem for the proposed principle at all, since lexical heads are not affected by the predictions. But assuming that numerals are lexical heads weakens the predictive force of the PFR, since there remain very few cases in which it actually can be violated.
Another explanation for (28) could rely on the phonetic similarity between the Italian and the French determiner (le [lɛ] and les [le] respectively): even if the determiner is spelt the Italian way, it could also be interpreted as the French [le], in the sense of phonetic spelling (cf. [47]). Perhaps this second hypothesis is farfetched for (28), since this would be the only string that is not spelt according to the standard orthography in this example.
However, in (29) below, the ”phonetic spelling” explanation is much more verisimilar. The message is obviously a conscious wordplay, mixing English and Swiss German:
with a schwa for the infinitive.
26. Je te phone demain pour t’ engueuler! :)I you phone tomorrow for you give a roasting‘I phone you tomorrow to give you a roasting.’
27. Wa söl i am Timo ez Säqe? CHasH mia pHone?what shall I to.the.DAT Timo now say Can.you me. DAT phone‘What shall I say to Timo now? Can you phone me?
Now, the 4-M model would only be contradicted if in these examples the English variant wasintended: the agreeing morpheme on the verb would not correspond to the language of the casemarked pronouns. But the fact that in (27) the complement pronoun mia is marked for dative hints
15 VP: verb particle.
Languages 2017, 2, 10 16 of 21
towards a German like phone: while phone takes a direct complement in English, the Swiss Germantranslation alüte takes an indirect complement.
3.5. How to Explain Apparent Counter-Examples to the Principle of the Functional Restriction
So far we have presented data that entirely support the two principles we are testing. However,we also found some data that appear problematic at first sight. Consider (28):
28. A proposito, sempre di quel capitolo, le trois grandes routesBy the way, always of this chapter the.f.pl. three big.f.pl. roads
de la persuasion sono le 3 implicazioni (forte, moyenne, nulle)?of the persuasion are the 3 implications strong medium null‘By the way, concerning the same chapter, the trois grandes routes de la persuasion are the 3 implications(strong, medium, zero)?’
Unexpectedly, this example shows an Italian determiner followed by a French quantifier. Relyingon the extended projection of the noun as presented in González Vilbazo [1], the determiner and thequantifier are both functional heads staying in D◦ and Q◦, respectively. These two heads belong to thesame extended projection, so they should be filled by lexical exponents of the same variety.
In the present case, however, we know that the texter is a native Italian speaker. Our explanationfor the theoretically impossible CS inside the nominal functional extended projection is based onthe assumption that the author does not analyse the components of the nominal expression one byone; she rather reanalyses the sequence trois grandes routes de la persuasion ‘three big roads of thepersuasion’ as one and the same proper noun relating to a specific philosophic or psychologic concept.This assumption is plausible, firstly because the writer is not French speaking and secondly becauseit seems to be a quotation of a concept that both the writer and the addressee have been taught in alecture they have attended together. If our assumption is correct, the PFR is not any longer violated:the Italian determiner simply combines with a French noun. According to the MFL, the sequencewould be analysed as an EL island. A further option to analyse this example is to regard numerals aslexical heads instead of quantifiers. Then they do not constitute a problem for the proposed principleat all, since lexical heads are not affected by the predictions. But assuming that numerals are lexicalheads weakens the predictive force of the PFR, since there remain very few cases in which it actuallycan be violated.
Another explanation for (28) could rely on the phonetic similarity between the Italian and theFrench determiner (le [lε] and les [le] respectively): even if the determiner is spelt the Italian way,it could also be interpreted as the French [le], in the sense of phonetic spelling (cf. [47]). Perhaps thissecond hypothesis is farfetched for (28), since this would be the only string that is not spelt accordingto the standard orthography in this example.
However, in (29) below, the ”phonetic spelling” explanation is much more verisimilar.The message is obviously a conscious wordplay, mixing English and Swiss German:
29. maybe wänn you are zrugg in züri at that uhrtime youmaybe when you are back in Zurich at that clock.time you
can just drop by for a kaffee if you likecan just drop by for a coffee if you like‘Maybe when you are back in Zurich at that time, you can just drop by for a coffee if you like.’
In theory, it should not be possible to combine the Swiss German complementizer wänn ‘when’with the English tensed verb are. But still, we do not think that the PFR was violated. The lexicalitem wänn is ambiguous, especially if we take into consideration that Swiss German people tend topronounce the English when [wen] as [vεn], which in turn gives rise to the suspicion that wänn canactually be interpreted as both the Swiss German [væn] and the pseudo-English [vεn].

Languages 2017, 2, 10 17 of 21
In addition, a genuine (Swiss) German wänn would trigger the V-final position of the tensed verb,cf. (30a) vs. (30b). But the V-final position is completely out with an English inflected verb, cf. (30c).
30. a. when you [arev back in Zurich] at that time
b. wänn du zu dere Ziit [z’Züri zrugg bischv]
c. *wänn you at that uhrtime [z’Züri zrugg arev]
We take this as evidence that wänn in (28) cannot be the ordinary Swiss German complementizerbut rather a spelling variant of the English complementizer. We want to emphasize that both theFHC and the MLF model also fail to give an alternative explanation faced with this example; here thepredictions of all the approaches we have introduced in Sections 1.2 and 1.3 make the same predictions.Furthermore, according to Myers-Scotton and Jake [16] (pp. 352–354), adverbial-like complementizersare often qualified as content morphemes in the 4M-model. These tend to occur in the EL-language ofCP2 (i.e., the embedded clause), which in this case is clearly English. In addition, it is not suitable toanalyse the Swiss German complementizer wänn as an EL island, because the C◦ head is supposed tobe in the matrix language of either the matrix CP or the embedded CP. However, the quantitativelypredominance of English in both the sentences, as well as the English word order in the embeddedclause do not indicate that one of the ML would in fact be Swiss German. It appears then that thereis no need of the concept of EL islands here, since we are able to give an alternative, more insightfulexplanation in terms of language system for this example.
Finding a reasonable explanation might be more challenging with regards to the three examplesof our corpus in which there seems to be a clash or rather a mixture of two distinct grammars, namelyFrench and German grammar. First, consider (31):
31. Commentca gehts à zuri? Je viens te voir en janvier, oki?how it goes.it at Zurich I come you.ACC see in January okay?‘How is it going in Zurich? I will come to visit you in January, okay?’
The sender mixes the two question tags meaning ‘how are you?’ of French comment ça va? andGerman wie geht’s?, respectively. The problem is that they are incompatible in the sense that theinflected verb stays in different positions in the two grammars; as we have seen in Section 1, theGerman V2-condition triggers its movement to C◦ whereas in French it remains in T◦. This leads to thefact that in the linear order the expletive subject of the question, ça and ‘s respectively, appear oncebefore and once after the verb (even if both stay in Spec,TP, i.e., the position reserved for the subject).When mixing up the two languages in a linear order like in (31), the subject appears twice. This isungrammatical in both languages. Therefore, for this example we want to propose an analysis that doesnot involve syntactic CS, but rather the insertion of a reanalyzed verbal item into the French syntax.
It is unlikely that the German verb geht moves to C◦ in the presence of the French preverbalsubject ça, if we do not want to assume a sort of loop by which the computational process could runtwice through one and the same syntactic position. Hence, we propose to analyze the whole Germanitem gehts resulting from the contraction of geht es as the inflected verb. More precisely, the speakerinserts gehts like an infinitival form, meaning ‘to go’ in V◦ in the syntactic derivation. From there, theverb moves to v◦ and T◦ to acquire functional information. The verb has to agree with the third personsingular in French grammar. Significantly, the most frequent and productive agreement morpheme(the morpheme for regular verbs) for third person singular is a zero morpheme in spoken French. If weare right and the item gehts is inserted as a chunk in the derivation, we expect it not to show overtagreement in French grammar (viz. gehts+Ø).16
16 A reviewer points out that example (31) may be analyzed as a “blend representation” in the sense of Goldrick et al. [48].The authors argue that a head, or alternatively an expletive constituent, can appear twice in a sentence with CS, i.e., once ineach of the languages involved in CS. However, since their model is based on an optimality theory approach, high-ranking

Languages 2017, 2, 10 18 of 21
This analysis clearly shows that the presence of an apparent syntactic CS (or grammatical CS)does not always imply an actual syntactic CS. Rather, grammar stops where unanalyzed (lexical) itemsare inserted in their actual form in the derivation, where in turn they are treated like any other item ofthe corresponding word class (e.g., verbs or nouns). These items, which are imitated but do apparentlynot carry the relevant syntactic features of the language they stem from, are probably better analyzedas real (syntactic) islands. This notion should however be restricted to CS containing syntactically notanalyzed chunks. These can be integrated in, or modified by the grammar of the extended projectionthey belong to, whereas EL islands of the MLF model seem not to be affected by the ML at all.
4. Conclusions
In the present study we tested two syntactic principles on CS: the Principle of Agreement andthe Principle of Functional Restriction. We have chosen to follow González Vilbazo [1] in consideringthe numerals and the determiners to be functional categories staying in the heads of the extendedprojection of D◦ and the verbal morphology to be the overt material of the functional categories of theextended projection of V◦.
In our corpus of spontaneous non-standard written data we did not find convincingcounterexamples to the principles. This is remarkable, because it is often claimed that in text messageseverything is possible, but see [49–51] for evidence that syntactic restrictions also hold in this type ofdata. Even if we have a lot of CS in the multilingual corpus, they do not seem to be random: once alanguage (or a grammar) has been chosen for the syntactic computation of an extended projection,all the functional heads of this projection have to conform to the chosen language. In addition, theagreement and subcategorization requirements of the head of a projection are always satisfied, evenif not obligatorily by morphologic exponents of the same language (especially when agreement isinvolved). The two principles seem to be robust, at least for CS between and inside Romance andGermanic varieties.
We have also seen that other proposed principles, namely Poplack’s [11] Equivalence Constraint,Belazi et al.’s [12] Functional Head Constraint, or Myers-Scotton and Jake’s 4-M model [15,16] makeless precise predictions and some of these have been falsified in our corpus. Even if the 4-M modelcould stand up to the test with the data of our limited corpus, as discussed in Section 1.3, not all itspredictions turn out to be tenable.
The fact that we could not find any single violation of the tested principles, which cannot beexplained by other factors, is striking. While uncovering interesting tendencies, the present article hasimportant limitations that need to be addressed. The data on which we tested the principles are scarceand we did not conduct a quantitative analysis. It must be stressed that violations may have beenoverlooked due to the semi-automatic searches on the corpus.
A second point relates to the language sample of which we disposed. Principles like theEquivalence Constraint may reveal themselves more useful when CS occurs between typologicallymore diversified languages. An investigation among Romance languages, English and German isperhaps too restricted in terms of variation and interplay that could reveal more insights into the coreprinciples of CS. Nevertheless, we could identify some interesting interactions between a language ofthe V2 type (German) and the SVO languages in our corpus concerning word ordering issues. In sum,further investigation based on the (manual) annotation of a sample of more diversified languages andvarieties may provide stronger evidence for universal syntactic restrictions on CS.
Acknowledgments: We would like to express our gratitude to the Swiss National Science Foundation(Berne, Switzerland) for financing the project “SMS communication in Switzerland: Facets of linguistic variation
constraints preclude expletives as the sole doubled element: “we should not observe doubling of expletive elements(e.g., English do) alone” [48] (p. 870).

Languages 2017, 2, 10 19 of 21
in a multilingual country”. Many thanks also to Elisabeth Stark (University of Zurich, Switzerland) for enablingthis research project.
Author Contributions: A.R.-T. and E.M. conceived the research and explored the data together, A.R.-T. performedall the formal analyses of the examples and wrote most parts of the paper. E.M. contributed to the discussion,wrote parts of the introduction (1.1 and 1.2) and was involved in the formal revision of the paper.
Conflicts of Interest: The funding sponsors had no role in the design of the study; in the collection, analyses, orinterpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
1. González Vilbazo, K. Die Syntax des Code-Switching. Esplugisch: Sprachwechsel an der Deutschen SchuleBarcelona. Ph D. Thesis, Universität zu Köln, Cologne, Germany, 2005.
2. Vogt, H. Language contacts. Word 1954, 10, 365–374. [CrossRef]3. Gumperz, J.J. Discourse Strategies, 1st ed.; Cambridge University Press: Cambridge, UK; New York, NY, USA,
1982.4. Auer, P. Bilinguales Sprechen: (Immer noch) Eine Herausforderung für die Linguistik. Sociolinguistica 2006,
20, 1–21. [CrossRef]5. Mondada, L. Le code-switching comme ressource pour l’organisation de la parole-en-interaction.
J. Lang. Contact 2007, 1, 168–197. [CrossRef]6. Alvarez-Cáccamo, C. From ‘switching code’ to ‘code-switching’: Towards a reconceptualization of
communicative codes. In Code-Switching in Conversation: Language, Interaction and Identity; Auer, P., Ed.;Routledge: London, UK; New York, NY, USA, 1998; pp. 29–50.
7. Morel, E.; Bucher, C.; Pekarek Doehler, S.; Siebenhaar, B. SMS communication as plurilingual communication:Hybrid language use as a challenge for classical code-switching categories. Lingüíst. Investig. 2012, 35,260–288.
8. Morel, E. Le Bricolage Plurilingue Dans La Communication Par Texto: Interprétations D'une Pratique EntreAffiliation Locale et Aspiration Globale. Ph D. Thesis, Université de Neuchâtel, Neuchătel, Switzerland, 2016.
9. Poplack, S.; Sankoff, D. Borrowing: The synchrony of integration. Linguistics 1984, 22, 99–135. [CrossRef]10. Gardner-Chloros, P. Code-Switching: An Introduction, 1st ed.; Cambridge University Press: London, UK;
New York, NY, USA, 2009.11. Poplack, S. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of
code-switching. Linguistics 1980, 18, 581–618. [CrossRef]12. Belazi, H.M.; Rubin, E.J.; Toribio, A.J. Code switching and X-Bar Theory: The functional head constraint.
Lingüíst. Inq. 1994, 25, 221–237.13. MacSwan, J. The architecture of the bilingual language faculty: Evidence from intrasentential code switching.
Biling. Lang. Cogn. 2000, 3, 37–54. [CrossRef]14. Myers-Scotton, C. Duelling Languages: Grammatical Structure in Codeswitching; Clarendon Press: Oxford,
UK, 1993.15. Myers-Scotton, C.; Jake, J. Four types of morpheme: Evidence from aphasia, code switching, and
second-language acquisition. Linguistics 2000, 38, 1053–1100. [CrossRef]16. Myers-Scotton, C.; Jake, J. A universal model of code-switching and bilingual language processing and
production. In The Cambridge Handbook of Linguistic Code-Switching; Bullock, B., Toribio, A.J., Eds.; CambridgeUniversity Press: London, UK; New York, NY, USA, 2009; pp. 336–357.
17. Bhatt, C. Die syntaktische Struktur der Nominalphrase im Deutschen, 1st ed.; Gunter Narr: Tübingen,Germany, 1990.
18. Alexiadou, A.; Haegeman, L.; Stavrou, M. Noun Phrase in the Generative Perspective, 1st ed.; Mouton deGruyter: Berlin, Germany; New York, NY, USA, 2007.
19. Cinque, G. The Syntax of Adjectives: A Comparative Study, 1st ed.; MIT Press: Cambridge, MA, USA, 2010.20. Cinque, G. Adverbs and Functional Heads. A Cross-linguistic Perspective; Oxford University Press: New York,
NY, USA, 1999.21. Chomsky, N. Lectures on Government and Binding: The Pisa Lectures, 1st ed.; Foris Publications: Dordrecht,
The Netherlands, 1981.

Languages 2017, 2, 10 20 of 21
22. Okasha, M. Structural Constraints on Arabic/English Code-Switching: Two Generations. Ph D. Thesis,University of South Carolina, Columbia, SC, USA, 1999.
23. Haegeman, L. Adverbial Clauses, Main Clause Phenomena, and the Composition of the Left Periphery, 1st ed.;Oxford University Press: New York, NY, USA, 2012.
24. Rizzi, L. The fine structure of the left periphery. In Elements of Grammar; Haegeman, L., Ed.; Kluwer:Dordrecht, The Netherlands; Boston, MA, USA; London, UK, 1997; pp. 281–337.
25. Rizzi, L.; Shlonsky, U. Strategies of subject extraction. In Interface + Recursion = Language? Chomsky'sMinimalism and the View from Syntax-Semantics; Sauerland, U., Gärtner, H.-M., Eds.; de Gruyter: Berlin,Germany; New York, NY, USA, 2007; pp. 115–160.
26. Bucher, C. SMS-User als glocal Player: Formale und funktionale Eigenschaften von Code-switching inSMS-Kommunikation. Networx 2016, 73.
27. Pekarek Doehler, S. Hallo! Voulez vous luncher avec moi hüt? Le “code switching” dans la communication parSMS. Lingüíst. Online 2011, 48, 49–70.
28. Thurlow, C.; Poff, M. Text messaging. In Pragmatics of Computer-Mediated Communication; Herring, S.C.,Stein, D., Virtanen, T., Eds.; Mouton de Gruyter: Berlin, Germany; Boston, MA, USA, 2013; pp. 163–188.
29. Bautista, M.L.S. Tagalog-English code switching as mode of discourse. Asia Pac. Educ. Rev. 2004, 5, 226–233.[CrossRef]
30. Carrier, M.; Benitez, S. The effect of bilingualism on communication efficiency in text messages (SMS).Multilingua 2010, 29, 167–183. [CrossRef]
31. Deumert, A.; Masinyana Oscar, S. Mobile languages choices: The use of English and isiXhosa in text messages(SMS). Engl. Worldw. J. Var. Engl. 2008, 29, 117–147.
32. Haggan, M. Text messaging in Kuwait. Is the medium the message? Multilingua 2007, 26, 427–449. [CrossRef]33. Chiluwa, I. Assessing the Nigerianness of SMS text-messages in English. Engl. Today 2008, 24, 51–56.
[CrossRef]34. Vold Lexander, K. Analyzing multilingual texting in Senegal: An approach for the study of mixed-language
SMS. In Language Mixing and Code-Switching in Writing: Approaches to Mixed-Language Written Discourse;Sebba, M., Mahootian, S., Jonsson, C., Eds.; Routledge: New York, NY, USA, 2012; pp. 146–169.
35. Al-Khatib, M.A.; Sabbah, E. Language Choice in Mobile Text Messages among Jordanian University Students.SKY J. Lingüíst. 2008, 21, 37–65.
36. Cougnon, L.-A. Langage et SMS: Une Étude Internationale Des Pratiques Actuelles. Cahiers du Cental. 8, 1st ed.;Presses universitaires de Louvain: Louvain-la-Neuve, Belgium, 2015.
37. Ledegen, G.; Richard, M. “jv me prendre un bois monumental the wood of the century g di”: Langues encontact dans quatre corpus oraux et écrits “ordinaires” à la Réunion. Glottopol 2007, 10, 86–100.
38. Moretti, B.; Stähli, A. L’italiano in contatto con il dialetto e altre lingue. Nuovi mezzi di comunicazione enuove diglossie. Lingüíst. Online 2011, 48, 71–82.
39. Grünert, M. Varietäten und Sprachkontakt in rätoromanischen SMS. Lingüíst. Online 2011, 48, 83–113.40. Cathomas, C.; Bucher, C.; Morel, E.; Ferretti, N. Same same but different: Code-Switching in Schweizer
SMS–ein Vergleich zwischen vier Sprachen. TRANEL 2015, 63, 171–189.41. Muysken, P. Bilingual Speech: A Typology of Code-Mixing, 1st ed.; Cambridge University Press: Cambridge,
UK; New York, NY, USA, 2000.42. Auer, P. Bilingual Conversation, 1st ed.; Benjamins: Amsterdam, The Netherlands, 1984.43. Myers-Scotton, C. Constructing the frame in intrasentential code-switching. Multilingua 1992, 11, 101–127.
[CrossRef]44. Stark, E.; Ruef, B.; Ueberwasser, S. Swiss SMS Corpus (2009–2014). University of Zurich. Available online:
https://sms.linguistik.uzh.ch (accessed on 10 November 2016).45. Lakshmanan, U.; Balam, O.; Bhatia, T.K. Introducing the special issue: Mixed verbs and linguistic creativity
in bi/multilingual communities. Languages 2016, 1, 9. [CrossRef]46. Otheguy, R.; García, O.; Reid, W. Clarifying translanguaging and deconstructing named languages:
A perspective from linguistics. Appl. Lingüíst. Rev. 2015, 6, 281–307. [CrossRef]47. Anis, J. Neography: Unconventional Spelling in French SMS Text Messages. In The Multilingual Internet.
Language, Culture, and Communication Online, 1st ed.; Herring, S., Ed.; Oxford University Press: Oxford, UK,2007; pp. 87–115.

Languages 2017, 2, 10 21 of 21
48. Goldrick, M.; Putnam, M.; Schwarz, L. Coactivation in bilingual grammars: A computational account ofcode mixing. Biling. Lang. Cogn. 2016, 19, 857–876. [CrossRef]
49. Dürscheid, Chr.; Stark, E. Anything goes? SMS, phonographisches Schreiben und Morphemkonstanz. In DieSchnittstelle von Morphologie und geschriebener Sprache; Neef, M., Scherer, C., Eds.; Mouton de Gruyter: Berlin,Germany, 2013; pp. 189–209.
50. Robert-Tissot, A. Le Sujet et son Absence dans les SMS Français. Une Analyse Syntaxique Basée sur leCorpus sms4science Suisse. Ph D. Thesis, Universität Zürich, Zürich, Switzerland, 2016.
51. Stark, E.; Robert-Tissot, A. Subject drop in Swiss French text messages. Lingüíst. Var. 2017, in press.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
Code-Switching by Phase
Luis López 1,*, Artemis Alexiadou 2,3 and Tonjes Veenstra 3
1 Department of Hispanic and Italian Studies, University of Illinois at Chicago, 601 South Morgan,Chicago, IL 60607, USA
2 Department of English and American Studies, Humboldt Universität zu Berlin, Unter den Linden 6,10099 Berlin, Germany; [email protected]
3 Leibniz-Zentrum Allgemeine Sprachwissenschaft (ZAS), Schützenstr. 18, 10117 Berlin, Germany;[email protected]
* Correspondence: [email protected]; Tel.: +1-3129965218
Academic Editors: Ji Young Shim and Tabea IhsaneReceived: 24 January 2017; Accepted: 19 June 2017; Published: 12 July 2017
Abstract: We show that the theoretical construct “phase” underlies a number of restrictionson code-switching, in particular those formalized under the Principle of Functional Restriction(González-Vilbazo 2005) and the Phonetic Form Interface Condition (MacSwan and Colina 2014). Thefundamental hypothesis that code-switching should be studied using the same tools that we use formonolingual phenomena is reinforced.
Keywords: code-switching; Principle of Functional Restriction; PF Interface Condition; phases
1. Introduction
Since the notion of “phase” was introduced to linguistic theory by Chomsky [1], a rich body ofwork has arisen that demonstrates its usefulness as a descriptive tool in syntax as well as the interfacesof syntax with other linguistic modules (see [2] for a clear introduction to phase theory, argumentsand development).
However, phases have been so far underused in the linguistic study of code-switching. Theonly articles that we are aware of that use phases productively are [3–5]. This is despite theeloquent argumentation proposed by Mahootian [6] and MacSwan [7] that any restrictions we findon code-switching should be accounted for using the same tools that we use to account for anyother phenomenon of linguistic competence. Despite the conspicuous scarcity of phase theory incode-switching research, we believe that phases can be very useful in resolving some long-standingempirical puzzles. In this contribution, we aim to show that this is the case with two particularlyintricate examples.
The first example is the network of phenomena that are bundled together in González-Vilbazo’sPrinciple of Functional Restriction (in the original: Prinzip der Funktionalen Restriktion) [8]. Amongother effects (which we discuss in due course), this principle excludes code-switching between anauxiliary and a participle:
1. *Du hast es ihm contado Ger/Spayou have.2 it him.DAT told [8] (p.88)
In example (1), we have the German auxiliary hast ‘have.2’ and the Spanish participle contado andthe result is unacceptable to Spanish/German bilinguals.
The second example involves the restrictions of code-switching within the word. Poplack proposesthe Free Morpheme Constraint (FMC) according to which there cannot be any code-switching that
Languages 2017, 2, 9; doi:10.3390/languages2030009 www.mdpi.com/journal/languages

Languages 2017, 2, 9 2 of 17
separates morphemes within the word [9]. This accounts for the ungrammaticality of one of the mostfamous examples in the code-switching literature:1
2. *Estoy eatiendo Spa/EngAm eating [9] (p. 581)
Poplack’s constraint metamorphosed into the PF Disjunction Theorem [7] and later the PFInterface Condition (PFIC) [10]. In these theoretical developments, the impossibility of (2) arisesas the consequence of contradictory phonetic requirements imposed on one word.
However, there are numerous counterexamples to the, as summarized in [11], which suggeststhat the FMC as well as the PFIC are tools that are too blunt to provide an adequate analysis. What wefind is that something like (3a) is acceptable while something like (3b) is not:
3. a. Cabreiert Spa/Ger‘angered’
b. Cabreierado
In (3a), the Spanish root cabre is attached to a German verbal derivational morpheme [ier] and theGerman participial inflection [t]. In (3b), the Spanish participial inflection is attached to the Germanderivational morpheme. We show that this and other contrasts also follow from phase theory.
The rest of this article is organized as follows. Section 2 introduces phase theory as well as ourown hypothesis, which we dub the Block-Transfer Hypothesis (BTH). According to the BTH, thematerial that is transferred to the interfaces within a phase is transferred in one block. Section 3 showshow the BTH accounts for the PFR and Section 4 discusses the FMC. Section 5 presents the conclusions.
2. Phases and Code-Switching
The notion of phase involves dividing the structure of the sentence into chunks, as represented in(4). In (4), the curly brackets represent the phases (see [1] et seq.)
4. {[CP C [TP T} {[vPv[√P√
} {[CP C [TP T} {[vP v [√P√
]]]]]]]]}
Starting from the bottom up, an uncategorized root and its complement form a Root Phrase whichis selected by v, a phase head [12]. This root has no grammatical properties and its selection of acomplement is purely a property of semantic selection (but for arguments that the root does not in factselect an internal argument, see [13–15]). If v is of the “initiator” type [16], it introduces the externalargument into the structure ([17]; cf. VoiceP in [18]). More often than not, v does not have an exponent.For instance, in the word ‘walked’, only the root and the past tense morphemes have an exponent; v isphonetically null. However, v may also have several exponents in the form of derivational morphemes.For instance, in solidify, the suffix [ify] is an exponent of v [19].
The vP+√
P chunk forms a phase, the vP phase, with v as the head of the phase.2 The vP is in turnselected by T, which is selected by C, forming the CP phase, with C as the head of the phase.
1 The FMC states that no switch can take place between a stem and a bound morpheme. We exemplify the FMC usingexample (2) for the sake of tradition, but it is in fact not a very good example. The verb eatiendo is inflected in the thirdconjugation and the third conjugation is not productive in Spanish. Consequently, the unacceptability of (2) can be accountedfor quite independently of the FMC.
2 In more recent approaches, what we call v here is split into two heads: v provides the structure with category label and voiceintroduces the external argument (see [20,21]). In this sort of framework, Voice would be a phase head while v would not(or rather v would be a phase head, whenever Voice is absent; see also [22] for some discussion on the role of Voice and vacross languages):
(i) {[CP C [TP T} {[Voice Voice [vP v [√P√
} {[CP C [TP T} {[vP v [√P√
]]]]]]]]]}.

Languages 2017, 2, 9 3 of 17
Phases have been used in three empirical domains. First, phases have been used in the theory oflocality: the complement domain of a phase is claimed to be a domain that is opaque to higher probingand therefore any movement must pass through the specifiers of phase heads.
Second, the head of a phase has been taken to be the locus of grammatical features. An earlyproposal along these lines is [19]. In this article, Marantz proposes that the lexical verb is nothingbut an array of semantic/conceptual features—in fact, purely a root without a mark for the syntacticcategory. The root becomes what we call a verb as the result of being selected by v, which additionallyattracts the root, forming an incorporated structure. Likewise, Chomsky [23] and Richards [24] putforth the idea that all the features that trigger syntactic dependencies originate in v and C (althougha mechanism of “inheritance” ensures that T and V do the actual job of setting up dependencies,see footnote 5). These ideas are crystallized in the Phase Head Hypothesis of González-Vilbazo andLópez [3,25]:
The Phase Head Hypothesis (PHH): The phase head determines grammatical properties ofits complement.
In the mentioned paper, word order, prosody and the expression of information structure areall determined by the phase head. In [4], several pieces of evidence are presented that confirm thatassignment of morphological case to verbal complements is dependent on v. The crucial data comesfrom light verb constructions, which are pervasive in code-switching varieties. In these constructions,the verbal predicate is split into two heads: a lexical head, usually with default verb morphology; and alight verb, which can be translated as ‘do’, and bears all the grammatical properties of the construction.In [3,4], it was argued that the light verb is a spell-out of v:3
5. a. Berist-ı srayb’n yapıyor. Tur/Gerreport-ACC write do.PROG
‘He is writing the report.’ Cited in [26] (p. 87); [4] (p. 318)
b. [√P Berist-ı srayb’n] yapıyor vP]
A third area where the phase notion has stimulated significant research is the interfaces withinterpretive systems. Chomsky links the completion of all operations within a phase with a “Transfer”of the information contained in the complement of the phase to the interpretive systems [29]. This“interpretation by phase” hypothesis has been explored in several pieces of work, particularly in theareas of information structure and PF (see [30,31], among many others).
Let us explore the notion of Transfer in more detail. Consider the diagram in (6):
For the purposes of this article, we maintain the simpler structure in which v performs a double function. Adopting themore complex structure would require some readjustments to our analysis but not change our fundamental proposal.
3 Muysken discusses parallel examples in Dutch/Turkish code-switching [27]. He claims that the Turkish light verb and theDutch verb form a unit, while the Dutch verb and the Dutch noun do not. Problems for such an approach are laid out in [28]on the basis of idiomatic constructions. In (ii), we have a VP-idiom from Dutch geen reet interesseren ‘to have no interest at all’combined with a Turkish light verb:
ii. Politiek essahtan [reet interesseren] yapıyor. Tur/DutchPolitics real.ABL ass interest do.PROG
‘Politics really does not interest me at all.‘Dutch: Politiek interesseert me echt geen reet.
The fact that an idiomatic interpretation is possible at all in the bilingual construction points towards a structure in whichthe Dutch VP forms a constituent to the exclusion of the Turkish light verb.

Languages 2017, 2, 9 4 of 17
Languages 2017, 2, 9 4 of 17
6.
In this example, C is the head of the phase. Once the C head has entered the derivation and all
the grammatical properties of C are satisfied, the TP is transferred to the interpretive components.
Exactly the same steps take place in the vP phase. Notice that although v is the head of the lower
phase, it transfers with T. Additionally, please note that the clausal structure is probably more
complex than (6), even in the simplest examples. T should be regarded as a cover term for functional
categories dedicated to tense, mood and aspect. Likewise, the complement of v may not be a root but
a complex structure that includes the root and functional categories related to event structure.
Let us now consider nominal phrases. We follow the proposal in [32] that the nominal phrase is
headed by K (=case) and assume the following structure:
7. {[KP K [DP D [NumP Num} {[nP n [√P √]]]]]}
The structure in (7) represents the following hypotheses: in a nominal phrase, a root is selected
by n, a categorizer. n is a phase head. n is selected by Number, which is itself the complement of D
and the latter a complement of K. K is also the head of a phase (see [2] for a discussion of nominal
phases and the phasehood of n). Notice that, as a consequence, the complement of K and K itself are
transferred in different phases, as shown in (8):
8.
Thus, in (8), D transfers with Num and n while K transfers with the vP. This will be the case for
the internal argument. As for the K head of the external argument, it transfers with C.
CP
C TP
Transfer T vP
v √P
Transfer
vP
v √P
√ KP
K DP
Transfer
In this example, C is the head of the phase. Once the C head has entered the derivation and all thegrammatical properties of C are satisfied, the TP is transferred to the interpretive components. Exactlythe same steps take place in the vP phase. Notice that although v is the head of the lower phase, ittransfers with T. Additionally, please note that the clausal structure is probably more complex than(6), even in the simplest examples. T should be regarded as a cover term for functional categoriesdedicated to tense, mood and aspect. Likewise, the complement of v may not be a root but a complexstructure that includes the root and functional categories related to event structure.
Let us now consider nominal phrases. We follow the proposal in [32] that the nominal phrase isheaded by K (=case) and assume the following structure:
7. {[KP K [DP D [NumP Num} {[nP n [√P√
]]]]]}
The structure in (7) represents the following hypotheses: in a nominal phrase, a root is selectedby n, a categorizer. n is a phase head. n is selected by Number, which is itself the complement of Dand the latter a complement of K. K is also the head of a phase (see [2] for a discussion of nominalphases and the phasehood of n). Notice that, as a consequence, the complement of K and K itself aretransferred in different phases, as shown in (8):
Languages 2017, 2, 9 4 of 17
6.
In this example, C is the head of the phase. Once the C head has entered the derivation and all
the grammatical properties of C are satisfied, the TP is transferred to the interpretive components.
Exactly the same steps take place in the vP phase. Notice that although v is the head of the lower
phase, it transfers with T. Additionally, please note that the clausal structure is probably more
complex than (6), even in the simplest examples. T should be regarded as a cover term for functional
categories dedicated to tense, mood and aspect. Likewise, the complement of v may not be a root but
a complex structure that includes the root and functional categories related to event structure.
Let us now consider nominal phrases. We follow the proposal in [32] that the nominal phrase is
headed by K (=case) and assume the following structure:
7. {[KP K [DP D [NumP Num} {[nP n [√P √]]]]]}
The structure in (7) represents the following hypotheses: in a nominal phrase, a root is selected
by n, a categorizer. n is a phase head. n is selected by Number, which is itself the complement of D
and the latter a complement of K. K is also the head of a phase (see [2] for a discussion of nominal
phases and the phasehood of n). Notice that, as a consequence, the complement of K and K itself are
transferred in different phases, as shown in (8):
8.
Thus, in (8), D transfers with Num and n while K transfers with the vP. This will be the case for
the internal argument. As for the K head of the external argument, it transfers with C.
CP
C TP
Transfer T vP
v √P
Transfer
vP
v √P
√ KP
K DP
Transfer
Thus, in (8), D transfers with Num and n while K transfers with the vP. This will be the case forthe internal argument. As for the K head of the external argument, it transfers with C.
We are now in a position to formulate our Block-Transfer Hypothesis:
Block-Transfer Hypothesis (BTH): The material that is transferred to the interfaces is sent in onefell swoop.

Languages 2017, 2, 9 5 of 17
Bilinguals have multiple externalization systems. They may even have more than one PF, asMacSwan argues [7], although this is a complex matter since PF is itself a complex grammatical module(see [33] for a discussion of PF in bilingual grammars).4 Let us adopt the simple assumption thatbilingual speakers have multiple PFs. The BTH ensures that, when a structure is transferred, it istransferred in one block to one of the PFs. The consequence of this hypothesis for code-switchingis the following: code-switching may take place at phase boundaries but not within the phase.Code-switching within the phase would entail transferring some material to one externalizationsystem while simultaneously transferring some other material to another externalization system. Thisis precisely what the BTH prevents.
Before we proceed with the empirical consequences of the BTH, it is worth pointing out that theBTH is not a novel theoretical construct. Rather, it is an explicit formulation of what is a universalimplicit assumption. All the literature on phases that we are aware of takes it for granted that phasestransfer in one shot and not piecemeal. Interestingly, this property of phases is only clearly visible incode-switching contexts.
3. The Principle of Functional Restriction
The PFR states the following (our translation) [8] (p. 67):
Functional restriction
a Let X and Y be functional categories.b Let X and Y be members of the extended projection of the same lexical category.c Let L1 and L2 be distinct languages.d Then:
9. [XP Spec [X’ XL1 [YP Spec [Y’ YL1/*L2 ZP ]]]]
In other words, it is illegal to code-switch between two functional heads that belong in the sameextended projection. The term “extended projection” is borrowed from [35]. As Grimshaw describesextended projections, the entire clause up to and including CP is an extended projection of the verb,while the entire KP is an extended projection of the noun. Thus, the PFR is a very strong and generalprinciple: it forbids code-switching between C and T and between any functional categories within theclause; it also forbids code-switching within the nominal phrase [35]. Although we think that the PFR,as stated in [8], is too strong, it does make some correct predictions, as we shall see.
The PFR seeks to account for two classes of phenomena: the impossibility of code-switchingbetween an auxiliary and a participle and the impossibility of code-switching between acomplementizer and its complement. We discuss here the first type of phenomenon, postponingthe other to the end of the section.
González-Vilbazo’s Spanish/German bilingual consultants were adamant in rejecting sentencessuch as the following, with a German auxiliary and a Spanish participle [8]:
10. *Du hast es Ihm contado Ger/Spayou have.2 it him.DAT told [8] (p. 88)
11. *Me ha dicho dass Hans el coche vendido hat Ger/SpaMe.DAT has said that Hans the car sold has [8] (p. 95)
4 The authors of [34] argue for a similar position on the basis of an in-depth study of code-blending between spoken Italianand Italian Sign Language.

Languages 2017, 2, 9 6 of 17
The symmetric form with a Spanish auxiliary and a German participle was not rejected as stronglyby González-Vilbazo’s participants for reasons unknown to us. We have tested the following sentenceswith three Spanish/English early bilinguals and their judgments are certain, in any combination ofauxiliary and participle (see also [36] for numerous pieces of data):
12. *You have contado esa historia Eng/Spatold that story
13. *Tú habías told that story Eng/Spayou had.2
Although González-Vilbazo does not discuss it [8], the PFR also prevents code-switching betweentwo auxiliaries. It is indeed the case that code-switching between ‘have’ and ‘be’ is ungrammatical,according to our Spanish/English bilingual consultants.
14. *El canciller había been running for officeThe chancellor had
15.* Thechancellor
had estado presentándose a elecciones
been presenting.SELF to elections
We conclude that there is indeed a restriction against code-switching between an auxiliary andits complement, thus confirming the PFR. What is interesting to us is that this aspect of the PFR isfully accountable within a phase system. Any heads between C and v belong in the same phase andtherefore the BTH predicts that they should transfer together to the same PF module. Let us see howwith the tree in (16), which exemplifies the relevant aspects of example (12):
Languages 2017, 2, 9 6 of 17
The symmetric form with a Spanish auxiliary and a German participle was not rejected as
strongly by González‐Vilbazo’s participants for reasons unknown to us. We have tested the
following sentences with three Spanish/English early bilinguals and their judgments are certain, in
any combination of auxiliary and participle (see also [36] for numerous pieces of data):
12. *You have contado esa historia Eng/Spa
told that story
13. *Tú habías told that story Eng/Spa
you had.2
Although González‐Vilbazo does not discuss it [8], the PFR also prevents code‐switching
between two auxiliaries. It is indeed the case that code‐switching between ‘have’ and ‘be’ is
ungrammatical, according to our Spanish/English bilingual consultants.
14. *El canciller había been running for office
The chancellor had
15. * The chancellor had estado presentándose a elecciones
been presenting.SELF to elections
We conclude that there is indeed a restriction against code‐switching between an auxiliary and
its complement, thus confirming the PFR. What is interesting to us is that this aspect of the PFR is
fully accountable within a phase system. Any heads between C and v belong in the same phase and
therefore the BTH predicts that they should transfer together to the same PF module. Let us see how
with the tree in (16), which exemplifies the relevant aspects of example (12):
16.
We take it for granted that the English auxiliary have has raised to T and not higher (see [37,38]
among many others) while the Spanish verb contado ‘told’ has raised to v and, possibly, a higher
category. The structure in (16) shows that the participle and the auxiliary are transferred in the same
phase. The BTH says that they should both be transferred to the same PF. Thus, the BTH correctly
predicts that (11)–(15) should be ungrammatical.
Aux
C
PtcPhave
T AuxP
TP
CP
t(have)
Ptc
contado
…
We take it for granted that the English auxiliary have has raised to T and not higher (see [37,38]among many others) while the Spanish verb contado ‘told’ has raised to v and, possibly, a highercategory. The structure in (16) shows that the participle and the auxiliary are transferred in the samephase. The BTH says that they should both be transferred to the same PF. Thus, the BTH correctlypredicts that (11)–(15) should be ungrammatical.

Languages 2017, 2, 9 7 of 17
Interestingly, the BTH can improve over the PFR with regards of the following apparentcounterexample: it is in fact possible to code-switch between the be auxiliary and its complement in aprogressive construction [36,39]:
17. Los ciudadanos están supporting the program Spa/EngThe citizens are [36] (p. 382)
Why is there this difference between the perfect and the progressive structures? The only accountthat we are aware of is MacSwan’s [40]. His proposal is that the auxiliary haber ‘have’ triggersrestructuring while estar ‘be’ does not. The only reliable test for restructuring is clitic climbing, butboth auxiliaries accept clitic climbing. Thus, it is unclear whether restructuring is the way to go. Datasuch as this are certainly beyond the scope of the PFR: in both perfect and progressive aspect, there isonly one lexical item and therefore only one extended projection.
Fortunately, the contrast between (11)–(15) and (17) falls directly under phase theory and the BTH.That is because it has been argued in the recent literature that progressive sentences have a phasebarrier between T and the vP. Laka argues for these on the basis of examples such as the followingBasque sentence [41]:
18. a. Emakume-a-k ogi-a jaten duwoman.DET.ERG bread.DET eat has
b. Emakume-a jaten ari daWoman. DET eat PROG is [41] (p. 173)
Example (18a) is a normal transitive sentence in Basque, in which the external argument ismarked with ergative case while the internal argument has no case morphology, usually interpretedas absolutive. Let us further assume that ergative in Basque is a dependent case [42,43], assigned toan argument in a structure if this argument is “in competition with” another argument in the samedomain. Keeping this in mind, consider (18b). In this example, both arguments appear in absolutivecase. This suggests that they are in different domains and therefore not in competition—in our terms,they are in different phases.
Likewise, Harwood has presented several arguments taken from English that the progressiveaspect is unique in, when present, being able to act as the clause-internal phase head, crucially denyingits complement phase status [44]. In other words, when progressive is present, it crucially extendsthe size of the clause-internal phase. This can be seen in, e.g., the scope of ellipsis: the progressivemorpheme [-ing] must always be included within the elliptical constituent, whereas the participle [-en]can be in or out (see [45] for the first description of these facts):
19. a. John has been kissed and Peter has been <e> too.
b. *John is being kissed and Peter is being <e> too.
Harwood argues in detail that when progressive is merged, the phrase headed by the predicationalvP is extended [44]. Thus, in our example in (17), it is not C that is the phase head, but rather theprogressive head realized by estar, which triggers a spell-out of its complement.
A possible approach to an analysis of progressive aspect is hinted at by Laka herself [41]. Weshould understand the progressive aspect as a locative adpositional phrase or case morpheme. Thereis evidence for a Prepositional Phrase (PP) analysis of the progressive aspect both in the grammar ofEnglish and in a broad comparative swath. A PP analysis for the English progressive was suggestedby Bolinger [46], and supportive evidence comes from the discussion on the diachronic developmentof the progressive out of a structure that contained a P head embedding a deverbal noun [47]. Forinstance, as observed in [46], progressive forms can be coordinated with PPs, e.g., They’are already in

Languages 2017, 2, 9 8 of 17
position and waiting for the call. In Spanish, as Bybee et al. note [48] (p. 130), the auxiliary used for theprogressive is estar, which has its origin in the Latin verb stare ‘to stand’. While arguably not much ofthe original meaning of the Latin source is preserved in estar, in Spanish, estar and not ser, is used toexpress location and temporary state. Finally, Bybee et al. argue that in the majority of the world’slanguages, a locative component can be identified in the progressive [48]. Thus, John is laughing = Johnis at laugh, e.g., Dutch: Jan is aan het lachen. We take it that it is a property of human language that a PPstructure underlies the progressive aspect.
Some authors have argued that PPs are phases (see the discussion in [2] and references therein).Following this line of thought, we conclude that the progressive aspect delineates a phase barrier. Thisis shown in (20):
Languages 2017, 2, 9 8 of 17
progressive is estar, which has its origin in the Latin verb stare ‘to stand’. While arguably not much of
the original meaning of the Latin source is preserved in estar, in Spanish, estar and not ser, is used to
express location and temporary state. Finally, Bybee et al. argue that in the majority of the world’s
languages, a locative component can be identified in the progressive [48]. Thus, John is laughing =
John is at laugh, e.g., Dutch: Jan is aan het lachen. We take it that it is a property of human language that
a PP structure underlies the progressive aspect.
Some authors have argued that PPs are phases (see the discussion in [2] and references therein).
Following this line of thought, we conclude that the progressive aspect delineates a phase barrier.
This is shown in (20):
20.
Given the cross‐linguistic pervasiveness of the PP structure to express progressive aspect and
the independent analysis of English developed by Harwood, we surmise that the structure in (20) is
a property of the progressive aspect in Universal Grammar. Since the auxiliary and the progressive
morpheme are in different phases, it follows that code‐switching between them should be
permissible. This accounts for the contrast between the ungrammatical (10)–(15) and the
grammatical (17), which is not predicted by the PRF.
The other type of code‐switching that the PRF is meant to prohibit is code‐switching between C
and TP. This is an area where, once again, contemporary research on phase theory can provide some
insight. González‐Vilbazo reports that examples in which the complementizer is in one language
and TP is in the other are unacceptable to Spanish/German bilinguals [8]. Consider the following
examples:
21. El Lehrer dijo que mañana no haría kommen Ger/Spa
The teacher said that tomorrow NEG do.COND come
‘The teacher said he would not come tomorrow.’
22. *Eduardo denkt que Elena Schreibt Sich im Sekretariat
Eduardo thinks that Elena Registers SELF in.DEF.DAT secretary’s office
‘Eduardo thinks that Elena registers at the secretary’s office.’
CP
TPC
v+[‐ing]
T AuxP
be
t(be)
Aux PP
P ingP
…
Given the cross-linguistic pervasiveness of the PP structure to express progressive aspect andthe independent analysis of English developed by Harwood, we surmise that the structure in (20) isa property of the progressive aspect in Universal Grammar. Since the auxiliary and the progressivemorpheme are in different phases, it follows that code-switching between them should be permissible.This accounts for the contrast between the ungrammatical (10)–(15) and the grammatical (17), which isnot predicted by the PRF.
The other type of code-switching that the PRF is meant to prohibit is code-switching between Cand TP. This is an area where, once again, contemporary research on phase theory can provide someinsight. González-Vilbazo reports that examples in which the complementizer is in one language andTP is in the other are unacceptable to Spanish/German bilinguals [8]. Consider the following examples:
Languages 2017, 2, 9 9 of 17
21. El Lehrer dijo que mañana no haría kommen Ger/SpaThe teacher said that tomorrow NEG do.COND come‘The teacher said he would not come tomorrow.’
22. *Eduardo denkt que Elena Schreibt Sich im SekretariatEduardo thinks that Elena Registers SELF in.DEF.DAT secretary’s office‘Eduardo thinks that Elena registers at the secretary’s office.’
23. Juan sabe dass ich mit Clara en el zoológico verabredet war.Juan knows that I with Clara in the zoo dated was‘Juan knows that I made a date with Clara in the zoo.’
24. *dass er mañana no haría kommenthat he tomorrow NEG do.COND come‘ . . . that he would not come tomorrow.’ [8] (pp. 68,77)
In example (21), the complementizer que ‘that’ is drawn from the Spanish lexicon and T, as reflectedin the inflection of the light verb haría ‘would do’ is also Spanish. Example (22) is ungrammaticalbecause C is Spanish while T is German, as reflected in the verb schreibt ‘writes’ The examples in(23) and (24) are the mirror image. Identical judgments are reported in [49] in Spanish/Englishand French/Arabic code-switching. It seems that this is a real fact about code-switching, for somecode-switching pairs.
The unacceptability of (23) and (24) appears, at first blush, to be accounted for withinGonzález-Vilbazo’s PFR: Code-switching between C and TP is ruled out because they are members ofthe same extended projection. However, closer inspection of the data shows that there are a numberof challenges to the generalization that code-switching between C and TP is not possible. It seems tobe the case that when C is spelled out with a complementizer, the result tends to sound degraded,as González-Vilbazo argues. However, when the subordinate clause is fronted by a wh-phrase, thesentence is fully acceptable (see [50] for a detailed discussion of wh-movement in code-switching):
25. Ich weiß nicht, welches Buch Juan compró. Ger/SpaI know not which book John bought [25] (p. 5)
26. I don’t remember tus colegas han comprado this week. Eng/Spayour colleagues have.3.PL bought [50] (p. 106)
Generally speaking, as long as there is some content in Spec,C, code-switching seems tobe possible:
27. Puesto/ya que Juan ist spät angekommen . . .placed/already that Juan is late arrived‘Since Juan arrived late . . . ’ [25] (p. 4)
Thus, it seems that what the examples in (24) and (26) show is not a general prohibition ofcode-switching between C and TP, but rather a more specific prohibition of code-switching between Cand TP if Spec,C is empty. We are grateful to an anonymous reviewer for the suggestion that [51] canbe useful in this context. Ott argues that in free relative clauses, as in matrix CPs, the complementizeris transferred together with its complement. This is because after feature inheritance, C has nouninterpretable features that need to be valued or checked and Full Interpretation requires that it

Languages 2017, 2, 9 10 of 17
be removed.5 In embedded interrogatives, the interpretable [Q] feature ensures that the C remainspresent in the next phase.
This suffices to account for the difference in acceptability between (21)–(24) and (25). In (25), Cdoes not transfer with the TP and therefore can be spelled out in a different externalization system. In(22) and (24), C transfers with its complement and the BTH requires that C and TP transfer together—ifthey do not, we obtain an ungrammatical result. As for (25), notice that the complementizer is not aplain featureless complementizer because it is one of the two-piece formula puesto que that introducesa causal adjunct.
Additionally, when we find code-switching between C and TP, we see that the TP alters itsgrammatical properties and becomes more similar to the language of C, regardless of how the syntacticterminals spell-out. Let us reconsider example (26). The wh-phrase is English and all the lexical itemsin the subordinate clause are English. Interestingly, the word order in the subordinate clause followsan English pattern. In a fully Spanish clause, you expect to see subject–verb inversion in the presenceof an argument wh-phrase. This inversion does not take place in (26) because the complementizer inthis language is an English complementizer, which does not trigger inversion. Something similar isapparent in (27). Notice that the word order in the subordinate clause is Aux+Verb. This is unexpectedin a German subordinate clause, which is obligatorily head final (modulo embedded verb second,cf. [52]). González-Vilbazo and López argue that the reason why we obtain this unusual word orderis because the complementizer is Spanish, which then imposes a Spanish-like word order in thesubordinate clause [25].
Notice that the data in (26) and (27) cannot be accounted for with the PRF, which would predictthat both would be ungrammatical. Additionally, notice that the most popular approach to thegrammatical properties of code-switching, Carol Myers-Scotton’s Matrix Language Frame does notpredict these data either (see [53]). In this model, INFL determines the matrix language, and thereforethe word order of the main constituents in the clause. However, (26) and (27) show that this cannot bethe case, it must be C that decides on this matter. We obtain a double advantage because the claim that“C does it” can be integrated into the well-developed framework of phase theory while the claim that“INFL does it” is an isolated stipulation.
4. Switches within the Word
Poplack famously claimed that code-switching could only take place between free morphemesand could never take place between two morphemes within the same word [9]. Later research hasshown that this restriction is too strong. There are a number of examples in the literature of apparentcode-switching within the word:6
5 Chomsky suggests that the uninterpretable phi-features and EPP of T are in fact inherited from C [23]. The notion of featureinheritance is introduced in [23] as a way to solve an apparent paradox of this system: (i) syntactic dependencies emanatefrom phase heads and (ii) T establishes syntactic dependencies although it is not a phase head. The mechanism of inheritanceallows for non-phase heads to establish dependencies.
6 Thus, we have to be careful to distinguish between verbal borrowings and code-switched verbs. See [54] for a comprehensiveoverview of loanword adaptation strategies in the languages of the world. Wohlgemuth identifies three such strategies,ranging from treating the borrowed verb stem like a native one without any morphosyntactic adaptation, as in (28), orapplying a verbalizer of some kind so that the loan verb can then be inflected, as in (29) and (30), to using a light verbstrategy, as exemplified in (5) above.

Languages 2017, 2, 9 11 of 17
28. Ne ni-k-amar-oa in Maria Nah/SpaI 1SG-3SG-love-VSF IN Maria‘I love Maria.’ [55] (p. 276)
29. Er war ganz schön cabreiert Ger/Spahe was completely pretty angered‘He was pissed off.’ [8] (p. 132)
30. I katt-inc-kon-ified this house Eng/TelBuild-DO-SELF
‘I had this house built for myself.’ [56] (p. 163)
On the other hand, it is also clear that not everything goes. These are four generalizations that wecan extract from the literature and our own research:
1. It is possible to code-switch between a derivational morpheme and the root. However, it is notpossible to code-switch between a derivational morpheme and an inflectional morpheme [8] (p. 131).This generalization can be exemplified using the word cabreiert ‘angered’:
31.√
cabre] ier ]v t[participle] ]v
This word is formed by taking the Spanish root√
cabre, to which the German derivationalmorpheme [ier] has been attached and it is inflected with German inflectional morphemes. In contrast,words such as the ones in (34) are not possible:
32. a. * Er war cabre-t. Ger/Spa
b. * Er war cabre-ier-ado
c. * auf einem Stuhl-oon a chair.M [8] (p. 141)
In (32a), we have added German inflection to the Spanish root with an ungrammatical result.Likewise, in (32b), we have added Spanish participle morphology on a German verbal derivationalmorpheme and the result is equally ungrammatical. Finally, in (32c), a Spanish inflectional morphemehas been added to the German word stuhl. Although the German word is masculine, and the Spanishinflection is the masculine marker, the result is thoroughly ungrammatical.7
2. The previous generalization bears one interesting exception: case morphology. The literature showsmany examples that suggest that it is possible to add case morphemes to words that belong “in theother language”. However, as far as we know, this has never been remarked upon. The following is anexample from our own fieldwork with Turkish/German bilinguals:
7 Alexiadou et al. [20] and Alexiadou [57] discuss cases of Greek-German code-switching, where examples of the type in(32c) are grammatical. While the German word is feminine, it is assigned a Greek declension class (neuter) and case. Asin Greek exponents of declension class, gender, case, and number are all fused, (iii) could be viewed as a sub-case of ourgeneralization 2:
iii. to matratz-ithe mattress-NEUT.ACC

Languages 2017, 2, 9 12 of 17
33. Bewerbung-u schreiben yapmase lazım. Tur/Gerapplication.ACC write do.PRES.SG must‘She must write the application.’
Notice in particular that the German word Bewerbung is a complex word, which includes theGerman nominalizing morpheme [ung].
3. Although morphemes from two languages can be used to build a word, the phonology of theword has to belong to one or the other language. For instance, in example (29), the pronunciation ofcabreiert is “German”, with both tokens of /r/ pronounced as velar trills. This fact is accounted forwith MacSwan’s PF Disjunction Theorem [7] (p. 230) (later transformed into the PF Interface Condition(PFIC) in [10] (p. 191)). MacSwan’s idea can be summarized as follows: PF takes the syntactic word asthe unit of analysis. The phonology of a language consists of a set of ranked constraints (see [58] for anintroduction to constraint-based phonology). Obviously, no two languages have the same ranking ofconstraints—German, for instance, has a high ranked constraint that forces its voiceless stops to beaspirated, but in Spanish this constraint is very low. Bilinguals have two phonologies, which meansthat they have two rankings of constraints, one for each language. Thus, if a word such as cabreiert isfed to PF, one set of constraints will have to yield to the other. This phenomenon seems to be related tothe structure of the phonological word and therefore phase theory is not part of it. However, it leadsus to the fourth puzzle, which is indeed dependent on phase theory.
4. The fourth generalization is the following: the derivational morpheme decides the PF of thewhole word. That is, in the word cabreiert, the German suffix decides on the phonology of the wholeword—and the [r] of
√cabre sounds like a German velar trill and not a Spanish alveolar tap. The
experimental design in [59] is particularly apt to show the point. Stefanich and Cabrelli use Englishnonce words such as zarp and they elicit from bilingual subjects the production of these words witha Spanish morphology, as in zarpeando [59]. The point is how they pronounce the initial segment: asa voiced fricative (English phonology) or as a voiceless fricative (Spanish phonology). Their resultsshow that bilinguals strongly prefer to pronounce zarpeando with a voiceless initial segment: the affixhas influenced the pronunciation of the root. This is a puzzle that falls outside of the scope of the PFICbecause the PFIC only requires the pronunciation to be homogeneous; it makes no prediction as towhether the root or the grammatical morpheme should win out.
Let us see how these puzzles can be accounted for using our BTH. The first puzzle tells us thatthe derivational morpheme does not need to be in the same language as the root but it has to be in thesame language as the inflectional morphemes. The phase system accounts for this directly under theassumption that a derivational morpheme is a spell-out of a categorial morpheme, v or n. The root,which is the complement of v or n, is transferred independently of the derivational morpheme. On theother hand, the derivational morpheme and the inflectional morphemes are transferred in the samephase. The following diagram shows this with the help of the example cabreiert:
Languages 2017, 2, 9 12 of 17
Condition (PFIC) in [10] (p. 191)). MacSwan’s idea can be summarized as follows: PF takes the
syntactic word as the unit of analysis. The phonology of a language consists of a set of ranked
constraints (see [58] for an introduction to constraint‐based phonology). Obviously, no two
languages have the same ranking of constraints—German, for instance, has a high ranked constraint
that forces its voiceless stops to be aspirated, but in Spanish this constraint is very low. Bilinguals
have two phonologies, which means that they have two rankings of constraints, one for each
language. Thus, if a word such as cabreiert is fed to PF, one set of constraints will have to yield to the
other. This phenomenon seems to be related to the structure of the phonological word and therefore
phase theory is not part of it. However, it leads us to the fourth puzzle, which is indeed dependent
on phase theory.
4. The fourth generalization is the following: the derivational morpheme decides the PF of the whole
word. That is, in the word cabreiert, the German suffix decides on the phonology of the whole
word—and the [r] of √cabre sounds like a German velar trill and not a Spanish alveolar tap. The
experimental design in [59] is particularly apt to show the point. Stefanich and Cabrelli use English
nonce words such as zarp and they elicit from bilingual subjects the production of these words with a
Spanish morphology, as in zarpeando [59]. The point is how they pronounce the initial segment: as a
voiced fricative (English phonology) or as a voiceless fricative (Spanish phonology). Their results
show that bilinguals strongly prefer to pronounce zarpeando with a voiceless initial segment: the affix
has influenced the pronunciation of the root. This is a puzzle that falls outside of the scope of the
PFIC because the PFIC only requires the pronunciation to be homogeneous; it makes no prediction
as to whether the root or the grammatical morpheme should win out.
Let us see how these puzzles can be accounted for using our BTH. The first puzzle tells us that
the derivational morpheme does not need to be in the same language as the root but it has to be in
the same language as the inflectional morphemes. The phase system accounts for this directly under
the assumption that a derivational morpheme is a spell‐out of a categorial morpheme, v or n. The
root, which is the complement of v or n, is transferred independently of the derivational morpheme.
On the other hand, the derivational morpheme and the inflectional morphemes are transferred in the
same phase. The following diagram shows this with the help of the example cabreiert:
34.
The second puzzle tells us that there is one type of inflectional morpheme that is independent of
whatever inflectional or derivational morphemes it c‐commands: the case morphology. Phase theory
can account for this directly. Consider again the tree in (8). This tree shows that K is the head of the
nominal phase. As a consequence, the complement of K transfers independently of K (K itself
transfers with a different phase, either the v phase or the C phase).
The examples in (35) solidify this argument. In Turkish, verbs of motion may govern one of two
cases in the complement. They can govern locative case, to indicate location, or dative case, to
indicate motion into a place. German has a similar distinction, but in this language dative indicates
location and accusative indicates motion into a place.
‐t
vPInf
Transfer√ v
cabre‐ ‐ier‐
InflP

Languages 2017, 2, 9 13 of 17
The second puzzle tells us that there is one type of inflectional morpheme that is independent ofwhatever inflectional or derivational morphemes it c-commands: the case morphology. Phase theorycan account for this directly. Consider again the tree in (8). This tree shows that K is the head of thenominal phase. As a consequence, the complement of K transfers independently of K (K itself transferswith a different phase, either the v phase or the C phase).
The examples in (35) solidify this argument. In Turkish, verbs of motion may govern one of twocases in the complement. They can govern locative case, to indicate location, or dative case, to indicatemotion into a place. German has a similar distinction, but in this language dative indicates locationand accusative indicates motion into a place.
35. a. Parkhaus-a fahren yapıyor Ger/Turparking garage-DAT drive do.PROG
‘Driving into the parking garage’
b. Parkhaus-da fahren yapıyorparking garage-LOC drive do.PROG
‘Driving inside the parking garage’
Example (35) is of a light verb construction in which the light verb is in Turkish and the lexicalverb and the complement are in German. Following [3], we assume that the light verb is the spell-outof v. The complement of v is the phrase parkhaus-a/da fahren, which we take to be a root phrase withsome default verbal morphology attached to it (alternatively, we can adopt the assumptions mentionedin footnote 2 and take the light verb to be the spell-out of voice and its complement a vP):
Languages 2017, 2, 9 13 of 17
35. a. Parkhaus‐a Fahren yapıyor Ger/Tur
parking garage‐DAT Drive do.PROG
‘Driving into the parking garage’
b. Parkhaus‐da Fahren Yapıyor
parking garage‐LOC Drive do.PROG
‘Driving inside the parking garage’
Example (35) is of a light verb construction in which the light verb is in Turkish and the lexical
verb and the complement are in German. Following [3], we assume that the light verb is the spell‐out
of v. The complement of v is the phrase parkhaus‐a/da fahren, which we take to be a root phrase with
some default verbal morphology attached to it (alternatively, we can adopt the assumptions
mentioned in footnote 2 and take the light verb to be the spell‐out of voice and its complement a vP):
36.
The Phase Head Hypothesis tells us that the grammatical properties of the phase are dependent
on the phase head, including morphological case assignment. Notice that the phase head in (36) is a
Turkish v—consequently, as predicted by the PHH, the case morphology on the complement
follows the patterns of Turkish (locative for location, dative for motion) and the case morphology
spells out as in Turkish. Thus, the tree in (36) shows that K and DP belong in different phases and
that K belongs in the v phase. This is all in agreement with the BTH.8
We want to elaborate a little more on this. K is a member of the v phase, but it is itself the head
of the phase which is composed of the nominal projections up to DP. Since K in (38) is Turkish, we
predict that the complement DP must have Turkish properties. This seems to be the case: if the DP
had a German structure, it would have to include an overt determiner.
8 An anonymous reviewer points out that in (37) the root and the K are in different languages, in apparent
contravention of the BTH. This is an interesting observation, for which we can only provide a provisional
explanation. The BTH seems to make good predictions with constituents that carry the same categorial
feature in a broad sense, i.e., they belong to the same extended projection. Thus, the BTH works with the
aspect, mood and tense features of the verb or with the nominal features of the noun. However, it does
not seem to affect constituents whose categorial feature is distinct from the head of the phase. In this
particular case, K is a nominal feature merged within a verbal phase. Despite the BTH, it seems that K
does not seem to need to spell‐out in the same language as the other constituents in the vP phase. Thus,
we reformulate the BTH tentatively as follows: all the constituents in a phase that share a categorial
feature are sent to the externalization systems in one block.
vP
parkhaus
K
yapıyor
v
√
√P
KP
Transfer
fahr(en)
‐a/da
DP
The Phase Head Hypothesis tells us that the grammatical properties of the phase are dependenton the phase head, including morphological case assignment. Notice that the phase head in (36) is aTurkish v—consequently, as predicted by the PHH, the case morphology on the complement followsthe patterns of Turkish (locative for location, dative for motion) and the case morphology spells out asin Turkish. Thus, the tree in (36) shows that K and DP belong in different phases and that K belongs inthe v phase. This is all in agreement with the BTH.8
8 An anonymous reviewer points out that in (37) the root and the K are in different languages, in apparent contravention ofthe BTH. This is an interesting observation, for which we can only provide a provisional explanation. The BTH seems tomake good predictions with constituents that carry the same categorial feature in a broad sense, i.e., they belong to the sameextended projection. Thus, the BTH works with the aspect, mood and tense features of the verb or with the nominal featuresof the noun. However, it does not seem to affect constituents whose categorial feature is distinct from the head of the phase.In this particular case, K is a nominal feature merged within a verbal phase. Despite the BTH, it seems that K does not seem

Languages 2017, 2, 9 14 of 17
We want to elaborate a little more on this. K is a member of the v phase, but it is itself the headof the phase which is composed of the nominal projections up to DP. Since K in (38) is Turkish, wepredict that the complement DP must have Turkish properties. This seems to be the case: if the DP hada German structure, it would have to include an overt determiner.
The data in (37) corroborate this prediction. Auer and Muhamedova show that Russian/Kazakhbilinguals can code-switch between a Kazakh case morpheme and a Russian DP—except that theRussian DP becomes almost unrecognizable because all its grammatical properties have to adapt to thephase head K. In example (37), the Russian noun ploshchod ‘square’ should trigger femenine concordon the adjective stariy ‘old’ [60]. However, the adjective appears in a default, masculine form. Weargue that the reason lies in the case morpheme: the case morpheme is Kazakh and Kazakh has nogender. Assume that concord, like other grammatical properties, is dependent on the phase head. Ifconcord is triggered by K and K comes from Kazakh, concord is not possible. The Russian noun, on itsown, cannot trigger gender concord.
37. anau stariy ploshchod’-ti ne-ler-di zöndedi Russ/Kazthis old square-ACC thing-PL-ACC renovated‘This old square and so (were) renovated.’ [60] (p. 43)
Thus, example (37) confirms our broader generalization that the head of the phase determines thegrammatical structure of its complement.
Let us now move onto the final puzzle. Recall that the phonetic structure of a word must bedecided by the derivational morpheme. The solution to this puzzle must be obvious by now: Thederivational morpheme is the spell-out of a categorizing morpheme (n, v, etc.), and this morpheme isthe head of a phase. The PHH tells us that the head of a phase determines the grammatical propertiesof the phase. It follows that the phonetic properties of the root will be consistent with those of thederivational morpheme. As Embick argues extensively [12], a phase head fixes the phonology and theinterpretation of the root, in addition to providing categorial information. Crucially, in word-internalmixing patterns, we expect one phonology and not two, and this is apparently what we find, see [61].9
Let us conclude this section. Traditional approaches to code-switching have claimed thatcode-switching within the word is unacceptable ([7,9,10]) but empirical counterexamples have beenaccumulating over the years. We have shown that these empirical counterexamples are not random—onthe contrary, they are fully rational within phase theory.
5. Conclusions
The theoretical construct “phase” has become a fundamental tool in linguistic theory since itwas first proposed by Chomsky [1]. In this contribution, we have shown that phases can also beusefully deployed to account for some old puzzles in code-switching data, to wit, the empiricalgeneralizations formalized in the Principle of Functional Restriction and the PF Interface Condition.Additionally, we have shown that phases have a broader empirical scope than the PFC and the PFIC,since they can account for phenomena that neither the PFR nor the PFIC are designed to analyze. The
to need to spell-out in the same language as the other constituents in the vP phase. Thus, we reformulate the BTH tentativelyas follows: all the constituents in a phase that share a categorial feature are sent to the externalization systems in one block.
9 An anonymous reviewer suggests that the wanna contraction in English is an example of phonetically dependent materialwhich looks in the phonetics upwards, i.e., outside the phase, since it undergoes T-to-C movement and forms a phonetic unitwith the matrix verb. This suggests, as the reviewer observes, that the order in which the material looks in the phoneticsis not pre-ordained (downwards, as in our example, or upwards in the wanna contraction). The authors of [61] presentevidence that the wanna contraction is sensitive to prosodic phrasing, and there is currently a vivid debate in the literatureas to whether or not prosodic and syntactic phases match. As in the case of the wanna contraction, there is movement to ahigher head; we can assume, following [63] among others, that this movement extends the phase, which would make theanalysis of the wanna pattern compatible with our general assumptions.

Languages 2017, 2, 9 15 of 17
fundamental hypothesis that code-switching should be studied as any other expression of humanlinguistic competence is reinforced.
Throughout the article, we have argued that the phase system provides some analyticaladvantages over its competitors. We argued that the BTH has an advantage over PFR in [8] and MatrixLanguage Model in [53], to the extent that it provides an account for data surrounding code-switchesbetween C and TP as well as the special case of the progressive aspect. We have shown that it also hasan empirical advantage over [7,10], which forbid any form of code-switching within the word. Wehave shown that code-switching within the word is possible and we have also shown that the phasesystem explains how it can happen (see also [64]). All in all, it seems to us that phase theory, coupledwith distributed morphology, is a promising path to take in the analysis of code-switching.
Acknowledgments: Financial support for this research came from the Federal Ministry of Education andResearch (BMBF) of Germany (grant number 01UG0711; Tonjes Veenstra), and a DFG award AL 554/8-1 (ArtemisAlexiadou), which are hereby gratefully acknowledged. Luis López gratefully acknowledges a fellowship fromthe Alexander von Humboldt Foundation (Bonn, Germany) and the hospitality of the Leibniz-Zentrum fürAllgemeine Sprachwissenschaft (Berlin, Germany) that made it possible. We are thankful to two anonymousreviewers for their comments and suggestions, as well as Dan Bondarenko, Manuel Leonetti, José-Luis Mendívil,Sergio Ramos, and Daniel Vergara.
Author Contributions: The first author wrote the first draft of the paper, which underwent several revisions andrewrites with input from all three authors.
Conflicts of Interest: The authors declare no conflict of interest.
References
1. Chomsky, N. Minimalist Inquiries: The Framework. In Step by Step: Essays on Minimalist Syntax in Honorof Howard Lasnik; Martin, R., Michaels, D., Uriagereka, J., Eds.; MIT Press: Cambridge, MA, USA, 2000;pp. 89–155.
2. Citko, B. Phase Theory: An Introduction; Cambridge University Press: Cambridge, UK, 2014.3. González-Vilbazo, K.; López, L. Little v and parametric variation. Nat. Lang. Linguist. Theory 2012, 30, 33–77.
[CrossRef]4. Veenstra, T.; López, L. Little v and cross-linguistic variation. Evidence from code switching and Surinamese
creoles. In Theoretical Approaches to Linguistic Variation; Bidese, E., Cognola, F., Moroni, M.C., Eds.;John Benjamins: Amsterdam, The Netherlands, 2016; pp. 317–336.
5. Alexiadou, A. Building verbs in language mixing varieties. Zeitschrift für Sprachwissenschaft 2017, 36, 165–192.[CrossRef]
6. Mahootian, S. A Null Theory of Code Switching. Ph.D. Thesis, Northwestern University, Evanston, IL, USA,1993.
7. MacSwan, J. A Minimalist Approach to Intrasentential Code Switching; Garland Press: New York, NY, USA, 1999.8. González-Vilbazo, K. Die Syntax des Code-Switching. Esplugisch: Sprachwechsel an der Deutschen Schule
Barcelona. Ph.D. Thesis, University of Cologne, Cologne, Germany, 2005.9. Poplack, S. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of
code-switching. Linguistics 1980, 18, 581–618. [CrossRef]10. MacSwan, J.; Colina, S. Some consequences of language design: Code switching and the PF interface.
In Grammatical Theory and Bilingual Codeswitching; MacSwan, J., Ed.; MIT Press: Cambridge, MA, USA, 2014;pp. 185–200.
11. Jake, J.; Myers-Scotton, C.; Gross, S. Making a minimalist approach to codeswitching work: Adding thematrix language. Biling. Language Cogn. 2002, 5, 69–91. [CrossRef]
12. Embick, D. Localism and Globalism in Morphology and Phonology; MIT Press: Cambridge, MA, USA, 2010.13. Alexiadou, A. Roots don’t take complements. Theor. Linguist. 2014, 40, 287–298. [CrossRef]14. Borer, H. Taking Form; Oxford University Press: Oxford, UK, 2013.15. Lohndal, T. Phrase Structure and Argument Structure; Oxford University Press: Oxford, UK, 2014.16. Ramchand, G. Verb Meaning and the Lexicon; Cambridge University Press: Cambridge, UK, 2008.17. Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 1995.

Languages 2017, 2, 9 16 of 17
18. Kratzer, A. Severing the external argument from the verb. In Phrase Structure and the Lexicon; Rooryck, J.,Zaring, L., Eds.; Kluwer: Dordrecht, The Netherlands, 1996; pp. 109–137.
19. Marantz, A. No escape from syntax: Don’t try morphological analysis in the privacy of your own lexicon.In University of Pennsylvania Working Papers in Linguistics, Proceedings of the 21st Penn Linguistics Colloquium,University of Pennsylvania, Philadelphia, PA, USA, 22–23 February 1997; Dimitradis, S., Surek-Klark, W., Eds.;Penn Linguistics Club: Philadelphia, PA, USA, 1997; pp. 201–225.
20. Alexiadou, A.; Anagnostopoulou, E.; Schäfer, F. External Arguments in Transitivity Alternations: A LayeringApproach; Oxford University Press: Oxford, UK, 2015.
21. Harley, H. External arguments and the Mirror Principle: On the distinctness of Voice and v. Linguastic 2013,125, 34–57. [CrossRef]
22. Alexiadou, A.; Lohndal, T. On the division of labor between roots and functional structure. In The VerbalDomain; D’Alessandro, R., Franco, I., Gallego, A.J., Eds.; Oxford University Press: Oxford, UK, 2017;pp. 85–104.
23. Chomsky, N. On phases. In Interface+Recursion=Language? Sauerland, U., Gärtner, H.M., Eds.; Mouton deGruyter: Berlin, Germany, 2008; pp. 1–31.
24. Richards, M. On feature-inheritance: An argument from the phase impenetrability condition. Linguist. Inq.2007, 38, 563–572. [CrossRef]
25. González-Vilbazo, K.; López, L. Phase switching. Presented at Workshop Code-Switching in the BilingualChild: Within and across the Clause, University of Wuppertal, Wuppertal, Germany, 18–20 April 2013.
26. Backus, A. Two in One. Bilingual Speech of Turkish Immigrants in The Netherlands; Tilburg University Press:Tilburg, The Netherlands, 1996.
27. Muysken, P. From Colombo to Athens: Areal and Universalist Perspectives on Bilingual Compound Verbs.Languages 2016, 1, 2. [CrossRef]
28. Veenstra, T. Innovations/Properties of the third Kind: On light verbs in language-mixing from an I-languageperspective. In Proceedings of the AThEME Workshop on Language Contact from an I-Language Perspective,Donostia-San Sebastian, Spain, 27–28 October 2016.
29. Chomsky, N. Derivation by Phase. In Ken Hale: A Life in Language; Kenstowicz, M., Ed.; MIT Press: Cambridge,MA, USA, 2001; pp. 1–54.
30. Fox, D.; Pesetsky, D. Cyclic linearization of syntactic structure. Theor. Linguist. 2005, 31, 1–45. [CrossRef]31. Kratzer, A.; Selkirk, E. Phase theory and prosodic spell-out: The case of verbs. Linguist. Rev. 2007, 24, 93–125.
[CrossRef]32. Bittner, M.; Hale, K. The Structural Determination of Case and Agreement. Linguist. Inquiry 1996, 27, 1–68.33. López, L. Code switching and linguistic theory. Minimalism, Distributed Morphology and the search for an
integrated model of bilingual grammars. Presented at Bilingualism in the Hispanic and Lusophone World,Florida State University, Tallahasee, FL, USA, 7–29 January 2017.
34. Donati, C.; Branchini, C. Challenging linearization: Simultaneous mixing in the production of bimodalbilinguals. In Challenges to Linearization; Biberauer, T., Roberts, I., Eds.; de Gruyter Mouton: Berlin, Germany,2013; pp. 93–128.
35. Grimshaw, J. Extended Projection; Manuscript; Brandeis University: Waltham, MA, USA, 1990.36. Giancaspro, D. Code-switching at the auxiliary-VP boundary. Linguist. Approaches Biling. 2015, 5, 379–407.
[CrossRef]37. Emonds, J. A Transformational Approach to English Syntax: Root, Structure-preserving and Local Transformations;
Academic Press: New York, NY, USA, 1976.38. Pollock, J.Y. Verb Movement, Universal Grammar and the Structure of IP. Linguist. Inquiry 1989, 20, 365–424.39. Dussias, P. Spanish-English code-mixing at the auxiliary phrase: Evidence for eye movement data. Rev. Int.
Lingüíst. Iberoam. 2003, 2, 7–34.40. MacSwan, J. Codeswitching and generative grammar: A critique of the MLF model and some remarks on
“modified minimalism”. Biling. Language Cogn. 2005, 8, 1–22. [CrossRef]41. Laka, I. Deriving split ergativity in the progressive. In Ergativity. Emerging Issues; Johns, A., Massam, D.,
Ndayiragije, J., Eds.; Springer: Dordrecht, The Netherlands, 2006; pp. 173–196.42. Marantz, A. Case and licensing. In ESCOL 91, Proceedings of the Eighth Eastern States Conference on Linguistics,
University of Maryland, Baltimore, MD, USA, 11–13 October 1991; Westphal, G.F., Ao, B., Chae, H.R., Eds.; OhioState University Press: Columbus, OH, USA, 1992; pp. 234–253.

Languages 2017, 2, 9 17 of 17
43. Baker, M. Case: Its Principles and Parameters; Cambridge University Press: Cambridge, UK, 2015.44. Harwood, W. Being progressive is just a phase: Celebrating the uniqueness of progressive aspect under a
phase-based analysis. Nat. Language Linguist. Theory 2015, 33, 523–573. [CrossRef]45. Zagona, K. Verb Phrase Syntax; Springer: Dordrecht, The Netherlands, 1988.46. Bolinger, D. The nominal in the progressive. Linguist. Inquiry 1971, 2, 246–250.47. Alexiadou, A. Nominal vs. verbal-ing constructions and the development of the English progressive. Engl.
Linguist. Res. 2013, 2, 126–140. [CrossRef]48. Bybee, J.; Perkins, R.; Pagliuca, W. Tense, Aspect, and Modality in the Languages of the World; The University of
Chicago Press: Chicago, IL, USA, 1994.49. Belazi, H.M.; Rubin, E.J.; Toribio, A.J. Code Switching and X-Bar Theory: The Functional Head Constraint.
Linguist. Inquiry 1994, 25, 221–237.50. Ebert, S. The Morphosyntax of WH-Questions: Evidence from English-Spanish Code-Switching. Ph.D.
Thesis, UIC, Chicago, IL, USA, 2014, unpublished.51. Ott, D. A note on relative clauses and the theory of phases. Linguist. Inquiry 2011, 42, 183–192. [CrossRef]52. Heycock, C. Embedded root phenomena. In The Blackwell Companion to Syntax; van Riemsdijk, H.,
Everaert, M., Eds.; Blackwell: Oxford, UK, 2005; pp. 174–209.53. Myers-Scotton, C. Contact Linguistics. Bilingual Encounters and Grammatical Outcomes; Oxford University
Press: Oxford, UK, 2002.54. Wohlgemuth, J. A Typology of Verbal Borrowings; De Gruyter Mouton: Berlin, Germany, 2009.55. MacSwan, J. A Minimalist Approach to Intrasentential Code Switching. Spanish-Nahuatl Bilingualism in
Central Mexico. Ph.D. Thesis, University of California, Los Angeles, CA, USA, 1997.56. Bandi-Rao, S.; DenDikken, M. Light switches: On v as a pivot in codeswitching, and the nature of the ban on
word-internal switches. In Grammatical Theory and Bilingual Code-Switching; MacSwan, J., Ed.; MIT Press:Cambridge, MA, USA, 2014; pp. 161–184.
57. Alexiadou, A. Remarks on the morpho-syntax of code switching. In Proceedings of the 9th internationalconference on Greek linguistics, University of Chicago, IL, USA, 29–31 October 2009; Chatzopoulou, K,Ioannidou, A., Yoon, S., Eds.; Ohio State University Press: Columbus, OH, USA, 2011; pp. 44–55.
58. McCarthy, J. A Thematic Guide to Optimality Theory; Cambridge University Press: Cambridge, UK, 2002.59. Stefanich, S.; Cabrelli, J. Phonological Spell-Out of Intra-Word Code-Switching by Early Spanish/English Bilinguals;
UIC: Chicago, IL, USA, 2017; unpublished manuscript.60. Auer, P.; Muhamedova, R. ‘Embedded language’ and ‘matrix language’ in insertional language mixing:
Some problematic cases. Riv. Linguist. 2005, 17, 35–54.61. González-Vilbazo, K. The bilingual sound machine: Phonology by phase. Presented at the University of
Florida, Gainesville, FL, USA, 2015.62. Ackema, P.; Neeleman, A. Context sensitive Spell-Out. Nat. Language Linguist. Theory 2003, 21, 681–735.
[CrossRef]63. Den Dikken, M. Phase extension. Theor. Linguist. 2007, 33, 1–41.64. Alexiadou, A.; Åfarli, T.A.; Grimstad, M.B. Language Mixing: A Distributed Morphology approach. In NELS
45, Proceedings of the Forty-Fifth Annual Meeting of the North East Linguistic Society, MIT, Cambridge, MA, USA,31 October–2 November 2014; Bui, Ö., Ed.; GLSA: Amherst, MA, USA, 2015; pp. 25–38.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
Clausal Subordination and the Structure of theVerbal Phrase
Marcel den Dikken 1,2
1 Department of English Linguistics, Eötvös Loránd University, Rákóczi út 5, 1088 Budapest, Hungary;[email protected]
2 Research Institute for Linguistics, Hungarian Academy of Sciences, Benczúr u. 33, P.O. Box 360,1394 Budapest, Hungary; Tel.: +36-1-321-4830
Academic Editors: Tabea Ihsane and Maria del Carmen Parafita CoutoReceived: 4 February 2017; Accepted: 21 April 2017; Published: 3 May 2017
Abstract: In his first approach to recursion in clausal embedding, Chomsky (1957) postulatesa proform in the matrix clause linked to an independently constructed clause that, via an applicationof the generalised transformation, eventually becomes the matrix verb’s complement. Chomsky (1965)replaces this with a direct clausal embedding analysis, with clausal recursion in the base componentof the grammar. I argue here that, while direct clausal recursion is certainly needed, an update tothe Chomsky’s (1957) approach (minus the application of the generalised transformation) deservesa prominent place in syntactic theory as well. The discussion is based on data from Dutch, German,and Hungarian. This paper addresses the role of presuppositionality in the context of clausalcoordination, the analysis of the so-called wh-scope marking construction, and the importance ofAgree in connection with a subordinate clause’s transparency or opacity to extraction. Central inthe analysis is a perspective on the structure of the verbal phrase which accommodates two discretestructural positions for the object.
Keywords: clausal subordination; proform; object positions; recursion; presuppositionality; wh-scopemarking; Agree
1. Introduction
In the first approach to recursion in clausal embedding in the transformational-generativeframework (see [1]), the matrix clause contained a proform linked to an independently constructedclause that, after association with the proform and subsequent elimination of this proform via thegeneralised transformation, ended up serving as the subordinate clause. (1) sums this up.
1. a. John believes that Mary is pregnantJohn believes that Mary was kissed by Bill
b. [S John believes it][S’ that [S Mary is pregnant/was kissed by Bill]]
c. [S John believes [S’ that [S Mary is pregnant/was kissed by Bill]]]
In [2], Chomsky abandons this proform-based approach to clausal recursion, and substitutes itwith a direct clausal embedding analysis: the matrix verb selects the subordinate clause directly asits object, in the base component, which includes a base rule rewriting VP as V + S’. Appropriatelyupdated, the Aspects approach is a staple of mainstream generative theory today—and there can beno doubt that we need it. But there is reason to believe that an update of (1b), the hallmark of theSyntactic Structures approach [1], deserves a prominent place in current syntactic theorising as well.
Languages 2017, 2, 5; doi:10.3390/languages2020005 www.mdpi.com/journal/languages

Languages 2017, 2, 5 2 of 12
In this paper,1 I will present an analysis of clausal subordination that mobilises both directrecursion and a proform-based strategy, each addressing different subspecies of embedding ofa clause within a larger clause. The empirical discussion will be based on data from Dutch, German,and Hungarian. This last language is particularly informative thanks to the fact that (to recycle the oldadage used frequently with reference to Hungarian in other contexts) it wears (1b) on its sleeve.
This paper is structured as follows. In Section 2, I begin by looking at the role of presuppositionalityin the context of clausal coordination, showing that in Hungarian the distribution of a proleptic pronounassociated to the clause (very much as in (1b)) plays a key part in determining whether the subordinateclause gets a presuppositional reading or not, whereas in Dutch it is the placement of the subordinateclause vis-à-vis the verbal cluster that determines this. Section 3 provides a structural perspectiveon object positions and presuppositionality which allows us to understand the empirical pictureemerging from Section 2. In Section 4, I subsequently apply the insights gained from Sections 2 and 3to an analysis of the so-called wh-scope marking construction, with particular emphasis on Germanand Hungarian. Section 5 adds a note on the role of Agree in determining whether a subordinateclause is transparent or opaque to extraction. Section 6 concludes.
2. Clausal Subordination and Presuppositionality
Hungarian clausal subordination constructions participate in three different syntactic patterns.In one, which looks very much like what we find in English, the matrix verb combines directly withthe subordinate clause. We see this in the a-examples in (2) (for hisz ‘believe’, a bridge verb in the senseof [4]) and (3) (for beismer ‘confess’, a factive verb). In the second pattern, the verb combines withan accusative pronoun (azt ‘it. ACC’) in addition to the subordinate clause. This is illustrated in theb-examples in (2) and (3). The third pattern differs from the second in featuring the proform úgy ‘so’ inlieu of azt, and in being available only for bridge verbs: (3c) is ungrammatical.
2. a. János hiszi, hogy Mari terhes (Hungarian)János believes that Mari pregnant
b. János azt hiszi, hogy Mari terhesJános it-ACC believes that Mari pregnant
c. János úgy hiszi, hogy Mari terhesJános so/thus believes that Mari pregnant‘János believes that Mari is pregnant.’
3. a. János beismeri, hogy Mari terhes (Hungarian)János admits/confesses that Mari pregnant
b. János beismeri azt, hogy Mari terhesJános admits/confesses it-ACC that Mari pregnant
c. * János beismeri úgy, hogy Mari terhesJános admits/confesses so/thus that Mari pregnant‘János admits/confesses that Mari is pregnant.’
1 This paper is based on Sections 2.3 and 3.4.3 of [3], to which the reader is referred for additional discussion, within thebroader context of the question of whether syntactic structures are built from the bottom up (as in mainstream generativeapproaches) or from the top down.

Languages 2017, 2, 5 3 of 12
The interpretation of (2a) is not necessarily the same as that of (2b) or (2c): when azt or úgy isabsent, the hogy ‘that’ clause in bridge-verb constructions has a strong tendency to be interpretedas denoting “a proposition (without a necessary commitment to its truth) about which the complexsentence makes an assertion”, in the words of de Cuba and Ürögdi [5] (p. 37). De Cuba and Ürögdishow convincingly that the proposition denoted by the embedded clause in sentences of the type in (2a)is not presupposed to be true (it can in fact be known to be a lie), so the effect of omitting azt or úgy in (2)is not equivalent to “factivity” (cf. (3)). But the content of this proposition does have to be taken to bepart of the common ground—and it is in this sense that I will use the term “presuppositional” in thiswork (close to de Cuba and Ürögdi’s “referential”, though by their own admission that their evidencethat the CP in sentences such as (2a) is a referring expression is “impressionistic at best” [5] (p. 45)).Thus, the hogy ‘that’ clause in bridge-verb constructions lacking proleptic azt/úgy shows a strongtendency to be interpreted presuppositionally, similar to but not quite in the same way as in factive-verbconstructions. In factive-verb constructions, azt can be absent or present (cf. (3a,b)); but the otherproform, úgy, cannot be used.2
So in Hungarian, though both bridge verbs and factive verbs allow their subordinate clause toco-occur with the proform azt, the absence of this pronoun usually has a presuppositionalising effect onthe embedded clause in the case of bridge verbs. In Dutch, we see a similar presuppositionalising effectwith bridge-verb complements, this time manifesting itself in terms of linear order. When a subordinateclause is placed in the Mittelfeld, to the left of the verbal cluster, it is obligatorily interpretedpresuppositionally: thus, the interpretation of (4a) is on a par with that which reference [5] describesfor Hungarian (2a); to get the “ordinary” non-presuppositional interpretation, the subordinate clausehas to be placed in the Nachfeld, following the verbal cluster. For factive verbs (5), placement of thesubordinate clause to the left or to the right of the cluster has no interpretive effect. Although placinga finite clause in the Mittelfeld is always a marked option in Dutch, the result is typically less markedwith factive verbs than with bridge verbs, precisely because a presuppositional interpretation for thesubordinate clause is guaranteed with factives.
4. a. dat Jan [dat Marie zwanger is] gelooft (Dutch)that Jan that Marie pregnant is believes
b. dat Jan gelooft [dat Marie zwanger is]that Jan believes that Marie pregnant is
5. a. dat Jan [dat Marie zwanger is] betreurt (Dutch)that Jan that Marie pregnant is regrets
b. dat Jan betreurt [dat Marie zwanger is]that Jan regrets that Marie pregnant is
These contrasts between bridge-verb and factive constructions point to an important structuraldifference between factive and non-factive constructions with regard to the way the syntax integratesthe subordinate clause into the structure of the complex sentence. A proper syntactic understanding ofhow this comes about will tell us a lot about the way clausal subordination works in natural language,and how the grammar should operate in order to deal adequately with the syntax of clausal hypotaxis.
2 While it is entirely beyond dispute that úgy is entirely unusable in factive constructions, de Cuba and Ürögdi [5] (p. 39),assert that azt can be used in factives only when it (and hence its associate, the embedded clause) is contrastively focused,and is deviant in a neutral sentence. De Cuba and Ürögdi base this claim on examples (featuring the verb sajnál ‘regret’)in which azt is in an immediately preverbal position, for which it is indeed true that azt has to be focused. But from (3b),it is immediately apparent that it cannot be claimed in general that when azt is present in factive constructions, it must becontrastively focused: in (3b), postverbal azt is grammatical and unmistakably not a contrastive focus. I take (3b) to establishthat there is no focus condition at work on the use of azt with factive verbs.

Languages 2017, 2, 5 4 of 12
3. Object Positions, Proforms and Presuppositionality
In this section, I argue that the observations about Hungarian and Dutch made in Section 2translate structurally into a syntactic analysis in which the verb phrase accommodates two objectpositions—much like the way the clause accommodates (at least) two subject positions. One objectposition is the familiar complement-of-V position; the other is a specifier position—either the specifierof the projection of the verbal root (VP) or that of a functional category (e.g., AspP) projecting betweenv and VP. For simplicity (and since nothing hinges on the choice between these options here), I willwork in this paper with the structure in (6), where the higher of the two object positions is SpecVP(see [6–12], i.a., for relevant discussion).
6. a. [vP SUBJECT [v’ v [VP <OBJECT> [V’ V <OBJECT>]]]]
Whenever the occupant of SpecVP is an argument (i.e., receives a θ-role in this position), it isinterpreted presuppositionally—i.e., outside the domain of existential closure (see [13]), which, for theobject in (6), is the V’ (see [3] (Section 2.3.1.2) and [12] for discussion).3
This link between the thematic object’s occupancy of SpecVP and its presuppositionalinterpretation immediately addresses the contrast between (4a) and (4b) in Dutch. When thesubordinate clause appears in SpecVP, it surfaces to the left of the verb (which, in non-root contexts,is spelled out at V in Dutch) and occurs in the Mittelfeld; it obligatorily receives a presuppositionalinterpretation, thanks to being outside V’. On a non-presuppositional interpretation, the subordinateclause is in the complement-of-V position, which, for clauses, is linearised to the right of the verb inDutch.4
The structure in (6), with its two positions for objects, also helps us solve the puzzle posed by theHungarian examples in (2) and (3). The proposal runs as follows.5
With factive verbs such as beismer ‘admit/confess’, SpecVP is always projected, because thecomplement-of-V position is occupied by a secondary predicate headed by “FACT”—a developmentof the classic approach to factives in [16], but with FACT now serving as a secondary predicate at thelevel of the VP (rather than as the head of a complex noun phrase, as in Kiparsky and Kiparsky’soriginal proposal).6 The occupant of SpecVP is the subject of V + FACT. Just as in copular sentences,this subject can be either the subordinate CP itself (cf. [that Mary is pregnant] is a fact) or a proform
3 A reviewer asks how the text statement jibes with the grammaticality of John never gave a unicorn a bath, for which the existenceof unicorns is not presupposed. The reviewer’s question is built on the premise that in the double-object construction, theindirect object occupies the SpecVP position in (6). However, although I follow [6] in exploiting both the complement-of-Vposition and the SpecVP position for objects, I am not a proponent of his proposal for the syntax of ditransitives. In [14],I argue in depth for an analysis of ditransitives and dative shift, mobilising a small clause in the complement of V. Theindirect object is thus not (necessarily) in the SpecVP position; and even if at some point it does end up there, the occupantof SpecVP will be a predicate (a null-headed PP containing the Goal; [14], not an argument. So the indirect object is perfectlywelcome to be non-presuppositional.
4 On the linearisation of V vis-à-vis a CP in its complement, see Biberauer et al.’s Final-over-Final Constraint (FoFC) [15]in (i), and also [3] (Section 2.3.1.5). Final-over-Final Constraint. A head-initial category cannot be the immediate structuralcomplement of a head-final category within the same extended projection
5 With regard to the underlying representations adopted, this proposal is very different from the approach that de Cubaand Ürögodi [5] take to largely the same set of facts. For them, the key difference between what they call “referential”and “non-referential” complement clauses (for me, “presuppositional” and “non-presuppositional” ones) lies in their size:referential ones are CPs, the others are cPs embedding CP, in a “CP-recursion” kind of configuration. The specifier positionof each of these clauses provides a base position for a “clausal expletive”, whose interpretation depends on its insertion site.See footnotes 2 and 7 in this paper for a critique of some of the details of [5].
6 One might think (as did one of the reviewers of this paper) that to accommodate both the analysis of factive-verbconstructions and that of complex noun phrases of the type the fact that S, the present approach needs two differentstructures for fact/FACT: (one as in (7), the other as a head taking CP as its complement. I emphasise, however, thatthe classic clausal complementation analysis for the fact that S is arguably incorrect, and that a structure in which fact isa predicate of the that-clause, along the same lines as (7a), is superior (see [17,18] for discussion). Thus, rather than modellingthe analysis of factive-verb constructions on the classic complementation approach to the fact that S, my proposal models theanalysis of the fact that S on that in (7a). In this way, the present analysis preserves Kiparsky and Kiparsky’s elegance ofa single structure pertaining to both constructions involving fact/FACT [16].

Languages 2017, 2, 5 5 of 12
linked to an extraposed CP outside VP (cf. it is a fact [that Mary is pregnant]).7 Whenever it occurs infactive-verb constructions, the pronominal proform is a thematic argument of the complex predicateformed by the verb and the secondary predicate FACT.
Since with factive verbs the complement-of-V position is always occupied by the abstractsecondary predicate FACT, this position is never available for the subordinate CP. In (7a), the CPoccupies the SpecVP position. The secondary predicate FACT, occupying the complement-of-V position,forms a complex predicate with V and introduces its argument in SpecVP.8 In (7b), the argument of thecomplex predicate V + FACT is the proform occupying SpecVP, coindexed with the CP in extraposedposition. So in factive-verb constructions, the CP is always associated with the θ-role assigned toSpecVP, which ensures that it is always given a presuppositional interpretation, regardless of which ofthe two structures in (7) is built.9
7. a. [vP SUBJECT [v’ v [VP <OBJECT> [V’ V <OBJECT>]]]]
b. [vP SUBJECT [v’ v [VP PROFORMi = ARG [V’ V [PRED FACT]]]]] [CP ... ]i
With verbs such as hisz ‘believe’, when azt is not present, the subordinate clause has a choiceof positions: it can either take the complement-of-V position, as in (8a.i), or be mapped into theSpecVP position, so that it comes to behave exactly like the object clause of a factive verb (cf. (7a)and (8a.ii)). (Of course a blend of (8a.i) and (8a.ii), with a CP in each of the two positions in the VP,is uninterpretable: V’s argument structure accommodates no more than one propositional argument).
8. a.i [vP SUBJECT [v’ v [VP V [CP ... ]]]]
a.ii [vP SUBJECT [v’ v [VP [CP ... ] [V’ V]]]
Hungarian speakers, for whom the presuppositional interpretation of the hogy-clause in (2a)is categorical, select (8a.ii) over (8a.i) whenever no proform is present.10 But categoricalpresuppositionality for (2a) is not the norm: it is, for most speakers, merely a strong tendency (as I notedin the paragraph below (3)). With verbs such as hisz ‘believe’, it will usually be possible to map thesubordinate clause into the complement-of-V position.
Whenever azt is present with verbs such as hisz ‘believe’, it once again occupies SpecVP, just as inconstructions with factive verbs. But whereas in factive-verb constructions azt is an argument of thecomplex predicate V + FACT, in bridge-verb constructions this azt is not an argument but a secondarypredicate for the complement clause occupying the complement-of-V position, as in (8b), which recalls
7 Regarding the relationship between the proform and the extraposed CP, and the structural position of the extraposed CP,I am partial to an asyndetic coordination approach along the lines of [19,20]. The sharing of presuppositionality between theproform and the peripheral CP is straightforward in this approach: asyndetic specification generally evinces a matching ofthe referential properties of the proform and the associate (cf. Dutch ik zoek hem, die vent van hiernaast/* iemand van hiernaast‘I am looking for him, that guy next door/* someone next door’ vs. ik zoek wat, iets lekkers ‘I am looking for something,something delicious’). For de Cuba and Ürögodi [5], the proform in the specifier of cP or CP “inherits the properties of thephrase it stands for. In particular, we suggest that there is Spec-Head agreement for referentiality in clausal complements” [5](p. 42). This proposal is technically problematic. Referentiality (or specificity or presuppositionality) is not a property of C:it is a property of the clause. One never finds that interpretive (i.e., semantic or pragmatic) properties of phrases are sharedwith their specifiers (thus, consider the following question–answer pair: A: what did you see? B: I saw [it RAIN]—here it is notreferential, hence not focused, but it legitimately serves as the specifier of the focused constituent corresponding to what inthe question).
8 The V-head in this VP structure can be thought of as a contentful RELATOR of the secondary predicate and its subject. One ofmy reviewers asks why the secondary predicate in (7) cannot be overt when a factive verb spells out V (* I regret that sheis pregnant a fact). It CAN be when an epistemic verb such as consider lexicalises V (I consider that she is pregnant a fact).This suggests an answer to the reviewer’s question: factive verbs are composites of V and FACT.
9 A reviewer wonders why there should be an alternation between (7a) and (7b). A fact regarding the distribution of CPs(holding for both English-type languages and Hungarian) is that they often avoid being in specifier positions and “extrapose”instead, with a proleptic pronoun taking the argument position, as in (7b). Why CPs avoid specifier positions remainsunclear, especially because this is not an absolute ban.
10 On a top-down approach to structure building (see [3] and references there), this preference for (8a.ii) over (8a.i) can beunderstood as the desire to insert CP into the first possible position within VP.

Languages 2017, 2, 5 6 of 12
Moro’s analysis of sentences such as it’s that she’s pregnant, for which he treats it as the predicate of thethat-clause [21].11
8. b. [vP SUBJECT [v’ v [VP PROFORM=PRED [V’ V [CP ... ]]]]]
In (8b), even though the SpecVP position is occupied, we get no presuppositional reading forthe subordinate clause. That is because the subordinate clause itself occupies the complement-of-Vposition, which is within the nuclear scope (V’), and SpecVP is occupied by a predicate, not by the CPor a placeholder for it. Even with the predicate being assigned a presuppositional interpretation in thesemantics, this does not accrue to its subject: in a copular inversion construction such as the winnermust be someone from New York, the fact that the predicate nominal occupies SpecTP, a position outsidethe nuclear scope, does not prevent the notional subject someone from New York (which is inside thenuclear scope) from being interpreted non-specifically.
As far as the distribution of presuppositional readings in bridge and non-bridge constructionsis concerned, the analyses in (7) and (8) make exactly the right predictions. This analysis of thebridge/factive dichotomy also directly explains the fact that azt alternates with úgy ‘so’ in bridge-verbconstructions but not with factives (recall the c–examples in (2) and (3)). This falls out once we realisethat úgy ‘so’ is always a predicate: it has no argumental functions. Placing úgy in SpecVP in (7b)would cause a clash between the fact that a θ-role is assigned to this position by the complex predicateV + FACT and the fact that úgy tolerates no θ-role. In (8b), by contrast, azt plays a predicational role;replacing it with úgy should be perfectly fine, and indeed it is, as we saw in (2c). We see the samealternation between az and úgy with semi-copulas such as látszik ‘seem/appear’, as in (9). Here, sincethere is, in fact, no other predicate around (látszik is merely a copula), az and úgy play the role ofprimary predicate for the hogy-clause.
9. a. az látszik, hogy Mari terhes (Hungarian)it seems that Mari pregnant
b. úgy látszik, hogy Mari terhesso seems that Mari pregnantboth: ‘it seems/appears that Mari is pregnant.’
11 Moro projects it in it’s that she’s pregnant as the predicate of a canonical predication structure, and has it change placeswith its subject (the CP) via predicate inversion [21]. In (8b), I model the predication relation between azt and the CPas a “reverse predication” or “predicate-specifier structure”, in the sense of [17]. The fact that azt in SpecVP in (8b) hasaccusative case and controls definite agreement with the matrix verb does not subtract from its treatment as a secondarypredicate. Predicates in Hungarian often host case morphology. When they serve as primary predicates of a finite clause,as in (i.a), they are nominative (which is morphologically invisible), under concord with the nominative subject; whenthey find themselves in the complement of a verb such as tart “consider”, the case they bear is dative (see (i.b)), becausethat is the case that the RELATOR of the secondary predication relation below tart happens to assign (put differently, theRELATOR = -nak; see [17]. In general, predicates in Hungarian take on the case that is available to them in their structuralenvironment. In the structural environment in which azt occurs in (8b), azt is the closest potential goal for v qua accusativecase assigner. Because the proform in (8b) is in a structural case relation with v, it also controls definiteness agreement withthe finite verb—which hence comes out with definite inflection. When úgy ‘so’ occupies the SpecVP position instead of azt(recall (2c)), a definiteness agreement and accusative case assignment relation between it and v is impossible because úgy isnot nominal. So v skips úgy altogether, and targets the CP in the complement-of-V position as its Agree-goal when úgy ispresent instead of azt.
i. a. magyar vagyok, és az apám is az volt (Hungarian)Hungarian am and the father. 1SG(NOM) also it(NOM) was‘I am Hungarian, and my father was, too.’
b. magyar vagyok, és annak is tartom magamHungarian am and it. DAT also feel myself‘I am Hungarian, and so I feel, too.’
Languages 2017, 2, 5 7 of 12
A reviewer points to two respects in which the distributions of the proleptic proforms azt andúgy are different in the realm of bridge-verb constructions. One is that insertion of sentential negationin (2c) is ungrammatical while it is perfectly fine in (2a). The examples in (10) (provided by the reviewerand verified by me with another native speaker) illustrate this:
10. a. azt nem gondolta, hogy Mari terhes (Hungarian)it.ACC not thought that Mari pregnant
b. * úgy nem gondolt, hogy Mari terhesso/thus not thought that Mari pregnant‘he doesn’t think that Mari is pregnant.’
The other difference between azt and úgy with bridge verbs is that the string azt+hogy-clause canbe fronted as a unit (either via ordinary topicalisation or via left dislocation; in the latter case, János isimmediately preceded by a resumptive proform—the second azt in (11a)) while fronting of the stringúgy+hogy-clause is impossible:
11. a. azt, hogy Mari terhes, (azt) János is mondta (Hungarian)it.ACC
that Mari pregnant it. ACC János also said
b. * úgy, hogy Mari terhes, (azt/úgy) János is mondtaso/thus that Mari pregnant it. ACC/so János also said
These two observations are probably relatable to a single factor: movement of úgy. The grammaticalityof (11a) suggests that azt can stay within the node in which it forms a constituent with the hogy-clause;12
the ill-formedness of (11b) suggests that úgy cannot. If, indeed, úgy must leave its base position, theungrammaticality of (10b) falls out as a case of intervention (an “inner island” effect in the terminologyof [22]): úgy, a non-referential expression (a predicate), must move out of the verb phrase but in sodoing crosses the negation operator, which blocks the relation between the moved úgy and its trace.The grammaticality of (10a) (which has the same linear order as (10b): azt, too, is to the left of nem “not”)is then left to be dealt with. One possibility would be to assign this azt referential (hence argumental)status (so that it is immune to the inner island)—which would lead to a presuppositional interpretationof CP. Alternatively, azt is, like úgy, a predicate, but unlike úgy in (10b), the azt in (10a) has not crossedover the sentential negation operator: though it occurs to the left of nem, the morphological marker ofsentential negation, it remains below the abstract operator (outside TP) supplying the semantics ofnegation (see [3] (chapter 3) for some relevant discussion). These remarks are tentative. There clearlyis much more to be said about these examples. They should be revisited in future research.
The analyses of clausal subordination in (7) and (8) and the brief remarks about (10) providea natural launching pad for an approach to so-called wh-scope marking constructions that findsa natural home for the “wh-expletive” that occurs in them.13 I turn to this next.
4. On the Syntax of wh-Scope Marking
In the wh-scope marking constructions (also known as partial wh-movement constructions)in (12a) (from German) and (13a) (from Hungarian), we are dealing with root wh-questions in
12 On the analysis for prolepsis with azt/úgy proposed in (8b), the string PROFORM + CP can front as a constituent by way of“remnant verb phrase” movement, with azt, hogy Mari terhes in (11a) minimally instantiating a remnant VP and azt sitting inSpecVP. (Given that the verb raises to a position quite high up the tree in (11a), the constituent dominating azt + CP andexcluding the verb could even be vP.) Much of what I say in the rest of this paragraph can be transposed, mutatis mutandis,to de Cuba and Ürögodi’s analysis [5], with “SpeccP” or (on a treatment of azt in (10a) as a referential element, as in the firstalternative for the analysis of (10a) mentioned below) “SpecCP” substituted for “SpecVP”.
13 De Cuba and Ürögodi also discuss the link between proleptic azt and the “wh-expletive” mit [5].

Languages 2017, 2, 5 8 of 12
which the wh-constituents wer and ki have matrix scope, just as in the long-distance wh-frontingconstructions in (12b) and (13b) (which are dispreferred, to a greater or lesser degree, whence the “%”).But in (12a) and (13a), the wh-operators wer and ki are not at the left edge of the matrix clause: theirscope is marked by an “expletive” wh-element corresponding to English what.
12. a. was glaubt Hans, wer schwanger ist? (German)what believe Hans who pregnant is
b. % wer glaubt Hans, dass ___ schwanger istwho believe Hans that pregnant isboth: ‘who does Hans believe is pregnant?’
13. a. mit hisz János, hogy ki terhes? (Hungarian)what believe.3SG.INDEF János that who pregnant
b. % ki hiszi János, hogy ___ terhes?who believe.3SG.DEF János that pregnantboth: ‘who does János believe is pregnant?’
In Hungarian, it is clear that the verb agrees with this “wh-expletive” and assigns case to it:mit in (13a) bears the accusative case particle -t, and the inflectional form of hisz ‘believe’ is fromthe indefinite/subjective agreement paradigm, unlike what we see in (13b), where hiszi agrees indefiniteness with the finite subordinate clause (which the grammar of Hungarian treats as definite).This property of (13a) makes it plausible to assume that upstairs, (13a) is the wh-counterpart to (2b),with mit replacing azt (see [23] for the original insight): while accusative azt is definite and triggersa form of the matrix verb from the definite/objective conjugation, accusative mit is indefinite andcooccurs with indefinite/subjective inflection. Thinking of (13a) along these lines, and bearing in mindthe treatment of azt in (2b) presented in (7b), we immediately procure an analysis of the wh-scopemarking construction that finds a home for the “wh-expletive”: it originates in the SpecVP position,with the subordinate clause occupying the complement-of-V position.
Rizzi [24] notes that German wh-scope marking constructions with bridge verbs resist the presenceof a sentential negation in the upstairs clause (see also [25], [26] (p. 378)), in contradistinction to theirlong wh-fronting counterparts:
14. a. * was glaubst du nicht, mit wemHans sich dort treffen wird? (German)what believe you not with whom Hans REFL there meet will
b. mit wem glaubst du nicht, dass Hans sich dort treffen wird?with whom believe you not that Hans REFL there meet will‘who don’t you think that Hans will meet there?’
In Hungarian, this effect of negation also manifests itself clearly in the wh-scope markingconstruction: (15) is systematically rejected when nem is included in it (see [23]). What is particularlyinteresting in the context of the discussion earlier in this paper, however, is that Horvath points outthat the wh-scope marking construction in (16a) is immune to the presence of matrix negation whilelong A‘–fronting of the meaningful wh-constituent across the negation leads to an ill-formed result,as shown in (16b) [23] (p. 536).
15. mit (* nem) gondolsz, hogy ki fog elmenni? (Hungarian)what-ACC not think-2SG.INDEF that who(NOM) will PV-go

Languages 2017, 2, 5 9 of 12
16. a. mit nem ismert be János, hogy hányszor hamisította az aláírásodat? (Hungarian)what not admitted János that how.many.times forged the signature-2SG-ACC
b. * hányszor nem ismerte be János, hogy hamisította az aláírásodat?‘how many times didn’t János admit that he had forged your signature?’
The ungrammaticality of (16b) is an inner island effect induced by overt-syntactic fronting ofa non-argumental wh-expression.14 The intervention effect seen in (15) and also in German (14a) canbe assimilated to (16b) if the wh-scope marker (German was, Hungarian mit) is a non-argumentalwh-operator in these cases. By this logic, mit in (16a) should be an argumental wh-expression: otherwise,it would be difficult to account for its immunity to nem-intervention.
The difference between the intervention-sensitive examples of the wh-scope marking constructionin (14a) and (15), on the one hand, and the sentence in (16a), on the other, lies in the nature ofthe matrix verb (non-factive glauben, gondol ‘think’ versus factive beismer ‘admit, confess’)—and,concomitantly, in the (non-)presuppositional nature of the complement clause. This is systematic:whenever a matrix verb is used whose CP complement is presuppositional (or D-linked, in Horvath’sterms [23]), no intervention effect manifests itself in the wh-scope marking construction.
We can make immediate sense of this in light of the discussion in Section 3. There, I argued that thecomplement position of a factive verb is always taken by an abstract secondary predicate FACT, and thatthe SpecVP position is occupied by the argument of that secondary predicate—the subordinate clauseitself, or a proleptic object (in which case the clause is merged as a satellite; see fn. 7). An argumentalexpression in the SpecVP position receives a presuppositional interpretation. Thus (7a), above, directlyaccounts for the presuppositional status of the factive object clause. And (7b) does so indirectly, byinterpreting the proform as presuppositional/D-linked, and having the clause associated to it viaa relationship of apposition. It is (7b) that, by realising the proform as the wh-element mit, gives riseto the wh-scope marking construction in (16a). The thing to note is that mit here is an argumentalwh-expression, immune to the inner island set up by the negation.
In the syntax of bridge-verb constructions with a place-holder for the complement clause,the proform is once again in SpecVP, as in (8b). But here, the proform in SpecVP does not playthe role of an argument: it is the CP in the complement-of-V position that serves as the argument;the proform is a secondary predicate of this CP, in a reverse predication structure. The hypothesisthat the proform in the SpecVP position of bridge-verb constructions is not an argumental expressionhad already accounted for the non-presuppositional interpretation of the complement clause inbridge-verb constructions—and it now also derives the intervention effect seen in German (14a) andHungarian (15): building a non-argumental bare wh-dependency across a scope-taking element isimpossible (see also (16b)).
5. A Note on wh-Dependencies across a Subordinate Clause
In wh-scope marking constructions such as Hungarian (13a), movement of the “real”wh-constituent into the matrix clause, across the CP “associate” of the wh-scope marker, is neverallowed, regardless of how the “real” wh and the wh-scope marker are ordered vis-à-vis one another:
17. a. * ki mit hisz hogy ___ terhes? (Hungarian)who what believe.3SG.INDEF that pregnant
b. * mit ki hisz hogy ___ terhes?what who believe.3SG.INDEF that pregnant
14 See [3] (Section 3.4.3) for detailed discussion and analysis of “intervention effects” with non-argument dependencies.

Languages 2017, 2, 5 10 of 12
The ungrammaticality of the examples in (17) is arguably a consequence of the fact that thehogy-clause here is not an Agree-goal for the verb: the verb hisz in these sentences, as in (11a), bearsindefinite/subjective inflection, agreeing with the scope marker mit rather than the finite hogy-clause(which is definite). As shown forcefully by Rackowski and Richards [27] and Van Urk and Richards [28],subordinate domains are transparent for extraction only if they are Agree-goals.
For speakers who are tolerant of long-distance-fronting in Hungarian, (13b) is grammatical.This falls out from the fact that the matrix verb in (13b) bears definite/objective inflection (hiszi),agreeing in definiteness with the hogy-clause from which extraction is taking place. In [3], I show indepth that the hypothesis that filler–gap dependencies can be established only across domains thatserve as Agree-goals for higher probes gives us a purchase on the entire spectrum of “strong island”effects. I refer the reader to this work for details and discussion.
6. Conclusions and Consequences
A non-presuppositional subordinate clause can be generated as the verb’s complement. But thegrammar also countenances the possibility of base-generating a proform in the higher of the two objectpositions (SpecVP) and associating the subordinate clause to this proform, in the spirit of (1b): this iswhat happens in (7b), with factive matrix verbs. Bridge-verb constructions can mimic the structurein (7b), but the proform in (8b) has properties that are very different from those of the occupant ofSpecVP in (7b): instead of being an argument, it serves as a secondary predicate for the CP, which in (8b)(unlike in (7b)) occupies the complement-of-V position.
Chomsky’s original proposal for the syntax of clausal subordination (see [1]) has now morphedinto an analysis that encompasses both bridge-verb and factive-verb constructions, makes sense ofthe distribution and form of the proforms, accounts for extraction, and takes care of the case andagreement facts. In Chomsky’s original proposal, the clause associated to the proform is not mergedinto the structure of the complex sentence as an independent constituent, alongside the proform: rather,the subordinate clause is merged in via an application of the generalised transformation, which effacesthe proform and turns the embedded clause into the verb’s object. The proposal advanced in thispaper has no business with the generalised transformation: the proform, whenever present, never getsreplaced; the proform and the CP each occupy their own positions in the tree, with the CP to whichthe proform is associated sitting in the complement-of-V position in bridge-verb constructions, and ina clause-peripheral position in factive-verb constructions with an overt object pronoun.
In the structure in (8b), the proform must be merged into the structure before the subordinateCP is merged in the complement-of-V position. This is so because the predicative proform and theverbal root must form a complex predicate that takes the CP in the complement-of-V position as itssubject. Such a complex predicate can only be formed, in the structure in (8b), if this structure is builtfrom the top down. On a bottom-up derivation, CP is first merged directly with the verb, at the V’juncture. At this point, CP is interpreted as an argument of the verb. Upon the subsequent arrival ofthe predicative proform in the SpecVP position, we could countenance a predication relation betweenthe complex predicate “proform + V” only by revising the conclusion, drawn at the V’ juncture, thatCP is an argument of V alone. Such a revision would amount to a derivation that is not strictly cyclic.
The top-down approach, by contrast, delivers the complex predicate “proform + V” before CPis merged into the structure. Upon merger of CP in the complement-of-V position (the last positionreached in the course of the top-down structure-building process), CP is interpreted right away as theargument of the complex predicate formed by the proform in SpecVP and the V-head. No revision ofa conclusion drawn earlier is necessary—the derivation proceeds strictly cyclically.
The outcome of this discussion of clausal subordination thus bears, in an important way, on thedirectionality of structure building. In [3], the pros and cons of top-down and bottom-up structurebuilding and syntactic derivation are discussed at much greater length. The interested reader isreferred to this work for further details.

Languages 2017, 2, 5 11 of 12
Acknowledgments: I would like to thank the editors of this issue of Languages for inviting me to contributea paper to it, the two anonymous reviewers for their superb feedback, and Éva Dékány for important discussion.Part of the research done for this work was financially supported by Hungarian Scientific Research Fund (OTKA)grant #84217, to Balázs Surányi, which is very gratefully acknowledged.
Conflicts of Interest: The author declares no conflict of interest.
References
1. Chomsky, N. Syntactic Structures; Mouton: The Hague, The Netherlands, 1957.2. Chomsky, N. Aspects of the Theory of Syntax; MIT Press: Cambridge, MA, USA, 1965.3. Den Dikken, M. Dependency and Directionality; Cambridge University Press: Cambridge, UK, 2017.4. Erteschik-Shir, N. On the Nature of Island Constraints. Ph.D. Thesis, Massachusetts Institute of Technology,
Cambridge, MA, USA, June 1973.5. De Cuba, C.; Ürögdi, B. Eliminating factivity from syntax: Sentential complements in Hungarian.
In Approaches to Hungarian; den Dikken, M., Vago, R., Eds.; John Benjamins: Amsterdam, The Netherlands,2009; pp. 29–64.
6. Larson, R. On the double object construction. Linguist. Inq. 1988, 19, 335–391.7. Hale, K.; Keyser, S.J. Argument structure and the lexical expression of syntactic relations. In The View from
Building 20; Hale, K., Keyser, S.J., Eds.; MIT Press: Cambridge, MA, USA, 1993; pp. 53–109.8. Barbiers, S. Microvariation in negation in varieties of Dutch. In Syntactic Microvariation; Barbiers, S.,
Cornips, L., van der Kleij, S., Eds.; Meertens Institute Electronic Publications in Linguistics: Amsterdam,The Netherlands, 2002; pp. 13–40.
9. Bowers, J. Arguments as Relations; MIT Press: Cambridge, MA, USA, 2010.10. Resenes, M.; den Dikken, M. Semi-clefts as a window on the syntax of predication and the ‘object of’ relation.
In Proceedings of the Annual Meeting of the Chicago Linguistic Society, Chicago, IL, USA, January 2012;Chicago Linguistic Society: Chicago, IL, USA.
11. Den Dikken, M. Raising the subject of the ‘object of’ relation. In 50 Years Later: Reflections on Chomsky’sAspects; Gallego, Á., Ott, D., Eds.; MITWPL: Cambridge, MA, USA, 2015; pp. 85–98.
12. Den Dikken, M. Differential object marking and the structure of transitive clauses. In Linguistic Variation:Structure and Interpretation; Bellucci, G., Franco, L., Lorusso, P., Eds.; Mouton de Gruyter: Berlin, Germany;New York, NY, USA, 2017, in press.
13. Diesing, M. Indefinites; MIT Press: Cambridge, MA, USA, 1992.14. Den Dikken, M. Particles. In On the Syntax of Verb-Particle, Triadic and Causative Constructions; Oxford
University Press: Oxford, UK; New York, NY, USA, 1995.15. Biberauer, T.; Holmberg, A.; Roberts, I. A syntactic universal and its consequences. Linguist. Inq. 2014, 45,
169–225. [CrossRef]16. Kiparsky, P.; Kiparsky, C. Fact. In Progress in Linguistics; Bierwisch, M., Heidolph, K.E., Eds.; Mouton: The
Hague, The Netherlands, 1970; pp. 143–173, [Reprinted in Semantics. An Interdisciplinary Reader; Steinberg,D., Jakobovits, L., Eds.; Cambridge University Press: Cambridge, UK.].
17. Stowell, T.A. Origins of phrase structure. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge,MA, USA, September 1981.
18. Den Dikken, M. Relators and Linkers: The Syntax of Predication, Predicate Inversion, and Copulas; MIT Press:Cambridge, MA, USA, 2006.
19. Koster, J. Extraposition as Parallel Construal; University of Groningen: Groningen, The Netherlands, 2000.20. De Vries, M. Specifying coordination: An investigation into the syntax of dislocation, extraposition and
parenthesis. In Language and Linguistics: Emerging Trends; Dreyer, C., Ed.; Nova: New York, NY, USA, 2009;pp. 37–98.
21. Moro, A. The Raising of Predicates: Predicative Noun Phrases and the Theory of Clause Structure; CambridgeUniversity Press: Cambridge, UK, 1997.
22. Ross, J.R. Inner islands. In Proceedings of the Tenth Annual Meeting of the Berkeley Linguistics Society,Berkeley, CA, USA, 17–20 February 1984; Berkeley Linguistic Society: University of California, Berkeley, CA,USA, 1984; pp. 258–265.

Languages 2017, 2, 5 12 of 12
23. Horvath, J. The status of ‘Wh-expletives’ and the partial Wh-movement construction in Hungarian. Nat. Lang.Linguist. Theor. 1997, 15, 509–572. [CrossRef]
24. Rizzi, L. Relativized Minimality; MIT Press: Cambridge, MA, USA, 1990.25. Höhle, T.N. The w-...w-construction: Appositive or scope-indicating? In Papers on wh-Scope Marking; Lutz, U.,
Müller, G., Eds.; Universität Stuttgart/Universität Tübingen/IBM Deutschland: Tübingen, Germany, 1996;pp. 37–58.
26. Reis, M. On the parenthetical features of German was...w-constructions and how to account for them.In wh-Scope Marking; Lutz, U., Müller, G., von Stechow, A., Eds.; John Benjamins: Amsterdam,The Netherlands, 2000; pp. 359–407.
27. Rackowski, A; Richards, N. Phase edge and extraction: A Tagalog case study. Linguist. Inq. 2005, 36, 565–599.[CrossRef]
28. Van Urk, C.; Richards, N. Two components of long-distance extraction: Successive cyclicity in Dinka. Linguist.Inq. 2015, 46, 113–155. [CrossRef]
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).

languages
Article
Language Mixing and Diachronic Change: AmericanNorwegian Noun Phrases Then and Now
Brita Ramsevik Riksem
Department of Language and Literature, Faculty of Humanities, Norwegian Universityof Science and Technology, 7491 Trondheim, Norway; [email protected]; Tel.: +47-7359-6987
Academic Editors: Ji Young Shim, Tabea Ihsane and Maria del Carmen Parafita CoutoReceived: 20 December 2016; Accepted: 3 April 2017; Published: 20 April 2017
Abstract: This article investigates the diachronic development of language mixing within nounphrases in the heritage language American Norwegian. By comparing data collected in the 1930sand 1940s with recently collected data, I present and discuss patterns showing systematic changes,specifically concerning the categories number and definiteness. Moreover, I propose two potentialanalyses of these patterns based on an exoskeletal approach to grammar. This theoretical frameworkcrucially separates the abstract syntactic structure from its phonological exponents, and the analysesthat are discussed consider both the structure and the exponents as the origins of the change.
Keywords: American Norwegian; diachronic change; exoskeletal approach to grammar; languagemixing; noun phrase
1. Introduction
Language mixing, in the form of utterances consisting of both English and Norwegian items, is atypical attribute of the heritage language American Norwegian (AmNo). This variety of Norwegianfinds its origin in the language of the many immigrants who settled in North America in the centuryprior to 1920, and it is still spoken today by some of their descendants. Previous studies have shownthat mixing of English and Norwegian typically involves English content items occurring together withNorwegian functional material [1–5]. This article pursues the question of whether or not these mixingpatterns are persistent over time, and it presents data showing that systematic, diachronic changes canbe found. Furthermore, it explores changes in the underlying grammar that can potentially explain theobserved patterns.
The focus of this article is AmNo noun phrases showing a mix of English and Norwegian items.Comparisons of newly collected data with data from the 1930s and 1940s show overall stability inthe main patterns of mixing. Still, some systematic changes are found. Examples of language mixingwithin AmNo noun phrases are given in (1), where the data in (1a–c) show the typical mixing pattern,i.e., English content items with Norwegian functional material, and (1d–e) are examples that I willargue are the results of diachronic change: omission of functional morphology and the use of Englishfunctional items. Notice that the accompanying references show which corpus the utterance is drawnfrom, either Einar Haugen’s collections from the 1930s and 1940s [6] or the recently established Corpusof American Norwegian Speech (CANS) [7], as well as the associated page number, in the case ofHaugen [6], or informant code, in the case of CANS [7]. The two corpora will be introduced anddiscussed in more detail in Section 3. Moreover, all English items throughout this article are boldfaced,and I use English spelling in all examples even though Haugen [6] uses a more phonetic spelling.
Languages 2017, 2, 3; doi:10.3390/languages2020003 www.mdpi.com/journal/languages

Languages 2017, 2, 3 2 of 29
The underscore in (1d) and subsequent examples, indicates the position of missing functional material,from the point of view of Norwegian.1
1. a. det andre crew-et [6] (p. 571)the.N other crew-DF.SG.N‘the other crew’.
b. eg fekk arbeid på railroad-en [6] (p. 590)I got work at railroad-DF.SG.M‘I got a job at the railroad’.
c. ikke mange party-er [6] (p.587)not many party-INDF.PL.M/F
‘not many parties’.
d. den stor-e building_ [7]; chicago_IL_01gkthe.M/F big-DF building
e. mange lawyer-s [7]; sunburg_MN_03gmmany lawyer-PL
‘many lawyers’.
The outline of the article is as follows. Section 2 introduces AmNo, both in terms of its historicalbackground and the material that is available, and in Section 3, the two corpora under investigationare presented, as well as some methodological concerns. This somewhat lengthy introduction to theempirical material is intended to give the reader some insight into the environment and conditionssurrounding AmNo during its lifespan, as well as to establish the comparability of the two corporaunder investigation. Section 4 presents the theoretical backdrop of the article and provides an analysisof the typical mixing patterns. Data showing diachronic change are presented in Section 5, and possibleanalyses of these changes are proposed and discussed in Section 6. Section 7 concludes the article.
2. The Heritage Language American Norwegian
AmNo is a Norwegian variety that emerged in communities of Norwegian immigrants whosettled in North America (mainly the U.S.) roughly from the mid-1800s until the 1920s, and is stillspoken by some of their descendants. This section provides an overview of some main events in theperiod of Norwegian immigration and the immigrants’ new lives in America, as well as an introductionto the available AmNo data. For a more comprehensive discussion of the AmNo language and societysee [6–10] and references therein.
2.1. Historical Background
The first Norwegian immigrants to America left Norway in 1825, and in the yearsbetween approximately 1850 and 1920, this escalated into a mass migration. According toHaugen [6] (pp. 28–29), as many as 810,000 Norwegians immigrated to the U.S. in the period from1836–1930, a number nearly equal to the entire population of Norway in 1800. Upon arriving in the U.S.,many Norwegian immigrants settled in the Midwest (in particular Wisconsin, Illinois, and Minnesota),gradually forming large Norwegian settlements, where important institutions such as churches,hospitals, retirement homes, and newspapers were quickly established [10].
1 The following annotations are used in the glosses: DEF: Definiteness, DF: Definite, INDF: Indefinite, NUM: Number, PL:Plural, SG: Singular, GEN: Gender, M: Masculine, F: Feminine, N: Neuter. I have only provided a detailed glossary for therelevant noun phrases.

Languages 2017, 2, 3 3 of 29
The conditions for, or necessity of, speaking English changed over the years following the firstwave of immigration. The very first immigrants were forced to learn the language of the new country,English, in order to settle and live there. However, as the Norwegian settlements grew, this necessitydiminished, and one could basically find everything one needed within the Norwegian-speakingcommunity. Engaging in work, politics or social life outside the Norwegian settlement, on the otherhand, required knowledge of English, and the children went to English-language schools. Subsequently,AmNo gradually turned into a language primarily used in the home and the church, the spheres mostshielded from the English-speaking environment.
From the 1920s onward, the climate surrounding the Norwegian language in America changed.Immigration slowed down, Norwegian newspapers ceased publication, and major social and religiousinstitutions switched to English as their main language. Moreover, the language became an obstaclefor children, who typically entered school as AmNo monolinguals and faced teaching conducted inEnglish. These issues, reinforced by a stigma against speaking Norwegian or speaking English with aforeign accent, led many parents to choose not to pass the language on to the next generation [6,11].This severe decline notwithstanding, AmNo is still spoken in some areas, especially in the rural areasof the Midwest.
2.2. Heritage Languages
The Norwegian-speaking communities in the U.S. were always islands within the largercommunity in which English was, and is, the dominant language. Such immigrant languagecommunities, situated in the midst of a larger, dominating language community, are recognizedas heritage languages (HL), and their speakers as heritage speakers (HS). Definitions of these terms isgiven by Rothman [12]:
A language qualifies as a heritage language if it is a language spoken at home or otherwisereadily available for young children, and crucially this language is not a dominant languageof the larger (national) society. [ . . . ] From a purely linguistic point of view, we assume thatan individual qualifies as a heritage speaker, if and only if he or she has some command ofthe heritage language acquired naturalistically.
Rothman [12] (p. 156)
As can be understood from this definition, a heritage language is acquired in childhood throughnaturalistic input, and HS are therefore considered native speakers of the HL [13]. However, at somepoint, typically when starting school, the speaker is introduced to the dominant language of thecommunity, which in most cases eventually becomes the HS’ own dominant language. This makesHS an interesting group of language users. On the one hand, the heritage language is their nativelanguage, but compared to monolinguals of the non-heritage variety of the language in question,they often do not reach the same level of competence. On the other hand, their competence mightresemble that of L2 learners of the language, but HS will typically outperform L2 learners in manyareas (see [14,15]). This tension has been discussed in several works and attributed to incompleteacquisition [16,17], or attritio [14,18]. Others have suggested that the grammar of HL should not beconsidered incomplete or impaired, just different, e.g., [19]. I return to these questions in Section 6.
In the case of AmNo specifically, the speakers in question are native speakers of AmNo, whoacquired English as an L2. For the majority, English has also been their dominant language throughoutmost of their life. When they speak AmNo, it is clear that it is a variety of Norwegian; the majorityof both lexical and functional items are Norwegian. However, English items occur frequently. Muchwork has been done documenting and researching AmNo, most of which focuses on the Norwegianproperties of the language (see [9,10] and references therein). Language mixing in AmNo has alsobeen investigated [1–5], and this is the phenomenon under investigation in the current article as well.The novelty of the current article, however, lies in a detailed investigation of aspects of the nominal

Languages 2017, 2, 3 4 of 29
domain, providing the first systematic diachronic study of language mixing in AmNo. In the nextsubsection, I present the available data.
2.3. Data
The following timeline in Figure 1 gives a rough overview of the available AmNo material.
Languages 2017, 2, 3 4 of 28
2.3. Data
The following timeline in Figure 1 gives a rough overview of the available AmNo material.
Figure 1. Overview of American Norwegian (AmNo) data.
Already around the turn of the 20th century, AmNo had gained the attention of researchers,
when Nils Flaten and George Flom both published articles about the language variant [20–22].
Neither Flaten nor Flom collected large corpora, but in their articles, they included lists of English
words occurring in AmNo. In 1931, Didrik A. Seip and Ernst W. Selmer interviewed and recorded
several AmNo speakers, but unfortunately, this material was neither used much nor maintained very
well. Many of the recordings were unfortunately broken or lost, and the quality of what remains is
quite poor (remaining recordings are available in [23]). In the 1930s and 1940s, Einar Haugen carried
out extensive fieldwork, which is presented and discussed in his two‐volume work The Norwegian
Language in America [6]. Arnstein Hjelde collected new data in the 1980s, and he was especially
interested in a specific Norwegian dialect, trøndersk [8]. The most recent data collection effort started
in 2010, under the auspices of the Norwegian in America (NorAmDiaSyn) project, and is still ongoing
at the time of this writing. These data have been made available in the online CANS [7] created at the
Text Laboratory at the University of Oslo, Norway. The diachronic comparisons in this article are
based primarily on the material collected by Haugen [6] and the material in CANS [7], as these are
the most extensive corpora and include a variety of dialects. These two corpora are introduced in the
next section.
3. Introducing the Corpora and the Method
3.1. Haugen (1953)
Einar Haugen collected data from 1936 to 1948 [6]. At this time, the usage of Norwegian was
already declining, and many cornerstone institutions in the Norwegian settlements, e.g., newspapers,
social networks, and churches, were debating, or in fact carrying out, a switch to English as their
main language. Nevertheless, Haugen describes communities where Norwegian was still spoken,
churches occasionally had services in Norwegian, and the Norwegian newspaper Decorah‐Posten was
still circulated [6] (pp. 605–617). Although there was considerable variation among the communities,
it would be fair to say that, in general, there was still a vital environment for the Norwegian language
at the time of Haugen’s data gathering.
Haugen’s material consists of data from 260 informants, mainly from Wisconsin, collected
through questionnaires, field notes and recordings. The first volume of his work is primarily a
discussion of the AmNo society, whereas the second deals specifically with the linguistic data. The
most relevant parts for the current article are the chapter discussing the grammar of English
loanwords (i.e., what I refer to as mixed items), the selected vocabulary of English loans, which
comprise 10% of the 3000 items he registered, and the appendix presenting the communities and
informants studied.
Although some of Haugen’s recordings are available online [24], I rely on his written materials
and his own discussion of them, as the recordings are not transcribed and not of the best
sound quality.
1930s and 1940s: Haugen [6]
2017 1850 1920
1900‐1904: Flaten [20], Flom [21,22]
1931: Seip and Selmer [23]
1980s: Hjelde [8]
2010 Corpus of American
Norwegian Speech [7]
Figure 1. Overview of American Norwegian (AmNo) data.
Already around the turn of the 20th century, AmNo had gained the attention of researchers,when Nils Flaten and George Flom both published articles about the language variant [20–22]. NeitherFlaten nor Flom collected large corpora, but in their articles, they included lists of English wordsoccurring in AmNo. In 1931, Didrik A. Seip and Ernst W. Selmer interviewed and recorded severalAmNo speakers, but unfortunately, this material was neither used much nor maintained very well.Many of the recordings were unfortunately broken or lost, and the quality of what remains is quitepoor (remaining recordings are available in [23]). In the 1930s and 1940s, Einar Haugen carried outextensive fieldwork, which is presented and discussed in his two-volume work The Norwegian Languagein America [6]. Arnstein Hjelde collected new data in the 1980s, and he was especially interested in aspecific Norwegian dialect, trøndersk [8]. The most recent data collection effort started in 2010, underthe auspices of the Norwegian in America (NorAmDiaSyn) project, and is still ongoing at the time ofthis writing. These data have been made available in the online CANS [7] created at the Text Laboratoryat the University of Oslo, Norway. The diachronic comparisons in this article are based primarily onthe material collected by Haugen [6] and the material in CANS [7], as these are the most extensivecorpora and include a variety of dialects. These two corpora are introduced in the next section.
3. Introducing the Corpora and the Method
3.1. Haugen (1953)
Einar Haugen collected data from 1936 to 1948 [6]. At this time, the usage of Norwegian wasalready declining, and many cornerstone institutions in the Norwegian settlements, e.g., newspapers,social networks, and churches, were debating, or in fact carrying out, a switch to English as theirmain language. Nevertheless, Haugen describes communities where Norwegian was still spoken,churches occasionally had services in Norwegian, and the Norwegian newspaper Decorah-Posten wasstill circulated [6] (pp. 605–617). Although there was considerable variation among the communities, itwould be fair to say that, in general, there was still a vital environment for the Norwegian language atthe time of Haugen’s data gathering.
Haugen’s material consists of data from 260 informants, mainly from Wisconsin, collected throughquestionnaires, field notes and recordings. The first volume of his work is primarily a discussion of theAmNo society, whereas the second deals specifically with the linguistic data. The most relevant partsfor the current article are the chapter discussing the grammar of English loanwords (i.e., what I refer toas mixed items), the selected vocabulary of English loans, which comprise 10% of the 3000 items heregistered, and the appendix presenting the communities and informants studied.

Languages 2017, 2, 3 5 of 29
Although some of Haugen’s recordings are available online [24], I rely on his written materialsand his own discussion of them, as the recordings are not transcribed and not of the best sound quality.
3.2. The Corpus of American Norwegian Speech
The most recent corpus available at present, CANS [7], captures the language as spoken nearly100 years after the decline of immigration. Speakers were recruited through advertisements specificallyseeking Norwegian-speaking persons whose ancestors had emigrated from Norway prior to 1920 andwho had learnt the language at home from family members. Most informants recruited for thiscollection came from remote locations in the Midwest, where the Norwegian culture is still evident incafes, shops, folk music, and handcrafting [9,25]. Usage of the language, on the other hand, varies.Some informants reported that they speak AmNo on a daily basis, whereas others might not havespoken AmNo since their parents passed away several years prior. All informants were, however,relatively fluent in AmNo [9]. Due to the challenges they faced, for instance at school, many haverefrained from passing the language on to the next generation, meaning that these speakers mayrepresent the last generation of AmNo speakers.
CANS is available online, and recordings of 50 individuals have so far been transcribed andpublished [7].2 The corpus has two levels of transcription, one broad phonological transcription andone standardized transcription (Bokmål3), and sound and video files are provided. Individual itemsin the corpus are tagged with a variety of different grammatical categories, making it searchable.However, English items are not tagged in an equally detailed manner, and I have thus conductedcertain specific searches to find these. The tag “x” provides all items not found in the Norwegiandictionary, which includes the English items, and through a process of manually sorting these items,1265 English nouns remain.4 These were subsequently sorted according to context. Seventy-fiveEnglish nouns occur without any context at all and 156 nouns appear in a smaller (e.g., a phrase) orlarger English context. Most interesting for the purpose of the present article are the 1034 Englishitems that are found in an otherwise Norwegian context. The following discussions will be based onthis sample.
3.3. Some Methodological Considerations
The two corpora presented in the subsections above clearly capture AmNo at two different stagesof its development. Some methodological remarks should be made regarding the composition of theinformant groups, and the form of the CANS corpus.
First, when discussing HS, first generation immigrants are typically not included as these speakershave acquired the language in circumstances with more exposure, and with no pressure from adominant language [15]. On the other hand, one can argue that first generation immigrants shouldbe included as they too are speakers of a minority language in their current society, and that theirlanguage may show contact-induced differences similar to other HS (see, e.g., [3,14]). In this article,I do not present arguments supporting either side of this issue. However, I include first generationimmigrants in the group of HS from the 1930s and 1940s, as Haugen does not separate these speakersfrom the others in his material. His description and discussion of AmNo grammar are thus based ona heterogeneous group of AmNo speakers. Still, Haugen provides a complete list of his informantsand to which generation they belong. This list reveals that the majority are in fact second or latergeneration speakers of AmNo, thus unquestionably HS. I therefore assume that Haugen’s overall
2 The collection of data is still ongoing as of the time of this writing (early 2017), and the corpus will be expanded in the future.3 Bokmål is one of the two written standards of Norwegian. See [26,27] for discussion of the Norwegian language situation.4 Proper nouns, fixed expressions, and repetitions within the same immediate utterance have been excluded from the count,
and for words with a potential lexical overlap between English and Norwegian, I have used the sound files to determinewhether they have an English-like or a Norwegian-like pronunciation, and sorted them accordingly.

Languages 2017, 2, 3 6 of 29
findings represent a typical heritage speaker, and I rely on Haugen’s evaluations and commentaries asan authentic description of AmNo at the time.
A second concern, especially relevant when doing diachronic comparisons of the two corpora,is the fact that there is no established family link between the two groups of speakers. As far as weknow, the speakers in CANS [7] are neither the same speakers, nor the children of the speakers inHaugen [6], meaning that we lack information about their input and competence throughout life.Nevertheless, based on the CANS speakers’ ages and locations, we can assume that the group ofspeakers discussed by Haugen represent the parents/grandparents from whom the CANS speakerslearnt AmNo, and thus the grammar discussed by Haugen represent the input that the CANS speakersreceived. In other words, even if the two corpora are not directly connected in terms of family relations,a comparison of the two will still show the general development of AmNo over these years.
A brief comment should also be offered regarding the new corpus and the data drawn fromit. As an online corpus, CANS is not fixed in the same way as other corpora and may be subject toadditions, updates, and improvements. In practice, this means that the details of the corpus maychange over time. The data presented and discussed in this article were drawn from the corpus in April2016, and I have not considered any later updates. In addition, random searches have demonstratedthat a few English items are incorrectly not tagged “x”. In order to make the data employed inthis article as clear as possible, these data are not included in the numerical description above, butI will occasionally use them as examples of specific phenomena. A footnote is provided in thesespecific cases.
In Section 5 and onwards, I compare the data collected by Haugen and in CANS and presentchanges in the patterns of language mixing within noun phrases. Before going into this material, I willbriefly introduce the theoretical background for the article in the next section, as well as a descriptionand illustrative examples of what can be considered the typical or main pattern of language mixing inAmNo noun phrases. This will serve as the foundation for investigating potential changes.
4. Theoretical Background
4.1. Language Mixing
In this article, I employ the term “language mixing” to describe the phenomenon underinvestigation, namely the occurrence of English items in AmNo.5 This type of mixing is whatMyusken [28] (p. 3) refers to as insertion, i.e., the “insertion of material [ . . . ] from one languageinto a structure from the other language”, and occurs quite frequently in AmNo noun phrases,forming a recognizable pattern where English nouns appear with Norwegian determiners and suffixesin a Norwegian word order [1,4]. Examples of this are presented in (1a–c), repeated here as (2)for convenience.
2. a. det andre crew-et [6] (p. 571)the.N other crew-DF.SG.N‘the other crew’.
b. eg fekk arbeid på railroad-en [6] (p. 590)I got work at railroad-DF.SG.M‘I got a job at the railroad’.
c. ikke mange party-er [6] (p.587)not many party-INDF.PL.M/F
‘not many parties’.
5 The terms “code-switching” and “borrowing” are also frequently used to describe this phenomenon. See [1] for discussionof these terms and how they relate to each other.

Languages 2017, 2, 3 7 of 29
From a formal perspective, there are two main ways of approaching and analyzing languagemixing: to posit special constraints to account for mixing data [29,30], or to assume that mixing isconstrained by the same principles as monolingual speech [31–37]. In the literature, the latter approachis referred to as a Null Theory [31] or constraint-free approach to language mixing [33].
I assume that Null Theory should be the null hypothesis. However, key empirical insights fromthe other model appear too essential to be overlooked. Myers-Scotton [29] observes that one of thelanguages involved is more prominent in cases of language mixing. This is referred to as the MatrixLanguage (ML), and it provides both word order and functional morphemes in the mixed utterances.The other language(s), the Embedded Language(s) (EL), can only contribute content items. I arguethat an exoskeletal model, which I will employ in this article, can account for these asymmetriccontributions and at the same time be a Null Theory of language mixing. Although I acknowledge thisempirical asymmetry, an essential distinction is that I nevertheless do not adopt Myers-Scotton’s notionof ML and EL as theoretical primitives. Instead, I use the terms “main” and “secondary” languagequite informally as descriptive or observational terms.
4.2. Exoskeletal Approaches to Grammar
To analyze these data, I employ a late-insertion exoskeletal model. The term “exoskeletal” unitesa family of grammatical analyses [38–48]. These works may differ in terms of how they accountfor details in the syntactic structure and its derivation, but the shared, fundamental core is theassumption that abstract syntactic structures are generated independently of the lexical items that willrealize them. These approaches are all motivated by monolingual data, meaning that they are notspecially designed to handle language mixing, but do nevertheless prove to be good analytical toolsfor bilingual grammars. The specific model employed in the current article relates mainly to the worksby Borer [31–43], Åfarli [44], Lohndal [46,47], and Marantz [38,39]. Additionally, the current approachalso incorporates insights from Distributed Morphology (DM), e.g., [49–51], especially concerning theprocess of late insertion, which I will discuss below. In DM, the lexicon is split into three separatelists: syntactic terminals, vocabulary items, and encyclopedic information. The encyclopedia holds“world-knowledge”, which is not relevant for the grammar, and thus is not discussed in this article.The first and second lists, however, are important in the late-insertion exoskeletal model and howlanguage mixing is analyzed.
The first list holds abstract syntactic components, which are used to build structures, forminga syntactic frame or template for the sentence. There are two different types of terminals in this list:roots and functional features or feature bundles. The properties of roots and how they are structuredin the syntax is a much-debated question (see, e.g., [52]), however not one that I will delve into hereas it is not crucial for the purpose of the current discussions and analyses. Importantly, roots areconsidered devoid of any grammatical features. Roots also therefore lack a lexical category, which isinstead syntactically assigned. Following Marantz [39], Arad [53], Pylkkänen [54], and Embick andMarantz [55], I assume that the category is assigned by combining the root with a category-defininghead, constituting a complex I will informally refer to as the stem. Moreover, I assume that roots havesome core yet underspecified phonological and semantic properties (cf. [53]).
Functional features are the second type of syntactic terminals in this list, and they are consideredproperties of the abstract syntactic structure. Moreover, features in this context are restricted to formalmorphological features, and these may be bundled in different projections.
Phonological content is provided in the process of Spell-Out, or in DM, Vocabulary Insertion.In this process, vocabulary items, or phonological exponents, from the second list are accessed andinserted. For the two types of syntactic terminals, this process is radically different. FollowingArad [53], I assume that a root alone is unavailable for Spell-Out and can only be phonologicallyrealized in combination with a category-defining head. In other words, the stem is spelled out asone unit. This position in the structure emerges as relatively open, with few restrictions for insertion,meaning that content items from any language and of any kind may in principle be inserted.

Languages 2017, 2, 3 8 of 29
Spell-Out of functional features or feature bundles, on the other hand, is a more restricted process,regulated by the Subset Principle:6
The phonological exponent of a Vocabulary item is inserted into a morpheme in theterminal string if the item matches all or a subset of the grammatical features specifiedin the terminal morpheme. Insertion does not take place if the Vocabulary item containsfeatures not present in the morpheme. Where several Vocabulary items meet the conditionsfor insertion, the item matching the greatest number of features specified in the terminalmorpheme must be chosen.
Halle [56]
In other words, insertion of functional exponents is a competitive process, where the exponentthat best matches the features specified in the syntactic terminal wins and is inserted. However,the exponent cannot be specified for any features that are not represented in the structure. Thestructure in (3) serves as a simplified illustration of this process.
3.
Languages 2017, 2, 3 8 of 28
Spell‐Out of functional features or feature bundles, on the other hand, is a more restricted
process, regulated by the Subset Principle:6
The phonological exponent of a Vocabulary item is inserted into a morpheme in the
terminal string if the item matches all or a subset of the grammatical features specified in
the terminal morpheme. Insertion does not take place if the Vocabulary item contains
features not present in the morpheme. Where several Vocabulary items meet the conditions
for insertion, the item matching the greatest number of features specified in the terminal
morpheme must be chosen.
Halle [56]
In other words, insertion of functional exponents is a competitive process, where the exponent
that best matches the features specified in the syntactic terminal wins and is inserted. However, the
exponent cannot be specified for any features that are not represented in the structure. The structure
in (3) serves as a simplified illustration of this process.
3.
Here, the phonological exponent of X should be the best possible match to the feature bundle
[A,B]. In case a complete match is available, this will rule out any alternative exponents specified for
only [A] or [B]. Furthermore, an exponent with the specifications [A,B,C] would not be allowed for
insertion at this terminal, as the feature [C] is not part of the syntactic structure.7
These different restrictions on Spell‐Out of functional and substantial material will capture the
empirical asymmetry in language mixing: content items from any language can be inserted in the
stem position, whereas the most appropriate functional exponents typically are provided by the
language of the syntactic frame. Hence, content items from any language are predicted to acquire the
functional properties of the language specifying the syntactic frame. Notice, however, that this does
not mean that structures bear language tags in our grammars. Instead, structures are composed of
functional features, and a specific language is recognized by the features that are active in the
language and how they are combined [59]. In other words, when describing something as a
Norwegian structure, I mean a structure composed of features in a combination that it is typically
associated with Norwegian.
In the next subsections, I will introduce the structure of the AmNo noun phrase (DP) and the
typical mixing patterns seen in AmNo to demonstrate how a late‐insertion exoskeletal model offers
an insightful analysis of these data.
6 Terminals holding functional features or feature bundles are referred to as morphemes in the DM
literature. 7 The mechanisms presented here imply Underspecification, which plays an important role in DM. The
basic assumption is that vocabulary items are underspecified for syntactico‐semantic features. Hence, one
vocabulary item can spell out several syntactic positions, but in cases where multiple exponents compete for the
same position, the more specified one is inserted. As pointed out by an anonymous reviewer, other studies have
shown that bilinguals simultaneously activate elements from both languages, and a model has been proposed
in which multiple elements may be present simultaneously in a position in the linguistic structure, referred to
as co‐activation or blends. See [57,58] for discussion of such an analysis.
Here, the phonological exponent of X should be the best possible match to the feature bundle[A,B]. In case a complete match is available, this will rule out any alternative exponents specified foronly [A] or [B]. Furthermore, an exponent with the specifications [A,B,C] would not be allowed forinsertion at this terminal, as the feature [C] is not part of the syntactic structure.7
These different restrictions on Spell-Out of functional and substantial material will capture theempirical asymmetry in language mixing: content items from any language can be inserted in the stemposition, whereas the most appropriate functional exponents typically are provided by the language ofthe syntactic frame. Hence, content items from any language are predicted to acquire the functionalproperties of the language specifying the syntactic frame. Notice, however, that this does not meanthat structures bear language tags in our grammars. Instead, structures are composed of functionalfeatures, and a specific language is recognized by the features that are active in the language and howthey are combined [59]. In other words, when describing something as a Norwegian structure, I meana structure composed of features in a combination that it is typically associated with Norwegian.
In the next subsections, I will introduce the structure of the AmNo noun phrase (DP) and thetypical mixing patterns seen in AmNo to demonstrate how a late-insertion exoskeletal model offers aninsightful analysis of these data.
4.3. The Structure of (American) Norwegian Noun Phrases
Norwegian is the main language in AmNo and provides the structural frames. In this section, I willtherefore introduce and discuss the Norwegian DP structure and thereafter employ this framework inan analysis of mixed AmNo noun phrases.
6 Terminals holding functional features or feature bundles are referred to as morphemes in the DM literature.7 The mechanisms presented here imply Underspecification, which plays an important role in DM. The basic assumption is
that vocabulary items are underspecified for syntactico-semantic features. Hence, one vocabulary item can spell out severalsyntactic positions, but in cases where multiple exponents compete for the same position, the more specified one is inserted.As pointed out by an anonymous reviewer, other studies have shown that bilinguals simultaneously activate elements fromboth languages, and a model has been proposed in which multiple elements may be present simultaneously in a position inthe linguistic structure, referred to as co-activation or blends. See [57,58] for discussion of such an analysis.

Languages 2017, 2, 3 9 of 29
Norwegian DPs, like Scandinavian DPs in general, can be quite complex, and they have beenthoroughly studied in various works [60–62]. The obligatory components of the Norwegian nounphrase are the stem (i.e., the root together with its categorizer), one (or more) functional projectionsabove the stem, and finally a D layer.8 Norwegian nouns are inflected for three functional categories:definiteness, number and gender, which will be recognizable through affixes and associated wordsin the noun phrase. The basic structure employed in this article is presented in (4) (see [4] for amore elaborate discussion of the different projections in this model, or [62] for an in-depth study ofNorwegian DPs in general).
4.
Languages 2017, 2, 3 9 of 28
4.3. The Structure of (American) Norwegian Noun Phrases
Norwegian is the main language in AmNo and provides the structural frames. In this section, I
will therefore introduce and discuss the Norwegian DP structure and thereafter employ this
framework in an analysis of mixed AmNo noun phrases.
Norwegian DPs, like Scandinavian DPs in general, can be quite complex, and they have been
thoroughly studied in various works [60–62]. The obligatory components of the Norwegian noun
phrase are the stem (i.e., the root together with its categorizer), one (or more) functional projections
above the stem, and finally a D layer.8 Norwegian nouns are inflected for three functional categories:
definiteness, number and gender, which will be recognizable through affixes and associated words
in the noun phrase. The basic structure employed in this article is presented in (4) (see [4] for a more
elaborate discussion of the different projections in this model, or [62] for an in‐depth study of
Norwegian DPs in general).
4.
At the bottom of this structure is the stem, which is composed of a root and a category‐defining
head, in this case a nominalizer. Following from the discussion in the previous subsection, I assume
that the root needs to be merged with such a categorizer in order to be spelled out.
Immediately above the stem, we find a functional projection (F) holding a bundle of the features
gender, number and definiteness. In the literature, there are various alternatives as to how these are
structured, for example with two ([62]) or three separate projections ([63]). For the purpose of the
analyses in the current article, however, such a detailed structure is not necessary. Moreover, the
AmNo data exploited here do not provide new insight into the division of the functional features in
the structure, so number and definiteness are combined into one projection. The most debatable issue
in (4) is presumably gender, as a notable part of the literature argues that gender is a property of the
nominalizer, thus part of the nominal stem [62,64,65]. Language mixing gives reason to argue that
gender is positioned higher in the structure. Consider, for instance, English derived stems like
settlement, township, and building, which are attested in the AmNo material [6–8]. Assuming that the
derivational suffixes are realizations of the nominalizer, n, these data show that stems are available
for mixing. Thus, if gender were considered a property of the stem, we would not expect the pattern
where English stems are mixed into AmNo and assigned to different gender categories.9
I thus assume that the stem is generally the item being drawn from the secondary language in
language mixing, and that gender is positioned in the higher functional structure of the Norwegian
DP together with number and definiteness. The interplay between the functional features in F will
8 The Norwegian DP may also include weak quantifiers, adjectives, pre‐ or post‐nominal possessors and
post‐nominal prepositional phrases. A discussion of these is beyond the scope of the current article. See [62] for
details. 9 An alternative analysis could be that in case of language mixing the speaker has established two separate
entries for nouns in their list of vocabulary items, one without gender (the English version) and one with gender
(the Norwegian version). Due to the uneconomical status of this analysis, I will not pursue it.
At the bottom of this structure is the stem, which is composed of a root and a category-defininghead, in this case a nominalizer. Following from the discussion in the previous subsection, I assumethat the root needs to be merged with such a categorizer in order to be spelled out.
Immediately above the stem, we find a functional projection (F) holding a bundle of the featuresgender, number and definiteness. In the literature, there are various alternatives as to how theseare structured, for example with two [62] or three separate projections [63]. For the purpose of theanalyses in the current article, however, such a detailed structure is not necessary. Moreover, theAmNo data exploited here do not provide new insight into the division of the functional featuresin the structure, so number and definiteness are combined into one projection. The most debatableissue in (4) is presumably gender, as a notable part of the literature argues that gender is a propertyof the nominalizer, thus part of the nominal stem [62,64,65]. Language mixing gives reason to arguethat gender is positioned higher in the structure. Consider, for instance, English derived stems likesettlement, township, and building, which are attested in the AmNo material [6–8]. Assuming that thederivational suffixes are realizations of the nominalizer, n, these data show that stems are availablefor mixing. Thus, if gender were considered a property of the stem, we would not expect the patternwhere English stems are mixed into AmNo and assigned to different gender categories.9
I thus assume that the stem is generally the item being drawn from the secondary language inlanguage mixing, and that gender is positioned in the higher functional structure of the NorwegianDP together with number and definiteness. The interplay between the functional features in F willdetermine which functional exponent is most appropriate for insertion. Furthermore, in a NorwegianDP the stem complex obligatorily moves to F, possibly due to some nominal feature, meaning that theexponent of F will materialize as a suffix on the noun stem [62].
On top of the noun phrase is a D projection, holding a feature bundle of the correspondingunvalued functional features. These get their valuation through a probe-goal relation (Agree) between
8 The Norwegian DP may also include weak quantifiers, adjectives, pre- or post-nominal possessors and post-nominalprepositional phrases. A discussion of these is beyond the scope of the current article. See [62] for details.
9 An alternative analysis could be that in case of language mixing the speaker has established two separate entries for nounsin their list of vocabulary items, one without gender (the English version) and one with gender (the Norwegian version).Due to the uneconomical status of this analysis, I will not pursue it.

Languages 2017, 2, 3 10 of 29
D and F.10 Noun phrases constituting arguments in Norwegian typically require an overt realizationof the DP domain. This is accomplished either by moving FP to Spec-DP, or by inserting a separatedeterminer or demonstrative in D (see [62] for discussion).11 The latter alternative results in thephenomenon known as double definiteness, i.e., the co-occurrence of definiteness in the determinerand in the suffix. In phrases involving an adjective or a weak quantifier, double definiteness isobligatory as FP is prevented from moving to the DP domain by intervening projections [62].
4.4. Typical Mixing Patterns in AmNo Noun Phrases and How to Analyze Them
Since Norwegian is the main language in AmNo, we can expect to find mixed noun phrases with aNorwegian structure and Norwegian functional exponents into which English stems are incorporated.This is, in fact, the pattern described by both Flaten [20] and Haugen [6]:
Some words are, indeed, used without any appreciable difference in pronunciation, butmore generally the root, or stem, is taken and Norse inflections are added as required bythe rules of the language.
Flaten [20] (p. 115)
A single form is usually imported and is then given whatever endings the language requiresto make it feel like a proper word and to express the categories which this particularlanguage requires its words to express.
Haugen [6] (p. 440)
Moreover, this is also the main pattern of mixing in the most recently collected material [4].As discussed above, this pattern is predicted by the exoskeletal model: AmNo speakers producestructures with functional features typical for Norwegian, the main language. The Subset Principlerequires these to be spelled out by the most appropriate exponents, namely the Norwegian functionalexponents. The stem, on the other hand, is drawn from English, and acquires Norwegian functionalproperties by being inserted into such a structure.
Some examples are shown in (5), where English stems occur with a Norwegian indefinite article(5a), or with a Norwegian functional suffix and in a Norwegian word order (5b–d). Note that eventhough the noun phrase alone is shown here, these DPs are all part of larger Norwegian utterances.
5. a. et rent towel [6] (p. 601)a.INDF.SG.N clean.INDF.SG.N towel‘a clean towel’.
b. harvest-en [6] (p. 579)harvest-DF.SG.M‘the havest’.
c. field-a [6] (p. 575)field-DF.SG.F‘the field’.
d. trunk-en min [6] (p. 603)trunk-DF.SG.M my‘my trunk’.
10 In cases involving a weak quantifier or an adjective, these will be generated in separate projections between D and F andwill also have unvalued corresponding features. See [62] for discussion.
11 Note that Julien [62] proposes a separate projection for demonstratives. However, for convenience, I analyze both determinersand demonstratives as exponents of D (see also [66]).

Languages 2017, 2, 3 11 of 29
The exoskeletal model serves as a good analytical tool for these cases of mixing, and as an example,the structure of (5b) harvesten ‘the harvest’ prior to movement of the stem complex is presented in (6).
6.
Languages 2017, 2, 3 11 of 28
‘the field’.
d. trunk‐en min [6] (p. 603)
trunk‐DF.SG.M my
‘my trunk’.
The exoskeletal model serves as a good analytical tool for these cases of mixing, and as an
example, the structure of (5b) harvesten ‘the harvest’ prior to movement of the stem complex is
presented in (6).
6.
The structure generated in (6) is a typical Norwegian structure, where feature bundles composed
of definiteness, number, and gender are present in F and D, and in (6) the features of D have already
been valued by Agree with F. The structure also shows the inserted phonological exponents
(boldfaced). The mechanisms are as follows: the English lexical item harvest has been inserted into the
stem position, which is possible since this position does not have strict requirements for insertion.
The functional feature bundle in F, on the other hand, is spelled out by a Norwegian exponent
offering a complete match with the relevant features: definite, singular, masculine. In the next step
(not shown here), I assume that the stem obligatorily moves to F, yielding the complex form harvesten,
and that this complex subsequently moves to Spec‐DP in order to fulfil the interpretability
requirements of the DP domain in Norwegian (see [62]).
This brief overview of the analysis of the typical mixing pattern in AmNo noun phrases serves
two purposes. First, it demonstrates that the late‐insertion exoskeletal model is a good analytical tool
for analyzing this type of language mixing. See also [1,4] for a more in‐depth discussion and analysis
of the typical mixing pattern in AmNo. Second, this discussion is relevant as the basis for
investigating potential diachronic changes in language mixing, which is the topic of the following
sections.
5. Diachronic Change
In this section, I compare data from Haugen [6] and CANS [7] and show that diachronic changes
can be found in the mixing patterns. Due to the limits of this article, I will not discuss the DP
exhaustively, but focus on how gender, number, and definiteness are realized by suffixes on the noun
stem or on determiners or demonstratives in D. The data are discussed separately: Haugen in
Section 5.1., and CANS in Section 5.2. In the former subsection, I also include a brief introduction to
how gender, number, and definiteness are typically realized in a Norwegian structure.12 Please recall
12 Notice that this article discusses the data on a population level, considering the two corpora as two
different stages in the development of AmNo. There are without a doubt individual differences in both groups,
and studying individuals would possibly yield additional insights. However, discussing changes on a
The structure generated in (6) is a typical Norwegian structure, where feature bundles composedof definiteness, number, and gender are present in F and D, and in (6) the features of D have alreadybeen valued by Agree with F. The structure also shows the inserted phonological exponents (boldfaced).The mechanisms are as follows: the English lexical item harvest has been inserted into the stem position,which is possible since this position does not have strict requirements for insertion. The functionalfeature bundle in F, on the other hand, is spelled out by a Norwegian exponent offering a completematch with the relevant features: definite, singular, masculine. In the next step (not shown here),I assume that the stem obligatorily moves to F, yielding the complex form harvesten, and that thiscomplex subsequently moves to Spec-DP in order to fulfil the interpretability requirements of the DPdomain in Norwegian (see [62]).
This brief overview of the analysis of the typical mixing pattern in AmNo noun phrases servestwo purposes. First, it demonstrates that the late-insertion exoskeletal model is a good analytical toolfor analyzing this type of language mixing. See also [1,4] for a more in-depth discussion and analysisof the typical mixing pattern in AmNo. Second, this discussion is relevant as the basis for investigatingpotential diachronic changes in language mixing, which is the topic of the following sections.
5. Diachronic Change
In this section, I compare data from Haugen [6] and CANS [7] and show that diachronic changescan be found in the mixing patterns. Due to the limits of this article, I will not discuss the DPexhaustively, but focus on how gender, number, and definiteness are realized by suffixes on thenoun stem or on determiners or demonstratives in D. The data are discussed separately: Haugen inSection 5.1, and CANS in Section 5.2. In the former subsection, I also include a brief introduction tohow gender, number, and definiteness are typically realized in a Norwegian structure.12 Please recallthat when referring to specific examples, data from Haugen [6] are accompanied by the page numberwhere the examples can be found, and data from CANS [7] by the informant code.
12 Notice that this article discusses the data on a population level, considering the two corpora as two different stages in thedevelopment of AmNo. There are without a doubt individual differences in both groups, and studying individuals wouldpossibly yield additional insights. However, discussing changes on a population level, as in the present article, will providea general overview of potential changes and their development, which is beneficial to a study on the individual level inthe future.

Languages 2017, 2, 3 12 of 29
5.1. Haugen (1953)
5.1.1. Gender
Gender in Norwegian is non-transparent. This means that one cannot tell the gender of a nounfrom the phonological or semantic properties of the noun itself. Instead, gender is revealed by affixesand associated words.13 Previous studies have documented and mapped the gender distribution ofnouns in both non-heritage Norwegian [69] and in AmNo [6,70–73]. Without going into the detailsof these studies, they all establish that masculine is the predominant gender of Norwegian nouns,accounting for 50% or more of nouns, whereas feminine and neuter each cover a smaller percentage,which may wary across different dialects.
In mixed AmNo phrases, English nouns are also assigned to one of the three genders inNorwegian, despite the fact that English nouns do not have gender.14 Table 1 shows the distribution inHaugen’s material.
Table 1. Gender distribution among English nouns in Haugen (1953).
Haugen [6]
M 71.6%F 1.6%N 8.2%
Alternating gender 18.6%
M: Masculine; F: Feminine; N: Neuter.
Haugen bases these numbers on a sample of 317 noun stems in his material. All three gendersare used, and similar to the distribution of the native Norwegian vocabulary, masculine is the mostfrequent gender. In this selection, 59 nouns, or 18.6% of the total, vacillated between genders, which isnot surprising considering that many nouns are assigned different genders in different Norwegiandialects (see, e.g., [75]).
5.1.2. Number
Plurality is typically expressed as a functional suffix both in Norwegian and in English, and theNorwegian plural suffix additionally varies according to gender. In Haugen’s [6] material, Englishnouns in plural phrases typically occur with a Norwegian suffix. In fact, Haugen states that a loanword“almost universally [was] given the most common plural ending of the gender to which it had beenassigned” [6] (p. 450). Some examples are provided in (7).
13 Notice that there is discussion in the literature concerning whether the definite suffix in Norwegian is a marker for genderor rather for declension class [67,68]. I assume that the suffix expresses gender, and will analyze it accordingly.
14 The interest of this article is the distribution across the different genders, and not the process of how an individual nounis assigned a specific gender. This presumably relies on a number of factors not addressed in the present article, such asphonology, conceptual content, convention, and it can vary among different varieties of Norwegian. See [61,74] for anapproach that is compatible with the late-insertion exoskeletal model.

Languages 2017, 2, 3 13 of 29
7. a. piec[e]-ar [6] (p. 450)piece-INDF.PL.M
b. creek-ar [6] (p. 450)creek-INDF.PL.M
c. bluff-er [6] (p. 563)bluff-INDF.PL.F
d. field-er [6] (p. 757)field-INDF.PL.F
e. team- [6] (p. 450)team-INDF.PL.N
f. store- [6] (p. 598)store-INDF.PL.N
However, one English inflectional form is attested in Haugen’s material, and that is the pluralsuffix -s. In accounting for the usage of this suffix, Haugen splits the speakers into two groups:pre-bilingual borrowers and childhood bilinguals. Pre-bilingual borrowers are those who acquiredEnglish in adulthood, and are not considered “true” bilinguals. Haugen suggests that these speakerswere not aware of the plural value of -s, consequently producing cases where the -s is present both insingular and plural, e.g., in cookies (used in both SG and PL), and with Norwegian suffixes in addition,e.g., car-s-ar ‘car-PL-INDF.PL.M’ and bean-s-en ‘bean-PL-DF.SG.M’ [6] (pp. 450–451). Haugen concludesthat these speakers took the -s to be part of the noun stem.
The second group, the childhood bilinguals, occasionally uses the -s in its correct plural functionand as a replacement for a Norwegian alternative. This is, according to Haugen, limited to indefinitecases, and foreshadowing the diachronic development, Haugen comments that the usage “naturallyincreased as time went on” [6] (p. 451).
5.1.3. Definiteness
As discussed above, definiteness in Norwegian is expressed both in F and in D. Due to the stemcomplex obligatorily moving to F, the exponent of F in a definite phrase materializes as a functionalsuffix on the noun stem, commonly called the definite article. The realization of D, on the other hand,can be fulfilled either by FP moving further to Spec-DP or by spelling out D with a separate determineror demonstrative.
Concerning definiteness, Haugen gives two clear restrictions for AmNo: “Whether wordswere singular or plural [ . . . ] they had to add the N[orwegian] definite article under appropriatecircumstances” [6] (p. 451) and “E[nglish] the would not be acceptable” [6] (p. 451). In other words,in definite phrases, realization of Norwegian functional exponents is obligatory. Some examples aregiven in (8).
8. a. railroad-en [6] (p. 590)railroad-DF.SG.M
b. field-a [6] (p. 575)field-DF.SG.F
c. det crew-et [6] (p. 571)the.N crew-DF.SG.N

Languages 2017, 2, 3 14 of 29
In the next subsection, I consider the more recently collected data and show how some of thepatterns and restrictions discussed by Haugen have changed.
5.2. Corpus of American Norwegian Speech
This section provides data from CANS [7] showing patterns of language mixing deviating fromthe ones attested in Haugen [6]. The basis of the discussion is the 1034 English nouns occurring in aNorwegian context in CANS, see Section 3.2. above. Thus, due to the relatively limited amount of datain the corpus, the following presentation serves primarily to describe a trend of diachronic change.
5.2.1. Gender
When accounting for gender distribution in the most recent AmNo material, I have considered allsingular forms where gender is revealed by the indefinite article or the definite suffix. Although pluralforms are also sensitive to gender, these are excluded due to the syncretism of plural masculine andfeminine in many Norwegian dialects and in the written standard, Bokmål. What remains is a sampleof 292 nouns. Their distribution is presented in Table 2.15
Table 2. Gender distribution among English nouns in Corpus of American Norwegian Speech (CANS).
CANS [7]
M 66.1%F 6.5%N 6.2%
Alternating gender 21.2%
Similar to Haugen’s findings presented in Table 1, the category of alternating gender in Table 2includes the nouns that vacillate between genders. This group covers roughly one fifth of the nouns,whereas 66.1% of the nouns are masculine, 6.5% feminine and 6.2% neuter.16
Comparing these numbers with earlier material, the distribution of gender appears to be relativelystable; see Table 3.17 Generally, around 70% of the nouns are masculine, whereas feminine and neutereach are assigned to less than 15% of the nouns. The group of nouns with alternating genders in themost recent material is quite large, which may indicate some uncertainty in the gender system (see [73]for discussion). However, as there is no clear developmental pattern or obvious diachronic change,the question of gender will not be discussed further in this article.
Table 3. Development of gender distribution among English nouns in American Norwegian (AmNo).
Flom [68] Haugen [6] Hjelde [69] CANS [7]
M 71% 71.6% 70.7% 66.1%F 5% 1.6% 10.5% 6.5%N 16% 8.2% 15.7% 6.5%
Alternating gender 8% 18.6% 3.1% 21.2%
15 This distribution concerns English nouns mixed into AmNo. For gender distribution among Norwegian nouns in CANS,see [72,73].
16 The numbers are based on tokens in the selection. Counting types instead would provide a slightly, but not radically,different picture with 79% masculine, 7.6% feminine, 7.6% neuter and 5.7% alternating gender.
17 Notice that Hjelde’s [71] numbers for feminine and neuter are slightly higher than in the other distributions, which may bedue to the fact that Hjelde isolated one specific dialect in his study.

Languages 2017, 2, 3 15 of 29
5.2.2. Number
As discussed above, Haugen [6] separated his informants into two groups: pre-bilingualborrowers and childhood bilinguals. All of the speakers represented in CANS were born in theUS or Canada and belong to the latter group, and similar to Haugen’s findings for this group, bothNorwegian plural suffixes and the English plural suffix -s are used by the CANS speakers. Someexamples are given in (9), where (9a,b) show phrases with the Norwegian suffixes, and (9c–f) showcases with the English suffix.
9. a. ti kid-er [7]; portland_ND_01gmten kid-INDF.PL.M/F
b. boss-er [7]; coon_valley_WI_06gmboss-INDF.PL.M/F
c. mange lawyer-s [7]; sunburg_MN_03gmmany lawyer-PL
d. fem dialect-s [7]; portland_ND_01gmfive dialect-PL
e. andre tool-s [7]; sunburg_MN_03gmother tool-PL
f. alle slags pill-s [7]; westby_WI_02gmall kinds of pill-PL
In light of Haugen’s [6] study, the fact that both Norwegian and English plural suffixes are attestedin CANS is not surprising. What is interesting as a possible sign of diachronic change, however, is thedistribution of these two realizations. Haugen does not provide any quantitative measures of thedistribution, but since loanwords “almost universally” were given Norwegian plural suffixes, we mustassume that the English plural suffix was used in a clear minority of cases. In CANS, on the otherhand, this picture is reversed. Out of all 175 plural phrases involving an English noun, 103 are realizedwith the English plural -s, compared to 37 cases with the Norwegian suffix. The remaining 35 phrasesare realized without any plural suffix, which I will return to below. Among the cases with the plural -s,the vast majority are indefinite phrases, as in the examples in (9c–f) above. However, in CANS [7] the-s occasionally occurs in definite phrases. Some examples are given in (10).
10. a. alle disse minute-s [7]; stillwater_MN_01gmall these minute-PL
b. disse lutefisk dinner-s [7]; westby_WI_03gkthese lutefisk dinner-PL
c. de samme gene-s18 [7]; flom_MN_02gmthe same gene-PL
18 This phrase is not included in the count described in Section 3.2, due to being part of a repetition.

Languages 2017, 2, 3 16 of 29
The pattern in (10) is not found in Haugen [6], and the attestations in the new corpus are notfrequent (10 attested examples). A common property is, nevertheless, that in addition to the pluralsuffix -s, they have a Norwegian exponent of definiteness in the higher projection, D.19
A third pattern, not mentioned by Haugen, is plural phrases without any suffix at all. This patternis found primarily in indefinite cases, as shown in (11).
11. a. fem seks hour_ [7]; chicago_IL_01gkfive six hour
b. flere store_ [7]; westby_WI_03gkmore store
c. mange memorial_ [7]; webster_SD_01gmmany memorial
It is, however, challenging to provide a reliable estimate of the prevalence of such cases, since theyare often impossible to confirm as plurals. The examples in (11) are given away by their quantifiers.20
5.2.3. Definiteness
Concerning definiteness, the majority of the relevant cases in CANS [7] behave the same wayas described by Haugen [6] (and expected in a Norwegian structure): they receive the definite suffixas expected, and the determiner or demonstrative is present in relevant cases [4]. Nevertheless,two patterns of change are found.
The first pattern of change is omission of the functional suffix. Among definite singulars, 98phrases occur without the definite suffix. Some examples follow in (12).
19 One phrase may, based on its context, be considered an instance where the -s occurs alone in a definite phrase: hun har tickets‘she has the tickets’ ([7]; coon_valley_WI_02gm), but it is the sole example of its kind.
20 Two possible definite cases are also attested: disse garter snake_ ‘these garter snake’ ([7]; sunburg_MN_03gm) and dissedeer_ ‘these deer’ ([7]; stillwater_MN_01gm). However, since the latter is a possible English realization of plural deer, and theformer is produced after hesitation, this pattern is very limited.

Languages 2017, 2, 3 17 of 29
12. a. den school_ [7]; gary_MN_01gmthat.M/F school
b. den birdhouse_ [7]; coon_valley_WI_12gmthat.M/F birdhouse
c. denne cheese_21 [7]; blair_WI_04gkthis.M/F cheese
d. den store building_ [7]; chicago_IL_01gkthe.M/F big building
e. det gamle stuff_ [7]; chicago_IL_01gkthe.N old stuff
f. det norske settlement_ [7]; albert_lea_MN_01gkthe.N Norwegian settlement
g. det første trip_ [7]; westby_WI_06gmthe.N first trip
h. nephew_ min [7]; portland_ND_02gknephew my.M/F
i. family_ min [7]; portland_ND_01gmfamily my.M/F
(12a–g) show cases where the characteristic double definiteness in Norwegian is expected,but definiteness is only expressed by the determiner or demonstrative.22 The latter two examples,(12h,i), show phrases with a post-nominal suffix where the definite suffix is expected, but omitted.23
Notice that this pattern is not exclusive to the mixed phrases, as there are examples of the definitesuffix being omitted in “all-Norwegian” phrases also, as in (13).24 This might indicate that the changeis not directly connected to the mixed items, but is rather a more general process.
21 This phrase is not included in the count presented in Section 3.2, as the item cheese is not tagged “x”, even though cheese isnot a common Norwegian vocabulary item.
22 Notice that the adjectives in question also show that the phrase is definite, as they have the weak inflection -e, which istypical for definite cases.
23 Family terms are often used without the definite suffix, e.g., far min ‘my father’ and mor mi ‘my mother’, but arguably this isnot equally common with nevø ‘nephew’, or with familie ‘family’ as in (12h,i).
24 Norwegian noun phrases can be realized with only a determiner or demonstrative and without the functional suffix,primarily in a formal or written-like style. As these informants are not formally educated in Norwegian, I consider itpossible, but not very likely, that they are using this style of speech.

Languages 2017, 2, 3 18 of 29
13. a. denne skole_ [7]; harmony_MN_01gkthis.M/F school
b. den sommer_ [7]; coon_valley_WI_12gmthat.M/F summer
c. dette land [7]; chicago_IL_01gkthis.N country
d. dette brød_ [7]; blair_WI_07gmthis.N bread
e. disse nabolag_ [7]; chicago_IL_01gkthese neighborhood
The second change is the usage of the English determiner the, which was described as unacceptableby Haugen. Although not frequent, 20 cases are attested in CANS where the determiner the occurstogether with a Norwegian noun or in an otherwise Norwegian structure. Some examples are givenin (14), and all these examples are part of a larger Norwegian utterance.
14. a. the by [7]; chicago_IL_01gkthe city
b. the ungdom [7]; harmony_MN_01gkthe youth
c. the gamle kirke [7]; chicago_IL_01gkthe old church
d. the penger [7]; albert_lea_MN_01gkthe money
A common property of the phrases in (14) is that they additionally lack the definite suffix, whichwould have been expected in a corresponding Norwegian noun phrase. However, in about half of the20 phrases, the English determiner the co-occurs with such a Norwegian definite suffix, as in (15).
15. a. the gård-en [7]; gary_MN_01gmthe farm-DF.SG.M
b. the rest-en [7]; vancouver_WA_03ukthe rest-DF.SG.M
c. the andre dag-en [7]; vancouver_WA_01gmthe other day-DF.SG.M
d. the samme tid-a [7]; albert_lea_MN_01gkthe same time-DF.SG.F
As CANS enables the researcher to listen to the recordings of these AmNo speakers, it is worthmentioning that the phonology of the determiner varies, and a possible objection could concern thesimilarities between the and the Norwegian neuter determiner det. These two may in fact sound quitesimilar, especially if the is pronounced with an alveolar stop instead of a dental fricative. However,two arguments support the analysis of these as English determiners. First, a prenominal determinerwould, in most cases, be an alien element in a Norwegian structure without the definite suffix as

Languages 2017, 2, 3 19 of 29
in (14) (see also footnote 24). Secondly, the phrases where a prenominal determinative is expected inNorwegian, e.g., in the phrases requiring double definiteness, are primarily masculine, as in (15a–c).This means the appropriate Norwegian determiner would be den, which is not equally similar to theEnglish the.
5.2.4. The Indefinite Article
In addition to the comparisons of Haugen [6] and CANS [7] so far, a brief comment on theindefinite article needs to be added. Haugen [6] does not mention or discuss any generalizationsor irregularities concerning the indefinite article. Thus, we must assume that its usage follows anexpected Norwegian pattern in Haugen’s material. In the new corpus, however, the domain of theindefinite article also seems to be subject to diachronic change, and in parallel to the discussion ofdefinite phrases above, these changes materialize as either omitting the article (60 attested cases) or,in a few cases, using the English a (I have found 8 such cases). Some examples are provided in (16),with the relevant context included.
16. a. så du fikk _ candybar [7]; webster_SD_01gmthen you got a candybar
b. han hadde #25 _ stor steam engine [7]; rushford_MN_01gmhe had a big steam engine
c. det er _ bluebird som sitter ute [7]; coon_valley_WI_01gkit is a bluebird that sits outside
d. a stort hus [7]; albert_lea_MN_01gka big house
e. a spiker [7]; flom_MN_02gma nail
These patterns are less frequent than in the definite phrases, but they still do occur.
5.3. Interim Summary of the Findings
In this section, I have compared Haugen [6] to CANS [7] and presented systematic changesbetween the corpora concerning the categories gender, number, and definiteness in mixed nounphrases. Concerning gender, the main interest in this article is the distribution across the three gendersof Norwegian, where no remarkable change was found when comparing today’s AmNo to Haugen [6]and other previous AmNo collections. Hence, I decided to focus on number and definiteness in therest of the article.
In the case of number, Haugen describes two patterns concerning the realization of plurality.In most cases, the appropriate Norwegian suffix is added, but among a subgroup of his informants,the childhood bilinguals, the English suffix -s is attested. In CANS both these patterns are attested, andthe English plural -s is used in most cases. In addition, a new pattern is attested, namely the omissionof a functional suffix in plural phrases.
Concerning definiteness, two patterns that are unattested in Haugen’s material are found inCANS: definite functional suffixes are omitted in several phrases, and the English determiner the issometimes used instead of a Norwegian alternative. Interestingly, omission of functional material and
25 # marks a brief pause.

Languages 2017, 2, 3 20 of 29
usage of English determiners are also attested in indefinite phrases in CANS, which is something thatis not discussed by Haugen.
Summing up, the data show two main patterns of change in the AmNo noun phrases:
1. Omission of functional suffixes, both in plural and/or definite cases2. Usage of English functional exponents
In the next section, I will continue the discussion of the patterns that diverge from the typicalpattern of mixing in AmNo, and explore how the observed changes can potentially be explained bychanges in the underlying grammar. Furthermore, I briefly address some limitations when it comes toinvestigating diachronic changes in a language like AmNo.
6. Analysis and Discussion
From the perspective of the exoskeletal model, two different scenarios can explain changes likethe ones presented in Section 5.2: on the one hand, we could assume that the structure is intact,but the exponents have changed. On the other hand, we could assume that the observed changeis a result of the structure itself changing. Both scenarios would disrupt the process of insertion,facilitating realizations diverging from the expected patterns. In this section, I explore these twoalternatives separately.
6.1. Change in the Exponent
In the first scenario, we assume that the abstract syntactic frame is intact, and the observed changeis caused by the functional exponents and/or their conditions for insertion. Support for this alternativeis found in the Missing Surface Inflection Hypothesis (MSIH) [76,77]. This hypothesis was proposedbased on evidence from second language acquisition and claims that the absence of overt morphologydoes not necessarily mean the absence of functional categories in the syntax. Instead, the lack of overtlyrealized functional exponents may be due to the learner not having established the complete set ofexponents or by a failure to meet matching conditions between the exponent and the structure [76].For the AmNo speakers, we can in a parallel manner assume that the structure is generated as expected,but that their repertoire of phonological exponents and corresponding versatility concerning insertionmay be reduced, creating obstacles in the spell-out process.
A key word in the MSIH is avoidance, as the learner is taken to prefer a missing form over afaulty inflection [76]. In other words, when the speaker is in doubt, she will, consciously or not, avoidinserting any exponent in order to prevent mismatches.26 Considering the AmNo data discussedabove, such a strategy of avoidance could explain the cases where the speaker omits functional suffixes.Take for instance the examples in (17), where the Norwegian definite suffix is omitted, but the phraseis still accompanied by a Norwegian determiner or demonstrative.
17. a. den birdhouse_ [7]; coon_valley_WI_12gmthat.M/F birdhouse
b. den store building_ [7]; chicago_IL_01gkthe.M/F big building
c. det første trip_ [7]; vancouver_WA_01gmthe.N first trip
These data may serve as evidence of the presence of an underlying structure even if the overtmorphology is lacking, as argued by the MSIH. The argument follows from the assumption that the
26 According to Gass and Selinker [78], avoidance is a typical phenomenon in L2 acquisition.

Languages 2017, 2, 3 21 of 29
features in D are valued through a probe-goal relation with the features in F: the determiners in (17)vary according to gender, (17a,b) being either masculine or feminine, and (17c) neuter. As the valuationof the gender feature in D requires a corresponding gender feature in F, the gender feature must bespecified in F, presumably together with number and definiteness, even if this feature bundle is notrealized by a phonological exponent. A possible structure for (17a) is shown in (18). As in similar casesdiscussed above, the stem complex will move to F obligatorily, but because the functional exponent isavoided in this position, the stem will surface without a functional suffix.
18.
Languages 2017, 2, 3 20 of 28
that.M/F birdhouse
b. den store building_ [7]; chicago_IL_01gk
the.M/F big building
c. det første trip_ [7]; vancouver_WA_01gm
the.N first trip
These data may serve as evidence of the presence of an underlying structure even if the overt
morphology is lacking, as argued by the MSIH. The argument follows from the assumption that the
features in D are valued through a probe‐goal relation with the features in F: the determiners in (17)
vary according to gender, (17a,b) being either masculine or feminine, and (17c) neuter. As the
valuation of the gender feature in D requires a corresponding gender feature in F, the gender feature
must be specified in F, presumably together with number and definiteness, even if this feature bundle
is not realized by a phonological exponent. A possible structure for (17a) is shown in (18). As in
similar cases discussed above, the stem complex will move to F obligatorily, but because the
functional exponent is avoided in this position, the stem will surface without a functional suffix.
18.
Nevertheless, the hypothesis does not necessarily entail that the speaker does not know the
appropriate exponent at all. Such an approach would imply that the speaker never uses the functional
suffix, which is easily tested by checking all relevant noun phrases produced by the speaker in
question. A random check of the speakers who produced the examples in (17) shows that this
implication is strongly questionable. These speakers do produce the definite suffixes in other similar
phrases, suggesting that they do have this exponent in their list of vocabulary items. The realization,
however, is variable, both in mixed and unmixed phrases, indicating that they are experiencing
difficulties with the connection between the exponent and the features in the structure.
Furthermore, usage of the English plural ‐s can also be considered an effect of a similar avoidance
strategy: the speaker avoids a potential mismatch, for instance with the gender feature in the
Norwegian structure, by using an exponent from their dominant language. This is possible since the
inserted exponent, given the Subset Principle, does not have to match all features in the feature
bundle; matching with a subset is sufficient. In comparison, English does not have an alternative
exponent to replace the definite suffix, leaving omission as the only available avoidance strategy.
However, the English determiner the could be a replacement in cases when the speaker is unsure
about which Norwegian determiner to insert.
The MSIH is therefore one potential approach to analyzing changing or diverging linguistic
patterns, and incorporating it into the exoskeletal model provides an analysis like the one in (18).
Reduced exposure to and practice in AmNo emerge as probable factors that could cause a reduced
repertoire of functional exponents and increased uncertainty in how to the use them. However, a
concern is that the MSIH lacks clear predictions as to where and how the missing inflections will take
Nevertheless, the hypothesis does not necessarily entail that the speaker does not know theappropriate exponent at all. Such an approach would imply that the speaker never uses the functionalsuffix, which is easily tested by checking all relevant noun phrases produced by the speaker in question.A random check of the speakers who produced the examples in (17) shows that this implication isstrongly questionable. These speakers do produce the definite suffixes in other similar phrases,suggesting that they do have this exponent in their list of vocabulary items. The realization, however,is variable, both in mixed and unmixed phrases, indicating that they are experiencing difficulties withthe connection between the exponent and the features in the structure.
Furthermore, usage of the English plural -s can also be considered an effect of a similar avoidancestrategy: the speaker avoids a potential mismatch, for instance with the gender feature in theNorwegian structure, by using an exponent from their dominant language. This is possible since theinserted exponent, given the Subset Principle, does not have to match all features in the feature bundle;matching with a subset is sufficient. In comparison, English does not have an alternative exponentto replace the definite suffix, leaving omission as the only available avoidance strategy. However,the English determiner the could be a replacement in cases when the speaker is unsure about whichNorwegian determiner to insert.
The MSIH is therefore one potential approach to analyzing changing or diverging linguisticpatterns, and incorporating it into the exoskeletal model provides an analysis like the one in (18).Reduced exposure to and practice in AmNo emerge as probable factors that could cause a reducedrepertoire of functional exponents and increased uncertainty in how to the use them. However,a concern is that the MSIH lacks clear predictions as to where and how the missing inflections will takeplace, as well as clear restrictions in the model, and quite problematically, anything could potentiallybe explained as avoidance. In the next section, I will discuss the possibility that these diachronicchanges are caused by certain changes in the syntactic structure.
6.2. Change in the Structure
The second scenario that could explain the observed changes, seen from an exoskeletal perspective,is that the structures themselves may be changing. This has been suggested in studies of other HL,e.g., heritage Russian [18,79], heritage Spanish [80], and heritage German [81], all of which concludethat the heritage language in question seems to have fundamentally different structures than its native

Languages 2017, 2, 3 22 of 29
counterpart. Polinsky [18] suggests that the changes she finds between heritage and non-heritagespeakers of Russian, and between children and adult HS, are the result of a structural reanalysis ofthe heritage grammar. She further contends that this is a process taking place over the lifespan of theHS in the absence of consistent input. In a similar vein, Putnam and Sánchez [19] argue in favor ofa reanalysis of heritage grammars. In their analysis, the levels of activation for comprehension andproduction purposes play a crucial role in the development and maintenance of a heritage grammar;difficulties for HS can be due to reduced activation and availability of functional features, complicatingthe exercise of mapping them in the ways expected in monolingual variants of the language. The resultmay be a progressive reassembly of the features.
In the case of AmNo and the patterns of diachronic change in language mixing, the data suggestthat such a structural reanalysis of grammar could be going on. In the exoskeletal model, this couldtake the form of features or feature bundles either being rearranged or erased from the structure, whichwould in turn have consequences for insertion of functional exponents. In many cases, a rearrangementof the structural outfit of the DP would mean that certain Norwegian functional exponents would notfit anymore. Given the Subset Principle, phonological exponents holding features not specified in thestructure cannot be inserted, and supposing that the structural outfit of the noun phrase is changed,a Norwegian exponent could turn out to be “too specific”, i.e., specified for features not present in thestructure and thus blocked from insertion. In fact, changes in the structural composition of the nounphrase would instead allow, or even give preference to, insertion of English exponents.
As an example, consider the usage of the English plural -s. A couple of examples are given in (19).
19. a. mange lawyer-s [7]; sunburg_MN_03gmmany lawyer-PL
b. fem dialect-s [7]; portland_ND_01gmfive dialect-PL
Norwegian functional suffixes are typically also specified for gender in the plural, whereasassociated words such as adjectives, quantifiers and determiners are not. The use of the English pluralinflection could thus be seen as an indication that the representation of gender is diminished for thefunctional suffixes. If so, the Norwegian exponents for the suffix would be blocked from insertiondue to holding a gender feature not specified in the structure, and the English exponent would be thepreferred alternative (see [4] for discussion of the plural -s in AmNo).
Importantly, the development of reanalyzed structural patterns in a heritage language is describedas a gradual process, potentially one where the dominating language gradually takes the place of theoriginal structure, which is a typical trajectory in the development of a minority language, e.g., [19,79].Lower exposure to lexical items in the heritage language means lower levels of activation of certainfunctional features. This, combined with an increased exposure to the dominant language, makes thefeatures of the heritage language vulnerable for replacement [19]. In the case of AmNo, English has adominating role both for the individual speakers and in the community at large. Hence, the possibilityof English structures taking over for AmNo structures is not an unlikely scenario. This is also supportedby the way in which some changes take form. For instance, the omission of Norwegian definite suffixescomplies with an English structure where such suffixes do not exist, and the usage of English functionalmaterial suggests that the feature bundles in the structure are designed in such a way that these areconsidered the most appropriate exponents, following the Subset Principle.
The gradual nature of the change is especially striking in the definite phrases with the Englishdeterminer the, where some patterns appear to be in an intermediate stage. As discussed inSection 5.2.3., half of the attested phrases occurred with both the English determiner and the Norwegiandefinite suffix, whereas the second half followed a typical English pattern realizing only the determiner.In the former group of these examples, one can argue that English influence is ongoing, allowing theinsertion of an English determiner, but not yet complete, as the Norwegian functional suffix indicates

Languages 2017, 2, 3 23 of 29
an underlying typical Norwegian feature bundle, spelled out by a Norwegian functional exponent.In the latter group, however, the influence of English is more pronounced as these examples follow atypical English DP pattern. In fact, as I will argue below, these examples may be described as Englishstructures with Norwegian stems incorporated into them. Some examples are given in (20), where(20a,b) represent the intermediate stage and (20c,d) the potential full English influence in AmNonominal structures:27
20. a. the gård-en [7]; gary_MN_01gmthe farm-DF.SG.M
b. the rest-en [7]; vancouver_WA_03ukthe rest-DF.SG.M
c. the by [7]; chicago_IL_01gkthe city
d. the ungdom [7]; harmony_MN_01gkthe youth
Possible structures for the two stages of mixing in (20) are shown in (21) and (22). The formershows the intermediate stage, represented by (20a), and the latter shows a case where a Norwegiannoun is inserted into an English structure, as may be the case in (20c). Notice also that (21) and (22)show structures prior to movement, and that the stem complex will move to F.
21.
Languages 2017, 2, 3 22 of 28
the usage of English functional material suggests that the feature bundles in the structure are
designed in such a way that these are considered the most appropriate exponents, following the
Subset Principle.
The gradual nature of the change is especially striking in the definite phrases with the English
determiner the, where some patterns appear to be in an intermediate stage. As discussed in
Section 5.2.3., half of the attested phrases occurred with both the English determiner and the
Norwegian definite suffix, whereas the second half followed a typical English pattern realizing only
the determiner. In the former group of these examples, one can argue that English influence is
ongoing, allowing the insertion of an English determiner, but not yet complete, as the Norwegian
functional suffix indicates an underlying typical Norwegian feature bundle, spelled out by a
Norwegian functional exponent. In the latter group, however, the influence of English is more
pronounced as these examples follow a typical English DP pattern. In fact, as I will argue below, these
examples may be described as English structures with Norwegian stems incorporated into them.
Some examples are given in (20), where (20a,b) represent the intermediate stage and (20c,d) the
potential full English influence in AmNo nominal structures:27
20. a. the gård‐en [7]; gary_MN_01gm
the farm‐DF.SG.M
b. the rest‐en [7]; vancouver_WA_03uk
the rest‐DF.SG.M
c. the by [7]; chicago_IL_01gk
the city
d. the ungdom [7]; harmony_MN_01gk
the youth
Possible structures for the two stages of mixing in (20) are shown in (21) and (22). The former
shows the intermediate stage, represented by (20a), and the latter shows a case where a Norwegian
noun is inserted into an English structure, as may be the case in (20c). Notice also that (21) and (22)
show structures prior to movement, and that the stem complex will move to F.
21.
27 An alternative approach suggests that these are cases where the Norwegian determiner has been
relexified by the English determiner the. Even though the process of relexification may be a considerable factor
in language development and change, I argue that this is not plausible in these specific cases as a (Norwegian)
determiner would not typically be expected in cases like (20).
22.
Languages 2017, 2, 3 23 of 28
22.
In both (21) and (22), the feature bundle in D is reduced compared to its Norwegian counterpart,
allowing the insertion of the English determiner. The main difference is found in F, where gender is
presumably a key component. If a gender feature were present in the underlying structure,
Norwegian functional exponents would be preferred over the English alternatives. However, if the
structure has been reanalyzed and the gender feature is weakened, then the Norwegian exponent
would be blocked, since inserting exponents specified for features other than those present in the
structure would constitute a violation of the Subset Principle. Hence, I assume that the gender feature
is preserved in F in the intermediate cases like (21), whereas in cases like (22), the displacement of the
Norwegian structure by English has progressed further, eliminating the gender feature. The structure
in (22) may now be considered an English structure where a Norwegian noun stem is inserted.
Parallel to the discussion in Section 6.1. above, positing changes in the syntactic structure is one
possible approach to analyzing diachronic changes in AmNo. Considering its language environment
over the past century, combined with the change going in a more English direction (e.g. without
definite suffixes and with English functional exponents), it appears promising to analyze the changes
as a structural reanalysis due to influence from English. Nevertheless, the two scenarios for change
are not necessarily mutually exclusive. On the contrary, they may be two parallel trajectories to
language change, and the observed change may be the result of a combination of the two.
Notice, however, that my discussion of changes in AmNo is based on a relatively limited sample
of mixed noun phrases, and future expansions of CANS will bring new data, potentially
corroborating the patterns discussed in this article. Studies of individual speakers and of diachronic
changes in other domains of the grammar would also provide a clearer picture of the development
and the potential impact of English in the structural reanalysis of AmNo.
6.3. The Nature of the Change
This article is primarily concerned with the explanation of the observed diachronic changes in
AmNo as possible effects of changes in its grammar. However, a related question concerns the
historical and sociolinguistic conditioning of these changes. As this is not the main focus of the
current article, I will not go into an elaborate discussion of this question, but there are some crucial
limitations to be addressed when investigating diachronic changes in a language like AmNo.
Cross‐linguistic influence from the dominating language, English, has already been introduced
and discussed in Section 6.2. In addition, changes in heritage grammars are often considered to be
the result of incomplete acquisition or attrition [14,16–18,80]. Incomplete acquisition suggests that the
HS, due to being introduced to the dominant language, experience a delay or break in the acquisition
of the heritage language, hindering them from developing it in the same way as monolingual
speakers of that variety [16,17]. Attrition, on the other hand, refers to a weakening or loss of linguistic
competence that the speaker once mastered [14,18].
27 An alternative approach suggests that these are cases where the Norwegian determiner has been relexified by the Englishdeterminer the. Even though the process of relexification may be a considerable factor in language development and change,I argue that this is not plausible in these specific cases as a (Norwegian) determiner would not typically be expected in caseslike (20).

Languages 2017, 2, 3 24 of 29
In both (21) and (22), the feature bundle in D is reduced compared to its Norwegian counterpart,allowing the insertion of the English determiner. The main difference is found in F, where gender ispresumably a key component. If a gender feature were present in the underlying structure, Norwegianfunctional exponents would be preferred over the English alternatives. However, if the structurehas been reanalyzed and the gender feature is weakened, then the Norwegian exponent would beblocked, since inserting exponents specified for features other than those present in the structure wouldconstitute a violation of the Subset Principle. Hence, I assume that the gender feature is preserved inF in the intermediate cases like (21), whereas in cases like (22), the displacement of the Norwegianstructure by English has progressed further, eliminating the gender feature. The structure in (22) maynow be considered an English structure where a Norwegian noun stem is inserted.
Parallel to the discussion in Section 6.1. above, positing changes in the syntactic structure is onepossible approach to analyzing diachronic changes in AmNo. Considering its language environmentover the past century, combined with the change going in a more English direction (e.g., withoutdefinite suffixes and with English functional exponents), it appears promising to analyze the changesas a structural reanalysis due to influence from English. Nevertheless, the two scenarios for change arenot necessarily mutually exclusive. On the contrary, they may be two parallel trajectories to languagechange, and the observed change may be the result of a combination of the two.
Notice, however, that my discussion of changes in AmNo is based on a relatively limited sampleof mixed noun phrases, and future expansions of CANS will bring new data, potentially corroboratingthe patterns discussed in this article. Studies of individual speakers and of diachronic changes in otherdomains of the grammar would also provide a clearer picture of the development and the potentialimpact of English in the structural reanalysis of AmNo.
6.3. The Nature of the Change
This article is primarily concerned with the explanation of the observed diachronic changesin AmNo as possible effects of changes in its grammar. However, a related question concerns thehistorical and sociolinguistic conditioning of these changes. As this is not the main focus of the currentarticle, I will not go into an elaborate discussion of this question, but there are some crucial limitationsto be addressed when investigating diachronic changes in a language like AmNo.
Cross-linguistic influence from the dominating language, English, has already been introducedand discussed in Section 6.2. In addition, changes in heritage grammars are often considered to be theresult of incomplete acquisition or attrition [14,16–18,80]. Incomplete acquisition suggests that the HS,due to being introduced to the dominant language, experience a delay or break in the acquisition ofthe heritage language, hindering them from developing it in the same way as monolingual speakers ofthat variety [16,17]. Attrition, on the other hand, refers to a weakening or loss of linguistic competencethat the speaker once mastered [14,18].
In the case of AmNo and its development over the past decades, there are some factors preventingus from determining which of these scenarios best reflect the linguistic situation. As already discussedin Section 3, speakers described in both Haugen’s [6] material and in CANS [7] are descendants ofimmigrants who came to North America prior to 1920, and the corpora thus enable a comparison overa span of decades. The lack of (established) relationship between the speakers in the two corpora,also discussed in Section 3, is nevertheless a limiting factor. In order to study an effect of incompleteacquisition carefully, one needs data about the input of the learner, and a study of attrition requiresdata from the early production of the speaker, neither of which are available from the two corporaunder consideration here. Since there is no established relationship between the speakers in the twocorpora, we cannot study the younger speakers’ input to evaluate their acquisition. Moreover, as thespeakers in CANS were already adults and elderly people at the time of recording, we are unableto determine whether their grammars have been stable throughout their lives or if they have lostlinguistic skills due to attrition.

Languages 2017, 2, 3 25 of 29
Also, in order to properly investigate cross-linguistic influence, more data would be required,documenting for instance the speakers’ competence in their dominant language. This is not providedby any of the corpora. Nevertheless, as discussed above, the dominance of English both in theindividual speakers and in the larger language community suggests that the speakers of AmNo wouldbe experiencing an influence from English to some degree.
Comparing the two corpora thus means studying HL in a retrospective fashion. On the one hand,this enables a study of different stages in its development, but at the same time potential conclusionsare limited due to the lack of a relation or direct link between them. As already mentioned in Section 3,however, based on the speakers’ ages and places of origin, we can argue that the speakers from the1930s and 1940s represent the type of input that the CANS speakers received, and thus establish anindirect link between them. In addition, as the speakers in Haugen [6] in the vast majority of casesused loanwords with the appropriate Norwegian inflection, the diverging patterns attested in CANScan in fact be considered a diachronic development in AmNo. Nevertheless, as the developmentaltrajectory cannot be traced for the individual speakers, these diachronic changes are best described astendencies of change in the language community.
7. Conclusions
This article has investigated the heritage language AmNo and whether its patterns of languagemixing are persistent over time. A comparison of mixed AmNo noun phrases from the 1930s and1940s [6] and the present [7] shows that the overall pattern of language mixing is stable, but somesystematic diachronic changes are attested. The purpose of this article has thus been twofold: first,to describe the changes, focusing on changes in the exponence of number and definiteness, and second,to explore potential changes in the underlying grammar which could explain the observed changes.
The diachronic changes in the categories number and definiteness can be summed up as two mainpatterns: omission of functional exponents and usage of English functional exponents such as theplural suffix -s and the determiner the. These patterns are studied based on an exoskeletal approachto grammar where the main component is a separation of the abstract, syntactic structure and thephonological exponents realizing it. The article then discusses two possible scenarios for how toaccount for the observed changes: they could be due to changes in the phonological exponents,i.e., their conditions for insertion into the syntactic structure, or they could be due to a change in theunderlying syntactic structure itself. Both alternatives would disrupt the process of insertion, andthey are not necessarily mutually exclusive. However, based on the observed patterns of change inthe data, I argue that a structural reanalysis of AmNo grammar is occurring. Moreover, the articlealso discusses why one should be careful when drawing conclusions concerning diachronic changesin AmNo. Although the two corpora under consideration provide valuable insights into AmNo attwo different stages in its development, they are nevertheless not directly connected in terms of familyrelations between speakers, and the nature of the changes is therefore not easily determined. Futurestudies of individual competences, however, will presumably provide more knowledge of changes inthe underlying grammars, and how they can explain the observed patterns.
In a broader context, the present article shows that the patterns of language mixing are stableover time, although not completely resistant to change. The observed changes in AmNo support thisanalysis, suggesting that (heritage) grammars may change under conditions of reduced input andactivation. This takes place as a gradual reanalysis of the structures under the influence of the dominantlanguage, and may be reinforced by a diminishing repertoire of functional exponents. Moreover, toreach insights into the nature of change in heritage grammars, input, competence, and gradual changeshould be sufficiently documented and taken into consideration.
Acknowledgments: I would like to thank three anonymous reviewers for very helpful comments and suggestions.I am also grateful to Tor Anders Åfarli (Norwegian University of Science and Technology, Norway) and TerjeLohndal (Norwegian University of Science and Technology & UiT The Artic University of Norway, Norway) forvaluable discussions as well as detailed and constructive comments.

Languages 2017, 2, 3 26 of 29
Conflicts of Interest: The author declares no conflict of interest.
Abbreviations
Glossary of Linguistic Codes Used in the Glosses
DEF DefinitenessDF DefiniteF FeminineGEN GenderINDF IndefiniteM MasculineN NeuterNUM NumberPL PluralSG Singular
References
1. Grimstad, M.B.; Lohndal, T.; Åfarli, T.A. Language mixing and exoskeletal theory: A case study ofword-internal mixing in American Norwegian. Nordlyd 2014, 41, 213–237. [CrossRef]
2. Alexiadou, A.; Lohndal, T.; Åfarli, T.A.; Grimstad, M.B. Language Mixing: A Distributed Morphologyapproach. In NELS 45, Proceedings of the Forty-Fifth Annual Meeting of the North East Linguistic Society, MIT,Cambridge, MA, USA, 31 October–2 November 2014; Bui, Ö., Ed.; GLSA: Amherst, MA, USA, 2015; pp. 25–38.
3. Åfarli, T.A. Hybrid verb forms in American Norwegian and the analysis of the syntactic relation betweenthe verb and its tense. In German Heritage Languages in North America; Johannessen, J.B., Salmons, J.C.,Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2015;pp. 161–177.
4. Riksem, B.R. Language Mixing in American Norwegian Noun Phrases. J. Lang. Contact 2017, in press.5. Riksem, B.R.; Grimstad, M.B.; Lohndal, T.; Åfarli, T.A. Language mixing within verbs and nouns in American
Norwegian. J. Comp. Ger. Linguist. 2017, in press.6. Haugen, E. The Norwegian Language in America: A Study in Bilingual Behavior; University of Philadelphia Press:
Philadelphia, PA, USA, 1953; Volumes I–II.7. Johannessen, J.B. The Corpus of American Norwegian Speech (CANS). In NEALT Proceedings Series Vol. 23,
Proceedings of the 20th Nordic Conference of Computational Linguistics (NoDaLiDa 2015), Institute of the LithuanianLanguage, Vilnius, Lithuania, 11–13 May 2015; Megyesi, B., Ed.; ACL Anthology: Stockholm, Sweden, 2015;pp. 297–300.
8. Hjelde, A. Trøndsk talemål i Amerika; Tapir: Trondheim, Norway, 1992.9. Johannessen, J.B.; Salmons, J. Innledning. Norsk Lingvistisk Tidsskrift 2012, 30, 139–148.10. Johannessen, J.B.; Salmons, J. The study of Germanic heritage languages in the Americas. In German Heritage
Languages in North America; Johannessen, J.B., Salmons, J.C., Eds.; John Benjamins Publishing Company:Amsterdam, The Netherlands; Philadelphia, PA, USA, 2015; pp. 1–17.
11. Lovoll, O.S. Norwegian Newsarticles in America; Minnesota Historical Society Press: St. Paul, MN, USA, 2010.12. Rothman, J. Understanding the nature and outcomes of early bilingualism: Romance languages as heritage
languages. Int. J. Biling. 2009, 13, 155–163. [CrossRef]13. Rothman, J.; Treffers-Daller, J. A prolegomenon to the construct of the native speaker: Heritage speaker
bilinguals are natives too! Appl. Ling. 2014, 35, 93–98. [CrossRef]14. Pascual y Cabo, D.; Rothman, J. The (Il)logical problem of heritage speaker bilingualism and incomplete
acquisition. Appl. Ling. 2012, 33, 1–7.15. Benmamoun, E.; Montrul, S.; Polinsky, M. Heritage languages and their speakers: Opportunities and
challenges for linguistics. Theor. Ling. 2013, 39, 129–181. [CrossRef]16. Montrul, S. Incomplete Acquisition in Bilingualism. Re-examining the Age Factor; John Benjamins Publishing
Company: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2008.17. Polinsky, M. Incomplete acquisition: American Russian. J. Slav. Ling. 2006, 14, 191–262.

Languages 2017, 2, 3 27 of 29
18. Polinsky, M. Reanalysis in adult heritage language: A case for attrition. Stud. Second Lang. Acquis. 2011, 33,305–328. [CrossRef]
19. Putnam, M.T.; Sánchez, L. What’s so incomplete about incomplete acquisition? A prolegomenon to modelingheritage language grammars. Ling. Approaches Biling. 2013, 3, 478–508. [CrossRef]
20. Flaten, N. Notes on the American-Norwegian with vocabulary. Dialect Notes 1900–1904, 2, 115–126.21. Flom, G.T. English elements in Norse dialects of Utica, Wisconsin. Dialect Notes 1900–1904, 2, 257–268.22. Flom, G.T. English loanwords in American Norwegian as spoken in the Koshkonong settlement, Wisconsin.
Am. Speech 1926, 1, 541–558. [CrossRef]23. Seip, D.A.; Selmer, E.W. Seip og Selmers voksrull-opptak av norsk-amerikanske informanter. Available online:
http://www.tekstlab.uio.no/nota/NorDiaSyn/dialekt_seip_og_selmer.html (accessed on 6 April 2017),audio files with Norwegian dialects.
24. Haugen, E. Einar Haugens opptak av norskamerikanere i 1935–1948. Available online: http://tekstlab.uio.no/norskiamerika/opptak/haugen.html (accessed on 6 April 2017), audio files with Norwegian dialects.
25. Hjelde, A. “Folkan mine, dæm bære snakke norsk”—norsk i Wisconsin frå 1940-talet og fram til i dag.Norsk Lingvistisk Tidsskrift 2012, 30, 183–203.
26. Venås, K. On the choice between two written standards in Norway. In Language Conflict and LanguagePlanning; Jahr, E.H., Ed.; Mouton de Gruyter: Berlin, Germany, 1993; pp. 263–278.
27. Vikør, L.S. The Nordic Languages: Their Status and Interrelations; Nordic Language Secretariat PublicationNo. 14; Novus Press: Oslo, Norway, 1995.
28. Muysken, P. Bilingual Speech; Cambridge University Press: Cambridge, UK, 2000.29. Myers-Scotton, C. Duelling Languages: Grammatical Structure in Code Switching; Oxford University Press:
Oxford, UK, 1993.30. Myers-Scotton, C. Contact Linguistics: Bilingual Encounters and Grammatical Outcomes; Oxford University
Press: Oxford, UK, 2002.31. Mahootian, S. A Null Theory of Code-Switching. Ph.D. Dissertation, Northwestern University,
Evanston, IL, USA, 1993.32. Belazi, H.M.; Rubin, E.J.; Toribio, A.J. Code switching and X-bar theory. Ling. Inq. 1994, 25, 221–237.33. MacSwan, J. A Minimalist Approach to Intrasentential Code Switching; Garland Press: New York, NY, USA, 1999.34. MacSwan, J. The architecture of the bilingual faculty: Evidence from intrasentential code switching.
Bilingualism 2000, 3, 37–54. [CrossRef]35. MacSwan, J. Codeswitching and generative grammar: A critique of the MLF model and some remarks on
“modified minimalism”. Biling. Lang. Cognit. 2005, 8, 1–22. [CrossRef]36. MacSwan, J. Generative approaches to code-switching. In The Cambridge Handbook of Linguistic Code-switching;
Bullock, B.E., Toribio, A.J., Eds.; Cambridge University Press: Cambridge, UK, 2009; pp. 309–335.37. MacSwan, J. Programs and proposals in codeswitching research: Unconstraining theories of bilingual
language mixing. In Grammatical Theory and Bilingual Codeswitching; MacSwan, J., Ed.; MIT Press:Cambridge, MA, USA, 2014; pp. 1–33.
38. van Hout, A. Event Semantics of Verb Frame Alternations. Ph.D. Dissertation, Tilburg University,Tilburg, The Netherlands, 1996.
39. Marantz, A. No escape from syntax: Do not try morphological analysis in the privacy of your ownlexicon. In University of Pennsylvania Working Papers in Linguistics, Proceedings of the 21st Annual PennLinguistics Colloquium, University of Pennsylvania, Philadelphia, PA, USA, 22–23 February 1997; Dimitriadis, S.,Surek-Clark, W., Eds.; Penn Linguistics Club: Philadelphia, PA, USA, 1997; pp. 201–225.
40. Marantz, A. Verbal argument structure: Events and participants. Lingua 2013, 130, 152–168. [CrossRef]41. Borer, H. Structuring Sense I: In Name Only; Oxford University Press: Oxford, UK, 2005.42. Borer, H. Structuring Sense II: The Normal Course of Events; Oxford University Press: Oxford, UK, 2005.43. Borer, H. Structuring Sense III: Taking Form; Oxford University Press: Oxford, UK, 2013.44. Åfarli, T.A. Do verbs have argument structure? In Argument Structure; Reuland, E., Bhattacharya, T., Spathas, G.,
Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2007;pp. 1–16.
45. Ramchand, G. Verb Meaning and the Lexicon: A First Phase Syntax; Cambridge University Press:Cambridge, UK, 2008.

Languages 2017, 2, 3 28 of 29
46. Lohndal, T. Without Specifiers: Phrase Structure and Argument Structure. Ph.D. Dissertation, University ofMaryland, College Park, MD, USA, 2012.
47. Lohndal, T. Phrase Structure and Argument Structure: A Case-Study of the Syntax Semantics Interface; OxfordUniversity Press: Oxford, UK, 2014.
48. Alexiadou, A.; Anagnostopoulou, E.; Schäfer, F. External Arguments in Transitivity Alternations: A LayeringApproach; Oxford University Press: Oxford, UK, 2015.
49. Harley, H.; Noyer, R. Distributed Morphology. Glot Int. 1999, 4, 3–9.50. Alexiadou, A. Functional Structure in Nominals: Nominalization and Ergativity; John Benjamins Publishing
Company: Amsterdam, The Netherlands; Philadelphia, PA, USA, 2001.51. Embick, D.; Noyer, R. Distributed morphology and the syntax morphology interface. In The Oxford Handbook
of Linguistic Interfaces; Ramchand, G., Reiss, C., Eds.; Oxford University Press: Oxford, UK, 2007; pp. 289–324.52. Harley, H. On the identity of roots. Theor. Ling. 2014, 40, 225–276. [CrossRef]53. Arad, M. Roots and Patterns: Hebrew Morpho-Syntax; Springer: Dordrecht, The Netherlands, 2005.54. Pylkkänen, L. Introducing Argument; MIT Press: Cambridge, MA, USA, 2008.55. Embick, D.; Marantz, A. Architecture and blocking. Ling. Inq. 2008, 39, 1–53. [CrossRef]56. Halle, M. Distributed morphology: Impoverishment and fission. In MIT Working Papers in Linguistics
30. PF: Articles at the Interface; Bruening, B., Kang, Y., McGinnis, M., Eds.; MIT: Cambridge, MA, USA, 1997;pp. 425–449.
57. Goldrick, M.; Putnam, M.; Schwarz, L. Coactivation in bilingual grammars: A computational account ofcode mixing. Biling. Lang. Cognit. 2016, 19, 857–876. [CrossRef]
58. Goldrick, M.; Putnam, M.; Schwarz, L. The future of code mixing research: Integrating psycholinguistics andformal grammatical theories. Biling. Lang. Cognit. 2016, 19, 903–906. [CrossRef]
59. Embick, D. The Morpheme: A Theoretical Introduction; Mouton de Gruyter: Berlin, Germany; Boston, MA, USA, 2015.60. Delsing, L.-O. The Internal Structure of Noun Phrases in the Scandinavian Languages. A Comparative Study.
Ph.D. Dissertation, University of Lund, Lund, Sweden, 1993.61. Vangsnes, Ø.A. The Identification of Functional Architecture. Ph.D. Dissertation, University of Bergen,
Bergen, Norway, 1999.62. Julien, M. Nominal Phrases from a Scandinavian Perspective; John Benjamins Publishing Company:
Amsterdam, The Netherlands; Philadelphia, PA, USA, 2005.63. Nygård, M.; Åfarli, T.A. On the structure of gender assignment. Indian Ling. 2015, 76, 67–76.64. Kramer, R. Gender in Amharic: A morphosyntactic approach to natural and grammatical gender. Lang. Sci.
2014, 43, 102–115. [CrossRef]65. Alexiadou, A. Inflection class, gender and DP-internal structure. In Explorations in Nominal Inflection;
Müller, G., Gunkel, L., Zifonun, G., Eds.; Mouton de Gruyter: Berlin, Germany, 2004; pp. 21–50.66. Myklebust, A. “Hva er de derre greiene der?”: En syntaktisk analyse av komplekse demonstrativ i muntlig
norsk. Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2012.67. Enger, H.-O. On the relation between gender and declension—A diachronic perspective from Norwegian.
Stud. Lang. 2004, 28, 51–82. [CrossRef]68. Lødrup, H. Hvor mange genus er det i Oslo-dialekten? Maal og Minne 2011, 2, 120–136.69. Trosterud, T. Genus i norsk er regelstyrt. Norsk lingvistisk tidsskrift 2001, 19, 29–58.70. Flom, G.T. The gender of English loan-nouns in Norse dialects in America; A contribution to the study of the
development of grammatical gender. J. Eng. Germ. Philol. 1903, 5, 1–31.71. Hjelde, A. The gender of English nouns in American Norwegian. In Language Contact across the Atlantic;
Ureland, P.S., Clarkson, I., Eds.; Max Niemeyer Verlag: Tübingen, Germany, 1996; pp. 297–312.72. Johannessen, J.B.; Larsson, I. Complexity matters: On gender agreement in heritage Scandinavian.
Front. Psychol. 2015, 6, 1842. [CrossRef] [PubMed]73. Lohndal, T.; Westergaard, M. Grammatical gender in American Norwegian heritage language: Stability or
attrition? Front. Psychol. 2016, 7. [CrossRef] [PubMed]74. Picallo, M.C. Gender and number in Romance. Lingue e Linguaggio 2008, VII, 47–66.75. Enger, H.-O. The role of core and non-core semantic rules in gender assignment. Lingua 2009, 119, 1281–1299.
[CrossRef]76. Lardiere, D. Mapping features to forms in second language acquisition. In Second Language Acquisition and
Linguistic Theory; Archibald, J., Ed.; Blackwell: Malden, MA, USA; Oxford, UK, 2000; pp. 102–129.

Languages 2017, 2, 3 29 of 29
77. Prévost, P.; White, L. Missing surface inflection or impairment in second language acquisition? Evidencefrom tense and agreement. Second Lang. Res. 2000, 16, 103–133. [CrossRef]
78. Gass, S.M.; Selinker, L. Second Language Acquisition. An Introductory Course, 3rd ed.; Routledge:New York, NY, USA, 2008.
79. Polinsky, M. Structure vs. use in heritage language. Ling. Vanguard 2016, 2. [CrossRef]80. Scontras, G.; Fuchs, Z.; Polinsky, M. Heritage language and linguistic theory. Front. Psychol. 2015, 6.
[CrossRef] [PubMed]81. Yager, L.; Hellmold, N.; Joo, H.-A.; Putnam, M.T.; Rossi, E.; Stafford, C.; Salmons, J. New structural patterns
in moribund grammar: Case marking in heritage German. Front. Psychol. 2015, 6, 1716. [CrossRef] [PubMed]
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open accessarticle distributed under the terms and conditions of the Creative Commons Attribution(CC BY) license (http://creativecommons.org/licenses/by/4.0/).




















